ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0001] Настоящее изобретение относится к технологиям компьютерного зрения. Более конкретно, настоящее изобретение относится к способам и электронным устройствам для обнаружения трехмерных объектов или для понимания сцены, реализуемых с помощью нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[0002] RGB-изображения являются доступным и универсальным источником данных. Поэтому в последнее время активно исследуются способы обнаружения трехмерных объектов на основе RGB. Монокулярные RGB-изображения обеспечивают визуальные признаки сцены и ее объектов, но они не содержат исчерпывающей информации о геометрии сцены и абсолютном масштабе данных. Поэтому для ряда приложений чрезвычайно полезно иметь возможность точно и надежно обнаруживать трехмерные объекты на таких изображениях. При наличии монокулярного изображения способы обнаружения трехмерных объектов на основе глубокого обучения способны только определить масштаб данных. Более того, из RGB-изображений невозможно получить непротиворечивую геометрию сцены, так как некоторые области могут быть не видны. Однако использование нескольких захваченных в известных положениях изображений могло бы способствовать получению большей информации о сцене, чем монокулярное RGB-изображение. Поэтому некоторые известные способы обнаружения трехмерных объектов реализуют многоракурсный вывод (inference). Эти способы получают прогнозы независимо для каждого монокулярного RGB-изображения, а затем эти прогнозы объединяются.
[0003] Все основанные на RGB способы обнаружения трехмерных объектов предназначены для использования в сценах помещений или в уличных сценах и работают при определенных предположениях о сцене и объектах. Например, способы для применения в уличных сценах обычно оцениваются на транспортных средствах. Как правило, транспортные средства одной категории имеют похожий размер, они расположены на земле, и их проекции на виде "с высоты птичьего полета" (BEV) не пересекаются в нормальных, не аварийных условиях. Соответственно, проекция плоскости BEV содержит много информации о трехмерном местоположении транспортного средства. Таким образом, задача обнаружения трехмерных объектов для применения в уличных сценах в облаке точек может быть эффективно сведена к задаче обнаружения двумерных объектов в плоскости BEV. В то же время предметы в сценах помещений могут иметь разную высоту и располагаться в пространстве произвольно, поэтому их проекции на плоскость пола несут мало информации об их трехмерном положении. В целом, разработка способов обнаружения трехмерных объектов на основе RGB имеет свойство зависеть от конкретной области. С учетом вышесказанного важно отметить, что сети обнаружения объектов, используемые в известных способах, обычно имеют сложную и слабо разработанную структуру, потому что они, по всей вероятности, имеют нейросетевые архитектуры самого сложного типа для построения, отладки и использования.
Сущность изобретения
[0004] Предложенная технология и связанные с ней технические решения решают или, по меньшей мере, минимизируют проблемы, встречающиеся в известных технических решениях для обнаружения объектов в сцене или для понимания сцены на основе по меньшей мере одного монокулярного изображения. При этом, в отличие от известных способов, в предлагаемом техническом решении многоракурсные входные данные доступны сразу и их легко получить как во время стадии обучения, так и во время стадии вывода (например, с помощью обычной цифровой камеры электронного устройства). Поэтому многоракурсные входные данные применяются не только для вывода, но и для обучения. Как во время обучения, так и во время вывода, предлагаемое техническое решение принимает захваченные в известных положениях многоракурсные входные данные с произвольным количеством видов; это количество может быть уникальным для каждых многоракурсных входных данных. В данном контексте захваченные в известных положениях (posed) входные данные/изображения означают, что каждое RGB-изображение имеет соответствующее известное положение камеры. Кроме того, предлагаемое техническое решение может принимать захваченные в известных положениях монокулярные входные данные (рассматриваемые как частный случай многоракурсных входных данных). Также предлагаемое техническое решение хорошо работает на чисто монокулярных эталонах (то есть в случае вывода на основе одного монокулярного RGB-изображения).
[0005] Для накопления информации из множества входных данных предлагаемое техническое решение строит воксельное представление трехмерного пространства. Такой унифицированный подход (через построенное воксельное представление трехмерного пространства) используется в предлагаемом техническом решении для обнаружения объектов как в сценах помещений, так и в уличных сценах, а также, по меньшей мере, частично, для понимания сцены. Понимание сцены рассматривается в данном случае как подзадача основной задачи обнаружения объектов. Затем, в зависимости от того, является ли данная сцена сценой помещения или уличной сценой, или от того, необходимо ли выполнять понимание сцены, способ может быть настроен на выбор и применение (возможно, на основе одного или нескольких критериев) соответствующей головной части (термин "головная часть" означает один или несколько последних сверточных слоев, применяемых в основной нейронной сети) в основной нейронной сети без изменения мета-архитектуры основной нейронной сети. "Мета-архитектура" в настоящем изобретении может означать, по меньшей мере, получение одного или нескольких изображений, извлечение двумерной карты признаков из изображений (с помощью двумерной CNN), проецирование двумерной карты признаков в трехмерное пространство и агрегирование признаков в трехмерной карте признаков. Примеры головных частей, которые будут подробно описаны ниже, включают в себя, но без ограничения, часть для обнаружения объектов в уличных сценах, часть для обнаружения объектов в сценах помещений и часть для понимания сцены. Другие головные части на основе облака точек, известные из предшествующего уровня техники, также могут быть использованы в предлагаемом изобретении благодаря предложенной мета-архитектуре основной нейронной сети.
[0006] В предлагаемом техническом решении окончательные прогнозы получают из трехмерных карт признаков или их двумерных представлений (в варианте осуществления способа для применения в уличных сценах), что соответствует постановке задачи обнаружения на основе облака точек. Исходя из этого, как вкратце упоминалось выше, можно без каких-либо модификаций использовать стандартные промежуточную часть и головную часть детектора объектов на основе облака точек. Модели глубокого обучения для обнаружения двумерных/трехмерных объектов обычно можно разделить на 3 блока: опорную часть (backbone), промежуточную часть (neck) и головную часть (head). В данном контексте "опорная часть" означает любую нейронную сеть или по меньшей мере один или несколько слоев нейронной сети, которые отвечают за извлечение признаков, "промежуточная часть" означает любую нейронную сеть или по меньшей мере один или несколько слоев нейронной сети, которые отвечают за уточнение признаков (например, 2D в 2D в предлагаемой двумерной CNN или 3D в 3D в предлагаемой трехмерной CNN. "Головная часть" означает любую конечную нейронную сеть или по меньшей мере один или несколько конечных слоев нейронной сети, например, для оценки рамок объектов (расположение, размер) и категорий (например, стул, стол, автомобиль и т.д.).
[0007] В итоге, можно прийти к следующему заключению: предложенное техническое решение обеспечивает по меньшей мере тройной результат: (1) в нем используется сквозное обучение для многоракурсного обнаружения объектов на основе только захваченных в известных положениях RGB-изображений; это значительно упрощает сбор обучающих данных, так как для обучения требуются только легко получаемые/доступные обычные монокулярные RGB-изображения; (2) используется новая полносверточная нейронная сеть обнаружения объектов, которая работает как в монокулярном, так и в многоракурсном режиме, что повышает универсальность сети; (3) предлагаемая нейронная сеть обнаружения объектов имеет модульную конструкцию, поэтому можно использовать различные зависящие от конкретной области головные части и промежуточные части без изменения мета-архитектуры основной сети; построение магистрали из строительных блоков помогает разработать надежное и эффективное решение; (4) и наконец, точность обнаружения объектов предлагаемыми техническими решениями превосходит все известные технические решения, использующие нейросетевые архитектуры, обученные на обучающих наборах данных (ScanNet, SUN RGB-D, KITTI и nuScenes), наиболее часто используемых для обнаружения объектов.
[0008] В первом аспекте настоящего изобретения предложен способ обнаружения трехмерных объектов с использованием нейронной сети для обнаружения объектов, содержащей часть для извлечения двумерных признаков, часть для извлечения трехмерных признаков, часть для обнаружения объектов в уличных сценах, которые предобучены сквозным способом на основе только захваченных в известных положениях монокулярных изображений. Способ включает в себя этапы, на которых: получают одно или несколько монокулярных изображений; извлекают двумерные карты признаков из каждого из одного или нескольких монокулярных изображений путем пропускания одного или нескольких монокулярных изображений через часть для извлечения двумерных признаков; создают усредненный трехмерный воксельный объем на основе двумерных карт признаков; извлекают двумерное представление трехмерных карт признаков из усредненного трехмерного воксельного объема путем пропускания усредненного трехмерного воксельного объема через кодировщик части для извлечения трехмерных признаков, и выполняют обнаружение трехмерных объектов как обнаружение двумерных объектов в плоскости вида "с высоты птичьего полета" (BEV), причем обнаружение двумерных объектов в плоскости BEV реализуют путем пропускания двумерного представления трехмерных карт признаков через часть для обнаружения объектов в уличных сценах, содержащую параллельные двумерные сверточные слои для классификации и определения местоположения. Способ согласно первому аспекту изобретения настоящего изобретения адаптирован для работы в уличных сценах. Таким образом способ согласно первому аспекту настоящего изобретения может выполняться, например, электронным устройством, снабженным по меньшей мере одной камерой для обнаружения нулевого или большего количества трехмерных объектов в окружающей области транспортного средства.
[0009] Во втором аспекте настоящего изобретения предложен способ обнаружения трехмерных объектов с использованием нейронной сети для обнаружения объектов, содержащей часть для извлечения двумерных признаков, часть для извлечения трехмерных признаков, часть для обнаружения объектов в сценах помещений, которые предобучены сквозным способом на основе только захваченных в известных положениях монокулярных изображений. Способ содержит этапы, на которых: получают одно или несколько монокулярных изображений; извлекают двумерные карты признаков из каждого из одного или нескольких монокулярных изображений путем пропускания одного или нескольких монокулярных изображений через часть для извлечения двумерных признаков; создают усредненный трехмерный воксельный объем на основе двумерных карт признаков; извлекают уточненные карты трехмерных объектов из усредненного трехмерного воксельного объема путем пропускания усредненного трехмерного воксельного объема через часть для извлечения трехмерных объектов, и выполняют обнаружение трехмерных объектов путем пропускания уточненных трехмерных карт признаков через часть для обнаружения объектов в сценах помещений, использующую плотное воксельное представление промежуточных признаков и содержащую трехмерные сверточные слои для классификации, центрированности и определения местоположения. Способ согласно второму аспекту изобретения может выполняться электронным устройством, снабженным по меньшей мере одной камерой для обнаружения нулевого или большего количества трехмерных объектов в окружающей области данного электронного устройства. Неограничивающие примеры электронного устройства, использованного в способе согласно второму аспекту изобретения включают в себя, смартфон, планшет, умные очки, мобильный робот.
[0011] В модификации второго аспекта изобретения предложен способ понимания сцены с использование нейронной сети обнаружения объектов. Сеть обнаружения объектов в этой модификации содержит часть для понимания сцены, которая предобучена сквозным способом, и способ дополнительно содержит этапы, на которых: выполняют глобальный средний пулинг извлеченных двумерных карт признаков для получения тензора, представляющего извлеченные двумерные карты признаков, и оценивают конфигурацию (layout) сцены путем пропускания тензора через часть для понимания сцены, сконфигурированную для совместной оценки поворота камеры и трехмерной конфигурации сцены. Часть для понимания сцены содержит две параллельные ветви: два полносвязных слоя, которые выводят трехмерную конфигурацию сцены, и два других полносвязных слоя, которые оценивают поворот камеры.
[0012] В третьем аспекте изобретения предложено электронное устройство, установленное на транспортном средстве, снабженном по меньшей мере одной камерой. Данное электронное устройство содержит процессор, сконфигурированный для реализации способа по первому аспекту изобретения для обнаружения нулевого или большего количества трехмерных объектов в окружающей области транспортного средства.
[0013] В четвертом аспекте изобретения предложено электронное устройство, снабженное по меньшей мере одной камерой. Данное электронное устройство содержит процессор, сконфигурированный для реализации способа по второму аспекту изобретения для обнаружения нулевого или большего количества трехмерных объектов в окружающей области электронного устройства. Неограничивающими примерами электронного устройства являются смартфон, планшет, умные очки, мобильный робот.
[0014] В пятом аспекте изобретения предложено электронное устройство, снабженное по меньшей мере одной камерой. Данное электронное устройство содержит процессор, сконфигурированный для реализации способа согласно модификации второго аспекта изобретения для обнаружения нулевого или большего количества трехмерных объектов в окружающей области электронного устройства. Неограничивающими примерами электронного устройства являются смартфон, планшет, умные очки, мобильный робот.
[0015] В седьмом аспекте изобретения предложен считываемый компьютером носитель, хранящий выполняемые компьютером инструкции, которые при исполнении процессором побуждают процессор выполнять способ согласно первому аспекту, второму аспекту или модификации второго аспекта.
Краткое описание чертежей
[0016] Представленные выше и другие аспекты, признаки и преимущества настоящего изобретения станут более очевидными из следующего подробного описания вместе с прилагаемыми чертежами, на которых изображено следующее:
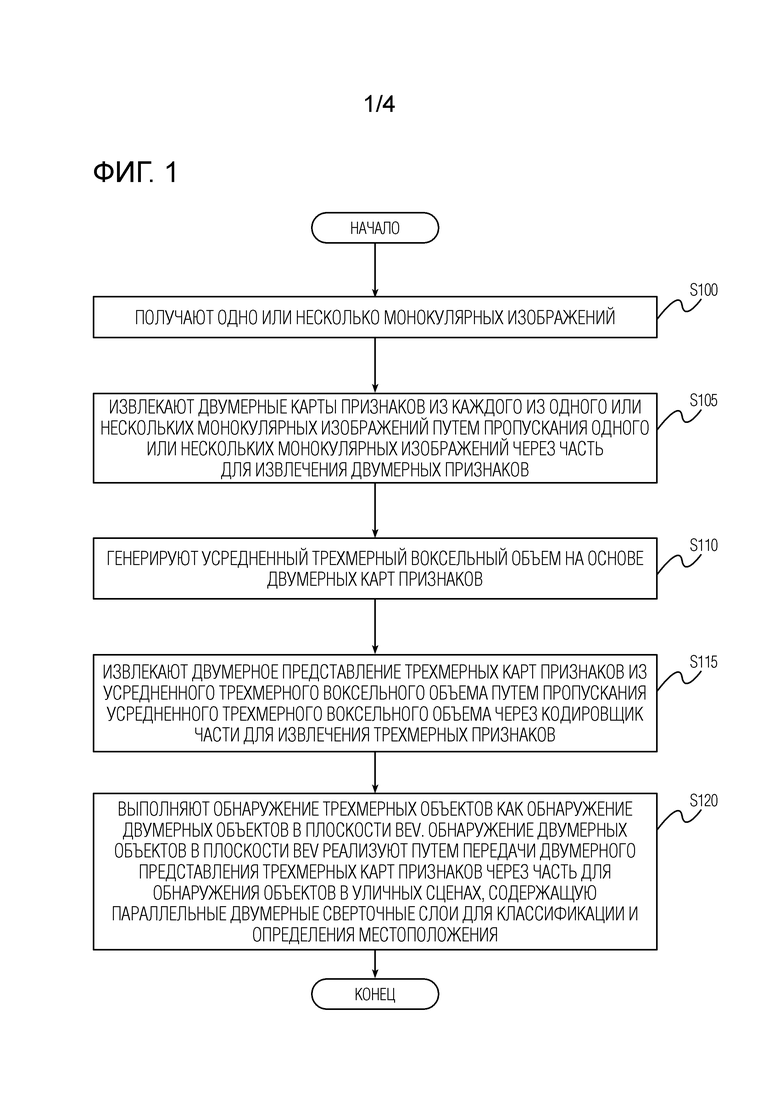
Фиг.1 - блок-схема способа обнаружения трехмерных объектов с использованием предобученной нейронной сети обнаружения объектов, имеющей часть для обнаружения объектов в уличных сценах, согласно первому варианту осуществления настоящего изобретения.
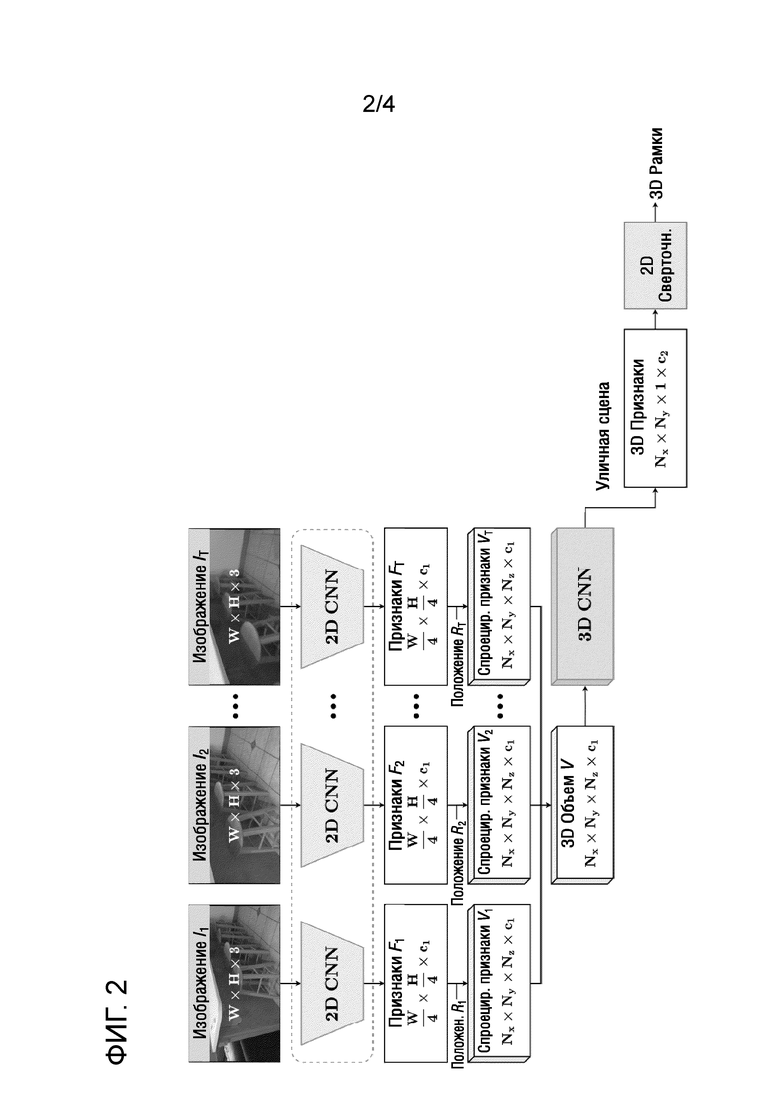
Фиг.2 - схематичное представление конкретных частей архитектуры предобученной нейронной сети для обнаружения объектов и операций способа обнаружения трехмерных объектов согласно первому варианту осуществления настоящего изобретения.
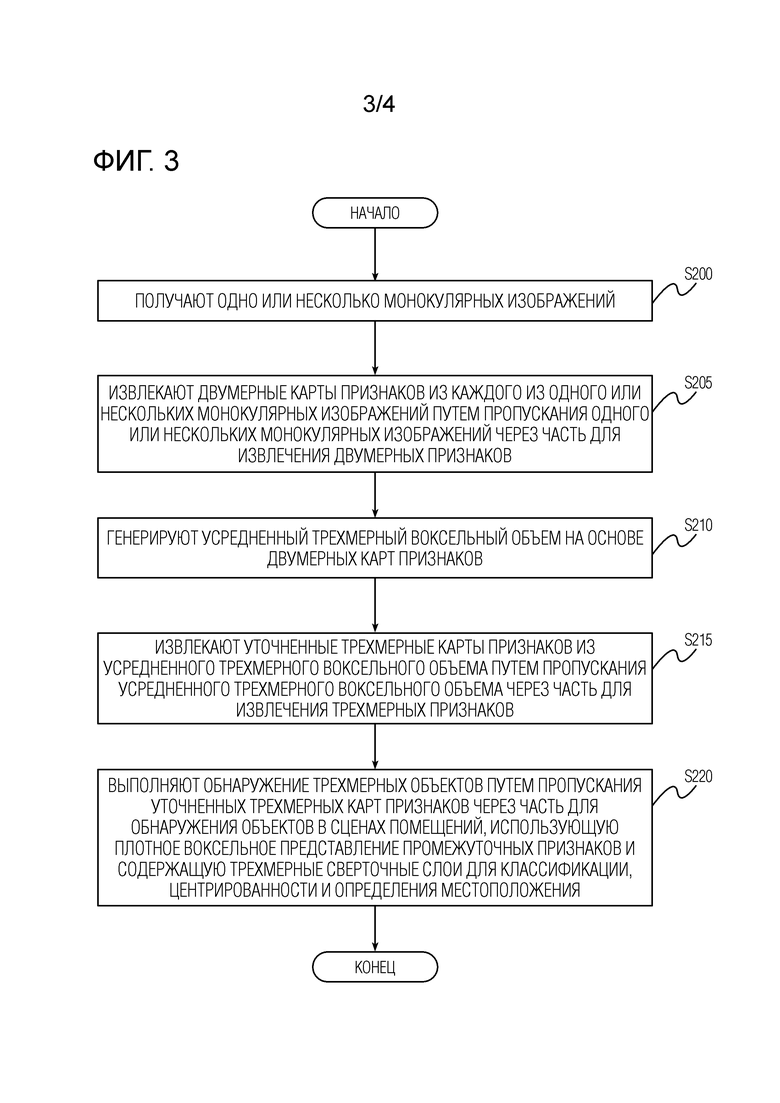
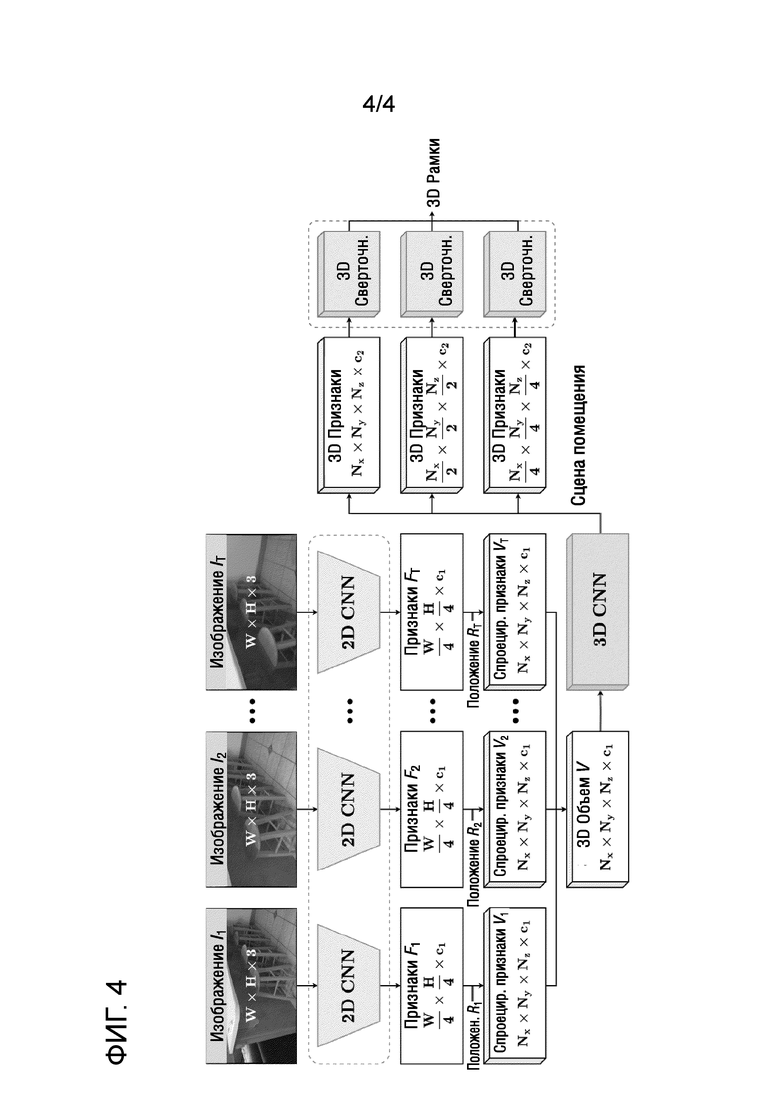
Фиг.3 - блок-схема способа обнаружения трехмерных объектов с использованием предобученной нейронной сети обнаружения объектов, имеющей часть для обнаружения объектов в сценах помещений согласно второму варианту осуществления настоящего изобретения.
Фиг.4 - схематичное представление конкретных архитектурных частей предобученной нейронной сети для обнаружения объектов и операций способа обнаружения трехмерных объектов согласно второму варианту осуществления настоящего изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0017] Техническое решение, раскрытое в настоящей заявке, принимает или иным образом получает набор монокулярных изображений произвольного размера вместе с положениями камеры для таких изображений. Положения камеры можно оценить по изображениям любым известным способом, например, MVS (Multi-View Stereo), SLAM (Simultaneous Localization And Mapping (Одновременная локализация и отображение), трекинг камеры и т.п. В качестве альтернативы, оценочные положения камеры, связанные с соответствующими изображениями набора монокулярных изображений, могут быть приняты или иным образом получены в качестве дополнительной информации в любой подходящей форме. Набор изображений может включать в себя одно или несколько изображений. Изображения в этом наборе могут быть, но без ограничения, RGB-изображениями или любыми другими цветными изображениями.
[0018] Затем предложенное техническое решение извлекает признаки (например, в виде двумерных карт признаков) из одного или нескольких изображений, используя часть для извлечения двумерных признаков основной нейронной сети обнаружения объектов. Любая двумерная сверточная опорная часть, например VGGNet, ResNet, ResNet-50, MobileNet или другие сверточные нейронные сети (CNN) могут использоваться в качестве части для извлечения двумерных признаков. Затем извлеченные признаки изображения проецируются в трехмерный воксельный объем. Для каждого вокселя спроецированные признаки из нескольких изображений агрегируются любым известным способом, например путем простого поэлементного усреднения. Затем воксельный объем с спроецированными и агрегированными признаками передается в часть для извлечения трехмерных признаков основной нейронной сети обнаружения объектов. Часть для извлечения трехмерных признаков может быть трехмерной сверточной сетью, так называемой "промежуточной частью". Выходные данные (например, в виде трехмерных карт признаков) части для извлечения трехмерных признаков поступают на вход части для обнаружения объектов основной нейронной сети обнаружения объектов. Часть обнаружения объектов может быть образована, но без ограничения, последними несколькими сверточными слоями, так называемой "головной частью" в основной нейронной сети обнаружения объектов. Часть для обнаружения объектов обучена выполнять обнаружение объекта. Например, часть для обнаружения объектов может выполнять обнаружение объекта путем прогнозирования признаков ограничивающей рамки для каждой привязки. Привязка (anchor) представляет собой один или несколько кандидатов местоположения в трехмерном пространстве, возможно, с дополнительными элементами априорной информации, такими как средний размер объекта или его соотношение сторон. Полученные ограничивающие рамки обнаруженных объектов можно параметризовать как (x, y, z, w, h, l, и), где (x; y; z) - координаты центра ограничивающей рамки; w, h, l - ширина, высота и длина, соответственно, а и - угол поворота вокруг оси z. Операции, кратко описанные выше, будут описаны подробно ниже со ссылками на прилагаемые фигуры. Проецирование двумерных признаков и трехмерная промежуточная сеть могут быть реализованы, например, как описано в работах (1) Z. Murez, T. van As, J. Bartolozzi, A. Sinha, V. Badrinarayanan, and A. Rabinovich. Atlas: End-to-end 3D scene reconstruction from posed images (Сквозная реконструкция трехмерной сцены из захваченных в известных положениях изображений), 2020 или (2) J. Hou, A. Dai, and M. NieЯner. 3D-sis: 3D semantic instance segmentation of RGB-d scans (Сегментация семантических 3D экземпляров сканирований RGB-d), 2019.
[0019] Далее будет более подробно описан способ согласно первому варианту осуществления настоящего изобретения со ссылками на фиг.1 и фиг.2. На фиг.1 представлена блок-схема способа обнаружения трехмерных объектов с использованием предобученной нейронной сети обнаружения объектов (также называемой "основная нейронная сеть"), имеющей часть для обнаружения объектов в уличных сценах согласно варианту осуществления настоящего изобретения. Способ запускается и переходит на этап S100 приема одного или нескольких монокулярных изображений. Как кратко упоминалось выше, одно или несколько монокулярных изображений могут быть RGB-изображениями или любыми другими цветными изображениями в одном из различных форматов. Пусть It ∈ RW×H×3 будет t-м изображением в множестве T изображений. Здесь T>1 в случае многоракурсных входных данных и T=1 для одиночных входных данных.
[0020] Затем способ переходит на этап S105 извлечения двумерных карт признаков из каждого из одного или нескольких монокулярных изображений путем пропускания одного или нескольких монокулярных изображений через часть для извлечения двумерных признаков, показанную на фиг.2 как "2D CNN". Часть для извлечения двумерных признаков выводит четыре двумерные карты признаков форм 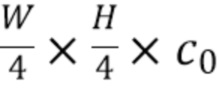 ,
, 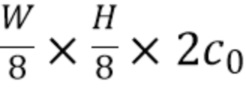 ,
, 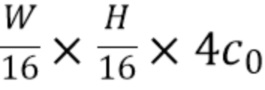 , и
, и 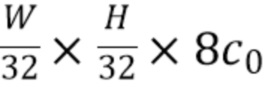 . Конкретное количество (т.е. четыре) двумерны карт признаков, выводимых частью для извлечения двумерных признаков, а также конкретные заданные формы выходных двумерны карт признаков не следует рассматривать в качестве ограничений настоящей технологии, поскольку также возможны другие количества двумерных карт признаков и другие формы двумерных карт признаков. В качестве альтернативы, могут быть выведены и использованы впоследствии всего три или всего две двумерные карты признаков.
. Конкретное количество (т.е. четыре) двумерны карт признаков, выводимых частью для извлечения двумерных признаков, а также конкретные заданные формы выходных двумерны карт признаков не следует рассматривать в качестве ограничений настоящей технологии, поскольку также возможны другие количества двумерных карт признаков и другие формы двумерных карт признаков. В качестве альтернативы, могут быть выведены и использованы впоследствии всего три или всего две двумерные карты признаков.
[0021] Признаки в полученных двумерных картах признаков затем можно агрегировать, например, через сеть признаковой пирамиды (FPN), которая выдает один тензор Ft формы 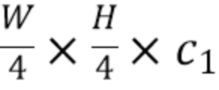 .
. 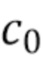 и
и 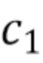 являются зависящими от опорной части; конкретные заранее определенные значения и будут представлены ниже в качестве примера. Карты признаков F1-FT, имеющие агрегированные признаки, показаны на фиг.2 для соответствующих входных изображений I1-IT.
являются зависящими от опорной части; конкретные заранее определенные значения и будут представлены ниже в качестве примера. Карты признаков F1-FT, имеющие агрегированные признаки, показаны на фиг.2 для соответствующих входных изображений I1-IT.
[0022] Затем способ переходит на этап S110 генерации усредненного трехмерного воксельного объема на основе двумерных карт признаков. Для t-х входных данных извлеченная двумерная карта признаков Ft затем проецируется в трехмерный воксельный объем  . Ось z задана перпендикулярной плоскости пола, ось x направлена вперед, а ось y ортогональна обеим осям x и z. Для каждого набора данных (например, ScanNet, SUN RGB-D, KITTI и nuScenes) существуют известные пространственные пределы, оцененные эмпирически для всех трех осей. Обозначим эти пределы как xmin, xmax, ymin, ymax, zmin, zmax. Для фиксированного размера вокселя s пространственные ограничения можно сформулировать как Nxs=xmax−xmin, Nys=ymax−ymin, Nzs=zmax−zmin. Затем можно использовать модель камеры с точечной диафрагмой, но без ограничения, для определения соответствия между 2D координатами (u, v) в двумерной карте признаков Ft и 3D координатами (x, y, z) в объеме Vt:
. Ось z задана перпендикулярной плоскости пола, ось x направлена вперед, а ось y ортогональна обеим осям x и z. Для каждого набора данных (например, ScanNet, SUN RGB-D, KITTI и nuScenes) существуют известные пространственные пределы, оцененные эмпирически для всех трех осей. Обозначим эти пределы как xmin, xmax, ymin, ymax, zmin, zmax. Для фиксированного размера вокселя s пространственные ограничения можно сформулировать как Nxs=xmax−xmin, Nys=ymax−ymin, Nzs=zmax−zmin. Затем можно использовать модель камеры с точечной диафрагмой, но без ограничения, для определения соответствия между 2D координатами (u, v) в двумерной карте признаков Ft и 3D координатами (x, y, z) в объеме Vt:
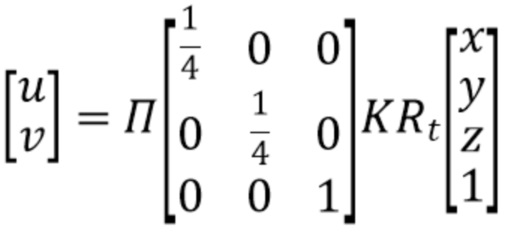 ,
,
[0023] K и Rt - матрицы внутренних и внешних параметров камеры, соответственно, а Р - перспективное отображение. Внутренние параметры матрицы внутренних параметров камеры определяют положение и ориентацию камеры по отношению к системе координат мира. Внешние параметры матрицы внешних параметров камеры позволяют осуществлять преобразования между координатами камеры и пиксельными координатами в кадре изображения. Конкретные значения внутренних и внешних параметров могут быть заданы для камеры в результате процесса калибровки камеры.
[0024] После проецирования двумерных карт признаков все воксели вдоль луча камеры заполняются теми же признаками, что и соответствующая двумерная карта (карты) признаков. При необходимости может быть определена двоичная маска Mt. Форма двоичной маски Mt может соответствовать форме объема Vt. Эта двоичная маска указывает, находится ли каждый воксель внутри усеченной пирамиды камеры, т.е. является ли данный воксель "внутренним (видимым) вокселем" или нет. Таким образом, для каждого изображения It маска Mt может быть определена как:
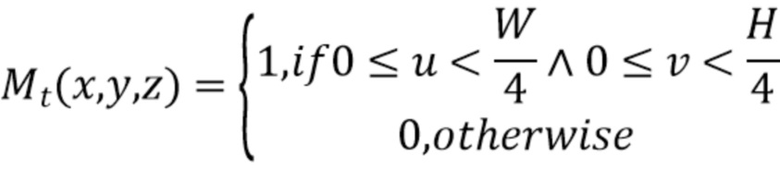
[0025] Затем двумерная карта признаков Ft проецируется для каждого внутреннего (т.е. действительного) вокселя в объеме Vt:
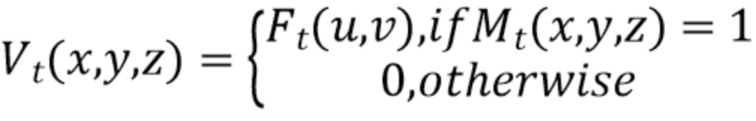
[0026] На фиг.2 показаны внутренние объемы V1-VT со спроецированными признаками, соответствующими картам признаков F1-FT, имеющим агрегированные признаки, для соответствующих входных изображений I1-IT.
[0027] Агрегированная двоичная маска M представляет собой сумму M1,…,Mt:
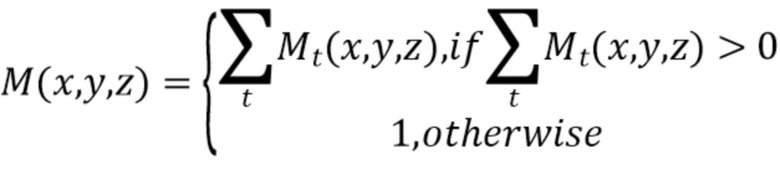
[0028] В заключение, генерируется усредненный трехмерный воксельный объем V путем усреднения спроецированных признаков в объемах V1,…,Vt по внутренним вокселям:
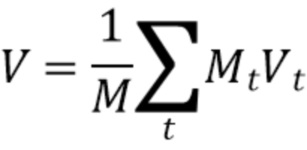
[0029] На фиг.2 показан усредненный трехмерный воксельный объем V формы 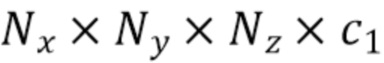 , сгенерированный на основе внутренних объемов V1-VT со спроецированными признаками, соответствующими картам признаков F1-FT, имеющим агрегированные признаки, для соответствующих входных изображений I1-IT.
, сгенерированный на основе внутренних объемов V1-VT со спроецированными признаками, соответствующими картам признаков F1-FT, имеющим агрегированные признаки, для соответствующих входных изображений I1-IT.
[0030] Поскольку часть для обнаружения объектов в уличных сценах принимает двумерные карты признаков, необходимо получить двумерное представление сгенерированного трехмерного воксельного объема для использования в предложенном способе. Поэтому, возвращаясь к фиг.1, после того, как сгенерирован усредненный трехмерный воксельный объем V, способ переходит на этап S115 извлечения двумерного представления трехмерных карт признаков из усредненного трехмерного воксельного объема. Этот этап выполняется путем пропускания усредненного трехмерного воксельного объема только через кодировщик части для извлечения трехмерных признаков, показанной на фиг.2 как "3D CNN". Часть для извлечения трехмерных признаков, используемая на данном этапе, может соответствовать архитектуре кодировщик-декодер, раскрытой в вышеупомянутой работе (1).
[0031] После прохождения через несколько трехмерных сверточных слоев и слоев понижающей дискретизации кодировщика части для извлечения трехмерных признаков усредненный трехмерный воксельный объем V формы преобразуется в тензор формы 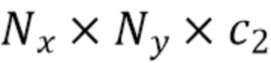 , являющийся двумерным представлением трехмерных карт признаков усредненного трехмерного воксельного объема. Полученный тензор формы представляет собой выходные данные (показан на фиг.2 как "3D признаки") части для извлечения трехмерных признаков. Благодаря этапу S115 задачу обнаружения трехмерных объектов в трехмерном пространстве можно свести к задаче обнаружения двумерных объектов в плоскости BEV. Обе части - часть для извлечения трехмерных признаков, показанная на фиг.2 как "3D CNN" и часть для обнаружения объектов в уличных сценах, показанная на фиг.2 как "2D Conv" для данного варианта осуществления способа, содержат 2D свертки.
, являющийся двумерным представлением трехмерных карт признаков усредненного трехмерного воксельного объема. Полученный тензор формы представляет собой выходные данные (показан на фиг.2 как "3D признаки") части для извлечения трехмерных признаков. Благодаря этапу S115 задачу обнаружения трехмерных объектов в трехмерном пространстве можно свести к задаче обнаружения двумерных объектов в плоскости BEV. Обе части - часть для извлечения трехмерных признаков, показанная на фиг.2 как "3D CNN" и часть для обнаружения объектов в уличных сценах, показанная на фиг.2 как "2D Conv" для данного варианта осуществления способа, содержат 2D свертки.
[0032] И наконец, после получения тензора формы , являющегося представлением усредненного трехмерного воксельного объема V в плоскости BEV, способ переходит на этап S120 выполнения обнаружения трехмерных объектов в форме обнаружения двумерных объектов в плоскости BEV. Обнаружение двумерных объектов в плоскости BEV реализуется путем передачи двумерного представления трехмерных карт признаков через часть для обнаружения объектов в уличных сценах, содержащую параллельные двумерные сверточные слои для классификации и определения местоположения. "Параллельность" по отношению к слоям в данном контексте означает, что выходные данные предпоследнего сверточного слоя подаются на 2 конечных слоя (один для классификации, другой для определения местоположения), которые не зависят друг от друга, т.е. обработка в этих слоях может выполняться одновременно. Таким образом, задача обнаружения трехмерных объектов в уличных сценах переформулируется в способе согласно первому варианту осуществления в задачу обнаружения двумерных объектов в плоскости BEV.
[0033] В качестве части для обнаружения объектов в уличных сценах в данном варианте осуществления способа может использоваться, но без ограничения, работающая с двумерными привязками головная часть, продемонстрировавшая свою эффективность в работах (3) A. H. Lang, S. Vora, H. Caesar, L. Zhou, J. Yang, and O. Beijbom. Pointpillars: Fast encoders for object detection from point clouds (Быстрые кодировщики для обнаружения объектов из облаков точек), 2019, и (4) Y. Yan, Y. Mao, and B. Li. Second: Sparsely embedded convolutional detection (Разреженно-встроенное сверточное обнаружение), 2018, на наборах данных KITTI и nuScenes. Любая другая головная часть на основе облака точек может использоваться с предлагаемой основной нейронной сетью обнаружения объектов.
[0034] Поскольку способы трехмерного обнаружения для применения в уличных сценах обычно оцениваются на транспортных средствах или других объектах, находящихся на дороге или рядом с ней (например, на пешеходах, объектах дорожной инфраструктуры, таких как дорожная разметка и дорожные знаки), все такие объекты имеют аналогичный заданный масштаб и принадлежат к фиксированным категориям. Для одномасштабного и одноклассового обнаружения часть для обнаружения объектов в уличных сценах содержит два параллельных сверточных 2D слоя. Один слой оценивает вероятность класса, а другой регрессирует семь параметров ограничивающей рамки объекта, если он обнаружен.
[0035] Входные данные в часть для обнаружения объектов в уличных сценах. Этими входными данными, как уже вкратце отмечалось выше, является тензор формы . Конкретное значение 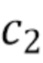 предопределено и будет проиллюстрировано ниже.
предопределено и будет проиллюстрировано ниже.
[0036] Выходные данные части для обнаружения объектов в уличных сценах. Для каждой привязки в 2D BEV часть для обнаружения объектов в уличных сценах возвращает вероятность p класса и ограничивающую 3D рамку, например, как следующий набор из семи элементов:
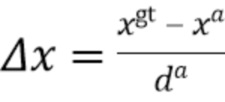 ,
, 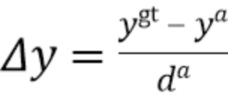 ,
, 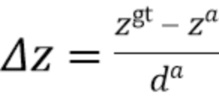 ,
, 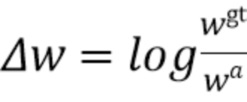 ,
, 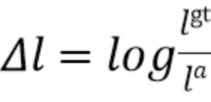 ,
, 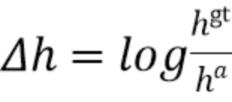 ,
, 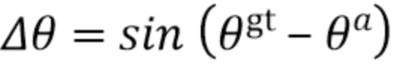 .
.
[0037] При этом .gt и .a, соответственно, обозначают истинные ограничивающие рамки (ground truth) и ограничивающие рамки привязки. Длина диагонали 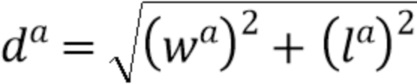 ограничивающей рамки постоянна для всех привязок, поскольку они расположены в плоскости BEV и вычисляются для одного класса объектов (например, автомобилей).
ограничивающей рамки постоянна для всех привязок, поскольку они расположены в плоскости BEV и вычисляются для одного класса объектов (например, автомобилей).
[0038] Потери. Для обучения части для обнаружения объектов в уличных сценах можно использовать следующую функцию потерь, но без ограничений. Общие потери в уличных сценах могут включать в себя несколько членов потерь, а именно сглаженное среднее абсолютное отклонение как потерю местоположения Lloc, фокальную потерю для классификации Lcls и перекрестно-энтропийную потерю для направления Ldir. В целом, общие потери в уличных сценах можно сформулировать, например, следующим образом:
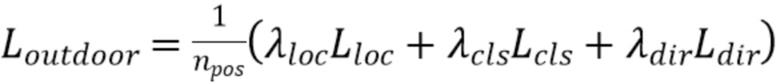 ,
,
[0039] 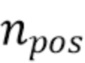 - это количество положительных привязок; привязка считается положительной, если хотя бы один истинный объект соответствует этой привязке.
- это количество положительных привязок; привязка считается положительной, если хотя бы один истинный объект соответствует этой привязке. 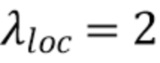 ,
, 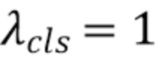 ,
, 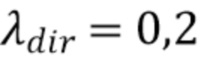 , но без ограничения указанными значениями.
, но без ограничения указанными значениями.
[0040] Как было описано выше со ссылками на фиг.1 и фиг.2, основная нейронная сеть обнаружения объектов, используемая в способе обнаружения трехмерных объектов согласно первому варианту осуществления настоящего изобретения, создает трехмерное воксельное представление пространства. Таким образом, она может использовать головную часть или промежуточную часть из любого из известных способов обнаружения трехмерных объектов на основе облака точек. Следовательно, вместо трудоемкой реализации нестандартной и сложной архитектуры можно использовать современные головные части с соответствующими способами и без дополнительных модификаций. Таким образом, модульная конструкция нейронной сети обнаружения объектов, используемой в способе обнаружения объектов согласно первому варианту осуществления настоящего изобретения, обеспечивает повышенную гибкость и упрощает процесс разработки. Однако следует понимать, что конструкции головной части для способов применения в уличных сценах и в сценах помещений существенно различаются.
[0041] Вариант осуществления способа, описанный со ссылками на фиг.1 и фиг.2, адаптирован для применения в уличных сценах и может исполняться электронным устройством транспортного средства, оснащенного по меньшей мере одной камерой, для обнаружения нулевого или большего количества трехмерных объектов в окружающей области транспортного средства. Такое электронное устройство может быть системой автономного вождения транспортного средства или, по меньшей мере, ее частью. Такая система может содержать по меньшей мере одну или несколько камер, установленных на транспортном средстве и сконфигурированных для захвата изображений окружения транспортного средства вокруг транспортного средства, и процессор, сконфигурированный для выполнения или запуска различных операций, связанных с транспортным средством. Следует понимать, что изобретение, раскрытое в настоящей заявке, не претендует на техническое решение автономного вождения как такового, но оно может быть частью такого технического решения для транспортного средства, ответственной за обнаружение трехмерных объектов.
[0042] Теперь обратимся к более подробному описанию способа согласно второму варианту настоящего изобретения со ссылками на фиг.3 и фиг.4. На фиг.3 представлена блок-схема способа обнаружения трехмерных объектов с использованием предобученной нейронной сети обнаружения объектов, имеющей часть для обнаружения объектов в сценах помещений согласно второму варианту осуществления настоящего изобретения. Поскольку этапы S200, S205, S210 способа согласно второму варианту осуществления (в сценах помещений) соответствуют этапам S100, S105, S110 первого варианта осуществления способа (в уличных сценах) повторные описания этапов S200, S205, S210 будут опущены для краткости. Кроме того, поскольку мета-архитектура (т.е. 2D CNN, 3D CNN плюс дополнительные операции между ними, как показано на фиг.2 и 4) основной нейронной сети обнаружения объектов в обоих вариантах предложенного и описанного способа остается одинаковой, описание мета-архитектуры, показанной на фиг.4, также будет опущено для краткости.
[0043] Обращаясь теперь к фиг.3 и фиг.4, после того, как был сгенерирован усредненный трехмерный воксельный объем V, способ переходит на этап S215 извлечения уточненных (например, если вводятся трехмерные признаки, выводятся уточненные трехмерные признаки, соответствующие введенным трехмерным признакам) трехмерных карт признаков из усредненного трехмерного воксельного объема. Этот этап выполняется путем пропускания усредненного трехмерного воксельного объема через всю архитектуру сверточного трехмерного кодировщика-декодера части для извлечения трехмерных признаков, показанной на фиг.4 как "3D CNN". Часть извлечения трехмерных признаков может соответствовать архитектуре кодировщик-декодер, раскрытой в вышеупомянутом документе (1).
[0044] Каждый слой архитектуры кодировщик-декодер, используемой на данном этапе, содержит остаточные блоки с заранее определенным количеством трехмерных сверточных слоев с ядром заранее определенного размера. В одном примере заданное количество трехмерных сверточных слоев равно двум, а заданный размер ядра равен трем. Для понижающей дискретизации применяются свертки с ядром заданного размера и заданным шагом свертки (stride). В одном примере заданный размер ядра сверток, связанных с понижающей дискретизацией, равен трем, а заданный шаг свертки равен двум. Повышающая дискретизация может выполняться, например, посредством трилинейной интерполяции с последующей сверткой с ядром заданного размера. В одном примере размер ядра свертки, связанной с повышающей дискретизацией, равен единице. Однако настоящее изобретение не ограничивается значениями параметров, указанных в приведенных выше примерах, поскольку возможны другие конкретные значения этих параметров, которые могут быть определены эмпирически на основе таких факторов, как, например, область применения предложенного способа и вычислительные/аппаратные/иные возможности устройства, предназначенного для реализации предложенного способа. В результате этапа S215 декодер части извлечения трехмерных признаков выводит уточненные трехмерные карты признаков (в неограничивающем примере - количество таких выводимых карт равно трем) следующих форм:
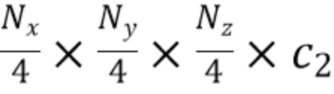 ,
, 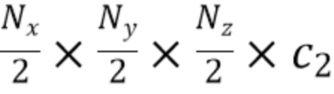 ,
, 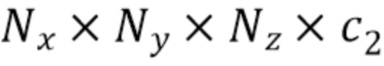 .
.
Далее будет проиллюстрировано конкретное значение . В одном примере 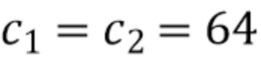 , чтобы не увеличивать занимаемую память в процессе вычислений в части для извлечения трехмерных признаков. Уточненные трехмерные карты признаков показаны на фиг.4 как "3D признаки".
, чтобы не увеличивать занимаемую память в процессе вычислений в части для извлечения трехмерных признаков. Уточненные трехмерные карты признаков показаны на фиг.4 как "3D признаки".
[0045] Как было описано выше со ссылками на фиг.3 и фиг.4, основная нейронная сеть обнаружения объектов, используемая в способе обнаружения трехмерных объектов согласно второму варианту осуществления настоящего изобретения, также (аналогично первому варианту осуществления) строит трехмерное воксельное представление пространства. Поэтому она также может использовать промежуточную часть или головную часть из любого из известных способов обнаружения трехмерных объектов на основе облака точек. Следовательно, вместо продолжительной реализации заказной и сложной архитектуры можно использовать современные промежуточные части и/или головные части с соответствующими способами и без дальнейших модификаций. Таким образом, модульная конструкция нейронной сети обнаружения объектов, используемой в способе обнаружения трехмерных объектов согласно второму варианту осуществления настоящего изобретения, обеспечивает, аналогично первому варианту осуществления настоящего изобретения, повышенную гибкость и упрощает процесс разработки. Тем не менее, следует учитывать, что конструкции головных частей для способов применения в уличных сценах и в сценах помещений существенно различаются.
[0046] И наконец, после извлечения уточненных трехмерных карт признаков способ согласно второму варианту осуществления переходит на этап S220 выполнения обнаружения трехмерных объектов. Этот этап реализуется путем пропускания уточненных трехмерных карт признаков через часть для обнаружения объектов в сценах помещений, которая использует плотное воксельное представление промежуточных признаков и содержит трехмерные сверточные слои для классификации, центрированности и определения местоположения. Все современные способы обнаружения трехмерных объектов в сценах помещений выполняют глубокое голосование Хафа для представления разреженных облаков точек. В отличие от этого, способ согласно второму варианту осуществления следует работе (1) и использует плотное воксельное представление промежуточных признаков. Насколько известно авторам, не существует части для обнаружения объектов в сценах помещений для обнаружения трехмерных объектов, которая была бы плотной, трехмерной и многомасштабной.
[0047] Конструкция части для обнаружения объектов в сценах помещений может следовать, например, способу двумерного обнаружения FCOS, описанному в работе (5) - Z. Tian, C. Shen, H. Chen, and T. He. FCOS: Fully convolutional one-stage object detection (Полностью сверточное одноступенчатое обнаружение объектов), 2019. Исходная головная часть FCOS, описанная в (5), принимает двумерные признаки из FPN и оценивает двумерные ограничивающие рамки с помощью двумерных сверточных слоев. Чтобы адаптировать FCOS для трехмерного обнаружения, двумерные свертки исходной FCOS заменены в настоящем изобретении трехмерными свертками, чтобы часть для обнаружения объектов в сценах помещений могла обрабатывать трехмерные входные данные. Согласно FCOS для выбора местоположений потенциальных объектов может применяться центральная выборка. В неограничивающем примере может быть выбрано 9 (3×3) кандидатов. Количество кандидатов может быть больше или меньше указанного. Поскольку предлагаемый способ работает в трехмерном пространстве, предел местоположений кандидатов для каждого объекта может быть установлен равным заранее определенному количеству (например, 27, 3×3×3). Результирующая часть для обнаружения объектов в сценах помещений содержит три трехмерных сверточных слоя для классификации, определения местоположения и центрированности, соответственно, с общими весами для всех масштабов объектов.
[0048] Входные данные в часть для обнаружения объектов в сценах помещений. Многомасштабные входные данные в часть для обнаружения объектов в сценах помещений могут содержать, как уже вкратце отмечалось выше, три тензора форм , , и .
[0049] Выходные данные части для обнаружения объектов в сценах помещений. Для каждого трехмерного местоположения (xa; ya; za) и каждого из трех осей головная часть оценивает вероятность p класса, центрированность c и трехмерную ограничивающую рамку, как, например, следующий кортеж из семи элементов:
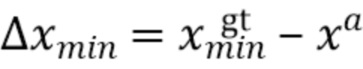 ,
, 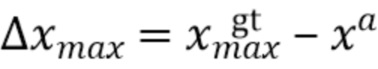 ,
,
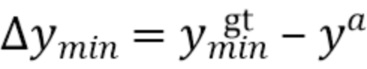 ,
, 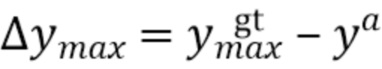 ,
,
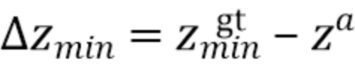 ,
, 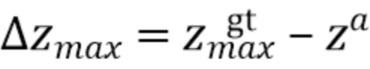 , и.
, и.
[0050] При этом 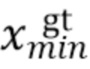 ,
, 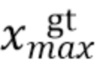 ,
, 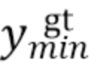 ,
, 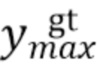 ,
, 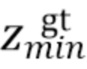 ,
, 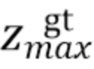 , соответственно, обозначают минимальные и максимальные координаты вдоль соответствующих осей истинной ограничивающей рамки.
, соответственно, обозначают минимальные и максимальные координаты вдоль соответствующих осей истинной ограничивающей рамки.
[0051] Потери. Функция потерь, описанная в документе (5), модифицирована и используется для обучения части для обнаружения объектов в сценах помещений, используемой во втором варианте осуществления способа, предложенного в данном документе. Модифицированная функция общих потерь включает в себя фокальную потерю для классификации Lcls, кросс-энтропийную потерю для центрированности Lcntr и потерю метрики степени пересечения между двумя ограничивающими рамками (Intersection-over-Union, IoU) для местоположения Lloc. Поскольку способ согласно второму варианту осуществления (для работы в сценах помещений) решает задачу трехмерного обнаружения вместо задачи двумерного обнаружения, двумерная потеря IoU заменяется повернутой трехмерной потерей IoU. Кроме того, истинная центрированность обновляется третьим измерением. Итоговые общие потери для сцен помещений можно сформулировать, например, следующим образом:
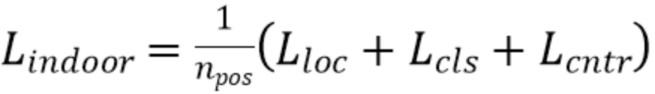 ,
,
[0052] где npos - количество положительных трехмерных местоположений.
[0053] Вариант осуществления способа, описанный со ссылками на фиг.3 и фиг.4, адаптирован для использования в сценах помещений и может выполняться электронным устройством, оснащенным по меньшей мере одной камерой для обнаружения нулевого или большего количества трехмерных объектов в окружающей области электронного устройства. Электронное устройство во втором варианте осуществления способа может быть одним из, например, смартфона, планшета, умных очков или мобильного робота. Если электронным устройством является смартфон, планшет или умные очки, пользователи могут направлять камеры таких устройств в разные стороны для обнаружения объектов, попадающих в поле зрения этих камер. В этом случае такие устройства могут, например, служить в качестве устройств, которые помогают пользователям с ослабленным зрением перемещаться по помещению и находить различные объекты, например, посредством синтезируемых голосовых подсказок, дающих информацию о нулевом или большем количестве обнаруженных объектов или информацию об их местоположении.
[0054] Если электронным устройством является мобильный робот, например мобильный робот-уборщик, электронное устройство может быть самим роботом или, по меньшей мере, его частью. Такое электронное устройство может содержать по меньшей мере одну или несколько камер, установленных на корпусе робота и выполненных с возможностью захвата изображений окружения вокруг робота, и процессор, сконфигурированный для выполнения или запуска различных операций, связанных с роботом. Следует понимать, что предложенное изобретение не претендует на техническое решение для навигации робота и управления движениями робота как такового, но оно может быть частью такого технического решения для робота, ответственной за обнаружение трехмерных объектов.
[0055] Способ согласно модификации второго варианта осуществления (не показанный на фигурах) адаптирован для понимания сцены, включая оценку положения камеры и определение конфигурации помещения. В способе согласно данной модификации второго варианта осуществления основная нейронная сеть обнаружения объектов дополнительно содержит предобученную часть для понимания сцены. В некоторых критериях сравнительного анализа для помещения задача обнаружения трехмерных объектов может быть сформулирована как подзадача понимания сцены. Следуя работе (6) Y. Nie, X. Han, S. Guo, Y. Zheng, J. Chang и J. J. Zhang. Total 3D understanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image (Полное понимание 3D: Совместное определение конфигурации, позы объекта и реконструкция сетки для сцен помещений по одному изображению), 2020, повороты камеры и конфигурации помещений могут быть спрогнозированы в настоящей модификации второго варианта осуществления способа. Часть для понимания сцены в этой модификации второго варианта осуществления способа обучается и конфигурируется для совместной оценки поворота Rt камеры и трехмерной конфигурации сцены. Эта часть для понимания сцены состоит из двух параллельных ветвей: два полносвязных слоя выводят трехмерную конфигурацию сцены, а два других полносвязных слоя оценивают повороты камеры.
[0056] Входные данные в часть для понимания сцены. Входными данными является один тензор формы 8c0, полученный путем глобального среднего пулинга выходных данных части для извлечения двумерных признаков.
[0057] Выходные данные из части для понимания сцены. Часть для понимания сцены выводит положение камеры, например, как кортеж из тангажа в и крена г, и рамку трехмерной конфигурации (представляющую собой рамку, приближенную к помещению), например, как кортеж из 7 элементов (x, y, z, w, l, h, и). Угол рыскания и смещение можно установить равными нулю.
[0058] Потери. Потери, используемые в (6), модифицированы для приведения их в соответствие с подзадачей, которая должна быть решена в данной модификации второго варианта способа. Соответственно, потеря Llayout конфигурации как повернутая потеря 3D IoU между рамками спрогнозированной и истинной конфигурации; это та же потеря, которая используется для части для обнаружения объектов в сценах помещений согласно второму варианту осуществления способа, описанному выше. Для оценки поворота камеры, 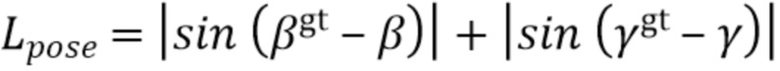 используется по существу аналогично Lloc в первом варианте осуществления способа. В целом, общие потери для обучения части для понимания сцены можно сформулировать, например, следующим образом:
используется по существу аналогично Lloc в первом варианте осуществления способа. В целом, общие потери для обучения части для понимания сцены можно сформулировать, например, следующим образом:
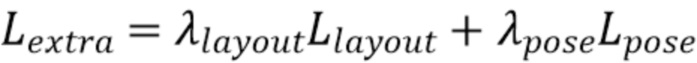 ,
,
[0059] где лlayout=0,1 и лpose=1,0, но без ограничения указанными значениями.
[0060] Подобно второму варианту осуществления способа, модификация второго варианта осуществления способа, описанного выше, адаптирована для понимания сцен помещений и может выполняться электронным устройством, оснащенным по меньшей мере одной камерой для обнаружения нулевого или большего количества трехмерных объектов в окружающей области электронного устройства, оценки положения камеры и определения конфигурации помещения. Электронное устройство во втором варианте осуществления способа может быть одним из, например, смартфона, планшета, умных очков или мобильного робота. Если электронным устройством является смартфон, планшет или умные очки, пользователи могут направлять камеры таких устройств в разные стороны в помещении, чтобы понять характеристики сцены и содержимое сцены, попадающее в поля зрения камер. В этом случае такие устройства могут, например, служить в качестве устройств, которые помогают пользователям с ослабленным зрением перемещаться по помещению и находить различные объекты, например, с помощью синтезированных голосовых подсказок, дающих информацию о сцене.
[0061] Если электронным устройством является мобильный робот, например, мобильный робот-уборщик, электронное устройство может быть самим роботом или, по меньшей мере, его частью. Такое электронное устройство может содержать по меньшей мере одну или несколько камер, установленных на корпусе робота и выполненных с возможностью захвата изображений сцены вокруг робота, и процессор, сконфигурированный для выполнения или запуска различных операций, связанных с роботом. Следует понимать, что изобретение, раскрытое в настоящей заявке, не претендует на то, чтобы быть техническим решением для навигации робота и управления движениями робота как такового, но оно может быть частью такого технического решения для робота, ответственной за понимание сцены.
[0062] Кроме того, предлагается третий вариант осуществления способа, в котором способ адаптирован для автоматического выбора промежуточной части и/или головной части в зависимости от рабочих условий или решаемых задач. В качестве примера, если скорость электронного устройства, реализующего способ, превышает заданный порог (например, 4 км в час), или координаты GPS электронного устройства, реализующего способ, указывают на то, что текущее положение электронного устройства находится на улице, и/или соответствующая функция активирована на электронном устройстве (например, функция обнаружения объектов в настройках камеры), способ может переключиться на ветвь обработки и архитектуру, описанные выше со ссылками на фиг.1 и фиг.2.
[0063] В другом примере, если скорость электронного устройства, реализующего способ, ниже заданного порога (например, 4 км в час), или координаты GPS электронного устройства, реализующего способ, указывают на то, что текущее положение электронного устройства находится в помещении, и/или на электронном устройстве активирована соответствующая функция (например, функция обнаружения объектов в настройках камеры), способ может переключиться на ветвь обработки и архитектуру, описанные выше со ссылками на фиг.2 и 3. Другие примерные реализации такого автоматического переключения будут понятны специалисту в данной области на основе приведенных выше примеров.
[0064] Далее будут описаны наборы данных, которые можно использовать для обучения и оценки предложенной нейронной сети обнаружения объектов согласно первому варианту осуществления способа (в уличных сценах), второму варианту осуществления способа (в сценах помещений), модификации второго варианта способа (понимание сцены) или третьего варианта способа (способного осуществлять автоматическое переключение между ветвями обработки и архитектурами или их частями в зависимости от рабочих условий или поставленных задач).
[0065] В настоящем изобретении для обучения нейронных сетей или оценки нейронных сетей используются четыре набора данных: ScanNet, SUN RGB-D, KITTI и nuScenes. SUN RGB-D и KITTI ориентированы на монокулярный режим, а для ScanNet и nuScenes проблема обнаружения решается в многоракурсном режиме.
[0066] KITTI. Набор данных KITTI для обнаружения объектов является самым существенным эталоном применения в уличных сценах для обнаружения монокулярных трехмерных объектов. Он состоит из 3711 обучающих, 3768 проверочных и 7518 тестовых изображений. Вся разметка к трехмерным объектам в этом наборе данных имеет какой-либо уровень сложности: легкий, средний и сложный. Предложенный способ обнаружения трехмерных объектов оценивался по результатам на умеренных объектах из тестовой выборки. Предлагаемый способ оценивался на объектах категории транспортных средств.
[0067] nuScenes. Набор данных nuScenes обеспечивает данные для разработки алгоритмов решения задач, связанных с автономным вождением. Он содержит облака точек LiDAR, RGB-изображения, снятые шестью камерами, сопровождаемые измерениями IMU и GPS. Этот набор данных охватывает 1000 видеопоследовательностей, каждая из которых записана в течение 20 секунд, всего 1,4 миллиона изображений и 390000 облаков точек. Обучающая группа охватывает 28130 сцен, а тестовая группа содержит 6019 сцен. Разметка содержит 1,4 млн объектов, разделенных на 23 категории. Точность трехмерного обнаружения измерялась на категории транспортных средств. В этом тесте вычисляются не только метрика средней точности (AP), но и средняя ошибка линейного перемещения (ATE), средняя ошибка масштаба (ASE) и средняя ошибка ориентации (AOE).
[0068] SUN RGB-D. Набор данных SUN RGB-D является одним из первых и наиболее известных трехмерных наборов данных со сценами помещений. Он содержит 10335 изображений, снятых в различных местах в помещениях, а также соответствующие карты глубины, полученные с помощью четырех различных датчиков и положений камеры. Обучающая группа состоит из 5285 кадров, а остальные 5050 кадров составляют проверочное подмножество. Разметка содержит 58657 объектов. Для каждого кадра предусмотрена конфигурация помещения.
[0069] ScanNet. Набор данных ScanNet содержит 1513 сканов, охватывающих более 700 уникальных сцен помещений, из которых 1201 сканов относится к обучающей группе, а 312 сканов используются для проверки. В целом, этот набор данных содержит более 2,5 миллионов изображений с соответствующими картами глубины и положениями камеры, а также реконструированные облака точек с трехмерной семантической разметкой. Трехмерные ограничивающие рамки оцениваются по семантическим облакам точек в соответствии со стандартным протоколом. Полученные ограничивающие рамки объекта выровнены по осям, поэтому угол поворота и для ScanNet не прогнозировался.
[0070] Подробности реализации (следующая информация предназначена не для ограничения, а только для достаточности раскрытия). Трехмерный объем. В качестве средства извлечения признаков, то есть части для извлечения двумерных признаков, может использоваться ResNet-50. Соответственно, количество сверток в первом сверточном блоке c0 может быть задано как 256. Размер c1 признаков трехмерного объема может быть предварительно установлен равным 64. Для наборов данных со сценами помещений размер c2 выводимых признаков может быть установлен равным c1, чтобы не увеличивать объем памяти, используемый во время уточнения. Для наборов данных с уличными сценами c2 можно установить равным 256.
[0071] Сцены помещений и уличные сцены имеют разные абсолютные масштабы. Поэтому пространственные размеры объема признаков для каждого набора данных могут быть установлены с учетом предметной области. Таким образом, например, размер s вокселя можно установить равным 0,32 метра для наборов данных с уличными сценами. Минимальные и максимальные значения для всех трех осей для наборов данных с уличными сценами также соответствуют диапазонам облаков точек для класса транспортных средств. Для выбора ограничений набора данных со сценами помещений размер помещения можно рассматривать как 6,4×6,4×256 метра. Для повышения эффективности памяти размер s вокселя можно увеличить вдвое с 0,04 до 0,08.
[0072] Обучение. Во время обучения Lindoor/Lextra оптимизируется для наборов данных со сценами помещений, а Loutdoor оптимизируется для наборов данных с уличными сценами. Может использоваться оптимизатор Adam с начальной скоростью обучения, установленной на 0,0001, и уменьшением веса 0,0001. Эта реализация может быть основана на фреймворке MMDetection и использует настройки обучения по умолчанию. Сеть можно обучить за 12 эпох, а скорость обучения можно уменьшить в десять раз после 8-й и 11-й эпох. Для ScanNet, SUN RGB-D и KITTI каждую сцену можно показывать сети три раза в каждой эпохе обучения. Для обучения, распределения одной сцены (многоракурсный сценарий) или четырех изображений (монокулярный сценарий) использовалось 8 графических процессоров Nvidia Tesla P40 на каждый графический процессор. Во время обучения можно произвольно применять отображение по горизонтали, и размер входных данных в монокулярных экспериментах можно изменять не более чем на 25% от их исходного разрешения. Кроме того, в сценах помещений трехмерные воксельные представления могут быть расширены аналогично способам на основе облака точек, поэтому центр воксельной сетки может быть смещен не более чем на 1 м вдоль каждой оси.
[0073] Вывод. Во время стадии вывода выходные данные могут быть отфильтрованы с помощью алгоритма Rotated NMS, который применяется к проекциям объектов на плоскость земли.
[0074] Другие реализации и подробности. Раскрытый способ может выполняться/реализовываться на любом пользовательском/электронном устройстве (например, смартфоне, планшете, навигационной системе, бортовом оборудовании, ноутбуке, умных часах и т.д.). Такие пользовательские/электронные устройства или любые другие вычислительные устройства могут быть снабжены вычислительными средствами, включая, без ограничения, процессор, нейронный процессор (NPU), графический процессор (GPU). Без ограничения перечисленным, вычислительные средства могут быть реализованы как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA) или система на кристалле (SoC). Такие пользовательские устройства или любые другие пользовательские вычислительные устройства могут также содержать память (RAM, ROM), (сенсорный) экран, средства ввода-вывода, камеру, средства связи и так далее.
[0075] Предлагаемое техническое решение также может быть реализовано на считываемом компьютером носителе, на котором хранятся исполняемые компьютером инструкции, которые при выполнении средствами обработки или вычислений устройства побуждают устройство выполнять любой этап (этапы) предложенного технического решения. Любые типы данных обрабатываются интеллектуальными системами, обученными с использованием описанных выше способов. Фаза обучения может выполняться в режиме онлайн или офлайн. Обученные нейронные сети (в форме весов и других параметров/исполняемых компьютером инструкций) могут быть переданы на пользовательское устройство и сохранены на нем для использования во время стадии вывода (в процессе использования).
[0076] По меньшей мере одна из множества частей/модулей может быть реализована с помощью модели искусственного интеллекта (AI). Функция, связанная с AI, может выполняться через энергонезависимую память, энергозависимую память и процессор. Процессор может включать в себя один или несколько процессоров. При этом один или несколько процессоров могут быть процессором общего назначения, например центральным процессором (ЦП), процессором приложений (AP) или т.п., блоком обработки только графики, таким как графический процессор (GPU), блоком обработки изображений (VPU) и/или специализированный процессором AI, таким как нейронный процессор (NPU).
[0077] Один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным рабочим правилом или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Заранее определенное рабочее правило или модель искусственного интеллекта предоставляется посредством обучения или тренировки. В данном контексте предоставление посредством обучения означает, что путем применения обучающего алгоритма к множеству обучающих данных создается заранее определенное рабочее правило или модель AI с желаемой характеристикой. Обучение может выполняться на том же устройстве, на котором выполняется AI согласно варианту осуществления, и/или может быть реализовано через отдельный сервер/систему.
[0078] Модель AI может содержать множество слоев нейронной сети. Каждый слой имеет множество значений весов и выполняет операцию слоя посредством вычисления предыдущего слоя и операции на множестве весов. Примеры нейронных сетей включают, без ограничения перечисленным, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
[0079] Алгоритм обучения представляет собой способ обучения заранее определенного целевого устройства с использованием множества обучающих данных, чтобы побуждать, разрешать или давать команду целевому устройству выполнять определение или прогнозирование. Примеры алгоритмов обучения включают, без ограничения, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
[0080] Предложенное изобретение может быть реализовано в системах мобильных роботов/навигации транспортных средств или в качестве мобильных приложений, осуществляющих понимание сцены и распознавание объектов. Раскрытое изобретение предназначено для анализа сцены и распознавания объектов. Полученные результаты могут быть использованы в широком спектре задач, где решения принимаются на основе сцены и ее объектов. Например, предложенный способ, при его исполнении в виде программного обеспечения, может снабжать системы мобильных роботизированных устройств и системы навигации транспортных средств пространственной информацией для планирования траектории, захвата и манипулирования объектами. Кроме того, в мобильном приложении предложенное решение можно использовать для автоматической генерации подсказок о сцене для пользователя.
[0081] Раскрытое изобретение предназначено для обнаружения и распознавания трехмерных объектов и оценки их пространственного положения. Формулировка задачи следует классической постановке задачи обнаружения трехмерных объектов, сформулированной сообществом ученых, занимающихся компьютерным зрением.
[0082] Предлагаемое техническое решение может быть реализовано в виде программного решения в мобильных роботизированных устройствах/системах навигации транспортных средств или запущено на смартфонах в составе мобильного приложения. Для реализации предлагаемого технического решения рассматриваемое устройство должно соответствовать техническим требованиям, а именно, иметь достаточный объем оперативной памяти и вычислительных ресурсов. Требуемый объем ресурсов зависит от функции устройства, параметров камеры и требований к производительности.
[0083] Следует понимать, что не все технические эффекты, упомянутые в данном документе, необходимо использовать в любом и каждом варианте осуществления настоящей технологии. Например, варианты осуществления могут быть реализованы без использования пользователем некоторых из этих технических эффектов, в то время как другие варианты осуществления могут быть реализованы при использовании пользователем других технических эффектов или вообще без них.
[0084] Для специалистов в данной области техники могут быть очевидны модификации и усовершенствования описанных выше реализаций настоящей технологии. Приведенное выше описание предназначено скорее для примера, а не для ограничения. Следовательно, объем настоящей технологии ограничен исключительно объемом прилагаемой формулы изобретения.
[0085] Хотя раскрытые выше реализации были описаны и показаны со ссылками на конкретные этапы, выполняемые в определенном порядке, следует понимать, что эти этапы могут быть объединены, разделены на части или выполняться в другом порядке, не выходя за рамки настоящего изобретения. Соответственно, порядок и группировка этапов не являются ограничением настоящей технологии. Использование формы единственного числа по отношению к любому элементу, раскрытому в этой заявке, не исключает того, что в фактической реализации может быть два или более таких элемента и наоборот.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| Способ управления бортовыми системами беспилотных транспортных средств при помощи нейронных сетей на основе архитектуры трансформеров | 2024 |
|
RU2841111C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| СПОСОБ РЕКОНСТРУКЦИИ 3D-МОДЕЛИ ОБЪЕКТА | 2020 |
|
RU2779271C2 |
| СПОСОБ ОБУЧЕНИЯ СВЕРТОЧНОЙ НЕЙРОННОЙ СЕТИ ДЛЯ ВОССТАНОВЛЕНИЯ ИЗОБРАЖЕНИЯ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ КАРТЫ ГЛУБИНЫ ИЗОБРАЖЕНИЯ (ВАРИАНТЫ) | 2018 |
|
RU2698402C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| СПОСОБ ОЦЕНКИ ГЛУБИНЫ СЦЕНЫ ПО ИЗОБРАЖЕНИЮ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2761768C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
Настоящее изобретение относится к технологиям компьютерного зрения и более конкретно к способам и электронным устройствам для обнаружения трехмерных объектов или для понимания сцены, реализуемым по меньшей мере частично с помощью нейронных сетей. Технический результат заключается в повышении точности обнаружения трехмерных объектов в монокулярных изображениях. Технический результат достигается за счет получения монокулярных изображений; извлечения двумерных карт признаков из монокулярных изображений путем пропускания одного или нескольких монокулярных изображений через часть для извлечения двумерных признаков; создания усредненного трехмерного воксельного объема на основе двумерных карт признаков; извлечения двумерного представления трехмерных карт признаков из усредненного трехмерного воксельного объема путем пропускания усредненного трехмерного воксельного объема через кодировщик части для извлечения трехмерных признаков и выполнения обнаружения трехмерных объектов как обнаружение двумерных объектов в плоскости вида "с высоты птичьего полета" (BEV), причем обнаружение двумерных объектов в плоскости BEV реализуют путем пропускания двумерного представления трехмерных карт признаков через часть для обнаружения объектов в уличных сценах, содержащую параллельные двумерные сверточные слои для классификации и определения местоположения. 5 н. и 12 з.п. ф-лы, 4 ил.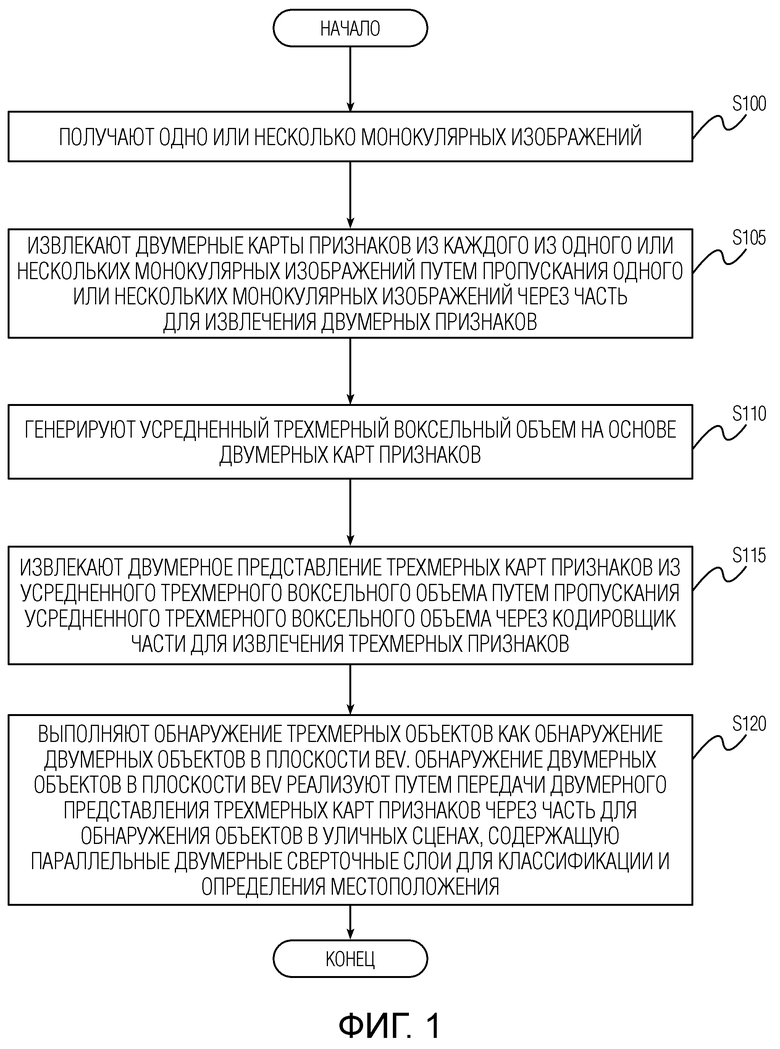
1. Способ обнаружения трехмерных объектов с использованием нейронной сети для обнаружения объектов, содержащей часть для извлечения двумерных признаков, часть для извлечения трехмерных признаков, часть для обнаружения объектов в уличных сценах, которые предобучены сквозным способом на основе только захваченных в известных положениях монокулярных изображений, включающий в себя этапы, на которых:
получают (S100) одно или несколько монокулярных изображений;
извлекают (S105) двумерные карты признаков из каждого из одного или нескольких монокулярных изображений путем пропускания одного или нескольких монокулярных изображений через часть для извлечения двумерных признаков;
создают (S110) усредненный трехмерный воксельный объем на основе двумерных карт признаков;
извлекают (S115) двумерное представление трехмерных карт признаков из усредненного трехмерного воксельного объема путем пропускания усредненного трехмерного воксельного объема через кодировщик части для извлечения трехмерных признаков, и
выполняют (S120) обнаружение трехмерных объектов как обнаружение двумерных объектов в плоскости вида "с высоты птичьего полета" (BEV), причем обнаружение двумерных объектов в плоскости BEV реализуют путем пропускания двумерного представления трехмерных карт признаков через часть для обнаружения объектов в уличных сценах, содержащую параллельные двумерные сверточные слои для классификации и определения местоположения.
2. Способ по п.1, отличающийся тем, что данный способ пригоден для применения в уличных сценах и выполняется электронным устройством транспортного средства, снабженным по меньшей мере одной камерой для обнаружения нулевого или большего количества трехмерных объектов в окружающей области данного транспортного средства.
3. Способ по п.1, в котором дополнительно для каждого изображения из одного или нескольких монокулярных изображений агрегируют признаки в двумерных картах признаков, соответствующих изображению, через сеть признаковой пирамиды (FPN).
4. Способ по п.1, в котором на этапе создания (S110) усредненного трехмерного воксельного объема дополнительно выполняют следующие этапы:
для каждого изображения из одного или нескольких монокулярных изображений создают трехмерный воксельный объем, соответствующий изображению, используя модель камеры с точечной диафрагмой, определяющую соответствие между двумерными координатами в соответствующих двумерных картах признаков и трехмерными координатами в трехмерном воксельном объеме;
для каждого трехмерного воксельного объема определяют двоичную маску, соответствующую трехмерному воксельному объему, причем двоичная маска указывает для каждого вокселя в трехмерном воксельном объеме, находится ли данный воксель внутри усеченной пирамиды камеры соответствующего изображения;
для каждого трехмерного воксельного объема, соответствующего двоичной маске, и соответствующих двумерных карт признаков проецируют признаки двумерных карт признаков для каждого внутреннего вокселя в трехмерный воксельный объем, как определено двоичной маской;
создают агрегированную двоичную маску путем агрегирования двоичных масок, определенных для трехмерных воксельных объемов всех из одного или нескольких монокулярных изображений; и
создают усредненный трехмерный воксельный объем путем усреднения признаков, спроецированных в трехмерные воксельные объемы всех из одного или нескольких монокулярных изображений для каждого внутреннего вокселя в усредненном трехмерном воксельном объеме, как определено агрегированной двоичной маской.
5. Способ по п.1, в котором нейронную сеть обнаружения объектов обучают на одном или нескольких обучающих наборах данных с уличными сценами путем оптимизации функции общих потерь для уличных сцен на основе, по меньшей мере, потери местоположения, фокальной потери для классификации и перекрестной энтропийной потери для направления.
6. Способ обнаружения трехмерных объектов с использованием нейронной сети для обнаружения объектов, содержащей часть для извлечения двумерных признаков, часть для извлечения трехмерных признаков, часть для обнаружения объектов в сценах помещений, которые предобучены сквозным способом на основе только захваченных в известных положениях монокулярных изображений, содержащий этапы, на которых:
получают (S200) одно или несколько монокулярных изображений;
извлекают (S205) двумерные карты признаков из каждого из одного или нескольких монокулярных изображений путем пропускания одного или нескольких монокулярных изображений через часть для извлечения двумерных признаков;
создают (S210) усредненный трехмерный воксельный объем на основе двумерных карт признаков;
извлекают (S215) уточненные карты трехмерных объектов из усредненного трехмерного воксельного объема путем пропускания усредненного трехмерного воксельного объема через часть для извлечения трехмерных объектов, и
выполняют (S220) обнаружение трехмерных объектов путем пропускания уточненных трехмерных карт признаков через часть для обнаружения объектов в сценах помещений, использующую плотное воксельное представление промежуточных признаков и содержащую трехмерные сверточные слои для классификации, центрированности и определения местоположения.
7. Способ по п.6, отличающийся тем, что данный способ пригоден для применения в сценах помещений и выполняется электронным устройством, снабженным по меньшей мере одной камерой для обнаружения нулевого или большего количества трехмерных объектов в окружающей области данного электронного устройства, причем электронное устройство представляет собой одно из смартфона, планшета, умных очков, мобильного робота.
8. Способ по п.6, в котором дополнительно для каждого изображения из одного или нескольких монокулярных изображений признаков агрегируют признаки в двумерных картах признаков, соответствующих изображению, через сеть признаковой пирамиды (FPN).
9. Способ по п.6, в котором на этапе создания (S210) усредненного трехмерного воксельного объема дополнительно выполняют следующие этапы:
для каждого изображения из одного или нескольких монокулярных изображений создают трехмерный воксельный объем, соответствующий изображению, используя модель камеры с точечной диафрагмой, определяющую соответствие между двумерными координатами в соответствующих двумерных картах признаков и трехмерными координатами в трехмерном воксельном объеме;
для каждого трехмерного воксельного объема определяют двоичную маску, соответствующую трехмерному воксельному объему, причем двоичная маска указывает для каждого вокселя в трехмерном воксельном объеме, находится ли данный воксель внутри усеченной пирамиды камеры соответствующего изображения;
для каждого трехмерного воксельного объема, соответствующего двоичной маске, и соответствующих двумерных карт признаков проецируют признаки двумерных карт признаков для каждого внутреннего вокселя в трехмерный воксельный объем, как определено двоичной маской;
создают агрегированную двоичную маску путем агрегирования двоичных масок, определенных для трехмерных воксельных объемов всех из одного или нескольких монокулярных изображений; и
создают усредненный трехмерный воксельный объем путем усреднения признаков, спроецированных в трехмерные воксельные объемы всех из одного или нескольких монокулярных изображений для каждого внутреннего вокселя в усредненном трехмерном воксельном объеме, как определено агрегированной двоичной маской.
10. Способ по п.6, в котором нейронную сеть обнаружения объектов обучают на одном или нескольких обучающих наборах данных со сценами помещений путем оптимизации функции общих потерь для сцен помещений на основе, по меньшей мере, фокальной потери для классификации, перекрестной энтропийной потери для центрированности и потери метрики степени пересечения между двумя ограничивающими рамками (IoU) для определения местоположения.
11. Способ по п.6, в котором нейронная сеть обнаружения объектов дополнительно содержит часть для понимания сцены, которая предобучена сквозным способом, причем способ дополнительно содержит этапы, на которых:
выполняют глобальный средний пулинг извлеченных двумерных карт признаков для получения тензора, представляющего извлеченные двумерные карты признаков, и
оценивают конфигурацию сцены путем пропускания тензора через часть для понимания сцены, сконфигурированную для совместной оценки поворота камеры и трехмерной конфигурации сцены;
часть для понимания сцены содержит две параллельные ветви: два полносвязных слоя, которые выводят трехмерную конфигурацию сцены, и два других полносвязных слоя, которые оценивают поворот камеры.
12. Способ по п.11, отличающийся тем, что данный способ пригоден для применения в сценах помещений и выполняется электронным устройством, снабженным по меньшей мере одной камерой для понимания сцены в окружающей области электронного устройства, причем электронное устройство является одним из смартфона, планшета, умных очков, мобильного робота.
13. Способ по п.11, в котором часть для понимания сцены нейронной сети обнаружения объектов обучают на одном или нескольких обучающих наборах данных со сценами помещений путем оптимизации общей функции потери понимания сцены на основе, по меньшей мере, потери конфигурации и потери оценки поворота камеры.
14. Электронное устройство, установленное на транспортном средстве, снабженном по меньшей мере одной камерой, отличающееся тем, что данное электронное устройство содержит процессор, сконфигурированный для реализации способа по любому из пп.1-5 для обнаружения нулевого или большего количества трехмерных объектов в окружающей области транспортного средства.
15. Электронное устройство, снабженное по меньшей мере одной камерой, отличающееся тем, что данное электронное устройство содержит процессор, сконфигурированный для реализации способа по любому из пп.6-13 для обнаружения нулевого или большего количества трехмерных объектов в окружающей области электронного устройства.
16. Электронное устройство по п.15, в котором электронное устройство представляет собой смартфон, планшет, умные очки или мобильный робот.
17. Считываемый компьютером носитель, хранящий выполняемые компьютером инструкции, которые при их исполнении процессором побуждают процессор выполнять способ по любому из пп. 1-5 или 6-13.
| US 9424461 B1, 23.08.2016 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 10970518 B1, 06.04.2021 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Способ распознавания объектов на изображении | 2018 |
|
RU2693267C1 |

