Настоящее изобретение относится к обработке аудиосигналов и, в частности, к устройству и способу для реализации улучшенного понижающего микширования, в частности, для реализации улучшенных характеристик направленного понижающего микширования для трехмерного (3D) аудио.
Растущее число громкоговорителей используется для пространственного воспроизведения звука. Хотя унаследованное воспроизведение с объемным звуком (например, 5.1) ограничено одной плоскостью, вводятся новые форматы каналов с приподнятыми динамиками в контексте воспроизведения трехмерного аудио.
Сигналы, которые должны быть воспроизведены по громкоговорителям, ранее были непосредственно связаны с конкретными динамиками и сохранялись и передавались дискретно или параметрически. Можно сказать, что для этого вида форматов, они связаны с однозначно заданным числом и позициями громкоговорителей системы воспроизведения звука. Соответственно, требуется учитывать конкретный формат воспроизведения перед передачей или сохранением аудиосигнала.
Тем не менее, уже существуют некоторые исключения из этого принципа. Например, многоканальные аудиосигналы (например, пять аудиоканалов объемного звучания или, например, аудиоканалы объемного звучания 5.1) должны быть микшированы с понижением для воспроизведения по двухканальным компоновкам стереогромкоговорителей. Предусмотрены правила для того, как воспроизводить пять каналов объемного звучания на двух громкоговорителях стереосистемы.
Кроме того, когда были введены стереоканалы, было предусмотрено правило для того, как воспроизводить аудиоконтент двух стереоканалов посредством одного моногромкоговорителя.
Поскольку возрастает число форматов и в силу этого число вариантов того, как позиционируются громкоговорители, практически невозможно учитывать компоновку громкоговорителей системы воспроизведения перед передачей или сохранением. Соответственно, требуется адаптировать входящие аудиосигналы к фактической компоновке громкоговорителей.
Различные способы могут использоваться для понижающего микширования от объемного звука до двухканального стерео. По-прежнему широко используемое понижающее микширование во временной области с помощью статических коэффициентов понижающего микширования зачастую упоминается в качестве понижающего ITU-микширования [5]. Другие подходы на основе понижающего микширования во временной области (частично с динамическим регулированием коэффициентов понижающего микширования) используются в кодерах на основе технологий матричного объемного звучания [6], [7].
В [3] раскрыто то, что источники прямого звука, смешиваемые с задними каналами, свертываемыми в двухканальную стереопанораму, могут быть неразличимыми вследствие маскирования или иначе маскировать другие источники звука.
В ходе разработки технологий пространственного кодирования аудио (SAC) алгоритмы частотно-избирательного понижающего микширования введены в качестве части кодера [8], [9]. В частности, могут уменьшаться расцвечивания звука, и балансирование уровня и стабильность локализации источников звука поддерживается посредством применения энергетического выравнивания к результирующим аудиоканалам. Энергетическое выравнивание также выполняется в других системах понижающего микширования [9], [10], [12].
Для случая, когда задние каналы содержат только окружающий звук, такой как реверберация, сокращение объемного окружения (реверберация, объемность) разрешается в понижающем ITU-микшировании [5] посредством ослабления задних каналов многоканального сигнала. Если задние каналы также содержат прямой звук, это ослабление не является надлежащим, поскольку прямые части заднего канала также будут ослабляться в понижающем микшировании. Следовательно, рассматривается более сложный алгоритм ослабления объемного окружения.
Аудиокодеки, такие как AC-3 и HE-AAC, предоставляют средство передачи вместе с аудиопотоком так называемых метаданных, включающих в себя коэффициенты понижающего микширования для понижающего микширования с пяти до двух аудиоканалов (стерео). Число выбранных аудиоканалов (центральных, задних каналов) в результирующем стереосигнале управляется посредством передаваемых значений усиления. Хотя эти коэффициенты могут быть зависимыми от времени, обычно они остаются постоянными в течение определенной длительности одного элемента программы.
Решение, используемое в матричной системе Logic7, вводит сигнально-адаптивный подход, который ослабляет задние каналы, только если они считаются полностью окружающими. Это достигается посредством сравнения мощности передних каналов с мощностью задних каналов. Допущение в отношении этого подхода заключается в том, что если задние каналы содержат исключительно объемное окружение, они имеют значительно меньшую мощность по сравнению с передними каналами. Чем большую мощность имеют передние каналы по сравнению с задними каналами, тем больше задние каналы ослабляются в процессе понижающего микширования. Это допущение может быть истинным для некоторых формирований объемного звучания, в частности, с классическим контентом, но это допущение не является истинным для различных других сигналов.
Следовательно, очень важно, если предоставляются усовершенствованные принципы для обработки аудиосигналов.
Задача настоящего изобретения заключается в том, чтобы предоставлять усовершенствованные принципы для обработки аудиосигналов. Задача настоящего изобретения достигается решается устройства по п. 1, посредством системы по п. 13, посредством способа по п. 14 и посредством компьютерной программы по п. 15.
Предоставляется устройство для формирования двух или более выходных аудиоканалов из трех или более входных аудиоканалов. Устройство содержит приемный интерфейс для приема трех или более входных аудиоканалов и для приема вспомогательной информации. Кроме того, устройство содержит понижающий микшер для понижающего микширования трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать два или более выходных аудиоканала. Число выходных аудиоканалов меньше числа входных аудиоканалов. Вспомогательная информация указывает характеристику, по меньшей мере, одного из трех или более входных аудиоканалов или характеристику одной или более звуковых волн, записанных в одном или более входных аудиоканалов, либо характеристику одного или более источников звука, которые испускают одну или более звуковых волн, записанных в одном или более входных аудиоканалов.
Варианты осуществления основаны на таком принципе, чтобы передавать вспомогательную информацию вместе с аудиосигналами, чтобы направлять процесс преобразования формата из формата входящего аудиосигнала в формат системы воспроизведения.
Согласно варианту осуществления, понижающий микшер может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством модификации, по меньшей мере, двух входных аудиоканалов из трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать группу модифицированных аудиоканалов, и посредством комбинирования каждого модифицированного аудиоканала упомянутой группы модифицированных аудиоканалов для того, чтобы получать упомянутый выходной аудиоканал.
В варианте осуществления, понижающий микшер, например, может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством модификации каждого входного аудиоканала из трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать группу модифицированных аудиоканалов, и посредством комбинирования каждого модифицированного аудиоканала упомянутой группы модифицированных аудиоканалов для того, чтобы получать упомянутый выходной аудиоканал.
Согласно варианту осуществления, понижающий микшер, например, может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством формирования каждого модифицированного аудиоканала из группы модифицированных аудиоканалов посредством определения весового коэффициента в зависимости от входного аудиоканала из одного или более входных аудиоканалов и в зависимости от вспомогательной информации и посредством применения упомянутого весового коэффициента к упомянутому входному аудиоканалу.
В варианте осуществления, вспомогательная информация может указывать величину объемного окружения каждого из трех или более входных аудиоканалов. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от величины объемного окружения каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
Согласно другому варианту осуществления, вспомогательная информация может указывать диффузность каждого из трех или более входных аудиоканалов или направленность каждого из трех или более входных аудиоканалов. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от диффузности каждого из трех или более входных аудиоканалов или в зависимости от направленности каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
В дополнительном варианте осуществления, вспомогательная информация может указывать направление поступления звука. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от направления поступления звука, чтобы получать два или более выходных аудиоканала.
В варианте осуществления, каждый из двух или более выходных аудиоканалов может представлять собой канал громкоговорителя для управления громкоговорителем.
Согласно варианту осуществления, устройство может быть выполнено с возможностью подавать каждый из двух или более выходных аудиоканалов в громкоговоритель группы из двух или более громкоговорителей. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от каждой предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя и в зависимости от каждой фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя, чтобы получать два или более выходных аудиоканала. Каждая фактическая позиция громкоговорителя второй группы из двух или более фактических позиций громкоговорителя может указывать позицию громкоговорителя группы из двух или более громкоговорителей.
В варианте осуществления, каждый входной аудиоканал из трех или более входных аудиоканалов может назначаться предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя. Каждый выходной аудиоканал из двух или более выходных аудиоканалов может назначаться фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя. Понижающий микшер может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов в зависимости, по меньшей мере, от двух из трех или более входных аудиоканалов, в зависимости от предполагаемой позиции громкоговорителя каждого из упомянутых, по меньшей мере, двух из трех или более входных аудиоканалов и в зависимости от фактической позиции громкоговорителя упомянутого выходного аудиоканала.
Согласно варианту осуществления, каждый из трех или более входных аудиоканалов содержит аудиосигнал аудиообъекта из трех или более аудиообъектов. Вспомогательная информация содержит, для каждого аудиообъекта из трех или более аудиообъектов, позицию аудиообъекта, указывающую позицию упомянутого аудиообъекта. Понижающий микшер выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от позиции аудиообъекта каждого из трех или более аудиообъектов, чтобы получать два или более выходных аудиоканала.
В варианте осуществления, понижающий микшер выполнен с возможностью микшировать с понижением четыре или более входных аудиоканала в зависимости от вспомогательной информации для того, чтобы получать три или более выходных аудиоканала.
Кроме того, предоставляется система. Система содержит кодер для кодирования трех или более необработанных аудиоканалов для того, чтобы получать три или более кодированных аудиоканала, и для кодирования дополнительной информации относительно трех или более необработанных аудиоканалов для того, чтобы получать вспомогательную информацию. Кроме того, система содержит устройство согласно одному из вышеописанных вариантов осуществления для приема трех или более кодированных аудиоканалов в качестве трех или более входных аудиоканалов, для приема вспомогательной информации и для формирования, в зависимости от вспомогательной информации, двух или более выходных аудиоканалов из трех или более входных аудиоканалов.
Кроме того, предоставляется способ для формирования двух или более выходных аудиоканалов из трех или более входных аудиоканалов. Способ содержит:
- прием трех или более входных аудиоканалов и прием вспомогательной информации; и
- понижающее микширование трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать два или более выходных аудиоканала.
Число выходных аудиоканалов меньше числа входных аудиоканалов. Входные аудиоканалы содержат запись звука, испускаемого посредством источника звука, и при этом вспомогательная информация указывает характеристику звука или характеристику источника звука.
Кроме того, предоставляется компьютерная программа для реализации вышеописанного способа при выполнении на компьютере или в процессоре сигналов.
Далее подробнее описываются варианты осуществления настоящего изобретения в отношении чертежей, на которых:
Фиг. 1 представляет собой устройство для понижающего микширования трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала согласно варианту осуществления,
Фиг. 2 иллюстрирует понижающий микшер согласно варианту осуществления,
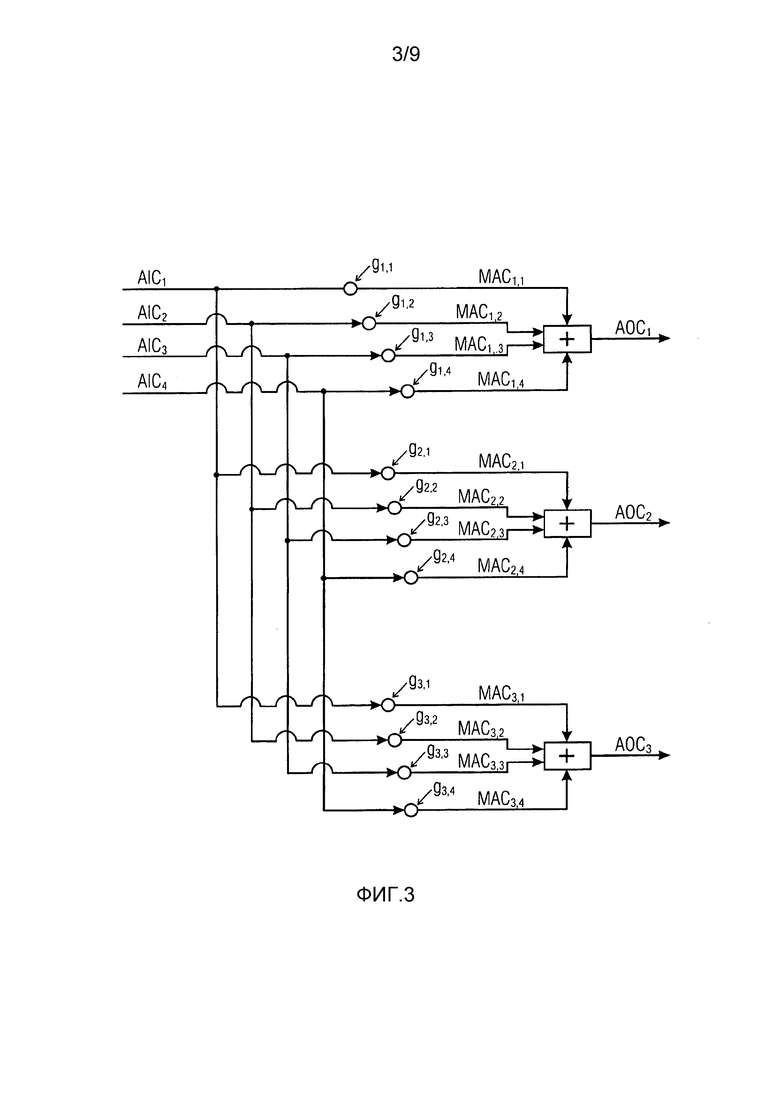
Фиг. 3 иллюстрирует сценарий согласно варианту осуществления, в котором каждый из выходных аудиоканалов формируется в зависимости от каждого из входных аудиоканалов,
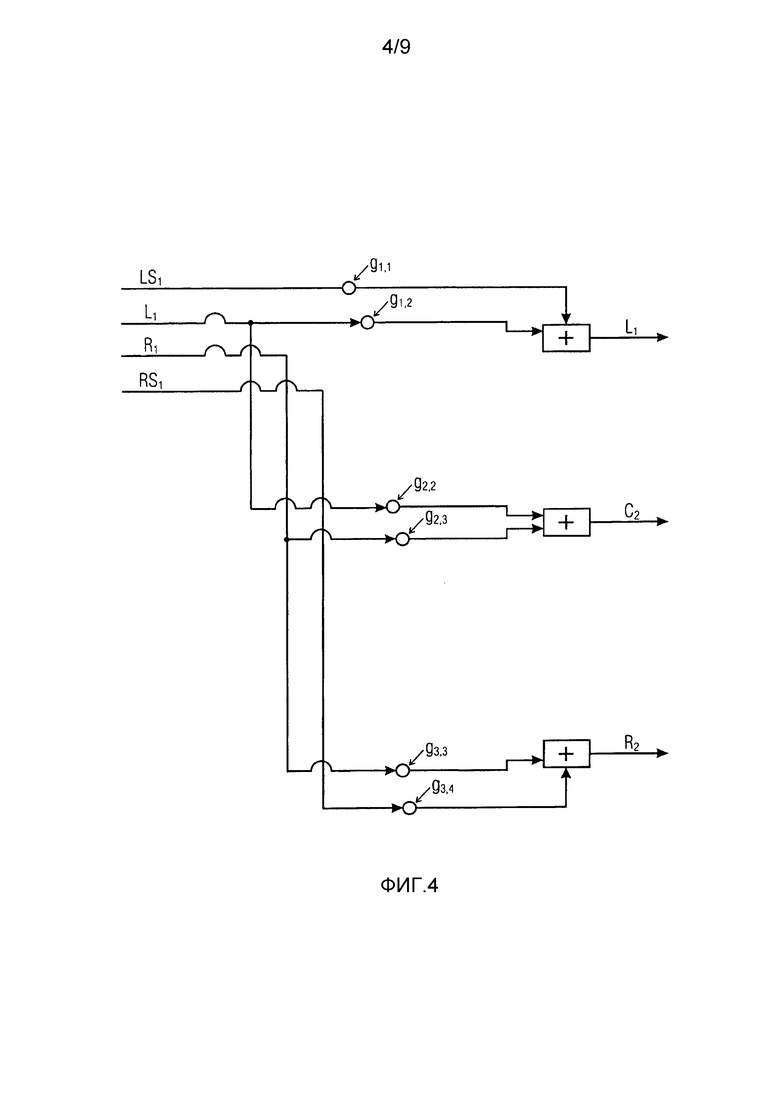
Фиг. 4 иллюстрирует другой сценарий согласно варианту осуществления, в котором каждый из выходных аудиоканалов формируется в зависимости от точно двух из входных аудиоканалов,
Фиг. 5 иллюстрирует преобразование передаваемых сигналов на основе пространственного представления в фактические позиции громкоговорителя,
Фиг. 6 иллюстрирует преобразование приподнятых пространственных сигналов в другие уровни возвышения,
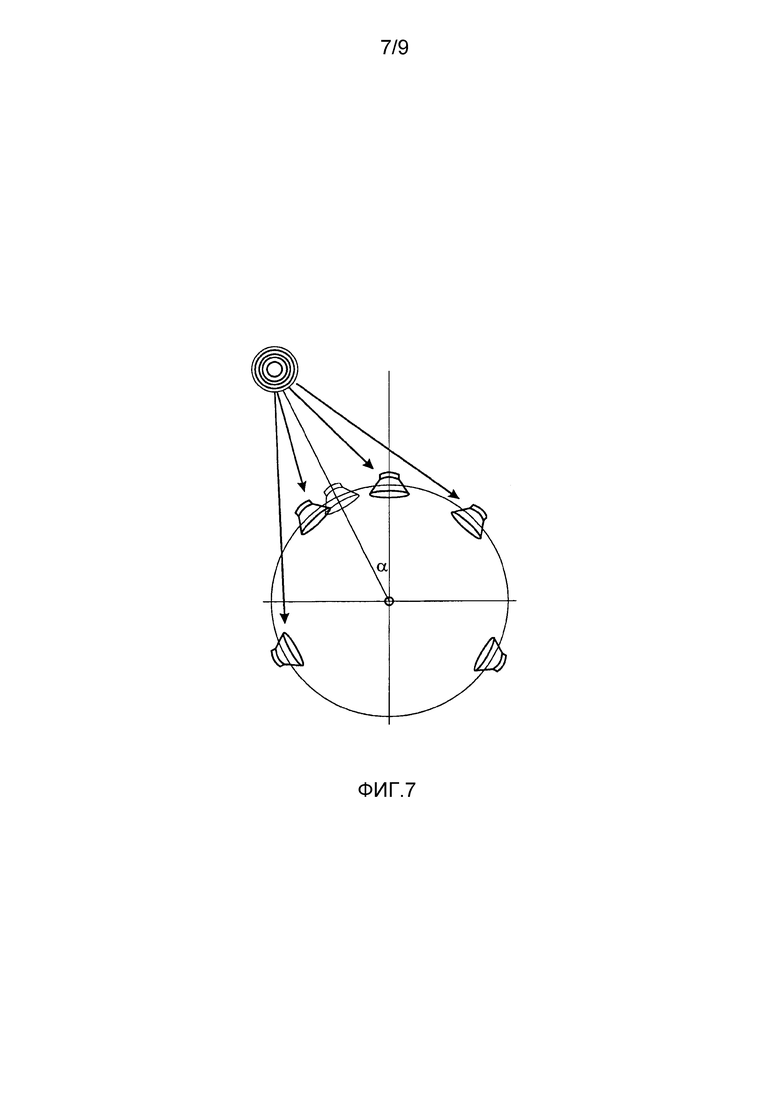
Фиг. 7 иллюстрирует такой рендеринг исходного сигнала для различных позиций громкоговорителя,
Фиг. 8 иллюстрирует систему согласно варианту осуществления, и
Фиг. 9 является другой иллюстрацией системы согласно варианту осуществления.
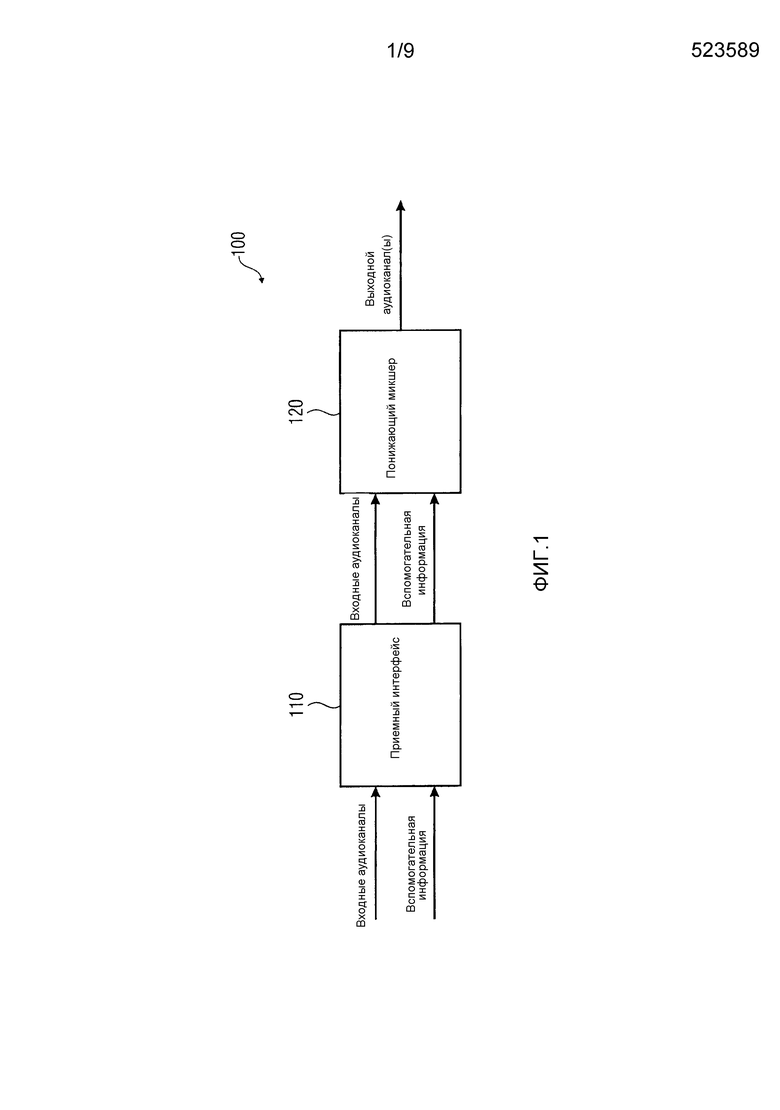
Фиг. 1 иллюстрирует устройство 100 для формирования двух или более выходных аудиоканалов из трех или более входных аудиоканалов согласно варианту осуществления.
Устройство 100 содержит приемный интерфейс 110 для приема трех или более входных аудиоканалов и для приема вспомогательной информации.
Кроме того, устройство 100 содержит понижающий микшер 120 для понижающего микширования трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать два или более выходных аудиоканала.
Число выходных аудиоканалов меньше числа входных аудиоканалов. Вспомогательная информация указывает характеристику, по меньшей мере, одного из трех или более входных аудиоканалов или характеристику одной или более звуковых волн, записанных в одном или более входных аудиоканалов, либо характеристику одного или более источников звука, которые испускают одну или более звуковых волн, записанных в одном или более входных аудиоканалов.
Фиг. 2 иллюстрирует понижающий микшер 120 согласно варианту осуществления на дополнительной иллюстрации. Направляющая информация, проиллюстрированная на фиг. 2, является вспомогательной информацией.
Фиг. 7 иллюстрирует рендеринг исходного сигнала для различных позиций громкоговорителя. Передаточные функции рендеринга могут зависеть от углов (азимутальных и возвышения), например, указывающих направление поступления звуковой волны, могут зависеть от расстояния, например, расстояния от источника звука до записывающего микрофона и/или могут зависеть от диффузности, причем эти параметры, например, могут быть частотно-зависимыми.
В отличие от подходов на основе понижающего микширования вслепую, например, подходов на основе ненаправленного понижающего микширования, согласно вариантам осуществления, управляющая информация или дескриптивная информация должна передаваться вместе с аудиосигналом, чтобы оказывать влияние на процесс понижающего микширования на стороне приемного устройства сигнальной цепочки. Эта вспомогательная информация может вычисляться на стороне отправляющего устройства/кодера сигнальной цепочки или может предоставляться из пользовательского ввода. Вспомогательная информация, например, может передаваться в потоке битов, например, мультиплексироваться с кодированным аудиосигналом.
Согласно конкретному варианту осуществления, понижающий микшер 120, например, может быть выполнен с возможностью микшировать с понижением четыре или более входных аудиоканала в зависимости от вспомогательной информации для того, чтобы получать три или более выходных аудиоканала.
В варианте осуществления, каждый из двух или более выходных аудиоканалов, например, может представлять собой канал громкоговорителя для управления громкоговорителем.
Например, в конкретном дополнительном варианте осуществления, понижающий микшер 120 может быть выполнен с возможностью микшировать с понижением семь входных аудиоканалов для того, чтобы получать три или более выходных аудиоканала. В другом конкретном варианте осуществления, понижающий микшер 120 может быть выполнен с возможностью микшировать с понижением девять входных аудиоканалов для того, чтобы получать три или более выходных аудиоканала. В конкретном дополнительном варианте осуществления, понижающий микшер 120 может быть выполнен с возможностью микшировать с понижением 24 канала для того, чтобы получать три или более выходных аудиоканала.
В другом конкретном варианте осуществления, понижающий микшер 120 может быть выполнен с возможностью микшировать с понижением семь или более входных аудиоканалов для того, чтобы получать точно пять выходных аудиоканалов, например, чтобы получать пять аудиоканалов пятиканальной системы объемного звучания. В дополнительном конкретном варианте осуществления, понижающий микшер 120 может быть выполнен с возможностью микшировать с понижением семь или более входных аудиоканалов для того, чтобы получать точно шесть выходных аудиоканалов, например, шесть аудиоканалов системы объемного звучания 5.1.
Согласно варианту осуществления, понижающий микшер может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством модификации, по меньшей мере, двух входных аудиоканалов из трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать группу модифицированных аудиоканалов, и посредством комбинирования каждого модифицированного аудиоканала упомянутой группы модифицированных аудиоканалов для того, чтобы получать упомянутый выходной аудиоканал.
В варианте осуществления, понижающий микшер, например, может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством модификации каждого входного аудиоканала из трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать группу модифицированных аудиоканалов, и посредством комбинирования каждого модифицированного аудиоканала упомянутой группы модифицированных аудиоканалов для того, чтобы получать упомянутый выходной аудиоканал.
Согласно варианту осуществления, понижающий микшер 120, например, может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством формирования каждого модифицированного аудиоканала из группы модифицированных аудиоканалов посредством определения весового коэффициента в зависимости от входного аудиоканала из одного или более входных аудиоканалов и в зависимости от вспомогательной информации и посредством применения упомянутого весового коэффициента к упомянутому входному аудиоканалу.
Фиг. 3 иллюстрирует такой вариант осуществления. Каждый выходной аудиоканал (AOC1, AOC2, AOC3) зависит от каждого из входных аудиоканалов (AIC1, AIC2, AIC3, AIC4).
Например, рассмотрим первый выходной аудиоканал AOC1.
Понижающий микшер 120 выполнен с возможностью определять весовой коэффициент g1,1, g1,2, g1,3, g1,4 для каждого входного аудиоканала AIC1, AIC2, AIC3, AIC4 в зависимости от входного аудиоканала и в зависимости от вспомогательной информации. Кроме того, понижающий микшер 120 выполнен с возможностью применять каждый весовой коэффициент g1,1, g1,2, g1,3, g1,4 к своему входному аудиоканалу AIC1, AIC2, AIC3, AIC4.
Например, понижающий микшер может быть выполнен с возможностью применять весовой коэффициент к своему входному аудиоканалу посредством умножения каждой выборки временной области входного аудиоканала на весовой коэффициент (например, когда входной аудиоканал представлен во временной области). Альтернативно, например, понижающий микшер может быть выполнен с возможностью применять весовой коэффициент к своему входному аудиоканалу посредством умножения каждого спектрального значения входного аудиоканала на весовой коэффициент (например, когда входной аудиоканал представлен в спектральной области, частотной области или частотно-временной области). Полученные модифицированные аудиоканалы (MAC1,1, MAC1,2, MAC1,3, MAC1,4), получающиеся в результате применения весовых коэффициентов g1,1, g1,2, g1,3, g1,4, затем комбинируются, например, суммируются, для того чтобы получать один из выходных аудиоканалов AOC1.
Второй выходной аудиоканал AOC2 определен аналогично посредством определения весовых коэффициентов g2,1, g2,2, g2,3, g2,4, посредством применения каждого из весовых коэффициентов к своему входному аудиоканалу AIC1, AIC2, AIC3, AIC4 и посредством комбинирования результирующих модифицированных аудиоканалов MAC2,1, MAC2,2, MAC2,3, MAC2,4.
Аналогично, третий выходной аудиоканал AOC2 определен аналогично посредством определения весовых коэффициентов g3,1, g3,2, g3,3, g3,4, посредством применения каждого из весовых коэффициентов к своему входному аудиоканалу AIC1, AIC2, AIC3, AIC4 и посредством комбинирования результирующих модифицированных аудиоканалов MAC3,1, MAC3,2, MAC3,3, MAC3,4.
Фиг. 4 иллюстрирует вариант осуществления, в котором каждый из выходных аудиоканалов формируется не посредством модификации каждого входного аудиоканала из трех или более входных аудиоканалов, но при этом каждый из выходных аудиоканалов формируется посредством модификации только двух из входных аудиоканалов и посредством комбинирования этих двух входных аудиоканалов.
Например, на фиг. 4, четыре канала принимаются как входные аудиоканалы (LS1=левый входной канал объемного звучания; L1=левый входной канал; R1=правый входной канал; RS1=правый входной канал объемного звучания), и должны формироваться три выходных аудиоканала (L2=левый выходной канал; R2=правый выходной канал; C2=центральный выходной канал) посредством понижающего микширования входных аудиоканалов.
На фиг. 4, левый выходной канал L2 формируется в зависимости от левого входного канала LS1 объемного звучания и в зависимости от левого входного канала L1. С этой целью, понижающий микшер 120 формирует весовой коэффициент g1,1 для левого входного канала LS1 объемного звучания в зависимости от вспомогательной информации и формирует весовой коэффициент g1,2 для левого входного канала L1 в зависимости от вспомогательной информации и применяет каждый из весовых коэффициентов к своему входному аудиоканалу для того, чтобы получать левый выходной канал L2.
Кроме того, центральный выходной канал C2 формируется в зависимости от левого входного канала L1 и в зависимости от правого входного канала R1. С этой целью, понижающий микшер 120 формирует весовой коэффициент g2,2 для левого входного канала L1 в зависимости от вспомогательной информации и формирует весовой коэффициент g2,3 для правого входного канала R1 в зависимости от вспомогательной информации и применяет каждый из весовых коэффициентов к своему входному аудиоканалу для того, чтобы получать центральный выходной канал C2.
Кроме того, правый выходной канал R2 формируется в зависимости от правого входного канала R1 и в зависимости от правого входного канала RS1 объемного звучания. С этой целью, понижающий микшер 120 формирует весовой коэффициент g3,3 для правого входного канала R1 в зависимости от вспомогательной информации и формирует весовой коэффициент g3,4 для правого входного канала RS1 объемного звучания в зависимости от вспомогательной информации и применяет каждый из весовых коэффициентов к своему входному аудиоканалу для того, чтобы получать левый выходной канал R2.
Варианты осуществления настоящего изобретения обусловлены посредством следующих изысканий.
Предшествующий уровень техники предоставляет коэффициенты понижающего микширования в качестве метаданных в потоке битов.
Один подход должен заключается в том, чтобы дополнять предшествующий уровень техники посредством коэффициентов частотно-избирательного понижающего микширования, дополнительных каналов (например, аудиоканалов, из исходной конфигурации каналов, например, информации высоты) и/или дополнительных форматов, которые должны использоваться в целевой конфигурации каналов. Другими словами, матрица понижающего микширования для форматов трехмерного аудио должна быть расширена посредством дополнительных каналов формата ввода, в частности, посредством каналов высоты форматов трехмерного аудио. Относительно дополнительных форматов множество форматов вывода должно поддерживаться посредством трехмерного аудио. Тогда как для 5.0- или 5.1-сигнала, понижающее микширование может осуществляться только для стерео- или возможно моно-, в конфигурациях каналов, содержащих большее число каналов, следует принимать во внимание, что несколько форматов вывода являются релевантными. Для 22.2-каналов они могут представлять собой моно-, стерео-, 5.1- или различные 7.1-варианты и т.д.
Тем не менее, должны значительно повышаться ожидаемые скорости передачи битов для передачи этих расширенных коэффициентов. Для конкретных форматов, может быть целесообразным задавать дополнительные коэффициенты понижающего микширования и комбинировать их с существующими метаданными понижающего микширования (см. 7.1-проект в MPEG, выходной документ N12980).
В контексте трехмерного аудио, ожидаемых комбинаций конфигураций каналов на стороне отправляющего устройства и приемного устройства множество, и объем данных выходит за рамки допустимых скоростей передачи битов. Тем не менее, снижение избыточности (например, кодирование методом Хаффмана) позволяет уменьшать объем данных до допустимой пропорции.
Кроме того, коэффициенты понижающего микширования, как описано выше, могут характеризоваться параметрически.
Тем не менее, при этом по-прежнему ожидаемые скорости передачи битов должны значительно увеличиваться в силу такого подхода.
Из вышеозначенного следует то, что, в общем, на практике неосуществимо расширение установленных подходов, причем одна причина заключается в том, что как следствие, скорости передачи данных должны становиться непропорционально высокими.
Общая спецификация понижающего микширования во временной области может формулироваться следующим образом:
yn(t)=cnm*xm(t),
где y(t) является выходным сигналом понижающего микширования, x(t) является входным сигналом, n является индексом входного аудиоканала, m является индексом выходного канала. Коэффициент понижающего микширования m-ого входного канала в n-ом выходном канале соответствует cnm. Известным примером является понижающее микширование 5-канального сигнала и двухканального стереосигнала с помощью:
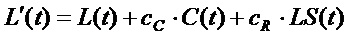
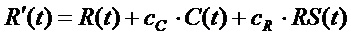
Коэффициенты понижающего микширования являются статическими и применяются к каждой выборке аудиосигнала. Они могут добавляться в качестве метаданных в поток аудиобитов. Термин "коэффициенты частотно-избирательного понижающего микширования" используется в отношении возможности использования отдельных коэффициентов понижающего микширования для конкретных полос частот. В комбинации с изменяющимися во времени коэффициентами понижающее микширование на стороне декодера может управляться из кодера. Спецификация понижающего микширования для аудиокадра в таком случае становится следующей:
yn(k, s)=cnm(k)*xm(k, s),
где k является полосой частот (например, гибридной QMF-полосой частот), s представляет собой подвыборки гибридной QMF-полосы частот.
Как описано выше, передача этих коэффициентов приводит к высоким скоростям передачи битов.
Варианты осуществления настоящего изобретения обеспечивают использование дескриптивной (описательной) вспомогательной информации. Понижающий микшер 120 выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от такой (дескриптивной) вспомогательной информации для того, чтобы получать два или более выходных аудиоканала.
Дескриптивная информация относительно аудиоканалов, комбинации аудиоканалов или аудиообъектов позволяет улучшать процесс понижающего микширования, поскольку могут учитываться характеристики аудиосигналов.
В общем, такая вспомогательная информация указывает характеристику, по меньшей мере, одного из трех или более входных аудиоканалов или характеристику одной или более звуковых волн, записанных в одном или более входных аудиоканалов, либо характеристику одного или более источников звука, которые испускают одну или более звуковых волн, записанных в одном или более входных аудиоканалов.
Примерами для вспомогательной информации могут быть один или более из следующих параметров:
- отношение "прямой/обработанный сигнал"
- величина объемного окружения
- диффузность
- направленность
- ширина источника звука
- расстояние между источниками звука
- направление поступления
Определения этих параметров известны для специалистов в данной области техники. На предмет определения этих параметров следует обратиться к прилагаемой литературе (см.[1] -[24]). Например, определение для величины объемного окружения предоставляется в [15], [16], [17], [18], [19] и [14]. Определение для отношения "прямой/обработанный сигнал" может сразу извлекаться из определения для "прямого/окружающего", как известно специалистам в данной области техники. Термины "направленность" и "диффузность" поясняются в [21] и также известны специалистам в данной области техники.
Предлагаемые параметры предоставляются в качестве вспомогательной информации для того, чтобы направлять процесс рендеринга, формирующий N-канальный выходной сигнал из M-канального входного сигнала, при этом в случае понижающего микширования, N меньше M.
Параметры, которые предоставляются в качестве вспомогательной информации, не обязательно являются постоянными. Вместо этого, параметры могут варьироваться во времени (параметры могут быть зависимыми от времени).
В общем, вспомогательная информация может содержать параметры, которые доступны частотно-избирательным способом.
Применение передаваемой вспомогательной информации осуществляется при постобработке/рендеринге на стороне декодера. Оценка параметров и их взвешивание зависит от целевой конфигурации каналов и дополнительных характеристик на стороне визуального представления.
Упомянутые параметры могут быть связаны с каналами, группами каналов или объектов.
Параметры могут использоваться в процессе понижающего микширования для того, чтобы определять взвешивание канала или объекта во время понижающего микширования посредством понижающего микшера 120.
Рассмотрим следующий пример. Если канал высоты содержит исключительно реверберацию и/или отражения, это может иметь отрицательный эффект на качество звука во время понижающего микширования. В этом случае, его доля в аудиоканале, получающемся в результате понижающего микширования, следовательно, должна быть небольшой. Следовательно, при управлении понижающим микшированием высокое значение параметра "величина объемного окружения" приводит к низким коэффициентам понижающего микширования для этого канала. В отличие от этого, если он содержит прямые сигналы, он должен отражаться до большей степени в аудиоканале, получающемся в результате понижающего микширования, и, следовательно, приводить к более высоким коэффициентам понижающего микширования (к более высокому весовому коэффициенту).
Например, каналы высоты формирования трехмерного аудио могут содержать компоненты прямого сигнала, а также отражения и реверберацию в целях огибания. Если эти каналы высоты смешиваются с каналами горизонтальной плоскости, это приводит к нежелательным результатам в результирующем микшировании, тогда как приоритетный аудиоконтент прямых компонентов должен быть микширован с понижением в полном объеме.
Информация может использоваться для того, чтобы регулировать коэффициенты понижающего микширования (при необходимости частотно-избирательным способом). Этот замечание применимо ко всем вышеуказанным упомянутым параметрам. Частотная избирательность может обеспечивать более точное управление понижающим микшированием.
Например, весовой коэффициент, который применяется к входному аудиоканалу для того, чтобы получать модифицированный аудиоканал, может определяться, соответственно, в зависимости от соответствующей вспомогательной информации.
Например, если приоритетные каналы (например, левый, центральный или правый канал системы объемного звучания) должны формироваться в качестве выходных аудиоканалов, а не фоновых каналов (к примеру, левого канала объемного звучания или правого канала объемного звучания системы объемного звучания), то:
- Если вспомогательная информация указывает то, что величина объемного окружения входного аудиоканала является высокой, то небольшой весовой коэффициент для этого входного аудиоканала может определяться для формирования приоритетного выходного аудиоканала. Посредством этого, модифицированный аудиоканал, получающийся в результате этого входного аудиоканала, только немного учитывается для формирования соответствующего выходного аудиоканала.
- Если вспомогательная информация указывает то, что величина объемного окружения входного аудиоканала является низкой, то больший весовой коэффициент для этого входного аудиоканала может определяться для формирования приоритетного выходного аудиоканала. Посредством этого, модифицированный аудиоканал, получающийся в результате этого входного аудиоканала, в основном учитывается для формирования соответствующего выходного аудиоканала.
В варианте осуществления, вспомогательная информация может указывать величину объемного окружения каждого из трех или более входных аудиоканалов. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от величины объемного окружения каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
Например, вспомогательная информация может содержать параметр, указывающий величину объемного окружения для каждого входного аудиоканала из трех или более входных аудиоканалов. Например, каждый входной аудиоканал может содержать части окружающего сигнала и/или части прямого сигнала. Например, величина объемного окружения входного аудиоканала может указываться в качестве вещественного числа ai, при этом i указывает один из трех или более входных аудиоканалов, и при этом ai, например, может находиться в диапазоне 0≤ai≤≤1; ai=0 может указывать то, что соответствующий входной аудиоканал не содержит частей окружающего сигнала; ai=1 может указывать то, что соответствующий входной аудиоканал содержит только части окружающего сигнала. В общем, величина объемного окружения входного аудиоканала, например, может указывать число частей окружающего сигнала во входном аудиоканале.
Например, возвращаясь к фиг. 3, в варианте осуществления, может быть определено, что части окружающего сигнала всегда являются нежелательными. Соответствующий понижающий микшер 120 может определять весовые коэффициенты по фиг. 3, например, согласно формуле:
gc,i=(1-ai)/4, при этом c  {1, 2, 3}; i {1, 2, 3, 4}; 0≤ai≤1
{1, 2, 3}; i {1, 2, 3, 4}; 0≤ai≤1
В таком варианте осуществления, все весовые коэффициенты определяются как равные для каждого из трех или более выходных аудиоканалов.
Тем не менее, для других вариантов осуществления, может быть определено, что для некоторых выходных аудиоканалов, объемное окружение является более допустимым, чем для других выходных аудиоканалов. Например, может быть определено, что в варианте осуществления согласно фиг. 3, объемное окружение является более допустимым для первого выходного аудиоканала AOC1 и для третьего выходного аудиоканала AOC3, чем для второго выходного аудиоканала AOC2. Затем соответствующий понижающий микшер 120 может определять весовые коэффициенты по фиг. 3, например, согласно формуле:
g1,i=(1-(ai/2))/4, при этом i {1, 2, 3, 4}; 0≤ai≤1
g2,i=(1-ai)/4, при этом i {1, 2, 3, 4}; 0≤ai≤1
g3,i=(1-(ai/2))/4, при этом i {1, 2, 3, 4}; 0≤ai≤1
В таком варианте осуществления, весовые коэффициенты одного из трех или более выходных аудиоканалов определяются отлично от весовых коэффициентов другого из трех или более выходных аудиоканалов.
Весовые коэффициенты по фиг. 4 могут определяться аналогично двум примерам, описанным относительно фиг. 3, например, аналогично первому примеру, следующим образом:
g1,1=(1-ai)/2; g1,2=(1-ai)/2; g2,2=(1-ai)/2;
g2,3=(1-ai)/2; g3,3=(1-ai)/2; g3,4=(1-ai)/2;
Весовые коэффициенты gc,i по фиг. 3 и фиг. 4 также может определяться любым другим требуемым, подходящим способом.
Согласно другому варианту осуществления, вспомогательная информация может указывать диффузность каждого из трех или более входных аудиоканалов или направленность каждого из трех или более входных аудиоканалов. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от диффузности каждого из трех или более входных аудиоканалов или в зависимости от направленности каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
В таком варианте осуществления, вспомогательная информация, например, может содержать параметр, указывающий диффузность для каждого входного аудиоканала из трех или более входных аудиоканалов. Например, каждый входной аудиоканал может содержать части рассеянного сигнала и/или части прямого сигнала. Например, диффузность входного аудиоканала может указываться в качестве вещественного числа di, при этом i указывает один из трех или более входных аудиоканалов, и при этом di, например, может находиться в диапазоне 0≤di≤1; di=0 может указывать то, что соответствующий входной аудиоканал не содержит частей рассеянного сигнала; di=1 может указывать то, что соответствующий входной аудиоканал содержит только части рассеянного сигнала. В общем, диффузность входного аудиоканала, например, может указывать число частей рассеянного сигнала во входном аудиоканале.
Весовые коэффициенты gc,i могут определяться в примере по фиг. 3, например, следующим образом:
gc,i=(1-di)/4, при этом c {1, 2, 3}; i {1, 2, 3, 4}; 0≤di≤1
или, например, следующим образом:
g1,i=(1-(di/2))/4, при этом i {1, 2, 3, 4}; 0≤di≤1
g2,i=(1-di)/4, при этом i {1, 2, 3, 4}; 0≤di≤1
g3,i=(1-(di/2))/4, при этом i {1, 2, 3, 4}; 0≤di≤1
или любым другим подходящим, требуемым способом.
Альтернативно, вспомогательная информация, например, может содержать параметр, указывающий направленность для каждого входного аудиоканала из трех или более входных аудиоканалов. Например, направленность входного аудиоканала может указываться в качестве вещественного числа di, при этом i указывает один из трех или более входных аудиоканалов, и при этом di, например, может находиться в диапазоне 0≤diri≤1; diri=0 может указывать то, что части сигнала соответствующего входного аудиоканала имеют низкую направленность; diri=1 может указывать то, что части сигнала соответствующего входного аудиоканала имеют высокую направленность.
Весовые коэффициенты gc,i могут определяться в примере по фиг. 3, например, следующим образом:
gc,i=diri/4, при этом c {1, 2, 3}; i {1, 2, 3, 4}; 0≤diri≤1
или, например, следующим образом:
g1,i=0,125+diri/8, при этом i {1, 2, 3, 4}; 0≤diri≤1
g2,i=diri/4, при этом i {1, 2, 3, 4}; 0≤diri≤1
g3,i=0,125+diri/8, при этом i {1, 2, 3, 4}; 0≤diri≤1
или любым другим подходящим, требуемым способом.
В дополнительном варианте осуществления, вспомогательная информация может указывать направление поступления звука. Понижающий микшер может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от направления поступления звука, чтобы получать два или более выходных аудиоканала.
Например, направление поступления представляет собой, к примеру, направление поступления звуковой волны. Например, направление поступления звуковой волны, записанное посредством входного аудиоканала, может указываться в качестве, может указываться в качестве угла ϕi, при этом I указывает один из трех или более входных аудиоканалов, при этом ϕi, например, может находиться в диапазоне 0°≤ϕi<360°. Например, звуковые части звуковых волн, имеющих направление поступления, близкое к 90°, должны иметь высокий весовой коэффициент, а звуковые волны, имеющие направление поступления близкое к 270°, должны иметь низкий весовой коэффициент или вообще не должны иметь весовой коэффициент в выходном аудиосигнале. Весовые коэффициенты gc,i могут определяться в примере по фиг. 3, например, следующим образом:
gc,i=(1+sin ϕi)/8, при этом c {1, 2, 3}; i {1, 2, 3, 4}; 0°≤ϕi<360°
Когда направление поступления 270° является более допустимым для выходных аудиоканалов AOC1 и AOC3, чем для выходного аудиоканала AOC2, то весовые коэффициенты gc,i, например, могут определяться следующим образом:
g1,i=(1,5+(sin ϕi)/2)/8, при этом i {1, 2, 3, 4}; 0°≤ϕi<360°
g2,i=(1+sin ϕi)/8, при этом i {1, 2, 3, 4}; 0°≤ϕi<360°
g3,i=(1,5+(sin ϕi)/2)/8, при этом i {1, 2, 3, 4}; 0°≤ϕi<360°
или любым другим подходящим, требуемым способом.
Чтобы реализовывать воспроизведение аудиосигналов для различных настроек громкоговорителя посредством использования дескриптивной вспомогательной информации, например, могут использоваться один или более из следующих параметров:
- направление поступления (горизонтальное и вертикальное)
- разность относительно слушателя
- ширина источника ("диффузность")
В частности, для объектно-ориентированного трехмерного аудио, эти параметры могут использоваться для управления преобразованием объекта в громкоговорители целевого формата.
Кроме того, эти параметры, например, могут быть доступны частотно-избирательным способом.
Диапазон значений "диффузности": точечный источник – плоская волна – всенаправленно поступающая волна. Следует отметить, что диффузность может отличаться от объемного окружения. (Возьмем, например, голоса из ниоткуда в психоделических художественных фильмах).
Согласно варианту осуществления, устройство 100 может быть выполнено с возможностью подавать каждый из двух или более выходных аудиоканалов в громкоговоритель группы из двух или более громкоговорителей. Понижающий микшер 120 может быть выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от каждой предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя и в зависимости от каждой фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя, чтобы получать два или более выходных аудиоканала. Каждая фактическая позиция громкоговорителя второй группы из двух или более фактических позиций громкоговорителя может указывать позицию громкоговорителя группы из двух или более громкоговорителей.
Например, входной аудиоканал может назначаться предполагаемой позиции громкоговорителя. Кроме того, первый выходной аудиоканал формируется для первого громкоговорителя в первой фактической позиции громкоговорителя, и второй выходной аудиоканал формируется для второго громкоговорителя во второй фактической позиции громкоговорителя. Если расстояние между первой фактической позицией громкоговорителя и предполагаемой позицией громкоговорителя меньше расстояния между второй фактической позицией громкоговорителя и предполагаемой позицией громкоговорителя, то, например, входной аудиоканал оказывает большее влияние на первый выходной аудиоканал по сравнению со вторым выходным аудиоканалом.
Например, могут формироваться первый весовой коэффициент и второй весовой коэффициент. Первый весовой коэффициент может зависеть от расстояния между первой фактической позицией громкоговорителя и предполагаемой позицией громкоговорителя. Второй весовой коэффициент может зависеть от расстояния между второй фактической позицией громкоговорителя и предполагаемой позицией громкоговорителя. Первый весовой коэффициент превышает второй весовой коэффициент. Для формирования первого выходного аудиоканала первый весовой коэффициент может применяться к входному аудиоканалу для того, чтобы формировать первый модифицированный аудиоканал. Для формирования второго выходного аудиоканала второй весовой коэффициент может применяться к входному аудиоканалу для того, чтобы формировать второй модифицированный аудиоканал. Дополнительные модифицированные аудиоканалы аналогично могут формироваться для других выходных аудиоканалов и/или для других входных аудиоканалов, соответственно. Каждый выходной аудиоканал из двух или более выходных аудиоканалов может формироваться посредством комбинирования его модифицированных аудиоканалов.
Фиг. 5 иллюстрирует такое преобразование передаваемых сигналов на основе пространственного представления в фактические позиции громкоговорителя. Предполагаемые позиции 511, 512, 513, 514 и 515 громкоговорителя принадлежат первой группе предполагаемых позиций громкоговорителя. Фактические позиции 521, 522 и 523 громкоговорителя принадлежат второй группе фактических позиций громкоговорителя.
Например, то, как входной аудиоканал для предполагаемого громкоговорителя в предполагаемой позиции 512 громкоговорителя оказывает влияние на первый выходной аудиосигнал для первого реального громкоговорителя в первой фактической позиции 521 громкоговорителя и второй выходной аудиосигнал для второго реального громкоговорителя во второй фактической позиции 522 громкоговорителя, зависит от того, как близко предполагаемая позиция 512 (или ее виртуальная позиция 532) находится к первой фактической позиции 521 громкоговорителя и ко второй фактической позиции 522 громкоговорителя. Чем ближе предполагаемая позиция громкоговорителя к фактической позиции громкоговорителя, тем большее влияние входной аудиоканал имеет на соответствующий выходной аудиоканал.
На фиг. 5, f указывает входной аудиоканал для громкоговорителя в предполагаемой позиции 512 громкоговорителя; g1 указывает первый выходной аудиоканал для первого фактического громкоговорителя в первой фактической позиции 521 громкоговорителя, g2 указывает второй выходной аудиоканал для второго фактического громкоговорителя во второй фактической позиции 522 громкоговорителя, α указывает азимутальный угол, и β указывает угол возвышения, при этом азимутальный угол α и угол β возвышения, например, указывают направление от фактической позиции громкоговорителя к предполагаемой позиции громкоговорителя или наоборот.
В варианте осуществления, каждый входной аудиоканал из трех или более входных аудиоканалов может назначаться предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя. Например, когда предполагается, что входной аудиоканал должен воспроизводиться посредством громкоговорителя в предполагаемой позиции громкоговорителя, то этот входной аудиоканал назначается этой предполагаемой позиции громкоговорителя. Каждый выходной аудиоканал из двух или более выходных аудиоканалов может назначаться фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя. Например, когда выходной аудиоканал должен воспроизводиться посредством громкоговорителя в фактической позиции громкоговорителя, то этот выходной аудиоканал назначается этой фактической позиции громкоговорителя. Понижающий микшер может быть выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов в зависимости, по меньшей мере, от двух из трех или более входных аудиоканалов, в зависимости от предполагаемой позиции громкоговорителя каждого из упомянутых, по меньшей мере, двух из трех или более входных аудиоканалов и в зависимости от фактической позиции громкоговорителя упомянутого выходного аудиоканала.
Фиг. 6 иллюстрирует преобразование приподнятых пространственных сигналов в другие уровни возвышения. Передаваемые пространственные сигналы (каналы) представляют собой каналы для динамиков в плоскости приподнятых динамиков, либо для динамиков в плоскости неприподнятых динамиков. Если все реальные громкоговорители расположены в одной плоскости громкоговорителя (в плоскости неприподнятых динамиков), каналы для динамиков в плоскости приподнятых динамиков должны быть поданы в динамики плоскости неприподнятых динамиков.
С этой целью, вспомогательная информация содержит информацию относительно предполагаемой позиции 611 громкоговорителя динамика в плоскости приподнятых динамиков. Соответствующая виртуальная позиция 631 в плоскости неприподнятых динамиков определяется посредством понижающего микшера, и модифицированные аудиоканалы, сформированные посредством модификации входного аудиоканала для предполагаемого приподнятого динамика, формируются в зависимости от фактических позиций 621, 622, 623, 624 громкоговорителя для фактически доступных динамиков.
Частотная избирательность может использоваться для осуществления более точного управления понижающим микшированием. При использовании примера "величины объемного окружения", канал высоты может содержать как пространственные компоненты, так и прямые компоненты. Частотные компоненты, имеющие различные свойства, могут характеризоваться соответствующим образом.
Согласно варианту осуществления, каждый из трех или более входных аудиоканалов содержит аудиосигнал аудиообъекта из трех или более аудиообъектов. Вспомогательная информация содержит, для каждого аудиообъекта из трех или более аудиообъектов, позицию аудиообъекта, указывающую позицию упомянутого аудиообъекта. Понижающий микшер выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от позиции аудиообъекта каждого из трех или более аудиообъектов, чтобы получать два или более выходных аудиоканала.
Например, первый входной аудиоканал содержит аудиосигнал первого аудиообъекта. Первый громкоговоритель может быть расположен в первой фактической позиции громкоговорителя. Второй громкоговоритель может быть расположен во второй фактической позиции громкоговорителя. Расстояние между первой фактической позицией громкоговорителя и позицией первого аудиообъекта может быть меньше расстояния между второй фактической позицией громкоговорителя и позицией первого аудиообъекта. После этого формируются первый выходной аудиоканал для первого громкоговорителя и второй выходной аудиоканал для второго громкоговорителя, так что аудиосигнал первого аудиообъекта имеет большее влияние в первом выходном аудиоканале по сравнению со вторым выходным аудиоканалом.
Например, могут формироваться первый весовой коэффициент и второй весовой коэффициент. Первый весовой коэффициент может зависеть от расстояния между первой фактической позицией громкоговорителя и позицией первого аудиообъекта. Второй весовой коэффициент может зависеть от расстояния между второй фактической позицией громкоговорителя и позицией второго аудиообъекта. Первый весовой коэффициент превышает второй весовой коэффициент. Для формирования первого выходного аудиоканала первый весовой коэффициент может применяться к аудиосигналу первого аудиообъекта для того, чтобы формировать первый модифицированный аудиоканал. Для формирования второго выходного аудиоканала второй весовой коэффициент может применяться к аудиосигналу первого аудиообъекта для того, чтобы формировать второй модифицированный аудиоканал. Дополнительные модифицированные аудиоканалы аналогично могут формироваться для других выходных аудиоканалов и/или для других аудиообъектов, соответственно. Каждый выходной аудиоканал из двух или более выходных аудиоканалов может формироваться посредством комбинирования его модифицированных аудиоканалов.
Фиг. 8 иллюстрирует систему согласно варианту осуществления.
Система содержит кодер 810 для кодирования трех или более необработанных аудиоканалов для того, чтобы получать три или более кодированных аудиоканала, и для кодирования дополнительной информации относительно трех или более необработанных аудиоканалов для того, чтобы получать вспомогательную информацию.
Кроме того, система содержит устройство 100 согласно одному из вышеописанных вариантов осуществления для приема трех или более кодированных аудиоканалов в качестве трех или более входных аудиоканалов, для приема вспомогательной информации и для формирования, в зависимости от вспомогательной информации, двух или более выходных аудиоканалов из трех или более входных аудиоканалов.
Фиг. 9 иллюстрирует другую иллюстрацию системы согласно варианту осуществления. Проиллюстрированная направляющая информация является вспомогательной информацией. M кодированных аудиоканалов, кодированных посредством кодера 810, подаются в устройство 100 (указываемое посредством "понижающего микширования") для формирования двух или более выходных аудиоканалов. N выходных аудиоканалов формируются посредством понижающего микширования M кодированных аудиоканалов (входных аудиоканалов устройства 820). В варианте осуществления, применимо N<M.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
Изобретаемый разложенный сигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронночитаемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат энергонезависимый носитель хранения данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
ДОКУМЕНТЫ
[1] J.M. Eargle: Stereo/Mono Disc Compatibility: A Survey of the Problems, 35th AES Convention, октябрь 1968 года.
[2] P. Schreiber: Four Channels and Compatibility, J. Audio Eng. Soc., том 19, издание 4, апрель 1971 года (2).
[3] D. Griesinger: Surround from stereo, Workshop #12, 115th AES Convention, 2003 год.
[4] E. C. Cherry (1953): Some experiments on the recognition of speech, with one and with two ears, Journal of the Acoustical Society of America 25, 975979.
[5] ITU-R Recommendation BS.775-1 Multi-channel Stereophonic Sound System with or without Accompanying Picture, International Telecommunications Union, Geneva, Switzerland, 1992-1994 гг.
[6] D. Griesinger: Progress in 5-2-5 Matrix Systems, 103rd AES Convention, сентябрь 1997 года.
[7] J. Hull: Surround sound past, present and future, Dolby Laboratories, 1999 год, www.dolby.com/tech/
[8] C. Faller, F. Baumgarte: Binaural Cue Coding Applied to Stereo and Multi-Channel Audio Compression, 112th AES Convention, Мюнхен, 2002 год.
[9] C. Faller, F. Baumgarte: Binaural Cue Coding Part II: Schemes and Applications, IEEE Trans. Speech and Audio Proc., том 11, номер 6, стр. 520-531, ноябрь 2003 года.
[10] J. Breebaart, J. Herre, C. Faller, J. Rdn, F. Myburg, S. Disch, H. Purnhagen, G. Hotho, M. Neusinger, K. Kjrling, W. Oomen: MPEG Spatial Audio Coding/MPEG Surround: Overview and Current Status, 119th AES Convention, октябрь 2005 года.
[11] ISO/IEC 14496-3, Chapter 4.5.1.2.2.
[12] B. Runow, J. Deigmöller: Optimierter Stereo – Downmix von 5.1-Mehrkanalproduktionen (An optimized Stereo Downmix of the multichannel audio production), 25. Tonmeistertagung – VDT international convention, ноябрь 2008 года.
[13] J. Thompson, A. Warner, B. Smith: An Active Multichannel Downmix Enhancement for Minimizing Spatial and Spectral Distortions, 127 AES Convention, октябрь 2009 года.
[14] C. Faller: Multiple-Loudspeaker Playback of Stereo Signals. JAES, том 54, издание 11, стр. 1051-1064; ноябрь 2006 года.
[15] AVENDANO, Carlos u. JOT, Jean-Marc: Ambience Extraction and Synthesis from Stereo Signals for Multi-Channel Audio Mix-Up. In: Proc.or IEEE Internat. Conf. on Acoustics, Speech and Signal Processing (ICASSP), май 2002 года.
[16] US 7,412,380 B1: Ambience extraction and modification for enhancement and upmix of audio signals.
[17] US 7,567,845 B1: Ambience generation for stereo signals.
[18] US 2009/0092258 A1: CORRELATION-BASED METHOD FOR AMBIENCE EXTRACTION FROM TWO-CHANNEL AUDIO SIGNALS.
[19] US 2010/0030563 A1: Uhle, Walther, Herre, Hellmuth, Janssen: APPARATUS AND METHOD FOR GENERATING AN AMBIENT SIGNAL FROM AN AUDIO SIGNAL, APPARATUS AND METHOD FOR DERIVING A MULTI-CHANNEL AUDIO SIGNAL FROM AN AUDIO SIGNAL AND COMPUTER PROGRAM.
[20] J. Herre, H. Purnhagen, J. Breebaart, C. Faller, S. Disch, K. Kjörling, E. Schuijers, J. Hilpert и F. Myburg, The Reference Model Architecture for MPEG Spatial Audio Coding, presented at the 118th Convention of the Audio Engineering Society, J. Audio Eng. Soc. (Abstracts), том 53, стр. 693, 694 (июль/август 2005 года), статья на конференции номер 6447.
[21] Ville Pulkki: Spatial Sound Reproduction with Directional Audio Coding. JAES, том 55, издание 6, стр. 503-516; июнь 2007 года.
[22] ETSI TS 101 154, Chapter C.
[23] MPEG-4 downmix metadata.
[24] DVB downmix metadata.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОСУЩЕСТВЛЕНИЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ SAOC ОБЪЕМНОГО (3D) АУДИОКОНТЕНТА | 2014 |
|
RU2666239C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ УЛУЧШЕННОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ | 2014 |
|
RU2660638C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ЭФФЕКТИВНОГО КОДИРОВАНИЯ МЕТАДАННЫХ ОБЪЕКТОВ | 2014 |
|
RU2666282C2 |
| ПРИНЦИП ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИО ДЛЯ АУДИОКАНАЛОВ И АУДИООБЪЕКТОВ | 2014 |
|
RU2641481C2 |
| ПАРАМЕТРИЧЕСКОЕ СОВМЕСТНОЕ КОДИРОВАНИЕ АУДИОИСТОЧНИКОВ | 2006 |
|
RU2376654C2 |
| ДЕКОДЕР, КОДЕР И СПОСОБ ИНФОРМИРОВАННОЙ ОЦЕНКИ ГРОМКОСТИ С ИСПОЛЬЗОВАНИЕМ ОБХОДНЫХ СИГНАЛОВ АУДИООБЪЕКТОВ В СИСТЕМАХ ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ КОДИРОВАНИЯ АУДИО | 2014 |
|
RU2651211C2 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ МНОЖЕСТВА АУДИООБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИИ НАПРАВЛЕНИЯ ВО ВРЕМЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ ИЛИ УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОПТИМИЗИРОВАННОГО КОВАРИАЦИОННОГО СИНТЕЗА | 2021 |
|
RU2826540C1 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ МНОЖЕСТВА АУДИООБЪЕКТОВ ИЛИ УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ДВУХ ИЛИ БОЛЕЕ РЕЛЕВАНТНЫХ АУДИООБЪЕКТОВ | 2021 |
|
RU2823518C1 |
| ДЕКОДЕР, КОДЕР И СПОСОБ ИНФОРМИРОВАННОЙ ОЦЕНКИ ГРОМКОСТИ В СИСТЕМАХ ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ КОДИРОВАНИЯ АУДИО | 2014 |
|
RU2672174C2 |
| КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ АУДИООБЪЕКТОВ | 2012 |
|
RU2618383C2 |




Изобретение относится к средствам направленного понижающего микширования для трехмерного аудио. Технический результат заключается в повышении эффективности кодирования аудиосигналов. Устройство для понижающего микширования трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала, содержит приемный интерфейс для приема трех или более входных аудиоканалов и для приема вспомогательной информации. Кроме того, устройство содержит понижающий микшер для понижающего микширования трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать два или более выходных аудиоканала. Число выходных аудиоканалов меньше числа входных аудиоканалов. Вспомогательная информация указывает характеристику по меньшей мере одного из трех или более входных аудиоканалов или характеристику одной или более звуковых волн, записанных в одном или более входных аудиоканалов, либо характеристику одного или более источников звука, которые испускают одну или более звуковых волн, записанных в одном или более входных аудиоканалов. 4 н. и 6 з.п. ф-лы, 9 ил.
1. Устройство (100) для формирования двух или более выходных аудиоканалов из трех или более входных аудиоканалов, при этом устройство (100) содержит:
- приемный интерфейс (110) для приема трех или более входных аудиоканалов и для приема вспомогательной информации, и
- понижающий микшер (120) для понижающего микширования трех или более входных аудиоканалов в зависимости от вспомогательной информации с использованием весового коэффициента для каждого входного аудиоканала для того, чтобы получать два или более выходных аудиоканала,
при этом число выходных аудиоканалов меньше числа входных аудиоканалов,
при этом вспомогательная информация указывает характеристику по меньшей мере одного из трех или более входных аудиоканалов или характеристику одной или более звуковых волн, записанных в одном или более входных аудиоканалов, либо характеристику одного или более источников звука, которые испускают одну или более звуковых волн, записанных в одном или более входных аудиоканалов, и
при этом понижающий микшер выполнен с возможностью определять весовой коэффициент для каждого входного аудиоканала в зависимости от вспомогательной информации,
причем устройство (100) выполнено с возможностью подавать каждый из двух или более выходных аудиоканалов в громкоговоритель группы из двух или более громкоговорителей,
причем понижающий микшер (120) выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от каждой предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя и в зависимости от каждой фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя, чтобы получать два или более выходных аудиоканала,
причем каждая фактическая позиция громкоговорителя второй группы из двух или более фактических позиций громкоговорителя указывает позицию громкоговорителя группы из двух или более громкоговорителей,
причем каждый входной аудиоканал из трех или более входных аудиоканалов назначается предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя,
причем каждый выходной аудиоканал из двух или более выходных аудиоканалов назначается фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя,
причем понижающий микшер (120) выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов в зависимости по меньшей мере от двух из трех или более входных аудиоканалов, в зависимости от предполагаемой позиции громкоговорителя каждого из упомянутых по меньшей мере двух из трех или более входных аудиоканалов и в зависимости от фактической позиции громкоговорителя упомянутого выходного аудиоканала,
причем вспомогательная информация содержит величину объемного окружения каждого из трех или более входных аудиоканалов, и
при этом понижающий микшер (120) выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от величины объемного окружения каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
2. Устройство (100) по п. 1, в котором понижающий микшер (120) выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством модификации по меньшей мере двух входных аудиоканалов из трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать группу модифицированных аудиоканалов, и посредством комбинирования каждого модифицированного аудиоканала упомянутой группы модифицированных аудиоканалов для того, чтобы получать упомянутый выходной аудиоканал.
3. Устройство (100) по п. 2, в котором понижающий микшер (120) выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством модификации каждого входного аудиоканала из трех или более входных аудиоканалов в зависимости от вспомогательной информации для того, чтобы получать группу модифицированных аудиоканалов, и посредством комбинирования каждого модифицированного аудиоканала упомянутой группы модифицированных аудиоканалов для того, чтобы получать упомянутый выходной аудиоканал.
4. Устройство (100) по п. 2 или 3, в котором понижающий микшер (120) выполнен с возможностью формировать каждый выходной аудиоканал из двух или более выходных аудиоканалов посредством формирования каждого модифицированного аудиоканала из группы модифицированных аудиоканалов посредством определения весового коэффициента в зависимости от входного аудиоканала из одного или более входных аудиоканалов и в зависимости от вспомогательной информации и посредством применения упомянутого весового коэффициента к упомянутому входному аудиоканалу.
5. Устройство (100) по любому из пп. 1-3,
в котором вспомогательная информация указывает диффузность каждого из трех или более входных аудиоканалов или направленность каждого из трех или более входных аудиоканалов, и
при этом понижающий микшер (120) выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от диффузности каждого из трех или более входных аудиоканалов или в зависимости от направленности каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
6. Устройство (100) по любому из пп. 1-3,
в котором вспомогательная информация указывает направление поступления звука, и
при этом понижающий микшер (120) выполнен с возможностью микшировать с понижением три или более входных аудиоканала в зависимости от направления поступления звука, чтобы получать два или более выходных аудиоканала.
7. Устройство (100) по любому из пп. 1-3, в котором понижающий микшер (120) выполнен с возможностью микшировать с понижением четыре или более входных аудиоканала в зависимости от вспомогательной информации для того, чтобы получать три или более выходных аудиоканала.
8. Система для кодирования трех или более необработанных аудиоканалов и для формирования двух или более выходных аудиоканалов, причем система содержит:
- кодер (810) для кодирования трех или более необработанных аудиоканалов для того, чтобы получать три или более кодированных аудиоканала, и для кодирования дополнительной информации относительно трех или более необработанных аудиоканалов для того, чтобы получать вспомогательную информацию, и
- устройство (100) по одному из предшествующих пунктов для приема трех или более кодированных аудиоканалов в качестве трех или более входных аудиоканалов, для приема вспомогательной информации и для формирования, в зависимости от вспомогательной информации, двух или более выходных аудиоканалов из трех или более входных аудиоканалов.
9. Способ для формирования двух или более выходных аудиоканалов из трех или более входных аудиоканалов, при этом способ содержит этапы, на которых:
- принимают три или более входных аудиоканала и принимают вспомогательную информацию, и
- микшируют с понижением три или более входных аудиоканала в зависимости от вспомогательной информации с использованием весового коэффициента для каждого входного аудиоканала для того, чтобы получать два или более выходных аудиоканала,
при этом число выходных аудиоканалов меньше числа входных аудиоканалов, и
при этом вспомогательная информация указывает характеристику по меньшей мере одного из трех или более входных аудиоканалов или характеристику одной или более звуковых волн, записанных в одном или более входных аудиоканалов, либо характеристику одного или более источников звука, которые испускают одну или более звуковых волн, записанных в одном или более входных аудиоканалов, и
при этом весовой коэффициент определяют для каждого входного аудиоканала в зависимости от вспомогательной информации,
причем каждый из двух или более выходных аудиоканалов подают в громкоговоритель группы из двух или более громкоговорителей,
причем три или более входных аудиоканала микшируют с понижением в зависимости от каждой предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя и в зависимости от каждой фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя, чтобы получать два или более выходных аудиоканала,
причем каждая фактическая позиция громкоговорителя второй группы из двух или более фактических позиций громкоговорителя указывает позицию громкоговорителя группы из двух или более громкоговорителей,
причем каждый входной аудиоканал из трех или более входных аудиоканалов назначается предполагаемой позиции громкоговорителя первой группы из трех или более предполагаемых позиций громкоговорителя,
причем каждый выходной аудиоканал из двух или более выходных аудиоканалов назначается фактической позиции громкоговорителя второй группы из двух или более фактических позиций громкоговорителя,
причем каждый выходной аудиоканал из двух или более выходных аудиоканалов формируют в зависимости по меньшей мере от двух из трех или более входных аудиоканалов, в зависимости от предполагаемой позиции громкоговорителя каждого из упомянутых по меньшей мере двух из трех или более входных аудиоканалов и в зависимости от фактической позиции громкоговорителя упомянутого выходного аудиоканала,
причем вспомогательная информация содержит величину объемного окружения каждого из трех или более входных аудиоканалов, и
при этом микширование с понижением трех или более входных аудиоканалов выполняют в зависимости от величины объемного окружения каждого из трех или более входных аудиоканалов для того, чтобы получать два или более выходных аудиоканала.
10. Компьютерно-читаемый носитель, содержащий компьютерную программу для реализации способа по п. 9 при выполнении на компьютере или в процессоре сигналов.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7412380 B1, 12.08.2008 | |||
| US 7567845 B1, 28.07.2009 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ АУДИОСИГНАЛА | 2007 |
|
RU2417549C2 |

