ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее описание относится к удалению искривлений из отсканированного или сфотографированного изображения документа.
УРОВЕНЬ ТЕХНИКИ
[0002] Оптическое распознавание символов (OCR) представляет собой электронное преобразование отсканированных или сфотографированных изображений машинописного или печатного текста в машиночитаемый текст.OCR может использоваться для оцифровки печатных текстов, чтобы их можно было редактировать в электронном виде, производить в них поиск, отображать их в онлайн-режиме, и используется в таких процессах, как преобразование текста в речь, извлечение данных и интеллектуальный анализ текста. При получении изображения документа могут возникнуть искажения перспективы или иные искажения изображения документа. Искажение изображения документа может привести к искажению или деформации объектов или текста в изображении документа.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В одном из аспектов, способ включает определение границ по меньшей мере части документа в исходном изображении. Документ содержит по меньшей мере одну первую строку текста. Способ дополнительно включает определение множества символов в документе. Способ дополнительно включает определение некоторых из символов в качестве множества фрагментов слов. Способ дополнительно включает создание множества первых полиномов, которые аппроксимируют точки символов во фрагментах слов. Способ дополнительно включает создание второго полинома, который аппроксимирует точки символов по меньшей мере первого фрагмента слова и второго фрагмента слова среди фрагментов слов и соответствует первой строке текста. Способ дополнительно включает определение по меньшей мере одного коэффициента растяжения для первой строки текста на основании максимальной длины участка между границами и длины второго полинома. Способ дополнительно включает отображение по меньшей мере одним устройством обработки частей исходного изображения вдоль первой строки текста на новые позиции в исправленном изображении на основе второго полинома и коэффициента растяжения.
[0004] Варианты реализации могут содержать любые, все или никакие из представленных ниже особенностей. Точки символов могут быть расположены вдоль базовых линий фрагментов слов. Второй полином может определять один или более вторых углов, соответствующих углам наклона вдоль второго полинома. Способ может дополнительно включать пошаговый обход существующих позиций в исходном изображении, при этом размер шага может быть меньше размера пикселя в исходном изображении. Отображение фрагментов может включать отображение каждой существующей позиции на новые позиции на основе вторых углов, коэффициента растяжения и размера шага. Первые полиномы могут определять множество первых углов, представляющих углы наклона вдоль первых полиномов. Второй полином может определять множество вторых углов, соответствующих углам наклона вдоль второго полинома. Способ может дополнительно включать подтверждение того, что некоторые из первых углов соответствуют пороговому уровню точности для первого фрагмента слова, а некоторые из соответствующих вторых углов соответствуют пороговому уровню точности для второго фрагмента слова. Способ может включать проверку того, что первый фрагмент слова и второй фрагмент слова находятся по меньшей мере на пороговом расстоянии от по меньшей мере некоторой второй строки текста в документе рядом с первой строкой текста. Пороговое расстояние может быть основано на среднем расстоянии между полиномами, соответствующим строкам текста в документе. Способ может включать проверку того, что второй полином находится в пределах порогового уровня схожести по меньшей мере с третьим полиномом, соответствующим по меньшей мере второй строке текста в документе. Способ может включать интерполяцию цвета для каждой новой позиции в новых позициях исправленного изображения на основе цветов из пикселей исходного изображения в окрестности части среди частей исходного изображения, которая соответствует новой позиции. Этот способ может включать предварительную обработку исходного изображения. Предварительная обработка может включать выполнение одного или более из следующих действий: применение гамма-фильтра к исходному изображению, нормализация ширины и высоты исходного изображения, регулировка яркости исходного изображения или бинаризация глубины цвета исходного изображения. Определение границ может быть основано на детектировании или на алгоритме детектирования границ. Новые положения фрагментов слов могут удалить искажение первой строки текста в исправленном изображении. Способ может включать создание по меньшей мере одного интерполированного полинома между вторым полиномом и третьим полиномом, что соответствует по меньшей мере одной второй строке текста документа. Способ может дополнительно включать сопоставление частей исходного изображения между первой строкой текста и второй строкой текста в новых позициях в исправленном изображении на интерполированном полиноме.
[0005] В одном из вариантов реализации постоянное машиночитаемое запоминающее устройство, содержащее хранимые на нем инструкции, при исполнении по меньшей мере одним устройством обработки вызывает в устройстве обработки процесс определения границ по меньшей мере части документа в исходном изображении. Документ содержит по меньшей мере одну первую строку текста. Эти команды дополнительно вызывают в устройстве обработки процесс определения множества символов в документе. Эти команды дополнительно вызывают в устройстве обработки процесс определения некоторых из символов как множества фрагментов слов. Эти команды дополнительно вызывают формирование устройством обработки множества первых полиномов, которые аппроксимируют точки символов во фрагментах слов. Эти команды дополнительно вызывают формирование устройством обработки второго полинома, который аппроксимирует точки символов по меньшей мере в первом фрагменте слова и во втором фрагменте слова среди фрагментов слова и соответствует первой строке текста. Эти команды дополнительно вызывают определение устройством обработки по меньшей мере одного коэффициента растяжения для первой строки текста на основании максимальной длины участка между границами и длины второго полинома. Эти команды дополнительно вызывают отображение устройством обработки частей исходного изображения вдоль первой строки текста на новые позиции в исправленном изображении на основе второго полинома и коэффициента растяжения.
[0006] В одном из вариантов реализации система включает по меньшей мере одно устройство хранения данных, в котором хранятся команды. Система дополнительно содержит по меньшей мере одно устройство обработки для выполнения команд с целью определения границ по меньшей мере части документа в исходном изображении. Документ содержит по меньшей мере одну первую строку текста. Устройство обработки дополнительно определяет множество символов в документе. Устройство обработки дополнительно определяет некоторые из символов в качестве множества фрагментов слов. Устройство обработки дополнительно формирует множество первых полиномов, которые аппроксимируют точки символов во фрагментах слов. Устройство обработки дополнительно формирует второй полином, который аппроксимирует точки символов по меньшей мере первого фрагмента слова и второго фрагмента слова среди фрагментов слов и соответствует первой строке текста. Устройство обработки дополнительно определяет по меньшей мере один коэффициент растяжения в первой строке текста на основании максимальной длины участка между границами и длины второго полинома. Устройство обработки дополнительно отображает части исходного изображения вдоль первой строки текста на новые позиции в восстановленном изображении на основе второго полинома и коэффициента растяжения.
Варианты реализации могут содержать любые, все или никакие из представленных ниже особенностей. Точки символов могут быть расположены вдоль базовых линий фрагментов слов. Второй полином может определять один или более вторых углов, соответствующих углам наклона вдоль второго полинома. Устройство обработки может дополнительно выполнять пошаговый обход существующих позиций в исходном изображении, при этом размер шага может быть меньше размера пикселя в исходном изображении. Для отображения фрагментов устройство обработки может дополнительно отображать каждую существующую позицию на новые позиции на основе вторых углов, коэффициента растяжения и размера шага. Первые полиномы могут определять множество первых углов, представляющих углы наклона вдоль первых полиномов. Второй полином может определять множество вторых углов, соответствующих углам наклона вдоль второго полинома. Устройство обработки может дополнительно подтверждать, что некоторые из первых углов соответствуют пороговому уровню точности для первого фрагмента слова, а некоторые из соответствующих вторых углов соответствуют пороговому уровню точности для второго фрагмента слова. Устройство обработки может дополнительно выполнять проверку того, что первый фрагмент слова и второй фрагмент слова находятся по меньшей мере на пороговом расстоянии от по меньшей мере некоторой второй строки текста в документе рядом с первой строкой текста. Пороговое расстояние может быть основано на среднем расстоянии между полиномами, соответствующим строкам текста в документе. Устройство обработки может дополнительно выполнять проверку того, что второй полином находится в пределах порогового уровня схожести по меньшей мере с одним третьим полиномом, соответствующим по меньшей мере одной второй строке текста в документе. Новые положения фрагментов слов могут удалить искажение первой строки текста в восстановленном изображении. Устройство обработки может дополнительно создавать по меньшей мере один интерполированный полином между вторым полиномом и третьим полиномом, что соответствует по меньшей мере одной второй строке текста документа. Устройство обработки может дополнительно выполнять отображение частей исходного изображения между первой строкой текста и второй строкой текста в новых позициях в исправленном изображении на интерполированном полиноме.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0007] На Фиг. 1А представлена блок-схема системы исправления изображения для устранения искажений или искривлений в исходном изображении.
[0008] На Фиг. 1В представлен пример различных символов и различных признаков символов, которые могут использоваться для создания полиномов.
[0009] На Фиг. 2А-В представлены схемы примера системы для устранения искажения или искривления на изображении документа.
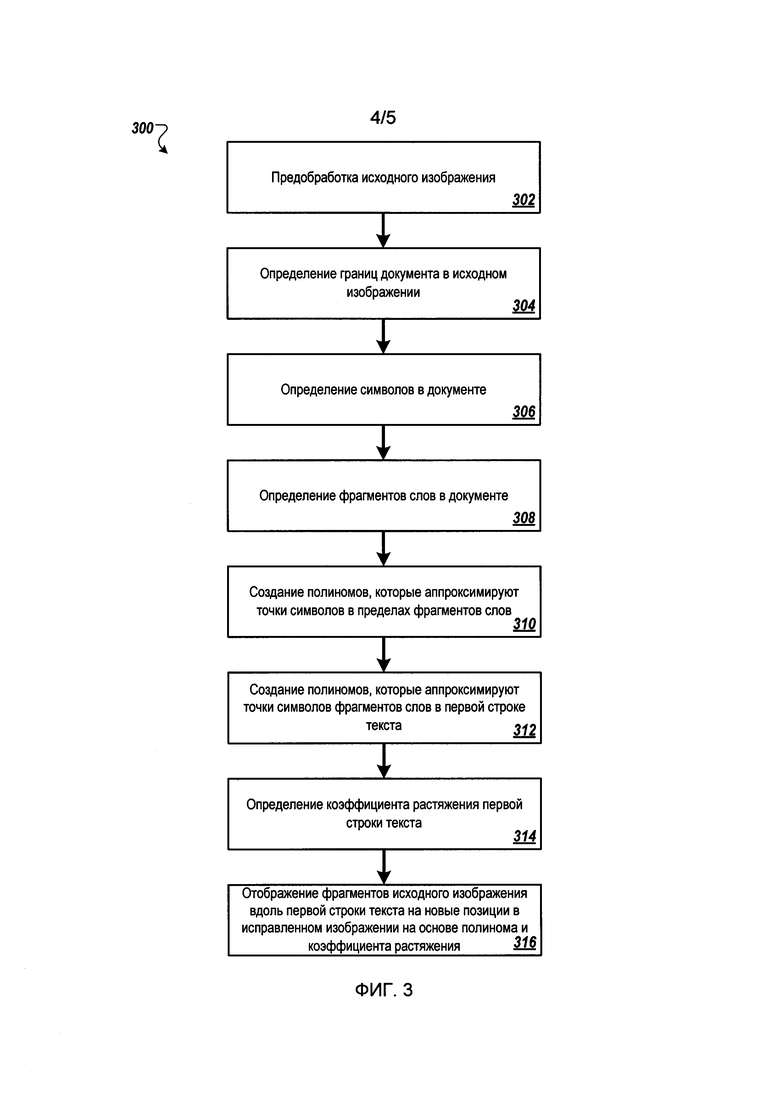
[0010] На Фиг. 3 представлена блок-схема, показывающая пример процесса устранения искривления на изображении документа.
[0011] На Фиг. 4 представлена схема примера вычислительной системы.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0012] В настоящем документе описаны системы и методики восстановления изображения, искривленного или искаженного документа. Отсканированное или сфотографированное изображение со строками текста может содержать искажения или искривления в строках текста. Например, если исходная физическая копия была измята, согнута или иным способом искажена или искривлена, то получаемое в результате отсканированное или сфотографированное изображение документа также может быть искажено или искривлено и может включать строки текста, которые более не представляют прямой линии, или слова в строках текста могут казаться скошенным или под наклоном, или символы могут быть сдвинуты относительно друг друга. Искажение или искривление также может быть вызвано углом камеры, которая снимает изображение документа, относительно положения или ориентации документа (как, например, при съемке ручной камерой, наклоненной в одном или более направлениях относительно поверхности документа). Это может привести к ошибкам или опущениям при оптическом распознавании символов текста в документе. Помимо того, распознанный текст может быть помещен не в ту же строку, что и остальной текст, после выполнения оптического распознавания символов, даже несмотря на то, что текст мог быть в одной строке в исходной физической копии документа до искажения исходной физической копии и последующего искажения отсканированного изображения.
[0013] Аспекты настоящего изобретения направлены на устранение указанных выше и иных недостатков путем повторного отображения или устранения искривления отсканированного или сфотографированного изображения либо частей отсканированного или сфотографированного изображения на новые позиции в исправленном или восстановленном изображении, где устраняется искажение или искривление документа в связи со сканированием или фотографированием смятых мест, мест с изломами или иных искажений физического экземпляра документа. Согласно некоторым вариантам реализации, для распознания символов в изображении документа может использоваться оптическое распознавание символов. Распознанные символы могут быть объединены в слова или фрагменты слов. В соответствии с некоторыми вариантами реализации, могут использоваться технологии анализа документа DA для определения связных компонентов на основе технологии кодирования длин серий (RLE) и для совмещения связных компонентов в слова или фрагменты слов. А именно могут быть проанализированы признаки документа с целью определения слов или фрагментов слов. В некоторых вариантах реализации для обнаружения и распознавания символов и определения слов и фрагментов слов может использоваться оптическое распознавание символов (OCR). Затем может создаваться первое множество полиномов на основе точек вдоль символов каждого фрагмента слова, например, вдоль базовой линии фрагментов слова. Может создаваться второе множество полиномов из точек вдоль символов фрагментов слова для подклейки и создания строки текста. Могут быть определены фрагменты слова, находящиеся в одной строке с учетом соответствующих расстояний до одной или более других строк текста. Для каждого полинома, представляющего строку текста, могут быть определены коэффициенты растяжения на основе длины полинома по отношению к максимальной длине полиномов в пределах детектированных границ документа. После этого для отображения фрагментов исходного изображения на новые позиции в исправленном изображении может быть использовано второе множество полиномов и коэффициенты растяжения.
[0014] Описанные в настоящем документе системы и методики могут обеспечить одно или более следующих преимуществ. Во-первых, системы и методики могут устранить искажение строк текста в документе. Во-вторых, системы и методики могут облегчить для человека чтение строк текста в документе или облегчить распознавание с помощью оптического распознавания символов.
[0015] На Фиг. 1 представлена блок-схема системы исправления изображения 100 для устранения искажений или искривлений в исходном изображении 102. Система исправления изображений 100 может получать исходное изображение 102 через интерфейс 104. Интерфейс 104 может быть представлен аппаратным обеспечением, например, устройством сетевого интерфейса, портом связи или съемным носителем данных. Система исправления изображения 100 включает процессор 106 или устройство обработки, которое выполняет инструкции по устранению искажения строк текста в исходном изображении 102. Команды могут включать модуль предобработки 108, модуль оптического распознавания символов и/или модуль анализа документа (модуль OCR/DA) 110 и модуль исправления изображения 112.
[0016] Процессор 106 может выполнять команды модуля предобработки 108 для выполнения операций предобработки для исходного изображения 102. Например, операции предобработки могут включать применение к исходному изображению 102 гамма-фильтра для уменьшения количества шума на исходном изображении 102. Исходное изображение 102 документа может содержать шум, полученный, как из исходной физической копии документа, так и не из исходной физической копии документа, например, пятна и другие артефакты сканирования или съемки изображения документа. Этот шум может быть вызван инородными объектами (например, пылью или грязью) на сканирующей поверхности или на исходной физической копии документа. Для определения шума в виде разрывов между пикселями и соседними пикселями к пикселям в исходном изображении 102 может применяться гамма-фильтр. При выявлении разрыва, который не является частью более крупного признака в исходном изображении 102, например, границы между двумя областями с различной окраской, к пикселям в разрыве может применяться правило для замены пикселей на другие значения цвета, например, на значения соседних пикселей.
[0017] Операции предобработки также могут включать нормализацию ширины и высоты исходного изображения 102. Например, нормализация может включать уменьшение или расширение исходного изображения 102 до конкретного числа пикселей по ширине и конкретного числа пикселей по высоте (например, восемьсот пикселей по ширине и шестьсот пикселей по высоте для небольшого документа, например, чека о покупке, или большее количество пикселей по высоте для более крупного документа с большим количеством строк текста или большим количеством пикселей по ширине для более широких строк текста). Уменьшение исходного изображения 102 до определенного числа пикселей на основе количества текста может привести к сокращению времени, необходимого для обработки исходного изображения 102, без значительного сокращения точности оптического распознавания символов и/или устранения искажения.
[0018] Операции предобработки могут дополнительно включать выравнивание яркости исходного изображения 102, например, путем выравнивания теней или бликов в исходном изображении 102. Выравнивание теней или бликов в исходном изображении 102 в определенных диапазонах тонов цвета или затенения может улучшить определение границ в исходном изображении 102, например, границ документа или границ между символами и фоном документа. Выравнивание теней или бликов в исходном изображении 102 в определенных диапазонах тонов цвета или затенения может также сократить необнаружение ложных признаков в исходном изображении 102, например, линий сгиба или смятия в физической копии документа.
[0019] Операции предобработки также могут включать бинаризацию глубины цвета исходного изображения 102 (например, до монохромного, черного или белого, или полутонового изображения). Бинаризация может быть адаптивной, при этом отдельные измерения яркости и насыщенности отдельных частей исходного изображения 102 используются при выборе значений для пикселей в каждом отдельном фрагменте. Бинаризация может способствовать лучшему оптическому распознаванию символов текста в исходном изображении 102 за счет обеспечения значительного контраста между фоном исходного изображения 102 и текстом исходного изображения 102.
[0020] Процессор 106 может выполнить команды модуля OCR/DA 110 для определения и/или распознавания символов в исходном изображении 102, которые могли быть предварительно обработаны в соответствии с описанием в настоящем документе. При выполнении команд модуля OCR/DA 110 также могут быть определены и/или распознаны слова или фрагменты слов, состоящие из символов. Модуль OCR/DA 110 может определять связные компоненты в исходном изображении 102 с помощью кодирования длин серий (RLE). Например, модуль OCR/DA 110 может определять серии пикселей конкретного цвета (например, белого) в исходном изображении 102 для определения и/или распознавания слов или фрагментов слов. Модуль OCR/DA 110 может классифицировать некоторые из распознанных символов и/или фрагментов слов как уверенный текст, неуверенный текст, случайные символы, «несимволы» (например, точки или запятые) или специальные символы (например, дефисы, пунктиры, знаки равенства, звездочки и т.д.).
[0021] В некоторых вариантах реализации модуль OCR/DA 110 (или иной модуль, например, модуль исправления изображений 112) может определять, что длинная строка текста, которая может включать специальные символы и/или повторяющиеся символы, является сепаратором между частями документа. Например, длинная строка может быть строкой, которая проходит в основном через весь документ, например, до левого и/или правого полей документа, которые обычно не включают текст.
[0022] Процессор 106 выполняет команды модуля исправления изображений 112 для устранения искажения в исходном изображении 102. Выполнение команд модуля исправления изображения 112 приводит к созданию полиномов, которые аппроксимируют точки символов во фрагментах слов. Точки могут лежать вдоль символов в пределах фрагментов слов, например, на базовой линии символов. При выполнении команд модуля исправления изображений 112 определяются фрагменты слов, лежащие в одной строке текста, и формируется полином, аппроксимирующий точки символов фрагментов слов в строке текста. Помимо того, при выполнении команд модуля исправления изображения 112 определяется коэффициент растяжения для строки текста на основе длины строки текста, представленной полиномом, относительно общей ширины документа, например, максимальной длины полиномов в документе. Наконец, при выполнении команд модулем исправления изображения 112 выполняется отображение частей (например, отдельных пикселей) исходного изображения 102 вдоль строки текста в новые позиции в исправленном изображении 114 на основе сформированного полинома и коэффициента растяжения. Некоторые аспекты указанных выше операций, выполняемых модулем исправления изображений 112, описаны более подробно ниже со ссылкой на Фиг. 2А-В и Фиг. 3.
[0023] Процессор 106 может хранить исходное изображение 102 и/или исправленное изображение 114 в устройстве хранения данных 116. Процессор 106 может также передавать исправленное изображение 114, например, в другую систему или устройство через интерфейс 104 или другой интерфейс.
[0024] На Фиг. 1В представлен пример различных символов 120 и различных признаков 122a-d символов 120, которые могут использоваться для создания полиномов. Модуль исправления изображений 112 для создания полинома может использовать точки, расположенные вдоль одного или более признаков 122a-d символов 120. Третий признак 122 с представлен базовой линией символов 120. Базовая линия символов в слове - это типографический термин, обозначающий линию, поверх которой обычно находятся символы конкретного шрифта. При этом некоторые символы могут иметь подстрочные элементы, которые опускаются ниже базовой линии, как, например, в случае с буквами "g," "j," "p," "q" и "y" в нижнем регистре, и точки, где эти символы пересекают базовую линию, например, могут использоваться для создания полиномов. В альтернативном варианте точки, используемые для создания полиномов, могут быть расположены вдоль другого признака символов, например, высоты прописных букв, высоты подстрочного элемента или медианной линии символов. Первый признак 122а - это высота прописной буквы (например, высота прописных букв выше базовой линии до любого превышения). Четвертый признак 122d - это высота подстрочного элемента или свисающей линии ("beard line") (например, высота части символа, которая проходит ниже базовой линии). Второй признак 122b является медианой, срединной или средней линией (например, половина расстояния от базовой линии до высоты прописной буквы или меньшей высоты строчной буквы над базовой линией до любого превышения).
[0025] На Фиг. 2А-В представлены схемы примера процесса 200 для устранения искажения или искривления на исходном изображении 202. В некоторых вариантах реализации система исправления изображения 100 может выполнять процесс 200. В некоторых вариантах реализации исходное изображение 202 может быть изображением документа 203, например, квитанции или чека. Документ 203 содержит несколько строк текста. В некоторых вариантах реализации в одной или более строках текста могут содержаться большие разрывы между словами, например, разрывы между названиями купленных позиций в левой части документа 203 и суммами покупки в долларах и центах в правой части документа 203. В некоторых вариантах реализации сочетание больших разрывов между словами в строке и искажение документа 203 в исходном изображении 202 может стать препятствием для определения в ходе процесса OCR того, что слова находятся в одной строке текста.
[0026] Процесс 200 включает определение или детектирование краев, или границ документа 203 в исходном изображении 202. Например, процессор 106 может выполнять команды модуля предобработки 108, модуля OCR/DA 110 и/или модуля исправления изображений 112 для определения границ документа 203 на исходном изображении 202. Границы могут быть изображены в исходном изображении 202 как фрагменты линии вокруг внешнего края документа 203. Определение границ может включать определение фрагментов линии вокруг внешнего края документа 203 в исходном изображении 202. Уверенность может быть мерой уровня определенности в том, что детектированный объект является линией, и в том, что объект является границей документа 203 в исходном изображении 202. Например, блеклая, прерванная, широкая и/или наклонная линия и/или линия, которая не совпадает с соседними фрагментами границ, может иметь низкий уровень уверенности, а темная сплошная, узкая и/или вертикальная или горизонтальная линия, совпадающая с соседними фрагментами границ, может иметь высокий уровень уверенности.
[0027] Процесс 200 может включать определение одного или более первых фрагментов границы 204a-d документа 203 в исходном изображении 202 с высоким уровнем уверенности или соответствующих заданному пороговому уровню уверенности. Первые два из первых фрагментов границ 204а-b расположены напротив вторых двух из первых фрагментов границ 204c-d. Процесс 200 также может включать определение одного или более вторых фрагментов границ 206а-b документа 203 в исходном изображении 202 с низким уровнем уверенности или тех, что не соответствуют пороговому уровню уверенности. Низкий уровень уверенности или несоответствие пороговому уровню может быть вызвано отсутствием фрагментов границ документа 203 в исходном изображении 202. В некоторых вариантах реализации процесс 200 может включать получение вторых фрагментов границ 206a-b из разрывов в первых фрагментах границ 204a-d. Процесс 200 также может включать выполнение одной или более из описанных ранее операций предобработки в документе 203 внутри первых фрагментов границ 204a-d и/или вторых фрагментов границ 206a-b.
[0028] Процесс 200 включает распознавание символов в исходном изображении 202 и определение фрагментов слова в пределах распознанных символов, например, первого фрагмента слова 208, нескольких вторых фрагментов слова 210а-d и нескольких третьих фрагментов слова 212а-с. Фразы «первый фрагмент слова», «второй фрагмент слова» и «третий фрагмент слова» используются для иллюстрации и не указывают на то, что на данном этапе было установлено, что фрагменты слова находятся в различных строках или группах. Например, процессор 106 может выполнять команды, выдаваемые модулем OCR/DA 110 для распознавания символов и фрагментов слов. Первый фрагмент слова 208 включает последовательность знаков равенства. Вторые фрагменты слов 210a-d включают "Total," "2," "item(s)," и "$11.50." Третьи фрагменты слов 212а-с включают "Sales," "Tax," и "$1.09." В некоторых вариантах реализации процесс 200 может выполнить распознавание не всего слова, как, например, "Tot" во второй части слова 210а. В некоторых вариантах реализации процесс 200 может распознать символы и/или часть слова, но уровень уверенности при распознавании символов и/или части слова, полученных в результате OCR исходного изображения 202, может не соответствовать пороговому уровню уверенности. Например, в связи с искажением или шумом в документе 203 на исходном изображении 202 процесс 200 может не распознать символы и/или фрагмент слова по меньшей мере с пороговым уровнем уверенности.
[0029] Затем процесс 200 включает создание первого полинома 214, который аппроксимирует точки символов в первом фрагменте слова 208, одного или более вторых полиномов 216a-d, которые аппроксимируют точки символов во вторых фрагментах слов 210a-d, и одного или более третьих полиномов 218а-с, которые аппроксимируют точки символов в третьих фрагментах слов 212а-с соответственно. Процесс 200 может включать определение точек по признакам символов в каждом фрагменте слова с последующим фитированием (подгонкой) полинома к точкам каждого фрагмента слова. Например, процессор 106 может выполнять команды модуля исправления изображений 112 для определения точек вдоль символов и для создания полиномов, аппроксимирующих точки символов в пределах фрагментов слов. Поэтому точки могут, например, быть точками, которые лежат вдоль, пересекают или соприкасаются с признаками символов, например, с базовой линией символов.
[0030] В некоторых вариантах реализации полином может иметь первую степень (т.е. быть линейным), вторую степень (т.е. быть квадратичным) или более высокую степень (т.е. быть кубическим и т.д.). Например, модуль исправления изображения 112 может определить, что фрагмент слова является коротким, и затем аппроксимировать короткий фрагмент слова путем фитирования линейной функции к точкам короткого фрагмента слова без уменьшения возможности устранения искажения из короткого фрагмента слова. Модуль исправления изображения 112 может определить, что фрагмент слова является длинным или что множество из нескольких фрагментов слов является длинным, с последующей аппроксимацией длинного фрагмента слова или множества из нескольких фрагментов слов путем фитирования функции более высокой степени, например, квадратичной или кубической функции, к длинному фрагменту или нескольким фрагментам слов с целью устранения искажения из длинного фрагмента или нескольких фрагментов слов. Подгонка полинома более низкого порядка к фрагменту слова может обеспечить сокращение времени обработки фрагментов слов по сравнению с полиномом более высокого порядка.
[0031] Точки символов, использующиеся для создания полиномов, могут быть расположены вдоль базовых линий первого фрагмента слова 208 и вторых фрагментов слова 210a-d, например, в местах, где части символов соприкасаются с базовой линией или аналогично для символов, которые не соприкасаются с базовой линией. Как вариант точки, используемые для создания полиномов, могут быть расположены вдоль другого признака символов, например, медианной линии символов, высоты подстрочного элемента или высоты прописных букв символов.
[0032] Процесс 200 включает создание "склеенного" полинома 220, который аппроксимирует точки символов нескольких из вторых фрагментов слов 210a-d и соответствует строке текста в документе 203 в пределах исходного изображения 202, например, путем фитирования склеенного полинома 220 к точкам символов нескольких из вторых фрагментов слов 210a-d. Например, процессор 106 может выполнять команды модуля исправления изображений 112 для создания склеенного полинома 220, который аппроксимирует точки символов нескольких из вторых фрагментов слов 210a-d и соответствует строке текста в документе 203 в пределах исходного изображения 202.
[0033] Процессор 106 может определить некоторые полиномы, например, первый полином 214, как уже готовую завершенную строку текста. Например, процессор 106 может определить, что символы в первом фрагменте слова 208 проходят через весь или почти весь документ 203 (например, в пределах заданного порогового расстояния от границ документа 203) в исходном изображении 202. Полином, являющийся полной строкой текста или проходящий через документ 203, может считаться опорным или разделительным полиномом, представляющим опорную точку или разделительную линию либо строку. В некоторых вариантах реализации строка сепаратора включает специальный символ (например, видимые символы помимо цифр или букв алфавита для языка в документе 203, например, знак равенства, дефис, пунктир, звездочка и т.д.) и/или повторяющийся символ, например, повторяющийся знак равенства, повторяющийся дефис, повторяющийся пункт или повторяющиеся звездочки. Процессор 106 может выявить первый полином 214 в качестве опорного или разделительного за счет определения того, что первая часть слова 208 включает повторяющийся и/или специальный символ, например, повторяющийся знак равенства. Линия сепаратора и соответствующий полином сепаратора могут использоваться для подклейки соседних полиномов для отдельных фрагментов слов.
[0034] В рамках создания склеенного полинома 220 процесс 200 может включать определение нескольких из вторых фрагментов слов 210a-d, которые должны быть подклеены или совмещены, путем расчета вероятности того, что несколько из вторых фрагментов слов 210a-d находятся в пределах одной строки текста. Например, процессор 106 может выполнять команды модуля исправления изображения 112 для определения нескольких из вторых фрагментов слов 210a-d путем расчета вероятности того, что несколько из вторых фрагментов слов 210a-d находятся в одной строке текста.
[0035] Процесс 200 может выполнять расчет вероятностей путем расчета вертикальных расстояний между первым полиномом 214 и третьими полиномами 218а-с и между третьими полиномами 218а-с и вторыми полиномами 216a-d. Процесс 200 включает определение того, что расстояние между двумя полиномами меньше, чем среднее вертикальное расстояние между полиномами в исходном изображении 202. Если это так, то процесс 200 определяет, что дополнительные строки между двумя полиномами отсутствуют. Например, процессор 106 может определить необходимость подклеивания или слияния двух самых левых из третьих полиномов 218a-b в связи с близостью двух самых левых из третьих полиномов 218a-b (например, модуль OCR/DA 110 может определить, что они оба являются частью одной фразы). Модуль OCR/DA 110 может быть неспособен определить, что третий полином 218с справа является частью той же фразы, что два самых левых из третьих полиномов 218a-b, в связи с горизонтальным расстоянием между ними и/или искажением исходного изображения 202. Процессор 106 может выполнять команды модуля исправления изображений 112, чтобы определить то, что третий полином 218с справа, а также два самых левых из третьих полиномов 218a-b находятся на расстоянии от первого полинома 214 (например, разделительной линии), которое меньше или в пределах заданного порогового значения от среднего расстояния между строками полиномов. Соответствующим образом процессор 106 определяет, что между третьими полиномами 218а-с и первым полиномом 214 дополнительные строки присутствовать не могут, и создает склеенный полином для третьих полиномов 218а-с.
[0036] Аналогичным образом процессор 106 может определить, что расстояния между соответствующими точками вдоль третьих полиномов 218а-с и вторых полиномов 216a-d меньше или находятся в пределах порогового значения среднего расстояния.
Соответствующим образом процессор 106 определяет, что между третьими полиномами 218а-с и вторыми полиномами 216a-d дополнительные строки присутствовать не могут, и создает склеенный полином для вторых полиномов 216a-d. В некоторых вариантах реализации процессор 106 начинает от сепаратора, если он существует, и затем действует по направлению от сепаратора вертикально через полиномы (например, вверх и/или вниз от сепаратора до тех пор, пока другой сепаратор не станет ближе к текущему полиному).
[0037] Процесс 200 также может рассчитать вероятности того, что несколько из вторых фрагментов слов 210a-d находятся в одной строке текста, путем расчета величин первых углов между одним или более первых углов наклона каждого из вторых полиномов 216a-d и горизонталью, а также вторых углов между вторыми углами наклона склеенного полинома 220, которые соответствуют положениям первых углов наклона, и горизонталью. Процесс 200 может затем включать сравнение первых углов со вторыми соответственно (или первых углов наклона со вторыми), чтобы определить, насколько хорошо склеенный полином 220 соответствует вторым полиномам 216a-d. Например, первый угол 222 включает угол наклона второго полинома 216с во второй части слова 210с, а второй угол 224 включает угол наклона подклеенного полинома 220 в точке, соответствующей первому углу 222. Процессор 106 может вычислить величину первого угла 222 и второго угла 224 после нахождения производных полиномов в соответствующей точке, в которой производится сравнение полиномов. Затем процессор 106 может определить, выходит ли разница между первым углом 222 и вторым углом 224 за пороговый уровень сходства (т.е. разница слишком велика). Если это так, процессор 106 в дальнейшем не включает точки второго полинома 216с в продление линии для подклеенного полинома 220.
[0038] Процесс 200 может далее вычислить вероятности, проверяя, что соседние подклеенные полиномы (или полиномы для полных строк / строк разделителей) не выходят за пороговый уровень сходства друг с другом. Если полиномы не укладываются в пороговый уровень сходства, процесс 200 может включать итеративное удаление отдельных точек фрагментов слов из подклеенных полиномов до достижения предельного уровня сходства. Кроме того, в процессе 200 вероятности могут вычисляться путем проверки наличия пересечений подклеенных полиномов друг с другом (например, путем определения наличия решения для системы полиномов или координат х-у в общем). Если полиномы пересекаются, процесс 200 может включать итеративное удаление отдельных точек фрагментов слов из подклеенного полинома до тех пор, пока подклеенные полиномы не перестанут пересекаться. Далее в процессе 200 вероятности могут вычисляться путем проверки того, что каждый из подклеенных/законченных полиномов построен на базе заранее определенного предельного количества точек фрагментов слов.
[0039] Процесс 200 может включать использование других критериев для определения необходимости склеивания фрагментов слов и аппроксимации полиномов между склеенными фрагментами слов. В одном из примеров критерия модуль 112 исправления изображения может склеивать фрагменты слов в ответ на обнаружение факта, что минимальное расстояние по вертикали между полиномами для фрагментов слов, склеиваемых по горизонтали вдоль полиномов, меньше или равно определенному предельному вертикальному расстоянию, например, определенному количеству пикселей или нулю. В некоторых вариантах реализации изобретения модуль 112 исправления изображения может нормализовать расстояние по вертикали между полиномами, исходя из высоты склеиваемых фрагментов слов (например, разделяя расстояние между полиномами на соответствующую высоту фрагментов слов в том же положении по горизонтали или на среднюю высоту фрагментов слов).
[0040] В другом примере критерия модуль 112 исправления изображения может склеивать фрагменты слов, обнаружив, что расстояние по горизонтали между самой правой точкой первого фрагмента слова и самой левой точкой второго фрагмента слова справа от первого фрагмента слова в строке текста меньше или равно предельному расстоянию по горизонтали, например, определенному количеству пикселей. В некоторых вариантах реализации изобретения модуль 112 исправления изображения может нормализовать расстояние по горизонтали между фрагментами слов, исходя из ширины или длины фрагментов слов (например, путем деления расстояния между фрагментами слов по горизонтали на максимальную ширину или длину фрагментов слов).
[0041] В других примерах критерия модуль 112 исправления изображения может склеивать фрагменты слов, определив, что разница между углами базовых линий фрагментов слов в точках на концах фрагментов слов не выходит за предельное значение. Модуль 112 исправления изображения может склеивать фрагменты слов, определив, что разница между углами наклона базовых линий склеенных фрагментов слов и базовых линий законченных полиномов, имеющих те же точки, не выходит за предельное значение. Модуль 112 исправления изображения может склеивать фрагменты слов, определив, что разница между высотой склеиваемых фрагментов слов не выходит за предельное значение (т.е. средняя высота фрагментов слов приблизительно одинакова). Модуль 112 исправления изображения может склеивать первый фрагмент слова со вторым, который содержит шум или неидентифицируемые символы, определив, что шум или неидентифицируемые символы находятся между первым и третьим фрагментом слова, которые не содержат шум или неидентифицируемые символы. Модуль 112 исправления изображения может склеивать фрагменты слов, определив, что качество или вероятность распознавания символов в склеиваемых фрагментах слов соответствует пороговому уровню по качеству или уверенности распознавания. Модуль 112 исправления изображения может аппроксимировать полиномы таким образом, чтобы углы наклона первой строки склеиваемых фрагментов слов соответствовали углам наклона соседних строк склеиваемых фрагментов слов.
[0042] После склейки полиномов исходное изображение 202 может содержать набор склеенных и (или) законченных полиномов, которые аппроксимируют строки текста документа 203, например, склеенный полином 220 и первый полином 214, но некоторые области исходного изображения 202 могут не содержать соответствующих склеенных и (или) законченных полиномов, это могут быть области, в которых OCR/подклейка было не достоверным (например, третий фрагмент слова 212а-с) и/или области между строками текста. Процесс 200 может включать создание в этих областях между склеенными/законченными полиномами таких интерполированных полиномов, что каждый пиксель и (или) область исходного изображения 202 имеет связанный с ним полином. Например, модуль 112 исправления изображения может усреднять расстояние между каждым склеенным, законченным и (или) интерполированным полиномом в каждом горизонтальном положении для определения вертикальной координаты. Затем модуль 112 исправления изображения может создавать интерполированный полином через усредненное положение между склеенными/законченными/интерполированным полиномами. Модуль 112 исправления изображения может повторять этот процесс до тех пор, пока каждый пиксель и/или область исходного изображения 202 не будет иметь соответствующего полинома.
[0043] Процесс 200 включает определение коэффициентов растяжения каждого склеенного/законченного полинома. Коэффициент растяжения показывает, насколько необходимо растянуть исходное изображение 202 вдоль каждого из полиномов, чтобы устранить искажения исходного изображения 202. Например, процессор 106 может выполнить инструкции модуля 112 исправления изображения для вычисления максимальной длины полиномов в детектированных границах документа 203 на исходном изображении 202, например, когда с высокой/предельной степенью уверенности известны противоположные составляющие первых фрагментов границы 204a-d. Длину каждого склеенного, завершенного или интерполированного полинома можно сравнить с максимальной длиной, чтобы определить коэффициент растяжения подклеенного/завершенного/интерполированного полинома. Например, процессор 106 может определить коэффициент растяжения как отношение длины подклеенного/завершенного/интерполированного полинома к максимальной длине (например, разделив максимальную длину на длину склеенного/завершенного/интерполированного полинома или наоборот).
[0044] В некоторых реализациях изобретения коэффициент растяжения может быть постоянным вдоль всех соответствующих подклеенных/завершенных/ интерполированных полиномов. Например, модуль 112 исправления изображения может поровну делить разницу между длиной склеенного/завершенного/интерполированного полинома (или ширину противоположных элементов первых фрагментов границы 204a-d склеенного/завершенного/интерполированного полинома) и максимальной шириной между точками склеенного/завершенного/интерполированного полинома. В других случаях коэффициент растяжения по длине склеенного/завершенного интерполированного полинома может изменяться. Например, модуль 112 исправления изображения может использовать больше одной разности в точках рядом с концами подклеенных/завершенных/ интерполированных полиномов, где могут встречаться большие искажения.
[0045] Процесс 200 может включать применение гауссова сглаживания к подклеенным/завершенным/интерполированным полиномам на исходном изображении 202. Например, модуль 112 исправления изображения может использовать гауссово сглаживание к склеенным/завершенным/ интерполированным полиномам для сглаживания границ склеенных/завершенных/ интерполированных полиномов и(или) дополнительного устранения шума исходного изображения 202.
[0046] Как показано на Фиг. 2В, процесс 200 также включает установление соответствия между фрагментами исходного изображения по строкам текста с новыми положениями на исправленном изображении 226, исходя из углов наклона соответствующих склеенных/завершенных/ интерполированных полиномов и соответствующих коэффициентов растяжения. Процесс 200 может включать проход по существующим положениям исходного изображения 202 с размером шага меньше размера пикселя исходного изображения 202 (например, половина или четверть пикселя) и отображение каждого из существующих положений на каждом шаге на новое положение на основе склеенных/завершенных/ интерполированных полиномов, коэффициентов растяжения и размеров шага. В других случаях размер шага может быть равен размеру пикселя исходного изображения 202 или иметь размер нескольких пикселей.
[0047] Например, процессор 106 может выполнять инструкции модуля 112 исправления изображения по проходу по исходному изображению 202 с указанным размером шага. Процессор 106 может начать, например, с поиска центральной линии 228 исходного изображения 202. Затем процессор 106 может начать с верха центральной линии 228 и сдвигаться влево и вправо, а затем спуститься вниз по центральной линии 228 и продолжать работу и т.д. В некоторых вариантах реализации изобретения процесс 200 начинает с центральной линии 228, поскольку угол наклона полиномов, вероятно, будет ближе к нулю рядом с центральной линией 228. Размер шага в направлении влево и вправо может отличаться от размера шага в направлении вверх и вниз.
[0048] В каждой точке исходного изображения 202 процессор 106 отображает точку из существующего положения 230 в новое положение 232. Процессор 106 может представить существующее положение 230 координатой "х" по горизонтальной оси и координатой "у" по вертикальной оси. Процессор 106 может представить новое положение 232 по горизонтальной оси как координату "х" с добавлением коэффициента растяжения (k) для подклеенного/завершенного/интерполированного полинома, который соответствует координатам х/у, умноженного на размер шага (s) и косинус угла наклона (а) в точке подклеенного/завершенного/ интерполированного полинома, которая соответствует координатам х/у (то есть новая координата "х"=х+k*s*cos(a)). Процессор 106 может представить новое положение 232 по вертикальной оси как координату "у" с добавлением коэффициента растяжения (k) для склеенного/завершенного/ интерполированного полинома, который соответствует координатам х/у, умноженного на размер шага (s) и косинус угла наклона (а) в точке склеенного/завершенного/ интерполированного полинома, которая соответствует координатам х/у (то есть новая координата "у"=у+k*s*cos(a)).
[0049] В некоторых реализациях изобретения процесс 200 может включать сохранение одного или более отображений, которые отображают каждый пиксель исходного изображения 202 на определенный угол наклона в точке на одном из соответствующих склеенных/завершенных/ интерполированных полиномов, и коэффициента растяжения, который соответствует склеенному/завершенному/ интерполированному полиному или точке на склеенном/завершенном/ интерполированном полиноме. Например, модуль 112 исправления изображения может сохранять отображение каждого пикселя в устройстве хранения данных 116, другом устройстве хранения данных или в памяти. Затем модуль 112 исправления изображения может использовать сохраненное отображение для отображения существующих положений пикселей исходного изображения 202 на новые положения. Затем модуль 112 исправления изображения может использовать сохраненное отображение для отображения существующих положений пикселей исходного изображения 202 на новые положения. Модуль 112 исправления изображений также может использовать сохраненные отображения для определения в новом положении на исправленном изображении 226 ранее существовавшего положения на исходном изображении 202, из которого было порождено новое положение.
[0050] Кроме того, процесс 200 может включать интерполяцию цвета для нового положения 232 на исправленном изображении 226 на основе интерполяции цветов (например, цветовых значений) пикселей исходного изображения 202 вблизи нового положения 232. Например, процессор 106 может выполнять инструкции модуля исправления изображения 112 для интерполяции цвета в новом положении 232 как среднего значения цветов пикселей исходного изображения 202, соседствующих с новым положением 232, например, пикселей, которые непосредственно окружают данный пиксель (то есть касаются или расположены по диагонали от данного пикселя), или пикселей, которые расположены за один или два пикселя от данного пикселя. Модуль 112 исправления изображения может сохранять интерполированный цвет в исправленном изображении 226 и (или) в устройстве хранения данных 116.
[0051] На Фиг. 3 представлена блок-схема, на которой представлен пример процесса 300 устранения искажения или искривления из изображения документа в соответствии с некоторыми аспектами того же раскрытия изобретения. Процесс 300 может выполняться, например, системой, такой как система 100 исправления изображения, или процессом 200. Для удобства представления в приводимом описании система 100 исправления изображения и процесс 200 используются как примеры для описания процесса 300. Однако для осуществления процесса 300 может использоваться другая система или сочетание систем.
[0052] Процесс 300 может начинаться на шаге 302 с предварительной обработки исходного изображения. В некоторых вариантах реализации изобретения предварительная обработка может включать одно или более применений к исходному изображению гамма-фильтра, нормализацию ширины и высоты исходного изображения, выравнивание яркости исходного изображения или бинаризацию цветовой глубины исходного изображения. Например, предварительную обработку исходного изображения 202 может выполнять модуль 108 предварительной обработки.
[0053] На шаге 304 процесс 300 включает определение контуров по меньшей мере части документа в исходном изображении. Документ содержит по меньшей мере одну первую строку текста. В некоторых реализациях определение границ может быть основано на алгоритме детектирования линий или на алгоритме детектирования границ. Например, модуль 108 предварительной обработки, модуль 110 OCR/DA и (или) модуль 112 исправления изображения могут определять первые фрагменты границы 204a-d и вторые фрагменты границы 206a-b документа 203 в исходном изображении 202.
[0054] На шаге 306 процесс 300 включает определение символов в документе. На шаге 308 процесс 300 включает определение элементов символов как фрагментов слов. Например, модуль 110 OCR/DA может определять первый фрагмент 208 слова, вторые фрагменты 210a-d слова и третьи фрагменты 212а-с слова, а также символы внутри фрагментов слов, используя OCR. Кроме того, модуль 110 OCR/DA может определять связные компоненты внутри исходного изображения 202, которые могут объединяться в слова или первый фрагмент 208 слова, вторые фрагменты 210a-d слова и третьи фрагменты 212а-с слова. В некоторых реализациях изобретения модуль 110 OCR/DA может определять окружающие символы, используя OCR. Модуль 110 OCR/DA может анализировать исходное изображение 202 документа 203 и свойства исходного изображения 202.
[0055] На шаге 310 процесс 300 включает создание первых полиномов, которые аппроксимируют точки символов во фрагментах слов. В некоторых реализациях точки символов могут лежать вдоль базовых линий фрагментов слов. Например, модуль 112 исправления изображения может создавать первый полином 214, вторые полиномы 216a-d и третьи полиномы 218а-с, которые аппроксимируют точки, лежащие на базовых линиях первого фрагмента 208 слова, вторых фрагментов 210a-d слова и третьих фрагментов 212а-с слова соответственно.
[0056] На шаге 312 процесс 300 включает создание второго полинома, который аппроксимирует точки символов по меньшей мере первого фрагмента слова и второго фрагмента слова среди фрагментов слов и выполняет сопоставление с первой строкой текста. В некоторых вариантах реализации изобретения уверенность в первом фрагменте при определении символов первого фрагмента слова среди фрагментов слов, соответствует пороговому уровню уверенности, а уверенность во втором фрагменте при определении символов второго фрагмента слова среди фрагментов слов, не соответствует пороговому уровню уверенности. В некоторых реализациях изобретения уверенность в первом фрагменте может основываться на оптическом распознавании символов первого фрагмента слова, а уверенность во втором фрагменте может основываться на оптическом распознавании символов второго фрагмента слова. Например, модуль 112 исправления изображения может создавать склеенный полином 220 для точек на вторых полиномах 216a-d и вторых фрагментов 210a-d слов.
[0057] В некоторых реализациях изобретения первые полиномы определяют множество первых углов, представляющих углы наклона вдоль первых полиномов, а вторые полиномы определяют множество вторых углов, представляющих наклоны вдоль вторых полиномов. Процесс 300 может дополнительно включать подтверждение того, что некоторые из первых углов соответствуют пороговому уровню точности для первого фрагмента слова, а некоторые из соответствующих вторых углов соответствуют пороговому уровню точности для второго фрагмента слова.
[0058] В некоторых реализациях изобретения процесс 300 может включать проверку того, что первый фрагмент слова и второй фрагмент слова находятся по меньшей мере на пороговом расстоянии от по меньшей мере некоторой второй строки текста в документе рядом с первой строкой текста. Пороговое расстояние может быть основано на среднем расстоянии между полиномами, которые соответствуют строкам текста в документе. В некоторых реализациях процесс 300 может дополнительно включать подтверждение того, что второй полином находится в пределах порогового уровня схожести по меньшей мере с третьим полиномом, соответствующим по меньшей мере второй строке текста в документе. Например, процесс 300 может включать подтверждение того, что второй полином находится в пределах порогового уровня схожести по меньшей мере с третьим полиномом, соответствующим по меньшей мере второй строке текста в документе.
[0059] На шаге 314 процесс 300 включает определение по меньшей мере одного коэффициента растяжения для первой строки текста на основании максимальной длины участка между границами и длины второго полинома. Например, модуль 112 исправления изображения определяет коэффициент растяжения подклеенного полинома 220.
[0060] На шаге 316 процесс 300 включает сопоставление по меньшей мере одним устройством обработки частей исходного изображения в первой строке текста с новыми позициями в исправленном изображении на основе второго полинома и коэффициента растяжения. В некоторых вариантах реализации изобретения отображение фрагментов исходного изображения в новые положения на исправленном изображении устраняет искажения первой строки текста в исправленном изображении. В некоторых реализациях второй полином определяет один или более вторых углов, соответствующих наклонам вдоль второго полинома. Процесс 300 может также включать проход по существующим положениям исходного изображения с шагом меньше размера пикселя исходного изображения, а отображение фрагментов может включать отображение каждого из существующих положений на новые положения, исходя из вторых углов коэффициента растяжения и размера шага. Например, модуль 112 исправления изображения может проходить по исходному изображению 202 и использовать склеенные/завершенные полиномы и коэффициент растяжения для отображения фрагментов исходного изображения 202 на исправленное изображение 226 (то есть отображать существующее положение 230 на исходном изображении 202 на новое положение 232 на исправленном изображении 226). В некоторых реализациях изобретения процесс 300 может включать интерполяцию цвета для каждого нового положения в новых положениях исправленного изображения на основе цветов из пикселей исходного изображения в окрестности части среди частей исходного изображения, которая соответствует новой позиции.
[0061] Для упрощения объяснения процессы в настоящем описании изобретения изображены и описаны в виде последовательности действий. Однако действия в соответствии с настоящим описанием изобретения могут выполняться в различном порядке и (или) одновременно с другими действиями, не представленными и не описанными в настоящем документе. Кроме того, не все проиллюстрированные действия могут быть необходимы для реализации процессов в соответствии с настоящим описанием изобретения. Кроме того, специалистам в этой области техники будет понятно, что эти процессы могут быть представлены и другим образом - в виде последовательности взаимосвязанных состояний через диаграмму состояний или событий. Кроме того, следует учесть, что процессы, раскрываемые в данном описании, могут храниться в изделиях для упрощения транспортировки и передачи этих процессов в вычислительные устройства. Термин «изделие» в настоящем документе означает компьютерную программу, доступную посредством любого машиночитаемого устройства или носителя данных.
[0062] На Фиг. 4 приведена схема, иллюстрирующая пример машины в виде вычислительной системы 400. Вычислительная система 400 выполняет один или более наборов инструкций 426, которые заставляют машину выполнять одну или более рассматриваемых в этом документе методологий. Эта машина может работать в качестве сервера или клиентского устройства в сетевой среде «клиент-сервер» или как одноранговая машина в одноранговой (или распределенной) сети. Такой машиной может быть персональный компьютер (ПК), планшетный ПК, телевизионная приставка (STB), карманный персональный компьютер (PDA), сотовый телефон, веб-устройство, сервер, маршрутизатор, коммутатор или мост либо любая машина, которая может выполнять набор команд (последовательных или иных), определяющих действия, которые будут предприняты этой машиной. В дальнейшем, несмотря на то, что на рисунке изображена одна машина, термин «машина» также будет включать в себя любые наборы машин, которые по отдельности или совместно выполняют набор (или несколько наборов) инструкций 426, осуществляя любой один или более рассматриваемых в этом документе способов.
[0063] Вычислительная система 400 содержит процессор 402 (например, процессор, ЦПУ и т.д.), основную память 404 (например, постоянное запоминающее устройство (ПЗУ), флеш-память, динамическую оперативную память (ДОП) (например, синхронную ДОП (СДОП) или ДОП (РДОП) и т.д.), статическую память 406 (например, флеш-память, статическую оперативную память (СОП) и т.д.) и запоминающее устройство 416, которые могут обмениваться информацией друг с другом с помощью шины 408.
[0064] Процессор 402 представляет собой одно или более обрабатывающих устройств общего назначения, например микропроцессоров, центральных процессоров или аналогичных устройств. В частности, процессор 402 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW), процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 402 также может представлять собой одно или более устройств обработки специального назначения, например заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.д. Процессор 402 выполнен с возможностью исполнения инструкций модуля 108 предварительной обработки, модуля 110 OCR/DA и (или) модуля 112 исправления изображения для выполнения операций и шагов, рассматриваемых в этом документе.
[0065] Вычислительная система 400 может также содержать устройство сетевого интерфейса 422, которое обеспечивает связь с другими машинами по сети 418, например, по локальной сети (LAN), корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 400 также может включать блок видеодисплея 410 (например, жидкокристаллический дисплей (LCD) или электронно-лучевой монитор (CRT)), алфавитно-цифровое устройство ввода 412 (например, клавиатуру), устройство управления курсором 414 (например, мышь) и устройство генерации сигналов 420 (например, динамик).
[0066] Устройство хранения данных 416 может включать машиночитаемый носитель данных 424, на котором хранятся наборы инструкций 426 модуля 108 предварительной обработки, модуля 110 OCR/DA и (или) модуля 112 исправления изображения, реализующие любую одну или несколько технологий или функций, описанных в настоящем документе. Наборы инструкций 426 модуля 108 предварительной обработки, модуля 110 OCR/DA и (или) модуля 112 исправления изображения могут также располагаться полностью или как минимум частично в основной памяти 404 и/или в процессоре 402 во время их выполнения вычислительной системой 400, основная память 404 и процессор 402 также формируют машиночитаемый носитель данных. Наборы инструкций 426 могут также передаваться или приниматься по сети 418 с помощью устройства сетевого интерфейса 422.
[0067] В то время как пример машиночитаемого носителя данных 424 показан как единый носитель, термин «машиночитаемый носитель данных» следует понимать как единый носитель либо множество таких носителей (например, централизованную или распределенную базу данных и/или соответствующие кэши и серверы), в которых хранятся наборы команд 426. Термин «машиночитаемый носитель данных» может включать любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более технологий настоящего изобретения. Термин «машиночитаемый носитель данных» может включать, в частности, устройства твердотельной памяти, оптические и магнитные носители.
[0068] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0069] Некоторые части описания предпочтительных вариантов реализации представлены в виде алгоритмов и символического представления операций с битами данных в памяти компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сконструирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти этапы требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и манипулировать ими. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0070] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они представляют собой просто удобные метки, применяемые к этим величинам. Если не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «определение», «предоставление», «активация», «поиск», «выбор» и т.д., относятся к операциям и процессам вычислительной системы или подобного электронного вычислительного устройства, которые управляют данными, представленными в виде физических (электронных) величин в регистрах и памяти вычислительной системы, и преобразуют их в другие данные, аналогичным образом представленные в виде физических величин в памяти или регистрах вычислительной системы либо в других подобных устройствах хранения, передачи или отображения информации.
[0071] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или реконфигурируется с помощью компьютерной программы, хранящейся в компьютере. Подобная компьютерная программа может храниться на машиночитаемом носителе данных, включая, но не ограничиваясь этим списком, любые типы дисков, включая гибкие диски, оптические диски, компакт-диски, не предназначенные для перезаписи (CD-ROM), магнитно-оптические диски, постоянные запоминающие устройства (ROM), оперативную память (RAM), стираемые программируемые постоянные запоминающие устройства (EPROM), стираемые электрическим сигналом программируемые постоянные запоминающие устройства (EEPROM), магнитные или оптические карты или другие типы носителей, используемые для хранения инструкций в электронном виде.
[0072] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X содержит А; X включает в себя В; или X включает и А и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «an», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант осуществления» или «один вариант осуществления» либо «реализация» или «одна реализация» не означает одинаковый вариант реализации, если такое описание не приложено. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используется как метки для обозначения различных элементов, они не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
[0073] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Другие варианты реализации будут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СИСТЕМЫ ОБРАБОТКИ ИЗОБРАЖЕНИЙ МАТЕМАТИЧЕСКИХ ВЫРАЖЕНИЙ | 2014 |
|
RU2596600C2 |
| УЛУЧШЕНИЕ КОНТРАСТА И СНИЖЕНИЕ ШУМА НА ИЗОБРАЖЕНИЯХ, ПОЛУЧЕННЫХ С КАМЕР | 2017 |
|
RU2721188C2 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| СПОСОБ И СИСТЕМА ПОДГОТОВКИ СОДЕРЖАЩИХ ТЕКСТ ИЗОБРАЖЕНИЙ К ОПТИЧЕСКОМУ РАСПОЗНАВАНИЮ СИМВОЛОВ | 2016 |
|
RU2628266C1 |
| СПОСОБ И СИСТЕМА ЭФФЕКТИВНОЙ ПОДГОТОВКИ СОДЕРЖАЩИХ ТЕКСТ ИЗОБРАЖЕНИЙ К ОПТИЧЕСКОМУ РАСПОЗНАВАНИЮ СИМВОЛОВ | 2016 |
|
RU2636097C1 |
| РЕДАКТИРОВАНИЕ ТЕКСТА НА ИЗОБРАЖЕНИИ ДОКУМЕНТА | 2016 |
|
RU2642409C1 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕОБХОДИМОСТИ ОБУЧЕНИЯ ЭТАЛОНА ПРИ ВЕРИФИКАЦИИ РАСПОЗНАННОГО ТЕКСТА | 2014 |
|
RU2641225C2 |
| СПОСОБ УЛУЧШЕНИЯ КАЧЕСТВА РАСПОЗНАВАНИЯ ОТДЕЛЬНОГО КАДРА | 2017 |
|
RU2657181C1 |
| ВЕРИФИКАЦИЯ РЕЗУЛЬТАТОВ ОПТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ | 2016 |
|
RU2634194C1 |
| УСТРОЙСТВА И СПОСОБЫ, КОТОРЫЕ ПОРОЖДАЮТ ПАРАМЕТРИЗОВАННЫЕ СИМВОЛЫ ДЛЯ ПРЕОБРАЗОВАНИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ В ЭЛЕКТРОННЫЕ ДОКУМЕНТЫ | 2013 |
|
RU2625020C1 |



Изобретение относится к области распознавания символов. Технический результат заключается в повышении точности устранения искажений. Способ для устранения искривлений изображения документа включает: определение границ по меньшей мере фрагмента документа в исходном изображении, определение множества символов в документе, определение некоторых из символов в качестве множества фрагментов слов, создание множества первых полиномов, создание второго полинома, определение по меньшей мере одного коэффициента растяжения для первой строки текста, отображение по меньшей мере одним устройством обработки частей исходного изображения вдоль первой строки текста на новые позиции в исправленном изображении на основе второго полинома и коэффициента растяжения. 3 з. и 17 н.п. ф-лы, 6 ил.
1. Способ для устранения искривлений изображения документа, включающий:
определение границ по меньшей мере фрагмента документа в исходном изображении, при этом документ содержит по меньшей мере одну первую строку текста;
определение множества символов в документе;
определение некоторых из символов в качестве множества фрагментов слов;
создание множества первых полиномов, которые аппроксимируют точки символов, расположенные вдоль одной из множества базовых линий каждого фрагмента слова;
создание второго полинома, который аппроксимирует точки символов, расположенные вдоль одной из множества базовых линий по меньшей мере первого фрагмента слова и второго фрагмента слова среди фрагментов слов, и соответствует первой строке текста;
определение по меньшей мере одного коэффициента растяжения для первой строки текста для того, чтобы растянуть исходное изображение вдоль второго полинома, чтобы устранить искривления изображения документа, где коэффициент растяжения определяется на основании максимальной длины участка между границами и длины второго полинома;
отображение по меньшей мере одним устройством обработки частей исходного изображения вдоль первой строки текста на новые позиции в исправленном изображении на основе второго полинома и коэффициента растяжения.
2. Способ по п. 1, отличающийся тем, что множество базовых линий фрагмента слова включает базовую линию символов фрагмента слова, медианную линию символов фрагмента слова, высоту прописных символов фрагмента слова, высоту подстрочных элементов символов фрагмента слова.
3. Способ по п. 1, отличающийся тем, что второй полином определяет один или более вторых углов, представляющих углы наклона вдоль второго полинома, и отличающийся тем, что способ дополнительно содержит пошаговый обход существующих позиций в исходном изображении с размером шага меньше размера пикселя в исходном изображении, и отличающийся тем, что отображение фрагментов включает отображение каждого из существующих фрагментов на новые позиции на основе вторых углов, коэффициента растяжения и размера шага.
4. Способ по п. 1, отличающийся тем, что первые полиномы определяют множество первых углов, представляющих углы наклона вдоль первых полиномов, и отличающийся тем, что второй полином определяет множество вторых углов, представляющих углы наклона вдоль второго полинома, и отличающийся тем, что способ дополнительно содержит проверку того, что некоторые из первых углов для первого фрагмента слова и второго фрагмента слова находятся в пределах порогового уровня точности от соответствующих вторых углов.
5. Способ по п. 1, дополнительно включающий проверку того, что первый фрагмент слова и второй фрагмент слова находятся на расстоянии не менее порогового по меньшей мере от одной второй строки текста в документе рядом с первой строкой текста, и отличающийся тем, что пороговое расстояние основано на среднем расстоянии между полиномами, соответствующими строкам текста в документе.
6. Способ по п. 1, дополнительно включающий проверку того, что второй полином находится в пределах порогового уровня схожести по меньшей мере с третьим полиномом, соответствующим по меньшей мере второй строке текста в документе.
7. Способ по п. 1, дополнительно включающий интерполяцию цвета для каждой новой позиции в новых позициях исправленного изображения на основе цветов из пикселей исходного изображения в окрестности части среди частей исходного изображения, которая соответствует новой позиции.
8. Способ по п. 1, дополнительно включающий предварительную обработку исходного изображения, отличающийся тем, что предварительная обработка может включать выполнение одного или более из следующих действий: применение гамма-фильтра к исходному изображению, нормализация ширины и высоты исходного изображения, выравнивание яркости исходного изображения или бинаризация глубины цвета исходного изображения.
9. Способ по п. 1, отличающийся тем, что определение границ основано на алгоритме детектирования линий или алгоритме детектирования границ.
10. Способ по п. 1, отличающийся тем, что новые позиции фрагментов устраняют искажение в первой строке текста в исправленном изображении.
11. Способ по п. 1, дополнительно включающий:
создание по меньшей мере одного интерполированного полинома между вторым полиномом и третьим полиномом, что соответствует по меньшей мере одной второй строке текста документа; и
сопоставление частей исходного изображения между первой строкой текста и второй строкой текста в новых позициях в исправленном изображении на интерполированном полиноме.
12. Постоянный машиночитаемый носитель данных, содержащий сохраненные на нем команды для устранения искривлений изображения документа, которые при выполнении по меньшей мере одним устройством обработки вызывают
выполнение устройством обработки следующих действий:
определение границ по меньшей мере фрагмента документа в исходном изображении, при этом документ содержит по меньшей мере одну первую строку текста;
определение множества символов в документе;
определение некоторых из символов в качестве множества фрагментов слов;
создание множества первых полиномов, которые аппроксимируют точки символов, расположенные вдоль одной из множества базовых линий каждого фрагмента слова;
создание второго полинома, который аппроксимирует точки символов, расположенные вдоль одной из множества базовых линий по меньшей мере первого фрагмента слова и второго фрагмента слова среди фрагментов слов, и соответствует первой строке текста;
определение по меньшей мере одного коэффициента растяжения для первой строки текста для того, чтобы растянуть исходное изображение вдоль второго полинома, чтобы устранить искривления изображения документа, где коэффициент растяжения определяется на основании максимальной длины участка между границами и длины второго полинома;
отображение устройством обработки частей исходного изображения вдоль первой строки текста на новые позиции в исправленном изображении на основе второго полинома и коэффициента растяжения.
13. Система для устранения искривлений изображения документа, включающая следующие компоненты:
по меньшей мере одно устройство хранения данных, в котором хранятся команды;
по меньшей мере одно устройство обработки для выполнения команд со
следующими целями:
определение границ по меньшей мере фрагмента документа в исходном изображении, при этом документ содержит по меньшей мере одну первую строку текста;
определение множества символов в документе;
определение некоторых из символов в качестве множества фрагментов слов;
создание множества первых полиномов, которые аппроксимируют точки символов, расположенные вдоль одной из множества базовых линий каждого фрагмента слова;
создание второго полинома, который аппроксимирует точки символов, расположенные вдоль одной из множества базовых линий по меньшей мере первого фрагмента слова и второго фрагмента слова среди фрагментов слов, и соответствует первой строке текста;
определение по меньшей мере одного коэффициента растяжения для первой строки текста для того, чтобы растянуть исходное изображение вдоль второго полинома, чтобы устранить искривления изображения документа, где коэффициент растяжения определяется на основании максимальной длины участка между границами и длины второго полинома;
отображение частей исходного изображения вдоль первой строки текста на новые позиции в исправленном изображении на основе второго полинома и коэффициента растяжения.
14. Система по п. 13, отличающаяся тем, что множество базовых линий фрагмента слова включает базовую линию символов фрагмента слова, медианную линию символов фрагмента слова, высоту прописных символов фрагмента слова, высоту подстрочных элементов символов фрагмента слова.
15. Система по п. 13, отличающаяся тем, что второй полином определяет один или более вторых углов, представляющих углы наклона вдоль второго полинома, и отличающаяся тем, что устройство обработки дополнительно выполняет пошаговый обход существующих позиций в исходном изображении с размером шага меньше размера пикселя в исходном изображении, и отличающаяся тем, что устройство обработки дополнительно выполняет отображение фрагментов, которое включает отображение каждого из существующих фрагментов на новые позиции на основе вторых углов, коэффициента растяжения и размера шага.
16. Система по п. 13, отличающаяся тем, что первые полиномы определяют множество первых углов, представляющих углы наклона вдоль первых полиномов, и отличающаяся тем, что второй полином определяет множество вторых углов, представляющих углы наклона вдоль второго полинома, и отличающаяся тем, что устройство обработки дополнительно выполняет проверку того, что некоторые из первых углов для первого фрагмента слова и второго фрагмента слова находятся в пределах порогового уровня точности от соответствующих вторых углов.
17. Система по п. 13, отличающаяся тем, что устройство обработки дополнительно выполняет проверку того, что первый фрагмент слова и второй фрагмент слова находятся на расстоянии не менее порогового по меньшей мере от одной второй строки текста в документе рядом с первой строкой текста, и отличающаяся тем, что пороговое расстояние основано на среднем расстоянии между полиномами, соответствующими строкам текста в документе.
18. Система по п. 13, отличающаяся тем, что устройство обработки дополнительно выполняет проверку того, что второй полином находится в пределах порогового уровня схожести по меньшей мере с одним третьим полиномом, соответствующим по меньшей мере одной второй строке текста в документе.
19. Система по п. 13, отличающаяся тем, что новые позиции фрагментов устраняют искажение в первой строке текста в исправленном изображении.
20. Система по п. 13, отличающаяся тем, что устройство обработки дополнительно выполняет следующие действия:
создание по меньшей мере одного интерполированного полинома между вторым полиномом и третьим полиномом, что соответствует по меньшей мере одной второй строке текста документа;
сопоставление частей исходного изображения между первой строкой текста и второй строкой текста в новых позициях в исправленном изображении на интерполированном полиноме.
| СПОСОБ ПРИВЕДЕНИЯ В СООТВЕТСТВИЕ ЗАПОЛНЕННОЙ МАШИНОЧИТАЕМОЙ ФОРМЫ И ЕЕ ШАБЛОНА ПРИ НАЛИЧИИ ИСКАЖЕНИЙ (ВАРИАНТЫ) | 2003 |
|
RU2251738C2 |
| RU 2012127786 A, 10.01.2014 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |

