УРОВЕНЬ ТЕХНИКИ
[0001] Глубокая нейронная сеть (DNN) обещает значительные улучшения точности для приложений комплексной обработки сигналов, включая распознавание речи и обработку изображений. Мощь DNN происходит из ее глубокой и широкой сетевой структуры, имеющей очень большое число параметров. Например, было показано, что скрытая марковская модель на основе контекстно-зависимой глубокой нейронной сети (CD-DNN-HMM) превосходит обыкновенную модель смеси гауссовых распределений (CD-GMM-HMM) в отношении многих задач автоматического распознавания речи (ASR). Однако, превосходная производительность CD-DNN-HMM влечет за собой гораздо большие затраты во время выполнения, так как DNN используют гораздо больше параметров, чем традиционные системы. Таким образом, хотя CD-DNN-HMM были развернуты с высокой точностью на серверах или других компьютерных системах, имеющих обширные вычислительные ресурсы и ресурсы хранения, развертывание DNN на устройствах, которые имеют ограниченные вычислительные ресурсы и ресурсы хранения, таких как смартфоны, носимые устройства или развлекательные системы, является вызовом.
[0002] Еще, при распространенности таких устройств и потенциальной пользе, которую DNN представляет приложениям, таким как ASR и обработка изображений, индустрия имеет твердый интерес в присутствии DNN на этих устройствах. Общим подходом к этой проблеме является уменьшение размерностей DNN, например, посредством уменьшения числа узлов в скрытых слоях и числа целей сенонов в слое вывода. Но хотя этот подход уменьшает размер модели DNN, потеря точности (например, вероятность ошибки в кодовом слове) увеличивается значительно и страдает эксплуатационное качество.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] Это краткое изложение сущности изобретения предоставлено для введения подборки концепций в упрощенной форме, которые дополнительно описаны ниже в подробном описании. Это краткое изложение сущности изобретения не предназначено для идентификации ключевых признаков или существенных признаков заявленного изобретения, также не предназначено для использования в качестве помощи в определении объема заявленного изобретения.
[0004] Варианты осуществления данного изобретения направлены на системы и способы предоставления более точной модели DNN с уменьшенным размером для развертывания на устройствах посредством "обучения" развернутой DNN на основании DNN с большей емкостью (числом скрытых узлов). Чтобы обучить DNN с меньшим числом скрытых узлов, DNN-"учитель" большего размера (с большей точностью) используется для обучения меньшей DNN-"студента". В частности, как будет дополнительно описано, вариант осуществления данного изобретения использует свойство распределения вывода DNN посредством минимизирования расхождения между распределениями выводов DNN-студента малого размера и DNN-учителя большего размера, с использованием непомеченных данных, таких как нетранскрибированные данные. DNN-студент может быть обучен на основании непомеченных (или нетранскрибированных) данных посредством прохождения непомеченных обучающих данных через DNN-учитель, чтобы сгенерировать цель обучения. Без необходимости в помеченных (или транскрибированных) обучающих данных, для обучения становится доступно гораздо больше данных, тем самым дополнительно повышая точность DNN-студента для обеспечения более лучшей аппроксимации комплексных функций из DNN-учителя большего размера. DNN-студент можно итеративно оптимизировать, пока ее вывод не сойдется с выводом DNN-учителя. Таким образом, DNN-студент приближается к поведению учителя, так что независимо от вывода учителя, студент будет приблизительно соответствовать даже там, где учитель может ошибаться. Вариант осуществления данного изобретения таким образом особенно подходит для предоставления приложений точной обработки сигналов (например, ASR или обработки изображений), на смартфонах, развлекательных системах или аналогичных устройствах потребительской электроники.
[0005] Некоторые варианты осуществления данного изобретения включают в себя предоставление более точной модели DNN (например, малого или стандартного размера) посредством обучения модели DNN на основании даже большей "гигантской" DNN-учителя. Например, модель DNN стандартного размера для развертывания на сервере может быть сгенерирована с использованием процедур обучения учитель-студент, описанных в настоящем документе, при этом DNN-студент является моделью DNN стандартного размера, и DNN-учитель является DNN гигантского размера, которая может быть реализована как обученный ансамбль многочисленных DNN с разными шаблонами ошибок. В варианте осуществления, ансамбль обучается посредством комбинирования выводов членов ансамбля с помощью коэффициентов автоматически обученной комбинации, используя, например, критерий перекрестной энтропии, последовательный критерий, критерий ошибки по методу наименьших квадратов, критерий ошибки по методу наименьших квадратов с неотрицательным ограничением, или аналогичные критерии.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение проиллюстрировано в качестве примера, а не ограничения, на прилагаемых чертежах, на которых подобные ссылочные номера указывают аналогичные элементы, и на которых:
[0007] Фиг. 1 является блок-схемой примерной архитектуры системы, в которой вариант осуществления данного изобретения может быть использован;
[0008] Фиг. 2 изображает аспекты иллюстративного представления модели DNN, в соответствии с вариантом осуществления данного изобретения;
[0009] Фиг. 3 изображает аспекты иллюстративного представления обучения DNN-студента меньшего объема на основании DNN-учителя большего объема с использованием непомеченных данных, в соответствии с вариантом осуществления данного изобретения;
[0010] Фиг. 4 изображает аспекты иллюстративного представления модели ансамблевой DNN-учителя, в соответствии с вариантом осуществления данного изобретения;
[0011] Фиг. 5 изображает схему последовательности операций способа генерирования классификатора DNN с уменьшенным размером посредством обучения на основании большей модели DNN, в соответствии с вариантами осуществления данного изобретения;
[0012] Фиг. 6 изображает схему последовательности операций способа генерирования обученной модели DNN на основании модели ансамблевой DNN-учителя, в соответствии с вариантами осуществления данного изобретения; и
[0013] Фиг. 7 является блок-схемой примерного вычислительного окружения, подходящего для использования в реализации вариантов осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0014] Предмет настоящего изобретения описывается здесь со спецификой, чтобы отвечать установленным требованиям. Однако, само описание не предназначено для ограничения объема этого патента. Напротив, авторы изобретения предполагают, что заявленный предмет мог бы также быть осуществлен другими путями, чтобы включать в себя разные этапы или комбинации этапов, аналогичных этапам, описанным в этом документе, совместно с другими настоящими и будущими технологиями. Более того, хотя термины "этап" и/или "блок" могут быть использованы в настоящем документе, чтобы означать разные элементы используемых способов, данные термины не следует интерпретировать как предполагающие какой-либо конкретный порядок среди или между различными этапами, раскрытыми в настоящем документе, если только порядок индивидуальных этапов не описан явно.
[0015] Различные аспекты технологии, описанной в настоящем документе, в основном направлены, среди прочего, на системы, способы и машиночитаемые носители для предоставления первой модели DNN с уменьшенным размером для развертывания на устройствах посредством "обучения" первой DNN на основании второй DNN с большей емкостью (числом скрытых узлов). Чтобы обучить DNN с меньшим числом скрытых узлов, DNN-"учитель" большего размера (с большей точностью) используется для обучения меньшей DNN-"студента". В частности, вариант осуществления данного изобретения использует свойство распределения вывода DNN посредством минимизирования расхождения между распределениями выводов DNN-студента малого размера и стандартной (или большего размера) DNN-учителем, с использованием непомеченных данных, таких как нетранскрибированные данные. DNN-студент может быть обучен на основании непомеченных (или нетранскрибированных) данных, так как ее цель обучения получена посредством прохождения непомеченных обучающих данных через DNN-учитель. Без необходимости в помеченных (или транскрибированных) обучающих данных, гораздо больше данных становится доступно для обучения, тем самым дополнительно повышая точность DNN-студента для обеспечения более лучшей аппроксимации комплексных функций из DNN-учителя большого размера.
[0016] Как будет дополнительно описано, в одном варианте осуществления, DNN-студент итеративно оптимизируется, пока ее вывод не сойдется с выводом DNN-учителя. Таким образом, DNN-студент приближается к поведению учителя, так что независимо от вывода учителя, студент будет приблизительно соответствовать даже там, где учитель может ошибаться. Некоторые варианты осуществления данного изобретения таким образом особенно подходят для предоставления приложений точной обработки сигналов (например, ASR или обработки изображений), на смартфонах, развлекательных системах или аналогичных устройствах потребительской электроники. К тому же, некоторые из этих вариантов осуществления данного изобретения могут быть объединены с другими технологиями, чтобы дополнительно улучшить производительность во время выполнения для CD-DNN-HMM, такими как матрицы низкого ранга, используемые в слоях вывода или всех слоях, чтобы дополнительно уменьшить число параметров и затраты CPU, 8-битовое квантование для оценки SSE (потоковых SIMD-расширений), и/или технологии с пропусканием кадров или предсказанием.
[0017] В некоторых вариантах осуществления данного изобретения, развертываемая модель DNN (например, малая или модель стандартного размера) определяется посредством обучения развертываемой модели DNN на основании даже большей "гигантской" DNN-учителя. Например, модель DNN стандартного размера для развертывания на сервере (или DNN меньшего размера для развертывания на мобильном устройстве) может быть сгенерирована с использованием процедур обучения учитель-студент, описанных в настоящем документе, при этом DNN-студент является моделью DNN стандартного размера (или моделью DNN меньшего размера) и DNN-учитель является DNN гигантского размера. DNN гигантского размера может быть реализована как обученный ансамбль многочисленных DNN с разными шаблонами ошибок, в варианте осуществления. Ансамбль может быть обучен посредством комбинирования выводов членов ансамбля с помощью коэффициентов автоматически обученной комбинации, используя, например, критерий перекрестной энтропии, последовательный критерий, критерий ошибки по методу наименьших квадратов, критерий ошибки по методу наименьших квадратов с неотрицательным ограничением, или аналогичные критерии.
[0018] Как описано выше, преимущество некоторых вариантов осуществления, описанных в настоящем документе, состоит в том, что модель DNN-студента может быть обучена с использованием непомеченных (или нетранскрибированных) данных, так как ее цель обучения (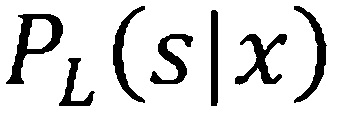 , как будет дополнительно описано) получена посредством прохождения непомеченных обучающих данных через DNN-учитель. Так как пометка (или транскрибирование) данных для обучения стоит времени и денег, доступен гораздо меньший объем помеченных (или транскрибированных) данных по сравнению с непомеченными данными. (Помеченные (или транскрибированные) данные могут быть использованы для обучения DNN-учителя.) Без необходимости в транскрибированных (или помеченных) обучающих данных, гораздо больше данных становится доступно для обучения DNN-студента, чтобы приблизительно соответствовать поведению DNN-учителя. При большем объеме обучающих данных, доступных для покрытия пространства конкретного признака, точность развернутой модели DNN (-студента) даже дополнительно увеличивается. Это преимущество особенно полезно для сценариев индустрии с большим объемом доступных непомеченных данных из-за контура обратной связи развертывания (при этом развернутые модели предоставляют свои данные использования разработчикам приложений, которые используют данные для дополнительной адаптации будущих версий приложения). Например, многие поисковые механизмы используют такой контур обратной связи развертывания.
, как будет дополнительно описано) получена посредством прохождения непомеченных обучающих данных через DNN-учитель. Так как пометка (или транскрибирование) данных для обучения стоит времени и денег, доступен гораздо меньший объем помеченных (или транскрибированных) данных по сравнению с непомеченными данными. (Помеченные (или транскрибированные) данные могут быть использованы для обучения DNN-учителя.) Без необходимости в транскрибированных (или помеченных) обучающих данных, гораздо больше данных становится доступно для обучения DNN-студента, чтобы приблизительно соответствовать поведению DNN-учителя. При большем объеме обучающих данных, доступных для покрытия пространства конкретного признака, точность развернутой модели DNN (-студента) даже дополнительно увеличивается. Это преимущество особенно полезно для сценариев индустрии с большим объемом доступных непомеченных данных из-за контура обратной связи развертывания (при этом развернутые модели предоставляют свои данные использования разработчикам приложений, которые используют данные для дополнительной адаптации будущих версий приложения). Например, многие поисковые механизмы используют такой контур обратной связи развертывания.
[0019] Возвращаясь теперь к Фиг. 1, предоставляется блок-схема, показывающая аспекты одного примера архитектуры системы, подходящей для реализации варианта осуществления данного изобретения и обозначенной в общем как система 100. Следует понимать, что эти и другие компоновки, описанные в настоящем документе, изложены только в качестве примеров. Таким образом, система 100 представляет только один пример из подходящих архитектур вычислительных систем. Другие компоновки и элементы (например, пользовательские устройства, хранилища данных и т.д.) могут быть использованы в дополнение к показанным компоновкам и элементам, или вместо них, и некоторые элементы могут быть вовсе опущены для ясности. К тому же, многие из элементов, описанных в настоящем документе, являются функциональными объектами, которые могут быть реализованы как дискретные или распределенные компоненты или совместно с другими компонентами, и в любой подходящей комбинации и размещении. Различные функции, описанные в настоящем документе, которые выполняются одним или более объектами, могут быть выполнены аппаратными средствами, программно-аппаратными средствами и/или программным обеспечением. Например, различные функции или сервисы могут быть выполнены процессором, исполняющим инструкции, хранящиеся в памяти.
[0020] Среди не показанных других компонентов, система 100 включает в себя сеть 110, коммуникационно соединенную с одним или более источником(ами) 180 данных, хранилище 106, клиентские устройства 102 и 104, и генератор 120 моделей DNN. Компоненты, показанные на Фиг. 1, могут быть реализованы на одном или более вычислительных устройствах или могут их использовать, таких как вычислительное устройство 700, описанное применительно к Фиг. 7. Сеть 110 может включать в себя, без ограничения, одну или более локальных сетей (LAN) и/или глобальных сетей (WAN). Такие сетевые окружения находятся обыкновенно в офисах, корпоративных компьютерных сетях, сетях Интранет и Интернет. Следует понимать, что любое число источников данных, компонентов хранения или хранилищ данных, клиентских устройств и генераторов моделей DNN, могут быть использованы внутри системы 100 в рамках объема настоящего изобретения. Каждый может содержать одиночное устройство или многочисленные устройства, взаимодействующие в распределенном окружении. Например, генератор 120 моделей DNN может быть обеспечен посредством многочисленных вычислительных устройств или компонентов, скомпонованных в распределенном окружении, которые совместно предоставляют функциональность, описанную в настоящем документе. Дополнительно, другие непоказанные компоненты могут также быть включены в сетевое окружение.
[0021] Примерная система 100 включает в себя один или более источник(ов) 180 данных. Источник(и) 180 данных содержит(ат) ресурсы данных для обучения моделей DNN, описанных в настоящем документе. Данные, предоставленные источником(ами) 180 данных могут включать в себя помеченные и непомеченные данные, такие как транскрибированные и нетранскрибированные данные. Например, в варианте осуществления, данные включают в себя один или более наборов речевых звуков (звуков) и могут также включать в себя соответствующую информацию транскрипции или метки сенонов, которые могут быть использованы для инициализации модели DNN-учителя. В варианте осуществления, непомеченные данные в источнике(ах) 180 данных предоставляются посредством одного или более контуров обратной связи развертывания, как описано выше. Например, данные использования из произнесенных поисковых запросов, выполняемых на поисковых механизмах, могут быть предоставлены как нетранскрибированные данные. Другие примеры источников данных могут включать в себя, в качестве примера и не ограничения, аудио на разговорном языке или источники изображений, включающие в себя потоковые звуки или видео; веб-запросы; камеру мобильного устройства или аудиоинформацию; потоки веб-камеры; потоки смарт-очков и смарт-часов; системы обслуживания заказчиков; потоки камер безопасности; веб-документы; каталоги; пользовательские потоки; журналы SMS; журналы мгновенной передачи сообщений; транскрипции проговариваемых слов; взаимодействия пользователя с игровой системой, такие как голосовые команды или захваченные изображения (например, изображения камеры глубины); твиты; записи чата или видеовызовов; или медиаданные социальных сетей. Конкретный(е) источник(и) 180 данных может(гут) быть определен(ы) на основе приложения, в том числе, являются ли данные по своей природе специфичными для области данными (например, данными, относящимися только к развлекательным системам, например) или общими (неспецифичными для области).
[0022] Примерная система 100 включает в себя клиентские устройства 102 и 104, которые могут содержать любой тип вычислительного устройства, где желательно иметь DNN-систему на устройстве и, в частности, при этом устройство имеет ограниченные вычислительные ресурсы и/или ресурсы хранения по сравнению с более мощным сервером или вычислительной системой. Например, в одном варианте осуществления, клиентские устройства 102 и 104 могут иметь один тип вычислительного устройства, описанного здесь относительно Фиг. 7. В качестве примера и не ограничения, пользовательское устройство может быть осуществлено как персональный цифровой помощник (PDA), мобильное устройство, смартфон, смарт-часы, смарт-очки (или другое носимое смарт-устройство), переносной компьютер, планшет, пульт управления, развлекательная система, компьютерная система транспортного средства, встроенный контроллер системы, электрическое бытовое устройство, домашняя компьютерная система, система безопасности, устройство потребительской электроники, или другое аналогичное электронное устройство. В одном варианте осуществления, клиентское устройство способно принять входные данные, такие как аудиоинформация и информация изображения, используемые DNN-системой, описанной в настоящем документе, которая функционирует в устройстве. Например, клиентское устройство может иметь микрофон или линейный вход для приема аудиоинформации, камеру для приема видеоинформации или информации изображения, или компонент связи (например, функциональность Wi-Fi) для приема такой информации от другого источника, такого как Интернет или источник 108 данных.
[0023] Используя вариант осуществления модели DNN-студента, описанный в настоящем документе, клиентское устройство 102 или 104 и модель DNN-студента обрабатывают введенные данные для определения используемой компьютером информации. Например, используя один вариант осуществления DNN-студента, функционирующий на клиентском устройстве, запрос, произнесенный пользователем, может быть обработан для определения намерения пользователя (т.е., чего просит пользователь). Аналогично, полученная камерой информация может быть обработана для определения форм, признаков, объектов, или других элементов в информации или видео.
[0024] Примерные клиентские устройства 102 и 104 включены в систему 100 для обеспечения примерного окружения, в котором могут быть развернуты модели DNN-студента (или меньшего размера), созданные посредством вариантов осуществления данного изобретения. Хотя, предполагается, что аспекты моделей DNN, описанных в настоящем документе, могут функционировать на одном или более клиентских устройствах 102 и 104, также предполагается, что некоторые варианты осуществления данного изобретения не включают в себя клиентские устройства. Например, DNN-студент стандартного размера или большего размера может быть осуществлена на сервере или в облаке. К тому же, хотя Фиг. 1 показывает два примерных клиентских устройства 102 и 104, может быть использовано больше или меньше устройств.
[0025] Хранилище 106 обычно хранит информацию включающую в себя данные, компьютерные инструкции (например, инструкции реализованной программными средствами программы, стандартные программы или сервисы), и/или модели, используемые в вариантах осуществления данного изобретения, описанных в настоящем документе. В варианте осуществления, хранилище 106 хранит данные от одного или более источника(ов) 180 данных, одну или более моделей DNN (или классификаторов DNN), информацию для генерирования и обучения моделей DNN, и используемую компьютером информацию, выводимою одной или более моделями DNN. Как показано на Фиг. 1, хранилище 106 включает в себя модели DNN 107 и 109. Модель 107 DNN представляет собой модель DNN-учителя, и модель 109 DNN представляет собой модель DNN-студента, имеющую меньший размер, чем модель 107 DNN-учителя. Дополнительные сведения и примеры моделей DNN описываются применительно к Фиг. 2-4. Хотя для ясности изображено как одиночный компонент хранения данных, хранилище 106 может быть осуществлено как одно или более хранилищ информации, включающих в себя память на клиентском устройстве 102 или 104, генератор 120 моделей DNN или в облаке.
[0026] Генератор 120 моделей DNN содержит компонент 122 доступа, компонент 124 инициализации, компонент 126 доступа и компонент 128 оценки. Генератор 120 моделей DNN, в общем, отвечает за генерирование моделей DNN, таких как классификаторы CD-DNN-HMM, описанные в настоящем документе, включающее в себя создание новых моделей DNN (или адаптирование существующих моделей DNN) посредством инициализации и обучения модели DNN-"студента" на основании обученной модели DNN-учителя, на основе данных из источника(ов) 180 данных. Модели DNN, сгенерированные генератором 120 моделей DNN, могут быть развернуты на клиентском устройстве, таком как устройство 104 или 102, сервере или другой компьютерной системе. В одном варианте осуществления, генератор 120 моделей DNN создает классификатор CD-DNN-HMM уменьшенного размера для развертывания на клиентском устройстве, которое может иметь ограниченные вычислительные ресурсы и ресурсы хранения, посредством обучения инициализированной модели DNN-"студента", чтобы приблизительно соответствовать обученной модели DNN-учителя, имеющей больший размер модели (например, число параметров), чем студент. В другом варианте осуществления, генератор 120 моделей DNN создает классификатор DNN для развертывания на клиентском устройстве, сервере или другой компьютерной системе посредством обучения инициализированной модели DNN-"студента", чтобы приблизительно соответствовать обученной модели DNN-учителя гигантского размера, имеющей больший размер модели (например, число параметров), чем студент, при этом модель DNN-учителя гигантского размера содержит ансамбль других моделей DNN.
[0027] Генератор 120 моделей DNN и его компоненты 122, 124, 126 и 128 могут быть осуществлены как набор скомпилированных компьютерных инструкций или функций, программные модули, сервисы компьютерного программного обеспечения или компоновка процессов, выполняющихся на одной или более компьютерных системах, таких как вычислительное устройство 700, описанное применительно к Фиг. 7, например. Генератор 120 моделей DNN, компоненты 122, 124, 126 и 128, функции, выполняемые этими компонентами, или сервисы, выполняемые этими компонентами, могут быть реализованы на соответствующем(их) слое(ях) абстракции вычислительных(ой) систем(ы), таком(их) как слой операционной системы, слой приложений, аппаратный слой и т.д. В качестве альтернативы, или в дополнение, функциональность этих компонентов, генератор 120 моделей DNN и/или варианты осуществления данного изобретения, описанные в настоящем документе, могут быть выполнены, по меньшей мере частично, посредством одного или более компонентов аппаратной логики. Например, и без ограничения, иллюстративные типы компонентов аппаратной логики, которые могут быть использованы, включают в себя программируемые пользователем вентильные матрицы (FPGA), специализированные интегральные микросхемы (ASIC), стандартные части специализированных интегральных микросхем (ASSP), системы "система на кристалле" (SOC), сложные программируемые логические устройства (CPLD) и т.д.
[0028] Продолжая с Фиг. 1, компонент 122 доступа в основном отвечает за осуществление доступа к обучающим данным и их предоставление генератору 120 моделей DNN из одного или более источников 108 данных и моделей DNN, таких как модели DNN 107 и 109. В некоторых вариантах осуществления, компонент 122 доступа может осуществлять доступ к информации о конкретном клиентском устройстве 102 или 104, такой как информация, касающаяся вычислительных ресурсов и/или ресурсов хранения, доступных на клиентском устройстве. В некоторых вариантах осуществления, эта информация может быть использована для определения оптимального размера модели DNN, сгенерированной генератором 120 моделей DNN, для развертывания на конкретном клиентском устройстве.
[0029] Компонент 124 инициализации в основном отвечает за инициализацию необученной модели DNN-"студента", и в некоторых вариантах осуществления инициализацию модели DNN-учителя для обучения студента. В некоторых вариантах осуществления, компонент 124 инициализации инициализирует модель DNN-студента конкретного размера (или модель не большую, чем конкретный размер) на основе ограничений клиентского устройства, на котором может быть развернута обученная модель DNN-студента, и может инициализировать DNN-студент на основе модели DNN-учителя (большей модели DNN). Например, в варианте осуществления, компонент 124 инициализации принимает от компонента 122 доступа полностью обученную DNN-учитель размером NT, которая уже обучена согласно способам, известным специалистам в данной области техники, и информацию об ограничениях клиентского устройства, на котором должна быть развернута обученная DNN-студент. DNN-учитель может быть инициализирована и/или обучена для специфичного для области приложения (как например, распознавание лиц или произносимые запросы для развлекательной системы) или для общих целей. На основе принятой информации, компонент 124 инициализации создает первоначальную, необученную модель DNN-студента с подходящим размером модели (на основе ограничений клиентского устройства). В одном варианте осуществления, модель DNN-студента может быть создана посредством копирования и разделения модели DNN-учителя на меньшую модель (меньшее число узлов). Как модель DNN-учителя, необученная модель DNN-студента включает в себя число скрытых слоев, которое может быть равно числу слоев учителя, или DNN-студент может содержать иное число скрытых слоев, чем модель DNN-учителя. В одном варианте осуществления, размер модели DNN-студента, включая число или узлы или параметры для каждого слоя, меньше, чем NT, размер учителя. Примерная модель DNN, подходящая для использования в качестве DNN-студента, описана применительно к Фиг. 2. В этом примере, модель CD-DNN-HMM наследует свою структуру модели, включающую в себя набор речевых звуков, топологию HMM, и связывание контекстно-зависимых состояний, непосредственно от обыкновенной системы CD-GMM-HMM, которая может существовать предварительно.
[0030] В одном варианте осуществления, компонент 124 инициализации создает и инициализирует необученную модель DNN-студента посредством присвоения случайных чисел весам узлов в модели (т.е., весам матрицы W). В другом варианте осуществления, компонент 124 инициализации принимает от компонента 122 доступа данные для предварительно обученной модели DNN-студента, такие как нетранскрибированные данные, которые используется для установки первоначальных весов узлов для модели DNN-студента.
[0031] В некоторых вариантах осуществления, компонент 124 инициализации также инициализирует или создает модель DNN-учителя. В частности, используя помеченные или транскрибированные данные из источника(ов) 180 данных, предоставленные компонентом 122 доступа, компонент 124 инициализации может создать модель DNN-учителя (которая может быть предварительно обучена) и предоставить инициализированную, но необученную модель DNN-учителя, компоненту 126 доступа для обучения. Аналогично, компонент 124 инициализации может создать модель ансамблевой DNN-учителя посредством определения множества моделей под-DNN (например, создания и передачи компоненту 126 доступа для обучения или идентификации уже существующей модели(ей) DNN), которые должны быть включены как члены ансамбля). В этих вариантах осуществления, компонент 124 инициализации может также определить взаимосвязи между слоем вывода ансамбля и слоями вывода моделей-членов под-DNN (например, принимая необработанное среднее выводов моделей-членов), или может предоставить компоненту 126 доступа для обучения инициализированную, но не обученную, ансамблевую DNN-учитель.
[0032] Компонент 126 доступа в основном отвечает за обучение DNN-студента на основе учителя. В частности, компонент 126 доступа принимает от компонента 124 инициализации и/или компонента 122 доступа необученную (или предварительно обученную) модель DNN, которая будет студентом, и обученную модель DNN, которая будет служить в качестве учителя. (Также предполагается, что модель DNN-студента может быть обучена, но может быть дополнительно обучена согласно вариантам осуществления, описанным в настоящем документе.) Компонент 126 доступа также принимает непомеченные данные от компонента 122 доступа для обучения DNN-студента.
[0033] Компонент 126 доступа способствует обучению DNN-студента посредством итеративного процесса с помощью компонента 128 оценки, который предоставляет одинаковые непомеченные данные моделям DNN-учителя и студента, оценивает распределения выводов моделей DNN для определения ошибки распределения вывода DNN-студента относительно учителя, выполняет обратное распространение в отношении модели DNN-студента на основе ошибки для обновления модели DNN-студента, и повторяет этот цикл, пока распределения выводов не сойдутся (или иначе, будут находиться достаточно близко). В некоторых вариантах осуществления, компонент 126 доступа обучает DNN-студента согласно способам 500 и 600, описанным применительно к Фиг. 5 и 6, соответственно.
[0034] В некоторых вариантах осуществления, компонент 126 доступа также обучает модель DNN-учителя. Например, в одном варианте осуществления, DNN-учитель обучается с использованием помеченных (или транскрибированных) данных согласно способам, известным специалистам в данной области техники. В некоторых вариантах осуществления, используя ансамблевую DNN-учитель, компонент 126 доступа обучает ансамблевую DNN-учитель. В качестве примера и не ограничения, компонент 126 доступа может обучить ансамбль посредством комбинирования выводов членов ансамбля с помощью коэффициентов автоматически обученной комбинации, используя, например, критерий перекрестной энтропии, последовательный критерий, критерий ошибки по методу наименьших квадратов, критерий ошибки по методу наименьших квадратов с неотрицательным ограничением или аналогичные критерии.
[0035] Компонент 128 оценки в основном отвечает за оценивание модели DNN-студента для определения, достаточно ли она обучена, чтобы приблизительно соответствовать учителю. В частности, в варианте осуществления, компонент 128 оценки оценивает распределения выводов DNN-студента и учителя, определяет разницу (которая может быть определена как сигнал ошибки) между выводами, и также определяет, продолжает ли студент улучшаться, или не улучшается ли студент больше (т.е., распределение вывода студента показывает отсутствие дальнейшей тенденции к схождению с выводом учителя). В одном варианте осуществления, компонент 128 оценки вычисляет расхождение Кульбака-Лейблера (KL) между распределениями выводов и, совместно с компонентом 126 доступа, пытается минимизировать расхождение посредством итеративного процесса, описанного применительно к компоненту 126 доступа. Некоторые варианты осуществления оценщика 128 могут использовать регрессию, среднеквадратичную ошибку (MSE), или другие аналогичные подходы для минимизации расхождения между выводами DNN-учителя и студента.
[0036] В дополнение к определению сигнала ошибки, некоторые варианты осуществления компонента 128 оценки, определяют, завершить ли еще одну итерацию (например, еще одну итерацию, содержащую: обновление DNN-студента на основе ошибки, прохождение непомеченных данных через DNN-учитель и студент, и оценивание их распределения выводов). В частности, некоторые варианты осуществления компонента 128 оценки применяют порог, для определения схождения распределений выводов DNN-учителя и DNN-студента. Если порог не удовлетворяется, итерация может продолжиться, тем самым дополнительно обучая студента для приблизительного соответствия учителю. Если порог удовлетворяется, то определяется схождение (указывающее, что распределение вывода студента является достаточно близким к распределению вывода DNN-учителя), и DNN-студент может считаться обученной и далее может быть развернута на клиентском устройстве или компьютерной системе. В качестве альтернативы, в некоторых вариантах осуществления, компонент 128 оценки определяет, продолжить ли осуществлять итерацию, на основе того, продолжает ли студент показывать улучшение (т.е., движется ли распределение вывода студента к схождению с распределением вывода учителя в течение многочисленных успешных итераций, указывая, что DNN-студент продолжает улучшаться с последующими итерациями). В таких вариантах осуществления, пока студент улучшается, итеративное обучение продолжается. Но в одном варианте осуществления, где обучение студента стоит (т.е., распределения выводов DNN-студента не становятся ближе к распределениям выводов DNN-учителя за несколько итераций), то "занятия закончены", и модель DNN-студента может считаться обученной. В одном варианте осуществления, схождение может быть определено, где распределения выводов DNN-студента не становятся ближе к распределениям выводов DNN-учителя в течение нескольких итераций. В некоторых вариантах осуществления, компонент 128 оценки оценивает DNN-студента согласно способам 500 и 600, описанным применительно к Фиг. 5 и 6, соответственно.
[0037] Возвращаясь теперь к Фиг. 2, предоставляются аспекты иллюстративного представления примерного классификатора DNN и в общем называются классификатором 200 DNN. Этот примерный классификатор 200 DNN включает в себя модель 201 DNN. (Фиг. 2 также показывает данные 202, которые показаны в целях понимания, но которые не считаются частью классификатора 200 DNN.) В одном варианте осуществления, модель 201 DNN содержит модель CD-DNN-HMM и может быть осуществлена как конкретная структура отображенных вероятностных взаимосвязей ввода в набор соответствующих выводов, такая как иллюстративно изображенная на Фиг. 2. Вероятностные взаимосвязи (показаны как соединенные линии между узлами 205 каждого слоя) могут быть определены посредством обучения. Таким образом, в некоторых вариантах осуществления данного изобретения, модель 201 DNN задается согласно ее обучению. (Необученная модель DNN, вследствие этого, может считаться имеющей иную внутреннюю структуру, чем внутренняя структура модели DNN, которая была обучена.) Глубокая нейронная сеть (DNN) может быть рассмотрена как обыкновенный многослойный перцептрон (MLP) со многими скрытыми слоями (таким образом, глубокая). В некоторых вариантах осуществления данного изобретения, три аспекта, способствующие превосходной производительности CD-DNN-HMM, включают в себя: моделирование сенонов напрямую, даже если могут быть тысячи сенонов; использование DNN вместо неглубоких MLP; и использование длинных контекстных окон кадров в качестве ввода.
[0038] Со ссылкой на Фиг. 2, ввод и вывод модели 201 DNN обозначены как 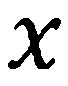 и
и  (210 и 250 по Фиг. 2), соответственно. Обозначим входной вектор в слое
(210 и 250 по Фиг. 2), соответственно. Обозначим входной вектор в слое 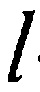 (220 по Фиг. 2) как
(220 по Фиг. 2) как 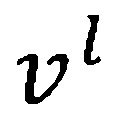 (при
(при 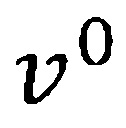 =), матрицу весов как
=), матрицу весов как 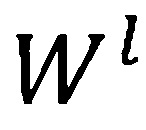 , и вектор отклонения как
, и вектор отклонения как 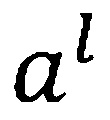 . Тогда, для DNN с L скрытыми слоями (240 по Фиг. 2), выводом -ого скрытого слоя является:
. Тогда, для DNN с L скрытыми слоями (240 по Фиг. 2), выводом -ого скрытого слоя является:
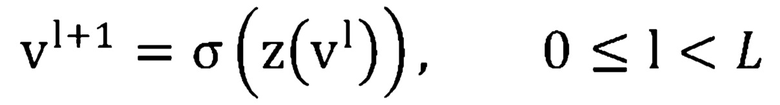
где 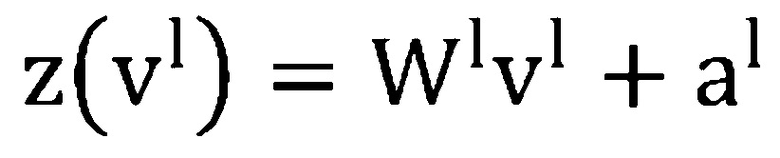 и
и 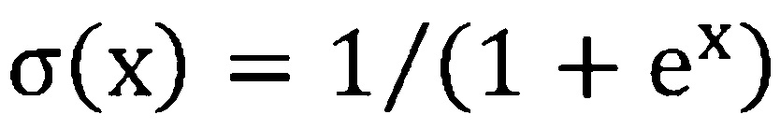 является сигмоидной функцией, применяемой поэлементно.
является сигмоидной функцией, применяемой поэлементно.
Апостериорная вероятность (т.е., вывод DNN) составляет:
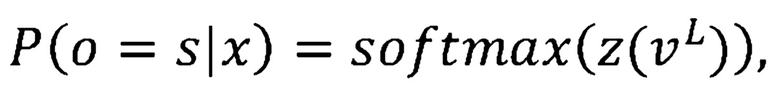
где 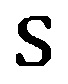 принадлежит набору сенонов (также известных как связанные состояния трифонов).
принадлежит набору сенонов (также известных как связанные состояния трифонов).
[0039] На основании этого, функция плотности вероятности эмиссии состояний HMM 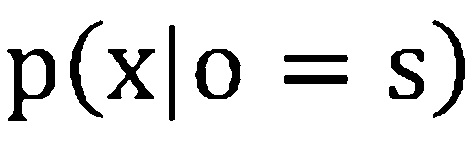 может быть вычислена посредством преобразования апостериорной вероятности состояния
может быть вычислена посредством преобразования апостериорной вероятности состояния 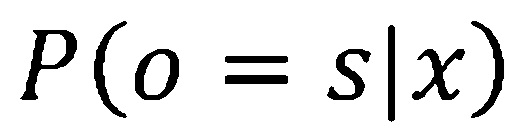 в:
в:
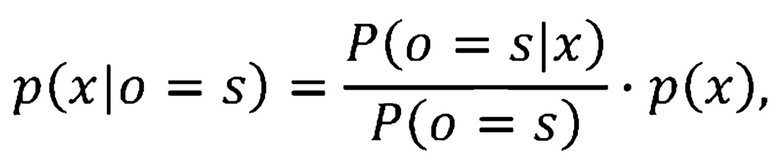
где 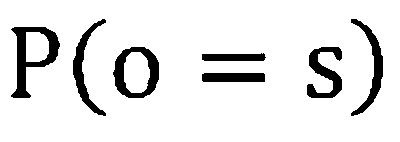 - априорная вероятность состояния , и
- априорная вероятность состояния , и 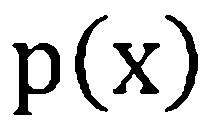 не зависит от состояния и может быть сброшена во время оценки.
не зависит от состояния и может быть сброшена во время оценки.
[0040] В некоторых вариантах осуществления данного изобретения, CD-DNN-HMM (модель 201 DNN) наследует структуру модели, включающую в себя набор речевых звуков, топологию HMM и связывание контекстно-зависимых состояний непосредственно от системы CD-GMM-HMM, которая может быть предварительно определена. К тому же, в варианте осуществления, метки сенонов, используемые для обучения DNN, могут быть извлечены на основании принудительного выравнивания, сгенерированного с использованием CD-GMM-HMM. В некоторых вариантах осуществления, критерий обучения (подходящий для обучения DNN-учителя) используется для минимизации перекрестной энтропии, которая уменьшается для минимизации отрицательного логарифмического правдоподобия, так как каждый кадр имеет только одну метку цели 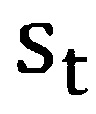 :
:

Параметры модели DNN могут быть оптимизированы с помощью обратного распространения с использованием стохастического градиентного спуска или аналогичного способа, известного специалисту в данной области техники.
[0041] Возвращаясь теперь к Фиг. 3, иллюстративно предоставлены аспекты системы 300 для обучения меньшей DNN-студента на основании большей DNN-учителя, в соответствии с вариантом осуществления данного изобретения. Примерная система 300 включает в себя DNN-учитель 302 и меньшую DNN-студент 301, которая изображена как имеющая меньше узлов на каждом из своих слоев 341. Как описано ранее, в одном варианте осуществления данного изобретения, DNN-учитель 302 содержит обученную модель DNN, которая может быть обучена согласно стандартным способам, известным специалисту в данной области техники (таким как способ, описанный применительно к Фиг. 2). В другом варианте осуществления, DNN-учитель может быть обучен так, как описано применительно к обучающему компоненту 126 по Фиг. 1. И в том и другом случае, предполагается, что есть хороший учитель (т.е., обученная DNN-учитель), на основании которой следует обучать DNN-студент. К тому же, DNN-студент 301 и DNN-учитель 302 могут быть осуществлены как CD-DNN-HMM, имеющая число скрытых слоев 341 и 342, соответственно. В варианте осуществления, показанном на Фиг. 3, DNN-студент 301 имеет распределение 351 вывода, и DNN-учитель 302 имеет распределение 352 вывода одинакового размера, хотя сама DNN-студент 301 меньше, чем DNN-учитель 302.
[0042] Первоначально, DNN-студент 301 является необученной, или может быть предварительно обученной, но еще не была обучена DNN-учителем. (Также предполагается, что DNN-студент 301 может быть обучен, но что точность DNN-студента 301 может быть дополнительно улучшена посредством обучения на основании DNN-учителя.) В варианте осуществления, система 300 может быть использована для обучения DNN-студента 301 на основании DNN-учителя 302 с использованием итеративного процесса, пока распределение 351 вывода DNN-студента 301 не будет сходиться (или иначе приблизительно соответствовать) с распределением 352 вывода DNN-учителя 302. В частности, для каждой итерации, малая порция непомеченных (или нетранскрибированных) данных 310 предоставляется и DNN-студенту 301, и DNN-учителю 302. Используя прямое распространение, определяется апостериорное распределение (распределение 351 и 352 вывода). Сигнал 360 ошибки затем определяется из распространения 351 и 352. Сигнал ошибки может быть вычислен посредством определения расхождения KL между распределениями 351 и 352 или посредством использования регрессии, MSE или другого подходящего способа, и может быть определен с использованием компонента 128 оценки по Фиг. 1. (Термин "сигнал", как в "сигнале ошибки", является термином данной области техники и не означает, что сигнал ошибки содержит кратковременный сигнал, такой как распространяемый сигнал связи. Скорее, в некоторых вариантах осуществления, сигнал ошибки содержит вектор.) Варианты осуществления, которые определяют расхождение KL, обеспечивают преимущество над другими альтернативами, такими как регрессия или MSE, так как минимизация расхождения KL является эквивалентном минимизации перекрестной энтропии распределений, как дополнительно описано в способе 500 по Фиг. 5. Если распределение 351 вывода DNN-студента 301 сошлось с распределением 352 вывода DNN-учителя 302, то DNN-студент 301 считается обученной. Однако, если вывод не сошелся, и в некоторых вариантах осуществления вывод все еще кажется сходящимся, то DNN-студент 301 обучается на основе ошибки. Например, как показано на этапе 370, используя обратное распространение, веса DNN-студента 301 обновляются с использованием сигнала ошибки.
[0043] Как описано ранее, некоторые варианты осуществления могут определить схождение с использованием порога, при этом определяется, распределение 351 DNN-студента 301 сошлось с распределением 352 DNN-учителя 302, где ошибка ниже точно определенного порога, который может быть предварительно определен и также может быть основан на точно определенном приложении DNN (или типе данных 310, используемых DNN) или размере DNN-студента. Например, ожидается, что DNN-студент, которая близка к тому же числу параметров, как DNN-учитель, достигнет лучшего схождения (меньшего сигнала ошибки и таким образом более высокой точности), чем DNN-студент, которая гораздо меньше, чем DNN-учитель. Система 300 может также определить схождение или иначе прекратить осуществления итераций, если определено, что сигнал ошибки более не становится меньше в течение последующих итераций. Другими словами, студент обучился всему, что он мог от учителя для доступных данных.
[0044] Возвращаясь к Фиг. 4, предоставляются аспекты одного примерного варианта осуществления DNN-учителя 402. DNN-учитель 402 содержит модель ансамблевой DNN-учителя. Модель ансамблевой DNN включает в себя множество под-DNN, показанных как под-DNN-1 421 до под-DNN-K 423. (Для ясности показаны только две под-DNN; однако, предполагается, что варианты осуществления модели ансамблевой DNN-учителя могут включать в себя две или более под-DNN, например один вариант осуществления может включать в себя десятки (или более) под-DNN.) Преимущество ансамблевой DNN-учителя состоит в том, что вывод обученного ансамбля является даже более точным, так как он включает в себя все голоса членов ансамбля (под-DNN). В одном варианте осуществления, ансамблевая DNN-учитель 402 содержит огромную ансамблевую DNN, которая может быть даже слишком большой даже для практического развертывания, нежели чем в целях обучения меньшей DNN-студента, которая может быть развернута на сервере, клиентском устройстве или другом вычислительном устройстве.
[0045] В некоторых вариантах осуществления, ансамблевые под-DNN, такие как DNN-1 421 и DNN-K 423, могут быть DNN с разными нелинейными блоками (например, сигмоидный, выпрямительный, максимизирующий, или другие блоки), разные структуры (например, стандартная DNN с прямым распространением, сверточная нейронная сеть (CNN), рекуррентная нейронная сеть (RNN), RNN с долгой краткосрочной памятью, или другие структуры), разные стратегии обучения (например, стандартное обучение, выпадение с разными факторами, или другие стратегии), разные топологии (варьирующиеся по числу слоев и узлов, например), и/или обученные с помощью разных данных. Такие вариации дают в результате разные шаблоны ошибок и таким образом обеспечивают лучшую DNN-учитель. Как показано на Фиг. 4, выводом 450 ансамблевой сети (DNN-учителя 402) все равно является апостериорный вектор, с такой же размерностью, как и вывод каждой из ее под-DNN, такой как 451 под-DNN-1 421 и вывод 453 под-DNN-K 423. В некоторых вариантах осуществления, конкретные модели под-DNN, которые являются членами ансамбля, могут быть определены на основе доступности моделей DNN для функционирования в качестве под-DNN для ансамбля; приложения, прикладного окружения или оперативного окружения ансамблевой DNN, или приложения, прикладного окружения или оперативного окружения DNN-студента, которая должна быть обучена ансамблевой DNN; доступных обучающих данных; или данных, ввод которых ожидается в DNN-студент, обученную ансамблевой DNN, например. В этих вариантах осуществления, компонент 124 инициализации по Фиг. 1 (или аналогичный сервис) может определить конкретную под-DNN, которая должна быть включена в ансамбль.
[0046] Выводы под-DNN могут быть объединены в один вывод 450 посредством необработанного среднего, посредством взвешенного голосования (например, если известно, что некоторые под-DNN выполняются лучше для некоторых приложений или областей, таких как развлечение, и присваивается больший вес этим под-DNN), или посредством целевой функции, которая обучает ансамбль. В частности, соединения между каждым выводом под-DNN и итоговым слоем 450 вывода могут быть обучены с использованием одного или более критериев, например, посредством комбинирования апостериорного вектора вывода из каждой под-DNN с помощью коэффициентов автоматически обученной комбинации, используя, в качестве примера и не ограничения, критерий перекрестной энтропии, последовательный критерий, критерий ошибки по методу наименьших квадратов, критерий ошибки по методу наименьших квадратов с неотрицательным ограничением или аналогичные критерии. В одном варианте осуществления, ансамблевая DNN-учитель 402 обучения компонентом 126 доступа по Фиг. 1.
[0047] Возвращаясь теперь к Фиг. 5, представляется схема последовательности операций, иллюстрирующая один примерный способ 500 генерирования классификатора DNN с уменьшенным размером для развертывания в компьютерной системе посредством обучения меньшей модели DNN на основании большей модели DNN. В способе 500, меньшая модель DNN играет роль DNN-студента, тогда как большая DNN служит в качестве "учителя", для приблизительного соответствия которой обучается меньшая DNN. Варианты осуществления способа 500 могут осуществляться с использованием компонентов (включая модели DNN), описанных на Фиг. 1-4.
[0048] На высоком уровне, один вариант осуществления способа 500 итеративно оптимизирует DNN-студент, на основе разницы между ее выводом и выводом учителя, пока она не сойдется с DNN-учителем. Таким образом, DNN-студент приближается к поведению учителя, так что независимо от вывода учителя, студент будет приблизительно соответствовать даже там, где учитель может ошибаться. Когда обучена, модель DNN-студента может быть развернута как классификатор в компьютерной системе, такой как смартфон, развлекательные системы или аналогичные устройства потребительской электроники с ограниченными вычислительными ресурсами и ресурсами хранения в сравнении с компьютерной системой, поддерживающей модель DNN-учителя.
[0049] На этапе 510, определяется первая модель DNN. Первая модель DNN служит в качестве DNN-учителя для обучения DNN-"студента" на дальнейших этапах способа 500. Первая модель DNN, или "DNN-учитель", может быть определена на основе предназначенного приложения для DNN-студента, при развертывании в качестве классификатора на вычислительном устройстве. Например, DNN-учитель может быть специализированной для ASR, если обученная DNN-студент предназначена для развертывания как часть ASR-системы на мобильном устройстве, например. В одном варианте осуществления, определенная DNN-учитель уже обучена и к ней может быть осуществлен доступ из хранилища компонентом доступа, таким как компонент 122 доступа по Фиг. 1. В другом варианте осуществления, определенная DNN-учитель инициализируется (что может быть выполнено с использованием компонента 124 инициализации по Фиг. 1) и обучается (что может быть выполнено с использованием компонента 126 доступа по Фиг. 1). В одном варианте осуществления, где DNN-учитель обучается на этапе 510, помеченные или транскрибированные данные могут быть использованы согласно способам, известным в области обучения моделей DNN, таким как использование градиентной оптимизации или процедура неконтролируемого жадного послойного обучения. В одном варианте осуществления, модель DNN-учителя обучается посредством итеративного процесса применения прямого распространения помеченных данных, сравнения распределения вывода с помеченной информацией для определения ошибки, обновления параметров DNN, и повторение до тех пор, пока ошибка не будет минимизирована.
[0050] В одном варианте осуществления, DNN-учитель содержит CD-DNN-HMM. В качестве альтернативы, DNN-учитель может использовать нелинейные блоки (например, сигмоидный, выпрямительный, максимизирующий, или другие блоки); иметь структуры, такие как стандартная DNN с прямым распространением, сверточная нейронная сеть (CNN), рекуррентная нейронная сеть (RNN), RNN с долгой краткосрочной памятью, или другие структуры; и/или обучаться согласно различным стратегиям обучения (например, стандартное обучение, выпадение с разными факторами, или другие стратегии), например. В одном варианте осуществления этапа 510, модель DNN-учителя содержит модель ансамблевой DNN, содержащую множество моделей под-DNN. В таких вариантах осуществления, модель ансамблевой DNN может быть определена как описано применительно к Фиг. 4 и этапам 610-630 способа 600 (Фиг. 6).
[0051] На этапе 520, инициализируется вторая модель DNN. Вторая модель DNN служит в качестве "DNN-студента" для обучения на основании DNN-учителя, определенной на этапе 510. В некоторых вариантах осуществления, вторая DNN, или "DNN-студент", создается и/или инициируется компонентом инициализации, как описано применительно к компоненту 124 инициализации по Фиг. 1. Например, на этапе 520, DNN-студента может быть создана (или иначе, определена, если используется предварительно существующая модель DNN-студента) как имеющая меньший размер (например, небольшое число параметров или узлов на слой), чем DNN-учитель и может также иметь иное число скрытых слоев, чем DNN-учитель. В некоторых вариантах осуществления, размер DNN-студента определяется на основе клиентского устройства, на котором обученная DNN-студент будет развернута в качестве классификатора, например, на основе вычислительных ограничений и ограничений хранения клиентского устройства. DNN-студент может также быть определен на основе предназначенного приложения (например, ASR, обработка изображений и т.д.) обученной DNN-студента при развертывании в качестве классификатора.
[0052] В одном варианте осуществления, на этапе 520, DNN-студент создается посредством копирования и деления DNN-учителя, определенной на этапе 510, для создания DNN-студента с уменьшенной размерностью. DNN-студент может быть инициализирован посредством приема обучающих данных и выполнения неконтролируемого предварительного обучения модели DNN-студента, в варианте осуществления. Например, нетранскрибированные данные могут быть приняты и использованы для установления первоначальных весов узлов для модели DNN-студента (т.е., весов матрицы W, такой как описано применительно к Фиг. 2). В другом варианте осуществления, этап 520 включает в себя инициализацию необученной модели DNN-студента посредством присвоения весам узлов в модели случайных чисел. В одном варианте осуществления, модель DNN-студента создается или инициализируется для наследования структуры модели, включающей в себя набор речевых звуков, топологию HMM и связывание контекстно-зависимых состояний, от обыкновенной CD-GMM-HMM системы, которая может быть предварительно существующей.
[0053] На этапе 530, принимается набор непомеченных данных для обучения DNN-студента, инициализированной на этапе 520. Непомеченные данные могут быть приняты компонентом доступа, как описано применительно к компоненту 122 доступа по Фиг. 1. Например, непомеченные данные могут быть приняты из хранилища и/или могут быть приняты (или в конечном счете получены) из контура обратной связи развертывания. Непомеченные данные могут содержать нетранскрибированные данные, в одном варианте осуществления.
[0054] Так как могут быть доступны большие объемы непомеченных обучающих данных (например, данных, полученных из одного или более контуров обратной связи развертывания), один вариант осуществления этапа 530 содержит прием большого объема непомеченных данных для использования в обучении DNN-студента на последующих этапах способа 500. Хотя этап 530 показан как одиночный этап в способе 500, предполагается, что непомеченные данные для обучения могут быть приняты по необходимости во время этапов способа 500. Например, в одном варианте осуществления, с каждой итерацией этапов 540-560, новая порция (или поднабор) непомеченных данных может быть принята и использована для определения распределения выводов.
[0055] На этапах 540-560, DNN-студент обучается с использованием итеративного процесса для оптимизации его распределения вывода, чтобы приблизительно соответствовать распределению вывода DNN-учителя; например, в одном варианте осуществления, этапы 540-560 повторяются пока распределение вывода студента не сойдется в достаточной степени с распределением вывода учителя (или иначе не станет близким с ним). При каждой итерации, DNN-студент обновляется на основе разницы или ошибки его распределения вывода относительно распределения вывода DNN-учителя, пока не будет достигнуто достаточное схождение. В некоторых вариантах осуществления, один или более полных переборов обучающих данных используются в течении последовательных итераций для предоставления разнообразного ввода для DNN-учителя и студента.
[0056] На этапе 540, с использованием поднабора непомеченных обучающих данных, принятых на этапе 530, определяются распределение вывода для DNN-учителя и распределение вывода для DNN-студента. Распределения выводов для DNN-учителя и DNN-студента могут быть определены посредством компонента доступа как описано применительно к компоненту 126 доступа по Фиг. 1. В одном варианте осуществления, поднабор обучающих данных содержит мини-пакет, который вводится в DNN-учитель и DNN-студент (один и тот же мини-пакет подается обоим моделям DNN). На основании этого определяется распределение вывода для DNN-учителя и DNN-студента. В одном варианте осуществления, мини-пакет содержит 256 выборок или "кадров" нетранскрибированных обучающих данных.
[0057] Например, в одном варианте осуществления, для каждого мини-макета, прямое распространение проводится на DNN-учителя и студента для определения распределений выводов (апостериорных распределений). В частности, апостериорное распределение для сенона при входных обучающих данных для DNN-учителя и DNN-студента может быть обозначено как для DNN-учителя или большей (где "L" предполагает больший) и 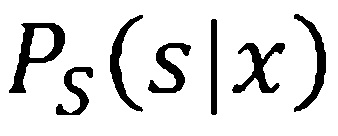 для DNN-студента. Соответственно, в варианте осуществления этапа 540, прямое распространение применяется для вычисления и для DNN-учителя и DNN-студент, соответственно.
для DNN-студента. Соответственно, в варианте осуществления этапа 540, прямое распространение применяется для вычисления и для DNN-учителя и DNN-студент, соответственно.
[0058] На этапе 550, распределение вывода DNN-студента оценивается против распределения вывода DNN-учителя. Процесс оценки по этапу 550 может быть осуществлен компонентом оценки, как описано применительно к компоненту 128 оценки по Фиг. 1. В одном варианте осуществления этапа 550, из распределения выводов, определенных на этапе 540 (определенных из мини-пакета или поднабора обучающих данных, использованных на этапе 540), сначала определяется разница между распределением вывода DNN-студента и распределением вывода DNN-учителя. (Разница может быть выражена как "ошибка" или "сигнал ошибки" между выводом студента и выводом учителя.) Затем, на основе этой разницы, определяется, сошлись ли распределение вывода DNN-студента и распределение вывода DNN-учителя. Например, может быть определено, что выводы сошлись, где их разница (или ошибка) достаточно мала, или не становится ли разница, в течение нескольких операций, меньше (предполагая, что обучение DNN-студента остановилось, так как ее распределение вывода более не имеет тенденцию к схождению с DNN-распределением вывода учителя).
[0059] Например, порог (который может называться порогом схождения или разницы) может быть применен для определения схождения, на основе того, является ли сигнал ошибки достаточно малым (например, ниже порогового значения), указывая, что производительность студента приблизительно соответствует производительности учителя. Другими словами, студент теперь обучен, и больше нет необходимости продолжать итерации. В одном варианте осуществления, порог является предварительно определенным и/или может быть основан на размере DNN-студента или предназначенном приложении для DNN-студента, при развертывании в качестве классификатора на вычислительном устройстве. В качестве альтернативы, оценка, определенная на этапе 550, может сравнивать сигналы ошибок или разницы, определенные за последние итерации этапа 540, чтобы определить, становится ли меньше сигнал ошибки (предполагая, что DNN-студент продолжает улучшаться в результате обучения) или более не становится меньше (предполагая, что DNN-студент, или более конкретно его апостериорное распределение, эффективно достиг схождения с апостериорным распределением DNN-учителя).
[0060] Продолжая с этапом 550, разница между распределениями выводов может быть определена посредством определения расхождение Кульбака-Лейблера (KL) между апостериорными распределениями, посредством использования регрессии, или посредством аналогичных способов для минимизирования расхождения между выводами DNN-учителя и студента. Например, в одном варианте осуществления, где апостериорные распределения для DNN-учителя и DNN-студента определяются как и , соответственно, для заданного набора обучающих данных 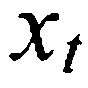 , t=1 до T, расхождение KL между этими двумя распределениями составляет:
, t=1 до T, расхождение KL между этими двумя распределениями составляет:
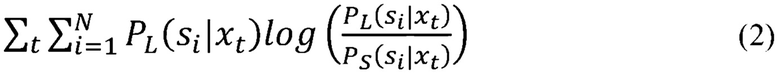
где N является общим числом сенонов.
[0061] Так как варианты осуществления способа 500 обучают DNN-студент для приблизительного соответствия обученной DNN-учителю, оптимизируются только параметры DNN-студента. Соответственно, минимизирование вышеуказанного расхождения KL является эквивалентом минимизированию перекрестной энтропии:
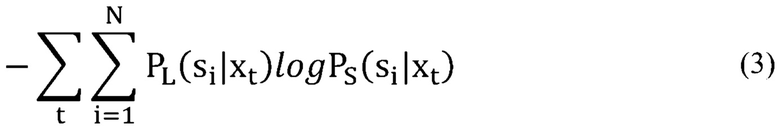
так как 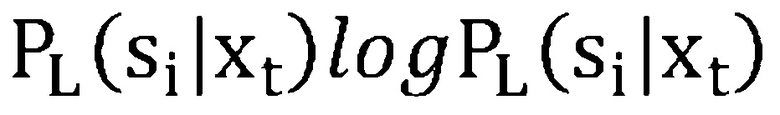 не имеет влияния на оптимизацию параметров DNN-студента. Критерий обучения из уравнения (3) выше является общей формой стандартного критерия обучения DNN в уравнении (1), описанном применительно к Фиг. 2, где для каждого кадра, только одна размерность равняется 1 и остальные равняются 0. В отличие от этого, в уравнении (3) каждая размерность может иметь ненулевое значение (хотя оно может быть очень небольшим). (Это иллюстрирует, почему модель DNN, сгенерированная согласно способу, описанному в настоящем документе, является иной, является более точной, чем модель DNN, обученная с таким же размером, но обученная согласно стандартным критериям обучения.) Использование расхождения KL для определения сигнала ошибки между распределениями выводов учителя и студента обеспечивает преимущество над другими альтернативами, такими как регрессия или MSE, так как минимизирование расхождения KL является эквивалентом минимизированию перекрестной энтропии распределений.
не имеет влияния на оптимизацию параметров DNN-студента. Критерий обучения из уравнения (3) выше является общей формой стандартного критерия обучения DNN в уравнении (1), описанном применительно к Фиг. 2, где для каждого кадра, только одна размерность равняется 1 и остальные равняются 0. В отличие от этого, в уравнении (3) каждая размерность может иметь ненулевое значение (хотя оно может быть очень небольшим). (Это иллюстрирует, почему модель DNN, сгенерированная согласно способу, описанному в настоящем документе, является иной, является более точной, чем модель DNN, обученная с таким же размером, но обученная согласно стандартным критериям обучения.) Использование расхождения KL для определения сигнала ошибки между распределениями выводов учителя и студента обеспечивает преимущество над другими альтернативами, такими как регрессия или MSE, так как минимизирование расхождения KL является эквивалентом минимизированию перекрестной энтропии распределений.
[0062] На этапе 555, на основе оценки, определенной на этапе 550, способ 500 переходит к этапу 560 или этапу 570. В частности, если на этапе 550 определяется, что схождение между распределением вывода DNN-студента с DNN-учителя не было достигнуто (например, порог схождения или разницы не был удовлетворен, или что вывод DNN-студента продолжает улучшаться), то способ 500 переходит к этапу 560, где DNN-студент обновляется на основе сигнала ошибки (или разницы), определенного на этапе 550. Однако, если на этапе 550 определяется, что схождение было достигнуто, или что сигнал ошибки более не становится меньше (предполагая, что DNN-студент более не улучшается в результате обучения), то способ 500 переходит к этапу 570. (Другими словами, для DNN-студента "занятия окончены".)
[0063] В одном варианте осуществления, этап 555 также определяет, произошел ли уже полный перебор обучающих данных. Если произошел (если все из обучающих данные были использованы по меньшей мере однажды), и схождение достигнуто (или сигнал ошибки более не становится меньше), то способ 500 переходит к этапу 570. Но если все из данных еще не были применены, то способ 500 переходит к этапу 560 и повторяет итерации, в этом варианте осуществления.
[0064] На этапе 560, DNN-студент обновляется на основе оценки, определенной на этапе 550. DNN-студент может быть обновлена компонентом доступа, как описано применительно к компоненту 126 доступа по Фиг. 1. В одном варианте осуществления, разница между распределением вывода DNN-студента и DNN-учителя, определенная на этапе 550, используется для обновления параметров или весов узлов DNN-студента, что может быть выполнено с использованием обратного распространения. Обновление DNN-студента таким образом способствует обучению распределения вывода DNN-студента для более точного соответствия распределению вывода DNN-учителя.
[0065] В варианте осуществления, вывод уравнения (3) используется для обновления DNN-студента посредством обратного распространения. Для каждой итерации, обратное распространение может быть применено с использованием вывода уравнения (3) для обновления DNN-студента, тем самым дополнительно обучая DNN-студента для приблизительного соответствия учителю. Вслед за этапом 560, способ 500 переходит обратно к этапу 540, где поднабор (или мини-пакет) обучающих данных используется для определения распределения вывода для DNN-учителя и теперь обновленного DNN-студента. В одном варианте осуществления, с каждой итерацией, новый поднабор или мини-пакет используется на этапе 540, все из данных в наборе непомеченных обучающих данных (принятых на этапе 530) не будут использованы. Полный перебор обучающих данных может быть применен до переработки обучающих данных.
[0066] На этапе 570, предоставляется обученная DNN-студент. На основе определения из этапа 550, распределение вывода обученной DNN-студента достаточно сошлось с распределением вывода DNN-учителя, или DNN-студент более не показывает знаков улучшения. В одном варианте осуществления, обученная DNN-студент развертывается как классификатор DNN в вычислительной системе или вычислительном устройстве, таком как клиентское устройство 102 или 104 по Фиг. 1. Например, обученная DNN-студент может быть развернута на смартфон или смарт-очках. На основе модели DNN-учителя и обучающих данных, обученная DNN-студент может быть специализированной для конкретного приложения (например, обработки изображений или ASR) или общей.
[0067] Как описано ранее, преимущество некоторых вариантов осуществления способа 500 состоит в том, что DNN-студент обучается с использованием непомеченных (или нетранскрибированных) данных, так как ее цель обучения (, которой является распределение вывода DNN-учителя) получается посредством прохождения непомеченных обучающих данных через модель DNN-учителя. Без необходимости в помеченных или транскрибированных обучающих данных, для обучения становится доступно гораздо больше данных. Кроме того, при большем объеме обучающих данных, доступных для покрытия пространства конкретного признака, точность развернутой модели DNN (-студента) даже дополнительно увеличивается.
[0068] Возвращаясь теперь к Фиг. 6, представляется схема последовательности операций, иллюстрирующая один примерный способ 600 генерирования обученной модели DNN для развертывания в качестве классификатора в компьютерной системе посредством обучения модели DNN на основании модели ансамблевой DNN. В способе 600, модель ансамблевой DNN играет роль "учителя", тогда как модель DNN, которая обучается, играет роль "студента". Модель DNN-студента по способу 600 может быть обучена, чтобы приблизительно соответствовать модели ансамблевой DNN-учителя, аналогичным описанному в способе 500 образом (Фиг. 5). Одно преимущество ансамблевой DNN-учителя состоит в том, что вывод обученного ансамбля является даже более точным, так как он включает в себя все голоса членов ансамбля (под-DNN). Варианты осуществления способа 600 могут осуществляться с использованием компонентов (включая модели DNN), описанных на Фиг. 1-4. В частности, Фиг. 4 описывает вариант осуществления для модели ансамблевого учителя, которая подходит для использования в некоторых вариантах осуществления способа 600.
[0069] На этапе 610, определяются множество моделей DNN, которые должны быть включены как под-DNN в модель ансамблевой DNN. Множество моделей DNN могут быть определены посредством компонента инициализации и/или компонента доступа, как описано применительно к компоненту 124 инициализации и компоненту 122 доступа по Фиг. 1, и DNN-учителя 402, описанной применительно к Фиг. 4. В некоторых вариантах осуществления, под-DNN, определенные для включения в ансамблевую DNN-учитель, могут содержать DNN или аналогичные структуры с разными нелинейными блоками (например, сигмоидный, выпрямительный, максимизирующий, или другие блоки), разные типы структур (например, стандартная DNN с прямым распространением, сверточная нейронная сеть (CNN), рекуррентная нейронная сеть (RNN), RNN с долгой краткосрочной памятью, или другие структуры), могут быть обучены согласно разным стратегиям обучения (например, стандартное обучение, выпадение с разными факторами, или другие стратегии), иметь разные топологии (варьирующиеся по числу слоев и узлов, например), и/или могут быть обучены с помощью разных данных. Такие вариации могут дать в результате разные шаблоны ошибок и таким образом обеспечивают лучшую DNN-учитель.
[0070] В некоторых вариантах осуществления, конкретные модели под-DNN, которые являются членами ансамбля, могут быть определены на основе доступности моделей DNN для функционирования в качестве под-DNN для ансамбля; приложения, прикладного окружения или оперативного окружения ансамблевой DNN, или приложения, прикладного окружения или оперативного окружения DNN-студента, которая должна быть обучена ансамблевой DNN; доступных обучающих данных; или обучающих данных, ввод которых ожидается в DNN-студент, обученную ансамблевой DNN, например. В этих вариантах осуществления, компонент 124 инициализации по Фиг. 1 (или аналогичный сервис) может определить конкретную под-DNN, которая должна быть включена в ансамбль.
[0071] На этапе 620, модель ансамблевой DNN-учителя генерируется с использованием множества под-DNN, определенных на этапе 610. Модель ансамблевой DNN-учителя может быть сгенерирована компонентом инициализации как описано применительно к компоненту 124 инициализации по Фиг. 1, и, в одном варианте осуществления, может быть аналогична примерной модели ансамблевой DNN-учителя 402, описанной применительно к Фиг. 4. На этапе 620, выводы ансамблевой сети содержат апостериорный вектор, представляющий распределение вывода (или апостериорное распределение) модели ансамблевой DNN-учителя. В одном варианте осуществления, апостериорный вектор имеет ту же размерность, как вывод каждой из под-DNN. В одном варианте осуществления, ансамблевая DNN-учитель 402 содержит огромную ансамблевую DNN, которая может быть даже слишком большой даже для практического развертывания, нежели чем в целях обучения меньшей DNN-студента, которая может быть развернута на сервере, клиентском устройстве или другом вычислительном устройстве.
[0072] На этапе 630, обучается ансамблевая DNN-учитель. Модель ансамблевой DNN-учителя может быть обучена посредством компонента доступа, как описано применительно к компоненту 126 доступа по Фиг. 1, или как описано применительно к Фиг. 4. В одном варианте осуществления, под-DNN уже обучены. В качестве альтернативы, под-DNN могут быть обучены (так как описано применительно к этапу 510 способа 500) до обучения ансамблевой DNN-учителя. В одном варианте осуществления, этап 630 содержит комбинирование выводов под-DNN в вектор, представляющий апостериорное распределение вывода для ансамбля, посредством использования необработанного среднего выводов под-DNN, посредством взвешенного голосования (например, если известно, что некоторые под-DNN выполняются лучше для некоторых приложений или областей, таких как развлечение, и присваивается больший вес этим выводам под-DNN), или посредством целевой функции. В частности, соединения между каждым распределением вывода под-DNN и вектором, представляющим распределение вывода для ансамбля, могут быть обучены с использованием одного или более критериев, как например, посредством комбинирования апостериорного вектора вывода каждой под-DNN с помощью коэффициентов автоматически обученной комбинации, используя критерий перекрестной энтропии, последовательный критерий, критерий ошибки по методу наименьших квадратов, критерий ошибки по методу наименьших квадратов с неотрицательным ограничением, или аналогичные критерии.
[0073] На этапе 640, ансамблевая DNN-учитель, сгенерированная и обученная на предыдущих этапах способа 600, используется для обучения DNN-студента. Обучение может проводиться посредством компонента доступа, как описано применительно к компоненту 126 доступа по Фиг. 1. Варианты осуществления этапа 640 могут быть осуществлены как описано на этапах 520-560 способа 500, при этом ансамблевая DNN-учитель функционирует как DNN-учитель из способа 500. В некоторых вариантах осуществления этапа 640, DNN-студент инициализируется согласно этапу 520 способа 500.
[0074] После завершения этапа 640, на этапе 650, обученная DNN-студент может быть развернута в вычислительной системе. В одном варианте осуществления, обученная DNN-студент развертывается как описано на этапе 570 способа 500. В некоторых вариантах осуществления, DNN-студент по способу 600 содержит DNN стандартного размера, которая может быть развернута в компьютерной системе, такой как сервер, нежели чем клиентское устройство.
[0075] Соответственно, были описаны различные аспекты технологии, направленной на системы и способы предоставления более точного классификатора DNN с уменьшенным размером для развертывания на вычислительных устройствах посредством "обучения" развернутой DNN из DNN-учителя с большей емкостью (числом скрытых узлов). Классификаторы DNN, обученные согласно некоторым вариантам осуществления данного изобретения, особенно подходят для представления приложений точной обработки сигналов (например, ASR или обработка изображений), на смартфонах, развлекательных системах, или аналогичных устройствах потребительской электроники с ограниченными вычислительными ресурсами и ресурсами хранения в сравнении с более мощными серверами и вычислительными системами. Также описаны варианты осуществления, которые применяют процессы обучения учитель-студент, описанные в настоящем документе, с использованием модели ансамблевой DNN для учителя, при этом ансамблевая DNN-учитель может быть обучена до обучения DNN-студента.
[0076] Понятно, что некоторые признаки, подкомбинации и модификации вариантов осуществления, описанных в настоящем документе, являются полезными и могут быть использованы в других вариантах осуществления без ссылки на другие признаки или подкомбинации. Более того, порядок и последовательности этапов, показанных в примерных способах 500 и 600 не подразумевают ограничение объема настоящего изобретения каким-либо образом, и в действительности, этапы могут осуществляться в разных последовательностях в рамках вариантов осуществления изобретения. Такие вариации и их комбинации также предполагаются находящимися в рамках объема вариантов осуществления данного изобретения.
[0077] После описания различных вариантов осуществления данного изобретения, теперь описывается примерное вычислительное окружение, подходящее для реализации вариантов осуществления данного изобретения. Со ссылкой на Фиг. 7, предусматривается примерное вычислительное устройство и в общем называется вычислительным устройством 700. Вычислительное устройство 700 является всего одним примером подходящего вычислительного окружения и не предназначено для предложения какого-либо ограничения в отношении объема использования или функциональности данного изобретения. Вычислительное устройство 700 не должно интерпретироваться как имеющее какую-либо зависимость или требование, относящееся к какому-либо одному или комбинации проиллюстрированных компонентов.
[0078] Варианты осуществления данного изобретения могут быть описаны в основном контексте компьютерного кода или используемых машиной инструкций, включая используемые компьютером или машиноисполняемые инструкции, такие как программные модули, машиноисполняемые или другой машиной, такой как персональный цифровой помощник, смартфон, планшетный ПК или другое карманное устройство. В основном, программные модули, включающие в себя стандартные программы, программы, объекты, компоненты, структуры данных и подобные, относятся к коду, который выполняет конкретные задачи или реализует конкретные абстрактные типы данных. Варианты осуществления данного изобретения могут быть применены на практике в разнообразии конфигураций систем, включающих в себя карманные устройства, потребительскую электронику, компьютеры общего назначения, более специализированные вычислительные устройства и т.д. Варианты осуществления данного изобретения могут также быть применены на практике в распределенных вычислительных средах, где задачи выполняются устройствами удаленной обработки, которые связаны через сеть связи. В распределенном вычислительном окружении, программные модули могут быть размещены как на локальных, так и на удаленных компьютерных носителях информации, в том числе запоминающих устройствах.
[0079] Со ссылкой на Фиг 7, вычислительное устройство 700 включает в себя шину 710, которая прямо или косвенно связывает следующие устройства: память 712, один или более процессоров 714, один или более компонентов 716 представления, один или более портов 718 ввода/вывода (I/O), один или более компонентов 720 I/O и иллюстративный блок 722 электропитания. Шина 710 представляет собой то, что может быть одной или более шинами (такой как адресная шина, шина данных или их комбинация). Хотя различные блоки по Фиг. 7 показаны линиями для ясности, в реальности, эти блоки представляют логические, необязательно фактические, компоненты. Например, компонент представления, такой как устройство отображения, может считаться компонентом I/O. Также, процессоры имеют память. Авторы настоящего изобретения понимают, что такова природа данной области техники, и повторяют, что схема по фиг. 7 является лишь иллюстративной для примерного вычислительного устройства, которое может быть использовано применительно к одним или более вариантами осуществления настоящего изобретения. Различие не делается между такими категориями как "рабочая станция", "сервер", "переносной компьютер", "карманное устройство" и т.д., так как все они могут предполагаться в рамках объема по Фиг. 7 и со ссылкой на "вычислительное устройство".
[0080] Вычислительное устройство 700 обычно включает в себя разнообразие машиночитаемых носителей.
Машиночитаемыми носителями могут быть любые доступные носители, к которым можно осуществить доступ посредством вычислительного устройства 700, и включают в себя как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители. В качестве примера, и не ограничения, машиночитаемые носители могут содержать компьютерные носители информации и среды связи. Компьютерные носители информации включают в себя и энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Компьютерные носители информации включают в себя, но не ограничены этим, RAM, ROM, EEPROM, flash-память или другую технологию памяти, CD-ROM, универсальные цифровые диски (DVD) или другие накопители на оптических дисках, магнитные кассеты, магнитные пленки, накопители на магнитных дисках или другие магнитные запоминающие устройства, или любые другие носители, которые могут быть использованы для хранения желаемой информации и к которым можно осуществить доступ посредством вычислительного устройства 700. Компьютерные носители информации не содержат сигналы сами по себе. Обычно, среды связи осуществляют машиночитаемые инструкции, структуры данных, программные модули, или другие данные в модулированном сигнале данных, как например, несущая волна или другой транспортный механизм, и включают в себя любые среды доставки информации. Термин "модулированный сигнал данных" означает сигнал, у которого один или более его параметров задаются или изменяются таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения, среды связи включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные, инфракрасные и другие беспроводные среды. Комбинации любого из вышеуказанного также должны быть включены в объем машиночитаемых носителей.
[0081] Память 712 включает в себя компьютерные носители информации в виде энергозависимой и энергонезависимой памяти. Память может быть съемной, несъемной или их комбинацией. Примерные аппаратные устройства включают в себя твердотельную память, накопители на жестких дисках, накопители на оптический дисках, и т.д. Вычислительное устройство 700 включает в себя один или более процессоров 714, которые считывают данные из различных объектов, таких как память 712 или компоненты 720 I/O. Компонент(ы) 716 представления представляет(ют) указатели данных пользователю или другому устройству. Примерные компоненты представления включают в себя устройство отображения, динамик, печатающий компонент, вибрирующий компонент и подобное.
[0082] Порты 718 I/O обеспечивают вычислительному устройству 700 возможность логического соединения с другими устройствами, включающими в себя компоненты 720 I/O, некоторые из которых могут быть встроенными. Иллюстративные компоненты включают в себя микрофон, джойстик, игровой контроллер, спутниковую тарелку, сканер, принтер, устройство беспроводной связи и т.д. Компоненты 720 I/O могут предоставить естественный пользовательский интерфейс (NUI), который обрабатывает жесты в воздухе, голос или другие физиологические вводы, генерируемые пользователем. В некоторых случаях, вводы могут быть переданы соответствующему элементу сети для дальнейшей обработки. NUI может реализовать любую комбинацию из распознавания речи, распознавания касания или стилуса, распознавания лиц, биометрического распознавания, распознавания жестов, как на экране, так и вблизи экрана, жестов в воздухе, отслеживание головы и глаз, и распознавания касания, ассоциированного с дисплеями на вычислительном устройстве 700. Вычислительное устройство 700 может быть оборудовано камерами глубины, такими как системы стереоскопических камер, системы инфракрасных камер, системы RGB-камер и их комбинации, для обнаружения и распознавания жестов. Дополнительно, вычислительное устройство 700 может быть оборудовано акселерометрами или гироскопами, которые обеспечивают возможность обнаружения движения. Вывод акселерометров или гироскопов может быть предоставлен дисплею вычислительного устройства 700 для визуализации дополненной реальности или виртуальной реальности с эффектом присутствия.
[0083] Многие разные компоновки различных изображенных компонентов, так же как и не показанных компонентов, возможны без отступления от объема формулы изобретения ниже. Варианты осуществления настоящего изобретения были описаны скорее с иллюстративным намерением, чем ограничительным. Альтернативные варианты осуществления будут понятны читателям этого раскрытия после и в результате его прочтения. Альтернативные средства реализации вышеупомянутого могут быть завершены без отступления от объема формулы изобретения ниже. Некоторые признаки и подкомбинации являются полезными и могут быть использованы без ссылки на другие признаки и подкомбинации и предполагаются в рамках объема формулы изобретения.
[0084] Хотя изобретение было описано на языке, характерном для структурных признаков или действий, следует понимать, что объем изобретения, определяемый прилагаемой формулой изобретения, не обязательно ограничен конкретными признаками или описанными выше действиями. Скорее, конкретные признаки и действия, описанные выше, раскрыты как примеры реализации формулы изобретения, и другие эквивалентные признаки и действия предназначены находится в рамках объема формулы изобретения.
[0085] Соответственно, в первом аспекте, вариант осуществления данного изобретения направлен на один или более машиночитаемых носителей, имеющих машиноисполняемые инструкции, осуществленные в нем, которые при исполнении вычислительной системой, имеющей процессор и память, предписывают вычислительной системе выполнить способ генерирования классификатора DNN для развертывания на вычислительном устройстве. Способ включает в себя определение первой модели DNN как модели DNN-учителя, инициализацию второй модели DNN как модели DNN-студента, и прием набора непомеченных обучающих данных. Способ также включает в себя, для некоторого числа итераций: (a) с использованием поднабора из набора обучающих данных, определение распределения вывода учителя для модели DNN-учителя и распределения вывода студента для модели DNN-студента; (b) определение оценки распределения вывода студента против распределения вывода учителя, причем оценка, включающая в себя разницу; и (c) на основе оценки, обновление модели DNN-студента для минимизации разницы. Способ дополнительно включает в себя предоставление модели DNN-студента в качестве обученного классификатора DNN, при этом число итераций основывается на определенной оценке.
[0086] В некоторых вариантах осуществления по первому аспекту, определение оценки распределения вывода студента против распределения вывода учителя содержит определение схождения между распределением вывода студента и распределением вывода учителя, и при этом число итераций является числом раз, которое этапы (a)-(c) выполняются, пока не будет определено схождение. В некоторых вариантах осуществления по первому аспекту, расхождение Кульбака-Лейблера используется для определения оценки распределения вывода студента против распределения вывода учителя, и при этом определенная оценка содержит сигнал ошибки, и в дополнительных некоторых вариантах осуществления модель DNN-студента обновляется с использованием обратного распространения на основе сигнала ошибки.
[0087] В некоторых вариантах осуществления по первому аспекту, распределение вывода учителя и распределение вывода студента определяются посредством прямого распространения с использованием поднабора данных. В некоторых вариантах осуществления по первому аспекту, первая модель DNN определяется на основании уже обученной модели DNN. В некоторых вариантах осуществления по первому аспекту, первая модель DNN содержит модель ансамблевой DNN. В некоторых вариантах осуществления по первому аспекту, вторая модель DNN инициализируется на основе первой модели DNN или инициализируется со случайными весовыми значениями, и при этом вторая модель DNN является предварительно обученной. В некоторых вариантах осуществления по первому аспекту, вторая модель DNN является частью механизма CD-DNN-HMM. В некоторых вариантах осуществления по первому аспекту, поднабор из набора обучающих данных содержит мини-пакет, и при этом разный мини-пакет данных используется для каждой итерации с числом итераций, пока не будут использованы все из набора обучающих данных. Один вариант осуществления данного изобретения включает в себя классификатор DNN, развернутый на клиентском устройстве и сгенерированный в результате исполнения, вычислительной системой, исполняемых компьютером инструкций по первому аспекту.
[0088] Во втором аспекте, предусматривается компьютерно-реализуемый способ генерирования обученной модели DNN для развертывания в качестве классификатора на компьютерной системе. Способ включает в себя определение множества моделей DNN, которые должны быть включены как под-DNN в модель ансамблевой DNN, и сборку модели ансамблевой DNN с использованием под-DNN, тем самым делаю каждую из множества под-DNN членом ансамбля. Способ также включает в себя обучение модели ансамблевой DNN. Способ также включает в себя инициализацию модели DNN-студента и обучение модели DNN-студента с использованием обученной модели ансамблевой DNN как DNN-учитель. Способ дополнительно включает в себя предоставление модели DNN-студента в качестве классификатора DNN.
[0089] В некоторых вариантах осуществления по второму аспекту, множество моделей DNN, которые должны быть включены как под-DNN в модель ансамблевой DNN, определяются на основе предназначенного приложения для классификатора DNN, развернутого на компьютерной системе. В некоторых вариантах осуществления по второму аспекту, под-DNN содержат модели DNN, которые (a) имеют разные нелинейные блоки, (b) имеют разные типы структур, (c) обучаются согласно разным стратегиям обучения, (d) имеют разные топологии, или (e) обучаются с помощью разных данных. В некоторых вариантах осуществления по второму аспекту, обучение модели ансамблевой DNN содержит комбинирование распределений выводов членов ансамбля посредством обученной комбинации коэффициентов с использованием критерия перекрестной энтропии, последовательного критерия, критерия ошибки по методу наименьших квадратов, или критерия ошибки по методу наименьших квадратов с неотрицательным ограничением.
[0090] В некоторых вариантах осуществления по второму аспекту, обучение модели DNN-студента содержит: (a) прием мини-пакета непомеченных обучающих данных; (b) с использованием мини-пакета, определение распределения вывода учителя для модели DNN-учителя и распределения вывода студента для модели DNN-студента посредством прямого распространения мини-пакета в модели DNN-студента и модели DNN-учителя; (c) определение оценки распределения вывода студента против распределения вывода учителя, причем оценка, содержащая сигнал ошибки; и (d) на основе оценки, определение, достигли ли распределение вывода студента и распределение вывода учителя схождения: (i) если определено, что распределение вывода студента и распределение вывода учителя сошлись, то предоставление модели DNN-студента для развертывания на клиентском устройстве; и (ii) если определено, что распределение вывода студента и распределение вывода учителя не сошлись, то обновление модели DNN-студента на основе определенной оценки и повторение этапов (a)-(d). Некоторые варианты осуществления дополнительно включают в себя, где модель DNN-студента является частью механизма CD-DNN-HMM, и где мини-пакет, который принимается на этапе (a), содержит поднабор обучающих данных, которые еще не были использованы на этапе (b).
[0091] В третьем аспекте, предусматривается основанный на DNN классификатор, развернутый на клиентском устройстве и созданный согласно процессу. Процесс включает в себя (a) определение первой модели DNN как модели DNN-учителя и (b) инициализацию второй модели DNN как модели DNN-студента. Процесс также включает в себя (c) прием набора непомеченных обучающих данных и (d) с использованием поднабора из набора обучающих данных, определение распределения вывода учителя для модели DNN-учителя и распределения вывода студента для модели DNN-студента. Процесс также включает в себя (e) определение оценки распределения вывода студента против распределения вывода учителя. Процесс дополнительно включает в себя (f) на основе оценки, определение, достигли ли распределение вывода студента и распределение вывода учителя схождения: если определено, что распределение вывода студента и распределение вывода учителя сошлись, то предоставление модели DNN-студента для развертывания на клиентском устройстве; и если определено, что распределение вывода студента и распределение вывода учителя не сошлись, то обновление модели DNN-студента на основе определенной оценки и повторение этапов (d)-(f).
[0092] В одном варианте осуществления по третьему аспекту, модель DNN-студента является частью механизма CD-DNN-HMM, расхождение Кульбака-Лейблера используется для определения оценки распределения вывода студента против распределения вывода учителя, причем определенная оценка содержит сигнал ошибки, модель DNN-студента обновляется с использованием обратного распространения на основе сигнала ошибки, и классификатор DNN развертывается на клиентском устройстве как часть системы автоматического распознавания речи.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ГЕНЕРИРОВАНИЯ ВОЛНОВОЙ ФОРМЫ | 2021 |
|
RU2803488C2 |
| РАСПОЗНАВАНИЕ СМЕШАННОЙ РЕЧИ | 2015 |
|
RU2686589C2 |
| СПОСОБ ИНТЕРПРЕТАЦИИ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2689818C1 |
| КОМПЬЮТЕРНЫЕ СИСТЕМЫ, ВЫЧИСЛИТЕЛЬНЫЕ КОМПОНЕНТЫ И ВЫЧИСЛИТЕЛЬНЫЕ ОБЪЕКТЫ, ВЫПОЛНЕННЫЕ С ВОЗМОЖНОСТЬЮ РЕАЛИЗАЦИИ УМЕНЬШЕНИЯ ОБУСЛОВЛЕННОГО ВЫБРОСОВЫМИ ЗНАЧЕНИЯМИ ДИНАМИЧЕСКОГО ОТКЛОНЕНИЯ В МОДЕЛЯХ МАШИННОГО ОБУЧЕНИЯ | 2020 |
|
RU2813245C1 |
| ДОСТОВЕРНЫЙ КЛАССИФИКАТОР | 2016 |
|
RU2720448C2 |
| Способ локального генерирования и представления потока обоев и вычислительное устройство, реализующее его | 2020 |
|
RU2768551C1 |
| СПОСОБ И СИСТЕМА СТАТИЧЕСКОГО АНАЛИЗА ИСПОЛНЯЕМЫХ ФАЙЛОВ НА ОСНОВЕ ПРЕДИКТИВНЫХ МОДЕЛЕЙ | 2020 |
|
RU2759087C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| Способ диагностики острого коронарного синдрома | 2020 |
|
RU2733077C1 |
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ПАКЕТИРОВАНИЯ ЗАПРОСОВ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ ОБРАБОТКИ ОБРАБАТЫВАЮЩИМ БЛОКОМ | 2021 |
|
RU2810916C2 |
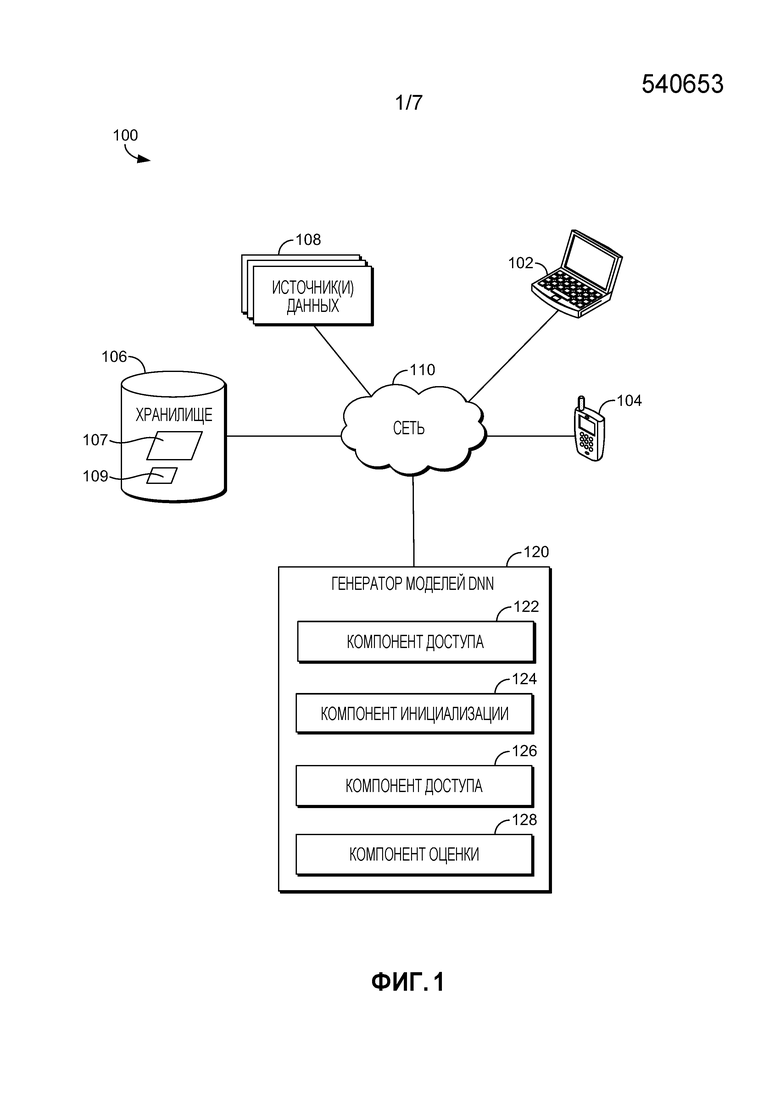
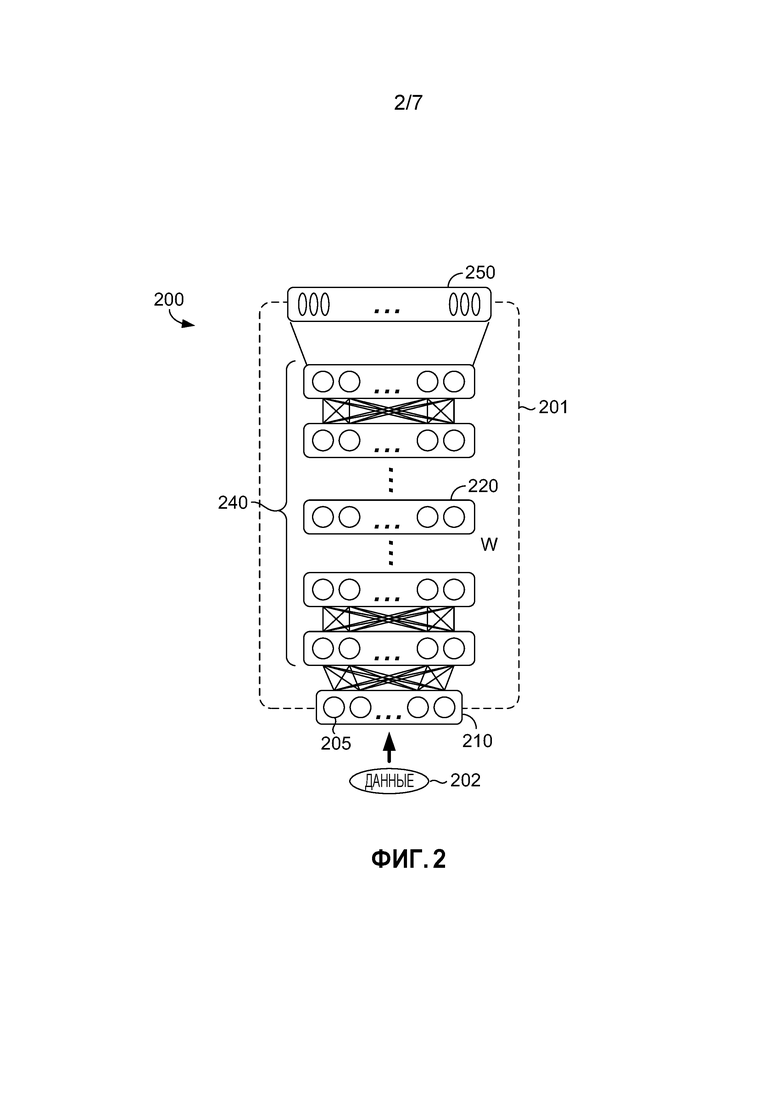
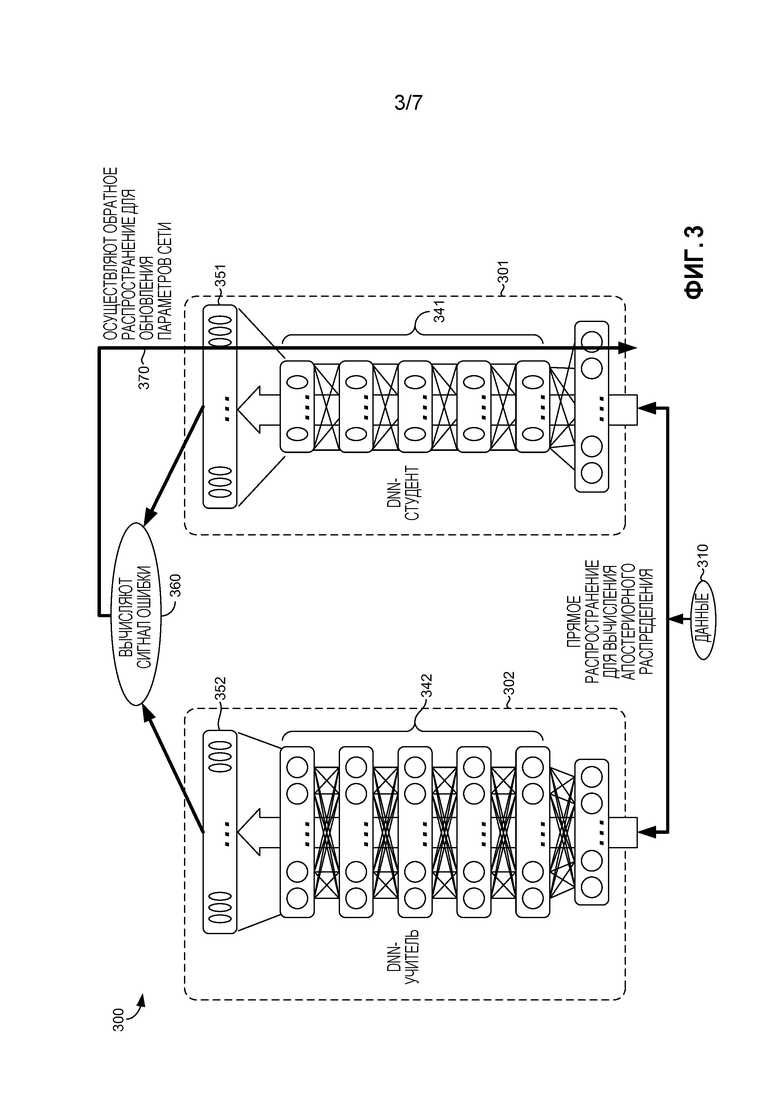
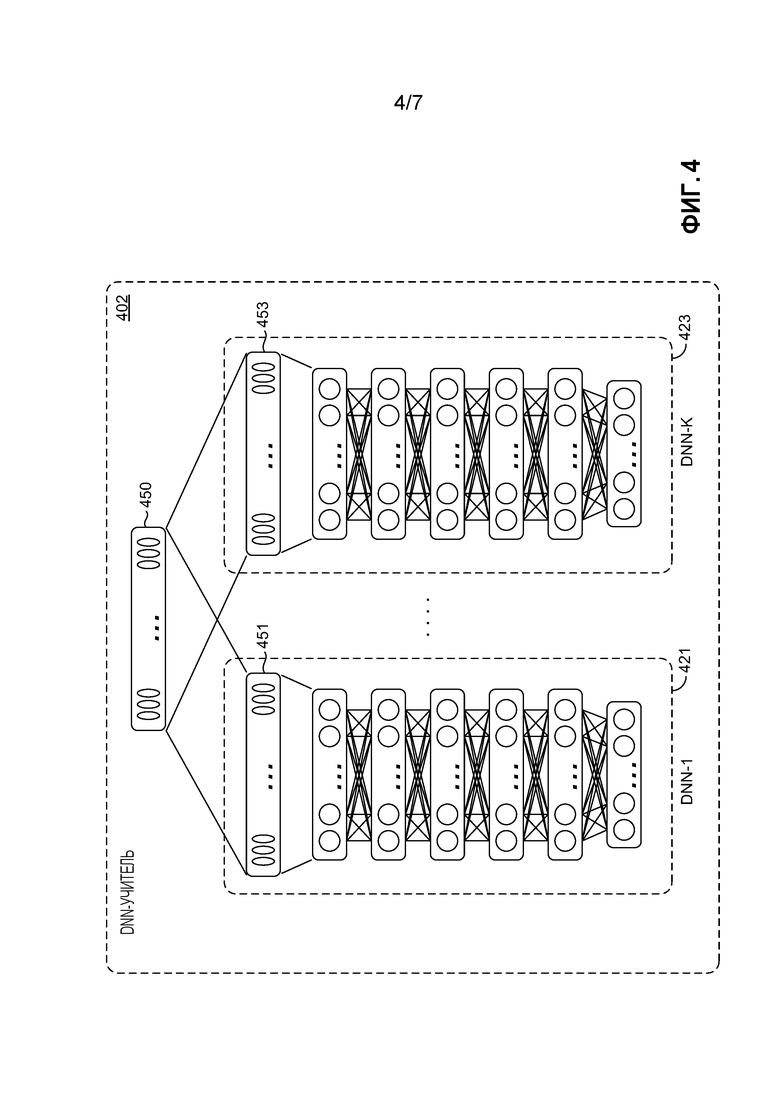
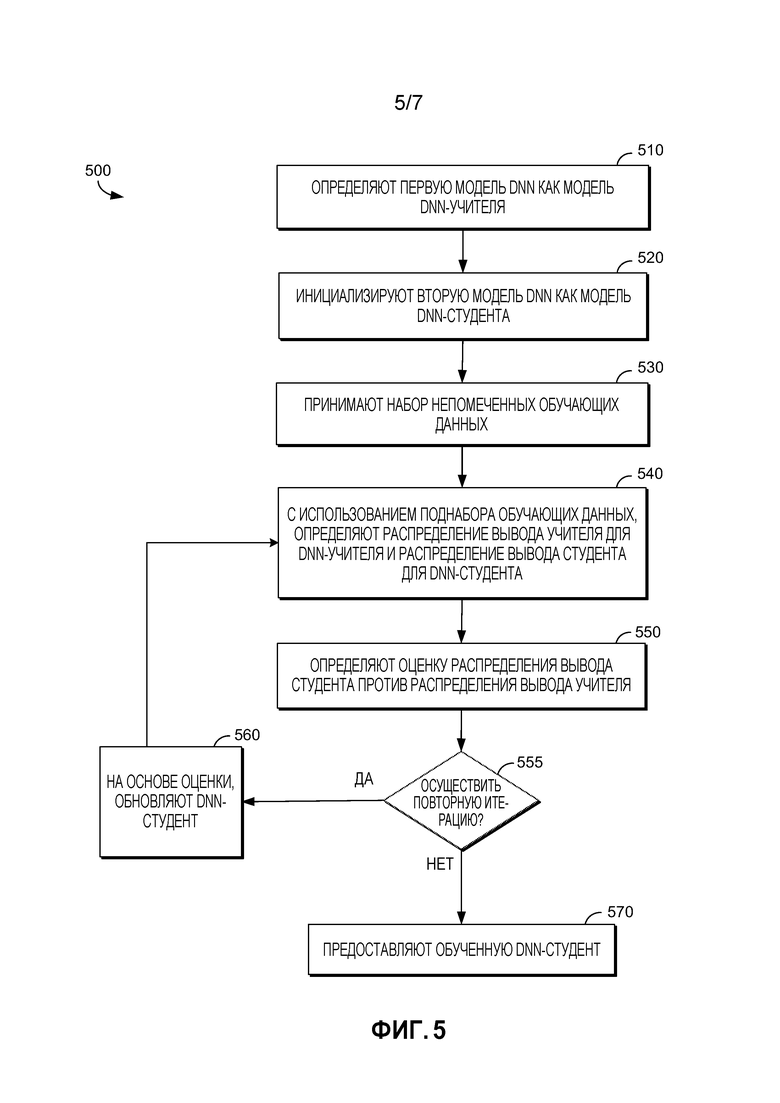
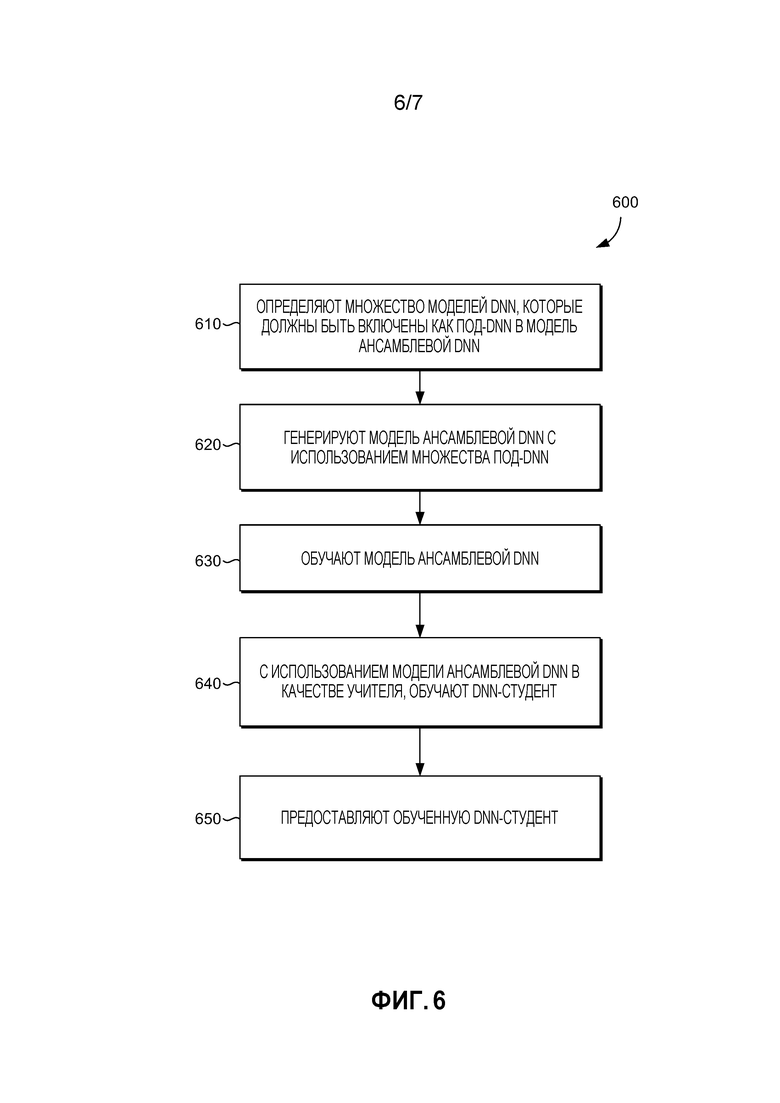
Изобретение относится к области алгоритмов машинного обучения. Техническим результатом является повышение точности модели DNN (Глубокая нейронная сеть) с уменьшенным размером. Для генерирования классификатора DNN посредством "обучения" модели DNN-"студента" на основании большей, более точной модели DNN-"учителя", DNN-студент может быть обучен на основании непомеченных обучающих данных посредством прохождения непомеченных обучающих данных через DNN-учитель, которая может быть обучена на основании помеченных данных. Итеративный процесс применяется для обучения DNN-студента посредством минимизирования расхождения распределений выводов на основании моделей DNN-учителя и студента. Для каждой итерации до схождения разница в выводах этих двух DNN используется для обновления модели DNN-студента, и выводы определяются снова, с использованием непомеченных обучающих данных. 3 н. и 7 з.п. ф-лы, 7 ил.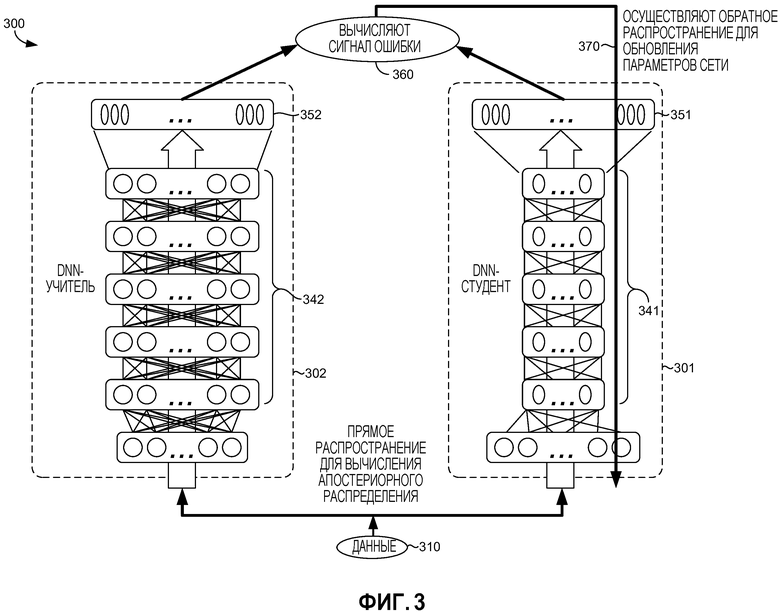
1. Один или более машиночитаемых носителей, на которых воплощены машиноисполняемые инструкции, которые при их исполнении вычислительной системой, имеющей процессор и память, предписывают вычислительной системе выполнять способ генерирования классификатора DNN для развертывания на вычислительном устройстве, причем способ содержит этапы, на которых:
определяют первую модель DNN как модель DNN-учителя;
инициализируют вторую модель DNN как модель DNN-студента;
принимают набор непомеченных обучающих данных;
в течение некоторого числа итераций:
(a) с использованием поднабора из набора обучающих данных определяют распределение вывода учителя для модели DNN-учителя и распределение вывода студента для модели DNN-студента;
(b) определяют оценку распределения вывода студента по отношению к распределению вывода учителя, каковая оценка включает в себя разницу;
(c) на основе данной оценки обновляют модель DNN-студента для минимизации разницы; и
предоставляют модель DNN-студента в качестве обученного классификатора DNN, при этом число итераций основывается на упомянутой определенной оценке.
2. Один или более машиночитаемых носителей по п. 1, при этом определение оценки распределения вывода студента по отношению к распределению вывода учителя содержит определение схождения между распределением вывода студента и распределением вывода учителя и при этом число итераций является числом раз, за которое этапы (a)-(c) выполняются, пока не будет определено схождение.
3. Один или более машиночитаемых носителей по п. 1, при этом для определения оценки распределения вывода студента по отношению к распределению вывода учителя используется расхождение Кульбака-Лейблера, причем упомянутая определенная оценка содержит сигнал ошибки, при этом модель DNN-студента обновляется с использованием обратного распространения на основе сигнала ошибки, причем распределение вывода учителя и распределение вывода студента определяются посредством прямого распространения с использованием поднабора данных.
4. Один или более машиночитаемых носителей по п. 1, при этом первая модель DNN содержит модель ансамблевой DNN, причем вторая модель DNN инициализируется на основе первой модели DNN или инициализируется со случайными весовыми значениями, при этом вторая модель DNN является частью инфраструктуры CD-DNN-HMM.
5. Один или более машиночитаемых носителей по п. 1, при этом упомянутый поднабор из набора обучающих данных содержит мини-пакет, причем отличающийся от других мини-пакет данных используется для каждой итерации из упомянутого числа итераций, пока не будут использованы все из набора обучающих данных.
6. Классификатор DNN, развернутый на клиентском устройстве и сгенерированный в результате исполнения вычислительной системой машиноисполняемых инструкций по п. 1.
7. Компьютерно-реализуемый способ генерирования обученной модели DNN для развертывания в качестве классификатора на компьютерной системе, содержащий этапы, на которых:
определяют множество моделей DNN, которые должны быть включены как под-DNN в модель ансамблевой DNN;
собирают модель ансамблевой DNN с использованием под-DNN, тем самым делая каждую из множества под-DNN членом ансамбля;
обучают модель ансамблевой DNN;
инициализируют модель DNN-студента;
обучают модель DNN-студента с использованием обученной модели ансамблевой DNN в качестве DNN-учителя; и
предоставляют модель DNN-студента в качестве классификатора DNN.
8. Компьютерно-реализуемый способ по п. 7, в котором множество моделей DNN, которые должны быть включены как под-DNN в модель ансамблевой DNN, определяются на основе намеченного приложения для классификатора DNN, развернутого на компьютерной системе, при этом под-DNN содержат модели DNN, которые (a) имеют разные нелинейные блоки, (b) имеют разные типы структур, (c) обучаются согласно разным стратегиям обучения, (d) имеют разные топологии или (e) обучаются с помощью разных данных.
9. Компьютерно-реализуемый способ по п. 7, в котором обучение модели ансамблевой DNN содержит этап, на котором комбинируют распределения выводов членов ансамбля посредством обученной комбинации коэффициентов с использованием критерия перекрестной энтропии, последовательного критерия, критерия ошибки по методу наименьших квадратов или критерия ошибки по методу наименьших квадратов с неотрицательным ограничением.
10. Компьютерно-реализуемый способ по п. 7, в котором обучение модели DNN-студента содержит этапы, на которых:
(a) принимают мини-пакет непомеченных обучающих данных;
(b) с использованием мини-пакета определяют распределение вывода учителя для модели DNN-учителя и распределение вывода студента для модели DNN-студента посредством прямого распространения мини-пакета в модели DNN-студента и модели DNN-учителя;
(c) определяют оценку распределения вывода студента по отношению к распределению вывода учителя, каковая оценка содержит сигнал ошибки; и
(d) на основе этой оценки определяют, достигли ли распределение вывода студента и распределение вывода учителя схождения:
(i) если определено, что распределение вывода студента и распределение вывода учителя сошлись, то предоставляют модель DNN-студента для развертывания на клиентском устройстве, и
(ii) если определено, что распределение вывода студента и распределение вывода учителя не сошлись, то обновляют модель DNN-студента на основе упомянутой определенной оценки и повторяют этапы (a)-(d).
| US 7835910 B1, 16.11.2010 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| CN 103544705 A, 29.01.2014 | |||
| CN 103955702 A, 30.07.2014 | |||
| КЛАССИФИКАТОР НА ОСНОВЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ВЫДЕЛЕНИЯ АУДИО ИСТОЧНИКОВ ИЗ МОНОФОНИЧЕСКОГО АУДИО СИГНАЛА | 2006 |
|
RU2418321C2 |

