ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способу распознавания речи. Данное изобретение также относится к электронному устройству и компьютерному программному продукту.
УРОВЕНЬ ТЕХНИКИ
Распознавание речи используется во многих приложениях, например при вызове по имени в мобильных терминалах, доступе к корпоративным данным по телефонным линиям, мультирежимном речевом браузинге веб-страниц, голосовом вводе коротких сообщений (SMS), почтовых сообщений и т.д.
В распознавании речи одна из проблем относится к преобразованию устного фрагмента речи в форме сигнала акустической формы волны в текстовую строку, представляющую произнесенные слова. На практике это очень сложно обеспечить без ошибок распознавания. Ошибки не обязательно имеют серьезные последствия в приложении, если могут быть вычислены точные меры достоверности, которые показывают вероятность того, что данное слово или фраза нераспознаны.
В распознавании речи ошибки в основном классифицируются на три следующие категории.
Ошибка ввода
Пользователь ничего не говорит, но, несмотря на это, командное слово распознается; либо пользователь произносит слово, которое не является командным словом и командное слово также распознается.
Ошибка стирания
Пользователь произносит командное слово, но ничего не распознается.
Ошибка замещения
Командное слово, произнесенное пользователем, распознается как другое командное слово.
В теоретически оптимальном решении распознаватель речи не делает ни одной из указанных ошибок. Однако в практических ситуациях распознаватель речи может делать ошибки всех указанных типов. Для пригодности интерфейса пользователя важным является создание распознавателя речи таким образом, чтобы удельный вес различных типов ошибок был оптимальным. Например, при голосовой активации, когда устройство, активируемое голосом, ожидает целыми часами некоторого слова активации, важно, чтобы устройство ошибочно не активировалось случайным образом. Также важно, чтобы командные слова, произнесенные пользователем, распознавалось с хорошей точностью. В данном случае, однако, более важно, чтобы не было ошибочных активации. На практике это означает, что пользователь должен повторять произнесенное командное слово более часто, чтобы оно было распознано корректно с достаточной вероятностью.
При распознавании числовой последовательности почти все ошибки существенны в равной степени. Любая ошибка в распознавании чисел в последовательности приводит к неверной числовой последовательности. Также ситуация, при которой пользователь не говорит ничего, а число тем не менее распознается, является некомфортной для пользователя. Однако ситуация, в которой пользователь произносит число невнятно, и число не распознается, может быть исправлена пользователем путем произнесения чисел более внятно.
Распознавание единственного командного слова в настоящее время является весьма типичной функцией, реализованной распознаванием речи. Например, распознаватель речи может спросить пользователя: «Желаете ли вы принять звонок?», с ожиданием от пользователя ответа либо «да», либо «нет». В таких ситуациях, где существует очень мало альтернативных командных слов, командные слова часто, если не всегда, распознаются корректно. Другими словами, число ошибок замещения в таких ситуациях очень мало. Одна проблема в распознавании единственного командного слова заключается в том, что произнесенная команда не распознается вообще, либо неподходящее слово распознается как командное слово.
Множество существующих автоматических систем распознавания аудиоактивности (ASR) включают препроцессор обработки сигналов, который преобразует волновую форму аудиоактивности в параметры признаков. Один из наиболее часто используемых признаков - мел-частотные кепстральные коэффициенты (Mel Frequency Cepstrum Coefficients, MFCC). Кепстр - это обратное дискретное косинусное преобразование (Inverse Discrete Cosine Transform, IDCT) логарифма кратковременного спектра мощности сигнала. Одно из преимуществ при использовании таких коэффициентов состоит в том, что они уменьшают размерность спектрального вектора аудиоактивности.
Распознавание речи обычно основывается на стохастическом моделировании речевого сигнала, например, с использованием Скрытых Марковских Моделей (Hidden Markov Models, НММ). В методах НММ неизвестный речевой образец сравнивается с известными эталонными образцами (сопоставление образцов). В методе НММ создаются речевые образцы, и этот этап генерации речевого образца моделируется с применением модели изменения состояний в соответствии с методом Маркова. Рассматриваемая модель изменения состояний, таким образом, является моделью НММ. В этом случае распознавание речи на принятых речевых образцах выполняется путем задания вероятности наблюдения на речевых образцах в соответствии со скрытой Марковской моделью. В распознавании речи с использованием метода НММ модель НММ сначала формируется для каждого слова, которое нужно распознать, т.е. для каждого эталонного слова. Эти модели НММ сохраняются в памяти распознавателя речи. Когда распознаватель речи принимает речевой образец, вычисляется вероятность наблюдения для каждой модели НММ в памяти и как результат распознавания берется эквивалентное слово для модели НММ с наибольшей вероятностью наблюдения. Таким образом, для каждого слова-образца вычисляется вероятность того, что это есть слово, произнесенное пользователем. Вышеуказанная наибольшая вероятность наблюдения описывает сходство принятого речевого образца и ближайшей модели НММ, т.е. ближайшего эталонного речевого образца. Другими словами, модель НММ является последовательностью векторов признаков как кусочно-линейный стационарный процесс, для которого каждый стационарный сегмент будет ассоциирован со специфическим состоянием модели НММ. Векторы признаков обычно формируются из кадров, кадр за кадром, кадры формируются из приходящего аудиосигнала. При использовании модели М фрагмент речи O={O1,…,От} моделируется как последовательность дискретных стационарных состояний S={SL,…,SN} (N<=T) с мгновенными переходами между этими состояниями.
В идеальном варианте должна быть модель НММ для каждого возможного фрагмента речи. Однако в действительности это недостижимо для всех, кроме некоторых очень ограниченных, задач. Фраза может быть моделирована как последовательность слов. Для дальнейшего снижения числа параметров и для устранения необходимости нового обучения каждый раз, когда новое слово добавлено в лексикон, модели слов часто состоят из связанных элементов частей слов. Наиболее широко используемый элемент - это речевые звуки (фоны), которые являются акустической реализацией лингвистических категорий, называемых фонемами. Фонемы - это категории речевых звуков, которые достаточны для дифференцирования различных слов в языке. Для моделирования сегмента, соответствующего фону, обычно используется одно или более состояние модели НММ. Модели слова состоят из соединения моделей фонов или фонем (ограниченных произношением из лексикона), а модели фраз состоят из соединения моделей слов (ограниченных грамматикой).
Распознаватель речи выполняет сопоставление образцов на акустическом речевом сигнале для вычисления наиболее вероятной последовательности слов. Оценка вероятности фрагмента речи - это побочный продукт декодирования, который сам по себе показывает насколько надежно сопоставление. Для того чтобы быть полезной мерой достоверности, эта оценка вероятности должна сравниваться с оценкой правдоподобия всех альтернативных конкурирующих фрагментов речи, например:
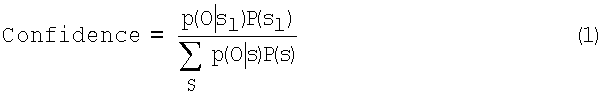
где О - акустический сигнал, s1 - конкретный фрагмент речи, p(O|s1) - акустическое правдоподобие фрагмента речи s1, и P(s1) - априорная вероятность фрагмента речи. Знаменатель в вышеуказанном уравнении - нормализующий член, который представляет комбинированную оценку любого фрагмента речи, который может быть произнесен (включая s1). На практике нормализующий член не может быть вычислен напрямую, потому что число фрагментов речи, которое нужно просуммировать, бесконечно.
Однако нормализующий член может быть аппроксимирован, например, посредством обучения специальным текстом независимой модели речи и использования оценки правдоподобия, полученной декодированием фрагмента речи с помощью этой модели, как нормализующего члена. Если модель речи достаточно сложна и хорошо обучена, ожидаемая оценка правдоподобия будет хорошей аппроксимацией знаменателя в уравнении (1).
Недостаток вышеприведенного приближения к оценке достоверности заключается в необходимости использования специальной модели речи для декодирования речи. Это означает дополнительные вычислительные затраты в процессе декодирования, поскольку вычисленный нормализующий член не имеет отношения к тому, какой фрагмент речи выбран распознавателем как наиболее вероятный. Он нужен только для определения доверительной оценки.
Альтернативно, аппроксимация может быть основана на гауссовых смесях, которые оцениваются в наборе модели, безотносительно к тому, частью каких слов они являются. Это более простая аппроксимация, поскольку при этом не нужно определение дополнительных гауссовых смесей. Неудобство этой аппроксимации состоит в том, что определяемые гауссовы смеси могут соответствовать очень малому подмножеству гауссовых смесей в наборе модели, поэтому аппроксимация будет необъективной и неточной.
Акустический набор модели, например скрытые Марковские модели, обычно могут содержать 25000-100000 гауссовых смесей для задач с большим словарем. Вероятности модели НММ могут быть вычислены суммированием значений правдоподобия этих индивидуальных гауссовых смесей

где о - вектор наблюдения размерностью D, m - вектор средней величины, и σ - вектор дисперсии.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение предоставляет средство речевого распознавания, в котором определяется и используется аппроксимация нормализующего члена в уравнении (1). Эта аппроксимация возможна при использовании так называемых подпространственных скрытых Марковских моделей (подпространственных НММ) для акустического моделирования. Подпространственные скрытые Марковские модели описаны более подробно в публикации "Subspace Distribution Clustering Hidden Markov Model", Enrico Bocchieri and Brian Mak, IEEE Transactions on Speech And Audio Processing, том 9, номер 3, март 2001.
В соответствии с первым аспектом настоящего изобретения предлагается способ распознавания речи, содержащий:
- прием кадров, содержащих выборки аудиосигнала;
- формирование вектора признаков, содержащего первое число компонентов вектора для каждого кадра;
- проецирование вектора признаков по меньшей мере на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно первому числу;
- определение для каждого проецированного вектора набора моделей смешивания, который обеспечивает наивысшую вероятность наблюдения;
- анализ набора моделей смешивания для определения результата распознавания;
- определение меры достоверности для результата распознавания, когда результат распознавания найден, это определение включает:
- определение вероятности того, что результат распознавания корректен;
- определение нормализующего члена путем выбора для каждого состояния среди указанного набора моделей смешивания одной модели смешивания, которая обеспечивает наивысшее правдоподобие; и
- деление этой вероятности на указанный нормализующий член;
при этом способ включает также сравнение меры достоверности с пороговым значением для определения того, достаточно ли надежен результат распознавания.
В соответствии со вторым аспектом настоящего изобретения предлагается электронное устройство, содержащее:
- вход для приема аудиосигнала;
- аналого-цифровой преобразователь для формирования выборок из аудиосигнала;
- организатор для размещения выборок аудиосигнала в кадры;
- экстрактор признаков для формирования вектора признаков, содержащего первое число компонентов вектора для каждого кадра, и для проецирования вектора признаков по меньшей мере на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно первому числу;
калькулятор вероятности для определения для каждого проецированного вектора набора моделей смешивания, который обеспечивает наивысшую вероятность наблюдения, и анализа набора моделей смешивания для определения результата распознавания;
- определитель достоверности для определения меры достоверности для результата распознавания, когда результат распознавания найден, это определение включает:
- определение вероятности того, что результат распознавания корректен;
- определение нормализующего члена путем выбора для каждого состояния среди указанного набора моделей смешивания одной модели смешивания, которая обеспечивает наивысшее правдоподобие; и
- деление этой вероятности на указанный нормализующий член;
- компаратор для сравнивания меры достоверности с пороговым значением для определения того, достаточно ли надежен результат распознавания.
В соответствии с третьим аспектом настоящего изобретения предлагается компьютерный программный продукт, содержащий машинные инструкции для выполнения распознавания речи, содержащего:
- прием кадров, содержащих выборки аудиосигнала;
- формирование вектора признаков, содержащего первое число компонентов вектора для каждого кадра;
- проецирование вектора признаков по меньшей мере на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно первому числу;
- определение для каждого проецированного вектора набора моделей смешивания, который обеспечивает наивысшее правдоподобие наблюдения;
- анализ набора моделей смешивания для определения результата распознавания;
- определение меры достоверности для результата распознавания, когда результат распознавания найден, это определение включает:
- определение вероятности того, что результат распознавания корректен;
- определение нормализующего члена путем выбора для каждого состояния среди указанного набора моделей смешивания одной модели смешивания, которая обеспечивает наивысшее правдоподобие; и
- деление этой вероятности на указанный нормализующий член;
при этом компьютерный программный продукт включает также машинные инструкции для сравнения меры достоверности с пороговым значением, для определения того, достаточно ли надежен результат распознавания.
При использовании настоящего изобретения надежность распознавания речи может быть улучшена по сравнению с известными способами и распознавателями речи.
Кроме того, становятся меньше требования к памяти для хранения эталонных образцов по сравнению с распознавателями речи, которым нужно больше эталонных образцов. Способ распознавания речи настоящего изобретения может также выполнять распознавание речи быстрее, чем известные способы распознавания речи.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Далее данное изобретение будет описано более подробно со ссылками на прилагаемые чертежи, на которых:
фиг.1 иллюстрирует беспроводное коммуникационное устройство в соответствии с примером реализации данного изобретения в виде упрощенной схемы, и
фиг.2 демонстрирует способ в соответствии с примером реализации данного изобретения в виде блок-схемы.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Далее будут рассмотрены некоторые теоретические основы подпространственных моделей НММ, которые использованы в способе данного изобретения. Подпространственные модели НММ характеризуются более компактным представлением модели по сравнению с обычными моделями НММ. Это достигается кластеризацией компонентов вектора признаков D-размерного вектора признаков в ряде подпространств (n). Для n=1 (одно подпространство размерности D) подпространственная модель НММ превращается в обычную модель НММ в D-размерном пространстве признаков. Максимальное число подпространств равно размерности (D) исходного пространства признаков, где каждое подпространство имеет размерность 1.
Подпространственное представление делает возможным квантовать подпространства, используя относительно небольшие кодовые книги, например кодовые книги с 16-256 элементами на одно подпространство. Каждая композиция представлена тогда индексами (m1,…,mN) кодовых слов в N подпространственных кодовых книгах. Это представление имеет два последствия. Во-первых, набор модели может быть представлен в очень компактной форме, во-вторых, вычисление правдоподобия для смесей в каждом состоянии модели НММ может быть выполнено более эффективно (быстрее) путем предварительного вычисления и совместного использования промежуточных результатов.
Настоящее изобретение базируется в основном на втором свойстве, указанном выше. Для наблюдаемого вектора признаков, О, вероятность гауссовой смеси (m1,…,mN) вычисляется следующим образом:

В уравнении (2) предполагается диагональная ковариантность. Первое произведение с индексом k уравнения (2) вычисляется над рядом подпространств (K), а второе произведение с индексами d (1,…,N) вычисляется над индивидуальными компонентами признаков внутри подпространства. Члены Ok, µsmk и σ2smk - проекция наблюдаемого вектора признаков, средний вектор и вектор дисперсии m-ой компоненты смеси s-го состояния на к-й поток соответственно. Член N() - гауссова функция плотности вероятности состояния s. Из-за того, что подпространственные кодовые книги относительно невелики, член

может быть предварительно вычислен и кэширован перед определением вероятностей индивидуальных смесей. Это и делает определение вероятностей смесей в наборе подпространственной модели НММ более быстрым, чем в обычном наборе модели.
Как было уже упомянуто в данном описании, мера достоверности показывает вероятность того, что данное слово или фраза были неправильно распознаны. Следовательно, мера достоверности должна быть рассчитана для определения того, достаточно ли надежен результат распознавания или нет. В данном изобретении мера достоверности основана на подпространственном кэше, который вычислен каким-либо образом при использовании подпространственных моделей НММ.
Нормализующий член уравнения (1) для фрагмента речи вычисляется как:

Этот нормализующий член соответствует модели НММ с числом состояний (s), равным числу кадров (Т) в рассматриваемом аудиосигнале, и одним компонентом смеси на состояние. Компонент m смеси имеет наивысшее возможное правдоподобие в подпространственном разбиении данного набора модели. Смеси в этой специальной модели НММ могут в действительности не появляться в любых других моделях НММ в наборе модели, и, следовательно, нормализующий член всегда является правдоподобием, которое больше или равно правдоподобию любого данного фрагмента речи. Другими словами, нормализующий член - это аппроксимация намного более объемного вычисления, в котором для каждого кадра выполняются следующие шаги. Определяется смесь с наивысшей оценкой, что означает вычисление, например, 25000 значений правдоподобия (если существует 25000 смесей), чтобы найти смесь с наивысшей оценкой. При использовании подпространственных моделей НММ нормализующий член уравнения (3) может быть вычислен намного быстрее, потому что время вычисления не зависит от числа смесей, а зависит только от числа потоков (К в уравнении 3) и размера используемых кодовых книг. Например, если сформированы 39 потоков с размерностью 1 и использованы кодовые книги с 32 элементами для каждого потока, тогда для каждой кодовой книги определяется одно правдоподобие смеси, что означает необходимость вычисления только 32 значений правдоподобия смесей.
Далее функция распознавателя 8 речи в соответствии с предпочтительной реализацией данного изобретения будет описана более подробно, со ссылками на электронное устройство 1 на фиг.1 и блок-схему на фиг.2. Распознаватель 8 речи подключен к электронному устройству 1 (например, беспроводному коммуникационному устройству), однако очевидно, что распознаватель 8 речи может быть частью электронного устройства 1, где некоторые операционные блоки могут быть общими для распознавателя 8 речи и электронного устройства 1. Распознаватель 8 речи может также быть реализован как модуль, который подключен внутренне или внешне к электронному устройству 1. Электронное устройство 1 не обязательно должно быть беспроводным коммуникационным устройством, и может являться компьютером, замком, телевизором, игрушкой и другим устройством, где могут использоваться возможности распознавания речи.
Для возможности распознавания речи в распознавателе 8 речи сформирована модель НММ (шаг 201) для каждого слова, которое нужно распознать, т.е. для каждого эталонного слова. Они могут быть сформированы, например, обучением распознавателя 8 речи с помощью определенного обучающего материала. Также на основе этих моделей НММ сформированы подпространственные модели НММ (шаг 202). В примере реализации настоящего изобретения N-потоковые подпространственные модели НММ могут быть получены путем разбиения пространства признаков размерности D на N подмножеств с признаками dk так, что

Каждая из исходных гауссовых смесей проецируется на каждое подпространство признаков для получения n подпространственных гауссовых смесей. Результирующие подпространственные модели НММ квантуют, например, с использованием кодовых книг, и квантованные модели НММ сохраняют в памяти 14 (шаг 203) распознавателя 8 речи.
Для выполнения распознавания речи акустический сигнал (аудиосигнал, речь) преобразуется известным образом в электрический сигнал посредством микрофона, например микрофона 2 беспроводного коммуникационного устройства 1. Частотная характеристика речевого сигнала обычно ограничена диапазоном частот до 10 кГц, например в диапазоне частот от 100 Гц до 10 кГц, но изобретение не ограничено только таким диапазоном частот. Однако частотная характеристика речи не является постоянной во всем диапазоне частот, обычно низких частот присутствует больше, чем высоких. Более того, частотная характеристика речи различна для различных людей.
Электрический сигнал, генерированный микрофоном 2, усиливается, если необходимо, в усилителе 3. Усиленный сигнал преобразуется в цифровую форму с помощью аналого-цифрового преобразователя 4 (ADC). Аналого-цифровой преобразователь 4 формирует выборки, представляющие амплитуду сигнала в момент выборки. Аналого-цифровой преобразователь 4 обычно формирует выборки сигнала с определенным интервалом, т.е. с определенной частотой. Сигнал разделяется на речевые кадры, это означает, что за одно время обрабатывается некоторая длина аудиосигнала. Длина кадра обычно составляет несколько миллисекунд, например 20 мс. В данном примере кадры передают к распознавателю 8 речи через блок ввода/вывода 6а, 6b и шину интерфейса 7.
Распознаватель 8 речи также содержит речевой процессор 9, в котором выполняются вычисления для распознавания речи. Речевой процессор 9 может быть, например, цифровым сигнальным процессором (DSP).
Выборки аудиосигнала являются входными данными 204 для речевого процессора 9. В речевом процессоре 9 выборки обрабатываются кадр за кадром, т.е. обрабатывается каждая выборка одного кадра для выполнения выделения признака на речевом кадре. На шаге 205 выделения признака формируется вектор признаков для каждого речевого кадра, который является входной информацией для распознавателя 8 речи. Коэффициенты вектора признаков относятся к некоторому типу спектральных признаков кадра. Векторы признаков формируются в блоке выделения признаков 10 речевого процессора с использованием выборок аудиосигнала. Этот блок выделения признаков 10 может быть реализован, например, как набор фильтров, каждый из которых имеет определенную полосу пропускания. Все фильтры перекрывают полную полосу частот аудиосигнала. Полосы пропускания фильтров могут частично перекрываться с некоторыми другими фильтрами блока выделения признаков 10. Выходные сигналы фильтров преобразуются, например, дискретным косинусным преобразованием (DCT), где результат преобразования является вектором признаков. В данном примере реализации настоящего изобретения векторы признаков являются 39-мерными векторами, но ясно, что изобретение не ограничено только такими векторами. В данном примере реализации векторы признаков являются мел-частотными кепстральными коэффициентами (MFCC). 39-мерные векторы таким образом содержат 39 признаков: 12 признаков MFCC, нормализованная мощность и их первые и вторые производные по времени (12+1+13+13=39).
В речевом процессоре 9 вычисляется вероятность наблюдения (например, в блоке вычисления вероятности 11) для каждой модели НММ, находящейся в памяти, с использованием векторов признаков; и, как результат распознавания, на шаге 206 получается эквивалент слова для модели НММ с наивысшей вероятностью наблюдения. Таким образом, для каждого эталонного слова вычисляется вероятность того, что пользователь произнес именно это слово. Вышеуказанная наибольшая вероятность наблюдения описывает сходство принятого речевого образца и ближайшей модели НММ, т.е. ближайшего эталонного речевого образца.
Когда эквивалент слова (слов) найден, блок 12 вычисления меры достоверности речевого процессора 9 вычисляет (шаг 207) меру достоверности для эквивалента слова для определения надежности результата распознавания. Мера достоверности вычисляется с помощью уравнения (1), в котором знаменатель заменен уравнением (3):

Вычисленная мера достоверности может затем быть сравнена (шаг 208) с пороговым значением, например, в блоке сравнения 13 речевого процессора 9. Если сравнение показывает, что мера достоверности высоко достаточна, результат распознавания (т.е. эквивалент слова (слов)) может быть затем использован как результат распознавания фрагмента речи (шаг 209). Эквивалент слова (слов) или указатель (например, индекс в таблице) эквивалента слова (слов) передается в беспроводное коммуникационное устройство 1, в котором, например, управляющий блок 5 определяет операции, которые необходимо выполнить на основе эквивалента слова. Эквивалент слова может быть командным словом, когда выполняется команда, соответствующая эквиваленту слова. Команда может быть, например, ответом на звонок, набором номера, запуском приложения, написанием короткого сообщения и т.д.
В ситуации, когда сравнение показывает слишком малую величину, определяется, что результат распознавания может быть недостаточно надежным. В этом случае речевой процессор 9 может информировать (шаг 210) беспроводное коммуникационное устройство 1 о том, что распознавание было неуспешным, и, например, пользователь может быть запрошен повторить фрагмент речи.
Речевой процессор 9 может также использовать языковую модель при определении произнесенного слова. Языковая модель может быть особенно пригодна в случае, если вычисленные наблюдаемые вероятности показывают, что могли быть произнесены два или более слов. Причиной этого может быть, например, тот факт, что произношение таких двух или более слов почти идентично. Тогда языковая модель может указывать, которое из слов было бы наиболее подходящим в данном контексте. Например, произношение слов «too» и «two» очень близко между собой, а контекст может указывать, какое из этих слов корректно.
Настоящее изобретение может быть в значительной степени реализовано как программное обеспечение, например как машинные инструкции для речевого процессора 9 и/или управляющего блока 5.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| ПОВТОРНОЕ РАСПОЗНАВАНИЕ РЕЧИ С ВНЕШНИМИ ИСТОЧНИКАМИ ДАННЫХ | 2016 |
|
RU2688277C1 |
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| КЛАССИФИКАЦИЯ И КОДИРОВАНИЕ АУДИОСИГНАЛОВ | 2015 |
|
RU2668111C2 |
| КЛАССИФИКАЦИЯ И КОДИРОВАНИЕ АУДИОСИГНАЛОВ | 2015 |
|
RU2765985C2 |
| СПОСОБЫ СИНТЕЗА И КОДИРОВАНИЯ РЕЧИ | 2010 |
|
RU2557469C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПОВЫШЕНИЯ РАЗБОРЧИВОСТИ РЕЧИ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ ДАТЧИКОВ | 2004 |
|
RU2373584C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |

Изобретение относится к распознаванию речи. Способ распознавания речи, включающий прием кадров, содержащих выборки аудиосигнала; формирование вектора признаков, содержащего первое число компонентов вектора для каждого кадра; проецирование вектора признаков по меньшей мере на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно первому числу; установление для каждого проецированного вектора набора моделей смешивания, который обеспечивает наивысшую вероятность наблюдения; и анализ набора моделей смешивания для определения результата распознавания. Когда результат распознавания найден, определяют меру достоверности результата распознавания; это определение включает определение вероятности того, что результат распознавания корректен, определение нормализующего члена и деление этой вероятности на нормализующий член. Технический результат - повышение надежности и эффективности распознавания речи. 3 н. и 11 з.п. ф-лы, 2 ил.
1. Способ распознавания речи, включающий:
прием кадров, содержащих выборки аудиосигнала;
формирование вектора признаков, содержащего первое число компонентов вектора, для каждого кадра;
проецирование вектора признаков, по меньшей мере, на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно первому числу;
установление для каждого проецированного вектора набора моделей смешивания, который обеспечивает наивысшую вероятность наблюдения;
анализ набора моделей смешивания для определения результата распознавания;
определение меры достоверности для результата распознавания, когда результат распознавания найден, причем это определение включает:
определение вероятности того, что результат распознавания корректен;
определение нормализующего члена путем выбора для каждого состояния среди указанного набора моделей смешивания одной модели смешивания, которая обеспечивает наивысшее правдоподобие,
при этом указанный нормализующий член соответствует модели смешивания с числом состоянии, равным числу кадров в рассматриваемом аудиосигнале, и одной компонентной смеси для каждого состоянии; и
деление этой вероятности на указанный нормализующий член,
при этом способ также включает сравнение меры достоверности с пороговым значением для определения того, достаточно ли надежен результат распознавания.
2. Способ по п.1, в котором меру достоверности вычисляют с помощью следующего уравнения:
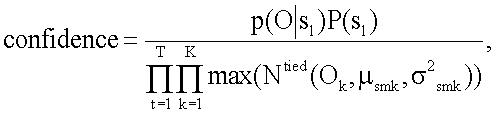
где О - вектор признаков указанного аудиосигнала;
S1 - конкретный фрагмент речи из указанного аудиосигнала;
p(O\s1) - акустическое правдоподобие указанного конкретного фрагмента речи s1;
p(s1) - априорная вероятность указанного конкретного фрагмента речи;
Ok - проекция вектора признаков на k-е подпространство;
µsmk - среднее значение m-й компоненты смеси s-го состояния на k-е подпространство;
σ2 smk - вектор дисперсии m-й компоненты смеси s-го состояния на k-е подпространство;
N() - гауссова функция плотности вероятности состояния s;
К - число подпространств; и
Т - число кадров в указанном аудиосигнале.
3. Способ по п.1 или 2, в котором каждое подпространство представлено кодовой книгой, и модели смешивания указывают индексом в кодовой книге.
4. Способ по п.1 или 2, в котором векторы признаков формируют путем определения мел-частотных кепстральных коэффициентов для каждого кадра.
5. Электронное устройство для распознавания речи, содержащее:
вход для ввода кадров, содержащих выборки, сформированные на основе аудиосигнала;
блок выделения признаков для формирования вектора признаков, содержащего первое число компонент вектора для каждого кадра, и для проецирования вектора признаков, по меньшей мере, на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно первому числу;
блок вычисления вероятности для установления, для каждого проецированного вектора, набора моделей смешивания, который обеспечивает наивысшую вероятность наблюдения, и для анализа набора моделей смешивания для определения результата распознавания;
определитель достоверности для определения меры достоверности результата распознавания, когда результат распознавания найден, причем это определение включает:
определение вероятности того, что результат распознавания корректен;
определение нормализующего члена путем выбора для каждого состояния среди указанного набора моделей смешивания одной модели смешивания, которая обеспечивает наивысшее правдоподобие, при этом указанный нормализующий член соответствует модели смешивания с числом состояний, равным числу кадров в рассматриваемом аудиосигнале, и одной компонентной смеси для каждого состояния; и
деление этой вероятности на указанный нормализующий член;
компаратор для сравнивания меры достоверности с пороговым значением для определения того, достаточно ли надежен результат распознавания.
6. Электронное устройство по п.5, также содержащее:
вход для ввода аудиосигнала;
аналого-цифровой преобразователь для формирования выборок из указанного аудиосигнала;
организатор для разделения выборок аудиосигнала на указанные кадры.
7. Электронное устройство по п.5 или 6, также содержащее кодовую книгу для каждого подпространства.
8. Электронное устройство по п.7, в котором модели смешивания указываются индексом в кодовой книге.
9. Электронное устройство по п.5 или 6, в котором блок извлечения признаков содержит средство для формирования векторов признаков путем определения мел-частотных кепстральных коэффициентов для каждого кадра.
10. Электронное устройство по п.5 или 6, которое представляет собой беспроводной терминал.
11. Машиночитаемый носитель, на котором хранятся машинные инструкции для выполнения процессором, при этом машинные инструкции, при выполнении их процессором обеспечивают распознавание речи, включающее:
прием кадров, содержащих выборки аудиосигнала;
формирование вектора признаков, содержащего первое число компонентов вектора, для каждого кадра;
проецирование вектора признаков, по меньшей мере, на два подпространства так, что число компонент каждого проецированного вектора признаков меньше чем первое число, а общее число компонент проецированного вектора признаков равно указанному первому числу;
установление, для каждого проецированного вектора, набора моделей смешивания, который обеспечивает наивысшую вероятность наблюдения;
анализ набора моделей смешивания для определения результата распознавания;
определение меры достоверности для результата распознавания, когда результат распознавания найден, причем это определение включает:
определение вероятности того, что результат распознавания корректен;
определение нормализующего члена путем выбора для каждого состояния среди указанного набора моделей смешивания одной модели смешивания, которая обеспечивает наивысшее правдоподобие, при этом указанный нормализующий член соответствует модели смешивания с числом состояний, равным числу кадров в рассматриваемом аудиосигнале, и одной компонентной смеси для каждого состояния; и
деление этой вероятности на указанный нормализующий член,
при этом машиночитаемый носитель включает также машинные инструкции для сравнения меры достоверности с пороговым значением для определения того, достаточно ли надежен результат распознавания.
12. Машиночитаемый носитель по п.11, где указанное определение меры достоверности для результата распознавания включает вычисление меры достоверности с помощью следующего уравнения:
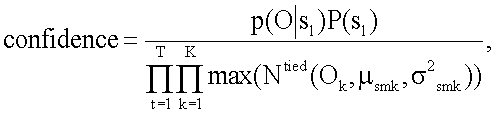
где О - вектор признаков указанного аудиосигнала;
s1 - конкретный фрагмент речи из указанного аудиосигнала;
p(O\s1) - акустическое правдоподобие указанного конкретного фрагмента речи s1;
p(s1) - априорная вероятность указанного конкретного фрагмента речи;
Ok - проекция вектора признаков на k-е подпространство;
µsmk - среднее значение m-й компоненты смеси s-го состояния на k-е подпространство;
σ2 smk - вектор дисперсии m-й компоненты смеси s-го состояния на k-е подпространство;
N() - гауссова функция плотности вероятности состояния s;
К - число подпространств; и
Т - число кадров в указанном акустическом сигнале.
13. Машиночитаемый носитель по п.11 или 12, содержащий машинные инструкции для представления каждого подпространства кодовой книгой и для указания моделей смешивания индексом в кодовой книге.
14. Машиночитаемый носитель по п.11 или 12, содержащий машинные инструкции для формирования векторов признаков путем определения мел-частотных кепстральных коэффициентов для каждого кадра.
| УСТРОЙСТВО РАСПОЗНАВАНИЯ РЕЧИ | 1999 |
|
RU2223554C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ изготовления фильтрующего материала и устройство для его осуществления | 1987 |
|
SU1457967A1 |
| СПОСОБ ПРЕОБРАЗОВАНИЯ РЕЧИ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 1999 |
|
RU2166804C2 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| US 5710866 A, 1998.01.20. | |||

