ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящая заявка испрашивает приоритет согласно предварительной патентной заявке США №61/818784, поданной 2 мая 2013 г., содержимое которой включено в данный документ по ссылке.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
1. ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] Настоящее изобретение относится к области предиктивной оценки, а более конкретно, к кредитной оценке.
2. ОПИСАНИЕ ПРЕДШЕСТВУЮЩЕГО УРОВНЯ ТЕХНИКИ
[0003] Подходы, описанные в этом разделе, являются подходами, которые могут быть осуществлены, но необязательно подходами, которые были ранее задуманы или осуществлены. Поэтому подходы, описанные в этом разделе, могут не быть предшествующим уровнем техники по отношению к формуле изобретения в этой заявке и не предполагают быть предшествующим уровнем техники посредством включения в этот раздел.
[0004] Кредитная оценка назначает вероятность просрочки платежа фирме, т.е. вероятность невыполнения обязательств. Существует два вида кредитной оценки, а именно, субъективная и статистическая. Субъективная оценка создается кредитным менеджером на основе суждения и опыта кредитного менеджера. Статистическая оценка является результатом статистического анализа кредитного досье фирмы, чтобы представлять кредитоспособность этой фирмы.
[0005] В статистике регрессионный анализ является статистическим процессом для оценки соотношений между переменными. Он включает в себя способы моделирования и анализа нескольких переменных, когда фокусируется на соотношении между зависимой переменной и одной или более независимыми переменными. Регрессионный анализ помогает понять, как типичное значение зависимой переменной изменяется, когда любая переменная из независимых переменных изменяется, в то время как другие независимые переменные зафиксированы.
[0006] Точность регрессионного анализа зависит, в частности, от формы модели, которая используется, и от выбора независимых переменных, т.е. хорошо сформированная модель и правильный выбор независимых переменных, может вести к более точному результату.
[0007] Данные, которые должны быть анализированы для кредитной оценки, типично хранятся в базе данных. Вследствие увеличившихся объемов формируемых, хранимых и обрабатываемых сегодня данных, операционные базы данных конструируются, категоризируются и форматируются для операционной эффективности (например, производительности, скорости обработки и емкости хранения). Исходные данные, найденные в этих операционных базах данных, зачастую существуют как строки и столбцы чисел и кода, который кажется смущающим и непонятным для специалистов по анализу деловой активности и специалистов, принимающих решения. Кроме того, диапазон и широта исходных данных, хранящихся в современных базах данных, представляет более трудным нахождение пригодной к использованию информации.
[0008] Таким образом, существует необходимость в способе, который анализирует данные из одной или более баз данных, чтобы разрабатывать модель и идентифицировать и выбирать независимые переменные, для регрессионного анализа.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0009] Целью настоящего изобретения является предоставление способа, который анализирует данные из одной или более баз данных, чтобы разрабатывать модель, и идентифицировать и выбирать независимые переменные, для регрессионного анализа.
[0010] Дополнительной целью настоящего изобретения является предоставление способа, который использует модель, чтобы оценивать данные, касающиеся рассматриваемой фирмы, чтобы формировать кредитную оценку для рассматриваемой фирмы.
[0011] Чтобы удовлетворять этим целям, предоставляется способ, который включает в себя применение компьютера, чтобы выполнять операции (a) приема, из источника данных, посредством электронной связи, описателя фирмы, (b) сопоставления упомянутого описателя с данными в базе данных, таким образом, предоставляя соответствие, при этом упомянутые данные включают в себя уникальный идентификатор упомянутой фирмы, (c) сохранения в журнал сигнала, который включает в себя упомянутый уникальный идентификатор, (d) подсчета количества сигналов, которые включают в себя упомянутый уникальный идентификатор в упомянутом журнале, таким образом, предоставляя число упомянутых сигналов для упомянутого уникального идентификатора, и (e) вычисления кредитной оценки для упомянутой фирмы на основе упомянутого числа сигналов. Также предоставляется система, которая выполняет способ, и устройство хранения, которое управляет процессором, чтобы выполнять способ.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
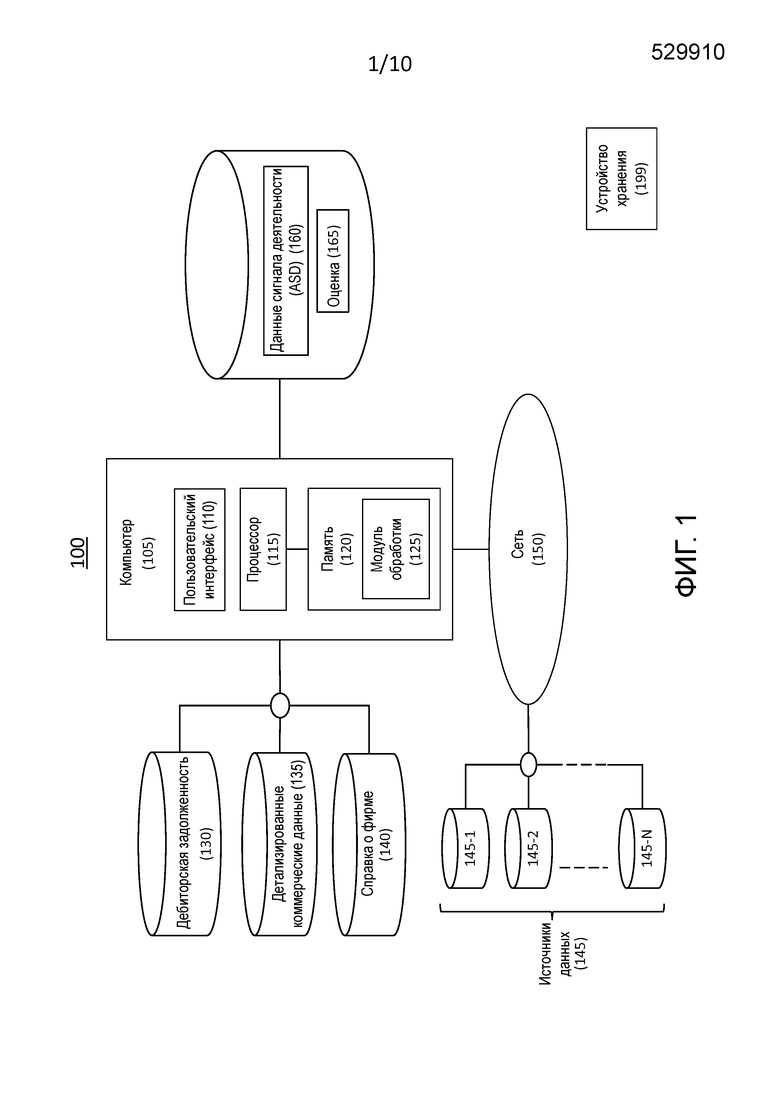
[0012] Фиг. 1 – это блок-схема системы для применения способов, раскрытых в данном документе.
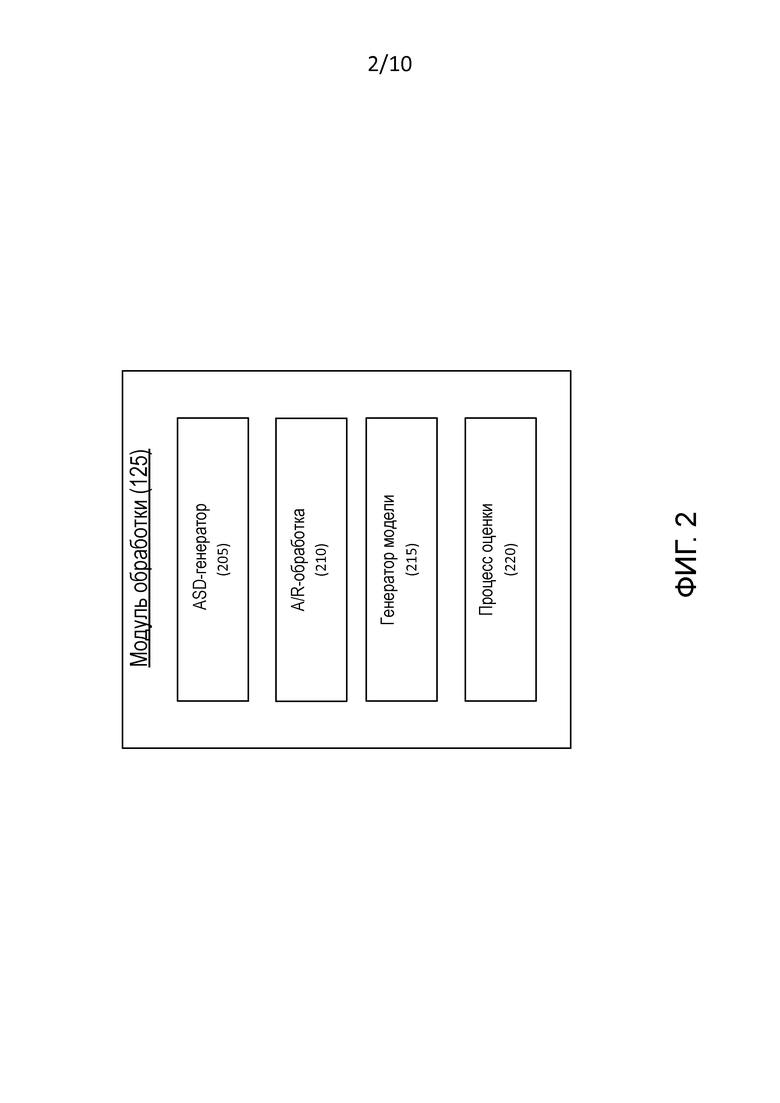
[0013] Фиг. 2 – это блок-схема модуля обработки системы на фиг. 1.
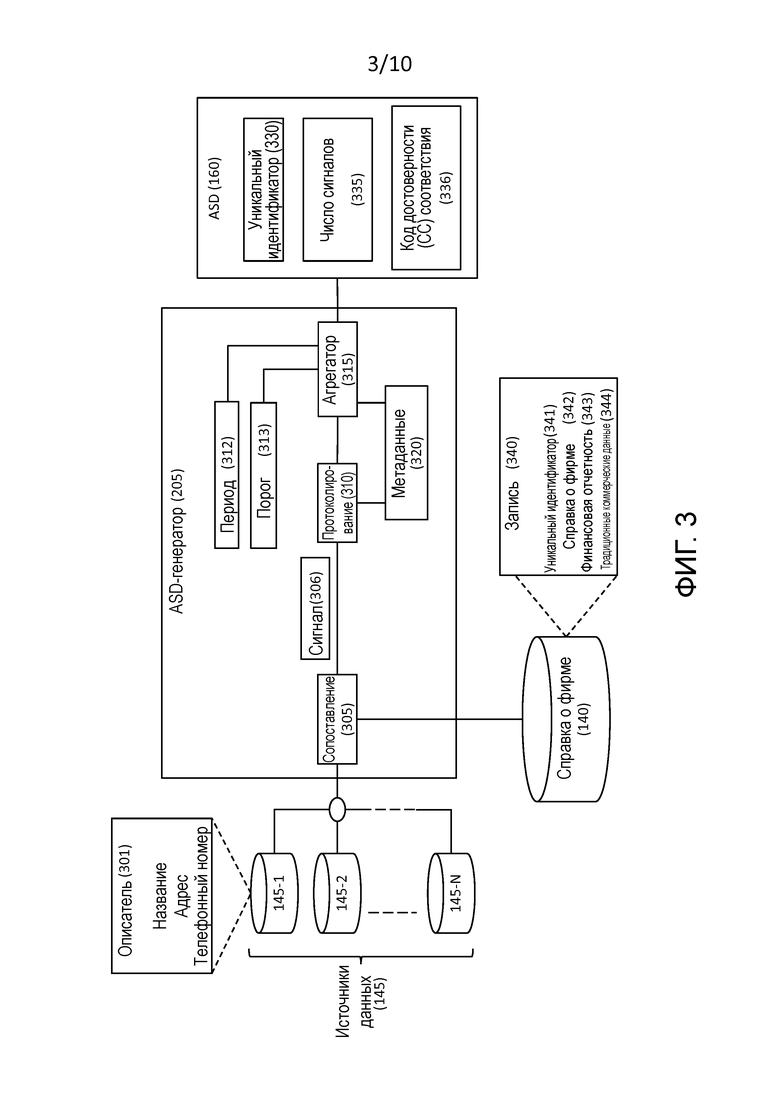
[0014] Фиг. 3 – это блок-схема генератора сигнала деятельности, который является компонентом модуля обработки на фиг. 2.
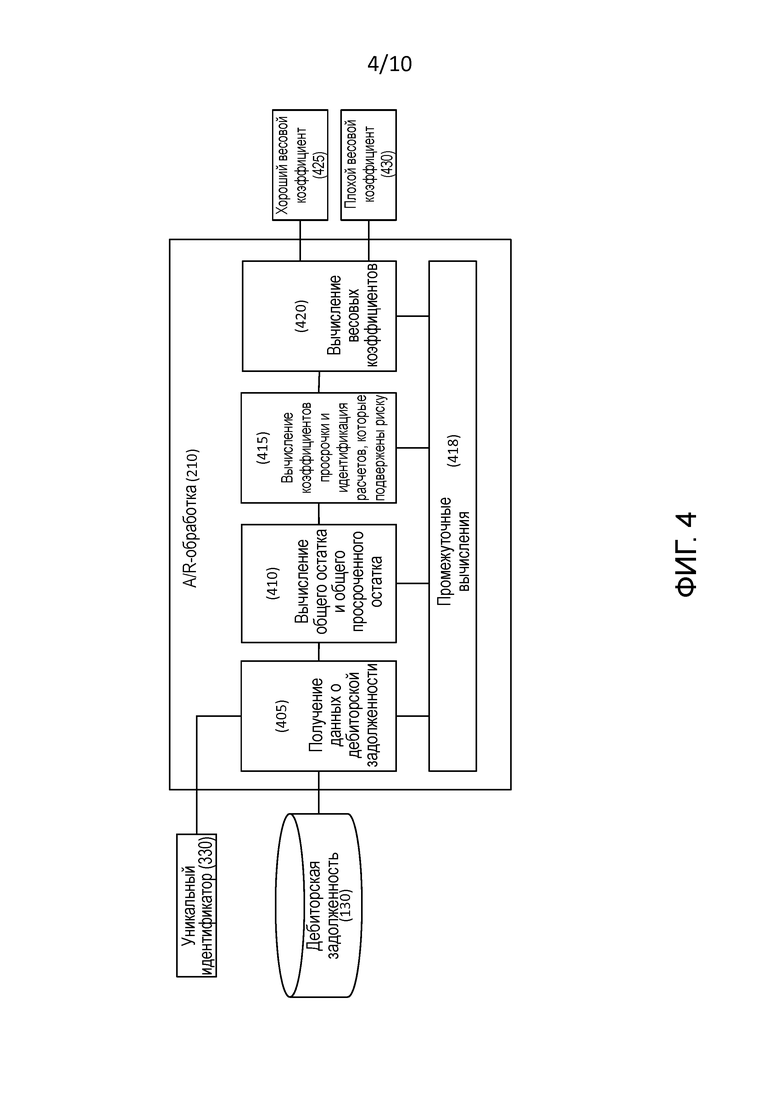
[0015] Фиг. 4 – это блок-схема модуль обработки дебиторской задолженности, который является компонентом модуля обработки на фиг. 2.
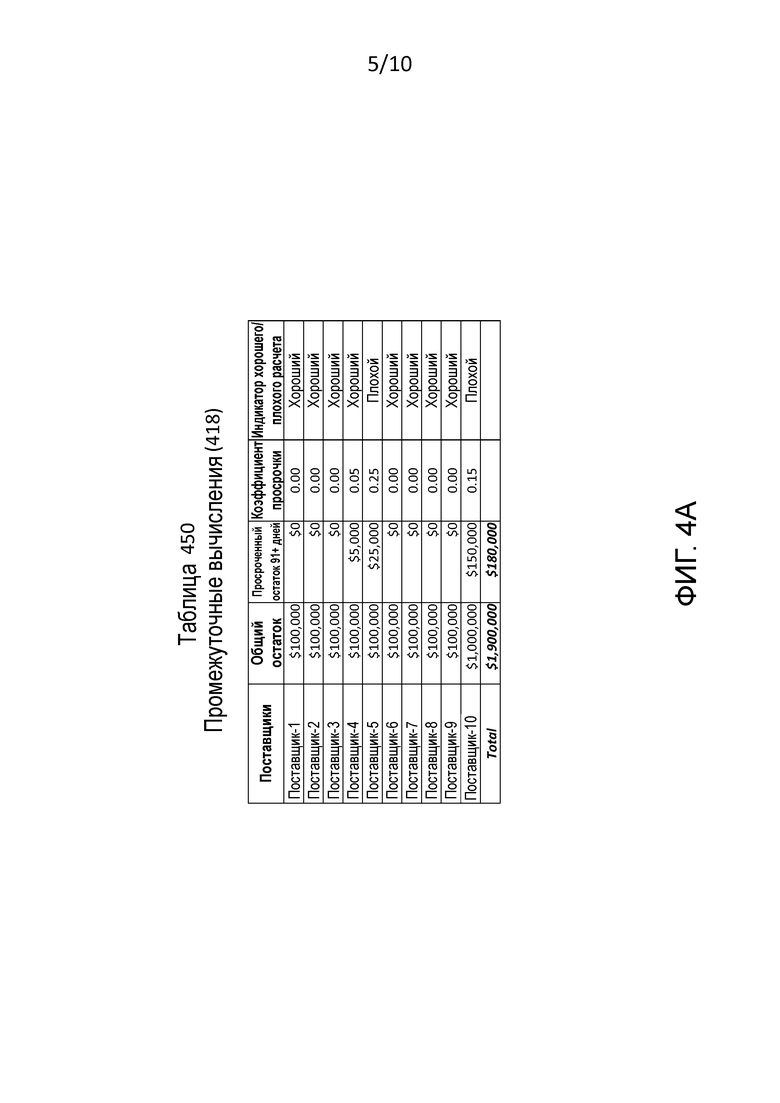
[0016] Фиг. 4A – это иллюстрация таблицы, которая перечисляет примерные промежуточные калькуляции, выполняемые посредством модуля обработки дебиторской задолженности на фиг. 4.
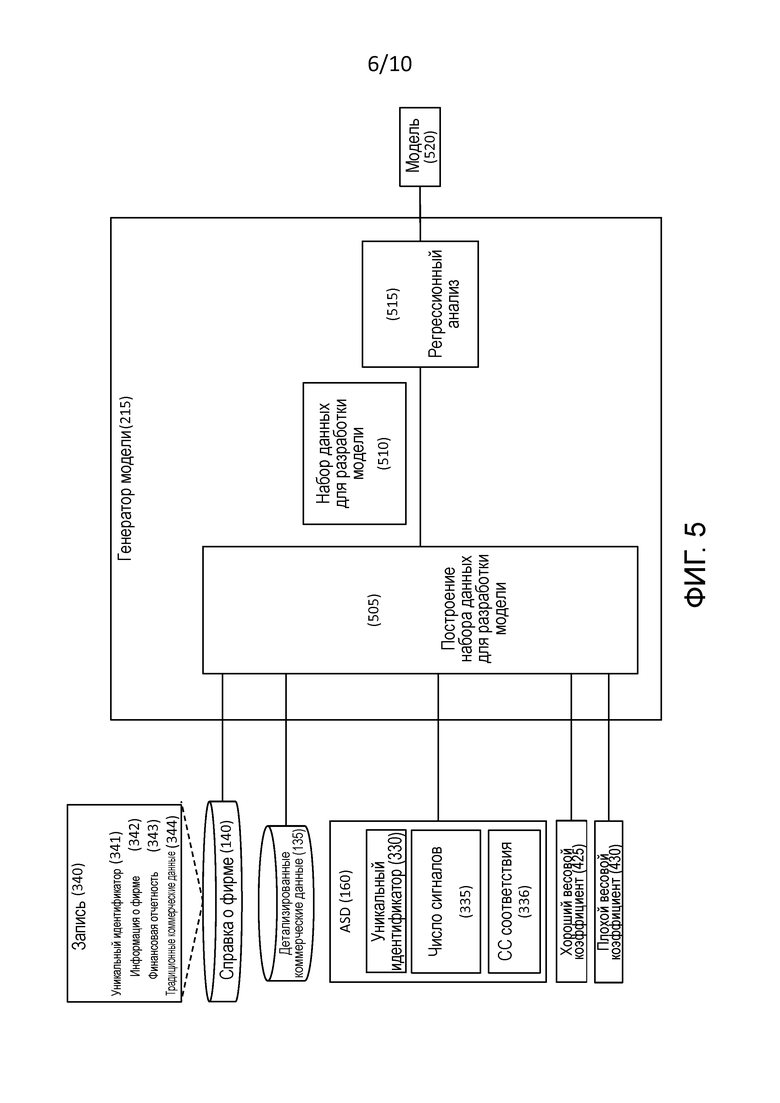
[0017] Фиг. 5 – это блок-схема генератора модели, который является компонентом модуля обработки на фиг. 2.
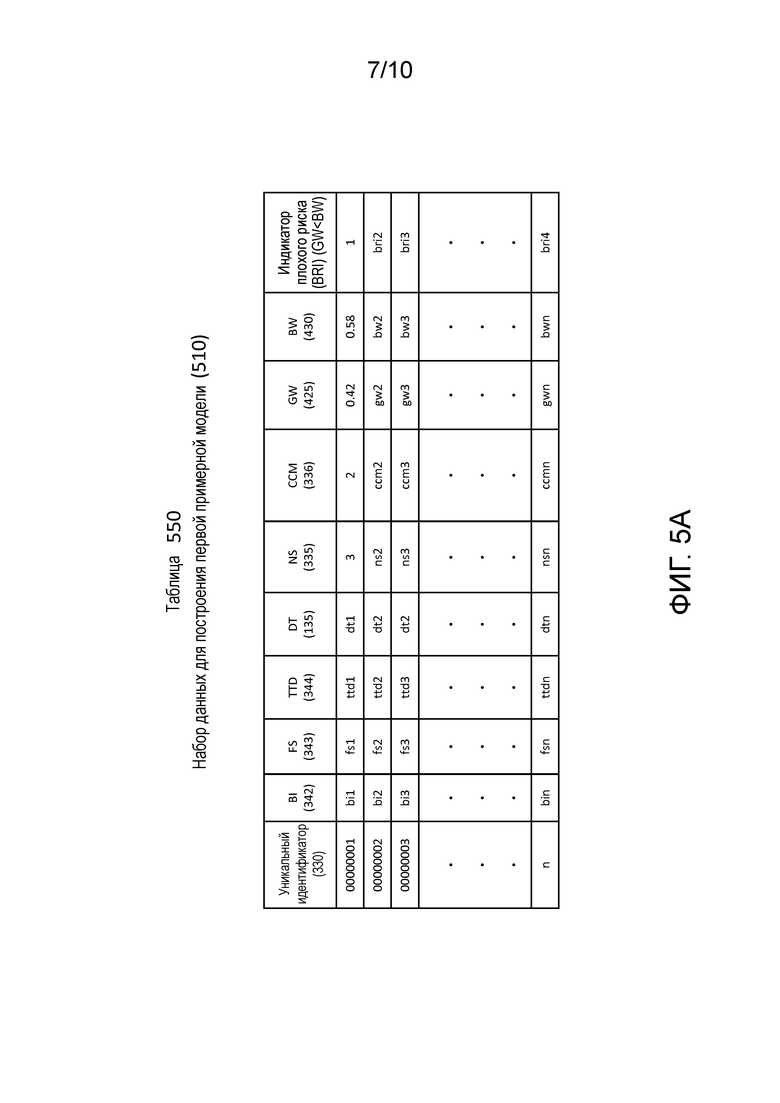
[0018] Фиг. 5A – это иллюстрация таблицы, которая показывает набор данных для разработки первой примерной модели, созданный посредством генератора модели на фиг. 5.
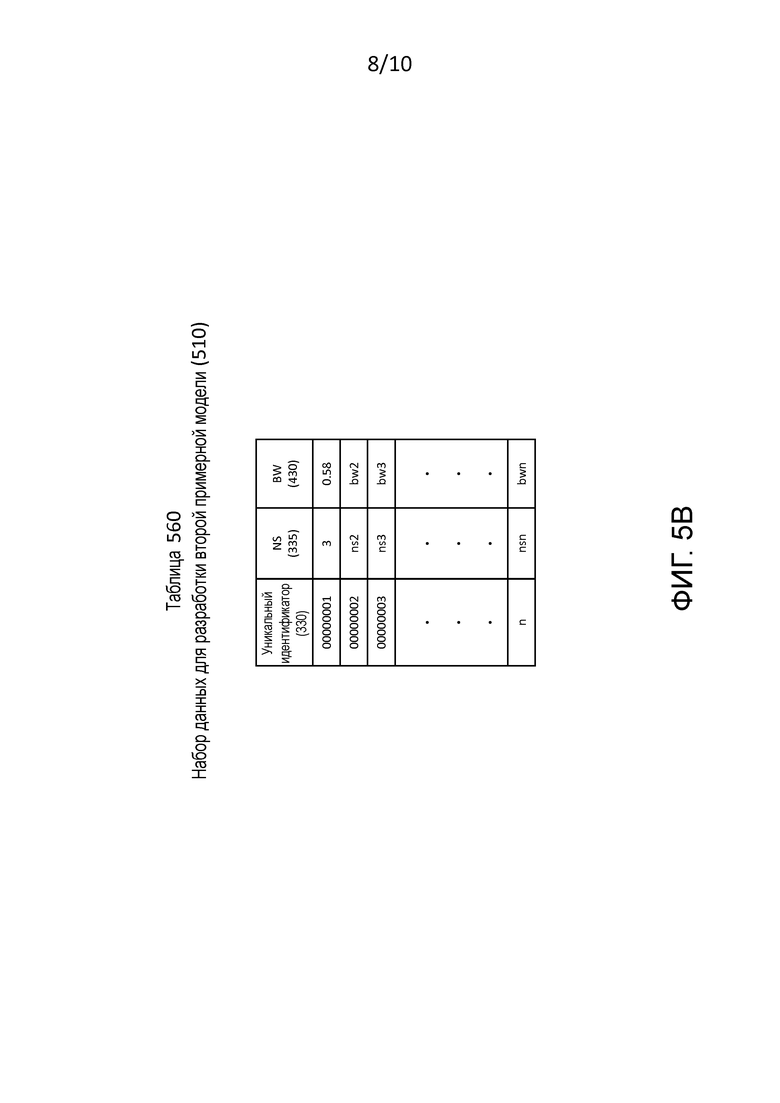
[0019] Фиг. 5B – это иллюстрация таблицы, которая показывает набор данных для разработки второй примерной модели, созданный посредством генератора модели на фиг. 5.
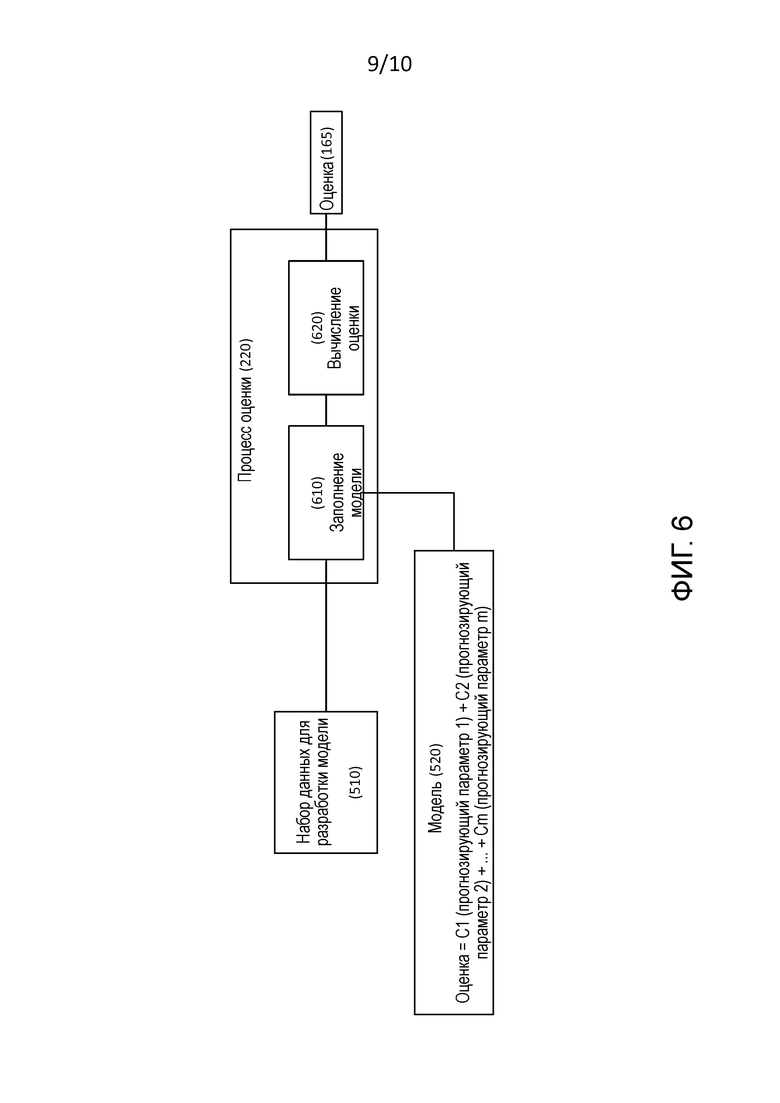
[0020] Фиг. 6 – это блок-схема процесса оценки, который является компонентом модуля обработки на фиг. 2.
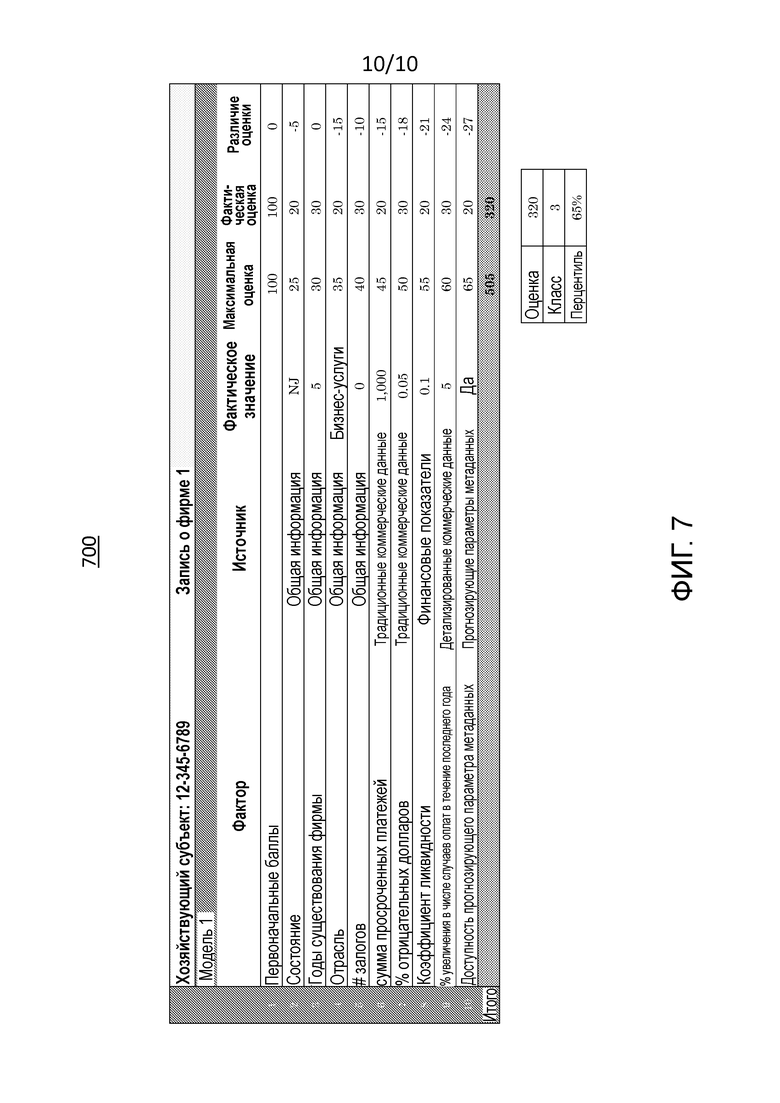
[0021] Фиг. 7 – это таблица, которая показывает пример оценочной карточки для одной фирмы, оцениваемой в соответствии с процессом оценки на фиг. 6.
[0022] Компонент или признак, который является общим для более, чем одного чертежа, указан с помощью одного и того же ссылочного номера на каждом из чертежей.
ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0023] Настоящее изобретение предоставляет систему и способ для вычисления вероятности того, что рассматриваемая фирма не выполняет своих обязательств по платежу. Система и способ используют статистические оценки, где назначение вероятности эмпирически получается и может быть эмпирически утверждено. Вероятность вычисляется на основе данных, называемых в данном документе сигналами деятельности, принадлежащими действиям невыплат рассматриваемой фирмы. Сигналы деятельности получаются из процессов ведения документации, проводимых другими фирмами. Вероятность того, что рассматриваемая фирма не выполняет своих обязательств, получается из математического метода нахождения соотношения между просроченными платежами и данными, касающимися рассматриваемой фирмы. Модель, которая разрабатывается и используется системой, предоставляет определение плохой деятельности для фирм, в значительной степени не выполняющих свои обязательства. Процесс оценки использует модель, чтобы формировать оценку для рассматриваемой фирмы.
[0024] Фиг. 1 – это блок-схема системы 100 для применения способов, раскрытых в данном документе. Система 100 включает в себя (a) компьютер 105, (b) источники 145-1 и 145-2 по 145-N данных, совокупно называемые источниками 145 данных, которые соединены с возможностью обмена данными с компьютером 105 через сеть 150.
[0025] Сеть 150 является сетью передачи данных. Сеть 150 может быть частной сетью или сетью общего пользования и может включать в себя любую из (a) персональной сети, например, охватывающей комнату, (b) локальной вычислительной сети, например, охватывающей здание, (c) университетской вычислительной сети, например, охватывающей территорию университета, (d) городской вычислительной сети, например, охватывающей город, (e) глобальной вычислительной сети, например, охватывающей область, которая связывает между городскими, региональными или национальными границами, или (f) Интернета. Передачи данных проводятся через сеть 150 посредством электронных сигналов и оптических сигналов.
[0026] Каждый из источников 145 данных является объектом, организацией или процессом, который предоставляет информацию, т.е., данные, о фирме. Примеры источников 145 данных включают в себя реестры фирм, телефонные книги, данные о кадровом обеспечении, данные по платежам на уровне счетов-фактур с дебиторами по расчетам, и запросы фирмы о других фирмах.
[0027] Компьютер 105 обрабатывает данные от источников 145 данных, а также обрабатывает данные, которые обозначены в данном документе как данные 130 о дебиторской задолженности, детализированные коммерческие данные 135 и справочные данные 140 о фирме, и создает данные, обозначенные как данные сигнала деятельности (ASD) 160 и оценку 165.
[0028] Данные 130 о дебиторской задолженности являются данными о дебиторской задолженности, которые были получены от множества фирм, которые поставили товары или услуги другим фирмам, или кредите. Данные 130 о дебиторской задолженности относительно интересующей компании получаются от поставщиков товаров или услуг интересующей компании. Например, предположим, что компания B является поставщиком товаров или услуг для компании A. Компания B, в своих книгах, покажет сумму дебиторской задолженности, причитающуюся от компании A. На практике, вероятно, будет много компаний, которые поставляют товары или услуги компании A, и, по существу, данные о дебиторской задолженности для компании A будут включать в себя данные о дебиторской задолженности относительно компании A от этих многих компаний.
[0029] Детализированные коммерческие данные 135 являются другими данными относительно интересующей компании, и могут быть получены из данных 130 о дебиторской задолженности. Примеры детализированных коммерческих данных 135 включают в себя число просроченных счетов за последние шесть месяцев и общую сумму долга.
[0030] Справочные данные 140 о фирме – это данные, которые описывают фирму. Например, для рассматриваемой фирмы, справочные данные 140 о фирме будут включать в себя уникальный идентификатор рассматриваемой фирмы, информацию о фирме, финансовую отчетность и традиционные коммерческие данные. Уникальный идентификатор – это идентификатор, который уникально идентифицирует рассматриваемую фирму. Номер универсальной системы нумерации данных (DUNS) может служить в качестве такого уникального идентификатора. Информация о фирме – это информация о фирме, такая как число работников, годы существования фирмы и отрасль экономической деятельности, например, розничная торговля, в которой фирма категоризирована. Финансовая отчетность – это финансовая информация, такая как коэффициенты ликвидности, т.е. (текущие активы – товарно-материальные запасы)/текущие обязательства, и общая сумма обязательств. Традиционные коммерческие данные – это информация, такая как сумма просрочки в тридцать дней или более, число случаев просрочки оплат на тридцать дней или больше и число удовлетворяющих требованиям случаев оплаты.
[0031] ASD 160 – это структура данных, которая содержит информацию о компаниях, где информация извлекается из данных, полученных из источников 145 данных. В целом, что касается рассматриваемой компании, ASD 160 указывает уровень обработки данных другими компаниями, имеющими отношение к рассматриваемой компании.
[0032] Оценка 165 является кредитной оценкой, которая представляет кредитоспособность фирмы, для которой кредитная оценка назначена.
[0033] Данные 130 о дебиторской задолженности, детализированные коммерческие данные 135, справочные данные 140 о фирме, ASD 160 и оценка 165 хранятся в одной или более базах данных. Одна или более баз данных могут быть сконфигурированы как единственное устройство хранения или как распределенная система хранения, имеющая множество независимых устройств хранения. Хотя в системе 100 одна или более баз данных показаны как непосредственно соединенные с компьютером 105, они могут быть расположены удаленно от, и связаны с, компьютером 105 посредством сети 150.
[0034] Компьютер 105 включает в себя пользовательский интерфейс 110, процессор 115 и память 120, соединенную с процессором 115. Хотя компьютер 105 представлен в данном документе как автономное устройство, он не ограничивается этим, а вместо этого может быть соединен с другими устройствами (не показаны) в распределенной системе обработки. Пользовательский интерфейс 110 включает в себя устройство ввода, такое как клавиатура или подсистема распознавания речи, чтобы предоставлять возможность пользователю сообщать информацию и выборы команд процессору 115.
[0035] Пользовательский интерфейс 110 также включает в себя устройство вывода, такое как дисплей или принтер, или синтезатор речи. Устройство управления курсором, такое как мышь, трекбол или джойстик, предоставляет возможность пользователю манипулировать курсором на дисплее для сообщения дополнительной информации и выборов команд процессору 115.
[0036] Процессор 115 является электронным устройством, сконфигурированным из логической схемы, которая реагирует и выполняет инструкции.
[0037] Память 120 является материальным компьютерно-читаемым устройством хранения, закодированным с компьютерной программой. В этом отношении, память 120 хранит данные и инструкции, т.е., программный код, которые являются считываемыми и исполняемыми посредством процессора 115 для управления операциями процессора 115. Память 120 может быть реализована в оперативном запоминающем устройстве (RAM), накопителе на жестком диске, постоянном запоминающем устройстве (ROM) или их комбинации. Одним из компонентов памяти 120 является модуль 125 обработки.
[0038] Модуль 125 обработки – это модуль инструкций, которые являются считываемыми посредством процессора 115, и которые управляют процессором 115, чтобы выполнять оценку фирмы, т.е., оценивание фирмы посредством назначения вероятности просроченной задолженности, которая преобразуется в оценку просроченной задолженности, т.е. оценку 165. Модуль 125 обработки выводит результаты в пользовательский интерфейс 110 и может также направлять вывод на удаленное устройство (не показано) через сеть 150.
[0039] В настоящем документе мы описываем операции, выполняемые посредством модуля 125 обработки или его подчиненных процессов. Однако операции фактически выполняются посредством компьютера 105, а более конкретно, процессора 115.
[0040] Термин "модуль" используется в данном документе, чтобы обозначать функциональную операцию, которая может быть осуществлена либо как автономный компонент, либо как объединенная конфигурация из множества подчиненных компонентов. Таким образом, модуль 125 обработки может быть реализован как единый модуль или как множество модулей, которые работают во взаимодействии друг с другом. Кроме того, хотя модуль 125 обработки описывается в данном документе как устанавливаемый в памяти 120, и, следовательно, реализуется в программном обеспечении, он может быть реализован в любом из аппаратных средств (например, электронной схеме), микропрограммного, программного обеспечения или их комбинации.
[0041] В то время как модуль 125 обработки указан как уже загруженный в память 120, он может быть сконфигурирован на устройстве 199 хранения для последующей загрузки в память 120. Устройство 199 хранения является материальным компьютерно-читаемым носителем хранения, который хранит на себе модуль 125 обработки. Примеры устройства 199 хранения включают в себя компакт-диск, магнитную ленту, постоянное запоминающее устройство, оптические носители хранения, накопитель на жестком диске или блок памяти, состоящий из множества параллельных накопителей на жестком диске, и флэш-накопитель универсальной последовательной шины (USB). Альтернативно, устройство 199 хранения может быть оперативным запоминающим устройством или другим типом электронного устройства хранения, расположенным на удаленной системе хранения и соединенным с компьютером 105 через сеть 150.
[0042] На практике, источники 145 данных, данные 130 о дебиторской задолженности, детализированные коммерческие данные 135 и справочные данные 140 о фирме будут содержать данные, представляющие множество, например, миллионы, элементов данных. Таким образом, на практике, данные не могут быть обработаны человеком, а вместо этого потребуют компьютера, такого как компьютер 105.
[0043] Фиг. 2 – это блок-схема модуля 125 обработки. Модуль 125 обработки включает в себя несколько подчиненных модулей, а именно, генератор 205 данных сигнала деятельности (ASD), обработку 210 дебиторской задолженности (A/R), генератор 215 модели и процессор 220 оценки. Вкратце:
(a) ASD-генератор 205 анализирует данные из источников 145 данных и создает ASD 160, которые, как упомянуто выше, относительно рассматриваемой компании, указывают уровень деятельности обработки, другими компаниями, имеющими отношение к рассматриваемой компании;
(b) A/R-обработка 210 анализирует данные 130 о дебиторской задолженности от поставщиков рассматриваемых фирм и создает весовые коэффициенты, которые указывают, действительно ли рассматриваемые фирмы не имеют задолженности в отношении своих платежей по обязательствам, или не уплатили свои платежи по обязательствам;
(c) генератор 215 модели обрабатывает различные данные о фирме, ASD 160 и весовые коэффициенты из A/R-обработки 210 и на их основе формирует модель для оценки фирмы; и
(d) процесс 220 оценки использует модель от генератора 215 модели, чтобы создавать оценку 165.
Каждый из ASD-генератора 205, A/R-обработки 210, генератора 215 модели и процесса 220 оценки описывается более подробно ниже.
[0044] Фиг. 3 – это блок-схема ASD-генератора 205, который, как упомянуто выше, анализирует данные из источников 145 данных и создает ASD 160. ASD-генератор 205 включает в себя процесс 305 сопоставления, процесс 310 регистрации и агрегатор 315.
[0045] Источники 145 данных, как упомянуто выше, являются объектами, организациями или процессами, которые предоставляют информацию, т.е., данные, о фирме. Формат данных не особенно уместного для работы системы 100, но в целях примера мы предположим, что данные организованы в записи. Описатель 301 является примером такой записи и содержит данные, которые описывают различные аспекты фирмы, например, название, адрес и номер телефона. На практике описатель 301 может включать в себя множество таких аспектов.
[0046] Процесс 305 сопоставления принимает, или иначе получает, из источников 145 данных, описатель 301 и сопоставляет описатель 301 с данными в справочных данных 140 о фирме.
[0047] Атрибуты описателя 301 заполнены не согласующимся образом для каждой фирмы в источниках 145 данных. Компьютер 105 использует доступную информацию описателя 301 и на основе этой информации создает свое наилучшее возможное соответствие. В качестве примера, давайте предположим, что максимально необходимой информацией, чтобы добиваться самого точного соответствия, является наличие информации о названии фирмы и ее телефонном номере. Примерный источник 145-2 данных и описатель 301 предоставили информацию только о названии фирмы. Это ограничивает нашу точность для сопоставления, но компьютер 105 берет информацию из этого описателя 301 и исследует базу данных 140, чтобы находить запись о фирме с наивысшей достижимой точностью и соответствием.
[0048] Справочные данные 140 о фирме, как упомянуто выше, являются данными, которые описывают фирму. Справочные данные 140 о фирме организованы в записи. Одна такая запись, т.е. запись 340, является показательным примером. Запись 340 включает в себя уникальный идентификатор 341, информацию 342 о фирме, финансовую отчетность 343 и традиционные коммерческие данные 344.
[0049] Сопоставление, когда используется в данном документе, означает исследование устройства хранения данных на предмет данных, например, исследование базы данных на предмет записи, которая наилучшим образом соответствует данному запросу. Таким образом, процесс 305 сопоставления исследует справочные данные 140 о фирме на предмет данных, которые наилучшим образом соответствуют описателю 301.
[0050] Наилучшее соответствие необязательно является корректным соответствием, и, таким образом, процесс 305 сопоставления, при поиске соответствия, также предоставляет код достоверности, который указывает уровень достоверности того, что соответствие является корректным. Например, код достоверности 5 может указывать, что соответствие почти определенно является корректным, а код достоверности 1 может указывать, что соответствие имеет относительно низкую уверенность в том, что является корректным.
[0051] Процесс 305 сопоставления, при поиске соответствия, формирует сигнал 306, который включает в себя:
(a) идентификацию источника, из которого данные были приняты;
(b) время (которое включает в себя дату), в которое сопоставление было выполнено; и
(c) уникальный идентификатор 341;
(d) код достоверности.
[0052] Процесс 310 регистрации принимает сигнал 306 и вводит его в журнал, обозначенный в данном документе как метаданные 320.
[0053] На практике, ASD-генератор 205, или каждый из его подчиненных процессов, т.е. процесс 305 сопоставления, процесс 310 регистрации и агрегатор 315, будут работать в цикле обработки так, чтобы обрабатывать множество описателей из источников 145 данных. Таким образом, процесс 205 сопоставления будет производить множество сигналов, где сигнал 306 просто является одним таким сигналом.
[0054] Таблица 1 перечисляет некоторые примерные метаданные 320.
Идентификатор
.
.
.
.
.
.
.
.
.
.
[0055] Например, строка 1 таблицы 1 показывает, что процесс 305 сопоставления создал первый сигнал, т.е. сигнал 1, который указывает, что процесс 305 сопоставления, в момент времени t0, сопоставил описатель 301 из источника 145-2 данных с данными в справочных данных 140 о фирме. Сопоставление указывает, что описатель 301 касается фирмы, идентифицированной посредством уникального идентификатора 00000001, и соответствие имеет код достоверности 2. На практике метаданные 320 будут содержать множество, например, миллионы строк данных.
[0056] Агрегатор 315 собирает данные из метаданных 320, чтобы создавать ASD 160. Более конкретно, агрегатор 315 рассматривает метаданные 320, которые попадают в период времени, т.е. период 312, и для каждого уникального идентификатора поддерживает общее число сигналов и общее число соответствий, имеющих код достоверности больше или равный порогу 313. Таким образом, для рассматриваемой фирмы, ASD 160 включает в себя уникальный идентификатор 330, число сигналов 335 и код достоверности (CC) соответствия 336. Число сигналов 335 является общим числом сигналов для конкретного уникального идентификатора, которые были сопоставлены в течение периода 312. CC соответствия 336 является общим числом таких соответствий, которые имеют код достоверности больше или равный порогу 313.
[0057] Например, обращаясь к таблице 1, предположим, что период 312 определяет период времени от t0 до t4, и что порог 313 определяет пороговое значение, равное 3. Таблица 2 перечисляет соответствующие примерные данные для ASD 160.
(уникальный идентификатор 330)
(число сигналов 335)
код достоверности,
больший или равный порогу
(CC соответствия 336)
[0058] Таблица 2 показывает, что, в течение периода от t0 до t4, для уникального идентификатора 00000001, было всего 3 сигнала (см. таблицу 1, сигналы 1, 3 и 4), и из этих 3 сигналов, 2 из них были для соответствий, имеющих код достоверности больше или равный 3 (см. таблицу 1, строки 3 и 4). Хотя не показано в таблице 2, ASD 160 могут включать в себя другую информацию, полученную из сигнала 306, например, идентификацию источников 145 данных, которые предоставили данные, которые получили в результате наибольшего числа соответствий, имеющих код достоверности больше или равный порогу 313. На практике период 312 будет иметь продолжительность, например, 12 месяцев, который предоставляет возможность ASD-генератору 205 собирать значительное число событий. По существу, ASD 160 будет включать в себя множество, например, миллионы, строк данных.
[0059] Фиг. 4 является блок-схемой A/R-обработки 210, которая, как упомянуто выше, анализирует данные 130 о дебиторской задолженности от поставщиков рассматриваемой фирмы, и создает весовые коэффициенты, которые указывают, действительно ли рассматриваемая фирма не имеет задолженности в отношении своих платежей по обязательствам, или имеет просрочку по своим платежам по обязательствам.
[0060] Во время выполнения, A/R-обработка 210 производит промежуточные вычисления 418. Фиг. 4A является иллюстрацией таблицы, т.е., таблицей 450, которая перечисляет примерные промежуточные вычисления 418.
[0061] A/R-обработка 210 начинается с этапа 405.
[0062] На этапе 405 A/R-обработка 210 получает данные 130 о дебиторской задолженности для рассматриваемой фирмы, которая идентифицирована посредством уникального идентификатора 330. Более конкретно, для каждого поставщика, т.е., кредитора, рассматриваемой фирмы, A/R-обработка 210 получает остаток, который приходится на поставщика от рассматриваемой фирмы, и сумму из этого остатка, которая просрочена, например, просрочена на 91 или более дней. Эта информация сохраняется во внутренних вычислениях 418.
[0063] Таблица 450 показывает, например, что рассматриваемая фирма (a) должна Поставщику-1 100000$, из которых 0$ просрочено на 91 или более дней, и (b) должна Поставщику-10 1000000$, из которых 150000$ просрочены на 91 или более дней.
[0064] С этапа 405 A/R-обработка 210 переходит к этапу 410.
[0065] На этапе 410 A/R-обработка 210 вычисляет общий остаток задолженности рассматриваемой фирмы, и сумму из этого общего остатка, которая просрочена на 91 или более дней. Эта информация сохраняется во внутренних вычислениях 418.Таблица 450 показывает, например, (a) общий остаток задолженности равен 1900000$, и (b) из этого общего остатка 180000$ просрочены на 91 или более дней.
[0066] С этапа 410 A/R-обработка 210 переходит к этапу 415.
[0067] На этапе 415 A/R-обработка 210 вычисляет коэффициенты просроченной задолженности и идентифицирует счета, которые подвержены риску.
[0068] Одним способом оценки кредитования рассматриваемой фирмы будет вычисление отношения (a) общего просроченного остатка к (b) общему остатку задолженности. Если отношение больше конкретного значения, например 0,10, что указывает, что более чем некоторый конкретный процент, например 10%, просрочен, рассматриваемая фирма будет классифицирована как имеющая плохой кредитный риск. С помощью данных, представленных в таблице 450.
Общий просроченный остаток/общий остаток задолженности = 180000/1900000=0,095 EQU 1
Таким образом, EQU 1 указывает, что менее 10% является просрочкой, и что рассматриваемая фирма не будет классифицирована как имеющая плохой кредитный риск.
[0069] Однако рассматриваемая фирма может быть в хороших личных отношениях с одним поставщиком услуги, но запаздывать по своим взаимным расчетам с другой. Чтобы устранять эту проблему, A/R-обработка 210 рассматривает просрочку платежа для каждого отдельного поставщика и, таким образом, объединяет различные степени просрочки в определение плохого кредитного риска. Более конкретно, для каждого поставщика, A/R-обработка 210 вычисляет коэффициент просрочки как отношение (a) просроченного остатка к (b) остатку задолженности, как показано в EQU 2.Если коэффициент просрочки больше конкретного значения, например, 0,10, расчет рассматриваемой фирмы с этим поставщиком идентифицируется как имеющий плохой кредитный риск.
Коэффициент просрочки=просроченный остаток/остаток задолженности EQU 2
Для Поставщика-5:
Коэффициент просрочки=25000/100000=0,25 EQU 3
Для Поставщика-10:
Коэффициент просрочки=150 000/1 000 000=0,15 EQU 4
Таким образом, что касается Поставщика-5 и Поставщика-10, счет рассматриваемой фирмы классифицируется как имеющий плохой кредитный риск.
[0070] С этапа 415 A/R-обработка 210 переходит к этапу 420.
[0071] На этапе 420, для рассматриваемой фирмы, A/R-обработка 210 вычисляет хороший весовой коэффициент 425 и плохой весовой коэффициент 430.
[0072] Чтобы вычислять хороший вес 425, A/R-обработка 210 вычисляет общую сумму задолженности поставщикам, для которых счета обозначены как хорошие, т.е., хорошие общие суммы, и затем вычисляет отношение (a) хорошей общей суммы к (b) общему остатку задолженности. В настоящем примере, показанном в таблице 450, хорошая общая сумма является общей суммой задолженности Поставщикам-1, 2, 3, 4, 6, 7, 8 и 9. Здесь, хорошая общая сумма=800000, и:
Хороший весовой коэффициент=хорошая общая сумма/общий остаток задолженности=800000/1900000=0,42 EQU 5
[0073] Чтобы вычислять плохой весовой коэффициент 430, A/R-обработка 210 вычисляет общую сумму задолженности поставщикам, для которых расчеты обозначены как плохие, т.е. плохую общую сумму, и затем вычисляет отношение (a) плохой общей суммы к (b) общему остатку задолженности. В текущем примере, показанном в таблице 450, плохая общая сумма является общей суммой задолженности Поставщикам 5 и 10.Здесь, плохая общая сумма =1100000, и:
Плохой весовой коэффициент = плохая общая сумма/общий остаток задолженности=1100000/1900000=0,58 EQU 6
[0074] Отметим, что сумма хорошего весового коэффициента и плохого весового коэффициента равна 1, т.е. 0,42+0,58=1. Эти весовые коэффициенты могут также быть масштабированы, например, в масштабе, равном 100, и в настоящем примере хороший весовой коэффициент будет принимать значение, равное 42, а плохой весовой коэффициент будет принимать значение, равное 58.
[0075] Взгляд на характер платежей фирмы на уровне счетов предоставляет возможность взвешивания сальдо задолженности по отношению к общей сумме задолженностей фирмы, что фиксирует истинный показатель деятельности фирмы по отношению к множеству поставщиков и тенденции фирмы.
[0076] Фиг. 5 является блок-схемой генератора 215 модели, который, как упомянуто выше, обрабатывает различные данные фирмы, ASD 160 и весовые коэффициенты из A/R-обработки 210 и на основе этого формирует модель для оценки фирмы. Генератор 215 модели начинает с этапа 505.
[0077] На этапе 505 генератор 215 модели принимает справочные данные 140 о фирме, детализированные коммерческие данные 135, ASD 160, хороший весовой коэффициент 425 и плохой весовой коэффициент 430 и строит набор 510 данных для разработки модели.
[0078] Фиг. 5A является иллюстрацией таблицы, т.е. таблицей 550, которая показывает набор 510 данных для разработки первой примерной модели.
[0079] Таблица 550 имеет строку заголовка, которая перечисляет:
(1) уникальный идентификатор;
(2) прогнозирующие параметры:
(a) информацию о фирме (BI) 342;
(b) финансовую отчетность (FS) 343;
(c) традиционные коммерческие данные (TTD) 344;
(d) детализированные коммерческие (DT) данные 135;
(e) число сигналов (NS) 335; и
(f) код достоверности соответствия (CCM) 336;
(g) хороший весовой коэффициент (GW) 425; и
(h) плохой весовой коэффициент (BW) 430; и
(3) индикатор плохого риска (BRI).
[0080] На этапе 550 каждый уникальный идентификатор идентифицирует рассматриваемую фирму. Например, рассматриваемую фирму, которая соответствует уникальному идентификатору 00000001. Прогнозирующие параметры являются элементами данных, которые характеризуют рассматриваемую фирму. Может быть любое число уникальных идентификаторов и любое число прогнозирующих параметров, а на практике будет множество, например, миллионы, уникальных идентификаторов и множество, например, сотни, прогнозирующих параметров. Дополнительно, на практике, каждый из прогнозирующих параметров в таблице 550 представляет множество прогнозирующих параметров. Например, на практике, вместо одного столбца для информации о фирме будут столбцы для числа работников, лет существования фирмы и отрасли экономической деятельности. Прогнозирующие параметры рассматриваются как независимые переменные для регрессионного анализа. Отметим, например, что каждая из числа сигналов (NS) 335, кода достоверности соответствия (CCM) 336, хорошего весового коэффициента (GW) 425 и плохого весового коэффициента (BW) 430 является независимой переменной.
[0081] Также в таблице 550 ячейки в столбце, обозначенном как индикатор плохого риска (BRI) содержат значение, равное "1", когда рассматриваемая фирма рассматривается как имеющая плохой риск, например, когда хороший весовой коэффициент рассматриваемой фирмы меньше ее плохого весового коэффициента. Ячейка будет содержать значение, равное "0", когда рассматриваемая фирма рассматривается как не имеющая плохой риск. Назначение хорошего риска или плохого риска может быть основано на любой желаемой комбинации прогнозирующих параметров. Индикатор плохого риска рассматривается как зависимая переменная в целях регрессионного анализа.
[0082] Зависимая переменная в статистической модели является показателем, который мы пытаемся прогнозировать с помощью множества прогнозирующих параметров, т.е., независимых переменных. Генератор 215 модели, таким образом, различает между хорошим характером платежа и плохим характером платежа по обязательствам между рассматриваемой фирмой и поставщиком, чтобы определять зависимую переменную, в этом случае, индикатор плохого риска.
[0083] Фиг. 5B является иллюстрацией таблицы, т.е. таблицей 560, которая показывает набор 510 данных для разработки второй примерной модели.
[0084] Таблица 560 имеет строку заголовка, которая перечисляет:
(1) уникальный идентификатор; и
(2) прогнозирующие параметры:
(a) число сигналов (NS) 335; и
(b) плохой весовой коэффициент (BW) 430.
[0085] Отметим, например, что каждая из числа сигналов (NS) 335 и плохого весового коэффициента (BW) 430 является независимой переменной. В данной таблице 560 индикатор плохого риска, т.е., зависимая переменная, может быть получен из плохого весового коэффициента (BW) 430. Например, если плохой весовой коэффициент больше или равен 0,50, тогда индикатор плохого риска предполагает быть равным 1.
[0086] С этапа 550 генератор 215 модели переходит к этапу 515.
[0087] На этапе 515 генератор 215 модели выполняет регрессионный анализ по набору 510 данных для разработки модели и формирует регрессионную модель, т.е. модель 520.EQU 7 является общей формой модели 520.
Оценка=C1 (прогнозирующий параметр 1)+C2 (прогнозирующий параметр 2)+ … +Cm (прогнозирующий параметр m) EQU 7
[0088] Модель 520, таким образом, является уравнением, которое состоит из последовательности переменных и коэффициентов, которые были вычислены для каждой переменной. Например, в случае, когда набор 510 данных для разработки модели является таким, как показано в таблице 560, значения числа сигналов (NS) 335 и плохого весового коэффициента (BW) 430, т.е. независимых переменных, будут служить в качестве прогнозирующих параметров в EQU 7.
[0089] Фиг. 6 является блок-схемой процесса 220 оценки, который, как упомянуто выше, использует модель от генератора 215 модели, чтобы производить оценку 165. Процесс 220 оценки начинается с этапа 610.
[0090] На этапе 610 процесс 220 оценки получает данные из набора 510 данных для разработки модели и заполняет модель 520.С этапа 610 процесс 220 оценки переходит к этапу 620.
[0091] На этапе 620 процесс 220 оценки оценивает заполненную модель с этапа 610 и, таким образом, формирует оценку 165. В случае, когда заполненная модель 520 включает в себя конкретную независимую переменную, например, число сигналов (NS) 335, оценка 165 будет основана на, т.е. будет функцией, этой независимой переменной.
[0092] Фиг. 7 является таблицей 700, которая показывает пример оценочной карточки для одной фирмы, оцениваемой в соответствии с процессом 220 оценки. Примерный список прогнозирующих параметров, т.е. факторов, иллюстрирует, сколько баллов от каждого прогнозирующего параметра скапливается в общую оценку. Исходная оценка сопоставляется с процентильным баллом и значением класса, которое было определено на основе распределения генеральной совокупности. Перцентиль имеет диапазон от 1 до 100, где "100" означает наименее рискованный. Перцентиль создается на основе оценки распределения генеральной совокупности. Это создает ранг для генеральной совокупности. Класс, в качестве примера, определенный в диапазоне 1-5, основывается на распределении записей по генеральной совокупности. Наименее рискованные 10% совокупности находятся в классе 1; следующие 20% назначены классу 2. Средние 40% находятся в классе 3.Следующие более рискованные 20% совокупности классифицированы в класс 4. Наиболее рискованные 10% совокупности назначены классу 5. Процессор 115 подготавливает отчет, который включает в себя таблицу 700, и предоставляет отчет пользователю компьютера 105 посредством пользовательского интерфейса 110 или пользователю удаленного устройства (не показано) посредством сети 150.
[0093] В опытной эксплуатации всего 3300000 фирм были использованы, чтобы разработать модель 520. Сделки, сообщенные по этим фирмам, были классифицированы в одну из двух категорий: "Хорошую", которая определена как имеющая менее чем 91 день просрочки, и "Плохую", которая определена как сильно просроченная и, по сути, имеющая 91 или более дней просрочки по своим срокам выполнения обязательств. Хорошие счета оплачены в срок или с минимальными задержками по своим обязательствам. Во время разработки модели каждая фирма была взвешена на основе своего процента "хороших" сделок и "плохих" сделок. Если, например, для конкретной фирмы, 30% от общей суммы задолженности имеет 91 или более дней просрочки, а 70% имеет менее 91 дня просрочки, тогда эта компания взвешивается как на 70% "хорошая" и на 30% "плохая". Из 3300000-й совокупности приблизительно 10,2% счетов по сделкам, ассоциированных с этими фирмами, были "плохими" или сильно просроченными.
[0094] В процессе разработки модели данные собираются минимум из двух периодов времени, назначенных в качестве окна наблюдения и окна исполнения. Окно наблюдения определяет период времени, в течение которого собираются все идентификационные и характеристические данные. Окно исполнения определяет продолжительность времени, когда счета отслеживаются, чтобы изучать характер их оплаты. Моментальный снимок данных представляет временной интервал, в котором модель была разработана, и представляет любой другой временной интервал. Прогнозирующие переменные или независимые переменные, которые в комбинации могут определять результат, и схемы сегментации, которые классифицируют записи в различные группы аналогичных характеристик, определяются из этого моментального снимка.
[0095] В примерном варианте осуществления используемый моментальный снимок наблюдения был февралем 2011 г., а моментальный снимок исполнения был двенадцатью месяцами с марта 2011 г. по февраль 2012 г. Из данных окна наблюдения был проведен исчерпывающий анализ данных, чтобы определять такие переменные, которые статистически являются самыми значимыми факторами для прогнозирования сильной просрочки и вычисления соответствующих весовых коэффициентов для каждой.
[0096] Система 100 создает прогнозирующие параметры с помощью данных внутренних операций фирмы, определенных из метаданных и гранулярных уровней коммерческих данных. Мы обнаружили, что данные из наших метаданных 320 о созданных операционных процедурах являются значимыми прогнозирующими параметрами в наших моделях, особенно для записей с ограниченной деловой активностью или без деловой активности. Мы также использовали детализированные коммерческие данные, чтобы лучше различать хорошие и плохие характеры платежей. Этот источник данных предоставил набор значимых прогнозирующих параметров.
[0097] Способы, описанные в данном документе, являются примерными и не должны истолковываться как предполагающие какое-либо конкретное ограничение на настоящее изобретение. Должно быть понятно, что различные альтернативы, комбинации и модификации могут быть задуманы специалистами в области техники. Например, этапы, ассоциированные с процессами, описанными в данном документе, могут быть выполнены в любом порядке, пока иное не указано или не продиктовано самими этапами.
[0098] Термины "содержит" или "содержащий" должны интерпретироваться как указывающие присутствие заявленных признаков, целых частей, этапов или их компонентов или групп. Использование единственного числа в отношении любых раскрытых элементов не исключает их множественности.
| название | год | авторы | номер документа |
|---|---|---|---|
| СОСТАВЛЕНИЕ СЕТЕВОЙ КАРТЫ КРЕДИТНОГО ПОВЕДЕНИЯ | 2012 |
|
RU2573198C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ КРЕДИТНЫМИ ПОРТФЕЛЯМИ | 2010 |
|
RU2469401C2 |
| АВТОМАТИЗИРОВАННАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ И МОНИТОРИНГА ИНВЕСТИЦИОННЫХ ПОРТФЕЛЕЙ АКЦИЙ | 2016 |
|
RU2630169C1 |
| УСОВЕРШЕНСТВОВАНИЕ ЗАПРОСА ДЛЯ ПОИСКА БАЗЫ ДАННЫХ | 2011 |
|
RU2653246C1 |
| СИСТЕМА УПРАВЛЕНИЯ КРЕДИТНО-ФИНАНСОВЫМИ ОПЕРАЦИЯМИ ХИМИКО-ТЕХНОЛОГИЧЕСКОГО ПРЕДПРИЯТИЯ | 2004 |
|
RU2279134C2 |
| ИНФОРМАЦИОННО-АНАЛИТИЧЕСКАЯ СИСТЕМА КОМПЛЕКСНОЙ ОЦЕНКИ ДЕЯТЕЛЬНОСТИ КРЕДИТНЫХ ОРГАНИЗАЦИЙ | 2016 |
|
RU2621417C1 |
| ПОДПИСКА НА СОДЕРЖИМОЕ | 2006 |
|
RU2475829C2 |
| СИСТЕМА И СПОСОБ УЧЕТА ПЛАТЕЖЕЙ ПО КРЕДИТУ С ОБРАТНОЙ СВЯЗЬЮ ДЛЯ УПРАВЛЕНИЯ УСТРОЙСТВОМ, КОТОРОЕ БЫЛО КУПЛЕНО В КРЕДИТ | 2011 |
|
RU2481638C1 |
| СИСТЕМА ФОРМИРОВАНИЯ ФИНАНСОВОЙ И УПРАВЛЕНЧЕСКОЙ ОТЧЕТНОСТЕЙ ПО МЕЖДУНАРОДНЫМ СТАНДАРТАМ ФИНАНСОВОЙ ОТЧЕТНОСТИ (МСФО) | 2018 |
|
RU2682479C1 |
| СИСТЕМЫ И СПОСОБЫ ДЛЯ ПРОВЕДЕНИЯ СОСТАВНОЙ ТРАНЗАКЦИИ ОПЛАТЫ СЧЕТА | 2011 |
|
RU2628326C1 |
Изобретение относится к области предикативной оценки. Технический результат направлен на повышение точности обработки данных. В способе принимают из источника данных посредством электронной связи описатель фирмы, сопоставляют упомянутый описатель с данными в базе данных, сохраняют в журнал сигнал, подсчитывают количество сигналов, включают упомянутое число сигналов в качестве независимой переменной в набор данных. Далее получают из базы данных, остаток и сумму из упомянутого остатка задолженности. Вычисляют общую сумму задолженности упомянутой фирмы упомянутому множеству поставщиков. Обозначают, что фирма имеет плохой кредитный риск в отношении каждого из упомянутых поставщиков, вычисляют общую сумму задолженности упомянутому набору поставщиков, вычисляют отношение упомянутой плохой общей суммы к упомянутому общему остатку задолженности, включают упомянутый плохой весовой коэффициент в качестве независимой переменной, выполняют регрессионный анализ по упомянутому набору данных, получая таким образом модель для вычисления кредитной оценки для упомянутой фирмы. 3 н. и 6 з.п. ф-лы, 2 табл., 10 ил.
1. Способ точной обработки данных для кредитной оценки, содержащий этапы, на которых применяют компьютер, чтобы выполнять операции, которые включают в себя этапы, на которых:
принимают из источника данных посредством электронной связи описатель фирмы;
сопоставляют упомянутый описатель с данными в базе данных, получая таким образом соответствие, при этом упомянутые данные включают в себя уникальный идентификатор упомянутой фирмы;
сохраняют в журнал сигнал, который включает в себя упомянутый уникальный идентификатор;
подсчитывают количество сигналов, которые включают в себя упомянутый уникальный идентификатор, в упомянутом журнале, получая таким образом число упомянутых сигналов для упомянутого уникального идентификатора;
включают упомянутое число сигналов в качестве независимой переменной в набор данных;
получают из базы данных, в отношении каждого из множества поставщиков упомянутой фирмы,
(а) остаток, который причитается упомянутому поставщику от упомянутой фирмы, получая таким образом остаток задолженности упомянутому поставщику,
и (b) сумму из упомянутого остатка задолженности, которая просрочена, получая таким образом просроченный остаток для упомянутого поставщика;
вычисляют общую сумму задолженности упомянутой фирмы упомянутому множеству поставщиков, получая таким образом общий остаток задолженности;
вычисляют, для каждого упомянутого поставщика, отношение (а) упомянутого просроченного остатка для упомянутого поставщика к (b) упомянутому остатку задолженности упомянутому поставщику, получая таким образом соответствующий коэффициент просрочки для упомянутого поставщика;
обозначают, что упомянутая фирма имеет плохой кредитный риск в отношении каждого из упомянутых поставщиков, имеющего соответствующий коэффициент просрочки больше порогового коэффициента просрочки, получая таким образом набор поставщиков, для которых расчеты обозначены как плохие;
вычисляют общую сумму задолженности упомянутому набору поставщиков, для которых расчеты обозначены как плохие, получая таким образом плохую общую сумму;
вычисляют отношение (а) упомянутой плохой общей суммы к (b) упомянутому общему остатку задолженности, получая таким образом плохой весовой коэффициент;
включают упомянутый плохой весовой коэффициент в качестве независимой переменной в упомянутый набор данных;
выполняют регрессионный анализ по упомянутому набору данных, получая таким образом модель; и
используют упомянутую модель для вычисления кредитной оценки для упомянутой фирмы.
2. Способ по п. 1,
при этом упомянутое сопоставление также обеспечивает код, который указывает уровень достоверности того, что упомянутое соответствие является корректным,
при этом упомянутые операции также включают в себя этапы, на которых:
сохраняют упомянутый код в упомянутый журнал; и подсчитывают количество сигналов, которые (а) включают в себя упомянутый уникальный идентификатор, в упомянутом журнале и (b) указывают, что упомянутый уровень достоверности больше или равен конкретному пороговому уровню достоверности, получая таким образом подсчитанное число достоверных соответствий для упомянутого уникального идентификатора, и
включают упомянутое подсчитанное число достоверных соответствий для упомянутого уникального идентификатора в качестве независимой переменной в упомянутый набор данных.
3. Способ по п. 1,
при этом упомянутые операции также включают в себя этап, на котором сохраняют в упомянутый журнал соответствующее время, в которое упомянутое сопоставление получило упомянутое соответствие,и
при этом упомянутый подсчет включает в себя только упомянутые сигналы, которые указывают, что упомянутое соответствующее время попадает в конкретный период времени.
4. Система точной обработки данных для кредитной оценки, содержащая:
процессор и
память, которая содержит инструкции, которые считываются упомянутым процессором для управления упомянутым процессором, чтобы:
принимать, из источника данных, посредством электронной связи, описатель фирмы;
сопоставлять упомянутый описатель с данными в базе данных, получая таким образом соответствие, при этом упомянутые данные включают в себя уникальный идентификатор упомянутой фирмы;
сохранять в журнал сигнал, который включает в себя упомянутый уникальный идентификатор;
подсчитывать количество сигналов, которые включают в себя упомянутый уникальный идентификатор, в упомянутом журнале, получая таким образом число упомянутых сигналов для упомянутого уникального идентификатора;
включать упомянутое число сигналов в качестве независимой переменной в набор данных;
получать из базы данных, в отношении каждого из множества поставщиков упомянутой фирмы, (а) остаток, который причитается упомянутому поставщику от упомянутой фирмы, получая таким образом остаток задолженности упомянутому поставщику, и (b) сумму из упомянутого остатка задолженности, которая просрочена, получая таким образом просроченный остаток для упомянутого поставщика;
вычислять общую сумму задолженности упомянутой фирмы упомянутому множеству поставщиков, получая таким образом общий остаток задолженности;
вычислять, для каждого упомянутого поставщика, отношение (а) упомянутого просроченного остатка для упомянутого поставщика к (b) упомянутому остатку задолженности упомянутому поставщику, получая таким образом соответствующий коэффициент просрочки для упомянутого поставщика;
обозначать, что упомянутая фирма имеет плохой кредитный риск в отношении каждого из упомянутых поставщиков, имеющего соответствующий коэффициент просрочки больше порогового коэффициента просрочки, получая таким образом набор поставщиков, для которых расчеты обозначены как плохие;
вычислять общую сумму задолженности упомянутому набору поставщиков, для которых расчеты обозначены как плохие, получая таким образом плохую общую сумму;
вычислять отношение (а) упомянутой плохой общей суммы к (b) упомянутому общему остатку задолженности, получая таким образом плохой весовой коэффициент;
включать упомянутый плохой весовой коэффициент в качестве независимой переменной в упомянутый набор данных;
выполнять регрессионный анализ по упомянутому набору данных, получая таким образом модель; и
использовать упомянутую модель для вычисления кредитной оценки для упомянутой фирмы.
5. Система по п. 4,
при этом упомянутые инструкции, чтобы выполнять упомянутое сопоставление, также управляют упомянутым процессором, чтобы обеспечивать код, который указывает уровень достоверности того, что упомянутое соответствие является корректным,
при этом упомянутые инструкции также управляют упомянутым процессором, чтобы:
сохранять упомянутый код в упомянутый журнал; и
подсчитывать количество сигналов, которые (а) включают в себя упомянутый уникальный идентификатор в упомянутом журнале и (b) указывают, что упомянутый уровень достоверности больше или равен конкретному пороговому уровню достоверности, получая таким образом подсчитанное число достоверных соответствий для упомянутого уникального идентификатора, и
включать упомянутое подсчитанное число достоверных соответствий для упомянутого уникального идентификатора в качестве независимой переменной в упомянутый набор данных.
6. Система по п. 4,
при этом упомянутые инструкции также управляют упомянутым процессором, чтобы сохранять в упомянутый журнал соответствующее время, в которое упомянутое сопоставление с упомянутым описателем получило упомянутое соответствие, и
при этом для подсчета упомянутого количества сигналов, упомянутый процессор включает в себя только упомянутые сигналы, которые указывают, что упомянутое соответствующее время попадает в конкретный период времени.
7. Устройство хранения для точной обработки данных для кредитной оценки, содержащее инструкции, которые считываются процессором для управления упомянутым процессором, чтобы:
принимать, из источника данных, посредством электронной связи, описатель фирмы;
сопоставлять упомянутый описатель с данными в базе данных, получая таким образом соответствие, при этом упомянутые данные включают в себя уникальный идентификатор упомянутой фирмы;
сохранять в журнал сигнал, который включает в себя упомянутый уникальный идентификатор;
подсчитывать количество сигналов, которые включают в себя упомянутый уникальный идентификатор, в упомянутом журнале, получая таким образом число упомянутых сигналов для упомянутого уникального идентификатора;
включать упомянутое число сигналов в качестве независимой переменной в набор данных;
получать из базы данных, в отношении каждого из множества поставщиков упомянутой фирмы, (а) остаток, который причитается упомянутому поставщику от упомянутой фирмы, получая таким образом остаток задолженности упомянутому поставщику, и (b) сумму из упомянутого остатка задолженности, которая просрочена, получая таким образом просроченный остаток для упомянутого поставщика;
вычислять общую сумму задолженности упомянутой фирмы упомянутому множеству поставщиков, получая таким образом общий остаток задолженности;
вычислять, для каждого упомянутого поставщика, отношение (а) упомянутого просроченного остатка для упомянутого поставщика к (b) упомянутому остатку задолженности упомянутому поставщику, получая таким образом соответствующий коэффициент просрочки для упомянутого поставщика;
обозначать, что упомянутая фирма имеет плохой кредитный риск в отношении каждого из упомянутых поставщиков, имеющего соответствующий коэффициент просрочки больше порогового коэффициента просрочки, получая таким образом набор поставщиков, для которых расчеты обозначены как плохие;
вычислять общую сумму задолженности упомянутому набору поставщиков, для которых расчеты обозначены как плохие, получая таким образом плохую общую сумму;
вычислять отношение (а) упомянутой плохой общей суммы к (b) упомянутому общему остатку задолженности, получая таким образом плохой весовой коэффициент;
включать упомянутый плохой весовой коэффициент в качестве независимой переменной в упомянутый набор данных;
выполнять регрессионный анализ по упомянутому набору данных, получая таким образом модель; и
использовать упомянутую модель для вычисления кредитной оценки для упомянутой фирмы.
8. Устройство хранения по п. 7,
при этом упомянутые инструкции, чтобы выполнять упомянутое сопоставление, также управляют упомянутым процессором, чтобы обеспечить код, который указывает уровень достоверности того, что упомянутое соответствие является корректным,
при этом упомянутые инструкции также управляют упомянутым процессором, чтобы:
сохранять упомянутый код в упомянутый журнал; и
подсчитывать количество сигналов, которые (а) включают в себя упомянутый уникальный идентификатор в упомянутом журнале и (b) указывают, что упомянутый уровень достоверности больше или равен конкретному пороговому уровню достоверности, получая таким образом подсчитанное число достоверных соответствий для упомянутого уникального идентификатора, и
включать упомянутое подсчитанное число достоверных соответствий для упомянутого уникального идентификатора в качестве независимой переменной в упомянутый набор данных.
9.Устройство хранения по п. 7,
при этом упомянутые инструкции также управляют упомянутым процессором, чтобы сохранять в упомянутый журнал соответствующее время, в которое упомянутое сопоставление с упомянутым описателем получило упомянутое соответствие, и
при этом для подсчета упомянутого количества сигналов упомянутый процессор включает в себя только упомянутые сигналы, которые указывают, что упомянутое соответствующее время попадает в конкретный период времени.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| RU 2010108923 A, 20.09.2011. | |||

