ОБЛАСТЬ ТЕХНИКИ
[01] Настоящая технология относится к генеративному моделированию и, в частности, к способу и серверу для генерирования волновой формы.
УРОВЕНЬ ТЕХНИКИ
[02] Генеративное моделирование представляет собой задачу неконтролируемого обучения в машинном обучении, которая включает в себя автоматическое обнаружение и изучение регулярностей или закономерностей во входных данных таким образом, чтобы модель можно было использовать для генерирования или вывода новых примеров, которые могли бы быть правдоподобно извлечены из исходного набора данных. В процессе обучения большая совокупность данных в определенной области может быть собрана (например, миллионы изображений, предложений или звуков и т.д.) и может быть использована для обучения генеративной модели генерировать или синтезировать подобные данные.
[03] Например, в генеративных состязательных сетях (GAN) используется методика обучения генеративной модели путем постановки задачи как задачи контролируемого (supervised) обучения с двумя подмоделями: моделью генератора, которая обучается генерировать новые примеры, и моделью дискриминатора, которая пытается классифицировать примеры как «настоящие» (из данной области), либо «поддельные» (сгенерированные). Две модели обучаются вместе в состязательной игре с нулевой суммой, пока модель дискриминатора не удается обмануть примерно в половине случаев, что означает, что модель генератора генерирует правдоподобные примеры.
[04] В другом примере модели нормализующих потоков (NF) представляют собой семейство генеративных моделей с легко обрабатываемыми распределениями, где как выборка, так и оценка плотности могут быть эффективными и точными. Применения включают в себя генерирование изображений, моделирование шума, генерирование видео, генерирование аудио, генерирование графов, обучение с подкреплением, компьютерную графику и физику.
[05] Генерирование речи используется во множестве различных приложений, от умных помощников до синтетических голосов для людей, не способных говорить самостоятельно. Различные способы генерирования искусственных голосов были разработаны, но было трудно эффективно создавать реалистичные и стилизованные голоса.
[06] Генерирование изображений используется во множестве различных приложений, в том числе алгоритмах повышения разрешения и восстановлении изображений. Различные способы генерирования искусственных изображений были разработаны, но было трудно создавать данные реалистичных изображений эффективным образом.
[07] Патентная заявка США № 2020/402497 раскрывает систему с сетью NF ученика для изучения распределения спектрограмм CNN-учителя.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[08] Целью настоящей технологии является устранение по меньшей мере некоторых проблем, имеющихся в предшествующем уровне техники. Варианты осуществления настоящей технологии могут обеспечить и/или расширить сферу применения подходов и/или способов достижения целей и задач настоящей технологии.
[09] В некоторых аспектах настоящей технологии обеспечен процесс дистилляции знаний между моделью учителя и моделью ученика с образованием сети «учитель-ученик». Более конкретно, модель учителя воплощается как предварительно обученная основанная на потоке модель, имеющая обратимые блоки, а модель ученика воплощается как необученная модель прямого распространения (feed-forward), имеющая необратимые блоки.
[10] Разработчики настоящей технологии разработали сеть учитель-ученик, в которой архитектура ученика в некотором смысле «приносит в жертву» обратимость архитектуры учителя в обмен на более компактную и эффективную модель по сравнению с архитектурой учителя. Использование более компактных и эффективных моделей вместо соответствующих основанных на потоке моделей полезно для ряда различных реализуемых компьютером приложений, таких как синтез речи и суперразрешение.
Основанные на потоке модели
[11] Вообще говоря, основанная на потоке генеративная модель является генеративной моделью, которая явно моделирует распределение вероятностей с использованием вероятностного закона изменения переменной для преобразования простого распределения в сложное. Прямое моделирование правдоподобия может обеспечить многие преимущества. Например, отрицательное логарифмическое правдоподобие может быть непосредственно вычислено и минимизировано как функция потерь. Кроме того, новые выборки могут быть сгенерированы путем осуществления выборки из исходного распределения и применения преобразования потока. Для сравнения, многие альтернативные способы генеративного моделирования, такие как вариационный автоэнкодер (VAE) и генеративная состязательная сеть (GAN), явно не представляют функцию правдоподобия.
[12] Следует отметить, что основанные на потоке модели могут использовать различные классы преобразований потока, например авторегрессионные и двудольные преобразования. Авторегрессионные преобразования включают в себя авторегрессионный поток (AF) и обратный авторегрессионный поток (IAF). AF похожи на авторегрессионные модели, которые позволяют проводить параллельную оценку плотности, но выполняют последовательный синтез. Для сравнения, IAF допускает параллельный синтез, но выполняет последовательную оценку плотности, что делает обучение на основе правдоподобия очень медленным. Вторая группа включает в себя двудольные преобразования, которые обеспечивают эффективное обучение на основе правдоподобия и параллельный синтез. Однако двудольные потоки обычно менее выразительны, чем AF. Следовательно, для достижения сопоставимой емкости им требуется больше слоев и большее число параметров.
[13] Вообще говоря, нормализующий поток (NF) является преобразованием простого распределения вероятностей (например, стандартного нормального) в более сложное распределение с помощью последовательности обратимых и дифференцируемых отображений. Плотность выборки можно оценить, преобразовав ее обратно к исходному простому распределению, а затем вычислив произведение i) плотности обратно преобразованной выборки при этом распределении и ii) связанного изменения объема, вызванного последовательностью обратных преобразований. Изменение объема является произведением абсолютных значений определителей Якоби для каждого преобразования, как того требует формула замены переменных. Результатом этого подхода является механизм построения новых семейств распределений путем выбора начальной плотности и последующего объединения некоторого числа параметризованных, обратимых и дифференцируемых преобразований. Новая плотность может быть получена выборкой (путем выполнения выборки из начальной плотности и применения преобразований), и плотность в выборке (т.е. правдоподобие) может быть вычислена.
[14] Разработчики настоящей технологии осознали, что модели NF представляют собой мощный класс генеративных моделей, демонстрирующих хорошую производительность в нескольких связанных с речью и зрением проблемах. Как упоминалось выше, эти модели используют формулу замены переменных, которая обеспечивает «нормализованную» плотность после применения обратимых преобразований. Обратимые преобразования таких моделей могут комбинироваться друг с другом, и в смысле «потока», для создания более сложных обратимых преобразований. В отличие от других генеративных моделей, модели NF обратимы, обладают легко обрабатываемыми правдоподобиями и обеспечивают стабильное обучение. Поскольку модели NF допускают точное вычисление правдоподобия с помощь формулы замены переменных, их можно обучить, применяя методики максимизации правдоподобия. Как упоминалось выше, это свойство делает модели NF более желательными в некоторых ситуациях, чем, например, модели GAN, которые требуют состязательной оптимизации и могут страдать от исчезающих градиентов, коллапса режима, колебаний или циклического поведения.
[15] Некоторые NF могут быть выполнены с возможностью генерирования выходных данных на основе входного шума; тем не менее, другие NF могут дополнительно «обусловливаться» на основе входных обусловливающих данных. Условные NF набирают популярность в различных практических приложениях, связанных с речью и зрением, в частности для синтеза волновых форм (waveforms), суперразрешения изображений и генерирования облаков точек. Разработчики настоящей технологии разработали способы и системы, которые используют основанные на условном потоке модели для суперразрешения изображений и синтеза речи.
Приложения суперразрешения
[16] Суперразрешение (SR) является одной из фундаментальных проблем обработки изображений, которая направлена на улучшение качества изображений с низким разрешением (LR) путем повышения их разрешения до изображений с высоким разрешением (HR) с естественными высокочастотными деталями. Разработчики настоящей технологии осознали, что большинство подходов к SR изображений используют модели GAN, которые может быть трудно обучить из-за нестабильности состязательной оптимизации. Чтобы устранить этот недостаток, можно использовать модель SRFlow. О том, как можно реализовать модель SRFlow, рассказывается в статье под названием «SRFlow: Learning the Super-Resolution Space with Normalizing Flow», опубликованной в 2020 году под авторством Lugmayr и др., содержимое которой полностью включено в настоящий документ по ссылке.
[17] Вообще говоря, модель SRFlow имеет основанную на потоке архитектуру для оценки полного условного распределения естественных изображений HR, соответствующих определенному изображению LR, параметры которой обучаются путем максимизации правдоподобия. В частности, архитектура модели SRFlow состоит из кодера LR, который обеспечивает характерные признаки изображений LR в сеть с обратимым потоком. Потоковая сеть принимает соответствующее кодирование LR вместе с выборкой из начального распределения 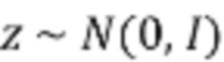 и преобразует их в изображение SR. Кодер LR представляет собой популярную архитектуру SR прямого распространения, основанную на блоках остаточной в остаточной плотности (RRDB). Этот блок применяет несколько остаточных и плотных пропускающих (skip) соединений без каких-либо слоев пакетной нормализации. Чтобы сформировать представление LR на нескольких уровнях, активации после каждого блока RRDB конкатенируются. Потоковая сеть организована в L уровней, каждый из которых работает с разрешением
и преобразует их в изображение SR. Кодер LR представляет собой популярную архитектуру SR прямого распространения, основанную на блоках остаточной в остаточной плотности (RRDB). Этот блок применяет несколько остаточных и плотных пропускающих (skip) соединений без каких-либо слоев пакетной нормализации. Чтобы сформировать представление LR на нескольких уровнях, активации после каждого блока RRDB конкатенируются. Потоковая сеть организована в L уровней, каждый из которых работает с разрешением 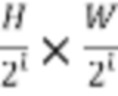 , где
, где 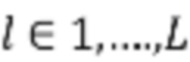 - индекс уровня, а
- индекс уровня, а  - разрешение HR. Каждый уровень сначала выполняет операцию сжатия (squeeze), которая вдвое уменьшает пространственное разрешение. За операцией сжатия следует переходный этап, на котором изучается линейная обратимая интерполяция между соседними пикселями. Затем применяется последовательность условных потоковых этапов. В конце каждого уровня 50% каналов отделяются для оценки правдоподобия. Каждый потоковый этап состоит из четырех слоев. Сначала применяются слой нормализации активации (actnorm) и свертка 1×1. Затем следуют аффинный инжектор и условные слои аффинной связи.
- разрешение HR. Каждый уровень сначала выполняет операцию сжатия (squeeze), которая вдвое уменьшает пространственное разрешение. За операцией сжатия следует переходный этап, на котором изучается линейная обратимая интерполяция между соседними пикселями. Затем применяется последовательность условных потоковых этапов. В конце каждого уровня 50% каналов отделяются для оценки правдоподобия. Каждый потоковый этап состоит из четырех слоев. Сначала применяются слой нормализации активации (actnorm) и свертка 1×1. Затем следуют аффинный инжектор и условные слои аффинной связи.
[18] В некоторых вариантах осуществления настоящей технологии разработчики настоящей технологии разработали сеть учитель-ученик, в которой модель учителя представляет собой модель SRFlow, а модель ученика представляет собой модель прямого распространения, обучаемую для использования в приложениях SR вместо соответствующей модели SRFlow.
Приложения синтеза речи
[19] Синтез речи может быть достигнут с помощью глубоких нейронных моделей, которые иногда называют «нейронными вокодерами». Следует отметить, что нейронный вокодер может синтезировать волновые формы во временной области, которые могут быть обусловлены мел-спектрограммами из модели «текст в спектрограмму».
[20] Большинство современных нейронных вокодеров представляют собой авторегрессионные модели, которые обеспечивают хорошую производительность, но страдают от медленного процесса последовательной генерации. Требования к среде выполнения авторегрессионных вокодеров ограничивают их использование в приложениях реального времени. Разработчики настоящей технологии осознали, что существует потребность в методиках, направленных на ускорение вывода таких моделей. Существуют также вокодеры на основе GAN, однако они, как правило, уступают авторегрессионным вокодерам по точности воспроизведения речи.
[21] Разработчики настоящей технологии осознали, что основанные на потоке модели могут успешно применяться для параллельного синтеза волновых форм с точностью воспроизведения, сравнимой с авторегрессионными моделями. Такие основанные на потоке вокодеры включают в себя модель WaveGlow. О том, как можно реализовать модель WaveGlow, рассказывается в статье под названием «WaveGlow: A Flow-Based Generative Network For Speech Synthesis», опубликованной 31 октября 2019 года под авторством Prenger и др., содержимое которой полностью включено в настоящий документ по ссылке.
[22] Вообще говоря, вокодер WaveGlow содержит последовательность двудольных потоковых этапов. Каждый потоковый этап состоит из обратимой свертки 1×1, за которой следует условный слой аффинной связи. Вокодер WaveGlow обусловливается мел-спектрограммами с повышенной дискретизацией через слои аффинной связи с блоками WaveNet. О том, как можно реализовать блок WaveNet, рассказывается в статье под названием «Wavenet: A Generative Model For Raw Audio», опубликованной 19 сентября 2016 года под авторством Aäron van den Oord и др., содержимое которой полностью включено в настоящий документ по ссылке.
[23] В некоторых вариантах осуществления настоящей технологии разработчики настоящей технологии разработали сеть учитель-ученик, в которой модель учителя представляет собой вокодер WaveGlow, а модель ученика представляет собой вокодер прямого распространения, обучаемый для использования в приложениях синтеза речи вместо соответствующего вокодера WaveGlow.
[24] Чтобы обеспечить точное вычисление правдоподобия, архитектуры NF должны состоять из обратимых модулей, которые также поддерживают эффективное вычисление своего определителя Якоби. В последнее время было разработано большое количество таких модулей, в том числе авторегрессионные, двудольные, линейные и остаточные преобразования. Хотя некоторые модули более эффективны, чем другие, NF обычно уступают аналогам с прямым распространением с точки зрения времени вывода. В частности, авторегрессионные потоки используют медленную процедуру последовательной генерации, в то время как двудольные потоки могут требовать большого числа подмодулей с низкой выразительной силой. Более того, обратимость ограничивает размер карт активации между модулями, что приводит к возникновению узких мест и, следовательно, непрактично более глубоких моделей.
[25] Однако во многих практических приложениях явная оценка плотности может не потребоваться во время вывода. Как упоминалось ранее, разработчики настоящей технологии осознали, что обратимостью NF можно пожертвовать ради улучшения времени выполнения и потребления памяти. Разработчики осознали, что на стадии обучения можно извлечь выгоду из стабильного обучения с целью явного правдоподобия от NF, а при развертывании можно получить эффективный вывод из более компактных архитектур прямого распространения.
Дистилляция знаний
[26] В некоторых аспектах настоящей технологии разработчики изобрели процесс дистилляции знаний из предварительно обученных основанных на потоках моделей в компактные и более эффективные архитектуры прямого распространения без свойства обратимости архитектур NF.
[27] Дистилляция знаний представляет собой одну из самых популярных методик сжатия и ускорения для больших моделей и ансамблей нейронных сетей. Вообще говоря, идея дистилляции знаний состоит в обучении эффективного ученика на прогнозах, производимых учителем, требующим больших вычислительных ресурсов. Можно сказать, что раскрытая в данном документе методика дистилляции знаний устраняет вычислительную неэффективность основанных на потоках моделей и позволяет передавать знания от NF в сети прямого распространения, которые не обязательно должны быть обратимыми.
[28] В по меньшей мере некоторых вариантах осуществления настоящей технологии разработаны способы обучения и структура ученика, которые позволяют осуществлять дистилляцию знаний из условных NF в модели прямого распространения с более быстрым выводом и/или меньшим потреблением памяти. Предполагается, что в по меньшей мере некоторых реализациях настоящей технологии раскрытые в данном документе процессы дистилляции могут привести к более быстрому выводу без заметной потери качества.
Процедура дистилляции
[29] Со ссылкой на Фигуру 4 изображено представление сети 400 учитель-ученик, предусмотренной в некоторых вариантах осуществления настоящей технологии. Сеть 400 учитель-ученик содержит модель учителя, представляющую связанную с учителем часть 402 сети 400, и модель ученика, представляющую связанную с учеником часть 404 сети 400. Следует отметить, что представление сети 400, проиллюстрированное на Фигуре 4, является упрощенным представлением реальной сети учитель-ученик, которая может использоваться в различных реализациях настоящей технологии. О том, как можно реализовать сеть 400 учитель-ученик в некоторых вариантах осуществления настоящей технологии, рассказывается в статье под названием «Distilling the Knowledge from Normalizing Flows», которая приложена к настоящему документу.
[30] Связанная с учителем часть 402 содержит блоки 412-1, 412-2,…, 412-3 и 412-4 потоковых этапов. Следует отметить, что блоки с 412-1 по 412-4 потоковых этапов являются обратимыми блоками. Следовательно, можно сказать, что связанная с учителем часть 402 представляет собой обратимую (основанную на потоке) модель. Связанная с учеником часть 404 содержит блоки 424-1,… и 414-2 прямого распространения. Следовательно, можно сказать, что связанная с учеником часть 404 представляет собой необратимую модель (прямого распространения).
[31] Как в связанную с учителем часть 402, так и в связанную с учеником часть 404 вводят набор 410 входных данных, включающий в себя выборку 406 шума (входной шум) и контекстную информацию 408 (обусловливающий элемент). Разработчики настоящей технологии осознали, что использование одного и того же набора 410 входных данных для связанной с учителем части 402 и связанной с учеником части 404 позволяет обучать необратимую, с прямым распространением, модель ученика на основе обратимой, основанной на потоке модели учителя.
[32] Таким образом, набор 410 входных данных может использоваться связанной с учителем частью 402 для генерирования выводимой учителем выборки 422, а также связанной с учеником частью 404 для генерирования выводимой учеником выборки 424. Выводимая учителем выборка 422 и выводимая учеником выборка 424 могут использоваться для вычисления функции 460 потерь. В примере, проиллюстрированном на Фигуре 4, модель 450 извлечения признаков может использоваться для извлечения признаков из выводимой учителем выборки 422 и выводимой учеником выборки 424 для дальнейшего использования функцией 460 потерь.
[33] Теперь будет обсуждаться то, как связанная с учителем часть 402 и связанная с учеником часть 404 могут быть спроектированы специалистом в данной области техники, ознакомившимся с изложенными в данном документе принципами. Однако для формирования сети учитель-ученик, имеющей основанную на потоке модель учителя и модель ученика прямого распространения, могут использоваться другие архитектуры, помимо тех, которые не исчерпывающим образом описаны в данном документе.
Структура учителя
[34] Связанная с учителем часть 402 может быть реализована в форме предварительно обученной основанной на условном потоке модели, которая определяет детерминированное биективное отображение из выборки 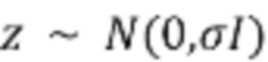 шума и контекстной информации
шума и контекстной информации 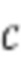 в выходную выборку
в выходную выборку 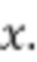 Разработчики настоящей технологии поняли, что это отображение может быть аппроксимировано более эффективной моделью, контролируемым образом, с использованием целевой функции потерь. В частности, комбинация потерь «восстановления» и потерь «признаков» может использоваться функцией 460 потерь. В некоторых реализациях функция 460 потерь во время обучения может быть определена как:
Разработчики настоящей технологии поняли, что это отображение может быть аппроксимировано более эффективной моделью, контролируемым образом, с использованием целевой функции потерь. В частности, комбинация потерь «восстановления» и потерь «признаков» может использоваться функцией 460 потерь. В некоторых реализациях функция 460 потерь во время обучения может быть определена как:
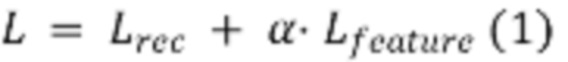
где 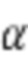 представляет собой гиперпараметр, который может быть использован для балансировки соответствующих членов потерь. Предполагается, что комбинация потерь восстановления и потерь признаков может использоваться для ряда приложений, таких как приложения синтеза речи и приложения суперразрешения.
представляет собой гиперпараметр, который может быть использован для балансировки соответствующих членов потерь. Предполагается, что комбинация потерь восстановления и потерь признаков может использоваться для ряда приложений, таких как приложения синтеза речи и приложения суперразрешения.
[35] Для потери восстановления можно использовать, например, среднюю L1-норму между связанной с учеником выборкой и связанной с учителем выборкой:
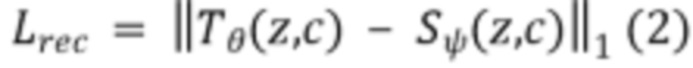
где 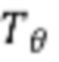 и
и 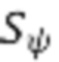 соответствуют, соответственно, моделям учителя и ученика из сети 400 учитель-ученик.
соответствуют, соответственно, моделям учителя и ученика из сети 400 учитель-ученик.
[36] Для потери признаков может использоваться, например, расстояние между набором представлений признаков сгенерированных выборок.
[37] В тех реализациях, где сеть 400 учитель-ученик должна использоваться для приложений SR, как например во время дистилляции модели SRFlow, потеря признаков может в качестве примера представлять собой перцептивное расстояние между генерируемыми изображениями, которое вычисляется с помощью метрики обученной перцептивной схожести фрагментов изображений (LPIPS). Модель 450 извлечения признаков может быть реализована как предварительно обученная модель 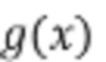 VGG16 (модель сверточной нейронной сети) для вычисления LPIPS. В этом случае перцептивную потерю можно определить следующим образом:
VGG16 (модель сверточной нейронной сети) для вычисления LPIPS. В этом случае перцептивную потерю можно определить следующим образом:
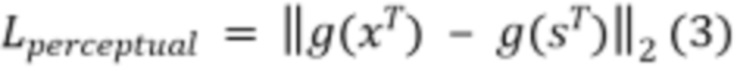
[38] В тех реализациях, где сеть 400 учитель-ученик должна использоваться для приложений синтеза речи, таких как дистилляция модели WaveGlow, в качестве примера может использоваться потеря на основе кратковременного преобразования Фурье (STFT) с несколькими разрешениями, которая представляет собой сумму потерь на основе STFT с различными параметрами анализа (т.е. размер FFT, размер окна и сдвиг кадра).
[39] Например, одна потеря на основе STFT может представлять собой сумму члена спектральной конвергенции (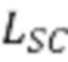 ) и члена логарифмической абсолютной величины STFT (
) и члена логарифмической абсолютной величины STFT (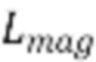 ). Потеря на основе STFT с несколькими разрешениями для
). Потеря на основе STFT с несколькими разрешениями для 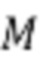 разрешений может быть определена как:
разрешений может быть определена как:
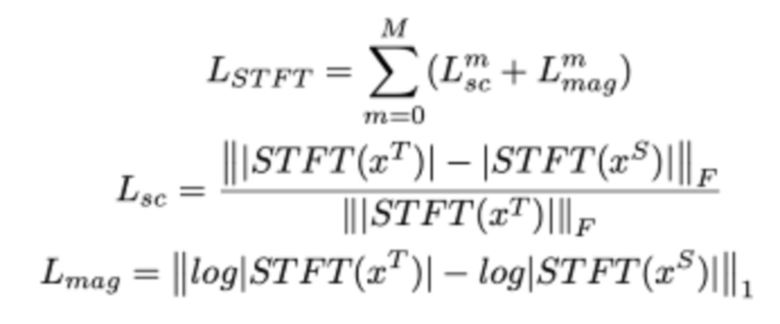
где 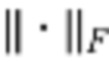 и
и 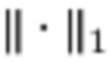 соответственно обозначают нормы Фробениуса и L1, а
соответственно обозначают нормы Фробениуса и L1, а 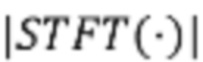 обозначает абсолютные величины STFT.
обозначает абсолютные величины STFT.
[40] Разработчики настоящей технологии осознали, что после процесса дистилляции модели учеников прямого распространения способны извлекать выборки из скрытого распределения основанной на потоке модели учителя, и это позволяет им генерировать различные выходные выборки для определенных входных данных и/или использовать скрытую геометрию для выполнения операций редактирования.
Структура ученика
[41] Со ссылкой на Фигуру 5 изображено представление первой архитектуры 502 ученика, которая может использоваться для приложений SR. Например, первая архитектура 502 ученика может использоваться для проектирования модели ученика SRFlow во время дистилляции модели учителя SRFlow. Однако следует отметить, что другие архитектуры для моделей ученика и учителя могут использоваться в других реализациях для приложений SR, не выходя за рамки настоящей технологии.
[42] Вообще говоря, модель ученика SRFlow состоит из L уровней. На каждом уровне активации с предыдущего уровня конкатенируются с соответствующим вектором  шума и представлением LR и пропускаются через последовательность блоков RRDB. Затем применяются переходный этап и операция разжатия (unsqueeze). Операция разжатия удваивает пространственное разрешение карт признаков и уменьшает размерность их каналов в 4 раза.
шума и представлением LR и пропускаются через последовательность блоков RRDB. Затем применяются переходный этап и операция разжатия (unsqueeze). Операция разжатия удваивает пространственное разрешение карт признаков и уменьшает размерность их каналов в 4 раза.
[43] На Фигуре 5 также проиллюстрировано представление второй архитектуры 504 ученика, которая может использоваться для приложений синтеза речи. Например, вторая архитектура 502 ученика может использоваться для проектирования модели ученика WaveGlow во время дистилляции модели учителя WaveGlow. Однако следует отметить, что другие архитектуры для моделей ученика и учителя могут использоваться в других реализациях для приложений синтеза речи, не выходя за рамки настоящей технологии.
[44] Вообще говоря, модель ученика WaveGlow представляет собой последовательность условных блоков WaveNet. Каждый блок WaveNet организован в несколько остаточных слоев, каждый из которых состоит из расширенной (dilated) свертки, за которой следует блок управляемой активации и свертка 1×1. Мел-спектрограммы с повышенной дискретизацией добавляются к промежуточным активациям перед блоком управляемой активации. В отличие от модели учителя WaveGlow, модель ученика WaveGlow не вводит шум между промежуточными блоками WaveNet, а получает z в самом начале.
[45] Как упоминалось выше, независимо от конкретной реализации основанной на потоке модели учителя и модели ученика прямого распространения, разработчики настоящей технологии разработали сеть учитель-ученик, в которой архитектура ученика в некотором смысле «жертвует» обратимостью архитектуры учителя в обмен на более компактную и эффективную модель. Архитектура модели ученика (такая как первая архитектура 502 ученика и вторая архитектура 504 ученика) может обладать некоторыми сходствами с архитектурой, соответствующей основанной на потоке модели учителя, однако, в некоторых реализациях настоящей технологии, могут присутствовать заметные различия.
[46] Во-первых, в отличие от основанной на потоке модели учителя, слои ученика могут быть организованы в обратном порядке, поскольку модель ученика может представлять «обратный проход» (последовательность блоков) учителя.
[47] Во-вторых, потоковые слои заменяются широко используемыми модулями прямого распространения для соответствующих задач. В тех реализациях, где сеть 400 учитель-ученик должна использоваться для приложений SR, как, например, во время дистилляции модели SRFlow, потоковые этапы модели учителя SRFlow могут в качестве примера заменяться собранными в пачку RRDB в соответствующей модели ученика SRFlow. В тех реализациях, где сеть 400 учитель-ученик должна использоваться для приложений синтеза речи, как, например, во время дистилляции модели WaveGlow, потоковые этапы модели учителя WaveGlow могут в качестве примера заменяться блоками WaveNet в модели ученика WaveGlow.
[48] В-третьих, поскольку модель ученика прямого распространения больше не должна быть обратимой, число скрытых каналов между модулями модели ученика может меняться. Изменение числа скрытых каналов может сократить число узких мест в модели ученика прямого распространения. Разработчики настоящей технологии поняли, что для таких архитектур учеников может требоваться меньшее количество блоков, чем для соответствующей архитектуры учителя, для достижения аналогичной производительности.
[49] В-четвертых, в моделях условных NF контекстная информация постоянно вводится через условные потоковые слои. После замены этих слоев эту информацию в сеть необходимо вводить. В тех реализациях, где сеть 400 учитель-ученик должна использоваться для приложений SR, как, например, во время дистилляции модели SRFlow, кодирования LR в модели ученика SRFlow могут в качестве примера конкатенироваться с промежуточными активациями в начале каждого уровня. В тех реализациях, где сеть 400 учитель-ученик должна использоваться для приложений синтеза речи, как например во время дистилляции модели WaveGlow, модель ученика WaveGlow может сохранять свой изначальный обусловливающий механизм через блоки WaveNet.
[50] В первом широком аспекте настоящей технологии обеспечен способ генерирования волновой формы на основе спектрограммы и входного шума. Спектрограмма была сгенерирована на основе текста. Волновая форма является цифровым аудио представлением текста. Способ является исполняемым посредством сервера. Способ содержит получение сервером обученного основанного на потоке вокодера, включающего в себя множество обратимых блоков. Обученный основанный на потоке вокодер был обучен генерировать волновую форму на основе спектрограммы и входного шума. Способ содержит получение сервером необученного вокодера прямого распространения, включающего в себя множество необратимых блоков. Причем обученный основанный на потоке вокодер и необученный вокодер прямого распространения образуют сеть учитель-ученик. Способ содержит выполнение процесса обучения в сети учитель-ученик. Во время определенной итерации обучения процесса обучения способ содержит: генерирование сервером связанной с учителем волновой формы посредством обученного основанного на потоке вокодера с использованием первой спектрограммы и первого входного шума, генерирование сервером связанной с учеником волновой формы посредством необученного вокодера прямого распространения с использованием первой спектрограммы и первого входного шума, генерирование сервером значения потерь для данной итерации обучения с использованием связанной с учителем волновой формы и связанной с учеником волновой формы, и обучение сервером необученного вокодера прямого распространения генерировать волновую форму с использованием значения потерь для аппроксимации отображения между первым входным шумом и связанной с учителем волновой формы основанного на потоке вокодера. Способ содержит получение сервером спектрограммы и входного шума. Способ содержит использование сервером обученного вокодера прямого распространения вместо обученного основанного на потоке вокодера для генерирования волновой формы на основе спектрограммы и входного шума.
[51] В некоторых вариантах осуществления способа спектрограмма представляет собой мел-масштабированную спектрограмму.
[52] В некоторых вариантах осуществления способа входной шум представляет собой нормальное распределение значений шума.
[53] В некоторых вариантах осуществления способа способ дополнительно содержит сохранение сервером обученного вокодера прямого распространения в хранилище.
[54] В некоторых вариантах осуществления способа значение потерь представляет собой комбинацию значения основанных на восстановлении потерь и значения основанных на признаках потерь, при этом значение основанных на восстановлении потерь представляет различие между связанной с учителем волновой формой и связанной с учеником волновой формой, а значение основанных на признаках потерь представляет различие между признаками связанной с учителем волновой формы и признаками связанной с учеником волновой формы.
[55] В некоторых вариантах осуществления способа обученный основанный на потоке вокодер представляет собой основанный на условном нормализующем потоке вокодер.
[56] В некоторых вариантах осуществления способа обученный вокодер прямого распространения представляет собой основанный на сверточной нейронной сети (CNN) вокодер.
[57] Во втором широком аспекте настоящей технологии обеспечен способ генерирования выходных данных с использованием входных обусловливающих данных и входного шума. Способ является исполняемым посредством сервера. Способ содержит получение сервером обученной основанной на условном потоке модели, включающей в себя множество обратимых блоков, причем обученная основанная на условном потоке модель была обучена генерировать выходные данные на основе входных обусловливающих данных и входного шума. Способ содержит получение сервером необученной модели прямого распространения, включающей в себя множество необратимых блоков, при этом обученная основанная на условном потоке модель и необученная модель прямого распространения образуют сеть учитель-ученик. Способ содержит выполнение процесса обучения в сети учитель-ученик. Во время определенной итерации обучения процесса обучения способ содержит: генерирование сервером связанных с учителем выходных данных посредством обученной основанной на условном потоке модели с использованием первых входных обусловливающих данных и первого входного шума, генерирование сервером связанных с учеником выходных данных посредством необученной модели прямого распространения с использованием первых входных обусловливающих данных и первого входного шума, генерирование сервером значения потерь для данной итерации обучения с использованием связанных с учителем выходных данных и связанных с учеником выходных данных, и обучение сервером необученной модели прямого распространения посредством использования значения потерь для аппроксимации отображения между первым входным шумом и связанными с учителем выходными данными основанной на условном потоке модели. Способ содержит получение сервером входных обусловливающих данных и входного шума. Способ содержит использование сервером обученной модели прямого распространения вместо обученной основанной на условном потоке модели для генерирования выходных данных на основе входных обусловливающих данных и входного шума.
[58] В некоторых вариантах осуществления способа обученная основанная на условном потоке модель представляет собой обученный основанный на условном потоке вокодер, при этом обученная модель прямого распространения представляет собой обученный вокодер прямого распространения, причем входные обусловливающие данные представляют собой спектрограмму, а выходные данные представляют собой волновую форму.
[59] В некоторых вариантах осуществления способа обученная основанная на условном потоке модель представляет собой обученную основанную на условном потоке модель улучшения изображения, при этом обученная модель прямого распространения представляет собой обученную модель улучшения изображения прямого распространения, причем входные обусловливающие данные представляют собой первое изображение, выходные данные представляют собой второе изображение, причем второе изображение имеет более высокое разрешение, чем первое изображение.
[60] В третьем широком аспекте настоящей технологии обеспечен сервер генерирования волновой формы на основе спектрограммы и входного шума. Спектрограмма была сгенерирована на основе текста. Волновая форма является цифровым аудио представлением текста. Сервер выполнен с возможностью получения обученного основанного на потоке вокодера, включающего в себя множество обратимых блоков, причем обученный основанный на потоке вокодер был обучен генерировать волновую форму на основе спектрограммы и входного шума. Сервер выполнен с возможностью получения необученного вокодера прямого распространения, включающего в себя множество необратимых блоков, причем обученный основанный на потоке вокодер и необученный вокодер прямого распространения образуют сеть учитель-ученик. Сервер выполнен с возможностью выполнения процесса обучения в сети учитель-ученик. Во время определенной итерации обучения процесса обучения сервер выполнен с возможностью: генерирования связанной с учителем волновой формы посредством обученного основанного на потоке вокодера с использованием первой спектрограммы и первого входного шума, генерирования связанной с учеником волновой формы посредством необученного вокодера прямого распространения с использованием первой спектрограммы и первого входного шума, генерирования значения потерь для данной итерации обучения с использованием связанной с учителем волновой формы и связанной с учеником волновой формы, и обучения необученного вокодера прямого распространения генерировать волновую форму с использованием значения потерь для аппроксимации отображения между первым входным шумом и связанной с учителем волновой формы основанного на потоке вокодера. Сервер выполнен с возможностью получения спектрограммы и входного шума. Сервер выполнен с возможностью использования обученного вокодера прямого распространения вместо обученного основанного на потоке вокодера для генерирования волновой формы на основе спектрограммы и входного шума.
[61] В некоторых вариантах осуществления сервера спектрограмма представляет собой мел-масштабированную спектрограмму.
[62] В некоторых вариантах осуществления сервера входной шум представляет собой нормальное распределение значений шума.
[63] В некоторых вариантах осуществления сервера сервер дополнительно выполнен с возможностью сохранения обученного вокодера прямого распространения в хранилище.
[64] В некоторых вариантах осуществления сервера значение потерь представляет собой комбинацию значения основанных на восстановлении потерь и значения основанных на признаках потерь, при этом значение основанных на восстановлении потерь представляет различие между связанной с учителем волновой формой и связанной с учеником волновой формой, а значение основанных на признаках потерь представляет различие между признаками связанной с учителем волновой формы и признаками связанной с учеником волновой формы.
[65] В некоторых вариантах осуществления сервера обученный основанный на потоке вокодер представляет собой основанный на условном нормализующем потоке вокодер.
[66] В некоторых вариантах осуществления сервера обученный вокодер прямого распространения представляет собой основанный на сверточной нейронной сети (CNN) вокодер.
[67] В контексте настоящего описания «сервер» представляет собой компьютерную программу, которая работает на соответствующем аппаратном обеспечении и способна принимать запросы (например, от устройств) по сети и выполнять эти запросы или вызывать выполнение этих запросов. Аппаратное обеспечение может быть одним физическим компьютером или одной физической компьютерной системой, но ни то, ни другое не является обязательным для настоящей технологии. В настоящем контексте использование выражения «сервер» не предполагает, что каждая задача (например, принятые инструкции или запросы) или какая-либо конкретная задача будут приняты, выполнены или вызваны для выполнения одним и тем же сервером (т.е. тем же самым программным обеспечением и/или аппаратным обеспечением); данное выражение предполагает, что любое количество программных элементов или аппаратных устройств может быть задействовано в приеме/отправке, выполнении или вызове для выполнения любой задачи или запроса, или последствий любой задачи или запроса; и все это программное обеспечение и аппаратное обеспечение может быть одним сервером или многочисленными серверами, причем оба данных случая включены в выражение «по меньшей мере один сервер».
[68] В контексте настоящего описания «устройство» представляет собой любое компьютерное аппаратное обеспечение, которое способно выполнять программное обеспечение, подходящее для соответствующей решаемой задачи. Таким образом, некоторые (неограничивающие) примеры устройств включают в себя персональные компьютеры (настольные ПК, ноутбуки, нетбуки и т.д.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что устройству, действующему как устройство в данном контексте, не запрещается действовать как сервер для других устройств. Использование термина «устройство» не исключает использования многочисленных устройств при приеме/отправке, выполнении или вызове выполнения какой-либо задачи или запроса, или последствий любой задачи или запроса, или этапов любого описанного в данном документе способа.
[69] В контексте настоящего описания «база данных» представляет собой любую структурированную совокупность данных, независимо от ее конкретной структуры, программное обеспечение для администрирования базы данных, или компьютерное аппаратное обеспечение, на котором данные хранятся, реализуются или их делают доступными для использования иным образом. База данных может размещаться на том же аппаратном обеспечении, что и процесс, который хранит или использует информацию, хранящуюся в базе данных, или она может размещаться на отдельном аппаратном обеспечении, например на выделенном сервере или множестве серверов.
[70] В контексте настоящего описания выражение «информация» включает в себя информацию любого характера или вида, который способен храниться в базе данных любым образом. Таким образом, информация включает в себя, но без ограничения, аудиовизуальные произведения (изображения, фильмы, звуковые записи, презентации и т.д.), данные (данные о местоположении, численные данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д.
[71] В контексте настоящего описания, если специально не указано иное, подразумевается, что термин «компонент» включает в себя программное обеспечение (соответствующее конкретному аппаратному контексту), которое является как необходимым, так и достаточным для реализации конкретной функции (функций), на которую ссылаются.
[72] В контексте настоящего описания предполагается, что выражение «используемый компьютером носитель хранения информации» включает в себя носители любого характера и вида, в том числе RAM, ROM, диски (CD-ROM, DVD, дискеты, накопители на жестких дисках и т.д.), USB-ключи, твердотельные накопители, ленточные накопители и т.д.
[73] В контексте настоящего описания слова «первый», «второй», «третий» и т.д. используются в качестве прилагательных только для того, чтобы позволить отличать существительные, которые они модифицируют, друг от друга, а не для описания какой-либо особой взаимосвязи между такими существительными. Таким образом, например, следует понимать, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо конкретного порядка, типа, хронологии, иерархии или ранжирования (например) таких серверов, равно как и их использование (само по себе) не означает, что какой-либо «второй сервер» должен обязательно существовать в любой определенной ситуации. Кроме того, как обсуждается в других контекстах данного документа, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента фактически являются одним и тем же элементом реального мира. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут быть одним и тем же программным обеспечением и/или аппаратным обеспечением, в других случаях они могут представлять собой разное программное обеспечение и/или аппаратное обеспечение.
[74] Каждая из реализаций настоящей технологии обладает по меньшей мере одним из вышеупомянутых аспектов и/или цели, но не обязательно имеет их все. Следует понимать, что некоторые аспекты настоящей технологии, которые возникли в попытке достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или удовлетворять другим целям, которые не описаны в данном документе явным образом.
[75] Дополнительные и/или альтернативные признаки, аспекты и преимущества реализаций настоящей технологии станут очевидными из нижеследующего описания, сопроводительных чертежей и приложенной формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[76] Для лучшего понимания настоящей технологии, а также других аспектов и ее дополнительных признаков, ссылка приводится на нижеследующее описание, которое должно использоваться в сочетании с сопроводительными чертежами, на которых:
[77] Фигура 1 иллюстрирует систему, подходящую для реализации неограничивающих вариантов осуществления настоящей технологии.
[78] Фигура 2 иллюстрирует представление механизма генерирования речи, размещенного на сервере с Фигуры 1, как это предусмотрено в некоторых реализациях настоящей технологии.
[79] Фигура 3 иллюстрирует представление механизма генерирования изображения, размещенного на сервере, как это предусмотрено в некоторых реализациях настоящей технологии.
[80] Фигура 4 иллюстрирует представление сети учитель-ученик, размещенной на сервере, как это предусмотрено в некоторых вариантах осуществления настоящей технологии.
[81] Фигура 5 иллюстрирует представление первой архитектуры ученика, которая используется механизмом генерирования речи, и второй архитектуры ученика, которая используется механизмом генерирования изображения, как это предусмотрено в некоторых реализациях настоящей технологии.
[82] Фигура 6 иллюстрирует итерацию обучения модели ученика на основе модели учителя из сети учитель-ученик, как это предусмотрено в некоторых реализациях настоящей технологии.
[83] Фигура 7 представляет собой схематичное представление способа, исполняемого сервером, в соответствии с по меньшей мере некоторыми неограничивающими вариантами осуществления настоящей технологии.
[84] Приложение A представлено в конце настоящего описания. Приложение A включает в себя копию еще не опубликованной статьи под названием «Distilling the Knowledge from Normalizing Flows». В этой статье приводится дополнительная информация об уровне техники, описание реализаций неограничивающих вариантов осуществления настоящей технологии, а также некоторые дополнительные примеры. Данная статья полностью включена в настоящий документ посредством ссылки во всех тех юрисдикциях, где такое включение по ссылке разрешено.
ПОДРОБНОЕ ОПИСАНИЕ
[85] Со ссылкой на Фигуру 1 проиллюстрировано схематичное представление системы 100, причем система 100 подходит для реализации неограничивающих вариантов осуществления настоящей технологии. Следует четко понимать, что изображенная система 100 является лишь иллюстративной реализацией настоящей технологии. Таким образом, нижеследующее описание предназначено лишь для того, чтобы использоваться в качестве описания иллюстративных примеров настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. В некоторых случаях то, что считается полезными примерами модификаций системы 100, также может быть изложено ниже. Это делается просто для помощи в понимании и, опять же, не для определения объема или установления границ настоящей технологии.
[86] Эти модификации не являются исчерпывающим списком и, как будет понятно специалисту в данной области техники, возможны другие модификации. Кроме того, те случаи, когда этого не было сделано (т.е. когда не было представлено примеров модификаций), не следует интерпретировать так, что никакие модификации не являются возможными и/или что описанное является единственным способом реализации такого элемента в настоящей технологии. Специалисту в данной области будет понятно, что это, вероятно, не так. Кроме того, следует понимать, что в некоторых случаях система 100 может предоставлять простые реализации настоящей технологии, и что в таких случаях они представлены для помощи в понимании. Специалисты в данной области поймут, что различные реализации настоящей технологии могут иметь большую сложность.
[87] Вообще говоря, система 100 выполнена с возможностью обеспечения визуальных и/или звуковых указаний пользователю 102. Например, звуковое указание 152 (речевые высказывания или «генерируемые машиной высказывания») может быть обеспечено электронным устройством 104 (или просто «устройством 104») пользователю 102. В другом примере визуальное указание 154 (визуальное представление цифрового изображения или «сгенерированного машиной» цифрового изображения) может быть обеспечено устройством 104 пользователю 102. Различные компоненты системы 100 и то, как эти компоненты могут быть сконфигурированы для обеспечения звукового указания 152 и визуального указания 154, теперь будут описаны по очереди.
Пользовательское устройство
[88] Как упоминалось ранее, система 100 содержит устройство 104. Реализация устройства 104 конкретным образом не ограничена, но, в качестве примера, устройство 104 может быть реализовано как персональный компьютер (настольные компьютеры, ноутбуки, нетбуки и т.д.), устройство беспроводной связи (например, смартфон, сотовый телефон, планшет, умная колонка и подобное), а также сетевое оборудование (например, маршрутизаторы, коммутаторы и шлюзы). Как таковое, устройство 104 иногда может именоваться «электронным устройством», «конечным пользовательским устройством», «клиентским электронным устройством» или просто «устройством». Следует отметить, что тот факт, что устройство 104 связано с пользователем 102, не обязательно предполагает или подразумевает какой-либо режим работы - например необходимость входа в систему, необходимость регистрации или тому подобное.
[89] Предполагается, что устройство 104 содержит аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их комбинацию), как известно в данной области техники, для обеспечения или воспроизведения звукового указания 152. Например, устройство 104 может содержать один или более микрофонов для обнаружения или захвата звука и один или более динамиков для обеспечения или воспроизведения звукового указания 152.
[90] Предполагается, что устройство 104 содержит аппаратное обеспечение и/или программное обеспечение и/или микропрограммное обеспечение (или их комбинацию), как известно в данной области техники, для обеспечения или воспроизведения звукового указания 154. Например, устройство 104 может иметь экран или другой компонент отображения для визуализации и отображения визуального указания 154.
[91] В некоторых вариантах осуществления устройство 104 может содержать аппаратное и/или программное обеспечение, и/или микропрограммное обеспечение (или их комбинацию), как известно в данной области техники, для выполнения приложения интеллектуального персонального помощника (IPA) (не проиллюстрировано). Вообще говоря, цель приложения IPA, также известного как «чат-бот», состоит в том, чтобы позволить пользователю 102 отправлять запросы в форме речевых высказываний и, в ответ, обеспечивать пользователю 102 ответы в форме речевых высказываний (например, звукового указания 152).
[92] Предоставление запросов и обеспечение ответов могут быть выполнены приложением IPA через пользовательский интерфейс на основе естественного языка. Вообще говоря, пользовательский интерфейс на основе естественного языка в приложении IPA может быть любым типом компьютерно-человеческого интерфейса, в котором лингвистические явления, такие как слова, фразы, предложения и тому подобное, выступают в качестве элементов управления пользовательского интерфейса для извлечения, выбора, модификации или иного генерирования данных в приложении IPA.
[93] Например, когда произносимые высказывания пользователя 102 обнаруживаются (т.е. захватываются) устройством 104, приложение IPA может использовать свой пользовательский интерфейс на основе естественного языка для анализа произносимых высказываний пользователя 102 и извлечения из них данных, которые указывают запросы пользователя. Кроме того, данные, указывающие ответы, принимаемые устройством 104, анализируются пользовательским интерфейсом на основе естественного языка в приложении IPA для того, чтобы обеспечить или воспроизвести произносимые высказывания (например, звуковое указание 152), указывающие эти ответы.
[94] В по меньшей мере некоторых вариантах осуществления настоящей технологии, как станет очевидно из приведенного ниже описания, электронное устройство 104 может быть выполнено с возможностью приема данных для воспроизведения звукового указания 152 от сервера 106. Это означает, что в некоторых вариантах осуществления сервер 106 может быть выполнен с возможностью синтеза волновых форм в реальном времени и передачи данных, представляющих эти волновые формы (например, в сегментах), на устройство 104, которое, в свою очередь, выполнено с возможностью использования этих данных для воспроизведения звукового указания 152 для пользователя 102.
[95] В других вариантах осуществления устройство 104 может содержать аппаратное обеспечение и/или программное обеспечение, и/или микропрограммное обеспечение (или их комбинацию), как известно в данной области техники, для выполнения приложения улучшения изображения. Вообще говоря, цель приложения улучшения изображения состоит в обеспечении возможности пользователю 102 предоставить изображение низкого качества и, в ответ, обеспечить пользователю 102 улучшенную версию этого изображения (например, визуальное указание 154).
[96] В по меньшей мере некоторых вариантах осуществления настоящей технологии, как станет очевидно из приведенного ниже описания, электронное устройство 104 может быть выполнено с возможностью приема данных для отображения звукового указания 154 от сервера 106. Это означает, что в некоторых вариантах осуществления сервер 106 может быть выполнен с возможностью использования процесса суперразрешения (SR) для повышения разрешения и/или улучшения деталей в цифровом изображении низкого качества, и передачи данных, представляющих это изображение SR, на устройство 104, которое в свою очередь выполнено с возможностью использования этих данных для отображения визуального указания 154 для пользователя 102.
Сеть связи
[97] В иллюстративном примере системы 100 устройство 104 коммуникативно связано с сетью 110 связи для доступа и передачи пакетов данных на/от сервера 106 и/или других веб-ресурсов (не показаны). В некоторых неограничивающих вариантах осуществления настоящей технологии сеть 110 связи может быть реализована как Интернет. В других неограничивающих вариантах осуществления настоящей технологии сеть 110 связи может быть реализована иначе, например как какая-либо глобальная сеть связи, локальная сеть связи, частная сеть связи и подобное. То, как реализуется линия связи (отдельно не пронумерованная) между устройством 104 и сетью 110 связи, будет зависеть, среди прочего, от того, как реализуется устройство 104.
[98] Просто как пример, а не как ограничение, в тех вариантах осуществления настоящей технологии, в которых устройство 104 реализуется как устройство беспроводной связи (например, как смартфон), линия связи может быть реализована как линия беспроводной связи (такая как, но без ограничения, линия сети связи 3G, линия сети связи 4G, Wireless Fidelity или WiFi® для краткости, Bluetooth® и подобное). В тех примерах, в которых устройство 104 реализуется как ноутбук, линия связи может быть либо беспроводной (такой как Wireless Fidelity или WiFi® для краткости, Bluetooth® или подобное), либо проводной (такой как Ethernet-соединение).
Сервер
[99] Как упоминалось ранее, система 100 также содержит сервер 106, который может быть реализован как обычный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 106 может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Само собой разумеется, сервер 106 может быть реализован в любом другом подходящем аппаратном, программном и/или микропрограммном обеспечении, или в их комбинации. В проиллюстрированном неограничивающем варианте осуществления настоящей технологии сервер 106 является единственным сервером. В альтернативных неограничивающих вариантах осуществления настоящей технологии функциональные возможности сервера 106 могут быть распределены и могут быть реализованы посредством многочисленных серверов.
[100] Вообще говоря, сервер 106 выполнен с возможностью синтеза волновых форм для обеспечения звукового указания 152 и/или для генерирования цифровых изображений SR для отображения визуального указания 154. Можно сказать, что сервер 106 может использоваться для приложений синтеза речи и/или приложений суперразрешения в различных реализациях настоящей технологии.
[101] В некоторых вариантах осуществления сервер 106 может принимать текст и в ответ генерировать волновую форму, представляющую произнесенный текст. Для этой цели сервер 106 может иметь механизм 130 генерирования речи. Вообще говоря, механизм 130 генерирования речи содержит один или более алгоритмов машинного обучения, которые позволяют серверу 106 синтезировать «выходные аудиоданные», представляющие текст. Как будет описано более подробно ниже со ссылкой на Фигуру 2 механизм 130 генерирования речи может содержать первую модель, выполненную с возможностью генерирования мел-спектрограммы на основе входных текстовых данных, и вторую модель, выполненную с возможностью использования этой мел-спектрограммы для синтеза волновой формы. Можно сказать, что первая модель представляет собой модель «текст в спектрограмму». Можно также сказать, что вторая модель представляет собой нейронный вокодер, выполненный с возможностью синтеза волновых форм во временной области, которые могут быть обусловлены мел-спектрограммами из модели «текст в спектрограмму».
[102] В других вариантах осуществления сервер 106 может принимать цифровое изображение низкого качества и в ответ генерировать цифровое изображение высокого качества. Для этой цели сервер 106 может иметь механизм 140 генерирования изображения. Вообще говоря, механизм 140 генерирования изображения содержит один или более алгоритмов машинного обучения, которые позволяют серверу 106 выполнять SR-обработку цифровых изображений. Как будет описано более подробно ниже со ссылкой на Фигуру 3, механизм 130 генерирования речи может содержать модель, выполненную с возможностью генерирования изображения SR путем повышения разрешения изображения LR до более высокого разрешения.
[103] Сервер 106 может иметь доступ к устройству памяти (не проиллюстрированному). Сервер 106 выполнен с возможностью использования устройства памяти для сохранения данных, обрабатываемых по меньшей мере некоторыми компонентами механизма 130 генерирования речи и/или механизма 140 генерирования изображения. В некоторых вариантах осуществления устройство памяти может быть составной частью сервера 106. Однако предполагается, что устройство памяти может быть устройством памяти, удаленным от сервера 106, не выходя за рамки настоящей технологии.
[104] В по меньшей мере одном варианте осуществления настоящей технологии устройство памяти может представлять собой устройство «графического процессора» (GPU). Вообще говоря, устройство GPU содержит специализированный процессор с выделенной памятью, который обычно выполняет операции с плавающей запятой, требуемые для рендеринга графики. Устройства памяти типа GPU можно оптимизировать для моделей глубокого обучения, поскольку они могут обрабатывать несколько вычислений одновременно. Другими словами, модели глубокого обучения можно обучать быстрее, используя устройства памяти типа GPU, в отличие от устройств типа «центральный процессор» (CPU), выполняя операции параллельно (в одно и то же время), а не последовательно (одну за другой).
[105] Действительно, устройства памяти типа GPU могут иметь большое число ядер, что обеспечивает возможность лучшего вычисления многочисленных параллельных процессов. Кроме того, вычисления при глубоком обучении должны обрабатывать огромные объемы данных, что делает пропускную способность устройств памяти типа GPU наиболее подходящей.
[106] Фактически, несколько параметров могут сделать GPU более предпочтительными, чем CPU, для приложений глубокого обучения. Пропускная способность является одной из основных причин, почему GPU быстрее для вычислений, чем CPU. С большими наборами данных CPU задействуют много памяти при обучении модели. С одной стороны, вычисление огромных и сложных задач задействует много тактовых циклов в устройстве памяти типа CPU. CPU выполняют задания последовательно и имеют сравнительно меньше ядер. С другой стороны, GPU поставляются с выделенной памятью VRAM (Video RAM). Кроме того, для обучения модели с помощью глубокого обучения требуется большой набор данных, отсюда и большие вычислительные операции с точки зрения памяти. Для эффективного вычисления данных устройство памяти типа GPU может быть более подходящим выбором - чем больше количество вычислений, тем большее преимущество может иметь устройство памяти типа GPU над устройством памяти типа CPU.
Система базы данных
[107] Сервер 106 коммуникативно связан с системой 120 базы данных. Вообще говоря, система 120 базы данных выполнена с возможностью сохранения информации, извлекаемой и/или генерируемой сервером 106 во время обработки. Например, система 120 базы данных может принимать данные от сервера 106, которые были извлечены и/или сгенерированы сервером 106 во время обработки, для их временного и/или постоянного сохранения и может обеспечивать сохраненные данные серверу 106 для их дальнейшего использования.
[108] Система 120 базы данных может быть выполнена с возможностью сохранения данных спектрограмм и данных волновых форм. Вообще говоря, данные спектрограмм и данные волновых форм могут использоваться сервером 106 для обучения по меньшей мере некоторых компонентов механизма 130 генерирования речи. Например, сервер 105 может быть выполнен с возможностью генерирования определенной спектрограммы на основе определенной волновой формы, тем самым формируя пару спектрограмма-волновая форма. Сервер 106 может генерировать и сохранять в базе 120 данных большое число таких пар спектрограмм-волновых форм для обучения вокодера. В по меньшей мере некоторых вариантах осуществления определенная пара спектрограмма-волновая форма может использоваться для генерирования группы обучающих наборов для вокодера. Например, спектрограмма и волновая форма из определенной пары могут быть разделены на ряд соответствующих частей, и причем пара из первой части спектрограммы и первой части волновой формы может использоваться вместе во время первой итерации обучения, а пара из второй части спектрограммы и второй части волновой формы может использоваться вместе во время второй итерации обучения.
[109] Система 120 базы данных может быть выполнена с возможностью сохранения данных изображений. Вообще говоря, данные изображений могут использоваться сервером 106 для обучения по меньшей мере некоторых компонентов механизма 140 генерирования изображения. Например, сервер 106 может быть выполнен с возможностью генерирования изображения LR на основе определенного изображения HR, тем самым формируя пару изображений LR-HR. Сервер 106 может использовать различные методики понижающей дискретизации для генерирования определенного изображения LR. Сервер 106 может генерировать и сохранять в базе 120 данных большое число таких пар изображений LR-HR для обучения алгоритмов SR. В по меньшей мере некоторых вариантах осуществления определенная пара изображений LR-HR может использоваться для генерирования группы обучающих наборов для алгоритма SR. Например, изображение LR и изображение HR из определенной пары могут быть разделены на ряд соответствующих частей, и причем пара из первой части изображения LR и первой части изображения HR может использоваться вместе во время первой итерации обучения, а пара из второй части изображения LR и второй части изображения HR может использоваться вместе во время второй итерации обучения.
[110] Система 120 базы данных может быть выполнена с возможностью сохранения данных шума. Вообще говоря, данные шума могут использоваться сервером 106 для обучения и/или использования по меньшей мере некоторых компонентов механизма 130 генерирования речи и механизма 140 генерирования изображения. Например, система 120 базы данных может хранить множество распределений шума, таких как нормальные распределения шума. Эти распределения шума могут использоваться во время фазы использования основанного на потоке вокодера. Эти распределения шума могут использоваться во время фаз обучения и использования вокодера прямого распространения. Эти распределения шума могут дополнительно использоваться во время фазы использования основанного на потоке алгоритма SR. Эти распределения шума могут также использоваться во время фаз обучения и использования алгоритма SR прямого распространения.
Механизм генерирования речи
[111] Со ссылкой на Фигуру 2 изображено представление того, как механизм 130 генерирования речи может быть выполнен с возможностью использования входных текстовых данных 200 и входного шума 225 для генерирования волновой формы 230. Сервер 106 может получать входные текстовые данные 200 различными способами. В одном неограничивающем примере входные текстовые данные 200 могут представлять собой контент, который должен быть обеспечен пользователю 102.
[112] Независимо от того, как сервер 106 получает и/или генерирует входные текстовые данные 200, цель состоит в том, чтобы обработать эти текстовые входные данные 200 механизмом 130 генерирования речи для генерирования волновой формы 230 (имеющейся в аудио представлении этих текстовых входных данных 200), чтобы она могла быть обеспечена пользователю 102 в качестве сгенерированного машиной высказывания. С этой целью механизм 130 генерирования речи содержит модель 210 «текст в спектрограмму», выполненную с возможностью генерирования спектрограммы 215 на основе входных текстовых данных 200, и вокодер 220, выполненный с возможностью синтеза волновой формы 230 на основе спектрограммы 215 и входного шума 225.
[113] То, как модель 210 «текст в спектрограмму» реализуется, конкретным образом не ограничено. В одном неограничивающем примере сервер 106 может быть выполнен с возможностью использования определенного алгоритма машинного обучения, который был обучен генерировать данные спектрограмм на основе входных текстовых данных. В одной неограничивающей реализации настоящей технологии модель 210 «текст в спектрограмму» может быть реализована через «Tacotron», что является архитектурой машинного обучения «последовательность в последовательность» для создания амплитудных спектрограмм из последовательности символов. В некоторых вариантах осуществления спектрограмма 215 может быть мел-спектрограммой, что означает, что одна из осей на спектрограмме имеет мел-шкалу.
[114] В контексте настоящей технологии вокодер 220 воплощается как вокодер прямого распространения. Можно сказать, что вокодер 220 прямого распространения является генеративной моделью прямого распространения, выполненной с возможностью синтеза волновой формы на основе спектрограммы 215 и входного шума 225. Вокодер 220 прямого распространения может быть обучен путем выполнения процесса дистилляции соответствующего основанного на потоке вокодера. Процесс дистилляции определенного основанного на потоке вокодера для обучения вокодера 220 прямого распространения был описан выше со ссылкой на Фигуру 4. В по меньшей мере некоторых реализациях настоящей технологии вокодер 220 прямого распространения может иметь первую архитектуру 502 ученика, описанную выше со ссылкой на Фигуру 5. Кроме того, в некоторых вариантах осуществления настоящей технологии вокодер 220 прямого распространения может быть обучен и использован аналогично тому, как это раскрыто в статье, приложенной к данному документу.
Механизм генерирования изображения
[115] Со ссылкой на Фигуру 3 изображено представление того, как механизм 140 генерирования изображения может быть выполнен с возможностью использования изображения 300 LR и входного шума 325 для генерирования изображения 330 HR. Сервер 106 может получать изображение 300 LR различными способами.
[116] Независимо от того, как сервер 106 получает изображение 300 LR, цель состоит в том, чтобы обработать изображение 300 HR посредством механизма 140 генерирования изображения для синтеза пикселей SR, чтобы они могли быть обеспечены пользователю 102 в качестве сгенерированного машиной изображения. С этой целью механизм 140 генерирования изображения содержит модель 320 SR прямого распространения. Можно сказать, что модель 320 SR прямого распространения является генеративной моделью прямого распространения, выполненной с возможностью синтеза изображения HR на основе изображения 300 LR и входного шума 325. Модель 320 прямого распространения может быть обучена путем выполнения процесса дистилляции соответствующей основанной на потоке модели SR. Процесс дистилляции определенной основанной на потоке модели SR для обучения модели 320 SR прямого распространения был описан выше со ссылкой на Фигуру 4. В по меньшей мере некоторых реализациях настоящей технологии модель 320 SR прямого распространения может иметь вторую архитектуру 504 ученика, описанную выше со ссылкой на Фигуру 5. Кроме того, в некоторых вариантах осуществления настоящей технологии вокодер 220 прямого распространения может быть обучен и использован аналогично тому, как это раскрыто в статье, приложенной к данному документу.
[117] В некоторых вариантах осуществления настоящей технологии сервер 106 может быть выполнен с возможностью исполнения способа 700, проиллюстрированного на Фигуре 7. Различные этапы способа 700 теперь будут обсуждаться более подробно со ссылкой на Фигуру 6 и Фигуру 7.
ЭТАП 702: получение обученного основанного на потоке вокодера, включающего в себя множество обратимых блоков
[118] Способ 700 начинается на этапе 702, на котором сервер 106 получает обученный основанный на потоке вокодер 602. Обученный основанный на потоке вокодер включает в себя множество 612 обратимых блоков. Обученный основанный на потоке вокодер был обучен генерировать волновую форму на основе пары из спектрограммы (обусловливающий элемент) и входного шума.
[119] В некоторых вариантах осуществления предполагается, что сервер 106 может быть выполнен с возможностью сначала обучать основанный на потоке вокодер 602. Например, сервер 106 может извлекать пары спектрограмма-волновая форма, хранящиеся в базе 120 данных, и использовать их для генерирования множества наборов обучающих данных. Затем сервер 106 может быть выполнен с возможностью выполнения большого числа итераций обучения на основе множества наборов обучающих данных.
[120] В по меньшей мере некоторых вариантах осуществления настоящей технологии спектрограммы, используемые во время обучения и использования основанного на условном потоке вокодера, могут быть мел-масштабированными спектрограммами. Следует отметить, что определенный входной шум во время фазы использования основанного на условном потоке вокодера может представлять нормальное распределение значений шума, из которого можно выполнять выборку для генерирования соответствующей волновой формы. Основанный на условном потоке вокодер может быть реализован как основанный на нормализующем потоке вокодер.
ЭТАП 704: получение необученного вокодера прямого распространения, включающего в себя множество необратимых блоков
[121] Способ 700 переходит на этап 704, на котором сервер 106 получает необученный вокодер 604 прямого распространения. Необученный вокодер 604 прямого распространения включает в себя множество 614 необратимых блоков. Предполагается, что вокодер 604 прямого распространения может быть реализован как основанный на определенной сверточной нейронной сети (CNN) вокодер.
[122] Сервер 106 может быть выполнен с возможностью формирования сети 600 учитель-ученик, включающей в себя обученный основанный на потоке вокодер 602 в качестве модели учителя и необученный вокодер 604 прямого распространения в качестве модели ученика. Сервер 106 может быть выполнен с возможностью осуществления процесса дистилляции для дистилляции знаний из обученного основанного на потоке вокодера 602 в необученный вокодер 604 прямого распространения.
ЭТАП 706: выполнение процесса обучения в сети учитель-ученик
[123] Способ 700 переходит на этап 706, на котором сервер 106 выполнен с возможностью исполнения процесса обучения в сети 600 учитель-ученик, при котором модель ученика обучается на основе модели учителя. Процесс обучения включает в себя некоторое число итераций обучения. Можно сказать, что определенная итерация обучения сети 600 учитель-ученик включает в себя итерацию использования модели учителя и итерацию обучения модели ученика.
[124] Как проиллюстрировано на Фигуре 6, сервер 106 может использовать обученный основанный на потоке вокодер 602 для генерирования связанной с учителем волновой формы 622 с использованием первой спектрограммы 608 и первого входного шума 606, которые вместе формируют пару 610 обусловливающий элемент-входной шум.
[125] В некоторых вариантах осуществления можно сказать, что определенный потоковый этап (например, обратимый блок) обученного основанного на потоке вокодера 602 может принимать обусловливающий элемент (первую спектрограмму 608) для определения параметров представления аффинной связи. Затем эти параметры могут быть применены к выборке шума из упомянутого шума (первого входного шума 225). Когда определенная волновая форма синтезируется таким образом на основе обусловливающего элемента, можно сказать, что основанный на потоке вокодер имеет «степень свободы» для генерирования данной волновой формы, поскольку некоторое число волновых форм может быть сгенерировано для одного и того же обусловливающего элемента. Таким образом, обеспечение входного шума во время фазы использования основанного на потоке вокодера позволяет, в некотором смысле, зафиксировать эту степень свободы так, чтобы вокодер синтезировал определенную волновую форму, которая соответствует обусловливающему элементу и входному шуму. Основанный на потоке вокодер может выполнять выборку из входного шума во время генерирования определенной волновой формы.
[126] Также, как проиллюстрировано на Фигуре 6, сервер 106 может использовать пару 610 обусловливающий элемент-входной шум в качестве входных данных в необученный вокодер 604 прямого распространения для генерирования связанной с учеником волновой формы 624. Следует отметить, что в контексте настоящей технологии сервер 106 выполнен с возможностью использования одной и той же пары обусловливающий элемент-входной шум для генерирования связанной с учителем волновой формы 622 обученным основанным на потоке вокодером 602 и для генерирования связанной с учеником волновой формы 624 необученным вокодером 624 прямого распространения.
[127] Сервер 106 затем выполнен с возможностью генерирования значения 650 потерь для данной итерации обучения с использованием связанной с учителем волновой формы 622 и связанной с учеником волновой формы 624. В качестве примера значение 650 потерь может представлять собой комбинацию (i) значения основанных на восстановлении потерь, представляющего различие между связанной с учителем волновой формой 622 и связанной с учеником волновой формой 624, и (ii) значения основанных на признаках потерь, представляющего различие между признаками связанной с учителем волновой формы 622 и связанной с учеником волновой формы 624.
[128] Сервер 106 также выполнен с возможностью обучения необученного вокодера 604 прямого распространения с использованием значения 650 потерь. Например, обучение необученного вокодера 604 прямого распространения может выполняться контролируемым образом, в том числе с циклом 670 обратного распространения ошибки, выполняемым на основе значения 650 потерь. Можно сказать, что сервер 106 может таким образом обучить необученный вокодер 604 прямого распространения для аппроксимации отображения между по меньшей мере первым входным шумом 606 и связанной с учителем волновой формой 622. Можно также сказать, что сервер 106 может таким образом обучить необученный вокодер 604 прямого распространения для аппроксимации отображения между парой 610 обусловливающий элемент-входной шум и связанной с учителем волновой формой 622.
[129] Следует отметить, что большое число таких итераций обучения может происходить во время процесса обучения в сети 600 учитель-ученик, не выходя за рамки настоящей технологии.
ЭТАП 708: получение спектрограммы и входного шума
[130] Способ 700 переходит на этап 708, на котором сервер 106 выполнен с возможностью получения определенной спектрограммы и определенного входного шума. Например, сервер 106 может быть выполнен с возможностью генерирования спектрограммы 215 на основе текста 200. Кроме того, сервер 106 может извлекать входной шум 225 из базы 120 данных и/или генерировать входной шум 225 во время итерации использования теперь обученного вокодера прямого распространения.
ЭТАП 710: использование обученного вокодера прямого распространения вместо обученного основанного на потоке вокодера для генерирования волновой формы на основе спектрограммы и входного шума
[131] Способ 700 переходит на этап 710, на котором сервер 106 выполнен с возможностью использования теперь обученного вокодера 604 прямого распространения вместо обученного основанного на потоке вокодера 602 для генерирования волновой формы 230 на основе спектрограммы 215 и входного шума 225.
[132] Модификации и улучшения вышеописанных реализаций настоящей технологии могут стать очевидными для специалистов в данной области техники. Предшествующее описание предназначено для того, чтобы быть примерным, а не ограничивающим. Поэтому предполагается, что объем настоящей технологии ограничен лишь объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ синтеза речи с передачей достоверного интонирования клонируемого образца | 2020 |
|
RU2754920C1 |
| ОБУЧЕНИЕ DNN-СТУДЕНТА ПОСРЕДСТВОМ РАСПРЕДЕЛЕНИЯ ВЫВОДА | 2014 |
|
RU2666631C2 |
| Способ и сервер для определения обучающего набора для обучения алгоритма машинного обучения (MLA) | 2020 |
|
RU2817726C2 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823016C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823015C1 |
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ПАКЕТИРОВАНИЯ ЗАПРОСОВ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ ОБРАБОТКИ ОБРАБАТЫВАЮЩИМ БЛОКОМ | 2021 |
|
RU2810916C2 |
| Неконтролируемое восстановление голоса с использованием модели безусловной диффузии без учителя | 2023 |
|
RU2823017C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПЕРЕВОДУ | 2020 |
|
RU2770569C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ГЕНЕРИРОВАНИЯ МОДИФИЦИРОВАННОГО АУДИО ДЛЯ ВИДЕО | 2022 |
|
RU2832236C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПРЕОБРАЗОВАНИЯ ТЕКСТА В РЕЧЬ | 2020 |
|
RU2775821C2 |
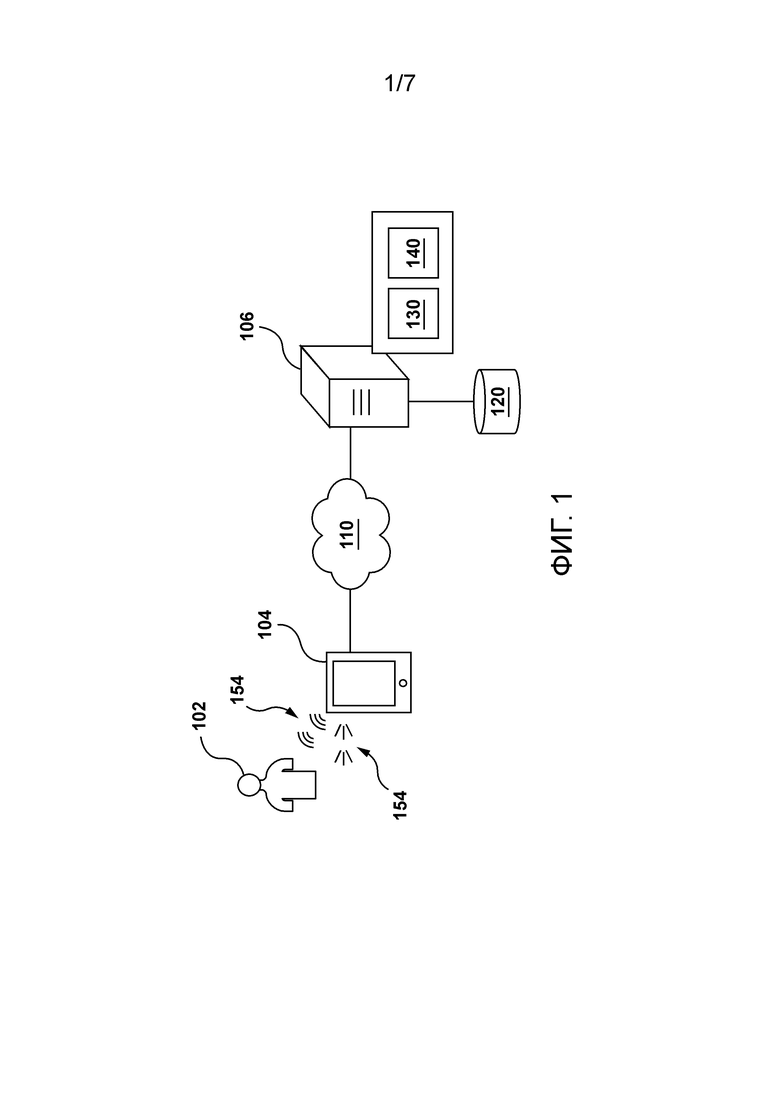
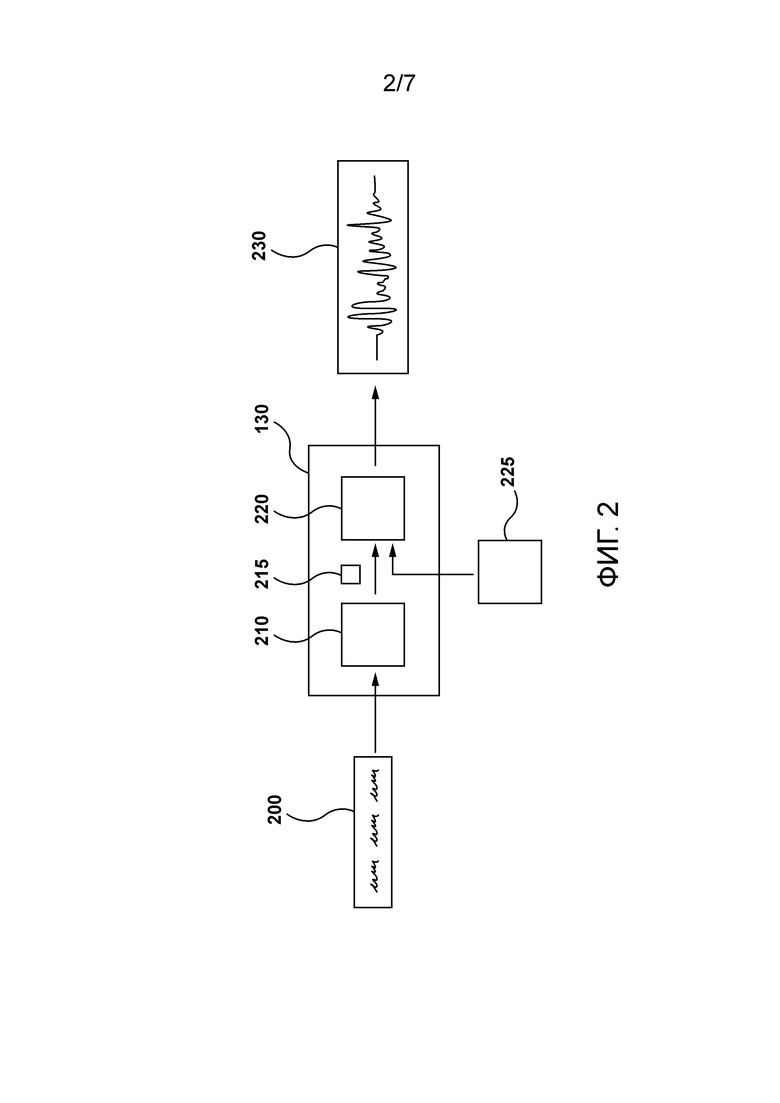
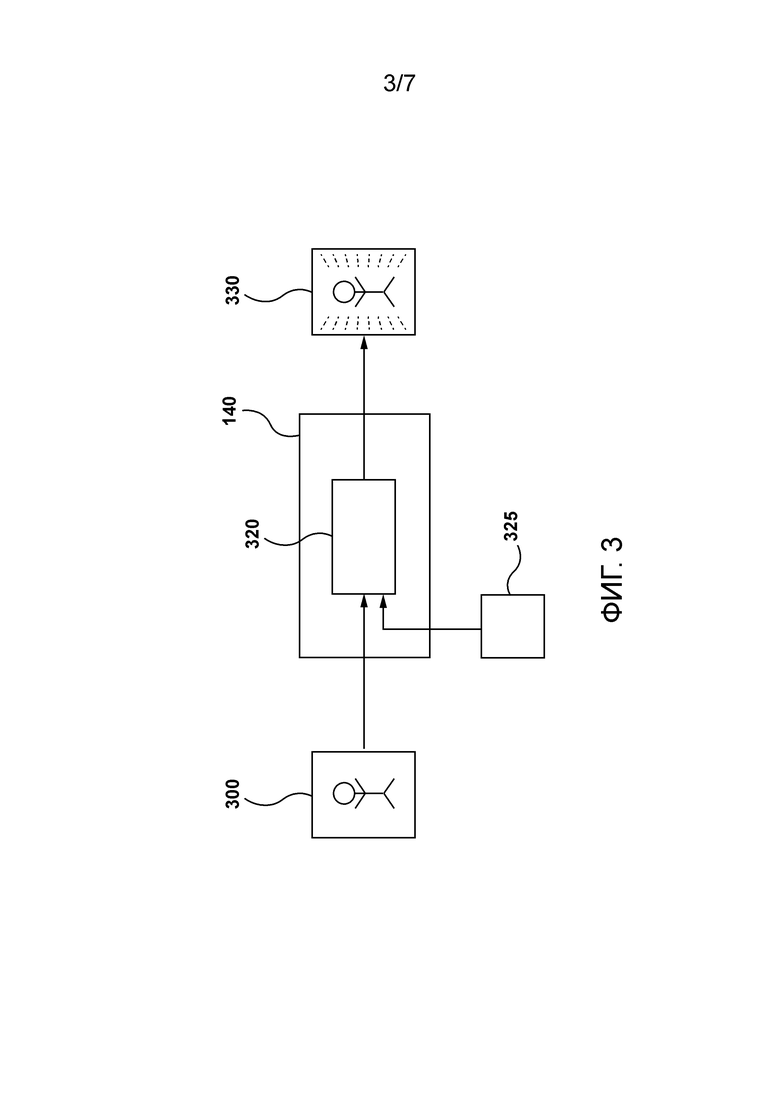
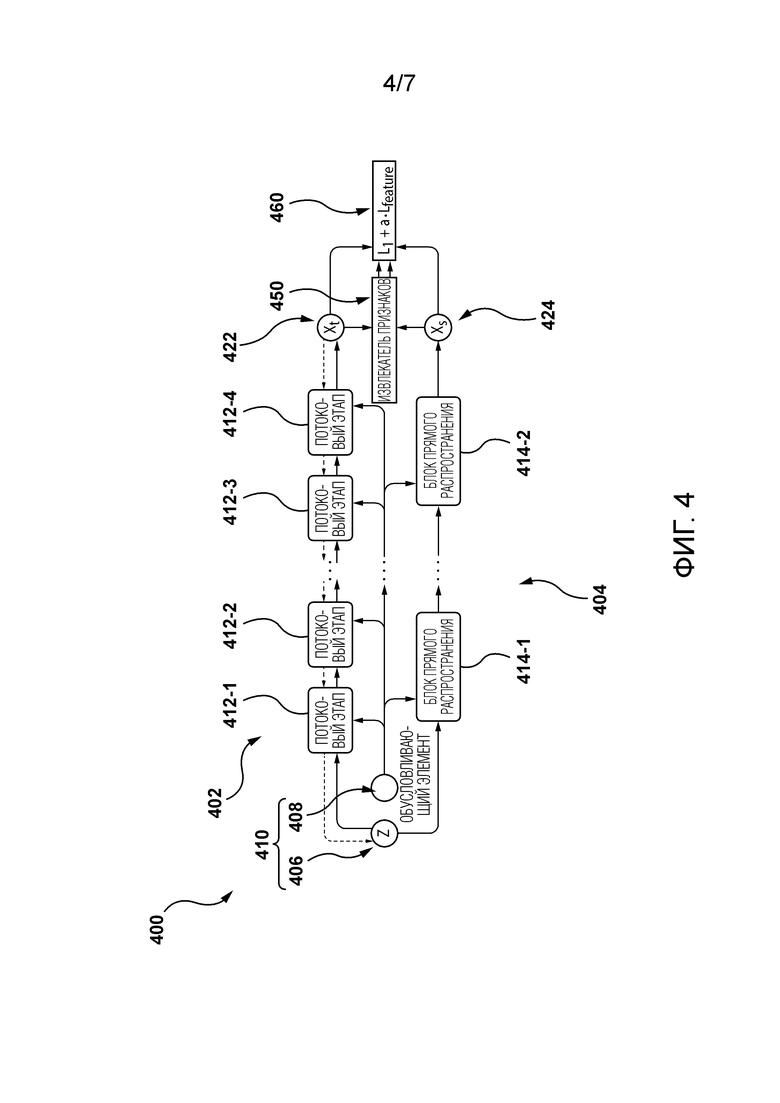
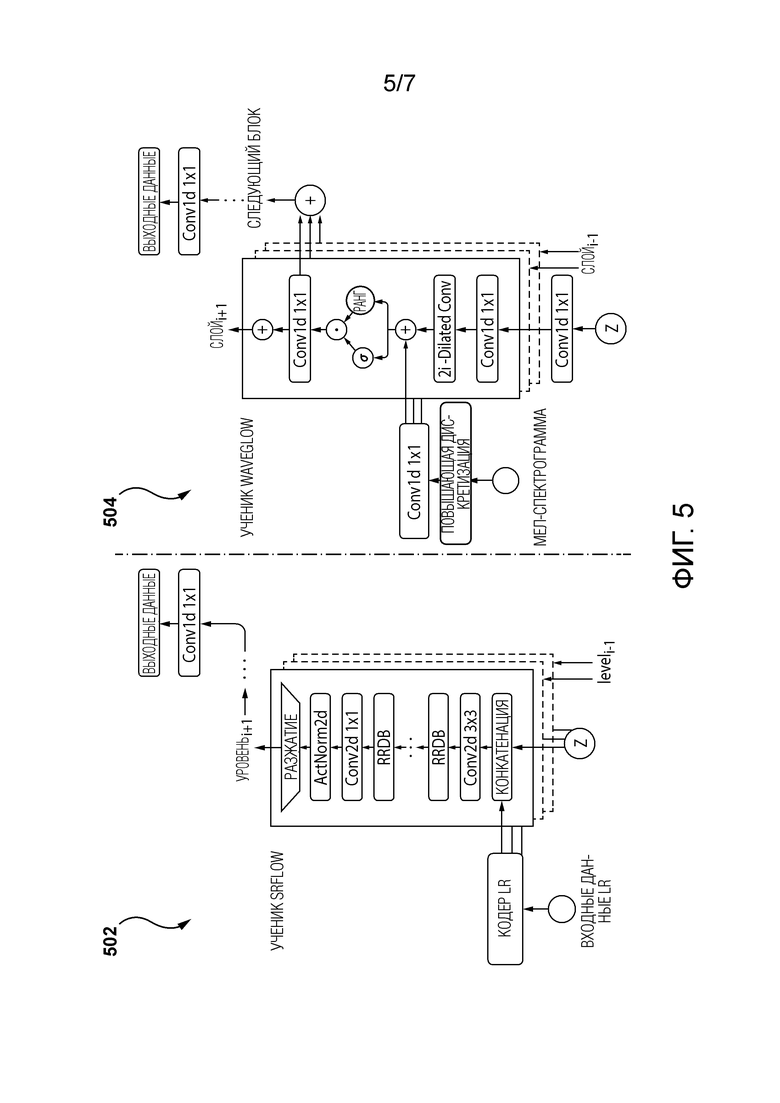
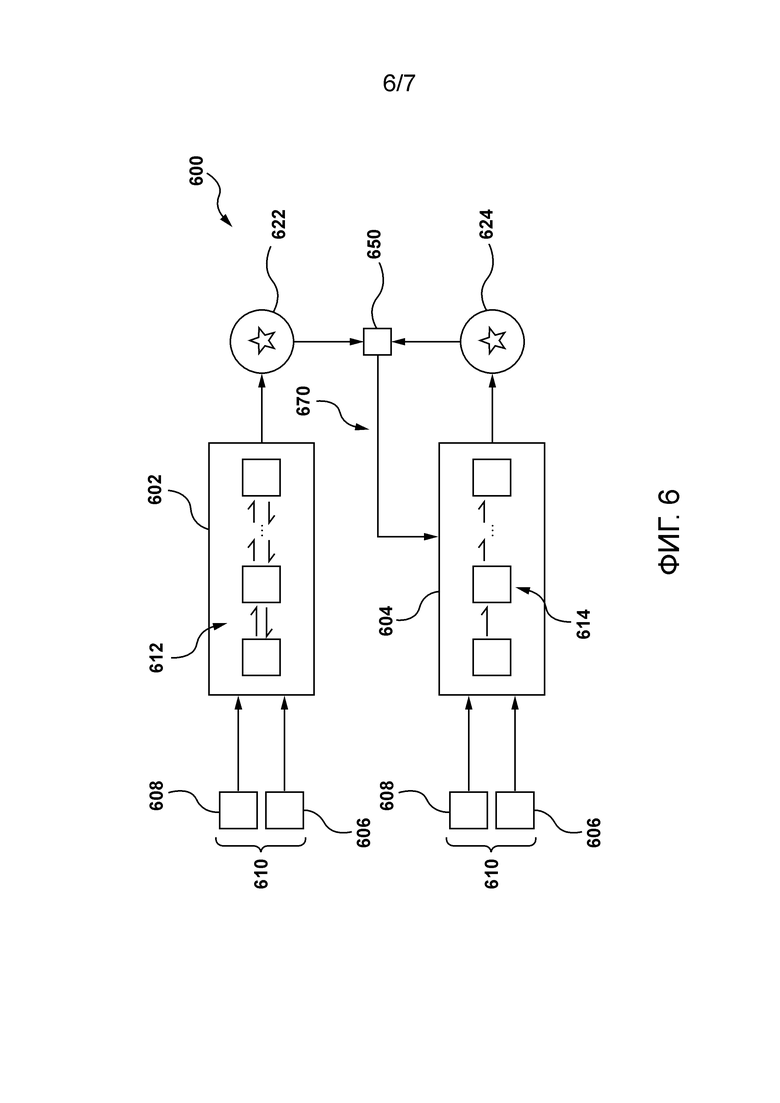
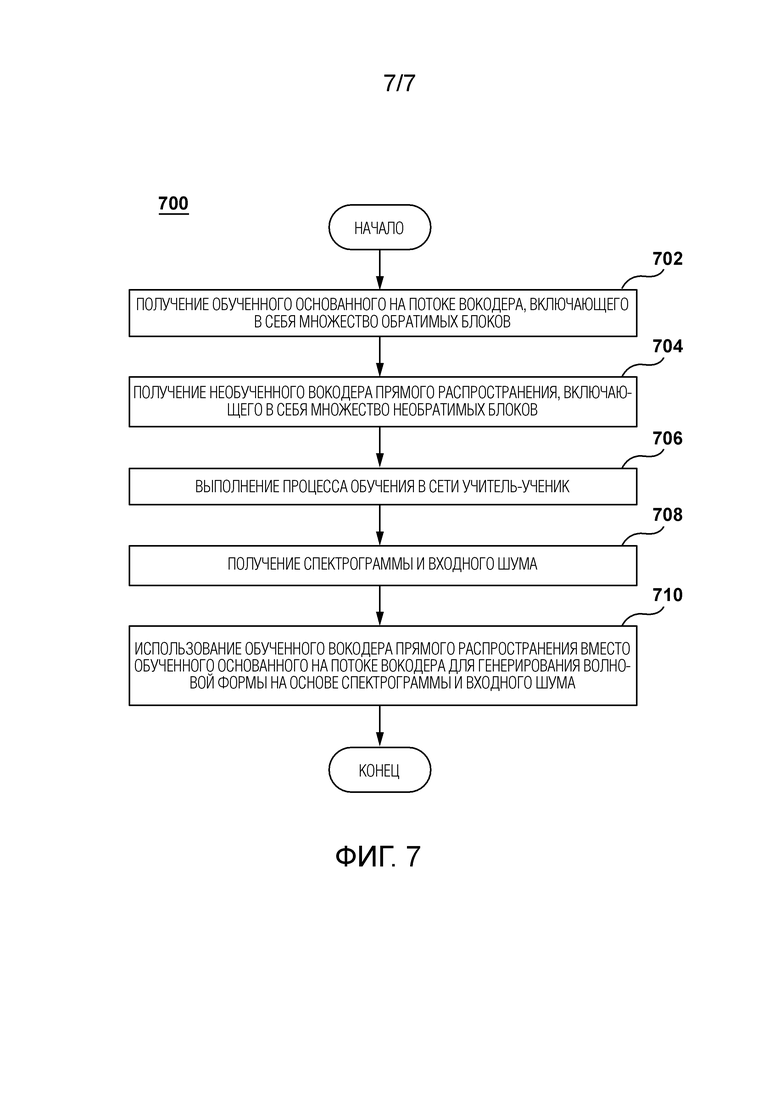
Изобретение относится к области генерирования аудио представлением текста. Техническим результатом является повышение эффективности генерирования реалистичных аудио представлений текста. Способ включает в себя получение обученного, основанного на потоке вокодера, включающего в себя обратимые блоки, и необученного вокодера прямого распространения, включающего в себя необратимые блоки, которые образуют сеть учитель-ученик, выполнение процесса обучения в сети учитель-ученик, во время которого сервер генерирует (i) связанную с учителем волновую форму посредством обученного основанного на потоке вокодера с использованием первой спектрограммы и первого входного шума, (ii) связанную с учеником волновую форму посредством необученного вокодера прямого распространения с использованием первой спектрограммы и первого входного шума и (iii) значение потерь для определенной итерации обучения с использованием связанной с учителем волновой формы и связанной с учеником волновой формы. Затем сервер обучает необученный вокодер прямого распространения генерировать волновую форму. Обученный вокодер прямого распространения используется вместо обученного основанного на потоке вокодера для генерирования волновых форм на основе спектрограмм и входных шумов. 3 н. и 14 з.п. ф-лы, 7 ил.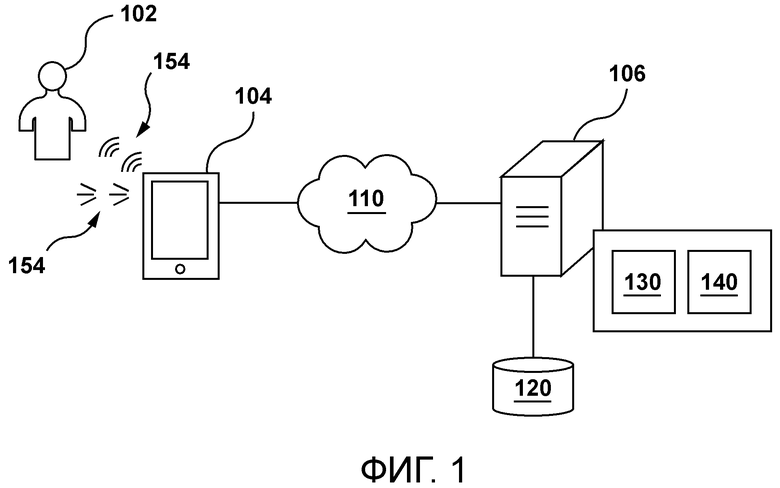
1. Способ генерирования волновой формы на основе спектрограммы и входного шума, причем спектрограмма была сгенерирована на основе текста, волновая форма является цифровым аудио представлением текста, причем способ является исполняемым посредством сервера и содержит:
получение сервером обученного основанного на потоке вокодера, включающего в себя множество обратимых блоков, причем обученный основанный на потоке вокодер был обучен генерировать волновую форму на основе спектрограммы и входного шума;
получение сервером необученного вокодера прямого распространения, включающего в себя множество необратимых блоков,
причем обученный основанный на потоке вокодер и необученный вокодер прямого распространения образуют сеть учитель-ученик;
выполнение процесса обучения в сети учитель-ученик, причем во время определенной итерации обучения процесса обучения:
генерирование сервером связанной с учителем волновой формы посредством обученного основанного на потоке вокодера с использованием первой спектрограммы и первого входного шума;
генерирование сервером связанной с учеником волновой формы посредством необученного вокодера прямого распространения с использованием первой спектрограммы и первого входного шума;
генерирование сервером значения потерь для данной итерации обучения с использованием связанной с учителем волновой формы и связанной с учеником волновой формы; и
обучение сервером необученного вокодера прямого распространения генерировать волновую форму с использованием значения потерь для аппроксимации отображения между первым входным шумом и связанной с учителем волновой формы основанного на потоке вокодера;
получение сервером спектрограммы и входного шума; и
использование сервером обученного вокодера прямого распространения вместо обученного основанного на потоке вокодера для генерирования волновой формы на основе спектрограммы и входного шума.
2. Способ по п. 1, в котором спектрограмма представляет собой мел-масштабированную спектрограмму.
3. Способ по п. 1, в котором входной шум представляет собой нормальное распределение значений шума.
4. Способ по п. 1, при этом способ дополнительно содержит сохранение сервером обученного вокодера прямого распространения в хранилище.
5. Способ по п. 1, в котором значение потерь представляет собой комбинацию значения основанных на восстановлении потерь и значения основанных на признаках потерь,
значение основанных на восстановлении потерь представляет различие между связанной с учителем волновой формой и связанной с учеником волновой формой, и
значение основанных на признаках потерь представляет различие между признаками связанной с учителем волновой формы и признаками связанной с учеником волновой формы.
6. Способ по п. 1, в котором обученный основанный на потоке вокодер представляет собой основанный на условном нормализующем потоке вокодер.
7. Способ по п. 1, в котором обученный вокодер прямого распространения представляет собой основанный на сверточной нейронной сети (CNN) вокодер.
8. Способ генерирования выходных данных с использованием входных обусловливающих данных и входного шума, причем способ является исполняемым сервером и содержит:
получение сервером обученной основанной на условном потоке модели, включающей в себя множество обратимых блоков, причем обученная основанная на условном потоке модель была обучена генерировать выходные данные на основе входных обусловливающих данных и входного шума;
получение сервером необученной модели прямого распространения, включающей в себя множество необратимых блоков,
причем обученная основанная на условном потоке модель и необученная модель прямого распространения образуют сеть учитель-ученик;
выполнение процесса обучения в сети учитель-ученик, причем во время определенной итерации обучения процесса обучения:
генерирование сервером связанных с учителем выходных данных посредством обученной основанной на условном потоке модели с использованием первых входных обусловливающих данных и первого входного шума,
генерирование сервером связанных с учеником выходных данных посредством необученной модели прямого распространения с использованием первых входных обусловливающих данных и первого входного шума,
генерирование сервером значения потерь для данной итерации обучения с использованием связанных с учителем выходных данных и связанных с учеником выходных данных; и
обучение сервером необученной модели прямого распространения посредством использования значения потерь для аппроксимации отображения между первым входным шумом и связанными с учителем выходными данными основанной на условном потоке модели;
получение сервером входных обусловливающих данных и входного шума; и
использование сервером обученной модели прямого распространения вместо обученной основанной на условном потоке модели для генерирования выходных данных на основе входных обусловливающих данных и входного шума.
9. Способ по п. 8, в котором обученная основанная на условном потоке модель представляет собой обученный основанный на условном потоке вокодер, при этом обученная модель прямого распространения представляет собой обученный вокодер прямого распространения, причем входные обусловливающие данные представляют собой спектрограмму, выходные данные представляют собой волновую форму.
10. Способ по п. 8, в котором обученная основанная на условном потоке модель представляет собой обученную основанную на условном потоке модель улучшения изображения, при этом обученная модель прямого распространения представляет собой обученную модель улучшения изображения прямого распространения, причем входные обусловливающие данные представляют собой первое изображение, выходные данные представляют собой второе изображение, причем второе изображение имеет более высокое разрешение, чем первое изображение.
11. Сервер генерирования волновой формы на основе спектрограммы и входного шума, причем спектрограмма была сгенерирована на основе текста, волновая форма является цифровым аудио представлением текста, причем сервер выполнен с возможностью:
получения обученного основанного на потоке вокодера, включающего в себя множество обратимых блоков, причем обученный основанный на потоке вокодер был обучен генерировать волновую форму на основе спектрограммы и входного шума;
получения необученного вокодера прямого распространения, включающего в себя множество необратимых блоков,
причем обученный основанный на потоке вокодер и необученный вокодер прямого распространения образуют сеть учитель-ученик;
выполнения процесса обучения в сети учитель-ученик, причем во время определенной итерации обучения процесса обучения сервер выполнен с возможностью:
генерирования связанной с учителем волновой формы посредством обученного основанного на потоке вокодера с использованием первой спектрограммы и первого входного шума;
генерирования связанной с учеником волновой формы посредством необученного вокодера прямого распространения с использованием первой спектрограммы и первого входного шума;
генерирования значения потерь для данной итерации обучения с использованием связанной с учителем волновой формы и связанной с учеником волновой формы; и
обучения необученного вокодера прямого распространения генерировать волновую форму с использованием значения потерь для аппроксимации отображения между первым входным шумом и связанной с учителем волновой формы основанного на потоке вокодера;
получения спектрограммы и входного шума; и
использования обученного вокодера прямого распространения вместо обученного основанного на потоке вокодера для генерирования волновой формы на основе спектрограммы и входного шума.
12. Сервер по п. 11, в котором спектрограмма представляет собой мел-масштабированную спектрограмму.
13. Сервер по п. 11, в котором входной шум представляет собой нормальное распределение значений шума.
14. Сервер по п. 11, при этом сервер дополнительно выполнен с возможностью сохранения обученного вокодера прямого распространения в хранилище.
15. Сервер по п. 11, в котором значение потерь представляет собой комбинацию значения основанных на восстановлении потерь и значения основанных на признаках потерь,
значение основанных на восстановлении потерь представляет различие между связанной с учителем волновой формой и связанной с учеником волновой формой, и
значение основанных на признаках потерь представляет различие между признаками связанной с учителем волновой формы и признаками связанной с учеником волновой формы.
16. Сервер по п. 11, в котором обученный основанный на потоке вокодер представляет собой основанный на условном нормализующем потоке вокодер.
17. Сервер по п. 11, в котором обученный вокодер прямого распространения представляет собой основанный на сверточной нейронной сети (CNN) вокодер.
| Способ регенерирования сульфо-кислот, употребленных при гидролизе жиров | 1924 |
|
SU2021A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 11017761 B2, 25.05.2021 | |||
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| СПОСОБЫ СИНТЕЗА И КОДИРОВАНИЯ РЕЧИ | 2010 |
|
RU2557469C2 |
| Способ и сервер для синтеза речи по тексту | 2015 |
|
RU2632424C2 |
