ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в общем относится к вычислительным системам, а в частности - к системам и способам распознавания символов с использованием искусственного интеллекта.
УРОВЕНЬ ТЕХНИКИ
[002] Методы оптического распознавания символов (OCR) могут использоваться для распознавания текстов на различных языках. Например, изображение документа, содержащего текст (например, печатный или написанный от руки), можно получить путем сканирования документа. Некоторые методы OCR могут явным образом разделить текст на изображении на отдельные символы и применить операции распознавания к каждому символу отдельно. При использовании для текста на языках, которые содержат слитное письмо, такой подход может привести к появлению ошибок. Кроме того, для проверки распознанных слов текста некоторые методы OCR могут использовать поиск по словарю. Эти методы могут установить высокий показатель уверенности для слова, найденного в словаре, даже если слово не имеет смысла при чтении в предложении текста.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] В одном варианте осуществления способ включает получение изображения текста. Текст на изображении содержит одно или более слов в одном или более предложениях. Этот способ также включает получение изображения текста в качестве первых исходных данных для набора обученных моделей машинного обучения, получение одного или более конечных выходных данных из набора обученных моделей машинного обучения, а также извлечение из одного или более конечных выходных данных одного или более предполагаемых предложений из текста на изображении. Каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов.
[004] В другом варианте осуществления - способ обучения набора моделей машинного обучения для выявления вероятной последовательности слов каждого из одного или более предложений на изображении текста. Этот способ включает создание обучающих данных для набора моделей машинного обучения. Создание обучающих данных включает создание позитивных примеров, содержащих первые тексты и создание негативных примеров, содержащих вторые тексты и распространение ошибок. Эти вторые тексты включают варианты, которые имитируют как минимум одну ошибку распознавания одного или более символов, одной или более последовательностей символов или одной или более последовательностей слов. Этот способ также включает генерацию исходной обучающей выборки, содержащей позитивные примеры и негативные примеры, а также генерацию целевых выходных данных для этой исходной обучающей выборки. Целевые выходные данные выявляют одно или более предполагаемых предложений. Каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов. Этот способ предоставляет обучающие данные для обучения набора моделей машинного обучения на (i) исходной обучающей выборке и (ii) целевых результатах.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[005] Для более полного понимания настоящего изобретения ниже приводится подробное описание, в котором для примера, а не с целью ограничения, оно иллюстрируется со ссылкой на чертежи, на которых:
[006] На Фиг. 1 изображена схема компонентов верхнего уровня для примера архитектуры системы в соответствии с одним или более вариантами реализации настоящего изобретения.
[007] На Фиг. 2 представлен пример кластера в соответствии с одним или более вариантами реализации настоящего изобретения.
[008] На Фиг. 3А представлен пример нормализации строки текста для приведения к одинаковой высоте в ходе предварительной обработки в соответствии с одним или более вариантами реализации настоящего изобретения.
[009] На Фиг. 3В представлен пример разделения строки текста на фрагменты в ходе предварительной обработки в соответствии с одним или более вариантами реализации настоящего изобретения.
[0010] На Фиг. 4 изображена блок-схема примера способа обучения одной или более моделей машинного обучения в соответствии с одним или более вариантами реализации настоящего изобретения.
[0011] На Фиг. 5 приведен пример обучающей выборки, используемой для обучения одной или более моделей машинного обучения, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0012] На Фиг. 6 изображена блок-схема примера способа использования одной или более моделей машинного обучения для распознавания текста на изображении в соответствии с одним или более вариантами реализации настоящего изобретения.
[0013] На Фиг. 7 представлены примеры модулей системы распознавания символов, которая распознает одну или более последовательностей символов для каждого слова в тексте в соответствии с одним или более вариантами реализации настоящего изобретения.
[0014] На Фиг. 8А представлен пример извлечения признаков в каждой позиции изображения с использованием кодировщика кластеров в соответствии с одним или более вариантами реализации настоящего изобретения.
[0015] На Фиг. 8В представлен пример слова с точками деления, выявленными кластером, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0016] На Фиг. 9 представлен пример архитектуры сверточной нейронной сети, используемой в кодировщиках, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0017] На Фиг. 10 представлен пример применения сверточной нейронной сети к изображению с целью выявления характеристик изображения с использованием фильтров в соответствии с одним или более вариантами реализации настоящего изобретения.
[0018] На Фиг. 11 представлен пример рекуррентной нейронной сети, используемой в кодировщиках, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0019] На Фиг. 12 представлен пример архитектуры рекуррентной нейронной сети, используемой в кодировщиках, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0020] На Фиг. 13 представлен пример архитектуры полносвязной нейронной сети, используемой в кодировщиках, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0021] На Фиг. 14 изображена блок-схема примера способа использования декодировщика для распознавания последовательностей символов в словах на изображении в соответствии с одним или более вариантами реализации настоящего изобретения.
[0022] На Фиг. 15 изображена блок-схема примера способа использования модели машинного обучения для символов для определения наиболее вероятной последовательности символов в контексте слов в соответствии с одним или более вариантами реализации настоящего изобретения.
[0023] На Фиг. 16 изображен пример использования модели машинного обучения для символов, описанный со ссылкой на способ на Фиг. 15, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0024] На Фиг. 17 изображена блок-схема другого примера способа использования модели машинного обучения для символов для определения наиболее вероятной последовательности символов в контексте слов в соответствии с одним или более вариантами реализации настоящего изобретения.
[0025] На Фиг. 18 изображен пример использования модели машинного обучения для символов, описанный со ссылкой на способ на Фиг. 17, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0026] На Фиг. 19 изображен пример использования модели машинного обучения для символов, реализованной в виде рекуррентной нейронной сети, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0027] На Фиг. 20 изображен пример архитектуры модели машинного обучения для символов, реализованной в виде сверточной нейронной сети, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0028] На Фиг. 21 изображена блок-схема примера способа использования модели машинного обучения для слов для определения наиболее вероятной последовательности слов в контексте предложений в соответствии с одним или более вариантами реализации настоящего изобретения.
[0029] На Фиг. 22 изображен пример использования модели машинного обучения для слов, описанный со ссылкой на способ на Фиг. 21, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0030] На Фиг. 23 изображена блок-схема другого примера способа использования модели машинного обучения для слов для определения наиболее вероятной последовательности слов в контексте предложения в соответствии с одним или более вариантами реализации настоящего изобретения.
[0031] На Фиг. 24 изображен пример архитектуры модели машинного обучения для слов, реализованной в виде комбинации рекуррентной нейронной сети и сверточной нейронной сети, в соответствии с одним или более вариантами реализации настоящего изобретения.
[0032] На Фиг. 25 изображен пример вычислительной системы, которая может выполнять один или более способов, описанных в настоящем документе, в соответствии с одним или более вариантами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0033] В некоторых случаях обычные методики распознавания символов могут явным образом разделять текст на отдельные символы и применять операции распознавания к каждому символу отдельно. Эти методики плохо подходят для распознавания слитного письма, которое используется в документах на арабском языке, фарси, рукописном тексте и т.п. Например, ошибки могут возникнуть при делении слова на отдельные символы, что приведет к новым ошибкам на последующей стадии посимвольного распознавания.
[0034] Кроме того, стандартные методики распознавания символов могут производить проверку распознаваемых слов текста, сверяясь со словарем. Например, распознаваемое слово может быть определено в конкретном тексте, после чего может быть произведен поиск этого слова в словаре. Если искомое слово обнаружено в словаре, то распознанному слову назначается высокий численный показатель «уверенности». Из возможных вариантов распознанных слов может быть выбрано слово с максимальным показателем уверенности.
[0035] Так, в результате распознавания с использованием стандартных методик распознавания символов может быть получено пять вариантов слов: «ail», «all», «0il», «аМ», «oil». При оценке этих вариантов по словарным словам: «ail», «0il» (первый символ - ноль) и «аМ» при использовании стандартных методик могут получить низкие показатели уверенности, потому что эти слова отсутствуют в заданном словаре. Эти слова не могут быть возвращены в качестве результатов распознавания. С другой стороны, слова «all» и «oil» могут пройти проверку словарем и могут быть представлены в качестве результатов распознавания по стандартной методике с высокой степенью уверенности. Однако стандартная методика не может принимать во внимание символы в контексте слова или слова в контексте предложения. По этой причине результаты распознавания могут быть ошибочными или очень неточными.
[0036] Варианты реализации настоящего изобретения предполагают решение этих проблем за счет использования набора моделей машинного обучения (например, нейронных сетей) для эффективного распознавания текста. В частности, некоторые варианты реализации изобретения не предполагают явного разделения текста на символы. Вместо этого некоторые варианты реализации изобретения используют набор нейронных сетей для одновременного определения точек деления символов в словах и распознавания символов. Этот набор моделей машинного обучения может быть обучен на корпусе текстов. В некоторых вариантах реализации изобретения набор моделей машинного обучения может хранить информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях, а также о сочетаемости символов и частотности их совместного употребления в реальных словах.
[0037] В настоящем документе могут попеременно использоваться термины «символ», «буква» и «кластер». Кластер может означать элементарный неделимый графический элемент (например, графемы или лигатуры), который связывается общим логическим значением. Кроме того, термин «слово» может означать последовательность символов, а термин «предложение» может означать последовательность слов.
[0038] После обучения набор моделей машинного обучения может использоваться для распознавания символов, посимвольного анализа для выбора наиболее вероятных символов в контексте слова и анализа по словам для выбора наиболее вероятных слов в контексте предложения. Таким образом, некоторые варианты реализации изобретения могут позволять использовать набор моделей машинного обучения для определения наиболее вероятного результата распознавания символов в контексте слова и слова в контексте предложения. Например, изображение текста может быть введено в набор обученных моделей машинного обучения для получения одного или более итоговых результатов. Из текста на изображении может быть извлечено одно или более предварительных предложений. Каждое из предварительных предложений может содержать вероятную последовательность слов, и каждое из слов может содержать вероятные последовательности символов.
[0039] В качестве итогового результата описанных в данном документе методик распознавания для демонстрации могут быть выбраны предварительные предложения, содержащие наиболее вероятную последовательность слов. Продолжим рассматривать пример с выбранными выше словами («all» и «oil»). При вводе выбранных слов в одну или более моделей машинного обучения, описанных в этом документе, можно рассмотреть эти слова в контексте предложения (например, «These instructions apply to («all» или «oil») tAAs submitted by customers») и выбрать в качестве распознанного слова «all», потому что оно лучше подходит к предложению применительно к другим словам предложения, чем «oil». Использование набора моделей машинного обучения может повысить качество результатов распознавания текстов, содержащих символы слитного и (или) раздельного письма, принимая во внимание контекст других символов слова и других слов в предложении. Варианты реализации изобретения могут применяться к изображениям как с печатным, так и с рукописным текстом на любом подходящем языке. Кроме того, отдельные используемые модели машинного обучения (например, сверточные нейронные сети) могут особенно хорошо подходить для эффективного распознавания текста и могут повысить скорость обработки вычислительным устройством.
[0040] На Фиг. 1 изображена схема компонентов верхнего уровня для примера системной архитектуры 100 в соответствии с одним или более вариантами реализации настоящего изобретения. Системная архитектура 100 включает вычислительное устройство 110, хранилище 120 и сервер 150, подключенный к сети 130. Сеть 130 может быть сетью общественного пользования (например, Интернет), частной сетью (например, локальная сеть (LAN) или распределенной сетью (WAN)), а также их комбинацией.
[0041] Вычислительное устройство 110 может выполнять распознавание символов, используя искусственный интеллект для эффективного распознавания текстов, содержащих одно или более предложений. Каждое из распознаваемых предложений может содержать одно или более слов. Каждое из распознаваемых слов может содержать один или более символов (например, кластеров). На Фиг. 2 приведен пример двух кластеров, 200 и 201. Как отмечалось выше, кластер может быть элементарным неделимым графическим элементом, который связывается общим логическим значением с другими кластерами. В некоторых языках, включая арабский, одна и та же буква имеет несколько вариантов записи, в зависимости от ее положения (например, в начале, в середине, в конце или отдельно) в слове.
[0042] Например, как здесь показано, буква с названием «Айн» записывается как первый графический элемент 202 (например, кластер) при помещении в конце слова, второй графический элемент 204 при помещении в середине слова, третий графический элемент 206 при помещении в начале слова и четвертый графический элемент 208 при отдельном помещении. Кроме того, буква с названием «Алиф» записывается как первый графический элемент 210 при помещении в конец или середину слова и как второй графический элемент 212 при помещении в начало слова или отдельно. Соответственно, для распознавания в некоторых вариантах реализации изобретения может приниматься во внимание положение буквы в слове, например, для сочетания разных вариантов записи одной и той же буквы в различных положениях в слове, могут оцениваться возможные графические элементы буквы в каждом положении.
[0043] Согласно Фиг. 1 вычислительное устройство 110 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, которое в состоянии использовать технологии, описанные в этом изобретении. Документ 140, содержащий текст на арабском языке, может быть получен вычислительным устройством 110. Следует отметить, что может быть получен текст, напечатанный или написанный от руки на любом языке. Документ 140 может содержать одно или более предложений, каждое из которых содержит одно или более слов, состоящих из одного или более символов.
[0044] Документ 140 может быть получен любым подходящим способом. Например, вычислительное устройство 110 может получить цифровую копию документа 140 путем сканирования документа 140 или фотографирования документа 140. Таким образом, может быть получено изображение 141 текста, содержащего предложения, слова и символы, входящие в документ 140. Кроме того, в тех вариантах реализации изобретения, где вычислительное устройство 110 представляет собой сервер, клиентское устройство, которое подключается к серверу по сети 130, может загружать цифровую копию документа 140 на сервер. В тех вариантах реализации изобретения, где вычислительное устройство 110 является клиентским устройством, соединенным с сервером по сети 130, клиентское устройство может загружать документ 140 с сервера.
[0045] Изображение текста 141 может использоваться для обучения набора моделей машинного обучения или может быть новым документом, для которого следует выполнить распознавание. Соответственно, на предварительных этапах обработки изображение 141 текста, входящего в документ 140, можно подготовить для обучения набора моделей машинного обучения или для последующего распознавания. Например, в изображении 141 текста могут быть вручную или автоматически выбраны строки текста; могут быть отмечены символы; строки текста можно нормализовать, масштабировать и (или) бинаризовать.
[0046] Нормализация может быть выполнена до обучения набора моделей машинного обучения и (или) распознавания текста на изображении 141 для приведения строки текста к одинаковой высоте (например, 80 пикселей). На Фиг. 3А представлен пример нормализации строки текста в ходе предварительной обработки в соответствии с одним или более вариантами реализации настоящего изобретения. Сначала может быть найден центр 300 текста по максимумам интенсивности (наибольшее скопление темных точек на бинаризованном изображении). Высота 302 текста может быть вычислена исходя из центра 300 по среднему отклонению темных пикселей от центра 300. Кроме того, путем добавления отступов (блоков) вертикального пространства сверху и снизу текста формируются столбцы фиксированной высоты. В результате можно получить изображение 304 без искажений. Изображение 304 без искажений можно масштабировать.
[0047] Кроме того, в ходе предварительной обработки текст на изображении 141, полученном из документа 140, может быть разделен на фрагменты текста, как показано на Фиг. 3В. Как было показано, строка разделяется на фрагменты текста автоматически по просветам, имеющим определенный цвет (например, белый), которые превышают пороговое значение (например, 10) по ширине в пикселях. Выбор строк текста на изображении текста может увеличить скорость обработки при распознавании текста за счет одновременной обработки более коротких строк текста, например вместо одной длинной строки текста. Прошедшие предварительную обработку и калиброванные изображения 141 текста могут быть использованы для обучения набора моделей машинного обучения или использованы в качестве исходных данных для набора обученных моделей машинного обучения для получения наиболее вероятного текста.
[0048] Согласно Фиг. 1 вычислительное устройство 110 может содержать систему распознавания символов 112. Система распознавания символов 112 может содержать инструкции, сохраненные на одном или более физических машиночитаемых носителях данных вычислительного устройства 110 и выполняемые на одном или более устройствах обработки вычислительного устройства 110. В одном из вариантов реализации система распознавания символов 112 может использовать набор обученных моделей машинного обучения 114, которые обучены и использованы для предсказания предложений в тексте на изображении 141. Система распознавания символов 112 также может предварительно обрабатывать полученные изображения для использования этих изображений для обучения моделей машинного обучения 114 и (или) применения набора обученных моделей машинного обучения 114 к изображениям. В некоторых вариантах реализации набор обученных моделей машинного обучения 114 может быть частью системы распознавания символов 112 или может быть доступен для обращения с другой машины (например, сервера 150) через систему распознавания символов 112. На основе результата работы набора обученных моделей машинного обучения 114 система распознавания символов 112 может извлечь одно или более предполагаемых предложений из текста на изображении 141.
[0049] Сервер 150 может быть стоечным сервером, маршрутизатором, персональным компьютером, карманным персональным компьютером, мобильным телефоном, портативным компьютером, планшетным компьютером, фотокамерой, видеокамерой, нетбуком, настольным компьютером, медиацентром или их сочетанием. Сервер 150 может содержать систему обучения 151. Набор моделей машинного обучения 114 может ссылаться на артефакт модели, созданный обучающей системой 151 с использованием обучающих данных, которые содержат обучающие входные данные и соответствующие целевые выходные данные (правильные ответы на соответствующие обучающие входные данные). Обучающая система 151 может находить в обучающих данных шаблоны, которые связывают обучающие входные данные с целевыми выходными данными (предсказанным ответом), и предоставлять модели машинного обучения 114, которые используют эти шаблоны. Как более подробно будет описано ниже, набор моделей машинного обучения 114 может быть составлен, например, из одного уровня линейных или нелинейных операций (например, машина опорных векторов [SVM]) или может представлять собой глубокую сеть, то есть модель машинного обучения, составленную из нескольких уровней нелинейных операций. Примерами глубоких сетей являются нейронные сети, включая сверточные нейронные сети, рекуррентные нейронные сети с одним или более скрытыми слоями и полносвязные нейронные сети.
[0050] Сверточная нейронная сеть включает архитектуры, которые могут обеспечить эффективное распознавание образов. Сверточные нейронные сети могут включать несколько сверточных слоев и субдискретизирующих слоев, которые применяют фильтры к частям изображения текста для обнаружения определенных признаков. Таким образом, сверточная нейронная сеть включает операцию свертки, которая поэлементно умножает каждый фрагмент изображения на фильтры (например, матрицы) и суммирует результаты в аналогичной позиции выходного изображения (примеры архитектур приведены на Фиг. 9 и 20).
[0051] Рекуррентные нейронные сети включают функциональность для обработки информационных последовательностей и сохранения информации о предыдущих вычислениях в контексте скрытого слоя. Таким образом, рекуррентные нейронные сети могут иметь «память» (примеры архитектур показаны на Фиг. 11, 12 и 19). Сохранение и анализ информации о предыдущих и последующих позициях в последовательности символов в слове улучшают распознавание символов слитного письма, так как ширина символа может среди прочего превышать одну или две позиции в слове.
[0052] В полносвязной нейронной сети каждый нейрон может передавать полученный на входе сигнал на вход всех остальных нейронов, а также самому себе. Пример архитектуры полносвязной нейронной сети показан на Фиг. 13.
[0053] Как было указано выше, набор большего количества моделей машинного обучения 114 может быть обучен распознавать наиболее вероятный текст на изображении 141, используя обучающие данные, как более подробно будет описано ниже со ссылкой на способ 400 на Фиг. 4. После обучения набора моделей машинного обучения 114 набор моделей машинного обучения 114 может быть использован в системе распознавания символов 112 для анализа новых изображений текста. Например, система распознавания символов 112 может получать на входе изображение текста 141, полученное из документа 140, для анализа с помощью набора моделей машинного обучения 114. Система распознавания символов 112 может получать один или более итоговых результатов от набора обученных моделей машинного обучения и может извлекать из итоговых результатов одно или более предполагаемых предложения из текста на изображении 141. Эти предполагаемые предложения могут содержать вероятную последовательность слов, и каждое слово может содержать вероятную последовательность символов. В некоторых вариантах реализации изобретения вероятные символы слов выбираются исходя из контекста слова (например, в зависимости от других символов слова), а вероятные слова предложения выбираются исходя из контекста предложения (например, в зависимости от других слов в предложении).
[0054] Хранилище 120 представляет собой постоянную память, которая в состоянии сохранять документы 140 и (или) изображения текстов 141, а также структуры данных для разметки, организации и индексации изображений текстов 141. Хранилище 120 может располагаться на одном или более запоминающих устройствах, таких как основная память, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то что хранилище изображено отдельно от вычислительного устройства 110, в одной из реализаций изобретения хранилище 120 может быть частью вычислительного устройства 110. В некоторых вариантах реализации хранилище 120 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище содержимого 120 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, например объектно-ориентированная база данных, реляционная база данных и т.д., которая может находиться на сервере или одной или более различных машинах, подключенных к нему через сеть 130.
[0055] На Фиг. 4 приведена блок-схема примера способа 400 обучения набора моделей машинного обучения 114 для выявления вероятной последовательности слов для каждого из одного или более предложений на изображении 141 текста в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 400 может осуществляться при помощи логической схемы обработки данных, которая может включать аппаратные средства (электронные схемы, специализированную логическую плату и т.д.), программное обеспечение (например, выполняться на универсальной ЭВМ или же на специализированной вычислительной машине) или комбинацию первого и второго. Способ 400 и (или) каждая из его отдельных функций, процедур, подпрограмм или операций может выполняться одним или более процессорами вычислительного устройства (например, вычислительной системы 2500 на Фиг. 25), реализующего этот способ. В некоторых вариантах осуществления способ 400 может осуществляться в одном потоке обработки. При альтернативном подходе способ 400 может выполняться в двух или более потоках обработки, каждый из потоков может реализовывать одну или более отдельных функций, процедур, подпрограмм или операций этих способов. Способ 400 может выполняться на обучающей системе 151 с Фиг. 1.
[0056] В целях простоты объяснения способ 400 в настоящем описании изобретения изложен и наглядно представлен в виде последовательности действий. Однако действия в соответствии с настоящим описанием изобретения могут выполняться в различном порядке и (или) одновременно с другими действиями, не представленными и не описанными в настоящем документе. Кроме того, не все проиллюстрированные действия могут быть необходимыми для реализации способа 400 в соответствии с настоящим описанием изобретения. Кроме того, специалистам в данной области техники должно быть понятно, что способ 400 может быть представлен и иным образом в виде последовательности взаимосвязанных состояний через диаграмму состояний или событий.
[0057] На шаге 410 блок-схемы обрабатывающее устройство может генерировать обучающие данные для одной или более моделей машинного обучения 114. Обучающие данные для набора моделей машинного обучения 114 могут включать позитивные примеры и негативные примеры. На шаге 412 обрабатывающее устройство может генерировать позитивные примеры, содержащие первые тексты. Позитивные примеры могут быть получены из документов, опубликованных в Интернете, загруженных документов и т.п. В некоторых реализациях метода, позитивные примеры включают корпуса текстов (например, Concordance). Под корпусами текстов может иметься в виду набор корпусов текстов, который может включать многочисленные наборы текстов. Также негативные примеры могут включать корпуса текстов и распространение ошибок, как будет подробнее описано ниже.
[0058] На шаге 414 обрабатывающее устройство может генерировать негативные примеры, содержащие вторые текстоы и распространение ошибок. Негативные примеры могут быть динамически созданы путем преобразования текстов, выполненных разными шрифтами, например путем наложения шумов и искажений 500, аналогичных тем, которые возникают при сканировании, как показано на Фиг. 5. Таким образом, эти вторые тексты могут включать варианты, которые имитируют как минимум одну ошибку распознавания одного или более символов, одной или более последовательностей символов или одной или более последовательностей слов. Генерация негативных примеров может включать использование позитивных примеров и наложение частотно встречающихся ошибок распознавания на позитивные примеры.
[0059] Для генерации ошибок распознавания, использующихся для генерации негативных примеров обрабатывающее устройство может разделять корпус текстов на первое подмножество (например, 5% корпуса текстов) и второе подмножество (например, 95% корпуса текстов). Обрабатывающее устройство может распознавать напечатанные и искаженные изображения текстов, содержащие первое подмножество. Могут быть использованы реальные изображения текстов и/или синтетические изображения текстов. Обрабатывающее устройство может верифицировать распознавание текста, определяя распределение ошибок распознавания в распознанном тексте из первого подмножества. Ошибки распознавания могут содержать один или более неправильно распознанных символов, последовательностей символов или последовательностей слов, выпадающие символы и т.д. Другими словами, ошибки распознавания могут обозначать любые некорректно распознанные символы. Ошибки распознавания могут присутствовать на уровне одного символа, в последовательности из двух символов (биграммы), последовательности из трех символов (триграммы) и т.д. Обрабатывающее устройство может получать негативные примеры, изменяя второе подмножество с учетом распределения ошибок.
[0060] На шаге 416 обрабатывающее устройство может генерировать исходную обучающую выборку, содержащую позитивные примеры и негативные примеры. На шаге 418 обрабатывающее устройство может генерировать целевые выходные данные для исходной обучающей выборки. Целевые выходные данные могут выявлять в тексте одно или более предполагаемых предложений. Одно или более предполагаемых предложений могут содержать вероятную последовательность слов.
[0061] На шаге 420 обрабатывающее устройство может предоставлять обучающие данные для обучения набора моделей машинного обучения 114 на (i) исходной обучающей выборке и (ii) целевых результатах. Набор моделей машинного обучения 114 может изучать сочетаемость символов в последовательностях символов и частотность их употребления в последовательностях символов и (или) сочетаемость слов в последовательностях слов и частотность их употребления в последовательностях слов. Таким образом, модели машинного обучения 114 могут учиться оценивать как символы в слове, так и слово целиком. В некоторых вариантах реализации изобретения в ходе процесса обучения может быть получен вектор признаков, который представляет собой последовательность чисел, характеризующих символ, последовательность символов или последовательность слов.
[0062] После обучения набор моделей машинного обучения 114 может быть настроен на обработку нового изображения текста и генерировать один или более результатов, указывающих на вероятную последовательность слов для каждого из одного или более предполагаемых предложений. Каждое слово в каждой позиции вероятной последовательности слов может быть выбрано исходя из контекста слова в соседней позиции (или любой другой позиции в последовательности слов), и каждый символ в последовательности символов может быть выбран исходя из контекста символа в соседней позиции (или любой другой позиции в слове).
[0063] На Фиг. 6 изображена блок-схема примера способа 600 использования одной или более моделей машинного обучения 114 для распознавания текста на изображении в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 600 включает операции, выполняемые вычислительным устройством 110. Способ 600 может выполняться аналогичным или сходным образом, как описано выше по отношению к способу 400. Способ 600 может выполняться обрабатывающими устройствами вычислительного устройства 110 и выполнять систему распознавания символов 112.
[0064] На шаге 610 обрабатывающее устройство может получить изображение 141 текста. Текст на изображении 141 содержит одно или более слов в одном или более предложениях. Каждое слово может включать один или более символов. В некоторых вариантах реализации изобретения обрабатывающее устройство может проводить предварительную обработку изображения 141, как описано выше.
[0065] На шаге 620 обрабатывающее устройство может передать изображение 141 текста в качестве исходных данных на вход набору обученных моделей машинного обучения 114. На шаге 630 обрабатывающее устройство может получать от набора обученных моделей машинного обучения 114 один или более итоговых результатов. На шаге 640 обрабатывающее устройство может извлекать из одного или более итоговых результатов одно или более предполагаемых предложений из текста на изображении 141. Каждое из одного или более предполагаемых предложений может содержать вероятные последовательности слов.
[0066] Набор моделей машинного обучения может включать первую модель машинного обучения (например, комбинацию сверточной нейронной сети (сетей), рекуррентной нейронной сети (сетей) и полносвязной нейронной сети (сетей)), обученную получать изображение текста в качестве первых исходных данных и генерировать для первых исходных данных первый промежуточный результат, вторую модель машинного обучения (например, модель машинного обучения для символов), обученную получать декодированный первый промежуточный результат в качестве вторых исходных данных и генерировать для вторых исходных данных второй промежуточный результат, и третью модель машинного обучения (например, модель машинного обучения для слов), обученную получать второй промежуточный результат в качестве третьих исходных данных и генерировать для третьих исходных данных один или более итоговых результатов.
[0067] Эти первые модели машинного обучения могут быть реализованы в виде кодировщика кластеров 700 и кодировщика точек деления 702, которые выполняют распознавание, как показано на Фиг. 7. Реализации и (или) архитектуры кодировщика кластеров 700 и кодировщика точек деления 702 дополнительно рассматриваются ниже со ссылкой на Фиг. 8А/8В, 9, 10, 11, 12 и 13. Операции распознавания текста в этом варианте реализации изобретения описываются на примере арабского языка, однако следует понимать, что эти операции могут быть применены к любому другому тексту, включая рукописный текст и (или) обычную побуквенную запись при печати. Кодировщик кластеров 700 и кодировщик точки деления 702 могут каждый содержать аналогичные обученные модели машинного обучения, такие как сверточную нейронную сеть 704, рекуррентную нейронную сеть 706 и полносвязную нейронную сеть 708, включая полносвязный выходной слой 710. Кодировщик кластеров 700 и кодировщик точек деления 702 конвертируют изображение 141 (например, изображение строки) в последовательность признаков текста на изображении 141, которая является первым промежуточным результатом. В некоторых реализациях, нейронные сети в кодировщике кластеров 700 и кодировщике точек деления 702 могут быть объединены в один кодировщик, который генерирует множество выходных данных, связанных с последовательностью признаков текста на изображении 141, в качестве первых промежуточных исходных данных. Эти признаки могут содержать информацию, относящуюся к графическим элементам, представляющим один или более символов одного или более слов в одном или более предложениях, и точкам деления, если графические элементы соединены.
[0068] Кодировщик кластеров 700 может проходить по изображению 141, используя фильтры. Каждый фильтр может иметь высоту, равную высоте изображения или менее, и может извлекать определенные признаки в каждой позиции. Кодировщик кластеров 700 может использовать комбинацию обученных моделей машинного обучения для извлечения информации, относящейся к графическим элементам, путем перемножения значений одного или более фильтров и значений каждого пикселя в каждой позиции изображения 141. Значения фильтров могут выбираться таким образом, чтобы при их умножении на значения пикселей в определенных положениях можно было извлечь информацию. Информация, относящаяся к графическим элементам, указывает, можно ли связать определенную позицию в изображении 141 с графическим элементом, кодом Unicode, соответствующим символу, представленному графическим элементом, и (или) является ли текущая позиция точкой деления.
[0069] Например, на Фиг. 8А представлен пример извлечения признаков в каждой позиции изображения 141 с использованием кодировщика кластера в соответствии с одним или более вариантами реализации настоящего изобретения. Кодировщик кластеров 700 может применять в первой позиции 801 один или более фильтров для извлечения признаков, относящихся к графическим элементам. Кодировщик кластеров 700 может сдвигать один или более фильтров во вторую позицию 802 для извлечения тех же признаков во второй позиции 802. Кодировщик кластеров 700 может повторять эту операцию по всей длине изображения 141. Соответственно, результатом может быть информация о признаках в каждой позиции изображения 141, а также информация о длине изображения 141, рассчитанной в позициях. На Фиг. 8В представлен пример слова с точками деления 803 и выявленным кластером 804.
[0070] Кодировщик точек деления 702 может выполнять операции, схожие с операциями кодировщика кластеров 700, но настроен на извлечение других признаков. Например, для каждой позиции изображения 141, к которой применен один или более фильтров кодировщика точки деления 702, кодировщик точки деления 702 может извлекать информацию о том, содержит ли соответствующая позиция точку деления, код Unicode символа справа от точки деления или код Unicode символа слева от точки деления.
[0071] Реализации и (или) архитектуры кодировщика кластеров 700 и кодировщика точек деления 702 подробно рассматриваются здесь со ссылкой на Фиг. 9, 10, 11, 12 и 13. Как было отмечено ранее, каждый кодировщик 700 и 702 содержит сверточную нейронную сеть, рекуррентную нейронную сеть, полносвязную нейронную сеть и полносвязный выходной слой. Сверточная нейронная сеть может преобразовать двумерное изображение 141, содержащее текст (например, арабское слово), в одномерную последовательность признаков (например, признаков кластеров для кодировщика кластеров 700 и признаков точек деления для кодировщика точек деления 702). Далее для каждого кодировщика кластеров 700 и кодировщика точек деления 702 последовательность признаков может быть закодирована с помощью рекуррентной нейронной сети и полносвязной нейронной сети.
[0072] На Фиг. 9 представлен пример архитектуры сверточной нейронной сети 704, используемой в кодировщиках 700 и 702, в соответствии с одним или более вариантами реализации настоящего изобретения. Сверточная нейронная сеть 704 имеет архитектуру для эффективного распознавания образов. Сверточная нейронная сеть 704 содержит операцию свертки, которая может осуществлять умножение каждой позиции изображения на один или более фильтров (например, матриц свертки), как описано выше, поэлементно, с суммированием результата и его записью в аналогичной позиции выходного изображения. Сверточная нейронная сеть 704 может применяться к полученному изображению 141 текста.
[0073] Сверточная нейронная сеть 704 содержит входной слой и несколько сверточных и субдискретизирующих слоев. Например, сверточная нейронная сеть 704 может содержать первый слой, который является по типу входным слоем, второй слой, который является по типу сверточным слоем и имеет функцию активации линейной ректификации (ReLU), третий слой, который является по типу субдискретизирующим слоем, четвертый слой, который является по типу сверточным слоем и имеет функцию активации ReLU, пятый слой, который является по типу субдискретизирующим слоем, шестой слой, который является по типу сверточным слоем и имеет функцию активации ReLU, седьмой слой, который является по типу сверточным слоем и имеет функцию активации ReLU, восьмой слой, который является по типу субдискретизирующим слоем, девятый слой, который является по типу сверточным слоем и имеет функцию активации ReLU.
[0074] На входном слое значение пикселя изображения 141 приводится к диапазону значений [-1, 1] в зависимости от интенсивности цвета. За входным слоем идет сверточный слой с функцией активации линейной ректификации (ReLU). В этом сверточном слое значение предварительно обработанного изображения 141 умножается на значения одного или более фильтров 1000, как показано на Фиг. 10. Фильтр представляет собой матрицу пикселей с определенными размерами и значениями. Каждый фильтр обнаруживает определенный признак. Фильтры применяются к позициям при прохождении изображения 141. Например, первая позиция может быть выбрана, и фильтры могут применяться к верхнему левому углу. Значения каждого фильтра могут быть умножены на оригинальные значения пикселей изображения 141 (поэлементное умножение), и эти произведения могут суммироваться, давая в результате одно число 1002.
[0075] Фильтры могут сдвигаться по изображению 141 на следующую позицию в соответствии с операцией свертки, и процесс свертки может повторяться для следующей позиции изображения 141. Каждая уникальная позиция введенного изображения 141 после применения одного или более фильтров может производить число. После того как один или более фильтров пройдут по каждой позиции, будет получена матрица, которая называется картой признаков 1004. Далее применяется функция активации (например, ReLU), которая может заменить отрицательные числа на нули и оставить положительные числа неизменными. Информация, полученная при операции свертки и при применении функции активации, может быть сохранена и передана на следующий слой сверточной нейронной сети 704.
[0076] В колонке 900 («Размер выходного тензора») приведена информация о размере тензора (например, массива компонентов), полученного из определенного слоя. Например, на слое номер два, имеющем тип сверточного слоя с функцией активации ReLU, результатом будет тензор из шестнадцати карт признаков размера 76×W, где W - общая длина исходного изображения, а 76 - высота после свертки.
[0077] В колонке 902 («Описание») содержится информация о параметрах, используемых в каждом слое. Например, T указывает количество фильтров, Kh указывает высоту фильтров, Kw указывает ширину фильтров, Ph указывает количество белых пикселей, добавляемых при свертке по вертикальным границам, Pw указывает количество белых пикселей, добавляемых при свертке по горизонтальным границам, Sh указывает шаг свертки в вертикальном направлении и Sw указывает шаг свертки в горизонтальном направлении.
[0078] Получаемая со второго слоя (сверточного слоя с функцией активации ReLU) информация поступает как исходная на третий слой, который является субдискретизирующим слоем. В третьем слое выполняется операция по снижению дискретизации пространственных размеров (ширины и высоты), в результате размер карт признаков уменьшается. Например, размер карт признаков может уменьшиться в два раза, потому что фильтры могут иметь размер 2×2.
[0079] Далее в третьем слое может быть выполнено нелинейное уплотнение карт признаков. Например, если некоторые признаки уже были обнаружены в предыдущей операции свертки, то для дальнейшей обработки уже не нужно подробное изображение, и оно уплотняется до менее подробных картинок. В субдискретизирующем слое при применении фильтра к изображению 141 умножение не производится. Вместо этого выполняется более простая математическая операция, например поиск наибольшего числа в позиции на изображении 141. Найденное наибольшее число заносится в карты признаков, и фильтры перемещаются в следующую позицию, и операция повторяется до достижения конца изображения 141.
[0080] Результат третьего слоя используется в качестве исходных данных для четвертого слоя. Обработка изображения 141 с использованием сверточной нейронной сети 704 может продолжаться применением каждого последовательного слоя, пока каждый из слоев не выполнит свою операцию. По завершении сверточная нейронная сеть 704 может выдавать в качестве результата сто двадцать восемь признаков (например, признаков, относящихся к кластерам, признаков, относящихся к точкам деления) с девятого слоя (сверточный слой с функцией активации ReLU), и этот результат может быть использован в качестве исходных данных для рекуррентной нейронной сети соответствующего кодировщика кластеров 700 и кодировщика точек деления 702.
[0081] Пример рекуррентной нейронной сети 706, используемой кодировщиками 700 и 702, приведен на Фиг. 11. Рекуррентные нейронные сети могут обрабатывать последовательности информации (например, последовательности признаков) и сохранять информацию о предыдущих вычислениях в контексте скрытого слоя 1100. Соответственно, рекуррентная нейронная сеть 706 может использовать скрытый слой 1100 в качестве памяти для извлечения информации о предыдущих вычислениях. Входной слой 1102 может получать первую последовательность признаков из сверточной нейронной сети 704 в качестве входных данных. Скрытый слой 1104 может анализировать последовательность признаков, результаты анализа могут быть записаны в контекст скрытого слоя 1100 и затем переданы в выходной слой 1106.
[0082] Вторая последовательность признаков может поступить на входной слой 1102 рекуррентной нейронной сети 706. При обработке второй последовательности признаков в скрытом слое 1104 может приниматься во внимание контекст, записанный при обработке первой последовательности признаков. В некоторых вариантах реализации изобретения результаты обработки второй последовательности признаков могут перезаписывать контекст скрытого слоя 1100 и могут быть переданы в выходной слой 1106.
[0083] В некоторых вариантах реализации изобретения рекуррентная нейронная сеть 706 может быть двунаправленной рекуррентной нейронной сетью. В двунаправленных рекуррентных нейронных сетях обработка информации может производиться от первого направления ко второму направлению (например, слева направо) и от второго направления к первому направлению (например, справа налево). Таким образом, контексты скрытого слоя 1100 сохраняют информацию о предыдущих позициях на изображении 141 и о последующих позициях на изображении 141. Рекуррентная нейронная сеть 706 может объединять информацию, полученную при проходе обработки последовательности признаков в обоих направлениях, и выдавать объединенную информацию.
[0084] Следует отметить, что запись и анализ информации о предыдущей и последующей позициях могут улучшить распознавание слитного письма, поскольку ширина символа может превышать одну или две позиции. Для точного определения точек деления может использоваться информация о том, какие кластеры находятся в соседних позициях (например, слева и справа) от точки деления.
[0085] На Фиг. 12 представлен пример архитектуры рекуррентной нейронной сети 706, используемой в кодировщиках 700 и 702, в соответствии с одним или более вариантами реализации настоящего изобретения. Рекуррентная нейронная сеть 706 может содержать три слоя: первый слой, который является по типу входным слоем, второй слой, который является по типу прореживающим слоем (dropout), и третий слой, который является по типу двунаправленным слоем (например, рекуррентная нейронная сеть, двунаправленные управляемые рекуррентные нейроны (GRU), сеть с долгой краткосрочной памятью (LSTM) или другая подходящая двунаправленная нейронная сеть).
[0086] Последовательность из ста двадцати восьми признаков, полученная из сверточной нейронной сети 704, может быть подана на вход входного слоя рекуррентной нейронной сети 706. Эта последовательность может быть обработана прореживающим слоем (например, слоем регуляризации), чтобы избежать переобучения рекуррентной нейронной сети 706. Третий слой (двунаправленный слой) может объединять информацию, полученную при проходе в обоих направлениях. В некоторых вариантах реализации изобретения в качестве третьего слоя может использоваться двунаправленный GRU; это может привести к получению в качестве результата двухсот пятидесяти шести признаков. В другом варианте реализации изобретения в качестве третьего слоя может использоваться двунаправленная рекуррентная нейронная сеть; это может привести к получению в качестве результата пятисот двенадцати признаков.
[0087] В другом варианте реализации изобретения вместо рекуррентной нейронной сети для получения результата (например, последовательности из ста двадцати восьми признаков) от первой сверточной нейронной сети может использоваться вторая сверточная нейронная сеть. Вторая сверточная нейронная сеть может быть реализована с использованием более широкиех фильтров, которые будут вмещать более широкие позиции на изображении 141 для обеспечения работы с кластерами, находящимися на соседних позициях (например, прилегающими кластерами) с кластером в текущей позиции, и анализа изображения последовательности символов за один прием.
[0088] Кодировщики 700 и 702 могут продолжать распознавание текста на изображении 141 с помощью рекуррентной нейронной сети 706, пересылая ее результат в полносвязную нейронную сеть 708. На Фиг. 13 представлен пример архитектуры полносвязной нейронной сети, используемой в кодировщиках 700 и 702, в соответствии с одним или более вариантами реализации настоящего изобретения. Полносвязная нейронная сеть 708 может содержать три слоя, например первый слой, который является по типу входным слоем, второй слой, который является по типу полносвязным слоем и имеет функцию активации линейной ректификации (ReLU), и третий слой, который является по типу полносвязным выходным слоем 710.
[0089] Входной слой полносвязной нейронной сети 708 может получать признаки, выданные в качестве результата рекуррентной нейронной сетью 706. Полносвязный слой нейронной сети может выполнять математическое преобразование последовательности признаков, выдавая в качестве результата тензор с размером последовательности двухсот пятидесяти шести признаков (С’). Третий слой (полносвязный выходной слой) может получать в качестве исходных данных последовательность признаков, выданную в качестве результата вторым слоем. Для каждого признака в полученной последовательности признаков полносвязный выходной слой может вычислить М соседних признаков выходной последовательности. В результате последовательность признаков удлиняется в М раз. Удлинение последовательности может компенсировать уменьшение длины после выполнения операций сверточной нейронной сетью 704. Например, при обработке изображения сверточная нейронная сеть 704, описанная выше, может сжать данные так, что восьми колонкам пикселей приведена в соответствие одна колонока пикселей. Таким образом, М в иллюстрированном примере равно восьми. Однако может использоваться любое подходящее М исходя из сжатия, выполняемого сверточной нейронной сетью 704.
[0090] Следует понимать, что сверточная нейронная сеть 704 может сжимать данные изображения, рекуррентная нейронная сеть 706 может обрабатывать сжатые данные, и на выходном полносвязном слое полносвязной нейронной сети 708 сжатые данные могут разжиматься. Последовательность признаков, относящихся к графическим элементам, представляющим кластеры и точки деления, которая выдается первыми моделями машинного обучения (например, сверточной нейронной сетью 704, рекуррентной нейронной сетью 706 и полносвязной нейронной сетью 708) каждого из кодировщиков 702 и 704, может считаться первым промежуточным результатом, как было указано выше. Первый промежуточный результат может передаваться в качестве исходных данных декодировщику 712 (показан на Фиг. 7) для обработки.
[0091] Первый промежуточный результат может обрабатываться декодировщиком 712 с получением первого промежуточного результата декодировщика, который передается в качестве исходных данных второй модели машинного обучения (например, модели машинного обучения для символов). Декодировщик 712 может декодировать последовательность признаков текста на изображении 141 и выдавать в качестве результата одну или более последовательностей символов для каждого слова в одной или более последовательностях текста на изображении 141. Таким образом, декодировщик 712 может выдавать в качестве первого промежуточного результата декодировщика распознанную одну или более последовательностей символов.
[0092] Декодировщик 712 может быть реализован в виде инструкций с использованием методов динамического программирования. Методики динамического программирования позволяют решать сложные задачи, разделяя их на несколько подзадач меньшего размера. Например, обрабатывающее устройство, выполняющее инструкции для решения первой подзадачи, может использовать полученные данные для решения второй подзадачи, и так далее. Решение последней подзадачи даст искомый ответ сложной задачи. В некоторых вариантах осуществления изобретения декодировщик решает сложную задачу определения последовательности символов, представленной на изображении 141.
[0093] Например, на Фиг. 14 изображена блок-схема примера способа 1400 использования декодировщика 712 для распознавания последовательностей символов в словах на изображении 141 в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 1400 включает операции, выполняемые вычислительным устройством 110. Способ 1400 может выполняться аналогичным или сходным образом, как описано выше по отношению к способу 400. Способ 1400 может выполняться обрабатывающими устройствами вычислительного устройства 110 и выполнять систему распознавания символов 112.
[0094] На шаге 1410 обрабатывающее устройство может определять координаты первой позиции и последней позиции изображения. В некоторых вариантах осуществления изобретения первая позиция и последняя позиция содержат как минимум один отличающийся по цвету (например, небелый) пиксель.
[0095] На шаге 1420 обрабатывающее устройство может получать последовательность точек деления исходя как минимум из координат первой позиции и последней позиции. В одном из вариантов осуществления изобретения обрабатывающее устройство может определять, является ли последовательность точек деления правильной. Например, последовательность точек деления может быть правильной, если между двумя точками деления нет третьей точки деления, если между двумя точками деления находится единственный символ и если выход слева от текущей точки деления совпадает с выходом справа от предыдущей точки деления и т.д.
[0096] На шаге 1430 обрабатывающее устройство может определять пары соседних точек деления исходя из последовательности точек деления. На шаге 1440 обрабатывающее устройство может определять код Unicode или другой подходящий код каждого символа, расположенного между каждой из пар соседних точек деления. В некоторых вариантах осуществления изобретения определение кода Unicode каждого символа может включать подбор максимального значения функции оценки (например, определение кода Unicode, который получает максимальное значение функции оценки кластера исходя из последовательности признаков).
[0097] На шаге 1450 обрабатывающее устройство может определять одну или более последовательностей символов для каждого слова исходя из кода Unicode каждого символа, расположенного между парами соседних точек деления. Одна или более последовательностей символов для каждого слова могут быть получены при декодировании первого промежуточного результата. В некоторых вариантах реализации декодировщик 712 может выдавать в качестве результата только наиболее вероятный признак распознавания изображения (например, последовательность символов для каждого слова). В другом варианте реализации изобретения декодировщик 712 может выдавать в качестве результата набор вероятных признаков распознавания изображения (например, последовательности символов для каждого слова). В вариантах реализации изобретения с получением нескольких вариантов распознавания (например, нескольких последовательностей символов) наиболее вероятная последовательность символов может определяться второй моделью машинного обучения (например, символьной моделью машинного обучения). Вторая модель машинного обучения может быть обучена так, чтобы выдавать в качестве результата второй промежуточный результат, который содержит одну или более вероятных последовательностей символов для каждого слова, входящих в декодированный первый промежуточный результат, как более подробно будет описано ниже.
[0098] На Фиг. 15 изображена блок-схема примера способа 1500 использования второй модели машинного обучения (например, символьной модели машинного обучения) для определения наиболее вероятной последовательности символов в контексте слов в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 1500 включает операции, выполняемые вычислительным устройством 110. Способ 1500 может выполняться аналогичным или сходным образом, как описано выше по отношению к способу 400. Способ 1500 может выполняться обрабатывающими устройствами вычислительного устройства 110 и выполнять систему распознавания символов 112. Способ 1500 может выполнять посимвольный анализ результатов распознавания (декодированного первого промежуточного результата) для выбора наиболее вероятных символов в контексте слова. Символьная модель машинного обучения, описанная в способе 1500, может получать последовательность символов из первой модели машинного обучения и выдавать в качестве результата индекс уверенности от 0 до 1 в том, что последовательность символов является настоящим словом.
[0099] На Фиг. 16 изображен пример использования символьной модели машинного обучения, описанный со ссылкой на способ на Фиг. 15, в соответствии с одним или более вариантами реализации настоящего изобретения. Для исключения двусмысленного толкования ниже будут совместно рассмотрены Фиг. 15 и Фиг. 16.
[00100] На шаге 1510 обрабатывающее устройство может получить показатель уверенности 1600 для первой последовательности символов 1601 (например, декодированного первого промежуточного результата), подавая на вход обученной символьной модели машинного обучения первую последовательность символов 1601. На шаге 1520 обрабатывающее устройство может определить символ 1602, который был распознан с наивысшим показателем уверенности в первой последовательности символов, и заменить его символом 1604 с наименьшим показателем уверенности, чтобы получить вторую последовательность символов 1603.
[00101] На шаге 1530 обрабатывающее устройство может получить второй показатель уверенности 1606 для второй последовательности символов 1603, подавая на вход обученной символьной модели машинного обучения вторую последовательность символов 1603. Обрабатывающее устройство может повторять шаги 1520 и 1530 требуемое количество раз, или пока показатель уверенности превышает предварительно определенное пороговое значение. На шаге 1540 обрабатывающее устройство может выбрать последовательность символов, которая имеет самый высокий показатель уверенности.
[00102] На Фиг. 17 изображена блок-схема другого примера 1700 способа использования символьной модели машинного обучения для определения наиболее вероятной последовательности символов в контексте слов в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 1700 включает операции, выполняемые вычислительным устройством 110. Способ 1700 может выполняться аналогичным или сходным образом, как описано выше по отношению к способу 400. Способ 1700 может выполняться обрабатывающими устройствами вычислительного устройства 110 и выполнять систему распознавания символов 112. Способ 1700 может выполнять посимвольный анализ результатов распознавания (декодированного первого промежуточного результата) для выбора наиболее вероятных символов в контексте слова. Способ 1700 может быть реализован как способ лучевого поиска, который расширяет наиболее перспективный узел в ограниченном множестве. Способ лучевого поиска может рассматриваться как оптимизированный вариант поиска по первому наилучшему совпадению, который имеет уменьшенные требования к памяти за счет отбрасывания неподходящих кандидатов.
[00103] На Фиг. 18 изображен пример использования символьной модели машинного обучения, описанный со ссылкой на способ на Фиг. 17, в соответствии с одним или более вариантами реализации настоящего изобретения. Для исключения двусмысленного толкования ниже будут совместно рассмотрены Фиг. 17 и Фиг. 18. Как показано на Фиг. 18, может существовать несколько вариантов распознавания символов (1800 и 1802) с относительно высокими показателями уверенности (например, вероятными символами) для каждой позиции (1804) слова на изображении 141. Наиболее вероятными вариантами являются варианты с наивысшими показателями уверенности (1806).
[00104] На шаге 1710 обрабатывающее устройство может определить N вероятных символов для первой позиции 1808 в последовательности символов, представляющих слово, исходя из результатов распознавания образов для декодированного первого промежуточного результата. Поскольку операции символического анализа иллюстрируются на примере арабского языка, позиции отсчитываются в направлении справа налево. Первая позиция находится в крайнем правом положении. N (1810) в иллюстрирующем примере равно 2, так что обрабатывающее устройство выбирает два наилучших варианта распознавания - это символы «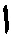 » и «
» и «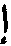 », как показано на 1812.
», как показано на 1812.
[00105] На шаге 1720 обрабатывающее устройство может определить N вероятных символов («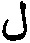 » и «
» и «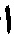 ») для второй позиции в последовательности символов и совместить их с N вероятных символов («» и «») для первой позиции для получения последовательностей символов. Аналогичным образом могут быть созданы четыре последовательности символов, каждая из которых содержит два символа (
») для второй позиции в последовательности символов и совместить их с N вероятных символов («» и «») для первой позиции для получения последовательностей символов. Аналогичным образом могут быть созданы четыре последовательности символов, каждая из которых содержит два символа (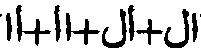 ), как показано в 1814.
), как показано в 1814.
[00106] На шаге 1730 обрабатывающее устройство может оценить созданные последовательности символов и выбрать N вероятных последовательностей символов. Обрабатывающее устройство может принимать во внимание показатели уверенности, полученные для символов при распознавании, и оценку, полученную в качестве результата от обученной модели машинного обучения. На приведенном примере из четырех двухсимвольных последовательностей могут быть выбраны две: «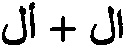 ».
».
[00107] На шаге 1740 обрабатывающее устройство может определить N вероятных символов для следующей позиции в последовательности символов и совместить их с N вероятных символьных последовательностей для получения объединенных последовательностей символов. Таким образом, в приведенном примере обрабатывающее устройство сгенерирует четыре трехсимвольных последовательности: «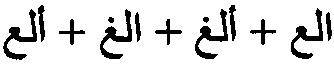 » в 1816.
» в 1816.
[00108] На шаге 1750 после добавления следующего символа обрабатывающее устройство может вернуться к предыдущей позиции в последовательности символов и повторно оценить символ в контексте ближайших символов (например, соседних символов справа и (или) слева от добавленного символа) или других символов в различных позициях последовательности символов. Это может повысить точность при анализе распознавания, позволяя рассматривать каждый символ в контексте слова.
[00109] На шаге 1760 обрабатывающее устройство может определить N вероятных последовательностей символов из объединенных последовательностей символов как наилучшие последовательности символов. Как показано на приведенном примере, обрабатывающее устройство выбирает N (2) (например, «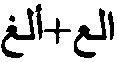 ») из четырех трехсимвольных последовательностей, принимая во внимание показатели уверенности, полученные для символов при распознавании, и оценку, полученную от обученной модели машинного обучения для символов.
») из четырех трехсимвольных последовательностей, принимая во внимание показатели уверенности, полученные для символов при распознавании, и оценку, полученную от обученной модели машинного обучения для символов.
[00110] На шаге 1770 обрабатывающее устройство может определить, был ли выбран последний символ в слове. Если последний символ не выбран, то обрабатывающее устройство может вернуться к выполнению шага 1740 для выбора N вероятных символов для следующей позиции и их объединения с N выбранных вероятных последовательностей символов для получения объединенных последовательностей символов, пока не будут созданы N символьных последовательностей, включающих каждый символ слова. Если последний символ выбран, посимвольный анализ может быть завершен, и могут быть выбраны N символьных последовательностей, включающих каждый символ слова.
[00111] Описанная выше модель машинного обучения для символов, также именуемая в данном описании символьной моделью машинного обучения, в контексте способов 1500 и 1700 может быть реализована при помощи различных нейронных сетей. Например, можно использовать рекуррентную нейронную сеть (приведенную на Фиг. 19), настроенную на хранение информации. Также для реализации символьной модели машинного обучения можно использовать сверточную нейронную сеть (приведена на Фиг. 20). Кроме того, можно использовать нейронную сеть, в которой обработка последовательностей может производиться в направлении слева направо, справа налево или в обоих направлениях, в зависимости от направления и сложности букв. Кроме того, нейронные сети могут рассматривать анализируемые символы в контексте слова, принимая во внимание символы на других позициях (например, слева, справа, слева и справа) с анализируемым символом в текущей позиции, в зависимости от направления обработки последовательностей.
[00112] На Фиг. 19 изображен пример использования символьной модели машинного обучения, реализованной в виде рекуррентной нейронной сети 1900, в соответствии с одним или более вариантами реализации настоящего изобретения. Рекуррентная нейронная сеть 1900 может содержать первый слой 1902, представленный в виде таблицы соответствия. В этом слое 1902 каждому символу 1904 ставится в соответствие эмбединг 1906 (вектор признаков). Таблица соответствия может содержать по вертикали значения каждого символа и один специальный символ «unknown» («неизвестно») 1908 (неизвестный или низкочастотный символ конкретного языка). Векторы признаков могут иметь длину 8-32, и 64-128 чисел. Размер вектора может подстраиваться в зависимости от языка.
[00113] Второй слой 1910 представляет собой GRU, LSTM или двунаправленную LSTM. Третий слой 1912 также представляет собой GRU, LSTM или двунаправленную LSTM. Четвертый слой 1914 является полносвязным слоем. Этот слой 1914 добавляет результат предыдущих слоев к весам и в качестве результата выдает показатель уверенности от 0 до 1 после применения функции активации. В некоторых вариантах реализации изобретения может использоваться сигмоидная функция активации. Между слоями может использоваться слой регуляризации 1916, например прореживающий слой или слой пакетной нормализации (batchNorm).
[00114] На Фиг. 20 изображен пример архитектуры модели машинного обучения для символов, реализованной в виде сверточной нейронной сети 2000, в соответствии с одним или более вариантами реализации настоящего изобретения. Сверточная нейронная сеть 2000 может содержать первый слой, представленный в виде таблицы соответствия. В первом слое каждому символу назначается эмбединг вектора признаков 2002. Таблица соответствия может содержать по вертикали значения каждого символа и один специальный символ «unknown» («неизвестно») (неизвестный или низкочастотный символ конкретного языка). Векторы признаков могут иметь длину 8-32, и 64-128 чисел. Размер вектора может подстраиваться в зависимости от языка.
[00115] Второй слой 2004 содержит К сверточных слоев. В качестве исходных данных для каждого слоя может быть взята последовательность символьных эмбедингов. Последовательность символьных эмбедингов подвергается операции «свертка по времени» (2006), которая представляет собой операцию свертки, аналогичную операции, описанной при упоминании архитектуры сверточной нейронной сети 704, описанной выше со ссылкой на Фиг. 9 и 10.
[00116] Свертка может производиться фильтрами различного размера (например, 8×2, 8×3, 8×4, 8×5), где первое число соответствует размеру эмбединга. Количество фильтров может быть равно количеству чисел в эмбединге. Для фильтра размера 2 (2008) эмбединги первых двух символов могут быть умножены на веса этих фильтров. Фильтр размера 2 можно сдвинуть на шаг в один эмбединг и умножить эмбединги второго и третьего символов на фильтр. Фильтр можно сдвигать до конца последовательности эмбедингов. Далее аналогичные процессы можно выполнить с фильтрами размера 3, размера 4, размера 5 и т.д.
[00117] К результатам, полученным при проходах фильтров, применяемых к эмбедингам, может быть применена функция активации ReLU 2010. Кроме того, к результатам функции активации ReLU могут применяться фильтры MaxOverTimePooling (пулинг «по времени»). Фильтры MaxOverTimePooling находят максимальные значения в эмбедингах и передают их на следующий слой. Эта комбинация свертки, активации и пулинга может выполняться настраиваемое количество раз. Третий слой 2014 включает конкатенацию. Этот слой 2014 может получать результаты из функции MaxOverTimePooling и объединять их, получая в результате вектор признаков. Этот вектор признаков может содержать последовательность чисел, описывающих данный символ.
[00118] Используя символьную модель машинного обучения, варианты реализации изобретения могут получать в качестве исходных данных первый промежуточный результат декодировщика и создавать второй промежуточный результат. Второй промежуточный результат может содержать одну или более вероятных последовательностей символов для каждого слова, выбранного из одной или более последовательностей символов для каждого слова, входящего в декодированный первый промежуточный результат. После определения наиболее вероятных последовательностей символов для одного или более слов в одном или более предложениях текста на изображении 141 в третьей модели машинного обучения (например, словной модели машинного обучения, также именуемой в данном описании моделью машинного обучения для слов) можно выполнить пословный анализ для определения предложений, включающих одно или более вероятных слов, исходя из контекста предложений. Таким образом, третья модель машинного обучения может получать второй промежуточный результат и создавать один или более итоговых результатов, которые используются для извлечения одного или более определенных предложений из текста на изображении 141.
[00119] На Фиг. 21 изображена блок-схема примера способа 2100 использования третьей модели машинного обучения (например, модели машинного обучения для слов) для определения наиболее вероятной последовательности слов в контексте предложений в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 2100 включает операции, выполняемые вычислительным устройством 110. Способ 2100 может выполняться аналогичным или сходным образом, как описано выше по отношению к способу 400. Способ 2100 может выполняться обрабатывающими устройствами вычислительного устройства 110 и выполнять систему распознавания символов 112. Перед выполнением способа 210 обрабатывающее устройство может получать второй промежуточный результат (одна или более вероятных последовательностей символов для каждого слова в одном или более предложениях) от второй модели машинного обучения (модель машинного обучения для символов).
[00120] На Фиг. 22 изображен пример использования модели машинного обучения для слов, описанный со ссылкой на способ на Фиг. 21, в соответствии с одним или более вариантами реализации настоящего изобретения. Для исключения двусмысленного толкования ниже будут совместно рассмотрены Фиг. 21 и Фиг. 22.
[00121] На шаге 2110 обрабатывающее устройство может создавать первую последовательность слов 2208, используя слова (последовательности символов) с максимальными показателями уверенности в каждой позиции предложения. В примере, показанном на Фиг. 22, к словам с максимальными показателями уверенности относятся: «These» для первой позиции 2202, «instructions» для второй позиции 2204, «apply» для третьей позиции 2206 и т.д. В некоторых вариантах реализации изобретения выбранные слова могут быть собраны в предложение без нарушения их последовательного порядка. Например, «These» не сдвигается на вторую позицию 2204 или третью позицию 2206.
[00122] На шаге 2120 обрабатывающее устройство может определять показатель уверенности 2210 для первой последовательности слов 2208, подавая на вход словной модели машинного обучения первую последовательность слов 2208. Эта словная модель машинного обучения может выдавать в качестве результата показатель уверенности 2210 для первой последовательности слов 2208.
[00123] На шаге 2130 обрабатывающее устройство может определить слово (2212), которое было распознано с наивысшим показателем уверенности в первой последовательности слов 2208, и заменить его словом (2214) с меньшим показателем уверенности, чтобы получить вторую последовательность слов 2216. Как показано, слово «apply» (2212) с максимальной уверенностью 0,95 заменяется словом «awfy» (2214) с меньшей уверенностью 0,3.
[00124] На шаге 2140 обрабатывающее устройство может определять показатель уверенности другой последовательности слов 2216, подавая на вход другую последовательность слов 2216 в словную модель машинного обучения. На шаге 2150 обрабатывающее устройство может определять, превышает ли показатель уверенности для последовательности слов установленный порог. Если это так, последовательность слов, показатель уверенности для которой превышает установленный порог, может быть выбрана. Если это не так, обрабатывающее устройство может вернуться к выполнению шагов 2130 и 2140 для создания дополнительных предложений указанное число раз или до обнаружения комбинации слов, показатель уверенности для которой превышает установленный порог. Если выполнение шагов повторено указанное число раз без достижения установленного порога, то в конце полного набора сгенерированных комбинаций слов обрабатывающее устройство может выбрать комбинацию слов, получившую максимальный показатель уверенности.
[00125] На Фиг. 23 изображена блок-схема другого примера способа 2300 использования модели машинного обучения для слов для определения наиболее вероятной последовательности символов в контексте слов в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 2300 включает операции, выполняемые вычислительным устройством 110. Способ 2300 может выполняться аналогичным или сходным образом, как описано выше по отношению к способу 400. Способ 2300 может выполняться обрабатывающими устройствами вычислительного устройства 110 и выполнять систему распознавания символов 112. Способ 2300 может быть реализован как способ лучевого поиска, который расширяет наиболее перспективный узел в ограниченном множестве. Способ лучевого поиска может рассматриваться как оптимизированный вариант поиска по первому наилучшему совпадению, который имеет уменьшенные требования к памяти за счет отбрасывания неподходящих кандидатов. В предполагаемых предложениях для каждой позиции может быть несколько вариантов с высоким показателем уверенности (например, вероятных), и способ 2310 может выбирать N наиболее вероятных вариантов для каждой позиции предложений.
[00126] На шаге 2210 обрабатывающее устройство может определить N вероятных слов для первой позиции в последовательности слов, представляющей предложение, исходя из второго промежуточного результата (например, одной или более последовательностей символов для каждого слова). На шаге 2220 обрабатывающее устройство может определить N вероятных слов для второй позиции в последовательности слов и совместить их с N вероятных слов в первой позиции для получения последовательностей слов.
[00127] На шаге 2230 обрабатывающее устройство может оценить последовательности слов, полученные с помощью обученной модели машинного обучения для слов, и выбрать N вероятных последовательностей слов. При выборе обрабатывающее устройство может принимать во внимание показатели уверенности, полученные для слов при распознавании или определенные обученной моделью машинного обучения для символов, а также оценку, полученную как результат от обученной модели машинного обучения для слов. На шаге 2240 обрабатывающее устройство может выбрать N вероятных слов для следующей позиции и совместить их с N вероятных последовательностей символов для получения объединенных последовательностей слов.
[00128] На шаге 2250 обрабатывающее устройство может после добавления другого слова вернуться к предыдущей позиции в последовательности слов и повторно оценить слово в контексте соседних слов (то есть, в контексте предложения) или других слов в различных позициях в последовательности слов. Шаг 2250 может помочь добиться большей точности распознавания, рассматривая слово в каждой позиции в контексте других слов предложения. На шаге 2260 обрабатывающее устройство может выбрать N вероятных последовательностей слов из объединенных последовательностей слов.
[00129] На шаге 2270 обрабатывающее устройство может определить, было ли выбрано последнее слово в предложении. Если нет, обрабатывающее устройство может вернуться к шагу 2240 для продолжения выбора вероятных слов для следующей позиции. Если да, пословный анализ может быть завершен, и обрабатывающее устройство может выбрать наиболее вероятную последовательность слов как предполагаемое предложение из числа N последовательностей слов (например, предложений).
[00130] Описанная выше модель машинного обучения для слов в контексте способов 2100 и 2300 может быть реализована при помощи различных нейронных сетей. Нейронные сети могут иметь архитектуры, сходные с описанными ранее для модели машинного обучения для символов. Например, модель машинного обучения для слов может быть реализована в виде рекуррентных нейронных сетей (приведены на Фиг. 19). Также для реализации модели машинного обучения для слов можно использовать сверточную нейронную сеть (приведена на Фиг. 20). В обученной модели машинного обучения эмбединги могут соответствовать словам и группам слов, которые объединены в категории (например, «неизвестно», «число», «дата»).
[00131] Дополнительная архитектура 2400 реализации модели машинного обучения для слов приведена на Фиг. 24. Пример архитектуры 2400 реализует модель машинного обучения для слов как комбинацию сверточной нейронной сети, реализующей модель машинного обучения для символов (приведена на Фиг. 20) и рекуррентной нейронной сети для слов. Соответственно, архитектура 2400 может вычислять векторы признаков на уровне 2402 последовательности символов и вычислять признаки на уровне 2404 последовательности слов.
[00132] На Фиг. 25 изображен пример вычислительной системы 2500, которая может выполнять один или более способов, описанных в настоящем документе, в соответствии с одним или более вариантами реализации настоящего изобретения. В одном из примеров вычислительная система 2500 может соответствовать вычислительному устройству, способному выполнять систему распознавания символов 112, представленную на Фиг. 1. В другом примере вычислительная система 2500 может соответствовать вычислительному устройству, способному запускать систему обучения 151, представленную на Фиг. 1. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных здесь способов или нескольких таких способов.
[00133] Пример вычислительной системы 2500 включает устройство обработки 2502, основное запоминающее устройство 2504 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например, синхронное DRAM (SDRAM)), статическое запоминающее устройство 2506 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 2516, которые взаимодействуют друг с другом по шине 2508.
[00134] Устройство обработки 2502 представляет собой одно или более устройств обработки общего назначения, таких как микропроцессор, центральный процессор или т.п. В частности, устройство обработки 2502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Устройство обработки 2502 также может представлять собой одно или более устройств обработки специального назначения, таких как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Устройство обработки 2502 настраивается для выполнения инструкций в целях выполнения рассматриваемых в этом документе операций и шагов.
[00135] Вычислительная система 2500 может дополнительно включать устройство сетевого интерфейса 2522. Вычислительная система 2500 может также включать видеомонитор 2510 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 2512 (например, клавиатуру), устройство управления курсором 2514 (например, мышь) и сигнальное устройство 2520 (например, громкоговоритель). В одном из иллюстративных примеров видео дисплей 2510, устройство буквенно-цифрового ввода 2512 и устройство управления курсором 2514 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[00136] Запоминающее устройство 2516 может включать машиночитаемый носитель 2524, в котором хранятся команды 2526 (например, система распознавания символов 112 или система обучения 151), реализующие одну или более методологий или функций, описанных в данном документе. Команды 2526 могут также находиться полностью или по меньшей мере частично в основном запоминающем устройстве 2504 и (или) в устройстве обработки 2502 во время выполнения вычислительной системой 2500, основным запоминающим устройством 2504 и устройством обработки 2502, также содержащими машиночитаемый носитель информации. Команды 2526 могут дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 1122.
[00137] Несмотря на то что машиночитаемый носитель данных 2524 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также может включать любой носитель, который может хранить, кодировать или содержать набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как включающий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[00138] Несмотря на то что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться (по крайней мере частично) одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[00139] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[00140] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[00141] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сконструирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00142] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «настройка» и т.п., относятся к действиям компьютерной системы или подобного электронного вычислительного устройства либо к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин в регистрах компьютерной системы и памяти, в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[00143] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[00144] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[00145] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[00146] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанная в настоящем документе как «пример», не должна обязательно рассматриваться как предпочтительная или преимущественная по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя А; X включает в себя В; или X включает и А, и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «a» и «an», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» либо «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
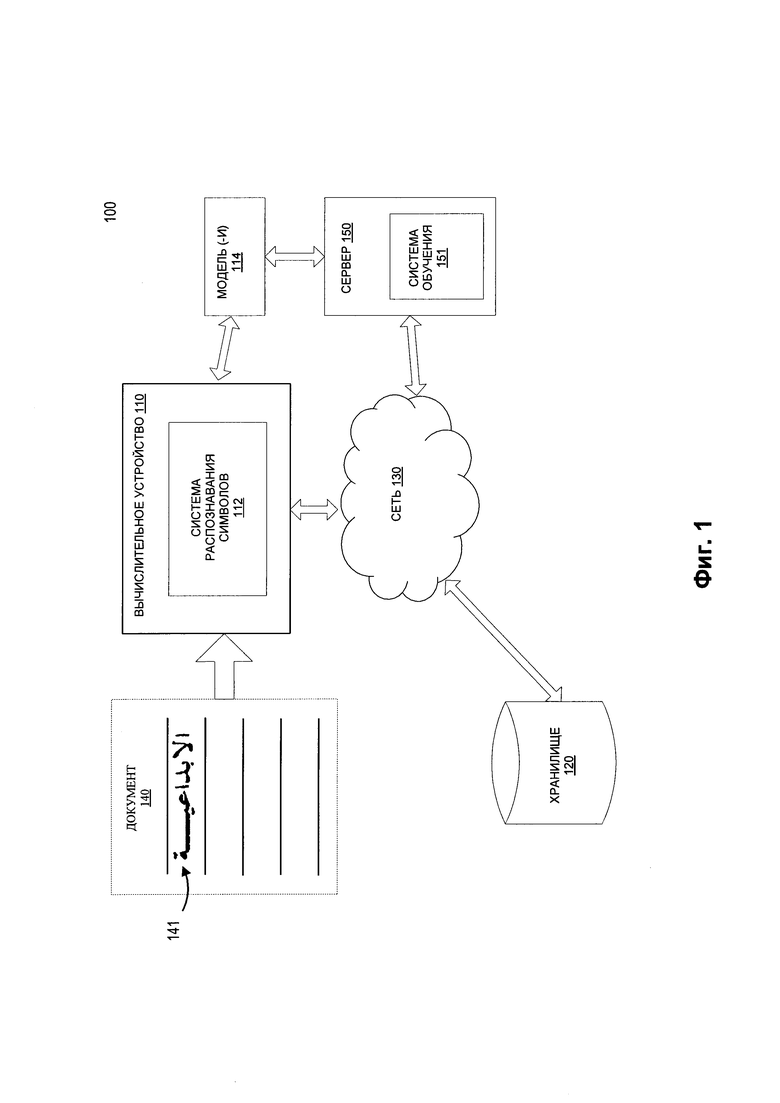
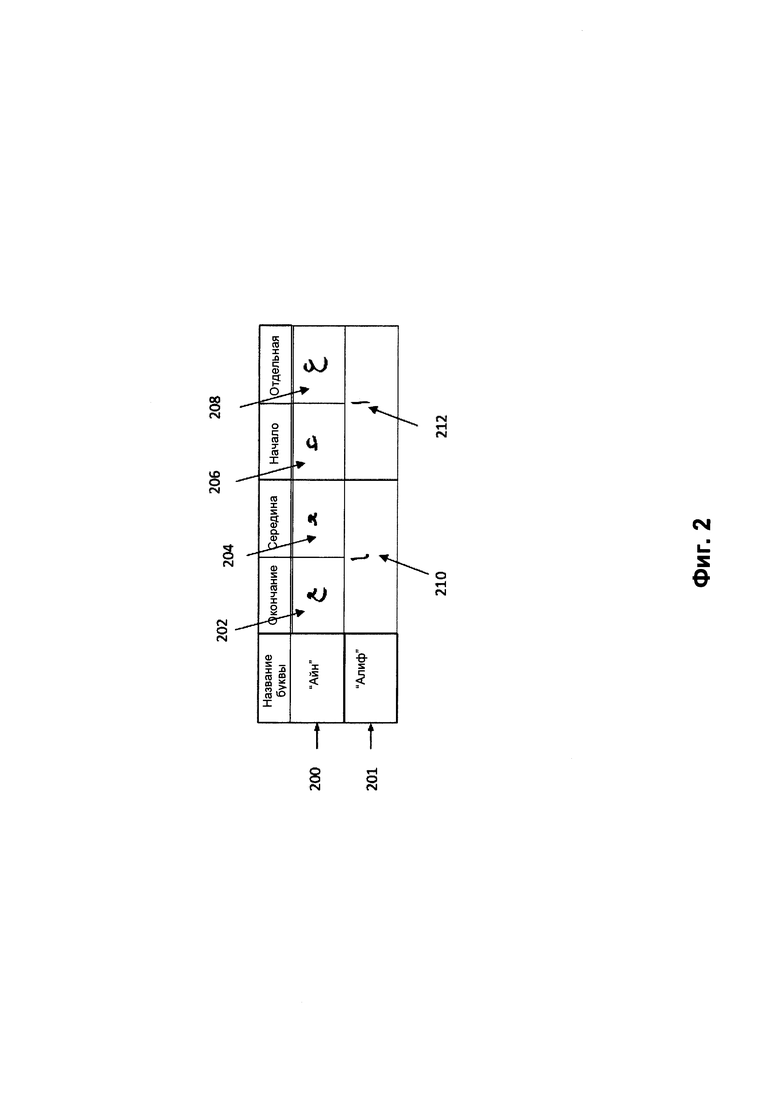
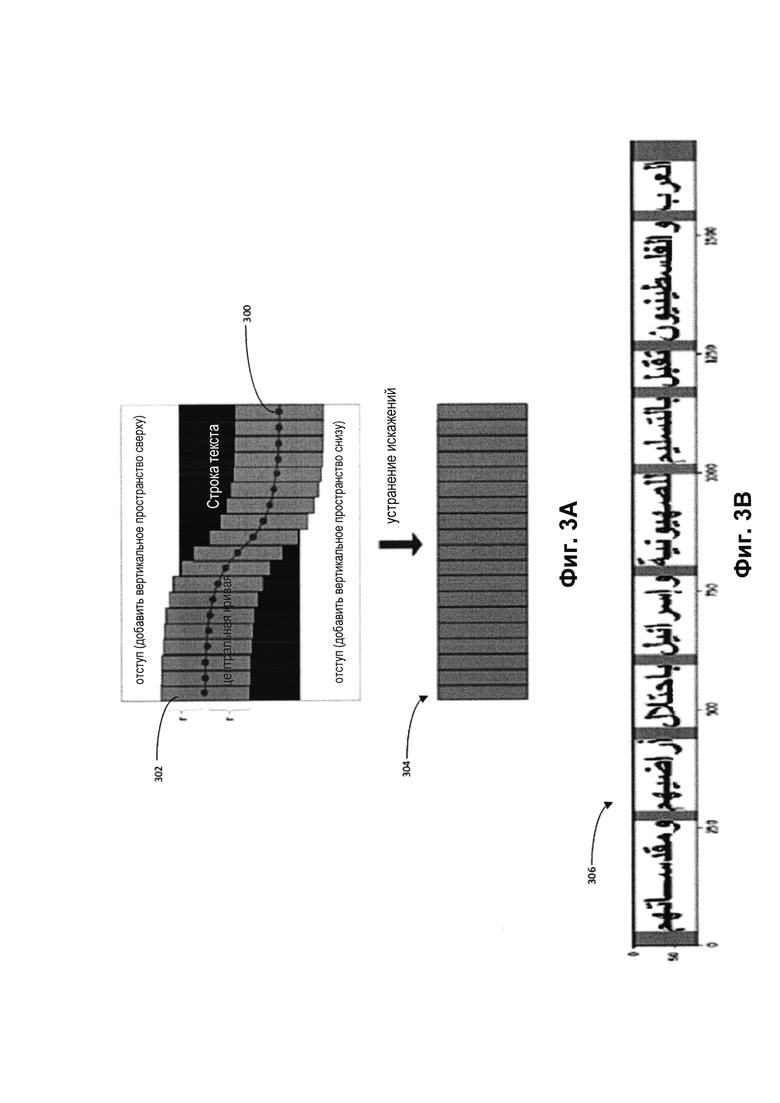
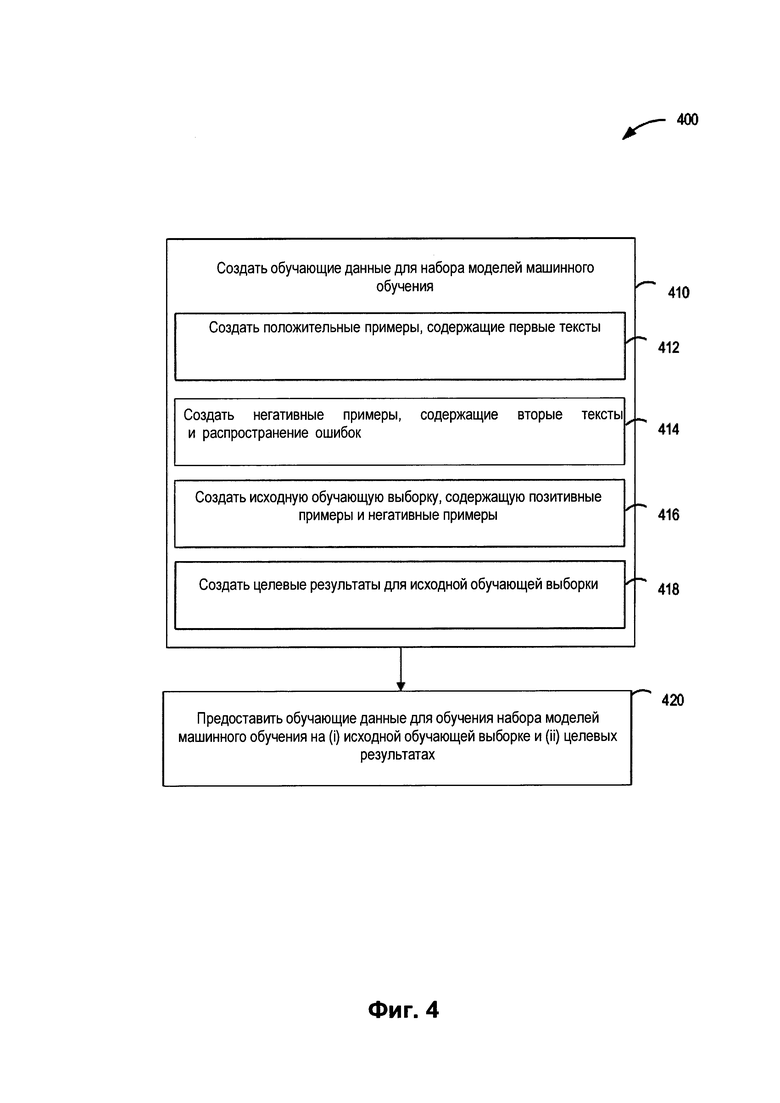

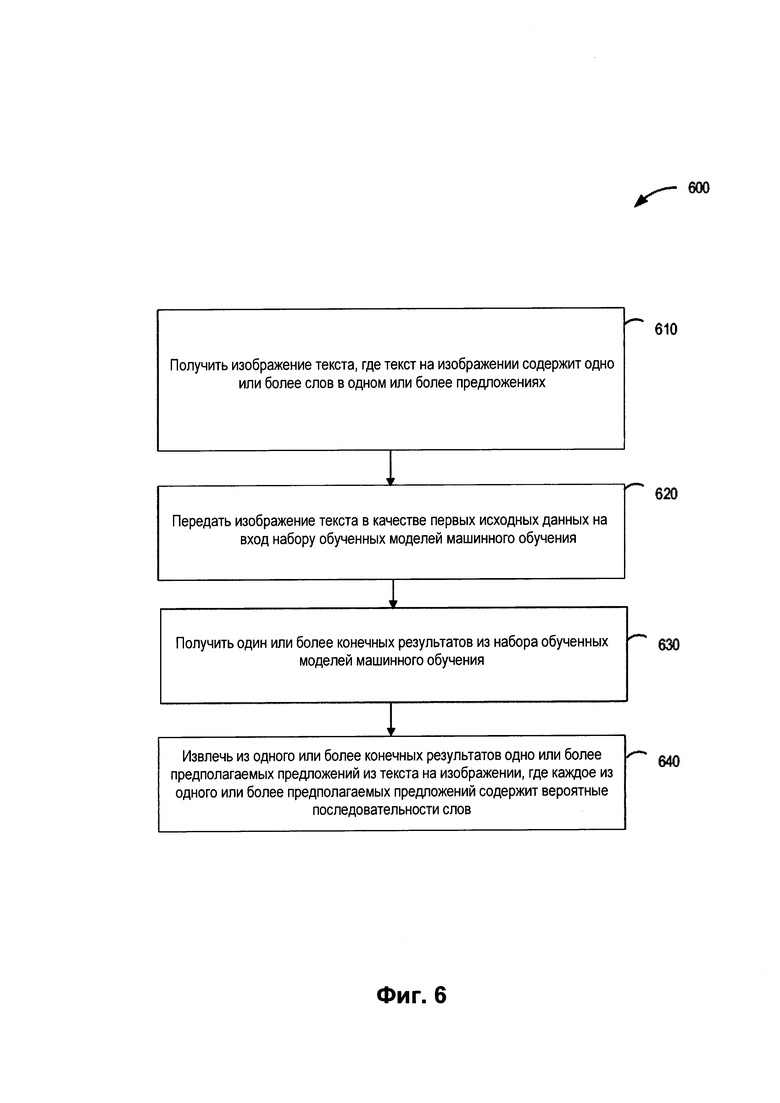
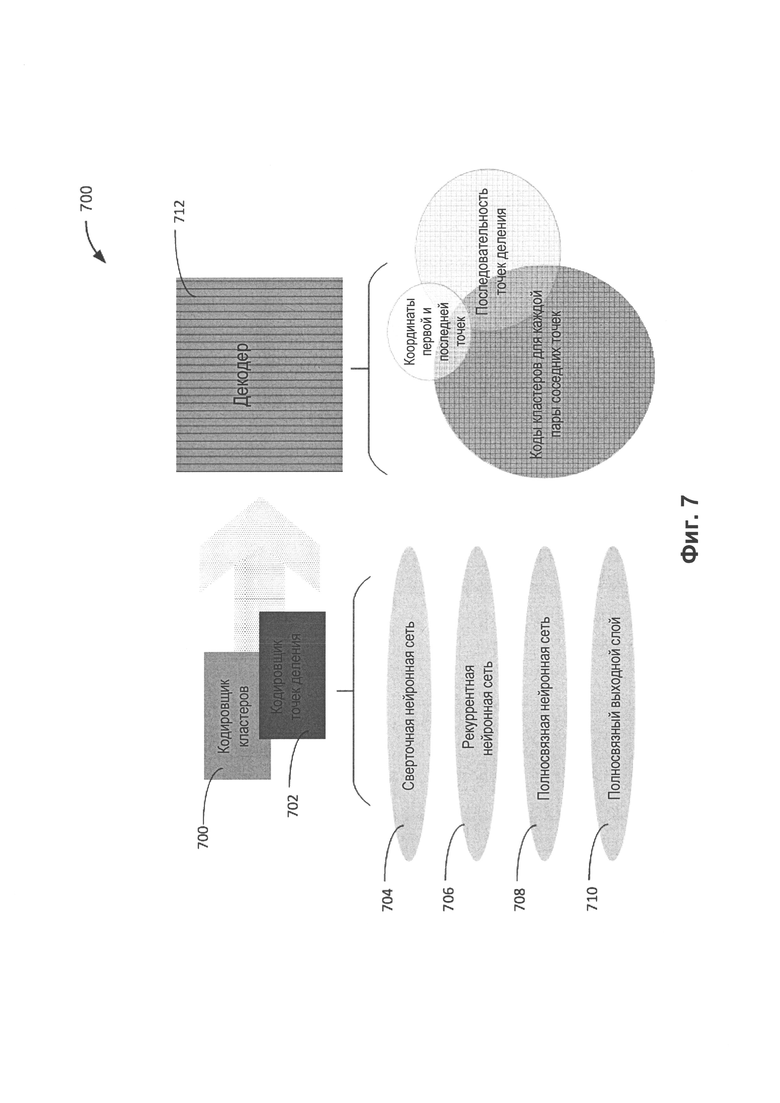
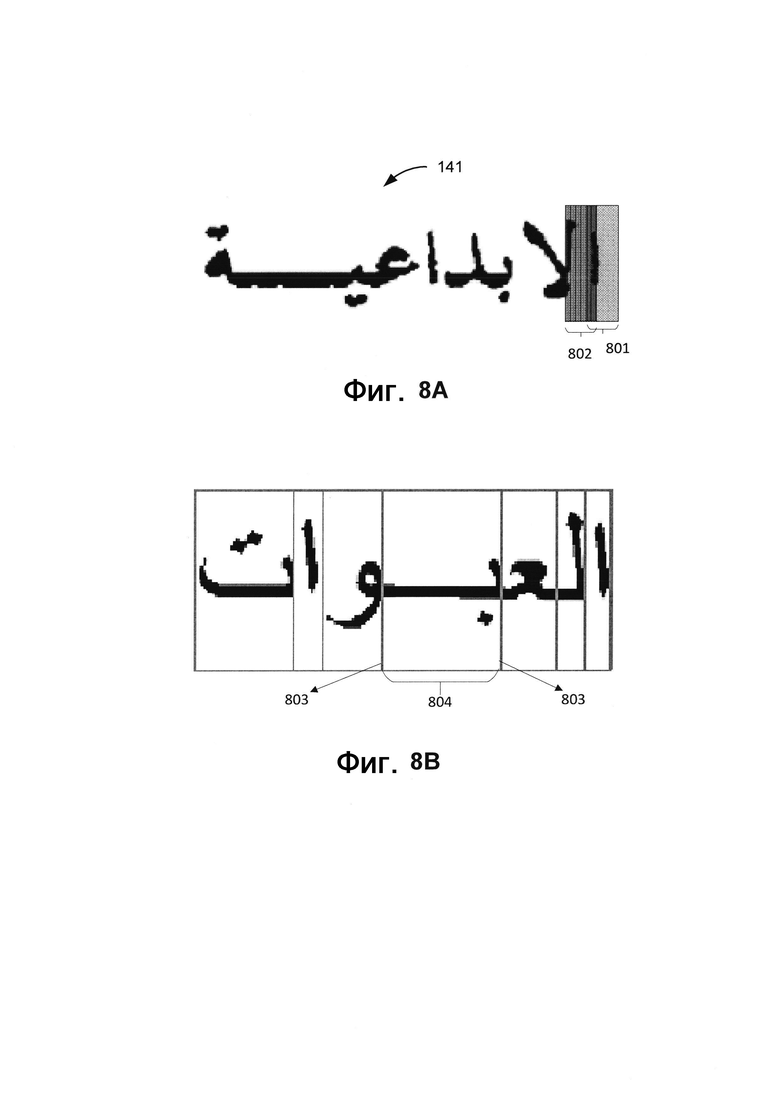
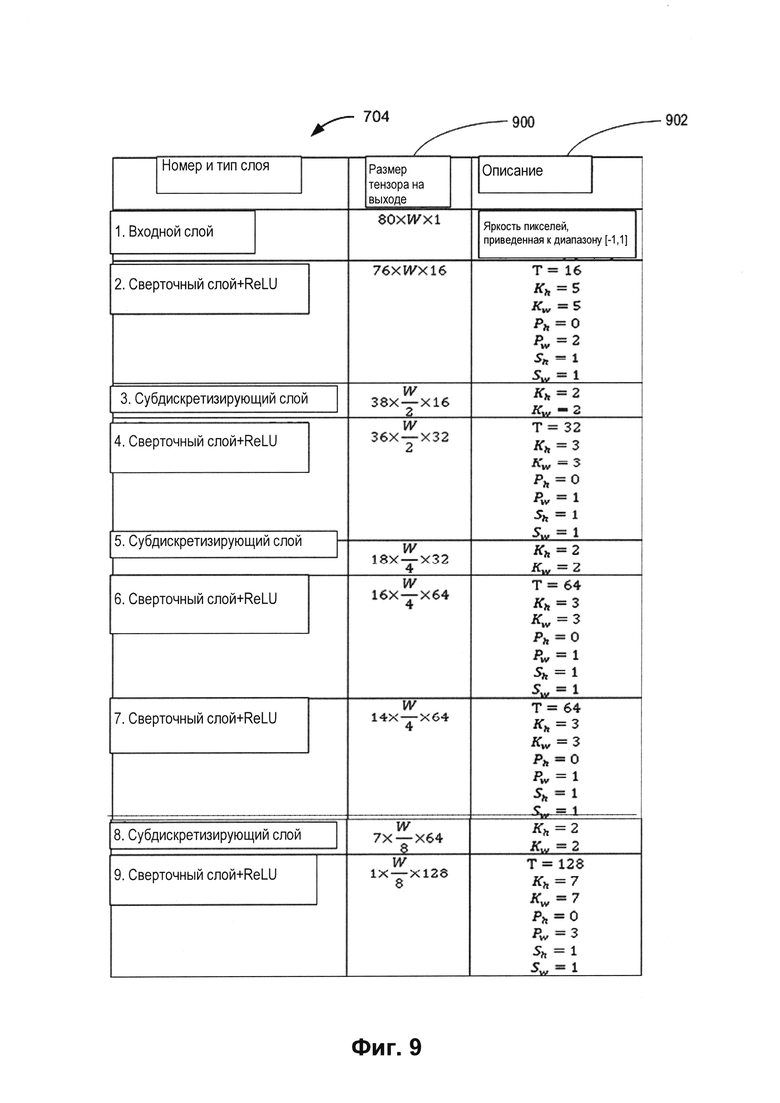
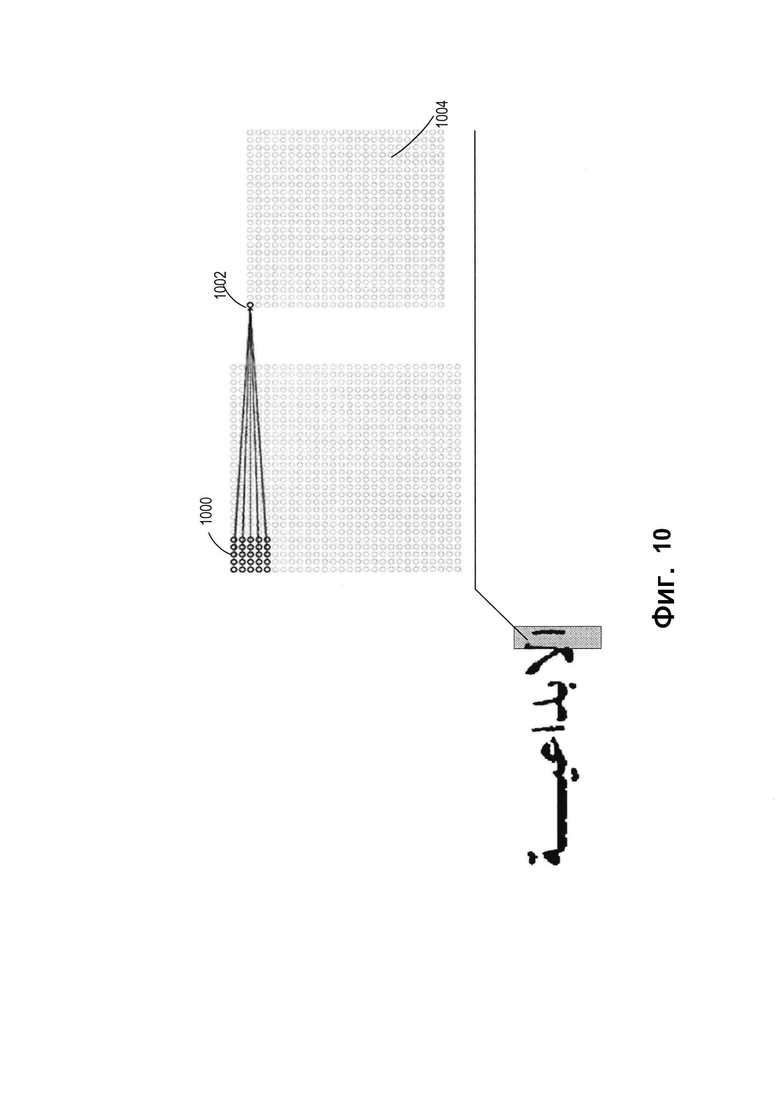

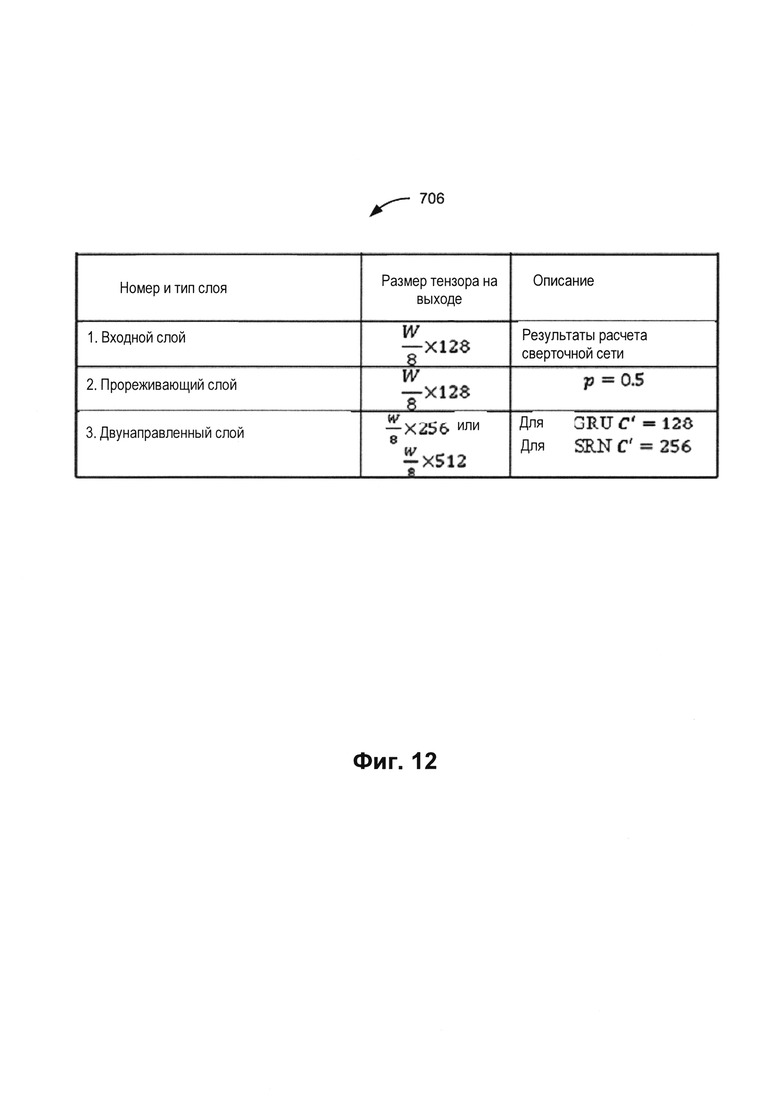
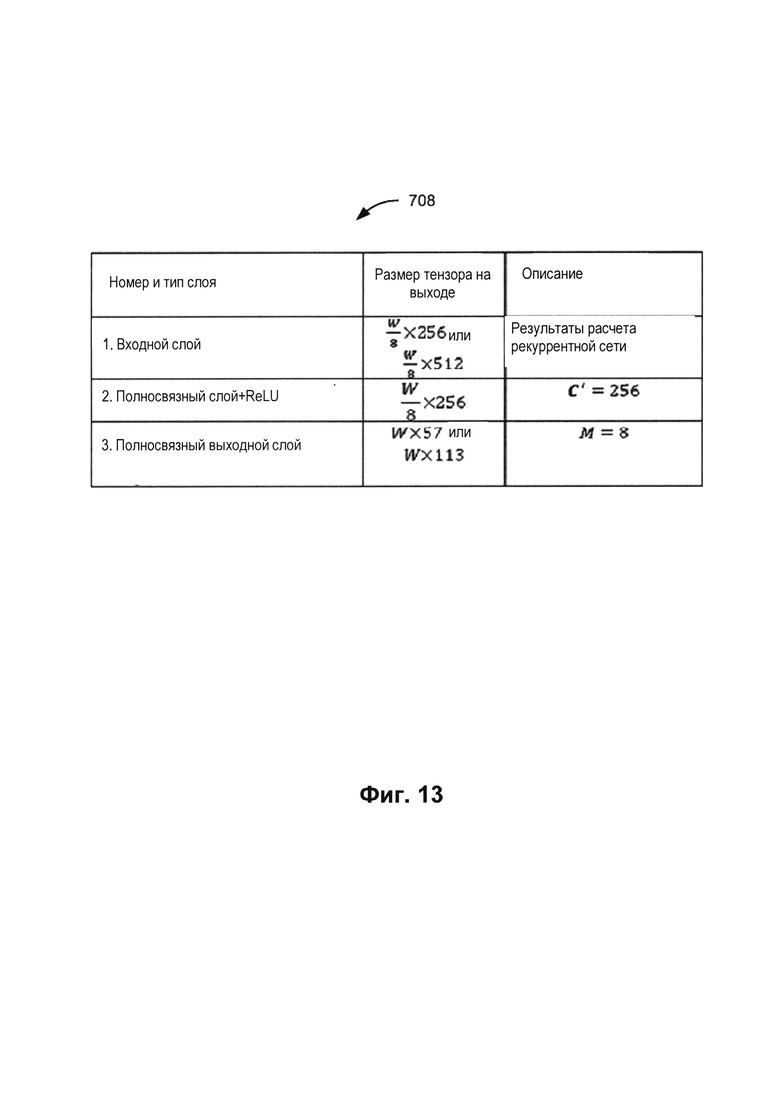
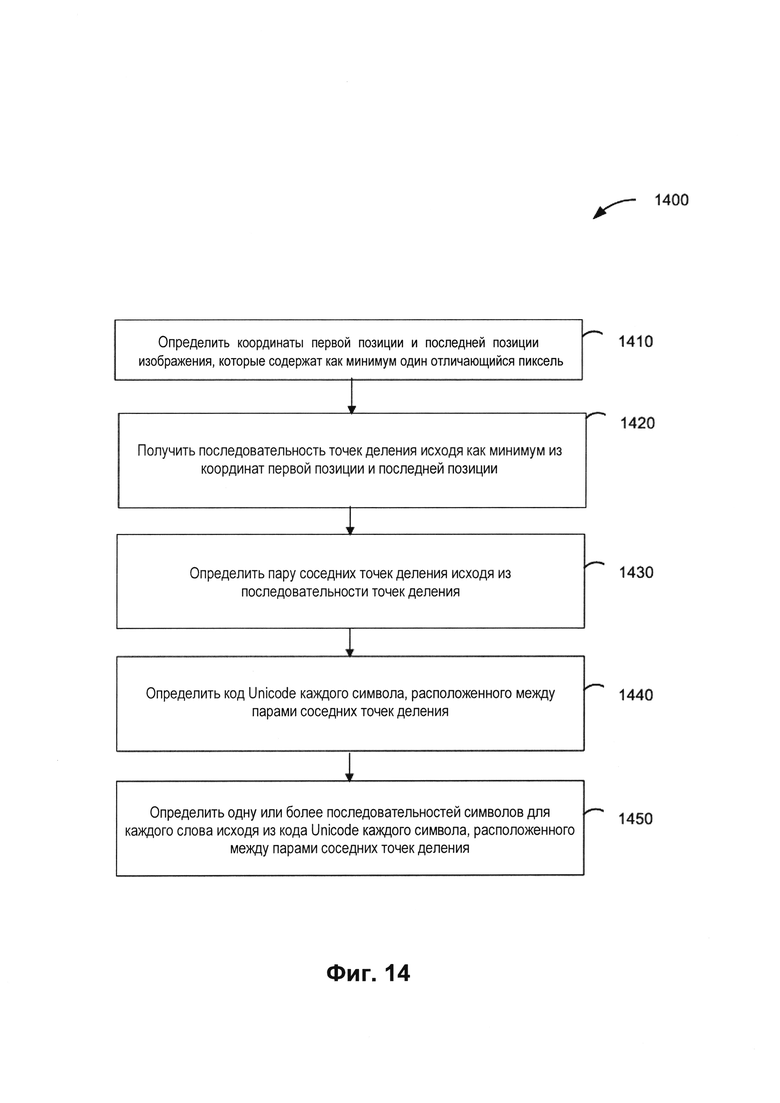
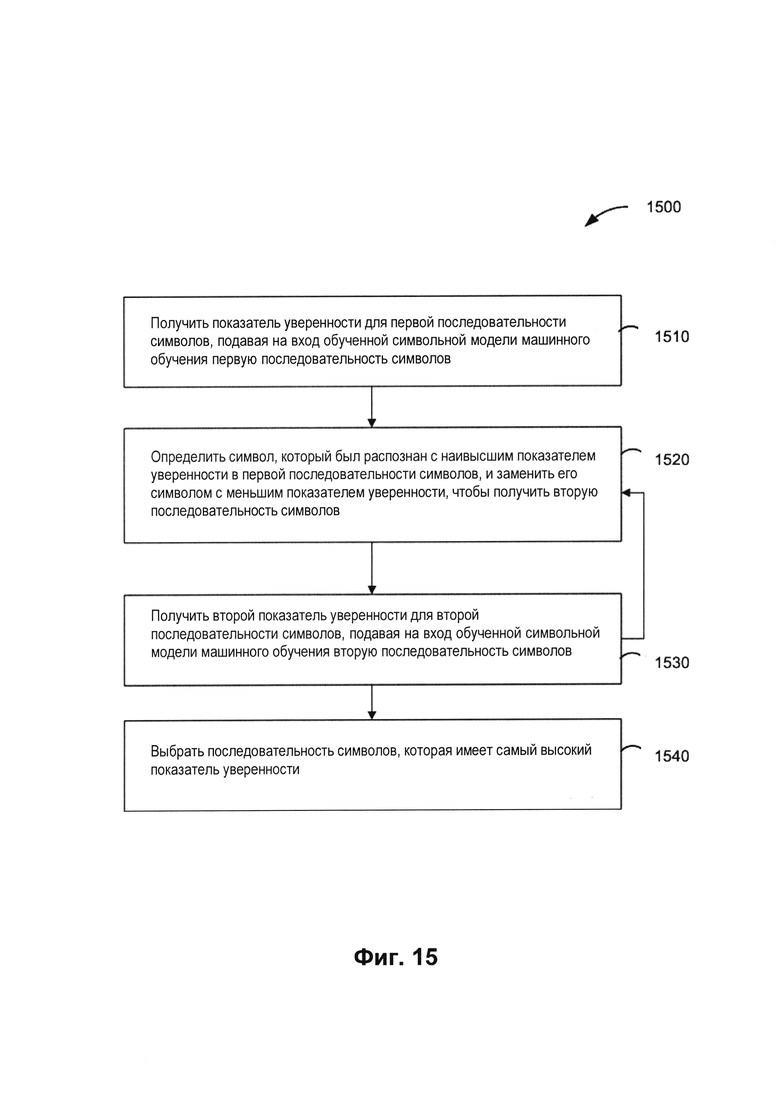
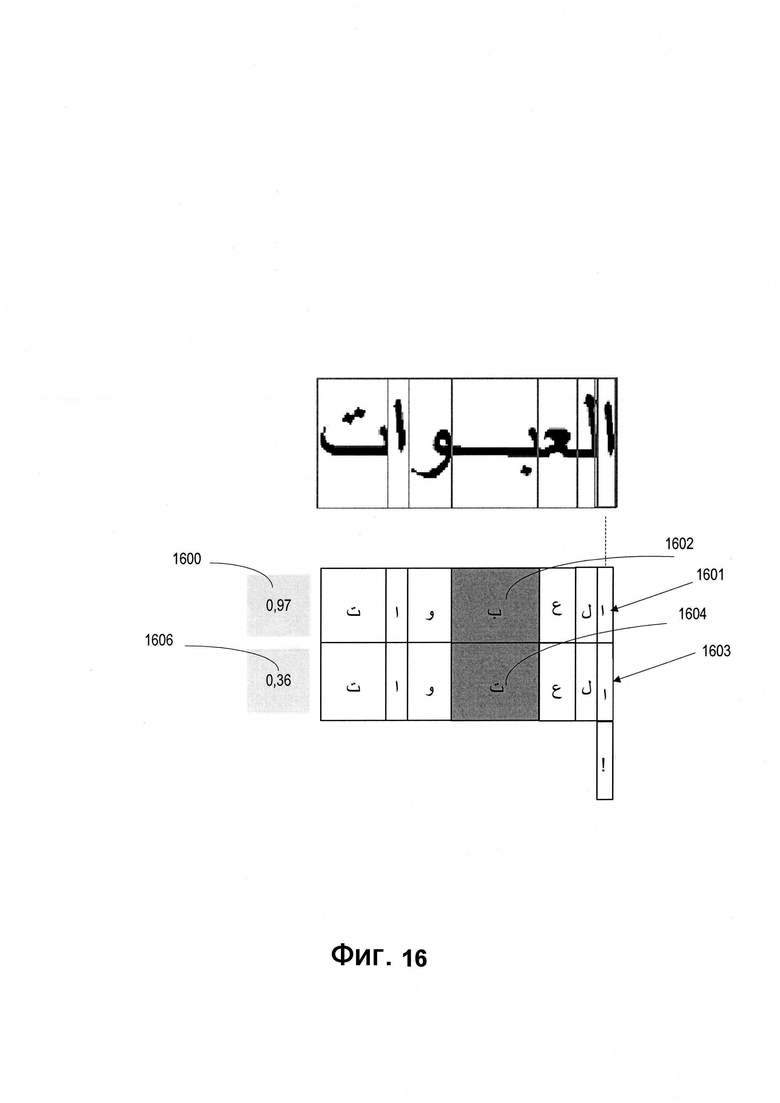
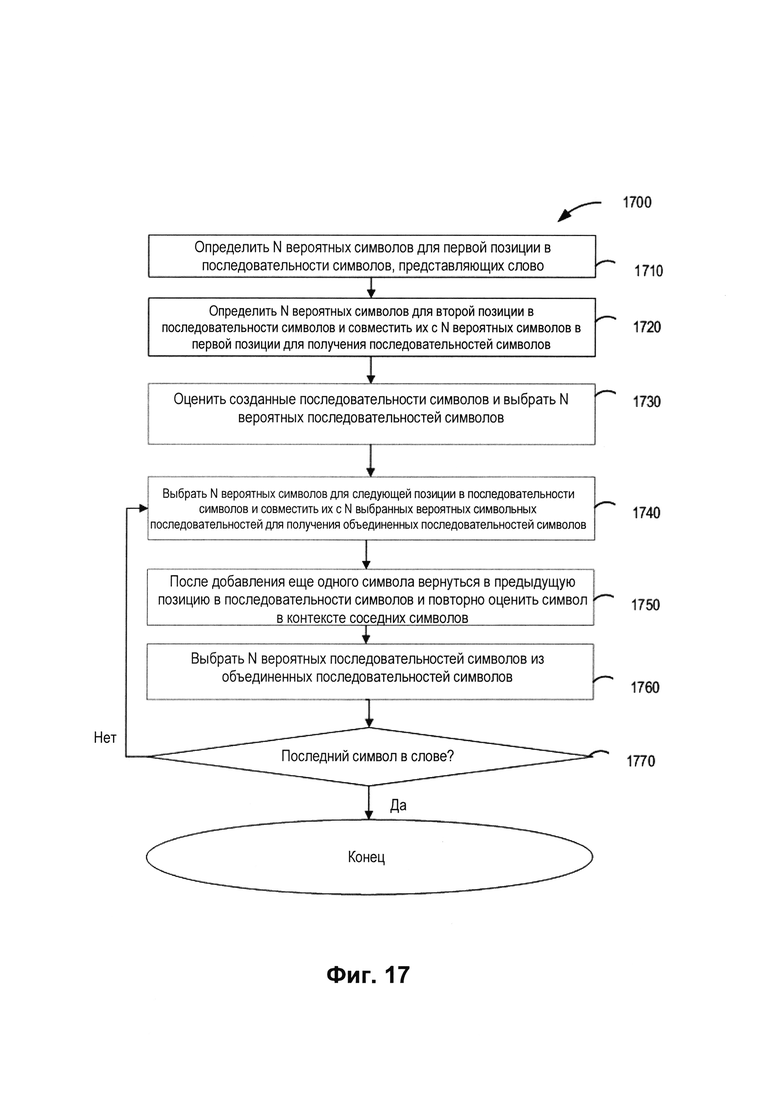
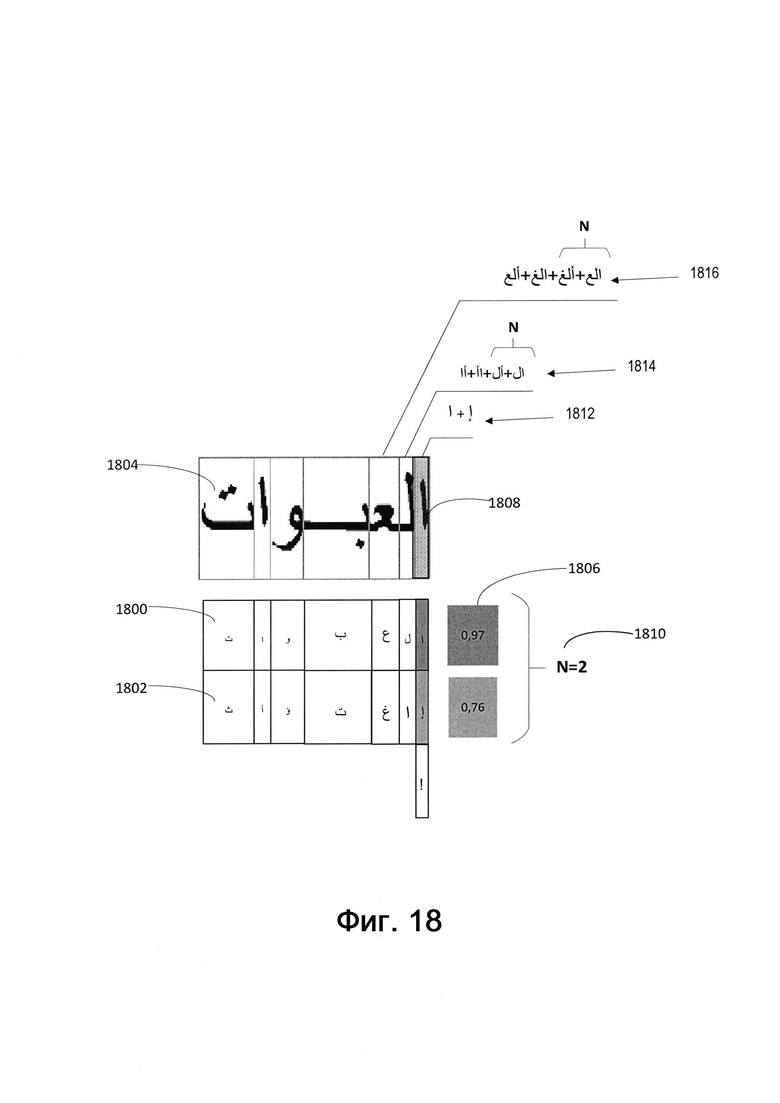
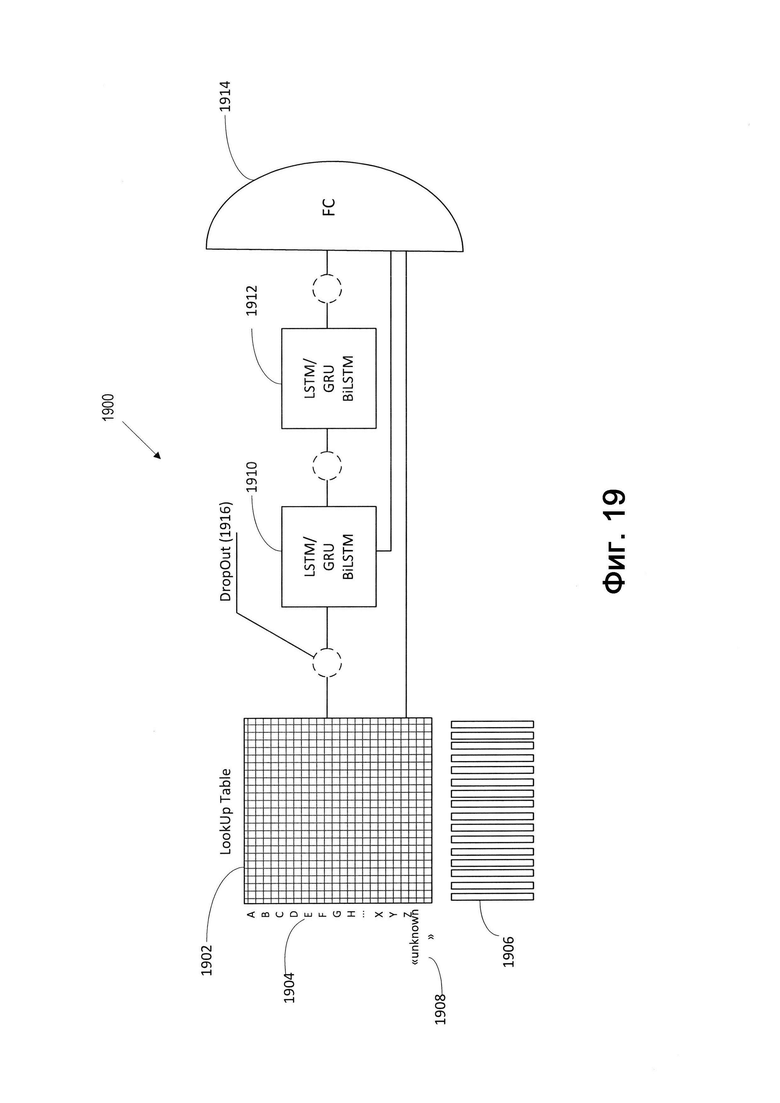
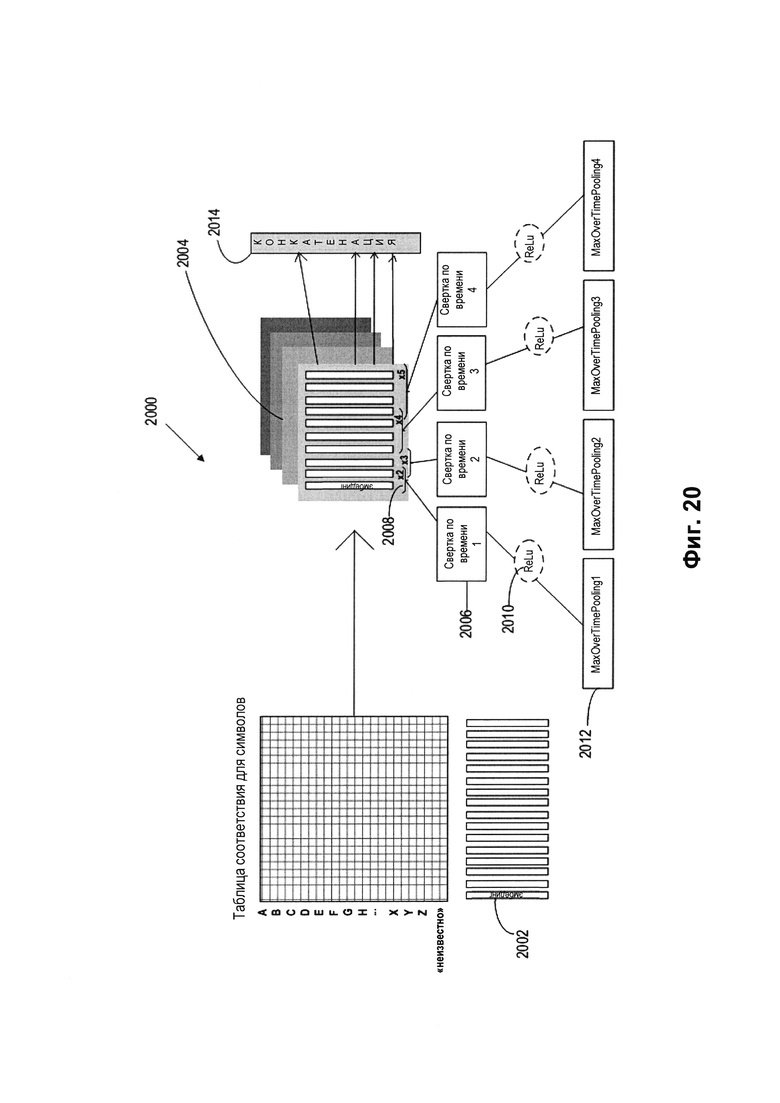
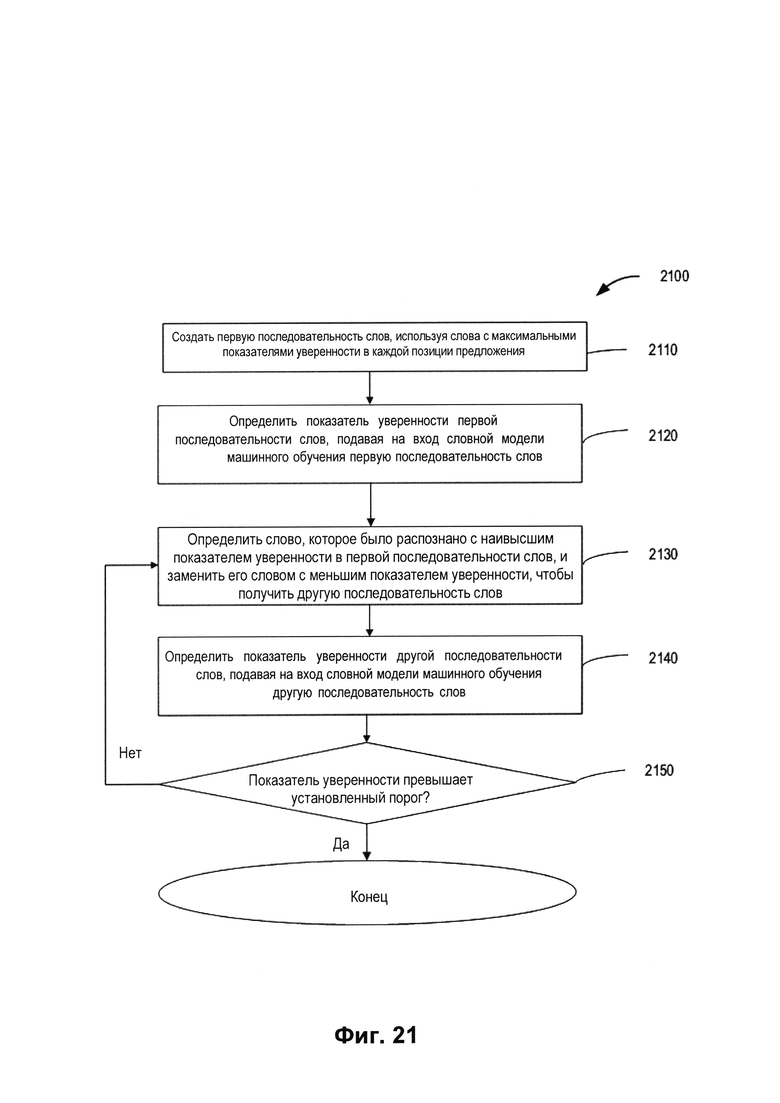
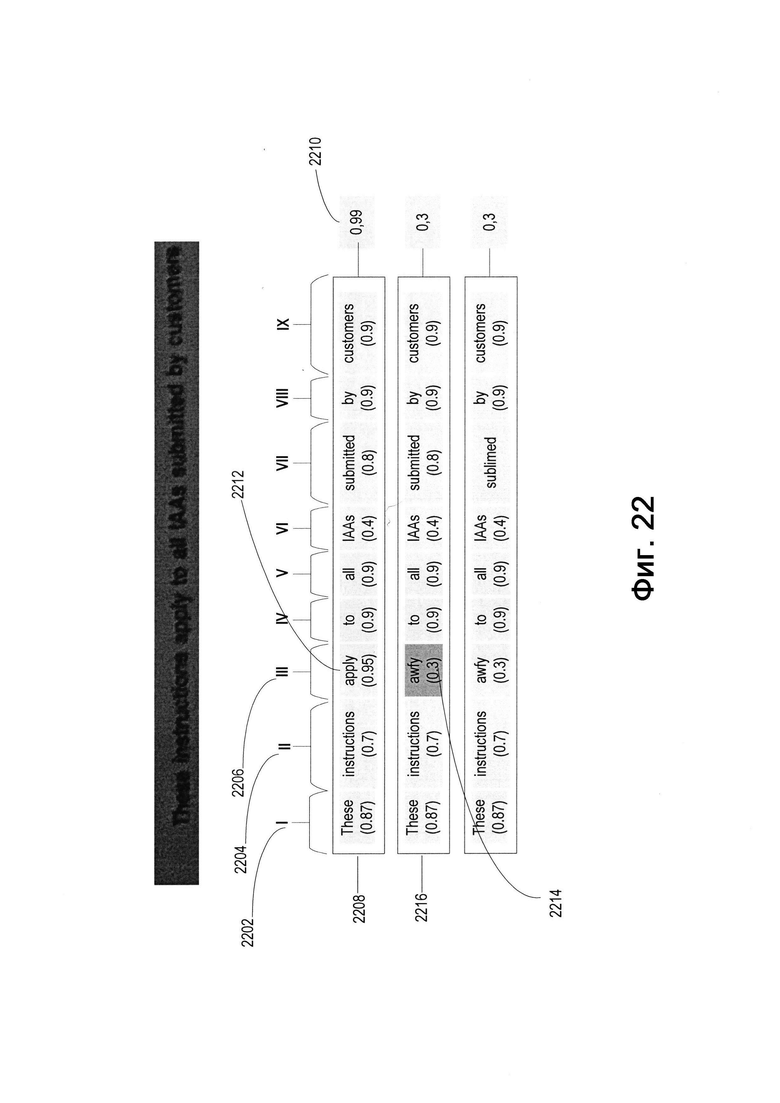
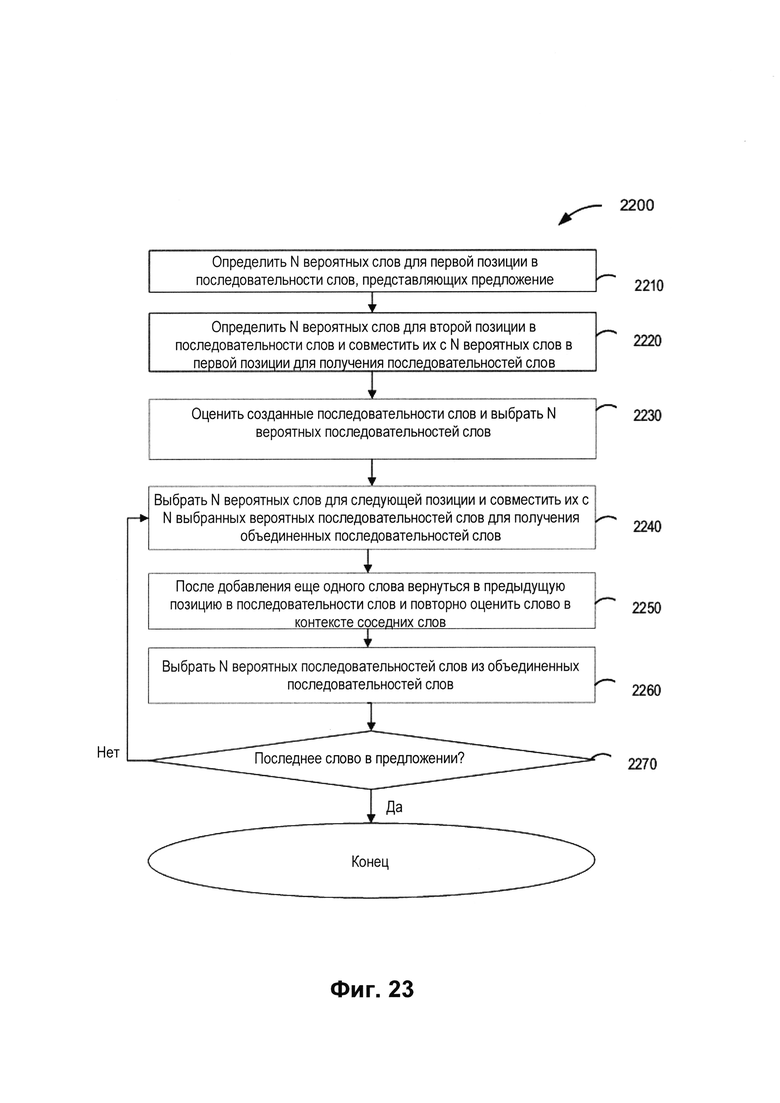
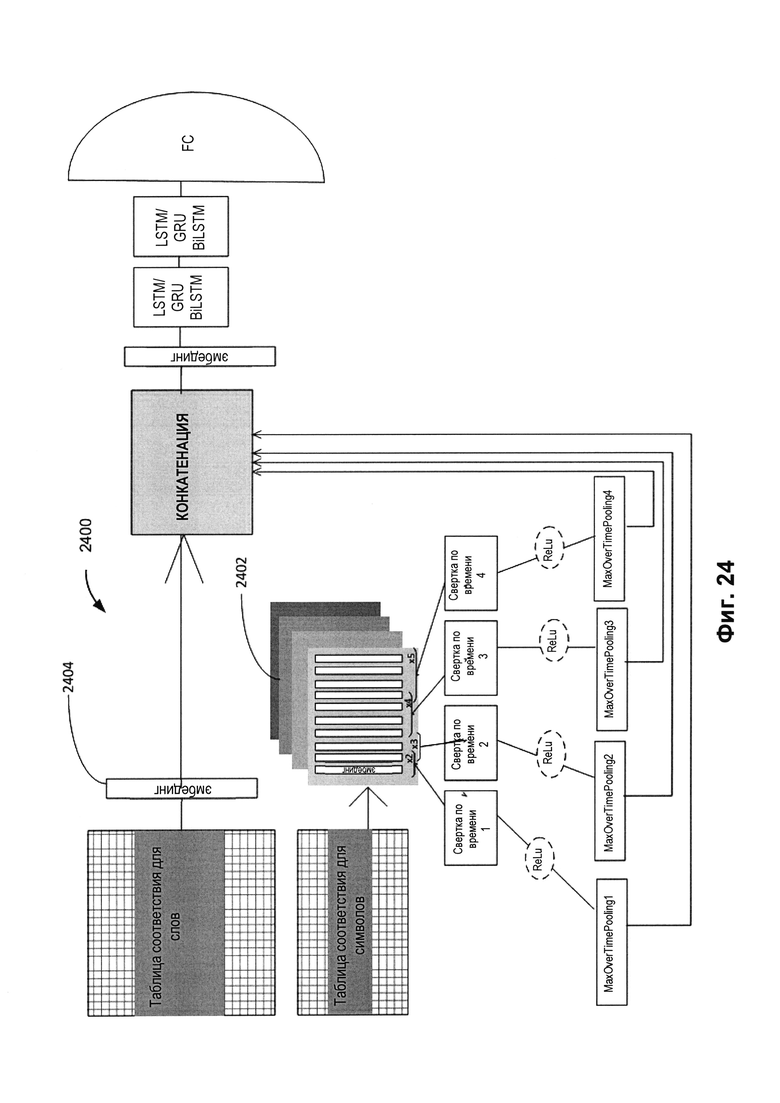
Изобретение относится к системам и способам распознавания символов с использованием искусственного интеллекта. Технический результат заключается в повышении эффективности распознавания текста за счет использования набора моделей машинного обучения, позволяющих осуществлять анализ контекста слов текста на изображении с высоким качеством. Такой результат достигается благодаря тому, что способ включает получение изображения текста, при этом текст на изображении содержит одно или более слов в одном или более предложениях; получение изображения текста в качестве первых исходных данных для набора обученных моделей машинного обучения, хранящего информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях; получение одного или более конечных выходных данных от набора обученных моделей машинного обучения, а также извлечение из одного или более конечных выходных данных одного или более предполагаемых предложений из текста на изображении. Каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов. 4 н. и 17 з.п. ф-лы, 27 ил.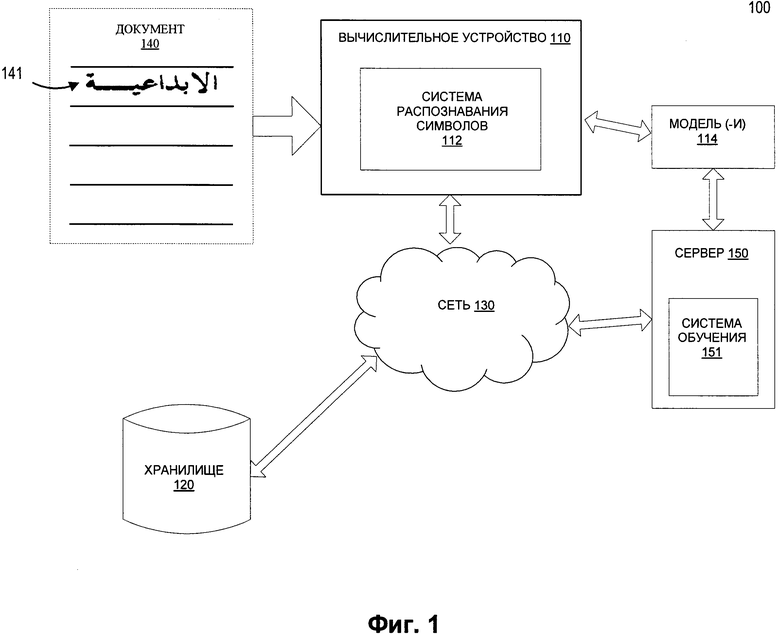
1. Способ распознавания текста, включающий:
получение изображения текста, где текст на изображении содержит одно или более слов в одном или более предложениях;
передачу изображения текста в качестве первых исходных данных набору обученных моделей машинного обучения, хранящему информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях;
получение одного или более конечных выходных данных от набора обученных моделей машинного обучения; и
извлечение из одного или более конечных выходных данных одного или более предполагаемых предложений из текста на изображении, где каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов.
2. Способ по п. 1, отличающийся тем, что набор обученных моделей машинного обучения включает:
первые модели машинного обучения, обученные получать изображение текста в качестве начальных исходных данных и генерировать первый промежуточный результат для начальных исходных данных;
вторую модель машинного обучения, обученную получать декодированный первый промежуточный результат в качестве вторых исходных данных и генерировать второй промежуточный результат для вторых исходных данных; и
третью модель машинного обучения, обученную получать второй промежуточный результат в качестве третьих исходных данных и генерировать один или более итоговых результатов для третьих исходных данных.
3. Способ по п. 2, отличающийся тем, что:
первый промежуточный результат содержит последовательность признаков текста на изображении, признаки содержат информацию, относящуюся к графическим элементам, представляющим один или более символов одного или более слов в одном или более предложениях, и точки деления, если графические элементы соединены; и
второй промежуточный результат, содержащий одну или более вероятных последовательностей символов для каждого слова, выбранного из одной или более последовательностей символов для каждого слова, входящего в декодированный первый промежуточный результат.
4. Способ по п. 2, отличающийся тем, что первые модели машинного обучения генерируют первый промежуточный результат путем:
извлечения информации, относящейся к графическим элементам, путем умножения значений одного или более фильтров на значения каждого пикселя в каждой позиции изображения, сложения произведений значений для получения единственного числа для каждого из одного или более фильтров и применения функции активации к единственному числу каждого из одного или более фильтров, где информация, относящаяся к графическим элементам, указывает, можно ли связать определенную позицию в изображении с графическим элементом и кодом Unicode, соответствующим символу, представленному графическим элементом; и
извлечения информации, относящейся к точкам деления, путем умножения значений одного или более дополнительных фильтров на значения каждого пикселя в каждой позиции изображения, сложения произведений значений для получения единственного числа для каждого из одного или более фильтров и применения функции активации к единственному числу каждого из одного или более фильтров, где информация, относящаяся к точкам деления, указывает, содержит ли соответствующая позиция точку деления, код Unicode символа справа от точки деления или код Unicode символа слева от точки деления.
5. Способ по п. 2, отличающийся тем, что декодированный первый промежуточный результат создается декодером на основе первого промежуточного результата, причем получение декодированного первого промежуточного результата включает:
определение координат первой позиции и последней позиции изображения, которые содержат как минимум один пиксель, отличающийся по цвету;
получение последовательности точек деления исходя как минимум из координат первой позиции и последней позиции;
определение пары соседних точек деления исходя из последовательности точек деления;
определение кода Unicode каждого символа, расположенного между парами соседних точек деления; и
определение одной или более последовательностей символов для каждого слова исходя из кода Unicode каждого символа, расположенного между парами соседних точек деления.
6. Способ по п. 2, отличающийся тем, что первая модель машинного обучения содержит первую комбинацию из первой сверточной нейронной сети, первой рекуррентной нейронной сети и первой полносвязной нейронной сети, обученные извлекать информацию, относящуюся к графическим элементам, и вторую комбинацию из второй сверточной нейронной сети, второй рекуррентной нейронной сети и второй полносвязной нейронной сети, обученные извлекать информацию, относящуюся к точкам деления.
7. Способ по п. 2, где первая модель машинного обучения включает комбинацию из одной или более сверточных нейросетей, одной или более рекуррентных нейросетей и одной или более полносвязных нейросетей, обученных извлекать информацию, связанную с графическими элементами, или информацию, связанную с точками деления.
8. Способ по п. 3, отличающийся тем, что вторая модель машинного обучения содержит модель машинного обучения для символов, обученную выбирать вероятный символ для каждой позиции каждого слова в одной или более последовательностях символов для генерации второго промежуточного результата, содержащего одну или более последовательностей символов для каждого слова.
9. Способ по п. 8, отличающийся тем, что выбор вероятного символа для каждой позиции каждого слова основан на показателе уверенности каждого вероятного символа в каждой позиции каждого слова или на вероятном символе, совместимом с другим вероятным символом в позиции, соседней с вероятным символом в каждой позиции каждого слова.
10. Способ по п. 8, отличающийся тем, что третья модель машинного обучения включает модель машинного обучения для слов, обученную выбирать вероятное слово для каждой позиции каждого из одного или более предложений из одной или более последовательностей символов для каждого слова для создания одного или более итоговых результатов, содержащих для третьих исходных данных один или более итоговых результатов, содержащих одну или более вероятных последовательностей слов для каждого из одного или более предложений.
11. Способ по п. 10, отличающийся тем, что выбор вероятного слова для каждой позиции каждого из одного или более предложений основан на показателе уверенности каждого вероятного слова в каждой позиции каждого из одного или более предложений или основан на вероятном слове, совместимом с другим вероятным словом в другой позиции каждого из одного или более предложений.
12. Способ по п. 1, отличающийся тем, что как минимум одно слово содержит как минимум два соединенных символа.
13. Способ по п. 1, отличающийся тем, что набор моделей машинного обучения обучен на обучающей выборке, содержащей позитивные примеры, которые включают первые тексты и негативные примеры, которые включают вторые тексты и распространение ошибок, вторые тексты включают варианты, которые имитируют ошибки распознавания как минимум одного символа, последовательности символов или последовательности слов, основанные на распространении ошибок.
14. Способ по п. 1, в котором набор моделей машинного обучения хранит информацию о сочетаемости символов и частотности их совместного употребления в реальных словах.
15. Способ создания обучающих данных для обучения набора моделей машинного обучения, позволяющий обеспечить выявление вероятной последовательности слов для каждого из одного или более предложений на изображении текста, включающий:
создание обучающих данных для набора моделей машинного обучения, где создание обучающих данных включает:
создание позитивных примеров, содержащих первые тексты;
создание негативных примеров, содержащих вторые тексты и распространение ошибок, где вторые тексты включают варианты, которые имитируют как минимум одну ошибку распознавания одного или более символов, одной или более последовательностей символов или одной или более последовательностей слов, основанную на распространении ошибок;
создание исходной обучающей выборки, содержащей позитивные примеры и негативные примеры; и
создание целевых выходных данных для исходной обучающей выборки, где целевые выходные данные выявляют одно или более предполагаемых предложений, где каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов; и
предоставление обучающих данных для обучения набора моделей машинного, хранящего информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях, на (i) исходной обучающей выборке и (ii) целевых результатах.
16. Способ по п. 15, отличающийся тем, что создание негативных примеров включает в себя также:
разделение позитивных примеров на первое подмножество и второе подмножество; распознавание текста из первого подмножества;
определение распределения ошибок распознавания в распознанном тексте из первого подмножества, причем распределение ошибок включает один или более неправильно распознанных символов, последовательностей символов или последовательностей слов; и
получение негативных примеров путем изменения второго подмножества с учетом распределения ошибок.
17. Способ по п. 15, отличающийся тем, что набор моделей машинного обучения настроен на обработку нового изображения текста и создание одного или более результатов, указывающих на вероятную последовательность слов для каждого из одного или более предполагаемых предложений, где каждое слово в каждой позиции вероятной последовательности слов выбирается исходя из контекста слова в другой позиции.
18. Постоянный машиночитаемый носитель информации, содержащий инструкции, которые при исполнении приводят к выполнению обрабатывающим устройством операций, включающих:
получение изображения текста, где текст на изображении содержит одно или более слов в одном или более предложениях;
передачу изображения текста в качестве первых исходных данных набору обученных моделей машинного обучения, где набор моделей машинного обучения хранит информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях;
получение одних или более конечных выходных данных от набора обученных моделей машинного обучения; и
извлечение из одних или более конечных выходных данных одного или более предполагаемых предложений из текста на изображении, где каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов.
19. Машиночитаемый носитель информации по п. 18, отличающийся тем, что набор обученных моделей машинного обучения содержит:
первые модели машинного обучения, обученные получать изображение текста в качестве начальных исходных данных и генерировать первый промежуточный результат для начальных исходных данных;
вторую модель машинного обучения, обученную получать декодированный первый промежуточный результат в качестве вторых исходных данных и генерировать второй промежуточный результат для вторых исходных данных; и
третью модель машинного обучения, обученную получать второй промежуточный результат в качестве третьих исходных данных и генерировать один или более итоговых результатов для третьих исходных данных.
20. Машиночитаемый носитель информации по п. 19, отличающийся тем, что первая модель машинного обучения содержит комбинацию из одной или более сверточных нейронных сетей, одной или более рекуррентных нейронных сетей и одной или более полносвязных нейронных сетей, обученную извлекать информацию, относящуюся к графическим элементам, и информацию, относящуюся к точкам деления.
21. Система для распознавания текста, выполненная с возможностью использования набора моделей машинного обучения, хранящего информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях, включающая:
устройство памяти, в котором хранятся инструкции;
устройство обработки, подключенное к устройству памяти, причем устройство обработки предназначено для выполнения инструкций для:
получения изображения текста, где текст на изображении содержит одно или более слов в одном или более предложениях;
передачи изображения текста в качестве первых исходных данных набору обученных моделей машинного обучения;
получения одного или более конечных выходных данных от набора обученных моделей машинного обучения; и
извлечения из одного или более конечных выходных данных одного или более предполагаемых предложений из текста на изображении, где каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов.
| Проволокопротяжный механизм | 1978 |
|
SU708412A1 |
| US 20170098140 A1, 06.04.2017 | |||
| ВЫЯВЛЕНИЕ СЛОВОСОЧЕТАНИЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2618374C1 |
| US 20100310172 A1, 09.12.2010 | |||
| СПОСОБ ИЗГОТОВЛЕНИЯ ОБОЛОЧКИ В СОСТОЯНИИ СВЕРХПЛАСТИЧНОСТИ | 1992 |
|
RU2047409C1 |
| US 9141877 B2, 22.09.2015. | |||

