ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в общем относится к вычислительным системам, более конкретно к системам и способам оптического распознавания символов (OCR).
УРОВЕНЬ ТЕХНИКИ
[0002] Оптическое распознавание символов (OCR) представляет собой осуществляемое на компьютере преобразование изображений текста (включая машинописный, написанный от руки или напечатанный текст) в электронные документы в машинной кодировке.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более аспектами настоящего раскрытия изобретения описанный в примере способ оптического распознавания символов (OCR) серии изображений с символами некоторого алфавита может включать получение текущего изображения из серии изображений исходного документа, причем текущее изображение хотя бы частично перекрывает предыдущее изображение из серии изображений; выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующей ему разметки текста; определение с использованием распознанного текста и соответствующей ему разметки текста множества текстовых артефактов для каждого текущего изображения и предыдущего изображения, причем каждый текстовый артефакт представлен символьной последовательностью, которая обладает частотой встречаемости в распознанном тексте ниже пороговой частоты; определение для каждого текущего и предыдущего изображений соответствующего множества опорных точек, причем каждая опорная точка ассоциируется с по крайней мере одним текстовым артефактом из множества текстовых артефактов; вычисление с использованием координат соответствующих опорных точек текущего и предыдущего изображений параметров преобразования координат предыдущего изображения в координаты текущего изображения; связывание с помощью преобразования координат как минимум части распознанного текста с кластером из множества кластеров символьных последовательностей, причем распознанный текст создается путем обработки текущего изображения, а символьные последовательности создаются путем обработки одного или более ранее полученных изображений из серии изображений; определение для каждого кластера строки-медианы, представляющей кластер символьных последовательностей; и получение с использованием этой строки-медианы итогового распознанного текста, соответствующего хотя бы части исходного документа.
[0004] В соответствии с одним или более аспектами настоящего раскрытия изобретения описанная в примере система оптического распознавания символов (OCR) серии изображений с символами некоторого алфавита может включать память, устройство обработки, подключенное к памяти, причем устройство обработки предназначено для получения текущего изображения из серии изображений исходного документа, причем текущее изображение хотя бы частично перекрывает предыдущее изображение из серии изображений; выполнения оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующей ему разметки текста; определения с использованием распознанного текста и соответствующей ему разметки текста множества текстовых артефактов для каждого текущего изображения и предыдущего изображения, причем каждый текстовый артефакт представлен символьной последовательностью, которая обладает частотой встречаемости в распознанном тексте ниже пороговой частоты; определения для каждого текущего и предыдущего изображений соответствующего множества опорных точек, причем каждая опорная точка ассоциируется с по крайней мере одним текстовым артефактом из множества текстовых артефактов; вычисления с использованием координат соответствующих опорных точек текущего и предыдущего изображений параметров преобразования координат предыдущего изображения в координаты текущего изображения; связывания с помощью преобразования координат как минимум части распознанного текста с кластером из множества кластеров символьных последовательностей, причем распознанный текст создается путем обработки текущего изображения, а символьные последовательности создаются путем обработки одного или более ранее полученных изображений из серии изображений; определения для каждого кластера строки-медианы, представляющей кластер символьных последовательностей; и получения с использованием этой строки-медианы итогового распознанного текста, соответствующего хотя бы части исходного документа.
[0005] В соответствии с одним или более аспектами настоящего раскрытия изобретения описанный в примере постоянный машиночитаемый носитель данных может включать исполняемые инструкции, которые при исполнении их вычислительным устройством приводят к получению текущего изображения из серии изображений исходного документа, причем текущее изображение хотя бы частично перекрывает предыдущее изображение из серии изображений; выполнению оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующей ему разметки текста; определению с использованием распознанного текста и соответствующей ему разметки текста множества текстовых артефактов для каждого текущего изображения и предыдущего изображения, причем каждый текстовый артефакт представлен символьной последовательностью, которая обладает частотой встречаемости в распознанном тексте ниже пороговой частоты; определению для каждого текущего и предыдущего изображений соответствующего множества опорных точек, причем каждая опорная точка ассоциируется по крайней мере одним текстовым артефактом из множества текстовых артефактов; вычислению с использованием координат соответствующих опорных точек текущего и предыдущего изображений параметров преобразования координат предыдущего изображения в координаты текущего изображения; связыванию с помощью преобразования координат как минимум части распознанного текста с кластером из множества кластеров символьных последовательностей, причем распознанный текст создается путем обработки текущего изображения, а символьные последовательности создаются путем обработки одного или более ранее полученных изображений из серии изображений; определению для каждого кластера строки-медианы, представляющей кластер символьных последовательностей; и получению с использованием этой строки-медианы итогового распознанного текста, соответствующего хотя бы части исходного документа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, но не ограничивается только ими, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, в которых:
[0007] На Фиг. 1 показана блок-схема одного иллюстративного примера способа выполнения оптического распознавания символов (OCR) серии изображений, содержащих текстовые символы, в соответствии с одним или более аспектами настоящего изобретения;
[0008] На Фиг. 2А-2В схематически показана фильтрация обнаруженных опорных точек с помощью инвариантных геометрических признаков группировок опорных точек в соответствии с одним или более аспектами настоящего изобретения;
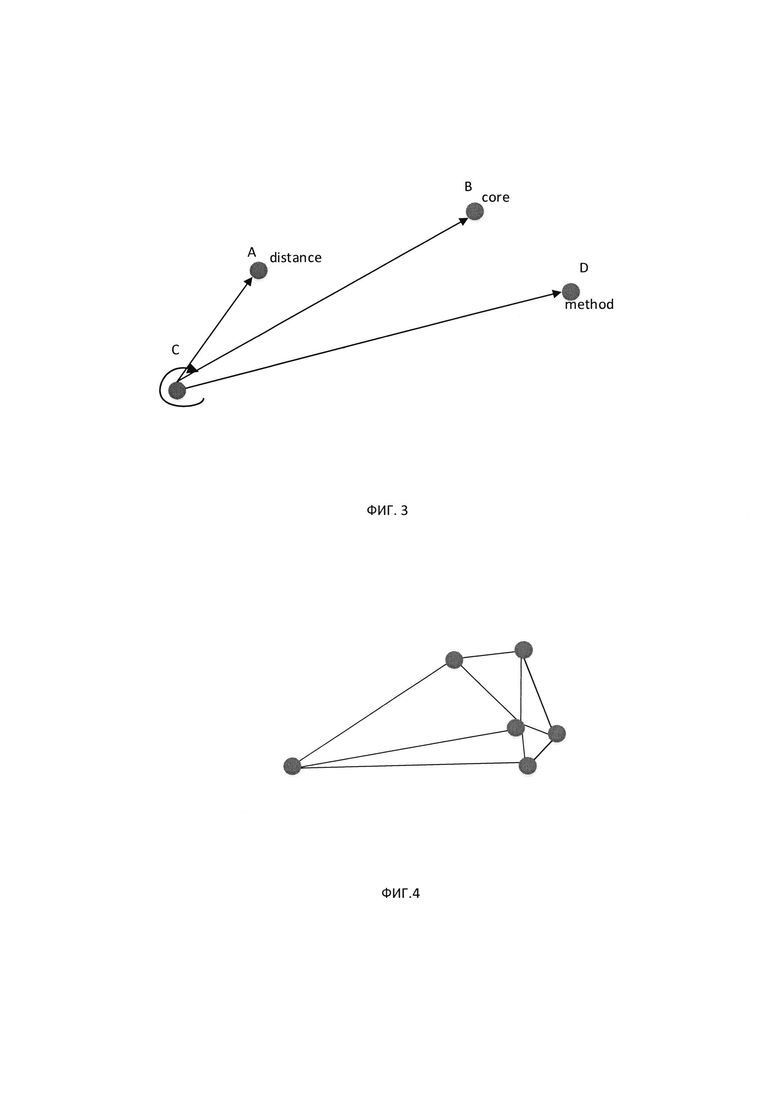
[0009] На Фиг. 3 схематически показан пример обхода векторов, соединяющих случайно выбранную точку (например, начало координат координатной плоскости, связанной с изображением) и каждую из опорных точек в порядке их числовых обозначений, в соответствии с одним или более аспектами настоящего изобретения;
[00010] На Фиг. 4 схематически показан пример топологии геометрических фигур, образованных линиями, соединяющими случайно выбранный набор опорных точек, в соответствии с одним или более аспектами настоящего изобретения;
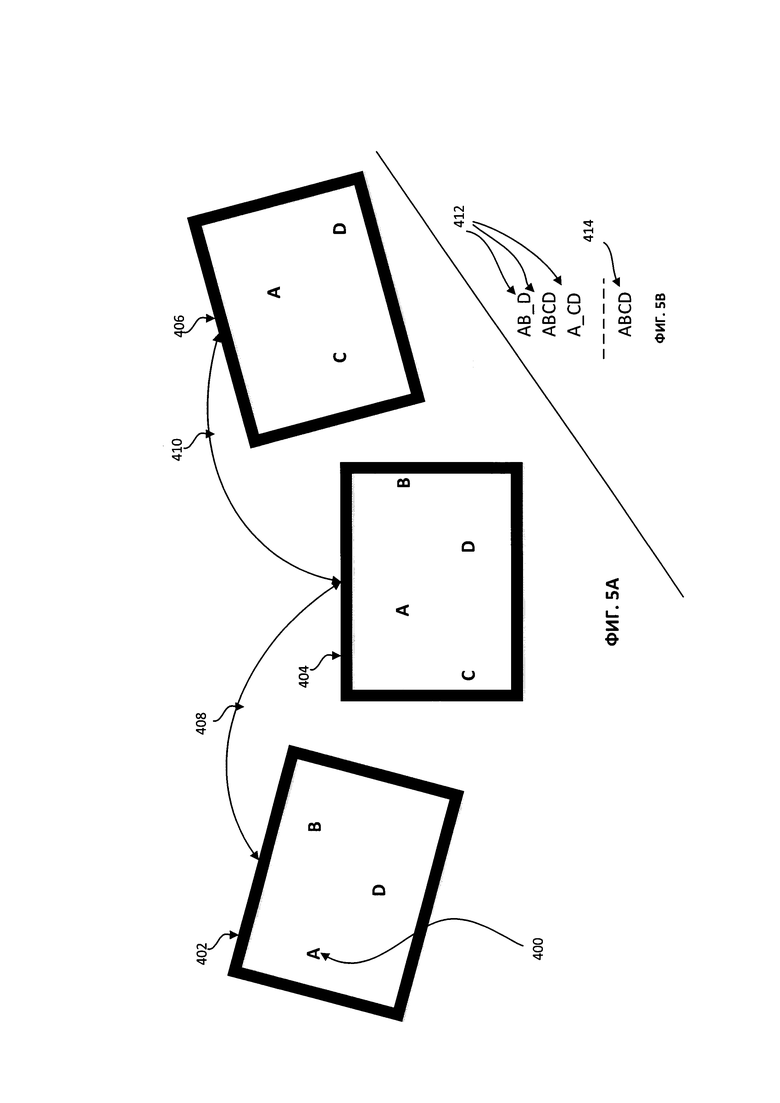
[00011] На Фиг. 5А-5В схематически показан пример серии из трех изображений, проективное преобразование между парами изображений и соответствующие символьные последовательности, полученные при оптическом распознавании соответствующих изображений, в соответствии с одним или более аспектами настоящего изобретения;
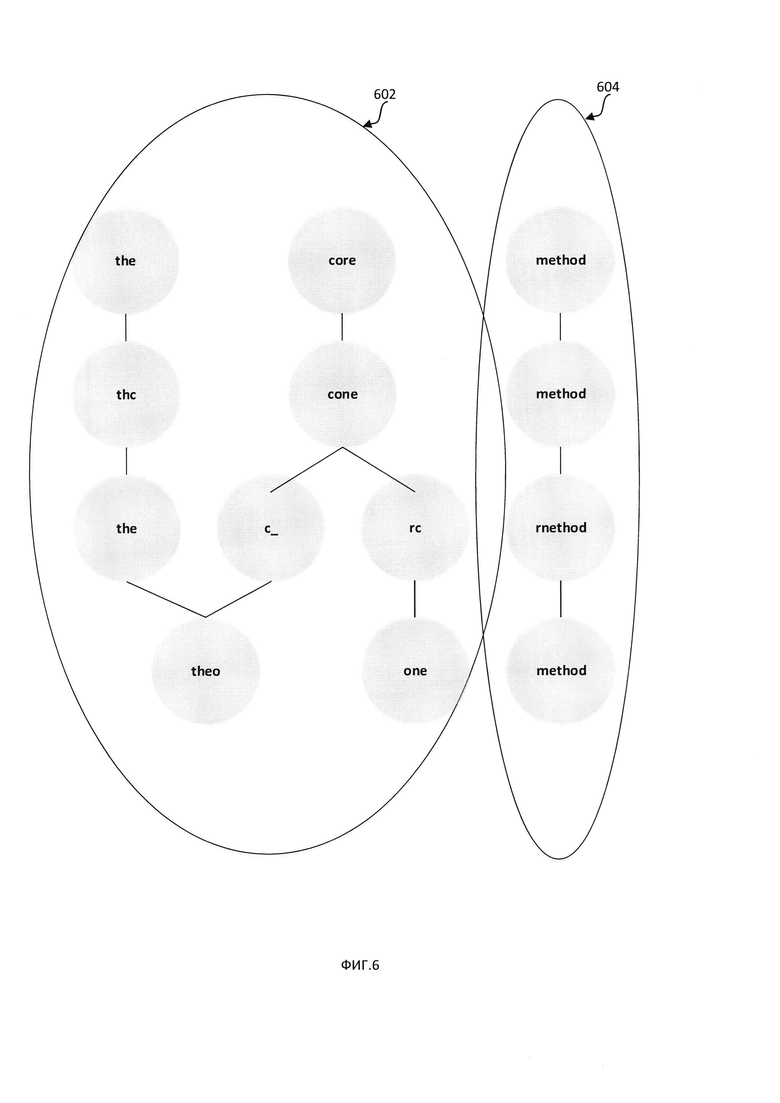
[00012] На Фиг. 6 схематически показан пример графа, состоящего из множества кластеров вершин, где каждый кластер представляет две или более совпадающих символьных последовательностей, в соответствии с одним или более аспектами настоящего изобретения;
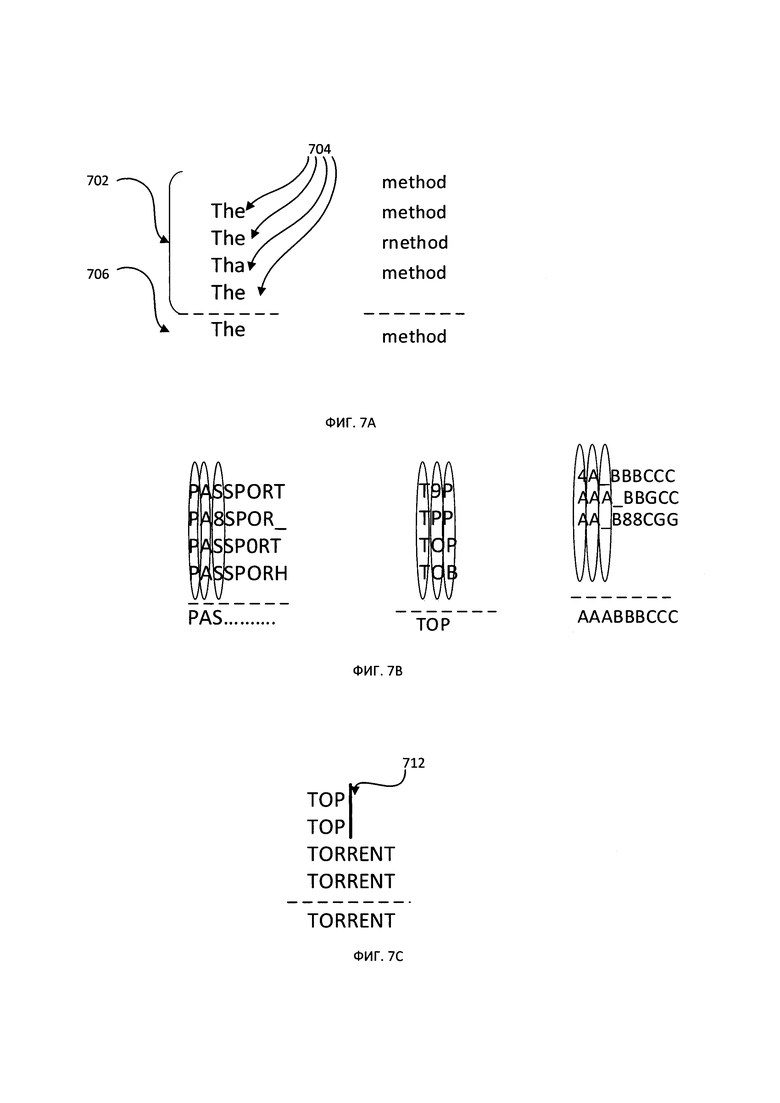
[00013] На Фиг. 7А-7С схематически показано определение строки-медианы среди множества символьных последовательностей, представляющих результаты оптического распознавания символов соответствующих фрагментов изображений, в соответствии с одним или более аспектами настоящего изобретения; а также
[00014] На Фиг. 8 приведена схема иллюстративного примера вычислительной системы, в которой реализованы способы настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00015] В настоящем документе описываются способы и системы для оптического распознавания символов (OCR) серии изображений с символами некоторого алфавита. Алфавиты, символы которых могут обрабатываться с помощью систем и способов, описанных в настоящем документе, включают истинные символьные алфавиты, которые содержат отдельные символы или глифы, соответствующие отдельным звукам, а также иероглифические алфавиты, которые содержат отдельные символы, соответствующие более крупным блокам, таким как слоги или слова.
[00016] В приведенном ниже описании термин «документ» должен толковаться широко, как отсылка к разнообразным типам текстовых носителей, включая, помимо прочего, печатные и написанные от руки документы, баннеры, постеры, знаки, рекламные щиты и (или) другие физические объекты, несущие видимые текстовые символы на одной или более поверхностях. «Изображение документа» в настоящем документе означает изображение как минимум части исходного документа (например, страницы бумажного документа).
[00017] Система оптического распознавания символов (OCR) может получить изображение документа и преобразовать полученное изображение в машиночитаемый формат, допускающий поиск и содержащий текстовую информацию, извлеченную из изображения бумажного документа. Процесс оптического распознавания может быть затруднен различными дефектами изображения, такими как цифровой шум, блики, смаз, расфокусировка и т.д., которые обычно могут быть вызваны дрожанием камеры, недостаточным освещением, неправильно выбранной выдержкой или диафрагмой и (или) другими ухудшающими качество обстоятельствами или причинами. В то время как обычные способы оптического распознавания могут не всегда правильно осуществлять распознавание символов в присутствии указанных выше и других дефектов изображения, системы и способы, описанные в этом документе, могут значительно повысить качество оптического распознавания за счет анализа серии изображений (например, серии видеокадров или фотоснимков) документа, что будет более подробно описано ниже.
[00018] Кроме того, в определенных условиях исходный документ невозможно вместить в одно изображение без значительных потерь качества изображения. Риск потери качества изображения может быть сокращен путем получения серии частично перекрывающихся изображений различных фрагментов исходного документа, которые тем не менее нельзя будет использовать для последующего проведения распознавания обычными способами оптического распознавания. Системы и способы, описанные в этом документе, могут эффективно объединять результаты процедуры распознавания символов, выполненной для нескольких фрагментов документа, позволяя получить текст исходного документа.
[00019] В некоторых вариантах реализации изобретения текст, полученный системами и способами оптического распознавания, описанными в этом документе, может быть дополнительно обработан, например, способами машинного перевода, для перевода исходного текста на другой естественный язык.
[00020] В иллюстративном примере компьютерная система, реализующая способ, описанный в этом документе, может получать серию изображений (например, серию видеокадров или фотоснимков) исходного документа. Эти изображения могут отображать как минимум частично перекрывающиеся фрагменты документа и могут отличаться масштабом изображения, ракурсом, выдержкой, диафрагмой, яркостью изображения, наличием бликов, наличием внешних объектов, которые как минимум частично закрывают исходный текст, и (или) других элементов изображения, визуальных артефактов и параметров способа получения изображения.
[00021] Эта компьютерная система может выполнять оптическое распознавание символов как минимум выбранных изображений полученной серии изображений для получения соответствующей информации о тексте и его разметки. Информация о разметке может связывать распознаваемые символы и (или) группы символов с их положением на исходном изображении. Для объединения результатов распознавания символов, выполняемого для последовательно полученных изображений, компьютерная система может сравнивать текст и разметку, полученные при оптическом распознавании текущего изображения с текстом и разметкой, полученными при оптическом распознавании одного или более ранее обработанных изображений.
[00022] В соответствии с одним или более аспектами настоящего изобретения компьютерная система может сопоставлять текстовые артефакты в результатах оптического распознавания символов, соответствующих паре изображений (например, паре следующих друг за другом кадров в серии изображений), с целью определения опорных точек для построения взаимного преобразования координат изображений, где каждое преобразование координат пересчитывает координаты предыдущего изображения в координаты следующего за ним изображения из пары изображений, что будет более подробно описано ниже. Текстовые артефакты, которые используются для определения опорных точек, могут быть представлены символьными последовательностями (например, словами), имеющими низкую частоту встречаемости в тексте, полученном в результате оптического распознавания символов (например, частоту, которая не превышает определенный порог).
[00023] Информация о разметке, связанная с обнаруженными текстовыми артефактами, позволяет определить как минимум одну опорную точку, соответствующую каждому текстовому артефакту в каждой паре изображений. В иллюстративном примере опорная точка может соответствовать центру и (или) углам минимального описывающего прямоугольника уникальной или редко встречающейся символьной последовательности.
[00024] После этого координаты опорной точки могут использоваться для построения взаимного преобразования координат изображений. Каждое преобразование координат затем может использоваться для сравнения положений различных распознанных символьных последовательностей в соответствующих изображениях с последующим определением в результатах оптического распознавания символов, полученных путем обработки серии изображений, кластеров символьных последовательностей, которые, вероятно, соответствуют одному и тому же фрагменту исходного документа.
[00025] Для каждого кластера совпадающих символьных последовательностей может быть определена строка-медиана, представляющая результат оптического распознавания символов соответствующего фрагмента изображения. В некоторых вариантах реализации изобретения строка-медиана может быть определена как символьная последовательность, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей кластера. Расстояние редактирования, которое в иллюстративном примере может быть представлено расстоянием Левенштейна, между первой символьной последовательностью и второй символьной последовательностью может быть равно минимальному числу односимвольных преобразований (т.е. вставок, удалений или замещений), необходимых для преобразования первой символьной последовательности во вторую символьную последовательность.
[00026] Тексты, полученные в результате оптического распознавания символов каждого отдельного изображения, могут отличаться одним или более словами, присутствующими или отсутствующими в каждом результате оптического распознавания символов, вариациями в символьных последовательностях, соответствующих словам исходного текста, и (или) порядком символьных последовательностей. Для восстановления правильного порядка символьных последовательностей исходного документа можно проанализировать множество перестановок символьных последовательностей, которые соответствуют обнаруженным кластерам, для определения медианы, которая имеет минимальную сумму тау-расстояний Кенделла до всех прочих перестановок. Тау-расстояние Кенделла между первой и второй перестановками может быть равно минимальному количеству операций по обмену, необходимых для алгоритма пузырьковой сортировки для преобразования первой перестановки во вторую перестановку.
[00027] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, но не ограничиваются только ими.
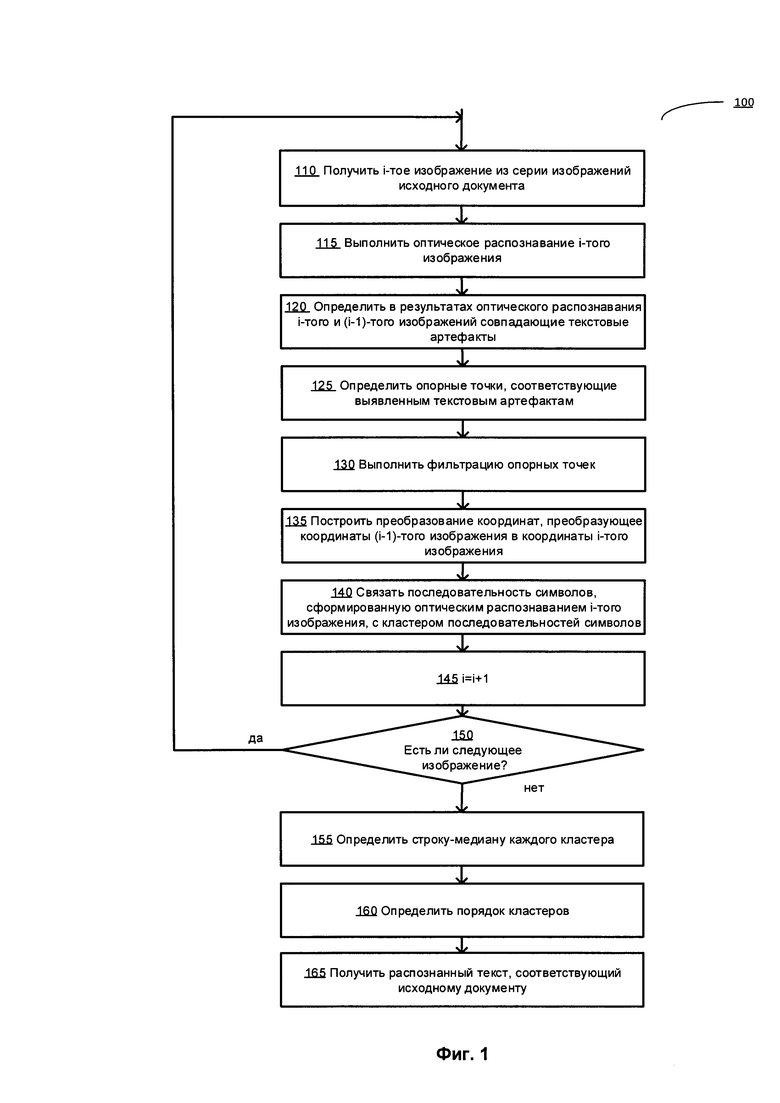
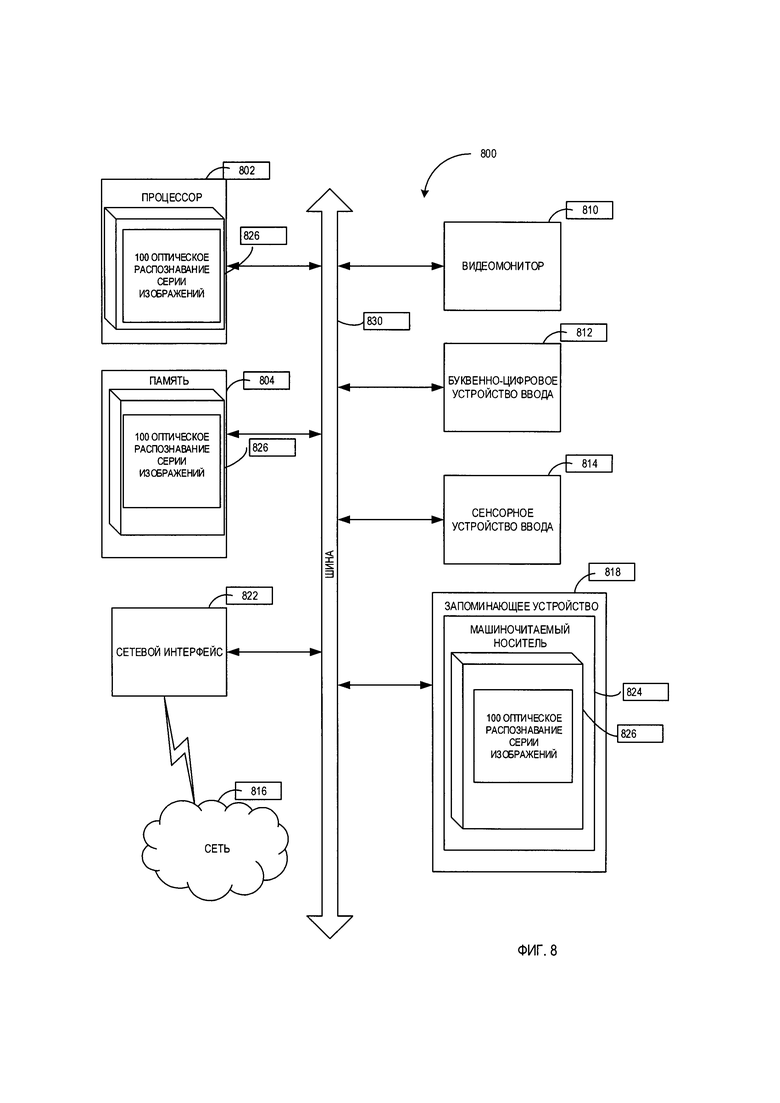
[00028] На Фиг. 1 показана блок-схема одного иллюстративного примера способа 100 выполнения оптического распознавания серии изображений, содержащих текстовые символы, в соответствии с одним или более аспектами настоящего изобретения. Способ 100 и (или) каждая из его отдельных функций, стандартных программ, подпрограмм или операций может выполняться с помощью одного или более процессоров компьютерного устройства (например, примера вычислительной системы 800 на Фиг. 8), в котором реализован этот способ. В некоторых вариантах реализации изобретения способ 100 может выполняться в одном потоке обработки. Кроме того, способ 100 может выполняться, используя два или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В иллюстративном примере потоки обработки, в которых реализован способ 100, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 100, могут выполняться асинхронно друг относительно друга. Таким образом, в то время как Фиг. 1 и соответствующее описание содержат операции по способу 100 в определенном порядке, различные реализации способа могут выполнять как минимум некоторые из указанных операций параллельно и (или) в случайно выбранном порядке.
[00029] Для ясности и конкретности настоящее описание предполагает, что обработка каждого изображения исходного документа инициируется после получения изображения компьютерной системой, реализующей способ, и что обработка, по существу, завершается до получения следующего изображения. Однако в различных альтернативных вариантах реализации изобретения обработка следующих друг за другом изображений может перекрываться по времени (например, может выполняться в различных потоках или процессах, выполняемых одним или более процессорами). Кроме того, два или более изображения могут помещаться в буфер и обрабатываться асинхронно относительно получения других изображений из множества изображений, получаемых компьютерной системой, реализующей способ.
[00030] Настоящее раскрытие изобретения ссылается на «пару изображений» из серии изображений (например, серии видеокадров или фотоснимков) исходного документа. Эти изображения могут отображать как минимум частично перекрывающиеся фрагменты документа и могут отличаться масштабом изображения, ракурсом, выдержкой, диафрагмой, яркостью изображения, наличием бликов, наличием внешних объектов, которые как минимум частично закрывают исходный текст, и (или) других элементов изображения, визуальных артефактов и параметров способа получения изображения. В иллюстративном примере пара изображений может выбираться из двух или более следующих друг за другом изображений из полученной серии изображений. В этом документе два изображения по отдельности указываются как «текущее изображение» (также обозначенное как «i-тое изображение» на Фиг. 1) и «предыдущее изображение» (также обозначенное как «(i-1)-тое изображение» на Фиг. 1).
[00031] В блоке 110 компьютерная система реализует способ, позволяющий получить текущее изображение из серии изображений.
[00032] В блоке 115 компьютерная система может выполнить оптическое распознавание символов текущего изображения с получением распознанного текста и информации о разметке. Информация о разметке может связывать распознанные символы и (или) группы символов с их положением на исходном изображении.
[00033] В блоке 120 компьютерная система может идентифицировать совпадающие текстовые артефакты в результатах оптического распознавания символов пары изображений. Текстовые артефакты могут быть представлены в виде символьной последовательности (например, слов), имеющей низкую частоту встречаемости в тексте, полученном в результате оптического распознавания символов (например, частоту, не превышающую определенный порог, который может быть установлен равным 1 для указания на уникальную символьную последовательность). В иллюстративном примере редко встречающееся слово может быть обнаружено путем сортировки слов, полученных в результате оптического распознавания символов, по их частоте и выбора слова, имеющего минимальную частоту встречаемости. В некоторых вариантах реализации изобретения в способе могут использоваться только символьные последовательности, относительная длина которых превышает определенную минимальную длину, поскольку более короткие символьные последовательности дают менее надежные опорные точки.
[00034] В блоке 125 вычислительная система может использовать информацию о разметке, связанную с обнаруженными текстовыми артефактами, для определения как минимум одной опорной точки, соответствующей каждому текстовому артефакту в каждом изображении пары изображений. В иллюстративном примере опорная точка, связанная с определенной символьной последовательностью, может быть представлена в качестве центра минимального описывающего прямоугольника символьной последовательности. В другом иллюстративном примере две или более опорных точек, связанных с определенной символьной последовательностью, могут быть представлены в качестве углов минимального описывающего прямоугольника символьной последовательности.
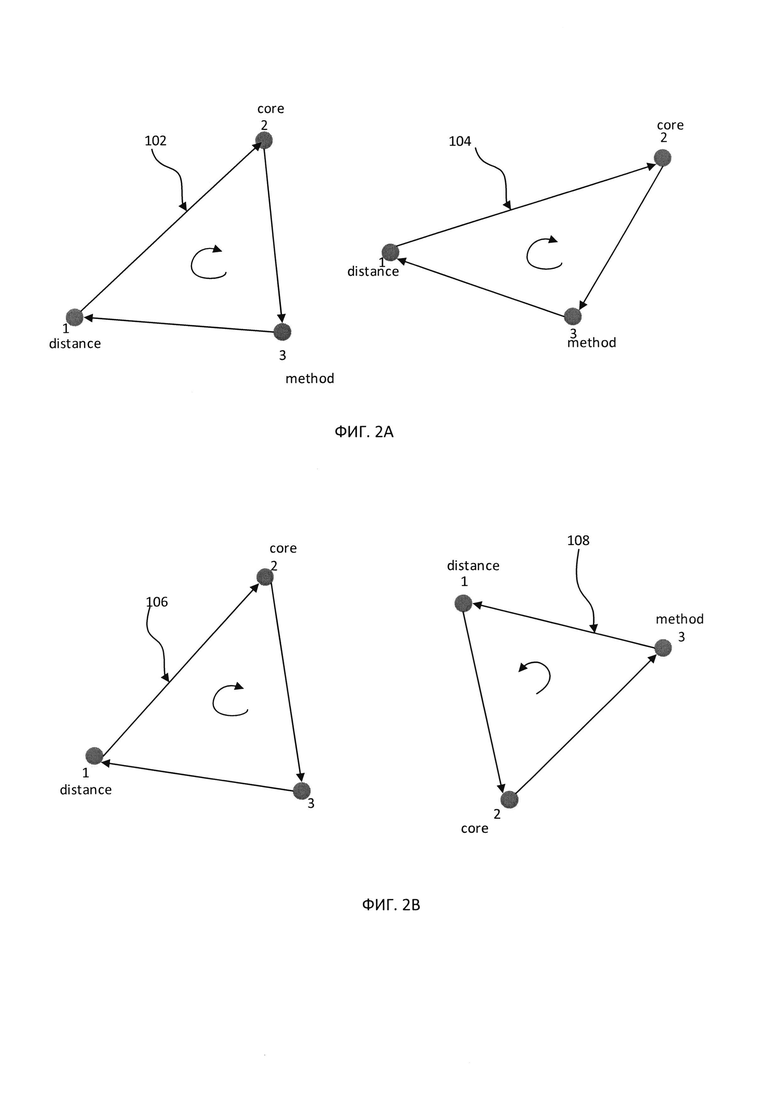
[00035] В блоке 130 вычислительная система может проверять обнаруженные опорные точки и исключать как минимум некоторые из них, принимая во внимание выбранный критерий фильтрации. В иллюстративном примере компьютерная вычислительная система может проверять, что случайно выбранные группы совпадающих опорных точек демонстрируют определенные геометрические признаки, которые инвариантны относительно выбранных изображений. Как схематически показано на Фиг. 2А-2В, такой инвариантный геометрический признак может быть представлен направлением обхода как минимум трех совпадающих опорных точек. В примере на Фиг. 2А три редко встречающихся слова («distance», «core» и «method») используются для получения соответствующих опорных точек 1, 2 и 3. Центры минимальных описывающих прямоугольников, соответствующих символьный последовательностей каждого из изображений документов, позволяют получить прямоугольники 102 и 104. В примере на Фиг. 2А на каждом из двух изображений направление обхода треугольников по опорным точкам в порядке их числовых обозначений остается одинаковым (по часовой стрелке), и поэтому опорные точки 1, 2 и 3, вероятно, соответствуют совпадающим символьным последовательностям на двух изображениях, а значит, могут быть использованы для выполнения последующих операций способа.
[00036] И наоборот, в примере на Фиг. 2В для прямоугольника 106, соответствующего первому изображению документа, обход треугольников по опорным точкам в порядке их числовых обозначений производится по часовой стрелке, а для прямоугольника 108, соответствующего второму изображению документа, обход треугольников по опорным точкам в порядке их числовых обозначений производится против часовой стрелки, поэтому опорные точки 1, 2 и 3, вероятно, соответствуют различным символьным последовательностям на двух изображениях, а значит, должны быть исключены.
[00037] Как схематически показано на Фиг. 3, дополнительный или альтернативный инвариантный геометрический признак может быть представлен направлением обхода векторов, соединяющих случайно выбранную точку (например, начало координат координатной плоскости, связанной с изображением) и каждую из опорных точек в порядке их числовых обозначений. Как схематически показано на Фиг. 4, дополнительный или альтернативный инвариантный геометрический признак может быть представлен топологией геометрических фигур, образованных линиями, соединяющими случайно выбранный набор опорных точек.
[00038] В различных вариантах реализации изобретения можно использовать альтернативные способы определения признаков изображений, формирования опорных точек и (или) фильтрации опорных точек.
[00039] Рассмотрим снова Фиг. 1: в блоке 135 вычислительная система может строить преобразование координат, преобразуя координаты одного изображения из пары изображений в координаты другого изображения из пары изображений. Предложенный способ предполагает, что как минимум для выбранной пары изображений координаты случайно выбранной точки первого изображения можно получить, применив проективное преобразование к координатам той же точки второго изображения.
[00040] «Проективное преобразование» в этом документе означает преобразование, отображающее линии на линии, но не обязательно сохраняющее параллельность. Проективное преобразование может быть выражено следующими уравнениями:
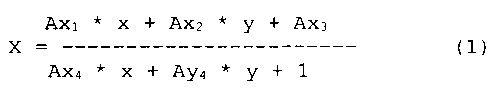
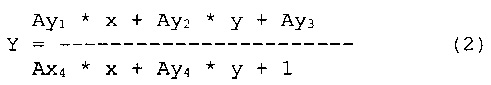
где (х,у) и (X,Y) - координаты случайно выбранной точки на первом и втором изображениях соответственно. Коэффициенты преобразования Ax1, Ах2, Ах3, Ах4, Ay1, Ау2, Ау3 и Ау4 могут быть вычислены исходя из известных координат как минимум четырех опорных точек на каждом из двух изображений, что позволит получить систему из восьми уравнений с восемью переменными. После вычисления коэффициентов преобразования уравнений (1) и (2) можно применить к координатам случайно выбранных точек первого изображения и вычислить координаты той же самой точки на втором изображении.
[00041] В некоторых вариантах реализации изобретения для данной пары изображений при операциях, описанных в блоках 125-130, могут определяться более четырех пар опорных точек; в этом случае определенная с избыточностью система может быть разрешена с помощью способов регрессионного анализа, например способа наименьших квадратов.
[00042] На Фиг. 5А схематически показана серия из трех изображений (402, 404 и 406), где координаты первого изображения 402 могут быть преобразованы в координаты второго изображения 404 путем применения проективного преобразования 408, а координаты второго изображения 404 могут быть преобразованы в координаты третьего изображения 406 путем применения проективного преобразования 410.
[00043] Вернемся снова к Фиг. 1: в блоке 140 вычислительная система может ассоциировать одну или более символьных последовательностей, полученных в результате оптического распознавания символов текущего изображения, с кластером совпадающих символьных последовательностей, полученных в результате оптического распознавания символов ранее обработанных изображений. Вычислительная система может использовать указанные ранее преобразования координат для сравнения положения распознанных символьных последовательностей на текущем и предыдущих изображениях и распознавать таким образом группы символьных последовательностей, которые, вероятно, соответствуют одному и тому же фрагменту исходного документа.
[00044] В иллюстративном примере для случайно выбранных символьных последовательностей в тексте, полученном в результате оптического распознавания символов текущего изображения, этот способ может обнаруживать одну или более совпадающих символьных последовательностей, полученных при оптическом распознавании символов других изображений из серии изображений. Отметим, что «совпадающие символьные последовательности» в этом документе обозначают как точно совпадающие, так и приблизительно совпадающие символьные последовательности. В иллюстративном примере на Фиг. 5В три совпадающие символьные последовательности 412, соответствующие изображениям 402, 404 и 406, представляют собой три разные серии, которые приблизительно совпадают в результате применения способов, описанных в этом документе.
[00045] В некоторых вариантах реализации изобретения компьютерная система может создавать граф, вершины которого представляют символьные последовательности из множества изображений, а ребра соединяют символьные последовательности, которые были определены как совпадающие (то есть соответствующие одному и тому же фрагменту исходного текста) путем применения описанного выше взаимного преобразования координат изображений. Как схематически показано на Фиг. 6, полученный граф будет содержать множество кластеров вершин, где каждый кластер соответствует двум или более совпадающим символьным последовательностям. Вершины внутри каждого кластера соединены соответствующими ребрами, причем отдельные кластеры могут быть изолированы или слабо связаны друг с другом. На Фиг. 6 показаны два кластера (602, 604), соответствующие символьным последовательностям, полученным при оптическом распознавании двух исходных строк: «the core» и «method».
[00046] Еще раз рассмотрим Фиг. 1: в блоке 145 вычислительная система может увеличивать значение счетчика, указывающее на текущее изображение в серии изображений. Отметим, что операции в блоке 145 представлены на Фиг. 1 для улучшения читаемости соответствующего описания и во многих реализациях способа могут быть удалены.
[00047] В блоке 150 вычислительная система может определить, существует ли следующее изображение серии; если это так, способ может вернуться к блоку 110.
[00048] В блоке 155 вычислительная система может определить строку-медиану каждого кластера совпадающих символьных последовательностей так, чтобы найденная строка-медиана представляла результат оптического распознавания символов соответствующего фрагмента изображения.
[00049] Как схематически показано на Фиг. 7А, каждый кластер 702 может содержать множество совпадающих символьных последовательностей 704, а результат оптического распознавания символов соответствующего фрагмента изображения может быть представлен строкой-медианой 706. В некоторых вариантах реализации изобретения строка-медиана может быть определена как символьная последовательность, имеющая минимальную сумму расстояний редактирования до всех символьных последовательностей кластера. Расстояние редактирования, которое в иллюстративном примере может быть представлено расстоянием Левенштейна, между первой символьной последовательностью и второй символьной последовательностью может быть равно минимальному числу односимвольных преобразований (т.е. вставок, удалений или замещений), необходимых для преобразования первой символьной последовательности во вторую символьную последовательность.
[00050] В некоторых вариантах реализации изобретения вычислительная сложность определения строки-медианы может быть уменьшена путем применения некоторых эвристических способов. В иллюстративном примере компьютерная система может эвристически определять аппроксимацию строки-медианы нулевого порядка. Затем компьютерная система может выравнивать символьные последовательности, используя точно совпадающие символы каждой последовательности, как схематично показано на Фиг. 7В. В другом иллюстративном примере вычислительная система может связывать с каждой символьной последовательностью кластера весовой коэффициент, отражающий положение символьной последовательности в изображении или величину уверенности оптического распознавания символов. Как схематично показано на Фиг. 7С, кластер 712 содержит четыре символьных последовательности: ТОР, ТОР, TORRENT, TORRENT. Первые две символьные последовательности соответствуют частям слов, поскольку расстояние от границы минимального описывающего прямоугольника символьной последовательности до границы изображения меньше ширины пробела. Поэтому значение показателя уверенности оптического распознавания символов для первых двух символьных последовательностей значительно ниже значения показателя уверенности оптического распознавания символов для двух других символьных последовательностей, и в качестве строки-медианы способ, принимающий во внимание значение показателя уверенности оптического распознавания символов, выберет символьную последовательность TORRENT.
[00051] Обратимся еще раз к Фиг. 1: в блоке 160 вычислительная система может определить порядок, в котором символьные последовательности, представляющие вышеуказанные кластеры, должны следовать в итоговом тексте. Как было указано выше в этом документе, изображения, соответствующие исходному документу, могут отображать как минимум частично перекрывающиеся фрагменты документа и могут отличаться масштабом изображения, ракурсом, выдержкой, диафрагмой, яркостью изображения, наличием бликов, наличием внешних объектов, которые как минимум частично закрывают исходный текст, и (или) других элементов изображения, визуальных артефактов и параметров способа получения изображения. Поэтому тексты, полученные в результате оптического распознавания символов каждого отдельного изображения, могут отличаться одним или более словами, присутствующими или отсутствующими в отдельных результатах оптического распознавания символов, вариациями символьных последовательностей, соответствующих словам исходного текста, и (или) порядком символьных последовательностей, как схематично показано на Фиг. 5В.
[00052] В некоторых вариантах реализации изобретения вычислительная система может сравнивать множество перестановок символьных последовательностей, которые представляют обнаруженные кластеры. Медианная перестановка может быть определена как перестановка, имеющая минимальную сумму тау-расстояний Кенделла до всех прочих перестановок. Тау-расстояние Кенделла между первой и второй перестановками может быть равно минимальному количеству операций перестановки, необходимых для алгоритма пузырьковой сортировки для преобразования первой перестановки во вторую перестановку символов. В указанном выше иллюстративном примере на Фиг. 5В медианная перестановка представлена последовательностью ABCD.
[00053] Как указывалось выше в этом документе, исходный документ невозможно вместить в одно изображение без значительных потерь качества изображения. Риск потери качества изображения может быть сокращен путем получения последовательности частично перекрывающихся изображений различных фрагментов исходного документа, которые тем не менее нельзя будет использовать для последующего проведения распознавания обычными способами оптического распознавания. Описанная выше операция определения медианной перестановки может быть использована для объединения результатов распознавания символов, выполненного для нескольких фрагментов документа, то есть для эффективного «сшивания» результатов оптического распознавания символов отдельных изображений для получения текста исходного документа.
[00054] В различных вариантах реализации изобретения операции, описанные в блоках 155 и 160, могут выполняться в обратной последовательности или параллельно. Кроме того, в некоторых вариантах реализации изобретения определенные операции, описанные в блоках 155 и (или) 160, могут быть пропущены.
[00055] Обратимся еще раз к Фиг. 1: в блоке 165 вычислительная система может использовать упорядочивание символьных последовательностей, представляющие вышеуказанные кластеры, для получения итогового текста исходного документа.
[00056] Как было указано выше в этом документе, текст, полученный системами и способами оптического распознавания символов, описанными в этом документе, может быть дополнительно обработан, например, способами машинного перевода, для перевода исходного текста на другой естественный язык. Поскольку способы, описанные в этом документе, позволяют реконструировать исходный текст, а не только отдельные слова, то способы машинного перевода могут использовать синтаксический и (или) семантический анализ исходного текста для повышения качества перевода.
[00057] На Фиг. 8 представлена схема компонентов примера вычислительной системы 800, внутри которой исполняется набор команд, которые вызывают выполнение вычислительной системой любого из способов или нескольких способов настоящего изобретения. Вычислительная система 800 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 800 может работать в качестве сервера или клиента в сетевой среде «клиент/сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 800 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любое множество вычислительных систем, которые по отдельности или совместно выполняют набор (или несколько наборов) команд для выполнения одного или более способов, обсуждаемых в настоящем документе.
[00058] Пример вычислительной системы 800 включает процессор 802, основную память 804 (например, постоянное запоминающее устройство (ПЗУ) или динамическую оперативную память (DRAM)) и устройство хранения данных 818, которые взаимодействуют друг с другом по шине 830.
[00059] Процессор 802 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.д. В частности, процессор 802 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW) или процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 802 также может представлять собой одно или более устройств обработки специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 802 настроен на выполнение команд 826 для осуществления операций и функций способа 100 выполнения оптического распознавания серии изображений, содержащих символы текста, как описано выше в этом документе.
[00060] Вычислительная система 800 может дополнительно включать устройство сетевого интерфейса 822, устройство визуального отображения 810, устройство ввода символов 812 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 814.
[00061] Устройство хранения данных 818 может содержать машиночитаемый носитель данных 824, в котором хранится один или более наборов команд (826), и в котором реализован один или более способов или функций настоящего изобретения. Команды 826 также могут находиться полностью или по меньшей мере частично в основной памяти 804 и (или) в процессоре 802 во время выполнения их в вычислительной системе 800, при этом оперативная память 804 и процессор 802 также представляют собой машиночитаемый носитель данных. Команды 826 дополнительно могут передаваться или приниматься по сети 816 через устройство сетевого интерфейса 822.
[00062] В некоторых вариантах реализации изобретения инструкции 826 могут включать инструкции способа 100 выполнения оптического распознавания серии изображений, содержащих символы текста, как описано выше в этом документе. Несмотря на то что машиночитаемый носитель данных 824, показанный в примере на Фиг. 8, является единым носителем, термин «машиночитаемый носитель» может включать один носитель или несколько носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любого одного или более способов настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельной памяти, а также к оптическим и магнитным носителям.
[00063] Описанные в документе способы, компоненты и функции могут быть реализованы дискретными компонентами оборудования, либо они могут быть интегрированы в функции других аппаратных компонентов, таких как ASICS, FPGA, DSP или подобных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00064] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[00065] Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Здесь и в целом алгоритмом называется логически непротиворечивая последовательность операций, приводящих к требуемому результату. Операции требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать их и манипулировать ими. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.п.
[00066] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами, и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано иначе, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и устройствах памяти вычислительной системы, в другие данные, аналогично представленные в виде физических величин в устройствах памяти или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00067] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно приводится в действие или перенастраивается с помощью программы, хранящейся в компьютере. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, в частности, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носитель любого типа, подходящий для хранения электронной информации.
[00068] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации изобретения станут очевидными специалистам в данной области техники после прочтения и понимания приведенного выше описания. Таким образом, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые охватываются формулой изобретения.
Изобретение относится к средствам выполнения оптического распознавания символов серий изображений с текстовыми символами. Технический результат заключается в повышении качества оптического распознавания за счет анализа серии изображений. Выполняют оптическое распознавание символов (OCR) текущего изображения для получения распознанного текста и соответствующей ему разметки текста. Определяют для каждого текущего и предыдущего изображений соответствующего множества опорные точки, причем каждая опорная точка ассоциируется с по крайней мере одним текстовым артефактом из множества текстовых артефактов. Вычисляют с использованием координат соответствующие опорные точки текущего и предыдущего изображений параметров преобразования координат предыдущего изображения в координаты текущего изображения. Связывают с помощью преобразования координат как минимум часть распознанного текста с кластером из множества кластеров символьных последовательностей. Определяют для каждого кластера строку-медиану, представляющую кластер символьных последовательностей. Получают с использованием этой строки-медианы итоговый распознанный текст, соответствующий хотя бы части исходного документа. 3 н. и 17 з.п. ф-лы, 12 ил.
1. Способ для объединения результатов распознавания серии изображений, включающий:
получение с помощью устройства обработки текущего изображения из серии изображений исходного документа, причем текущее изображение хотя бы частично перекрывает предыдущее изображение из серии изображений;
выполнение оптического распознавания символов (OCR) текущего изображения для получения распознанного текста и соответствующей разметки текста;
определение, используя распознанный текст и соответствующую разметку текста, множества текстовых артефактов для каждого текущего изображения и предыдущего изображения, причем каждый текстовый артефакт представлен символьной последовательностью, которая обладает частотой встречаемости в распознанном тексте ниже пороговой частоты;
определение для каждого текущего и предыдущего изображений соответствующего множества опорных точек, причем каждая опорная точка ассоциируется с по крайней мере одним текстовым артефактом из множества текстовых артефактов;
вычисление, используя координаты соответствующих опорных точек текущего и предыдущего изображений, параметров преобразования координат предыдущего изображения в координаты текущего изображения;
связывание, используя преобразование координат, как минимум части распознанного текста с кластером из множества кластеров символьных последовательностей, причем распознанный текст создается путем обработки текущего изображения, а символьные последовательности создаются путем обработки одного или более ранее полученных изображений из серии изображений;
определение для каждого кластера строки-медианы, представляющей кластер символьных последовательностей; а также
получение, используя строку-медиану, итогового распознанного текста, соответствующего хотя бы части исходного документа.
2. Способ по п. 1, отличающийся тем, что текущее изображение и предыдущее изображение представляют следующие друг за другом изображения из серии изображений исходного документа.
3. Способ по п. 1, отличающийся тем, что текущее изображение и предыдущее изображение могут отличаться не менее чем по одному из параметров: масштаб изображения, ракурс, яркость изображения или наличие внешнего объекта, закрывающего хотя бы часть исходного документа.
4. Способ по п. 1, отличающийся тем, что определение опорной точки включает в себя также определение центра минимального описывающего прямоугольника соответствующего текстового артефакта.
5. Способ по п. 1, дополнительно включающий фильтрацию найденных опорных точек с использованием инвариантных геометрических признаков группировок опорных точек.
6. Способ по п. 1, отличающийся тем, что преобразование координат выполняется путем проективного преобразования.
7. Способ по п. 1, отличающийся тем, что строка-медиана имеет минимальную сумму значений предварительно определенного показателя в кластере символьных последовательностей.
8. Способ по п. 7, отличающийся тем, что предварительно определенный показатель представляет собой расстояние редактирования между строкой-медианой и символьной последовательностью в множестве символьных последовательностей.
9. Способ по п. 1, отличающийся тем, что получение строки-медианы включает применение весовых коэффициентов к каждой символьной последовательности в кластере символьных последовательностей.
10. Способ по п. 1, отличающийся тем, что определение множества кластеров символьных последовательностей включает в себя также:
получение графа, содержащего множество узлов, в котором каждый узел соответствует символьной последовательности, причем граф также содержит множество ребер, в котором ребро соединяет первую символьную последовательность, полученную в результате оптического распознавания символов хотя бы части первого изображения из серии изображений, и вторую символьную последовательность, полученную в результате оптического распознавания символов хотя бы части второго изображения из серии изображений.
11. Способ по п. 1, дополнительно включающий:
определение с учетом разметки текста порядка кластеров символьных последовательностей.
12. Способ по п. 1, отличающийся тем, что распознанный текст предоставляется на первом естественном языке; способ дополнительно включает:
перевод полученного распознанного текста на второй естественный язык.
13. Система для объединения результатов распознавания серии изображений, включающая:
память;
устройство обработки, подключенное к памяти, причем устройство обработки способно:
получать текущее изображение из серии изображений исходного документа, причем текущее изображение хотя бы частично перекрывает предыдущее изображение из серии изображений;
выполнять оптическое распознавание символов (OCR) текущего изображения для получения распознанного текста и соответствующей разметки текста;
определять, используя распознанный текст и соответствующую разметку текста, множество текстовых артефактов для каждого текущего изображения и предыдущего изображения, причем каждый текстовый артефакт представлен символьной последовательностью, которая обладает частотой встречаемости в распознанном тексте ниже пороговой частоты;
определять для каждого текущего и предыдущего изображений соответствующее множество опорных точек, причем каждая опорная точка ассоциируется с по крайней мере одним или более текстовым артефактом из множества текстовых артефактов;
вычислять, используя координаты соответствующих опорных точек текущего и предыдущего изображений, параметры преобразования координат предыдущего изображения в координаты текущего изображения;
связывать, используя преобразование координат, как минимум часть распознанного текста с кластером из множества кластеров символьных последовательностей, причем распознанный текст создается путем обработки текущего изображения, а символьные последовательности создаются путем обработки одного или более ранее полученных изображений из серии изображений;
определять для каждого кластера строку-медиану, представляющую кластер символьных последовательностей; а также
получать, используя строку-медиану, итоговый распознанный текст, соответствующий хотя бы части исходного документа.
14. Система по п. 13, отличающаяся тем, что определение опорной точки включает в себя также определение центра минимального описывающего прямоугольника соответствующего текстового артефакта.
15. Система по п. 13, отличающаяся тем, что строка-медиана имеет минимальную сумму значений предварительно определенных показателей в кластере символьных последовательностей.
16. Система по п. 13, отличающаяся тем, что определение множества кластеров символьных последовательностей включает в себя также:
получение графа, содержащего множество узлов, в котором каждый узел соответствует символьной последовательности, причем граф также содержит множество ребер, в котором ребро соединяет первую символьную последовательность, полученную в результате оптического распознавания символов хотя бы части первого изображения из серии изображений, и вторую символьную последовательность, полученную в результате оптического распознавания символов хотя бы части второго изображения из серии изображений.
17. Энергонезависимый машиночитаемый носитель данных, содержащий исполняемые команды, которые при выполнении в устройстве обработки служат для объединения результатов распознавания серии изображений и заставляют это устройство обработки:
получать текущее изображение из серии изображений исходного документа, причем текущее изображение хотя бы частично перекрывает предыдущее изображение из серии изображений;
выполнять оптическое распознавание символов (OCR) текущего изображения для получения распознанного текста и соответствующей разметки текста;
определять, используя распознанный текст и соответствующую разметку текста, множество текстовых артефактов для каждого текущего изображения и предыдущего изображения, причем каждый текстовый артефакт представлен символьной последовательностью, которая обладает частотой встречаемости в распознанном тексте ниже пороговой частоты;
определять для каждого текущего и предыдущего изображений соответствующее множество опорных точек, причем каждая опорная точка ассоциируется с по крайней мере одним текстовым артефактом из множества текстовых артефактов;
вычислять, используя координаты соответствующих опорных точек текущего и предыдущего изображений, параметры преобразования координат предыдущего изображения в координаты текущего изображения;
связывать, используя преобразование координат, как минимум часть распознанного текста с кластером из множества кластеров символьных последовательностей, причем распознанный текст создается путем обработки текущего изображения, а символьные последовательности создаются путем обработки одного или более ранее полученных изображений из серии изображений;
определять для каждого кластера строку-медиану, представляющую кластер символьных последовательностей; а также
получать, используя строку-медиану, итоговый распознанный текст, соответствующий хотя бы части исходного документа.
18. Энергонезависимый машиночитаемый носитель данных по п. 17, отличающийся тем, что определение опорной точки включает в себя также определение центра минимального описывающего прямоугольника соответствующего текстового артефакта.
19. Энергонезависимый машиночитаемый носитель данных по п. 17, отличающийся тем, что строка-медиана имеет минимальную сумму значений предварительно определенных показателей по отношению к кластеру символьных последовательностей.
20. Энергонезависимый машиночитаемый носитель данных по п. 17, отличающийся тем, что определение множества кластеров символьных последовательностей включает в себя также:
получение графа, содержащего множество узлов, в котором каждый узел соответствует символьной последовательности, причем граф также содержит множество ребер, в котором ребро соединяет первую символьную последовательность, полученную в результате оптического распознавания символов хотя бы части первого изображения из серии изображений, и вторую символьную последовательность, полученную в результате оптического распознавания символов хотя бы части второго изображения из серии изображений.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Устройство для сравнения п-разрядных двоичных чисел | 1975 |
|
SU561959A1 |
| US 8401332 B2, 19.03.2013 | |||
| СПОСОБ РАЗРЕШЕНИЯ ПРОТИВОРЕЧИВЫХ ВЫХОДНЫХ ДАННЫХ ИЗ СИСТЕМЫ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ (OCR), ГДЕ ВЫХОДНЫЕ ДАННЫЕ ВКЛЮЧАЮТ В СЕБЯ БОЛЕЕ ОДНОЙ АЛЬТЕРНАТИВЫ РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ СИМВОЛА | 2008 |
|
RU2436156C1 |

