Область техники, к которой относится изобретение
Предлагаемое изобретение относится в общем к обработке трехмерных изображений, и более конкретно к рендерингу трехмерной (3D) модели аватара пользователя, и может быть применено в системах дополненной и виртуальной реальности (AR/VR), видеоиграх, телеконференциях и т.п.
Уровень техники
Аватар - графическое представление пользователя в виртуальной среде, призванное индивидуализировать пользователя и отражать определенные специфические черты характера, внешности, статус и т.п. данного конкретного пользователя. До недавнего времени в виртуальной сетевой среде, такой как, например, веб-сайты, Интернет-форумы, сервисы мгновенных сообщений и тому подобное, в качестве аватара использовалось неподвижное или подвижное двумерное (2D) изображение, выбранное или созданное конкретным пользователем. По мере расширения возможностей виртуальной и дополненной реальности, многопользовательских сетевых видеоигр, сервисов телеконференций и т.п. в качестве аватара также стало использоваться трехмерное (3D) изображение, в частности 3D модель, которая может в той или иной степени индивидуализироваться в соответствии с предпочтениями конкретного пользователя в зависимости от возможностей соответствующей среды, в которой используется 3D модель.
Однако в некоторых применениях, прежде всего в телеконференциях, многопользовательских сетевых видеоиграх и т.п. существует потребность в трехмерном аватаре пользователя, который мог бы, с одной стороны, по возможности наиболее детально отражать внешность, одежду (реальную или измененную в соответствии с предпочтениями пользователя) и т.п. конкретного пользователя, а с другой стороны - максимально точно и детально повторять движения, мимику и т.п. пользователя, которого представляет аватар.
В недавние годы были разработаны сложные и мощные трехмерные модели человеческого тела без текстур, которые имитируют форму тела, включая деформации лицевых мышц и рук (см. источники [30, 44]). Эти модели основаны на полигональной геометрии и формируются путем обучения на основе нескольких имеющихся наборов данных, полученных сканированием тела человека. Однако моделирование одежды и волос в буквальном смысле добавляют дополнительный уровень сложности в разработке таких 3D моделей, что может быть еще более проблематичным при моделировании внешности пользователя, и для чего доступен лишь небольшой объем трехмерных данных. В то же время, создание реалистичных трехмерных аватаров невозможно без моделирования одежды и волос.
В известном решении, раскрытом в источнике [23], используется ранняя порождающая модель для создания трехмерной модели человека в одежде, которая преобразует рендеры параметрической модели тела человека в карты анализа (семантического сегментирования) человека, которые затем преобразуются в изображения человека.
В другом решении, раскрытом в источнике [27], используются способы формирования изображений человека на основании позы, которые синтезируют изображения человека в новых позах или в новой одежде с использованием входных данных в виде одного изображения за счет изменения формы элементов при преобразовании из позы в изображение (см. источники [36, 10, 9, 13]), прогнозирования координат на поверхности в исходном и целевом кадрах (см. источник [4]) или выборок из карт текстур в цветовом пространстве RGB (см. источники [28, 12]).
В ситуации обработки видеоизображения в источнике [42] раскрыто решение, в котором обучают систему, преобразующую последовательность поз тела в соответствующее непрерывное во времени монокулярное видеоизображение, а в источнике [34] раскрыто решение, в котором рендеры суставов тела преобразуются в координаты поверхности тела в одежде, которые используются для формирования выборок из обучаемого стека текстур в цветовом пространстве RGB, что позволяет обеспечить повышенное качество изображения.
Геометрическое разложение текстуры помогает в определении невидимых участков и обобщении для формирования изображений для поз, не показанных на входных изображениях, однако ошибки в регрессии координат поверхности приводят к многочисленным видимым артефактам изображения, в особенности в области лица и рук моделируемого человека.
В источниках [3, 2, 6, 24, 15] описаны решения, в которых на основании одного изображения или множества изображений человека формируется карта текстур и смещения для модели тела, которая затем может быть использована при формировании рендеров с любой точки обзора и изображающих человека в произвольной позе. Однако качество формирования рендеров для аватара пользователя в известных решениях ограничено характеристики классических процессов графической обработки.
В источниках [41, 46, 25, 35] описано преобразование позы в изображение при обработке видеоизображения в режиме малого количества кадров, в котором целевой внешний вид модели пользователя определяется несколькими изображениями. Однако при этом обеспечивается невысокое качество формируемого изображения.
Раскрытие изобретения
Данный раздел, раскрывающий различные аспекты и варианты выполнения заявляемого изобретения, предназначен для представления краткой характеристики заявляемых объектов изобретения и вариантов его выполнения. Подробная характеристика технических средств и методов, реализующих сочетания признаков заявляемых изобретений, приведена ниже. Ни данное раскрытие изобретения, ни нижеприведенное подробное описание и сопровождающие чертежи не следует рассматривать как определяющие объем заявляемого изобретения. Объем правовой охраны заявляемого изобретения определяется исключительно прилагаемой формулой изобретения.
С учетом вышеуказанных недостатков известных решений из уровня техники в области формирования изображений трехмерной модели пользователя для различных пространственных положений, ракурсов, поз и т.п., техническая проблема, решаемая настоящим изобретением состоит в повышении качества и достоверности формируемых изображений аватара пользователя при большем количестве различных поз и ракурсов, для которых может быть сформировано изображение аватара.
Задача изобретения состоит в создании способа и системы формирования изображений трехмерной модели аватара пользователя с улучшенным рендерингом трехмерной модели с использованием одной или более нейросетей.
Технический результат, достигаемый при использовании изобретения, состоит в создании фотореалистичного трехмерного аватара пользователя с возможностью его анимации на основании параметров позы тела, включая параметры мимики и положения рук.
Для решения вышеуказанной задачи в первом аспекте изобретения предусмотрен способ создания аватара пользователя, содержащий этапы, на которых: получают входные данные в виде одного или более кадров изображения пользователя; извлекают из полученных входных данных параметры s формы тела, характеризующие форму тела пользователя, параметры p позы, характеризующие позу пользователя на одном или более кадрах изображения пользователя, и параметры C камеры, характеризующие ракурс, с которого сняты упомянутые один или более кадров изображения пользователя; формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя; формируют L-канальную нейросетевую текстуру, характеризующую особенности внешности пользователя, на основе обработки упомянутых одного или более кадров изображения пользователя; накладывают L-канальную нейросетевую текстуру на деформируемую полигональную структуру; выполняют рендеринг аватара пользователя в новой позе и/или с нового ракурса посредством нейросети рендеринга; и производят обучение параметров нейросети рендеринга и нейросетевой текстуры путем их подстройки для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя из полученных входных данных.
Во втором аспекте данная задача решается способом рендеринга аватара пользователя, содержащим этапы, на которых: получают входные данные в виде параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу аватара, параметров C камеры, характеризующих ракурс, с которого должен быть изображен аватар; формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя; накладывают обученную L-канальную нейросетевую текстуру на деформируемую полигональную структуру; и выполняют рендеринг аватара пользователя в новой позе и/или с нового ракурса посредством обученной нейросети рендеринга, причем обучение нейросетевой текстуры и нейросети рендеринга осуществляется путем подстройки параметров нейросетевой текстуры и нейросети рендеринга для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя.
В одном или более вариантах выполнения способов по первому и второму вышеуказанным аспектам настоящего изобретения нейросеть рендеринга может иметь сверточную архитектуру. Число L каналов L-канальной нейросетевой текстуры может быть равно 16. Параметры нейросети рендеринга могут обучаться совместно с порождающей моделью L-канальных нейросетевых текстур, и L-канальная нейросетевая текстура аватара может получаться посредством вывода в обученной порождающей модели и дальнейшей подстройки. Обучение нейросети рендеринга и порождающей модели L-канальных нейросетевых текстур может осуществляться по принципу состязательных сетей. Нейросеть рендеринга в соответствии со способами согласно изобретению определяется выражением 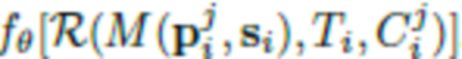 , где
, где 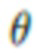 - параметры нейросети, R - функция нейротекстурирования, M - деформируемая полигональная структура, определяемая параметрами p позы и параметрами s формы тела, C - параметры камеры, T - L-канальная нейротекстура.
- параметры нейросети, R - функция нейротекстурирования, M - деформируемая полигональная структура, определяемая параметрами p позы и параметрами s формы тела, C - параметры камеры, T - L-канальная нейротекстура.
В третьем аспекте вышеуказанная задача решается системой для создания аватара пользователя, содержащей: память, в которой сохранены компьютерные программные команды; и один или более процессоров, которые, под управлением упомянутых компьютерных программных команд, выполнен(ы) с возможностью: получения входных данных в виде одного или более кадров изображения пользователя; извлечения из полученных входных данных параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу пользователя на одном или более кадрах изображения пользователя, и параметров C камеры, характеризующих ракурс, с которого сняты упомянутые один или более кадров изображения пользователя; формирования деформируемой полигональной структуры в качестве трехмерной модели тела пользователя; формирования L-канальной нейросетевой текстуры, характеризующей особенности внешности пользователя, на основе обработки упомянутых одного или более кадров изображения пользователя; наложения L-канальной нейросетевой текстуры на деформируемую полигональную структуру; выполнения рендеринга аватара пользователя в новой позе и/или с нового ракурса посредством нейросети рендеринга; и обучения параметров нейросети рендеринга и нейросетевой текстуры путем их подстройки для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя из полученных входных данных.
В четвертом аспекте вышеуказанная задача решается системой рендеринга аватара пользователя, содержащей: память, в которой сохранены компьютерные программные команды; и один или более процессоров, которые, под управлением упомянутых компьютерных программных команд, выполнен(ы) с возможностью: получения входных данных в виде параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу аватара, параметров C камеры, характеризующих ракурс, с которого должен быть изображен аватар; формирования деформируемой полигональной структуры в качестве трехмерной модели тела пользователя; наложения обученной L-канальной нейросетевой текстуры на деформируемую полигональную структуру; и выполнения рендеринга аватара пользователя в новой позе и/или с нового ракурса посредством обученной нейросети рендеринга, причем обучение нейросетевой текстуры и нейросети рендеринга осуществляется путем подстройки параметров нейросетевой текстуры и нейросети рендеринга для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя.
В пятом и шестом аспектах настоящего изобретения вышеуказанная задача решается машиночитаемыми носителями, на которых сохранены компьютерные программные команды, побуждающие систему для создания аватара пользователя или систему рендеринга аватара пользователя выполнять способы создания аватара пользователя или рендеринга аватара пользователя по вышеуказанным аспектам настоящего изобретения при выполнении компьютерных программных команд одним или более процессорами.
Специалистам в данной области техники будет очевидно, что помимо вышеперечисленных объектов изобретения изобретательский замысел, лежащий в основе настоящего изобретения, может быть реализован в форме других объектов изобретения, таких как одно или более устройств, компьютерный программный продукт, компьютерная программа, система, способ и т.п.
Краткое описание чертежей
Чертежи приведены в настоящем документе для облегчения понимания сущности настоящего изобретения. Чертежи являются схематичными и выполнены не в масштабе. Чертежи служат исключительно в качестве иллюстрации и не предназначены для определения объема настоящего изобретения.
На Фиг. 1 проиллюстрирована нейросетевая модель для рендеринга поверхности трехмерного аватара пользователя согласно настоящему изобретению;
На Фиг. 2 показана принципиальная схема способа формирования изображения аватара пользователя согласно изобретению;
На Фиг. 3 проиллюстрирован пример входных изображений двух людей и аватаров, полученных способом согласно изобретению, в различных позах и по-разному ориентированных по отношению к камере.
Осуществление изобретения
Предлагаемое изобретение основано на использовании модели искусственного интеллекта, включающей в себя один или более нейросетевых слоев. Предлагаемый подход, также называемый в контексте настоящего изобретения нейросетевым рендерингом аватара пользователя, позволяет создавать трехмерные реалистичные аватары в полный рост или выполнять их рендеринг из одного или более изображений пользователя. Более конкретно, в способах согласно изобретению может быть использовано видеоизображение пользователя, но в принципе в соответствии с изобретением для рендеринга аватара пользователя может быть достаточно и одного или более фотоизображений.
В основе предлагаемого подхода лежит использование деформируемой трехмерной полигональной структуры (также называемой в контексте настоящего изобретения словом «меш» (от англ. mesh - сеть) или «трехмерной (3D) моделью «голого» человека»). В качестве неограничивающего примера, в качестве полигональной структуры может использоваться модель SMPL-X (см., например, источник [30]). Полигональная структура используется в изобретении, в частности, для моделирования и анимации общей геометрии тела аватара в 3D.
Поверх упомянутой трехмерной модели тела в предлагаемом изобретении применяется многоканальная нейросетевая текстура (для определения нейросетевой текстуры см., например, источник [38]) и нейросеть рендеринга, которые в итоге позволяют формировать изображения аватара пользователя с одеждой и волосами.
Создание аватара пользователя может осуществляться путем подстройки нейросетевой текстуры и параметров нейросети рендеринга под набор изображений пользователя, выполняемой с целью обучения нейросетевой текстуры и/или нейросети рендеринга. Подстройка параметров происходит при помощи градиентной оптимизации, причем градиент расхождения между предсказанными и действительным изображениями подсчитывается по методу обратного распространения ошибки. При подобном создании аватара количество изображений пользователя должно быть достаточно большим (в частности, пользователь должен быть сфотографирован со всех ракурсов).
Таким образом, первый вклад изобретения по отношению к уровню техники состоит в том, что сочетание деформируемой трехмерной полигональной структуры и нейросетевых текстур («нейротекстур») позволяет моделировать внешний вид аватара пользователя в полный рост при наличии свободной одежды и волос у аватара и позволяет учитывать геометрические особенности трехмерного аватара пользователя, отсутствующие в параметрических моделях тела пользователя.
Второй вклад изобретения в уровень техники состоит в обеспечении возможности создания или рендеринга трехмерного аватара пользователя в желаемой позе и/или с желаемого ракурса на основании всего лишь одного или более фотоизображений пользователя благодаря использованию порождающей модели.
В соответствии с одним аспектом настоящего изобретения предложен способ создания аватара пользователя, содержащий этапы, на которых: получают входные данные в виде одного или более кадров изображения пользователя; извлекают из полученных входных данных параметры s формы тела, характеризующие форму тела пользователя, параметры p позы, характеризующие позу пользователя на одном или более кадрах изображения пользователя, и параметры C камеры, характеризующие ракурс, с которого сняты упомянутые один или более кадров изображения пользователя; формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя; формируют L-канальную нейросетевую текстуру, характеризующую особенности внешности пользователя, на основе обработки упомянутых одного или более кадров изображения пользователя; накладывают L-канальную нейросетевую текстуру на деформируемую полигональную структуру; выполняют рендеринг аватара пользователя в новой позе и/или с нового ракурса посредством нейросети рендеринга; и производят подстройку (обучение) параметров нейросети рендеринга и нейросетевой текстуры, путем их подстройки для достижениядобиваясь соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя из полученных входных данных.
В соответствии с другим аспектом настоящего изобретения предложен рендеринга аватара пользователя, содержащий этапы, на которых: получают входные данные в виде параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу аватара, параметров C камеры, характеризующих ракурс, с которого должен быть изображен аватар; формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя; накладывают обученную L-канальную нейросетевую текстуру на деформируемую полигональную структуру; и выполняют рендеринг аватара пользователя в новой позе и/или с нового ракурса посредством обученной нейросети рендеринга, причем обучение нейросетевой текстуры и нейросети рендеринга осуществляется путем подстройки параметров нейросетевой текстуры и нейросети рендеринга для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя.
Нейросеть рендеринга, применяемая в способах согласно изобретению, предпочтительно имеет сверточную архитектуру. Следует понимать, что специалистам в данной области техники могут быть очевидны и другие архитектуры нейросетей, пригодные для применения в практической реализации настоящего изобретения.
В качестве неограничивающего примера, число L каналов L-канальной нейросетевой текстуры равно 16. Однако данное число каналов нейросетевой текстуры соответствует одному предпочтительному варианту выполнения изобретения, и число каналов нейросетевой текстуры в контексте настоящего изобретения не ограничено данным значением, а может составлять большее или меньшее число каналов. Параметры нейросети рендеринга обучаются совместно с порождающей моделью L-канальных нейросетевых текстур, и L-канальная нейросетевая текстура аватара получается посредством вывода в обученной порождающей модели и дальнейшей подстройки, как будет подробно описано ниже. Обучение нейросети рендеринга и порождающей модели L-канальных нейросетевых текстур осуществляется по принципу состязательных сетей.
Ключевым компонентом предлагаемого решения является генерирующая (порождающая) нейросеть для создания нейротекстуры аватара пользователя. Генерирующая нейросеть основана, в качестве неограничивающего примера, на генераторе StyleGANv2 (см., например, источник [20]). Таким образом, для построения трехмерной (3D) модели аватара пользователя в соответствии с предлагаемым изобретением требуются следующие три компонента: формирование (например, рендеринг) полигональной структуры, формирование нейротекстур и рендеринг посредством нейросети рендеринга. Эти три компонента согласно изобретению по существу объединены в один общий процесс, который обучается состязательным методом на основе большого набора данных изображений людей в полный рост.
Кроме того, в соответствии с изобретением решается задача обеспечения того, чтобы внешний вид формируемого аватара оставался неизменным в различных позах и ракурсах, что обеспечивается дополнительной дискриминаторной нейросетью, а также посредством модификации процесса обучения вышеупомянутого процесса, состоящего из указанных трех компонентов.
Далее будет рассмотрен первый из вышеуказанных компонентов процесса согласно изобретению, а именно формирование полигональной структуры, соответствующей в общем трехмерной модели тела человека, которая используется в качестве основы для рендеринга аватара пользователя. Как указано выше, данную полигональную структуру также можно назвать по существу моделью «голого» человека в том смысле, что она соответствует обобщенной трехмерной модели тела человека без учета волос, одежды и т.п.
Рассматриваемую полигональную структуру можно также назвать полигональной структурой с фиксированной топологией, которая управляется параметрами позы и одним или более векторами параметров формы тела, полученными в качестве входных данных по результатам обработки одного или более входных изображений. Для формирования полигональной структуры используются параметры позы, формы тела из входных данных, получаемых в виде последовательности изображений, таких как видеоизображение пользователя или по меньшей мере одно фотоизображение пользователя.
Ниже будет описан процесс согласно изобретению в одном или более вариантах выполнения, в которых формирование деформируемой полигональной структуры сочетается с формированием нейротекстуры и применением нейросети рендеринга для получения аватара пользователя на основе входного видеоизображения.
Модель деформируемой полигональной структуры (также называемая в контексте данного изобретения моделью «голого» человека), которая может быть основана, в качестве неограничивающего примера, на известной модели SMPL-X, формирует полигональную структуру с фиксированной топологией  , управляемую вектором параметров p позы и вектором параметров s формы тела. К полигональной структуре с фиксированной топологией может быть применена заданная функция нейротекстурирования, определяемая как R(M;T;C), в которой задействована полигональная структура с фиксированной топологией M, L-канальная нейротекстура T и камера C, при этом результатом работы этой функции нейротекстурирования является L-канальное растрирование полигональной структуры с нейротекстурой с использованием z-буферного алгоритма.
, управляемую вектором параметров p позы и вектором параметров s формы тела. К полигональной структуре с фиксированной топологией может быть применена заданная функция нейротекстурирования, определяемая как R(M;T;C), в которой задействована полигональная структура с фиксированной топологией M, L-канальная нейротекстура T и камера C, при этом результатом работы этой функции нейротекстурирования является L-канальное растрирование полигональной структуры с нейротекстурой с использованием z-буферного алгоритма.
В качестве нейротекстуры в предлагаемом изобретении используется L-канальная текстура T, которая, в качестве неограничивающего примера, имеет число каналов L=16. Следует отметить, однако, что число каналов в нейротекстуре не ограничено 16, и может быть использовано другое меньшее или большее целое положительное число каналов. L-канальная нейротекстура используется для кодирования локальной фотометрической и геометрической информации (включая особенности геометрии модели аватара данного пользователя, которые отсутствуют в параметрической деформируемой полигональной структуре.
Далее к нейротекстуре, нанесенной поверх деформируемой полигональной структуры, применяется нейросеть рендеринга f с обучаемыми параметрами для преобразования результата функции нейротекстурирования (в виде растрированного изображения) R в четырехканальное изображение I того же размера, в котором первые три канала соответствуют красному, зеленому и синему (RGB) цветовым каналам, а четвертый канал соответствует маске переднего плана.
В предлагаемом изобретении аватар A характеризуется параметрами sA формы тела и нейротекстурой TA. Путем использования предварительно обученной нейросети рендеринга fΘ может быть выполнен рендеринг аватара пользователя для произвольной позы p и произвольных параметров камеры (иными словами, ракурса или точки обзора, из которой зритель «смотрит» на аватар) C. В качестве неограничивающего примера, в соответствии с настоящим изобретением процесс рендеринга трехмерного аватара пользователя выполняется со скоростью около 25 кадров в секунду при разрешении изображений в один мегапиксель.
Нейросеть рендеринга предварительно обучается при помощи следующего процесса. При наличии коллекции видеоизображений нескольких людей может быть выполнен рендеринг их аватаров посредством приспособления нейросетевой модели согласно изобретению. Так, предположим, что для человека i, имеется набор кадров видеоизображения 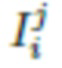 , где
, где  . Выполняется сегментирование человека и фона, например, с применением способа, описанного в источнике [11]. Следует отметить, что данный способ сегментирования указан исключительно в качестве неограничивающего примера, и могут также применяться и другие способы сегментирования, которые будут очевидны специалистам в данной области техники.
. Выполняется сегментирование человека и фона, например, с применением способа, описанного в источнике [11]. Следует отметить, что данный способ сегментирования указан исключительно в качестве неограничивающего примера, и могут также применяться и другие способы сегментирования, которые будут очевидны специалистам в данной области техники.
Далее применяются параметры формы тела Si и параметры позы 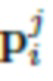 , а также параметры камеры
, а также параметры камеры 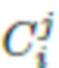 , которые соответствуют отдельным кадрам. Применение этих параметров с адаптацией к конкретной модели основано, в качестве неограничивающего примера, на модифицированном алгоритме SMPLify-X (см., например, источник [30]), который накладывает ограничения на параметры формы тела, которые должны быть общими для множества кадров.
, которые соответствуют отдельным кадрам. Применение этих параметров с адаптацией к конкретной модели основано, в качестве неограничивающего примера, на модифицированном алгоритме SMPLify-X (см., например, источник [30]), который накладывает ограничения на параметры формы тела, которые должны быть общими для множества кадров.
Затем выполняется оптимизация параметров нейросети рендеринга, а также нейротекстур Ti для всех людей из коллекции видеоизображений с использованием обратного распространения ошибки путем минимизации функции перцептуальных потерь (см., например, источник [17]), функции состязательных потерь (см., например, источник [16]) и функции потерь на сопоставление признаков (см., например, источник [40]) между контрольными изображениями 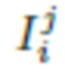 и изображениями, полученными путем рендеринга .
и изображениями, полученными путем рендеринга .
Упомянутые функции потерь используются при этом для заполнения цветовых каналов, в то время как для контрольных изображений и прогнозируемых масок используется функция потерь на перекрестную энтропию. Важно отметить, что при прогнозировании маски все пиксели, относящиеся к параметрической модели тела, назначаются переднему плану.
Предварительное обучение нейросети рендеринга на основе коллекции видеоизображений нескольких людей позволяет выполнять рендеринг аватара пользователя на основе по меньшей мере одного входного видеоизображения. Так, в качестве неограничивающего примера, в одной практической реализации способа согласно изобретению выполняли предварительное обучение нейросети рендеринга на наборе данных от 56 людей, для которых были собраны многие тысячи кадров изображений. В итоге посредством использования предварительно обученной нейросети рендеринга, оценки позы, формы тела и параметров камеры для ограниченного количества кадров, изображающих пользователя, формирования нейротекстуры для данного пользователя и последующей оптимизации нейротекстуры посредством обратного распространения соответствующих функций потерь осуществлялось создание аватара. После создания аватара, осуществлялся рендеринг аватара для данного пользователя в различных позах и с различных ракурсов.
Выше изобретение было описано главным образом в отношении рендеринга аватара пользователя на основании видеоизображения данного пользователя, которое содержит большое количество кадров изображения пользователя. Однако изобретение не ограничено использованием видеоизображения пользователя в качестве входных данных, и в одном или более вариантах реализации в качестве входных данных для рендеринга аватара пользователя достаточно использования небольшого количества (одного или более) фотоизображений данного пользователя. В этом случае в дополнение к вышеописанным средствам в изобретении применяется порождающая (генерирующая) модель, которая по существу является дополнением к описанному выше процессу нейросетевого рендеринга аватара пользователя.
Обучение аватара по методу обратного распространения ошибок позволяет получать аватары из относительно коротких видеоизображений или даже из нескольких соответствующим образом распределенных кадров фотоизображения (так, чтобы каждая часть поверхности пользователя была показана по меньшей мере на одном виде). В некоторых практических вариантах осуществления может быть реализован рендеринг аватара в полный рост из одного изображения пользователя в наиболее информативной позе. Однако для реализации этого системе, реализующей процесс согласно изобретению, необходимо иметь возможность оценивать ту часть аватара, которая скрыта на этом изображении. Для решения данной задачи в одном или более вариантах выполнения изобретения и применяется порождающая модель для нейротекстур, которая может быть использована при рендеринге аватара пользователя на основе одного или более кадров фотоизображения пользователя.
Используемая порождающая (генерирующая) модель, названная авторами настоящего изобретения моделью StylePeople, основана на разработках в области применения нейросетей в моделировании двухмерных изображений с высоким разрешением (см., например, источники [18, 7, 19]), и в частности она является дальнейшим развитием известной нейросетевой модели Style-GANv2 (см., например, источник [20]). Следует отметить, что при обучении порождающей модели используется попарный дискриминатор, который гарантирует соответствие между позами для одного и того же аватара.
Модель Style-GANv2 (см., например, источник [20]) в общем применяется для моделирования изображений с высоким разрешением. Осуществляется обучение многослойного перцептрона (MLP) 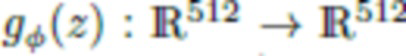 и сверточной нейросети
и сверточной нейросети 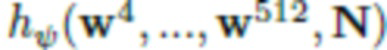 , которая принимает в качестве входных данных набор из 512-мерных «стилевых векторов», управляющих генерацией с различными величинами разрешающей способности (от 4×4 до 512×512) посредством механизма модуляции-демодуляции. Кроме того, используется также набор из N «шумовых карт» с упомянутыми величинами разрешающей способности. В результате получается порождающая модель
, которая принимает в качестве входных данных набор из 512-мерных «стилевых векторов», управляющих генерацией с различными величинами разрешающей способности (от 4×4 до 512×512) посредством механизма модуляции-демодуляции. Кроме того, используется также набор из N «шумовых карт» с упомянутыми величинами разрешающей способности. В результате получается порождающая модель 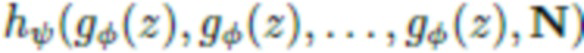 , в которой случайный вектор z обрабатывается посредством многослойного перцептрона (MLP) и затем используется в качестве входных данных в нейросеть рендеринга.
, в которой случайный вектор z обрабатывается посредством многослойного перцептрона (MLP) и затем используется в качестве входных данных в нейросеть рендеринга.
В основе алгоритма предсказания (вывода) в используемой порождающей модели для получения аватара пользователя из одного или более фотоизображений лежит так называемое расширенное пространство генерации (см., например, источники [19, 1]), обучение вспомогательных кодирующих нейростей (см., например, источники [20, 26]), использование потерь на сопоставление признаков в дискриминаторе (см., например, источник [29]), а также точная настройка порождающей модели для достижения наилучшего соответствия (см., например, источники [47, 5, 29]).
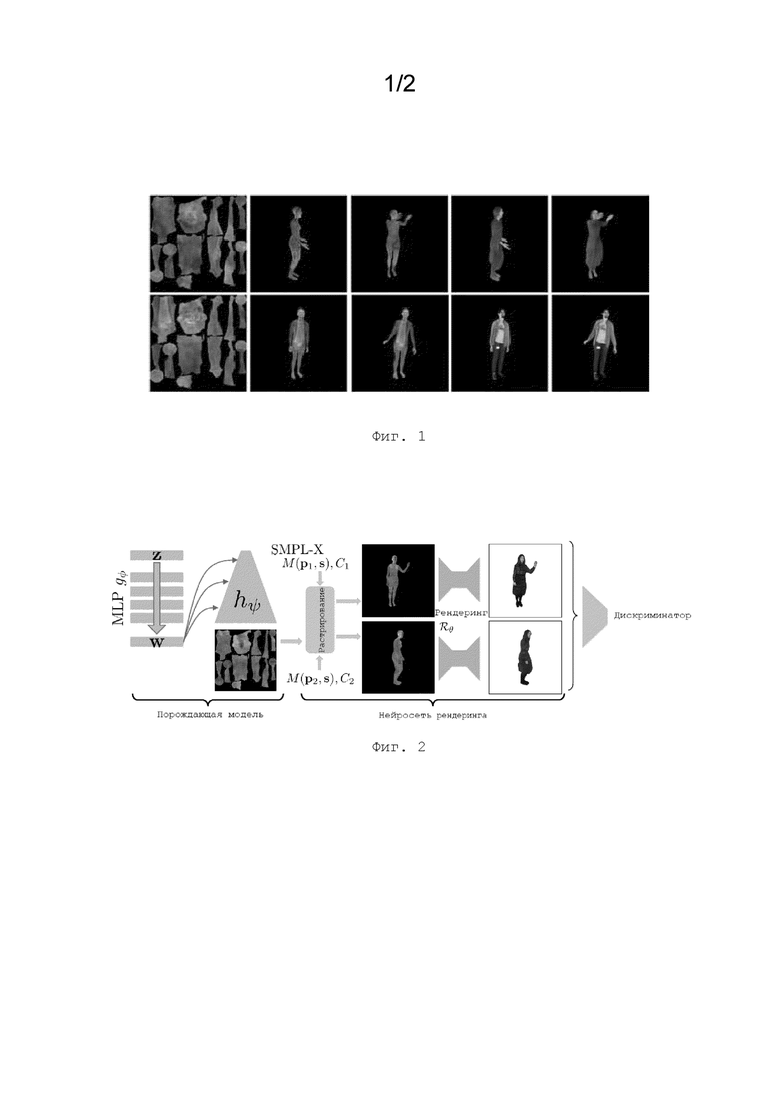
На Фиг. 2 проиллюстрирован примерный вариант выполнения изобретения, в котором используется порождающая модель, основанная на упомянутой выше модели StyleGANv2, а также нейросеть рендеринга, описанная выше. В данном случае порождающая модель используется для формирования нейротекстур, которые накладываются на полигональные структуры SMPL-X, после чего выполняется обработка сочетания нейротекстур и полигональной структуры посредством упомянутой нейросети рендеринга. Также на Фиг. 2 показан дискриминатор, который задействуется на этапе состязательного обучения нейросети рендеринга и который оценивает пару изображений одного и того же человека.
Порождающая модель согласно рассматриваемому варианту выполнения изобретения имеет два существенных отличия от известной модели StyleGANv2 по источнику [20]. Во-первых, как указано выше, в данном случае она выводит L-канальную нейротекстуру, а не RGB-изображение. Во-вторых в предлагаемом подходе выполняется конкатенация входных данных нескольких последующих слоев нейросети рендеринга с 16-канальной картой спектральных координат для вершин полигональной структуры, преобразованных в пространство нейротекстур, для обеспечения генератору определенной информации о топологии частей нейротекстуры. При обучении также производится выборка поз и форм тела из обучающего набора данных, а также наложение формируемых нейротекстур на деформируемые полигональные структуры модели «голого» человека. Затем получаемые полигональные структуры с наложенными нейротекстурами обрабатываются нейросетью рендеринга, которая обучена в качестве части порождающей модели.
В общем случае, изображения, формируемые порождающей моделью, вычисляются с использованием следующего выражения:
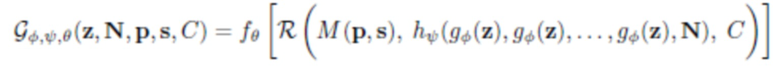 , (1)
, (1)
где z и N - переменные, которые выбираются из единичных нормальных распределений, в то время как переменные, характеризующие позу, камеру и формы тела, выбираются из эмпирического распределения в наборе обучающих данных.
Состязательное обучение нейросетевой модели искусственного интеллекта осуществляется под управлением дискриминатора, аналогичного используемому в архитектуре StyleGANv2, однако в общем случае в процессе согласно изобретению используется несколько типов дискриминаторов:
1) Унарный дискриминатор в общем соответствует применяемому в известной модели Style-GANv2, и он основан на использовании отдельных изображений (как сформированных порождающей моделью, так и реальных изображений) и главным образом применяется для оценки качества изображений.
2) Бинарный дискриминатор основан в общем на той же известной модели, но в нем используются пары изображений, а не единичные отдельные изображения. Каждый «настоящий» пример берется из двух сегментированных кадров одного видеоизображения с сегментацией. Для получения «поддельного» примера формируются два экземпляра - 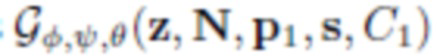 и
и 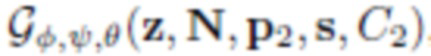 , где z, N (и, соответственно, нейротекстура), а также параметры s формы тела являются общими для обоих экземпляров. Параметры p1, p2 позы и положения C1, C2 камеры являются различными в каждой паре изображений и соответствуют двум кадрам одного и того же видеоизображения. Таким образом, назначение дискриминатора состоит как в оценке визуальной «реалистичности» примеров, так и в обеспечении сохранения идентичности при смене положения камеры и смене позы.
, где z, N (и, соответственно, нейротекстура), а также параметры s формы тела являются общими для обоих экземпляров. Параметры p1, p2 позы и положения C1, C2 камеры являются различными в каждой паре изображений и соответствуют двум кадрам одного и того же видеоизображения. Таким образом, назначение дискриминатора состоит как в оценке визуальной «реалистичности» примеров, так и в обеспечении сохранения идентичности при смене положения камеры и смене позы.
3) Дискриминатор лиц использует отдельные изображения, полученные кадрированием вокруг области лица (как для настоящих изображений, так и для синтезированных) и используется для повышения качества рендеринга лиц в порождающей модели.
При обучении модели искусственного интеллекта в способе согласно изобретению может выполняться дополнительный этап регуляризации для обеспечения сохранения идентичности, поскольку одно только использование попарного дискриминатора является недостаточным. При регуляризации используются три дополнительных технических приема. Первый прием состоит в обучении предиктора 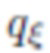 , который использует сформированные изображения
, который использует сформированные изображения 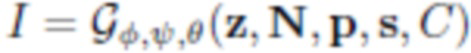 и пытается восстановить вектор
и пытается восстановить вектор 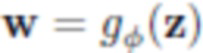 . Потери при обучении
. Потери при обучении 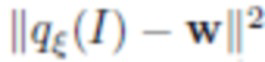 компенсируются путем обратного распространения ошибки по всей порождающей модели, что гарантирует целостность изображений, формируемых с использованием одной и той же нейротекстуры.
компенсируются путем обратного распространения ошибки по всей порождающей модели, что гарантирует целостность изображений, формируемых с использованием одной и той же нейротекстуры.
Второй прием в регуляризации состоит в том, чтобы гарантировать, что нейросеть рендеринга является ковариантной по отношению к геометрическому преобразованию ее входных данных в пределах определенной плоскости. Это обеспечивается тем, что к растрированным изображениям 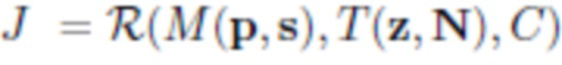 применяют случайное жесткое преобразование Tr в пределах некоторой плоскости, обрабатывают исходные и преобразованные входные данные посредством сети
применяют случайное жесткое преобразование Tr в пределах некоторой плоскости, обрабатывают исходные и преобразованные входные данные посредством сети 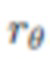 рендеринга, после чего применяют штрафную функцию к разности между
рендеринга, после чего применяют штрафную функцию к разности между 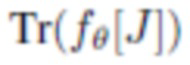 и
и 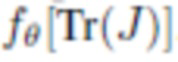 .
.
Наконец, третий прием выполняется для снижения влияния плохо сегментированных изображений из набора обучающих данных, а также тех изображений, где по меньшей мере часть тела пользователя не видна, маски переднего плана в формируемых выборках принудительно покрывают всю полигональную структуру, полученную в качестве входных данных. Для этого в качестве окончательной сегментации переднего плана вместо дискретизированнной маски сегментирования используется ее сочетание с бинарной маской полигональной структуры.
Как указано выше, предлагаемая порождающая модель может использоваться для создания и/или рендеринга аватаров реальных пользователей на основании одного или более (нескольких) фотоизображений. Так, при наличии одного изображения человека в полный рост оценивается маска сегментирования, параметры p позы и параметры s формы тела, а также параметры C камеры. Затем минимизируются потери на адаптацию между сегментированным входным изображением и полученным посредством рендеринга 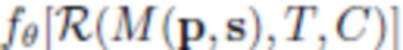 изображением путем регулирования получаемой текстуры при помощи обратного распространения ошибки. При наличии изображения человека I (с оцененной маской сегментирования) оцениваются параметры s формы тела, параметры p позы для полигональной структуры SMPL-X, и параметры камеры C. Целью дальнейшей обработки является формирование такой нейротекстуры T, при которой нейросеть рендеринга выдает изображение, которое соответствует наблюдаемому изображению. Параметризация нейротекстуры осуществляется посредством сверточного генератора
изображением путем регулирования получаемой текстуры при помощи обратного распространения ошибки. При наличии изображения человека I (с оцененной маской сегментирования) оцениваются параметры s формы тела, параметры p позы для полигональной структуры SMPL-X, и параметры камеры C. Целью дальнейшей обработки является формирование такой нейротекстуры T, при которой нейросеть рендеринга выдает изображение, которое соответствует наблюдаемому изображению. Параметризация нейротекстуры осуществляется посредством сверточного генератора 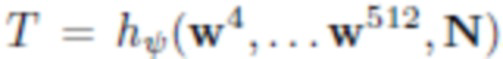 , и таким образом оптимизация выполняется по отношению к 512-мерным «стилевым векторам» w4,... w512 и тензорам шума N. Стилевые векторы инициализируются выходными данными предиктора
, и таким образом оптимизация выполняется по отношению к 512-мерным «стилевым векторам» w4,... w512 и тензорам шума N. Стилевые векторы инициализируются выходными данными предиктора 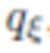 , и в процессе оптимизации применяется регуляризация тензоров шума N. При необходимости, в качестве последнего этапа оптимизации выполняется тонкая регулировка параметров
, и в процессе оптимизации применяется регуляризация тензоров шума N. При необходимости, в качестве последнего этапа оптимизации выполняется тонкая регулировка параметров 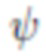 порождающей модели
порождающей модели 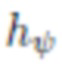 . Параметры
. Параметры  нейросети рендеринга не изменяются процессом адаптации.
нейросети рендеринга не изменяются процессом адаптации.
В одном или более конкретных вариантах выполнения настоящего изобретения процесс оптимизации получает на входе набор изображений одного и того же человека I, и более конкретно 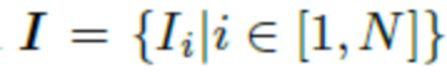 . Инициализируются латентные переменные w путем пропускания изображений I через одну или более предварительно обученных кодирующих нейросетей. Если доступно более одного изображения на входе (т.е. N > 1), прогнозируемые латентные переменные усредняются для всей совокупности изображений. Для простоты рассмотрим пример, в котором на входе имеется только одно изображение I. Оптимизация выполняется по (i) латентным переменным w, (ii) параметрам генератора h, и (iii) тензорам шума N для дополнительной минимизации различия между полученным изображением
. Инициализируются латентные переменные w путем пропускания изображений I через одну или более предварительно обученных кодирующих нейросетей. Если доступно более одного изображения на входе (т.е. N > 1), прогнозируемые латентные переменные усредняются для всей совокупности изображений. Для простоты рассмотрим пример, в котором на входе имеется только одно изображение I. Оптимизация выполняется по (i) латентным переменным w, (ii) параметрам генератора h, и (iii) тензорам шума N для дополнительной минимизации различия между полученным изображением 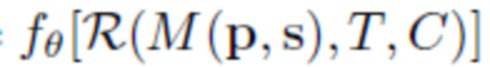 и I. В качестве последнего этапа оптимизации выполняется непосредственная оптимизация значений нейротекстуры только за 100 итераций.
и I. В качестве последнего этапа оптимизации выполняется непосредственная оптимизация значений нейротекстуры только за 100 итераций.
При оптимизации используется множество функций потерь, например функция потерь LPIPS (см. источник [48]) между полученным изображением и входным изображением, среднеквадратическое отклонение (Mean Squared Error (MSE)) между полученным изображением и входным изображением, средняя абсолютная ошибка (Mean Absolute Error (MAE)) в отклонении латентных переменных w от значений при инициализации, прогнозируемых кодирующей нейросетью, MAE в отклонении параметров генератора h от исходных значений, MAE в отклонении нейротекстуры от значений нейротекстуры, оптимизированных в начале упомянутого последнего этапа, функция потерь LPIPS ([48]) для областей лица в полученных и входных изображениях, функция потерь при сопоставлении признаков, основанная на обученном дискриминаторе лиц (см. источник [29]). В случае, если на входе доступно несколько изображений, функции потерь усредняются по всей совокупности изображений.
Если параметризация текстуры является избыточной (т.е. количество элементов нейротекстуры обычно превышает количество наблюдений в I), для адаптации к наблюдаемому изображению доступны очень различные наборы латентных переменных, которые приводят к различным уровням обобщения по отношению к новым позам и параметрам камеры.
При этом в одном или более конкретных вариантах выполнения настоящего изобретения используется обучение так называемых кодирующих нейросетей, которые инициализируют латентные переменные w для получения хорошего обобщения по отношению к новым позам и параметрам камеры. Для этого на основе порождающей модели для генерации нейротекстур формируется набор данных синтетических выборок. В частности, для получения k-ой выборки случайным и независимым образом получаются значения 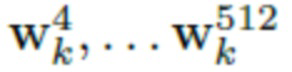 посредством выборки z значений и их обработки посредством перцептрона. Тензоры шума получают из нормального распределения, и сверточный генератор формирует случайную нейротекстуру. Затем нейротекстура накладывается на случайное изображение тела из обучающей выборки, находящегося в позе, приближенной к «А»-образной позе и снятое по существу фронтально расположенной камерой.
посредством выборки z значений и их обработки посредством перцептрона. Тензоры шума получают из нормального распределения, и сверточный генератор формирует случайную нейротекстуру. Затем нейротекстура накладывается на случайное изображение тела из обучающей выборки, находящегося в позе, приближенной к «А»-образной позе и снятое по существу фронтально расположенной камерой.
Затем нейросеть рендеринга формирует изображение Ik для случайного аватара в «A»-образной позе. После этого обучается так называемая А-кодирующая нейросеть 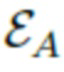 для восстановления векторов
для восстановления векторов 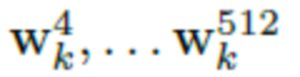 из изображения Ik, который обучается посредством функции потерь L1 на синтетических данных, полученных только от порождающей модели, описанной выше.
из изображения Ik, который обучается посредством функции потерь L1 на синтетических данных, полученных только от порождающей модели, описанной выше.
В дополнение к вышеупомянутой A-кодирующей нейросети, обучаемой только на синтетических данных и пригодной для изображений аватаров в «А»-образной позе, в одном или более вариантах выполнения изобретения может дополнительно обучаться «общая» кодирующая нейросеть (так называемая G-кодирующая нейросеть), обучение которой основано как на синтетических данных, так и на реальном поднаборе пар кадров из видеоизображения. Для обучения на основе реальных данных G-кодирующая нейросеть 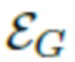 получает пары реальных изображений
получает пары реальных изображений 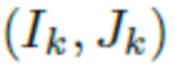 , извлеченных из одного и того же видеоизображения одного и того же человека, прогнозирует латентные переменные
, извлеченных из одного и того же видеоизображения одного и того же человека, прогнозирует латентные переменные 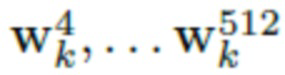 на основании
на основании 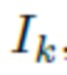 , дополняет их случайными тензорами шума N, в результате чего получается нейротекстура
, дополняет их случайными тензорами шума N, в результате чего получается нейротекстура 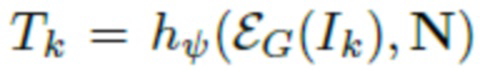 , которая далее накладывается на полигональную структуру, которая деформируется для создания определенной позы, после чего выполняется рендеринг на основании параметров SMPL-X
, которая далее накладывается на полигональную структуру, которая деформируется для создания определенной позы, после чего выполняется рендеринг на основании параметров SMPL-X 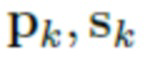 и параметров камеры
и параметров камеры 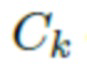 , полученных из изображения
, полученных из изображения 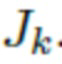 . Затем применяется упомянутая выше функция потерь LPIPS между и
. Затем применяется упомянутая выше функция потерь LPIPS между и 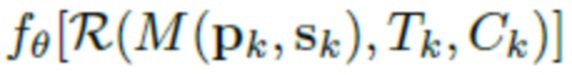 , которая используется в качестве функции потерь по отношению к реальным данным. К синтетическим данным, аналогично описанной выше кодирующей нейросети
, которая используется в качестве функции потерь по отношению к реальным данным. К синтетическим данным, аналогично описанной выше кодирующей нейросети  , используется функция потерь L1 между синтетическими и прогнозируемыми латентными векторами. Эти две функции потерь равным образом суммируются для обучения параметров кодирующей нейросети
, используется функция потерь L1 между синтетическими и прогнозируемыми латентными векторами. Эти две функции потерь равным образом суммируются для обучения параметров кодирующей нейросети 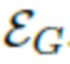 .
.
Основной смысл применения кодирующих нейросетей состоит в том, что каждый уровень кодирующей нейросети прогнозирует латентный вектор, соответствующий разрешению генератора на данном уровне. За основу обучаемых кодирующих нейросетей авторами изобретения принята сеть EfficientNet-B7 (см., например, источник [37]), предварительно обученная на основе ImageNet (см., например, источник [32]).
За счет использования в способе согласно изобретению полигональной структуры с наложенной на нее нейротекстурой и ее обработки посредством нейросети рендеринга, обученной на основе порождающей модели, достигается технический эффект, состоящий в обеспечении рендеринга аватара пользователя с возможностью его анимации на основании параметров позы тела, включая параметры мимики и положения рук. В результате получается реалистичное видеоизображение трехмерной модели аватара пользователя.
Предлагаемое решение согласно изобретению может быть реализовано с использованием любого вычислительного устройства, обладающего достаточной вычислительной мощностью (например, графического процессора GPU)) и экраном дисплея. В качестве неограничивающего примера, в настоящем изобретении также предложены система для создания аватара пользователя и система рендеринга аватара пользователя, содержащие память, в которой сохранены компьютерные программные команды, и один или более процессоров, которые, под управлением упомянутых компьютерных программных команд, выполнен(ы) с возможностью реализации функций, соответствующих этапам способов создания аватара пользователя и рендеринга аватара пользователя на основе описанных выше средств и методов.
Специалистам в данной области техники будут очевидны различные сочетания аппаратных и программных средств, которые могут реализовывать систему согласно второму аспекту настоящего изобретения. Как указано выше, система содержит один или более процессоров, в качестве неограничивающего примера - один или более графических процессоров (GPU), а также память (постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM) и т.п.), сохраняющую компьютерные программные команды для реализации соответствующих алгоритмов обработки и других операций, описанных выше для способа по первому аспекту настоящего изобретения. Специалистам в данной области техники будет очевидно, что упомянутые программные команды могут быть реализованы на любом подходящем языке программирования и/или с использованием любой подходящей среды программирования, в виде машиноисполняемого кода и т.п. Кроме того, компьютерные программные команды, управляющие одним или более процессорами для реализации способа согласно изобретению могут быть сохранены на любом подходящем виде машиночитаемого носителя, такого как постоянный машиночитаемый носитель, энергозависимый и/или энергонезависимый машиночитаемый носитель, а также могут быть переданы по любой подходящей проводной и/или беспроводной сети передачи данных. Обработка для выполнения алгоритмов, лежащих в основе способа согласно изобретению, может выполняться на основе одного или более компьютеров общего пользования, расположенных в одном месте или распределенных и соединенных одной или более сетями передачи данных и т.п. Кроме одного или более процессоров могут также использоваться одна или более программируемых логических интегральных схем (FPGA), один или более микропроцессоров и т.п. Объем изобретения не ограничен каким-либо конкретным сочетанием программных и/или аппаратных средств для реализации вышеописанных алгоритмов.
Для создания и/или рендеринга аватаров необходимы входные данные в виде фото- и видеоизображений. Для анализа изображений, а также для реализации одной или более нейросетей, лежащих в основе настоящего изобретения, может использоваться соответствующее программное обеспечение или микропрограммное обеспечение, которое может быть реализовано в виде одной или более компьютерных программ, компьютерных программных элементов, программных модулей и т.п. Упомянутое программное обеспечение может быть сохранено в одном или более элементах памяти системы согласно второму аспекту изобретения.
Изобретение может быть применено в различных сценариях реализации виртуального «удаленного присутствия» пользователя, в частности, в системах дополненной и виртуальной реальности (AR/VR), видеоиграх, телеконференциях, отображении на трехмерных (3D) дисплеях и т.п. Кроме того, изобретение может также применяться в любых сценариях отображения изображений пользователей на обычных двумерных (2D) дисплеях. В отличие от известных решений, предлагаемое изобретение реализует рендеринг изображений на основе нейросетевой модели искусственного интеллекта для формирования по меньшей мере одного изображения аватара пользователя в другой позе и/или с другого ракурса по сравнению со входными изображениями, с отображением таких элементов изображения аватара пользователя, как одежда и/или волосы, поверх модели тела, основанной на параметрической полигональной структуры, а также на основе сочетания глубоких порождающих моделей для двумерных (2D) изображений, применяемых для формирования текстур на основе нейросетей, и нейросетевого рендеринга.
Способы согласно изобретению могут быть реализованы посредством электронного устройства и/или системы, способных реализовывать нейросети, описанные выше.
В отличие от известных решений из уровня техники, в которых требуется по меньшей мере несколько десятков изображений для каждой сцены, в соответствии с настоящим изобретением предлагается использование деформируемой полигональной структуры (т.н. модели «голого» человека) с наложенной на нее L-канальной нейротекстурой, моделирующей особенности строения тела, а также одежду, волосы и т.п., с последующей обработкой посредством нейросети рендеринга. Использование порождающей модели, как описано выше, позволяет создавать фотореалистичный аватар пользователя на основании нескольких кадров фото- или видеоизображения.
Специалистам в данной области техники будет понятно, что выше описаны и показаны на чертежах лишь некоторые из возможных примеров технических приемов и материально-технических средств, которыми могут быть реализованы варианты выполнения настоящего изобретения. Приведенное выше подробное описание вариантов выполнения изобретения не предназначено для ограничения или определения объема правовой охраны настоящего изобретения.
Другие варианты выполнения, которые могут входить в объем настоящего изобретения, могут быть предусмотрены специалистами в данной области техники после внимательного прочтения вышеприведенного описания с обращением к сопровождающим чертежам, и все такие очевидные модификации, изменения и/или эквивалентные замены считаются входящими в объем настоящего изобретения. Все источники из уровня техники, приведенные и рассмотренные в настоящем документе, настоящим включены в данное описание путем ссылки, насколько это применимо.
При том, что настоящее изобретение описано и проиллюстрировано с обращением к различным вариантам его выполнения, специалистам в данной области техники будет понятно, что в нем могут быть выполнены различные изменения в его форме и конкретных подробностях, не выходящие за рамки объема настоящего изобретения, который определяется только нижеприведенной формулой изобретения и ее эквивалентами.
Список литературы
[1] Rameen Abdal, Yipeng Qin и Peter Wonka. Image2stylegan: How to embed images into the stylegan latent space? Опубликовано в Proc. ICCV, стр. 4432-4441, 2019.
[2] Thiemo Alldieck, Marcus Magnor, Bharat Lal Bhatnagar, Christian Theobalt и Gerard Pons-Moll. Learning to reconstruct people in clothing from a single rgb camera. Опубликовано в Proc. CVPR, стр. 1175-1186, 2019.
[3] Thiemo Alldieck, Marcus Magnor, Weipeng Xu, Christian Theobalt и Gerard Pons-Moll. Video based reconstruction of 3d people models. Опубликовано в Proc. CVPR, стр. 8387-8397, 2018.
[4] Rıza Alp Güler, Natalia Neverova и Iasonas Kokkinos. Densepose: Dense human pose estimation in the wild. Опубликовано в Proc. CVPR, стр. 7297-7306, 2018.
[5] David Bau, Hendrik Strobelt, William S. Peebles, Jonas Wulff, Bolei Zhou, Jun-Yan Zhu и Antonio Torralba. Semantic photo manipulation with a generative image prior. ACM Trans. Graph., 38(4):59:1-59:11, 2019.
[6] Bharat Lal Bhatnagar, Garvita Tiwari, Christian Theobalt, and Gerard Pons-Moll. Multi-garment net: Learning to dress 3d people from images. Опубликовано в Proc. ICCV, стр. 5420-5430, 2019.
[7] Andrew Brock, Jeff Donahue и Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. Опубликовано в International Conference on Learning Representations, 2018.
[8] Vasileios Choutas, Georgios Pavlakos, Timo Bolkart, Dimitrios Tzionas и Michael J. Black. Monocular expressive body regression through body-driven attention. Опубликовано в Proc. ECCV, 2020.
[9] Haoye Dong, Xiaodan Liang, Ke Gong, Hanjiang Lai, Jia Zhu и Jian Yin. Soft-gated warping-gan for pose-guided person image synthesis. Опубликовано в Proc. NeurIPS, стр. 474-484, 2018.
[10] Patrick Esser, Ekaterina Sutter и Björn Ommer. A variational u-net for conditional appearance and shape generation. Опубликовано в Proc. CVPR, стр. 8857-8866, 2018.
[11] Ke Gong, Yiming Gao, Xiaodan Liang, Xiaohui Shen, Meng Wang и Liang Lin. Graphonomy: Universal human parsing via graph transfer learning. Опубликовано в Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, стр. 7450-7459, 2019.
[12] Artur Grigorev, Artem Sevastopolsky, Alexander Vakhitov и Victor Lempitsky. Coordinate-based texture inpainting for pose-guided image generation. Опубликовано в Proc. CVPR, 2019.
[13] Xintong Han, Xiaojun Hu, Weilin Huang и Matthew R Scott. Clothflow: A flow-based model for clothed person generation. Опубликовано в Proc. ICCV, стр. 10471-10480, 2019.
[14] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler и Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Опубликовано в I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan и R. Garnett, редакторы, Advances in Neural Information Processing Systems 30, стр. 6626-6637. 2017.
[15] Zeng Huang, Yuanlu Xu, Christoph Lassner, Hao Li и Tony Tung. Arch: Animatable reconstruction of clothed humans. arXiv preprint arXiv:2004.04572, 2020.
[16] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou и Alexei A. Efros. Image-to-image translation with conditional adversarial networks. Опубликовано в Proc. CVPR, 2017.
[17] Justin Johnson, Alexandre Alahi и Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. Опубликовано в Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, редакторы, Proc. ECCV, 2016.
[18] Tero Karras, Timo Aila, Samuli Laine и Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. Опубликовано в International Conference on Learning Representations, 2018.
[19] Tero Karras, Samuli Laine и Timo Aila. A style-based generator architecture for generative adversarial networks. Опубликовано в Proc. CVPR, стр. 4401-4410, 2019.
[20] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen и Timo Aila. Analyzing and improving the image quality of StyleGAN. CoRR, abs/1912.04958, 2019.
[21] Diederik P Kingma и Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
[22] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig и Vittorio Ferrari. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. IJCV, 2020.
[23] Christoph Lassner, Gerard Pons-Moll и Peter V Gehler. A generative model of people in clothing. Опубликовано в Proc. ICCV, стр. 853-862, 2017.
[24] Verica Lazova, Eldar Insafutdinov и Gerard Pons-Moll. 360-degree textures of people in clothing from a single image. Опубликовано в Proc. 3DV, стр. 643-653. IEEE, 2019.
[25] Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma и Shenghua Gao. Liquid warping gan: A unified framework for human motion imitation, appearance transfer and novel view synthesis. Опубликовано в Proc. ICCV, стр. 5904-5913, 2019.
[26] Elizaveta Logacheva, Roman Suvorov, Oleg Khomenko, Anton Mashikhin и Victor Lempitsky. Deeplandscape: Adversarial modeling of landscape videos. Опубликовано в Proc. ECCV, стр. 256-272. Springer, 2020.
[27] Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuytelaars и Luc Van Gool. Pose guided person image generation. Опубликовано в Proc. NeurIPS, стр. 406-416, 2017.
[28] Natalia Neverova, Riza Alp Guler и Iasonas Kokkinos. Dense pose transfer. Опубликовано в Proc. ECCV, стр. 123-138, 2018.
[29] Xingang Pan, Xiaohang Zhan, Bo Dai, Dahua Lin, Chen Change Loy и Ping Luo. Exploiting deep generative prior for versatile image restoration and manipulation. Proc. ECCV, 2020.
[30] Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas и Michael J. Black. Expressive body capture: 3d hands, face, and body from a single image. Опубликовано в Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019.
[31] Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro и Daniel Cohen-Or. Encoding in style: a stylegan encoder for image-to-image translation. arXiv preprint arXiv:2008.00951, 2020.
[32] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein и др. Imagenet large scale visual recognition challenge. IJCV, 115(3):211-252, 2015.
[33] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, Xi Chen и Xi Chen. Improved techniques for training gans. Опубликовано в D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, and R. Garnett, редакторы, Advances in Neural Information Processing Systems 29, стр. 2234-2242. 2016.
[34] Aliaksandra Shysheya, Egor Zakharov, Kara-Ali Aliev, Renat Bashirov, Egor Burkov, Karim Iskakov, Aleksei Ivakhnenko, Yury Malkov, Igor Pasechnik, Dmitry Ulyanov и др. Textured neural avatars. Опубликовано в Proc. CVPR, стр. 2387-2397, 2019.
[35] Aliaksandr Siarohin, Stéphane Lathuiliére, Sergey Tulyakov, Elisa Ricci и Nicu Sebe. First order motion model for image animation. Опубликовано в Proc. NeurIPS, стр. 7135-7145, 2019.
[36] Aliaksandr Siarohin, Enver Sangineto, Stéphane Lathuiliére и Nicu Sebe. Deformable gans for pose-based human image generation. Опубликовано в Proc. CVPR, стр. 3408-3416, 2018.
[37] Mingxing Tan и Quoc V Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019.
[38] Justus Thies, Michael Zollhöfer и Matthias Nießner. Deferred neural rendering: Image synthesis using neural textures. ACM Transactions on Graphics (TOG), 38(4):1-12, 2019.
[39] Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang и Jan Kautz. Mocogan: Decomposing motion and content for video generation. Опубликовано в Proc. CVPR, стр. 1526-1535, 2018.
[40] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz и Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. Опубликовано в Proc. CVPR, стр. 8798-8807. IEEE Computer Society, 2018.
[41] Ting-Chun Wang, Ming-Yu Liu, Andrew Tao, Guilin Liu, Bryan Catanzaro и Jan Kautz. Few-shot video-to-video synthesis. Опубликовано в Proc. NeurIPS, стр. 5014-5025, 2019.
[42] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz и Bryan Catanzaro. Video-to-video synthesis. Опубликовано в Proc. NeurIPS, стр. 1144-1156, 2018.
[43] Zhou Wang, Alan C. Bovik, Hamid R. Sheikh и Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600-612, 2004.
[44] Donglai Xiang, Hanbyul Joo и Yaser Sheikh. Monocular total capture: Posing face, body, and hands in the wild. In Proc. CVPR, 2019.
[45] Zhixuan Yu, Jae Shin Yoon, In Kyu Lee, Prashanth Venkatesh, Jaesik Park, Jihun Yu и Hyun Soo Park. Humbi: A large multiview dataset of human body expressions, 2020.
[46] Polina Zablotskaia, Aliaksandr Siarohin, Bo Zhao и Leonid Sigal. Dwnet: Dense warp-based network for poseguided human video generation. Опубликовано в Proc. BMVC, 2019.
[47] Egor Zakharov, Aliaksandra Shysheya, Egor Burkov и Victor Lempitsky. Few-shot adversarial learning of realistic neural talking head models. Опубликовано в Proc. ICCV, стр. 9459-9468, 2019.
[48] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman и Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. Опубликовано в Proc. CVPR, стр. 586-595, 2018.
[49] Kaiyang Zhou, Xiatian Zhu, Yongxin Yang, Andrea Cavallaro и Tao Xiang. Learning generalisable omni-scale representations for person re-identification. arXiv preprint arXiv:1910.06827, 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИСТАНЦИОННОГО ВЫБОРА ОДЕЖДЫ | 2020 |
|
RU2805003C2 |
| Способ построения представления сцены с прямой коррекцией для синтеза изображения в реальном времени | 2022 |
|
RU2799237C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |

Изобретение относится к средствам для создания и рендеринга трехмерной модели аватара пользователя и может быть применено в системах дополненной и виртуальной реальности, видеоиграх, телеконференциях. Технический результат заключается в обеспечении возможности создания или рендеринга фотореалистичного трехмерного аватара пользователя в желаемой позе и/или с желаемого ракурса на основании всего лишь одного или более фотоизображений пользователя. Способ рендеринга аватара содержит этапы, на которых: получают параметры s формы тела, характеризующие форму тела пользователя, параметры p позы, характеризующие желаемую позу аватара пользователя, и параметры C камеры, характеризующие желаемый ракурс; формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя; накладывают L-канальную нейросетевую текстуру, характеризующую особенности внешности пользователя; и выполняют рендеринг аватара пользователя посредством предварительно обученной нейросети рендеринга, причем обучение нейросетевой текстуры и нейросети рендеринга осуществляется путем подстройки параметров нейросетевой текстуры и нейросети рендеринга для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя. 6 н. и 10 з.п. ф-лы, 3 ил.
1. Способ создания аватара пользователя, содержащий этапы, на которых:
- получают входные данные в виде одного или более кадров изображения пользователя;
- извлекают из полученных входных данных параметры s формы тела, характеризующие форму тела пользователя, параметры p позы, характеризующие позу пользователя на одном или более кадрах изображения пользователя, и параметры C камеры, характеризующие ракурс, с которого сняты упомянутые один или более кадров изображения пользователя;
- формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя с использованием параметров s формы тела и параметров p позы;
- формируют L-канальную нейросетевую текстуру, характеризующую особенности внешности пользователя, на основе обработки упомянутых одного или более кадров изображения пользователя;
- накладывают L-канальную нейросетевую текстуру на деформируемую полигональную структуру;
- выполняют рендеринг аватара пользователя в новой позе и/или с нового ракурса посредством нейросети рендеринга и
- производят обучение параметров нейросети рендеринга и нейросетевой текстуры путем их подстройки для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя из полученных входных данных.
2. Способ по п. 1, в котором нейросеть рендеринга имеет сверточную архитектуру.
3. Способ по п. 1, в котором число L каналов L-канальной нейросетевой текстуры равно 16.
4. Способ по п. 1, в котором параметры нейросети рендеринга обучаются совместно с порождающей моделью L-канальных нейросетевых текстур и L-канальная нейросетевая текстура аватара получается посредством вывода в обученной порождающей модели и дальнейшей подстройки.
5. Способ по п. 4, в котором обучение нейросети рендеринга и порождающей модели L-канальных нейросетевых текстур осуществляется по принципу состязательных сетей.
6. Способ по п. 1, в котором нейросеть рендеринга определяется выражением 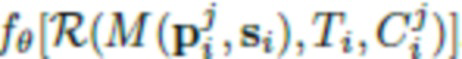 , где
, где 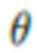 - параметры нейросети, R - функция нейротекстурирования, M - деформируемая полигональная структура, определяемая параметрами p позы и параметрами s формы тела, C - параметры камеры, T - L-канальная нейротекстура, i - пользователь, в отношении которого осуществляется создание аватара, j - номер изображения в наборе изображений
- параметры нейросети, R - функция нейротекстурирования, M - деформируемая полигональная структура, определяемая параметрами p позы и параметрами s формы тела, C - параметры камеры, T - L-канальная нейротекстура, i - пользователь, в отношении которого осуществляется создание аватара, j - номер изображения в наборе изображений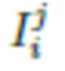 .
.
7. Способ рендеринга аватара пользователя, содержащий этапы, на которых:
- получают входные данные в виде параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу аватара, параметров C камеры, характеризующих ракурс, с которого должен быть изображен аватар;
- формируют деформируемую полигональную структуру в качестве трехмерной модели тела пользователя с использованием параметров s формы тела и параметров p позы;
- накладывают обученную L-канальную нейросетевую текстуру на деформируемую полигональную структуру и
- выполняют рендеринг аватара пользователя в новой позе и/или с нового ракурса посредством обученной нейросети рендеринга,
- причем обучение нейросетевой текстуры и нейросети рендеринга осуществляется путем подстройки параметров нейросетевой текстуры и нейросети рендеринга для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя.
8. Способ по п. 7, в котором нейросеть рендеринга имеет сверточную архитектуру.
9. Способ по п. 7, в котором число L каналов L-канальной нейросетевой текстуры равно 16.
10. Способ по п. 7, в котором параметры нейросети рендеринга обучаются совместно с порождающей моделью L-канальных нейросетевых текстур и L-канальная нейросетевая текстура аватара получается посредством вывода в обученной порождающей модели и дальнейшей подстройки.
11. Способ по п. 10, в котором обучение нейросети рендеринга и порождающей модели L-канальных нейросетевых текстур осуществляется по принципу состязательных сетей.
12. Способ по п. 1, в котором нейросеть рендеринга определяется выражением , где - параметры нейросети, R - функция нейротекстурирования, M - деформируемая полигональная структура, определяемая параметрами p позы и параметрами s формы тела, C - параметры камеры, T - L-канальная нейротекстура, i - пользователь, в отношении которого осуществляется создание аватара, j - номер изображения в наборе изображений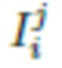 .
.
13. Система для создания аватара пользователя, содержащая:
- память, в которой сохранены компьютерные программные команды; и
- один или более процессоров, которые, под управлением упомянутых компьютерных программных команд, выполнен(ы) с возможностью:
- получения входных данных в виде одного или более кадров изображения пользователя;
- извлечения из полученных входных данных параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу пользователя на одном или более кадрах изображения пользователя, и параметров C камеры, характеризующих ракурс, с которого сняты упомянутые один или более кадров изображения пользователя;
- формирования деформируемой полигональной структуры в качестве трехмерной модели тела пользователя с использованием параметров s формы тела и параметров p позы;
- формирования L-канальной нейросетевой текстуры, характеризующей особенности внешности пользователя, на основе обработки упомянутых одного или более кадров изображения пользователя;
- наложения L-канальной нейросетевой текстуры на деформируемую полигональную структуру;
- выполнения рендеринга аватара пользователя в новой позе и/или с нового ракурса посредством нейросети рендеринга и
- обучения параметров нейросети рендеринга и нейросетевой текстуры путем их подстройки для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя из полученных входных данных.
14. Система рендеринга аватара пользователя, содержащая:
- память, в которой сохранены компьютерные программные команды; и
- один или более процессоров, которые, под управлением упомянутых компьютерных программных команд, выполнен(ы) с возможностью:
- получения входных данных в виде параметров s формы тела, характеризующих форму тела пользователя, параметров p позы, характеризующих позу аватара, параметров C камеры, характеризующих ракурс, с которого должен быть изображен аватар;
- формирования деформируемой полигональной структуры в качестве трехмерной модели тела пользователя с использованием параметров s формы тела и параметров p позы;
- наложения обученной L-канальной нейросетевой текстуры на деформируемую полигональную структуру и
- выполнения рендеринга аватара пользователя в новой позе и/или с нового ракурса посредством обученной нейросети рендеринга,
- причем обучение нейросетевой текстуры и нейросети рендеринга осуществляется путем подстройки параметров нейросетевой текстуры и нейросети рендеринга для достижения соответствия получаемых изображений аватара пользователя и одного или более кадров изображения пользователя.
15. Машиночитаемый носитель, на котором сохранены компьютерные программные команды, побуждающие систему для создания аватара пользователя выполнять способ создания аватара пользователя по любому из пп. 1-6 при выполнении компьютерных программных команд одним или более процессорами.
16. Машиночитаемый носитель, на котором сохранены компьютерные программные команды, побуждающие систему рендеринга аватара пользователя выполнять способ рендеринга аватара пользователя по любому из пп. 7-12 при выполнении компьютерных программных команд одним или более процессорами.
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| TERRO CARRAS et al.: "ANALYZING AND IMPROVING THE IMAGE QUALITY OF STYLEGAN", 03.12.2019, [найдено 22.12.2021] | |||
| Аппарат для электролиза воды | 1924 |
|
SU1912A1 |
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| СПОСОБ ОБРАБОТКИ ДВУХМЕРНОГО ИЗОБРАЖЕНИЯ И РЕАЛИЗУЮЩЕЕ ЕГО ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПОЛЬЗОВАТЕЛЯ | 2018 |
|
RU2703327C1 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ РЕАЛИСТИЧНОГО 3D АВАТАРА ПОКУПАТЕЛЯ ДЛЯ ВИРТУАЛЬНОЙ ПРИМЕРОЧНОЙ | 2015 |
|
RU2615911C1 |

