Настоящее изобретение относится к кодированию, декодированию и обработке аудиосигналов, и в частности к кодеру, декодеру и способу, которые используют концепции остатка для параметрического кодирования аудиообъектов.
В последнее время параметрические методы для эффективной с точки зрения частоты следования битов (битрейта) передачи/сохранения аудиосцен, содержащих многочисленные аудиообъекты, были предложены в области кодирования аудио (см., например, [BCC], [JSC], [SAOC], [SAOC1] и [SAOC2]) и основанного на имеющейся информации разделения источников (см., например, [ISS1], [ISS2], [ISS3], [ISS4], [ISS5] и [ISS6]). Эти методы направлены на реконструкцию желаемой аудиосцены вывода или желаемого объекта аудиоисточника на основании дополнительной побочной информации, описывающей переданные и/или сохраненные аудиосцены и/или объекты аудиоисточника в аудиосцене.
Фиг. 5 представляет общий вид системы SAOC (SAOC = пространственное кодирование аудиообъектов), иллюстрирующий принцип таких параметрических систем с использованием примера SAOC MPEG (MPEG = Экспертная группа по движущемуся изображению) (см., например, [SAOC], [SAOC1] и [SAOC2]).
Общая обработка проводится избирательным по времени/частоте путем и может быть описана следующим образом:
Кодер 510 SAOC, в частности, средство 530 оценки побочной информации кодера 510 SAOC извлекает побочную информацию, описывающую характеристики максимум 32 входных сигналов s1…s32 аудиообъектов (отношения, в их простейшей форме, мощностей объектов сигналов аудиообъектов). Микшер 520 кодера 510 SAOC осуществляет понижающее микширование сигналов s1…s32 аудиообъектов для получения моно или 2-х канального результата микширования сигналов (то есть, одного или двух сигналов понижающего микширования) с использованием коэффициентов d1,1…d32,2 усиления понижающего микширования.
Сигнал(ы) понижающего микширования и побочная информация передаются или сохраняются. С этой целью аудиосигнал(ы) понижающего микширования могут быть кодированы с использованием аудиокодера 540. Аудиокодер 540 может быть хорошо известным перцептивным аудиокодером, например, аудиокодером MPEG-1 Layer II или III (другими словами .mp3), аудиокодером усовершенствованного кодирования аудио (AAC) MPEG и так далее.
На стороне приемника соответствующий аудиодекодер 550, например, перцептивный аудиодекодер, такой как аудиодекодер MPEG-1 Layer II или III (другими словами .mp3), аудиодекодер усовершенствованного кодирования аудио (AAC) MPEG и так далее, декодирует кодированный аудиосигнал(ы) понижающего микширования.
Декодер 560 SAOC концептуально пытается восстановить исходные сигналы (аудио)объектов ("разделение объектов") из упомянутого одного или двух сигналов понижающего микширования с использованием переданной и/или сохраненной побочной информации, например, посредством использования разделителя 570 виртуальных объектов. Эти аппроксимированные сигналы s1,est…s32,est (аудио)объектов затем микшируются средством 580 воспроизведения декодера 560 SAOC в целевую сцену, представленную посредством максимум 6 каналами y1,est…y6,est вывода аудио с использованием матрицы воспроизведения (описываемой коэффициентами r1,1…r32,6). Выходные данные могут представлять собой одноканальное, 2-канальное стерео или 5.1 многоканальную целевую сцену (например, один, два или шесть сигналов вывода аудио).
Вследствие основных ограничений параметрической оценки аудиообъектов на стороне декодирования в большинстве случаев, желаемая целевая сцена вывода не может быть сгенерирована идеально. На предельных рабочих точках (например, сольное воспроизведение одного аудиообъекта) часто обработка больше не может достичь адекватного субъективного звука. С этой целью схема SAOC была расширена посредством внедрения расширенных аудиообъектов (EAO) (т.е. аудиообъектов с расширенными возможностями)(см., например, [Dfx], см., например, более того, [SAOC]). Аудиообъекты, которые кодируются в качестве EAO, демонстрируют улучшенную способность отделения от других (обычных) не являющихся расширенными аудиообъектов (не-EAO), кодируемых в том же самом сигнале понижающего микширования, за счет увеличенной скорости передачи побочной информации. Концепция EAO предусматривает для каждого EAO ошибку предсказания (остаточный сигнал) параметрической модели.
Фиг. 6 представляет оценку остатка на стороне кодера, схематично иллюстрируя вычисление остаточных сигналов для каждого EAO. В кодере SAOC остаточные сигналы (вплоть до 4 EAO) оцениваются с использованием извлеченной параметрической побочной информации (PSI) и исходных сигналов источника, кодированных по форме волны и включенных в битовый поток SAOC в качестве не являющейся параметрической побочной информации об остатке (RSI). Более подробно, декодер SAOC PSI для EAO 610 генерирует оцененные сигналы sest,EAO аудиообъектов из понижающего микширования X. Узел 620 генерирования RSI затем генерирует вплоть до четырех остаточных сигналов sres,RSI,{1,…,4} на основе сгенерированных оцененных сигналов sest,EAO аудиообъектов и на основе исходных сигналов s1,…,s4 аудиообъектов EAO.
Фиг. 7 представляет базовую структуру декодера SAOC с поддержкой EAO, иллюстрируя концептуальный общий вид схемы обработки EAO, интегрированной в цепь декодирования/транскодирования SAOC (транскодирование = преобразование данных из одного кодирования в другое кодирование).
Параметры, ориентированные на сигнал понижающего микширования, а именно коэффициенты предсказания канала (CPC) получаются из параметрической побочной информации (PSI) посредством узла 710 оценки CPC.
CPC вместе с сигналом понижающего микширования подаются в блок-Два-в-N 720 (блок-ДВN). Блок-ДВN 720 концептуально пытается оценить EAO (sest,EAO) из переданного сигнала (X) понижающего микширования и обеспечить оцененное понижающее микширование не-EAO (Xest,nonEAO), состоящее только из не-EAO.
Переданные/сохраненные (и декодированные) остаточные сигналы (sres, RSI) используются посредством узла 730 обработки RSI для улучшения оценок EAO (sest, EAO) и соответствующего понижающего микширования только объектов не-EAO (XnonEAO).
Согласно уровню техники, на следующем этапе узел 730 обработки RSI подает сигнал понижающего микширования не-EAO (XnonEAO) в процессор 740 понижающего микширования SAOC (узел декодирования PSI) для оценки объектов не-EAO sest,nonEAO. Узел 740 декодирования PSI передает оцененные аудиообъекты не-EAO sest,nonEAO узлу 750 воспроизведения. Более того, узел обработки RSI непосредственно подает расширенные EAO 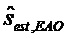 в узел 750 воспроизведения. Узел 750 воспроизведения затем генерирует моно или стерео выходные сигналы на основе оцененных аудиообъектов не-EAO sest,nonEAO и на основе расширенных EAO .
в узел 750 воспроизведения. Узел 750 воспроизведения затем генерирует моно или стерео выходные сигналы на основе оцененных аудиообъектов не-EAO sest,nonEAO и на основе расширенных EAO .
Система уровня техники имеет следующие недостатки:
До применения остаточных сигналов к вычислению EAO в декодере SAOC ориентированные на понижающее микширование CPC должны быть вычислены из переданной/сохраненной параметрической побочной информации.
Все сигналы понижающего микширования должны быть обработаны в пределах концепции остатка SAOC вне зависимости от их пригодности для обработки EAO.
Концепция остатка SAOC может быть использована только с одно- или двухканальными результатами микширования сигналов вследствие ограничений блока-ДВN. Концепция остатка EAO не может быть использована в комбинации с многоканальными результатами микширования (например, 5.1-многоканальными результатами микширования).
Кроме того, вследствие соответствующей вычислительной сложности их оценки, обработка EAO SAOC устанавливает ограничения на число EAO (то есть, до 4).
Из-за этих ограничений концепция обработки остатка EAO SAOC не может быть применена к многоканальным (например, 5.1) сигналам понижающего микширования или использована для более чем 4 EAO.
Поэтому было бы предпочтительно обеспечить улучшенные концепции для кодирования аудиосигнала, декодирования аудиосигнала и обработки аудиосигнала.
Целью настоящего изобретения является обеспечение улучшенных концепций для кодирования аудиосигнала, декодирования аудиосигнала и обработки аудиосигнала. Цель настоящего изобретения решается декодером по пункту 1, генератором остаточных сигналов по пункту 11, кодером по пункту 19, системой по пункту 21, кодированным сигналом по пункту 22, способом по пункту 23, способом по пункту 24 и компьютерной программой по пункту 25.
Обеспечен декодер. Декодер содержит узел параметрического декодирования для генерирования множества первых оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом упомянутые три или более сигналов понижающего микширования кодируют множество исходных сигналов аудиообъектов, при этом узел параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов. Более того, декодер содержит узел обработки остатка для генерирования множества вторых оцененных сигналов аудиообъектов посредством модификации одного или более из упомянутых первых оцененных сигналов аудиообъектов, при этом узел обработки остатка сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от одного или более остаточных сигналов.
Вариант осуществления представляет объектно-ориентированную концепцию остатка, которая улучшает воспринимаемое качество EAO. В отличие от системы уровня техники, представленная концепция не ограничивается ни числом сигналов понижающего микширования, ни числом EAO. Представлены два способа для получения связанных с объектами остаточных сигналов. Каскадная концепция, с помощью которой энергия остаточного сигнала итерационно сокращается с увеличением числа EAO ценой более высокой вычислительной сложности, и вторая концепция с меньшей вычислительной сложностью, в которой все остатки оцениваются одновременно.
Кроме того, варианты осуществления обеспечивают улучшенную концепцию применения объектно-ориентированных остаточных сигналов на стороне декодера, и концепции с уменьшенной сложностью, предназначенные для сценариев применения, в которых только EAO подвергаются манипулированию на стороне декодера, или модификация не-EAO ограничивается масштабированием усиления.
Согласно варианту осуществления узел обработки остатка может быть сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от по меньшей мере трех остаточных сигналов. Декодер адаптирован с возможностью генерирования по меньшей мере трех каналов вывода аудио на основе упомянутого множества вторых оцененных сигналов аудиообъектов.
Согласно варианту осуществления декодер дополнительно может содержать узел модификации понижающего микширования. Узел обработки остатка может определять один или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов. Узел модификации понижающего микширования может быть адаптирован с возможностью удаления определенного одного или более вторых оцененных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования. Узел параметрического декодирования может быть сконфигурирован с возможностью определения одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов на основе упомянутых трех или более модифицированных сигналов понижающего микширования.
В конкретном варианте осуществления узел модификации понижающего микширования может, например, быть адаптирован с возможностью применения формулы 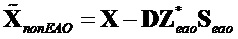 .
.
Более того, декодер может быть адаптирован с возможностью проведения двух или более итеративных шагов. Для каждого итеративного шага, узел параметрического декодирования может быть адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов. Более того для упомянутого итеративного шага, узел обработки остатка может быть адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации упомянутого сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов. Кроме того, для упомянутого итеративного шага, узел модификации понижающего микширования может быть адаптирован с возможностью удаления упомянутого сигнала аудиообъекта из упомянутого множества вторых оцененных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для модификации упомянутых трех или более сигналов понижающего микширования. На следующем итеративном шаге, следующем за упомянутым итеративным шагом, узел параметрического декодирования может быть адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, которые были модифицированы.
В варианте осуществления каждый из упомянутого одного или более остаточных сигналов может указывать различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого одного или более первых оцененных сигналов аудиообъектов.
Согласно варианту осуществления, в котором узел обработки остатка может быть адаптирован с возможностью генерирования упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации пяти или более упомянутых первых оцененных сигналов аудиообъектов, при этом узел обработки остатка может быть сконфигурирован с возможностью модификации упомянутых пяти или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от пяти или более остаточных сигналов.
В другом варианте осуществления декодер может быть сконфигурирован с возможностью генерирования семи или более каналов вывода аудио на основе упомянутого множества вторых оцененных сигналов аудиообъектов.
Согласно дополнительному варианту осуществления декодер может быть адаптирован с возможностью не определять коэффициенты предсказания канала для определения упомянутого множества вторых оцененных сигналов аудиообъектов. Варианты осуществления обеспечивают концепции, так что вычисление коэффициентов предсказания канала, которые до сих пор были необходимы для декодирования в SAOC уровня техники, больше не является необходимым для декодирования.
В дополнительном варианте осуществления декодер может быть декодером SAOC.
Более того, обеспечен генератор остаточных сигналов. Генератор остаточных сигналов содержит узел параметрического декодирования для генерирования множества оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом упомянутые три или более сигналов понижающего микширования кодируют множество исходных сигналов аудиообъектов, при этом узел параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов. Более того, генератор остаточных сигналов содержит узел оценки остатка для генерирования множества остаточных сигналов на основе упомянутого множества исходных сигналов аудиообъектов и на основе упомянутого множества оцененных сигналов аудиообъектов, так что каждый из упомянутого множества остаточных сигналов является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого множества оцененных сигналов аудиообъектов.
В варианте осуществления узел оценки остатка может быть адаптирован с возможностью генерирования по меньшей мере пяти остаточных сигналов на основе по меньшей мере пяти исходных сигналов аудиообъектов из упомянутого множества исходных сигналов аудиообъектов и на основе по меньшей мере пяти оцененных сигналов аудиообъектов из упомянутого множества оцененных сигналов аудиообъектов.
В варианте осуществления генератор остаточных сигналов может дополнительно содержать узел модификации понижающего микширования, адаптированный c возможностью модификации упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования. Узел параметрического декодирования может быть сконфигурирован с возможностью определения одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов на основе упомянутых трех или более модифицированных сигналов понижающего микширования.
В варианте осуществления узел модификации понижающего микширования может, например, быть сконфигурирован с возможностью модификации упомянутых трех или более исходных сигналов понижающего микширования для получения упомянутых трех или более модифицированных сигналов понижающего микширования посредством удаления одного или более из упомянутого множества исходных сигналов аудиообъектов из упомянутых трех или более исходных сигналов понижающего микширования.
В другом варианте осуществления узел модификации понижающего микширования может, например, быть сконфигурирован с возможностью модификации упомянутых трех или более исходных сигналов понижающего микширования для получения упомянутых трех или более модифицированных сигналов понижающего микширования посредством генерирования одного или более модифицированных сигналов аудиообъектов на основе одного или более из оцененных сигналов аудиообъектов и на основе одного или более из остаточных сигналов, и посредством удаления упомянутого одного или более модифицированных сигналов аудиообъектов из упомянутых трех или более исходных сигналов понижающего микширования. Например, каждый из упомянутого одного или более модифицированных сигналов аудиообъектов может быть сгенерирован посредством узла модификации понижающего микширования посредством модификации одного из оцененных сигналов аудиообъектов, при этом узел модификации понижающего микширования может быть адаптирован с возможностью модификации упомянутого оцененного сигнала аудиообъекта в зависимости от одного из упомянутого одного или более остаточных сигналов.
В обоих вариантах осуществления, описанных выше по тексту, узел модификации понижающего микширования может, например, быть адаптирован с возможностью применения формулы 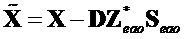 , в которой
, в которой 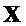 является понижающим микшированием, которое должно быть модифицировано, в которой
является понижающим микшированием, которое должно быть модифицировано, в которой 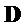 указывает информацию понижающего микширования, в которой
указывает информацию понижающего микширования, в которой 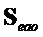 содержит исходные сигналы аудиообъектов, которые должны быть удалены, или модифицированные сигналы аудиообъектов, в которой
содержит исходные сигналы аудиообъектов, которые должны быть удалены, или модифицированные сигналы аудиообъектов, в которой 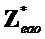 указывает местоположения сигналов, которые должны быть удалены, и в которой
указывает местоположения сигналов, которые должны быть удалены, и в которой 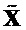 является модифицированным сигналом понижающего микширования. Например, местоположение (позиция) сигнала аудиообъекта соответствует местоположению (позиции) его аудиообъекта в списке всех объектов.
является модифицированным сигналом понижающего микширования. Например, местоположение (позиция) сигнала аудиообъекта соответствует местоположению (позиции) его аудиообъекта в списке всех объектов.
Согласно варианту осуществления генератор остаточных сигналов может быть адаптирован с возможностью проведения двух или более итеративных шагов. Для каждого итеративного шага узел параметрического декодирования может быть адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов. Более того, для упомянутого итеративного шага узел оценки остатка может быть адаптирован с возможностью определения ровно одного остаточного сигнала из упомянутого множества остаточных сигналов посредством модификации упомянутого сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов. Кроме того, для упомянутого итеративного шага узел модификации понижающего микширования может быть адаптирован с возможностью модификации упомянутых трех или более сигналов понижающего микширования. На следующем итеративном шаге, следующем за упомянутым итеративным шагом, узел параметрического декодирования может быть адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, которые были модифицированы.
В варианте осуществления обеспечен кодер для кодирования множества исходных сигналов аудиообъектов посредством генерирования трех или более сигналов понижающего микширования, посредством генерирования параметрический побочной информации и посредством генерирования множества остаточных сигналов. Кодер содержит генератор понижающего микширования для обеспечения упомянутых трех или более сигналов понижающего микширования, указывающих понижающее микширование упомянутого множества исходных сигналов аудиообъектов. Более того, кодер содержит средство оценки параметрический побочной информации для генерирования параметрический побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов, для получения параметрической побочной информации. Кроме того, кодер содержит генератор остаточных сигналов согласно одному из описанных выше по тексту вариантов осуществления. Узел параметрического декодирования генератора остаточных сигналов адаптирован с возможностью генерирования множества оцененных сигналов аудиообъектов посредством повышающего микширования упомянутых трех или более сигналов понижающего микширования, обеспеченных посредством генератора понижающего микширования, при этом сигналы понижающего микширования кодируют упомянутое множество исходных сигналов аудиообъектов. Узел параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, сгенерированной средством оценки параметрический побочной информации. Узел оценки остатка генератора остаточных сигналов адаптирован с возможностью генерирования упомянутого множества остаточных сигналов на основе упомянутого множества исходных сигналов аудиообъектов и на основе упомянутого множества оцененных сигналов аудиообъектов, так что каждый из упомянутого множества остаточных сигналов указывает различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого множества оцененных сигналов аудиообъектов.
В варианте осуществления кодер может быть кодером SAOC.
Более того, обеспечена система. Система содержит кодер согласно одному из описанных выше по тексту вариантов осуществления для кодирования множества исходных сигналов аудиообъектов посредством генерирования трех или более сигналов понижающего микширования, посредством генерирования параметрический побочной информации и посредством генерирования множества остаточных сигналов. Кроме того, система содержит декодер согласно одному из описанных выше по тексту вариантов осуществления, при этом декодер сконфигурирован с возможностью генерирования множества каналов вывода аудио на основе упомянутых трех или более сигналов понижающего микширования, генерируемых посредством кодера, на основе параметрической побочной информации, генерируемой посредством кодера и на основе упомянутого множества остаточных сигналов, генерируемых посредством кодера.
Кроме того, обеспечен кодированный аудиосигнал. Кодированный аудиосигнал содержит три или более сигналов понижающего микширования, параметрическую побочную информации и множество остаточных сигналов. Упомянутые три или более сигналов понижающего микширования являются понижающим микшированием множества исходных сигналов аудиообъектов. Параметрическая побочная информация содержит параметры, указывающие побочную информацию об упомянутом множестве исходных сигналов аудиообъектов. Каждый из упомянутого множества остаточных сигналов является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из множества оцененных сигналов аудиообъектов.
Более того, обеспечен способ. Способ содержит:
- Генерирование множества первых оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом упомянутые три или более сигналов понижающего микширования кодируют множество исходных сигналов аудиообъектов, при этом генерирование упомянутого множества первых оцененных сигналов аудиообъектов содержит повышающее микширование упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов. И:
- Генерирование множества вторых оцененных сигналов аудиообъектов посредством модификации одного или более из упомянутых первых оцененных сигналов аудиообъектов, при этом генерирование множества вторых оцененных сигналов аудиообъектов содержит модификацию упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от одного или более остаточных сигналов.
Кроме того, обеспечен другой способ. Упомянутый способ содержит:
- Генерирование множества оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом упомянутые три или более сигналов понижающего микширования кодируют множество исходных сигналов аудиообъектов, при этом генерирование упомянутого множества оцененных сигналов аудиообъектов содержит повышающее микширование упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов. И:
- Генерирование множества остаточных сигналов на основе упомянутого множества исходных сигналов аудиообъектов и на основе упомянутого множества оцененных сигналов аудиообъектов, так что каждый из упомянутого множества остаточных сигналов является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого множества оцененных сигналов аудиообъектов.
Более того, обеспечена компьютерная программа для реализации одного из описанных выше по тексту способов при исполнении на компьютере или процессоре сигналов.
В дальнейшем варианты осуществления настоящего изобретения описаны более подробно со ссылками на фигуры, на которых представлено следующее:
Фиг. 1A иллюстрирует декодер согласно варианту осуществления,
Фиг. 1B иллюстрирует декодер согласно другому варианту осуществления, при этом декодер дополнительно содержит средство воспроизведения,
Фиг. 2A иллюстрирует генератор остаточных сигналов согласно варианту осуществления,
Фиг. 2B иллюстрирует кодер согласно варианту осуществления,
Фиг. 3 иллюстрирует систему согласно варианту осуществления,
Фиг. 4 иллюстрирует кодированный аудиосигнал согласно варианту осуществления,
Фиг. 5 представляет общий вид системы SAOC, иллюстрирующий принцип таких параметрических систем с использованием примера SAOC MPEG,
Фиг. 6 представляет оценку остатка на стороне кодера, схематично иллюстрируя вычисление остаточных сигналов для каждого EAO,
Фиг. 7 представляет базовую структуру декодера SAOC с поддержкой EAO, иллюстрирующую концептуальный общий вид схемы обработки EAO, интегрированной в цепь декодирования/транскодирования SAOC,
Фиг. 8 представляет концептуальный общий вид представленной схемы параметрического и основанного на остатке кодирования аудиообъектов согласно варианту осуществления,
Фиг. 9 представляет концепцию для совместной оценки остаточного сигнала для каждого сигнала EAO на стороне кодера согласно варианту осуществления,
Фиг. 10 иллюстрирует концепцию совместного декодирования остатка на стороне декодера согласно варианту осуществления,
Фиг.11 иллюстрирует генератор остаточных сигналов согласно варианту осуществления, при этом генератор остаточных сигналов дополнительно содержит узел модификации понижающего микширования,
Фиг. 12 иллюстрирует декодер согласно варианту осуществления, при этом декодер дополнительно содержит узел модификации понижающего микширования,
Фиг. 13 иллюстрирует концепцию вычисления остаточных компонентов каскадным способом на стороне кодера согласно варианту осуществления,
Фиг. 14 иллюстрирует каскадно-включаемый узел "декодирования RSI", используемый в комбинации с каскадным вычислением остатка на стороне декодера согласно варианту осуществления,
Фиг. 15 иллюстрирует генератор остаточных сигналов согласно варианту осуществления, использующему каскадную концепцию, и
Фиг. 16 иллюстрирует декодер согласно варианту осуществления, использующему каскадную концепцию,
Фиг. 2A иллюстрирует генератор 200 остаточных сигналов согласно варианту осуществления.
Генератор 200 остаточных сигналов содержит узел 230 параметрического декодирования для генерирования множества оцененных сигналов аудиообъектов (оцененного сигнала #1 аудиообъекта, … оцененного сигнала #M аудиообъекта) посредством повышающего микширования трех или более сигналов понижающего микширования (сигнала #1 понижающего микширования, сигнала #2 понижающего микширования, сигнала #3 понижающего микширования, …, сигнала #N понижающего микширования). Упомянутые три или более сигналов понижающего микширования (сигнал #1 понижающего микширования, сигнал #2 понижающего микширования, сигнал #3 понижающего микширования, …, сигнал #N понижающего микширования) кодируют множество исходных сигналов аудиообъектов (исходный сигнал #1 аудиообъекта, …, исходный сигнал #M аудиообъекта). Узел 230 параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования (сигнала #1 понижающего микширования, сигнала #2 понижающего микширования, сигнала #3 понижающего микширования, …, сигнала #N понижающего микширования) в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов (исходном сигнале #1 аудиообъекта, …, исходном сигнале #M аудиообъекта).
Более того, генератор 200 остаточных сигналов содержит узел 240 оценки остатка для генерирования множества остаточных сигналов (остаточного сигнала #1, …, остаточного сигнала #M) на основе упомянутого множества исходных сигналов аудиообъектов (исходного сигнала #1 аудиообъекта, …, исходного сигнала #M аудиообъекта) и на основе упомянутого множества оцененных сигналов аудиообъектов (оцененного сигнала #1 аудиообъекта, …, оцененного сигнала #M аудиообъекта), так что каждый из упомянутого множества остаточных сигналов (остаточного сигнала #1, …, остаточного сигнала #M) является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов (исходного сигнала #1 аудиообъекта, …, исходного сигнала #M аудиообъекта) и одним из упомянутого множества оцененных сигналов аудиообъектов (оцененного сигнала #1 аудиообъекта, … оцененного сигнала #M аудиообъекта).
Кодер согласно описанному выше по тексту варианту осуществления преодолевает ограничения SAOC (см. [SAOC]) уровня техники.
Настоящие системы SAOC проводят понижающее микширование посредством использования одного или более блоков-два-в-один или одного или более блоков три-в-два. Среди прочего, из-за этих основных ограничений, настоящие системы SAOC могут осуществлять понижающее микширование сигналов аудиообъектов в, самое большое, два канала понижающего микширования/два сигнала понижающего микширования.
Обеспечены концепции для генераторов остаточных сигналов и для кодеров, что позволяет преодолевать ограничения SAOC, так что кодирование аудиообъектов теперь является преимущественным для систем передачи, которые используют более двух каналов передачи.
В варианте осуществления узел 240 оценки остатка адаптирован с возможностью генерирования по меньшей мере пяти остаточных сигналов на основе по меньшей мере пяти исходных сигналов аудиообъектов из упомянутого множества исходных сигналов аудиообъектов и на основе по меньшей мере пяти оцененных сигналов аудиообъектов из упомянутого множества оцененных сигналов аудиообъектов.
Фиг. 2B иллюстрирует кодер согласно варианту осуществления. Кодер с Фиг. 2B содержит генератор 200 остаточных сигналов.
Более того, кодер содержит генератор 210 понижающего микширования для обеспечения упомянутых трех или более сигналов понижающего микширования (сигнала #1 понижающего микширования, сигнала #2 понижающего микширования, сигнала #3 понижающего микширования, …, сигнала #N понижающего микширования), указывающих понижающее микширование упомянутого множества исходных сигналов аудиообъектов (исходного сигнала #1 аудиообъекта, …, исходного сигнала #M аудиообъекта, дополнительного исходного сигнала(ов) аудиообъекта)).
Относительно исходного сигнала #1 аудиообъекта, …, исходного сигнала #M аудиообъекта, узел 240 оценки остатка генерирует остаточный сигнал (остаточный сигнал #1, ..., остаточный сигнал #M). Таким образом, исходный сигнал #1 аудиообъекта, …, исходный сигнал #M аудиообъекта относятся к расширенным аудиообъектам (EAO).
Однако, как видно на Фиг. 2B, по выбору, могут существовать дополнительные исходные сигнал(ы) аудиообъектов, которые подвергаются понижающему микшированию, но для которых никакие остаточные сигналы не будут генерироваться. Эти дополнительные исходные сигнал(ы) аудиообъектов относятся таким образом к не являющимся расширенными аудиообъектам (не-EAO).
Кодер с Фиг. 2B дополнительно содержит средство 220 оценки параметрический побочной информации для генерирования параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов (исходном сигнале #1 аудиообъекта, …, исходном сигнале #M аудиообъекта, дополнительном исходном сигнале(ах) аудиообъекта), для получения параметрической побочной информации. В варианте осуществления с Фиг. 2B, средство оценки параметрический побочной информации также учитывает исходные сигналы аудиообъектов (дополнительные исходные сигнал(ы) аудиообъектов), относящиеся к не-EAO.
В варианте осуществления, число исходных сигналов аудиообъектов может быть равным числу остаточных сигналов, например, когда все исходные сигналы аудиообъектов относятся к EAO.
В других вариантах осуществления, однако, число остаточных сигналов может отличаться от числа исходных сигналов аудиообъектов и/или может отличаться от числа оцененных сигналов аудиообъектов, например, когда исходные сигналы аудиообъектов относятся к не-EAO.
В некоторых вариантах осуществления, кодер является кодером SAOC.
Фиг. 1A иллюстрирует декодер согласно варианту осуществления.
Декодер содержит узел 110 параметрического декодирования для генерирования множества первых оцененных сигналов аудиообъектов (1-го оцененного сигнала #1 аудиообъекта, … 1-го оцененного сигнала #M аудиообъекта) посредством повышающего микширования трех или более сигналов понижающего микширования (сигнала #1 понижающего микширования, сигнала #2 понижающего микширования, сигнала #3 понижающего микширования, …, сигнала #N понижающего микширования), при этом упомянутые три или более сигналов понижающего микширования (сигнал #1 понижающего микширования, сигнал #2 понижающего микширования, сигнал #3 понижающего микширования, …, сигнал #N понижающего микширования) кодируют множество исходных сигналов аудиообъектов, при этом узел 110 параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования (сигнала #1 понижающего микширования, сигнала #2 понижающего микширования, сигнала #3 понижающего микширования, …, сигнала #N понижающего микширования) в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов.
Более того, декодер содержит узел 120 обработки остатка для генерирования множества вторых оцененных сигналов аудиообъектов (2-ого оцененного сигнала #1 аудиообъекта, … 2-го оцененного сигнала #M аудиообъекта) посредством модификации одного или более из упомянутых первых оцененных сигналов аудиообъектов (1-го оцененного сигнала #1 аудиообъекта, … 1-го оцененного сигнала #M аудиообъекта), при этом узел 120 обработки остатка сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов (1-го оцененного сигнала #1 аудиообъекта, … 1-го оцененного сигнала #M аудиообъекта) в зависимости от одного или более остаточных сигналов (остаточного сигнала #1, …, остаточного сигнала #M).
Декодер согласно описанному выше по тексту варианту осуществления преодолевает ограничения SAOC (см. [SAOC]) уровня техники.
Кроме того, настоящие системы SAOC проводят повышающее микширование посредством использования одного или более блоков-один-в-два (блоков ОВД) или одного или более блоков-два-в-три (блоков ДВТ). Среди прочего, из-за этих ограничений сигналы аудиообъектов, кодируемые более чем с двумя сигналами понижающего микширования/каналами понижающего микширования, не могут подвергаться повышающему микшированию посредством декодеров SAOC уровня техники.
Обеспечены концепции для декодеров, что позволяет преодолевать ограничения SAOC, так что кодирование аудиообъектов в настоящее время является преимущественным для систем передачи, которые используют более двух каналов передачи.
Фиг. 1B иллюстрирует декодер согласно другому варианту осуществления, при этом декодер дополнительно содержит узел 130 воспроизведения для генерирования упомянутого множества каналов вывода аудио (канала #1 вывода аудио, …, канала #R вывода аудио) из упомянутых вторых оцененных сигналов аудиообъектов (2-го оцененного сигнала #1 аудиообъекта, … 2-го оцененного сигнала #M аудиообъекта) в зависимости от информации воспроизведения. Например, информация воспроизведения может быть матрицей воспроизведения и/или коэффициентами матрицы воспроизведения и узел 130 воспроизведения может быть сконфигурирован с возможностью применения матрицы воспроизведения в отношении упомянутых вторых оцененных сигналах аудиообъектов (2-ого оцененного сигнала #1 аудиообъекта, … 2-ого оцененного сигнала #M аудиообъекта) для получения упомянутого множества каналов вывода аудио (канала #1 вывода аудио, …, канала #R вывода аудио).
Согласно варианту осуществления узел 120 обработки остатка сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от по меньшей мере трех остаточных сигналов. Декодер адаптирован с возможностью генерирования упомянутых по меньшей мере трех каналов вывода аудио на основе упомянутого множества вторых оцененных сигналов аудиообъектов.
В другом варианте осуществления каждый из упомянутого одного или более остаточных сигналов указывает различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого одного или более первых оцененных сигналов аудиообъектов.
Согласно варианту осуществления узел 120 обработки остатка адаптирован с возможностью генерирования упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации пяти или более из упомянутых первых оцененных сигналов аудиообъектов. Узел 120 обработки остатка адаптирован с возможностью модификации упомянутых пяти или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от пяти или более остаточных сигналов.
В другом варианте осуществления декодер сконфигурирован с возможностью генерирования семи или более каналов вывода аудио на основе упомянутого множества вторых оцененных сигналов аудиообъектов.
Согласно дополнительному варианту осуществления декодер адаптирован с возможностью не определять коэффициенты предсказания канала для определения упомянутого множества вторых оцененных сигналов аудиообъектов.
В дополнительном варианте осуществления, декодер является декодером SAOC.
Фиг. 3 иллюстрирует систему согласно варианту осуществления. Система содержит кодер 310 согласно одному из описанных выше по тексту вариантов осуществления для кодирования множества исходных сигналов аудиообъектов (исходного сигнала #1 аудиообъекта, …, исходного сигнала #M аудиообъекта) посредством генерирования трех или более сигналов понижающего микширования, посредством генерирования параметрический побочной информации и посредством генерирования множества остаточных сигналов. Кроме того, система содержит декодер 320 согласно одному из описанных выше по тексту вариантов осуществления, при этом декодер 320 сконфигурирован с возможностью генерирования множества вторых оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, генерируемых посредством кодера 310, на основе параметрической побочной информации, генерируемой посредством кодера 310 и на основе упомянутого множества остаточных сигналов, генерируемых посредством кодера 310.
Фиг. 4 иллюстрирует кодированный аудиосигнал согласно варианту осуществления. Кодированный аудиосигнал содержит три или более сигналов 410 понижающего микширования, параметрическую побочную информации 420 и множество остаточных сигналов 430. Упомянутые три или более сигналов 410 понижающего микширования являются понижающим микшированием множества исходных сигналов аудиообъектов. Параметрическая побочная информация 420 содержит параметры, указывающие побочную информацию об упомянутом множестве исходных сигналов аудиообъектов. Каждый из упомянутого множества остаточных сигналов 430 является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из множества оцененных сигналов аудиообъектов.
В последующем, обеспечен общий вид концепции согласно варианту осуществления.
Фиг. 8 представляет концептуальный общий вид представленной схемы параметрического и основанного на остатке кодирования аудиообъектов согласно варианту осуществления, при этом схема кодирования демонстрирует передовой сигнал понижающего микширования и передовую поддержку EAO.
На стороне кодера средство 220 оценки параметрический побочной информации ("узел генерирования PSI") вычисляет PSI для оценки сигналов объектов на декодере, используя характеристики, связанные с понижающим микшированием и источником. Узел 245 генерирования RSI вычисляет для каждого сигнала объекта, который должен быть расширен, информацию об остатке посредством анализа различий между оцененными и исходными сигналами объектов. Узел 245 генерирования RSI может, например, содержать узел 230 параметрического декодирования и узел 240 оценки остатка.
На стороне декодера узел 110 параметрического декодирования (узел "декодирования PSI") оценивает сигналы объекта из сигналов понижающего микширования с данной PSI. На втором этапе узел 120 обработки остатка (узел "декодирования RSI") использует RSI для улучшения качества оцененных сигналов объектов, которые должны быть расширены. Все сигналы объектов (расширенных и нерасширенных аудиообъектов) могут, например, быть переданы узлу 130 воспроизведения для генерирования целевой сцены вывода.
Следует отметить, что нет необходимости учитывать все сигналы понижающего микширования. Сигналы понижающего микширования могут быть исключены из вычисления, если можно пренебречь их вкладом в оценку или/и оценку и расширение сигналов объектов.
Для простоты понимания, этапы обработки на Фиг. 8 и последующих фигурах представлены в качестве отдельных узлов обработки. На практике, они могут быть эффективно объединены для сокращения вычислительной сложности.
В последующем, обеспечена концепция совместного кодирования/декодирования остатка.
Фиг. 9 изображает концепцию для совместной оценки остаточного сигнала для каждого сигнала EAO на стороне кодера согласно варианту осуществления.
Узел 230 параметрического декодирования (узел "декодирования PSI") вырабатывает оценку сигналов аудиообъектов (оцененных сигналов sest,PSI,{1,…,M} аудиообъектов принимая в качестве входных данных оцененную PSI и сигнал(ы) понижающего микширования. Оцененные сигналы sest,PSI{1,…,M} аудиообъектов сравниваются с исходными неизмененными сигналами s1,…,sM источника в узле 240 оценки остатка (узел "оценки RSI"). Узел 240 оценки остатка обеспечивает элемент sres,RSI,{1,…,M} остаточного сигнала/сигнала ошибки для каждого аудиообъекта, который должен быть расширен.
Фиг. 10 отображает узел "декодирования RSI", используемый в комбинации с совместным вычислением остатка в декодере. В частности, Фиг. 10 иллюстрирует концепцию совместного декодирования остатка на стороне декодера согласно варианту осуществления.
Упомянутые (первые) оцененные сигналы sest,PSI,{1,…,M} аудиообъектов из узла 110 параметрического декодирования (узла "декодирования PSI") подаются вместе с информацией об остатке ("побочной информацией об остатке") в узел 120 обработки остатка ("декодирования RSI"). Узел 120 обработки остатка вычисляет из (побочной) информации об остатке и оцененных сигналов sest,PSI,{1,…,M} аудиообъектов упомянутые вторые оцененные сигналы sest,RSI,{1,…,M} аудиообъектов, например, сигналы расширенных и нерасширенных аудиообъектов, и вырабатывает упомянутые вторые оцененные сигналы sest,RSI,{1,…,M} аудиообъектов, например, сигналы расширенных и нерасширенных аудиообъектов в качестве вывода узла 120 обработки остатка.
Дополнительно, может быть произведена повторная оценка не-EAO (не проиллюстрировано на Фиг. 10). EAO удаляются из результата микширования сигналов и оставшиеся не-EAO повторно оцениваются из этого результата микширования. Это дает улучшенную оценку этих объектов по сравнению с оценкой по результату микширования сигналов, который содержит все сигналы объектов. Эта повторная оценка может быть пропущена, если целью является манипулирование только сигналами расширенных объектов в результате микширования.
Фиг. 11 иллюстрирует генератор остаточных сигналов согласно варианту осуществления, при этом.
На Фиг. 11 генератор 200 остаточных сигналов дополнительно содержит узел 250 модификации понижающего микширования, адаптированный c возможностью модификации упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования.
Узел 230 параметрического декодирования сконфигурирован с возможностью определения одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов на основе упомянутых трех или более модифицированных сигналов понижающего микширования.
Затем, узел 240 оценки остатка может, например, определять один или более остаточных сигналов на основе упомянутого одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов.
В варианте осуществления узел 250 модификации понижающего микширования может, например, быть сконфигурирован с возможностью модификации упомянутых трех или более исходных сигналов понижающего микширования для получения упомянутых трех или более модифицированных сигналов понижающего микширования посредством удаления одного или более из упомянутого множества исходных сигналов аудиообъектов из упомянутых трех или более исходных сигналов понижающего микширования.
В другом варианте осуществления узел 250 модификации понижающего микширования может, например, быть сконфигурирован с возможностью модификации упомянутых трех или более исходных сигналов понижающего микширования для получения упомянутых трех или более модифицированных сигналов понижающего микширования посредством генерирования одного или более модифицированных сигналов аудиообъектов на основе одного или более из оцененных сигналов аудиообъектов и на основе одного или более из остаточных сигналов, и посредством удаления упомянутого одного или более модифицированных сигналов аудиообъектов из упомянутых трех или более исходных сигналов понижающего микширования. Например, каждый из упомянутого одного или более модифицированных сигналов аудиообъектов может быть сгенерирован посредством узла модификации понижающего микширования посредством модификации одного из оцененных сигналов аудиообъектов, при этом узел модификации понижающего микширования может быть адаптирован с возможностью модификации упомянутого оцененного сигнала аудиообъекта в зависимости от одного из упомянутого одного или более остаточных сигналов.
В обоих вариантах осуществления, описанных выше по тексту, узел модификации понижающего микширования может, например, быть адаптирован с возможностью применения формулы
,
в которой является понижающим микшированием, которое должно быть модифицировано,
в которой указывает связанную информацию понижающего микширования,
в которой содержит исходные сигналы аудиообъектов, которые должны быть удалены, или модифицированные сигналы аудиообъектов, которые должны быть удалены,
в которой указывает местоположения сигналов, которые должны быть удалены, и
в которой является модифицированным сигналом понижающего микширования.
Например, местоположение (позиция) сигнала аудиообъекта соответствует местоположению (позиции) его аудиообъекта в списке всех объектов.
Фиг. 12 иллюстрирует декодер согласно варианту осуществления.
В варианте осуществления с Фиг. 12 декодер дополнительно содержит узел 140 модификации понижающего микширования.
Узел 120 обработки остатка определяет один или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов.
Узел 140 модификации понижающего микширования адаптирован с возможностью удаления определенного одного или более вторых оцененных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования.
Узел 110 параметрического декодирования сконфигурирован с возможностью определения одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов на основе упомянутых трех или более модифицированных сигналов понижающего микширования.
Узел 120 обработки остатка может затем, например, определять один или более дополнительных вторых оцененных сигналов аудиообъектов на основе определенного одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов.
В конкретном варианте осуществления узел 130 модификации понижающего микширования может, например, быть адаптирован с возможностью применения формулы:
.
для удаления упомянутого одного или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов, определяемых посредством узла 120 обработки остатка, из упомянутых трех или более сигналов понижающего микширования, для получения трех или более модифицированных сигналов понижающего микширования, при этом
указывает упомянутые три или более сигналов понижающего микширования до их модификации
указывает упомянутые три или более модифицированных сигналов понижающего микширования
 указывает матрицу понижающего микширования
указывает матрицу понижающего микширования
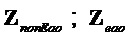 указывает субматрицу отображения, обозначающую позиции (местоположения) EAO
указывает субматрицу отображения, обозначающую позиции (местоположения) EAO
(Для больших подробностей о конкретных вариантах этого варианта осуществления см. описание ниже по тексту).
В нижеследующем, представлена каскадная концепция кодирования/декодирования остатка.
Фиг. 13 иллюстрирует концепцию вычисления остаточных компонентов каскадным путем на стороне кодера согласно варианту осуществления. По сравнению с концепцией совместного вычисления остатка, каскадный подход сокращает на каждом итеративном шаге энергию остаточной энергии за счет более высокой вычислительной сложности. На каждом шаге, один из исходных сигналов аудиообъектов (sM) (или, в альтернативном варианте осуществления, оцененный сигнал аудиообъекта; см. пунктирные стрелки 2461, 2462) расширенного аудиообъекта удаляется из результата микширования сигналов (понижающего микширования) до того, как результат микширования сигналов (понижающее микширование) передается на следующий узел 2452 обработки. Таким образом, число сигналов объектов в результате микширования сигналов (понижающем микшировании) уменьшается с каждым шагом обработки. Посредством этого улучшается оценка сигнала расширенного аудиообъекта (упомянутого второго оцененного сигнала аудиообъекта) на следующем шаге, таким образом успешно сокращая энергию остаточных сигналов.
(Следует отметить, что в альтернативном варианте осуществления, где на каждом итеративном шаге оцененный сигнал аудиообъекта удаляется из результата микширования сигналов, подузлы 2501, 2502 модификации понижающего микширования не нуждаются в приеме исходных сигналов sM аудиообъектов.
Наоборот, в варианте осуществления, где на каждом итеративном шаге исходный сигнал аудиообъекта удаляется из результата микширования сигналов, подузлы 2501, 2502 модификации понижающего микширования не нуждаются в приеме оцененных сигналов аудиообъектов.)
Более подробно, Фиг. 13 иллюстрирует множество подузлов 2451, 2452 генерирования RSI. Упомянутое множество подузлов 2451, 2452 генерирования RSI вместе формируют узел генерирования RSI.
Каждый из упомянутого множества подузлов 2451, 2452 генерирования RSI содержит подузел 2301 параметрического декодирования. Упомянутое множество подузлов 2301 параметрического декодирования вместе формируют узел параметрического декодирования. Подузлы 2301 параметрического декодирования генерируют упомянутые первые оцененные сигналы sest,PSI,{1,…,M} аудиообъектов.
Каждый из упомянутого множества подузлов 2451, 2452 генерирования RSI содержит подузел 2401 оценки остатка. Упомянутое множество подузлов 2401 оценки остатка вместе формируют узел оценки остатка. Подузлы 2401 оценки остатка генерируют упомянутые вторые оцененные сигналы sest,RSI,M, sest,RSI,M-1 аудиообъектов.
Более того, Фиг. 13 иллюстрирует множество подузлов 2501, 2502 модификации понижающего микширования. Каждый из подузлов 2501, 2502 модификации понижающего микширования вместе формируют узел модификации понижающего микширования.
Фиг. 14 представляет каскадно-включаемый узел "декодирования RSI", используемый в комбинации с каскадным вычислением остатка на стороне декодера согласно варианту осуществления.
На каждом шаге, один из сигналов объектов, который должен быть расширен, оценивается посредством подузла 1101 параметрического декодирования ("декодирования PSI") (для получения одного из упомянутых первых оцененных сигналов sest,PSI,M аудиообъектов), и упомянутый один из упомянутых первых оцененных сигналов sest,PSI,M аудиообъектов затем обрабатывается вместе с соответствующим остаточным сигналом sres,RSI,M посредством подузла 1201 обработки остатка ("обработка RSI"), чтобы выработать расширенную версию сигнала sest,RSI,M объекта (одного из упомянутых вторых оцененных сигналов аудиообъектов). Сигнал sest,RSI,M расширенного объекта стирается из сигнала понижающего микширования посредством подузла 1401 модификации понижающего микширования ("модификации понижающего микширования") до того, как модифицированные сигналы понижающего микширования подаются в следующий подузел 1252 декодирования остатка ("декодирования остатка").
Как и в концепции совместного кодирования/декодирования остатка, не-EAO могут быть повторно оценены.
Более подробно, Фиг.14 иллюстрирует множество подузлов 1251, 1252 декодирования остатка. Упомянутое множество подузлов 1251, 1252 декодирования остатка вместе формируют узел декодирования остатка.
Каждый из упомянутого множества подузлов 1251, 1252 декодирования остатка содержит подузел 1101 параметрического декодирования. Упомянутое множество подузлов 1101 параметрического декодирования вместе формируют узел параметрического декодирования. Подузлы 1101 параметрического декодирования генерируют упомянутые первые оцененные сигналы sest,PSI,{1,…,M} аудиообъектов.
Каждый из упомянутого множества подузлов 1251, 1252 декодирования остатка содержит подузел 1201 обработки остатка. Упомянутое множество подузлов 1201 обработки остатка вместе формируют узел обработки остатка. Подузлы 1201 обработки остатка генерируют упомянутые вторые оцененные сигналы sest,RSI,M, sest,RSI,M-1 аудиообъектов.
Более того, Фиг. 14 иллюстрирует множество подузлов 1401, 1402 модификации понижающего микширования. Каждый из подузлов 1401, 1402 модификации понижающего микширования вместе формируют узел модификации понижающего микширования.
Фиг. 15 иллюстрирует генератор остаточных сигналов согласно варианту осуществления, использующему каскадную концепцию.
На Фиг. 15 генератор остаточных сигналов содержит узел 250 модификации понижающего микширования.
Генератор 200 остаточных сигналов адаптирован с возможностью проведения двух или более итеративных шагов:
Для каждого итеративного шага, узел 230 параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов.
Более того, для упомянутого итеративного шага, узел 240 оценки остатка адаптирован с возможностью определения ровно одного остаточного сигнала из упомянутого множества остаточных сигналов посредством модификации упомянутого сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов.
Кроме того, для упомянутого итеративного шага, узел 250 модификации понижающего микширования адаптирован с возможностью модификации упомянутых трех или более сигналов понижающего микширования.
На следующем итеративном шаге, следующем за упомянутым итеративным шагом, узел 230 параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, которые были модифицированы.
Фиг. 16 иллюстрирует декодер согласно варианту осуществления, использующему каскадную концепцию. На Фиг. 16 декодер также содержит узел 140 модификации понижающего микширования.
Декодер с Фиг. 16 адаптирован с возможностью проведения двух или более итеративных шагов:
Для каждого итеративного шага, узел 110 параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов.
Более того, для упомянутого итеративного шага, узел 120 обработки остатка адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации упомянутого сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов.
Кроме того, для упомянутого итеративного шага, узел 140 модификации понижающего микширования адаптирован с возможностью удаления упомянутого сигнала аудиообъекта из упомянутого множества вторых оцененных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для модификации упомянутых трех или более сигналов понижающего микширования.
На следующем итеративном шаге, следующем за упомянутым итеративным шагом, узел 110 параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, которые были модифицированы.
В нижеследующем, описывается математический вывод на примере концепции совместного кодирования/декодирования остатка:
Далее по тексту используется нижеследующая система обозначений:
Величины:
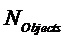 - число сигналов аудиообъектов
- число сигналов аудиообъектов
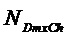 - число сигналов понижающего микширования
- число сигналов понижающего микширования
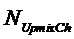 - число каналов повышающего микширования
- число каналов повышающего микширования
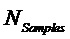 - число обработанных данных
- число обработанных данных
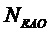 - число EAO
- число EAO
Члены:
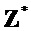 - звездный оператор (
- звездный оператор ( ) обозначает сопряженное транспонирование данной матрицы
) обозначает сопряженное транспонирование данной матрицы
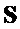 - исходный сигнал аудиообъекта, обеспеченный кодеру (размера
- исходный сигнал аудиообъекта, обеспеченный кодеру (размера  )
)
- матрица понижающего микширования (размера 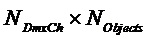 )
)
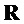 - матрица воспроизведения (размера
- матрица воспроизведения (размера 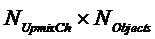 )
)
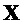 - аудиосигнал
- аудиосигнал 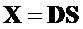 понижающего микширования (размера
понижающего микширования (размера 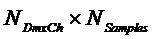 )
)
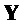 - идеальный выходной аудиосигнал
- идеальный выходной аудиосигнал 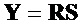 (размера
(размера 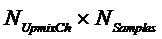 )
)
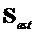 - параметрически реконструированный сигнал объекта, аппроксимирующий
- параметрически реконструированный сигнал объекта, аппроксимирующий  , заданный как
, заданный как 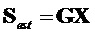 (размера )
(размера )
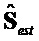 - вывод декодера, содержащий все оценки сигналов не-EAO (параметрически оцененных) и EAO (параметрически плюс остаток), размера
- вывод декодера, содержащий все оценки сигналов не-EAO (параметрически оцененных) и EAO (параметрически плюс остаток), размера
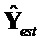 - выходной аудиосигнал повышающего микширования, аппроксимирующий
- выходной аудиосигнал повышающего микширования, аппроксимирующий  , заданный как
, заданный как 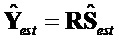 (размера )
(размера )
- субматрица отображения, обозначающая местоположения не-EAO и EAO в списке всех объектов. Следует отметить 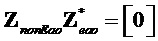 (размера
(размера 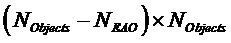 ;
;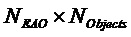 ). Матрицы отображения не-EAO
). Матрицы отображения не-EAO 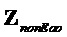 и соответствующего
и соответствующего 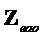 задаются как
задаются как

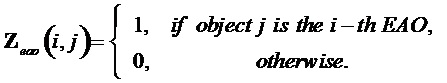
Например, для  и объекты номер 2 и 4 являются EAO, эти матрицы являются
и объекты номер 2 и 4 являются EAO, эти матрицы являются
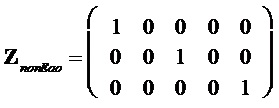 ,
,  .
.
 - субматрица понижающего микширования, соответствующая не-EAO, заданная как
- субматрица понижающего микширования, соответствующая не-EAO, заданная как 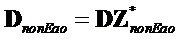 (размера
(размера  )
)
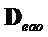 - субматрица понижающего микширования, соответствующая EAO, заданная как
- субматрица понижающего микширования, соответствующая EAO, заданная как 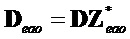 (размера
(размера 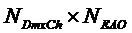 )
)
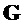 - матрица параметрической оценки источника (размера
- матрица параметрической оценки источника (размера 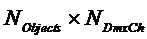 )
)
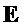 - ковариационная матрица объектов (размера
- ковариационная матрица объектов (размера 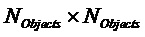 )
)
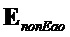 - ковариационная субматрица, соответствующая не-EAO, заданная как
- ковариационная субматрица, соответствующая не-EAO, заданная как 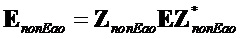 (размера
(размера 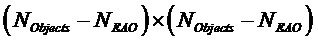 )
)
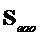 - сигнал EAO, содержащий реконструкции EAO (размера
- сигнал EAO, содержащий реконструкции EAO (размера 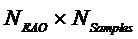 )
)
 - сигнал не-EAO, содержащий реконструкции не-EAO (размера
- сигнал не-EAO, содержащий реконструкции не-EAO (размера 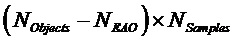 )
)
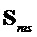 - остаточные сигналы для EAO (размера )
- остаточные сигналы для EAO (размера )
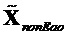 - модифицированный сигнал понижающего микширования, содержащий только сигналы не-EAO; вычисленный как разность между понижающим микшированием SAOC и понижающим микшированием реконструированных EAO (размера )
- модифицированный сигнал понижающего микширования, содержащий только сигналы не-EAO; вычисленный как разность между понижающим микшированием SAOC и понижающим микшированием реконструированных EAO (размера )
Все введенные матрицы (в общем) изменяются во времени и по частоте.
В настоящий момент рассматривается общий способ с повторной оценкой сигнала не-EAO на стороне декодера:
Общий способ может быть описан в качестве подхода с двумя этапами, где на первом извлекают все сигналы EAO из соответствующего сигнала понижающего микширования, а затем реконструируют все сигналы не-EAO, учитывая EAO. Сигналы объектов восстанавливаются из сигнала () понижающего микширования с использованием PSI ( ,
, ) и включенного остаточного сигнала ().
) и включенного остаточного сигнала ().
Считается, что конечный воспроизводимый выходной сигнал 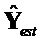 задается как:
задается как:
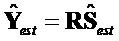 .
.
Выходной сигнал 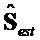 объекта декодера может быть представлен в качестве следующей суммы:
объекта декодера может быть представлен в качестве следующей суммы:
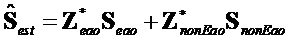 .
.
Сигнал EAO вычисляется из понижающего микширования с помощью матрицы 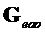 параметрической реконструкции EAO и соответствующих остатков EAO следующим образом:
параметрической реконструкции EAO и соответствующих остатков EAO следующим образом:
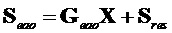 .
.
Сигнал не-EAO вычисляется из модифицированного понижающего микширования с помощью матрицы 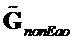 параметрической реконструкции не-EAO следующим образом:
параметрической реконструкции не-EAO следующим образом:
 .
.
Модифицированный сигнал понижающего микширования определяется как разность между понижающим микшированием и соответствующим понижающим микшированием реконструированных EAO следующим образом, таким образом, стирая EAO из сигнала понижающего микширования:
.
Здесь матрицы параметрической реконструкции объекта для EAO и для не-EAO определяются с использованием PSI (, ) следующим образом:
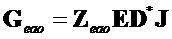 ,
,  ,
,
 ,
, 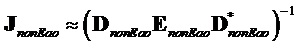
В нижеследующем описывается упрощенный способ "А" без повторной оценки сигнала не-EAO на стороне декодера:
Если в результате микширования сигналов манипулируют только EAO, целевая сцена может быть интерпретирована как линейная комбинация сигналов понижающего микширования и сигналов EAO. Поэтому, дополнительная повторная оценка сигналов не-EAO может быть пропущена. Общий способ с повторной оценкой сигнала не-EAO может быть упрощен до процедуры с одним этапом:
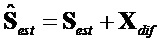 .
.
Сигнал 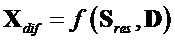 содержит переданные остаточные сигналы EAO и члены компенсации остатка, так что нижеследующее определение устанавливает:
содержит переданные остаточные сигналы EAO и члены компенсации остатка, так что нижеследующее определение устанавливает:
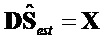 .
.
Это условие является достаточным для воспроизведения любой акустической сцены, которая ограничивается только манипулированием EAO.
С 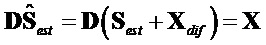 и
и 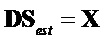 следующее ограничение для члена
следующее ограничение для члена 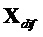 должно быть выполнено:
должно быть выполнено:
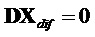 .
.
Член 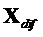 состоит из компонентов, которые определяются посредством кодера (и передаются или сохраняются)
состоит из компонентов, которые определяются посредством кодера (и передаются или сохраняются) 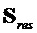 и компонентов
и компонентов 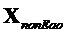 , которые должны быть определены с использованием этого уравнения.
, которые должны быть определены с использованием этого уравнения.
С использованием определений матрицы (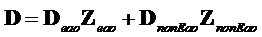 ) понижающего микширования и члена (
) понижающего микширования и члена (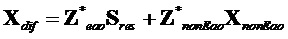 ) компенсации можно вывести следующее уравнение:
) компенсации можно вывести следующее уравнение:
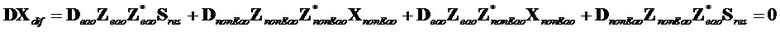
С 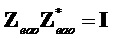 ,
, 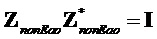 и ,
и ,  уравнение может быть сокращено до:
уравнение может быть сокращено до:
 .
.
Решение линейного уравнения для 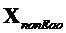 дает:
дает:
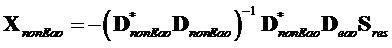 .
.
После решения этой системы линейных уравнений желаемая целевая сцена может быть вычислена как следующая сумма члена параметрического предсказания и члена расширения остатка в качестве:
, , 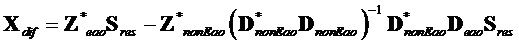 .
.
В нижеследующем обеспечивается упрощенный способ "В" без повторной оценки сигнала не-EAO на стороне декодера:
Рассмотрение члена 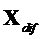 компенсации как указано выше по тексту (
компенсации как указано выше по тексту (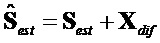 ) для параметрического предсказания сигнала
) для параметрического предсказания сигнала 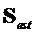 и представление его в качестве следующей функции
и представление его в качестве следующей функции 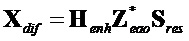 остаточных сигналов
остаточных сигналов 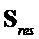 приводит к:
приводит к:
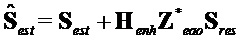
Альтернативная формулировка содержит три следующих части, включающих в себя надлежащую линейную комбинацию сигналов (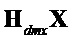 ) понижающего микширования, расширенных объектов (
) понижающего микширования, расширенных объектов (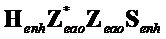 ) и нерасширенных объектов (
) и нерасширенных объектов (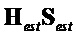 ) так, что следует:
) так, что следует:
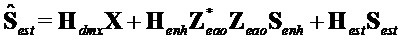 .
.
Матрицы имеют размеры 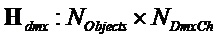 ,
, 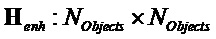 ,
, 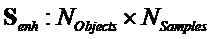 и
и 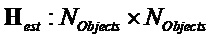 .
.
Предполагая 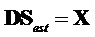 и определение
и определение 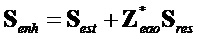 , это может быть записано как:
, это может быть записано как:
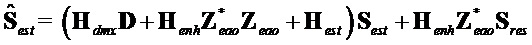
Сравнивая упомянутое и вышеуказанное определения реконструированных сигналов следует, что:
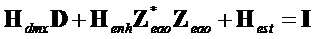 .
.
Можно вывести член 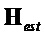 как:
как:
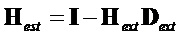 .
.
Ошибка в конечной реконструкции будет минимизирована, когда минимизирован вклад нерасширенных сигналов. Таким образом, имея целью 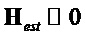 можно решить член
можно решить член 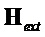 из системы линейных уравнений:
из системы линейных уравнений:
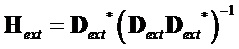 .
.
где расширенная матрица  понижающего микширования и матрица
понижающего микширования и матрица 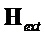 повышающего микширования задаются как конкатенированные матрицы:
повышающего микширования задаются как конкатенированные матрицы:
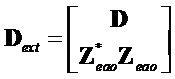 и
и 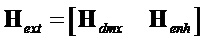 и таким образом
и таким образом 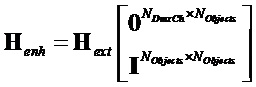
После решения этой системы линейных уравнений желаемый поправочный член 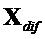 может быть получен как:
может быть получен как:
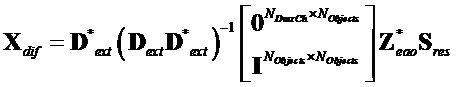 ,
,
Приводя к конечным выводам из , .
В нижеследующем рассматривается упрощенный способ "С":
Если манипулируют только EAO произвольным образом, любая целевая сцена может быть сгенерирована посредством линейной комбинации сигналов понижающего микширования и EAO. Следует отметить, что вместо понижающего микширования, также может быть использовано понижающее микширование со стертыми EAO. Целевая сцена может быть идеально сгенерирована, если обработка остатка идеально восстанавливает EAO. Воспроизведение любой целевой сцены может быть сделано с использованием определения двухкомпонентных матриц 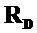 и
и 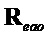 воспроизведения для понижающего микширования и реконструкций EAO. Матрицы имеют размеры
воспроизведения для понижающего микширования и реконструкций EAO. Матрицы имеют размеры 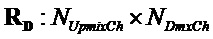 и
и 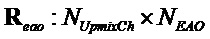 . Целевая матрица
. Целевая матрица 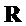 воспроизведения может быть представлена в качестве произведения комбинированных матриц воспроизведения и матрицы понижающего микширования как
воспроизведения может быть представлена в качестве произведения комбинированных матриц воспроизведения и матрицы понижающего микширования как
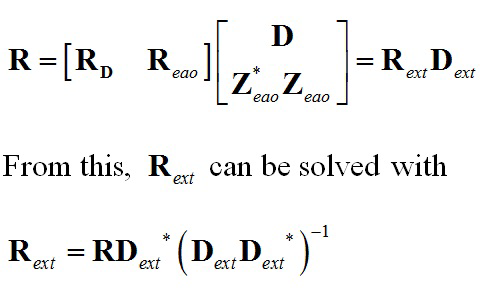
Отсюда, Rext может быть решена с помощью:
и субматрицы и 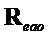 могут быть извлечены из решения с помощью
могут быть извлечены из решения с помощью 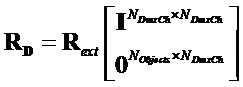 и
и 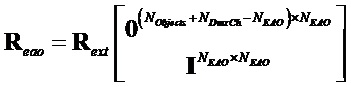
Целевая сцена в настоящий момент может быть вычислена как:
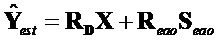 ,
,
где 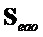 содержит полные реконструкции EAO и задается (как указано выше по тексту) .
содержит полные реконструкции EAO и задается (как указано выше по тексту) .
Аналогичное уравнение может быть сформулировано для воспроизведения цели с использованием понижающего микширования с EAO, стертыми из микширования, посредством вычитания 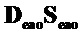 из понижающего микширования.
из понижающего микширования.
В нижеследующем, описывается другой математический вывод и дополнительные подробности о концепции совместного кодирования/декодирования остатка, и обеспечивается унификация между общим способом и упрощением "A".
Ниже в описании применяется следующая система обозначений. Если для некоторых элементов следующая система обозначений является несовместимой с системой обозначений, обеспеченной выше по тексту, в дальнейшем в описании, для этих элементов применяется только следующая система обозначений.
Определения:
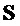 - сигналы объектов размера
- сигналы объектов размера 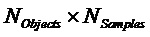
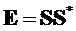 - ковариационная матрица объектов размера
- ковариационная матрица объектов размера 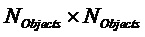
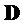 - матрицей понижающего микширования размера
- матрицей понижающего микширования размера 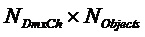
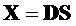 - сигнал понижающего микширования размера
- сигнал понижающего микширования размера 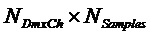
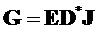 - матрица повышающего микширования размера
- матрица повышающего микширования размера 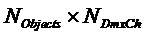
 - матрица воспроизведения размера
- матрица воспроизведения размера 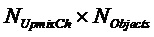
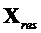 - остаточные сигналы размера
- остаточные сигналы размера 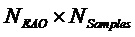
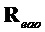 - матрица размера
- матрица размера 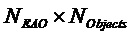 , обозначающая позиции (местоположения) EAO, заданная как
, обозначающая позиции (местоположения) EAO, заданная как

 - матрица размера
- матрица размера 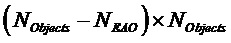 , обозначающая позиции (местоположения) не-EAO, заданная как
, обозначающая позиции (местоположения) не-EAO, заданная как

Субматрицы некоторых из вышеуказанных, соответствующих не-EAO, могут быть заданы с помощью матриц выборки как:
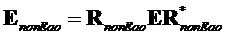
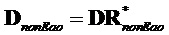
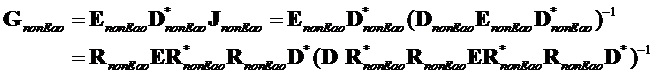
В последующем обеспечивается другое подробное математическое описание об общем способе (с повторной оценкой сигнала не-EAO на декодере):
Сигналы объектов восстанавливаются из понижающего микширования с использованием побочной информации и включенных остаточных сигналов. Вывод из декодера 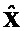 производится следующим образом
производится следующим образом
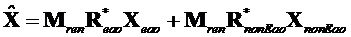 .
.
Член 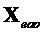 EAO размера
EAO размера 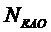 с EAO вычисляется следующим образом
с EAO вычисляется следующим образом
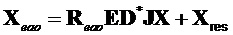 ,
,
где член  остаточного сигнала размера содержит остаточные сигналы для EAO.
остаточного сигнала размера содержит остаточные сигналы для EAO.
Член 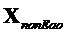 не-EAO размера
не-EAO размера 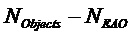 , содержащий не-EAO, вычисляется как
, содержащий не-EAO, вычисляется как
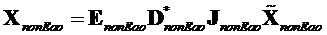 ,
, 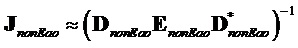
где модифицированный сигнал понижающего микширования, содержащий только сигналы не-EAO, вычисляется как разность между понижающим микшированием SAOC и понижающим микшированием реконструированных EAO.
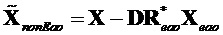 .
.
Ковариационная субматрица 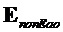 размера
размера 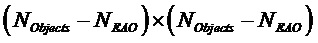 , соответствующая не-EAO, вычисляется как
, соответствующая не-EAO, вычисляется как
.
Субматрица  понижающего микширования размера
понижающего микширования размера 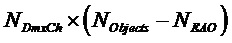 , соответствующая не-EAO, вычисляется как
, соответствующая не-EAO, вычисляется как
.
В нижеследующем обеспечивается другое подробное математическое описание об упрощенном способе "А" (без повторной оценки сигнала не-EAO на декодере):
Сигналы объектов восстанавливаются из понижающего микширования с использованием побочной информации и включенных остаточных сигналов. Конечный вывод из декодера производится следующим образом
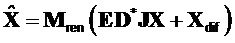 .
.
Член 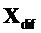 размера
размера 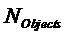 включает в себя остаточные сигналы
включает в себя остаточные сигналы 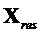 для EAO и предсказанный член
для EAO и предсказанный член 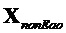 для не-EAO следующим образом
для не-EAO следующим образом
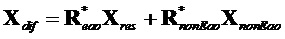
Предсказанный член оценивается следующим образом
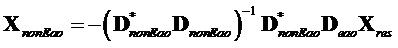
Субматрица 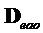 понижающего микширования, соответствующая EAO, и
понижающего микширования, соответствующая EAO, и  , соответствующая регулярным объектам, задаются как
, соответствующая регулярным объектам, задаются как
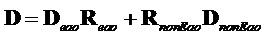 .
.
В последующем рассматривается особый случай матрицы 1 воспроизведения:
Рассмотрим следующий особый случай подобной понижающему микшированию матрицы 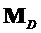 воспроизведения размера
воспроизведения размера 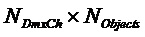 с произвольной модификацией EAO и только однородным масштабированием (по сравнению с понижающим микшированием) не-EAO.
с произвольной модификацией EAO и только однородным масштабированием (по сравнению с понижающим микшированием) не-EAO.
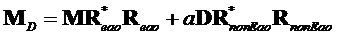 .
.
Ниже по тексту обеспечивается подробное математическое описание общего способа:
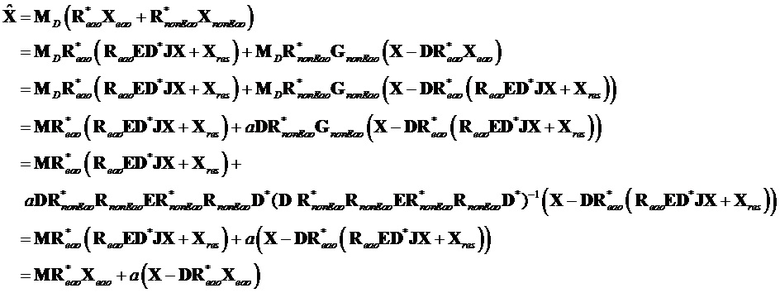
Ниже по тексту обеспечивается подробное математическое описание упрощенного способа "А":

Может быть видно, что два результата идентичны, когда выполняется предложение матрицы воспроизведения.
Ниже по тексту рассматривается особый случай матрицы 2 воспроизведения:
Налагая дополнительное ограничение на структуру матрицы 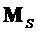 воспроизведения размера
воспроизведения размера 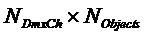 : все не-EAO модифицируются только посредством общего масштабного коэффициента
: все не-EAO модифицируются только посредством общего масштабного коэффициента 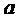 в сравнении с понижающим микшированием и также все EAO модифицируются только посредством общего масштабного коэффициента
в сравнении с понижающим микшированием и также все EAO модифицируются только посредством общего масштабного коэффициента 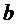 в сравнении с понижающим микшированием.
в сравнении с понижающим микшированием.

Продолжая от полученных ранее результатов, выводом системы будет
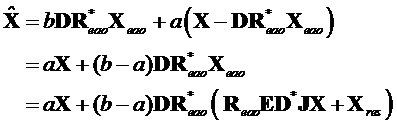
Хотя некоторые аспекты были описаны в контексте устройства, понятно, что эти аспекты также представляют собой описание соответствующего способа, в котором блок или устройство соответствует этапу способа или особенности этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока или элемента или особенности соответствующего устройства.
Обладающий признаками изобретения разложенный сигнал может быть сохранен на цифровом носителе данных или может быть передан по передающей среде, такой как беспроводная передающая среда или проводная передающая среда, такая как Интернет.
В зависимости от некоторых требований реализации, варианты осуществления настоящего изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении. Реализация может быть выполнена с использованием цифрового носителя данных, например дискеты, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронным образом считываемые управляющие сигналы, сохраненные на нем, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, так что выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением содержат, невременной носитель данных, имеющий электронным образом считываемые управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой таким образом, что выполняется один из способов, описанных в этом документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в качестве компьютерного программного продукта с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, быть сохранен на машиночитаемом носителе.
Другие варианты осуществления включают в себя компьютерную программу для выполнения одного из способов, описанных в этом документе, сохраненных на машиночитаемом носителе.
Другими словами, вариантом осуществления обладающего признаками изобретения способа, таким образом, является компьютерная программа, имеющая программный код для выполнения одного из способов, описанных в этом документе, когда компьютерная программа выполняется на компьютере.
Другим вариантом осуществления обладающих признаками изобретения способов, таким образом, является носитель данных (или цифровой носитель данных, или считываемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
Дополнительным вариантом осуществления обладающего признаками изобретения способа, таким образом, является, поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в этом документе. Поток данных или последовательность сигналов, например, может быть сконфигурирована с возможностью передачи через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер или программируемое логическое устройство, сконфигурированное или адаптированное с возможностью выполнения одного из способов, описанных в этом документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в этом документе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для выполнения некоторых или всех функциональных возможностей способов, описанных в этом документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в этом документе. В общем, способы предпочтительно выполняются посредством любого аппаратного устройства.
Описанные выше варианты осуществления иллюстрируют лишь принципы настоящего изобретения. Следует понимать, что модификации и вариации компоновок и деталей, описанных в этом документе, будут очевидны для специалистов в данной области техники. Поэтому ограничение предполагается только объемом приложенной формулы изобретения, а не конкретными деталями, представленных в этом документе описанием и пояснением вариантов осуществления.
Список использованной литературы
[BCC] C. Faller and F. Baumgarte, “Binaural Cue Coding - Part II: Schemes and applications,” IEEE Trans. on Speech and Audio Proc., vol. 11, no. 6, Ноябрь 2003
[JSC] C. Faller, “Parametric Joint-Coding of Audio Sources”, 120th AES Convention, Париж, 2006
[SAOC1] J. Herre, S. Disch, J. Hilpert, O. Hellmuth: "From SAC To SAOC - Recent Developments in Parametric Coding of Spatial Audio", 22nd Regional UK AES Conference, Cambridge, UK, Апрель 2007
[SAOC2] J. Engdegård, B. Resch, C. Falch, O. Hellmuth, J. Hilpert, A. Hölzer, L. Terentiev, J. Breebaart, J. Koppens, E. Schuijers and W. Oomen: " Spatial Audio Object Coding (SAOC) - The Upcoming MPEG Standard on Parametric Object Based Audio Coding", 124th AES Convention, Амстердам 2008.
[SAOC] ISO/IEC, “MPEG audio technologies - Part 2: Spatial Audio Object Coding (SAOC),” ISO/IEC JTC1/SC29/WG11 (MPEG) International Standard 23003-2:2010.
[ISS1] M. Parvaix and L. Girin: “Informed Source Separation of underdetermined instantaneous Stereo Mixtures using Source Index Embedding”, IEEE ICASSP, 2010
[ISS2] M. Parvaix, L. Girin, J.-M. Brossier: “A watermarking-based method for informed source separation of audio signals with a single sensor”, IEEE Transactions on Audio, Speech and Language Processing, 2010
[ISS3] A. Liutkus and J. Pinel and R. Badeau and L. Girin and G. Richard: “Informed source separation through spectrogram coding and data embedding”, Signal Processing Journal, 2011
[ISS4] A. Ozerov, A. Liutkus, R. Badeau, G. Richard: “Informed source separation: source coding meets source separation”, IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2011
[ISS5] Shuhua Zhang and Laurent Girin: “An Informed Source Separation System for Speech Signals”, INTERSPEECH, 2011
[ISS6] L. Girin and J. Pinel: “Informed Audio Source Separation from Compressed Linear Stereo Mixtures”, AES 42nd International Conference: Semantic Audio, 2011
[Dfx] C. Falch and L. Terentiev and J. Herre: “Spatial Audio Object Coding with Enhanced Audio Object Separation”, 10th International Conference on Digital Audio Effects, 2010
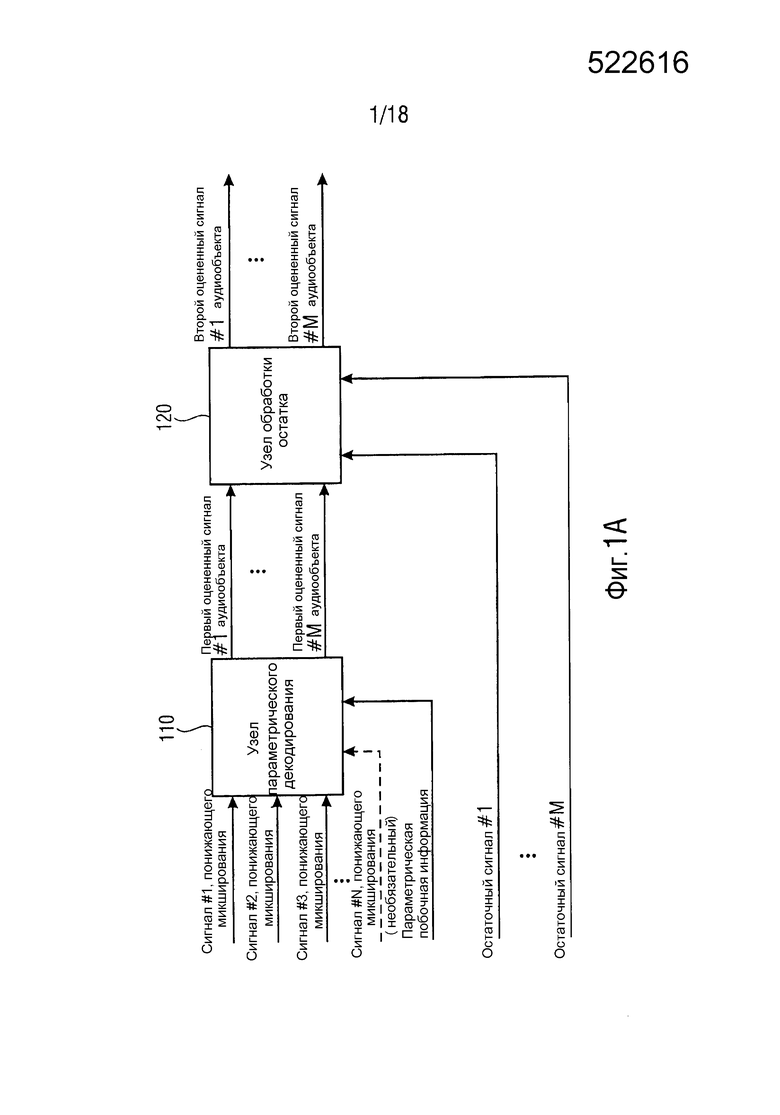
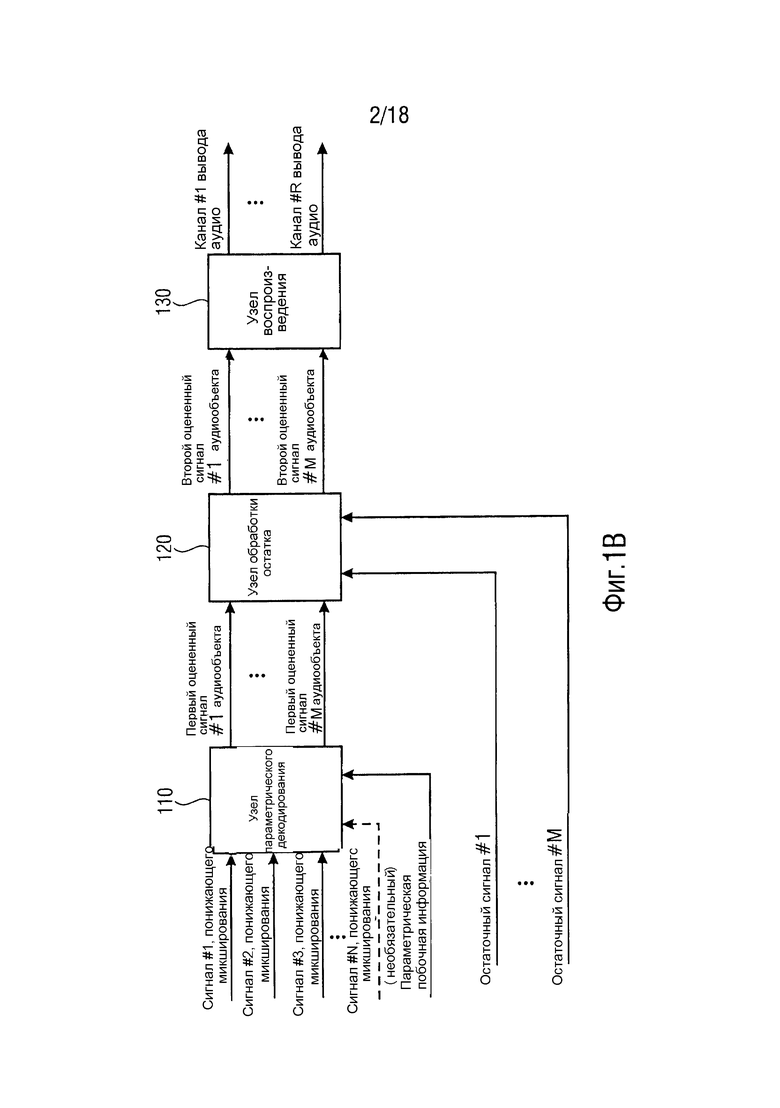
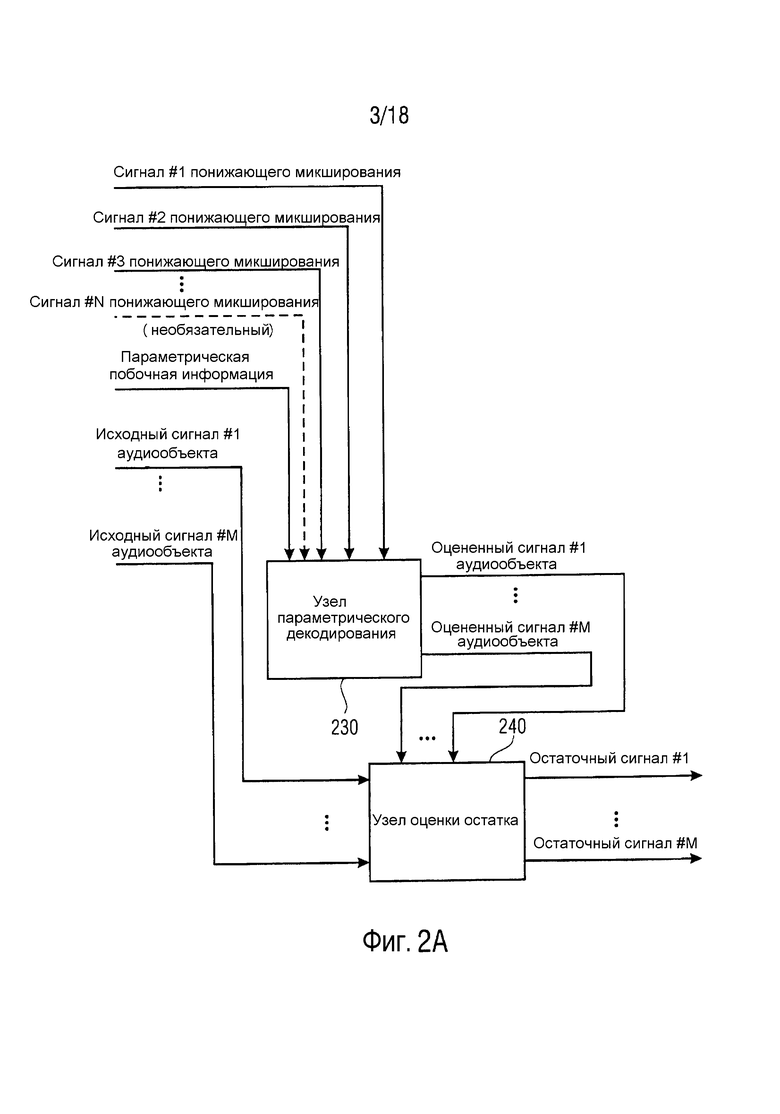
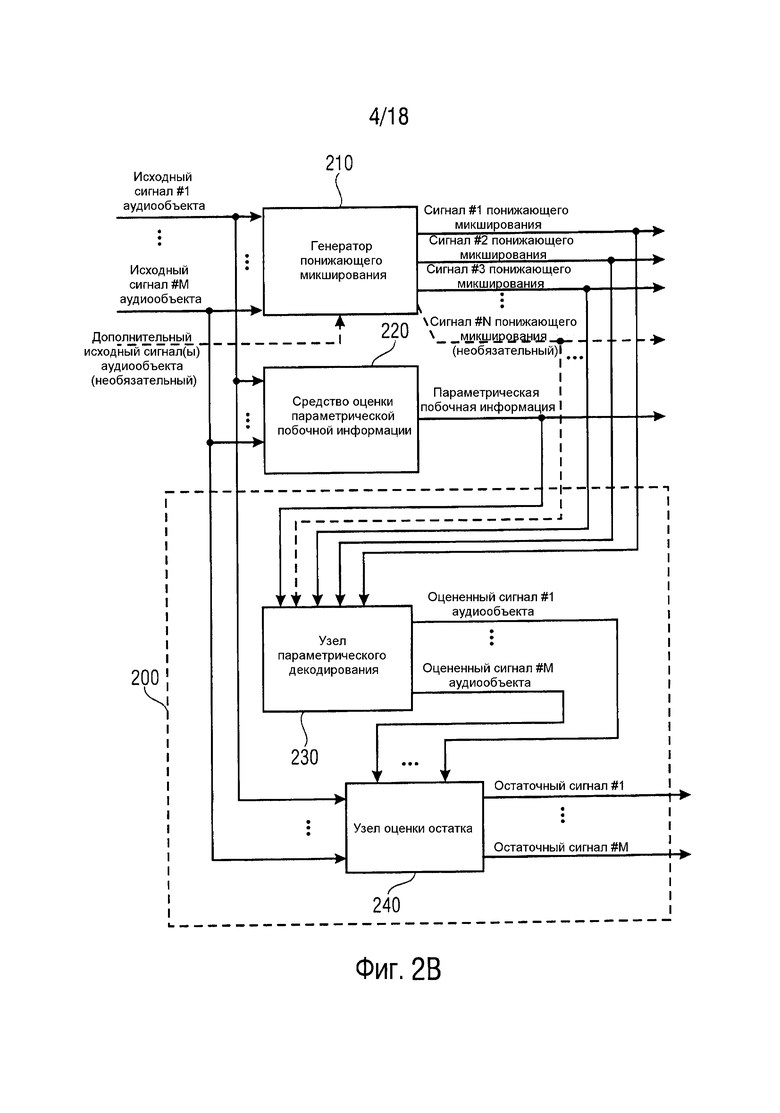
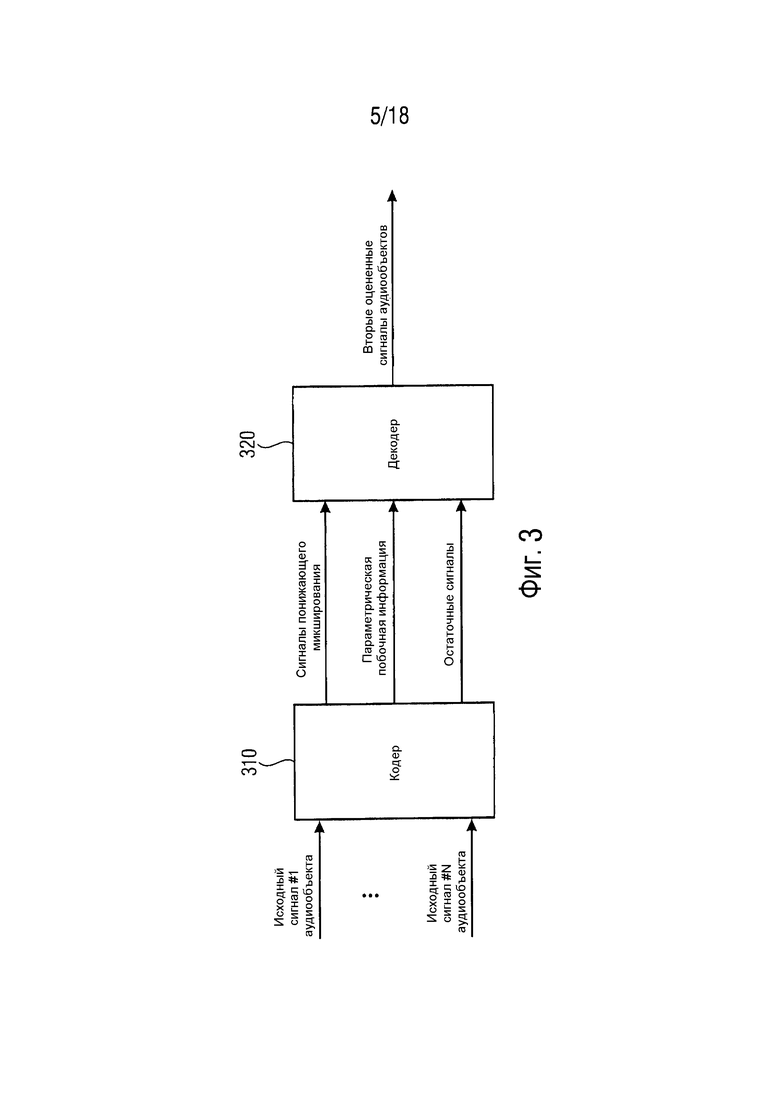
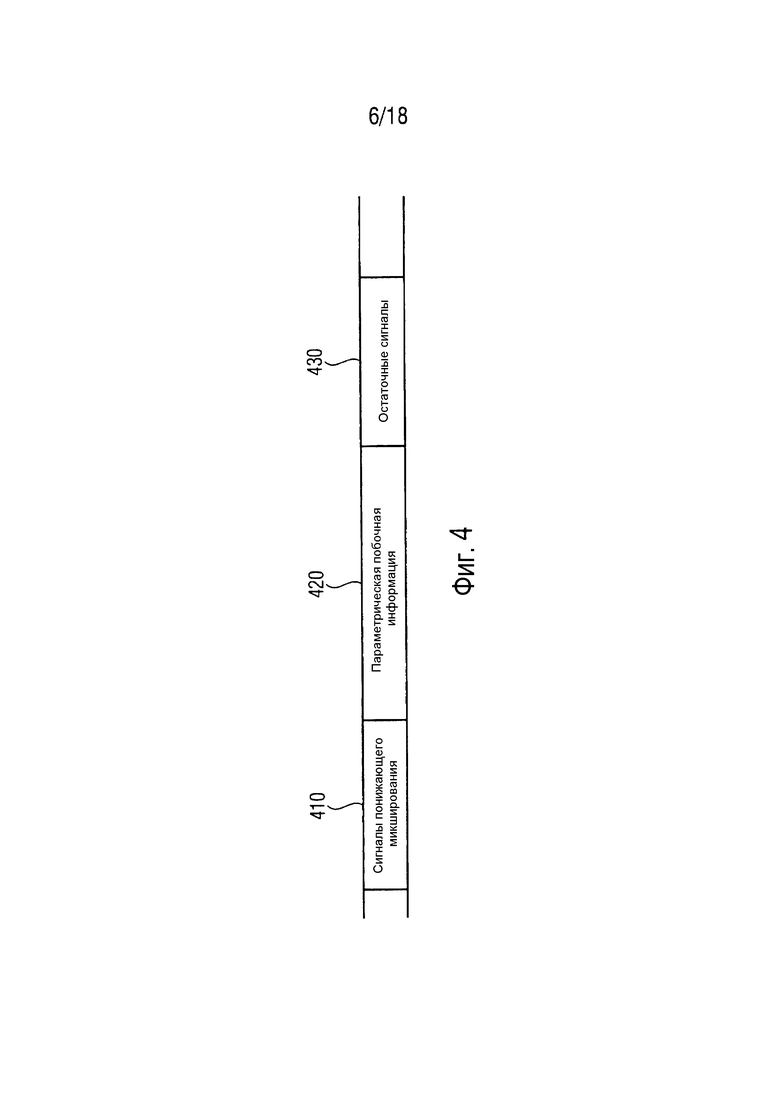
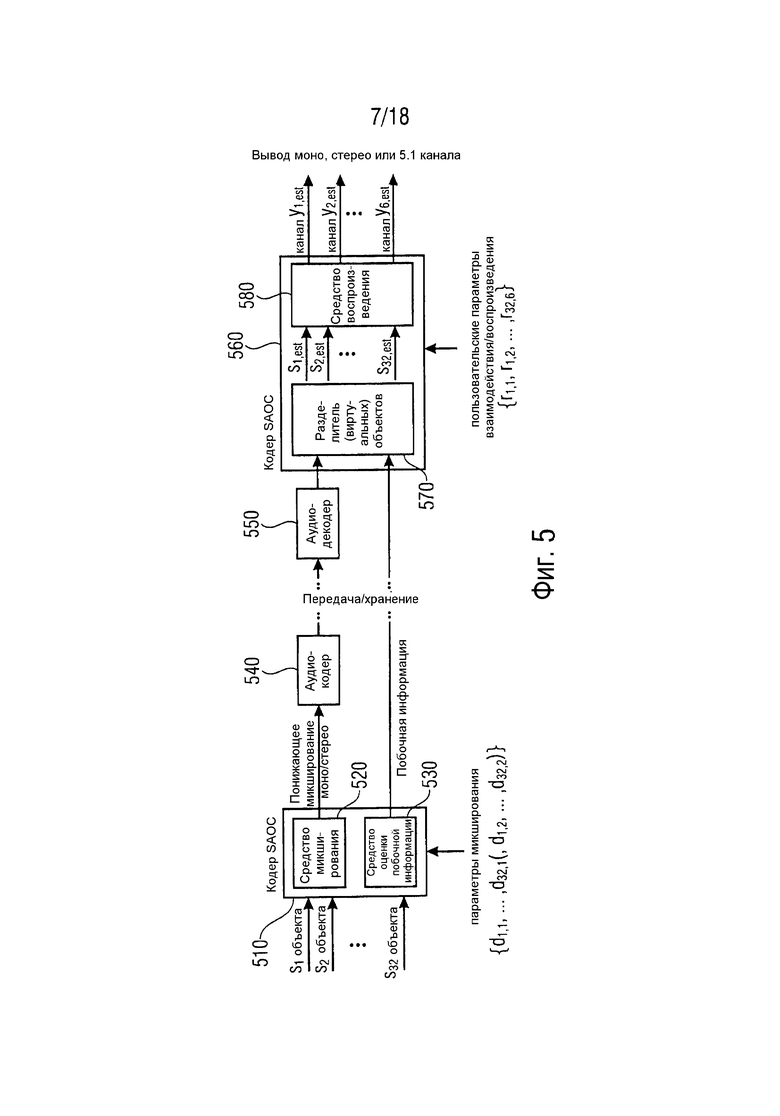
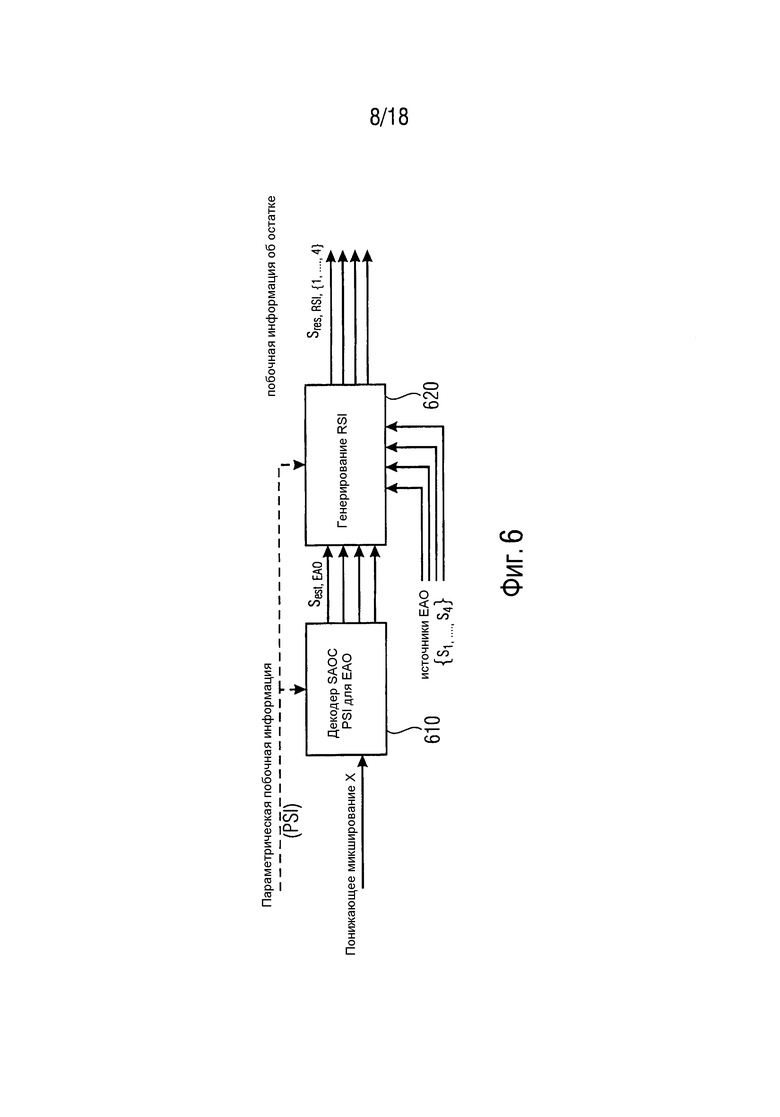
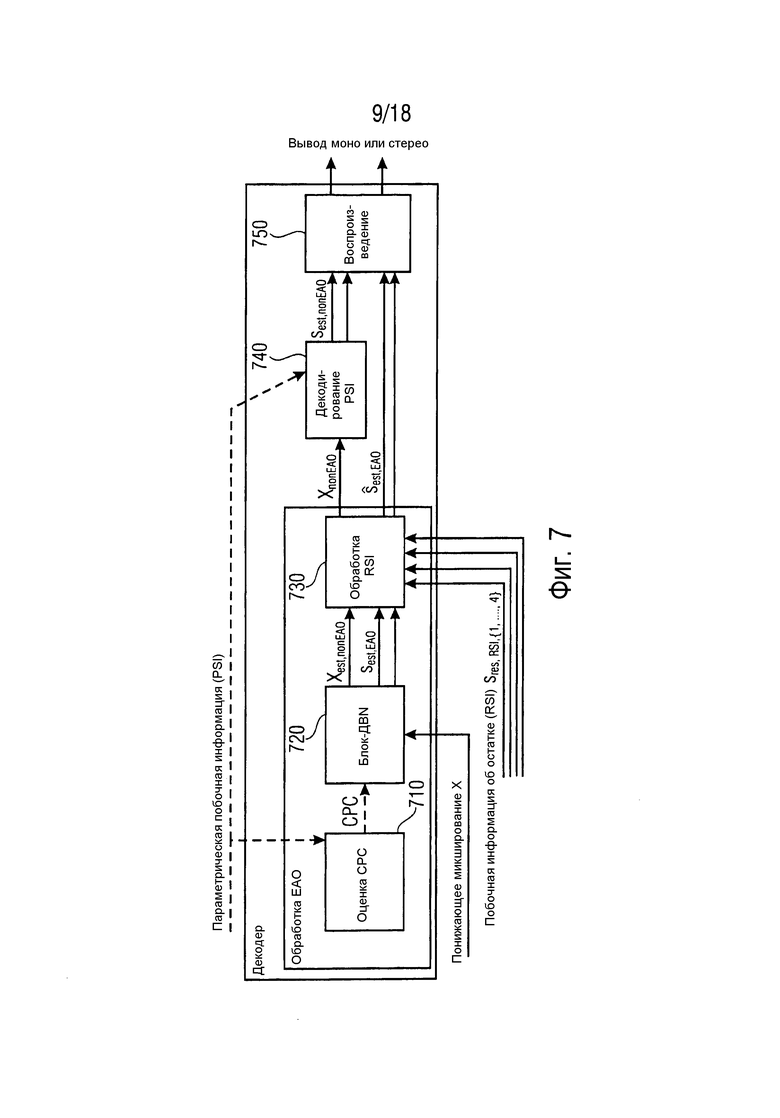
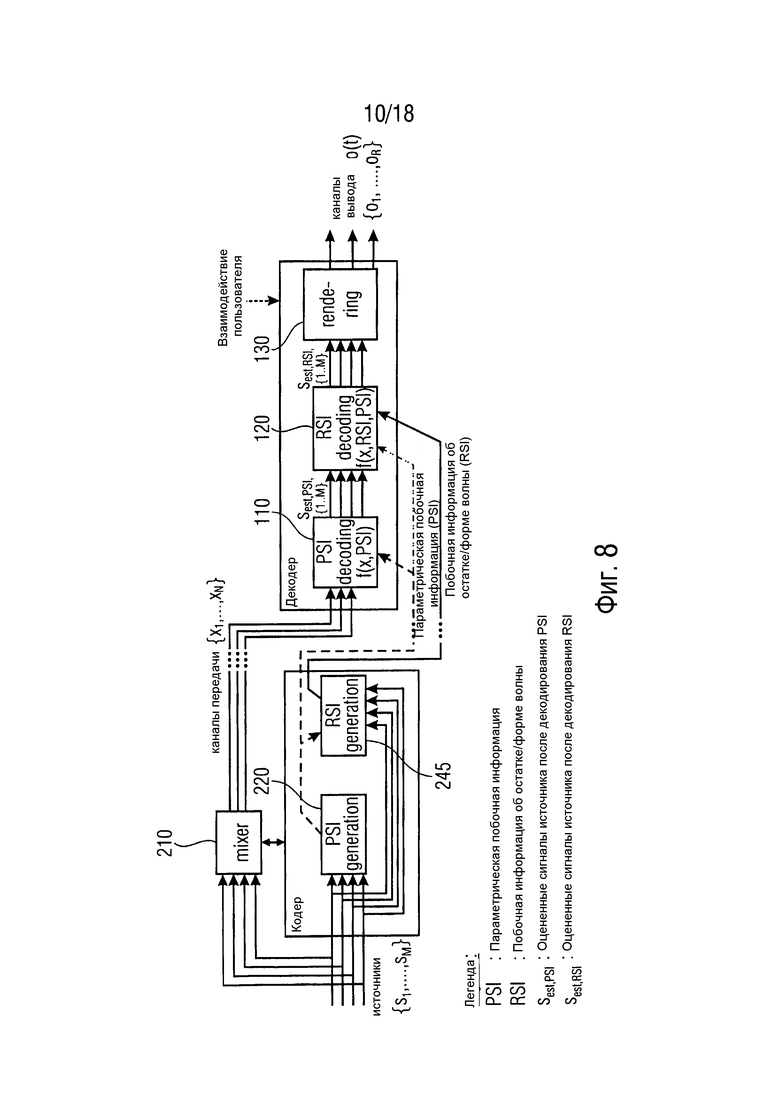
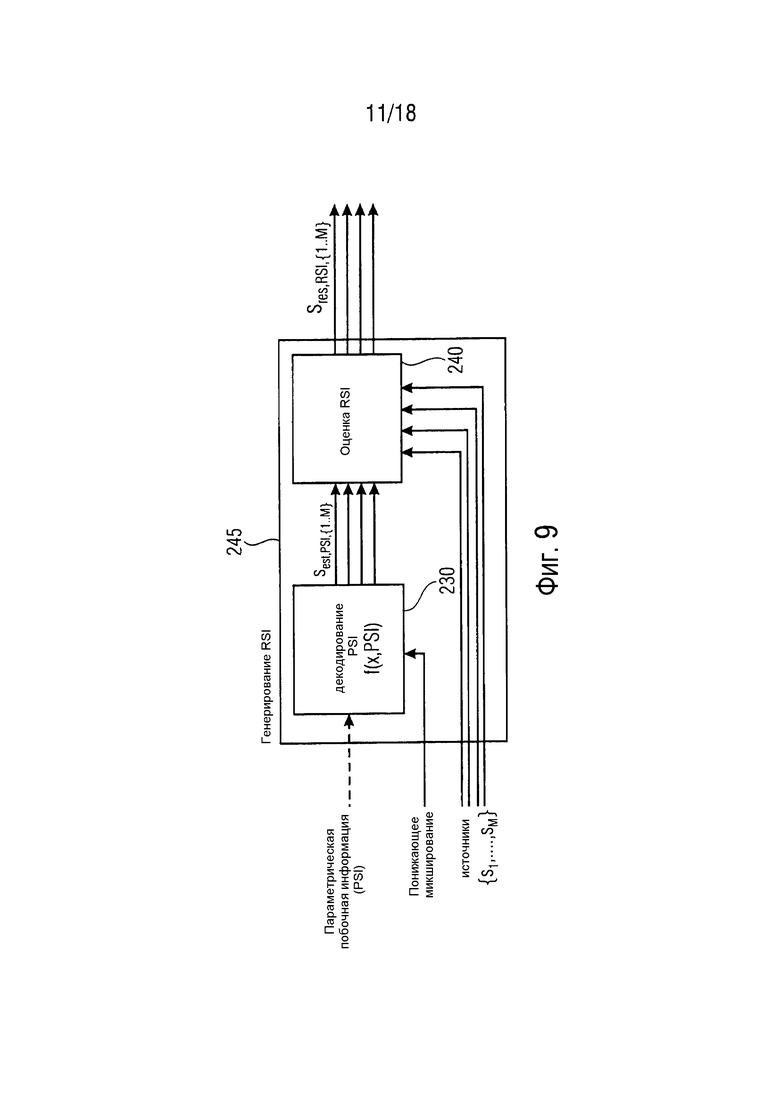
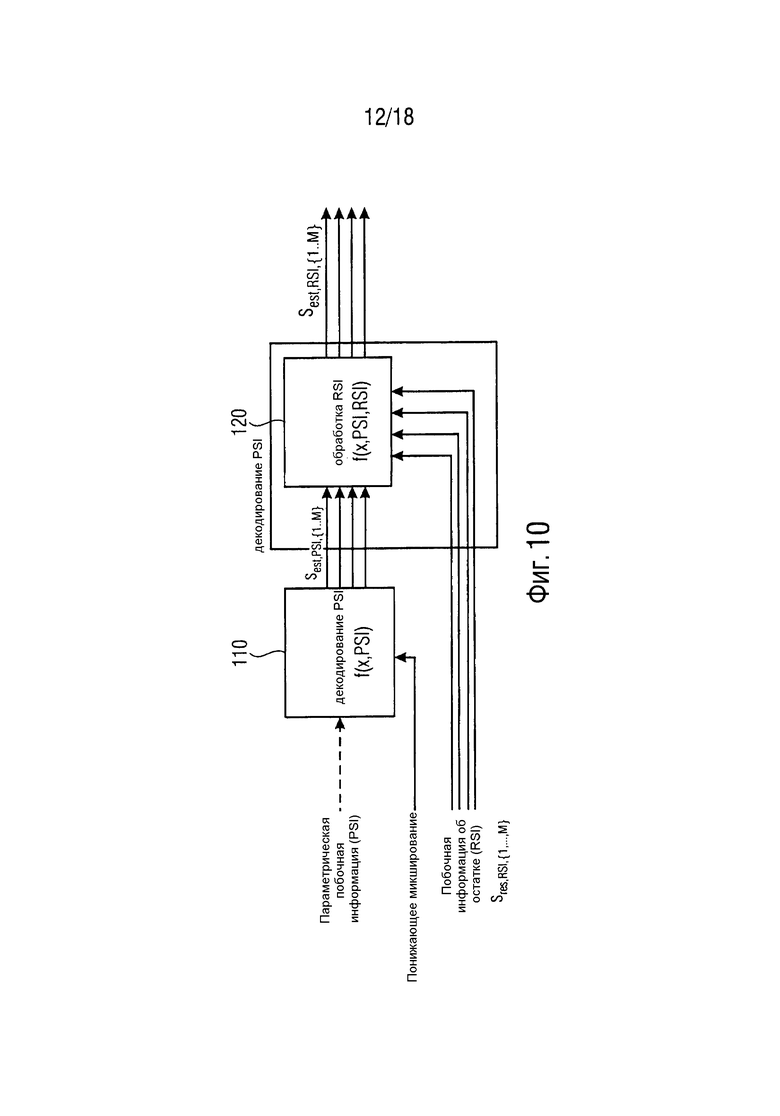
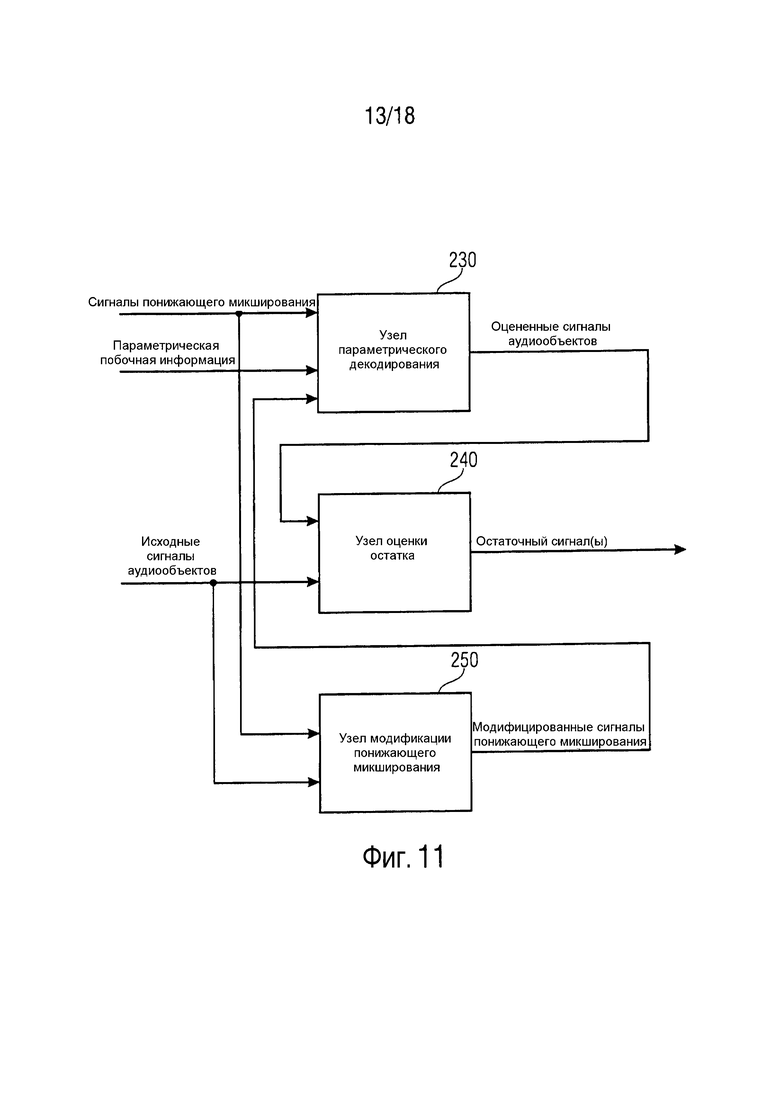
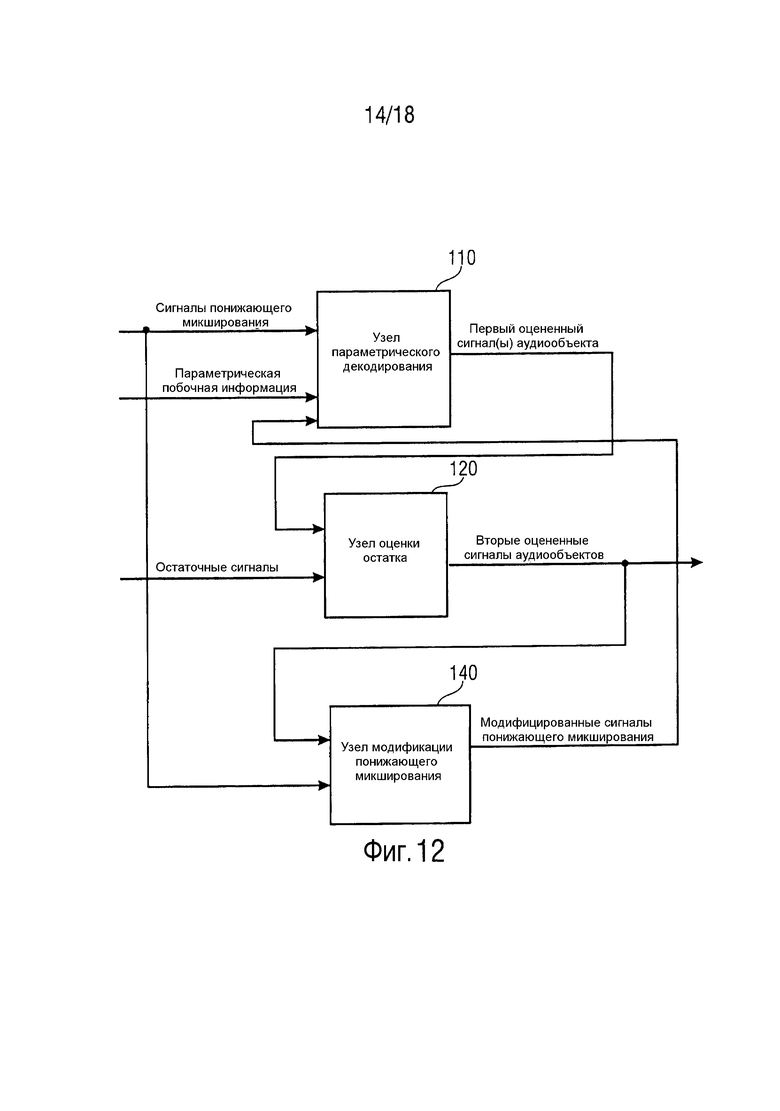
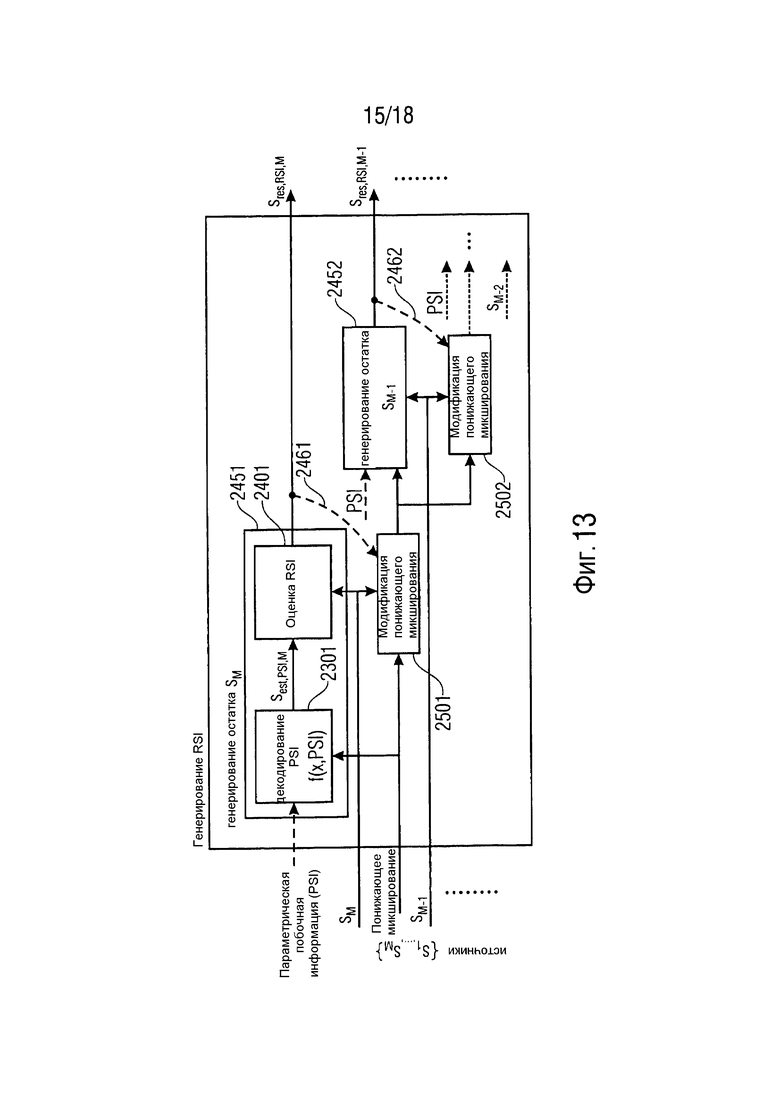
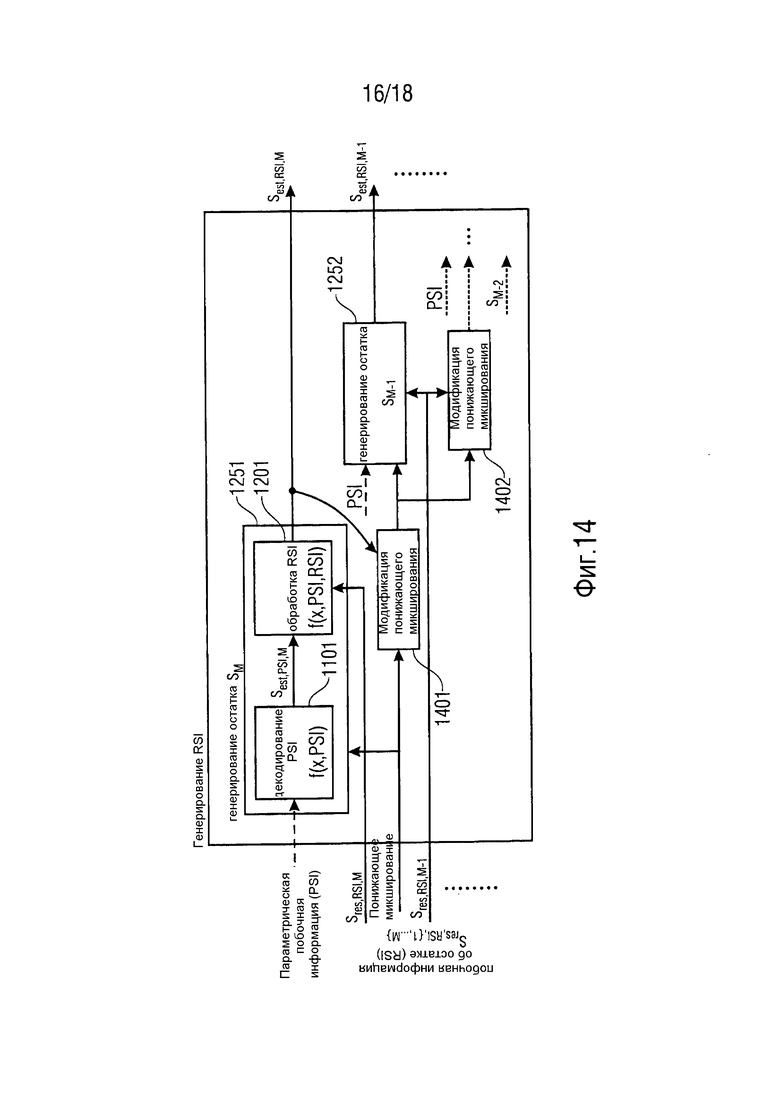
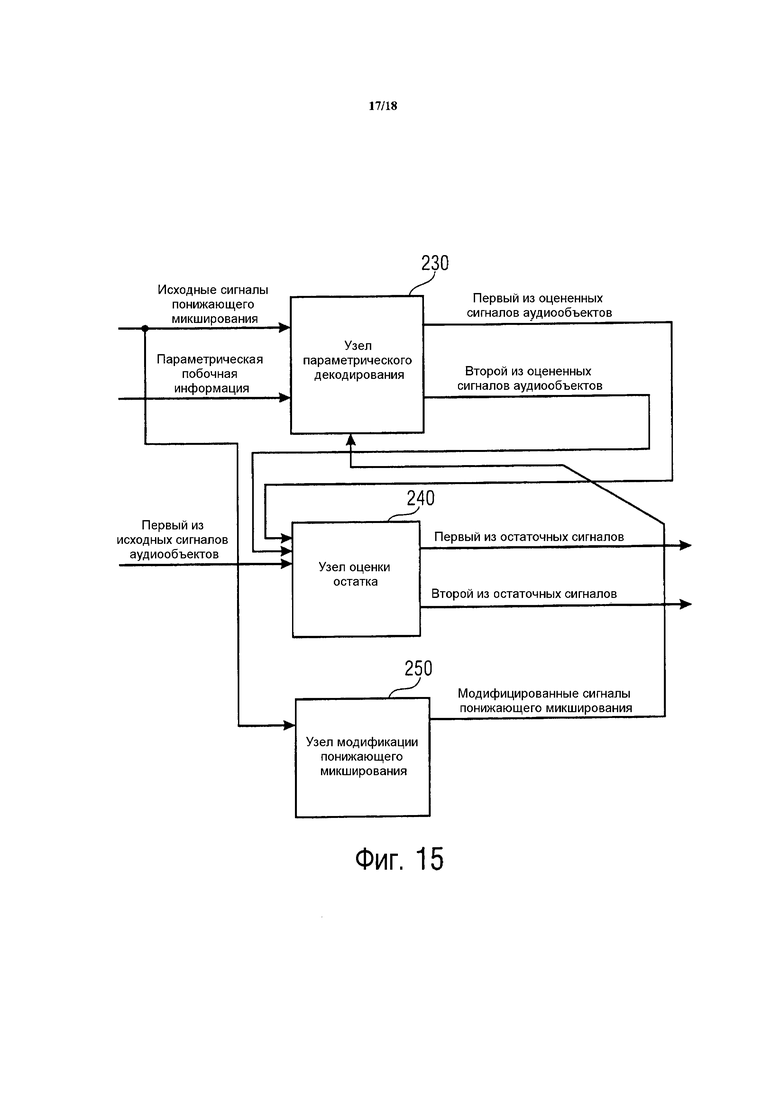
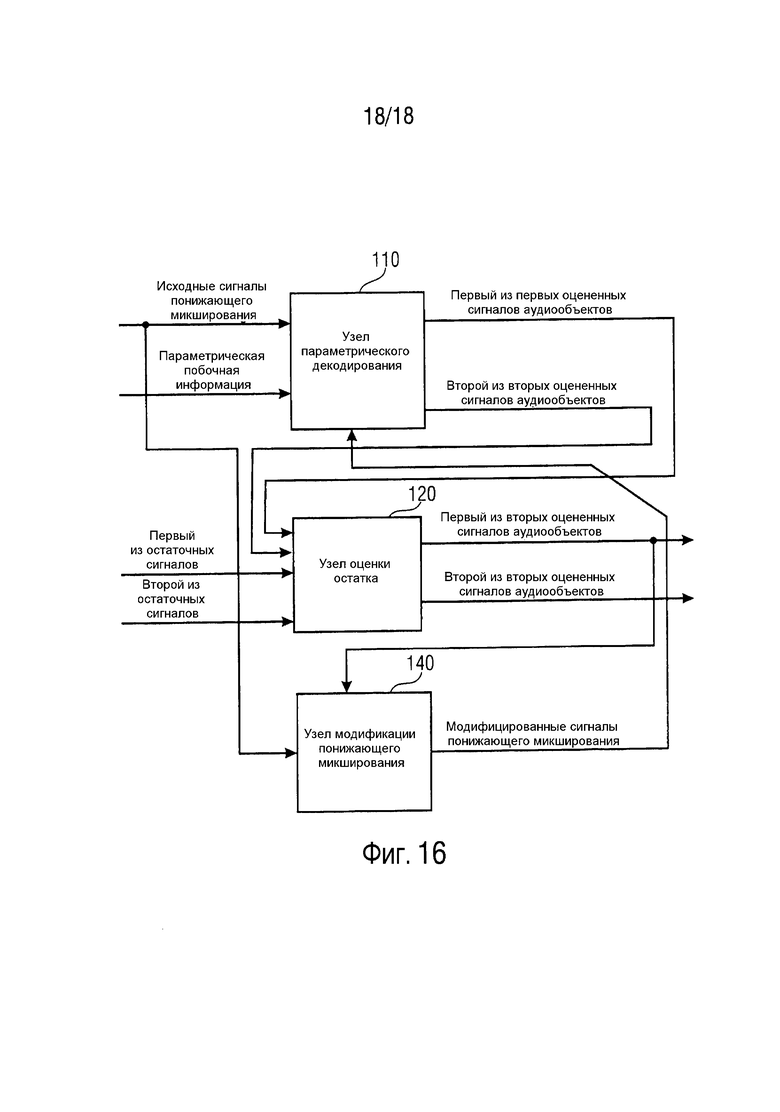
Изобретение относится к средствам для параметрического кодирования аудио. Технический результат заключается в повышении эффективности кодирования. Декодер содержит узел параметрического декодирования для генерирования множества первых оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования. Узел параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов. Более того, декодер содержит узел обработки остатка для генерирования множества вторых оцененных сигналов аудиообъектов посредством модификации одного или более из упомянутых первых оцененных сигналов аудиообъектов. Узел обработки остатка сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от одного или более остаточных сигналов. 9 н. и 17 з.п. ф-лы, 18 ил.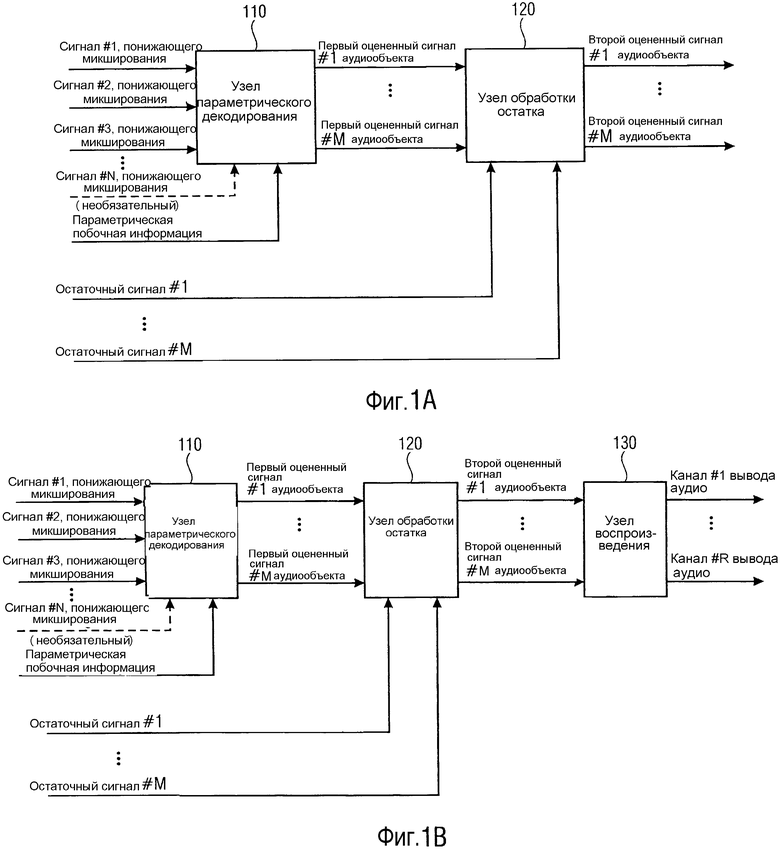
1. Декодер, содержащий:
узел (110) параметрического декодирования для генерирования множества первых оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом множество исходных сигналов аудиообъектов закодированы в упомянутых трех или более сигналах понижающего микширования, при этом узел (110) параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов, и
узел (120) обработки остатка для генерирования множества вторых оцененных сигналов аудиообъектов посредством модификации одного или более из упомянутых первых оцененных сигналов аудиообъектов, при этом узел (120) обработки остатка сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от одного или более остаточных сигналов.
2. Декодер по п. 1,
при этом узел (120) обработки остатка сконфигурирован с возможностью модификации упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от по меньшей мере трех остаточных сигналов, и
при этом декодер адаптирован с возможностью генерирования по меньшей мере трех каналов вывода аудио на основе упомянутого множества вторых оцененных сигналов аудиообъектов.
3. Декодер по п. 1,
при этом декодер дополнительно содержит узел (140) модификации понижающего микширования, адаптированный с возможностью удаления одного или более сигналов аудиообъектов упомянутого множества вторых оцененных сигналов аудиообъектов, определяемых посредством узла (120) обработки остатка, из упомянутых трех или более сигналов понижающего микширования, для получения трех или более модифицированных сигналов понижающего микширования, и
при этом узел (110) параметрического декодирования сконфигурирован с возможностью определения одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов на основе упомянутых трех или более модифицированных сигналов понижающего микширования.
4. Декодер по п. 3,
при этом узел (140) модификации понижающего микширования адаптирован с возможностью применения формулы:
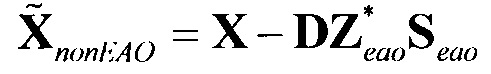
для удаления упомянутого одного или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов, определяемых посредством узла (120) обработки остатка, из упомянутых трех или более сигналов понижающего микширования, для получения трех или более модифицированных сигналов понижающего микширования,
при этом
X представляет собой упомянутые три или более сигналов понижающего микширования до их модификации,
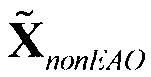 представляет собой упомянутые три или более модифицированных сигналов понижающего микширования,
представляет собой упомянутые три или более модифицированных сигналов понижающего микширования,
D представляет собой информацию понижающего микширования,
S eao представляет собой по меньшей мере один сигнал, содержащий упомянутый один или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов, и
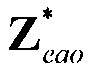 представляет собой местоположения упомянутого одного или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов.
представляет собой местоположения упомянутого одного или более сигналов аудиообъектов из упомянутого множества вторых оцененных сигналов аудиообъектов.
5. Декодер по п. 3,
при этом декодер адаптирован с возможностью проведения двух или более итеративных шагов,
при этом для каждого итеративного шага узел (110) параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов,
при этом для упомянутого итеративного шага узел (120) обработки остатка адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации упомянутого сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов,
при этом для упомянутого итеративного шага узел (140) модификации понижающего микширования адаптирован с возможностью удаления упомянутого сигнала аудиообъекта из упомянутого множества вторых оцененных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для модификации упомянутых трех или более сигналов понижающего микширования, и
при этом для следующего итеративного шага, следующего за упомянутым итеративным шагом, узел (110) параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества первых оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, которые были модифицированы.
6. Декодер по п. 1, при этом каждый из упомянутого одного или более остаточных сигналов указывает различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого одного или более первых оцененных сигналов аудиообъектов.
7. Декодер по п. 1,
при этом узел (120) обработки остатка адаптирован с возможностью генерирования упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации пяти или более из упомянутых первых оцененных сигналов аудиообъектов,
при этом узел (120) обработки остатка сконфигурирован с возможностью модификации упомянутых пяти или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от пяти или более остаточных сигналов.
8. Декодер по п. 1, при этом декодер сконфигурирован с возможностью генерирования семи или более каналов вывода аудио на основе упомянутого множества вторых оцененных сигналов аудиообъектов.
9. Декодер по п. 1, при этом декодер адаптирован с возможностью не определять коэффициенты предсказания канала для определения упомянутого множества вторых оцененных сигналов аудиообъектов.
10. Декодер по п. 1, при этом декодер является декодером SAOC.
11. Генератор (200) остаточных сигналов, содержащий:
узел (230) параметрического декодирования для генерирования множества оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом множество исходных сигналов аудиообъектов закодированы в упомянутых трех или более сигналах понижающего микширования, при этом узел (230) параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов, и
узел (240) оценки остатка для генерирования множества остаточных сигналов на основе упомянутого множества исходных сигналов аудиообъектов и на основе упомянутого множества оцененных сигналов аудиообъектов, так что каждый из упомянутого множества остаточных сигналов является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого множества оцененных сигналов аудиообъектов.
12. Генератор (200) остаточных сигналов по п. 11,
при этом генератор (200) остаточных сигналов дополнительно содержит узел (250) модификации понижающего микширования, адаптированный с возможностью модификации упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования, и
при этом узел (230) параметрического декодирования сконфигурирован с возможностью определения одного или более сигналов аудиообъектов из упомянутых первых оцененных сигналов аудиообъектов на основе упомянутых трех или более модифицированных сигналов понижающего микширования.
13. Генератор (200) остаточных сигналов по п. 12, при этом узел (250) модификации понижающего микширования сконфигурирован с возможностью модификации упомянутых трех или более исходных сигналов понижающего микширования для получения упомянутых трех или более модифицированных сигналов понижающего микширования посредством удаления одного или более из упомянутого множества исходных сигналов аудиообъектов из упомянутых трех или более исходных сигналов понижающего микширования.
14. Генератор остаточных сигналов по п. 13,
при этом узел (250) модификации понижающего микширования адаптирован с возможностью применения формулы:
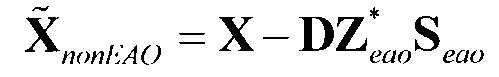
для удаления упомянутого одного или более из упомянутого множества исходных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования,
при этом
X представляет собой упомянутые три или более сигналов понижающего микширования до их модификации,
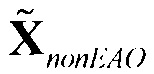 представляет собой упомянутые три или более модифицированных сигналов понижающего микширования,
представляет собой упомянутые три или более модифицированных сигналов понижающего микширования,
D представляет собой информацию понижающего микширования,
S eao представляет собой по меньшей мере один сигнал, содержащий упомянутый один или более из упомянутого множества исходных сигналов аудиообъектов, и
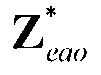 представляет собой местоположения упомянутого одного или более из упомянутого множества исходных сигналов аудиообъектов.
представляет собой местоположения упомянутого одного или более из упомянутого множества исходных сигналов аудиообъектов.
15. Генератор (200) остаточных сигналов по п. 12, при этом узел (250) модификации понижающего микширования сконфигурирован с возможностью модификации упомянутых трех или более исходных сигналов понижающего микширования для получения упомянутых трех или более модифицированных сигналов понижающего микширования посредством генерирования одного или более модифицированных сигналов аудиообъектов на основе одного или более из оцененных сигналов аудиообъектов и на основе одного или более из остаточных сигналов, и посредством удаления упомянутого одного или более модифицированных сигналов аудиообъектов из упомянутых трех или более исходных сигналов понижающего микширования.
16. Генератор остаточных сигналов по п. 15,
при этом узел (250) модификации понижающего микширования адаптирован с возможностью применения формулы:
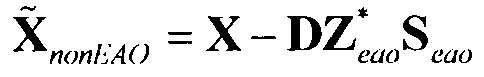
для удаления упомянутого одного или более модифицированных сигналов аудиообъектов из упомянутых трех или более сигналов понижающего микширования для получения трех или более модифицированных сигналов понижающего микширования,
при этом
X представляет собой упомянутые три или более сигналов понижающего микширования до их модификации,
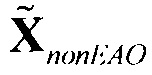 представляет собой упомянутые три или более модифицированных сигналов понижающего микширования,
представляет собой упомянутые три или более модифицированных сигналов понижающего микширования,
D представляет собой информацию понижающего микширования,
S eao представляет собой упомянутый один или более модифицированных сигналов аудиообъектов, и
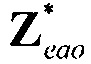 представляет собой местоположения упомянутого одного или более модифицированных сигналов аудиообъектов.
представляет собой местоположения упомянутого одного или более модифицированных сигналов аудиообъектов.
17. Генератор (200) остаточных сигналов по п. 12,
при этом генератор (200) остаточных сигналов адаптирован с возможностью проведения двух или более итеративных шагов,
при этом для каждого итеративного шага узел (230) параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов,
при этом для упомянутого итеративного шага узел (240) оценки остатка адаптирован с возможностью определения ровно одного остаточного сигнала из упомянутого множества остаточных сигналов посредством модификации упомянутого сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов,
при этом для упомянутого итеративного шага узел (250) модификации понижающего микширования адаптирован с возможностью модификации упомянутых трех или более сигналов понижающего микширования, и
при этом для следующего итеративного шага, следующего за упомянутым итеративным шагом, узел (230) параметрического декодирования адаптирован с возможностью определения ровно одного сигнала аудиообъекта из упомянутого множества оцененных сигналов аудиообъектов на основе упомянутых трех или более сигналов понижающего микширования, которые были модифицированы.
18. Генератор (200) остаточных сигналов по п. 11, при этом узел (240) оценки остатка адаптирован с возможностью генерирования по меньшей мере пяти остаточных сигналов на основе по меньшей мере пяти исходных сигналов аудиообъектов из упомянутого множества исходных сигналов аудиообъектов и на основе по меньшей мере пяти оцененных сигналов аудиообъектов из упомянутого множества оцененных сигналов аудиообъектов.
19. Кодер для кодирования множества исходных сигналов аудиообъектов посредством генерирования трех или более сигналов понижающего микширования, посредством генерирования параметрический побочной информации и посредством генерирования множества остаточных сигналов, при этом кодер содержит:
генератор (210) понижающего микширования для обеспечения упомянутых трех или более сигналов понижающего микширования, указывающих понижающее микширование упомянутого множества исходных сигналов аудиообъектов,
средство (220) оценки параметрической побочной информации для генерирования параметрический побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов, для получения параметрической побочной информации, и
генератор (200) остаточных сигналов по одному из пп. с 11 по 18,
при этом узел (230) параметрического декодирования генератора (200) остаточных сигналов адаптирован с возможностью генерирования множества оцененных сигналов аудиообъектов посредством повышающего микширования упомянутых трех или более сигналов понижающего микширования, обеспеченных посредством генератора (210) понижающего микширования, при этом множество исходных сигналов аудиообъектов закодированы в упомянутых трех или более сигналах понижающего микширования, при этом узел (230) параметрического декодирования сконфигурирован с возможностью повышающего микширования упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, сгенерированной средством (220) оценки параметрической побочной информации, и
при этом узел (240) оценки остатка генератора (200) остаточных сигналов адаптирован с возможностью генерирования упомянутого множества остаточных сигналов на основе упомянутого множества исходных сигналов аудиообъектов и на основе упомянутого множества оцененных сигналов аудиообъектов, так что каждый из упомянутого множества остаточных сигналов указывает различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого множества оцененных сигналов аудиообъектов.
20. Кодер по п. 19, при этом кодер является кодером SAOC.
21. Система для кодирования множества исходных сигналов аудиообъектов и для генерирования множества первых оцененных сигналов аудиообъектов и множества вторых оцененных сигналов аудиообъектов, содержащая:
кодер (310) по п. 19 или 20 для кодирования упомянутого множества исходных сигналов аудиообъектов посредством генерирования трех или более сигналов понижающего микширования, посредством генерирования параметрический побочной информации и посредством генерирования множества остаточных сигналов, и
декодер (320) по одному из пп. с 1 по 10, при этом декодер (320) сконфигурирован с возможностью генерирования упомянутого множества вторых оцененных сигналов аудиообъектов на основе сгенерированных посредством кодера (310) упомянутых трех или более сигналов понижающего микширования, на основе сгенерированной посредством кодера (310) параметрической побочной информации и на основе сгенерированного посредством кодера (310) упомянутого множества остаточных сигналов.
22. Считываемый компьютером носитель, содержащий кодированный аудиосигнал, содержащий три или более сигналов (410) понижающего микширования, параметрическую побочную информации (420) и множество остаточных сигналов (430),
при этом упомянутые три или более сигналов (410) понижающего микширования являются понижающим микшированием множества исходных сигналов аудиообъектов,
при этом параметрическая побочная информация (420) содержит параметры, указывающие побочную информацию об упомянутом множестве исходных сигналов аудиообъектов,
при этом каждый из упомянутого множества остаточных сигналов (430) является разностным сигналом, указывающим различие между одним из упомянутого множества исходных аудиосигналов и одним из множества оцененных сигналов аудиообъектов.
23. Способ генерирования множества первых оцененных сигналов аудиообъектов и множества вторых оцененных сигналов аудиообъектов, содержащий:
генерирование упомянутого множества первых оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом множество исходных сигналов аудиообъектов закодированы в упомянутых трех или более сигналах понижающего микширования, при этом генерирование упомянутого множества первых оцененных сигналов аудиообъектов содержит повышающее микширование упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов, и
генерирование упомянутого множества вторых оцененных сигналов аудиообъектов посредством модификации одного или более из упомянутых первых оцененных сигналов аудиообъектов, при этом генерирование множества вторых оцененных сигналов аудиообъектов содержит модификацию упомянутого одного или более из упомянутых первых оцененных сигналов аудиообъектов в зависимости от одного или более остаточных сигналов.
24. Способ генерирования множества остаточных сигналов, содержащий:
генерирование множества оцененных сигналов аудиообъектов посредством повышающего микширования трех или более сигналов понижающего микширования, при этом множество исходных сигналов аудиообъектов закодированы в упомянутых трех или более сигналах понижающего микширования, при этом генерирование упомянутого множества оцененных сигналов аудиообъектов содержит повышающее микширование упомянутых трех или более сигналов понижающего микширования в зависимости от параметрической побочной информации, указывающей информацию об упомянутом множестве исходных сигналов аудиообъектов, и
генерирование упомянутого множества остаточных сигналов на основе упомянутого множества исходных сигналов аудиообъектов и на основе упомянутого множества оцененных сигналов аудиообъектов, так что каждый из упомянутого множества остаточных сигналов является разностным сигналом, указывающим различие между одним из упомянутого множества исходных сигналов аудиообъектов и одним из упомянутого множества оцененных сигналов аудиообъектов.
25. Считываемый компьютером носитель, содержащий компьютерную программу для реализации способа по п. 23 при исполнении на компьютере или процессоре сигналов.
26. Считываемый компьютером носитель, содержащий компьютерную программу для реализации способа по п. 24 при исполнении на компьютере или процессоре сигналов.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ТОПЛИВНАЯ КОМПОЗИЦИЯ | 1995 |
|
RU2077550C1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| RU 2010154749 A, 10.07.2012. | |||

