Изобретение относится к области вычислительной техники, а именно к области передачи информации из памяти модуля-источника модулю-приемнику, и может быть использовано при реализации традиционных сетевых протоколов с использованием стандартной шины PCI-Express и подключения HS-контроллера.
Известно (RU Патент 2110838, опубл. 10.05.1998) устройство для оптимизации организации доступа к общей шине во время передачи данных с прямым доступом к памяти, содержащее центральный процессор, блок оперативной памяти, не менее двух внешних каналов связи, входы-выходы которых подключены к системной шине устройства, связанной с выходом генератора. Каждый из внешних каналов связи содержит первый инвертор, вход которого связан с выходом генератора через системную шину, второй инвертор, вход которого соединен с выходом первого инвертора, выход второго инвертора соединен с первым входом первого элемента И, второй вход которого соединен с выходом генератора через системную шину, выход первого элемента И соединен с входом первого элемента ИЛИ - НЕ, выход которого соединен с входом первого буферного драйвера и первым входом второго элемента И, второй вход которого соединен с выходом первого инвертора, выход второго элемента И соединен с первым входом второго элемента ИЛИ - НЕ, выход которого соединен с входом второго буферного драйвера.
Известное устройство обеспечивает эффективное использование процессорной шины при прямом доступе в память за счет оригинальной схемы арбитража, но не имеет средств реализации VI интерфейсов, в том числе не позволяет производить автоматическую выборку новых заданий на передачу (без участия процессора) и динамически подцеплять новые цепочки на передачу пакетов данных.
В ходе проведения патентно-информационного поиска не выявлен источник информации, который мог бы быть использован в качестве ближайшего аналога.
Техническая задача, решаемая посредством данного способа, состоит в разработке аппаратного интерфейса, на базе которого можно было программно-аппаратным образом реализовать стандарт VI-интерфейсов.
Технический результат, достигаемый при реализации разработанного способа, состоит в сокращении затрат процессорного времени на многочисленные копирования данных из памяти в память, которые имели место в традиционных сетевых протоколах, а также повышении эффективности использования пропускной способности сети.
Для достижения указанного технического результата предложено использовать разработанный способ организации прямого доступа в память при передаче информации между физическими объектами. При реализации разработанного способа для передачи данных в формате PCI-Express пакетов между модулем-источником и модулем-приемником использованы аппаратные блоки прямого доступа в память, выполненные с возможностью динамического управления цепочками заданий на отправку и прием данных, входящие в состав HS-контроллеров, выполненных с возможностью обеспечить эффективный обмен данными между памятью модулей при минимальном участии процессоров с аппаратным ограничением пропускной способности канала передачи данных и предоставлением гарантированных временных интервалов доступа к разделяемым ресурсам процессорной шины на базе использования стандарта VI (виртуальных интерфейсов) и стандартной шины PCI-Express и подключения HS-контроллера, при этом в рамках стандарта VI обмен данных происходит между парой процессов в различных процессорах по принципу «точка-точка», причем для каждого из процессов дуплексный канал обмена представляет собой виртуальный интерфейс, который с программной точки зрения состоит из пары рабочих очередей, одна из которых представляет собой очередь заданий на отправку, а другая на прием, при этом стандарт VI представляет собой стандарт виртуальных интерфейсов, разработанный фирмами Intel, Compaq, Microsoft, а используемый HS-контроллер выполнен как проект, реализованный на ПЛИС.
При реализации прикладного программного средства HS-шина была предназначена для передачи данных между модулями (из памяти в память) с минимальным участием процессоров в этой деятельности. Задание на пересылку для контроллера формировалось процессором модуля-источника в памяти; передача адреса задания контроллеру инициировало начало передачи. О завершении передачи процессоры модуля-источника и модуля-приемника могли быть уведомлены контроллером. Примерно эта же идея лежит в основе разработанного фирмами Intel, Compaq, Microsoft стандарта Виртуальных Интерфейсов (VI). Мотивацией для его создания было стремление сократить затраты процессорного времени на многочисленные копирования данных из памяти в память, которые имели место, например, в традиционных сетевых протоколах (а заодно и повысить эффективность использования пропускной способности сети).
Повышение эффективности в VI достигалось за счет обеспечения доступа контроллеров непосредственно к той памяти, где данные генерировались или потреблялись. При этом допускалось, чтобы данные не обязаны были лежать в памяти единым массивом, а могли быть в ней рассеяны там, где они были сгенерированы или должны быть потреблены.
Настоящая работа предназначена для определения, каким требованиям должен удовлетворять аппаратный интерфейс, чтобы на его базе можно было программно-аппаратным образом реализовать стандарт VI-интерфейсов.
В рамках стандарта VI обмен данных производится между парой процессов в различных процессорах по принципу «точка-точка». Каждому из процессов дуплексный канал обмена представляет собой виртуальный интерфейс, который с программной точки зрения представляет собой пару рабочих очередей, т.н. дескрипторов, которые в дальнейшем будут представлены VI-заданиями. Одна из очередей представляет собой очередь заданий на отправку, соответственно другая на прием.
Стандарт VI-интерфейсов предусматривает возможность создания т.н. очередей завершения, куда складываются уведомления о завершении обработки VI-заданий очередей одного или нескольких VI-интерфейсов. При этом вовсе не обязательно, чтобы входная очередь была привязана к очереди завершения на том основании, что к ней привязана выходная очередь этого интерфейса, и наоборот. Необязательно привязывать каждую рабочую очередь к какой-либо очереди завершения. Для VI-интерфейсов очередей завершения может быть несколько, хотя может и не быть вообще.
В рамках стандарта VI имеется 3 модели обмена данными:
1. Стандартная модель SEND/RECEIVE, когда после установления соединения принимающий конец подготавливает несколько пустых буферов, а передающий конец - несколько буферов, заполненных данными, после чего передающий конец стартует передачу.
Задания на прием/передачу для этой модели на обоих концах канала обмена имеют сходную структуру.
2А. Модель прямого удаленного доступа к памяти (RDMA - Remote Direct Memory Access) по записи.
2B. Модель прямого удаленного доступа к памяти по чтению.
Стандарт VI разрешает не реализовывать модель 2В и эта модель в VI для «Соло» реализовываться не будет.
Согласно варианту стандарта, принадлежащего Intel, VI-задание имеет два варианта формата:
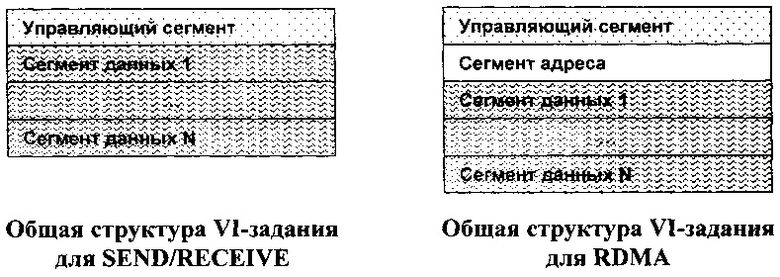
каждый из которых представляет собой некоторый заголовок с присоединенным массивом ссылок на буфера данных (плюс длины буферов и т.д.). Массивы имеют переменную длину.
Полный интерфейс VI признан излишне сложным для аппаратной реализации. Поэтому вводится более простой аппаратный интерфейс, а библиотеки реализации интерфейса VI обеспечивают связь между исходными конструкциями VI и аппаратным интерфейсом HS-контроллера.
Одному VI-заданию ставится в соответствие целая цепочка (т.е. однонаправленный список) аппаратных заданий - т.н. ТСВ (от Task Control Block) - по одному на каждый Сегмент адреса или на Сегмент данных. Последний ТСВ цепочки маркируется признаком ЕОС=1 (End Of Chain). В этот ТСВ упрятывается информация, относящаяся к VI-заданию в целом.
Очередь VI-заданий на прием для одного VI-интерфейса преобразуется в очередь ТСВ, провязанную из таких цепочек ТСВ; все очереди VI-заданий на передачу (т.е. для всех VI-интерфейсов) провязываются из таких цепочек ТСВ в 2 общие очереди ТСВ (по числу используемых приоритетов). Провязывание осуществляется имеющимися в каждом ТСВ указателями Next_TCB (поле NEXT_TCB_ADDRESS) на следующий ТСВ. Признаком конца очереди ТСВ служит нулевое значение такого указателя.
На фиг. 1 проиллюстрирована очередь ТСВ на прием (более простая по сравнению с очередью на отправку - за счет отсутствия смеси VI-заданий из разных VI-интерфейсов и отсутствия ТСВ для RDMA). Пунктирными стрелками показано соответствие между сегментами отдельных VI-заданий и ТСВ. Сплошными прямыми стрелками показаны ссылки из ТСВ на исходные VI-задания. Биты ЕОС - End Of Chain маркируют концы цепочек, соответствующих одному VI-заданию.
Рабочие очереди ТСВ, как и VI, располагаются в памяти.
В некотором смысле аналогом очереди завершения для VI-интерфейса является общая очередь уведомлений о завершении обслуживания ТСВ для всех рабочих очередей ТСВ, реализованная как аппаратное FIFO в контроллере. В целях экономии ресурсов ПЛИС и процессорного времени на обработку уведомлений общая очередь уведомлений содержит ссылки только на те обслуженные ТСВ, которые являются хвостовыми в цепочках (т.е. фактически она представляет собой очередь уведомлений на VI-задания). Кроме ссылок там содержится также информация о статусе завершения.
На каждый процессор МОСа (Модуль обработки сигнала) резервируется:
- 256 очередей заданий ТСВ для приема (Receive);
- 2 очереди ТСВ для передачи (одна высокоприоритетная, другая низкоприоритетная);
- 1 очередь завершения.
Транспортный канал, реализующий обмен между двумя VI-интерфейсами, должен поддерживать передачу служебной информации, а именно:
I. Он должен маркировать посылку последнего пакета данных, относящегося к последнему ТСВ цепочки как таковой.
II. Он должен маркировать отсылаемые данные, соответствующие сегменту адреса VI-задания типа RDMA для специальной обработки этих данных контроллером на удаленном конце.
Требование I обеспечивает поддержку синхронизации передачи и приема VI-заданий типа Send/Recv в соответствии с правилом стандарта VI: «передача, выполняющаяся по одному VI-заданию типа Send, должна быть принята по единственному VI-заданию типа Recv».
Требование II обеспечивает предполагаемую стандартом VI возможность осуществления передач типа RDMA Write без участия в пересылке программного агента на удаленном конце.
Адреса головных ТСВ очередей сообщаются контроллеру путем записи адреса в некоторый, собственный для каждой очереди регистр CURRENT_TCB_ADDRESS. Контроллер копирует [частично] эти ТСВ в собственную память (т.н. ТСВ-регистры) и исполняет.
Исполнение ТСВ заключается:
- для очередей на отправку - в передаче данных, адресованных в ТСВ, по каналам связи;
- для очередей на прием - в размещении прибывших данных по адресам, указанным в ТСВ.
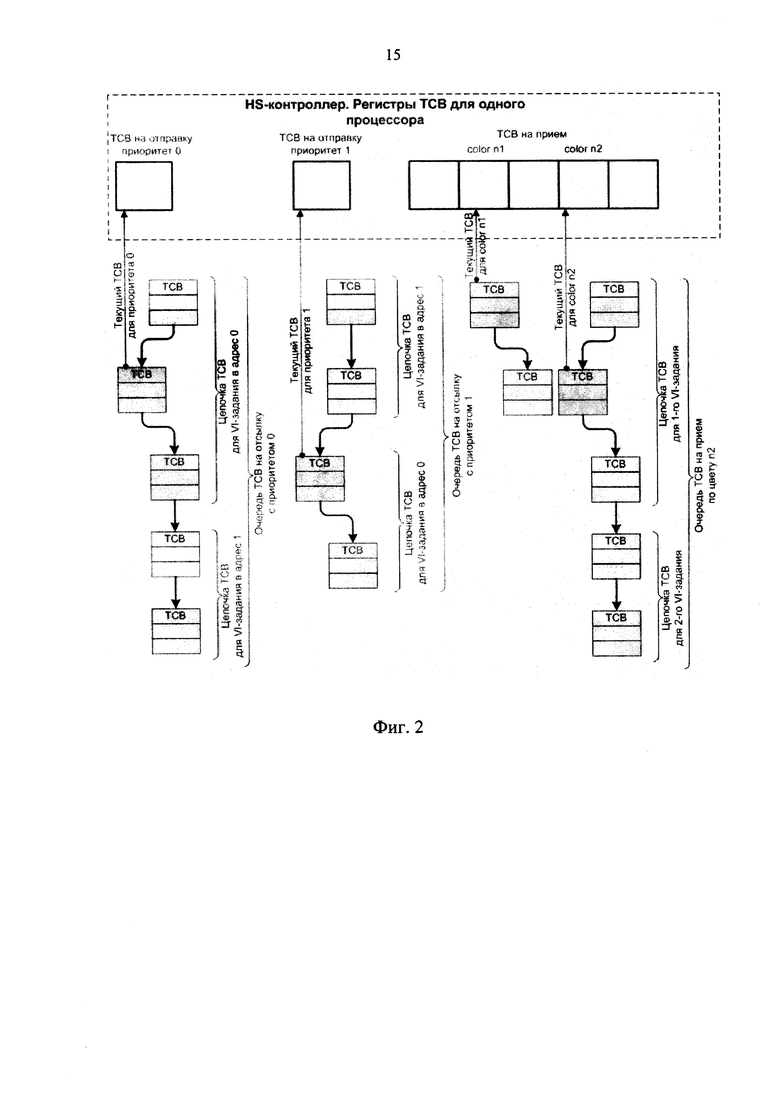
Далее контроллер перебирает блоки ТСВ каждой очереди уже самостоятельно (пока не требуется пополнения очередей). Процесс проходит следующим образом, как показано на фиг. 2, где более темным цветом здесь выделены т.н. текущие ТСВ, (частичные) образы которых загружены в данный момент в контроллер.
Предполагается, что контроллер имеет единственный передатчик на кластер и обслуживает ТСВ на отправку по следующей правилу - пока не обслужен очередной ТСВ, не предпринимается попытка обслуживания другого.
Очередность обслуживания ТСВ устанавливается следующая:
1) если непуста очередь с приоритетом 0 хотя бы у одного из двух процессоров, то поочередно обслуживаются именно эти очереди до их исчерпания;
2) если пусты очереди с приоритетом 0 у обоих процессоров, то поочередно обслуживаются эти очереди.
Завершая исполнение цепочки, контроллер помещает уведомление о завершении этой цепочки в аппаратную очередь завершения (уведомления о завершении цепочек на отправку и на прием помещаются в эту очередь вперемешку).
Предполагается, что программы с обоих концов канала обмена будут заняты постоянной «подкачкой» новых цепочек ТСВ-заданий. В этой, на первый взгляд, чисто программной деятельности должен участвовать и контроллер.
Новая цепочка ТСВ-заданий, отвечающая одному VI-заданию, должна быть полностью подготовлена в памяти программным образом заблаговременно (подсоединение к очереди отдельных ТСВ не допускается!). Далее корректировкой нулевого указателя в хвостовом ТСВ очереди производится программное подсоединение цепочки к очереди. Контроллер извещается об изменении состояния очереди «дверным звонком» - записью в особый регистр DOORBELL адреса бывшего хвостового ТСВ, у которого нулевой указатель на следующий ТСВ был откорректирован.
Как уже упоминалось, имеется особая модель обмена RDMA Write, когда с приемной стороны программное участие отсутствует вовсе. Для выполнения такого обмена в очередь на отправку ставится цепочка, головным ТСВ которой является ТСВ особого типа. Этот ТСВ указывает на пакет, который после передачи по каналам связи послужит в качестве ТСВ на приемном конце. (Этим ТСВ контроллер просто вытеснит из ТСВ-регистров текущий ТСВ на прием, который сам же контроллер туда поместил перед этим, считав его из очереди в памяти). В соответствии с внеплановым ТСВ, пришедшим по каналу связи, и будут размещаться идущие вслед за ним данные, отосланные в соответствии с заданиями остальных ТСВ цепочки на отправку.
Управление разрешением прерываний производится оперативно установкой/снятием бита маски для логического номера VI-очереди. Этот логический номер - VI_IDX «зашивается» в ТСВ. Прерывание может происходить только по границам цепочек.
Обработка уже обслуженных ТСВ (в т.ч. их исключение из очередей) производится программно на основе вычитки аппаратной очереди завершения. Начало этой вычитки может быть инициировано как синхронно, так и асинхронно - по прерыванию или по времени.
Работа контроллера может осуществляться только в довольно сложном взаимодействии с программным обеспечением. ПО должно участвовать в следующих операциях:
1) динамическое подсоединение цепочек к очередям;
2) исключение уже обслуженных ТСВ из очередей на основе очереди завершения (разгрузке очередей);
3) поддержка состояния VI-очередей;
4) установка обработчиков завершения обслуживания VI-заданий/цепочек ТСВ.
Пункты1, 2, 4 осуществляются с участием контроллера.
Реализация разработанного способа приводит к сокращению затрат процессорного времени на многочисленные копирования данных из памяти в память, которые имели место в традиционных сетевых протоколах, а также повышению эффективности использования пропускной способности сети.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО ДЛЯ ПРИЕМА И ПЕРЕДАЧИ ДАННЫХ С ВОЗМОЖНОСТЬЮ ОСУЩЕСТВЛЕНИЯ ВЗАИМОДЕЙСТВИЯ С OpenFlow КОНТРОЛЛЕРОМ | 2014 |
|
RU2584471C1 |
| Способ, устройство, сетевое устройство, носитель информации для передачи данных | 2021 |
|
RU2834599C1 |
| Способ сетевого взаимодействия средств коммутации, приема и передачи данных | 2024 |
|
RU2832404C1 |
| ИСПОЛЬЗОВАНИЕ АУТЕНТИФИЦИРОВАННЫХ МАНИФЕСТОВ ДЛЯ ОБЕСПЕЧЕНИЯ ВНЕШНЕЙ СЕРТИФИКАЦИИ МНОГОПРОЦЕССОРНЫХ ПЛАТФОРМ | 2014 |
|
RU2599340C2 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2618367C1 |
| Высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой | 2016 |
|
RU2635896C1 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2579140C1 |
| СПОСОБ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ИНФОРМАЦИИ В ГЕТЕРОГЕННОЙ МНОГОПРОЦЕССОРНОЙ СИСТЕМЕ НА КРИСТАЛЛЕ (СнК) | 2022 |
|
RU2790094C1 |
| ФИЗИЧЕСКИЙ УРОВЕНЬ ВЫСОКОПРОИЗВОДИТЕЛЬНОГО МЕЖСОЕДИНЕНИЯ | 2013 |
|
RU2599971C2 |
| РАДИОСИСТЕМА ЛЕТАТЕЛЬНОГО АППАРАТА | 2011 |
|
RU2564434C2 |

Изобретение относится к вычислительной технике. Технический результат заключается в сокращении затрат процессорного времени на многочисленные копирования данных из памяти в память. Способ организации прямого доступа в память при передаче информации между физическими объектами, в котором для передачи данных в формате PCI-Express пакетов между модулем-источником и модулем-приемником использованы аппаратные блоки прямого доступа в память, выполненные с возможностью динамического управления цепочками заданий на отправку и прием данных, входящие в состав HS-контроллеров, выполненных с возможностью обеспечить эффективный обмен данными между памятью модулей при минимальном участии процессоров с аппаратным ограничением пропускной способности канала передачи данных и предоставлением гарантированных временных интервалов доступа к разделяемым ресурсам процессорной шины на базе использования стандарта VI (виртуальных интерфейсов) и стандартной шины PCI-Express и подключения HS-контроллера, при этом в рамках стандарта VI обмен данных происходит между парой процессов в различных процессорах по принципу «точка-точка», причем для каждого из процессов дуплексный канал обмена представляет собой виртуальный интерфейс, который состоит из пары рабочих очередей: очередь на отправку и очередь на прием. 2 ил.
Способ организации прямого доступа в память при передаче информации между физическими объектами, характеризуемый тем, что для передачи данных в формате PCI-Express пакетов между модулем-источником и модулем-приемником использованы аппаратные блоки прямого доступа в память, выполненные с возможностью динамического управления цепочками заданий на отправку и прием данных, входящие в состав HS-контроллеров, выполненных с возможностью обеспечить эффективный обмен данными между памятью модулей при минимальном участии процессоров с аппаратным ограничением пропускной способности канала передачи данных и предоставлением гарантированных временных интервалов доступа к разделяемым ресурсам процессорной шины на базе использования стандарта виртуальных интерфейсов (VI) и стандартной шины PCI-Express и подключения HS-контроллера, при этом в рамках стандарта VI обмен данных происходит между парой процессов в различных процессорах по принципу «точка-точка», причем для каждого из процессов дуплексный канал обмена представляет собой виртуальный интерфейс, который с программной точки зрения состоит из пары рабочих очередей, одна из которых представляет собой очередь заданий на отправку, а другая - на прием, при этом стандарт VI представляет собой стандарт виртуальных интерфейсов, разработанный фирмами Intel, Compaq, Microsoft, а используемый HS-контроллер выполнен как проект, реализованный на ПЛИС.
| US 7953876 B1, 31.05.2011 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| H | |||
| SHOJANIA "An Overview of Virtual Interface Architecture (VIA)", опубл | |||
| Способ очистки нефти и нефтяных продуктов и уничтожения их флюоресценции | 1921 |
|
SU31A1 |
| Virtual Interface Architecture Specification, Version 1.0, December 16, 1997, опубл | |||
| Пишущая машина для тюркско-арабского шрифта | 1922 |
|
SU24A1 |
| ОБЛЕГЧЕННЫЙ ПРОТОКОЛ ВВОДА/ВЫВОДА | 2004 |
|
RU2388039C2 |

