Область изобретения
Настоящее изобретение относится к технологиям, позволяющим улучшить кодирование, распределение, и декодирование трехмерного акустического поля. В частности, настоящее изобретение относится к технологиям кодирования аудиосигналов вместе с пространственной информацией независящим от демонстрационного комплекса методом; и для оптимального декодирования для данной демонстрационной системы, либо комплекса громкоговорителей, либо наушников.
Предшествующий уровень техники
При многоканальном воспроизведении и прослушивании слушатель обычно окружен множеством громкоговорителей. Как правило, одной задачей воспроизведения является создание акустического поля, в котором слушатель может воспринимать намеченные местоположения источников звука, например, расположение музыканта в группе. Различные комплексы громкоговорителей могут создавать различные пространственные впечатления. Например, стандартные стереокомплексы могут убедительно воссоздавать акустическую сцену в пространстве между двумя громкоговорителями, но не справляются с такой задачей при углах вне пространства между двумя громкоговорителями.
Комплексы с большим количеством громкоговорителей, окружающих слушателя, могут достигать лучшего пространственного впечатления при большем наборе углов. Например, одним из наиболее широко известных стандартов комплексов нескольких громкоговорителей является Surround 5.1 (ITU-R775-1), состоящий из 5 громкоговорителей, расположенных по азимутам -30, 0, 30, -110, 110 градусов вокруг слушателя, где 0 обозначает фронтальное направление. Однако такой комплекс не может справиться со звуком, расположенным выше горизонтальной плоскости слушателя.
Для увеличения впечатления погружения у слушателя настоящие тенденции заключаются в том, чтобы использовать комплексы громкоговорителей с большим количеством громкоговорителей, включая громкоговорители, расположенные на разной высоте. Одним из примеров является система 22.2, разработанная Hamasaki из NHK, Япония, которая состоит из 24 громкоговорителей, расположенных на трех различных высотах.
В настоящем, парадигма производства пространственного аудио в профессиональных применениях таких комплексов заключается в том, чтобы предоставить одну аудиодорожку для каждого канала, используемого при воспроизведении. Например, для стереокомплекса требуются две аудиодорожки; для комплекса 5.1 требуется шесть аудиодорожек, и т.п. Эти дорожки, обыкновенно, появляются на этапе постпроизводства, хотя их и можно создать непосредственно на этапе записи для вещания. Стоит отметить, что во многих случаях несколько громкоговорителей используют для того, чтобы воспроизводить один и тот же аудиоканал. Так обстоит дело в случае большинства кинотеатров 5.1, где каждый surround канал проигрывают через три или более громкоговорителей. Таким образом, в этих случаях, несмотря на то, что количество громкоговорителей может превышать 6, количество различных аудиоканалов по-прежнему 6, и, суммарно, проигрывается только 6 различных сигналов.
Одним из следствий этой парадигмы "одной дорожки на канал" является то, что работа, выполняемая на этапах записи и постпроизводства, связывается с демонстрационным комплексом, на котором будет демонстрироваться создаваемое информационное содержимое (контент). На этапе записи, например, при трансляции, тип и расположение используемых микрофонов, и метод микширования определяется как функция от комплекса, на котором будет воспроизводиться событие. Аналогично, при производстве носителя, инженеры постпроизводства должны знать детали комплекса, на котором будет демонстрироваться контент, и позаботиться о каждом из каналов. Неудача при попытке правильно установить демонстрационную схему с несколькими громкоговорителями, для которой был доработан контент, приведет к снижению качества воспроизведения. Если контент будет демонстрироваться на различных комплексах, то на этапе постпроизводства необходимо создать несколько версий. Это приводит к увеличению финансовых затрат и затрат времени.
Другим следствием этой парадигмы "одной дорожки на канал" является размер требуемых данных. С одной стороны, без дополнительного кодирования, парадигма требует столько дорожек, сколько используют каналов. С другой стороны, если необходимо предоставить несколько версий, то их предоставляют либо отдельно, что, опять-таки, увеличивают размер данных, либо выполняют некое преобразование по снижению количества каналов, что ухудшает качество результата.
И наконец, последним недостатком парадигмы "одной дорожки на канал" является то, что произведенный таким образом контент не выдерживает проверки временем. Например, 6 дорожек, присутствующие в данном фильме, произведенном для комплекса 5.1, не включают в себя источники звука, расположенные над слушателем, и не полностью задействуют комплексы, в которых громкоговорители расположены на различных высотах. В настоящее время существует несколько технологий, способных предоставить пространственное аудио, не зависящее от демонстрационной системы. Возможно, простейшей технологией является векторный амплитудный перенос (VBAP). Она основана на подаче одного и того же моносигнала на громкоговорители, ближайшие к намеченному расположению источника звука, с регулировкой громкости для каждого громкоговорителя. Такая система может работать для двухмерных или трехмерных (с высотами) комплексов, обычно, выбирая два или три, соответственно, ближайших громкоговорителя. Одно из достоинств этого способа заключается в том, что он обеспечивает большую зону наилучшего восприятия, что означает, что в комплексе громкоговорителей есть большая область, в которой звук воспринимают как исходящий из намеченного направления. Однако этот способ неприменим ни к воспроизведению полей реверберирующего звука, таких, как присутствующие в реверберационных камерах, ни для воспроизведения источников звука с большим разнесением. В лучшем случае, с применением этих способов можно воспроизвести первые отражения звука, издаваемого источниками, но тем не менее этот способ предоставляет дорогое и низкокачественное решение.
Другой технологией, способной предоставить пространственное аудио, независящее от демонстрационной системы, является амбиофония. Эту технологию разработал в 70-х Michael Gerzon, она предоставляет полную методологию цепи кодирования-декодирования. При кодировании сохраняется набор сферических гармоник акустического поля в одной точке. Нулевой порядок (W) соответствует тому, что запишет всенаправленный микрофон, расположенный в этой точке. Первый порядок, состоящий из трех сигналов (X, Y, Z), соответствует тому, что запишут в этой точке три микрофона с диаграммой направленности в виде восьмерки, выровненные по осям декартовой системы координат. Сигналы более высоких порядков соответствуют тому, что запишут микрофоны в более сложных схемах расположения. Существует также кодирование амбиофонии смешанного порядка, когда используют только часть набора сигналов каждого порядка; например, при использовании только сигналов W, X, Y из амбиофонии первого порядка, таким образом, игнорируя сигнал Z. Несмотря на то, что генерация сигналов за пределами первого порядка несложна на этапе постпроизводства, либо при помощи моделирования акустического поля, при записи настоящего акустического поля микрофонами это осложняется; и в самом деле, до недавнего времени, для применения в профессиональных областях, были доступны только микрофоны, способные измерять сигналы нулевого и первого порядков. Пример микрофонов амбиофонии первого порядка представляют собой микрофоны Soundfield, и более современные TetraMic. При декодировании, после специфицирования комплекса нескольких громкоговорителей (количество и положение каждого громкоговорителя), сигнал, направляемый на каждый громкоговоритель, обычно определяют, требуя максимального совпадения акустического поля, созданного комплексом в целом, с намеченным полем (либо созданным на этапе постпроизводства, либо том, с которого были записаны сигналы). Помимо независимости от демонстрационной системы, дополнительными преимуществами данной технологии является высокий уровень обеспечиваемой ею манипуляции (в основном, вращением и масштабированием звуковой сцены), и ее способность точно воспроизводить реверберационное поле.
Однако технология амбиофонии ограничена двумя основными недостатками: неспособностью воспроизводить близкие источники звука, и малый размер зоны наилучшего восприятия. Концепцию близких или разнесенных источников звука используют в данном контексте как обозначающую угловую ширину воспринимаемой звуковой картины. Первая проблема происходит из факта того, что, даже при попытке воспроизвести очень узкий источник звука, амбиофоническое декодирование задействует больше громкоговорителей, чем расположено вблизи намеченной позиции источника. Вторая проблема происходит из того факта, что, несмотря на расположение в зоне наилучшего восприятия, волны, исходящие из каждого громкоговорителя, фазово суммируются для создания желаемого акустического поля, вне зоны наилучшего восприятия, волны создают некорректную фазовую интерференцию. Это изменяет окраску звука, и, что более важно, звук представляется исходящим из громкоговорителя, расположенного ближе к слушателю, из-за общеизвестного эффекта психоакустического предпочтения. Для фиксированного размера комнаты прослушивания, единственным способом уменьшить обе проблемы является увеличение используемого порядка амбиофонии, но это подразумевает быстрый рост в количестве задействованных каналов и громкоговорителей.
Стоит отметить, что существует еще одна технология, способная точно воспроизводить произвольное звуковое поле, так называемый синтез волнового поля (WFS). Однако эта технология требует расположения громкоговорителей на удалении один от другого менее, чем в 15-20 сантиметрах, что требует дополнительных аппроксимаций (и, соответственно, потери качества) и сильно увеличивает количество требуемых громкоговорителей; существующие комплексы используют между 100 и 500 громкоговорителей, что сужает область ее применения до событий очень высокого уровня подготовки.
Требуется обеспечить технологию, способную предоставлять пространственный аудиоконтент, который можно распределять независимо от демонстрационного комплекса, как двумерный, так и трехмерный; который, после специфицирования комплекса, можно декодировать для использования ее полных возможностей; которая способна воспроизводить все типы акустических полей (узкие источники, реверберационные или диффундирующие поля) для всех слушателей в пространстве, то есть с большой областью наилучшего восприятия; и которая не требует использования большого количества громкоговорителей. Это обеспечит возможность создавать контент, пригодный для использования в будущем, в том смысле, что она будет легко адаптироваться ко всем существующим и будущим комплексам из нескольких громкоговорителей, и даст возможность кинотеатрам или домашним пользователям выбирать комплекс из нескольких громкоговорителей, который максимально соответствует их целям и задачам, обеспечивая при этом уверенность в том, что найдется большое количество контента, который сможет полностью использовать возможности выбранного ими комплекса.
Сущность изобретения
Способ и устройство для кодирования аудио с пространственной информацией независящим от демонстрационного комплекса образом, и декодирование и оптимальное воспроизведение для любого данного демонстрационного комплекса, включая и комплексы с громкоговорителями, расположенными на разных высотах, и наушники.
Изобретение основано на способе для кодирования некоего входного аудиоматериала, в формат, независящий от демонстрации, путем распределения его в две группы: первая группа содержит в себе аудио, которое требует точно направленной локализации; вторая группа содержит аудио, для которого достаточно локализации, обеспечиваемой технологией амбиофонии низкого порядка.
Все аудио в первой группе кодируется в виде набора раздельных моноаудиодорожек с соответствующими метаданными. Количество отдельных моноаудиодорожек не ограничено, однако, в некоторых вариантах осуществления можно накладывать определенные ограничения, как описано ниже. Метаданные должны содержать в себе информацию о точном времени, когда необходимо воспроизвести каждую такую аудиодорожку, а также пространственную информацию, описывающую, по меньшей мере, направление источника сигнала в каждый момент времени. Все аудио во второй группе кодируют в набор аудиодорожек, представляющих собой данный порядок амбиофонических сигналов. В идеальном случае присутствует один набор амбиофонических каналов, хотя в определенных вариантах осуществления можно использовать более одного.
При воспроизведении, когда становится известна демонстрационная система, первую группу аудиодорожек декодируют для воспроизведения с использованием стандартных алгоритмов переноса, которые используют небольшое количество громкоговорителей поблизости от намеченного положения аудиоисточника. Второй набор аудиоканалов декодируют для воспроизведения с использованием амбиофонических декодеров, оптимизированных для данной демонстрационной системы.
Эти способ и устройство решают вышеописанные проблемы, как это описано далее.
Во-первых, это позволяет этапам записи аудио, постпроизводства и распространения обычных материалов проходить независимо от комплексов, на которых будет демонстрироваться контент. Одним из следствий этого факта является то, что созданный этим способом контент пригоден для использования в будущем, в том смысле, что его можно легко адаптировать к любому произвольному комплексу нескольких громкоговорителей как существующему, так и созданному в будущем. Этому качеству также удовлетворяет и технология амбиофонии.
Во-вторых, появляется возможность корректно воспроизводить очень узкие источники. Их кодируют в индивидуальные аудиодорожки, вместе с ассоциированными метаданными направления, позволяя использовать декодирующие алгоритмы, использующие меньшее количество громкоговорителей вокруг намеченного места расположения аудиоисточника, такие как двумерный или трехмерный векторный амплитудный перенос. В противоположность этому, амбиофония требует использования очень высоких порядков для достижения таких результатов, с соответственным увеличением количества связанных дорожек, данных, и сложности декодирования.
В-третьих, этот способ и устройство способны в большинстве ситуаций обеспечить большую область наилучшего восприятия, таким образом, увеличивая область оптимальной реконструкции звукового поля. Это достигается путем отделения в первую группу аудиодорожек всех частей аудио, которые будут приводить к уменьшению области наилучшего восприятия. Например, в варианте осуществления, проиллюстрированном на фиг.8, и описанном ниже, прямой звук диалога кодируют в виде отдельной аудиодорожки с информацией о направлении, с которого он исходит, в то время как реверберантная часть кодируется в виде набора дорожек амбиофонии первого порядка. Таким образом, большая часть публики воспринимает прямой звук этого источника как исходящий из правильного местоположения, главным образом из нескольких громкоговорителей в намеченном направлении; таким образом, из прямого звука устраняют эффекты дефазированной окраски и предшествования, что закрепляет звуковое изображение в его правильном местоположении.
В-четвертых, количество данных, в большей части случаев кодирования аудио для комплексов нескольких громкоговорителей, уменьшается, по сравнению с парадигмой одной дорожки на канал, и по сравнению с кодированием амбиофонии более высокого порядка. Этот факт обеспечивает преимущество для целей хранения и распространения. Для этого есть две причины. С одной стороны, назначение звука высокой степени направленности к списку воспроизведения узкого аудио позволяет использовать для реконструкции остальной части звуковой сцены амбиофонию всего лишь первого порядка, состоящей из разнесенного, диффундированного или с невысокой степенью направленности звука. Таким образом, 4 дорожек группы амбиофонии первого порядка достаточно. Напротив, для корректной реконструкции узких источников требуется, например, 16 аудиоканалов для третьего, или 25 для четвертого порядка. С другой стороны, количество узких источников, требующих одновременного проигрывания, во многих случаях невелико; это так, например, для фильма, где в список воспроизведения узкого аудио входят только диалоги и некоторые спецэффекты. Более того, все аудио в группе списка воспроизведения узкого аудио представляет собой набор дорожек с длительностью, соответствующей только длительности данного источника аудио. Например, аудио, соответствующее автомобилю, находящемуся в одной сцене в течение трех секунд, имеет длительность только в три секунды. Таким образом, в примере применения к фильму, где необходимо создать звуковую дорожку фильма для комплекса 22.2, в парадигме одной дорожки на канал потребуется 24 аудиодорожки, и кодирование амбиофонии третьего порядка потребует 16 аудиодорожек. Напротив, в предлагаемом формате, независящем от демонстрации, потребуется только 4 аудиодорожки полной длительности, плюс набор отдельных аудиодорожек различной длительности, которые уменьшают таким образом, чтобы они покрывали только намеченную длительность узких источников аудио.
Краткое описание чертежей
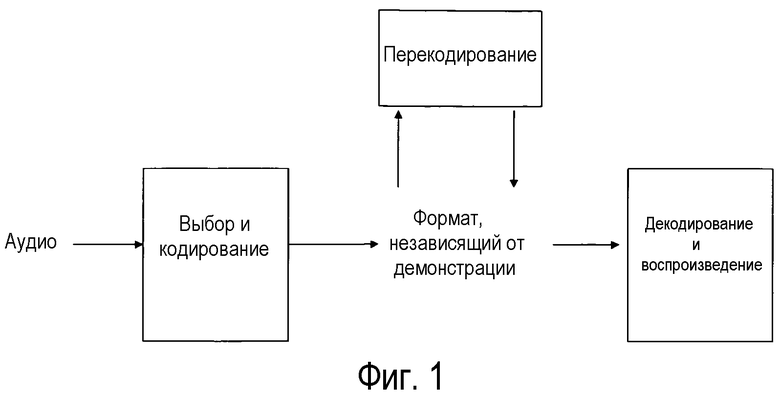
На фиг.1 показан вариант осуществления способа для, имея данный набор начальных звуковых дорожек, выбора и кодирования их, и наконец, декодирования и оптимального воспроизведения в произвольном демонстрационном комплексе.
На фиг.2 показана схема предлагаемого формата, независящего от демонстрации, с двумя группами аудио: списка воспроизведения узкого аудио с пространственной информацией и дорожками амбиофонии.
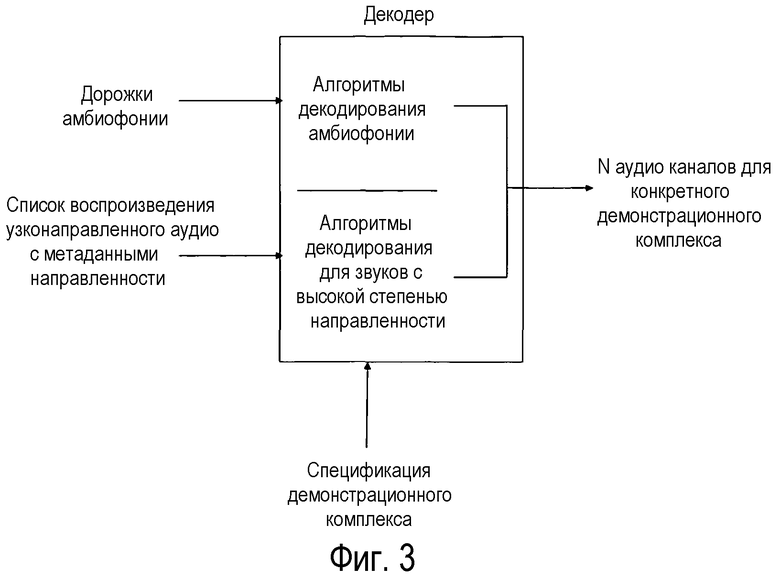
На фиг.3 показан декодер, использующий различные алгоритмы для обработки любой из групп аудио.
На фиг.4 показан вариант осуществления способа, которым можно перекодировать две группы аудио.
На фиг.5 показан вариант осуществления, в котором независящий от демонстрации формат можно основать на аудиопотоках, вместо полных аудиофайлов, сохраненных на дисках или в памяти других типов.
На фиг.6 показан дополнительный вариант осуществления способа, в котором независящий от демонстрации формат вводят в декодер, который может воспроизводить контент в любом демонстрационном комплексе.
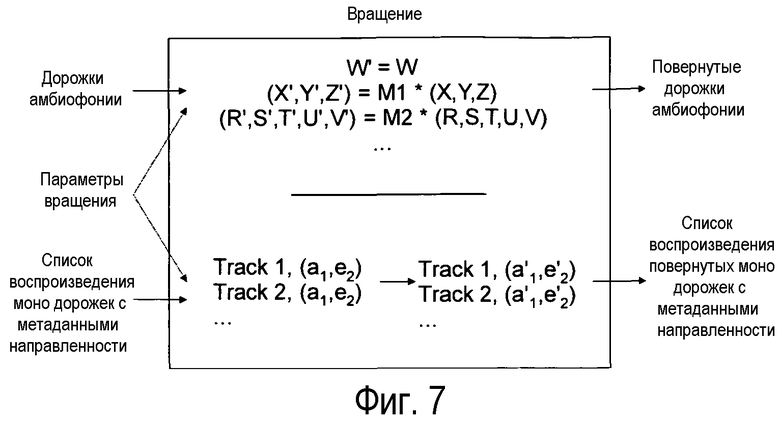
На фиг.7 показаны некоторые технические детали процесса ротации, который соответствует простым операциям, проводимым с обеими группами аудио.
На фиг.8 показан вариант осуществления способа в рабочем окружении аудиовизуального постпроизводства.
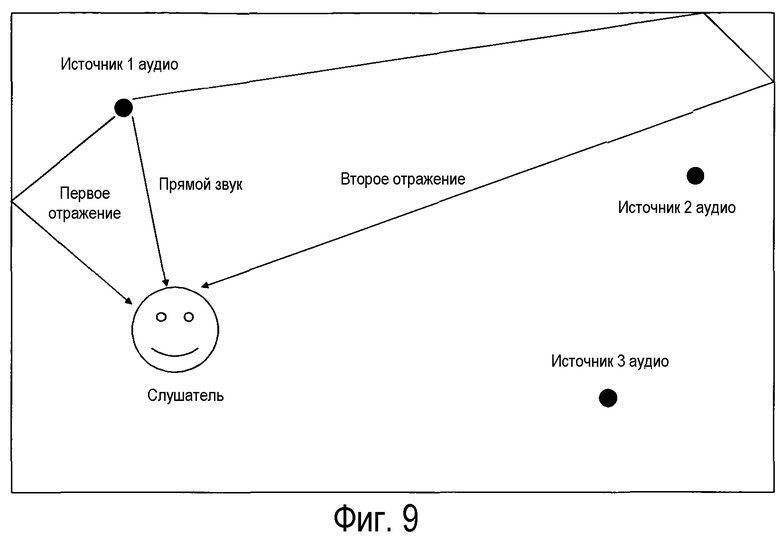
На фиг.9 показан дополнительный вариант осуществления, в виде части производства аудио и постпроизводства в виртуальной сцене (например, в анимационном кино или трехмерной игре).
На фиг.10 показан дополнительный вариант осуществления способа, в виде части цифрового сервера фильмов.
На фиг.11 показан альтернативный вариант осуществления способа для кино, в котором контент можно декодировать до распределения.
Подробное описание предпочтительных вариантов осуществления
На фиг.1 показан вариант осуществления способа для, имея данный набор начальных аудиодорожек, выбора и кодирования их, и, наконец, декодирования и оптимального воспроизведения в произвольном демонстрационном комплексе. Таким образом, для данного расположения громкоговорителей, пространственное звуковое поле будет реконструировано максимально качественно, адаптировано для имеющихся громкоговорителей, и увеличивая область оптимального воспроизведения до максимально возможного предела. Первоначальный звук может исходить из любого источника, например: используя любой тип микрофона с любой диаграммой направленности или любой амплитудно-частотной чувствительностью; используя амбиофонические микрофоны, способные выдавать амбиофонические сигналы любого порядка или смешанного порядка; или используя синтезированное аудио, или спецэффекты, такие как комнатная реверберация.
Процесс выбора и кодирования состоит из создания двух групп дорожек из первоначального аудио. Первая группа состоит из тех частей аудио, которые требуют узкой локализации, в то время как вторая группа состоит из оставшегося аудио, для которого достаточно направленности данного порядка амбиофонии. Аудиосигналы, распределенные в первую группу, содержат в моноаудиодорожках, вместе с пространственными метаданными о направлении источника во времени, и временем первоначального воспроизведения.
Выбор представляет собой процесс, проводимый пользователем, хотя над некоторыми типами первоначального аудио можно выполнять действия по умолчанию. В общем случае (т.е. для не амбиофонических аудиодорожек), пользователь определяет, для каждого элемента изначального аудио, направление источника и тип источника: узкий или амбиофонический источник, в соответствии с описанными ранее группами кодирования. Углы направления можно определить, например, азимутом и углом возвышения источника по отношению к слушателю, и его можно указывать как фиксированные значения для дорожки, или как данные, изменяющиеся со временем. Если для некоторых дорожек направление не указывают, можно определить назначение по умолчанию, например, назначая таким дорожкам данное фиксированное постоянное направление.
Дополнительно, углы направления может сопровождать параметр разнесения. Термины разнесенный и узкий, в данном контексте необходимо понимать как угловую ширину воспринимаемой звуковой картины источника. Например, можно квантифицировать разнесение, используя значения на интервале [0, 1], где значение 0 обозначает точно направленный звук (то есть звук, исходящий от только одного четко определенного направления), и значение 1 обозначает звук, исходящий со всех направлений с одинаковой энергетикой.
Для некоторых типов первоначальных дорожек, можно определить действия по умолчанию. Например, дорожки, идентифицированные как стереопары, можно помещать в амбиофоническую группу с азимутами -30 и 30 градусов для левого и правого каналов, соответственно. Дорожки, идентифицированные как surround 5.1 (ITU-R775-1), можно, аналогично, назначать на азимуты -30, 0, 30, -110, 110 градусов. И, наконец, дорожки, идентифицированные как амбиофонические первого порядка (или B-формат), можно назначать в группу амбиофонии без запроса дополнительной информации о направленности.
Процесс кодирования с фиг.1 получает вышеупомянутую определенную пользователем информацию и выдает независящий от демонстрации аудиоформат с пространственной информацией, как описано на фиг.2. Выходные данные процесса кодирования представляют собой, для первой группы, набор моноаудиодорожек с аудиосигналами, соответствующими различным источникам звука, с ассоциированными пространственными метаданными, включающими в себя направления источника в соответствии с данной системой отсчета, или параметрами разнесения аудио. Выходные данные процесса преобразования для второй группы аудио представляют собой один единый набор амбиофонических дорожек выбранного порядка (например, 4 дорожки, если выбрана амбиофония первого порядка), который соответствует смешению всех источников в амбиофонической группе.
Затем, выходные данные процесса кодирования использует декодер, который использует информацию о выбранном демонстрационном комплексе для создания одной аудиодорожки или поток аудио для каждого канала комплекса.
На фиг.3 показан декодер, использующий различные алгоритмы для обработки каждой из групп аудио. Группу амбиофонических дорожек декодируют с использованием подходящих для конкретного комплекса амбиофонических декодеров. Дорожки в списке воспроизведения узконаправленного аудио декодируют, используя алгоритмы, подходящие для этой цели; они используют пространственную информацию из метаданных каждой дорожки для декодирования, обычно, с использованием очень малого количества громкоговорителей вокруг намеченного местоположения каждой дорожки. Одним из примеров такого алгоритма является векторный амплитудный перенос. Метаданные времени используют для начала воспроизведения каждого такого аудио в правильный момент. Наконец, декодированные каналы отправляются для воспроизведения на громкоговорители или наушники.
На фиг.4 показан дополнительный вариант осуществления способа, которым две группы аудио можно перекодировать. В общем случае, процесс перекодирования принимает на вход список воспроизведения узконаправленного аудио, содержащий в себе N разных аудиодорожек с ассоциированными метаданными направленности, и набор амбиофонических дорожек данного порядка P, и данный тип смеси A (например, она может содержать в себе все дорожки нулевого и первого порядка, но только две дорожки, соответствующие сигналам второго порядка). Выходные данные процесса перекодирования представляет собой список воспроизведения узконаправленного аудио, который содержит в себе М разных аудиодорожек с ассоциированными метаданными направленности, и набор амбиофонических дорожек данного порядка Q, с данным типом смеси B. В процессе перекодирования, M, Q, B могут отличаться от N, P, A, соответственно.
Перекодирование можно использовать, например, для уменьшения количества содержащихся данных. Этого можно достигнуть, например, путем выбора одной или нескольких дорожек, содержащихся в списке воспроизведения узконаправленного аудио, и переназначения их в группу амбиофонии, конвертируя, с использованием ассоциированной с монодорожкой информации направленности моно, в амбиофонию. В этом случае, становится возможным достигнуть M<N, за счет использования амбиофонической локализации для перекодированного аудио узкой направленности. С этой же целью можно уменьшить количество дорожек амбиофонии, например, оставив только те, которые необходимы для воспроизведения в плоскостных демонстрационных комплексах. В тех случаях, когда количество сигналов амбиофонии для данного P описывается формулой (P+1)*2, уменьшение до плоскостных комплексов уменьшает это количество до 1+2*P.
Другим применением процесса перекодирования является уменьшение количества одновременных аудиодорожек, требуемых данным списком воспроизведения узконаправленного аудио. Например, в вещательных применениях желательно ограничить количество аудиодорожек, которые проигрываются одновременно. Опять-таки, этого можно добиться, переназначив ряд дорожек из списка воспроизведения узконаправленного аудио в группу амбиофонии.
Список воспроизведения узконаправленного аудио может содержать в себе необязательные метаданные, описывающие релевантность содержащегося в нем аудио, которое представляет из себя описание важности декодирования каждого из аудио с использованием алгоритмов для узконаправленных источников. Эти метаданные можно использовать для автоматического назначения наименее релевантного аудио в группу амбиофонии.
Другое использование процесса перекодирования заключается в том, чтобы просто позволить пользователю назначать аудио в списке воспроизведения узконаправленного аудио в группу амбиофонии, или для изменения порядка и типа смешения группы амбиофонии с эстетическими целями. Также возможно назначать аудио из группы амбиофонии в список воспроизведения узконаправленного аудио: одной из возможностей является выбор части дорожки нулевого порядка и назначения ей пространственных метаданных вручную; другой возможностью является использование алгоритмов, которые вычисляют месторасположения источника из дорожек амбиофонии, такие как алгоритм DirAC.
На фиг.5 показан дополнительный вариант осуществления настоящего изобретения, в котором предлагаемый формат, независящий от демонстрации, может быть основан на аудиопотоках, вместо полных аудиофайлов, хранимых на дисках или других типах памяти. В вещательных сценариях использования полоса пропускания, выделенная под аудио, ограничена и фиксирована, и, вследствие этого, количество аудиоканалов, которые можно одновременно передавать. Предлагаемый способ состоит, во-первых, в разделении существующих аудиопотоков между двумя группами, потоков узкой направленной и амбиофонических потоков, и, во-вторых, перекодировании промежуточного файлового формата, независящего от демонстрации, в ограниченное количество потоков.
Такое перекодирование использует технологии, описанные в предыдущих параграфах, для уменьшения, если требуется, количества одновременных дорожек и для части узконаправленного аудио (переназначая дорожки с низкой релевантностью в группу амбиофонии), и для амбиофонической части (путем удаления амбиофонических компонент).
У передачи аудио есть дополнительные особенности, такие, как необходимость конкатенации дорожек узконаправленного аудио в непрерывные потоки, и необходимость перекодировать метаданные направленности узконаправленного аудио в доступные методы передачи. Если формат передачи аудио не позволяет передавать такие метаданные направленности, нужно выделить одну аудиодорожку для передачи этих метаданных, соответственным образом перекодированных.
Следующий простой пример должен послужить целям более детального объяснения. Рассмотрим звуковую дорожку фильма, в предлагаемом формате, не зависящем от демонстрации, использующий амбиофонию первого порядка (4 канала) и список воспроизведения узконаправленного аудио, с максимальным количеством каналов одновременного воспроизведения, равным 4. Эту звуковую дорожку нужно передать на цифровой телевизор, используя только 6 его каналов. Как показано на фиг.5, перекодирование использует 3 канал амбиофонии (удаляя канал Z) и два канала узконаправленного аудио (таким образом, переназначая максимум две одновременно воспроизводимые дорожки в группу амбиофонии).
Необязательно, предлагаемый формат, независящий от демонстрации, может использовать компрессию аудиоданных. Ее можно использовать при обоих типах предлагаемого формата, независящего от демонстрации: файловом и потоковом. Когда используют психоакустические форматы с потерями, компрессия может влиять на качество пространственной реконструкции.
На фиг.6 показан дополнительный вариант осуществления этого способа, в котором формат, не зависящий от демонстрации, подают на вход декодера, способного воспроизвести контент в любом демонстрационном комплексе. Специфицирование демонстрационного комплекса можно выполнить несколькими различными путями. Декодер может обладать стандартными предварительными настройками, такими, как surround 5.1 (ITU-R775-1), из которых пользователь может выбрать совпадающий с его демонстрационным комплексом. Выбор может предусматривать необязательную подстройку, для подстройки более точного совпадения с месторасположением громкоговорителей конкретной пользовательской конфигурации. Существует необязательная возможность использовать некую систему автоопределения, способную локализовать местоположение каждого громкоговорителя, например, при помощи звуковой, ультразвуковой, или инфракрасной технологии. Спецификацию демонстрационного комплекса можно переконфигурировать неограниченное количество раз, обеспечивая для пользователя возможность адаптироваться к любому существующему или будущему демонстрационному комплексу. Декодер может обладать множеством выходов, так, чтобы различные процессы декодирования можно было бы выполнять одновременно, для одновременного воспроизведения в различных комплексах. В идеале, декодирование выполняется до любого возможного уравнивания системы воспроизведения.
В том случае, если в качестве системы воспроизведения используются наушники, декодирование выполняют способами стандартной технологии стереофонии. Используя одну или различные базы данных функций передачи, учитывающей особенности восприятия (HRTF), возможно производить пространственный звук, используя алгоритмы, адаптированные для обеих групп аудио, предлагаемых в настоящем способе: списка воспроизведения узконаправленного аудио и дорожек амбиофонии. Обычно этого добиваются, используя вышеописанные алгоритмы для декодирования на виртуальный комплекс из нескольких громкоговорителей, и, затем, свертывая каждый канал с HRTF, соответствующему местоположению виртуального громкоговорителя.
Один из дополнительных вариантов осуществления способа позволяет осуществлять, на этапе демонстрации, финальное вращение всей звуковой сцены как для демонстрации в комплексе из нескольких громкоговорителей, так и для наушников. Это может оказаться полезным в различных случаях. В одном из применений, пользователь в наушниках может обладать механизмом отслеживания положения головы, измеряющий параметры ориентации его головы для соответствующего вращения всей звуковой сцены.
На фиг.7 показаны некоторые технические детали, касающиеся процесса поворота, который соответствует простым операциям с обеими группами аудио. Вращение дорожек амбиофонии выполняют, применяя различные матрицы вращения к каждому порядку амбиофонии. Эта процедура хорошо известна. С другой стороны, пространственные метаданные, ассоциированные с каждой дорожкой из списка воспроизведения узконаправленного аудио можно модифицировать простым вычислением азимута и угла возвышения источника, с которых этот звук воспримет пользователь с данной ориентацией. И снова, это представляет собой простое обычное вычисление.
На фиг.8 показан вариант осуществления способа в рабочем окружении аудиовизуального постпроизводства. Пользователь обладает всем контентом в его постпроизводственном программном обеспечении, которое может представлять собой рабочую станцию обработки цифрового звука. Пользователь указывает направление каждого источника, нуждающегося в локализации, используя либо стандартные, либо специальные модули. Для генерации предлагаемого промежуточного формата, не зависящего от демонстрации, она выбирает аудио, которое должно быть кодировано в список воспроизведения монодорожек, и аудио, которое будет кодировано в группу амбиофонии. Это назначение можно осуществлять разными путями. В одном из вариантов осуществления, пользователь, при помощи модуля, назначает коэффициент направленности для каждого из источников аудио; это назначение затем используют для автоматического назначения всех источников с коэффициентом направленности, превышающим данное значение, в список воспроизведения узконаправленного аудио, и оставшееся аудио в группу амбиофонии. В другом варианте осуществления, некоторые назначения выполняет программное обеспечение; например, реверберантная часть всего аудио, равно как и все аудио, которое было записано с использованием амбиофонических микрофонов, можно назначить в группу амбиофонии, если иное не указано пользователем. Как альтернатива, все назначения можно осуществлять вручную.
Когда назначения завершены, программное обеспечение использует специальные модули для генерации списка воспроизведения узконаправленного аудио и дорожек амбиофонии. В этой процедуре кодируют метаданные о пространственных свойствах списка воспроизведения узконаправленного аудио. Аналогично, направление, и, необязательно, разнесение, аудиоисточников, которые назначены в группу амбиофонии, используют для трансформации моно или стерео в амбиофонию, путем применения стандартных алгоритмов. Таким образом, результатом этапа постпроизводства аудио является промежуточный формат, не зависящий от демонстрации, со списком воспроизведения узконаправленного аудио и набором каналов амбиофонии данного порядка и смешения.
В этом варианте осуществления может оказаться полезной генерация более одного набора каналов амбиофонии для создания других версий. Например, если будут производить версии одного и того же фильма на разных языках, полезным будет закодировать во второй набор дорожек амбиофонии все аудио, имеющее отношение к диалогам, включая реверберантную часть диалогов. Используя данный способ, единственное изменение, которое потребуется для производства версии на другом языке, состоит в замене сухих диалогов, содержащихся в списке воспроизведения узконаправленного аудио, и реверберантной части диалогов, содержащихся во втором наборе дорожек амбиофонии.
На фиг.9 показан дополнительный вариант осуществления данного способа, как части производства аудио и постпроизводства в виртуальной сцене (например, в анимационном фильме или трехмерной игре). В виртуальной сцене, доступна информация о месторасположении и ориентации источников звука и слушателя. Возможно также наличие информации о трехмерной геометрии сцены, равно как и о материалах, в ней присутствующих. Необязательный расчет реверберации можно автоматически вычислять, используя моделирование акустики комнаты. В этом контексте, кодирование звуковой сцены в промежуточный формат, не зависящий от демонстрации, можно упростить. С одной стороны, возможно назначить аудиодорожки каждому источнику, и кодировать положение по отношению к слушателю в каждый момент, просто автоматически рассчитывая их из соответственных местоположений и ориентаций, вместо того, чтобы указывать их позднее, на этапе постпроизводства. Также можно решить, как много реверберации кодировать в группу амбиофонии, присваивая прямой звук каждого источника, равно как и определенное число первых отражений звука, в список воспроизведения узконаправленного аудио, и оставшуюся часть реверберации в группу амбиофонии.
На фиг.10 показан дополнительный вариант осуществления способа, как части цифрового сервера кино. В этом случае, один и тот же аудиоконтент можно распределять по кинотеатрам в описанном формате, не зависящем от демонстрации, состоящем из списка воспроизведения узконаправленного аудио, плюс набора дорожек амбиофонии. В каждом кинотеатре можно установить декодер, со спецификацией конкретного комплекса из нескольких громкоговорителей, который можно вводить вручную, либо при помощи механизма автоопределения какого-либо типа. В частности, автоматическое определение комплекса можно легко встроить в систему, которая, одновременно, вычисляет уравнивание, необходимое для каждого громкоговорителя. Этот этап может состоять из измерения импульсной реакции каждого громкоговорителя в данном кинотеатре, для вычисления и местоположения громкоговорителя, и обратного фильтра, требующегося для его уравнивания. Измерение импульсной реакции, которое можно выполнять различными существующими способами (такими, как синусоидальной развертки или последовательностями MLS), и соответствующее вычисление местоположения громкоговорителя представляет собой процедуру, которую не надо выполнять часто, но, напротив, только когда характеристики места размещения или комплекса изменяются. В любом случае, после того, как декодер обладает спецификацией комплекса, контент можно декодировать оптимальным образом в формат одной дорожки на канал, готовый к воспроизведению.
На фиг.11 показан альтернативный вариант осуществления способа для кино, в котором контент можно декодировать до распределения. В этом случае декодер должен обладать спецификацией каждого комплекса кино, так, чтобы можно было генерировать несколько версий одной дорожки на канал, которые затем распределяют. Это применение полезно, например, для доставки контента в кинотеатры, не оборудованные декодером, совместимым с предлагаемым в настоящем документе форматом, независящим от демонстрации. Также это может оказаться полезным для проверки или сертификации качества аудио, которое адаптировано для конкретного комплекса до его распределения.
В дополнительном варианте осуществления этого способа, некоторые из списка воспроизведения узконаправленного аудио можно редактировать без обращения к изначальному мастер-проекту. Например, некоторые из метаданных, описывающих положение источников или их разнесение, можно изменять.
Несмотря на то, что предшествующее показано и описано со ссылкой на конкретные варианты осуществления изобретения, специалисты в данной области поймут, что различные другие изменения формы и подробностей можно выполнять без отхода от области и духа данного изобретения. Необходимо понимать, что различные изменения можно вносить для адаптации к различным вариантам осуществления, без отхода от широких концепций, раскрытых в данном документе и описанных в приложенной формуле изобретения.






Изобретение относится к средствам кодирования аудиосигналов и относящейся к ним пространственной информации в формат, не зависящий от схемы воспроизведения. Технический результат заключается в обеспечении технологии, способной представлять пространственный аудиоконтент независящим от демонстрационного способа методом. Назначают первый набор аудиосигналов в первую группу. Кодируют первую группу в качестве набора моноаудиодорожек с ассоциированными метаданными, описывающими направление источника сигнала каждой дорожки по отношению к позиции записи и время начала его воспроизведения. Назначают второй набор аудиосигналов во вторую группу. Кодируют вторую группу в качестве, по меньшей мере, одного набора дорожек амбиофонии данного порядка и смешения порядков. Генерируют две группы дорожек, содержащих первый и второй набор аудиосигналов. 6 н. и 20 з.п. ф-лы, 11 ил.
1. Способ кодирования аудиосигналов и относящейся к ним пространственной информации в формат, не зависящий от схемы воспроизведения, причем способ включает в себя:
a. назначение первого набора аудиосигналов в первую группу, и кодирование первой группы в качестве набора моноаудиодорожек с ассоциированными метаданными, описывающими направление источника сигнала каждой дорожки по отношению к позиции записи и время начала его воспроизведения;
b. назначение второго набора аудиосигналов во вторую группу, и кодирование второй группы в качестве, по меньшей мере, одного набора дорожек амбиофонии данного порядка и смешения порядков; и
c. генерирование двух групп дорожек, содержащих первый и второй набор аудиосигналов.
2. Способ по п.1, дополнительно содержащий кодирование параметров разнесения, ассоциированных с дорожками в наборе моноаудиодорожек.
3. Способ по п.1, дополнительно содержащий кодирование дополнительных параметров направленности, ассоциированных с дорожками в наборе моноаудиодорожек.
4. Способ по п.1, дополнительно содержащий получение направления источника сигналов для дорожек в первом наборе из любого трехмерного представления сцены, содержащей звуковые источники, ассоциированные с дорожками, и положение записи.
5. Способ по п.1, дополнительно содержащий назначение направления источника сигналов для дорожек в первом наборе в соответствии с предварительно определенными правилами.
6. Способ по п.1, дополнительно содержащий кодирование параметров направленности для каждой дорожки в первом наборе либо в виде фиксированных постоянных значений, либо значений, изменяющихся со временем.
7. Способ по п.1, дополнительно содержащий кодирование метаданных, описывающих спецификацию используемого формата амбиофонии, например, порядок амбиофонии, тип смешения порядков, коэффициенты усиления дорожек, и упорядочивание дорожек.
8. Способ по п.1, дополнительно содержащий кодирование времени начала воспроизведения, ассоциированное с дорожками амбиофонии.
9. Способ по п.1, дополнительно содержащий кодирование входных моносигналов с ассоциированными данными направленности в дорожки амбиофонии данного порядка и смешения порядков.
10. Способ по п.1, дополнительно содержащий кодирование любых входных многоканальных сигналов в дорожки амбиофонии данного порядка и смешения порядков.
11. Способ по п.1, дополнительно содержащий кодирование любых входных амбиофонических сигналов любого порядка и смешения порядков в дорожки амбиофонии, возможно, другого данного порядка и смешения порядков.
12. Способ по п.1, дополнительно содержащий перекодирование формата, не зависящего от схемы воспроизведения, причем перекодирование включает в себя, по меньшей мере, одно из следующего:
a. назначение дорожек из набора монодорожек в набор амбиофонии;
b. назначение частей аудио из набора амбиофонии в набор монодорожек, возможно, включая полученную информацию о направленности из амбиофонических сигналов;
c. изменение порядка или смешения порядков набора дорожек амбиофонии;
d. изменение метаданных направленности, ассоциированных с набором монодорожек;
e. изменение дорожек амбиофонии посредством выполнения операций, таких как вращение и масштабирование.
13. Способ по п.12, дополнительно содержащий перекодирование формата, не зависящего от схемы воспроизведения, в формат, применимый для широковещательной передачи, причем перекодирование удовлетворяет следующим ограничениям: фиксированное количество непрерывных аудиопотоков, использование доступных протоколов для передачи метаданных, содержащихся в формате, независящем от схемы воспроизведения.
14. Способ по п.1, дополнительно содержащий декодирование формата, не зависящего от схемы воспроизведения для данного комплекса из нескольких громкоговорителей, причем декодирование использует спецификацию позиций нескольких громкоговорителей для:
a. декодирования набора монодорожек с использованием алгоритмов, применимых для воспроизведения узконаправленных звуковых источников;
b. декодирования набора дорожек амбиофонии при помощи алгоритмов, адаптированных для порядка дорожек и смешения порядков, и для специфицированного комплекса.
15. Способ по п.14, дополнительно содержащий использование параметров разнесения, и, возможно, других пространственных метаданных, ассоциированных с набором монодорожек для использования алгоритмов декодирования, применимых для специфицированного разнесения.
16. Способ по п.14, дополнительно содержащий использование стандартных предварительных настроек схем воспроизведения, например, стерео и surround 5.1, ITU-R775-1.
17. Способ по п.14, дополнительно содержащий декодирование для наушников, посредством стандартной технологии стереофонии, с использованием баз данных функций передачи, учитывающей особенности восприятия.
18. Способ по п.14, дополнительно содержащий использование параметров управления вращением, для выполнения вращения полной звуковой сцены, причем такие параметры управления могут быть сформированы, например, устройствами, отслеживающими положение головы.
19. Способ по п.14, дополнительно содержащий использование технологии для автоматического получения позиции громкоговорителей, для определения спецификации комплекса для использования декодером.
20. Способ по п.14 или 17, в котором выходные данные декодирования сохраняют в качестве набора аудиодорожек, вместо непосредственного воспроизведения.
21. Способ по п.1, 12, 13, 14 или 17, при помощи которого аудиосигналы, целиком или частично, кодируются в сжатые аудиоформаты.
22. Аудиокодер для кодирования аудиосигналов и относящейся к ним пространственной информации в формат, не зависящий от схемы воспроизведения, причем кодер включает в себя:
a. кодер для назначения первого набора аудиосигналов в первую группу и кодирования первой группы в набор монодорожек с информацией о направленности и времени начала воспроизведения;
b. кодер для назначения второго набора аудиосигналов во вторую группу и кодирования второй группы в набор дорожек амбиофонии любого порядка и смешения порядков; и
c. кодер для генерации двух групп дорожек, содержащих первый и второй набор аудиосигналов.
23. Перекодировщик аудио для перекодирования аудио во входном формате, не зависящем от схемы воспроизведения, причем перекодировщик выполнен с возможностью выполнения, по меньшей мере, одного из нижеследующего:
a. назначать дорожки из набора монодорожек в набор амбиофонии;
b. назначать части аудио из набора амбиофонии в набор монодорожек, по возможности включая полученную из сигналов амбиофонии информацию о направленности;
c. изменять порядок или смешение порядков набора дорожек амбиофонии;
d. изменять метаданные направленности, ассоциированные с набором монодорожек;
e. изменять дорожки амбиофонии посредством таких операций, как вращение и масштабирование.
24. Аудиодекодер для декодирования формата, не зависящего от схемы воспроизведения, для данной системы воспроизведения с N каналами, причем формат, не зависящий от схемы воспроизведения, генерируют в соответствии со способом по п.1, причем аудиодекодер содержит:
a. декодер для декодирования набора монодорожек с информацией о направленности и времени начала воспроизведения в N аудиоканалов на основании спецификации комплекса воспроизведения,
b. декодер для декодирования набора дорожек амбиофонии в N аудиоканалов на основании спецификации комплекса воспроизведения,
c. микшер для смешения выходных данных двух предыдущих декодеров для генерации N выходных аудиоканалов, готовых для воспроизведения или сохранения.
25. Система для кодирования и перекодирования пространственного аудио в формате, не зависящем от схемы воспроизведения, и для декодирования и воспроизведения в любом комплексе нескольких громкоговорителей, или для наушников, причем система содержит:
a. аудиокодер для кодирования набора аудиосигналов и относящейся к ним пространственной информации в формат, не зависящий от схемы воспроизведения, как в п.22,
b. перекодировщик и преобразователь аудио для манипулирования и перекодирования аудио во входном формате, не зависящем от схемы воспроизведения, как в п.23,
c. аудиодекодер для декодирования формата, не зависящего от схемы воспроизведения, для данной системы воспроизведения, либо комплекса нескольких громкоговорителей, либо наушников, как в п.24.
26. Преобразователь аудио для манипулирования аудио во входном формате, не зависящем от схемы воспроизведения, причем выходные данные преобразуются в соответствии со способом по п.12.
| FR 2847376 A1, 21.05.2004 | |||
| US 2008004729 A1, 03.01.2008 | |||
| US 2007269063 A1, 22.11.2007 | |||
| WO 9318630 A1, 16.09.1993 | |||
| Резьбовое соединение | 1985 |
|
SU1416769A1 |
| WO 2007074269 A1, 05.07.2007 | |||
| US 6628787 B1, 30.09.2003 | |||
| DE 102005008366 A1, 24.08.2006 | |||
| US 6718042 B1, 06.04.2004 | |||
| RU 2009115648 A, 19.09.2007 | |||

