По настоящей заявке испрашивается приоритет на основании патентной заявки Китая № 201510827530.8, поданной 24 ноября 2015 г., все содержание которой включено в настоящую заявку посредством ссылки.
Область техники, к которой относится изобретение
Настоящее раскрытие в целом относится к области обработки данных и более конкретно к способу и устройству для построения шаблона и способу и устройству для идентификации информации.
Уровень техники
В повседневной жизни пользователь часто получает короткие сообщения, такие как короткие сообщения напоминания о разговорном балансе и короткие сообщения уведомления об остатке трафика от операторов, или другую информацию, такую как короткие сообщения об информации учетной записи и короткие сообщения об оплате по кредитной карте от банков. Все эти короткие сообщения применяются для уведомления пользователя о некоторой цифровой информации, такой как разговорный баланс, баланс учетной записи, остаток трафика и т.д., с целью своевременного предоставления пользователю такой информации.
Раскрытие изобретения
Для повышения точности идентификации информации в настоящем раскрытии предлагаются способ и устройство для построения шаблона, и способ и устройство для идентификации информации.
Согласно первому аспекту настоящего раскрытия, предлагается способ построения шаблона. Способ содержит: получение множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу; в случае если исходная информация содержит заданное ключевое слово, маркировку заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов; сегментирование выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов; извлечение множества заданных характеристик из одного или более слов, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово; построение шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик; и обучение шаблона на основе результатов маркировки в обучающем множестве образцов.
Согласно одному примеру, процесс извлечения множества заданных характеристик из одного или более слов содержит: извлечение множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат; или извлечение множества заданных характеристик из одного или более слов посредством проверки по приросту информации.
Согласно одному примеру, процесс построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик содержит: построение наивного байесовского классификатора с характеристическим словом в множестве заданных характеристик и заданным ключевым словом, при этом соответствующие характеристические слова в наивном байесовском классификаторе независимы друг от друга.
Согласно одному примеру, процесс обучения шаблона на основе результатов маркировки в обучающем множестве образцов содержит: для каждого характеристического слова в наивном байесовском классификаторе, подсчет количества выражений, которые содержат характеристическое слово и заданное ключевое слово и представляют собой первое выражение, на основе результатов маркировки в обучающем множестве образцов; получение обученного наивного байесовского классификатора на основе соответствующих характеристических слов, заданного ключевого слова и указанного количества.
Согласно одному примеру, процесс маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов содержит: в случае если исходная информация содержит цифровую информацию, маркировку цифровой информации на основе множества заданных ключевых слов для получения обучающего множества образцов, причем множество заданных ключевых слов содержит информацию, указывающую атрибуты цифровой информации.
Согласно второму аспекту настоящего раскрытия, предлагается способ идентификации информации. Способ содержит: получение по меньшей мере одного выражения в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово; сегментирование выражения с целью получения одного или более слов и извлечение множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово; идентификацию результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона.
Согласно одному примеру, способ также содержит: в случае если существует ряд выражений, чьи результаты маркировки представляют собой заданный результат маркировки, принятие заданного ключевого слова в выражении, обладающем наибольшей вероятностью быть идентифицированным, в качестве информации заданного результата маркировки.
Согласно одному примеру, процесс извлечения множества заданных характеристик из одного или более слов содержит: извлечение множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат; или извлечение множества заданных характеристик из одного или более слов посредством проверки по приросту информации.
Согласно одному примеру, заданное ключевое слово представляет собой цифровую информацию, и результат маркировки представляет собой атрибут цифровой информации.
Согласно третьему аспекту настоящего раскрытия, предлагается устройство для построения шаблона. Устройство содержит: модуль получения образцов, выполненный с возможностью получения множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу; модуль обработки образцов, выполненный с возможностью, в случае если исходная информация содержит заданное ключевое слово, маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов; модуль осуществления сегментирования, выполненный с возможностью сегментирования выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов; модуль извлечения характеристик, выполненный с возможностью извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово; модуль построения шаблона, выполненный с возможностью построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик; модуль обучения шаблона, выполненный с возможностью обучения шаблона на основе результатов маркировки в обучающем множестве образцов.
Согласно одному примеру, модуль извлечения характеристик выполнен с возможностью извлечения множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат или проверки по приросту информации.
Согласно одному примеру, модуль построения шаблона выполнен с возможностью построения наивного байесовского классификатора с характеристическим словом в множестве заданных характеристик и заданным ключевым словом, причем соответствующие характеристические слова в наивном байесовском классификаторе независимы друг от друга.
Согласно одному примеру, модуль обучения шаблона выполнен с возможностью, для каждого характеристического слова в наивном байесовском классификаторе, подсчета количества выражений, которые содержат характеристическое слово и заданное ключевое слово и представляют собой первое выражение, на основе результатов маркировки в обучающем множестве образцов, и получения обученного наивного байесовского классификатора на основе соответствующих характеристических слов, заданного ключевого слова и указанного количества.
Согласно одному примеру, заданное ключевое слово представляет собой цифровую информацию, и результаты маркировки представляют собой атрибуты цифровой информации.
Согласно четвертому аспекту настоящего раскрытия, предлагается устройство для идентификации информации. Устройство содержит: модуль получения выражений, выполненный с возможностью получения по меньшей мере одного выражения в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово; модуль извлечения слов, выполненный с возможностью сегментирования выражения с целью получения одного или более слов и извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово; модуль осуществления идентификации, выполненный с возможностью идентификации результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона.
Согласно одному примеру, модуль осуществления идентификации выполнен с возможностью, в случае если существует ряд выражений, чьи результаты маркировки представляют собой заданный результат маркировки, принятия заданного ключевого слова в выражении, обладающем наибольшей вероятностью быть идентифицированным, в качестве информации заданного результата маркировки.
Согласно одному примеру, модуль извлечения слов выполнен с возможностью извлечения множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат или проверки по приросту информации.
Согласно одному примеру, заданное ключевое слово представляет собой цифровую информацию, и результаты маркировки представляют собой атрибуты цифровой информации.
Согласно пятому аспекту настоящего раскрытия, предлагается устройство для построения шаблона. Устройство содержит: процессор; память для хранения инструкций, исполняемых процессором; причем процессор выполнен с возможностью: получения множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу; в случае если исходная информация содержит заданное ключевое слово, маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов; сегментирования выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов; извлечения множества заданных характеристик из одного или более слов, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово; построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик; и обучения шаблона на основе результатов маркировки в обучающем множестве образцов.
Согласно четвертому аспекту настоящего раскрытия, предлагается устройство для идентификации информации. Устройство содержит: процессор; память для хранения инструкций, исполняемых процессором; причем процессор выполнен с возможностью: получения по меньшей мере одного выражения в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово; сегментирования выражения с целью получения одного или более слов и извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово; идентификации результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона.
Согласно техническим решениям, предлагаемым в настоящем раскрытии, строят шаблон для идентификации путем обучения шаблона на основе образцов, содержащих заданное ключевое слово, и идентифицируют результат маркировки заданного ключевого слова в информации, таким образом, повышается точность идентификации информации.
Следует понимать, что вышеприведенное общее раскрытие изобретения и последующее подробное раскрытие изобретения приведены исключительно в качестве примера и не ограничивают сущность настоящего изобретения.
Краткое описание чертежей
Прилагаемые графические материалы, включенные в настоящее описание и составляющие его часть, изображают варианты осуществления настоящего изобретения и совместно с описанием служат для разъяснения основных положений настоящего изобретения.
На фиг. 1 представлена блок-схема способа построения шаблона согласно одному из примеров осуществления.
На фиг. 2 представлена блок-схема другого способа построения шаблона согласно одному из примеров осуществления.
На фиг. 3 представлено схематическое изображение системы для идентификации цифровой информации в коротком сообщении при использовании способов, предложенных в настоящем раскрытии, согласно одному из примеров осуществления.
На фиг. 4 представлена блок-схема другого способа построения шаблона согласно одному из примеров осуществления.
На фиг. 5 представлена блок-схема другого способа построения шаблона согласно одному из примеров осуществления.
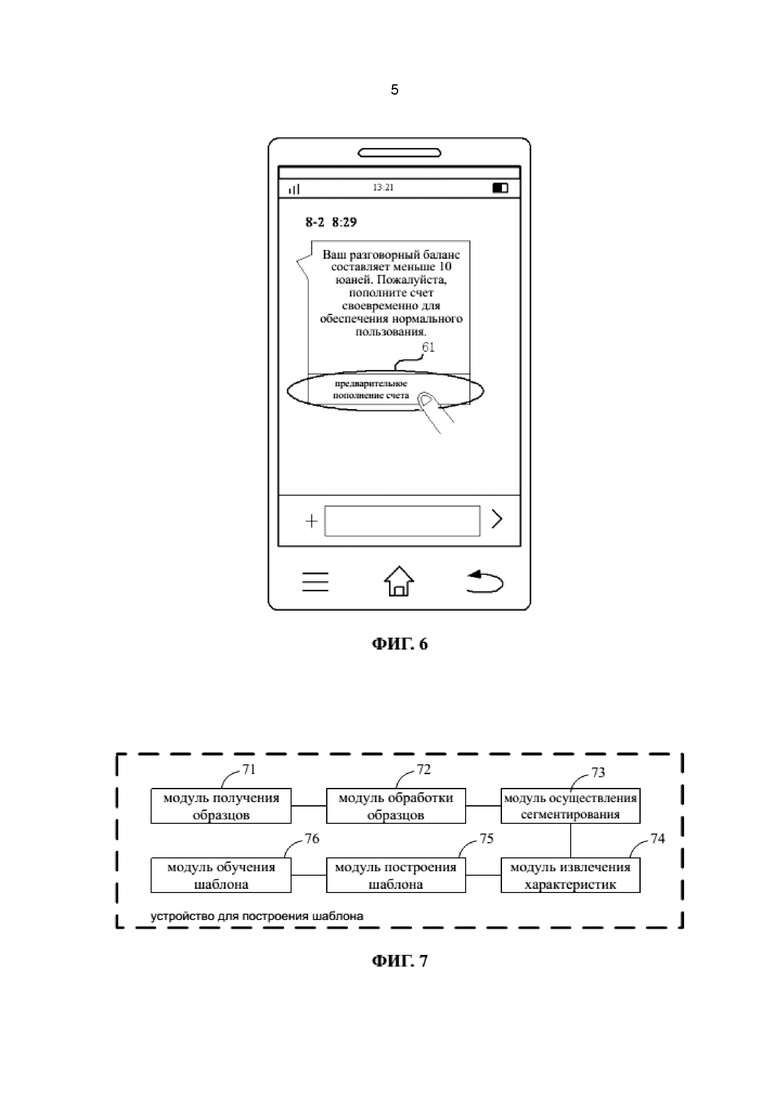
На фиг. 6 представлено схематическое изображение режима отображения упрощенного интерфейса согласно одному из примеров осуществления.
На фиг. 7 представлена структурная схема устройства для построения шаблона согласно одному из примеров осуществления.
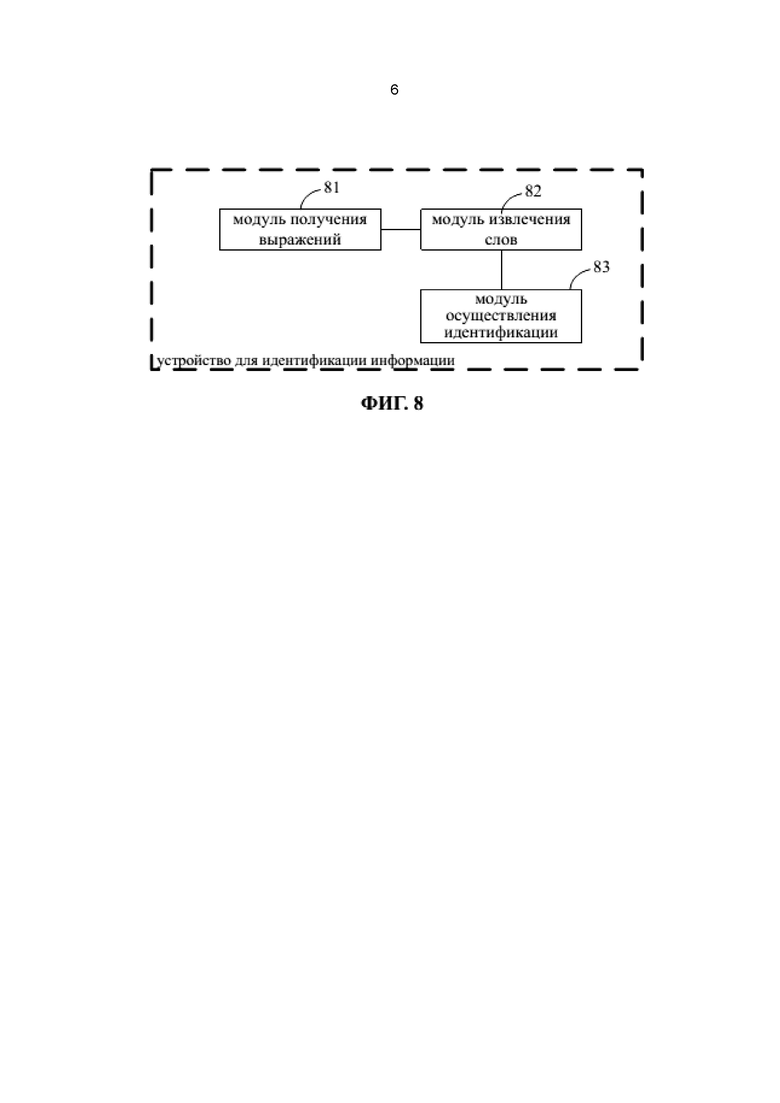
На фиг. 8 представлена структурная схема устройства для идентификации информации согласно одному из примеров осуществления.
На фиг. 9 представлена структурная схема устройства для идентификации информации согласно одному из примеров осуществления.
На фиг. 10 представлена структурная схема устройства для построения шаблона согласно одному из примеров осуществления.
Осуществление изобретения
Теперь обратимся к подробному описанию вариантов осуществления, примеры которых представлены на прилагаемых чертежах. В нижеследующем описании даются ссылки на прилагаемые чертежи, на которых одинаковые ссылочные номера на разных чертежах обозначает одинаковые или подобные элементы, если не указано обратное. Реализации, описанные в последующих приведенных в качестве примера вариантах осуществления, не представляют всех реализаций, согласующихся с настоящим изобретением. Напротив, они являются исключительно примерами устройств и способов, согласующихся с аспектами, относящимися к настоящему раскрытию, в соответствии с изложенным в прилагаемой формуле изобретения.
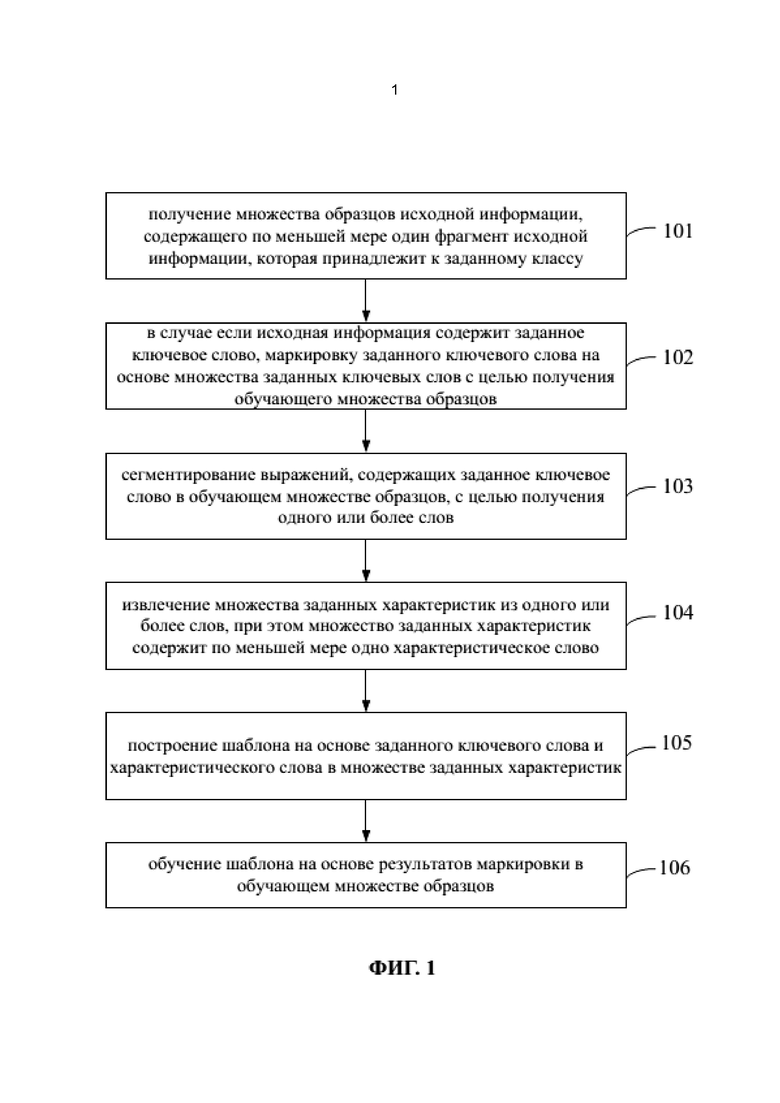
Согласно настоящему раскрытию, предлагается способ для идентификации класса информации с использованием построенного шаблона. Например, шаблон может применяться для идентификации класса цифровой информации в коротком сообщении, отправленном оператором, или может применяться для идентификации иной информации. На фиг. 1 представлена блок-схема способа построения шаблона согласно одному из примеров осуществления, при этом способ содержит следующие этапы.
На этапе 101 получают множество образцов исходной информации, причем множество образцов исходной информации содержит по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу.
В качестве примера идентификации короткого сообщения, отправленного оператором, исходная информация может являться коротким сообщением, отправленным оператором, и может быть перенаправлена на устройство для построения шаблона посредством смартфона, когда исходная информация получена смартфоном. Заданный класс исходной информации может являться классом информации, подлежащем идентификации посредством шаблона, подлежащего построению. Например, если шаблон для идентификации информации об оплате за телефонную связь в коротком сообщении, посланном оператором, подлежит построению, то множество образцов исходной информации может содержать по меньшей мере одно короткое сообщение, содержащее информацию об оплате за телефонную связь, а класс оплаты за телефонную связь является заданным классом.
На этапе 102, в случае если исходная информация содержит заданное ключевое слово, то ключевое слово маркируют на основе множества заданных ключевых слов с целью получения обучающего множества образцов.
Например, заданное ключевое слово, в частности, класс заданного ключевого слова может быть промаркирован, когда идентифицируют класс исходной информации. Например, когда смартфон получает короткое сообщение «ваш разговорный баланс составляет 12 юаней» для уведомления о разговорном балансе, отправленное оператором, заданное ключевое слово является «12», а маркировка заданного ключевого слова состоит в маркировке класса заданного ключевого слова. Например, «12» является разговорным балансом, а не поступлением. После того, как заданное ключевое слово в исходной информации промаркировано в множестве образцов исходной информации, множество образцов исходной информации можно назвать обучающим множеством образцов.
На этапе 103 сегментируют выражения, содержащие заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов.
Например, слова, полученные посредством сегментирования, могут также содержать заданное ключевое слово. В примере короткого сообщения, отправленного оператором, слова, полученные посредством сегментирования короткого сообщения для уведомления о разговорном балансе, отправленного оператором, содержит и заданное ключевое слово «12», и другие слова, такие как «ваш», «разговорное время» и т.д.
На этапе 104 извлекают множество заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово.
Например, в словах, полученных посредством сегментирования на этапе 103, некоторые слова, такие как «ах», «ок» и т.д., могут быть бесполезны при идентификации класса заданного ключевого слова и, таким образом, могут быть отфильтрованы, а остальные слова могут использоваться для построения шаблона. Характеристические слова, содержащиеся в множестве заданных характеристик, могут быть указанными остальными словами.
На этапе 105 строят шаблон на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик.
Шаблон можно строить посредством различных подходов. Например, шаблон может быть построен путем использования классификатора на основе характеристического слова, полученного посредством вышеприведенного этапа и заданного ключевого слова.
На этапе 106 шаблон обучают на основе результатов маркировки в обучающем множестве образцов.
После обучения шаблон может являться шаблоном для идентификации класса информации. Например, когда фрагмент информации или контента, содержащегося в информации, вводят в шаблон, шаблон может выдать класс информации или получить вероятности того, что информация принадлежит соответствующим известным классам.
В способе построения шаблона согласно данному варианту осуществления шаблон для идентификации строят и обучают на основе обучающего множества образцов, содержащего заданное ключевое слово, так что шаблон может использоваться для идентификации класса информации, и повышается точность идентификации информации.
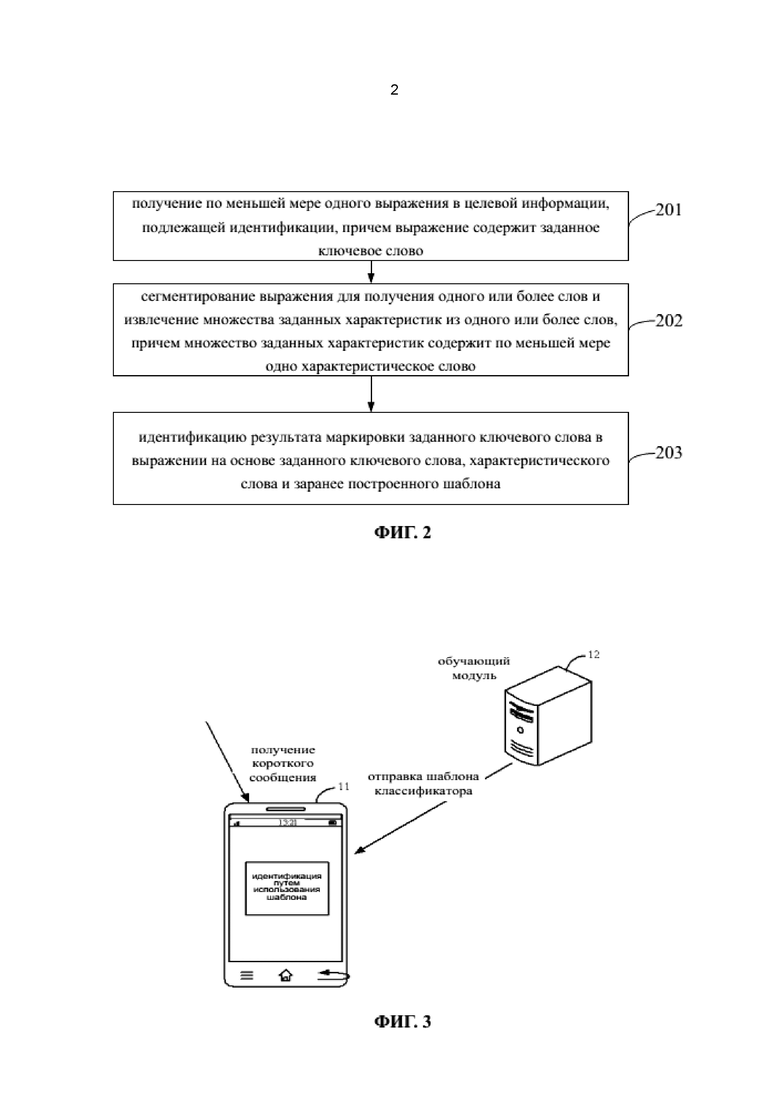
На фиг. 2 представлена блок-схема способа идентификации информации согласно одному из примеров осуществления. Способ может использоваться для идентификации класса информации посредством использования обученного шаблона на фиг. 1, и может содержать следующие этапы.
На этапе 201 получают по меньшей мере одно выражение в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово.
Например, когда целевая информация представляет собой короткое сообщение, отправленное оператором, в коротком сообщении может быть получено по меньшей мере одно выражение, например, выражение «как поживаете» и другое выражение «ваш разговорный баланс составляет 12 юаней». По меньшей мере одно выражение может содержать заданное ключевое слово, например, цифра разговорного баланса.
На этапе 202 выражение сегментируют для получения одного или более слов и извлекают множество заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово.
На этапе 203 результат маркировки заданного ключевого слова в выражении идентифицируют на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона.
Например, класс информации может быть идентифицирован на основе обученного шаблона посредством идентификации результата маркировки заданного ключевого слова в целевой информации. В примере идентификации короткого сообщения, отправленного оператором, может быть идентифицировано, что результат маркировки заданного ключевого слова представляет собой разговорный баланс, путем использования шаблона.
В способе для идентификации информации согласно данному варианту осуществления, класс информации может быть идентифицирован путем использования заранее построенного шаблона, так что может быть повышена точность идентификации информации.
Ниже описывается применение способа, предложенного в настоящем раскрытии, при идентификации короткого сообщения, отправленного оператором, при этом в качестве примера берется идентификация цифровой информации в коротком сообщении. Сначала приведены несколько примеров идентификации цифровой информации в коротком сообщении.
Например, для короткого сообщения «ваш баланс составляет менее 10 юаней» информация «баланс – 10 юаней» может быть идентифицирована путем использования указанного способа, т.е. идентифицируют цифровое значение класса».
Например, для короткого сообщения «ваш остаток трафика в текущем месяце составляет 845 Мб» информация «остаток трафика – 845 Мб» может быть идентифицирована путем использования указанного способа.
Например, для короткого сообщения «ваш предоставленный баланс составляет 344 юаней, пожалуйста, подтвердите», информация «предоставленный баланс – 344 юаней» может быть идентифицирована путем использования указанного способа.
Короткие сообщения, полученные пользователем от оператора могут включать в себя множество классов коротких сообщений, например, короткие сообщения, упомянутые в вышеперечисленных вариантах осуществления. Более того, короткое сообщение иногда может включать в себя множество классов цифровой информации. Класс цифровой информации, подлежащей идентификации с помощью указанного способа, может быть задан заранее и, таким образом, может называться «заданный класс».
Предполагается, что «разговорный баланс» определяется как заданный класс в способе для идентификации информации. Когда короткое сообщение, полученное пользователем, представляет собой «ваш предоставленный баланс составляет 344 юаней, пожалуйста, подтвердите», хотя короткое сообщение также включает в себя цифру 344, оно не принадлежит к заданному классу; так что способ может возвратить нулевой результат, т.е. цифровая информация класса «разговорный баланс» не найдена. Если идентифицировано, что цифровая информация «10» в коротком сообщении «ваш разговорный баланс составляет менее 10 юаней» принадлежит к классу «разговорный баланс», цифра «10» возвращается в качестве цифры, подлежащей идентификации.
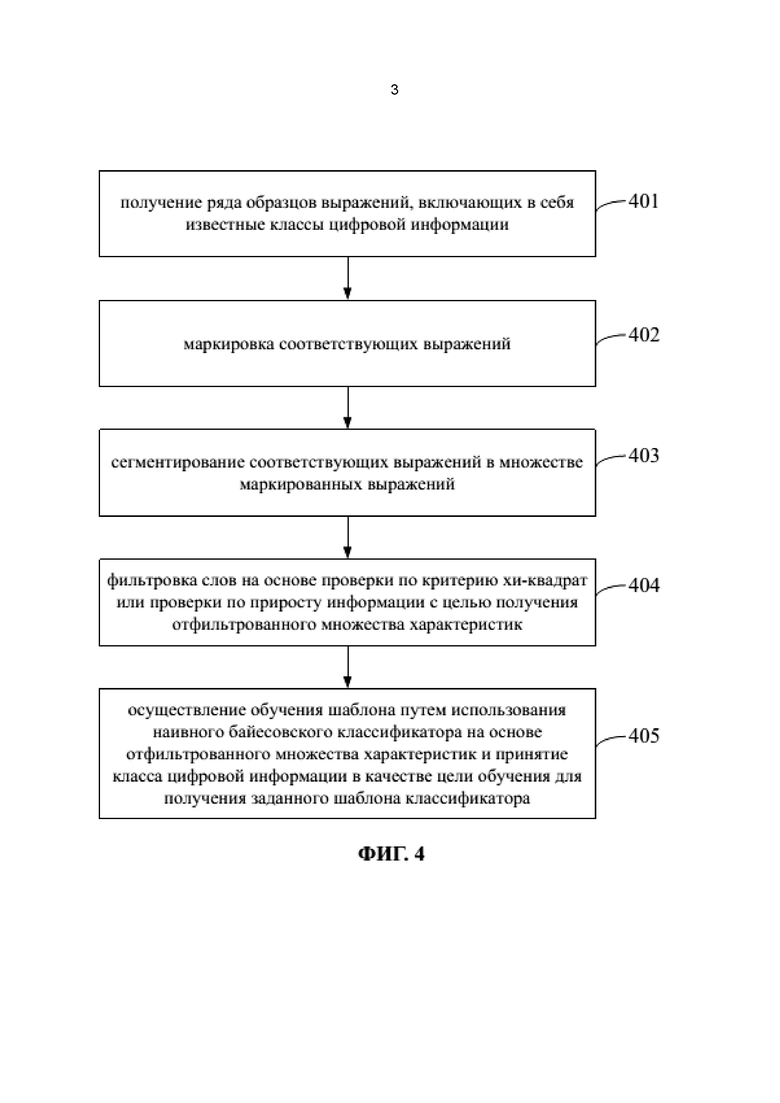
На фиг. 3 представлена система для идентификации цифровой информации в коротком сообщении при использовании способа, предложенного в настоящем раскрытии. Как показано на фиг. 3, система может содержать интеллектуальный терминал 11 и сервер 12. Интеллектуальный терминал 11 может быть смартфоном пользователя, способным получать короткое сообщение от оператора. Сервер 12 может сообщаться со смартфоном для обмена информацией между ними.
В примерах настоящего раскрытия для идентификации цифровой информации необходимо применение шаблона. В данных примерах шаблон может называться шаблоном классификатора, который применяется для идентификации класса цифровой информации в коротком сообщении. Шаблон классификатора может быть получен сервером 12 посредством обучения шаблона на основе собранных образцов и может быть отправлен в интеллектуальный терминал 11. Интеллектуальный терминал 11 идентифицирует цифровую информацию в коротком сообщении путем применения шаблона. Согласно примеру идентификации разговорного баланса путем применения способа, предлагаемого в настоящем раскрытии, ниже описываются процесс обучения шаблона на сервере и процесс идентификации цифровой информации путем применения шаблона в смартфоне.
Процесс обучения шаблона на сервере состоит в следующем.
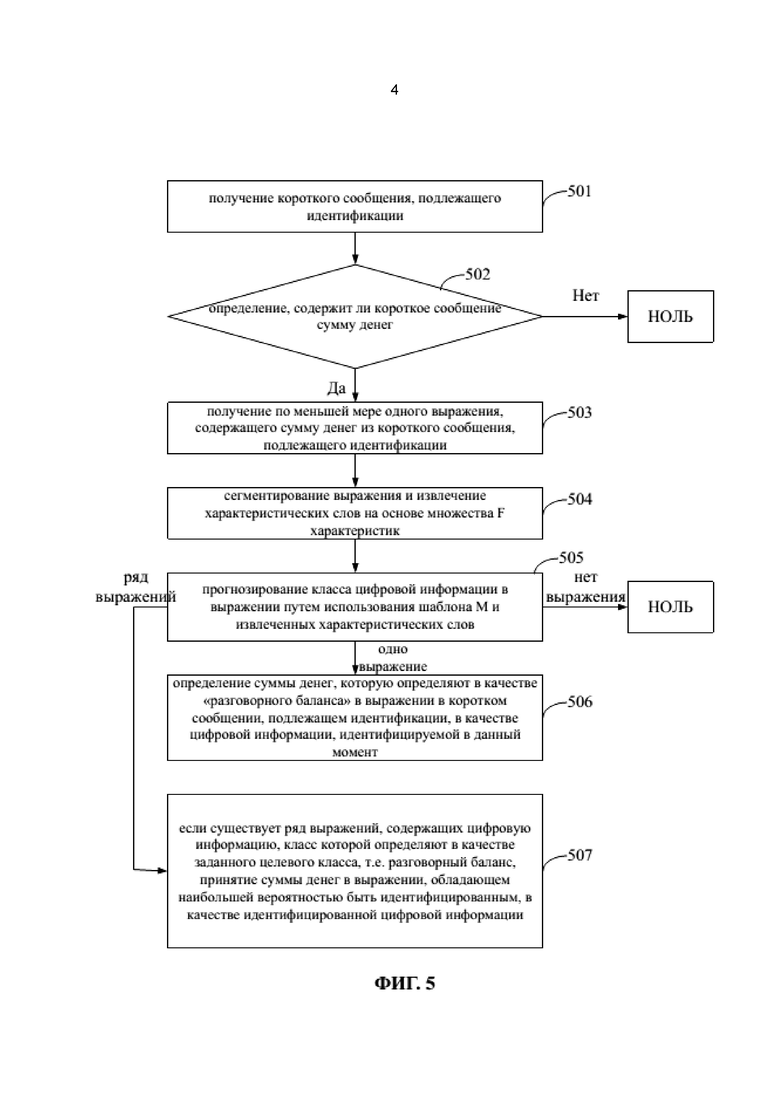
На фиг. 4 представлена блок-схема процесса обучения шаблона в соответствии с одним из примеров осуществления. Сервер может обучать шаблон путем использования последовательности, показанной на фиг. 4, включающей в себя нижеследующие этапы, причем в качестве примера взята идентификация разговорного баланса.
На этапе 401 получают ряд образцов выражений, включающих известные классы цифровой информации.
Образцы для обучения шаблона могут быть получены на данном этапе. Например, сервер может собирать короткие сообщения, отправленные оператором, причем короткие сообщения представляют собой исходную информацию. Сервер может собирать короткие сообщения, отправленные оператором, следующим образом: ряд терминалов (например, смартфонов) активно перенаправляют короткие сообщения, отправленные оператором, на сервер до получения коротких сообщений; или сервер периодически получает короткие сообщения, отправленные оператором, от терминалов. В данном примере идентификации разговорного баланса, собранные короткие сообщения, отправленные оператором, могут содержать по меньшей мере одно короткое сообщение для уведомления о разговорном балансе.
После получения короткого сообщения выражение, содержащее сумму денег, может быть извлечено из короткого сообщения, при этом сумма денег может быть идентифицирована путем использования регулярного выражения. Регулярное выражение представляет собой логическую формулу для оперирования в символьной строке, т.е. конструирования «контрольной строки» с помощью некоторых специальных символов, которые определены заранее, и любой комбинации специальных символов и фильтрации символьной строки путем использования «контрольной строки».
Множество выражений, содержащих сумму денег, идентифицируют в качестве «Т». Например, множество Т содержит такие выражения как «ваш разговорный баланс составляет 64.8 юаней», «ваш баланс по договору составляет 924 юаней», «ваш предоставленный баланс составляет 344 юаней» и т.д.
На этапе 402 соответствующие выражения могут маркировать.
Например, классы цифровой информации в соответствующих выражениях могут быть идентифицированы на данном этапе, при этом цифровая информация, такая как 64.8, 924 и т.д. в выражениях может называться заданным ключевым словом, содержащимся в исходной информации. В данном примере классы слов могут быть маркированы вручную; согласно другим сценариям применения, классы слов могут быть маркированы автоматически сервером на основе множества заданных ключевых слов, причем множество заданных ключевых слов может содержать заданные ключевые слова и информацию их класса. Например, множество заданных ключевых слов содержит информацию, указывающую на атрибуты цифровой информации, и цифровую информацию в исходной информации маркируют на основе множества ключевых слов.
В одном примере имя класса может быть настроено. Например, может быть три класса в данном примере: «разговорный баланс», «иной баланс» и «не баланс». Для пояснения, классы цифровой информации в выражениях на этапе 401 маркируют, например, маркируют 64.8 как «разговорный баланс», маркируют 924 как «иной баланс» и маркируют 344 как «не баланс». Множество маркированных классов может быть названо T_tag, при этом соответствующие выражения в этом множестве содержат цифровую информацию, и классы цифровой информации известны.
Множество маркированных образцов исходной информации может быть названо обучающим множеством образцов, в котором заданное ключевое слово в исходной информации маркировано, например, 64.8 маркировано как «разговорный баланс».
На этапе 403 соответствующие выражения в множестве маркированных выражений сегментируют.
Например, выражения в множестве T-Tag сегментируют на этом этапе с целью получения одного или более слов, таких как «ваш», «разговорный», «баланс», «64.8», «юаней», «платеж по договору», «составляет» и т.д., причем заданное ключевое слово, например, «64.8» содержится в одном или более словах. Эти слова, полученные путем сегментирования, могут называться «характеристические слова», а множество характеристических слов идентифицируют в качестве W.
На этапе 404 слова фильтруют на основе проверки по критерию хи-квадрат или проверки по приросту информации для получения отфильтрованного множества характеристик.
Например, в характеристических словах, полученных путем сегментирования на этапе 303, некоторые слова являются бесполезными для обучения класса и, таким образом, могут быть отфильтрованы, так что характеристические слова могут быть оптимизированы. Характеристические слова на этом этапе могут быть отфильтрованы на основе проверки по критерию хи-квадрат или проверки по приросту информации.
При проверке по критерию хи-квадрат квантуют важность между характеристиками и классами, причем чем выше важность, тем выше балл характеристики, и тем выше вероятность того, что данная характеристика будет сохранена. При проверке по приросту информации измерение значимости заключается в том, как много информации несет характеристика для системы классификатора, при этом чем больше информации несет характеристика, тем более значима эта характеристика. Степени значимости характеристических слов могут квантоваться на основе проверки по критерию хи-квадрат или проверки по приросту информации, так что выборку оптимизируют. Оптимизированное множество характеристических слов идентифицируют в качестве F. Например, некоторые слова, такие как «составляет», «ваш» и т.д. могут быть отфильтрованы из характеристических слов на этапе 403. На самом деле этот этап предназначен для извлечения множества заданных характеристик из одного или более слов, полученных путем сегментирования, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово, и характеристическое слово представляет собой оставшееся характеристическое слово.
На этапе 405 шаблон обучают путем использования наивного байесовского классификатора на основе отфильтрованного множества характеристик с целью получения заданного шаблона классификатора, принимая класс цифровой информации в качестве цели обучения.
Например, принимая в качестве цели обучения класс суммы денег, множество T_tag обучают путем использования множества F характеристических слов, которое получено путем фильтровки на этапе 404, причем шаблон могут обучать путем использования наивного байесовского классификатора. Основной способ классификации наивного байесовского классификатора состоит в следующем: на основе статистических материалов вычисляют вероятности соответствующих классов на основе некоторых характеристик с целью реализации классификации. В сценариях, в которых количество образцов относительно низкое, и шаблон обучают на основе коротких текстов, наивный байесовский классификатор может достигнуть наилучшего эффекта классификации. В данном примере могут быть вычислены вероятности того, что характеристическое слово принадлежит к соответствующим классам. Шаблон, полученный путем обучения, обозначают в качестве М.
На данном этапе шаблон строят на основе заданного ключевого слова и множества заданных характеристик и обучают на основе результатов маркировки в обучающем множестве образцов. Например, результаты маркировки в обучающем множестве образцов содержат «маркировку 64.8 как разговорный баланс»; цифры в образцах маркируют их классами; и шаблон наивного байесовского классификатора может быть построен на основе характеристических слов, таких как «разговорный», «баланс» и т.д., извлеченных из коротких сообщений; соответствующие характеристические слова в наивном байесовском классификаторе независимы друг от друга. Шаблон могут обучать, и обученный наивный байесовский классификатор может получать класс некоторой информации.
Например, когда обучают шаблон, для каждого характеристического слова в наивном байесовском классификаторе подсчитывают количество выражений, которые содержат характеристическое слово и заданное ключевое слово и являются первым выражением, на основе результатов маркировки в обучающем множестве образцов. Обученный наивный байесовский классификатор получают на основе соответствующих характеристических слов, заданного ключевого слова и указанного количества. Обученный наивный байесовский классификатор может использоваться для получения вероятностей того, что соответствующие характеристические слова принадлежат к соответствующим классам.
В данном варианте осуществления сервер может получать шаблон классификатора путем обучения образцов выражений и отправлять шаблон классификатора на смартфон для идентификации заданного целевого класса цифровой информации в коротких сообщениях, так что точность идентификации цифровой информации повышается.
Сервер отправляет шаблон М на смартфон после получения шаблона посредством обучения, так что смартфон может использовать шаблон для идентификации цифровой информации в коротких сообщениях.
Процесс идентификации цифровой информации в смартфоне состоит в следующем.
На фиг. 5 представлена блок-схема способа идентификации информации согласно одному из примеров осуществления. Смартфон может идентифицировать цифровую информацию путем использования шаблона в соответствии с последовательностью, показанной на фиг. 5. Согласно примеру идентификации разговорного баланса, способ содержит следующие этапы.
На этапе 501 получают короткое сообщение, подлежащее идентификации.
Например, на этом этапе смартфон может получить короткое сообщение от оператора, которое является целевой информацией, подлежащей идентификации.
На этапе 502 определяют, содержит ли короткое сообщение, подлежащее идентификации, сумму денег.
На этом этапе, если результат определения утвердительный, то алгоритм продолжается на этапе 503; или иначе, возвращает НОЛЬ.
На этапе 503 по меньшей мере одно выражение, содержащее сумму денег, извлекают из короткого сообщения, подлежащего идентификации.
Например, короткое сообщение, подлежащее идентификации, может содержать ряд выражений. Например, короткое сообщение «ваш предоставленный баланс составляет 344 юаней, пожалуйста, подтвердите и свяжитесь с нами, если у вас есть какие-либо вопросы» содержит множество выражений, и на этом этапе может быть выбрано выражение, содержащее цифровую информацию. Согласно данному примеру, цифровая информация является суммой денег. Например, «ваш предоставленный баланс составляет 344 юаней» является выражением, содержащим цифровую информацию, а «пожалуйста, свяжитесь с нами, если у вас есть какие-либо вопросы» является выражением, не содержащим цифровую информацию, и, таким образом, не выбирается. Выражение содержит заданное ключевое слово, например, цифровую информацию «344».
На этапе 504 выражение сегментируют, и извлекают характеристические слова на основе множества F характеристик.
Например, на этом этапе слова, принадлежащие к множеству F характеристик, полученному в варианте осуществления на фиг. 4, могут быть извлечены из выражения, полученного на этапе 503, на основе множества F характеристик; и другие слова могут быть не выбраны.
На этапе 505 прогнозируют класс цифровой информации в выражении путем использования шаблона М и извлеченных характеристических слов.
На этом этапе результат маркировки цифры в коротком сообщении может быть идентифицирован на основе обученного шаблона, извлеченных характеристических слов, заданного ключевого слова и т.д. Таким образом, идентифицируют класс цифровой информации. Например, могут идентифицировать, является ли цифра в коротком сообщении разговорным балансом. Для любого выражения вероятности того, что сумма денег в выражении принадлежит к соответствующим классам (т.е. «разговорный баланс», «иной баланс» или «не баланс»), получают на основе вероятностей того, что каждое характеристическое слово в выражении принадлежит к соответствующим классам. Класс, обладающий наибольшей вероятностью, является классом, к которому относится сумма денег в выражении.
Если не существует выражения, содержащего сумму денег, которую определяют в качестве «разговорного баланса» в коротком сообщении, подлежащем идентификации, то возвращается Ноль, как показано на фиг. 5. Если существует только одно выражение, содержащее сумму денег, которую определяют в качестве «разговорного баланса» в коротком сообщении, подлежащем идентификации, то переходят на этап 506; если существует ряд выражений, содержащих сумму денег, которую определяют в качестве «разговорного баланса», то переходят на этап 507.
На этапе 506 сумму денег, которую определяют в качестве «разговорного баланса» в выражении в коротком сообщении, подлежащем идентификации, могут определять в качестве цифровой информации, идентифицируемой в данный момент.
На этапе 507, если существует ряд выражений, содержащих цифровую информацию, прогнозируемый класс которой является заданным целевым классом, т.е. разговорный баланс, сумму денег в выражении, обладающем наибольшей вероятностью быть идентифицированным в качестве разговорного баланса, принимают в качестве идентифицированной цифровой информации.
На этом этапе существует ряд выражений, чьи результаты маркировки являются заданным результатом маркировки, т.е. существует ряд выражений, содержащих разговорный баланс, и заданное ключевое слово в выражении, обладающем наибольшей вероятностью быть идентифицированным, принимают в качестве информации заданного результата маркировки.
Согласно данному примеру, разговорный баланс пользователя может быть автоматически идентифицирован из короткого сообщения, полученного пользователем от оператора, и класс короткого сообщения прогнозируют путем использования шаблона классификатора, так что точность классификационного прогнозирования сравнительно выше.
Более того, следует понимать, что сервер может периодически обновлять шаблон. Например, сервер может периодически собирать некоторые новые образцы коротких сообщений и получать новые образцы выражений из новых образцов коротких сообщений, причем новые образцы выражений содержат известные классы цифровой информации. Сервер может переобучать шаблон на основе новых образцов выражений и отправлять обновленный шаблон классификатора в смартфон после получения нового шаблона классификатора, так что смартфон может идентифицировать цифровую информацию на основе нового шаблона.
Согласно примерам настоящего раскрытия, после идентификации цифровой информации в коротких сообщениях, может существовать ряд приложений, способных осуществлять некоторые действия приложения и выполнять обработку на основе результата идентификации с целью облегчения жизни людей. Например, когда значение идентифицированной цифровой информации меньше или равно числовому пороговому значению, то пользователю может быть обеспечено напоминание на основе цифровой информации. Напоминание может применяться для напоминания пользователю о предварительном пополнении счета, когда разговорный баланс слишком низок, или для напоминания пользователю о пополнении трафика, когда остаток трафика слишком мал.
Ниже представлены два примера напоминания о цифровой информации, например, напоминания о разговорном балансе.
Согласно одному примеру, предполагается, что пороговое значение разговорного баланса составляет 15 юаней. Когда определяют, что разговорный баланс пользователя составляет 10 юаней, что меньше порогового значения, путем вышеприведенного способа идентификации информации, может быть обеспечен упрощенный интерфейс в коротком сообщении для регулирования цифровой информации, так что пользователь может регулировать цифровую информацию через упрощенный интерфейс. При этом процесс регулирования цифровой информации может являться совершением предварительного пополнения счета пользователем для увеличения разговорного баланса, и пользователь может войти в интерфейс для предварительного совершения пополнения счета через упрощенный интерфейс.
На фиг. 6 представлен режим отображения упрощенного интерфейса. Как показано на фиг. 6, смартфон получает короткое сообщение от оператора и идентифицирует, что короткое сообщение содержит то, что разговорный баланс составляет 10 юаней, что меньше, чем заданное пороговое значение в 15 юаней, посредством способа идентификации информации согласно настоящему раскрытию. Упрощенный интерфейс 61 может быть отображен в нижней части короткого сообщения, при этом упрощенный интерфейс 61 может называться «предварительное пополнение счета». Разумеется, упрощенный интерфейс 61 может также называться другим именем, например, «быстрое пополнение счета», «пополните счет немедленно» или т.п.
Пользователь может кликнуть на упрощенный интерфейс 61 для входа в интерфейс для совершения предварительного пополнения счета, например, войти на веб-сайт пополнения счета для совершения предварительного пополнения счета. Этот режим отображения упрощенного интерфейса позволяет пользователю переходить в интерфейс для совершения предварительного пополнения счета, непосредственно кликнув на упрощенный интерфейс в коротком сообщении после просмотра короткого сообщения, так что эффективность операций пополнения счета значительно увеличивается по сравнению с традиционным режимом, в котором пользователю необходимо выйти из короткого сообщения, найти, а затем войти в интерфейс для совершения предварительного пополнения счета.
Согласно другому примеру, когда идентифицируют, что разговорный баланс пользователя составляет 10 юаней, что меньше заданного порогового значения, смартфон может также запросить обновленное значение цифровой информации из терминала, отправляющего короткое сообщение, подлежащее идентификации. Например, после того, как оператор мобильной связи China Mobile отправит пользователю короткое сообщение с напоминанием о разговорном балансе, пользователь использует смартфон все время, так что у пользователя остается все меньше и меньше разговорного баланса. Согласно данному примеру, смартфон может активно запрашивать изменения разговорного баланса, например, запрашивая разговорный баланс один раз каждый день. Запрашивание может быть установлено в фоновом режиме, не заметном для пользователя.
Когда определяют, что цифровая информация меньше или равна пороговому предупреждающему значению, на основе запрашиваемого обновленного значения, например, разговорный баланс пользователя составляет 2 юаня, и смартфон вскоре будет отключен, смартфон может отобразить предупреждающее уведомление с цифровой информацией, например, неожиданно возникающее предупреждающее уведомление, для напоминания пользователю о своевременном пополнении счета. Этот пример предлагается исходя из предположения, что некоторый пользователь забудет пополнить счет после получения короткого сообщения с напоминанием о разговорном балансе, что приведет к отключению смартфона, что скажется на использовании пользователем смартфона. Посредством такого решения смартфон может контролировать изменения разговорного баланса в фоновом режиме и уведомлять пользователя о своевременном пополнении счета путем отображения порогового предупреждающего значения, так что отключения смартфона можно избежать.
На фиг. 7 представлена структурная схема устройства для построения шаблона согласно одному из примеров осуществления. Устройство может применяться для реализации способов построения шаблона согласно настоящему раскрытию и применимо, например, к серверу. Как показано на фиг. 7, устройство может содержать модуль 71 получения образцов, модуль 72 обработки образцов, модуль 73 осуществления сегментирования, модуль 74 извлечения характеристик, модуль 75 построения шаблона и модуль 76 обучения шаблона.
Модуль 71 получения образцов выполнен с возможностью получения множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, принадлежащей к заданному классу.
Модуль 72 обработки образцов выполнен с возможностью, в случае, если исходная информация содержит заданное ключевое слово, маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов.
Модуль 73 осуществления сегментирования выполнен с возможностью сегментирования выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов.
Модуль 74 извлечения характеристик выполнен с возможностью извлечения множества заданных характеристик из одного или более слов, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово.
Модуль 75 построения шаблона выполнен с возможностью построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик.
Модуль 76 обучения шаблона выполнен с возможностью обучения шаблона на основе результатов маркировки в обучающем множестве образцов.
Кроме того, модуль 74 извлечения характеристик выполнен с возможностью извлечения множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат или проверки по приросту информации.
Кроме того, модуль 75 построения шаблона выполнен с возможностью построения наивного байесовского классификатора с характеристическим словом в множестве заданных характеристик и заданным ключевым словом, при этом соответствующие характеристические слова в наивном байесовском классификаторе независимы друг от друга.
Кроме того, модуль 76 обучения шаблона выполнен с возможностью, для каждого характеристического слова в наивном байесовском классификаторе, подсчета количества выражений, которые содержат характеристическое слово и заданное ключевое слово и являются первым выражением, на основе результатов маркировки в обучающем множестве образцов, и получения обученного наивного байесовского классификатора на основе соответствующих характеристических слов, заданного ключевого слова и указанного количества.
Кроме того, заданное ключевое слово представляет собой цифровую информацию, и результаты маркировки представляют собой атрибуты цифровой информации.
На фиг. 8 представлена структурная схема устройства для идентификации информации согласно одному из примеров осуществления. Устройство может использоваться для реализации способа идентификации информации согласно настоящему раскрытию, и может быть применимо, например, к интеллектуальному терминалу. Как показано на фиг. 8, устройство может содержать модуль 81 получения выражений, модуль 82 извлечения слов и модуль 83 осуществления идентификации.
Модуль 81 получения выражений выполнен с возможностью получения по меньшей мере одного выражения в целевой информации, подлежащей идентификации, при этом выражение содержит заданное ключевое слово.
Модуль 82 извлечения слов выполнен с возможностью сегментирования выражения для получения одного или более слов и извлечения множества заданных характеристик из одного или более слов, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово.
Модуль 83 осуществления идентификации выполнен с возможностью идентификации результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона.
Кроме того, модуль 83 осуществления идентификации выполнен с возможностью, в случае, если существует ряд выражений, чьи результаты маркировки являются заданным результатом маркировки, принятия заданного ключевого слова в выражении, обладающем наибольшей вероятностью быть идентифицированным, в качестве информации заданного результата маркировки.
Кроме того, модуль 82 извлечения слов выполнен с возможностью извлечения множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат или проверки по приросту информации.
Кроме того, заданное ключевое слово представляет собой цифровую информацию, и результат маркировки представляет собой атрибут цифровой информации.
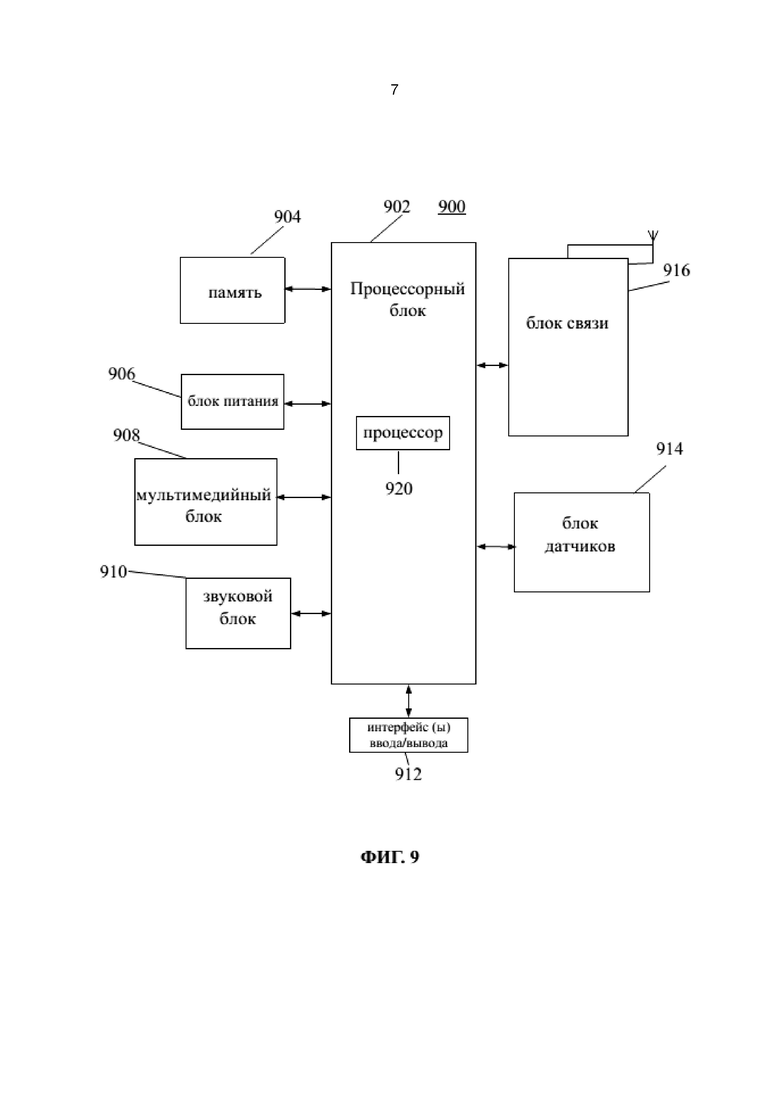
На фиг. 9 представлена структурная схема аппарата 900 для идентификации информации согласно одному из примеров осуществления. Например, аппарат 900 может быть мобильным телефоном, компьютером, цифровым широковещательным терминалом, устройством обмена сообщениями, игровой консолью, планшетом, медицинским устройством, спортивным тренажером, карманным персональным компьютером и т. п.
Согласно фиг.9, аппарат 900 может содержать один или более из следующих компонентов: процессорный блок 902, память 904, блок 906 питания, мультимедийный блок 908, звуковой блок 910, интерфейс 912 ввода/вывода (I/O), блок 914 датчиков и блок 916 связи.
Процессорный блок 902 обычно управляет всеми операциями аппарата 900, такими как операции, связанные с отображением, телефонными звонками, передачей данных, операциями с камерой и операциями записи. Процессорный блок 902 может содержать один или более процессоров 918 для выполнения инструкций по осуществлению способов идентификации информации согласно настоящему раскрытию. Более того, процессорный блок 902 может содержать один или более модулей, способствующих взаимодействию между процессорным блоком 902 и другими блоками. Например, процессорный блок 902 может содержать мультимедийный модуль, способствующий взаимодействию между процессорным блоком 902 и мультимедийным блоком 908.
Память 904 выполнена с возможностью хранения данных различных типов данных для обеспечения работы аппарата 900. Примеры таких данных могут включать в себя инструкции для любых приложений или способов, выполняемых на аппарате 900, контактные данные, данные телефонной книжки, сообщения, изображения, видео и т. п. Память 904 может быть реализована с использованием любого типа энергозависимых или энергонезависимых запоминающих устройств или их комбинации, например, статическое оперативное запоминающее устройство (статическое ОЗУ), электрически стираемое перепрограммируемое постоянное запоминающее устройство (ЭСППЗУ), стираемое перепрограммируемое постоянное запоминающее устройство (СППЗУ), программируемое постоянное запоминающее устройство (ППЗУ), постоянное запоминающее устройство (ПЗУ), магнитное запоминающее устройство, флеш-память, магнитный или оптический диск.
Блок 906 питания обеспечивает питание для различных блоков аппарата 900. Блок 906 питания может содержать систему управления питанием, один или более источников питания и любые другие компоненты, связанные с генерацией, управлением и распределением энергии для аппарата 900.
Мультимедийный блок 908 содержит экран, обеспечивающий интерфейс вывода между аппаратом 900 и пользователем. В некоторых вариантах осуществления экран может содержать жидкокристаллический дисплей (ЖКД) и сенсорную панель (СП). Если экран содержит сенсорную панель, то экран может быть реализован как сенсорный экран для приема входных сигналов от пользователя. Сенсорная панель содержит один или более датчиков для обнаружения прикосновений, проводок и жестов на сенсорной панели. Датчики прикосновения могут не только обнаруживать границы прикосновения или проводок, но также определять период времени и давление, связанное с прикосновением или проводкой. В некоторых вариантах осуществления мультимедийный блок 908 содержит фронтальную камеру и/или заднюю камеру. Фронтальная камера и задняя камера могут принимать внешние мулитимедийные данные, когда аппарат 900 находится в рабочем режиме, например, режиме фотографирования или режиме видео. Как фронтальная камера, так и задняя камера могут являться неподвижными системами оптических линз или иметь возможность фокусировки и увеличения.
Звуковой блок 910 выполнен с возможностью выдачи и/или приема звуковых сигналов. Например, звуковой блок 910 содержит микрофон, выполненный с возможностью приема внешних звуковых сигналов, когда аппарат 900 находится в рабочем режиме, например, в режиме разговора, режиме записи или режиме распознавания голоса. Принятый звуковой сигнал может быть далее сохранен в памяти 904 или передан через блок 916 связи. В некоторых вариантах осуществления звуковой блок 910 также содержит динамик для выдачи звуковых сигналов.
Интерфейс 912 ввода/вывода обеспечивает интерфейс между процессорным блоком 902 и периферийными модулями интерфейса, периферийными модулями интерфейса могут являться, например, клавиатура, нажимаемое колесико, кнопки и т. п. Кнопки могут включать в себя, но не ограничиваться, кнопку «Домой», кнопку громкости, кнопку запуска и кнопку блокировки.
Блок 914 датчиков содержит один или более датчиков для обеспечения оценок состояния различных частей аппарата 900. Например, блок 914 датчиков может обнаруживать состояние открыто/закрыто аппарата 900, относительное расположение компонентов (например, экрана и клавиатуры аппарата 900), изменение положения аппарата 900 или компонента аппарата 900, наличие или отсутствие контакта пользователя с аппаратом 900, ориентация или ускорение/замедление аппарата 900 и изменение температуры аппарата 900. Блок 914 датчиков может содержать датчик приближения, выполненный с возможностью обнаружения наличия рядом находящегося объекта без физического контакта. Блок 914 датчиков может также содержать датчик света, такой как КМОП или ПЗС преобразователь изображений, для использования в приложениях, связанных с построением изображений. В некоторых вариантах осуществления блок 314 датчиков может также содержать акселерометр, гироскоп, магнитный датчик, датчик давления или температурный датчик.
Блок 916 связи выполнен с возможностью обеспечения связи, проводной или беспроводной, между аппаратом 900 и другими устройствами. Аппарат 900 может осуществлять доступ в беспроводную сеть на основе стандарта связи, например, WiFi, 2G или 3G или их комбинации. В одном из вариантов осуществления блок 916 связи принимает широковещательный сигнал или сопряженную широковещательную информацию от внешней системы управления широковещательной передачей через широковещательный канал. В одном из вариантов осуществления блок 916 связи также содержит модуль связи малого радиуса действия (NFC) для обеспечения связи на коротких расстояниях. Например, модуль NFC может быть реализован на основе технологии радиочастотной идентификации (RFID), технологии ассоциации передачи данных в инфракрасном диапазоне (IrDA), технологии сверхширокополосной (UWB) связи, технологии Bluetoth (BT) и других технологий.
В примерах осуществления настоящего изобретения аппарат 900 может быть реализован с помощью одного или более компонентов из числа специализированных интегральных микросхем (ASIC), процессоров цифровых сигналов (DSP), устройств цифровой обработки сигналов (DSPD), программируемых логических устройств (PLD), программируемых пользователем вентильных матриц (FPGA), контроллеров, микроконтроллеров, микропроцессоров или други электронных компонентов, для выполнения раскрытых выше способов.
В примерах осуществления настоящего изобретения также предусмотрен долговременный машиночитаемый носитель информации, содержащий инструкции, например, имеющиеся в памяти 904, выполняемые процессором 918 в аппарате 900, для осуществления раскрытых выше способов. Например, долговременный машиночитаемый носитель информации может являться ПЗУ, ОЗУ, CD-ROM, магнитной лентой, гибким диском, оптическим устройством хранения данных и т. п.
На фиг. 10 представлена структурная схема устройства 1000 для построения шаблона согласно одному из примеров осуществления. Например, устройство 1000 может представлять собой сервер. Как показано на фиг. 10, устройство 1000 содержит процессорный блок 1022, который содержит один или более процессоров, и ресурсы памяти, представленные в виде памяти 1032 для хранения инструкций, например, прикладных программ, выполняемых процессорным блоком 1022. Прикладные программы, хранимые в памяти 1032, могут содержать один или более модулей, каждый из которых может содержать множество инструкций. Кроме того, процессорный блок 1022 может быть выполнен с возможностью выполнения инструкций для реализации способов построения шаблона согласно настоящему раскрытию.
Устройство 1000 может также содержать блок 1026 питания, выполненный с возможностью осуществления управления питанием в устройстве 1000, интерфейс 1050 проводной или беспроводной сети, выполненный с возможностью соединения устройства 1000 с сетью, и интерфейс 1058 ввода/вывода. Устройство 1000 может работать на базе операционной системы, такой как Windows ServerTM, Mac OS XTM, UnixTM, LinuxTM, FreeBSDTM или т.п., хранимой в памяти 1032.
Иные варианты осуществления настоящего изобретения должны быть понятны специалисту в данной области техники из рассмотрения спецификации и осуществления на практике настоящего раскрытия. Подразумевается, что данная заявка охватывает любые варианты, назначения или доработки настоящего раскрытия, исходя из его основных принципов и включает в себя такие отступления от настоящего раскрытия, которые могут следовать из известной информации или обычной практики в данной области техники. Предполагается, что данная спецификация и примеры осуществления будут рассматриваться только в качестве примеров, включенных в объем и предмет настоящего изобретения, указанного в нижеследующей формуле изобретения.
Следует понимать, что идея настоящего изобретения не ограничена конкретной конструкцией, которая была раскрыта выше и проиллюстрирована на прилагаемых чертежах, и что могут быть сделаны различные модификации и изменения без отступления от объема настоящего изобретения. Предполагается, что объем настоящего изобретения ограничен только прилагаемой формулой изобретения.
Изобретение относится к области вычислительной техники для обработки данных. Технический результат заключается в повышении точности идентификации информации для построения текстового шаблона. Технический результат достигается за счет получения выражения, которое содержит заданное ключевое слово и представляет собой цифровую информацию, сегментирования выражения для получения одного или более слов и извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит характеристическое слово, идентификации результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона, при этом результат маркировки представляет собой атрибут заданного ключевого слова, и определения класса информации для целевой информации на основании результата маркировки заданного ключевого слова. 6 н. и 12 з.п. ф-лы, 9 ил.
1. Способ для построения шаблона, содержащий:
получение множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу;
в случае если исходная информация содержит заданное ключевое слово, маркировку заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов;
сегментирование выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов;
извлечение множества заданных характеристик из одного или более слов, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово;
построение шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик; и
обучение шаблона на основе результатов маркировки в обучающем множестве образцов.
2. Способ по п. 1, отличающийся тем, что процесс извлечения множества заданных характеристик из одного или более слов содержит:
извлечение множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат; или
извлечение множества заданных характеристик из одного или более слов посредством проверки по приросту информации.
3. Способ по п. 1, отличающийся тем, что процесс построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик содержит:
построение наивного байесовского классификатора с характеристическим словом в множестве заданных характеристик и заданным ключевым словом, при этом соответствующие характеристические слова в наивном байесовском классификаторе независимы друг от друга.
4. Способ по п. 3, отличающийся тем, что процесс обучения шаблона на основе результатов маркировки в обучающем множестве образцов содержит:
для каждого характеристического слова в наивном байесовском классификаторе подсчет количества выражений, которые содержат характеристическое слово и заданное ключевое слово и представляют собой первое выражение, на основе результатов маркировки в обучающем множестве образцов;
получение обученного наивного байесовского классификатора на основе соответствующих характеристических слов, заданного ключевого слова и указанного количества.
5. Способ по п. 4, отличающийся тем, что процесс маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов содержит:
в случае если исходная информация содержит цифровую информацию, маркировку цифровой информации на основе множества заданных ключевых слов с целью получения обучающего множества образцов, причем множество заданных ключевых слов содержит информацию, указывающую атрибуты цифровой информации.
6. Способ идентификации информации в интеллектуальном терминале, содержащий:
получение по меньшей мере одного выражения в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово, которое представляет собой цифровую информацию;
сегментирование выражения для получения одного или более слов и извлечение множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово;
идентификацию результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона, при этом результат маркировки представляет собой атрибут заданного ключевого слова; и
определение класса информации для целевой информации на основании результата маркировки заданного ключевого слова.
7. Способ по п. 6, отличающийся тем, что дополнительно содержит:
в случае если существует ряд выражений, чьи результаты маркировки представляют собой заданный результат маркировки, принятие заданного ключевого слова в выражении, обладающем наибольшей вероятностью быть идентифицированным, в качестве информации заданного результата маркировки.
8. Способ по п. 6, отличающийся тем, что процесс извлечения множества заданных характеристик из одного или более слов содержит:
извлечение множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат; или
извлечение множества заданных характеристик из одного или более слов посредством проверки по приросту информации.
9. Устройство для построения шаблона, содержащее:
модуль получения образцов, выполненный с возможностью получения множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу;
модуль обработки образцов, выполненный с возможностью, в случае если исходная информация содержит заданное ключевое слово, маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов;
модуль осуществления сегментирования, выполненный с возможностью сегментирования выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов;
модуль извлечения характеристик, выполненный с возможностью извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово;
модуль построения шаблона, выполненный с возможностью построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик;
модуль обучения шаблона, выполненный с возможностью обучения шаблона на основе результатов маркировки в обучающем множестве образцов.
10. Устройство по п. 9, отличающееся тем, что модуль извлечения характеристик выполнен с возможностью извлечения множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат или проверки по приросту информации.
11. Устройство по п. 9, отличающееся тем, что модуль построения шаблона выполнен с возможностью построения наивного байесовского классификатора с характеристическим словом в множестве заданных характеристик и заданным ключевым словом, причем соответствующие характеристические слова в наивном байесовском классификаторе независимы друг от друга.
12. Устройство по п. 11, отличающееся тем, что модуль обучения шаблона выполнен с возможностью для каждого характеристического слова в наивном байесовском классификаторе подсчета количества выражений, которые содержат характеристическое слово и заданное ключевое слово и представляют собой первое выражение, на основе результатов маркировки в обучающем множестве образцов, и получения обученного наивного байесовского классификатора на основе соответствующих характеристических слов, заданного ключевого слова и указанного количества.
13. Устройство по п. 12, отличающееся тем, что заданное ключевое слово представляет собой цифровую информацию, и результаты маркировки представляют собой атрибуты цифровой информации.
14. Интеллектуальный терминал, содержащий:
модуль получения выражений, выполненный с возможностью получения по меньшей мере одного выражения в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово, которое представляет собой цифровую информацию;
модуль извлечения слов, выполненный с возможностью сегментирования выражения для получения одного или более слов и извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово;
модуль осуществления идентификации, выполненный с возможностью идентификации результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона и с возможностью определения класса информации для целевой информации на основании результата маркировки заданного ключевого слова, причем результат маркировки представляет собой атрибут заданного ключевого слова.
15. Интеллектуальный терминал по п. 14, отличающийся тем, что модуль осуществления идентификации выполнен с возможностью, в случае если существует ряд выражений, чьи результаты маркировки представляют собой заданный результат маркировки, принятия заданного ключевого слова в выражении, обладающем наибольшей вероятностью быть идентифицированным, в качестве информации заданного результата маркировки.
16. Интеллектуальный терминал по п. 14, отличающийся тем, что модуль извлечения слов выполнен с возможностью извлечения множества заданных характеристик из одного или более слов посредством проверки по критерию хи-квадрат или проверки по приросту информации.
17. Устройство для построения шаблона, содержащее:
процессор;
память для хранения инструкций, исполняемых процессором,
причем процессор выполнен с возможностью:
получения множества образцов исходной информации, содержащего по меньшей мере один фрагмент исходной информации, которая принадлежит к заданному классу;
в случае если исходная информация содержит заданное ключевое слово, маркировки заданного ключевого слова на основе множества заданных ключевых слов с целью получения обучающего множества образцов;
сегментирования выражений, содержащих заданное ключевое слово в обучающем множестве образцов, с целью получения одного или более слов;
извлечения множества заданных характеристик из одного или более слов, при этом множество заданных характеристик содержит по меньшей мере одно характеристическое слово;
построения шаблона на основе заданного ключевого слова и характеристического слова в множестве заданных характеристик; и
обучения шаблона на основе результатов маркировки в обучающем множестве образцов.
18. Интеллектуальный терминал, содержащий:
процессор;
память для хранения инструкций, исполняемых процессором,
причем процессор выполнен с возможностью:
получения по меньшей мере одного выражения в целевой информации, подлежащей идентификации, причем выражение содержит заданное ключевое слово, которое представляет собой цифровую информацию;
сегментирования выражения с целью получения одного или более слов и извлечения множества заданных характеристик из одного или более слов, причем множество заданных характеристик содержит по меньшей мере одно характеристическое слово;
идентификации результата маркировки заданного ключевого слова в выражении на основе заданного ключевого слова, характеристического слова и заранее построенного шаблона, причем результат маркировки представляет собой атрибут заданного ключевого слова; и
определения класса информации для целевой информации на основании результата маркировки заданного ключевого слова.
| US 8023974 B1, 20.09.2011 | |||
| US 7386560 B2, 10.06.2008 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СИСТЕМА ДЛЯ ИДЕНТИФИКАЦИИ ПЕРЕФРАЗИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ТЕХНОЛОГИИ МАШИННОГО ПЕРЕВОДА | 2004 |
|
RU2368946C2 |

