В настоящей заявке испрашивается приоритет по патентной заявке Китая 201510511468.1, поданной 19 августа 2015 г., которая целиком включена в настоящее описание посредством ссылки.
Область техники, к которой относится изобретение
Настоящее изобретение в целом относится к области обработки естественных языков, а в частности к способу и устройству для обучения классификатора и распознавания типа.
Уровень техники
Практическим применением обработки естественных языков является распознавание содержания коротких сообщений и извлечение сообщений.
Известен способ распознавания, который может быть показан на примере распознавания коротких сообщений на тему дня рождения. Способ распознавания для мобильных устройств содержит предварительное задание множества ключевых слов; распознавание содержания короткого сообщения, чтобы определить, включает ли его содержание все ключевые слова или часть ключевых слов; и определение, является ли данное короткое сообщение сообщением, содержащим дату рождения.
Раскрытие изобретения
Учитывая то, что в известных технических решениях использование ключевых слов не является надежным способом для выполнения распознавания типа, в настоящем изобретении предложен способ и устройство для обучения классификатора и распознавания типа.
Согласно настоящему изобретению в его первом аспекте, предлагается способ обучения классификатора. Способ содержит: извлечение из информации для отбора образцов фраз, содержащих целевое ключевое слово; присвоение бинарных меток образцам фраз, чтобы получить обучающее множество образцов на основе принадлежности каждого из образцов фраз целевому классу; разбиение на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; выделение заданного характеристического множества из множества слов, при этом заданное характеристическое множество содержит по меньшей мере одно характеристическое слово; построение классификатора на основе характеристических слов в заданном характеристическом множестве; и обучение классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов.
Согласно примеру осуществления изобретения, выделение заданного характеристического множества из множества слов содержит: выделение заданного характеристического множества из множества слов на основе критерия хи-квадрат; или выделение заданного характеристического множества из множества слов на основе прироста информации.
Согласно примеру осуществления изобретения, построение классификатора на основе характеристических слов в заданном характеристическом множестве содержит: построение байесовского наивного классификатора с характеристическими словами в заданном характеристическом множестве, причем в байесовском наивном классификаторе соответствующие характеристические слова являются независимыми друг от друга.
Согласно примеру осуществления изобретения, обучение классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов содержит: для каждого характеристического слова в байесовском наивном классификаторе – вычисление первой условной вероятности того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, вычисление второй условной вероятности того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу, на основе результатов присвоения бинарных меток в обучающем множестве образцов; и получение обученного байесовского наивного классификатора на основе каждого характеристического слова, первой условной вероятности и второй условной вероятности.
Согласно настоящему изобретению в его втором аспекте, предлагается способ распознавания типа. Способ содержит: выделение фраз, содержащих целевое ключевое слово, из исходной информации; формирование характеристического множества из исходной информации на основе характеристических слов, которые принадлежат к заданному характеристическому множеству, в выделенных фразах, при этом выделение характеристических слов в заданном характеристическом множестве производят на основе результатов разбиения на слова образцов фраз, содержащих целевое ключевое слово; ввод характеристического множества исходной информации в обученный классификатор для предсказания, причем указанный классификатор предварительно строят на основе характеристических слов в заданном характеристическом множестве; и получение результата предсказания классификатора, при этом результат предсказания представляет, принадлежит ли исходная информация целевому классу.
Согласно примеру осуществления изобретения, ввод характеристического множества исходной информации в обученный классификатор для предсказания содержит: вычисление первой вероятности предсказания того, что исходная информация принадлежит целевому классу, и второй вероятности предсказания того, что исходная информация не принадлежит целевому классу, путем ввода каждого характеристического слова в характеристическом множестве исходной информации в обученный байесовский наивный классификатор; предсказание, принадлежит ли исходная информация целевому классу на основе соотношения численных значений первой вероятности предсказания и второй вероятности предсказания; при этом байесовский наивный классификатор содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, причем первая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, а вторая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу.
Согласно примеру осуществления изобретения, способ дополнительно содержит извлечение целевой информации из исходной информации, когда получено предсказание, что исходная информация принадлежит целевому классу.
Согласно примеру осуществления изобретения, целевая информация представляет собой дату рождения, а извлечение целевой информации из исходной информации содержит: выделение даты рождения из исходной информации посредством надлежащего выражения (regular expression); или выделение даты приема исходной информации в качестве даты рождения.
Согласно настоящему изобретению в его третьем аспекте, предлагается устройство для обучения классификатора, при этом устройство содержит: модуль выделения фраз, выполненный с возможностью извлечения образцов фраз, содержащих целевое ключевое слово, из информации для отбора; модуль присвоения меток фразам, выполненный с возможностью присвоения образцам фраз бинарных меток, чтобы получить обучающее множество образцов на основе принадлежности каждого образца фразы целевому классу; модуль разбиения фраз на слова, выполненный с возможностью разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; модуль выделения характеристических слов, выполненный с возможностью выделения заданного характеристического множества из множества слов, при этом заданное характеристическое множество содержит по меньшей мере одно характеристическое слово; модуль построения классификатора, выполненный с возможностью построения классификатора на основе характеристических слов в заданном характеристическом множестве; и модуль обучения классификатора, выполненный с возможностью обучения классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов.
Согласно примеру осуществления изобретения, модуль выделения характеристических слов выполнен с возможностью выделения заданного характеристического множества из множества слов на основе критерия хи-квадрат; или модуль выделения характеристических слов выполнен с возможностью выделения заданного характеристического множества из множества слов на основе прироста информации.
Согласно примеру осуществления изобретения, модуль построения классификатора выполнен с возможностью построения байесовского наивного классификатора с характеристическими словами в заданном характеристическом множестве, причем в байесовском наивном классификаторе соответствующие характеристические слова являются независимыми друг от друга.
Согласно примеру осуществления изобретения, модуль обучения классификатора содержит: вычислительный субмодуль, выполненный с возможностью вычисления первой условной вероятности того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, и второй условной вероятности того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу, для каждого характеристического слова в байесовском наивном классификаторе на основе результатов присвоения бинарных меток в обучающем множестве образцов; и обучающий субмодуль, выполненный с возможностью получения обученного байесовского наивного классификатора на основе каждого характеристического слова, первой условной вероятности и второй условной вероятности.
Согласно настоящему изобретению в его четвертом аспекте, предлагается устройство для распознавания типа. Устройство содержит: модуль исходного выделения, выполненный с возможностью выделения фраз, содержащих целевое ключевое слово, из исходной информации; модуль характеристического выделения, выполненный с возможностью формирования характеристического множества исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству, причем выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образца фразы, содержащей целевое ключевое слово; модуль характеристического ввода, выполненный с возможностью ввода характеристического множества исходной информации в обученный классификатор для предсказания, причем классификатор предварительно построен на основе характеристических слов в заданном характеристическом множестве; и модуль получения результата, выполненный с возможностью получения результата предсказания классификатора, который представляет, принадлежит ли исходная информация целевому классу.
Согласно примеру осуществления изобретения, модуль характеристического ввода содержит: вычислительный субмодуль, выполненный с возможностью вычисления первой вероятности предсказания того, что исходная информация принадлежит целевому классу, и второй вероятности предсказания того, что исходная информация не принадлежит целевому классу, путем ввода каждого характеристического слова характеристического множества исходной информации в обученный байесовский наивный классификатор; и субмодуль предсказания, выполненный с возможностью предсказания того, принадлежит ли исходная информация целевому классу на основе соотношения численных значений первой вероятности предсказания и второй вероятности предсказания; причем обученный байесовский наивный классификатор содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, при этом первая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, а вторая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу.
Согласно примеру осуществления изобретения, устройство дополнительно содержит модуль извлечения информации, выполненный с возможностью извлечения целевой информации из исходной информации, когда получено предсказание, что исходная информация принадлежит целевому классу.
Согласно примеру осуществления изобретения, целевая информация представляет собой дату рождения, и модуль извлечения информации выполнен с возможностью извлечения даты рождения из исходной информации посредством надлежащего выражения; или модуль извлечения информации выполнен с возможностью извлечения даты приема исходной информации в качестве даты рождения.
Согласно настоящему изобретению в его пятом аспекте, предлагается устройство для обучения классификатора. Устройство содержит: процессор и память для хранения инструкций, исполняемых процессором, при этом процессор выполнен с возможностью: извлечения образцов фраз, содержащих целевое ключевое слово из информации для отбора; присвоения бинарных меток образцам фраз, чтобы получить обучающее множество образцов на основе принадлежности каждого образца фразы целевому классу; разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; выделения заданного характеристического множества из множества слов, причем множество характеристических слов содержит по меньшей мере одно характеристическое слово; построения классификатора на основе характеристических слов в заданном характеристическом множестве; и обучения классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов.
Согласно настоящему изобретению в его шестом аспекте, предлагается устройство для распознавания типа. Устройство содержит: процессор и память для хранения инструкций, исполняемых процессором, при этом процессор выполнен с возможностью: извлечения фраз, содержащих ключевое слово из исходной информации; формирования характеристического множества из исходной информации на основе характеристических слов, которые принадлежат к характеристическому множеству, в выделенных фразах, при этом выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образцов фраз, содержащих целевое ключевое слово; ввода характеристического множества исходной информации в обученный классификатор для предсказания, причем указанный классификатор предварительно построен на основе характеристических слов в заданном характеристическом множестве; и получения результата предсказания классификатора, при этом результат предсказания представляет, принадлежит ли исходная информация целевому классу.
Варианты осуществления настоящего изобретения могут дать по меньшей мере некоторые из следующих полезных технических эффектов: путем разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; выделения заданного характеристического множества из данного множества слов, и построения классификатора на основе характеристических слов в заданном характеристическом множестве, можно решить проблему, свойственную известным техническим решениям, и состоящую в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday” (день рождения). Поскольку извлечение характеристических слов в заданном характеристическом множестве производится путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым могут быть достигнуты более точные результаты распознавания.
Следует понимать, что как предыдущее общее описание, так и последующее подробное описание являются лишь примерами и не ограничивают собой идею настоящего изобретения.
Краткое описание чертежей
Прилагаемые чертежи, которые включены в настоящее описание и составляют его часть, иллюстрируют варианты осуществления, соответствующие настоящему изобретению, и вместе с описанием служат для разъяснения изобретения.
Фиг. 1 изображает блок-схему алгоритма, иллюстрирующую способ для обучения классификатора в соответствии с вариантом осуществления изобретения.
Фиг. 2 изображает блок-схему алгоритма, иллюстрирующую способ для обучения классификатора в соответствии с другим вариантом осуществления изобретения.
Фиг. 3 изображает блок-схему алгоритма, иллюстрирующую способ для распознавания типа в соответствии с вариантом осуществления изобретения.
Фиг. 4 изображает блок-схему алгоритма, иллюстрирующую способ для распознавания типа в соответствии с другим вариантом осуществления изобретения.
Фиг. 5 изображает блок-схему устройства для обучения классификатора в соответствии с вариантом осуществления изобретения.
Фиг. 6 изображает блок-схему устройства для обучения классификатора в соответствии с другим вариантом осуществления изобретения.
Фиг. 7 изображает блок-схему устройства для распознавания типа в соответствии с вариантом осуществления изобретения.
Фиг. 8 изображает блок-схему устройства для распознавания типа в соответствии с другим вариантом осуществления изобретения.
Фиг. 9 изображает блок-схему, иллюстрирующую устройство для обучения классификатора или устройство для распознавания типа в соответствии с вариантом осуществления изобретения.
Осуществление изобретения
Ниже будет приведено подробное описание примеров осуществления изобретения, примеров, которые проиллюстрированы прилагаемыми чертежами. Нижеприведенное описание относится к прилагаемым чертежам, в которых одинаковые номера в различных чертежах представляют одинаковые или подобные элементы, если не оговорено иное. Реализации, предложенные в нижеследующем описании примеров осуществления, не представляют все реализации, соответствующие изобретению. Напротив, они являются лишь примерами устройств и способов, которые соответствуют аспектам изобретения, изложенным в прилагаемой формуле изобретения.
В силу многообразия и сложности выражений на естественном языке, прямое использование целевого ключевого слова для выполнения распознавания типа не является надежным способом. Для примера, короткое сообщение, содержащее целевое ключевое слово “birthday” (день рождения) или “born” (рожденный), может иметь следующий вид:
короткое сообщение 1: “Xiaomin, tomorrow is not his birthday, please do not buy a cake.” («Сяомин, завтра не его день рождения, пожалуйста, не покупай торт»),
короткое сообщение 2: “Darling, is today your birthday ?” («Дорогая, сегодня твой день рождения?»),
короткое сообщение 3: “My son was born in last year’s today.” («Мой сын родился в сегодняшний день в прошлом году.»),
короткое сообщение 4: “The baby who was born on May 20 has a good luck.” («Ребенок, который родился 20 мая, счастливый».).
В вышеприведенных четырех коротких сообщениях только третье сообщение является сообщением, которое содержит истинную дату рождения; ни одно из остальных трех сообщений не является сообщением, содержащим действительную дату рождения.
Для надежного распознавания типа короткого сообщения вариант осуществления настоящего изобретения предлагает способ распознавания, основанный на использовании классификатора. Способ распознавания содержит два этапа: первый этап – обучение классификатора и второй этап – использование классификатора для распознавания типа.
Для реализации вышеуказанных двух этапов используются следующие разные варианты осуществления изобретения.
Первый этап – обучение классификатора
Фиг. 1 изображает блок-схему алгоритма, иллюстрирующую способ обучения классификатора согласно примеру осуществления. Алгоритм может содержать следующие шаги.
На шаге 101 из информации для отбора (sample information) извлекают образец фразы (sample clause), содержащий целевое ключевое слово (target keyword).
В качестве варианта, информация для отбора может представлять собой информацию любого следующего вида: короткое сообщение, электронное письмо, микроблог или информацию мгновенного сообщения. Варианты осуществления настоящего изобретения не накладывают ограничений на классы информации для отбора.
Всякая информация для отбора может содержать по меньшей мере одну фразу, при этом фраза, содержащая целевое ключевое слово, является образцом фразы.
На шаге 102 присваивают бинарную метку образцу фразы, чтобы получить обучающее множество образцов (sample training set) исходя из принадлежности каждого образца фразы к целевому классу (target class).
На шаге 103 осуществляют разбиение на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов.
На шаге 104 из множества слов выделяют заданное характеристическое множество (specified characteristic set), при этом заданное характеристическое множество содержит по меньшей мере одно характеристическое слово (characteristic word).
На шаге 105 конструируют классификатор на основе характеристических слов в заданном характеристическом множестве.
Как вариант, классификатор может представлять собой байесовский наивный классификатор (Naïve Bayes classifier).
На шаге 106 обучают классификатор по результатам присвоения бинарных меток в множестве обучающих образцов.
Итак, способ обучения классификатора в соответствии с настоящим изобретением, содержащий разбиение на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; выделение заданного характеристического множества из множества слов, и построение классификатора на основе характеристических слов в заданном характеристическом множестве, может решить проблему, свойственную известным техническим решениям, и состоящую в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку характеристические слова в заданном характеристическом множестве извлекают путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым могут быть достигнуты более точные результаты распознавания.
Фиг. 2 изображает блок-схему алгоритма, иллюстрирующую способ обучения классификатора согласно другому примеру осуществления. Способ может содержать следующие шаги.
На шаге 201 получают совокупную информацию для отбора, содержащую целевое ключевое слово.
Целевое ключевое слово относят к целевому классу. К примеру, когда целевой класс представляет собой информацию, содержащую истинную дату рождения, в число целевых ключевых слов входят слова “birthday” и “born”.
Чем большее количество информации для отбора содержит целевое ключевое слово, тем более точным будет обученный классификатор. Когда информация для отбора относится к классу коротких сообщений, то, например, информация для отбора может содержать:
образец 1 короткого сообщения: “Xiaomin, tomorrow is not his birthday, please do not buy a cake.”
образец 2 короткого сообщения: “Darling, is today your birthday?”
образец 3 короткого сообщения: “My son was born in last year’s today.”
Образец 4 короткого сообщения: “The baby who was born on May 20 has a good luck.”
Образец 5 короткого сообщения: “The day, on which my son was born, is April Fool’s Day” («Мой сын родился в апреле в День Смеха»),
и так далее, тому подобные сообщения, которые здесь приведены не будут.
На шаге 202 из информации для отбора выделяют образец фразы, содержащий целевое ключевое слово.
Всякая информация для отбора может содержать по меньшей мере одну фразу. Указанная фраза относится к предложению, которое не содержит знаков пунктуации. Например,
образец 1 фразы, извлеченной из образца 1 короткого сообщения: “tomorrow is not his birthday”,
образец 2 фразы, извлеченной из образца 2 короткого сообщения: “is today your birthday”,
образец 3 фразы, извлеченной из образца 3 короткого сообщения:” My son was born in last year’s today”,
образец 4 фразы, извлеченной из образца 4 короткого сообщения: “The baby who was born on May 20 has a good luck”,
образец 5 фразы, извлеченной из образца 5 короткого сообщения: “on which my son was born”.
На шаге 203 присваивают бинарную метку образцу фразы, чтобы получить обучающее множество образцов исходя из принадлежности каждого образца фразы к целевому классу.
Как вариант, значение бинарной метки равно 1 или 0; когда образец фразы принадлежит к целевому классу, ему присваивают метку 1; когда образец фразы не принадлежит к целевому классу, ему присваивают метку 0.
Например, образец 1 фразы получает метку 0; образец 2 фразы получает метку 0; образец 3 фразы получает метку 1; образец 4 фразы получает метку 0; и образец 5 фразы получает метку 1.
Обучающее множество образцов может включать в себя множество образцов фраз.
На шаге 204 выполняют разбиение на слова каждого образца фразы в множестве обучающих образцов, чтобы получить множество слов.
Например, разбивают на слова образец 1 фразы, чтобы получить пять слов “tomorrow”, “is”, “not”, “his” и “birthday”; разбивают на слова образец 2 фразы, чтобы получить пять слов “darling”, “is”, “today”, “your” и “birthday”; разбивают на слова образец 3 фразы, чтобы получить восемь слов “my”, “son”, “was”, “born”, “in”, “last”, “year’s” и “today”; разбивают на слова образец 4 фразы, чтобы получить двенадцать слов “the”, “baby”, “who”, “was”, “born”, “on”, “May”, “20”, “has”, “a”, “good” и “luck”; разбивают на слова образец 5 фразы, чтобы получить двенадцать слов “the”, “day”, “on”, “which”, “my”, “son”, “was”, “born”, “is”, “April”, “Fool’s” и “Day”.
То есть, множество слов сможет содержать следующие слова: “tomorrow”, “is”, “not”, “his”, “birthday”, “is”, “today”, “your”, “my”, “son”, “was”, “born”, “in”, “last”, “year’s”, “the”, “baby”, “who”, “was”, “born”, “on”, “May”, “20”, “has”, “a”, “good” and “luck”, “on”, “which”, и т.п.
На шаге 205 из множества слов выделяют заданное характеристическое множество на основе критерия хи-квадрат или прироста информации.
В множестве слов, полученном путем разбиения фраз на слова, некоторые слова имеют бόльшую важность, а некоторые слова имеют меньшую важность, поэтому не все слова подходят для применения в качестве характеристического слова. Для выделения характеристических слов можно использовать два различных подхода.
Первый способ: характеристические слова, релевантности которых по отношению к целевому классу соответствуют верхним n значениям, выделяют из множества слов на основе критерия хи-квадрат, чтобы сформировать заданное характеристическое множество F.
Критерий хи-квадрат может проверить релевантность каждого слова целевому классу. Чем выше релевантность, тем в большей степени подходит слово для использования в качестве характеристического слова, соответствующего целевому классу.
Например, способ выделения характеристического слова на основе критерия хи-квадрат содержит следующие этапы:
1.1. Рассчитывают общее число N образцов фраз в обучающем множестве образцов;
1.2. Вычисляют частоту А, с которой каждое слово появляется в образце фразы, принадлежащем к целевому классу; вычисляют частоту В, с которой каждое слово появляется в образце фразы, не принадлежащем к целевому классу; вычисляют частоту С, с которой каждое слово не появляется в образце фразы, принадлежащем к целевому классу; и вычисляют частоту D, с которой с которой каждое слово не появляется в образце фразы, не принадлежащем к целевому классу;
1.3. Вычисляют значение хи-квадрат для каждого слова по следующей формуле:
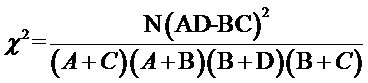
1.4. Каждому из слов дают оценку на основе соответствующего значения хи-квадрат от высокой до малой, и верхние n слов выбирают в качестве характеристических слов.
Второй способ: характеристические слова, прирост информации для которых соответствует верхним n значениям, выделяют из множества слов исходя из прироста информации, чтобы сформировать заданное характеристическое множество F.
Термин прирост информации касается величины информативности слова по отношению к обучающему множеству образцов. Чем более информативным является слово, тем в большей степени данное слово подходит для использования в качестве характеристического слова.
Например, способ выделения характеристического слова на основе прироста информации содержит следующие этапы:
2.1. Рассчитывают число N1 образцов фраз, принадлежащих целевому классу, и число N2 образцов фраз, не принадлежащих целевому классу;
2.2. Вычисляют частоту А, с которой каждое слово появляется в образце фразы, принадлежащей к целевому классу; вычисляют частоту В, с которой каждое слово появляется в образце фразы, не принадлежащей к целевому классу; вычисляют частоту С, с которой каждое слово не появляется в образце фразы, принадлежащей к целевому классу; и вычисляют частоту D, с которой каждое слово не появляется в образце фразы, не принадлежащей к целевому классу;
2.3. Вычисляют информационную энтропию по следующей формуле:
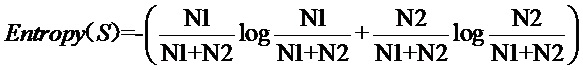
2.4. Вычисляют прирост информации для каждого слова по следующей формуле:
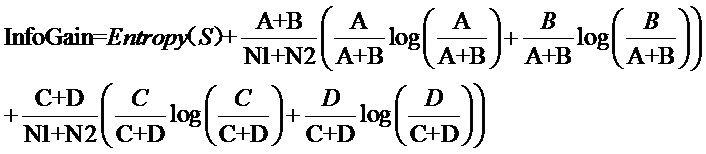
2.5. Каждому слову дают оценку исходя из величины прироста информации от большой до малой, и верхние n слов выбирают в качестве характеристических слов.
На шаге 206 создают байесовский наивный классификатор с характеристическими словами в заданном характеристическом множестве, причем в байесовском наивном классификаторе характеристические слова являются независимыми друг от друга.
Байесовский наивный классификатор - это классификатор, который выполняет предсказание на основе первой условной вероятности и второй условной вероятности каждого характеристического слова. Для любого характеристического слова первая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, принадлежат к целевому классу, а вторая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат к целевому классу.
В процедуре обучения байесовского наивного классификатора необходимо вычислять первую условную вероятность и вторую условную вероятность каждого характеристического слова на основе обучающего множества образцов.
Например, имеются 100 образцов фраз, содержащих характеристическое слово “today”, при этом 73 образца фраз принадлежат целевому классу, а 27 образцов фраз не принадлежат целевому классу. Тогда первая условная вероятность характеристического слова “today” равна 0,73, а вторая условная вероятность характеристического слова “today” равна 0,27.
На шаге 207 первую условную вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, и вторую условную вероятность того, что что фразы, содержащие характеристическое слово, не принадлежат целевому классу вычисляют для каждого характеристического слова в байесовском наивном классификаторе, исходя из результатов присвоения бинарных меток в обучающем множестве образцов.
На шаге 208 получают обученный байесовский наивный классификатор, основанный на каждом характеристическом слове, первой условной вероятности и второй условной вероятности.
Таким образом, способ обучения классификатора в соответствии с настоящим изобретением, содержащий разбиение на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; выделение заданного характеристического множества из данного множества слов, и построение классификатора на основе характеристических слов в заданном характеристическом множестве, может решить проблему, свойственную известным техническим решениям, и состоящую в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку характеристические слова в заданном характеристическом множестве извлекают путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым могут быть достигнуты более точные результаты распознавания.
В данном варианте осуществления характеристические слова извлекают из каждой фразы обучающего множества образцов на основе критерия хи-квадрат или прироста информации, при этом могут быть выделены характеристические слова, которые лучшим образом влияют на точность классификации, и тем самым увеличивают точность классификации байесовского наивного классификатора.
Второй этап – это использование классификатора для распознавания типа
Фиг. 3 изображает блок-схему алгоритма, иллюстрирующую способ распознавания типа в соответствии с примером осуществления изобретения. В способе распознавания типа используют обученный классификатор, полученный согласно вариантам осуществления, представленным на фиг. 1 или фиг. 2. Способ может содержать следующие этапы.
На шаге 301 из исходной информации извлекают образец фразы, содержащей целевое ключевое слово.
В качестве варианта, исходная информация (информация для отбора) может представлять собой информацию любого следующего вида: короткое сообщение, электронное письмо, микроблог или информацию мгновенного сообщения. Варианты осуществления настоящего изобретения не накладывают ограничений на классы информации для отбора. Всякая исходная информация может содержать по меньшей мере одну фразу.
На шаге 302 формируют характеристическое множество из исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству, причем характеристические слова в заданном характеристическом множестве выделяют на основе результатов разбиения на слова образцов фраз, содержащих целевые ключевые слова.
На шаге 303 характеристическое множество из исходной информации вводят в обученный классификатор для предсказания, причем указанный классификатор предварительно построен на основе характеристических слов в заданном характеристическом множестве.
Как вариант, классификатор представляет собой байесовский наивный классификатор.
На шаге 304 получают результат предсказания классификатора, который представляет, принадлежит ли исходная информация целевому классу.
В итоге, способ распознавания типа в соответствии с настоящим изобретением, содержащий выделение характеристических слов из фраз, исходя из заданного характеристического множества для использования в качестве характеристического множества исходной информации, и затем ввод характеристического множества в обученный классификатор для предсказания, который предварительно построен на основе характеристических слов в заданном характеристическом множестве, может решить проблему, свойственную существующим техническим решениям, состоящую в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку характеристические слова в заданном характеристическом множестве извлекают путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым могут быть достигнуты точные результаты распознавания.
Фиг. 4 изображает блок-схему алгоритма, иллюстрирующую способ распознавания типа в соответствии с другим примером осуществления изобретения. В способе распознавания типа используют обученный классификатор, полученный согласно вариантам осуществления, представленным на фиг. 1 или фиг. 2. Способ может содержать следующие этапы.
На шаге 401 производится обнаружение, содержит ли исходная информация целевое ключевое слово.
Как вариант, исходная информация может представлять собой короткое сообщение; например, исходная информация может иметь вид “my birthday is on July 28, today is not my birthday!” («мой день рождения 28 июля, сегодня не мой день рождения!»).
Целевое ключевое слово относится к целевому классу. Например, когда целевым классом является информация, содержащая истинную дату рождения, среди целевых слов будут слова “birthday” и “born”.
Алгоритм обнаруживает, содержит ли исходная информация целевое ключевое слово. Если да, то алгоритм переходит к шагу 402; в противном случае алгоритм завершает работу.
На шаге 402, если исходная информация содержит целевое ключевое слово, то алгоритм из исходной информации извлекает фразу, содержащую целевое ключевое слово.
Например, если исходная информация содержит ключевое слово “birthday”, то из исходной информации извлекается фраза “my birthday is on July 28”.
На шаге 403 формируют характеристическое множество исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству, при этом выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образца фразы, содержащей целевые ключевые слова.
Например, заданное характеристическое множество может включать в себя слова: “tomorrow”, “is”, “not”, “his”, “birthday”, “is”, “today”, “your”, “my”, “son”, “was”, “born”, “in”, “last”, “year’s”, “the”, “baby” и т.д.
Характеристические слова фразы “my birthday is on July 28”, которые принадлежат заданному характеристическому множеству, включают в себя “my”, “birthday” и “is”. Эти три слова “my”, “birthday” и “is” используются в качестве характеристического множества исходной информации.
На шаге 404 каждое характеристическое слово в характеристическом множестве исходной информации алгоритм вводит в обученный байесовский наивный классификатор и производит вычисление первой вероятности предсказания, что исходная информация принадлежит к целевому классу, и второй вероятности предсказания, что исходная информация не принадлежит к целевому классу.
Обученный байесовский наивный классификатор содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, при этом первая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, а вторая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу.
Первая вероятность предсказания исходной информации равна произведению первых условных вероятностей всех характеристических слов в характеристическом множестве исходной информации.
Например, когда первая условная вероятность слова “my” равна 0,3, первая условная вероятность слова “birthday” равна 0,65, а первая условная вероятность слова “is” равна 0,7, первая вероятность предсказания исходной информации будет равна 0,3х0,65х0,7=0,11375.
Вторая вероятность предсказания исходной информации равна произведению вторых условных вероятностей всех характеристических слов в характеристическом множестве исходной информации.
Например, когда вторая условная вероятность слова “my” равна 0,2, вторая условная вероятность слова “birthday” равна 0,35, а вторая условная вероятность слова “is” равна 0,3, вторая вероятность предсказания исходной информации будет равна 0,2х0,35х0,3=0,021.
На шаге 405 алгоритм делает предсказание о принадлежности исходной информации к целевому классу на основе соотношения числовых значений первой вероятности предсказания и второй вероятности предсказания.
Когда первая вероятность предсказания больше второй вероятности предсказания, результатом предсказания будет вывод, что исходная информация принадлежит целевому классу.
Например, 0,11375 больше, чем 0,021, поэтому исходная информация принадлежит к целевому классу, то есть исходная информация содержит истинную дату рождения.
Когда вторая вероятность предсказания больше первой вероятности предсказания, результатом предсказания будет вывод, что исходная информация не принадлежит целевому классу.
На шаге 406, если алгоритм предсказывает, что исходная информация принадлежит целевому классу, производится извлечение целевой информации из исходной информации.
Данный шаг может быть реализован следующими способами.
Во-первых, производится извлечение даты рождения из исходной информации посредством надлежащего выражения (regular expression).
Во-вторых, производится извлечение даты приема исходной информации в качестве даты рождения.
В-третьих, алгоритм пытается извлечь дату рождения из исходной информации посредством надлежащего выражения. Если дата рождения не может быть извлечена посредством надлежащего выражения, то производится извлечение даты приема исходной информации в качестве даты рождения.
В итоге, способ распознавания типа в соответствии с настоящим изобретением, содержащий выделение характеристических слов из фраз, исходя из заданного характеристического множества для использования в качестве характеристического множества исходной информации, и затем ввод характеристического множества в обученный классификатор для предсказания, который предварительно построен на основе характеристических слов в заданном характеристическом множестве, может решить проблему, свойственную существующим техническим решениям, состоящую в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку характеристические слова в заданном характеристическом множестве извлекают путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым могут быть достигнуты точные результаты распознавания.
Способ распознавания типа, соответствующий настоящему изобретению, дополнительно содержит: после предсказания того, что исходная информация принадлежит к целевому классу – извлечение целевой информации из исходной информации, и ввод в действие выделенной целевой информации, такой как дата рождения, дата поездки для обеспечения последующей информационной поддержки – автоматического формирования напоминаний, календарных меток и т.п.
Следует отметить, что рассмотренные выше варианты осуществления используют целевой класс, то есть информацию, содержащую действительную дату рождения, в качестве примера, однако применение вышеописанного способа не ограничено единственным целевым классом. Целевой класс может также представлять собой информацию, содержащую действительную дату поездки, информацию, содержащую действительную дату отпуска и т.п.
Нижеследующий вариант осуществления изобретения представляет устройство, которое позволяет осуществить способ, соответствующий настоящему изобретению. Те подробности, которые не будут раскрыты в устройстве, соответствующем настоящему изобретению, можно найти в описании вариантов осуществления способов, соответствующих настоящему изобретению.
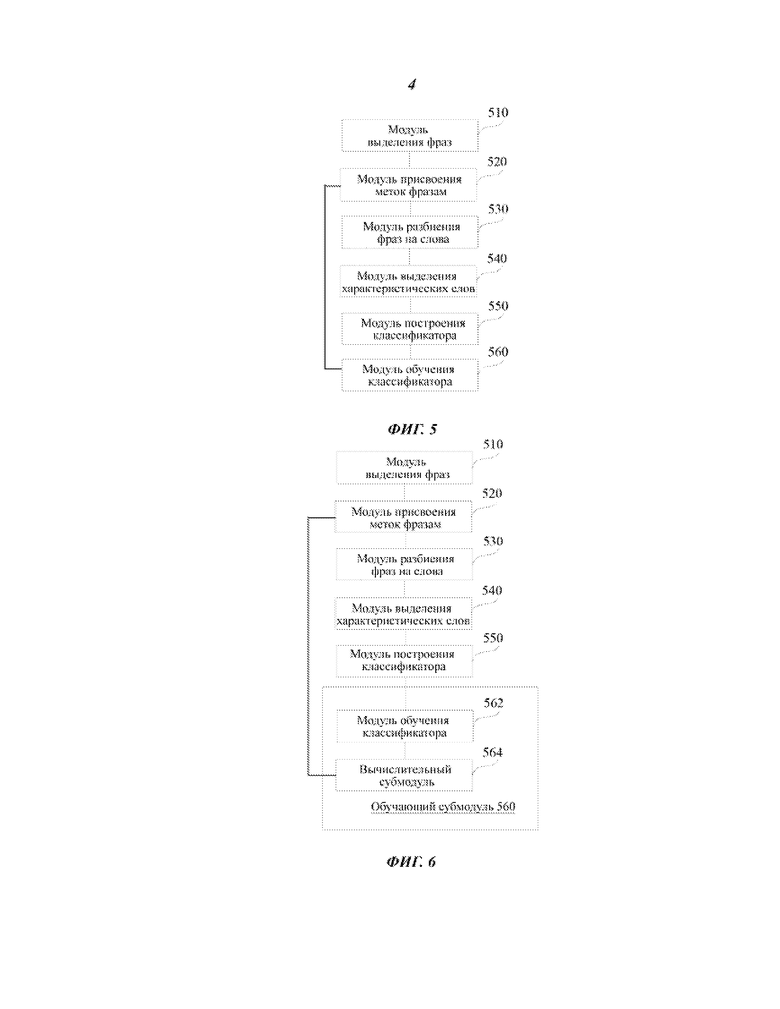
Фиг. 5 изображает блок-схему устройства для обучения классификатора, соответствующего настоящему изобретению. Как показано на фиг. 5, устройство для обучения классификатора содержит помимо других возможных следующие компоненты: модуль 510 выделения фраз, выполненный с возможностью извлечения образца фразы, содержащей целевое ключевое слово из информации для выборки; модуль 520 присвоения меток фразам, выполненный с возможностью присвоения бинарной метки определенному образцу фразы, чтобы получить обучающее множество образцов, в основе которого лежит принадлежность каждого образца фразы целевому классу; модуль 530 разбиения фраз на слова, выполненный с возможностью разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; модуль 540 выделения характеристических слов, выполненный с возможностью выделения заданного характеристического множества из множества слов, причем заданное характеристическое множество содержит по меньшей мере одно характеристическое слово; модуль 550 построения классификатора, выполненный с возможностью построения классификатора на основе характеристических слов в заданном характеристическом множестве; модуль 560 обучения классификатора, выполненный с возможностью обучения классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов.
Итак, в устройстве для обучения классификатора в соответствии с вариантом осуществления настоящего изобретения, путем разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов, выделения из множества слов заданного характеристического множества, и построения классификатора, основанного на характеристических словах в заданном характеристическом множестве, может быть решена проблема, свойственная существующим техническим решениям, состоящая в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку извлечение характеристических слов в заданном характеристическом множестве производится путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым может быть достигнута точность результатов распознавания.
Фиг. 6 изображает блок-схему устройства для обучения классификатора, соответствующего другому варианту осуществления настоящего изобретения. Как показано на фиг.6, устройство для обучения классификатора содержит помимо других возможных следующие компоненты: модуль 510 выделения фраз, выполненный с возможностью извлечения образца фразы, содержащей целевое ключевое слово из информации для выборки; модуль 520 присвоения меток фразам, выполненный с возможностью присвоения бинарной метки определенному образцу фразы, чтобы получить обучающее множество образцов, в основе которого лежит принадлежность каждого образца фразы целевому классу; модуль 530 разбиения фраз на слова, выполненный с возможностью разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; модуль 540 выделения характеристических слов, выполненный с возможностью выделения заданного характеристического множества из множества слов, причем заданное характеристическое множество содержит по меньшей мере одно характеристическое слово; модуль 550 построения классификатора, выполненный с возможностью построения классификатора на основе характеристических слов в заданном характеристическом множестве; модуль 560 обучения классификатора, выполненный с возможностью обучения классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов.
В качестве варианта, модуль 540 выделения характеристических слов выполнен с возможностью выделения заданного характеристического множества из множества слов на основе критерия хи-квадрат; или модуль 540 выделения характеристических слов выполнен с возможностью выделения заданного характеристического множества из множества слов на основе прироста информации.
В качестве варианта, модуль 550 построения классификатора выполнен с возможностью построения байесовского наивного классификатора с характеристическими словами в заданном характеристическом множестве, причем в байесовском наивном классификаторе характеристические слова являются независимыми по отношению друг к другу.
В качестве варианта, модуль 560 обучения классификатора содержит: вычислительный субмодуль 562, выполненный с возможностью вычисления первой условной вероятности того, что фразы, содержащие характеристическое слово, принадлежат к целевому классу, и второй условной вероятности того, что фразы, содержащие характеристическое слово, не принадлежат к целевому классу для каждого характеристического слова в байесовском наивном классификаторе, основанном на результатах присвоения бинарных меток в обучающем множестве образцов; и обучающий субмодуль 564, выполненный с возможностью получения обученного байесовского наивного классификатора, основанного на каждом характеристическом слове, первой условной вероятности и второй условной вероятности.
В итоге, в способе распознавания типов, соответствующем настоящему изобретению, путем выделения характеристических слов из фраз, опираясь на заданное характеристическое множество, предназначенное для использования в качестве характеристического множества исходной информации, и затем ввода данного характеристического множества для предсказания в обученный классификатор, который предварительно построен на основе характеристических слов в заданном характеристическом множестве, можно решить проблему, свойственную существующим техническим решениям, заключающуюся в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку извлечение характеристических слов в заданном характеристическом множестве производится путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым может быть достигнута точность результатов распознавания.
Фиг. 7 изображает блок-схему устройства для распознавания типа, которое соответствует варианту осуществления настоящего изобретения. Как показано на фиг. 7, устройство для распознавания типа, помимо других возможных компонентов, содержит: модуль 720 исходного выделения, выполненный с возможностью выделения фраз, содержащих целевое ключевое слово, из исходной информации; модуль 740 характеристического выделения, выполненный с возможностью формирования характеристического множества исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству, причем выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образца фразы, содержащей целевые ключевые слова; модуль 760 характеристического ввода, выполненный с возможностью ввода характеристического множества исходной информации в обученный классификатор для предсказания, причем классификатор предварительно построен на основе характеристических слов в заданном характеристическом множестве; модуль 780 получения результата, выполненный с возможностью получения результата предсказания классификатора, который представляет, принадлежит ли исходная информация целевому классу.
Итак, в устройстве распознавания типа, соответствующем варианту осуществления настоящего изобретения, путем выделения характеристических слов из фраз, опираясь на заданное характеристическое множество, предназначенное для использования в качестве характеристического множества исходной информации, и затем ввода данного характеристического множества для предсказания в обученный классификатор, который предварительно построен на основе характеристических слов в заданном характеристическом множестве, можно решить проблему, свойственную существующим техническим решениям, заключающуюся в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку извлечение характеристических слов в заданном характеристическом множестве производится путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым может быть достигнута точность результатов распознавания.
Фиг. 8 изображает блок-схему устройства для распознавания типа, которое соответствует варианту осуществления настоящего изобретения. Как показано на фиг. 8, устройство для распознавания типа, помимо других возможных компонентов, содержит: модуль 720 исходного выделения, выполненный с возможностью выделения фраз, содержащих целевое ключевое слово, из исходной информации; модуль 740 характеристического выделения, выполненный с возможностью формирования характеристического множества исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству, причем выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образца фразы, содержащей целевые ключевые слова; модуль 760 характеристического ввода, выполненный с возможностью ввода характеристического множества исходной информации в обученный классификатор для предсказания, причем классификатор предварительно построен на основе характеристических слов в заданном характеристическом множестве; модуль 780 получения результата, выполненный с возможностью получения результата предсказания классификатора, который представляет, принадлежит ли исходная информация целевому классу.
В качестве варианта, модуль характеристического ввода содержит: вычислительный субмодуль 762, выполненный с возможностью вычисления первой вероятности предсказания того, что исходная информация принадлежит целевому классу, и второй вероятности предсказания того, что исходная информация не принадлежит целевому классу путем ввода каждого характеристического слова в характеристическом множестве исходной информации в обученный байесовский наивный классификатор; субмодуль 764 предсказания, выполненный с возможностью предсказания принадлежности исходной информации целевому классу на основе соотношения численных значений первой вероятности предсказания и второй вероятности предсказания; причем обученный байесовский наивный классификатор содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, при этом первая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу, а вторая условная вероятность – это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу.
В качестве варианта, устройство дополнительно содержит модуль 790 извлечения информации, выполненный с возможностью извлечения целевой информации из исходной информации, когда сделано предсказание, что исходная информация принадлежит целевому классу.
Как вариант, целевой информацией является дата рождения; модуль 790 извлечения информации выполнен с возможностью извлечения даты рождения из исходной информации посредством надлежащего выражения; или модуль 790 извлечения информации выполнен с возможностью извлечения даты приема исходной информации в качестве даты рождения.
Итак, в устройстве распознавания типа, соответствующем варианту осуществления настоящего изобретения, путем выделения характеристических слов из фраз, опираясь на заданное характеристическое множество, предназначенное для использования в качестве характеристического множества исходной информации, и затем ввода данного характеристического множества для предсказания в обученный классификатор, который предварительно построен на основе характеристических слов в заданном характеристическом множестве, можно решить проблему, свойственную существующим техническим решениям, заключающуюся в том, что результат распознавания не является надежным, когда для выполнения анализа класса коротких сообщений используется просто ключевое слово, например, “birthday”. Поскольку извлечение характеристических слов в заданном характеристическом множестве производится путем разбиения на слова образца фразы, содержащего целевое ключевое слово, классификатор может точно предсказать фразу, содержащую целевое ключевое слово, и тем самым может быть достигнута точность результатов распознавания.
Устройство распознавания типа, соответствующее варианту осуществления настоящего изобретения, дополнительно содержит: после предсказания, что исходная информация принадлежит целевому классу – извлечение целевой информации из исходной информации, и ввод в действие выделенной целевой информации, такой как дата рождения, дата поездки для обеспечения последующей информационной поддержки – автоматического формирования напоминаний, календарных меток и т.п.
Что касается устройства для данного варианта осуществления, то конкретные приемы, посредством которых соответствующие модули выполняют операции, были подробно описаны выше в связи с соответствующими способами, и далее подробно рассматриваться не будут.
Пример варианта осуществления настоящего изобретения представляет собой устройство для обучения классификатора, которое может реализовать способ для обучения классификатора, предлагаемый в настоящем изобретении. Такое устройство содержит: процессор и память для хранения инструкций, исполняемых процессором, причем процессор выполнен с возможностью: извлечения образца фразы, содержащей целевое ключевое слово из информации для выборки; присвоения бинарной метки образцу фразы, чтобы получить обучающее множество фраз по признаку принадлежности каждого образца фразы целевому классу; разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов; выделения заданного характеристического множества из множества слов, причем заданное характеристическое множество содержит по меньше мере одно характеристическое слово; построения классификатора на основе характеристических слов в заданном характеристическом множестве; обучения классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов.
Пример варианта осуществления настоящего изобретения представляет собой устройство для распознавания типа, которое может реализовать способ распознавания типа, предлагаемый в настоящем изобретении. Устройство содержит: процессор и память для хранения инструкций, исполняемых процессором, причем процессор выполнен с возможностью: извлечения фраз, содержащих целевое ключевое слово из исходной информации; формирования характеристического множества из исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству; при этом выделение характеристических слов в заданном характеристическом множестве выполняется на основе результатов разбиения на слова образца фразы, содержащей целевые ключевые слова; ввода характеристического множества исходной информации для предсказания в обученный классификатор, предварительно построенный на основе характеристических слов в заданном характеристическом множестве; получения результата предсказания классификатора, который представляет, принадлежит ли исходная информация целевому классу.
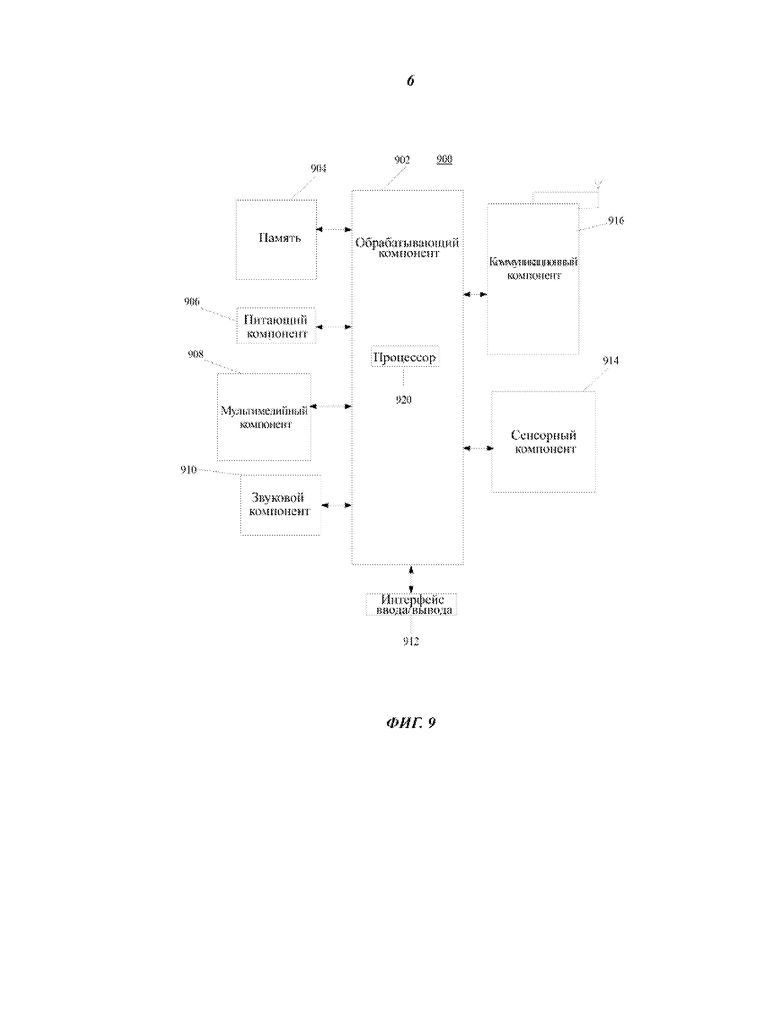
Фиг. 9 изображает блок-схему, иллюстрирующую устройство 900 для обучения классификатора или устройство для распознавания типа, соответствующее примеру осуществления настоящего изобретения. К примеру, устройство 900 может представлять собой мобильный телефон, компьютер, цифровой вещательный терминал, устройство обмена сообщениями, игровую консоль, планшет, медицинское устройство, тренажерное оборудование, персональный цифровой помощник и т.п.
Согласно фиг. 9 устройство 900 может содержать один или более из следующих компонентов: обрабатывающий компонент 902, память 904, питающий компонент 906 питания, мультимедийный компонент 908, звуковой компонент 910, интерфейс 912 ввода/вывода (I/O, Input/Output), сенсорный компонент 914 и коммуникационный компонент 916.
Обрабатывающий компонент 902 обычно управляет операциями устройства 900 в целом, например операциями, связанными с дисплеем, телефонными вызовами, обменом данными, операциями камеры и операциями записи. Обрабатывающий компонент 902 может содержать один или более процессоров 918 для исполнения инструкций в целях выполнения части этапов или всех этапов вышеописанных способов. Более того, обрабатывающий компонент 902 может содержать один или более модулей, которые обеспечивают взаимодействие между обрабатывающим компонентом 902 и другими компонентами. Например, обрабатывающий компонент 902 может содержать мультимедийный модуль, чтобы обеспечивать взаимодействие между мультимедийным компонентом 908 и обрабатывающим компонентом 902.
Память 904 выполнена с возможностью сохранения данных различного типа для поддержки работы устройства 900. Примеры таких данных включают в себя инструкции для всяких приложений или способов, которые работают в устройстве 900 – данные контактов, данные телефонной книги, сообщения, изображения, видео и т.п. Память 904 может быть реализована с использованием устройств энергозависимой и энергонезависимой памяти любого типа, или сочетания таких устройств, например, статических оперативных запоминающих устройств (SRAM, Static Random Access Memory), электрически стираемых программируемых постоянных запоминающих устройств (EEPROM, Electrically Erasable Programmable Read-Only Memory), стираемых программируемых постоянных запоминающих устройств (EPROM, Erasable Programmable Read-Only Memory), программируемых постоянных запоминающих устройств (PROM, Programmable Read-Only Memory), постоянных запоминающих устройств (ROM, Read-Only Memory), магнитной памяти, флеш пямяти, магнитных или оптических дисков.
Питающий компонент 906 обеспечивает питание для различных компонентов устройства 900. Питающий компонент 906 может содержать систему управления питанием, один или более источников питания и любых других элементов, связанных с выработкой энергии, управлением и распределение питания для устройства 900.
Мультимедийный компонент 908 содержит экран, обеспечивающий выходной интерфейс между устройством 900 и пользователем. Согласно некоторым вариантам осуществления изобретения, экран может содержать жидкокристаллический дисплей (LCD, Liquid Crystal Display) и сенсорную панель (TP, Touch Panel). Если экран содержит сенсорную панель, то экран может быть выполнен в виде сенсорного экрана, чтобы принимать сигналы команд от пользователя. Сенсорная панель содержит один или более датчиков прикосновения, чтобы воспринимать прикосновения, скользящие движения и жесты на панели. Датчики прикосновения могут воспринимать не только границу касания или скользящего движения, но также могут чувствовать период времени и давление, связанные с касанием или скольжением. В некоторых конструкциях мультимедийный компонент 908 содержит фронтальную камеру и/или заднюю камеру. Фронтальная камера и задняя камера могут принимать внешнюю мультимедийную информацию, в то время как устройство 900 находится в рабочем режиме, например в режиме фотографирования или записи видео. Каждая из камер - фронтальная и задняя может быть оснащена фиксированной системой объектива, или может иметь возможности фокусирования и масштабирования.
Звуковой компонент 910 выполнен с возможностью приема и/или передачи аудиосигналов. Например, звуковой компонент 910 содержит микрофон (“MIC”), выполненный с возможностью приема внешнего аудиосигнала, когда устройство 900 находится в рабочем режиме, например в режиме вызова, режиме записи или режиме распознавания голоса. Принимаемый аудиосигнал может быть дополнительно сохранен в памяти 904 или передан через коммуникационный компонент 916. В некоторых конструкциях звуковой компонент 910 дополнительно содержит громкоговоритель для выдачи аудиосигналов наружу.
Интерфейс 912 I/O обеспечивает взаимодействие между обрабатывающим компонентом 902 и периферийными интерфейсными модулями. Периферийными интерфейсными модулями, например, являются клавиатура, колесо-кнопка, кнопки и т.п. В число кнопок, помимо других возможных, может входить кнопка исходного состояния (home), кнопка громкости, кнопка пуска и кнопка блокировки.
Сенсорный компонент 914 содержит один или более датчиков для оценки состояния устройства 900 в различных аспектах. Например, сенсорный компонент 914 может обнаруживать открытое/закрытое состояние устройства 900, относительное положение элементов (например, дисплея и клавиатуры устройства 900), изменение положения устройства 900 или компонента устройства 900, наличие или отсутствие контакта пользователя с устройством 900, ориентацию или ускорение/торможение устройства 900, и изменение температуры устройства 900. Сенсорный компонент 914 может содержать датчик приближения, выполненный с возможностью обнаружения присутствия вблизи предмета без какого-либо физического контакта. Сенсорный компонент 914 может также содержать датчик света, например, датчик изображения на комплементарных структурах "металл-оксид-полупроводник" (CMOS, Complementary Metal-Oxide-Semiconductor) или на ПЗС-структурах (CCD, Charge-Coupled Device) для использования в задачах работы с изображениями. В некоторых вариантах осуществления сенсорный компонент 914 может также содержать датчик ускорения, гироскопический датчик, магнитный датчик, датчик давления или датчик температуры.
Коммуникационный компонент 916 выполнен с возможностью осуществления связи, проводной или беспроводной между устройством 900 и другими устройствами. Устройство 900 может получать доступ к сети беспроводной связи, основанной на таких стандартах связи, как WiFi, 2G и 3G или из комбинации. Согласно примеру осуществления изобретения, коммуникационный компонент 916 принимает сигнал вещания или информацию, связанную с вещанием, из внешней системы управления вещанием через канал вещания. Согласно примеру осуществления, коммуникационный компонент 916 дополнительно содержит модуль беспроводной связи ближнего радиуса действия (NFC, Near-Field Communication) для обеспечения связи в ближней зоне. Например, модуль NFC может быть реализован на основе RFID-технологии (технологии радиочастотной идентификации), на основе стандарта IrDA (ассоциации инфракрасной передачи данных), на основе технологии сверхширокой полосы пропускания (UBW, Ultra-Wide Band), на основе технологии Bluetooth (BT), а также других технологий.
Согласно примерам осуществления, для выполнения вышеописанных способов устройство 900 может быть реализовано на специализированных интегральных схемах (ASIC, application specific integrated circuit), цифровых сигнальных процессорах (DSP, digital signal processor), на устройствах цифровой обработки сигналов (DSPD, digital signal processing device), программируемых логических устройствах (PLD, programmable logic device), программируемых пользователем вентильных матрицах (FPGA, field programmable gate array), контроллерах, микроконтроллерах, микропроцессорах или других электронных компонентах.
Согласно примерам осуществления, также предусмотрена среда постоянного хранения считываемой компьютером информации, содержащая инструкции, такие, какие включены в память 904, которые может исполнять процессор 918 в устройстве 900 для осуществления вышеописанных способов. Например, среда постоянного хранения считываемой компьютером информации может представлять собой ПЗУ (ROM), ОЗУ (RAM), CD-ROM, магнитную ленту, гибкий диск, оптическое устройство хранения данных и т.п.
Для специалистов в данной области из рассмотрения данного описания и раскрытых вариантов реализации должна быть понятна возможность других вариантов осуществления настоящего изобретения. Предполагается, что данная заявка охватывает любые разновидности, области применения или доработки настоящего изобретения, которые следуют его принципам, включая такие отступления от настоящего описания, которые идут в рамках известной или общепринятой практики в данной области. Данное описание и варианты осуществления следует рассматривать лишь как примеры, а истинная идея и объем изобретения обозначены прилагаемой формулой изобретения.
Следует понимать, что идея изобретения не ограничивается строго конструкцией, которая была раскрыта выше и проиллюстрирована прилагаемыми чертежами, и что в границах идеи и объема изобретения могут быть сделаны различные модификации конструкции и внесены изменения. Предполагается, что объем изобретения ограничен только пунктами прилагаемой формулы изобретения.




Изобретение относится к области обработки естественных языков. Техническим результатом является повышение точности результатов распознавания информации. В способе обучения классификатора информации выполняют извлечение образцов фраз, содержащих целевое ключевое слово, из информации для отбора. Присваивают бинарные метки образцам фраз, чтобы получить обучающее множество образцов на основе принадлежности каждого из образцов фраз целевому классу. Разбивают на слова каждый образец фраз в обучающем множестве образцов, чтобы получить множество слов. Выделяют заданное характеристическое множество из множества слов, содержащее характеристические слова. Выполняют построение классификатора на основе характеристических слов и обучение классификатора на основе результатов присвоения бинарных меток в обучающем множестве образцов. 6 н. и 8 з.п. ф-лы, 9 ил.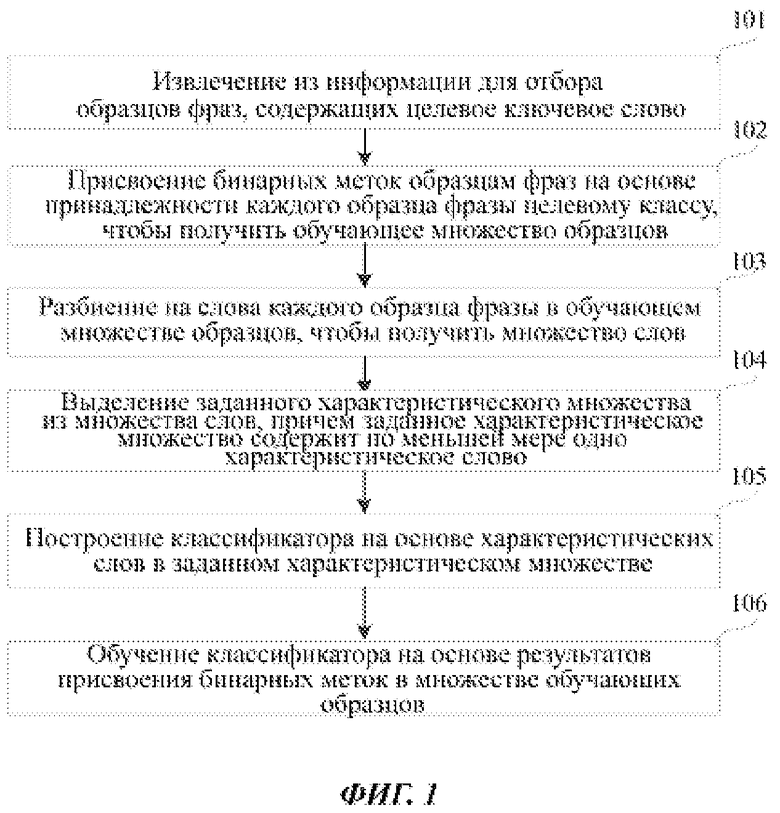
1. Способ обучения классификатора информации, содержащий:
извлечение образцов фраз, содержащих целевое ключевое слово, из информации для отбора;
присвоение бинарных меток образцам фраз, чтобы получить обучающее множество образцов на основе принадлежности каждого из образцов фраз целевому классу информации;
разбиение на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов;
выделение заданного характеристического множества из множества слов, при этом заданное характеристическое множество содержит по меньшей мере одно характеристическое слово;
построение классификатора информации на основе характеристических слов в заданном характеристическом множестве; и
обучение классификатора информации на основе результатов присвоения бинарных меток в обучающем множестве образцов,
при этом обучение классификатора информации на основе результатов присвоения бинарных меток в обучающем множестве образцов содержит:
для каждого характеристического слова в классификаторе информации вычисление первой условной вероятности того, что фразы, содержащие характеристическое слово, принадлежат целевому классу информации, и вычисление второй условной вероятности того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу информации, на основе результатов присвоения бинарных меток в обучающем множестве образцов; и
получение обученного классификатора информации на основе соответствующих характеристических слов, первой условной вероятности и второй условной вероятности.
2. Способ по п. 1, отличающийся тем, что выделение заданного характеристического множества из множества слов содержит:
выделение заданного характеристического множества из множества слов на основе критерия хи-квадрат; или
выделение заданного характеристического множества из множества слов на основе прироста информации.
3. Способ по п. 1, отличающийся тем, что построение классификатора на основе характеристических слов в заданном характеристическом множестве содержит:
построение байесовского наивного классификатора с характеристическими словами в заданном характеристическом множестве, причем в байесовском наивном классификаторе соответствующие характеристические слова являются независимыми друг от друга.
4. Способ распознавания типа информации, содержащий:
выделение фраз, содержащих целевое ключевое слово, из исходной информации;
формирование характеристического множества из исходной информации на основе характеристических слов, которые принадлежат к заданному характеристическому множеству, в выделенных фразах, при этом выделение характеристических слов в заданном характеристическом множестве производят на основе результатов разбиения на слова образцов фраз, содержащих целевое ключевое слово;
ввод характеристического множества исходной информации в обученный классификатор информации для предсказания, причем указанный классификатор информации предварительно строят на основе характеристических слов в заданном характеристическом множестве; и
получение результата предсказания классификатора информации, при этом результат предсказания представляет, принадлежит ли исходная информация целевому классу информации,
при этом ввод характеристического множества исходной информации в обученный классификатор информации для предсказания содержит:
вычисление первой вероятности предсказания того, что исходная информация принадлежит целевому классу информации, и второй вероятности предсказания того, что исходная информация не принадлежит целевому классу информации, путем ввода каждого характеристического слова в характеристическом множестве исходной информации в обученный классификатор информации;
предсказание, принадлежит ли исходная информация целевому классу информации на основе соотношения численных значений первой вероятности предсказания и второй вероятности предсказания;
при этом классификатор информации содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, причем первая условная вероятность - это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу информации, а вторая условная вероятность - это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу информации.
5. Способ по п. 4, отличающийся тем, что дополнительно содержит:
извлечение целевой информации из исходной информации, когда получено предсказание, что исходная информация принадлежит целевому классу информации.
6. Способ по п. 5, отличающийся тем, что целевая информация представляет собой дату рождения, а извлечение целевой информации из исходной информации содержит:
выделение даты рождения из исходной информации посредством надлежащего выражения; или
выделение даты приема исходной информации в качестве даты рождения.
7. Устройство для обучения классификатора информации, содержащее:
модуль выделения фраз, выполненный с возможностью извлечения образцов фраз, содержащих целевое ключевое слово, из информации для отбора;
модуль присвоения меток фразам, выполненный с возможностью присвоения образцам фраз бинарных меток, чтобы получить обучающее множество образцов на основе принадлежности каждого образца фразы целевому классу информации;
модуль разбиения фраз на слова, выполненный с возможностью разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов;
модуль выделения характеристических слов, выполненный с возможностью выделения заданного характеристического множества из множества слов, при этом заданное характеристическое множество содержит по меньшей мере одно характеристическое слово;
модуль построения классификатора, выполненный с возможностью построения классификатора информации на основе характеристических слов в заданном характеристическом множестве; и
модуль обучения классификатора, выполненный с возможностью обучения классификатора информации на основе результатов присвоения бинарных меток в обучающем множестве образцов,
при этом модуль обучения классификатора содержит:
вычислительный субмодуль, выполненный с возможностью вычисления первой условной вероятности того, что фразы, содержащие характеристическое слово, принадлежат целевому классу информации, и второй условной вероятности того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу информации, для каждого характеристического слова в классификаторе информации на основе результатов присвоения бинарных меток в обучающем множестве образцов; и
обучающий субмодуль, выполненный с возможностью получения обученного классификатора информации на основе каждого характеристического слова, первой условной вероятности и второй условной вероятности.
8. Устройство по п. 7, отличающееся тем, что
модуль выделения характеристических слов выполнен с возможностью выделения заданного характеристического множества из множества слов на основе критерия хи-квадрат; или
модуль выделения характеристических слов выполнен с возможностью выделения заданного характеристического множества из множества слов на основе прироста информации.
9. Устройство по п. 7, отличающееся тем, что
модуль построения классификатора выполнен с возможностью построения байесовского наивного классификатора с характеристическими словами в заданном характеристическом множестве, причем в байесовском наивном классификаторе соответствующие характеристические слова являются независимыми друг от друга.
10. Устройство для распознавания типа информации, содержащее:
модуль исходного выделения, выполненный с возможностью выделения фраз, содержащих целевое ключевое слово, из исходной информации;
модуль характеристического выделения, выполненный с возможностью формирования характеристического множества исходной информации на основе характеристических слов в выделенных фразах, которые принадлежат характеристическому множеству, причем выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образца фразы, содержащей целевое ключевое слово;
модуль характеристического ввода, выполненный с возможностью ввода характеристического множества исходной информации в обученный классификатор информации для предсказания, причем классификатор информации предварительно построен на основе характеристических слов в заданном характеристическом множестве; и
модуль получения результата, выполненный с возможностью получения результата предсказания классификатора информации, который представляет, принадлежит ли исходная информация целевому классу информации,
при этом модуль характеристического ввода содержит:
вычислительный субмодуль, выполненный с возможностью вычисления первой вероятности предсказания того, что исходная информация принадлежит целевому классу информации, и второй вероятности предсказания того, что исходная информация не принадлежит целевому классу информации, путем ввода каждого характеристического слова характеристического множества исходной информации в обученный классификатор информации; и
субмодуль предсказания, выполненный с возможностью предсказания того, принадлежит ли исходная информация целевому классу информации на основе соотношения численных значений первой вероятности предсказания и второй вероятности предсказания;
причем обученный классификатор информации содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, при этом первая условная вероятность - это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу информации, а вторая условная вероятность - это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу информации.
11. Устройство по п. 10, отличающееся тем, что дополнительно содержит: модуль извлечения информации, выполненный с возможностью извлечения целевой информации из исходной информации, когда получено предсказание, что исходная информация принадлежит целевому классу информации.
12. Устройство по п. 11, отличающееся тем, что целевая информация представляет собой дату рождения, и
модуль извлечения информации выполнен с возможностью извлечения даты рождения из исходной информации посредством надлежащего выражения; или
модуль извлечения информации выполнен с возможностью извлечения даты приема исходной информации в качестве даты рождения.
13. Устройство для обучения классификатора информации, содержащее:
процессор; и
память для хранения инструкций, исполняемых процессором, при этом процессор выполнен с возможностью:
извлечения образцов фраз, содержащих целевое ключевое слово из информации для отбора;
присвоения бинарных меток образцам фраз, чтобы получить обучающее множество образцов на основе принадлежности каждого образца фразы целевому классу информации;
разбиения на слова каждого образца фразы в обучающем множестве образцов, чтобы получить множество слов;
выделения заданного характеристического множества из множества слов, причем множество характеристических слов содержит по меньшей мере одно характеристическое слово;
построения классификатора информации на основе характеристических слов в заданном характеристическом множестве;
вычисления для каждого характеристического слова в классификаторе информации первой условной вероятности того, что фразы, содержащие характеристическое слово, принадлежат целевому классу информации, и второй условной вероятности того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу информации, на основе результатов присвоения бинарных меток в обучающем множестве образцов; и
получения обученного классификатора информации на основе каждого характеристического слова, первой условной вероятности и второй условной вероятности.
14. Устройство для распознавания типа информации, содержащее:
процессор; и
память для хранения инструкций, исполняемых процессором,
при этом процессор выполнен с возможностью:
извлечения фраз, содержащих ключевое слово из исходной информации;
формирования характеристического множества из исходной информации на основе характеристических слов, которые принадлежат к характеристическому множеству, в выделенных фразах, при этом выделение характеристических слов в заданном характеристическом множестве производится на основе результатов разбиения на слова образцов фраз, содержащих целевое ключевое слово;
ввода характеристического множества исходной информации в обученный классификатор информации для предсказания, причем указанный классификатор информации предварительно построен на основе характеристических слов в заданном характеристическом множестве;
вычисления первой вероятности предсказания того, что исходная информация принадлежит целевому классу информации, и второй вероятности предсказания того, что исходная информация не принадлежит целевому классу информации, путем ввода каждого характеристического слова в характеристическом множестве исходной информации в обученный классификатор информации;
предсказания, принадлежит ли исходная информация целевому классу информации на основе соотношения численных значений первой вероятности предсказания и второй вероятности предсказания; и
получения результата предсказания классификатора информации, при этом результат предсказания представляет, принадлежит ли исходная информация целевому классу предсказания,
при этом классификатор информации содержит первую условную вероятность и вторую условную вероятность каждого характеристического слова, причем первая условная вероятность - это вероятность того, что фразы, содержащие характеристическое слово, принадлежат целевому классу информации, а вторая условная вероятность - это вероятность того, что фразы, содержащие характеристическое слово, не принадлежат целевому классу информации.
| CN 103885934 A, 25.06.2014 | |||
| CN 103336766 A, 02.10.2013 | |||
| CN 103246686 A, 14.08.2013 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ КЛАССИФИКАЦИИ ДОКУМЕНТОВ ПО КАТЕГОРИЯМ | 2012 |
|
RU2491622C1 |

