Область техники, к которой относится изобретение
Изобретение относится к приложениям виртуальной примерки, приложениям телеприсутствия, в частности, изобретение относится к моделированию реалистичной одежды, носимой людьми, и реалистичному моделированию людей в 3D.
Описание известного уровня техники
Моделирование реалистичной одежды, носимой людьми, является важной частью комплексной задачи реалистичного моделирования людей в 3D. Его непосредственные практические применения включают виртуальную примерку одежды, а также повышение реалистичности человеческих аватаров для систем телеприсутствия. Сложность моделирования одежды обусловлена тем, что предметы одежды обладают широким разнообразием геометрии (включая топологические изменения) и внешнего вида (включая большое разнообразие текстильных рисунков, принтов, а также сложную отражательную способность тканей). В частности, особенно сложной задачей при моделировании является обеспечение взаимосвязи между одеждой и телом человека.
Моделирование геометрии одежды. Многие существующие методы моделируют геометрию одежды, используя один или несколько заранее определенных шаблонов одежды с фиксированной топологией. В одной из более ранних работ, DRAPE [13], обучение осуществляется на физическом моделировании (PBS) и позволяет изменять позу и форму для каждой полученной в результате обучения сетки одежды. В более современных работах шаблоны одежды обычно представлены в виде смещений относительно сетки SMPL [34]. Такой метод используется в ClothCap [46] и в нем захватываются более мелкие детали, полученные в результате обучения из нового набора данных 4D-сканирования. В работе DeepWrinkles [29] также решается проблема моделирования мелкозернистых складок с использованием карт нормалей, создаваемых условным GAN. GarNet [15] включает в себя двухпотоковую архитектуру и позволяет моделировать сетку одежды на реалистичном уровне, который почти соответствует PBS, но при этом на два порядка быстрее. TailorNet [44] следует тому же подходу к шаблонам на основе SMPL, что и [46, 7], но моделирует деформации одежды одновременно в зависимости от позы, формы и стиля (в отличие от предыдущей работы). Он также демонстрирует более высокую скорость предсказания, чем [15].
Система CAPE [36] использует модель генеративной формы на основе графовой ConvNet, которая позволяет формировать условия, выбирать и сохранять мелкие детали формы в 3D сетках.
Несколько других работ восстанавливают геометрию одежды одновременно с сеткой всего тела из данных изображения. BodyNet [55] и DeepHuman [64] представляют собой методы на основе вокселей, которые напрямую выводят объемную форму одетого тела из одного изображения. В SiCloPe [42] авторы изобретения используют аналогичный подход, но синтезируют силуэты предметов для восстановления большего количества деталей. HMR [25] использует модель тела SMPL для оценки позы и формы по входному изображению. Некоторые методы, такие как PIFu [51] и ARCH [19], используют сквозные неявные функции для трехмерной реконструкции одетого человека и могут обобщаться на сложную топологию одежды и волос, в то время как PIFuHD [52] восстанавливает 3D поверхность с более высоким разрешением, используя двухуровневую архитектуру. MouldingHumans [11] прогнозирует окончательную поверхность на основе оцененных "видимых" и "скрытых" карт глубины. MonoClothCap [59] демонстрирует многообещающие результаты в динамическом моделировании деформации одежды с временной когерентностью на основе видео. В последней работе Yoon et al. [62] разработан относительно простой, но эффективный конвейер для целевого переноса сетки одежды на основе шаблонов.
Моделирование внешнего вида одежды. Большое количество работ сосредоточено на прямом переносе одежды из изображения в изображение, минуя 3D моделирование. Так работы [23, 16, 56, 60, 21] решают задачу переноса желаемого предмета одежды в соответствующую область человека на их изображениях. CAGAN [23] является одной из первых работ, в которых было предложено использовать условную GAN для переноcа изображения в изображение для решения этой задачи. VITON [16] следует идее создания изображения и использует непараметрическое геометрическое преобразование, которое делает всю процедуру двухэтапной, как в SwapNet [48], но с разницей в формулировке задачи и обучающих данных. CP-VTON [56] обеспечивает дополнительное улучшение [16] путем включения полностью обучаемого преобразования сплайна типа тонкой пластинки, за которым следуют CP-VTON+ [40], LAVITON [22], Ayush et al. [5] и ACGPN [60]. Хотя вышеупомянутые работы основаны на предобученных парсерах и оценщиках позы, работа Issenhuth et al. [21] обеспечивает конкурентоспособное качество изображения и значительное ускорение за счет использования настройки преподаватель/ученик для извлечения самого существенного из стандартного конвейера виртуальной примерки. Получающаяся в результате сеть-студент не привлекает дорогостоящую сеть человеческого анализа во время предсказания. В совсем недавней работе VOGUE [31] обучает StyleGAN2 [27] с учетом позы и находит оптимальную комбинацию скрытых кодов для создания высококачественных примерочных изображений.
В некоторых методах для обучения модели и предсказания используется как двумерная, так и трехмерная информация. Cloth-VTON [39] использует 3D деформацию для реалистичного целевого переноса 2D шаблона одежды. Pix2Surf [41] позволяет в цифровом виде преобразовывать текстуру изображений одежды розничного интернет-магазина в 3D поверхность виртуальных предметов одежды, позволяя осуществлять виртуальную 3D примерку в реальном времени. В другом релевантном исследовании этот сценарий целевого переноса ткани с одним шаблоном расширен на одежду, состоящую из нескольких предметов, с непарными данными [43], создание изображений манекенщиц с высоким разрешением в изготовленной на заказ одежде [61] или редактирование стиля человека на введенном изображении [17].
Объединенное моделирование геометрии и внешнего вида. Octopus [2] и Multi-Outfit Net (MGN) [7] восстанавливают текстурированную сетку одетого тела на основе модели SMPL+D. Во втором методе сетка одежды обрабатывается отдельно от сетки тела, что дает возможность перенести эту одежду на другого субъекта. Tex2Shape [4] предлагает интересную структуру, которая превращает задачу регрессии формы в проблему преобразования изображения в изображение. В [53] представлена параметрическая генеративная модель, основанная на обучении, которая может поддерживать любой тип материала одежды, форму тела и большинство топологий одежды. Совсем недавно метод StylePeople [20] объединил моделирование полигональной сетки тела с нейронным рендерингом, так что и геометрия одежды, и текстура кодируются в нейронной текстуре [54]. Подобно работе [20], предлагаемый подход к моделированию внешнего вида также основан на нейронном рендеринге, однако предлагаемая обработка геометрии является более явной.
В предлагаемом изобретении наблюдается преимущество по сравнению с [20] более явного геометрического моделирования, особенно для свободной одежды.
Сущность изобретения
Предлагается новый подход к моделированию человеческой одежды на основе облаков точек (множества точек), аппаратное обеспечение, содержащее программные продукты, которые реализуют способ геометрического моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела человека, обучается глубокая модель, которая может прогнозировать облака точек для различных видов одежды, различных поз и различных форм человеческого тела. Примечательно, что одна и та же модель может работать с одеждой различных типов и топологий. Используя обученную модель, можно выводить геометрию новых видов одежды из всего лишь одного изображения, и выполнять целевой перенос одежды на новые тела в новых позах. Предлагаемая геометрическая модель дополнена моделированием внешнего вида, которое использует геометрию облака точек в качестве геометрического каркаса и применяет нейронную графику на основе множества точек.
для захвата внешнего вида одежды из видео и для ревизуализации захваченной одежды. Аспекты геометрического моделирования и моделирования внешнего вида предлагаемого метода оценивались в сравнении с недавно предложенными методами, и была установлена эффективность моделирования одежды на основе множества точек.
Предлагаемое геометрическое моделирование отличается от предыдущих работ тем, что используются другие представления (облака точек), которые придают предлагаемому методу топологическую гибкость, возможность моделировать одежду отдельно от тела, а также обеспечивают геометрический каркас для моделирования внешнего вида с помощью нейронного рендеринга.
В отличие от упомянутых подходов к целевому переносу внешнего вида одежды предлагаемый метод использует явные трехмерные геометрические модели без опоры на индивидуальные шаблоны фиксированной топологии.
С другой стороны, предлагаемая часть моделирования внешнего вида требует последовательности видео, в то время как некоторые из упомянутых известных работ используют одно или несколько изображений.
Обсуждение модели наложения облака точек. Цель этой модели состоит в том, чтобы захватить геометрию различных видов человеческой одежды, наложенных на человеческих телах с различными формами и позами, используя облака точек. Предлагается скрытая модель для таких облаков точек, которую можно подогнать к одному изображению или к более исчерпывающим данным. Далее описывается комбинация наложения облака точек с нейронным рендерингом, которая позволяет захватить внешний вид одежды из видео.
Предложено аппаратное средство, содержащее программные продукты, которые реализуют способ отображения одежды на человеке, адаптируемой к позе тела и форме тела, на основе модели наложения облака точек, причем способ содержит этапы, на которых: используют облако точек и нейронную сеть, которая синтезирует такие облака точек для захвата/моделирования геометрии предметов одежды; используют дифференцируемый нейронный рендеринг на основе множества точек для захвата внешнего вида предметов одежды.
Предложен способ обучения сети наложения для моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, причем способ содержит обеспечение (захват или получение) набора кадров людей.
Для обучения сети наложения используется инфраструктура для обучения нейронных сетей и кодовые векторы одежды. Под инфраструктурой подразумевается некоторый набор серверов - машин, содержащих центральный процессор, графический ускоритель, материнскую плату и другие компоненты современного компьютера, объединенные в один кластер, или по меньшей мере один такой сервер с минимальным объемом оперативной памяти 32 ГБ и минимальном объемом видеопамяти 18 ГБ.
При этом набор кадров означает набор сигналов, записанных на жесткий диск, на которых каждый человек одет в одежду и где кадры представляют собой последовательности видео, на которых каждый человек выполняет последовательность движений; для каждого кадра вычисляется сетка Skinned Multi-Person Linear (SMPL) для позы и формы тела человека в кадре; для каждого кадра вычисляется сетка одежды в позе и форме тела человека в кадре; создается исходное облако точек в форме набора вершин упомянутых сеток Skinned Multi-Person Linear (SMPL) для каждого кадра; для кодирования стиля одежды для каждого человека задается произвольно инициализированный d-мерный кодовый вектор; исходные облака точек и кодовые векторы одежды подаются в сеть наложения, конкретно, исходные облака точек подаются на вход нейронной сети преобразователя кода сети наложения, а кодовые векторы одежды подаются на вход нейронной сети кодировщика MLP (Multi-Person Linear); кодовый вектор одежды обрабатывается нейронной сетью кодировщиком MLP, и его вывод передается в нейронную сеть преобразователя облака, которая деформирует исходное введенное облако точек с учетом вывода нейронной сети кодировщика MLP и выводит спрогнозированное облако точек одежды для каждого кадра; после обработки всех кадров из набора кадров людей получают предобученную сеть наложения, а именно веса обученной нейронной сети кодировщика MLP, веса обученной нейронной сети преобразователя облака, кодовые векторы одежды кодированных стилей всех людей; с помощью предобученной сети наложения соответствующий стиль одежды, соответствующий одному из векторов и одному из облаков точек, накладывается на любую форму тела и любую позу, выбранную пользователем.
Также предложен способ получения спрогнозированного облака точек одежды и кодового вектора одежды из изображения материального человека в одежде для моделирования этой одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, способ заключается в том, что: захватывают с помощью устройства обнаружения изображение материального человека в одежде; прогнозируют сетку SMPL с желаемой позой и формой тела по этому изображению методом SMPLify; создают исходное облако точек в форме вершин упомянутой сетки Skinned Multi-Person Linear (SMPL) для изображения; прогнозируют двоичную маску одежды, соответствующую пикселям данной одежды на изображении, с помощью упомянутой сети сегментации; инициализируют случайными значениями d-мерный кодовый вектор одежды для кодирования стиля одежды для данного изображения; подают исходное облако точек и кодовый вектор одежды в предобученную сеть наложения, обученную в соответствии с пунктом 1; получают спрогнозированное облако точек одежды из вывода предобученной сети наложения; проецируют облако точек одежды на черно-белое изображение с заданными параметрами камеры изображения человека; сравнивают путем вычисления функции потерь проекцию этого спрогнозированного облака точек на изображении с истинной бинарной маской одежды, соответствующей пикселям одежды на изображении, через расстояние фаски между двумерными облаками точек, которые являются проекциями 3D облаков точек; оптимизируют кодовый вектор одежды на основе вычисленной функции потерь;
накладывают в соответствии с полученным кодовым вектором одежды спрогнозированное облако точек одежды изображения на любую форму тела и любую позу тела, выбранную пользователем.
Также предлагается способ моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, заключающийся в том, что: обеспечивают поток цветного видео первого человека; выбирают пользователем любую одежду согласно любому видео второго человека в одежде; посредством операционного блока компьютерной системы: получают спрогнозированное облако точек одежды и кодовый вектор одежды согласно способу по пункту 2 для любого кадра видео; инициализируют случайными значениями n-мерный вектор дескриптора внешнего вида для каждой точки облака точек, которая отвечает за цвет; генерируют блоком растеризации 16-канальный тензор изображения с использованием 3D координат каждой точки и нейронного дескриптора каждой точки, и двоичную черно-белую маску, соответствующую пикселям изображения, покрытого этими точками; обрабатывают рендерной сетью 16-канальный тензор изображения вместе с двоичной черно-белой маской для получения цветного RGB изображения и маски одежды; оптимизируют веса рендерной сети и значения дескрипторов внешнего вида в соответствии с истинной последовательностью видео человека для получения желаемого внешнего вида одежды; отображают пользователю на экране видео первого человека в одежде второго человека в виде спрогнозированного визуализированного изображения в одежде с заданной позой и формой тела, причем пользователь может вводить видео любого человека и видеть полученную в результате обучения цветную модель одежды, перенацеленную на новые формы тела и позы, визуализированные поверх этого нового видео, то есть, одевать изображение персонажа из любого видео в любую одежду, выбранную пользователем. При этом реальный человек является пользователем, который отображает пользователю цветную модель одежды на этом пользователе.
Также предлагается система для моделирования одежды человека с использованием предложенного способа, содержащая: устройство обнаружения, подключенное к компьютерной системе, содержащей операционный блок, подключенный к экрану дисплея и блоку выбора; причем устройство обнаружения выполнено с возможностью захвата потока цветного видео первого реального человека в реальном времени; блок выбора выполнен с возможностью позволить пользователю выбирать любую одежду по любому видео второго человека в одежде; экран дисплея выполнен с возможностью отображать упомянутого первого человека в реальном времени в одежде, выбранной пользователем из упомянутых видео в соответствии с данными, полученными от операционного блока. При этом пользователем является первый человек.
По меньшей мере, один из множества модулей (блоков) может быть реализован через модель AI. Функция, связанная с AI, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или несколько процессоров. При этом один или несколько процессоров могут быть процессором общего назначения, например, центральным процессором (ЦП), процессором приложений (AP) или т.п., блоком обработки только графики, таким как графический процессор (GPU), блоком обработки изображений (VPU) и/или специализированным процессором AI, таким как нейронный процессор (NPU).
Один или несколько процессоров управляют обработкой входных данных в соответствии с заранее определенным рабочим правилом или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Заранее определенное рабочее правило или модель искусственного интеллекта предоставляется посредством обучения или обучения.
В данном контексте предоставление посредством обучения означает, что путем применения обучающего алгоритма к множеству обучающих данных создается заранее определенное рабочее правило или модель AI с желаемой характеристикой. Обучение может выполняться на том же устройстве, на котором выполняется AI согласно варианту осуществления, и/или может быть реализовано через отдельный сервер/систему.
Модель AI может состоять из множества уровней нейронной сети. Каждый уровень имеет множество значений весов и выполняет операцию уровня посредством вычисления предыдущего уровня и операции на множестве весов. Примеры нейронных сетей включают, без ограничения перечисленным, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
Алгоритм обучения - это метод обучения заранее определенного целевого устройства (например, робота) с использованием множества обучающих данных, чтобы побуждать, разрешать или давать команду целевому устройству выполнять определение или прогнозирование. Примеры алгоритмов обучения включают, без ограничения, обучение с учителем, обучение без учителя, обучение с частичным привлечением учителя или обучение с подкреплением.
Согласно данному изобретению, в способе электронного устройства способ распознавания может получать выходные данные, распознавая изображение в изображении, с использованием данных изображения в качестве входных данных для модели искусственного интеллекта. Модель искусственного интеллекта может быть получена путем обучения. В данном контексте "полученный путем обучения" означает, что заранее определенное рабочее правило или модель искусственного интеллекта, сконфигурированную для выполнения желаемой функции (или цели), получают путем обучения базовой модели искусственного интеллекта несколькими частями обучающих данных с помощью алгоритма обучения. Модель искусственного интеллекта может включать в себя множество уровней нейронной сети. Каждый из множества уровней нейронной сети включает в себя множество весовых значений и выполняет вычисления нейронной сетью путем вычисления между результатом вычисления на предыдущем уровне и множеством весовых значений.
Визуальное понимание - это метод распознавания и обработки вещей, как это делает человеческое зрение, и включает в себя, например, распознавание объекта, отслеживание объекта, поиск изображения, распознавание человека, распознавание сцены, трехмерную реконструкцию/локализацию или улучшение изображения.
Согласно данному изобретению, в способе электронного устройства способ рассуждений или прогнозирования может использовать модель искусственного интеллекта для рекомендации/выполнения с использованием данных. Процессор может выполнять операцию предварительной обработки на данных для преобразования в форму, подходящую для использования в качестве ввода в модель искусственного интеллекта. Модель искусственного интеллекта может быть получена путем обучения. В данном контексте "полученный путем обучения" означает, что заранее определенное рабочее правило или модель искусственного интеллекта, сконфигурированную для выполнения желаемой функции (или цели), получают путем обучения базовой модели искусственного интеллекта несколькими частями обучающих данных с помощью алгоритма обучения. Модель искусственного интеллекта может включать в себя несколько уровней нейронной сети. Каждый из нескольких уровней нейронной сети включает в себя множество весовых значений и выполняет вычисления нейронной сети путем вычисления между результатом вычисления на предыдущем уровне и множеством весовых значений.
Прогнозирование методом рассуждений - это метод логических рассуждений и прогнозирования путем определения информации, который включает в себя, например, рассуждения на основе знаний, прогнозирование оптимизации, планирование на основе предпочтений или рекомендации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Представленные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления со ссылками на прилагаемые чертежи, на которых:
Фиг.1 иллюстрирует предлагаемый метод моделирования геометрии различных предметов одежды с использованием облаков точек (в нижнем ряду показаны произвольные цвета точек).
Фиг.2 - результаты сетей наложения с цветовой кодировкой.
Фиг.3 - сеть наложения, которая преобразует облако точек тела (слева) и код одежды (сверху) в облако точек одежды, адаптируемой к позе тела и форме тела.
Фиг.4 - процесс оценки (оптимизации) кода одежды при наличии одного изображения человека.
Фиг.5 - применение нейронной графики на основе множества точек для моделирования внешнего вида одежды.
Фиг.6 - спрогнозированные геометрии в проверочных позах, подогнанные к одному кадру (слева).
Фиг.7 - иллюстрация того, что предлагаемый метод позволяет также перенацелить геометрию и внешний вид на новые формы тела.
Фиг.8 - сравнение результатов целевого переноса внешнего вида согласно предлагаемому способу на новые позы, которые невидимы во время подгонки, между предлагаемым способом и системой StylePeople (многокадровый вариант), которая использует сетку SMPL в качестве базовой геометрии и основывается только на нейронном рендеринге для "наращивания" свободной одежды в рендерах.
Подробное описание
Предлагаемое изобретение позволяет одеть человека, захваченного (или выбранного, или взятого) из одного изображения или видео, в одежду человека, захваченного (или выбранного, или взятого) из другого изображения или видео. Также предлагаемое изобретение обеспечивает визуализацию видео реального человека, возможно, в реальном времени, на экране, при этом человек может выбрать одежду любого другого человека, захваченного (или выбранного, или взятого) из любых видео или изображений, и увидеть свое изображение в выбранной им одежде, возможно, в реальном времени.
Таким образом, настоящее изобретение может быть полезно для замены, в случае необходимости, физического присутствия пользователя для примерки одежды его виртуальным присутствием. Это может быть особенно актуально во время пандемии, а также для людей с ограниченными возможностями или просто для удобства любого человека, поскольку это позволяет человеку примерить любую одежду в любое время. При этом человек может находиться в магазине, но ему не нужно ходить между вешалками и переодеваться.
Кроме того, человек может использовать компьютер, ноутбук, смартфон для примерки одежды, и соответствующие устройства могут использоваться для наложения моделей одежды на видео человека, стоящего и/или движущегося перед камерой.
Также изобретение позволяет одевать человека с любой картинки или видео в одежду любого другого человека.
Такое решение можно использовать также в системах телеприсутствия для более четкой прорисовки одежды на теле людей, более реалистичной визуализации их волос и для "переодевания" человеческих аватаров.
Предлагаемое геометрическое моделирование отличается от известных решений тем, что используются различные представления (облака точек), которые придают предлагаемому методу топологическую гибкость, возможность моделирования одежды отдельно от тела, а также обеспечивается геометрическая основа для моделирования внешнего вида с помощью нейронного рендеринга.
В основу изобретения положена задача модифицировать и обрабатывать изображение или набор изображений (последовательность видеокадров). Эти изображения, безусловно, являются материальными объектами, а именно, изображение представляет собой набор сигналов, хранящийся в памяти любого подходящего устройства (например, компьютера, машиночитаемого носителя, смартфона и т.п.), и это изображение принимается любым подходящим устройством (например, фотоаппаратом, смартфоном, устройством обнаружения и т.п.) от материального захваченного объекта (человека), и изображение обрабатывается в соответствии с настоящим изобретением.
В отличие от упомянутых подходов к целевому переносу внешнего вида одежды, в предлагаемом изобретении используются явные трехмерные геометрические модели, при этом без опоры на индивидуальные шаблоны с фиксированной топологией.
С другой стороны, часть моделирования внешнего вида в соответствии с изобретением требует последовательности видео, в то время как в некоторых из упомянутых работ используется одно или несколько изображений.
Объединенное моделирование геометрии и внешнего вида. Octopus [2] и Multi-Outfit Net (MGN) [7] восстанавливают текстурированную сетку одетого тела на основе модели SMPL+D.
На фиг.1 показан предлагаемый способ моделирования геометрии различных видов одежды с использованием облаков точек (в нижнем ряду - произвольные цвета точек).
Облака точек получают путем передачи сеток модели Skinned Multi-Person Linear (SMPL) человеческого тела, состоящих из 6890 вершин и 13776 граней, каждая из которых получена с помощью некоторого метода, прогнозирующего данное изображение (например, SMPLify [8]), и скрытых кодовых векторов одежды, состоящих из 8 действительных чисел, каждое из которых определено в процессе обучения, через предобученную глубокую сеть. Кроме того, предлагаемый метод позволяет моделировать внешний вид одежды с помощью нейронной графики на основе множества точек (пример моделирования внешнего вида показан в верхнем ряду на фиг.1). Внешний вид одежды может быть захвачен из последовательности видео, в то время как для геометрического моделирования на основе множества точек достаточно одного кадра. Последовательность видео представляет собой видео, на котором человек выполняет произвольные движения тела в своей одежде, показывая одежду с разных сторон (например, поворачиваясь на месте на 360 градусов). Такое видео можно получить, например, путем съемки человека камерой мобильного устройства или отдельной профессиональной камерой.
"Точечное моделирование" означает "моделирование облаков точек", этот метод является предметом настоящего изобретения. В результате моделирования на основе облаков точек получается реконструкция геометрии одежды в виде 3D облака точек, которая может выполняться на основе одного изображения (фотографии человека в одежде). Для этого достаточно одного изображения, так как одной из частей предлагаемого метода является оптимизация скрытого кода (8-мерного вектора) одежды для одной картинки. Предлагаемое изобретение представляет собой систему, которая а) моделирует одежду в виде 3D облаков точек, позволяя реконструировать ее структуру (геометрию) по одному изображению человека в одежде, а также адаптировать эту реконструкцию к новым позам и формам тела; б) при наличии не одной фотографии, а целой последовательности кадров (видео) человека в одежде система может реконструировать не только структуру (геометрию) одежды, но и ее фактуру (внешний вид).
Предлагаемое решение можно использовать для приложений телеприсутствия в дополненной реальности, виртуальной реальности, на 3D дисплеях и т.п. Его также можно использовать на обычных 2D экранах в программах/средах, где требуется показать изображения людей в одежде.
В соответствии с настоящим изобретением создаются реалистичные модели одежды людей, которые могут быть анимированы поверх моделей сетки тела для произвольных параметров позы тела и формы тела; деформируемая геометрия одежды захватывается облаком точек, геометрическая модель новой одежды может быть создана из всего одного изображения, реалистичная модель одежды, подходящая для ревизуализации, может быть создана из видео.
Основной новизной предлагаемого изобретения является
- использование облаков точек и нейронной сети, которая синтезирует такие облака точек для захвата и моделирования геометрии одежды;
- использование дифференцируемой нейронной визуализации на основе множества точек для захвата внешнего вида одежды.
Данное решение может быть реализовано с помощью любого устройства с достаточно мощным вычислительным блоком (например, графическим процессором) и экраном, такого как, например, компьютер, смартфон. Кроме того, решение может храниться на машиночитаемом носителе с инструкциями для исполнения на компьютере. Для создания моделей одежды нужны фотоснимки или видео.
Моделирование реалистичной одежды, которую носят люди, является важной частью комплектной задачи реалистичного моделирования людей в 3D. Сложность моделирования одежды обусловлена тем, что одежда обладает большим разнообразием геометрии (включая топологические изменения) и внешнего вида (включая большое разнообразие текстильных текстур, принтов и сложной отражающей способности ткани). Еще одной сложной задачей является физическое моделирование статического и динамического взаимодействия ткани с телом.
Предлагается новый подход к моделированию одежды. В предлагаемом подходе геометрия одежды моделируется в виде относительно разреженного облака точек. С помощью предложенного недавно синтетического датасета смоделированной одежды обучается объединенная геометрическая модель разнообразных видов одежды человека. Эта модель описывает конкретную одежду скрытым кодовым вектором (кодом одежды) размерности d, где d - некоторое положительное целое число (в предлагаемых экспериментах d=8, гиперпараметр, настраиваемый в процессе обучения). Код одежды - это d-мерный числовой вектор, то есть упорядоченный набор d действительных чисел, где d - некоторое натуральное число. Для данного кода одежды и данной геометрии человеческого тела (для которой используется наиболее популярный формат SMPL) глубокая нейронная сеть (сеть наложения) затем прогнозирует облако точек, которое аппроксимирует геометрию одежды, наложенной на тело.
Основным преимуществом предложенной модели является ее способность охватывать различные предметы одежды с различной топологией, используя одно скрытое пространство кодов одежды и одну сеть наложения. Это возможно благодаря выбору представления облаком точек и использованию потерь, характерных для облака точек, во время обучения объединенной модели. После обучения модель способна обобщаться на новую одежду, извлекать ее геометрию из данных и накладывать полученную одежду на тела различной формы и в новых позах. С помощью предлагаемой модели можно получить геометрию одежды всего по одному изображению.
Предлагаемый метод распространяется не только на получение геометрии, но и на моделирование внешнего вида. При этом используются идеи дифференцируемого рендеринга и нейронной графики на основе множества точек. При наличии последовательности видео одежды, носимой человеком, захватываются фотометрические свойства одежды с помощью нейронных дескрипторов, прикрепленных к точкам в облаке точек, и параметры рендерной сети (декодера). Подгонка нейронных дескрипторов точек и рендерной сети (которая захватывает фотометрические свойства) осуществляется совместно с оценкой кода одежды (который захватывает геометрию одежды) в одном и том же процессе оптимизации. После подгонки одежду можно реалистично перенести и ревизуализировать на новых телах и в новых позах.
В ходе экспериментов оценивалась способность предложенной геометрической модели захватывать деформируемую геометрию новой одежды с использованием облаков точек. Затем тестировалась способность предлагаемого полного метода захватывать геометрию и текстуру одежды из видео, а также ревизуализировать полученную в результате обучения одежду для новых целей.
Сначала рассмотрим модель наложения облака точек. Целью этой модели является захват геометрии разнообразной человеческой одежды, наложенной на человеческие тела с различными формами и позами с использованием облаков точек. Предложена скрытая модель таких облаков точек, которую можно подогнать к одному изображению или к более полным данным. Далее будет описана комбинация наложения облака точек с нейронным рендерингом, которая позволяет захватывать внешний вид одежды из видео.
Наложение облаков точек
Обучалась модель, использующая генеративную скрытую оптимизацию (GLO) [9]. Набор данных для обучения содержит набор из N комплектов одежды, каждый из которых ассоциирован с d-мерным вектором z (кодом одежды). Таким образом, произвольно инициализируется 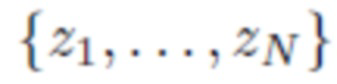 , где
, где 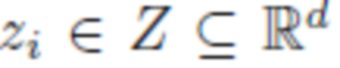 для всех i=1, … ,N. В данном случае
для всех i=1, … ,N. В данном случае 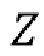 - это пространство кодового вектора одежды, а
- это пространство кодового вектора одежды, а 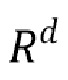 - d-мерное пространство действительных чисел (пространство действительных векторов длины d).
- d-мерное пространство действительных чисел (пространство действительных векторов длины d).
Во время обучения для каждого комплекта одежды рассматривается его форма для разнообразного набора человеческих поз. Целевые формы задаются набором геометрий. В предлагаемом случае использовался синтетический датасет CLOTH3D [6], который предоставляет формы в виде сеток различной топологии. В этом датасете каждый субъект одет в комплект одежды и выполняет некоторую последовательность движений. Для каждого комплекта одежды i для каждого кадра j в соответствующей последовательности выбирались точки из сетки данной одежды для получения облака точек 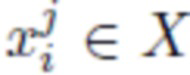 , где X обозначает пространство облаков точек фиксированного размера (в предлагаемых экспериментах используется 8192). Длина обучающей последовательности i-й одежды обозначается как Pi. Также допускается, что дана сетка
, где X обозначает пространство облаков точек фиксированного размера (в предлагаемых экспериментах используется 8192). Длина обучающей последовательности i-й одежды обозначается как Pi. Также допускается, что дана сетка 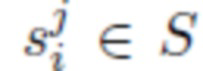 тела, и предлагаемые эксперименты работают с форматом сетки SMPL [28] (следовательно, S обозначает пространство сеток SMPL для различных параметров формы тела и параметров позы тела). Путем объединения всего получен датасет
тела, и предлагаемые эксперименты работают с форматом сетки SMPL [28] (следовательно, S обозначает пространство сеток SMPL для различных параметров формы тела и параметров позы тела). Путем объединения всего получен датасет 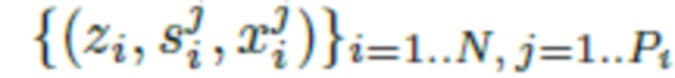 кодов одежды, сеток SMPL и облаков точек одежды.
кодов одежды, сеток SMPL и облаков точек одежды.
Поскольку задачей изобретения является обучение прогнозированию геометрии в новых позах и для новых форм тела, введена функция наложения 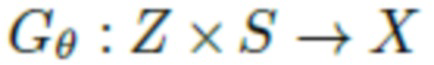 , которая преобразует скрытый код и сетку SMPL (характеризующую обнаженное тело) в облако точек одежды. В данном случае θ обозначает обучаемые параметры данной функции. Затем выполняется обучение путем оптимизации следующей цели:
, которая преобразует скрытый код и сетку SMPL (характеризующую обнаженное тело) в облако точек одежды. В данном случае θ обозначает обучаемые параметры данной функции. Затем выполняется обучение путем оптимизации следующей цели:
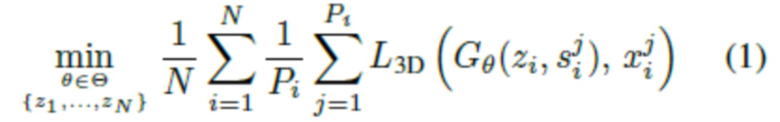
θ - параметры сети наложения, подлежащие оптимизации;
θ - тензорное пространство параметров сети наложения;
z1, … , zN - кодовые векторы одежды, подлежащие оптимизации;
N - количество обучающих объектов;
Pi - количество поз тела обучающего объекта номер i;
L3D - функция потерь, измеряющая качество 3D реконструкции (расстояние между двумя облаками точек);
Gθ - сеть наложения;
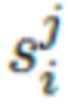 - 3D облако точек, выбранное с поверхности обрезанной (удалены вершины кистей, ступней и головы) сетки SMPL человеческого тела объекта номер i в позе тела номер j;
- 3D облако точек, выбранное с поверхности обрезанной (удалены вершины кистей, ступней и головы) сетки SMPL человеческого тела объекта номер i в позе тела номер j;
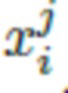 - 3D облако точек истинной одежды объекта номер i в позе тела номер j.
- 3D облако точек истинной одежды объекта номер i в позе тела номер j.
Целью уравнения (1) является средняя потеря при реконструкции для обучающих облаков точек на обучающем наборе данных. Таким образом, потеря L3D является потерей при 3D реконструкции. В предлагаемых экспериментах использовался приближенный алгоритм для вычисления расстояния движителя Земли (Earth Mover's Distance) [32] в зависимости от потери при трехмерной реконструкции. Следует отметить, что поскольку эта потеря измеряет расстояние между облаками точек и пренебрегает всеми топологическими свойствами, предложенная формулировка обучения естественным образом подходит для обучения предметов одежды с различной топологией.
Оптимизация выполняется совместно на параметрах предложенной функции наложения  и на скрытом коде одежды
и на скрытом коде одежды 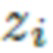 для всех i=1,…,N. В соответствии с [9], чтобы упорядочить процесс, во время оптимизации коды одежды обрезаются до единичного шара.
для всех i=1,…,N. В соответствии с [9], чтобы упорядочить процесс, во время оптимизации коды одежды обрезаются до единичного шара.
Таким образом, процесс оптимизации устанавливает скрытое пространство кода одежды и параметры функции наложения.
Сеть наложения. Функция наложения 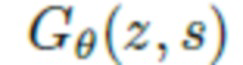 реализуется как нейронная сеть, которая берет сетку SMPL s и преобразует это облако точек в облако точек одежды. В последнее время облака точек стали полноправными (почти) членами в мире глубокого обучения, поскольку был предложен ряд архитектур, способных вводить и/или выводить облака точек и работать с ними. В предлагаемой работе используется представленная недавно архитектура преобразователя облака (Cloud Transformer) [37] благодаря отличным результатам в целом ряде разнообразных задач.
реализуется как нейронная сеть, которая берет сетку SMPL s и преобразует это облако точек в облако точек одежды. В последнее время облака точек стали полноправными (почти) членами в мире глубокого обучения, поскольку был предложен ряд архитектур, способных вводить и/или выводить облака точек и работать с ними. В предлагаемой работе используется представленная недавно архитектура преобразователя облака (Cloud Transformer) [37] благодаря отличным результатам в целом ряде разнообразных задач.
Преобразователь облака состоит из блоков, каждый из которых последовательно выполняет растеризацию, свертку и дерастеризацию облака точек в полученных путем обучения положениях, зависящих от данных. Таким образом, преобразователь облака деформирует входное облако точек (полученное из сетки SMPL, как обсуждается ниже) в выходное облако точек x на нескольких блоках. Для уменьшения вычислительной сложности и требований к памяти используется упрощенная версия преобразователя облака с одноглавыми блоками. В противном случае авторы следовали архитектуре генератора, предложенной в [37] для реконструкции формы на основе изображения, которая в их случае принимала облако точек (выбранное из единичной сферы) и вектор (вычисленный сетью кодирования изображений) на входе и выводила облако точек формы, показанной на изображении. Эта часть архитектуры нейронной сети, состоящая из преобразователя облака, идентична части, предложенной авторами в [37] для задачи реконструкции облака точек по изображению (за исключением модификации "одноглавые блоки", то есть в предлагаемом изобретении уменьшено количество параллельно включенных "голов" преобразователя). Под "их случаем" подразумевается исходная архитектура "преобразователя облака для реконструкции облака точек на основе изображения", на вход которой поступает изображение и облако точек в виде одной трехмерной сферы точек.
В предлагаемом случае входное облако точек и вектор (код одежды - это упорядоченный набор из 8 действительных чисел, который сначала инициализируется случайными значениями, а затем во время обучения изменяет свои значения так, чтобы один вектор соответствовал одному определенному стилю одежда) различны и соответствуют сетке SMPL и коду одежды, соответственно. Сетка SMPL в данном случае является синонимом термина "3D модель", то есть ее следует читать как "3D модель SMPL". Что же касается 3D модели SMPL, то она представляет собой набор из 6890 вершин, каждая с 3D координатами, и 13776 треугольников (граней), каждый из которых состоит из трех вершин. Эта 3D модель была предложена в 2016г. в работе [34], упомянутой в списке цитирований, и была создана для точного моделирования человеческого тела различных форм и в различных позах. Облако точек, кодирующее положение тела и форму тела человека, и вектор, кодирующий желаемый стиль одежды человека, являются разными объектами, подаваемыми на вход сети наложения отдельно друг от друга и в разных точках ввода.
Более конкретно, чтобы ввести сетку SMPL в архитектуру преобразователя облака, авторы сначала удаляют части сетки, соответствующие голове, ступням и кистям рук. Затем авторы рассматривают вершины как оставшееся облако точек. Вершинами в данном случае являются точки, указанные в модели SMPL, которых всего 6890, и которые соединены ребрами. Каждая вершина имеет порядковый номер в модели SMPL и свои собственные 3D координаты, и набор всех этих 6890 вершин представляет собой не что иное, как 3D облако точек, подобное человеческому телу. Таким образом, авторы удаляют части 3D модели SMPL человеческого тела, связанные с кистями, ступнями и головой, и берут оставшиеся вершины из этой 3D модели в качестве входного облака точек (3D облако точек, взятое с поверхности обрезанной сетки SMPL человеческого тела объекта номер i в позе тела номер j). Кроме этих 6890 точек берется определенное количество точек, полученных путем взятия средних точек ребер, соединяющих эти вершины, чтобы придать облаку точек большую плотность. Для уплотнения облака точек авторы также добавляют в это облако точек средние точки ребер сетки SMPL (3D модели). Полученное облако точек (которое сформировано сеткой SMPL и отражает изменение позы и формы) вводится в преобразователь облака.
В соответствии с [37] в преобразователь облака вводится скрытый код z одежды через соединения AdaIn [18], которые модулируют сверточные карты внутри блоков растеризации-дерастеризации. Из скрытого кода z через перцептрон прогнозируются конкретные веса и смещения для каждого соединения AdaIn, что является обычной процедурой для генераторов на основе стилей [26]. Авторы отмечают, что несмотря на хорошие результаты, полученные с помощью (упрощенной) архитектуры преобразователя облака, можно использовать другие архитектуры глубокого обучения, оперирующие с облаками точек (например, PointNet [47]).
Также следует отметить, что морфинг, реализуемый сетью наложения, имеет сильно нелокальный характер (т.е. предлагаемая модель не просто вычисляет локальные смещения вершин) и согласован между одеждой и позами (фиг.2). На фиг.2 показаны результаты сетей наложения с цветовой кодировкой. Каждый ряд соответствует какой-то позе. Крайнее левое изображение показывает ввод в сеть наложения. Остальные столбцы соответствуют трем кодам одежды. Цветовое кодирование соответствует спектральным координатам на поверхности сетки SMPL. Цветовое кодирование показывает, что преобразование наложения имеет явно нелокальный характер (т.е. сеть наложения не просто вычисляет локальные смещения). Кроме того, цветовое кодирование выявляет соответствия между аналогичными частями облаков точек одежды на выходах сети наложения.
Сеть наложения прогнозирует не только локальные смещения каждой точки из облака точек входной модели SMPL, но и значительно изменяет положение точек, так что конечное спрогнозированное облако напоминает геометрию одежды. Например, точки, которые изначально находились на кисти 3D модели тела SMPL, становятся точками низа одежды, то есть они "перетекают" сверху вниз, что не является локальным изменением их положения и указывает на способность сети существенно преобразовывать входное облако для уменьшения функции потерь.
Детали сети наложения
На фиг.3 показана сеть наложения, которая преобразует облако точек тела (слева) и код одежды (вверху) в облако точек одежды, адаптируемой к позе тела и форме тела.
Слева и вверху находятся два ввода сети наложения, которые представляют собой 3D облако точек (Mx3 на фиг.3), выбранное из обрезанной сетки SMPL, и d-мерный кодовый вектор одежды (d=8 в предлагаемых экспериментах), соответственно. GLO - это метод генеративной скрытой оптимизации [9], используемый для обучения векторов кода одежды. Кодовый вектор одежды (Z0 на фиг.3) обрабатывается нейронной сетью многослойного перцептрона (MLP) (кодировщиком), и ее вывод затем передается в нейронную сеть преобразователя облака. Преобразователь облака деформирует входное облако точек с учетом вывода нейронной сети MLP (кодировщика) и выдает спрогнозированное 3D облако точек одежды.
Чтобы построить сплошной геометрический априор на одежде, предлагаемую функцию наложения Gθ предобучают на синтетическом датасете Cloth3D.
Этот процесс разделен на обучающую и проверочную части, в результате чего получают N=6475 обучающих последовательностей видео. Поскольку большинство последовательных кадров имеют общую позу/геометрию одежды, для обучения рассматривается только каждый 10-й кадр. Как описано в разделе "Наложение облака точек", авторы случайным образом инициализируют {z1,…,zN}, где 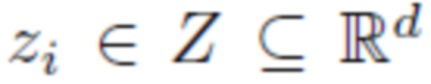 для каждого единичного элемента i в этом датасете. В этих экспериментах была задана относительно низкая размерность скрытого кода, d=8, чтобы избежать переобучения во время последующей подгонки формы одного изображения (как описано в разделе "Наложение облака точек").
для каждого единичного элемента i в этом датасете. В этих экспериментах была задана относительно низкая размерность скрытого кода, d=8, чтобы избежать переобучения во время последующей подгонки формы одного изображения (как описано в разделе "Наложение облака точек").
В кодировщик MLP, состоящий из 5 полносвязных слоев, передаются коды одежды zi для получения 512-мерного скрытого представления. Затем это представление передается в ветвь AdaIn сети преобразователя облака. Информация о позе и теле поступает в облаке точек SMPL с удаленными вершинами кистей, ступней и головы, см. фиг.1. Сеть наложения выводит 3D облака точек с 8,192 точками во всех предложенных экспериментах. В качестве функции потерь было выбрано приблизительное расстояние движителя Земли [32], и каждый вектор GLO и сеть наложения оптимизировались одновременно с использованием Адама [28].
Хотя предобучение обеспечивает высоко экспрессивные априоры для платьев и юбок, разнообразие более облегающих комплектов одежды несколько ограничено. Гипотетически этот эффект в основном обусловлен большим предпочтением комбинезонов в категориях облегающей одежды Cloth3D.
Оценка кода одежды
После предобучения сети наложения на большом синтетическом датасете [6] можно смоделировать геометрию невиданной ранее одежды. Подгонку можно выполнить как к одному, так и к нескольким изображениям. Для одного изображения авторы оптимизируют код одежды z*, чтобы он соответствовал маске сегментации одежды на изображении.
Этот процесс проиллюстрирован на фиг.4. Более подробно, двоичная маска одежды прогнозируется путем пропускания данного RGB изображения через сеть Graphonomy [12] и объединения всех семантических масок, соответствующих одежде (в правой части фиг.4). Авторы также подогнали сетку SMPL к человеку на изображении, используя метод Simplify [8]. Затем предобученная сеть наложения генерирует облако точек, когда вводится некоторый исходный код одежды (в верхней левой части фиг.4). Также на входе в сеть наложения находится некоторое исходное облако точек, полученное из обрезанной модели SMPL (как было описано выше) для этого изображения (в левой части фиг.4). Затем облако точек одежды, которое было спрогнозировано сетью наложения на основе этого вектора и этого облака точек, проецируется на новое черно-белое изображение с теми параметрами камеры, с которыми была получена истинная черно-белая маска одежды (в середине фиг.4). Затем эти две черно-белые маски сравниваются путем вычисления функции потерь на двухмерной фаске, и эта ошибка распространяется на входной код одежды, значения которого изменяются так, чтобы функция потерь давала все меньшие и меньшие значения. В процессе оптимизации значения кода одежды, которые подаются на вход сети наложения, изменяются, при этом остальные параметры системы не меняются: "Заморозка" на фиг.4 означает, что параметры сети наложения остаются неизменными в течение процесса оптимизации.
Для сложных комплектов одежды авторы наблюдали нестабильность в процессе оптимизации, где часто 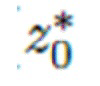 приводит к нежелательным локальным минимумам. Для стабилизации этой подгонки авторы начинают с нескольких случайных начальных значений
приводит к нежелательным локальным минимумам. Для стабилизации этой подгонки авторы начинают с нескольких случайных начальных значений  независимо (в предлагаемых экспериментах Т=4).
независимо (в предлагаемых экспериментах Т=4).
После нескольких этапов оптимизации определяется средний вектор одежды
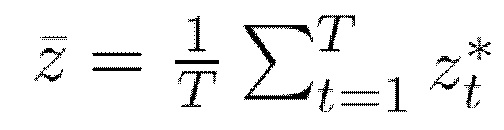 и затем продолжается оптимизация от
и затем продолжается оптимизация от 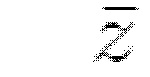 до схождения. Было замечено, что этот простой метод постоянно обеспечивает точные коды одежды.
до схождения. Было замечено, что этот простой метод постоянно обеспечивает точные коды одежды.
Обычно при оптимизации гипотезы T выполняется 100 этапов обучения. После усреднения оптимизация занимает 50-400 этапов в зависимости от сложности геометрии одежды.
Моделирование внешнего вида
Рендеринг на основе множества точек. Большинство приложений моделирования одежды выходят за рамки геометрического моделирования и также требуют моделирования внешнего вида. Недавно было показано, что облака точек обеспечивают хорошую геометрическую основу для нейронного рендеринга [1, 58, 38]. Авторы этих работ следуют принципу моделирования с помощью нейронной графики на основе множества точек (NPBG) [1] для добавления моделирования внешнего вида к предлагаемой системе.
На фиг.5 показано применение нейронной графики на основе множества точек для моделирования внешнего вида одежды. Обучались набор нейронных дескрипторов внешнего вида и рендерная сеть, которые позволяют преобразовать растеризацию облака точек одежды (слева) в его реалистичное маскированное изображение (справа).
Начиная слева, имеются фиксированное 3D облако точек и набор обучаемых нейронных дескрипторов, причем к каждой точке облака точек присоединен один 16-мерный (n-мерный) вектор дескриптора внешнего вида. Затем это облако точек с присоединенными обучаемыми дескрипторами внешнего вида передается в блок растеризации, где дифференцируемый растеризатор учитывает перекрытие облака точек и сетки SMPL человеческого тела и генерирует 16-канальный тензор изображения, используя 3D координаты каждой точки и нейронный дескриптор каждой точки ("псевдоцветное изображение" на фиг.5). Он также генерирует двоичную черно-белую маску растеризации, соответствующую пикселям изображения, покрытого точками. Затем 16-канальный тензор изображения передается в рендерную сеть вместе с двоичной черно-белой маской растеризации, и сеть прогнозирует конечное 3-канальное RGB изображение и конечную двоичную маску силуэта одежды.
Таким образом, при моделировании внешнего вида определенной одежды с кодом z к каждой из M точек в облаке точек, моделирующем его геометрию, присоединяются p-мерные скрытые векторы внешнего вида 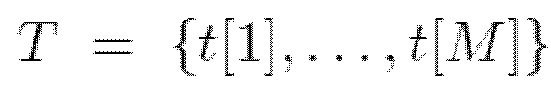 . Также вводится рендерная сеть
. Также вводится рендерная сеть  с обучаемыми параметрами
с обучаемыми параметрами  . Для получения реалистичной визуализации одежды с заданными позой s тела и положением C камеры сначала вычисляется облако точек
. Для получения реалистичной визуализации одежды с заданными позой s тела и положением C камеры сначала вычисляется облако точек 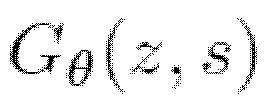 , а затем это облако точек растеризуется на сетку изображения с разрешением
, а затем это облако точек растеризуется на сетку изображения с разрешением 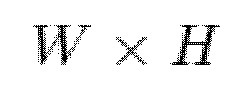 с использованием параметров камеры и нейронного дескриптора t[m] в качестве псевдоцвета m-й точки. Результат растеризации, представляющий собой p-канальное изображение, объединяется с масками растеризации, которые указывают ненулевые пиксели, а затем они обрабатываются (преобразуются) в цветное RGB изображение одежды и маску одежды (т.е. изображение с предлагаемым числом каналов) рендерной сетью
с использованием параметров камеры и нейронного дескриптора t[m] в качестве псевдоцвета m-й точки. Результат растеризации, представляющий собой p-канальное изображение, объединяется с масками растеризации, которые указывают ненулевые пиксели, а затем они обрабатываются (преобразуются) в цветное RGB изображение одежды и маску одежды (т.е. изображение с предлагаемым числом каналов) рендерной сетью 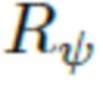 с обучаемыми параметрами
с обучаемыми параметрами  .
.
Во время растеризации также учитывается сетка SMPL тела и не растеризуются точки, закрытые телом. В качестве рендерной сети используется упрощенная сеть U-net [50].
Захват внешнего вида из видео
Предлагаемый метод позволяет захватывать внешний вид одежды на видео. Для этого выполняется двухэтапная оптимизация. На первом этапе оптимизируется код одежды путем минимизации потери фаски между проекциями облака точек и масками сегментации, как было описано в предыдущем разделе. Затем совместно оптимизируются скрытые векторы T внешнего вида и параметры рендерной сети . Для второго этапа используется (1) потеря восприятия [24] между маскированным видео и изображением RGB, визуализированным предлагаемой моделью, и (2) потеря Дайса между маской сегментации и маской визуализации, спрогнозированной рендерной сетью.
Для оптимизации внешнего вида требуется видео с человеком, вся поверхность тела которого видна хотя бы в одном кадре. В предлагаемых экспериментах обучающие последовательности состоят из 600-2800 кадров для каждого человека. На графическом процессоре NVIDIA Tesla P40 весь процесс занимает около 10 часов.
После оптимизации полученную модель одежды можно визуализировать для форм SMPL тела в произвольных позах, обеспечивая изображения RGB и маски сегментации.
Эксперименты
Были осуществлены оценка геометрического моделирования и моделирования внешнего вида согласно предлагаемому методу и сравнение с известными датасетами. Для оценки на этих двух этапах использовались два датасетов видео людей. Датасет PeopleSnapsot, представленный в [3], содержит 24 видео, на которых люди в различной одежде поворачиваются в позу А. Что касается одежды, на них отсутствуют примеры людей в юбках и поэтому не раскрываются все преимущества предлагаемого метода. Также оценивалась часть датасета AzurePeople, представленного в [20]. В этой части содержится видео восьми человек в одежде различной сложности, снятые с пяти RGBD Kinect камер.
Использовались не только изображения юбок, но наличие таких изображений показывает универсальность предлагаемого метода в плане моделирования различных топологий одежды. Например, 3D модель брюк и 3D модель юбки имеют разную связь между вершинами, и преимущество предлагаемой системы состоит в том, что она может спрогнозировать, по меньшей мере, обе эти топологии, чего не могут сделать многие другие современные методы (большинство из них вообще не реконструирует юбки ни в какой приемлемой форме).
Камеры RGBD Kinect. Для обоих датасетов были созданы маски сегментации ткани с помощью метода Graphonomy [12] и сетки SMPL с помощью SMPLify [8]. Для запуска всех методов в сравнении также были спрогнозированы ключевые точки Openpose [10], UVI рендеры DensePose [14] и сетки SMPL-X [45].
В дополнение к описанному выше оценочному датасету также использовался датасет Cloth3D [6] для обучения предлагаемой геометрической метамодели.
Набор данных Cloth3D содержит 11,3 тысяч элементов одежды с различной геометрией, смоделированных в виде сеток, наложенных на 8,5 тысяч тел SMPL, изменяющих позы. В подгонке используется моделирование на основе физики.
Восстановление геометрии одежды
В данной серии экспериментов оценивалась способность предложенного метода восстановить геометрию одежды из одного фотоснимка.
Предлагаемый метод позволяет реконструировать 3D геометрию одежды по одному фотоснимку. На примере одного конкретного рисунка: одежда из одного рисунка реконструируется предлагаемой системой и системами, с которыми сравнивается предлагаемый метод. Затем реконструированные 3D модели одежды помещаются в позу, которую предположительно не видели ранее эти системы во время обучения. Сама поза выбирается случайным образом из предложенного отдельного набора поз, ранее извлеченных из фотографий людей в разных позах. Сами изображения, из которых взяты позы, нигде не показываются, используется только поза из них.
При оценке качества оценщик видит три вещи на одной картинке: в центре картинки - изображение человека в одежде, которую нужно реконструировать, с одной стороны от него (слева или справа) - 3D геометрия этой одежды, реконструированная предложенным методом в новой позе, с другой стороны от нее (слева или справа) 3D геометрия этой одежды, реконструированная другим методом в этой же новой позе.
Каждый раз 3D геометрия одежды отображается в виде облака точек, визуализированного поверх модели SMPL человеческого тела (в случае предложенного метода) или визуализированной 3D сетки всего тела вместе с одеждой (в случае других методов). Освещение для визуализации одинаковое и постоянное, цвет для всех вершин всех 3D моделей одинаковый и постоянный (серый).
Сравнивались результаты следующих трех методов:
1. Метод Tex2Shape [4], прогнозирующий смещения вершин сетки SMPL в пространстве текстуры. Он идеально подходит для датасета снимков людей Snapshot, но менее пригоден для последовательностей AzurePeople с юбками и платьями.
2. Сетевой метод Multi-outfit [7] прогнозирует одежду, наложенную поверх моделей SMPL тела. Он предлагает виртуальный гардероб предварительно подогнанных комплектов одежды, а также может подгонять новые комплекты одежды из одного изображения.
3. Предлагаемый метод на основе множества точек, прогнозирующий геометрию одежды по облаку точек.
В сравниваемых системах использовались различные форматы для восстановления одежды (облако точек, смещения вершин, сетки). Более того, они фактически решают несколько различные проблемы, например, предлагаемый метод и сетка Multi-outfit восстанавливают одежду, а Tex2Shape восстанавливает сетки, включающие в себя одежду, тело и волосы. Однако все три системы поддерживают целевой перенос на новые позы. Поэтому авторы решили оценить относительную эффективность этих трех методов с помощью пользовательского исследования, оценивающего реалистичность целевого переноса одежды.
Пользователям были представлены триплеты изображений, где среднее изображение показывает предложенную фотографию, а боковые изображения показывают результаты двух сравниваемых методов (в виде рендеров с затемненной сеткой для одной и той же новой позы). Результаты таких парных сравнений (предпочтения пользователей) для 1,5 тысяч пользовательских сравнений показаны в таблице. 1.

В первой строке таблицы представлены результаты пользовательского исследования на датасете PeopleSnapshot. Во второй строке таблицы представлены результаты на датасете AzurePeople. В первом столбце представлено сравнение геометрии одежды, спрогнозированной с помощью предлагаемого метода и метода Tex2Shape, во втором столбце - сравнение геометрии одежды, спрогнозированной с помощью предлагаемого метода и метода MGN, в третьем столбце - сравнение геометрии одежды, спрогнозированной предложенным методом и методом Octopus. В каждой ячейке таблицы первое число (перед "vs") - это доля пользователей, которые предпочли геометрию одежды, спрогнозированную предлагаемым методом, а второе число (после "vs") - доля пользователей, которые предпочли геометрию одежды, спрогнозированную методом, записанным в соответствующем столбце. Таблица 1: результаты пользовательского исследования, в котором пользователи сравнивали качество восстановления 3D геометрии одежды (подогнанной к одному изображению). Предлагаемый метод оказался более предпочтительным на датасете AzurePeople с более свободной одеждой, в то время как ранее предложенные методы лучше подходят для более облегающей одежды с фиксированной топологией.
Пользователи отдали убедительное предпочтение предлагаемому методу в случае датасета AzurePeople, который содержит юбки и платья, тогда как Tex2Shape и MGN оказались предпочтительнее для датасета PeopleSnapshot с более облегающей одеждой с фиксированной топологией. На фиг.6 показаны типичные случаи, а в дополнительных материалах представлены более обширные качественные сравнения. Следует отметить, что в пользовательском исследовании предлагаемые точки показаны серыми, чтобы исключить влияние фактора цвета на выбор пользователя. На фиг.6 показаны спрогнозированные геометрии в проверочных позах, подогнанные к одному кадру (обучающее изображение слева). Более подробно, первый столбец (обучающее изображение) показывает изображение (один ряд - одно изображение), на котором обучались предлагаемая система и работы, с которыми осуществляется сравнение. Задача заключалась в том, чтобы максимально точно реконструировать 3D геометрию одежды по изображению. Каждый из следующих столбцов представляет результаты адаптации полученной путем обучения геометрии одежды к новой, невиданной ранее позе каждым соответствующим методом: системой Tex2Shape [4] во втором столбце, методом Multi-outfit Net (MGN) [7] в третьем столбце, методом Octopus [2] в предлагаемом столбце. В последнем столбце показаны результаты адаптации к новой позе геометрии одежды, спрогнозированной предлагаемой системой. Для предлагаемого метода (справа) геометрия определяется облаком точек, в то время как для Tex2Shape и Multi-outfit Net (MGN) выводы основаны на сетке. Предлагаемый метод позволил реконструировать платье, в то время как другие методы не справились с этой задачей (нижний ряд). Следует отметить, что предлагаемый метод также позволяет реконструировать более облегающую одежду (верхний ряд), хотя в этом случае лучший результат дает Tex2Shape с его подходом, основанным на смещении. Для полноты картины в дополнительных материалах представлены дополнительные сравнения предлагаемого метода с системой Octopus [2], которая не идеально подходит для реконструкции по одной фотографии.
Моделирование внешнего вида
Предлагаемый конвейер моделирования внешнего вида оценивался относительно системы StylePeople [20] (многокадровый вариант), которая во многих отношениях является наиболее близким аналогом предлагаемой системы. StylePeople подгоняет нейронную текстуру сетки SMPL-X вместе с рендерной сетью, используя видео человека и обратное распространение.
Для сравнения система StylePeople была модифицирована для создания масок одежды вместе с изображениями RGB и сегментацией переднего плана. Оба метода обучались отдельно на каждом человеке из датасетов AzurePeople и PeopleSnapshot.
Затем сравнивались изображения одежды, сгенерированные для контрольных представлений, по трем показателям, которые измеряют визуальное сходство с истинными изображениями, а именно: расстояние полученного в результате обучения перцептивного сходства (LPIPS) [63], структурное сходство (SSIM) [57] и его многомасштабная версия (MS-SSIM).
Результаты этого сравнения представлены в таблице 2, а качественное сравнение показано на фиг.8.
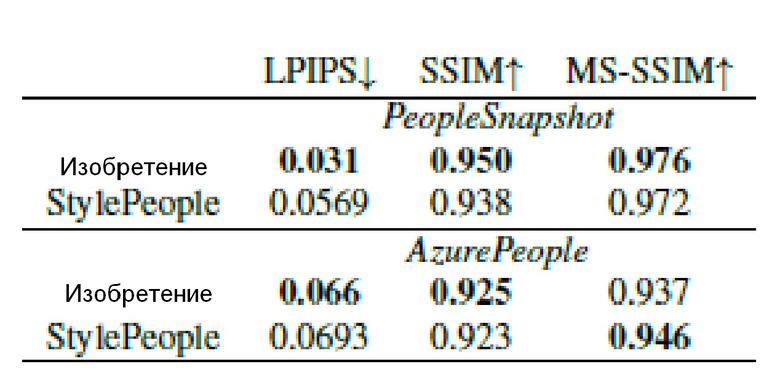
Таблица 2: Количественные сравнения с системой StylePeople на двух тестовых датасетах с использованием общих показателей изображения. Предлагаемый метод превосходит StylePeople по большинству показателей благодаря более точному геометрическому моделированию. При этом верхняя часть таблицы отражает оценку на датасете PeopleSnapshot, нижняя часть таблицы - результаты на датасете AzurePeople. Первая строка в каждом разделе соответствует предложенному методу, вторая строка - методу StylePeople. В первом столбце приведены значения полученного в результате обучения расстояния перцептивного сходства (LPIPS) [63]. Во втором столбце - значения показателя структурного сходства (SSIM) [57]. В третьем столбце приведены значения многомасштабной версии SSIM (MS-SSIM). Все эти показатели были рассчитаны на основе прогнозов предлагаемого метода и прогнозов метода StylePeople и усреднены по соответствующему датасету. Результаты, представленные в этой таблице, свидетельствуют, что предлагаемый метод превосходит метод StylePeople для обоих датасетов по всем показателям, за исключением случая показателя MS-SSIM на датасете AzurePeople. Предположительно, это связано с использованием более сложной рендерной сетью по сравнению с той, которая используется в предлагаемом методе (более упрощенной). Это преимущество подтверждается визуальным анализом количественных результатов (фиг.8).
На фиг.1 проиллюстрированы дополнительные результаты для предложенных методов. Представлен ряд комплектов одежды различной топологии и типа, перенацеленных на новые позы из обоих тестовых датасетов. И наконец, на фиг.7 проиллюстрированы примеры целевого переноса геометрии и внешнего вида одежды на новые формы тела согласно предлагаемому методу. Более конкретно, первый ряд и первый столбец иллюстрируют геометрию одежды, полученную в результате обучения из одной фотографии первого объекта из датасета PeopleSnapshot, второй столбец - внешний вид, полученный в результате обучения из видео этого объекта. Следующие два столбца в первом ряду показывают пример адаптации этих полученных в результате обучения геометрии и внешнего вида к новой, невиданной ранее форме человеческого тела. Точно такая же информация отображается во втором ряду, но для другого субъекта из датасета PeopleSnapshot.
На фиг.7 проиллюстрировано, что предлагаемый метод позволяет также перенацелить геометрию и внешний вид на новые формы тела. Целевой перенос внешнего вида хорошо работает для одежды однородного цвета, но могут искажаться детали принтов (например, в области груди в нижнем ряду).
На фиг.8 представлено сравнение результатов целевого переноса внешнего вида предлагаемого метода на новые позами, невиданные во время подгонки между предлагаемым методом и системой StylePeople (вариант с несколькими снимками), которая использует сетку SMPL в качестве базовой геометрии и основывается только на нейронном рендеринге для "наращивания" свободной одежды в рендерах. Более конкретно, из датасета AzurePeople было выбрано 6 субъектов с соответствующими им последовательностями видео с 4 камер. Кроме того, для каждого из этих субъектов был произвольно выбран один фотоснимок из их последовательностей видео (столбцы 1, 4 и 7). Для каждого фотоснимка геометрию одежды получили в результате обучения в соответствии с предложенным методом оценки кода одежды, описанным ранее. Затем получили в результате обучения внешний вид каждого субъекта с учетом геометрии его одежды и видео с 4 камер, и с прогнозировали внешний вид для нового контрольного вида с камеры и в новой контрольной позе тела. Результаты предлагаемого метода представлены в столбцах 3, 6 и 9. Затем метод StylePeople [20] также получил такие же последовательности видео этих субъектов, его прогноз на том же новом виде камеры и в той же новой контрольной позе теле показаны в столбцах 2, 5 и 8. Как и ожидалось, предлагаемая система дает более четкие результаты для более свободной одежды благодаря использованию более точного геометрического каркаса.
Выводы и ограничения
Предлагается новый подход к моделированию человеческой одежды на основе облаков точек. Предлагается генеративная модель для одежды различной формы и топологии, которая позволяет захватить геометрию невиданных ранее комплектов одежды и перенацелить ее на новые позы и формы тела. Отсутствие топологии в предлагаемом геометрическом представлении (облаке точек) особенно подходит для моделирования одежды ввиду большого разнообразия форм и составов одежды в реальной жизни. Кроме геометрического моделирования используются идеи нейронной графики на основе множества точек для захвата внешнего вида одежды и ревизуализации полных моделей одежды (геометрия+внешний вид) в новых позах на новых телах.
Предлагаемый текущий подход к моделированию внешнего вида требует последовательности видео, чтобы захватить внешний вид одежды, что потенциально можно решить путем расширения генеративного моделирования на нейронные дескрипторы аналогично генеративной нейронной модели текстуры из [20]. Кроме того, возможности предлагаемой модели сильно ограничены в моделировании динамики ткани, и для расширения предлагаемой модели в этом направлении может быть полезна некоторая интеграция предлагаемого метода с моделированием на основе физики (конечные элементы). И наконец, предлагаемая модель ограничена одеждой, подобной представленной в датасете Cloth3D. Предметы одежды, отсутствующие в этом датасете (например, шляпы), не могут быть захвачены предложенным методом.
Предлагаемая система моделирования одежды на человеке и подгонки одежды с помощью предлагаемого способа может содержать устройство обнаружения, подключенное к компьютерной системе. Таким устройством обнаружения может быть простая видео/фотокамера. Компьютерная система может содержать операционный блок, подключенный к экрану и блоку выбора. Операционный блок является частью компьютерной системы, реализующей предложенный способ. Компьютерная система может быть, например, одной из компьютера, ноутбука, смартфона и любого другого подходящего электронного устройства; экран может быть дисплеем компьютера, ноутбука, смартфона или любым другим подходящим дисплеем. Блок выбора является интерфейсом, с помощью которого пользователь может выбирать видео и изображения с понравившейся одеждой для примерки.
Устройство обнаружения захватывает поток цветного видео реального человека, например пользователя, в реальном времени, это видео отображается на экране в реальном времени. Человек может выбрать с помощью блока выбора любой желаемый предмет одежды в соответствии с любым видео, на котором изображен человек в этом предмете одежды. Изображения человека и изображения, выбранные человеком, обрабатываются операционным блоком. В результате человек может увидеть себя, возможно, в реальном времени, в выбранной одежде.
Представленные выше примерные варианты осуществления являются примерами и не должны рассматриваться как ограничивающие. Кроме того, описание примерных вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и многие альтернативы, модификации и вариации будут очевидны специалистам в данной области техники.
Литература
[1] K. Aliev, A. Sevastopolsky, M. Kolos, D. Ulyanov, and V. S.
Lempitsky. Neural point-based graphics. In A. Vedaldi, H. Bischof, T. Brox, and J. Frahm, editors, Proc. ECCV, volume 12367 of Lecture Notes in Computer Science, pages 696-712. Springer, 2020.
[2] T. Alldieck, M. Magnor, B. L. Bhatnagar, C. Theobalt, and
G. Pons-Moll. Learning to reconstruct people in clothing from a single rgb camera. In Proc. CVPR, 2019.
[3] T. Alldieck, M. Magnor, W. Xu, C. Theobalt, and G. Pons-Moll. Video based reconstruction of 3d people models. InProc. CVPR, pages 8387-8397, 2018.
[4] T. Alldieck, G. Pons-Moll, C. Theobalt, and M. Magnor. Tex2shape: Detailed full human body geometry from a single image. In Proc. 3DV, 2019.
[5] K. Ayush, S. Jandial, A. Chopra, and B. Krishnamurthy. Powering virtual try-on via auxiliary human segmentation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Oct 2019.
[6] H. Bertiche, M. Madadi, and S. Escalera. Cloth3d: Clothed 3d humans. In Proc. ECCV, 2020.
[7] B. L. Bhatnagar, G. Tiwari, C. Theobalt, and G. Pons-Moll. Multi-outfit net: Learning to dress 3d people from images. In Proc. ICCV. IEEE, oct 2019.
[8] F. Bogo, A. Kanazawa, C. Lassner, P. V. Gehler, J. Romero, and M. J. Black. Keep it SMPL: automatic estimation of 3d human pose and shape from a single image. In B. Leibe, J. Matas, N. Sebe, and M. Welling, editors, Proc. ECCV, volume 9909 of Lecture Notes in Computer Science, pages 561-578. Springer, 2016.
[9] P. Bojanowski, A. Joulin, D. Lopez-Paz, and A. Szlam. Optimizing the latent space of generative networks. In Proc. ICML, 2019.
[10] Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh. Openpose: realtime multi-person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence, 43(1):172-186, 2019.
[11] V. Gabeur, J.-S. Franco, X. Martin, C. Schmid, and G. Rogez. Moulding humans: Non-parametric 3d human shape estimation from single images. 2019.
[12] K. Gong, Y. Gao, X. Liang, X. Shen, M. Wang, and L. Lin. Graphonomy: Universal human parsing via graph transfer learning. In Proc. CVPR, 2019.
[13] P. Guan, L. Reiss, D. Hirshberg, A. Weiss, and M. J. Black. DRAPE: DRessing Any PErson. ACM Trans. on Graphics (Proc. SIGGRAPH), 31(4):35:1-35:10, July 2012.
[14]  N. Neverova, and I. Kokkinos. Densepose: Dense human pose estimation in the wild. In Proc. CVPR, pages 7297-7306, 2018.
N. Neverova, and I. Kokkinos. Densepose: Dense human pose estimation in the wild. In Proc. CVPR, pages 7297-7306, 2018.
[15] E. Gundogdu, V. Constantin, A. Seifoddini, M. Dang, M. Salzmann, and P. Fua. Garnet: A two-stream network for fast and accurate 3d cloth draping. In Proc. ICCV, 2019.
[16] X. Han, Z. Wu, Z. Wu, R. Yu, and L. S. Davis. Viton: An image-based virtual try-on network. In Proc. CVPR, 2018.
[17] W.-L. Hsiao, I. Katsman, C.-Y. Wu, D. Parikh, and K. Grauman. Fashion++: Minimal edits for outfit improvement. In Proc. ICCV, 2019.
[18] X. Huang and S. Belongie. Arbitrary style transfer in realtime with adaptive instance normalization. In Proc. ICCV, 2017.
[19] Z. Huang, Y. Xu, C. Lassner, H. Li, and T. Tung. Arch: Animatable reconstruction of clothed humans. In Proc. CVPR, 2020.
[20] K. Iskakov, A. Grigorev, A. Ianina, R. Bashirov, I. Zakharkin, A. Vakhitov, and V. Lempitsky. Stylepeople: A generative model of fullbody human avatars. In Proc. CVPR, 2021.
[21] T. Issenhuth, J. Mary, and C. Calauz`enes. Do not mask what you do not need to mask: a parser-free virtual try-on. In Proc. ECCV, 2020.
[22] H. Jae Lee, R. Lee, M. Kang, M. Cho, and G. Park. Laviton:
A network for looking-attractive virtual try-on. In Proc. ICCV, Oct 2019.
[23] N. Jetchev and U. Bergmann. The conditional analogy gan: Swapping fashion articles on people images. In Proc. ICCV, 2017.
[24] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Proc. ECCV, 2016.
[25] A. Kanazawa, M. J. Black, D. W. Jacobs, and J. Malik. Endto- end recovery of human shape and pose. In Proc. CVPR, 2018.
[26] T. Karras, S. Laine, and T. Aila. A style-based generator architecture for generative adversarial networks. In Proc. CVPR, pages 4401-4410. Computer Vision Foundation /IEEE, 2019.
[27] T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila. Analyzing and improving the image quality of stylegan. In Proc. CVPR, 2020.
[28] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization, 2017.
[29] Z. Laehner, D. Cremers, and T. Tung. Deepwrinkles: Accurate and realistic clothing modeling. In Proc. ECCV, 2018.
[30] S. Laine, J. Hellsten, T. Karras, Y. Seol, J. Lehtinen, and T. Aila. Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics, 39(6), 2020.
[31] K. M. Lewis, S. Varadharajan, and I. Kemelmacher-Shlizerman. Vogue: Try-on by stylegan interpolation optimization, 2021.
[32] M. Liu, L. Sheng, S. Yang, J. Shao, and S.-M. Hu. Morphing and sampling network for dense point cloud completion. arXiv preprint arXiv:1912.00280, 2019.
[33] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1- 248:16, Oct. 2015.
[34] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia), 34(6):248:1-248:16, Oct. 2015.
[35] M. M. Loper and M. J. Black. OpenDR: An approximate differentiable renderer. In Proc. ECCV, volume 8695 of Lecture Notes in Computer Science, pages 154-169. Springer International Publishing, Sept. 2014.
[36] Q. Ma, J. Yang, A. Ranjan, S. Pujades, G. Pons-Moll, S. Tang, and M. J. Black. Learning to Dress 3D People in Generative Clothing. In Proc. CVPR.
[37] K. Mazur and V. Lempitsky. Cloud transformers, 2020.
[38] M. Meshry, D. B. Goldman, S. Khamis, H. Hoppe, R. Pandey, N. Snavely, and R. Martin-Brualla. Neural rerendering in the wild. In Proc. CVPR, June 2019.
[39] M. R. Minar and H. Ahn. Cloth-vton: Clothing threedimensional reconstruction for hybrid image-based virtual try-on. In Proceedings of the Asian Conference on Computer Vision (ACCV), November 2020.
[40] M. R.Minar, T. T. Tuan, H. Ahn, P. Rosin, and Y.-K. Lai. Cpvton+: Clothing shape and texture preserving image-based virtual try-on. In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2020.
[41] A. Mir, T. Alldieck, and G. Pons-Moll. Learning to transfer texture from clothing images to 3d humans. In Proc. CVPR. IEEE, June 2020.
[42] R. Natsume, S. Saito, Z. Huang, W. Chen, C. Ma, H. Li, and S. Morishima. Siclope: Silhouette-based clothed people. In Proc. CVPR, 2019.
[43] A. Neuberger, E. Borenstein, B. Hilleli, E. Oks, and S. Alpert. Image based virtual try-on network from unpaired data. In Proc. CVPR, June 2020.
[44] C. Patel, Z. Liao, and G. Pons-Moll. Tailornet: Predicting clothing in 3d as a function of human pose, shape and outfit style. In Proc. CVPR, 2020.
[45] G. Pavlakos, V. Choutas, N. Ghorbani, T. Bolkart, A. A. Osman, D. Tzionas, and M. J. Black. Expressive body capture: 3d hands, face, and body from a single image. In Proc. CVPR, pages 10975-10985, 2019.
[46] G. Pons-Moll, S. Pujades, S. Hu, and M. Black. Clothcap:
Seamless 4d clothing capture and retargeting. ACM Transactions on Graphics, (Proc. SIGGRAPH), 36(4), 2017. Two first authors contributed equally.
[47] C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proc. CVPR, pages 77-85. IEEE Computer Society, 2017.
[48] A. Raj, P. Sangkloy, H. Chang, J. Hays, D. Ceylan, and J. Lu. Swapnet: Image based outfit transfer. Proc. ECCV, pages 679-695, 2018.
[49] N. Ravi, J. Reizenstein, D. Novotny, T. Gordon, W.-Y. Lo, J. Johnson, and G. Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020.
[50] O. Ronneberger, P.Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI), volume 9351 of LNCS, pages 234-241. Springer, 2015. (available on arXiv:1505.04597 [cs.CV]).
[51] S. Saito, Z. Huang, R. Natsume, S. Morishima, A. Kanazawa, and H. Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proc. ICCV, 2019.
[52] S. Saito, T. Simon, J. Saragih, and H. Joo. Pifuhd: Multilevel pixel-aligned implicit function for high-resolution 3d human digitization. In Proc. ICCV, 2020.
[53] Y. Shen, J. Liang, and M. C. Lin. Gan-based outfit generation using sewing pattern images. In Proc. ECCV, 2020.
[54] J. Thies, M. Zollh¨ofer, and M. Nieβner. Deferred neural rendering: Image synthesis using neural textures. ACM Transactions on Graphics (TOG), 2019.
[55] G. Varol, D. Ceylan, B. Russell, J. Yang, E. Yumer, I. Laptev, and C. Schmid. BodyNet: Volumetric inference of 3D human body shapes. In Proc. ECCV, 2018.
[56] B.Wang, H. Zheng, X. Liang, Y. Chen, L. Lin, and M. Yang. Toward characteristic-preserving image-based virtual try-on network. In Proc. ECCV, 2018.
[57] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600-612, 2004.
[58] O. Wiles, G. Gkioxari, R. Szeliski, and J. Johnson. SynSin: End-to-end view synthesis from a single image. In Proc. CVPR, 2020.
[59] D. Xiang, F. Prada, C. Wu, and J. Hodgins. Monoclothcap: Towards temporally coherent clothing capture from monocular rgb video. In Proc. 3DV, 2020.
[60] H. Yang, R. Zhang, X. Guo, W. Liu, W. Zuo, and P. Luo. Towards photo-realistic virtual try-on by adaptively generating$preserving image content. In Proc. CVPR, 2020.
[61] G. Yildirim, N. Jetchev, R. Vollgraf, and U. Bergmann.
Generating high-resolution fashion model images wearing custom outfits. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Oct 2019.
[62] J. S. Yoon, K. Kim, J. Kautz, and H. S. Park. Neural 3d clothes retargeting from a single image, 2021.
[63] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric, 2018.
[64] Z. Zheng, T. Yu, Y.Wei, Q. Dai, and Y. Liu. Deephuman: 3d human reconstruction from a single image. In Proc. ICCV, October 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ДИСТАНЦИОННОГО ВЫБОРА ОДЕЖДЫ | 2020 |
|
RU2805003C2 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| НЕЙРОСЕТЕВОЙ ПЕРЕНОС ВЫРАЖЕНИЯ ЛИЦА И ПОЗЫ ГОЛОВЫ С ИСПОЛЬЗОВАНИЕМ СКРЫТЫХ ДЕСКРИПТОРОВ ПОЗЫ | 2020 |
|
RU2755396C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| НЕЙРОСЕТЕВОЙ РЕНДЕРИНГ ТРЕХМЕРНЫХ ЧЕЛОВЕЧЕСКИХ АВАТАРОВ | 2021 |
|
RU2775825C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| ВИЗУАЛИЗАЦИЯ РЕКОНСТРУКЦИИ 3D-СЦЕНЫ С ИСПОЛЬЗОВАНИЕМ СЕМАНТИЧЕСКОЙ РЕГУЛЯРИЗАЦИИ НОРМАЛЕЙ TSDF ПРИ ОБУЧЕНИИ НЕЙРОННОЙ СЕТИ | 2023 |
|
RU2825722C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |


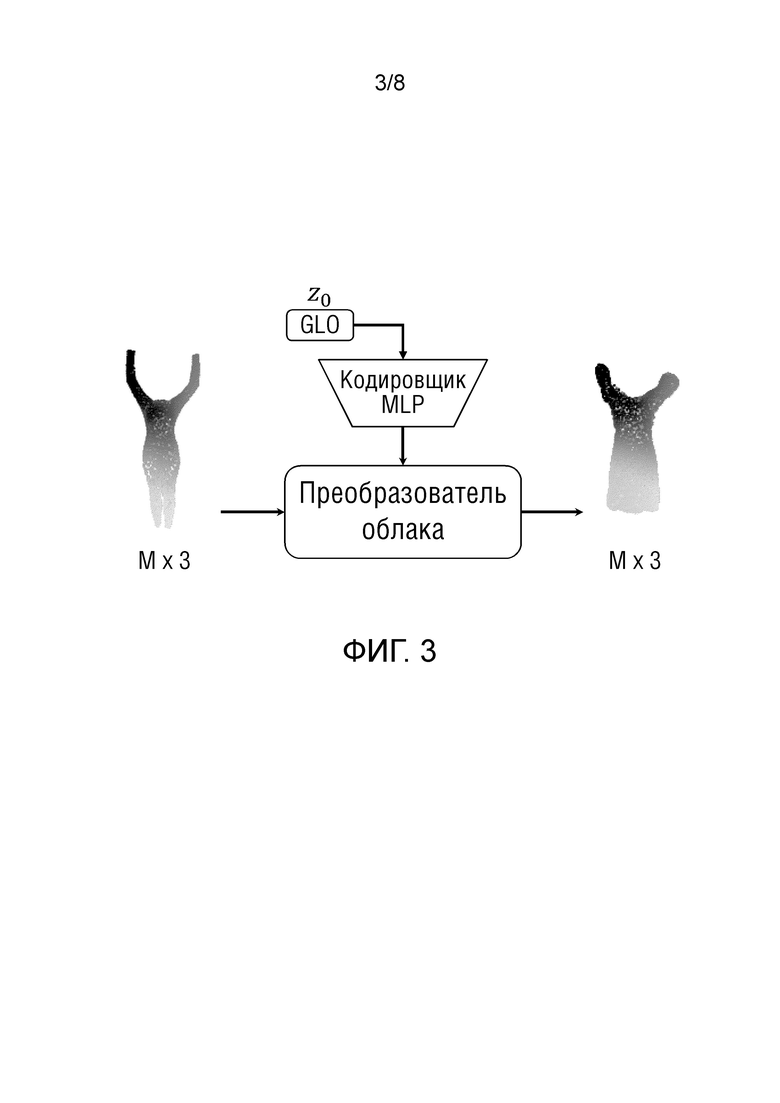
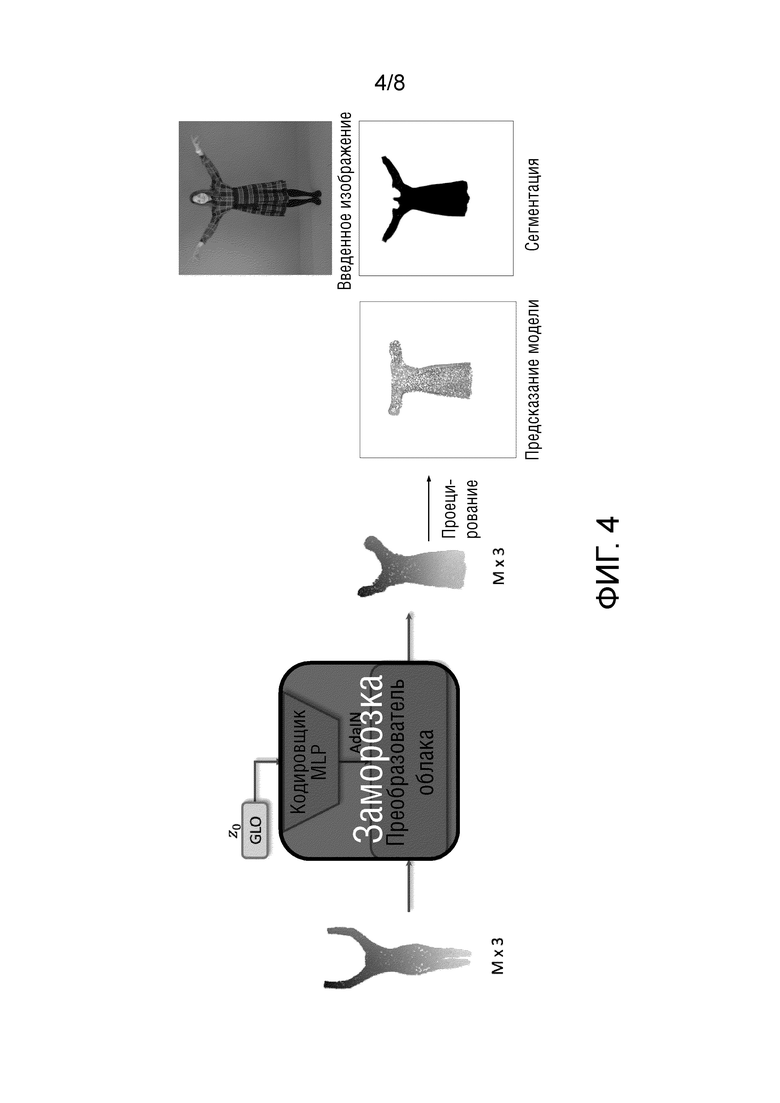
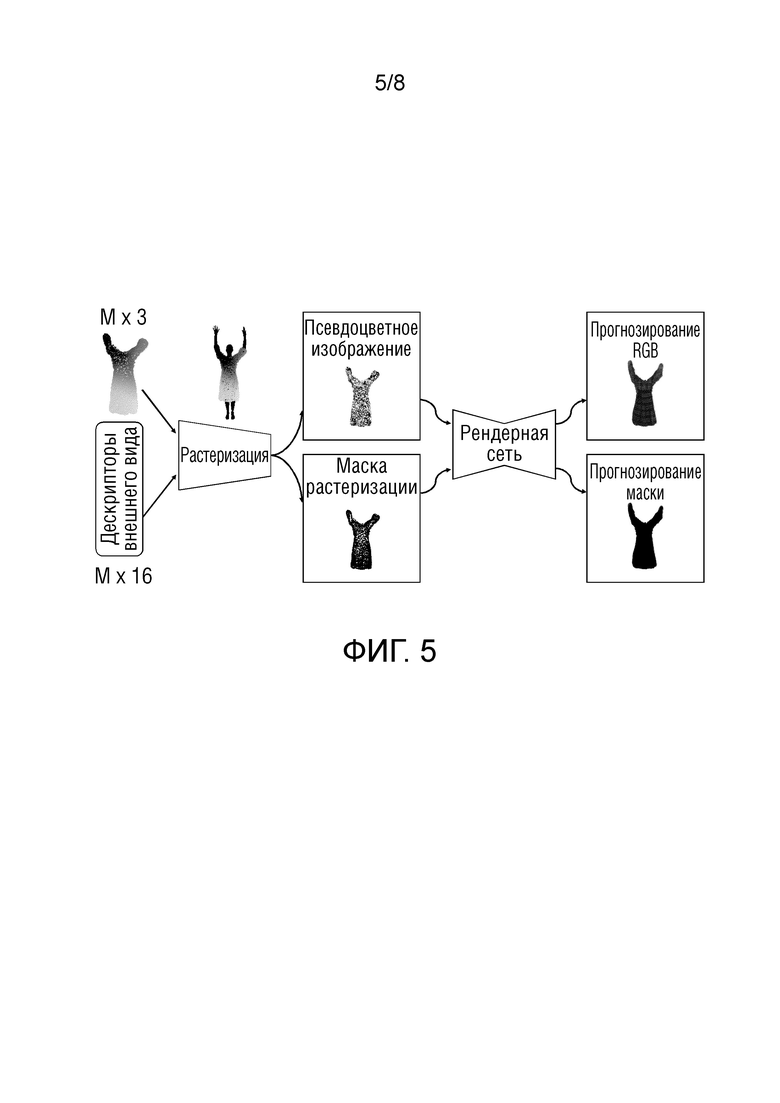
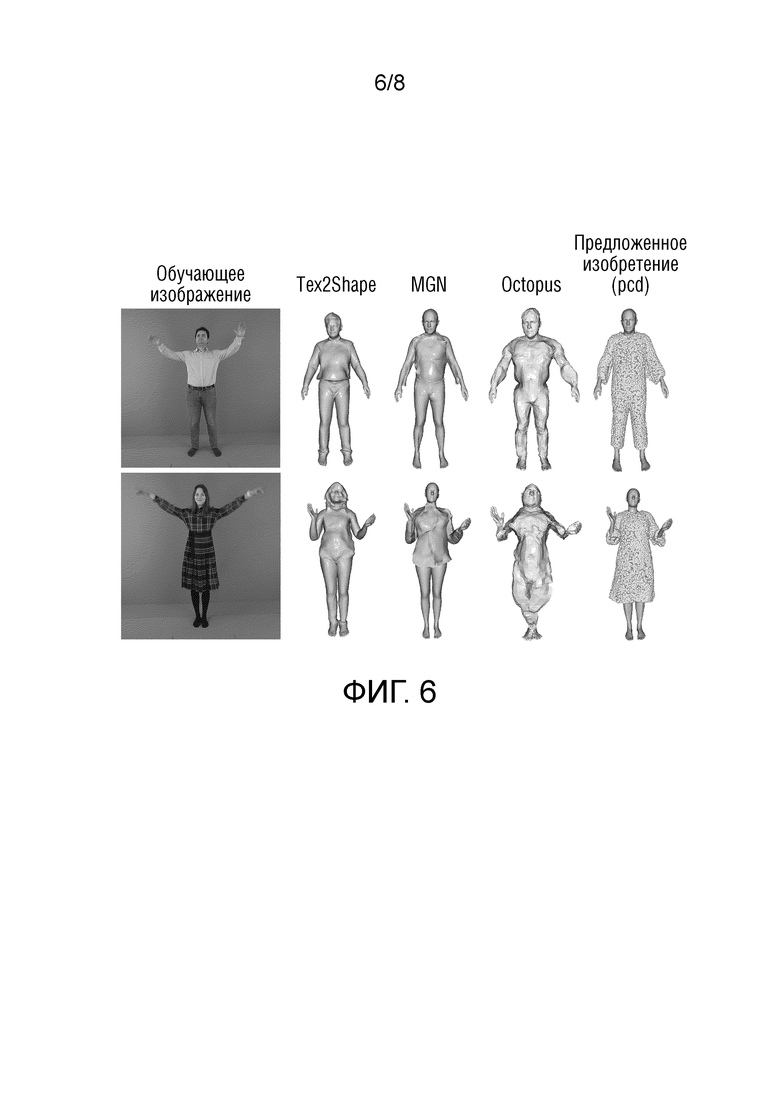
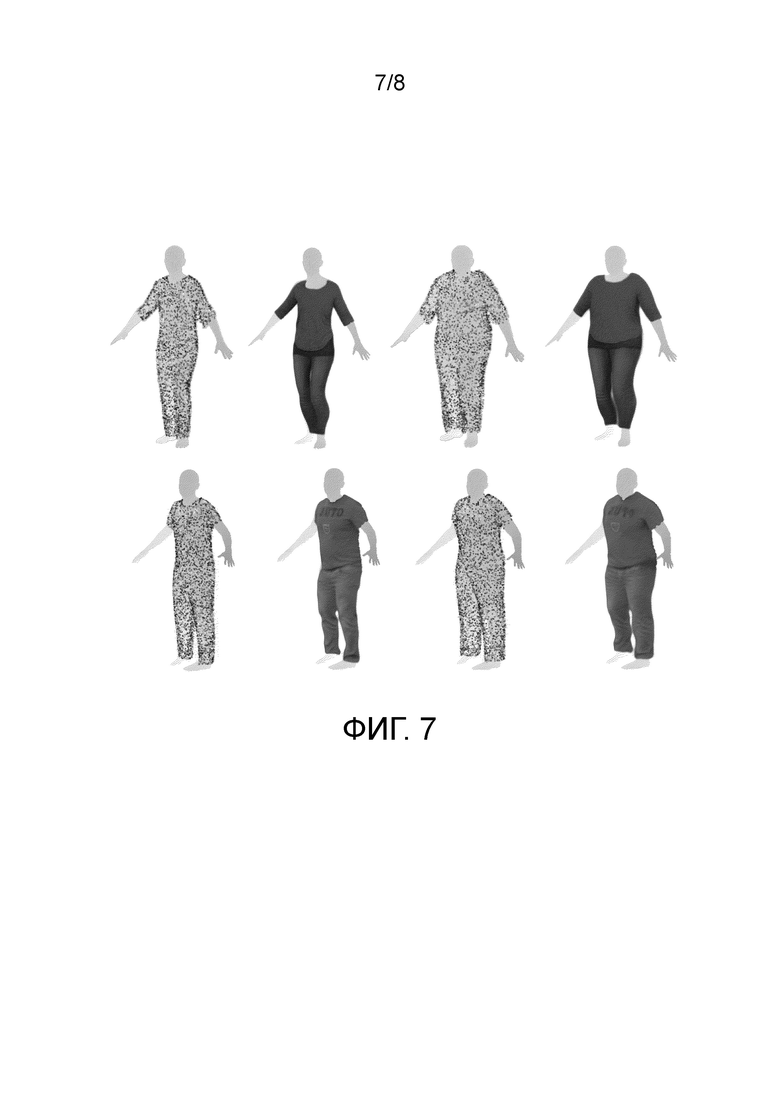

Изобретение относится к моделированию реалистичной одежды, носимой людьми, и реалистичному моделированию людей в 3D. Технический результат заключается в возможности генерирования изображений человека в одежде, выбранной на другом человеке. В способе обучения сети наложения для моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, обеспечивают набор кадров людей, в котором каждый человек одет в одежду и в котором кадры представляют собой последовательность видео, на которых каждый человек совершает последовательность движений; вычисляют для каждого кадра сетку Skinned Multi-Person Linear (SMPL) для позы и формы тела человека в кадре; вычисляют для каждого кадра сетку одежды для позы и формы тела человека в кадре; создают исходное облако точек в форме набора вершин упомянутых сеток Skinned Multi-Person Linear (SMPL) для каждого кадра; задают произвольно инициализированный d-мерный кодовый вектор для кодирования стиля одежды для каждого человека; подают исходные облака точек и кодовые векторы одежды в сеть наложения, а именно: подают исходные облака точек на вход нейронной сети преобразователя облака сети наложения, а кодовые векторы одежды - на вход нейронной сети кодировщика MLP (многослойного перцептрона); обрабатывают кодовый вектор одежды посредством нейронной сети кодировщика MLP и затем передают его вывод в нейронную сеть преобразователя облака, которая деформирует введенное исходное облако точек с учетом вывода нейронной сети кодировщика MLP и выводит спрогнозированное облако точек одежды для каждого кадра; после обработки всех кадров из набора кадров людей получают предобученную сеть наложения, а именно: веса обученной нейронной сети кодировщика MLP, веса обученной нейронной сети преобразователя облака, кодовые векторы одежды кодированных стилей для всех людей; накладывают посредством предобученной сети наложения подходящий стиль одежды, соответствующий одному из векторов и одному из облаков точек, на любую форму тела и любую позу, выбранную пользователем. 4 н. и 2 з.п. ф-лы, 8 ил., 2 табл.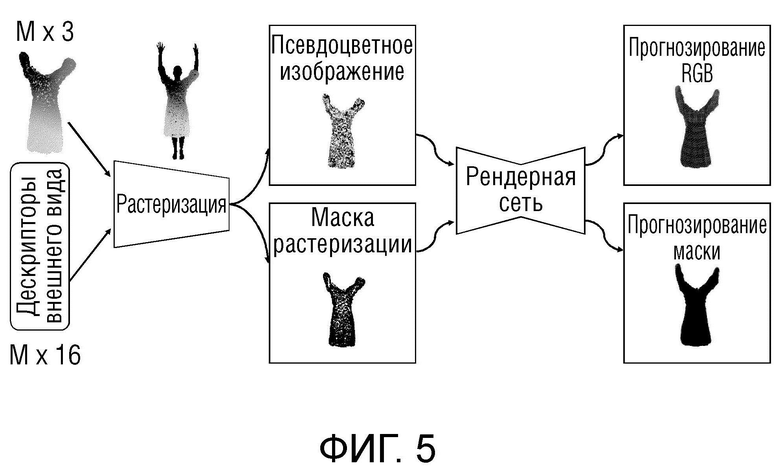
1. Способ обучения сети наложения для моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, заключающийся в том, что:
обеспечивают набор кадров людей, в котором каждый человек одет в одежду, и в котором кадры представляют собой последовательность видео, на которых каждый человек совершает последовательность движений;
вычисляют для каждого кадра сетку Skinned Multi-Person Linear (SMPL) для позы и формы тела человека в кадре;
вычисляют для каждого кадра сетку одежды для позы и формы тела человека в кадре;
создают исходное облако точек в форме набора вершин упомянутых сеток Skinned Multi-Person Linear (SMPL) для каждого кадра;
задают произвольно инициализированный d-мерный кодовый вектор для кодирования стиля одежды для каждого человека;
подают исходные облака точек и кодовые векторы одежды в сеть наложения, а именно: подают исходные облака точек на вход нейронной сети преобразователя облака сети наложения, а кодовые векторы одежды - на вход нейронной сети кодировщика MLP (многослойного перцептрона);
обрабатывают кодовый вектор одежды посредством нейронной сети кодировщика MLP и затем передают его вывод в нейронную сеть преобразователя облака, которая деформирует введенное исходное облако точек с учетом вывода нейронной сети кодировщика MLP и выводит спрогнозированное облако точек одежды для каждого кадра;
после обработки всех кадров из набора кадров людей получают предобученную сеть наложения, а именно: веса обученной нейронной сети кодировщика MLP, веса обученной нейронной сети преобразователя облака, кодовые векторы одежды кодированных стилей для всех людей;
накладывают посредством предобученной сети наложения подходящий стиль одежды, соответствующий одному из векторов и одному из облаков точек, на любую форму тела и любую позу, выбранную пользователем.
2. Способ получения спрогнозированного облака точек одежды и кодового вектора одежды из изображения материального человека в одежде для моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, заключающийся в том, что:
захватывают с помощью устройства обнаружения изображение материального человека в одежде;
прогнозируют сетку SMPL с желаемой позой и формой тела по этому изображению методом SMPLify;
создают исходное облако точек в форме вершин упомянутой сетки Skinned Multi-Person Linear (SMPL) для изображения;
прогнозируют двоичную маску одежды, соответствующую пикселям данной одежды на изображении, с помощью упомянутой сети сегментации;
инициализируют случайными значениями d-мерный кодовый вектор одежды для кодирования стиля одежды для данного изображения;
подают исходное облако точек и кодовый вектор одежды в предобученную сеть наложения, обученную в соответствии с п.1,
получают спрогнозированное облако точек одежды из вывода предобученной сети наложения;
проецируют облако точек одежды на черно-белое изображение с заданными параметрами камеры изображения человека;
сравнивают путем вычисления функции потерь проекцию этого спрогнозированного облака точек на изображении с истинной двоичной маской одежды, соответствующей пикселям одежды на изображении, через расстояние фаски между двумерными облаками точек, которые являются проекциями 3D-облаков точек;
оптимизируют кодовый вектор одежды на основе вычисленной функции потерь;
накладывают в соответствии с полученным кодовым вектором одежды спрогнозированное облако точек одежды изображения на любую форму тела и любую позу тела, выбранную пользователем.
3. Способ моделирования одежды на человеке, в котором одежда адаптируется к позе тела и форме тела любого человека, заключающийся в том, что:
обеспечивают поток цветного видео первого человека;
выбирают, посредством пользователя, любую одежду согласно любому видео второго человека в одежде;
посредством операционного блока компьютерной системы:
получают спрогнозированное облако точек одежды и кодовый вектор одежды согласно способу по п.2 для любого кадра видео;
инициализируют случайными значениями n-мерный вектор дескриптора внешнего вида для каждой точки облака точек, которая отвечает за цвет;
генерируют блоком растеризации 16-канальный тензор изображения с использованием 3D-координат каждой точки и нейронного дескриптора каждой точки, и двоичную черно-белую маску, соответствующую пикселям изображения, покрытого этими точками;
обрабатывают рендерной сетью 16-канальный тензор изображения вместе с двоичной черно-белой маской для получения цветного RGB изображения и маски одежды;
оптимизируют веса рендерной сети и значения дескрипторов внешнего вида в соответствии с истинной последовательностью видео человека для получения желаемого внешнего вида одежды;
отображают пользователю на экране видео первого человека в одежде второго человека в виде спрогнозированного визуализированного изображения в одежде с заданной позой и формой тела, причем пользователь может вводить видео любого человека и видеть полученную в результате обучения цветную модель одежды, перенацеленную на новые формы тела и позы, визуализированные поверх этого нового видео, то есть, одевать изображение персонажа из любого видео в любую одежду, выбранную пользователем.
4. Способ по п.3, в котором реальный человек является пользователем, который отображает пользователю цветную модель одежды на этом пользователе.
5. Система для моделирования одежды на человеке с использованием способа по п.3, содержащая:
устройство обнаружения, подключенное к компьютерной системе, содержащей операционный блок, подключенный к экрану дисплея и блоку выбора;
причем устройство обнаружения выполнено с возможностью захвата потока цветного видео первого реального человека в реальном времени;
блок выбора выполнен с возможностью позволить пользователю выбирать любую одежду по любому видео второго человека в одежде;
экран дисплея выполнен с возможностью отображать упомянутого первого человека в реальном времени в одежде, выбранной пользователем из упомянутых видео в соответствии с данными, полученными от операционного блока.
6. Система по п.5, в которой пользователем является первый человек.
| MATTHEW LOPER и др., "SMPL: a skinned multi-person linear model", ACM Transactions on Graphics, Volume 34, Issue 6, November 2015, Доступно по адресу: https://dl.acm.org/doi/pdf/10.1145/2816795.2818013 | |||
| СИСТЕМА АВТОМАТИЗИРОВАННОГО ВИРТУАЛЬНОГО ПРОЕКТИРОВАНИЯ ИЗДЕЛИЯ ОДЕЖДЫ ДЛЯ ПОЛЬЗОВАТЕЛЕЙ И СПОСОБ ЕЕ ОСУЩЕСТВЛЕНИЯ | 2019 |
|
RU2718362C1 |
| НЕЙРОННАЯ ТОЧЕЧНАЯ ГРАФИКА | 2019 |
|
RU2729166C1 |
| CN 108269302 B, 07.08.2020 | |||
| US 20210049811 A1, 18.02.2021 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРОВЕРКИ ЯИЦ | 2011 |
|
RU2583687C2 |
| US | |||

