Область техники
[001] Настоящее техническое решение относится к способам и системам для создания обучающего объекта для обучения алгоритма машинного обучения.
Уровень техники
[002] С постоянно растущим объемом данных, хранящихся на различных серверах, задача эффективного поиска становится все более важной. Например, в сети Интернет доступны миллионы ресурсов и множество поисковых систем (например, GOOGLE™, YAHOO! ™, YANDEX™, BAIDU™ и так далее), которые предоставляют пользователям удобные инструменты поиска релевантной информации, которая соответствует поисковому намерению пользователя.
[003] Обычно сервер поисковой системы выполняет функцию поискового робота. Конкретнее, поисковая система выполняет функцию робота, который «посещает» различные ресурсы, доступные в Интернете и индексирует их содержимое. Конкретные алгоритмы и программы поисковых роботов могут быть различны, но на высшем уровне основной задачей поискового робота является (i) идентифицировать конкретный ресурс в Интернете, (ii) идентифицировать ключевые темы, связанные с конкретным ресурсом (темы представлены ключевыми словами и тому подобным), и (iii) индексировать ключевые темы по отношению к конкретному ресурсу.
[004] После того как поисковая система получает поисковый запрос от пользователя, она идентифицирует все просмотренные ресурсы, которые потенциально релевантны поисковому запросу пользователя. Поисковая система далее выполняет поисковое ранжирование для ранжирования идентифицированных потенциальных релевантных ресурсов. Ключевой задачей поискового ранжирования является организация идентифицированных результатов поиска путем расположения потенциально наиболее релевантных результатов в верхней части списка результатов поиска. Поисковое ранжирование выполняется различными способами, некоторые из которых включают в себя алгоритмы машинного обучения (MLA) для ранжирования результатов поиска. Поисковое ранжирование выполняется различными способами, некоторые из которых включают в себя алгоритмы машинного обучения (MLA) для ранжирования результатов поиска.
[005] Обычный алгоритм машинного (MLA) обучения, который используется при поисковом ранжировании, обучается с помощью обучающих наборов данных. Обычно, обучающий набор данных включает в себя документ (например, веб-ресурс), который потенциально релевантен (или соответствует) обучающему поисковому запросу.
[006] Платформы краудсорсинга, например, Amazon Mechanical Turk™, позволяют оценивать размечать большие наборы данных за короткие сроки и с меньшими затратами по сравнению с профессиональными экспертами. Тем не менее, эксперты на платформах краудсорсинга в общем случае являются непрофессиональными могут сильно отличаться друг от друга по уровню экспертизы, и полученные отметки могут быть «с помехами» - в том смысле, что назначенные отметки, которые назначаются данному объекту различными экспертами могут очень существенно различаться. Например, некоторые эксперты могут быть слишком консервативны (т.е. ставить хорошие отметки только очень релевантными объектам), а другие эксперты могут быть более мягкими при проставлении отметок.
[007] Обычно, для достижения средней отметки вычисляется большинство голосов среди отметок «с помехами» для каждого объекта. Тем не менее, данное решение игнорирует какую-либо разницу между работниками, что может приводить к плохим результатам, если большинство экспертов, работающих над данной задачей, являются низкоквалифицированными.
[008] Другой стандартный подход основан на предположении о скрытой отметке, при котором подразумевается, что все эксперты воспринимают одно и то же скрытое истинное значение, и далее это значение изменяется экспертами в соответствии с выбранной ими моделью отметки. Как следствие, модели отметки, созданные с учетом этого предположения, воспринимают любые отличия в отметках «с помехами» для объекта как ошибки, допущенные работниками.
[009] Обычные способы снижения «помех» включают в себя очистку данных и присваивание весовых коэффициентов. Коротко говоря, очистка от помех аналогична «поиску выбросов» и по сути означает отфильтровывание выбранных отметок, которые «похожи» по каким-то причинам на неверно отмеченные. При подходе, включающем в себя весовые коэффициенты, ни одна из выбранных отметок полностью не отбрасывается, вместо этого их влияние на алгоритм машинного обучения контролируется с помощью весовых коэффициентов, которые представляют собой значимость конкретной отметки. Способы очистки от помех и подход с использованием весовых коэффициентов основываются на предположении о существовании «единственной истинной отметки» для каждого цифрового обучающего документа.
РАСКРЫТИЕ
[0010] Задачей предлагаемой технологии является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[0011] Варианты осуществления настоящего технического решения были разработаны с учетом определения разработчиками по меньшей мере одного технического недостатка, связанного с известным уровнем техники.
[0012] Без установления каких-либо ограничений, разработчики настоящей технологии считают, что традиционные подходы к созданию средней отметки не способны объяснить конкретные несогласованности между отметками, проставленными экспертами, что является стандартной ситуацией для некоторых типов объектов. Например, известно, что при оценке релевантности документов по поисковым запросам, даже опытные эксперты могут расходиться во мнениях касательно истинной отметки (т.е. истинной релевантности данного документа для поискового запроса) для конкретных документов. В самом деле, для правильного установления соответствия отметки с документом на основе поискового запроса, необходимо учитывать множество аспектов объекта, например, релевантность, новизна, охват, бренд, дизайн и так далее. С учетом такой сложной задачи, даже самый опытный эксперт может обладать личными предпочтениями касательно ценности различных аспектов, что приводит к разнице в выборе отметок. Разработчики полагают, что по факту это означает, что единственная истинная отметка объекта не существует, вместо нее объект обладает конкретным распределением возможных истинных воспринимаемых отметок. Аналогичные проблемы, хоть и в несколько более сложной форме, присутствуют в системе отметки документов на основе краудсорсинга.
[0013] Следовательно, разработчики настоящей технологии стремятся устранить на вышеупомянутые недостатки, связанные с традиционными подходами к созданию средних отметок, путем разработки настройки отметки документов, в которой нет предположения о существовании единственной истинной отметки для объекта, и вместо этого каждый объект обладает различными «субъективными, но истинными» воспринимаемыми отметками. Таким образом, варианты осуществления настоящей технологии нацелены на создание распределения средней отметки в форме распределения воспринимаемых отметок. Распределение средней отметки может также включать в себя оценку вероятности, связанную с каждой из воспринимаемых отметок.
[0014] Первым объектом настоящей технологии является исполняемый на компьютере способ создания обучающего объекта для обучения алгоритма машинного обучения, обучающий объект включает в себя цифровой обучающий документ и назначенную отметку. Способ выполняется на обучающем сервере. Способ включает в себя: получение цифрового обучающего документа, который будет использован в обучении; передачу через сеть передачи данных цифрового обучающего документа множеству экспертов, передача далее включает в себя указание на диапазон возможных отметок для экспертов, диапазон возможных отметок включает в себя по меньшей мере первую возможную отметку и вторую возможную отметку; получение от каждого из множества экспертов выбранной отметки для формирования набора выбранных отметок; создание распределения средней отметки на основе набора выбранных отметок, распределение средней отметки представляет собой диапазон воспринимаемых отметок для цифрового обучающего документа и связанную отметку вероятности для каждой из воспринимаемых отметок; и обучение алгоритма машинного обучения с использованием цифрового обучающего документа и распределения средней отметки.
[0015] В некоторых вариантах осуществления способа, способ далее включает в себя определение параметра экспертизы для каждого из множества экспертов на основе набора выбранных отметок; и определение параметра сложности цифрового обучающего документа на основе набора выбранных отметок.
[0016] В некоторых вариантах осуществления способа, параметр экспертизы независим от оцениваемого цифрового обучающего документа; и параметр сложности независим от какого-либо эксперта, оценивающего цифровой обучающий документ.
[0017] В некоторых вариантах осуществления способа, распределение средней отметки определяется путем определения конкретного для эксперта распределения воспринимаемой отметки для каждого эксперта из множества экспертов; агрегирования каждого конкретного для эксперта распределения воспринимаемой отметки из множества экспертов.
[0018] В некоторых вариантах осуществления способа, конкретное для эксперта распределение воспринимаемой отметки для данного эксперта определяется следующим образом. Для первой возможной отметки: определение присущей эксперту оценки вероятности того, что данный эксперт выберет первую возможную отметку; определение условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринял первую возможную отметку, будет наиболее релевантной отметкой для цифрового обучающего документа; и агрегирование присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для первой отметки. Для второй отметки: определение присущей эксперту оценки вероятности того, что данный эксперт выберет вторую возможную отметку; определение условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринял вторую возможную отметку, будет наиболее релевантной отметкой для цифрового обучающего документа; агрегирование присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для второй отметки. Далее, агрегирование воспринимаемой оценки, конкретной для первой отметки, и воспринимаемой оценки, конкретной для второй отметки.
[0019] В некоторых вариантах осуществления способа, присущая эксперту оценка вероятности определяется на основе по меньшей мере конкретного для эксперта параметра тенденции.
[0020] В некоторых вариантах осуществления способа, способ дополнительно включает в себя определение для данного эксперта конкретного для эксперта параметра тенденции на основе по меньшей мере истории оценок данного эксперта.
[0021] В некоторых вариантах осуществления способа, распределение средней отметки получают путем максимизации вероятности выбранной отметки путем использования формулы:
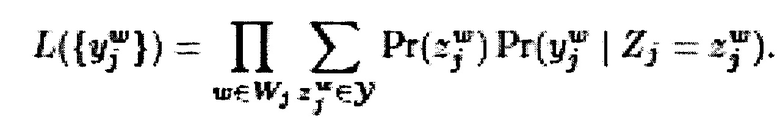
[0022] В некоторых вариантах осуществления способа, формула вычисляется с помощью по меньшей мере одной модифицированной модели на основе (i) модели Дэвида-Скен, (ii) генеративной модели отметок, возможностей и сложностей (GLAD) и (iii) принципа минимакса энтропии.
[0023] В некоторых вариантах осуществления способа, множество экспертов включает в себя первого эксперта и второго эксперта и выбранная отметка, полученная от первого эксперта, отличается от выбранной отметки, полученной от второго эксперта.
[0024] В некоторых вариантах осуществления способа, алгоритм машинного обучения выполняется приложением ранжирования сервера поискового ранжирования, и при этом обучение происходит с целью повышения точности алгоритма машинного обучения.
[0025] В некоторых вариантах осуществления способа, повышение точности представляет собой улучшение релевантности поискового результата в ответ на поисковый запрос.
[0026] В некоторых вариантах осуществления способа, обучающий сервер является сервером поискового ранжирования.
[0027] Другим объектом настоящей технологии является обучающий сервер для обучения приложения ранжирования, приложение ранжирования предназначено для ранжирования результатов поиска. Обучающий сервер включает в себя сетевой интерфейс для коммуникативного соединения к сети передачи данных и процессор, соединенный с сетевым интерфейсом. Процессор выполнен с возможностью осуществлять: получение цифрового обучающего документа, который будет использован в обучении; передачу через сеть передачи данных цифрового обучающего документа множеству экспертов, передача далее включает в себя указание на диапазон возможных отметок для экспертов, диапазон возможных отметок включает в себя по меньшей мере первую возможную отметку и вторую возможную отметку; получение от каждого из множества экспертов выбранной отметки для формирования набора выбранных отметок; создание распределения средней отметки на основе набора выбранных отметок, распределение средней отметки представляет собой диапазон воспринимаемых отметок для цифрового обучающего документа и связанную оценку вероятности для каждой из воспринимаемых отметок; и обучение алгоритма машинного обучения с использованием цифрового обучающего документа и распределения средней отметки.
[0028] В некоторых вариантах осуществления обучающего сервера, процессор дополнительно выполнен с возможностью осуществлять определение параметра экспертизы для каждого из множества экспертов на основе набора выбранных отметок; и определение параметра сложности цифрового обучающего документа на основе набора выбранных отметок.
[0029] В некоторых вариантах осуществления обучающего сервера, параметр экспертизы независим от оцениваемого цифрового обучающего документа; и параметр сложности независим от какого-либо эксперта, оценивающего цифровой обучающий документ.
[0030] В некоторых вариантах осуществления обучающего сервера, распределение средней отметки определяется процессором, который выполнен с возможностью осуществлять определение конкретного для эксперта распределения воспринимаемой отметки для каждого эксперта из множества экспертов; и агрегирование каждого конкретного для эксперта распределения воспринимаемой отметки из множества экспертов.
[0031] В некоторых вариантах осуществления обучающего сервера, конкретное для эксперта распределение воспринимаемой отметки для данного эксперта определяется процессором. Процессор далее выполнен с возможностью осуществлять, для первой возможной отметки: определение присущей эксперту оценки вероятности того, что данный эксперт выберет первую возможную отметку; определение условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринял первую возможную отметку, будет наиболее релевантной отметкой для цифрового обучающего документа; и агрегирование присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для первой отметки. Процессор далее выполнен с возможностью осуществлять, для второй отметки: определение присущей эксперту оценки вероятности того, что данный эксперт выберет вторую возможную отметку; определение условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринял вторую возможную отметку, будет наиболее релевантной отметкой для цифрового обучающего документа; агрегирование присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для второй отметки. Процессор далее выполнен с возможностью осуществлять агрегирование воспринимаемой оценки, конкретной для первой отметки, и воспринимаемой оценки, конкретной для второй отметки.
[0032] В некоторых вариантах осуществления обучающего сервера, присущая эксперту оценка вероятности определяется на основе по меньшей мере конкретного для эксперта параметра тенденции.
[0033] В некоторых вариантах осуществления обучающего сервера, процессор далее выполнен с возможностью осуществлять определение для данного эксперта конкретного для эксперта параметра тенденции на основе по меньшей мере истории оценок данного эксперта.
[0034] В некоторых вариантах осуществления обучающего сервера множество экспертов включает в себя первого эксперта и второго эксперта и выбранная отметка, полученная от первого эксперта, отличается от выбранной отметки, полученной от второго эксперта.
[0035] В некоторых вариантах осуществления обучающего сервера, алгоритм машинного обучения выполняется приложением ранжирования сервера поискового ранжирования, и при этом обучение происходит с целью повышения точности алгоритма машинного обучения.
[0036] В некоторых вариантах осуществления обучающего сервера, повышение точности представляет собой улучшение релевантности поискового результата в ответ на поисковый запрос.
[0037] В некоторых вариантах осуществления обучающего сервера, обучающий сервер является сервером поискового ранжирования.
[0038] В контексте настоящего описания, если четко не указано иное, «электронное устройство», «пользовательское устройство», «сервер» и «компьютерная система» подразумевают под собой аппаратное и/или системное обеспечение, подходящее к решению соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и так далее), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и так далее) и/или их комбинацию.
[0039] В контексте настоящего описания, если четко не указано иное, "машиночитаемый носитель" и "память" подразумевает под собой носитель абсолютно любого типа и характера, не ограничивающие примеры включают в себя ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB-ключи, флеш-карты, твердотельные накопители и накопители на магнитной ленте.
[0040] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0041] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0042] На Фиг. 1 представлена система, подходящая для реализации неограничивающих вариантов осуществления настоящей технологии.
[0043] На Фиг. 2 представлена принципиальная схема создания присущей эксперту оценки вероятности.
[0044] На Фиг. 3 представлена принципиальная схема создания назначенной отметки.
[0045] На Фиг. 4 представлена принципиальная схема создания конкретного для эксперта распределения воспринимаемой отметки.
[0046] На Фиг. 5 представлена блок-схема способа создания обучающего объекта, способ выполняется обучающем сервером, изображенном на Фиг. 1, способ выполняется в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем.
ОСУЩЕСТВЛЕНИЕ
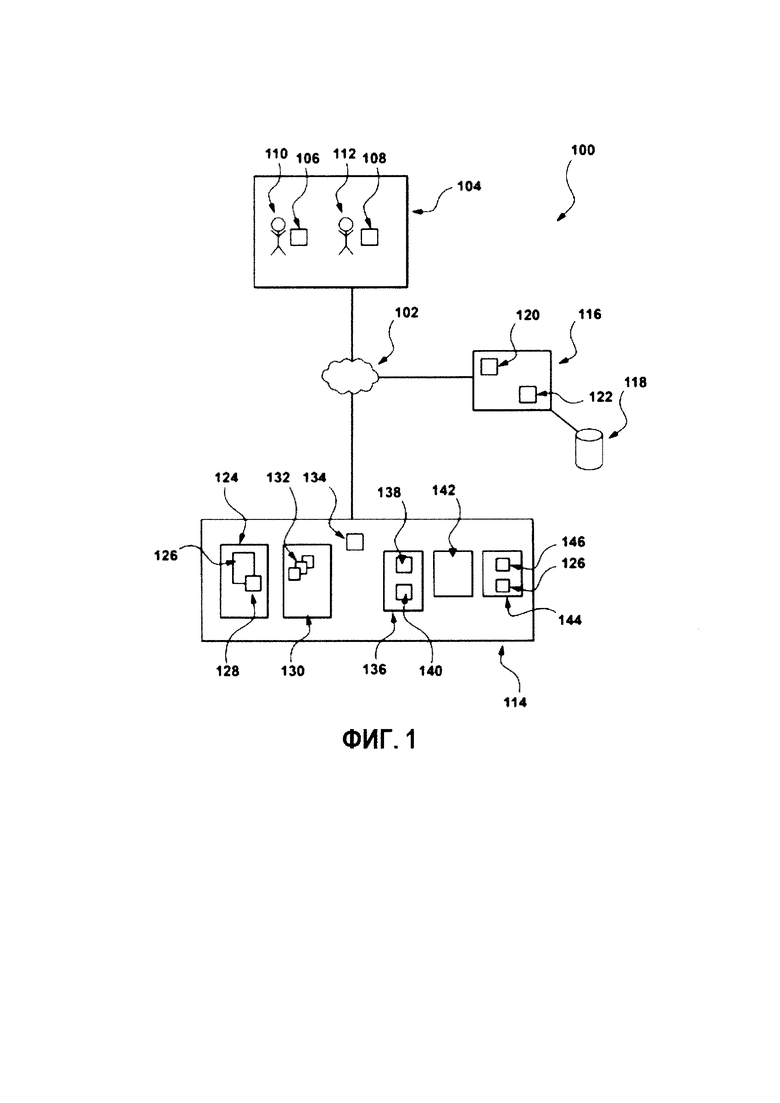
[0047] На Фиг. 1 представлена система 100, реализованная в соответствии с вариантами осуществления настоящей технологии. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0048] Система 100 включает в себя сеть 102 передачи данных, которая обеспечивает связь между различными компонентами системы 100, которые с ней коммуникативно связаны. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 102 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящего технического решения, сеть 102 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п. Сеть 102 передачи данных может поддерживать обмен сообщениями и данными в открытом формате или в зашифрованном виде, с использованием известных стандартов шифрования.
[0049] Система 100 включает в себя множество электронных устройств 104, множество электронных устройств 104 коммуникативно соединено с сетью 102 передачи данных. В представленных вариантах осуществления технологи, множество электронных устройств 104 включает в себя первое электронное устройство 106 и второе электронное устройство 108. Следует отметить, что конкретное количество устройств во множестве электронных устройств 104 никак конкретно не ограничено, и, в общем случае, можно утверждать, что множество электронных устройств 104 содержит по меньшей мере два электронных устройства, таких как те, что представлены в данном примере.
[0050] Первое электронное устройство 106 связано с первым экспертом 110 и, таким образом, иногда может упоминаться как «первое клиентское устройство». Следует отметить, что тот факт, что первое электронное устройство 106 связано с первым экспертом 110, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, регистрации, или чего-либо подобного. Варианты первого электронного устройства 106 конкретно не ограничены, но в качестве примера перового электронного устройства 106 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), беспроводные устройства связи (мобильные телефоны, смартфоны, планшеты и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы).
[0051] Второе электронное устройство 108 связано со вторым экспертом 112 и, таким образом, иногда может упоминаться как «второе клиентское устройство». Следует отметить, что тот факт, что второе электронное устройство 108 связано со вторым экспертом 112, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, регистрации, или чего-либо подобного. Варианты второго электронного устройства 108 конкретно не ограничены, но в качестве примера второго электронного устройства 108 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), беспроводные устройства связи (мобильные телефоны, смартфоны, планшеты и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы).
[0052] К сети 102 передачи данных также присоединены обучающий сервер 114 и сервер 116 поискового ранжирования. Несмотря на то, что в представленном варианте осуществления технологии обучающий сервер 114 и сервер 116 поискового ранжирования представлены как отдельные элементы, их функциональность может быть выполнена одним сервером.
[0053] Способы, в соответствии с которыми будет реализован обучающий сервер 114 и сервер 116 поискового ранжирования, никак конкретно не ограничены. Например, оба обучающий сервер 114 и сервер 116 поискового ранжирования могут представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что обучающий сервер 114 и сервер 116 поискового ранжирования могут представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном неограничивающем варианте осуществления настоящей технологии, каждый из обучающего сервера 114 и сервера 116 поискового ранжирования является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность обучающего сервера 114 и сервера 116 поискового ранжирования может быть разделена, и может выполняться с помощью нескольких серверов.
[0054] Несмотря на то, что обучающий сервер 114 и сервер 116 поискового ранжирования были в целях иллюстрации описаны как работающие на одном аппаратном обеспечении, это не является обязательным.
[0055] В некоторых вариантах осуществления настоящей технологии, сервер 116 поискового ранжирования находится под контролем и/или управлением поисковой системы, например, поисковой системы YANDEX™ компании ООО «Яндекс», расположенной по адресу: 119021, Москва, ул. Льва Толстого, дом 16. Тем не менее, сервер 116 поискового ранжирования может быть реализован иначе (например, через локальный поисковик и так далее). Сервер 116 поискового ранжирования выполнен с возможностью поддерживать поисковую базу 118 данных, которая содержит указание на различные ресурсы, доступные через сеть 102 передачи данных.
[0056] Процесс заполнения и поддержания поисковой базы 118 данных в общем случае известен как «сбор информации», когда приложение 120 поискового робота, которое выполняется сервером 116 поискового ранжирования, выполнено с возможностью «посещать» различные веб-сайты и веб-страницы, доступные через сеть 102 передачи данных и индексировать их содержимое (например, связывать данный веб-ресурс с одним или несколькими ключевыми словами). В некоторых вариантах осуществления настоящей технологии, приложение 120 поискового робота поддерживает поисковую базу 118 данных как «инвертированный индекс». Следовательно, приложение 120 поискового робота сервера 116 поискового ранжирования выполнено с возможностью сохранять информацию о проиндексированных веб-ресурсах в поисковой базе 118 данных.
[0057] Когда сервер 116 поискового ранжирования получает поисковый запрос от эксперта (например, «как раньше выйти на пенсию»), сервер 116 поискового ранжирования выполнен с возможностью выполнять приложение 112 ранжирования. Приложение 112 ранжирования выполнено с возможностью получать доступ к поисковой базе 118 данных для получения указания на множество ресурсов, которые потенциально релевантны введенному поисковому запросу. В данном примере, приложение 112 ранжирования дополнительно выполнено с возможностью ранжировать таким образом полученные потенциальные релевантные ресурсы, чтобы они могли быть представлены в ранжированном порядке на странице результатов поиска (SERP), причем на странице результатов поиска наиболее релевантные ранжированные ресурсы расположены в верхней части списка.
[0058] С этой целью, приложение 122 ранжирования выполнено с возможностью выполнять алгоритм ранжирования. В некоторых вариантах осуществления настоящей технологии, алгоритм ранжирования представляет собой алгоритм машинного обучения (MLA). В некоторых вариантах осуществления настоящей технологии, приложение 160 ранжирования реализует алгоритм на основе нейронной сети, алгоритм на основе деревьев принятия решений, MLA на основе обучения ассоциативным правилам, MLA на основе глубинного обучения, MLA индуктивно логически запрограммированный MLA, MLA на основе метода опорных векторов, MLA на основе кластеризации, Байесову сеть, MLA на основе обучения с подкреплением, MLA на основе репрезентативного обучения, MLA на основе метрик схожести, MLA на основе разреженного словаря и MLA на основе генетического алгоритма и так далее.
[0059] В некоторых вариантах осуществления настоящей технологии, приложение 122 ранжирования реализует алгоритм машинного обучения на основе обучения с учителем. В других вариантах осуществления настоящей технологии, приложение 122 ранжирования реализует алгоритм машинного обучения на основе частичного обучения с учителем.
[0060] В рамках этих вариантов осуществления технологии, приложение 122 ранжирования может быть использован в двух фазах - обучающей фазе, где приложение 122 ранжирования «обучается» для выведения формулы алгоритма машинного обучения - и в фазе действия, где приложение 122 ранжирования используется для ранжирования документов с помощью формулы алгоритма машинного обучения.
[0061] В некоторых вариантах осуществления настоящей технологии, обучающий сервер 114 находится под контролем и/или управлением платформы краудсорсинга, например платформы YANDEXTOLOKA™, предоставляемой компанией YANDEX™. Тем не менее, может быть использована любая другая коммерческая или собственная платформа краудсорсинга. Тем не менее, важно иметь в виду, что несмотря на то что варианты осуществления настоящей технологии будут описаны с использованием краудсорсной отметке документа в качестве примера, описанная здесь технология может применяться к отметке документов профессиональными экспертами и так далее.
[0062] В некоторых вариантах осуществления настоящей технологии, множество электронных устройств 104 может представлять собой часть набора профессиональных экспертов и, таким образом, эксперты (первый эксперт 110, второй эксперт 112) могут являться профессиональными экспертами. Альтернативно, множество электронных устройств 104 может представлять собой часть набора краудсорсинговых экспертов и, таким образом, эксперты (первый эксперт 110 и второй эксперт 112) могут являться участниками краудсорсинга.
[0063] В других вариантах осуществления технологии, множество электронных устройств 104 может быть частично разделено - некоторые из множества электронных устройств 104 могут являться частью профессиональных экспертов, а другие из множества электронных устройств 104 могут быть частью набора экспертов краудсорсинга. Таким образом, первый эксперт 110 может быть профессиональным экспертом; а второй эксперт 112 может быть участником краудсорсинга.
[0064] Обучающий сервер 114 включает в себя базу 124 данных краудсорсинга. База 124 данных краудсорсинга выполнена с возможностью получать и сохранять цифровой обучающий документ 126, который будет оценен множеством электронных устройств 104. В контексте настоящей технологии, термин «цифровой обучающий документ» относится к задаче, предлагаемой одному или нескольким экспертам, на получение необходимых услуг, идеи или содержимого с помощью отметок. Таким образом, цифровой обучающий документ 126 включает в себя диапазон возможных отметок 128, из которых эксперты должны выбирать конкретную отметку. Способ, согласно которому база 124 данных краудсорсинга получает цифровой обучающий документ 126, никак не ограничен и, например, может передаваться администратором (не показано) в связи с платформой краудсорсинга.
[0065] Несмотря на то что в представленном варианте осуществления технологии, база 124 данных краудсорсинга содержит только один цифровой обучающий документ 126, следует отметить, что конкретное число цифровых обучающих документов 126 никак конкретно не ограничено, и, в общем случае, можно утверждать, что база 124 данных краудсорсинга содержит по меньшей мере один цифровой обучающий документ 126, и диапазон возможных отметок 128 включает в себя по меньшей мере 2 возможные отметки (описано ниже).
[0066] Обучающий сервер 114 включает в себя базу 130 данных истории экспертов. База 130 данных истории экспертов выполнена с возможностью хранить некоторые или все данные, указывающие на предыдущую историю отметок/ярлыков для каждого из экспертов, связанных со множеством электронных устройств 104. В некоторых вариантах осуществления настоящей технологии, обучающий сервер 114 выполнен с возможностью анализировать данные, содержащиеся в базе 130 данных истории экспертов для создания и хранения набора конкретных для экспертов параметров 132 тенденции в базе 130 данных истории экспертов.
[0067] В контексте настоящей технологии, термин «конкретный для эксперта параметр тенденции» представляет собой характеристики назначения отметки для каждого из экспертов, связанных со множеством электронных устройств 104 (т.е. первым экспертом 110 и вторым экспертом 112).
[0068] Например, на основе предыдущих активностей по отметке, обучающий сервер 114 может определять, что первый эксперт 110 является категоричным экспертом (на основе того, что первый эксперт 110 имеет тенденцию к выбору только крайних отметок из всего диапазона возможных отметок 128).
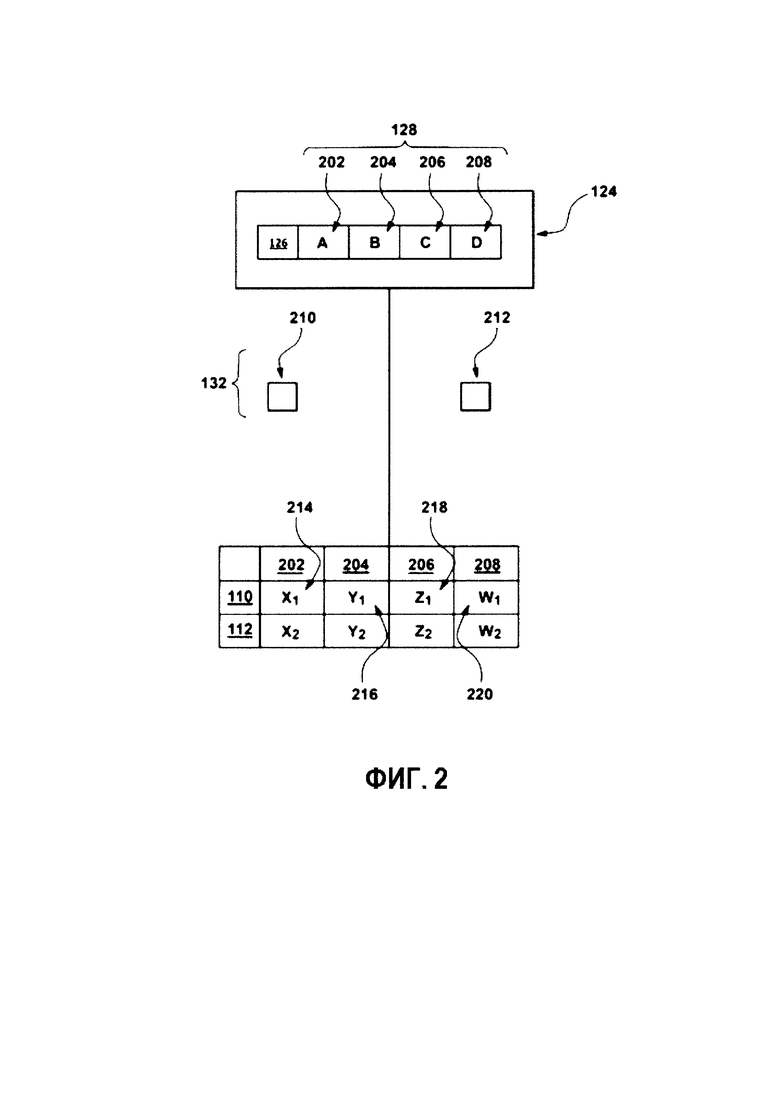
[0069] Таким образом, в ситуации когда первого эксперта 110 просят выбрать конкретную отметку из диапазона возможных отметок 128 (например, от 1 до 5, наиболее релевантно будет 5) цифрового обучающего документа 126 для данного запроса, первый эксперт 110 имеет тенденцию назначения либо 1, либо 5, и с малой вероятностью будет выбирать промежуточные значения.
[0070] Альтернативно, обучающий сервер 114 может определять, что второй эксперт 112 является нерешительным экспертом (на основе того, что второй эксперт 112 имеет тенденцию к выбору только промежуточных отметок из всего диапазона возможных отметок 128).
[0071] Например, в ситуации когда второго эксперта 112 просят выбрать конкретную отметку из диапазона возможных отметок 128 (например, от 1 до 5, наиболее релевантно будет 5) цифрового обучающего документа 126 для данного запроса, второй эксперт 112 с малой вероятностью выберет 1 или 5, и имеет тенденцию выбирать промежуточные значения (например, 2, 3 и 4).
[0072] На основе по меньшей созданного набора конкретных для экспертов параметров 132 тенденции и диапазона возможных отметок 128, обучающий сервер 114 дополнительно выполнен с возможностью создавать присущую эксперту оценку 134 вероятности для каждой отметки из диапазона возможных отметок 128. Термин «присущая эксперту оценка вероятности» относится к вероятности того, что данная отметка из диапазона возможных отметок 128 выбирается экспертом, связанным с конкретным для эксперта параметром тенденции (подробнее описано ниже).
[0073] Со ссылкой на Фиг. 2, схематически представлен способ создания присущей эксперту оценки 134 вероятности. Как было отмечено ранее, база 124 данных краудсорсинга включает в себя цифровой обучающий документ 126 и диапазон возможных отметок 128. В данном примере, диапазон возможных отметок 128 включает в себя четыре возможных отметки, конкретнее - первую возможную отметки 202, вторую возможную отметку 204, третью возможную отметку 206 и четвертую возможную отметку 208.
[0074] В представленном варианте, набор конкретного для эксперта параметра 132 тенденции включает в себя конкретный для первого эксперта параметр 210 тенденции и конкретный для второго эксперта параметр 212 тенденции. Конкретный для первого эксперта параметр 210 тенденции связан с первым экспертом 110. Конкретный для второго эксперта параметр 212 тенденции связан со вторым экспертом 112.
[0075] На основе диапазона возможных отметок 128 и конкретного для первого эксперта параметра 210 тенденции, обучающий сервер 114 выполнен с возможностью вычислять присущую эксперту оценку 134 вероятности для возможных отметок (первая возможная отметка 202, вторая возможная отметка 204, третья возможная отметка 206 и четвертая возможная отметка 208) для первого эксперта 110. Следует отметить, что присущая эксперту оценка 134 вероятности определяется независимо от фактической отметки, выбранной данным экспертом (например, в данном случае - первым экспертом 110).
[0076] В данном примере, на основе по меньшей мере конкретного для первого эксперта параметра 210 тенденции, диапазона возможных отметок 128 и цифрового обучающего документа 126, обучающий сервер 114 вычисляет присущую эксперту оценку 134 вероятности для первого эксперта 110 следующим образом: присущая оценка 214 вероятности первой отметки составляет процент X1, присущая оценка 216 вероятности второй отметки составляет процент Y1, присущая оценка 218 вероятности третьей отметки составляет процент Z1, и присущая оценка 220 вероятности четвертой отметки составляет процент W1.
[0077] Способ, в соответствии с которым определяется присущая эксперту оценка 134 вероятности для первого эксперта 110 (присущая оценка 214 вероятности первой отметки, присущая оценка 216 вероятности второй отметки, присущая оценка 218 вероятности третьей отметки и присущая оценка 220 вероятности четвертой отметки) никак конкретно не ограничен, и может быть определен с помощью любой вероятностной модели.
[0078] Обучающий сервер 114 также выполнен с возможностью вычислять присущую эксперту оценку 134 вероятности для второго эксперта 112 аналогичным образом (присущая эксперту оценка 134 вероятности для второго эксперта не пронумерована).
[0079] Возвращаясь к описанию Фиг. 1, обучающий сервер 114 выполнен с возможностью передавать цифровой обучающий документ 126 с диапазоном возможных отметок 128 каждому из множества электронных устройств 104 через сеть 102 передачи данных, вместе с инструкцией, чтобы затем передавать и хранить выбранные отметки каждого эксперта (каждого из первого эксперта 110 и второго эксперта 112) в базе 136 данных краудсорсинга.
[0080] В зависимости от конкретных вариантов осуществления технологии, эксперты (например, первый эксперт 110 и второй эксперт 112) получают инструкции по отметке, например, без установления ограничений:
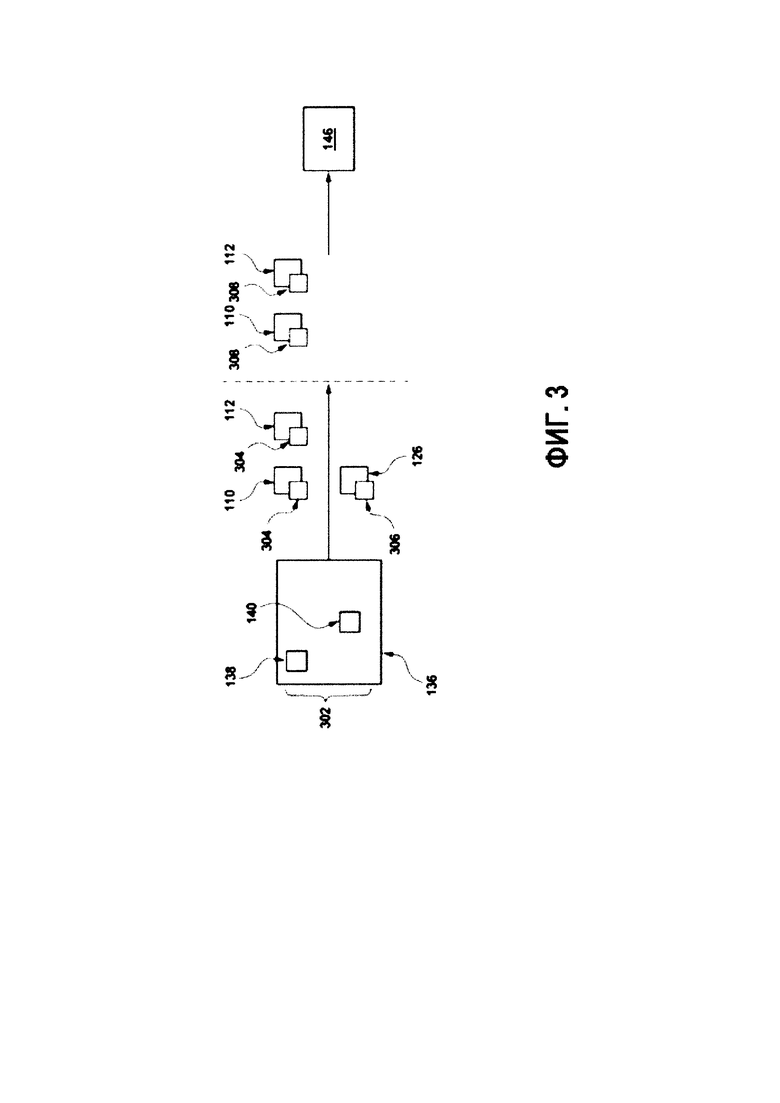
- С помощью диапазона возможных отметок 128, классифицировать цифровой обучающий документ 126 (например, изображение) на искреннюю улыбку (Duchenne smile) и неискреннюю улыбку (non-Duchenne smile);
- С помощью диапазона возможных отметок 128, оценить релевантность цифрового обучающего документа 126 (например, пару запрос-URL) по шкале от «1» до «5»;
- С помощью диапазона возможных отметок 128, классифицировать цифровой обучающий документ (например, веб-страницу) в одну из четырех категорий в зависимости от наличия контента для взрослых.
[0081] В приведенном примере, первый эксперт 110 выбрал при оценке цифрового обучающего документа 126 в диапазоне возможных отметок 128, первую выбранную отметку 138. Например, если первый эксперт 110 выбрал вторую возможную отметку 204, первая выбранная отметка 138 является второй возможной отметкой 204 (т.е. значение первой выбранной отметки 138 соответствует значению второй возможной отметки 204). А второй эксперт 112 выбрал вторую выбранную отметку 140. Например, если второй эксперт 112 выбрал первую возможную отметку 202, вторая выбранная отметка 140 является первой возможной отметкой 202 (т.е. значение второй выбранной отметки 140 соответствует значению первой возможной отметки 202).
[0082] Обучающий сервер 114 далее включает в себя приложение 142 обработки. Приложение 142 обработки выполнено с возможностью создавать обучающий объект 144 с помощью обучения приложения 122 ранжирования. В некоторых вариантах осуществления настоящей технологии, обучающий объект 114 включает в себя цифровой обучающий документ 126 и назначенную отметку 146. В некоторых вариантах осуществления настоящей технологии, назначенная отметка 146 является распределением средней отметки. В соответствии с вариантами осуществления настоящей технологии, распределение средней отметки представляет собой диапазон воспринимаемых отметок экспертами, связанными со множеством электронных устройств 104 (первый эксперт 110 и второй эксперт 112), с соответствующей оценкой вероятности для каждой из воспринимаемых отметок.
[0083] В контексте настоящего описания термин «воспринимаемая отметка» относится к данной отметке из диапазона возможных отметок 128, которая воспринимается данным экспертом как наиболее релевантная для задачи, связанной с цифровым обучающим документом 126.
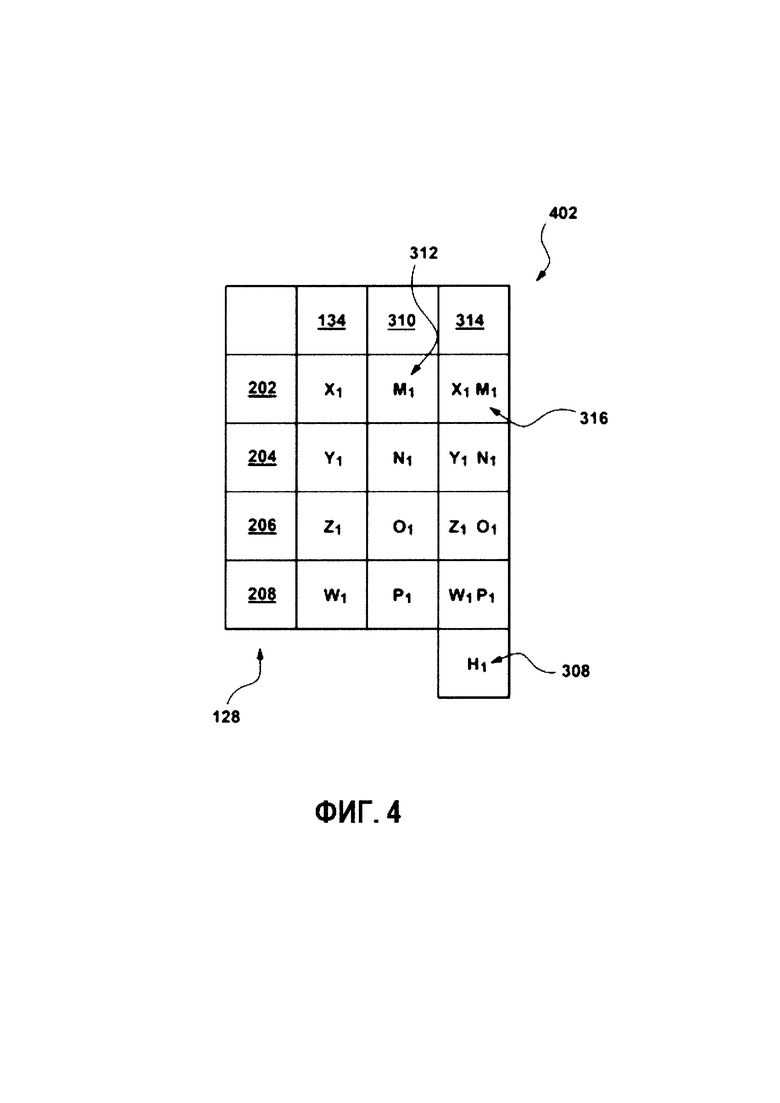
[0084] Например, первый эксперт 110 при выборе первой выбранной отметки 148 так же оценивает релевантность каждой из возможных отметок (первую возможную отметку 202, вторую возможную отметку 204, третью возможную отметку 206 и четвертую возможную отметку 208). Другими словами, первый эксперт 110 воспринимает релевантность каждой возможной отметки (первой возможной отметки 202, второй возможной отметки 204, третьей возможной отметки 206 и четвертой возможной отметки 208) и выбирает первую выбранную отметку 138. Тем не менее, в некоторых ситуациях, отметка, которая была воспринята экспертом как наиболее релевантная, не обязательно является той же самой, что и выбранная экспертом отметка. Например, первый эксперт 110 мог воспринимать первую возможную отметку 202 как наиболее релевантную, но выбирает вторую возможную отметку 204. Эти «помехи» могут быть вызваны различными факторами, например, человеческим фактором при выборе неправильной отметки, неуверенности эксперта, присущей эксперту предвзятостью, неоднозначностью задачи отметки и множеством других факторов.
[0085] Со ссылкой на Фиг. 3, схематически представлен способ создания назначенной отметки 146. При получении выбранных отметок (первой выбранной отметки 138, второй выбранной отметки 140) от множества электронных устройств 104, выбранные отметки сохранены в базу 136 данных краудсорсинга. В представленном примере, база 136 данных краудсорсинга содержит набор выбранных отметок 302. Набор выбранных отметок 302 содержит первую выбранную отметку 138, которая была выбрана первым экспертом 110, и вторую выбранную отметку 140, которая была выбрана вторым экспертом 112. Излишне говорить, что несмотря на то, что набор выбранных отметок 302 представлен как содержащий только две отметки - т.е. первую выбранную отметку 138 и вторую выбранную отметку 140, он не ограничивается таким вариантом и может содержать больше выбранных отметок.
[0086] На основе набора выбранных отметок 302, приложение 142 обработки выполнено с возможностью определять параметр 304 экспертизы для каждого эксперта (первого эксперта 110 и второго эксперта 112). Способ, в соответствии с которым определяется параметр 304 экспертизы, никак не ограничен, и может, например, определяться с помощью принципа минимакса энтропии или другими способами. Параметр 304 экспертизы является объективной экспертизой эксперта, и не зависит от цифрового обучающего документа 126. Другими словами, значение параметра 304 экспертизы для каждого эксперта не меняется в зависимости от типа цифрового обучающего документа 126.
[0087] Приложение 142 обработки далее выполнено с возможностью вычислять параметр 306 сложности цифрового обучающего документа 126 на основе набора выбранных отметок 302. Способ, в соответствии с которым определяется параметр 306 сложности, никак не ограничен, и может, например, определяться с помощью принципа минимакса энтропии или другими способами. Параметр 306 сложности не зависит от эксперта (первого эксперта 110 и второго эксперта 112), который выполняет соответствующую задачу. Другими словами, значение параметра 306 сложности не меняется в зависимости от эксперта, который выполняет задачу.
[0088] В некоторых вариантах осуществления настоящей технологии, на основе параметра 304 экспертизы и параметра 306 сложности, приложение 142 обработки выполнено с возможностью определять конкретное для каждого эксперта распределение 308 воспринимаемой отметки (первого эксперта 110 и второго эксперта 112).
[0089] В контексте настоящего описания термин «конкретное для каждого эксперта распределение воспринимаемой отметки» относится к распределению воспринимаемой оценки для данного эксперта (первого эксперта 110 и второго эксперта 112) и связанной с ним оценки вероятности.
[0090] Конкретное для каждого эксперта распределение 308 воспринимаемой отметки для данного эксперта является суммой всех присущих экспертам оценок 134 вероятности для данной воспринимаемой отметки (которая может представлять собой первую возможную отметку 202, вторую возможную отметку 204, третью возможную отметку 206 и четвертую возможную отметку 208), умноженной на условную оценку 310 вероятности, связанную с данной воспринимаемой отметкой. В некоторых вариантах осуществления настоящей технологии, термин «условная оценка вероятности» представляет собой вероятность того, что выбранная отметка данного эксперта, которому была предоставлена воспринимаемая отметка в диапазоне возможных отметок 128, является наиболее релевантной отметкой для цифрового обучающего документа 126. Условная оценка вероятности вычисляется для выбранной отметки на основе серии «условий», и каждое условие заключается в том, что каждый эксперт воспринимает данную отметок из диапазона возможных отметок 128 как наиболее подходящую.
[0091] Со ссылкой на Фиг. 4, схематически представлен способ создания конкретного для каждого эксперта распределения 308 воспринимаемой отметки. В таблице 402 представлены различные данные для определения конкретного для каждого эксперта распределения 308 воспринимаемой отметки для первого эксперта 110.
[0092] Первая колонка таблицы 402 соответствует диапазону возможных отметок 128 для цифрового обучающего документа 126, конкретнее, первой возможной отметке 202, второй возможной отметке 204, третьей возможной отметке 206 и четвертой возможной отметке 208. Вторая колонка таблицы 402 соответствует присущей эксперту оценке 134 вероятности. Таким образом, вероятность X1 является присущей оценкой 214 вероятности первой отметки для первой возможной отметки 202, вероятность Y1 является присущей оценкой 216 вероятности второй отметки для второй возможной отметки 204, вероятность Z1 является присущей оценкой 218 вероятности третьей отметки 206 для третьей возможной отметки, и вероятность W1 является присущей оценкой 220 вероятности четвертой отметки 208.
[0093] Третья колонка таблицы 402 соответствует условной оценке 310 вероятности. С учетом того что первый эксперт 110 выбрал вторую возможную отметку 204, значение M1, которое представляет собой условную оценку 312 вероятности первой отметки, будет представлять собой вероятность того, что первый эксперт 110 воспринимает первую возможную отметку 202 как наиболее релевантную (несмотря на то, что первый эксперт выбрал вторую возможную отметку 204). Другими словами, предполагается, что первый эксперт 110 хотел выбрать первую возможную отметку 202, что является условной вероятностью второй возможной отметки 204 (т.е. первый эксперт 110 умышленно или неумышленно выбрал возможную отметку 204, несмотря на то что первый эксперт 110 воспринимал первую возможную отметку 202 как наиболее подходящую). В некоторых вариантах осуществления настоящей технологии, параметр 304 экспертизы и параметр 306 сложности используются как весовые факторы при вычислении условной оценки 310 вероятности. Процесс идентификации условной оценки 310 вероятности для каждой другой возможной отметки выполняется аналогичным образом.
[0094] Четвертая колонка таблицы 402 соответствует конкретной для отметки воспринимаемой оценке 314. Конкретная для отметки воспринимаемая оценка 314 представляет собой вероятность того, что данная отметка была воспринята как релевантная первым экспертом 110. В данном примере, конкретная для первой оценки воспринимаемая оценка 316, которая обладает значением X1M1, определяется путем умножения присущей оценки 214 вероятности первой отметки и условной оценки 312 вероятности первой отметки. Процесс идентификации конкретной для отметки воспринимаемой оценки 314 для каждой другой возможной отметки выполняется аналогичным образом.
[0095] Таблица 402 также включает в себя сумму всех конкретных для отметок воспринимаемых оценок 314, которая представляет собой конкретное для эксперта распределение 308 воспринимаемой отметки.
[0096] Несмотря на то что на Фиг. 4 показан только примерный вариант определения конкретного для эксперта распределения 308 воспринимаемой отметки для первого эксперта 110, конкретное для эксперта распределение 308 воспринимаемой отметки для второго эксперта 112 определяется аналогичным образом.
[0097] Возвращаясь к Фиг. 3, назначенная отметка 146 в виде распределения средней отметки создается путем агрегации конкретного для эксперта распределения 308 воспринимаемой отметки для первого эксперта 110 и конкретного для эксперта распределения 308 воспринимаемой отметки для второго эксперта 112 (а также конкретных для экспертов распределений 308 воспринимаемой отметки других потенциально присутствующих в системе 100 экспертов).
[0098] В общем случае, распределение средней отметки может быть получено путем максимизации вероятности 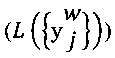 помех выбранных отметок
помех выбранных отметок 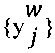 , что представлено путем следующей псевдо-формулы:
, что представлено путем следующей псевдо-формулы:
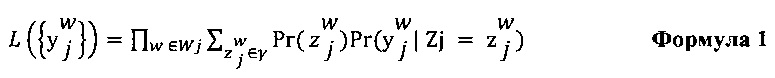
Где:
- w представляет собой данного эксперта (т.е. первого эксперта 110 или второго эксперта 112);
- W представляет собой множество экспертов, связанных со множеством электронных устройств 1128;
- j представляет собой цифровой обучающий документ 126;
- 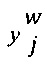 представляет собой выбранную отметку (т.е. первую выбранную отметку 138 или вторую выбранную отметку 140) данным экспертом w (т.е. первым экспертом 110 или вторым экспертом 112) для цифрового обучающего документа j (т.е. цифрового обучающего документа 126);
представляет собой выбранную отметку (т.е. первую выбранную отметку 138 или вторую выбранную отметку 140) данным экспертом w (т.е. первым экспертом 110 или вторым экспертом 112) для цифрового обучающего документа j (т.е. цифрового обучающего документа 126);
- 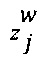 представляет собой воспринимаемую отметку данного эксперта (т.е. первого эксперта 110 или второго эксперта 112) при оценке цифрового обучающего документа 126;
представляет собой воспринимаемую отметку данного эксперта (т.е. первого эксперта 110 или второго эксперта 112) при оценке цифрового обучающего документа 126;
- Zj представляет собой случайную переменную, которая представляет возможные выводы из 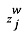 .
.
- γ представляет собой диапазон возможных отметок 128;
- 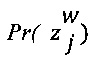 представляет собой присущую для эксперта оценку 134 вероятности данной отметки;
представляет собой присущую для эксперта оценку 134 вероятности данной отметки;
- 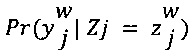 представляет собой условную оценку 310 вероятности, которая определяется с помощью параметра 304 экспертизы данного эксперта (показан как ew) и параметра 306 сложности цифрового обучающего документа 126 (показан как dj).
представляет собой условную оценку 310 вероятности, которая определяется с помощью параметра 304 экспертизы данного эксперта (показан как ew) и параметра 306 сложности цифрового обучающего документа 126 (показан как dj).
[0099] Настоящая технология может использовать модифицированные обычные модели для выполнения вышеописанной формулы вероятности помех, например, (i) модель Дэвида-Скена, (ii) генеративную модель отметок, возможностей и сложностей (GLAD), и (iii) принцип минимакса энтропии (ММЕ) для вычисления распределения средней отметки.
[00100] Как было указано ранее, обычные модели основаны на предположении о том, что цифровой обучающий документ 126 обладает единой истинной отметкой. Таким образом, обычные способы определения средней отметки (как единой оценки) выполняются путем максимизации совместной вероятности выбранных отметок и скрытой (т.е. неизвестной) истинной отметки, что представлено следующей формулой:
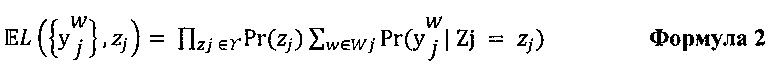
Где zj представляет собой скрытую истинную отметку.
[00101] Модель Дэвида-Скена
[00102] В модели Дэвида-Скена вектор априорных вероятностей возможной отметки, который является истинной отметкой (параметр р), определяется следующим образом: 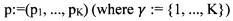 . Параметр ew экспертизы представляет собой матрицу неточностей размером K×K. Значимость выбранной отметки как истинной отметки определяется по следующей формуле:
. Параметр ew экспертизы представляет собой матрицу неточностей размером K×K. Значимость выбранной отметки как истинной отметки определяется по следующей формуле: 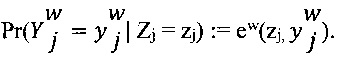
[00103] В соответствии с некоторыми вариантами осуществления настоящей технологии, модель Дэвида-Скена модифицируется следующим образом: (i) для каждого цифрового обучающего документа 126, вектор qj=(qj,1, …, qj,K) берется из распределения Дирихле PQ:=Dir(p), этот вектор qj является параметром мультиноминального распределения воспринимаемых отметок для цифрового обучающего документа 126; (2) когда первый эксперт 110 (например) просматривает цифровой обучающий документ 126, сначала воспринимаемая отметка берется из мультиноминального распределения Mult(qj), а далее выбранная отметка (например, первая выбранная отметка 138) берется из мультиноминального распределения 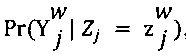 , которое по определению равно
, которое по определению равно 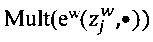 , где
, где 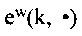 означает k-тую строку матрицы неточностей параметра 304 экспертизы.
означает k-тую строку матрицы неточностей параметра 304 экспертизы.
[00104] Генеративная модель отметок, возможностей и сложностей (GLAD)
[00105] В модели GLAD вектор априорных вероятностей возможной отметки, который является истинной отметкой (параметр р), также определяется следующим образом: р:=(р1, …, pK). Условная вероятность 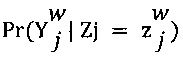 по определению равна
по определению равна 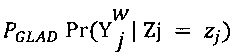 , где
, где 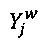 является случайной переменной, значение которой является наблюдаемой отметкой с помехами, которая назначена данным экспертом w цифровому обучающему документу j.
является случайной переменной, значение которой является наблюдаемой отметкой с помехами, которая назначена данным экспертом w цифровому обучающему документу j. 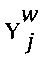 определяется на основе значения zj с вероятностью
определяется на основе значения zj с вероятностью 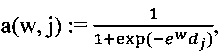 или с вероятностью 1-a(w,j), и значение берется из набора {1, …, K}\{zj}.
или с вероятностью 1-a(w,j), и значение берется из набора {1, …, K}\{zj}.
[00106] В соответствии с некоторыми вариантами осуществления настоящей технологии, модель GLAD модифицируется следующим образом: (1) для цифрового обучающего документа 126, вектор qj выбирается из распределения Дирихле PQ:=Dir(p); и (2) воспринимаемая отметка выбирается из мультиноминального распределения Mult(qj), и далее, выбранная отметка 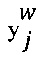 (например, первая выбранная отметка 138) создается из
(например, первая выбранная отметка 138) создается из 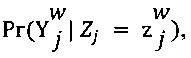 что по определению равно
что по определению равно 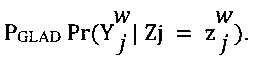
[00107] Принцип минимакса энтропии (ММЕ)
[00108] В соответствии с принципом минимакса энтропии, параметр ew экспертизы представляет собой матрицу размера K×K и параметр dj сложности также является матрицей размера K×K. С учетом этих параметров, для каждого работника w и каждого цифрового обучающего документа j, условная вероятность 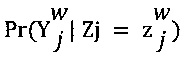 (см. Формулу 2) по определению равна
(см. Формулу 2) по определению равна 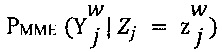 , что обладает вероятностью
, что обладает вероятностью 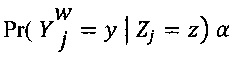 ехр
ехр 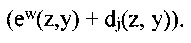
[00109] В соответствии с некоторыми вариантами осуществления настоящей технологии, принцип минимакса энтропии модифицируется следующим образом: (1) для каждого цифрового обучающего документа 126, вектор су создается из распределения Дирихле PQ:=Dir(p); и (2) для данного эксперта (например, первого эксперта 110) и цифрового обучающего документа 126, воспринимаемая отметка выбирается из мультиноминального распределения Mult(qj), и далее, выбранная отметка (например, выбранная отметка 138) выбирается из 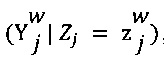 , что по определению равно РММЕ
, что по определению равно РММЕ 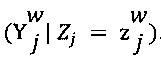
[00110] Варианты осуществления настоящей технологии основаны на предположении разработчиков о том, что использование обучающего объекта 144 в виде цифрового обучающего документа 126 и распределения средней отметки в виде назначенной «отметки» для обучения приложения 122 ранжирования улучшает точность приложения 122 ранжирования. Без установления каких-либо ограничений или рамок какой-либо теории, варианты осуществления настоящей технологии основываются на предположении о том, что большее количество информации в отношении выбранных отметок (первой выбранной отметки 138, второй выбранной отметки 140) и информации об экспертах (первого эксперта 110, второго эксперта 112) для обучения приложения 122 ранжирования, приложение 122 ранжирования будет выдавать улучшенные результаты.
[00111] Например, если группе экспертов выдается задание «идентифицировать данный цвет» для получения набора данных для обучения приложения 122 ранжирования, обычным способом создания средней оценки является выбор большинством голосующих (например, «красный», поскольку 51% проголосовал за вариант «красный»). Тем не менее, в некоторых вариантах осуществления настоящей технологии, диапазон субъективных, но истинных отметок будет предоставлен приложению 122 ранжирования для обучения («51% воспринимает этот цвет как «красный», 29% как «фуксия» и 20% как «розовый»). Таким образом, в сравнении с текущим уровнем техники, где обучающий объект связан со значимостью каждой отметки, в настоящей технологии обучающий объект представляет собой вычисленную вероятность воспринимаемых экспертами (первым экспертом 110, вторым экспертом 112) отметок.
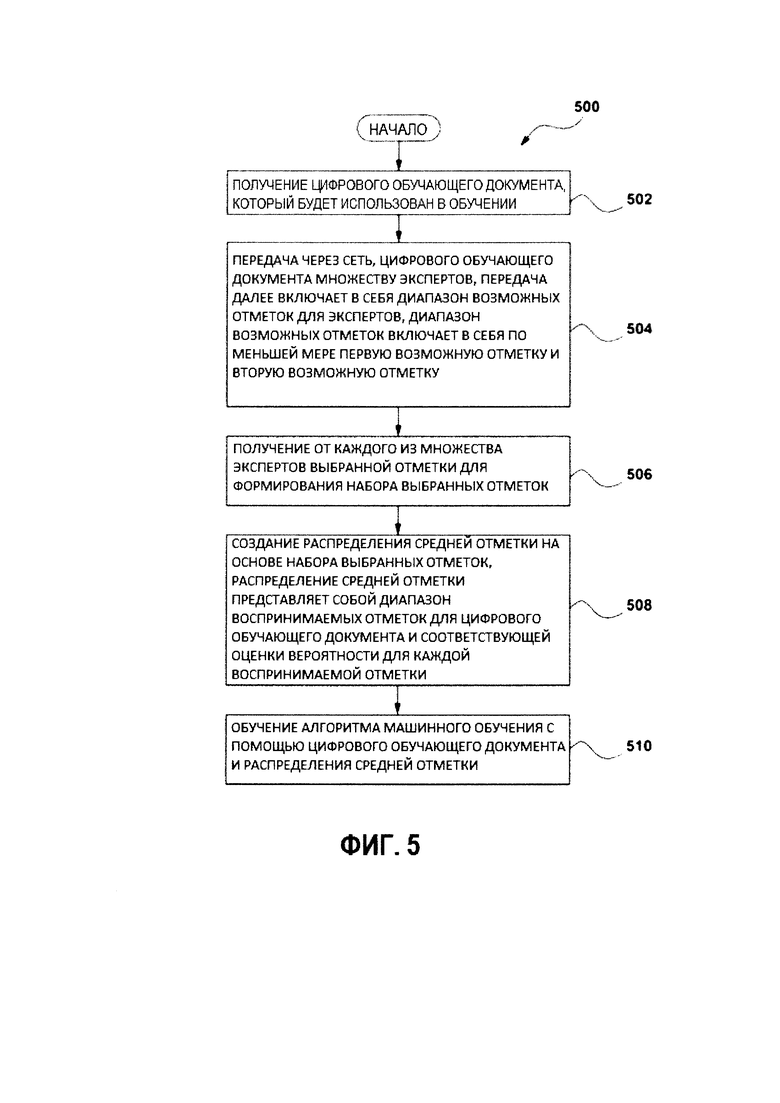
[00112] С учетом представленной архитектуры и представленных примеров, возможно выполнить исполняемый на компьютере способ создания обучающего объекта для обучения алгоритма машинного обучения (например, приложения 122 ранжирования). На Фиг. 5 представлена блок-схема способа 500, реализованного в соответствии с вариантами осуществления настоящего технического решения, не ограничивающими его объем. Процесс 500 может выполняться обучающим сервером 114.
[00113] Этап 502 - получение цифрового обучающего документа, который будет использован в обучении
[00114] Способ 500 начинается с выполнения этапа 502, на котором обучающий сервер 114 получает цифровой обучающий документ 126.
[00115] В некоторых вариантах осуществления настоящей технологии, цифровой обучающий документ 126 является веб-страницей. В альтернативных вариантах осуществления настоящей технологии, цифровой обучающий документ 126 является изображением, текстом или медиа-файлом.
[00116] Этап 504 - передача через сеть цифрового обучающего документа множеству экспертов, передача далее включает в себя диапазон возможных отметок для экспертов, диапазон возможных отметок включает в себя по меньшей мере первую возможную отметку и вторую возможную отметку
[00117] На этапе 504, обучающий сервер 114 передает через сеть 102 передачи данных цифровой обучающий документ 126 и диапазон возможных отметок 128 множеству электронных устройств 104 для оценки.
[00118] В некоторых вариантах осуществления настоящей технологии, инструкция по отметке передается множеству электронных устройств 104 вместе с цифровым обучающим документом 126 и диапазоном возможных отметок 128.
[00119] В некоторых вариантах осуществления технологии, инструкция по отметке представляет собой по меньшей мере одну из задач категоризации или ранжирования.
[00120] Этап 506 - получение от каждого из множества экспертов выбранной отметки для формирования набора выбранных отметок
[00121] На этапе 506 обучающий сервер 114 получает от каждого эксперта с помощью соответствующего одного из множества электронных устройств 104 (первого эксперта 110, второго эксперта 112) выбранные отметки (первую выбранную отметку 130 и вторую выбранную отметку 140) для формирования набора выбранных отметок 302.
[00122] Этап 508 - создание распределения средней отметки на основе набора выбранных отметок, распределение средней отметки представляет собой диапазон воспринимаемых отметок для цифрового обучающего документа и соответствующей оценки вероятности для каждой воспринимаемой отметки; и
[00123] На этапе 508, на основе набора выбранных отметок 302, обучающий сервер 114 создает назначенную отметку 146 в виде распределения средней отметки.
[00124] Этап 510 - обучение алгоритма машинного обучения с помощью цифрового обучающего документа и распределения средней отметки.
[00125] На этапе 510 обучающий сервер 114 передает цифровой обучающий документ 126 и назначенную отметку 146 в виде распределения средней отметки приложению 122 ранжирования сервера 116 поискового ранжирования.
[00126] В некоторых вариантах осуществления настоящей технологии, приложение 122 ранжирование выполнено с возможностью исполнять алгоритм машинного обучения, и обучение приложения 122 ранжирования включает в себя обучение алгоритма машинного обучения.
[00127] Приложение 122 ранжирования выполнено с возможностью использовать цифровой обучающий документ 126 и назначенную отметку 146 для обучения алгоритма машинного обучения.
[00128] В конкретных вариантах осуществления способа 400, обучение основано на задаче улучшения релевантности результата поиска в ответ на поисковый запроса сервером 116 поискового ранжирования.
[00129] С учетом вышеописанных вариантов осуществления технического решения, которые были описаны и показаны со ссылкой на конкретные этапы, выполненные в определенном порядке, следует иметь в виду, что эти этапы могут быть совмещены, разделены, обладать другим порядком выполнения - все это не выходит за границы настоящего технического решения. Соответственно, порядок и группировка этапов не является ограничением для настоящей технологии.
[00130] Излишне говорить, что несмотря на что настоящая технология был описана с двумя экспертами (первым экспертом 110 и вторым экспертом 112), которые оценивают один цифровой обучающий документ 126, это было сделано исключительно для облегчения понимания, а не установления ограничений. Специалисту в данной области техники очевидно, что для правильного обучения и оптимизации приложения 122 ранжирования потребуется большее число экспертов и цифровых обучающих документов.
[00131] Таким образом, по меньшей мере некоторые неограничивающие варианты осуществления настоящей технологии, описанные выше, можно изложить следующим образом в виде пронумерованных пунктов.
[00132] ПУНКТ 1. Исполняемый на компьютере способ (500) создания обучающего объекта (144) для обучения алгоритма машинного обучения, обучающий объект (144) включает в себя цифровой обучающий документ (126) и назначенную отметку (146), способ выполняется на обучающем сервере (114), способ включает в себя:
получение (502) цифрового обучающего документа (126), который будет использован в обучении;
передача (504) через сеть (102) передачи данных, цифрового обучающего документа (126) множеству экспертов (110, 112), передача далее включает в себя диапазон возможных отметок (128) для экспертов (110, 112), диапазон возможных отметок (128) включает в себя по меньшей мере первую возможную отметку (202) и вторую возможную отметку (204);
получение (506) от каждого из множества экспертов (110, 112) выбранной отметки (138, 140) для формирования набора выбранных отметок (302);
создание распределения (146) средней отметки на основе набора выбранных отметок (302), распределение (146) средней отметки представляет собой диапазон воспринимаемых отметок (202, 204, 206, 208) для цифрового обучающего документа (126) и соответствующей оценки вероятности для каждой воспринимаемой отметки (202, 204, 206, 208); и
обучение алгоритма машинного обучения с помощью цифрового обучающего документа (126) и распределения (146) средней отметки.
[00133] ПУНКТ 2. Способ по п. 1, дополнительно включающий в себя:
определение параметра (304) экспертизы для каждого из множества экспертов (110, 112) на основе набора выбранных отметок (302); и
определение параметра (306) сложности цифрового обучающего документа (126) на основе набора выбранных отметок (302).
[00134] ПУНКТ 3. Способ по п. 2, в котором:
параметр (304) экспертизы независим от оцениваемого цифрового обучающего документа (126); и
параметр (306) сложности независим от какого-либо эксперта (110, 112), оценивающего цифровой обучающий документ (126).
[00135] ПУНКТ 4. Способ по п. 3, в котором распределение (146) средней отметки определяется с помощью:
определения конкретного для эксперта распределения (308) воспринимаемой отметки для каждого из множества экспертов (100, 112);
агрегирования каждого конкретного для эксперта распределения (308) воспринимаемой отметки для множества экспертов (100, 112).
[00136] ПУНКТ 5. Способ по п. 4, в котором конкретное для эксперта распределение (308) воспринимаемой отметки для данного эксперта (110) определяется с помощью:
для первой возможной отметки (202):
определения присущей для эксперта оценки (134) первой возможной отметки (202), выбранной данным экспертом (110);
определения условной оценки (312) вероятности на основе по меньшей мере параметра (304) экспертизы и параметра (306) сложности, условная оценка (312) вероятности представляет собой вероятность того, что выбранная отметка (138), предоставленная данному эксперту (110), который воспринимал первую возможную отметку (202), будет наиболее релевантной для цифрового обучающего документа (126); и
агрегирования присущей эксперту оценки (134) вероятности и условной оценки (312) вероятности для получения воспринимаемой оценки (316), конкретной для первой отметки;
для второй возможной отметки (204):
определения присущей для эксперта оценки (134) второй возможной отметки (204), выбранной данным экспертом (110);
определения условной оценки (312) вероятности на основе по меньшей мере параметра (304) экспертизы и параметра (306) сложности, условная оценка (312) вероятности представляет собой вероятность того, что выбранная отметка (138), предоставленная данному эксперту (110), который воспринимал вторую возможную отметку (204), будет наиболее релевантной для цифрового обучающего документа (126);
агрегирования присущей эксперту оценки (134) вероятности и условной оценки (310) вероятности для получения воспринимаемой оценки (318), конкретной для второй отметки;
агрегирования воспринимаемой оценки (316), конкретной для первой отметки, и воспринимаемой оценки (318), конкретной для второй отметки.
[00137] ПУНКТ 6. Способ по п. 5, в котором присущая эксперту оценка (134) вероятности определяется на основе по меньшей мере конкретного для эксперта (110) параметра (132) тенденции.
[00138] ПУНКТ 7. Способ по п. 6, который дополнительно включает в себя определение для данного эксперта (110) конкретного для эксперта параметра (132) тенденции на основе по меньшей мере истории оценок данного эксперта.
[00139] ПУНКТ 8. Способ по любому из пп. 1-7, в котором распределение (146) средней отметки получают путем максимизации вероятности выбранной отметки (138, 140), используя формулу:
[00140] ПУНКТ 9. Способ по п. 8, в котором формула вычисляется с помощью по меньшей мере одной модифицированной модели на основе (i) модели Dawid и Skene, (ii) модели GLAD, и (iii) принципа минимакса энтропии.
[00141] ПУНКТ 10. Способ по любому из пп. 1-9, в котором множество экспертов (110, 112) включает в себя первого эксперта (110) и второго эксперта (112) и выбранная отметка (138), полученная от первого эксперта (110), отличается от выбранной отметки (140), полученной от второго эксперта (112).
[00142] ПУНКТ 11. Способ по любому из пп. 1-10, в котором алгоритм машинного обучения выполняется приложением (122) ранжирования сервера (116) поискового ранжирования, и при этом обучение происходит с целью повышения точности алгоритма машинного обучения.
[00143] ПУНКТ 12. Способ по п. 11, в котором представляет собой улучшение релевантности поискового результата в ответ на поисковый запрос.
[00144] ПУНКТ 13. Способ по п. 12, в котором обучающий сервер (114) является сервером (116) поискового ранжирования.
[00145] ПУНКТ 14. Обучающий сервер (114) для обучения приложения (122) ранжирования, приложение (122) для ранжирования результатов поиска, обучающий сервер (114) включает в себя:
сетевой интерфейс для коммуникативного соединения сети передачи данных;
процессор соединен с сетевым интерфейсом, процессор выполнен с возможностью выполнять способ по любому из пп. 1-13.
[00146] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления настоящего технического решения. Например, варианты осуществления настоящего технического решения могут быть выполнены без проявления некоторых технических результатов, другие могут быть выполнены с проявлением других технических результатов или вовсе без них.
[00147] Некоторые из этих этапов, а также процессы передачи-получения сигнала являются хорошо известными в данной области техники и поэтому для упрощения были опущены в некоторых частях данного описания. Сигналы могут быть переданы-получены с помощью оптических средств (например, оптоволоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00148] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ОБУЧЕНИЯ МОДУЛЯ РАНЖИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОБУЧАЮЩЕЙ ВЫБОРКИ С ЗАШУМЛЕННЫМИ ЯРЛЫКАМИ | 2016 |
|
RU2632143C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| СПОСОБ И СИСТЕМА ВЫБОРА ПОТЕНЦИАЛЬНО ОШИБОЧНО РАНЖИРОВАННЫХ ДОКУМЕНТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2664481C1 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2021 |
|
RU2824338C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
| Система и способ для формирования обучающего набора для алгоритма машинного обучения | 2020 |
|
RU2790033C2 |
Изобретение относится к способу создания обучающего объекта для обучения алгоритма машинного обучения. Технический результат заключается в создании распределения средней отметки релевантности документа поисковому запросу в форме распределения воспринимаемых отметок. Способ включает в себя: получение цифрового обучающего документа, который будет использован в обучении; передачу цифрового обучающего документа множеству экспертов, передача далее включает в себя указание на диапазон возможных отметок для экспертов, диапазон возможных отметок включает в себя по меньшей мере первую возможную отметку и вторую возможную отметку; получение от каждого из множества экспертов выбранной отметки для формирования набора выбранных отметок; создание распределения средней отметки на основе набора выбранных отметок, распределение средней отметки представляет собой диапазон воспринимаемых отметок для цифрового обучающего документа и связанную оценку вероятности для каждой из воспринимаемых отметок; и обучение алгоритма машинного обучения с использованием цифрового обучающего документа и распределения средней отметки. 2 н. и 22 з.п. ф-лы, 5 ил.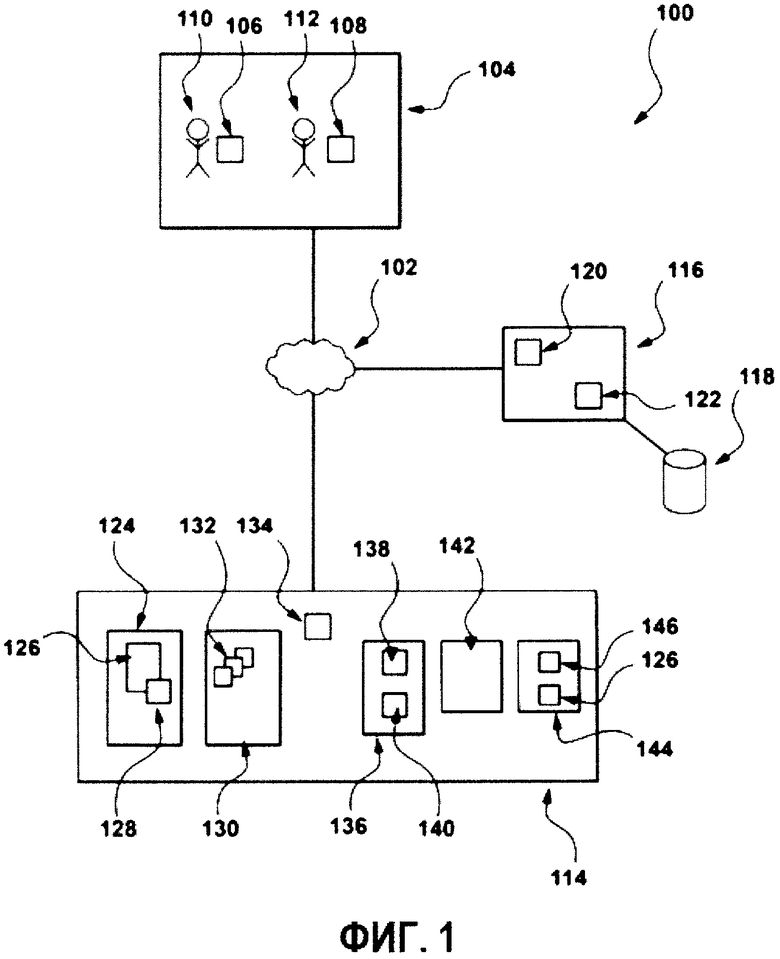
1. Исполняемый на компьютере способ обучения алгоритма машинного обучения с помощью обучающего объекта, включающего в себя цифровой документ и назначенную отметку релевантности документа поисковому запросу, включающий:
получение цифрового обучающего документа, который будет использован в обучении;
передачу через сеть цифрового обучающего документа множеству экспертов, передача также включает в себя диапазон возможных отметок релевантности документа поисковому запросу для экспертов, диапазон возможных отметок включает в себя по меньшей мере первую возможную отметку и вторую возможную отметку;
получение от каждого из множества экспертов выбранной отметки для формирования набора выбранных отметок;
создание распределения средней отметки на основе набора выбранных отметок, распределение средней отметки представляет собой диапазон воспринимаемых отметок для цифрового обучающего документа и соответствующей оценки вероятности того, что отметка будет наиболее релевантной для цифрового обучающего документа, для каждой воспринимаемой отметки; и
обучение алгоритма машинного обучения с помощью цифрового обучающего документа и распределения средней отметки.
2. Способ по п. 1, в котором дополнительно выполняют:
определение параметра экспертизы для каждого из множества экспертов на основе набора выбранных отметок; и
определение параметра сложности цифрового обучающего документа на основе набора выбранных отметок.
3. Способ по п. 2, в котором:
параметр экспертизы независим от оцениваемого цифрового обучающего документа; и
параметр сложности независим от какого-либо эксперта, оценивающего цифровой обучающий документ.
4. Способ по п. 3, в котором распределение средней отметки определяют с помощью:
определения конкретного для эксперта распределения воспринимаемой отметки для каждого из множества экспертов;
агрегирования каждого конкретного для эксперта распределения воспринимаемой отметки для множества экспертов.
5. Способ по п. 4, в котором конкретное для эксперта распределение воспринимаемой отметки для данного эксперта определяют с помощью:
для первой возможной отметки:
определения присущей для эксперта оценки первой возможной отметки, выбранной данным экспертом;
определения условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринимал первую возможную отметку, будет наиболее релевантной для цифрового обучающего документа; и
агрегирования присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для первой отметки;
для второй возможной отметки:
определения присущей для эксперта оценки второй возможной отметки, выбранной данным экспертом;
определения условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринимал вторую возможную отметку, будет наиболее релевантной для цифрового обучающего документа;
агрегирования присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для второй отметки;
агрегирования воспринимаемой оценки, конкретной для первой отметки, и воспринимаемой оценки, конкретной для второй отметки.
6. Способ по п. 5, в котором присущую эксперту оценку вероятности определяют на основе по меньшей мере конкретного для эксперта параметра тенденции.
7. Способ по п. 6, в котором дополнительно выполняют определение для данного эксперта конкретного для эксперта параметра тенденции на основе по меньшей мере истории оценок данного эксперта.
8. Способ по п. 1, в котором распределение средней оценки получают путем максимизации вероятности выбранной оценки путем использования формулы:
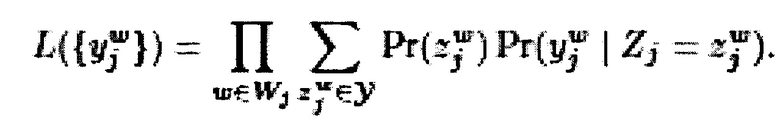
где:
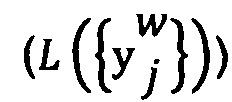 - вероятность помех выбранных отметок
- вероятность помех выбранных отметок 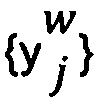 ;
;
w представляет собой данного эксперта;
W представляет собой множество экспертов, связанных со множеством электронных устройств;
j представляет собой цифровой обучающий документ;
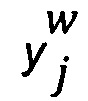 представляет собой выбранную отметку данным экспертом w для цифрового обучающего документа j;
представляет собой выбранную отметку данным экспертом w для цифрового обучающего документа j;
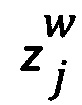 представляет собой воспринимаемую отметку данного эксперта при оценке цифрового обучающего документа;
представляет собой воспринимаемую отметку данного эксперта при оценке цифрового обучающего документа;
Zj представляет собой случайную переменную, которая представляет возможные выводы из 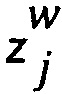 ;
;
γ представляет собой диапазон возможных отметок;
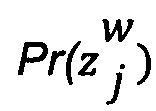 представляет собой присущую для эксперта оценку вероятности данной отметки;
представляет собой присущую для эксперта оценку вероятности данной отметки;
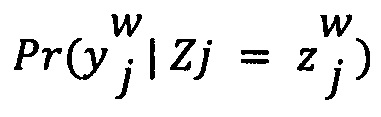 представляет собой условную оценку вероятности, которая определяется с помощью параметра экспертизы данного эксперта и параметра сложности цифрового обучающего документа.
представляет собой условную оценку вероятности, которая определяется с помощью параметра экспертизы данного эксперта и параметра сложности цифрового обучающего документа.
9. Способ по п. 8, в котором формула вычисляется с помощью по меньшей мере одной модифицированной модели на основе модели Dawid и Skene, модели GLAD и принципа минимакса энтропии.
10. Способ по п. 1, в котором множество экспертов включает в себя первого эксперта и второго эксперта и выбранная отметка, полученная от первого эксперта, отличается от выбранной отметки, полученной от второго эксперта.
11. Способ по п. 1, в котором алгоритм машинного обучения выполняется приложением ранжирования сервера поискового ранжирования, и при этом обучение происходит с целью повышения точности алгоритма машинного обучения.
12. Способ по п. 11, в котором осуществляют улучшение релевантности поискового результата в ответ на поисковый запрос.
13. Способ по п. 12, в котором обучающий сервер является сервером поискового ранжирования.
14. Обучающий сервер для обучения алгоритма машинного обучения, который выполняется приложением ранжирования, обучающий сервер включает в себя:
сетевой интерфейс для коммуникативного соединения сети передачи данных;
процессор, соединенный с сетевым интерфейсом и выполненный с возможностью осуществлять:
получение цифрового обучающего документа, который будет использован в обучении;
передачу через сеть цифрового обучающего документа множеству экспертов, передача также включает в себя диапазон возможных отметок релевантности документа поисковому запросу для экспертов, диапазон возможных отметок включает в себя по меньшей мере первую возможную отметку и вторую возможную отметку;
получение от каждого из множества экспертов выбранной отметки для формирования набора выбранных отметок;
создание распределения средней отметки на основе набора выбранных отметок, распределение средней отметки представляет собой диапазон воспринимаемых отметок для цифрового обучающего документа и соответствующей оценки вероятности того, что отметка будет наиболее релевантной для цифрового обучающего документа, для каждой воспринимаемой отметки; и
обучение алгоритма машинного обучения с помощью цифрового обучающего документа и распределения средней отметки.
15. Обучающий сервер по п. 14, в котором процессор дополнительно выполнен с возможностью осуществлять:
определение параметра экспертизы для каждого из множества экспертов на основе набора выбранных отметок; и
определение параметра сложности цифрового обучающего документа на основе набора выбранных отметок.
16. Обучающий сервер по п. 15, в котором:
параметр экспертизы независим от оцениваемого цифрового обучающего документа; и
параметр сложности независим от какого-либо эксперта, оценивающего цифровой обучающий документ.
17. Обучающий сервер по п. 16, в котором распределение средней отметки определяется процессором, который выполнен с возможностью выполнять:
определение конкретного для эксперта распределения воспринимаемой отметки для каждого из множества экспертов;
агрегирование каждого конкретного для эксперта распределения воспринимаемой отметки для множества экспертов.
18. Обучающий сервер по п. 17, в котором конкретное для эксперта распределение воспринимаемой отметки для данного эксперта определяется процессором, который выполнен с возможностью осуществлять:
для первой возможной отметки:
определение присущей для эксперта оценки первой возможной отметки, выбранной данным экспертом;
определение условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринимал первую возможную отметку, будет наиболее релевантной для цифрового обучающего документа; и
агрегирование присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для первой отметки;
для второй возможной отметки:
определение присущей для эксперта оценки второй возможной отметки, выбранной данным экспертом;
определение условной оценки вероятности на основе по меньшей мере параметра экспертизы и параметра сложности, условная оценка вероятности представляет собой вероятность того, что выбранная отметка, предоставленная данному эксперту, который воспринимал вторую возможную отметку, будет наиболее релевантной для цифрового обучающего документа;
агрегирование присущей эксперту оценки вероятности и условной оценки вероятности для получения воспринимаемой оценки, конкретной для второй отметки;
агрегирование воспринимаемой оценки, конкретной для первой отметки, и воспринимаемой оценки, конкретной для второй отметки.
19. Обучающий сервер по п. 18, в котором процессор выполнен с дополнительной возможностью определять присущую эксперту оценку вероятности на основе по меньшей мере конкретного для эксперта параметра тенденции.
20. Обучающий сервер по п. 19, в котором процессор выполнен с дополнительной возможностью определять для данного эксперта конкретного для эксперта параметра тенденции на основе по меньшей мере истории оценок данного эксперта.
21. Обучающий сервер по п. 14, в котором множество экспертов включает в себя первого эксперта и второго эксперта и выбранная отметка, полученная от первого эксперта, отличается от выбранной отметки, полученной от второго эксперта.
22. Обучающий сервер по п. 14, в котором алгоритм машинного обучения выполняется приложением ранжирования сервера поискового ранжирования, и при этом обучение происходит с целью повышения точности алгоритма машинного обучения.
23. Обучающий сервер по п. 22, в котором процессор выполнен с возможностью осуществлять улучшение релевантности поискового результата в ответ на поисковый запрос.
24. Обучающий сервер по п. 23, в котором обучающий сервер является сервером поискового ранжирования.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 6697998 B1, 24.12.2004 | |||
| СПОСОБ ИНФОРМАЦИОННОГО ПОИСКА (ВАРИАНТЫ) И КОМПЬЮТЕРНАЯ СИСТЕМА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2011 |
|
RU2506636C2 |

