ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в общем относится к вычислительным системам, более конкретно, к системам и способам оптического распознавания символов (OCR).
УРОВЕНЬ ТЕХНИКИ
[0002] Оптическое распознавание символов (OCR) представляет собой осуществляемое на компьютере преобразование изображений текста (включая машинописный, написанный от руки или напечатанный текст) в электронные документы в машинной кодировке.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
В соответствии с одним или более вариантами реализации настоящего изобретения пример способа выполнения оптического распознавания символов (OCR) серии изображений, содержащих символы определенного алфавита может включать: получение обрабатывающим устройством текущего изображения из серии изображений исходного документа, где текущее изображение как минимум частично перекрывается с предыдущим изображением из серии изображений; выполнение оптического распознавания символов (OCR) текущего изображения для получения текста OCR и соответствующей разметки текста; связывание с использованием преобразования координат как минимум части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений; выявление первой строки-медианы, представляющей первый кластер символьной последовательности, исходя из первого подмножества изображений в серии изображений; выявление первого поля шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер, и разметки текста текущего изображения; анализ последовательности символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона; выявление для первого кластера строки-медианы второго уровня, соответствующей кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей; получение с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа; нормализация одной или более текстовых последовательностей из первого кластера для соответствия этих последовательностей символов первым параметрам первого поля шаблона; выявление строки-медианы второго уровня, представляющей кластер последовательностей символов, исходя из множества нормализованных последовательностей символов; где нормализация включает выявление одного или более несоответствующих символов в последовательности символов, где несоответствующие символы - это символы, которые не удовлетворяют первым параметрам первого поля шаблона, и замену несоответствующих символов в последовательности символов пустыми местами; где анализ последовательностей символов из первого кластера для выявления подходящих последовательностей символов включает фильтрацию символьных последовательностей из первого кластера для фильтрации «мусорных» последовательностей символов; где строка-медиана второго уровня является ограниченной строкой-медианой, удовлетворяющей вторым параметрам первого поля шаблона; и далее включающий определение, что строка-медианы второго уровня не может быть выявлена; и выявление для кластера третьей строки-медианы, представляющей кластер символьных последовательностей, исходя из второго подмножества изображений из серии изображений, отличающегося от первого подмножества изображений; где второе подмножество серии изображений включает первое подмножество серии изображений. Способ также может включать выявление шаблона документа, соответствующего исходному документу, исходя как минимум из разметки текста, полученной с помощью OCR и выявленной первой строки-медианы, при этом шаблон документа выбирается из набора шаблонов документов. Способ также может включать, если будет определено, что шаблон документа для исходного документа не может быть выявлен с достаточной степенью уверенности; выявление четвертой строки-медианы, представляющей кластер символьных последовательностей, исходя из третьего подмножества изображений серии изображений, отличающегося от первого подмножества изображений.
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения пример системы для выполнения оптического распознавания символов (OCR) в серии изображений, содержащих символы определенного алфавита может включать: запоминающее устройство, обрабатывающее устройство, подключенное к запоминающему устройству, причем обрабатывающее устройство предназначено для выполнения следующих операций: получение обрабатывающим устройством текущего изображения из серии изображений исходного документа, где текущее изображение как минимум частично перекрывается с предыдущим изображением из серии изображений; выполнение оптического распознавания символов (OCR) текущего изображения для получения текста OCR и соответствующей разметки текста; связывание с использованием преобразования координат как минимум части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений; выявление первой строки-медианы, представляющей первый кластер символьной последовательности, исходя из первого подмножества изображений в серии изображений; выявление первого поля шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер и разметки текста текущего изображения; анализ последовательности символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона; выявление для первого кластера строки-медианы второго уровня, соответствующей кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей; получение с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа; нормализация одной или более текстовых последовательностей из первого кластера для соответствия этих последовательностей символов первым параметрам первого поля шаблона; выявление для первого кластера строки-медианы второго уровня, представляющей кластер последовательностей символов, исходя из множества нормализованных последовательностей символов; где нормализация включает выявление одного или более несоответствующих символов в последовательности символов, где несоответствующие символы - это символы, которые не удовлетворяют первым параметрам первого поля шаблона, и замену несоответствующих символов в последовательности символов пустыми местами; где анализ последовательностей символов из первого кластера для выявления подходящих последовательностей символов включает фильтрацию символьных последовательностей из первого кластера для фильтрации «мусорных» последовательностей символов; где строка-медиана второго уровня является ограниченной строкой-медианой, удовлетворяющей вторым параметрам первого поля шаблона; и далее включает определение, что строка-медиана второго уровня не может быть выявлена; и выявление для кластера третьей строки-медианы, представляющей кластер символьных последовательностей, исходя из второго подмножества изображений из серии изображений, отличающегося от первого подмножества изображений; где второе подмножество серии изображений включает первое подмножество серии изображений.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их обрабатывающим устройством приводят к выполнению обрабатывающим устройством операций, включающих в себя: получение обрабатывающим устройством текущего изображения из серии изображений исходного документа, где текущее изображение как минимум частично перекрывается с предыдущим изображением из серии изображений; выполнение оптического распознавания символов (OCR) текущего изображения для получения текста OCR и соответствующей разметки текста; связывание с использованием преобразования координат как минимум части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений; выявление первой строки-медианы, представляющей первый кластер символьной последовательности, исходя из первого подмножества изображений в серии изображений; выявление первого поля шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер и разметки текста текущего изображения; анализ последовательности символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона; выявление для первого кластера строки-медианы второго уровня, соответствующей кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей; получение с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа; нормализация одной или более текстовых последовательностей из первого кластера для соответствия этих последовательностей символов перовым параметрам первого поля шаблона; выявление для первого кластера строки-медианы второго уровня, представляющей кластер последовательностей символов, исходя из множества нормализованных последовательностей символов; где нормализация включает выявление одного или более несоответствующих символов в последовательности символов, где несоответствующие символы - это символы, которые не удовлетворяют первым параметрам первого поля шаблона, и замену несоответствующих символов в последовательности символов пустыми местами; где анализ последовательностей символов из первого кластера для выявления подходящих последовательностей символов включает фильтрацию символьных последовательностей из первого кластера для фильтрации «мусорных» последовательностей символов; где строка-медиана второго уровня является ограниченной строкой-медианой, удовлетворяющей вторым параметрам первого поля шаблона; и далее включает определение, что строка-медиана второго уровня не может быть выявлена; и выявление для кластера третьей строки-медианы, представляющей кластер символьных последовательностей, исходя из второго подмножества изображений из серии изображений, отличающегося от первого подмножества изображений; где второе подмножество серии изображений включает первое подмножество серии изображений.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0005] Настоящее изобретение иллюстрируется с помощью примеров, но не ограничивается только ими, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, в которых:
[0006] На Фиг. 1 показана блок-схема одного из иллюстративных примеров способа выполнения оптического распознавания символов (OCR) серии изображений, содержащих символы текста, в соответствии с одним или более вариантами реализации настоящего изобретения;
[0007] На Фиг. 2А-2В схематически показан пример последовательности из трех изображений, проективные преобразования между парами изображений и соответствующие последовательности символов, полученные при OCR соответствующих изображений, в соответствии с одним или более вариантами реализации настоящего изобретения;
[0008] На Фиг. 3 схематически иллюстрируется граф, содержащий множество кластеров в узлах, так что каждый кластер представляет две или более совпадающих символьных последовательности, в соответствии с одним или более вариантами реализации настоящего изобретения;
[0009] На Фиг. 4А-4С схематически иллюстрируется выявление строки-медианы среди множества последовательностей символов, представляющих результаты OCR соответствующих фрагментов изображения, в соответствии с одним или более вариантами реализации настоящего изобретения;
[00010] На Фиг. 5 схематически иллюстрируется двухуровневое выявление строки-медианы среди множества последовательностей символов, представляющих результаты OCR соответствующих фрагментов изображения, в соответствии с одним или более вариантами реализации настоящего изобретения; и
[00011] На Фиг. 6 приведена схема иллюстративного примера вычислительной системы, в которой реализованы способы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00012] В настоящем документе описываются способы и системы для оптического распознавания символов (OCR) серии изображений с символами некоторого алфавита. Алфавиты, символы которых могут обрабатываться с помощью систем и способов, описанных в настоящем документе, включают истинные символьные алфавиты, которые содержат отдельные символы или глифы, соответствующие отдельным звукам, а также иероглифические алфавиты, которые содержат отдельные символы, соответствующие более крупным блокам, таким как слоги или слова.
[00013] В приведенном ниже описании термин «документ» должен толковаться широко, как отсылка к разнообразным типам текстовых носителей, включая, помимо прочего, печатные и написанные от руки документы, баннеры, постеры, знаки, рекламные щиты и (или) другие физические объекты, несущие видимые текстовые символы на одной или более поверхностях. «Изображение документа» в настоящем документе означает изображение как минимум части исходного документа (например, страницы бумажного документа).
[00014] В частности, документы в приведенном ниже описании содержат поля. Термин «поле» должен толковаться расширительно, как относящийся к широкому спектру областей документа, содержащих текст, включая поля в опросном листе, фамилию, дату или другую информацию в паспорте или водительских правах и т.д.
[00015] Система оптического распознавания символов (OCR) может получить изображение документа и преобразовать полученное изображение в машиночитаемый формат, допускающий поиск и содержащий текстовую информацию, извлеченную из изображения бумажного документа. Процесс оптического распознавания может быть затруднен различными дефектами изображения, такими как цифровой шум, блики, смаз, расфокусировка и т.д., которые обычно могут быть вызваны дрожанием камеры, недостаточным освещением, неправильно выбранной выдержкой или диафрагмой и (или) другими ухудшающими качество обстоятельствами или причинами. В то время как обычные способы оптического распознавания могут не всегда правильно осуществлять распознавание символов в присутствии указанных выше и других дефектов изображения, системы и способы, описанные в этом документе, могут значительно повысить качество оптического распознавания за счет анализа серии изображений (например, серии видеокадров или фотоснимков) документа, что будет более подробно описано ниже.
[00016] Кроме того, в определенных условиях исходный документ невозможно вместить в одно изображение без значительных потерь качества изображения. Риск потери качества изображения может быть сокращен путем получения серии частично перекрывающихся изображений различных фрагментов исходного документа, которые тем не менее нельзя будет использовать для последующего проведения распознавания обычными способами оптического распознавания. Системы и способы, описанные в этом документе, могут эффективно объединять результаты процедуры распознавания символов, выполненной для нескольких фрагментов документа, позволяя получить текст исходного документа
[00017] В некоторых вариантах осуществления текст, полученный с помощью систем и способов OCR, описанных в этом документе, может подвергаться дополнительной обработке, например, для извлечения конкретных данных, верификации и сбора данных.
[00018] В иллюстративном примере компьютерная система, реализующая способ, описанный в этом документе, может получать серию изображений (например, серию видеокадров или фотоснимков) исходного документа. Эти изображения могут отображать как минимум частично перекрывающиеся фрагменты документа и могут отличаться масштабом изображения, ракурсом, выдержкой, диафрагмой, яркостью изображения, наличием бликов, наличием внешних объектов, которые как минимум частично закрывают исходный текст, и (или) других элементов изображения, визуальных артефактов и параметров способа получения изображения.
[00019] Эта компьютерная система может выполнять оптическое распознавание символов как минимум выбранных изображений полученной серии изображений для получения соответствующей информации о тексте и его разметки. Информация о разметке может связывать распознаваемые символы и (или) группы символов с их положением на исходном изображении. Для объединения результатов распознавания символов, выполняемого для последовательно полученных изображений, компьютерная система может сравнивать текст и разметку, полученные при оптическом распознавании текущего изображения с текстом и разметкой, полученными при оптическом распознавании одного или более ранее обработанных изображений.
[00020] В соответствии с одним или более вариантами реализации настоящего изобретения вычислительная система может выявлять кластеры последовательностей символов, которые, вероятно, соответствуют одному и тому же фрагменту исходного документа. Эти аспекты настоящего изобретения подробно описаны в заявке на патент США (U.S. Patent Application) №: 15/168,548, с названием «ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ В СЕРИИ ИЗОБРАЖЕНИЙ» Алексея Калюжного, поданной 31 мая 2016 года.
[00021] Для каждого кластера совпадающих символьных последовательностей может быть определена строка-медиана, представляющая результат оптического распознавания символов соответствующего фрагмента изображения. В некоторых вариантах реализации изобретения строка-медиана может быть определена как символьная последовательность, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей кластера. Расстояние редактирования, которое в иллюстративном примере может быть представлено расстоянием Левенштейна, между первой символьной последовательностью и второй символьной последовательностью может быть равно минимальному числу односимвольных преобразований (т.е. вставок, удалений или замещений), необходимых для преобразования первой символьной последовательности во вторую символьную последовательность.
[00022] Тексты, полученные при OCR каждого отдельного изображения, могут отличаться одним или более словами, присутствующими или отсутствующими в каждом из результатов OCR, вариациями в последовательностях символов, представляющих слова исходного текста, порядком последовательностей символов и (или) наличием так называемых «мусорных» символов, то есть артефактов, созданных системой из-за дефектов изображений, которые отсутствуют в документе.
[00023] Для дополнительного повышения качества распознавания символов после выявления медиан для одного или более кластеров система выявляет в документе поля, соответствующие как минимум некоторым из кластеров.
[00024] Поле в документе обычно относится к определенному типу, исходя из формата информации, которая, как ожидается, будет присутствовать в этом поле. Например, в поле «Дата рождения» мы ожидаем обнаружить последовательность символов, представляющую собой календарную дату, в поле «Штат» мы ожидаем обнаружить последовательность символов, представляющую собой название штата США или код штата из двух букв. Этот тип информации для поля может быть выражен как один или более параметров для последовательности символов, находящейся в этом поле. Параметры поля могут включать последовательность символов, соответствующую определенному формату (например, формат даты, характеристики шрифта и т.д.), последовательность символов, образующую словарное слово (определенного языка, из определенного списка слов и т.д.), последовательность символов, образующую определенное регулярное выражение (например, телефонный номер, номер (карточки) социального страхования, адрес, электронная почта и т.д.).
[00025] Исходя из типа поля, выявленного для определенного кластера, система фильтрует и (или) нормализует последовательности символов, соответствующие этому кластеру. Полученное множество отфильтрованных/нормализованных последовательностей символов может использоваться для построения медианы второго уровня. Эта медиана второго уровня, построенная на основе набора отфильтрованных /нормализованных последовательностей символов, дает более точную реконструкцию текста в выявленном поле.
[00026] Таким образом, описанные в настоящем документе системы и способы позволяют стабильно улучшать результат извлечения конкретных данных из документа, устранив серии ошибок в результатах OCR серии изображений, такие ошибки как необнаруженный текст или систематические ошибки, которые появляются под определенным углом и (или) связаны с определенным шрифтом.
[00027] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
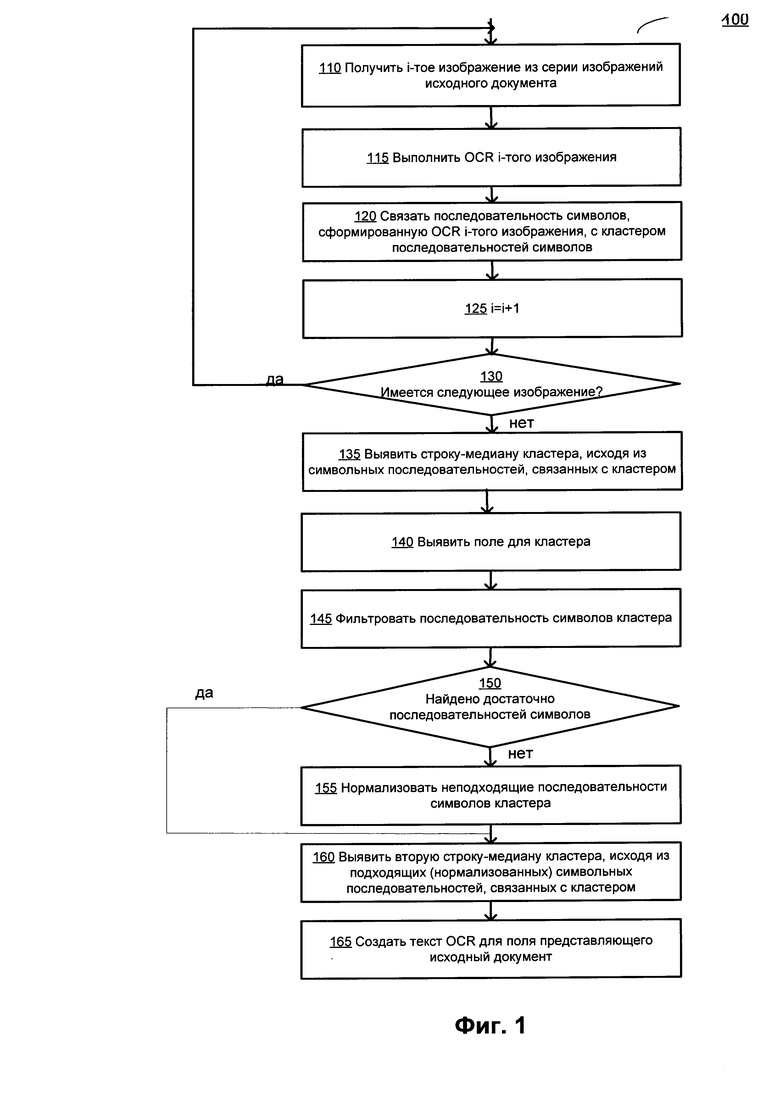
[00028] На Фиг. 1 показана блок-схема одного иллюстративного примера способа 100 выполнения оптического распознавания серии изображений, содержащих текстовые символы, в соответствии с одним или более аспектами настоящего изобретения. Способ 100 и (или) каждая из его отдельных функций, стандартных программ, подпрограмм или операций может выполняться с помощью одного или более процессоров компьютерного устройства (например, примера вычислительной системы 800 на Фиг. 8), в котором реализован этот способ. В некоторых вариантах реализации изобретения способ 100 может выполняться в одном потоке обработки. Кроме того, способ 100 может выполняться, используя два или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В иллюстративном примере потоки обработки, в которых реализован способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 100, могут выполняться асинхронно друг относительно друга. Таким образом, в то время как Фиг. 1 и соответствующее описание содержат операции по способу 100 в определенном порядке, различные реализации способа могут выполнять как минимум некоторые из указанных операций параллельно и (или) в случайно выбранном порядке.
[00029] Для ясности и конкретности настоящее описание предполагает, что обработка каждого изображения исходного документа инициируется после получения изображения компьютерной системой, реализующей способ, и что обработка, по существу, завершается до получения следующего изображения. Однако в различных альтернативных вариантах реализации изобретения обработка следующих друг за другом изображений может перекрываться по времени (например, может выполняться в различных потоках или процессах, выполняемых одним или более процессорами). Кроме того, два или более изображения могут помещаться в буфер и обрабатываться асинхронно относительно получения других изображений из множества изображений, получаемых компьютерной системой, реализующей способ.
[00030] Настоящее раскрытие изобретения ссылается на "серию изображений" (например, серии видеокадров или фотоснимков) исходного документа. Эти изображения могут отображать как минимум частично перекрывающиеся фрагменты документа и могут отличаться масштабом изображения, ракурсом, выдержкой, диафрагмой, яркостью изображения, наличием бликов, наличием внешних объектов, которые как минимум частично закрывают исходный текст, и (или) других элементов изображения, визуальных артефактов и параметров способа получения изображения. В иллюстративном примере изображения могут выбираться среди следующих друг за другом изображений из полученной серии изображений. В этом документе изображения по отдельности указываются как «текущее изображение» (также обозначенное как «i-тое изображение» на Фиг. 1).
[00031] В блоке 110 компьютерная система реализует способ, позволяющий получить текущее изображение из серии изображений.
[00032] В блоке 115 компьютерная система может выполнить оптическое распознавание символов текущего изображения с получением распознанного текста и информации о разметке. Информация о разметке может связывать распознанные символы и (или) группы символов с их положением на исходном изображении.
[00033] На шаге 120 вычислительная система может связывать одну или более последовательностей символов, полученных с помощью OCR текущего изображения, с кластером совпадающих последовательностей символов, полученных при OCR ранее обработанных изображений. Вычислительная система может использовать преобразования координат, чтобы сравнить положения распознанной последовательности символов на текущем и предыдущем изображении и таким образом определить группы последовательностей символов, которые, вероятно, представляют один и тот же фрагмент исходного документа.
[00034] На Фиг. 2А схематически показана серия из трех изображений (202, 204 и 206), где координаты первого изображения 202 могут быть преобразованы в координаты второго изображения 204 путем применения проективного преобразования 208, а координаты второго изображения 204 могут быть преобразованы в координаты третьего изображения 206 путем применения проективного преобразования 210.
[00035] В одном из иллюстративных примеров для случайно выбранной последовательности символов из текста, полученного при оптическом распознавании символов текущего изображения, этот способ может выявить один или более совпадающих последовательностей символов, полученных при оптическом распознавании символов на других изображениях из серии изображений. Следует заметить, что «совпадающие последовательности символов» в настоящем документе соответствуют как точно совпадающим, так и нестрого совпадающим последовательностям символов. На иллюстративном примере на Фиг. 2В три совпадающие последовательности символов 212, соответствующие изображениям 202, 204 и 206, представлены тремя различными последовательностями, которые нестрого совпадают в рамках методов настоящего изобретения.
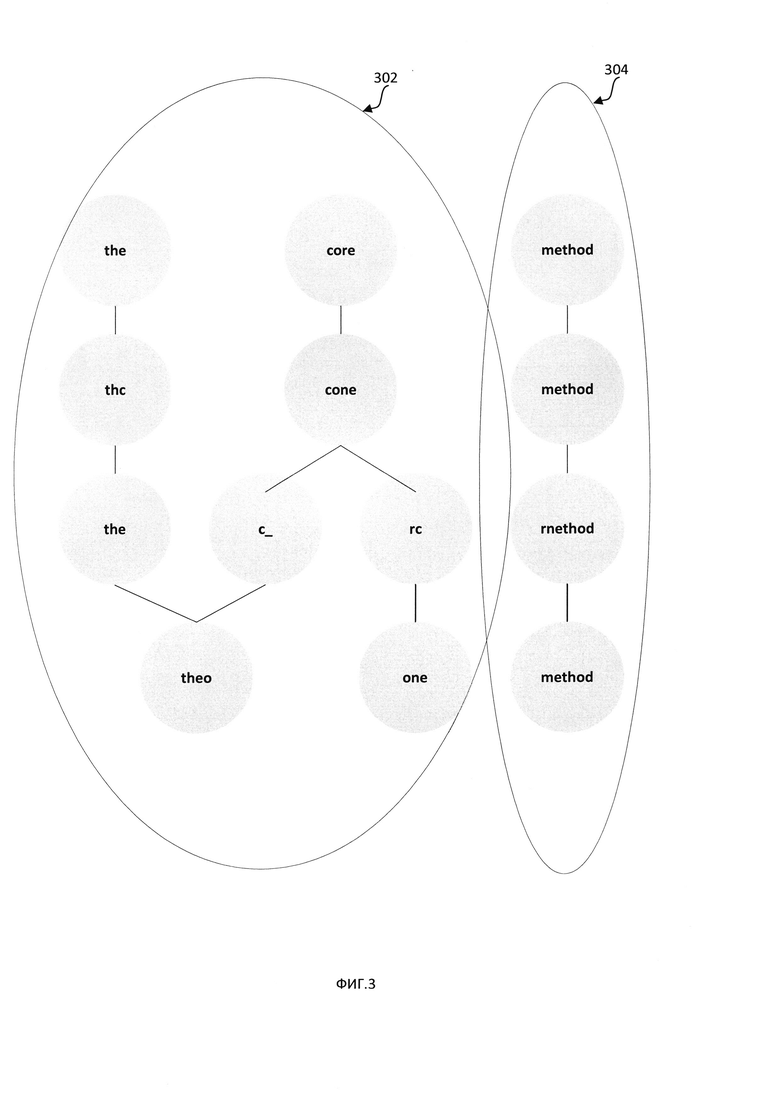
[00036] В некоторых вариантах реализации изобретения компьютерная система может создавать граф, вершины которого представляют символьные последовательности из множества изображений, а ребра соединяют символьные последовательности, которые были определены как совпадающие (то есть соответствующие одному и тому же фрагменту исходного текста) путем применения описанного выше взаимного преобразования координат изображений. Как схематически показано на Фиг. 3, полученный граф будет содержать множество кластеров вершин, где каждый кластер соответствует двум или более совпадающим символьным последовательностям. Вершины внутри каждого кластера соединены соответствующими ребрами, причем отдельные кластеры могут быть изолированы или слабо связаны друг с другом. На Фиг. 3 показаны два кластера (302, 304), соответствующие символьным последовательностям, полученным при оптическом распознавании двух исходных строк: «the core» и «method».
[00037] Вернемся снова к Фиг. 1, на шаге 125 вычислительная система может увеличить счетчик, указывающий на текущее изображение в серии изображений. Следует заметить, что операции, происходящие на шаге 125, представлены на Фиг. 1 для улучшения читаемости соответствующего описания, и в некоторых вариантах реализации способа могут быть опущены.
[00038] На шаге 130 вычислительная система может определить, существует ли следующее изображение; если это так, способ может возвратиться обратно к шагу 110.
[00039] На шаге 135 вычислительная система может выявлять строку-медиану одного или более кластеров совпадающих последовательностей символов такую, что выявленная строка-медиана будет представлять результат OCR соответствующего фрагмента изображения. В некоторых вариантах осуществления система использует набор последовательных изображений заранее определенного размера для выявления строки-медианы, исходя из последовательностей символов, соответствующих изображениям из набора. В других вариантах осуществления изображения в наборе не образуют последовательность. В некоторых вариантах осуществления набор разных размеров используется для различных кластеров. В некоторых вариантах осуществления размер набора определяется динамически.
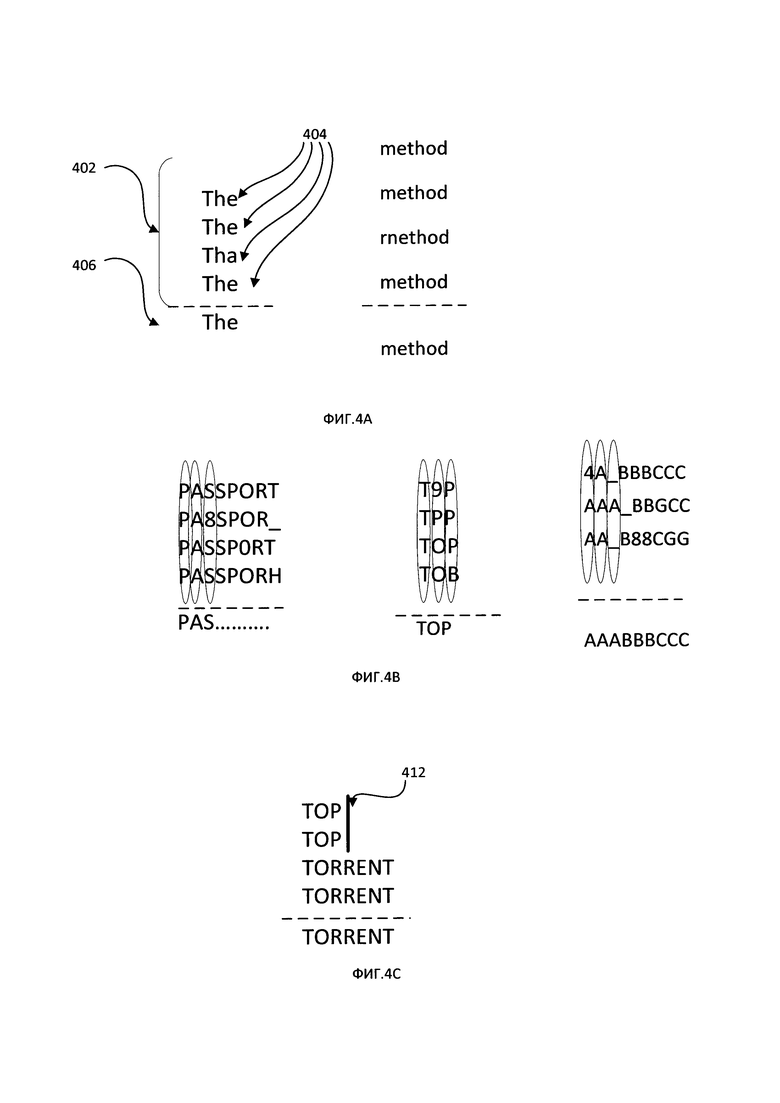
[00040] Как схематически показано на Фиг. 4А, каждый кластер 402 может содержать множество совпадающих символьных последовательностей 404, а результат оптического распознавания символов соответствующего фрагмента изображения может быть представлен строкой-медианой 406. В некоторых вариантах реализации изобретения строка-медиана может быть определена как символьная последовательность, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей кластера. Расстояние редактирования, которое в иллюстративном примере может быть представлено расстоянием Левенштейна, между первой символьной последовательностью и второй символьной последовательностью может быть равно минимальному числу односимвольных преобразований (т.е. вставок, удалений или замещений), необходимых для преобразования первой символьной последовательности во вторую символьную последовательность.
[00041] В некоторых вариантах реализации изобретения вычислительная сложность определения строки-медианы может быть уменьшена путем применения некоторых эвристических способов. В иллюстративном примере компьютерная система может эвристически определять аппроксимацию строки-медианы нулевого порядка. Затем компьютерная система может выравнивать символьные последовательности, используя точно совпадающие символы каждой последовательности, как схематично показано на Фиг. 4В. В другом иллюстративном примере вычислительная система может связывать с каждой символьной последовательностью кластера весовой коэффициент, отражающий положение символьной последовательности в изображении или величину уверенности оптического распознавания символов. Как схематично показано на Фиг. 4С, кластер 412 содержит четыре символьных последовательности: TOP, TOP, TORRENT, TORRENT. Первые две символьные последовательности соответствуют частям слов, поскольку расстояние от границы минимального описывающего прямоугольника символьной последовательности до границы изображения меньше ширины пробела. Поэтому значение показателя уверенности оптического распознавания символов для первых двух символьных последовательностей значительно ниже значения показателя уверенности оптического распознавания символов для двух других символьных последовательностей, и в качестве строки-медианы способ, принимающий во внимание значение показателя уверенности оптического распознавания символов, выберет символьную последовательность TORRENT.
[00042] Вернемся снова к Фиг. 1, на шаге 140 вычислительная система выявляет поля шаблона, соответствующего одному или более кластерам последовательностей символов. В некоторых вариантах осуществления заранее известно, какой шаблон соответствует документу. В этом случае, используя известный шаблон и информацию о разметке (получена для документа на шаге 115), система выявляет, какое поле в известном шаблоне соответствует какому кластеру последовательностей символов.
[00043] В некоторых вариантах осуществления мы не знаем заранее, какой шаблон соответствует документу. В этом случае система может выявить соответствующий шаблон, исходя из строк-медиан кластеров (получены на шаге 135) и информации о разметке (получена на шаге 115). В некоторых вариантах осуществления система выявляет соответствующий шаблон из набора шаблонов, полученных заранее. В других вариантах осуществления система может создавать новый шаблон, исходя из строк-медиан кластеров и информации о разметке.
[00044] Независимо от того, известен ли шаблон заранее или выявляется системой, информация о разметке, полученная в процессе OCR, и строки-медианы кластеров используются системой для определения принадлежности конкретного кластера к конкретному полю шаблона.
[00045] В некоторых вариантах осуществления система, после попытки выявить шаблон, соответствующий документу, определяет, что этот шаблон не может быть выявлен с удовлетворительным уровнем уверенности. В некоторых вариантах осуществления, если уверенный шаблон не может быть найден, система возвращается к шагу 135 на Фиг. 1 и выявляет строку-медиану для кластера с другим набором изображений. В некоторых вариантах осуществления размер набора изображений изменяется, обычно увеличивается; в других вариантах осуществления система выбирает изображения из набора не последовательно и т.д.
[00046] На шаге 145 вычислительная система фильтрует символьные последовательности, соответствующие кластеру, исходя из поля шаблона, выявленного для этого кластера на шаге 140. Как говорилось ранее, поле в шаблоне обычно принадлежит к определенному типу. Система использует этот тип поля для фильтрации последовательностей символов, соответствующих кластеру, для выявления подходящих последовательностей символов, удовлетворяющих параметрам выявленного поля. Например, если тип поля определен как «Дата в формате мм/дд/гггг», то из последовательностей символов (1) «11/22/2011», (2) «11/22/2014», (3) «11/23/2011», (4) «11122/2011», (5) «14/22/2о11», (6) «11/22/011», (7) «∧∧12/02I2017_», (8) «_I2/02/20I7.», (9) «_I2/o2/S017_» только последовательности символов (1), (2) и (3) соответствуют этому типу поля. Последовательности символов (4)-(9) не соответствуют выявленному полю и будут отфильтрованы.
[00047] На шаге 150 система определяет, достаточно ли количества подходящих последовательностей символов для выявления строки-медианы второго уровня в кластере. В некоторых вариантах осуществления заранее задается предельное количество последовательностей символов, необходимых для выявления строки-медианы второго уровня в кластере. Если количество подходящих символьных последовательностей, найденных при фильтрации, превышает предельное количество, система переходит к шагу 160.
[00048] В других вариантах осуществления система определяет достаточное количество подходящих последовательностей символов другими способами. В некоторых вариантах осуществления определение 150 не выполняется, и система после фильтрации автоматически выполняет нормализацию 155 для последовательностей символов.
[00049] На шаге 155 система выполняет операцию нормализации неподходящих последовательностей символов, соответствующих кластеру, чтобы они соответствовали типу поля, определенному для кластера. В ходе процесса нормализации последовательность символов анализируется, и символы, не соответствующие требованиям типа поля, заменяются пустыми местами.
[00050] Например, последовательности символов (4)-(6) до нормализации могут давать следующие подходящие последовательности символов:
[00051] (4) «11122/2011» → «11 22/2011»
[00052] (5) «14/22/2о11» → «1 /22/2 11»
[00053] (6) «11/22/Z011» → «11/22/ 011»
[00054] (7) «∧∧12/02I2017_» → «12/02 2017»
[00055] (8) «_I2/02/20I7.» -> «2/02/20 7.»
[00056] (9) «_I2/o2/S017_» → «2/2/ 017»
[00057] В некоторых вариантах осуществления фильтрация 145 выполняется одновременно с нормализацией 155. В других вариантах осуществления фильтрация 145 выполняется первой, а операция нормализации 155 применяется только к набору не подходящих последовательностей символов, выявленных при фильтрации 145.
[00058] На шаге 160 система выявляет строку-медиану второго уровня для кластера. Строка-медиана второго уровня выявляется, исходя из подходящих последовательностей символов (из шага 145) и нормализованных последовательностей символов (из шага 155).
[00059] В некоторых вариантах осуществления система использует способ строки-медианы с наложенными внешними ограничениями для выявления строки-медианы второго уровня. Способ ограниченной строки-медианы включает использование жесткого внешнего параметра, определенного для кластера на основе соответствующего типа поля. Этот жесткий внешний параметр для ограниченной строки-медианы обычно отличается от параметров, используемых для фильтрации (нормализации) последовательности символов на шаге 145, 155. Этот жесткий внешний параметр может быть, например, требованием, чтобы все последовательности символов, использованные для определения строки-медианы второго уровня, входили в определенный список слов (например, в список имен, список фамилий, список названия стран и т.д.) или совпадали со словом из определенного набора слов или фраз, заранее определенного для этого поля, и т.д.
[00060] Например, наш набор заранее определенных подходящих слов включает список имен, и для выявления строки-медианы с помощью способа ограниченной строки-медианы используются следующие последовательности символов:
[00061] (1) NLCK
[00062] (2) NICK
[00063] (3) RICK
[00064] (4) HIOK
[00065] (5) NLCK
[00066] В этом примере, если мы ищем обычную строку-медиану, будут выбраны последовательности символов с минимальным расстоянием до всех последовательностей символов. В данном случае это будет NLCK, и это не лучший результат. Если система использует список имен, варианты (2) и (3) могут быть возможным результатом, так как они оба содержат словарные слова. Однако при использовании ограниченной строки-медианы системой будет выявлен правильный результат (2), поскольку результат (2) имеет меньшую сумму значений расстояний редактирования до всех оставшихся последовательностей символов (1, 3, 4, 5) в кластере, чем результат (3).
[00067] На Фиг. 5 иллюстрируется двухуровневое выявление строки-медианы среди множества последовательностей символов, представляющих результаты OCR соответствующих фрагментов изображения. 1-й слой последовательностей символов 520 включает все последовательности символов (502, 504, 505, 506 и т.д.), созданные OCR и связанные с кластером. Первая строка-медиана 542 получается, исходя из первого подмножества последовательностей символов 530 (см. шаг 135, Фиг. 1). 2-й слой символьных последовательностей 560 включает только последовательности символов, которые являются подходящими и/или нормализованы 552, 554 относительно типа поля для поля 582, выявленного для кластера (выявлен на шаге 145, 155, Фиг. 1). Строка-медиана второго уровня основана на подмножестве 570 последовательностей символов 552, 554 и т.д. из 2-го слоя (выявлены на шаге 160, Фиг. 1). Извлеченные данные 580 документа могут содержать идентификатор поля 582 для поля, соответствующего кластеру (поле выявлено на шаге 140, Фиг. 1), и строку-медиану второго уровня 584, полученную по настоящему способу.
[00068] В некоторых вариантах осуществления подмножества 530 и 570 могут иметь разный размер. В некоторых вариантах осуществления размер подмножества 2-го слоя последовательностей символов больше, чем размер подмножества 1-го слоя последовательностей символов.
[00069] Возвращаясь к Фиг. 1, на шаге 165 система создает данные для поля, связанного с кластером, исходя из строки-медианы второго уровня, определенной для этого кластера.
[00070] Если одно или более данных поля не были определены в ходе этого процесса, то есть система не выявила строку-медиану второго уровня как минимум для некоторых полей, процесс может быть повторен с другим набором изображений.
[00071] На Фиг. 6 представлена схема компонентов примера вычислительной системы 600, внутри которой исполняется набор команд, которые вызывают выполнение вычислительной системой любого из способов или нескольких способов настоящего изобретения. Вычислительная система 600 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 600 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 600 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любое множество вычислительных систем, которые по отдельности или совместно выполняют набор (или несколько наборов) команд для выполнения одного или более способов, обсуждаемых в настоящем документе.
[00072] Пример вычислительной системы 600 включает процессор 602, основную память 604 (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 618, которые взаимодействуют друг с другом по шине 630.
[00073] Процессор 602 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.д. В частности, процессор 602 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW) или процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 602 также может представлять собой одно или более устройств обработки специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 602 настроен на выполнение команд 626 для осуществления операций и функций способа 100 выполнения оптического распознавания серии изображений, содержащих символы текста, как описано выше в этом документе.
[00074] Вычислительная система 600 может дополнительно включать устройство сетевого интерфейса 622, устройство визуального отображения 610, устройство ввода символов 612 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 614.
[00075] Устройство хранения данных 618 может содержать машиночитаемый носитель данных 624, в котором хранится один или более наборов команд (626), и в котором реализован один или более способов или функций настоящего изобретения. Команды 626 также могут находиться полностью или по меньшей мере частично в основной памяти 604 и (или) в процессоре 602 во время выполнения их в вычислительной системе 600, при этом оперативная память 604 и процессор 602 также представляют собой машиночитаемый носитель данных. Команды 626 дополнительно могут передаваться или приниматься по сети 616 через устройство сетевого интерфейса 622.
[00076] В некоторых вариантах реализации изобретения инструкции 626 могут включать инструкции способа 100 выполнения оптического распознавания серии изображений, содержащих символы текста, как описано выше в этом документе. Несмотря на то что машиночитаемый носитель данных 624, показанный в примере на Фиг. 6, является единым носителем, термин «машиночитаемый носитель» может включать один носитель или несколько носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любого одного или более способов настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельной памяти, а также к оптическим и магнитным носителям.
[00077] Описанные в документе способы, компоненты и функции могут быть реализованы дискретными компонентами оборудования, либо они могут быть интегрированы в функции других аппаратных компонентов, таких как ASICS, FPGA, DSP или подобных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00078] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[00079] Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Здесь и в целом алгоритмом называется логически непротиворечивая последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать их и манипулировать ими. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.п.
[00080] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано иначе, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, аналогично представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00081] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно приводится в действие или перенастраивается с помощью программы, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, в частности, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носитель любого типа, подходящий для хранения электронной информации.
[00082] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации изобретения станут очевидными специалистам в данной области техники после прочтения и понимания приведенного выше описания. Таким образом, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые охватываются формулой изобретения.


Изобретение относится к выполнению распознавания серии изображений, содержащих текстовые символы. Технический результат заключается в повышении качества оптического распознавания. Связывают с использованием преобразования координат части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки ранее полученных изображений из серии изображений. Выявляют первую строку-медиану, представляющую первый кластер символьной последовательности, исходя из первого подмножества изображений. Выявляют первое поле шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер, и разметки текста текущего изображения. Анализируют последовательность символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона. Выявляют для первого кластера строки-медианы второго уровня, соответствующие кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей. Получают с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа. 3 н. и 17 з.п. ф-лы, 9 ил.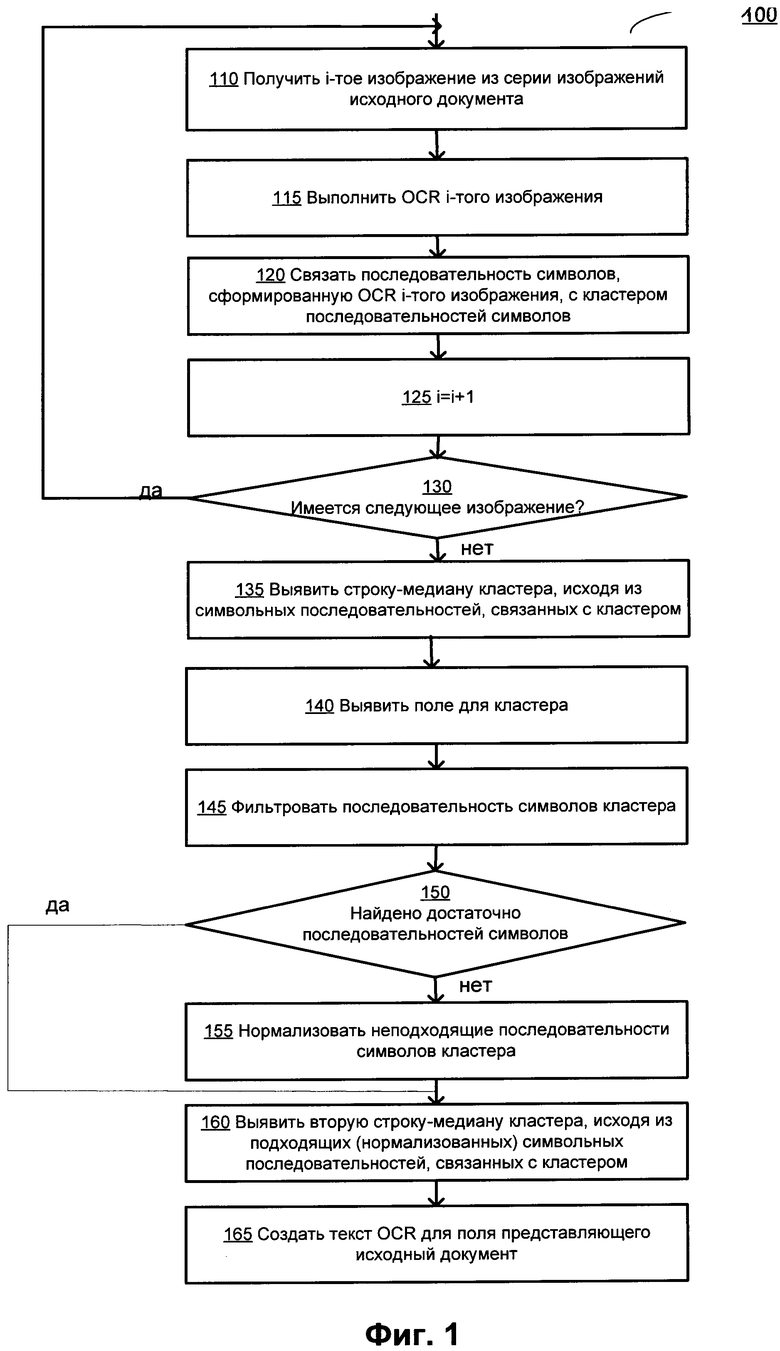
1. Способ извлечения данных из документа, включающий:
получение обрабатывающим устройством текущего изображения из серии изображений исходного документа, где текущее изображение как минимум частично перекрывается с предыдущим изображением из серии изображений;
выполнение оптического распознавания символов (OCR) текущего изображения для получения текста OCR и соответствующей разметки текста;
связывание с использованием преобразования координат как минимум части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений;
выявление первой строки-медианы, представляющей первый кластер символьной последовательности, исходя из первого подмножества изображений в серии изображений;
выявление первого поля шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер, и разметки текста текущего изображения;
анализ последовательностей символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона;
выявление для первого кластера строки-медианы второго уровня, соответствующей кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей;
получение с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа.
2. Способ по п. 1, дополнительно включающий:
нормализацию одной или более текстовых последовательностей из первого кластера для установления соответствия этих последовательностей символов первым параметрам первого поля шаблона;
выявление для первого кластера строки-медианы второго уровня, представляющей кластер последовательностей символов, исходя из множества нормализованных последовательностей символов.
3. Способ по п. 2, отличающийся тем, что нормализация включает:
выявление одного или более несоответствующих символов в последовательности символов, где несоответствующие символы - это символы, которые не удовлетворяют первым параметрам первого поля шаблона;
замену несоответствующих символов в последовательности символов пустыми местами.
4. Способ по п. 1, отличающийся тем, что анализ последовательностей символов из первого кластера для выявления подходящих последовательностей символов включает:
фильтрацию символьных последовательностей из первого кластера для фильтрации «мусорных» последовательностей символов.
5. Способ по п. 1, отличающийся тем, что строка-медиана второго уровня является ограниченной строкой-медианой, удовлетворяющей вторым параметрам первого поля шаблона.
6. Способ по п. 1, дополнительно включающий:
определение того, что строку-медиану второго уровня выявить не удается;
и выявление для кластера третьей строки-медианы, представляющей кластер символьных последовательностей, исходя из второго подмножества изображений из серии изображений, отличающегося от первого подмножества изображений.
7. Способ по п. 6, отличающийся тем, что второе подмножество серии изображений включает первое подмножество серии изображений.
8. Способ по п. 1, дополнительно включающий:
выявление шаблона документа, соответствующего исходному документу, исходя как минимум из разметки текста, полученной с помощью OCR, и выявленной первой строки-медианы.
9. Способ по п. 8, отличающийся тем, что шаблон документа выбирается из набора шаблонов документов.
10. Способ по п. 8, отличающийся тем, что дополнительно включает:
определение того, что шаблон документа для исходного документа не может быть определен с достаточной степенью уверенности;
выявление четвертой строки-медианы, представляющей кластер символьных последовательностей, исходя из третьего подмножества изображений серии изображений, отличающегося от первого подмножества изображений.
11. Система извлечения данных из документа, включающая:
запоминающее устройство (ЗУ);
устройство обработки, подключенное к запоминающему устройству, причем устройство обработки предназначено для выполнения следующих действий:
получение обрабатывающим устройством текущего изображения из серии изображений исходного документа, где текущее изображение как минимум частично перекрывается с предыдущим изображением из серии изображений;
выполнение оптического распознавания символов (OCR) текущего изображения для получения текста OCR и соответствующей разметки текста;
связывание с использованием преобразования координат как минимум части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений;
выявление первой строки-медианы, представляющей первый кластер символьной последовательности, исходя из первого подмножества изображений в серии изображений;
выявление первого поля шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер, и разметки текста текущего изображения;
анализ последовательности символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона;
выявление для первого кластера строки-медианы второго уровня, соответствующей кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей; и
получение с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа.
12. Система по п. 11, дополнительно включающая:
нормализацию одной или более текстовых последовательностей из первого кластера для установления соответствия этих последовательностей символов первым параметрам первого поля шаблона;
выявление для первого кластера строки-медианы второго уровня, представляющей кластер последовательностей символов, исходя из множества нормализованных последовательностей символов.
13. Система по п. 12, отличающаяся тем, что нормализация включает:
выявление одного или более несоответствующих символов в последовательности символов, где несоответствующие символы - это символы, которые не удовлетворяют первым параметрам первого поля шаблона;
замену несоответствующих символов в последовательности символов пустыми местами.
14. Система по п. 11, отличающаяся тем, что анализ последовательностей символов из первого кластера для выявления подходящих последовательностей символов включает:
фильтрацию символьных последовательностей из первого кластера для фильтрации «мусорных» последовательностей символов.
15. Система по п. 11, отличающаяся тем, что строка-медиана второго уровня является ограниченной строкой-медианой, удовлетворяющей вторым параметрам первого поля шаблона.
16. Система по п. 11, дополнительно включающая:
определение того, что строку-медиану второго уровня выявить не удается; и
выявление для кластера третьей строки-медианы, представляющей кластер символьных последовательностей, исходя из второго подмножества изображений из серии изображений, отличающегося от первого подмножества изображений.
17. Система по п. 11, дополнительно включающая:
выявление шаблона документа, соответствующего исходному документу, исходя как минимум из разметки текста, полученной с помощью OCR, и выявленной первой строки-медианы.
18. Система по п. 17, дополнительно включающая:
определение того, что шаблон документа для исходного документа не может быть определен с достаточной степенью уверенности;
выявление четвертой строки-медианы, представляющей кластер символьных последовательностей, исходя из третьего подмножества изображений серии изображений, отличающегося от первого подмножества изображений.
19. Машиночитаемый постоянный носитель данных, содержащий исполняемые команды, направленные на извлечение данных из документа, которые при выполнении в обрабатывающем устройстве заставляют это обрабатывающее устройство осуществлять:
получение обрабатывающим устройством текущего изображения из серии изображений исходного документа, где текущее изображение как минимум частично перекрывается с предыдущим изображением из серии изображений;
выполнение оптического распознавания символов (OCR) текущего изображения для получения текста OCR и соответствующей разметки текста;
связывание с использованием преобразования координат как минимум части текста OCR с первым кластером из множества кластеров символьных последовательностей, где текст OCR получен путем обработки текущего изображения, и где последовательности символов получены путем обработки одного или более ранее полученных изображений из серии изображений;
выявление первой строки-медианы, представляющей первый кластер символьной последовательности, исходя из первого подмножества изображений в серии изображений;
выявление первого поля шаблона из шаблона документа, соответствующего первому кластеру, исходя из первой строки-медианы, представляющей первый кластер, и разметки текста текущего изображения;
анализ последовательности символов первого кластера для выявления подходящих последовательностей символов, причем подходящие последовательности символов удовлетворяют первым параметрам первого поля шаблона;
выявление для первого кластера строки-медианы второго уровня, соответствующей кластеру символьных последовательностей, исходя из множества подходящих символьных последовательностей; и
получение с помощью строки-медианы второго уровня итогового текста OCR, представляющего как минимум часть первого поля шаблона исходного документа.
20. Носитель по п. 19, дополнительно содержащий команды, которые при выполнении в обрабатывающем устройстве заставляют это обрабатывающее устройство осуществлять:
нормализацию одной или более текстовых последовательностей из первого кластера для установления соответствия этих последовательностей символов первым параметрам первого поля шаблона;
выявление для первого кластера строки-медианы второго уровня, представляющей кластер последовательностей символов, исходя из множества нормализованных последовательностей символов.
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 9058536 B1, 16.06.2015 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ СЕРИИ ИЗОБРАЖЕНИЙ | 2016 |
|
RU2613849C1 |

