Изобретение относится к способам поиска информации, размещенной на локальных и удаленных устройствах хранения данных. В частности, изобретение относится к способам поиска размещенных на устройствах хранения данных электронных документов, семантически и стилистически похожих на выбранный документ.
Известен метод поиска и извлечения документов при помощи приложений для автоматического персонализированного поиска в базе данных по патенту US 5926812, класс G06F 017/30. Известный способ включает следующую последовательность действий. Определяют множество слов, наиболее часто встречаемых в документах, хранимых в архиве на пользовательском устройстве. При этом учитывается число вхождений слов в документы и их важность, определяемая расположением в заголовках, пересылают полученное множество слов удаленному устройству хранения данных и осуществляют поиск на нем документов, соответствующих упомянутому множеству слов. Формируют множество документов, соответствующих запросу, извлекают из архива, хранимого на удаленном устройстве документов, имеющих наивысшую степень сходства с документами, хранимыми на пользовательском устройстве, и отображают их пользователю.
Недостатком данного способа является низкая точность поиска в связи с тем, что не учитываются связи между словами в формируемом множестве. При этом изобретение не предусматривает расширение поисковых запросов какими-либо аналогами (морфологическими словоформами и синонимами). Т.е. метод осуществляет поиск документов, похожих лишь по текстовому содержимому, и не позволяет находить документы, имеющие смысловое и стилистическое сходство с выбранным документом.
Известен метод и устройство для поиска текста с помощью сигнатур документов по патенту US 6029167, класс G06F 017/00. Метод позволяет кодировать фрагменты текстов документов при помощи последовательности маркеров и включает следующую последовательность действий. Каждому фрагменту присваивается идентифицирующий маркер. Закодированный фрагмент сравнивают с закодированными таким же образом фрагментами, хранимыми в базе данных. Сравнение осуществляют по последовательностям маркеров, присущих фрагментам. В случае обнаружения в базе данных фрагментов, похожих на выбранный (с идентичными маркерами), осуществляют извлечение из базы данных документов, содержащих фрагменты, похожие на выбранный. После чего осуществляют сравнение выбранного фрагмента с найденными в базе данных документами при помощи поиска по последовательным строкам символов, либо каждое слово из исходного фрагмента сравнивают с каждым словом из найденных документов.
Недостатком данного способа является то, что поиск документов и их фрагментов осуществляется лишь по формальным признакам соответствия слов, т.е. метод осуществляет поиск похожих лишь по текстовому содержимому и не позволяет находить документы, имеющие смысловое и стилистическое сходство с выбранным.
Следующим недостатком изобретения является низкая оперативность в связи с тем, что каждое слово из исходного фрагмента сравнивают с каждым словом из найденных документов.
Наиболее близким по технической сущности к заявляемому изобретению (прототипом) является способ поиска похожих по смысловому содержимому электронных документов, размещенных на устройствах хранения данных (патент RU №2420800, МПК G06F 17/30, 10.01.2011 г.). Он включает следующую последовательность действий. Определяются параметры поиска путем задания правил формирования множества уникальных слов. Формируют множество взвешенных уникальных слов и взвешенных связей между ними, на основе которых строят семантическую сеть, и производят поиск похожих по смыслу документов путем сравнения семантических сетей двух документов.
Недостатком этого способа является невысокая точность поиска в массиве документов различного стиля (газетные статьи, новостные сообщения, уведомления чата, почта и др.), обусловленная тем, что при проведении поиска не учитываются стилистические особенности документов.
Задачей изобретения является разработка способа поиска похожих электронных документов, размещенных на устройствах хранения данных, повышающего точность поиска в массиве документов различного стиля.
Эта задача решается тем, что в способ поиска похожих электронных документов, размещенных на устройствах хранения данных после загрузки двух электронных документов с устройств хранения данных, задания правил формирования множества уникальных слов, формирования семантических сетей пары текстов, поиска общих уникальных слов для пары документов, вычисления коэффициента общих ключевых слов, вычисления коэффициента удаленности векторов весов общих уникальных слов, вычисления коэффициента удаленности матриц весов связей общих уникальных слов, вычисления комплексного коэффициента близости пары текстов по смыслу дополнительно введены процедура задания правил формирования стилистических образов документов, процедура формирования стилистических образов документов, процедура сравнения стилистических образов документов на подобие, процедура ранжирования найденных в результате поиска документов с учетом семантического и стилистического подобия.
Введение новых процедур позволяет повысить точность поиска подобных электронных документов в массиве документов различного стиля.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обусловливающих тот же технический результат, который достигнут в заявляемом способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Заявленный способ поясняется чертежами, на которых показано:
фиг.1 - блок-схема реализации способа поиска похожих электронных документов, размещенных на устройствах хранения данных;
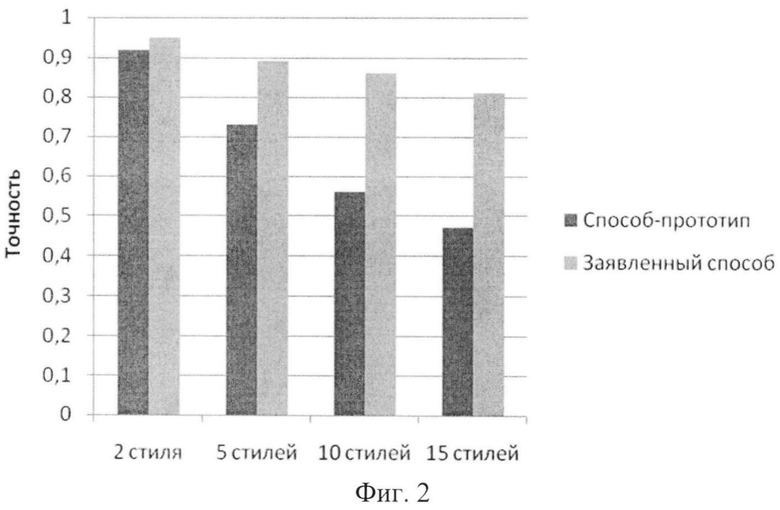
фиг.2 - сравнение результатов имитационного моделирования для способа-прототипа и заявленного способа.
Алгоритм сравнения пары текстовых документов (вычисление коэффициента близости), представленный на фиг.1, включает:
Блок №1 - осуществляют загрузку двух электронных документов, один из которых указан пользователем в качестве эталона, с устройств хранения данных.
Блок №2 - задают правила формирования множества уникальных слов, такие как минимальный вес уникального слова, позволяющий включить его в формируемое множество, и максимальное число уникальных слов.
Блок №3 - формируют семантические сети пар документов, представляющие собой набор взвешенных уникальных слов и взвешенных связей между ними. Для построения семантической сети используется модуль обработки документов определенного типа. Все уникальные слова за счет морфологических преобразований приводятся к нормальной форме.
Блок №4 - осуществляют поиск общих уникальных слов для пары электронных документов путем попарного сравнением каждого уникального слова из семантической сети первого документа с каждым уникальным словом из семантической сети второго документа с учетом синонимии слов.
Блок №5 - вычисляют коэффициент k1, показывающий долю общих уникальных слов и рассчитывающийся как отношение суммы весов уникальных слов, общих для этих документов, к сумме весов всех уникальных слов обоих документов.
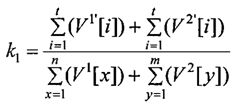 ,
,
где V1′ - массив весов общих уникальных слов первого документа;
V2′ - массив весов общих уникальных слов второго документа;
t - количество общих уникальных слов обоих документов;
V1 - массив весов уникальных слов первого документа;
V2 - массив весов уникальных слов второго документа;
n - количество уникальных слов первого документа;
m - количество уникальных слов второго документа.
Блок №6 - вычисляют коэффициент удаленности векторов общих уникальных слов (k2) путем измерения евклидова расстояния между двумя векторами весов общих уникальных слов:
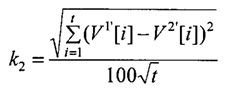
Блок №7 - вычисляют коэффициент удаленности матриц весов связей общих уникальных слов (k3) путем расчета евклидова расстояния между матрицами связи общих уникальных слов:
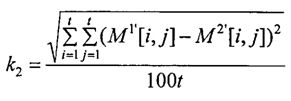 ,
,
где М1′ - матрица связности весов общих уникальных слов первого документа;
М2′ - матрица связности весов общих уникальных слов второго документа;
Блок №8 - вычисляют комплексный коэффициент близости пары текстов по смыслу (K):
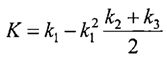
Блок №9 - осуществляют задание правил формирования стилистических образов, характеризующих стилистические особенности документов. В качестве стилистических образов принимаются матрицы частот переходов (Поддубный В.В., Шевелев О.Г., Фатыхов А.А. сравнительный анализ эффективности алгоритмов распознавания авторства текстов по частотам переходов // Вестн. Том. гос. ун-та. 2006. №290. С.232-234). В качестве правил формирования определяются размер матриц частот переходов и осуществляется выбор элементов таких матриц (биграммы, триграммы и т.д.).
Блок №10 - формируют стилистические образы документов. В матрицы частот переходов заносятся данные о переходах между элементами матриц, полученные из документов.
Блок №11 - сравнивают стилистические образы документов на подобие путем вычисления коэффициент сходства стилистических образов документов (5), например, с помощью статистики хи-квадрат (Поддубный В.В., Шевелев О.Г., Фатыхов А.А. сравнительный анализ эффективности алгоритмов распознавания авторства текстов по частотам переходов // Вестн. Том. гос. ун-та. 2006. №290. С.232-234), рассчитывающейся по формуле:
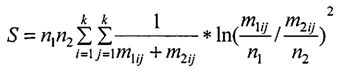
где m1ijm2ij - число переходов из i элемента в j в матрицах частот переходов 1 и 2 документов соответственно;
n1in2i - общее число переходов из i элемента в матрицах частот переходов 1 и 2 документов соответственно, причем 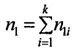
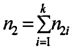 .
.
Коэффициент сходства стилистических образов документов принимает значения в интервале от 0 до 1. Причем, чем ниже значение коэффициента, тем более похожи друг на друга стилистические образы.
Блок №12 - осуществляют ранжирование найденных в результате поиска документов с учетом семантического и стилистического подобия путем вычисления обобщенного коэффициента близости пары текстов (H) на основе коэффициента близости пары текстов по смыслу (K) и коэффициента сходства стилистических образов документов(S):
H=α*K+β*(1-S),
где α и β - коэффициенты значимости семантической и стилистической составляющих соответственно, причем α+β=1;
K - коэффициент близости пары текстов по смыслу;
S - коэффициент сходства стилистических образов.
Коэффициенты значимости определяют вклад семантической и стилистической составляющих в зависимости от задачи поиска и принимают значения в интервале от 0 до 1. Чем выше коэффициент, тем больший вклад вносится соответствующей составляющей. В общем случае они задаются значениями, равными 0.5.
Коэффициент H отнормирован от 0 до 1: значение 1 означает полную идентичность текстов, а 0 - полное несоответствие.
Для примера возьмем несколько электронных документов - «A», «B» и «C». «A» определим в качестве эталона. Необходимо определить сходство документов «B» и «C», причем «A» и «C» - документы одного стиля.
На первом этапе осуществляют вычисление коэффициента близости пар текстов по смыслу. Для пары текстов «A» и «B» коэффициент K=0,751, для «A» и «C» коэффициент K=0,727.
На втором этапе формируют стилистические эталоны в виде матриц частот переходов для двух документов и сравнивают их на подобие. Для пары текстов «A» и «B» коэффициент сходства стилистических образов документов S=0,352, для «A» и «C» - S=0,0187.
На последнем этапе вычисляют обобщенный коэффициент близости пары текстов при равных коэффициентах значимости (где α=0,5 и β=0,5).
Для пары текстов «A» и «B»:
H=0,5*0,751+0,5*(1-0,352)=0,6995.
Для пары текстов «A» и «C»:
H=0,5*0,727+0,5*(1-0,0187)=0,85415.
Несмотря на большую близость по смыслу документ «B» имеет различные стилистические особенности по сравнению с документом-эталоном. Полученное в результате расчетов значение обобщенного коэффициента 0,85415 (против 0,6995) говорит о большем стилистическом и смысловом сходстве документа «C» по отношению к документу «A», нежели документа «B».
Правомерность теоретических предпосылок проверялась с помощью имитационных моделей системы-прототипа и системы, реализующей заявленный способ поиска похожих электронных документов, размещенных на устройствах хранения данных.
Показателем эффективности способов поиска похожих электронных документов, размещенных на устройствах хранения данных, является точность.
Для оценки качества функционирования разработанного способа были проведены эксперименты по поиску похожих электронных документов. С этой целью были сформированы эталонные документы различных стилей, по которым затем осуществлялся поиск. Тестовый массив электронных документов составлял 500 файлов. Были проведены эксперименты, показывающие зависимость точности поиска от количества различных стилей в массиве электронных документов, в котором осуществляется поиск (фиг.2).
Результаты, представленные на фиг.2, подтверждают существенное повышение точности поиска при внедрении нового способа.
Промышленная применимость изобретения обусловлена тем, что устройство, реализующее предложенный способ, может быть осуществлено с помощью современной элементной базы с достижением указанного в изобретении назначения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОИСКА ПОХОЖИХ ПО СМЫСЛОВОМУ СОДЕРЖИМОМУ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ, РАЗМЕЩЕННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2009 |
|
RU2420800C2 |
| СПОСОБ ПОИСКА ПОДОБНЫХ ФАЙЛОВ, РАЗМЕЩЁННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2018 |
|
RU2663474C1 |
| СПОСОБ И СИСТЕМА ПЕРЕФРАЗИРОВАНИЯ ТЕКСТА | 2023 |
|
RU2814808C1 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| СПОСОБ АВТОМАТИЧЕСКОЙ ИТЕРАТИВНОЙ КЛАСТЕРИЗАЦИИ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ, СПОСОБ ПОИСКА В СОВОКУПНОСТИ КЛАСТЕРИЗОВАННЫХ ПО СЕМАНТИЧЕСКОЙ БЛИЗОСТИ ДОКУМЕНТОВ И МАШИНОЧИТАЕМЫЕ НОСИТЕЛИ | 2014 |
|
RU2556425C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫСТРАИВАНИЯ ДИАЛОГА С ПОЛЬЗОВАТЕЛЕМ В УДОБНОМ ДЛЯ ПОЛЬЗОВАТЕЛЯ КАНАЛЕ | 2018 |
|
RU2688758C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА ДЛЯ ЦИФРОВОГО АССИСТЕНТА | 2022 |
|
RU2796208C1 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
Изобретение относится к способам поиска на устройствах хранения данных электронных документов, похожих стилистически и по смыслу на выбранный документ. Техническим результатом является повышение точности поиска подобных электронных документов в массиве документов различного стиля. В способе поиска похожих по смысловому содержимому электронных документов, размещенных на устройствах хранения данных, осуществляют загрузку двух электронных документов. Определяют параметры поиска путем задания правил формирования множества уникальных слов, формируют множество взвешенных уникальных слов и взвешенных связей между ними. Строят семантическую сеть и производят поиск похожих по смыслу документов путем сравнения семантических сетей. При этом дополнительно задают правила формирования стилистических образов документов путем определения размера матриц частот переходов и выбора элементов матриц частот переходов. Причем элементы матриц частот переходов представляют собой одно из: биграммы и триграммы. Затем формируют матрицы частот переходов документов и сравнивают матрицы частот переходов документов на подобие путем вычисления коэффициента сходства. 2 ил.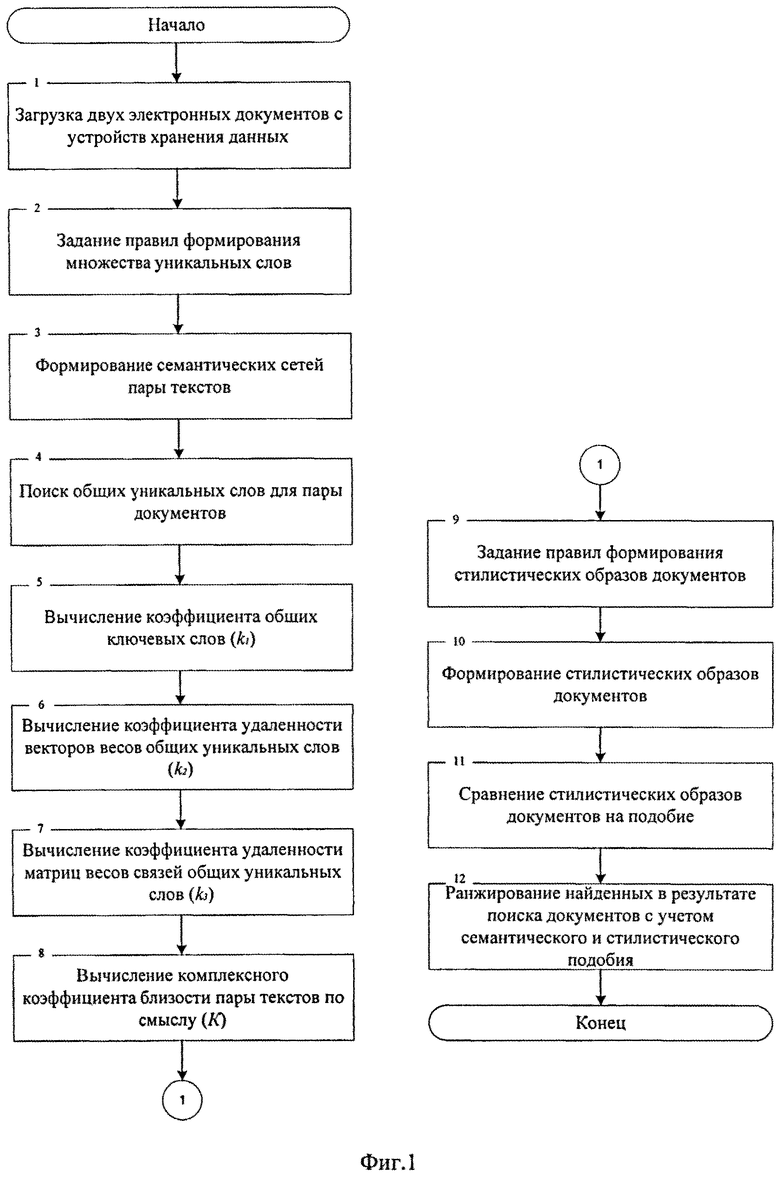
Способ поиска похожих электронных документов, размещенных на устройствах хранения данных, заключающийся в том, что осуществляют загрузку двух электронных документов с устройств хранения данных, определяют параметры поиска путем задания правил формирования множества уникальных слов, формируют множество взвешенных уникальных слов и взвешенных связей между ними, строят семантическую сеть и производят поиск похожих по смыслу документов путем сравнения семантических сетей, отличающийся тем, что дополнительно задают правила формирования стилистических образов документов путем определения размера матриц частот переходов и выбора элементов матриц частот переходов, причем элементы матриц частот переходов представляют собой одно из: биграммы и триграммы; формируют матрицы частот переходов документов, сравнивают матрицы частот переходов документов на подобие путем вычисления коэффициента сходства.
| СПОСОБ ПОИСКА ПОХОЖИХ ПО СМЫСЛОВОМУ СОДЕРЖИМОМУ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ, РАЗМЕЩЕННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2009 |
|
RU2420800C2 |
| Всасывающее сопло для пневматического транспорта | 1949 |
|
SU80597A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Устройство для обмотки сердечника длинномерным материалом | 1976 |
|
SU610760A1 |
| US 6029167 A, 22.02.2000. | |||

