ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[001] Настоящее изобретение описывает систему и метод языкового перевода текста в общем и в частности систему для совместного перевода.
УРОВЕНЬ ТЕХНИКИ
[002] Сбор и обмен информацией с любой научной, коммерческой, политической или социальной целью зачастую требует быстрого и эффективного перевода текста, чтобы множество знаний и идей стали полезны в глобальном масштабе. Компьютерные программы, которые переводят автоматически с одного языка на другой (“программы машинного перевода”), в принципе могут удовлетворить данную потребность, и такие программы были разработаны и продолжают разрабатываться для множества языков. Для формального стиля изложения на глубоко исследованных языках (в отличие от неформального, идиоматического или разговорного стиля), такие программы машинного перевода демонстрируют достаточно адекватное качество перевода.
[003] Для более трудных или менее исследованных языков (например, арабского языка), однако, существующие программы машинного перевода не работают хорошо даже для формального общения (например, Современного Стандартного Арабского языка) и они особенно слабы в случае неформального, разговорного и идиоматического общения. Аналогично, там, где требуется качественный точней перевод, машинного перевода самого по себе становится недостаточно даже для хорошо исследованных языков (например, английского, французского, испанского, немецкого и других языков).
[004] Профессиональные переводчики в принципе могут обеспечить качественные переводы для трудных языков и неформальных коммуникаций, но Интернет-приложения требуют постоянной доступности и оперативного реагирования, что не может быть гарантировано в случае использования существующих подходов к организации работы профессиональных переводчиков.
[005] В свете вышесказанного, необходим метод и система, способные обеспечить эффективное использование баз памяти переводов при одновременной работе над переводом текста больших команд профессиональных переводчиков.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[006] Изобретение состоит в следующем:
[007] Настоящее изобретение обеспечивает систему и метод перевода с языка исходного файла. Система состоит из веб-сервера, принимающего и обрабатывающего данные исходного файла для перевода, базы данных для хранения переведенного текста, обработанных исходных файлов и терминов глоссария, модуля сегментации, предназначенного для разбиения исходного файла на множество сегментов, модуля обработки, выполняющего поиск соответствующих данным сегментам существующих данных, для нахождения полных и/или частично совпадающих сегментов из уже переведенных ранее текстов, модуля машинного перевода для формирования машинного перевода сегмента, модуля поиска терминологии для нахождения использованных в сегменте терминов из глоссария и пользовательского интерфейса, доступного одновременно для множества пользователей, выполняющего отображение машинного перевода, полных и частичных совпадений из памяти переводов, терминов из глоссариев, и обеспечивающего возможность выполнения профессионального перевода исходного файла. Система и метод могут быть представлены в виде исполняемого кода (программного обеспечения), аппаратного обеспечения или их комбинации.
[008] В другом аспекте настоящего изобретения для каждого сегмента, сохраненного в базе данных, модуль обработки ищет точное или частичное соответствие с ранее переведенными предложениями, ищет термины из глоссария и машинные переводы предложения. В реализации системы множество пользователей может получить одновременный доступ к пользовательскому интерфейсу системы, и переводы выполненные каждым пользователем передаются из пользовательского интерфейса на сервер и сохраняются в базу данных. В пользовательском интерфейсе также могут отображаться выполненные ранее другими пользователями сегменты, полностью или частично совпадающие с переводимым сегментом.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ СХЕМ
[009] Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми графическими схемами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие графические схемы:
[010] Рис.1 - диаграмма потока данных, иллюстрирующая распределенную систему языкового перевода, реализованную в соответствии с настоящим изобретением.
[011] Рис.2 - диаграмма потока данных, иллюстрирующая метод автоматического предварительного перевода, используемый в модуле предварительного перевода 118, который в свою очередь является частью распределенной системы языкового перевода, реализованной в соответствии с настоящим изобретением.
[012] Рис.3 - схематически иллюстрирует взаимодействие слоя интеграции внешних информационных систем и распределенной системы языкового перевода, реализованной в соответствии с настоящим изобретением.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[013] В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
[014] Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
[015] Настоящее изобретение направлено на обеспечение системы и метода для быстрого, эффективного и более надежного языкового перевода посредством распределенной сетевой системы языкового перевода.
[016] Распределенная сетевая система языкового перевода - это распределенная сеть профессиональных переводчиков и систем машинного перевода, которые взаимодействуют через программные и пользовательские интерфейсы системы и выполняют совместно в режиме реального времени перевод текстов, для которых недостаточно применения исключительно машинного перевода или традиционно организованного профессионального перевода, включая перевод динамических коммуникаций и других текстов создаваемых в различных информационных средах.
[017] В реализации настоящего изобретения система является доступной через сеть интернет облачной платформой, доступ профессиональных переводчиков к системе обеспечивается через интерфейс пользователя, открываемый в веб-браузере, в интерфейсе реализованы отдельные окна для управления проектом перевода и для одновременного перевода и редактирования текста несколькими исполнителями в режиме реального времени. Распределенная сетевая система языкового перевода обеспечивает инструментарий для агрегирования ресурсов большого числа переводчиков, с разными режимами доступности, с различными профессиональными навыками, как профессиональных переводчиков, так и компьютерных систем машинного перевода, для эффективного выполнения высококачественных переводов в режиме реального времени.
[018] В реализации настоящего изобретения, перевод выполняется путем разбиения исходного текста на сегменты, выполнение по сегменту поиска терминологии и поиска совпадений в базе памяти переводов, последующей одновременной отправки каждого сегмента на перевод нескольким системам машинного перевода. При этом каждый источник данных (глоссарий, память переводов, система машинного переводов) обладает собственным рейтингом качества, метрикой совпадения и/или собственной уверенности в выдаваемом результате, вычисляемых для каждого сегмента индивидуально. Причем результаты поиска по терминологии и базам памяти переводов используются для дополнительной индивидуальной настройки систем машинного перевода, а частичные совпадения с исходным сегментом, найденные в базе памяти переводов, используются для подстановки в итоговый машинный перевод той части сегмента, которая совпадает. Затем, принимая во внимание рейтинг каждой системы машинного перевода и значения метрик для каждого сегмента, как собственных для каждой системы машинного перевода, так и внешних (учитывающих как гладкость текста в целом, так и внутренние факторы, такие как количество фрагментов/фраз, из которых собран перевод, встречается ли терминология из глоссария в сегменте и т.д.), выбирается вариант машинного перевода с наилучшими значениями автоматических метрик.
[019] Распределенная сетевая система перевода основывается на технологии памяти переводов, призванной повысить эффективность перевода, состоящей из хранилища параллельных сегментов и подсистемы поиска, позволяющей выполнять как поиск с условиями, накладываемыми только на язык оригинала, так и поиск с условиями, накладываемыми одновременно и на язык оригинала и на язык перевода. В базе памяти переводов хранятся переведенные ранее сегменты, чтобы в дальнейшем не нужно было выполнять перевод повторно с чистого листа. Таким образом, одна из главных функций базы памяти переводов - это поиск переведенных ранее сегментов, схожих с вновь переводимым сегментом, а также сравнение сегментов их переводов, а также отдельных фраз и слов в данных сегментах.
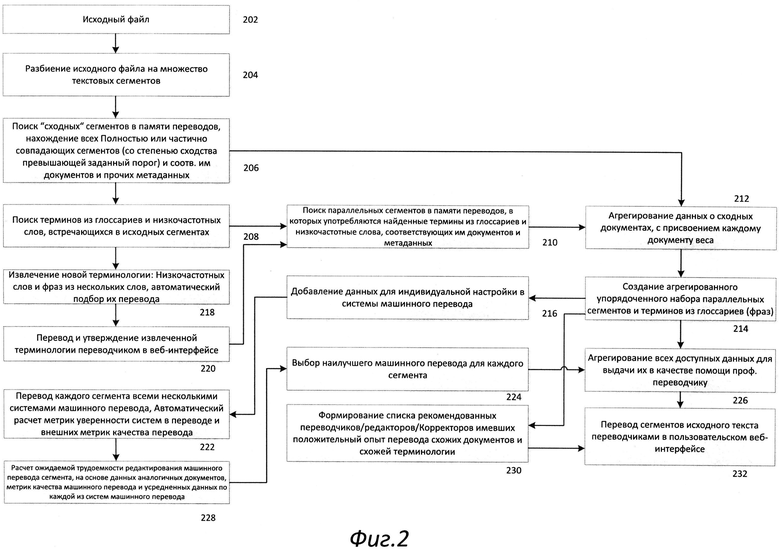
[020] На Рис.1 представлена диаграмма, распределенную сетевую систему перевода, являющую собой пример реализации в соответствии с настоящим изобретением. Как показано на Рис.1, распределенную сетевую систему перевода 100 обслуживает множество заказчиков перевода 102 желающих получить перевод исходных файлов 104. Множество заказчиков перевода 102 соединяются с удаленным веб-сервером 112 посредством сети Интернет 110 с помощью пользовательского интерфейса 106 и веб-браузера. Исходный файл 104 загружается на сервер 112 посредством сети интернет 110. После того, как исходный файл 104 загружен на веб-сервер 112, модуль сегментации 114 обрабатывает исходный файл 104 и разбивает его на текст на множество сегментов. Множество сегментом, каждый из которых содержит часть исходного текста файла 104 затем обрабатывается модулем предварительного перевода 118, который находит для каждого исходного сегмента соответствующие ему ресурсы из базы лингвистических ресурсов 116, а именно находит полностью совпадающие сегменты в памяти переводов, находит частично совпадающие сегменты в памяти переводов, находит термины глоссария, встречающиеся в сегменте, а также для каждого слова сегмента определяет соответствующие ему записи в морфологическом частотном словаре. База лингвистических ресурсов 116 состоит из морфологического частотного словаря, глоссариев, и базы памяти переводов, с переведенными ранее сегментами, дополненными метаданными документов, в которые входили данные сегменты, а также данными об истории работы над каждым сегментом, т.е. какой исполнитель какой этап рабочего процесса выполнил для данного сегмента, какие изменения он внес в текст перевода, а также записи всех действий выполненных им в интерфейсе системы в процессе работы над данным сегментом. Таким образом, в модуле предварительного перевода 118 для каждого найденного в памяти переводов сегмента определяется документ, к которому он относится, кто именно выполнял перевод сегмента (какая система машинного перевода была использована, кто был переводчиком, кто редактором, кто корректором, и т.д.). А также количественные оценки качества работы, полученные каждым из перечисленных исполнителей по данному документу (если проводился экспертный анализ качества перевода). Далее основываясь на предварительно настроенных правилах предварительного перевода, применяемых на уровне каждого сегмента, которые могут дополнительно изменять в каждом конкретном проекте перевода, в модуле предварительного перевода 118 формируется предварительный автоматический перевод а файла, содержащий для каждого сегмента полностью и частично совпадающие сегменты из памяти переводов, термины из глоссария, а также варианты машинного перевода сформированные различными системами машинного перевода. Правила предварительного перевода, применяются на уровне каждого отдельного сегмента и определяют какой именно из вариантов перевода будет использован по умолчанию, а также какие этапы работ с данным сегментом должны быть выполнены профессиональными исполнителями людьми, в зависимости от выбранного по умолчанию варианта перевода и автоматической оценки его качества и необходимого объема доработок.
[021] В примере реализации настоящего изобретения, память переводов представляет из себя систему хранения и поиска параллельных сегментов (предложений, фраз или фрагментов предложений) - представляющих из себя пару исходный текст и текст перевода. Память переводов используется для того, чтобы помочь переводчику в переводе текста и накапливает уже переведенные ранее сегменты, чтобы избежать их повторного перевода с чистого листа в дальнейшем. Данная функция выполняется за счет поиска по базе памяти переводов для вновь переводимого сегмента полностью и частично совпадающих с ним ранее переведенных сегментов. Для установления степени совпадения ранее переведенных сегментов со вновь переводимым сегментом используется метрика соответствия, отражающая степень совпадения текста вновь переводимого сегмента с текстом оригинала переведенного ранее и хранящегося в базе данных сегмента.
[022] Множество исполнителей (переводчиков) 108 подключаются к платформе 100 посредством веб-интерфейса 106. Сегменты, являющиеся результатом работы модуля сегментации текста 114 передаются для обработки в модуль предварительного перевода 118, который формирует предварительный перевод исходного файла 104 (который может в том числе содержать наилучший вариант машинного перевода из множества вариантов, полученных от доступных систем машинного перевода), набор профессиональных операций, которые должны быть выполнены для каждого сегмента, а также набор рекомендуемых профессиональных переводчиков/редакторов/корректоров с указанием для каждого из них его рейтинга и метрики предпочтительности его привлечения к работе над данным конкретным документом. Пользовательский веб-интерфейс 106 содержит различные интерфейсные окна для управления проектом и для непосредственной работы над переводом и редактированием текста перевода, при этом возможно одновременное редактирование одного документа многими переводчиками/редакторами/корректорами/ревьюверами и т.д. С помощью соответствующего веб-интерфейса 108 переводчик может просматривать перевод исходного файла 104 с учетом предварительного перевода, выполненного модулем предварительного перевода 118, а также переводов выполненных или отредактированных другими переводчиками/редакторами/корректорами/ревьюверами, при этом база памяти переводов автоматически пополняется по мере ввода переводчиками перевода новых сегментов и при редактировании выполненных ранее автоматических или профессиональных переводов и изменения и новые добавления отображаются автоматически в режиме реального времени в результатах поиска.
[023] Переводы сегментов, которые вводятся или редактируются профессиональными переводчиками 108 после формирования их предварительного перевода в модуле предварительного перевода 118 (различные сегменты могут проходить через различные стадии профессиональной работы, что также определяется в результате работы модуля 118), автоматически проверяются после их сохранения соответствующим исполнителем на корректность перевода терминологии в соответствии с глоссарием и корректность прохождения прочих автоматических правил контроля качества, настроенных для данного файла. По результатам данных проверок у сегмента может быть выставлен специальный флаг, сигнализирующий о том, что автоматически зафиксирована потенциальная ошибка, приведено ее описание, кроме того по каждому сегменту исполнитель в веб-интерфейсе видит предысторию работы по нему - кто именно вносил изменения на каких этапах работ и какие изменения вносились, кроме того видны комментарии внесенные предыдущими исполнителями по данному сегменту, в которые исполнители могут включить обоснование причин, по которым был выбран вариант перевода, не проходящий автоматической верификации. Каждый сегмент документа должен пройти все стадии рабочего процесса, определенного на уровне документа, за исключением тех случаев, когда в результате работы модуля предварительного перевода 118 часть стадий для отдельных сегментов может пропускаться.
[024] На Рис.2 приведена диаграмма иллюстрирующая работу модуля предварительного перевода, входящего в состав распределенной сетевой системы перевода, реализованной в соответствии с настоящим изобретением. В блок 202 на вход поступает исходный файл 104, загруженный через пользовательский веб-интерфейс сетевой распределенной системы или поступившей через обращение к программным интерфейсам системы (API). Исходный файл 104 может иметь как текстовое, так и бинарное представление; затем исходный файл 104 обрабатывается программным фильтром, соответствующим формату файла, для извлечения содержимого файла в виде текста. В блоке 204, текстовое содержимое исходного файла 104 разбивается на сегменты программным разборщиком, совместимым с языком задания правил сегментации SRX (Segmentation Rule Exchange). Полученные сегменты затем сохраняются в базе данных вместе со специально сформированным XML-файлом с бинарными вставками, содержащим информацию, необходимую для последующей сборки переведенного файла с сохранением форматирования исходного файла 104.
[025] Процесс разбиения текста на сегменты может быть наглядно представлен следующим образом: курсор двигается по тексту, по одному символу за раз. В каждой позиции курсора проверяются правила, состоящие из шаблона на предшествующий текст и шаблона на последующий текст, правила проверяются в соответствии с заданным для них порядком, чтобы сначала убедиться совпадает ли текст, предшествующий текущей позиции курсора с одним из шаблонов для предшествующего текста, после чего проверяется соответствие текста следующего после текущей позиции курсора связанному с данным шаблоном шаблону на последующий текст. Если текст соответствует обоим шаблонам, то либо курсор передвигается в следующую позицию без вставки границы разбиения сегментов, если эти шаблоны соответствуют правилу-исключению, либо вставляется граница разбиения сегментов, если шаблоны соответствуют правилу разбиения.
[026] В блоке 206, для каждого сегмента исходного документа 104, сохраненного в базе данных, выполняется поиск полных и частичных совпадений по переведенным ранее сегментам, хранящимся в базе памяти переводов 116. Также выполняется поиск терминов из глоссариев входящих в данный сегмент. Кроме того для каждого слова сегмента устанавливаются ссылки на соответствующие ему записи в морфологическом частотном словаре. Для каждого полностью или частично совпадающего сегмента, найденного в памяти переводов 116, также загружается информация о документе, в который он входит, использованных при переводе документа лингвистических ресурсах (глоссарии, базы памяти переводов, системы машинного перевода). Сюда также входит информация об исполнителях, работавших над документом и над каждым конкретным сегментом документа, полученных ими профессиональных оценках качества и метриках производительности работы и объема вносимых исправлений на каждом из этапов рабочего процесса по каждому из сегментов документа Соответственно используются как метрики полученные для конкретного найденного сегмента, так и усредненные значения метрик для документа в целом.
[027] В момент добавления в индекс базы памяти переводов 116 каждого нового переведенного (параллельного) сегмента, добавляемый сегмент разбивается на отдельные слова, а затем по каждому отдельному слову выполняется поиск по морфологическим частотным словарям, содержащим все допустимые формы каждого слова, указание на то какая из форм данного слова является базовой, а также различные дополнительные метаданные, описывающие как концепт в целом (например, часть речи или метрика частоты употребления), так и каждую из форм (род, падеж и т.д.). К каждому слову, таким образом, приписывается ссылка на соответствующую ему запись в словаре. Одному слову может соответствовать несколько возможных записей, в таком случае к нему приписываются все они. Данная информация включается в многопараметрический индекс, что позволяет впоследствии находить, например, все сегменты, в которых употреблено заданное слово, в любой из его допустимых форм. Текст перевода сегмента анализируется аналогичным образом, и полученная информация также включается в индекс, что также позволяет в дальнейшем находить сегменты, у которых в оригинале заданное слово в употреблено в любой из его допустимых форм, а в переводе некоторое другое слово употреблено в любой из его допустимых форм, или наоборот заданное слово не встречается в переводе ни в одной из его допустимых форм, для выполнения таких запросов не требуется выполнять перебор всех возможных форм слова, достаточно указать ссылку на базовую форму и искомые значения прочих метаданных. Также на основе такого анализа выстраивается пословное соответствие текста оригинала и перевода, т.е. для каждого слова оригинала находится соответствующее ему слово перевода (при этом отдельные слова, как в тексте оригинала, так и в тексте перевода могут не иметь соответствий, т.е. им соответствует пустое множество). Для каждого слова также выполняется поиск по всем глоссариям данного клиента и общедоступным глоссариям 208, ссылки на соответствующие записи в глоссарии также сохраняются в поисковом индексе, в случае нахождения для очередного слова терминов в глоссариях, состоящих из нескольких слов, выполняется проверка вхождения в сегмент остальных слов из глоссарного термина (проверка также выполняется на уровне наличия слова в любой из допустимых форм). Кроме того, слова, частота употребления которых, указанная в словаре, ниже заданного фиксированного порогового значения, помечаются как низкочастотные. Пороговое значение выбирается эмпирическим путем для каждого языка индивидуально.
[028] В блоке 206, для каждого сегмента создается набор параллельных сегментов (вариантов перевода) найденных из памяти переводов, к каждому из которых приписывается метрика степени сходства параллельного сегмента из памяти переводов с исходным сегментом. Как было описано выше, в процессе помещения нового параллельного сегмента в индекс базы памяти переводов выполняется анализ каждого слова сегмента по морфологическим словарям. В процессе поиска параллельных сегментов схожих с исходным сегментом слово, употребленное в различных формах в тексте исходного сегмента и в найденном параллельном сегменте, рассматривается как одно и то же слово, соответственно при вычислении метрики сходства сегментов, метрика уменьшается минимально в случае различий в формах употребления слова. Гораздо сильнее метрика сходства сегментов уменьшается в случае, когда в исходном сегменте есть слова, которых нет в параллельном сегменте и наоборот, когда в параллельном сегменте есть слова отсутствующие в исходном сегменте.
[029] В блоке 208, текст исходного сегмента разбивается на отдельные слова и затем для каждого слова выполняется поиск по морфологическому частотному словарю, в результате чего слову присваивается ссылка на возможные базовые формы слова и соответствующие метаданные, как общие для базовой формы (например, часть речи), так и соответствующие форме, в которой данное слово употреблено в исходном сегменте (падеж, склонение и т.д.). Словарь содержит для каждой базовой формы слова данные о частоте употребления данного слова. Слова исходного сегмента, имеющую частоту употребления (которая определяется на общем языковом корпусе) ниже пороговой, помечаются как низкочастотные. Для каждого слова также выполняется поиск по всем глоссариям данного клиента и общедоступным глоссариям 208, ссылки на соответствующие записи в глоссарии также сохраняются в поисковом индексе, в случае нахождения для очередного слова терминов в глоссариях, состоящих из нескольких слов, выполняется проверка вхождения в сегмент остальных слов из глоссарного термина (проверка также выполняется на уровне наличия слова в любой из допустимых форм) и в случае вхождения такого термина в сегмент целиком, данная информация также сохраняется в индексе, в том числе помечается какие именно слова входят в данный термин. Затем, основываясь на правилах извлечение терминологии и агрегированных данных, собранных по всем сегментам документа, определяется список терминов являющихся кандидатами на включение в глоссарий для данного проекта. Применяется два типа критериев для отбора терминов-кандидатов: лингвистические и статистические. Лингвистические критерии содержат правила определяющие допустимые и недопустимые сочетания слов (по частям речи, например), а также набор стоп-слов, которые не включаются в термины. Например, лингвистическое правило может определять что фраза состоящая из двух существительных является допустимой для извлечения. Статистические критерии задают минимальную частоту вхождений терминов в текст, при котором термины извлекаются, при этом различным лингвистическим правилам может соответствовать различная минимальная частота вхождений, кроме того частота может изменяться индивидуально менеджером проекта перевода в зависимости от стадии проекта, покрытия терминологии уже существующими глоссариями и т.д. В результате определяется набор терминов-кандидатов для включения в глоссарий, который сохраняется в базу данных в блоке 218. Менеджер проекта может далее назначить исполнителя ответственного за перевод данных терминов, переводчик просматривает отобранные термины и переводит их в блоке 220 посредством веб-интерфейса 106. В данном интерфейсе переводчик видит варианты перевода данных терминов, найденные в памяти переводов клиента (если термины там встречаются), варианты перевода терминов, предлагаемые в других общедоступных глоссариях и общедоступных базах памяти переводов, он также видит контекст употребления данных терминов в исходном тексте. Переведенные и верифицированные термины передаются в блок 208 и в конечном итоге включаются в агрегированные наборы лингвистических ресурсов, формируемые в блоке 214.
[030] Как было описано ранее, в процессе добавления параллельного сегмента в базу памяти переводов 116, информация о найденных в сегменте терминах из глоссария и низкочастотных словах добавляется в индекс. В блоке 210 выполняется поиск по индексу памяти переводов 116 параллельных сегментов, в которых встречаются низкочастотные слова и термины из глоссария, найденные в исходном сегменте, и таким образом определяется набор схожих параллельных сегментов, в которых встречаются такие же низкочастотные слова и термины из глоссариев. Для каждого параллельного сегмента, включенного в данный набор, вычисляется метрика совпадения терминологии с точки зрения машинного перевода:
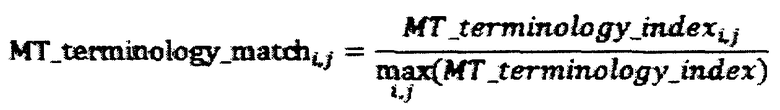
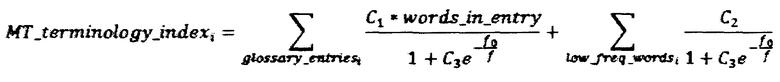
Где индекс i обозначает исходный сегмент, индекс j обозначает схожий сегмент из построенного набора, f - частота употребления соответствующего слова из морфологического частотного словаря. Константы C1, C2, C3, f0 выбираются эмпирическим путем для каждого языка, чтобы обеспечить максимальную корреляцию с профессиональными оценками сходства сегментов и максимизацию строковых метрик качества машинного перевода, построенного на текстах, отфильтрованных в соответствии с приведенным алгоритмом расчета MT_terminology_matchi,j. MT_terminology_indexi,j рассчитывается по той же формуле, что и MT_terminology_indexi, с той разницей, что в расчет включаются только слова и термины, встречающиеся в оригинале обоих сегментов. Кроме того для каждой пары сегментов i и j сохраняется набор совпадающих в них слов, в том числе со ссылками на термины глоссариев. Слова считаются совпадающими, если совпадают их базовые формы, то есть слова, употребленные в различных формах, считаются совпадающими и включаются в расчет. Термины глоссария gtossary_entriesi и glossary_entriesj учитываются по факту их вхождения в текст оригинала, совпадает ли перевод терминов в параллельном сегменте с переводом приведенным в глоссарии - не имеет значения для вычисления данной метрики.
Для каждой пары отобранных таким образом сегментов также вычисляется метрика совпадения сегментов в целом, по той же формуле, что и метрика, используемая для оценки степени совпадения сегментов из памяти переводов.
Для подбора оптимальных профессиональных исполнителей (переводчиков, редакторов, корректоров и т.д.) для работы над текстом, вычисляется также метрика совпадения терминологии с точки зрения профессионального перевода:
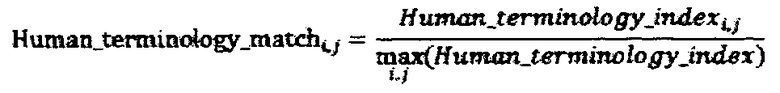
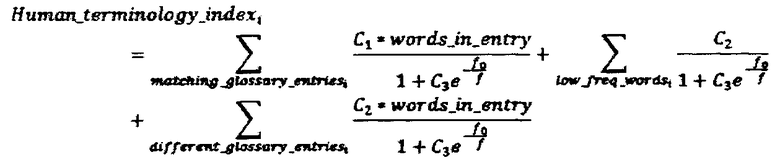
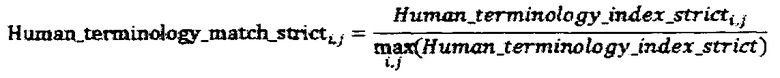
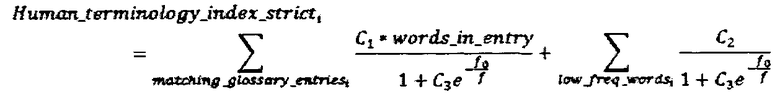
Где matching_glossary_entriesi - это термины глоссария, найденные в параллельном сегменте, для которых соответствующий им перевод в тексте сегмента совпадает с переводом приведенным в глоссарии. different_glossary_entriesi - это термины глоссария, найденные в параллельном сегменте, для которых соответствующий им перевод в тексте сегмента отличается от перевода приведенного в глоссарии, такого рода термины включаются в расчет метрики только при выполнении хотя бы одного из следующих условии: термин глоссария содержит более одного слова или термин глоссария является низкочастотным словом.
[031] Для каждого сходного с исходным сегмента, отобранного в блоке 210, и каждого частично совпадающего сегмента из памяти переводов, найденного в блоке 206 мы определяем документы, к которым они относятся, и этапы рабочего процесса, использованные для данных документов: системы машинного перевода, персоналии работавших над документом исполнителей (переводчиков, редакторов, корректоров и т.д.), производительность их работы и строковые метрики, модификаций внесенных на каждом из этапов рабочего процесса. Первичные данные о производительности работы исполнителей (переводчиков, редакторов, корректоров и т.д.) собираются в режиме реального времени в пользовательском веб-интерфейсе 106, интерфейс собирает, сохраняет и затем отправляет на сервер данные обо всех действиях пользователя, обо всех данных введенных с клавиатуры, всех кликах мышкой на элементах интерфейса и составных событиях, таких как вход в поле редактирования перевода сегмента, выход из поля редактирования перевода сегмента, подстановка текста из памяти переводов, глоссария или от машинного перевода. Также вычисляются и метрики характеризующие объем внесенных в текст изменений. Вычисляется два типа метрик: метрики, вычисляемые исключительно на основе сравнения исходных и финальных строк (например, расстояние Левенштейна), и метрики, принимающие во внимание действия выполняемые пользователями в ходе редактирования текста (данные введенные с клавиатуры, клики мышкой на элементах интерфейса и составные события). При расчете времени потраченного на перевод или редактирование перевода сегмента учитываются также и периоды неактивности, когда веб-интерфейс терял фокус, либо когда интервал времени между двумя последовательными действиями превышает заданный порог.
[032] Блок 210 повторяется для каждого сегмента исходного текста, в результате чего формируется набор сходных параллельных сегментов из памяти переводов 116. При этом один параллельный сегмент из памяти переводов 116 может быть включен в число сходных сегментов для нескольких сегментов исходного текста.

Где MT_terminology_document_matchj - это метрика сходства параллельного сегмента j из памяти переводов 116 с исходным документом, i - индекс сегментов исходного текста, имеющих положительное значение MT_terminology_matchi,j метрики сходства с данным параллельным сегментом j, N - количество различных сегментов исходного документа с положительным значением данной метрики (два идентичных с точки зрения текста сегмента документа, расположенные в различных местах документа, считаются различными сегментами в данном случае).
Аналогичная формула используется для расчета Human_terminology_matchj
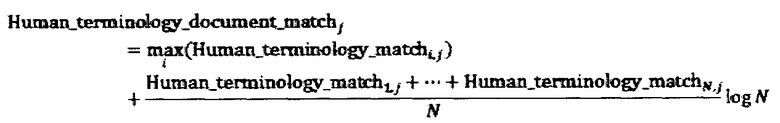
[033] В блоке 212 для каждого документа, для которого мы нашли сходные сегменты в блоках 210 и 206, мы можем таким образом рассчитать метрику сходства документа в целом с нашим исходным документом.


Где TM_match_metricj - это метрика сходства между сегментами, применяемая для поиска и ранжирования совпадений с базой памяти переводов описанная в параграфе
[028], нормированная так, чтобы принимать значения в интервале (0,1], m - переведенный ранее документ, words_totalm - количество слов в документе m. C4, C5 - константы, заранее определенные эмпирическим путем.
[034] Для каждого ранее переведенного документа 106 мы можем определить глоссарии и базы памяти переводов, которые были в явном виде выбраны при переводе данного документа заказчиком перевода, либо менеджером проекта. В блоке 214 мы формируем четыре набора лингвистических ресурсов для исходного документа:
(1) В явном виде выбранные для данного документа заказчиком или менеджером проекта глоссарии и базы памяти переводов;
(2) Упорядоченный по приоритету набор ресурсов для индивидуальной настройки моделей перевода систем машинного перевода:
1. набор терминов из глоссариев в явном виде выбранных для данного документа;
2. набор параллельных сегментов из баз памяти перевода, в явном виде выбранных для данного документа;
3. для каждого переведенного ранее документа, для которого значение метрики MT_document_similaritym превышает эмпирически заданную пороговую величину (ресурсы отсортированы в соответствии со значением метрики MT_document_similaritym, ресурсы документов, имеющих большее значение метрики, получают более высокий приоритет), мы добавляем в набор следующие данные:
a. набор терминов из глоссариев в явном виде выбранных для данного документа, включаются только термины, содержащие не менее двух слов;
b. параллельные сегменты из данного документа;
c. набор параллельных сегментов из баз памяти перевода, в явном виде выбранных для данного документа;
(3) Упорядоченный по приоритету набор ресурсов для индивидуальной настройки моделей языка (для языка, на который выполняется перевод) систем машинного перевода:
1. набор параллельных сегментов из баз памяти перевода, в явном виде выбранных для данного документа;
2. для всех документов, у которых значение метрики Human_document_similaritym превышает эмпирически заданную пороговую величину (ресурсы отсортированы в соответствии со значением метрики Human_document_similaritym, ресурсы документов, имеющих большее значение метрики, получают более высокий приоритет), мы добавляем в набор следующие данные:
a. параллельные сегменты из данного документа;
b. набор параллельных сегментов из баз памяти перевода, в явном виде выбранных для данного документа;
(4) Набор сегментов исходного документа, к каждому из которых привязан упорядоченный набор следующих данных:
1. частично совпадающие с исходным сегментом сегменты из памяти переводов - сюда включаются только сегменты, входящие в набор данных (2), сегменты упорядочены в соответствии со значениями метрики соответствия сегментов, используемой для поиска по базам памяти переводов;
2. схожие сегменты с положительным значением метрики Human_terminology_match_stricti,j - сюда включаются только сегменты, входящие в набор данных (2), сегменты упорядочены в соответствии со значениями метрики соответствия сегментов, используемой для поиска по базам памяти переводов;
для каждого параллельного сегмента включенного в данный набор, в набор также включается пословное выравнивание оригинала и перевода сегмента;
[035] В блоке 226 набор данных (1) может выгружаться в отдельный файл, который может быть выгружен из системы через веб-интерфейс и использован для перевода исходного файла в любой внешней среде. В случае если дальнейшая работа над переводом документа выполняется исполнителями через веб-интерфейс системы, эти данные сохраняются в базе данных 106 и впоследствии отображаются в качестве подсказок исполнителям (переводчикам, редакторам, корректорам и т.д.) при работе над каждым соответствующим сегментом.
[036] В блоке 216 наборы данных (2) и (3) добавляются в статистические и основанные на моделях языка системы машинного перевода для индивидуальной настройки машинного перевода, с более высоким приоритетом в иерархии данных, чем общие данные, использованные для обучения систем. Данные добавляются с более высоким приоритетом в иерархии данных чем общие данные, кроме того каждому перечисленному выше подмножеству данных приписывается индивидуальный приоритет, исходя из порядка сортировки данных, описанного выше. В случае необходимости, после добавления данных ресурсов, автоматически выполняется до-обучение или переобучение системы машинного перевода.
[037] В блоке 222 выполняется предварительный машинный перевод каждого сегмента исходного текста, всеми доступными системами машинного перевода, которые предварительно выбраны для данного исходного документа. Для каждой системы машинного перевода, имеющей возможность индивидуальной настройки, выполняется индивидуальная настройка в блоке 216 с помощью наборов данных (2) и (3), созданных в блоке 214. Каждый сегмент, отправляемый на машинный перевод каждой из систем машинного перевода, сопровождается набором данных (4) созданным для данного сегмента в блоке 214. Набор данных (4) используется следующим образом: мы берем каждый параллельный сегмент из набора (4) из числа частично совпадающих с исходным сегментов и определяем набор слов (подстрок) совпадающих с исходным сегментом, для каждого совпадающего набора слов мы определяем с помощью пословного выравнивания, построенного при добавлении параллельного сегмента в память переводов, соответствующий им в данном параллельном сегменте перевод. Затем мы рассматриваем возможные сочетания различных подстрок, с целью получения наибольшего покрытия текста исходного сегмента, при этом в качестве дополнительных к базовым подстрокам (полученным на основе одного параллельного сегмента) добавляются только подстроки, состоящие из нескольких слов или содержащие низкочастотные слова. В результате мы получаем набор из множества вариантов покрытия исходного сегмента подстроками с переводами из частично совпадающих с ним параллельных сегментов из памяти переводов.
Затем мы берем набор сегментов с положительным значением метрики Human_terminology_match_stricti,j из набора данных (4) и извлекаем из них, с помощью пословного выравнивания, построенного при добавлении параллельного сегмента в память переводов, варианты перевода низкочастотных слов и терминов из глоссария (для каждого слова и термина может извлекаться несколько вариантов перевода с различными допустимыми словоформами). После чего данные варианты перевод добавляются в качестве подстрок сегмента с переводом в те варианты покрытия, в которых данные слова и термины еще не входят ни в одну из подстрок сегмента с переводом.
Таким образом, для каждого исходного сегмента мы получаем набор из множества вариантов покрытия исходного сегмента подстроками, содержащими перевод данной подстроки. Для каждого варианта покрытия сегмента подстроками мы определяем процент совпадения, который рассчитывается как отношение количества символов сегмента покрытых подстроками, к общему количеству символов сегмента.
Каждый такой вариант разметки сегмента подстроками с переводом затем отправляется в каждую из доступных систем машинного перевода. Для каждого поступившего на вход варианта разметки сегмента, каждая система машинного перевода формирует перевод сегмента и сопутствующую ему метрику уверенности системы в качестве перевода, если система поддерживает расчет такой метрики. Для каждого варианта перевода, независимо от создавшей его системы машинного перевода также вычисляется единая метрика, характеризующая степень гладкости текста перевода с точки зрения языка перевода (например, может использоваться метрика, имеющая в своей основе расчета перплексивности - степени неопределенности в вероятностной модели языка), при этом используется статистическая модель языка перевода и индивидуально настроенная в блоке 216. После чего мы исключаем варианты машинного перевода, содержащие некорректную терминологию (терминология проверяется на соответствие глоссариям, в явном виде выбранным для данного проекта). Затем, для каждой системы машинного перевода мы выбираем перевод с наибольшим значением метрики собственной уверенности в качестве перевода самой системы машинного перевода, если данная система ее формирует, либо перевод с наилучшим значением нашей собственной метрики гладкости текста на основе перплексивности. Значения метрик сохраняются в базе данных вместе с самими вариантами машинного перевода.
[038] В реализации настоящего изобретения, в процессе работы переводчика (а также редактора, корректора и т.д.) над переводом или редактированием сегмента посредством пользовательского веб-интерфейса 106, все его действия в данном веб-интерфейсе, включая нажатия клавиш клавиатуры, нажатия мышкой на элементах интерфейса, использование служебных сочетаний клавиш и т.д., фиксируются и отправляются на сервер, где они сохраняются в базу данных. Основываясь на этих исходных данных, асинхронно рассчитываются индивидуальные метрики производительности и качества, такие как время, затраченное на перевод (а также редактирование или корректуру) сегмента, а также количество существенных изменений внесенных в текст перевода сегмента (например, замена одного слова на другое, особенно для низкочастотных слов) и несущественных изменений (изменения в окончаниях слов для их согласования и т.д.). Изменения фиксируются на каждом этапе рабочего процесса по отношению к варианту перевода, который был после выполнения предыдущего этапа рабочего процесса (например, изменения внесенные редактором после переводчика, или переводчикам после системы машинного перевода). Кроме того, для отдельных сегментов переведенного документа может быть выборочно проведена профессиональная оценка качества перевода. Данная профессиональная оценка качества базируется на методологии классификации ошибок, в рамках которой специалист лингвистического контроля качества выполняет скрупулезный анализ перевода каждого из сегментов, включенных в выборку (обычно небольшую), и фиксирует для каждого сегмента типы и критичность найденных ошибок, в соответствии с утвержденными правилами классификации ошибок. Оба типа метрик используются совместно для присвоения репутационной оценки исполнителю (переводчику, редактору или корректору).
Для каждого сегмента, в котором выполнялось редактирование машинного перевода, мы вычисляем количество следующих событий: (1) существенные изменения в переводе терминологии (перефразировка) - когда одно или несколько слов заменяются на другие слова, (2) изменение порядка слов, (3) согласование слов (изменение окончаний слов, особенно в языках со сложными правилами согласования и богатой морфологией и т.д.). Затем мы рассчитываем для каждой системы машинного перевода ожидаемое количество изменений, как табличную функцию от длины сегмента и значений метрик собственной уверенности системы машинного перевода в качестве перевода или внешней метрики гладкости перевода, основанной на расчете перплексивности текста для соответствующей статистической модели языка перевода:

Для каждого исполнителя мы также обладаем данными обо всех сегментами над которыми он работал ранее, и в частности обо всех сегментах для которых он выполнял редактирование машинного перевода. Мы можем рассчитать объем внесенных им изменений каждого типа и суммарное время проведенное над редактированием сегмента. Далее мы можем рассчитать для каждого исполнителя и каждой системы машинного перевода набор констант t1, t2, t3, обеспечивающих наилучшую линейную интерполяцию на собранном наборе первичных данных:
 ,
,
[039] Основываясь на значениях метрик машинного перевода, рассчитанных для каждого перевода сегмента в блоке 222, длины исходного сегмента и табличных функций для ожидаемого количества изменений каждого типа, которые мы определили ранее для каждой системы машинного перевода, мы рассчитываем ожидаемое количество изменений для машинного перевода каждого сегмента. После чего мы выбираем вариант машинного перевода с наименьшим ожидаемым количеством изменений (изменения разного типа включаются с различными весами, соответствующими значениям констант t1, t2, t3 усредненным по всей базе данных). Если несколько вариантов перевода получают близкие значения данной метрики, то из них выбирается вариант с наибольшим процентом покрытия текста сегментам подстроками с переводом. Выбранный вариант перевода, вместе с ожидаемым количеством изменений каждого типа сохраняется в базу данных и включается в агрегированный набор данных, формируемый в блоке 226.
[040] Для каждого параллельного сегмента из памяти переводов включенного в набор (3), предназначенный для индивидуальной настройки статистической модели языка, созданный в блоке 214, мы имеем полный набор данных о рабочем процессе, имевшем место при переводе документа: кто выполнял перевод (или редактирование машинного перевода), кто выполнял редактирование и корректуру и т.д. Мы также можем установить документы содержащие данные сегменты, профессиональные оценки качества, проставленные специалистами лингвистического контроля качества для выборок из текста документов, автоматически собранные метрики количества изменений разных типов (изменение в переводе термина, изменение порядка слов, согласование слов) внесенных в текст перевода сегментов редакторами и корректорами после переводчика (или редактора машинного перевода), а также время, затраченное ими на изменение каждого сегмента. В блоке 230 мы затем рассчитываем взвешенную метрику качества перевода для каждого исполнителя (переводчика, редактора, корректора и т.д.) принимавшего участие в работе над переводом документов, включенных в набор (3):

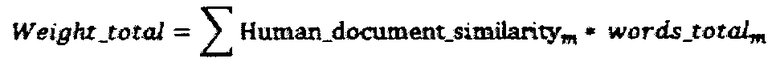
Где LQA_metricm - это нормированная профессиональная оценка качества перевода, рассчитанная для подмножества выборки из документа m, включающего только профессионально оцененные сегменты, в работе над которыми принимал участие данный исполнитель.
Основываясь на рассчитанном значении метрики LQA_total мы исключаем из дальнейшего рассмотрения исполнителей, для которых метрика имеет значение ниже эмпирически определенного порога. Данный порог в основном зависит от требований к качеству перевода, заданных для данного проекта менеджером проекта на этапе его создания и первоначальной настройки. Затем выполняется кластеризация результатов метрики LQA_total, после чего исполнители внутри каждого кластера упорядочиваются в соответствии со значением метрики Weight_total. Таким образом, в блоке 230 формируется отсортированный список предпочтительных исполнителей для работы над переводом данного исходного документа.
Для каждого переводчика мы также определяем ожидаемое время редактирования машинного перевода данного исходного документа. Ожидаемое время редактирования машинного перевода рассчитывается исходя из значений констант t1, t2, t3 для каждого переводчика и каждой системы машинного перевода и вариантов машинного перевода выбранных для каждого из сегментов в блоке 224 и значений ожидаемого количества исправлений каждого типа, приписанных к данному машинному переводу сегмента.
[041] Менеджер проекта просматривает набор рекомендованных для проекта исполнителей (переводчиков, редакторов, корректоров и т.д.), ожидаемое время и трудоемкость редактирования машинного перевода и статистику проекта, включающую количество различных совпадений с памятью переводов, количество вхождений терминов из глоссария, а также объем данных и метрики сходства, рассчитанные для наборов данных, сформированных в блоке 214. Менеджер проекта также располагает в веб-интерфейсе системы данными о доступности рекомендованных исполнителей, подгружаемыми из системы управления проектами перевода, и принимает окончательное решение о составе исполнителей, после чего инициирует в веб-интерфейсе системы отправку приглашений к участию в проекте множеству выбранных исполнителей. Данное решение также может быть принято и автоматически, на основе доступных в режиме реального времени данных о доступности исполнителей, прогнозируемой загруженности каждого из исполнителей по другим принятым им проектам и требуемым сроком сдачи перевода данного проекта.
[042] После получения уведомления о приглашении к участию в проекте перевода, каждый соответствующий исполнитель (переводчик, редактор, корректор и т.д.) подтверждает либо отклоняет данное приглашение. После подтверждения участия, назначенный исполнитель в блоке 232 входит в систему и посредством пользовательского веб-интерфейса 106 приступает к работе над переводом документа. Системой поддерживается два типа проектов: последовательные, когда каждый следующий этап рабочего процесса начинается только после того как полностью завершен предыдущий этап рабочего процесса над всем документом, и параллельные, когда этапы рабочего процесса выполняются последовательно на уровне каждого отдельного сегмента, при этом в документе могут одновременно присутствовать сегменты находящиеся на различных этапах рабочего процесса.
[043] После того как все сегменты документа проходят все заданные стадии рабочего процесса и перевод документа завершен, перевод поступает в блок 128, в котором формируется итоговый файл перевода. Переведенный документ 130 имеет такой же текстовый или бинарный формат файла, что и исходный файл. Переведенный документ формируется из текста перевода каждого сегмента и файла метаданных, созданного при разборе исходного файла в модуле сегментации 114.
[044] Переведенный документ 130 затем автоматически передается заказчику перевода посредством пользовательского веб-интерфейса, из которого заказчик выгружает переведенный файл. Если исходные файлы поступили из некой внешней информационной системы, то переведенные файлы могут быть помещены в эту же систему посредством программных API интерфейсов, содержащихся в слое интеграции 302.
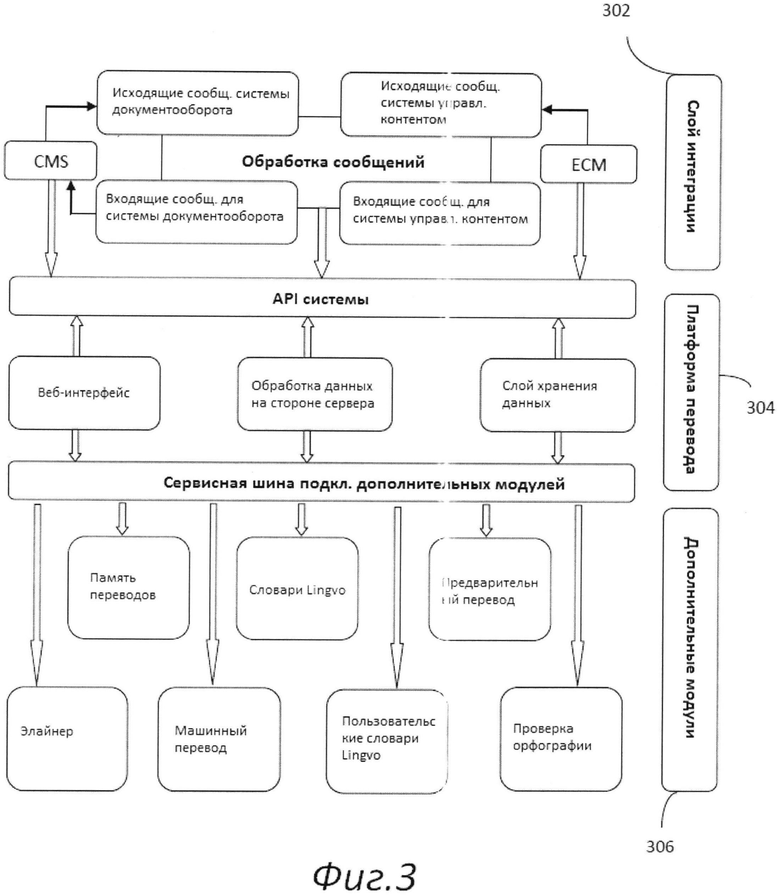
[045] Рис.3 представляет собой схематическую иллюстрацию платформы, представляющую собой реализацию описанной в настоящем изобретении распределенной сетевой системы перевода. В соответствии с Рис.3, платформа состоит из трех слоев: слой интеграции 302, платформа перевода 304 и дополнительные модули 306. Слой интеграции 302 обеспечивает загрузку в систему исходных файлов на перевод 102 и конвертацию исходных файлов в набор текстовых сегментов. Интеграционный слой 302 представлен в реализации системы, если в качестве источников исходных файлов используются внешние информационные системы, такие как системы вправления контентом, системы документооборота, или порталы общего назначения. Слой платформы перевода 304 включает в себя пользовательский веб-интерфейс, модули обработки данных на стороне сервера и слой хранения данных. Пользовательский веб-интерфейс обеспечивает интерфейс для доступа в систему для переводчиков, менеджеров проектов, редакторов, корректоров, специалистов лингвистического контроля качества, специалистов по терминологии, представителей заказчика перевода и т.д. Пользовательский веб-интерфейс содержит отдельные интерфейсные окна для настройки и управления проектом и для непосредственной работы над переводов и редактированием документа (с возможностью одновременной работы над переводом множества исполнителей). Обработка данных на стороне сервера включает в себя преобразование исходных файлов в различные форматы, валидацию перевода, предварительный перевод документов и т.д. Слой дополнительных модулей 306 включает в словари ABBYY Lingvo™ и прочие словари, системы машинного перевода, используемые для предварительного перевода документов с последующим редактированием, элайнера, создающего из параллельных документов произвольных форматов и верстки XML-файл пригодный для экспорта в память переводов, а также модуля контроля орфографии и пунктуации. Другие необходимые подсистемы, также могут быть интегрированы с системой посредством интеграционной шины с программными API интерфейсами.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И МЕТОД ИНТЕЛЛЕКТУАЛЬНОГО АВТОМАТИЧЕСКОГО ВЫБОРА ИСПОЛНИТЕЛЕЙ ПЕРЕВОДА | 2017 |
|
RU2667030C1 |
| СИСТЕМА И МЕТОД УПРАВЛЕНИЯ ПРОЕКТАМИ ЯЗЫКОВОГО ПЕРЕВОДА | 2018 |
|
RU2696326C1 |
| СЕГМЕНТ ДАННЫХ О ПЕРЕВОДЕ | 2002 |
|
RU2295150C2 |
| АДАПТИВНЫЙ МАШИННЫЙ ПЕРЕВОД | 2004 |
|
RU2382399C2 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| УНИВЕРСАЛЬНОЕ ПРЕДСТАВЛЕНИЕ ТЕКСТА С ВОЗМОЖНОСТЬЮ ПОДДЕРЖКИ РАЗЛИЧНЫХ ФОРМАТОВ ДОКУМЕНТОВ И ТЕКСТОВАЯ ПОДСИСТЕМА | 2014 |
|
RU2579888C2 |
| СПОСОБ ДЛЯ ОТОБРАЖЕНИЯ СУБТИТРОВ В ПРОЦЕССЕ ВОСПРОИЗВЕДЕНИЯ МЕДИАКОНТЕНТА (ВАРИАНТЫ) | 2017 |
|
RU2668721C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| ПЕРЕВОДЧЕСКИЙ СЕРВИС НА БАЗЕ ЭЛЕКТРОННОГО СООБЩЕСТВА | 2015 |
|
RU2604984C1 |
Изобретение относится к языковому переводу текста. Техническим результатом является повышение скорости, эффективности и точности перевода. Распределенная сетевая система перевода обеспечивает обращение к распределенной сети профессиональных переводчиков и систем машинного перевода (МП), совместно выполняющих перевод в режиме реального времени. Система состоит из облачных серверов, пользовательского интерфейса, модуля сегментации, выполняющего разбиение исходного файла на множество сегментов, модуля предварительного перевода, базы памяти переводов, морфологических словарей, модуля глоссариев, модуля создания сопутствующих данных, формирующего набор данных для подсказки исполнителям и для индивидуальной настройки систем МП на перевод данного документа, модуля пословного выравнивания, модуля обработки МП, выбирающего наилучший вариант перевода, модуля определения множества рекомендуемых к работе над переводом документа исполнителей, модуля, собирающего данные обо всех действиях, выполненных исполнителями в веб-интерфейсе, модуля, выполняющего сборку итоговых переводов каждого отдельного сегмента в итоговый файл с переводом. 2 н. и 11 з.п. ф-лы, 3 ил.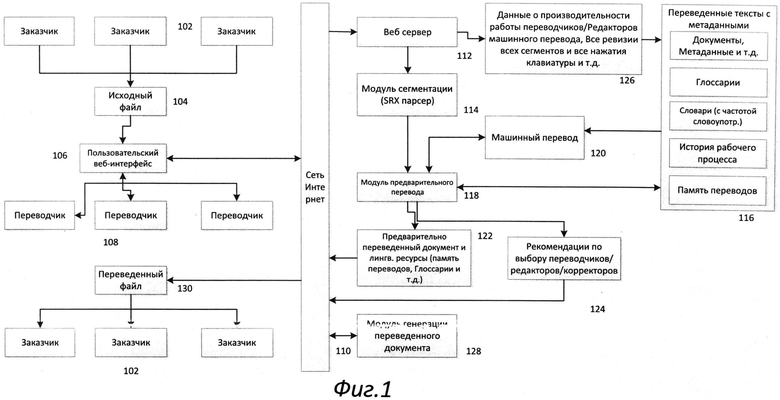
1. Сетевая распределенная система языкового перевода для перевода исходных файлов, состоящая из:
облачных доступных по сети серверов, одновременно доступных для множества исполнителей и множества заказчиков перевода, подключающихся к серверам посредством сети Интернет;
пользовательского интерфейса, позволяющего множеству заказчиков перевода загружать исходные файлы на перевод в систему языкового перевода и получать информацию о предлагаемых исполнителями вариантах перевода терминологии, а также просматривать и утверждать глоссарии для проекта;
модуля сегментации, выполняющего разбиение исходного файла на множество логических сегментов и отправляющего данные сегменты на перевод в модуль предварительного перевода;
базы памяти переводов, хранящей переведенные ранее логические сегменты и позволяющей выполнять поиск сегментов, схожих с заданным сегментом;
морфологических словарей, содержащих информацию о различных допустимых формах слов и метаданных, соответствующих как концепту в целом, так и отдельным словоформам, в том числе частоте употребления слов, а также позволяющих устанавливать соответствие между словами в тексте оригинала и перевода сегмента и соответствующими им записями в словаре;
модуля глоссариев, позволяющего хранить термины глоссария и находить их вхождения в тексте оригинала и перевода сегментов, в том числе для терминов, состоящих из нескольких слов;
модуля создания сопутствующих данных, выполняющего поиск соответствующих исходному сегменту сегментов в памяти переводов, рассчитывающего степень их сходства и степень сходства использованной в них терминологии и формирующего набор данных для подсказки исполнителям и для индивидуальной настройки систем машинного перевода на перевод данного документа;
модуля пословного выравнивания, устанавливающего соответствие между словами оригинала и перевода параллельного сегмента;
модуля обработки машинного перевода, выбирающего наилучший машинный перевод сегмента из множества вариантов, сформированных каждой системой машинного перевода, и агрегирующего эти переводы для всех сегментов документа;
модуля определения множества рекомендуемых к работе над переводом документа исполнителей, опираясь на историю выполненных ими ранее работ и профессиональные оценки качества, выставленные для документов, сходных с исходным файлом на перевод;
модуля, собирающего данные обо всех действиях, выполненных исполнителями в веб-интерфейсе работы над переводом документов;
модуля, выполняющего сборку итоговых переводов каждого отдельного сегмента в итоговый файл с переводом.
2. Система по п. 1, в которой в памяти переводов хранятся проиндексированные логические сегменты и их перевод вместе с соответствующими сегменту метаданными.
3. Система по п. 2, в которой в состав метаданных, хранящихся совместно с проиндексированными логическими сегментами, входят данные о времени работы с сегментом, исполнителях, выполнявших перевод, количество изменений разных типов, внесенных в перевод различными исполнителями, а также профессиональные оценки качества, присвоенные данному логическому сегменту специалистами лингвистического контроля качества.
4. Система по п. 1, в которой логические сегменты могут представлять собой фразы, предложения, части предложений или идиоматические выражения.
5. Система по п. 1, в которой исходному логическому сегменту ставятся в соответствие параллельные логические сегменты из памяти переводов в соответствии с метрикой сходства сегментов, представляющей собой метрику совпадения двух строк, принимающую во внимание возможность наличия нескольких различных допустимых словоформ у одного и того же слова.
6. Система по п. 1, в которой в пользовательском интерфейсе в режиме реального времени отображается перевод логических сегментов, выполненных множеством исполнителей, работающих над переводом документа в данный момент.
7. Система по п. 1, в которой перевод может выполняться как профессиональными переводчиками, так и системами машинного перевода.
8. Система по п. 1, в которой исполнители выбраны из группы, включающей переводчиков, редакторов, корректоров.
9. Способ перевода исходного файла с языка оригинала на язык перевода, состоящий из следующих этапов:
получения запроса на перевод исходного файла в распределенной сетевой системе;
разбиения исходного файла на множество логических сегментов;
поиска сходных сегментов и сегментов со сходной терминологией в базе лингвистических ресурсов, состоящей из переведенных ранее параллельных логических сегментов, словарей и глоссариев, с расчетом метрики качества для найденных в памяти переводов логических сегментов;
отправки множественных запросов на перевод каждого сегмента нескольким системам машинного перевода, расположенным в распределенной сети, с передачей каждой системе машинного перевода сопутствующего исходному документу набора данных для индивидуальной настройки системы машинного перевода, а также передачей для каждого сегмента набора вариантов перевода части его текста для выполнения машинного перевода частей, у которых вариант перевода отсутствует, и сборки итогового варианта машинного перевода;
создания набора вариантов перевода на основе сегментов, сходных с исходным сегментом, в которых части текста исходного сегмента размечены вариантами перевода из сходных сегментов, а части, у которых вариант перевода отсутствует, переводятся в соответствии с глоссариями, словарями и фразами, сформированными системами машинного перевода из баз памяти переводов;
сбора множества вариантов перевода сегмента от различных систем машинного перевода;
выбора наилучшего варианта машинного перевода из числа полученных вариантов;
выбора наиболее подходящих профессиональных исполнителей, зарегистрированных в системе, исходя из прогнозируемого уровня качества их работы, который рассчитывается на основе переведенных ранее документов, сходных с данным исходным документом;
направления приглашений принять участие в работе над проектом выбранным исполнителям;
предоставления множеству исполнителей пользовательского веб-интерфейса для одновременной многопользовательской работы над переводом в режиме реального времени;
сборки переводов отдельных сегментов в итоговый переведенный файл.
10. Способ по п. 9, в котором исходный файл может иметь как текстовый, так и бинарный формат.
11. Способ по п. 9, в котором профессиональная оценка качества перевода рассчитывается путем фиксации типа и критичности ошибок в выборке сегментов переведенного документа, перевод документа может быть выполнен как с нуля переводчиком, так и путем редактирования предварительного машинного перевода.
12. Способ по п. 9, в котором наилучший вариант машинного перевода выбирается как среди базовых вариантов перевода, так и вариантов перевода, сформированных путем применения усовершенствованной технологии работы с памятью переводов, в которой создается набор вариантов перевода с разметкой текста исходного сегмента частями параллельных сегментов из памяти переводов, с указанием варианта перевода данной части, с подстановкой системой машинного перевода неразмеченных частей из глоссария, словаря либо набора фраз, сформированного системой машинного перевода из памяти переводов.
13. Способ по п. 9, в котором переведенные сегменты исходного документа сохраняются в память переводов для дальнейшего использования.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 6789093 B2, 07.09.2004 | |||
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ПЕРЕВОДА С ОДНОГО ЯЗЫКА НА ДРУГОЙ | 2004 |
|
RU2357285C2 |

