ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
[0001] Настоящая заявка испрашивает на приоритет предварительной заявки на патент США № 61/793,044, поданной 15 марта 2013 года, содержание которой включено в настоящий документ по ссылке.
УРОВЕНЬ ТЕХНИКИ
1. ОБЛАСТЬ ТЕХНИКИ
[0002] Настоящее раскрытие относится к ситуациям, в которых информация была преобразована среди двух или более языков или систем письма с получением второго, третьего и многопорядкового представлений первоначальной информации.
2. ОПИСАНИЕ ПРЕДШЕСТВУЮЩЕГО УРОВНЯ ТЕХНИКИ
[0003] Подходы, описанные в этом разделе, являются подходами, которым могли следовать, но не обязательно подходами, которые ранее предлагались или которым следовали. Таким образом, подходы, описанные в этом разделе, могут не представлять собой предшествующий уровень техники для формулы изобретения в этой заявке и не признаются как представляющие собой предшествующий уровень техники посредством включения в этот раздел.
[0004] Настоящее описание имеет отношение к области автоматизированного лингвистического преобразования данных с конкретным фокусом на преобразовании между разными орфографиями (например, с письменности русской кириллицы на латинскую письменность) в пределах заданных контекстов (таких как названия коммерческих предприятия).
[0005] Методики предшествующего уровня техники удовлетворительно не преобразовывают разные части названия на первом языке в название на втором языке. В этом контексте "разные части" относятся к семантическим элементам, таким как названия, географические названия, имена нарицательные, качественные прилагательные, суффиксы объединения и так далее. Например, может иметься потребность преобразовать название коммерческого предприятия в России, которое исходно записано на кириллице, в латинскую письменность, которая "понятна" говорящей на немецком языке аудитории. Методики предшествующего уровня техники обычно подходили к этой проблеме, выполняя однозначное отображение и/или прямой перевод. В этом контексте, "однозначное отображение" относится к хранению и извлечению отдельного слова на целевом языке, которое было отображено на слово в исходных данных (название). В этом контексте "прямой перевод" относится к переводу значения слова (или всего названия) с исходного языка на целевой язык. Таким образом, методики предшествующего уровня техники достигли преобразований, которые "удобно произносимы", но которые, например, не преобразовывают описательную часть названия коммерческого предприятия на язык, который может понять носитель немецкого языка.
[0006] Другая проблема методик предшествующего уровня техники состоит в том, что в случае, когда методика производит ошибочный перевод или преобразование, методика не имеет никакого автоматического способа улучшения качества перевода или преобразования. Таким образом, методики предшествующего уровня техники не извлекают уроки из опыта и не используют его в своих интересах.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0007] Обеспечен способ, который включает в себя разбор строки символов на ее графемы и формирование шаблона символов, который представляет абстракцию графем. Также обеспечена система, которая выполняет способ, и запоминающее устройство, которое содержит команды для управления процессором для выполнения способа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
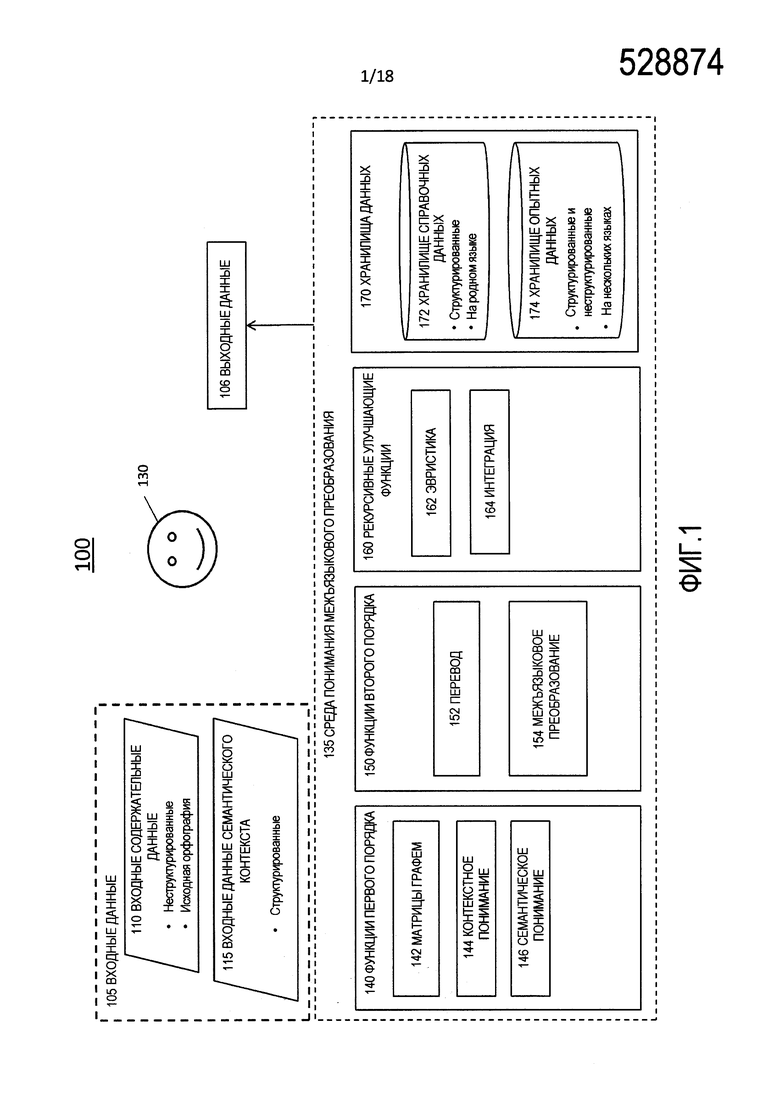
[0008] Фиг. 1 является блок-схемой логической структуры процесса для автоматизированного лингвистического преобразования данных.
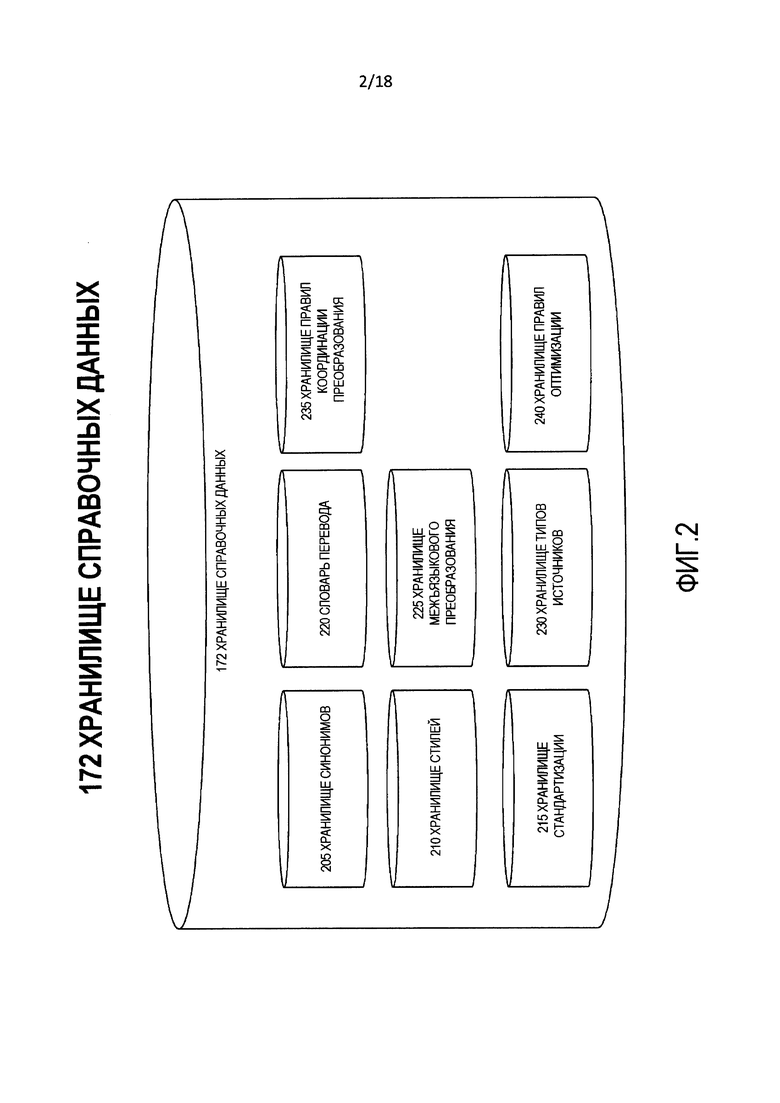
[0009] Фиг. 2 является блок-схемой логической структуры хранилища справочных данных, используемого процессом на фиг. 1.
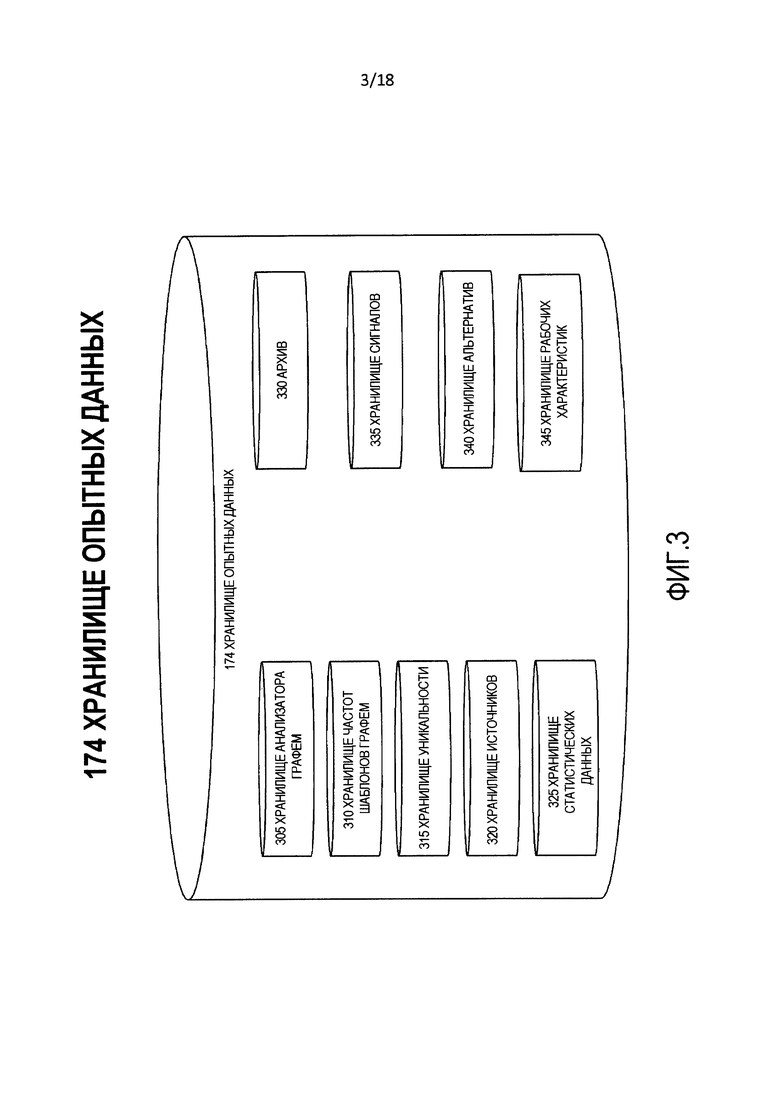
[0010] Фиг. 3 является блок-схемой логической структуры хранилища опытных данных, используемого процессом на фиг. 1.
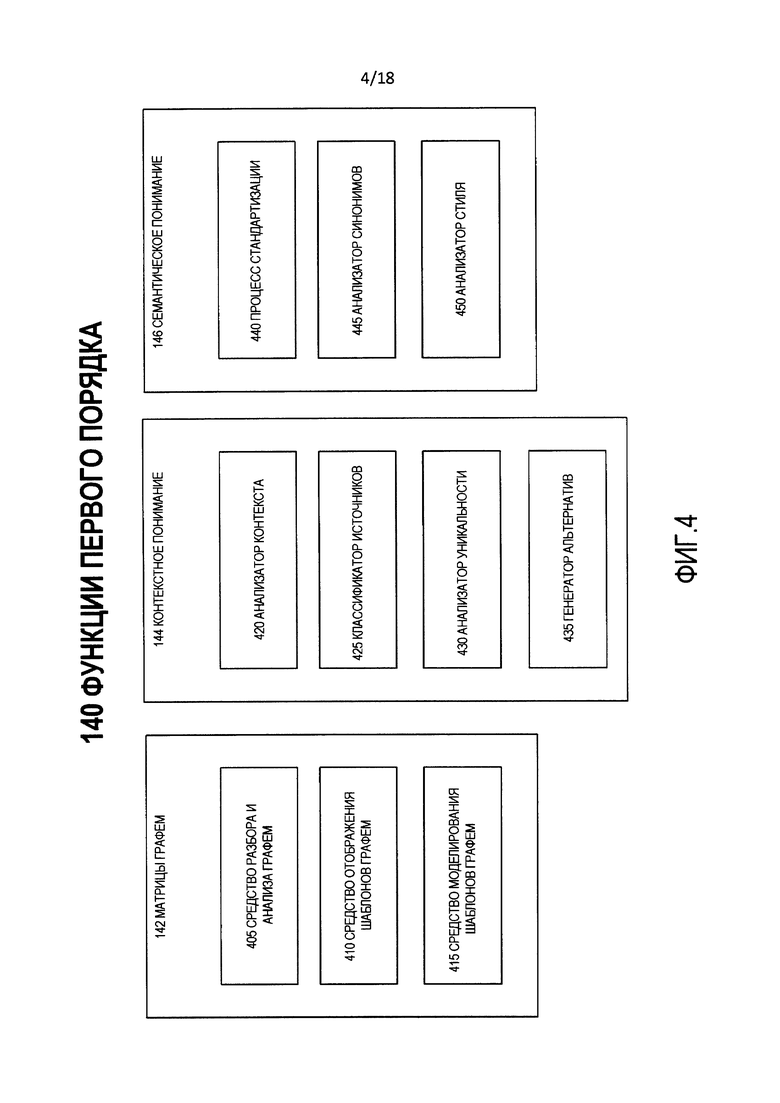
[0011] Фиг. 4 является блок-схемой логической структуры функций первого порядка процесса на фиг. 1.
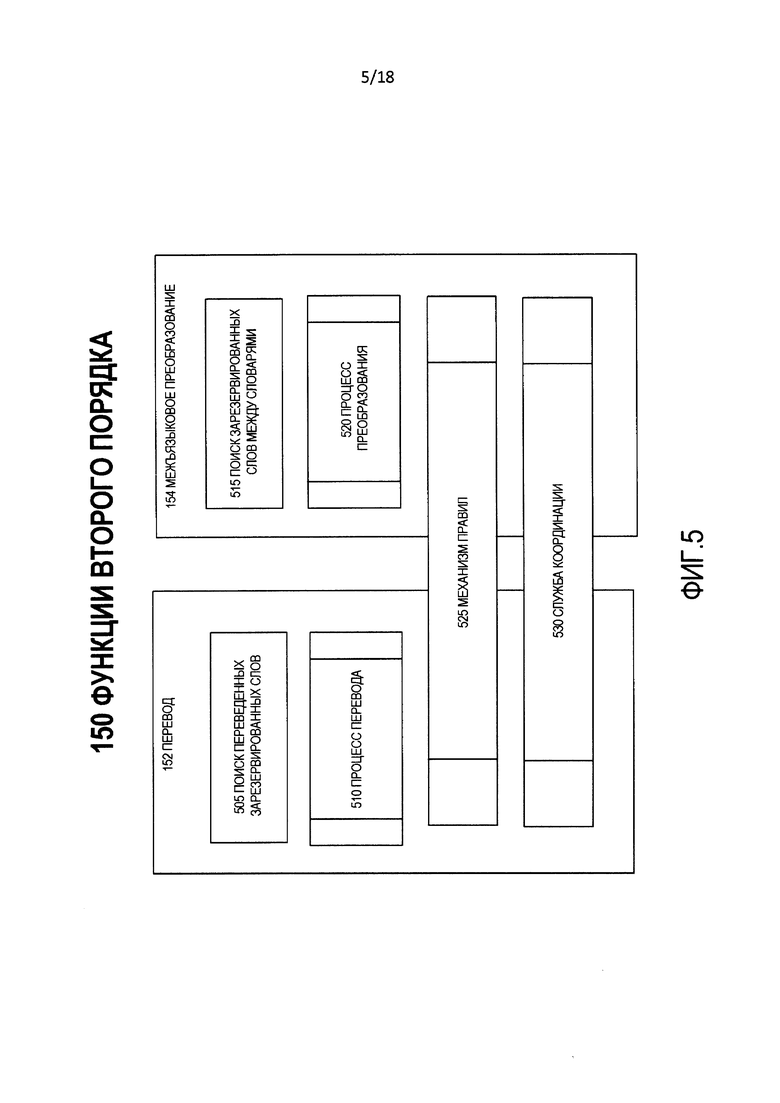
[0012] Фиг. 5 является блок-схемой логической структуры функций второго порядка процесса на фиг. 1.
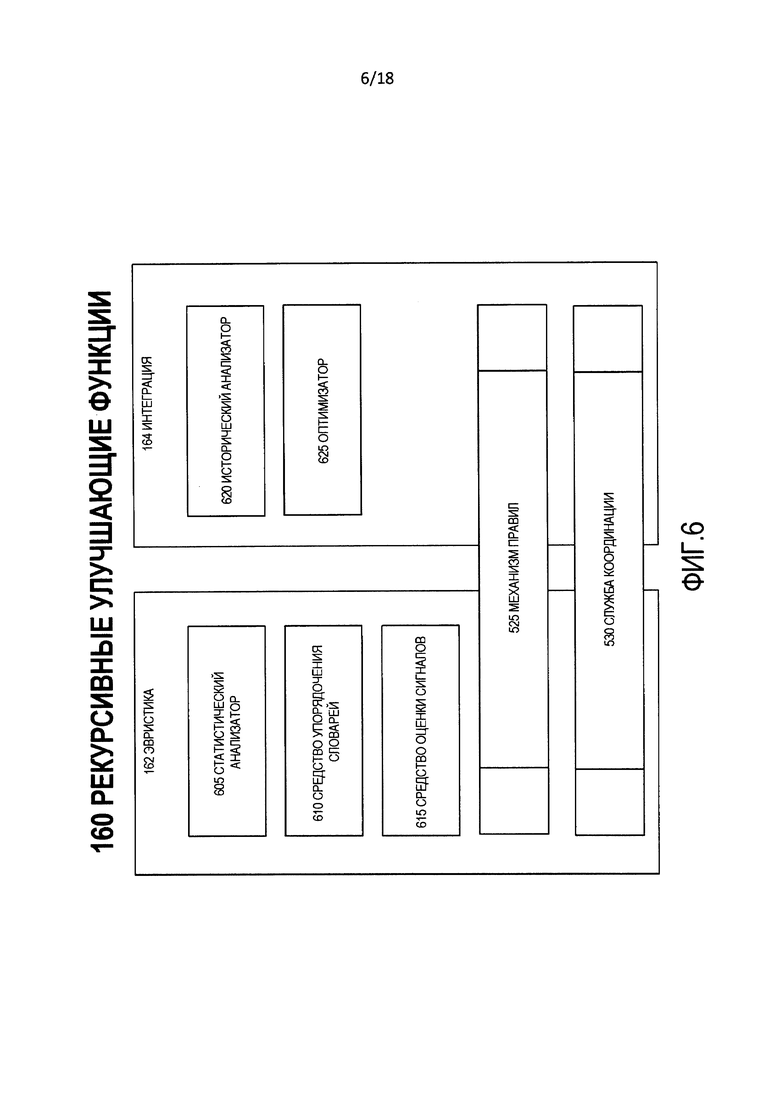
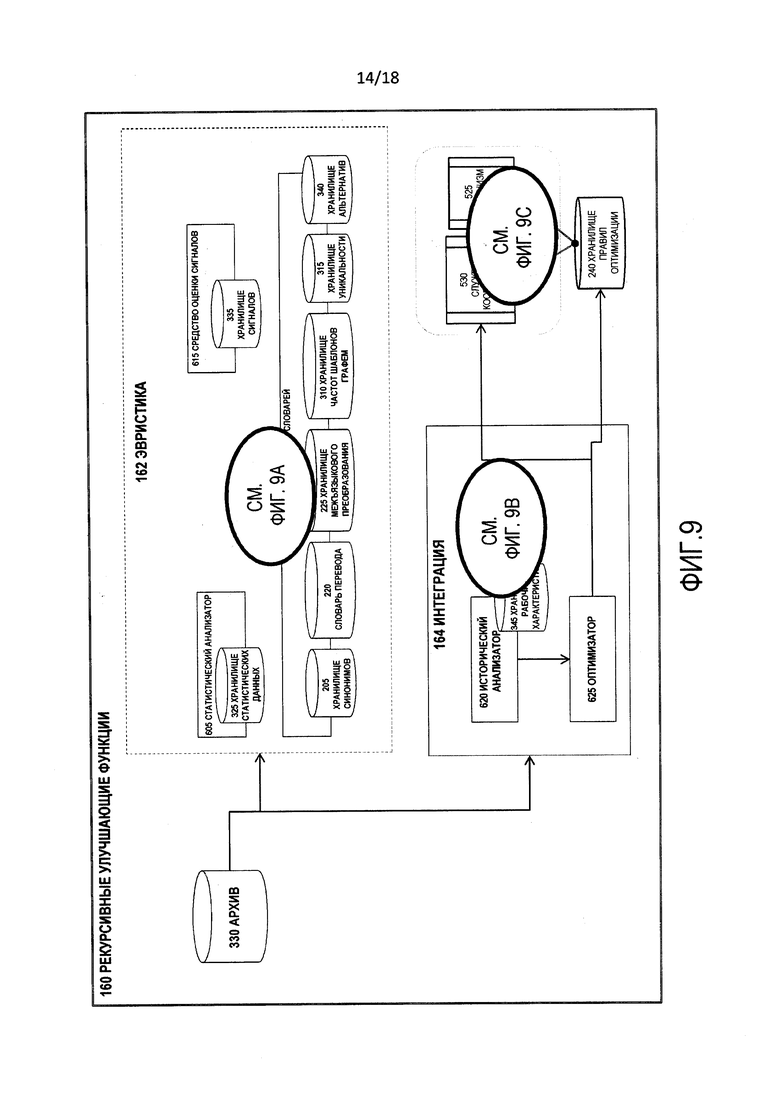
[0013] Фиг. 6 является блок-схемой логической структуры рекурсивных улучшающих функций процесса на фиг. 1.
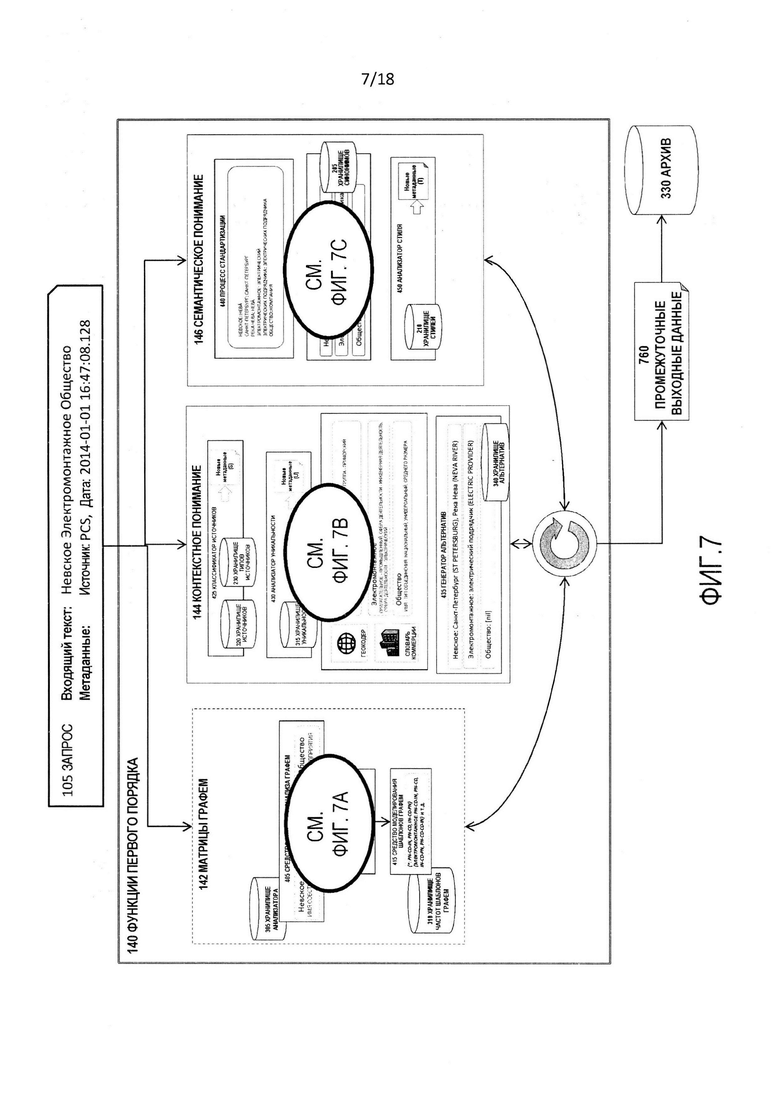
[0014] Фиг. 7 является блок-схемой последовательности операций иллюстративной операции функций первого порядка процесса на фиг. 1.
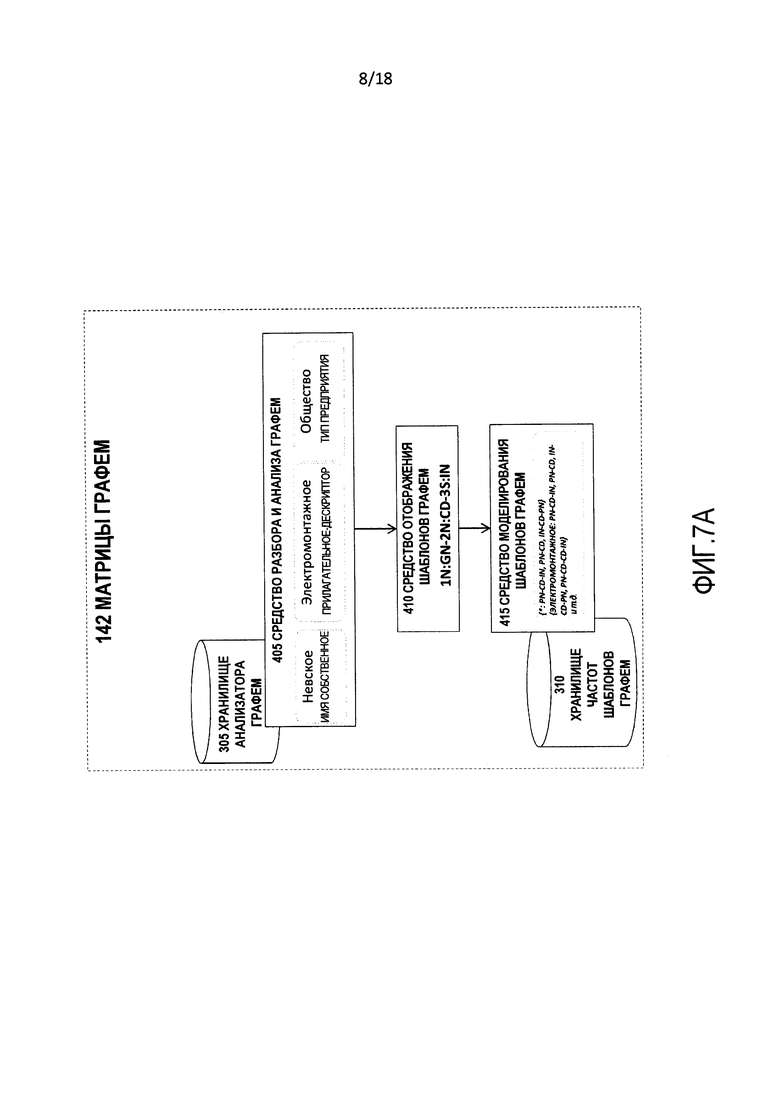
[0015] Фиг. 7А является детализацией части фиг. 7 и изображает блок-схему последовательности операций иллюстративной операции, выполняемой процессом матриц графем.
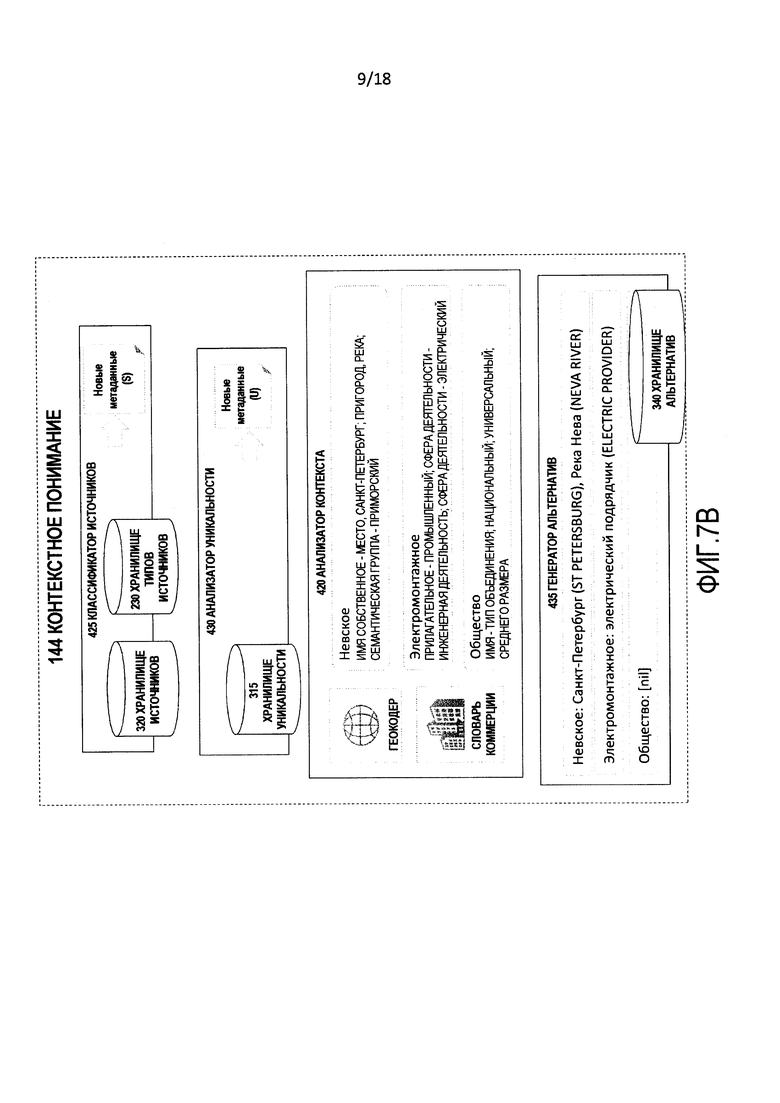
[0016] Фиг. 7B является детализацией части фиг. 7 и изображает блок-схему последовательности операций иллюстративной операции, выполняемой процессом контекстного понимания.
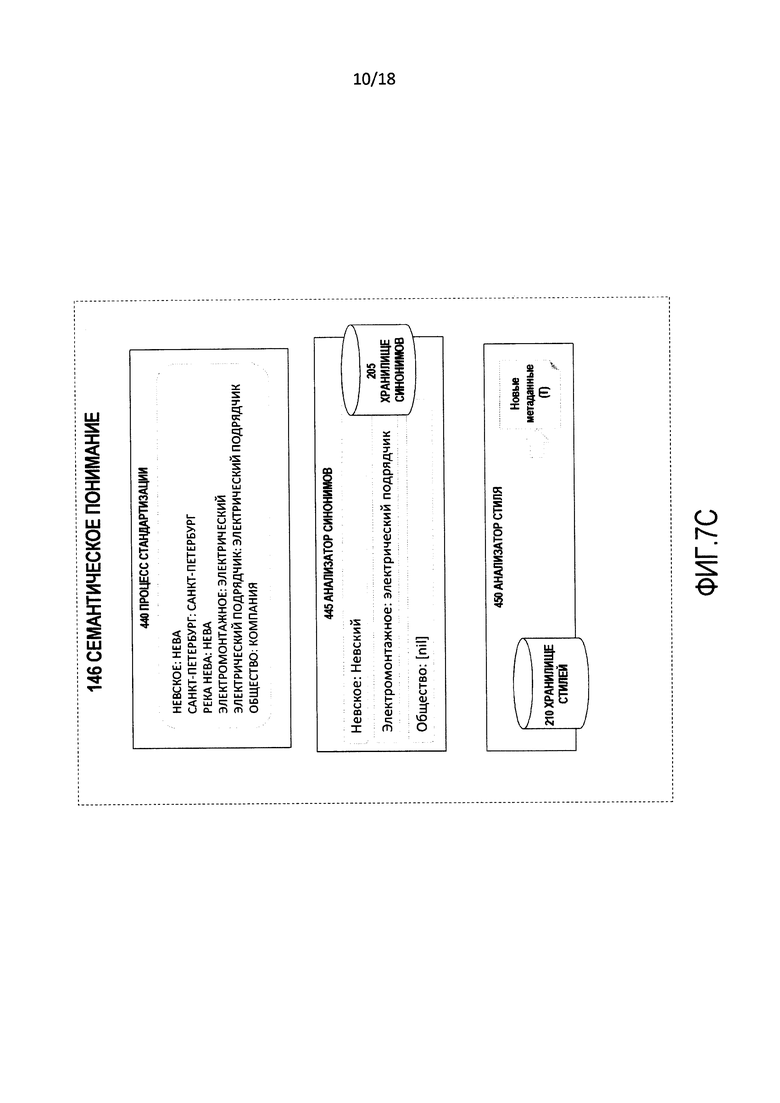
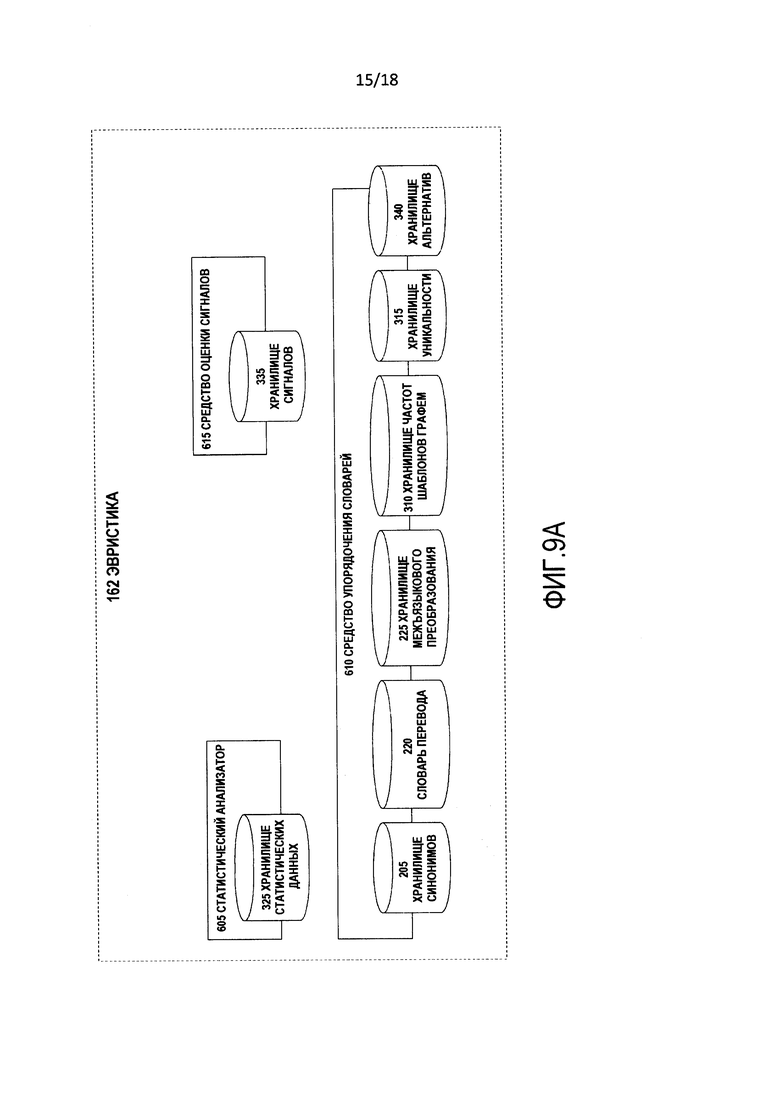
[0017] Фиг. 7C является детализацией части фиг. 7 и изображает блок-схему последовательности операций иллюстративной операции, выполняемой процессом семантического понимания.
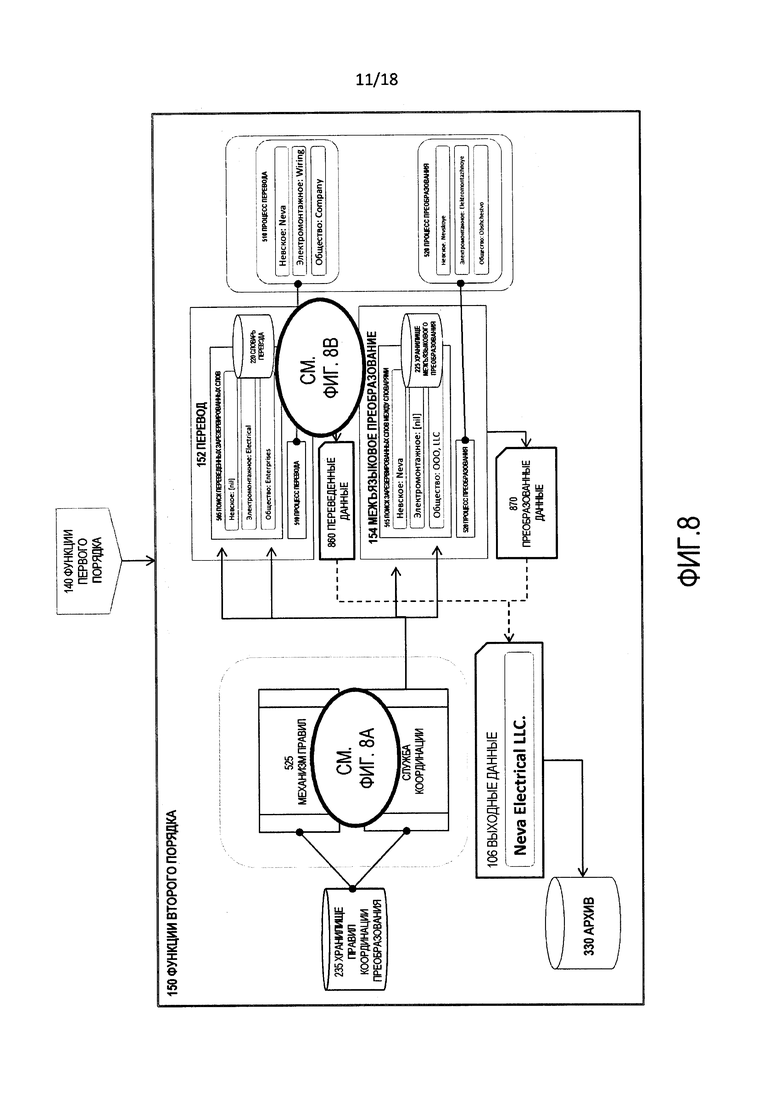
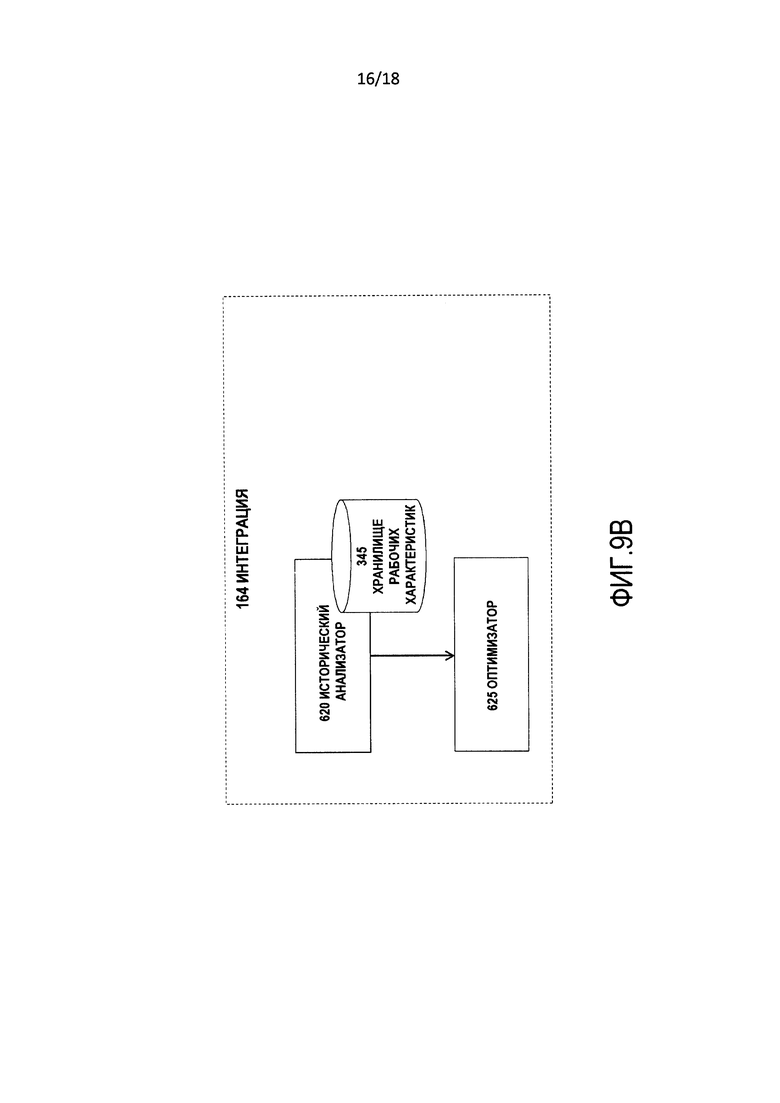
[0018] Фиг. 8 является блок-схемой последовательности операций иллюстративной операции функций второго порядка процесса на фиг. 1.
[0019] Фиг. 8А является детализацией части фиг. 8 и изображает взаимодействие механизма правил и службы координации с хранилищем правил координации преобразования.
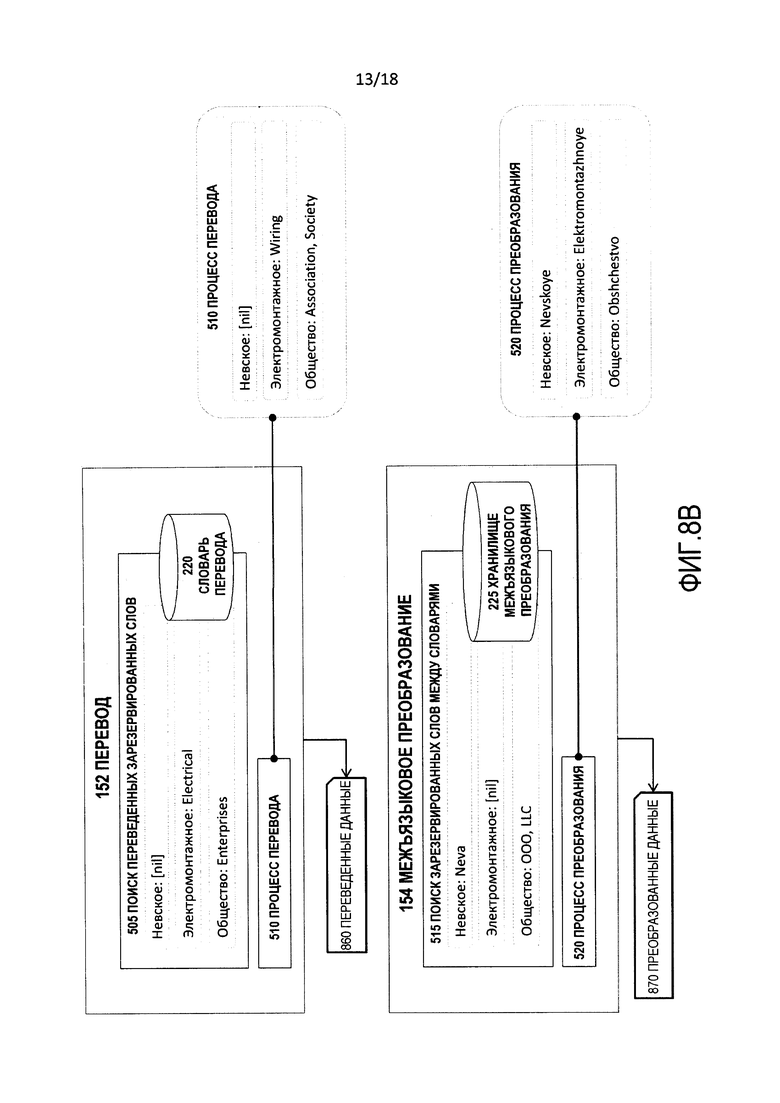
[0020] Фиг. 8B изображает обработку посредством перевода и межъязыкового преобразования примера русской кириллицы.
[0021] Фиг. 9 является блок-схемой последовательности операций иллюстративной операции рекурсивных улучшающих функций.
[0022] Фиг. 9А является детализацией части фиг. 9 и изображают символическое представление процесса эвристики и хранилища данных, на которые ссылаются субкомпоненты процесса эвристики.
[0023] Фиг. 9B является детализацией части фиг. 9 и изображает процесс интеграции и хранилища данных, на которые ссылаются субкомпоненты процесса интеграции.
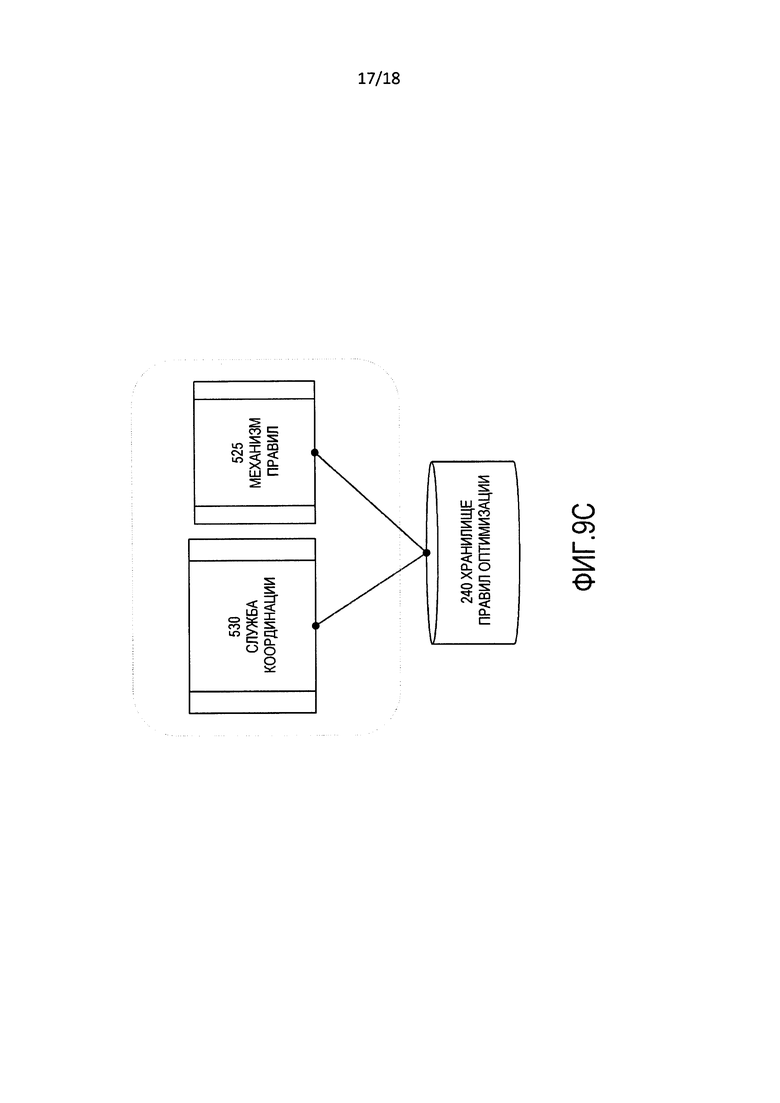
[0024] Фиг. 9C изображает символическое представление механизма правил и службы координации.
[0025] Фиг. 10 является блок-схемой системы, которая использует описанные здесь способы.
[0026] Компонент или признак, который является общим для более чем одного чертежа, обозначен одним и тем же ссылочным номером на каждом из чертежей.
ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0027] Термин "межъязыковой", который используется здесь, и термин "идеографический", который используется в предварительной заявке на патент США № 61/793,044, оба означают "находящийся между или имеющий отношение к двум или более языкам".
[0028] Фиг. 1 является блок-схемой логической структуры процесса 100 для автоматизированного лингвистического преобразования данных. Процесс 100 принимает от пользователя 130, который может являться человеком или запрашивающей системой, входные данные 105, которые предоставляются среде 135 понимания межъязыкового преобразования, и производит выходные данные 106, являющиеся версией входных данных 105, которые были преобразован между двумя или более языками или системами письма. Процесс 100 производит второе, третье и многопорядковое представления входных данных 105, и таким образом, обеспечивает пользователю 130 понимание, которое превосходит буквальную транскрипцию между исходной и целевой орфографиями.
[0029] Процесс 100 обеспечивает пользователю 130 понимание, включающее в себя, но без ограничения, вывод подобия в конкретной области интер-лингвистического, т.е., между языками, или интер-орфографического, т.е., между системами письма, семантического и не семантического, контекстного и не контекстного межъязыкового преобразования или перевода. Процесс 100 обеспечивает пользователя 130 способностью распознать, проанализировать, сравнить, противопоставить или очищать информацию, содержащуюся во входных данных 105, с помощью нескольких одновременных морфологий, т.е., информации, представленной на одном или более языках или в системах письма, для транскрипции входных данных 105 между или среди различных языков, письменностей или систем письма (морфологий), посредством, среди прочего, идентификации имманентных элементов или атрибутов признаков для входных данных 105. Эти имманентные элементы служат в качестве родственных, допускающих осмысленное сравнение данных, которые произошли из несопоставимых морфологий.
[0030] Входные данные 105 включают в себя входные содержательные данные 110 и входные данные 115 семантического контекста.
[0031] Входные содержательные данные 110 являются предметными данными входящего ввода как такового, которые обычно являются названием коммерческого предприятия, выраженным на конкретном языке и в системе письма (орфографии). Входные содержательные данные 110 "не структурированы" в том смысле, что нет каких-либо указаний, присущих содержанию входных содержательных данных 110, которые помогают выполнению процесса 100.
[0032] Входные данные 115 семантического контекста являются контекстными данными, которые могут быть обнаружены или выведены, среди прочего, из анализа входных данных 105, контекста, истории или обстановки, в которой обеспечены входные данные 105, или метаданными входных данных 105. Входные данные 115 семантического контекста рассматриваются как "структурированные", поскольку это метаданные о входных содержательных данных 110, например, источник входных содержательных данных 110, дата приема входных содержательных данных 110 и система, которая передала входные содержательные данные 110 системе, которая выполняет процесс 100.
[0033] Процесс 100 включает в себя функциональность по нескольким подобластям или функциональным субагрегациям в среде 135 понимания межъязыкового преобразования, а именно, функции 140 первого порядка, функции 150 второго порядка и рекурсивные улучшающие функции 160. Среда 135 понимания межъязыкового преобразования также включает в себя хранилища 170 данных.
[0034] Хранилища 170 данных являются средствами хранения данных и включают в себя хранилище 172 справочных данных и хранилище 174 опытных данных. Хранилище 174 опытных данных обновляется на основе опыта, полученного во время выполнения процесса 100. Хранилище 172 справочных данных обновляется в соответствии с объективными правилами и стандартами, а не на основе опыта, полученного посредством выполнения процесса 100. Разделение хранилищ 170 данных на хранилище 172 справочных данных и хранилище 174 опытных данных предназначено только для удобства объяснения и не обязательно отражает физическое разделение соответствующих хранилищ.
[0035] Функции 140 первого порядка являются множеством функций, которые работают над входящими входными данными, т.е., входными данными 105 и включают в себя три субкомпонента, а именно, матрицы 142 графем, контекстное понимание 144 и семантическое понимание 146.
[0036] Функции 150 второго порядка являются множеством функций и процессов, которые работают над комбинацией входных данных 105 и выходных данных функций 140 первого порядка. Функции 170 второго порядка включают в себя два субкомпонента, а именно, перевод 152 и межъязыковое преобразование 154.
[0037] Рекурсивные улучшающие функции 160 являются множеством функций, которые работают над результатами функций 140 первого порядка и функций 150 второго порядка, а также другими входными данными, которые получены из распознавания и анализа рабочих характеристик процесса 100, чтобы повысить эффективность и производительность процесса 100. Такой анализ включает в себя курирование и синтез справочных данных, которые находятся в хранилище 174 опытных данных. Рекурсивные улучшающие функции 160 включают в себя два субкомпонента, а именно, эвристику 162 и интеграцию 164.
[0038] Фиг. 2 является блок-схемой логической структуры хранилища 172 справочных данных. Хранилище 172 справочных данных включает в себя:
(a) хранилище 205 синонимов, которое хранит множества синонимов и альтернативные записи для конкретных слов или других лингвистических субкомпонентов;
(b) хранилище 210 стилей, которое содержит информацию и качественные данные, такие как относительные весовые коэффициенты или оценки, о стилистических аспектах письменного языка;
(c) хранилище 215 стандартизации, которое содержит правила и словари для помощи в стандартизации слов, фраз или других лингвистических субкомпонентов;
(d) словарь 220 перевода, который содержит правила для перевода конкретных слов, фраз или других лингвистических субкомпонентов из исходной орфографии в целевую орфографии и потенциальных переводов между этими двумя орфографиями (то есть, исходной орфографией и целевой орфографией);
(e) хранилище 225 межъязыкового преобразования, которое содержит правила для межъязыкового преобразования конкретных слов, фраз или других лингвистических субкомпонентов из исходной орфографии в целевую орфографию и потенциальных межъязыковых преобразований между этими двумя орфографиями (то есть, исходной орфографией и целевой орфографией).
(f) хранилище 230 типов источников, которое содержит информацию о типах источников данных;
(g) хранилище 235 правил координации преобразования, которое содержит правила координации; и
(h) хранилище 240 правил оптимизации, которое содержит правила для оптимизации всей системы.
[0039] Фиг. 3 является блок-схемой логической структуры хранилища 174 опытных данных. Хранилище 174 опытных данных включает в себя:
(a) хранилище 305 анализатора графем, которое содержит словари и правила для разбора и анализа графем;
(b) хранилище 310 частот шаблонов графем, которое содержит частотности графем;
(c) хранилище 315 уникальности, которое содержит правила, таблицы частот и словари, имеющие отношение к уникальности слов, фраз и других лингвистических субкомпонентов;
(d) хранилище 320 источников, которое содержит информацию о конкретных источниках данных;
(e) хранилище 325 статистических данных, которое содержит статистику, сформированную при выполнении субкомпонентов среды 135 понимания межъязыкового преобразования;
(f) архив 330, который содержит все выходные данные обработки входных данных 105 среды 135 понимания межъязыкового преобразования;
(g) хранилище 335 сигналов, которое содержит, среди прочего, семафоры и оценки, полученные из рабочих характеристик среды 135 понимания межъязыкового преобразования;
(h) хранилище 340 альтернатив, которое содержит альтернативные записи для конкретных слов, фраз и других лингвистических субкомпонентов; и
(i) хранилище 345 рабочих характеристик, которое содержит статистику, относящуюся к ключевым показателям рабочих характеристик для среды 135 понимания межъязыкового преобразования.
[0040] Фиг. 4 является блок-схемой логической структуры функций 140 первого порядка. Как отмечено ранее, функции 140 первого порядка включают в себя матрицы 142 графем, контекстное понимание 144 и семантическое понимание 146.
[0041] Матрицы 142 графем являются коллекцией подпроцессов компонентов, которые работают над входными данными 105 на самых базовых семантических уровнях, например, сокращение входных данных 105 до их основных графем. Матрицы 142 графем включают в себя средство 405 разбора и анализа графем, средство 410 отображения шаблонов графем и средство 415 моделирования шаблонов графем.
[0042] Средство 405 разбора и анализа графем выполняет разбор и анализируют входные данные 105 с использованием, среди прочего, словарей и метаданных, хранящихся в хранилище 305 анализатора графем, чтобы распознать и присвоить атрибуты семантическим элементам, которые подаются в другие процессы.
[0043] Средство 410 отображения шаблонов графем использует выходные данные средства 405 разбора и анализа графем и снимает неоднозначность, т.е., расщепляет семантические шаблоны содержания входных данных 105 символическим образом. Выходные данные средства 410 отображения шаблонов графем являются символическим шаблоном, т.е., абстрагированным представлением, которое раскрывает структуру содержания входных данных 105. Примером такого разрешения неоднозначности будет преобразование "Jim's Mowing Springvale" в "PN-CD-GL", где "PN" обозначает имя собственное, "CD" обозначает коммерческое описание, и "GL" обозначает географическое местоположение.
[0044] Средство 415 моделирования шаблонов графем берет выходные данные модуля средства 410 отображения шаблонов графем и использует данные в хранилище 310 частот шаблонов графем, чтобы различить шаблоны, которые подобны составляющим графемам входных данных 105. Тест на подобие является больше чем поверхностным подобием шаблона.
[0045] Контекстное понимание 144 является коллекцией подпроцессов компонентов, которые работают над входными данные 105 на контекстном уровне. Таким образом, они анализируют входные данные 105 с учетом атрибутов и признаков, которые происходят из источника, времени и содержания входных данных 105, но выше семантического анализа базового уровня графемы. Контекстное понимание 144 включает в себя анализатор 420 контекста, классификатор 425 источников, анализатор 430 уникальности и генератор 435 альтернатив.
[0046] Анализатор 420 контекста анализирует входные данные 105 посредством анализа их содержания на уровне, который сосредотачивается на совокупном значении содержания, а также атрибутов, сформированных средством 410 отображения шаблонов графем и средством 415 моделирования шаблонов графем. Этот анализ включает в себя анализ содержания входных данных 105, чтобы найти, среди прочего, "специальную терминологию" и "жаргон", и могут иметь ссылку на функции, такие как геокодеры, т.е. службы, которые разрешают идентифицирующая информацию географических объектов, и промышленные словари, например, отраслевые списки акронимов для конкретной страны на конкретном языке. Основными выходными данными анализатора 420 контекста являются метаданные об анализе, выполненном анализатором 420 контекста, то есть, классификации и определения характеристик содержания входных данных 105.
[0047] Может иметься несколько итераций обработки между анализатором 420 контекста и компонентами матриц 142 графем по мере уточнения классификаций и шаблонов.
[0048] Классификатор 425 источников анализирует метаданные источников о входных данных 105, которые обеспечены в пределах входных данных 115 семантического контекста, имея ссылку на исторические данные об источниках и типах источников предыдущих входных данных для процесса 100, исторические данные содержатся хранилище 320 источников и хранилище 230 типов источников. Выходными данными классификатора 425 источников являются описательные данные о структуре (такие как данные о стиле, тональной и грамматической структуре) и качественные аспекты (такие как достоверность, точность, изменчивость, полнота и сложность) типичных входных данных из источников, которые являются теми же или аналогичными источнику входных данных 105.
[0049] Анализатор 430 уникальности анализирует входные данные 105 на уникальность на уровне слов (или других лингвистических субкомпонентов), а также уникальность групп слов или фраз относительно различных исходных уровней с учетом хранилища 315 уникальности как справочных данных. Выходными данными анализатора 430 уникальности являются оценки, которые описывают относительную уникальность входных данных 105 и их составных частей.
[0050] Генератор 435 альтернатив формирует альтернативные слова (или другие представлений в графемах), фразы и названия для составных частей входных данных 105. Эти альтернативы являются контекстными (что означает, что они основаны не на стандартных таблицах частот или правилах уровня языка), основаны на опыте и берутся из хранилища 340 альтернатив в качестве источника.
[0051] Семантическое понимание 146 является набором подпроцессов компонентов, которые работают над входными данными 105 на уровне языка. Таким образом, они работают на уровне предполагаемого лингвистического контекста входных данных (например, русская кириллица или более специфический "язык", такой как русская кириллица, для наименования правительственных органов). Семантическое понимание 146 включает в себя процесс 440 стандартизации, анализатор 445 синонимов и анализатор 450 стиля.
[0052] Процесс 440 стандартизации выполняет процессы очистки, разбора и стандартизации над входными данными 105, чтобы создать "наилучший стандартный ракурс" их содержания. Процесс 440 стандартизации использует данные в хранилище 215 стандартизации.
[0053] Анализатор 445 синонимов анализирует слова или другие лингвистические субкомпоненты входных данных 105, чтобы получить синонимы как альтернативы для заданного языка входных данных 105. Анализатор 445 синонимов использует хранилище 205 синонимов.
[0054] Анализатор 450 стиля анализирует стиль языка входных данных 105 (в том числе наблюдения относительно тональности, формальности, жаргона, акронимов, сокращений и т.д.) и вычисляет оценки и индикаторы, чтобы представлять заданный в виде атрибута стиль. Анализатор 450 стиля использует данные в хранилище 345 стилей. Выходными данными анализатора 450 стиля являются оценки и признаки, которые описывают стилистические качества входных данных 105.
[0055] Фиг. 5 является блок-схемой логической структуры функций 150 второго порядка. Как отмечено ранее, функции второго порядка включают в себя перевод 152 и межъязыковое преобразование 154. Функции 150 второго порядка используют механизм 525 правил и службу 530 координации.
[0056] Механизм 525 правил использует правила, содержащиеся в хранилище 235 правил координации преобразования.
[0057] Служба 530 координации является системой потока операций, которая использует потоки операций и логическую схему принятия решений, содержащиеся в хранилище 235 правил координации преобразования.
[0058] Механизм 525 правил и служба 530 координации работают совместно по функциям 150 второго порядка, то есть, по переводу 152 и межъязыковому преобразованию 154 для упорядочения выходных данных составных частей функций 140 первого порядка, чтобы установить расположение входных данных 105 и их составных частей.
[0059] Потоки операций и множества правил, исполняемые механизмом 525 правил и службой 530 координации, содержатся в хранилище 235 правил координации преобразования. Эти потоки операций и правила используют признаки, оценки и другие данные, которые формируют выходные данные функций 140 первого порядка.
[0060] Перевод 152 состоит из подпроцессов, которые преобразовывают слова (или другие лингвистические субкомпоненты) из входных данных 105 между языками. В связи с этим перевод 152 включает в себя поиск 505 переведенных зарезервированных слов и процесс 510 перевода.
[0061] Поиск 505 переведенных зарезервированных слов является процессом, посредством которого части входных данных 105, включающие в себя метаданные и варианты, сформированные функциями 140 первого порядка, анализируются с использованием словаря 220 перевода, чтобы произвести их потенциальные специализированные или основанные на специальной терминологии переводы.
[0062] Процесс 510 перевода переводит части входных данных 105, включающих в себя метаданные и варианты, сформированные функциями 140 первого порядка, между языками, например, русским и английским языками. Процесс 510 перевода может включать в себя вызов веб-сервисов, приложений и других систем, которые выполняют функции перевода.
[0063] Межъязыковое преобразование 154 состоит из нескольких подпроцессов, которые переводят слова (или другие лингвистические субкомпоненты) из входных данных 105 между языками. Межъязыковое преобразование 154 включает в себя поиск 515 зарезервированных слов между словарями и процесс 520 преобразования.
[0064] Поиск 515 зарезервированных слов между словарями является процессом, посредством которого части входных данных 105, включающие в себя метаданные и варианты, сформированные функциями первого порядка 140, анализируются с использованием словаря 220 транслитерации, чтобы произвести потенциальные переводы, которые являются специализированными или основанными на специальной терминологии преобразованиями входных данных 105 или их частей.
[0065] Процесс 520 преобразования транслитерирует части входных данных 105 между письменностями (например, из греческой письменности в латинскую письменность). Процесс 520 преобразования может включать в себя вызов веб-сервисов, приложений и других систем, которые выполняют функции транслитерации.
[0066] Фиг. 6 является блок-схемой логической структуры рекурсивных улучшающих функций 160. Как отмечено ранее, рекурсивные улучшающие функции 160 включают в себя эвристику 162 и интеграцию 164. Механизм 525 правил и служба 530 координации, которые используются функциями 150 второго порядка, также используется рекурсивными улучшающими функциями 160 и работают совместно по эвристике 162 и интеграции 164, чтобы произвести оптимизацию и улучшения эффективности и производительности процесса 100.
[0067] Как упомянуто выше, служба 530 координации является системой потока операций, которая в контексте рекурсивных улучшающих функций 160 использует потоки операций и логическую схему принятия решений, содержащиеся в хранилище 240 правил оптимизации.
[0068] Эвристика 162 является коллекцией подпроцессов компонентов, которые постоянно анализируют выходные данные (содержащиеся в архиве 330) всех субкомпонентов среды 135 понимания межъязыкового преобразования, а также выходные данные 106, которые хранятся в архиве 330, чтобы оптимизировать рабочие характеристики процесса 100 в соответствии с наблюдаемым поведением. Процесс 100 посредством эвристики 162 является самоусовершенствующимся. Таким образом, эвристика 162 учится на опыте и изменяет или повторно упорядочивает потоки операций, исполняемые в рамках процесса 100, чтобы произвести самые оптимальные или диспозитивные результаты. Эвристика 162 включает в себя статистический анализатор 605, средство 610 упорядочения словарей и средство 615 оценки сигналов.
[0069] Статистический анализатор 605 выполняет статистические анализы, такие как частотный анализ фраз слов или других лингвистических субкомпонентов входных данных 105, и измерения основной тенденции через исторические данные исторических входных и выходных данных процесса 105 среды 135 понимания межъязыкового преобразования, содержащихся в архиве 330 и в хранилище 174 опытных данных, чтобы создать оценки и другие признаки, которые сохраняются в хранилище 325 статистики, и которые могут использоваться в качестве ресурса при настройке функций 140 первого порядка и функций 150 второго порядка посредством интеграции 164.
[0070] Средство 610 упорядочения словарей использует, среди прочего, выходные данные статистического анализатора 605, чтобы создать или обновить потоки операций, которые повторно упорядочивают порядок словарей, в том числе хранилища 225 межъязыкового преобразования, хранилища 205 синонимов, хранилища 310 частот шаблонов графем, хранилища 315 уникальности и хранилища 340 альтернатив, с тем чтобы самые оптимальные или диспозитивные записи возвращались процессами, которые используют эти хранилища (например, извлечение данных из хранилища 310 частот шаблонов графем310).
[0071] Средство 615 оценки сигналов исполняет подпрограммы для присвоения атрибутов приоритета различным признакам и метрикам, полученным из рабочих характеристик процесса 100, и отправляет эти оценки в хранилище 335 сигналов.
[0072] Интеграция 164 является коллекцией подпроцессов компонентов, которые используют, среди прочего, выходные данные эвристики 162 и затем обеспечивают входные данные потокам операций, исполняемым механизмом 525 правил и службой 530 координации для внесения изменений в процессы и подпрограммы в пределах субкомпонентов среды 135 понимания межъязыкового преобразования, чтобы увеличить эффективность и производительность рабочих характеристик процесса 100. Эти изменения записываются как записи в хранилище 240 правил оптимизации. В связи с этим интеграция 164 включает в себя исторический анализатор 620 и оптимизатор 625.
[0073] Исторический анализатор 620 анализирует признаки рабочих характеристик (в том числе, но без ограничения, времена выполнения, использование ресурсов, использование хранилищ данных, присвоение атрибутов качества и достоверности и оценки отзывов пользователей) среды 135 понимания межъязыкового преобразования во время выполнения процесса 100. Признаки рабочих характеристик записываются в хранилище 345 рабочих характеристик историческим анализатором 620, и признаки рабочих характеристик считываются оптимизатором 625 для выбора процессов для обновления или модификации.
[0074] Оптимизатор 625 использует, среди прочего, признаки рабочих характеристик, сформированные историческим анализатором 620, и выполняет обновления хранилища 240 правил оптимизации и инициирует выполнение подпрограмм оптимизации в механизме 525 правил и службе 530 координации.
[0075] Фиг. 7 является блок-схемой последовательности операций функций 140 первого порядка для примера русской кириллицы.
[0076] Фиг. 7А является детализацией части фиг. 7 и изображают блок-схему последовательности операций, выполняемой матрицами 142 графем, для примера русской кириллицы.
[0077] Фиг. 7B является детализацией части фиг. 7 и изображает блок-схему последовательности операций, выполняемой контекстным пониманием 144, для примера русской кириллицы.
[0078] Фиг. 7C является детализацией части фиг. 7 и изображает блок-схему последовательности операций, выполняемой семантическим пониманием 146, для примера русской кириллицы.
[0079] Согласно фиг. 7 функции 140 первого порядка принимают входные данные 105, которые в этом примере представляют собой текст "Невское электромонтажное общество" на русской кириллице как содержательные данные 110 запроса из источника "Partner Collection System" 1 января 2014 года как входные данные 115 семантического контекста. Функции 140 первого порядка производят промежуточные выходные данные 760, которые сохраняются в архиве 330.
[0080] Согласно фиг. 7А средство 405 разбора и анализа графем выполняет разбор входных данных 105 и, имея ссылку на хранилище 305 анализатора графем, присваивает классификации составным частям (графемам, словам, фразам и т.д.) содержательных данных 110 запроса.
[0081] В этом примере средство 405 разбора и анализа графем анализирует входные содержательные данные 110 и классифицирует их, как показано в таблице 1.
[0082] Средство 410 отображения шаблонов графем берет входные содержательные данные 110 и метаданные (показанные выше в столбцах 2 и 3 в таблице 1), сформированные средством 405 разбора и анализа графем, и создает "шаблон графем", который является абстракцией грамматической и семантической структуры содержательных данных 110 запроса.
[0083] В этом примере средство 410 отображения шаблонов графем производит шаблон: 1N:GN-2N:CD-3S:IN, означающий, что входные данные состоят из двух основных частей, названия (N) и суффикса (S), а также трех детализированных частей: географического названия (GN), коммерческого описания (CD) и суффикса объединения (IN).
[0084] Средство 415 моделирования шаблонов графем берет выходные данные средства 410 отображения шаблонов графем и выполняет поиск в хранилище 310 частот шаблонов графем, чтобы найти шаблоны, которые являются существенным образом подобными.
[0085] Таблица 2 представляет пример некоторых шаблонов, извлеченных средством 415 моделирования шаблонов графем. На практике также будут извлечены другие шаблоны, такие как показанные на фиг. 7А, внутри средства 415 моделирования шаблонов графем.
[0086] Согласно фиг. 7B классификатор 425 источников анализирует метаданные источников входных данных (входных данных 115 семантического контекста). В этом примере источник "Partner Collection System" найден с помощью ключа "PCS", и классификатор 425 источников извлекает из хранилища 320 источников метаданные, показанные в таблице 3.
[0087] Список метаданных в таблице 2 является лишь иллюстративный и не представляет замкнутое множество.
[0088] Анализатор 420 контекста берет входные данные 105 и выходные данные матриц 142 графем и, имея ссылку на геокодеры и коммерческие словари, производит детализированные классификации составных частей (слов и фраз или эквивалентов) содержания входных данных 105. В этом примере детализированные классификации показаны в таблице 4.
[0089] Новые метаданные, (т.е., анализ контекста, показанный в таблице 4) могут быть сохранены как коды или маркеры для эффективного использования другими компонентами.
[0090] Генератор 435 альтернатив берет входные данные 105 и, имея ссылку на хранилище 340 альтернатив, формирует альтернативные данные, показанные в таблице 5.
[0091] Анализатор 430 уникальности берет входные данные 105 (включающие в себя выходные данные других частей функций 140 первого порядка) и, имея ссылку на хранилище 315 уникальности, формирует оценки уникальности, т.е., оценки, которые обозначают уникальность частей входных данных 105. Оценки уникальности для настоящего примера показаны в таблице 6.
[0092] Анализатор 430 уникальности при формировании оценок уникальности также принимает во внимание дополнительные данные, сформированные генератором 435 альтернатив.
[0093] Согласно фиг. 7C процесс 440 стандартизации стандартизирует содержание входных данных 105 (включающих в себя альтернативы, сформированные генератором 43 альтернатив) с использованием зависящих от словаря правил (в этом случае соответствующим словарем является "Русские коммерческими названия на кириллице"). В этом примере входные данные могут быть стандартизированы, как показано в таблице 7.
[0094] Анализатор 445 синонимов выполняет поиск входных данных 105 и их частей в хранилище 205 синонимов, чтобы сформировать синонимы, как показано, например, в таблице 8, для составных частей входных данных 105 и альтернатив, сформированных генератором 435 альтернатив.
[0095] Анализатор 450 стиля анализирует стиль входных данных 105 по нескольким измерениям и создает метаданные для выражения этого анализа. В примере анализатор 450 стиля производит выходные данные, показанные в таблице 9.
[0096] В таблице 9 столбец "Метаданные стиля" изображает, в качестве примера, присвоение входным данным "Невское Электромонтажное Общество" оценок на основе стиля, которые классифицируют стиль входных данных 105 на основе таких измерений, как использование специфического для языка жаргона, использование акронимов и грамматическая формальность структуры входных данных 105.
[0097] Фиг. 8 является блок-схемой последовательности операций иллюстративной операции функций 150 второго порядка с использованием входных данных на русской кириллице в качестве примера.
[0098] Фиг. 8А является детализацией части фиг. 8 и изображает взаимодействие механизма 525 правил и службы 530 координации с хранилищем 235 правил координации преобразования, чтобы проиллюстрировать их отношения с обработкой примера на русской кириллице на фиг. 8.
[0099] Согласно фиг. 8А входные данные 105 и все выходные данные функций 140 первого порядка использованы механизмом 525 правил, который, имея ссылки на все эти данные и хранилище 235 правил координации преобразования, формирует управляемые данными правила ("потоки операций"), которые затем сохраняются в хранилище 235 правил координации преобразования, и эти потоки операций определяют следующую серию этапов в процессе 100 для расположения входных данных 105.
[00100] Служба 530 координации исполняет потоки операций, предписанные механизмом 525 правил и сохраненные в хранилище 235 правил координации преобразования.
[00101] Таблица 10 перечисляет этапы потока операций, предписанные механизмом 525 правил, для настоящего примера.
[00102] Этапы потока операций, показанные в таблице 10, являются только маленьким подмножеством команд, которые потребуются для этого примера. Полный набор включал бы в себя действия над многими модификациями входных данных 105 и их частей с присвоенными атрибутами, сформированных функциями 140 первого порядка.
[00103] Фиг. 8B является детализацией части фиг. 8 и изображает иллюстративные данные, обрабатываемые переводом 152 и межъязыковым преобразованием 154, для примера русской кириллицы на фиг. 8. В связи с этим перевод 152 производит переведенные данные 860, и межъязыковое преобразование 154 производит преобразованные данные 870.
[00104] На фиг. 8 переведенные данные 860 и преобразованные данные 870 объединяются, чтобы произвести выходные данные 106. В частности, механизм 525 правил применяет правила к результатам перевода 152 и межъязыкового преобразования 154, чтобы собрать конечный результат, т.е., выходные данные 106, которые сохраняются в архиве 330.
[00105] Таблица 11 показывает иллюстративное содержание переведенных данных 860 и преобразованных данных 870.
[00106] Таблица 12 показывает финальную синтезированную версию, которая становится выходными данными 106.
[00107] Таким образом, "Невское Электромонтажное Общество" было преобразовано в "NEVA ELECTRICAL LLC".
[00108] Фиг. 9 является блок-схемой последовательности операций иллюстративной операции рекурсивных улучшающих функций 160. Фиг. 9 изображает символическое представление рекурсивных улучшающих функций 160 и хранилища данных, на которые ссылаются субкомпоненты рекурсивных улучшающих функций 160.
[00109] Фиг. 9А является детализацией части фиг. 9 и изображают эвристику 162 и ее субкомпоненты статистический анализатор 605, средство 615 оценки сигналов и средство 610 упорядочения словарей, а также хранилища данных, с которыми взаимодействуют эти субкомпоненты.
[00110] Фиг. 9B является детализацией части фиг. 9 и изображает интеграцию 164 и хранилища данных, на которые ссылаются субкомпоненты интеграции 164.
[00111] Фиг. 9C является детализацией части фиг. 9 и изображает взаимодействие механизма 525 правил и службы 530 координации с хранилищем 240 правил оптимизации.
[00112] Таким образом, процесс 100 является способом, который включает в себя:
(a) разбор входных данных 105, т.е. строки символов, на ее графемы (см. фиг. 7А, средство 405 разбора и анализа графем); и
(b) формирование шаблона символов, который представляет абстракцию графем (см. фиг. 7 А, средство 410 отображения шаблонов графем).
[00113] Шаблон символов включает в себя группу символов, которая соответствует графеме в графемах входных данных 105. Например, на фиг. 7А шаблон "1N:GN-2N:CD-3S:IN" включает в себя группу символов "CD", которая соответствует обозначению "коммерческого описания" и отображается средством 410 отображения шаблонов графем, имеющим ссылку на хранилище 305 анализатора графем.
[00114] Процесс 100 также включает в себя прием из источника данных информации о графеме. Например, см. фиг. 7B, анализатор 420 контекста.
[00115] На фиг. 7А средство 410 отображения шаблонов графем, шаблон символов включает в себя последовательность первой группы символов, например, GN и вторую группу символов, например, CD. GN соответствует первой графеме в графемах входных данных 105, и CD соответствует второй графеме в графемах входных данных 105. Со ссылкой на фиг. 8А, процесс 100 дополнительно включает в себя (a) выбор процесса из множества процессов на основе последовательности и (b) исполнение процесса над строкой символов.
[00116] Процесс 100 в результате получает комбинацию перевода, т.е., переведенные данные 860, и межъязыкового преобразования, т.е., преобразованные данные 870, строки символов.
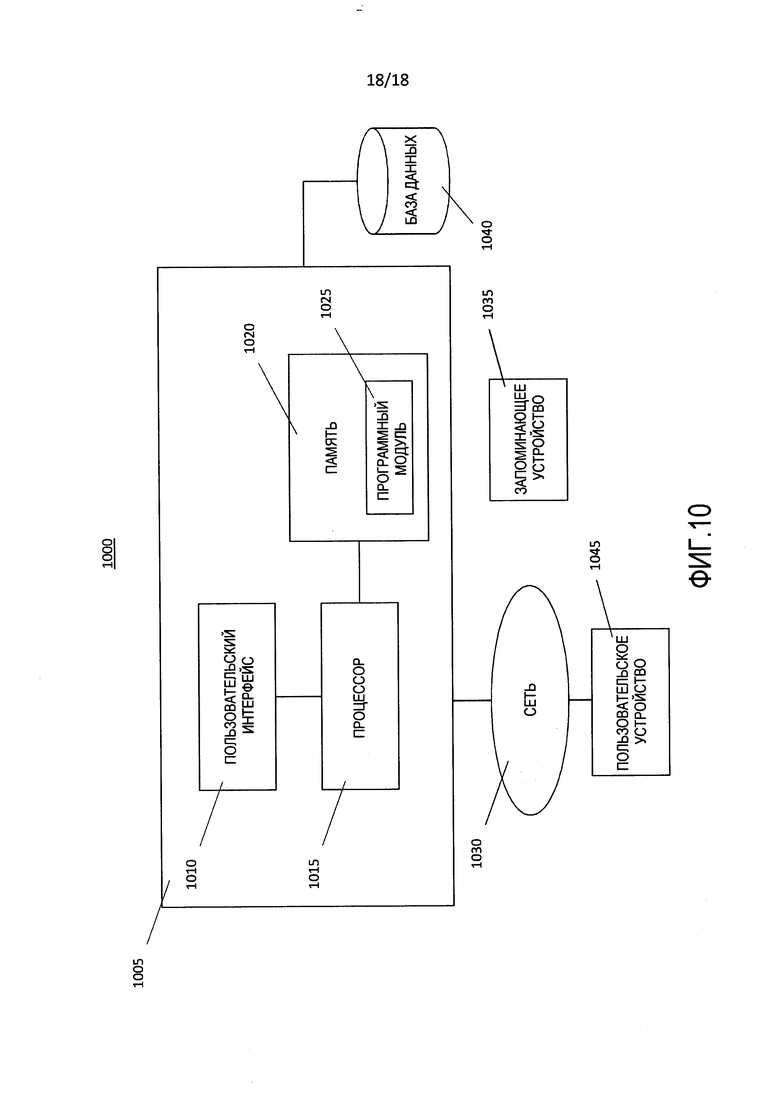
[00117] Фиг. 10 является блок-схемой системы 1000, которая использует описанные здесь способы. Система 1000 включает в себя компьютер 1005, соединенный с сетью передачи данных, т.е. сетью 1030, такой как Интернет.
[00118] Компьютер 1005 включает в себя пользовательский интерфейс 1010, процессор 1015 и память 1020. Хотя компьютер 1005 представлен здесь как автономное устройство, он не ограничен этим, и вместо этого может быть соединен с другими устройствами (не показаны) в системе распределенной обработки.
[00119] Пользовательский интерфейс 1010 включает в себя устройство ввода, такое как клавиатура или подсистема распознавания речи, для предоставления возможности пользователю 130 передать информацию и выборы команд процессору 1015. Пользовательский интерфейс 1010 также включает в себя устройство вывода, такое как дисплей или принтер. Средство управления курсором, такое как мышь, шаровой манипулятор или джойстик, позволяет пользователю 130 управлять курсором на дисплее для передачи дополнительной информации и выборов команд процессору 1015.
[00120] Система 1000 также включает в себя пользовательское устройство 1045, которое с возможностью связи соединено с компьютером 1005 через сеть 1030. Пользователь 130 может взаимодействовать с компьютером 205 посредством пользовательского устройства 1045 в качестве альтернативы пользовательскому интерфейсу 1010.
[00121] Процессор 1015 является электронным устройством, сформированным из логической схемы, которая отвечает на команды и исполняет их.
[00122] Память 1020 является непереходным машиночитаемым устройством, закодированным с помощью компьютерной программой. В связи с этим память 1020 хранит данные и команды, которые могут читаться и исполняться процессором 1015, для управления работой процессора 1015. Память 1020 может быть реализована в оперативном запоминающем устройстве (ОЗУ; RAM), накопителе на жестком диске, постоянном запоминающем устройстве (ПЗУ; ROM) или их комбинации. Один из компонентов памяти 1020 является программным модулем 1025.
[00123] Программный модуль 1025 содержит команды для управления процессором 1015, чтобы исполнять описанные здесь способы. Например, под управлением программного модуля 1025 процессор 1015 исполняет процессы способа 100. Термин "модуль" использован здесь для обозначения функциональной операции, которая может быть воплощена либо как автономный компонент, либо как интегрированная конфигурация множества зависимых компонентов. Таким образом, программный модуль 1025 может быть реализован как единственный модуль или как множество модулей, которые работают в сотрудничестве друг с другом. Кроме того, хотя программный модуль 1025 описан здесь как установленный в памяти 1020, и, таким образом, реализованный в программном обеспечении, он может быть реализован в любом из аппаратных средств (например, в электронной схеме), программно-аппаратного обеспечения, программного обеспечения или их комбинации.
[00124] Процессор 1015 принимает ввод 105 либо через сеть 1030, либо через пользовательский интерфейс 1010. Ввод 105 может быть обеспечен компьютеру 1005 и, таким образом, процессу 100 пользователем 130 посредством пользовательского интерфейса 1010 или пользовательского устройства 1045. Ввод 105 также может быть обеспечен автоматизированным процессом, например, получен из файлов, предоставленных с использованием пакетных машинных возможностей, функционирующих в компьютере 1005 или на удаленном устройстве (не показано), которое соединено с компьютером 1005 через сеть 1030. Хранилища 170 данных могут являться компонентами компьютера 1005, например, храниться в пределах памяти 1020, или могут быть расположены как внешние по отношению к компьютеру 1005, например, в базе 1040 данных или в базе данных (не показана), к которой компьютер 1005 выполняет доступ через локальную сеть (не показана) или через сеть 1030. Процессор 1015 возвращает выходные данные 106 либо через сеть 1030, либо через пользовательский интерфейс 1010.
[00125] Хотя программный модуль 1025 обозначен как уже загруженный в память 1020, он может быть сформирован на запоминающем устройстве 1035 для последующей загрузки в память 1020. Запоминающее устройство 1035 также является непереходным машиночитаемым устройством, закодированным с помощью компьютерной программы, и может являться любым традиционным устройством хранения, которое хранит в себе программный модуль 1025. Примеры запоминающего устройства 1035 включают в себя гибкий диск, компакт-диск, магнитную ленту, постоянное запоминающее устройство, оптические запоминающие носители, карту флэш-памяти универсальной последовательной шины (USB), цифровой универсальный диск или накопитель со сжатием данных. Запоминающее устройство 1035 также может являться оперативным запоминающим устройством или электронным запоминающим устройством другого типа, расположенным в удаленной системе хранения и соединенным с компьютером 1005 через сеть 1030.
[00126] Технические преимущества процесса 100 и системы 1000 включают в себя улучшенную точность выходной информации и увеличенную масштабируемость операции, а также внедрение процессов обучения с обратной связью, которые позволяют процессу 100 выполняться с увеличивающейся точностью со временем.
[00127] Описанные здесь методики являются иллюстративными и не должны быть истолкованы как подразумевающие какое-либо конкретное ограничение настоящего раскрытия. Следует понимать, что специалистами в области техники могут быть созданы различные альтернативы, комбинации и модификации. Например, этапы, связанные с описанными здесь процессами, могут быть выполнены в любом порядке, если иначе не определено или продиктовано самими этапами. Предполагается, что настоящее раскрытие охватывает все такие альтернативы, модификации и вариации, которые находятся в пределах объема приложенной формулы изобретения.
[00128] Термины "содержит" или "содержащий" должны интерпретироваться как определение присутствия сформулированных признаков, целых чисел, этапов или компонентов, но не исключение присутствия одного или более других признаков, целых чисел, этапов или компонентов или их групп. Использование единственного числа не исключает не исключает наличия множеств.
Изобретение относится к области автоматизированного лингвистического преобразования данных с конкретным фокусом на преобразовании между разными орфографиями (например, с письменности русской кириллицы на латинскую письменность) в пределах заданных контекстов (таких как названия коммерческих предприятий). Техническим результатом является повышение точности лингвистических преобразований. В способе лингвистического преобразования данных принимают входные данные, которые включают в себя строку символов на первом языке и данные семантического контекста, касающиеся источника входных данных. Разбирают строку символов в ее графемы и формируют шаблон символов, который представляет абстракцию графем. Анализируют данные семантического контекста и шаблон символов в соответствии с правилами для выдачи потенциального межъязыкового преобразования шаблона символов. Преобразуют строку символов из первого языка во второй язык в соответствии с потенциальным межъязыковым преобразованием. Анализируют признаки рабочих характеристик относительно преобразования и обновляют правила на основе признаков рабочих характеристик. 3 н. и 15 з.п. ф-лы, 18 ил., 12 табл.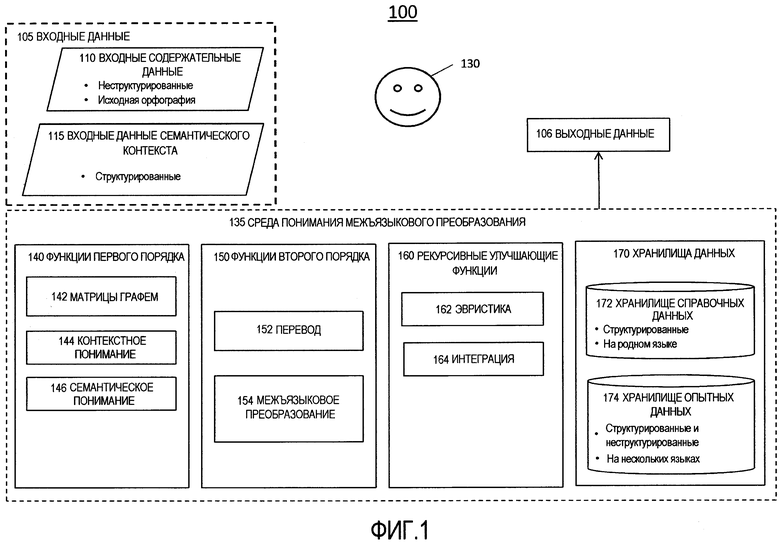
1. Способ лингвистического преобразования данных, содержащий этапы, на которых:
принимают входные данные, которые включают в себя а) строку символов на первом языке, и б) данные семантического контекста, касающиеся источника этих входных данных;
разбирают строку символов в ее графемы; и
формируют шаблон символов, который представляет абстракцию упомянутых графем,
анализируют эти данные семантического контекста и шаблон символов в соответствии с правилами для выдачи потенциального межъязыкового преобразования этого шаблона символов;
преобразуют строку символов из первого языка во второй язык в соответствии с потенциальным межъязыковым преобразованием с выдачей преобразования;
анализируют признаки рабочих характеристик относительно этого преобразования; и
обновляют правила на основе признаков рабочих характеристик.
2. Способ по п. 1, в котором упомянутый шаблон символов включает в себя группу символов, которая соответствует графеме в упомянутых графемах, и которая отображается на источник.
3. Способ по п. 2, дополнительно содержащий этап, на котором извлекают из упомянутого источника информацию об упомянутой графеме.
4. Способ по п. 1,
в котором упомянутый шаблон символов включает в себя последовательность первой группы символов и второй группы символов,
причем упомянутая первая группа символов соответствует первой графеме в упомянутых графемах,
причем упомянутая вторая группа символов соответствует второй графеме в упомянутых графемах, и
причем упомянутый способ дополнительно содержит этапы, на которых:
выбирают на основе упомянутой последовательности процесс из множества процессов; и
исполняют упомянутый процесс над упомянутой строкой символов.
5. Способ по п. 4, в котором упомянутый процесс в результате дает комбинацию перевода и межъязыкового преобразования упомянутой строки символов.
6. Способ по п. 1,
в котором анализ данных семантического контекста и шаблона символов выполняют в соответствии с предпочтениями и атрибутами, и он выдает а) потенциальные значения и потенциальные межъязыковые стратегии расположения шаблона символов, б) информацию для информирования будущей итерации этого способа, и
причем способ дополнительно включает в себя после выполнения анализа данных семантического контекста и шаблона символов, и перед преобразованием:
выбор оптимальной межъязыковой стратегии для соответствующих частей шаблона символов, имеющей отношение к а) анализу данных семантического контекста и шаблону символов, б) правилам, предпочтениям и атрибутам, и полученной посредством обучения из предшествующей итерации способа.
7. Система для лингвистического преобразования данных, содержащая:
процессор; и
память, которая с возможностью связи соединена с упомянутым процессором, и которая содержит команды, читаемые упомянутым процессором, для побуждения упомянутого процессора выполнять следующие действия:
принимать входные данные, которые включают в себя а) строку символов на первом языке, и б) данные семантического контекста, касающиеся источника этих входных данных;
разбирать эту строку символов на ее графемы; и
формировать шаблон символов, который представляет абстракцию упомянутых графем,
анализировать эти данные семантического контекста и шаблон символов в соответствии с правилами для выдачи потенциального межъязыкового преобразования этого шаблона символов;
преобразовывать строку символов из первого языка во второй язык в соответствии с потенциальным межъязыковым преобразованием с выдачей преобразования;
анализировать признаки рабочих характеристик относительно этого преобразования; и
обновлять правила на основе признаков рабочих характеристик.
8. Система по п. 7, в которой упомянутый шаблон символов включает в себя группу символов, которая соответствует графеме в упомянутых графемах, и которая отображается на источник.
9. Система по п. 8, в которой упомянутые команды также побуждают упомянутый процессор выполнять следующее действие:
извлекать из упомянутого источника информацию об упомянутой графеме.
10. Система по п. 7,
в которой упомянутый шаблон символов включает в себя последовательность первой группы символов и второй группы символов,
причем упомянутая первая группа символов соответствует первой графеме в упомянутых графемах,
причем упомянутая вторая группа символов соответствует второй графеме в упомянутых графемах, и
причем упомянутые команды также побуждают упомянутый процессор выполнять следующие действия:
выбирать на основе упомянутой последовательности процесс из множества процессов; и
исполнять упомянутый процесс над упомянутой строкой символов.
11. Система по п. 10, в которой упомянутый процесс в результате дает комбинацию перевода и межъязыкового преобразования упомянутой строки символов.
12. Система по п. 7,
в которой анализ данных семантического контекста и шаблона символов выполняют в соответствии с предпочтениями и атрибутами, и он выдает а) потенциальные значения и потенциальные межъязыковые стратегии расположения шаблона символов, б) информацию для информирования будущей итерации этого способа, и
причем способ дополнительно включает в себя после выполнения анализа данных семантического контекста и шаблона символов, и перед преобразованием:
выбор оптимальной межъязыковой стратегии для соответствующих частей шаблона символов, имеющей отношение к а) анализу данных семантического контекста и шаблону символов, б) правилам, предпочтениям и атрибутам, и полученной посредством обучения из предшествующей итерации способа.
13. Запоминающее устройство, содержащее команды, считываемые процессором, для побуждения упомянутого процессора выполнять следующие действия:
принимать входные данные, которые включают в себя а) строку символов на первом языке, и б) данные семантического контекста, касающиеся источника этих входных данных;
разбирать строку символов в ее графемы; и
формировать шаблон символов, который представляет абстракцию упомянутых графем,
анализировать эти данные семантического контекста и шаблон символов в соответствии с правилами для выдачи потенциального межъязыкового преобразования этого шаблона символов;
преобразовывать строку символов из первого языка во второй язык в соответствии с потенциальным межъязыковым преобразованием с выдачей преобразования;
анализировать признаки рабочих характеристик относительно этого преобразования; и
обновлять правила на основе признаков рабочих характеристик.
14. Запоминающее устройство по п. 13, в котором упомянутый шаблон символов включает в себя группу символов, которая соответствует графеме в упомянутых графемах, и которая отображается на источник.
15. Запоминающее устройство по п. 14, в котором упомянутые команды также побуждают упомянутый процессор выполнять следующее действие:
извлекать из упомянутого источника информацию об упомянутой графеме.
16. Запоминающее устройство по п. 13,
в котором упомянутый шаблон символов включает в себя последовательность первой группы символов и второй группы символов,
причем упомянутая первая группа символов соответствует первой графеме в упомянутых графемах,
причем упомянутая вторая группа символов соответствует второй графеме в упомянутых графемах, и
причем упомянутые команды также побуждают упомянутый процессор выполнять следующие действия:
выбирать на основе упомянутой последовательности процессе из множества процессов; и
исполнять упомянутый процесс над упомянутой строкой символов.
17. Запоминающее устройство по п. 16, в котором упомянутый процесс в результате дает комбинацию перевода и межъязыкового преобразования упомянутой строки символов.
18. Запоминающее устройство по п. 13,
в котором анализ данных семантического контекста и шаблона символов выполняют в соответствии с предпочтениями и атрибутами, и он выдает а) потенциальные значения и потенциальные межъязыковые стратегии расположения шаблона символов, б) информацию для информирования будущей итерации этого способа, и
причем команды, считываемые процессором, дополнительно побуждают процессор после выполнения анализа данных семантического контекста и шаблона символов, и перед преобразованием, выполнять:
выбор оптимальной межъязыковой стратегии для соответствующих частей шаблона символов, имеющей отношение к а) анализу данных семантического контекста и шаблону символов, б) правилам, предпочтениям и атрибутам, и полученной посредством обучения из предшествующей итерации способа.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 6411932 B1, 25.06.2002 | |||
| ГИБКИЙ ПЕРЕВОД ОТОБРАЖЕНИЯ | 2006 |
|
RU2436146C2 |

