ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в целом относится к вычислительным системам и способам, в частности к системам и способам оптического распознавания символов (OCR), включая системы и способы OCR для извлечения информации из структурированных документов (жестких форм).
УРОВЕНЬ ТЕХНИКИ
[002] Оптическое распознавание символов (OCR) представляет собой реализованное вычислительными средствами преобразование изображений текстов (включая типографский, рукописный или печатный текст) в машиночитаемые электронные документы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] Одним из вариантов реализации изобретения является способ, включающий: (а) получение устройством обработки вычислительной системы текущего изображения из серии изображений копии шаблонного документа при этом созданный по шаблону документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле; (b) выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста; (с) определение параметров преобразования координат для преобразования координат текущего изображения в координаты шаблона, при этом шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа; (d) определение в распознанном тексте для текущего изображения в системе координат шаблона, фрагмента текста, который соответствует информационному полю как минимум одного информационного поля; (е) связывание в системе координат шаблона текстового фрагмента, который соответствует информационному полю, с одним или более кластерами последовательностей символов, при этом текстовый фрагмент получен путем обработки текущего изображения, и при этом последовательности символов получены путем обработки ранее полученных изображений из серии изображений; (f) создание для каждого кластера из одного или более кластеров медианной строки, соответствующей кластеру последовательностей символов информационного поля; и (g) создание с помощью медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
[004] Другим вариантом осуществления изобретения является способ, включающий: (а) получение с помощью устройства обработки вычислительной системы текущего изображения из серии изображений копии шаблонного документа при этом текущее изображение по крайней мере частично совпадает с предыдущим изображением из серии изображений, и шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле; (b) выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат для каждого символа распознанного текста; (с) определение параметров преобразования координат для преобразования координат предыдущего изображения в координаты текущего изображения; (d) привязка по крайней мере части распознанного текста к одному или более кластерам последовательностей символов, при этом распознанный текст получен при обработке текущего изображения, и при этом последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений; (е) определение параметров преобразования координат для преобразования координат текущего изображения из серии изображений в координаты шаблона шаблонного документа, и при этом шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа; (f) определение в системе координат шаблона одного или более кластеров последовательностей символов, которые соответствуют информационному полю, как минимум для одного информационного поля; (g) получение для каждого из одного или более кластеров, соответствующих информационному полю, медианной строки, представляющей кластер последовательностей символов информационного поля; и (h) получение с помощью медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля в копии шаблонного документа.
[005] Другим вариантом реализации изобретения является система, включающая: А) память, выполненную с возможностью сохранения шаблона шаблонного документа, который состоит по крайней мере из одного статического элемента и по крайней мере из одного информационного поля, так что шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа; В) устройство обработки, соединенное с памятью, причем устройство обработки выполнено с возможностью: (а) получения текущего изображения из серии изображений копии шаблонного документа; (b) выполнения оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста; (с) определения параметров преобразования координат для преобразования координат текущего изображения в координаты шаблона; (d) определения в распознанном тексте для текущего изображения в системе координат шаблона фрагмента текста, который соответствует информационному полю для как минимум одного информационного поля; (е) привязки в системе координат шаблона фрагмента текста, который соответствует информационному полю, к одному или более кластерам последовательностей символов, где фрагмент текста получен при обработке текущего изображения и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений; (f) создания для каждого кластера из одного или более кластеров медианной строки, представляющей кластер последовательностей символов информационного поля; и (g) создания с помощью медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
[006] Другим вариантом реализации изобретения является система, включающая: А) память, выполненную с возможностью сохранения шаблона шаблонного документа, который состоит по крайней мере из одного статического элемента и по крайней мере из одного информационного поля, так что шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа; В) устройство обработки, соединенное с памятью, причем устройство обработки выполнено с возможностью: (а) получения текущего изображения из серии изображений копии шаблонного документа; (b) выполнения оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат для каждого символа распознанного текста; (с) определения параметров преобразования координат для преобразования координат предыдущего изображения в координаты текущего изображения; (d) привязки по крайней мере части распознанного текста к одному или более кластерами последовательностей символов, где распознанный текст получен путем обработки текущего изображения и где последовательности символов получены путем обработки одного или более ранее полученных изображений в серии изображений; (е) определения параметров преобразования координат для преобразования координат текущего изображения из серии изображений в координаты шаблона; (f) определения в системе координат шаблона одного или более кластеров последовательностей символов, которые соответствуют информационному полю для как минимум одного информационного поля; (g) получения для каждого из одного или более кластеров, соответствующих информационному полю, медианной строки, представляющей кластер последовательностей символов информационного поля; и (h) получения с использованием медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
[007] Еще одним из вариантов осуществления изобретения является машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые при выполнении в обрабатывающем устройстве заставляют это обрабатывающее устройство выполнять операции, включающие: (а) получение устройством обработки вычислительной системы текущего изображения из серии изображений копии шаблонного документа при этом шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле; (b) выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста; (с) определение параметров преобразования координат для преобразования координат текущего изображения в координаты шаблона, при этом шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа; (d) определение в распознанном тексте для текущего изображения в системе координат шаблона фрагмента текста, который соответствует информационному полю как минимум одного информационного поля; (е) связывание в системе координат шаблона фрагмента текста, который соответствует информационному полю, с одним или более кластерами последовательностей символов, при этом фрагмент текста получен путем обработки текущего изображения, и при этом последовательности символов получены путем обработки ранее полученных изображений из серии изображений; (f) создание для каждого кластера из одного или более кластеров медианной строки, соответствующей кластеру последовательностей символов информационного поля; и (g) создание с помощью медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
[008] И еще одним из вариантов осуществления изобретения является машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые при выполнении в обрабатывающем устройстве заставляют это обрабатывающее устройство выполнять операции, включающие: (а) получение текущего изображения серии изображений копии шаблонного документа причем текущее изображение по крайней мере частично совпадает с предыдущим изображением серии изображений, и шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле; (b) выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат для каждого символа распознанного текста; (с) определение параметров преобразования координат для преобразования координат предыдущего изображения в координаты текущего изображения; (d) привязка как минимум части распознанного текста к одному или более кластерам последовательностей символов, причем распознанный текст получен путем обработки текущего изображения, и последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений; (е), определение параметров преобразования координат для преобразования координат текущего изображения из серии изображений в координаты шаблона шаблонного документа при этом шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа; (f) определение в системе координат шаблона одного или более кластеров последовательностей символов, которые соответствуют информационному полю как минимум одного информационного поля; (g) получение для каждого из одного или более кластеров, соответствующих информационному полю, медианной строки, соответствующей кластеру последовательностей символов информационного поля; и (h), получение с использованием медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
ЧЕРТЕЖИ
[009] На Фиг. 1 схематично изображено сопоставление результатов оптического распознавания символов (OCR) для каждого из изображений 102, 104, 106 и 108 серии изображений шаблонного документа с шаблоном 112 шаблонного документа.
[0010] На Фиг. 2 изображена блок-схема одного иллюстративного примера способа автоматизированного извлечения данных из одного или более информационных полей шаблонного документа с использованием серии изображений документа.
[0011] На Фиг. 3 схематично изображено соответствие результатов оптического распознавания символов (OCR) для пар изображений в последовательности изображений шаблонного документа и последующее сопоставление комбинированного результата OCR для последовательности изображений шаблонного документа с шаблоном шаблонного документа.
[0012] На Фиг. 4 изображена блок-схема другого иллюстративного примера способа автоматизированного извлечения данных из одного или более информационных полей шаблонного документа с использованием серии изображений документа.
[0013] На Фиг. 5 схематически изображены водительские права штата Калифорния в качестве иллюстративного примера шаблонного документа, который имеет один или более статических элементов и одно или более информационных полей.
[0014] На Фиг. 6 схематически изображена вычислительная система, которая может использоваться для реализации способов, раскрываемых в настоящем изобретении.
ПОДРОБНОЕ ОПИСАНИЕ
Сопутствующие документы
[0015] Следующие документы, полностью включенные в данный документ посредством ссылок, могут быть полезны для понимания раскрытия настоящего изобретения: а) Патентная заявка США №15/168,548, подана 31 мая 2016 г. и b) Патентная заявка США №15/168,525, подана 31 мая 2016 г.
Раскрытие сущности изобретения
[0016] В этом разделе описаны способы и системы для осуществления оптического распознавания символов (OCR) серии изображений, содержащих символы определенной системы письменности. Системы письменности, символы которых могут быть обработаны с помощью систем и способов, описанных в этом документе, включают алфавиты с отдельными символами, или глифами, соответствующими отдельным звукам, а также иероглифические системы письменности с отдельными символами, соответствующими более крупным блокам, таким как слоги или слова.
[0017] Предлагаемые способы могут быть особенно полезны для оптического распознавания символов в шаблонных документах. В некоторых вариантах реализации изобретения предлагаемые способы позволяют производить автоматический ввод данных из информационных полей физических копий документов, например бумажных копий документов, в информационные системы и (или) базы данных с помощью вычислительных систем, оборудованных или соединенных с камерой. В отдельных вариантах реализации изобретения вычислительная система может представлять собой мобильное устройство, например планшет, сотовый телефон или карманный персональный компьютер, оборудованный камерой. В некоторых вариантах реализации изобретения автоматический ввод данных может производиться в интерактивном режиме. Большинство или все этапы способов настоящего изобретения могут выполняться непосредственно вычислительной системой, например мобильным устройством.
[0018] Существующие способы извлечения данных из бумажных документов, такие как ABBYY FlexiCapture, обычно используют только одно изображение документа. Отдельное изображение может содержать один или более дефектов, таких как цифровой шум, расфокусировка или низкая резкость изображения, блики и т.д., которые обычно вызваны дрожанием камеры, недостаточным освещением, неправильно выбранной выдержкой или диафрагмой и (или) другими условиями и затрудняющими обстоятельствами. По этой причине данные, извлеченные из одиночного изображения документа, могут содержать ошибки оптического распознавания символов. Способы извлечения данных, раскрываемые в настоящем изобретении, используют серию изображений документа. В то время как отдельное изображение в серии может содержать один или более дефектов, в результате чего соответствующие результаты OCR (извлеченные данные) отдельного изображения могут содержать ошибки, комбинированные результаты OCR (извлеченные данные) нескольких изображений серии могут значительно повысить качество извлекаемых данных по сравнению с данными, извлекаемыми из одного изображения документа, благодаря уменьшению или устранению статистических ошибок и фильтрации случайных событий. Таким образом, способы извлечения данных, раскрываемые в настоящем изобретении, исключительно шумоустойчивы, поскольку случайные ошибки при распознавании отдельных символов документа, которые могут быть при обработке отдельных изображений, не повлияют на итоговый результат оптического распознавания символов и (или) извлечения данных.
[0019] В некоторых вариантах реализации изобретения с точки зрения пользователя процесс получения данных из документа выглядит следующим образом. Пользователь может запустить приложение, в основе которого лежит один из раскрываемых способов, на вычислительной системе, например на мобильном устройстве, и активировать режим приложения, который может запустить процесс получения серии изображений документа с помощью камеры, которая является неотъемлемой частью вычислительной системы или подключена к вычислительной системе. Во многих вариантах реализации раскрываемого способа вычислительная система, такая как мобильное устройство, не сохраняет полученные изображения в своей памяти. Активация режима может инициировать получение и обработку изображений серии процессором вычислительной системы, например мобильного устройства. В некоторых вариантах реализации изобретения пользователь может выбрать сканируемую часть документа, наводя на эту часть документа перекрестье видоискателя, который может быть виден на экране вычислительной системы. Например, пользователь может установить перекрестье видоискателя, видимое на экране мобильного устройства, на нужную часть документа. Отдельные изображения серии не обязательно должны содержать весь документ. Таким образом, в некоторых вариантах реализации изобретения как минимум некоторые отдельные изображения серии могут содержать только части документа, частично перекрывающие друг друга. В некоторых вариантах реализации изобретения камера может двигаться над документом, сканируя его. Рекомендуется, чтобы при таком сканировании захватывались все фрагменты или части документа. Во многих вариантах реализации изобретения такое сканирование выполняется пользователем вручную. Процессор, выполняющий один из способов настоящего изобретения, может определять соответствующие информационные поля, из которых следует получить или извлечь данные/информацию/текст с помощью оптического распознавания символов, в каждом из полученных изображений серии на постоянной основе. В интерфейсе приложения результат такого определения может быть показан следующим образом: процессор, выполняющий один из способов раскрываемого изобретения, может обмениваться информацией с экраном или дисплеем вычислительной системы, выделяя на экране или дисплее отдельные фрагменты изображения, на которых были определены информационные поля, и демонстрировать пользователю полученные или извлеченные данные/информацию/текст для подтверждения верности данных. Процессор также может предоставлять пользователю на экране или дисплее указания о том, в каком направлении следует перемещать камеру для получения следующих изображений.
[0020] Термин «шаблонный документ» может относиться к документу, который включает шаблон или разметку, не изменяющиеся для отдельных документов, относящихся к определенному типу шаблонных документов. Примеры шаблонных документов включают, но не ограничиваются, формы для заполнения, анкеты, счета-фактуры и документы, удостоверяющие личность, такие как паспорта и водительские права. Шаблонные документы обычно содержат одно или более информационных полей. Количество информационных полей, их дизайн и положение неизменны для отдельных документов, относящихся к одному типу шаблонных документов.
[0021] В некоторых вариантах реализации изобретения шаблонный документ может иметь не менее одного статического элемента и не менее одного информационного поля. Термин «статический элемент» относится к элементу, который остается одинаковым как по содержанию, так и по положению, для всех отдельных документов, которые относятся к конкретному типу шаблонного документа. Термин «информационное поле» относится к полю, которое содержит различную информацию для каждого отдельного документа, который относится к конкретному типу шаблонного документа. На Фиг. 5 в качестве примера шаблонного документа приведены водительские права штата Калифорния. На Фиг. 5 элементы 512, 514 и 516 являются статическими, они присутствуют на всех водительских правах штата Калифорния, использующих этот шаблон. С другой стороны, элементы 502, 504 и 506 представляют информационные поля, они содержат информацию, которая является индивидуальной для каждых конкретных водительских прав. В некоторых вариантах реализации изобретения информационное поле может иметь соответствующий ему статический элемент, который может, например, определять тип информации, представленной в этом информационном поле. Например, на Фиг. 5 каждое из информационных полей 502, 504 и 506 имеет соответствующий статический элемент (512, 514, 516 соответственно). В некоторых вариантах реализации изобретения информационное поле может не иметь соответствующего статического элемента. На Фиг. 5 примером такого информационного поля является запись о домашнем адресе.
[0022] Раскрываемые в этом изобретении способы могут использовать шаблон шаблонного документа. Использование шаблона может позволить автоматически определить, относится ли обрабатываемый документ к известному типу шаблонных документов для этого шаблон сохраняется в памяти вычислительной системы, например мобильного устройства. Использование шаблона также может позволить определить положение текущего изображения (из серии изображений) шаблонного документа относительно шаблона шаблонного документа в ситуации, когда текущее изображение содержит только часть или фрагмент шаблонного документа.
[0023] Шаблон шаблонного документа может содержать: а) информацию, например текст и информацию о положении, например координаты одного или более статических элементов документа, и b) информацию о положении, например координаты, одного или более информационных полей документа. Рекомендуется, чтобы шаблон содержал информацию о текстовом содержимом и координатах всех статических элементов документа, а также о координатах всех информационных полей. Рекомендуется, чтобы шаблон представлял собой не изображение части документа, а изображение всего документа.
[0024] Шаблон шаблонного документа можно получить различными способами. Например, шаблон шаблонного документа можно подготовить из электронной версии шаблонного документа. Если электронная версия шаблонного документа недоступна, шаблон можно подготовить с помощью методов оптического распознавания символов из физической копии, например бумажной копии шаблонного документа. Копия шаблонного документа для шаблона может быть пустой копией шаблонного документа, то есть копией шаблонного документа с незаполненными (не содержащими текста/информации) информационными полями, или заполненной копией шаблонного документа, то есть копией шаблонного документа с заполненными (содержащими текст/информацию) информационными полями. В некоторых вариантах реализации изобретения получение шаблона шаблонного документа из физической копии шаблонного документа может включать: а) получение копии всего шаблонного документа; b) выполнение оптического распознавания символов (OCR) полученного изображения для получения результатов OCR, которые включают распознанный текст и соответствующую информацию о разметке, включая координаты каждого символа и группы символов в распознанном тексте; с) определение из результатов OCR координат одного или более информационных полей шаблонного документа. Определение в пункте с) может включать идентификацию одного или более информационных полей в результатах OCR. В некоторых вариантах реализации изобретения подобная идентификация может выполняться вручную. Идентифицированным полям может быть назначена соответствующая идентификация. Например, на Фиг. 5 полям 502, 504 и 506 может быть назначена идентификация «номер водительских прав», «фамилия» и «имя» соответственно. Для каждого нового типа шаблонных документов шаблон можно получить из первого изображения копии шаблонного документа, которая обработана в вычислительной системе.
Способ один
[0025] В одном из вариантов реализации изобретения способ OCR может включать а) сравнение каждого изображения из серии изображений копии шаблонного документа с шаблоном шаблонного документа для обнаружения стека данных (кластера последовательностей символов), который соответствует определенному информационному полю шаблонного документа; и b) определение наилучшего (наиболее точного) результата OCR в серии изображений с использованием медианной строки и медианной перестановки кластеров последовательностей символов, собранных из разных изображений серии, для определенного информационного поля шаблонного документа.
[0026] На Фиг. 1 схематично изображено сопоставление или сравнение каждого изображения 102, 104, 106 и 108 из серии изображений копии шаблонного документа с шаблоном 112 шаблонного документа. Для каждого изображения из серии оптическое распознавание символов (OCR) может предоставить распознанный текст и соответствующую ему разметку, включая координаты каждого символа распознанного текста. На Фиг. 1 элемент 132 иллюстрирует распознанный текст с изображения 102. Шаблон может содержать следующую информацию: текст, который соответствует одному или более статическим элементам, таким как заголовок документа, названия соответствующих информационных полей, примеры заполнения информационных полей и т д., координаты каждого символа одного или более статических элементов и координаты одного или более информационных полей. На Фиг. 1 на шаблоне 112 элементы 142 соответствуют статическим элементам, а элемент 144 соответствует информационному полю. Сопоставление или сравнение изображения из серии с шаблоном может включать проективное преобразование для пары «каждое изображение из серии/шаблон». На Фиг. 1 показано такое проективное преобразование как элементы 122, 124, 126 и 128.
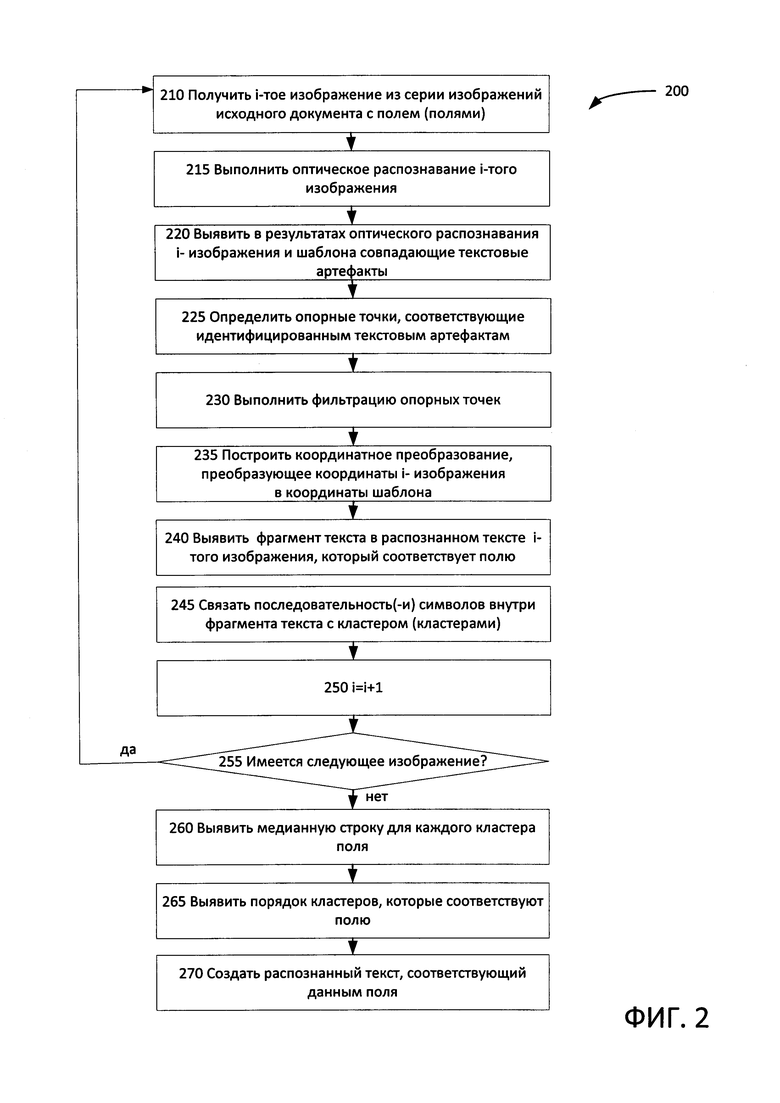
[0027] На Фиг. 2 приведена блок-схема одного иллюстративного примера способа оптического распознавания символов для серии изображений шаблонного документа. Способ и (или) каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться одним или более процессорами компьютерной системы, выполняющей этот способ. В некоторых вариантах реализации способ 200 может выполняться в одном потоке обработки. Кроме того, способ 200 может выполняться с использованием двух или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В качестве иллюстративного примера потоки обработки, реализующие способ 200, могут быть синхронизованы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы реализующие способ 200 потоки обработки могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то, что Фиг. 2 и соответствующее описание содержат список операций для способа 200 в определенном порядке, в различных вариантах реализации способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[0028] Для ясности и краткости настоящее описание предполагает, что обработка каждого изображения шаблонного документа начинается после получения изображения вычислительной системой, реализующей способ, и что эта обработка в значительной степени завершается до получения следующего изображения. Однако в различных альтернативных реализациях изобретения обработка последовательных изображений может совпадать по времени (например, может выполняться в различных потоках или процессах, которые выполняются на одном или более процессорах). Кроме того, два или более изображений могут быть помещены в буфер и обрабатываться асинхронно с учетом получения других изображений из множества изображений, поступающих в вычислительную систему, реализующую способ.
[0029] В некоторых вариантах реализации изобретения два последовательных изображения серии могут не перекрываться.
[0030] Кроме того, в некоторых вариантах реализации изобретения два последовательных изображения из серии могут пересекаться по крайней мере частично.
[0031] В некоторых вариантах реализации изобретения изображения из серии могут отображать по крайней мере частично перекрывающиеся фрагменты документа и отличаться масштабом изображения, углом съемки, выдержкой, диафрагмой, яркостью изображения, наличием бликов, присутствием внешних объектов, которые по крайней мере частично закрывают оригинальный текст, и (или) другими особенностями изображения, визуальными артефактами и параметрами процесса визуализации.
[0032] Изображение, называемое далее в тексте «текущим изображением», на Фиг. 2 отмечено как «i-тое изображение».
[0033] На шаге 210 вычислительная система реализует способ, которым можно получить текущее изображение (из серии изображений) копии шаблонных документов. Текущее изображение может быть, например, получено с помощью камеры. В некоторых вариантах реализации изобретения камера может быть неотъемлемой частью вычислительной системы. В других вариантах реализации изобретения камера может быть отдельным устройством, выполненным с возможностью передачи изображений в вычислительную систему.
[0034] На шаге 215 вычислительная система может выполнять распознавание текущего изображения, что позволит получить результаты OCR, т.е. распознанный текст (текст OCR) и соответствующую информацию о разметке, которая может содержать координаты каждого символа распознанного текста. Информация о разметке может связывать один или более символов распознанного текста и (или) одну или более групп символов распознанного текста.
[0035] На шаге 220 вычислительная система может определить один или более совпадающих текстовых артефактов, например один или более символов и одну или более групп символов, в результатах OCR текущего изображения и шаблона шаблонного документа, который может храниться в памяти вычислительной системы. Текстовые артефакты могут быть представлены последовательностью символов (например, словами), имеющими низкую частоту появления в текстах, полученных в результате OCR (например, частоту, не превышающую определенного порога частоты, который может быть установлен равным 1 для указания на уникальную последовательность символов). В иллюстративном примере редко встречающееся слово может быть определено путем сортировки слов, полученных в результате OCR в зависимости от частоты и выбора наиболее редко встречающихся слов. В некоторых реализациях способа могут использоваться только последовательности символов, длина которых превышает определенный порог длины, потому что более короткие последовательности символов создают менее надежные опорные точки.
[0036] На шаге 225 вычислительная система может использовать информацию о разметке, привязанную к идентифицированным текстовым артефактам, чтобы распознать по крайней мере одну опорную точку, относящуюся к каждому текстовому артефакту, в пределах пары «каждое изображение из серии/шаблон». В иллюстративном примере опорная точка, привязанная к идентифицированной последовательности символов, может быть представлена центром минимального описывающего прямоугольника последовательности символов. В другом иллюстративном примере две или более опорные точки, привязанные к идентифицированной последовательности символов, могут быть представлены углами минимального описывающего прямоугольника последовательности символов.
[0037] На шаге 230 вычислительная система может проверить идентифицированные опорные точки и отбросить по крайней мере некоторые из них, используя выбранные критерии фильтрации. Фильтрация опорных точек раскрыта, например, в заявках на патенты США №№15/168,548 и 15/168,525, включая Фиг. 2А-2В, 3 и 4, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0038] На шаге 235 вычислительная система может выполнить преобразование координат, преобразующее координаты текущего изображения в координаты шаблона. Описанный в настоящем документе способ предполагает, что как минимум для выбранных пар «каждое изображение из серии/шаблон» координаты произвольной выбранной точки на первом изображении могут быть получены применением проективного преобразования к координатам той же точки на втором изображении.
[0039] Под «проективным преобразованием» здесь подразумевается преобразование, переводящее линии в линии, но не обязательно сохраняя параллельность. Проективное преобразование может быть описано следующими уравнениями:
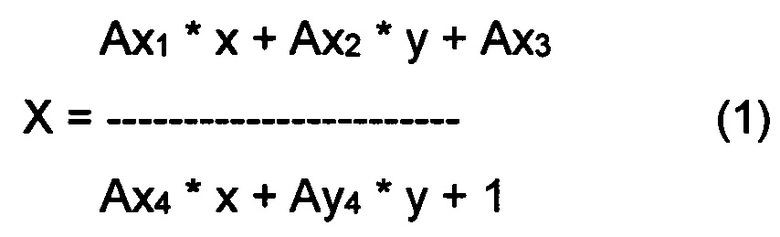
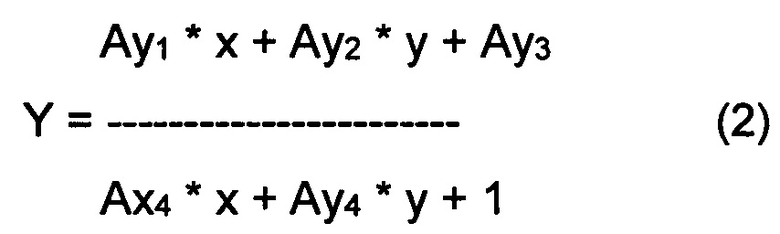
где (x, y) и (X, Y) представляют собой координаты случайно выбранной точки на первом изображении (текущем изображении) и втором изображении (шаблоне) соответственно. Коэффициенты преобразования Ax1, Ах2, Ах3, Ах4, Ay1, Аy2, Аy3 и Аy4 могут определяться, исходя из известных координат не менее чем четырех опорных точек на каждом из двух изображений, которые должны создавать систему из восьми уравнений с восемью неизвестными. После определения коэффициентов преобразования уравнения (1) и (2) можно применить к координатам случайно выбранной точки первого изображения, чтобы получить координаты той же точки на втором изображении.
[0040] В некоторых реализациях настоящего изобретения в ходе операций, относящихся к шагам 225-230, для данной пары «каждое изображение из серии/шаблон» могут быть определены более чем четыре пары опорных точек, в этом случае определенная с избыточностью система может быть решена методами регрессионного анализа, такими как метод наименьших квадратов. Преобразование координат между изображениями с использованием опорных точек раскрыто, например, в заявках на патенты США №№15/168,548 и 15/168,525, включая Фиг. 5А, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0041] На шаге 240 вычислительная система может накладывать шаблон на текущее изображение (преобразуя его в координаты шаблона), чтобы идентифицировать один или более текстовых фрагментов, которые соответствуют одному или более информационным полям шаблонного документа. Таким образом, вычислительная система может отбросить статическую часть (т.е. часть, которая соответствует одному или более статическим элементам шаблонного документа) текущего изображения, и формируя из части фрагмента текста, которая соответствует одному или более информационным полям текущего изображения, стек данных, который может содержать одну или более последовательностей символов, таких как слово.
[0042] На шаге 245 компьютер может привязать одну или более последовательностей символов, например слов, в части текстового фрагмента, которые соответствуют одному или более информационным полям текущего изображения, к кластеру совпадающих последовательностей символов, полученных с помощью OCR ранее обработанных изображений. Связывание последовательности символов с кластером совпадающих последовательностей символов раскрывается, например, в заявках на патенты США №№15/168,548 и 15/168,525, см., например, Фиг. 5А-5В, 6, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки. В предпочтительном варианте реализации изобретения вычислительная система может привязать одну или более последовательностей символов, например слов, в части текстового фрагмента, которые соответствуют одному или более информационным полям текущего изображения, к кластеру совпадающих последовательностей символов, полученных с помощью OCR ранее обработанных изображений.
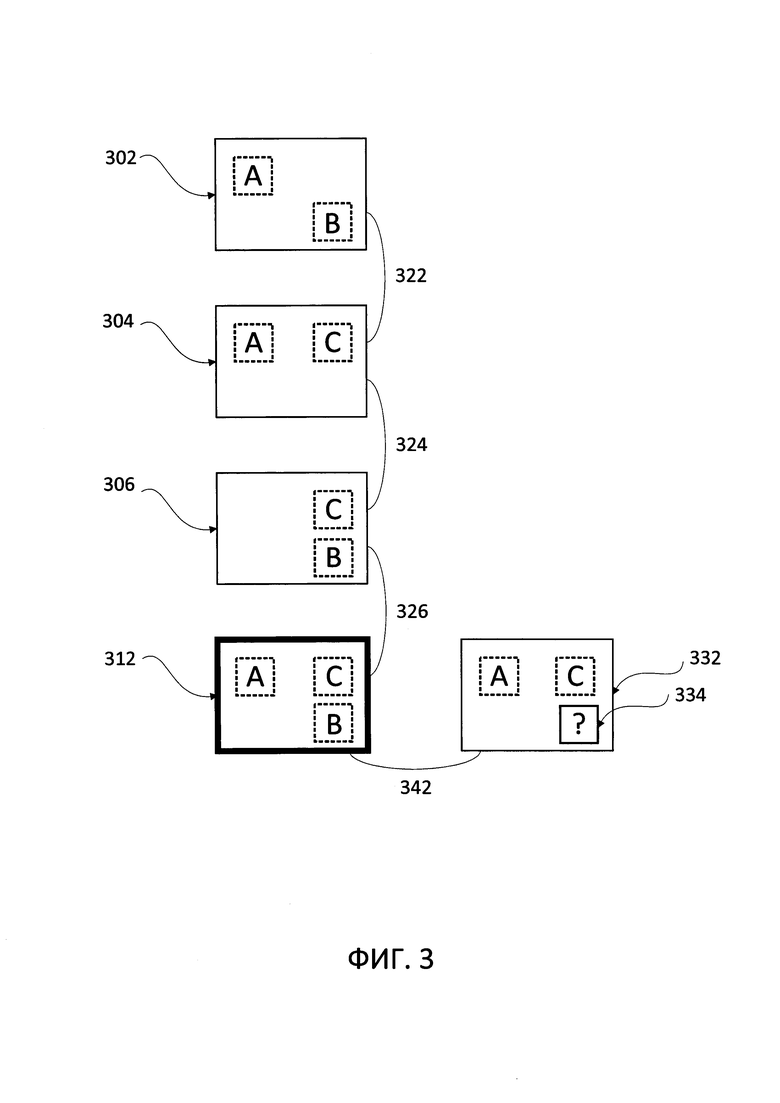
[0043] На шаге 250 вычислительная система может увеличить счетчик для текущего изображения в серии изображений. Операции, происходящие на шаге 250, представлены на Фиг. 2 для улучшения читаемости соответствующего описания и в некоторых вариантах реализации способа могут быть опущены.
[0044] На шаге 255 вычислительная система может определить наличие следующего изображения в серии изображений. Если оно имеется, способ может вернуться назад к шагу 210.
[0045] На шаге 260 вычислительная система может определить для кластера совпадающих последовательностей символов медианную строку, которая соответствует информационному полю обработанной копии шаблонного документа такую, что эта медианная строка представляет результаты OCR серии изображений обработанной копии шаблонного документа для фрагмента документа, который соответствует информационному полю. Определение медианной строки для кластеров совпадающих символьных последовательностей раскрывается, например, в заявках на патенты США №№15/168,548 и 15/168,525, см., например, Фиг. 7А-С, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки. Рекомендуется, чтобы вычислительная система идентифицировала медианную строку для каждого кластера совпадающих последовательностей символов, который соответствует отдельному информационному полю обработанной копии шаблонного документа, выполняя эту операцию для каждого информационного поля шаблонного документа.
[0046] Если отдельное информационное поле содержит несколько, т.е. более одной, последовательностей символов, таких как слова (например, информационное поле домашнего адреса может состоять из нескольких слов), то затем на шаге 265 вычислительная система может определять порядок, в котором последовательности символов, соответствующие вышеупомянутым кластерам (медианные строки кластеров), должны появиться в итоговом тексте, который соответствует информационному полю. Например, изображения, соответствующие исходному документу, могут отображать по крайней мере частично перекрывающиеся фрагменты документа и отличаться масштабом изображения, углом съемки, выдержкой, диафрагмой, яркостью изображения, наличием бликов, присутствием внешних объектов, которые по крайней мере частично закрывают оригинальный текст, и (или) другими особенностями изображения, визуальными артефактами и параметрами процесса визуализации. Таким образом, тексты, созданные при OCR каждого отдельного изображения, могут отличаться одним или более имеющимися или отсутствующими словами в каждом результате OCR, вариациями в последовательностях символов, представляющих слова исходного текста, и/или порядком последовательностей символов.
[0047] В некоторых реализациях изобретения вычислительная система может сравнивать множество перестановок последовательностей символов, которые соответствуют обнаруженным кластерам. Медианная перестановка может быть определена как перестановка, имеющая минимальную сумму тау-расстояний Кендалла по сравнению со всеми другими перестановками. Тау-расстояние Кендалла между первой и второй перестановками может быть равно минимальному числу операций обмена в алгоритме пузырьковой сортировки для преобразования первой перестановки во вторую перестановку. Определение порядка кластеров раскрыто, например, в заявках на патенты США №№15/168,548 и 15/168,525, которые полностью включены в настоящий документ с помощью ссылки.
[0048] В различных реализациях настоящего изобретения операции, описанные на шаге 260 и 265, могут выполняться в обратной последовательности или параллельно. Кроме того, в некоторых реализациях настоящего изобретения некоторые операции, описанные на шаге 260 и (или) 265, могут быть пропущены.
[0049] На шаге 270 вычислительная система может создать итоговый распознанный текст, соответствующий определенному информационному полю шаблонного документа. В предпочтительном варианте реализации изобретения вычислительная система создает итоговый распознанный текст для каждого информационного поля шаблонного документа. Если отдельное информационное поле содержит только одну последовательность символов, например слово, вычислительная система может создать итоговый распознанный текст для такого поля непосредственно из медианной строки, определенной на шаге 260. Если отдельное информационное поле содержит несколько, т.е. более одной, последовательностей символов, например слов, вычислительная система может создать итоговый распознанный текст для такого поля после идентификации порядка соответствующих последовательностей символов на шаге 265.
Способ два
[0050] В другом варианте реализации изобретения способ OCR может включать а) сравнение или сопоставление результатов OCR для серии изображений копии шаблонного документа для получения выровненного стека результатов OCR для серии и b) сравнение или сопоставление выровненного стека результатов OCR для серии в координатах последнего изображения серии с шаблоном шаблонного документа (наложение шаблона) и определение лучшего (наиболее точного) результата OCR серии изображений с использованием медианной строки и медианной перестановки для каждого информационного поля шаблонного документа.
[0051] На Фиг. 3 приведена схематичная иллюстрация серии изображений 302, 304 и 306 копии шаблонного документа. Результаты OCR для изображения 304 сравниваются/сопоставляются (322) с результатами OCR изображения 302, а результаты OCR для изображения 306 сравниваются/сопоставляются (324) с результатами OCR изображения 304. В результате этого сравнения/сопоставления получен выровненный стек 312. Выровненный стек 312 сравнивается/ сопоставляется (342) с шаблоном 332 шаблонного документа для определения лучшего (самого точного) OCR результата серии изображений, используя медианную строку, медианную перестановку для информационного поля В (334) шаблонного документа.
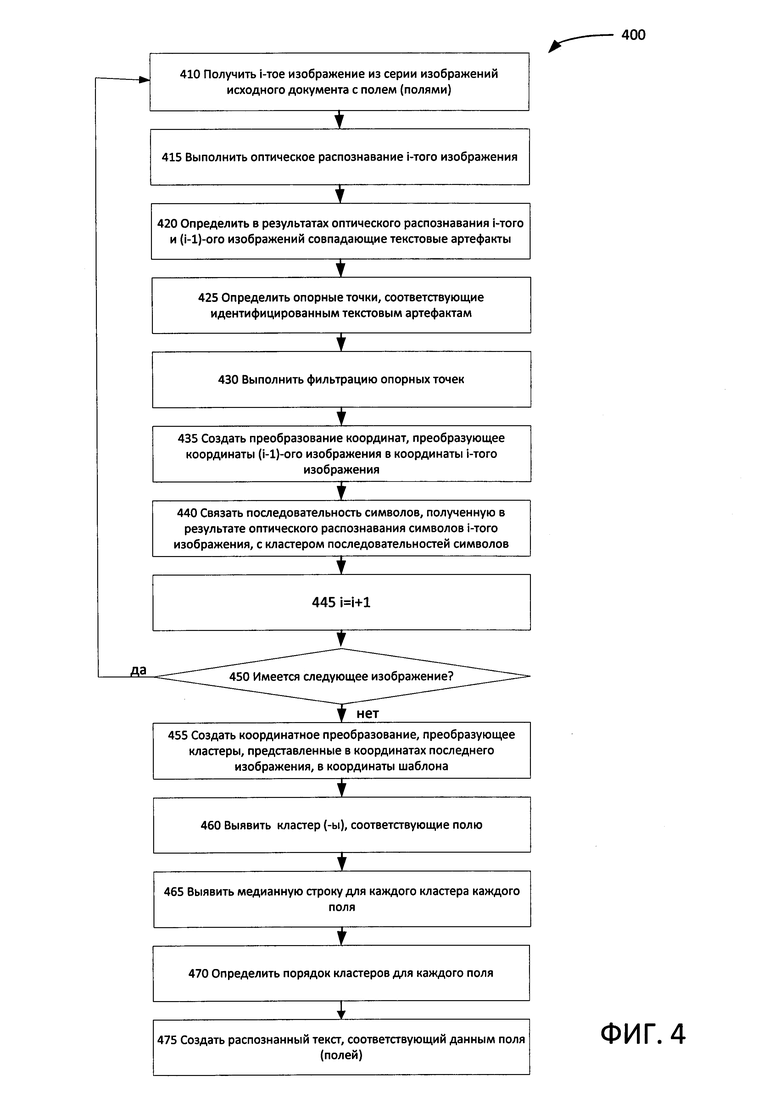
[0052] На Фиг. 4 приведена блок-схема другого иллюстрирующего примера способа оптического распознавания символов для серии изображений шаблонного документа. Способ и (или) каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться одним или более процессорами компьютерной системы, выполняющей этот способ. В некоторых вариантах реализации способ 400 может выполняться в одном потоке обработки. Кроме того, способ 400 может выполняться в двух или более потоках обработки, при этом в каждом потоке будет выполняться одна или более отдельных функций, процедур, подпрограмм или операций способа. В иллюстрирующем примере процессы обработки, реализующие способ 400, могут быть синхронизированы (например, с помощью семафоров, критических секций и/или других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, реализующие способ 400, могут выполняться асинхронно по отношению друг к другу. Поэтому, хотя Фиг. 4 и соответствующее описание содержат операции способа 400 в определенном порядке, различные реализации способа могут выполняться (по крайней мере некоторые из перечисленных операций) параллельно и (или) в произвольно выбранном порядке.
[0053] Для ясности и краткости настоящее описание предполагает, что обработка каждого изображения шаблонного документа начинается после получения изображения вычислительной системой, реализующей способ, и что эта обработка в значительной степени завершается до получения следующего изображения. Однако в различных альтернативных реализациях изобретения обработка последовательных изображений может совпадать по времени (например, может выполняться в различных потоках или процессах, которые выполняются на одном или более процессорах). Кроме того, два или более изображений могут быть помещены в буфер и обрабатываться асинхронно с учетом получения других изображений из множества изображений, поступающих в вычислительную систему, реализующую способ.
[0054] В некоторых вариантах реализации изобретения изображения из серии могут отображать по крайней мере частично перекрывающиеся фрагменты документа и отличаться масштабом изображения, углом съемки, выдержкой, диафрагмой, яркостью изображения, наличием бликов, присутствием внешних объектов, которые по крайней мере частично закрывают оригинальный текст, и (или) другими особенностями изображения, визуальными артефактами и параметрами процесса визуализации. Два изображения по отдельности именуются в настоящем документе «текущим изображением» (также называется «i-тым изображением» на Фиг. 4) и «предыдущим изображением» (также называется «(i-1)-тым изображением» на Фиг. 4).
[0055] В целом шаги 410-450 в основном идентичны шагам 110-150, которые раскрыты в заявках на патенты США №№15/168,548 и 15/168,525, см. Фиг. 1, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0056] На шаге 410 вычислительная система реализующая способ может получить текущее изображение из серии изображений копии шаблонного документа. Шаблонный документ может содержать один или более статических элементов и одно или более информационных полей. Текущее изображение может быть, например, получено с помощью камеры. В некоторых вариантах реализации изобретения камера может быть неотъемлемой частью вычислительной системы. В других вариантах реализации изобретения камера может быть отдельным устройством, выполненным с возможностью передачи полученных изображений в вычислительную систему.
[0057] На шаге 415 вычислительная система может выполнять распознавание текущего изображения, что позволит получить результаты OCR, т.е. распознанный текст (текст OCR) и соответствующую информацию о разметке, которая может содержать координаты каждого символа распознанного текста.
[0058] На шаге 420 вычислительная система может определить совпадающие текстовые артефакты в результатах OCR, соответствующих паре изображений, которыми могут быть, например, текущее и предыдущее изображения. Текстовые артефакты могут быть представлены последовательностью символов (например, словами), имеющими низкую частоту появления в текстах, полученных в результате OCR (например, частоту, не превышающую определенного порога частоты, который может быть установлен равным 1 для указания на уникальную последовательность символов). В иллюстративном примере редко встречающееся слово может быть определено путем сортировки слов, полученных в результате OCR в зависимости от частоты и выбора наиболее редко встречающихся слов. В некоторых реализациях способа могут использоваться только последовательности символов, длина которых превышает определенный порог длины, потому что более короткие последовательности символов создают менее надежные опорные точки.
[0059] На шаге 425 вычислительная система может использовать информацию о разметке, такую как координаты, привязанную к идентифицированным текстовым артефактам, чтобы распознать по крайней мере одну опорную точку, относящуюся к каждому текстовому артефакту для каждого изображения из пары изображений. В иллюстративном примере опорная точка, привязанная к идентифицированной последовательности символов, может быть представлена центром минимального прямоугольника, описывающего последовательность символов. В другом иллюстративном примере две или более опорных точек, привязанные к идентифицированной последовательности символов, могут быть представлены углами минимального прямоугольника, описывающего последовательность символов.
[0060] На шаге 430 вычислительная система может проверить идентифицированные опорные точки и отбросить по крайней мере некоторые из них, используя выбранные критерии фильтрации. В иллюстративном примере вычислительная система может убедиться, что произвольно выбранные группы совпадающих опорных точек имеют некоторые геометрические особенности, которые инвариантны для выбранных изображений. Фильтрация опорных точек раскрыта, например, в заявках на патенты США №№15/168,548 и 15/168,525, включая Фиг. 2А-2В, 3 и 4, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0061] На шаге 435 вычислительная система может создавать преобразование координат, преобразующее координаты одного изображения в паре изображений в координаты второго изображения в паре изображений. Описанный в настоящем документе способ предполагает, что как минимум для выбранных пар изображений координаты произвольной выбранной точки на первом изображении могут быть получены применением проективного преобразования к координатам той же точки на втором изображении.
[0062] Рекомендуется, чтобы вычислительная система создавала преобразование координат, преобразуя координаты предыдущего изображения в координаты текущего изображения.
[0063] Под «проективным преобразованием» здесь подразумевается преобразование, переводящее линии в линии, но не обязательно сохраняя параллельность. Проективное преобразование может быть описано следующими уравнениями:

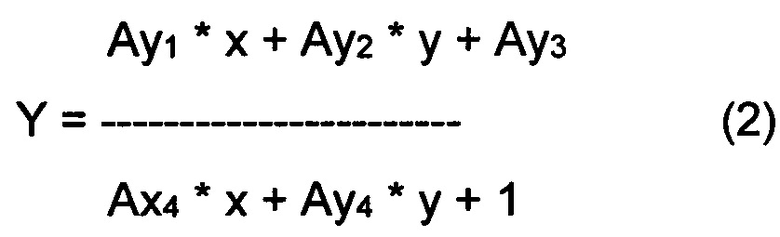
где (x, y) и (X, Y) представляют собой координаты случайно выбранной точки на первом изображении и втором изображении соответственно. Коэффициенты преобразования Ax1, Ах2, Ах3, Ах4, Ay1, Аy2, Аy3 и Ay4 могут определяться, исходя из известных координат не менее чем четырех опорных точек на каждом из двух изображений, которые должны создавать систему из восьми уравнений с восемью неизвестными. После определения коэффициентов преобразования уравнения (1) и (2) можно применить к координатам случайно выбранной точки первого изображения, чтобы получить координаты той же точки на втором изображении.
[0064] В некоторых реализациях настоящего изобретения в ходе операций, относящихся к шагам 425-430, для данной пары каждого изображения могут быть определены более чем четыре пары опорных точек, в этом случае чрезмерно определенная система может быть решена методами регрессионного анализа, такими как метод наименьших квадратов.
[0065] Преобразование координат раскрыто, например, в заявках на патенты США №№15/168,548 и 15/168,525, включая Фиг. 5А, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0066] На шаге 440 вычислительная система может связывать одну или более последовательностей символов, полученных с помощью OCR текущего изображения, с одним или более кластерами совпадающих последовательностей символов, полученных при OCR ранее обработанных изображений. Вычислительная система может использовать преобразования координат, указанные выше, чтобы сравнить положения распознанной последовательности символов на текущем и предыдущем изображении и таким образом определить группы последовательностей символов, которые, вероятно, представляют собой один и тот же фрагмент оригинального документа. Связывание последовательности символов с кластером совпадающих последовательностей символов раскрывается, например, в заявках на патенты США №№15/168,548 и 15/168,525, включая Фиг. 5А-5В, 6, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0067] На шаге 445 вычислительная система может увеличить счетчик для текущего изображения в серии изображений. Следует заметить, что операции, происходящие на шаге 445, представлены на Фиг. 4 для улучшения читаемости соответствующего описания и в некоторых вариантах реализации способа могут быть опущены.
[0068] На шаге 450 вычислительная система может определить, существует ли следующее изображение; если это так, способ возвращается обратно к шагу 410.
[0069] На шаге 455 вычислительная система может выполнять преобразование координат, трансформирующее координаты последнего изображения в паре изображений в координаты шаблона шаблонного документа. Такое преобразование трансформирует один или более кластеров соответствующих последовательностей символов, которые были получены путем обработки всех изображений серии, в координаты шаблона.
[0070] Преобразование координат на шаге 455 может производиться аналогично преобразованию координат на шаге 435.
[0071] На шаге 460 вычислительная система может идентифицировать кластер последовательностей символов, который соответствует конкретному информационному полю в обработанной копии шаблонного документа из одного или более кластеров совпадающих последовательностей символов путем сравнения одного или более кластеров в координатах шаблона с самим шаблоном.
[0072] На шаге 465 вычислительная система может определить медианную строку для кластера последовательностей символов, которая соответствует отдельному информационному полю обработанной копии шаблонного документа такую, что медианная строка представляет результаты OCR фрагмента текущего изображения, который соответствует информационному полю. Определение медианной строки для кластеров последовательностей символов раскрывается, например, в заявках на патенты США №№15/168,548 и 15/168,525, см., например, Фиг. 7А-С, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки. Рекомендуется, чтобы вычислительная система идентифицировала медианную строку для каждого кластера совпадающих последовательностей символов, который соответствует отдельному информационному полю обработанной копии шаблонного документа, выполняя эту операцию для каждого информационного поля шаблонного документа.
[0073] Если отдельное информационное поле содержит несколько, т.е. более одной, последовательности символов, таких как слова (например, информационное поле домашнего адреса может состоять из нескольких слов), то затем на шаге 470 вычислительная система может определять порядок, в котором последовательности символов, соответствующие вышеупомянутым кластерам (медианные строки кластеров), должны появиться в итоговом тексте, который соответствует информационному полю. Например, изображения, соответствующие исходному документу, могут отображать по крайней мере частично перекрывающиеся фрагменты документа и отличаться масштабом изображения, углом съемки, выдержкой, диафрагмой, яркостью изображения, наличием бликов, присутствием внешних объектов, которые по крайней мере частично закрывают оригинальный текст, и (или) другими особенностями изображения, визуальными артефактами и параметрами процесса визуализации. Таким образом, тексты, созданные при OCR каждого отдельного изображения, могут отличаться одним либо более имеющимися или отсутствующими словами в каждом результате OCR, вариациями в последовательностях символов, представляющих слова исходного текста, и/или порядком последовательностей символов.
[0074] В некоторых реализациях изобретения вычислительная система может сравнивать множество перестановок последовательностей символов, которые соответствуют обнаруженным кластерам. Медианная перестановка может быть определена как перестановка, имеющая минимальную сумму тау-расстояний Кендалла по сравнению со всеми другими перестановками. Тау-расстояние Кендалла между первой и второй перестановками может быть равно минимальному числу операций обмена в алгоритме пузырьковой сортировки для преобразования первой перестановки во вторую перестановку символов. Определение порядка кластеров раскрывается, например, в заявках на патенты США №№15/168,548 и 15/168,525, см., например, Фиг. 5В, а также соответствующий текст, который полностью включен в настоящий документ посредством ссылки.
[0075] В различных реализациях настоящего изобретения операции, описанные в шаге 465 и 470, могут выполняться в обратной последовательности или параллельно. Кроме того, в отдельных реализациях настоящего изобретения некоторые операции, описанные в шаге 465 и (или) 470, могут быть пропущены.
[0076] На шаге 475 вычислительная система может создать итоговый распознанный текст, соответствующий определенному информационному полю копии шаблонного документа. В предпочтительном варианте реализации изобретения вычислительная система создает итоговый распознанный текст для каждого информационного поля обработанной копии шаблонного документа. Если отдельное информационное поле содержит только одну последовательность символов, например слово, вычислительная система может создать итоговый распознанный текст для такого поля непосредственно из медианной строки, определенной на шаге 465. Если отдельное информационное поле содержит несколько, т.е. более одной, последовательностей, например слов, вычислительная система может создать итоговый распознанный текст для такого поля после идентификации порядка соответствующих последовательностей символов на шаге 470.
[0077] По крайней мере одно преимущество метода, который показан на Фиг. 2, состоит в том, что он обеспечивает лучшую идентификацию объектов благодаря меньшей погрешности при вычислении преобразования координат. По крайней мере одно преимущество второго метода, который показан на Фиг. 4, - более высокая надежность. Отдельные изображения содержат больше текста, чем шаблон. Поэтому успешное распознавание некоторых статических элементов по крайней мере на одном изображении серии может гарантировать успешное наложение шаблона, даже если те же статические элементы будут плохо распознаны на многих других изображениях серии.
[0078] Вычислительная система может быть, например, вычислительной системой, показанной на Фиг. 6. Вычислительная система может представлять из себя устройство, способное выполнить набор команд (последовательных или иных), которые определяют операции, выполняемые этой вычислительной системой. Например, это может быть персональный компьютер (ПК), планшет, приемник цифрового телевидения (STB), карманный персональный компьютер (КПК) или сотовый телефон.
[0079] На Фиг. 6 представлена более подробная схема компонентов примера вычислительной системы 600, внутри которой исполняется набор инструкций, которые вызывают выполнение вычислительной системой любого из способов или нескольких способов настоящего изобретения. Вычислительная система 600 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 600 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер» или в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 600 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, хотя показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[0080] Пример вычислительной системы 600 включает в себя процессор 602, оперативную память 604 (например, постоянное запоминающее устройство (ПЗУ)) или динамическую оперативную память (DRAM)) и устройство хранения данных 618, которые взаимодействуют друг с другом через шину 630.
[0081] Процессор 602 может быть представлен одним или более универсальными устройствами обработки данных, например микропроцессором, центральным процессором и т.д. В частности, процессор 602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 602 также может представлять собой одно или более устройств обработки специального назначения, например заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.д. Процессор 602 сконфигурирован так, чтобы выполнять инструкции 626 для выполнения операций и функций одного из методов Фиг. 2 или Фиг. 4.
[0082] Вычислительная система 600 может дополнительно содержать устройство сетевого интерфейса 622, устройство визуального отображения 610, устройство ввода символов 612 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 614.
[0083] Устройство хранения данных 618 может включать машиночитаемый носитель данных 624, в котором хранится один или более наборов команд 626, в которых реализован один или более методов или функций, описанных в данном варианте реализации изобретения. Команды 626 во время выполнения их в вычислительной системе 600 также могут находиться полностью или по меньшей мере частично в основной памяти 604 и (или) в процессоре 602, при этом оперативная память 604 и процессор 602 также составляют машиночитаемый носитель данных. Команды 626 также могут передаваться или приниматься по сети 616 через устройство сетевого интерфейса 622.
[0084] В некоторых вариантах реализации инструкции 626 могут включать инструкции для выполнения одной или более функций или методов, показанных на Фиг. 2 и 4. В то время как машиночитаемый носитель данных 624 показан в примере на Фиг. 6 как единый носитель, термин «машиночитаемый носитель данных» следует понимать, как единый носитель либо множество таких носителей (например, централизованную или распределенную базу данных и/или соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Соответственно, термин «машиночитаемый носитель данных» также включает, в частности, устройства твердотельной памяти, оптические и магнитные носители.
[0085] Описанные в документе способы, компоненты и функции могут быть реализованы дискретными компонентами оборудования, либо они могут быть интегрированы в функции других аппаратных компонентов, таких как ASICS, FPGA, DSP или подобных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[0086] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0087] Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передать сущность своей работы другим специалистам в данной области. Здесь и в целом алгоритмом называется логически непротиворечивая последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0088] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано особо, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.д. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, аналогично представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы либо иных устройствах хранения, передачи или отображения такой информации.
[0089] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или реконфигурируется с помощью компьютерной программы, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, в частности, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носитель любого типа, подходящий для хранения электронной информации. Следует понимать, что вышеприведенное описание носит иллюстративный, а не ограничительный характер.
[0090] Различные другие варианты реализации станут очевидными специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2017 |
|
RU2673016C1 |
| СПОСОБЫ И СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2017 |
|
RU2673015C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2613849C1 |
| ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ | 2016 |
|
RU2634194C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2619712C1 |
| ИСПОЛЬЗОВАНИЕ НЕСКОЛЬКИХ КАМЕР ДЛЯ ВЫПОЛНЕНИЯ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ | 2017 |
|
RU2661760C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ДОКУМЕНТОВ С НЕКОПЛАНАРНЫМИ ОБЛАСТЯМИ | 2019 |
|
RU2721186C1 |
| СПОСОБ УЛУЧШЕНИЯ КАЧЕСТВА РАСПОЗНАВАНИЯ ОТДЕЛЬНОГО КАДРА | 2017 |
|
RU2657181C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| УСТРАНЕНИЕ ИСКРИВЛЕНИЙ ИЗОБРАЖЕНИЯ ДОКУМЕНТА | 2016 |
|
RU2621601C1 |



Группа изобретений относится к технологиям оптического распознавания символов (OCR). Техническим результатом является повышение качества извлекаемых данных и обеспечение шумоусточивости. Предложен способ извлечения данных из серии изображений шаблонного документа. Способ содержит этап, на котором осуществляют получение обрабатывающим устройством вычислительной системы текущего изображения из серии изображений копии шаблонного документа, где шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле. Далее, согласно способу, выполняют оптическое распознавание символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста. А также, определяют параметры преобразования координат для преобразования координат текущего изображения в координаты шаблона на основании координат опорных точек текущего изображения и шаблона. При этом шаблон содержит текст и координаты как минимум одного статического элемента шаблонного документа и координаты как минимум одного информационного поля шаблонного документа. 6 н. и 21 з.п. ф-лы, 6 ил.
1. Способ извлечения данных из серии изображений шаблонного документа, включающий:
(a) получение обрабатывающим устройством вычислительной системы текущего изображения из серии изображений копии шаблонного документа, где шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле;
(b) выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста;
(c) определение параметров преобразования координат для преобразования координат текущего изображения в координаты шаблона на основании координат опорных точек текущего изображения и шаблона, где шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа и ii) координаты как минимум одного информационного поля шаблонного документа;
(d) определение в тексте OCR текущего изображения в системе координат шаблона фрагмента текста, который соответствует информационному полю как минимум одного информационного поля;
(e) привязку в системе координат шаблона фрагмента текста, который соответствует информационному полю, к одному или более кластерам последовательностей символов, где фрагмент текста получен путем обработки текущего изображения и где последовательности символов получены путем обработки одного или более полученных предыдущих изображений из серии изображений;
(f) получение для каждого кластера из одного или более кластеров медианной строки, представляющей кластер последовательностей символов информационного поля; и
(g) получение с использованием медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
2. Способ извлечения данных из серии изображений шаблонного документа, включающий:
(а) получение с помощью обрабатывающего устройства вычислительной системы текущего изображения из серии изображений копии шаблонного документа, причем текущее изображение по крайней мере частично совпадает с предыдущим изображением из серии изображений, и шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле;
(b) выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста;
(c) определение параметров преобразования координат для преобразования координат предыдущего изображения в координаты текущего изображения на основании координат опорных точек текущего изображения и предыдущего изображения;
(d) привязку как минимум части распознанного текста к одному или более кластерам последовательностей символов, где распознанный текст получен путем обработки текущего изображения и где последовательности символов получены путем обработки одного или более полученных ранее изображений из серии изображений;
(e) определение параметров преобразования координат для преобразования координат текущего изображения из серии изображений в координаты шаблона копии шаблонного документа, где шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа, и ii) координаты как минимум одного информационного поля шаблонного документа;
(f) определение в системе координат шаблона одного или более кластеров последовательностей символов, которые соответствуют информационному полю как минимум одного информационного поля;
(g) получение для каждого из одного или более кластеров, соответствующих информационному полю, медианной строки, представляющей кластер последовательностей символов информационного поля; и
(h) получение с использованием медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
3. Способ по п. 1, дополнительно включающий:
определение с использованием полученного в b) распознанного текста множества текстовых артефактов для каждого из текущего изображения и шаблона, где каждый текстовый артефакт представлен последовательностью символов, которая имеет частоту появления в распознанном тексте ниже пороговой частоты;
определение для каждого текущего изображения и шаблона соответствующего множества опорных точек, где каждая опорная точка связана как минимум с одним текстовым артефактом из множества текстовых артефактов и
где указанное выше определение параметров преобразования координат использует координаты совпадающих опорных точек текущего изображения и шаблона.
4. Способ по п. 2, дополнительно включающий:
определение с использованием полученного в b) распознанного текста множества текстовых артефактов для каждого изображения из текущего изображения и предыдущего изображения, где каждый текстовый артефакт представлен в виде последовательности символов с частотой появления в распознанном тексте ниже пороговой частоты; определение для каждого изображения из текущего изображения и предыдущего изображения соответствующего множества опорных точек, где каждая опорная точка привязана как минимум к одному текстовому артефакту из множества текстовых артефактов и где указанное определение параметров преобразования координат использует координаты совпадающих опорных точек текущего изображения и предыдущего изображения.
5. Способ по п. 3, в котором определение множества артефактов дополнительно включает определение центра минимального описывающего прямоугольника соответствующего текстового артефакта.
6. Способ по п. 3, дополнительно включающий фильтрацию определенных опорных точек с использованием инвариантных геометрических признаков группировок опорных точек.
7. Способ по п. 1 или 2, в котором преобразование координат первого изображения в координаты второго изображения или шаблона представляет собой проективное преобразование, которое позволяет для произвольно выбранной точки на первом изображении определить ее координаты путем применения проективного преобразования к координатам той же точки на втором изображении или шаблоне.
8. Способ по п. 1 или 2, в котором медианная строка имеет минимальную сумму значений заранее определенного показателя в кластере последовательностей символов.
9. Способ по п. 8, в котором заранее определенный показатель представлен расстоянием редактирования между медианной строкой и последовательностью символов множества последовательностей символов.
10. Способ по п. 1 или 2, в котором указанное выше получение медианной строки включает применение весовых коэффициентов к каждой последовательности символов кластера последовательностей символов.
11. Способ по п. 2, в котором текущее изображение и предыдущее изображение являются последовательными изображениями серии изображений.
12. Способ по п. 2, в котором текущее изображение и предыдущее изображение отличаются как минимум одним параметром из нескольких: масштаб изображения, угол съемки, яркость изображения или наличие внешних объектов, которые перекрывают как минимум часть копии документа.
13. Способ по п. 1 или 2, в котором привязка к одному или более кластерам последовательностей символов дополнительно включает определение порядка множественных кластеров.
14. Способ по п. 13, в котором определение порядка множественных кластеров включает идентификацию медианной перестановки кластеров.
15. Способ по п. 14, в котором медианная перестановка кластеров имеет минимальную сумму тау-расстояний Кендалла для всех остальных перестановок, где тау-расстояние Кендалла между первой и второй перестановками может быть равно минимальному числу операций обмена в алгоритме пузырьковой сортировки для преобразования первой перестановки во вторую перестановку символов.
16. Способ по п. 1 или 2, дополнительно включающий получение серии изображений с помощью камеры и передачу серии изображений обрабатывающему устройству.
17. Способ по п. 1 или 2, дополнительно выводящий итоговый распознанный текст на дисплей вычислительной системы.
18. Способ по п. 1 или 2, дополнительно включающий получение инструкций от пользователя вычислительной системы для получения следующего изображения в серии.
19. Способ по п. 1 или 2, дополнительно включающий перемещение итогового распознанного текста в базу данных.
20. Система извлечения данных из серии изображений шаблонного документа, содержащая:
A) память, выполненную с возможностью хранения шаблона шаблонного документа, который включает как минимум один статический элемент и по крайней мере одно информационное поле, причем шаблон включает i) текст и координаты как минимум одного статического элемента шаблонного документа, и ii) координаты как минимум одного информационного поля шаблонного документа;
B) устройство обработки, подключенное к памяти, предназначенное для:
(a) получения текущего изображения из серии изображений копии шаблонного документа;
(b) выполнения оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста;
(c) определения параметров преобразования координат для преобразования координат текущего изображения в координаты шаблона на основании координат опорных точек текущего изображения и шаблона;
(d) определения в распознанном тексте текущего изображения в системе координат шаблона фрагмента текста, который соответствует информационному полю как минимум одного информационного поля;
(e) привязки в системе координат шаблона фрагмента текста, который соответствует информационному полю, к одному или более кластерам последовательностей символов, где фрагмент текста получен путем обработки текущего изображения и где последовательности символов получены путем обработки одного или более полученных ранее изображений из серии изображений;
(f) получения для каждого кластера из одного или более кластеров медианной строки, представляющей кластер последовательностей символов информационного поля; и
(g) получения с использованием медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
21. Система извлечения данных из серии изображений шаблонного документа, содержащая:
А) память, сконфигурированную для хранения шаблона шаблонного документа, который включает как минимум один статический элемент и по крайней мере одно информационное поле, причем шаблон включает i) текст и координаты как минимум одного статического элемента шаблонного документа, и ii) координаты как минимум одного информационного поля шаблонного документа.
В) устройство обработки, подключенное к памяти, предназначенное для:
(a) получения текущего изображения из серии изображений копии шаблонного документа;
(b) выполнения оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста;
(c) определения параметров преобразования координат для преобразования координат предыдущего изображения в координаты текущего изображения на основании координат опорных точек текущего изображения и предыдущего изображения;
(d) привязки как минимум части текста OCR к одному или более кластерам последовательностей символов, где распознанный текст получен путем обработки текущего изображения и где символьные последовательности получены путем обработки одного или более полученных ранее изображений из серии изображений;
(e) определения параметров преобразования координат для преобразования координат текущего изображения из серии изображений в координаты шаблона;
(f) определения в системе координат шаблона одного или более кластеров последовательностей символов, которые соответствуют информационному полю как минимум одного информационного поля;
(g) получения для каждого из одного или более кластеров, соответствующих информационному полю, медианной строки, представляющей кластер последовательностей символов информационного поля; и
(h) получения с использованием медианной строки каждого из одного или более кластеров итогового распознанного текста, который соответствует исходному тексту информационного поля копии шаблонного документа.
22. Система по п. 20 или 21, дополнительно содержащая камеру для получения серии изображений и передачи серии изображений обрабатывающему устройству.
23. Система по п. 22, которая является мобильным устройством.
24. Машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые при выполнении в вычислительном устройстве заставляют это вычислительное устройство:
(a) получать текущее изображение из серии изображений копии шаблонного документа, где шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле;
(b) выполнять оптическое распознавание символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста;
(c) определять параметры преобразования координат для преобразования координат текущего изображения в координаты шаблона на основании координат опорных точек текущего изображения и шаблона, где шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа, и ii) координаты как минимум одного информационного поля шаблонного документа;
(d) определять в распознанном тексте текущего изображения в системе координат шаблона фрагмент текста, который соответствует информационному полю как минимум одного информационного поля;
(e) привязывать в системе координат шаблон фрагмента текста, который соответствует информационному полю, к одному или более кластерам последовательностей символов, где фрагмент текста получен путем обработки текущего изображения и где последовательности символов получены путем обработки одного или более полученных ранее изображений из серии изображений;
(f) получать для каждого кластера из одного или более кластеров медианную строку, представляющую кластер последовательностей символов, для информационного поля; и
(g) получать с использованием медианной строки каждого из одного или более кластеров итоговый распознанный текст, который соответствует исходному тексту информационного поля копии шаблонного документа.
25. Машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые направлены на извлечение данных из серии изображений шаблонного документа и при выполнении которых в вычислительном устройстве заставляют это вычислительное устройство:
(a) получать текущее изображение из серии изображений копии шаблонного документа, причем текущее изображение по крайней мере частично совпадает с предыдущим изображением серии изображений, и шаблонный документ имеет по крайней мере один статический элемент и по крайней мере одно информационное поле;
(b) выполнять оптическое распознавание символов (OCR) текущего изображения для получения распознанного текста и соответствующих координат каждого символа распознанного текста;
(c) определять параметры преобразования координат для преобразования координат предыдущего изображения в координаты текущего изображения на основании координат опорных точек текущего изображения и предыдущего изображения;
(d) привязывать как минимум часть текста OCR к одному или более кластерам последовательностей символов, где распознанный текст получен путем обработки текущего изображения и где символьные последовательности получены путем обработки одного или более полученных ранее изображений из серии изображений;
(e) определять параметры преобразования координат для преобразования координат текущего изображения из серии изображений в координаты шаблона шаблонного документа, где шаблон содержит i) текст и координаты как минимум одного статического элемента шаблонного документа, и ii) координаты как минимум одного информационного поля шаблонного документа;
(f) определять в системе координат шаблона один или более кластеров последовательностей символов, которые соответствуют информационному полю как минимум одного информационного поля;
(g) получать для каждого из одного или более кластеров, соответствующих информационному полю, медианную строку, представляющую кластер последовательностей символов информационного поля; и
(h) получать с использованием медианной строки каждого из одного или более кластеров итоговый распознанный текст, который соответствует исходному тексту информационного поля копии шаблонного документа.
26. Способ по п. 4, в котором определение множества артефактов дополнительно включает определение центра минимального описывающего прямоугольника соответствующего текстового артефакта.
27. Способ по п. 4, дополнительно включающий фильтрацию определенных опорных точек с использованием инвариантных геометрических признаков группировок опорных точек.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 9058536 B1, 16.06.2015 | |||
| СПОСОБ ПРИВЕДЕНИЯ В СООТВЕТСТВИЕ ЗАПОЛНЕННОЙ МАШИНОЧИТАЕМОЙ ФОРМЫ И ЕЕ ШАБЛОНА ПРИ НАЛИЧИИ ИСКАЖЕНИЙ (ВАРИАНТЫ) | 2003 |
|
RU2251738C2 |
| СПОСОБ МНОГОЭТАПНОГО АНАЛИЗА ИНФОРМАЦИИ РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2002 |
|
RU2234734C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА С ПРИМЕНЕНИЕМ НАСТРАИВАЕМОГО КЛАССИФИКАТОРА | 2002 |
|
RU2234126C2 |

