Область техники
[0001] Настоящее изобретение относится в общем к области оптического распознавания символов (OCR) видеоматериалов, и, более конкретно, к системам и способу использования данных предыдущего кадра для OCR кадров видеоматериалов.
Уровень техники
[0002] Одним из вариантов использования оптического распознавания символов (OCR) является распознавание текста, присутствующего в видеоматериалах, например, видеозаписях или видеосъемке в режиме реального времени, сделанной пользователем с помощью видеокамеры, мобильного устройства с возможностями записи видео и т.д. Текст, присутствующий в видеоматериалах, обычно присутствует на снятых видеосъемкой объектах, таких как страницы текста, уличные таблички, меню ресторанов и т.д. При обнаружении наличия текста содержащаяся в нем информация может быть использована в будущем. Обнаруженный текст можно распознать и/или использовать для сжатия видеоинформации или других целей в дальнейшем. Распознанный текст в дальнейшем можно прочесть и преобразовать в голосовой сигнал, используя одну из многих технологий преобразования текста в речь, для людей, испытывающих затруднения с чтением текста. Распознанный текст также может быть немедленно после съемки переведен на другой язык, так что пользователь сможет прочесть или услышать (с помощью технологии преобразования текста в речь) перевод текста, снятого камерой, направленной на текст на иностранном языке.
[0003] Обработка видео может быть реализована простым применением одной из технологий анализа структуры документа к каждому последовательному отдельному кадру или каждому кадру в выборке кадров видео из видеоматериала. Однако такой подход является очень медленным или очень неэкономичным в смысле процессорных ресурсов и потребления энергии, потому что он не в состоянии использовать дублируемость, присутствующую в большинстве реальных сценариев захвата видео. Таким образом, существует потребность в повышении эффективности и результативности обработки видеоматериалов. Для иллюстрации настоящего изобретения далее для распознавания символов (OCR) будут использоваться образцы видеокадров.
Раскрытие изобретения
[0004] Настоящим заявителем было обнаружено, что текст в видеоматериалах часто присутствует в ряде последовательных видеокадров, и положение текста в этих видеокадрах слабо изменяется от кадра к кадру. Например, если пользователь хочет перевести уличную табличку, он наведет камеру на табличку и будет ее удерживать, пока не снимет хотя бы несколько видеокадров, причем положение таблички будет меняться незначительно. Также пользователь может захотеть перевести страницу текста или ресторанное меню, перемещая камеру по тексту, в этом сценарии также один и тот же текст обычно присутствует на нескольких видеокадрах, пока камера перемещается над ним, и положение текста на кадрах меняется относительно медленно. Таким образом, для эффективного OCR видеокадров видеоматериала можно использовать данные с предыдущих кадров.
[0005] Например, данные предыдущего кадра для OCR видеокадров видеоматериала можно использовать следующим образом. При проведении обработки OCR видеокадра, если было установлено, что это не первый кадр видеоматериала и предшествующий или предыдущий видеокадр или видеокадры уже были обработаны, данные OCR, созданные во время проведения OCR предыдущего видеокадра или видеокадров, могут быть использованы при проведении OCR текущего видеокадра. В частности, расположение текста на предыдущем видеокадре или видеокадрах можно использовать для определения расположения текста на текущем видеокадре. Кроме того, если как минимум часть текста с предыдущего видеокадра присутствует на текущем видеокадре, эту часть нет необходимости подвергать OCR повторно, вместо этого можно использовать результаты проведения OCR этого текста с предыдущего видеокадра или видеокадров.
[0006] В одном случае пример способа проведения OCR кадра видеоматериала включает получение кадра из видеоматериала аппаратным процессором, извлечение из памяти данных о предыдущем кадре, связанным с видеоматериалом, и обработку аппаратным процессором как минимум части кадра для обнаружения одной или более текстовых строк, при этом проведение OCR части кадра включает как минимум одну операцию из следующих: использование данных предыдущего кадра для обнаружения в части кадра как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте в данных предыдущего кадра, использование как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, для обнаружения в части кадра как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных предыдущего кадра, использование как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату из данных предыдущего кадра, для обнаружения как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату, описанному в данных предыдущего кадра, для обнаружения в части кадра как минимум одной текстовой строки, аналогичной как минимум одной текстовой строке из данных предыдущего кадра.
[0007] В одном случае пример системы для проведения OCR кадра видеоматериала включает компьютерный процессор, настроенный для приема кадра видеоматериала, память, соединенную с процессором и настроенную для хранения данных предыдущего кадра, связанных с видеоматериалом; где процессор дополнительно настраивается для вызова механизма OCR для обнаружения в части кадра как минимум одной текстовой строки, где механизм OCR включает как минимум один элемент из следующих: модуль обнаружения связных компонент, настроенный на использование данных из предыдущего кадра для обнаружения в части кадра как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных предыдущего кадра, модуль обнаружения символов-кандидатов, настроенный на использование не менее одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных предыдущего кадра, для обнаружения в части кадра как минимум одного символа-кандидата, аналогичного хотя бы одному символу-кандидату, описанному в данных предыдущего кадра, модуль обнаружения текстов-кандидатов, настроенный на использование как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных предыдущего кадра, для обнаружения в части кадра как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату из данных предыдущего кадра, модуль обнаружения текстовых строк, настроенный на использование как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату из данных предыдущего кадра, для обнаружения в части кадра как минимум одной текстовой строки, аналогичной как минимум одной текстовой строке, описанной в данных предыдущего кадра.
[0008] В одном случае пример компьютерного программного продукта, который хранится на энергонезависимом машиночитаемом носителе данных, содержит выполняемые компьютером команды для проведения OCR кадра видеоматериала, включая команды для: получения аппаратным процессором кадра из видеоматериала, извлечения из памяти данных о предыдущем кадре, связанном с видеозаписью и выполнения аппаратным процессором обработки как минимум части кадра для обнаружения одной или более текстовых строк, при которой выполнение OCR части кадра включает как минимум одну из следующих операций: использование данных предыдущего кадра для обнаружения в части кадра как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных предыдущего кадра, использование как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных предыдущего кадра, для обнаружения в части кадра как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных предыдущего кадра, использование как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных предыдущего кадра, для обнаружения в части кадра как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату, описанному в данных предыдущего кадра и использование как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату, описанному в данных предыдущего кадра, для обнаружения в части кадра как минимум одной текстовой строки, аналогичной как минимум одной текстовой строке, описанной в данных предыдущего кадра.
[0009] Некоторые аспекты также включают как минимум одно из следующих действий: перевод как минимум одной строки текста на другой язык и преобразование как минимум одной текстовой строки в аудиоформат.
[0010] В некоторых случаях аналогичность включает как минимум одну аналогичность положения в кадре, аналогичность по ориентации в кадре, аналогичность по форме и аналогичность по содержанию.
[0011] В некоторых случаях данные предыдущего кадра содержат только данные о небольшой части кадра, сопровождаемые частью кадра.
[0012] В некоторых случаях как минимум одно описание связной компоненты из данных предыдущего кадра содержит положение связной компоненты в кадре, ориентацию связной компоненты в кадре и форму связной компоненты.
[0013] В некоторых случаях как минимум одно описание символа-кандидата в данных предыдущего кадра содержит положение символа-кандидата в кадре, ориентацию символа-кандидата в кадре и форму символа-кандидата.
[0014] В некоторых случаях как минимум одно описание текста-кандидата в данных предыдущего кадра содержит положение текста-кандидата в кадре, ориентацию текста-кандидата в кадре и форму текста-кандидата.
[0015] В некоторых случаях описание как минимум одной текстовой строки в данных предыдущего кадра содержат положение текстовой строки в кадре, ориентацию текстовой строки в кадре и содержимое текстовой строки.
[0016] В некоторых случаях аппаратный процессор, используемый для выполнения OCR части кадра, и как минимум один аппаратный процессор, используемый для генерации данных предыдущего кадра, являются разными аппаратными процессорами.
[0017] В некоторых случаях аппаратный процессор, используемый для выполнения OCR части кадра, и как минимум один аппаратный процессор, используемый для генерации данных предыдущего кадра, представляют собой разные ядра одного многоядерного процессора.
[0018] Некоторые случаи также включают хранение в памяти данных нового кадра, включающих как минимум одно из как минимум одной обнаруженной связной компоненты, как минимум один обнаруженный символ-кандидат, как минимум один обнаруженный текст-кандидат и как минимум одну обнаруженную текстовую строку.
[0019] В некоторых случаях выполнение OCR части кадра также включает как минимум одно из: обнаружение в части кадра как минимум одной связной компоненты, не аналогичной связным компонентам, описанным в данных предыдущего кадра, обнаружение в части кадра как минимум одного символа-кандидата, не аналогичного символам-кандидатам, описанным в данных предыдущего кадра, обнаружение в части кадра как минимум одного текста-кандидата, не аналогичного текстам-кандидатам, описанным в данных предыдущего кадра и обнаружение в части кадра как минимум одной текстовой строки, не аналогичной текстовым строкам, описанным в данных предыдущего кадра.
[0020] В одном случае пример способа проведения OCR кадра видеоматериала включает проведение аппаратным процессором OCR первой части первого кадра для генерации данных первого кадра, при этом обработка OCR первой части первого кадра включает обнаружение как минимум одной связной компоненты в первой части первого кадра с целью добавления как минимум одного описания связной компоненты в данные первого кадра, обнаружение символа-кандидата в первой части первого кадра для добавления как минимум одного описания символа-кандидата в данные первого кадра, обнаружение текста-кандидата в первой части первого кадра для добавления описания как минимум одного текста-кандидата в данные первого кадра, и обнаружение строки текста (текстовой строки) в первой части первого кадра для добавления как минимум одного описания строки текста в данные первого кадра, а также обработка OCR с помощью аппаратного процессора второй части второго кадра, следующего по времени за первым кадром, где проведение OCR второй части второго кадра включает как минимум одну из следующих операций: обнаружение связной компоненты во второй части второго кадра с помощью данных первого кадра для обнаружения хотя бы одной связной компоненты, аналогичной как минимум одной связной компоненте, обнаруженной на первом кадре, обнаружение символов-кандидатов во второй части второго кадра с помощью данных первого кадра для обнаружения хотя бы одного символа-кандидата, аналогичного хотя бы одному символу-кандидату, обнаруженному на первом кадре, обнаружение текста-кандидата во второй части второго кадра с помощью данных первого кадра для обнаружения хотя бы одного текста-кандидата, аналогичного хотя бы одному тексту-кандидату, обнаруженному в первом кадре, и обнаружение строки текста во второй части второго кадра с помощью данных первого кадра для обнаружения хотя бы одной строки текста, аналогичной хотя бы одной строке текста, обнаруженной в первом кадре, где аналогичность включает хотя бы один признак из аналогичности положения в кадре, аналогичности ориентации в кадре и аналогичности содержимого.
[0021] В некоторых случаях очертание второй части второго кадра содержит очертание первой части первого кадра.
[0022] В некоторых случаях как минимум одно описание связной компоненты содержит расположение связной компоненты на первом кадре, ориентацию связной компоненты на первом кадре и форму связной компоненты.
[0023] В некоторых случаях как минимум одно описание символа-кандидата содержит положение символа-кандидата на первом кадре, ориентацию символа-кандидата на первом кадре и форму символа-кандидата.
[0024] В некоторых случаях как минимум одно описание текста-кандидата содержит положение текста-кандидата на первом кадре, ориентацию текста-кандидата на первом кадре и форму текста-кандидата.
[0025] В некоторых случаях как минимум одно описание строки текста содержит положение строки текста на первом кадре, ориентацию строки текста на первом кадре и содержание строки текста.
[0026] В некоторых случаях аппаратный процессор, используемый для OCR, который обрабатывает первую часть первого кадра, и аппаратный процессор, используемый для OCR второй части второго кадра, представляют собой разные процессоры.
[0027] В некоторых случаях аппаратный процессор, используемый для OCR, который обрабатывает первую часть первого кадра, и аппаратный процессор, используемый для OCR второй части второго кадра, представляют собой разные ядра одного многоядерного процессора.
[0028] Приведенный выше упрощенный обзор примеров предназначен для базового понимания настоящего изобретения. Этот обзор не является развернутым описанием всех предполагаемых примеров, а также не предназначен для обозначения ключевых или критических элементов всех примеров или описания области действия некоторых или всех примеров настоящего изобретения. Его единственное предназначение в том, чтобы представить в упрощенной форме один или более примеров в качестве предисловия к более подробному описанию изобретения, которое приведено ниже. Для завершения изложенного выше следует сказать, что один или более примеров настоящего изобретения включают особенности, описанные и особо подчеркнутые в формуле изобретения.
[0029] Техническим результатом описанного выше изобретения является оптимизация оптического распознавания символов (OCR) видеоматериалов. Для оптимизации оптического распознавания символов (OCR) изобретение использует дублируемость, присутствующую в большинстве реальных сценариев захвата видео. В частности, если как минимум часть текста с предыдущего видеокадра присутствует на текущем видеокадре, эту часть нет необходимости подвергать OCR повторно, вместо этого можно использовать результаты проведения OCR этого текста с предыдущего видеокадра или видеокадров. Таким образом, изобретение позволяет сократить время и число операций, необходим для выполнения распознавания символов (OCR) кадров видеоматериалов, содержащих повторяющуюся информацию.
Краткое описание чертежей
[0030] Прилагающиеся чертежи, которые включены в это описание изобретения и являются его частью, иллюстрируют один или более примеров к настоящему изобретению и совместно с подробным описанием служат для пояснения его принципов и реализации.
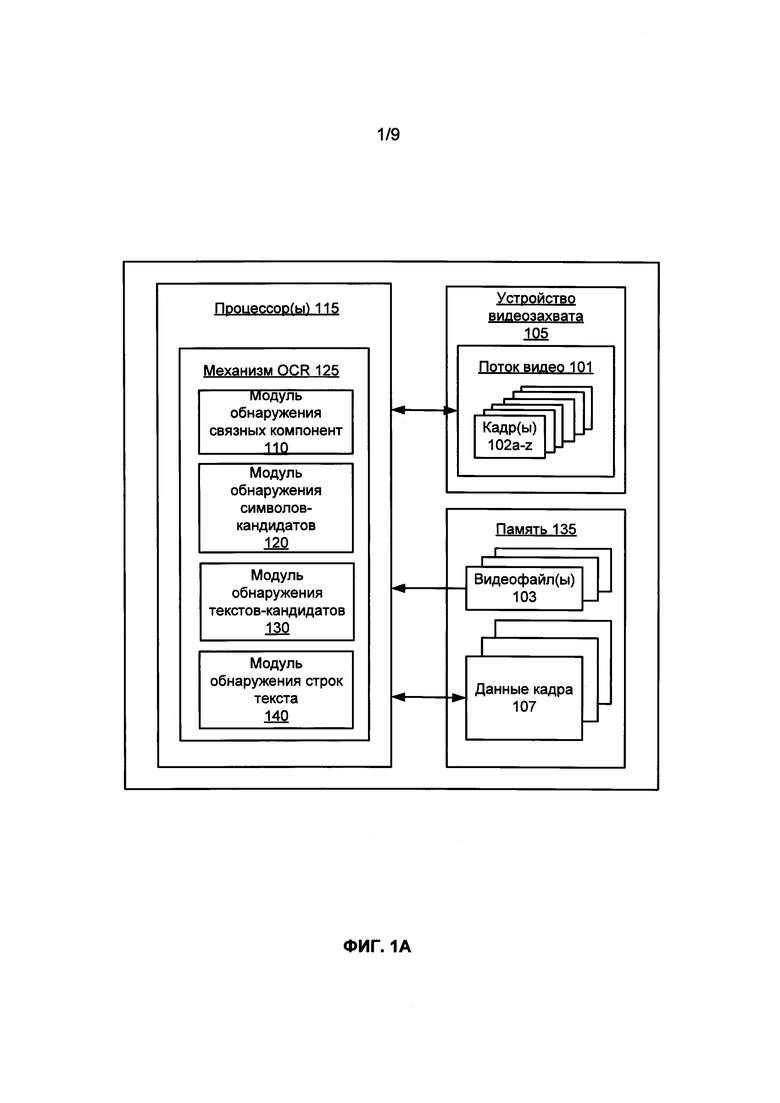
ФИГ. 1А иллюстрирует блок-схему примера системы для использования данных предыдущего кадра для OCR видеокадров из видеоматериалов в соответствии с одним примером.
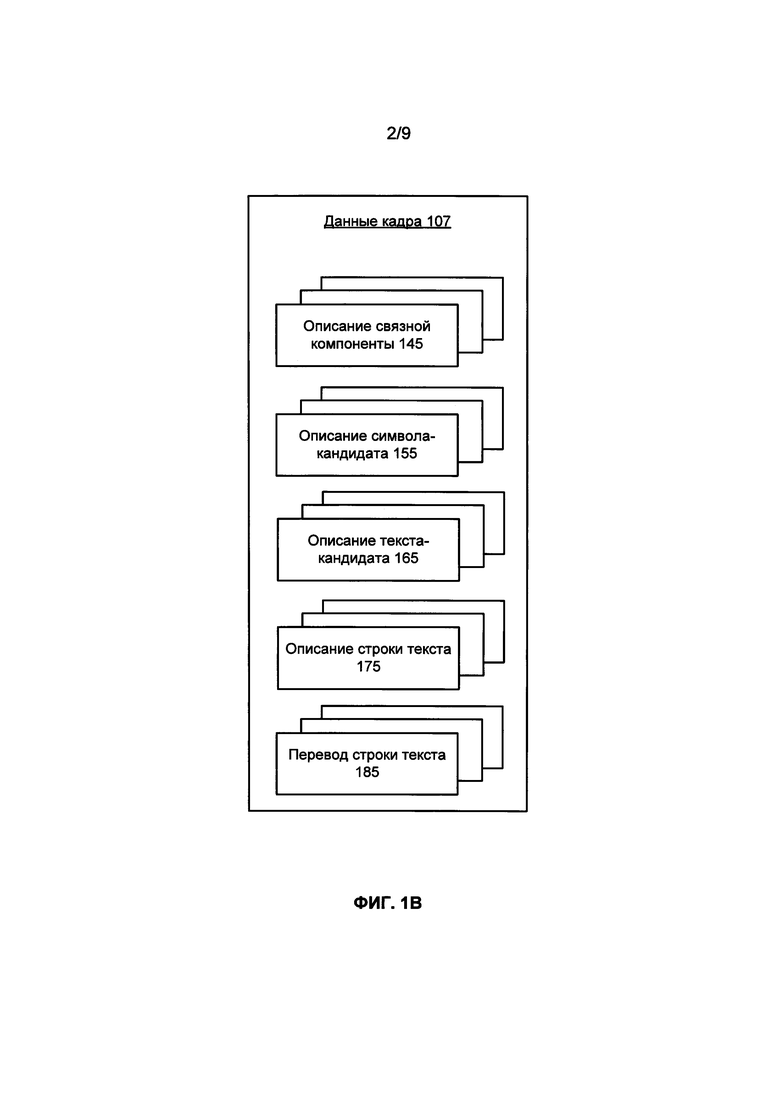
ФИГ. 1В иллюстрирует блок-схему примера структуры данных для хранения данных видеокадров для проведения OCR видеокадров из видеоматериалов в соответствии с одним примером.
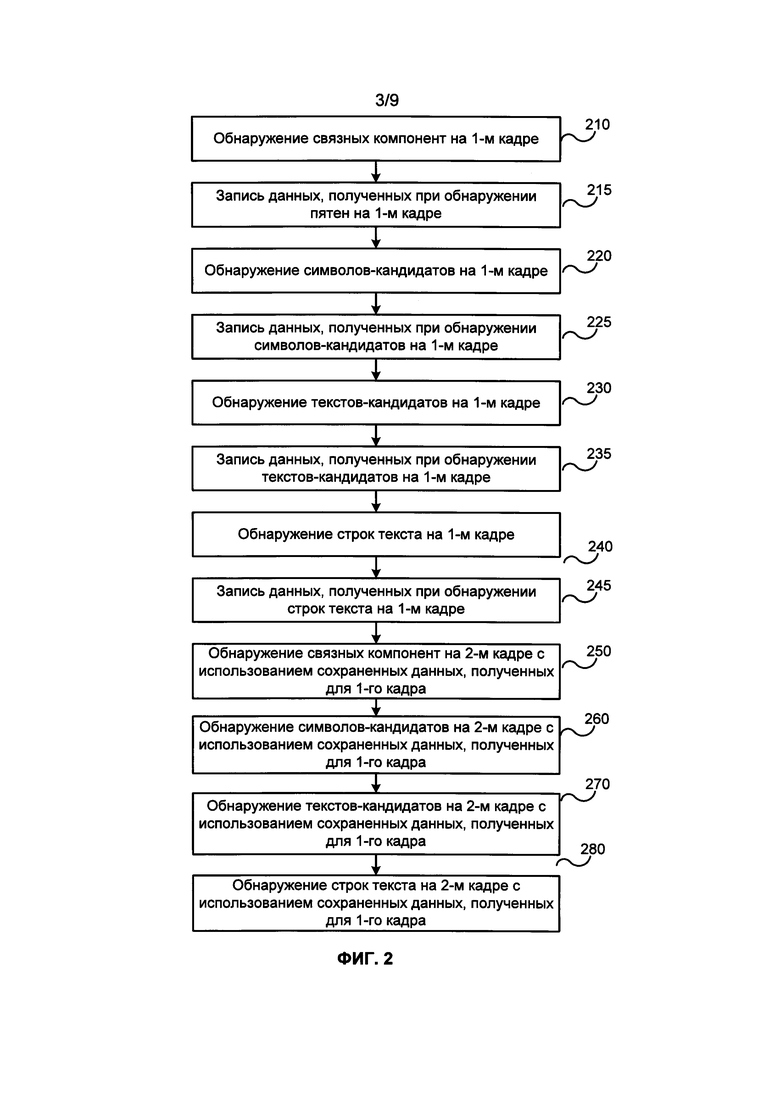
ФИГ. 2 иллюстрирует блок-схему примера способа использования данных предыдущего кадра для проведения OCR видеокадров из видеоматериалов в соответствии с одним примером.
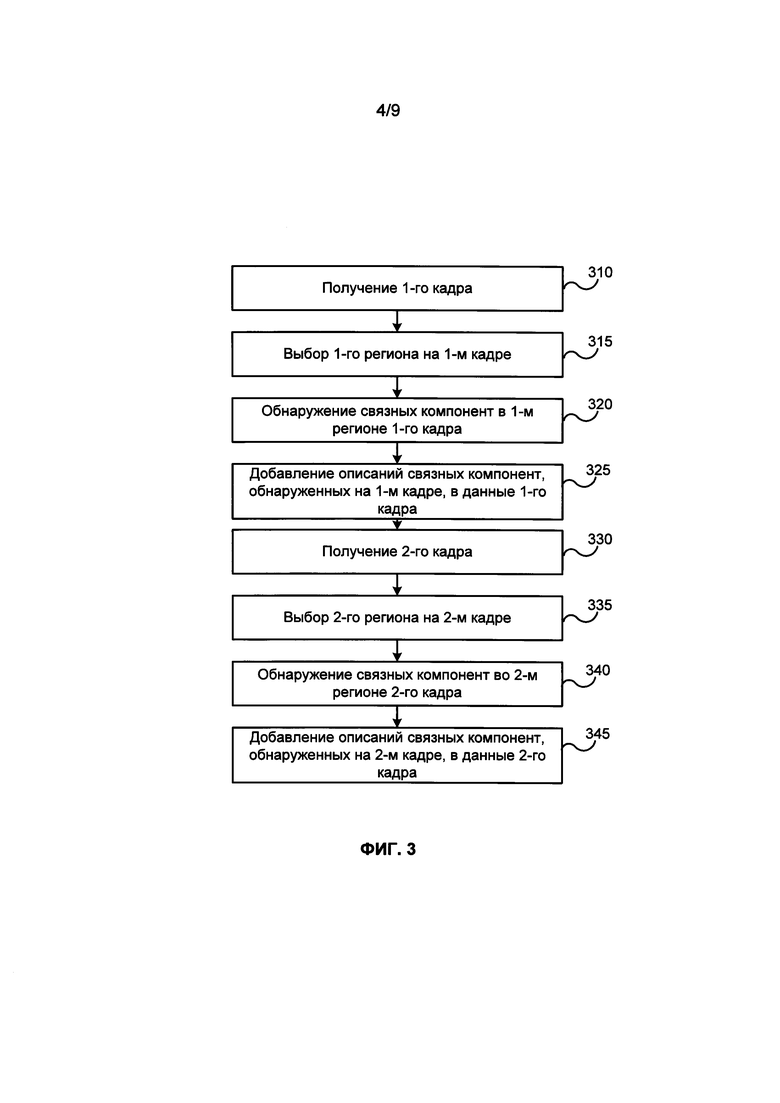
ФИГ. 3 иллюстрирует блок-схему примера способа обнаружения связных компонент в соответствии с одним примером.
ФИГ. 4 иллюстрирует блок-схему примера способа обнаружения символа-кандидата в соответствии с одним примером.
ФИГ. 5 иллюстрирует блок-схему примера способа обнаружения текста-кандидата в соответствии с одним примером.
ФИГ. 6 иллюстрирует блок-схему примера способа обнаружения текстовой строки в соответствии с одним примером.
ФИГ. 7 иллюстрирует блок-схему примера способа использования данных предыдущего кадра для проведения OCR видеокадров из видеоматериалов в соответствии с одним примером.
ФИГ. 8 иллюстрирует пример компьютерной системы общего назначения, такой как персональный компьютер или сервер, которая может использоваться для реализации раскрываемых систем и способов использования данных предыдущего кадра для OCR кадров из видеоматериалов в соответствии с одним примером.
Подробное описание
[0031] Примеры в этом документе описаны в контексте системы, способа и программного продукта для компьютеров для проведения OCR видеокадров из видеоматериалов. Специалисты среднего уровня в данной области техники смогут осознать, что приведенное ниже описание является исключительно иллюстративным и не предназначено для каких-либо ограничений. Такие специалисты в данной области техники легко могут предложить другие примеры, сохраняющие преимущества настоящего изобретения. Ниже будут даны подробные ссылки на варианты реализации, показанные на прилагаемых чертежах. Одни и те же указатели ссылок, насколько это возможно, будут использоваться для всех чертежей и последующего описания, чтобы ссылаться на одинаковые или схожие элементы.
[0032] ФИГ. 1А и 1В демонстрируют пример системы 100 для использования данных предыдущего кадра для OCR видеокадров из видеоматериалов в соответствии с одним примером настоящего изобретения. Система 100 может быть реализована на устройстве пользователя, таком как мобильный телефон, настольный компьютер, персональный компьютер, цифровая видеокамера или устройство обработки данных другого типа. В одном из примеров, проиллюстрированном на ФИГ. 1А, система 100 может включать устройство видеозахвата 105, например, цифровую видеокамеру. Устройство видеозахвата 105 может включать как минимум оптику для видеосъемки, включая объектив, через который можно захватывать видео, и сенсор изображения для получения цифровых изображений через оптику камеры. Устройство видеозахвата 105 отправляет поток 101 несжатых необработанных цифровых изображений (например, видеокадры 102a-z) процессору 115 для выполнения OCR. В другом случае цифровое видео может храниться в памяти 135 (например, ОЗУ или флэш-памяти) системы 100 в виде сжатого видеофайла 103, такого как Flash, AVI, QuickTime, MPEG-4, Windows Media Video или в другом формате сжатого видео. Ниже приводятся примеры видеоматериалов, содержащих временную последовательность видеокадров.
[0033] В одном из примеров система 100 может использовать для проведения OCR видеоматериалов 101 или файлов 103 один процессор 115 (например, ЦП компьютера, процессор для обработки изображений, процессор для цифровой обработки сигналов, графический процессор и т.д.) или специализированную заказную интегральную схему (ASIC). В другом примере система 100 может использовать для проведения OCR видеоматериалов несколько параллельно работающих процессоров 115 или один многоядерный процессор 115 (например, Intel Core Duo®). Например, как будет более подробно описано далее в этом документе, проведение OCR видеокадров из видеоматериала может распределяться между несколькими параллельно работающими процессорами 115 или между разными ядрами одного многоядерного процессора 115.
[0034] Независимо от конкретной реализации процессор 115 настраивается для выполнения механизма оптического распознавания символов (OCR) 125. Механизм OCR 125 получает видеокадры из видеоматериалов, например, несжатый видеопоток 101, создаваемый устройством захвата видеоизображения 105 или сжатый видеофайл 103, сохраненный в памяти 135, и выполняет OCR текста, имеющегося в полученных кадрах видеоизображения. Обработка может включать обнаружение связных компонент, запись описания связных компонент, обнаружение символов-кандидатов, запись описания символов-кандидатов, обнаружение текстов-кандидатов, запись описания текстов-кандидатов, обнаружение строк текста, этапы описания строк текста и другие действия. Эти этапы будут подробно описаны ниже. Механизм 125 OCR может быть реализован в виде программного обеспечения, например, автономной программы для настольного компьютера или мобильного приложения, в виде веб-приложения, исполняемого с помощью веб-браузера, или в качестве фонового процесса (или программы), исполняемой программным обеспечением видеозахвата или воспроизведения видео пользовательского устройства. В одном из примеров механизм 125 OCR может содержать множество функциональных модулей, включая, но не ограничиваясь, модуль 110 обнаружения связных компонент, модуль 120 обнаружения символов-кандидатов, модуль 130 обнаружения текстов-кандидатов и модуль 140 обнаружения строк текста. В одном из примеров все функциональные модули механизма 125 OCR могут полностью выполняться процессором 115 пользовательского устройства. В другом примере некоторые модули могут выполняться процессором 115, а другие модули - удаленным сетевым сервером. Например, механизм OCR 125 может дополнительно содержать модуль перевода, который может выполнять перевод обнаруженного текста (строк текста) на различные языки. Поскольку перевод текста обычно является весьма ресурсоемким процессом, для экономии вычислительных ресурсов системы 100 он может выполняться удаленным сетевым сервером.
[0035] В одном из примеров данные о кадрах 107 сохраняются в память 135 в ходе обработки видеокадров, относящихся к одному видеоматериалу (например, потоку 101 видео или видеофайлу 103). Как показано на ФИГ. 1В, данные кадра 107 могут включать, помимо прочего, описание связной компоненты 145 для каждого обработанного кадра видео или группы последовательно идущих кадров, описания символов-кандидатов 155 для одного или нескольких связных компонент в каждом обработанном кадре видео или группе последовательно идущих кадров, описания текстов-кандидатов 165 для одного или нескольких символов-кандидатов в каждом обработанном кадре видео или группе последовательно идущих кадров, описания строк текста 175 для одного или нескольких текстов-кандидатов в каждом обработанном кадре видео или группе последовательно идущих кадров и необязательные переводы текстовых строк 185 для одной или более текстовых строк в каждом обработанном кадре видео или группе последовательно идущих кадров.
[0036] В одном из примеров модуль обнаружения связных компонент 110 может быть настроен на выполнение обнаружения связных компонент в получаемых кадрах видео. Обнаружение связных компонент основано на математических методах поиска в графических изображениях регионов, отличающихся по свойствам, например, яркости или цвету от областей, окружающих эти регионы. Связная компонента представляет собой регион цифрового изображения, такой, что некоторые свойства этого региона постоянны или изменяются в заданном диапазоне значений, все точки связной компоненты могут в определенном смысле считаться похожими. Если выражать интересующее нас свойство в виде функции положения в цифровом изображении, можно выделить два основных типа детекторов связных компонент: (i) дифференциальные методы, которые основаны на производных функций по положению и (ii) методы, основанные на локальных экстремумах, которые основаны на поиске локальных минимумов и максимумов функций.
[0037] В одном из примеров обнаружение связных компонент может выполняться для всего видеокадра 102 или только для части видеокадра. Например, сначала для обнаружения связных компонент может быть обработана часть видеокадра, ближайшая к центру изображения. Затем при наличии последующих видеокадров часть изображения, в которой были обнаружены связные компоненты и проводились дальнейшие действия по OCR, расширяется, так что текст в центре изображения, который наиболее интересен пользователю, распознается раньше, чем текст на периферии изображения.
[0038] Модуль обнаружения связных компонент 110 может использовать, например, алгоритмы, предоставленные IJBlob, библиотеки анализа связных компонент и анализа формы, описанные в статье Wagner, Т and Lipinksi, Н 2013 IJBlob: An ImageJ Library for Connected Component Analysis and Shape Analysis. Journal of Open Research Software 1:e6, DOI: http://dx.doi.org/10.5334/jors.ae. Общий подход к обнаружению связных компонент состоит в бинаризации, при которой серое или цветное изображение преобразуется в черно-белое, исходя из того, превышает ли значение изображения определенное граничное значение. Другой способ обнаружения связных компонент известен в профессиональных кругах как MSER, максимально стабильные экстремальные регионы.
[0039] После обнаружения связной компоненты его свойства и параметры или любой поднабор его свойств и параметров, например, положение связной компоненты на видеокадре, форма связной компоненты, ориентация связной компоненты, количество отверстий, центр тяжести, замкнутая область, зона выпуклой оболочки, периметр, периметр выпуклой оболочки, степень приближения к окружности, коэффициент сужения, диаметр Фере, минимальный диаметр Фере, длинная сторона минимального ограничивающего прямоугольника, короткая сторона минимального ограничивающего прямоугольника, соотношение сторон, отношение площадь/периметр, отношение тензоров моментов инерции, количество горизонтальных штрихов с кодированием RLE (кодирование длины серий), количество вертикальных штрихов с кодированием RLE, модуль разности средних значений серого внутри и снаружи региона связной компоненты, отклонение уровней серого внутри региона, отклонение уровней серого снаружи региона, HOG (гистограмма ориентированных градиентов), температура внешнего контура, фрактальная размерность прямоугольника, моменты региона, центральные моменты региона, собственное значение главной оси, собственное значение малой оси, удлинение, выпуклость, компактность, ориентация и внешний контур в виде цепного кода Фримана, могут быть записаны или сохранены в памяти системы 135, формируя описание связных компонент 145. Описание связных компонент 145 может быть сохранено для каждой обнаруженной связной компоненты; это описание добавляется к данным кадра 107 для видеокадра, в котором обнаружена связная компонента.
[0040] После обнаружения пятен в примере модуль обнаружения символов-кандидатов 120 обнаруживает связные компоненты, которые могут соответствовать символам естественного языка (то есть символы-кандидаты), и связные компоненты, которые не могут соответствовать символам естественного языка (или как минимум не похожи на отображение символов), например, используя такие алгоритмы, как классификатор AdaBoost и/или SVM (метод опорных векторов) и/или случайный лес. Следует отметить, что для символов разных языков могут использоваться разные алгоритмы обнаружения символов (например, для английского, русского, китайского, арабского языка и т.д.).
[0041] После обнаружения в связных компонентах видеокадра символов-кандидатов соответствующее описание связной компоненты 145 может быть помечено в системной памяти 135 для дальнейшего проведения OCR и/или оставшиеся описания связных компонент 145 могут быть помечены в системной памяти 135 как исключенные из дальнейшего проведения OCR, кроме того, к соответствующему описанию связной компоненты 145 и данным кадра 107, записанным или сохраненным в системной памяти 135, могут быть добавлены дополнительные данные, полученные для каждой связной компоненты при выполнении алгоритмов обнаружения символов-кандидатов. Эти пометки и дополнительные данные могут образовать описание 155 символа-кандидата для каждого символа-кандидата, добавленного к данным 107 кадра для видеокадра, на котором обнаружены связные компоненты.
[0042] В одном из примеров при выполнении обнаружения связных компонент на видеокадре 102b описания связных компонент 145, обнаруженных при поиске связных компонент на предыдущем видеокадре 102а (такие, как положение связной компоненты на видеокадре, его форма, ориентация связных компонент и т.д., как указано выше в этом документе) могут использоваться для обнаружения идентичных или похожих связных компонент на текущем видеокадре 102b. Предыдущий видеокадр может быть видеокадром, непосредственно предшествующим текущему видеокадру по времени, или любым предыдущим видеокадром. Например, если все связные компоненты, обнаруженные на предыдущем видеокадре 102а, сосредоточены в определенном регионе этого видеокадра, как минимум сначала обнаружение связных компонент будет производиться в этом же регионе текущего видеокадра 102b. В одном из примеров данные о перемещении кадра относительно снимаемой сцены, полученные, например, с помощью одного из алгоритмов нахождения движения, могут использоваться для обнаружения предполагаемого положения рассматриваемого региона текущего кадра на предыдущем кадре. Если связная компонента, найденная на текущем видеокадре 102b, имеет сильное сходство по положению, форме, ориентации и/или другим характеристикам и параметрам с связной компонентой на предыдущем видеокадре 102а, эти две связные компоненты на разных видеокадрах могут распознаваться как соответствующие одному и тому же объекту, который наблюдается устройством видеозахвата 105, например, одной и той же букве на поверхности. В этом случае часть последующей обработки связной компоненты на текущем видеокадре для получения некоторых данных этой связной компоненты может быть необязательна, потому что вместо них могут использоваться данные, сохраненные после получения их для этой связной компоненты на предыдущем видеокадре. Например, если связная компонента на предыдущем видеокадре была определена в качестве символа-кандидата, аналогичную связную компоненту на текущем видеокадре можно считать символом-кандидатом без выполнения алгоритмов обнаружения символа-кандидата.
[0043] После обнаружения на видеокадре нескольких символов-кандидатов в одном из примеров для группировки как минимум части символов-кандидатов в кластеры, соответствующие блокам текста, например, словам, предложениям, абзацам и т.д., может использоваться модуль обнаружения текста-кандидата 130, например, использующий алгоритм поиска минимального остовного дерева и/или алгоритм иерархической кластеризации (например, с одиночной связью). Обнаруженные кластеры символов-кандидатов соответствуют обнаруженным текстам-кандидатам.
[0044] При обнаружении текста-кандидата его характеристики и параметры или любой поднабор характеристик и параметров, например, положение на видеокадре, форма, ориентация и символы-кандидаты, образующие текст-кандидат, могут быть записаны или сохранены в системной памяти 135, образуя описание текста-кандидата 165. Описание текста-кандидата 165 для каждого обнаруженного текста-кандидата может сохраняться, эти описания добавляются к данным кадра 107 для видеокадра, в котором были обнаружены тексты-кандидаты.
[0045] После обнаружения текстов-кандидатов, в одном из примеров модуль обнаружения текста 140 выполняет алгоритмы поиска текста в текстах-кандидатах. Эти алгоритмы принимают на вход текст-кандидат (т.е. кластер выбранных связных компонент) и возвращают текстовую строку, которую представляет этот кластер связных компонент, (результат распознавания) и информацию о расположении этой строки, например, ее размер, длину и ширину, ее ориентацию, ее охватывающий прямоугольник и т.д.
[0046] При выполнении обнаружения текстов-кандидатов в видеокадре для обнаружения текстов-кандидатов на текущем видеокадре могут использоваться тексты-кандидаты, обнаруженные на предыдущем видеокадре (например, положение кластеров символов-кандидатов на видеокадре, их форма и ориентация символов-кандидатов и т.д., как указано выше в этом документе). Например, если все тексты-кандидаты, обнаруженные на предыдущем видеокадре 102а, расположены в определенном регионе видеокадра, как минимум первичное обнаружение текстов-кандидатов может проводиться только для символов-кандидатов в этом регионе текущего видеокадра 102b. Если обнаруженный кластер символов-кандидатов (то есть текст-кандидат) на текущем видеокадре аналогичен по положению, форме, ориентации и другим характеристикам и параметрам обнаруженному кластеру символов-кандидатов (то есть тексту-кандидату) на предыдущем видеокадре, эти два текста-кандидата на разных видеокадрах могут считаться представляющими один объект, например, ту же группу слов на поверхности, что и текст-кандидат из предыдущего видеокадра. В таких случаях последующая обработка текста-кандидата из текущего видеокадра для получения некоторых данных, относящихся к этому тексту-кандидату, может не понадобиться, так как вместо них можно будет использовать данные, полученные и сохраненные для текста-кандидата из предыдущего видеокадра. Например, если текст-кандидат из предыдущего видеокадра был определен как представляющий некоторую строку текста, и аналогичный текст-кандидат присутствует на текущем видеокадре, в данные текущего кадра можно добавить описание строки текста, основанное на описании строки текста для текста-кандидата из предыдущего кадра, не выполняя алгоритмы обнаружения строки текста.
[0047] После обнаружения строки текста ее параметры, такие как положение на видеокадре, размер, длина и ширина, ориентация и содержание записываются или сохраняются в системной памяти 115, образуя описание строки текста 175. Описание строки текста 175 может сохраняться для любой обнаруженной строки текста, эти описания добавляются к данным кадра 107 для видеокадра, на котором были обнаружены тексты-кандидаты. В одном из примеров описание текстовой строки можно использовать для перевода обнаруженного текста на другой язык в интерактивном режиме с заменой текста на кадре его переводом на другой язык. В этом случае перевод строки текста 185 также может быть сохранен в данных кадра 107 и использован для замены аналогичного текста на последующих кадрах без необходимости повторного выполнения перевода текста для каждого последующего кадра.
[0048] В одном из примеров выполнение OCR видеокадров видеоматериала может распределяться между несколькими процессорами 115, работающими параллельно, или между несколькими ядрами одного многоядерного процессора 115. Каждый последующий видеокадр, обрабатываемый системой 100, может обрабатываться любым из модулей 110, 120, 130 и 140, выполняемых на одном процессоре 115, или на процессоре, который отличается от процессора, использованного для обработки предыдущего видеокадра, или на другом ядре процессора 115, работающем параллельно для повышения эффективности. Например, пока один процессор 115 или ядро процессора 115 обрабатывает первый видеокадр, второй видеокадр захватывается и передается на обработку второму процессору или другому ядру процессора 115, данные первого кадра накапливаются в памяти и используются для обработки второго видеокадра.
[0049] ФИГ. 2 иллюстрирует пример способа использования данных предыдущего кадра для проведения OCR видеокадров видеоматериала в соответствии с одним из примеров. В одном из примеров на шаге 210 может производиться обнаружение связных компонент с целью обнаружения связных компонент на первом видеокадре после его захвата. Обнаружение связных компонент может производиться для всего первого видеокадра или только для части первого видеокадра. Например, на шаге 210 для обнаружения связных компонент может производиться обработка части первого видеокадра, наиболее близкой к центру изображения.
[0050] После обнаружения связной компоненты, на шаге 215 его свойства и параметры или любой поднабор его свойств и параметров, например, положение связной компоненты на первом видеокадре, форма связной компоненты, ориентация связной компоненты, количество отверстий, центр тяжести, замкнутая область, зона выпуклой оболочки, периметр, периметр выпуклой оболочки, степень приближения к окружности, коэффициент сужения, диаметр Фере, минимальный диаметр Фере, длинная сторона минимального ограничивающего прямоугольника, короткая сторона минимального ограничивающего прямоугольника, соотношение сторон, отношение площадь/периметр, отношение тензоров моментов инерции, количество горизонтальных штрихов с кодированием RLE (кодирование длины серий), количество вертикальных штрихов с кодированием RLE, модуль разности средних значений серого внутри и снаружи региона связной компоненты, отклонение уровней серого внутри региона, отклонение уровней серого снаружи региона, HOG (гистограмма ориентированных градиентов), температура внешнего контура, Фрактальная размерность прямоугольника, моменты региона, центральные моменты региона, собственное значение главной оси, собственное значение малой оси, удлинение, выпуклость, компактность, ориентация и внешний контур в виде цепного кода Фримана, могут быть записаны или сохранены в памяти системы 135, формируя описание связной компоненты. Описание связной компоненты может сохраняться для каждой обнаруженной связной компоненты, эти описания добавляются к данным первого кадра.
[0051] После обнаружения на первом видеокадре нескольких связных компонент, в одном из примеров на шаге 220 обнаруживаются связные компоненты, которые могут соответствовать символам (то есть символы-кандидаты) и связные компоненты, которые не могут соответствовать символам (или как минимум не похожи на отображение символов), например, используя такие алгоритмы, как классификатор AdaBoost и/или SVM (метод опорных векторов) и/или случайный лес.
[0052] На шаге 225, после обнаружения символов-кандидатов среди связных компонент на первом видеокадре соответствующие описания связных компонент могут быть помечены в системной памяти 135 для последующего проведения OCR и/или остальные описания связных компонент могут быть помечены в системной памяти 135 как исключенные из последующего OCR, кроме того, к данным первого кадра, сохраненным или записанным в системной памяти 135, для каждой связной компоненты могут быть добавлены дополнительные данные, полученные при выполнении алгоритмов обнаружения символов-кандидатов. Эти пометки и дополнительные данные могут формировать описание символа-кандидата для каждого символа-кандидата, добавленного к данным первого кадра.
[0053] После обнаружения на первом видеокадре нескольких символов-кандидатов, в одном из примеров, на шаге 230 как минимум некоторые из символов-кандидатов группируются в кластеры, соответствующие блокам текста, таким как слова, например, с помощью алгоритма поиска минимального остовного дерева и/или алгоритма иерархической кластеризации (например, с одиночной связью). Эти обнаруженные кластеры символов-кандидатов соответствуют обнаруженным текстам-кандидатам первого видеокадра.
[0054] После обнаружения текстов-кандидатов на первом видеокадре их свойства и параметры или любой поднабор их свойств и параметров, например, их положение на первом видеокадре, их форма, ориентация, символы-кандидаты, образующие текст-кандидат, могут быть записаны или сохранены в системной памяти 135, образуя описание текста-кандидата на шаге 235. Описание текста-кандидата для любого обнаруженного на первом видеокадре текста-кандидата можно сохранить, это описание будет добавлено к данным первого кадра.
[0055] После обнаружения на первом видеокадре текстов-кандидатов, в одном из примеров на шаге 240 используются алгоритмы для обнаружения в текстах-кандидатах строк текста.
[0056] После обнаружения текста его параметры, такие как положение на первом видеокадре, размер, длина и ширина, ориентация и содержание сохраняются или записываются на шаге 245 в системную память 135, образуя описание строки текста. Описание строки текста для любой обнаруженной на первом видеокадре строки текста может быть сохранено, эти описания добавляются к данным первого кадра.
[0057] После захвата первого видеокадра датчиком изображения, подключенным к оптике камеры для получения изображений, датчик изображения, подключенный к оптике камеры для получения изображений, захватывает второй видеокадр.
[0058] При обнаружении связных компонент на втором видеокадре на шаге 250 может использоваться тот же алгоритм или алгоритмы, что и для первого видеокадра на шаге 210. Описания связных компонент для каждой обнаруженной на втором видеокадре связной компоненты могут сохраняться, при этом описания добавляются к данным второго кадра.
[0059] Обнаружение связных компонент на шаге 250 может выполняться для всего второго видеокадра или только для части второго видеокадра. Часть второго видеокадра, на которой были обнаружены связные компоненты и для которой выполнялись дальнейшие действия, может быть увеличена по сравнению с такой же частью на первом видеокадре, чтобы, например, текст в центре изображения, который, вероятно, больше интересует пользователя, распознавался раньше, чем текст на периферии изображения.
[0060] При выполнении обнаружения связных компонент на втором видеокадре на шаге 250, описания связных компонент, полученные при обнаружении связных компонент на первом видеокадре (например, положение связных компонент на видеокадре, их форма, ориентация связных компонент и т.д., как было описано ранее в этом документе), могут использоваться для обнаружения связных компонент на втором видеокадре. Например, если все связные компоненты, найденные на первом видеокадре, сосредоточены в определенном регионе первого видеокадра, как минимум сначала обнаружение связных компонент на втором видеокадре на шаге 250 может производиться только в этом регионе второго видеокадра.
[0061] После обнаружения связных компонент на втором видеокадре, в одном из примеров на втором кадре на шаге 260 обнаруживаются связные компоненты, которые могут соответствовать символам (то есть символы-кандидаты) и связные компоненты, которые не могут соответствовать символам (или как минимум не похожи на отображение символов), при этом используются те же алгоритмы, что и для первого видеокадра на шаге 220. Описания символов-кандидатов для каждого символа-кандидата на шаге 260 могут добавляться к данным второго кадра.
[0062] Если связная компонента, обнаруженная на втором видеокадре, в достаточной степени соответствует по положению, ориентации и/или другим свойствам и параметрам пятну с первого видеокадра, эти две связные компоненты на разных видеокадрах могут распознаваться как соответствующие одному объекту, снятому камерой, например, как одной букве на поверхности. В таких случаях часть последующей обработки связной компоненты на втором видеокадре для получения данных, относящихся к этой связной компоненте, является необязательной, так как вместо них будут использоваться данные, полученные и сохраненные для этой связной компоненты на первом видеокадре. Например, если связная компонента на первом видеокадре была определена как символ-кандидат, аналогичная связная компонента на втором видеокадре может быть признана символом-кандидатом без выполнения алгоритмов обнаружения символов-кандидатов.
[0063] После обнаружения символов-кандидатов на втором видеокадре, в одном из примеров на шаге 270 как минимум некоторые из символов-кандидатов группируются в кластеры, соответствующие блокам текста, например, словам, с помощью того же алгоритма или алгоритмов, которые использовались для этого на первом видеокадре, на шаге 230. Эти обнаруженные кластеры символов-кандидатов соответствуют обнаруженным текстам-кандидатам на втором видеокадре. Описания текстов-кандидатов для каждого обнаруженного текста-кандидата на втором видеокадре могут быть сохранены, эти описания добавляются к данным второго кадра на шаге 270.
[0064] После обнаружения текстов-кандидатов на втором видеокадре, в одном из примеров на шаге 280 для обнаружения строк текста в текстах-кандидатах на втором видеокадре используются те же алгоритмы, которые использовались для обнаружения строк текста в текстах-кандидатах на первом видеокадре. Описание строки текста для каждой обнаруженной на втором видеокадре строки текста может быть сохранено; эти описания добавляются к данным второго кадра на шаге 280.
[0065] При выполнении обнаружения текстов-кандидатов на втором видеокадре тексты-кандидаты, обнаруженные на первом видеокадре (например, положения кластеров символов-кандидатов на видеокадре, их форма и ориентация символов-кандидатов и т.д., как изложено ранее в этом документе) могут использоваться для обнаружения текстов-кандидатов на втором видеокадре. Например, если все тексты-кандидаты, найденные на первом видеокадре, расположены в определенном регионе первого видеокадра, как минимум сначала обнаружение текстов-кандидатов на втором видеокадре на шаге 250 может производиться только в соответствующем регионе второго видеокадра. Например, обнаруженный на втором видеокадре кластер символов-кандидатов (то есть текст-кандидат), аналогичный по положению, форме, ориентации и другим свойствам и параметрам обнаруженному на первом видеокадре кластеру символов-кандидатов (то есть тексту-кандидату), может считаться отображающим тот же самый объект, например, то же слово или группу слов, что и текст-кандидат на втором видеокадре. В таких случаях часть последующей обработки текста-кандидата на втором видеокадре с целью получения данных, относящихся к тексту-кандидату, можно не производить, поскольку вместо этого можно использовать данные, полученные и сохраненные для текста-кандидата на первом видеокадре. Например, если текст-кандидат на первом видеокадре был определен как содержащий строку текста, и на втором видеокадре присутствует аналогичный текст-кандидат, к данным второго кадра можно добавить описание строки текста на основе описания текстовой строки для текста-кандидата из данных для первого кадра, не выполняя алгоритмы поиска строк текста.
[0066] Каждый видеокадр, обрабатываемый в соответствии с ФИГ. 2, может обрабатываться тем же процессором, другим процессором или другим ядром процессора параллельно для повышения эффективности. Например, пока один процессор или ядро процессора обрабатывает первый видеокадр, второй видеокадр передается для обработки второму процессору или ядру процессора, при этом данные первого кадра накапливаются в памяти и используются для обработки второго видеокадра.
[0067] ФИГ. 3 иллюстрирует блок-схему примера способа обнаружения связных компонент. В примере, приведенном на ФИГ. 1, этот способ выполняется модулем обнаружения связных компонент 110. На шаге 310 происходит получение первого видеокадра. На шаге 315 происходит выбор региона, в котором были найдены связные компоненты на первом видеокадре. На шаге 320 обнаруживаются связные компоненты на первом видеокадре внутри выбранного первого региона. На шаге 325 описания связных компонент, обнаруженных на первом видеокадре, добавляются к данным первого кадра. На шаге 330 происходит получение второго видеокадра. На шаге 335 производится выбор второго региона, в котором выполняется обнаружение связных компонент на втором видеокадре. Второй регион обычно больше и включает первый регион. На шаге 340 производится обнаружение связных компонент в выбранном втором регионе второго видеокадра. На шаге 345 описания связных компонент, обнаруженных на втором видеокадре, добавляются к данным второго видеокадра.
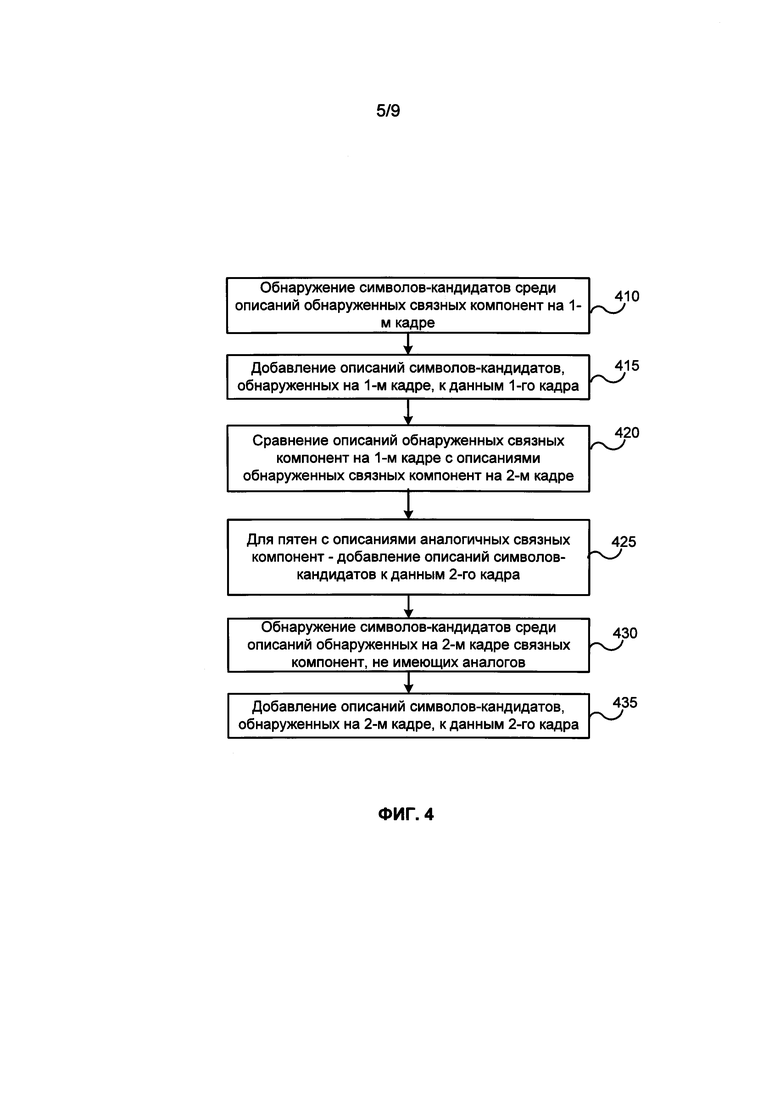
[0068] ФИГ. 4 иллюстрирует блок-схему примера способа обнаружения символов-кандидатов. В примере, приведенном на ФИГ. 1, этот способ выполняется модулем 120 обнаружения символов-кандидатов. На шаге 410 производится обнаружение символов-кандидатов среди описаний связных компонент, обнаруженных на первом видеокадре. На шаге 415 описания символов-кандидатов, обнаруженных на первом видеокадре, могут быть добавлены к данным первого кадра. На шаге 415 к описаниям связных компонент могут быть добавлены логические значения, показывающие, является ли связная компонента символом-кандидатом. На шаге 420 описания связных компонент, обнаруженных на первом видеокадре, сравниваются с описаниями связных компонент, найденных на втором видеокадре, для того, чтобы найти на втором видеокадре связные компоненты, аналогичные связным компонентам на первом видеокадре. Если связная компонента на первом видеокадре была определена в качестве символа-кандидата, аналогичная связная компонента на втором видеокадре может рассматриваться в качестве символа-кандидата без выполнения алгоритмов обнаружения символов-кандидатов. На шаге 425 описания символов-кандидатов для этих связных компонент добавляются к данным второго кадра. На шаге 430 производится обнаружение символов-кандидатов в описаниях связных компонент, обнаруженных на втором видеокадре, для которых в данных первого кадра нет описаний аналогичных связных компонент. На шаге 435 описания символов-кандидатов, обнаруженных на втором видеокадре на шаге 430, могут быть добавлены к данным второго кадра.
[0069] ФИГ. 5 иллюстрирует блок-схему примера способа обнаружения текстов-кандидатов. В примере, приведенном на ФИГ. 1, этот способ исполняется модулем обнаружения текстов-кандидатов 130. На шаге 510 среди найденных в данных первого кадра символов-кандидатов обнаруживаются тексты-кандидаты. На шаге 515 описания текстов-кандидатов, обнаруженных в данных первого кадра, добавляются к данным первого кадра. На шаге 520 описания символов-кандидатов, обнаруженных на первом видеокадре, сравниваются с описаниями символов-кандидатов, обнаруженных на втором видеокадре, для того, чтобы обнаружить символы-кандидаты на втором видеокадре, которые аналогичны символам-кандидатам на первом видеокадре. Если символ-кандидат (или группа символов-кандидатов) на первом видеокадре была определена как текст-кандидат, аналогичный символ-кандидат (или группу символов-кандидатов) на втором видеокадре можно рассматривать в качестве текста-кандидата, не выполняя алгоритмы обнаружения текстов-кандидатов. На шаге 525 описания текстов-кандидатов для этих символов-кандидатов добавляются к данным второго кадра. На шаге 530 обнаруживаются тексты-кандидаты для описаний символов-кандидатов, обнаруженных на втором видеокадре, которые не имеют соответствующих им описаний символов-кандидатов в данных первого кадра. На шаге 535 описания текстов-кандидатов, обнаруженных на втором видеокадре на шаге 530, могут быть добавлены к данным второго кадра.
[0070] ФИГ. 6 иллюстрирует блок-схему примера способа обнаружения текста. В примере, приведенном на ФИГ. 1А, этот способ может быть выполнен модулем обнаружения текста 140. На шаге 610 производится обнаружение строк текста среди текстов-кандидатов, обнаруженных на первом видеокадре. На шаге 615 описания строк текста, обнаруженных на первом видеокадре, могут быть добавлены к данным первого кадра. На шаге 620 описания текстов-кандидатов, обнаруженных на первом видеокадре, сравниваются с описаниями текстов-кандидатов, обнаруженных на втором видеокадре, для того, чтобы найти на втором видеокадре тексты-кандидаты, аналогичные текстам-кандидатам на первом видеокадре. Если было обнаружено, что текст-кандидат на первом видеокадре содержит строку текста, аналогичный текст-кандидат на втором видеокадре может считаться содержащим ту же строку текста без выполнения алгоритмов обнаружения текста. На шаге 625 к данным второго кадра добавляются описания текстовых строк для таких текстов-кандидатов. На шаге 630 обнаруживаются строки текста для тех текстов-кандидатов, обнаруженных на втором видеокадре, которые не имеют аналогичных текстов-кандидатов на первом видеокадре. На шаге 635 описания строк текста, обнаруженных на втором видеокадре на шаге 630, могут быть добавлены к данным второго кадра.
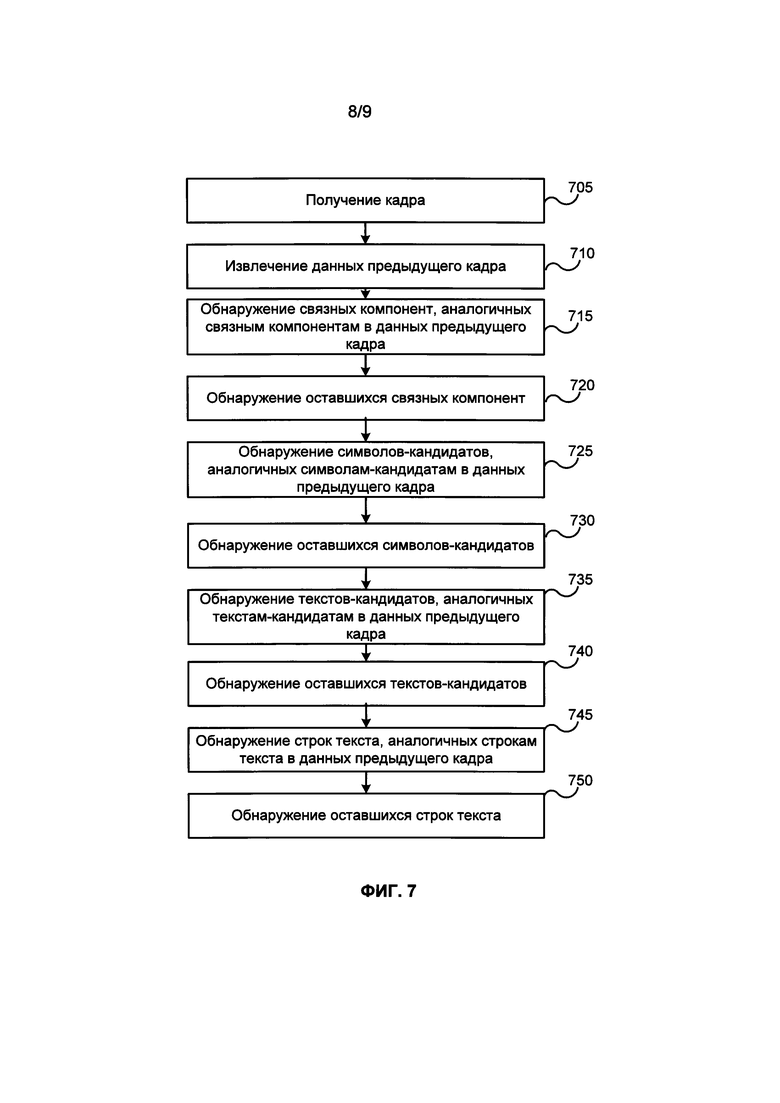
[0071] ФИГ. 7 иллюстрирует блок-схему примера способа использования данных предыдущего кадра для проведения OCR видеокадров из видеоматериалов в соответствии с одним примером. В этом примере на шаге 705 видеокадр получается из видеопотока 101, создаваемого устройством видеозахвата 105 или из видеофайла 103, хранящегося в памяти 135. На шаге 710 из памяти 135 извлекаются данные, собранные для предыдущего видеокадра или видеокадров.
[0072] На шаге 715 на видеокадре обнаруживаются связные компоненты в тех местах, на которых их наличие ожидается на основе сходства со связными компонентами, обнаруженными на предыдущих кадрах и записанными в данных предыдущих кадров. На шаге 720 на видеокадре обнаруживаются другие связные компоненты, если они имеются. Описания всех обнаруженных связных компонент могут сохраняться в памяти 135 для использования при проведении OCR последующих кадров.
[0073] На шаге 725 на видеокадре обнаруживаются символы-кандидаты среди связных компонент, аналогичных связным компонентам, которые были признаны символами-кандидатами на предыдущих кадрах, в соответствии с данными предыдущих кадров. На шаге 730 на видеокадре обнаруживаются другие символы-кандидаты, если они имеются. Описания всех обнаруженных символов-кандидатов могут сохраняться в памяти 135 для использования при проведении OCR последующих кадров.
[0074] На шаге 735 на видеокадре обнаруживаются тексты-кандидаты среди символов-кандидатов, аналогичных символам-кандидатам, которые были собраны в тексты-кандидаты на предыдущих кадрах, в соответствии с данными предыдущих кадров. На шаге 740 на видеокадре обнаруживаются другие тексты-кандидаты, если они имеются. Описания всех обнаруженных текстов-кандидатов могут сохраняться в памяти 135 для использования при проведении OCR последующих кадров.
[0075] На шаге 745 на видеокадре обнаруживаются строки текста среди текстов-кандидатов, аналогичных текстам-кандидатам, которые были обнаружены на предыдущих кадрах, в соответствии с данными предыдущих кадров. На шаге 750 на видеокадре обнаруживаются другие строки текста, если они имеются. Описания всех обнаруженных строк текста могут сохраняться в памяти 135 для использования при проведении OCR последующих кадров.
[0076] ФИГ. 8 демонстрирует пример компьютерной системы общего назначения (которая может быть персональным компьютером или сервером) 20, которая может использоваться для реализации систем и способов использования данных предыдущего видеокадра для проведения OCR видеокадров из видеоматериалов. Компьютерная система 20 включает центральный процессор 21, системную память 22 и системную шину 23, к которой подключены различные компоненты системы, включая память, связанную с центральным процессором 21. Системная шина 23, реализованная как любая шинная структура, известная по существующему уровню техники, в свою очередь содержит шину обмена с памятью или контроллер обмена с памятью, шину периферийных устройств и локальную шину, которая может взаимодействовать с шинами другой архитектуры. Системная память включает постоянную память (ПЗУ) 24 и оперативную память (ОЗУ) 25. Базовая система ввода-вывода (БИОС) 26 содержит базовые процедуры, например, происходящие во время загрузки операционной системы с использованием ПЗУ 24, которые обеспечивают обмен информацией между элементами компьютера 20.
[0077] Компьютер 20, в свою очередь, содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи съемных магнитных дисков 29 и привод оптических дисков 30 для чтения и записи съемных оптических дисков 31, таких как CD-ROM, DVD-ROM и других оптических носителей информации. Жесткий диск 27, привод магнитных дисков 28 и привод оптических дисков 30 подключены к системной шине 23 через интерфейс жесткого диска 32, интерфейс привода магнитных дисков 33 и интерфейс привода оптических дисков 34, соответственно. Приводы и соответствующие информационные носители являются энергонезависимыми модулями для хранения компьютерных команд, структур данных, модулей программ и других данных компьютера 20.
[0078] Компьютер 20 может включать один или более приводов жестких дисков 27, съемных магнитных дисков 29 и съемных оптических дисков 31, однако следует понимать, что возможно использование компьютерных носителей информации 56 других типов, которые могут хранить данные в машиночитаемой форме (твердотельные устройства, карты флэш-памяти, цифровые диски, оперативная память (ОЗУ) и т.д.), которые подключены к системной шине 23 через контроллер 55.
[0079] Компьютер 20 имеет файловую систему 36, в которой записана операционная система 35, а также дополнительные программные приложения 37, другие модули программ 38 и данные программ 39. Пользователь может вводить в компьютер 20 команды и информацию, используя устройства ввода (клавиатуру 40, мышь 42). Могут использоваться и другие устройства ввода (не показаны) микрофон, джойстик, игровой контроллер, сканер и т.д. Эти устройства ввода обычно подключаются к компьютерной системе 20 через последовательный порт 46, который в свою очередь подключен к системной шине, но они могут подключаться и другими способами, например, с использованием параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или дисплей другого типа также подключен к системной шине 23 через интерфейс, например, видеоадаптер 48. Кроме монитора 47 персональный компьютер может быть оборудован другими периферийными устройствами вывода (не показаны), например, акустической системой, принтером и т.д.
[0080] Компьютер 20 может работать в сетевой среде, используя сетевое подключение к одному или более удаленным компьютерам 49. Удаленный компьютер (или компьютеры) 49 могут быть также представлены персональными компьютерами или серверами, имеющими большинство элементов или все элементы, перечисленные выше при описании характеристик компьютера 20. В компьютерной сети также могут присутствовать другие устройства, например, маршрутизаторы, сетевые станции, пиры или другие узлы сети.
[0081] Сетевые соединения могут формировать локальную компьютерную сеть (LAN) 50 и распределенную сеть (WAN). Эти сети могут использоваться в корпоративных компьютерных сетях или внутренних сетях компании, обычно они имеют доступ к Интернету. В сетях LAN или WAN компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей компьютер 20 может использовать для обеспечения связи с глобальной компьютерной сетью, такой как Интернет, модем 54 или другие модули. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 через последовательный порт 46. Следует заметить, что сетевые соединения приведены только для примера и не обязательно отображают точную конфигурацию сети, то есть в реальности существуют и другие способы организовать соединение одного компьютера с другим с помощью специальных коммуникационных модулей.
[0082] В различных примерах системы и способы, описанные в этом документе, могут быть реализованы в оборудовании, программах, встроенном программном обеспечении или различных комбинациях этих средств. При реализации в программном обеспечении способы могут храниться в виде одной или более инструкций или кода на энергонезависимом машиночитаемом носителе. К машиночитаемым носителям относятся и накопители данных. В качестве примера, но не для введения ограничений, подобные машиночитаемые носители могут включать ОЗУ, ПЗУ, ЭСППЗУ, CD-ROM, флэш-память или другие типы электрических, магнитных или оптических носителей информации, или другие носители, которые могут использоваться для переноса или хранения требуемого программного кода в виде инструкций или структур данных, и доступ к которым может осуществляться процессором компьютера общего назначения.
[0083] Для различных примеров системы и способы описаны в настоящем изобретении в терминах модулей. Термин "модуль", используемый в этом документе, относится к реальным устройствам, компонентам или наборам компонентов, реализованным с использованием оборудования, например, заказных специализированных интегральных схем (ASIC) или программируемых логических матриц (FPGA), или сочетания оборудования и программного обеспечения, например, микропроцессорной системы и набора инструкций для реализации функциональности модуля, которые (при выполнении) превращают микропроцессорную систему в специализированное устройство. Также модуль может быть реализован в виде сочетания аппаратного и программного обеспечения, с выделением одних функций только в оборудовании, а других - в сочетании оборудования и программного обеспечения. В некоторых вариантах реализации как минимум часть, а иногда и все модули могут выполняться процессором компьютера общего назначения (например, таким, который более подробно описан на ФИГ. 1А выше). Таким образом, каждый модуль может быть реализован множеством возможных конфигураций и не может ограничиваться конкретными вариантами реализации, приведенными здесь в качестве примеров.
[0084] Для наглядности в этом документе не приводятся все обычные свойства описываемых примеров. Следует понимать, что при разработке любых реальных реализаций настоящего изобретения для достижения конкретных целей разработчиков необходимо будет предпринимать множество решений по реализации, и что эти конкретные цели могут быть различными для разных реализаций и разных разработчиков. Следует понимать, что разработка может быть сложной и ресурсоемкой задачей, но при этом останется обычной инженерной работой для специалистов среднего уровня, использующих преимущества этого изобретения.
[0085] Кроме того, следует понимать, что используемая в этот документе фразеология или терминология предназначена для описания, но не ограничения, так что терминология или фразеология настоящего описания может быть интерпретирована специалистом среднего уровня с учетом имеющихся в этом документе принципов и инструкций в сочетании со знаниями специалиста соответствующего профиля. Кроме того, не предполагается назначение терминам, используемым в описании или пунктах формулы изобретения, необычного или особого значения, если об этом не сказано отдельно.
[0086] Различные примеры, приводимые в этом документе, охватывают существующие и будущие известные эквиваленты известных модулей, упомянутых в настоящем документе в качестве иллюстрации. Кроме того, несмотря на приведенные и описываемые примеры и варианты применения, для средних специалистов, использующих преимущества этого изобретения, ясно, что многие модификации, не описанные выше, можно осуществить, не отходя от описанных здесь принципов изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| РЕКОНСТРУКЦИЯ ДОКУМЕНТА ИЗ СЕРИИ ИЗОБРАЖЕНИЙ ДОКУМЕНТА | 2017 |
|
RU2659745C1 |
| СПОСОБ УЛУЧШЕНИЯ КАЧЕСТВА РАСПОЗНАВАНИЯ ОТДЕЛЬНОГО КАДРА | 2017 |
|
RU2657181C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2613849C1 |
| ОБНАРУЖЕНИЕ БЛИКА В КАДРЕ ДАННЫХ ИЗОБРАЖЕНИЯ | 2014 |
|
RU2653461C2 |
| СПОСОБЫ И СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2017 |
|
RU2673016C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2619712C1 |
| СПОСОБЫ И СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2017 |
|
RU2673015C1 |
| УЛУЧШЕНИЕ КОНТРАСТА И СНИЖЕНИЕ ШУМА НА ИЗОБРАЖЕНИЯХ, ПОЛУЧЕННЫХ С КАМЕР | 2017 |
|
RU2721188C2 |
| ВВОД ДАННЫХ ИЗ СЕРИИ ИЗОБРАЖЕНИЙ, СООТВЕТСТВУЮЩИХ ШАБЛОННОМУ ДОКУМЕНТУ | 2016 |
|
RU2634192C1 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |



Группа изобретений относится к технологиям оптического распознавания символов (OCR) кадров видеоматериалов с целью обнаружения в них текстов на естественных языках. Техническим результатом является оптимизация OCR видеоматериалов. Предложен способ проведения оптического распознавания символов (OCR) в кадре видеоматериала. Способ содержит этап, на котором получают первый кадр из видеоматериала посредством аппаратного процессора. Далее выполняют OCR как минимум части первого кадра для генерации данных первого кадра. При этом выполнение OCR как минимум части первого кадра включает обнаружение связных компонент в как минимум части первого кадра для добавления как минимум одного описания связной компоненты к данным первого кадра, а также обнаружение символов-кандидатов в как минимум части первого кадра для добавления как минимум одного описания символа-кандидата к данным первого кадра. Также согласно способу осуществляют обнаружение текстов-кандидатов в как минимум части первого кадра для добавления как минимум одного описания текста-кандидата к данным первого кадра, и обнаружение строк текста в первой части первого кадра для добавления как минимум одного описания строки текста к данным первого кадра. 3 н. и 41 з.п. ф-лы, 9 ил.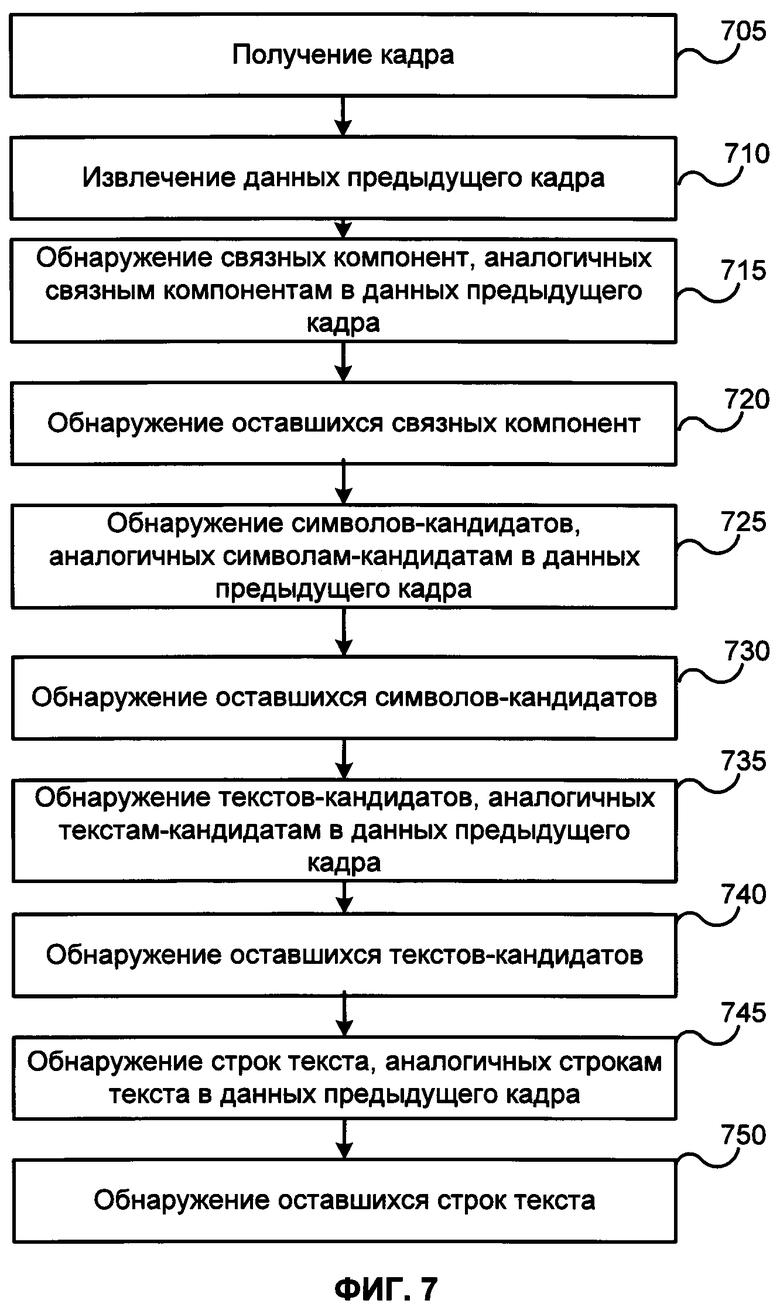
1. Способ проведения оптического распознавания символов (OCR) в кадре видеоматериала, который включает:
получение аппаратным процессором первого кадра из видеоматериала,
выполнение аппаратным процессором OCR как минимум части первого кадра для генерации данных первого кадра, где выполнение OCR как минимум части первого кадра включает как минимум одно из следующих действий:
обнаружение связных компонент в как минимум части первого кадра для добавления как минимум одного описания связной компоненты к данным первого кадра,
обнаружение символов-кандидатов в как минимум части первого кадра для добавления как минимум одного описания символа-кандидата к данным первого кадра,
обнаружение текстов-кандидатов в как минимум части первого кадра для добавления как минимум одного описания текста-кандидата к данным первого кадра, и
обнаружение строк текста в первой части первого кадра для добавления как минимум одного описания строки текста к данным первого кадра, и
сохранение в памяти данных первого кадра, и
получение аппаратным процессором второго кадра из множества кадров видеоматериала, следующих за первым кадром, и
извлечение из памяти данных первого кадра, связанного с видеоматериалом, и
выполнение аппаратным процессором OCR как минимум части второго кадра для обнаружения одной или более текстовых строк, причем выполнение OCR части второго кадра включает как минимум одно из следующих действий:
использование данных первого кадра для обнаружения в части второго кадра как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных первого кадра,
использование как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных первого кадра, для обнаружения в части второго кадра как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных первого кадра,
использование как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных первого кадра, для обнаружения в части второго кадра как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату, описанному в данных первого кадра, и
использование как минимум одного текста-кандидата, аналогичного тексту-кандидату, описанному в данных первого кадра, для обнаружения в тексте второго кадра как минимум одной строки текста, аналогичной как минимум одной строке текста, описанной в данных первого кадра.
2. Способ по п. 1, дополнительно содержащий как минимум один из следующих шагов:
перевод как минимум одной обнаруженной текстовой строки на другой язык и преобразование как минимум одной обнаруженной текстовой строки в речь.
3. Способ по п. 1, где аналогичность включает как минимум один из следующих признаков:
аналогичность положения во втором кадре, аналогичность ориентации во втором кадре, аналогичность формы и аналогичность содержания.
4. Способ по п. 1, где данные первого кадра содержат только данные о небольшой части второго кадра в пределах рассматриваемой части второго кадра.
5. Способ по п. 1, где как минимум одно описание связной компоненты в данных первого кадра содержит:
положение связной компоненты на первом кадре, ориентацию связной компоненты на первом кадре и форму связной компоненты.
6. Способ по п. 1, где как минимум одно описание символа-кандидата в данных первого кадра содержит:
положение символа-кандидата на первом кадре, ориентацию символа-кандидата на первом кадре и форму символа-кандидата.
7. Способ по п. 1, где как минимум одно описание текста-кандидата в данных первого кадра содержит:
положение текста-кандидата на первом кадре, ориентацию текста-кандидата на первом кадре и форму текста-кандидата.
8. Способ по п. 1, где как минимум одно описание строки текста в данных первого кадра содержит:
положение строки текста на первом кадре, ориентацию строки текста на первом кадре и содержание строки текста.
9. Способ по п. 1, где аппаратный процессор, используемый для выполнения OCR части второго кадра и как минимум один аппаратный процессор, используемый для генерации данных первого кадра, являются разными процессорами.
10. Способ по п. 1, где аппаратный процессор, используемый для выполнения OCR части второго кадра и как минимум один аппаратный процессор, используемый для генерации данных первого кадра, являются разными ядрами одного многоядерного процессора.
11. Способ по п. 1, также включающий сохранение в памяти данных нового кадра, содержащих как минимум одну из следующих структур:
как минимум одну обнаруженную связную компоненту, как минимум один обнаруженный символ-кандидат, как минимум один обнаруженный текст-кандидат и как минимум одну обнаруженную строку текста.
12. Способ по п. 1, в котором проведение OCR части второго кадра также включает как минимум одно из следующих действий:
обнаружение в части второго кадра как минимум одной связной компоненты, не аналогичной связным компонентам, описанным в данных первого кадра,
обнаружение в части второго кадра как минимум одного символа-кандидата, не аналогичного символам-кандидатам, описанным в данных первого кадра,
обнаружение в части второго кадра как минимум одного текста-кандидата, не аналогичного текстам-кандидатам, описанным в данных первого кадра, и
обнаружение в части второго кадра как минимум одной строки текста, не аналогичной строкам текста, описанным в данных первого кадра.
13. Система для проведения OCR кадра видеоматериала, которая содержит:
аппаратный процессор, настроенный на получение кадра из видеоматериала;
память, соединенную с процессором и настроенную на хранение данных первого кадра, связанного с видеоматериалом, и
где процессор дополнительно настроен на выполнение механизма OCR для обнаружения одной или более строк текста в как минимум части второго кадра,
при этом механизм OCR включает один или более следующих блоков:
модуль обнаружения связных компонент для использования данных первого кадра для обнаружения в части второго кадра как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных первого кадра;
модуль обнаружения символов-кандидатов для использования как минимум одной связной компоненты, аналогичной связной компоненте, описанной в данных первого кадра, для обнаружения в части второго кадра как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных первого кадра,
модуль обнаружения текстов-кандидатов для использования как минимум одного символа-кандидата, аналогичного символу-кандидату, описанному в данных первого кадра, для обнаружения в части второго кадра как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату, описанному в данных первого кадра,
модуль обнаружения строк текста для использования как минимум одного текста-кандидата, аналогичного тексту-кандидату, описанному в данных первого кадра, для обнаружения в части второго кадра как минимум одной строки текста, аналогичной как минимум одной строке текста, описанной в данных первого кадра.
14. Система по п. 13, где механизм OCR дополнительно настроен для выполнения как минимум одной из следующих операций:
перевода как минимум одной обнаруженной строки текста на другой язык и преобразования как минимум одной обнаруженной строки текста в речь.
15. Система по п. 13, где аналогичность включает как минимум один из следующих признаков:
аналогичность положения во втором кадре, аналогичность ориентации во втором кадре, аналогичность формы и аналогичность содержания.
16. Система по п. 13, где данные первого кадра содержат только данные о небольшой части второго кадра в пределах части второго кадра.
17. Система по п. 13, где как минимум одно описание связной компоненты в данных первого кадра содержит:
положение связной компоненты на первом кадре, ориентацию связной компоненты на первом кадре и форму связной компоненты.
18. Система по п. 13, где как минимум одно описание символа-кандидата в данных первого кадра содержит:
положение символа-кандидата на первом кадре, ориентацию символа-кандидата на первом кадре и форму символа-кандидата.
19. Система по п. 13, где как минимум одно описание текста-кандидата в данных первого кадра содержит:
положение текста-кандидата на первом кадре, ориентацию текста-кандидата на первом кадре и форму текста-кандидата.
20. Система по п. 13, где как минимум одно описание строки текста в данных первого кадра содержит:
положение строки текста на первом кадре, ориентацию строки текста на первом кадре и содержание строки текста.
21. Система по п. 13, где аппаратный процессор, используемый для выполнения OCR части второго кадра и как минимум один аппаратный процессор, используемый для генерации данных первого кадра, являются разными процессорами.
22. Система по п. 13, где аппаратный процессор, используемый для выполнения OCR части второго кадра и как минимум один аппаратный процессор, используемый для генерации данных первого кадра, являются разными ядрами одного многоядерного процессора.
23. Система по п. 13, где механизм OCR также настроен на сохранение в памяти данных нового кадра, содержащих как минимум одну из следующих структур:
как минимум одну обнаруженную связную компоненту, как минимум один обнаруженный символ-кандидат, как минимум один обнаруженный текст-кандидат и как минимум одну обнаруженную строку текста.
24. Система по п. 13, где механизм OCR дополнительно настроен на выполнение как минимум одной из следующих операций:
обнаружение в части второго кадра как минимум одной связной компоненты, не аналогичной связным компонентам, описанным в данных первого кадра,
обнаружение в части второго кадра как минимум одного символа-кандидата, не аналогичного символам-кандидатам, описанным в данных первого кадра,
обнаружение в части второго кадра как минимум одного текста-кандидата, не аналогичного текстам-кандидатам, описанным в данных первого кадра, и
обнаружение в части второго кадра как минимум одной строки текста, не аналогичной строкам текста, описанным в данных первого кадра.
25. Машиночитаемый носитель данных, содержащий исполняемые процессором инструкции для выполнения OCR кадра видеоматериала, включая инструкции для:
получения аппаратным процессором первого кадра из видеоматериала;
выполнения аппаратным процессором OCR как минимум части первого кадра для генерации данных первого кадра, где выполнение OCR как минимум части первого кадра включает как минимум одно из следующих действий:
обнаружение связных компонент в как минимум части первого кадра для добавления как минимум одного описания связной компоненты к данным первого кадра,
обнаружение символов-кандидатов в как минимум части первого кадра для добавления как минимум одного описания символа-кандидата к данным первого кадра,
обнаружение текстов-кандидатов в как минимум части первого кадра для добавления как минимум одного описания текста-кандидата к данным первого кадра, и
обнаружение строк текста в первой части первого кадра для добавления как минимум одного описания строки текста к данным первого кадра, и
сохранение в памяти данных первого кадра и получение аппаратным процессором второго кадра из множества кадров видеоматериала, следующих за первым кадром; и
извлечения из памяти данных первого кадра, связанного с видеоматериалом, и
выполнения аппаратным процессором OCR как минимум части второго кадра для обнаружения одной или более текстовых строк, где выполнение OCR части второго кадра включает как минимум один из следующих пунктов:
использование данных первого кадра для обнаружения в части второго кадра как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных первого кадра,
использование как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, описанной в данных первого кадра, для обнаружения в части второго кадра как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных первого кадра,
использование как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, описанному в данных первого кадра, для обнаружения в части второго кадра как минимум одного текста-кандидата, аналогичного как минимум одному тексту-кандидату, описанному в данных первого кадра, и
использование как минимум одного текста-кандидата, аналогичного тексту-кандидату, описанному в данных первого кадра, для обнаружения в тексте второго кадра как минимум одной строки текста, аналогичной как минимум одной строке текста, описанной в данных первого кадра.
26. Машиночитаемый носитель данных по п. 25, где выполнение OCR части второго кадра также включает как минимум одно из следующих действий:
перевод как минимум одной обнаруженной текстовой строки на другой язык и преобразование как минимум одной обнаруженной текстовой строки в речь.
27. Машиночитаемый носитель данных по п. 25, где аналогичность включает как минимум один из следующих признаков:
аналогичность положения во втором кадре, аналогичность ориентации во втором кадре, аналогичность формы и аналогичность содержания.
28. Машиночитаемый носитель данных по п. 25, где данные первого кадра содержат только данные о небольшой части второго кадра в пределах рассматриваемой части второго кадра.
29. Машиночитаемый носитель данных по п. 25, где как минимум одно описание связной компоненты в данных первого кадра содержит:
положение связной компоненты на первом кадре, ориентацию связной компоненты на первом кадре и форму связной компоненты.
30. Машиночитаемый носитель данных по п. 25, где как минимум одно описание символа-кандидата в данных первого кадра содержит:
положение символа-кандидата на первом кадре, ориентацию символа-кандидата на первом кадре и форму символа-кандидата.
31. Машиночитаемый носитель данных по п. 25, где как минимум одно описание текста-кандидата в данных первого кадра содержит:
положение текста-кандидата на первом кадре, ориентацию текста-кандидата на первом кадре и форму текста-кандидата.
32. Машиночитаемый носитель данных по п. 25, где как минимум одно описание строки текста в данных первого кадра содержит:
положение строки текста на первом кадре, ориентацию строки текста на первом кадре и содержание строки текста.
33. Машиночитаемый носитель данных по п. 25, где аппаратный процессор, используемый для выполнения OCR части второго кадра и как минимум один аппаратный процессор, используемый для генерации данных первого кадра, являются разными процессорами.
34. Машиночитаемый носитель данных по п. 25, где аппаратный процессор, используемый для выполнения OCR части второго кадра и как минимум один аппаратный процессор, используемый для генерации данных первого кадра, являются разными ядрами одного многоядерного процессора.
35. Машиночитаемый носитель данных по п. 25, также включающий сохранение в памяти данных нового кадра, содержащих как минимум одну из следующих структур:
как минимум одну обнаруженную связную компоненту, как минимум один обнаруженный символ-кандидат, как минимум один обнаруженный текст-кандидат и как минимум одну обнаруженную строку символов.
36. Машиночитаемый носитель данных по п. 25, где выполнение OCR части второго кадра также включает как минимум одно из следующих действий:
обнаружение в части второго кадра как минимум одной связной компоненты, не аналогичной связным компонентам, описанным в данных первого кадра,
обнаружение в части второго кадра как минимум одного символа-кандидата, не аналогичного символам-кандидатам, описанным в данных первого кадра,
обнаружение в части второго кадра как минимум одного текста-кандидата, не аналогичного текстам-кандидатам, описанным в данных первого кадра, и
обнаружение в части второго кадра как минимум одной строки текста, не аналогичной строкам текста, описанным в данных первого кадра.
37. Способ проведения оптического распознавания символов (OCR) кадра видеоматериала, который включает:
выполнение аппаратным процессором OCR первой части первого кадра для генерации данных первого кадра, где выполнение OCR первой части первого кадра включает как минимум одно из следующих действий:
обнаружение связных компонент в первой части первого кадра для добавления как минимум одного описания связной компоненты к данным первого кадра,
обнаружение символов-кандидатов в первой части первого кадра для добавления как минимум одного описания символа-кандидата к данным первого кадра,
обнаружение текстов-кандидатов в первой части первого кадра для добавления как минимум одного описания текста-кандидата к данным первого кадра, и
обнаружение строк текста в первой части первого кадра для добавления как минимум одного описания строки текста к данным первого кадра, и
выполнение аппаратным процессором OCR второй части второго кадра, следующего после первого кадра, где выполнение OCR второй части второго кадра включает как минимум одно из действий:
обнаружение связных компонент во второй части второго кадра с использованием данных первого кадра для обнаружения как минимум одной связной компоненты, аналогичной как минимум одной связной компоненте, обнаруженной на первом кадре,
обнаружение символов-кандидатов во второй части второго кадра с использованием данных первого кадра для обнаружения как минимум одного символа-кандидата, аналогичного как минимум одному символу-кандидату, обнаруженному на первом кадре,
обнаружение текстов-кандидатов во второй части второго кадра с использованием данных первого кадра для обнаружения как минимум одного описания текста-кандидата, аналогичного как минимум одному тексту-кандидату, обнаруженному на первом кадре, и
обнаружение строк текста во второй части второго кадра с использованием данных первого кадра для обнаружения как минимум одного описания строки текста,
аналогичной как минимум одной строке текста, обнаруженной на первом кадре; где аналогичность включает как минимум:
аналогичность положения в первом кадре, аналогичность ориентации в первом кадре, аналогичность формы и аналогичность содержания.
38. Способ по п. 37, где вторая часть второго кадра содержит первую часть первого кадра.
39. Способ по п. 37, где как минимум одно описание связной компоненты содержит:
положение связной компоненты на первом кадре, ориентацию связной компоненты на первом кадре и форму связной компоненты.
40. Способ по п. 37, где как минимум одно описание символа-кандидата содержит:
положение символа-кандидата на первом кадре, ориентацию символа-кандидата на первом кадре и форму символа-кандидата.
41. Способ по п. 37, где как минимум одно описание текста-кандидата содержит:
положение текста-кандидата на первом кадре, ориентацию текста-кандидата на первом кадре и форму текста-кандидата.
42. Способ по п. 37, где как минимум одно описание строки текста содержит:
положение строки текста на первом кадре, ориентацию строки текста на первом кадре и содержание строки текста.
43. Способ по п. 37, где аппаратный процессор, используемый для выполнения OCR первой части первого кадра и аппаратный процессор, используемый для выполнения OCR второй части второго кадра, являются различными процессорами.
44. Способ по п. 37, где аппаратный процессор, используемый для выполнения OCR первой части первого кадра и аппаратный процессор, используемый для выполнения OCR второй части второго кадра, являются разными ядрами одного многоядерного процессора.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Роторный автомат сборки крепежа | 1988 |
|
SU1569162A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| RU 2012141988, 10.04.2014. | |||

