ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА РОДСТВЕННЫЕ ЗАЯВКИ
В этой заявке заявлен приоритет по предварительной заявке на патент США №. 62/058,157, поданной 1 октября 2014, которая включена в данный документ посредством ссылки в полном объеме.
ОБЛАСТЬ ТЕХНИКИ
Изобретение, раскрытое в данном документе, в основном относится к аудио кодированию. В частности, оно относится к способу и устройству усиления диалога в декодере аудио системы. Изобретение дополнительно относится к способу и устройству кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог.
УРОВЕНЬ ТЕХНИКИ
В традиционных аудио системах используется канально-ориентированный подход. Каждый канал может, например, представлять контент одной звуковой колонки или одной последовательности звуковых колонок. Возможные схемы кодирования для таких систем включают дискретное многоканальное кодирование или параметрическое кодирование, такое как MPEG Surround.
Совсем недавно был разработан новый подход. Этот подход является объектно-ориентированным, что может являться преимуществом при кодировании сложных аудио окружений, например, в кинематографических приложениях. В системах, использующих объектно-ориентированный подход, трехмерное аудио окружение представляется аудио объектами с их сопряженными метаданными (например, метаданные позиционирования). Эти аудио объекты двигаются вокруг в трехмерном аудио окружении во время воспроизведения аудио сигнала. Система может дополнительно содержать так называемые опорные каналы, которые могут быть описаны как сигналы, которые напрямую размечаются для непосредственного вывода каналов, например, традиционной аудио системы, как описано выше.
Усиление диалога является способом усиления или увеличения уровня диалога относительно других компонентов, таких как музыка, фоновые звуки и звуковые эффекты. Объектно-ориентированный аудио контент может быть хорошо приспособлен для усиления диалога, поскольку диалог может быть представлен отдельными объектами. Однако в некоторых ситуациях аудио окружение может содержать огромное количество объектов. Для уменьшения сложности и количества данных, необходимых для представления аудио окружения, аудио окружение может быть упрощено посредством уменьшения количества аудио объектов, то есть посредством группирования объектов. Этот подход может вводить микширование между диалогом и другими объектами в некоторых кластерах объектов.
Включение возможностей усиления диалога для таких аудио кластеров в декодере аудио системы может приводить к увеличению вычислительной сложности декодера.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Приведенные в качестве примера варианты реализации изобретения будут далее описаны со ссылкой на сопроводительные графические материалы, на которых:
Фиг. 1 иллюстрирует обобщенную блок схему высококачественного декодера для усиления диалога в аудио системе в соответствии с примерами вариантов реализации изобретения,
Фиг. 2 иллюстрирует первую обобщенную блок схему декодера низкой сложности для усиления диалога в аудио системе в соответствии с примерами вариантов реализации изобретения,
Фиг. 3 иллюстрирует вторую обобщенную блок схему декодера низкой сложности для усиления диалога в аудио системе в соответствии с примерами вариантов реализации изобретения,
Фиг. 4 описывает способ кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, в соответствии с примерами вариантов реализации изобретения,
Фиг. 5 иллюстрирует обобщенную блок схему кодировщика для кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, в соответствии с примерами вариантов реализации изобретения.
Все фигуры являются схематическими и, в основном, только демонстрируют части, необходимые для разъяснения изобретения, причем другие части могут быть опущены или условно предполагаемы. Пока не указано иное, аналогичные номера ссылок относятся к одинаковым номерам частей в различных Фигурах.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Ввиду выше сказанного, объектом является обеспечение кодировщиков и декодеров и сопряженных способов, способствующих уменьшению сложности усиления диалога в декодере.
I. Обзор – Декодер
В соответствии с первым аспектом, приведенные в качестве примера варианты реализации изобретения, предлагают способы декодирования, декодеры и компьютерные программные продукты для декодирования. Предлагаемые способы, декодеры и компьютерные программные продукты могут, в основном, иметь одинаковые элементы и преимущества.
В соответствии с приведенными в качестве примера вариантами реализации изобретения обеспечивается способ усиления диалога в декодере аудио системы, включающий этапы: получения множества сигналов понижающего микширования, при этом сигналы понижающего микширования являются результатом понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, получения дополнительной информации, указывающей на коэффициенты, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования, получения данных, определяющих, какой из множества аудио объектов представляет собой диалог, изменения коэффициентов с применением параметра усиления и данных, определяющих, какой из множества аудио объектов представляет собой диалог, и реконструирования по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог, с применением измененных коэффициентов.
Параметр усиления обычно доступен пользователю в настройках декодера. Пользователь может, например, использовать дистанционное управление для увеличения громкости диалога. Следовательно, параметр усиления обычно не передается декодеру кодировщиком в аудио системе. Во многих случаях параметр усиления преобразуется как коэффициент усиления диалога, но он также может преобразовываться как коэффициент ослабления диалога. Более того, параметр усиления может относиться конкретным частотам диалога, например, частотно зависимому усилению или ослаблению диалога.
В контексте настоящего изобретения под термином диалог следует понимать, что в некоторых вариантах реализации изобретения улучшается только важный диалог, а не, например, фоновая болтовня и любые отражающиеся версии диалога. Диалог может содержать беседу между людьми, а также монолог, повествование или другую речь.
Используемый в данном описании аудио объект относится к элементу аудио окружения. Аудио объект обычно содержит аудио сигнал и дополнительную информацию, такую как положение объекта в трехмерном пространстве. Дополнительная информация обычно используется для оптимальной интерпретации аудио объекта на данной системе воспроизведения. Термин аудио объект также охватывает кластер аудио объектов, то есть кластер объектов. Кластер объектов представляет смесь по меньшей мере двух аудио объектов и обычно содержит смесь аудио объектов, таких как аудио сигнал и дополнительная информация, такая как положение кластеров объектов в трехмерном пространстве. По меньшей мере два аудио объекта в кластере объектов могут быть микшированы на основании их индивидуальных пространственных положений, которые являются близкими, и пространственного положения кластера объектов, которое выбирается как среднее между индивидуальными положениями объектов.
Используемый здесь сигнал понижающего микширования относится к сигналу, который является комбинацией по меньшей мере одного аудио объекта из множества аудио объектов. Другие сигналы аудио окружения, такие как опорные каналы, может также объединятся в сигнал понижающего микширования. Количество сигналов понижающего микширования обычно (но не обязательно) меньше, чем сумма количеств аудио объектов и опорных каналов, объясняя, почему сигналы понижающего микширования упоминаются как понижающее микширование. Сигнал понижающего микширования может также упоминаться как кластер понижающего микширования.
Используемая в данном документе дополнительная информация может также упоминаться как метаданные.
В контексте настоящего изобретения под термином дополнительная информация, указывающая на коэффициенты, следует понимать, что коэффициенты либо напрямую присутствуют в дополнительной информации, отправленной, например, в потоке данных из кодировщика, или что они рассчитаны из данных, присутствующих в дополнительной информации.
В соответствии с настоящим способом коэффициенты, позволяющие реконструкцию множества аудио объектов, изменены для обеспечения усиления позже реконструированного по меньшей мере одного аудио объекта, представляющего собой диалог. По сравнению с традиционным способом осуществления усиления реконструированного по меньшей мере одного аудио объекта, представляющего собой диалог, после его реконструкции, то есть без изменения коэффициентов, позволяющих реконструкцию, настоящий способ обеспечивает уменьшенную математическую сложность и, таким образом, вычислительную сложность декодера, реализующего настоящий способ.
В соответствии с примерами вариантов реализации изобретения этап изменения коэффициентов с применением параметра усиления включает умножение коэффициентов, которые позволяют реконструкцию по меньшей мере одного объекта, представляющего собой диалог, с параметром усиления. Это вычислительно низкая по сложности операция изменения коэффициентов, которая по-прежнему поддерживает взаимное соотношение между коэффициентами.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает: расчет коэффициентов, позволяющих реконструкцию множества аудио объектов из множества сигналов понижающего микширования из дополнительной информации.
В соответствии с приведенными в качестве примера вариантами реализации изобретения, этап реконструкции по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог, включает реконструкцию по меньшей мере только одного объекта, представляющего собой диалог.
Во многих случаях сигналы понижающего микширования могут соответствовать интерпретации или выводу аудио окружения заданной конфигурации звуковых колонок, например, стандартной конфигурации 5. 1. В таких случаях декодирование низкой сложности может достигаться реконструированием только аудио объектов, представляющих собой диалог, который следует усилить, то есть, без выполнения полной реконструкции всех аудио объектов.
В соответствии с приведенными в качестве примера вариантами реализации изобретения, реконструкция по меньшей мере только одного объекта, представляющего собой диалог, не включает декорреляцию сигналов понижающего микширования. Это уменьшает сложность этапа реконструкции. Более того, поскольку не все аудио объекты реконструированы, то есть качество аудио контента, который следует интерпретировать, может быть уменьшено для этих аудио объектов с применением декорреляции, в случае, если реконструкция по меньшей мере одного объекта, представляющего собой диалог, не улучшит ощущаемое аудио качество усиленного интерпретируемого аудио контента. Следовательно, декорреляция может быть пропущена.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает этап: объединения реконструированного по меньшей мере одного объекта, представляющего собой диалог, с сигналами понижающего микширования как по меньшей мере одного отдельного сигнала. Следовательно, реконструированный по меньшей мере один объект не требуется снова микшировать или объединять с сигналами понижающего микширования. Следовательно, в соответствии с данным вариантом реализации изобретения информация, описывающая микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудио системы не требуется.
В соответствии с приведенными в качестве примера вариантами реализации изобретения, способ дополнительно включает получение данных с пространственной информацией, соответствующих пространственным положениям множества сигналов понижающего микширования и по меньшей мере одного объекта, представляющего собой диалог, и интерпретирование множества сигналов понижающего микширования и реконструированного по меньшей мере одного объекта, представляющего собой диалог, на основании данных с пространственной информацией.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает объединение сигналов понижающего микширования и реконструированного по меньшей мере одного объекта, представляющего собой диалог, используя информацию, описывающую микширования по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудио системы. Сигналы понижающего микширования могут быть микшированы с понижением для поддержки неизменного-аудио-выхода (AAO) для конкретной конфигурации звуковых колонок (например, конфигурации 5.1 или конфигурации 7.1), то есть сигналы понижающего микширования могут быть использованы напрямую для воспроизведения на такой конфигурации звуковых колонок. Посредством объединения сигналов понижающего микширования и реконструированного по меньшей мере одного объекта, представляющего собой диалог, усиление диалога достигается одновременно с прежней поддержкой AAO. Иными словами, в соответствии с некоторыми вариантами реализации изобретения реконструированный и с усилением диалога по меньшей мере один объект, представляющий собой диалог, микшируется обратно в сигналы понижающего микширования снова для прежней поддержки AAO.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает интерпретацию комбинации сигналов понижающего микширования и реконструированного по меньшей мере одного объекта представляющего собой диалог.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает получение информации, описывающей микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудио системы. Кодировщик аудио системы уже может обладать этим типом информации на случай понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, или информация может быть легко рассчитана кодировщиком.
В соответствии с приведенными в качестве примера вариантами реализации изобретения, полученная информация, описывающая микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, кодируется посредством энтропийного кодирования. Это может уменьшить требуемую скорость передачи данных для передачи информации.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает этапы: получения данных с пространственной информацией, соответствующих пространственным положениям множества сигналов понижающего микширования и по меньшей мере одного объекта, представляющего собой диалог, и расчета информации, описывающей микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудио системы на основании данных пространственной информации. Преимуществом этого варианта реализации изобретения может быть то, что скорость передачи данных, необходимая для передачи потока данных, содержащего сигналы понижающего микширования и дополнительную информацию кодировщику уменьшается, поскольку пространственная информация, соответствующая пространственным положениям множества сигналов понижающего микширования и по меньшей мере одного объекта, представляющего собой диалог, может в любом случае быть получена декодером, и получение декодером дополнительной информации или данных не требуется.
В соответствии с приведенными в качестве примера вариантами реализации изобретения этап расчета информации, описывающей микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, включает применение функции которая размечает пространственное положение по меньшей мере одного объекта, представляющего собой диалог, в пространственные положения множества сигналов понижающего микширования. Функция может, например, являться алгоритмом 3D панорамирования, такого как алгоритм векторного амплитудного панорамирования (VBAP). Может использоваться любая другая подходящая функция.
В соответствии с приведенными в качестве примера вариантами реализации изобретения этап реконструкции по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог, включает реконструирование множества аудио объектов. В этом случае способ может включать получение данных с пространственной информацией, соответствующих пространственным положениям множества аудио объектов, и интерпретацию реконструированного множества аудио объектов на основании данных с пространственной информацией. Поскольку усиление диалога выполняется на коэффициентах, позволяющих реконструкцию множества аудио объектов, как описано выше, реконструкция множества аудио объектов и интерпретирование в реконструированный аудио объект, которые оба являются матричными операциями, может быть объединено в одну операцию, что уменьшит сложность двух операций.
В соответствии с примерами вариантов реализации изобретения предусматривается машиночитаемый носитель, содержащий команды компьютерного кода, выполненные с возможностью воплощения любого способа первого аспекта при выполнении на устройстве, обладающем свойствами процессора.
В соответствии с приведенными в качестве примера вариантами реализации изобретения предусматривается декодер усиления диалога в аудио системе. Декодер содержит ступень получения, выполненную с возможностью: получения множества сигналов понижающего микширования, при этом сигналы понижающего микширования являются результатом понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, получения дополнительной информации, указывающей на коэффициенты, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования, и получения данных, определяющих, какой из множества аудио объектов представляет собой диалог. Декодер дополнительно содержит ступень изменения, выполненную с возможностью изменения коэффициентов с применением параметра усиления и данных, определяющих, какой из множества аудио объектов представляет собой диалог, при этом декодер дополнительно содержит ступень реконструкции, выполненную с возможностью реконструкции по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог, используя измененные коэффициенты.
II. Обзор – Кодировщик
В соответствии со вторым аспектом приведенные в качестве примера варианты реализации изобретения предлагают способы кодирования, кодировщики, и компьютерные программные продукты для кодирования. Предлагаемые способы, кодировщики и компьютерные программные продукты могут в основном обладать одинаковыми элементами и преимуществами. В основном, элементы второго аспекта могут обладать теми же преимуществами, что и соответствующие элементы первого аспекта.
В соответствии с приведенными в качестве примера вариантами реализации изобретения предусматривается способ кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, включающий этапы: определения множества сигналов понижающего микширования, являющихся результатом понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, определения дополнительной информации, указывающей на коэффициенты, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования, определения данных, определяющих, какой из множества аудио объектов представляет собой диалог, и формирование потока данных, содержащего множество сигналов понижающего микширования, дополнительную информацию и данные, определяющие, какой из множества аудио объектов представляет собой диалог.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает этапы определения пространственной информации, соответствующей пространственному положению множества сигналов понижающего микширования, и по меньшей мере одного объекта, представляющего собой диалог, и включения указанной пространственной информации в поток данных.
В соответствии с приведенными в качестве примера вариантами реализации изобретения этап определения множества сигналов понижающего микширования дополнительно включает определение информации, описывающей микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования. Эта информация, описывающая микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, в соответствии с данным вариантом реализации изобретения, включена в поток данных.
В соответствии с приведенными в качестве примера вариантами реализации изобретения определенная информация, описывающая микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, кодируется с применением энтропийного кодирования.
В соответствии с приведенными в качестве примера вариантами реализации изобретения способ дополнительно включает этапы определения пространственной информации, соответствующей пространственным положениям множества аудио объектов, и включения пространственной информации, соответствующей пространственным положениям множества аудио объектов, в поток данных.
В соответствии с приведенными в качестве примера вариантами реализации изобретения предусматривается машиночитаемый носитель, содержащий команды компьютерного кода, предназначенные для воплощения любого способа второго аспекта при выполнении на устройстве, обладающим свойствами процессора.
В соответствии с приведенными в качестве примера вариантами реализации изобретения предусматривается кодировщик для кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог. Кодировщик содержит ступень понижающего микширования, выполненную с возможностью: определения множества сигналов понижающего микширования, являющегося результатом понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, определения дополнительной информации, содержащей указывающую на коэффициенты, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования, и ступень кодирования, выполненную с возможностью: формирования потока данных, содержащего множество сигналов понижающего микширования и дополнительную информацию, причем поток данных дополнительно содержит данные, определяющие, какой из множества аудио объектов представляет собой диалог.
III. Примеры вариантов реализации изобретения
Как описано выше, усиление диалога состоит в увеличении уровня диалога относительно других аудио компонентов. В случае хорошей организации при создании контента, контент объекта хорошо подходит для усиления диалога, поскольку диалог может быть представлен отдельными объектами. Параметрическое кодирование объектов (то есть кластеров объектов или сигналов понижающего микширования) может вводить микширование между диалогом и другими объектами.
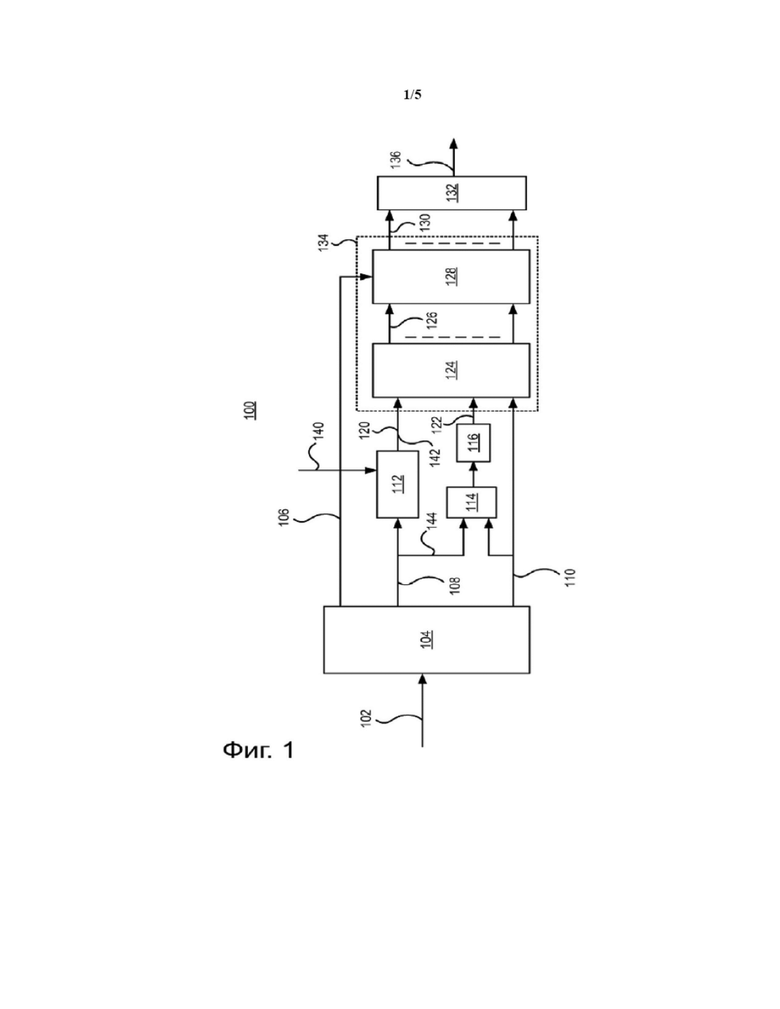
Декодер усиления диалога, микшируемый в такие кластеры объектов, будет описан ниже со ссылками на Фигуры 1-3. Фиг. 1 демонстрирует обобщенную блок схему высококачественного декодера 100 усиления диалога в аудио системе в соответствии с приведенными в качестве примера вариантами реализации изобретения. Декодер 100 получает поток данных 102 на ступени получения 104. Ступень получения 104 может также рассматриваться как базовый декодер, который декодирует поток данных 102 и выводит декодированный контент потока данных 102. Поток данных 102 может, например, содержать множество сигналов понижающего микширования 110, или кластеры понижающего микширования, которые являются результатом понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог. Ступень получения, следовательно, обычно содержит компонент декодера понижающего микширования, который может быть выполнен с возможностью декодирования частей потока данных 102 для формирования сигналов понижающего микширования 110, таких, чтобы они были совместимы с системой декодирования звука декодера, такой как стандарты Dolby Digital Plus или MPEG, такой AAC, USAC или MP3. Поток данных 102 может дополнительно содержать дополнительную информацию 108, указывающую на коэффициенты, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования. Для эффективного усиления диалога поток данных 102 может дополнительно содержать данные 108, определяющие, какой из множества аудио объектов представляет собой диалог. Эти данные 108 могут являться частью дополнительной информации 108 или могут быть отдельно от дополнительной информации 108. Как подробно описано ниже, дополнительная информация 108 обычно содержит коэффициенты сухого повышающего микширования, которые могут быть преобразованы в матрицу сухого повышающего микширования C, и коэффициенты влажного повышающего микширования, которые могут быть преобразованы в матрицу влажного повышающего микширования P.
Декодер 100 дополнительно содержит ступень изменения 112, выполненную с возможностью изменения коэффициентов, указанных в дополнительной информации 108, с применением параметра усиления 140, и данных 108, определяющих, какой из множества аудио объектов представляет собой диалог. Параметр усиления 140 может быть получен ступенью изменения 112 любым подходящим способом. В соответствии с вариантами реализации изобретения ступень изменения 112 изменяет и матрицу сухого повышающего микширования C, и матрицу влажного повышающего микширования P по меньшей мере коэффициенты, соответствующие диалогу.
Ступень изменения 112, следовательно, воплощает желаемое усиление диалога в коэффициенты, соответствующие объекту с диалогом(ами). В соответствии с одним вариантом реализации изобретения этап изменения коэффициентов с применением параметра усиления 140 включает умножение коэффициентов, которые позволяют реконструкцию по меньшей мере одного объекта, представляющего собой диалог, с параметром усиления 140. Иными словами, изменение включает фиксированное усиление коэффициентов, соответствующих объекту с диалогом.
В некоторых вариантах реализации изобретения декодер 100 дополнительно содержит ступень предварительной декорреляции 114 и ступень декорреляции 116. Эти две ступени 114, 116 вместе формируют декоррелированные версии комбинаций сигналов понижающего микширования 110, которые будут использоваться позже для реконструкции (например, для повышающего микширования) множества аудио объектов из множества сигналов понижающего микширования 110. Как может быть видно на Фиг. 1, дополнительная информация 108 может являться входной для ступени предварительной декорреляции 114 до изменения коэффициентов в ступени изменения 112. В соответствии с вариантами реализации изобретения коэффициенты, указанные в дополнительной информации 108, преобразуются в измененную матрицу сухого повышающего микширования 120, измененную матрицу влажного повышающего микширования 142 и матрицу предварительной декорреляции Q, упомянутую как ссылка 144 в Фиг. 1. Измененная матрица влажного повышающего микширования используется для повышающего микширования декоррелирующих сигналов 122 в ступени реконструкции 124, как описано ниже.
Матрица предварительной декорреляции Q используется ступенью предварительной декорреляции 114 и в соответствии с вариантами реализации изобретения может быть рассчитана как:
Q = (abs P)TC
где abs P обозначает матрицу, полученную в результате абсолютных значений элементов неизмененной матрицы влажного повышающего микширования P, а C означает неизмененную матрицу сухого повышающего микширования.
Предусмотрены альтернативные способы вычисления коэффициентов предварительной декорреляции Q на основании матрицы сухого повышающего микширования C и матрицы влажного повышающего микширования P. Например, это может быть рассчитано как Q = (abs P0)T C, где матрица P0 получена нормированием каждого столбца матрицы P.
Расчет матрицы предварительной декорреляции Q включает только расчеты с относительно низкой сложностью и, таким образом, может легко быть реализована на стороне декодера. Однако в соответствии с некоторыми вариантами реализации изобретения матрица предварительной декорреляции Q включается в дополнительную информацию 108.
Иными словами, декодер может быть предназначен для расчета коэффициентов, позволяющих реконструкцию множества аудио объектов 126 из множества сигналов понижающего микширования из дополнительной информации. Таким образом, матрица предварительной декорреляции не подвергается каким-либо изменениям сделанным относительно коэффициентов в ступени изменения, что может быть преимуществом, поскольку, если матрица предварительной декорреляции изменена, процесс декорреляции в ступени предварительной декорреляции 114 и ступени декорреляции 116 может вводить дополнительное усиление диалога, которое может быть нежелательно. В соответствии с другими вариантами реализации изобретения дополнительная информация является входной для ступени предварительной декорреляции 114 после момента изменения коэффициентов в ступени изменения 112. Поскольку декодер 100 является высококачественным декодером, он может быть предназначен для реконструкции всего множества аудио объектов. Это делается на ступени реконструкции 124. Таким образом, ступень реконструкции 124 декодера 100 получает сигналы понижающего микширования 110, декоррелированные сигналы 122 и измененные коэффициенты 120, 142, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования 110. Ступень реконструкции, следовательно, может параметрически реконструировать аудио объекты 126 до интерпретации аудио объектов в выходную конфигурацию аудио системы, например, выходной канал 7.1.4. Однако во многих случаях это обычно не случается, поскольку реконструкция аудио объекта на ступени реконструкции 124 и воспроизведение на ступени интерпретации 128 являются матричными операциями, которые могут быть объединены (отмечено пунктирной линией 134) для реализации вычислительной эффективности. Для интерпретации аудио объектов в правильном положении в трехмерном пространстве поток данных 102 дополнительно включает данные 106 с пространственной информацией, соответствующей пространственным положениям множества аудио объектов.
Можно отметить, что в соответствии с некоторыми вариантами реализации изобретения декодер 100 будет выполнен с возможностью обеспечения реконструированных объектов в качестве выходных, таких, которые могут быть обработаны и интерпретированы вне декодера. В соответствии с этим вариантом реализации изобретения декодер 100 в результате выводит реконструированные аудио объекты 126 и не содержит ступень интерпретирования 128.
Реконструкция аудио объектов обычно выполняется в области частот, например, области квадратурных зеркальных фильтров (QMF). Однако может не требоваться вывода аудио во временной области. Поэтому декодер дополнительно содержит ступень преобразования 132, в которой интерпретированные сигналы 130 трансформируются во временную область, например, посредством банка инверсных квадратурных зеркальных фильтров (IQMF). В соответствии с некоторыми вариантами реализации изобретения преобразование на ступени преобразования 132 во временную область может быть выполнено до интерпретации сигналов на ступени интерпретирования 128.
В итоге, вариант воплощения декодера, описанный со ссылкой на Фиг. 1, эффективно реализует усиление диалога посредством изменения коэффициентов, позволяющих реконструкцию множества аудио объектов из множества сигналов понижающего микширования до момента реконструкции аудио объектов. Осуществление усиления на коэффициентах обходится в несколько умножений на кадр, по одному для каждого коэффициента, относящегося к диалогу на количество диапазонов частот. Скорее всего в типичных случаях количество умножений будет эквивалентно количеству каналов понижающего микширования (например, 5-7) на количество диапазонов параметров (например, 20-40), но может быть большим, если диалог также получает вклад при декорреляции. При сравнении, решение существующего уровня техники для осуществления усиления диалога в реконструированных объектах приводит к умножению для каждого семпла на количество диапазонов частот на два для сложного сигнала. Обычно это приведет к 16 * 64 * 2 = 2048 умножениям на кадр, часто больше.
Системы аудио кодирования/декодирования обычно разбивают частотно-временное пространство на частотно/временные фрагменты, например, посредством применения подходящих банков фильтров для ввода аудио сигналов. Поскольку частотный/временной фрагмент в основном означает часть частотно-временного пространства, соответствующего временному интервалу и диапазону частот. Временной интервал может обычно соответствовать длительности кадра времени, используемого в аудио системе кодирования/декодирования. Частотный диапазон является частью всего диапазона частот полного диапазона частот аудио сигнала/объекта, который кодируется или декодируется. Частотный диапазон может обычно соответствовать одному или нескольким соседним диапазонам частот, определяемых банком фильтров, используемым при кодировании/декодировании системы. В случае, если частотный диапазон соответствует нескольким соседним диапазонам частот, определяемым банком фильтров, то это позволяет иметь неодинаковые диапазоны частот в процессе декодирования аудио сигнала, например, более широкие диапазоны частот для более высоких частот аудио сигнала.
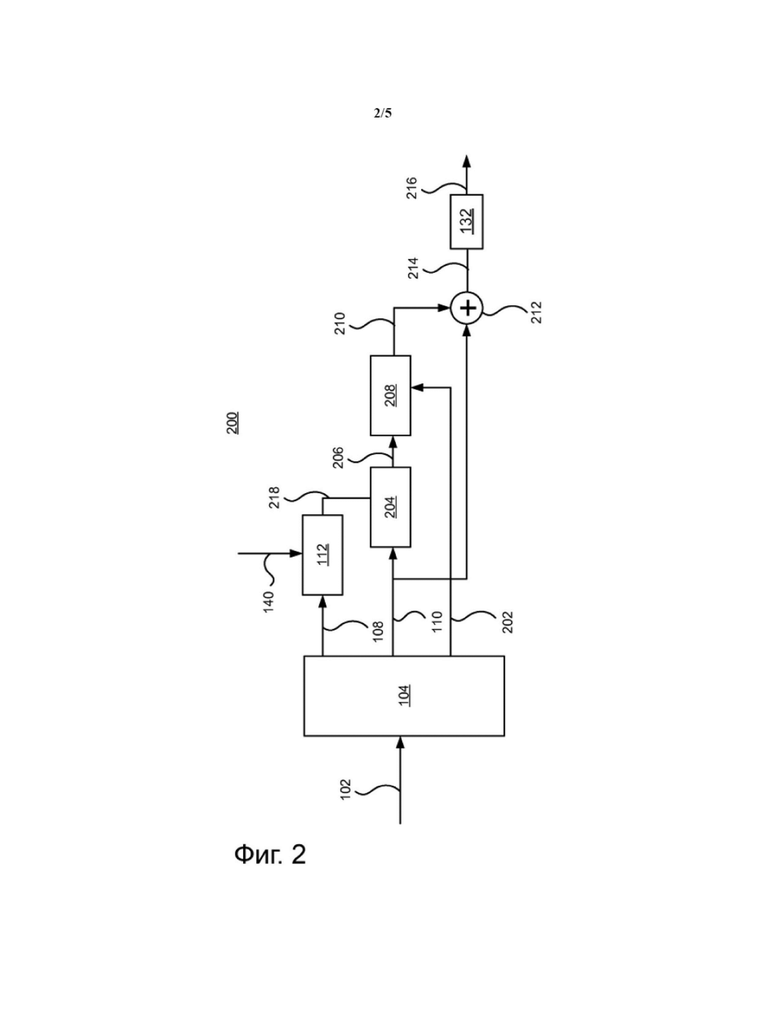
В альтернативном режиме вывода для экономии сложности декодера понижающие микшированные объекты не реконструируются. Сигналы понижающего микширования в этом варианте реализации изобретения рассматриваются как сигналы, которые интерпретируются напрямую в выходную конфигурацию, например, выходную конфигурацию 5.1. Это также известно как режим работы неизменного-аудио-выхода (AAO). Фиг. 2 и 3 описывают декодеры 200, 300, которые позволяют усиление диалога даже для данного варианта реализации изобретения низкой сложности.
Фиг. 2 описывает декодер 200 усиления диалога низкой сложности в аудио системе в соответствии с первыми приведенными в качестве примера вариантами реализации изобретения. Декодер 100 получает поток данных 102 на ступень получения 104 или основной декодер. Ступень получения 104 может быть выполнен, как описано со ссылкой на Фиг. 1. Следовательно, ступень получения выводит дополнительную информацию 108 и сигналы понижающего микширования 110. Коэффициенты, указанные дополнительной информацией 108, изменяются параметром усиления 140, как описано выше, ступенью изменения 112, с той разницей, что следует принять во внимание то, что диалог уже присутствует в сигнале понижающего микширования 110 и, следовательно, параметр усиления, возможно, следует пропорционально уменьшить до использования для изменения дополнительной информации 108, как описано далее. Дополнительно отличие может состоять в том, что поскольку декорреляция применяется в декодере низкой сложности 200 (как описано далее), ступень изменения 112 только изменяет коэффициенты сухого повышающего микширования в дополнительной информации 108 и, следовательно, пренебрегает любыми коэффициентами влажного повышающего микширования присутствующими в дополнительной информации 108. В некоторых вариантах реализации изобретения корректирование может принимать во внимание потери мощности в прогнозировании объекта с диалогом, вызванной отсутствием вклада декоррелятора. Изменение ступенью изменения 112 обеспечивает то, что объекты с диалогом реконструированы как усиленные сигналы таким образом, что при объединении с сигналами понижающего микширования, дадут в результате усиление диалога. Измененные коэффициенты 218 и сигналы понижающего микширования вводятся в ступень реконструкции 204. В ступени реконструкции, только по меньшей мере один объект, представляющий собой диалог, может быть реконструирован с применением измененных коэффициентов 218. Для дополнительного уменьшения сложности декодирования декодера 200, реконструкция по меньшей мере одного объекта, представляющего собой диалог, в ступени реконструкции 204 не включает декорреляцию сигналов понижающего микширования 110. Таким образом, ступень реконструкции 204 генерирует сигнал(ы) усиления диалога 206. Во многих вариантах реализации изобретения ступень реконструкции 204 является частью ступени реконструкции 124, причем указанная часть относится к реконструкции по меньшей мере одного объекта, представляющего собой диалог.
Для прежнего вывода сигналов в соответствии с поддерживаемой конфигурацией вывода, то есть выходной конфигурацией в которой сигналы понижающего микширования 110 были понижающим образом микшированы для поддержки (например, 5.1 или 7.1 сигналов окружения), сигналы усиленного диалога 206 снова нуждаются в понижающем микшировании в сигналы понижающего микширования 110, или объединении с данными сигналами. По этой причине декодер содержит ступень адаптивного микширования 208, которая использует информацию 202, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудио системы для микширования объектов усиления диалога обратно в представление 210, которое соответствует тому, как объекты с диалогом представлены в сигналах понижающего микширования 110. Это представление затем объединяется 212 с сигналом понижающего микширования 110 таким образом, что объединенные сигналы 214 в результате содержат усиленный диалог.
Описанные выше концептуальные этапы усиления диалога во множестве сигналов понижающего микширования могут быть реализованы единственной матричной операцией матрицы D, которая представляет один частотно-временной фрагмент множества сигналов понижающего микширования 110:
Db = D + MD уравнение 1
где Db является результатом измененного понижающего микширования 214, содержащего усиленные диалоговые части. Измененная матрица M получается из:
M = GC уравнение 2
где G является [число каналов понижающего микширования, число объектов с диалогом] матрицей усиления понижающего микширования, то есть информация 202, описывающая микширование то как по меньшей мере одного объекта, представляющий собой диалог, в непосредственно декодируемый частотно-временной фрагмент D из множества сигналов понижающего микширования 110. C является [число объектов с диалогом, число каналов понижающего микширования] матрицей измененных коэффициентов 218.
Альтернативная реализация усиления диалога во множестве сигналов понижающего микширования может быть реализована матричной операцией на векторе столбца X [число каналов понижающего микширования], в котором каждый элемент представляет отдельный частотно-временной семпл множества сигналов понижающего микширования 110:
Xb = EX уравнение 3
где Xb является результатом измененного понижающего микширования 214, содержащего части усиленного диалога. Матрица изменений E получается из:
E = I + GC уравнение 4
где I является [число каналов понижающего микширования, число каналов понижающего микширования] идентичной матрицей, G является [число канала понижающего микширования, число объекта с диалогом] матрицей усиления понижающего микширования, то есть информация 202, описывающая микширование по меньшей мере одного объекта, представляющего собой диалог, в непосредственно декодируемое множество сигналов понижающего микширования 110 и C является [число объектов с диалогом, число каналов понижающего микширования] матрицей измененных коэффициентов 218.
Матрица E рассчитана для каждого диапазона частот и временного семпла в кадре. Обычно данные для матрицы E передаются один раз на кадр, и матрица рассчитывается для каждого временного семпла в частотно-временном фрагменте посредством интерполяции с соответствующей матрицей в предшествующем кадре.
В соответствии с некоторыми вариантами реализации изобретения информация 202 является частью потока данных 102 и содержит коэффициенты понижающего микширования, которые используются кодировщиком в аудио системе для понижающего микширования объектов с диалогом в сигналы понижающего микширования.
В некоторых вариантах реализации изобретения сигналы понижающего микширования не соответствуют каналам конфигурации звуковых колонок. В таком варианте реализации изобретения выгодно интерпретировать сигналы понижающего микширования согласно местоположениям соответствующих звуковым колонкам конфигурации, используемой для воспроизведения. Для этих вариантов реализации изобретения поток данных 102 может содержать данные позиционирования для множества сигналов понижающего микширования 110.
Приведенный в качестве примера синтаксис потока данных, соответствующий такой полученной информации 202 будет описан сейчас. Объекты с диалогом могут микшироваться в более чем один сигнал понижающего микширования. Следовательно, коэффициенты понижающего микширования для каждого канала понижающего микширования могут кодироваться в поток данных в соответствии с приведенной ниже таблицей:
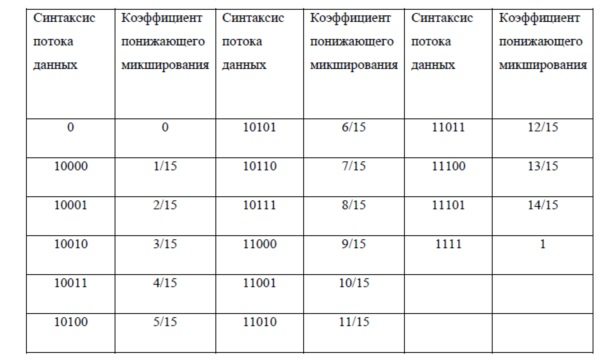
Таблица 1, синтаксис коэффициентов понижающего микширования
Поток данных, представляющий коэффициенты понижающего микширования для аудио объекта, который является результатом такого понижающего микширования, что 5-й из 7 сигналов понижающего микширования содержит только объект с диалогом, имеющий следующий вид:0000111100. Соответственно, поток данных, представляющий коэффициенты понижающего микширования для аудио объекта, который понижающим образом микширован для 1/15 в 5-й сигнал понижающего микширования и 14/15 в 7-ы сигнал понижающего микширования, таким образом, выглядит следующим образом: 000010000011101.
С этим синтаксисом значение 0 передается наиболее часто, поскольку объекты с диалогом обычно не находятся во всех сигналах понижающего микширования, а, наиболее вероятно, лишь в одном сигнале понижающего микширования. Поэтому коэффициенты понижающего микширования могут преимущественно кодироваться с применением энтропийного кодирования, определенного в приведенной выше таблице. Затрата на один бит больше на ненулевые коэффициенты и только 1 для 0 значения дает среднюю длину слова ниже 5 бит для большинства случаев. Например, 1/7 * (1 [бит] * 6 [коэффициенты] + 5 [бит] * 1 [коэффициент]) = 1. 57 бит на коэффициент в среднем в случае, если объект с диалогом представлен в одном выходе 7 сигналов понижающего микширования. Кодирование всех коэффициентов напрямую с 4 битами стоит 1/7 * (4 [бита] * 7 [коэффициенты]) = 4 бит на коэффициент. Только если объекты с диалогом находятся в 6 или 7 сигналах понижающего микширования (на выходе 7 сигналов понижающего микширования), это более затратно, чем прямое кодирование. Применение энтропийного кодирования, как описано выше, уменьшает требуемую скорость передачи данных для передачи коэффициентов понижающего микширования.
В альтернативном варианте для передачи коэффициентов понижающего микширования может быть использовано кодирование Хаффмана.
В соответствии с другими вариантами реализации изобретения, информация 202, описывающая микширование то как по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудио системы, не получена декодером, а, вместо этого, рассчитана на ступени получения 104, или на другой подходящей ступени декодера 200. Это уменьшает требуемую скорость передачи данных для передачи потока данных 102, получаемого декодером 200. Этот расчет может основываться на данных пространственной информации, соответствующей пространственным положениям множества сигналов понижающего микширования 110 и по меньшей мере одного объекта, представляющего собой диалог. Такие данные обычно уже известны декодеру 200, поскольку они обычно включаются в поток данных 102 кодировщиком аудио системы. Расчет может включать применение функции, которая размечает пространственное положение по меньшей мере одного объекта, представляющего собой диалог, в пространственные положения множества сигналов понижающего микширования 110. Алгоритм может быть алгоритмом 3D панорамирования, например, алгоритмом векторного амплитудного панорамирования (VBAP). VBAP является способом для позиционирования виртуальных источников звука, например, объектов с диалогом, в произвольных направлениях с применением предварительных установок множества физических источников звука, например, звуковых колонок, то есть выходная конфигурация звуковых колонок. Поэтому такие алгоритмы могут повторно использоваться для расчета коэффициентов понижающего микширования с применением положения сигналов понижающего микширования в качестве положения звуковых колонок.
Используя ссылку на представленные выше уравнения 1 и 2, G рассчитывается при предположении rendCoef = R(spkPos, sourcePos), где R алгоритм 3D панорамирования (например, VBAP) для обеспечения интерпретации вектора коэффициентов rendCoef [nbrSpeakers x 1] для объекта с диалогом, расположенным в sourcePos(например, Декартовы координаты) интерпретирован в nbrSpeakers каналы понижающего микширования, расположенные на spkPos (матрице, где каждый ряд соответствует координатам сигнала понижающего микширования). Затем G получается из следующего уравнения:
G=[rendCoef1,rendCoef2,…,rendCoefn ] уравнение 5
где rendCoefi являются коэффициентами интерпретации для объекта с диалогом i, из n объектов с диалогами.
Поскольку реконструкция аудио объектов обычно выполняется в области QMF, как описано выше со ссылкой на Фиг. 1, и может требоваться выведение звука во временной области, декодер 200 дополнительно содержит ступень преобразования 132, в которой объединенные сигналы 214 преобразуются в сигналы 216 во временной области, например, посредством применения инверсного QMF.
В соответствии с вариантами реализации изобретения декодер 200 может дополнительно содержать ступень интерпретирования (не показана) вверх по потоку относительно ступени преобразования 132 или вниз по потоку за ступенью преобразования 132. Как оговорено выше, сигналы понижающего микширования в некоторых случаях не соответствуют каналам конфигурации звуковых колонок. В таком варианте реализации изобретения выгодно интерпретировать сигналы понижающего микширования согласно положению соответствующих звуковым колонкам конфигурации, используемой для воспроизведения. Для этих вариантов реализации изобретения поток данных 102 может содержать данные позиционирования для множества сигналов понижающего микширования 110.
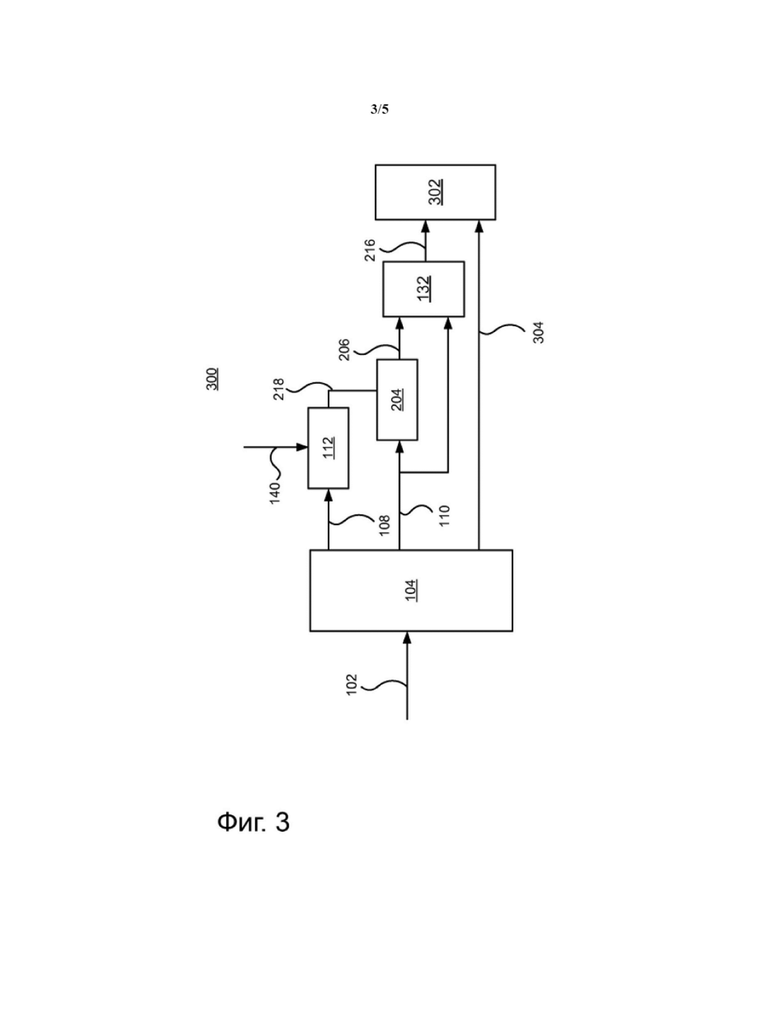
Альтернативный вариант реализации изобретения декодера усиления диалога низкой сложности в аудио системе показан на Фиг. 3. Основное отличие между декодером 300, показанным на Фиг. 3, и описанным выше декодером 200 состоит в том, что реконструированные объекты с усиленным диалогом 206 не объединяются с сигналами понижающего микширования 110 снова после ступени реконструкции 204. Вместо этого, реконструированный по меньшей мере один объект усиленного диалога 206 объединяется с сигналами понижающего микширования 110 как по меньшей мере один отдельный сигнал. Пространственная информация для по меньшей мере одного объекта с диалогом, который обычно уже известен декодеру 300 как описано выше, используется для интерпретации дополнительного сигнала 206 вместе с интерпретацией сигналов понижающего микширования в соответствии с информацией пространственного позиционирования 304 для множества сигналов понижающего микширования, после или до преобразования дополнительного сигнала 206 во временную область ступенью преобразования 132, как описано выше.
Для обоих вариантов реализации изобретения декодера 200, 300, описанных со ссылкой на Фигуры 2-3, следует принимать во внимание, что диалог уже присутствует в сигнале понижающего микширования 110, и что реконструированный объект с усиленным диалогом 206 добавляется к этому вне зависимости, объединяются они с сигналами понижающего микширования 110, как описано со ссылкой на Фиг. 2, или они объединяются с сигналами понижающего микширования 110, как описано со ссылкой на Фиг. 3. Следовательно, параметр усиления gDE требует вычитания, например, 1, если величина параметра усиления рассчитана на основании того, что существующий диалог в сигналах понижающего микширования обладает величиной 1.
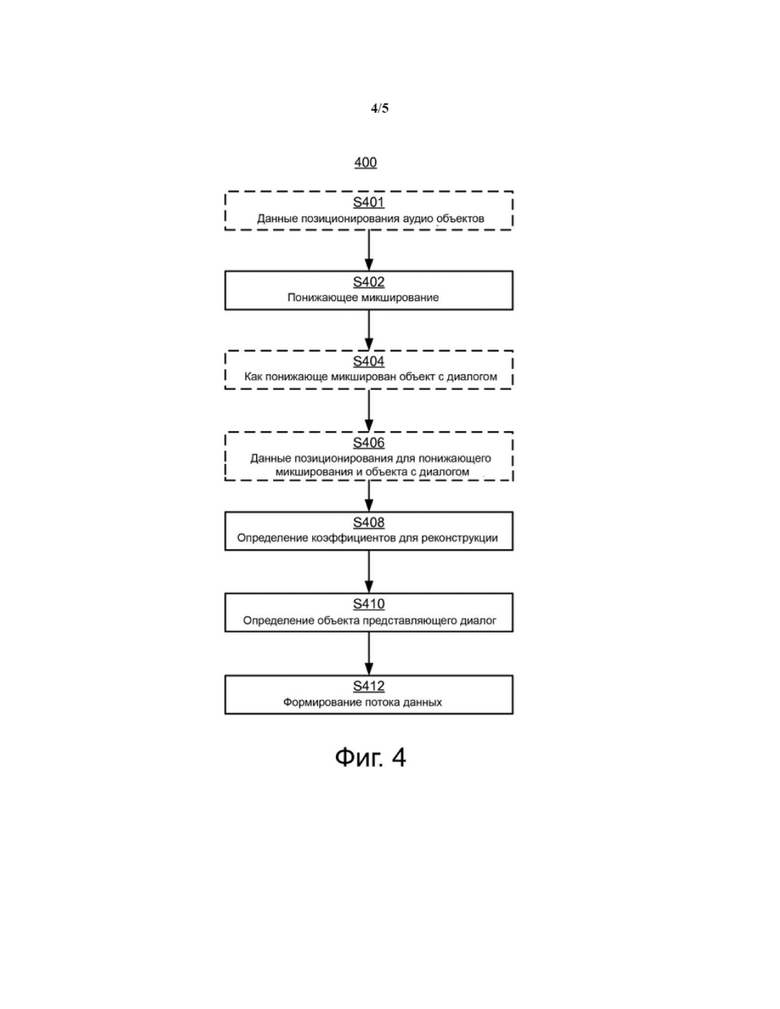
Фиг. 4 описывает способ 400 для кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, в соответствии с приведенными в качестве примера вариантами реализации изобретения. Следует отметить, что порядок этапов способа 400, показанный на Фиг. 4, показан в качестве примера.
Первый этап способа 400 является необязательным этапом определения S401 пространственной информации, соответствующей пространственным положениям множества аудио объектов. Обычно аудио объект сопровождается описанием того, где каждый объект должен интерпретироваться. Это обычно делается в терминах координат (например, Декартовых, полярных, и т. д.).
Второй этап способа является этапом определения S402 множества сигналов понижающего микширования, являющихся результатом понижающего микширования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог. Это также может упоминаться как этап понижающего микширования.
Например, каждый из сигналов понижающего микширования может быть линейной комбинацией множества аудио объектов. В других вариантах реализации изобретения каждый диапазон частот в сигнале понижающего микширования может содержать различные комбинации множества аудио объектов. Система аудио кодирования, которая реализует этот способ, следовательно, содержит компонент понижающего микширования, который определяет и кодирует сигналы понижающего микширования из аудио объектов. Кодированные сигналы понижающего микширования, например, могут быть сигналами окружения 5.1 или 7.1, которые обратно совместимы с установленными системами декодирования звука таких стандартов как Dolby Digital Plus или MPEG, таких как AAC, USAC или MP3, таким образом, что достигается AAO.
Этап определения S402 множества сигналов понижающего микширования может необязательно включать определение S404 информации, описывающей микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования. Во многих вариантах реализации изобретения коэффициенты понижающего микширования следуют из выполнения операций понижающего микширования. В некоторых вариантах реализации изобретения это может быть сделано посредством сравнения объекта(ов) с диалогом с сигналами понижающего микширования с применением алгоритма минимальной среднеквадратической ошибки (MMSE).
Существует множество способов реализации понижающего микширования аудио объектов, например, может использоваться алгоритм который понижающим образом микширует объекты, которые пространственно близки друг к другу. В соответствии с этим алгоритмом, определяется, в каких положениях в пространстве существуют концентрации объектов. Это затем используется как центры положений сигнала понижающего микширования. Это всего лишь один пример. Другой пример включает поддержание объектов с диалогом отдельно от других аудио объектов, если возможно, в случае понижающего микширования, для улучшения отделения диалога и для дополнительного упрощения усиления диалога на стороне декодера.
Четвертый этап способа 400 является необязательным этапом определения S406 пространственной информации, соответствующей пространственным положениям множества сигналов понижающего микширования. В случае пропускания необязательного этапа определения S401 пространственной информации, соответствующей пространственным положениям множества аудио объектов, этап S406 дополнительно включает определение пространственной информации, соответствующей пространственным положениям по меньшей мере одного объекта, представляющего собой диалог.
Пространственная информация обычно известна при определении S402 множества сигналов понижающего микширования, как описано выше.
Следующий этап способа является этапом определения S408 дополнительной информации, указывающей на коэффициенты, позволяющие реконструкцию множества аудио объектов из множества сигналов понижающего микширования. Эти коэффициенты могут также упоминаться как параметры повышающего микширования. Параметры повышающего микширования могут, например, определяться из сигналов понижающего микширования и аудио объектов, например, при MMSE оптимизации. Параметры повышающего микширования обычно содержат коэффициенты сухого повышающего микширования и коэффициенты влажного повышающего микширования. Коэффициенты сухого повышающего микширования определяют линейное размечение сигнала понижающего микширования, аппроксимирующего кодируемые аудио сигналы. Коэффициенты сухого повышающего микширования, следовательно, являются коэффициентами, определяющими количественные характеристики линейного преобразования, принимая сигналы понижающего микширования в качестве входной и выходной последовательности аудио сигналов, аппроксимирующих кодируемые аудио сигналы. Определенная последовательность коэффициентов сухого повышающего микширования может, например, определять линейное размечение сигнала понижающего микширования, соответствующего минимальной среднеквадратической ошибке аппроксимации аудио сигнала, то есть среди последовательностей линейных размечений сигнала понижающего микширования определяется последовательность коэффициентов сухого повышающего микширования, которая может определять линейное размечение лучше всего аппроксимирующее аудио сигнал в смысле наименьших средних квадратов.
Коэффициенты влажного повышающего микширования могут, например, определяться на основании разницы между или при сравнении ковариации аудио сигналов как полученных и ковариации аудио сигналов как аппроксимированных линейным размечением сигнала понижающего микширования.
Иными словами, параметры повышающего микширования могут соответствовать элементам матрицы повышающего микширования, которая позволяет реконструкцию аудио объектов из сигналов понижающего микширования. Параметры повышающего микширования обычно рассчиваются на основании сигнала понижающего микширования и аудио объектов относительно индивидуальных частотных/временных фрагментов. Следовательно, параметры повышающего микширования определяются для каждого частотного/временного фрагмента. Например, матрица повышающего микширования (содержащая коэффициенты сухого повышающего микширования и коэффициенты влажного повышающего микширования) может быть определена для каждого частотного/временного фрагмента.
Шестой этап способа кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, показанный на Фиг. 4, является этапом определения S410 данных, определяющий, какой из множества аудио объектов представляет собой диалог. Обычно множество аудио объектов может сопровождаться метаданными, указывающими, который из объектов содержит диалог. В альтернативном варианте может использоваться детектор речи, что известно из данной области техники.
Заключительный этап описанного способа является этапом S412 формирования потока данных, содержащего по меньшей мере множество сигналов понижающего микширования, как определено на этапе понижающего микширования S402, дополнительную информацию, как определено на этапе S408, на котором были определены коэффициенты для реконструкции, и данные, определяющие, какой из множества аудио объектов представляет собой диалог, как описано выше со ссылкой на этап S410. Поток данных может также содержать данные, выводимые или определяемые упомянутыми выше необязательными этапами S401, S404, S406, S408.
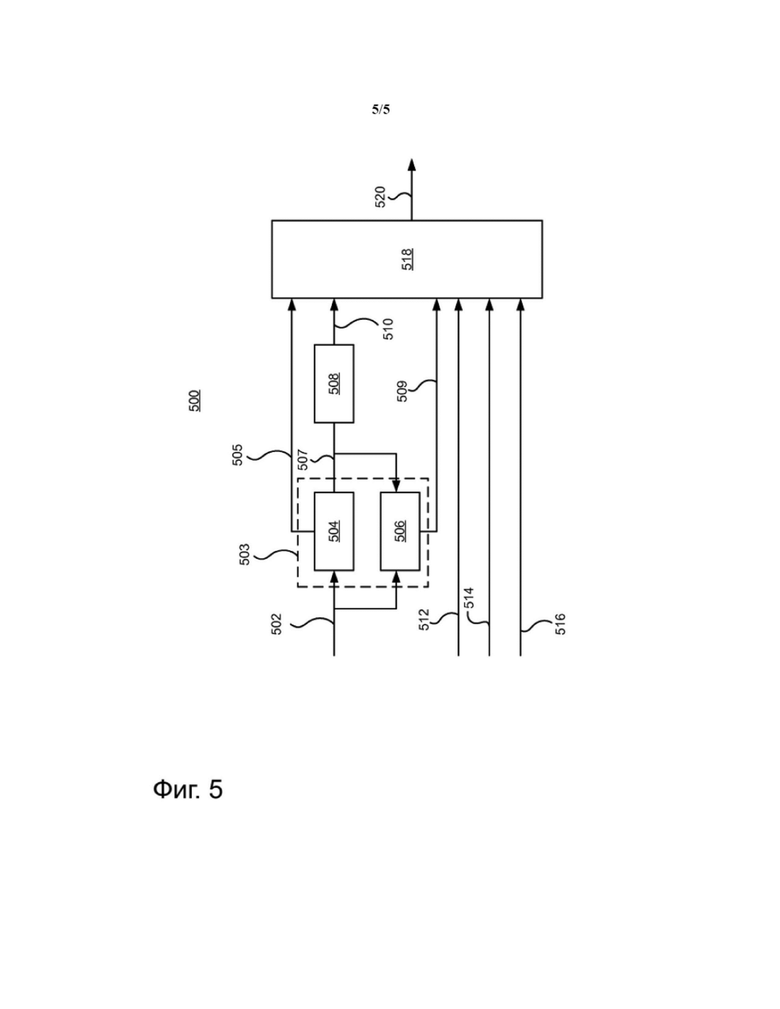
На Фиг. 5 в качестве примера продемонстрирована блок схема кодировщика 500. Кодировщик предназначен для кодирования множества аудио объектов, содержащего по меньшей мере один объект, представляющий собой диалог, и, в заключение, для передачи потока данных 520, который может быть получен любым из декодеров 100, 200, 300, как было описано выше со ссылкой на Фигуры 1-3.
Декодер содержит ступень понижающего микширования 503, которая содержит компонент понижающего микширования 504 и компонент расчета параметров реконструкции 506. Компонент понижающего микширования получает множество аудио объектов 502, содержащего по меньшей мере один объект, представляющий собой диалог, и определяет множество сигналов понижающего микширования 507, которое является результатом понижающего микширования множества аудио объектов 502. Сигналами понижающего микширования, например, могут быть сигналы окружения 5.1 или 7.1. Как описано выше, множество аудио объектов 502 могут актуально являться множеством кластеров объектов 502. Это означает, что вверх по потоку относительно компонента понижающего микширования 504 может существовать компонент группирования (не показан), который определяет множество кластеров объектов из большего множества аудио объектов.
Компонент понижающего микширования 504 может дополнительно определять информацию 505, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования.
Множество сигналов понижающего микширования 507 и множество аудио объектов (или кластеров объектов) получены компонентом расчета параметров реконструкции 506, который определяет, например, используя оптимизацию минимальной среднеквадратичной ошибки (MMSE), дополнительную информацию 509, указывающую на коэффициенты, позволяющие реконструкцию множества аудио объектов множества сигналов понижающего микширования. Как описано выше, дополнительная информация 509 обычно содержит коэффициенты сухого повышающего микширования и коэффициенты влажного повышающего микширования.
Приведенный в качестве примера кодировщик 500 может дополнительно включать компонент кодировщика понижающего микширования 508, который может быть выполнен с возможностью кодирования сигналов понижающего микширования 507 таким образом, чтобы они были обратно совместимы с установленными системами декодирования звука таких стандартов как Dolby Digital Plus или MPEG, таких как AAC, USAC или MP3.
Кодировщик 500 дополнительно включает мультиплексор 518, который объединяет по меньшей мере кодированные сигналы понижающего микширования 510, дополнительную информацию 509 и данные 516, определяющие, какой из множества аудио объектов представляет собой диалог в потоке данных 520. Поток данных 520 может также содержать информацию 505, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, который может кодироваться посредством энтропийного кодирования. Более того, поток данных 520 может содержать пространственную информацию 514, соответствующую пространственному положению множества сигналов понижающего микширования и по меньшей мере один объект, представляющий собой диалог. Дополнительно, поток данных 520 может содержать пространственную информацию 512, соответствующую пространственным положениям множества аудио объектов в потоке данных.
Вкратце, это изобретение относится к области аудио кодирования, в частности, оно относится к области пространственного аудио кодирования, в котором аудио информация представлена множеством аудио объектов, содержащим по меньшей мере один объект с диалогом. В частности, изобретение предоставляет способ и устройство усиления диалога в декодере аудио системы. Кроме того, это изобретение предоставляет способ и устройство для кодирования таких аудио объектов, позволяя усиление диалога декодером аудио системы.
Эквиваленты, расширения, альтернативы и прочее
Дополнительные варианты реализации настоящего изобретения будут очевидны для специалиста в данной области техники после изучения приведенного выше описания. Даже если настоящее описание и графические материалы не описывают варианты реализации изобретения и примеры, изобретение не ограничивается этими конкретными примерами. Многочисленные модификации и варианты могут быть реализованы без выхода за объем настоящего изобретения, который определяется приложенной формулой изобретения. Любые обозначения ссылок, встречающиеся в формуле изобретения, не следует рассматривать как ограничивающие границы её объема.
Дополнительно, изменения описанных вариантов реализации изобретения могут быть понятны и использованы специалистом в данной области техники, использующим описание, из изучения графических материалов, описания, и приложенной формулы изобретения. В формуле изобретения, слово "содержит" не исключает другие элементы или этапы, и использование единственного числа не исключает множественного числа. Сам по себе факт, что конкретные меры упоминаются во взаимно различающихся зависимых пунктах формулы, не означает, что комбинация этих мер не может быть использована для преимущества.
Устройства и способы, описанные в данном документе выше, могут быть реализованы в виде программного обеспечения, встроенного программного обеспечения, аппаратного обеспечения или их комбинации. При реализации в виде аппаратного обеспечения, разделение задач между функциональными единицами, упоминаемыми выше в описании, не обязательно соответствует единицам физических устройств; напротив, один физический компонент может иметь множество функций и одна задача может решаться работой нескольких объединенных физических компонентов. Определенные компоненты или все компоненты могут быть воплощены как программное обеспечение, выполняемое цифровым сигнальным процессором или микропроцессором, или может быть воплощено как аппаратное обеспечение или как специализированная интегральная схема. Такое программное обеспечение может быть распределено на машиночитаемом носителе, который может содержать носитель данных компьютера (или постоянный носитель) и передающую среду (или временный носитель). Как хорошо известно специалисту в данной области техники, термин машиночитаемый носитель включает как временный, так и постоянный, портативный и стационарный носитель, воплощенный любым способом или технологией для хранения информации, такой как машиночитаемые инструкции, структуры данных, программные модули и другие данные. Машиночитаемый носитель включает, без ограничений, ОЗУ, ПЗУ, электрически-стираемое программируемое ПЗУ, флэш-память или другие технологии памяти, компакт-диски формата CD-ROM, компакт-диски формата DVD или другие хранилища на оптических дисках, магнитных кассетах, магнитной пленке, магнитных дисковых хранилищах или других магнитных запоминающих устройствах, или любые другие носители, которые могут использоваться для хранения желаемой информации и которые могут быть доступны компьютеру. Дополнительно, специалисту в данной области техники хорошо известно, что передающая среда обычно включает машиночитаемые инструкции, структуры данных, программные модули или другие данные в модулированном данными сигнале таком как несущая волна или другой механизм передачи данных и содержит любую среду передачи информации.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДЕР, ДЕКОДЕР И СПОСОБЫ ДЛЯ ОБРАТНО СОВМЕСТИМОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ С ПЕРЕМЕННЫМ РАЗРЕШЕНИЕМ | 2013 |
|
RU2669079C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ УЛУЧШЕННОГО ПРОСТРАНСТВЕННОГО КОДИРОВАНИЯ АУДИООБЪЕКТОВ | 2014 |
|
RU2660638C2 |
| ПРИНЦИП ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИО ДЛЯ АУДИОКАНАЛОВ И АУДИООБЪЕКТОВ | 2014 |
|
RU2641481C2 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ МНОЖЕСТВА АУДИООБЪЕКТОВ С ИСПОЛЬЗОВАНИЕМ ИНФОРМАЦИИ НАПРАВЛЕНИЯ ВО ВРЕМЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ ИЛИ УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОПТИМИЗИРОВАННОГО КОВАРИАЦИОННОГО СИНТЕЗА | 2021 |
|
RU2826540C1 |
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ МНОЖЕСТВА АУДИООБЪЕКТОВ ИЛИ УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ДВУХ ИЛИ БОЛЕЕ РЕЛЕВАНТНЫХ АУДИООБЪЕКТОВ | 2021 |
|
RU2823518C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ОСУЩЕСТВЛЕНИЯ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ SAOC ОБЪЕМНОГО (3D) АУДИОКОНТЕНТА | 2014 |
|
RU2666239C2 |
| ДЕКОДЕР, КОДЕР И СПОСОБ ИНФОРМИРОВАННОЙ ОЦЕНКИ ГРОМКОСТИ С ИСПОЛЬЗОВАНИЕМ ОБХОДНЫХ СИГНАЛОВ АУДИООБЪЕКТОВ В СИСТЕМАХ ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ КОДИРОВАНИЯ АУДИО | 2014 |
|
RU2651211C2 |
| ДЕКОДЕР, КОДЕР И СПОСОБ ИНФОРМИРОВАННОЙ ОЦЕНКИ ГРОМКОСТИ В СИСТЕМАХ ОСНОВЫВАЮЩЕГОСЯ НА ОБЪЕКТАХ КОДИРОВАНИЯ АУДИО | 2014 |
|
RU2672174C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ СИНТЕЗИРОВАНИЯ ВЫХОДНОГО СИГНАЛА | 2008 |
|
RU2439719C2 |
| УСОВЕРШЕНСТВОВАННЫЙ МЕТОД КОДИРОВАНИЯ И ПАРАМЕТРИЧЕСКОГО ПРЕДСТАВЛЕНИЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО ОБЪЕКТА ПОСЛЕ ПОНИЖАЮЩЕГО МИКШИРОВАНИЯ | 2007 |
|
RU2485605C2 |
Изобретение относится к средствам пространственного аудиокодирования, когда аудиоинформация представлена множеством аудиообъектов, содержащим по меньшей мере один объект с диалогом. Технический результат заключается в повышении эффективности кодирования аудио. Получают множество сигналов понижающего микширования, при этом сигналы понижающего микширования являются результатом понижающего микширования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог. Получают дополнительную информацию, указывающую на коэффициенты, позволяющие реконструкцию множества аудиообъектов из множества сигналов понижающего микширования. Получают данные, определяющие, какой из множества аудиообъектов представляет собой диалог. Изменяют коэффициенты, используя параметр усиления и данные, определяющие, какой из множества аудиообъектов представляет собой диалог. Реконструируют по меньшей мере указанный по меньшей мере один объект, представляющий собой диалог, с применением измененных коэффициентов. 6 н. и 19 з.п. ф-лы, 5 ил., 1 табл.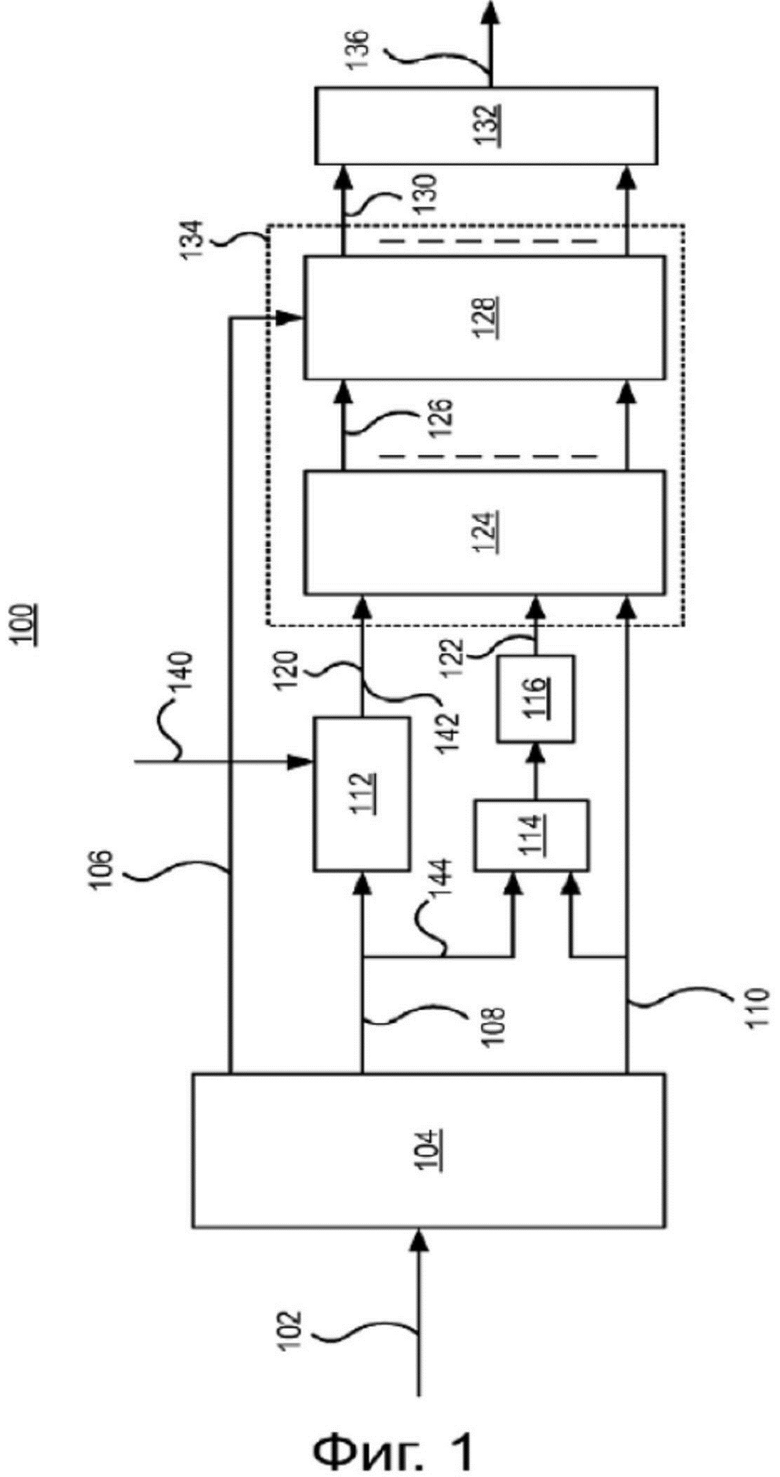
1. Способ усиления диалога в декодере аудиосистемы, включающий этапы, на которых:
- получают множество сигналов понижающего микширования, при этом сигналы понижающего микширования являются результатом понижающего микширования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог,
- получают дополнительную информацию, указывающую на коэффициенты, позволяющие реконструкцию множества аудиообъектов из множества сигналов понижающего микширования,
- получают данные, определяющие, какой из множества аудиообъектов представляет собой диалог,
- изменяют коэффициенты, используя параметр усиления и данные, определяющие, какой из множества аудиообъектов представляет собой диалог, и
- реконструируют по меньшей мере указанный по меньшей мере один объект, представляющий собой диалог с применением измененных коэффициентов.
2. Способ по п. 1, отличающийся тем, что на этапе изменения коэффициентов с применением параметра усиления умножают коэффициенты, позволяющие реконструкцию по меньшей мере одного объекта с параметром усиления, представляющего собой диалог.
3. Способ по любому из пп. 1, 2, дополнительно включающий этап, на котором:
- рассчитывают коэффициенты, позволяющие реконструкцию множества аудиообъектов из множества сигналов понижающего микширования из дополнительной информации.
4. Способ по любому из пп. 1, 2, отличающийся тем, что на этапе реконструкции по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог, осуществляют реконструкцию по меньшей мере только одного объекта представляющего собой диалог.
5. Способ по п. 4, отличающийся тем, что на этапе реконструкции по меньшей мере только одного объекта, представляющего собой диалог, не осуществляют декорреляцию сигналов понижающего микширования.
6. Способ по п. 4, дополнительно включающий этап, на котором:
- объединяют реконструированный по меньшей мере один объект, представляющий собой диалог, с сигналами понижающего микширования как по меньшей мере один отдельный сигнал.
7. Способ по п. 6, дополнительно включающий этапы, на которых:
- получают данные с пространственной информацией, соответствующие пространственным положениям множества сигналов понижающего микширования и по меньшей мере одного объекта, представляющего собой диалог, и
- интерпретируют множество сигналов понижающего микширования и по меньшей мере один реконструированный объект, представляющий собой диалог, на основании данных пространственной информации.
8. Способ по п. 4, дополнительно включающий этап, на котором:
- объединяют сигналы понижающего микширования и по меньшей мере один реконструированный объект, представляющий собой диалог, используя информацию, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудиосистемы.
9. Способ по п. 8, дополнительно включающий этапы, на которых: интерпретируют комбинацию сигналов понижающего микширования и по меньшей мере один реконструированный объект, представляющий собой диалог.
10. Способ по п. 8, дополнительно включающий этап, на котором:
- получают информацию, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудиосистемы.
11. Способ по п. 10, отличающийся тем, что полученную информацию, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, кодируют посредством энтропийного кодирования.
12. Способ по п. 8, дополнительно включающий этапы, на которых:
- получают данные с пространственной информацией, соответствующей пространственным положениям множества сигналов понижающего микширования и по меньшей мере одного объекта, представляющего собой диалог, и
- рассчитывают информацию, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования кодировщиком аудиосистемы на основании данных пространственной информации.
13. Способ по п. 12, отличающийся тем, что на этапе расчета применяют функцию, которая размечает пространственное положение по меньшей мере одного объекта, представляющего собой диалог, в пространственные положения множества сигналов понижающего микширования.
14. Способ по п. 13, отличающийся тем, что функция является алгоритмом 3D-панорамирования.
15. Способ по п. 1 или 2, отличающийся тем, что на этапе реконструкции по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог, осуществляют реконструкцию множества аудиообъектов.
16. Способ по п. 15, дополнительно включающий этапы, на которых:
- получают данные пространственной информации, соответствующие пространственным положениям множества аудиообъектов, и
- интерпретируют множество реконструированных аудиообъектов на основании данных пространственной информации.
17. Машиночитаемый носитель с командами для осуществления способа по любому из пп. 1-16.
18. Декодер усиления диалога в аудиосистеме, содержащий:
ступень получения, выполненную с возможностью:
- получения множества сигналов понижающего микширования, при этом сигналы понижающего микширования являются результатом понижающего микширования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог,
- получения дополнительной информации, указывающей на коэффициенты, позволяющие реконструкцию множества аудиообъектов из множества сигналов понижающего микширования, и
- получения данных, определяющих, какой из множества аудиообъектов представляет собой диалог,
ступень изменения, выполненную с возможностью:
- изменения коэффициентов с применением параметра усиления и данных, определяющих, какой из множества аудиообъектов представляет собой диалог,
ступень реконструкции, выполненную с возможностью:
- реконструкции по меньшей мере указанного по меньшей мере одного объекта, представляющего собой диалог с применением измененных коэффициентов.
19. Способ кодирования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог, включающий этапы, на которых:
- определяют множество сигналов понижающего микширования, являющегося результатом понижающего микширования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог,
- определяют дополнительную информацию, указывающую на коэффициенты, позволяющие реконструкцию множества аудиообъектов из множества сигналов понижающего микширования,
- определяют данные, определяющие, какой из множества аудиообъектов представляет собой диалог, и
- формируют поток данных, содержащий множество сигналов понижающего микширования, дополнительную информацию и данные, определяющие, какой из множества аудиообъектов представляет собой диалог.
20. Способ по п. 19, дополнительно включающий этапы, на которых:
- определяют пространственную информацию, соответствующую пространственному положению множества сигналов понижающего микширования и по меньшей мере одного объекта, представляющего собой диалог, и
- включают указанную пространственную информацию в поток данных.
21. Способ по п. 19 или 20, в котором на этапе определения множества сигналов понижающего микширования дополнительно определяют информацию, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, при этом способ дополнительно включает этап, на котором:
- включают информацию, описывающую микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования в потоке данных.
22. Способ по п. 21, отличающийся тем, что определенная информация, описывающая микширование по меньшей мере одного объекта, представляющего собой диалог, во множество сигналов понижающего микширования, кодируется с применением энтропийного кодирования.
23. Способ по любому из пп. 19, 20, дополнительно включающий этапы, на которых:
- определяют пространственную информацию, соответствующую пространственным положениям множества аудиообъектов, и
- включают пространственную информацию, соответствующую пространственным положениям множества аудиообъектов в потоке данных.
24. Машиночитаемый носитель с командами для осуществления способа по любому из пп. 19-23.
25. Кодировщик для кодирования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог, причем кодировщик содержит:
ступень понижающего микширования, выполненную с возможностью:
- определения множества сигналов понижающего микширования, являющегося результатом понижающего микширования множества аудиообъектов, содержащего по меньшей мере один объект, представляющий собой диалог,
- определения дополнительной информации, указывающей коэффициенты, позволяющие реконструкцию множества аудиообъектов из множества сигналов понижающего микширования, и
ступень кодирования, выполненную с возможностью:
- формирования потока данных, содержащего множество сигналов понижающего микширования и дополнительную информацию, причем поток данных дополнительно содержит данные, определяющие, какой из множества аудиообъектов, представляет собой диалог.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| ПОВЫШЕНИЕ РАЗБОРЧИВОСТИ РЕЧИ В ЗВУКОЗАПИСИ РАЗВЛЕКАТЕЛЬНЫХ ПРОГРАММ | 2008 |
|
RU2440627C2 |

