Область техники
[0001] Настоящее раскрытие относится к способу обработки двухмерного изображения и реализующему его вычислительному устройству пользователя. Более конкретно, настоящее раскрытие относится к созданию трехмерной модели лица пользователя и применению этой трехмерной модели лица пользователя к захватываемому пользователем двухмерному изображению.
Уровень техники
[0002] С ростом производительности доступных вычислительных устройств для пользователей открываются новые возможности. Одной из таких возможностей является возможность пользователя создавать свой трехмерный аватар, имитирующий мимику, движения и эмоции пользователя в реальном масштабе времени, для использования в общении.
Описание связанных документов уровня техники
[0003] Из уровня техники известна заявка на патент США, опубликованная 08.03.2018 как US2018068178 A1 (A1) и озаглавленная ʺReal-time Expression Transfer for Facial Reenactmentʺ, которая раскрывает способ отслеживания выражения лица пользователя и модификации этого выражения на изображении. Для этого авторы данного технического решения предлагают использовать нелинейную оптимизацию параметров камеры и модели на основе цвета и ключевых точек. Недостатками данного технического решения является активное использование мощных графических процессоров (GPU), что делает данное техническое решение непригодным для реализации на мобильных вычислительных устройствах, обладающих ограниченной производительностью. Кроме того, данное техническое решение предполагает использование дополнительного алгоритма обнаружения ключевых точек, который еще сильнее повышает системные требования, необходимые для реализации данного технического решение. Данное техническое решение может быть рассмотрено в качестве ближайшего аналога.
[0004] Из уровня техники также известны другие технические решения, описанные в заявках США на патенты: US2018182165 A1 и US2018197330 A1, опубликованных 28.06.2018 и 12.07.2018 и озаглавленных «Shape Prediction Model Compression For Face Alignment» и «Modeling Of A User's Face», соответственно. Заявка `165 раскрывает способ, который позволяет встроить 2D форму в изображение с использованием регрессии. Таким образом, поскольку получаемая модель является двухмерной и не содержит информации о глубине, данное техническое решение использует дополнительный алгоритм определения глубины, что негативно сказывается на системных требованиях. Заявка `330 раскрывает способ встраивания цветной трансформируемой модели в изображение с использованием функции потерь, основанной на оптических потоках. Однако, авторами данного технического решения предполагается реализация способа в архитектуре клиент-сервер. Кроме того, в данном техническом решении используется вычислительно затратный подход для определения ошибки.
[0005] Различные другие реализации известны в данной области техники, но, насколько можно разумно установить из их доступной документации, эти реализации не могут адекватно решить все проблемы, решаемые описанным в данной заявке изобретением.
Сущность изобретения
[0006] Настоящее изобретение решает вышеуказанные проблемы и позволяет встраивать трехмерный трансформируемый аватар в двухмерное изображение в реальном масштабе времени на мобильном вычислительном устройстве за счет применения обученной сверточной нейронной сети и использования линейной оптимизации для получения параметров встраиваемой модели. Кроме того, настоящее изобретение обеспечивает более устойчивую и корректную подгонку трехмерной модели лица к двухмерному изображению, на котором углы поворота и/или наклона человеческой головы относительно камеры являются существенными.
[0007] В первом аспекте настоящего раскрытия обеспечен способ обработки двухмерного изображения, содержащий этапы, на которых: получают двухмерное изображение; обрабатывают двухмерное изображение обученной сверточной нейронной сетью (CNN) для получения параметров камеры и параметров модели лица; создают трехмерную модель лица, применяя полученные параметры камеры и параметры модели лица к трансформируемой трехмерной модели лица, и выполняют наложение созданной трехмерной модели лица на область лица в двухмерном изображении. В другом аспекте настоящего раскрытия обеспечено вычислительное устройство (20) пользователя, реализующее способ по первому аспекту настоящего изобретения.
Краткое описание чертежей
[0007] Другие благоприятные эффекты настоящего изобретения станут очевидны обычному специалисту в данной области техники после ознакомления с нижеследующим подробным описанием различных вариантов его осуществления, а также с чертежами, на которых:
[Фиг. 1] Фигура 1 иллюстрирует предпочтительный вариант осуществления способа обработки двухмерного изображения.
[Фиг. 2] Фигура 2 иллюстрирует предпочтительный вариант осуществления обучения CNN.
[Фиг. 3] Фигура 3 иллюстрирует пример дополнительной опциональной части в архитектуре используемой сверточной нейронной сети (CNN), которая отвечает за обнаружение лица.
[Фиг. 4] Фигура 4 иллюстрирует примерную реализацию общей архитектуры используемой сверточной нейронной сети (CNN), а также пример конкатенации ограничивающей рамки с входными данными предпоследнего полносвязного слоя CNN.
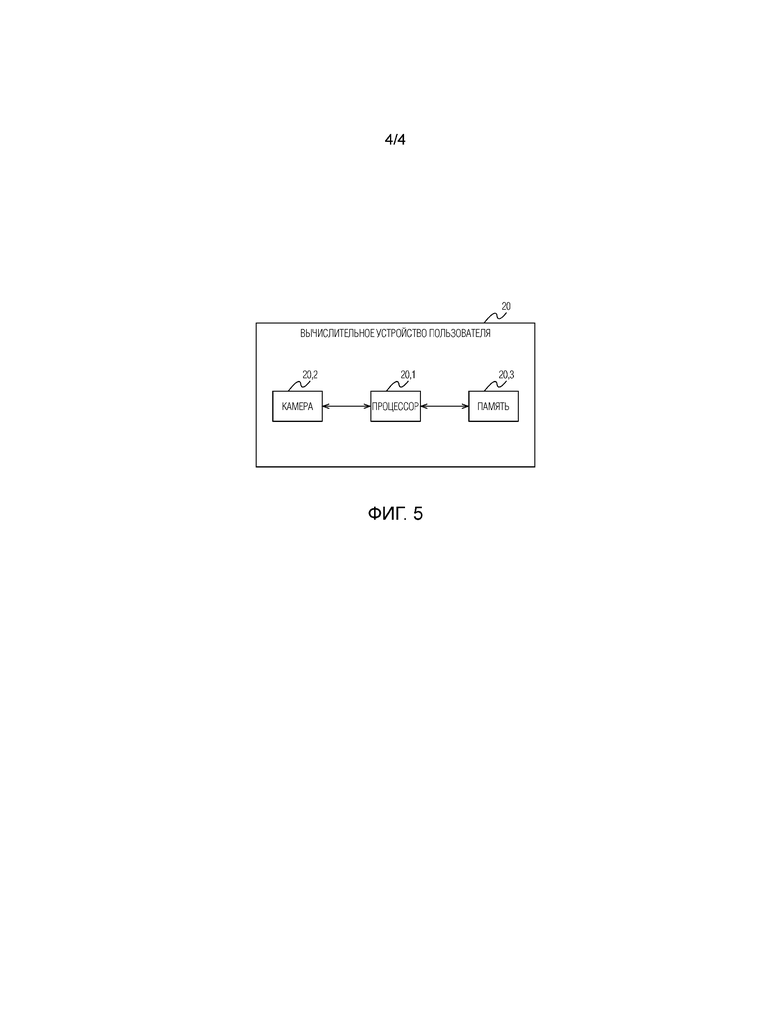
[Фиг. 5] Фигура 5 иллюстрирует предпочтительный вариант осуществления вычислительного устройства пользователя.
Подробное описание вариантов осуществления изобретения
[0008] Предпочтительные варианты осуществления настоящего изобретения ниже описаны более подробно со ссылкой на чертежи, на которых идентичные элементы на разных фигурах, по возможности, идентифицируются одинаковыми ссылочными позициями. Эти варианты осуществления представлены посредством пояснения настоящего изобретения, которыми, однако, не следует его ограничивать. Специалисты в данной области техники поймут после ознакомления с настоящим подробным описанием и чертежами, что могут быть сделаны различные модификации и варианты.
[0009] «Трансформируемая модель лица» представляет собой статистическую модель лица, основанную на анализе главных компонент (PCA). Данная модель может быть представлена как M=N+B , где N - нейтральная модель, также именуемая базовой трехмерной моделью лица, - параметры формы лица, B - базис лиц. Данную модель также можно представить как некоторое многомерное нормальное распределение со средним в точке N и набором собственных векторов B его ковариационной матрицы. Каждому вектор-столбцу матрицы B соответствует собственное значение
, где N - нейтральная модель, также именуемая базовой трехмерной моделью лица, - параметры формы лица, B - базис лиц. Данную модель также можно представить как некоторое многомерное нормальное распределение со средним в точке N и набором собственных векторов B его ковариационной матрицы. Каждому вектор-столбцу матрицы B соответствует собственное значение  , которое отвечает за информационную значимость этого вектора. Для описания модели, отражающей эмоции, вышеуказанная формула M может быть модифицирована как
, которое отвечает за информационную значимость этого вектора. Для описания модели, отражающей эмоции, вышеуказанная формула M может быть модифицирована как 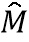 =N+B+Aα, где A - базис эмоции, α - вектор параметров эмоции. «Упрощенная Модель 'Камера-обскура'» представляет собой математическую зависимость между координатами некоторой точки в трехмерном пространстве и ее проекцией на плоскость изображения. Она может быть представлена следующими параметрами Υ=(tx, ty, tz, α, β, γ, f), где (tx, ty, tz) смещение по соответствующей оси, (α, β, γ) - углы поворота, f - фокусное расстояние. Проекция может быть получена как
=N+B+Aα, где A - базис эмоции, α - вектор параметров эмоции. «Упрощенная Модель 'Камера-обскура'» представляет собой математическую зависимость между координатами некоторой точки в трехмерном пространстве и ее проекцией на плоскость изображения. Она может быть представлена следующими параметрами Υ=(tx, ty, tz, α, β, γ, f), где (tx, ty, tz) смещение по соответствующей оси, (α, β, γ) - углы поворота, f - фокусное расстояние. Проекция может быть получена как  , где
, где  - координаты точки в исходном пространстве,
- координаты точки в исходном пространстве, 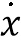 - спроецированные координаты точки,
- спроецированные координаты точки,  - фокусное расстояние,
- фокусное расстояние,  -матрица поворота. Если зафиксировать параметры в трансформируемой модели лица и параметры упрощенной модели 'Камера-обскура', то получится множество точек в трехмерном пространстве
-матрица поворота. Если зафиксировать параметры в трансформируемой модели лица и параметры упрощенной модели 'Камера-обскура', то получится множество точек в трехмерном пространстве  , которое в дальнейшем будет именоваться как «трехмерная модель лица». ʺВстраивание трансформируемой модели лицаʺ [от англ. ʺface model fittingʺ] является процессом нахождения трехмерной модели лица и параметров Υ, которые дают проекцию, наиболее похожую на лицо на двухмерном изображении.
, которое в дальнейшем будет именоваться как «трехмерная модель лица». ʺВстраивание трансформируемой модели лицаʺ [от англ. ʺface model fittingʺ] является процессом нахождения трехмерной модели лица и параметров Υ, которые дают проекцию, наиболее похожую на лицо на двухмерном изображении.
[0010] На фигуре 1 проиллюстрирован предпочтительный вариант осуществления способа обработки двухмерного изображения. Двухмерное изображение может быть получено на этапе S100. Двухмерное изображение может быть частью видеопотока, который захватывается камерой мобильного вычислительного устройства пользователя в режиме реального времени, или частью заранее сохраненного видеопотока. Кроме того, двухмерным изображением может быть одно или более изображений последовательности изображений, загружаемой из сети, например, из Интернета или облака.
[0011] На этапе S105 полученное двухмерное изображение может быть обработано предварительно обученной сверточной нейронной сетью (CNN), примерная архитектура которой проиллюстрирована на фигуре 4. Особенности данной архитектуры описаны ниже в абзаце [0025]. CNN может быть выполнена с возможностью получения параметров камеры и параметров модели лица и дополнительно может быть выполнена с возможностью обнаружения лица, и когда лицо обнаружено, получения упомянутых параметров. Благодаря наделению CNN дополнительной возможностью обнаружения лица на изображении, традиционно ресурсоемких процедур обнаружения лица можно избежать. Обнаружение лица на изображении, выполняемое посредством CNN, является менее ресурсоемкой операцией. Особенности обучения CNN будут описаны ниже со ссылкой на фигуру 2.
[0012] На этапе S110 трехмерная модель лица может быть создана путем применения полученных параметров камеры и параметров модели лица к трансформируемой трехмерной модели лица.
[0013] На этапе S115 может быть выполнено наложение созданной трехмерной модели лица на область лица в двухмерном изображении. При этом наложении может быть использована Упрощенная Модель 'Камера-обскура'.
[0014] На фигуре 2 проиллюстрирован предпочтительный вариант осуществления обучения CNN. На этапе S50 может быть получено множество изображений. Множество изображений может включать в себя изображения лиц в различных положениях. Кроме того, множество изображений должно быть как можно более разнообразным. Для создания разнообразия в изображения из упомянутого множества изображений могут быть внесены предыскажения, дополняющие или расширяющие эти изображения за счет различных преобразований над ними (добавление шума, различные повороты изображения, отражение изображения и т.д.)
[0015] На этапе S55 лица на изображениях полученного множества могут быть обнаружены. В предпочтительном варианте осуществления разметку областей лиц на изображениях обучающего множества проводят вручную. В другом варианте осуществления, разметка лиц на изображениях может быть проведена с помощью автоматизированного алгоритма, например, но без ограничения, Viola-Jones.
[0016] На этапе S60 может быть получена ограничивающая рамку каждого обнаруженного лица, которая определяет местоположение лица в пространстве соответствующего изображения. В дополнительном варианте осуществления, в получаемые ограничивающие рамки могут быть добавлены некоторые предыскажения. Например, может быть добавлен некоторый шум к положению рамки в пространстве (например, лицо может оказаться не в центре рамки, а где-нибудь у границы), а также ее размеру (может быть чуть больше/меньше лица и т.д.).
[0017] На этапе S65 может быть получено множество изображений лиц. На данном этапе из соответствующих изображений области лиц могут быть вырезаны на основе полученных ограничивающих рамок. Данный этап может быть реализован любым известным из уровня техники способом.
[0018] На этапе S70 каждое изображение из полученного множества изображений лиц может быть уменьшено до некоторого предопределенного размера nxn, например, 512×512, 256×256, 128×128 или любого другого размера.
[0019] На этапе S75 на каждом из уменьшенных изображений могут быть размечены ключевые точки лиц. Ключевые точки являются особенностями лица, например, но без ограничения, уголками глаз/губ, кончиком носа, произвольными точками, определяющими контур лица, носа, глаз, губ. В предпочтительном варианте осуществления разметку ключевых точек в обучающем наборе данных проводят вручную. В другом варианте осуществления, разметка ключевых точек может быть автоматизирована с помощью, например, но без ограничения, алгоритмов на основе активной модели формы, алгоритмов на каскадах или с помощью нейросетевого подхода. Данный этап может быть объединен с этапом S55 и/или S60, поскольку из размеченных ключевых точек лица, сама область лица и ограничивающая его рамка могут быть получены автоматически.
[0020] На этапе S80 могут быть созданы такие трехмерные модели лица и подобраны такие параметры камеры, которые наиболее близко соответствуют ключевым точкам лица. При этом параметры камеры подбираются решением нелинейной задачи оптимизации. Для решения этой задачи могут быть использованы, но без ограничения, алгоритмы Ньютона-Гаусса, Левенберга-Марквардта, градиентный спуск. При решении этой задачи параметры модели фиксируются. При поиске параметров может быть использовано либо нейтральное лицо, либо лицо, найденное на предыдущей итерации. Параметры трансформируемой модели лица подбираются решением линейной задачи оптимизации.
[0021] Линейная задача оптимизации для подбора параметров модели на этапе S80 может быть сформулирована в виде следующего функционала (1):
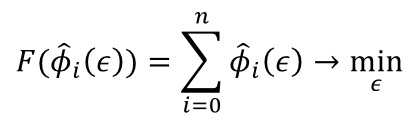 ,
,
 ,
,
где  - L2 норма,
- L2 норма,
 - i-ая ключевая точка,
- i-ая ключевая точка,
 - i-ая точка модели, описываемой формулой M=N+B, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица,
- i-ая точка модели, описываемой формулой M=N+B, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица,  ,
,
Параметры камеры:
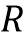 - матрица вращения с параметрами (α, β, γ),
- матрица вращения с параметрами (α, β, γ),
 - смещение,
- смещение,
- фокусное расстояние.
Решение именно линейной задачи оптимизации для подбора параметров модели вместо традиционной нелинейной задачи оптимизации позволяет еще больше снизить требования к вычислительным ресурсам, необходимым для реализации раскрытого в данной заявке способа. Параметры модели представляют собой коэффициенты линейной комбинации, которые используются при создании модели. Для решения данной задачи параметры камеры считаются константой. Для решения данной задачи оптимизации необходимо по формуле функционала (1) составить СЛАУ и решить ее в наименьших квадратах. Решение СЛАУ будет ответом на задачу оптимизации.
[0022] В одном варианте осуществления может быть дополнительно проведена регуляризация искомых параметров деформируемой модели лица. Регуляризация может быть проведена согласно следующей формуле:

где
 - i-тый оптимизируемый параметр,
- i-тый оптимизируемый параметр,
 собственное значение при i-ом базисном векторе. Тогда полная формула оптимизации (функционал 1) может быть записана в следующем виде:
собственное значение при i-ом базисном векторе. Тогда полная формула оптимизации (функционал 1) может быть записана в следующем виде:
 .
.
[0023] В другом варианте осуществления, когда имеется обрабатываемый раскрытым способом видеопоток, подбор параметров деформируемой модели лица может быть осуществлен не для одного изображения, а для нескольких.
В этом случае функционал (1) может быть записан следующим образом:

 где верхний индекс k-номер изображения.
где верхний индекс k-номер изображения.
[0024] В дополнительном варианте осуществления настоящего изобретения в дополнение к параметрам камеры и параметрам трансформируемой модели лица на этапе создания (S80) трехмерных моделей лица могут быть подобраны параметры эмоций, которые наиболее близко соответствуют ключевым точкам, причем этот подбор осуществляют решением следующей линейной задачи оптимизации, которая может быть сформулирована в виде следующего функционала (2):

 ,
,
где 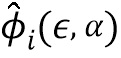 - L2 норма,
- L2 норма,
- i-ая ключевая точка,
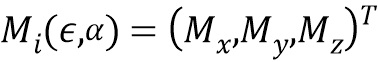 - i-ая точка отражающей эмоцию модели, описываемой формулой =N+B+Aα, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица, , A - базис эмоции, α - вектор параметров эмоции,
- i-ая точка отражающей эмоцию модели, описываемой формулой =N+B+Aα, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица, , A - базис эмоции, α - вектор параметров эмоции,
Параметры модели представляют собой коэффициенты линейной комбинации векторов базиса эмоций, которые используются при создании модели. Для решения данной задачи параметры камеры и формы лица считаются константой. Для решения данной задачи оптимизации необходимо по формуле функционала (2) составить СЛАУ и решить ее. Решение СЛАУ будет ответом на задачу оптимизации.
[0025] На этапе S85 CNN может быть обучена на следующих обучающих данных: трансформируемая трехмерная модель лица, упомянутое множество изображений, а также соответствующие упомянутому множеству изображений ограничивающие рамки, параметры камеры и параметры модели, которые наиболее близко соответствуют ключевым точкам. Данный этап позволяет наделить CNN возможностью, для некоторого произвольного двухмерного изображения, подаваемого на вход обученной CNN, определения параметров камеры и параметров модели, на основе которых может быть создана трехмерная модель лица, соответствующая лицу на упомянутом произвольном двухмерном изображении. Поскольку параметры модели определяются решением линейной задачи оптимизации, традиционно ресурсоемкие процедуры определения упомянутых параметров могут быть упрощены в этой части. Нейронная сеть на данном этапе дополнительно может быть обучена с использованием алгоритма оптимизации Adam.
[0026] В дополнительном варианте осуществления настоящего изобретения на этапе S85 обучения CNN может дополнительно использоваться функция потерь при неправильном принятии решений CNN на основе наблюдаемых ключевых точек лица. Данная оценка может быть реализована посредством сравнения (S85.1) созданных для некоторых произвольных изображений трехмерных моделей лица, параметры камеры и параметры лица которых, наиболее близко соответствующие ключевым точкам, подавались на вход обучения CNN, с трехмерными моделями лица, которые создаются на основе вывода CNN параметров камеры и параметров модели для соответствующих изображений, используя L2-норму разности. В качестве альтернативного варианта осуществления CNN может быть обучена с использованием нормы разности проекций ключевых точек лица в качестве функции потерь. В качестве альтернативного варианта осуществления CNN может быть обучена с использованием L2-нормы разности по параметрам камеры и L2-нормы разности по параметрам модели, при этом указанные функции потерь складываются с разными весами, которые являются макро-параметрами обучения.
[0027] В дополнительном варианте осуществления настоящего изобретения этап S85 обучения CNN может дополнительно содержать подачу ограничивающих рамок на вход предпоследнего полносвязного слоя CNN, как проиллюстрировано на фигуре 4. Таким образом, ограничивающие рамки могут объединяться с входными данными предпоследнего полносвязного слоя CNN. Должно быть понятно, что сверточные слои предназначены для извлечения особенностей двухмерного изображения, но не предназначены для работы с макроособенностями (например, ограничивающими рамками). Таким образом, ограничивающие рамки подаются на вход только полносвязного слоя CNN, который в данном варианте осуществления является, но без ограничения, предпоследним. В альтернативном варианте осуществления, количество полносвязных слоев может быть увеличено для усложнения нелинейности и, в свою очередь, увеличения мощности множества функций, которые могут быть приближены данной архитектурой CNN. Для реализации такой подачи в архитектуру CNN может быть добавлен (S85.2) по меньшей мере один дополнительный полносвязный слой, который наделяет CNN возможностью учесть параметры ограничивающей рамки для того, чтобы сделать правильный вывод о параметрах камеры Υ=(tx, ty, tz, α, β, γ, f).
[0028] На фигуре 5 проиллюстрирована блок-схема вычислительного устройства (20) пользователя, которое в одном варианте осуществления может представлять собой мобильное устройство пользователя, обладающее ограниченными ресурсами. Устройство (20), на котором может быть реализован раскрытый выше способ, может содержать, но без ограничения упомянутым, процессор (20.1), камеру (20.2) и память (20.3), хранящую считываемые и исполняемые процессором инструкции, которые при исполнении процессором побуждают процессор к выполнению любого этапа (этапов) раскрытого в данной заявке способа. Компоненты в устройстве (20) могут быть соединены друг с другом и с другими опциональными компонентами устройства любым подходящим способом, который будет очевиден обычному специалисту для реализации на таком устройстве заявленного способа. Устройство (20) может содержать другие не показанные на фигуре 6 компоненты и представлять собой, например, смартфон, планшет, очки виртуальной реальности, очки дополненной реальности, ПК, ноутбук, умные часы и т.д. В альтернативном варианте осуществления вычислительного устройства пользователя упомянутое устройство может содержать отдельные аппаратные блоки. В этом варианте осуществления, каждый аппаратный блок может отвечать за выполнение соответствующего этапа или подэтапа способа и именоваться соответствующим образом, например, аппаратный блок устройства, ответственный за создание (S110) трехмерной модели лица может именоваться блоком создания трехмерной модели лица, и т.д. Однако, заявленное изобретение не следует ограничивать только такой структурой блоков, поскольку специалисту будут понятны другие возможные структуры блоков в устройстве, при которых, в качестве примера, один аппаратный блок может отвечать за выполнение нескольких этапов или подэтапов раскрытого способа, или выполнение нескольких этапов или подэтапов раскрытого способа может быть разделено между двумя или более блоками. Кроме того, способ, раскрытый в данной заявке, может быть реализован посредством процессора, интегральной схемы специального назначения (ASIC), программируемой пользователем вентильной матрицы (FPGA), или как система на кристалле (SoC). Кроме того, способ, раскрытый в данной заявке, может быть реализован посредством считываемого компьютером носителя, на котором хранятся исполняемые компьютером инструкции, которые, при исполнении процессором компьютера, побуждают компьютер к выполнению раскрытого способа.
[0029] Используемые в данной заявке ссылочные позиции не следует интерпретировать как однозначно определяющие последовательность этапов, поскольку после ознакомления с вышеуказанным раскрытием, специалисту станут понятны другие модифицированные последовательности вышеописанных этапов. Ссылочные позиции использовались в этом описании и используются в нижеследующей формуле лишь в качестве сквозного указателя на соответствующий элемент заявки, который облегчает ее восприятие и гарантирует соблюдение единства терминологии.
[0030] Хотя данное изобретение было описано с определенной степенью детализации, следует понимать, что настоящее раскрытие было сделано только в качестве иллюстрации и что к многочисленным изменениям в деталях конструкций, компоновке частей устройства или этапов и содержания способов можно прибегать, не выходя за рамки объема изобретения, который определяется нижеследующей формулой изобретения.
Экспериментальные данные
[0031] Производительность раскрытого способа сравнивалась с решением EOS от Patric Huber, представляющим собой библиотеку легковесной подгонки 3D трансформируемой модели лица на современном языке программирования C++11/14 https://github.com/patrikhuber/eos.
Условия проведения измерений:
Массив видеоданных, в которых запечатлены повороты и наклоны человеческого лица на существенные углы.
И настоящее изобретение, и EOS обрабатывали видеопоток.
И в настоящем изобретении, и в EOS использовался обнаружитель лиц OpenCV Vioal-Jones (вариант осуществления настоящего изобретения, в котором лицо обнаруживается самой CNN, не применялся). Если лицевая рамка не обнаруживалась в текущем кадре, использовали ограничивающую рамку подогнанной формы с предыдущего кадра.
В EOS использовался обнаружитель ключевых точек http://www.jiansun.org/papers/CVPR14_FaceAlignment.pdf.
Качественная мера:
Эвклидово расстояние между ключевыми точками контрольных данных (ʺground truthʺ) и соответствующими ключевыми точками, получаемыми в результате работы сравниваемых решений, пропорционально редуцировались расстоянием между зрачками.
Ошибка вычислялась по следующей формуле: Ошибка=,,(спроецированные результирующие ключевые точки-ключевые точки контрольных данных)-2.-расстояние между зрачками.
Результаты:
Вывод:
Как показывают экспериментальные данные, настоящее изобретение уменьшает частоту ошибок подгонки 3D трансформируемой модели лица к двухмерному изображению и позволяет существенно сократить требуемое время работы.
Промышленная применимость
[0032] Настоящее изобретение может применяться в промышленности в качестве технического решения, обеспечивающего возможность точной и быстрой подгонки 3D трансформируемой модели лица к двухмерному изображению. Настоящее изобретение может применяться для создания трехмерного анимированного аватара пользователя, отражающего в истинном масштабе времени мимику и эмоции реального пользователя, на основе последовательности двухмерных изображений упомянутого пользователя, захватываемой монокулярной камерой мобильного вычислительного устройства пользователя. Кроме того, настоящее изобретение может применяться для определения настроения покупателя для предложения ему таргетированной рекламы, услуг или товаров, соответствующих его настроению. Настоящее изобретение также может применяться для создания роботов, которые будут воспринимать уделяемое им пользователями внимание для начала взаимодействия с ними. В данном случае, пользователь сможет указывать своими эмоциями действия, которые роботу необходимо осуществить, взаимодействовать/играть с роботом естественным образом, - как если бы робот был бы живым существом, а также получать различные новости/обратную связь от робота/дрона в зависимости от своего настроения. Другими полезными применениями данного раскрытия в промышленности являются: коррекция перспективных искажений камеры мобильного вычислительного устройства пользователя, улучшение внесшего вида лица на изображении, безопасность и аутентификация - новый способ аутентификации по персональной мимике и поведению, цифровое зеркало/макияж: точная форма без искажений.
Список позиционных обозначений
20 - вычислительное устройство пользователя;
20.1 - процессор;
20.2 - камера;
20.3 - память.



Настоящее изобретение относится к области подгонки трехмерной модели лица к двухмерному изображению лица. Технический результат заключается в обеспечении более устойчивой и корректной подгонки трехмерной модели лица к двухмерному изображению, на котором углы поворота и/или наклона человеческой головы относительно камеры являются существенными. В раскрытом способе обработки двухмерного изображения: получают двухмерное изображение; обрабатывают двухмерное изображение обученной сверточной нейронной сетью; создают трехмерную модель лица и выполняют наложение созданной трехмерной модели лица на область лица в двухмерном изображении. Заявленные изобретения позволяют встраивать трехмерный трансформируемый аватар в двухмерное изображение в реальном масштабе времени на мобильном вычислительном устройстве пользователя. 2 н. и 5 з.п. ф-лы, 5 ил.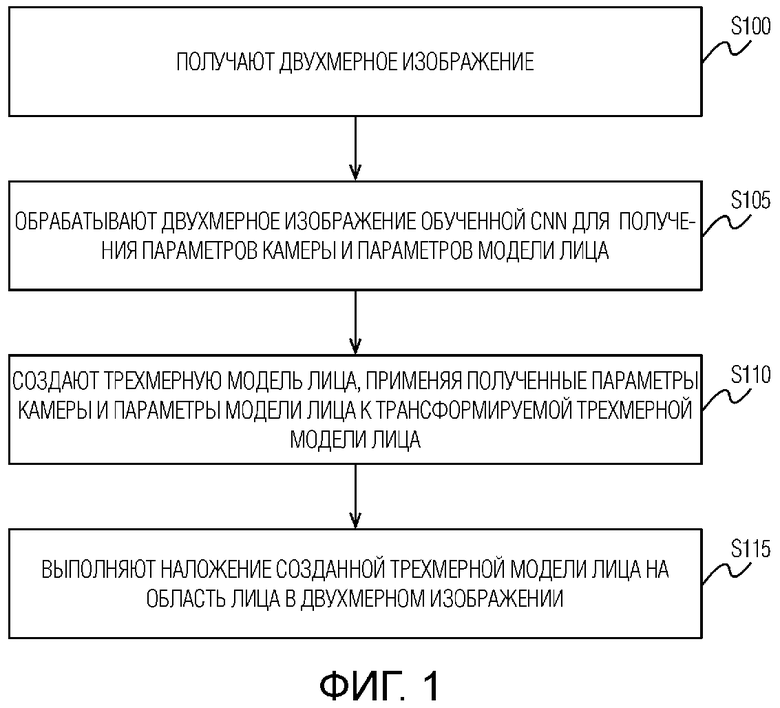
1. Способ обработки двухмерного изображения, содержащий этапы, на которых:
получают (S100) двухмерное изображение;
обрабатывают (S105) двухмерное изображение обученной сверточной нейронной сетью (CNN) для получения параметров камеры и параметров модели лица;
создают (S110) трехмерную модель лица, применяя полученные параметры камеры и параметры модели лица к трансформируемой трехмерной модели лица, и
выполняют наложение (S115) созданной трехмерной модели лица на область лица в двухмерном изображении,
при этом обученную CNN получают посредством выполнения этапов, на которых:
получают (S50) множество изображений;
обнаруживают (S55) лица на изображениях упомянутого множества;
получают (S60) ограничивающую рамку каждого обнаруженного лица, которая определяет местоположение лица в пространстве соответствующего изображения;
получают (S65) множество изображений лиц, вырезая из соответствующих изображений области лиц, ограниченные полученными ограничивающими рамками;
уменьшают (S70) каждое изображение из упомянутого множества изображений лиц до некоторого предопределенного размера nxn;
размечают (S75) ключевые точки лиц на каждом из уменьшенных изображений;
создают (S80) такие трехмерные модели лица, параметры камеры и параметры модели которых наиболее близко соответствуют ключевым точкам, при этом параметры камеры подбираются решением нелинейной задачи оптимизации, а параметры модели подбираются решением линейной задачи оптимизации;
обучают CNN (S85) с использованием обучающих данных: трансформируемой трехмерной модели лица, упомянутого множества изображений, а также соответствующих упомянутому множеству изображений ограничивающих рамок, параметров камеры и параметров модели, которые наиболее близко соответствуют ключевым точкам, чтобы наделить CNN возможностью, для некоторого произвольного двухмерного изображения, подаваемого на вход CNN, определения параметров камеры и параметров модели, на основе которых создается трехмерная модель лица, соответствующая лицу на упомянутом произвольном двухмерном изображении.
2. Способ по п. 1, в котором линейную задачу оптимизации для подбора параметров модели на этапе (S80) формулируют в виде следующего функционала:
 ,
,
 ,
,
где  - L2 норма,
- L2 норма,
 - i-я ключевая точка,
- i-я ключевая точка,
 - i-я точка модели, описываемой формулой M=N+B
- i-я точка модели, описываемой формулой M=N+B , где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица,
, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица,  ,
,
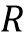 - матрица вращения,
- матрица вращения,
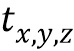 - смещение,
- смещение,
 - фокусное расстояние.
- фокусное расстояние.
3. Способ по п. 1, в котором этап, на котором обучают (S85) CNN, дополнительно содержит оценку потерь при неправильном принятии решений CNN на основе наблюдаемых данных, при этом оценка содержит следующий подэтап, на котором:
сравнивают (S85.1) созданные для некоторых изображений трехмерные модели лица, параметры камеры и параметры модели которых, наиболее близко соответствующие ключевым точкам, подавались на вход обучения CNN, с трехмерными моделями лица, которые создаются на основе вывода CNN параметров камеры и параметров модели для соответствующих изображений, используя L2-норму различия.
4. Способ по п. 1, в котором на этапе обучения (S85) CNN ограничивающие рамки подают на вход предпоследнего полносвязного слоя CNN,
при этом этап обучения CNN дополнительно содержит подэтап, на котором добавляют (S85.2) по меньшей мере один дополнительный полносвязный слой в архитектуру CNN, наделяющий CNN возможностью, для некоторого произвольного двухмерного изображения, подаваемого на вход CNN, обнаружения ограничивающей рамки лица на этом произвольном двухмерном изображении,
при этом этап, на котором обрабатывают (S105) двухмерное изображение обученной CNN, дополнительно содержит обнаружение упомянутой CNN лица, а получение параметров камеры и параметров модели упомянутой CNN осуществляют в ответ на обнаружение лица.
5. Способ по п. 1, в котором в дополнение к параметрам камеры и параметрам модели на этапе создания (S80) трехмерных моделей лица, подбирают параметры эмоций, которые наиболее близко соответствуют ключевым точкам, причем этот подбор осуществляют решением следующей линейной задачи оптимизации:
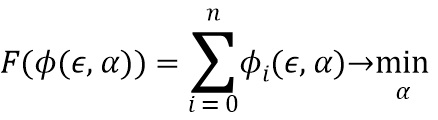 ,
,
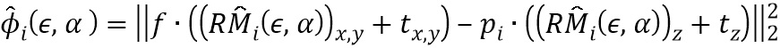 ,
,
где  - L2 норма,
- L2 норма,
- i-ая ключевая точка,
 - i-я точка отражающей эмоцию модели, описываемой формулой
- i-я точка отражающей эмоцию модели, описываемой формулой 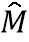 =N+B+Aα, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица, , A - базис эмоции, α - вектор параметров эмоции.
=N+B+Aα, где N - нейтральная трехмерная модель лица, B - базис лиц, - параметры формы лица, , A - базис эмоции, α - вектор параметров эмоции.
6. Способ по п. 1, в котором двухмерным изображением лица является видеопоток, заранее сохраненный в вычислительном устройстве пользователя или захватываемый камерой вычислительного устройства пользователя в режиме реального времени.
7. Вычислительное устройство (20) пользователя, содержащее:
процессор (20.1);
камеру (20.2), выполненную с возможностью захвата двухмерного изображения или последовательности двухмерных изображений;
память (20.3), хранящую обученную сверточную нейронную сеть (CNN) и инструкции, которые при исполнении процессором побуждают процессор к выполнению способа обработки двухмерного изображения или последовательности двухмерных изображений по любому из предшествующих пп. 1-6.
| US 2016379041 A1, 29.12.2016 | |||
| US 2018032796 A1, 01.02.2018 | |||
| СПОСОБ ОТОБРАЖЕНИЯ ТРЕХМЕРНОГО ЛИЦА ОБЪЕКТА И УСТРОЙСТВО ДЛЯ НЕГО | 2017 |
|
RU2671990C1 |
| US 2004223631 A1, 11.11.2004 | |||
| US 2006067573 A1, 30.03.2006. | |||

