Настоящее изобретение относится к способам поиска информации, размещенной на локальных и удаленных устройствах хранения данных. В частности, изобретение относится к способам поиска размещенных на устройствах хранения данных электронных документов, похожих по смысловому содержимому на выбранный документ.
Известен метод и устройство для поиска текста с помощью сигнатур документов по патенту US 6029167, класс G06F 017/00. Метод позволяет кодировать фрагменты текстов документов при помощи последовательности маркеров и включает следующую последовательность действий. Каждому фрагменту присваивается идентифицирующий маркер. Закодированный фрагмент сравнивают с закодированными таким же образом фрагментами, хранимыми в базе данных. Сравнение осуществляют по последовательностям маркеров, присущих фрагментам. В случае обнаружения в базе данных фрагментов, похожих на выбранный (с идентичными маркерами), осуществляют извлечение из базы данных документов, содержащих фрагменты, похожие на выбранный. После чего осуществляют сравнение выбранного фрагмента с найденными в базе данных документами при помощи поиска по последовательным строкам символов, либо каждое слово из исходного фрагмента сравнивают с каждым словом из найденных документов.
Недостатком данного способа является то, что поиск документов и их фрагментов осуществляется лишь по формальным признакам соответствия слов, т.е. метод осуществляет поиск похожих лишь по текстовому содержимому, и не позволяет находить документы, имеющие сходство с выбранным по смысловому содержимому.
Следующим недостатком изобретения является низкая оперативность в связи с тем, что каждое слово из исходного фрагмента сравнивают с каждым словом из найденных документов.
Известен метод поиска и извлечения документов при помощи приложений для автоматического персонализированного поиска в базе данных по патенту US 5926812, класс G06F 017/30. Известный способ включает следующую последовательность действий. Определяют множество слов, наиболее часто встречаемых в документах, хранимых в архиве на пользовательском устройстве. При этом учитывается число вхождений слов в документы и их важность, определяемая расположением в заголовках, пересылают полученное множество слов удаленному устройству хранения данных и осуществляют поиск на нем документов, соответствующих упомянутому множеству слов. Формируют множество документов, соответствующих запросу, извлекают из архива, хранимого на удаленном устройстве документов, имеющих наивысшую степень сходства с документами, хранимыми на пользовательском устройстве, и отображают их пользователю.
Недостатком данного способа является низкая точность поиска в связи с тем, что не учитываются связи между словами в формируемом множестве. При этом изобретение не предусматривает расширение поисковых запросов какими-либо аналогами (морфологическими словоформами и синонимами). Т.е. метод осуществляет поиск документов, похожих лишь по текстовому содержимому, и не позволяет находить документы, имеющие сходство с выбранным документом по смысловому содержимому.
Наиболее близким по своей технической сущности к заявленному является «Способ поиска хранимых на устройствах хранения данных электронных документов и их фрагментов» по Евразийскому патенту №002016 от 22.10.2001 г. (заявка №200100467 от 06.04.2001 г.), класс G06F 17/30. Способ, заключающийся в индексировании каждого сохраняемого в архиве документа, разбиении упомянутых документов на фрагменты и формировании тематик из одного и более фрагмента, определении параметров поиска, проведении поиска, ранжировании полученного в результате поиска списка фрагментов документов.
Недостатком этого способа является невысокая точность поиска, обусловленная тем, что при проведении поиска формируется множество уникальных слов и их весов, но не учитываются связи между уникальными словами и их веса; низкая скорость работы в связи с тем, что изначально формируется множество уникальных слов, что требует существенных временных затрат, а затем к этому множеству применяются правила, которые могут сократить полученное множество.
Техническим результатом, на которое направлено изобретение, является способ поиска похожих по смысловому содержимому электронных документов, обеспечивающий повышение точности, полноты и скорости поиска электронных документов, размещенных на устройствах хранения данных, за счет построение семантических сетей документов, отражающих их смысловой образ и представляемых в виде взвешенных уникальных слов (смысловых тем) и взвешенных связей между ними.
Указанный результат достигается за счет того, что определяют параметры поиска, производят поиск похожих по смыслу документов, затем ранжируют найденные в результате поиска документы, перед определением параметров поиска осуществляют загрузку двух электронных документов с устройств хранения данных, определяют параметры поиска путем задания правил формирования множества уникальных слов, формируют множество взвешенных уникальных слов и взвешенных связей между ними, на основе которых строят семантическую сеть, производят поиск похожих по смыслу документов путем сравнения семантических сетей двух документов.
Сущность изобретения поясняется чертежами, приведенными на фиг.1, фиг.2, фиг.3.
Фиг.1 - блок-схема сравнения пары текстовых документов (вычисление коэффициента близости);
Фиг.2 - структура программно-аппаратного комплекса, реализующего поиск похожих по смысловому содержимому электронных документов;
Фиг.3 - программно-аппаратный комплекс, реализующий поиск похожих по смысловому содержимому на эталонные документы клиента электронных документов, размещенных на устройствах хранения данных (хранилище книг).
Алгоритм сравнения пары текстовых документов (вычисление коэффициента близости), представленный на фиг.1, включает:
Блок №1 - осуществляют загрузку двух электронных документов, один из которых указан пользователем в качестве эталона, с устройств хранения данных.
Блок №2 - задают правила формирования множества уникальных слов, такие как минимальный вес уникального слова, позволяющий включить его в формируемое множество, и максимальное число уникальных слов.
Блок №3 - формируют семантические сети пар документов, представляющие собой набор взвешенных уникальных слов и взвешенных связей между ними. Максимальное значение веса уникального слова (темы документа), равное 100, соответствует ключевой (важнейшей) теме документа. Близкое к нулю значение веса темы показывает, что она лишь вскользь упомянута в документе, и в нем мало сведений, относящихся к данной теме.
Связи между парами уникальных слов (тем), в свою очередь, также имеют характеристики - веса связей (от 0 до 100). Большое значение веса связи от одной темы к другой, близкое к 100, указывает на то, что подавляющая часть информации в документе, касающаяся первой, касается в то же время и второй темы - первая тема почти всегда излагается в контексте второй. Малое значение веса отражает тот факт, что первая тема слабо связана со второй (излагается независимо от нее). Связь между парой тем сети всегда двусторонняя, однако, связь от первой темы ко второй не всегда имеет тот же самый вес, что и обратная - от второй к первой. Такое различие в весах может указывать на то, что одна тема является подтемой другой.
Таким образом, семантическая сеть документа может быть представлена взвешенным графом, узлы которого - уникальные слова, а дуги - связи между ними. Можно считать, что такой граф будет полносвязным, при этом веса некоторых дуг будут нулевыми. Математическая модель семантической сети представлена следующими элементами:
- массив уникальных слов текста Ui;
- массив весов уникальных слов текста Vi;
- матрица весов связей между любыми двумя уникальными словами Mi; где i - индекс текста. Все веса нормированы от 1 до 100.
Для построения семантической сети используется модуль обработки документов определенного типа. Все уникальные слова за счет морфологических преобразований приводятся к нормальной форме.
Блок №4 - осуществляют поиск общих уникальных слов для пары электронных документов путем попарного сравнением каждого уникального слова из семантической сети первого документа с каждым уникальным словом из семантической сети второго документа с учетом синонимии слов.
Блок №5 - вычисляют коэффициент k1, показывающий долю общих уникальных слов и рассчитывающийся как отношение суммы весов уникальных слов, общих для этих документов, к сумме весов всех уникальных слов обоих документов
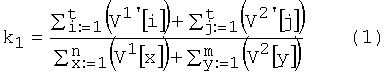
где V1' - массив весов общих уникальных слов первого документа;
V2' - массив весов общих уникальных слов второго документа;
t - количество общих уникальных слов обоих документов;
V1 - массив весов уникальных слов первого документа;
V2 - массив весов уникальных слов второго документа;
n - количество уникальных слов первого документа;
m - количество уникальных слов второго документа.
Этот коэффициент является наиболее значащим, т.к. он показывает смысловую близость, и нормируется от 0 до 1.
Блок №6 - вычисляют коэффициент удаленности векторов весов общих уникальных слов (k2) путем измерения евклидова расстояния между двумя векторами весов общих уникальных слов
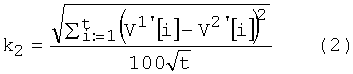
Блок №7 - вычисляют коэффициент удаленности матриц весов связей общих уникальных слов (k3) путем расчета евклидова расстояния между матрицами связи общих уникальных слов
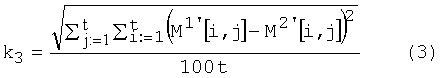
где M1' - матрица связности весов общих уникальных слов первого документа;
M2' - матрица связности весов общих уникальных слов второго документа.
Блок №8 - вычисляют комплексный коэффициент K (Алгоритм оценки массива текстов на семантическое сходство с эталоном [Текст] / А.Ю.Бородащенко, М.В.Бочков, А.Л.Салбиев // Информационные технологии. - М.: Издательство "Новые технологии", "Информационные технологии", 2008. №12. - 80 с. С.8-11)
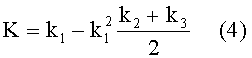
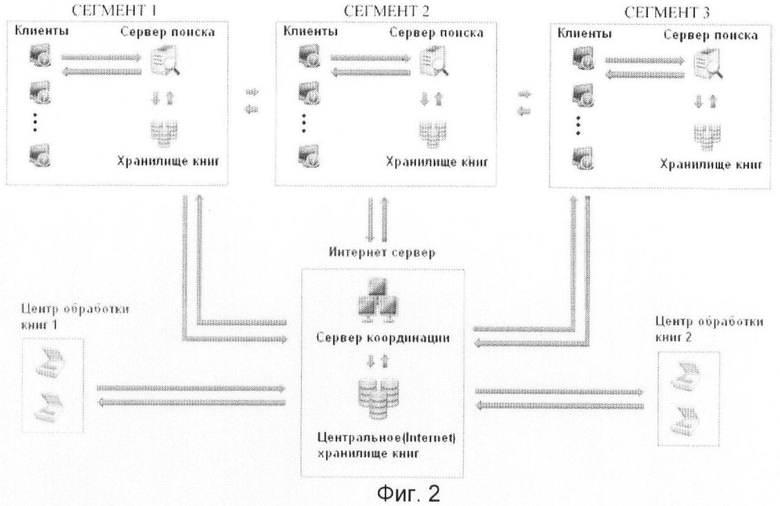
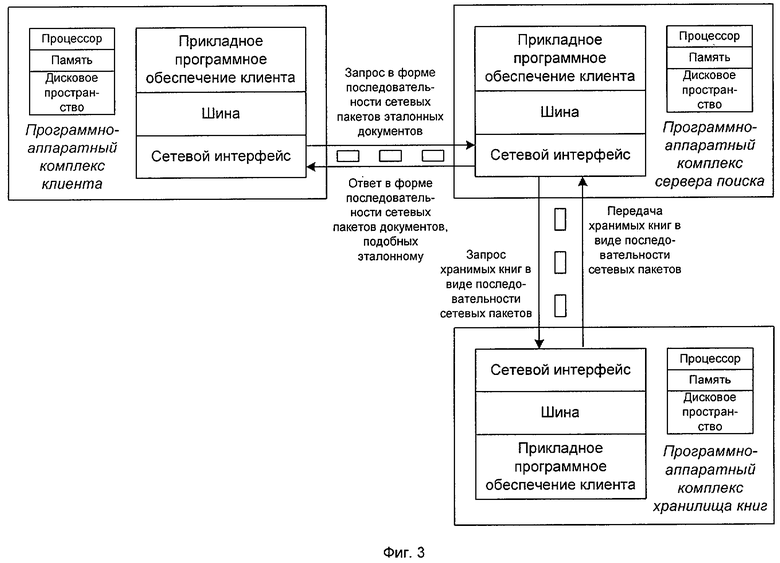
Изобретение может функционировать в различных устройствах хранения данных и компьютерных сетях, например, в базах данных, локальных компьютерных сетях, глобальной сети Интернет. Изобретение может быть реализовано в серверах поиска в корпоративной сети библиотеки, структура которой представлена на фиг.2. Клиент формирует запрос, состоящий из эталонного документа, подобные которому необходимо получить из хранилища книг (фиг.3). Запрос со стороны клиента в виде последовательности сетевых пакетов через сетевые интерфейсы передается на сервер поиска. Способ реализуется на сервере поиска в сегментах 1, 2 или 3 (фиг.2) и позволяет осуществлять поиск по запросам клиентов необходимых книг (документов) из хранилища книг в соответствии со способом, представленным на фиг.1. Существует возможность осуществления удаленного поиска в указанных сегментах, которую поддерживает Интернет сервер.
Промышленная применимость изобретения обусловлена возможностью его использования в распределенных вычислительных системах, где задачи выполняются удаленными вычислительными устройствами, которые объединены коммуникационной сетью, в том числе в программно-аппаратных комплексах. Предлагаемый способ позволяет оптимизировать поиск электронных документов близкой тематики, в том числе имеющих сходство не только в формальном, но и в смысловом значении.
Изобретение применимо в системах, связанных с получением, поиском, обработкой и хранением информации в компьютерных системах, и повышает эффективность работы с информацией, размещенной на устройствах хранения данных.
Настоящее изобретение обладает по сравнению с существующими аналогами рядом преимуществ, позволяющих существенно сократить временные затраты, требуемые для получения и обработки интересующих пользователя документов, повысить полноту и точность поиска, за счет построения семантических сетей документов, что позволяет осуществлять поиск документов, имеющих сходство с выбранным по смысловому содержимому. Изобретение определяет степень сходства выбранного и соответствующих ему найденных на устройствах хранения данных документов.
Заявленный способ был реализован в программно-аппаратном комплексе поиска похожих по смысловому содержимому документов.
Оператор выбирает текстовый документ, похожие на который необходимо найти, и указывает область поиска (устройство хранения данных или определенный каталог). При необходимости ускорить процесс поиска, тем самым понизить точность, или наоборот повысить точность, увеличив при этом временные затраты, оператор может изменить параметры поиска (минимальный вес уникального слова, максимальное количество уникальных слов), которые применяются для каждого документа. После чего для всех документов строится их семантическая сеть.
Семантическая сеть документа, похожие на который надо найти, поочередно сравнивается с семантическими сетями документов, среди которых осуществляется поиск, в результате чего вычисляется комплексный коэффициент близости для пары текстов (формула 4). Далее эти коэффициенты ранжируются по убыванию, в результате чего представляется ранжированный список найденных документов, похожих по смысловому содержимому на выбранный документ.
Для примера возьмем пару небольших электронных документов.
На первом шаге осуществляется загрузка выбранных документов:
Документ №1: «Александр PAP, директор программ России и СНГ Германского совета по внешней политике:
- Я думаю, что это очень сильный и честный ход президента, - говорит - Он показывает, что рассуждения о закулисных играх, о будущем преемнике как марионетке Путина абсолютно беспочвенны.
Российский президент сделал очень рискованный ход для себя: он пошел вразрез с интересами силовиков, которые не поддерживали Медведева, предлагали другие кандидатуры, а то и настаивали на третьем сроке Путина. Но теперь фракция силовиков в российском истеблишменте оказывается весьма ослабленной.
Для Запада же был дан ясный сигнал, что Россия делает ставку на экономические реформы и будет проводить политику открытости, продолжать интегрироваться в мировое сообщество».
Документ №2: «Медведев - преемник: Это позитивный сигнал Западу
Сегодня лидеры четырех партий - "Единой России", "Справедливой России", "Аграрной партии" и "Гражданской силы" предложили Путину кандидатуру Дмитрия Медведева в качестве претендента на пост Президента России. Путин выбор одобрил.
- Я думаю, что это очень сильный и честный ход президента, - говорит Александр РАР, директор программ России и СНГ Германского совета по внешней политике. - Он показывает, что рассуждения о закулисных играх, о будущем преемнике как марионетке Путина абсолютно беспочвенны.
Российский президент сделал очень рискованный ход для себя: он пошел вразрез с интересами силовиков, которые не поддерживали Медведева, предлагали другие кандидатуры, а то и настаивали на третьем сроке Путина. Но теперь фракция силовиков в российском истеблишменте оказывается весьма ослабленной.
Для Запада же был дан ясный сигнал, что Россия делает ставку на экономические реформы и будет проводить политику открытости, продолжать интегрироваться в мировое сообщество».
На втором шаге задаются параметры поиска в виде задания правил формирования множества уникальных слов (фиг.1, блок 2):
минимальный вес уникального слова - 40;
максимальное число уникальных слов - 10.
На третьем шаге (фиг.1) с помощью специального модуля строят семантические сети указанной пары электронных документов, представляющие собой набор взвешенных уникальных слов и взвешенных связей между ними:
Массив уникальных слов первого документа:
U1={1. 'ФРАКЦИЯ СИЛОВИКА', 2. 'ЭКОНОМИЧЕСКАЯ РЕФОРМА', 3. 'ПУТИН', 4. 'СИЛОВИК', 5. 'РОССИЯ'}
Массив их весов:
V1={42, 42, 48, 48, 100}
Матрица связности уникальных слов первого документа
Массив уникальных слов второго документа
U2={1. 'МЕДВЕДЕВ', 2. 'ПРЕЕМНИК', 3. 'ПУТИН', 4. 'РОССИЯ'}
Массив их весов:
V2={42, 42, 66, 100}
Матрица связности уникальных слов второго документа:
Далее в блоке 4 (фиг.1) осуществляется поиск общих уникальных слов, в результате чего формируется массив общих уникальных слов:
U:{1. 'ПУТИН', 2. 'РОССИЯ'}
Массив весов общих уникальных слов первого документа примет значение
V1'={48, 100},
второго документа
V2'={66, 100}
Матрица связности весов общих уникальных слов первого документа примет значение
второго документа
Число общих уникальных слов t=2
На 5-м шаге вычисляется коэффициент k1 по формуле 1
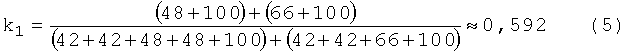
На 6-м шаге вычисляется коэффициент k2 по формуле 2
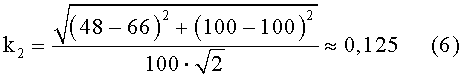
На 7-м шаге, аналогично коэффициенту k2 только для матриц связности M1' и M2', вычисляется коэффициент k3. В числителе корень суммы квадратов разностей элементов, находящихся на одинаковых позициях в матрицах связности уникальных слов, являющимися общими для первого и второго текстов
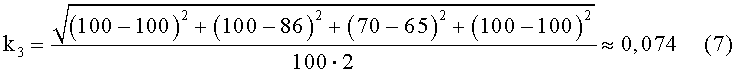
На 8-м шаге по формуле 4 вычисляется итоговый коэффициент K
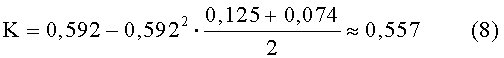
Коэффициент K отнормирован от 0 до 1: значение 1 означает полную идентичность текстов, а 0 - полное смысловое несоответствие.
Полученное в результате расчетов значение 0,557 говорит о смысловой похожести документа №1 и документа №2.
Если на втором шаге задать следующие параметры анализа:
минимальный вес уникального слова - 20;
максимальное число уникальных слов - 30,
то значение коэффициента K приблизительно составит 0,727 в результате повышения точности за счет выделения большего числа уникальных слов и связей между ними.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОИСКА ПОХОЖИХ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ, РАЗМЕЩЕННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2014 |
|
RU2571539C2 |
| СПОСОБ ПОИСКА ПОДОБНЫХ ФАЙЛОВ, РАЗМЕЩЁННЫХ НА УСТРОЙСТВАХ ХРАНЕНИЯ ДАННЫХ | 2018 |
|
RU2663474C1 |
| СПОСОБ ПОСТРОЕНИЯ СЕМАНТИЧЕСКОЙ МОДЕЛИ ДОКУМЕНТА | 2011 |
|
RU2487403C1 |
| СПОСОБ ПОЗИЦИОНИРОВАНИЯ ТЕКСТОВ В ПРОСТРАНСТВЕ ЗНАНИЙ НА ОСНОВЕ МНОЖЕСТВА ОНТОЛОГИЙ | 2009 |
|
RU2476927C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ | 2017 |
|
RU2662688C1 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СПОСОБ ПРЕОБРАЗОВАНИЯ ДАННЫХ ГЕОИНФОРМАЦИОННЫХ СИСТЕМ (ГИС), СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ И СПОСОБ ПОИСКА ПО СФОРМИРОВАННОЙ ЭТИМ СПОСОБОМ БАЗЕ ДАННЫХ | 2017 |
|
RU2669143C1 |
| ИДЕНТИФИКАЦИЯ СЕМАНТИЧЕСКИХ ВЗАИМООТНОШЕНИЙ В КОСВЕННОЙ РЕЧИ | 2008 |
|
RU2488877C2 |
| СПОСОБ (ВАРИАНТЫ) И СЕРВЕР ОБРАБОТКИ ТЕКСТА | 2016 |
|
RU2642413C2 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОГО ПРЕОБРАЗОВАНИЯ СТРУКТУРИРОВАННОГО МАССИВА ДАННЫХ | 2014 |
|
RU2571405C1 |
Изобретение относится к способам поиска на устройствах хранения данных электронных документов, похожих по смысловому содержимому на выбранный документ, и может функционировать в различных устройствах хранения данных и компьютерных сетях. Технический результат изобретения заключается в повышении точности и полноты поиска электронных документов. Определяют параметры поиска путем задания правил формирования множества уникальных слов, формируют множество взвешенных уникальных слов и взвешенных связей между ними, на основе которых строят семантическую сеть, производят поиск похожих по смыслу документов путем сравнения семантических сетей двух документов. 3 ил.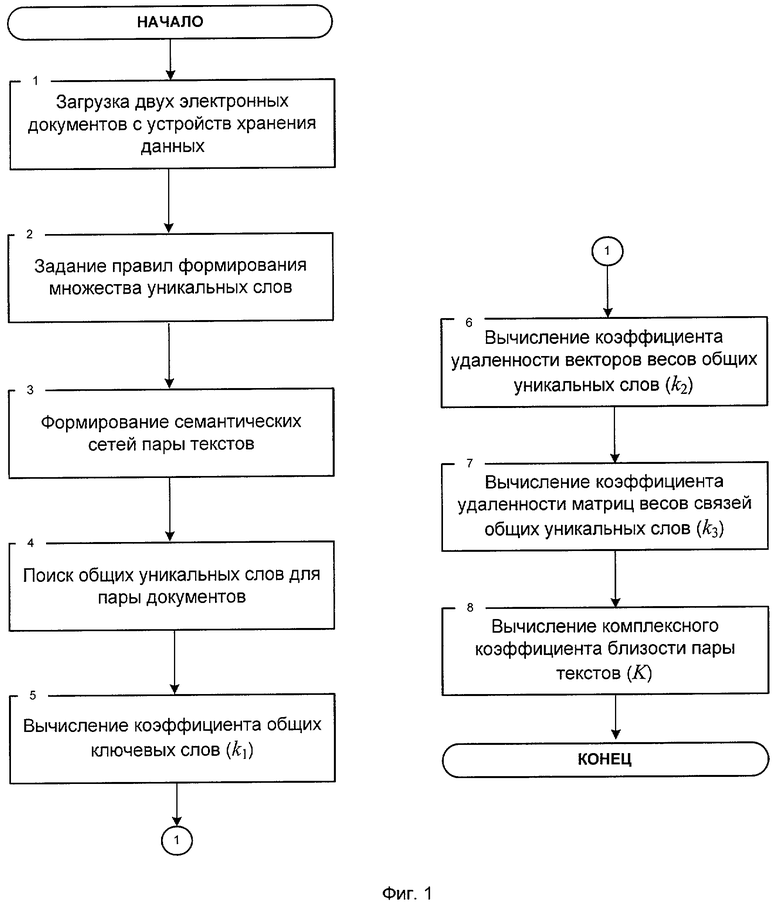
Способ поиска похожих по смысловому содержимому электронных документов, размещенных на устройствах хранения данных, заключающийся в том, что определяют параметры поиска, производят поиск похожих по смыслу документов, затем ранжируют найденные в результате поиска документы, отличающийся тем, что перед определением параметров поиска осуществляют загрузку двух электронных документов с устройств хранения данных, определяют параметры поиска путем задания правил формирования множества уникальных слов, формируют множество взвешенных уникальных слов и взвешенных связей между ними, на основе которых строят семантическую сеть, производят поиск похожих по смыслу документов путем сравнения семантических сетей двух документов.
| Токарный резец | 1924 |
|
SU2016A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| US 6189002 В1, 13.02.2001 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |

