Перекрестная ссылка на родственные заявки
[0001] Настоящая заявка испрашивает приоритет по непредварительной патентной заявке США № 14/089,377, поданной 25 ноября 2013 года Guangyu Shi и др. и озаглавленной "Масштабируемый прямой обмен данными между узлами через шину межсоединения периферийных компонентов типа экспресс (PCIe)", и испрашивает приоритет по предварительной патентной заявке США № 61/857,036, поданной 22 июля 2013 года Guangyu Shi и др. и озаглавленной "Масштабируемый прямой обмен данными между узлами через шину межсоединения периферийных компонентов типа экспресс", обе из которых включены в этот документ в полном объеме посредством ссылки.
Заявление касательно исследования или разработки финансируемого из федерального бюджета
[0002] Не применимо.
Ссылка на приложение микрофиши
[0003] Не применимо.
Уровень техники
[0004] Центры обработки данных могут содержать большие кластеры серверов. Серверы центра обработки данных могут принимать запросы от пользователей и отвечать на такие запросы. Например, серверы могут размещать данные и передавать такие данные пользователю после запроса. Сервер также может быть сконфигурирован с возможностью размещения процессов. Как таковой, пользователь может передавать запрос серверу для выполнения процесса, сервер может выполнять процесс, и затем сервер может отвечать пользователю результатами процесса. Сервер может содержать множество компонентов для обработки запросов пользователя и обмена данными с пользователем. Такие серверы могут быть соединены друг с другом с использованием различных сетевых устройств и технологий. Например, сервер может быть размещен в шасси и может быть соединен с другими серверами в другом шасси с использованием технологий уровня два (например, управления доступом к среде (MAC)) модели межсоединения открытых систем (OSI) и/или уровня три (например, протокола Интернет (IP)).
Сущность изобретения
[0005] В одном варианте осуществления, раскрытие включает в себя способ обмена данными через непрозрачный мост (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe), содержащий передачу первого отложенного сообщения записи на удаленный процессор через NTB, при этом первое отложенное сообщение записи указывает намерение переносить данные на удаленный процессор, и прием второго отложенного сообщения записи в ответ на первое отложенное сообщение записи, при этом второе отложенное сообщение записи указывает список адресов назначения для данных.
[0006] В другом варианте осуществления, раскрытие включает в себя способ обмена данными через NTB PCIe, содержащий передачу первого отложенного сообщения записи на удаленный процессор через NTB, при этом первое отложенное сообщение записи содержит запрос на считывание данных, и прием сообщения переноса данных, содержащего по меньшей мере некоторые из данных, запрашиваемых первым отложенным сообщением записи.
[0007] В другом варианте осуществления, раскрытие включает в себя процессор, содержащий очередь приема, очередь передачи и очередь завершения, и сконфигурированный с возможностью сопряжения с NTB PCIe, и считывания данных из и записи данных на множество удаленных процессоров посредством очереди приема, очереди передачи, очереди завершения и NTB PCIe без использования неотложенных сообщений.
[0008] Эти и другие признаки будут более четко понятны из последующего подробного описания, рассматриваемого вместе с сопроводительными чертежами и формулой изобретения.
Краткое описание чертежей
[0009] Для более полного понимания этого раскрытия, сейчас приводится упоминание последующего краткого описания, рассматриваемого в связи с сопроводительными чертежами и подробным описанием, при этом одинаковые ссылочные позиции представляют собой одинаковые части.
[0010] ФИГ. 1 представляет собой схематическое представление варианта осуществления дезагрегированной сетевой архитектуры центра обработки данных.
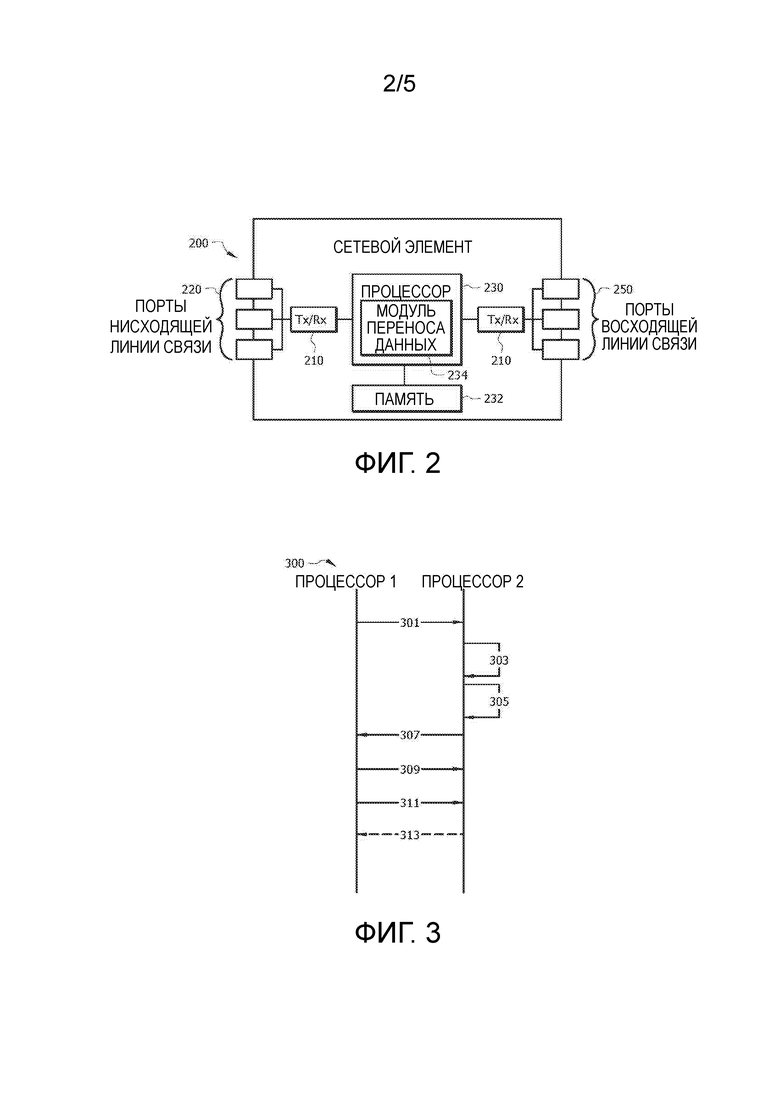
[0011] ФИГ. 2 представляет собой схематическое представление варианта осуществления сетевого элемента (NE), который может действовать как узел в пределах дезагрегированной сетевой архитектуры центра обработки данных.
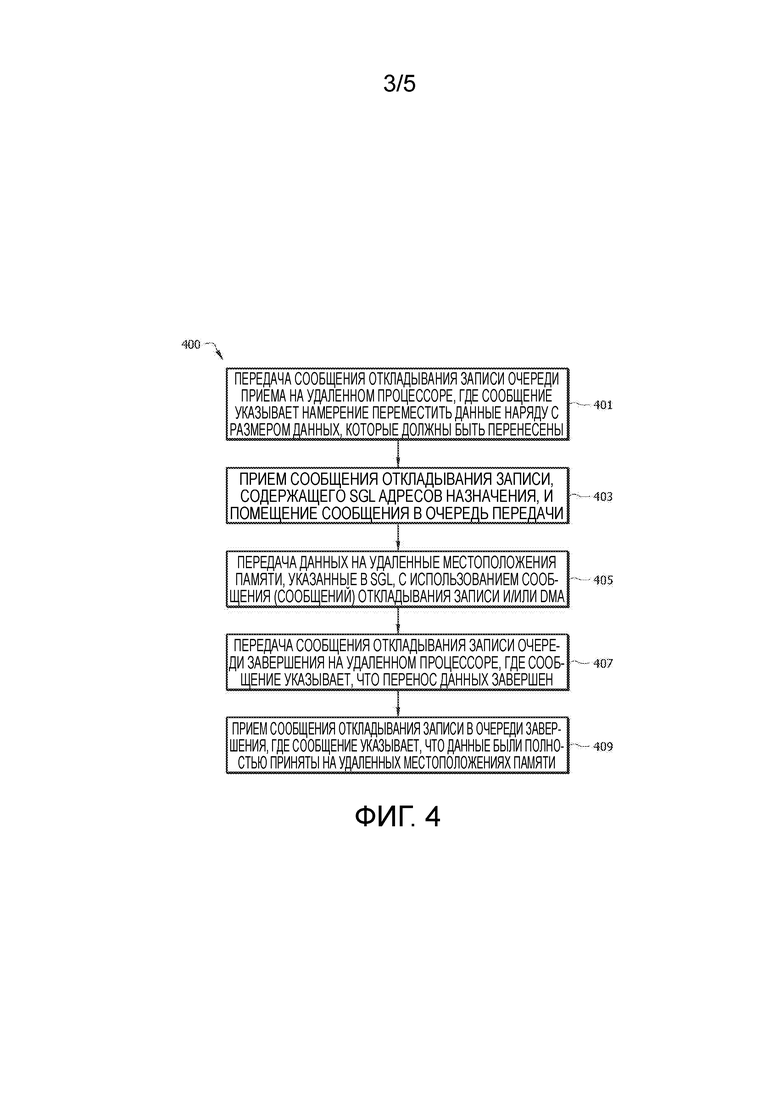
[0012] ФИГ. 3 представляет собой схему протокола варианта осуществления способа записи данных с использованием только сообщений откладывания записи.
[0013] ФИГ. 4 представляет собой блок-схему последовательности операций варианта осуществления другого способа записи данных с использованием только сообщений откладывания записи.
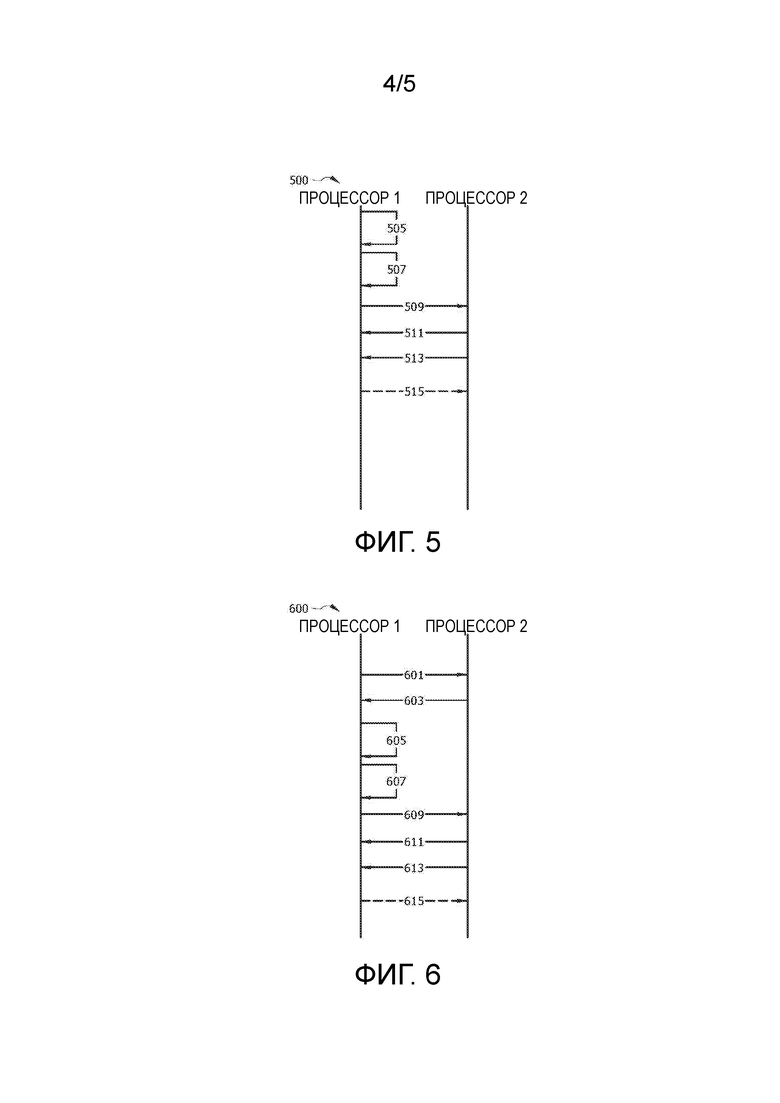
[0014] ФИГ. 5 представляет собой схему протокола варианта осуществления способа считывания данных с использованием только сообщений откладывания записи, когда размер данных известен.
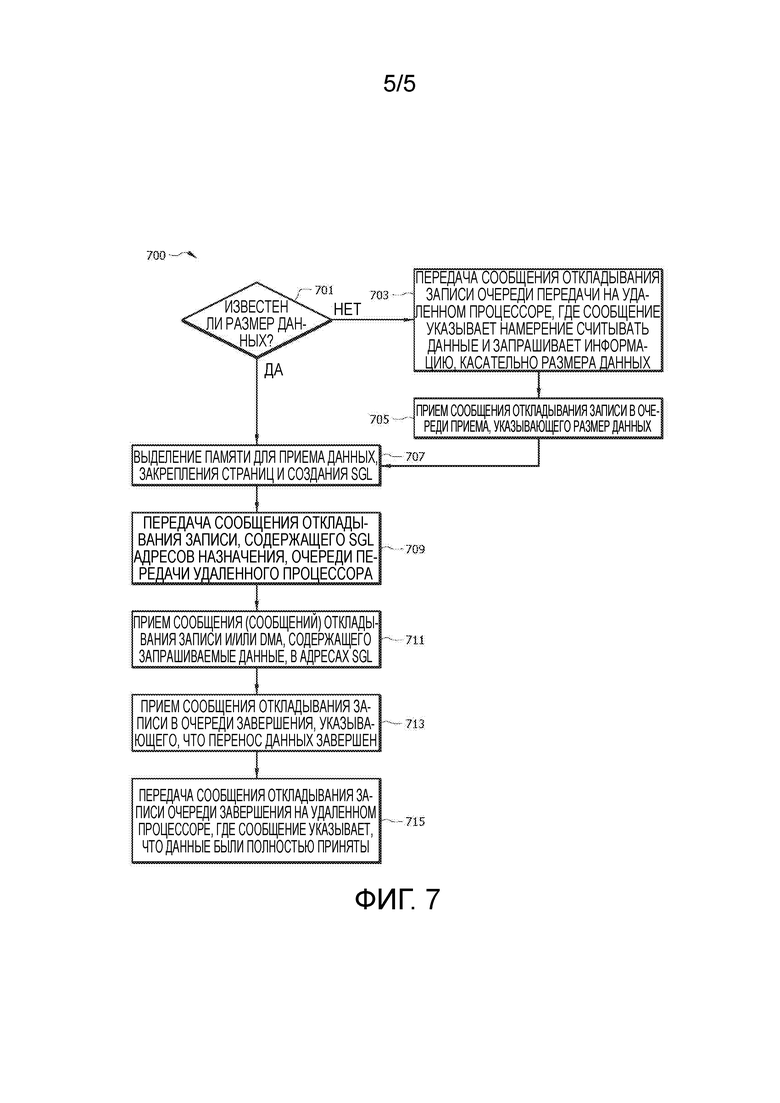
[0015] ФИГ. 6 представляет собой схему протокола варианта осуществления способа считывания данных с использованием только сообщений откладывания записи, когда размер данных неизвестен.
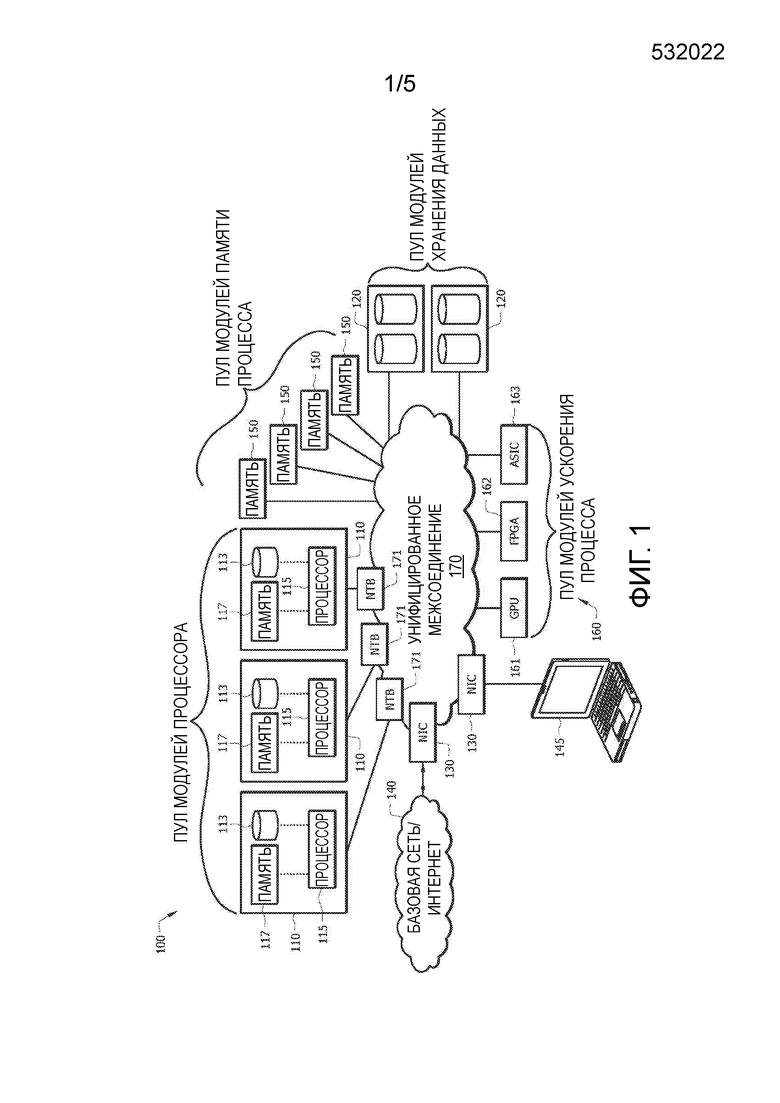
[0016] ФИГ. 7 представляет собой блок-схему последовательности операций другого варианта осуществления способа считывания данных с использованием только сообщений откладывания записи.
Подробное описание
[0017] Вначале следует понимать, что хотя иллюстративная реализация одного или более из вариантов осуществления обеспечена ниже по тексту, раскрытые системы и/или способы могут быть реализованы с использованием любого количества технологий, или существующих или известных в настоящий момент. Раскрытие никоим образом не должно быть ограничено иллюстративными реализациями, чертежами и технологиями, проиллюстрированными ниже по тексту, включая примерные проекты и реализации, проиллюстрированные и описанные в этом документе, но может быть модифицировано в пределах объема прилагаемой формулы изобретения наряду с ее полным объемом эквивалентов.
[0018] В противоположность архитектуре центра обработки данных, содержащей множество независимых серверов, дезагрегированная архитектура центра обработки данных может быть использована для поддержки пулов рабочих модулей. Такие рабочие модули могут и не быть размещены в общем шасси и могут быть соединены друг с другом методикой, которая позволяет совместное использование динамических ресурсов. Такие модули также могут быть спроектированы для совместимости с предыдущими версиями, так что обновления центра обработки данных могут быть предприняты на основе модуль за модулем с мелкоячеистостью вместо более дорогой основы сервер за сервером. Например, центр обработки данных, содержащий недостаточные ресурсы процессора, может быть оснащен одним дополнительным модулем процессора вместо того, чтобы быть обновленным полным сервером, содержащим процессоры, память, предназначенные схемы ускорения процесса, сетевую интерфейсную плату (NIC) и так далее. В дезагрегированной архитектуре, рабочие модули могут быть соединены посредством унифицированного межсоединения. Такое унифицированное межсоединение может быть развернуто с использованием шины межсоединения периферийных компонентов типа экспресс (PCIe). Модули процессора, соединенные через PCIe, каждый могут использовать локально значительное адресное пространство памяти. Такие модули процессора могут соединяться через непрозрачный мост (NTB) PCIe, который может переводить локально значительные адреса в адреса, понятные целой сети, и/или адресное пространство, используемое модулем удаленного процессора. Каждый процессор может быть ассоциирован с идентификатором запросчика (ID).
[0019] Системы PCIe могут использовать отложенные сообщения и неотложенное сообщение. Отложенное сообщение может быть сообщением, которое может быть интерпретировано ассоциированным аппаратным обеспечением как не требующее ответа. Сообщения записи памяти могут быть отложенными сообщениями. Неотложенное сообщение может быть сообщением, которое может быть интерпретировано ассоциированным аппаратным обеспечением как требующее ответа. Сообщения считывания памяти, сообщения записи и/или считывания ввода/вывода (I/O), и/или сообщения записи и/или считывания конфигурации могут быть неотложенными сообщениями. NTB может маршрутизировать сообщения посредством сохранения с учетом состояния соединения ID запросчика, ассоциированного с каждым неотложенным сообщением, в таблице поиска ID запросчика (R-LUT). После приема ответа на неотложенное сообщение-запрос, NTB может использовать R-LUT для определения, с каким сообщением-запросом ассоциируется ответ, и для определения, куда отправлять ответ. Таблицы R-LUT NTB не могут быть спроектированы для поддержки крупномасштабной возможности межсоединения. Например, R-LUT NTB может содержать недостаточное пространство памяти для поддержки более чем тридцати двух одновременно соединенных процессоров. Как таковая, R-LUT NTB PCIe может создавать сложности в развертывании крупномасштабных пулов ресурсов процессора в дезагрегированной архитектуре центра обработки данных.
[0020] В этом документе раскрывается механизм для обхода R-LUT NTB PCIe обратно совместимой методикой, чтобы позволять создание крупномасштабных пулов ресурсов процессора. Каждый процессор может быть сконфигурирован с возможностью обмена исключительно отложенными сообщениями (например, записями памяти), так как такие сообщения могут не расходовать доступные вхождения в R-LUT NTB PCIe. Управление такими отложенными сообщениями может быть осуществлено на уровне программного обеспечения (например, вместо уровня аппаратного обеспечения), так что такие отложенные сообщения могут или могут и не вызывать ответы по необходимости. Каждый процессор может быть сконфигурирован с возможностью содержать очередь приема (RX), очередь передачи (TX) и очередь завершения. Каждое отложенное сообщение может быть проанализировано на основе контента сообщения и помещено в ассоциированную очередь. Процессор может затем действовать на каждое сообщение на основе очереди, к которой было назначено сообщение. Например, сообщения, указывающие, что процессор должен подготовиться к приему переноса данных, могут быть помещены в очередь RX. Сообщения, указывающие, что процессор должен подготовиться к выполнению переноса данных, могут быть помещены в очередь TX. Сообщения, указывающие, что перенос данных завершен, могут быть помещены в очередь завершения. Посредством использования очередей RX, TX и завершения, процессор может настраивать и выполнять переносы данных (например, записи и считывания данных) с другими процессорами через NTB с использованием только отложенных сообщений (например, сообщений записи), и может посредством этого избегать ограничений масштабируемости, ассоциированных с R-LUT NTB. В то время как рассматриваемые в этом документе механизмы могут быть использованы для поддержки дезагрегированной архитектуры центра обработки данных, следует отметить, что такие механизмы могут быть использованы для поддержки возможности соединения на основе PCIe в любой другой архитектуре центра обработки данных, такой как центры обработки данных на основе серверов.
[0021] ФИГ. 1 представляет собой схематическое представление варианта осуществления дезагрегированной сетевой архитектуры 100 центра обработки данных. Сеть 100 может содержать пул модулей 110 процессора, пул модулей 150 памяти процесса, пул модулей 120 хранения данных, пул модулей 160 ускорения процесса и пул модулей 130 NIC, которые могут быть соединены посредством унифицированной сети 170 межсоединения. Модули 110 процессора, модули 150 памяти процесса, модули 120 хранения данных, модули 160 ускорения процесса, модули 130 NIC и унифицированная сеть 170 межсоединения могут быть размещены в общем центре обработки данных и не могут быть размещены в общем корпусе (например, каждый модуль может содержать отдельный сервер, блейд-сервер, сетевой элемент, шасси и так далее). Каждый пул модуля может содержать множество рабочих модулей, каждый из которых сконфигурирован с возможностью выполнения общей функции. Модули 110 процессора могут каждый совместно использовать доступ к ресурсам других модулей посредством унифицированной сети 170 межсоединения. Унифицированная сеть 170 межсоединения может использовать протокол, общий для всех модулей, такой как PCIe, который может позволять индивидуальным модулям обновляться, добавляться и/или удаляться без создания несовместимости модулей. Возможность модулей 110 процессора совместно использовать ресурсы, также может позволять балансировку загрузки для ресурсов и может сокращать узкие места процесса.
[0022] Каждый модуль (например, модули 110 процессора, модули 150 памяти процесса, модули 120 хранения данных, модули 160 ускорения процесса и/или модули 130 NIC) может содержать и/или состоять существенно из компонентов, необходимых для выполнения доли задачи, и может быть размещен в отдельном NE от всех других модулей. Например, модули 110 процессора могут содержать и/или состоять существенно из процессора 115, который может быть одиночным процессором и/или кластером процессорных элементов. Модуль 110 процессора также может необязательно содержать и/или состоять существенно из локальной памяти 117 процесса и локального хранилища 113, а также из компонентов передачи для соединения с унифицированной сетью 170 межсоединения и компонентов, связанных с питанием. Модули 110 процессора могут быть размещены на блейд-сервере, который может быть менее дорогим и физически более малым, чем серверы в стойках, и может быть неспособным обеспечивать полную функциональность без доступа к унифицированной сети 170 межсоединения. Модули 110 процессора могут работать с возможностью управления типичными задачами центра обработки данных, такими как управление хранением данных, размещение процессов, ответ на клиентские запросы и так далее.
[0023] Сеть 100 может содержать пул модулей 150 памяти процесса, которые могут содержать и/или состоять существенно из памяти (например, оперативного запоминающего устройства (RAM), кэш-памяти процессора и так далее), которая может сохранять данные процессора, связанные с активными процессами. Модули 150 памяти процесса могут содержать ресурсы хранения, которые могут быть выделены конкретному процессору 115, конкретному модулю 110 процессора и/или могут быть совместно используемыми множеством или модулями 110 процессора. Выделение модулей 150 памяти может динамически меняться на основе нужд сети 100 в точно определенное время. Модуль 150 памяти процесса может быть размещен на блейд-сервере. Например, модуль 150 памяти процесса может состоять существенно из памяти, компонентов передачи для поддержки соединения с унифицированной сетью 170 межсоединения и компонентов питания.
[0024] Сеть 100 может содержать пул модулей 120 хранения данных, которые могут содержать и/или состоять существенно из устройств хранения данных, сконфигурированных с возможностью хранения на длительный срок (например, дисководов, твердотельных накопителей, избыточных массивов из независимых дисков (RAID) и так далее). Модули 120 хранения данных могут содержать ресурсы хранения, которые могут быть выделены конкретному процессору 115, конкретному модулю 110 процессора и/или могут быть совместно используемыми множеством модулей 110 процессора. Выделение модулей 120 хранения данных может динамически меняться на основе нужд сети 100 в точно определенное время. Модуль 120 хранения данных может быть размещен на блейд-сервере. Например, модуль 120 хранения данных может состоять существенно из устройства (устройств) хранения данных, компонентов передачи для поддержки соединения с унифицированной сетью 170 межсоединения и компонентов питания.
[0025] Сеть 100 может содержать пул модулей 160 ускорения процесса, которые могут содержать и/или состоять существенно из ускорителей процесса, таких как специализированные интегральные схемы (ASIC) 163, программируемые пользователем вентильные матрицы (FPGA) 162, блоки обработки графики (GPU) 161, процессоры цифровых сигналов (DSP) и так далее. Ускорители процесса могут быть оптимизированы для специфической задачи и могут выполнять такие специфические задачи более быстро и/или эффективно, чем обычные блоки обработки (например, процессоры 115). Процессор 115 может стремиться к разгрузке всего или части конкретного процесса и может передавать запрос на выделение pecypcа модулям 160 ускорения процесса, и модули 160 ускорения процесса могут использовать ускорители процесса для завершения процесса и передачи получившихся в результате данных назад к запрашивающему процессору 115. Модули 160 ускорения процесса могут содержать ресурсы обработки, которые могут быть выделены конкретному процессору 115, конкретному модулю 110 процессора и/или могут быть совместно используемыми множеством или модулями 110 процессора. Выделение модуля 160 ускорения процесса может динамически меняться на основе нужд сети 100 в точно определенное время. Модуль 160 ускорения процесса может быть размещен на блейд-сервере. Например, модуль 160 ускорения процесса может состоять существенно из ускорителя процесса (например, ASIC 163, FPGA 162 и/или GPU 161), компонентов передачи для поддержки соединения с унифицированной сетью 170 межсоединения и компонентов питания.
[0026] Сеть 100 может содержать пул модулей 130 NIC, которые могут содержать и/или состоять существенно из NIC, сконфигурированных с возможностью обмена данными с базовой сетью 140 центра обработки данных, Интернетом и/или локальным устройством 145 клиента от имени других модулей. В качестве примера, модули 130 NIC могут содержать ресурсы возможности соединения, которые могут быть выделены конкретному процессору 115, конкретному модулю 110 процессора и/или могут быть совместно используемыми множеством модулей 110 процессора. Выделение модуля 130 NIC и/или ресурсов модуля 130 NIC может динамически меняться на основе нужд сети 100 в точно определенное время. В качестве другого примера, модули 130 NIC могут быть сконфигурированы с возможностью обмена данными с базовой сетью от имени модулей 110 процессора, модулей 160 ускорения процесса, модулей 150 памяти процесса, модулей 120 хранения или их комбинации. Как таковой, модуль 110 процессора может направлять другие модули на обмен выходными данными непосредственно с NIC 130 без возвращения модулю 110 процессора. Модуль 130 NIC может быть размещен на блейд-сервере. Например, модуль 130 NIC может состоять существенно из NIC для обмена данными с базовой сетью 140, компонентов передачи для поддержки соединения с унифицированной сетью 170 межсоединения и компонентов питания. Модули NIC также могут реализовывать удаленный прямой доступ к памяти (RDMA).
[0027] Пулы модулей (например, модулей 110 процессора, модулей 150 памяти процесса, модулей 120 хранения данных, модулей 160 ускорения процесса и/или модулей 130 NIC) могут быть соединены друг с другом посредством унифицированной сети 170 межсоединения. Унифицированная сеть 170 межсоединения может транспортировать обмен данными между модулями и/или пулами неблокирующей методикой. Унифицированная сеть 170 межсоединения может содержать любое аппаратное обеспечение и/или протоколы, которые могут быть совместимы со всеми модулями. Например, унифицированная сеть 170 межсоединения может содержать сеть PCI-e. Унифицированная сеть 170 межсоединения не может быть ограничена конкретным модулем (например, размещенным внутри блейд-сервера) и/или шасси и может быть маршрутизирована по всему центру обработки данных. Модули, содержащие компоненты, которые исходно не поддерживают соединения по унифицированной сети 170 межсоединения, могут содержать процессоры и/или другие компоненты соединения для поддержки возможности межсоединения.
[0028] Унифицированная сеть 170 межсоединения, например, может содержать множество NTB 171, совместимых с PCIe. NTB 171 может действовать в качестве шлюза для обмена данными, проходящего между конкретным процессором 115 и/или модулем 110 процесса и унифицированным межсоединением 170. В то время как каждый процессор 115 и/или модуль 110 процесса может быть соединен с логически предназначенным NTB 171, несколько NTB 171 могут или не могут быть размещены в одном физическом устройстве (не показано). Каждый процессор 115 и/или модуль 110 процессора может содержать локально значительное адресное пространство памяти, которое не может быть распознано другими процессорами 115, модулями 110 процессора и/или другими устройствами сети 100. Каждый NTB 171 может быть сконфигурирован с возможностью выполнения перевода сетевого адреса от имени процессора 115 и/или модуля 110 процессора, чтобы позволить обмен данными с другими процессорами и/или модулями. Например, первый NTB 171, соединенный с первым процессором 115, может переводить сообщения, адресуемые в адресном пространстве первого процессора 115, в адресное пространство, понятое по ту сторону унифицированного межсоединения 170 и наоборот. Подобным образом, второй NTB 171 может выполнять такие же переводы для соединенного второго процессора 115, что может позволить обмен данными между первым процессором 115 и вторым процессором 115 посредством перевода адреса на первом NTB 171 и втором NTB 171.
[0029] Процессоры 115 и/или модули 110 процессора могут обмениваться данными через NTB 171 посредством отложенных сообщений и неотложенных сообщений. Отложенное сообщение может не требовать ответ, в то время как неотложенное сообщение может требовать ответ. NTB 171 может содержать R-LUT. При приеме неотложенного сообщения, например, от удаленного процессора, NTB 171 может сохранять ID запросчика, ассоциированный с удаленным процессором, в R-LUT. После приема ответа на неотложенное сообщение, например, от локального процессора, NTB 171 может обращаться к R-LUT для определения, куда отправлять ответ. R-LUT NTB 171 могут быть с учетом состояния соединения и могут быть спроектированы для поддержки относительно небольшого количества процессоров (например, максимум восьми или тридцати двух). Как таковая, R-LUT NTB 171 может предотвращать масштабируемость сети 100 за пределами тридцати двух модулей 110 процессора. Однако процессоры 115 могут быть сконфигурированы с возможностью избегания R-LUT посредством использования только отложенных сообщений, что может позволить масштабируемость приблизительно до шестидесяти четырех тысяч процессоров. Для управления операциями с использованием только отложенных сообщений, процессоры 115 и/или модули 110 процессора могут быть необходимы для управления обменом данных на уровне программного обеспечения вместо уровня аппаратного обеспечения. Например, процессор 115 может быть сконфигурирован с очередью RX, очередью TX и очередью завершения. Очередь (очереди) RX, очередь (очереди) TX и очередь (очереди) завершения могут быть сконфигурированы в качестве очередей первый на входе - первый на выходе (FIFO). Процессоры 115 могут быть сконфигурированы с возможностью распознавания того, что отложенное сообщение записи может не вызывать запись и может вместо этого нести другую информацию. Процессоры 115 могут анализировать контенты входящего сообщения (например, пакета данных) и помещать сообщение в очередь согласно контенту сообщений, например, на основе адреса и/или на основе команды, закодированной в полезной нагрузке сообщения. Сообщения, относящиеся к предстоящей передаче данных, могут быть помещены в очередь TX, сообщения, связанные с предстоящим получением данных, могут быть помещены в очередь RX, и сообщения, связанные с завершением операции, могут быть помещены в очередь завершения. Процессор 115 и/или модули 110 процессора затем могут интерпретировать каждое сообщение на основе очереди, к которой было назначено сообщение.
[0030] ФИГ. 2 представляет собой схематическое представление варианта осуществления NE 200, который может действовать как узел (например, модуль 110 процессора) в пределах дезагрегированной сетевой архитектуры центра обработки данных, такой как дезагрегированная сетевая архитектура 100 центра обработки данных. Специалист в данной области техники распознает, что термин NE охватывает широкий спектр устройств, из которых NE 200 является лишь примером. NE 200 включен в целях ясности обсуждения, но никоим образом не предназначен для ограничения применения настоящего раскрытия конкретным вариантом осуществления NE или классом вариантов осуществления NE. По меньшей мере некоторые из признаков/способов, описанных в раскрытии, могут быть реализованы с использованием сетевого устройства или компонента, такого как NE 200. Например, признаки/способы в раскрытии могут быть реализованы с использованием аппаратного обеспечения, программно-аппаратного обеспечения и/или программного обеспечения, установленного для работы на аппаратном обеспечении. NE 200 может быть любым устройством, которое транспортирует кадры по сети, например, переключателем, маршрутизатором, мостом, сервером, клиентом и так далее. Как показано на ФИГ. 2, NE 200 может содержать приемопередатчики (Tx/Rx) 210, которые могут быть передатчиками, приемниками или их комбинацией. Tx/Rx 210 может быть сопряжен с множеством портов 220 нисходящей линии связи для передачи и/или приема кадров от других узлов, Tx/Rx 210, сопряженным со множеством портов 250 восходящей линии связи для передачи и/или приема кадров от других узлов. Процессор 230 может быть сопряжен с Tx/Rx 210 для обработки кадров и/или определения, каким узлам отправлять кадры. Процессор 230 может содержать один или более многоядерных процессоров и/или устройств 232 памяти, которые могут функционировать в качестве хранилищ данных, буферов и так далее. Процессор 230 может быть реализован в качестве обычного процессора или может быть частью одного или более из ASIC и/или DSP. Процессор 230 может содержать модуль 234 переноса данных, который может реализовывать очередь RX, очередь TX, очередь завершения и/или может реализовывать операции считывания и/или записи с использованием только сообщений откладывания для обхода R-LUT NTB PCIe. В альтернативном варианте осуществления, модуль 234 переноса данных может быть реализован в качестве инструкций, сохраненных в памяти 232, которые могут быть исполнены процессором 230. В другом альтернативном варианте осуществления, модуль 234 переноса данных может быть реализован на отдельных NE. Порты 220 нисходящей линии связи и/или порты 250 восходящей линии связи могут содержать в себе электрические и/или оптические компоненты передачи и/или приема. NE 200 может быть или может и не быть компонентом маршрутизации, который принимает решения о маршрутизации.
[0031] Следует понимать, что посредством программирования и/или загрузки исполняемых инструкций на NE 200, по меньшей мере одно из процессора 230, модуля 234 переноса данных, портов 220 нисходящей линии связи, Tx/Rx 210, памяти 232 и/или портов 250 восходящей линии связи меняется, частично преобразуя NE 200 в конкретную машину или устройство, например, многоядерную архитектуру пересылки, имеющую новую функциональность, изученную настоящим раскрытием. Фундаментальной основой для областей электротехники и программотехники является то, что функциональность, которая может быть реализована посредством загрузки исполняемого программного обеспечения на компьютер, может быть превращена в реализацию аппаратного обеспечения посредством хорошо известных правил проектирования. Решения между реализацией концепции в программном обеспечении против аппаратного обеспечения типично зависят от соображений стабильности проекта и количества блоков, которые должны быть произведены, а не от каких-либо проблем, вовлеченных в перевод от области программного обеспечения в область аппаратного обеспечения. В общем, проект, который все еще подвергается частому изменению, может быть предпочтителен для реализации в программном обеспечении, поскольку повторное развитие реализации аппаратного обеспечения является более дорогим, чем повторное развитие проекта программного обеспечения. В общем, проект, который является стабильным, который будет произведен в большом объеме, может быть предпочтителен для реализации в аппаратном обеспечении, например, в ASIC, поскольку для больших партий изготавливаемых изделий реализация аппаратного обеспечения может быть менее дорогой, чем реализация программного обеспечения. Часто проект может быть разработан и протестирован в форме программного обеспечения и позднее преобразован, посредством хорошо известных правил проектирования, в эквивалентную реализацию аппаратного обеспечения в специализированной интегральной схеме, которая реализует аппаратно инструкции программного обеспечения. Подобно тому, когда машина, управляемая новой ASIC, является конкретной машиной или устройством, компьютер, который был запрограммирован и/или загружен исполняемыми инструкциями, аналогично может быть представлен как конкретная машина или устройство.
[0032] ФИГ. 3 представляет собой схему протокола варианта осуществления способа 300 записи данных с использованием только сообщений откладывания записи. Например, способ 300 может быть реализован в процессоре (например, процессоре 115) и/или в модуле процессора (например, модуле 110 процессора). Такой процессор, упоминаемый в этом документе как первый процессор, локальный процессор, и/или процессор 1, может хотеть записывать данные на другой процессор, упоминаемый в этом документе как второй процессор, удаленный процессор, и/или процессор 2, через NTB PCIe, такой как NTB 171. В то время как процессор 1 может оперировать в сети 100, следует отметить, что процессор 1 также может быть размещен в любой другой сети на основе PCIe. Процессор 2 может или не может быть существенно аналогичным процессору 1 и может или не может быть размещен в одном и том же шасси, как процессор 1. Процессор 1 и процессор 2 оба могут быть сконфигурированы с очередью RX, очередью TX и очередью завершения.
[0033] Процессор 1 может быть осведомлен о размере данных, которые должны быть отправлены процессору 2. На этапе 301, процессор 1 может передавать сообщение откладывания записи (например, пакет данных) процессору 2. Сообщение откладывания записи на этапе 301 может содержать информацию, связанную с данными, которые должны быть отправлены, и может включать в себя размер данных. Так как процессор 1 может хотеть для процессора 2 принять данные, сообщение откладывания записи на этапе 301 может быть передано очереди RX процессора 2, например, на основе адреса, ассоциированного с очередью или на основе команды, закодированной в полезной нагрузке сообщения. Как только сообщение на этапе 301 достигает передней стороны очереди RX, процессор 2 может выполнять этап 303 посредством выделения памяти для приема данных на основе размера данных. Процессор 2 также может закреплять ассоциированные виртуальные страницы, чтобы предотвращать такие страницы и ассоциированные данные от выгружения (например, удаления из памяти к жесткому диску) до завершения записи, указанной на этапе 301. На этапе 305, процессор 2 может создавать список адресов назначения, такой как список распределения/сборки, содержащий адреса местоположений памяти, выделяемых для приема переданных данных. На этапе 307, процессор 2 может передавать сообщение откладывания записи процессору 1. Сообщение откладывания записи на этапе 307 может содержать список адресов назначения памяти (например, который сгенерирован на этапе 305). Так как сообщение откладывания записи на этапе 307 может относиться к передаче данных от процессора 1, сообщение откладывания записи может быть передано очереди TX процессора 1. Как только сообщение на этапе 307 достигает передней стороны очереди TX, процессор 1 может выполнять этап 309 посредством перемещения данных на адреса памяти, перечисленные в списке адресов назначения. Этап 307 может быть выполнен посредством передачи сообщения (сообщений) откладывания записи, содержащего данные, посредством использования прямого доступа к памяти (DMA) и так далее. На этапе 311, процессор 1 может передавать сообщение откладывания записи процессору 2, указывающее, что ассоциированный перенос данных был завершен. Так как сообщение откладывания записи на этапе 311 относится к завершению сообщения, сообщение откладывания записи на этапе 311 может быть передано очереди завершения процессора 2. После приема всех данных, процессор 2 также может передавать сообщение завершения откладывания записи процессору 1 на этапе 313. Сообщение на этапе 313 может указывать, что все данные были приняты процессором 2. Так как сообщение откладывания записи на этапе 313 относится к завершению сообщения, сообщение откладывания записи на этапе 313 может быть передано очереди завершения процессора 1. Этап 313 может быть необязательным. Этап 313 проиллюстрирован в качестве пунктирной стрелки на ФИГ. 3 для указания необязательной особенности этапа 313.
[0034] ФИГ. 4 представляет собой блок-схему последовательности операций варианта осуществления другого способа 400 записи данных с использованием только сообщений откладывания записи. Способ 400 может быть реализован локальным процессором (например, процессором 1), стремящимся записать данные на удаленный процессор (например, процессор 2), оба из которых могут быть по существу аналогичными процессорам, рассматриваемым со ссылкой на способ 300. На этапе 401, сообщение откладывания записи может быть передано очереди приема на удаленном процессоре (например, процессоре 2). Сообщение на этапе 401 может указывать намерение переместить данные наряду с размером данных, которые должны быть перенесены. На этапе 403, сообщение откладывания записи может быть принято от удаленного процессора. Сообщение откладывания записи на этапе 403 может содержать SGL адресов назначения и может быть помещено в очередь передачи. На этапе 405, сообщение (сообщения) откладывания записи и/или DMA может быть использовано для передачи данных на местоположения удаленной памяти, указанные в SGL. На этапе 407, сообщение откладывания записи может быть передано очереди завершения на удаленном процессоре. Сообщение на этапе 407 может указывать, что перенос данных завершен. На этапе 409, сообщение откладывания записи может быть принято в очереди завершения. Сообщение откладывания записи на этапе 409 может указывать, что данные были полностью приняты на местоположениях удаленной памяти, точно определяемых SGL, принятым на этапе 403.
[0035] ФИГ. 5 представляет собой схему протокола варианта осуществления способа 500 считывания данных с использованием только сообщений откладывания записи, когда размер данных известен. Способ 500 может быть реализован локальным процессором (например, процессором 1), стремящимся считывать данные из удаленного процессора (например, процессора 2), оба из которых могут быть по существу аналогичными процессорам, рассматриваемым со ссылкой на способы 300 и/или 400. На этапе 505, процессор 1 уже может быть осведомлен о размере данных, которые должны быть запрошены. Процессор 1 может быть осведомлен о размере данных, так как результат других протоколов, из-за ранее принятого сообщения, из-за связанного процесса, инициирующего запрос, указал размер данных, и так далее. Процессор 1 может выделять ассоциированную память и/или закреплять страницы методикой, аналогичной этапу 303 на основе априорного знания процессора о размере данных, которые должны быть запрошены. На этапе 507, процессор 1 может создавать список адресов назначения для данных методикой, аналогичной этапу 305. На этапе 509, процессор 1 может передавать сообщение откладывания записи процессору 2. Сообщение откладывания записи на этапе 509 может содержать запрос на считывание данных, указание данных для считывания и список адресов назначения, создаваемый на этапе 507. Так как сообщение откладывания записи на этапе 509 может относиться к передаче от процессора 2, сообщение откладывания записи на этапе 509 может быть передано очереди TX процессора 2. На этапе 511, процессор 2 может передавать запрашиваемые данные на адрес(а) назначения в адресе назначения посредством DMA, дополнительные сообщения откладывания записи и так далее методикой, аналогичной этапу 309. На этапе 513, процессор 2 может передавать сообщение откладывания записи, указывающее завершение переноса, методикой, аналогичной этапу 311. Сообщение откладывания записи на этапе 513 может быть передано очереди завершения процессора 1. Необязательно, процессор 1 может передавать сообщение откладывания записи завершения очереди завершения процессора 2 на этапе 515 методикой, аналогичной этапу 313.
[0036] ФИГ. 6 представляет собой схему протокола варианта осуществления способа считывания данных с использованием только сообщений откладывания записи, когда размер данных неизвестен. Способ 600 может быть реализован локальным процессором (например, процессором 1), стремящимся считывать данные из удаленного процессора (например, процессора 2), оба из которых могут быть по существу аналогичными процессорам, рассматриваемым со ссылкой на способы 300, 400 и/или 500. Способ 600 может быть по существу аналогичным способу 500, но может быть реализован, когда процессор 1 не осведомлен о размере данных, которые должны быть запрошены. На этапе 601, процессор 1 может передавать сообщение откладывания записи, указывающее намерение считывать данные из процессора 2 и идентифицирующее данные для считывания. Так как сообщение откладывания записи на этапе 601 может быть связано с передачей процессором 2, сообщение откладывания записи на этапе 601 может быть маршрутизировано очереди TX процессора 2. Как только сообщение на этапе 601 достигает передней стороны очереди TX, процессор 2 может приступать к этапу 603 и передавать сообщение откладывания записи процессору 1, указывающее размер данных для считывания. Так как сообщение откладывания записи на этапе 603 может быть связано с данными, которые должны быть приняты процессором 1, сообщение на этапе 603 может быть переслано очереди RX процессора 1. Как только сообщение на этапе 603 достигает передней стороны очереди RX, процессор 1 может приступать к этапу 605. Этапы 605, 607, 609, 611, 613 и 615 могут быть по существу аналогичными этапам 505, 507, 509, 511, 513 и 515.
[0037] ФИГ. 7 представляет собой блок-схему последовательности операций другого варианта осуществления способа 700 считывания данных с использованием только сообщений откладывания записи. Способ 700 может быть реализован локальным процессором (например, процессором 1), стремящимся считывать данные из удаленного процессора (например, процессора 2), оба из которых могут быть по существу аналогичными процессорам, рассматриваемым со ссылкой на способы 300, 400, 500 и/или 600. На этапе 701, способ 700 может определять, является ли размер данных для считывания известным. Способ 700 может приступать к этапу 707, если размер данных известен, и к этапу 703, если размер данных неизвестен. На этапе 703, сообщение откладывания записи может быть передано очереди передачи на удаленном процессоре. Сообщение на этапе 703 может указывать намерение считывать данные и запрашивать информацию, касательно размера ассоциированных данных. На этапе 705, сообщение откладывания записи может быть принято в очереди приема. Сообщение на этапе 705 может указывать размер запрашиваемых данных. Способ 700 затем может приступать к этапу 707. На этапе 707, память может быть выделена для приема данных на основе размера данных, ассоциированные страницы могут быть закреплены и может быть создан SGL выделяемых адресов памяти. На этапе 709, сообщение откладывания записи, содержащее SGL адресов назначения, может быть передано очереди передачи удаленного процессора. На этапе 711, сообщение (сообщения) откладывания записи и/или сообщения DMA, содержащие запрашиваемые данные, могут быть приняты в адресах назначения, перечисленных в SGL. На этапе 713, сообщение откладывания записи может быть принято в очереди завершения и может указывать, что перенос данных завершен. Необязательно, на этапе 715, сообщение откладывания записи может быть передано очереди завершения на удаленном процессоре. Сообщение откладывания записи на этапе 715 может указывать, что данные были полностью приняты в адресах назначения.
[0038] По меньшей мере раскрыт один вариант осуществления и вариации, комбинации, и/или модификации варианта (вариантов) осуществления и/или признаки варианта (вариантов) осуществления, сделанные обычным специалистом в данной области техники, находятся в пределах объема раскрытия. Альтернативные варианты осуществления, которые получаются из комбинирования, интегрирования и/или пропуска признаков варианта (вариантов) осуществления, также находятся в пределах объема раскрытия. Там где точно установлены области числовых значений или ограничения, такие точные области или ограничения следует понимать как включающие в себя повторяющиеся области или ограничения подобной величины, находящейся в пределах точно установленных областей или ограничений (например, от приблизительно 1 до приблизительно 10 включает в себя, 2, 3, 4 и так далее; больше чем 0.10 включает в себя 0.11, 0.12, 0.13 и так далее). Например, всякий раз, когда область числовых значений с более низкой границей, Rl, и более высокой границей, Ru, раскрыта, конкретно, раскрыто любое число, находящееся в пределах области. В частности, конкретно раскрыты следующие числа в пределах области: R=Rl+k * (Ru - Rl), при этом k является переменной, меняющейся от 1 процента до 100 процентов с увеличением в 1 процент, то есть, k равна 1 проценту, 2 процентам, 3 процентам, 4 процентам, 7 процентам, …, 70 процентам, 71 проценту, 72 процентам, …, 97 процентам, 96 процентам, 97 процентам, 98 процентам, 99 процентам или 100 процентам. Более того, любая область числовых значений, заданная двумя R числами, как задано выше по тексту, также конкретно раскрыта. Использование термина "приблизительно" означает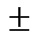 10% последующего числа, пока иначе не установлено. Использование термина "необязательно" в отношении к какому-либо элементу пункта, означает, что элемент требуется или, в качестве альтернативы, элемент не требуется, обе альтернативы находятся в пределах объема пункта. Использование более широких терминов, таких как содержит, включает в себя и имеющий, следует понимать как обеспечение поддержки для более узких терминов, таких как состоящий из, состоящий существенно из и составленный по существу из. Соответственно, объем охраны не ограничен описанием, изложенным выше по тексту, но задан формулой изобретения, которая последует, причем объем включает в себя все эквиваленты объекта изобретения формулы изобретения. Все без исключения пункты формулы изобретения включены в качестве дополнительного раскрытия в описание, и формула изобретения представляет собой вариант(ы) осуществления настоящего раскрытия. Обсуждение ссылки в раскрытии не является допущением того, что она является предшествующим уровнем техники, особенно какой-либо ссылки, которая имеет дату публикации после даты приоритета этой заявки. Раскрытия всех патентов, заявок на патент и публикаций, процитированных в раскрытии, включены посредством ссылки до такой степени, что они обеспечивают примерные, процедурные или другие добавочные детали для раскрытия.
10% последующего числа, пока иначе не установлено. Использование термина "необязательно" в отношении к какому-либо элементу пункта, означает, что элемент требуется или, в качестве альтернативы, элемент не требуется, обе альтернативы находятся в пределах объема пункта. Использование более широких терминов, таких как содержит, включает в себя и имеющий, следует понимать как обеспечение поддержки для более узких терминов, таких как состоящий из, состоящий существенно из и составленный по существу из. Соответственно, объем охраны не ограничен описанием, изложенным выше по тексту, но задан формулой изобретения, которая последует, причем объем включает в себя все эквиваленты объекта изобретения формулы изобретения. Все без исключения пункты формулы изобретения включены в качестве дополнительного раскрытия в описание, и формула изобретения представляет собой вариант(ы) осуществления настоящего раскрытия. Обсуждение ссылки в раскрытии не является допущением того, что она является предшествующим уровнем техники, особенно какой-либо ссылки, которая имеет дату публикации после даты приоритета этой заявки. Раскрытия всех патентов, заявок на патент и публикаций, процитированных в раскрытии, включены посредством ссылки до такой степени, что они обеспечивают примерные, процедурные или другие добавочные детали для раскрытия.
[0039] В то время как в настоящем раскрытии были обеспечены несколько вариантов осуществления, следует понимать, что раскрытые системы и способы могли бы быть осуществлены во многих других специфических формах без отклонения от сущности или объема настоящего раскрытия. Настоящие примеры нужно считать иллюстративными и не ограничивающими, и намерение не состоит в том, чтобы ограничиваться деталями, приведенными в этом документе. Например, различные элементы или компоненты могут быть сопряжены или интегрированы в другую систему, или некоторые признаки могут быть пропущены или не реализованы.
[0040] В дополнение, технологии, системы и способы, описанные и проиллюстрированные в различных вариантах осуществления как обособленные или отдельные, могут быть сопряжены или интегрированы с другими системами, модулями, технологиями или способами без отклонения от объема настоящего раскрытия. Другие элементы, показанные или рассматриваемые как сопряженные или непосредственно сопряженные или связанные друг с другом, могут быть косвенно сопряжены или связаны через некоторый интерфейс, устройство или промежуточный компонент или электрически или механически или иначе. Другие примеры изменений, замен и исправлений являются определимыми специалистом в данной области техники и могут быть сделаны без отклонения от сущности и объема, раскрытого в этом документе.
Группа изобретений относится к средствам обмена данными через непрозрачный мост (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe). Технический результат - создание механизма для обхода R-LUT NTB PCIe (таблицы поиска ID запросчика), что позволяет создавать крупномасштабные пулы ресурсов процессора, за счет обмена данными, в котором используются исключительно отложенные сообщения. Для этого предложен способ связи через непрозрачный мост (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe), содержащий передачу первого отложенного сообщения записи на удаленный процессор через NTB, при этом первое отложенное сообщение записи указывает намерение переносить данные на удаленный процессор, и прием второго отложенного сообщения записи в ответ на первое отложенное сообщение записи, при этом второе отложенное сообщение записи указывает список адресов назначения для данных. 3 н. и 17 з.п. ф-лы, 7 ил.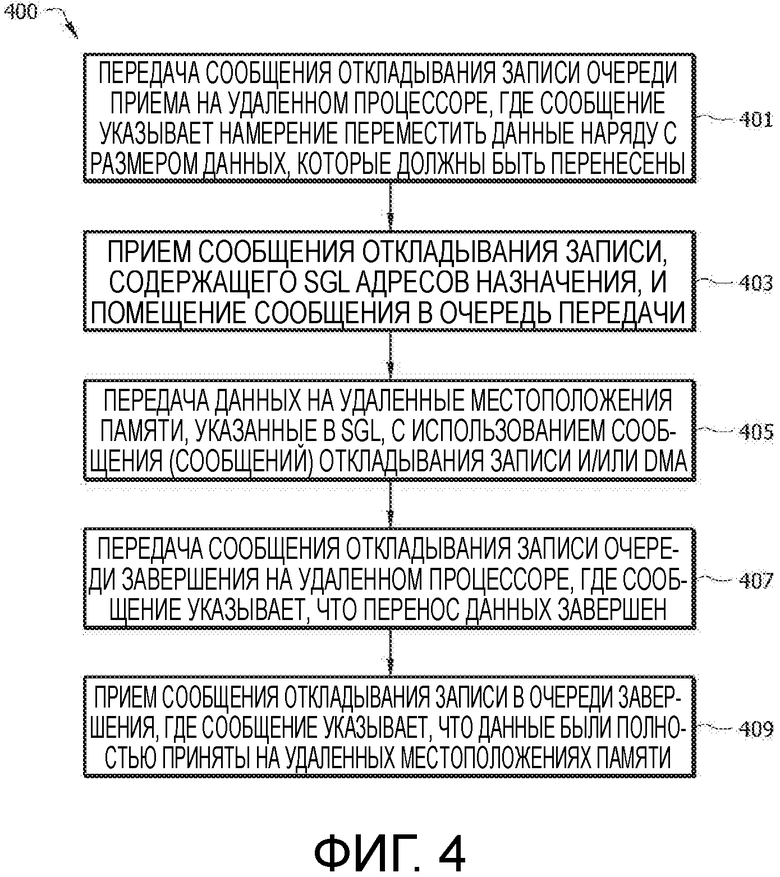
1. Способ связи через непрозрачный мост (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe), содержащий:
передачу первого отложенного сообщения записи на удаленный процессор через NTB, при этом упомянутое первое отложенное сообщение записи указывает намерение переносить данные на удаленный процессор; и
прием второго отложенного сообщения записи в ответ на упомянутое первое отложенное сообщение записи, при этом упомянутое второе отложенное сообщение записи указывает список адресов назначения для данных.
2. Способ по п. 1, дополнительно содержащий передачу третьего отложенного сообщения записи на адрес назначения, полученный из списка адресов назначения упомянутого второго отложенного сообщения записи, при этом упомянутое третье отложенное сообщение записи содержит данные.
3. Способ по п. 1, дополнительно содержащий передачу данных на адрес назначения, полученный из списка адресов назначения упомянутого второго отложенного сообщения записи, через прямой доступ к памяти (DMA).
4. Способ по п. 1, дополнительно содержащий передачу четвертого отложенного сообщения записи на удаленный процессор для указания завершения переноса данных.
5. Способ по п. 1, дополнительно содержащий прием пятого отложенного сообщения записи от удаленного процессора, которое указывает полное принятие данных.
6. Способ по п. 1, при этом обмен данными осуществляется без использования каких-либо неотложенных операций.
7. Способ по п. 1, при этом обмен данными осуществляется только в сообщениях, выбранных для обхода таблицы поиска идентификатора запросчика (R-LUT) NTB.
8. Способ по п. 7, при этом способ реализуется в локальном процессоре, и при этом упомянутый способ поддерживает обмен данными между локальным процессором и тридцатью двумя или более удаленными процессорами через NTB.
9. Способ обмена данными через непрозрачный мост (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe), содержащий:
передачу первого отложенного сообщения записи на удаленный процессор через NTB, при этом упомянутое первое отложенное сообщение записи содержит запрос на считывание данных; и
прием сообщения переноса данных, содержащего по меньшей мере некоторые из данных, запрашиваемых упомянутым первым отложенным сообщением записи, при этом сообщение переноса данных является отложенным сообщением.
10. Способ по п. 9, при этом упомянутое первое отложенное сообщение записи содержит адрес назначения для данных, и при этом сообщение переноса данных адресуется на адрес назначения.
11. Способ по п. 10, дополнительно содержащий прием второго отложенного сообщения записи от удаленного процессора, которое указывает завершение переноса данных, ассоциированного с запросом считывания упомянутого первого отложенного сообщения записи.
12. Способ по п. 11, дополнительно содержащий передачу третьего отложенного сообщения записи на удаленный процессор, которое указывает полное принятие данных, ассоциированных с запросом считывания упомянутого первого отложенного сообщения записи.
13. Способ по п. 9, при этом запрос считывания упомянутого первого отложенного сообщения записи указывает, что размер запрашиваемых данных неизвестен.
14. Способ по п. 9, дополнительно содержащий:
прием четвертого отложенного сообщения записи, указывающего размер запрашиваемых данных; и
до приема сообщения переноса данных, выделение памяти для приема данных на основе упомянутого четвертого отложенного сообщения записи.
15. Процессор для обмена данными через непрозрачный мост (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe), выполненный с возможностью обеспечения:
очереди приема;
очереди передачи; и
очереди завершения, и при этом упомянутый процессор сконфигурирован с возможностью:
сопряжения с непрозрачным мостом (NTB) шины межсоединения периферийных компонентов типа экспресс (PCIe); и
считывания данных из и записи данных на множество удаленных процессоров посредством очереди приема, очереди передачи, очереди завершения и NTB PCIe, используя исключительно отложенные сообщения.
16. Процессор по п. 15, при этом упомянутый процессор дополнительно сконфигурирован с возможностью:
приема отложенных сообщений записи; и
сохранения отложенных сообщений записи в очереди приема, очереди передачи и очереди завершения на основе контента отложенных сообщений записи.
17. Процессор по п. 16, при этом очередь передачи содержит структуру данных первый на входе - первый на выходе (FIFO), и при этом отложенные сообщения записи, указывающие запросы на передачу данных, сохраняются в очереди передачи.
18. Процессор по п. 16, при этом очередь приема содержит структуру данных первый на входе - первый на выходе (FIFO), и при этом отложенные сообщения записи, направляющие процессор на подготовку к приему данных, сохраняются в очереди приема.
19. Процессор по п. 16, при этом очередь завершения содержит структуру данных первый на входе - первый на выходе (FIFO), и при этом отложенные сообщения записи, указывающие, что перенос данных был завершен, сохраняются в очереди завершения.
20. Процессор по п. 15, при этом считывание данных из и запись данных на упомянутое множество удаленных процессоров посредством очереди приема, очереди передачи, очереди завершения выполняется без использования протокола удаленного прямого доступа к памяти (RDMA).
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Дозатор к машине для розлива водочных и винных изделий | 1954 |
|
SU101225A1 |

