ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к сетевым технологиям связи, в частности, к способу и устройству блокировки нежелательных сообщений электронной почты.
ПРЕДПОСЫЛКИ К СОЗДАНИЮ ИЗОБРЕТЕНИЯ
В системах электронной почты постоянно растет объем нежелательных сообщений, которые не только увеличивают продолжительность обработки пользователем нормальных сообщений, но и приводят к непроизводительному расходованию важных ресурсов почтовой системы, что затрудняет процесс получения пользователем полезной информации. Соответственно, необходимо решить указанную проблему нежелательных сообщений.
В настоящее время для предотвращения поступления нежелательных сообщений в почтовую систему обычно используют способ блокировки на основе строки. Для осуществления способа блокировки на основе строки требуется создать базу данных строк. Строка базы данных строк содержит значимое отдельное слово или фразу, при этом длина строки является относительно постоянной. База данных строк должна иметь определенные периодичность обновления и размер, причем размер базы данных строк по числу сканируемых строк может исчисляться миллионами. В практическом применении, при использовании строки из описанной выше базы данных строк полученное сообщение электронной почты подвергают фильтрации способом последовательного полнотекстового сканирования или сравнения по регулярным выражениям для определения, является ли полученное сообщение нежелательным сообщением или нормальным сообщением, с блокировкой полученного сообщения в случае определения в случае, если оно является нежелательным сообщением.
В процессе работы над настоящим изобретением автор изобретения выявил следующие недостатки известных технических решений.
Формирование строки с использованием отдельного значимого слова или фразы может привести к относительно высокому уровню ложных срабатываний, поскольку отдельное значимое слово или фраза может присутствовать не только в нежелательном сообщении, но в некоторых случаях и в нормальном сообщении, что приводит к ошибкам идентификации нежелательного сообщения.
Поскольку для фильтрации сообщений электронной почты используют полную строку из базы данных строк, описанный выше способ последовательного полнотекстового сканирования или сравнения с регулярным выражением не является эффективным при относительно большом размере базы данных строк, при этом неосуществима фильтрация принимаемых сообщений в режиме реального времени, что приводит к существенному ухудшению удобства использования.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Примеры осуществления настоящего изобретения описывают способ и устройство блокировки нежелательных сообщений, позволяющие уменьшить уровень ложных срабатываний при идентификации нежелательных сообщений и повысить эффективность фильтрации электронной почты.
Заявляемый способ блокировки нежелательных сообщений электронной почты содержит следующие этапы:
A) получают текстовые данные подлежащего фильтрации сообщения электронной почты;
B) определяют, содержат ли текстовые данные ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, при этом в случае, если текстовые данные содержат ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, то дополнительно определяют, содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк;
С) определяют, является ли сообщение электронной почты нежелательным сообщением в зависимости от результата дополнительного определения и согласно заранее заданным правилам идентификации; блокируют сообщение в случае, если оно является нежелательным сообщением.
Заявляемое устройство блокировки нежелательных сообщений содержит следующие компоненты:
модуль получения текстовых данных, сконфигурированный для получения текстовых данных подлежащего фильтрации сообщения электронной почты; модуль идентификации символов, сконфигурированный для определения, содержат ли текстовые данные ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, и в случае, если текстовые данные содержат ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, дополнительного определения, содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк;
модуль обработки сообщений, сконфигурированный для определения, в зависимости от результата дополнительного определения в модуле идентификации символов, а также согласно заранее заданным правилам идентификации, является ли сообщение электронной почты нежелательным сообщением, и блокировки сообщения, если оно является нежелательным сообщением.
Как видно из приведенного выше описания технических решений, представленных примерными вариантами осуществления настоящего изобретения, в примерных вариантах осуществления настоящего изобретения выполняют сканирование текстовых данных сообщения электронной почты по ключевому слову, затем, после обнаружения совпадения с ключевым словом, сканируют текстовые данные сообщения электронной почты по строке, соответствующей ключевому слову, что позволяет повысить скорость и эффективность сканирования, а также реализовать фильтрацию сообщений электронной почты в режиме реального времени даже в случае относительно большого размера базы данных строк.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Для более подробного объяснения технических решений на примерах вариантов осуществления изобретения использованы приведенные ниже схематичные сопроводительные чертежи. Следует понимать, что указанными сопроводительными чертежами проиллюстрированы лишь некоторые примеры осуществления настоящего изобретения, на основе которых специалистам в данной области техники будут очевидны и другие варианты осуществления настоящего изобретения.
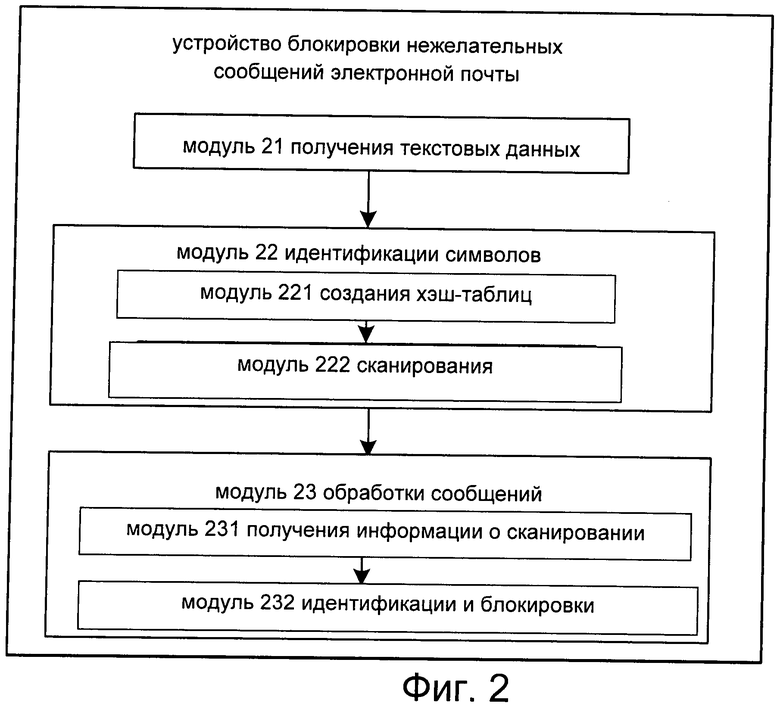
Фиг.1 представляет собой блок-схему, иллюстрирующую способ блокировки нежелательных сообщений электронной почты согласно одному из примерных вариантов осуществления.
Фиг.2 представляет собой схему конструкции, иллюстрирующую конкретное устройство блокировки нежелательных сообщений электронной почты согласно другому примерному варианту осуществления.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Примерными вариантами осуществления изобретения предусмотрено следующее: получают текстовые данные подлежащего фильтрации сообщения электронной почты; определяют, содержат ли полученные текстовые данные сообщения ключевое слово из строки в используемой для фильтрации сообщений базе данных строк; в случае, если полученные текстовые данные содержат указанное ключевое слово, дополнительно определяют, содержат ли текстовые данные строку, соответствующую указанному ключевому слову в базе данных строк. В зависимости от результата определения того, содержат ли текстовые данные строку, соответствующую ключевому слову в базе данных строк, а также согласно заранее заданным правилам идентификации определяют, является ли сообщение электронной почты нежелательным сообщением, после чего блокируют сообщение, если оно является нежелательным сообщением.
Дополнительно после приема подлежащего фильтрации сообщения электронной почты получают содержание заголовка и основного поля сообщения; затем содержание заголовка и основного поля объединяют для получения набора текстовых данных; полученные текстовые данные определяют как текстовые данные подлежащего фильтрации сообщения электронной почты. Предпочтительно предусмотрена возможность сохранения текстовых данных.
Дополнительно из одного или нескольких символьных блоков формируют строку, содержащуюся в базе данных строк. Символьный блок содержит по меньшей мере одно из следующего: английское слово, отдельное китайское слово, отдельная английская буква, половина отдельного китайского слова или полноширинный/полуширинный знак препинания.
Кроме того, база данных строк соответствует главной хэш-таблице и хэш-таблице ссылок, причем ключевое слово из строки, содержащейся в базе данных строк, а также информацию о длине строки, соответствующей ключевому слову, хранят в главной хэш-таблице, а полную информацию о символьной структуре строки, соответствующей ключевому слову, хранят в хэш-таблице ссылок.
В более подробном виде выполнение описанного выше определения происходит следующим образом: отбирают заданное число символов, начиная с первого символьного блока текстовых данных; выявляют, содержит ли главная хэш-таблица ключевое слово, соответствующее заданному числу символов, и, если содержит, получают информацию о длине (в частности, значение длины), соответствующую ключевому слову; согласно информации о длине выбирают соответствующую строку из текстовых данных; выявляют, содержит ли хэш-таблица ссылок выбранную строку и, если содержит, определяют однократное совпадение при сканировании текстовых данных; записывают число совпадений при сканировании текстовых данных, а также информацию о соответствующих ключевом слове и строке.
Если главная хэш-таблица не содержит ключевого слова, соответствующего заданному числу символов, или если хэш-таблица ссылок не содержит выбранной строки, то после сдвига назад на один символьный блок от первого символьного блока текстовых данных выбирают заданное число символов и обрабатывают выбранные символы согласно алгоритму обработки заданного числа символов, выбранных из первого символьного блока текстовых данных, до тех пор, пока не будет выявлено последнее заданное число символов в текстовых данных.
При этом главную хэш-таблицу и ссылочную хэш-таблицу создают следующим образом:
выбирают заданное число символов, начиная с первого символа в первой строке, содержащейся в базе данных строк; принимают выбранные символы в качестве ключевого слова; определяют, соответствует ли заданное число символов в первом символьном блоке из другой строки, отличной от первой строки в базе данных строк, ключевому слову, и если соответствует, записывают информацию о длине указанной другой строки и ключевое слово в главной хэш-таблице; при этом полную информацию о структуре другой строки записывают в хэш-таблице ссылок;
затем дополнительно определяют вторую строку, отличную от строки, записанной в хэш-таблице ссылок в базе данных строк; обрабатывают вторую строку согласно алгоритму обработки заданного числа символов, выбранных из первой строки, до тех пор, пока в главной хэш-таблице не будут записаны все фрагменты символов, выбранных, начиная с соответствующих первых символьных блоков всех строк в базе данных строк, а также информация об их длине, и пока в хэш-таблице ссылок не будет записана соответствующая полная информация о символьной структуре всех соответствующих строк.
При этом определение того, является ли сообщение электронной почты нежелательным сообщением, предусматривает следующее: если текстовые данные содержат строку, соответствующую ключевому слову в базе данных строк, при сканировании текстовых данных получают записанное число совпадений, при этом записывают и затем получают записанную информацию о соответствующем ключевом слове и строке;
в зависимости от записанного числа совпадений при сканировании текстовых данных, а также записанной информации о соответствующем ключевом слове и строке, на основе заранее заданных правил идентификации определяют, является ли данное сообщение электронной почты нежелательным сообщением, и блокируют сообщение, если оно является нежелательным сообщением.
При этом заранее заданные правила идентификации предусматривают следующее: сообщение электронной почты идентифицируют как нежелательное сообщение, если число совпадений при сканировании текстовых данных превышает заданное число совпадений; при этом в случае, если информацией о строке является длина совпавшей при сканировании строки, то заранее заданные правила идентификации предусматривают, в том числе, следующее: сообщение электронной почты идентифицируют как нежелательное сообщение в том случае, если число совпадений при сканировании текстовых данных превышает заданное число совпадений и длина совпавшей при сканировании строки превышает заданную длину.
Для облегчения понимания примерных вариантов осуществления настоящего изобретения дальнейшее описание содержит несколько конкретных примеров в сочетании с сопроводительными чертежами; при этом приведенные в описании примеры не ограничивают всех вариантов осуществления настоящего изобретения.
Схема хэширования представляет собой структуру хранения данных. В схеме хэширования установлено соответствие между адресом хранения данных и ключевым словом данных; при этом, благодаря установлению указанного соответствия, набору ключевых слов соответствует набор ячеек. При условии, что размер набора ячеек не выходит за границы допустимого диапазона, установление соответствия является гибким процессом. Типовая схема хэширования содержит главную хэш-таблицу и хэш-таблицу ссылок. Для практического применения главную хэш-таблицу и хэш-таблицу ссылок необходимо формировать по ситуации.
Алгоритм способа блокировки нежелательных сообщений электронной почты согласно одному из примерных вариантов осуществления показан на фиг.1; при этом способ содержит следующие этапы.
Этап 11: получают текстовые данные подлежащего фильтрации сообщения электронной почты.
В более подробном виде это происходит следующим образом: после приема подлежащего фильтрации сообщения электронной почты указанное сообщение декодируют и получают содержимое заголовка и основного поля сообщения; получают набор текстовых данных за счет непосредственного объединения содержимого заголовка и основного поля сообщения; затем полученные текстовые данные определяют как текстовые данные сообщения, подлежащего фильтрации на этапе 11.
При этом для упрощения блокировки на следующем этапе, в частности, на этапе, соответствующем показанному ниже этапу 13, сначала текстовые данные можно временно сохранить.
Этап 12: создают главную хэш-таблицу и хэш-таблицу ссылок на основе загруженной базы данных строк.
При этом, поскольку главную хэш-таблицу и хэш-таблицу ссылок создают на основе базы данных строк, можно считать, что имеется соответствие между базой данных строк и главной хэш-таблицей и хэш-таблицей ссылок.
Следует пояснить, что строка, содержащаяся в базе данных строк, сформирована из одного или нескольких символьных блоков. Символьный блок может представлять собой, в частности, по меньшей мере одно из следующего: английское слово, отдельное китайское слово, отдельная английская буква, половина отдельного китайского слова или полноширинный/полуширинный знак препинания. При этом очевидно, что строка, содержащаяся в базе данных строк, может представлять собой фрагмент строки с произвольной структурой, не обязательно значимое отдельное слово или фразу. Фрагмент строки может представлять собой по меньшей мере одно из следующего: английское слово, отдельное китайское слово, знак препинания, или любую комбинацию из перечисленного. В типовом практическом применении строка обычно присутствует в нежелательном сообщении или в нормальном сообщении. В качестве примера целесообразно рассмотреть ситуацию, когда строка, содержащаяся в базе данных строк, присутствует в нежелательном сообщении. Следует отметить, что ситуация, когда содержащаяся в базе данных строк строка присутствует в нежелательном сообщении, приведена в качестве примера. Что касается области применения примерных вариантов осуществления настоящего изобретения, указанная выше строка, содержащаяся в базе данных строк, в некоторых отдельных случаях также может присутствовать в нормальном сообщении, то есть в этих случаях строки одновременно задействованы в нормальном сообщении и в нежелательном сообщении. Если обе строки задействованы одновременно, предпочтительно обеспечить возможность сканирования и идентификации конкретных текстовых данных с помощью способа на основе, например, любого алгоритма статистической классификации и/или алгоритма классификации с использованием искусственного интеллекта. Например, два типа строк в нормальном сообщении и в нежелательном сообщении можно подготовить и протестировать с применением алгоритма Байеса для получения модели классификации и использовать полученную модель классификации для последующей идентификации текстового содержимого сообщений электронной почты. Очевидно, что на фиг.1 показан лишь один пример, не ограничивающий область применения примерных вариантов осуществления настоящего изобретения.
В указанном примере использована описанная выше схема хэширования, причем главную хэш-таблицу и хэш-таблицу ссылок создают на основе загруженной базы данных строк. Создание главной хэш-таблицы и хэш-таблицы ссылок происходит следующим образом:
последовательно сканируют строки в описанной выше базе данных строк от начала базы данных строк. Сначала в качестве хэш-индекса первого уровня принимают первые n символов первой строки. Для упрощения описания предположено, что n равно 2. Затем хэш-индекс первого уровня определяют ключевым словом, например ключевым словом "Саньлу", представляющим собой одно китайское слово, образованное из двух китайских иероглифов. Затем, используя ключевое слово в качестве индекса, проверяют другую, отличную от первой, строку в описанной выше базе данных строк и определяют, соответствуют ли первые два символа указанной другой строки ключевому слову. Если первые два символа другой строки соответствуют ключевому слову, получают полную информацию о структуре и длине другой строки.
В указанном примере предпочтительно обеспечить возможность хранения в главной хэш-таблице информации о длине всех строк, соответствующих ключевому слову, например "Саньлу", по первым двум китайским иероглифам. Структура главной хэш-таблицы приведена ниже в таблице 1. При этом соответствующую полную информацию о символьной структуре всех строк, соответствующих ключевому слову, например "Саньлу", по первым двум иероглифам, хранят в хэш-таблице ссылок. Структура хэш-таблицы ссылок приведена ниже в таблице 2. Из таблицы видно, что одно ключевое слово соответствует одной хэш-таблице ссылок. В схеме хэширования имеется только одна главная хэш-таблица для хранения всех ключевых слов и информации о длине строк, в которых первые n символов соответствуют ключевому слову; при этом схема может содержать множество хэш-таблиц ссылок, согласованных с соответствующими ключевыми словами в главной хэш-таблице.
После выполнения указанной выше обработки, содержащей выбор ключевого слова для первой строки и заполнение по ключевому слову таблицы 1 и таблицы 2, указанную обработку, содержащую выбор ключевого слова для первой строки и заполнение по ключевому слову таблицы 1 и таблицы 2, выполняют для другой строки, отличной от строки, уже записанной в хэш-таблице ссылок, проиллюстрированной в таблице 2 описанной выше базой данных строк; причем указанную обработку выполняют до тех пор, пока в главной хэш-таблице не будет записана информация о длине и первых n символах всех строк в базе данных строк и до тех пор, пока в хэш-таблице ссылок не будет сохранена соответствующая полная информация о структуре всех строк.
В результате выполнения вышеуказанных этапов можно создать главную хэш-таблицу и соответствующие хэш-таблицы ссылок, соотнесенные с базой данных строк.
Этап 13: сканируют текстовые данные сообщения электронной почты, используя главную хэш-таблицу и хэш-таблицу ссылок; согласно результату сканирования и заранее заданным правилам идентификации определяют, является ли данное сообщение электронной почты нежелательным сообщением; блокируют сообщение в случае, если оно является нежелательным сообщением.
После создания вышеописанных главной хэш-таблицы и хэш-таблицы ссылок из текстовых данных подлежащего фильтрации сообщения электронной почты выбирают строку, сформированную первыми n символами (где n может, в частности, принимать значение 2 или другое значение), начиная с первого символа текстовых данных, и затем выявляют, имеется ли в созданной главной хэш-таблице соответствующее выбранной строке ключевое слово. Если такое ключевое слово имеется, получают первое значение длины, соответствующее данной строке. Затем по первому значению длины получают соответствующую строку из текстовых данных и выявляют, имеется ли выбранная строка в хэш-таблице ссылок. Если такая строка имеется, определяют однократное совпадение при сканировании текстовых данных и записывают информацию, относящуюся к соответствующему ключевому слову и совпавшей при сканировании строке; если же указанная строка отсутствует, информацию не записывают. Затем главную хэш-таблицу снова проверяют относительно следующего значения длины, соответствующего строке, до тех пор, пока не будут выявлены все соответствующие строке значения длины.
При отсутствии в главной хэш-таблице соответствующего выбранной строке ключевого слова не требуется проверки хэш-таблицы ссылок. Затем, начиная со второго символа текстовых данных, выбирают строку с двумя символами. Выявляют, содержит ли главная хэш-таблица ключевое слово, соответствующее строке, выбранной, начиная со второго символа текстовых данных; повторяют указанные выше действия по выявлению и определению в отношении строки, выбранной, начиная с первого символа, до тех пор, пока не будет выявлена строка, сформированная из последних двух символов текстовых данных.
Затем, в зависимости от информации о числе совпадений при сканировании текстовых данных и информации, относящейся к соответствующему ключевому слову и совпавшей при сканировании строке, а также согласно заранее заданным правилам идентификации, определяют, является ли данное сообщение электронной почты нежелательным сообщением. Заранее заданные правила устанавливают по ситуации, например используют следующие правила идентификации: сообщение электронной почты идентифицируют как нежелательное сообщение, если число совпадений при сканировании текстовых данных превышает 5, или сообщение электронной почты идентифицируют как нежелательное сообщение, если число совпадений при сканировании текстовых данных превышает 4 и длина строки, с совпавшей при сканировании, больше 4.
Заранее заданные правила идентификации должны обеспечивать условия, при которых общий уровень ложных срабатываний был бы меньше допустимого нормативного значения уровня ложных срабатываний, например меньше 0,1%, при этом общий уровень блокировки был бы больше допустимого нормативного значения уровня блокировки, например больше 70%.
Затем идентифицированное нежелательное сообщение блокируют, при этом нормальное сообщение, не являющееся нежелательным сообщением, пропускают.
При вышеуказанном сканировании сообщения электронной почты сначала сканируют текстовые данные сообщения по ключевому слову, при этом если выявлено, что текстовые данные сообщения содержат ключевое слово, сканируют текстовые данные сообщения по строке, соответствующей ключевому слову. Это позволяет повысить скорость и эффективность сканирования.
Другой примерный вариант осуществления относится к устройству блокировки нежелательных сообщений электронной почты. Один из конкретных вариантов конструктивного исполнения устройства показан на фиг.2. В частности, устройство может содержать следующие компоненты:
модуль 21 получения текстовых данных, сконфигурированный для получения текстовых данных подлежащего фильтрации сообщения электронной почты;
модуль 22 идентификации символов, сконфигурированный для определения, содержат ли текстовые данные ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, и если содержат, для дополнительного определения, содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк;
модуль 23 обработки сообщений, сконфигурированный для: определения, является ли сообщение электронной почты нежелательным сообщением в зависимости от результата дополнительного определения в модуле 22 идентификации символов и согласно заранее заданным правилам идентификации, и блокировки сообщения, если оно является нежелательным сообщением. При этом результат дополнительного определения в модуле 22 идентификации символов может являться, в частности, результатом определения следующего: содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк.
Модуль 22 идентификации символов может содержать, в частности, следующие компоненты:
модуль 221 создания хэш-таблиц, сконфигурированный для создания главной хэш-таблицы и хэш-таблицы ссылок, соответствующих базе данных строк; при этом в главной хэш-таблице хранят ключевое слово из строки, содержащейся в базе данных строк, и информацию о длине строки, соответствующей ключевому слову, при этом в хэш-таблице ссылок хранят полную информацию о символьной структуре строки, соответствующей ключевому слову;
модуль 222 сканирования, сконфигурированный для отбора заданного числа символов, начиная с первого символьного блока в текстовых данных; выявления, содержит ли главная хэш-таблица ключевое слово, соответствующее заданному числу символов, и если содержит, получения информации о длине (в частности, значения длины), соответствующей ключевому слову, выбора, в зависимости от информации о длине соответствующей строки из текстовых данных; выявления, имеется ли выбранная строка в хэш-таблице ссылок, и если имеется, определения однократного совпадения при сканировании текстовых данных, записи числа совпадений при сканировании текстовых данных, а также информации о соответствующем ключевом слове и строке.
Если главная хэш-таблица не содержит ключевого слова, соответствующего заданному числу символов, либо хэш-таблица ссылок не содержит выбранной строки, то после сдвигания назад на один символьный блок от первого символа в текстовых данных выбирают заданное число символов, при этом символы, выбранные после сдвига назад на один символьный блок от первого символа в текстовых данных, обрабатывают согласно алгоритму обработки заданного числа символов, выбранных с первого символа в текстовых данных, до тех пор, пока не будет выявлено последнее заданное число символов в текстовых данных.
Модуль 23 обработки сообщений, в частности, содержит:
модуль 231 получения информации о сканировании, сконфигурированный для получения записанной информации о числе совпадений при сканировании текстовых данных, а также записанной информации о соответствующем ключевом слове и строке. В частности, информацию о числе совпадений при сканировании текстовых данных, а также информацию о соответствующем ключевом слове и строке записывают в том случае, если текстовые данные содержат строку, соответствующую ключевому слову в базе данных строк;
модуль 232 идентификации и блокировки, сконфигурированный для определения, является ли сообщение электронной почты нежелательным сообщением в зависимости от информации о числе совпадений при сканировании текстовых данных, информации о соответствующем ключевом слове и строке, а также согласно заранее заданным правилам идентификации, и для блокировки сообщения электронной почты в случае его идентификации как нежелательного сообщения.
Обычным специалистам в данной области техники будет очевидно, что все или некоторые этапы способа, описанного выше на примерных вариантах, могут быть реализованы компьютерной программой, управляющей соответствующими аппаратными средствами. Программу можно хранить на считываемом компьютером носителе данных. При выполнении программы можно осуществлять этапы описанных выше примерных вариантов способа. В частности, в качестве носителя данных можно использовать магнитный диск, оптический диск, постоянное запоминающее устройство ПЗУ (ROM) или оперативное запоминающее устройство ОЗУ (RAM), или другое аналогичное запоминающее устройство.
Резюмируя вышеизложенное: благодаря тому, что вместо отдельного слова или фразы используют фрагмент строки произвольной структуры, представленной только в нежелательном сообщении электронной почты, примеры осуществления настоящего изобретения позволяют устранить проблему ложного распознавания, присущую известным техническим решениям, и добиться относительно низкого уровня ложных срабатываний и относительно высокого уровня блокировки.
Использование в примерах осуществления настоящего изобретения при сканировании текстовых данных сообщения электронной почты схемы хэширования с главной хэш-таблицей и хэш-таблицей ссылок позволит существенно повысить эффективность и скорость сканирования, а также фильтровать сообщения электронной почты в режиме реального времени даже в случае относительно большого размера базы данных строк.
Приведенное выше описание относится только к предпочтительным примерным вариантам осуществления настоящего изобретения, не ограничивающим объем патентной защиты настоящего изобретения. Любые вариации или изменения, которые несложным образом могут быть реализованы специалистами в данной области техники, следует считать не выходящими за рамки объема патентной защиты настоящего изобретения. При этом объем патентной защиты настоящего изобретения следует определять на основе прилагаемой формулы изобретения.
Изобретение относится к области сетевых технологий связи, а именно к блокировке нежелательных сообщений электронной почты. Техническим результатом является повышение скорости и эффективности сканирования, а также реализации фильтрации сообщений электронной почты в режиме реального времени даже в случае относительно большого размера базы данных строк. Для этого получают текстовые данные подлежащего фильтрации сообщения электронной почты и определяют, содержат ли текстовые данные ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк. При наличии в текстовых данных ключевого слова из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, дополнительно определяют, содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк. И затем идентифицируют сообщение электронной почты как нежелательное сообщение в зависимости от результата дополнительного определения и согласно заранее заданным правилам идентификации, и блокируют сообщение электронной почты в случае, если оно является нежелательным сообщением. 2 н. и 8 з.п. ф-лы, 2 табл., 2 ил.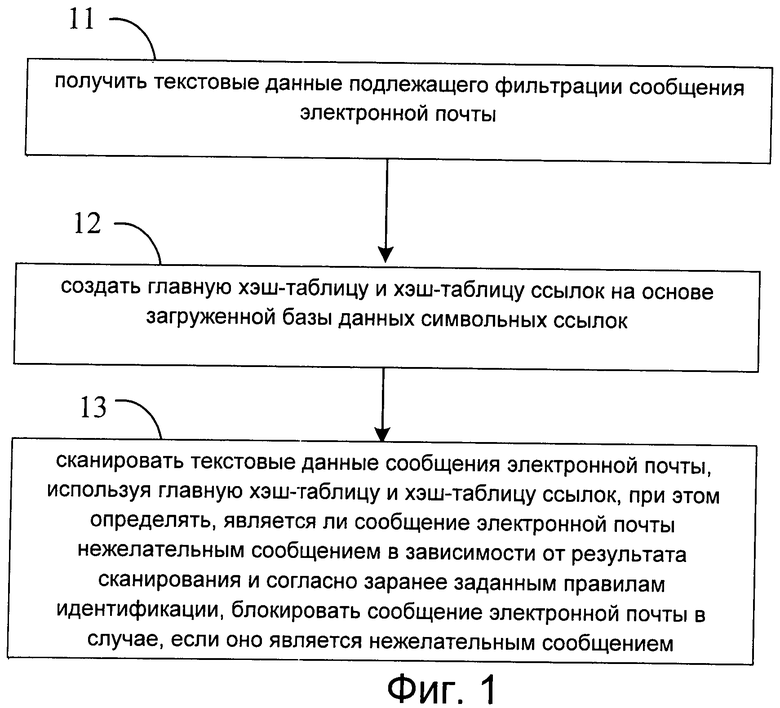
1. Способ блокировки нежелательных сообщений электронной почты, содержащий следующие этапы:
A) получают текстовые данные подлежащего фильтрации сообщения;
B) определяют, содержат ли текстовые данные ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, причем, если текстовые данные содержат ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, дополнительно определяют, содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк;
C) определяют, является ли сообщение электронной почты нежелательным сообщением в зависимости от результата дополнительного определения и согласно заранее заданным правилам идентификации, и блокируют сообщение электронной почты, если оно является нежелательным сообщением.
2. Способ по п.1, в котором этап А предусматривает следующее:
после приема подлежащего фильтрации сообщения электронной почты получают содержимое заголовка и основного поля сообщения;
объединяют содержимое заголовка и основного поля для получения текстовых данных; определяют полученные текстовые данные как текстовые данные подлежащего фильтрации сообщения электронной почты.
3. Способ по п.1, в котором строку, содержащуюся в базе данных строк, формируют из одного или нескольких символьных блоков; причем символьный блок содержит по меньшей мере одно из следующего: английское слово, отдельное китайское слово, одна английская буква, половина отдельного китайского слова или полноширинный/полуширинный знак препинания.
4. Способ по любому из пп.1-3, в котором база данных строк соответствует главной хэш-таблице и хэш-таблице ссылок; при этом в главной хэш-таблице хранят ключевое слово из строки, содержащейся в базе данных строк, а также информацию о длине строки, соответствующей ключевому слову, причем в хэш-таблице ссылок хранят полную информацию о символьной структуре строки, соответствующей ключевому слову; при этом этап В предусматривает следующее:
B1) отбирают заданное число символов, начиная с первого символа в текстовых данных; выявляют, содержит ли главная хэш-таблица ключевое слово, соответствующее заданному числу символов; в случае, если главная хэш-таблица содержит ключевое слово, соответствующее заданному числу символов, получают информацию о длине, соответствующую ключевому слову; в зависимости от информации о длине выбирают строку из текстовых данных; выявляют, содержит ли хэш-таблица ссылок выбранную строку; в случае, если хэш-таблица ссылок содержит выбранную строку, определяют однократное совпадение при сканировании текстовых данных, записывают число совпадений при сканировании текстовых данных, а также информацию о ключевом слове и строке, соответствующей ключевому слову;
B2) если главная хэш-таблица не содержит ключевое слово, соответствующее заданному числу символов, или если хэш-таблица ссылок не содержит выбранной строки, то после сдвига назад на один символьный блок от первого символа в текстовых данных выбирают заданное число символов и обрабатывают выбранные символы согласно алгоритму обработки заданного числа символов, выбранного с первого символа текстовых данных на этапе В1, до тех пор, пока не будет выявлено последнее заданное число символов в текстовых данных.
5. Способ по п.4, в котором главную хэш-таблицу и хэш-таблицу ссылок создают следующим образом:
B01) выбирают заданное число символов, начиная с первого символьного блока в первой строке, содержащейся в базе данных строк;
принимают выбранные символы в качестве ключевого слова; определяют, соответствует ли заданное число символов из первого символьного блока в другой строке, отличной от первой строки в базе данных строк, с ключевым словом и, если соответствует, записывают ключевое слово и информацию о длине другой строки в главной хэш-таблице; при этом в хэш-таблице ссылок записывают полную информацию о символьной структуре другой строки;
B02) выполняют дополнительное определение второй строки, отличной от строки, уже записанной в хэш-таблице ссылок в базе данных строк, и обрабатывают вторую строку согласно алгоритму обработки первой строки на этапе В01 до тех пор, пока для всех строк, содержащихся в базе данных строк, не будет завершено выполнение алгоритма обработки первой строки на этапе В01.
6. Способ по п.4, в котором этап С предусматривает следующее:
С1) получают записанное число совпадений при сканировании текстовых данных, а также записанную информацию о ключевом слове и строке, соответствующей ключевому слову;
С2) в зависимости от записанного числа совпадений при сканировании текстовых данных, записанной информации о ключевом слове и строке, соответствующей ключевому слову, а также согласно заранее заданным правилам идентификации определяют, является ли сообщение электронной почты нежелательным сообщением, и блокируют указанное сообщение в случае, если оно является нежелательным сообщением.
7. Способ по п.6, в котором заранее заданные правила идентификации предусматривают следующее: сообщение электронной почты идентифицируют как нежелательное сообщение, если число совпадений при сканировании текстовых данных превышает заданное число; при этом, если информацией о строке на этапе С1 является информация о длине строки, совпавшей при сканировании, то заранее заданные правила идентификации на этапе С2 предусматривают следующее: сообщение электронной почты идентифицируют как нежелательное сообщение, если число совпадений при сканировании текстовых данных превышает заданное число, и длина строки, совпавшей при сканировании, превышает заданную длину.
8. Устройство блокировки нежелательных сообщений электронной почты, содержащее:
модуль получения текстовых данных, сконфигурированный для получения текстовых данных подлежащего фильтрации сообщения электронной почты;
модуль идентификации символов, сконфигурированный для определения, содержат ли текстовые данные ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, причем в случае, если текстовые данные содержат ключевое слово из строки, содержащейся в используемой для фильтрации сообщений базе данных строк, для дополнительного определения, содержат ли текстовые данные строку, соответствующую ключевому слову, содержащемуся в базе данных строк;
модуль обработки сообщений, сконфигурированный для идентификации, в зависимости от результата дополнительного определения в модуле идентификации символов и согласно заранее заданным правилам идентификации, является ли сообщение электронной почты нежелательным сообщением, и блокировки сообщения электронной почты в случае, если оно является нежелательным сообщением.
9. Устройство по п.8, в котором модуль идентификации символов содержит:
модуль создания хэш-таблиц, сконфигурированный для создания главной хэш-таблицы и хэш-таблицы ссылок, соответствующих базе данных строк; при этом в главной хэш-таблице хранят ключевое слово из строки, содержащейся в базе данных строк, и информацию о длине строки, соответствующей ключевому слову, при этом в хэш-таблице ссылок хранят полную информацию о символьной структуре строки, соответствующей ключевому слову;
модуль сканирования, сконфигурированный для: отбора заданного числа символов, начиная с первого символьного блока в текстовых данных; выявления, содержит ли главная хэш-таблица ключевое слово, соответствующее заданному числу символов, и в случае, если главная хэш-таблица содержит ключевое слово, соответствующее заданному числу символов, для получения информации о длине, соответствующей ключевому слову; выбора строки из текстовых данных согласно информации о длине; выявления, содержит ли хэш-таблица ссылок выбранную строку, и если хэш-таблица ссылок содержит выбранную строку, определения однократного совпадения при сканировании текстовых данных, записи числа совпадений при сканировании текстовых данных, а также информации о ключевом слове и строке, соответствующей ключевому слову; при этом модуль сканирования сконфигурирован таким образом, что, если главная хэш-таблица не содержит ключевое слово, соответствующее заданному числу символов, или если хэш-таблица ссылок не содержит выбранную строку, то после сдвига назад на один символьный блок от первого символа в текстовых данных указанный модуль выбирает заданное число символов и обрабатывает символы, выбранные после сдвига назад на один символьный блок от первого символа в текстовых данных, согласно алгоритму обработки заданного числа символов, выбранных, начиная с первого символьного блока в текстовых данных, до тех пор, пока не будет выявлено последнее заданное число символов в текстовых данных.
10. Устройство по п.9, в котором модуль обработки сообщений содержит:
модуль получения информации о сканировании, сконфигурированный для получения записанного числа совпадений при сканировании текстовых данных, а также информации о ключевом слове и строке, соответствующей ключевому слову;
модуль идентификации и блокировки, сконфигурированный для определения, в зависимости от записанного числа совпадений при сканировании текстовых данных и записанной информации о ключевом слове и строке, соответствующей ключевому слову, а также согласно заранее заданным правилам идентификации, является ли сообщение электронной почты нежелательным сообщением, а также для блокировки сообщения электронной почты в случае, если оно является нежелательным сообщением.
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| RU 2003115902 A, 20.11.2004 | |||
| КОНТУР ОБРАТНОЙ СВЯЗИ ДЛЯ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОЙ РАССЫЛКИ | 2004 |
|
RU2331913C2 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ стабилизации или очистки хлороформа | 1929 |
|
SU20080A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |

