[0001] Настоящее изобретение в целом относится к вычислительным системам, а точнее -к системам и способам оптического распознавания символов (OCR).
УРОВЕНЬ ТЕХНИКИ
[0002] Оптическое распознавание символов (OCR) представляет собой реализованное вычислительными средствами преобразование изображений, содержащих текст (включая типографский, рукописный или печатный текст), в машиночитаемые электронные документы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами реализации настоящего изобретения пример способа выполнения оптического распознавания символов (OCR) на изображении, содержащем символы, может включать получение обрабатывающим устройством исходного изображения документа; идентификации месторасположения первой последовательности символов на исходном изображении; применение первого набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов; применение второго набора операций конвертации к первой части исходного изображения для получения второй конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) второй конвертированной части исходного изображения для получения второй распознанной первой последовательности символов; и объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов для получения объединенной первой последовательности символов; применение третьего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения третьей конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) третьей конвертированной части исходного изображения для получения третьей распознанной первой последовательности символов; объединение первой распознанной первой последовательности символов, второй распознанной первой последовательности символов и третьей распознанной первой последовательности символов для получения объединенной первой последовательности символов; и перевод полученной первой строки текста на второй естественный язык; где операции конвертации выбираются из группы операций конвертации, включающих изменение одной или более из следующих параметров изображения: разрешение, способ бинаризации, настройки исправления искажений, настройки устранения бликов, настройки устранения размытия и подавления шумов. В некоторых вариантах реализации этот способ включает шаги применения к первой части исходного изображения, содержащего местоположение первой последовательности символов, следующего набора операций конвертации с целью получения другой конвертированной части исходного изображения, а также выполнение оптического распознавания символов (OCR) на другой конвертированной части исходного изображения для получения другой распознанной первой последовательности символов заранее определенное количество раз. В некоторых вариантах реализации этот способ включает шаги определения качества полученной первой строки текста; сравнение обнаруженного качества полученной первой строки текста с заранее определенным порогом качества; в ответ на выявление того, что обнаруженное качество полученной первой строки текста не соответствует заранее определенному порогу качества, применение следующего набора операций конвертации к первой последовательности символов для создания другой конвертированной части исходного изображения, выполнение оптического распознавания символов (OCR) другой конвертированной первой последовательности символов для получения другой распознанной первой последовательности символов; объединение другой распознанной первой последовательности символов с ранее распознанной первой последовательности символов для получения в результате обновленной первой последовательности символов. В некоторых вариантах реализации объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов включает выявление медианной строки, соответствующей первой последовательности символов, или взвешенной медианной строки, соответствующей первой последовательности символов. В некоторых вариантах реализации выявление медианной строки, соответствующей первой строке текста, включает выявление расстояния редактирования между первой распознанной первой строкой текста и второй распознанной первой строкой текста или выявление расстояния Левенштейна между первой распознанной первой строкой текста и второй распознанной первой строкой текста.
[0004] В соответствии с одним или более вариантами реализации настоящего изобретения пример системы для осуществления оптического распознавания символов (OCR) серии изображений, содержащих символы определенной системы письменности, может включать запоминающее устройство, устройство обработки, подключенное к запоминающему устройству, причем устройство обработки предназначено для выполнения следующих операций: получение обрабатывающим устройством исходного изображения документа; идентификацию месторасположения первой последовательности символов на исходном изображении; применение первого набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов; применение второго набора операций конвертации к первой части исходного изображения для получения второй конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) второй конвертированной части исходного изображения для получения второй распознанной первой последовательности символов; и объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов для получения объединенной первой последовательности символов; применение третьего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения третьей конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) третьей конвертированной части исходного изображения для получения третьей распознанной первой последовательности символов; объединение первой распознанной первой последовательности символов, второй распознанной первой последовательности символов и третьей распознанной первой последовательности символов для получения объединенной первой последовательности символов; и перевод полученной первой строки текста на второй естественный язык; где операции конвертации выбираются из группы операций конвертации, включающих изменение одного или более из следующих параметров изображения: разрешение, способ бинаризации, настройки исправления искажений, настройки устранения бликов, настройки устранения размытия и подавления шумов. В некоторых вариантах реализации система выполнена с возможностью также применения следующего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания другой конвертированной части исходного изображения; выполнения оптического распознавания символов (OCR) другой конвертированной части исходного изображения для получения следующей распознанной первой последовательности символов заранее определенное количество раз. В некоторых вариантах реализации система выполнена с возможностью также определения качества полученной первой строки текста; сравнения обнаруженного качества полученной первой строки текста с заранее определенным порогом качества; в ответ на выявление того, что обнаруженное качество полученной первой строки текста не соответствует заранее определенному порогу качества, применения следующего набора операций конвертации к первой последовательности символов для создания другой конвертированной части исходного изображения; выполнения оптического распознавания символов (OCR) другой конвертированной первой последовательности символов для получения другой распознанной первой последовательности символов; объединения другой распознанной первой последовательности символов с ранее распознанной первой последовательности символов для получения в результате обновленной первой последовательности символов. В некоторых вариантах реализации объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов включает выявление медианной строки, соответствующей первой последовательности символов, или взвешенной медианной строки, соответствующей первой последовательности символов. В некоторых вариантах реализации выявление медианной строки, соответствующей первой строке текста, включает выявление расстояния редактирования между первой распознанной первой строкой текста и второй распознанной первой строкой текста или выявление расстояния Левенштейна между первой распознанной первой строкой текста и второй распознанной первой строкой текста.
[0005] В соответствии с одним или более вариантами реализации настоящего изобретения пример постоянного машиночитаемого носителя данных может включать исполняемые команды, которые при исполнении их обрабатывающим устройством приводят к выполнению обрабатывающим устройством операций, включающих в себя: получение обрабатывающим устройством исходного изображения документа; идентификацию месторасположения первой последовательности символов на исходном изображении; применение первого набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов; применение второго набора операций конвертации к первой части исходного изображения для получения второй конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) второй конвертированной части исходного изображения для получения второй распознанной первой последовательности символов; и объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов для получения объединенной первой последовательности символов; применение третьего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения третьей конвертированной части исходного изображения; выполнение оптического распознавания символов (OCR) третьей конвертированной части исходного изображения для получения третьей распознанной первой последовательности символов; объединение первой распознанной первой последовательности символов, второй распознанной первой последовательности символов и третьей распознанной первой последовательности символов для получения объединенной первой последовательности символов; и перевод полученной первой строки текста на второй естественный язык; где операции конвертации выбираются из группы операций конвертации, включающих изменение одного или более из следующих параметров изображения: разрешение, способ бинаризации, настройки исправления искажений, настройки устранения бликов, настройки устранения размытия и подавления шумов. В некоторых вариантах реализации система выполнена с возможностью также применения следующего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания другой конвертированной части исходного изображения; выполнения оптического распознавания символов (OCR) другой конвертированной части исходного изображения для получения следующей распознанной первой последовательности символов заранее определенное количество раз. В некоторых вариантах реализации система выполнена с возможностью также определения качества полученной первой строки текста; сравнения обнаруженного качества полученной первой строки текста с заранее определенным порогом качества; в ответ на выявление того, что обнаруженное качество полученной первой строки текста не соответствует заранее определенному порогу качества, применения следующего набора операций конвертации к первой последовательности символов для создания другой конвертированной части исходного изображения; выполнения оптического распознавания символов (OCR) другой конвертированной первой последовательности символов для получения другой распознанной первой последовательности символов; объединения другой распознанной первой последовательности символов с ранее распознанной первой последовательности символов для получения в результате обновленной первой последовательности символов. В некоторых вариантах реализации объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов включает выявление медианной строки, соответствующей первой последовательности символов, или взвешенной медианной строки, соответствующей первой последовательности символов. В некоторых вариантах реализации выявление медианной строки, соответствующей первой строке текста, включает выявление расстояния редактирования между первой распознанной первой строкой текста и второй распознанной первой строкой текста или выявление расстояния Левенштейна между первой распознанной первой строкой текста и второй распознанной первой строкой текста.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
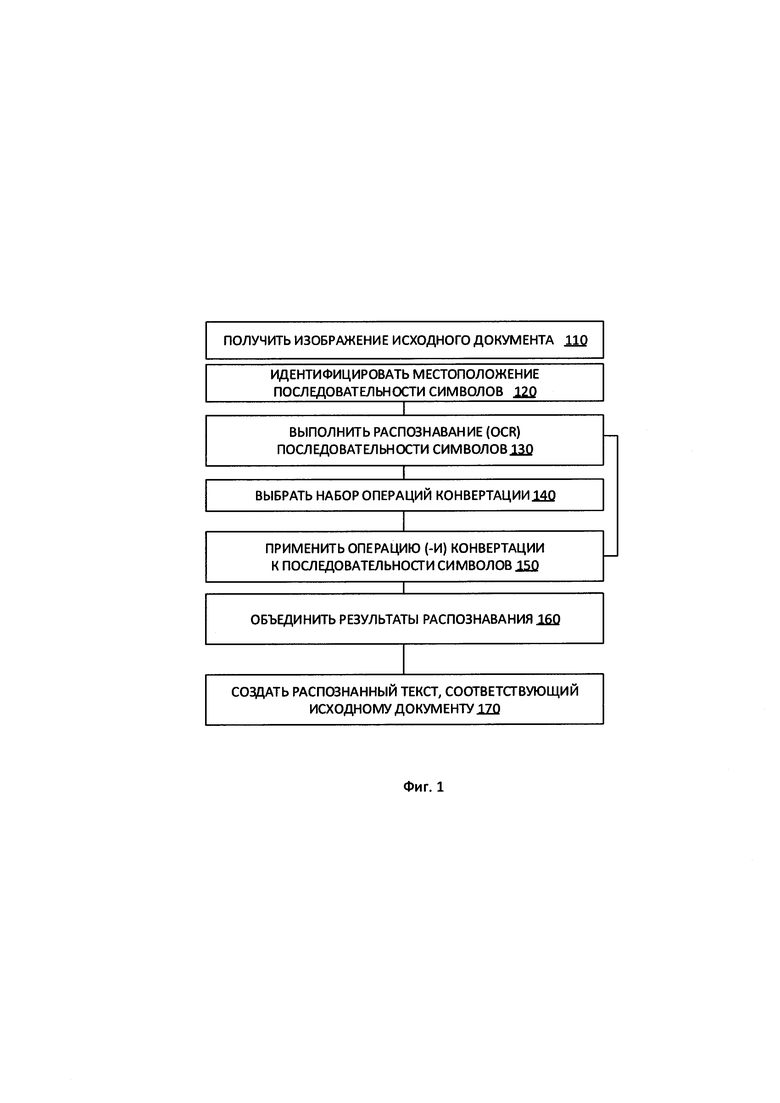
[0007] На Фиг. 1 приведена блок-схема иллюстративного примера способа выполнения оптического распознавания символов (OCR) на изображении, содержащем символы текста, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0008] На Фиг. 2 схематически иллюстрируется изображение с выявленными последовательностями символов.
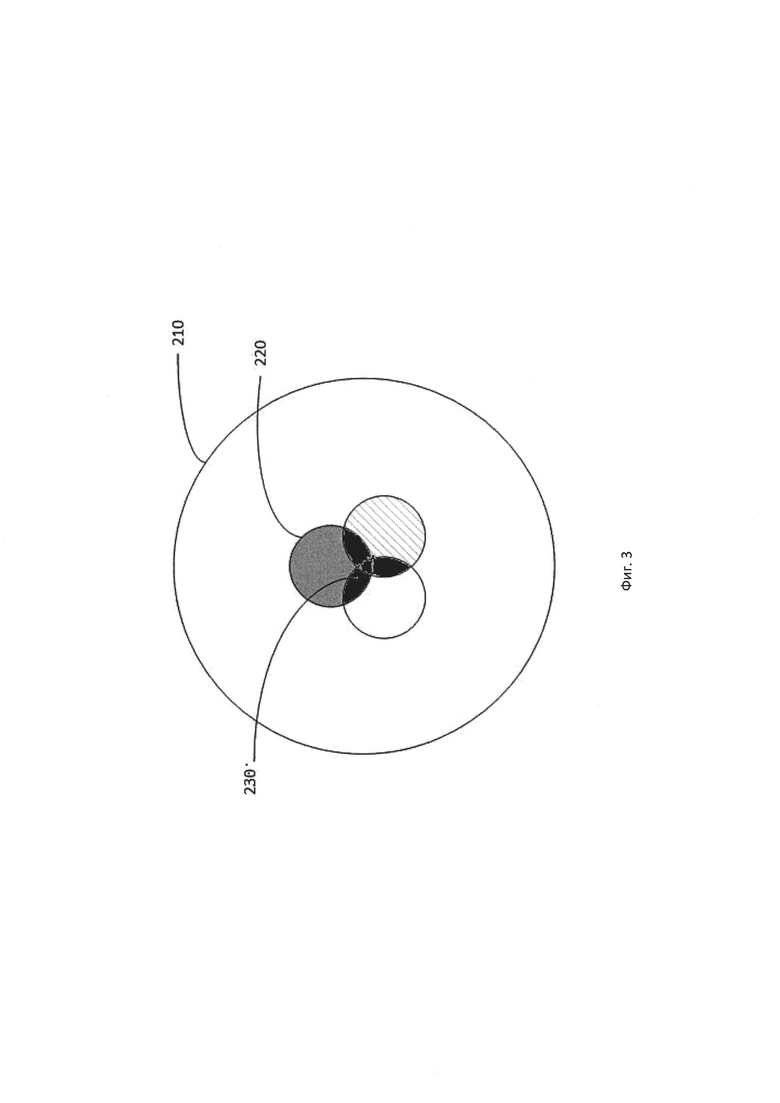
[0009] На Фиг. 3 схематически иллюстрируется концепция снижения количества ошибок распознавания за счет использования серии изображений, полученных в результате различных операций конвертации.
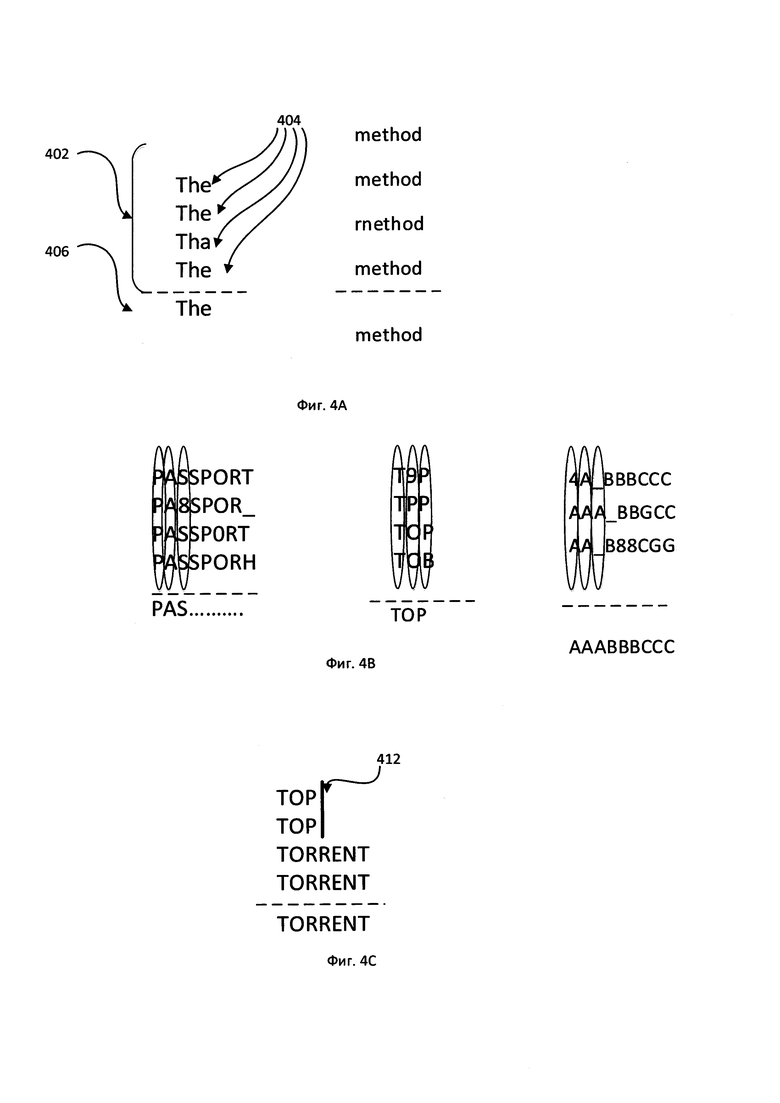
[00010] На Фиг. 4А-4С схематически иллюстрируется выявление медианной строки среди множества последовательностей символов, представляющих результаты OCR соответствующих фрагментов изображения, в соответствии с одним или более вариантами реализации настоящего изобретения.
[00011] На Фиг. 5 приведена схема иллюстративного примера вычислительной системы, в которой реализованы способы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00012] В этом разделе описаны способы и системы для осуществления оптического распознавания символов (OCR) одного или более изображений, содержащих символы определенного алфавита. Алфавиты, символы которых могут быть обработаны с помощью систем и способов, описанных в этом документе, включают алфавиты с отдельными символами, или глифами, соответствующими отдельным звукам, а также иероглифические системы письменности с отдельными символами, соответствующими более крупным блокам, таким как слоги или слова.
[00013] В приведенном ниже описании термин «документ» должен толковаться расширительно, как относящийся к широкому спектру носителей текста, включая, помимо прочего, печатные или написанные от руки бумажные документы, баннеры, постеры, знаки, рекламные щиты и (или) другие физические объекты, несущие видимые символы текста на одной или более поверхностях. В приведенном ниже описании термин «Изображение документа» относится к изображению как минимум части исходного документа (например, страницы бумажного документа).
[00014] Система оптического распознавания символов (OCR) может получать изображение документа и преобразовывать полученное изображение в машиночитаемый формат, допускающий поиск и содержащий текстовую информацию, извлеченную из изображения документа. Процесс OCR может быть затруднен различными дефектами изображения, такими как визуальный шум, расфокусировка или низкая резкость изображения, блики и т.д., которые обычно вызваны дрожанием камеры, недостаточным освещением, неправильно выбранной выдержкой или диафрагмой и (или) другими условиями и затрудняющими обстоятельствами. Если обычные способы OCR не всегда могут правильно выполнить распознавание символов при наличии указанных выше и других дефектов изображения, то системы и способы, описанные в этом документе, могут значительно повысить качество OCR за счет создания набора изображений и применения к изображению документа различных наборов операций конверсии, как более подробно описано ниже.
[00015] В некоторых вариантах реализации текст, полученный системами и способами OCR, описанными в этом документе, может быть дополнительно обработан, например при помощи способов машинного перевода для перевода исходного текста на другой естественный язык.
[00016] В иллюстративном примере вычислительная система, реализующая описанные в этом документе способы, может получать изображение исходного документа.
[00017] Вычислительная система может обнаружить часть изображения, содержащую последовательность символов, которая может образовывать слово, группу слов или строку текста. Система может применить к этой части изображения (или ко всему изображению) один или более наборов операций конвертации, создавая серию конвертированных частей изображения. Каждый набор операций конвертации может состоять из одной или более операций конвертации. Операции конвертации могут включать изменение разрешения части изображения, применение различных способов бинаризации, изменение настроек исправления искажений, настроек устранения бликов, настроек контроля размытия и изменение операций подавления шумов. Эти операции могут применяться к части изображения по отдельности или в группе, последовательно или параллельно.
[00018] Затем система может выполнять распознавание символов на этих различных вариантах части изображения (или всего изображения), получая серию распознанных последовательностей символов. Система объединяет распознанные последовательности символов, чтобы повысить качество распознавания.
[00019] Хорошо известно, что различные дефекты изображений создают различные типы ошибок распознавания. Фиг. 3 далее иллюстрирует этот факт. Окружность 210 представляет все возможные ошибки распознавания. Окружность 220 и похожие окружности представляют ошибки распознавания, сохранившиеся в документе после применения к изображению операции частичной конвертации. Область 230 представляет множество ошибок распознавания, которые могут возникнуть в документе при объединении результатов OCR, полученных с использованием различных наборов операций конвертации.
[00020] Для объединения распознанных последовательных символов может использоваться метод медианной строки. В этом методе для каждого стека совпадающих последовательностей символов может быть выявлена медианная строка, представляющая результат OCR соответствующего фрагмента изображения. В некоторых вариантах реализации медианная строка может быть выявлена как последовательность символов, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей стека. Расстояние редактирования, которое в одном из иллюстративных примеров может быть представлено расстоянием Левенштейна, между первой последовательностью символов и второй последовательностью символов может быть равно минимальному количеству редактирований единичных символов (например, вставок, удалений или замен), необходимых для преобразования первой последовательности символов во вторую последовательность символов.
[00021] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, а не способом ограничения.
[00022] На Фиг. 1 показана блок-схема одного из иллюстративных примеров способа 100 выполнения OCR изображения, содержащего символы текста, в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 100 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 500 на Фиг. 5), реализующей этот способ. В некоторых реализациях способ 100 может быть реализован в одном потоке обработки. В качестве альтернативы способ 100 может выполняться с использованием двух и более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций способа. В одном из иллюстративных примеров потоки обработки, в которых реализован способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). При альтернативном подходе потоки обработки, в которых реализован способ 100, могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то что Фиг. 1 и соответствующее описание содержат список операций для способа 100 в определенном порядке, в различных вариантах реализации способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[00023] Для ясности и краткости настоящее описание предполагает, что конвертация изображения исходного документа производится последовательно, и следующая конвертация начинается после того, как предыдущая конвертация будет в значительной степени завершена. Однако в различных альтернативных реализациях изобретения конвертация изображения может совпадать по времени (например, может выполняться в различных потоках или процессах, которые выполняются на одном или более процессорах). Вместо этого две или более конвертации могут быть помещены в буфер и обрабатываться асинхронно с учетом выполнения вычислительной системой, реализующей данный способ, других операций конвертации.
[00024] Настоящее изобретение ссылается на «изображение» (например, кадр видео или отдельное изображение) исходного документа. Это изображение может именоваться «исходным изображением», то есть изображением до применения системой операций конвертации. После применения системой этих операций ко всему исходному изображению или части исходного изображения это изображение / часть изображения могут именоваться «конвертированным изображением» / «конвертированной частью изображения».
[00025] На шаге 110 вычислительная система, реализующая способ, может получать исходное изображение. На шаге 120 вычислительная система может идентифицировать местоположение последовательности символов на изображении. Как показано на Фиг. 2, система может идентифицировать местоположение последовательностей символов путем сегментации, то есть путем выявления внутри изображения 200а множества прямоугольников, таких как прямоугольник 205, содержащих последовательности символов. Эти последовательности символов могут содержать буквы, цифры, специальные символы, знаки пунктуации и т.д. В этом способе может быть использован любой известный способ выявления местоположений последовательностей символов.
[00026] На шаге 130 система выполняет распознавание (OCR) последовательностей символов, местоположение которых было идентифицировано системой на шаге 120. Распознавание может выполняться с использованием любого известного способа, например корреляции матриц, выделения признаков или их комбинации.
[00027] На шаге 140 система выбирает набор операций конвертации, которые будут применяться к части исходного изображения, содержащей последовательность символов. В некоторых вариантах реализации изобретения набор операций конвертации применяется к исходному изображению документа в целом.
[00028] Операция конвертации представляет собой операцию преобразования, применяемую к изображению, которая изменяет изображение некоторым образом. Например, к операциям конвертации относятся изменение разрешения изображения, выполнение бинаризации изображения с использованием определенных настроек, исправление искажений, бликов или размытия, выполнение операций подавления шума и т.д.
[00029] Шаг 140 выбора набора операций конвертации может включать выбор операций из списка типов доступных операций и (или) выбор параметров для одной или более выбранных операций. Набор операций конвертации может включать одну или более операций конвертации. В некоторых вариантах реализации последовательность наборов операций конвертации / параметров операций определена заранее. В других вариантах реализации выбор наборов операций конвертации и (или) их параметров выполняется на основе обратной связи от системы. В некоторых вариантах в набор операций конвертации могут быть включены одинаковые операции конвертации с разными параметрами.
[00030] На шаге 150 система применяет выбранную операцию конвертации к изображению (или части изображения, содержащей последовательность символов), получая в результате конвертированное изображение, соответствующее выбранному набору операций конвертации.
[00031] После выполнения конвертации 150 изображения система повторяет шаги 130 выполнения распознавания последовательности символов, используя конвертированное изображение. При этом распознавании получается другая последовательность символов, которая может отличаться от последовательности символов, полученной с использованием исходного изображения.
[00032] В некоторых вариантах реализации система выполняет шаги 130-150 несколько раз для создания серии конвертированных изображений и соответствующей серии распознанных последовательностей символов. В некоторых вариантах реализации количество выполнений конвертации / распознавания определено заранее. В других вариантах реализации это количество определяется на основе обратной связи от системы.
[00033] На шаге 160 вычислительная система может объединять результаты распознавания серии модифицированных изображений. Система может выполнить объединение, выявляя медианную строку каждого стека совпадающих последовательностей символов, такую, что выявленная медианная строка должна соответствовать результату OCR соответствующего фрагмента изображения.
[00034] Как схематически показано на Фиг. 4А, каждый стек 402 может содержать множество совпадающих последовательностей символов 404, а результат OCR соответствующего фрагмента изображения может быть представлен медианной строкой 406. В некоторых вариантах реализации медианная строка может быть выявлена как последовательность символов, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей стека. Расстояние редактирования, которое в одном из иллюстративных примеров может быть представлено расстоянием Левенштейна, между первой последовательностью символов и второй последовательностью символов может быть равно минимальному количеству редактирований единичных символов (например, вставок, удалений или замен), необходимых для преобразования первой последовательности символов во вторую последовательность символов.
[00035] В некоторых вариантах реализации вычислительная сложность выявления медианной строки может быть уменьшена за счет применения определенных эвристических методов. В одном из иллюстративных примеров вычислительная система может эвристически выявить аппроксимацию нулевого порядка медианной строки. Затем вычислительная система может выровнять последовательности символов, используя строго совпадающие символы внутри каждой последовательности, как схематически показано на Фиг. 4В. В другом иллюстративном примере вычислительная система может вычислять взвешенную медиану, связывая с каждой последовательностью символов в стеке весовой коэффициент, отражающий положение последовательности символов в изображении или показатель уверенности распознавания. Как схематически показано на Фиг. 4С, стек 412 содержит четыре последовательности символов: TOP, TOP, TORRENT, TORRENT. Первые две последовательности символов соответствуют частям слов, так как расстояние от границы минимального описывающего прямоугольника последовательности символов до края изображения меньше, чем ширина пробела. Поэтому значение показателя уверенности распознавания для первых двух последовательностей символов значительно меньше, чем значение показателя уверенности распознавания для оставшихся двух последовательностей символов, и поэтому последовательность символов TORRENT будет выбрана в качестве медианной строки методом, который принимает во внимание значения уверенности распознавания.
[00036] В различных реализациях настоящего изобретения операции, описанные на шаге 130-150, могут выполняться в другой последовательности или параллельно. Кроме того, в некоторых реализациях настоящего изобретения некоторые операции, описанные на шаге 110-120, могут быть пропущены.
[00037] Если возвратиться к Фиг. 1, на шаге 170 вычислительная система может использовать полученные последовательности символов для получения итогового текста, соответствующего исходному документу.
[00038] Как отмечено выше в настоящем документе, текст, создаваемый системами и способами OCR, описанными в этом документе, может подвергаться дальнейшей обработке, например способами машинного перевода для перевода исходного текста на другой естественный язык. Поскольку описанные в этом документе способы позволяют реконструировать исходный текст, а не только отдельные слова, то для повышения качества машинного перевода способы машинного перевода могут использовать синтаксический и (или) семантический анализ.
[00039] На Фиг. 5 представлена более подробная схема компонентов примера вычислительной системы 500, внутри которой может быть исполнен набор инструкций, которые вызывают выполнение вычислительной системой любого одного или более способов настоящего изобретения. Вычислительная система 500 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 500 может работать в качестве сервера или клиента в сетевой среде «клиент / сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 500 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или более наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[00040] Пример вычислительной системы 500 включает процессор 502, основное запоминающее устройство 504 (например, постоянное запоминающее устройство (ПЗУ) или динамическое оперативное запоминающее устройство (ДОЗУ)) и устройство хранения данных 518, которые взаимодействуют друг с другом по шине 530.
[00041] Процессор 502 может быть представлен одним или более универсальными устройствами обработки данных, например микропроцессором, центральным процессором и т.п. В частности, процессор 502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW) или процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 502 также может представлять собой одно или более устройств обработки специального назначения, например заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 502 выполнен с возможностью исполнения инструкций 526 для выполнения операций и функций способа 100 выполнения OCR серии изображений, содержащих символы текста, как описано выше в этом документе.
[00042] Вычислительная система 500 может дополнительно включать устройство сетевого интерфейса 522, устройство визуального отображения 510, устройство ввода символов 512 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 514.
[00043] Устройство хранения данных 518 может содержать машиночитаемый носитель данных 524, в котором хранится один или более наборов команд 526, реализующих один или более из способов или функций настоящего изобретения. Команды 526 также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 504 и (или) в процессоре 502 во время выполнения их в вычислительной системе 500, при этом основное запоминающее устройство 504 и процессор 502 также представляют собой машиночитаемый носитель данных. Команды 526 дополнительно могут передаваться или приниматься по сети 516 через устройство сетевого интерфейса 522.
[00044] В некоторых вариантах реализации инструкции 526 могут включать команды способа 100 выполнения OCR серии изображений, содержащих символы текста, как описано выше в этом документе. Несмотря на то что машиночитаемый носитель данных 524, показанный в примере на Фиг. 5, является единым носителем, термин «машиночитаемый носитель» может включать один или более носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00045] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00046] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00047] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00048] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано дополнительно, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и запоминающих устройствах вычислительной системы, в другие данные, аналогично представленные в виде физических величин в запоминающих устройствах или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00049] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00050] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.

Группа изобретений относится к технологиям оптического распознавания символов на изображении, содержащем текстовые символы. Техническим результатом является повышение качества оптического распознавания символов (OCR) за счет создания набора изображений и применения к изображению документа различных наборов операций конверсии. Предложен способ улучшения распознавания. Способ содержит этап, на котором осуществляют получение устройством обработки исходного изображения документа. Далее согласно способу осуществляют идентификацию месторасположения первой последовательности символов на исходном изображении, применение первого набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения. Далее выполняют оптическое распознавание символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов. 3 н. и 17 з.п. ф-лы, 5 ил.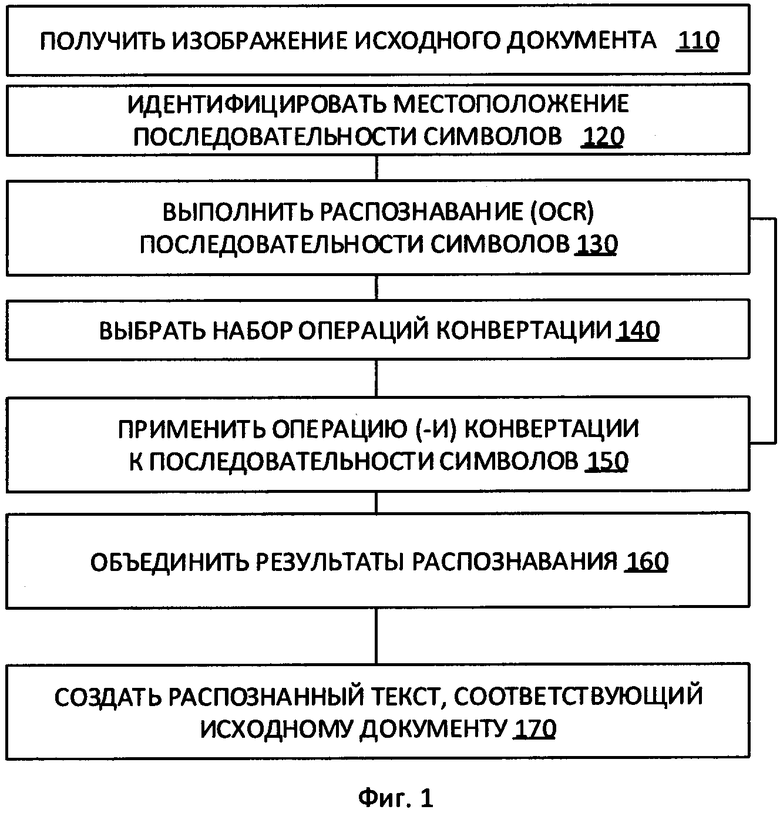
1. Способ улучшения качества распознавания, включающий:
получение устройством обработки исходного изображения документа;
идентификация месторасположения первой последовательности символов на исходном изображении;
применение первого набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения;
выполнение оптического распознавания символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов;
применение второго набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения второй конвертированной части исходного изображения;
выполнение оптического распознавания символов (OCR) второй конвертированной части исходного изображения для получения второй распознанной первой последовательности символов; и
объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов для получения объединенной первой последовательности символов.
2. Способ по п. 1, дополнительно включающий:
применение третьего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения третьей конвертированной части исходного изображения;
выполнение оптического распознавания символов (OCR) третьей конвертированной части исходного изображения для получения третьей распознанной первой последовательности символов; и
объединение первой распознанной первой последовательности символов, второй распознанной первой последовательности символов и третьей распознанной первой последовательности символов для получения объединенной первой последовательности символов.
3. Способ по п. 2, отличающийся тем, что операции конвертации выбираются из группы операций конвертации, включающей изменение одного или более из следующих параметров изображения: разрешение, способ бинаризации, настройки исправления искажений, настройки устранения бликов, настройки устранения размытия и подавления шумов.
4. Способ по п. 2, отличающийся тем, что набор операций конвертации включает первую операцию конвертации с первым набором параметров конвертации, вторую операцию конвертации со вторым набором параметров конвертации.
5. Способ по п. 2, также включающий выполнение следующих шагов:
применение следующего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания другой конвертированной части исходного изображения;
выполнение оптического распознавания символов (OCR) другой конвертированной части исходного изображения для получения другой распознанной первой последовательности символов;
заранее определенное количество раз.
6. Способ по п. 2, дополнительно включающий:
определение качества полученной первой строки текста;
сравнение определенного качества полученной первой строки текста с заранее определенным порогом качества;
в ответ на выявление того, что обнаруженное качество полученной первой строки текста не соответствует заранее определенному порогу качества, применение следующего набора операций конвертации к первой последовательности символов для создания другой конвертированной части исходного изображения;
выполнение оптического распознавания символов (OCR) другой конвертированной первой последовательности символов для получения другой распознанной первой последовательности символов;
объединение другой распознанной первой последовательности символов и предыдущей распознанной первой последовательности символов для получения обновленной первой последовательности символов.
7. Способ по п. 1, отличающийся тем, что объединение первой распознанной первой последовательности символов и второй распознанной первой последовательности символов включает выявление медианной строки, соответствующей первой последовательности символов.
8. Способ по п. 7, отличающийся тем, что выявление медианной строки, соответствующей первой последовательности символов, включает выявление расстояния редактирования между первой распознанной первой строкой текста и второй распознанной первой строкой текста.
9. Способ по п. 7, отличающийся тем, что выявление медианной строки, соответствующей первой последовательности символов, включает выявление расстояния Левенштейна между первой распознанной первой строкой текста и второй распознанной первой строкой текста.
10. Способ по п. 1, отличающийся тем, что первая последовательность символов предоставляется на первом естественном языке, способ также включает:
перевод полученной первой последовательности символов на второй естественный язык.
11. Система улучшения качества распознавания, содержащая:
запоминающее устройство (ЗУ);
устройство обработки, подключенное к запоминающему устройству, причем устройство обработки выполнено, чтобы:
получать (посредством устройства обработки) исходное изображение документа;
идентифицировать месторасположения первой последовательности символов на исходном изображении;
применять первый набор операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения;
выполнять оптическое распознавание символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов;
применять второй набор операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности
символов, для получения второй конвертированной части исходного изображения;
выполнять оптическое распознавание символов (OCR) второй конвертированной части исходного изображения для получения второй распознанной первой последовательности символов; и
объединять первую распознанную первую последовательность символов и вторую распознанную первую последовательность символов для получения объединенной первой последовательности символов.
12. Система по п. 11, дополнительно предназначенная, чтобы: применять третий набор операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения третьей конвертированной части исходного изображения;
выполнять оптическое распознавание символов (OCR) третьей конвертированной части исходного изображения для получения третьей распознанной первой последовательности символов; и
объединять первую распознанную первую последовательность символов, вторую распознанную первую последовательность символов и третью распознанную первую последовательность символов для получения объединенной первой последовательности символов.
13. Система по п. 12, отличающаяся тем, что операции конвертации выбираются из группы операций конвертации, включающей изменение одного или более из следующих параметров изображения: разрешение, способ бинаризации, настройки исправления искажений, настройки устранения бликов, настройки устранения размытия и подавления шумов.
14. Система по п. 12, отличающаяся тем, что набор операций конвертации включает первую операцию конвертации с первым набором параметров конвертации, вторую операцию конвертации со вторым набором параметров конвертации.
15. Система по п. 12, дополнительно предназначенная для:
применения следующего набора операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания другой конвертированной части исходного изображения;
выполнения оптического распознавания символов (OCR) другой конвертированной части исходного изображения для получения другой распознанной первой последовательности символов;
заранее определенное количество раз.
16. Система по п. 12, дополнительно предназначенная для:
определения качества полученной первой строки текста;
сравнения определенного качества полученной первой строки текста с заранее определенным порогом качества;
в ответ на выявление того, что обнаруженное качество полученной первой строки текста не соответствует заранее определенному порогу качества, применения следующего набора операций конвертации к первой последовательности символов для создания другой конвертированной части исходного изображения;
выполнения оптического распознавания символов (OCR) другой конвертированной первой последовательности символов для получения другой распознанной первой последовательности символов;
объединения другой распознанной первой последовательности символов и предыдущей распознанной первой последовательности символов для получения обновленной первой последовательности символов.
17. Система по п. 11, отличающаяся тем, что первая последовательность символов предоставляется на первом естественном языке, дополнительно предназначена для перевода первой последовательности символов на второй естественный язык.
18. Машиночитаемый постоянный носитель данных, содержащий исполняемые команды, которые при выполнении в обрабатывающем устройстве заставляют это обрабатывающее устройство:
получать исходное изображение физического документа;
идентифицировать месторасположение первой последовательности символов на исходном изображении;
применять первый набор операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для создания первой конвертированной части исходного изображения;
выполнять оптическое распознавание символов (OCR) первой конвертированной части исходного изображения для получения первой распознанной первой последовательности символов;
применять второй набор операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения второй конвертированной части исходного изображения;
выполнять оптическое распознавание символов (OCR) второй конвертированной части исходного изображения для получения второй распознанной первой последовательности символов; и
объединять первую распознанную первую последовательность символов и вторую распознанную первую последовательность символов для получения объединенной первой последовательности символов.
19. Машиночитаемый постоянный носитель данных по п. 18, дополнительно содержащий исполняемые команды, которые при выполнении в вычислительном устройстве заставляют это вычислительное устройство: применять третий набор операций конвертации к первой части исходного изображения, включающей местоположение первой последовательности символов, для получения третьей конвертированной части исходного изображения;
выполнять оптическое распознавание символов (OCR) третьей конвертированной части исходного изображения для получения третьей распознанной первой последовательности символов; и
объединять первую распознанную первую последовательность символов, вторую распознанную первую последовательность символов и третью распознанную первую последовательность символов для получения объединенной первой последовательности символов.
20. Машиночитаемый постоянный носитель данных по п. 18, отличающийся тем, что операции конвертации выбираются из группы операций конвертации, включающей изменение одного или более из следующих параметров изображения: разрешение, способ бинаризации, настройки исправления искажений, настройки устранения бликов, настройки устранения размытия и подавления шумов.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 7400768 B1, 15.07.2008 | |||
| US 5594815 A, 14.01.1997 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| СПОСОБ ОБРАБОТКИ ДАННЫХ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ (OCR), ГДЕ ВЫХОДНЫЕ ДАННЫЕ ВКЛЮЧАЮТ В СЕБЯ ИЗОБРАЖЕНИЯ СИМВОЛОВ С НАРУШЕННОЙ ВИДИМОСТЬЮ | 2008 |
|
RU2445699C1 |

