Изобретение относится к области вычислительной техники и может быть использовано при анализе и моделировании сложно формализуемых объектов и процессов, характеризующихся большим числом учитываемых параметров, что требует применения специализированных методов и инструментальных средств для многомерного анализа разнокачественной информации, определяющей свойства моделируемых объектов и процессов.
Известен способ кластеризации и сокращения размерности многомерных данных для их индексации и поиска [Заявка РФ №2000112647, МПК (G06F 17/30, от 10.04.2002 г.], при осуществлении которого многомерные данные разбивают на один или нескольких кластеров, для указанных одного или нескольких кластеров формируют и сохраняют информацию о кластеризации, создают один или нескольких таких кластеров сокращенной размерности и для одного или нескольких таких кластеров формируют информацию о сокращении размерности и сохраняют информацию о сокращении размерности.
Недостаток данного способа определяется тем, что в нем решение задачи кластеризации объектов, задаваемых параметрами, сводится к оцениванию данных параметров объектов кластеризации. Данные параметры ищутся в метрических пространствах X и Y, и на этапе обучения задают отображение G: X→Y, определенное на выборке обучения DG⊂X. На этапе же кластеризации по элементу из генеральной выборки x∈X ищется G(x)∈Y. Причем для кластеризации апостериорной информации элемент x∈DG задается его приближенным значением - элементом xδ∈X. Таким образом, рассматриваемую проблему следует рассматривать как задачу о приближенном вычислении значения абстрактной функции G(x) при неточно заданном аргументе х. Кроме этого оператор G определен не на всем Х(DG≠X), поскольку элемент генеральной выборки xδ не обязательно принадлежит DG и, следовательно, оператор G вполне непрерывен, т.е. нарушаются оба условия корректности задачи по Адамару [Тихонов А.Н., Гончарский А.В., Степанов В.В., Ягола А.Г. Численные методы решения некорректных задач. - М.: Наука. - 1990; Тихонов А.Н., Арсенин В.Я. Методы решения некорректных задач. - М.: Наука. - 1986; Бакушинский А.Б., Гончарский А.В. Итерационные методы решения некорректных задач. - М.: Наука. - 1988], что определяет данный класс задач как некорректные. Поэтому кластеризация согласно этому способу имеет низкую точность из-за его неустойчивости.
Известен способ автоматической кластеризации объектов [Заявка РФ №2003136467, МПК G06F 17/00, от 27.05.2005 г.], заключающийся в том, что определяют расстояние между всеми парами исходного множества объектов, выбирают два ближайших друг к другу объекта, соединяют их ребром и фиксируют длину этого ребра, затем отыскивают объект, ближайший к любому из уже рассмотренных объектов, соединяют его ребром и фиксируют длину этого ребра, указанную операцию поиска повторяют до исчерпания всех объектов, упорядочивают элементы массива длин ребер по возрастанию или по убыванию, полученные в результате определения длин ребер величины представляют собой радиусы кластеров, с помощью которых производят разбиение исходного множества объектов на кластеры, и в результате для каждого радиуса r получают k кластеров, представляющих собой подмножество объектов, принадлежащих области с радиусом r, после этого данные о величинах радиусов кластеров и числе полученных для этих радиусов кластеров заносят в двумерный массив данных, определяют количество повторений числа кластеров при различных радиусах, строят новый двумерный массив данных, определяют количество повторений числа кластеров при различных радиусах, строят новый двумерный массив, элементами которого являются число кластеров и соответствующее им число повторений, выбирают предпочтительное число кластеров и их радиусов, для чего из полученного массива выбирают такие значения числа кластеров и их радиусов, чтобы обеспечивалось максимальное повторение числа кластеров объектов при различных радиусах и при одновременном соблюдении минимальных значений радиусов различных кластеров, при этом в случае равенства число повторений кластеров, полученных при определении наиболее повторяющегося их числа, определяют величину удаленности кластеров друг от друга при различных значениях радиусов кластеров, а в качестве критерия принятия решения об окончании процесса разбиения исходного множества объектов принимают максимальное значение величины удаленности кластеров друг от друга при равном числе повторений данных кластеров.
Данный способ сводится к формированию из исходной выборки кластеров, и его наиболее целесообразно использовать на этапе формирования начальных кластеров, которые можно рассматривать как обучающие выборки, для дальнейшего последовательного накопления в них измерительных данных.
Недостаток данного способа-прототипа, как и первого аналога, определяется тем, что в нем решение задачи кластеризации объектов, задаваемых параметрами, сводится к оцениванию данных параметров объектов кластеризации. Данные параметры ищутся в метрических пространствах Х и Y, и на этапе обучения задают отображение G: X→Y, определенное на выборке обучения DG⊂X. На этапе же кластеризации по элементу из генеральной выборки x∈X ищется G(x)∈Y. Причем для кластеризации апостериорной информации элемент x∈DG задается его приближенным значением - элементом xδ∈X. Таким образом, рассматриваемую проблему следует рассматривать как задачу о приближенном вычислении значения абстрактной функции G(x) при неточно заданном аргументе x. Кроме этого оператор G определен не на всем X (DG≠X), поскольку элемент генеральной выборки Xδ не обязательно принадлежит DG и, следовательно, оператор G вполне непрерывен, т.е. нарушаются оба условия корректности задачи по Адамару [Тихонов А.Н., Гончарский А.В., Степанов В.В., Ягола А.Г. Численные методы решения некорректных задач. - М.: Наука. - 1990; Тихонов А.Н., Арсенин В.Я. Методы решения некорректных задач. - М.: Наука. - 1986; Бакушинский А.Б., Гончарский А.В. Итерационные методы решения некорректных задач. - М.: Наука. - 1988], что определяет данный класс задач как некорректные. Поэтому кластеризация согласно этому способу имеет низкую точность из-за его неустойчивости.
Задачей предлагаемого изобретения является повышение устойчивости способа последовательной кластеризации, что может быть достигнуто за счет контроля устойчивости кластера при введении в него элементов из генеральной выборки.
Контроль устойчивости кластера позволяет перенести качество работы способа формирования кластера, достигнутое на фиксированных объектах обучающей выборки, для произвольного элемента генеральной совокупности, тем самым повысить качество его работы на генеральной совокупности.
Решение задачи достигается тем, что в способе автоматической кластеризации объектов формируют из исходного множества выборки в виде начальных кластеров, например, аналогично способу по заявке РФ №2003136467, причем исходное множество формируется путем идентификации каждого классифицируемого объекта его параметром, задающим координату классифицируемого объекта в исходном множестве, и рассматривается как выборка обучения, которую формируют по показательному закону распределения, а данные о кластерах, полученные на этапе обучения, заносятся в соответствующие элементы блока памяти, которые используются при дальнейшем последовательном накоплении в них измерительной информации, на этапе обучения определяют также модель кластера Ki с количеством элементов Ni, удовлетворяющую минимуму риска Rмi(α) формирования модели кластера для коэффициента регуляризации α, которая определяется которая определяется центром множества объектов кластера
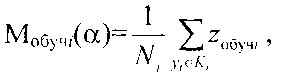
где zобучi - координата классифицируемого объекта кластера Ki, полученная на этапе обучения,
для каждого кластера Ki с радиусом ri задают вероятность допустимого отклонения b<<ri классифицируемого объекта по его параметру в виде координаты z′ из генеральной выборки от модели Мобучi(α) кластера Ki и определяют
верхний предел устойчивости кластера при введении в него объекта генеральной выборки с координатой z′ как
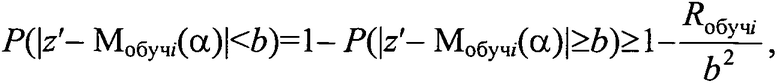
на этапе последовательной классификации измеряют координату z′ классифицируемого объекта в исходном множестве, определяют отклонение ΔMi модели кластера Ki с учетом нового объекта с координатой z′ из генеральной выборки от модели Мобучi(α) как
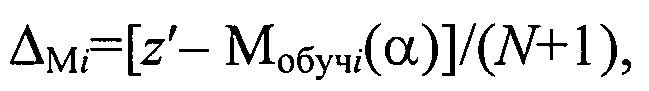
и если при коэффициенте регуляризации α=0 ΔM≤b, то объект генеральной выборки с координатой z′ включается в кластер Ki, а если при α≠0 ΔMi>b, то объект генеральной выборки с координатой z′ анализируется на предмет принадлежности к соседним кластерам, для чего по выражению для P(|z′-Мобучi(α)|<b) определяют коэффициент регуляризации αi для соседних сравниваемых кластеров Ki, чтобы он обеспечивал требуемые значения вероятности P(|z′-Mобучi(α)|<b) при заданных значениях риска Rобучi и отклонения b
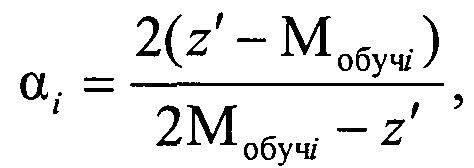
сравнивают коэффициенты регуляризации для данного кластеров Ki и включают объект генеральной выборки с координатой z′ в кластер Ki, для которого риск RMi(αi0)=Rобучi при максимальном коэффициенте регуляризации αi0, а сама регуляризованная координата объекта кластера Ki определяется как
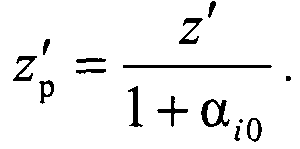
В заявляемом техническом решении исходное множество формируется путем идентификации каждого классифицируемого объекта его параметром, задающим координату классифицируемого объекта в исходном множестве, и рассматривается как выборка обучения, которую формируют по показательному закону распределения, а данные о кластерах, полученные на этапе обучения, заносятся в соответствующие элементы блока памяти, которые используются при дальнейшем последовательном накоплении в них измерительной информации, на этапе обучения определяют также модель кластера Ki с количеством объектов Ni, удовлетворяющую минимуму риска RMi(α) формирования модели кластера для коэффициента регуляризации α, которая определяется его центром
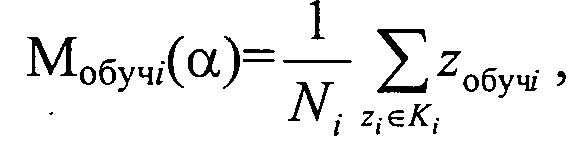
для каждого кластера задают вероятность допустимого отклонения b<<ri классифицируемого объекта по его параметру в виде координаты z′ из генеральной выборки от модели Мобучi(α) кластера Ki и определяют верхний предел устойчивости кластера при введении в него объекта генеральной выборки с координатой z′ как
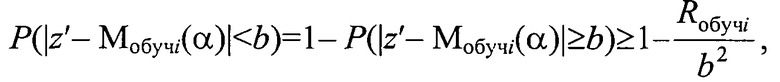
на этапе последовательной классификации измеряют координату z′ классифицируемого объекта в исходном множестве, определяют отклонение ΔMi модели кластера Ki с учетом нового объекта с координатой z′ из генеральной выборки от модели Мобучi(α) как
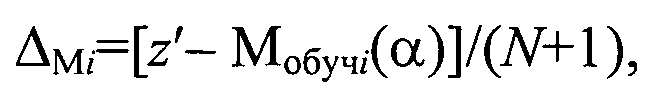
и если при коэффициенте регуляризации α=0 ΔM≤b, то объект генеральной выборки с координатой z′ включается в кластер Ki, а если при α≠0 ΔMi>b, то объект генеральной выборки с координатой z′ анализируется на предмет принадлежности к соседним кластерам, для чего по выражению для P(|z′-Мобучi(α)|<b) определяют коэффициент регуляризации αi для соседних сравниваемых кластеров Ki, чтобы он обеспечивал требуемые значения вероятности P(|z′-Мобучi(α)|<b) при заданных значениях риска Rобучi и отклонения b
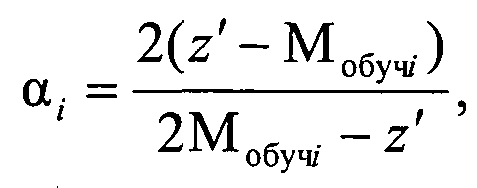
сравнивают коэффициенты регуляризации для данного кластеров Ki и включают объект генеральной выборки с координатой z′ в кластер Ki, для которого риск RMi(αi0)=Rобучi при максимальном коэффициенте регуляризации αi0, а сама регуляризованная координата объекта кластера Ki определяется как
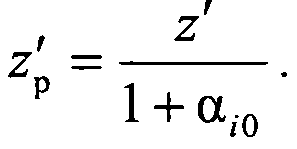
Сравнение заявляемого технического решения с известными способами-аналогами позволяет установить соответствие его критерию "новизна".
Признаки, отличающие заявляемое техническое решение, не выявлены в других технических решениях при изучении данной и смежной областей техники и, следовательно, обеспечивают заданному решению соответствие критерию "существенные отличия".
Для того чтобы сформулировать способ автоматической кластеризации объектов, осуществим общий анализ задачи кластеризации объектов, а для выделения признаков, отличающих заявляемое техническое решение, определим условия решения данной задачи.
I. Общий анализ задачи кластеризации
Решение задачи кластеризации объектов, задаваемых параметрами, сводится к оцениванию заданных параметров объектов кластеризации. Данные параметры рассматриваются как координаты классифицируемого объекта в исходных метрических пространствах Х и Y, где на этапе обучения определяется отображение G: X→Y, определяемое на выборке обучения DG∈X. На этапе же кластеризации по объектам из генеральной выборке x∈X ищется G(x)∈Y. При этом на этапе кластеризации апостериорной информации вместо параметра объекта x∈DG известно его приближенное значение - параметр объекта xδ∈X. Таким образом, рассматриваемую проблему следует рассматривать как задачу о приближенном вычислении значения оператора G(x) при неточно заданном аргументе x. Оператор G определен не на всем Х (DG≠X), поскольку элемент генеральной выборки xδ не обязательно принадлежит DG и, следовательно, для вполне непрерывного оператора G нарушаются оба условия корректности задачи по Адамару [Тихонов А.Н., Гончарский А.В., Степанов В.В., Ягола А.Г. Численные методы решения некорректных задач. - М.: Наука. 1990; Тихонов А.Н., Арсенин В.Я. Методы решения некорректных задач. - М.: Наука - 1986; Бакушинский А.Б., Гончарский А.В. Итерационные методы решения некорректных задач. - М.: Наука. - 1988], что определяет данный класс задач как некорректные. Некорректность задачи последовательной кластеризации элементов генеральной выборки требует регуляризации элемента z′ генеральной выборки при его кластеризации [Бакушинский А.Б., Гончарский А.В. Итерационные методы решения некорректных задач. - М.: Наука. - 1988]. При регуляризации элемента генеральной выборки z′ по параметру регуляризации а образуется континуум моделей элементов (кластеров) информационного поля информационно-измерительной системы для этапа классификации
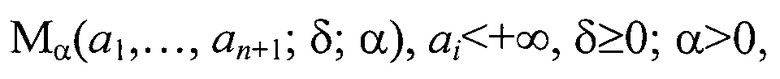
где α - коэффициент регуляризации, a1, …, an+1 - коэффициенты в уравнении разделительной гиперплоскости между кластерами, δ - точность определения модели.
Данная модель кластеризации определенная на этапе последовательной классификации на семействе всевозможных моделей, которые допускаются в ходе обучения, характеризуются устойчивостью в виде параметрического семейства отображения Mα(a1, …, an+1; δ; α). При оптимальном качестве решения задачи кластеризации на обучающей выборке при низкой устойчивости не приводит к получению наилучшего способа кластеризации с точки зрения генеральной совокупности объектов, поскольку требует работы со всей генеральной совокупности объектов, которая недоступна на этапе обучения, а также содержит зашумленную информацию.
При оценке качества принимаемого решения в настоящее время широко применяется функционал риска. Так, задача обучения способа кластеризации с признаковым описанием по обучающей выборке сводится к оптимизации параметрического функционала риска, который минимизирует невязку алгоритма кластеризации в виде отклонения текущих выходов алгоритма кластеризации от желаемых. Для оценки качества принятия решения при формировании модели кластера Ki на этапе обучения Мобучi используется также функционал риска. При этом, воспользовавшись оценкой среднего риска в виде эмпирического риска Rэмп, для конечного множества элементов [Вапник В.Н. Восстановление зависимостей по эмпирическим данным. - М.: Наука, 1979; Загороднюк В.Т., Михайлов А.А., Темирев А.П. Исследование функционала риска при параметрическом синтезе измерительных устройств. Ростов н/Д. Из-во СКНЦВШ. - 2001] можно определить условие, обеспечивающее минимум риска формирования кластера на обучающей выборке
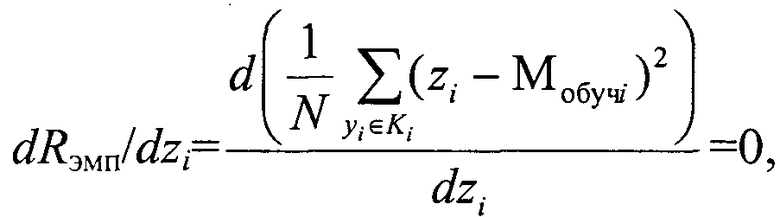
где zi - параметр объектов кластера Ki, N - количество элементов кластера Ki.
II. Определение условий решения задачи кластеризации
Для исследования условий оптимизации решения некорректной задачи кластеризации представим ее в общем виде как задачу решения операторного уравнения

где A=G-1, X=U, Y=Z, DG=AZ⊂U.
1. При решении данного операторного уравнения множество моделей, их устойчивость и вид решающего правила для получения регуляризованного элемента zp генеральной выборки z′ определяется с точностью до параметра регуляризации α. При этом задача выбора модели сводится к регуляризационной постановке, решение которой в соответствии с [Тихонов А.Н., Гончарский А.В., Степанов В.В., Ягола А.Г. Численные методы решения некорректных задач. - М.: Наука. 1990 с. 11 формула 5] имеет вид сглаживающего функционала 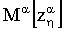
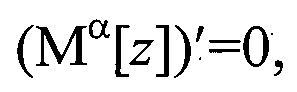
где 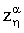
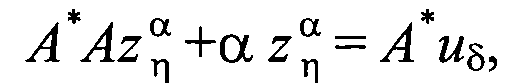
где А - оператор уравнения (1), А* - оператор, сопряженный к оператору А, δ>0 - погрешность задания правой части уравнения (1) uδ.
Решение данной задачи для А=1 (выбор элемента при кластеризации происходит без его преобразования) имеет вид
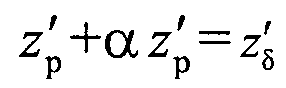
и сводится к проблеме выбора подходящего коэффициента регуляризации.
2. Критерий синтеза модели кластеризации должен быть выбран в виде компромисса между точностью модели на обучающей выборке и ее устойчивостью по отношению к элементу генеральной выборки z′. Устойчивость способа кластеризации для j-того объекта генеральной выборки определим вероятностью отклонения от выбранной модели кластера Мобучi, которая характеризуется риском Rобучi [Вапник В.Н. Восстановление зависимостей по эмпирическим данным. - М.: Наука, 1979; Михайлов А.А. Основы теории построения алгоритмов оценивания параметров по результатам измерения. Ростов н/Д, Из-во Рост. Ун-та. - 2002; Загороднюк В.Т., Михайлов А.А., Темирев А.П. Исследование функционала риска при параметрическом синтезе измерительных устройств. Ростов н/Д. Из-во СКНЦВШ. - 2001] на заданную величину b. Для определения условий устойчивости оптимальной модели кластера (в смысле выбранного функционала качества), полученной на этапе обучения, и используемой на генеральной выборке при кластеризации объекта z′ с отклонением на величину b, рассмотрим дискретную случайную величину Z={z,p(z)}. Предположим, что все ее значения z∈Z не отрицательны, и при этом предположении оценим вероятность события P(z≥A0) для некоторого числа А0>0. Имеем
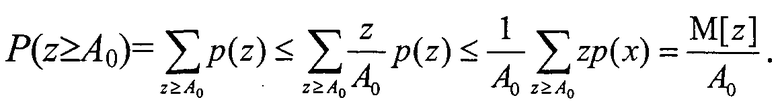
Первое из двух неравенств основано на том, что в области суммирования z/A0≥1. Второе неравенство справедливо потому, что, расширив область суммирования на все множество Z, к сумме добавляются только неотрицательные слагаемые (все значения x неотрицательны).
Пусть теперь Z={z,p(z)} - произвольная (необязательно неотрицательная) случайная величина. Для произвольного b>0 оценим вероятность P(|z′-Мобучi|≥b) отклонения случайной величины z′ от модели кластера на обучающей выборке Мобучi на величину, не меньшую, чем b. Для неотрицательной случайной величины |z′-Мобучi| получаем
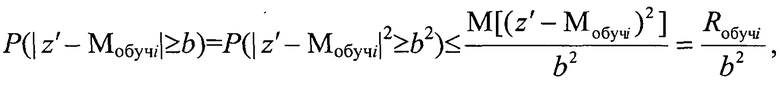
где Rобучi - риск принятой модели Мобучi.
Результат запишем в виде
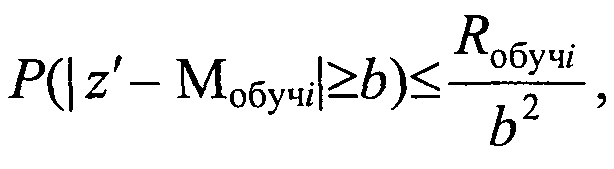
т.е.
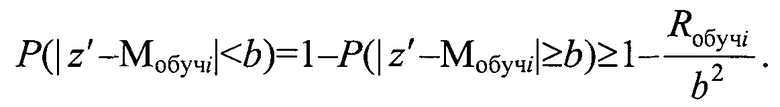
Для сохранения устойчивости оптимальной модели кластера, т.е. вероятности события Р(|z′-Мобучi|≥b) при заданном b и Rобучi, необходимо, чтобы коэффициент регуляризации а определился из условия сохранения условий устойчивости кластера, т.е. необходимо, чтобы риск кластера при добавлении в него нового элемента генеральной выборки z′ был бы равен риску начального кластера на обучающей выборке. Для определения данного условия сравним эмпирический риск модели кластера на обучающей выборке [Вапник В.Н. Восстановление зависимостей по эмпирическим данным. - М.: Наука, 1979, с. 187, ф. 6.3]
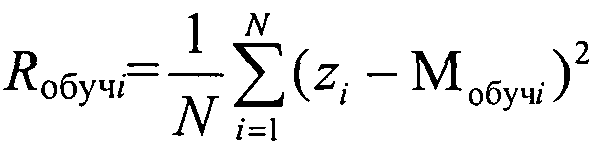
и риск кластера при добавлении в него нового элемента генеральной выборки
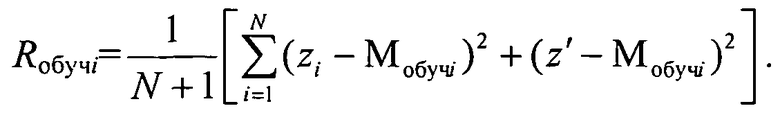
При этом
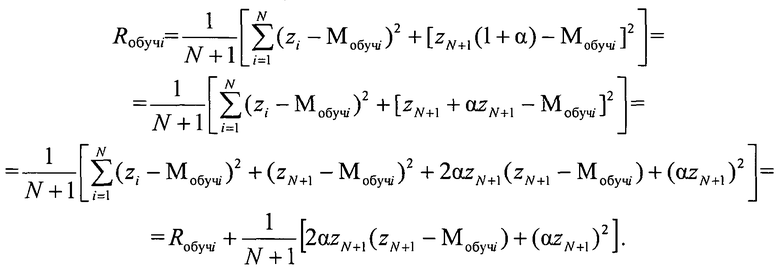
Из данного выражения имеем
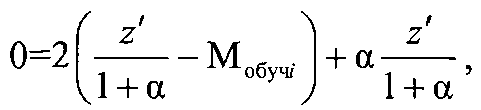
а коэффициент регуляризации а равен
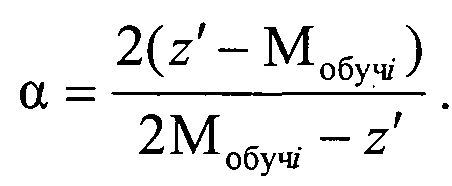
Таким образом, выражение для P(|z′-Mобучi|<b) позволяет внести иерархию на множестве моделей, делая одни решения более предпочтительными, чем другие, и воспользовавшись результатами кластеризации i-го объекта на обучающей выборке рассматриваемым алгоритмом, максимизировать нижнюю оценку устойчивости алгоритма классификации на генеральной совокупности.
3. В заключение анализа задачи кластеризации отметим, что при формировании модели Мобуч элементы выборки обучения следует выбирать из условия, что на ней достигается максимум
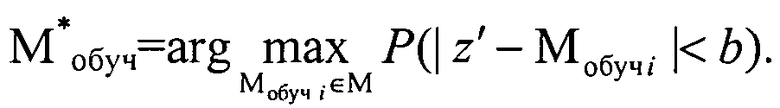
Для определения закона распределения элементов выборки обучения продифференцируем выражение P(|z′-Mобучi|<b) по Мобучi. Из выражения для P(|z′-Мобучi|<b) следует, что максимум устойчивости достигается при 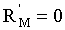
Проведенные исследования задачи кластеризации позволяют сформулировать способ автоматической кластеризации объектов, в котором исходное множество формируется путем идентификации каждого классифицируемого объекта его параметром, задающим координату классифицируемого объекта в исходном множестве, и рассматривается как выборка обучения, которую формируют по показательному закону распределения, а данные о кластерах, полученные на этапе обучения, заносятся в соответствующие элементы блока памяти, которые используются при дальнейшем последовательном накоплении в них измерительной информации, на этапе обучения определяют также модель кластера Ki с количеством объектов Ni, удовлетворяющую минимуму риска RMi(α) формирования модели кластера для коэффициента регуляризации α, которая определяется его центром
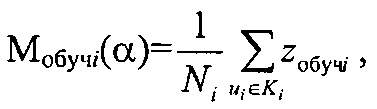
для каждого кластера задают вероятность допустимого отклонения b<<ri, классифицируемого объекта по его параметру в виде координаты z′ из генеральной выборки от модели Мобучi(α) кластера Ki и определяют верхний предел устойчивости кластера при введении в него объекта генеральной выборки с координатой z′ как
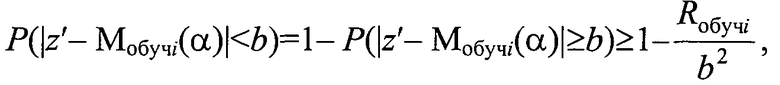
на этапе последовательной классификации измеряют координату z′ классифицируемого объекта в исходном множестве, определяют отклонение ΔMi модели кластера Ki с учетом нового объекта с координатой z′ из генеральной выборки от модели Мобучi(α) как
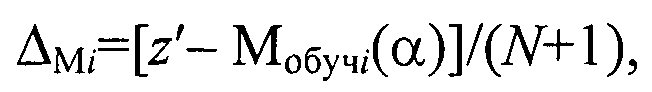
и если при коэффициенте регуляризации α=0 ΔM≤b, то объект генеральной выборки с координатой z′ включается в кластер Ki, а если при α≠0 ΔMi>b, то объект генеральной выборки с координатой z′ анализируется на предмет принадлежности к соседним кластерам, для чего по выражению для Р(|z′-Мобучi(α)|<b) определяют коэффициент регуляризации а, для соседних сравниваемых кластеров Ki, чтобы он обеспечивал требуемые значения вероятности P(|z′-Мобучi(α)|<b) при заданных значениях риска Rобучi и отклонения b
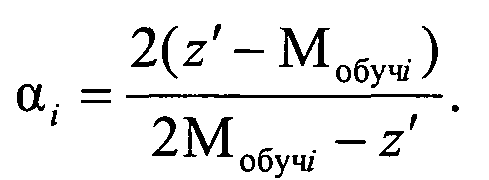
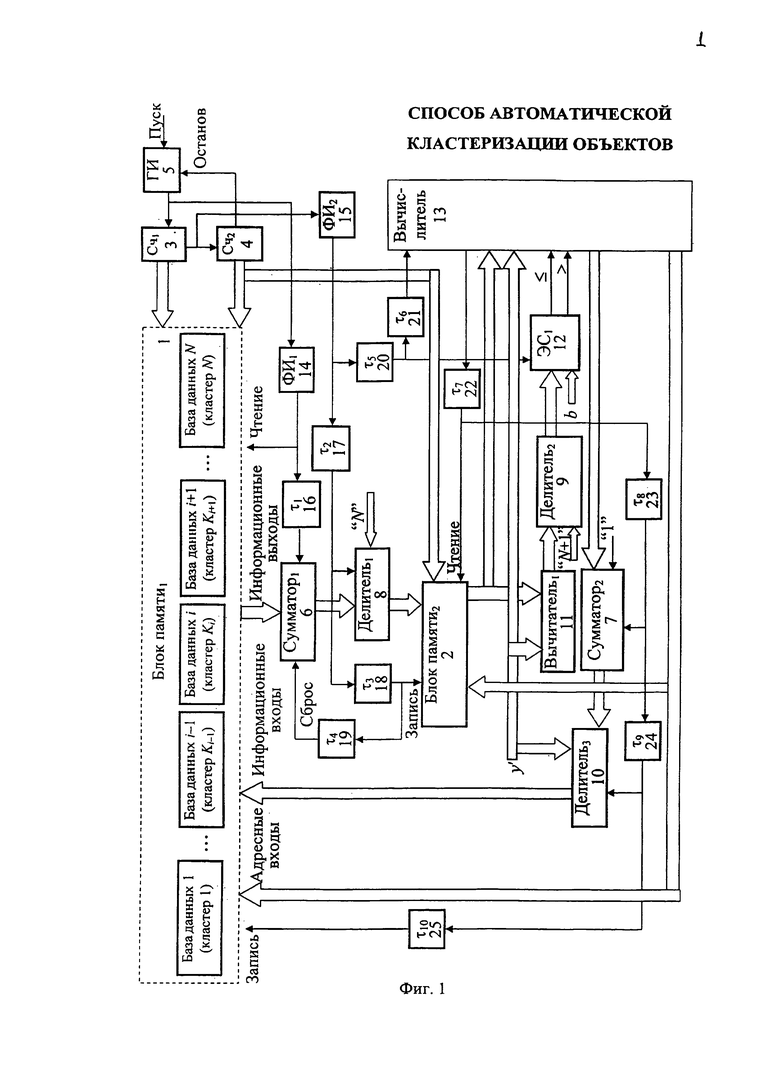
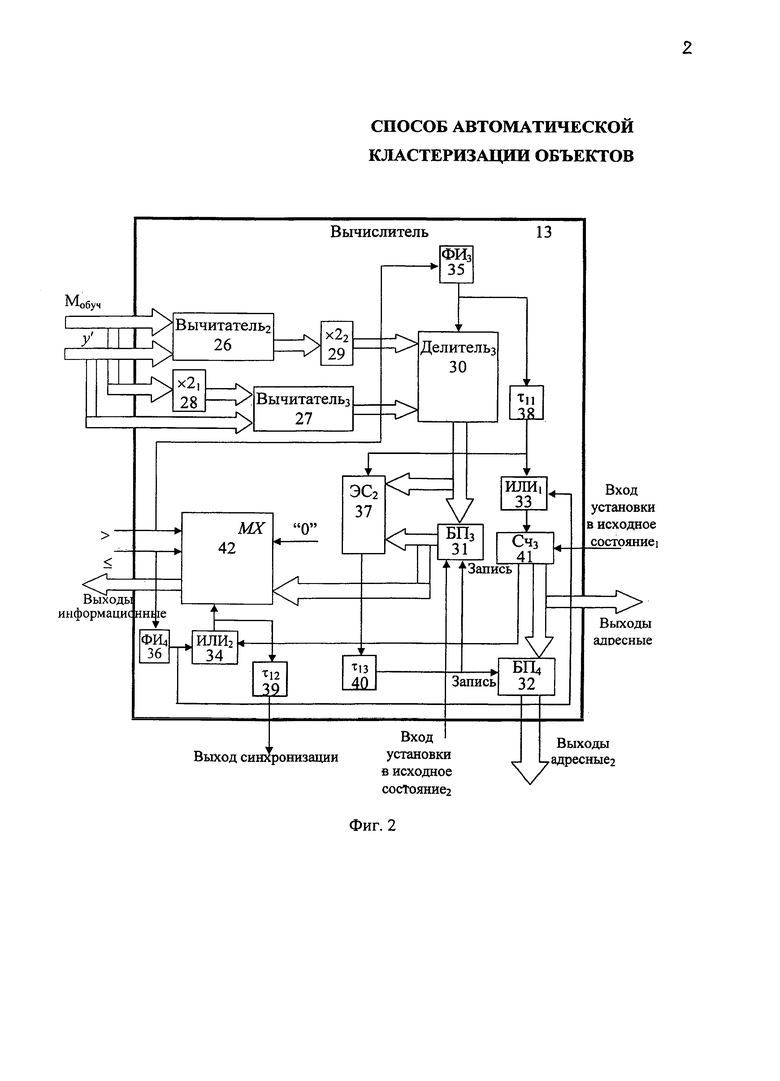
Для реализации предлагаемого способа может быть использовано устройство для накопления результатов классификации по способу автоматической кластеризации объектов, приведенное на фиг. 1, а реализация вычислителя данного устройства, предназначенного для определения коэффициента регуляризации а, приведена на фиг. 2.
Данное устройство содержит два блока памяти БП1 1, в которой заносятся данные, определяющие кластер, и БП2 2, два счетчика Сч1 3 и Сч2 4, генератор импульсов опорной частоты ГИ 5, два сумматора 6, 7, три делителя 8, 9, 10, первый вычитатель 11, первый элемент сравнения ЭС1 12, вычислитель 13, два формирователя импульсов ФИ1 14, ФИ2 15, десять элементов задержки импульсов τ1, …, τ10 16-25.
Вычислитель 13 (фиг. 1) предназначен для определения коэффициента регуляризации и содержит два вычитателя 26, 27, два умножителя 28, 29, третий делитель 30, два блока памяти БП3 31, БП4 32, два элемента "ИЛИ" 33, 34, третий и четвертый формирователь импульсов ФИ3 35, ФИ4 36, второй элемент сравнения ЭС2 37, а также три элемента задержки сигнала τ11, …, τ13 38-40, третий счетчик Сч3 41, мультиплексор MX 42.
В устройстве для накопления результатов классификации по способу автоматической кластеризации объектов информационные выходы блока памяти 1 подключены к информационным входам первого сумматора 6, а адресные входы блока памяти 1 для чтения соединены с выходами первого Сч1 3 и второго Сч2 4 счетчика. Счетный вход первого счетчика Сч1 3 соединен с выходом генератора импульсов ГИ 5, вход "Пуск" которого соединен с входом "Пуск" устройства, вход "Останов" с выходом второго счетчика Сч2 4. Выход генератора импульсов ГИ 5 через первый формирователь импульсов ФИ1 14 соединен с входом "Чтение" блока памяти 1 и через первый элемент задержки импульса τ1 16 с входом стробирования первого сумматора 6, информационные выходы которого соединены с первыми информационными входами первого делителя 8, вторые информационные входы которого соединены с информационными входами задания объема кластеров обучения N устройства. Вход стробирования первого делителя 8 соединен через второй элемент задержки импульсов 17 и второй формирователя импульсов 15 с выходом переноса первого счетчика Сч1 3 и счетным входом второго счетчика Сч2 4. Информационные выходы первого делителя 8 соединены с информационными входами второго блока памяти 2, адресные входы которого подключены к информационным выходам второго счетчика Сч2 4. Информационные выходы второго блока памяти 2 соединены с первыми информационными входами первого вычитателя 11 и первыми информационными входами вычислителя 13. Первые информационные входы третьего делителя 10, вторые информационные входы первого вычитателя 11, а также и вторые информационные входы вычислителя 13 соединены с входом задания параметра кластеризуемого элемента z′. Информационные выходы первого вычитателя 11 соединены с первыми информационными входами второго делителя 9, вторые информационные входы которого соединены с входами задания N+1, а информационные выходы соединены с первыми информационными входами первого элемента сравнения ЭС1 12. Выходы первого элемента сравнения ЭС1 12 подключены к входам "меньше и равно" и "больше" вычислителя 13, а вторые информационные входы элемента сравнения ЭС 12 соединены с входами задания параметра b. Вход стробирования первого делителя 8 через третий элемент задержки импульса τ3 18 соединен с входом "Запись" второго блока памяти 2 и далее через четвертый элемент задержки импульса τ4 19 с входом "Сброс" первого сумматора 6. Выход второго формирователя импульсов 15 соединен через пятый элемент задержки импульсов τ5 20 с входом стробирования элемента сравнения ЭС1 12 и далее через шестой элемент задержки импульсов τ6 21 с входом стробирования вычислителя 13. Информационные выходы вычислителя 13 соединены с первыми информационными входами сумматора 7, ко вторым информационным входам которого подключены входы "задания единицы", а информационные выходы соединены со вторыми информационными входами третьего делителя 10. Информационные выходы третьего делителя 10 соединены с информационными входами первого блока памяти 1, ко вторым адресным входам которого подключены адресные выходы вычислителя 13. Выход стробирования вычислителя 13 через седьмой элемент задержки импульса τ7 22 соединен с входом "Чтение" второго блока памяти 2 и далее через восьмой элемент задержки импульса τ8 23 с входом стробирования второго сумматора 7, а далее через девятый элемент задержки импульса τ9 24 с входом стробирования третьего делителя 10 и далее через десятый элемент задержки импульса τ10 25 с входом "Запись" блока памяти 1.
Входы задания Мобуч вычислителя 13 (фиг. 2) подключены к первым информационным входам второго вычитателя 26, а также через первый умножитель на два 29 к первым информационным входам третьего вычислителя 27. Входы задания z′ вычислителя 13 подключены ко вторым информационным входам второго вычитателя 26, а также ко вторым информационным входам третьего вычитателя 27. Информационные выходы второго вычитателя 26 через второй умножитель на два 29 соединены с первыми информационными входами третьего делителя 30, ко вторым информационным входам которого подключены информационные выходы третьего вычитателя 27. Информационные выходы третьего делителя соединены с входами третьего блока памяти 31 и с первыми информационными входами второго элемента сравнения ЭС2 37. Информационные выходы третьего блока памяти 31 соединены со вторыми информационными входами второго элемента сравнения ЭС2 37 и с первыми информационными входами мультиплексора MX 42, ко вторым информационным входам которого подключены входы задания нуля. Адресные входы мультиплексора MX 42 соединены с входами "меньше и равно" и "больше" вычислителя 13, а информационные выходы мультиплексора MX 42 соединены с информационными выходами вычислителя 13. Первые адресные выходы вычислителя 13 соединены с информационными выходами третьего счетчика Сч3 41 и информационными входами четвертого блока памяти БП4 32, а вторые адресные выходы вычислителя 13 соединены с информационными выходами четвертого блока памяти БП4 32. Выход второго элемента сравнения ЭС2 37 подключен через тринадцатый элемент задержки импульса τ13 40 к входам "Запись" третьего 31 и четвертого блока памяти БП4 32. Выход переноса третьего счетчика 41 соединен с первым входом второго элемента "ИЛИ" 34, второй вход которого соединен через четвертый формирователь импульсов ФИ4 36 с входом "меньше и равно" вычислителя 13, а выход соединен с входом стробирования мультиплексора MX 42 и через двенадцатый элемент задержки импульса τ12 39 с выходом синхронизации вычислителя 13. Вход "больше" вычислителя 13 соединен через третий формирователь импульсов ФИ3 35 с входом стробирования третьего делителя 30 и далее через одиннадцатый элемент задержки импульса τ11 38 соединен с входом стробирования второго элемента сравнения ЭС2 37 и через первый вход первого элемента "ИЛИ1" 33 соединен с входом четвертого формирователя импульсов ФИ4 36. Первый вход "Установки в исходное состояние1" вычислителя 13 соединен с входом установки в исходное состояние третьего счетчика 41, а второй вход "Установки в исходное состояние2" вычислителя 13 соединен с входом установки в исходное состояние третьего блока памяти БП3 31.
Устройство для автоматической кластеризации объектов, реализующее предлагаемый способ, работает следующим образом. В исходном состоянии в первый блок памяти 1 занесена обучающая выборка, распределенная по кластерам, сформированным, например, в соответствии со способом, приведенным во втором способе кластеризации, - прототипе по заявке №2003136467. При пуске генератора импульсов ГИ 5 ко входу "Пуск" на информационных выходах первого счетчика Сч1 3 формируются двоичные коды, задающие адреса элементов в рамках сформированных кластеров в первом блоке памяти 1. При переполнении первого счетчика Сч1 3 во втором счетчике Сч2 4 накапливается информация, на информационных выходах которого формируется адреса кластеров блока памяти 1. При этом в первом сумматоре 6 накапливается сумма всех элементов кластера, адреса которых задаются с информационных выходов первого счетчика 3, а адреса кластера задается на информационных выходах второго счетчика 4. Причем суммирование в первом сумматоре 6 осуществляется последовательно для всех элементов кластера. После опроса элементов кластера полученная сумма делится в первом делителе 8 на общее количество элементов в кластере N, в результате определяется модель кластера
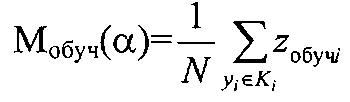
по импульсу переноса первого счетчика 3, задержанному вторым элементом задержки импульса τ2 17. Полученная модель кластера поступает во второй блок памяти 2, где записывается по адресу, задержанному третьим элементом задержки импульса τ3 18, после чего обнуляется первый сумматор 6 для определения модели последующего кластера. После определения модели всех кластеров, заданных в блоке памяти 1, устройство для автоматической кластеризации переходит к этапу непосредственной кластеризации последовательно поступившего для анализа значения элемента из генеральной выборки z′.
При этом в первом вычитателе 11 полученная модель Мобучi для i-кластера вычитается из поступившего для анализа нового значения элемента из генеральной выборки z′. Полученная разность делится на втором делителе 9 на значение N+1
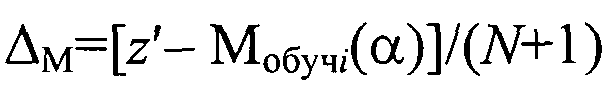
и сравнивается на первом элементе сравнения 12 с допустимым отклонением b классифицируемого элемента z′ генеральной выборки от полученной на этапе обучения модели Мобучi(α) кластера Ki. При условии, что полученный результат ΔM меньше b, на информационном выходе вычислителя 13 формируется ноль, который после суммирования с единицей во втором сумматоре 7 поступают третий делитель 10, на первый вход которого поступает регуляризуемый элемент z′. Полученный результат поступает в кластер, адрес которого формируется на адресных выходах вычислителя 13.
В случае если полученный на выходе второго делителя 9 результат ΔM больше b, то вычислитель 13 определяет значение регуляризирующего коэффициента α, который поступает на первые информационные входы второго сумматора 7. Результат суммирования на втором сумматоре 7, полученный на выходе второго сумматора 7 по сигналу с выхода восьмого элемента задержки импульса τ8 23, используется в третьем делителе 10 для получения регуляризованного значения zp, по сигналу стробирования с выхода девятого элемента задержки импульса τ9 24
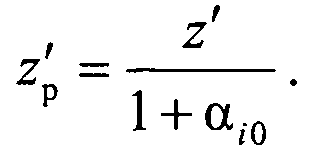
Полученное регуляризованное значение zp для объекта генеральной выборки z′ записывается по сигналу с выхода десятого элемента задержки импульса τ10 25 в соответствующий кластер, по адресу, сформированному на адресных выходах вычислителя 13.
Для вычисления коэффициента регуляризации α в вычислителе 13 при условии "меньше или равно" через второй элемент "ИЛИ2" 34 мультиплексор 42 включается и на его выход поступает "0" с входа задания "0", при этом импульс с выхода четвертого формирователя импульсов ФИ4 36 через первый элемент "ИЛИ1" 33 поступает на вход третьего счетчика Сч3 41, где и накапливается.
При условии "больше" на выходе ФИ3 35 формируется импульс синхронизации для делителя 30, а на втором и третьем вычислителях 26, 27 и первом и втором умножителях на два 28, 29 и третьем делителе 30 по данному импульсу реализуется выражение
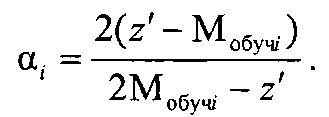
Полученное значение коэффициентов регуляризации а по стробирующему сигналу с выхода одиннадцатого элемента задержки импульса τ11 38 сравнивается на втором элементе сравнения ЭС2 37 с предыдущим его значением, которое хранится в третьем блоке памяти БП3 31 (в исходном состоянии во второй блок памяти БП3 31 заносится максимально возможное число, код которого состоит из двоичных единиц). Стробирующий сигнал третьего делителя 30 накапливается в третьем счетчике 41, выходной код которого определяет номер анализируемого кластера блока памяти 1. Если вновь определенный коэффициент регуляризации αi меньше предыдущего, то новый коэффициент регуляризации αi+1 записывается по сигналу с выхода второго элемента сравнения ЭС2 37, задержанному на тринадцатом элементе задержки импульса 40, в третий блок памяти 31 вместо предыдущего. При этом в четвертый блок памяти БП4 32 с выхода третьего счетчика 41 записывается номер кластера, которому соответствует меньший коэффициент регуляризации. Определенный таким образом минимальный коэффициент регуляризации окончания процесса проверки кластеров через мультиплексор MX 42 при поступлении стробирующего импульса с выхода переноса третьего счетчика 36 через второй элемент "ИЛИ2" 34 поступает на информационные выходы вычислителя 13. Импульсы стробирования МХ 42 через двенадцатый элемент задержки импульсов 39 поступают на выход синхронизации вычислителя 13. Одновременно с информационных выходов четвертого блока памяти 32 на выходе вычислителя 13 поступают адресные выходы, соответствующие кластеру, для которого коэффициент регуляризации минимален.
Таким образом, в устройстве по предлагаемому способу продолжается формирование кластеров в режиме поступления на его вход информации о классифицируемом объекте с сохранением качества и устойчивости кластеров, сформированных на этапе обучения.
Использование заявляемого технического решения позволит повысить устойчивость способа кластеризации объектов разного типа. Применение заявляемого технического решения наиболее целесообразно при анализе большого объема первичных экспериментальных данных в современных информационно-измерительных системах при решении задачи автоматизации извлечения знаний в системах искусственного интеллекта.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ФИЛЬТРАЦИИ И КЛАСТЕРИЗАЦИИ РЕЖИМОВ СЛОЖНОЙ РЕКТИФИКАЦИОННОЙ КОЛОННЫ | 2019 |
|
RU2706578C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ БЕЗ УЧИТЕЛЯ С АВТОМАТИЧЕСКИМ ОПРЕДЕЛЕНИЕМ ПАРАМЕТРОВ ОБУЧЕНИЯ МОДЕЛЕЙ | 2023 |
|
RU2818858C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2023 |
|
RU2816667C1 |
| СПОСОБ АДАПТИВНОГО ПРОГНОЗИРОВАНИЯ ОСТАТОЧНОГО РЕСУРСА ЭКСПЛУАТАЦИИ СЛОЖНЫХ ОБЪЕКТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2013 |
|
RU2533321C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ | 2023 |
|
RU2809719C1 |
| ОДНОВРЕМЕННОЕ РАСПОЗНАВАНИЕ АТРИБУТОВ ЛИЦ И ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПРИ ОРГАНИЗАЦИИ ФОТОАЛЬБОМОВ | 2018 |
|
RU2710942C1 |
| СПОСОБ ОБНАРУЖЕНИЯ И АВТОСОПРОВОЖДЕНИЯ ОБЪЕКТОВ ЦЕЛЕУКАЗАНИЯ ОПТИКО-ЭЛЕКТРОННОЙ СИСТЕМОЙ БЕСПИЛОТНОГО ЛЕТАТЕЛЬНОГО АППАРАТА | 2020 |
|
RU2748763C1 |
| УСТРОЙСТВО ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2831917C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ АНОМАЛЬНОГО ВЗАИМОДЕЙСТВИЯ УЗЛОВ ИНФОРМАЦИОННО-ВЫЧИСЛИТЕЛЬНОЙ СЕТИ | 2023 |
|
RU2805277C1 |
| Способ кластеризации электронных писем, являющихся спамом | 2021 |
|
RU2769633C1 |
Изобретение относится к области вычислительной техники и может быть использовано при анализе и моделировании сложно формализуемых процессов, характеризующихся большим числом учитываемых факторов, что требует применения специализированных методов и инструментальных средств для многомерного анализа разнокачественной информации. Техническим результатом является повышение устойчивости последовательной кластеризации. Способ автоматической кластеризации объектов содержит формирование из исходного множества классифицируемых объектов выборок в виде начальных кластеров, причем исходное множество формируется путем идентификации каждого классифицируемого объекта его параметром, задающим координату классифицируемого объекта в исходном множестве, и рассматривается как выборка обучения, которую формируют по показательному закону распределения, а данные о кластерах, полученные на этапе обучения, заносятся в соответствующие элементы блока памяти, которые используются при дальнейшем последовательном накоплении в них измерительной информации, на этапе обучения определяют также модель кластера Ki с количеством элементов Ni, удовлетворяющую минимуму риска RMi(α) формирования модели кластера. 2 ил.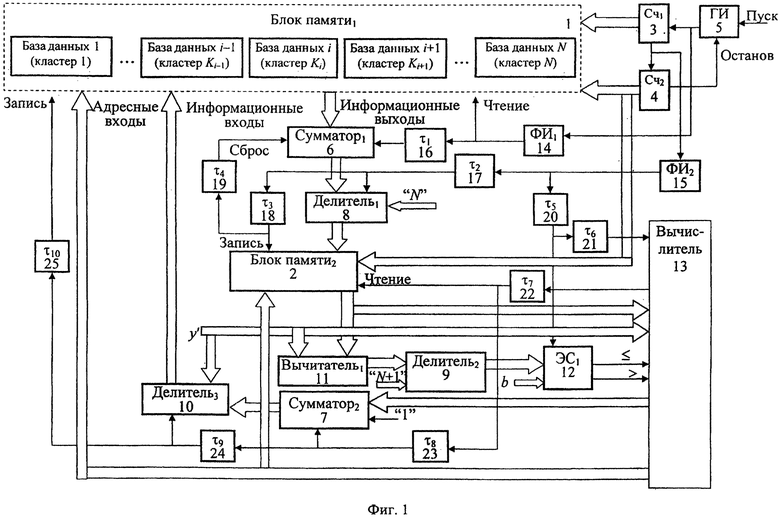
Способ автоматической кластеризации объектов, сводящийся к формированию из исходного множества классифицируемых объектов выборок в виде начальных кластеров, отличающийся тем, что исходное множество формируется путем идентификации каждого классифицируемого объекта его параметром, задающим координату классифицируемого объекта в исходном множестве, и рассматривается как выборка обучения, которую формируют по показательному закону распределения, а данные о кластерах, полученные на этапе обучения, заносятся в соответствующие элементы блока памяти, которые используются при дальнейшем последовательном накоплении в них измерительной информации, на этапе обучения определяют также модель кластера Ki с количеством элементов Ni, удовлетворяющую минимуму риска RMi(α) формирования модели кластера для коэффициента регуляризации α, которая определяется центром множества объектов кластера
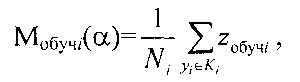
где zобучi - координата классифицируемого объекта кластера Ki, полученная на этапе обучения,
для каждого кластера Ki с радиусом ri задают вероятность допустимого отклонения b<<ri классифицируемого объекта по его параметру в виде координаты z′ из генеральной выборки от модели Мобучi(α) кластера Ki и определяют верхний предел устойчивости кластера при введении в него объекта генеральной выборки с координатой z′ как
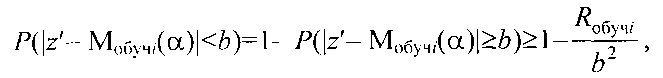
на этапе последовательной классификации измеряют координату z′ классифицируемого объекта в исходном множестве, определяют отклонение ΔMi модели кластера Ki с учетом нового объекта с координатой z′ из генеральной выборки от модели Мобучi(α) как
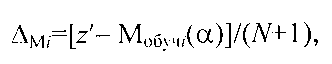
и если при коэффициенте регуляризации α=0 ΔM≤b, то объект генеральной выборки с координатой z′ включается в кластер Ki, а если при α≠0 ΔMi>b, то объект генеральной выборки с координатой z′ анализируется на предмет принадлежности к соседним кластерам, для чего по выражению для P(|z′-Мобучi(α)|<b) определяют коэффициент регуляризации αi для соседних сравниваемых кластеров Ki, чтобы он обеспечивал требуемые значения вероятности P(|z′-Мобучi(α)|<b) при заданных значениях риска Rобучi и отклонения b
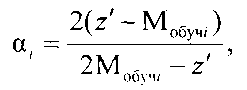
сравнивают коэффициенты регуляризации для данного кластеров Ki и включают объект генеральной выборки с координатой z′ в кластер Ki, для которого риск RMi(αi0)=Rобучi при максимальном коэффициенте регуляризации αi0, а сама регуляризованная координата объекта кластера Ki определяется как
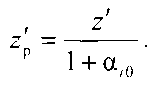
| RU 2007132411 A, 10.03.2009 | |||
| RU 2003136467 A, 27.05.2005 | |||
| RU 2000112647 A, 10.04.2002 | |||
| US 7676518 B2, 09.03.2010 | |||
| US 2011035379 A1, 10.02.2011 | |||
| US 7406456 B2, 29.07.2008 | |||
| US 5317741 A, 31.05.1994. |

