ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение описывает систему и метод интеллектуального автоматического выбора исполнителей перевода.
УРОВЕНЬ ТЕХНИКИ
Сбор и обмен информацией с любой научной, коммерческой, политической или социальной целью зачастую требует быстрого и эффективного перевода текста, чтобы множество знаний и идей стали полезны в глобальном масштабе. Компьютерные программы, которые переводят автоматически с одного языка на другой ("программы машинного перевода"), в принципе могут удовлетворить данную потребность, и такие программы были разработаны и продолжают разрабатываться для множества языков. Для формального стиля изложения на глубоко исследованных языках (в отличие от неформального, идиоматического или разговорного стиля), такие программы машинного перевода демонстрируют достаточно адекватное качество перевода. Для менее формального стиля изложения качество машинного перевода по-прежнему остается недостаточным для полноценного понимания смысла текстов. Для более трудных или менее исследованных языков (например, арабского языка), существующие программы машинного перевода не работают хорошо даже для формального общения (например, Современного Стандартного Арабского языка), и они особенно слабы в случае неформального, разговорного и идиоматического общения.
Аналогично, там, где требуется качественный точный перевод, машинного перевода самого по себе становится недостаточно даже для хорошо исследованных языков (например, английского, французского, испанского, немецкого и других языков).
Профессиональные переводчики способны обеспечивать качественные переводы для трудных языков и неформальных коммуникаций, но Интернет-приложения требуют постоянной доступности и оперативного реагирования, что не может быть гарантировано в случае использования существующих подходов к организации работы профессиональных переводчиков. Из уровня техники известна заявка US 2015/0120273 (A1) «NETWORKED LANGUAGE TRANSLATION SYSTEM AND METHOD», опубл. 30.04.2015. В данной заявке описывается технология автоматизированной работы переводчиков в распределенной системе, в которой осуществляют перевод исходного файла множеством переводчиков, подключенных к облачному серверу, также описан лексический, морфологический и синтаксический анализ логических сегментов, на которые разбивают исходный файл, и используют память переводов (translation memory) и модуль глоссариев для хранения терминов перевода.
Существенным недостатком данного технического решения является то, что в нем не обеспечивается возможность полностью автоматического подбора исполнителей для перевода.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Данное техническое решение направлено на устранение недостатков, присущих существующим решениям из уровня техники. Данное техническое решение направлено на расширение арсенала технических средств определенного назначения, в нашем случае - расширение арсенала технических средств интеллектуального автоматического выбора исполнителей перевода, а в качестве технического результата, достигаемого заявленным решением, может быть реализация заявленным изобретением указанного назначения, а именно, реализация интеллектуального автоматического выбора исполнителей перевода.
Данный технический результат достигается благодаря системе интеллектуального автоматического выбора исполнителей перевода, состоящая из:
облачного сетевого сервера, обеспечивающего доступ для множества исполнителей и множества заказчиков перевода, подключающихся к серверу посредством сети Интернет;
пользовательского интерфейса, позволяющего множеству заказчиков перевода загружать исходные файлы на перевод в систему интеллектуального автоматического выбора исполнителей перевода и получать информацию о предлагаемых исполнителях перевода;
базы памяти переводов, хранящей переведенные ранее тексты всех исполнителей в системе с выделенными в этих текстах ключевыми терминами; общего модуля глоссариев, выполненного в виде пронумерованных кластеров, в каждом из которых находятся выделенные в переведенных текстах ключевые термины, схожие по смыслу и, соответственно, близкие по тематике, при этом каждому термину присваивается номер кластера, которому он принадлежит;
индивидуальных модулей глоссариев для каждого исполнителя перевода, с указанием конкретной тематики в какой работает тот или иной исполнитель; модуля автоматического сопоставления терминологии переводимых исполнителями ранее текстов с терминологией исходного файла на перевод, при этом для терминов, выделенных из исходного файла на перевод, вычисляется, сколько раз каждый термин встретился в нем, таким образом, вычисляется терминологический вектор частот;
модуля расчета для каждого исполнителя перевода числовой характеристики близости терминологии исходного файла и терминологии исполнителя перевода и, выполняющего ранжирование по этой числовой характеристике исполнителей перевода;
модуля автоматической оценки и прогноза качества перевода исходного файла исполнителями перевода с учетом тематики документа;
модуля автоматического расчета скорости работы каждого исполнителя, выполняющего расчет количества переводимых слов в час; модуля автоматического ведения календаря работы исполнителей перевода, позволяющего в режиме реального времени анализировать доступность исполнителя перевода для работы, учитывать фактор его занятости при поиске исполнителя перевода;
модуль автоматического расчета стоимости перевода исходного файла и подбор исполнителей с учетом, указанной ими ставки в профиле;
модуля автоматической оптимизации выбора наиболее подходящих исполнителей перевода на основе перечисленных выше критериев.
Данный технический результат достигается так же благодаря способу интеллектуального автоматического выбора исполнителей перевода, состоящий из следующих этапов:
получение запроса на перевод исходного файла в распределенной сетевой системе;
выделение ключевой терминологии из исходного файла;
поиск сходной терминологии в общем глоссарии, состоящем в виде пронумерованных кластеров, в каждом из которых находятся выделенные в переведенных текстах ключевые термины, схожие по смыслу и, соответственно, близкие по тематике, при этом каждому термину присваивается номер кластера, которому он принадлежит; и
поиск сходной терминологии в индивидуальных глоссариях каждого переводчика, в которых указано в какой конкретно тематике работает тот или иной исполнитель;
сопоставление терминологии исполнителей с терминологией исходного файла на перевод, при этом для терминов, выделенных из исходного файла на перевод, вычисляется, сколько раз каждый термин встретился в нем, таким образом, вычисляется терминологический вектор частот; на основе этого сопоставления осуществление отбора исполнителей, работающих в тематике исходного файла;
автоматического анализа качества ранее переведенных текстов отобранных исполнителей;
автоматический расчет скорости работы каждого отобранного исполнителя;
анализ в режиме реального времени доступности отобранных для перевода исполнителей;
автоматический расчет стоимости перевода исходного файла у каждого отобранного исполнителя; и
на основе указанных выше этапов осуществление автоматического выбора наиболее подходящих исполнителей перевода.
В некоторых вариантах осуществления технического решения дополнительно осуществляют отбор исполнителей по языковой паре.
В некоторых вариантах осуществления технического решения система дополнительно содержит модуль синтаксической, морфологической и лингвистической фильтрация текста.
В некоторых вариантах осуществления технического решения глоссарии пополняются новыми терминами в ходе работы исполнителей по мере накопления ими новых переведенных текстов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
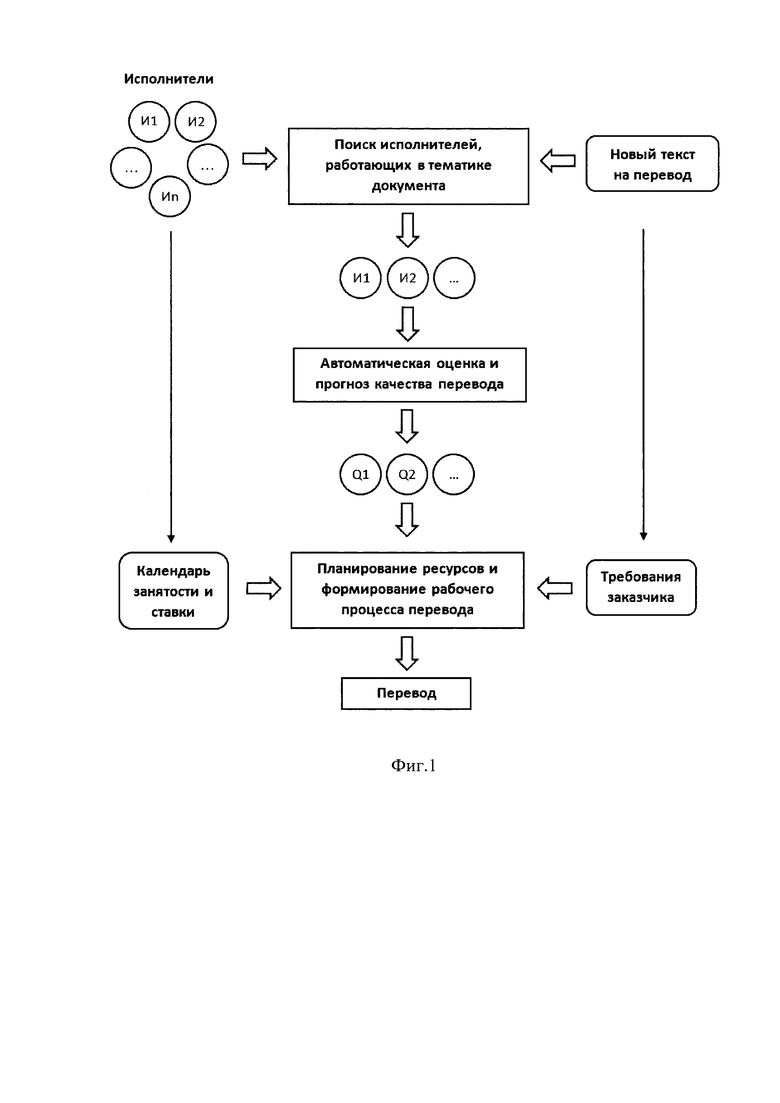
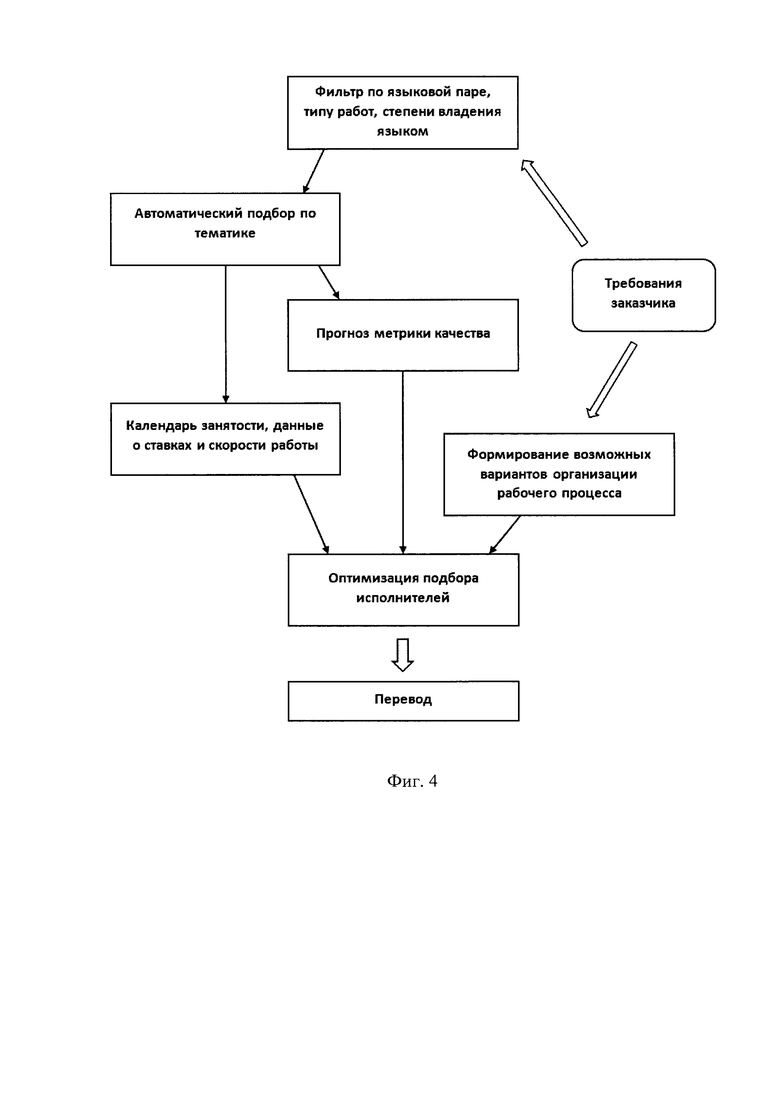
Фиг. 1 - изображает поиск исполнителей, работающих в тематике исходного документа на перевод;
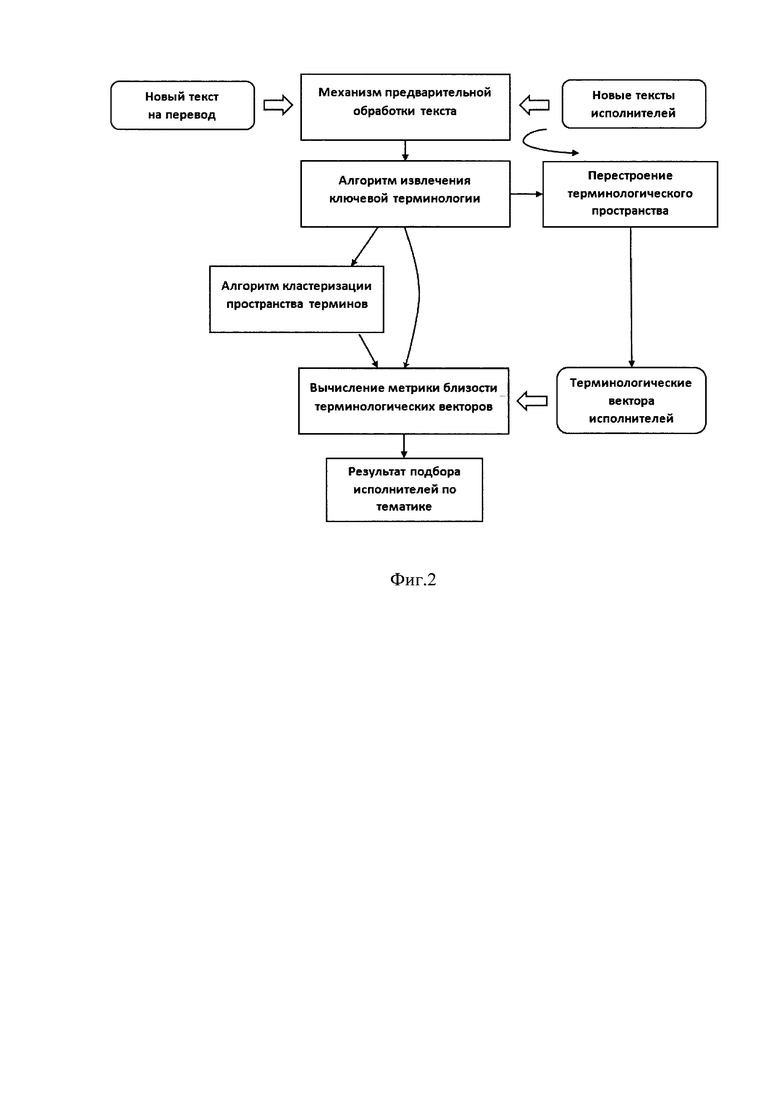
Фиг. 2 - изображает задачу подбора близких по тематике текстов для учета специфики задач перевода;
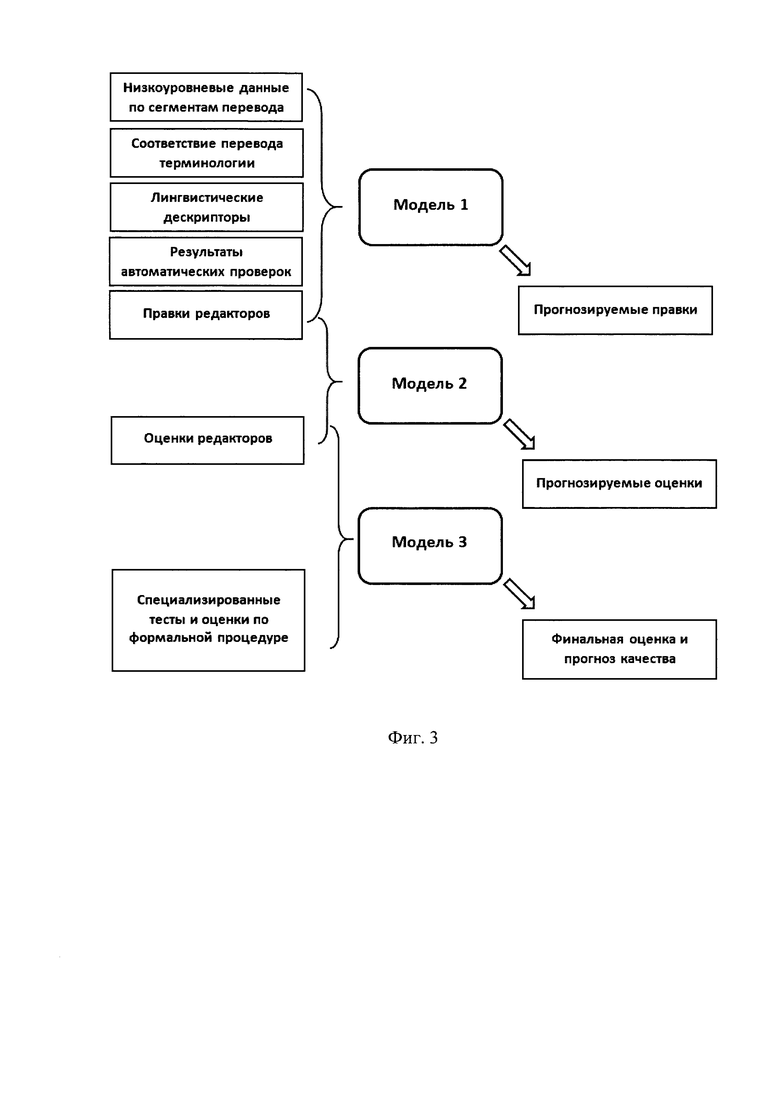
Фиг. 3 - отображает построение математических моделей построения оценки и прогнозирования качества переводов;
Фиг. 4 - отображает автоматический подбор исполнителей перевода соответствующих заданным критериям.
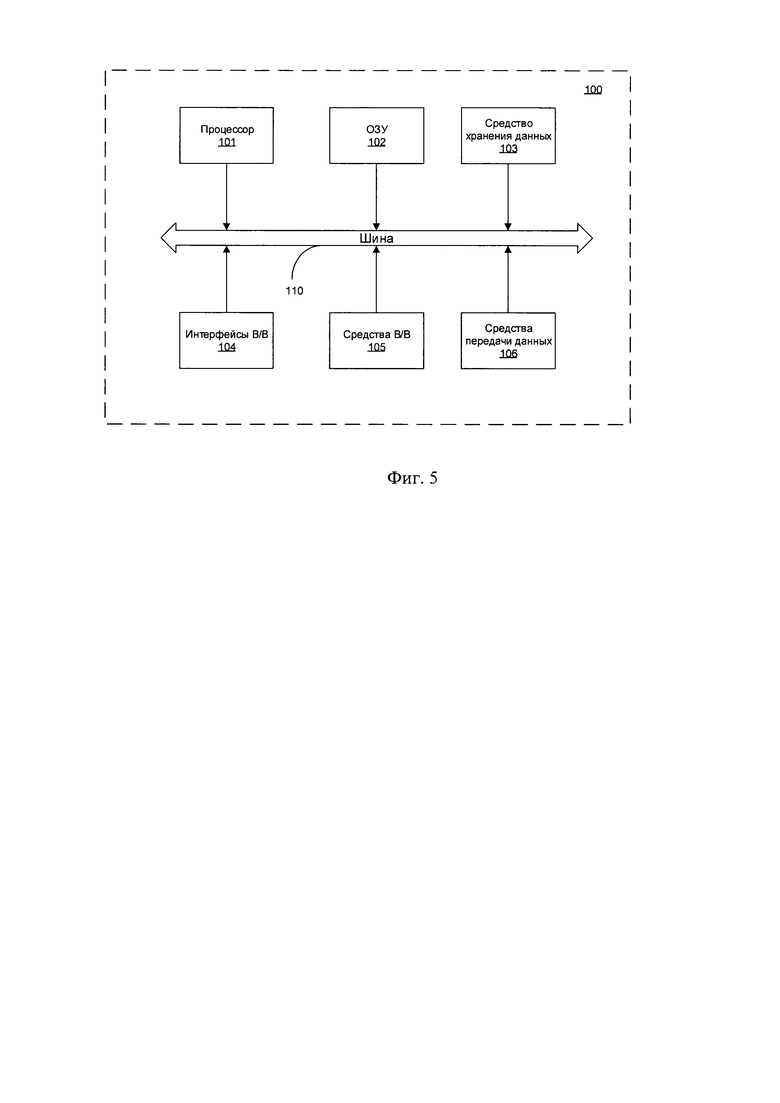
Фиг. 5 - представлен общий вид системы интеллектуального автоматического выбора исполнителей перевода, реализующей заявленный способ.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Перевод - это интеллектуальная деятельность, требующая высокой квалификации исполнителей, для ее качественного выполнения переводчику необходимо понять текст на языке оригинала и суметь его адекватно сформулировать на языке перевода в соответствии с нормами языка перевода. В практике реальной работы это означает, что переводчики - это крайне неоднородный ресурс, например, переводчик, выполняющий качественные литературные переводы, скорее всего, не сможет выполнить перевод технического или медицинского текста.
Подбор исполнителей и организация работы над проектом перевода является актуальнейшим вопросом на рынке лингвистических услуг. По всем же возможным тематикам и языковым парам оценить перевод не сможет ни один сотрудник компании.
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения. Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение системы и метода интеллектуального автоматического выбора исполнителей перевода. Заявленные система и метод интеллектуального автоматического выбора исполнителей перевода используют облачный сетевой сервер и распределенную сетевую систему языкового перевода - это распределенная сеть профессиональных переводчиков и инструментов для профессионального перевода (память переводов, системы машинного перевода и др.), которые взаимодействуют через программные и пользовательские интерфейсы системы и выполняют совместно в режиме реального времени перевод текстов, для которых недостаточно применения исключительно машинного перевода или традиционно организованного профессионального перевода, включая перевод динамических коммуникаций и других текстов создаваемых в различных информационных средах.
Распределенная сетевая система языкового перевода обеспечивает инструментарий для агрегирования ресурсов большого числа переводчиков, с разными режимами доступности, с различными профессиональными навыками, как профессиональных переводчиков, так и компьютерных систем машинного перевода, для эффективного выполнения высококачественных переводов в режиме реального времени.
Для поиска исполнителей перевода, из которых впоследствии будут отбираться оптимальные исполнители перевода для проекта, применяется алгоритм, состоящий из следующих шагов:
Выделение ключевой терминологии из всех текстов всех переводчиков в системе и составление общего модуля глоссариев на основе данной терминологии и индивидуальных глоссариев для каждого переводчика, с указанием конкретной тематики в какой работает тот или иной исполнитель. Это необходимо для уменьшения объема анализируемых данных, а также для разработки критерия подбора переводчика на основе его умения работать с конкретной терминологией.
Разбиение извлеченной терминологии всех исполнителей на классы. Классы определяются автоматически путем кластеризации с помощью машинного обучения.
Примером реализации такого алгоритма кластеризации можно использовать алгоритм K-means (алгоритм K-средних). Этот алгоритм работает по принципу максимизации расстояния между финальными кластерами. Этот алгоритм относится к классу алгоритмов квадратичной ошибки, поскольку конечной целью алгоритма является минимизировать среднеквадратическую ошибку разбиения, вычисляемую по формуле:

где X - совокупность данных, которые надо разбить на кластеры,
K - количество кластеров,
nj - количество элементов, попавших в кластер с номером j,
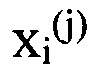 - i-тый элемент кластера с номером j,
- i-тый элемент кластера с номером j,
||a-b|| расстояние от элемента а до элемента b в метрическом пространстве.
Задача данного алгоритма заключается в минимизации суммы квадратов расстояний от всех элементов, подлежащих кластеризации, до центров кластеров, которым они принадлежат. После применения кластеризации, полученные кластеры нумеруются и каждому термину из глоссария присваивается номер кластера, которому он принадлежит. Каждый отдельный кластер далее называется обобщенной тематикой (квазитематикой). Всем корпусам текстов всех исполнителей ставятся в соответствие вектора тематик. Для этого для каждого текста переводчиков из общего корпуса системы вычисляются частоты попадания терминов в тот или иной кластер. Таким образом, каждый текст представлен в виде вектора с размерностью, равной количеству кластеров (точкой в многомерном пространстве), и про него известно, какому переводчику он принадлежит. Аналогичным способом вычисляется вектор тематик нового текста на перевод.
На основе детального сопоставления терминологии переводимых переводчиками ранее текстов осуществляют сравнение этой терминологии с терминологией файла, который необходимо перевести. Для терминов, выделенных из исходного текста на перевод, вычисляется, сколько раз каждый термин встретился в нем, таким образом, получается терминологический вектор частот (ai,…,аk).
Для каждого переводчика вычисляется числовая характеристика близости текста и исполнителя: 
где wi - частота данного термина в текстах подбираемого исполнителя (Т).
Далее из рассмотрения исключаются те переводчики, чьи тематические векторы имеют тематики, далекие от тематики исходного файла, который необходимо перевести, что позволяет сузить пространство переводчиков и уменьшить вычислительную нагрузку на систему.
Далее переводчики ранжируются по этой числовой характеристике и после чего на следующих этапах проходят дополнительный отбор на основе ограничений по качеству, стоимости и срокам, заданных клиентом.
После этого система переходит к автоматической оценки и прогноза качества перевода исходного файла исполнителями перевода. Для этого используется следующая информация:
- Анализ низкоуровневых данных по сегментам перевода - время, проведенное в сегменте, количество действий исполнителя, количество и тип правок между этапами работы (например, правки редактора после переводчика, правки клиента после редактора), нажатие определенных клавиш, использование элементов интерфейса, служебных сочетаний клавиш.
- Анализ соответствия перевода терминологии документа глоссарию проекта или автоматически созданной терминологии на этапе анализа тематик; если термины присутствуют в глоссарии проекта, но были неверно переведены в тексте - это классифицируется как серьезная ошибка. Если какие-то термины не присутствуют в глоссарии, но являются дескриптивными, то анализируется, как именно эти термины переводятся в других документах, попадающих в тот же тематический кластер, что и данный документ. Если в пределах кластера данные термины переводятся достаточно единообразно, т.е. существует статистически предпочтительный вариант перевода (один или несколько) для данной тематики, и перевод термина в документе не совпадает с ним, ошибка классифицируется как серьезная.
- Результаты автоматических проверок: правописание, грамматика, пунктуация, сохранение структуры и порядка тегов сегмента, сохранение плейсхолдеров, наличие лишних и двойных пробелов, контроль контекстных совпадений, сохранение дат и других числовых параметров, соблюдение регистра слов, наличие одинаковых переводов для разных исходных сегментов, и наоборот - разных переводов для одинаковых исходных сегментов, ошибочные повторы слов, сочетание латиницы и кириллицы в одном слове.
- Набор различных лингвистических дескрипторов (таких как средняя длина предложения, богатство лексики, сложность текста и пр.)
- Оценки экспертов (как интегральные согласно единому индексу качества, так и детальные, с классификацией ошибок).
Для построения автоматической оценки качества используются различные модели машинного обучения. Для этого:
- Строится модель корреляции между автоматически измеряемыми параметрами и правками (их объем и суть) на этапе редактуры.
- Строится модель корреляции между правками на этапе редактуры и человеческой (ручной оценкой) качества перевода.
- Проводится валидация и уточнение построенных моделей на фиксированных тестовых заданиях и результатах проверок по формальной процедуре с типизацией ошибок.
- Строится финальная модель корреляции между автоматически измеряемыми параметрами и конечной человеческой оценкой.
Далее построенная математическая модель используется для оценки и прогнозирования качества для всех выполненных переводов, включая те, в которых отсутствуют правки на этапе редактуры. Модель итерационно перестраивается по мере накопления новых данных (оценок, правок и т.д.) для повышения точности работы алгоритма.
Важным фактором при подборе исполнителей их готовность к выполнению задачи. Наиболее востребованные исполнители, как правило, более загружены работой. В продукте вся информация о каждом исполнителе доступна для анализа - текущие и планируемые проекты, данные о средней скорости работы. Это позволяет создать автоматический календарь работы исполнителя и дополнительно учитывать фактор его занятости при поиске. Учитывая фактор занятости переводчиков при построении процесса перевода, система помогает найти скрытые резервы, позволяя переводчику увеличить его заработок.
Кроме того, важным фактором при подборе исполнителей является скорость, при этом скорость работы исполнителя определяется автоматически на основе анализа количества переводимых слов в час.
Также с помощью модуля автоматического расчета стоимости перевода исходного файла осуществляют подбор исполнителей с учетом, указанной ими ставки в профиле, если эта ставка попадает под указанную заказчиком сумму, которую он готов потратить за перевод.
На основе указанных выше этапов и критериев отбора осуществляется автоматический выбор наиболее подходящих исполнителей перевода исходного файла.
После чего, отобранным исполнителям система направляет уведомления о приглашении к участию в проекте перевода, каждый соответствующий исполнитель подтверждает либо отклоняет данное приглашение. После подтверждения участия, назначенный исполнитель входит в систему и посредством пользовательского веб-интерфейса приступает к работе над переводом документа.
Переведенный документ затем автоматически передается заказчику перевода посредством пользовательского веб-интерфейса, из которого заказчик выгружает переведенный файл. Если исходные файлы поступили из некой внешней информационной системы, то переведенные файлы могут быть помещены в эту же систему посредством программных API интерфейсов, содержащихся в слое интеграции.
Кроме того, возможно дополнительно применить синтаксическую и морфологическую фильтрацию текста, например, очистка текста от метаинформации, тегов и форматирования, разметка частями речи, приведение слов к основной форме), а также лингвистическую фильтрацию.
Данное изобретение в различных своих вариантах осуществления выполнено в виде системы и способа, реализуемых на компьютере.
На Фиг. 5 представлен общий вид системы (100), реализующей заявленный способ.
Система интеллектуального автоматического выбора исполнителей перевода (100) может выполняться на базе широкого спектра электронно-вычислительных устройств, например, персонального компьютера, ноутбука, серверного кластера и т.п.
В общем случае система (100) содержит один или более процессоров (101), выполняющих основную вычислительную работу при реализации этапов способа.
Оперативную память (ОЗУ) (102), предназначенную для оперативного хранения команд, исполняемых одним или более процессорами (101). Средство хранения данных (103) может представлять собой жесткий диск (HDD), твердотельный накопитель (SSD), флэш-память (NAND-flash, EEPROM, Secure Digital и т.п.), оптический диск (CD, DVD, Blue Ray), мини диск или их совокупности.
Интерфейсы ввода/вывода (В/В) (104) представляют собой стандартные порты и средства сопряжения устройств и передачи данных, выбираемые исходя из необходимой конфигурации исполнения системы (100), в частности: USB (2.0, 3.0, USB-C, micro, mini), Ethernet, PCI, AGP, COM, LPT, PS/2, SATA, Fire Wire, Lightning и т.п.
Средства В/В (105) также выбираются из известного спектра различных устройств, например, клавиатура, тачпад, сенсорный дисплей, монитор, проектор, манипулятор мышь, джойстик, трекбол, световое перо, стилус, устройства вывода звука (колонки, наушники, встроенные динамики, зуммер) и т.п.
Средства передачи данных (106) выбираются из устройств, предназначенных для реализации процесса коммуникации между различными устройствами посредством проводной и/или беспроводной связи, в частности, таким устройствами могут быть: GSM модем, Wi-Fi приемопередатчик, Bluetooth или BLE модуль, GPS модуль, Глонасс модуль, NFC, Ethernet модуль и т.п. Компоненты системы (100) сопряжены посредством общей шины передачи данных (110).
Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| РАСПРЕДЕЛЕННАЯ СИСТЕМА И СПОСОБ ЯЗЫКОВОГО ПЕРЕВОДА | 2013 |
|
RU2546064C1 |
| СИСТЕМА И МЕТОД УПРАВЛЕНИЯ ПРОЕКТАМИ ЯЗЫКОВОГО ПЕРЕВОДА | 2018 |
|
RU2696326C1 |
| СЕГМЕНТ ДАННЫХ О ПЕРЕВОДЕ | 2002 |
|
RU2295150C2 |
| АДАПТИВНЫЙ МАШИННЫЙ ПЕРЕВОД | 2004 |
|
RU2382399C2 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| АДАПТИВНЫЙ КОНТЕКСТНО-ТЕМАТИЧЕСКИЙ МАШИННЫЙ ПЕРЕВОД | 2016 |
|
RU2628202C1 |
| ПЕРЕВОД СООБЩЕНИЙ, ПЕРЕДАВАЕМЫХ В ЭЛЕКТРОННОЙ ФОРМЕ | 2003 |
|
RU2332709C2 |
| СПОСОБ ОБУЧЕНИЯ АССОЦИАТИВНО-ЭТИМОЛОГИЧЕСКОМУ АНАЛИЗУ ПИСЬМЕННЫХ ТЕКСТОВ НА ИНОСТРАННЫХ ЯЗЫКАХ | 2018 |
|
RU2702148C2 |
| СПОСОБ ДЛЯ ОТОБРАЖЕНИЯ СУБТИТРОВ В ПРОЦЕССЕ ВОСПРОИЗВЕДЕНИЯ МЕДИАКОНТЕНТА (ВАРИАНТЫ) | 2017 |
|
RU2668721C1 |
Изобретение относится к системе и способу интеллектуального автоматического выбора исполнителей перевода. Технический результат заключается в автоматизации подбора исполнителей для перевода. Система состоит из облачного сетевого сервера, пользовательского интерфейса, базы памяти переводов, общего модуля глоссариев, индивидуальных модулей глоссариев для каждого исполнителя перевода, модуля автоматического сопоставления терминологии переводимых исполнителями ранее текстов с терминологией исходного файла на перевод, модуля расчета для каждого исполнителя перевода числовой характеристики близости терминологии исходного файла и терминологии исполнителя перевода, модуля автоматической оценки и прогноза качества перевода исходного файла исполнителями перевода с учетом тематики документа, модуля автоматического расчета скорости работы каждого исполнителя, модуля автоматического ведения календаря работы исполнителей перевода, модуля автоматического расчета стоимости перевода исходного файла и подбора исполнителей с учетом указанной ими ставки в профиле, модуля автоматической оптимизации выбора наиболее подходящих исполнителей перевода на основе перечисленных выше критериев. 2 н. и 6 з.п. ф-лы, 5 ил.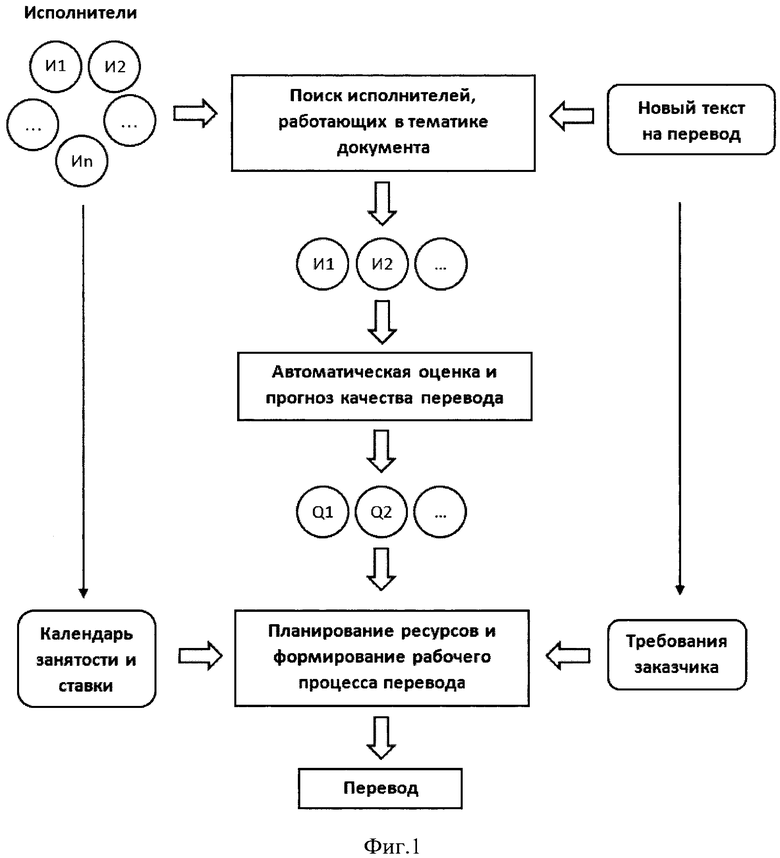
1. Система интеллектуального автоматического выбора исполнителей перевода, состоящая из:
облачного сетевого сервера, обеспечивающего доступ для множества исполнителей и множества заказчиков перевода, подключающихся к серверу посредством сети Интернет, и осуществляющего взаимодействие всех частей системы интеллектуального автоматического выбора исполнителей перевода; пользовательского интерфейса, позволяющего множеству заказчиков перевода загружать исходные файлы на перевод в систему интеллектуального автоматического выбора исполнителей перевода и получать информацию о предлагаемых исполнителях перевода;
базы памяти переводов, хранящей переведенные ранее тексты всех исполнителей переводов в системе с выделенными в этих текстах ключевыми терминами;
общего модуля глоссариев, выполненного в виде пронумерованных кластеров, в каждом из которых находятся выделенные в переведенных текстах ключевые термины, схожие по смыслу и соответственно близкие по тематике, при этом каждому термину присваивается номер кластера, которому он принадлежит;
индивидуальных модулей глоссариев для каждого исполнителя перевода, с указанием конкретной тематики в какой работает тот или иной исполнитель; модуля автоматического сопоставления терминологии переводимых исполнителями ранее текстов с терминологией исходного файла на перевод, при этом для терминов, выделенных из исходного файла на перевод, вычисляется, сколько раз каждый термин встретился в нем, таким образом вычисляется терминологический вектор частот;
модуля расчета для каждого исполнителя перевода числовой характеристики близости терминологии исходного файла и терминологии исполнителя перевода и, выполняющего ранжирование по этой числовой характеристике исполнителей перевода, исключая исполнителей перевода чьи тематические вектора имеют тематики, далекие от тематики исходного файла; модуля автоматической оценки и прогноза качества перевода исходного файла исполнителями перевода с учетом тематики документа и заданного клиентом критерия качества выполнения работы;
модуля автоматического расчета скорости работы каждого исполнителя, выполняющего расчет количества переводимых слов в час;
модуля автоматического ведения календаря работы исполнителей перевода, позволяющего в режиме реального времени анализировать доступность исполнителя перевода для работы, учитывать фактор его занятости при поиске исполнителя перевода и заданного клиентом критерия стоимости выполнения работы;
модуля автоматического расчета стоимости перевода исходного файла и подбор исполнителей с учетом указанной ими ставки в профиле и заданного клиентом критерия стоимости выполнения работы;
модуля автоматической оптимизации выбора наиболее подходящих исполнителей перевода с учетом тематики исходного файла и заданных клиентом критериев качества, стоимости и сроков выполнения работы.
2. Система по п. 1, в которой дополнительно отбор исполнителей осуществляется по языковой паре.
3. Система по п. 1, дополнительно содержащая модуль синтаксической, морфологической и лингвистической фильтраций текста.
4. Система по п. 1, в которой глоссарии пополняются новыми терминами в ходе работы исполнителей по мере накопления ими новых переведенных текстов.
5. Способ интеллектуального автоматического выбора исполнителей перевода, реализуемый системой по п. 1 формулы, состоящий из следующих этапов:
получение исходного файла на перевод;
выделение ключевой терминологии из исходного файла;
поиск сходной терминологии в общем глоссарии, состоящем в виде пронумерованных кластеров, в каждом из которых находятся выделенные в переведенных текстах ключевые термины, схожие по смыслу и соответственно близкие по тематике, при этом каждому термину присваивается номер кластера, которому он принадлежит; и
поиск сходной терминологии в индивидуальных глоссариях каждого переводчика, в которых указано в какой конкретно тематике работает тот или иной исполнитель;
сопоставление терминологии исполнителей с терминологией исходного файла на перевод, при этом для терминов, выделенных из исходного файла на перевод, вычисляется, сколько раз каждый термин встретился в нем, таким образом вычисляется терминологический вектор частот;
на основе этого сопоставления осуществление отбора исполнителей, работающих в тематике исходного файла, с исключением исполнителей перевода, чьи тематические вектора имеют тематики, далекие от тематики исходного файла;
автоматический анализ качества ранее переведенных текстов отобранных исполнителей согласно заданному клиентом критерию срока выполнения работы;
автоматический расчет скорости работы каждого отобранного исполнителя согласно заданному клиентом критерию срока выполнения работы;
анализ в режиме реального времени доступности отобранных для перевода исполнителей;
автоматический расчет стоимости перевода исходного файла у каждого отобранного исполнителя согласно заданному клиентом критерию стоимости выполнения работы; и
на основе указанных выше этапов осуществление автоматического выбора наиболее подходящих исполнителей перевода.
6. Способ по п. 5, в котором дополнительно отбирают исполнителей по языковой паре.
7. Способ по п. 5, в котором дополнительно осуществляют синтаксическую, морфологическую и лингвистическую фильтрации текста.
8. Способ по п. 5, в котором глоссарии пополняются новыми терминами в ходе работы исполнителей по мере накопления ими новых переведенных текстов.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| РАСПРЕДЕЛЕННАЯ СИСТЕМА И СПОСОБ ЯЗЫКОВОГО ПЕРЕВОДА | 2013 |
|
RU2546064C1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| CN 103218354 A, 24.07.2013 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |

