Изобретение относится к диагностическим системам и предназначено для диагностирования информационно-преобразующих элементов (ИПЭ) бортового оборудования (БО) воздушного судна (ВС) на основе машинного обучения. Под ИПЭ в изобретении подразумевается комплекс бортового оборудования (КБО) ВС, выполняющий свои функции через мультиплексный канал информационного обмена (МКИО). Способ позволяет реализовать процесс автоматического создания диагностических моделей ИПЭ БО любой сложности с увеличением глубины поиска места отказа при отказах систем КБО и их последующим восстановлением.
Известен метод диагностирования, реализуемый в экспертной системе (ЭС) функционального диагностирования авиационного радиоэлектронного оборудования [патент на полезную модель №77062 U1, G06F 15/00]. Данная ЭС содержит управляющий микропроцессор, измерительный блок, содержащий в своем составе первичные измерительные преобразователи (ПИП), вычислительную систему, включающую подсистему обработки информации (ПОИ), базу данных, систему управления базой данных (СУБД), базу знаний, базу экспертных знаний (БЭЗ), нейросетевую базу знаний (НСБЗ), систему управления базой знаний (СУБЗ), решатель (интерпретатор). Известная ЭС является вычислительной системой, в которую включены знания специалистов о некоторой конкретной проблемной области и которая в пределах этой области способна принимать экспертные решения. ЭС состоит из вычислительной системы и внешних устройств; управляющего микропроцессора, измерительного блока. Вычислительная система содержит базу знаний, базу данных, машину логического вывода (решатель, подсистему приобретения знаний и подсистему объяснений).
ЭС, построенная по указанному принципу, имеет следующие свойства: ЭС ограничена определенной сферой экспертизы - решение задач контроля и диагностики технического состояния бортового оборудования ЛА, способна рассуждать при сомнительных данных и объяснять полученные решения понятным способом, знания, которыми она оперирует, и механизм вывода - средство обработки знаний отделены друг от друга, целенаправленна на использование правил, на выходе выдает совет, а не информацию, которая подлежит трудоемкой обработке пользователем, строится так, чтобы имелась возможность постоянного наращивания системы. В ЭС диагностирования функции подсистемы приобретения знаний выполняет база знаний, а подсистема объяснений выполняет функции решателя машина логического вывода (МЛВ) (интерпретатор).
Предлагаемая ЭС позволяет, используя метод функционального диагностирования, проводить непрерывный анализ технического состояния объектов ЛА в процессе их работы по назначению, оперативно получать информацию о техническом состоянии бортового оборудования ЛА, позволяет проводить работы по диагностированию без нарушения функциональных связей.
ЭС, наряду с использованием традиционных знаний, хранящихся в БЗ, используя нейросетевую базу, позволяет формализовать перечисленные выше проблемы, возникающие в процессе эксплуатации авиационного оборудования. Проблема сложности объектов в нейросетевой базе знаний решается на основе обучения погрешности измерений, отказы первичных измерений-преобразователей информации могут компенсироваться на основе моделей ассоциативной нейронной сети (аналитическая избыточность).
Основным недостатком описанного метода диагностирования является наличие и использование за основу субъективных знаний экспертов ЭС в некоторой конкретной области, что при составлении диагностических моделей и наличии человеческого фактора, а также невозможности точного прогнозирования процессов изменения технического состояния авиационного радиоэлектронного оборудования в рамках его жизненного цикла, может приводить к неточности осуществления процесса диагностирования. Также недостатком данного метода является неавтономность обучения искусственной нейронной сети, используемой в ЭС, с целью формирования нейросетевой базы знаний. Отсутствие автоматизированности процесса формирования такой базы предполагает обучение с учителем: при обучении искусственной нейронной сети необходимо участие человека (оператора).
Однако сложность объекта контроля и диагностики, большая часть параметров которого не измеряется, содержит случайные (инструментальные и методические) погрешности. Чрезмерная сложность и отсутствие точной математической модели, существование критических (нерасчетных) режимов работ авиационного оборудования вызывает комплексные отказы измерителей и преобразователей системы. Все перечисленные выше проблемы снижают достоверность диагностирования технического состояния авиационного бортового оборудования. Также усложнение и увеличение элементной базы ЭС приводит к снижению надежности, отказоустойчивости и стойкости метода диагностики к изменяющимся внешним факторам.
Известен способ диагностирования, основанный на методе резервирования каналов конструктивно-функциональных модулей бортовых цифровых вычислителей летательных аппаратов на основе интеллектуальной диагностической системы в условиях интегрированной модульной авионики [патент на изобретение №2778366 C1, G06F 11/20]. Способ обеспечивает повышение отказоустойчивости за счет применения многоканального мониторинга интеллектуальной диагностической системой в режиме реального масштаба времени каналов обработки программного кода КФМ, что позволяет при достижении значения контролируемого параметра программного кода границ допусков функциональной зависимости (границ работоспособного состояния) заблаговременно реконфигурировать отказавший информационный канал КФМ (канал, в котором возник сбой) и использовать интеллектуальную диагностическую систему (ИДС) в режиме работы отказавшего канала БЦВС с индикацией о реконфигурации на функционирование ИДС летному экипажу. Технический результат рассматриваемого метода достигается тем, что в методе резервирования каналов КФМ БЦВС на основе ИДС реализуется принцип функционирования в интересах решения задачи автоматического построения модели подлежащего программной реконфигурации канала обработки информации за счет применения систем искусственного интеллекта, управляемого нейроконтроллером, что позволяет заблаговременно реконфигурировать отказавший канал КФМ на доступные вычислительные ресурсы ИДС в режиме БЦВС. При этом в ИДС происходит обучение (формирование моделей правильного функционирования КФМ БЦВС, функционирования в предотказном состоянии, функционирования в режиме отказа); запоминание (создание базы данных, включающих сформированные модели правильного функционирования КФМ с учетом упреждающих допусков), а также работа в режиме имитации БЦВС.
Недостатком данного метода является его узкая применяемость - предназначение заключается только для диагностирования и резервирования отказавших каналов КФМ БЦВС.
Известен наиболее близкий к заявляемому методу и выбранный в качестве прототипа способ и система для диагностирования промышленного объекта [патент на изобретение №2707423 С2, G06F 11/00]. Указанный технический результат достигается благодаря тому, что разработана система для диагностирования промышленного объекта, содержащая блок сбора данных, выполненный с возможностью сбора данных с комплекта датчиков промышленного объекта; блок модели промышленного объекта, выполненный с возможностью моделировать промышленный объект; блок анализа, выполненный с возможностью анализировать состояние промышленного объекта на основании данных, полученных от блока сбора данных, и модели промышленного объекта; причем блок анализа выполнен с возможностью делать заключение о нормальном или аномальном функционировании промышленного объекта на основании анализа; причем блок анализа выполнен с возможностью принимать данные об изменениях, внесенных в промышленный объект, и командовать блоку модели изменить модель в соответствии с внесенными изменениями. Сущность способа заключается в том, что с помощью комплекта датчиков, расположенных в элементах промышленного объекта, отслеживается состояние промышленного объекта. Далее данные с датчиков обрабатываются для диагностики состояния промышленного объекта. Данные с датчиков сопоставляются с данными, формируемыми заранее разработанной моделью промышленного объекта, по результатам сопоставления делается вывод об исправности промышленного объекта и его элементов, о необходимости ремонта и/или замены элементов промышленного объекта. Особенностью заявленного изобретения является использование инженерной модели промышленного объекта, наличие обратной связи, изменяющей модель промышленного объекта по данным о вмешательстве в работу промышленного объекта при устранении отказов, предотказных состояний и при выполнении сверхцикловых работ на плановых видах обслуживания (скрытых отказов). Технический результат, достигаемый данным решением, заключается в повышении точности диагностики промышленного объекта в части выявления предотказных состояний. Однако, несмотря на все положительные стороны изобретения, рассматриваемый способ и система для диагностирования промышленного объекта имеет ряд недостатков:
1. При отслеживании состояния по данным, полученным от датчиков, не учитываются возможные влияния внешних возмущающих воздействий, а также собственные шумы датчиков. Отсутствие учета влияния внешних возмущающих воздействий в конечном итоге может повлиять на результат по выводу об исправности промышленного объекта, то есть возможность возникновения ошибок первого и второго рода.
2. Отсутствие унификации. Для каждого промышленного объекта возникает необходимость установки специализированных датчиков самой широкой номенклатуры, что отрицательно влияет на экономический эффект, получаемый от использования разработанного способа и системы для диагностирования промышленного объекта.
3. Не автоматизирован процесс создания эталонных моделей для сравнения результатов, полученных от датчиков в режиме реального времени. Разрабатываемые модели создаются вручную, что зачастую для сложных объектов контроля не предоставляется возможным в полной мере.
Способ обеспечивает уменьшение времени восстановления отказавшей системы воздушного судна за счет применения многоканального контроля информационно-преобразующих элементов комплекса бортового оборудования модулем диагностики, программное обеспечение которого реализуется на основе комплексирования (ансамблирования) трех алгоритмов машинного обучения. Работа модуля диагностики осуществляется в режиме реального масштаба времени, что позволяет создавать на этапе испытаний комплекса бортового оборудования диагностические модели каждого информационно-преобразующего элемента (до конструктивно-съемной единицы: канала (субмодуля), с целью их диагностирования комплексным применением методов машинного обучения.
Технический результат изобретения достигается тем, что в способе диагностирования информационно-преобразующих элементов бортового оборудования воздушного судна на основе машинного обучения реализуется принцип функционирования в интересах решения задачи автоматического построения диагностических моделей, подлежащих контролю информационно-преобразующих каналов элементов бортового оборудования. Процесс диагностирования реализуется на отдельном унифицированном нейровычислительном модуле открытой архитектуры с типоразмером платы 6U с применением стандарта ГОСТ Р 52070-2003, а также с использованием комплексирования трех алгоритмов машинного обучения, что позволяет увеличить глубину поиска места отказа при наземном контроле, и, как следствие, уменьшить время восстановление комплекса, тем самым повысить его надежность. При этом в модуле диагностики происходит обучение (формирование кластеров, определяющих исправное техническое состояние каждого информационно-преобразующего элемента: кластер, сформированный координатами входного и выходного сигнала информационно-преобразующего элемента, для которого автоматически формируется диагностическая модель); фиксация (создание базы данных, включающих сформированные диагностические модели эталонного функционирования информационно-преобразующих элементов); отнесение данных контроля к одному из сформированных кластеров состояний.
Сущность изобретения заключается в том, что в модуле диагностики, построенном на основе функционирования трех алгоритмов машинного обучения, представленного в виде программного кода, и отдельного вычислительного модуля, происходит его автоматическое обучение в режиме реального масштаба времени. С определенной дискретностью через программаторы, обращающиеся к энергонезависимым постоянным запоминающим устройствам (ПЗУ), МКИО по ГОСТ Р 52070-2003, и с помощью программаторов записываются в соответствующие ячейки ПЗУ, согласно своих адресов оконечных устройств и подадресов передаваемых слов данных. При этом при диагностировании технического состояния информационно-преобразующих элементов комплекса бортового оборудования, индикация отказов в штатную бортовую автоматизированную систему контроля (БАСК) осуществляется в рамках присвоения каждому элементу приоритета очередности. Принцип формирования приоритета очередности заключается в системе функционирования и архитектуре проектирования бортовых цифровых вычислительных систем (БЦВС) в классе структур интегрированной авионики пятого поколения, в которой заложены алгоритмы присвоения более высокого ранга тем подсистемам управления информационного обеспечения летательного аппарата (ЛА), которые в большей степени соответствуют повышению эффективности использования ЛА в целом. Предлагаемый способ диагностирования комплекса бортового оборудования воздушного судна на основе машинного обучения, представляющий собой модуль диагностики, реализуется на отдельном унифицированном нейровычислительном модуле открытой архитектуры с типоразмером платы 6U с применением стандарта ГОСТ Р 52070-2003, а также с использованием комплексирования трех алгоритмов машинного обучения, программное обеспечение функционирования которых хранится в энергонезависимом ПЗУ модуля и используется по назначению в режиме реального времени при поадресном взаимодействии с информационно-преобразующими элементами бортового оборудования через МКИО.
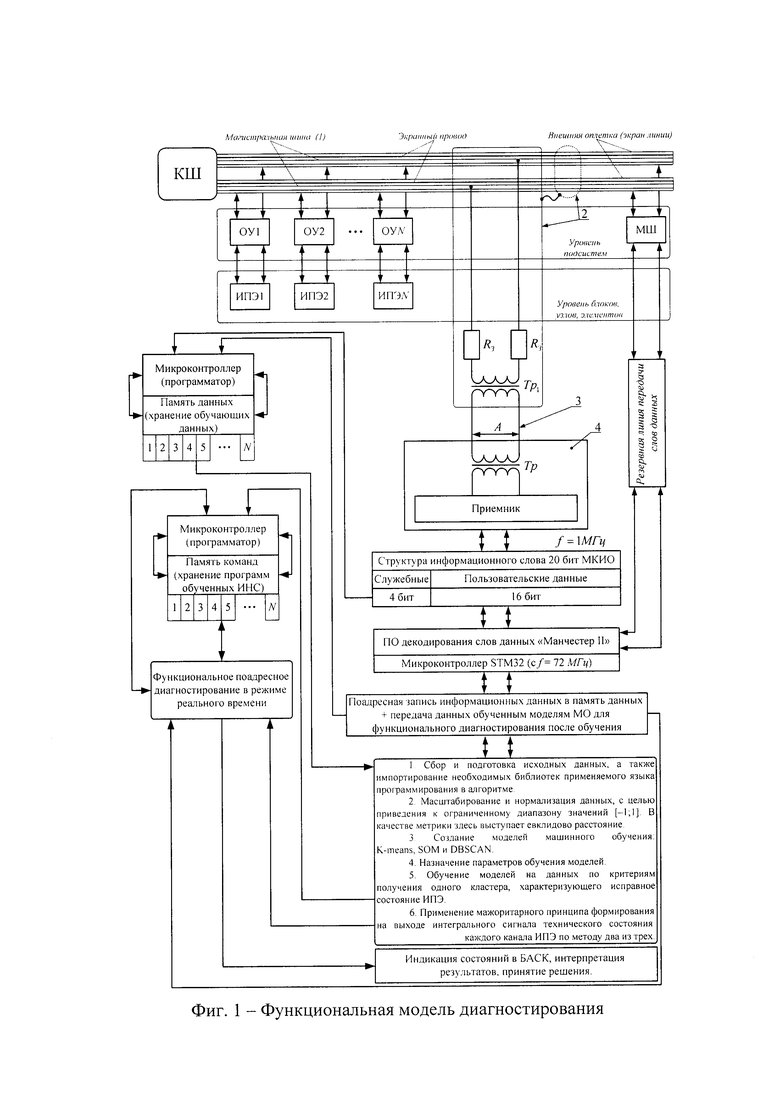
На фиг. 1 показана функциональная модель диагностирования, которая представляет собой последовательный процесс взаимодействия модуля диагностики через магистральную шину МКИО с оконечными устройствами и информационно-преобразующими элементами, входящими в их состав: КШ - контроллер шины; ОУ - оконечное устройство; МШ - монитор шины; ИПЭ - информационно-преобразующий элемент; 1 - магистральная шина; 2 - экран; 3 - шлейф; 4 - устройство интерфейса; Tp - трансформатор гальванической развязки; Тр1- согласующий трансформатор; Rз - защитный резистор; ПО - программное обеспечение; STM32 - микроконтроллер.
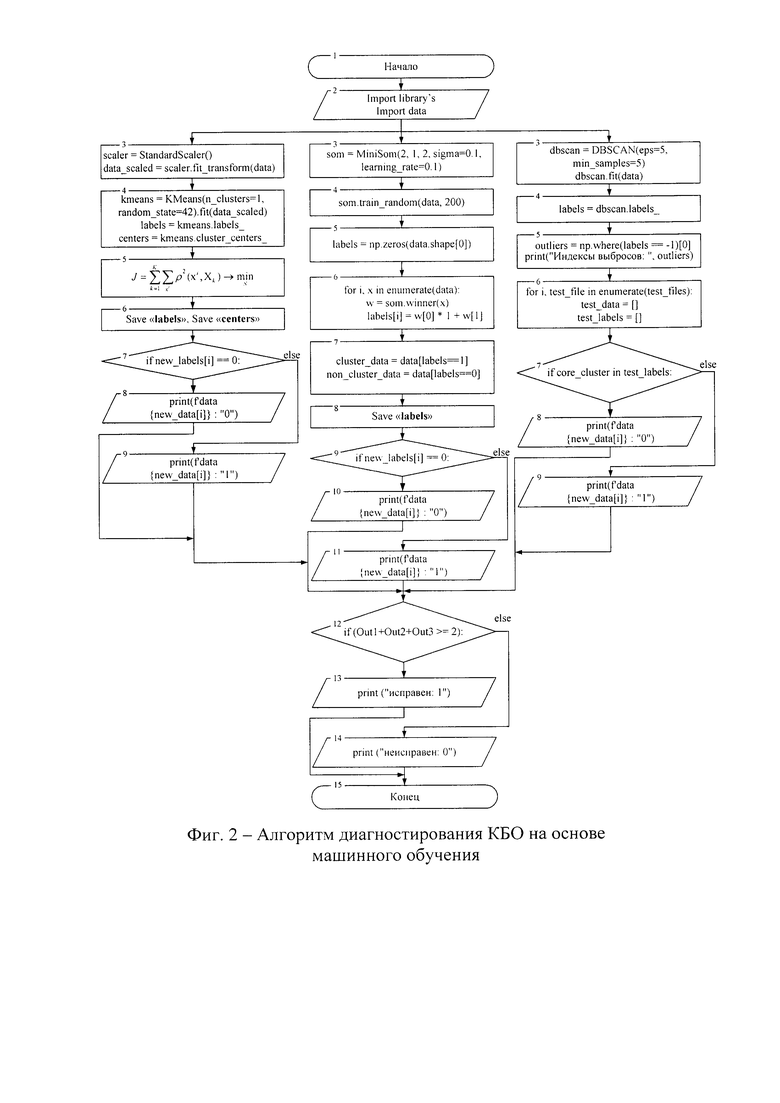
На фиг. 2 показан алгоритм диагностирования ИПЭ бортового оборудования на основе машинного обучения.
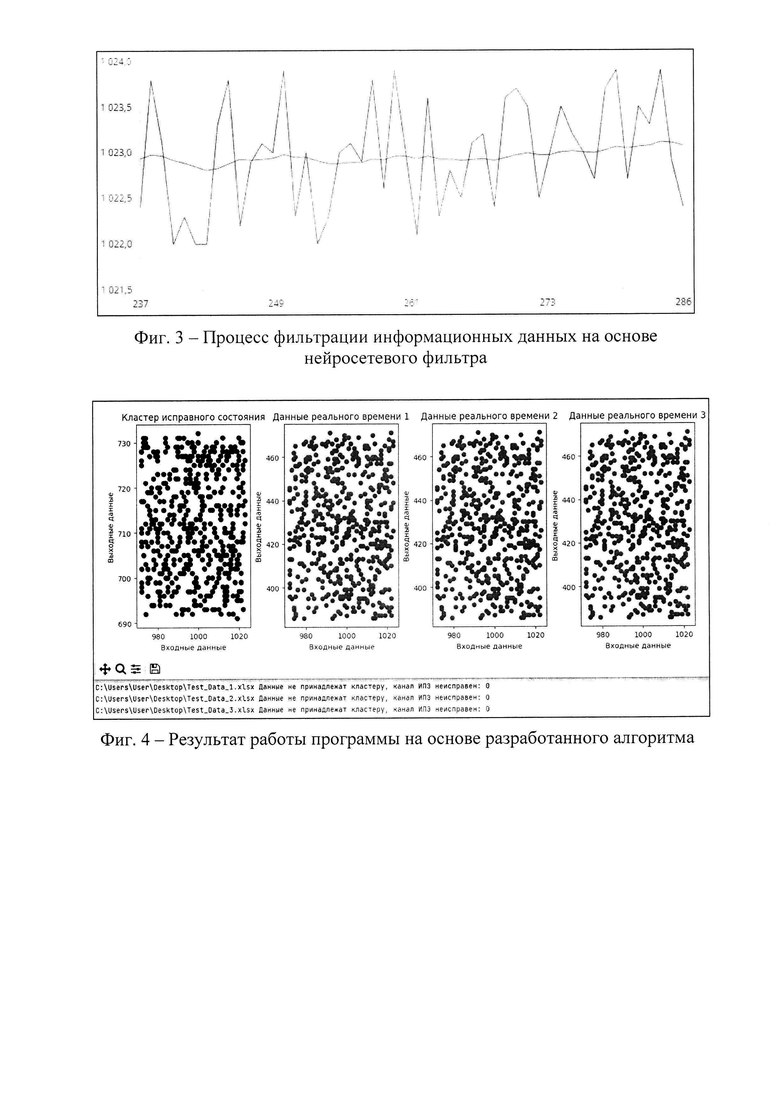
На фиг. 3 показан процесс фильтрации информационных данных на основе разработанного нейросетевого фильтра.
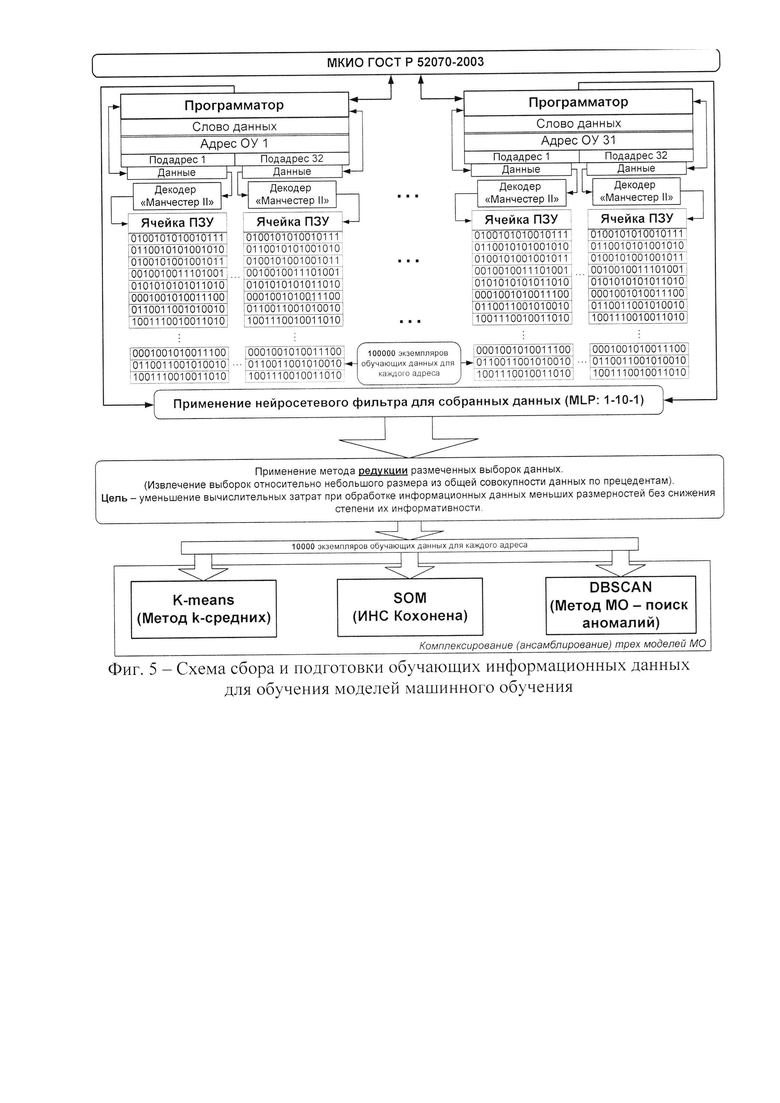
На фиг. 4 показан результат работы программы на основе разработанного алгоритма.
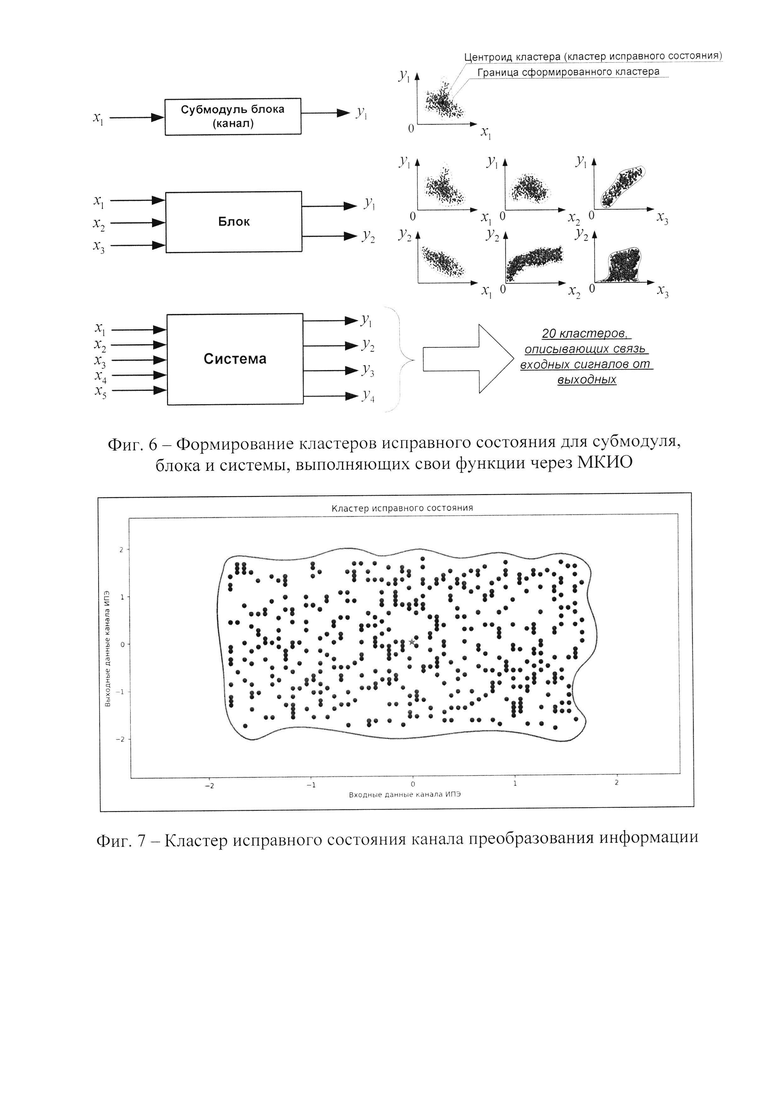
На фиг. 5 показана схема сбора и подготовки обучающих информационных данных для обучения моделей машинного обучения.
На фиг. 6 показан процесс формирования кластеров исправного состояния для субмодуля, блока и системы, выполняющих свои функции через МКИО.
На фиг. 7 представлен кластер исправного состояния канала преобразования информации.
При реализации способа диагностирования ИПЭ БО через МКИО использовался принцип формирования единственного кластера для каждого адреса данных, участвующих в информационном обмене через МКИО, который описывает исправное состояние каждого ИПЭ, входящего в состав ОУ с собственным уникальным адресом.
Согласно фиг. 1, на этапе испытаний борового оборудования осуществляется поадресный сбор обучающих информационных данных от объектов КБО, участвующих в информационном обмене, которые полностью описывают исправное состояние каждого элемента МКИО. При этом в модуле диагностики происходит обучение, которое предполагает формирование кластеров, определяющих исправное техническое состояние каждого ИПЭ. В дальнейшем в модуле диагностики осуществляется фиксация информационных данных, которая предполагает создание базы данных, а также отнесение данных контроля к одному из сформированных кластеров состояний. Последним этапом функционирования модуля диагностики является распознавание принадлежности данных конкретному кластеру в реальном времени с индикацией технических состояний в штатную бортовую автоматизированную систему контроля (БАСК).
Одним из методов, позволяющих эффективно решать задачи кластеризации, - метод К-средних (K-means). K-means - это алгоритм кластеризации, который используется для группирования данных в К. кластеров. Однако, когда K=1, алгоритм может быть эффективно использован для поиска аномалий в данных, то есть данных, соответствующих неисправному состоянию объекта контроля. Для этого алгоритм K-means с одним кластером применяется к данным, и центр кластера вычисляется как среднее значение всех точек данных. Затем расстояние между каждой точкой данных и центром кластера вычисляется, и точки данных, которые находятся на расстоянии больше определенного порога от центра кластера, считаются аномалиями.
Алгоритм K-means работает следующим образом:
1. Инициализация. Задаем количество кластеров K и выбираем случайным образом K точек из набора данных в качестве центров кластеров.
2. Присваивание. Каждый объект в наборе данных присваивается к ближайшему центру кластера на основе расстояния между объектом и центром кластера.
3. Обновление. Для каждого кластера вычисляется новый центр, который является средним значением всех объектов, принадлежащих кластеру.
4. Повторение. Шаги 2 и 3 повторяются до тех пор, пока центры кластеров не стабилизируются и не перестанут изменяться.
5. Результат. Когда центры кластеров не изменяются, кластеризация считается завершенной, и каждый объект принадлежит одному из К кластеров.
Этот метод основан на предположении о том, что аномальные точки будут находиться далеко от остальных точек данных и, следовательно, будут удалены от центра кластера.
Для определения порога расстояния можно использовать статистические методы, такие, как правило трех сигм, который определяет границу, выше которой находятся точки данных с высокой вероятностью быть аномалиями.
Основная идея алгоритма заключается в минимизации суммарного квадратичного отклонения точек кластера от центра этого кластера, то есть
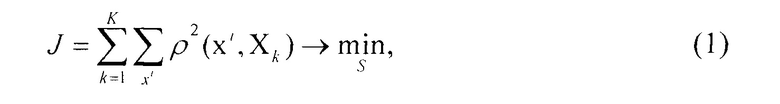
где K- известное число кластеров.
Идея адаптированного под решение задач диагностирования алгоритма K-means с одним кластером заключается в проверке декодированных информационных данных в реальном времени. При попадании значений входа и выхода в сформированный кластер исправного состояния, алгоритмом выводится сообщение «Данные принадлежат кластеру, канал ИПЭ исправен: 1». В случае если данные, полученные при информационном обмене между устройствами МКИО, не попадают в сформированный кластер исправного состояния, алгоритмом выводится сообщение «Данные не принадлежат кластеру, канал ИПЭ неисправен: 0».
Второй используемый в изобретении метод кластеризации - метод DBSCAN (Density-Based Spatial Clustering of Applications with Noise -пространственная кластеризация, основанная на плотности для приложений с шумами). Метод DBSCAN позволяет эффективно обнаруживать кластеры произвольной формы, а также точки-выбросы (шум), проявляя высокую чувствительность к изменению данных.
Если дан набор точек в некотором пространстве, алгоритм группирует вместе точки, которые тесно расположены друг с другом, а также помечает как выбросы точки, находящиеся одиноко в областях с малой плотностью (ближайшие соседи которых лежат далеко). DBSCAN не требует спецификации числа кластеров в данных априори в отличие от метода k-средних. DBSCAN может найти кластеры произвольной формы. Он может найти даже кластеры, полностью окруженные другими кластерами.
Адаптированный алгоритм DBSCAN работает следующим образом:
1. Производится выбор случайной точки из данных, которая не была еще не помечена.
2. Определяется, сколько точек находятся на расстоянии эпсилон от выбранной точки. Если число точек больше минимального количества точек, устанавливается новый кластер, иначе точка помечается как шум.
3. Если точка относится к кластеру, все точки, находящиеся на расстоянии ε от нее, также добавляются в кластер. Этот процесс продолжается, пока не будут добавлены все точки, находящиеся на расстоянии ε от выбранной точки.
4. Переход к следующей непомеченной точке и повторение шагов 2 и 3.
5. Алгоритм заканчивает работу, когда все точки были посещены.
Идея адаптированного под решение задач диагностирования алгоритма
DBSCAN с одним кластером заключается в проверке декодированных информационных данных в реальном времени. При попадании значений входа и выхода в сформированный кластер исправного состояния, алгоритмом выводится сообщение «Данные принадлежат кластеру, канал ИПЭ исправен: 1». В случае если данные, полученные при информационном обмене между устройствами МКИО, не попадают в сформированный кластер исправного состояния, алгоритмом выводится сообщение «Данные не принадлежат кластеру, канал ИПЭ неисправен: 0» и помечаются как выбросы.
Третий используемый в изобретении метод кластеризации - метод SOM (Self-Organizing Map), также известный как нейронная карта Кохонена. SOM - это вид нейронных сетей, используемых для кластеризации и визуализации многомерных данных. SOM представляет собой двухслойную нейронную сеть, состоящую из узлов (нейронов), организованных в виде двумерной сетки. Каждый узел соединен с соседними узлами и имеет вектор весов, который представляет собой многомерный вектор данных. SOM обучается на входных данных путем присваивания каждому входному вектору наиболее близкого узла на сетке. Затем узлы на сетке перемещаются ближе к своим ближайшим соседям, чтобы сократить расстояние между соседними узлами и улучшить качество кластеризации. SOM может использоваться для визуализации многомерных данных, таких как графики, изображения, текстовые документы, звуковые файлы, а также числовые данные, что позволяет исследовать их структуру, свойства и поведение во времени.
SOM является нейросетью, состоящей из двух слоев: входного и сетки. Входной слой содержит данные, которые необходимо кластеризовать, а сетка представляет собой двумерный массив нейронов, каждый из которых соответствует определенному кластеру.
В начале процесса обучения каждый нейрон в сетке инициализируется случайными весами. Затем для каждого входного вектора находится ближайший нейрон в сетке. Этот нейрон и его ближайшие соседи на сетке будут обновлены таким образом, чтобы их веса стали более похожими на входной вектор. Этот процесс повторяется многократно, пока нейроны в сетке не стабилизируются и не сформируют четкие кластеры. В результате обучения SOM создает карту, которая позволяет визуализировать данные. Каждый кластер на карте представляет собой группу похожих объектов, а расстояние между кластерами соответствует степени их различия.
В SOM нейроны активного слоя не упорядочены. В процессе обучения подстраиваются веса только одного нейрона-победителя каждой ИНС для ИПЭ. Каждый i-й нейрон 2-го слоя имеет собственный вектор весов Wi, который сравнивается с входным вектором x. Сравнение подразумевает вычисление расстояния между X и Wi, так что в слое Кохонена появляется нейрон-победитель с номером j, веса которого имеют минимальное расстояние до входного вектора:

В качестве метрики здесь выступает евклидово расстояние:
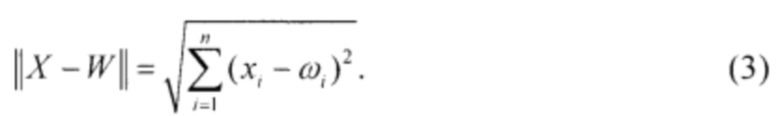
Если векторы X и W нормализованные, то в качестве меры близости можно использовать скалярное произведение. Выход нейрона можно описать формулой:

При этом выход нейрона j оказывается максимальным при одинаковых X и W:

Нормализация векторов выполняется по формулам:
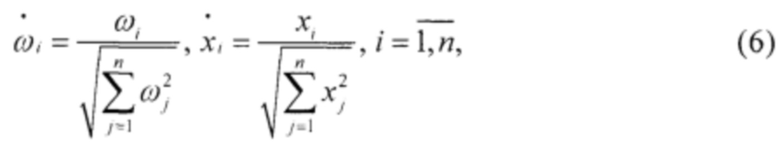
где 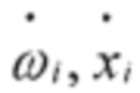 - нормализованные векторы, приведены к ограниченному диапазону значений [-1;1].
- нормализованные векторы, приведены к ограниченному диапазону значений [-1;1].
Результатом работы слоя конкурирующих нейронов в структуре программной части модуля диагностики при подаче на входной слой некоторого вектора X является определение нейрона, который имеет наибольший выходной сигнал yj (нейрон-победитель). Этот нейрон обладает весовым вектором Wj, который наиболее близок к входному вектору. Нейроны слоя Кохонена работают не изолированно, между ними существуют соревновательные связи, с помощью которых близкие нейроны усиливают сигналы друг друга.
Алгоритм SOM работает следующим образом. В начале работы алгоритма импортируются необходимые библиотеки. Затем данные считываются из файла «Arduino_Data_Learn1.xlsx» в переменную «data» с помощью функции «read_excel» из библиотеки «pandas». В алгоритме происходит обучение нейронной сети типа SOM на ранее загруженных данных. SOM разбивает данные на кластер и присваивает кластеру исправного состояния метку. Затем происходит вывод меток кластера и определение, принадлежат ли новые данные к кластеру, или нет. Далее данные разделяются на данные, принадлежащие и не принадлежащие кластеру, с выводом соответствующих сообщений.
В результате разработки трех частных алгоритмов диагностирования ИПЭ БО на основе машинного обучения, с целью повышения достоверности диагностики, а недопущения ложной идентификации данных реального времени (ошибок первого и второго рода), в изобретении используется комплексирование (ансамблирование) трех вышеуказанных алгоритмов. А также мажоритарный принцип формирования на выходе интегрального сигнала технического состояния каждого канала ИПЭ по методу два из трех. Общий алгоритм диагностирования ИПЭ БО на основе машинного обучения, решающий задачу идентификации принадлежности каждой точки данных, соответствующих входу и выходу ИПЭ, представлен на фиг. 2.
При сборе обучающей информации на данный процесс могут воздействовать различные внешние возмущающие воздействия. В конечном итоге собранные данные могут содержать шумы, ошибки и другие аномалии, которые могут привести к неправильной оценке технического состояния системы. Фильтрация данных позволяет устранить шумы и ошибки в данных, что повышает точность оценки технического состояния системы. Это особенно важно для систем, где даже малейшие отклонения могут привести к серьезным последствиям.
Кроме того, фильтрация данных может помочь снизить объем данных, которые нужно обрабатывать, что упрощает и ускоряет процесс идентификации технических состояний. В целом, использование фильтрации данных является необходимым для достижения более точной и надежной оценки технического состояния системы и повышения ее эффективности и безопасности, а также позволит избежать возникновения ошибок первого и второго рода при применении разработанных алгоритмов.
Для фильтрации данных был разработан нейросетевой фильтр. Основой разработанного нейросетевого фильтра является многослойный персептрон (Multi-Layer Perceptron, MLP) с одним скрытым слоем. MLP является одним из наиболее распространенных типов нейронных сетей, используемых для решения задач фильтрации, а также классификации и регрессии. Он состоит из одного или нескольких скрытых слоев, каждый из которых содержит несколько нейронов, а также входного и выходного слоев.
Процесс фильтрации информационных данных, реализуемый в разработанном фильтре, основан на использовании нейронной сети с одним скрытым слоем. Фильтрация происходит в два этапа: обучение сети и применение обученной сети для фильтрации данных.
На этапе обучения сети происходит подбор коэффициентов весов между нейронами таким образом, чтобы минимизировать ошибку предсказания выходного значения сети на тренировочных данных. Для этого используется метод обратного распространения ошибки «backpropagation», который заключается в последовательном вычислении ошибки и ее распространении через сеть в обратном направлении до входного слоя, где происходит обновление весов. В данном случае веса настраиваются с использованием градиентного спуска, в котором шаг обучения задается параметром «alpha».
На этапе применения обученной сети для фильтрации данных каждый входной сигнал проходит через сеть и получается выходное значение, которое и является отфильтрованным сигналом. Для этого сначала вычисляются значения на скрытом слое с помощью умножения входного сигнала на матрицу весов между входным и скрытым слоями, затем применяется функция активации (гиперболический тангенс) к полученным значениям. Затем значения на скрытом слое умножаются на матрицу весов между скрытым и выходным слоями, после чего применяется функция активации к полученным значениям, и это и является отфильтрованным сигналом.
В процессе обучения и применения сети графически отображается график исходных отфильтрованных данных, чтобы можно было визуально оценить эффективность фильтрации. Каждый нейрон в скрытом и выходном слоях соединен со всеми нейронами предыдущего слоя (полносвязная архитектура). Количество нейронов в скрытом слое выбрано на основе эмпирических наблюдений и может быть изменено в зависимости от конкретной задачи. График процесса фильтрации информационных данных, полученных в ходе проведения эксперимента, представлен на фиг. 3.
На основе разработанного алгоритма диагностирования ИПЭ БО, на примере собранных информационных данных было разработано программное обеспечение с использованием языка программирования Python, который является мультипарадигменным языком программирования, поддерживающим императивное, процедурное, структурное, объектно-ориентированное программирование, метапрограммирование, а также функциональное программирование. Задачи обобщенного программирования в данном языке решаются за счет динамической типизации данных.
Разработанная программа позволяет реализовать процесс комплексирования трех приведенных выше алгоритмов, а также мажоритарный принцип формирования на выходе интегрального сигнала технического состояния каждого канала ИПЭ по методу два из трех.
Для проверки работоспособности разработанного алгоритма, был спланирован и проведен эксперимент по сбору входных и выходных информационных данных, соответствующих исправному состоянию ИПЭ. В качестве ИПЭ был выбран восьмиканальный двунаправленный конвертер логических уровней 3,3-5 Вольт на микросхеме TXS0108E. Для проведения эксперимента был собрана схема датчика влажности и температуры HTU21D на базе микроконтроллера Arduino NANO, где TXS0108E - промежуточное (информационно-преобразующее) устройство, предназначенное для согласования логического уровня напряжения питания датчика HTU21D, который использует для своей работы постоянный ток напряжением 3,3 В.
Результат работы программы на тестовых данных (не входящих в кластер исправного состояния), представлен на фиг. 4.
Результат работы программы по формированию кластера исправного состояния канала конвертера TXS0108E, представлен на фиг. 7.
Способ реализуется следующим образом.
1. Сбор и подготовка исходных данных, а также импортирование необходимых библиотек применяемого языка программирования в алгоритме.
На этом шаге исходные данные представляют собой выборку, полученную в ходе проведения испытаний БО при различных режимах работы, которая поадресно фиксируется в память данных вычислительного модуля. Каждому адресу данных, полученных через обращение к МКИО, соответствует массив входных и выходных значений, которые описывают заведомо исправное техническое состояние диагностируемых ИПЭ. В процессе сбора обучающих данных их количество будет определяться из вычислительных возможностей модуля диагностики, а также возможностей постоянного запоминающего устройства (ПЗУ). На фиг. 5 представлена схема сбора и подготовки обучающих информационных данных для обучения моделей машинного обучения, используемых в разработанном алгоритме диагностирования ИПЭ БО.
Согласно фиг. 5, передаваемые информационные данные, входящие в состав слов данных (СД), а также имеющие в своей структуре подадрес передаваемых СД и адрес ОУ, являются данными, закодированными биполярным фазоманипулированным кодом «Манчестер II». С целью работы с исходными данными, согласно фиг. 5, СД декодируются, и с помощью программаторов записываются в соответствующие ячейки ПЗУ, согласно своих адресов ОУ и подадресов, передаваемых СД. Программатор - это программно-аппаратное устройство, предназначенное для записи информации в ПЗУ. Помимо записи, подобное устройство должно обеспечивать возможность считывания информации из ПЗУ микросхемы.
При сборе обучающей информации на данный процесс могут воздействовать различные внешние возмущающие воздействия.
Кроме того, фильтрация данных может помочь снизить объем данных, которые нужно обрабатывать, что упрощает и ускоряет процесс идентификации технических состояний. В целом, использование фильтрации данных является необходимым для достижения более точной и надежной оценки технического состояния системы и повышения ее эффективности и безопасности, а также позволит избежать возникновения ошибок первого и второго рода при применении разработанных алгоритмов. Таким образом, следующим этапом является применение разработанного нейросетевого фильтра на основе многослойных персептронов по схеме 1-10-1:1 нейрон во входном слое, 10 нейронов в скрытом слое, 1 нейрон в выходном слое.
Следующим этапом является применение метода редукции размеченных выборок данных, который позволит уменьшить вычислительные затраты при обработке информационных данных меньших размерностей без снижения степени их информативности.
Метод редукции размеченных выборок данных - это метод машинного обучения, который позволяет снизить затраты на разметку данных путем использования уже размеченных выборок.
Основной идеей метода является использование модели, которая уже обучена на размеченной выборке, для создания нового набора данных, который будет содержать только те примеры, которые модель с большой вероятностью классифицирует правильно. Таким образом, мы получаем новую размеченную выборку, которая содержит только наиболее информативные примеры, что позволяет улучшить качество кластеризации данных. Применение метода редукции размеченных выборок данных может быть особенно полезным в случае, когда разметка данных является очень затратной или сложной. В целом, метод редукции размеченных выборок данных является эффективным инструментом для улучшения качества кластеризации или классификации при ограниченных затратах на разметку данных. Предлагается использовать метод формирования и редукции выборок, который обеспечивает сохранение в сформированной подвыборке важнейших для последующего анализа топологических свойств исходной выборки.
Метод редукции размеченных выборок данных является одним из способов оптимизации процесса обработки больших объемов информации. Он заключается в извлечении небольших выборок данных из общей совокупности прецедентов, которые содержат информацию о конкретном объекте или явлении. Эти выборки могут быть использованы для анализа и прогнозирования свойств объектов, а также для обучения машинных алгоритмов.
Цель метода редукции размеченных выборок данных заключается в уменьшении вычислительных затрат при обработке информации. Это достигается за счет уменьшения размера выборок, что позволяет ускорить процесс их обработки. При этом степень информативности выборок сохраняется, так как они содержат все необходимые данные для анализа и прогнозирования свойств объектов. Таким образом, метод редукции размеченных выборок данных является эффективным способом оптимизации процесса обработки информации. Он позволяет уменьшить вычислительные затраты при сохранении степени информативности выборок, что делает его полезным инструментом для анализа и прогнозирования свойств объектов в различных областях.
С целью реализации метода редукции данных предлагается заменить обработку экземпляров исходной выборки на обработку их описаний в виде числовых скаляров, которые характеризуют положение экземпляров в пространстве признаков. При этом, заменив экземпляры, характеризующиеся N признаками, на представления в виде скаляров, мы отобразим N-мерное пространство признаков в одномерное пространство. Исходная выборка, будучи отображенной в одномерное пространство, позволит выделить на одномерной оси интервалы ее значений, соответствующие кластерам разных классов в исходном N-мерном пространстве. Определив границы интервалов на одномерной оси, можно найти ближайшие к ним экземпляры, которые и составят формируемую подвыборку. Приведенные выше идеи лежат в основе используемого метода.
Этап инициализации. Задается исходная выборка данных X=<x,y>.
Этап анализа характеристик классов. Разбить выборку X на K на подвыборок X(k), отдельных экземпляров каждого класса:
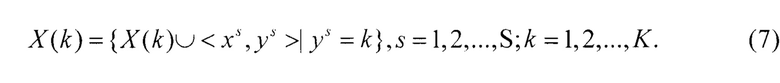
Для каждой подвыборки X(k) определяется по каждому признаку его минимальное 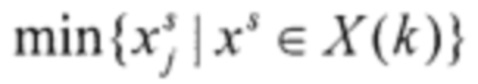 , максимальное
, максимальное 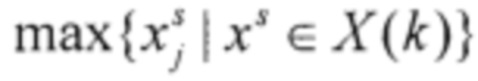 и среднее значения для экземпляров соответствующего класса:
и среднее значения для экземпляров соответствующего класса:
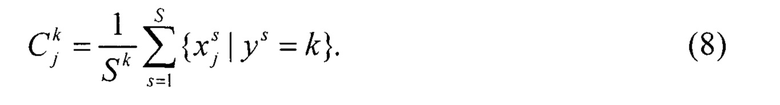
Для каждой подвыборки Х(k), k = 1, 2,…,K, определяются:
- частные поосевые нормированные расстояния от экземпляров до центров классов:
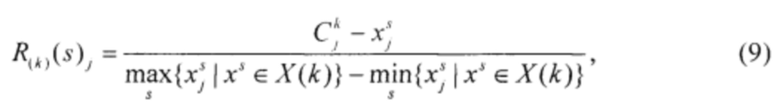
где s =1, 2,…, S, j=1, 2,…, N;
- нормированные расстояния экземпляров до центров классов:
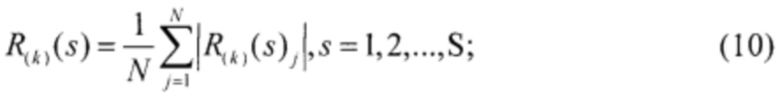
- нормированные расстояния между экземплярами:
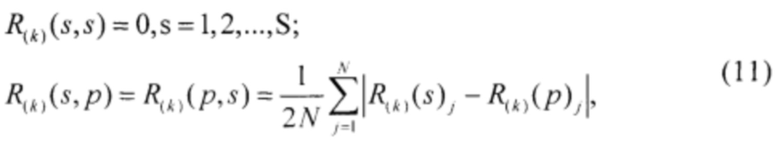
где s=1, 2, …,S, p=s+1, s+2, …,S.
Этап устранения дублирующихся экземпляров. Целью этапа является выделение подмножеств эквивалентных и существенно похожих экземпляров и замена каждого такого подмножества на один его экземпляр-представитель.
Четкий дубляж: из каждой группы одинаковых экземпляров каждой подвыборки следует оставить только один экземпляр.
Нечеткий дубляж: из каждой группы неодинаковых подобных экземпляров каждой подвыборки следует оставить только один экземпляр.
Этап выделения граничных экземпляров. Целью данного этапа является выявление экземпляров, находящихся вблизи границ классов, что позволит устранить остальные экземпляры, находящиеся внутри области класса. Вначале необходимо определить индексы для всех экземпляров выборки относительно центров всех подвыборок:
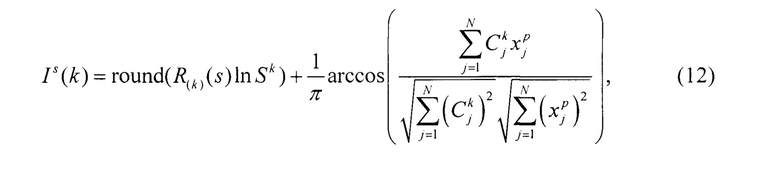
где round - функция округления до ближайшего целого числа.
Это позволит отобразить исходную выборку на одномерные оси I(k) (заметим, что при этом произойдет потеря части информации вследствие неявного квантования пространства признаков при преобразовании). Просматривая каждую одномерную ось I(k) можно выделить скопления (области пространства) близко расположенных экземпляров одного класса, выделив интервалы для каждого из них.
После чего из дальнейшего рассмотрения следует исключить экземпляры k-го класса, а также те экземпляры остальных классов, которые были включены в новую выборку:
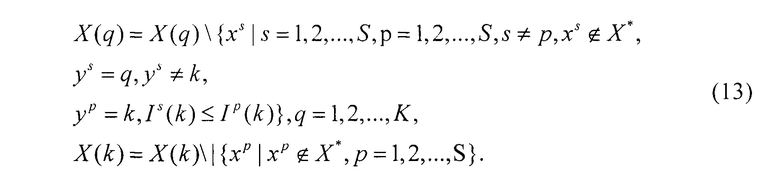
В результате выполнения предложенного метода будет сформирована выборка 
2. Масштабирование и нормализация данных, с целью приведения к ограниченному диапазону значений [-1;1]. В качестве метрики здесь выступает евклидово расстояние.
3. Создание моделей машинного обучения: K-means, SOM и DBSCAN.
На этом этапе производится создание используемых моделей машинного обучения для каждого сохраненного адреса и подадреса информационных данных, ввод их характеристик, назначение переменных для хранения промежуточных результат вычислений. Созданные модели машинного обучения обращаются через программаторы к каждому сохраненному массиву данных входа и выхода соответствующего ИПЭ. Таким образом, для каждого ИПЭ формируются 3 модели машинного обучения. На фиг. 6 представлен процесс формирования кластеров исправного состояния для субмодуля, блока и системы, выполняющих свои функции через МКИО.
4. Назначение параметров обучения моделей: количество нейронов, структура ИНС, метод обучения, функция активации (для SOM); количество кластеров, параметр «random_state» - это параметр, который используется в алгоритмах машинного обучения для установки начального состояния генератора случайных чисел (для K-means); параметров «eps» и «min_samples», которые определяют, как алгоритм будет проводить кластеризацию, «eps» определяет радиус окружности, в которой должно находиться не менее «min_samples» объектов для того, чтобы они были отнесены к одному кластеру (для DBSCAN).
5. Обучение моделей на данных по критериям получения одного кластера, характеризующего исправное состояние ИПЭ. Для определения границ кластеров целесообразно использовать статистические методы, такие, как правило трех сигм, который определяет границу, выше которой находятся точки данных с высокой вероятностью быть аномалиями. Правило трех сигм (или правило трех сигм Лапласа) в кластеризации используется для определения границ кластеров и выбросов в данных.
Согласно правилу трех сигм, если данные имеют нормальное распределение, то около 68% значений находятся в пределах одной стандартной ошибки σ от среднего значения, около 95% - в пределах двух σ, а 99,7% - в пределах трех σ.
На практике это означает, что если мы кластеризуем данные и определяем центры кластеров, то мы можем использовать правило трех сигм для определения границ каждого кластера.
Для этого вычисляется стандартное отклонение данных и умножается на 3. Затем это значение добавляется, или вычитается из среднего значения каждого кластера, чтобы определить границы кластеров. Если точки данных находятся за пределами границ кластеров, то они могут быть отнесены к выбросам и идентифицированы как точки данных, соответствующих неисправному состоянию.
Правило трех сигм является одним из методов определения границ кластеров и выбросов в данных и может быть использовано в сочетании с другими методами. При решении задачи кластеризации с помощью правила трех сигм, следует выполнить следующие шаги:
5.1. Вычислить среднее значение μ и стандартное отклонение σ для каждого измерения в кластере.
5.2. Определить диапазон μ±3σ для каждого измерения.
5.3. Исключить любые точки данных, которые находятся за пределами этого диапазона, как выбросы.
5.4. Повторить этот процесс для каждого кластера в наборе данных.
Результатом применения правила трех сигм к кластеризации может быть более чистый и точный кластеризованный набор данных, который исключает выбросы, которые могут быть причиной ошибок в анализе данных. Это позволит резервировать процесс идентификации данных, соответствующих неисправному состоянию и выходящих за границы сформированного кластера.
6. Применение мажоритарного принципа формирования на выходе интегрального сигнала технического состояния каждого канала ИПЭ по методу два из трех. Данный принцип используется с целью недопущения ложной идентификации данных реального времени алгоритмами (ошибок первого и второго рода).
7. Вывод соответствующих сообщений с учетом пункта 6, а также запись информации в штатную БАСК ВС.
Таким образом, выявлена причина низкой глубины поиска места отказа - сложность формализации диагностических моделей, что отрицательно влияет на эффективность технической эксплуатации (снижение коэффициента готовности ВС). Обоснована необходимость увеличения глубины поиска места отказа с применением методов машинного обучения, которые позволят автоматически создавать трудно формализуемые диагностические модели, повысив при этом коэффициент готовности ВС.
Разработан способ диагностирования комплекса бортового оборудования воздушных судов на основе машинного обучения через взаимодействие с мультиплексным каналом информационного обмена. Описанная в способе методика применения алгоритма диагностирования ИПЭ БО подразумевает последовательное описание выполняемых в алгоритме действий, а также подробно отражает процесс формирования исходных данных и правил интерпретации полученных выходных данных в ходе работы алгоритма. Разработанный способ диагностирования сочетает в себе комплексирование (ансамблирование) трех методов машинного обучения, а также мажоритарный принцип формирования на выходе интегрального сигнала технического состояния каждого канала ИПЭ БО. При этом применение алгоритма позволит повысить коэффициент готовности воздушного судна за счет минимизации времени восстановления ВС при отказах и неисправностях.
Отличительными особенностями разработанного способа являются:
- наличие единой унифицированной методической и алгоритмической основы построения и применения соответствующих диагностических моделей ИПЭ любой сложности для определения технического состояния всего КБО, выполняющего свои функции через МКИО в реальном времени;
- при сборе информационных данных, полученных через МКИО от ОУ, учитываются возможные влияния внешних возмущающих воздействий, а также собственные шумы датчиков. С целью устранения (компенсации) возмущающих воздействий, а также недопущения неправильной оценке технического состояния системы модулем диагностики был разработан нейросетевой фильтр, качество применения которого доказано в ходе проведенного эксперимента;
- возможность охвата контролем всего КБО ВС, выполняющего свои функции через МКИО: до тридцати одного ОУ, каждый из которых является отдельной системой ВС, и может включать до тридцати двух подадресов ОУ (блоков, модулей, субмодулей);
- процесс формирования кластеров, характеризующих исправное состояние каждого ИПЭ БО ВС, является полностью автоматическим и не предусматривает наличие оператора (человека): при решении задач формирования кластеров, применяется метод кластеризации, который предполагает применение стратегии «обучение без учителя»;
- разработанный способ диагностирования сочетает в себе комплексирование (ансамблирование) трех методов машинного обучения, а также мажоритарный принцип формирования на выходе интегрального сигнала технического состояния каждого канала ИПЭ БО по методу «два из трех» с целью повышения достоверности диагноза, а также недопущения возникновения ошибок первого и второго рода.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2023 |
|
RU2816667C1 |
| УСТРОЙСТВО ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2831917C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ ИНФОРМАЦИОННО-ПРЕОБРАЗУЮЩИХ ЭЛЕМЕНТОВ БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНОГО СУДНА НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2802976C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ БЕЗ УЧИТЕЛЯ С АВТОМАТИЧЕСКИМ ОПРЕДЕЛЕНИЕМ ПАРАМЕТРОВ ОБУЧЕНИЯ МОДЕЛЕЙ | 2023 |
|
RU2818858C1 |
| СИСТЕМА ФОРМИРОВАНИЯ ТЕХНОЛОГИЧЕСКОГО ГРАФИКА И МАРШРУТНО-ТЕХНОЛОГИЧЕСКИХ КАРТ ВЫПОЛНЕНИЯ ОПЕРАТИВНОГО ТЕХНИЧЕСКОГО ОБСЛУЖИВАНИЯ ГРУППЫ ВОЗДУШНЫХ СУДОВ | 2023 |
|
RU2825239C1 |
| Способ автоматизированного составления технологического графика выполнения регламентных работ на авиационной технике | 2024 |
|
RU2836063C1 |
| МЕТОД РЕЗЕРВИРОВАНИЯ КАНАЛОВ КОНСТРУКТИВНО-ФУНКЦИОНАЛЬНЫХ МОДУЛЕЙ БОРТОВЫХ ЦИФРОВЫХ ВЫЧИСЛИТЕЛЕЙ ЛЕТАТЕЛЬНЫХ АППАРАТОВ НА ОСНОВЕ ИНТЕЛЛЕКТУАЛЬНОЙ ДИАГНОСТИЧЕСКОЙ СИСТЕМЫ В УСЛОВИЯХ ИНТЕГРИРОВАННОЙ МОДУЛЬНОЙ АВИОНИКИ | 2021 |
|
RU2778366C1 |
| СПОСОБ АДАПТИВНОГО ПРОГНОЗИРОВАНИЯ ОСТАТОЧНОГО РЕСУРСА ЭКСПЛУАТАЦИИ СЛОЖНЫХ ОБЪЕКТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2013 |
|
RU2533321C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫЯВЛЕНИЯ ОБЪЕМНЫХ ОБРАЗОВАНИЙ ПОЧЕК НА КОМПЬЮТЕРНЫХ ТОМОГРАММАХ БРЮШНОЙ ПОЛОСТИ | 2024 |
|
RU2839531C1 |
| Программно-аппаратный комплекс, предназначенный для обучения и (или) дообучения алгоритмов обработки аэрокосмических изображений местности с целью обнаружения, локализации и классификации до типа авиационной и сухопутной техники | 2020 |
|
RU2747044C1 |
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности диагностики промышленного объекта в части выявления предотказных состояний. Способ диагностирования комплекса бортового оборудования воздушных судов на основе машинного обучения, содержащий этапы, на которых осуществляют сбор и подготовку исходных данных, определяют передаваемые информационные данные, входящие в состав, применяют нейросетевой фильтр на основе многослойных персептронов, осуществляют применение метода редукции размеченных выборок данных, осуществляют создание моделей машинного обучения K-means, SOM и DBSCAN, осуществляют назначение параметров обучения моделей, производится обучение моделей на данных по критериям получения одного кластера, характеризующего исправное состояние каждого информационно-преобразующего элемента, осуществляют передачу адресных данных в реальном времени обученным моделям, осуществляют применение мажоритарного принципа формирования на выходе интегрального сигнала технического состояния каждого канала информационно-преобразующего элемента по методу два из трех, выводят соответствующие сообщения об исправности/неисправности и производят запись информации в штатную бортовую автоматизированную систему контроля воздушного судна. 7 ил.
Способ диагностирования комплекса бортового оборудования воздушных судов на основе машинного обучения, содержащий этапы, на которых:
осуществляется сбор и подготовка исходных данных, а также импортирование необходимых библиотек применяемого языка программирования в алгоритме,
определяются передаваемые информационные данные, входящие в состав слов данных, а также имеющие в своей структуре подадрес передаваемых слов данных и адрес оконечных устройств, являющиеся данными, закодированными биполярным фазоманипулированным кодом «Манчестер II», и с целью работы с исходными данными, слова данных декодируются и с помощью программаторов записываются в соответствующие ячейки ПЗУ, согласно своим адресам оконечных устройств и подадресам передаваемых слов данных,
применяется разработанный нейросетевой фильтр на основе многослойных персептронов,
осуществляется применение метода редукции размеченных выборок данных, который позволит уменьшить вычислительные затраты при обработке информационных данных меньших размерностей без снижения степени их информативности,
осуществляется создание моделей машинного обучения K-means, SOM и DBSCAN,
осуществляется назначение параметров обучения моделей,
производится обучение моделей на данных по критериям получения одного кластера, характеризующего исправное состояние каждого информационно-преобразующего элемента,
осуществляется передача адресных информационных данных в реальном времени обученным моделям с целью функциональной диагностики,
осуществляется применение мажоритарного принципа формирования на выходе интегрального сигнала технического состояния каждого канала информационно-преобразующего элемента по методу два из трех,
выводятся соответствующие сообщения об исправности (неисправности), а также производится запись информации в штатную бортовую автоматизированную систему контроля воздушного судна.
| СТАНОК ДЛЯ ПРАВКИ ДИСКОВ АВТОМОБИЛЬНЫХ КОЛЕС | 2014 |
|
RU2567771C1 |
| СПОСОБ НЕПРЕРЫВНОГО КОНТРОЛЯ ЦЕЛОСТНОСТИ ВОЗДУШНЫХ СУДОВ НА ВСЕХ УЧАСТКАХ ПОЛЕТА | 2013 |
|
RU2542746C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИАГНОСТИРОВАНИЯ ПРОМЫШЛЕННОГО ОБЪЕКТА | 2018 |
|
RU2707423C2 |
| CN 109987252 A, 09.07.2019 | |||
| US 9969508 B2, 15.05.2018. | |||
