Настоящее изобретение относится к способу и системе конечного автомата для распознавания рабочего состояния сенсора.
В публикации US 2014/0182350 А1 раскрывается способ определения конца срока службы сенсора для непрерывного мониторирования гликемии (НМГ), включающий оценивание факторов риска с использованием функции конца срока службы для определения состояния сенсора в конце его срока службы и выдачу выходных данных, относящихся к состоянию сенсора в конце его срока службы. Эти факторы риска выбирают из перечня, включающего то, сколько суток сенсор находился в эксплуатации, было ли уменьшение чувствительности по выдаваемому сигналу, имеется ли заданная картина шумов, имеется ли заданная картина по концентрации кислорода, и расхождение между значениями референсной гликемии (глюкозы крови) и оценочными значениями глюкозы.
Публикация ЕР 2335584 А2 относится к способу проведения самодиагностической проверки и установки режима приостановки работы сенсора непрерывного мониторирования аналита в ответ на определенный результат такой самодиагностической проверки.
В публикации US 2015/164386 А1 предлагается использовать электрохимическую импедансную спектроскопию в сочетании с непрерывными мониторами гликемии и непрерывным мониторированием гликемии (НМГ) для обеспечения калибровки сенсора в условиях in vivo, анализа серьезных отказов (сенсора), интеллектуальной диагностики сенсора и обнаружения его неисправностей. Задана модель схемы замещения, элементы которой используются для характеристики поведения сенсора.
В публикации US 2010/323431 А1 раскрывается управляющая схема и способ управления дисплеем на бистабильных сегментах, каждый из которых способен переходить между включенным состоянием и выключенным состоянием посредством приложения напряжения. Напряжение прикладывается к устройству управления дисплеем от генератора подкачки заряда и подается на отдельные бистабильные сегменты через выходы устройства управления дисплеем в соответствии с командами управления дисплеем, выдаваемыми системным контроллером. Предусмотрено определение как уровня напряжения, подаваемого на бистабильный сегмент по меньшей мере с одного из выходов устройства управления дисплеем, так и уровня напряжения на генераторе подкачки заряда и их сравнение, соответственно, с допустимым уровнем напряжения на бистабильном сегменте и с допустимым уровнем напряжения на генераторе подкачки заряда. Если любой из зарегистрированных уровней напряжения недопустим, в системный контроллер может быть выдан сигнал неисправности.
Задачей настоящего изобретения является разработка системы конечного автомата и способа распознавания рабочего состояния сенсора, которые позволили ли бы более надежно предсказывать потенциальную проблему с рабочим состоянием.
Для решения этой задачи предложен способ распознавания рабочего состояния сенсора, охарактеризованный в независимом пункте 1 формулы изобретения. Кроме того, предложена система конечного автомата для осуществления способа распознавания рабочего состояния сенсора, охарактеризованная в независимом пункте 12 формулы изобретения. Частные варианты осуществления изобретения охарактеризованы в зависимых пунктах формулы изобретения.
Одним объектом изобретения является способ распознавания рабочего состояния сенсора. Предлагаемый в изобретении способ включает выполнение в конечном автомате следующих действий:
Способ распознавания рабочего состояния сенсора (7) для непрерывного мониторирования гликемии, включающий выполнение в конечном автомате следующих действий: прием данных непрерывного мониторирования, относящихся к работе сенсора и содержащих сжатые данные мониторирования; обеспечение обученного алгоритма обучения для распознавания рабочего состояния сенсора, характеризующего функцию сенсора, причем алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные и сжатые обучающие данные; распознавание рабочего состояния сенсора путем анализа данных непрерывного мониторирования при помощи обученного алгоритма обучения; и выдачу выходных данных, указывающих на распознанное рабочее состояние сенсора. При этом исторические данные состоят из данных, собранных, зарегистрированных и/или измеренных перед процессом распознавания рабочего состояния, а сжатые данные мониторирования и сжатые обучающие данные получают методом линейной регрессии и/или методом сглаживания в результате уменьшения их размера, причем на разных этапах сжатия данные мониторирования и обучающие данные содержат данные за секунду, данные за минуту и/или статистические данные, включающие в себя характеристические значения, такие как параметры сенсора, дисперсия, шум или скорость изменения.
Еще одним объектом изобретения является система конечного автомата. Система конечного автомата содержит один или несколько процессоров, выполненных с возможностью обработки данных и осуществления способа распознавания рабочего состояния сенсора для непрерывного мониторирования гликемии. Указанный способ включает: прием данных непрерывного мониторирования, относящихся к работе сенсора и содержащих сжатые данные мониторирования; обеспечение обученного алгоритма обучения для распознавания рабочего состояния сенсора, характеризующего функцию сенсора, причем алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные и сжатые обучающие данные; распознавание рабочего состояния сенсора путем анализа данных непрерывного мониторирования при помощи обученного алгоритма обучения; и выдачу выходных данных, указывающих на распознанное рабочее состояние сенсора. При этом исторические данные состоят из данных, собранных, зарегистрированных и/или измеренных перед процессом распознавания рабочего состояния, а сжатые данные мониторирования и сжатые обучающие данные получают методом линейной регрессии и/или методом сглаживания в результате уменьшения их размера, причем на разных этапах сжатия данные мониторирования и обучающие данные содержат данные за секунду, данные за минуту и/или статистические данные, включающие в себя характеристические значения, такие как параметры сенсора, дисперсия, шум или скорость изменения.
В соответствии с предложенными технологиями для распознавания рабочего состояния сенсора используется процесс машинного обучения. Тем самым реализован прогнозный метод для определения рабочего состояния сенсора с использованием алгоритма обучения, обученного в соответствии с набором обучающих данных и применяемого для анализа данных непрерывного мониторирования, относящихся к работе сенсора.
Например, изобретение позволяет прогнозировать ненормальности и/или неисправности в отношении работы сенсора, тем самым избегая потенциальных проблем в работе сенсора.
Алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные. Как указано выше, термин "исторические данные" в контексте настоящего изобретения относится к данным, собранным, зарегистрированным и/или измеренным перед процессом распознавания рабочего состояния. Исторические данные можно регистрировать или собирать перед началом сбора данных непрерывного мониторирования, принимаемых для распознавания рабочего состояния.
Набор обучающих данных можно собирать, регистрировать и/или измерять тем же самым сенсором и/или каким-либо другим сенсором. Сенсор, отличный от того, для которого распознают рабочее состояние, может быть сенсором того же типа.
Набор обучающих данных может содержать обучающие данные, указывающие на состояние сенсора, подлежащее распознаванию или прогнозированию. Например, набор обучающих данных может указывать на одно или несколько из следующих состояний: состояние производственного дефекта, состояние неисправной работы, состояние указания гликемического индекса и состояние указания анамнестического статуса.
Распознавание рабочего состояния может включать в себя по меньшей мере одно из следующего: распознавание у сенсора состояния производственного дефекта, указывающего на дефект, допущенный в процессе изготовления сенсора; распознавание у сенсора состояния неисправной работы, указывающего на неисправность сенсора; распознавание у сенсора состояния аномалии, указывающего на аномалию в работе сенсора; распознавание у сенсора состояния указания гликемического индекса, указывающего на гликемический индекс для пациента, в отношении которого предоставлены данные непрерывного мониторирования; и распознавание у сенсора состояния указания анамнестического статуса, указывающего на анамнестический статус для пациента, в отношении которого предоставлены данные непрерывного мониторирования. Распознавание состояния производственного дефекта сенсора может выполняться после изготовления сенсора. В качестве альтернативы или дополнения, распознавание состояния производственного дефекта может выполняться применительно к промежуточному продукту производственного процесса изготовления сенсора (к полуфабрикату сенсора), когда производственный процесс еще осуществляется. Аналогичным образом, распознавание состояния неисправной работы сенсора может быть частью производственного процесса или может быть связано с производственным процессом. В качестве альтернативы, предлагаемая в изобретении технология позволяет спрогнозировать состояние неисправной работы сенсора после завершения производственного процесса, например в случае применения сенсора для измерения. Распознавание состояния аномалии сенсора может выполняться в процессе измерения, например в реальном времени, когда происходит регистрация сенсором измерительных сигналов. Аналогичным образом, распознавание состояния указания гликемического индекса и/или распознавание состояния указания анамнестического статуса может выполняться в течение процесса измерения. В качестве альтернативы, такое распознавание может быть выполняться после завершения процесса измерения.
Гликемический индекс можно определять для пациента, например, в ответ на распознавание состояние указания сенсором гликемического индекса. Гликемический индекс это число, связанное с определенным типом пищи и указывающее влияние приема пищи на уровень глюкозы в крови человека (также называемый уровнем сахара). Значение "100" этого индекса может представлять стандарт, эквивалентное количество чистой глюкозы. В качестве дополнения или альтернативы, можно определять другие гликемические параметры, в том числе скорость изменения уровня глюкозы в крови, ускорение, схемы наступления событий, обусловленные, например, двигательной активностью пациента, приемом пищи, механической нагрузкой на сенсор в отношении состояния указания сенсором анамнестического статуса. В отношении состояния указания анамнестического статуса могут определяться потенциально анамнестические данные, такие как гликированный гемоглобин HbAlc или демографические данные, такие как возраст и/или пол пациента.
Обеспечение обученного алгоритма обучения может включать обеспечение по меньшей мере одного алгоритма обучения, выбранного из следующей группы: метод к ближайших соседей, метод (машина) опорных векторов, наивный байесовский метод (классификатор), метод деревьев решений, например ансамбля решающих деревьев ("случайный лес"), логистическая регрессия, например мультиномиальная логистическая регрессия, нейронная сеть и байесовская сеть. Особый интерес может представлять один следующих методов: наивный байесовский метод, метод ансамбля решающих деревьев и мультиномиальная логистическая регрессия. В предпочтительном варианте осуществления изобретения может использоваться алгоритм ансамбля решающих деревьев, для которого анализируются или автоматически включаются корреляция и взаимодействия между параметрами.
В этом варианте осуществления изобретения способ включает обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические данные.
Способ также может включать обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические данные.
Обучение может включать в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические обучающие данные, полученные в условиях in vivo, и/или исторические обучающие данные, полученные в условиях in vitro.
Обучение может включать в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические данные непрерывного мониторирования.
Обучение может включать в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим тестовые данные из следующей группы: тестовые данные от производителя, тестовые данные пациентов, персонализированные тестовые данные пациентов, популяционные тестовые данные, содержащие наборы данных от многих пациентов. Набор обучающих данных может быть получен на основе одних или нескольких таких различных тестовых данных для оптимизации набора обучающих данных в отношении одного или нескольких рабочих состояний сенсора.
Обучение может включать в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим обучающие данные, указывающие на один или несколько относящихся к сенсору параметров из следующей группы: значения тока на сенсоре, в частности значения тока на рабочем электроде сенсора в случае непрерывного мониторирования; значения напряжения на сенсоре, в частности значения напряжения на противоэлектроде сенсора или значения напряжения между электродом сравнения и рабочим электродом сенсора в случае непрерывного мониторирования; температура окружения сенсора во время измерения; чувствительность сенсора; смещение сигнала сенсора; и состояние калибровки сенсора. В зависимости от подлежащего распознаванию рабочего состояния может выбираться один или несколько относящихся к сенсору параметров. В отношении состояния калибровки сенсора, например, оно может указывать на то, когда была выполнена последняя калибровка.
Один или несколько относящихся к сенсору параметров могут включать в себя некоррелированные относящиеся к сенсору параметры и/или коррелированные относящиеся к сенсору параметры. Два или более относящихся к сенсору параметра могут быть коррелированными. В таком случае коррелированные относящиеся к сенсору параметры могут выбираться для распознавания рабочего состояния с учетом всех коррелированных относящихся к сенсору параметров. В случае же некоррелированных относящихся к сенсору параметров для распознавания рабочего состояния может выбираться один из некоррелированных относящихся к сенсору параметров. Некоррелированные относящиеся к сенсору параметры могут независимо обеспечивать возможность распознавания рабочего состояния.
Способ также может включать валидацию обученного алгоритма обучения в соответствии с набором валидационных данных, содержащим полученные измерением данные непрерывного мониторирования и/или полученные моделированием данные непрерывного мониторирования, указывающие по меньшей мере на одно из следующих состояний сенсора: состояние производственного дефекта, состояние неисправной работы, состояние указания гликемического индекса и состояние указания анамнестического статуса.
Способ также может включать валидацию обученного алгоритма обучения в соответствии с набором валидационных данных, содержащим сжатые валидационные данные, причем сжатые валидационные данные получают методом линейной регрессии и/или методом сглаживания.
Как указано выше, сжатые данные могут быть получены в результате уменьшения размера данных мониторирования или обучающих данных. Что касается метода сглаживания, могут использоваться модели ядерного сглаживания или сглаживания сплайном либо анализ временных рядов, которые сами по себе известны.
Данные непрерывного мониторирования могут выдаваться сенсором, представляющим собой полностью или частично имплантированный сенсор для непрерывного мониторирования гликемии (НМГ). В целом в контексте НМГ может определяться значение или уровень аналита, указывающее(-ий) на значение или уровень глюкозы в крови. Значение аналита может измеряться в интерстициальной жидкости. Измерение может выполняться подкожно или в условиях in vivo. НМГ может быть реализовано в виде осуществляемой почти в реальном времени или квазинепрерывно процедуры контроля, которая часто или автоматически выдает/обновляет значения аналита без взаимодействия с пользователем. В альтернативном варианте осуществления изобретения измерение аналита может проводиться при помощи расположенного в контактной линзе биосенсора через глазную жидкость или при помощи установленного на коже биосенсора путем трансдермального измерения в поту. Сенсор для НМГ может оставаться на месте его установки от нескольких суток до нескольких недель и затем подлежит замене.
Варианты осуществления изобретения, описанные выше в отношении способа, могут быть реализованы с соответствующими изменениями и в системе конечного автомата.
Ниже осуществление изобретения рассматривается со ссылкой на чертежи, на которых показано:
на фиг. 1 - вариант выполнения системы конечного автомата;
на фиг. 2 - блок-схема способа распознавания рабочего состояния сенсора в одном варианте его осуществления;
на фиг. 3 - обзор сбора данных для алгоритма обучения;
на фиг. 4 - график плотности тока, измеренного на рабочем электроде сенсора;
на фиг. 5 - свободное от ошибок измерение;
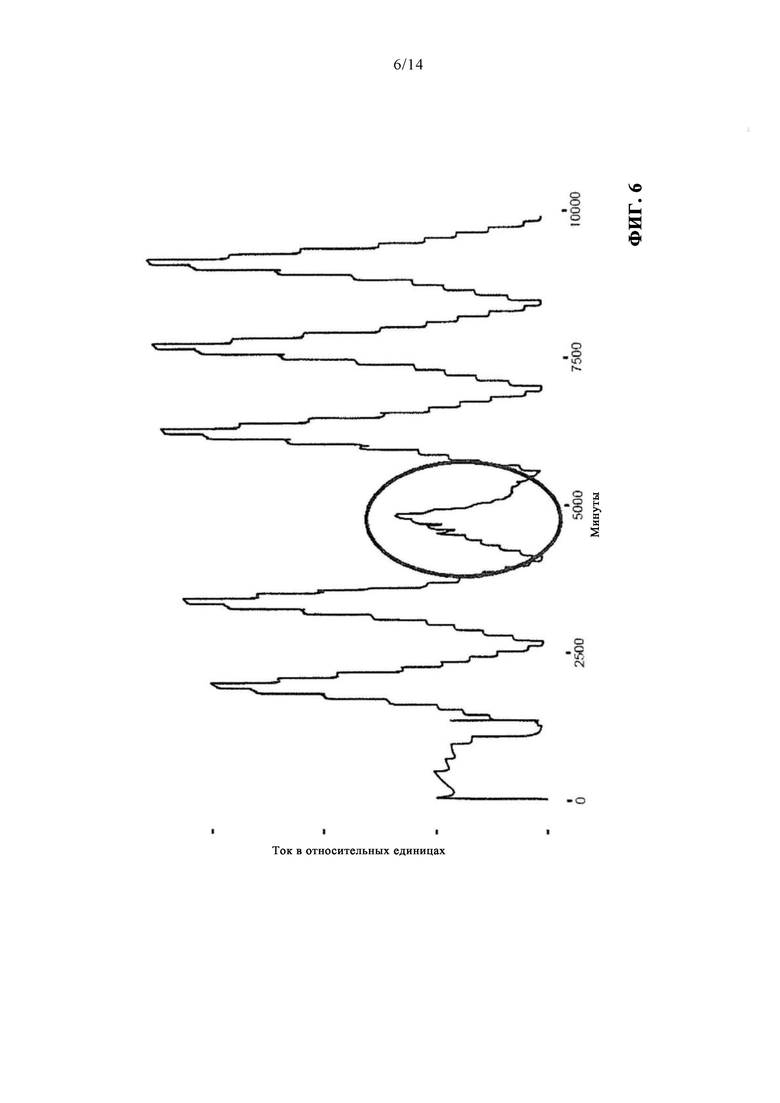
на фиг. 6 - измерение, имеющее жидкостную, т.е. обусловленную свойствами текучей среды, ошибку;
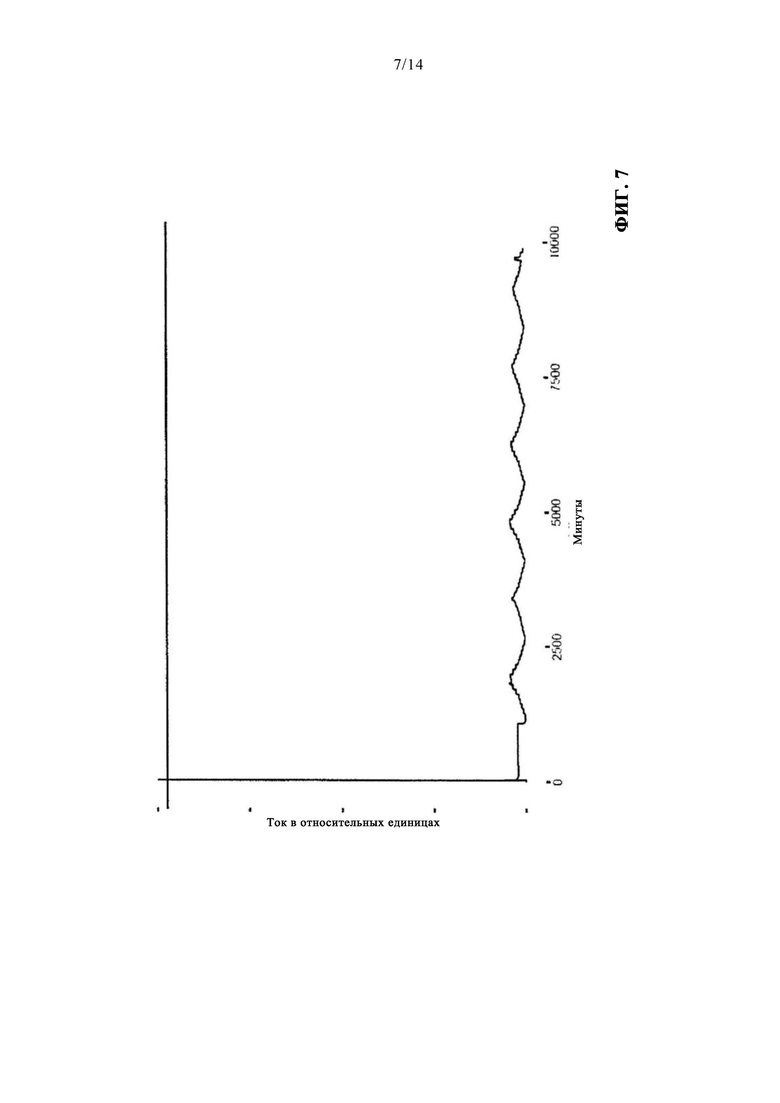
на фиг. 7 - измерение, имеющее ошибку по выходу тока за предел;
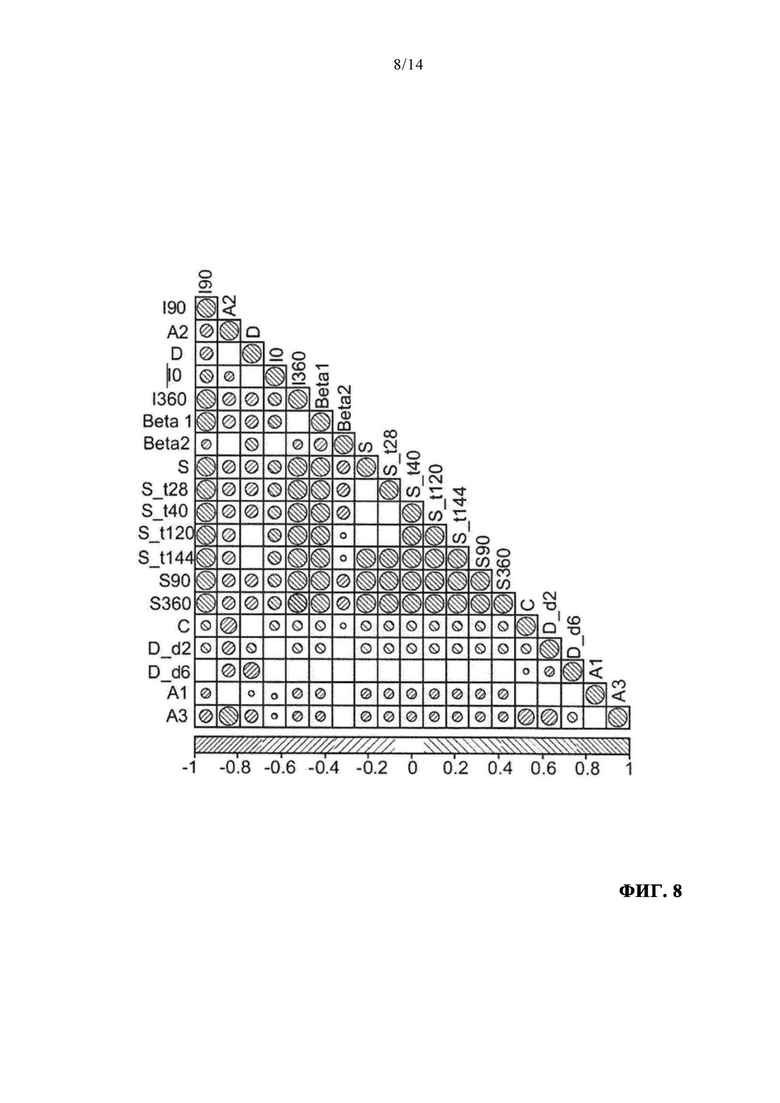
на фиг. 8 - степень корреляции между различными параметрами, используемыми с алгоритмом обучения;
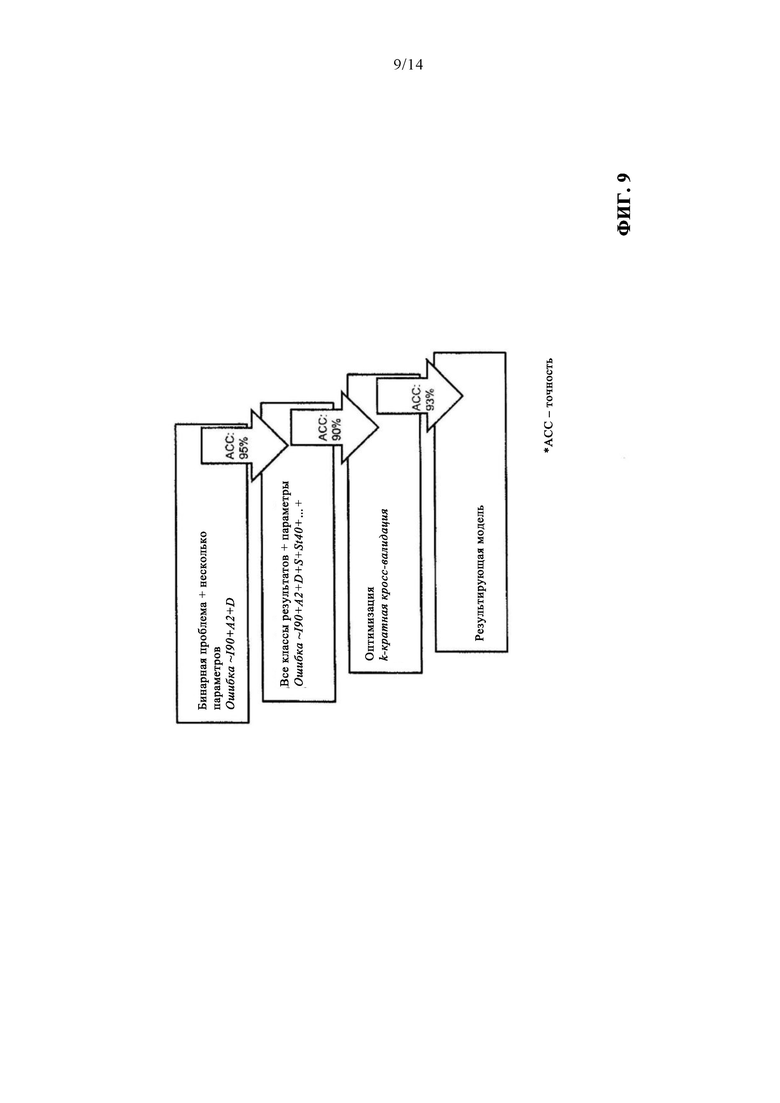
на фиг. 9 - иллюстрация адаптации характеристик модели ансамбля решающих деревьев с использованием гиперпараметров;
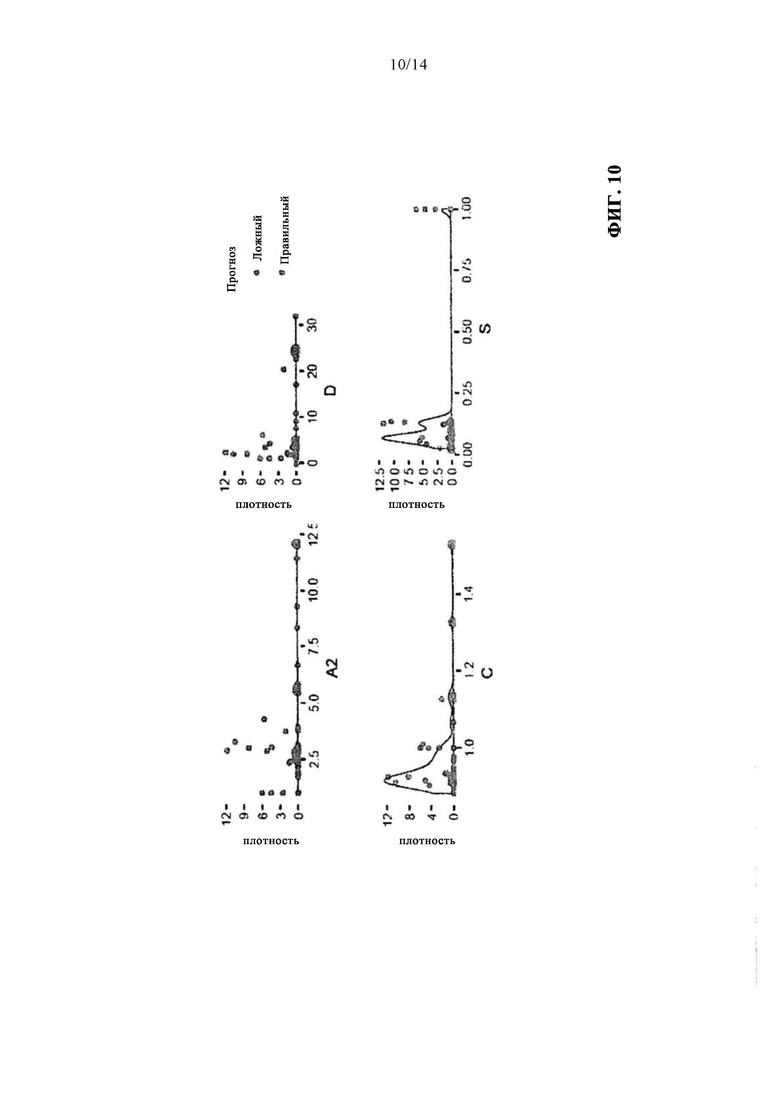
на фиг. 10 - иллюстрация ошибки прогноза при логистической регрессии;
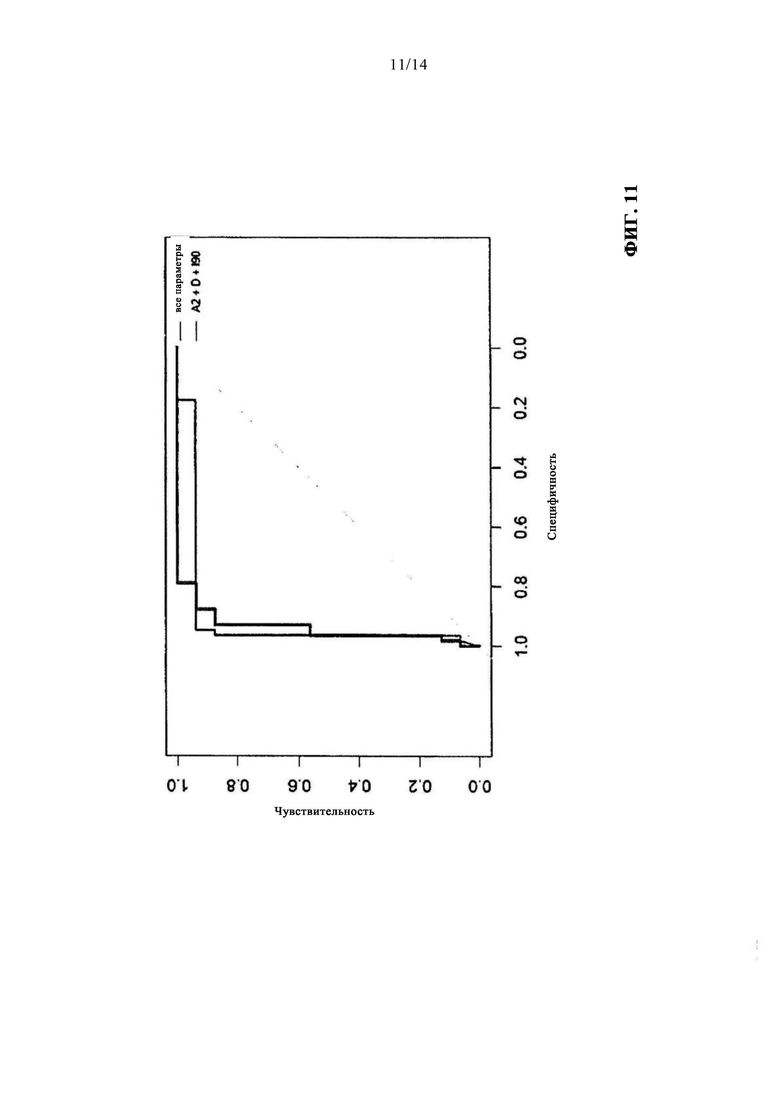
на фиг. 11 - рабочая характеристика приемника для логистической регрессии;
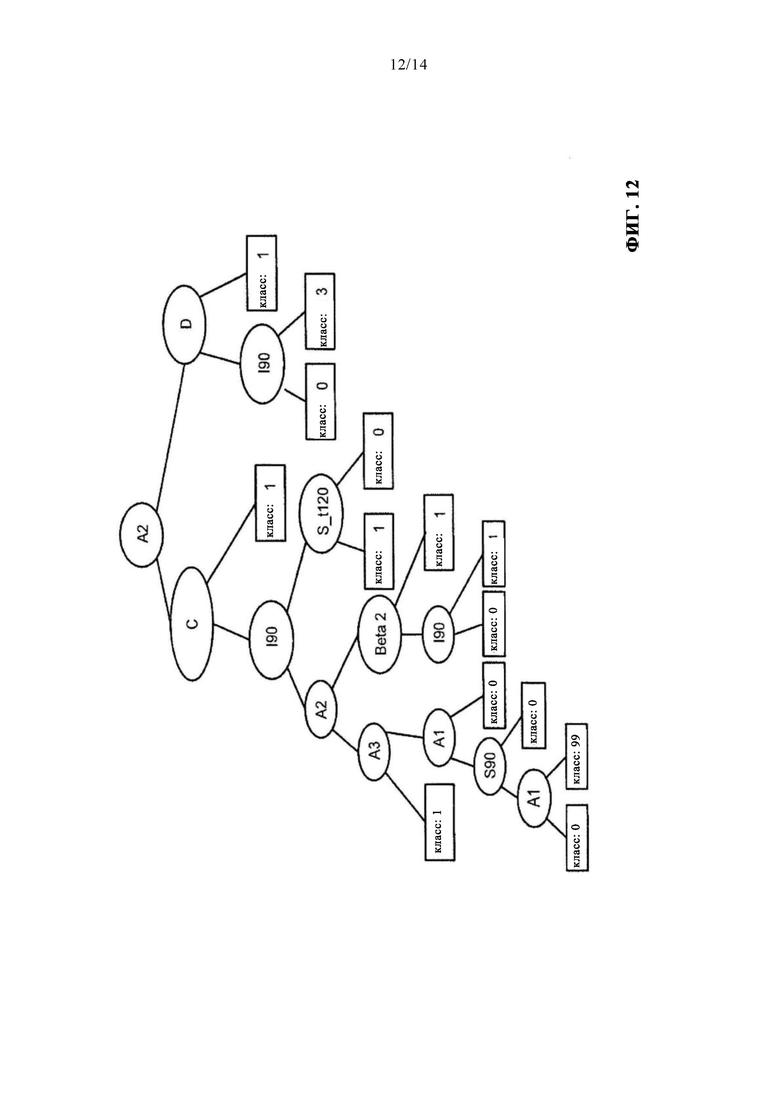
на фиг. 12 - пример дерева для модели ансамбля решающих деревьев;
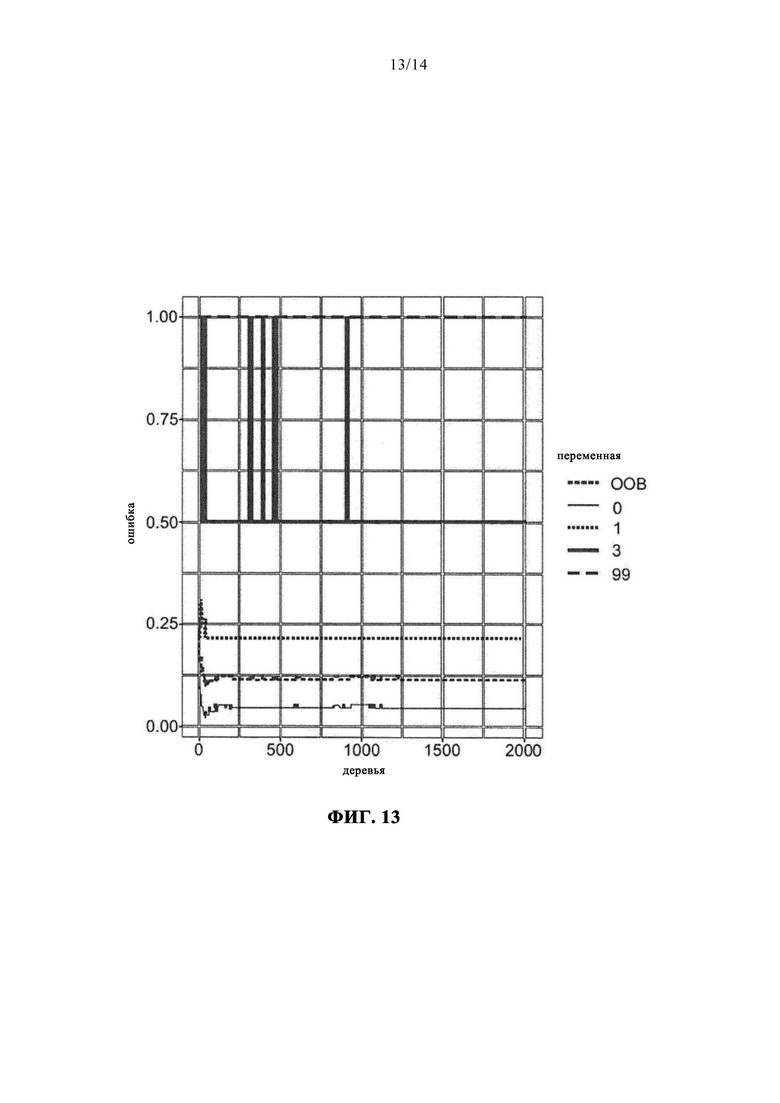
на фиг. 13 - рассматриваемая в качестве примера иллюстрация ошибки для метода ансамбля решающих деревьев;
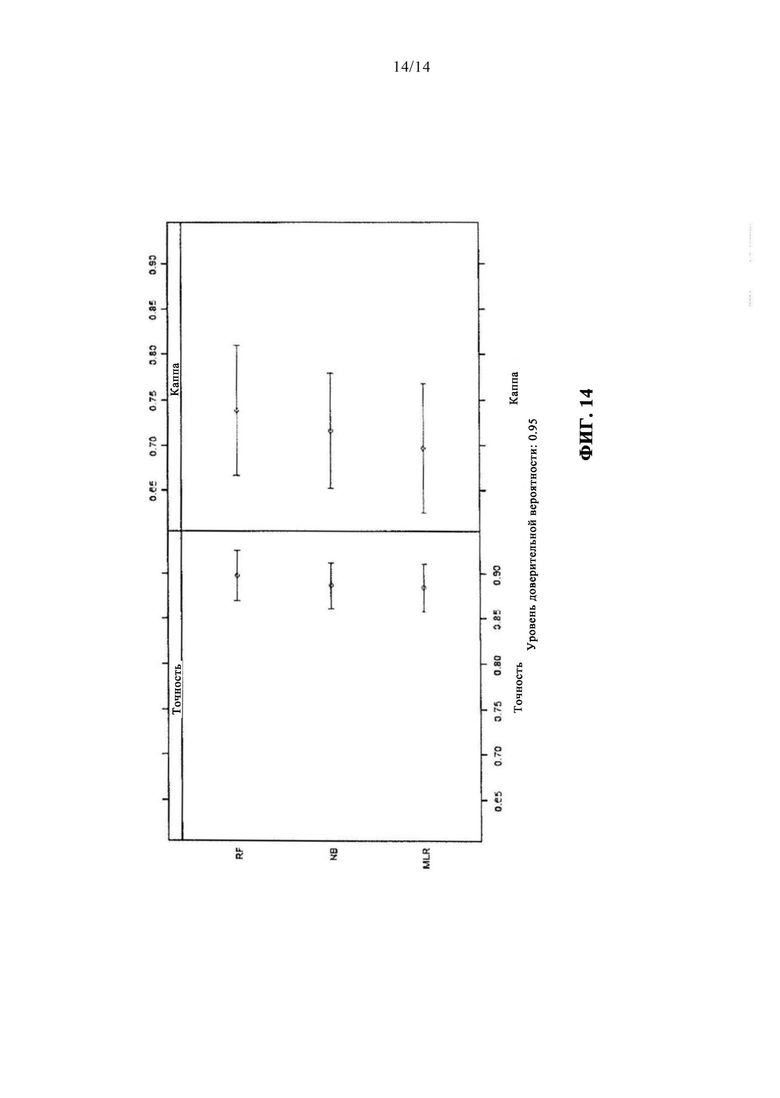
на фиг. - 14 сравнение точности различных рассматриваемых в качестве примеров алгоритмов обучения.
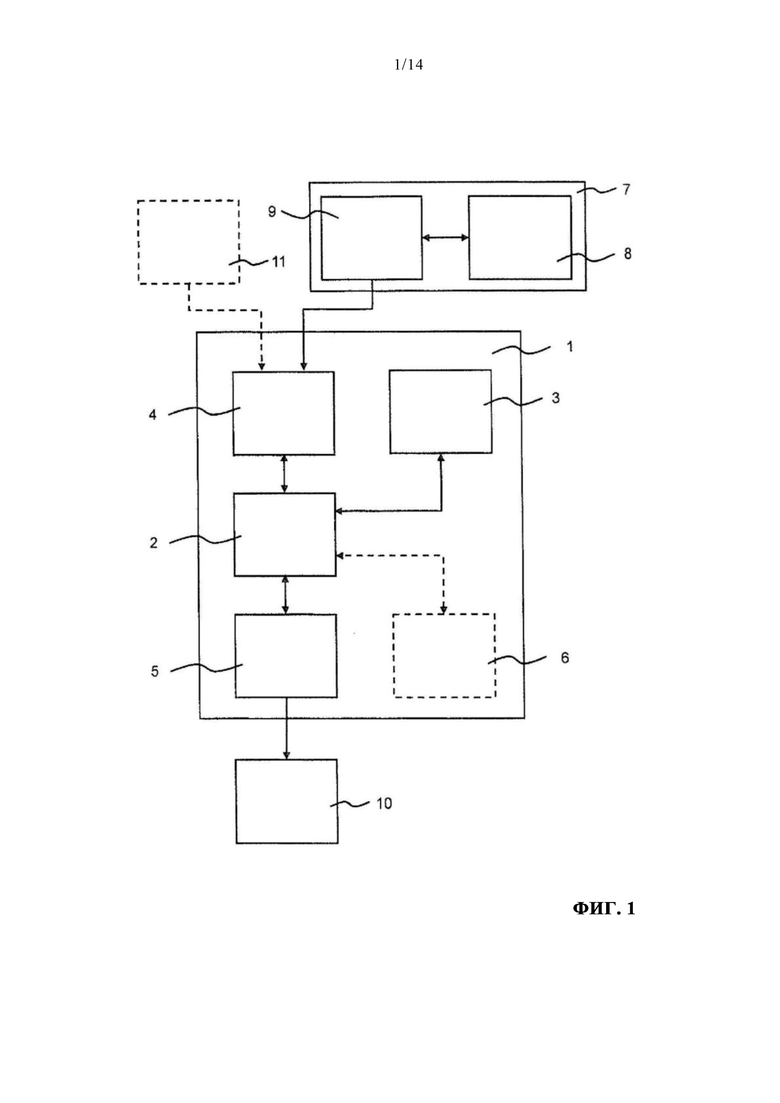
На фиг. 1 показан один вариант выполнения системы 1 конечного автомата, которая также может называться системой анализа состояний. Система конечного автомата содержит один или несколько процессоров 2, запоминающее устройство 3, интерфейс 4 ввода и интерфейс 5 вывода. В показанном варианте осуществления изобретения интерфейс 4 ввода и интерфейс 5 вывода выполнены в виде отдельных модулей. В качестве альтернативы такому выполнению как интерфейс 4 ввода, так и интерфейс 5 вывода могут быть объединены в одном модуле.
В еще одном варианте осуществления изобретения в системе 1 конечного автомата могут быть предусмотрены дополнительные функциональные элементы 7.
Прием данных непрерывного мониторирования, относящихся к работе сенсора 7, осуществляется одним или несколькими процессорами 2 посредством интерфейса 4 ввода. Сенсор 7 может быть подключен к интерфейсу 4 ввода системы 1 конечного автомата по проводам. В качестве альтернативы проводному соединению или в дополнение к нему может быть предусмотрено беспроводное соединение, например соединение по технологии Bluetooth, Wi-Fi или другой беспроводной технологии.
В показанном варианте осуществления изобретения сенсор 7 содержит чувствительный элемент 8 и блок 9 электроники. В этом варианте осуществления изобретения чувствительный элемент 8 и блок 9 электроники сенсора предусмотрены в одном корпусе 7 сенсора. В качестве альтернативы такой интегральной компоновке чувствительный элемент 8 и блок 9 электроники сенсора могут быть выполнены по отдельности и могут быть связаны проводным и/или беспроводным соединением.
В одном варианте осуществления изобретения данные непрерывного мониторирования могут выдаваться сенсором 7, представляющим собой полностью или частично имплантированный сенсор для непрерывного мониторирования гликемии (НМГ). В целом в контексте НМГ может определяться значение или уровень аналита, указывающее(-ий) назначение или уровень глюкозы в крови. Значение аналита может измеряться в интерстициальной жидкости. Измерение может выполняться подкожно или в условиях in vivo. НМГ может быть реализовано в виде осуществляемой почти в реальном времени или квазинепрерывно процедуры контроля, которая часто или автоматически выдает/обновляет значения аналита без взаимодействия с пользователем. В альтернативном варианте осуществления изобретения измерение аналита может проводиться при помощи расположенного в контактной линзе биосенсора через глазную жидкость или при помощи установленного на коже биосенсора путем трансдермального измерения в поту.
Сенсор для НМГ может оставаться на месте его установки от нескольких суток до нескольких недель и затем подлежит замене. Может использоваться передатчик для передачи информации о значении или уровне аналита, указывающего на уровень глюкозы, посредством беспроводной и/или проводной передачи данных от сенсора в приемник, такой как блок 9 электроники сенсора или интерфейс 4 ввода.
Через интерфейс 5 вывода выходные данные, указывающие распознанное рабочее состояние сенсора 7, выдаются в одно или несколько устройств 10 вывода. В качестве устройства 10 вывода может использоваться любое подходящее устройство вывода. Например, устройство 10 вывода может включать в себя отображающее устройство (дисплей). В качестве альтернативы дисплею или в дополнение к нему, устройство 10 вывода может включать в себя генератор тревожных сигналов, сеть передачи данных (информационную сеть) и/или одно или несколько других устройств обработки информации. В еще одном варианте осуществления изобретения (на чертеже не показанном) предусмотрено более одного устройства 10 вывода.
Одно или несколько устройств 10 вывода может быть подключено к интерфейсу 5 вывода системы 1 конечного автомата по проводам. В качестве альтернативы проводному соединению или в дополнение к нему может быть предусмотрено беспроводное соединение, например соединение по технологии Bluetooth, Wi-Fi или другой беспроводной технологии.
В альтернативном варианте осуществления изобретения устройство 10 вывода, или одно из нескольких устройств 10 вывода, встроено в систему 1 конечного автомата.
В одном варианте осуществления изобретения к интерфейсу 4 ввода подключено одно или несколько дополнительных устройств 11 ввода. Такие дополнительные устройства 11 ввода могут включать в себя один или несколько дополнительных сенсоров для сбора обучающих данных и/или валидационных данных для использования с алгоритмом обучения. Другие устройства 11 ввода также могут включать в себя, в качестве дополнения или альтернативы, датчики для получения других типов данных. Одним примером такого другого типа данных являются данные о температуре. Такие данные другого типа, получаемые датчиком, могут дополнительно анализироваться для распознавания рабочего состояния сенсора 7. В качестве дополнения или альтернативы, такие данные другого типа, получаемые датчиком, могут использоваться в качестве обучающих данных и/или валидационных данных. В качестве альтернативы или дополнения, одно или несколько дополнительных устройств 11 ввода может включать в себя сеть передачи данных (информационную сеть), внешнее устройство хранения данных, пользовательское устройство ввода, такое как клавиатура, мышь и т.п., одно или несколько других устройств обработки информации и/или любое другое устройство, подходящее для предоставления в систему 1 конечного автомата релевантных данных.
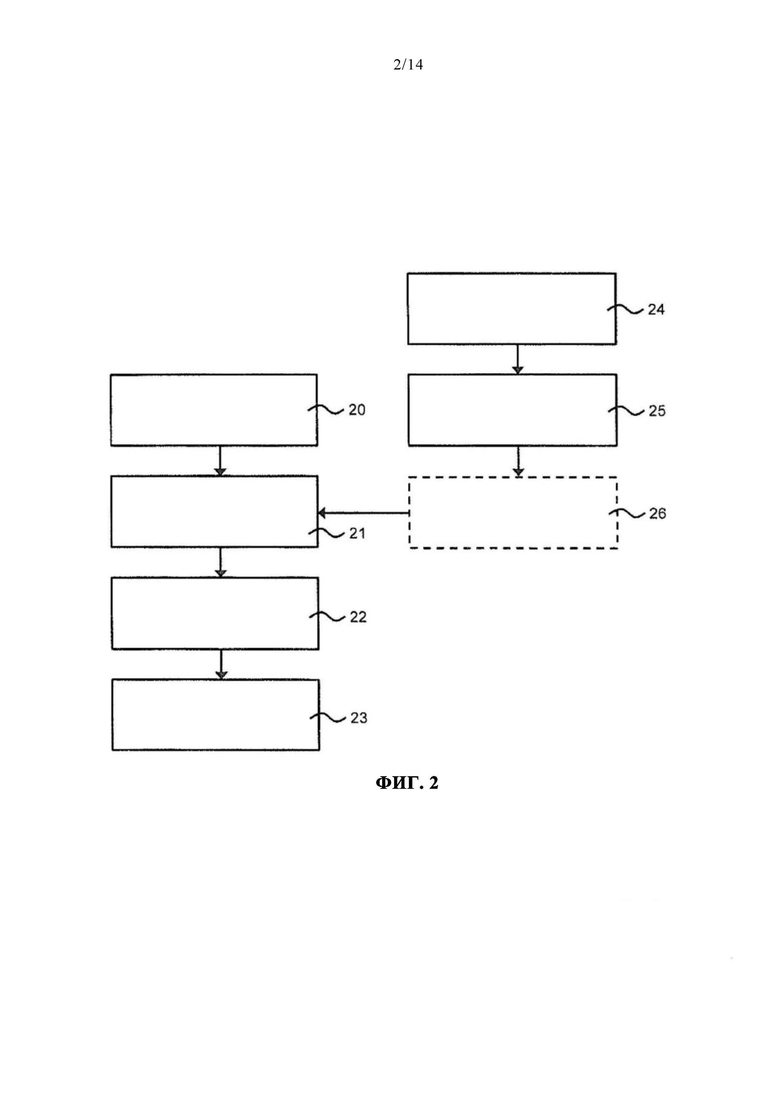
На фиг. 2 приведена блок-схема, иллюстрирующая осуществление способа распознавания рабочего состояния сенсора в одном его варианте.
На шаге 20 посредством интерфейса 4 ввода системы 1 конечного автомата принимают данные непрерывного мониторирования, относящиеся к работе сенсора 6.
Данные непрерывного мониторирования могут указывать на один или несколько относящихся к сенсору параметров. Такие относящиеся к сенсору параметры могут включать в себя значения тока на рабочем электроде сенсора, значения напряжения на противоэлектроде сенсора, значения напряжения между электродом сравнения и рабочим электродом, температуру окружения сенсора во время измерения, чувствительность сенсора, смещение сигнала сенсора и/или состояние калибровки сенсора. Относящиеся к сенсору параметры могут включать в себя некоррелированные относящиеся к сенсору параметры, коррелированные параметры сенсора или их комбинацию.
В одном варианте осуществления изобретения данные непрерывного мониторирования могут включать в себя сжатые данные мониторирования. В этом случае сжатые данные мониторирования определяют методом линейной регрессии и/или методом сглаживания.
На шаге 21 обеспечивают обученный алгоритм обучения. Алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные. Обученный алгоритм обучения может быть заложен в запоминающее устройство 3 системы 1 конечного автомата. В качестве альтернативы, обученный алгоритм обучения может предоставляться в один или несколько процессоров 2 из запоминающего устройства 3. В альтернативном варианте осуществления изобретения обученный алгоритм обучения предоставляется через интерфейс 4 ввода. Например, обученный алгоритм обучения может быть получен из внешнего устройства хранения данных. В других вариантах осуществления изобретения обученный алгоритм обучения может быть предусмотрен в одном или нескольких дополнительных функциональных элементах 7 или может предоставляться в один или несколько процессоров 2 из одного или нескольких дополнительных функциональных элементов 7.
В других вариантах осуществления изобретения порядок выполнения шагов 20 и 21 может быть изменен на обратный. В частном варианте осуществления изобретения обученный алгоритм обучения обеспечивают или предоставляют при включении сенсора 7 в работу. В качестве еще одной альтернативы, шаги 20 и 21 могут выполняться, полностью или частично, одновременно.
На шаге 22 посредством одного или нескольких процессоров 2 при помощи обученного алгоритма обучения анализируют данные непрерывного мониторирования. В вариантах осуществления изобретения, в которых обученный алгоритм обучения не содержится в процессоре 2, процессор 2 может осуществлять доступ к обученному алгоритму обучения для анализа данных непрерывного мониторирования. Путем анализа данных непрерывного мониторирования распознают рабочее состояние сенсора 7.
Рабочее состояние, распознанное для сенсора на шаге 22, может представлять собой одно из нескольких разных состояний. Например, может распознаваться состояние производственного дефекта сенсора, указывающее на дефект, допущенный в процессе изготовления сенсора, состояние неисправной работы сенсора, указывающее на неисправность сенсора, состояние аномалии сенсора, указывающее на аномалию в работе сенсора, состояние указания сенсором гликемического индекса, указывающее на гликемический индекс для пациента, в отношении которого предоставлены данные непрерывного мониторирования, и/или состояние указания сенсором анамнестического статуса, указывающее на анамнестический статус для пациента, в отношении которого предоставлены данные непрерывного мониторирования.
Затем, на шаге 23, на интерфейсе 5 вывода выдаются выходные данные, указывающие распознанное рабочее состояние сенсора.
В одном варианте осуществления изобретения способ распознавания рабочего состояния сенсора также может включать обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические данные.
На шаге 24, также обозначенном на фиг. 2, предоставляют набор обучающих данных, содержащий исторические данные. Исторические обучающие данные могут содержать исторические обучающие данные, полученные в условиях in vivo и указывающие на относящиеся к сенсору параметры, полученные во время работы сенсора 7 в живом организме. В качестве альтернативы или дополнения, исторические обучающие данные могут содержать исторические обучающие данные, полученные в условиях in vitro и указывающие на относящиеся к сенсору параметры, полученные, когда сенсор 7 не работал в живом организме.
Набор обучающих данных, предоставленный на шаге 24, может содержать исторические данные непрерывного мониторирования.
Набор обучающих данных может содержать тестовые данные от производителя, тестовые данные пациентов, персонализированные тестовые данные пациентов и/или популяционные тестовые данные, содержащие наборы данных от многих пациентов.
Обучающие данные могут указывать на один или несколько относящихся к сенсору параметров. Такие относящиеся к сенсору параметры могут включать в себя значения тока на рабочем электроде сенсора, значения напряжения на противоэлектроде сенсора, значения напряжения между электродом сравнения и рабочим электродом, температуру окружения сенсора во время измерения, чувствительность сенсора, смещение сигнала сенсора и/или состояние калибровки сенсора. Относящиеся к сенсору параметры могут включать в себя некоррелированные относящиеся к сенсору параметры, коррелированные параметры сенсора или их комбинацию.
В одном варианте осуществления изобретения набор обучающих данных может содержать сжатые обучающие данные. В этом случае сжатые обучающие данные получают методом линейной регрессии и/или методом сглаживания.
На шаге 25 алгоритм обучения обучают в соответствии с набором обучающих данных, предоставленных на шаге 24.
Алгоритм обучения может быть выбран из подходящих алгоритмов. Такие алгоритмы обучения включают в себя: метод k ближайших соседей, метод опорных векторов, наивный байесовский метод, метод деревьев решений, например ансамбля решающих деревьев ("случайный лес"), логистическую регрессию, например мультиномиальную логистическую регрессию, нейронную сеть и байесовскую сеть. Алгоритм обучения можно выбирать исходя из его пригодности к использованию с данными непрерывного мониторирования, анализируемыми на шаге 22.
Обучение алгоритма обучения на шаге 25 может осуществляться в системе 1 конечного автомата. В этом случае на шаге 24 набор обучающих данных может быть предоставлен в запоминающее устройство 3 системы 1 конечного автомата. В качестве альтернативы, набор обучающих данных может предоставляться в один или несколько процессоров 2 из запоминающего устройства 3. В альтернативном варианте осуществления изобретения набор обучающих данных предоставляется через интерфейс 4 ввода. Например, набор обучающих данных может быть получен из внешнего устройства хранения данных. В других вариантах осуществления изобретения набор обучающих данных может быть предусмотрен в одном или нескольких дополнительных функциональных элементах 7 или может предоставляться в один или несколько процессоров 2 и/или запоминающее устройство 3 из одного или нескольких дополнительных функциональных элементов 7.
В альтернативном варианте осуществления изобретения обучение алгоритма обучения на шаге 25 может осуществляться вне системы 1 конечного автомата. В этом варианте осуществления изобретения на шаге 24 набор обучающих данных обеспечивают любым подходящим образом, позволяющим обучить алгоритм обучения.
Еще один вариант осуществления изобретения может включать в себя шаг 26, на котором обученный алгоритм обучения валидируют в соответствии с набором валидационных данных. Набор валидационных данных содержит полученные измерением данные непрерывного мониторирования и/или полученные моделированием данные непрерывного мониторирования. Эти данные указывают по меньшей мере на одно из следующих состояний сенсора: состояние производственного дефекта, состояние неисправной работы, состояние указания гликемического индекса и состояние указания анамнестического статуса.
Валидация обученного алгоритма обучения на шаге 26 может осуществляться в системе 1 конечного автомата. В этом случае набор валидационных данных может быть предоставлен в запоминающее устройство 3 системы 1 конечного автомата. В качестве альтернативы, набор валидационных данных может предоставляться в один или несколько процессоров 2 из запоминающего устройства 3. В альтернативном варианте осуществления изобретения набор валидационных данных предоставляется через интерфейс 4 ввода. Например, набор валидационных данных может быть получен из внешнего устройства хранения данных. В других вариантах осуществления изобретения набор валидационных данных может быть предусмотрен в одном или нескольких дополнительных функциональных элементах 7 или может предоставляться в один или несколько процессоров 2 и/или запоминающее устройство 3 из одного или нескольких дополнительных функциональных элементов 7.
В альтернативном варианте осуществления изобретения валидация обученного алгоритма обучения на шаге 26 может осуществляться вне системы конечного автомата. В этом варианте осуществления изобретения набор валидационных данных обеспечивают любым подходящим образом, позволяющим валидировать алгоритм обучения.
В одном варианте осуществления изобретения набор валидационных данных может содержать сжатые валидационные данные. В этом случае сжатые валидационные данные получают методом линейной регрессии и/или методом сглаживания.
Далее описываются дополнительные аспекты.
Измерения для сбора данных непрерывного мониторирования выполняют при помощи множества сенсоров для непрерывного мониторирования гликемии.
Исходя из общепринятой последовательности рабочих этапов в области интеллектуального анализа данных (см. Shmueli и соавт., Data Mining for Business analytics - Concepts, Techniques, and Applications with XLMiner, 3-е изд., New York: John Wiley & Sons, 2016), который должен служить поддержкой для разработки модели, могут быть полностью или частично реализованы следующие шаги:
1. Постановка задачи.
2. Получение данных.
3. Анализ и фильтрация данных.
4. Уменьшение размеров, если необходимо.
5. Уточнение задачи (классификация, кластеризация, прогнозирование).
6. Обмен данными при обучении. Валидация и тестирование набора данных.
7. Выбор метода интеллектуального анализа данных (регрессия, нейронная сеть и т.д.).
8. Другие версии алгоритма (другие переменные).
9. Интерпретация результатов.
10. Встраивание модели в существующую систему.
Далее описывается процесс сбора данных, который может применяться в частном варианте осуществления изобретения.
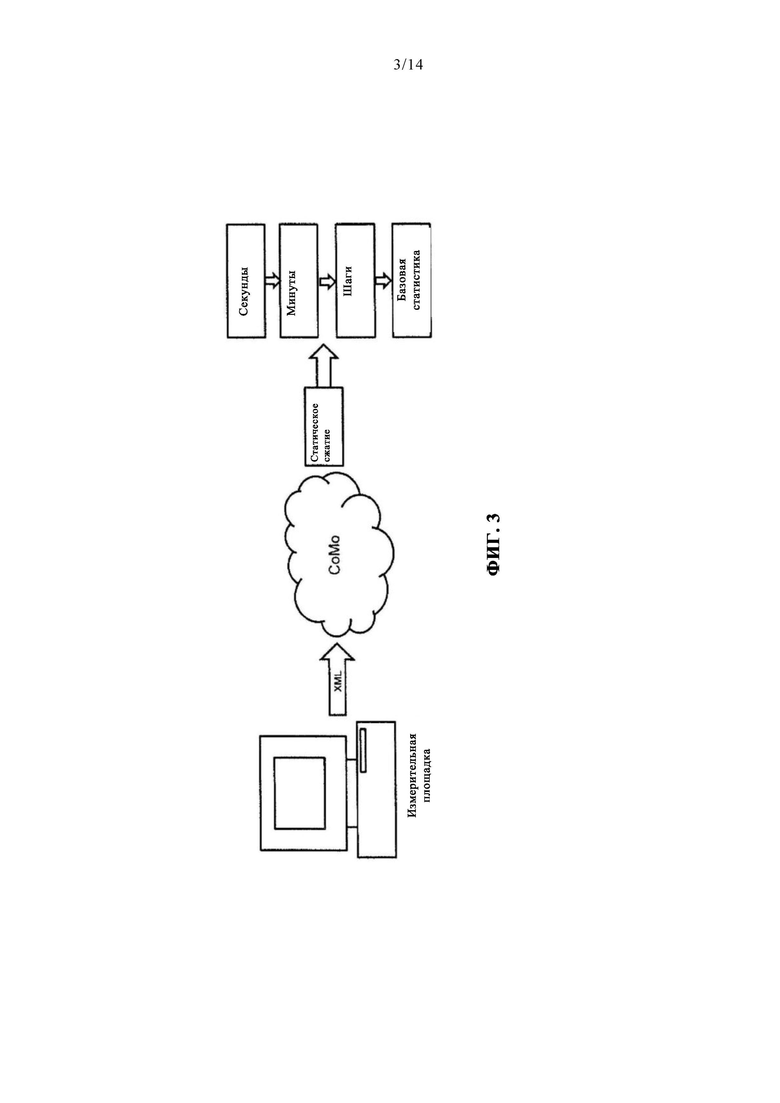
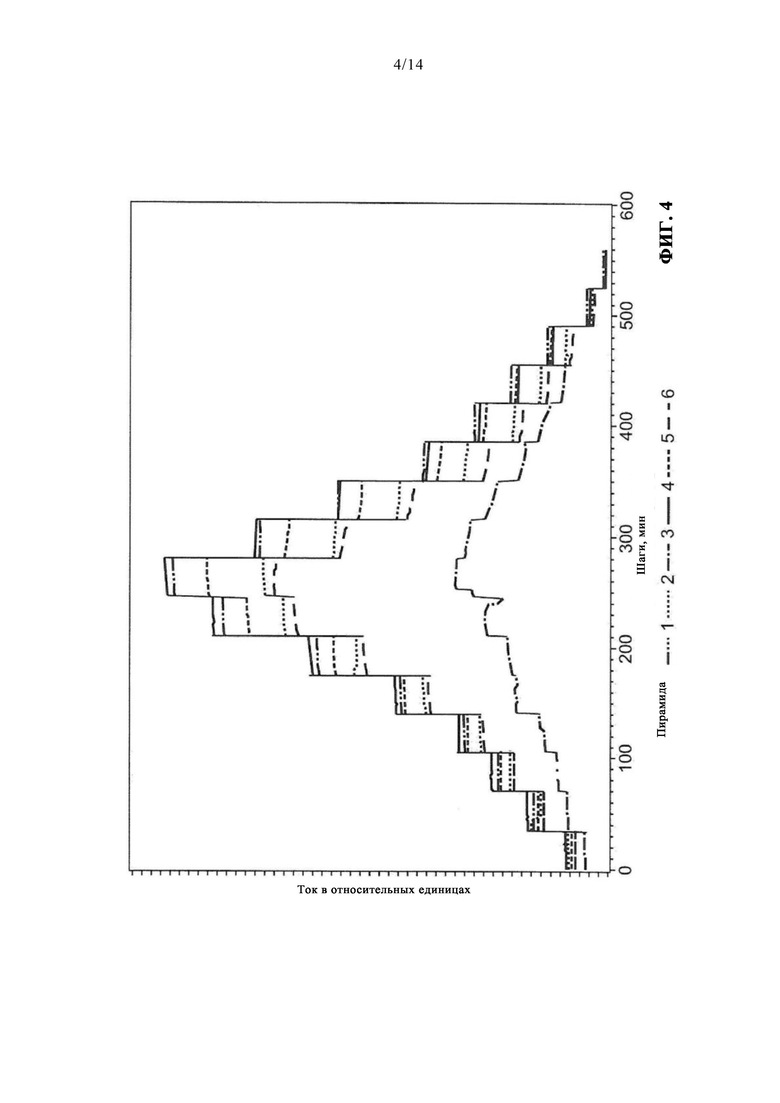
На измерительных площадках каждую секунду в каждом соответствующем канале могут регистрироваться значение тока на рабочем электроде сенсора, значение напряжения на противоэлектроде сенсора, значения напряжения между электродом сравнения и рабочим электродом. Температура раствора, в котором находятся сенсоры, может регистрироваться каждую минуту. Эти параметры могут сохраняться в файле, имеющем формат расширяемого языка разметки (Extensible Markup Language - XML). Затем этот XML-файл захватывается программой обработки данных СоМо, которая переводит его в так называемый эксперимент в виде набора данных SAS. На самом нижнем этапе этот эксперимент состоит из данных, относящихся к одной секунде. Как показано на фиг. 3, эти данные сжимаются посредством программы СоМо до значений за минуту. На этом шаге дополнительно генерируется описательная статистика, например, с минимумом, средним значением и максимумом за каждую минуту. Затем осуществляется сжатие до значений шагов. Такие шаги можно наблюдать как образующие пирамиду, показанную на фиг. 4. Последний этап сжатия - базовая статистика, соответствует отчету о характеристическом значении для каждого сенсора.
Сначала могут использоваться данные с наивысшего этапа сжатия - базовой статистики, поскольку доступ к более сложным данным может быть зарезервирован для случаев, в которых классификация с использованием более простых данных дает недостаточные результаты. Кроме того, классификация данных с временным разрешением, каковые имеются в минутном и секундном этапах, потребовало бы использования другого языка программирования, такого как Python.
Было определено множество серий тестов, например 16 таких серий, распределенных по измерительным площадкам, что при умножении на множество каналов дает, в одном примере, 256 записей данных.
Для идентификации ошибки каждого сенсора рассматривается графическая иллюстрация, приведенная на фиг. 4 для силы тока на рабочем электроде в минуту для каждого канала. Для измерения, проводившегося в течение семи суток, каждые сутки представлены отдельной кривой. Из-за того, что сенсоры подвергали суточной подготовке в форме предварительного набухания, проиллюстрировано только шесть суток. На фиг. 4 четко видно, что на третьи сутки канал 4 значительно отличается от других суток и таким образом уже не следует типичной форме пирамиды. Таким образом, канал 4 определен как неисправный.
После анализа и идентификации всех каналов серии тестов могут быть экспортированы из SAS в память. На последнем шаге серии тестов могут быть считаны из этой памяти в язык R и сохранены в качестве эталона.
Весь набор данных был разделен на три части: набор обучающих данных, набор валидационных данных, а также тестовый набор данных, представляющий данные непрерывного мониторирования.
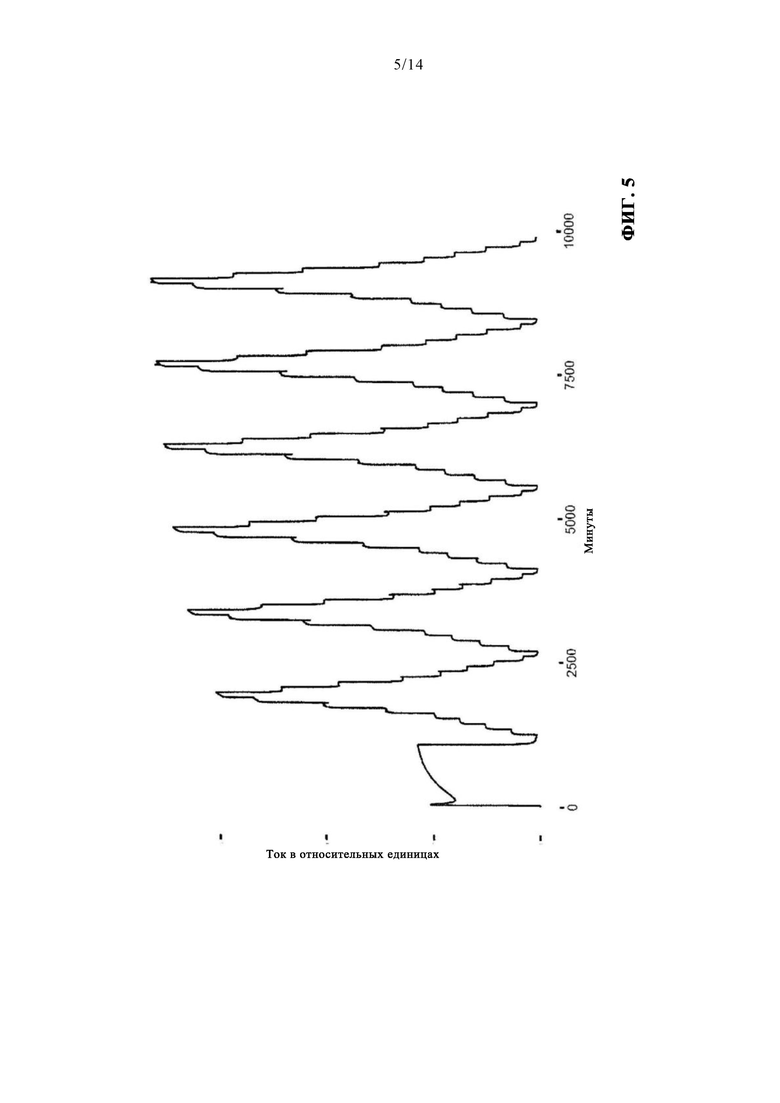
В альтернативном варианте осуществления изобретения посредством моделей должны идентифицироваться два типа ошибок, представляющих рабочее состояние сенсора. Речь идет о жидкостной ошибке, т.е. ошибке, обусловленной свойствами текучей среды, и ошибке по выходу тока за предел. Вначале за эталон может быть принят канал без ошибок, как показано на фиг. 5. Как и на фиг. 4, можно наблюдать форму пирамиды. Однако на фиг. 5 сутки не наложены графически друг на друга, а расположены последовательно. Поскольку решение о том, идентифицировать ли канал как неисправный, принимается на основании силы тока, для анализа в отношении индивидуальных ошибок также используется сила тока.
В этом варианте осуществления изобретения в фокусе обнаружения ошибок находится жидкостная ошибка. Поэтому выбираются данные за период времени с высоким объемом этих дефектов. Одной трудностью, связанной с этим типом ошибок, является большое многообразие проявлений, сопровождающих их возникновение. Вместе с тем, как показано на фиг. 6, можно наблюдать тенденцию к уменьшению измеренных значений. Причина возникновения этой ошибки заключается в конкретной измерительной площадке, и поэтому этот дефект также может называться ошибкой измерительной площадки. Ее причиной предположительно являются воздушные пузырьки в измерительной системе, которые могут возникать, например, по причине колебаний температуры. Воздушные пузырьки в жидкости могут образовываться из-за перебоя в притоке жидкости.
Ошибка по выходу тока за предел может появиться, когда сенсор введен в канал в начале теста (измерения). Сенсор на измерительной площадке помечают этим типом ошибки при регистрации превышения током порогового значения. Теперь сотруднику персонала на измерительной площадке можно снова ввести сенсор в канал, таким образом исправив ошибку. В качестве альтернативы, сенсор может быть окончательно помечен как неисправный. На фиг. 7 показана типичная ошибка по выходу тока за предел. По сравнению с фиг. 6, в начале измерения может быть установлено гораздо более высокое значение тока.
Для создания информативной системы обозначения данных отдельные ошибки можно снабжать разными кодами ошибок согласно таблице 1.

Анализ параметров
В альтернативном варианте осуществления изобретения сила линейной связи между переменными может определяться посредством коэффициента корреляции, который может иметь значения между -1 и 1. В случае значения "1", имеет место высокая положительная линейная корреляция. При взгляде на фиг. 8 видно, что параметр S3 60 коррелирует с очень большим числом других параметров.
Как указано выше, могут быть переменные, такие как ток, которые могут измеряться непосредственно на измерительной площадке. В одном варианте осуществления изобретения при сжатии данных используются линейная модель, а также сплайн-модель, оценивающие различные параметры. Вследствие того, что набор данных, который должен использоваться позднее, содержит сжатые данные, рассматривается использование интегрированных моделей.
Измеренные значения
Анализ условия нормального распределения, который согласно стандарту DIN 53804-1 может выполняться графически посредством квантиль-квантильных графиков, может представлять интерес для описательной статистики в отношении измеренных значений, представляющих относящиеся к сенсору параметры. Ось X квантиль-квантильного графика задана теоретическими квантилями, а ось Y эмпирическими квантилями. Распределенный по нормальному закону параметр дает прямую, иллюстрируемую на квантиль-квантильном графике в виде прямой линии. Кроме того, существуют различные критерии нормального распределения, такие как критерий хи-квадрат или критерий Шапиро-Уилка. Эти критерии проверки гипотезы определяют нулевую (основную) гипотезу как наличие нормального распределения, тогда как альтернативная гипотеза предполагает, что нормальное распределение отсутствует. Эти проверочные методы очень чувствительны к отклонениям. Таким образом, в одном варианте осуществления изобретения нормальное распределение можно анализировать посредством квантиль-квантильного графика для каждого параметра.
Измеренные значения могут включать в себя ток на сенсоре для разных концентраций глюкозы. Эти значения могут быть определены как медианные значения за определенный период времени и, в качестве дополнения или альтернативы, могут усредняться. Измеренные значения также могут включать в себя чувствительность сенсора. В качестве дополнения или альтернативы, измеренные значения могут включать в себя параметры, характерные для графиков, описывающих измеренные значения, такие как ток на сенсоре. Они, например, могут включать в себя дрейф и/или кривизну. В качестве дополнения или альтернативы, значения могут включать в себя статистические значения, относящиеся к другим измеренным значениям. Измеренные значения можно аппроксимировать с использованием других моделей, таких как линейная модель и/или сплайн-модель. Все или некоторые из измеренных значений и параметров можно определять при разных концентрациях глюкозы и/или для разных периодов времени.
Алгоритмы обучения
В частном варианте осуществления изобретения для алгоритма обучения выбирают несколько методов моделирования (см., например, Domingos, A Few Useful Things to Know About Machine Learning, Commun. ACM 55.10, S. 78-87. DOI: 10.1145/2347736.2347755, 2012) и анализируют их на предмет их преимуществ, а также недостатков. Кроме того, эти методы можно анализировать на предмет их совместимости с решаемой задачей, чтобы обеспечить возможность отбора подходящих методов. Ниже описываются методы, рассматриваемые в качестве примеров (Sammut и соавт., Encyclopedia of Machine Learning, 1st. Springer Publishing Company, Incorporated, 2011). Преимущества и недостатки этих методов сведены в таблице 2.
Метод k ближайших соседей
Цель этого метода заключается в классификации объекта с отнесением его к определенному классу, к которому уже были отнесены подобные объекты из обучающего количества, причем в качестве результата выводится класс, встречающийся чаще всего. Для определения близости объектов используется критерий подобия, такой, например, как евклидово расстояние. Этот метод очень хорошо подходит для значительно  количеств данных, которые в настоящем примере отсутствуют. Также по этой причине эта модель не принимается в рассмотрение для сравнения.
количеств данных, которые в настоящем примере отсутствуют. Также по этой причине эта модель не принимается в рассмотрение для сравнения.
Метод опорных векторов
Этот метод предусматривает вычисление гиперплоскости, классифицирующей объекты по классам. Для вычисления гиперплоскости расстояние вокруг границ класса должно быть максимизировано, и поэтому метод опорных векторов является одним из так называемых классификаторов с широкой разделяющей полосой или зазором (Large Margin Classifiers). Важным допущением этого метода является линейная разделимость данных, которая, однако, может быть расширена до векторных пространств более высокой размерности посредством перехода от скалярных произведений к произвольным ядрам (kernel trick). Для классификации с меньшим переобучением требуются большие количества данных, которые в некоторых вариантах осуществления изобретения отсутствуют.
Наивный байесовский метод
Допущение этого метода заключается в том, что имеющиеся переменные статистически независимы друг от друга. Для большинства случаев это допущение неверно. Тем не менее, во многих случаях наивным байесовским методом достигаются хорошие результаты в смысле достижения высокой степени корректных классификаций, даже если атрибуты коррелируют незначительно. Наивный байесовский метод отличается простотой работы и поэтому может быть принят к рассмотрению для выбора модели.
Логистическая регрессия
В связи с логистической регрессией для анализа вычисляется вероятность того, в какой степени характеристика зависимой переменной может быть отнесена к значениям независимых переменных.
Нейронные сети
Искусственные нейронные сети основаны на биологической структуре нейронов в мозге. Простая нейронная сеть состоит из нейронов, расположенных в трех слоях (уровнях). Этими слоями являются входной слой, скрытый слой и выходной слой. Между слоями все нейроны связаны друг с другом весами, которые шаг за шагом оптимизируют в фазе обучения. В настоящее время нейронные сети широко используются во многих областях, и поэтому характеризуются широким спектром разновидностей моделей. Есть множество гиперпараметров, которые необходимо определять по опытным значениям для оптимизации такой сети. В некоторых вариантах осуществления изобретения из соображений экономии времени эти гиперпараметры не определяют.
Метод деревьев решений
Метод деревьев решений представляет собой отсортированные, иерархические деревья, отличающиеся простотой и понятностью своего представления. Узлы, расположенные близко к корню, более значимы для классификации, чем узлы, расположенные близко к листовым вершинам. В одном варианте осуществления изобретения из-за того, что деревья решений часто испытывают проблемы, вызванные переобучением, для выбора модели рассматривают методологию ансамбля решающих деревьев ("случайный лес"). Этот метод состоит из множества деревьев решений, каждое из которых представляет частичное количество переменных.
Байесовские сети
Байесовская сеть - это направленный граф, иллюстрирующий многомерные распределения вероятностей. Узлы сети соответствуют случайным переменным, а границы показывают связи между ними. Возможное применение метода может находиться в области диагностики для иллюстрации причины симптомов болезни. Для разработки байесовской сети важно иметь возможность как можно подробнее описывать зависимости между переменными. Для ошибок, рассматриваемых в некоторых вариантах осуществления изобретения, генерирование такого графа практически неосуществимо.



Выбор метода
В частном варианте осуществления изобретения модели вначале рассматривают теоретически и анализируют в отношении их допущений, после чего происходит первая реализация, которую затем можно оптимизировать различными методами.
На первом шаге может использоваться бинарная проблема с линейной моделью, включающей в себя три переменные из общего количества. После этого представленные моделями алгоритмы обучения можно обучить с использованием всех классов и параметров на основании фактической задачи. Наконец, может быть выполнена адаптация характеристик модели в отношении имеющихся данных посредством гиперпараметров, таких, например, как число деревьев решений в случае метода ансамбля решающих деревьев. Иллюстрация в отношении этого процесса с использованием примера модели ансамбля решающих деревьев, приведена на фиг. 9. Сокращение АСС на этом чертеже означает точность, которая уменьшается с первой адаптацией, но затем повышается снова при выполнении шага оптимизации посредством кросс-валидации.
Наивный байесовский метод
Эта модель, которая может использоваться в одном варианте осуществления изобретения, основана на теореме Байеса и может служить простым и быстрым методом классификации данных. В таком варианте осуществления изобретения действует условие, что имеющиеся данные статистически независимы друг от друга и что они распределены по нормальному закону. Благодаря тому, что этот метод может определять относительные частоты (повторяемость) данных за один лишь проход, он считается простым, а также быстродействующим методом.
Согласно теореме Байеса, для вычисления условных вероятностей используется следующая формула:

Принимая допущение, что атрибуты присутствуют независимо друг от друга, наивный байесовский классификатор можно определить следующим образом:
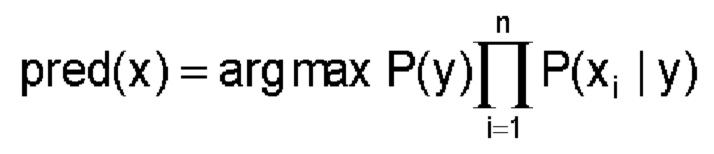
Эта функция всегда предсказывает наиболее вероятный класс y для атрибута xi при помощи правила апостериорного максимума. Последнее ведет себя подобно методу максимального правдоподобия, но со знанием априорного члена. При наличии в наборе данных метрических данных для вычисления условных вероятностей для Р(xi|у) требуется функция распределения. В одном варианте осуществления изобретения наивный байесовский метод также может опираться на нормальное распределение (Berthold и соавт., Guide to Intelligent Data Analysis: How to Intelligently Make Sense of Real Data, 1st, Springer Publishing Company, Incorporated, 2010). Несмотря на то, что в случае многих переменных НМГ речи о нормальном распределении не идет, наивный байесовский метод может использоваться, поскольку он может достигать высокой частоты правильных классификаций, несмотря некоторые отклонения от нормального распределения.
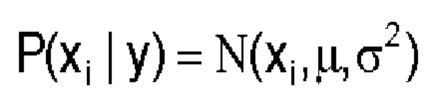
Среднее значение μ и дисперсию о вычисляют для каждого атрибута х1 и каждого класса у.
Благодаря тому, что в случае этой модели для хорошего прогноза (предсказания) достаточен меньший набор данных, в одном варианте осуществления изобретения на входе может использоваться только четыре измерения. В одном варианте осуществления изобретения для первой оценки может быть выбрано частичное количество располагаемых параметров, состоящее из А2, I90 и D.
Наивный байесовский метод может использоваться для определения вероятность ошибки при условии, что 190 появляется в одном классе.
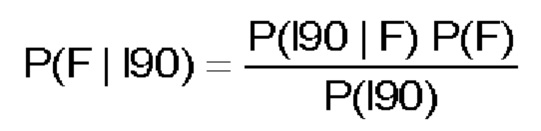
В одном варианте осуществления изобретения утверждений о типе ошибки делать не требуется. Чтобы не потребовалось осуществлять новую идентификацию данных, могут быть выбраны четыре измерительные площадки, содержащие только жидкостные ошибки, т.е. ошибки, обусловленные свойствами текучей среды. В этом случае код ошибки 0 может быть определен как отсутствие ошибки, а код ошибки 1 - как ошибка вообще. В таблице 3 иллюстрируется выдержка из набора входных данных в одном варианте использования наивного байесовского метода.
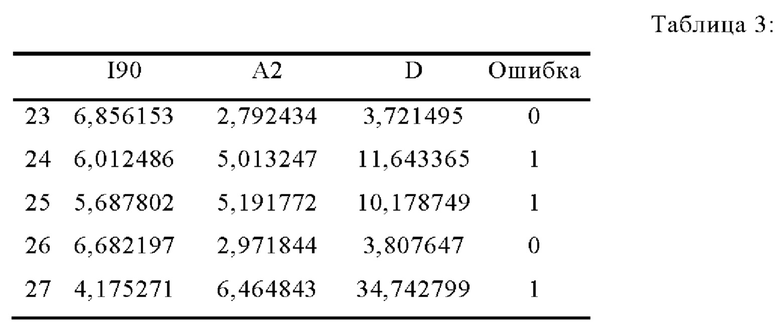
Как показано в таблице 4, данные на выходе модели могут включать в себя вычисленные априорные значения для классов. На следующем шаге могут вычисляться среднее значение, а также стандартное отклонение каждой переменной для класса 0 (нет ошибки) и для класса 1 (есть ошибка). Они могут служить для определения функции распределения переменной, исходя из нормального распределения.

Качество модели можно оценить посредством различных параметров выходных данных. Как показано в таблице 5, в одном варианте осуществления изобретения наиболее важными из этих выходных данных могут быть точность, чувствительность и специфичность.
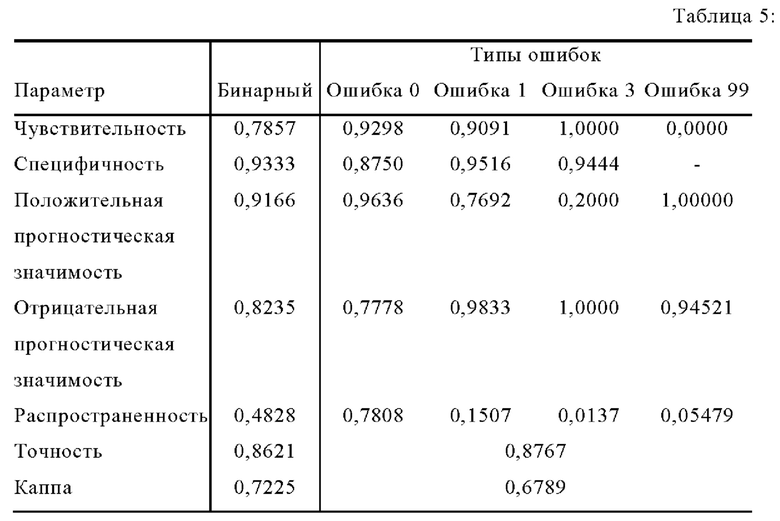
В одном варианте осуществления изобретения точность дает первое впечатление о результатах моделей и таким образом может использоваться для оценки качества.
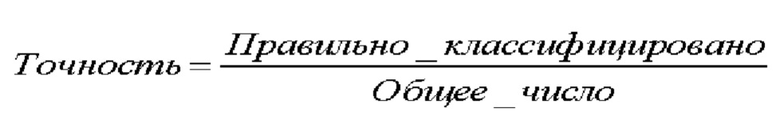
В некоторых вариантах осуществления изобретения для оценки значимости точности может использоваться значение каппа. Значение каппа статистическая метрика соответствия двух параметров качества, в данном варианте осуществления изобретения - соответствия наблюдаемой точности и ожидаемой точности. После вычисления наблюдаемой точности и ожидаемой точности значение каппа можно определить следующим образом:
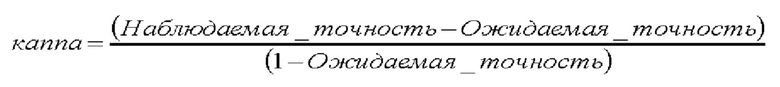
Существуют разные подходы к интерпретации значения каппа. Один такой подход, известный из работы Landis и соавт., The Measurement of Observer Agreement for Categorical Data, Biometrics 33, S. 159-174, 1977, обобщен в таблице 6:

В одном варианте осуществления изобретения можно определять положительную прогностическую значимость, отрицательную прогностическую значимость, чувствительность и специфичность.
Положительная прогностическая значимость показывает процентную долю значений, правильно классифицированных как ошибочные, из всех результатов, классифицированных как ошибочные (соответствует второму ряду четырехпольной таблицы).
Соответственно, отрицательная прогностическая значимость показывает процентную долю значений, правильно классифицированных как свободные от ошибок, из всех результатов, классифицированных как свободные от ошибок (соответствует второй строке четырехпольной таблицы).
Чувствительность показывает процентную долю объектов, правильно классифицированных как положительные, из фактически положительных результатов измерений.
Специфичность показывает процентную долю объектов, правильно классифицированных как отрицательные, из результатов измерений, фактически являющихся отрицательными.
В одном варианте осуществления изобретения прогноз бинарной модели с переменными А2, D и I90, а также холистической модели можно проиллюстрировать четырехпольной таблицей. В варианте осуществления изобретения, иллюстрируемом в таблице 7, бинарная модель имеет наибольшие сложности в области частоты ложноотрицательных результатов, что отражается в чувствительности ≈0,7857.

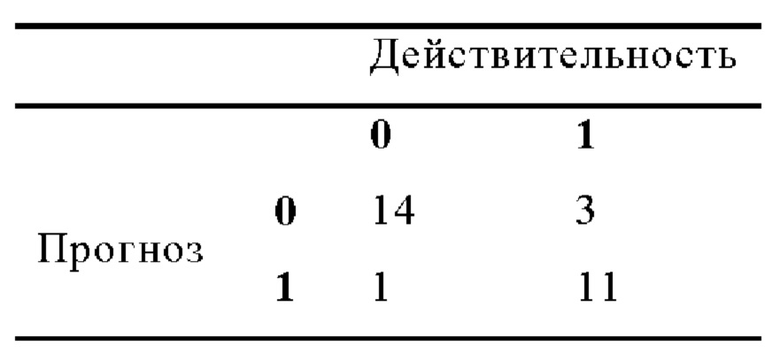
В альтернативном варианте осуществления изобретения после обсуждения наивного байесовского метода в контексте бинарного вопроса все типы ошибок и переменные можно затем выделить на втором этапе. Реализация может быть основана на всех имеющихся данных. Если точность, а также значение каппа ведут себя в обеих версиях модели аналогично, это может подкрепить тот тезис, что наивный байесовский метод с меньшим количеством данных уже может достичь хороших результатов.
Логистическая регрессия
Логистическая регрессия может быть реализована известным образом (Backhaus и соавт., Multivariate Analysemethoden: Eine anwendungsorientierte Einfuhrung, Springer, Berlin Heidelberg, 2015). Логистическая регрессия может использоваться для определения связи между проявлением независимой переменной и зависимой переменной. Обычно бинарная зависимая переменная Y кодируется как 0 или 1, т.е. единица означает наличие ошибки, а ноль отсутствие ошибки. Возможным применением логистической регрессии в контексте НМГ является определение того, связаны ли текущее значение, сплайн и чувствительность с проявлением ошибки.
В одном варианте осуществления изобретения логистическая регрессия может быть реализована при помощи обобщенной линейной модели (см., например, Dobson, An Introduction to Generalized Linear Models, Second Edition. Chapman & Hall/CRC Texts in Statistical Science, Taylor & Francis, 2010). Это может быть выгодным, так как линейные модели легко интерпретируются.
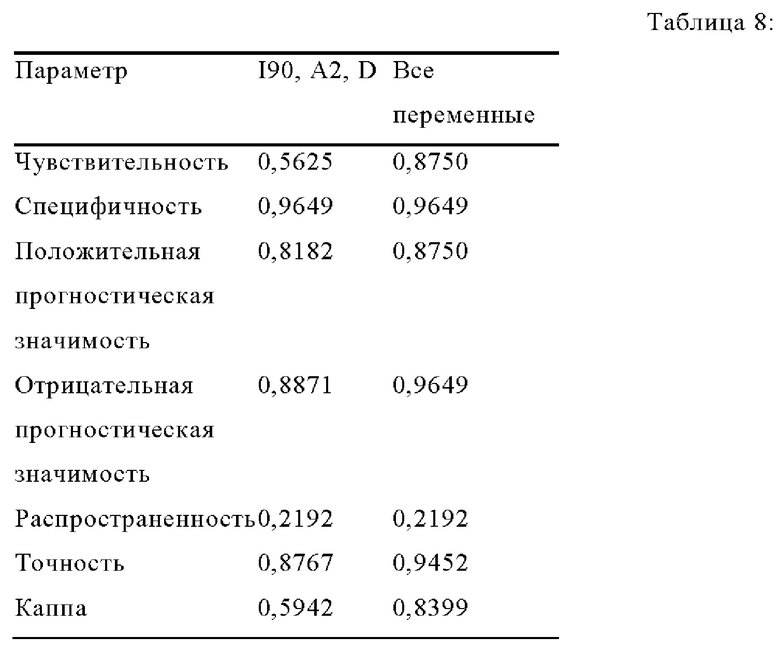
Оценка
В таблице 8 показано сравнение упрощенной модели с одном варианте осуществления изобретения, использующем переменные I90, А2 и D, с моделью, использующей все переменные. В этом варианте осуществления изобретения точность для модели, использующей все переменные, примерно на 7% выше точности для упрощенной модели, и это подсказывает, что упрощенная модель не использует переменные, релевантные для классификации.
Релевантные параметры можно определить методом обратного исключения (Sheather, A Modern Approach to Regression with R, Springer Science & Business Media, 2009) и информационного критерия Акаике (Aho K. и соавт., Model selection for ecologists: the worldviews of AIC andBIC, Ecology, 95: 631-636, 2014). Эти можно исследовать в отношении ошибки прогноза в случае логистической регрессии. На фиг. 10 показано, для одного варианта осуществления изобретения, плотность распределения переменных, а также положение ошибочно предсказанных значений. Поскольку последние присутствуют на границе распределения, а также в области результатов измерения без ошибки, правильный прогноз всех ошибочных измерений простыми ассоциативными правилами в этом варианте осуществления изобретения невозможен.
В одном варианте осуществления изобретения чувствительность и специфичность можно определять с использованием рабочей характеристики приемника (РХП). В этом случае идеальная кривая поднимается вначале вертикально, означая частоту ошибок 0%, а частота ложноположительных значений повышается лишь позже. Кривая, проходящая вдоль диагонали, указывает на случайный процесс. На фиг. 11 показана РХП для логистической регрессии в одном примере осуществления изобретения.
Мультиномиальная логистическая регрессия:
В мультиномиальной логистической регрессии зависимая переменная X может иметь более двух разных значений, что делает бинарную логистическую регрессию особым случаем мультиномиальной логистической регрессии.
Ансамбль решающих деревьев ("случайный лес")
Метод ансамбля решающих деревьев следует принципу бэггинга, который гласит, что комбинация нескольких методов классификации повышает точность классификации за счет обучения нескольких классификаторов разными выборками данных. В одном варианте осуществления изобретения может использоваться алгоритм ансамбля решающих деревьев, сам по себе известный (Breiman, Random Forests, Mach. Learn. 45.1, S. 5-32. DOI: 10.1023/A: 1010933404324, 2001).
В таком варианте осуществления изобретения при вводе в деревья решений нового элемента каждое дерево определяет в результате тот или иной класс. На следующем шаге на основании класса, предложенного большинством деревьев, определяется результирующий класс. На фиг. 12 показано дерево в одном примере осуществления изобретения.
Метод ансамбля решающих деревьев можно оптимизировать, используя, например, число деревьев и/или число узлов в дереве. На фиг. 13 для одного варианта осуществления изобретения приведен пример ошибки для метода ансамбля решающих деревьев, в котором вероятность ошибки в отношении ошибки по выходу тока за предел, колеблется между 50% и 100%. В этом примере все "другие ошибки" классифицированы ложно, как видно по линии вверху. Это может быть связано с малым числом появления ошибок по выходу тока за предел и других ошибок.
На фиг. 14 показано сравнение точности рассматриваемых в качестве примеров алгоритмов обучения в альтернативном варианте осуществления изобретения: мультиномиальная логистическая регрессия, наивный байесовский метод и ансамбль решающих деревьев. Слева представлены доверительные интервалы точности. Справа показаны значения каппа каждой модели.
Для этого варианта осуществления изобретения значение каппа позволяет сделать допущение тенденции, согласно которой точность мультиномиальной логистической регрессии менее значительна по сравнению с другими моделями.
Эта допущение подтверждается прогнозом обученных моделей для тестового набора данных в этом варианте осуществления изобретения, который иллюстрируется в четырехпольных таблицах, собранных в таблице 9. Результаты измерений из тестового набора данных были выбраны случайным образом для симулирования ввода фактических данных. Несмотря то что в тестовом наборе данных нет ошибки по выходу тока за предел, мультиномиальная логистическая регрессия ошибочно предсказывает этот тип ошибки. Наибольшие же проблемы у этой модели имеются с жидкостной ошибкой, для которой ни один случай не был классифицирован правильно.
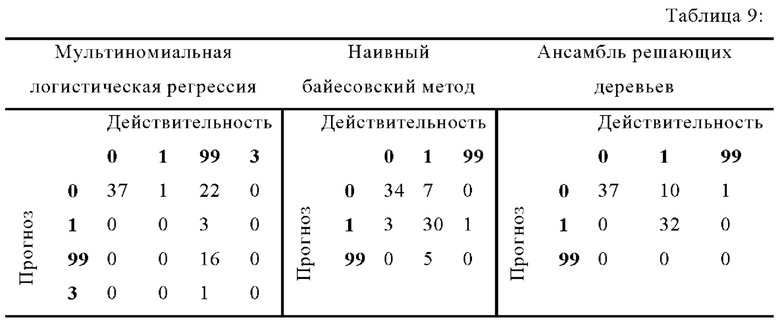
Для этого варианта осуществления изобретения мультиномиальная логистическая регрессия таким образом соответствует точности 66% и соответственно уступает наивному байесовскому методу с его 80% и методу ансамбля решающих деревьев с его 88% точности в отношении правильно классифицированных случаев. Первой возможной причиной этого могут быть корреляции между параметрами, которые могут приводить к искаженным оценкам и к увеличенным стандартным ошибкам. Однако наивный байесовский метод также требует, чтобы параметры не коррелировали, и эта модель достигает значительно лучших результатов для показанного варианта осуществления изобретения. Причина этого может быть в том, что наивный байесовский метод может достигать высокой точности уже с очень малыми количествами данных. С большими количествами данных для обучения моделей, точность наивного байесовского метода может сильно увеличиться, несмотря на корреляции параметров. Вместе с тем, также может нарушаться второе допущение мультиномиальной логистической регрессии - "независимость от иррелевантных альтернатив". Оно указывает, что коэффициент несогласия двух типов ошибок является независимым от всех других категорий откликов. Можно допустить, например, что на выбор класса результата "жидкостная ошибка" или "отсутствие ошибки" не влияет наличие "других ошибок".
В одном варианте осуществления изобретения метод ансамбля решающих деревьев обеспечивает наивысшую частоту правильно классифицированных случаев, составляющую 86%, причем множество неправильно классифицированных случаев прогнозируется как "отсутствие ошибки", хотя имеется жидкостная ошибка. Причиной того, что в этом варианте осуществления изобретения метод ансамбля решающих деревьев представляет наиболее успешную модель в отношении прогноза, может быть, с одной стороны, то, что древовидная структура позволяет распределить (организовать) параметры по их взаимодействиям. С другой стороны, метод ансамбля решающих деревьев может быть оптимизирован по сравнению с мультиномиальной логистической регрессией и наивным байесовским методом на языке R без больших усилий благодаря числу деревьев. Это может сделать возможным посредством графика ошибки по отношению к числу деревьев решений, показывающего число деревьев решений, при котором ошибка сходится в одной точке.
В качестве альтернативы сжатым данным могут использоваться несжатые данные. Для данных, имеющий временное разрешение, можно получить прогноз с использованием нейронных сетей, таких как рекуррентные сети. Рекуррентные нейронные сети имеют то преимущество, что перед созданием модели не требуется делать никаких допущений.
Изобретение относится к средствам распознавания рабочего состояния сенсора для непрерывного мониторирования гликемии. Технический результат заключается в повышении вероятности обнаружения потенциальной проблемы с рабочим состоянием сенсора. Принимают данные непрерывного мониторирования, относящиеся к работе сенсора и содержащие сжатые данные мониторирования. Осуществляют обеспечение обученного алгоритма обучения для распознавания рабочего состояния сенсора, характеризующего функцию сенсора, причем алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные и сжатые обучающие данные. Распознают рабочее состояние сенсора путем анализа данных непрерывного мониторирования при помощи обученного алгоритма обучения. Выдают выходные данные, указывающие на распознанное рабочее состояние сенсора. Исторические данные состоят из данных, собранных, зарегистрированных и/или измеренных перед процессом распознавания рабочего состояния. Сжатые данные мониторирования и сжатые обучающие данные получают методом линейной регрессии и/или методом сглаживания в результате уменьшения их размера, причем на разных этапах сжатия данные мониторирования и обучающие данные содержат данные за секунду, данные за минуту и/или статистические данные, включающие в себя характеристические значения, такие как параметры сенсора, дисперсия, шум или скорость изменения. 2 н. и 10 з.п. ф-лы, 9 табл., 14 ил.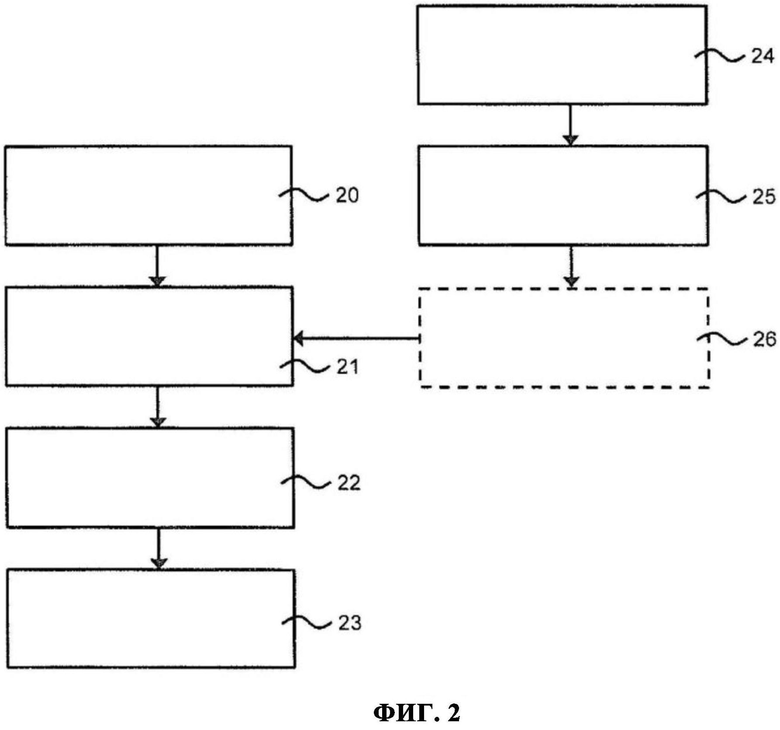
1. Способ распознавания рабочего состояния сенсора (7) для непрерывного мониторирования гликемии, включающий выполнение в конечном автомате следующих действий:
- прием (20) данных непрерывного мониторирования, относящихся к работе сенсора и содержащих сжатые данные мониторирования;
- обеспечение (21) обученного алгоритма обучения для распознавания рабочего состояния сенсора (7), характеризующего функцию сенсора, причем алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные и сжатые обучающие данные;
- распознавание рабочего состояния сенсора (7) путем анализа (22) данных непрерывного мониторирования при помощи обученного алгоритма обучения; и
- выдачу (23) выходных данных, указывающих на распознанное рабочее состояние сенсора (7),
причем:
- исторические данные состоят из данных, собранных, зарегистрированных и/или измеренных перед процессом распознавания рабочего состояния,
- сжатые данные мониторирования и сжатые обучающие данные получают методом линейной регрессии и/или методом сглаживания в результате уменьшения их размера, причем на разных этапах сжатия данные мониторирования и обучающие данные содержат данные за секунду, данные за минуту и/или статистические данные, включающие в себя характеристические значения, такие как параметры сенсора, дисперсия, шум или скорость изменения.
2. Способ по п. 1, в котором распознавание включает в себя по меньшей мере одно из следующего:
- распознавание у сенсора (7) состояния производственного дефекта, указывающего на дефект, допущенный в процессе изготовления сенсора (7);
- распознавание у сенсора (7) состояния неисправной работы, указывающего на неисправность сенсора;
- распознавание у сенсора (7) состояния аномалии, указывающего на аномалию в работе сенсора;
- распознавание у сенсора (7) состояния указания гликемического индекса, указывающего на гликемический индекс для пациента, в отношении которого предоставлены данные непрерывного мониторирования; и
- распознавание у сенсора (7) состояния указания анамнестического статуса, указывающего на анамнестический статус для пациента, в отношении которого предоставлены данные непрерывного мониторирования.
3. Способ по п. 1 или 2, в котором обеспечение (21) обученного алгоритма обучения включает в себя обеспечение по меньшей мере одного алгоритма обучения, выбранного из следующей группы:
- метод k ближайших соседей;
- метод опорных векторов;
- наивный байесовский метод;
- метод деревьев решений, например ансамбля решающих деревьев;
- логистическая регрессия, например мультиномиальная логистическая регрессия;
- нейронная сеть; и
- байесовская сеть.
4. Способ по одному из предыдущих пунктов, также включающий обучение (25) алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические данные.
5. Способ по п. 4, в котором обучение (25) включает в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические обучающие данные, полученные в условиях in vivo, и/или исторические обучающие данные, полученные в условиях in vitro.
6. Способ по п. 4 или 5, в котором обучение (25) включает в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим исторические данные непрерывного мониторирования.
7. Способ по одному из пп. 4-6, в котором обучение (25) включает в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим тестовые данные из следующей группы: тестовые данные от производителя, тестовые данные пациентов, персонализированные тестовые данные пациентов, популяционные тестовые данные, содержащие наборы данных от многих пациентов.
8. Способ по одному из пп. 4-7, в котором обучение (25) включает в себя обучение алгоритма обучения в соответствии с набором обучающих данных, содержащим обучающие данные, указывающие на один или несколько относящихся к сенсору (7) параметров из следующей группы: значения тока на сенсоре (7), в частности значения тока на рабочем электроде сенсора (7) в случае непрерывного мониторирования; значения напряжения на сенсоре (7) или значения напряжения между электродом сравнения и рабочим электродом сенсора; температура окружения сенсора (7) во время измерения; чувствительность сенсора (7); смещение сигнала сенсора (7); и состояние калибровки сенсора (7).
9. Способ по п. 8, в котором один или несколько относящихся к сенсору параметров включают в себя некоррелированные относящиеся к сенсору параметры и/или коррелированные относящиеся к сенсору параметры.
10. Способ по одному из пп. 2-9, также включающий валидацию (26) обученного алгоритма обучения в соответствии с набором валидационных данных, содержащим полученные измерением данные непрерывного мониторирования и/или полученные моделированием данные непрерывного мониторирования, указывающие по меньшей мере на одно из следующих состояний сенсора (7): состояние производственного дефекта, состояние неисправной работы, состояние указания гликемического индекса и состояние указания анамнестического статуса.
11. Способ по одному из предыдущих пунктов, также включающий валидацию обученного алгоритма обучения в соответствии с набором валидационных данных, содержащим сжатые валидационные данные, причем сжатые валидационные данные получают методом линейной регрессии и/или методом сглаживания.
12. Система (1) конечного автомата, содержащая один или несколько процессоров (2), выполненных с возможностью обработки данных и осуществления способа распознавания рабочего состояния сенсора (7) для непрерывного мониторирования гликемии, причем указанный способ включает:
- прием (20) данных непрерывного мониторирования, относящихся к работе сенсора и содержащих сжатые данные мониторирования;
- обеспечение (21) обученного алгоритма обучения для распознавания рабочего состояния сенсора (7), характеризующего функцию сенсора, причем алгоритм обучения обучен в соответствии с набором обучающих данных, содержащим исторические данные и сжатые обучающие данные;
- распознавание рабочего состояния сенсора (7) путем анализа (22) данных непрерывного мониторирования при помощи обученного алгоритма обучения; и
- выдачу (23) выходных данных, указывающих на распознанное рабочее состояние сенсора (7),
причем:
- исторические данные состоят из данных, собранных, зарегистрированных и/или измеренных перед процессом распознавания рабочего состояния,
- сжатые данные мониторирования и сжатые обучающие данные получают методом линейной регрессии и/или методом сглаживания в результате уменьшения их размера, причем на разных этапах сжатия данные мониторирования и обучающие данные содержат данные за секунду, данные за минуту и/или статистические данные, включающие в себя характеристические значения, такие как параметры сенсора, дисперсия, шум или скорость изменения.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| СИСТЕМА РАСПОЗНАВАНИЯ НЕДОСТАТОЧНОГО ЗАПОЛНЕНИЯ ДЛЯ БИОСЕНСОРА | 2010 |
|
RU2583133C2 |

