ОБЛАСТЬ ТЕХНИКИ
Настоящий документ относится к обработке изображений и оптическому распознаванию символов и, в частности, к способам и системам, которые определяют и характеризуют содержащие документы фрагменты изображений таким образом, чтобы к содержащим документы фрагментам изображений можно было применить методы оптического распознавания символов для извлечения информации из полученных изображений документов.
УРОВЕНЬ ТЕХНИКИ
Печатные документы на естественном языке по-прежнему представляют собой широко используемое средство связи между отдельными лицами, в организациях, для распространения информации среди потребителей информации, а также для операций обмена информацией различных видов. С появлением повсеместно используемых мощных вычислительных ресурсов, включая персональные вычислительные ресурсы, реализованные в смартфонах, планшетах, ноутбуках и персональных компьютерах, а также с распространением более мощных вычислительных ресурсов облачных вычислительных сервисов, центров обработки данных и корпоративных серверов организаций и предприятий, шифрование и обмен информацией на естественном языке все более часто выполняются в виде электронных документов. В отличие от печатных документов, которые по своей сути представляют собой изображения, электронные документы содержат последовательности цифровых кодов символов и знаков естественного языка. Поскольку электронные документы имеют перед печатными документами преимущества по стоимости, возможностям передачи и распространения, простоте редактирования и изменения, а также по надежности хранения, за последние 50 лет развилась целая отрасль, поддерживающая способы и системы преобразования печатных документов в электронные. Вычислительные способы и системы оптического распознавания символов совместно с электронными сканерами являются надежными и экономичными средствами получения изображений печатных документов и компьютерной обработки получаемых цифровых изображений содержащих текст документов с целью создания электронных документов, соответствующих печатным.
Раньше электронные сканеры представляли собой крупногабаритные настольные или напольные электронные устройства. Однако с появлением смартфонов, оснащенных камерами, а также других мобильных устройств формирования изображения с процессорным управлением появилась возможность получения цифровых изображений содержащих текст документов с помощью широкого диапазона различных типов широко распространенных переносных устройств, включая смартфоны, недорогие цифровые камеры, недорогие камеры видеонаблюдения, а также устройства получения изображений, встроенные в мобильные вычислительные приборы, включая планшетные компьютеры и ноутбуки. Цифровые изображения содержащих текст документов, создаваемые этими переносными устройствами и приборами, могут обрабатываться вычислительными системами оптического распознавания символов, в том числе приложениями оптического распознавания символов в смартфонах для создания соответствующих электронных документов.
К сожалению, создание изображений документов с помощью переносных устройств связано с повышенными уровнями шумов, оптическим смазом изображения, нестандартным положением и ориентацией устройства формирования изображения относительно документа, изображение которого требуется получить, мешающего освещения и эффектов контраста, вызванных неоднородными фонами, и других дефектов и недостатков содержащих текст цифровых изображений, полученных с помощью переносных устройств и приборов по сравнению со специализированными устройствами сканирования документов. Эти дефекты и недостатки могут значительно снизить производительность вычислительного оптического распознавания символов и значительно увеличить частоту ошибочного распознавания символов, а также привести к отказу способов и систем оптического распознавания символов при кодировании текста во всех или больших областях содержащих текст цифровых изображений. Таким образом, несмотря на то что переносные устройства и приборы получения изображений документов имеют значительные преимущества по стоимости и доступности для пользователя, им присущи недостатки, которые могут затруднить и исключить возможность создания электронных документов из содержащих текст цифровых изображений, полученных переносными устройствами и приборами. Кроме того, даже содержащие текст цифровые изображения, полученные с помощью стационарных систем формирования изображения, могут иметь дефекты и недостатки, которые могут привести к неудовлетворительным результатам применяемых позднее способов обработки изображений. По этой причине проектировщики и разработчики устройств, приборов для получения изображений и способов, систем оптического распознавания символов, а также пользователи устройств, приборов и систем оптического распознавания символов продолжают искать способы и системы для устранения дефектов и недостатков, присущих многим содержащим текст цифровым изображениям, включая содержащие текст цифровые изображения, полученные с помощью мобильных устройств, которые затрудняют дальнейшую вычислительную обработку содержащих текст цифровых изображений.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Настоящий документ относится к способам и подсистемам, которые выявляют и характеризуют содержащие документ фрагменты изображения в содержащем документ изображении. В одном варианте осуществления изобретения для каждого типа документа создается модель, представляющая собой набор признаков, которые извлекаются из набора изображений, о котором известно, что в нем содержится этот документ. С целью выявления и получения характеристик содержащего документ фрагмента изображения в изображении описанные в настоящем документе способы и подсистемы используются для извлечения признаков изображения, а затем для сопоставления признаков каждой модели из набора моделей с извлеченными признаками, чтобы выбрать модель, которая наилучшим образом соответствует извлеченным признакам. Затем содержащаяся в выбранной модели дополнительная информация используется для определения местоположения соответствующего документу фрагмента изображения, а также для обработки содержащего документ фрагмента изображения для коррекции различных искажений и дефектов с целью облегчения последующего извлечения данных из исправленного содержащего документ фрагмента изображения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг. 1 представлена архитектурная схема высокого уровня вычислительной системы, например, вычислительной системы, в которой реализована раскрываемая в этом документе подсистема распознавания содержащих документ фрагментов изображения.
На Фиг. 2A-D показаны два типа переносных устройств, предназначенных для получения изображений.
На Фиг. 3 показаны обычный настольный сканер и персональный компьютер, которые используются совместно для преобразования печатных документов в электронные документы, которые можно хранить в запоминающих устройствах и (или) в электронной памяти.
На Фиг. 4 показано типовое изображение с цифровым кодированием.
На Фиг. 5 показан один вариант цветовой модели RGB.
На Фиг. 6 показана другая цветовая модель «Оттенок-насыщенность-светлота» (HSL).
На Фиг. 7 показано формирование полутонового или бинаризованного изображения из цветного изображения.
На Фиг. 8A-N показаны модели, которые описывают преобразования первого изображения документа во второе изображение документа и способ выбора конкретной модели из множества моделей-кандидатов для описания конкретного преобразования для двух соответствующих изображений документа.
На Фиг. 9А-В показаны два документа, используемые в качестве примеров при обсуждении раскрываемых в настоящем описании способов и подсистем.
На Фиг. 10A-10J показаны некоторые из многочисленных проблем и задач, связанных с выявлением содержащих документ фрагментов цифрового изображения, особенно для цифрового изображения, полученного с помощью портативного смартфона или другого мобильного устройства с процессорным управлением.
На Фиг. 11A-F показан один подход к установлению соответствия между точками в глобальной системе координат и соответствующими точками в плоскости изображения камеры.
На Фиг. 12 показано выявление признаков методом SIFT.
Фиг. 13-18 содержат справочную информацию по различным концепциям, используемым методом SIFT для выявления признаков в изображениях.
На Фиг. 19A-D показан выбор кандидатов на ключевые точки в изображении.
На Фиг. 19Е показана фильтрация кандидатов на ключевые точки, или признаков, в пирамиде разностей гауссианов, полученных методом SIFT.
На Фиг. 19F показано, как назначается величина и ориентация признака из значений в пирамиде разностей гауссианов.
На Фиг. 19G показано вычисление дескриптора признака.
На Фиг. 19H-I показано простое приложение преобразования Хафа с одним параметром.
На Фиг. 19J-K показано использование точек SIFT для распознавания объектов в изображениях.
На Фиг. 20A-N представлен обзор способов и систем, к которым относится настоящий документ, а также подробное описание создания модели документа в соответствии со способами и системами настоящего изобретения.
На Фиг. 21A-D показаны блок-схемы процедуры «найти документы» (find documents), которая выявляет содержащие документ фрагменты в исходном изображении, как уже обсуждалось ранее со ссылкой на Фиг. 20А.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
Настоящий документ относится к способам и подсистемам, которые выявляют и характеризуют содержащие документ фрагменты изображений в содержащем документ изображении. Приведенное ниже обсуждение разбито на несколько подразделов, в том числе: (1) Обзор архитектуры вычислительных систем и цифровых изображений; (2) Пример способа выбора с использованием модели, похожей на RANSAC; (3) Область рассматриваемых проблем и несколько примеров типов документов; (4) Преобразования перспективы; (5) Детекторы признаков; и (6) заключительный подраздел, в котором обсуждаются способы и подсистемы, рассматриваемые в настоящем документе.
Обзор архитектуры вычислительных систем и цифровых изображений
На Фиг. 1 представлена схема архитектуры вычислительной системы верхнего уровня, подобной той вычислительной системе, в которой реализована раскрываемая в этом документе подсистема распознавания содержащих документ фрагментов изображения. Мобильные устройства получения изображений, включая смартфоны и цифровые камеры, могут быть изображены на диаграмме аналогичным образом, а также могут содержать процессоры, память и внутренние шины. Тем, кто знаком с современной наукой и технологиями, будет понятно, что программа управления или подпрограмма управления, включающая машинные команды, которые хранятся в физической памяти устройства с процессорным управлением, представляют собой компонент управления данным устройством и являются столь же физическими, реальными и важными, как и любой другой компонент электромеханического устройства, включая устройства формирования изображений. Компьютерная система содержит один или более центральных процессоров (ЦП) 102-105, один или более электронных модулей памяти 108, взаимосвязанных с ЦП через шину подсистемы ЦП/память 110 или несколько шин, первый мост 112, который соединяет шину подсистемы ЦП/память 110 с дополнительными шинами 114 и 116, либо другие виды средств высокоскоростного соединения, в том числе несколько высокоскоростных последовательных соединений. Эти шины или последовательные межсоединения в свою очередь соединяют ЦП и память со специализированными процессорами, такими как графический процессор 118, и с одним или более мостами 120, которые соединены по высокоскоростным последовательным каналам или несколькими контроллерами 122-127, такими как контроллер 127, которые предоставляют доступ к различным типам запоминающих устройств большой емкости 128, электронных дисплеев, устройств ввода и прочих подобных компонентов, подкомпонентов и вычислительных ресурсов.
На Фиг. 2A-D показаны два типа переносных устройств, предназначенных для получения изображений. На Фиг. 2А-С показана цифровая камера 202. Цифровая камера содержит объектив 204, кнопку спуска затвора 205, нажатие которой пользователем приводит к получению цифрового изображения, которое соответствует отраженному свету, попадающему в объектив 204 цифровой камеры. В задней части цифровой камеры, которая видна пользователю, когда он держит камеру при съемке цифровых изображений, имеются видоискатель 206 и жидкокристаллический дисплей видоискателя 208. С помощью видоискателя 206 пользователь может напрямую просматривать создаваемое объективом 204 камеры изображение, а с помощью жидкокристаллического (ЖК) дисплея 208 - просматривать электронное отображение создаваемого в настоящей момент объективом изображения. Обычно пользователь камеры настраивает фокус камеры с помощью кольца фокусировки 210, смотря при этом через видоискатель 206 или на жидкокристаллический экран видоискателя 208, чтобы выбрать требуемое изображение перед тем, как нажать на кнопку 205 спуска затвора для получения цифрового снимка изображения и его сохранения в электронной памяти цифровой камеры.
На Фиг. 2D показан типичный смартфон с передней стороны 220 и задней стороны 222. На задней стороне 222 имеется объектив 224 цифровой камеры и датчик приближения и (или) цифровой экспонометр 226. На передней стороне смартфона 220 может отображаться получаемое изображение 226 (под управлением приложения), аналогично работе жидкокристаллического дисплея 208 видоискателя цифровой камеры, а также может находиться сенсорная кнопка 228 спуска затвора, при прикосновении к которой происходит получение цифрового изображения и сохранение его в памяти смартфона.
На Фиг. 3 показаны обычный настольный сканер и персональный компьютер, которые используются совместно для преобразования печатных документов в электронные документы, которые можно хранить в запоминающих устройствах большой емкости и (или) в электронной памяти. В настольном сканере 302 имеется прозрачное стекло планшета 304, на которое помещен документ 306 лицевой стороной вниз. Запуск сканирования приводит к получению оцифрованного изображения отсканированного документа, которое можно передать на персональный компьютер (ПК) 308 для хранения на запоминающем устройстве большой емкости. Программа визуализации изображения сканируемого документа может отобразить оцифрованное отсканированное изображение документа для отображения на экране 310 устройства отображения 312 ПК. Настольный сканер обеспечивает более стабильную и точную платформу для получения изображения документа, чем переносное устройство, но он также может формировать изображения документа, в которых имеются проблемы контраста, искажения и другие дефекты.
На Фиг. 4 показано типовое изображение с цифровым кодированием. Кодированное изображение включает двухмерный массив пикселей 402. На Фиг. 4 каждый небольшой квадрат, например, квадрат 404, является пикселем, который обычно определяется как наименьшая часть детализации изображения, для которой предусматривается цифровая кодировка. Каждый пиксель представляет собой место, обычно представленное как пара цифровых значений, соответствующих значениям на осях прямоугольных координат x и y (406 и 408, соответственно). Таким образом, например, пиксель 404 имеет координаты x, y (39,0), а пиксель 412 имеет координаты (0,0). В цифровой кодировке пиксель представлен числовыми значениями, указывающими на то, как область изображения, соответствующая пикселю, представляется при печати, отображается на экране компьютера или ином дисплее. Обычно для черно-белых изображений для представления каждого пикселя используется единичное значение в интервале от 0 до 255 с числовым значением, соответствующим уровню серого, с которым отображается этот пиксель. Согласно общепринятому правилу значение «0» соответствует черному цвету, а значение «255» - белому. Для цветных изображений может применяться множество различных наборов числовых значений, указывающих на цвет. В одной широко используемой цветовой модели, показанной на Фиг. 4, каждый пиксель связан с тремя значениями, или координатами (r, g, b), которые указывают на яркость красного, зеленого и синего компонента цвета, отображаемого в соответствующей пикселю области.
На Фиг. 5 показан один вариант цветовой модели RGB. Тремя координатами основных цветов (r,g,b) представлен весь спектр цветов, как было показано выше со ссылкой на Фиг. 4. Цветовая модель может считаться соответствующей точкам в пределах единичного куба 502, в котором трехмерное цветовое пространство определяется тремя осями координат: (1) r 504; (2) g 506; и (3) b 508. Таким образом, координаты отдельного цвета находятся в диапазоне от 0 до 1 по каждой из трех цветовых осей. Например, чистый синий цвет максимально возможной яркости соответствует точке 510 по оси b с координатами (0,0,1). Белый цвет соответствует точке 512 с координатами (1,1,1,), а черный цвет - точке 514, началу системы координат с координатами (0,0,0).
На Фиг. 6 показана другая цветовая модель «Оттенок-насыщенность-светлота» (HSL). В этой цветовой модели цвета содержатся в трехмерной бипирамидальной призме 600, имеющей шестигранное сечение. Оттенок (h) связан с доминантной длиной волны излучения света, воспринимаемого наблюдателем. Значение оттенка изменяется от 0° до 360°, начиная с красного 602 при 0°, проходит через зеленый 604 при 120°, синий 606 при 240°, и заканчивается красным 602 при 360°. Насыщенность (s), изменяющаяся в интервале от 0 до 1, обратно связана с количеством белого и черного цвета, смешанного при определенной длине волны или оттенке. Например, чистый красный цвет 602 полностью насыщен при насыщенности s=1,0, в то время как розовый цвет имеет значение насыщенности меньше 1,0, но больше 0,0, белый цвет 608 является полностью ненасыщенным, для него s=0,0, а черный цвет 610 также является полностью ненасыщенным, для него s=0,0. Полностью насыщенные цвета располагаются по периметру среднего шестигранника, содержащего точки 602, 604 и 606. Шкала оттенков серого проходит от черного 610 до белого 608 по центральной вертикальной оси 612, представляющей полностью ненасыщенные цвета без оттенка, но с различными пропорциональными сочетаниями черного и белого. Например, черный цвет 610 содержит 100% черного цвета и совсем не содержит белый цвет, белый цвет 608 содержит 100% белого цвета и совсем не содержит черный цвет, а точка начала координат 613 содержит 50% черного цвета и 50% белого цвета. Светлота (l) представлена центральной вертикальной осью 612, она указывает на уровень освещенности, который изменяется от 0 для черного цвета 610 (l=0,0), до 1 для белого цвета 608 (l=1,0). Для произвольного цвета, представленного точкой 614 на Фиг. 6, оттенок определяется как угол θ 616 между первым вектором из исходной точки 613 к точке 602 и вторым вектором из исходной точки 613 к точке 620, в которой вертикальная линия 622, проходящая через точку 614, пересекает плоскость 624, включающую исходную точку 613 и точки 602, 604 и 606. Насыщенность представлена отношением расстояния представленной точки 614 от вертикальной оси 612 d' к длине горизонтальной линии, проходящей через точку 620 от исходной точки 613, к поверхности бипирамидальной призмы 600, d. Светлота представлена вертикальным расстоянием от репрезентативной точки 614 до вертикального уровня точки, представляющей черный цвет 610. Координаты конкретного цвета в цветовой модели (h, s, l), могут быть получены на основе координат цвета в цветовой модели RGB (r, g ,b) следующим образом:
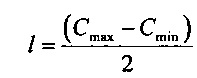 ,
,
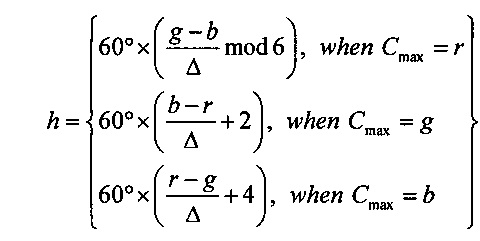 , и
, и
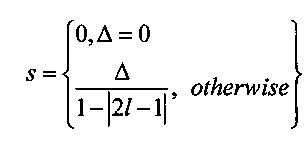 ,
,
где значения r, g и b соответствуют яркости красного, зеленого и синего первичных цветов, нормализованных на интервале [0, 1]; Cmax представляет нормализованное значение яркости, равное максимальному значению из r, g и b; Cmin представляет собой нормализованное значение яркости, равное минимальному значению из r, g и b; а Δ определяется как Cmax-Cmin.
На Фиг. 7 показано формирование полутонового или бинаризованного изображения из цветного изображения. В цветном изображении каждый пиксель обычно описывается тремя значениями: а, b и с 702. В разных цветовых моделях для представления конкретного цвета используются разные значения a, b и с. Полутоновое изображение содержит для каждого пикселя только одно значение яркости 704. Бинаризованное изображение является частным случаем полутонового изображения, которое имеет только два значения яркости «0» и «1». Обычно полутоновые изображения могут иметь 256 или 65 536 разных значений яркости для каждого пикселя, представленного байтом или 16-битным словом соответственно. Таким образом, чтобы преобразовать цветное изображение в полутоновое, три значения а, b и с цветных пикселей необходимо преобразовать в одно значение яркости для полутонового или бинаризованного изображения. На первом этапе три цветовых значения а, b и с преобразуются в значение яркости L, обычно находящееся в диапазоне [0,0, 1,0] 706. В некоторых цветовых моделях к каждому из цветовых значений 708 применяется функция, а результаты суммируются 710 для получения значения яркости. В других цветовых моделях каждое цветовое значение умножается на коэффициент, и полученные результаты суммируются 712, давая значение яркости. В других цветовых системах одно из трех значений цвета фактически является значением яркости 714. Наконец, в общем случае к трем цветовым значениям 716 применяется функция, которая дает значение яркости. Затем значение яркости квантуется 718, позволяя получить значение яркости оттенков серого в требуемом интервале, обычно [0, 255] для полутоновых изображений и (0,1) для бинаризованных изображений.
Пример выбора модели для способа типа RANSAC
На Фиг. 8A-N показаны модели, которые описывают преобразования первого изображения документа во второе изображение документа и способ выбора конкретной модели из множества моделей-кандидатов для описания конкретного преобразования для двух соответствующих изображений документа. Преобразования могут отражать различные типы физического или связанного с получением изображения искажения или изменения документа по отношению к нормализованному документу такого же типа. Например, нормализованный документ может представлять собой точное изображение сертификата или удостоверения определенного типа. При получении изображения такого сертификата или удостоверения в неидеальных условиях могут возникнуть различные типы искажения изображения вследствие нестандартного расположения и ориентации устройства формирования изображения по отношению к документу, отсутствия фокусировки и других подобных условий, вызывающих искажения. В другом примере сертификат или удостоверение, для которых получают изображение, могут быть физически искажены из-за того, что этот документ смяли, сложили, испачкали, либо в результате других таких физических событий, вызывающих искажения. В обсуждаемых ниже способах и системах для выявления конкретных типов фрагментов изображений документов из изображений выбирается преобразование для описания любых искажений или других различий между нормированным документом или эталонным документом, и соответствующим фрагментом изображения документа внутри изображения. Во многих случаях определение преобразования включает определение не только модели, но также одного или нескольких параметров модели, которые наилучшим образом соответствуют наблюдаемым искажениям и различиям нормализованного изображения и соответствующего фрагмента изображения. Один из способов определения параметров математической модели из множества наблюдаемых данных называется способом оценки параметров на основе случайных выборок (random sample consensus или RANSAC). В обсуждаемом ниже примере со ссылкой на Фиг. 8A-N используется похожий на RANSAC метод оценки параметров для определения параметра модели, который наилучшим образом согласует модель с наблюдаемыми данными. Цель этого примера - для общего случая проиллюстрировать похожие на RANSAC методы выбора модели параметров. В раскрываемых в настоящем описании способах и подсистемах используются различные похожие на RANSAC методы для нескольких более сложных типов подгонки параметров и построения модели.
На Фиг. 8А показан пример проблемной области, для которой используется похожий на RANSAC метод подгонки параметра, а также выбор модели для определения преобразования, которое связывает первое изображение image1 со вторым изображением image2. На Фиг. 8А первое изображение 802 и второе изображение 804 показаны в верхней части чертежа. Первое изображение 802 содержит пять темных объектов на светлом фоне, в том числе три темных объекта квадратной формы 806-808 и два объекта неправильной формы 809 и 810. Второе изображение 804 также содержит пять объектов, в том числе три объекта квадратной формы 811-813 и два объекта неправильной формы 814 и 815. Первое изображение представляет собой двумерную матрицу пикселей, индексированных координатами (x, y) 818, а второе изображение 804 представляет собой двумерную матрицу пикселей, индексированных координатами (x', y') 819. Предположение заключается в том, что некоторые объекты или все объекты второго изображении 804 связаны с объектами первого изображения с помощью математически выраженного преобразования. Прямое преобразование 820 включает функцию f(x, y), возвращающую соответствующие координаты (x', y') для точки с координатами (x, y) в первом изображении. Обратное преобразование 821 преобразует координаты пикселя второго изображения в координаты пикселя первого изображения. Третье предположение для конкретного примера проблемы заключается в том, что цвет и (или) яркость пикселя (x, y) в первом изображении равны цвету и (или) яркости соответствующего пикселя (x', y') во втором изображении 822 или что они близки.
На Фиг. 8B-D показаны три различные возможные модели, представленные математическими выражениями, для преобразования объектов первого изображения 802, показанного на Фиг. 8А, в соответствующие объекты второго изображения 804, показанного на Фиг. 8А. Первая возможность, показанная на Фиг. 8В, представляет собой вертикальное перемещение объектов первого изображения в соответствующие позиции, которые, если бы модель была правильной, совпадали бы с позициями соответствующих объектов второго изображения. На Фиг. 8В объекты первого изображения показаны как незаштрихованные объекты, такие как квадратный объект 806, в то время как объекты второго изображения показаны как заштрихованные объекты, имеющие границы в виде пунктирных линией, такие как объект 811. Приемлемое преобразование преобразует пиксели объектов первого изображения в соответствующие пиксели объектов второго изображения. В случае модели вертикального перемещения, показанной на Фиг. 8В, некоторые пиксели, расположенные внутри объектов первого изображения, такие как пиксели 823 и 824, преобразуются согласно показанному преобразованию в соответствующие пиксели 825 и 826, расположенные внутри объектов второго изображения. Однако в других случаях, например, для пикселей 827 и 828, расположенных внутри объектов первого изображения 807 и 809, рассматриваемое преобразование преобразует пиксели в точки 829 и 830, расположенные вне объектов. Таким образом, модель вертикального перемещения по-видимому не является особенно устойчивой и точной моделью преобразования объектов первого изображения в объекты второго изображения. Модель вертикального перемещения вниз показана 831 сбоку от составного изображения 832, приведенного на Фиг. 8В.
На Фиг. 8С показана модель горизонтального перемещения, при этом для иллюстрации используются те же понятия, что и на Фиг. 8В. Здесь также некоторые пиксели, такие как пиксель 833, преобразуются из объектов первого изображения в объекты второго изображения, в то время как другие пиксели, такие как пиксель 834, преобразуются из объектов первого изображения в места, расположенные вне объектов. Как и на Фиг. 8В, модель горизонтального перемещения влево схематически представлена 835 справа от составного изображения 836, показанного на Фиг. 8С.
Наконец, на Фиг. 8D показана третья модель преобразования объектов изображения image1 в изображение image2, в ней в целях иллюстрации используются те же понятия, которые использовались на Фиг. 8В и 8С. Эта модель представляет собой поворот изображения image1 на 45 градусов вокруг центральной точки изображения image1 в направлении против часовой стрелки, что показано представлением модели 837 справа от составного изображения 838, показанного на Фиг. 8D. В целом каждая точка каждого квадратного объекта первого изображения, например, точки 839-841, преобразуется в соответствующие квадратные объекты второго изображения. Однако объекты неправильной формы первого изображения 809 и 810 не преобразуются в объекты неправильной формы второго изображения 814 и 815. Тем не менее именно эта модель будет считаться наиболее правильной из трех описанных моделей, поскольку фактически второе изображение 804 на Фиг. 8А было получено из первого изображения 802 поворотом квадратных объектов на 45 градусов против часовой стрелки вокруг центральной точки изображения. Объекты неправильной формы намеренно не были преобразованы поворотом на 45 градусов. Этот пример показывает, что может существовать основная модель, которая представляет преобразование положений отдельных объектов, представляющих интерес в первом изображении, в положение этих объектов во втором изображении, и что могут существовать другие признаки изображения, включая шум, оптические искажения и другие признаки, которые не так легко преобразовать. Таким образом, процесс оценки различных возможных моделей, а также выбора наилучшего значения параметра модели может включать сравнение результатов для того, чтобы выбрать лучшую, хотя и не полностью объясняющую модель. Следует обратить внимание на то, что для каждой из моделей, показанных на Фиг. 8B-D, имеется один параметр, значение которого требуется определить. Две модели преобразования имеют параметр «расстояние перемещения», в то время как модель вращения имеет параметр «угол поворота». В общем случае для модели могут потребоваться два или более значений параметров, которые необходимо определить. Похожие на RANSAC методы были разработаны для решения общей задачи определения параметров модели.
На Фиг. 8E-N с помощью таблицы показаны входные и выходные характеристики, а также ряд блок-схем для основанного на методе RANSAC подхода к определению того, какая из моделей, показанных на Фиг. 8B-D, наилучшим образом объясняет преобразование объектов первого изображения 802 (Фиг. 8А) в различные положения на втором изображении 804, показанном на Фиг. 8А, а также определяет оптимальное значение параметров модели для входных данных.
На Фиг. 8Е показана таблица, которая включает характеристики трех моделей. Три строки 842-844 представляют преобразование при вертикальном перемещении вниз, показанное на Фиг. 8В, преобразование при горизонтальном перемещении влево, показанное на Фиг. 8С, и преобразование поворотом против часовой стрелки, показанное на Фиг. 8D. Столбцы таблицы соответствуют представленным рядами полям в записях. Таким образом, каждая модель включает текстовое описание, соответствующее столбцу 845, математическое выражение прямого преобразования, соответствующее столбцу 846, одно или несколько математических выражений обратного преобразования, соответствующие столбцу 847, а также различные неизменяемые параметры, используемые в похожем на RANSAC методе подгонки параметра, которые обсуждаются ниже, соответствующие столбцам 848-849. Каждая модель математически описывается одним переменным параметром: параметром р в первых двух моделях и параметром θ в третьей модели.
На Фиг. 8F показаны входные и выходные аргументы программы «найти модель» (find model) и подпрограммы «найти параметр» (find parameter). Программа «найти модель» получает в качестве входных данных два изображения 850 и 851, массив моделей 852 и указание количества моделей в массиве моделей 853. Эта программа оценивает каждую модель в отношении исходных изображений. Если выявлена приемлемо точная модель, объясняющая систематические различия между положениями и цветами объектов в двух изображениях, то программа «найти модель» возвращает индекс наилучшей модели, определенной в массиве «Models», а также значение параметра р или θ, используемое в математических выражениях для преобразования, представленного моделью 853. В противном случае программа «найти модель» возвращает индикацию ошибки 854. В подпрограмме «найти параметр» реализован похожий на RANSAC метод, определяющий значение параметра модели р, который наилучшим образом описывает входные данные. Подпрограмма «найти параметр» получает в качестве входных данных 855 два изображения и массив моделей и на выходе определяет долю пикселей первого изображения, которые правильно преобразуются моделью в преобразованные положения во втором изображении 856, наилучшее значение параметра модели р 857, а также общую ошибку приложения, характеризующую применение преобразования к первому изображению 858.
На Фиг. 8G приведена блок-схема программы «найти модель». На шаге 860а программа «найти модель» получает первое и второе изображение, массив «Models» и указание количества моделей или записей в массиве «Models». Изображения могут быть получены в виде ссылок на файлы изображений, в виде ссылок на массивы пикселей или с помощью других стандартных вычислительных методик ввода. На шаге 860b программа «найти модель» инициализирует несколько локальных переменных, включая следующие: (1) bestP - наилучшее значение параметра; (2) bestRatio - наилучшее отношение правильно преобразованных пикселей к общему количеству пикселей в первом изображении; (3) bestError - общая ошибка для наилучшей модели; и (4) bestModel - индекс массива «Models», соответствующий модели, которая лучше всего объясняет различия между изображениями image1 и image2. В цикле for на шагах 860C-860i рассматривается каждая модель в массиве «Models». На шаге 860d вызывается подпрограмма «найти параметр» (find parameter) для определения наилучшего значения параметра модели. Если возвращаемое подпрограммой «найти параметр» отношение превышает значение, хранящегося в локальной переменной best Ratio, которое было определено на шаге 860е, то локальные переменные на шаге 860f обновляются значениями, возвращенными подпрограммой «найти параметр» для рассматриваемой в текущий момент модели. В противном случае, если возвращаемое подпрограммой «найти параметр» отношение равно значению, сохраненному в локальной переменной bestRatio, и общая ошибка, возвращенная подпрограммой «найти параметр», меньше значения, хранящегося в локальной переменной bestError, то на шаге 860f локальные параметры обновляются. В противном случае, если переменная цикла / меньше, чем значение numModels - 1, что определено на шаге 860h, то переменная цикла увеличивается на шаге 860i, и происходит переход к шагу 860d для следующей итерации цикла for. Если после завершения цикла for сохраненный в локальной переменной индекс bestModel превышает значение -1, определенное на шаге 860j, то затем на шаге 860k возвращаются значения, сохраненные в локальных переменных bestP и bestModel. В противном случае на шаге 860l возвращается индикация ошибки. Таким образом, программа «найти модель» оценивает все модели в массиве «Models» и возвращает указание на модель, которая наилучшим образом описывает преобразование признаков между первым и вторым исходными изображениями, а также наилучшее значение параметра для этой модели. Однако если приемлемая модель не найдена, как описано далее ниже, то программа «найти модель» возвращает индикацию ошибки.
На Фиг. 8H-N показана подпрограмма «найти параметр», вызываемая на шаге 860d на Фиг. 8G. Это похожий на RANSAC метод определения наилучшего значения параметра для модели с одним параметром. Эта подпрограмма легко расширяется на определение нескольких значений параметров для моделей, имеющих два или более переменных параметра, однако при использовании простейших подходов объем дополнительных расчетов возрастает в геометрической прогрессии.
На Фиг. 8Н показана блок-схема высшего уровня для подпрограммы «найти параметр». На шаге 864а подпрограмма «найти параметр» принимает два изображения и конкретную модель для оценки того, как она выражает преобразование между двумя изображениями. На шаге 864b подпрограмма «найти параметр» подготавливает оба изображения к анализу, причем для ссылки на подготовленные изображения используются переменные data1 и data2. Подготовка изображения может включать изменение цветовой модели, превращение изображения в полутоновое, преобразование изображения в бинаризованное и другие подобные преобразования. На шаге 864 с инициализируется несколько локальных переменных, в том числе: (1)р - текущее наилучшее значение параметра; (2) error - текущая общая ошибка наилучшего определенного значения параметра на текущий момент; (3) i - переменная цикла; (4) alreadyEv - набор параметров, которые уже были ранее оценены в ходе текущего выполнения подпрограммы «найти параметр»; и (5) ratio - наилучшее отношение, уже определенное для текущего наилучшего значения параметра. В цикле while, состоящем из шагов 864d-864j, испытываются различные значения параметра модели, а наилучший параметр, опробованный во время выполнения цикла while, используется в качестве значения параметра, которое наиболее точно подгоняет модель к данным исходного изображения. Параметр модели maxItr управляет количеством различных значений опробованных параметров. В альтернативных вариантах реализации цикл while может прерываться, если найдено значение параметра, которое обеспечивает результат лучший, чем требуется пороговым значением. На шаге 864е вызывается подпрограмма «следующая модель» (next model) для определения и оценки следующего значения параметра. Если отношение правильно преобразованных пикселей к общему количеству пикселей, полученных при применении модели ко входным данным со значением параметра, превышающим значение, хранящееся в локальной переменной ratio, которая определена на шаге 864f, то локальные переменные ratio, р и error обновляются соответствующими значениями, возвращенными подпрограммой «следующая модель». Если отношение, возвращаемое подпрограммой «следующая модель» совпадает со значением, хранящемся в локальной переменной ratio (отношение), а общая ошибка, полученная при применении модели с рассматриваемым в настоящее время параметром к входным данным, меньше значения, хранящегося в локальной переменной error (ошибка), которое определено на шаге 864h, то локальные переменные ratio, р и error обновляются на шаге 864g. В любом случае, если на условных шагах 864f и 864h возвращаются значения true (истина), рассматриваемый в настоящее время параметр является наилучшим определенным до сих пор параметром. Затем, если переменная цикла i меньше значения maxItr - 1, которое определено на шаге 864i, то переменная цикла обновляется на шаге 864j, и происходит переход обратно к шагу 864е для еще одной итерации цикла while. Когда цикл while завершается, подпрограмма «найти параметр» на шаге 864k возвращает значения локальных переменных ratio, р и error. Следует обратить внимание на возможность того, что приемлемое значение параметра может быть не найдено, в этом случае локальные переменные ratio, р и error имеют те значения, с которыми они были инициализированы на шаге 864с. Фактически эти начальные значения указывают на состояние ошибки.
На Фиг. 8I показана блок-схема подпрограммы «найти ошибку» (find error). Эта подпрограмма определяет значение ошибки для двух пикселей, преобразованных текущей моделью при текущем значении параметра. На шаге 868а подпрограмма «найти ошибку» получает два пикселя u и v из наборов данных data1 и data2, соответственно, текущее значение параметра модели р, а также текущую модель. На шаге 868b подпрограмма «найти ошибку» назначает для локальной переменной а квадрат разности между значениями пикселей u и v. Эта разность может представлять собой отношение расстояния между значениями пикселей к максимально возможному различию значений пикселей или некоторую другую меру различий. На шаге 868с подпрограмма «найти ошибку» преобразует пиксель u в пиксель l согласно модели и текущему значению параметра. Другими словами, используя прямое преобразование для модели, подпрограмма «найти ошибку» вычисляет преобразованное положение для пикселя u. Далее, на шаге 868d, подпрограмма «найти ошибку» вычисляет квадрат расстояния между положениями точек v и l и записывает это значение в локальную переменную b. Можно использовать различные метрики расстояния, включая метрику городских кварталов или евклидово расстояние. Наконец, на шаге 868е подпрограмма «найти ошибку» вычисляет общую ошибку как квадратный корень из суммы локальных переменных а и b и возвращает вычисленную ошибку на шаге 868f.
На Фиг. 8J показана блок-схема высокого уровня для подпрограммы «следующая модель» (next model), вызываемой на шаге 864е (Фиг. 8Н). На шаге 872а подпрограмма «следующая модель» получает наборы данных data1 и data2, а также рассматриваемую в настоящее время модель - запись в массиве «Models». На шаге 872b подпрограмма «следующая модель» случайным образом выбирает n пикселей из набора данных data1 и помещает их в локальную переменную-множество set1. Значение n является одним из неизменяемых параметров модели, оно обсуждалось выше со ссылкой на Фиг. 8Е (848-849). На шаге 872с подпрограмма «следующая модель» случайным образом выбирает n пикселей из второго набора данных и помещает их в локальную переменную-множество set2. На шаге 872d локальные переменные num и nModel устанавливаются равными 0 и пустому множеству, соответственно. В цикле for на шагах 872e-872i подпрограмма «следующая модель» рассматривает каждую возможную пару пикселей (j, k) из локальных переменных-множеств set1 и set2, причем первый пиксель пары выбран из set1, а второй пиксель пары выбран из set2. На шаге 872f подпрограмма «следующая модель» вызывает подпрограмму «создать модель» (generate model) для создания и оценки нового значения параметра для входной модели, как описано ниже. Если на шаге 872g установлено, что значение nSize, возвращаемое подпрограммой «создать модель», больше значения, хранящегося в настоящее время в локальной переменной num, то локальные переменные num и nModel обновляются до соответствующих значений подпрограммой «создать модель» на шаге 872h. Если имеются другие пары пикселей для рассмотрения, что определяется в шаге 872i, то выполняется переход обратно на шаг 872f для еще одной итерации в цикле for, содержащем шаги 872e-872i. Наконец, на шаге 872j возвращаются значения, содержащиеся в текущей переменной-множестве или записи параметра nModel.
На Фиг. 8К показана блок-схема подпрограммы «создать модель» (generate model), вызываемой на шаге 872f, показанном на Фиг. 8J. На шаге 876а подпрограмма «создать модель» получает наборы set1 и set2, первоначально подготовленные входные данные data1 и data2, рассматриваемую в настоящее время модель и пару пикселей (i, j). Подпрограмма «создать модель» пытается сформировать значение параметра для рассматриваемой в настоящее время модели на основании пары пикселей (i, j). На шаге 876b локальные переменные nSize и nxtM устанавливаются равными 0 и пустому множеству, соответственно. На шаге 876с подпрограмма «создать модель» вызывает подпрограмму «оценить пару» (evaluate pair), чтобы определить, может ли пара пикселей (i, j) быть объяснена как преобразование в соответствии с моделью и выбранным значением параметра. Если на шаге 876d установлено, что процедура «оценить пару», возвращает значение «истина» (true), то затем на шаге 876е подпрограмма «создать модель» вызывает подпрограмму «заполнить модель» (fill model) с целью получить характеристики из множеств set1 и set2 для преобразования, представленного моделью с текущим значением параметра. Если на шаге 876f было установлено, что число пар пикселей со случайно выбранными наборами пикселей set1 и set2, которые объяснены моделью и текущим значением параметра, больше значения minFit, то на шаге 876g подпрограмма «создать модель» вызывает подпрограмму «закончить модель» (complete model) для формирования характеристик преобразования, содержащих текущую модель и выбранный параметр модели. Если на шаге 876h было установлено, что отношение cRatio для правильно преобразованных пикселей, возвращаемое подпрограммой «закончить модель», больше или равно значению minRatio, то возвращаемые значения nSize и nextM устанавливаются равными характеристикам, возвращаемым подпрограммой «закончить модель» на шаге 876i и выдаются на шаге 876j. Следует обратить внимание на то, что значения minFit и minRatio являются неизменяемыми значениями параметров, описанными выше со ссылкой на Фиг. 8Е. Если процедура «оценить пару» возвращает значение «ложь» (false), то начальные значения локальных переменных nSize и nxtM возвращаются на шаге 876k как индикация ошибки.
На Фиг. 8L показана блок-схема подпрограммы «оценить пару» (evaluate pair), она вызывается на шаге 876d (см. Фиг. 8К). На шаге 880а подпрограмма «оценить пару» получает два пикселя (j, k) в рассматриваемой в настоящее время модели. На шаге 880b подпрограмма «оценить пару» вычисляет значение параметра модели р в качестве параметра модели, который наилучшим образом преобразует положение j в положение k. Если значение параметра р уже оценивалось на шаге 880с, то процедура «оценить пару» возвращает значение «ложь» (false) на шаге 880d. В противном случае значение р добавляется к множеству alreadyEv на шаге 880е. На шаге 880f подпрограмма «оценить пару» вызывает подпрограмму «найти ошибку», чтобы определить ошибку, связанную с двумя пикселями j и k. Если на шаге 880g установлено, что ошибка, возвращаемая подпрограммой «найти ошибку», больше значения maxError, то подпрограмма «оценить пару» возвращает значение «ложь» (false) на шаге 880d. В противном случае на шаге 880h возвращаются значение «истина» (true) и вычисленная ошибка. Следует обратить внимание на то, что значение maxError является еще одним из параметров подгонки, рассмотренных выше со ссылкой на Фиг. 8Е.
На Фиг. 8М показана блок-схема подпрограммы «заполнить модель» (fill model), которая вызывается на шаге 876е на Фиг. 8K. На шаге 884а подпрограмма «заполнить модель» получает пару пикселей, текущие параметр модели и модель, случайным образом выбранные наборы пикселей set1 и set2, а также подготовленные входные данные data1 и data2. На шаге 884b подпрограмма «заполнить модель» устанавливает локальную переменную mSize равной 1, а локальная переменная-набор mSet включает полученную пару пикселей (i,j), и удаляет пиксели i и j из переменных-множеств set1 и set2. Затем, во вложенном цикле for с шагами 884c-884i, для каждого пикселя в set1 производится попытка согласования с пикселем в set2, используя рассматриваемую в настоящее время модель и текущее значение параметра для этой модели. Если два пикселя представляют собой преобразованную пару с ошибкой меньше maxError, что определяется на шаге 884f, то значение локальной переменной mSize увеличивается, рассматриваемая в настоящее время пара пикселей q и r добавляется к локальной переменной-набору mSet, пиксели q и r удаляются из переменных-наборов set1 и set2, а на шаге 884g выполняется выход из вложенного цикла for. На шаге 884j после завершения вложенных циклов for в локальной переменной mSize возвращается значение, которое отражает количество пикселей в случайным образом выбранном множестве set1, которые корректно преобразуются рассматриваемыми в настоящее время моделью и значением параметра. Именно это значение сравнивается с подгоняемым параметром minFit на шаге 876f на Фиг. 8К, чтобы определить, являются ли рассматриваемые в настоящее время модель и значение параметра приемлемой моделью для преобразования исходного изображения image1 в изображение image2.
На Фиг. 8N показана блок-схема подпрограммы «завершить модель» (complete model), которая вызывается на шаге 876g на Фиг. 8K. На шаге 888а подпрограмма «завершить модель» получает рассматриваемые в настоящее время модель и значение параметра model и р, а также входные наборы данных data1 и data2. На шаге 888b локальные переменные инициализируются со значением 0, в том числе: (1) переменная cRatio - отношение правильно преобразованных пикселей к общему количеству пикселей, (2) переменная cError - общая ошибка преобразования первого набора данных во второй набор данных с помощью модели и параметра модели и (3) переменная cSize - количество преобразуемых пикселей. Затем, в цикле for с шагами 888c-888i, каждый пиксель в исходном наборе данных преобразуется текущей моделью и значением параметра модели на шаге 888d, и если вычисленное положение пикселя находится в наборе данных data2, а ошибка, связанная с рассматриваемым в настоящее время пикселем и перемещенным пикселем, меньше значения maxError, как определено на шаге 888g, то значение локальной переменной cSize увеличивается, а ошибка для двух пикселей добавляется к общей ошибке cError на шаге 888h. На шаге 888j, после завершения цикла for, отношение правильно преобразованных пикселей к общему количеству пикселей cRatio вычисляется путем деления значения локальной переменной cSize на мощность входного набора данных data1.
Подпрограмма «найти параметр» не гарантирует возвращение приемлемого значения параметра для модели. Однако при выборе подходящих значений подгоняемых параметров весьма вероятно, что если модель достаточно точно выражает преобразование между двумя исходными изображениями, то будет найдено приемлемое значение параметра. Похожий на RANSAC метод можно использовать для подгонки параметров для множества различных типов моделей с целью объяснения различных наборов данных. Например, одно исходное изображение может быть каноническим или нормализованным изображением определенного типа документа, и дополнительные исходные изображения представляют собой различные изображения реальных документов того же типа документа, что и у исходного канонического документа или эталонного документа. В этом случае процедуру необходимо дополнить сравнением эталонного документа или канонического документа с несколькими изображениями для каждого набора, состоящего из одного или более значений параметров, вычисленных для подгонки модели к входным данным. Как уже обсуждалось выше, похожие на RANSAC методы могут соответствовать нескольким параметрам модели, имеющей несколько параметров. Типы входных данных также могут различаться. Единственным реальным ограничением является то, что несмотря на данные, должна существовать норма или критерии оценки для определения того, насколько хорошо преобразованные данные соответствуют входным данным, не имеющим эталона, либо которые не являются каноническими.
Текущая предметная область и несколько примеров типов документов
В настоящем документе рассматриваются способы, системы и подсистемы, которые определяют границы или очертания содержащих документы фрагментов изображений в цифровых изображениях. Из-за повсеместного использования смартфонов для получения изображений к цифровым изображениям документов, полученным с помощью смартфонов и других мобильных устройств, содержащих цифровые камеры, применяются многочисленные методы и приложения для обработки документов. Обычно в качестве первого шага или подпроцесса при интерпретации цифровых изображений документов используется цифровая обработка изображения для выявления фрагментов изображений в цифровом изображении, соответствующих различным типам содержащих текст документов, причем фрагменты изображений определены границами или краями физических документов, изображение которых получено с помощью цифровой камеры для получения цифрового изображения, содержащего фрагменты изображений документа. После выявления в цифровом изображении соответствующих документам фрагментов изображений можно применить множество методик и подсистем различных типов для извлечения информации из содержащих документы фрагментов изображений, в том числе способы и подсистемы оптического распознавание символов (OCR), которые преобразуют содержащие документы изображения или фрагменты изображений в соответствующие электронные документы, содержащие цифровые кодировки текста, а не изображения текста. Обычно электронный документ содержит цифровые значения, соответствующие текстовым символам, а также дополнительную информацию, закодированную в цифровом виде, которые регулируют и задают форматирование документа, шрифты символов, а также другую подобную информацию. Способы и подсистемы, раскрываемые в настоящем документе, направлены на выявление фрагментов изображений, соответствующих конкретным типам документов и цифровых изображений таким образом, чтобы для извлечения информации из содержащих документы фрагментов изображений могли применяться методы OCR и (или) другие методы обработки.
Во многих случаях подсистемы и методики цифровой обработки изображений направлены на извлечение информации из фрагментов изображений, соответствующих документам конкретного типа, например, водительских удостоверений, паспортов, страховых полисов, свидетельств военнослужащих и других подобных документов, которые имеют относительно точно заданные форматы, компоновки и организации. На Фиг. 9А-В показаны два документа, используемые в качестве примеров при обсуждении раскрываемых в настоящем описании способов и подсистем. На Фиг. 9А показано водительское удостоверение, а на Фиг. 9 В показаны первые две страницы паспорта. Как будет рассмотрено ниже, эти типы документов можно описать с помощью соответствующих эталонов. Фактически эти документы представляют собой физические записи или структуры данных, аналогичные записям и структурам данных, используемым при компьютерном программировании. Например, водительское удостоверение 902 на Фиг. 9А содержит шапку с аббревиатурой штата и аббревиатуру страны 904, название штата, выдавшего водительское удостоверение 905, и строку текста «Водительское удостоверение» (Driver License) 906. Все водительские удостоверения, выданные данным конкретным штатом по меньшей мере в течение некоторого последнего периода времени содержат одну и ту же идентичную шапку. Водительское удостоверение содержит две фотографии 908 и 910, причем размеры фотографий и их положения являются общими для всех выданных штатом водительских удостоверений. Кроме того, имеется множество информационных полей. В качестве одного примера, после общей отметки «4d LIC#» 912 следует номер водительского удостоверения 914, уникальный для каждого лица, которому выдано водительское удостоверение. Фамилия этого лица 916 и первое и второе имя этого лица 917-918 представлены в двух дополнительных информационных полях, которым предшествуют цифровые метки «1» и «2» 919 и 920.
Разворот паспорта, показанный на Фиг. 9В, также аналогичен записям или структурам данных, включая обитую графику, текст, фотографию стандартного размера в стандартном месте, а также несколько информационных полей, содержащих информацию, которая является уникальной или индивидуальной для физического лица, которому был выдан этот паспорт.
На Фиг. 10A-10J показаны некоторые из многочисленных проблем и задач, связанных с выявлением содержащих документ фрагментов изображений в цифровом изображении, особенно для цифрового изображения, полученного с помощью портативного смартфона или другого мобильного устройства с процессорным управлением. На Фиг. 10А приведен пример цифрового изображения, содержащий два содержащих документ фрагмента изображения. Цифровое изображение 1002 включает первый фрагмент изображения 1004, соответствующий водительскому удостоверению, и второй фрагмент изображения 1006, соответствующий первому развороту паспорта. Однако кроме этого цифровое изображение содержит различные участки фона и объекты 1008-1011. Первая проблема при выявлении фрагментов изображений, соответствующих изображениям документов, состоит в необходимости отличать эти фрагменты изображений от различных типов дополнительных признаков, шаблонов и объектов, содержащихся в цифровом изображении.
На Фиг. 10В-С иллюстрируются две дополнительные проблемы. Как показано на Фиг. 10В, угловая ориентация водительского удостоверения 1004 и паспорта 1006 отличается от угловой ориентации цифрового изображения 1016. Таким образом, угловая ориентация цифровых фрагментов изображений, соответствующих документам, например, углы ϕ 1018 и θ 1019 на Фиг. 10В, являются примерами параметров, которые могут иметь различные значения в зависимости от того, как было получено цифровое изображение и как документы были физически расположены перед получением изображения. Как показано на Фиг. 10С, другим параметром является масштаб изображения документа. В примере содержащего фрагменты изображений документа изображения 1002, показанном на Фиг. 10А, водительское удостоверение имеет границу 1018, а фрагмент изображения паспорта имеет границу 1020 определенного размера. Однако в зависимости от расстояния от цифровой камеры до этих документов размер фрагментов изображений может изменяться непрерывно в широком диапазоне размеров, как показано на Фиг. 10С пунктирными границами различных масштабов, такими как пунктирная граница 1022.
На Фиг. 10D-I показаны дополнительные проблемы, связанные с выявлением содержащих документы фрагментов изображений в цифровых изображениях, особенно полученных с помощью управляемых процессорами мобильных устройств, например, смартфонов. На Фиг. 10D показан квадратный документ 1024 в плоскости x, z трехмерного декартова пространства x, y, z 1026. На Фиг. 10Е документ повернут в плоскости x, z 1024 вокруг оси z, при этом получена повернутая версия документа 1028. На Фиг. 10F повернутая версия документа 1028 повернута вокруг проходящей через документ центральной горизонтальной линии, и получен дважды повернутый документ 1030. На Фиг. 10G-I показано изображение квадратного документа, сфотографированного при трех различных состояниях поворота, показанных на Фиг. 10D-F с помощью камеры, у которой внутренняя поверхность, на которой формируется изображение, направлена перпендикулярно к оси у. На Фиг. 10G изображение 1032 квадратного документа 1024 представляет собой точное воспроизведение документа, возможные различия определяют его масштаб или размер; фрагмент изображения документа зависит от увеличения объективом камеры и отображения снятого изображения на устройстве отображения. В отличие от него, изображение 1034 повернутого документа 1028 на Фиг. 10Е искажено, что показано на Фиг. 10Н. Полученное двухмерное изображение 1036 выглядит как параллелограмм, а не квадрат. Аналогичным образом показанное на Фиг. 10I изображение 1038 дважды повернутого документа 1030, ранее показанного на Фиг. 10F, в полученном цифровом изображении 1040 представляет собой еще сильнее искаженный параллелограмм. Таким образом, относительная ориентация поверхности съемки изображения в цифровой камере и снимаемого документа могут вводить различные вызванные относительной ориентацией искажения формы фрагмента изображения, соответствующего документу.
На Фиг. 10J показана еще одна проблема, связанная с выявлением содержащих документы фрагментов изображений в цифровом изображении. На Фиг. 10J камера перед получением изображения была смещена влево, в результате чего фрагмент изображения, соответствующий паспорту 1042 в полученном изображении 1044, теперь обрезан или усечен. Таким образом, представляющий паспорт фрагмент изображения не содержит полные границы или очертания для этого типа документа, что может создать серьезные проблемы при определении той части фрагмента изображения, которая вошла в цифровое изображение 1044.
Разумеется, могут возникнуть проблемы и задачи многих других типов в зависимости от различных параметров, связанных с получением изображений документов и с физическими документами, их расположением и ориентацией. Например, конкретное изображение может содержать только один фрагмент изображения документа, либо оно может содержать фрагменты изображений двух или более документов. Физические документы могут быть физически искажены в результате того, что документ скомкали, испачкали, разорвали, или с ним произошли другие подобные физические изменения. Документ может быть неправильно напечатан или смазан из-за неправильной подготовки документа. Из-за всех этих и дополнительных причин примитивный подход к идентификации в цифровых изображениях фрагментов документов может не обеспечивать точность и надежность, необходимую во многих приложениях. В настоящем документе описываются надежные и точные способы выявления содержащих документы фрагментов изображений в цифровых изображениях, несмотря на различные типы изменений, которые могут наблюдаться в цифровых изображениях, содержащих фрагменты изображений, соответствующие документам определенного типа.
Преобразования перспективы
На Фиг. 11A-F показан один подход к установлению соответствия между точками в глобальной системе координат и соответствующими точками в плоскости изображения камеры. На Фиг. 11А показана плоскость захвата изображения камеры, система координат камеры, совмещенная с глобальной системой координат, а также точка в трехмерном пространстве, изображение которой проецируется на плоскость захвата изображения камеры. На Фиг. 11А система координат камеры, включающая оси х, у и z, совмещена с системой глобальных координат X, Y и Z. Это обозначено на Фиг. 11А с помощью двойной маркировки осей х и X 1102, осей y и Y 1104, и осей z и Z 1106. Показано, что фотографируемая точка 1108 имеет координаты (Xp, Yp и Zp). Изображение этой точки в плоскости захвата изображения камеры 1110 имеет координаты (xi, yi). Центр виртуального объектива расположен в точке 1112, в координатах камеры (0, 0, l) и глобальных координатах (0, 0, l). Если точка 1108 находится в фокусе, то расстояние l между началом координат 1114 и точкой 1112 представляет собой фокусное расстояние камеры. В плоскости захвата изображения показан небольшой прямоугольник, его углы на одной диагонали совпадают с началом координат 1114 и точкой 1110 с координатами (xi, yi). Этот прямоугольник имеет горизонтальные стороны, включающие горизонтальную сторону 1116 длиной xi и вертикальные стороны, включающие вертикальную сторону 1118 длиной уi. Соответствующий прямоугольник имеет горизонтальные стороны длиной -Xp, включая горизонтальную сторону 1120 и вертикальные стороны длиной -Yp, включая вертикальную сторону 1122. Точка 1108 с глобальными координатами (-Xp, -Yp и Zp) и точка 1124 с глобальными координатами (0, 0, Zp) расположены в углах одной диагонали соответствующего прямоугольника. Следует обратить внимание на то, что положения двух прямоугольников инвертируются в точке 1112. Длина отрезка линии 1128 между точкой 1112 и точкой 1124 равна Zp - l. Углы, под которыми каждая из показанных на Фиг. 11а линий, проходящих через точку 1112, пересекает оси z u Z, равны по обе стороны от точки 1112. Например, угол 1130 равен углу 1132. Поэтому можно использовать соотношения между длинами подобных сторон подобных треугольников для получения выражений для координат в плоскости захвата изображения (xi, yi) точки, для которой формируется изображение, в трехмерном пространстве с глобальными координатами (Хр, Yp и Zp) 1134:
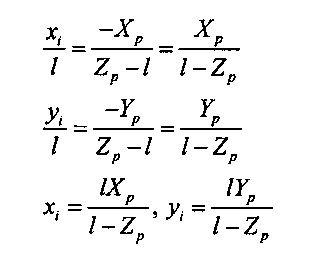
В общем случае система координат камеры не совмещена с системой глобальных координат. Поэтому требуется немного более сложный анализ для разработки функций или процессов, преобразующих точки трехмерного пространства в точки, расположенные в плоскости захвата изображения камеры.
На Фиг. 11В показаны матричные уравнения, которые описывают различные типы операций с точками в трехмерном пространстве. Преобразование 1134а перемещает первую точку с координатами (x, y, z) 1134b во вторую точку 1134с с координатами (x', y', z'). Это преобразование включает смещения в направлении х 1134d, в направлении у 1134е и в направлении z 1134f. Ниже для иллюстрации преобразования 1134а приводится матричное уравнение для преобразования 1134g. Следует отметить, что четвертое измерение добавлено к векторным представлениям точек для выражения преобразования в виде матричной операции. Значение «1» используется для четвертого измерения векторов; после вычисления координат преобразуемой точки его можно отбросить. Аналогичным образом операция масштабирования 1134h производит умножение каждой координаты вектора на масштабный коэффициент σх, σу и σz (соответственно 1134i, 1134j и 1134k). Матричное уравнение для операции масштабирования задается матричным уравнением 1134l. Наконец, точка может быть повернута вокруг каждой из трех координатных осей. На схеме 1134m показан поворот точки (x, y, z) в точку (x', y', z') путем поворота на угол γ радиан вокруг оси z. Матричное уравнение для этого поворота показано в виде матричного уравнения 1134n на Фиг. 11В. Матричные уравнения 1134о и 1134р описывают повороты вокруг осей x и y, соответственно, на углы α и β радиан, соответственно.
На Фиг. 11С-Е показан процесс вычисления изображения точек в трехмерном пространстве на плоскости захвата изображения произвольно ориентированной и расположенной камеры. На Фиг. 11С показана расположенная в произвольной точке и произвольным образом ориентированная камера. Камера 1136 установлена на штативе 1137, который позволяет наклонить камеру под углом α 1138 относительно вертикальной оси Z и повернуть ее на угол θ 1139 вокруг вертикальной оси. Штатив 1137 можно расположить в любом месте в трехмерном пространстве, его положение представлено вектором положения w0 1140 от начала системы глобальных координат 1141 к штативу 1137. Второй вектор r 1142 представляет относительное положение центра плоскости изображения 1143 в камере 1136 по отношению к штативу 1137. Ориентация и положение начала системы координат камеры совпадают с центром плоскости захвата изображения 1143 внутри камеры 1136. Плоскость захвата изображения 1143 лежит в плоскости x, y осей координат камеры 1144-1146. На Фиг. 11С показана камера, которая получает изображение точки w 1147, которой соответствует сформированное изображение точки w в виде точки изображения с 1148 в плоскости изображения 1143, лежащей внутри камеры. Вектор w0, который определяет положение штатива камеры 1137 на Фиг. 11С, показан как вектор
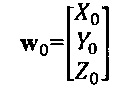 .
.
На Фиг. 11D-E показан процесс, с помощью которого координаты точки в трехмерном пространстве, например, точки, соответствующей вектору w в системе глобальных координат, преобразуются в плоскости захвата изображения произвольно расположенной и ориентированной камеры. Прежде всего на Фиг. 11D с помощью выражений 1150 и 1151 показано преобразование между глобальными координатами и однородными координатами h и обратное преобразование h-l. Прямой переход от глобальных координат 1152 к однородным координатам 1153 включает умножение каждой компоненты координат на произвольную константу к и добавление компонента четвертой координаты, имеющего значение k. Вектор w, соответствующий точке 1147 в фотографируемом камерой трехмерном пространстве, выражается как вектор-столбец, как показано в выражении 1154 на Фиг. 11D. Соответствующий вектор-столбец wh в однородных координатах показан в выражении 1155. Матрица Р - это матрица перспективного преобразования, которая приведена в выражении 1156 на Фиг. 11D. Матрица перспективного преобразования используется для осуществления преобразования глобальных координат в координаты камеры (1134 на Фиг. 11А), это преобразование обсуждалось выше со ссылкой на Фиг 11А. Форма вектора с в однородных координатах, соответствующая изображению 1148 точки 1147 ch, вычисляется с помощью умножения слева wh на матрицу перспективного преобразования, как показано в выражении 1157 на Фиг. 11D. Таким образом, выражение для ch в однородных координатах камеры 1158 соответствует однородному выражению для ch в глобальных координатах 1159. Обратное преобразование однородных координат 1160 используется для преобразования последнего в векторное выражение в глобальных координатах 1161 для вектора с 1162. Сравнение выражения в координатах камеры 1163 для вектора с с выражением для того же вектора в глобальных координатах 1161 показывает, что координаты камеры связаны с глобальными координатами преобразованиями (1134 на Фиг. 11А), описанными выше со ссылкой на Фиг. 11А. Обратная матрица перспективного преобразования Р-1 показана в выражении 1164 на Фиг. 11D. Обратную матрицу перспективного преобразования можно использовать для вычисления точки глобальных координат в трехмерном пространстве, соответствующей точке изображения, выраженной в координатах камеры, как показано выражением 1166 на Фиг. 11D. Следует отметить, что в общем случае координата Z фотографируемой камерой трехмерной точки не восстанавливается с помощью перспективного преобразования. Причина этого заключается в том, что все точки, расположенные перед камерой на линии от точки изображения до фотографируемой точки, отображаются в точке изображения. Для определения координаты Z фотографируемых камерой точек в трехмерном пространстве необходима дополнительная информация, например, информации о глубине, полученная из набора стереоизображений или информации о глубине, полученная с помощью отдельного датчика глубины.
На Фиг. 11Е показаны три дополнительные матрицы, которые представляют положение и ориентацию камеры в системе глобальных координат. Матрица преобразований 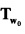 1170 представляет преобразование штатива камеры (1137 на Фиг. 11С) из его положения в трехмерном пространстве в начало координат (1141 на Фиг. 11С) глобальной системы координат. Матрица R представляет повороты на углы α и θ, необходимые для совмещения системы координат камеры с системой глобальных координат 1172. Матрица преобразования С 1174 представляет преобразование плоскости захвата изображения камеры со штатива камеры (1137 на Фиг. 11С) в положение плоскости захвата изображения в камере, представленной вектором r (1142 на Фиг. 11С). Полное выражение преобразования вектора точки в трехмерном пространстве wh в вектор, представляющий положение точки изображения в плоскости захвата изображения камеры ch, задается выражением 1176 на Фиг. 11Е. Вектор wh сначала умножают слева на матрицу преобразования 1170 для получения первого промежуточного результата, затем первый промежуточный результат умножают слева на матрицу R для получения второго промежуточного результата, второй промежуточный результат умножают слева на матрицу С для получения третьего промежуточного результата, а третий промежуточный результат умножают слева на матрицу перспективного преобразования Р для получения вектора ch. Выражение 1178 показывает обратное преобразование. Таким образом, в целом существует прямое преобразование из точек системы глобальных координат в точки изображения 1180, а при наличии достаточной информации также существует и обратное преобразование 1181. Именно прямое преобразование 1180 используется для создания двухмерных изображений из трехмерной модели или объекта, соответствующего произвольно ориентированным и расположенным камерам. Каждая точка на поверхности трехмерного объекта или модели преобразуется прямым преобразованием 1180 в точки на плоскости захвата изображения камеры.
1170 представляет преобразование штатива камеры (1137 на Фиг. 11С) из его положения в трехмерном пространстве в начало координат (1141 на Фиг. 11С) глобальной системы координат. Матрица R представляет повороты на углы α и θ, необходимые для совмещения системы координат камеры с системой глобальных координат 1172. Матрица преобразования С 1174 представляет преобразование плоскости захвата изображения камеры со штатива камеры (1137 на Фиг. 11С) в положение плоскости захвата изображения в камере, представленной вектором r (1142 на Фиг. 11С). Полное выражение преобразования вектора точки в трехмерном пространстве wh в вектор, представляющий положение точки изображения в плоскости захвата изображения камеры ch, задается выражением 1176 на Фиг. 11Е. Вектор wh сначала умножают слева на матрицу преобразования 1170 для получения первого промежуточного результата, затем первый промежуточный результат умножают слева на матрицу R для получения второго промежуточного результата, второй промежуточный результат умножают слева на матрицу С для получения третьего промежуточного результата, а третий промежуточный результат умножают слева на матрицу перспективного преобразования Р для получения вектора ch. Выражение 1178 показывает обратное преобразование. Таким образом, в целом существует прямое преобразование из точек системы глобальных координат в точки изображения 1180, а при наличии достаточной информации также существует и обратное преобразование 1181. Именно прямое преобразование 1180 используется для создания двухмерных изображений из трехмерной модели или объекта, соответствующего произвольно ориентированным и расположенным камерам. Каждая точка на поверхности трехмерного объекта или модели преобразуется прямым преобразованием 1180 в точки на плоскости захвата изображения камеры.
На Фиг. 11F показаны матричные уравнения, которые связывают два различных изображения объекта, если два различных изображения отличаются из-за относительных изменений положения, ориентации и расстояния от камеры до объектов, возникающих в связи с изменением относительного положения и ориентации камеры, положения и ориентации фотографируемых объектов или и того и другого. Поскольку при умножении квадратных матриц получается другая квадратная матрица, показанное на Фиг. 11Е уравнение 1176 можно кратко выразить формулой 1190 на Фиг. 11F. Это уравнение определяет положение точек изображения по положению соответствующих точек в трехмерном пространстве. Уравнение 1191 представляет вычисление точек во втором изображении из соответствующих точек в трехмерном пространстве, причем положение точек в трехмерном пространстве или их ориентация изменялась по отношению к соответствующим точкам, используемым для получения точек ch в первой операции создания изображения, представленной уравнением 1190. Матрицы Т, R и S в уравнении 1191 представляют операции перемещения, поворота и масштабирования. Уравнение 1190 можно переписать в виде уравнения 1192, умножив обе части уравнения 1190 на обратную матрицу М. Подставляя левую часть уравнения 1192 в уравнение 1191, получаем уравнение 1194, связывающее положения в первом изображении ch с положениями во втором изображении 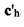 . Уравнение 1194 можно более кратко представить в виде уравнения 1195 и, как вариант, в виде уравнения 1196. Поскольку уравнение 1196 выражает зависимость между положениями точек на двух изображениях, координата z не представляет интереса, и уравнение 1196 можно переписать в виде уравнения 1197, где значения координаты z заменяются на 0. Представляя матрицу М* абстрактно в уравнении 1198, можно создать новую матрицу М** путем удаления третьей строки и третьего столбца из матрицы М*, как показано в уравнении 1199а. После удаления значений координаты z из векторов ch и получается уравнение 1199b. Если имеются четыре пары точек с известными координатами на каждом из двух изображений, то отношения между этими четырьмя парами точек можно выразить как уравнение 1199с. Это уравнение немного переопределено, но его можно использовать для определения с помощью известных методик значений девяти элементов матрицы М**. Таким образом, независимо от различий в части ориентации, положения и расстояния от камеры до набора объектов при двух различных операциях получения изображения, можно определить матрицу путем сравнения положений ряда известных соответствующих признаков на двух изображениях, что представляет собой [прямое] преобразование и обратное преобразование, связывающие эти два изображения.
. Уравнение 1194 можно более кратко представить в виде уравнения 1195 и, как вариант, в виде уравнения 1196. Поскольку уравнение 1196 выражает зависимость между положениями точек на двух изображениях, координата z не представляет интереса, и уравнение 1196 можно переписать в виде уравнения 1197, где значения координаты z заменяются на 0. Представляя матрицу М* абстрактно в уравнении 1198, можно создать новую матрицу М** путем удаления третьей строки и третьего столбца из матрицы М*, как показано в уравнении 1199а. После удаления значений координаты z из векторов ch и получается уравнение 1199b. Если имеются четыре пары точек с известными координатами на каждом из двух изображений, то отношения между этими четырьмя парами точек можно выразить как уравнение 1199с. Это уравнение немного переопределено, но его можно использовать для определения с помощью известных методик значений девяти элементов матрицы М**. Таким образом, независимо от различий в части ориентации, положения и расстояния от камеры до набора объектов при двух различных операциях получения изображения, можно определить матрицу путем сравнения положений ряда известных соответствующих признаков на двух изображениях, что представляет собой [прямое] преобразование и обратное преобразование, связывающие эти два изображения.
Детекторы признаков
Детекторы признаков - это другой тип методов обработки изображений, различные типы которых используются в способах и системах, раскрываемых ниже в настоящем описании. Конкретный детектор признаков, который называется «преобразование масштабно-инвариантных признаков» (SIFT), обсуждается более подробно в этом подразделе как пример различных детекторов признаков, которые могут использоваться в способах и подсистемах, раскрываемым в настоящем документе.
На Фиг. 12 показано обнаружение признаков методом SIFT. На Фиг. 12 приведено первое простое цифровое изображение 1202, которое включает в себя, как правило, не имеющий признаков фон 1204 и область затененного диска 1206. Применение метода обнаружения признаков SIFT к этому изображению формирует набор ключевых точек или признаков, таких как признаки 1208-1217, наложенные на копию 1220 исходного изображения, как показано на рисунке 12 справа от исходного изображения. По существу признаки - это особые точки в цифровом изображении, имеющие координаты (x, y) относительно осей координат изображения, которые обычно параллельны верхнему и левому краям изображения. Эти точки выбираются так, чтобы они были относительно инвариантными к преобразованию изображения, масштабированию и повороту, а также частично инвариантными к изменениям освещения и аффинным проекциям. Таким образом, в том случае, когда сначала получают изображение конкретного объекта для формирования канонического изображения объекта, признаки, которые формируются с помощью метода SIFT для этого первого канонического образа, можно использовать для выявления этого объекта на дополнительных изображениях, в которых получение изображения может во многом отличаться, включая перспективу, освещение, расположение объекта по отношению к камере, ориентацию объекта относительно камеры или даже физическое искажение объекта. Каждый признак, сформированный методом SIFT, кодируется, в виде набора значений и сохраняется в базе данных, в файле, в структуре, находящейся в памяти данных, или другом таком устройстве хранения данных. На Фиг. 12 сохраненные дескрипторы содержатся в таблице 1230, каждая строка которой представляет тот или иной признак. Каждая строка содержит несколько различных полей, соответствующих столбцам в таблице: (1) x 1231, x - координата признака; (2) y 1232, y - координата признака; (3) m 1233 - значение признака; (4) θ 1234 - угол ориентации признака; (5) σ 1235 - значение масштаба для признака; и (6) дескриптор 1236 - закодированный набор признаков локального окружения признака, который можно использовать для определения того, можно ли считать локальное окружение точки в другом изображении того же признака, который был выявлен в другом изображении.
Фиг. 13-18 содержат справочную информацию по различным концепциям, используемым методом SIFT для выявления признаков в изображениях. На Фиг. 13 показано дискретное вычисление градиента яркости. На Фиг. 13 показан небольшой квадратный участок 1302, который составляет часть цифрового изображения. Каждая клетка, например, клетка 1304, представляет пиксель, а числовое значение в клетке, например, значение «106» в клетке 1304 представляет яркости серого цвета. Допустим, пиксель 1306 имеет значение интенсивности «203». Этот пиксель и четыре его ближайшие соседа показаны в крестообразной схеме 1308 справа от участка цифрового изображения 1302. Рассмотрим левый ближайший соседний пиксель 1310 и правый ближайший соседний пиксель 1312; изменение значения яркости в направлении x, Δx, можно дискретно вычислить следующим образом:
Если рассмотреть нижний ближайший соседний пиксель 1314 и верхний ближайший соседний пиксель 1316, изменение яркости в вертикальном направлении Δу, можно вычислить следующим образом:
 .
.
Вычисленное значение Δx является оценкой частного дифференциала непрерывной функции яркости по координате x в центральном пикселе 1306:
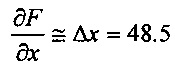 .
.
Оценочное значение частного дифференциала функции интенсивности F по координате у в центральном пикселе 1306 равно Δy:
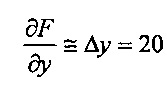 .
.
Градиент яркости в пикселе 1306 может быть рассчитан следующим образом:
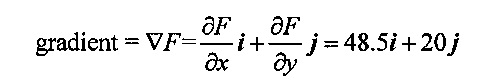
где i и j представляют собой единичные векторы в направлениях x и y. Модуль вектора градиента и угол вектора градиента далее рассчитываются следующим образом:
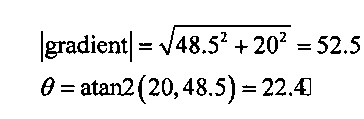 .
.
Направление вектора 1320 градиента яркости и угол θ 1322 показаны наложенными на часть 1302 цифрового изображения на Фиг. 13. Следует обратить внимание на то, что вектор градиента направлен в сторону наискорейшего возрастания яркости в пикселе 1306. Модуль вектора градиента указывает на ожидаемое увеличение яркости на единицу приращения в направлении градиента. Разумеется, поскольку градиент оценивается только с помощью дискретных операций, при показанном на Фиг. 13 вычислении направление и модуль градиента представлены исключительно расчетными значениями.
На Фиг. 14 показан градиент, рассчитанный для точки на непрерывной поверхности. На Фиг. 14 представлена непрерывная поверхность z=F(x, y). Непрерывная поверхность 1402 строится относительно трехмерной декартовой системы координат 1404 и имеет похожую на шляпу форму. На поверхности можно построить контурные линии, такие как контурная линия 1406, чтобы указать непрерывное множество точек с постоянным значением z. В конкретной точке 1408 на контуре, построенном на поверхности, вектор градиента 1410, рассчитанный для точки, расположен перпендикулярно к контурной линии и точкам в направлении максимального наклона вверх на поверхности от точки 1408.
Обычно вектор градиента яркости расположен перпендикулярно границе яркости, при этом чем больше модуль градиента, тем данная граница более четкая, т.е. тем больше разность в яркости пикселей с двух сторон границы. На Фиг. 15 показан ряд примеров градиента яркости. Каждый пример, например, пример 1502, содержит центральный пиксель, для которого рассчитывается градиент, а для расчета Δx и Δy используются четыре прилегающих пикселя. Границы с наибольшей яркостью показаны в первой колонке 1504. В этих случаях величина градиента составляет не менее 127,5, а в третьем случае 1506 - не менее 180,3. Относительно небольшая разность по границе, показанная в примере 1508, создает градиент величиной всего 3,9. Во всех случаях вектор градиента расположен перпендикулярно очевидному направлению границы яркости, проходящей через центральный пиксель.
Многие методы обработки изображений включают применение ядер к сетке пикселей, составляющей изображение. На Фиг. 16 показано применение ядра к изображению. На Фиг. 16 небольшая часть изображения 1602 представлена в виде прямоугольной сетки пикселей. Ниже изображения I 1602 показано небольшое ядро k 1604 размером 3×3. Ядро применяется к каждому пикселю изображения. В случае ядра 3×3, такого как ядро k 1604, показанное на Фиг. 16, для пикселей на границе можно использовать модифицированное ядро, также изображение можно раздвинуть, скопировав значения яркости для пикселей границы в описывающий прямоугольник из пикселей, чтобы иметь возможность применять ядро к каждому пикселю исходного изображения. Чтобы применить ядро к пикселю изображения, ядро 1604 численно накладывается на окрестность пикселя 1606 на изображении с такими же размерами в пикселях, как у ядра. Применение ядра к окрестности пикселя, к которому применяется ядро, позволяет получить новое значение для пикселя в преобразованном изображении, полученном применением ядра к пикселям исходного изображения. Для некоторых типов ядер новое значение пикселя, к которому применено ядро, In, вычисляется как сумма произведений значения ядра и пикселя, соответствующего значению 1608 ядра. В других случаях новое значение пикселя является более сложной функцией окрестности для пикселя и ядра 1610. В некоторых других типах обработки изображений новое значение пикселя формируется функцией, применяемой к окрестностям пикселя без использования ядра 1612.
На Фиг. 17 показана свертка ядра с изображением. Обычно ядро последовательно применяется к каждому пикселю изображения, в некоторых случаях к каждому пикселю изображения, не принадлежащему границе, или, в других случаях - для создания новых значений преобразованного изображения. На Фиг. 17 ядро 3×3, выделенное штриховкой 1702, было последовательно применено к первой строке пикселей, не принадлежащих границе на изображении 1704. Каждое новое значение, созданное в результате применения ядра к пикселю в исходном изображении 1706, было перенесено в преобразованное изображение 1707. Другими словами, ядро было последовательно применено к исходным окрестностям каждого пикселя в исходном изображении для создания преобразованного изображения. Этот процесс называется «сверткой» и слабо связан с математической операцией свертки, которая выполняется путем умножения изображений, к которым применено преобразование Фурье с последующим обратным преобразованием Фурье по произведению.
На Фиг. 18 показан некоторый пример ядра и методики обработки изображений на основе ядра. В процессе, называемом «медианной фильтрацией», значения яркости в окрестности исходного изображения 1802 были отсортированы 1804 по возрастанию модулей, и новым значением 1808 для соответствующей окрестности преобразованного изображения было выбрано медианное значение 1806. Гауссово сглаживание и очистка от шумов включают применение гауссова ядра 1810 ко всем окрестностям 1814 исходного изображения для создания значения для центрального пикселя окрестности 1816 в соответствующей окрестности обработанного изображения. Значения в гауссовом ядре рассчитываются по выражению, например, по выражению 1818 для создания дискретного представления гауссовой поверхности над окрестностью, образованной вращением кривой нормального распределения вокруг вертикальной оси, совпадающей с центральным пикселем. Горизонтальная и вертикальная компоненты градиента изображения для каждого пикселя могут быть получены применением соответствующих ядер градиента Gx 1820 and Gy 1822. Были указаны только три из множества различных типов методик обработки изображения на основе свертки.
Вернемся к методу SIFT; первая задача состоит в определении положения точек-кандидатов в изображении для обозначения в качестве признаков. Точки-кандидаты определяются с помощью серии шагов гауссовой фильтрации или сглаживания и повторной дискретизации, с тем чтобы создать первую пирамиду гауссианов, с последующим вычислением различия между соседними слоями в первой пирамиде гауссианов, чтобы получить вторую пирамиду, представляющую собой разность гауссианов (difference-of-Gaussians или DoG). Экстремальные точки в окрестностях пирамиды DoG выбираются в качестве признаков-кандидатов, причем максимальное значение точки в окрестности используется для определения значения масштаба признака-кандидата.
На Фиг. 19A-D показан выбор кандидатов на ключевые точки в изображении. На Фиг. 19А показаны изменения формы одномерной гауссовой кривой при увеличении значения параметра отклонения для кривой. Первая одномерная гауссова кривая 1902 получается с использованием начального параметра дисперсии 1903. При увеличении значения параметра дисперсии для получения второго параметра дисперсии 1904 получается более широкая гауссова кривая 1905. При увеличении параметра дисперсии гауссова кривая становится все шире и шире, см. серию гауссовых кривых 1902, 1905 и 1906-1907. Обычно свертывание гауссова ядра с изображением приводит к удалению мелких деталей и сглаживает изображение. При увеличении параметра дисперсии соответствующее гауссово ядро все сильнее удаляет детализацию из изображения, что приводит к усилению смаза изображения, поскольку значение, присвоенное центральному пикселю гауссовым ядром, является средним значением увеличивающегося количества соседних пикселей.
На Фиг. 19 В показано изменение масштаба изображения. В исходном изображении 1910 имеются десять строк пикселей и восемь столбцов пикселей. Пиксели этого изображения можно разбить на 20 групп из четырех пикселей 1912, причем каждой такой группе назначается среднее значение четырех пикселей. Затем для этих средних значений можно произвести повторную дискретизацию и получить изображение 1914, имеющее другой масштаб и меньшее число пикселей. В этом заключается один простейший метод изменения масштаба. В общем случае для изменения масштаба можно выбрать произвольный параметр изменения масштаба, при этом значения пикселей после изменения масштаба вычисляются из окрестностей точек сетки в исходном изображении на основе параметра изменения масштаба.
На Фиг. 19С показано построение первоначальной пирамиды гауссианов и второй пирамиды DoG. Первоначальная пирамида гауссианов 1920 начинается с исходного изображением 1922 как самого низкого уровня. Исходное изображение сглаживают с помощью гауссова ядра для получения соответствующего сглаженного изображения 1924. Символ «G» и вертикальная стрелка 1925 представляют операцию гауссова сглаживания. Далее для сглаженного изображения 1924 будет произведено изменение масштаба для получения изображения с измененным масштабом 1926. Эта операция изменения масштаба представлена символом «S» и стрелкой 1927. Затем изображение с измененным масштабом сглаживают путем применения фильтра Гаусса для получения сглаженного изображения с измененным масштабом 1928. Эти операции повторяют для создания последовательных двойных слоев первоначальной пирамиды гауссианов. Вторую пирамиду DoG 1930 получают путем вычисления разностного изображения от каждой пары соседних изображений в первоначальной пирамиде гауссианов 1920. Например, первое изображение 1932 во второй пирамиде DoG получают путем вычисления разности 1933 первых двух изображения 1922 и 1924 в первоначальной пирамиде гауссианов 1920. Поскольку гауссово ядро применяется к исходному изображению со все большими изменениями масштаба, операция сглаживания, представленная каждой последовательной гауссовой операцией сглаживания снизу до верха пирамиды гауссианов, эффективно производит сглаживание с большими значениями параметра дисперсии. Таким образом, при перемещении снизу до верха пирамиды гауссианов 1920 изображения становится все более смазанными. Значение масштаба 1936-1939, связанное с каждым слоем в пирамиде DoG 1930, отражает комбинированные эффекты изменения масштаба и гауссова сглаживания с большим значением параметра масштаба, указывающего на усиление смаза изображения.
На Фиг. 19D показан выбор признака-кандидата с использованием пирамиды DoG, полученной с помощью способов, описанных выше со ссылкой на Фиг. 19А-С. Точка на самом нижнем уровне пирамиды DoG, например, точка 1940, имеет соответствующие положения в изображениях на более высоких уровнях 1941 и 1942 в пирамиде DoG 1930. Окрестность 3×3 точки в каждом из трех последовательных слоев 1944-1946 представляет собой окрестность точки внутри пирамиды DoG. Если значение точки является максимальным значением в окрестности каждого слоя, то эта точка выбирается в качестве кандидата на точку признака. Более того, параметр масштаба, связанный с изображением, из которого выбирают слой окрестности для слоя окрестности, в котором эта точка имеет максимальное значение, выбирается в качестве масштаба для кандидата на точку признака (1235 на Фиг. 12). Таким образом, используя способ, изложенный со ссылкой на Фиг 19A-D, получают набор точек-кандидатов признаков вместе с параметрами x, y и σ для кандидата на точку признака.
Следует отметить, что приведенное выше описание является несколько упрощенным. Например, исходное изображение может быть добавлено в качестве самого нижнего уровня пирамиды Dog, и можно использовать минимизацию ряда Тейлора, чтобы точнее определить положения точек в слоях пирамиды гауссианов и пирамиды DoG. Фактически этот метод является приближением к построению пространства масштаба в виде лапласиана гауссианов - математической операции, на которой основано множество различных методов обработки изображений.
На Фиг. 19Е показана фильтрация кандидатов на ключевые точки, или признаки, в слоях DoG, полученные способом SIFT. Экстремальные значения в этих слоях являются кандидатами на ключевые точки или признаки. Поскольку процедура DoG имеет тенденцию усиливать точки, лежащие на краях, кандидаты на ключевые точки или признаки фильтруют для удаления кандидатов на ключевые точки или признаки, близкие к краям, а также кандидатов в ключевые точки или признаки и со значениями меньше минимального или порогового значения. Таким образом, для получения меньшего отфильтрованного набора признаков-кандидатов 1950d из исходного набора кандидатов на ключевые точки или признаки 1950а исключаются признаки-кандидаты со значениями меньше минимального или порогового значения или с отношением главных кривизн, превышающим значение, полученное с использованием другого порога r 1950с. Отношение главных кривизн получается из матрицы Гессе 1950е, которая описывает локальную кривизну поверхности.
На Фиг. 19F показано назначение величины и ориентации признака из значений в слое DoG. Рассматривают окрестность пикселя 1954а вокруг выявленного кандидата на ключевую точку 1954b. Для каждой точки в этой окрестности, например, для точки 1954с, оценивают градиент величины 1954d и угол ориентации 1954е, используя различия величин соседних пикселей. Гауссова взвешивающая поверхность 1954f строится над локальной окрестностью 1954а с помощью параметра гауссиана σ, равного значению ν, умноженному на значение масштаба для плоскости DoG 1954g. Высота 1954h взвешивающей поверхности относительно определенной точки t используется в качестве множителя вычисленного значения для пикселя с целью получения веса w 1954i. Затем взвешенные величины пикселей вводятся в гистограмму 1954j, которая включает 36 элементов для каждого диапазона в 10° вычисленных ориентаций градиента для пикселей. Величина и значение θ для самого высокого полученного пика 1954k используется в качестве величины и значения θ для признака 1954b. Любой пик на гистограмме, который больше или равен 80 процентам от высоты самого высокого пика, например, пика 1954l и 1954m, рассматривается как дополнительный признак, назначенный соответствующим величинам и значениям θ для этих пиков.
На Фиг. 19G показано вычисление дескриптора признака. На Фиг. 19G признак находится в положении 1956а внутри окрестности 1956b, содержащей 16×16 пикселей. Как и в случае гауссовой поверхности, построенной так, как показано на Фиг. 19F, аналогичная гауссова поверхность строится над окрестностью 1956b, как показано пунктирной окружностью 1956с на Фиг. 19G. Высота поверхности точки над точкой используется для взвешивания значений градиента, определенных для каждого пикселя в окрестности 1956b. Для каждой окрестности 4×4 в окрестности 1956b строится гистограмма, например, гистограмма 1956d, например, с окрестностью 4×4 1956е. Взвешенные величины для пикселей в каждой из окрестностей 4×4 помещаются в гистограмму в соответствии с вычисленными ориентациями градиентов для пикселей. В этом случае гистограмма имеет восемь элементов, причем каждый элемент, соответствующий диапазону 45° значений θ. Затем высоты или величины столбцов гистограмм вводятся в 128-элементной вектор 1956f и формируют дескриптор признака. Теперь завершено описание определения всех атрибутов признаков SIFT, показанных в виде столбцов в таблице 1230 на Фиг. 12.
Другой способ, используемый при идентификации и описании признаков SIFT, а также во многих других методах обработки изображений, называется преобразование Хафа (Hough transform). На Фиг. 19H-I показано простое применение преобразования Хафа с одним параметром. Это применение, для которого преобразование Хафа было первоначально предложено в контексте обработки изображений. Как показано на Фиг. 19Н, уравнения для линий на двумерной плоскости можно выразить в виде нормальной формы y=mx + b 1958а. На приведенном слева графике нанесены две линии: линия 1 1958b и линия 2 1958с. Уравнения y=mx + b для этих линий показаны как выражения 1958d и 1959е, соответственно. С другой стороны, эти линии могут быть представлены в виде r=x cos θ + y sin θ, как показано на приведенном справа графике 1958f на Фиг. 19Н. На этом графике те же две линии 1958b и 1958с снова построены в двумерной плоскости. Параметр r является кратчайшим расстоянием между линией и началом координат 1958g, которые определяют присвоения координат точкам в двумерной плоскости. Угол отрезка, который соединяет линию с началом координат, например, отрезок 1958h, показанный в виде отрезка пунктирной прямой линии, соединяющей линию 1958b с началом координат 1958g, по отношению к горизонтальной оси координат 1958i является параметром θ в форме уравнения линии r=x cos θ + y sin θ. Формы уравнения r=x cos θ + y sin θ - это выражения для двух линий 1958b и 1958с, показанные как выражения 1958j и 1958k под графиком 1958f.
На Фиг. 19I показан пример проблемы определения того, можно ли описать набор из трех точек данных, нанесенных на двумерную плоскость, как принадлежащий линии, и при положительном ответе на этот вопрос, получение уравнения этой линии. На графике 1960а, приведенном в правом верхнем углу Фиг. 19I, показан график из трех точек данных 1960b, 1960с, и 1960d, причем их декартовы координаты отображаются рядом с точками данных. Эти точки данных не лежат точно на одной линии, но они расположены близко к этой линии. В методе с преобразованием Хафа каждая точка данных определяет значения в пространстве параметров r/θ, соответствующие возможным линиям, на которых находится точка данных. Например, точка данных 1960b показана на графике 1960е как лежащая на семи различных линиях, указанных как отрезки пунктирных линий, такие как отрезок пунктирной линии 1960f. Эти линии находятся на одинаковом расстоянии друг от друга по своей ориентации с относительной ориентацией 22,5° 1960g. Параметры r и θ для каждой этих линий вычисляются из отрезков кратчайшего расстояния от каждой из этих линий до начала координат, таких как кратчайшее расстояние от отрезка линии 1960h, соединяющее линию 1960i с началом координат 1960j. Значения r и θ для каждой из возможных линий, на которых находится точка данных 1960b, затем приведены в таблице 1960k. Значения r и θ для линий, на которых могут располагаться точки данных 1960с и 1960d, аналогичным образом приведены в таблицах 1960l и 1960m. Эти табличные значения можно рассматривать как голос каждой точки данных для конкретных пар r/θ. Пространство параметров r/θ можно рассматривать как сетку из прямолинейных ячеек, причем каждая ячейка представляет небольшой диапазон значений r и θ. Ячейка, которая получит наибольшее количество голосов, показанных на Фиг. 19I звездочками, например, звездочка 1960n, выбирается в качестве значения r и θ в для наилучшей линии, совпадающей с положением точек данных. Эта линия 1960о показана на графике по отношению к точкам данных на графике 1960р в нижней правой части Фиг. 19I. На рисунке видно, что точки данных лежат очень близко к этой линии. Таким образом, преобразования Хафа можно описать как метод с голосованием за параметр, в котором точки данных голосуют за ячейки в пространстве параметров, которым они могут соответствовать, а ячейки, получившие наибольшее количество голосов, выбираются в качестве наборов-кандидатов для значений параметров математической модели относительного положения точек данных. Как правило, преобразование Хафа обычно применяется к выбору математических моделей с произвольным числом параметров.
На Фиг. 19J-K показано использование точек SIFT для распознавания объектов в изображениях. Как показано на Фиг. 19J, получается ряд различных изображений от Рl1 до Pn 1962а-е, которые включают конкретный объект. В общем случае каждое из этих различных изображений 1962а-е берется из разных углов и позиций по отношению к объекту, чтобы захватить множество различных способов, которыми объект может появиться в двумерном изображении. Набор признаков или ключевых точек SIFT определяется для каждого изображения и помещается в базу данных ключевых точек SIFT 1962f. Следует обратить внимание на то, что каждый признак или ключевая точка характеризуется обсуждавшимися выше атрибутами признака SIFT 1962g, а также атрибутом 1962h, соответствующим конкретному изображению или положению, из которого был извлечен этот признак. Также следует отметить, что признаки или ключевые точки выбираются для лежащих внутри конкретного объекта или вблизи его, и это необходимо охарактеризовать в последующих исходных изображениях.
На Фиг. 19K показано, как можно идентифицировать объект внутри исходного изображения. На Фиг. 19K исходное изображение, содержащее фрагмент изображения объекта 1964а, показано в правом верхнем углу рисунка. База данных признаков SIFT 1962f снова показана на Фиг. 19K в верхнем левом углу. На первом шаге признаки SIFT извлекаются из исходного изображения 1964а и сопоставляются с признаками SIFT в базе данных, как показано на Фиг. 19K, помеченной стрелкой 1964b и псевдокодом 1964с. При этом создается набор совпадений 1964d, в котором последовательные пары смежных строк представляют признак SIFT, извлеченный из исходного изображения и соответствующий признакам SIFT из базы данных. Совпадение, указанное в псевдокоде 1964с, основано на совпадении 128-элементных дескрипторов извлеченных признаков SIFT с дескрипторами хранящихся в базе данных признаков SIFT. Это осуществляется с помощью метода ближайших соседей, который находит в базе данных признак SIFT с ближайшим дескриптором, определенным по расстоянию в пространстве высокой размерности, до дескриптора рассматриваемой точки SIFT, извлеченной из исходного изображения. Однако для исключения ложных совпадений, совпадение регистрируется только тогда, когда отношение расстояний для наилучшим образом соответствующего дескриптора и следующего наилучшего дескриптора ниже, чем первое пороговое значение, а самое малое расстояние меньше второго порогового значения.
На следующем этапе, показанном вертикальной стрелкой 1964е, на основе преобразования Хафа осуществляется построение кластеров для группировки совпадений по положению. Каждое совпадение признака исходного изображения с признаками из базы данных может считаться голосом за конкретные преобразование x, y, масштаб и угол ориентации. Кластерам максимумов в четырехмерном пространстве Хафа соответствуют наиболее вероятные положения объектов. Затем похожий на RANSAC метод выбора, показанный горизонтальной стрелкой 1964f, используют для выбора наиболее вероятного положения объекта из кластеров, полученных путем преобразования Хафа. Затем можно использовать признаки в выбранном кластере для определения местоположения объекта в исходном изображении.
Способы и подсистемы, к которым относится настоящий документ
На Фиг. 20A-N представлен обзор способов и систем, к которым относится настоящий документ, а также подробное описание создания модели документа в соответствии со способами и системами настоящего изобретения. Как говорилось выше со ссылкой на Фиг. 9A-10J, настоящий документ относится к способам и системам обработки изображений различных типов хорошо определенных документов, сертификатов и других форм, содержащих информацию, которые могут быть описаны с помощью эталонов. Поскольку в процессе формирования изображения в него вносятся искажения различного типа, извлечение данных из таких изображений документов может быть трудной задачей.
На Фиг. 20А приводится краткий обзор способов и систем выявления содержащих документы фрагментов изображений на цифровых изображениях, определения границ содержащих документы фрагментов изображений, определения типа документа, соответствующего содержащему документ фрагменту изображения, и выравнивания, переориентации и изменения масштаба содержащего документ фрагмента изображения, при необходимости, для извлечения текстовой информации из содержащих документ фрагментов изображения. Изображение 2002а, подвергаемое воздействию раскрываемых в настоящем документе способов и систем, проходит первичную обработку 2002b для получения обработанного исходного изображения 2002с. Первичная обработка может включать изменение масштаба исходного изображения для нормализации масштаба исходного изображения в соответствии с наиболее подходящим для идентификации содержащих документ фрагментов на исходном изображении масштабом при сборе данных с ранее обработанных изображений. Первичная обработка может включать корректировку контрастности, создание полутоновых или бинаризованных изображений, необходимых для отдельных типов детекторов признаков, и другие подобные операции первичной обработки. Далее к обработанному исходному изображению применяются один или несколько детекторов признаков, и обнаруженные признаки 2002d используются в различных процессах распознавания и моделирования для получения характеристик 2002е и 2002f каждого отдельного содержащего документ фрагмента в обрабатываемом исходном изображении. Эти характеристики обычно содержат указание на тип документа, представленного содержащем документ фрагментом изображения 2002g, координаты углов или других важных точек содержащего документ фрагмента изображения 2002h, указание на угловую ориентацию содержащего документ фрагмента изображения относительно обрабатываемого исходного изображения 2002i и преобразование или математическую модель 2002j, которую можно применить к пикселям содержащего документ фрагмента изображения для изменения ориентации фрагмента изображения и коррекции перспективных и других искажений так, чтобы из представляющего документ фрагмента изображения можно было извлечь текстовую информацию. С использованием характеристик содержащего документ фрагмента изображения 2002е и 2002f содержащий документ фрагмент изображения извлекается из обрабатываемого исходного изображения 2002k и 2002l, после чего его ориентация меняется, и он подвергаются обработке для устранения искажений 2002m и 2002n, в результате получаются отдельные обработанные содержащие документы фрагменты изображения 2002о и 2002р, которые имеют такое качество, как если бы они были получены с помощью устройства захвата изображения, установленного так, чтобы записывать изображения, не имеющие перспективные искажения и другие типы искажений, масштаб которых совпадает с ожидаемым масштабом. Это позволяет математически совместить эталон типа документа с фрагментами изображений для выявления окон с конкретной информацией, например, информационного окна 2002s в содержащем документ фрагменте изображения, который содержит текстовую информацию определенного вида. Извлечение текстовой информации через эти информационные окна значительно облегчается и приводит к сведению воедино необходимой информации, содержащейся в содержащем документ фрагменте изображения, в базе данных документов 2002t или, в другом случае, в изображении или коде записи, которая выводится через интерфейс вывода или вводится с использованием API в приложения, получающие информацию.
На Фиг. 20В показана информация исходного изображения, которая используется для создания модели определенного типа документа. Эталон канонического изображения документа 2004а представляет собой изображение документа определенного типа, из которого удалена специфичная для документа информация и подробности. Например, эталонное изображение 2004а можно сравнить с изображением настоящих водительских прав, приведенным на Фиг. 9А, для оценки видов информации, сохраненной в эталонном изображении, и видов удаленной информации. Эталонное изображение 2004а содержит только ту информацию, которая будет выглядеть одинаково на изображениях различных документов этого типа. Например, все водительские права штата Вашингтон содержат идентичную информацию в шапке 2004b в верхней части водительских прав, различные нумерованные информационные поля, например, нумерованное поле «15 Sex» 2004с, и прямоугольные области 2004d и 2004е, которые содержат изображения человеческого лица. Эталонное изображение 2004а представляет собой изображение, имеющее стандартный масштаб и свободное от перспективных и других искажений. Кроме эталонного изображения также захватываются и сохраняются многие другие изображения (или изображения в различных положениях), содержащие стандартную информацию документа. На Фиг. 20В эталонное изображение и различные дополнительные изображения представлены прямоугольниками 2004e-i, с многоточиями 2004j, которые представляют дополнительные положения эталонного документа. Как говорилось выше при обсуждении Фиг. 19J, каждое дополнительное изображение (или изображение в дополнительном положении) захватывается с различной относительной ориентацией документа и устройства получения изображения.
Фиг. 20С иллюстрирует исходные данные, собранные из эталонного изображения и дополнительных изображений в различных положениях, которые используются для создания модели эталонного изображения и, в сущности, общей информации документа определенного типа. На Фиг. 20С эталонное изображение 2005е и изображения в дополнительных положениях 2005f, 2005g и 2005h снова представлены в виде столбца прямоугольников. Дополнительные столбцы на Фиг. 20С соответствуют различным типам детекторов признаков 2005j-2005m. Таким образом, на Фиг. 20С показана матрица или таблица, строки которой соответствуют эталонному изображению или эталонному изображению в дополнительных положениях, а столбцы - детекторам признаков. Каждая ячейка матрицы, например, ячейка 2005i, содержит признаки, извлеченные детектором соответствующего столбца, в котором расположена ячейка, для изображения, соответствующего строке, в которой расположена ячейка. Таким образом, исходными данными для создания модели являются все признаки, извлеченные всеми различными детекторами из всех различных изображений эталонных документов. Некоторые из детекторов в состоянии извлекать признаки, аналогичные описанным выше ключевым точкам или признакам SIFT, а другие детекторы могут обнаруживать изображения лиц, линии или другие геометрические фигуры, а также другие виды признаков.
На Фиг. 20D приведены некоторые структуры данных, которые содержат исходную информацию для создания модели, обсуждавшейся выше по отношению к Фиг. 20В-С, и другую полученную информацию. Эти структуры данных используются в последующих блок-схемах, которые иллюстрируют процесс создания модели. Первая структура данных, массив «images» 2006а, представляет собой массив ссылок 2006b на эталонное изображение и дополнительные изображения в различных положениях. Количество изображений описывается константой «NUM_IMAGES» 2006с. Каждое изображение содержит пиксели цифрового изображения 2006d в матрице пикселей размера IMAGE_X 2006е и IMAGE_Y 2006f. Кроме того, изображение содержит метаданные 2006g цифрового изображения, которые могут включать индикаторы цветовой модели, кодировку пикселей, тип документа и другую подобную информацию.
Структура данных признаков 2006j содержит различные информационные поля, значения которых описывают отдельные признаки, извлеченные из одного из изображений, ссылка на которое имеется в массиве «images». Эти поля могут включать поле image_index 2006k, которое содержит числовой индекс изображения, из которого был извлечен признак, поле detector_index 2006l, которое содержит индекс детектора, который использовался для извлечения индекса, различные характеристики признака 2006m, например, координаты x,y, тип признака, ориентацию и дополнительные координаты различных не точечных признаков, а также поле 2006n, которое представляет собой поле счета или аккумулятора, используемое при создании модели, как будет рассмотрено ниже. Структура данных featureSet 2006о представляет собой набор или коллекцию структур данных признаков. Массив «detectors» 2006р представляет собой массив ссылок 2006q на различные детекторы признаков 2006r, на Фиг. 20D представленные вызовом функции, которая получает ссылку на индекс изображения и возвращает ссылку на структуру данных «featureSet», которая содержит все признаки, извлеченные детектором из исходного изображения. Двухмерный массив «featureSets» 2006s представляет собой двухмерный массив 2006х ссылок на структуры данных «featureSet», соответствующие матрице, обсуждавшейся ранее со ссылкой на Фиг. 20С. Двухмерный массив «featureSets» индексируется по изображению и детектору. Наконец, массив «transforms» 2006у содержит математическую модель или матрицу преобразования для каждого изображения в определенном положении.
На Фиг. 20Е представлена первая блок-схема верхнего уровня для методики создания модели, которая используется для создания математических моделей документов, используемых на шаге выявления и оценки областей документа (2002d на Фиг. 20А) для выявления и получения характеристик содержащих документ фрагментов изображения в исходном изображении. На шаге 2008а способ создания модели получает массив изображений и детекторов, обсуждавшийся ранее со ссылкой на Фиг. 20D, а также соответствующие константы NUM_IMAGES и NUM_DETECTORS. Следует учитывать, что для удобства количество изображений и количество детекторов в описываемом варианте реализации изобретения закодированы как константы, однако они также могут храниться в виде переменных, передаваемых в качестве аргументов. На шаге 2008b способ создания модели выделяет место для двухмерного массива «featureSets» и массива «transforms», обсуждавшихся ранее со ссылкой на Фиг. 20D. Затем во вложенных циклах for на шагах 2008с-2008l процесс создания модели создает структуры данных «featureSet», содержащие извлеченные признаки для заполнения всех ячеек двухмерного массива «featureSets», обсуждавшегося ранее со ссылкой на Фиг. 20D. Каждая ячейка двухмерного массива «featureSets» содержит признаки, извлеченные из определенного изображения документа j, будь то эталонное изображение или изображение в определенном положении, с помощью того или иного детектора признаков k. На шаге 2008е подпрограмма «изменение масштаба» (scale change) определяет, следует ли выполнять изменение масштаба рассматриваемого изображения для оптимизации извлечения признаков детектором k. Если необходимо изменение масштаба, на шаге 2008f выполняется изменение масштаба, и переменная scaled (масштаб изменен) получает значение true (истина). В противном случае переменная scaled на шаге 2008g получает значение false (ложь). Текущий детектор k вызывается на шаге 2008h, чтобы создать следующую структуру данных featureSet, содержащую признаки, извлеченные рассматриваемым детектором k из текущего изображения j. Если переменная «масштаб изменен» (scaled) имеет значение «истина» (true), определенное на шаге 2008i, масштаб извлеченных признаков изменяется на шаге 2008j. На шаге 2008m происходит обращение к процедуре «найти совпадающие признаки» (find matching features), которая ведет подсчет наборов признаков эталонного изображения, извлеченных каждым детектором, для которых обнаружены соответствующие признаки, в наборах признаков, извлеченные теми же детекторами в изображениях в дополнительных положениях. В конце, на шаге 2008n, производится вызов подпрограммы «создать модель» (generate model) для создания модели документа в исходных изображениях.
В процессе создания модели используются преобразования для представления связи между признаками, извлеченными из изображения в определенном положении, и соответствующими признаками, извлеченными из эталонного изображения. В раскрываемых в настоящем документе способах и системах используются два вида преобразований. Если эталонное изображение и изображения в различных положениях были вручную аннотированы и содержат индикаторы границ содержащих документы фрагментов изображений, может быть использовано простое преобразование по относительным координатам для совмещения координат признаков, извлеченных из изображений в определенных положениях, с координатами признаков, извлеченных из эталонного изображения. Если аннотации границ в эталонном изображении и изображениях в различных положениях отсутствуют, вычисляется более общее преобразование матричной модели, рассмотренное выше со ссылкой на Фиг. 11A-F.
На Фиг. 20F показано относительное преобразование координат, преобразующее координаты изображения в координаты документа. Внешний прямоугольник 2010а на Фиг. 20F соответствует эталонному изображению или изображению в определенном положении. Внутренний прямоугольник 2010b соответствует содержащему документ фрагменту изображения внутри этого изображения. Координаты изображения x, y базируются на декартовой системе координат с координатой x, совпадающей с нижней границей 2010с изображения и координатой у, совпадающей с правой вертикальной границей изображения 2010d. Две точки 2010е и 2010f внутри изображения показаны со своими координатами изображения. Преобразование, показанное на Фиг. 20F, используется для преобразования этих координат изображения в точки в координатах документа. Координаты документа представляют собой координаты относительно координатной оси x документа, которая соответствует нижней границе 2010g содержащего документ фрагмента изображения, и координатной оси у, которая совпадает с левой вертикальной границей 2010h содержащего документ фрагмента изображения. Следует учитывать, что документ повернут относительно изображения 2010а на угол ϕ 2010i. В координатах документа длина нижней границы содержащего документ фрагмента изображения имеет значение «l», а длина вертикальной границы содержащего документ фрагмента изображения также имеет длину «l». Таким образом, координаты документа обычно являются долями от длин границ содержащего документ фрагмента изображения. Преобразование 2010j преобразует координаты изображения x, y в координаты документа xr, yr. Это включает перемещение начала координат системы координат изображения до совпадения с левым нижним углом содержащего документ фрагмента изображения 2010k, поворот преобразуемых осей координат на угол θ 2010l по часовой стрелке и последующее вычисление координат документа 2010m. Координаты документа для двух точек 2010е и 2010f показаны в выражениях 2010n и 2010о. Фиг. 20G демонстрирует другое преобразование координат документа, когда содержащий документ фрагмент изображения имеет трапецеидальную, а не прямоугольную форму.
На Фиг. 20Н приведена блок-схема «найти совпадающие признаки» (find matching features), вызываемой на шаге 2008m на Фиг. 20Е. На шаге 2012а эта подпрограмма определяет исходя из метаданных, привязанных к исходному изображению, имеются ли у изображения аннотированные границы. Если это так, переменная «границы» (borders) на шаге 2012b получает значение true, и вызывается процедура создания преобразования координат для изображений в определенных положениях, как обсуждалось выше со ссылкой на Фиг. 20F-G. В противном случае на шаге 2012d вызывается процедура «создать матричные преобразования» (create matrix transforms) для создания моделей матриц для преобразования координат изображения с целью преобразования содержащих документ фрагментов изображения, и на шаге 2012е переменная «границы» (borders) получает значение «ложь» (false). Во вложенных циклах for на шагах 2012f-2012l соответствия между признаками, извлеченными из изображений в различных положениях, и признаками, извлеченными из эталонного изображения, сводятся в ячейки таблицы, которая представляет собой двухмерный массив «featureSets», с помощью вызова процедуры «свести совпадения в таблицу» (tabulate matches) на шаге 2012h.
Фиг. 20I-K иллюстрируют логику процедуры «создать матричные преобразования», вызываемой на шаге 2012d Фиг. 20Н. Фиг. 20I представляет собой блок-схему процедуры «создать матричные преобразования». На шаге 2014а локальная переменная temp получает в качестве значения ссылку на структуру данных featureSet, которая инициализируется так, чтобы включать признаки, извлеченные детекторами из эталонного изображения. Затем во внешних циклах for на шагах 2014b-2014i происходит анализ всех изображений в различных положениях. К рассматриваемому изображению в определенном положении на шаге 2014с применяется способ генерации матричной модели по типу RANSAC для определения матрицы преобразования, наилучшим образом отражающей отношения между расположением признаков на изображении, находящимся в определенном положении, и расположением соответствующих признаков на эталонном изображении. Матричная модель рассматриваемого изображения в определенном положении помещается в массив «transforms» на шаге 2014d с индексом j. Затем во внутреннем цикле for на шагах 2014e-2014g каждый признак, удовлетворяющий матричной модели, из признаков изображения в определенном положении преобразуется с помощью матричной модели в соответствующий признак эталонного изображения, и значение в поле matched_count (количество совпадений) структуры данных признака увеличивается, показывая найденное совпадение рассматриваемого изображения в определенном положении с признаком эталонного изображения. После завершения внешних циклов for на шагах 2014b-2014i эталонные признаки фильтруются путем вызова процедуры «фильтрация» (filter) на шаге 2014j, и создается итоговое преобразование или модель для связи между изображениями в различных положениях и эталонным изображением путем вызова процедуры «создание окончательной модели» (final model generation) на шаге 2014k.
На Фиг. 20J показана блок-схема процедуры «фильтрация» (filter), вызываемой на шаге 2014j Фиг. 20I. На шаге 2016а процедура удаляет из набора признаков признаки, на которые ссылается локальная переменная temp со значением счетчика совпадений, равным 0. Другими словами, признаки эталонного изображения, не соответствующие ни одному изображению в различных положениях, удаляются. На шаге 2016b вычисляется среднее значение полей счетчиков совпадений оставшихся признаков. На шаге 2016с вычисляется пороговое значение как доля от среднего значения, вычисленного на шаге 2016b. Наконец, на шаге 2016d отбрасываются признаки, оставшиеся в наборе признаков, у которых в локальной переменной temp значение matched_count меньше расчетного порогового значения. Таким образом, при фильтрации отбрасываются все, кроме лучших, наиболее часто совпадающих признаков исходного изображения.
На Фиг. 20K представлена блок-схема процедуры «создание окончательной модели» (final model generation), вызываемой на шаге 2014k на Фиг. 201. В цикле for, на шагах 2018а-2018е (а конкретно - на шаге 2018b), вызывается еще один процесс генерации матричной модели по типу RANSAC для каждого изображения в определенном положении с целью вычисления преобразования между координатами изображения в определенном положении и координатами эталонного изображения. Генерация этой второй модели типа RANSAC использует ограничения близости как для выбора исходных случайно выбранных пар признаков, так и для дополнительных пар, удовлетворяющих модели, при уточнении модели. Признаки исходной модели требуют разделения в пространстве как минимум до порогового расстояния, добавляемые пары признаков, удовлетворяющие модели, также должны быть отделены в пространстве от ближайших признаков, удовлетворяющих модели, или признаков модели как минимум на пороговое расстояние. Это обеспечивает в общем более компактное и надежное преобразование.
На Фиг. 20L приведена блок-схема процедуры «составить таблицу совпадений» (tabulate matches), которая вызывается на шаге 2012h Фиг. 20Н. Во внешнем цикле for, на шагах 2020а-2020m рассматривается каждый полученный с помощью детектора k признак в созданном наборе признаков featureSet для эталонного изображения. Во внутреннем цикле for, на шагах 2020b-2020j, рассматривается каждый полученный с помощью детектора k признак, извлеченный из изображения в определенном положении j. Если локальная переменная «границы» (borders) имеет значение «истина» (true), как определено на шаге 2020с, то на шаге 2020d вычисляется расстояние между рассматриваемыми признаками f1 и f2 с использованием преобразования координат для изображения j в определенном положении. В противном случае на шаге 2020е с помощью матричного преобразования для изображения j в определенном положении вычисляется расстояние между f1 и f2. Если вычисленное расстояние между двумя признаками меньше первого порогового значения, что определяется на шаге 2020f, на шаге 2020g вычисляется общее расстояние между признаками, которое включает все специфичные для детектора характеристики, а также координаты положения. Если общее расстояние меньше порогового значения, что определяется на шаге 2020h, два признака считаются совпадающими, в результате значение поля matched_count в структуре данных признака f1 увеличивается на шаге 2020k. Затем происходит переход к шагу 20201 для выхода из внутреннего цикла for, поскольку в изображении найден признак, совпадающий с признаком f1. В противном случае, если для изображения в текущем положении рассматриваются дополнительные признаки f2, как определено на шаге 2020i, то переменной f2 на шаге 2020j в качестве значения назначается ссылка на следующий признак из множества признаков featureSet для изображения j в определенном положении и детектора k, и происходит переход к шагу 2020 с для следующей итерации внутреннего цикла for. После того как будут рассмотрены все изображения в различных положениях или будут обнаружены их совпадения с текущим признаком f1, и при наличии дополнительных признаков в множестве признаков featureSet для эталонного изображения, обнаруженных детектором k, как определено на шаге 20201, переменная f1 на шаге 2020m получает в качестве значения ссылку на следующий признак в featureSet для эталонного изображения и детектора k, и происходит обратный переход на шаг 2020b. Когда внешний цикл for прекращает работу, наличие совпадений между признаками эталонного изображения и признаками изображения j в том или ином положении, найденными детектором k, будет зафиксировано в структурах данных эталонного изображения feature внутри структуры данных эталонного изображения featureSet.
На Фиг. 20М показана блок-схема процедуры «сформировать модель» (generate model), вызываемой на шаге 2008п на Фиг. 20Е. Эта процедура использует глобальные переменные вызывающей подпрограммы. На шаге 2022а выделяется пул (pool) структуры данных featureSet, который инициализируется пустым множеством. В цикле for, на шагах 2022b-2022d, признаки, извлеченные каждым детектором k из эталонного изображения, значение поля Matched_count для которых больше порогового значения, добавляются в пул (pool) структуры данных featureSet. После прекращения работы цикла for на шагах 2022b-2022d возвращается ссылка на пул (pool) структуры данных featureSet. Эти признаки используются в процедуре «создать модели» (create models), которая рассматривается ниже, для создания модели типа документа исходных изображений, передаваемых в процедуру «создать модель» (create model), которая, в свою очередь, вызывается процедурой «generate model». Признаки в наборе признаков модели включают полные характеристики признаков, а также указание на создавшие их детекторы.
На Фиг. 20N приведена блок-схема процедуры «создать модели» (create models), которая создает модели для каждого типа документа, который должен быть выявлен и охарактеризован на исходных изображениях. На шаге 2024а процедура получает ссылку на массив «models», в который помещаются сгенерированные модели для разных типов документов, и двухмерный массив «r_images» эталонных изображений и изображений в различных положениях для каждого из типов документов. Кроме того, на шаге 2024а передаются различные значения параметров, включая различные пороговые значения и метаданные, необходимые для процедуры «создать модель», а также массив «detectors». В цикле for на шагах 2024b-2024h производится создание модели для каждого типа документа. На шаге 2024с изображения обрабатываемого типа документа подвергаются первичной обработке - нормализации масштаба, корректировке контрастности и другим подобным видам первичной обработки. На шаге 2024d вызывается процедура «создать модель» для создания набора признаков для рассматриваемого типа документа. На шаге 2024е полученный набор признаков вводится в модель текущего типа документов в массиве моделей. На шаге 2024f к модели в массиве моделей для этого типа документа добавляются дополнительные метаданные, связанные с типом документа.
На Фиг. 21A-D показаны блок-схемы процедуры «найти документы» (find documents), которая выявляет содержащие документы фрагменты изображений в исходном изображении, как уже обсуждалось ранее со ссылкой на Фиг. 20А. На Фиг. 21А приведена блок-схема процедуры «найти документы» (find documents). На шаге 2026а процедура получает ссылку на исходное изображение, набор моделей различных типов документов в массиве «models» и массив «results», в который помещаются получаемые в процедуре «найти документы» (find documents) характеристики обнаруженных документов. На шаге 2026b производится первичная обработка исходного изображения. Она может включать нормализацию масштаба, корректировку контрастности и другие шаги первичной обработки исходного изображения до состояния, позволяющего извлекать признаки и распознавать фрагменты изображения, содержащие документы. Кроме того, на шаге 2026b локальная переменная num получает значение 0. В цикле for на шагах 2026c-2026h к исходному изображению на шаге 2026d применяется каждая модель, соответствующая определенному типу документа, с целью выявления и получения характеристик фрагмента изображения, содержащего документ этого типа на исходном изображении. Когда процедура «применить модель» (apply model), вызываемая на шаге 2026d, идентифицирует фрагмент изображения, содержащий документ типа, соответствующего примененной модели, как определено в шаге 2026е, результаты, возвращаемые процедурой «применить модель», выводятся в массив «results» на шаге 2026f. В противном случае цикл for заканчивает работу, когда не остается неиспользованных моделей, или производится следующая итерация цикла for на шагах 2026с-2026h с увеличением переменной цикла m на шаге 2026h. Затем выполняется шаг 2002d на Фиг. 20А, в ходе которого выявляются и характеризуются содержащие документы фрагменты изображения путем повторного применения моделей типа документа к исходному изображению в цикле for на шагах 2026с-2026h.
На Фиг. 21В показана блок-схема процедуры «применить модель», вызываемой на шаге 2026d на Фиг. 21А. На шаге 2028а процедура «применить модель» получает исходное изображение и модель типа документа, применяемую к исходному изображению. На шаге 2028b процедура «применить модель» определяет из модели количество детекторов и их типы и помещает ссылки на эти детекторы в массив «detectors». Детекторы, необходимые для модели, - это те детекторы, которые в ходе создания модели обнаруживают в эталонном изображении и дополнительных изображениях в различных положениях те признаки, которые включаются в окончательную модель для заданного типа документа. На шаге 2028с процедура «применить модель» выделяет двумерный массив наборов признаков «featureSets», по два «featureSets» на детектор. Первый из этих наборов признаков содержит признаки модели, а второй - признаки, извлеченные из исходного изображения детектором, с которым связаны эти два набора признаков. Признаки могут извлекаться из исходного изображения на этом этапе или могут быть извлечены ранее при использовании другой модели. Другими словами, детектор применяется к каждому конкретному изображению только один раз, а извлеченные признаки используются многократно при применении модели к изображению, включая признаки модели, извлеченные этим детектором. В цикле for на шагах 2028d-2028h пары из наборов признаков, каждая из которых содержит признаки, выбранные из модели, и признаки, извлеченные из исходного изображения, помещаются в двухмерный массив «featureSets» для каждого детектора k. На шаге 2028i вызывается процедура «сопоставить признаки» (match features) для поиска соответствий в парах наборов признаков «featureSets», соответствующих детектору. Если процедура «сопоставить признаки» найдет достаточное число совпадений между признаками модели и признаками, извлеченными из исходного изображения, и если другие условия удовлетворены, процедура «сопоставить признаки» возвращает значение, указывающее, найдено ли изображение документа, соответствующее типу документа, связанному с моделью, примененной к исходному изображению. Если содержащие документ фрагменты изображения не найдены, как определяется на шаге 2028j, процедура «применить модель» возвращает отрицательный результат. В противном случае на шаге 2028k вызывается процедура «преобразование» (transform) для вычисления пространственного преобразования, отражающего связь между признаками, извлеченными из исходного изображения, и соответствующими признаками модели. На шаге 2028l вычисленное преобразование используется для преобразования угловых точек или других особых точек из модели документа в соответствующие точки исходного изображения. Координаты исходного изображения для этих особых точек, результаты преобразования и другие результаты на шаге 2028m образуют единый результат, который возвращается процедурой «применить модель». Результат включает информацию, которая служит для выявления и получения характеристик содержащих документ фрагментов изображения на исходном изображении, которые показаны в виде характеристической информации 2002f и 2002j на Фиг. 20А.
На Фиг. 21С показана блок-схема процедуры «сопоставить признаки», вызываемой на шаге 2028i на Фиг. 21В. В цикле for на шагах 2030а-2030f обрабатывается каждая пара из наборов признаков, соответствующая отдельному детектору и содержащая признаки, выбранные из модели, и признаки, извлеченные из исходного изображения. На шаге 2030b выполняется поиск совпадения признаков с использованием метрики расстояния, вычисленной исходя из характеристик, связанных с признаками. Эти характеристики могут включать дескрипторы, ориентацию, величину и другие характеристики, связанные с признаками, полученными с помощью определенного детектора k. На шаге 2030 с пары соответствующих признаков, полученные на шаге 2030b, обрабатываются с помощью преобразования Хафа, чтобы распределить пары признаков по ячейкам пространства преобразования Хафа Δθ/Δσ. Можно ожидать, что распределение пар соответствующих признаков не будет равномерным, но пары соответствующих признаков будут иметь тенденцию собираться неравномерно в одной точке сетки или в небольшом числе точек сетки, которые соответствуют общему преобразованию ориентации и масштаба исходного изображения в модель. Таким образом, на шаге 2030d признаки из пар, которые сопоставляются с точками в пространстве Δθ/Δσ, и для которых преобразованием Хафа было сопоставлено меньше порогового числа пар признаков, будут удалены как не имеющие пар признаки. Это позволяет использовать только совпадения пар признаков высокого качества, которые, по всей вероятности, будут соответствовать общему преобразованию ориентации и масштаба из исходного изображения в модель. После выборки пар признаков высокого качества при завершении цикла for на шагах 2030a-2030f к оставшимся признакам высокого качества на шаге 2030g применяются проверки на пороговые значения и распределение, чтобы определить, указывают ли совпадающие признаки на идентификацию фрагмента изображения, соответствующего типу документа, связанному с моделью, которая применяется к исходному изображению. Проверка на пороговые значения может потребовать, чтобы доля оставшихся признаков в общем количестве признаков модели была больше, чем пороговое значение доли. Проверка распределения может потребовать, чтобы были сгенерированы некоторые пороговые количества признаков на основе пороговой доли от общего количества детекторов. Например, если совпадение отмечается только для признаков, сгенерированных одним детектором, а для генерации модели использовались несколько детекторов, возможно, что отдельный детектор, с помощью которого были получены оставшиеся признаки, каким-то образом выдает аномальные результаты для конкретного исходного изображения. Оценка оставшихся признаков в некоторых вариантах реализации может включать дополнительные типы особенностей, а в других вариантах реализации может содержать только проверку пороговых значений. Процедура «сопоставить признаки» возвращает булево значение, которое сообщает, указывают ли оставшиеся признаки на признание содержащего документ фрагмента изображения соответствующим типу документа, который связан с применяемой моделью.
На Фиг. 21D показана блок-схема процедуры «преобразовать», вызываемой на шаге 2028k на Фиг. 21В. После того как было определено наличие достаточного количества совпадающих признаков между моделью и исходным изображением, чтобы указать на идентификацию содержащего документ фрагмента изображения на исходном изображении, сохраненные совпадающие признаки обрабатываются с использованием матричной модели типа RANSAC для преобразования положений признаков на модели в соответствующие положения на исходном изображении. Определение матричной модели типа RANSAC включает рассмотренные ранее ограничения близости, так что произвольно выбранные исходные пары модели отделены друг от друга расстоянием больше порогового, и что выбранные впоследствии признаки, удовлетворяющие матричной модели, также отделены от ранее выбранных признаков, удовлетворяющих матричной модели, расстоянием больше порогового. Обычно пары признаков, удовлетворяющих модели и полученные методом типа RANSAC, представляют собой значительно переопределенную систему по сравнению с матричной моделью соответствия между признаками модели и соответствующими признаками исходного изображения. Поэтому на шаге 2032b к матричной модели и удовлетворяющим модели признакам, полученным на шаге 2032а с помощью метода типа RANSAC, применяется способ оптимизации, например, метод сопряженного градиента или другой общеизвестный метод работы с переопределенными системами, чтобы получить оптимизированное и точное матричное преобразование, отражающее связь между положениями признаков модели и соответствующими точками исходного изображения.
Хотя настоящее изобретение описывается на примере конкретных вариантов реализации, предполагается, что оно не будет ограничено только этими вариантами. Специалистам в данной области техники будут очевидны возможные модификации в пределах сущности настоящего изобретения. Например, некоторые из множества различных параметров конструкции и реализации могут быть изменены для получения альтернативных вариантов реализации раскрываемых в настоящем изобретении способов и систем. Эти параметры могут затрагивать аппаратные уровни, операционные системы, языки программирования, модульную структуру, структуры управления, структуры данных и другие подобные параметры. Во многих случаях могут быть обеспечены различные варианты оптимизации. В качестве одного из примеров, на Фиг. 20L совпадения обнаруживаются путем полного перебора пар между признаками, извлеченными из эталонного изображения, и признаками, извлеченными из изображения в том или ином положении. Однако существуют более сложные способы, подразумевающие обработку ближайшего окружения, для выявления совпадающих точек в пространствах высокой размерности, включая метод LSH, который использует семейства хэш-функций. Могут быть использованы некоторые из множества различных видов детекторов признаков, каждый из которых генерирует различные виды характеристик признаков. При определении положения обнаруженного признака на изображении для детекторов геометрических признаков может потребоваться включение нескольких пар координат положения или другой информации. Совпадение признаков на основе метода ближайших соседей может требовать включения всех различных типов атрибутов извлекаемых признаков или только их подмножества.
Следует понимать, что представленное выше описание вариантов реализации настоящего изобретения приведено для того, чтобы любой специалист в данной области техники мог воспроизвести или применить настоящее изобретение. Специалистам в данной области техники будут очевидны возможные модификации представленных вариантов реализации, при этом общие принципы, представленные здесь, без отступления от сущности и объема настоящего изобретения, могут быть применены в рамках других вариантов реализации. Таким образом, подразумевается, что настоящее изобретение не ограничено представленными здесь вариантами реализации. Напротив, в его объем входят все возможные варианты реализации, согласующиеся с раскрываемыми в настоящем документе принципами и новыми отличительными признаками.
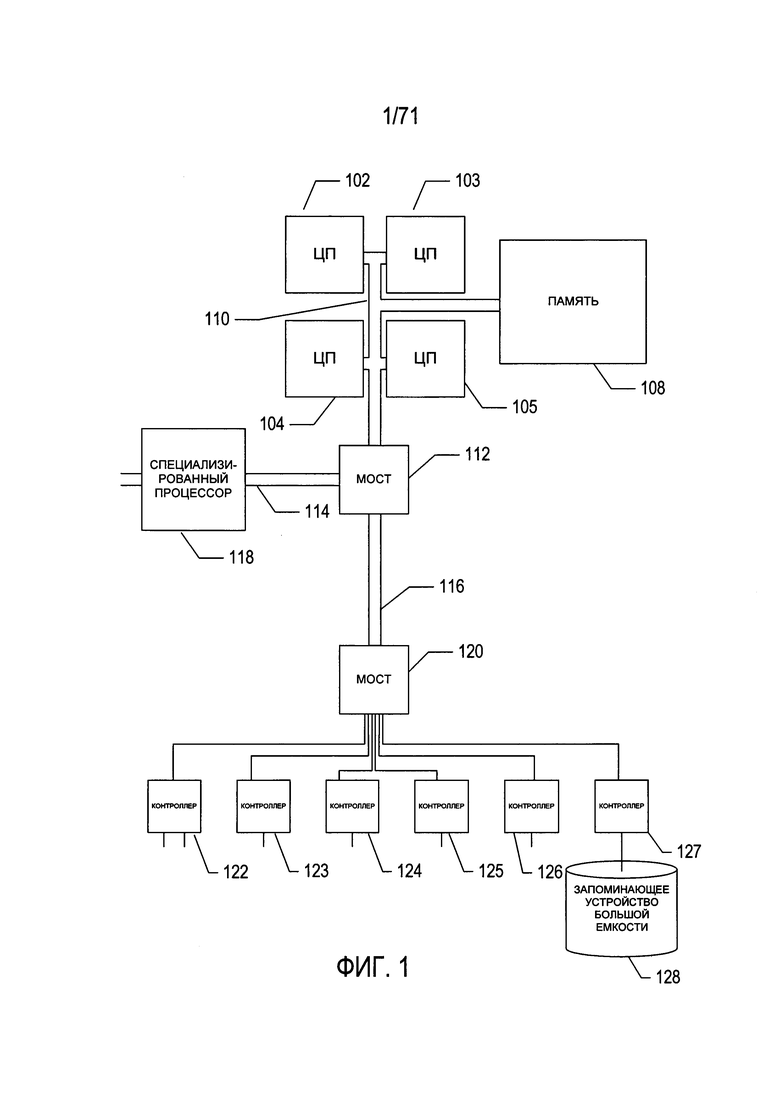

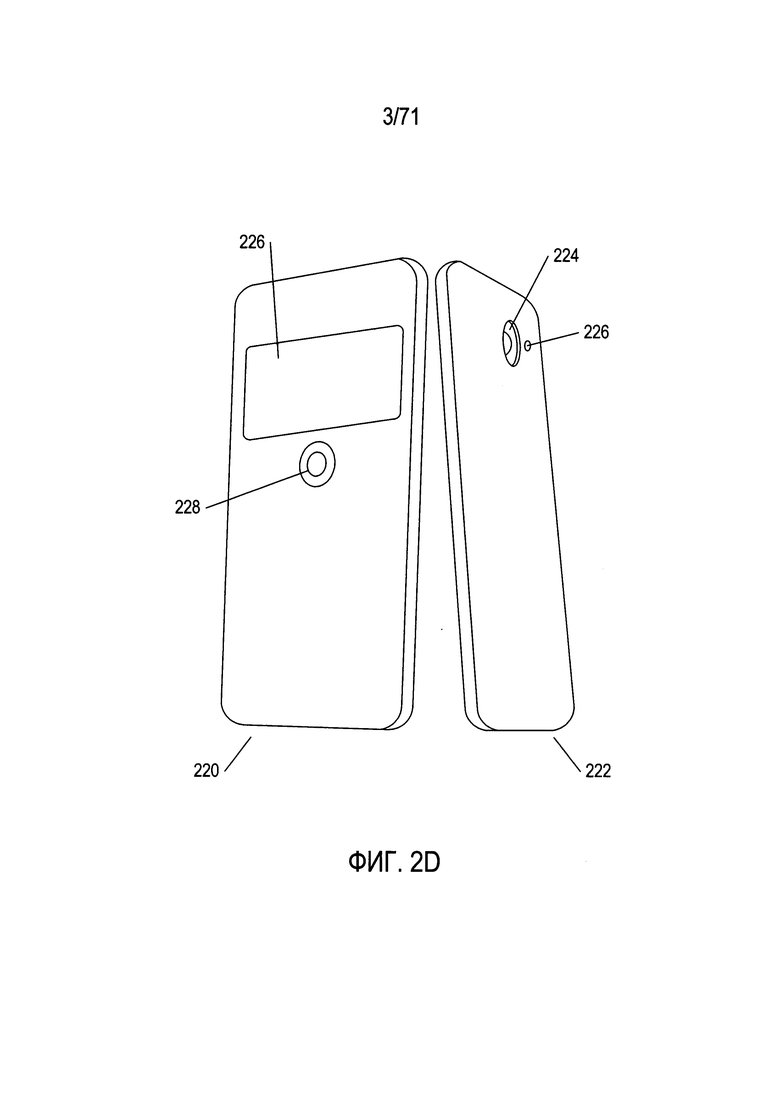
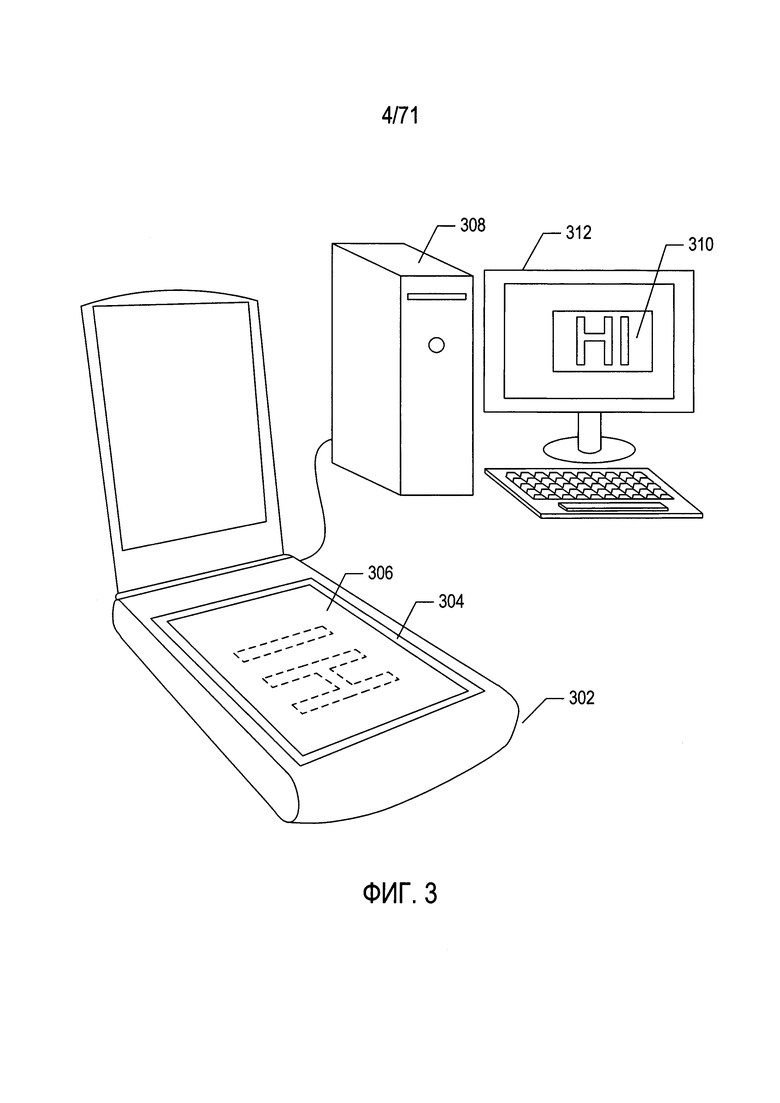
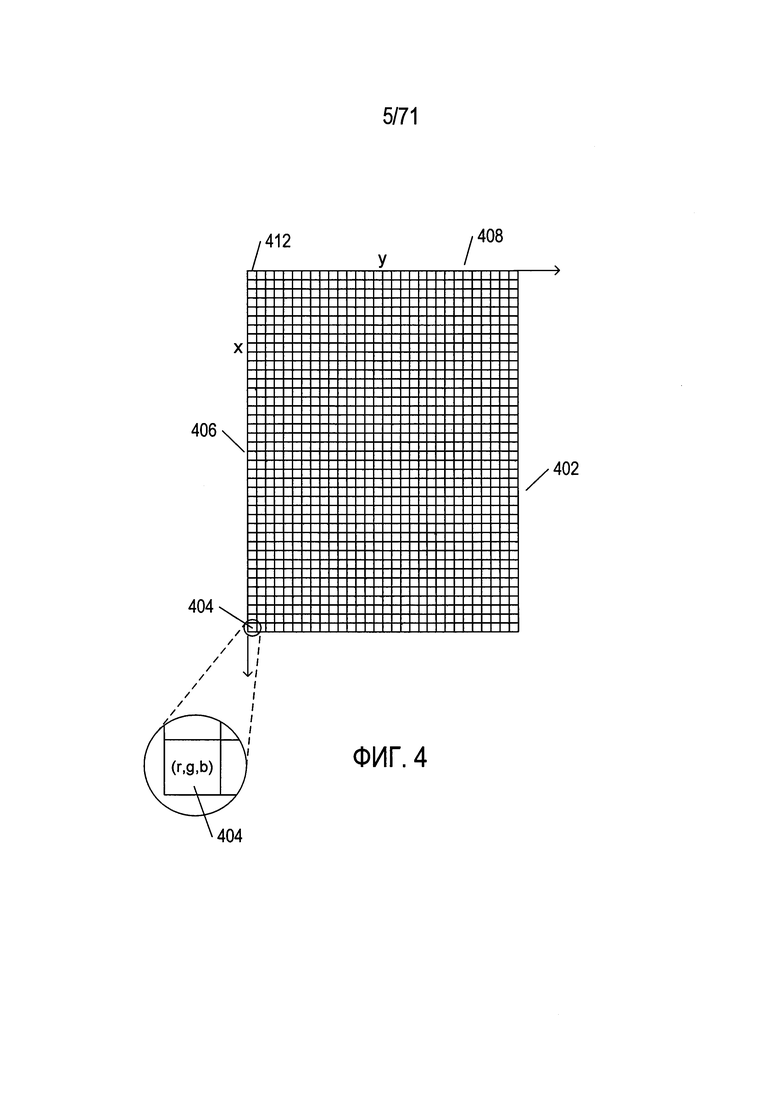
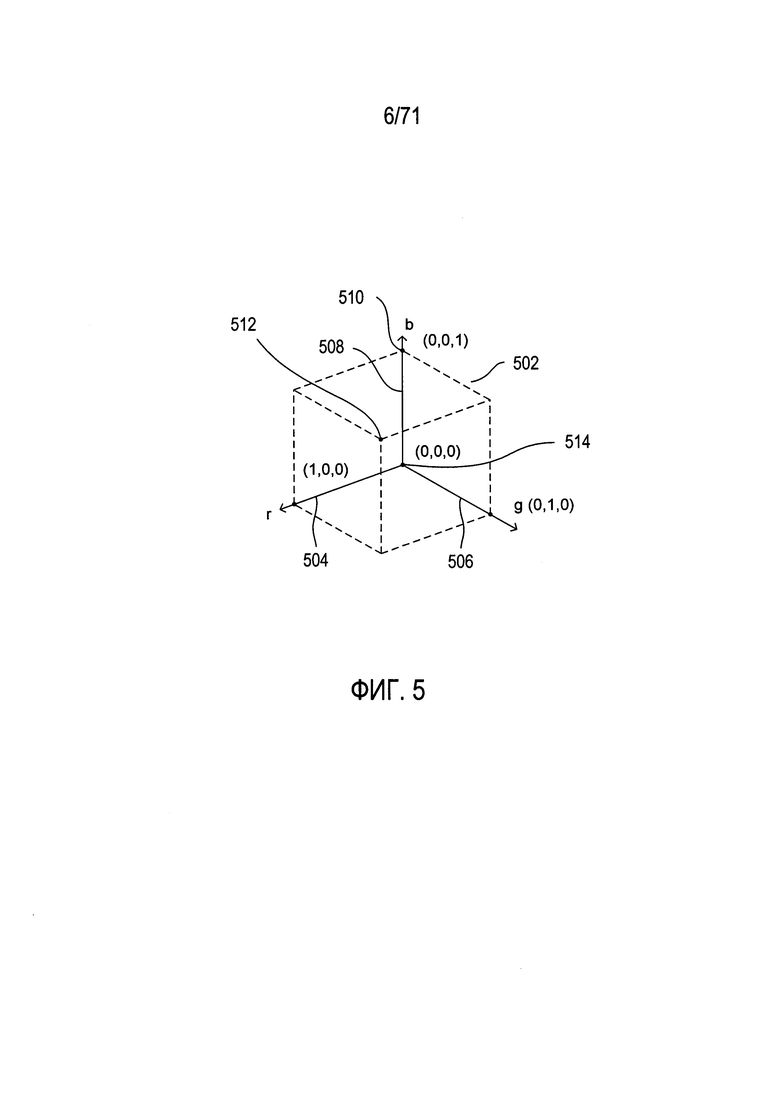
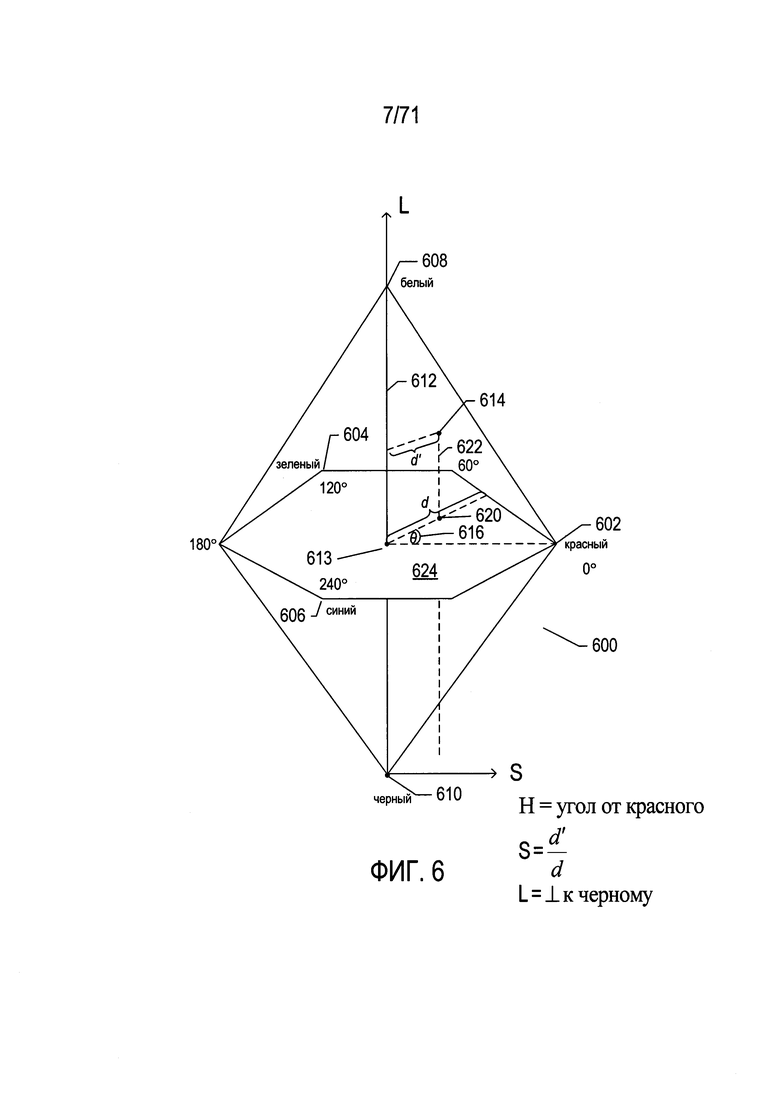
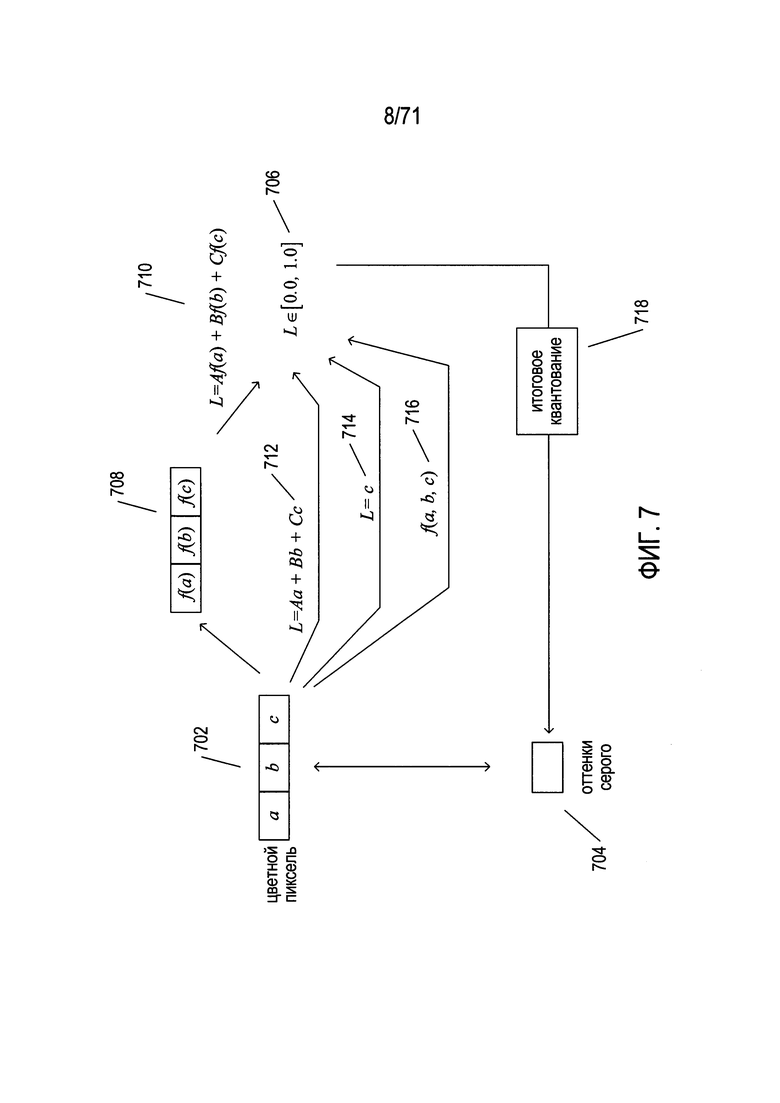
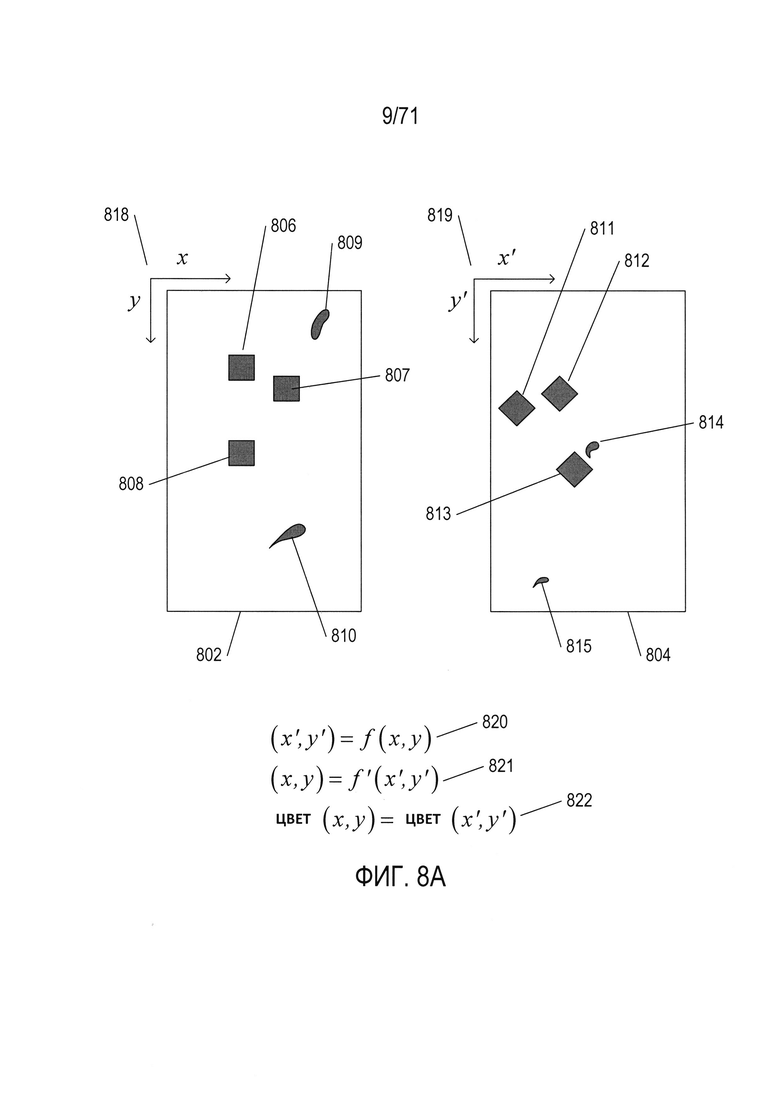
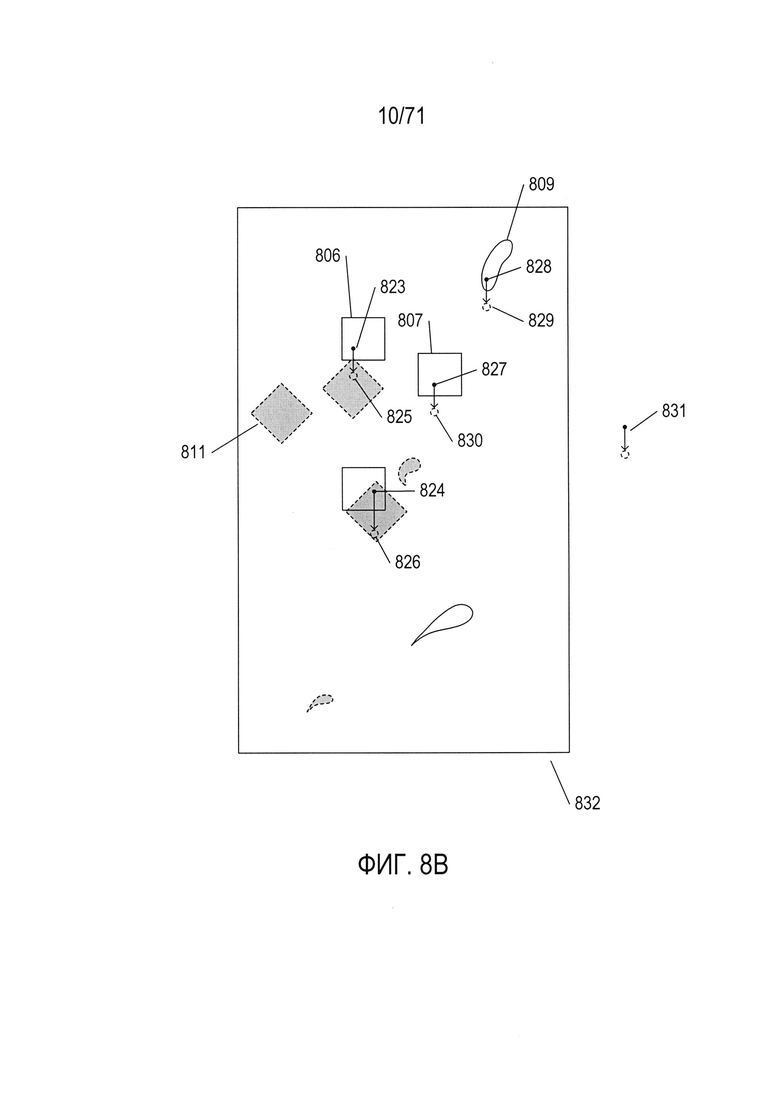
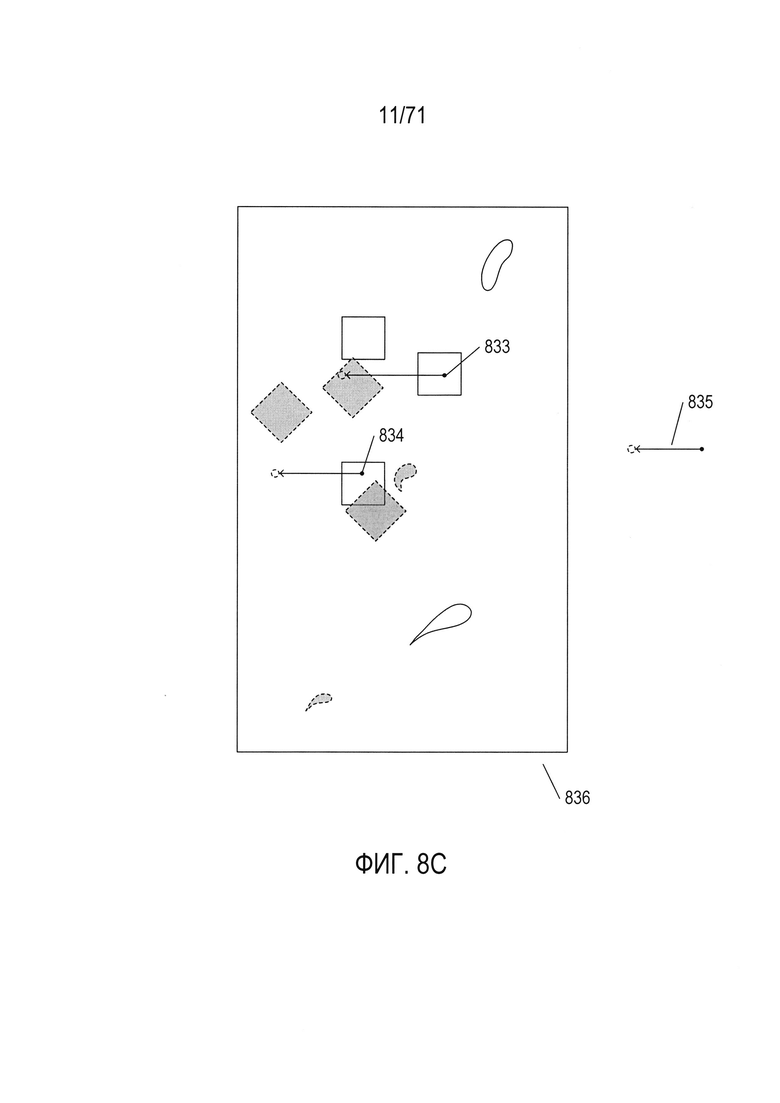
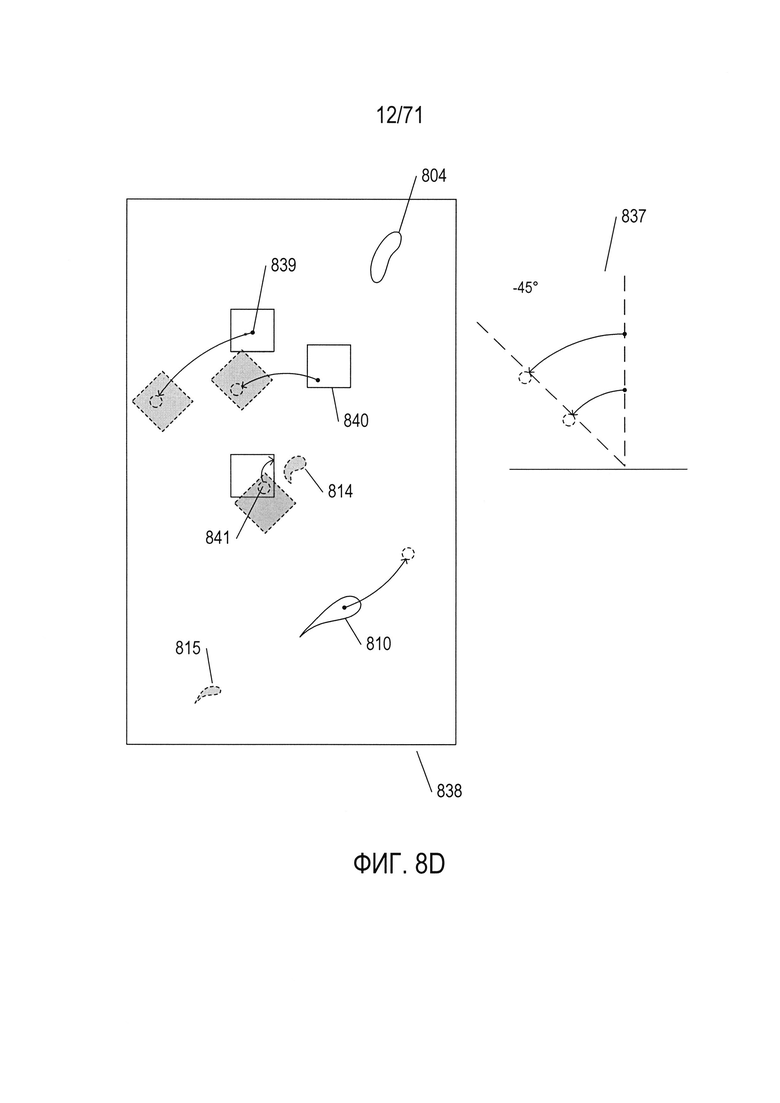
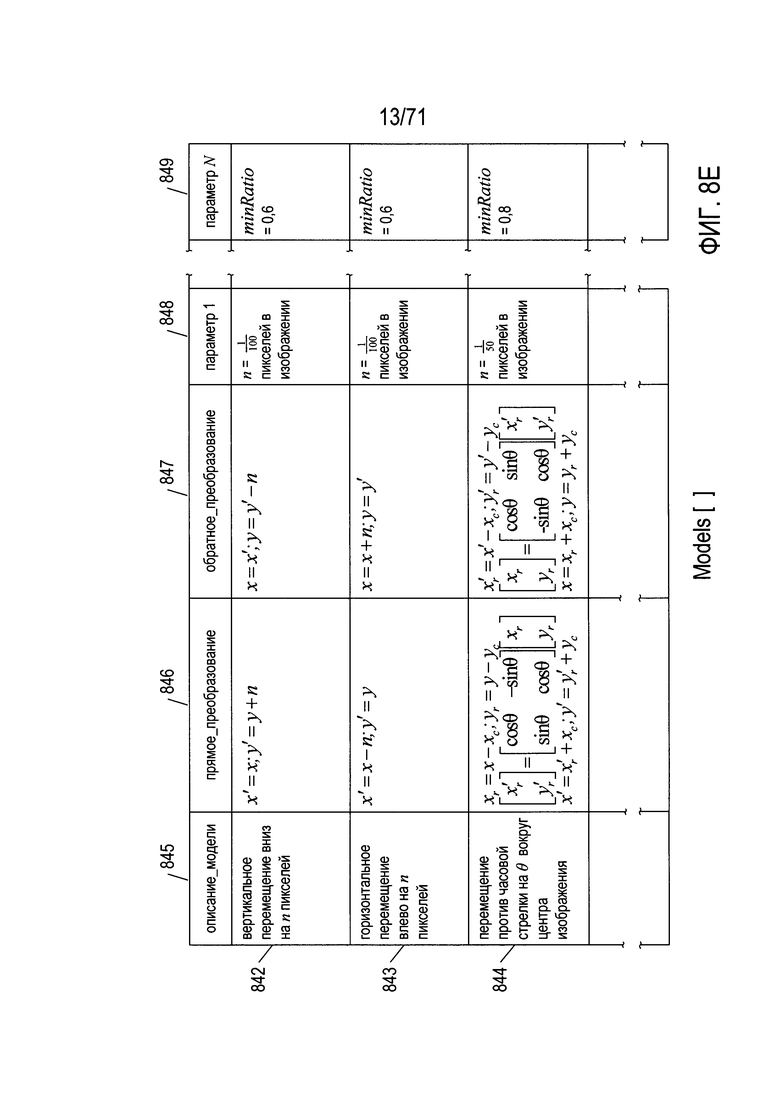
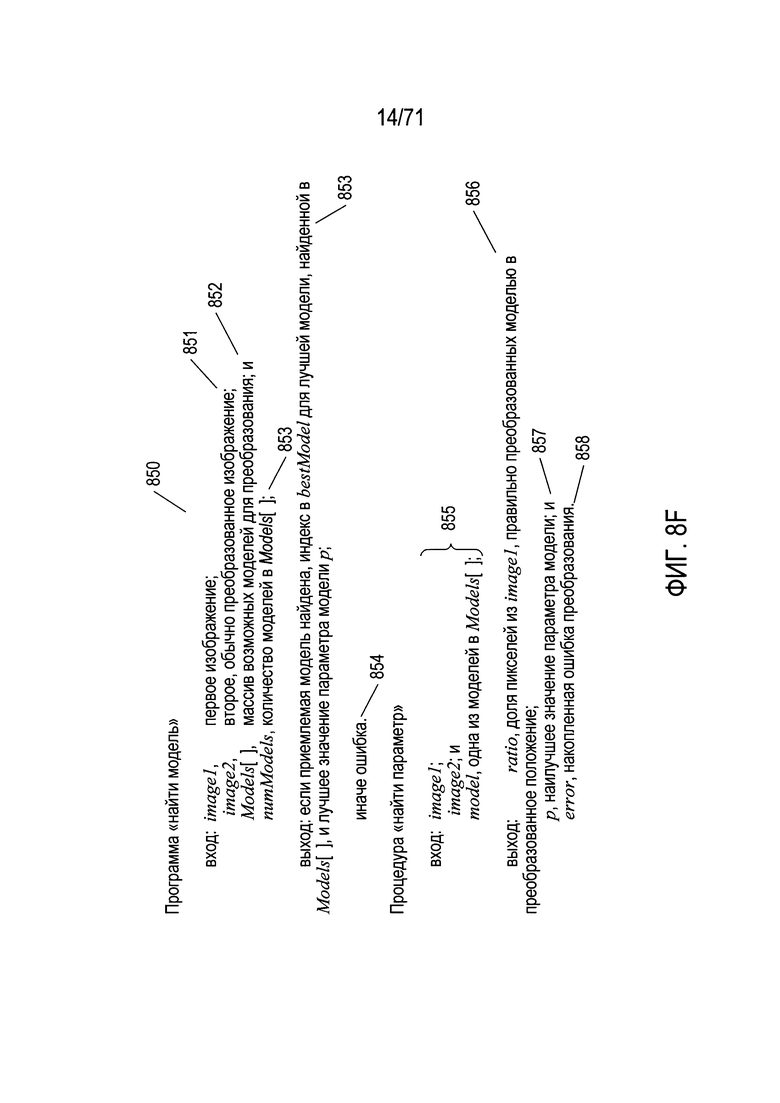
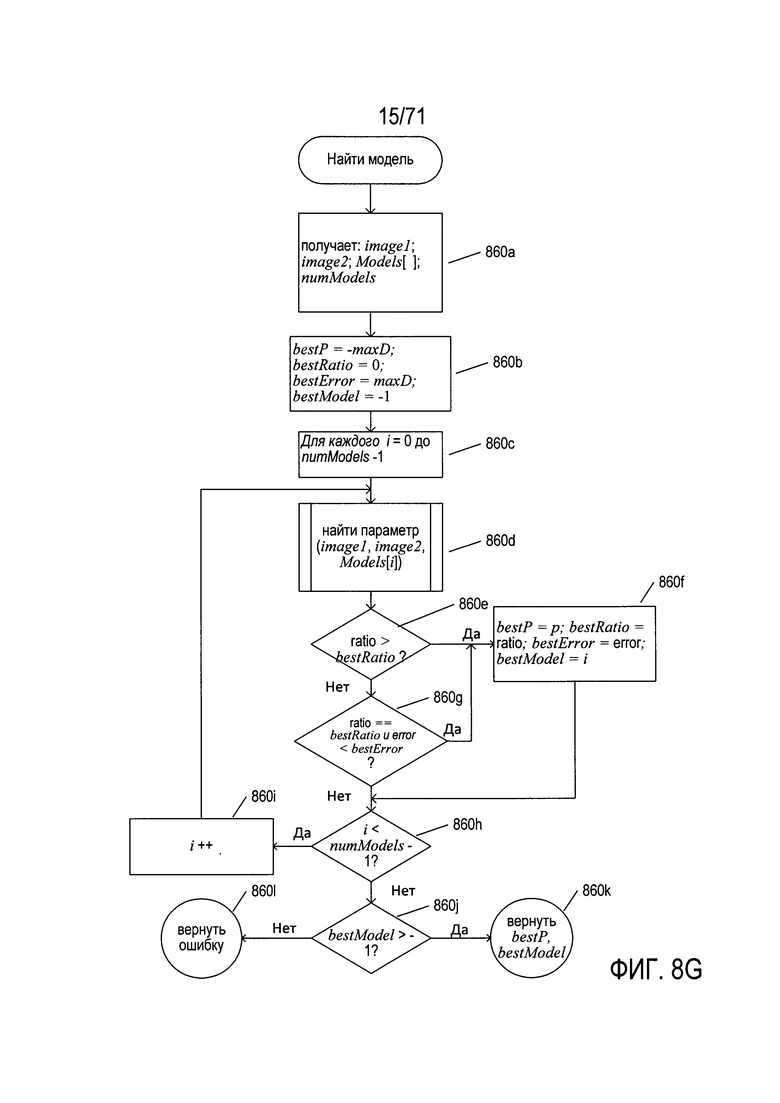
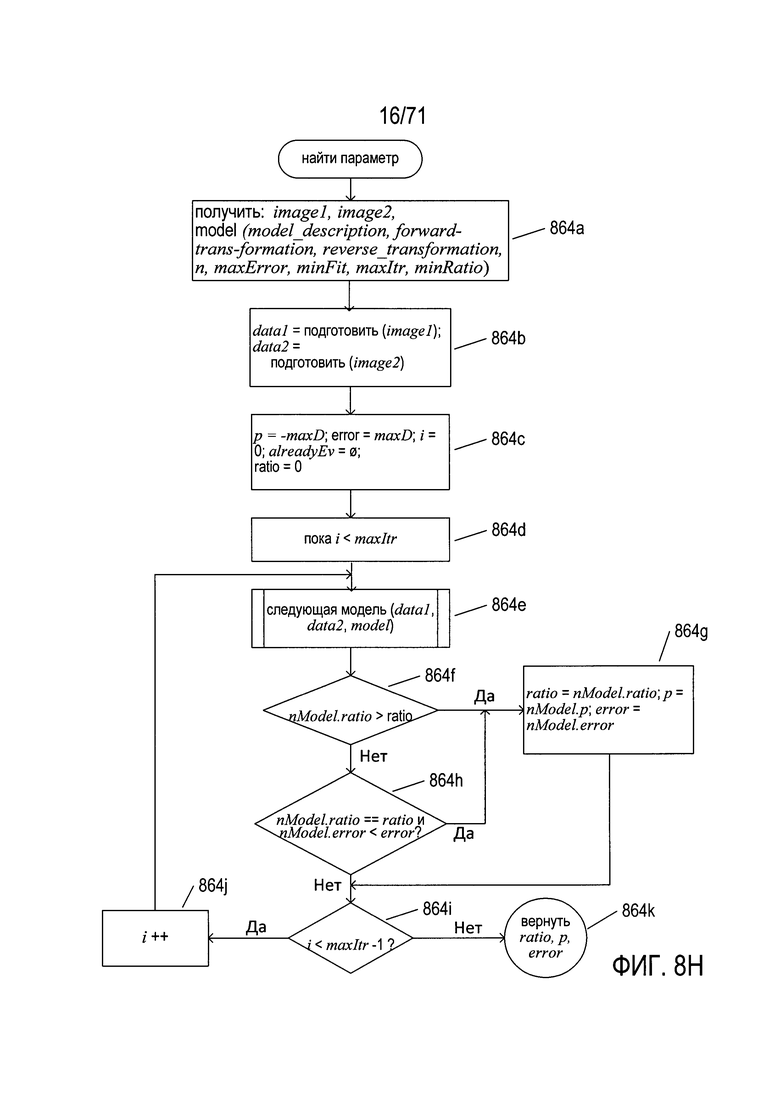
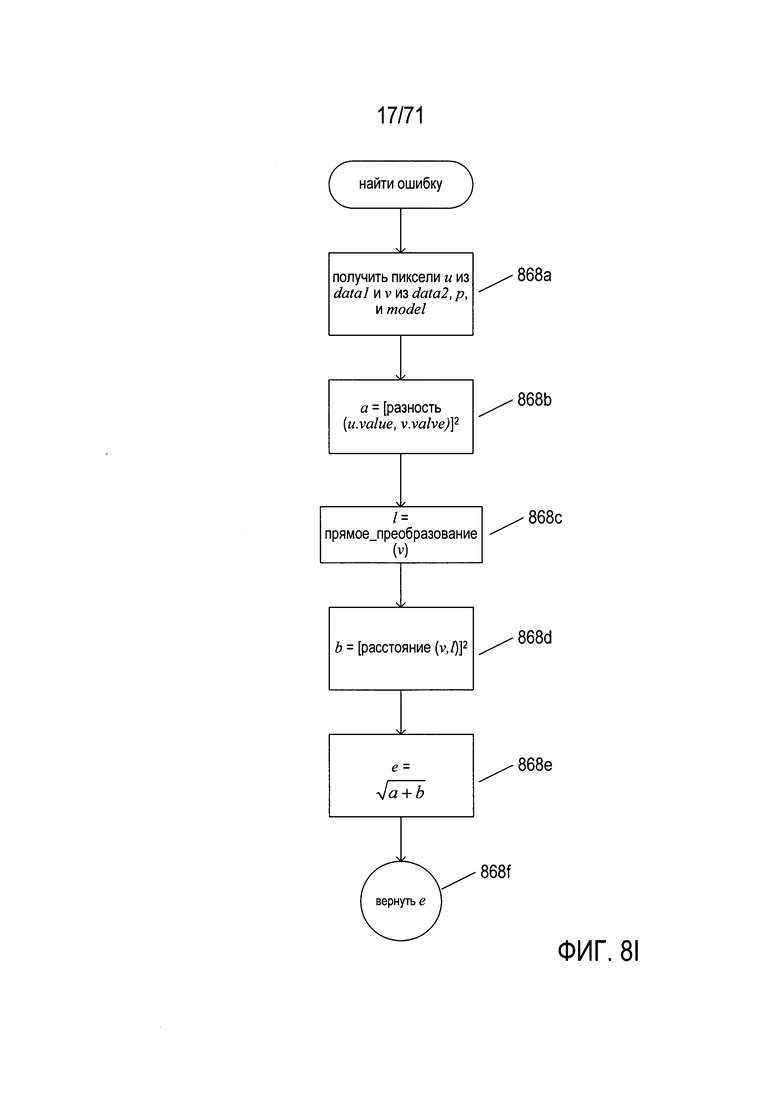
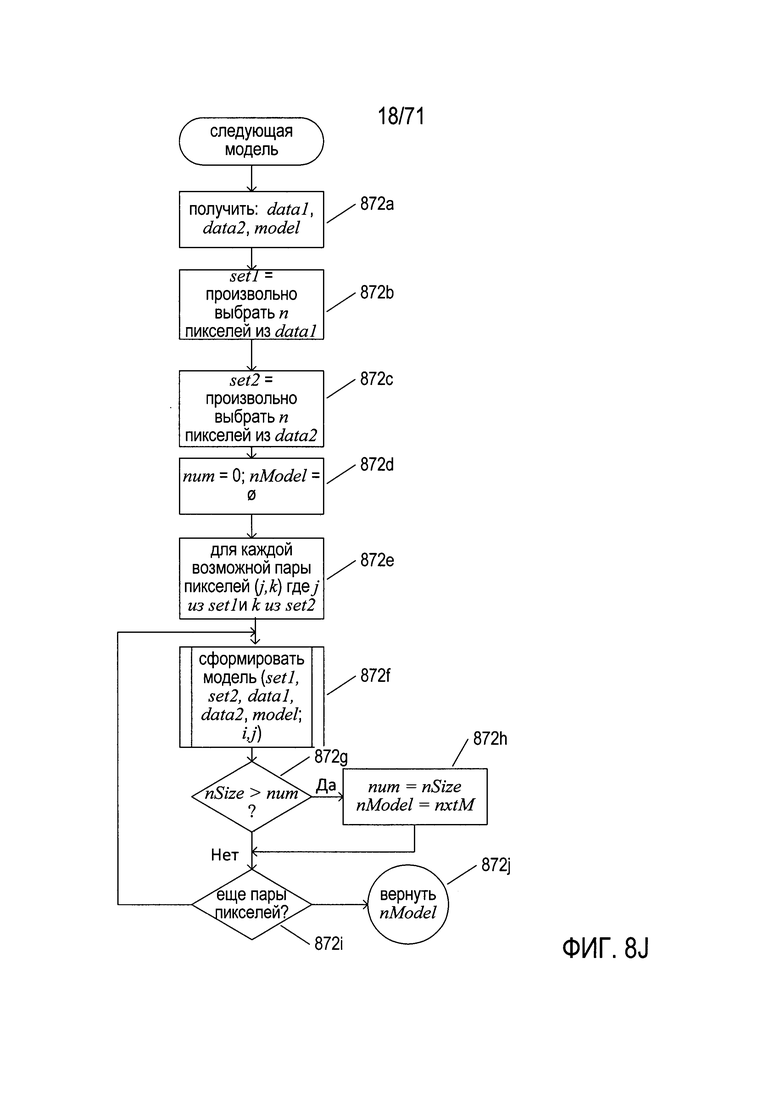
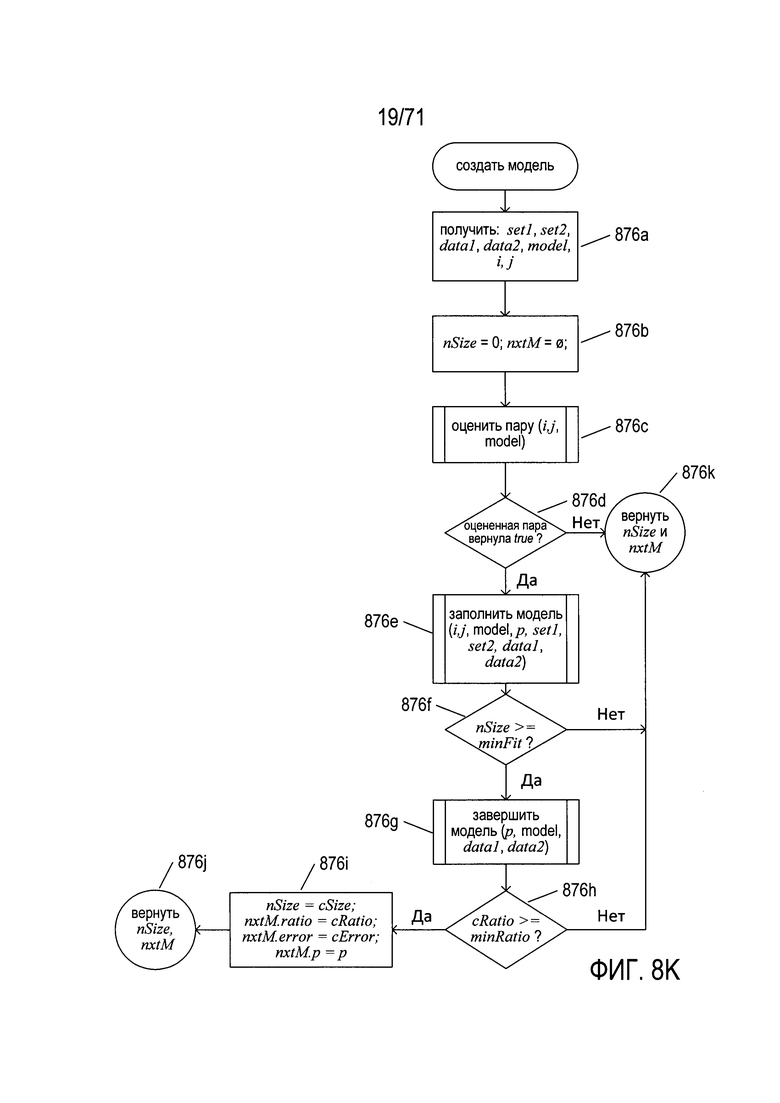
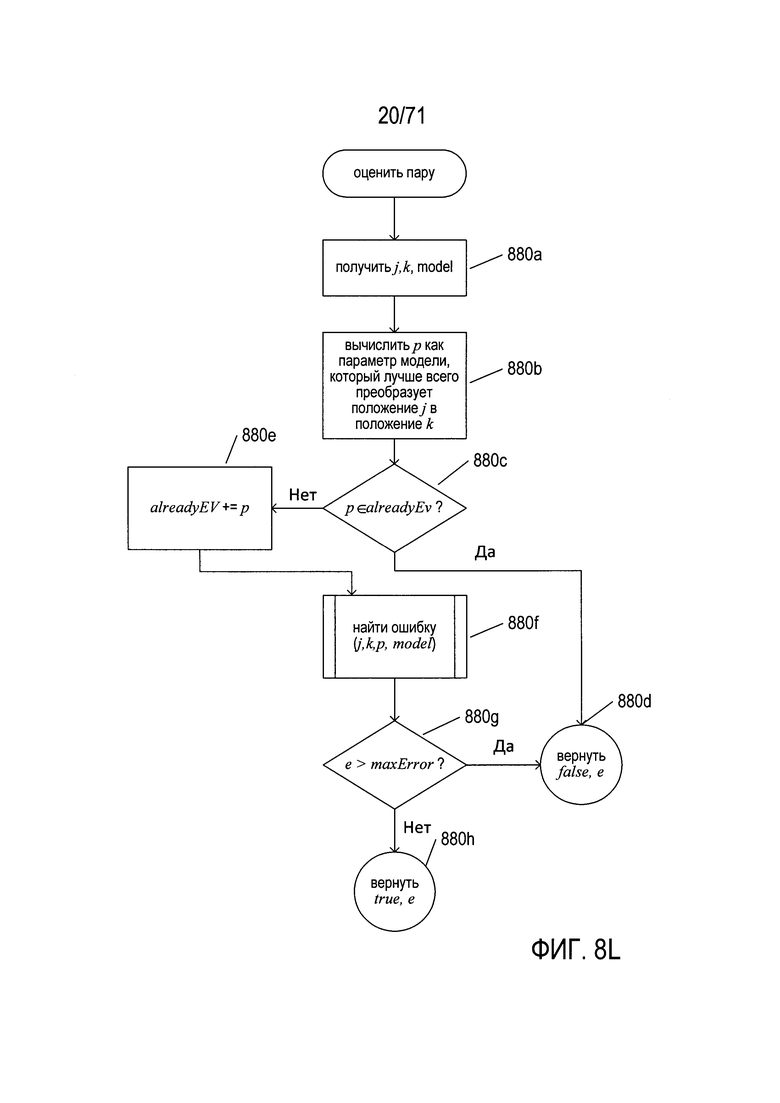
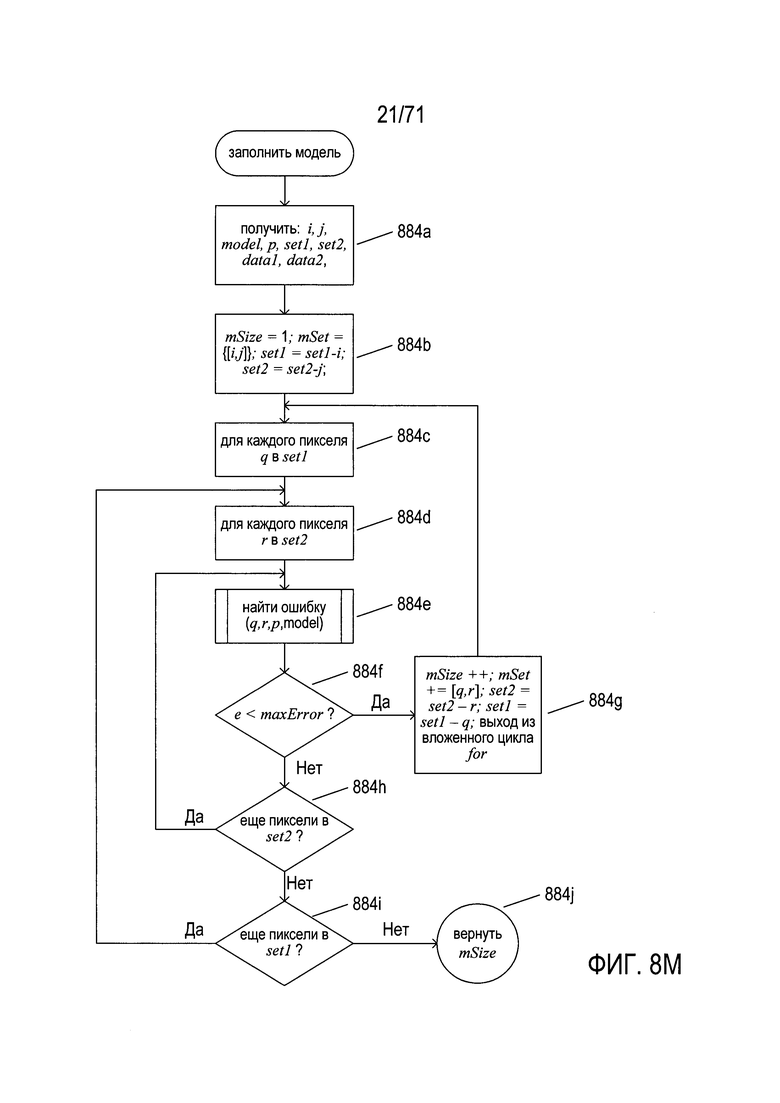
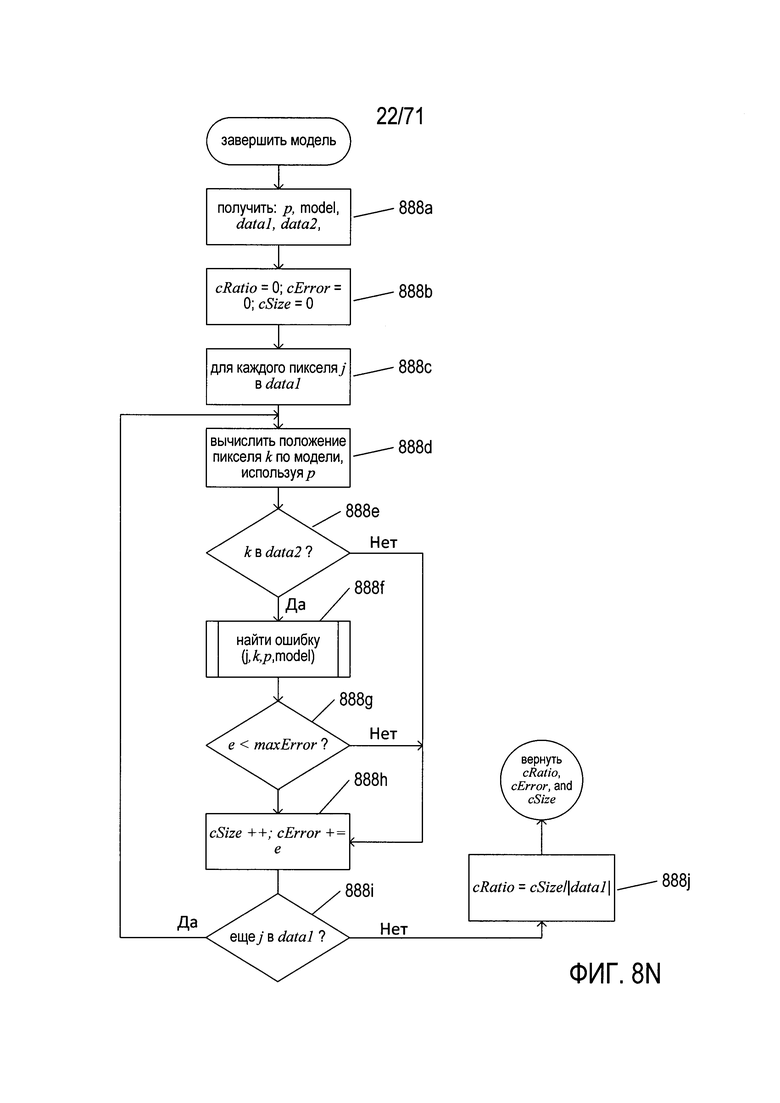
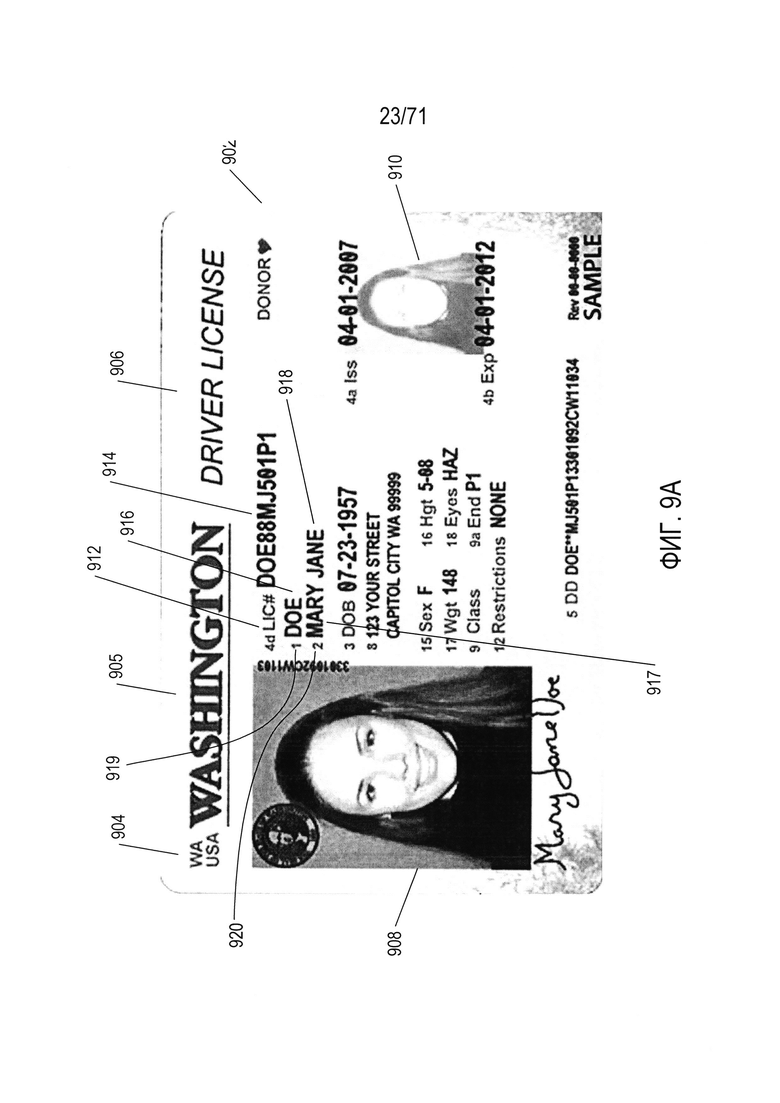

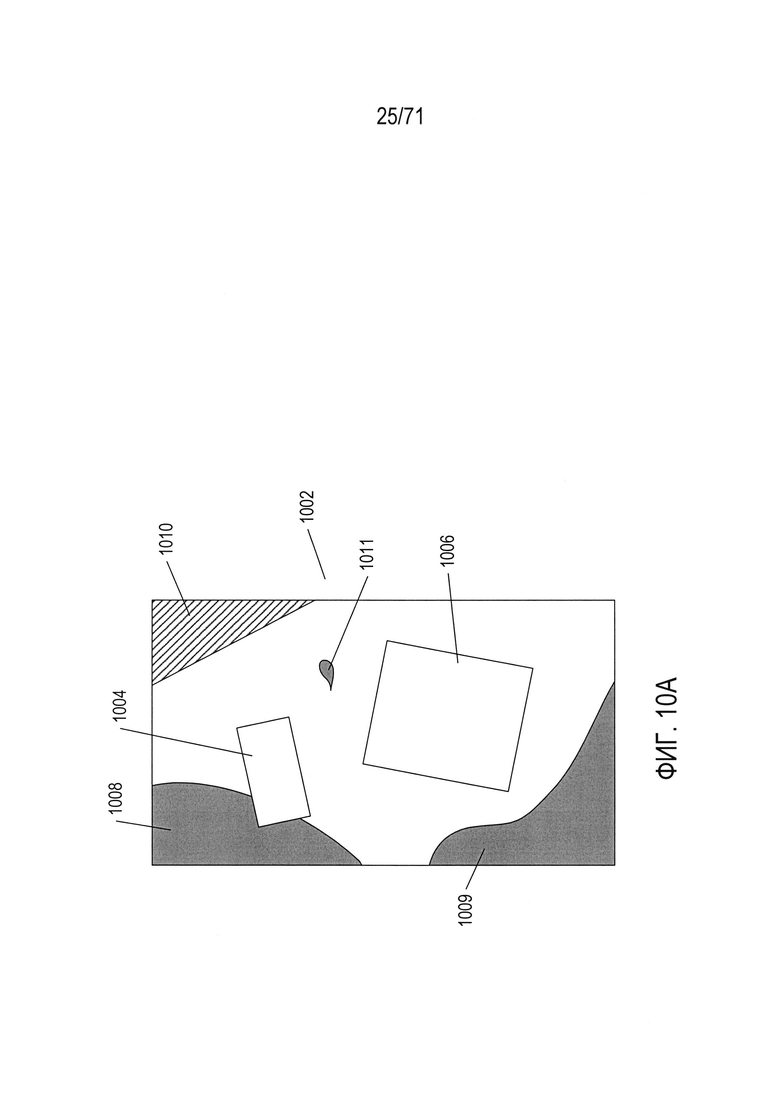
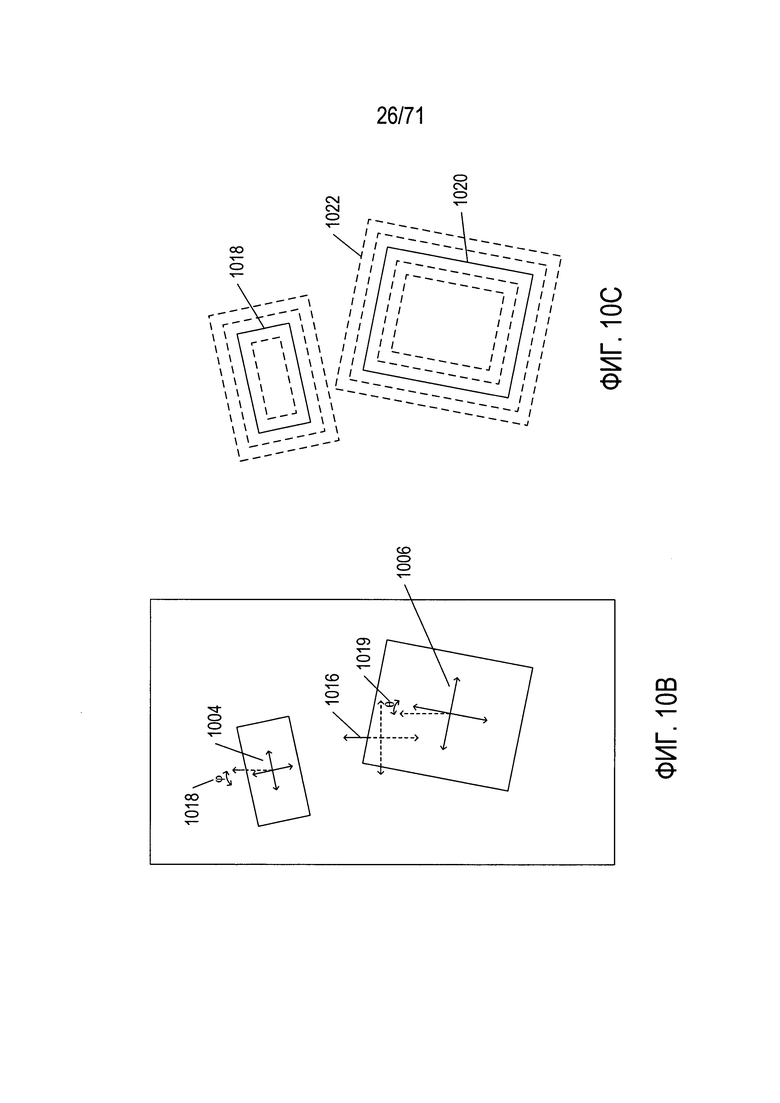
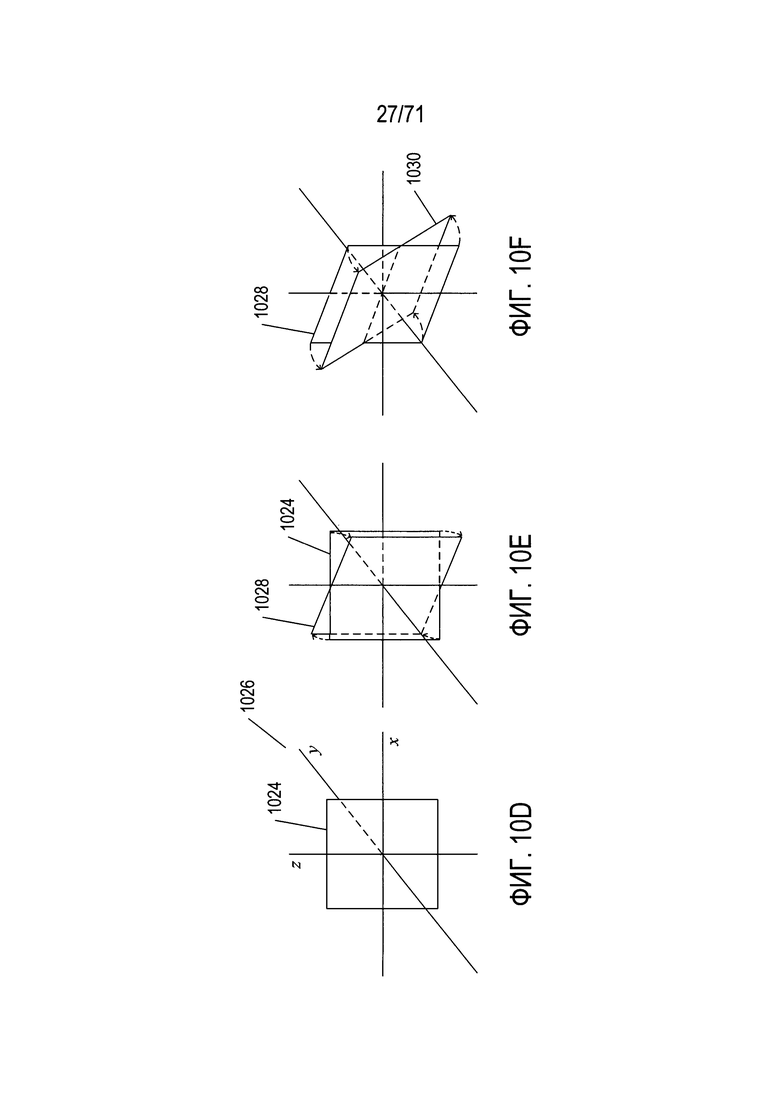
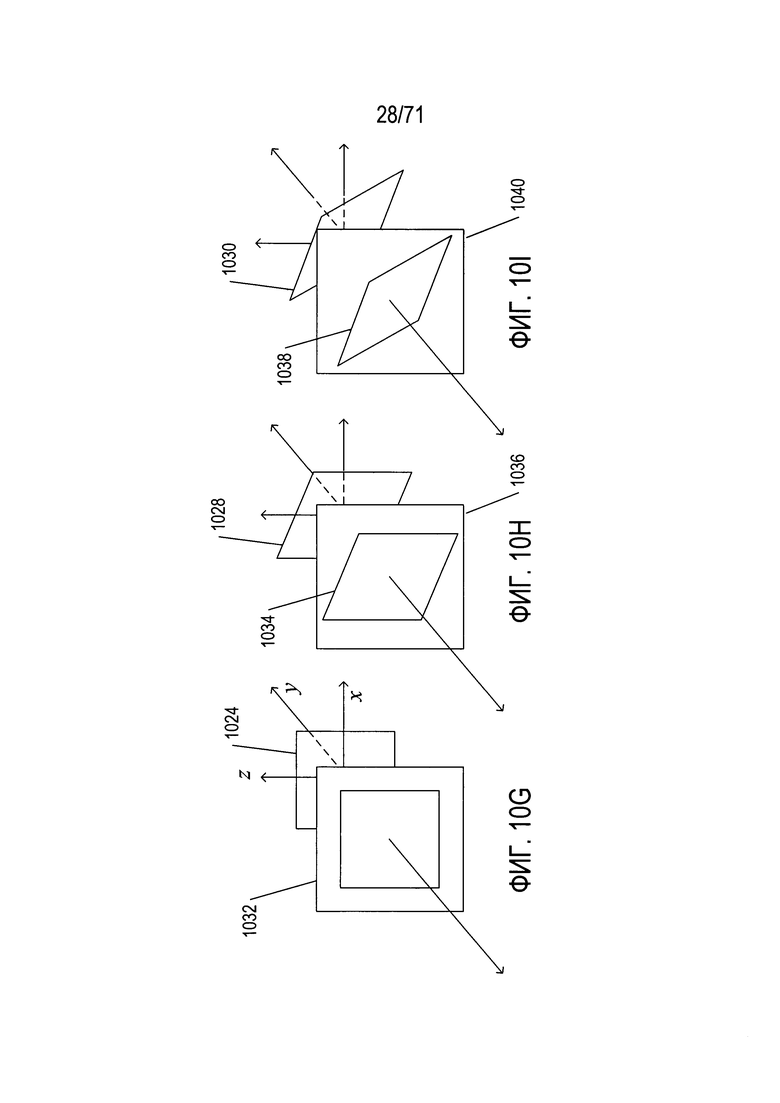
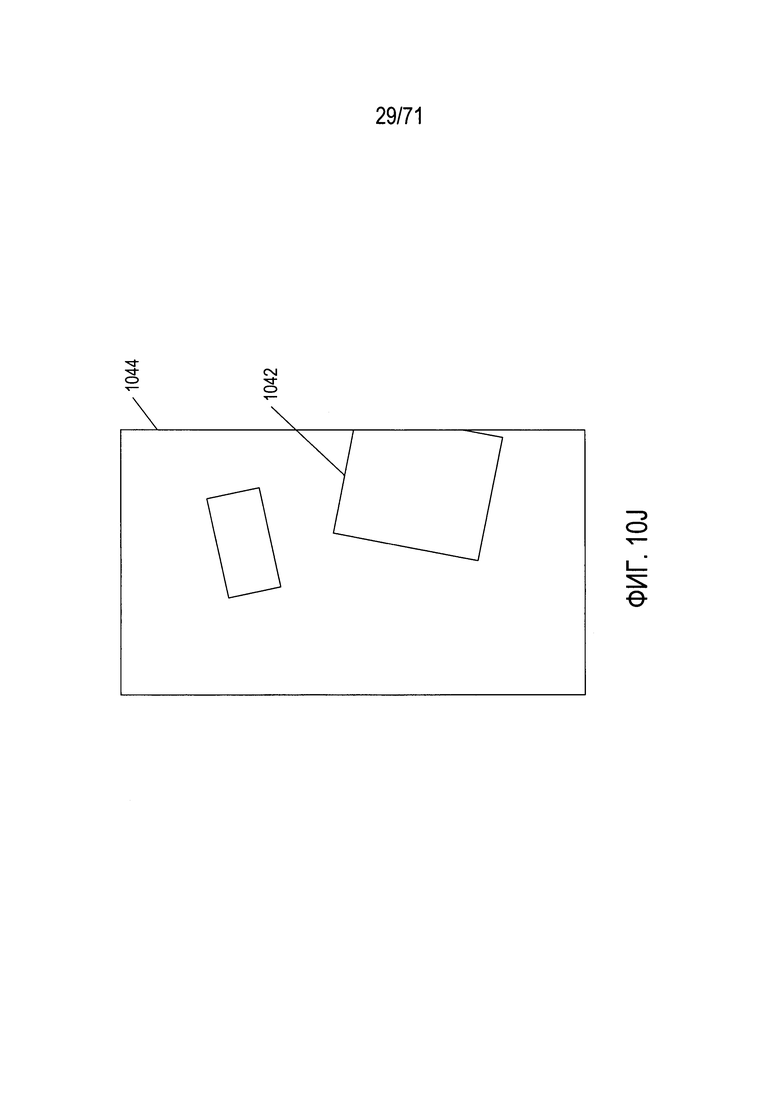
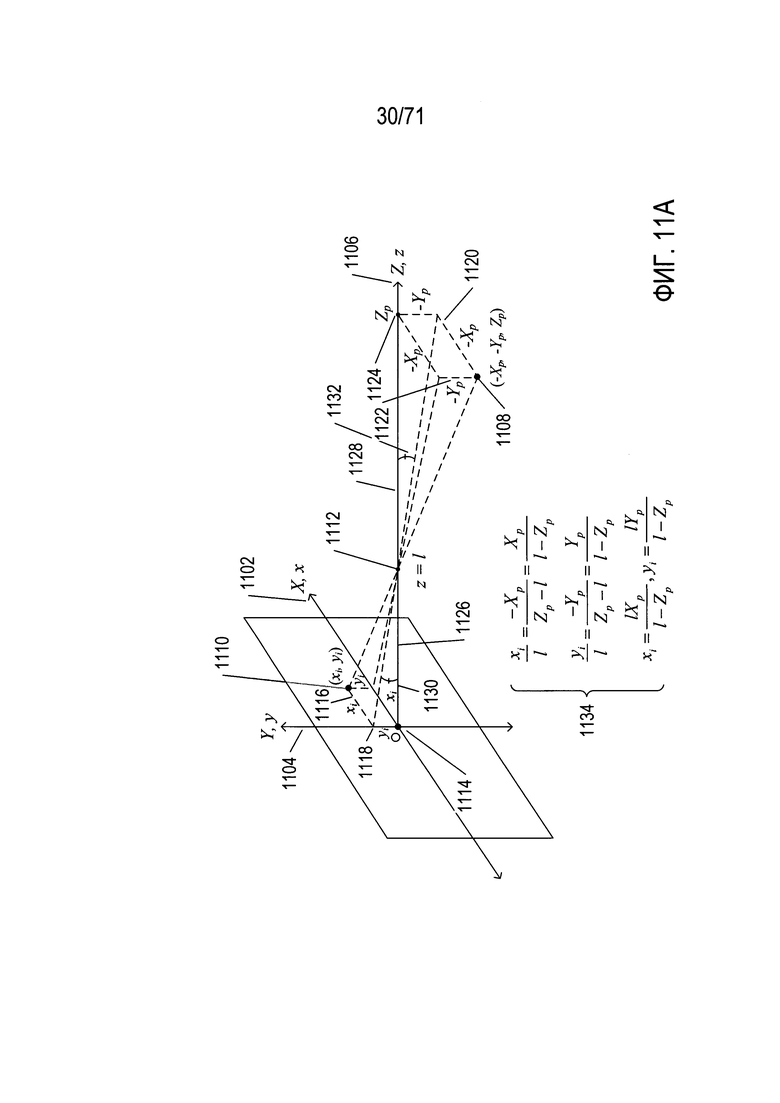
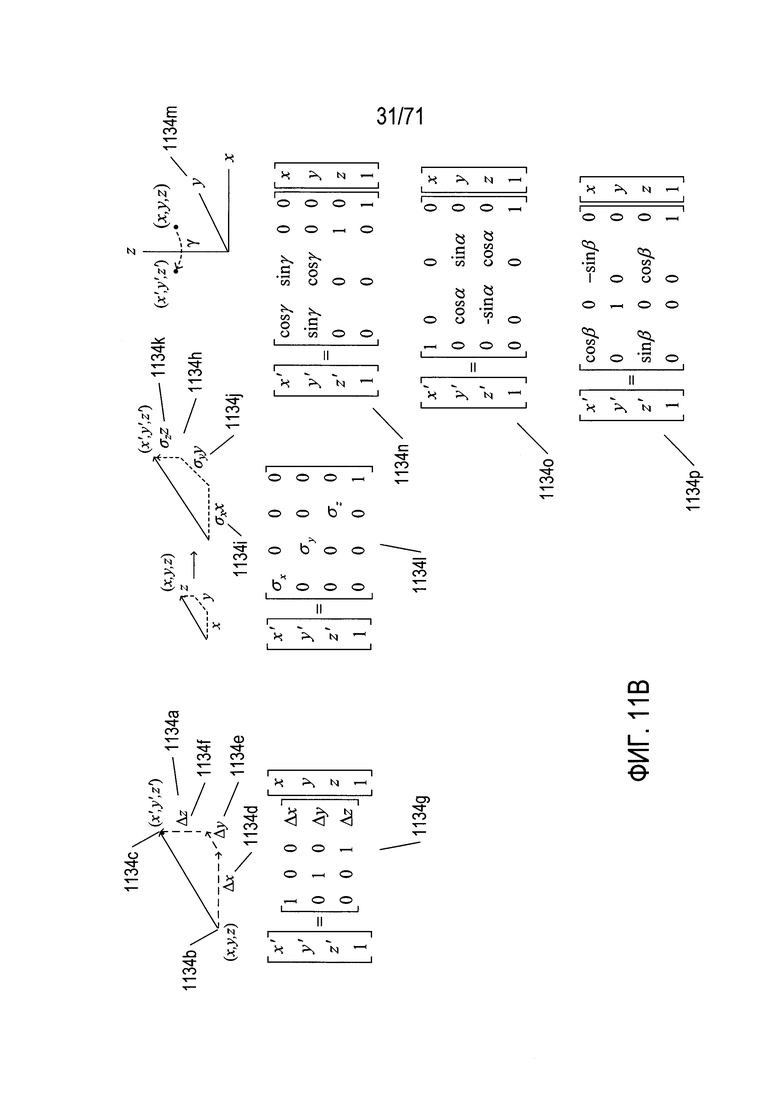
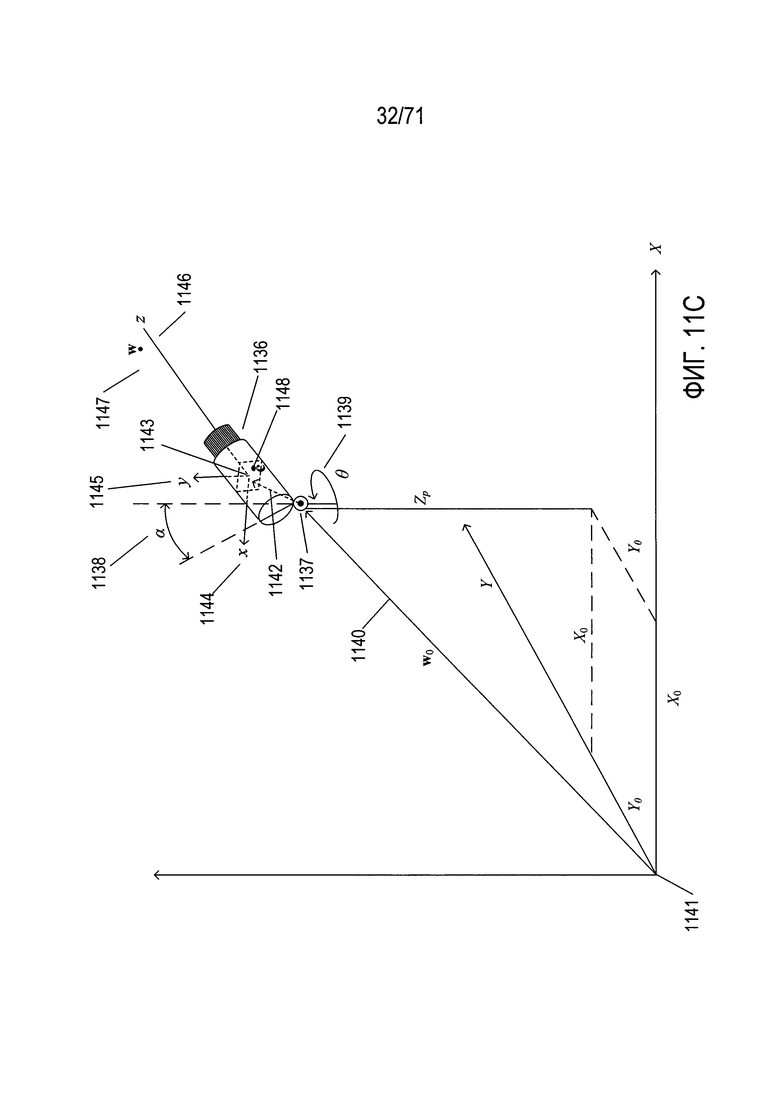
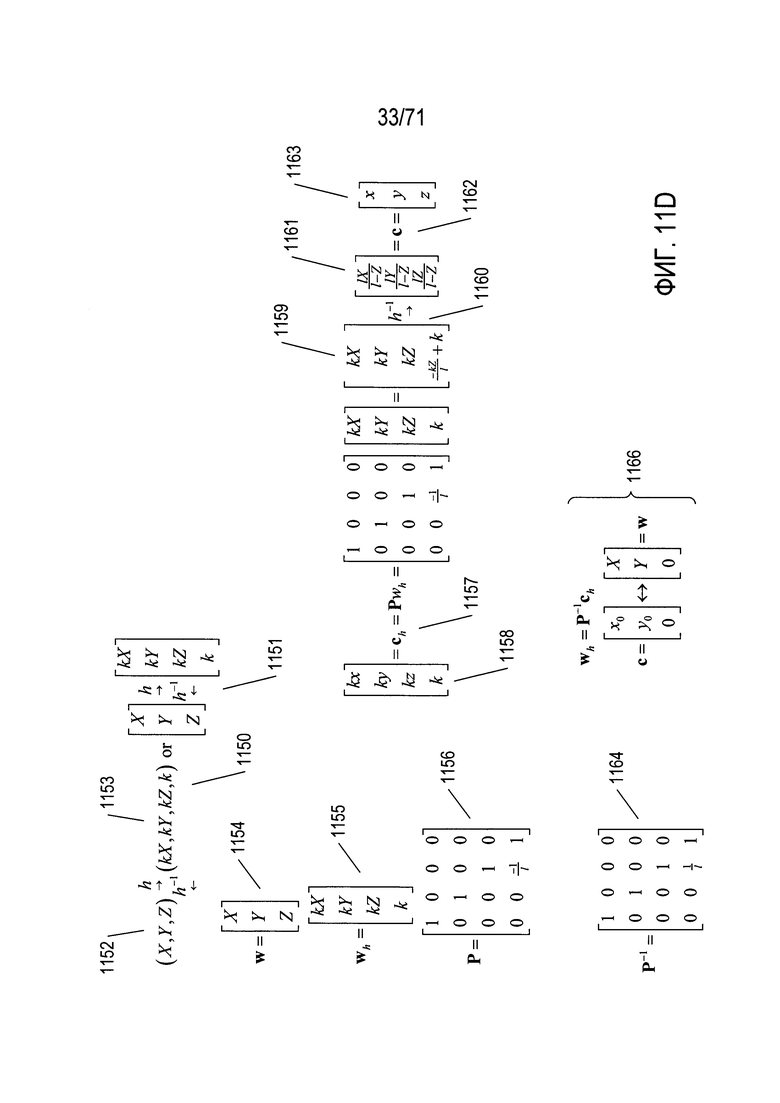
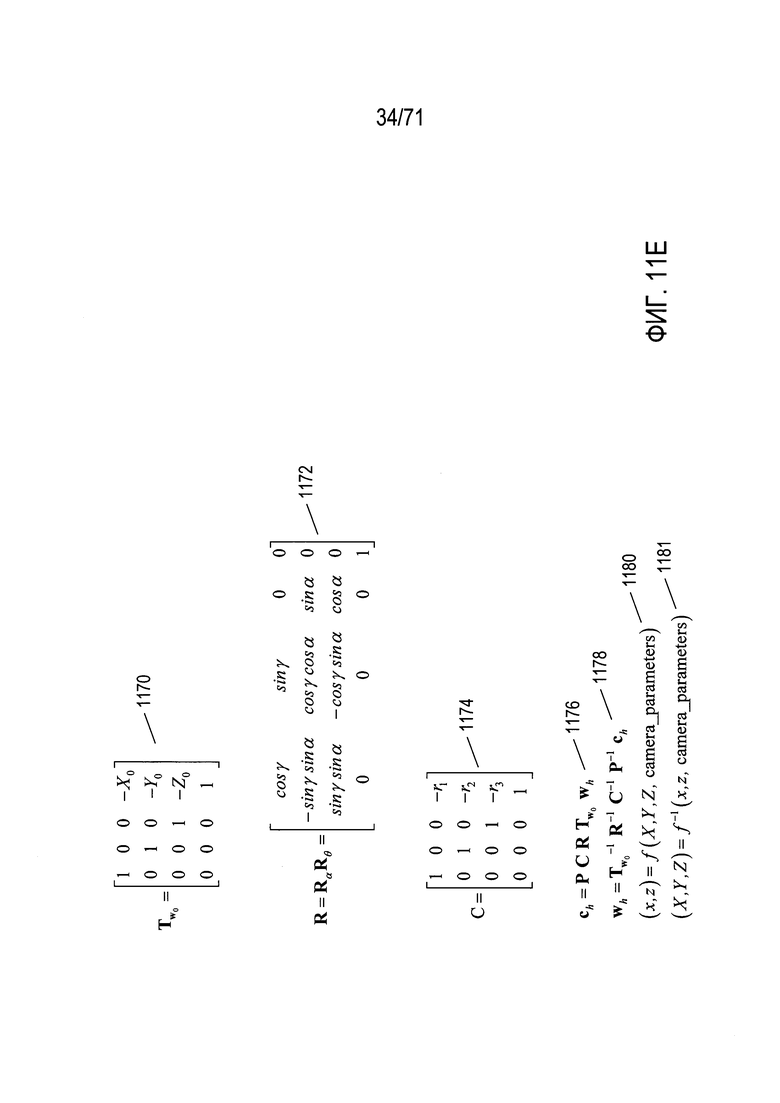
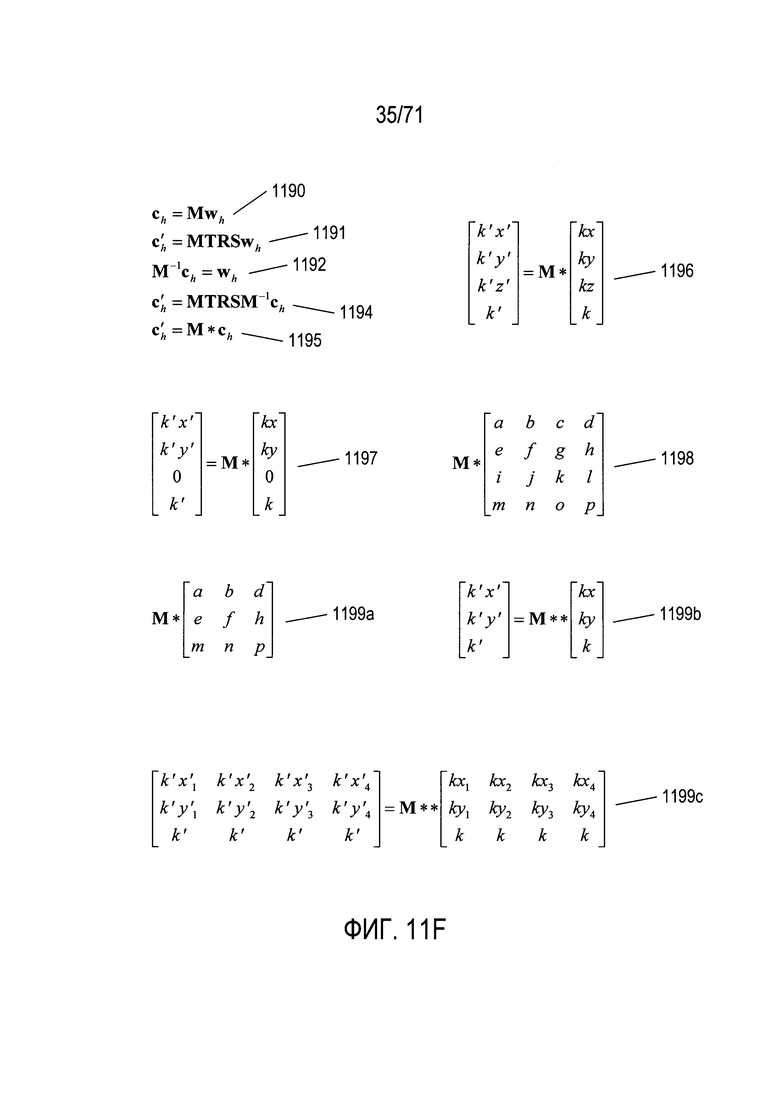
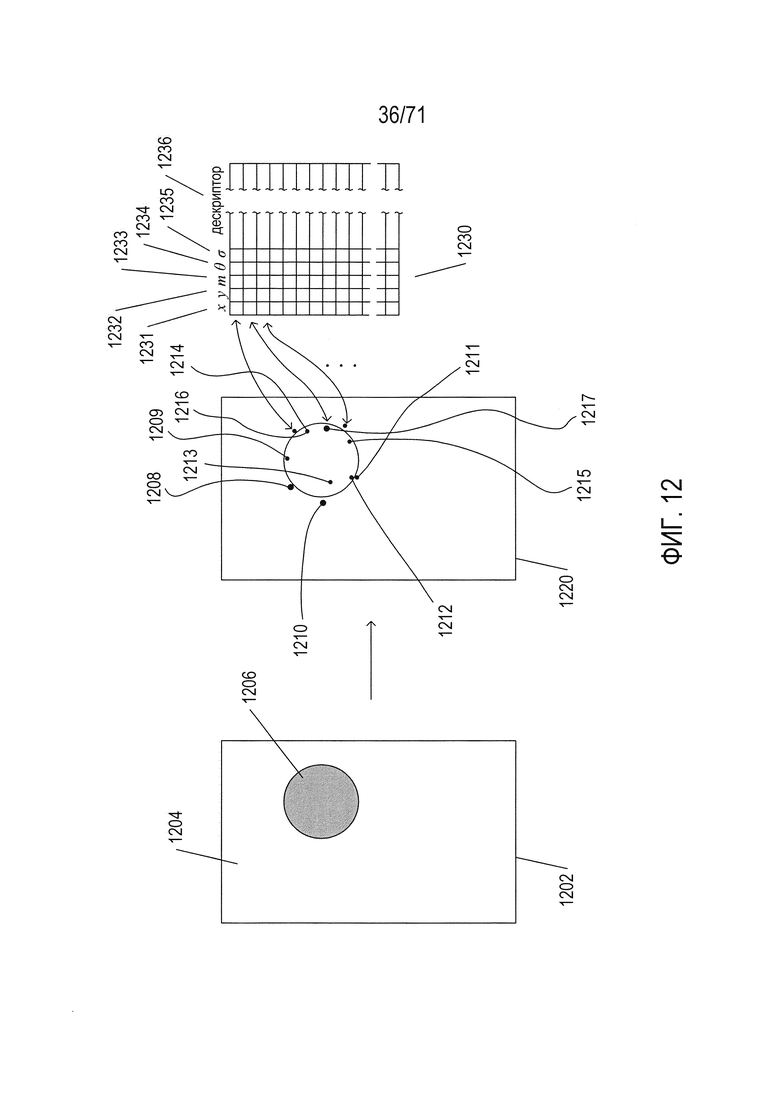
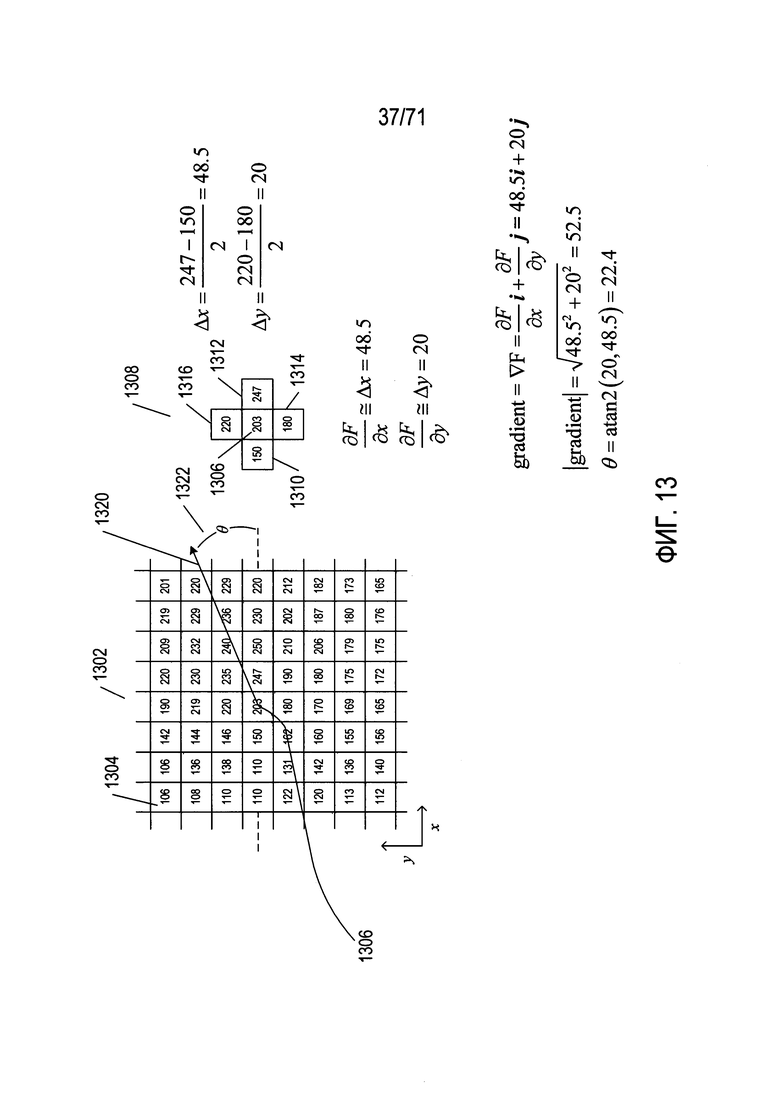
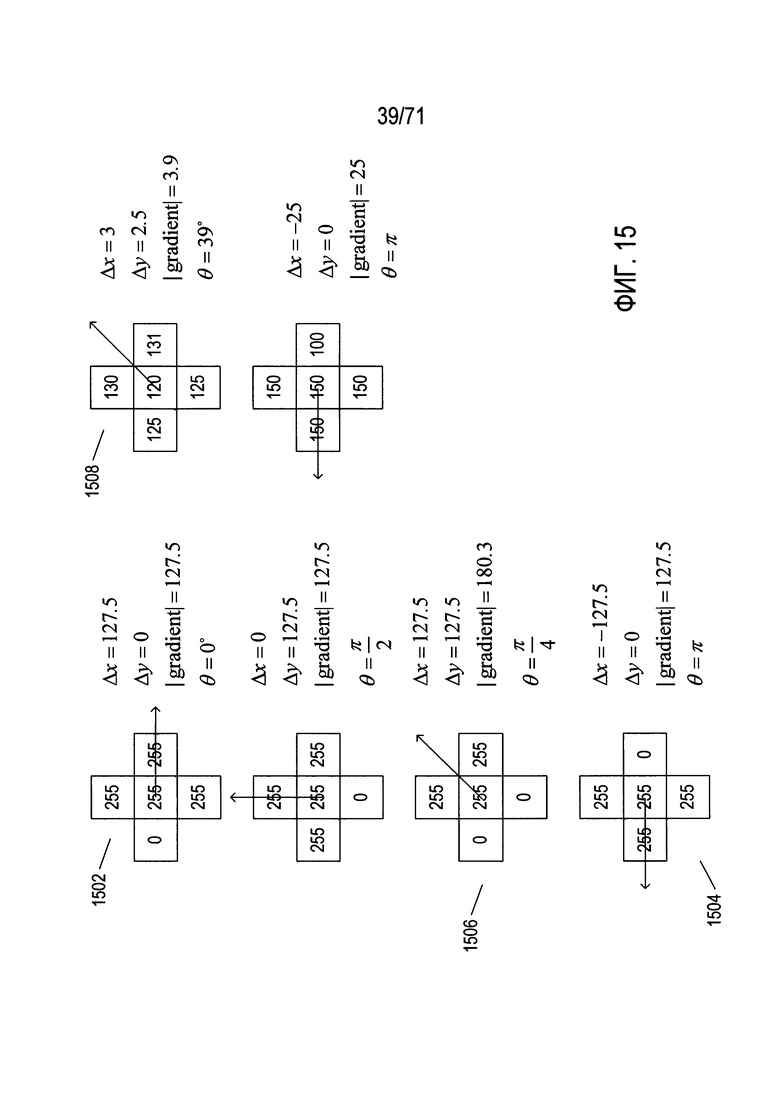
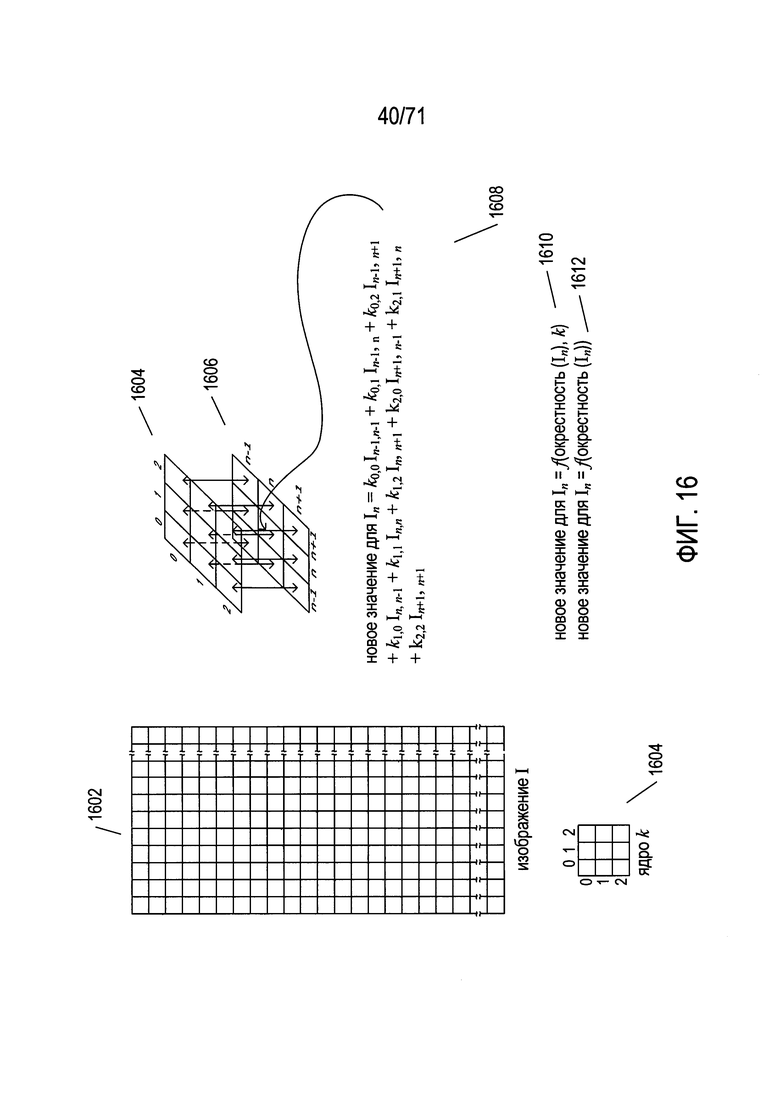
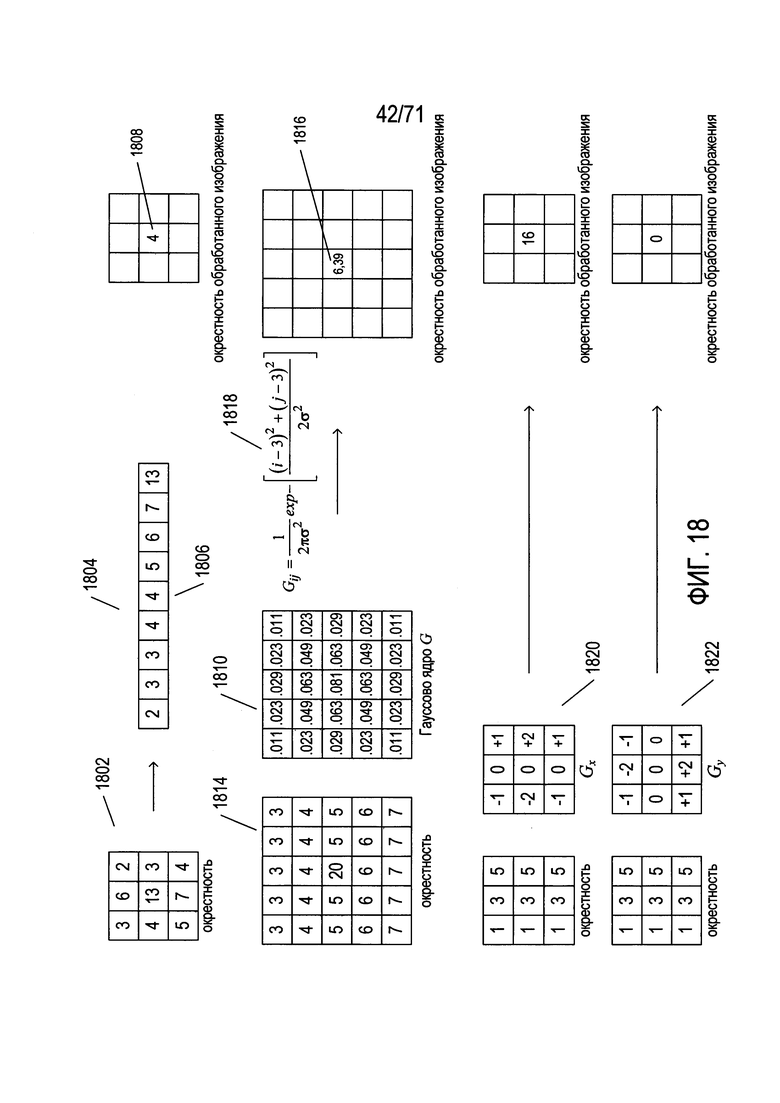
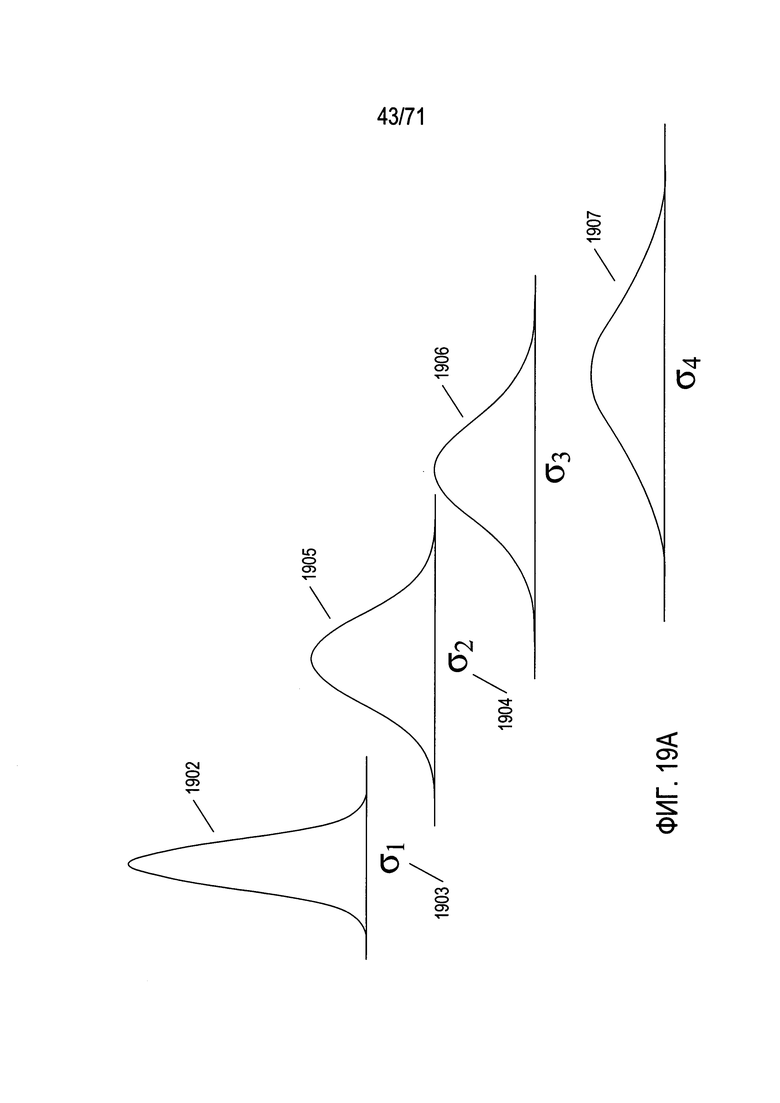
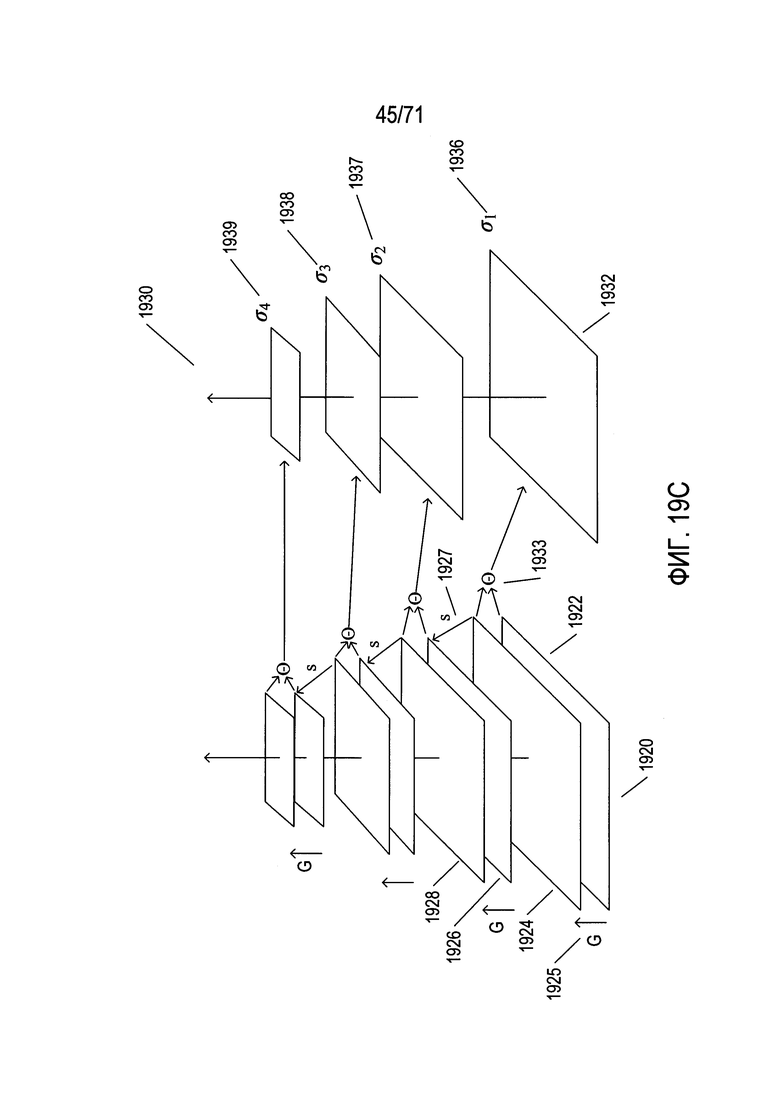
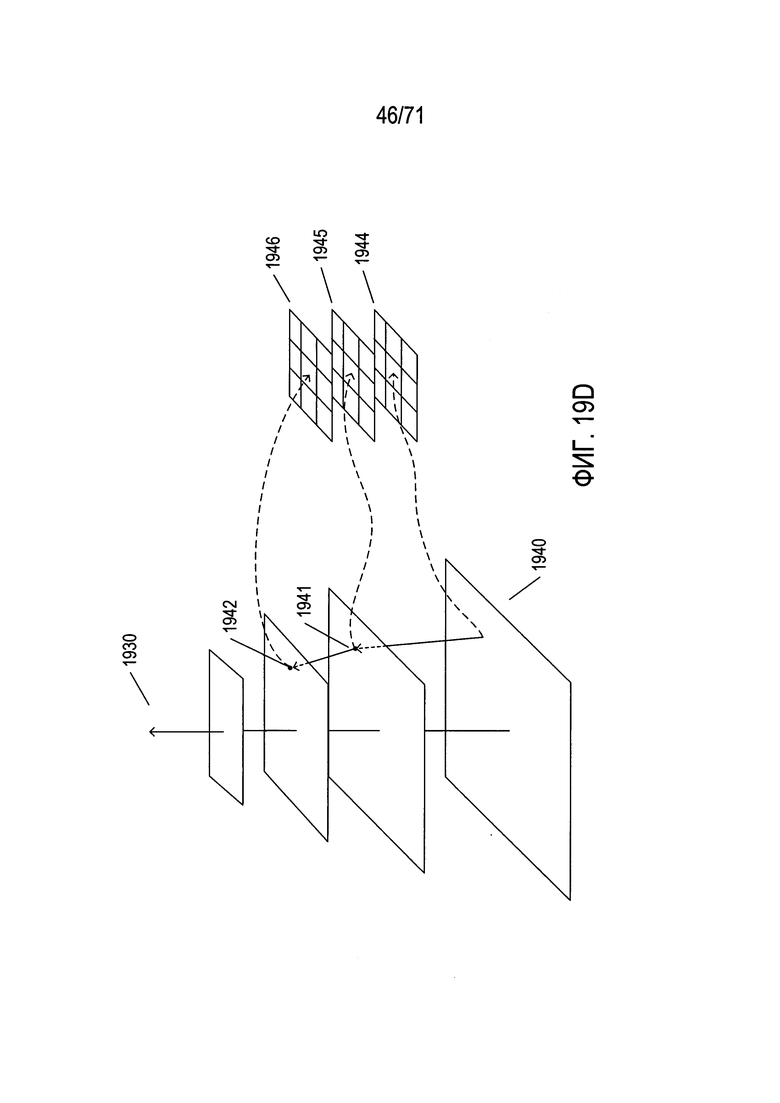
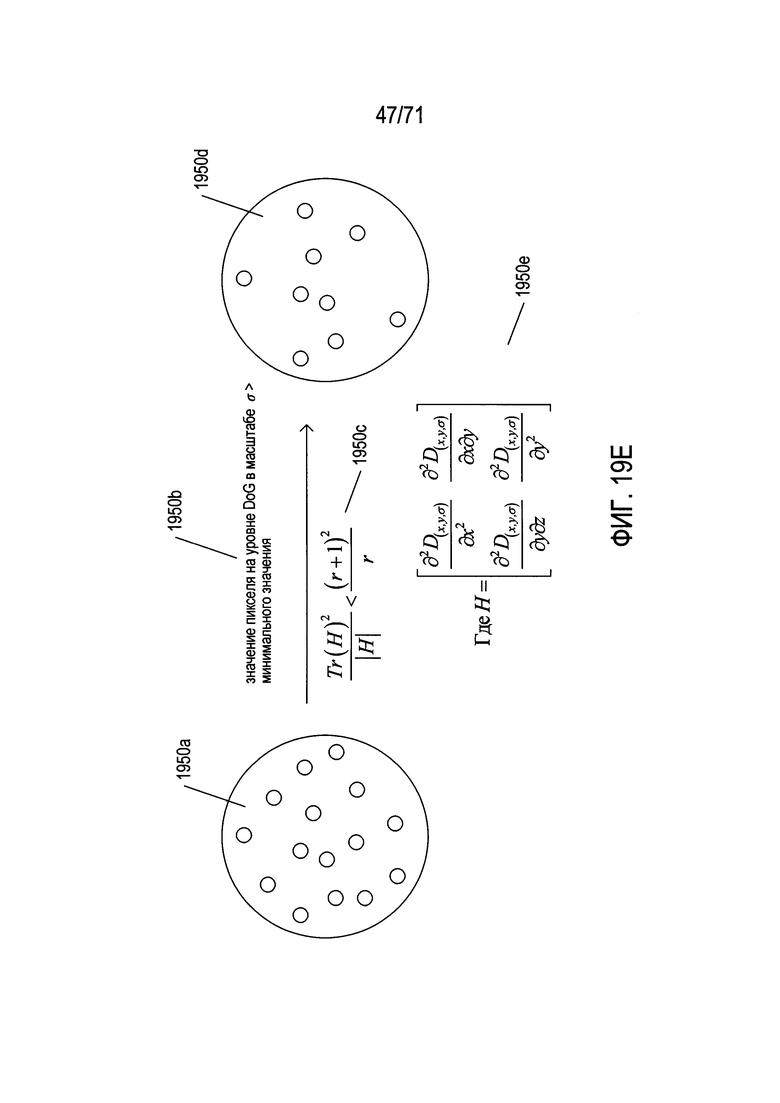
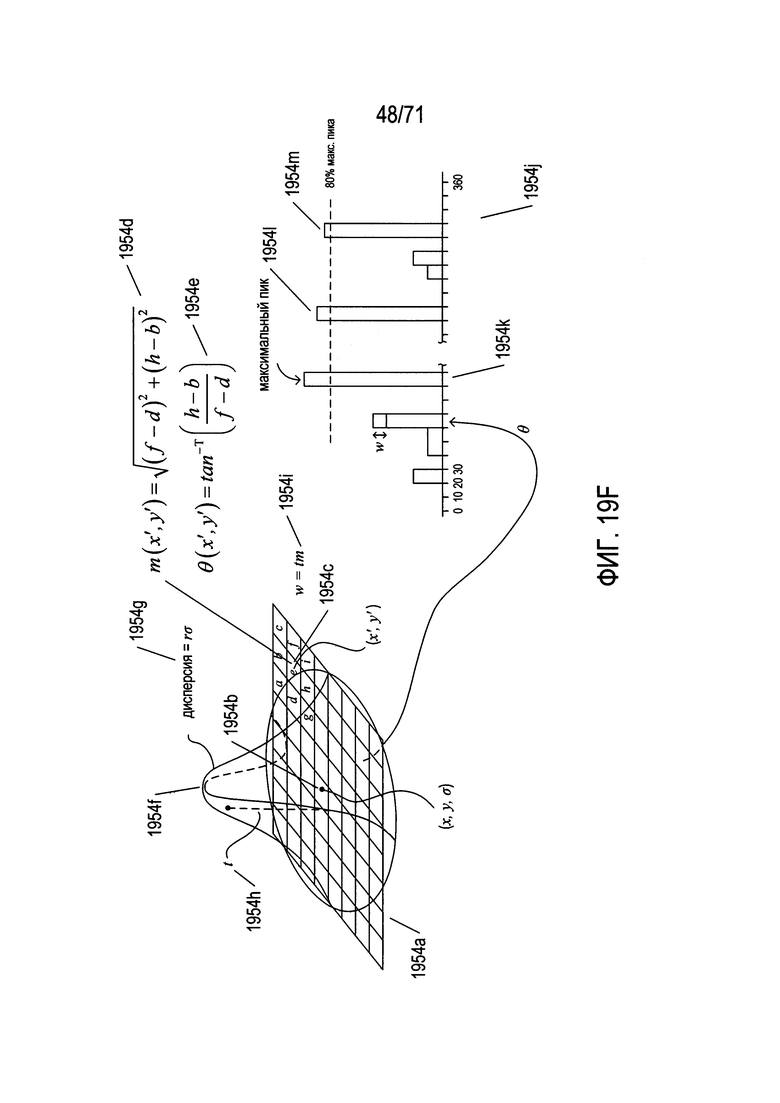

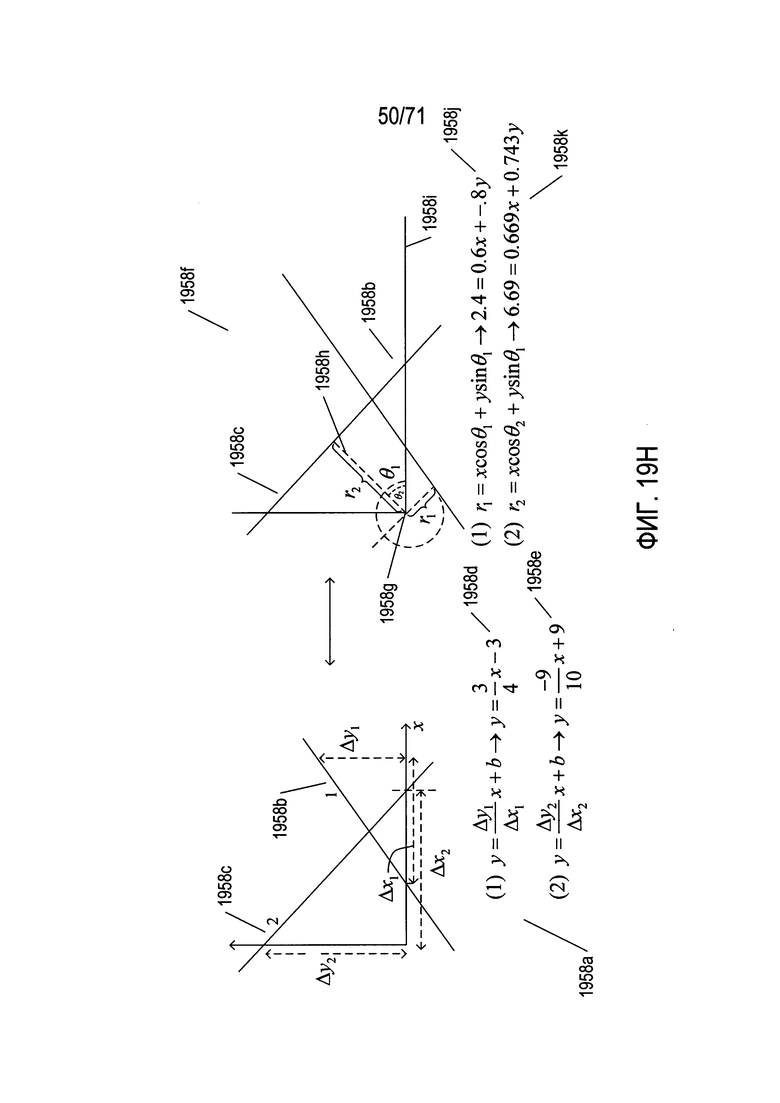
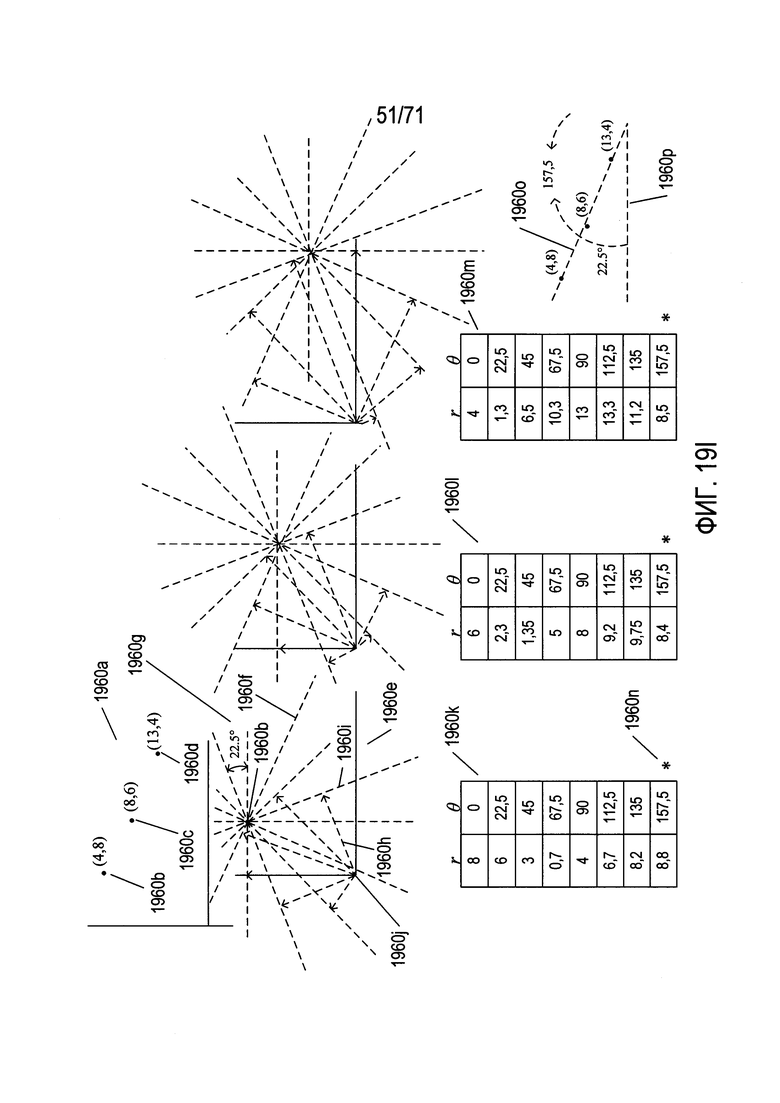
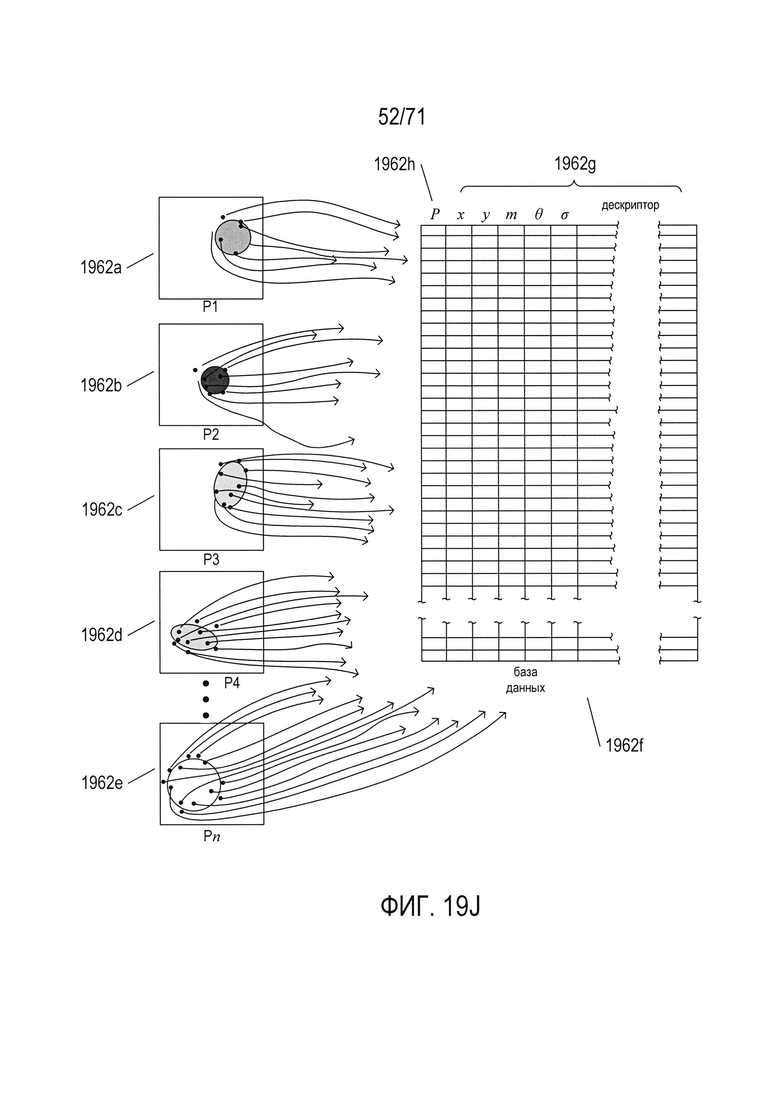
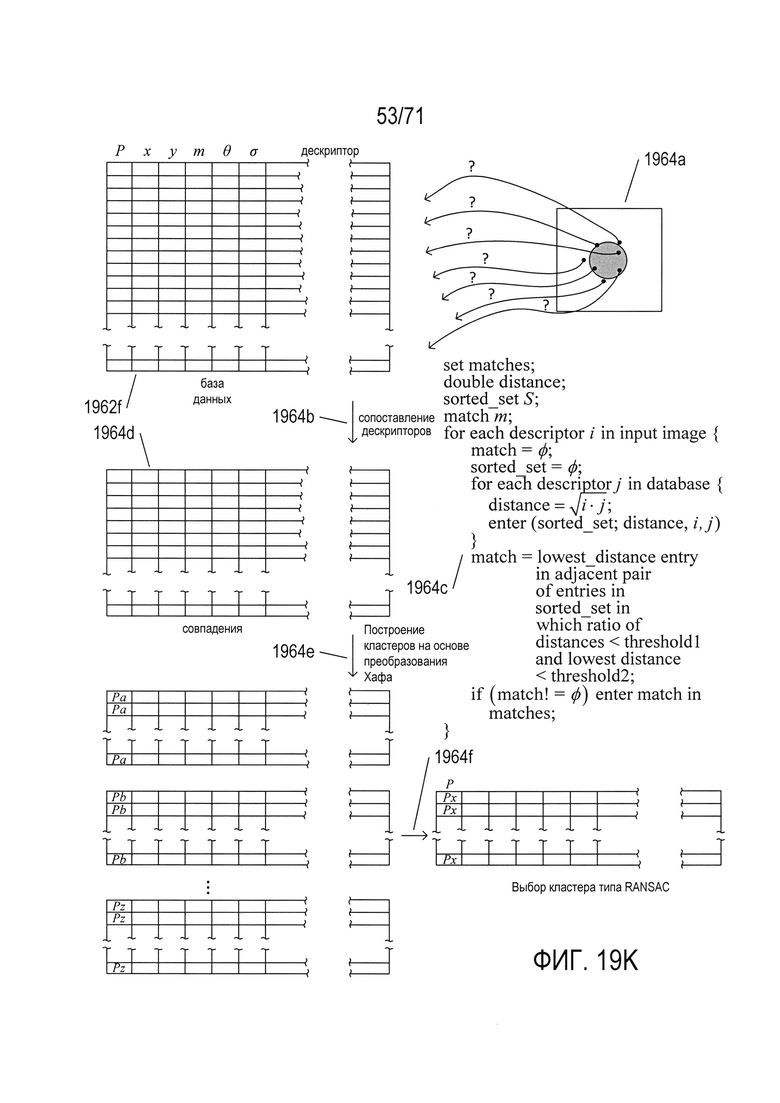
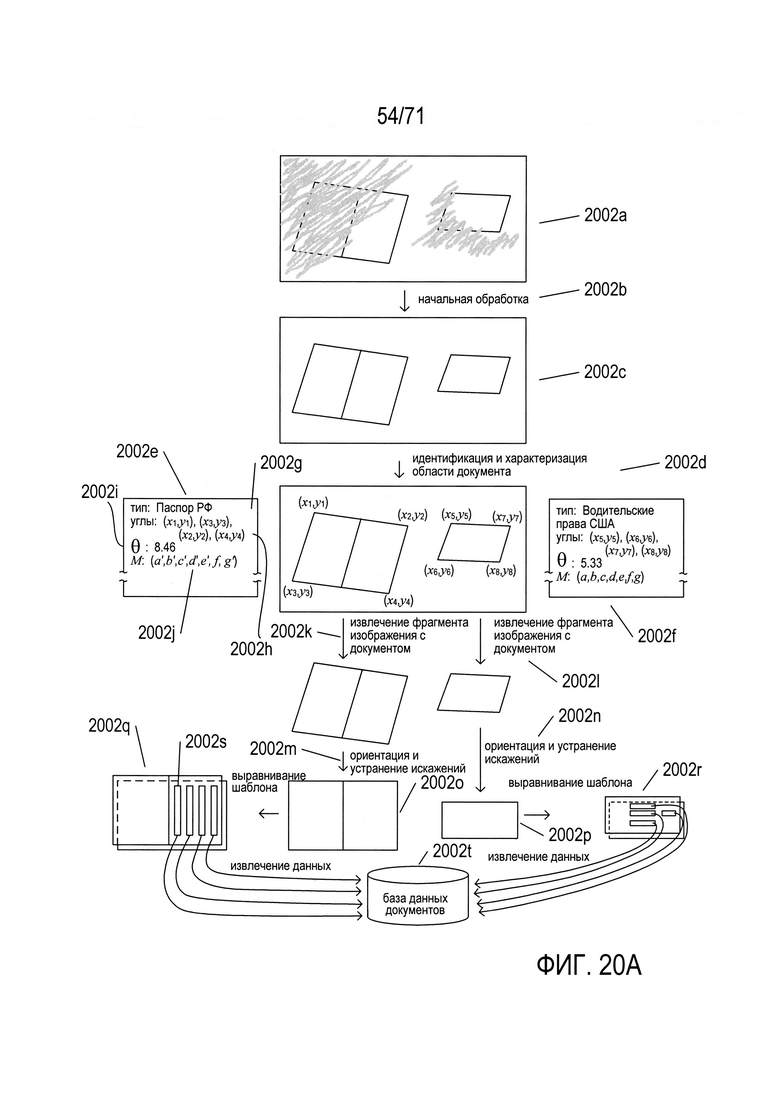
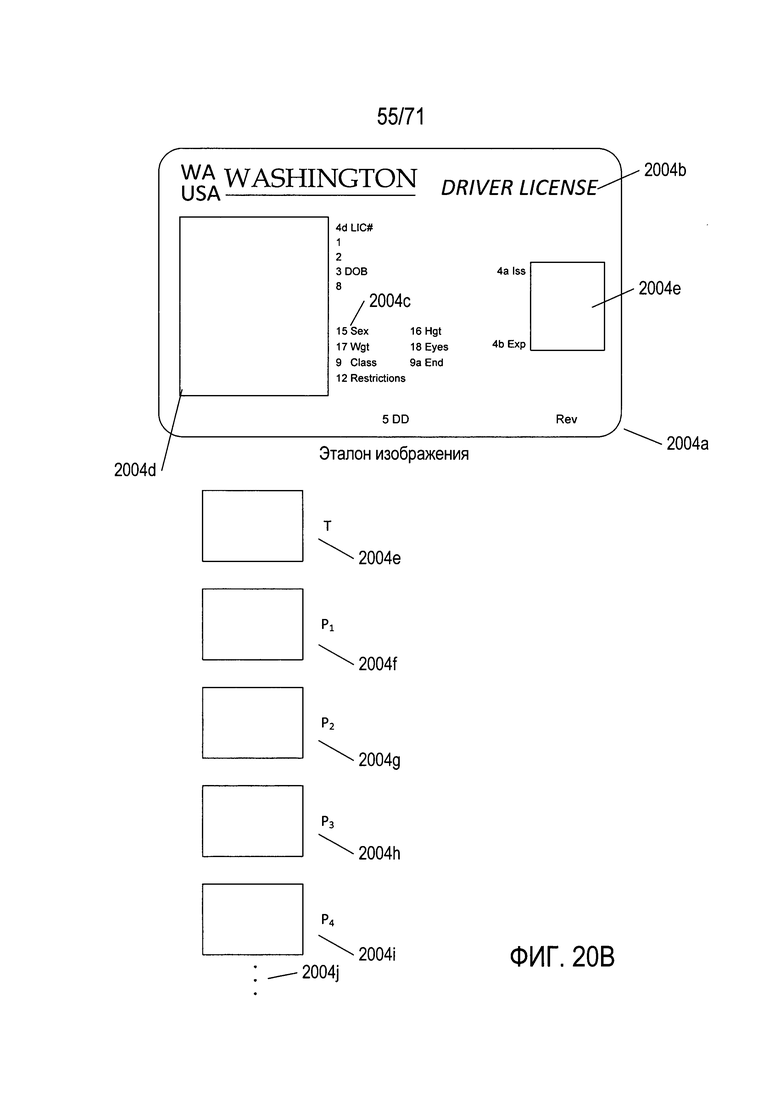
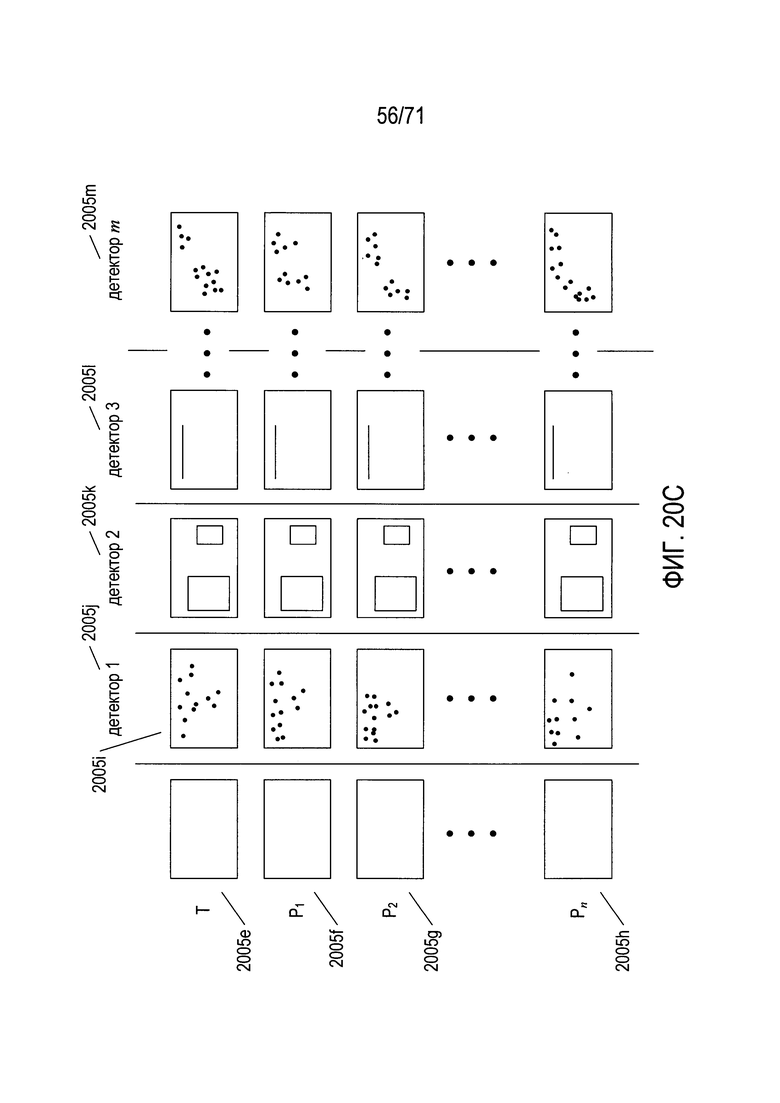
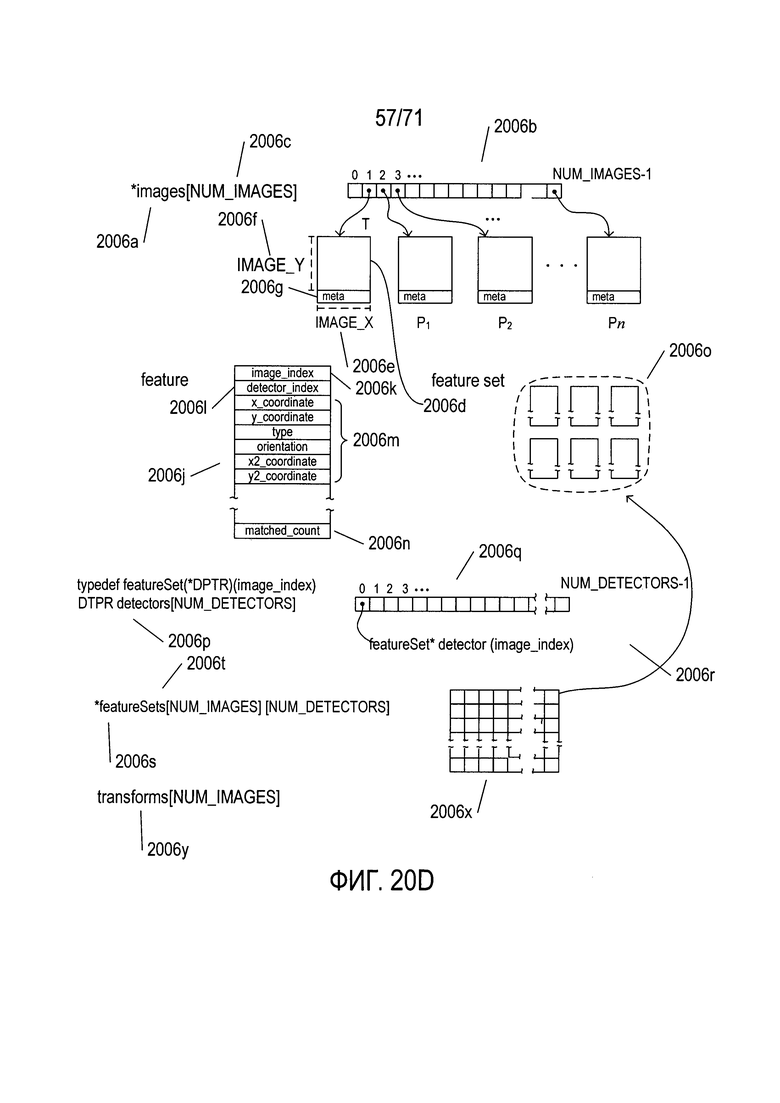
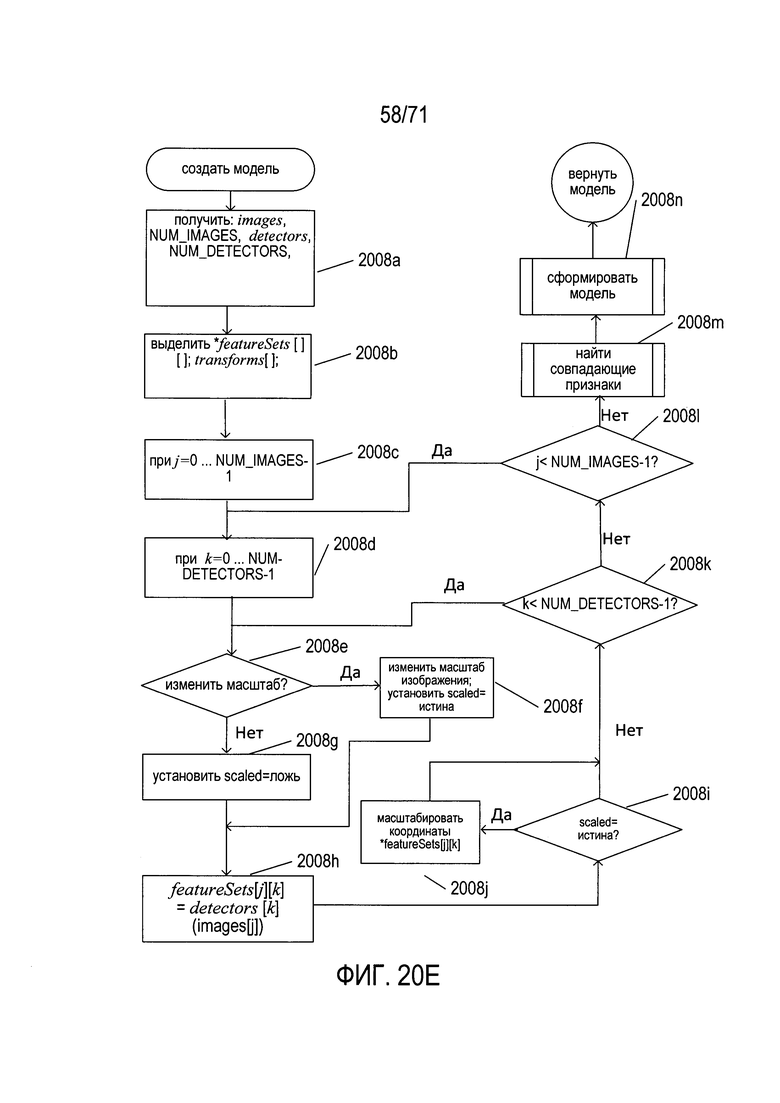

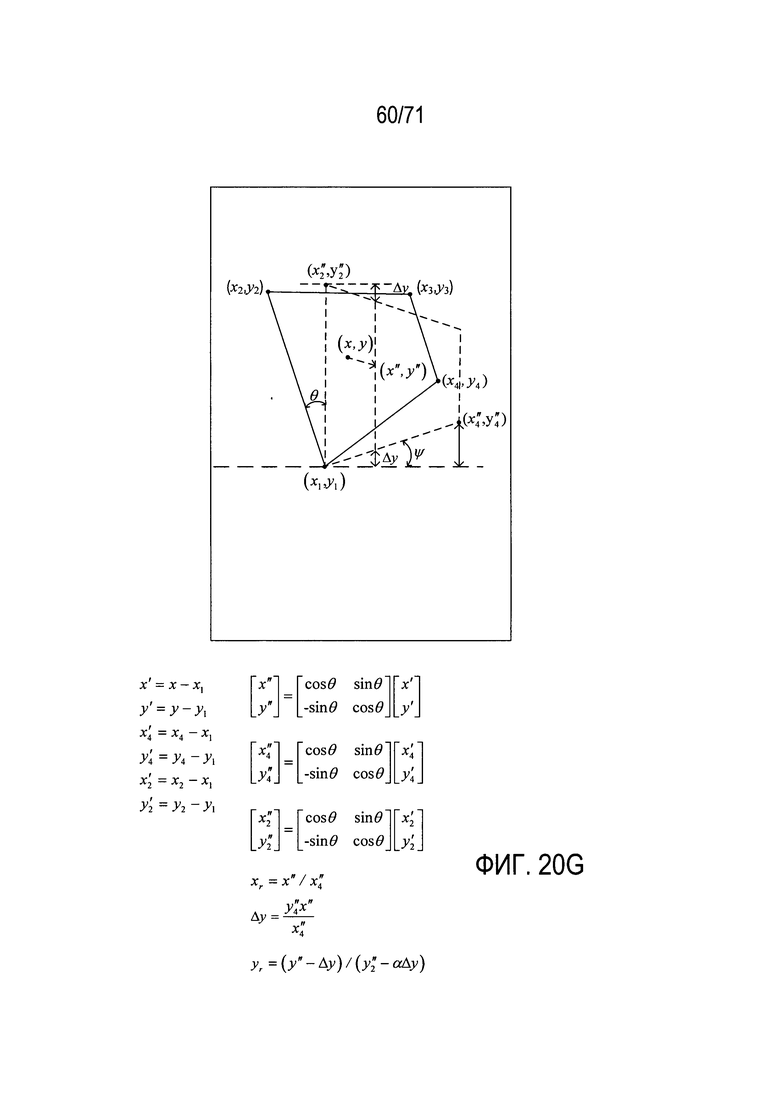

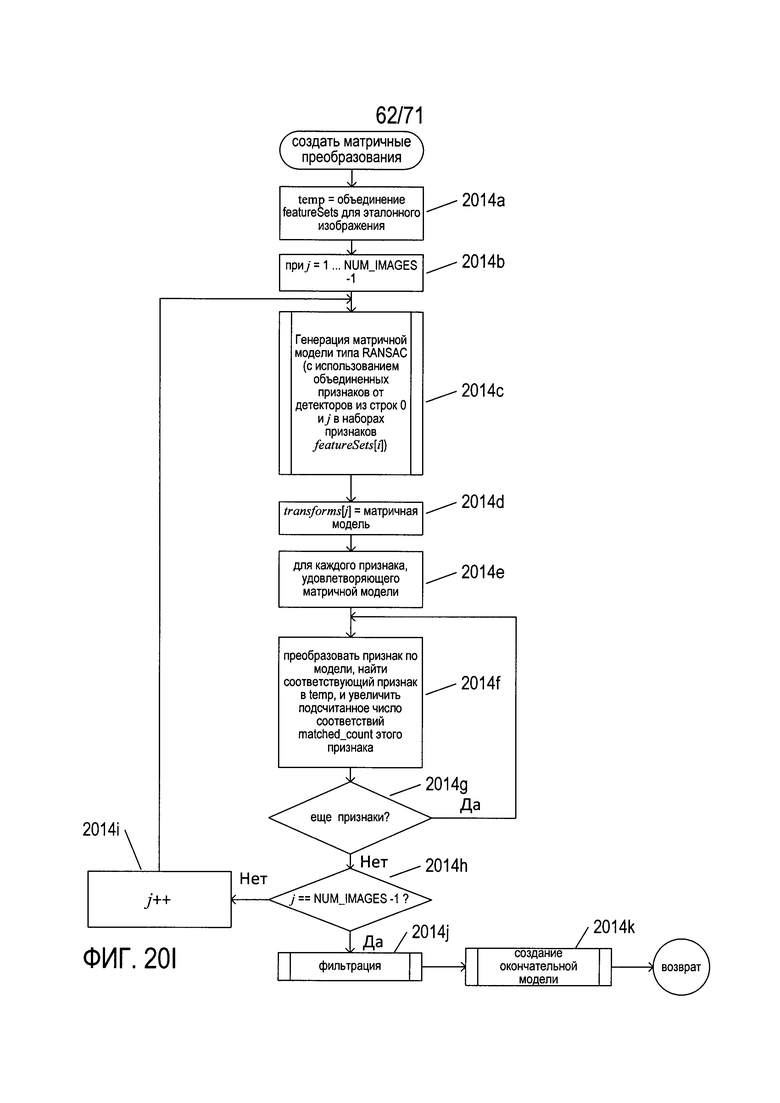
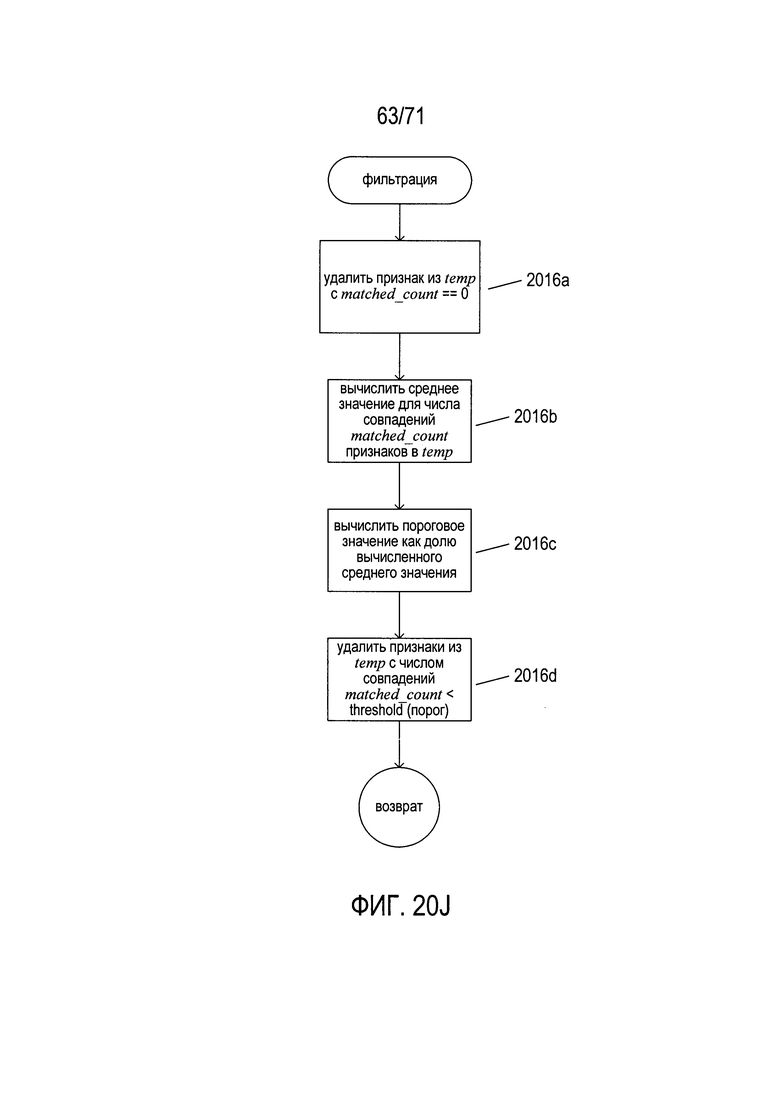
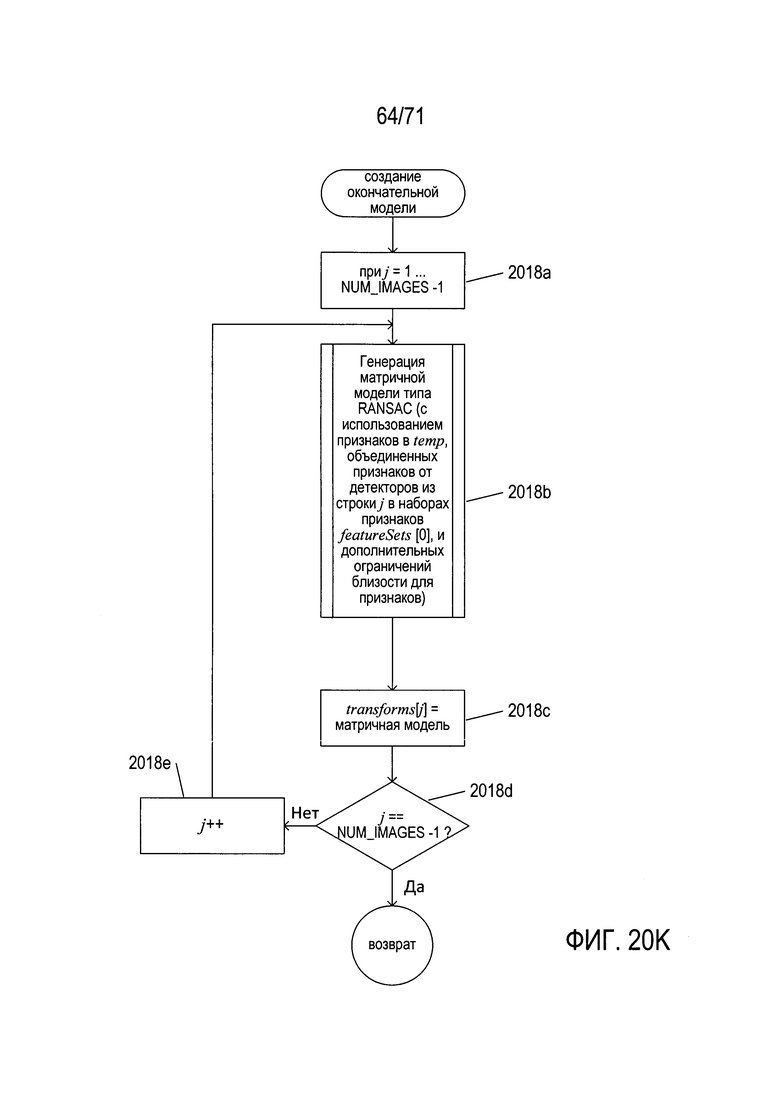
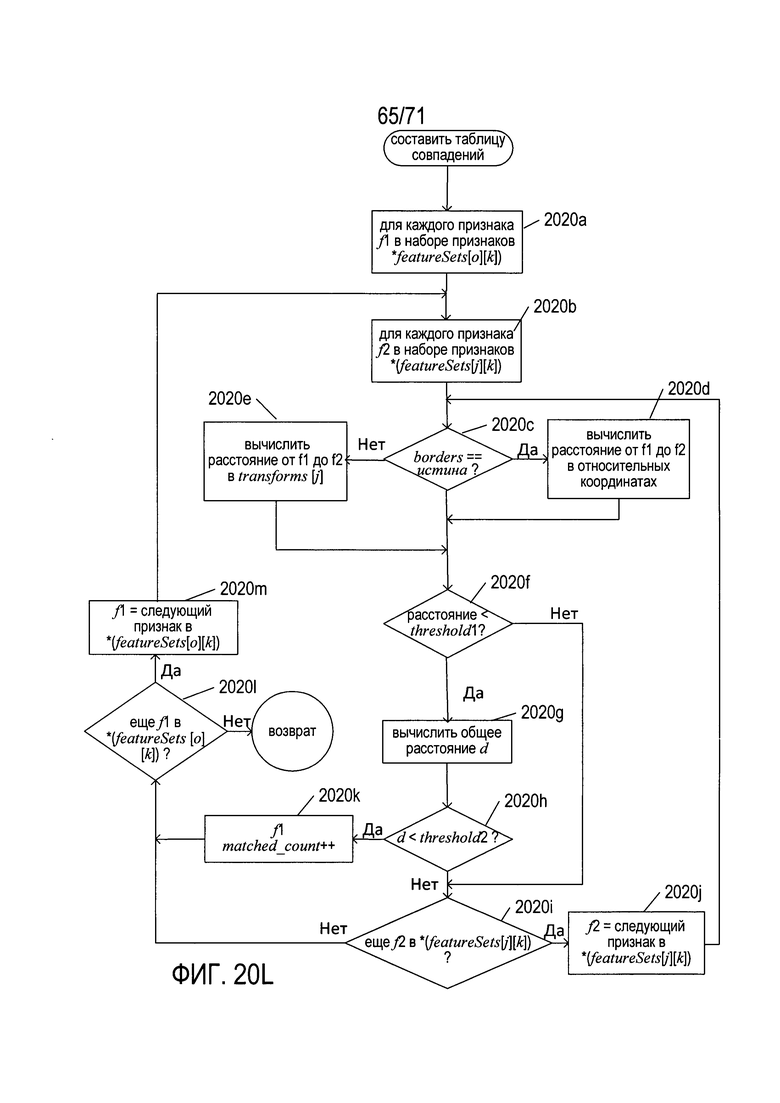

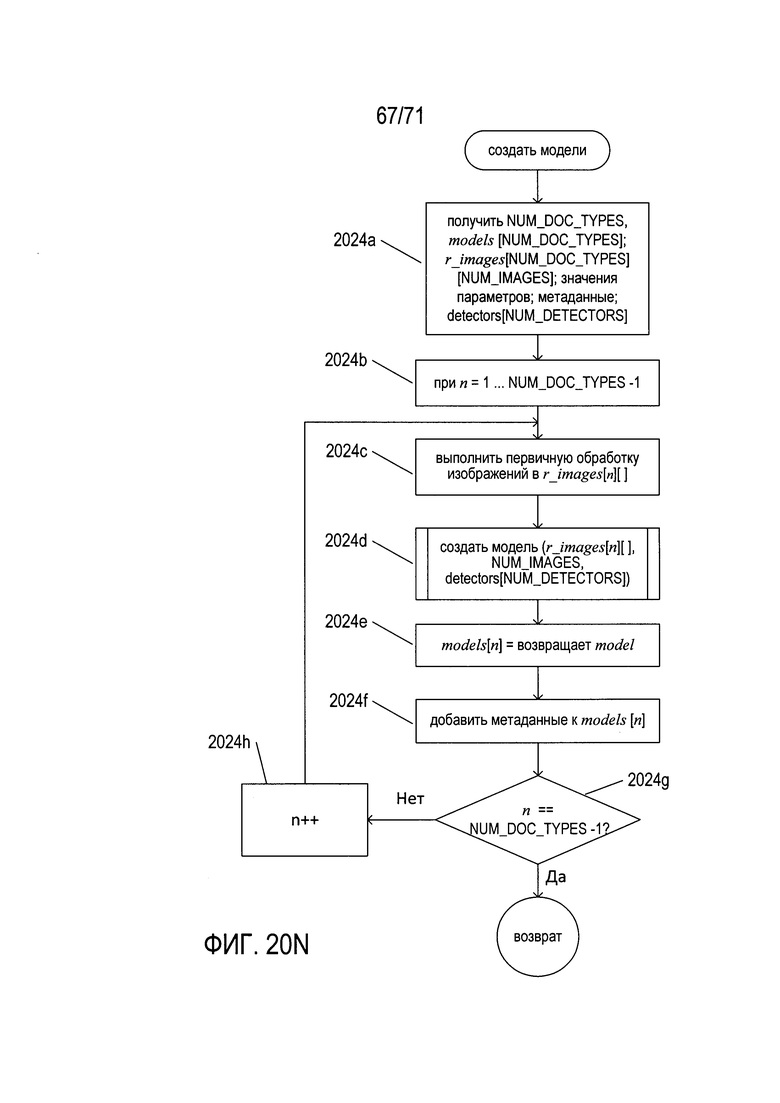
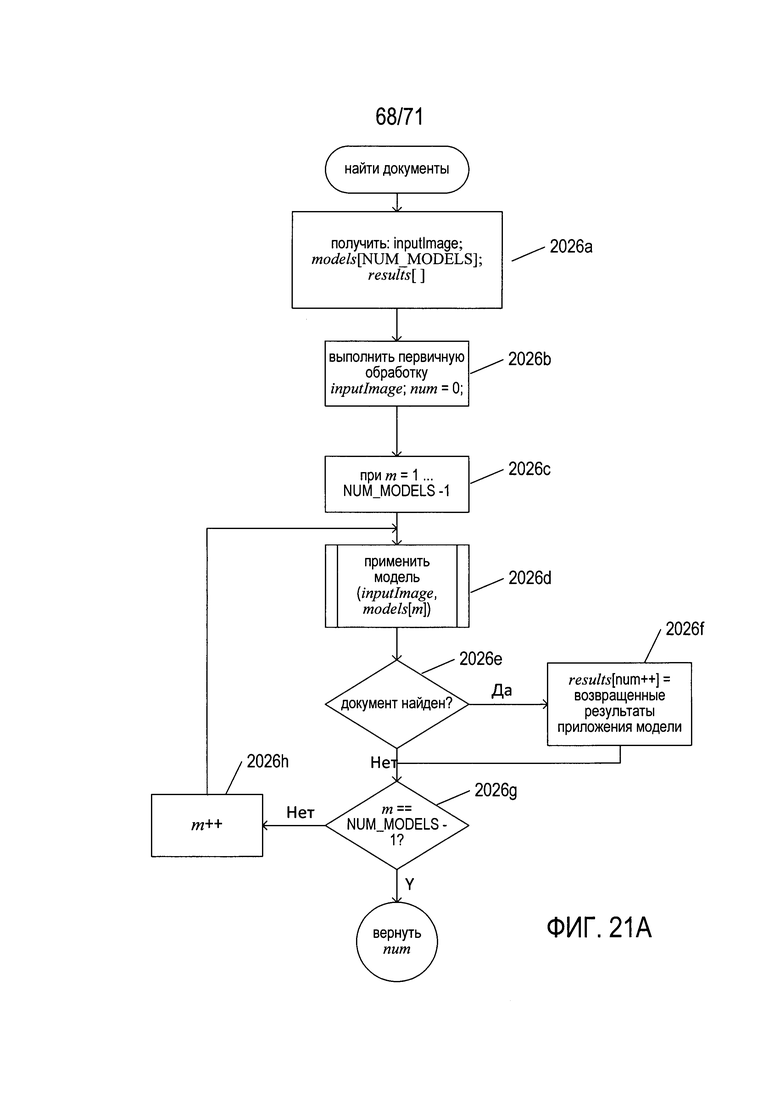
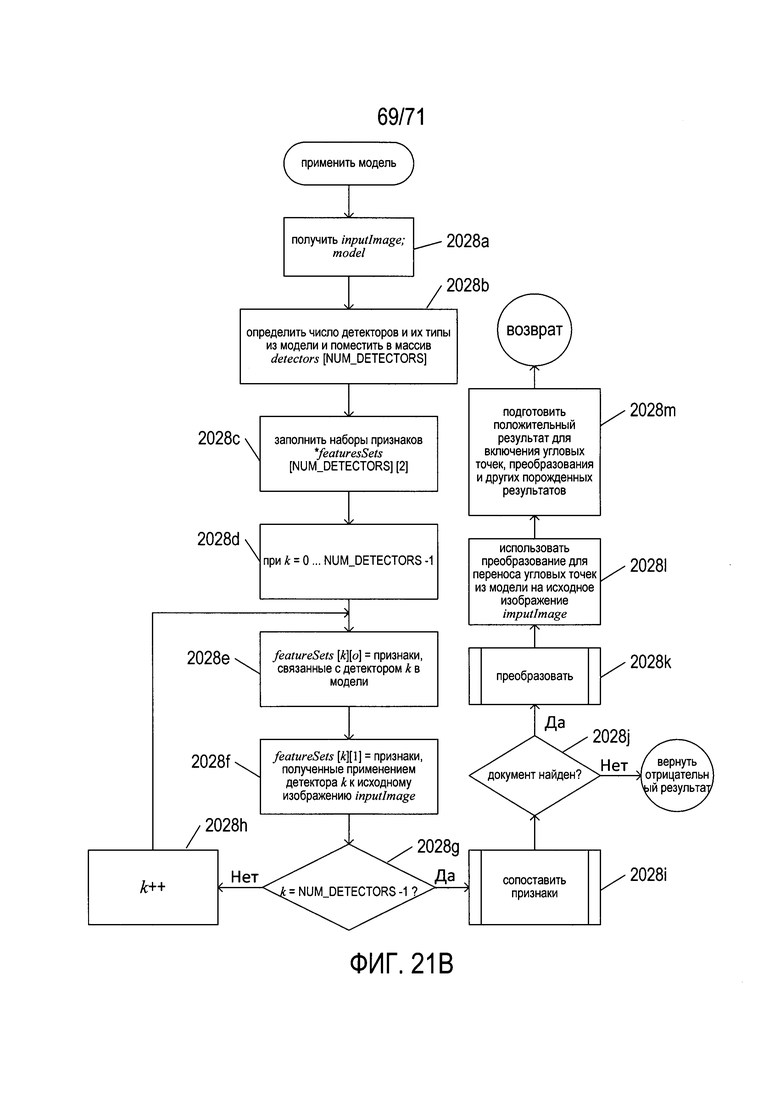
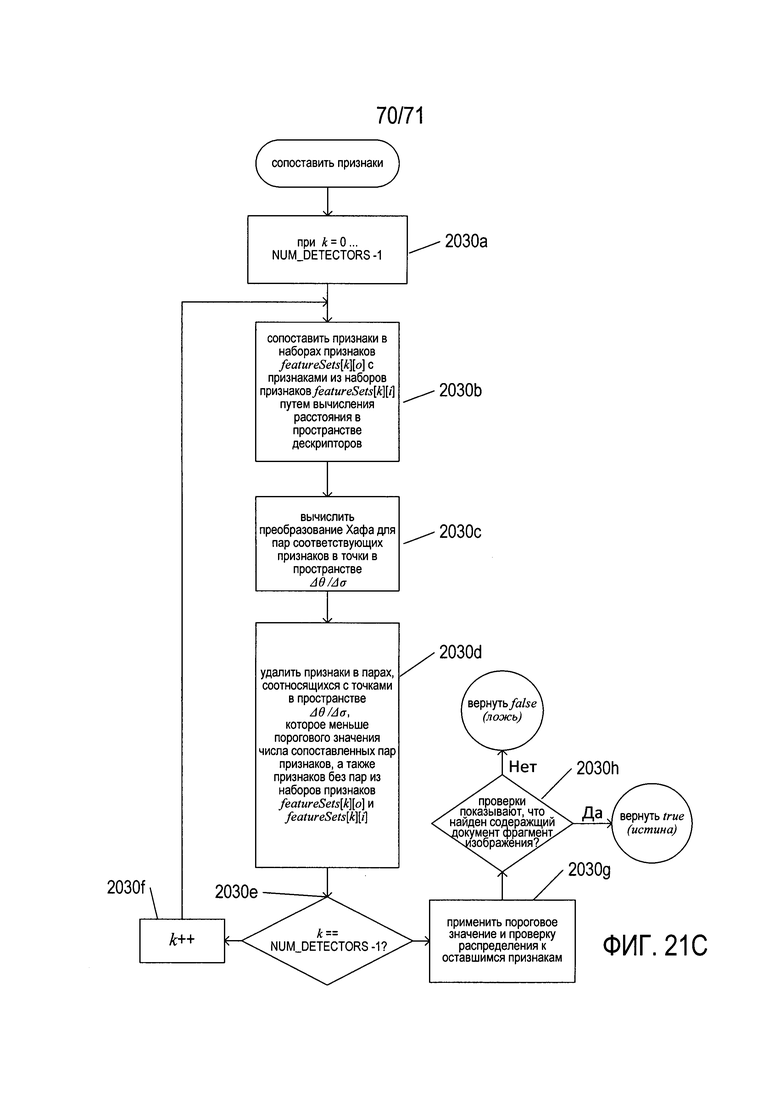
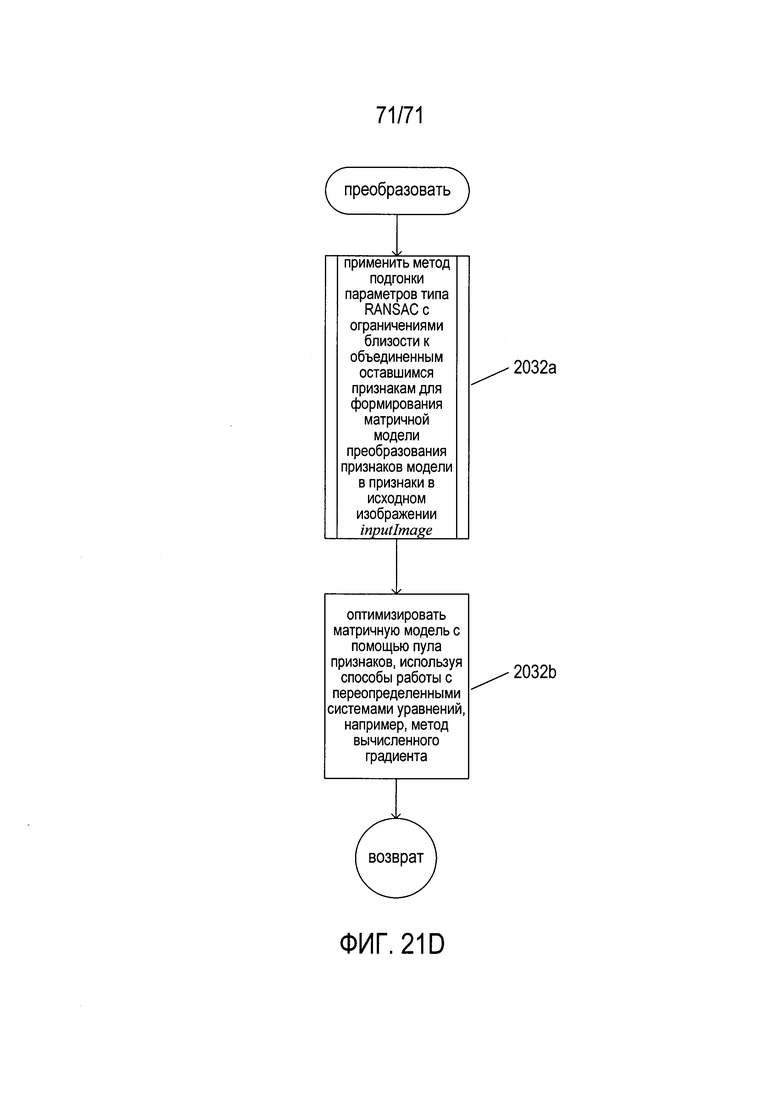
Изобретение относится к области обработки изображений и оптическому распознаванию символов. Технический результат – обеспечение выявления содержащих документ фрагментов на изображении. Система обработки содержащих документы изображений предназначена для: получения изображения, применения к полученному изображению детекторов признаков, причем каждый детектор признаков создает из изображения связанный с детектором набор признаков, для каждой из одной или более моделей типа документа; применения модели типа документа к полученному изображению, причем модель документа содержит набор признаков модели, для создания набора итоговых пар признаков; применения одной или более проверок к набору итоговых пар признаков и в случае установления наличия в изображении фрагмента изображения, содержащего соответствующий модели тип документа, применение преобразования, которое преобразует положения признаков модели в положения на изображении для создания и сохранения положений одной или более точек содержащего документ фрагмента изображения; и создания и сохранения ориентации содержащего документ фрагмента изображения. 3 н. и 17 з.п. ф-лы, 78 ил.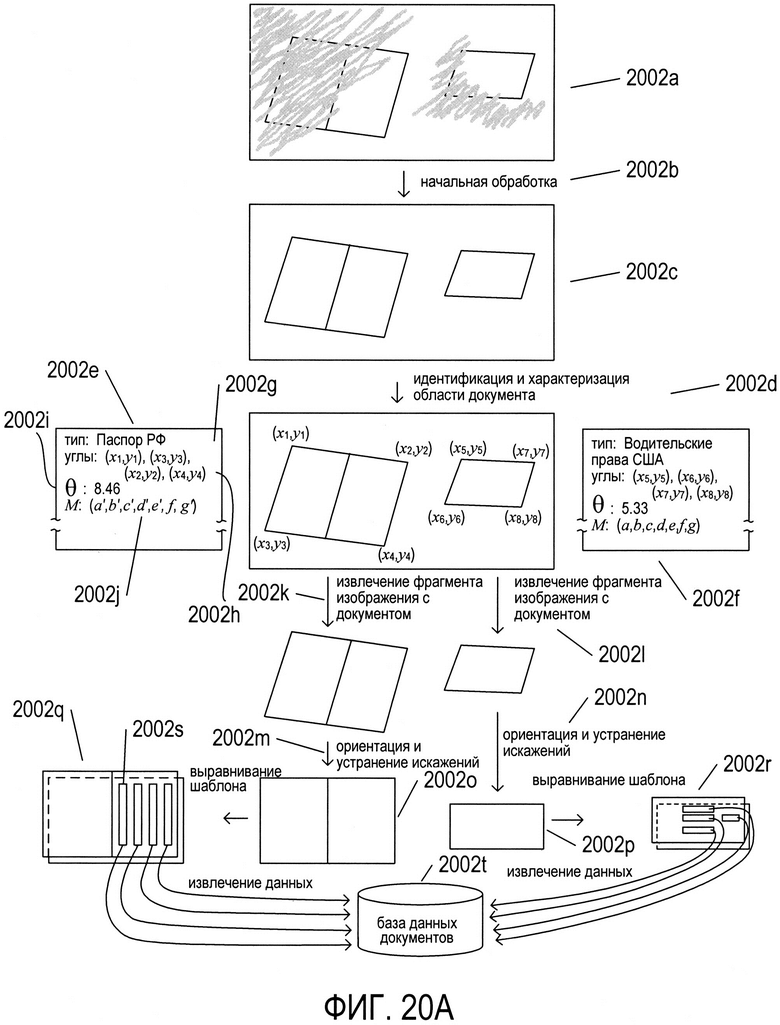
1. Система обработки содержащих документы изображений, содержащая:
память;
процессор; и
подсистему управления, предназначенную для получения изображения,
применения к полученному изображению одного или более детекторов признаков, причем каждый детектор признаков создает из изображения связанный с детектором набор признаков, и
для каждой из одной или более моделей типа документа
применения модели типа документа к полученному изображению, причем модель документа содержит набор признаков модели, для создания набора итоговых пар признаков, при этом каждая итоговая пара признаков включает первый признак из признаков модели и второй совпадающий признак из одного или более наборов признаков, созданных одним или более детекторами признаков,
применения одной или более проверок к набору итоговых пар признаков,
и в случае установления одной или более проверок наличия в изображении фрагмента изображения, содержащего соответствующий модели тип документа, применение преобразования, которое преобразует положения признаков модели в положения на изображении для создания и сохранения положений одной или более точек содержащего документ фрагмента изображения, и
создания и сохранения ориентации содержащего документ фрагмента изображения.
2. Система обработки содержащих документы изображений по п. 1, также включающая:
для каждого содержащего документ фрагмента изображения, присутствие которого в изображении определено,
использование положений одной или более точек в содержащем документ фрагменте изображения и ориентации содержащего документ фрагмента изображения для извлечения информации из содержащего документ фрагмента изображения.
3. Система обработки содержащих документы изображений по п. 1, отличающаяся тем, что модель типа документа применяется к полученному изображению следующим образом:
для каждого детектора, который обнаруживает признак модели, включенный в модель, сопоставление признаков, сформированных детектором из изображения, с признаками модели, обнаруженными детектором, для получения исходного набора совпадающих пар признаков,
распределение пар совпадающих признаков в пространстве преобразования, и
добавление пар признаков, сгруппированных в пространстве преобразования, к итоговому набору пар признаков.
4. Система обработки содержащих документы изображений по п. 3, отличающаяся тем, что сопоставление признаков, сформированных детектором из изображения, с признаками модели, обнаруженными детектором, также включает:
выбор, для каждого признака модели, ближайшего признака, сформированного детектором, где расстояние между признаком модели и признаками, сформированными детектором, определяется по метрике расстояния в пространстве значений атрибутов признаков, причем каждое измерение пространства соответствует атрибуту признака, и
выбор ближайшего признака как совпадающего, если расстояние между признаком модели и ближайшим признаком меньше порогового значения.
5. Система обработки содержащих документы изображений по п. 3, отличающаяся тем, что распределение пар совпадающих признаков в пространстве преобразования также включает:
вычисление разницы по двум или более атрибутам признаков между признаками модели и сформированными детектором признаками для каждой пары совпадающих признаков, и
распределение каждой пары совпадающих признаков в пространстве преобразования с размерами, соответствующими разнице между двумя значениями атрибутов признаков.
6. Система обработки содержащих документы изображений по п. 1, отличающаяся тем, что применение одной или более проверок к набору итоговых пар признаков для установления наличия в изображении фрагмента изображения, содержащего соответствующий модели тип документа, также включает:
применение одной или более проверок, определяющих отношение числа признаков модели в парах признаков итогового набора пар признаков к числу признаков модели в модели и сравнивающих это отношение с пороговым значением, и
проверок, определяющих отношение числа детекторов, создавших один или более признаков, включенных в итоговый набор пар признаков, к количеству детекторов, создавших один или более признаков модели, и сравнивающих это отношение с пороговым значением.
7. Система обработки содержащих документы изображений по п. 1, отличающаяся тем, что преобразование, которое преобразует положения признаков модели в положения на изображении, создается путем:
применения способа подгонки параметров для создания матричной модели, которая, будучи применена к координатному вектору точки на эталонном изображении документа, использованного для создания модели, дает соответствующий координатный вектор для точки на изображении.
8. Система обработки содержащих документы изображений по п. 7, отличающаяся тем, что метод подгонки параметров представляет собой метод подгонки параметров типа RANSAC, который использует ограничение близости при выборе исходной модели и при добавлении точек к модели.
9. Система обработки содержащих документы изображений по п. 7, отличающаяся тем, что применение преобразования, которое преобразует положения признаков модели в положения на изображении для создания и сохранения положений одной или более точек содержащего документ фрагмента изображения и для создания и сохранения ориентации содержащего документ фрагмента изображения, также включает:
выбор угловых точек документа на эталонном изображении документа,
использование матричной модели для преобразования пар координат, описывающих положение угловых точек документа на эталонном изображении, в соответствующие пары координат изображения, и
использование двух пар координат изображения в углах документа для вычисления линейного сегмента и использование линейного сегмента для вычисления ориентации линейного сегмента относительно границы изображения.
10. Система обработки содержащих документы изображений по п. 1, отличающаяся тем, что один или более детекторов признаков выявляют конкретные положения, геометрические признаки или признаки SIFT, создаваемые детектором признаков SIFT, и
отличающаяся тем, что признаки, созданные детекторами признаков, характеризуются значениями атрибутов.
11. Система обработки содержащих документы изображений по п. 10, отличающаяся тем, что значения атрибутов, характеризующие признаки, включают одно или более следующих значений атрибутов:
величина;
масштаб;
ориентация;
пара координат, определяющая положение; и
дескриптор с несколькими элементами.
12. Система обработки содержащих документы изображений, содержащая:
память;
процессор;
подсистему управления, предназначенную для:
получения эталонного изображения и дополнительных изображений в различных положениях,
применения к эталонному изображению и дополнительным изображениям в различных положениях одного или более детекторов признаков, причем каждый детектор признаков создает из каждого изображения связанный с детектором набор признаков,
накопления числа совпадений между каждым признаком эталонного изображения и признаками дополнительных изображений в различных положениях,
выполнения одной или более проверок признаков эталонного изображения и связанного с ними числа накопленных совпадений для выбора набора признаков модели, и
включения в модель каждого признака модели, а также указания детектора, с помощью которого был создан признак,
ссылки на эталонное изображение,
указания типа документа для эталонного документа, и
дополнительных метаданных, и
сохранения модели для последующего использования при выявлении в исходном изображении фрагментов изображения, содержащих документ данного типа.
13. Система обработки содержащих документы изображений по п. 12, дополнительно включающая преобразование, которое для каждого дополнительного изображения в том или ином положении сопоставляет признаки дополнительного изображения в том или ином положении с признаками эталонного изображения путем:
использования в первом методе подгонки параметров признаков, обнаруженных детекторами в изображении, находящемся в определенном положении, и признаков, обнаруженных детекторами в эталонном изображении, для создания первого преобразования, которое сопоставляет признаки, обнаруженные в изображении, находящемся в определенном положении, с соответствующими признаками эталонного изображения, и создает набор удовлетворяющих первому преобразованию признаков изображения в определенном положении;
фильтрации признаков эталонного изображения;
использования во втором методе подгонки параметров, который использует ограничения близости для исходных точек модели и точек, добавленных к модели как удовлетворяющие первому преобразованию, признаков, обнаруженных детекторами в изображении в определенном положении, и отфильтрованных признаков эталонного изображения для создания итогового преобразования, которое сопоставит признаки, обнаруженные в изображении в определенном положении, с соответствующими признаками эталонного изображения.
14. Система обработки содержащих документы изображений по п. 13, отличающаяся тем, что фильтрация признаков эталонного изображения также содержит:
преобразование удовлетворяющих первому преобразованию признаков изображения в определенном положении, при первом преобразовании, в координаты эталонного изображения;
ведение накопительного подсчета совпадений для каждого признака эталонного изображения, за счет
для каждого удовлетворяющего первому преобразованию признака изображения в определенном положении,
увеличения накопленного числа посчитанных совпадений для признака эталонного изображения с координатами, которые соответствуют координатам эталонного изображения, созданным при первом преобразовании для удовлетворяющего первому преобразованию признака изображения, находящегося в определенном положении;
удаление из признаков эталонного изображения тех признаков, посчитанное число совпадений которых равно 0;
вычисление среднего значения подсчитанного числа совпадений для оставшихся признаков эталонного изображения, и
удаление из признаков эталонного изображения тех признаков, подсчитанное накопленное число совпадений которых, разделенное на среднее число подсчитанных совпадений, меньше порогового значения.
15. Система обработки содержащих документы изображений по п. 12, дополнительно включающая преобразование, которое для каждого изображения в том или ином положении сопоставляет признаки изображения в том или ином положении с признаками эталонного изображения путем:
использования аннотаций для границ документа в изображении, находящемся в том или ином положении, и соответствующих аннотаций для границ документа в эталонном изображении для создания относительного преобразования координат, при котором сопоставляются точки изображения в определенном положении с соответствующими точками эталонного изображения.
16. Система обработки содержащих документы изображений по п. 12, отличающаяся тем, что накопление числа совпадений между каждым признаком эталонного изображения, для каждого детектора, и признаками изображения в том или ином положении выполняется следующим образом:
для каждого детектора ищутся совпадения созданных детектором признаков изображения в определенном положении с признаками соответствующего эталонного изображения, созданными детектором, путем преобразования признаков изображения в определенном положении в признаки эталонного изображения с использованием преобразования, созданного для изображения в определенном положении, и
ведется накопительный подсчет количества совпадений для каждого признака эталонного изображения.
17. Система обработки содержащих документы изображений по п. 12, отличающаяся тем, что эталонное изображение представляет собой изображение эталонного документа, содержащего только текст и линии, общие для всех документов этого типа.
18. Система обработки содержащих документы изображений по п. 12, отличающаяся тем, что каждое дополнительное изображение, находящееся в том или ином положении, получено при разных относительных положениях и /или ориентациях относительно устройства получения изображения.
19. Система обработки содержащих документы изображений по п. 12, отличающаяся тем, что один или более детекторов признаков выявляют конкретные положения, геометрические признаки или признаки SIFT, создаваемые детектором признаков SIFT, и
отличающаяся тем, что признаки, созданные детекторами признаков, характеризуются значениями атрибутов, причем значения атрибутов содержат одно или более из значений:
величина,
масштаб,
ориентация,
пара координат, определяющая положение, и
дескриптор с несколькими элементами.
20. Способ выявления одного или более содержащих документы фрагментов изображения внутри изображений, выполняющийся системой обработки содержащих документы изображений, включающий:
получение изображения,
применение к полученному изображению одного или более детекторов признаков, причем каждый детектор признаков создает из изображения связанный с детектором набор признаков, и
для каждой из одной или более моделей типа документа
применение модели типа документа к полученному изображению, причем модель документа содержит набор признаков модели, для создания набора итоговых пар признаков, при этом каждая итоговая пара признаков включает первый признак из признаков моделей и второй совпадающий признак из одного или более наборов признаков детекторов, созданных одним или более детекторами признаков,
применение одной или более проверок к набору итоговых пар, и
в случае установления одной или более проверок наличия в изображении фрагмента изображения, содержащего соответствующий модели тип документа, применение преобразования, которое преобразует положения признаков модели в положения на изображении для создания и сохранения положений одной или более точек содержащего документ фрагмента изображения, и
создание и сохранение ориентации содержащего документ фрагмента изображения.
| Токарный резец | 1924 |
|
SU2016A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 9224061 B1, 29.12.2015 | |||
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ДОКУМЕНТОВ | 2003 |
|
RU2254610C2 |

