Область техники, к которой относится изобретение
Настоящее изобретение относится, в общем, к области компьютерного зрения и компьютерной графики для создания изображения всего тела человека в разных позах и при разных положениях камеры и, в частности, к системе и способу синтеза двумерного изображения человека.
Описание предшествующего уровня техники
Одной из основных задач компьютерного зрения и компьютерной графики является захват и визуализация тела человека во всей его сложности в разных позах и условиях получения изображения. В последнее время возрос интерес к глубоким сверточным сетям (ConvNets) как альтернативе классических графических конвейеров. Появилась возможность реалистичной нейронной визуализации фрагментов тела, например, лица [48, 34, 29], глаз [18], рук [37] и т.д. В недавних работах была продемонстрирована способность таких сетей к созданию видов человека с изменяющейся позой, но при фиксированном положении камеры и в прилегающей к телу одежде [1, 9, 33, 53].
Настоящее изобретение, находящееся на пересечении нескольких областей исследований, тесно связано с очень большим количеством предыдущих работ, и некоторые из этих связей обсуждаются ниже.
Геометрическое моделирование тела человека. Создание аватаров всего тела из данных изображения давно стало одной из главных тем исследований в области компьютерного зрения. Традиционно аватар задается трехмерной геометрической сеткой определенной нейтральной позы, текстурой и механизмом скиннинга, которые трансформируют вершины сетки в соответствии с изменениями позы. Большая группа работ посвящена моделированию тела из 3D сканеров [40], зарегистрированных многовидовых последовательностей [42], а также последовательностей глубины и RGB-D [5, 55]. С другой стороны, существуют способы, которые подгоняют скинированные параметрические модели тела к одиночным изображениям [45, 4, 23, 6, 27, 39]. И наконец, начались исследования по созданию аватаров всего тела из монокулярных видео [3, 2]. Как и в последней группе работ, в настоящем изобретении аватар создается из видео или набора монокулярных видео в открытом доступе. Классический подход (компьютерная графика) к моделированию аватаров человека требует явного физически правдоподобного моделирования кожи, волос и склеры человека, отражения поверхности одежды, а также явного физически правдоподобного моделирования движения при изменениях позы. Несмотря на значительный прогресс в моделировании отражения [56, 13, 30, 58] и улучшение скиннинга и моделирования динамических поверхностей [46, 17, 35], метод компьютерной графики все еще требует значительных "ручных" усилий дизайнеров для достижения высокой реалистичности и для прохождения эффекта так называемой "зловещей долины" [36], особенно, если требуется визуализация аватаров в реальном времени.
Нейронное моделирование тела человека. Синтез изображений с помощью глубоких сверточных нейронных сетей является динамично развивающейся областью исследований [20, 15], и в последнее время много усилий направлено на синтез реалистичных лиц людей [28, 11, 47]. В отличие от традиционных представлений компьютерной графики глубокие ConvNets моделируют данные путем подгонки избыточного числа изучаемых весов к обучающим данным. Такие ConvNets избегают явного моделирования геометрии поверхности, отражения поверхности или движения поверхности при изменениях позы и поэтому не страдают от недостатка реалистичности соответствующих компонентов. С другой стороны, отсутствие укоренившихся геометрических или фотометрических моделей в этом методе означает, что обобщение применительно к новым позам и, в частности, новым точкам обзора камеры может быть проблематичным. За последние несколько лет значительный прогресс достигнут в области нейронного моделирования персонализированных моделей "говорящих голов" [48, 29, 34], волос [54], рук [37]. В течение нескольких последних месяцев несколько групп представили результаты нейронного моделирования всего тела [1, 9, 53, 33]. Хотя представленные результаты достаточно впечатляющие, они все еще ограничивают обучение, и тестовое изображение соответствует одному и тому же полю зрения камеры, что по опыту авторов значительно упрощает задачу по сравнению с моделированием внешнего вида тела с произвольной точки обзора. Цель настоящего изобретения состоит в том, чтобы расширить подход к нейронному моделированию тела для решения последней, более сложной задачи.
Модели с нейронным деформированием. В ряде недавних работ фотографию человека деформируют в новое фотореалистичное изображение с измененным направлением взгляда [18], измененным выражением лица/позой [7, 50, 57, 43] или измененной позой тела [50, 44, 38], причем поле деформирования оценивают с помощью глубокой сверточной сети (в то время как исходная фотография служит особым видом текстуры). Однако эти методы имеют ограниченную реалистичность и/или количество изменений, которые они могут смоделировать, поскольку они берут за основу одну фотографию данного человека в качестве ввода. В настоящем изобретении также текстура отделяется от геометрии поверхности/моделирования движения, но осуществляется обучение по видео, что позволяет решить более сложную задачу (многовидовую настройку для всего тела) и достичь более высокой реалистичности.
DensePose и связанные с нею методы. В основу предложенной системы положена параметризация поверхности тела (UV параметризация), аналогичной той, которая используется в классическом графическом представлении. Часть предложенной системы выполняет преобразование из позы тела в параметры поверхности (UV координаты) пикселей изображения. Тем самым настоящее изобретение приближается к методу DensePose [21] и более ранним работам [49, 22], которые предсказывают UV координаты пикселей изображения по входной фотографии. Кроме того, в настоящем изобретении используются результаты DensePose для предварительного обучения.
Основанное на текстуре представление многовидовых данных. Предложенная система также связана с методами, в которых текстуры извлекаются из коллекций многовидовых изображений [31, 19] или коллекций многовидовых видео [52] или единственного видео [41]. Предложенный метод также связан с системами сжатия видео и рендеринга с нефиксированной точкой обзора, например [52, 8, 12, 16]. В отличие от этих работ, предложенный метод ограничен сценами, содержащими одного человека. В то же время, предложенный метод направлен на обобщение не только новых полей зрения камеры, но также и новых поз пользователя, которые отсутствуют в обучающих видео. В этой группе наиболее близкой к изобретению является работа [59], так как в ней деформируют отдельные кадры набора многовидовых видео в соответствии с целевой позой для создания новых последовательностей. Однако они способны обрабатывать только те позы, которые имеют близкое совпадение в обучающем наборе, что является сильным ограничением, учитывая комбинаторный характер пространства конфигурации поз человека.
ЛИТЕРАТУРА:
[1] K. Aberman, M. Shi, J. Liao, D. Lischinski, B. Chen, and D. Cohen-Or. Deep video-based performance cloning. arXiv preprint arXiv:1808.06847, 2018.
[2] T. Alldieck, M. Magnor, W. Xu, C. Theobalt, and G. Pons-Moll. Detailed human avatars from monocular video. In 2018 International Conference on 3D Vision (3DV), pages 98-109. IEEE, 2018.
[3] T. Alldieck, M. Magnor, W. Xu, C. Theobalt, and G. Pons-Moll. Video based reconstruction of 3d people models. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[4] A. O. B˘alan and M. J. Black. The naked truth: Estimating body shape under clothing. In European Conference on Computer Vision, pages 15-29. Springer, 2008.
[5] F. Bogo, M. J. Black, M. Loper, and J. Romero. Detailed full-body reconstructions of moving people from monocular rgb-d sequences. In Proceedings of the IEEE International Conference on Computer Vision, pages 2300-2308, 2015.
[6] F. Bogo, A. Kanazawa, C. Lassner, P. Gehler, J. Romero, and M. J. Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In European Conference on Computer Vision, pages 561-578. Springer, 2016.
[7] J. Cao, Y. Hu, H. Zhang, R. He, and Z. Sun. Learning a high fidelity pose invariant model for high-resolution face frontalization. arXiv preprint arXiv:1806.08472, 2018.
[8] D. Casas, M. Volino, J. Collomosse, and A. Hilton. 4d video textures for interactive character appearance. In Computer Graphics Forum, volume 33, pages 371-380. Wiley Online Library, 2014.
[9] C. Chan, S. Ginosar, T. Zhou, and A. A. Efros. Everybody dance now. arXiv preprint arXiv:1808.07371, 2018.
[10] Q. Chen and V. Koltun. Photographic image synthesis with cascaded refinement networks. In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 1520-1529, 2017.
[11] Y. Choi, M. Choi, M. Kim, J.-W. Ha, S. Kim, and J. Choo. Stargan: Unified generative adversarial networks for multidomain image-to-image translation. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[12] A. Collet, M. Chuang, P. Sweeney, D. Gillett, D. Evseev, D. Calabrese, H. Hoppe, A. Kirk, and S. Sullivan. Highquality streamable free-viewpoint video. ACM Transactions on Graphics (TOG), 34(4):69, 2015.
[13] C. Donner, T. Weyrich, E. d'Eon, R. Ramamoorthi, and S. Rusinkiewicz. A layered, heterogeneous reflectance model for acquiring and rendering human skin. In ACM Transactions on Graphics (TOG), volume 27, page 140. ACM, 2008.
[14] A. Dosovitskiy and T. Brox. Generating images with perceptual similarity metrics based on deep networks. In Proc. NIPS, pages 658-666, 2016.
[15] A. Dosovitskiy, J. Tobias Springenberg, and T. Brox. Learning to generate chairs with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1538-1546, 2015.
[16] M. Dou, P. Davidson, S. R. Fanello, S. Khamis, A. Kowdle, C. Rhemann, V. Tankovich, and S. Izadi. Motion2fusion: real-time volumetric performance capture. ACM Transactions on Graphics (TOG), 36(6):246, 2017.
[17] A. Feng, D. Casas, and A. Shapiro. Avatar reshaping and automatic rigging using a deformable model. In Proceedings of the 8th ACM SIGGRAPH Conference on Motion in Games, pages 57-64. ACM, 2015.
[18] Y. Ganin, D. Kononenko, D. Sungatullina, and V. Lempitsky. Deepwarp: Photorealistic image resynthesis for gaze manipulation. In European Conference on Computer Vision, pages 311-326. Springer, 2016.
[19] B. Goldl¨ucke and D. Cremers. Superresolution texture maps for multiview reconstruction. In IEEE 12th International Conference on Computer Vision, ICCV 2009, Kyoto, Japan, September 27 - October 4, 2009, pages 1677-1684, 2009.
[20] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D.Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Gen-erative adversarial nets. In Advances in neural information processing systems, pages 2672-2680, 2014.
[21] R.A. G¨uler, N. Neverova, and I. Kokkinos. DensePose: Dense human pose estimation in the wild. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[22] R.A. G¨uler, G. Trigeorgis, E. Antonakos, P. Snape, S. Zafeiriou, and I. Kokkinos. DenseReg: Fully convolutional dense shape regression in-the-wild. In CVPR, volume 2, page 5, 2017.3
[23] N. Hasler, H. Ackermann, B. Rosenhahn, T. Thormahlen, and H.-P. Seidel. Multilinear pose and body shape estimation of dressed subjects from image sets. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, pages 1823-1830. IEEE, 2010.
[24] P. Isola, J. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In Proc. CVPR, pages 5967-5976, 2017.
[25] M. Jaderberg, K. Simonyan, A. Zisserman, and K. Kavukcuoglu. Spatial transformer networks. In Proc. NIPS, pages 2017-2025, 2015.
[26] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Proc. ECCV, pages 694-711, 2016.
[27] A. Kanazawa, M.J. Black, D.W. Jacobs, and J. Malik. End-to-end recovery of human shape and pose. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[28] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. In International Conference on Learning Representations, 2018.
[29] H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Nieβner, P. P'erez, C. Richardt, M. Zollh¨ofer, and C. Theobalt. Deep video portraits. arXiv preprint arXiv:1805.11714, 2018.
[30] O. Klehm, F. Rousselle, M. Papas, D. Bradley, C. Hery, B. Bickel, W. Jarosz, and T. Beeler. Recent advances in facial appearance capture. In Computer Graphics Forum, volume 34, pages 709-733. Wiley Online Library, 2015.
[31] V.S. Lempitsky and D.V. Ivanov. Seamless mosaicing of image-based texture maps. In 2007 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2007), 18-23 June 2007, Minneapolis, Minnesota, USA, 2007.
[32] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll'ar, and C.L. Zitnick. Microsoft COCO: Common objects in context. In European conference on computer vision, pages 740-755. Springer, 2014.
[33] L. Liu,W. Xu, M. Zollhoefer, H. Kim, F. Bernard, M. Habermann, W. Wang, and C. Theobalt. Neural animation and reenactment of human actor videos. arXiv preprint arXiv:1809.03658, 2018.
[34] S. Lombardi, J. Saragih, T. Simon, and Y. Sheikh. Deep appearance models for face rendering. ACM Transactions on Graphics (TOG), 37(4):68, 2018.
[35] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. Smpl: A skinned multi-person linear model. ACM Transactions on Graphics (TOG), 34(6):248, 2015.
[36] M. Mori. The uncanny valley. Energy, 7(4):33-35, 1970.
[37] F. Mueller, F. Bernard, O. Sotnychenko, D. Mehta, S. Sridhar, D. Casas, and C. Theobalt. Ganerated hands for realtime 3d hand tracking from monocular rgb. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[38] N. Neverova, R.A. G¨uler, and I. Kokkinos. Dense pose transfer. In the European Conference on Computer Vision (ECCV), September 2018.
[39] G. Pavlakos, L. Zhu, X. Zhou, and K. Daniilidis. Learning to estimate 3d human pose and shape from a single color image. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[40] G. Pons-Moll, J. Romero, N. Mahmood, and M.J. Black. Dyna: A model of dynamic human shape in motion. ACM Transactions on Graphics (TOG), 34(4):120, 2015.
[41] A. Rav-Acha, P. Kohli, C. Rother, and A.W. Fitzgibbon. Unwrap mosaics: a new representation for video editing. ACM Trans. Graph., 27(3):17:1-17:11, 2008. 3
[42] N. Robertini, D. Casas, E. De Aguiar, and C. Theobalt. Multi-view performance capture of surface details. International Journal of Computer Vision, 124(1):96-113, 2017.
[43] Z. Shu, M. Sahasrabudhe, R. Alp Guler, D. Samaras, N. Paragios, and I. Kokkinos. Deforming autoencoders: Unsupervised disentangling of shape and appearance. In the European Conference on Computer Vision (ECCV), September 2018.
[44] A. Siarohin, E. Sangineto, S. Lathuilire, and N. Sebe. Deformable gans for pose-based human image generation. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[45] J. Starck and A. Hilton. Model-based multiple view reconstruction of people. In IEEE International Conference on Computer Vision (ICCV), pages 915-922, 2003.
[46] I. Stavness, C.A. S'anchez, J. Lloyd, A. Ho, J.Wang, S. Fels, and D. Huang. Unified skinning of rigid and deformable models for anatomical simulations. In SIGGRAPH Asia 2014 Technical Briefs, page 9. ACM, 2014.
[47] D. Sungatullina, E. Zakharov, D. Ulyanov, and V. Lempitsky. Image manipulation with perceptual discriminators. In the European Conference on Computer Vision (ECCV), September 2018.
[48] S. Suwajanakorn, S.M. Seitz, and I. Kemelmacher-Shlizerman. Synthesizing Obama: learning lip sync from audio. ACM Transactions on Graphics (TOG), 36(4):95, 2017.
[49] J. Taylor, J. Shotton, T. Sharp, and A. Fitzgibbon. The Vitruvian manifold: Inferring dense correspondences for one shot human pose estimation. In Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, pages 103-110. IEEE, 2012. 3
[50] S. Tulyakov, M.-Y. Liu, X. Yang, and J. Kautz. Mocogan: Decomposing motion and content for video generation. In the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
[51] D. Ulyanov, V. Lebedev, A. Vedaldi, and V.S. Lempitsky. Texture networks: Feed-forward synthesis of textures and stylized images. In Proc. ICML, pages 1349-1357, 2016.
[52] M. Volino, D. Casas, J.P. Collomosse, and A. Hilton. Optimal representation of multi-view video. In Proc. BMVC, 2014.
[53] T.-C. Wang, M.-Y. Liu, J.-Y. Zhu, G. Liu, A. Tao, J. Kautz, and B. Catanzaro. Video-to-video synthesis. arXiv preprint arXiv:1808.06601, 2018.
[54] L. Wei, L. Hu, V. Kim, E. Yumer, and H. Li. Real-time hair rendering using sequential adversarial networks. In the European Conference on Computer Vision (ECCV), September 2018.
[55] A. Weiss, D. Hirshberg, and M. J. Black. Home 3d body scans from noisy image and range data. In Computer Vision (ICCV), 2011 IEEE International Conference on, pages 1951-1958. IEEE, 2011.
[56] T. Weyrich, W. Matusik, H. Pfister, B. Bickel, C. Donner, C. Tu, J. McAndless, J. Lee, A. Ngan, H.W. Jensen, et al. Analysis of human faces using a measurement-based skin reflectance model. In ACM Transactions on Graphics (TOG), volume 25, pages 1013-1024. ACM, 2006.
[57] O. Wiles, A. Sophia Koepke, and A. Zisserman. X2face: A network for controlling face generation using images, audio, and pose codes. In the European Conference on Computer Vision (ECCV), September 2018.
[58] E. Wood, T. Baltrusaitis, X. Zhang, Y. Sugano, P. Robinson, and A. Bulling. Rendering of eyes for eye-shape registration and gaze estimation. In Proceedings of the IEEE International Conference on Computer Vision, pages 3756-3764, 2015.
[59] F. Xu, Y. Liu, C. Stoll, J. Tompkin, G. Bharaj, Q. Dai, H.-P. Seidel, J. Kautz, and C. Theobalt. Video-based characters: creating new human performances from a multi-view video database. ACM Transactions on Graphics (TOG), 30(4):32, 2011.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Целью настоящего изобретения является создание системы и способа для синтеза двумерного изображения человека.
Настоящее изобретение позволяет обеспечить следующие преимущества:
- лучшее обобщение по сравнению с системами, использующими прямые сверточные преобразования между положениями суставов и значениями пикселей;
- высоко реалистичные визуализации;
- повышенную реалистичность создаваемых изображений;
- более быстрое обучение по сравнению с методом прямого преобразования.
Согласно одному аспекту настоящего изобретения предложен способ синтеза двумерного изображения человека, заключающийся в том, что: принимают (S101) трехмерные координаты положений суставов тела человека, заданные в системе координат камеры, причем трехмерные координаты положений суставов тела задают позу человека и точку обзора данного двумерного изображения; предсказывают (S102), используя обученный предиктор машинного обучения, стек карт назначений частей тела и стек карт координат частей тела на основе трехмерных координат положений суставов тела, причем стек карт координат частей тела задает координаты текстуры пикселей частей тела человека, стек карт назначений частей тела задает веса, причем каждый вес указывает вероятность того, что конкретный пиксель принадлежит конкретной части тела человека; извлекают (S103) из памяти ранее инициализированный стек карт текстур для частей тела человека, причем стек карт текстур содержит значения пикселей частей тела данного человека; восстанавливают (S104) двумерное изображение человека как взвешенную комбинацию значений пикселей, используя стек карт назначений частей тела, стек карт координат частей тела и стек карт текстур.
В дополнительном аспекте при получении обученного предиктора машинного обучения и ранее инициализированного стека карт текстур для частей тела человека: принимают (S201) множество изображений человека в разных позах и с разных точек обзора; получают (S202) трехмерные координаты положений суставов тела человека, заданные в системе координат камеры для каждого изображения из принятого множества изображений; инициализируют (S203) предиктор машинного обучения на основании трехмерных координат положений суставов тела и принятого множества изображений для получения параметров для предсказания стека карт назначений частей тела и стека карт координат частей тела; инициализируют (S204) стек карт текстур на основании трехмерных координат положений суставов тела и принятого множества изображений и сохраняют стек карт текстур в памяти; предсказывают (S205), используя текущее состояние предиктора машинного обучения, стек карт назначений частей тела и стек карт координат частей тела на основании трехмерных координат положений суставов тела; восстанавливают (S206) двумерное изображение человека как взвешенную комбинацию значений пикселей, используя стек карт назначений частей тела, стек карт координат частей тела и стек карт текстур, хранящийся в памяти; сравнивают (S207) восстановленное двумерное изображения с соответствующим истинным двумерным изображением из принятого множества изображений, чтобы выявить ошибку восстановления двумерного изображения; обновляют (S208) параметры обученного предиктора машинного обучения и значения пикселей в стеке карт текстур на основании результата сравнения; и повторяют этапы S205-S208 для восстановления разных двумерных изображений человека до тех пор, пока не будет удовлетворено заданное условие, представляющее собой по меньшей мере одно из выполнения заданного количества повторений, истечения заданного времени или отсутствия уменьшения ошибки восстановления двумерного изображения человека.
В другом дополнительном аспекте предиктор машинного обучения представляет собой одну из глубокой нейронной сети, глубокой сверточной нейронной сети, глубокой полносверточной нейронной сети, глубокой нейронной сети, обученной с функцией потерь восприятия, глубокой нейронной сети, обученной на генеративно-состязательной основе.
В еще одном дополнительном аспекте способ дополнительно содержит этапы, на которых: генерируют стек карт растрированных сегментов на основе трехмерных координат положений суставов тела, причем каждая карта из стека карт растрированных сегментов содержит растрированный сегмент, представляющий часть тела человека, при этом предсказание стека карт назначений частей тела и стека карт координат частей тела основано на стеке карт растрированных сегментов.
В другом дополнительном аспекте обученный предиктор машинного обучения переобучают для другого человека на основании множества изображений другого человека.
Согласно другому аспекту настоящего изобретения предложена система для синтеза двумерного изображения человека, содержащая процессор и память, содержащую команды, побуждающие процессор выполнять способ синтеза двумерного изображения человека.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Представленные выше и другие аспекты, существенные признаки и преимущества настоящего изобретения будут более понятны из следующего подробного описания в совокупности с прилагаемыми чертежами, на которых:
фиг. 1 изображает результаты текстурированного нейронного аватара для точек обзора, невидимых во время обучения;
фиг. 2 - общий вид системы текстурированного нейронного аватара;
фиг. 3 - блок-схема, иллюстрирующая один вариант осуществления способа синтеза двумерного изображения человека;
фиг. 4 - блок-схема, иллюстрирующая процесс получения обученного предиктора машинного обучения и стека карт текстур для частей тела человека.
В следующем описании используются одни и те же ссылочные обозначения для одинаковых элементов, изображенных на разных чертежах, если не указано иное, и их описание не дублируется.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Дальнейшее описание со ссылками на прилагаемые чертежи представлено, чтобы обеспечить исчерпывающее понимание разных вариантов осуществления настоящего изобретения, охарактеризованного формулой изобретения и ее эквивалентами. Оно включает в себя различные конкретные детали, способствующие этому пониманию, но являющиеся всего лишь примерными. Соответственно, специалистам будет понятно, что возможны различные изменения и модификации вариантов осуществления изобретения, описанных в данном документе, не выходящие за рамки объема настоящего раскрытия. Кроме того, для ясности и краткости изложения могут быть опущены описания общеизвестных функций и конструкций.
Термины и слова, используемые в следующем описании и формуле изобретения, не ограничены их библиографическими значениями, а просто используются автором для обеспечения ясного и правильного понимания настоящего раскрытия. Соответственно, специалистам будет понятно, что следующее описание разных вариантов осуществления изобретения представлено только в целях иллюстрации.
Следует понимать, что элементы, упомянутые в единственном числе, могут быть представлены несколькими элементами, если в контексте явно не указано иное.
Хотя в отношении элементов настоящего изобретения могут использоваться термины "первый", "второй" и т.д., понятно, что не следует истолковывать такие элементы как ограниченные данными терминами. Эти термины используются только для отличия одного элемента от других элементов.
Кроме того, термины "содержит", "содержащий", "включает" и/или "включающий" в данном контексте указывают на наличие заявленных признаков, целых чисел, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или нескольких других признаков, целых чисел, операций, элементов, компонентов и/или их групп.
В разных вариантах осуществления настоящего изобретения "модуль" или "блок" может выполнять по меньшей мере одну функцию или операцию и может быть реализован аппаратными средствами, программным обеспечением или их комбинацией. "Множество модулей" или "множество блоков" может быть реализовано по меньшей мере одним процессором (не показан) посредством его интеграции с по меньшей мере одним модулем, отличным от "модуля" или "блока", который должен быть реализован с помощью специального аппаратного средства.
Предложена система для обучения созданию нейронных аватаров всего тела. Система обучает глубокую сеть создавать визуализации всего тела человека для разных поз человека и положений камеры. Глубокой сетью может быть любая из глубокой нейронной сети, глубокой сверточной нейронной сети, глубокой полносверточной нейронной сети, глубокой нейронной сети, обученной с функцией потерь восприятия, глубокой нейронной сети, обученной на генеративно-состязательной основе. В процессе обучения система явно оценивает двумерную текстуру, описывающую внешний вид поверхности тела. Сохраняя явную оценку текстуры, система обходит явную оценку трехмерной геометрии кожи (поверхности) в любой момент. Вместо этого, во время тестирования система прямо преобразует конфигурацию характерных точек тела относительно камеры в координаты двумерной текстуры отдельных пикселей в кадре изображения. Система способна научиться создавать высоко реалистичные визуализации, обучаясь при этом на монокулярных видео. Сохранение явного представления текстуры в рамках архитектуры настоящего изобретения помогает ей обеспечить лучшее обобщение по сравнению с системами, которые используют прямые сверточные преобразования между положениями суставов и значениями пикселей.
Настоящее изобретение демонстрирует, как можно использовать современные глубокие сети для синтеза видео всего тела человека со свободной точкой обзора. Построенный нейронный аватар, который управляется трехмерными положениями суставов человека, может синтезировать изображение для произвольной камеры и обучается по набору монокулярных видео в открытом доступе (или даже единственного длинного видео).
Для цели настоящего изобретения под аватаром всего тела подразумевается система, которая способна визуализировать виды определенного человека в изменяющейся позе, заданной набором трехмерных положений суставов тела и разных положений камеры (фиг. 1). На фиг. 1 показаны результаты текстурированного нейронного аватара (без пост-обработки "видео в видео") для разных точек обзора во время обучения. Позиции 1-6 обозначают разные точки обзора камеры и изображения, полученные с точек обзора 1-6. В нижнем ряду на фиг. 1 изображения слева получены путем обработки ввода позы, показанной справа. В качестве входных данных используются положения суставов тела, а не углы суставов, поскольку такие положения легче оценить по данным с использованием систем захвата движения с маркером или без маркера. Для построения классического ("не нейронного") аватара по принципу стандартного конвейера компьютерной графики берут персонифицированную сетку тела пользователя в нейтральном положении, оценивают углы суставов по положениям сустава, выполняют скиннинг (деформирование нейтральной позы), оценивая тем самым трехмерную геометрию тела. Затем применяют преобразование текстуры с использованием предварительно вычисленной двумерной текстуры. И наконец, полученную текстурированную модель освещают с помощью определенной модели освещения и затем проецируют на поле зрения камеры. Таким образом, создание аватара человека в классическом конвейере требует персонализации процесса скиннинга, отвечающего за геометрию, и текстуры, отвечающей за внешний вид.
В разрабатываемых системах аватаров на основе глубоких сетях (нейронных аватаров) авторы стремятся сократить ряд ступеней классического конвейера и заменить их одной сетью, которая обучается преобразованию из ввода (расположение суставов тела) в вывод (двумерное изображение). Чтобы упростить задачу обучения, представление ввода можно дополнить дополнительными изображениями, например, результатами классического конвейера в [29, 33] или представлением DensePose [21] в [53]. Большое количество изучаемых параметров, способность обучаться по длинным видео и гибкость глубоких сетей позволяет нейронным аватарам моделировать внешний вид деталей, являющихся очень сложными для классического конвейера, таких как волосы, кожа, сложная одежда и очки, и т.д. Кроме того, привлекает концептуальная простота такого принципа "черного ящика". В то же время, хотя глубокие сети легко приспосабливаются к обучающим данным, отсутствие встроенных инвариантностей, характерных для модели, и объединение оценки формы и внешнего вида ограничивают способность таких систем к обобщению. В результате, предыдущие методы нейронной визуализации ограничивались либо частью тела (голова и плечи [29]), и/или конкретным полем зрения камеры [1, 9, 53, 33].
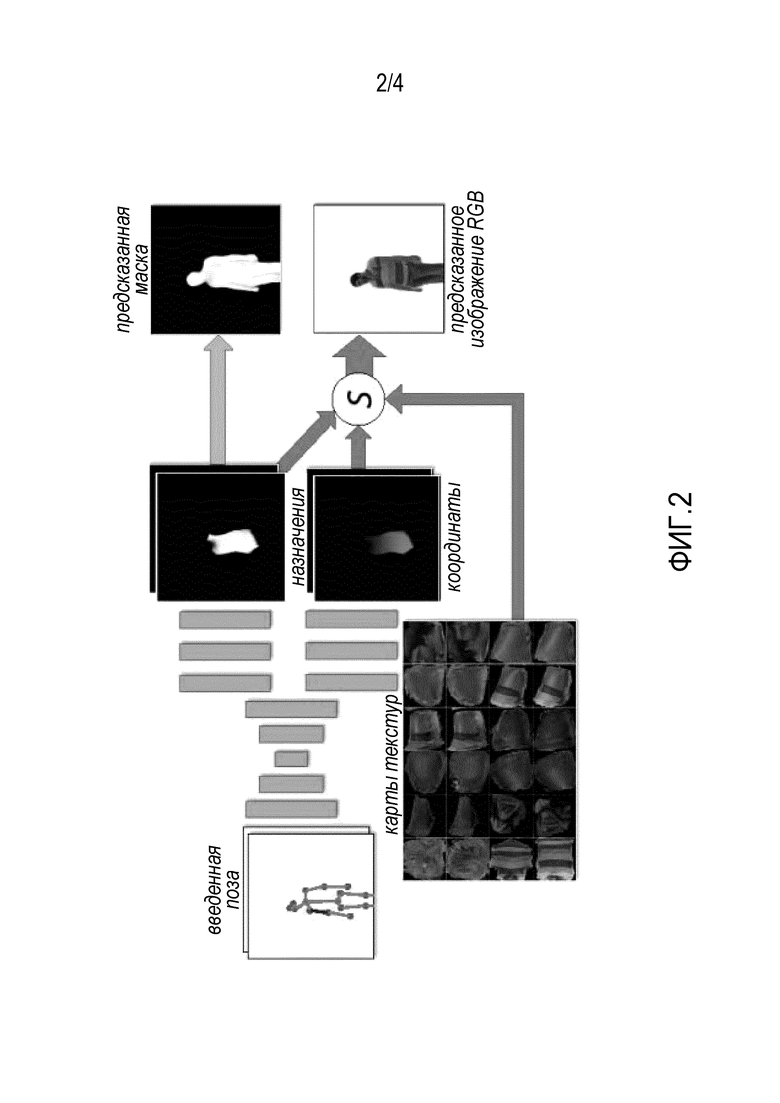
Предложенная система выполняет визуализацию всего тела и объединяет идеи классической компьютерной графики, а именно разделение геометрии и текстуры, с использованием глубоких сетей. В частности, подобно классическому конвейеру, система осуществляет явную оценку двумерных текстур частей тела. Двумерная текстура в классическом конвейере эффективно переносит внешний вид фрагментов тела через преобразования камерой и повороты тела. Следовательно, сохранение этого компонента в нейронном конвейере способствует обобщению таких преобразований. Роль глубокой сети в предложенном методе сводится к предсказанию координат текстур отдельных пикселей с учетом позы тела и параметров камеры (фиг. 2). Кроме того, глубокие сети предсказывают маску переднего плана/фона.
Сравнение эффективности текстурированного нейронного аватара, обеспечиваемого настоящим изобретением, с методом прямого преобразования "видео в видео" [53] показывает, что явная оценка текстур обеспечивает дополнительную способность обобщения и значительно улучшает реалистичность создаваемых изображений для новых видов. Существенные преимущества, обеспечиваемые настоящим изобретением, заключаются в том, что явное разделение текстур и геометрии позволяет получить сценарии обучения переноса, когда глубокая сеть переучивается на нового человека с небольшим количеством обучающих данных. И наконец, текстурированный нейронный аватар значительно ускоряет время обучения по сравнению с методом прямого преобразования.
Способы
Обозначения. Нижний индекс i используется для обозначения объектов, относящихся к i-му обучающему или тестовому изображению. Верхний индекс, например, 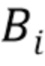 , обозначает стек карт (тензор третьего порядка/трехмерный массив), соответствующий i-му обучающему или тестовому изображению. Верхний индекс используется для обозначения конкретной карты (канала) в стеке, например
, обозначает стек карт (тензор третьего порядка/трехмерный массив), соответствующий i-му обучающему или тестовому изображению. Верхний индекс используется для обозначения конкретной карты (канала) в стеке, например 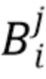 . Квадратные скобки используются для обозначения элементов, соответствующих конкретному положению изображения, например,
. Квадратные скобки используются для обозначения элементов, соответствующих конкретному положению изображения, например, 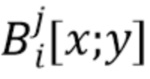 обозначает скалярный элемент в j-й карте стека , находящейся в положении
обозначает скалярный элемент в j-й карте стека , находящейся в положении 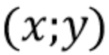 , а
, а 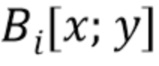 обозначает вектор элементов, соответствующий всем картам, выбранным в положении .
обозначает вектор элементов, соответствующий всем картам, выбранным в положении .
Ввод и вывод. В общем, требуется синтезировать изображения определенного человека с учетом его позы. Предполагается, что поза для i-го изображения поступает в виде трехмерных положений суставов, заданных в системе координат камеры. Тогда в качестве ввода в глубокую сеть рассматривается стек карт , в котором каждая карта содержит растрированный j-й сегмент (кость) "фигуры человека" (скелета), спроецированный на плоскость камеры. Для фиксации информации о третьей координате суставов осуществляется линейная интерполяция значения глубины между суставами, задающими сегменты, и интерполированные значения используются для задания значений на карте , соответствующих пикселям кости (пиксели, не закрытые j-й костью обнуляются). В целом, стек включает информацию о человеке и положении камеры.
В качестве вывода глубокая сеть создает изображение RGB (трехканальный стек) 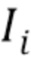 и одноканальную маску
и одноканальную маску 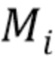 , задающую пиксели, которые покрыты аватаром. Во время обучения предполагается, что для каждого входного кадра i оцениваются введенные положения суставов и маска "истинного" переднего плана, и для их извлечения из необработанных видеокадров используются оценка трехмерной позы тела и семантическая сегментация человеком. Во время тестирования, учитывая истинное или синтетическое изображение фона
, задающую пиксели, которые покрыты аватаром. Во время обучения предполагается, что для каждого входного кадра i оцениваются введенные положения суставов и маска "истинного" переднего плана, и для их извлечения из необработанных видеокадров используются оценка трехмерной позы тела и семантическая сегментация человеком. Во время тестирования, учитывая истинное или синтетическое изображение фона 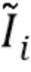 , создается окончательный вид сначала посредством предсказания and по позе тела, а затем посредством линейного вливания полученного аватара в изображение:
, создается окончательный вид сначала посредством предсказания and по позе тела, а затем посредством линейного вливания полученного аватара в изображение: 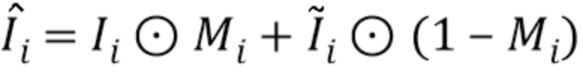 (где
(где  задает произведение "по положению", при котором RGB значения в каждом положении умножаются на значение маски в этом положении).
задает произведение "по положению", при котором RGB значения в каждом положении умножаются на значение маски в этом положении).
Прямое преобразование. Прямой подход, который рассматривается как основа настоящего изобретения, состоит в том, чтобы обучать глубокую сеть как сеть преобразования изображений, которая преобразует стек  карт в стеки карт и (обычно генерируются два выходных стека в двух ветвях, которые совместно осуществляют начальный этап обработки [15]). Как правило, преобразования между стеками карт можно реализовать с помощью глубокой сети, например, полносверточных архитектур. Точные архитектуры и потери для таких сетей активно исследуются [14, 51, 26, 24, 10]. В самых последних работах [1, 9, 53, 33] использовалось прямое преобразование (с разными модификациями) для синтеза вида человека для фиксированной камеры. В частности, система "видео в видео" [53] рассматривает сеть преобразования, которая генерирует следующий кадр видео, принимая за вводы последние три кадра, а также учитывая выводы системы для двух предыдущих кадров авторегрессивным образом. В нашем случае система "видео в видео" [53] модифицирована для получения изображения и маски:
карт в стеки карт и (обычно генерируются два выходных стека в двух ветвях, которые совместно осуществляют начальный этап обработки [15]). Как правило, преобразования между стеками карт можно реализовать с помощью глубокой сети, например, полносверточных архитектур. Точные архитектуры и потери для таких сетей активно исследуются [14, 51, 26, 24, 10]. В самых последних работах [1, 9, 53, 33] использовалось прямое преобразование (с разными модификациями) для синтеза вида человека для фиксированной камеры. В частности, система "видео в видео" [53] рассматривает сеть преобразования, которая генерирует следующий кадр видео, принимая за вводы последние три кадра, а также учитывая выводы системы для двух предыдущих кадров авторегрессивным образом. В нашем случае система "видео в видео" [53] модифицирована для получения изображения и маски:
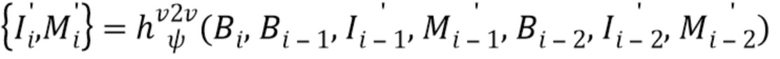 , (1)
, (1)
Здесь 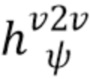 - регрессионная сеть "видео в видео" с обучаемыми параметрами
- регрессионная сеть "видео в видео" с обучаемыми параметрами 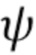 . Также предполагается, что обучающие или тестовые примеры i-1 и i-2 соответствуют предшествующим кадрам. Полученная система преобразования "видео в видео" обеспечивает надежную основу для настоящего изобретения.
. Также предполагается, что обучающие или тестовые примеры i-1 и i-2 соответствуют предшествующим кадрам. Полученная система преобразования "видео в видео" обеспечивает надежную основу для настоящего изобретения.
Текстурированный нейронный аватар. Принцип прямого преобразования основан на обобщающей способности глубоких сетей и вводит в систему очень мало предметно-ориентированных знаний. В качестве альтернативы применяется метод текстурированного аватара, в котором явно оцениваются текстуры частей тела, обеспечивая тем самым подобие внешнего вида поверхности тела при разных позах и камерах. Согласно принципу DensePose [21], тело разделяется на n частей, каждая из которых имеет двумерную параметризацию. Таким образом, предполагается, что в изображении человека каждый пиксель принадлежит одной из n частей или фону. В первом случае пиксель затем ассоциируется с координатами конкретной двумерной части. k-ая часть тела также ассоциируется с картой текстур 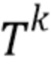 , которая оценивается во время обучения. Оцененные текстуры изучаются во время обучения и используются повторно для всех полей зрения камеры и всех поз.
, которая оценивается во время обучения. Оцененные текстуры изучаются во время обучения и используются повторно для всех полей зрения камеры и всех поз.
Введение описанной выше параметризации поверхности тела изменяет проблему преобразования. Для заданной позы, заданной , сеть преобразования теперь должна предсказать стек 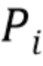 назначений частей тела и стек
назначений частей тела и стек 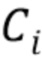 координат частей тела, где содержит n+1 карт неотрицательных чисел, которые в сумме дают единицу (то есть
координат частей тела, где содержит n+1 карт неотрицательных чисел, которые в сумме дают единицу (то есть 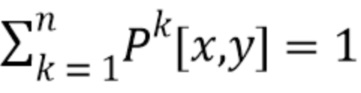 ), и содержит 2n карт реальных чисел от 0 до w, где w - пространственный размер (ширина и высота) карт текстур .
), и содержит 2n карт реальных чисел от 0 до w, где w - пространственный размер (ширина и высота) карт текстур .
Затем интерпретируют канал карты 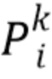 для k=0..n-1 как вероятность того, что пиксель принадлежит k-й части тела, а канал карты
для k=0..n-1 как вероятность того, что пиксель принадлежит k-й части тела, а канал карты 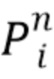 соответствует вероятности фона. Карты
соответствует вероятности фона. Карты  и
и 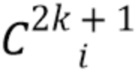 координат соответствуют координатам пикселей на k-й части тела. В частности, после предсказания назначений частей и координат частей тела изображение в каждом пикселе
координат соответствуют координатам пикселей на k-й части тела. В частности, после предсказания назначений частей и координат частей тела изображение в каждом пикселе 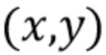 восстанавливается как взвешенная комбинация элементов текстуры, где веса и координаты текстуры предписываются картами назначений частей и картами координат, соответственно:
восстанавливается как взвешенная комбинация элементов текстуры, где веса и координаты текстуры предписываются картами назначений частей и картами координат, соответственно:
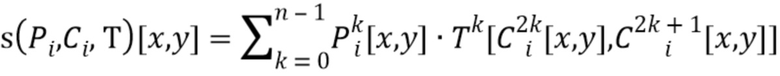 , (2)
, (2)
где 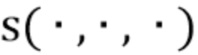 - функция выборки (слой), которая выдает стек карт RGB с учетом трех введенных аргументов. В работе (2) карты текстур семплируются в нецелочисленных положениях
- функция выборки (слой), которая выдает стек карт RGB с учетом трех введенных аргументов. В работе (2) карты текстур семплируются в нецелочисленных положениях 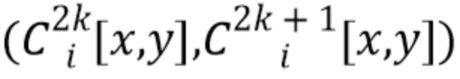 билинейным образом, так что
билинейным образом, так что 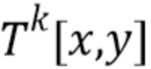 вычисляется как:
вычисляется как:
 , (3)
, (3)
для 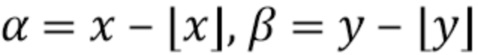 , как предложено в [25].
, как предложено в [25].
При обучении нейронного текстурированного аватара глубокую сеть 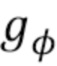 обучают с обучаемыми параметрами
обучают с обучаемыми параметрами 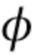 преобразованию входных стеков карт в назначения частей тела и координаты частей тела. Так как имеет две ветви (ʺголовыʺ),
преобразованию входных стеков карт в назначения частей тела и координаты частей тела. Так как имеет две ветви (ʺголовыʺ), 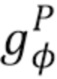 является ветвью, которая создает стек назначений частей тела, а
является ветвью, которая создает стек назначений частей тела, а 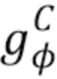 является ветвью, которая создает координаты частей тела. Для изучения параметров текстурированного нейронного аватара оптимизируются потери между созданным изображением и истинным изображением
является ветвью, которая создает координаты частей тела. Для изучения параметров текстурированного нейронного аватара оптимизируются потери между созданным изображением и истинным изображением 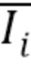 :
:
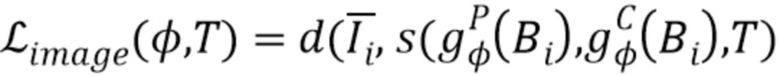 , (4)
, (4)
где 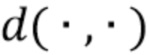 потери при сравнении двух изображений (точный выбор обсуждается ниже). При стохастической оптимизации градиент потерь (4) распространяется обратно через (2) как в сеть преобразования , так и на карты текстур , так что минимизация этой потери обновляет не только параметры сети, но и сами текстуры. Кроме того, обучение также оптимизирует потерю маски, которая измеряет несоответствие между маской истинного фона
потери при сравнении двух изображений (точный выбор обсуждается ниже). При стохастической оптимизации градиент потерь (4) распространяется обратно через (2) как в сеть преобразования , так и на карты текстур , так что минимизация этой потери обновляет не только параметры сети, но и сами текстуры. Кроме того, обучение также оптимизирует потерю маски, которая измеряет несоответствие между маской истинного фона 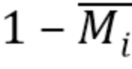 и предсказанием маски фона:
и предсказанием маски фона:
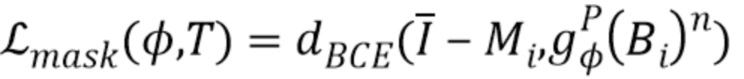 , (5)
, (5)
где  - потеря двоичной перекрестной энтропии, а
- потеря двоичной перекрестной энтропии, а 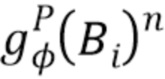 соответствует n-му (то есть фоновому) каналу предсказанного стека карт назначений частей. После обратного распространения взвешенной комбинации (4) и (5) параметры сети и карты текстур обновляются. В процессе обучения карты текстур изменяются (фиг. 2), а также изменяются и предсказания координат частей тела, поэтому обучение может свободно выбирать соответствующую параметризацию поверхностей частей тела.
соответствует n-му (то есть фоновому) каналу предсказанного стека карт назначений частей. После обратного распространения взвешенной комбинации (4) и (5) параметры сети и карты текстур обновляются. В процессе обучения карты текстур изменяются (фиг. 2), а также изменяются и предсказания координат частей тела, поэтому обучение может свободно выбирать соответствующую параметризацию поверхностей частей тела.
На фиг. 2 представлен общий вид системы текстурированного нейронного аватара. Входная поза задается как стек растеризаций "кости" (одна кость на канал; выделена на чертеже красным цветом). Ввод обрабатывается полносверточной сетью (показана оранжевым цветом) для создания стека карт назначений частей тела и стека карт координат частей тела. Эти стеки затем используются для выборки карт текстур тела в положениях, заданных стеком координат частей с весами, заданными стеком назначений частей, чтобы получить изображение RGB. Кроме того, последняя карта из стека карт назначений тела соответствует вероятности фона. Во время обучения маска и изображение RGB сравниваются с истиной, и полученные потери распространяются обратно посредством операции выборки в полносверточную сеть и на текстуру, что приводит к их обновлениям.
Постобработка "видео в видео". Хотя модель текстурированного нейронного аватара можно использовать в качестве автономного механизма нейронной визуализации, ее выход подвергается постобработке с помощью модуля обработки "видео в видео", который улучшает временное соответствие и добавляет вариации внешнего вида, зависящие от позы и точки обзора, которые невозможно смоделировать полностью, используя текстурированный нейронный аватар. Таким образом, рассматривается сеть 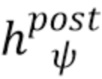 преобразования видео с обучаемыми параметрами, которая принимает в качестве ввода поток выходов текстурированного нейронного аватара:
преобразования видео с обучаемыми параметрами, которая принимает в качестве ввода поток выходов текстурированного нейронного аватара:
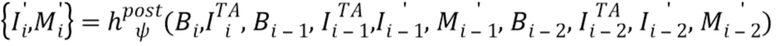 , (6)
, (6)
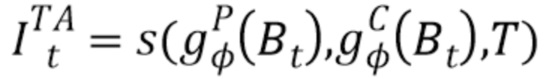 означает вывод текстурированного нейронного аватара в момент времени t (снова предполагается, что примеры i-1 и i-2 соответствуют предшествующим кадрам). Ниже представлено сравнение предложенной полной модели, т.е. текстурированного нейронного аватара с пост-обработкой (6), текстурированных нейронных аватаров без такой пост-обработки и базовой модели "видео в видео" (1), которое демонстрирует явное улучшение, достигнутое при использовании текстурированного нейронного аватара (с пост-обработкой или без нее).
означает вывод текстурированного нейронного аватара в момент времени t (снова предполагается, что примеры i-1 и i-2 соответствуют предшествующим кадрам). Ниже представлено сравнение предложенной полной модели, т.е. текстурированного нейронного аватара с пост-обработкой (6), текстурированных нейронных аватаров без такой пост-обработки и базовой модели "видео в видео" (1), которое демонстрирует явное улучшение, достигнутое при использовании текстурированного нейронного аватара (с пост-обработкой или без нее).
Инициализация текстурированного нейронного аватара. Для инициализации текстурированного нейронного аватара используется система DensePose [21]. В частности, имеется два варианта для инициализации . Во-первых, при большом количестве обучающих данных и их поступлении из нескольких обучающих монокулярных последовательностей DensePose может работать на обучающих изображениях, получая карты назначения частей и карты координат деталей. Затем предварительно обучается в качестве сети преобразования между стеками поз 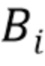 и выходами DensePose. В качестве альтернативы можно использовать "универсально" предварительно обученную , которая обучена преобразовывать стеки поз в выходы DensePose в автономном крупномасштабном наборе данных (авторы используют набор данных COCO [32]).
и выходами DensePose. В качестве альтернативы можно использовать "универсально" предварительно обученную , которая обучена преобразовывать стеки поз в выходы DensePose в автономном крупномасштабном наборе данных (авторы используют набор данных COCO [32]).
После инициализации преобразования DensePose инициализируются карты текстур следующим образом. Каждый пиксель в обучающих изображениях приписывается одной части тела (согласно прогнозу ) и конкретному пикселю текстуры на текстуре соответствующей части (согласно прогнозу ). Затем значение каждого пикселя текстуры инициализируется как среднее всех приписанных ему значений изображения (пиксели текстуры, которым назначены нулевые пиксели, инициализируются черным).
Потери и архитектуры.
Потери восприятия (VGG) [51, 26] используются в (4) для измерения различия между созданным и истинным изображением при обучении текстурированного нейронного аватара. Можно использовать любые другие стандартные потери для измерения таких различий.
Обучение переноса.
После того, как текстурированный нейронный аватар был обучен для определенного человека на основе большого количества данных, его можно переобучить для другого человека, используя намного меньше данных (так называемое обучение переноса). Во время переобучения новый стек карт текстур переоценивается с помощью описанной выше процедуры инициализации. После этого процесс обучения происходит обычным образом, но с использованием предварительно обученного набора параметров для инициализации.
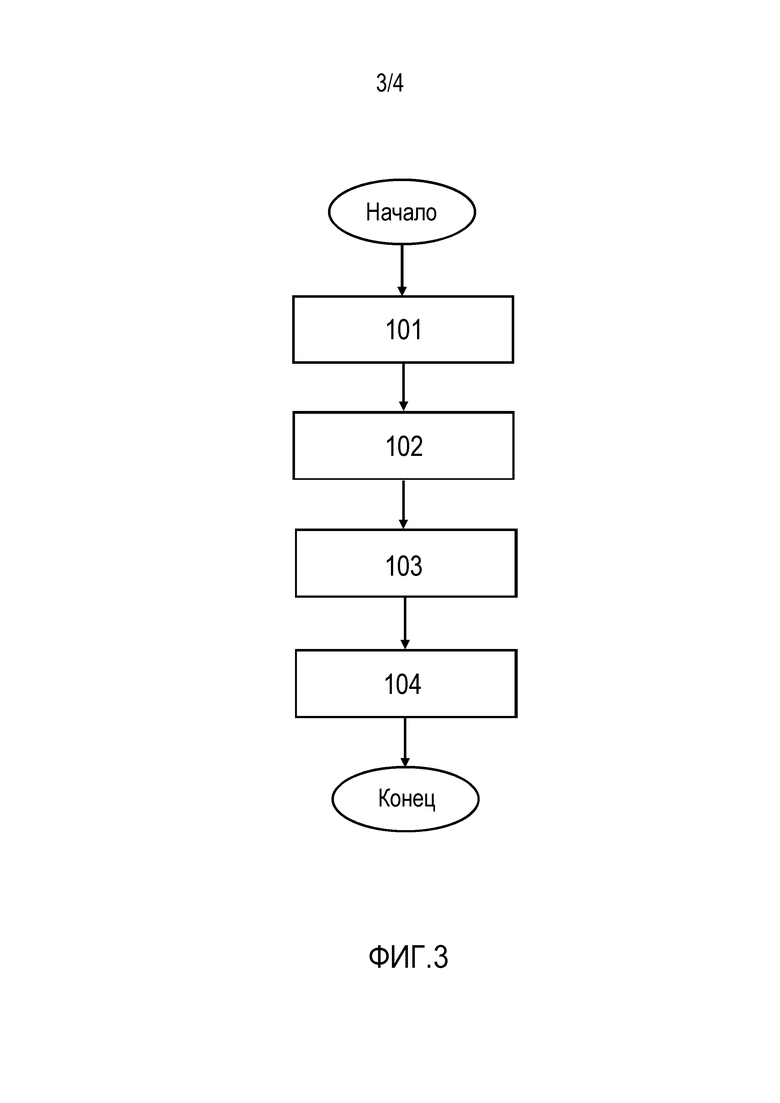
Один вариант осуществления способа синтеза двумерного изображения человека будет описан более подробно со ссылками на фиг. 3. Способ включает в себя этапы 101, 102, 103, 104.
На этапе 101 получают трехмерные координаты положения суставов тела человека, заданные в системе координат камеры. Трехмерные координаты положений суставов тела задают позу человека и точку обзора двумерного изображения, которое должно быть синтезировано.
На этапе 102 обученный предиктор машинного обучения прогнозирует стек карт назначений частей тела и стек карт координат частей тела на основании принятых трехмерных координат положений суставов тела. Стек карт координат частей тела задает координаты текстуры пикселей частей тела человека. Стек карт назначений частей тела задает веса. В стеке карт назначений частей тела каждый вес указывает на вероятность того, что определенный пиксель принадлежит конкретной части тела человека.
На этапе 103 из памяти извлекается ранее инициализированный стек карт текстур для частей тела человека. Этот стек карт текстур содержит значения пикселей частей тела человека.
На этапе 104 двумерное изображение человека восстанавливается как взвешенная комбинация значений пикселей с использованием стека карт назначений частей тела и стека карт координат частей тела, предсказанных на этапе 102, и стека карт текстур, извлеченных на этапе 103.
В качестве предиктора машинного обучения используется одна из глубокой нейронной сети, глубокой сверточной нейронной сети, глубокой полносверточной нейронной сети, глубокой нейронной сети, обученной с функцией потерь восприятия, глубокой нейронной сети, обученной на генеративно-состязательной основе.
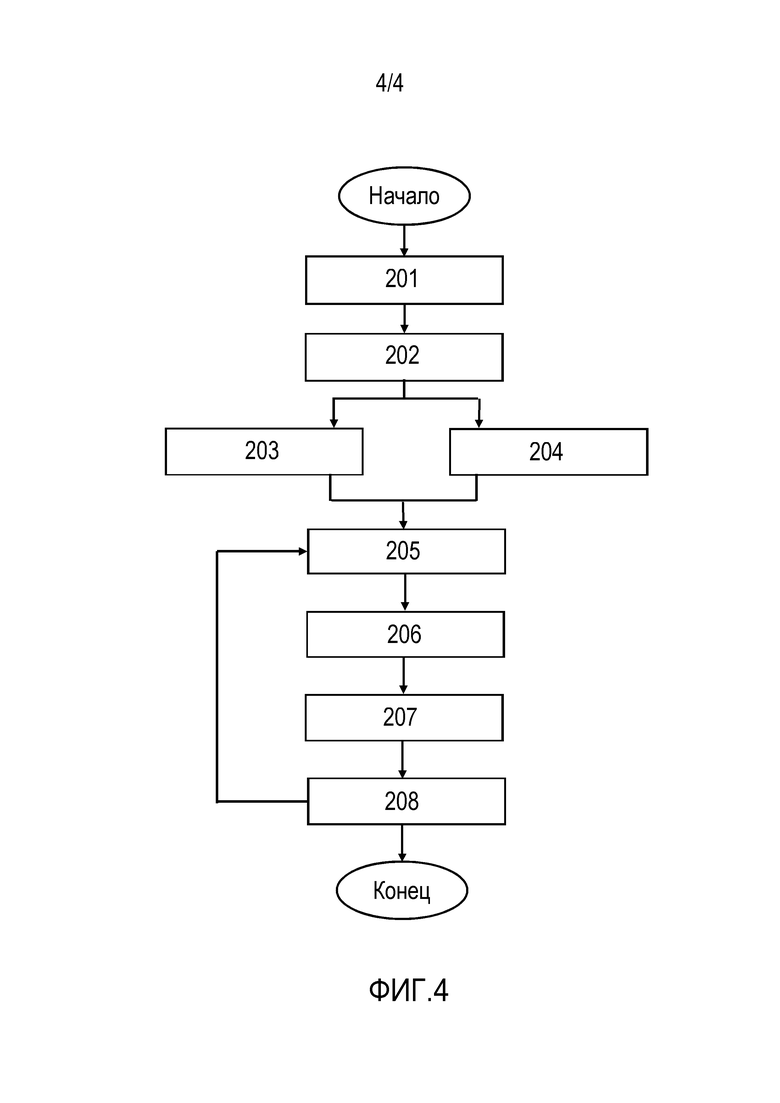
Процесс получения обученного предиктора машинного обучения и стека карт текстур для частей тела человека будет более подробно описан со ссылками на фиг. 4. В указанном процессе способ содержит этапы 201, 202, 203, 204, 205, 206, 207, 208. Этапы 203 и 204 могут выполняться одновременно или последовательно в любом порядке.
На этапе 201 принимают множество изображений человека в разных позах и с разных точек обзора.
На этапе 202 получают трехмерные координаты положений суставов тела человека, заданные в системе координат камеры, для каждого изображения из принятого множества изображений. Трехмерные координаты можно получить с использованием любого подходящего метода. Такие методы известны из уровня техники.
На этапе 203 предиктор машинного обучения инициализируют на основе трехмерных координат положений суставов тела и принятого множества изображений, чтобы получить параметры для предсказания стека карт назначений частей тела и стека карт координат частей тела.
На этапе 204 инициализируют стек карт текстур на основе трехмерных координат положений суставов тела и принятого множества изображений, и стек карт текстур сохраняют в памяти.
На этапе 205 предсказывают стек карт назначений частей тела и стек карт координат частей тела с использованием текущего состояния предиктора машинного обучения на основе трехмерных координат положений суставов тела.
На этапе 206 восстанавливают двумерное изображение человека как взвешенную комбинацию значений пикселей с использованием стека карт назначений частей тела, стека карт координат частей тела и стека карт текстур, хранящихся в памяти.
На этапе 207 восстановленное двумерное изображение сравнивают с истинным двумерным изображением, чтобы выявить ошибку восстановления двумерного изображения. Истинное двумерное изображение соответствует восстановленному двумерному изображению в данной позе человека и точке обзора. Истинное двумерное изображение выбирается из полученного множества изображений.
На этапе 208 параметры обученного предиктора машинного обучения и значения пикселей в стеке карт текстур обновляются на основе результата сравнения.
Затем этапы S205-S208 повторяются для восстановления разных двумерных изображений человека, пока не будет выполнено некоторое заданное условие. Заданным условием может быть по меньшей мере одно из выполнения заданного количества повторений, истечения заданного времени или отсутствия уменьшения ошибки восстановления двумерного изображения человека.
Обучение глубоких сетей хорошо известно из уровня техники, поэтому конкретные этапы обучения не описываются подробно.
В другом варианте предсказание (S102, S205) стека карт назначений частей тела и стека карт координат частей тела может быть основано на стеке карт растрированных сегментов. Стек карт растрированных сегментов создается на основе трехмерных координат положений суставов тела. Каждая карта из стека карт растрированных сегментов содержит растрированный сегмент, представляющий какую-либо часть тела человека.
В еще одном варианте обученный предиктор машинного обучения можно переобучить для другого человека на основе множества изображений этого другого человека.
Все описанные выше операции могут выполняться системой для синтеза двумерного изображения человека. Система для синтеза двумерных изображений человека содержит процессор и память. В памяти хранятся команды, побуждающие процессор реализовать способ синтеза двумерного изображения человека.
Поскольку варианты осуществления изобретения были описаны как реализуемые по меньшей мере частично программно-управляемым устройством обработки данных, следует понимать, что постоянный машиночитаемый носитель, содержащий такое программное обеспечение, в частности, оптический диск, магнитный диск, полупроводниковое запоминающее устройство или т.п., также следует рассматривать как вариант осуществления настоящего раскрытия.
Понятно, что варианты осуществления системы для синтеза двумерного изображения человека можно реализовать в виде разных функциональных блоков, схем и/или процессоров. Однако ясно, что можно использовать любое подходящее распределение функций между разными функциональными блоками, схемами и/или процессорами без ущерба для вариантов осуществления.
Эти варианты могут быть реализованы в любой подходящей форме, включая аппаратные средства, программное обеспечение, встроенное программное обеспечение или любую их комбинацию. Варианты осуществления можно реализовать по меньшей мере частично, как компьютерное программное обеспечение, работающее на одном или нескольких процессорах данных и/или процессорах цифровых сигналов. Элементы и компоненты любого варианта осуществления могут быть реализованы физически, функционально и логически любым подходящим способом. Действительно, выполняемые функции могут быть реализованы в одном блоке, множестве блоков или как часть других функциональных блоков. По существу, предложенные варианты осуществления можно реализовать в одном блоке или распределить физически и функционально между разными блоками, схемами и/или процессорами.
Представленное выше описание вариантов осуществления изобретения является иллюстративным, и модификации в конфигурации и реализации подпадают под объем настоящего описания. Например, хотя варианты осуществления изобретения описаны в общем со ссылкой на фиг. 1-4, эти описания являются примерными. Несмотря на то, что предмет изобретения был описан на языке, характерном для конструктивных признаков или методологических действий, подразумевается, что предмет, охарактеризованный в прилагаемой формуле изобретения, не обязательно ограничен конкретными признаками или действиями, описанными выше. Напротив, описанные выше конкретные признаки и действия раскрыты как примерные формы реализации формулы изобретения. Кроме того, изобретение не ограничено проиллюстрированным порядком выполнения этапов способа, и этот порядок может быть изменен специалистом без творческих усилий. Некоторые или все этапы способа могут выполняться последовательно или одновременно. Соответственно, объем воплощения изобретения ограничен только следующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИСТАНЦИОННОГО ВЫБОРА ОДЕЖДЫ | 2020 |
|
RU2805003C2 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| Система и способ для получения обработанного выходного изображения, имеющего выбираемый пользователем показатель качества | 2023 |
|
RU2823750C1 |
| НЕЙРОСЕТЕВОЙ РЕНДЕРИНГ ТРЕХМЕРНЫХ ЧЕЛОВЕЧЕСКИХ АВАТАРОВ | 2021 |
|
RU2775825C1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |

Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении возможности получения двухмерных изображений всего тела человека в разных позах и с разных точек обзора с использованием искусственного интеллекта. Способ синтеза двумерного изображения человека, в котором принимают трехмерные координаты положений суставов тела человека, заданные в системе координат камеры, причем трехмерные координаты положений суставов тела задают позу человека и точку обзора двумерного изображения; предсказывают, используя обученный предиктор машинного обучения, стек карт назначений частей тела и стек карт координат частей тела на основе трехмерных координат положений суставов тела, причем стек карт координат частей тела задает координаты текстур пикселей частей тела человека, стек карт назначений частей тела задает веса, причем каждый вес указывает вероятность того, что конкретный пиксель принадлежит конкретной части тела человека, при этом обученный предиктор машинного обучения обучен для множества разных поз человека и разных точек обзора человека; извлекают из памяти ранее инициализированный стек карт текстур для частей тела человека; и восстанавливают двумерное изображение человека как взвешенную комбинацию значений пикселей, используя стек карт назначений частей тела, стек карт координат частей тела и стек карт текстур. 2 н. и 4 з.п. ф-лы, 4 ил.
1. Способ синтеза двумерного изображения человека, заключающийся в том, что:
принимают (S101) трехмерные координаты положений суставов тела человека, заданные в системе координат камеры, причем трехмерные координаты положений суставов тела задают позу человека и точку обзора упомянутого двумерного изображения;
предсказывают (S102), используя обученный предиктор машинного обучения, стек карт назначений частей тела и стек карт координат частей тела на основе трехмерных координат положений суставов тела, причем стек карт координат частей тела задает координаты текстур пикселей частей тела человека, стек карт назначений частей тела задает веса, причем каждый вес указывает вероятность того, что конкретный пиксель принадлежит конкретной части тела человека, при этом обученный предиктор машинного обучения обучен для множества разных поз человека и разных точек обзора человека;
извлекают (S103) из памяти ранее инициализированный стек карт текстур для частей тела человека, причем стек карт текстур содержит значения пикселей частей тела данного человека; и
восстанавливают (S104) двумерное изображение человека как взвешенную комбинацию значений пикселей, используя упомянутый стек карт назначений частей тела, упомянутый стек карт координат частей тела и упомянутый стек карт текстур.
2. Способ по п. 1, в котором при получении обученного предиктора машинного обучения и ранее инициализированного стека карт текстур для частей тела человека:
принимают (S201) множество изображений человека в разных позах и с разных точек обзора;
получают (S202) трехмерные координаты положений суставов тела человека, заданные в системе координат камеры для каждого изображения из принятого множества изображений;
инициализируют (S203) предиктор машинного обучения на основании трехмерных координат положений суставов тела и принятого множества изображений для получения параметров для предсказания стека карт назначений частей тела и стека карт координат частей тела;
инициализируют (S204) стек карт текстур на основании трехмерных координат положений суставов тела и принятого множества изображений и сохраняют стек карт текстур в памяти;
предсказывают (S205), используя текущее состояние предиктора машинного обучения, стек карт назначений частей тела и стек карт координат частей тела на основании трехмерных координат положений суставов тела;
восстанавливают (S206) двумерное изображение человека как взвешенную комбинацию значений пикселей, используя стек карт назначений частей тела, стек карт координат частей тела и стек карт текстур, хранящийся в памяти;
сравнивают (S207) восстановленное двумерное изображения с соответствующим истинным двумерным изображением из принятого множества изображений, чтобы выявить ошибку восстановления двумерного изображения;
обновляют (S208) параметры обученного предиктора машинного обучения и значения пикселей в стеке карт текстур на основании результата сравнения; и
повторяют этапы S205-S208 для восстановления разных двумерных изображений человека до тех пор, пока не будет удовлетворено заданное условие, причем заданное условие представляет собой по меньшей мере одно из выполнения заданного количества повторений, истечения заданного времени или отсутствия уменьшения ошибки восстановления двумерного изображения человека.
3. Способ по п. 1 или 2, в котором предиктор машинного обучения представляет собой одну из глубокой нейронной сети, глубокой сверточной нейронной сети, глубокой полносверточной нейронной сети, глубокой нейронной сети, обученной с функцией потерь восприятия, глубокой нейронной сети, обученной на генеративно-состязательной основе.
4. Способ по п. 1 или 2, в котором дополнительно:
генерируют стек карт растрированных сегментов на основе трехмерных координат положений суставов тела, причем каждая карта из стека карт растрированных сегментов содержит растрированный сегмент, представляющий часть тела человека,
причем предсказание стека карт назначений частей тела и стека карт координат частей тела основано на стеке карт растрированных сегментов.
5. Способ по п. 2, в котором обученный предиктор машинного обучения переобучают для другого человека на основании множества изображений другого человека.
6. Система для синтеза двумерного изображения человека, содержащая:
процессор и
память, содержащую команды, побуждающие процессор выполнять способ синтеза двумерного изображения человека по любому из пп. 1-5.
| ROLAND KEHL et al | |||
| "Markerless tracking of complex human motions from multiple views", Computer Vision and Image Understanding, Volume 104, Issues 2-3, November-December 2006, опубл | |||
| Видоизменение пишущей машины для тюркско-арабского шрифта | 1923 |
|
SU25A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| EP 2930689 B1, 06.12.2017 | |||
| US 10002460 B2, 19.06.2018 | |||
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ РЕАЛИСТИЧНОГО 3D АВАТАРА ПОКУПАТЕЛЯ ДЛЯ ВИРТУАЛЬНОЙ ПРИМЕРОЧНОЙ | 2015 |
|
RU2615911C1 |

