ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение относится к автоматизированному распознаванию речи.
УРОВЕНЬ ТЕХНИКИ
[0002] Распознавание речи относится к транскрипции произнесенных слов в текст с использованием автоматизированного распознавателя речи (ASR). В традиционных системах ASR, принятый аудиосигнал преобразуется в компьютерно-считываемые звуки, которые затем сравниваются со словарем слов, которые связаны с данным языком.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] В общем случае, один аспект изобретения, описанный в этом описании изобретения, можно реализовать в способах, которые улучшают распознавание речи с использованием внешнего источника данных. Например, автоматизированный распознаватель речи может принимать аудиоданные, кодирующие речевой фрагмент и обеспечивать первоначальный вариант транскрипции речевого фрагмента с использованием первой языковой модели. Затем система может применять вторую, другую языковую модель к первоначальному варианту транскрипции для генерирования альтернативных вариантов транскрипции, которые (i) звучат фонетически аналогично первоначальному варианту транскрипции и (ii) с высокой степенью вероятности появляются в данном языке. Затем система может выбирать транскрипцию из вариантов транскрипции на основе (i) фонетического сходства между аудиоданными и вариантами транскрипции и (ii) правдоподобия варианта транскрипции, появляющегося в данном языке.
[0004] Реализации могут включать в себя один или более из следующих признаков. Например, в некоторых реализациях, способ включает в себя получение первоначального варианта транскрипции речевого фрагмента с использованием автоматизированного распознавателя речи, идентификацию, на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, одного или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции, генерирование одного или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов, и выбор транскрипции из вариантов транскрипции.
[0005] Другие версии включают в себя соответствующие системы, компьютерные программы, выполненные с возможностью осуществлять действия способов, закодированных на компьютерных запоминающих устройствах, и компьютерные программы, выполненные с возможностью предписывать вычислительному устройству осуществлять действия способов.
[0006] Одна или более реализаций может включать в себя следующие необязательные признаки. Например, в некоторых реализациях, языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включает в себя один или более терминов, отсутствующих в языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции. В некоторых аспектах, обе из языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, и языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включают в себя последовательность из одного или более терминов, но указывают, что последовательность имеет разные правдоподобия появления.
[0007] В некоторых аспектах, языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, указывает правдоподобия появления слов или последовательностей слов. В некоторых реализациях, действия включают в себя, для каждого из вариантов транскрипции, определение показателя правдоподобия, который отражает, насколько часто ожидается произнесение варианта транскрипции, и для каждого из вариантов транскрипции, определение показателя акустического совпадения, который отражает фонетическое сходство между вариантом транскрипции и речевым фрагментом, причем выбор транскрипции из вариантов транскрипции основан на показателях акустического совпадения и показателях правдоподобия. В некоторых аспектах, определение показателя акустического совпадения, который отражает фонетическое сходство между вариантом транскрипции и речевым фрагментом, включает в себя получение показателей акустического совпадения подслов от автоматизированного распознавателя речи, идентификацию подмножества показателей акустического совпадения подслов, которые соответствуют варианту транскрипции, и генерирование показателя акустического совпадения на основе подмножества показателей акустического совпадения подслов, которые соответствуют варианту транскрипции.
[0008] В некоторых аспектах, определение показателя правдоподобия, который отражает, насколько часто ожидается произнесение варианта транскрипции, включает в себя определение показателя правдоподобия на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции. В некоторых реализациях, генерирование одного или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов включает в себя замену идентифицированных одного или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции, на один или более терминов, которые уже присутствуют в первоначальном варианте транскрипции.
[0009] Технические преимущества могут включать в себя предоставление возможности использовать данные из внешнего источника данных при генерировании более точной транскрипции без модификации существующего автоматизированного распознавателя речи. Например, применение выходного сигнала автоматизированного распознавателя речи к обновленной языковой модели позволяет избегать вычислительно затратной перекомпиляции автоматизированного распознавателя речи для использования обновленной языковой модели. Другое преимущество может состоять в том, что система может распознавать дополнительные термины, отличные от терминов, которые может распознавать автоматизированный распознаватель речи, используемый для генерирования первоначальной транскрипции. Еще одно преимущество может состоять в том, что могут быть включены разные архитектуры языковых моделей, которые обычно непригодны для декодера распознавания речи в реальном времени. Например, текстовый файл, который включает в себя список всех песен, когда-либо прослушанных пользователем, может быть трудно эффективно включать в распознаватель речи в реальном времени. Однако в этой системе после того, как распознаватель речи выводит первоначальный вариант транскрипции, информация из текстового файла может быть включена для определения окончательной транскрипции.
[0010] Определение, аналогичны ли фонетически термины, предусматривают определение меры сходства и сравнение меры с порогом, или определение, превышает ли мера сходства меры сходства, относящиеся к другим парам терминов.
[0011] Подробности одной или более реализаций изложены в прилагаемых чертежах и нижеследующем описании. Другие возможные признаки и преимущества явствуют из описания, чертежей и формулы изобретения.
[0012] Другие реализации этих аспектов включают в себя соответствующие системы, устройство и компьютерные программы, выполненные с возможностью осуществлять действия способов, закодированные на компьютерных запоминающих устройствах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0013] фиг. 1 демонстрирует иллюстративную систему, которая может использоваться для улучшения распознавания речи с использованием внешнего источника данных.
[0014] фиг. 2 демонстрирует иллюстративный процесс для улучшения распознавания речи с использованием внешнего источника данных.
[0015] фиг. 3 - блок-схема вычислительных устройств, на которых могут быть реализованы описанные здесь процессы или их части.
[0016] В чертежах, аналогичные ссылочные позиции представляют соответствующие части.
ПОДРОБНОЕ ОПИСАНИЕ
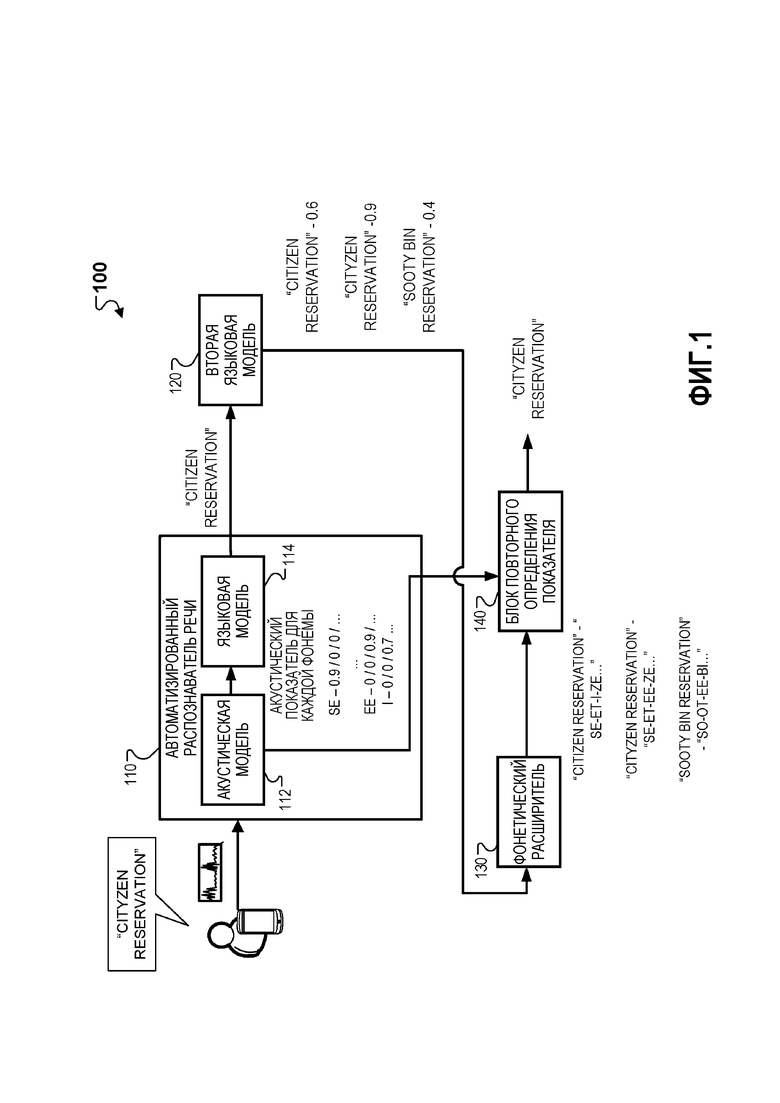
[0017] Фиг. 1 демонстрирует иллюстративную систему 100, которая может использоваться для улучшения распознавания речи с использованием внешнего источника данных. Кратко, система 100 может включать в себя автоматизированный распознаватель 110 речи (ASR), который включает в себя акустическую модель 112 и языковую модель 114, вторую языковую модель 120, фонетический расширитель 130 и блок 140 повторного определения показателя.
[0018] В частности, ASR 110 может принимать акустические данные, кодирующие речевой фрагмент. Например, ASR 110 может принимать акустические данные, соответствующие речевому фрагменту ʺCityZen reservationʺ. Акустические данные могут включать в себя, например, первичные данные формы волны, коэффициенты косинусного преобразования Фурье мел-правдоподобие или любое другое акустическое или фонетическое представление аудиосигнала.
[0019] Акустическая модель 112 ASR 110 может принимать акустические данные и генерировать акустические показатели для слов или подслов, например, фонем, соответствующих акустическим данным. Акустические показатели могут отражать фонетическое сходство между словами или подсловами и акустическими данными. Например, акустическая модель может принимать акустические данные для ʺCityZen reservationʺ и генерировать акустические показатели ʺSE - 0,9/0/0 /...,...EE - 0/0/0,9 /...I - 0/0,7/0 /....ʺ Иллюстративные акустические показатели могут указывать, что для фонемы ʺSEʺ существует 90%-ое акустическое совпадение для первого подслова в речевом фрагменте, 0%-ое акустическое совпадение для второго подслова в речевом фрагменте и 0%-ое акустическое совпадение для третьего подслова в речевом фрагменте, для фонемы ʺEEʺ существует 0%-ое акустическое совпадение для первого подслова в речевом фрагменте, 0%-ое совпадение для второго подслова в речевом фрагменте и 90%-ое совпадение для третьего подслова в речевом фрагменте, и для фонемы ʺIʺ существует 0%-ое акустическое совпадение для первого подслова в речевом фрагменте, 0%-ое акустическое совпадение для второго подслова в речевом фрагменте и 70%-ое акустическое совпадение для третьего подслова в речевом фрагменте. В вышеприведенном примере, акустическая модель 112 может выводить акустический показатель для каждой комбинации фонемы и позиции подслова в речевом фрагменте.
[0020] Акустическая модель 112 может генерировать акустические показатели на основе сравнения форм волны, указанных акустическими данными, с формами волны, указанными как соответствующие конкретным подсловам. Например, акустическая модель 112 может принимать акустические данные для речевого фрагмента ʺCityZen reservationʺ и идентифицировать, что начало акустических данных представляет форму волны, имеющую 90%-ое совпадение с сохраненной формой волны для фонемы ʺSE,ʺ и, в ответ, генерировать акустический показатель 0,9 для первой фонемы в речевом фрагменте, то есть фонемы ʺSEʺ.
[0021] Языковая модель 114 ASR 110 может принимать акустические показатели и генерировать первоначальный вариант транскрипции на основе акустических показателей. Например, языковая модель 114 ASR 110 может принимать акустические показатели ʺSE - 0,9/0/0 /...,...EE - 0/0/0,9 /...I - 0/0/0,7 /....ʺ, и, в ответ, генерировать первоначальный вариант транскрипции ʺCitizen reservationʺ.
[0022] Языковая модель 114 может генерировать первоначальный вариант транскрипции на основе правдоподобия присутствия последовательностей слов и акустических показателей. Например, языковая модель 114 может генерировать вариант транскрипции ʺCitizen reservationʺ на основе того, что правдоподобие присутствия слов "CityZen reservation" равно 0%, например, поскольку слово ʺCityZenʺ отсутствует в языковой модели 114, правдоподобие присутствия слов "Citizen reservation" равно 70%, акустические показатели для "CityZen reservation", которые указывают, что звучание речевого фрагмента акустически больше похоже на "City", после которого следует "Zen", чем "Citizen," и генерировать первоначальный вариант транскрипции "Citizen reservation".
[0023] В некоторых реализациях, языковая модель 114 может указывать правдоподобие последовательностей слов посредством показателя правдоподобия, и при генерировании первоначального варианта транскрипции языковая модель 114 может перемножать показатели акустического совпадения и показатели правдоподобия. Например, для фонем ʺSE-ET-EE-ZEʺ языковая модель 114 может перемножать показатели акустического совпадения 0,9, 0,9, 0,9, 0,7 с показателем правдоподобия 0,0 для ʺCityʺ, после которого следует ʺZenʺ, получая показатель 0, и для фонем ʺSE-ET-I-ZEʺ языковая модель 114 может перемножать показатели акустического совпадения 0,9, 0,9, 0,7, 0,9 с показателем правдоподобия 0,9 для ʺCitizenʺ, получая показатель 0,45, и затем выбирать слово ʺCitizenʺ, поскольку его показатель 0,45 лучше, чем показатель 0 для ʺCityʺ, после которого следует ʺZenʺ.
[0024] ASR 110 может выводить первоначальную транскрипцию, сгенерированную языковой моделью 114. Например, ASR 110 может выводить первоначальную транскрипцию ʺCitizen reservationʺ, сгенерированную языковой моделью 114, приняв акустические показатели на основе акустических данных для речевого фрагмента ʺCityZen reservationʺ.
[0025] Вторая языковая модель 120 может принимать первоначальную транскрипцию и генерировать дополнительные варианты транскрипции. Например, вторая языковая модель 120 может принимать первоначальную транскрипцию ʺCitizen reservationʺ и, в ответ, генерировать дополнительные транскрипции ʺCityZen reservationʺ и ʺSooty bin reservationʺ.
[0026] Вторая языковая модель 120 может генерировать дополнительные варианты транскрипции на основе идентификации одного или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции, и замены одного или более терминов, которые уже присутствуют в первоначальном варианте транскрипции, на идентифицированные один или более фонетически аналогичными терминов. Например, вторая языковая модель 120 может принимать первоначальный вариант транскрипции ʺCitizen reservationʺ, идентифицировать оба термина ʺCityZenʺ и ʺSooty binʺ как фонетически аналогичные термину ʺCitizenʺ, и, в ответ, генерировать дополнительные варианты транскрипции ʺCityZen reservationʺ и ʺSooty bin reservationʺ, заменяя ʺCitizenʺ на ʺCityZenʺ и ʺSooty binʺ, соответственно.
[0027] В некоторых реализациях, вторая языковая модель 120 может идентифицировать фонетически аналогичные термины на основе сохранения фонетических представлений слов и идентификации фонетически аналогичных терминов на основе сохраненных фонетических представлений. Например, вторая языковая модель 120 может сохранять информацию, которая указывает, что ʺCitizenʺ можно представить фонемами ʺSE-ET-I-ZE-ENʺ, и что ʺCityʺ и ʺZenʺ можно представить фонемами ʺSE-ET-EE-ZE-ENʺ, принимать термин ʺCitizenʺ в первоначальной транскрипции, определять, что термин соответствует фонемам ʺSE-ET-I-ZE-ENʺ, определять, что фонемы ʺSE-ET-I-ZE-ENʺ аналогичны фонемам ʺSE-ET-EE-ZE-ENʺ, которые связаны с ʺCityʺ и ʺZenʺ, и, в ответ, определять что термин ʺCitizenʺ фонетически аналогичен термину ʺCityZenʺ.
[0028] В некоторых реализациях, вторая языковая модель 120 может определять, насколько аналогично звучат фонемы, на основе акустических представлений фонем. Например, вторая языковая модель 120 может определять, что фонема ʺEEʺ и фонема ʺIʺ более аналогичны друг другу, чем фонема ʺEEʺ и фонема ʺZAʺ, на основе определения, что акустическое представление для фонемы ʺEEʺ более аналогично акустическому представлению фонемы ʺIʺ, чем акустическое представление фонемы ʺZAʺ. В некоторых реализациях, вторая языковая модель 120 может, дополнительно или альтернативно, идентифицировать фонетически аналогичные термины на основе явного указания аналогично звучащих слов. Например, вторая языковая модель 120 может включать в себя информацию, которая явно указывает, что ʺFloorʺ и ʺFlourʺ звучат фонетически аналогично.
[0029] Вторая языковая модель 120 может генерировать дополнительные варианты транскрипции на основе правдоподобия последовательности слов в присутствующих вариантах транскрипции. Например, вторая языковая модель 120 может определять, что последовательность слов ʺCityZen reservationʺ имеет высокое правдоподобие присутствия, и, в ответ, принимать решение выводить ʺCityZen reservationʺ в качестве дополнительного варианта. В другом примере, вторая языковая модель 120 может определять, что последовательность слов ʺSooty zen reservationʺ имеет низкое правдоподобие присутствия, и, в ответ, принимать решение не выводить ʺSooty zen reservationʺ в качестве дополнительного варианта.
[0030] В некоторых реализациях, вторая языковая модель 120 может генерировать варианты транскрипции на основе комбинации фонетического сходства с первоначальным вариантом транскрипции и правдоподобия присутствия варианта транскрипции. Например, вторая языковая модель 120 может принять решение не выводить ʺSooty zen reservationʺ, но выводить ʺSooty bin reservationʺ поскольку, хотя ʺSooty zen reservationʺ по звучанию фонетически больше походит на ʺCitizen reservationʺ, ʺSooty zen reservationʺ имеет очень низкое правдоподобие присутствия согласно второй языковой модели 120, и ʺSooty bin reservationʺ, хотя звучит чуть менее похоже на ʺCitizen reservationʺ, имеет умеренное правдоподобие присутствия.
[0031] Вторая языковая модель 120 может выводить варианты транскрипции с соответствующими показателями правдоподобия. Например, приняв ʺCitizen reservationʺ, вторая языковая модель 120 может выводить ʺCitizen reservationʺ, связанный с умеренным показателем правдоподобия 0,6, выводить ʺCityZen reservationʺ, связанный с высоким показателем правдоподобия 0,9, и выводить ʺSooty bin reservationʺ с умеренным показателем правдоподобия 0,4. Показатели правдоподобия могут отражать правдоподобие последовательности из одного или более слов в варианте транскрипции, присутствующим в данном языке.
[0032] В некоторых реализациях, вторая языковая модель 120 может определять показатель правдоподобия для варианта транскрипции на основе хранения показателей правдоподобия для последовательностей из одного или более слов, идентификации последовательностей из одного или более слов, находящихся в варианте транскрипции, и генерирования показателя правдоподобия для варианта транскрипции на основе показателей правдоподобия для последовательностей из одного или более слов, идентифицированных находящимися в варианте транскрипции. В одном примере, вторая языковая модель 120 может определять, что последовательности из ʺSooty binʺ и ʺreservationʺ находятся в варианте транскрипции ʺSooty bin reservationʺ и предварительно связаны с показателями правдоподобия 0,8 и 0,5, соответственно, и генерировать показатель правдоподобия для варианта транскрипции ʺSooty bin reservationʺ умножением показателей правдоподобия 0,8 и 0,5, в результате чего получается 0,4. В другом примере, вторая языковая модель 120 может определять, что вся последовательность ʺCityZen reservationʺ предварительно связана с показателем правдоподобия 0,9 и полностью совпадает с вариантом транскрипции ʺCityZen reservationʺ, и, в ответ, определять, что показатель правдоподобия варианта транскрипции ʺCityZen reservationʺ равен 0,9.
[0033] Фонетический расширитель 130 может принимать варианты транскрипции от второй языковой модели 120 и расширять варианты транскрипции на подслова. Например, фонетический расширитель 130 может принимать ʺCitizen reservationʺ и генерировать фонетическое расширение ʺSE-ET-I-ZE...ʺ, принимать ʺCityZen reservationʺ и генерировать фонетическое расширение ʺSE-ET-EE-ZE...ʺ, и принимать ʺSooty bin reservationʺ и генерировать фонетическое расширение ʺSO-OT-EE-BI...ʺ. В некоторых реализациях фонетический расширитель 130 может расширять варианты транскрипции на подслова на основе заранее определенных правил расширения. Например, правило может устанавливать, что ʺSOOʺ расширяется на фонему ʺSOʺ. В другом примере, правило может устанавливать, что слово ʺSootyʺ расширяется на фонемы ʺSO-OT-EEʺ.
[0034] Блок 140 повторного определения показателя может принимать фонетические расширения для каждого из вариантов транскрипции от фонетического расширителя, принимать соответствующий показатель правдоподобия для каждого из вариантов транскрипции от второй языковой модели 120, принимать акустические показатели от акустической модели 112, генерировать общий показатель для вариантов транскрипции на основе комбинации показателей правдоподобия и акустических показателей от акустической модели 112, и выбирать транскрипцию из вариантов транскрипции на основе общих показателей. Например, блок повторного определения показателя может принимать вариант транскрипции ʺCitizen reservationʺ, связанный с умеренным показателем правдоподобия 0,6 и фонетическим расширением ʺSE-ET-I-ZE...ʺ, вариант транскрипции ʺCityZen reservationʺ, связанный с высоким показателем правдоподобия 0,9 и фонетическим расширением ʺSE-ET-EE-ZE...ʺ, и вариант транскрипции ʺSooty bin reservationʺ, связанный с умеренным показателем правдоподобия 0,4 и фонетическим расширением ʺSO-OT-EE-BI...ʺ, принимать акустические показатели "SE - 0,9/0/0 /...,...EE - 0/0/0,9 /...I - 0/0,7/0 /....", генерировать общий показатель 0,8 для ʺCityZen reservationʺ, общий показатель 0,6 для ʺCitizen reservationʺ, и общий показатель 0,3 для ʺSooty bin reservationʺ, и выбирать ʺCityZen reservationʺ, поскольку он имеет наивысший общий показатель.
[0035] В некоторых реализациях, блок 140 повторного определения показателя может генерировать общий показатель на основе комбинации показателя правдоподобия и показателя акустического совпадения для варианта речевого фрагмента. Например, блок 140 повторного определения показателя может генерировать общий показатель 0,7 для варианта транскрипции, перемножая показатель правдоподобия 0,9 для варианта транскрипции и показатель акустического совпадения 0,8 для варианта транскрипции.
[0036] В некоторых реализациях, блок 140 повторного определения показателя может генерировать показатель акустического совпадения для варианта речевого фрагмента на основе акустических показателей от акустической модели 112 и фонетических расширений от фонетического расширителя 130. В частности, блок 140 повторного определения показателя может принимать фонетические расширения, которые включают в себя множественные подслова, идентифицировать акустические показатели, соответствующие каждому из множественных подслов, и генерировать показатель акустического совпадения для каждого варианта речевого фрагмента на основе акустических показателей множественных подслов, включенных в фонетическое расширение варианта речевого фрагмента. Например, блок 140 повторного определения показателя может принимать фонетическое расширение ʺSE-ET-EE-ZE...ʺ для ʺCityZen reservationʺ, идентифицировать акустические показатели, принятые от акустической модели 112 для каждой из фонем ʺSE-ET-EE-ZE...ʺ, и перемножать идентифицированные акустические показатели для генерирования показателя акустического совпадения для ʺCityZen reservationʺ.
[0037] В некоторых реализациях, блок 140 повторного определения показателя может не принимать все акустические показатели от акустической модели 112. Вместо этого, блок 140 повторного определения показателя может принимать фонетические расширения от фонетического расширителя 130 и запрашивать у акустический модели 112 только акустические показатели, которые соответствуют подсловам в фонетических расширениях, принятых от фонетического расширителя 130. Например, блок 140 повторного определения показателя может запрашивать у акустической модели 112 акустические показатели для фонем ʺSEʺ, ʺETʺ, ʺIʺ, ʺZEʺ и других фонем, которые появляются в фонетических расширениях, но не фонем ʺBAʺ, ʺFUʺ, ʺKAʺ, и других фонем, которые не появляются в фонетических расширениях.
[0038] В некоторых реализациях, блок 140 повторного определения показателя может учитывать другие факторы при выборе транскрипции из вариантов транскрипции. Например, блок 140 повторного определения показателя может идентифицировать текущее местоположение пользователя и взвешивать выбор к идентификации вариантов транскрипции, более тесно связанных с текущим местоположением пользователя. В другом примере, блок 140 повторного определения показателя может идентифицировать текущее время суток и взвешивать выбор к идентификации вариантов транскрипции, более тесно связанных с временем суток. В еще одном примере, блок 140 повторного определения показателя может идентифицировать предпочтения пользователя, обеспечивающего речевой фрагмент, и взвешивать выбор к идентификации вариантов транскрипции, более тесно связанных с идентифицированными предпочтениями пользователя.
[0039] Могут использоваться разные конфигурации системы 100, где функциональные возможности акустической модели 112, языковой модели 114, автоматизированного распознавателя 110 речи, второй языковой модели 120, фонетического расширителя 130 и блока 140 повторного определения показателя можно объединить, дополнительно разделять, распределять или взаимозаменять. Система 100 может быть реализована в едином устройстве или распределяться по множественным устройствам.
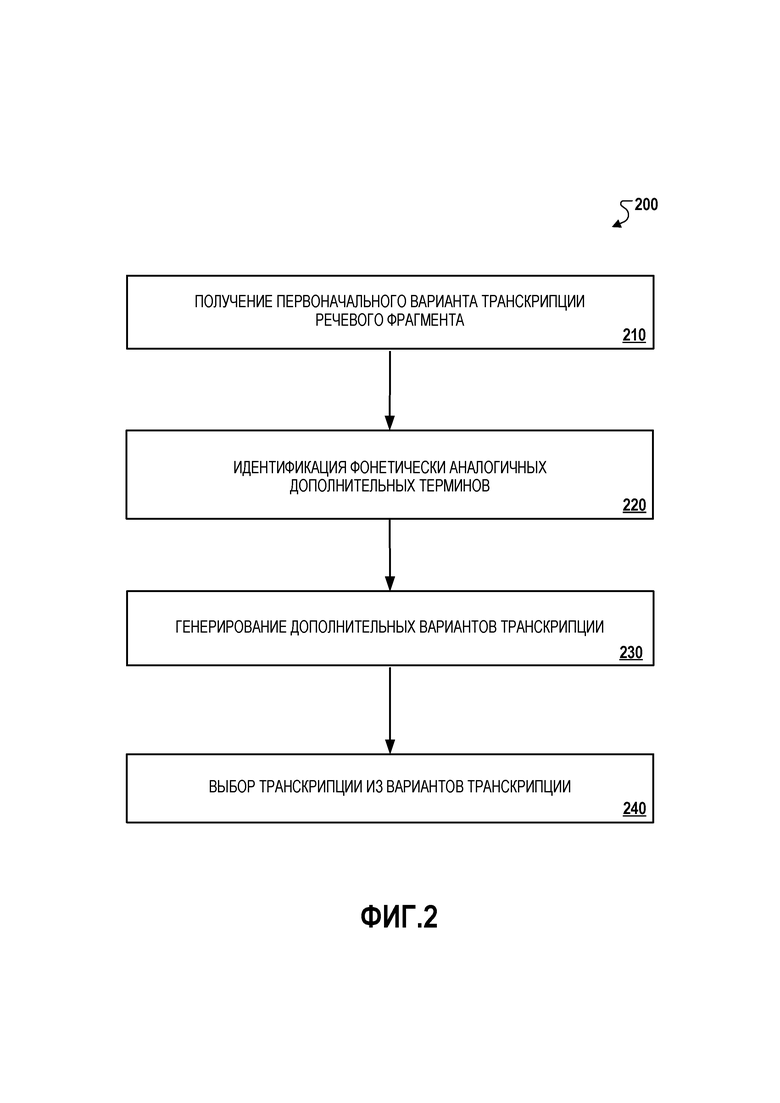
[0040] На фиг. 2 показана блок-схема операций иллюстративного процесса 200 для улучшения распознавания речи на основе внешних источников данных. Ниже описана обработка 200, осуществляемая компонентами системы 100, которые описаны со ссылкой на фиг. 1. Однако процесс 200 может осуществляться другими системами или конфигурациями системы.
[0041] Процесс 200 может включать в себя получение первоначального варианта транскрипции речевого фрагмента с использованием автоматизированного распознавателя речи (210). Например, автоматизированный распознаватель 110 речи может принимать акустические данные для речевого фрагмента ʺZaytinya reservationʺ и выводить первоначальный вариант транскрипции ʺSay tin ya reservationʺ.
[0042] Процесс 200 может включать в себя идентификацию, на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, одного или более дополнительных терминов, фонетически аналогичных первоначальному варианту транскрипции (220). Например, вторая языковая модель 120 может идентифицировать, что термины ʺZaytinyaʺ и ʺSay ten yaʺ звучат фонетически аналогично ʺSay tin yaʺ.
[0043] Процесс 200 может включать в себя генерирование одного или более дополнительных вариантов транскрипции на основе одного или более дополнительных терминов (230). Например, вторая языковая модель 120 может генерировать дополнительные варианты транскрипции ʺZaytinya reservationʺ и ʺSay ten ya reservationʺ на основе замены ʺSay tin yaʺ на ʺZaytinyaʺ и ʺSay ten yaʺ в первоначальном варианте речевого фрагмента ʺSay tin ya reservationʺ.
[0044] Процесс 200 может включать в себя выбор транскрипции из вариантов транскрипции (240). Например, блок 140 повторного определения показателя может выбирать транскрипцию ʺZaytinya reservationʺ из вариантов транскрипции ʺSay tin ya reservationʺ, ʺZaytinya reservationʺ и ʺSay ten ya reservationʺ. Выбор может базироваться на показателях правдоподобия и показателях акустического совпадения для каждого из вариантов транскрипции. Например, выбор может базироваться на идентификации варианта транскрипции с показателем правдоподобия, который указывает высокое правдоподобие варианта речевого фрагмента, присутствующего в данном языке, и показателем акустического совпадения, который указывает близкое акустическое сходство варианта речевого фрагмента с акустическими данными.
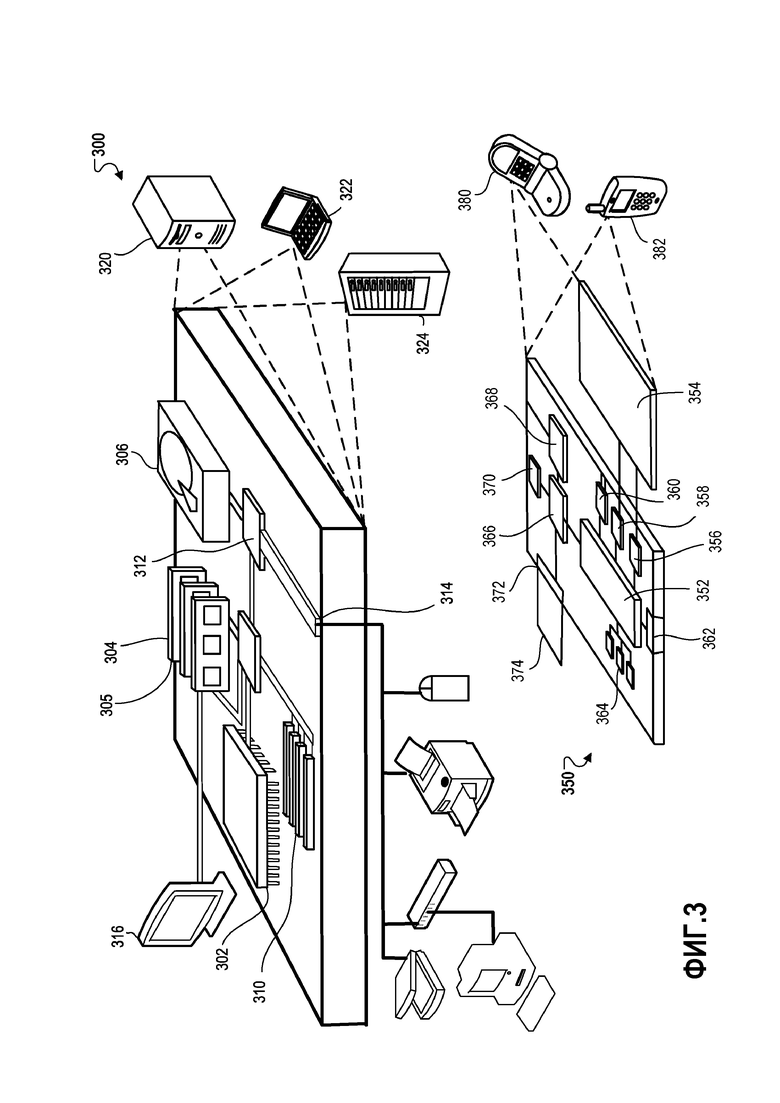
[0045] На фиг. 3 показана блок-схема вычислительных устройств 300, 350, которые могут использоваться для реализации систем и способов, описанных в этом документе, в качестве клиента или в качестве сервера или множества серверов. Вычислительное устройство 300 предназначено для представления различных форм цифровых компьютеров, например, портативных компьютеров, настольных компьютеров, рабочих станций, персональных цифровых помощников, серверов, ячеечных серверов, универсальных компьютеров и других подходящих компьютеров. Вычислительное устройство 350 предназначено для представления различных форм мобильных устройств, например, персональных цифровых помощников, сотовых телефонов, смартфонов и других аналогичных вычислительных устройств. Дополнительно вычислительное устройство 300 или 350 может включать в себя флеш-накопители на универсальной последовательной шине (USB). На флеш-накопителях на USB могут храниться операционные системы и другие приложения. Флеш-накопители на USB могут включать в себя компоненты ввода/вывода, например, беспроводной передатчик или разъем USB, который можно вставлять в порт USB другого вычислительного устройства. Показанные здесь компоненты, их соединения и отношения, и их функции, следует рассматривать только в порядке иллюстрации, но не ограничения, реализаций изобретения, описанного и/или заявленного в этом документе.
[0046] Вычислительное устройство 300 включает в себя процессор 302, память 304, запоминающее устройство 306, высокоскоростной интерфейс 308, подключенный к памяти 304 и высокоскоростным портам 310 расширения, и низкоскоростной интерфейс 312, подключенный к низкоскоростной шине 314 и запоминающему устройству 306. Все компоненты 302, 304, 306, 308, 310 и 312, соединены между собой с использованием различных шин, и могут быть установлены на общей материнской плате или другими способами при необходимости. Процессор 302 может обрабатывать инструкции, выполняющиеся на вычислительном устройстве 300, в том числе, инструкции, хранящиеся в памяти 304 или на запоминающем устройстве 306, для отображения графической информации для GUI на внешнем устройстве ввода/вывода, например, дисплее 316, подключенном к высокоскоростному интерфейсу 308. В других реализациях, множественные процессоры и/или множественные шины могут использоваться, при необходимости, совместно с множественными блоками памяти и типами памяти. Кроме того, множественные вычислительные устройства 300 могут быть соединены с каждым устройством, обеспечивающим части необходимых операций, например, банком серверов, группой ячеечных серверов или многопроцессорной системой.
[0047] В памяти 304 хранится информация в вычислительном устройстве 300. В одной реализации, память 304 представляет собой блок или блоки энергозависимой памяти. В другой реализации, память 304 представляет собой блок или блоки энергонезависимой памяти. Память 304 также может представлять собой другую форму компьютерно-считываемого носителя, например, магнитного или оптического диска.
[0048] Запоминающее устройство 306 способно обеспечивать хранилище данных большой емкости для вычислительного устройства 300. В одной реализации, запоминающее устройство 306 может представлять собой или содержать компьютерно-считываемый носитель, например, устройство флоппи-диск, устройство жесткого диска, устройство оптического диска или ленточное устройство, флеш-память или другое аналогичное твердотельное запоминающее устройство или массив устройств, включающий в себя устройства в сети области хранения или других конфигурациях. Компьютерный программный продукт может быть материально воплощен в носителе информации. Компьютерный программный продукт также может содержать инструкции, которые, при исполнении, осуществляют один или более способов, например, описанных выше. Носитель информации представляет собой компьютерно- или машиночитаемый носитель, например, память 304, запоминающее устройство 306 или память на процессоре 302.
[0049] Высокоскоростной контроллер 308 управляет широкополосными операциями для вычислительного устройства 300, тогда как низкоскоростной контроллер 312 управляет более узкополосными операциями. Такое выделение функций является только иллюстративной. В одной реализации, высокоскоростной контроллер 308 подключен к памяти 304, дисплею 316, например, через графический процессор или ускоритель, и к высокоскоростным портам 310 расширения, которые могут принимать различные карты расширения (не показаны). В реализации, низкоскоростной контроллер 312 подключен к запоминающему устройству 306 и низкоскоростному порту 314 расширения. Низкоскоростной порт расширения, который может включать в себя различные коммуникационные порты, например, USB, Bluetooth, Ethernet, беспроводного Ethernet, может быть подключен к одному или более устройствам ввода/вывода, например, клавиатуре, указательному устройству, паре микрофон/громкоговоритель, сканеру или через сетевой адаптер. Вычислительное устройство 300 может быть реализовано в нескольких разных формах, как показано на фигуре. Например, оно может быть реализовано в виде стандартного сервера 320, или несколько раз в группе таких серверов. Оно также может быть реализовано как часть системы 324 стойки серверов. Кроме того, оно может быть реализовано в персональном компьютере, например, портативном компьютере 322. Альтернативно, компоненты вычислительного устройства 300 можно объединить с другими компонентами в мобильном устройстве (не показано), например, устройстве 350. Каждое из таких устройств может содержать одно или более из вычислительных устройств 300, 350, и вся система может состоять из множественных вычислительных устройств 300, 350, осуществляющих связь друг с другом.
[0050] Вычислительное устройство 300 может быть реализовано в нескольких разных формах, как показано на фигуре. Например, оно может быть реализовано в виде стандартного сервера 320, или несколько раз в группе таких серверов. Оно также может быть реализовано как часть системы 324 стойки серверов. Кроме того, оно может быть реализовано в персональном компьютере, например, портативном компьютере 322. Альтернативно, компоненты вычислительного устройства 300 можно объединить с другими компонентами в мобильном устройстве (не показано), например, устройстве 350. Каждое из таких устройств может содержать одно или более из вычислительных устройств 300, 350, и вся система может состоять из множественных вычислительных устройств 300, 350, осуществляющих связь друг с другом.
[0051] Вычислительное устройство 350 включает в себя процессор 352, память 364 и устройство ввода/вывода, например, дисплей 354, интерфейс 366 связи и приемопередатчик 368, помимо других компонентов. Устройство 350 также может быть снабжено запоминающим устройством, например, микроприводом или другим устройством, для обеспечения дополнительного хранилища. Каждый из компонентов 350, 352, 364, 354, 366 и 368, соединены между собой с использованием различные шин, и некоторые компоненты могут быть установлены на общей материнской плате или другими способами при необходимости.
[0052] Процессор 352 может выполнять инструкции в вычислительном устройстве 350, в том числе инструкции, хранящиеся в памяти 364. Процессор может быть реализован как набор микросхем, состоящий из микросхем, которые включают в себя отдельные и множественные аналоговые и цифровые процессоры. Дополнительно, процессор может быть реализован с использованием разнообразных архитектур. Например, процессор 310 может представлять собой процессор CISC (с полным набором команд), процессор RISC (с сокращенным набором команд) или процессор MISC (с минимальным набором команд). Процессор может обеспечивать, например, для координации других компонентов устройства 350, например, управление пользовательскими интерфейсами, приложениями, выполняющимися устройством 350, и беспроводной связью, осуществляемой устройством 350.
[0053] Процессор 352 может осуществлять связь с пользователем через управляющий интерфейс 358 и интерфейс 356 дисплея, подключенный к дисплею 354. Дисплей 354 может представлять собой, например, TFT-дисплей (жидкокристаллический дисплей на тонкопленочных транзисторах) или дисплей OLED (на органических светодиодах) или другую подходящую технологию дисплея. Интерфейс 356 дисплея может содержать подходящую схему для возбуждения дисплея 354 для представления графической и другой информации пользователю. Управляющий интерфейс 358 может принимать команды от пользователя и преобразовывать их для подачи на процессор 352. Кроме того, может быть обеспечен внешний интерфейс 362, осуществляющий связь с процессором 352, для обеспечения связи в ближней зоне устройства 350 с другими устройствами. Внешний интерфейс 362 может обеспечивать, например, проводную связь в некоторых реализациях, или беспроводную связь в других реализациях, и также могут использоваться множественные интерфейсы.
[0054] В памяти 364 хранится информация в вычислительном устройстве 350. Память 364 может быть реализована в виде одного или более из компьютерно-считываемого носителя или носителей, блока или блоков энергозависимой памяти или блока или блоков энергонезависимой памяти. Дополнительная память 374 также может быть обеспечена и подключена к устройству 350 через интерфейс 372 расширения, который может включать в себя, например, интерфейс карты SIMM (модуля памяти с односторонним расположением микросхем). Такая дополнительная память 374 может обеспечивать дополнительное пространство хранения для устройства 350, или также может сохранять приложения или другую информацию для устройства 350. В частности, дополнительная память 374 может включать в себя инструкции для осуществления или дополнения процессов, описанных выше, и также может включать в себя защищенную информацию. Таким образом, например, дополнительная память 374 может быть обеспечена как модуль безопасности для устройства 350, и может быть запрограммирована инструкциями, которые допускают безопасное использование устройства 350. Кроме того, защищенные приложения могут быть обеспечены посредством карт SIMM, совместно с дополнительной информацией, например, размещения идентификационной информации на карте SIMM с защитой от атак.
[0055] Память может включать в себя, например, флеш-память и/или память NVRAM, как рассмотрено ниже. В одной реализации, компьютерный программный продукт материально воплощен в носителе информации. Компьютерный программный продукт содержит инструкции, которые, при исполнении, осуществляют один или более способов, например, описанных выше. Носитель информации представляет собой компьютерно- или машиночитаемый носитель, например, память 364, дополнительную память 374 или память на процессоре 352, который может приниматься, например, через приемопередатчик 368 или внешний интерфейс 362.
[0056] Устройство 350 может осуществлять беспроводную связь через интерфейс 366 связи, который, при необходимости, может включать в себя схему обработки цифрового сигнала. Интерфейс 366 связи может обеспечивать связь в различных режимах или протоколах, например, речевые вызовы GSM, обмен сообщениями SMS, EMS или MMS, CDMA, TDMA, PDC, WCDMA, CDMA2000 или GPRS, в том числе. Такая связь может осуществляться, например, посредством радиовероятностного приемопередатчика 368. Кроме того, может осуществляться связь ближнего действия, например, с использованием Bluetooth, WiFi или другого такого приемопередатчика (не показан). Кроме того, модуль 370 приема GPS (глобальной системы позиционирования) может выдавать дополнительные беспроводные данные, связанные с навигацией и определением местоположения на устройство 350, которые могут, при необходимости, использоваться приложениями, выполняющимися на устройстве 350.
[0057] Устройство 350 также может осуществлять звуковую связь с использованием аудиокодека 360, который может принимать произнесенную информацию от пользователя и преобразовывать ее в полезную цифровую информацию. Аудиокодек 360 может аналогично генерировать слышимый звук для пользователя, например, через громкоговоритель, например, в устройствах 350 телефонной трубки. Такой звук может включать в себя звук из речевых телефонных вызовов, может включать в себя записанный звук, например, речевые сообщения, музыкальные файлы и т.д. и также может включать в себя звук, сгенерированный приложениями, действующими на устройстве 350.
[0058] Вычислительное устройство 350 может быть реализовано в нескольких разных формах, как показано на фигуре. Например, оно может быть реализовано как сотовый телефон 480. Оно также может быть реализовано как часть смартфона 382, персонального цифрового помощника или другого аналогичного мобильного устройства.
[0059] Различные реализации описанных здесь систем и способов возможны в виде цифровой электронной схемы, интегральной схемы, специально сконструированных ASIC (специализированных интегральных схем), компьютерного оборудования, программно-аппаратного обеспечения, программного обеспечения и/или сочетаний таких реализаций. Эти различные реализации могут включать в себя реализацию в одной или более компьютерных программах, исполнимых и/или интерпретируемых в программируемой системе, включающей в себя, по меньшей мере, один программируемый процессор, специального или общего назначения, подключенный для приема данных и инструкций от, и для передачи данных и инструкций в, систему хранения, по меньшей мере, одно устройство ввода и по меньшей мере, одно устройство вывода.
[0060] Эти компьютерные программы (также известные как программы, программное обеспечение, прикладные программы или код) включают в себя машинные инструкции для программируемого процессора, и могут быть реализованы на высокоуровневом процедурном и/или объектно-ориентированном языке программирования и/или на ассемблере/машинном языке. Используемые здесь термины "машиночитаемый носитель", "компьютерно-считываемый носитель" относятся к любому компьютерному программному продукту, устройству и/или оборудованию, например, магнитным дискам, оптическим дискам, памяти, программируемым логическим устройствам (PLD), используемым для подачи машинных инструкций и/или данных на программируемый процессор, включающим в себя машиночитаемый носитель, который принимает машинные инструкции в качестве машиночитаемого сигнала. Термин "машиночитаемый сигнал" относится к любому сигналу, используемому для подачи машинных инструкций и/или данных на программируемый процессор.
[0061] Для обеспечения взаимодействия с пользователем, описанные здесь системы и методы могут быть реализованы на компьютере, имеющем устройство отображения, например, монитор типа CRT (электронно-лучевой трубки) или LCD (жидкокристаллического дисплея) для отображения информации пользователю и клавиатуру и указательное устройство, например, мышь или шаровой манипулятор, с помощью которого пользователь может обеспечивать ввод в компьютер. Для обеспечения взаимодействия с пользователем также могут использоваться другие виды устройств; например, обратная связь, предоставляемая пользователю, может принимать любую форму чувственной обратной связи, например, зрительной обратной связи, слуховой обратной связи или тактильной обратной связи; и ввод от пользователя может приниматься в любой форме, включающий в себя акустический, речевой или тактильный ввод.
[0062] Описанные здесь системы и методы могут быть реализованы в вычислительной системе, которая включает в себя скрытый компонент, например, сервер данных, или включает в себя компонент промежуточного программного обеспечения, например, сервер приложений, или включает в себя интерфейсный компонент, например, компьютер-клиент, имеющий графический пользовательский интерфейс или веб-браузер через который пользователь может взаимодействовать с реализацией описанных здесь систем и методов, или любой комбинацией таких скрытых, промежуточных программных или интерфейсных компонентов. Компоненты системы могут соединяться между собой носителем для передачи цифровых данных в любой форме, например, сети связи. Примеры сетей связи включают в себя локальную сеть ("LAN"), глобальную сеть ("WAN") и интернет.
[0063] Вычислительная система может включать в себя клиенты и серверы. Клиент и сервер, в общем случае, удалены друг от друга и обычно взаимодействуют через сеть связи. Отношение клиента и сервера обусловлено компьютерными программами, выполняющимися на соответствующих компьютерах, связанными друг с другом отношением клиент-сервер.
[0064] Было описано несколько вариантов осуществления. Тем не менее, следует понимать, что можно предложить различные модификации, не выходящие за рамки сущности и объема изобретения. Кроме того, последовательности логических операций, изображенные на фигурах, не требуют конкретного показанного порядка, или последовательного порядка, для достижения желаемых результатов. Кроме того, можно обеспечивать другие этапы, или исключать некоторые этапы из описанных последовательностей логических операций, и другие компоненты можно добавлять к, или удалять из, описанных систем. Соответственно, другие варианты осуществления подлежат включению в объем нижеследующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ РАСПОЗНАВАНИЯ РЕЧИ | 2006 |
|
RU2393549C2 |
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |
| АРХИТЕКТУРА РАСПОЗНАВАНИЯ ДЛЯ ГЕНЕРАЦИИ АЗИАТСКИХ ИЕРОГЛИФОВ | 2008 |
|
RU2477518C2 |
| СПОСОБ СИНТЕЗА РЕЧИ | 2009 |
|
RU2421827C2 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| УНИВЕРСАЛЬНЫЕ ОРФОГРАФИЧЕСКИЕ МНЕМОСХЕМЫ | 2005 |
|
RU2441287C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДОСТАВЛЕНИЯ ТЕКСТОВОГО СООБЩЕНИЯ | 2004 |
|
RU2320082C2 |
Изобретение относится к средствам для получения транскрипции речевого фрагмента. Технический результат заключается в повышении точности транскрипции речевого фрагмента. Получают первоначальный вариант транскрипции речевого фрагмента с использованием автоматизированного распознавателя речи. Идентифицируют, на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, один или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции. При этом определение, аналогичны ли фонетически термины, предусматривают определение меры сходства и сравнение меры с порогом, или определение, превышает ли мера сходства меры сходства, относящиеся к другим парам терминов. Генерируют один или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов. Выбирают транскрипцию из вариантов транскрипции. 3 н. и 17 з.п. ф-лы, 3 ил.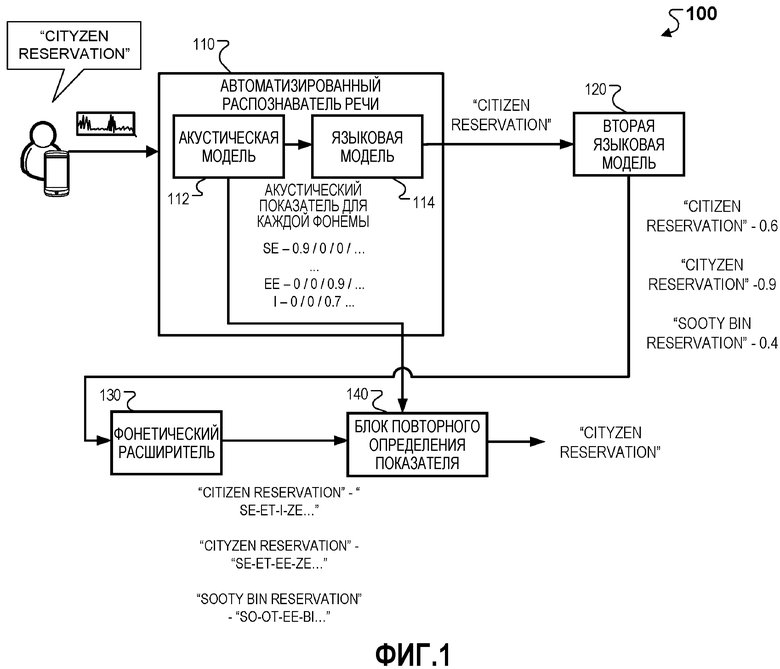
1. Компьютерно-реализуемый способ получения транскрипции речевого фрагмента, содержащий этапы, на которых:
получают первоначальный вариант транскрипции речевого фрагмента с использованием автоматизированного распознавателя речи;
идентифицируют, на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, один или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции;
генерируют один или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов и
выбирают транскрипцию из вариантов транскрипции.
2. Способ по п.1, в котором языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включает в себя один или более терминов, отсутствующих в языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции.
3. Способ по п.1 или 2, в котором обе из языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, и языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включают в себя последовательность из одного или более терминов, но указывают, что эта последовательность имеет разные вероятности появления.
4. Способ по любому из предыдущих пунктов, в котором языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, указывает вероятности появления слов или последовательностей слов.
5. Способ по любому из предыдущих пунктов, содержащий этапы, на которых:
для каждого из вариантов транскрипции, определяют вероятностный показатель, который отражает, насколько часто ожидается произнесение варианта транскрипции; и
для каждого из вариантов транскрипции, определяют показатель акустического совпадения, который отражает фонетическое сходство между вариантом транскрипции и речевым фрагментом,
причем выбор транскрипции из вариантов транскрипции основывается на показателях акустического совпадения и вероятностных показателях.
6. Способ по п.5, в котором этап определения показателя акустического совпадения, который отражает фонетическое сходство между вариантом транскрипции и речевым фрагментом, содержит этапы, на которых:
получают показатели акустического совпадения подслов от автоматизированного распознавателя речи;
идентифицируют подмножество показателей акустического совпадения подслов, которые соответствуют варианту транскрипции; и
генерируют показатель акустического совпадения на основе подмножества показателей акустического совпадения подслов, которые соответствуют варианту транскрипции.
7. Способ по п.5 или 6, в котором этап определения вероятностного показателя, который отражает, насколько часто ожидается произнесение варианта транскрипции, содержит этап, на котором определяют вероятностный показатель на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции.
8. Способ по любому из предыдущих пунктов, в котором этап генерирования одного или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов содержит этап, на котором заменяют идентифицированными одним или более терминами, фонетически аналогичными одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции, эти один или более терминов, которые уже присутствуют в первоначальном варианте транскрипции.
9. Система для получения транскрипции речевого фрагмента, содержащая один или более компьютеров и одно или более запоминающих устройств, хранящих инструкции, которые приспособлены при их исполнении на одном или более компьютерах предписывать одному или более компьютерам осуществлять операции, содержащие:
получение первоначального варианта транскрипции речевого фрагмента с использованием автоматизированного распознавателя речи;
идентификацию, на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, одного или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции;
генерирование одного или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов и
выбор транскрипции из вариантов транскрипции.
10. Система по п.9, в которой языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включает в себя один или более терминов, отсутствующих в языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции.
11. Система по п.9 или 10, в которой обе из языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, и языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включают в себя последовательность из одного или более терминов, но указывают, что эта последовательность имеет разные вероятности появления.
12. Система по любому из пп.9-11, в которой языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, указывает вероятности появления слов или последовательностей слов.
13. Система по любому из пп.9-12, в которой операции содержат:
для каждого из вариантов транскрипции, определение вероятностного показателя, который отражает, насколько часто ожидается произнесение варианта транскрипции; и
для каждого из вариантов транскрипции, определение показателя акустического совпадения, который отражает фонетическое сходство между вариантом транскрипции и речевым фрагментом,
причем выбор транскрипции из вариантов транскрипции основывается на показателях акустического совпадения и вероятностных показателях.
14. Система по п.13, в которой определение показателя акустического совпадения, который отражает фонетическое сходство между вариантом транскрипции и речевым фрагментом, содержит:
получение показателей акустического совпадения подслов от автоматизированного распознавателя речи;
идентификацию подмножества показателей акустического совпадения подслов, которые соответствуют варианту транскрипции; и
генерирование показателя акустического совпадения на основе подмножества показателей акустического совпадения подслов, которые соответствуют варианту транскрипции.
15. Система по п.13 или 14, в которой определение вероятностного показателя, который отражает, насколько часто ожидается произнесение варианта транскрипции, содержит определение вероятностного показателя на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции.
16. Система по любому из пп.9-15, в которой генерирование одного или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов содержит замену идентифицированными одним или более терминами, фонетически аналогичными одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции, этих одного или более терминов, которые уже присутствуют в первоначальном варианте транскрипции.
17. Долговременный машиночитаемый носитель, хранящий программное обеспечение, содержащее инструкции, исполняемые одним или более компьютерами, которые, при таком исполнении, предписывают одному или более компьютерам осуществлять операции, содержащие:
получение первоначального варианта транскрипции речевого фрагмента с использованием автоматизированного распознавателя речи;
идентификацию, на основе языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, одного или более терминов, фонетически аналогичных одному или более терминам, которые уже присутствуют в первоначальном варианте транскрипции;
генерирование одного или более дополнительных вариантов транскрипции на основе идентифицированных одного или более терминов и
выбор транскрипции из вариантов транскрипции.
18. Носитель по п.17, при этом языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включает в себя один или более терминов, отсутствующих в языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции.
19. Носитель по п.17, при этом обе из языковой модели, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, и языковой модели, используемой автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, включают в себя последовательность из одного или более терминов, но указывают, что эта последовательность имеет разные вероятности появления.
20. Носитель по п.17, при этом языковая модель, которая не используется автоматизированным распознавателем речи при генерировании первоначального варианта транскрипции, указывает вероятности появления слов или последовательностей слов.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 9047868 B1, 02.06.2015 | |||
| US 8041566 B2, 18.10.2011 | |||
| US 5839106 A, 17.11.1998 | |||
| 0 |
|
SU153322A1 | |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |

