Заявленное техническое решение относится к области распознавания документов. Распознавание строк является неотъемлемой частью любой системы распознавания документов. С ростом использования мобильных телефонов (смартфонов) и переносных терминалов все более актуальными становятся системы распознавания, работающие на самих устройствах (обладающих зачастую слабыми энергоэффективными вычислительными процессорами) без передачи изображения на сервер.
Из уровня техники известны различные способы распознавания документов. Однако, часть источников информации описывают системы распознавания в целом, причем как правило они рассчитаны на обработку черно-белых (то есть, предположение, что бумага белая, а текст в основном черный) документов на сервере: так, в патенте US 10943105 В2 (опублик. 09.03.2021) предложена общая схема системы извлечения информации из изображений счетов, однако распознавание строк там упомянуто лишь в общих словах (говорится, что после получения изображения одиночных строк их нужно распознать). То есть патент US 10943105 В2 (опублик. 09.03.2021) не определяет именно способ распознавания строки, а использует его верхнеуровнево.
В патентах US 10936862 В2 (опублик. 02.03.2021) и US 20180137350 А1 (опублик. 24.11.2020) одним коллективом предложена система распознавания строк и ее развитие. В обоих патентах система рассчитана на работу на сервер и не подходит для работы на конечном устройстве по своему построению.
В патенте ЕР 1598770 В1 (опублик. 10.12.2008) также описывает систему распознавания, также не рассчитанную на работу на конечным устройствах. Также в данной системе предполагается ряд этапов, которые пригодны лишь для документов с простым фоном, например, черный текст на белом листе бумаги, однако не пригодны для различных бланков со сложными фонами.
Задачей заявленного изобретения является устранение недостатков известного уровня техники. Технический результат заключается в обеспечении способа оптического распознавания текстовых строк на мобильном устройстве с изображений документов, основанный на полносверточной ИНС, квазисимвологиях и динамическом программировании, который позволяет обеспечить возможность распознавания изображения текстовой строки, без передачи данных на сервер, без ограничения общности на письменность или язык, которые содержит строка.
Поставленная задача решается, а заявленный технический результат достигается посредством заявленного способа оптического распознавания текстовых строк с изображений документов, основанный на полносверточной ИНС, квазисимвологиях и динамическом программировании.
На фигурах представлены:
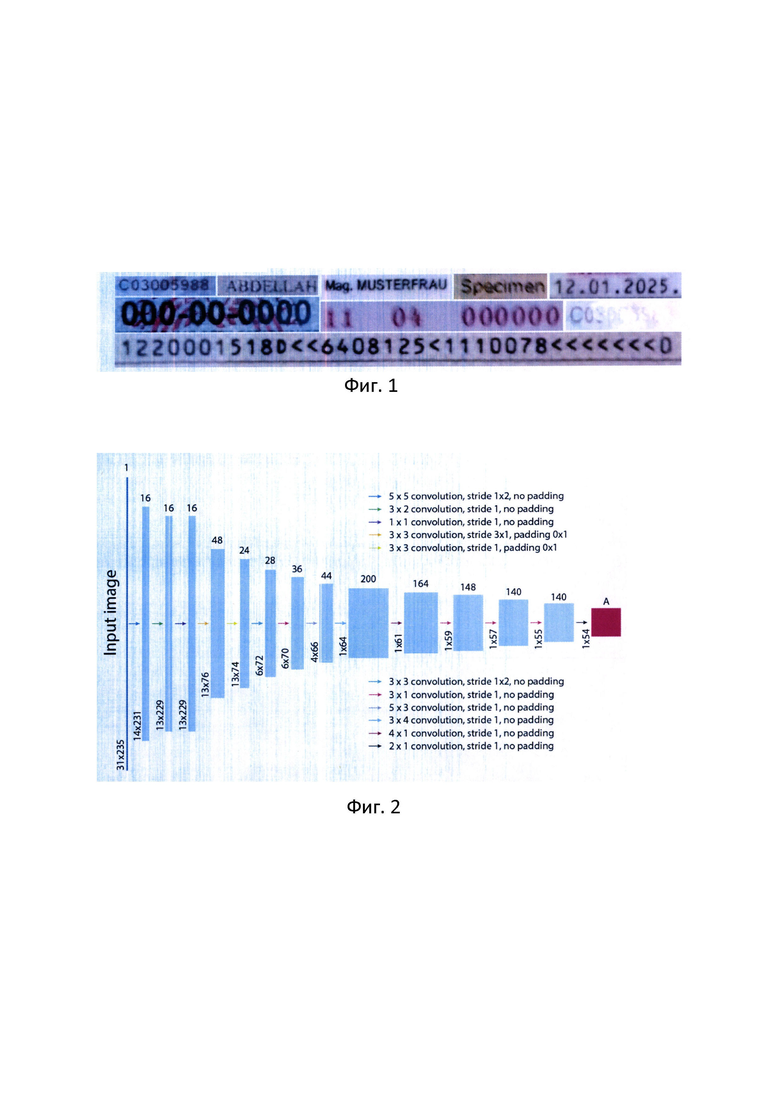
Фиг. 1: Примеры входных данных, подаваемых в модуль распознавания строк
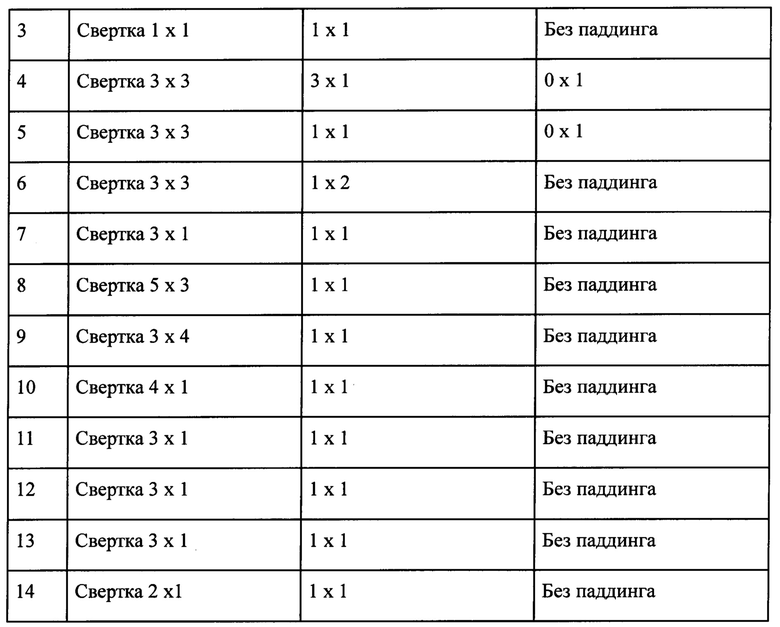
Фиг. 2: Архитектура полносверточной ИНС.
Заявленный способ оптического распознавания текстовых строк на мобильном устройстве с изображений документов, основанный на полносверточной ИНС с, квазисимвологиях и динамическом программировании заключается в том, что получают входное изображение, далее приводят входное изображение размера W × Н к изображению фиксированной высоты W × Н1,
применяют полносверточную нейронную сеть для получения проекции изображения на горизонтальную ось Р(х) размера W1× 1 × А, где А - размер алфавита распознавания,
строят проекцию Р1(х) размера W × 1 × А для получения полного соответствия между столбцами входного изображения и проекции,
с помощью динамического программирования на основе P1(x) строят путь сегментации строки с учетом предзаданных ограничений на ширину символов w ∈ [wmin, wmax],
при этом после построения проекции изображения на горизонтальную ось с помощью полносверточной сети, оценивают максимально допустимое число kmax символов на данном изображении по ширине изображения и ограничений на ширину символов w ∈ [wmin, wmax], которые установлены исходя из:
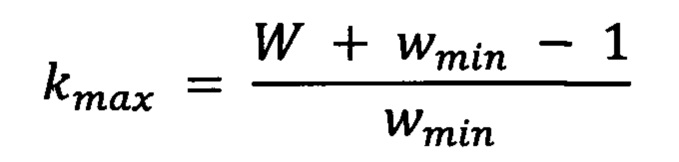
Далее, исходя из [wmin, wmax], задают начальные значения для столбцов, которые могут содержать начало первого символа, далее строят возможные пути в матрице размера W × kmax:
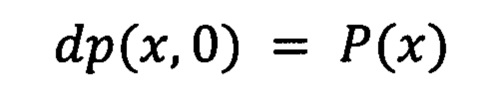
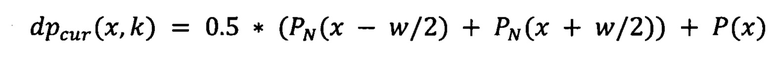
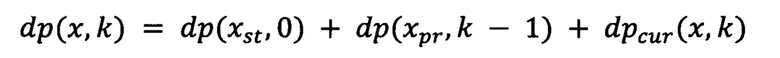
где PN - значения проекции строки для синтетического класса, xpr - столбец предыдущего лучшего состояния для текущего пути, k - индекс текущего символа, w - ширина символа.
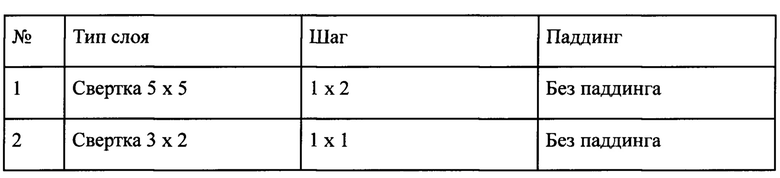
Архитектура полносверточной ИНС (см. фиг. 2) описана в Таблице 1. Данная сеть имеет 14 сверточных слоев (слоев другого типа в ней нет). Данная реализация принимает на вход изображение в градациях серого, т.е. одноканальное, размера 235 × 31, а выдает матрицу размера 54 × 1 × А, где А - размер распознаваемого алфавита, например, если мы распознаем заглавные буквы русского алфавита и пробел, то А=35, то есть 33 буквы, 1 пробел и 1 синтетический пин.
Таблица 1
Также помимо полносверточной сети с выходом размера W1 × 1 × А, в рамках данного подхода могут использоваться другие сети, применимые на изображения, например, метрические сети, у которых выход будет W1 × 1 × D, где D - размер вектора признаков изображения. Тогда после построения проекции дополнительно проводят выбор классов исходя из базы данных идеалов, хранящихся в рамках системы распознавания. Такой подход актуален для письменностей с большим число символов, например, для китайских иероглифов.
Теперь разберем подробнее предложенный синтетический класс, а именно класс "разрезов" между символами. Важно подчеркнуть, что в заявленном техническом решении не сегментируют строку на символы, а для каждого столбца изображения получают оценку вероятности разреза в нем (наравне с оценками обычных символов алфавита). Таким образом, само обучение сети может производится обратным распространением ошибки с помощью стохастического градиентного спуска, более современного метода ADAM и других аналогичных подходов.
Таким образом, ключевое решение заявленного способа заключается в добавлении к выходному набору пинов полносверточной нейронной сети синтетического класса "разрезов" между символами.
Для обучения сети с таким пином важна аннотация для данных, содержащая координаты начал и концов символов с точностью, до пикселя. Рассмотрим пример аннотации одной строки используемых данных.

Значения символов в виде кодов юникода в десятичной системе счисления представлены в массиве "values". Таким образом, в данном примере у нас строка из пяти символов. "line_rect" задает окаймляющий прямоугольник строки, "cuts_x" задает абсциссы разрезов между символами, "start_x" и "end_x" - абсциссы начала и конца каждого символа, "blines" задают горизонтальные линии, ограничивающие текст (по аналогии с типографией), а именно ординаты, где проходят так называемые ascender line, cap line, mean line, baseline, descender line, "let_blines" задают начало и конец каждой буквы по вертикали. Наличие "start_x", "end_x" и "cuts_x" является принципиальным для возможности обучения с использованием квазисимвологии (специальным синтетическим пином).
Для обучения сети были использованы синтезированные данные, так как получение подобной ручной аннотации - это долго, дорого и содержит множество ошибок. Также использование синтетических данных снимает ограничения на языки, так как для создания данных нужен текст (например, в файле.txt), шрифт (например, в файле.ttf) и фон (любое цветное изображение, соответствующее задаче).
Также при обучении возможно использование аугментации данных, то есть добавление искажений, например, смаз, гауссов шум, начертание дополнительных линий, в случаях, когда целевые данные для распознавания их содержат (например, как данные на фиг. 1).
Само по себе обучение нейронных сетей осуществляется на персональном компьютере с видеокартой или же на кластере с несколькими видеокартами стандартными методами обучения, например, стохастическим градиентным спуском.
Создание обучающих данных с правильными аннотациями осуществляется с помощью использования векторных представлений символов и их рендеринга на изображение. Аугментация данных может быть осуществлена как с помощью различных методов обработки изображений, так и с помощью нейросетевых моделей класса изображение-в-изображение.
Из литературы известна возможность создания полносверточных сетей, запускаемых на смартфоне, для решения задачи поиска и сегментации текста. Также есть ряд более сложных подходов, запускаемых на сервере, где полносверточная сеть является одним из этапов работы. В нашем подходе добавление синтетического пина даст возможность эффективно обучить полносверточые распознающие сети без их утяжеления.
Таким образом, сочетание должным образом созданных данных и нового подхода к применению полносверточной нейросети с квазисимвологией (синтетическим классом) позволяет распознавать текстовые строки непосредственно на мобильном устройстве без передачи изображений куда-либо.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| Способ нейросетевого распознавания рукописных текстовых данных на изображениях | 2024 |
|
RU2837308C1 |
| СПОСОБ И СИСТЕМА ПОИСКА ГРАФИЧЕСКИХ ИЗОБРАЖЕНИЙ | 2022 |
|
RU2807639C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ И ТАБЛИЦ В ДОКУМЕНТАХ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ГЛОБАЛЬНОГО КОНТЕКСТА ДОКУМЕНТА | 2019 |
|
RU2723293C1 |
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| ДЕТЕКТИРОВАНИЕ РАЗДЕЛОВ ТАБЛИЦ В ДОКУМЕНТАХ НЕЙРОННЫМИ СЕТЯМИ С ИСПОЛЬЗОВАНИЕМ ГЛОБАЛЬНОГО КОНТЕКСТА ДОКУМЕНТА | 2019 |
|
RU2721189C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ И ОЦЕНКИ ЕЕ ПОЛНОТЫ В ЭЛЕКТРОННЫХ ДОКУМЕНТАХ СЕТИ ИНТЕРНЕТ | 2013 |
|
RU2550543C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| ОБНАРУЖЕНИЕ ТЕКСТОВЫХ ПОЛЕЙ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2699687C1 |
| ПРЕДСКАЗАНИЕ ВЕРОЯТНОСТИ ПОЯВЛЕНИЯ СТРОКИ С ИСПОЛЬЗОВАНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ ВЕКТОРОВ | 2018 |
|
RU2712101C2 |
Изобретение относится к области информационных технологий, а именно к области распознавания документов. Технический результат заключается в обеспечении возможности распознавания изображения текстовой строки, без дополнительной передачи данных на сервер, без ограничения общности на письменность или язык, которые содержит строка. Заявленный способ оптического распознавания текстовых строк на мобильном устройстве с изображений документов, основанный на полносверточной ИНС, квазисимвологиях и динамическом программировании, заключается в том, что получают входное изображение, далее приводят входное изображение размера W × Н к изображению фиксированной высоты W × Нг, применяют полносверточную нейронную сеть для получения проекции изображения на горизонтальную ось Р(х) размера W1 × 1 × А, где А - размер алфавита распознавания, строят проекцию Р1(х) размера W × 1 × A для получения полного соответствия между столбцами входного изображения и проекции, с помощью динамического программирования на основе Р1(х) строят путь сегментации строки с учетом предзаданных ограничений на ширину символов w ∈ [wmin, wmax]. 2 ил.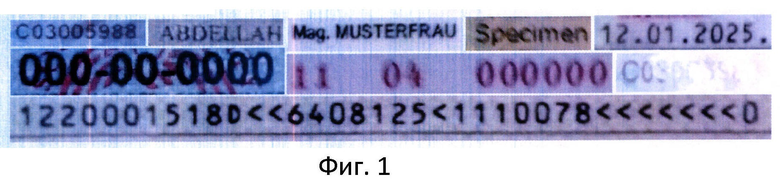
Способ оптического распознавания текстовых строк на мобильном устройстве с изображений документов, основанный на полносверточной ИНС, квазисимвологиях и динамическом программировании, заключающийся в том, что получают входное изображение, далее приводят входное изображение размера W × Н к изображению фиксированной высоты W × Н1,
применяют полносверточную нейронную сеть для получения проекции изображения на горизонтальную ось Р(x) размера W1 × 1 × А, где А - размер алфавита распознавания,
строят проекцию Р1(х) размера W × 1 × А для получения полного соответствия между столбцами входного изображения и проекции,
с помощью динамического программирования на основе Р1(х) строят путь сегментации строки с учетом предзаданных ограничений на ширину символов w ∈ [wmin, wmax],
при этом после построения проекции изображения на горизонтальную ось с помощью полносверточной сети, оценивают максимально допустимое число kmax символов на данном изображении по ширине изображения и ограничений на ширину символов w ∈ [wmin, wmax], которые установлены исходя из:
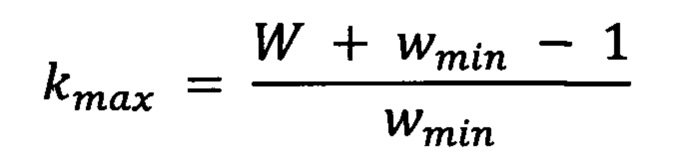 ,
,
далее, исходя из [wmin, wmax], задают начальные значения для столбцов, которые могут содержать начало первого символа, далее строят возможные пути в матрице размера W × kmax:
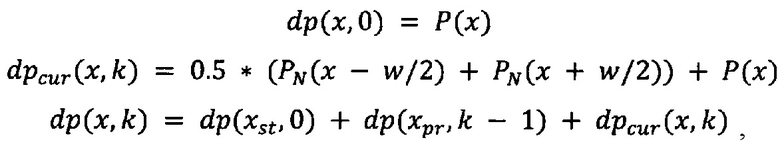
где PN - значения проекции строки для синтетического класса, xpr - столбец предыдущего лучшего состояния для текущего пути, k - индекс текущего символа, w - ширина символа.
| US 10943105 B2, 09.03.2021 | |||
| US 20180137350 А1, 17.05.2018 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБУЧЕНИЯ КЛАССИФИКАТОРА И РАСПОЗНАВАНИЯ ТИПА | 2015 |
|
RU2643500C2 |

