Область техники, к которой относится изобретение
Изобретение относится к вычислительным технологиям, в частности, к способу отображения содержимого персональной базы данных на экране электронно-вычислительной машины (ЭВМ), и может применяться, например, в локальных устройствах, таких как персональные компьютеры (ПК), ноутбуки, планшеты или мобильные устройства.
Уровень техники
Еще со времен появления первых файловых систем и файловых менеджеров перед пользователями остро стояла проблема удобства систематизации, то есть классификации и группировки, файлов на носителях информации и последующей навигации в содержимом последних с целью поиска необходимых электронных документов. В последнее время с увеличением объемов используемых носителей информации, наряду с ростом доступности электронных устройств и доступа в Интернет в целом, пользователи стали все чаще сталкиваться с этой проблемой.
Общеизвестная связка файловой системы и файлового менеджера решает обсуждаемую проблему посредством того, что путь до сохраненного в системе файла представляет собой набор тегов, каждый из которых в файловой системе представлен в виде каталога. Между каталогами имеются связи, формирующие дерево - иерархическую файловую структуру.
Недостатком такого подхода является то, что пользователь, работающий с файловой системой, обязан указывать список тегов (путь до файла) в строго определенном порядке, который определяет связи между тегами. Впоследствии для поиска документа необходимо воспроизвести не только сами теги, но и их порядок. Очевидно, что пользователь может забыть как сами теги, так и их порядок, что может привести к значительному увеличению времени, которое требуется для поиска искомых файлов данных. На помощь в такой ситуации приходит графическая визуализация (граф) тегов в виде дерева каталогов, которое упрощает этот процесс, позволяя воссоздать последовательность тегов начиная с первого, путем последовательного выбора наиболее подходящего тега из списка дочерних. Однако дерево каталогов полностью не решает указанной выше проблемы ввиду необходимости соблюдения строгости порядка указания тегов при записи файла и его поиске. Для упрощения запоминания такой последовательности пользователь вынуждено прибегает к классификации файлов по определенному признаку. В этом случае список тегов, то есть путь до файла, отображает положение файла в системе классификации, однако при этом возникает дополнительный существенный недостаток - путь до файла зачастую не связан с содержимым самого файла.
Более того, общеизвестно, что в процессе поиска информации человеческий мозг естественным образом выстраивает ассоциативную цепочку, позволяющую найти объект, в котором содержится искомая информация. Так, Г.Э. Яхъева в работе "Основы теории нейронных сетей", 2-ое издание М.: Национальный Открытый Университет "ИНТУИТ", 2016 раскрывает возможность использования ассоциативного мышления для восстановления забытых образов. С учетом этого, по мнению автора, для пользователя ЭВМ при работе с базой данных было бы удобно осуществлять навигацию и поиск в указанной базе данных искомых файлов данных не по их точному названию или местоположению (последовательности тегов), а по возникающим у пользователя ассоциациям с искомыми файлами данных. При этом поскольку такие ассоциации возникают в процессе работы когнитивных функций головного мозга пользователя, таких как память, мышление, понимание и т.д., то возникающие ассоциации могут не образовывать цепочку «от общего к частному», то есть могут быть просто набором произвольных и не группируемых между собой ассоциаций, индивидуальных для каждого человека и, более того, могут меняться ввиду постоянного получения человеком новых знаний или изменения результатов работы когнитивных функций его головного мозга. Соответственно, целесообразно обеспечить пользователю возможность создания персональной базы данных, в которой все файлы данных будут связаны с ассоциациями пользователя, а для поиска и навигации в указанной базе данных пользователю будет предоставлен интерфейс, обеспечивающий обновляемое отображение содержимого базы данных на основе заданных пользователем ассоциаций и их взаимосвязей.
Прототипом изобретения является граф, отображающий содержимое базы данных, содержащей множество файлов каждому из которых пользователем задан один или более тегов, ассоциирующихся у пользователя с указанным файлом, причем указанный граф выполнен в виде сети, каждый узел которой содержит пиктограмму уникального тега из числа заданных тегов, причем узлы сети попарно соединены связями, сформированными между каждой парой тегов, заданных одному файлу, известный из заявки на изобретение US 2013/0151517 А1, МПК G06F 17/30, дата публикации 13.06.2013. Согласно указанной заявке для поиска файлов пользователь сначала задает поисковый запрос с использованием ключевых слов и, в случае неудовлетворительного результата поиска, может дополнительно использовать упомянутый граф, чтобы выбрать другие возможные ассоциативные теги, присвоенные ранее искомым файлам, и использовать их для поиска указанных искомых файлов.
Недостатком графа по прототипу является то, что такой граф не отображает содержимое базы данных таким образом, чтобы пользователю было понятно, какая информация превалирует в базе данных и, соответственно, каким образом ее следует искать, при этом из содержания US 2013/0151517 А1 осталось вообще непонятно, каким образом формируются связи между тегами, которые согласно описанию формируются «автоматически». В частности, в описании прототипа не раскрыты ни принцип, ни алгоритм построения таких связей, что не позволяет понять, каким именно образом осуществляется построение сети тегов, и какова степень персонализации такой сети для пользователя. Поскольку в описании прототипа не раскрыт принцип построения связей между тегами, то граф по прототипу не обладает возможностью модификации или адаптации на случай изменения содержимого базы данных или взаимосвязи между содержимым. Наконец в US 2013/0151517 А1 не раскрыто, каким образом пользователь может осуществлять навигацию по графу и, соответственно, каким образом с помощью навигации в графе пользователь может осуществлять взаимодействие с содержимым персональной базы данных.
Раскрытие сущности изобретения
Техническая проблема, решаемая изобретением, заключается в получении способа отображения содержимого персональной базы данных на экране ЭВМ, который обеспечивает персональное, информативное и естественное для пользователя отображение содержимого указанной базы данных, и который позволяет осуществлять быстрое и интуитивно понятное взаимодействие пользователя с содержимым базы данных.
Технический результат состоит в обеспечении персональной интерактивности графического отображения содержимого персональной базы данных на экране ЭВМ, а также в устранении по меньшей мере одного из недостатков решений уровня техники. Благодаря заявленному изобретению при взаимодействии с базой данных, вместо, например, памяти или мышления, пользователь может задействовать зрительно-ассоциативные функции головного мозга, что для многих пользователей, как индивидуумов, представляется более естественным и простым, чем задействование памяти, логики и др. когнитивных функций головного мозга. Использование заявленного способа позволяет оптимизировать процесс отображения содержимого персональной базы данных с учетом индивидуальных особенностей восприятия пользователем информации, что также позволяет хранить, накапливать и анализировать персональную информацию наиболее эффективным способом.
Сущность предложенного способа заключается в следующем.
Способ отображения содержимого персональной базы данных на экране ЭВМ, причем персональная база данных содержит множество файлов данных, каждому из которых задан, по меньшей мере, один ассоциативный идентификатор (АИ), ассоциирующийся у пользователя с указанным файлом данных, при этом способ содержит получение первичного графа, содержащего графическое представление заданных ассоциативных идентификаторов в виде сети, каждый узел которой содержит пиктограмму уникального ассоциативного идентификатора из числа заданных ассоциативных идентификаторов, причем узлы сети попарно соединены таким образом, что между каждой парой пиктограмм, отображающих заданные одному файлу данных ассоциативные идентификаторы, сформирована связь. В отличие от прототипа данный способ содержит вычисление для каждого ассоциативного идентификатора весового коэффициента (m) субъективной значимости, определяющего размер его пиктограммы, вычисление для каждой связи весового коэффициента (n), определяющего параметр отображения указанной связи, и получение модифицированного графа в ответ на каждое вычисление, по меньшей мере, одного из указанных весовых коэффициентов (m, n).
В соответствии со способом, персональная база данных пользователя включает в себя множество файлов данных любого формата, записанных на встроенное в ЭВМ устройство хранения данных, либо в периферийное или внешнее «облачное» хранилище данных, к которому ЭВМ имеет подключение.
Указанная ЭВМ может представлять собой, например, одно из следующего: персональный компьютер, ноутбук, планшет, мобильное устройство или любое другое электронное устройство, осуществляющее взаимодействие с устройством хранения данных.
Файл данных может представлять собой, например, одно из следующего: текстовый документ, файл изображения, аудио-файл, видео-файл, мультимедиа-файл, гиперссылка, RSS-канал, лента новостей, информация, относящаяся к сессии чата и др.
Каждому из файлов данных, содержащихся в указанной персональной базе данных, пользователем задан, по меньшей мере, один ассоциативный идентификатор, ассоциирующийся у пользователя с указанным файлом данных, который записывается в указанную базу данных. Указанные ассоциативные идентификаторы предпочтительно задаются пользователем вручную с использованием устройства ввода, например, такого как мышь, клавиатура, сенсорная панель, микрофон, шаровой манипулятор, электронное перо, джойстик, цифровая камера, цифровая видеокамера, веб-камера, нейрокомпьютерный интерфейс и др.
В другом случае, чтобы задать файлу данных ассоциативный идентификатор, ассоциирующийся у пользователя с указанным файлом данных, пользователь выбирает подходящий ассоциативный идентификатор из множества предустановленных или ранее заданных ассоциативных идентификаторов.
Предпочтительно ассоциативным идентификатором является одна или несколько букв, цифр, знаков, символов или любая комбинация перечисленного. Например, ассоциативным идентификатором может быть по меньшей мере одно слово на естественном языке.
В соответствии со способом, получают первичный граф путем его отображения на экране ЭВМ. Экран ЭВМ может быть встроен в указанную ЭВМ, например, в виде дисплея, или может быть отдельным (от ЭВМ) периферийным устройством, например, монитором, проектором, нейрокомпьютерным интерфейсом и др. Первичный граф представляет собой графическое представление, в виде сети, всех ассоциативных идентификаторов, заданных пользователем множеству файлов данных, содержащихся в указанной базе данных пользователя. В указанной сети каждый узел представляет собой пиктограмму уникального ассоциативного идентификатора из числа заданных ассоциативных идентификаторов. Другими словами, на графе ассоциативные идентификаторы не повторяются. При этом узлы сети попарно соединены таким образом, что между каждой парой пиктограмм, отображающих заданные одному файлу данных ассоциативные идентификаторы, сформирована связь. Преимущество использования такого графа заключается в том, что содержимое персональной базы данных отображается пользователю не в виде набора тегов или имен файлов данных, которые зачастую никак не связаны с содержимым этих файлов данных, а в виде понятных пользователю и им же заданных ассоциативных идентификаторов - ассоциаций пользователя с содержимым файлов данных, сохраненных в персональной базе данных пользователя. Соответственно, для анализа содержимого базы данных и/или сохраненных в ней файлов данных пользователю не надо вспоминать соответствующую информацию, равно как и не надо открывать файлы данных. Вместо этого, благодаря отображаемым на графе ассоциациям пользователь может легко понять, что содержит вся персональная база данных в целом и/или отдельно взятые файлы данных из указанной базы данных.
На графе каждая пиктограмма отображается в виде геометрической фигуры и содержит изображение уникального ассоциативного идентификатора.
В случае когда граф является двухмерным, каждая пиктограмма графа отображается в виде плоской геометрической фигуры, внутри, снаружи или поверх контура которой изображен уникальный ассоциативный идентификатор. В качестве плоской геометрической фигуры может быть использован прямоугольник, квадрат, шестиугольник, окружность или любая другая подходящая плоская фигура, а также изображение.
В случае когда граф является трехмерным, каждая пиктограмма графа отображается в виде объемной геометрической фигуры, внутри, снаружи или поверх которой изображен ассоциативный идентификатор. В качестве объемной геометрической фигуры может быть использован, с текстурой или без, шар, куб, октаэдр или любая другая подходящая объемная фигура.
В соответствии со способом, для каждого ассоциативного идентификатора вычисляют весовой коэффициент (m) субъективной значимости такого ассоциативного идентификатора для пользователя. Предпочтительно, для каждого ассоциативного идентификатора весовой коэффициент (m) вычисляют на основании количества файлов данных, которым пользователем задан указанный ассоциативный идентификатор. Существует множество вариантов расчета весового коэффициента элемента из массива элементов и, по мнению автора изобретения, нет необходимости ограничиваться одним или несколькими из таких вариантов. В предпочтительном варианте способа, весовой коэффициент (m) вычисляют с учетом также количества сформированных связей между указанным ассоциативным идентификатором и остальными ассоциативными идентификаторами.
Весовой коэффициент (m) определяет размер пиктограммы, отображающей уникальный ассоциативный идентификатор. Чем больше значение весового коэффициента для конкретного ассоциативного идентификатора, тем больший размер на графе имеет пиктограмма, отображающая этот ассоциативный идентификатор. Другими словами, размер пиктограммы на графе зависит от значения весового коэффициента (m). В случае двухмерного графа весовой коэффициент (m) определяет площадь указанной пиктограммы, а в случае трехмерного графа - ее объем. В предпочтительном варианте, весовой коэффициент (m) дополнительно определяет, по меньшей мере, одно из следующего: форму, цвет, прозрачность, положение пиктограммы на графе.
В соответствии со способом, также вычисляют весовой коэффициент (n) связи, сформированной между каждыми двумя пиктограммами, то есть каждой парой ассоциативных идентификаторов, заданных одному файлу данных. Предпочтительно, указанный весовой коэффициент (n) вычисляют на сновании количества общих для указанной пары ассоциативных идентификаторов файлов данных. Тем не менее очевидно, что для вычисления значения весового коэффициента (n), определяющего степень ассоциативной связи между ассоциативными идентификаторами, существует множество различных алгоритмов. Например, можно использовать модифицированную бинарную меру сходства Сёренсена:
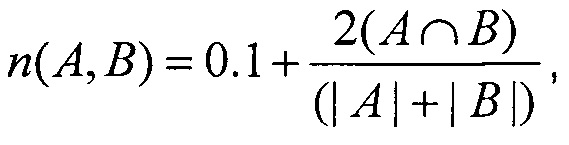
где 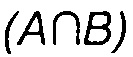 - количество файлов данных, которым заданы одновременно ассоциативные идентификаторы "А" и "B", а |А| и |В| - количество файлов данных, которым заданы ассоциативные идентификаторы "А" и "В", соответственно.
- количество файлов данных, которым заданы одновременно ассоциативные идентификаторы "А" и "B", а |А| и |В| - количество файлов данных, которым заданы ассоциативные идентификаторы "А" и "В", соответственно.
Весовой коэффициент (n) определяет один или более параметров отображения указанной связи на графе, причем параметры отображения могут быть выбраны из следующей группы: толщина, длина, цвет, прозрачность связи на графе.
Взаимное расположение пиктограмм, изображающих ассоциативные идентификаторы, оказывает значительное влияние на скорость взаимодействия пользователя с графом. Очевидно, что наиболее близкие по смыслу ассоциативные идентификаторы имеют наиболее сильную связь, а, следовательно, наибольший коэффициент (n), и поэтому должны располагаться ближе друг другу, чем ассоциативные идентификаторы со слабой связью между собой.
Для визуализации, соответствующей вышеуказанным требованиям, можно использовать один из известных алгоритмов укладки графа: пружинный алгоритм Eades (см. Eades P. A heuristic for graph drawing // Congressus Numerantium. 1984, 42, страницы 149-160), алгоритм Kamada и Kawai (см. Kamada Т., Kawai S. An algorithm for drawing general undirected graphs // Inform. Process. Lett. 1989, 31, страницы 7-15), силовую модель Fruchterman и Reingold (см. Branke J. Dynamic graph drawing // Drawing Graphs, Springer Lecture Notes In Computer Science. 2001, страницы 228-246) и многочисленные модификации этих алгоритмов.
В качестве примера будем использовать силовую модель. В этом случае вершины (узлы) графа соответствуют «заряженным частицам», между которыми действуют «силы притяжения и отталкивания». Возьмем весовой коэффициент (m) за аналог заряда, тогда узлы графа (они же пиктограммы ассоциативных идентификаторов) будут отталкиваться друг от друга с «силой», являющейся функцией расстояния между ними. «Силы притяжения» действуют между вершинами аналогично «силе гравитации», и определяются коэффициентом (n), то есть «силой» связи между парой ассоциативных идентификаторов. Обычно «силы притяжения» также являются функцией расстояния между вершинами.
В общем виде «энергию системы», всех элементов графа, можно выразить следующим образом:
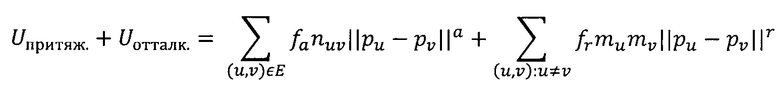
где Uпритяж. - «энергия притяжения», а Uотталк. - «энергия отталкивания» между вершинами u и v с координатами pu и pv, соответственно; mv - вес вершины v; nuv - вес связи между вершинами (u, v); а, r - показатели степени и ∈ R; fa, fr - коэффициенты, определяющие степень влияния каждого компонента на итоговую укладку графа, ∈ R. Общепринятыми ограничениями являются: fa>0, fr>0, а≥0, r≤0, т.е. «силы притяжения» растут, а «силы отталкивания» убывают с увеличением расстояния между пиктограммами.
Граф находится в равновесии, то есть его укладка завершена, когда «энергия» всей системы минимальна или, по крайней мере, «сила притяжения» и «сила отталкивания» равны. Под указанными «силами» подразумевается производная «энергии притяжения» и «энергии отталкивания» по расстоянию, соответственно. Конкретную реализацию механизмов укладки графов можно найти в ряде публикаций, например, в статье Пупырева С.Н., Тихонова А.В. "Визуализация динамических графов для анализа сложных сетей. Моделирование и анализ информационных систем. Т. 17, №1 (2010) сс.117-135".
В соответствии со способом, вместо первичного графа получают модифицированный граф в ответ на каждое вычисление, по меньшей мере, одного из указанных весовых коэффициентов (m, n). Указанное вычисление выполняют в ответ на, по меньшей мере, одно из следующего: добавление файла данных, удаление файла данных, добавление ассоциативного идентификатора, удаление ассоциативного идентификатора, формирование связи «ассоциативный идентификатор - ассоциативный идентификатор» («АИ-АИ») между ассоциативными идентификаторами, удаление связи «АИ-АИ». Когда коэффициенты (m, n) нормированы, то такое изменение может быть вызвано, например, изменением общего количества заданных ассоциативных идентификаторов в результате добавления нового ассоциативного идентификатора, либо удаления ранее заданного ассоциативного идентификатора. В другом случае, такое изменение может быть вызвано формированием новой связи между сохраненными в базу данных файлом данных и ассоциативным идентификатором. Преимуществом этого варианта является непрерывное изменение (перерасчет) связей между пиктограммами, что обеспечивает адаптацию отображаемого графа к изменению не только содержимого персональной базы данных, но и субъективного восприятия пользователем указанного содержимого, в частности, возникающих у пользователя ассоциаций с файлами данных, содержащимися в указанной персональной базе данных.
В предпочтительном варианте способа, дополнительно формируют связь между каждым ассоциативным идентификатором и каждым файлом данных, которому задан указанный ассоциативный идентификатор, причем для каждой такой связи пользователем задан весовой коэффициент (k), характеризующий субъективную степень соответствия указанного ассоциативного идентификатора указанному файлу данных, то есть то, насколько, по мнению пользователя, конкретный ассоциативный идентификатор соответствует файлу данных, которому он задан. Указанную связь не отображают на графе, однако вычисленные весовые коэффициенты (k) связей между файлом данных и связанными с ним ассоциативными идентификаторами учитывают при вычислении весового коэффициента (m). Преимуществом этого варианта является возможность корректировки степени соответствия ассоциативного идентификатора файлу данных, которому он задан, на основе активности пользователя при работе с системой.
В случае использования весовых коэффициентов (k), отличных от единицы, для вычисления весового коэффициента (m) можно, например, воспользоваться формулой:
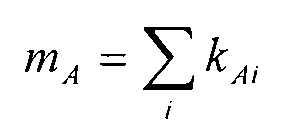
где mА - весовой коэффициент ассоциативного идентификатора "А", kАi - коэффициент связи между i-ым файлом данных и ассоциативным идентификатором "А".
Для удобства, в некоторых вариантах осуществления, значения весовых коэффициентов (k) могут быть нормированы.
Весовой коэффициент (k) может назначаться пользователем для каждой связи автоматически корректироваться во время работы с базой данных на основе частоты открытия указанного файла данных. Для уменьшения рутинной работы пользователя начальное значение весового коэффициента (k) может автоматически задаваться одинаковым для всех связей «ФД - АИ», либо же можно использовать известные методы определения соответствия ассоциативного идентификатора содержимому файла данных. Для текстовых документов, например, можно определять частоту вхождения словоформы, используемой в качестве ассоциативного идентификатора, в содержимое указанного текстового документа.
Граф содержимого персональной базы данных, отображаемый на экране ЭВМ в соответствии с изобретением, может также использоваться пользователем для навигации в содержимом базы данных и для поиска в указанной базе данных необходимых пользователю файлов данных.
Для этого в одном из предпочтительных вариантов, пиктограмма графа представляет собой выбираемый объект графа, который может быть выбран пользователем для поиска файлов данных, которым задан ассоциативный идентификатор, изображенный на выбранной пиктограмме. С использованием одного из перечисленных выше устройств ввода пользователь может выбирать одновременно одну или более пиктограмм графа для формирования поискового запроса.
При выборе пользователем одной или более пиктограмм графа, остальные пиктограммы графа могут временно скрываться, если весовые коэффициенты (m) изображенных на них ассоциативных идентификаторов превышают весовые коэффициенты (m) ассоциативных идентификаторов, изображенных на выбранных пользователем пиктограммах графа. При этом связь между двумя пиктограммами отображается на графе только тогда, когда обе пиктограммы, между которыми сформирована указанная связь, отображены на графе. Соответственно, в случае скрытия пиктограммы, все относящиеся к такой пиктограмме связи также скрываются. Таким образом, для пользователя обеспечивается возможность быстрой и удобной навигации по содержимому базы данных с учетом ассоциативной памяти пользователя, когда за отсутствием искомых ассоциаций среди более крупных пиктограмм, на которые пользователь обращает внимание в первую очередь, такие более крупные пиктограммы скрываются, и пользователь получает возможность сконцентрировать внимание на обращении к более мелким пиктограммам, отображающим ассоциации, которые при формировании персональной базы данных использовались пользователем реже.
В еще одном предпочтительном варианте способа, граф дополнительно содержит инструмент масштабирования графа (например, виртуальные кнопки изменения масштаба графа), при этом способ дополнительно содержит шаг, на котором, в случае невозможности выбора пользователем интересующих его пиктограмм, масштабируют граф для обеспечения возможности выбора пользователем интересующих его пиктограмм. Например, пользователь сначала может отмасштабировать граф таким образом, чтобы выяснить имеются ли вообще в базе данных другие ассоциативные идентификаторы, а, при положительном результате, указанное масштабирование необходимо, чтобы иметь возможность выбора пиктограмм таких ассоциативных идентификаторов, которые ввиду малых значений весовых коэффициентов (m) изначально вообще не отображались или не были заметны для пользователя из-за своего малого размера.
В соответствии с изобретением, предложенный способ может быть реализован посредством системы, содержащей: по меньшей мере, одно устройство хранения данных, выполненное с возможностью, по меньшей мере, записи, хранения и чтения на нем файлов данных; пользовательское устройство, выполненное с возможностью подключения к указанному, по меньшей мере, одному устройству хранения данных и содержащее, по меньшей мере, экран, процессор, память с сохраненными в ней машиночитаемыми инструкциями, исполнение которых процессором вызывает выполнение любого из вариантов заявленного способа, и орган управления, обеспечивающий возможность взаимодействия пользователя с содержимым рабочей области указанного экрана.
Отображение первичного и модифицированного графов в виде сети связанных между собой ассоциативных идентификаторов повышает информативность отображения содержимого персональной базы данных благодаря учитываемым при построении указанных графов весовым коэффициентам элементов графа, которые могут вычисляться автоматически в соответствии с используемыми алгоритмами их вычисления, либо могут задаваться пользователем вручную, как объяснено выше. В результате, согласно изобретению, на экране ЭВМ отображается граф, представляющий собой графическое представление всех заданных ассоциаций пользователя с содержимым персональной базы данных. Возможность выбора отображаемых на графе ассоциативных идентификаторов и их графическое представление позволяют дополнительно повысить информативность отображения содержимого персональной базы данных, так как такое отображение в наибольшей степени соответствует представлениям пользователя о содержимом базы данных. Кроме того, возможность выбора отображаемых на графе ассоциативных идентификаторов позволяет расширить функционал персональной базы данных пользователя. Например, позволяет осуществлять навигацию с целью анализа содержимого базы данных, а также позволяет осуществлять поиск необходимых пользователю файлов данных в базе данных.
В отличие от прототипа, изобретение обладает рядом отличительных признаков, которые не известны из уровня техники, что позволяет сделать вывод о новизне и соответствии предложенного способа условию патентоспособности «изобретательский уровень».
Изобретение может быть реализовано с помощью известных средств и методов, что позволяет сделать вывод о промышленной применимости предложенного способа.
В контексте заявленного изобретения под термином «персональная база данных» следует понимать сформированное пользователем множество файлов данных с заданными им метаданными, систематизированных так, что они могут быть найдены и обработаны с помощью ЭВМ.
Следует понимать, что предшествующее общее описание и нижеследующее подробное описание являются лишь примерами, служат для пояснения и не ограничивают изобретения, выраженного прилагаемой формулой изобретения.
Краткое описание чертежей
Прилагаемые к настоящей заявке и составляющие ее часть чертежи иллюстрируют и поясняют сущность предложенного способа.
На Фиг. 1 схематически показана структура первоначального графа персональной базы данных согласно изобретению.
На Фиг. 2 схематически показан модифицированный граф персональной базы данных согласно изобретению, в которую добавлен новый файл данных и связанные только с ним новые ассоциативные идентификаторы.
На Фиг. 3 схематически показан модифицированный граф персональной базы данных согласно изобретению, в которую добавлен новый файл данных, связанный с двумя новыми и одним ранее сохраненным в базу данных ассоциативными идентификаторами.
На Фиг. 4 схематически показан пример осуществления навигации в графе с Фиг. 3 согласно изобретению.
На Фиг. 5 схематически показан пример пользовательского интерфейса для поиска в персональной базе данных.
На Фиг. 6 схематически показан другой пример осуществления навигации в графе с Фиг. 3 согласно изобретению.
На Фиг. 7 схематически показан пример пользовательского интерфейса для поиска в персональной базе данных.
Осуществление изобретения
Предложенный способ может быть реализован при помощи ЭВМ следующим образом.
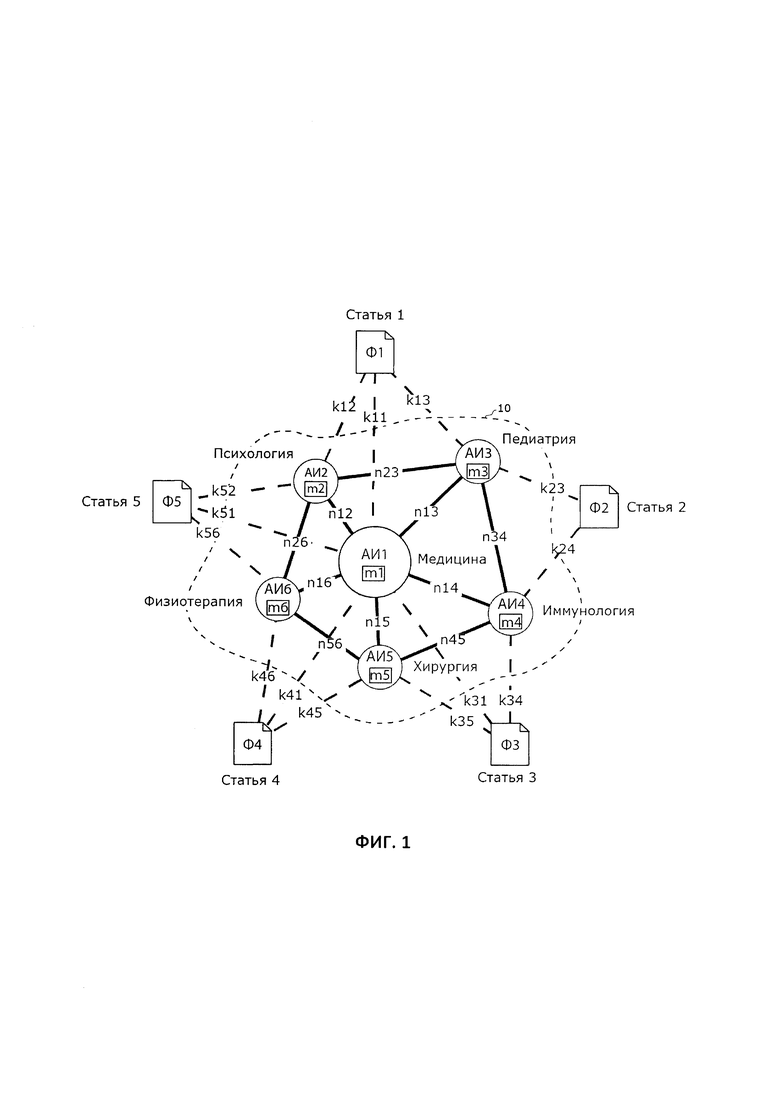
Пользователь осуществляет работу с персональной базой данных посредством ЭВМ с помощью специального программного обеспечения. В частности, пользователь добавляет в персональную базу данных, по меньшей мере, один файл данных, например, пять файлов данных (Ф1…Ф5), представляющих собой, соответственно, статьи с названиями «Статья_1», «Статья_2» и т.д., путем сохранения в указанной базе данных указанных пяти файлов данных и заданных им ассоциативных идентификаторов, причем каждому из указанных файлов данных задан, по меньшей мере, один ассоциативный идентификатор, субъективно ассоциирующийся у пользователя с соответствующим файлом данных. Такой ассоциативный идентификатор может представлять собой ассоциацию пользователя, например, с названием или содержимым файла данных. Например, пользователь задает указанным пяти файлам данных ассоциативные идентификаторы «Медицина» (АИ1), «Психология» (АИ2), «Педиатрия» (АИ3), «Иммунология» (АИ4), «Хирургия» (АИ5), «Физиотерапия» (АИ6) так, что для «Статьи_1» заданы АИ1, АИ2, АИ3, для «Статьи_2» заданы АИ3, АИ4, для «Статьи_3» заданы АИ1, АИ4, АИ5, для «Статьи_4» заданы АИ1, АИ5, АИ6, а для «Статьи_5» заданы АИ1, АИ2, АИ6. При этом для каждого ассоциативного идентификатора (АИ1…АИ6) вычисляют соответствующий весовой коэффициент (m1…m6) субъективной значимости такого ассоциативного идентификатора для пользователя. Кроме того, для каждой пары ассоциативных идентификаторов, заданных одному файлу данных, формируют связь, для которой вычисляют соответствующий весовой коэффициент (n). Так, например, для связи между АИ2 и АИ3 вычисляют весовой коэффициент (n23). При необходимости также вычисляют соответствующие весовые коэффициенты (k) субъективной степени соответствия каждого ассоциативного идентификатора файлу данных, которому он задан. Так, например, для показанной пунктиром связи между Ф1 и АИ1 вычисляют весовой коэффициент (k11). Таким образом, в соответствии со способом, на дисплее ЭВМ при помощи специального программного обеспечения получают первичный граф 10, схематически изображенный на Фиг. 1.
При этом на Фиг. 1 пунктирным контуром графа 10 показано, что именно отображается пользователю на экране ЭВМ. Так, первичный граф 10 включает в себя пиктограммы упомянутых ассоциативных идентификаторов (АИ1…АИ6), а также сформированные между указанными пиктограммами связи, показанные жирными сплошными линиями и имеющие весовые коэффициенты (n12, n13, n14, n15, n16, n23, n34, Поскольку АИ1 использовался пользователем чаще, то есть с ним связано большее количество файлов данных, то на графе 10 его пиктограмма показана более крупной по сравнению с остальными пиктограммами. Полученный таким образом граф позволяет дополнительно повысить информативность отображения содержимого персональной базы данных. В частности, глядя на граф 10, пользователь сразу понимает, что в персональной базе данных превалируют файлы данных, так или иначе связанные с медициной. При этом в решениях уровня техники пользователю просто отображался бы список файлов с названиями «Статья_1»-«Статья_6» внутри одного из каталогов, что не всегда позволило бы специалисту определить содержание указанных файлов и найти из них требуемый файл.
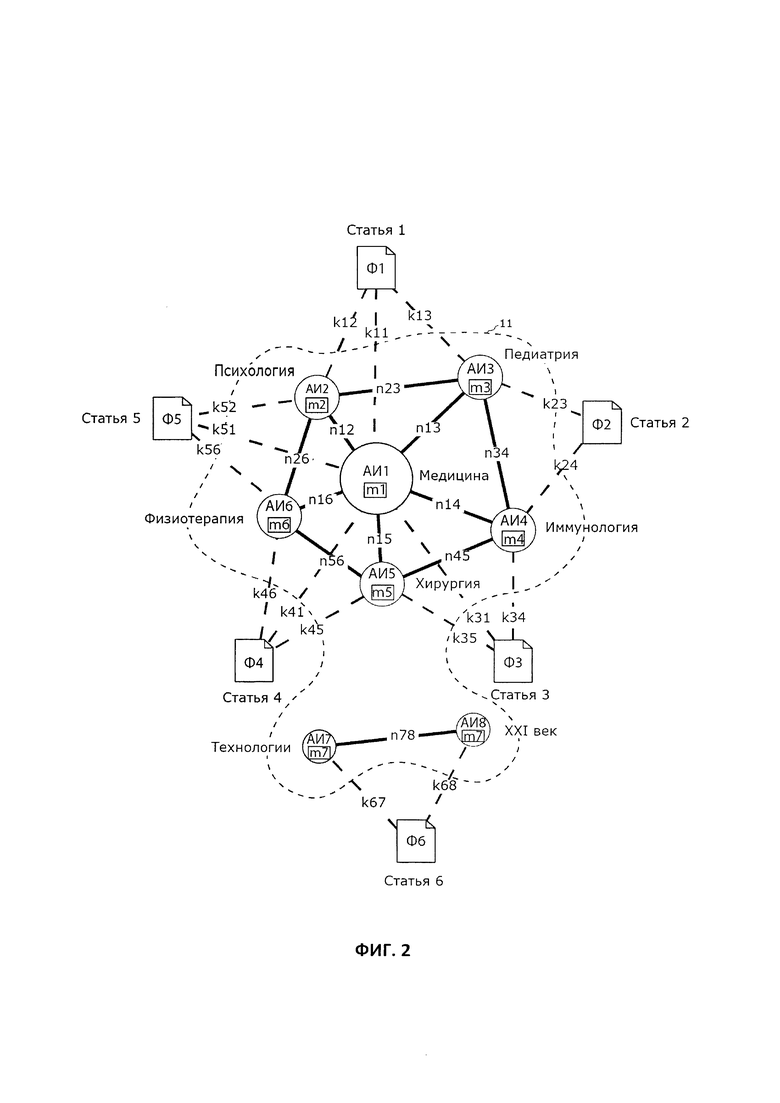
Далее пользователь добавляет в базу данных новый файл данных (Ф6), представляющий собой статью с названием «Статья_6», и, например, задает ему ассоциативные идентификаторы «Технологии» (АИ7) и «XXI век» (АИ8). При этом, в соответствии со способом, для указанных ассоциативных идентификаторов (АИ7, АИ8) вычисляют соответствующие весовые коэффициенты (m7, m8), вычисляют весовой коэффициент (n78) связи между АИ7 и АИ8, а, при необходимости, и весовые коэффициенты (k67, k68) субъективной степени соответствия ассоциативных идентификаторов (АИ7, АИ8) файлу данных «Статья_6». Соответственно, на экране ЭВМ получают модифицированный граф 11, схематически изображенный на Фиг. 2. Модифицированный граф 11 включает в себя группу связанных между собой пиктограмм ассоциативных идентификаторов (АИ1…АИ6) и расположенную в стороне от нее группу связанных между собой пиктограмм ассоциативных идентификаторов (АИ7, АИ8). Поскольку добавленные АИ7 и АИ8 не заданы ранее сохраненным в базу данных файлам данных, то связи между группой (АИ1…АИ6) и группой (АИ7, АИ8) отсутствуют. Таким образом, глядя на граф 11, пользователь сразу понимает, что в персональной базе данных пусть и превалируют статьи по медицинской тематике, однако также содержатся и статьи, относящиеся к технологиям XXI века.
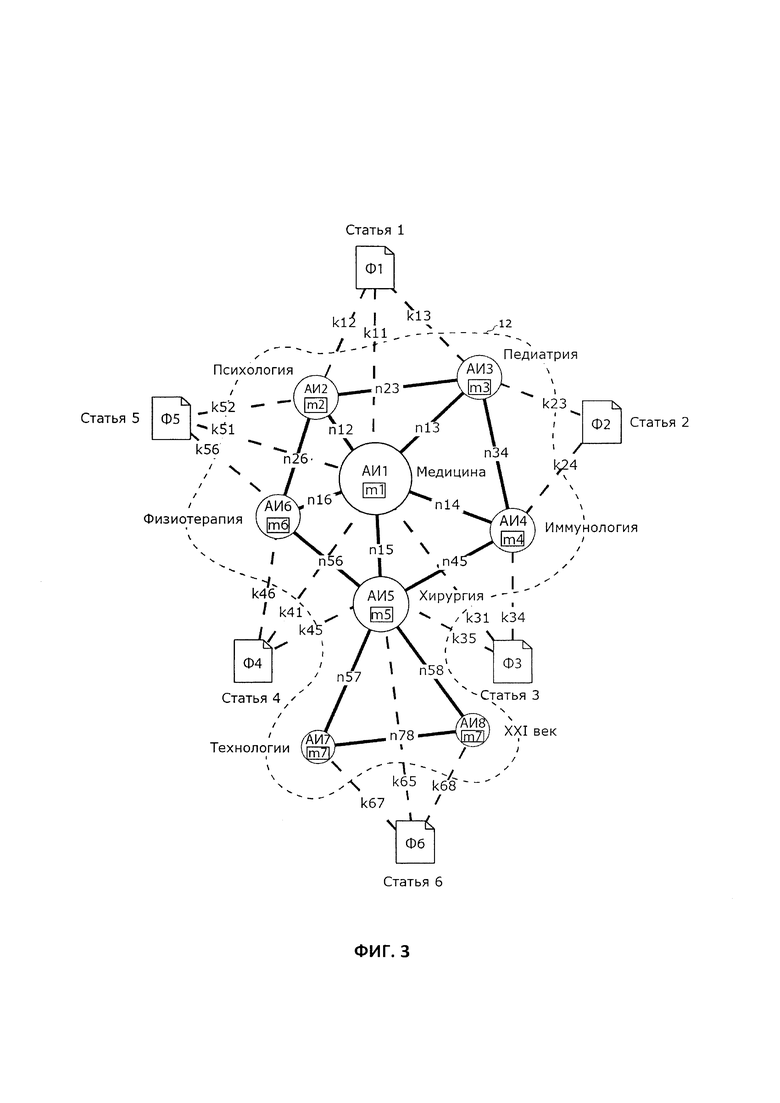
В альтернативном случае, добавляемому в базу данных новому файлу данных (Ф6), представляющему собой статью с названием «Статья_6», пользователь, в дополнение к новым ассоциативным идентификаторам «Технологии» (АИ7) и «XXI век» (АИ8), может задать уже содержащейся в базе данных ассоциативный идентификатор «Хирургия» (АИ5). В этом случае, согласно способу, в дополнение к весовым коэффициентам (m7, m8, n78,, о вычислении которых сказано выше, вычисляют весовой коэффициент (n57) связи между АИ7 и АИ5, весовой коэффициент (n58) связи между АИ8 и АИ5, а, при необходимости, и весовой коэффициент (k65), характеризующий субъективную степень соответствия ассоциативного идентификатора (АИ5) файлу данных «Статья_6». Соответственно, на экране ЭВМ получают модифицированный граф 12, схематически изображенный на Фиг. 3. Модифицированный граф 12 включает в себя группу связанных между собой пиктограмм ассоциативных идентификаторов (АИ1…АИ8). Причем поскольку добавленному файлу данных «Статья_6» заданы не только новые АИ7 и АИ8, но и уже содержащийся в базе данных (и, следовательно, на первичном графе 10) АИ5, то между пиктограммами АИ5, АИ7 и АИ8 формируются связи, отображаемые на модифицированном графе 12. При этом увеличивается размер пиктограммы АИ5, так как АИ5 теперь связан не с двумя файлами данных, как на первичном графе 10, а с тремя файлами данных, а именно со «Статьей_3», «Статьей_4» и «Статьей_6». Таким образом, глядя на граф 12, пользователь сразу понимает, что в персональной базе данных содержатся статьи по медицинской тематике, среди которых имеются статьи, относящиеся к технологиям в хирургии XXI века.
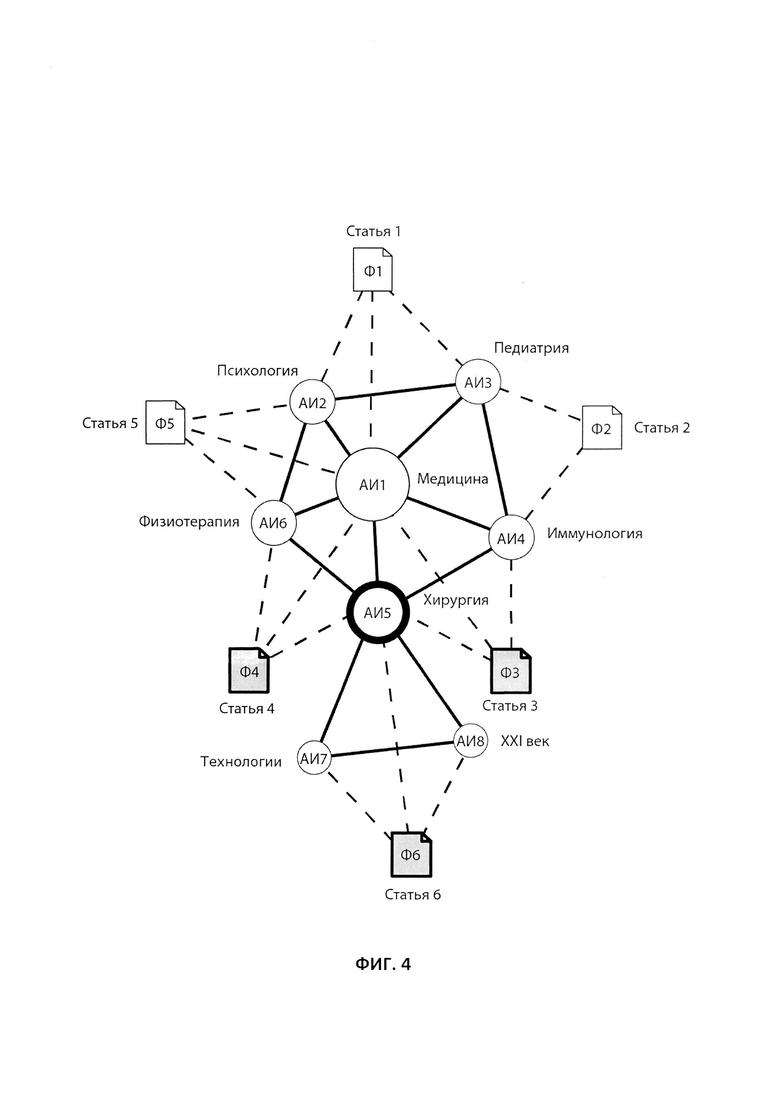
В одном из вариантов, пиктограмма графа представляет собой выбираемый объект графа, который может быть выбран пользователем для поиска файлов данных, которым задан ассоциативный идентификатор, изображенный на выбранной пиктограмме. На Фиг. 4 показано, что на модифицированном графе с Фиг. 3 пользователь посредством одного из устройств ввода, подключенных к ЭВМ, выбрал пиктограмму «Хирургия» (АИ5) с тем, чтобы сформировать поисковый запрос и найти все файлы данных, содержащиеся в его персональной базе данных и ассоциирующиеся у него с хирургией. Очевидно, что в приведенном примере, результатом такого поиска будет отображение пользователю списка документов, в частности, «Статьи_3», «Статьи_4» и «Статьи_6», поскольку всем указанным файлам данных задан ассоциативный идентификатор «Хирургия», как показано на Фиг. 4.
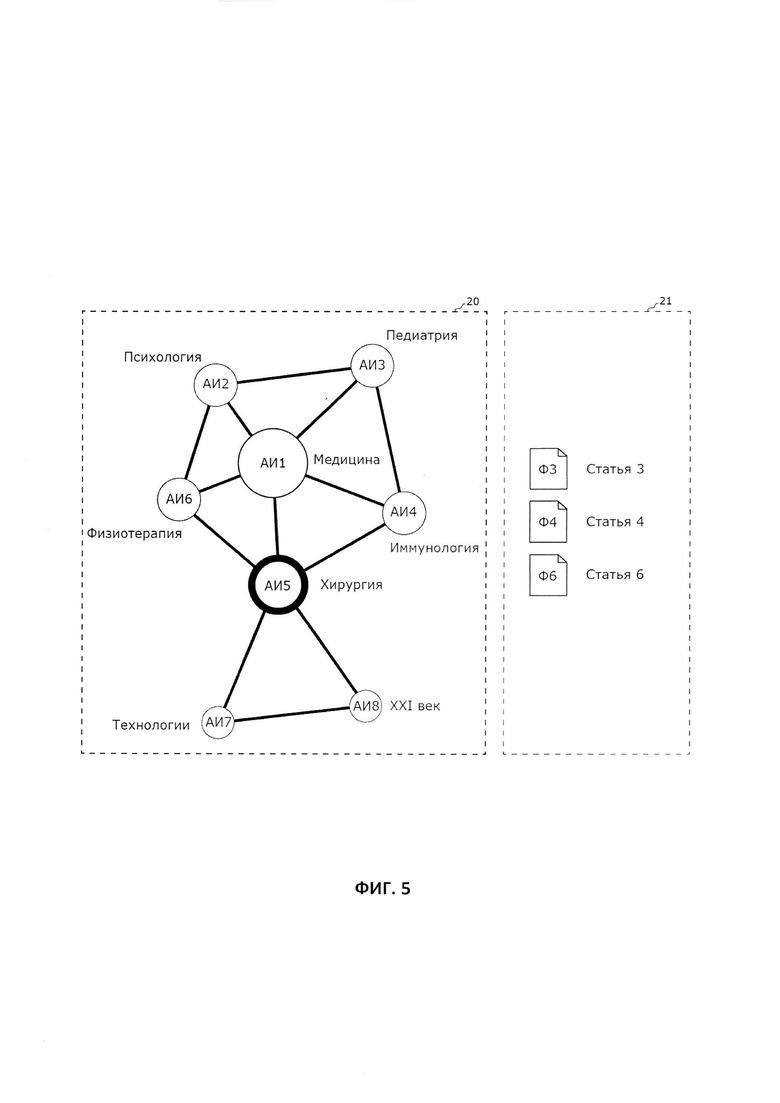
Для удобства пользователя, на экране ЭВМ может отображаться пользовательский интерфейс, рабочая область которого включает в себя область 20 для графа согласно изобретению и область 21 для вывода результатов поиска. На Фиг. 5 схематически показан пример такого пользовательского интерфейса, используемого, в частности, для поиска в нальной базе данных файлов данных согласно поисковому запросу с Фиг. 4.
Согласно примеру с Фиг. 5, на экране ЭВМ в области 20 отображается граф, на котором пользователем задан поисковый запрос посредством выбора пиктограммы «Хирургия» (АИ5). Указанный запрос может дополнительно содержать фильтр, определяющий метаинформацию файлов данных, подлежащих поиску. Например, такая метаинформация может включать в себя, по меньшей мере, одно из следующего: дата добавления файла данных в персональную базу данных, дата последнего изменения файла данных, тип файла данных и т.д. Далее осуществляют в базе данных поиск файлов данных, удовлетворяющих заданному пользователем поисковому запросу. В результате такого поиска, на экране ЭВМ в области 21 отображаются файлы данных (Ф3, Ф4, Ф6) с именами, соответственно, «Статья_3», «Статья_4» и «Статья_6» для последующего взаимодействия пользователя с найденными файлами данных. При этом указанные найденные файлы данных в списке результатов поиска по умолчанию упорядочены в соответствии с наибольшим значением весового коэффициента (k) связи «ФД - АИ», сформированной между выбранным ассоциативным идентификатором и каждым найденным в результате поиска файлом данных. Однако, по выбору пользователя также может применяться любой другой известный тип упорядочивания, например, по названию файла данных, по размеру, по частоте обращения пользователя к файлу данных и т.д.
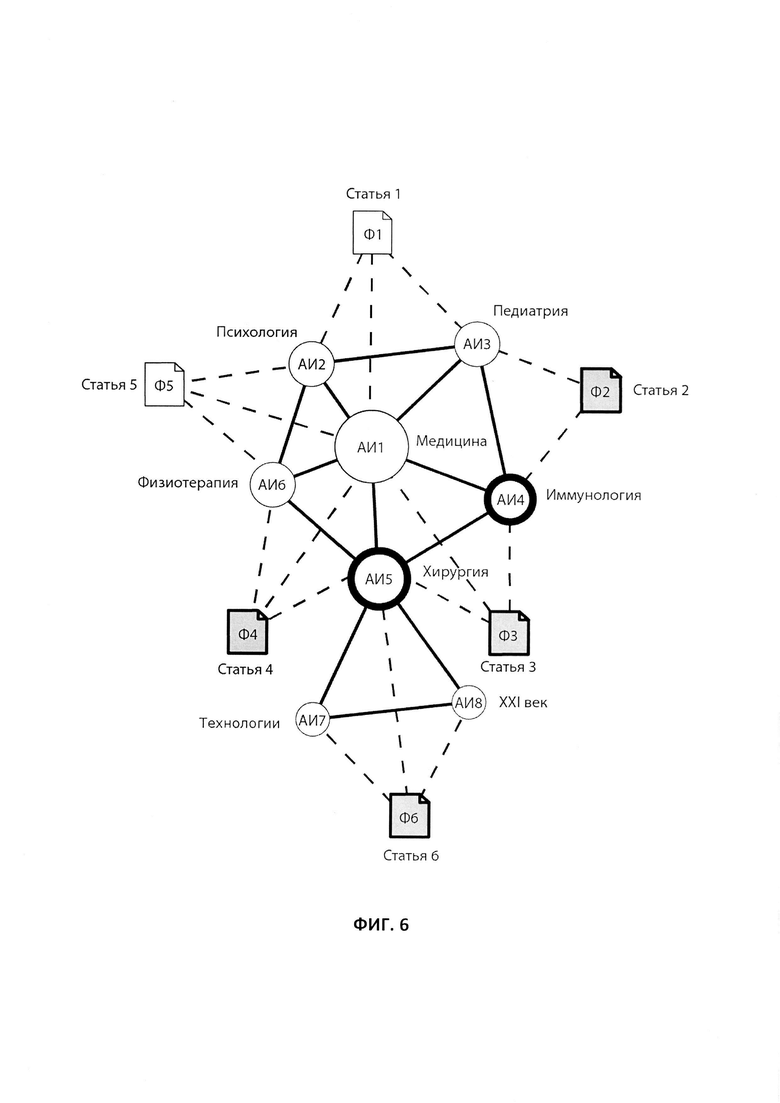
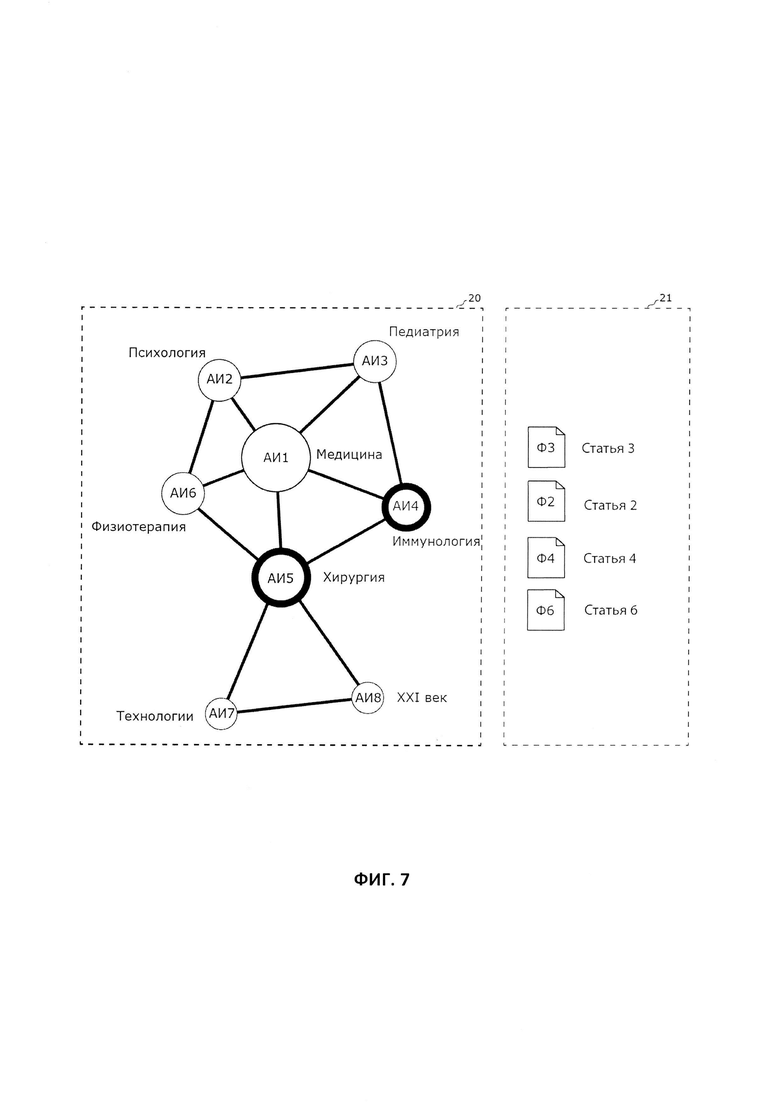
Пользователь также может выбрать на графе более одной пиктограммы для поиска необходимых ему файлов данных. Так, на Фиг. 6 показан пример графа, на котором пользователем выбраны сразу две пиктограммы - пиктограмма «Иммунология» (АИ4) и пиктограмма «Хирургия» (АИ5). Если в настройках графа пользователем предварительно задано условие «ИЛИ» для более гибкого вхождения результатов поиска в поисковый запрос, то в результате сформированного на Фиг. 6 поискового запроса на экране ЭВМ в области 21 будут отображаться файлы данных (Ф2, Ф3, Ф4, Ф6) с именами, соответственно, «Статья_2», «Статья_3», «Статья_4» и «Статья_6» для последующего взаимодействия пользователя с найденными файлами данных, как это показано на Фиг. 7. Если же в настройках графа пользователем задано условие «И» для точного вхождения результатов поиска в поисковый запрос, то для аналогичной ситуации, когда выбраны АИ4 и АИ5, на экране ЭВМ в области 21 будет отображаться только файл данных (Ф3) с именем «Статья_3» (данный вариант на чертежах не показан).
В случае выбора более одной пиктограммы графа, отображаемый список найденных в результате поиска файлов данных по умолчанию упорядочен в соответствии с наибольшим значением суммы весовых коэффициентов (k) связей, сформированных между выбранными ассоциативными идентификаторами и каждым найденным в результате поиска файлом данных.
Дополнительно, поисковый запрос может включать в себя дату последней модификации графа, причем модификация графа представляет собой каждое добавление, удаление, изменение размеров, по меньшей мере, одной пиктограммы графа и/или вычисление, удаление, изменение весового коэффициента (k), по меньшей мере, одной связи «ФД - АИ».
Заявленный технический результат обеспечивается за счет интерактивности отображаемого графа, который непрерывно модифицируется при изменении содержимого базы данных, либо изменении весовых коэффициентов, вычисленных для объектов графа, с учетом ассоциативного подхода пользователя к формированию содержимого персональной базы данных.
Другие варианты осуществления изобретения могут быть легко поняты специалистами в данной области техники на основании настоящего описания и практического использования раскрытого в нем изобретения. Настоящая заявка подразумевает охват всех разновидностей, использований или адаптаций настоящего изобретения, следующих из его общих принципов, и включает такие отклонения от изобретения, полагая их находящимися в известной или общепринятой практике в данной области техники. Настоящее описание и варианты осуществления следует рассматривать лишь в качестве примера, а фактический объем и сущность настоящего изобретения изложены в нижеприведенной формуле изобретения.
Следует понимать, что изобретение не ограничено точной структурой, описанной выше и показанной на чертежах, а без выхода за пределы своего объема может иметь разнообразные модификации и изменения. Объем изобретения ограничен только прилагаемой формулой изобретения.
Изобретение относится к вычислительной технике. Технический результат − обеспечение персональной интерактивности графического отображения содержимого персональной базы данных на экране ЭВМ. Способ отображения содержимого персональной базы данных на экране ЭВМ, причем персональная база данных содержит множество файлов данных, каждому из которых задан ассоциативный идентификатор, в котором: получают первичный граф, содержащий графическое представление заданных ассоциативных идентификаторов в виде сети, каждый узел которой содержит пиктограмму уникального ассоциативного идентификатора из числа заданных, причем узлы сети попарно соединены так, что между каждой парой пиктограмм, отображающих заданные одному файлу данных ассоциативные идентификаторы, сформирована связь; причем для каждого ассоциативного идентификатора вычисляют весовой коэффициент (m) субъективной значимости, определяющий размер его пиктограммы, а для каждой связи вычисляют весовой коэффициент (n), определяющий параметр отображения указанной связи, и получают модифицированный граф в ответ на каждое вычисление указанных весовых коэффициентов (m, n). 8 з.п. ф-лы, 7 ил.
1. Способ отображения содержимого персональной базы данных на экране ЭВМ, причем персональная база данных содержит множество файлов данных, каждому из которых задан, по меньшей мере, один ассоциативный идентификатор, ассоциирующийся у пользователя с указанным файлом данных, в котором:
получают первичный граф, содержащий графическое представление заданных ассоциативных идентификаторов в виде сети, каждый узел которой содержит пиктограмму уникального ассоциативного идентификатора из числа заданных ассоциативных идентификаторов, причем узлы сети попарно соединены таким образом, что между каждой парой пиктограмм, отображающих заданные одному файлу данных ассоциативные идентификаторы, сформирована связь;
отличающийся тем, что для каждого ассоциативного идентификатора вычисляют весовой коэффициент (m) субъективной значимости, определяющий размер его пиктограммы, а для каждой связи вычисляют весовой коэффициент (n), определяющий параметр отображения указанной связи, и
получают модифицированный граф в ответ на каждое вычисление, по меньшей мере, одного из указанных весовых коэффициентов (m, n).
2. Способ по п. 1, в котором дополнительно вычисляют весовой коэффициент (m) субъективной значимости каждого ассоциативного идентификатора с учетом количества файлов данных, которым пользователем задан указанный ассоциативный идентификатор, причем весовой коэффициент (m) субъективной значимости каждого ассоциативного идентификатора дополнительно определяет, по меньшей мере, одно из следующего: форму, цвет, прозрачность, положение пиктограммы на графе.
3. Способ по п. 2, в котором весовой коэффициент (m) субъективной значимости каждого ассоциативного идентификатора вычисляют с учетом также количества сформированных связей между указанным ассоциативным идентификатором и остальными ассоциативными идентификаторами.
4. Способ по п. 1, в котором весовой коэффициент (n) связи, сформированной между каждой парой ассоциативных идентификаторов, заданных одному файлу данных, вычисляют с учетом количества общих для указанной пары ассоциативных идентификаторов файлов данных, причем весовой коэффициент (n) связи дополнительно определяет, по меньшей мере, один из следующих параметров отображения: толщина, длина, цвет, прозрачность связи на графе.
5. Способ по п. 1, в котором дополнительно формируют связь «ФД - АИ» между каждым ассоциативным идентификатором и файлом данных, которому задан указанный ассоциативный идентификатор, и задают каждой такой связи «ФД - АИ» весовой коэффициент (k), характеризующий субъективную степень соответствия указанного ассоциативного идентификатора указанному файлу данных.
6. Способ по п. 4, в котором при вычислении весового коэффициента (n) связи, сформированной между каждой парой ассоциативных идентификаторов, заданных одному файлу данных, учитывают значения весовых коэффициентов (k) соответствующих связей «ФД-АИ».
7 Способ по п. 1, в котором каждая пиктограмма графа отображается в виде геометрической фигуры и содержит изображение уникального ассоциативного идентификатора.
8. Способ по п. 1, в котором по меньшей мере одна пиктограмма графа представляет собой выбираемый объект графа, который может быть выбран пользователем для формирования поискового запроса для поиска в персональной базе данных искомых файлов данных.
9. Способ по п. 1, в котором вычисление, по меньшей мере, одного из весовых коэффициентов (m, n) выполняют в ответ на одно из следующего: добавление файла данных, удаление файла данных, добавление ассоциативного идентификатора, удаление ассоциативного идентификатора, формирование связи между ассоциативными идентификаторами, удаление связи между ассоциативными идентификаторами.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| УСТРОЙСТВО ДЛЯ НАНЕСЕНИЯ ЗАЩИТНЫХ ПОКРЫТИЙ НА ИЗДЕЛИЯ СЛОЖНОЙ КОНФИГУРАЦИИ | 2001 |
|
RU2192503C1 |
| CN 102880687 A, 16.01.2013 | |||
| US 7305409 B2, 04.12.2007 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| RU 2012157159 A, 27.07.2014 | |||
| ОПРЕДЕЛЕНИЕ ПОРЯДКА ИНИЦИАЛИЗАЦИИ СТАТИСТИЧЕСКИХ ОБЪЕКТОВ | 2014 |
|
RU2656580C2 |
| FRANK VAN HAM et al., "Search, Show Context, Expland on Demand": Supporting Large Graph Exploration with Degree-of-Interest, IEEE TRANSACTIONS ON VISUALIZATION AND COMPUTER GRAPHICS, VOL | |||
| Прибор для нагревания перетягиваемых бандажей подвижного состава | 1917 |
|
SU15A1 |
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Инжектор отработанного пара для паровозов | 1924 |
|
SU953A1 |
| Размещено по адресу: https://ieeexplore.ieee.org/document/5290699. | |||

