Область техники, к которой относится изобретение
Настоящее изобретение относится к области распознавания речи, в частности к способу и системе для распознавания речи.
Уровень техники
Эффективность распознавания речи зачастую является субоптимальной, когда затрагивается большая грамматическая область поиска, такая как задача голосового поиска, которая охватывает большое число названий предприятий, запросов веб-поиска, запросов голосового набора номера и т.д. Три основных субоптимальности, которые зачастую проявляются, включают в себя длительную задержку распознавания, плохую точность распознавания и недостаточный грамматический охват.
Одно существующее мобильное приложение голосового поиска использует общенациональную грамматику, перечисляющую коммерческие предприятия, плюс грамматику местности на первом этапе и повторно распознает один и тот же фрагмент речи с помощью характерной для местности грамматики, перечисляющей коммерческие предприятия, на втором этапе (где местность была определена на первом этапе). Этот подход не решает проблему задержки, но может улучшать охват и точность в очень специфичных ситуациях. Другой подход пытается уменьшить вероятность ошибочного слова, выбирая среди выходных данных отдельных распознавателей на субфрагментарном уровне. Подход и его развития, в целом, предполагают, что каждый распознаватель делает попытку распознавания с помощью полной грамматики для задачи в целом.
Сущность изобретения
Последующий текст представляет упрощенную сущность, чтобы предоставить основное понимание некоторых аспектов изобретения, описанных в данном документе. Эта сущность не является всесторонним обзором, и она не предназначена для того, чтобы определять его ключевые/важнейшие элементы или ограничивать объем. Ее единственная цель - представить некоторые концепции в упрощенной форме в качестве вступления в более подробное описание, которое представлено далее.
Раскрытая архитектура принимает входные данные для распознавания и применяет различные варианты зависящих от контекста ограничений к входным данным для процесса распознавания. Отдельные варианты ограничений, взятые вместе, предоставляют общую контекстную область для предоставленных входных данных. Выполняя распознавание параллельно, например, в зависимости от этих образцов ограничений, задержка распознавания, точность распознавания и охват области распознавания улучшаются. Кроме того, процессом распознавания отдельных путей распознавания можно управлять посредством наложения временных ограничений на то, как долго система будет ожидать выводимого результата.
В контексте распознавания речи, архитектура применяет общую грамматику в форме разделения меньших отдельных зависящих от контекста грамматик для распознавания входных данных фрагмента речи, каждая из которых отвечает за конкретный контекст, такой как категория подзадачи, географический регион и т.д. Грамматики вместе охватывают всю область. Кроме того, несколько распознаваний могут работать параллельно по отношению к одним и тем же входным данным, причем каждый путь распознавания использует одну или более зависящих от контекста грамматик.
Множественные промежуточные результаты распознавания из различных путей «распознаватель-грамматика» согласуются посредством запуска повторного распознавания с помощью динамически составленной грамматики на основе множественных результатов распознавания и, потенциально, знаний другой области или выбора победителя с помощью статистического классификатора, работающего по классифицирующим признакам, извлеченным из множественных результатов распознавания и знаний другой области.
Для осуществления вышеуказанных и связанных целей определенные иллюстративные аспекты описаны в данном документе в связи с последующим описанием и прилагаемыми чертежами. Эти аспекты показывают различные способы, посредством которых принципы, раскрытые в данном документе, могут осуществляться на практике, и подразумевается, что все аспекты и их эквиваленты находятся в рамках заявленного объекта изобретения. Другие преимущества и новые признаки станут очевидными из следующего подробного описания при рассмотрении вместе с чертежами.
Краткое описание чертежей
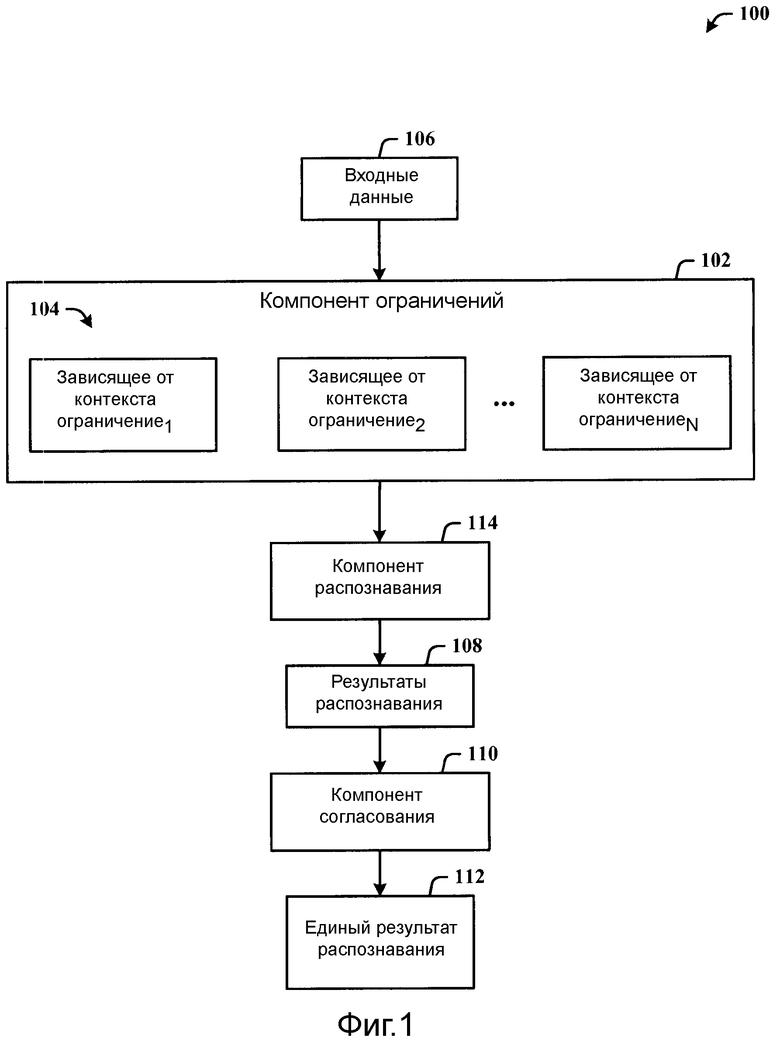
Фиг.1 иллюстрирует реализованную с помощью компьютера систему распознавания в соответствии с раскрытой архитектурой.
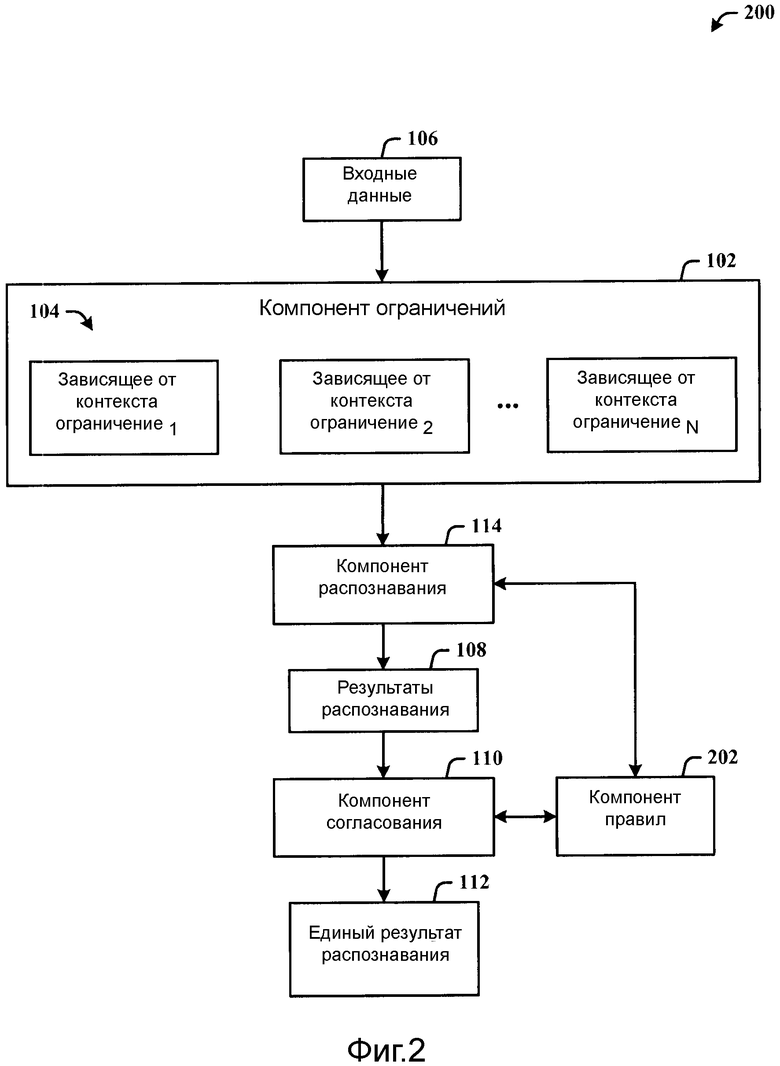
Фиг.2 иллюстрирует альтернативный вариант осуществления системы, который применяет правила для определения единого результата распознавания.
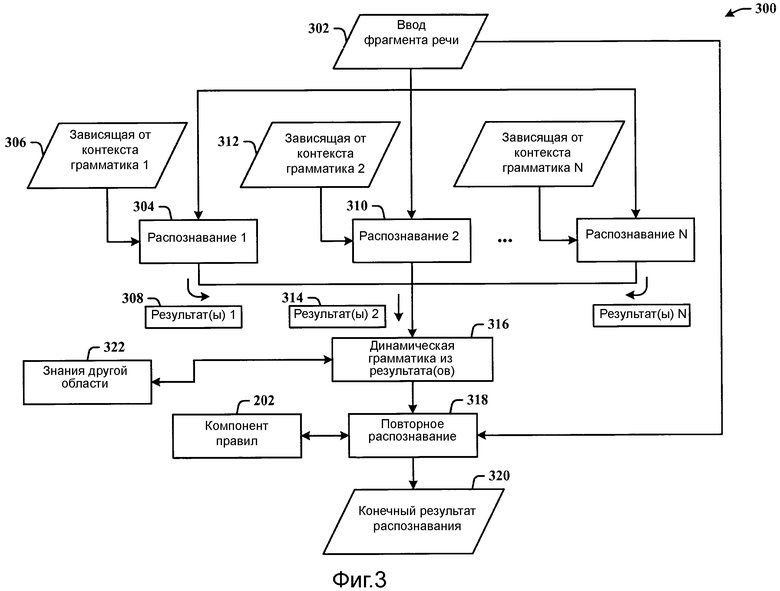
Фиг.3 иллюстрирует систему распознавания зависящих от контекста ограничений, которая применяет повторное распознавание, и где ограничения являются грамматиками для распознавания речи.
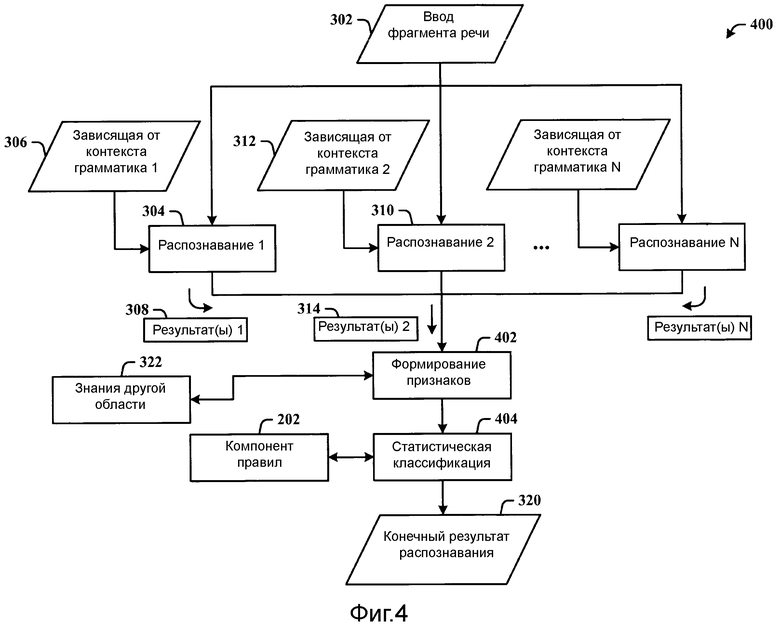
Фиг.4 иллюстрирует систему распознавания с зависящими от контекста ограничениями, которая применяет статистическую классификацию, и где ограничения являются грамматиками для параллельного распознавания речи.
Фиг.5 иллюстрирует реализованный с помощью компьютера способ распознавания.
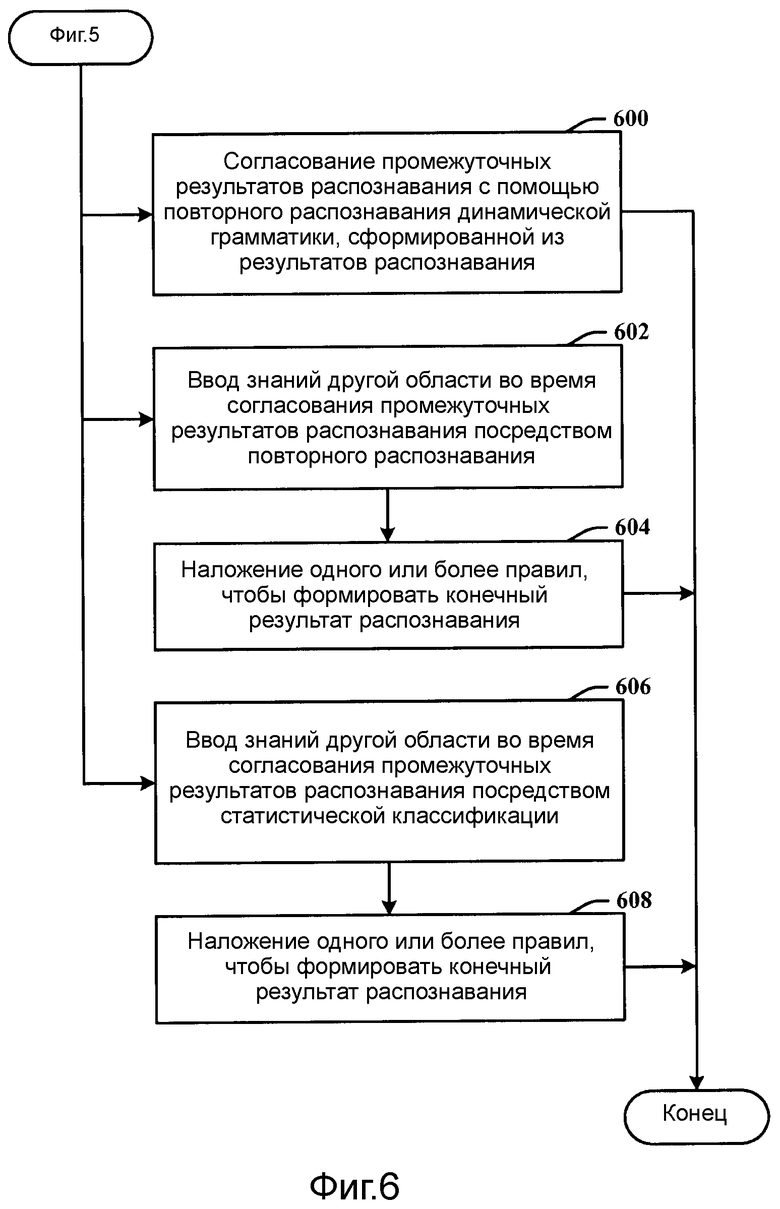
Фиг.6 иллюстрирует дополнительные аспекты способа на фиг.5.
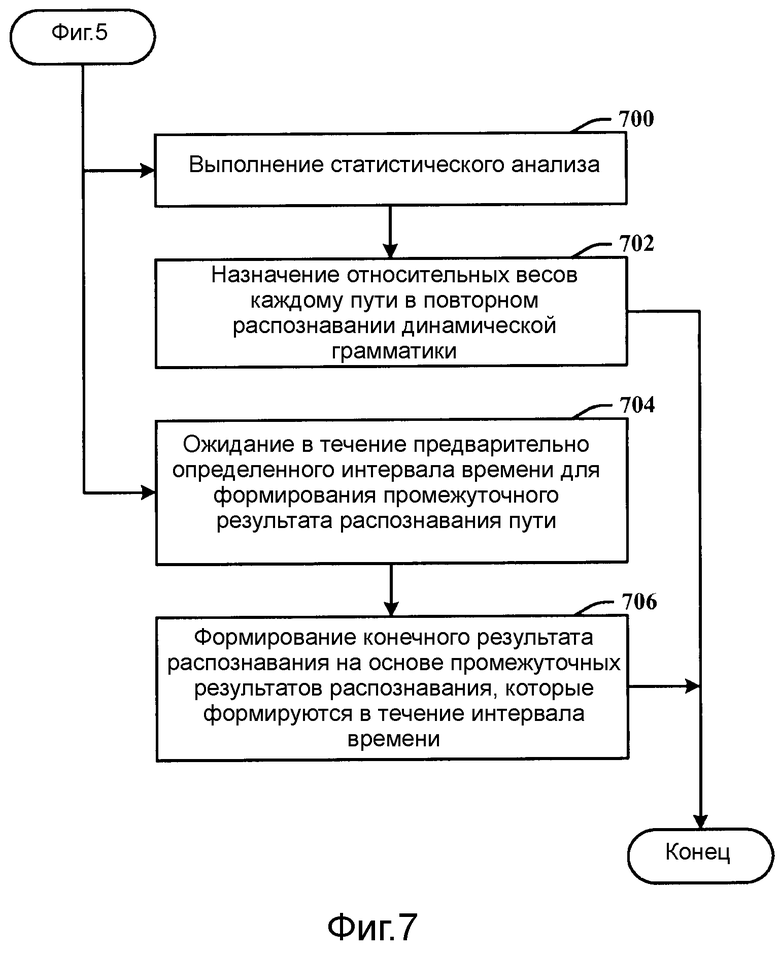
Фиг.7 иллюстрирует дополнительные аспекты способа на фиг.5.
Фиг.8 иллюстрирует блок-схему вычислительной системы, функционирующей, чтобы выполнять распознавание в соответствии с раскрытой архитектурой.
Фиг.9 иллюстрирует схематическую блок-схему вычислительного окружения, которое обеспечивает параллельное распознавание в соответствии с раскрытой архитектурой.
Подробное описание изобретения
Раскрытая архитектура является системой распознавания, которая сначала выполняет независимое распознавание одних и тех же входных данных (например, фрагмента речи) с использованием зависящих от контекста ограничений. Эти независимые распознавания могут выполняться либо последовательно, либо параллельно. Каждое из зависящих от контекста ограничений меньше, чем ограничение, которое пытается объединять все знания области. Согласование множественных результатов распознавания может выполняться с помощью последующего распознавания (повторного распознавания) и/или через статистическую классификацию.
Архитектура решает проблемы задержки распознавания, точности распознавания и недостаточного грамматического охвата, ассоциированные с традиционным подходом с одной грамматикой и одним распознаванием. Относительно задержки распознавания, каждый вариант распознавания при параллельном распознавании существует по отношению к меньшей грамматике, чем к одной большой грамматике, которая может охватывать те же задачи. Кроме того, этап повторного распознавания существует по отношению к небольшой динамической грамматике. Два объединенных этапа распознавания максимальной задержки из параллельных распознаваний, например, плюс задержка повторного распознавания могут иметь меньшую задержку, чем распознавание с одной большой грамматикой, особенно в непотоковых случаях.
С одним распознаванием точность распознавания зачастую теряется вследствие отсечения во время поиска предположения. Наличие множественных распознаваний смягчает это ограничение, поскольку может поддерживаться гораздо больший набор предположений. Кроме того, зависящие от контекста ограничения, такие как грамматики, более вероятно должны иметь более хорошую точность по фрагментам речи, например, из целевого контекста, чем единая, общая грамматика, охватывающая множество контекстов. Таким образом, существует большая вероятность, что результаты множественных распознаваний содержат правильный результат, и согласование множественных результатов распознавания с помощью повторного распознавания или классификатора более вероятно должно сформировать правильный результат, чем подход с одной грамматикой и одним распознаванием.
Относительно недостаточного охвата грамматики, например, зачастую существуют практические ограничения (например, аппаратные, программные) того, насколько большой может быть одна грамматика и/или насколько большими могут быть грамматики в одном распознавании. Запуск множества распознаваний параллельно, например, может значительно увеличить общий грамматический охват, поскольку каждое распознавание может потенциально работать в отдельных процессах программного обеспечения и/или аппаратных ресурсах.
Рассмотрим применение раскрытой архитектуры к крупномасштабной задаче распознавания речи. Последующий пример иллюстрирует концепцию с помощью задачи голосового поиска в качестве примера, которая может включать в себя неограниченный поиск веб-страниц, местных предприятий, персональных контактов и т.д. Варианты и улучшения возможны в различных частях решения.
Грамматика распознавания предоставляется как множество меньших и возможно перекрывающихся зависящих от контекста грамматик, каждая из которых охватывает конкретный поднабор оригинального пространства задачи. Контекст для разделения может быть основан на категории подзадачи (например, названия фирм в сравнении с названиями кинофильмов), географическом местоположении (например, фирмы в Калифорнии в сравнении с фирмами в Нью-Йорке), демографическими источниками (например, молодежно-ориентированное содержимое в сравнении с содержимым для взрослых) и т.д. Каждая зависящая от контекста грамматика может быть построена отдельно, привлекая знания, структуру и другую доступную информацию, релевантную для каждого контекста, чтобы максимизировать долю успешных попыток распознавания для ожидаемых входных пользовательских данных из каждого контекста.
Далее приводится ссылка на чертежи, на которых аналогичные ссылки с номерами используются для того, чтобы ссылаться на аналогичные элементы по всему описанию. В следующем описании, в целях пояснения, многие конкретные детали объяснены, чтобы обеспечить полное понимание изобретения. Тем не менее может быть очевидным, что новые варианты осуществления могут применяться на практике без этих конкретных деталей. В других случаях, распространенные структуры и устройства показаны в форме блок-схемы, чтобы упростить их описание. Намерение состоит в том, чтобы охватывать все модификации, эквиваленты, и варианты, попадающие в рамки сущности и объема заявленного предмета изобретения.
Фиг.1 иллюстрирует реализованную с помощью компьютера систему 100 распознавания в соответствии с раскрытой архитектурой. Система 100 включает в себя компонент 102 ограничений для зависящих от контекста ограничений 104 для процесса распознавания входных данных 106 в результаты 108 распознавания, и компонент 110 согласования для согласования результатов 108 распознавания в единый результат 112 распознавания.
Система 100 может дополнительно содержать компонент 114 распознавания для отдельного процесса распознавания соответствующих зависящих от контекста ограничений 104 параллельными способами и/или последовательно. Например, зависящие от контекста ограничения 104 могут включать в себя грамматики для процесса распознавания грамматик по отношению к входным данным 106 параллельными способами и/или последовательными способами. Отдельные наборы зависящих от контекста ограничений 104 могут включать в себя разделенный и пересекающийся охват контекста. Другими словами, один набор ограничений может иметь некое перекрывание с ограничениями из другого набора ограничений. Существует также случай, где некоторые наборы ограничений не перекрываются с ограничениями из других наборов ограничений.
Компонент 110 согласования может согласовывать результаты 108 распознавания с помощью повторного распознавания, чтобы повторно формировать единый результат 112 распознавания, применяя динамически составленную грамматику на основе результатов 108 распознавания.
Альтернативно, компонент 110 согласования может согласовывать результаты 108 с помощью статистического классификатора, который работает по классификационным признакам, извлеченным из результатов 108 распознавания, чтобы формировать единый результат 112 распознавания.
Процесс согласования может также обрабатывать релевантные для задачи данные, чтобы достигать единого результата 112 распознавания. Релевантные для задачи данные могут включать в себя, по меньшей мере, одно из распознанных строк, оценок достоверности уровня фрагмента речи и уровня субфрагмента речи, охвата речи, относительных задержек среди одновременных распознаваний, априорных вероятностей контекстов, относительной трудности каждого распознавания или согласованности между результатами распознавания. Кроме того, множество установленных вручную и/или автоматически полученных правил, отражающих конкретные требования задачи, могут влиять на процесс согласования множества гипотетических результатов распознавания.
Фиг.2 иллюстрирует альтернативный вариант осуществления системы 200, которая применяет правила для определения единого результата 112 распознавания. Система 200 включает в себя компонент 102 ограничений для зависящих от контекста ограничений 104 для процесса распознавания входных данных 106 в результаты 108 распознавания, и компонент 110 согласования для согласования результатов 108 распознавания в единый результат 112 распознавания, и компонент 114 распознавания для отдельного процесса распознавания соответствующих зависящих от контекста ограничений 104 параллельными способами и/или последовательно.
Компонент 202 правил предусматривается, чтобы применять правила (например, приоритет) для декларирования одного или более результатов 108 распознавания и/или единого результата 112 распознавания (например, конечного результата). Например, может быть создано и применено правило, которое определяет, что, если конкретный распознаватель возвращает конкретный результат с достаточно высокой оценкой достоверности, тогда этот результат может быть принят в качестве конечного для процесса этого соответствующего распознавателя или даже в качестве единого результата 112 распознавания.
Фиг.3 иллюстрирует систему 300 распознавания зависящих от контекста ограничений, которая применяет повторное распознавание, и где ограничения являются грамматиками для распознавания речи. Система 300 включает в себя N пар распознаватель-грамматика, работающих параллельно, где каждая пара включает в себя одну или более зависящих от контекста грамматик и распознаватель (обозначенных как распознавание N). Как иллюстрировано, грамматики являются различными, однако, может быть некоторое частичное совпадение одной грамматики с другой грамматикой, хотя это необязательно. Вместо создания и использования одной большой грамматики, как в существующих системах распознавания, система 300 поддерживает отдельные грамматики (вместо слияния в одну большую грамматику) и запускает распознавание входных данных 302 фрагмента речи по каждой из грамматик.
Другими словами, входные данные 302 фрагмента речи обрабатываются посредством первого распознавателя 304 и ассоциированной первой зависящей от контекста грамматики 306, создающих первый результат(ы) 308, а также посредством второго распознавателя 310 и ассоциированной второй зависящей от контекста грамматики 312, создающих второй результат(ы) 314, и т.д., до требуемого числа N распознавателей и грамматик, таким образом, создавая N результат(ов). Результат(ы) используются, чтобы формировать динамическую грамматику 316, которая может затем быть использована для повторного распознавания 318, чтобы выводить конечный результат 320 распознавания.
C другой стороны, с входным фрагментом 302 речи пользователя, отдельное распознавание запускается по отношению к каждой из зависящих от контекста грамматик. Это иллюстрируется как действие, происходящее параллельным образом в одно и то же время или приблизительно в одно и то же время. Каждое из параллельных распознаваний может применять один и тот же вид или различный вид распознавателя (например, встроенные в сравнении с сетевыми распознавателями, сетевые распознаватели с различными акустическими моделями и т.д.) и использовать одинаковые или различные параметры распознавания. Вплоть до максимального периода ожидания система 300 собирает все доступные результаты распознавания (например, результат(ы) 308, результат(ы) 314 и т.д.) и определяет конечный результат 320 распознавания посредством повторного распознавания.
Динамическая грамматика 316 формируется, чтобы включать в себя конкурирующие элементы, полученные из всех результатов распознавания, которые могут включать в себя строки распознавания, интерпретации и оценки достоверности из N лучших результатов распознавания, и/или структуру распознавания, если доступно. Повторное распознавание первоначальных входных данных 302 фрагмента речи выполняется по отношению к этой динамической грамматике 316. Результат повторного распознавания 318, включающий в себя оценки достоверности, принимается в качестве конечного результата 320 распознавания.
Необязательно, определенные правила приоритета могут быть включены компонентом 202 правил, чтобы объявлять конечный результат 320 распознавания, прежде чем все распознавания завершатся, например, если определенный распознаватель возвращает конкретный результат с достаточно высокой оценкой достоверности, этот результат может быть принят в качестве конечного. Необязательно, знания 322 другой области, которые являются релевантными для задачи, могут быть предоставлены в качестве входных данных для динамической грамматики, чтобы обеспечивать более сфокусированный процесс распознавания. Эти знания 322 могут включать в себя пользовательские предпочтения, содержимое, относящееся к тому, о чем говорится в фрагменте речи, аппаратным/программным средствам, местности и т.д.
Фиг.4 иллюстрирует систему 400 распознавания зависящих от контекста ограничений, которая применяет статистическую классификацию, и где ограничения являются грамматиками для параллельного распознавания речи. Множественные числовые и/или категориальные признаки 402 могут быть получены из всех результатов распознавания (например, результата(ов) 308, результата(ов) 314 и т.д.) и, потенциально, знаний 322 другой области, релевантных для задачи распознавания. Статистический классификатор используется, чтобы определять, насколько вероятно каждый результат отражает фактические пользовательские входные данные. Результат с наивысшей классификационной оценкой может быть выбран в качестве конечного результата 320 распознавания, и классификационная оценка может быть нормализована, чтобы быть конечной достоверностью распознавания.
Система 400 включает в себя N пар распознаватель-грамматика, работающих параллельно, где каждая пара включает в себя зависящую от контекста грамматику (обозначенную как зависящая от контекста грамматика N) и распознаватель (обозначенный как распознавание N). Как ранее иллюстрировано и описано, грамматики являются различными, однако, может быть некоторое частичное совпадение одной грамматики с другой грамматикой, хотя это необязательно. Вместо создания и использования одной большой грамматики, как в существующих системах распознавания, система 400 поддерживает отдельные грамматики (вместо слияния в одну большую грамматику) и запускает распознавание входных данных 302 фрагмента речи по каждой из грамматик.
Другими словами, входные данные 302 фрагмента речи обрабатываются посредством первого распознавателя 304 и ассоциированной первой зависящей от контекста грамматики 306, создающих первый результат(ы) 308, а также посредством второго распознавателя 310 и ассоциированной второй зависящей от контекста грамматики 312, создающих второй результат(ы) 314, и т.д., до требуемого числа N распознавателей и грамматик, таким образом, создавая N результат(ов). Результат(ы) (результат(ы) 308, результат(ы) 314, …, результат(ы) N) используются, чтобы формировать признаки 402, которые затем передаются для статистической классификации 404 для конечного результата 320 распознавания.
Как ранее иллюстрировано и описано на фиг.3, необязательно, определенные правила приоритета могут быть включены компонентом 202 правил, чтобы объявлять конечный результат 320 распознавания, прежде чем все распознавания завершатся, например, если определенный распознаватель возвращает конкретный результат с достаточно высокой оценкой достоверности, этот результат может быть принят в качестве конечного. Необязательно, знания 322 другой области, которые являются релевантными для задачи, могут быть предоставлены в качестве входных данных для динамической грамматики, чтобы обеспечивать более сфокусированный процесс распознавания. Эти знания 322 могут включать в себя пользовательские предпочтения, содержимое, относящееся к тому, о чем говорится в фрагменте речи, аппаратным/программным средствам, местности и т.д.
Отметим, что описание в данном документе охватывает то, как архитектура работает при приеме входных данных фрагмента речи пользователя в режиме онлайн. Другой аспект решения представлен для того, чтобы выбирать соответствующие настройки, признаки и т.д., используемые системой, в частности, во время согласования множества результатов распознавания. Для подхода с повторным распознаванием и подхода со статическим классификатором могут быть использованы данные режима обучения, и автономный процесс обучения может применяться, чтобы выбирать оптимальную конфигурацию и параметризацию.
Для подхода с повторным распознаванием также возможно необязательное выполнение статистического анализа, такого как регрессия, чтобы назначать относительные весовые коэффициенты путям в повторном распознавании динамической грамматики. Выводом знаний 322 другой области можно управлять, чтобы влиять на динамическую грамматику 316 для каждого процесса повторного распознавания.
В любом подходе один или более следующих признаков 402 могут быть применены, некоторые признаки непосредственно получаются из результатов параллельного распознавания, а другие признаки получаются из релевантных для задачи знаний. Признаки 402 могут включать в себя, но не только, распознанные строки, оценки достоверности на уровне фрагмента речи и уровне субфрагмента речи, охват речи (например, доля фрагмента речи, предполагаемая как речь), относительные задержки среди распознаваний (например, параллельных), априорные вероятности контекстов (например, как часто пользователь запрашивает названия предприятий по сравнению с результатами спортивных соревнований), относительную трудность каждого зависящего от контекста распознавания (например, запутанность зависящих от контекста грамматик в пределах точности распознавания контекста), допустимость каждой грамматики (например, грамматика веб-поиска может принимать большое разнообразие запросов) и согласованность между результатами распознавания.
Отметим, что отдельные процессы распознавания могут быть распределены между различными машинами, такими как сервер, клиенты или комбинация серверов и клиентов. Это применяется к параллельному распознаванию, а также к последовательному распознаванию как в сценарии классификации, так и повторного распознавания.
Предлагая другой способ, раскрытая архитектура является компьютерно-реализуемой системой распознавания, которая содержит компонент ограничений зависящих от контекста грамматик для процесса распознавания входных данных фрагмента речи в результаты распознавания, компонент распознавания для отдельного процесса распознавания входных данных фрагмента речи параллельными путями с помощью соответствующих зависящих от контекста грамматик и компонент согласования для согласования результатов распознавания в конечный результат распознавания.
Компонент согласования применяет динамически составленную грамматику из результатов распознавания и согласовывает результаты распознавания с помощью повторного распознавания, чтобы формировать конечный результат распознавания. Необязательно, компонент согласования согласовывает результаты распознавания, применяя статистический анализ, такой как регрессия, перед повторным распознаванием, чтобы определять конечный результат распознавания. Альтернативно, компонент согласования согласовывает результаты распознавания с помощью статистической классификации, которая работает по признакам, извлеченным из результатов распознавания, чтобы формировать конечный результат распознавания. Кроме того, компонент правил накладывает одно или более правил, которые задают определение конечного результата распознавания, и знания другой области могут влиять на признаки для согласования с помощью статистической классификации и динамическую грамматику для согласования с помощью повторного распознавания.
В данный документ включен набор блок-схем последовательности операций способа, представляющих примерные технологии для выполнения новых аспектов раскрытой архитектуры. Хотя в целях упрощения пояснения технологии одна или более технологий, показанных в данном документе, например, в форме блок-схемы алгоритма или блок-схемы последовательности операций, показаны и описаны как последовательность действий, необходимо понимать и принимать во внимание, что технологии не ограничены порядком действий, поскольку некоторые действия могут, в соответствии с ним, выполняться в другом порядке и/или параллельно с действиями, отличными от действий, показанных и описанных в данном документе. Например, специалисты в данной области техники должны понимать и принимать во внимание, что технология альтернативно может быть представлена как последовательность взаимосвязанных состояний или событий, к примеру, на диаграмме состояний. Кроме того, не все действия, проиллюстрированные в технологии, могут потребоваться для реализации изобретения.
Фиг.5 иллюстрирует реализованный с помощью компьютера способ распознавания. На этапе 500 отдельные зависящие от контекста грамматики принимаются для обработки входных данных фрагмента речи. На этапе 502 входные данные фрагмента речи распознаются параллельными путями с помощью соответствующей зависящей от контекста грамматики для каждого пути. На этапе 504 промежуточный результат распознавания формируется для каждого пути. На этапе 506 промежуточные результаты распознавания согласуются в конечный результат распознавания.
Фиг.6 иллюстрирует дополнительные аспекты способа на фиг.5. На этапе 600 промежуточные результаты распознавания согласовываются с помощью повторного распознавания для динамической грамматики, сформированной из результатов распознавания. На этапе 602 знания другой области вводятся во время согласования промежуточных результатов распознавания посредством повторного распознавания. На этапе 604 одно или более правил накладываются, чтобы формировать конечный результат распознавания. На этапе 606 знания другой области вводятся во время согласования промежуточных результатов распознавания посредством статистической классификации. На этапе 608 одно или более правил накладываются, чтобы формировать конечный результат распознавания.
Фиг.7 иллюстрирует дополнительные аспекты способа на фиг.5. На этапе 700 выполняется статистический анализ, такой как регрессия. Анализ выполняется по всем путям одновременно. На этапе 702 относительные весовые коэффициенты назначаются каждому пути в повторном распознавании динамической грамматики. На этапе 704 выжидается предварительно определенный интервал времени для формирования промежуточного результата распознавания пути. На этапе 706 конечный результат распознавания формируется на основе промежуточных результатов распознавания, которые формируются в течение интервала времени.
При использовании в данной заявке термины "компонент" и "система" предназначены, чтобы ссылаться на связанную с вычислительной машиной объектную сущность, либо аппаратные средства, сочетание аппаратных средств и программного обеспечения, программное обеспечение или программное обеспечение в ходе исполнения. Например, компонент может быть, но не только, процессом, запущенным на процессоре, процессором, жестким диском, несколькими накопителями хранения (оптического, твердотельного и/или магнитного носителя хранения), объектом, исполняемым файлом, потоком исполнения, программой и/или компьютером. В качестве иллюстрации, и приложение, запущенное на сервере, и сервер может быть компонентом. Один или более компонентов могут храниться внутри процесса и/или потока исполнения, и компонент может быть локализован на компьютере и/или распределен между двумя и более компьютерами. Слово "примерный" используется в материалах настоящей заявки, чтобы означать служащий в качестве примера, экземпляра или иллюстрации. Любой аспект или схема, описанные в данном документе как "примерные", не обязательно должны быть истолкованы как предпочтительные или преимущественные в сравнении с другими аспектами или схемами.
Обращаясь теперь к фиг.8, иллюстрируется блок-схема вычислительной системы 800, функционирующей, чтобы выполнять распознавание в соответствии с раскрытой архитектурой. Для того, чтобы предусмотреть дополнительный контекст для различных аспектов, фиг.8 и последующее обсуждение имеют намерение предоставлять краткое общее описание подходящей вычислительной системы 800, в которой различные аспекты могут быть реализованы. Хотя вышеприведенное описание дано в общем контексте компьютерно-исполняемых инструкций, которые могут выполняться на одном или более компьютеров, специалисты в данной области техники должны признавать, что вариант осуществления изобретения также может быть реализован в комбинации с другими программными модулями и/или как комбинация аппаратных средств и программного обеспечения.
Вычислительная система 800 для реализации различных аспектов включает в себя компьютер 802, имеющий процессор(ы) 804, системное запоминающее устройство 806 и системную шину 808. Процессор(ы) 804 может быть любым из различных предлагаемых на рынке процессоров, такие как однопроцессорные, многопроцессорные, одноядерные модули и многоядерные модули. Кроме того, специалисты в данной области техники должны принимать во внимание, что новые способы могут осуществляться на практике с другими конфигурациями компьютерных систем, включающими в себя миникомпьютеры, мэйнфреймы, а также персональные компьютеры (например, настольные, переносные компьютеры и т.д.), карманные вычислительные устройства, микропроцессорные или программируемые бытовые электронные приборы и т.п., каждое из которых может быть функционально связано с одним или более ассоциированных устройств.
Системное запоминающее устройство 806 может включать в себя энергозависимое (энергозависим.) запоминающее устройство 810 (например, оперативное запоминающее устройство (RAM)) и энергонезависимое (энергонезависим.) запоминающее устройство 812 (например, ROM, EPROM, EEPROM и т.д.). Базовая система ввода-вывода (BIOS) может сохраняться в энергонезависимом запоминающем устройстве 812 и включает в себя базовые процедуры, которые упрощают передачу данных и сигналов между компонентами в рамках компьютера 802, к примеру, во время запуска. Энергозависимое запоминающее устройство 810 также может включать в себя высокоскоростное RAM, к примеру, статическое RAM для кэширования данных.
Системная шина 808 предоставляет интерфейс для системных компонентов, включающих в себя, но не только, подсистему 806 запоминающего устройства для процессора(ов) 804. Системная шина 808 может быть любой из нескольких типов шинной структуры, которая дополнительно может соединяться с шиной запоминающего устройства (с или без контроллера запоминающего устройства) и периферийной шиной (например, PCI, PCIe, AGP, LPC и т.д.), с использованием любой из множества предлагаемых на рынке шинных архитектур.
Компьютер 802 дополнительно включает в себя подсистему(ы) 814 хранения данных и интерфейс(ы) 816 хранения данных для обеспечения взаимодействия(й) подсистемы 814 хранения данных с системной шиной 808 и другими требуемыми компьютерными компонентами. Подсистема(ы) 814 хранения данных может включать в себя, например, одно или более из жесткого диска (HDD), накопителя на гибких магнитных дисках (FDD) и/или накопителя хранения данных на оптических дисках (например, накопителя на CD-ROM, накопителя на DVD). Интерфейс(ы) 816 хранения данных может включать в себя такие интерфейсные технологии, как, например, EIDE, ATA, SATA и IEEE 1394.
Одна или более программ и данных могут быть сохранены в подсистеме 806 памяти, подсистеме 818 съемной памяти (например, по технологии форм-фактора флэш-памяти) и/или в подсистеме(ах) 814 хранения данных (например, оптической, магнитной, твердотельной), включающих в себя операционную систему 820, одну или более прикладных программ 822, других программных модулей 824 и программные данные 826.
Одна или более прикладных программ 822, другие программные модули 824 и программные данные 826 могут включать в себя компоненты, объекты и результаты системы 100 на фиг.1, компоненты, объекты и результаты системы 200 на фиг.2, компоненты, объекты и результаты системы 300 на фиг.3, компоненты, объекты и результаты системы 400 на фиг.4 и способы и дополнительные аспекты, предоставленные на фиг.5-7, например.
Как правило, программы включают в себя алгоритмы, способы, структуры данных, другие компоненты программного обеспечения и т.д., которые выполняют отдельные задачи или реализуют отдельные абстрактные типы данных. Все или части операционной системы 820, приложений 822, модулей 824 и/или данных 826 также могут кэшироваться в запоминающем устройстве, таком как, например, энергозависимое запоминающее устройство 810. Следует принимать во внимание, что раскрытая архитектура может быть реализована с различными предлагаемыми на рынке операционными системами или комбинациями операционных систем (например, как виртуальные машины).
Подсистема(ы) 814 хранения данных и подсистемы (806 и 818) запоминающего устройства служат в качестве компьютерно-читаемых носителей для энергозависимого и энергонезависимого хранения данных, структур данных, компьютерно-исполняемых инструкций и т.д. Компьютерно-читаемыми носителями могут быть любые доступные носители, доступ к которым может быть осуществлен посредством компьютера 802, и включает в себя энергозависимые и энергонезависимые носители, съемные и несъемные носители. Для компьютера 802, носители приспосабливают хранение данных в любом подходящем цифровом формате. Специалисты в данной области техники должны принимать во внимание, что могут использоваться другие типы компьютерно-читаемых носителей, такие как накопители на Zip-дисках, магнитная лента, карты флэш-памяти, картриджи и т.п., для сохранения компьютерно-исполняемых инструкций для выполнения новых способов раскрытой архитектуры.
Пользователь может взаимодействовать с компьютером 802, программами и данными с помощью внешних устройств 828 пользовательского ввода, такими как клавиатура и мышь. Другие внешние устройства 828 пользовательского ввода могут включать в себя микрофон, IR (инфракрасное) дистанционное управление, джойстик, игровой планшет, системы распознавания с камерами, перо, сенсорный экран, системы распознавания жестов (например, перемещение глаз, перемещение головы и т.д.) и/или т.п. Пользователь может взаимодействовать с компьютером 802, программами и данными с помощью встроенных устройств 830 пользовательского ввода, таких как сенсорная панель, микрофон, клавиатура и т.д., при этом компьютер 802 является портативным компьютером, например. Эти и другие устройства ввода подключаются к процессору(ам) 804 посредством интерфейса(ов) 832 устройства ввода-вывода через системную шину 808, но могут подключаться посредством других интерфейсов, таких как параллельный порт, последовательный порт IEEE 1394, игровой порт, USB-порт, IR-интерфейс и т.д. Интерфейс(ы) 832 устройства ввода-вывода также упрощает использование периферийных устройств 834 вывода, таких как принтер, аудиоустройств, видеокамер и т.д., к примеру, звуковой карты и/или встроенной поддержки аудиообработки.
Один или более графических интерфейсов 836 (также обычно называемых графическими процессорами (GPU)) предоставляют графические и видеосигналы между компьютером 802 и внешним дисплеем(ями) 838 (например, ЖК-дисплеем, плазменным дисплеем) и/или встроенными дисплеями 840 (например, для портативного компьютера). Графический интерфейс(ы) 836 также может быть изготовлен как часть компьютерной системной платы.
Компьютер 802 может работать в сетевом окружении (например, IP) с использованием логических соединений через подсистему 842 проводной/беспроводной связи с одной или более сетей и/или других компьютеров. Другие компьютеры могут включать в себя рабочие станции, серверы, маршрутизаторы, персональные компьютеры, микропроцессорные электронные бытовые устройства, равноправные устройства или другие общие сетевые узлы и в типичном варианте включают в себя многие или все элементы, описанные относительно компьютера 802. Логические соединения могут включать в себя возможности проводного/беспроводного подключения к локальной вычислительной сети (LAN), глобальной вычислительной сети (WAN), точке доступа и т.д. Сетевые окружения LAN и WAN являются общераспространенными в офисах и компаниях и упрощают корпоративные компьютерные сети, к примеру, сети intranet (локальная сеть, использующая технологии Интернет), все из которых могут подключаться к глобальной сети связи, например, сети Интернет.
При использовании в сетевом окружении, компьютер 802 подключается к сети через подсистему 842 проводной/беспроводной связи (например, сетевой интерфейсный адаптер, встроенную подсистему приемо-передающего устройства и т.д.), чтобы обмениваться данными с проводными/беспроводными сетями, проводными/беспроводными принтерами, проводными/беспроводными устройствами 844 ввода и т.д. Компьютер 802 может включать в себя модем или имеет другое средство для установления связи по сети. В сетевом окружении, программы и данные относительно компьютера 802 могут сохраняться в удаленном запоминающем устройстве/устройстве хранения данных, поскольку ассоциированы с распределенной системой. Будет принято во внимание, что показанные сетевые соединения являются примерными, и может быть использовано другое средство установления линии связи между компьютерами.
Компьютер 802 выполнен с возможностью обмениваться данными с проводными/беспроводными устройствами или объектами с использованием таких технологий радиосвязи, как семейство стандартов IEEE 802.xx, такие как беспроводные устройства, функционально расположенные в беспроводной связи (например, технологии модуляции по радиоинтерфейсу согласно IEEE 802.11), например, с принтером, сканером, настольным и/или портативным компьютером, персональным цифровым устройством (PDA), спутником связи, любым фрагментом оборудования или местоположением, ассоциированным с обнаруживаемым беспроводными средствами тегом (например, киоском, газетным киоском, уборной), и телефоном. Это включает в себя, по меньшей мере, беспроводные технологии Wi-Fi (или стандарт высококачественной беспроводной связи) для точек доступа, WiMax и Bluetooth™. Таким образом, связь может быть заранее заданной структурой, как в случае традиционной сети, или просто специальной связью, по меньшей мере, между двумя устройствами. Сети Wi-Fi используют радио-технологии, названные IEEE 802.11x (a, b, g и т.д.), чтобы предоставлять возможность защищенного, надежного высокоскоростного беспроводного соединения. Wi-Fi-сеть может использоваться для того, чтобы подключать компьютеры друг к другу к Интернету и к проводным сетям (которые используют среды и функции на основе IEEE 802.3).
Обращаясь теперь к фиг.9, иллюстрируется схематическая блок-схема вычислительного окружения 900, которое обеспечивает параллельное распознавание в соответствии с раскрытой архитектурой. Окружение 900 включает в себя один или более клиентов 902. Клиентом(ами) 902 могут быть аппаратные средства и/или программное обеспечение (к примеру, потоки, процессы, вычислительные устройства). Клиент(ы) 902 может размещать, например, cookie-файл(ы) и/или ассоциированную контекстную информацию.
Окружение 900 также включает в себя один или более серверов 904. Сервером(ами) 904 также могут быть аппаратные средства и/или программное обеспечение (к примеру, потоки, процессы, вычислительные устройства). Серверы 904, например, могут содержать потоки, чтобы выполнять преобразования, например, посредством применения архитектуры. Один из возможных обменов данными между клиентом 902 и сервером 904 может выполняться в форме пакета данных, выполненного с возможностью передачи между двумя или более вычислительными процессами. Пакет данных, например, может включать в себя cookie-файл и/или ассоциированную контекстную информацию. Окружение 900 включает в себя инфраструктуру 906 связи (например, глобальную сеть передачи данных, такую как сеть Интернет), которая может быть использована, чтобы содействовать связи между клиентом(ами) 902 и сервером(ами) 904.
Связь может быть облегчена посредством проводной (в том числе оптоволоконной) и/или беспроводной технологии. Клиент(ы) 902 функционально подключены к одному или более клиентских хранилищ 908 данных, которые могут быть использованы для того, чтобы сохранять информацию локально по отношению к клиенту(ам) 902 (например, cookie-файл(ы) и/или ассоциированную контекстную информацию). Аналогично, серверы 904 функционально подключены к одному или более серверных хранилищ 910 данных, которые могут быть использованы для того, чтобы сохранять информацию локально по отношению к серверам 904.
Клиент(ы) 902 могут включать в себя клиента, через которого голосовые сигналы принимаются для процесса распознавания посредством сервера(ов) 904 или другого клиента(ов) 902. Грамматики могут быть сохранены в клиентском хранилище(ах) 908 данных и/или серверном хранилище(ах) 910 данных.
То, что описано выше, включает в себя примеры раскрытой архитектуры. Конечно, невозможно описать каждую вероятную комбинацию компонентов и/или технологий, но специалистам в данной области техники будет понятно, что множество дополнительных комбинаций и перестановок являются допустимыми. Следовательно, подразумевается, что новая архитектура охватывает все такие изменения, модификации и варианты, которые попадают в пределы сущности и объема прилагаемой формулы изобретения. Кроме того, подразумевается, что термин "включает в себя", используемый либо в подробном описании, либо в формуле изобретения, аналогичен термину "содержит".
Изобретение относится к области распознавания речи. Техническими результатами являются уменьшение задержки распознавания речи, увеличение точности распознавания речи, а также увеличение общего грамматического охвата в распознавании речи. При распознавании речи применяется общая грамматика как набор зависящих от контекста грамматик для распознавания входных данных, каждая из которых отвечает за конкретный контекст. Грамматики вместе охватывают всю область. Используются множественные распознавания параллельно по отношению к одним и тем же входным данным, причем каждое распознавание использует зависящие от контекста грамматики. Множественные промежуточные результаты распознавания от различных пар распознаватель-грамматика согласуются посредством запуска повторного распознавания с помощью динамически составленной грамматики на основе множественных результатов распознавания и знаний другой области или выбора победителя с помощью статистического классификатора, работающего по классифицирующим признакам, извлеченным из множественных результатов распознавания и знаний другой области. 5 н. и 17 з.п. ф-лы, 9 ил.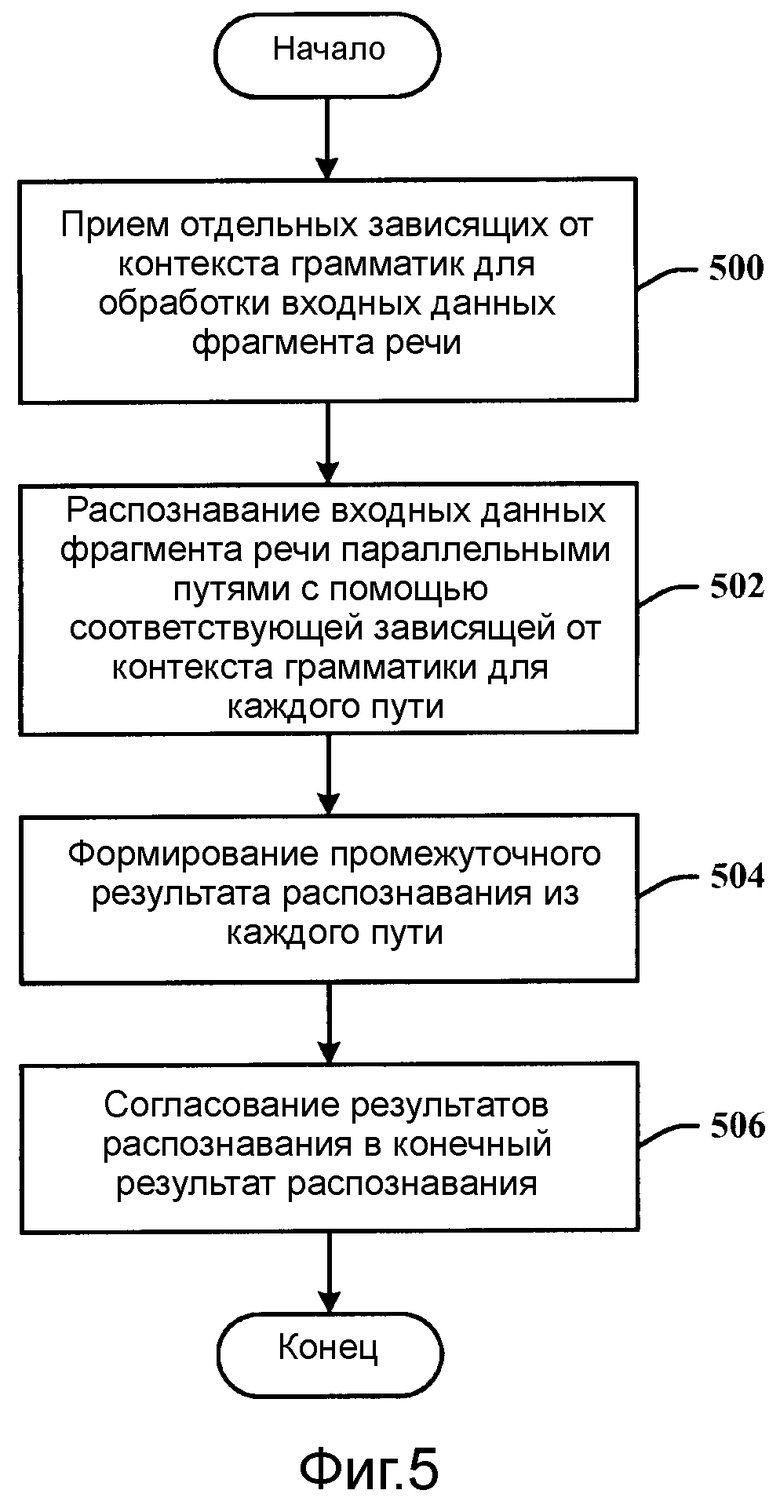
1. Компьютерно-реализуемая система распознавания речи, содержащая:
- компонент ограничений для множества зависящих от контекста ограничений, выполненный с возможностью обработки независимого распознавания одних и тех же входных данных по множеству путей распознавания в соответствующее множество результатов распознавания, причем отдельные варианты ограничений, взятые вместе, предоставляют общую контекстную область для входных данных;
- компонент согласования, выполненный с возможностью формирования динамической грамматики с использованием множества результатов распознавания и выполненный с возможностью выполнения регрессионного анализа для назначения относительных весовых коэффициентов каждому из путей распознавания в динамической грамматике и определения конечного результата распознавания; и
- микропроцессор, выполненный с возможностью исполнения компьютерно-исполняемых инструкций в памяти, связанных с компонентом ограничений и компонентом согласования.
2. Система по п. 1, в которой ограничения включают в себя грамматики для обработки распознавания входных данных параллельными путями.
3. Система по п. 1, в которой компонент согласования согласовывает результаты с помощью повторного распознавания, чтобы формировать единый результат распознавания.
4. Система по п. 3, в которой повторное распознавание применяет динамически составленную грамматику на основе результатов распознавания.
5. Система по п. 1, в которой компонент согласования согласовывает результаты с помощью статистического классификатора, который работает по классификационным признакам, извлеченным из результатов распознавания, чтобы формировать единый результат распознавания.
6. Система по п. 1, в которой зависящие от контекста ограничения включают в себя непересекающийся и пересекающийся охват контекста.
7. Система по п. 1, в которой обработка распознавания обрабатывает релевантные для задачи данные, чтобы достичь единого результата распознавания, причем релевантные для задачи данные включают в себя, по меньшей мере, одно из распознанных строк, оценок достоверности уровня фрагмента речи и уровня субфрагмента речи, охвата речи, относительных задержек среди одновременных распознаваний, априорных вероятностей контекстов, относительной трудности каждого распознавания или согласованности между результатами распознавания.
8. Система по п. 1, дополнительно содержащая компонент распознавания, сконфигурированный для отдельной обработки распознавания входных данных с помощью соответствующего зависящего от контекста ограничения в каждом из параллельных путей.
9. Система по п. 1, дополнительно содержащая компонент правил, выполненный с возможностью наложения одного или более правил, которые задают определение единого результата распознавания.
10. Компьютерно-считываемое запоминающее устройство, содержащее компьютерно-исполняемые инструкции, которые при исполнении в процессоре активируют систему распознавания речи, содержащую:
- компонент ограничений для множества зависящих от контекста ограничений, выполненный с возможностью выполнения обработки независимого распознавания одних и тех же входных данных по множеству путей распознавания в соответствующее множество результатов распознавания, причем отдельные варианты ограничений, взятые вместе, предоставляют общую контекстную область для входных данных; и
- компонент согласования, выполненный с возможностью формирования динамической грамматики с использованием множества результатов распознавания и выполненный с возможностью выполнения регрессионного анализа для назначения относительных весовых коэффициентов каждому из путей распознавания в динамической грамматике и определения конечного результата распознавания.
11. Компьютерно-считываемое запоминающее устройство по п. 10, причем компонент согласования применяет динамически составленную грамматику результатов распознавания и согласовывает результаты распознавания с помощью повторного распознавания, чтобы формировать конечный результат распознавания.
12. Компьютерно-считываемое запоминающее устройство по п. 10, причем компонент согласования согласовывает результаты распознавания с помощью классификации, которая работает по признакам, извлеченным из результатов распознавания, чтобы формировать конечный результат распознавания.
13. Компьютерно-считываемое запоминающее устройство по п. 10, дополнительно содержащее компонент правил для наложения одного или более правил, которые задают определение конечного результата распознавания, и знания другой области, которые влияют на признаки для согласования с помощью классификации и динамическую грамматику для согласования с помощью повторного распознавания.
14. Компьютерно-считываемое запоминающее устройство по п. 10, причем компонент согласования согласовывает результаты распознавания путем применения регрессионного анализа до повторного распознавания для определения конечного результата распознавания.
15. Компьютерно-реализуемый способ распознавания речи, выполняемый компьютерной системой, исполняющей компьютерно-считываемые инструкции, содержащий этапы, на которых:
- принимают грамматику распознавания, составленную из отдельных зависящих от контекста грамматик, каждая из которых охватывает конкретный поднабор оригинального пространства задачи, для обработки входных данных фрагмента речи;
- распознают входные данные фрагмента речи параллельными путями с помощью соответствующей зависящей от контекста грамматики для каждого пути;
- формируют промежуточный результат распознавания от каждого пути;
- формируют динамическую грамматику с использованием промежуточного результата распознавания от каждого пути;
- выполняют регрессионный анализ для назначения относительных весовых коэффициентов каждому из путей распознавания в динамической грамматике и определения конечного результата распознавания; и
- конфигурируют микропроцессор для исполнения инструкций в памяти, связанных с этапами приема, распознавания, формирования промежуточного распознавания, формирования динамической грамматики и выполнения.
16. Способ по п. 15, дополнительно содержащий этап, на котором согласовывают промежуточные результаты распознавания с помощью повторного распознавания динамической грамматики, сформированной из промежуточных результатов распознавания.
17. Способ по п. 15, дополнительно содержащий этапы, на которых:
- вводят знания другой области во время согласования промежуточных результатов распознавания посредством повторного распознавания; и
- накладывают одно или более правил, чтобы формировать конечный результат распознавания.
18. Способ по п. 15, дополнительно содержащий этапы, на которых:
- вводят знания другой области во время согласования промежуточных результатов распознавания посредством классификации; и
- накладывают одно или более правил, чтобы формировать конечный результат распознавания.
19. Способ по п. 15, дополнительно содержащий этапы, на которых:
- выполняют анализ классификации; и
- назначают относительные весовые коэффициенты каждому пути в динамической грамматике для повторного распознавания.
20. Способ по п. 15, дополнительно содержащий этапы, на которых:
- ожидают в течение предварительно определенного интервала времени для формирования промежуточного результата распознавания пути; и
- формируют конечный результат распознавания на основе промежуточных результатов распознавания, которые формируются в течение интервала времени.
21. Компьютерно-реализуемая система распознавания речи, содержащая:
- компонент ограничений для множества зависящих от контекста ограничений, выполненный с возможностью выполнения обработки независимого распознавания входных данных по множеству путей распознавания в соответствующее множество результатов распознавания, причем отдельные варианты ограничений, взятые вместе, предоставляют общую контекстную область для входных данных;
- компонент согласования, выполненный с возможностью формирования динамической грамматики с использованием множества результатов распознавания и выполненный с возможностью выполнения статистического анализа для назначения относительных весовых коэффициентов каждому из путей распознавания в динамической грамматике и определения конечного результата распознавания;
- компонент повторного распознавания, выполненный с возможностью обработки входных данных с использованием динамической грамматики, чтобы формировать конечный результат распознавания; и
- микропроцессор, выполненный с возможностью исполнения компьютерно-исполняемых инструкций в памяти, связанных с компонентом ограничений, компонентом согласования и компонентом повторного распознавания.
22. Компьютерно-реализуемый способ распознавания речи, выполняемый компьютерной системой, исполняющей компьютерно-считываемые инструкции, содержащий этапы, на которых:
- распознают входные данные фрагмента речи параллельными путями с помощью грамматики распознавания, которая содержит разные или пересекающиеся зависящие от контекста грамматики для каждого пути;
- формируют динамическую грамматику с использованием промежуточного результата распознавания от одного или более путей;
- выполняют статистический анализ для назначения относительных весовых коэффициентов каждому из путей распознавания в динамической грамматике;
- выполняют обработку повторного распознавания входных данных фрагмента речи, используя динамическую грамматику для формирования конечного результата распознавания; и
- конфигурируют микропроцессор для исполнения инструкций в памяти, связанных с этапами распознавания, формирования, выполнения статистического анализа и выполнения обработки повторного распознавания.
| US 6526380 B1, 25.02.2003 | |||
| US 6122613 A, 19.09.2000 | |||
| US 7184957 B2, 27.02.2007 | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| АВТОМАТИЧЕСКОЕ РАСПОЗНАВАНИЕ РЕЧИ | 1999 |
|
RU2216052C2 |

