Изобретение относится к области информационных технологий, а именно к области создания, сопровождения, анализа и использования баз данных, содержащих соответствующее лингвистическое обеспечение и нормативные документы, регламентирующие определенный род деятельности.
Известен способ хранения и выборки данных n-мерных интервалов (патент RU №2298221 от 12.07.05 г., МПК8 G06F 17/30), заключающийся в том, что формируют пространственную структуру данных с элементами в виде исходных n-мерных интервалов, определяют линзу, являющуюся 2 n-мерным интервалом оператора интервального запроса, представляющего собой инструкцию о выборке данных требуемых n-мерных интервалов с описанием заданного интервала и условий расположения относительно него требуемых, причем линзу определяют согласно розе интервалов, представляющей собой виртуальную двумерную геометрическую диаграмму областей таких 2 n-мерных точек в осях Хр и Yp их пространства, координатами которых являются соответствующие координаты p-проекций соответствующих этим точкам n-мерных интервалов, где p-проекция n-мерного интервала это его проекция на p-ось базиса его пространства; конструируют и сохраняют на физическом носителе информации оператор интервального запроса о выборке из структуры данных таких точек, которые покрываются этой линзой, выполняют с помощью этого оператора интервальный запрос к структуре, результатом чего будет множество данных 2 n-мерных точек, одновременно являющихся и данными соответствующих им искомых интервалов.
Недостатком этого способа является то, что он применим к двумерному пространству и позволяет систематизировать базу данных по двум характеристическим признакам, что существенно сужает область и возможности по хранению, идентификации и поиску информации, контролю взаимосвязей и полноты имеющейся информации в выделенной области.
Наиболее близким техническим решением, выбранным в качестве прототипа способа, является способ хранения данных для поддержки системы интеллектуального анализа (патент RU №2297665 от 28.04.03 г., МПК8 G06F 17/30), заключающийся в том, что, по меньшей мере, в одном хранилище данных сохраняют объекты, взаимодействуют с хранилищем данных посредством, по меньшей мере, одного первого механизма анализа, на основе первого набора правил, соответствующего первому механизму анализа, генерируют, по меньшей мере, один первый ключ, представляющий соответствующие характеристики объекта, с которым первый ключ соотнесен, направляют первый ключ, по меньшей мере, в один второй механизм анализа, на основе второго набора правил, соответствующего второму механизму анализа, генерируют, по меньшей мере, один второй ключ, представляющий соответствующие характеристики объекта, с которым второй ключ соотнесен, присоединяют первый и второй ключи к объектам и индексируют ключи и значения ключей, имеющиеся в хранилище данных, причем генерирование ключей в механизмах анализа и индексирование проводят раздельно.
Недостатком этого способа является то, что он предусмотрен для поиска информации методом последовательного сужения области поиска, что значительно увеличивает время поиска, в особенности при использовании его применительно к трехмерной базе знаний.
Известна справочная правовая система хранения и поиска данных (патент RU №2223537 от 22.11.01 г., МПК7 G06F 17/30, 17/40), содержащая блок выбора вида поиска, формирователь запроса, один выход которого связан с блоком проведения поиска, вход-выход которого соединен через соответствующие шины с базами данных системы, блоком отображения и контроллером, предназначенным для управления поиском данных, в систему введены блок выбора условий поиска, вход которого связан с выходом блока выбора вида поиска, первый выход которого связан со входом формирователя запроса, второй выход соединен со входом формирователя атрибутов фильтра, первый вход-выход которого связан со вторым входом-выходом формирователя запроса, второй вход-выход - с блоком памяти атрибутов фильтра, первый вход-выход формирователя запроса соединен с блоком памяти запросов.
Базами данных системы являются база данных правовой информации и/или база данных экономической информации, база данных энциклопедии ситуаций и/или база данных толкового словаря, и/или база данных последних изменений в законодательстве.
При этом блок выбора вида поиска выполнен с возможностью навигации по базам данных с поэтапным представлением отклассифицированных списков запрашиваемых документов и/или фрагментов документов. Система также может включать средство сортировки документов, связанное с памятью, указанное средство и память подключены через соответствующие шины системы к соответствующим блокам системы.
Средство сортировки документов предназначено для сортировки документов по дате издания документов или по юридической силе.
Система включает также средство поиска документов по заданному числу сходных признаков, связанное по соответствующим шинам с соответствующими блоками системы.
Недостатком этой системы является то, что она не обеспечивает представление информации, содержащейся в документах в предварительно обработанном виде, что увеличивает время получения необходимой информации, а также не гарантирует ее полноту и качество.
Наиболее близким техническим решением, выбранным в качестве прототипа, системы является вычислительная система для интеллектуального анализа данных (патент RU №2297665 от 28.04.03 г., МПК8 G06F 17/30), включающая в себя, по меньшей мере, одно хранилище данных, механизмы анализа более низкого уровня, механизмы анализа более высокого уровня, индексатор.
Система извлечения информации из данных, включающая в себя: по меньшей мере, одно хранилище, или склад данных, в котором содержатся объекты; по меньшей мере, один механизм анализа более низкого уровня, связанный с хранилищем данных и генерирующий выходные данные на основе первого набора правил, реализованных в указанном механизме анализа более низкого уровня; и, по меньшей мере, один механизм анализа более высокого уровня, принимающий выходные данные механизма анализа более низкого уровня и генерирующий свои выходные данные на основе второго набора правил, реализованных в указанном механизме анализа более высокого уровня, причем выходные данные механизмов анализа более низкого и более высокого уровней присоединены к объектам, содержащимся в хранилище данных.
В частных вариантах предложенной системы хранилище данных может представлять собой базу данных и может содержать вертикальные и горизонтальные таблицы. Вход в вертикальные таблицы может осуществляться с использованием выходных данных механизма анализа одного из вышеупомянутых уровней, а вход в горизонтальные таблицы - с использованием идентификации объекта. Выходными данными могут быть ключи, представляющие соответствующие характеристики объекта, которому эти ключи сопоставлены. Как альтернативный вариант, хранилищем данных может быть, например, файловая система.
При необходимости в системе может также использоваться индексатор, связанный с хранилищем данных, а также быстродействующая кэш-память на полупроводниках и процессор обработки запросов для выполнения запросов по меньшей мере от одного механизма анализа. Кроме того, с механизмами анализа могут быть связаны очереди работ.
В частном предпочтительном варианте индексатор содержит индексы ключей и значения ключей, имеющихся в структурах хранения данных, например, таблицах. Он также может содержать булевы индексы, хранящие значения "да" или "нет" на запросы по форме "имеет ли ключ k значение v?". Кроме того, индексатор может содержать интервальные индексы, хранящие интервалы значений ключей, а также индексы текста. При необходимости индексатор может представлять собой обобщенное воплощение текстового индексатора в виде инвертированного файла, индексирующего Web-документы и обеспечивающего интерфейс прикладного программирования (API) для поиска документов по ключевым словам.
В предпочтительном варианте индексатор может содержать определенные ключи, позволяющие осуществлять запросы в отношении конкретного объекта с применением булевой логики. Кроме того, в индексаторе могут содержаться графические данные, поддерживающие входящие и исходящие запросы.
Целесообразно, чтобы снабжение индексов метками и индексирование в индексаторе осуществлялось раздельно.
Недостатком этой системы является отсутствие программных средств для предварительного анализа области запроса базы данных на наличие и полноту необходимой документации по интересующему вопросу, что может привести к трудоемкому поиску несуществующей информации.
Технической задачей, на решение которой направлено предлагаемое изобретение, является формирование упорядоченной, организованной по определенным логическим, функциональным, иерархическим, семантическим правилам базы данных нормативной документации любого вида деятельности, разработанной с применением упрощенного специализированного языка (например - упрощенного технического русского на основе ASD STE-100 2007 г.), которая предназначена для анализа существующего состояния нормативно-информационного обеспечения в любой предметной области, определения недостающей информации в этой предметной области, разработки недостающей информации и ее использования при решении прикладных задач, поддержания базы знаний в актуальном состоянии, а также сокращение времени и затрат вычислительных ресурсов на обработку больших массивов данных с целью извлечения требуемой информации.
Поставленная задача решается в результате того, что применяются способ и система организации и функционирования базы данных нормативной документации, заключающиеся в представлении базы знаний в виде трехмерного информационного пространства, в котором полный идентификационный номер каждого предварительно подготовленного и проанализированного документа или его часта помещают в определенный кластер или кластеры, образованные ортами (единичными отрезками) характеристических признаков, позволяющими однозначно определить принадлежность документа или его части к тому или иному направлению области деятельности. Полный идентификационный номер документа формируют из кодов орт составляющих характеристических признаков и идентификационного номера документа. Если документ по какой-либо из осей определяется несколькими составляющими характеристических признаков, то код орта по этим осям заменяют нулевым значением, что в дальнейшем упрощает его поиск. Оригинал и отформатированную копию размещают отдельно с таблицами принадлежности к характеристическим признакам. Этот процесс выполняют со всеми существующими на данный момент документами выбранной области деятельности. Затем производят анализ каждого кластера на полноту определения ограниченной им сферы деятельности содержащимися в кластере документами. Результат анализа заносят в этот же кластер, что позволяет сделать вывод о необходимости разработки дополнительных документов или о доработке существующих, а также существенно облегчает работу над их созданием. При поступлении новых документов, действия по обработке и размещению документов и их характеристик в базе данных повторяются, что позволяет постоянно содержать базу данных в актуальном состоянии.
Система организации и функционирования базы данных нормативной документации содержит хранилище данных, систему управления базой данных (СУБД), включающую синтаксический анализатор, лингвистический анализатор, XML редактор и интеллектуальный анализатор, предназначенный для проверки по критериям полноты информации, интерфейс анализа и формирования данных, связанный с системным администратором и предназначенный для предварительного анализа документа и объема документации посредством синтаксического, лингвистического и интеллектуального анализаторов для определения характеристических признаков и их составляющих с присвоением кодовых обозначений и введением указанных данных в СУБД для присвоения трем осям трехмерного информационного пространства формируемой базы данных названий характеристических признаков, а также составления соответствующих кластеров с формированием их кодовых обозначений. Интерфейс формирования базы данных предназначен для связи системного администратора с редактором XML для перевода документа в XML формат с кодовыми обозначениями, при этом СУБД предназначен для расположения отформатированного документа в базе данных, синтаксический и лингвистический анализаторы предназначены также для определения принадлежности анализируемого документа к каждому кластеру трехмерного информационного пространства, при определении однозначного соответствия документа одному кластеру СУБД предназначен для формирования полного идентификационного номера документа из кода ортов и идентификационного номера и помещения документа в соответствующий кластер трехмерного информационного пространства базы данных, интерфейс пользователя предназначен для доступа к документу или информации с использованием сформированных кодовых обозначений через кластер трехмерного информационного пространства базы данных.
Интеллектуальная надстройка СУБД содержит механизм проверки ссылок, механизм проверки непротиворечивости информации, интеллектуальный анализатор, механизм генерации ссылок.
База данных содержит базу данных оригиналов документов, базу данных документов в формате XML с атрибутами, ключами и сгенерированными ссылками, трехмерное информационное пространство, состоящее из кластеров, образованных составляющими характеристических признаков какой-либо области деятельности, набор синтаксических правил для написания текстовой, нормативной документации, общую терминологическую базу, терминологические базы по предметным областям, критерии полноты документации в кластере, таблицы принадлежности документов к характеристическим признакам, базы шаблонов документов, критерии принадлежности документов к кластерам.
Графический интерфейс содержит интерфейс формирования базы данных, интерфейс анализа базы данных, интерфейс пользователя для поиска и анализа информации и интерфейс редактора для создания документов.
Таким образом, поиск и анализ необходимой информации производят не только традиционным путем с помощью формирования и обработки запроса (движение от пользователя к документу), но и в обратном направлении с помощью подготовки базы данных для ожидаемого пользователя (движение от документа к пользователю). В системе также предусмотрены средства для работы с базой данных, для поиска, контроля и анализа информации, документов, областей деятельности, для создания и корректировки документов системными администраторами, экспертами и пользователями в соответствии с правами доступа.
Таким образом, заявляемые способ и система организации и функционирования базы данных нормативной документации соответствует критерию изобретения «новизна». Сравнение заявляемого решения не только с прототипом, но и с другими защищенными патентами техническими решениями в данной области техники, не позволило выявить в них признаки, отличающие заявляемое решение от прототипа, что позволяет сделать вывод о соответствии критерию «изобретательский уровень». Заявляемое решение пригодно к осуществлению промышленным путем.
Способ и система иллюстрируются прилагаемыми чертежами:
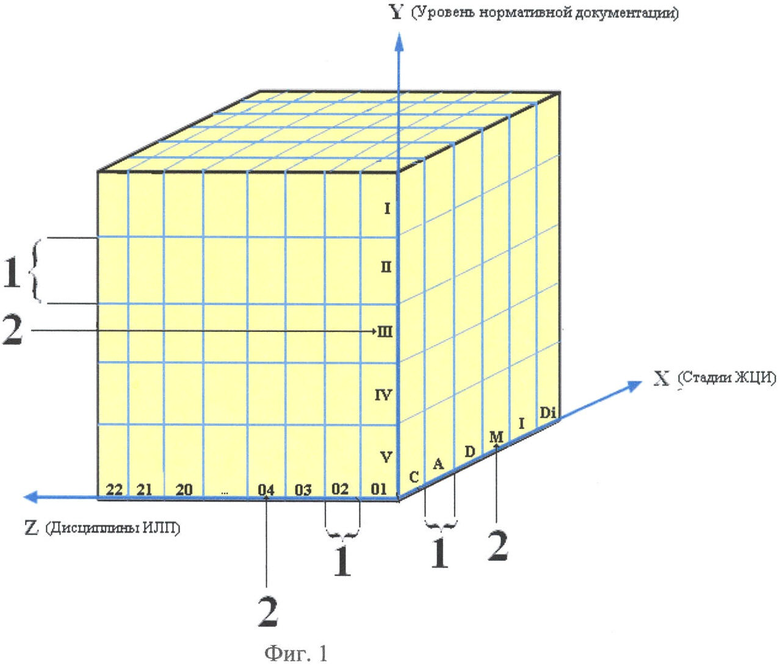
на фиг.1 изображена концепция системы базы данных нормативной документации Интегрированной Логистической Поддержки (ИЛП) (Послепродажного обслуживания (ППО)), расположенной по характеристическим признакам;
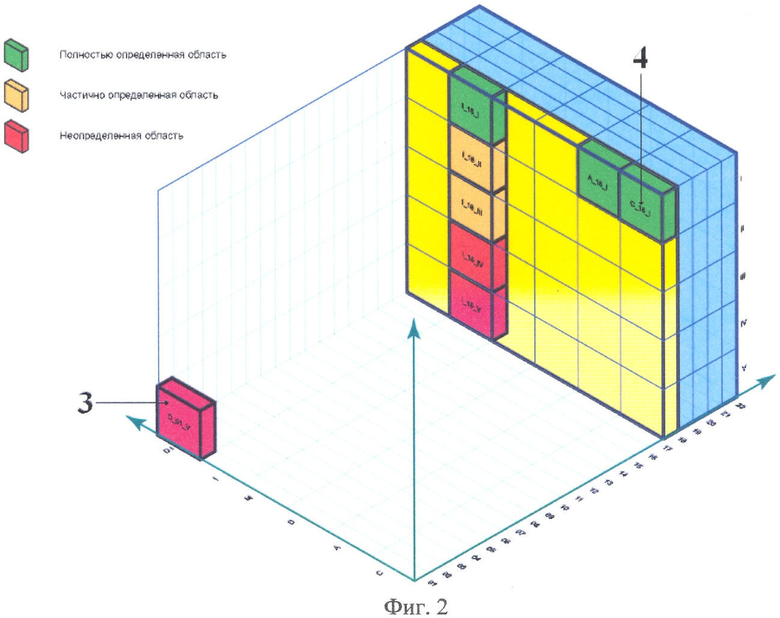
на фиг.2 изображен принцип построения базы данных нормативной документации, состоящей из кластеров;
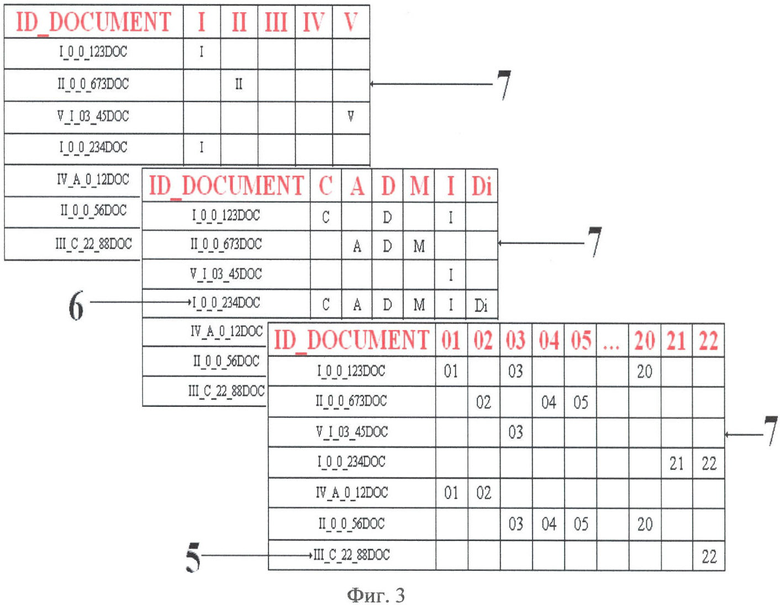
на фиг.3 изображены таблицы принадлежности к характеристическим признакам, хранимые вместе с оригиналами;
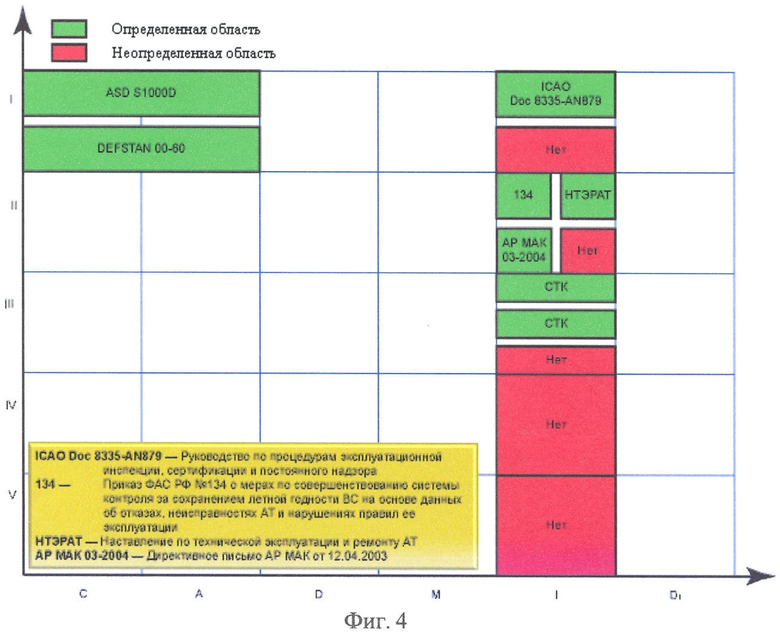
на фиг.4 изображен Вариант «среза» нормативной базы ИЛП в плоскости «Этапы Жизненного цикла (ЖЦ) - Уровень Нормативной документации (НД)» для области нормативных документов, регламентирующих сбор, обработку, анализ и использование информации об эксплуатации воздушного судна (ВС);
на фиг.5 изображена функциональная схема системы управления базой данных нормативной документации;
на фиг.6 изображена блок-схема системы управления базой данных нормативной документации.
Способ организации и функционирования базы данных нормативной документации осуществляют в несколько этапов.
1 этап - организация трехмерного информационного пространства базы данных нормативной документации.
Весь объем нормативной документации выбранной области деятельности (оригиналы документов) помещают в отдельную область базы данных.
Анализируют выбранную область деятельности, выбирают три основных характеристических признака и присваивают их названия координатным осям. Для примера, в качестве области деятельности рассмотрим ИЛП (ППО). За характеристические признаки ИЛП принимаем (Фиг.1): ось Х - этапы деятельности, характеризующие жизненный цикл изделия; ось Y - уровни нормативной документации (в данном примере уровни нормативно-технической документации); ось Z - направления деятельности, представляющие собой дисциплины ИЛП (ППО).
Определяют составляющие характеристических признаков и откладывают их на координатных осях.
Ортам (единичным отрезкам) - поз.1 (Фиг.1), которые определяют составляющие характеристических признаков, присваивают кодовые обозначения - поз.2 (Фиг.1).
Для этапов жизненного цикла изделий (ось X):
С (Concept) - предварительный этап (Техническое задание (ТЗ), Техпредложение);
A (Assessment) - этап проектирования (Эскизный, технический проекты);
D (Demonstration) - этап изготовления опытного образца и испытаний;
М (Manufacture) - этап сертификации и серийного производства;
I (In-service) - этап эксплуатации;
Di (Disposal) - этап утилизации.
Для уровней нормативной документации (ось Y):
I - Международные, государственные стандарты (ГОСТ, Федеральные авиационные правила (ФАЛ), ASD…);
II - Отраслевые стандарты (ОСТ);
III - Корпоративные стандарты (СТК);
IV - Стандарты предприятия (СТП);
V - Руководства, положения, методики, инструкции.
Для дисциплин ИЛП (ось Z):
01 - Управление ИЛП;
02 - Анализ логистической поддержки;
03 - Стоимость жизненного цикла изделий (ЖЦИ);
04 - Надежность и безопасность полетов;
05 - Эксплуатационная и ремонтная технологичность;
06 - Контролепригодность;
07 - Техническое обслуживание и ремонт (ТОиР);
08 - Готовность;
09 - Старение;
10 - Технические публикации;
11 - Управление архивом;
12 - Интеграция информационных систем;
13 - Поддержка программного обеспечения;
14 - Обучение и учебные средства;
15 - Людские ресурсы и человеческий фактор;
16 - Наземное оборудование;
17 - Инфраструктура;
18 - Послепродажная поддержка;
19 - Поддержка основного подрядчика;
20 - Поддержка снабжения;
21 - Упаковка, обращение, хранение и транспортировка;
22 - Утилизация.
Необходимо, чтобы эти обозначения характеризовали составляющие характеристических признаков так, как это принято на практике.
Из орт характеристических признаков образуют кластеры - поз.3 (фиг.2).
Составляют код каждого кластера - поз.4 (Фиг.2) из кодов соответствующих орт характеристических признаков.
Таким образом, получают трехмерное информационное пространство, состоящее из кластеров с присвоенными им кодами.
Это пространство помещают вместе с другими базами данных в общем хранилище информации, например в виде объектно-ориентированной базы данных.
2 этап - заполнение трехмерного информационного пространства базы данных нормативной документации.
Каждый документ переводят в формат XML, определяют ключи и атрибуты, ссылки для критериев поиска и анализа. Документ в отформатированном виде располагают в соответствующей области базы данных.
Каждый отформатированный документ анализируют на предмет принадлежности документа, части документа или информации, содержащейся в документе, каждому кластеру трехмерного информационного пространства.
Если документ удовлетворяет критериям принадлежности и однозначно соответствует только одному кластеру, то формируют полный идентификационный номер документа или его части, состоящий из кода ортов по трем осям и идентификационного номера документа - поз.5 (Фиг.3).
Если документ по какой-либо оси принадлежит нескольким кластерам, то код орта по этой оси заменяют нулевым значением - поз.6 (Фиг.3).
Сформированный полный идентификационный номер документа помещают в кластер или кластеры, к которым он принадлежит.
Для доступа к информации или документу через кластер формируют ключи, индексы и атрибуты и присоединяют их к документу в формате XML. По мере анализа документов заполняют таблицы принадлежности к характеристическим признакам - поз.7 (Фиг.3), хранящиеся в базе данных и позволяющие по полному идентификационному номеру определить составляющие характеристических признаков, к которым принадлежит документ.
3 этап - анализ каждого кластера на полноту определения ограниченной им сферы деятельности содержащимися в кластере документами.
Проверяют наличие документов в кластере и анализируют достаточность информации в этих документах по критериям полноты документации, используя надстройки базы данных.
Если документы в кластере отсутствуют, то область, ограниченная этим кластером, считается неопределенной - красные кластеры на Фиг.2.
Если документы в кластере имеются, но не полностью определяют его область, то область, ограниченная этим кластером, считается частично определенной - оранжевые кластеры на Фиг.2.
Если документы в кластере полностью отвечают критериям полноты документации, то область, ограниченная этим кластером, считается полностью определенной - зеленые кластеры на Фиг.2.
Результаты анализа помещают в проанализированный кластер и хранят вместе с полными идентификационными номерами документов. Это позволяет пользователю не только быстро обратиться к необходимым ему документам, но и сделать вывод о наличии в них необходимой информации. Для анализа более широкой области, определяющей одну составляющую или весь характеристический признак, делают срез трехмерного информационного пространства в выбранной плоскости - Фиг.4.
4 этап - наполнение базы данных недостающей нормативной документацией (создание документов).
Используя надстройки базы данных и результаты этапа 3:
- анализируют состояние обеспечения нормативной документацией любого направления выбранной области деятельности;
- принимают решение о необходимости создания нового или дополнения существующего документа, основываясь на том, что в каждом кластере трехмерного информационного пространства в идеальном случае должен содержаться только один документ, полностью описывающий ограниченную этим кластером область деятельности. Этим достигается простота и эффективность использования нормативной документации;
- выполняют разработку нормативных документов, используя базу шаблонов и критерии полноты документации;
- проводят этот документ по этапам 2 и 3 для определения качества и полноты информации и для помещения документа в трехмерное информационное пространство.
5 этап - использование базы данных нормативной документации.
С помощью средств базы данных:
- выбирают и находят нормативные документы по одному, двум или трем характеристическим признакам;
- осуществляют доступ к информации по интересующему вопросу;
- решают задачи, связанные с поиском основных и дополнительных документов по интересующим вопросам, используя механизмы ссылок, атрибуты и ключи, прикрепленные к информации.
6 этап - поддержание базы данных нормативной документации в актуальном состоянии.
На этом этапе постоянно ведут работу по вводу новых, разработанных на других уровнях и с использованием других средств документов, изъятию документов, утративших силу и актуальность.
Данные анализа этих документов на этапах 2-4 (учитывая уровень компетенции пользователя) доводят до разработчиков, ставя перед собой цель постоянного предварительного анализа документации с помощью данного способа и системы перед вводом документов в действие.
При помощи системы постоянно контролируют полноту и качество получаемой информации.
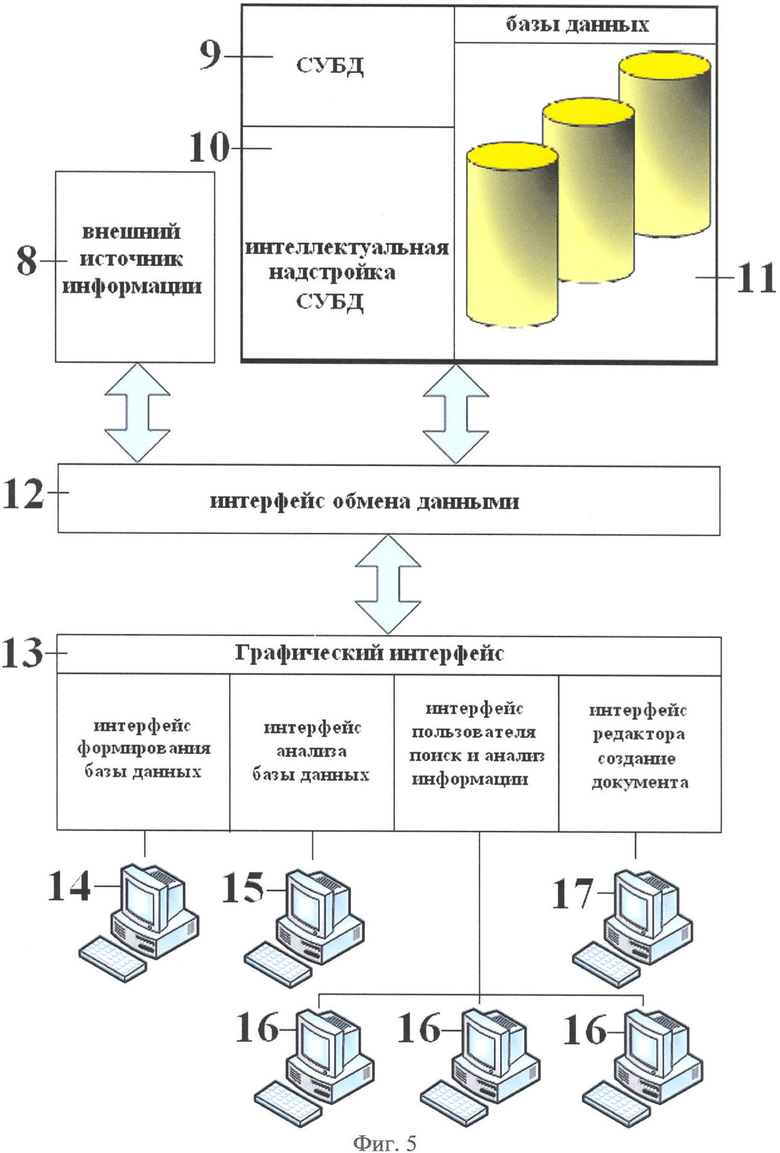
Система организации и функционирования базы данных нормативной документации предназначена для осуществления одноименного способа и состоит из (Фиг.5 и Фиг.6):
1. Внешнего источника информации -поз.8.
2. Системы управления базой данных (СУБД) - поз.9.
3. Интеллектуальной надстройки СУБД - поз.10, которая включает в себя:
- синтаксический анализатор (parser) - поз.10.1;
- лингвистический анализатор - поз.10.2;
- XML редактор - поз.10.3;
- механизм проверки ссылок - поз.10.4;
- механизм проверки непротиворечивости информации - поз.10.5;
- интеллектуальный анализатор - поз.10.6;
- механизмы генерации ссылок - поз.10.7 и 10.8.
4. Базы данных - поз.11, состоящей из:
- базы данных, содержащей оригиналы документов - поз.11.1;
- базы данных, содержащей документы в формате XML с атрибутами и ключами - поз.11.2;
- трехмерное информационное пространство, состоящее из кластеров, образованных составляющими характеристических признаков - поз.11.3;
- набор синтаксических правил для написания текстовой, нормативной документации - поз.11.4;
- общая терминологическая база - поз.11.5;
- терминологические базы по предметным областям - поз.11.6;
- критерии полноты документации в кластере - поз.11.7;
- таблицы принадлежности к характеристическим признакам - поз.11.8;
- база шаблонов документов - поз.11.9;
- критерии принадлежности документов - поз.11.10.
5. Интерфейс обмена данными - поз.12.
6. Графический интерфейс - поз.13, состоящий из:
- интерфейса формирования базы данных - поз.13.1;
- интерфейса анализа базы данных - поз.13.2;
- интерфейса пользователя для поиска и анализа информации - поз.13.3;
- интерфейса редактора для создания документов - поз.13.4.
7. Места системного администратора - поз.14.
8. Места эксперта - поз.15.
9. Мест пользователей - поз.16.
10. Места редактора - поз.17.
Система работает следующим образом.
На 1 этапе системный администратор с помощью интерфейса формирования базы данных (поз.13.1) вводит с внешнего источника информации в базу данных оригиналов (поз.11.1) весь объем нормативной документации определенного рода деятельности.
Затем, эксперт через интерфейс анализа базы данных (поз.13.2) выполняет предварительный анализ каждого документа и всего объема документации, используя синтаксический (поз.10.1), лингвистический (поз.10.2) и интеллектуальный (поз.10.6) анализаторы на предмет определения трех основных характеристических признаков и их составляющих. Для каждой составляющей вводятся кодовые обозначения.
Одновременно составляются или дополняются общая терминологическая база и терминологические базы по предметным областям. СУБД (поз.9), при помощи программного обеспечения, основываясь на введенных данных, присваивает трем осям названия характеристических признаков, единичным отрезкам составляющих характеристических признаков - названия и кодовые обозначения.
Из составляющих характеристических признаков СУБД (поз.9) составляет кластеры и формирует их коды. Далее из всей совокупности кластеров СУБД (поз.9) организует трехмерное информационное пространство (поз.11.3) и помещает его в виде объектно-ориентированной или реляционной базы данных в общую базу данных (поз.11).
На этапе 2 системный администратор с помощью интерфейса формирования базы данных (поз.13.1), используя XML редактор (поз.10.3), переводит каждый документ в формат XML, определяет ключи и атрибуты. Механизмы генерации ссылок (поз.10.7, 10.8) генерируют ссылки для критериев поиска и анализа.
Документ в отформатированном виде располагают в базе данных (поз.11.2), содержащей документы в формате XML с атрибутами и ключами. Далее, применяя синтаксический (поз.10.1), лингвистический (поз.10.2) и интеллектуальный (поз.10.6) анализаторы, эксперт определяет критерии принадлежности документов к каждому кластеру (поз.11.10) и анализирует каждый отформатированный документ на предмет принадлежности документа, части документа или информации, содержащейся в документе, каждому кластеру трехмерного информационного пространства.
Если документ удовлетворяет критериям принадлежности и однозначно соответствует только одному кластеру, то по команде эксперта СУБД (поз.9) формирует полный идентификационный номер документа или его части, состоящий из кода ортов по трем осям и идентификационного номера документа.
Если документ по какой-либо оси принадлежит нескольким кластерам, то код орта по этой оси СУБД (поз.9) заменяет нулевым значением.
Эти номера СУБД (поз.9) помещает в соответствующий кластер или кластеры и по мере анализа документов заполняет таблицы принадлежности к характеристическим признакам (поз.11.8), хранящиеся в базе данных.
Для доступа к информации или документу через кластер формируют ключи, индексы и атрибуты и присоединяют их к документу в формате XML.
На 3 этапе эксперт при помощи интеллектуального анализатора (поз.10.6), предназначенного для проверки по критериям полноты информации, определяет критерии полноты документации (поз.11.7) - общие и для каждого кластера.
Затем эксперт при помощи СУБД (поз.9) просматривает все кластеры на наличие документов и, если они имеются, при помощи интеллектуального анализатора (поз.10.6) анализирует эти документы и информацию, которая в них содержится по критериям полноты документации (поз.11.7).
Одновременно механизмы генерации ссылок (поз.10.7, 10.8) генерируют ссылки.
Информация о наличии документов и результаты анализа хранятся в кластере, к которому они относятся.
На этапе 4 редактор при помощи интерфейса редактора (поз.13.4) создает новый документ, опираясь на результаты этапа 3. При этом используется набор синтаксических правил (поз.11.4) для написания текстовой, нормативной документации, общая терминологическая база (поз.11.5) и терминологические базы по предметным областям (поз.11.6), критерии полноты документации в кластере (поз.11.7), базы шаблонов документов (поз.11.9).
Разработка документов ведется редактором и интеллектуальной надстройкой СУБД (поз.10). В процессе разработки документ проходит этапы 2 и 3 для принятия решения об его качестве и полноте.
5 этап осуществляется пользователем через интерфейс пользователя (поз.13.3).
СУБД (поз.9), совместно с интеллектуальной надстройкой СУБД (поз.10) осуществляет поиск необходимых документов и необходимой информации по запросу, сформулированному по определенным правилам, и выводит интересующую информацию или рекомендации на экран.
Обмен информацией между пользователем и системой ведется с использованием упрощенного специализированного языка.
На этапе 6 эксперты, при помощи интеллектуального анализатора, постоянно ведут анализ изменений в документации, анализируют новые документы, осуществляют связь с разработчиками, аннулируют утратившие силу документы.
Связь между СУБД (поз.9), базами данных (поз.11), интеллектуальной надстройкой СУБД (поз.10), внешним источником информации (поз.8) и графическим интерфейсом (поз.13) осуществляется через интерфейс обмена данными (поз.12), которые постоянно проверяются механизмом проверки ссылок (поз.10.4) и механизмом проверки непротиворечивости информации (поз.10.5).
Техническим результатом заявляемых системы и способа является создание упорядоченной, организованной по определенным логическим, функциональным, иерархическим, семантическим правилам базы данных нормативной документации, разработанной с применением упрощенного специализированного языка, которая предназначена для анализа существующего состояния нормативного информационного обеспечения в какой-либо предметной области, определения недостающей информации в этой предметной области, разработки недостающей информации, и ее использование при решении прикладных задач, поддержание базы данных в актуальном состоянии. При этом сокращаются время и затраты вычислительных ресурсов на обработку больших массивов данных с целью извлечения требуемой информации.
Пользователь системы может выбирать нормативные документы по одному, двум или трем характеристическим признакам, анализировать состояние базы данных нормативной документации по одному, двум или трем характеристическим признакам.
Способ и система позволяют оперативно оценить обеспеченность нормативной документацией выбранного кластера области деятельности и наличие взаимосвязи информации данного кластера с информацией других кластеров, а также, используя надстройки базы данных, разрабатывать нормативные документы, поддерживать базу в актуальном состоянии.
Концепцию организации трехмерного информационного пространства подтверждает тот факт, что деление нормативной документации широко применяется на практике, как при разработке, так и при использовании документов. Например, классификация документов по уровням нормативной документации, этапам и направлениям деятельности.
Способ и система организации и функционирования базы данных нормативной документации используются на предприятии.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ формирования и структурирования электронной базы данных | 2018 |
|
RU2696295C1 |
| СПОСОБ И СИСТЕМА АВТОМАТИЗИРОВАННОЙ ГЕНЕРАЦИИ И ЗАПОЛНЕНИЯ ВИТРИН ДАННЫХ С ИСПОЛЬЗОВАНИЕМ ДЕКЛАРАТИВНОГО ОПИСАНИЯ | 2022 |
|
RU2795902C1 |
| Система и способ организации электронного архива технической документации | 2019 |
|
RU2711721C1 |
| УСТРОЙСТВО ФОРМИРОВАНИЯ ИНФОРМАЦИОННО-МЕТОДИЧЕСКИХ РЕСУРСОВ КАФЕДРЫ | 2013 |
|
RU2573951C2 |
| СПОСОБ АНАЛИЗА И ПРОГНОЗА РАЗВИТИЯ СЛОЖНО ПОСТРОЕННОЙ СИСТЕМЫ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2010 |
|
RU2474873C2 |
| СИСТЕМА АНАЛИТИЧЕСКОГО ВЫЯВЛЕНИЯ ПРОБЛЕМНЫХ ВОПРОСОВ В НОРМАХ ПРАВОВОГО РЕГУЛИРОВАНИЯ | 2011 |
|
RU2479017C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ (СУБД) | 2018 |
|
RU2704873C1 |
| СПОСОБ ВВОДА И МНОГОУРОВНЕВОЙ ВЕРИФИКАЦИИ ИНТЕНСИВНО ПОСТУПАЮЩИХ ДАННЫХ В БОЛЬШИХ ИНФОРМАЦИОННО-АНАЛИТИЧЕСКИХ СИСТЕМАХ НАУКОМЕТРИЧЕСКОГО СОДЕРЖАНИЯ | 2020 |
|
RU2763458C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ТОВАРОВ НА ПРИНАДЛЕЖНОСТЬ К ОБЪЕКТАМ ЭКСПОРТНОГО КОНТРОЛЯ | 2001 |
|
RU2225031C2 |
| СПОСОБ ВЫЯВЛЕНИЯ ПЕРСОНАЛЬНЫХ ДАННЫХ ОТКРЫТЫХ ИСТОЧНИКОВ НЕСТРУКТУРИРОВАННОЙ ИНФОРМАЦИИ | 2013 |
|
RU2549515C2 |
Изобретение относится к области информационных технологий для создания, сопровождения, анализа и использования баз данных. Техническим результатом является повышение быстродействия и достоверности обработки данных с применением упрощенного языка, а также поддержания базы знаний в актуальном состоянии. В способе и системе базу знаний формируют в виде трехмерного информационного пространства, в котором данные о документе или его части определяют в кластер или кластеры, образованные единичными отрезками (ортами) характеристических признаков. Полный идентификационный номер документа формируют из кодов орт составляющих характеристических признаков и идентификационного номера документа. Производят анализ каждого кластера на полноту определения ограниченной им сферы деятельности содержащимися в кластере документами. Результат анализа заносят в этот же кластер. Поиск и анализ данных производят как с помощью формирования и обработки запроса, так и в обратном направлении с помощью подготовки базы данных для ожидаемого пользователя. В системе также предусмотрены средства для работы с базой данных, для поиска, контроля и анализа информации, документов, областей деятельности, для создания и корректировки документов системными администраторами, экспертами и пользователями в соответствии с правами доступа. 2 н. и 3 з.п. ф-лы, 6 ил.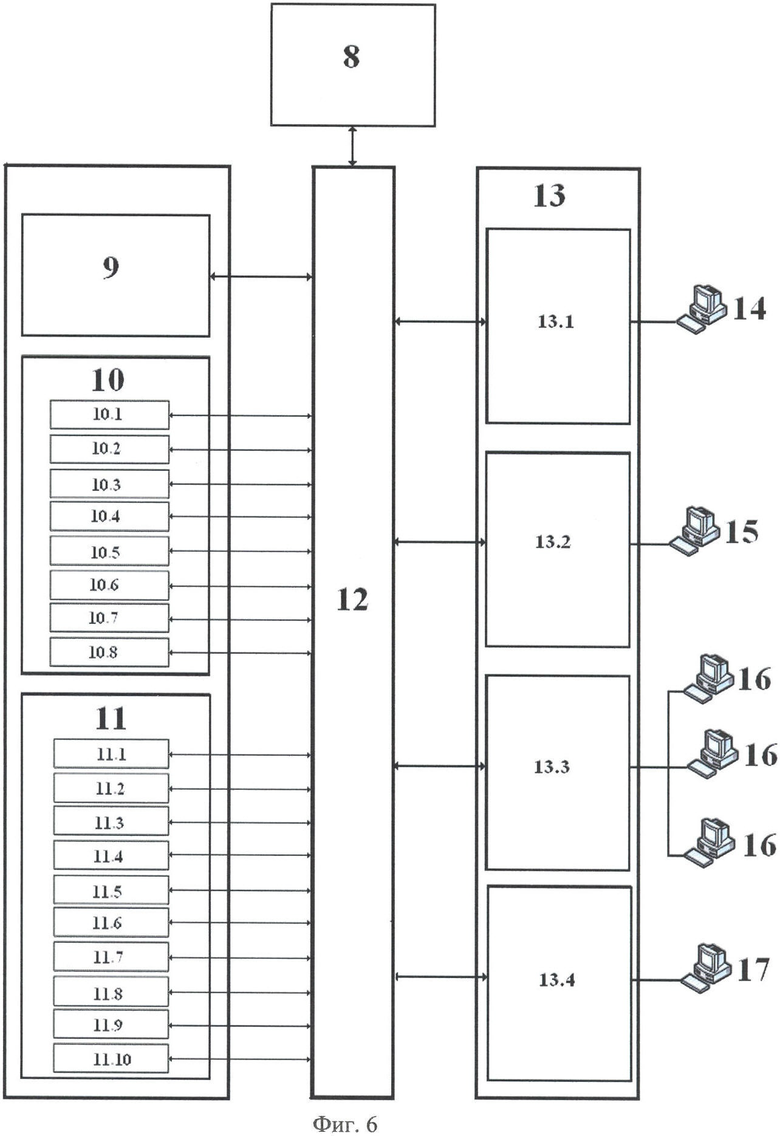
1. Способ организации и функционирования базы данных нормативной документации, заключающийся в том, что, по меньшей мере, в одном хранилище данных сохраняют объекты нормативной документации, взаимодействуют с хранилищем данных следующим образом: весь объем нормативной документации и содержащейся в ней информации по любой предметной области деятельности помещают в отдельную область базы данных и представляют в виде трехмерного информационного пространства, основываясь на практическом опыте и их градации, анализируют выбранную область деятельности, выбирают три основных характеристических признака и присваивают их названия координатным осям X, Y, Z, определяют составляющие характеристических признаков и откладывают их на координатных осях, образованных ортами (единичными отрезками), которые определяют составляющие характеристических признаков, присваивают кодовые обозначения, исходя из обозначений, применяемых на практике, из орт образуют кластеры - области трехмерного пространства, ограниченные единичными поверхностями единичных отрезков, из кодов соответствующих орт характеристических признаков составляют код каждого кластера, получают трехмерное информационное пространство, состоящее из кластеров с присвоенными им кодами, помещают образованное трехмерное информационное пространство вместе с другими базами данных в общем хранилище информации в виде объектно-ориентированной или реляционной базы данных, каждый документ переводят в формат XML, определяют ключи и атрибуты, ссылки для критериев поиска и анализа и в отформатированном виде располагают в соответствующей области базы данных, а затем анализируют на предмет принадлежности документа, части документа или информации, содержащейся в документе, кластерам трехмерного информационного пространства, формируют по трем осям полный идентификационный номер документа или его части, состоящий из кода ортов в зависимости от принадлежности к одному или нескольким кластерам и идентификационного номера документа, при этом если документ по какой-либо оси принадлежит нескольким кластерам, то код орта по этой оси заменяют нулевым значением, затем полный идентификационный номер документа помещают в кластер или кластеры, к которым принадлежит документ или часть содержащейся в нем информации, через кластер формируют ключи, индексы и атрибуты и присоединяют их к документу в формате XML, по мере анализа документов заполняют таблицы принадлежности документов к характеристическим признакам, хранящиеся в базе данных и позволяющие по полному идентификационному номеру определить составляющие характеристических признаков, к которым принадлежит документ, затем проверяют наличие документов в кластере и анализируют достаточность информации в этих документах по критериям полноты документации, используя надстройки базы данных, результаты анализа помещают в проанализированный кластер и хранят вместе с полными идентификационными номерами документов, для анализа более широкой области, определяющей одну составляющую или весь характеристический признак, делают срез трехмерного информационного пространства в выбранной плоскости, используя надстройки базы данных, анализируют состояние обеспечения нормативной документацией любого направления выбранной области деятельности и принимают решение о необходимости создания нового или дополнения существующего документа, основываясь на том, что в каждом кластере трехмерного информационного пространства в идеальном случае должен содержаться только один документ, полностью описывающий ограниченную этим кластером область деятельности, используя базу шаблонов и критерии полноты документации, выполняют разработку или корректировку нормативных документов, в процессе разработки, и в окончательной редакции новый документ итеративно вновь подвергают проведенному анализу для определения качества и полноты информации и для помещения документа в трехмерное информационное пространство, с помощью средств базы данных выбирают и находят нормативные документы по одному, двум или трем характеристическим признакам, осуществляют доступ к информации по интересующему вопросу, вводят (удаляют) информацию, контролируют полноту и качество получаемой информации, при этом при разработке трехмерного информационного пространства областей деятельности, если часть объема нормативной документации и составляющие характеристических признаков совпадают, аналогичные кластеры новой базы данных получают путем замещения их на существующие.
2. Система организации и функционирования базы данных нормативной документации, содержащая хранилище данных, систему управления базой данных (СУБД), включающую синтаксический анализатор, лингвистический анализатор, XML редактор и интеллектуальный анализатор, предназначенный для проверки по критериям полноты информации, интерфейс анализа и формирования данных, связанный с системным администратором и предназначенный для предварительного анализа документа и объема документации посредством синтаксического, лингвистического и интеллектуального анализаторов для определения характеристических признаков и их составляющих с присвоением кодовых обозначений и введением указанных данных в СУБД для присвоения трем осям трехмерного информационного пространства формируемой базы данных названий характеристических признаков, а также составления соответствующих кластеров с формированием их кодовых обозначений, интерфейс формирования базы данных предназначен для связи системного администратора с редактором XML для перевода документа в XML формат с кодовыми обозначениями, при этом СУБД предназначен для расположения отформатированного документа в базе данных, синтаксический и лингвистический анализаторы предназначены также для определения принадлежности анализируемого документа к каждому кластеру трехмерного информационного пространства, при определении однозначного соответствия документа одному кластеру СУБД предназначен для формирования полного идентификационного номера документа из кода ортов и идентификационного номера и помещения документа в соответствующий кластер трехмерного информационного пространства базы данных, интерфейс пользователя предназначен для доступа к документу или информации с использованием сформированных кодовых обозначений через кластер трехмерного информационного пространства базы данных.
3. Система организации и функционирования базы данных нормативной документации по п.2, отличающаяся тем, что интеллектуальная надстройка СУБД содержит механизм проверки ссылок, механизм проверки непротиворечивости информации, интеллектуальный анализатор, механизм генерации ссылок.
4. Система организации и функционирования базы данных нормативной документации по п.2, отличающаяся тем, что база данных содержит базу данных оригиналов документов, базу данных документов в формате XML с атрибутами, ключами и сгенерированными ссылками, трехмерное информационное пространство, состоящее из кластеров, образованных составляющими характеристических признаков какой-либо области деятельности, набор синтаксических правил для написания текстовой, нормативной документации, общую терминологическую базу, терминологические базы по предметным областям, критерии полноты документации в кластере, таблицы принадлежности документов к характеристическим признакам, базы шаблонов документов, критерии принадлежности документов к кластерам.
5. Система организации и функционирования базы данных нормативной документации по п.2, отличающаяся тем, что графический интерфейс содержит интерфейс формирования базы данных, интерфейс анализа базы данных, интерфейс пользователя для поиска и анализа информации и интерфейс редактора для создания документов.
| СИСТЕМА УЧЕТА, ПЛАНИРОВАНИЯ И КОНТРОЛЯ ПРИ СОВЕРШЕНИИ ДЕЙСТВИЙ С РЕСУРСАМИ (ВАРИАНТЫ) | 1998 |
|
RU2137198C1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОРГАНИЗАЦИИ ДАННЫХ | 2000 |
|
RU2268488C2 |

