ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0001] Настоящее изобретение в целом относится компьютерным системам и, более конкретно, к системам и способам генерации текстовых корпусов, содержащих реалистичные ошибки оптического распознавания символов (OCR), и обучению языковых моделей с использованием текстовых корпусов.
УРОВЕНЬ ТЕХНИКИ
[0002] Процесс оптического распознавания символов (OCR) может извлекать машиночитаемую текстовую информацию с возможностью поиска из содержащих знаки изображений на различных носителях (например, печатных или написанных от руки бумажных документах, баннерах, постерах, знаках, рекламных щитах и (или) других физических объектах, несущих видимые символы текста (включая закодированные символы текста, например, штрих-коды, баркоды) на одной или более поверхностях). Перед поступлением в процесс OCR исходные изображения могут подвергаться предварительной обработке одной или более сверточными нейронными сетями, которые исправляют определенные смоделированные дефекты.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более аспектами настоящего изобретения пример реализации способа обучения нейронных сетей обработки изображений с помощью синтетических фотореалистичных содержащих знаки изображений может включать создание вычислительной системой множества исходных изображений на основе исходных содержащих текст текстовых корпусов; наложение вычислительной системой одного или более смоделированных дефектов на множество исходных изображений для создания аугментированного набора изображений; формирование выходного текстового корпуса на основе аугментированного набора изображений; и обучение языковой модели для оптического распознавания символов с использованием полученного текстового корпуса.
[0004] В соответствии с одним или несколькими аспектами настоящего изобретения пример системы обучения нейронных сетей обработки изображений на основе фотореалистичных содержащих знаки изображений может включать: запоминающее устройство; устройство обработки, соединенное с запоминающим устройством, причем это устройство обработки настроено на: формирование начального множества изображений на основе исходного содержащего текст текстового корпуса; наложение одного или более смоделированных дефектов на начальное множество изображений с целью создания аугментированного множества изображений содержащих текст сегментов; формирование выходного текстового корпуса на основе аугментированного множества изображений; и обучение языковой модели для оптического распознавания символов с использованием полученного текстового корпуса.
[0005] В соответствии с одним или более аспектами настоящего изобретения пример постоянного машиночитаемого носителя данных может содержать исполняемые команды, которые при их исполнении устройством обработки обеспечивают выполнение следующих функций устройством обработки: генерация компьютерной системой начального множества изображений на основе исходных содержащих текст текстовых корпусов; наложение компьютерной системой одного или более смоделированных дефектов на начальное множество изображений для создания аугментированного набора изображений; формирование выходного текстового корпуса на основе аугментированного набора изображений; и обучение языковой модели для оптического распознавания символов с использованием полученного текстового корпуса.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, которые не являются ограничивающими; сущность изобретения должна становится более понятной ссылаясь к приведенному ниже подробному описанию изобретения во взаимосвязи с чертежами, где:
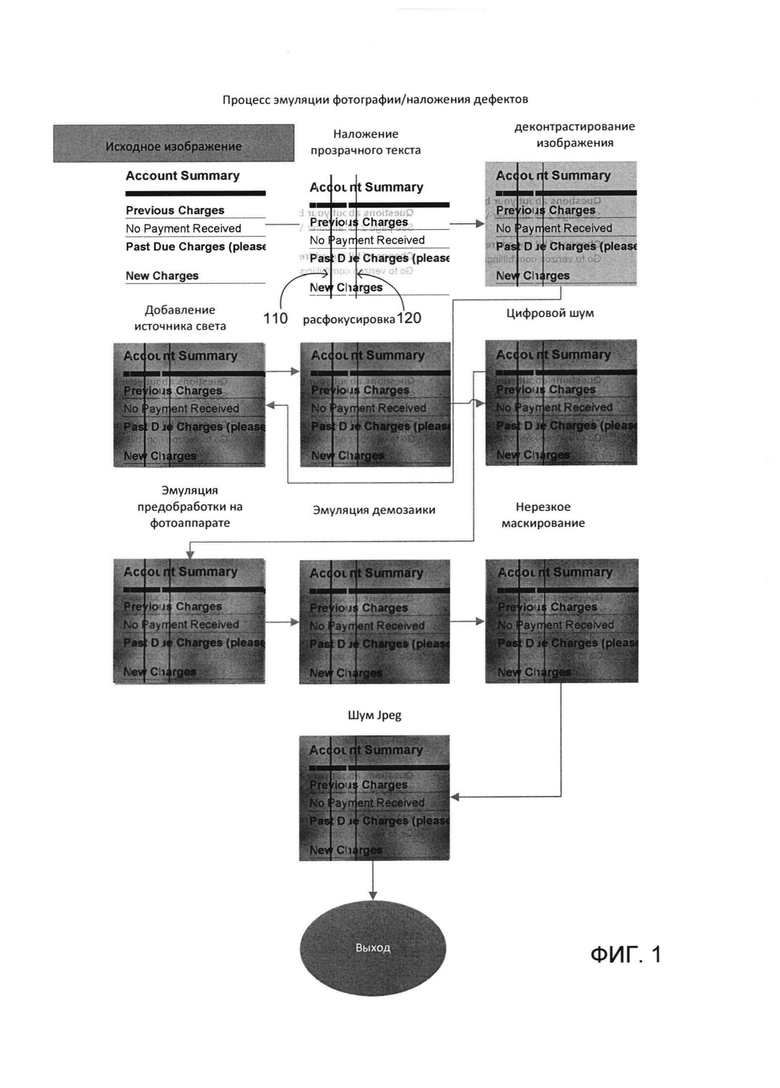
[0007] На Фиг. 1 изображен пример процесса эмуляции фотосъемки, реализованный в соответствии с одним или более вариантами реализации настоящего изобретения;
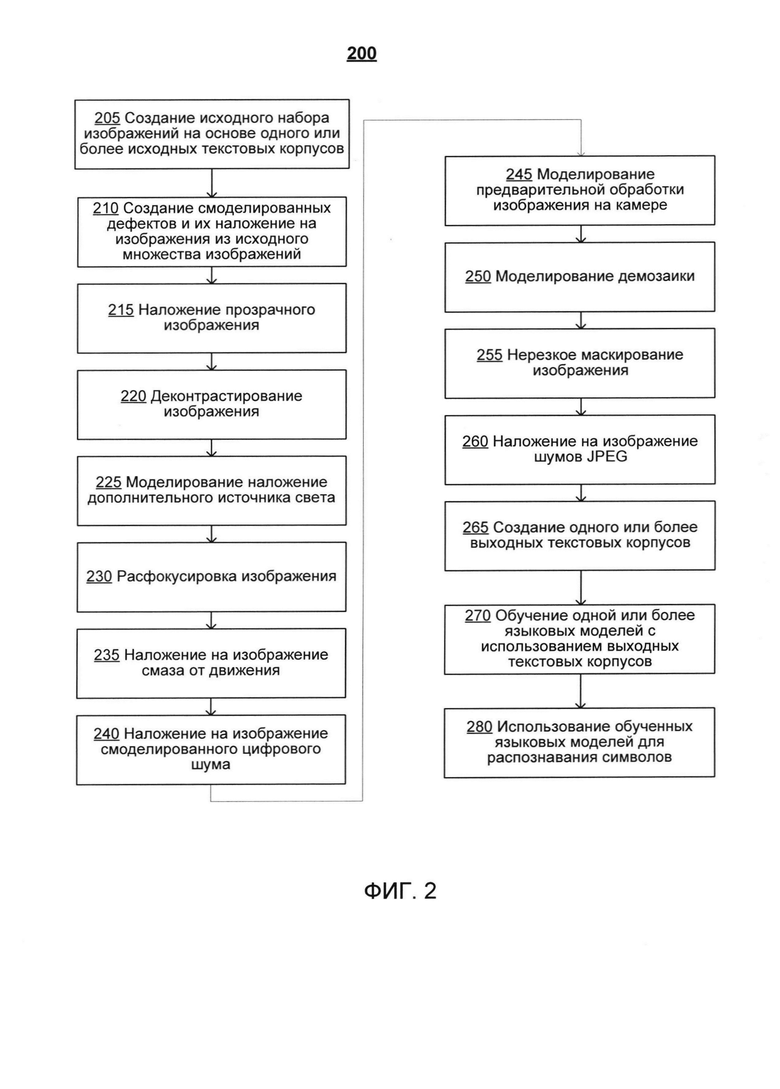
[0008] На Фиг. 2 изображена блок-схема примера реализации способа обучения языковой модели с использованием текстового корпуса, содержащего реалистичные ошибки OCR и контекстно-зависимую информацию, в соответствии с одним или более вариантами реализации настоящего изобретения;
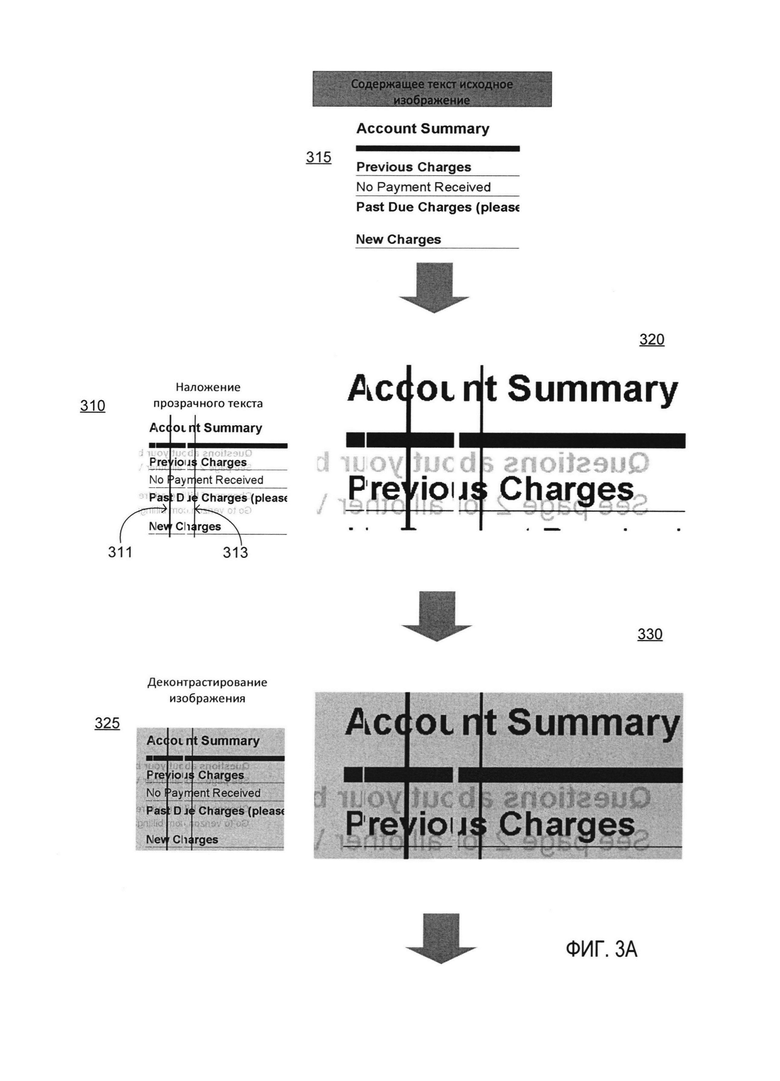
[0009] На Фиг. 3A-3D схематично изображены различные операции обработки изображения, которые могут использоваться для создания синтетических фотореалистичных изображений, содержащих знаки, в соответствии с одним или более вариантами реализации настоящего изобретения;
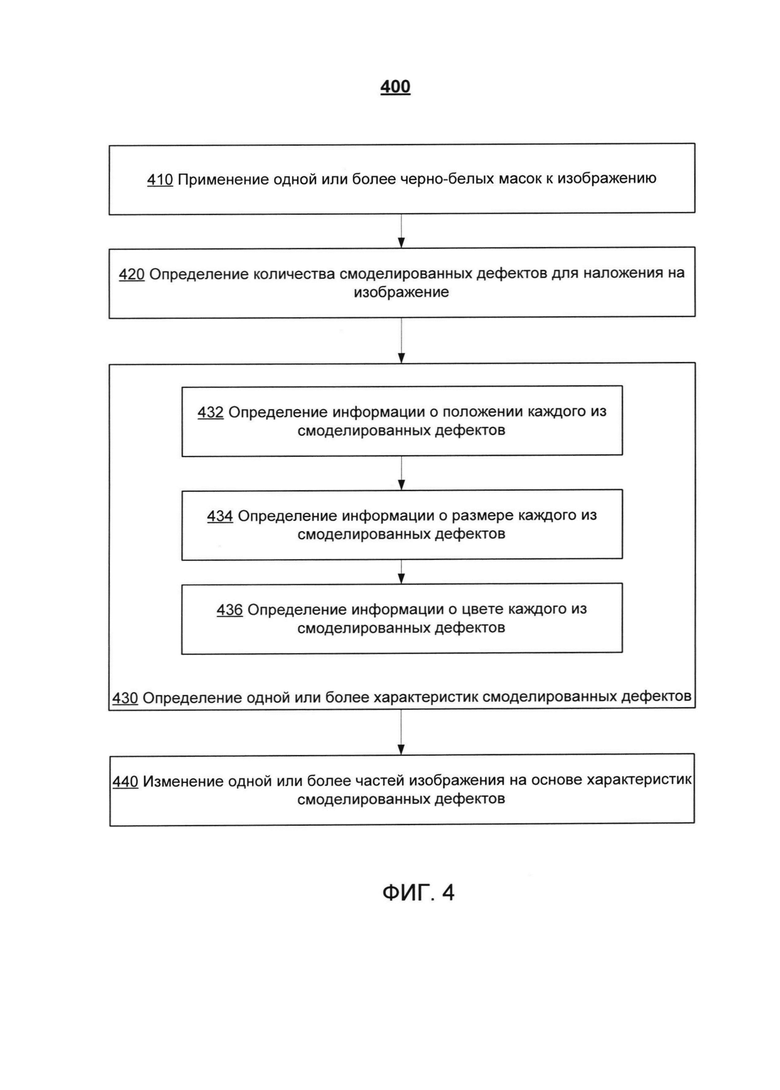
[00010] На Фиг. 4 приведен пример реализации способа для создания текстового корпуса, содержащего реалистичные ошибки OCR, в соответствии с одним или более вариантами реализации настоящего изобретения; и
[00011] На Фиг. 5 представлена схема компонентов примера вычислительной системы, которая может использоваться для реализации описанных в настоящем документе способов.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[00012] В настоящем документе описываются способы и системы формирования текстового корпуса, содержащего реалистичные ошибки оптического распознавания символов (OCR), и обучения языковых моделей с использованием текстовых корпусов.
[00013] Распознавание символов может включать распознавание текста или другого содержимого изображения с использованием машинных обучающих моделей, обученных для целей OCR («языковая модель»). Существующие способы обучения языковых моделей обычно используются для обучения языковых моделей путем выборки синтетических данных, полученных из текстовых корпусов. Например, в существующих способах может использоваться шум и образцы ошибок OCR, присутствующие в данном текстовом корпусе. При использовании таких способов ошибки OCR, присутствующие в тесте могут быть сформированы искусственно, например, с помощью таблиц вероятности ошибок для графем и символов. При этом существующие способы обучения языковых моделей являются неэффективными, поскольку синтетические ошибки OCR могут иметь низкое качество или являться неверными. Синтетические ошибки OCR также могут располагаться в неверных местах изображения и, таким образом, не представлять реальные ошибки OCR, имеющиеся в документе. По сути, существующие способы формирования синтетических данных для обучения языковых моделей могут быть неприменимыми для предоставления данных, представляющих реальные ошибки OCR, которые могут возникать в документах, создаваемых при OCR. Языковые модели, обученные с использованием таких синтетических данных, могут давать низкое качество результатов.
[00014] Системы и способы настоящего изобретения вносят значительные улучшения по сравнению с существующими способами обучения языковых моделей за счет предоставления способа формирования текстовых корпусов, содержащих реалистичные ошибки OCR, и обучения языковых моделей с помощью текстовых корпусов. Способ может включать создание множества изображений на основе исходного текстового корпуса, содержащего текст.Например, способ может реализовывать разделение текстового корпуса (например, из одного или более текстовых документов) на несколько сегментов и формирование изображения каждого из нескольких сегментов. Далее этот способ может реализовываться для добавления одного или более смоделированных дефектов к каждому из изображений. Смоделированные дефекты могут представлять любой дефект, который может присутствовать на изображении (также называемый «дефект изображения»), например, один или более дефектов печати, дефектов сканирования, дефектов фотографирования и т.д. Каждый из смоделированных дефектов может включать одну или более линий, пятен, и (или) иных дефектов, которые могут присутствовать в документе, обрабатываемом с помощью технологий OCR. После добавления смоделированных дефектов в изображение способ может выполнять OCR изображений для формирования обработанных OCR изображений. После обработки OCR изображения могут быть представлены с использованием способа в виде одного или более выходных текстовых корпусов. Соответствующим образом, полученные текстовые корпусы включают реалистичные ошибки OCR, которые могут содержать контекстно-зависимую информацию. Полученные текстовые корпусы затем могут использоваться для обучения моделей машинного обучения для выполнения OCR, например, языковых моделей с использованием вложенных слов и (или) символов. Использование выходных текстовых корпусов, полученных с помощью систем и способов по настоящему изобретению для обучения нейронных сетей для обработки языковых моделей, приводит к значительному повышению качества распознания изображений, что повышает общую эффективность различных применений, например, процесса оптического распознавания символов (OCR), при котором из изображений извлекается текстовая информация.
[00015] В одном из иллюстративных примеров вычислительная система, реализующая способы, описанные в настоящем документе, может выполнять процесс эмуляции фотосъемки, как схематично изображено на Фиг. 1. Этот процесс эмуляции фотосъемки может включать наложение прозрачного текста и одного или более смоделированных дефектов (например, дефектов 110 и (или) 120 на Фиг. 1) на исходное изображение, деконтрастирование изображения, эмуляцию дополнительного искусственного источника света на сцену изображения, расфокусировку изображения, добавление (наложение) цифрового шума, эмуляцию предобработки изображения на устройстве фиксации изображения (например, фотокамере), эмуляцию демозаики изображения, применение нерезкого маскирования изображения, добавление (наложение) в изображение шумов JPEG и (или) выполнение различных других операций обработки изображения. Эти операции обработки изображения приведут к получению аугментированного набора изображений объектов, содержащих знаки. Изображения, обработанные обученными нейронными сетями, могут использоваться в процессе OCR для извлечения из изображений текстовой информации. Различные варианты упомянутых выше способов и систем подробно описаны ниже в настоящем документе с помощью примеров, которые не накладывают ограничений.
[00016] На Фиг. 2 приведена блок-схема одного иллюстративного примера способа 200 обучения языковых моделей в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 200 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 500 на Фиг. 5), реализующей этот способ. В некоторых реализациях способ 200 может быть реализован в одном потоке обработки. Кроме того, способ 200 может выполняться, используя два или более потоков обработки, причем каждый поток выполняет одну или более отдельных функций, процедур, подпрограмм или операций способа. В одном из иллюстративных примеров потоки обработки, в которых реализован способ 200, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). В качестве альтернативы потоки обработки, в которых реализован способ 200, могут выполняться асинхронно по отношению друг к другу. Таким образом, несмотря на то, что Фиг. 2 и соответствующее описание содержат список операций для способа 200 в определенном порядке, в различных вариантах реализации способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[00017] В блоке 205 вычислительная система, реализующая способ, может сформировать исходное множество изображений на основе одного или более исходных текстовых корпусов. Каждый из исходных текстовых корпусов может включать один или более электронных документов, содержащих текст. В некоторых вариантах реализации изобретения один или более электронных документов может включать сплошной текст (например, один или более файлов в формате Rich Text Format (RTF)). В некоторых вариантах реализации изобретения текстовый корпус из исходного множества корпусов может являться электронным документом, содержащим непрерывный текст, и (или) включать в себя такой текст. Для формирования исходного множества изображений вычислительная система может разделить исходные текстовые корпуса на один или более сегментов. Каждый из сегментов может соответствовать одной или более страницам, линиям, строкам текста и т.д. В некоторых вариантах реализации изобретения исходный текстовый корпус может быть сегментирован на множество сегментов на основе одного или более заданных правил. Например, исходный текстовый корпус может быть сегментирован по границам слов. В другом примере исходный текстовый корпус может быть сегментирован таким образом, чтобы каждый из сегментов включал определенное количество символов (например, 80 символов в строке текста). В еще одном примере исходный текстовый корпус может быть сегментирован на предложения.
[00018] Каждое изображение из исходного множества изображений может представлять собой визуализацию (рендеринг) одного или более сегментов исходного текстового корпуса. Визуализация может быть выполнена с использованием различных шрифтов, разрешений и (или) других параметров процесса визуализации. В некоторых вариантах реализации изобретения исходное множество изображений может включать черно-белые изображения. Исходное множество изображений может храниться в одном или более файлах заранее определенного формата, например, файлах PDF. В некоторых вариантах реализации нейронные сети, обученные способами по настоящему изобретению, могут тестироваться (валидироваться) путем использования валидационных наборов изображений, содержащих известные тексты, которые могут быть визуализированы и растрированы с использованием заранее определенных или динамически регулируемых параметров визуализации и растеризации.
[00019] На шагах 210-260 вычислительная система может обрабатывать исходное множество изображений для получения набора аугментированных изображений. При обработке изображений в исходное множество изображений могут добавляться различные дефекты (например, дефекты и (или) искажения, в том числе, расфокусировка, смаз, блик и т.д.) путем добавления смоделированных дефектов, соответствующих дефектам изображения, в исходное множество изображений. Дефекты изображения могут представлять собой любые дефекты, которые могут присутствовать в изображениях, полученных методом фотографии, сканированных изображений, печатных изображениях и (или) изображениях, полученных любым иным способом. Например, множество аугментированных изображений может включать одно или более аугментированных изображений, включающих один или более дефектов, соответствующих дефектам изображения. Обработка исходного множества изображений и (или) создание аугментированных изображений может включать формирование изображений, содержащих смоделированные искажения изображений с различными параметрами, варьирующимися в зависимости от необходимых типов искажений, таким образом предоставляя возможность для создания неограниченных множеств искаженных изображений. В различных вариантах реализации по меньшей мере некоторые из операций, описанные ниже в настоящем документе со ссылкой на шаги 210-260, могут не выполняться; кроме того, порядок операций обработки изображения, описанных ниже в настоящем документе со ссылкой на шаги 210-260, может быть различным.
[00020] На шаге 210 вычислительная система может наложить один или более смоделированных дефектов на исходное множество изображений. К смоделированным дефектам могут относиться, например, одна или более линий (например, вертикальные линии, горизонтальные линии, линии иной подходящей ориентации), пятна (круглые пятна, эллиптические пятна и т.д.), и (или) любые иные дефекты, которые могут присутствовать в электронном документе (например, в документе, который может быть обработан с помощью OCR). В одном из вариантов реализации на исходное множество изображений могут быть наложены смоделированные дефекты одного типа (например, линии). Например, как показано на Фиг. 3А, смоделированные дефекты 311 и 313 могут быть наложены на исходное изображение 315, содержащее текст. Каждый из смоделированных дефектов 311 и 313 может содержать линию. В другом варианте реализации на исходное множество изображений накладывается несколько типов смоделированных дефектов (например, линии и пятна). Для наложения смоделированных дефектов вычислительная система может определить одну или более характеристик каждого из смоделированных дефектов, например, информацию о положении каждого из смоделированных дефектов (например, одна или более координат, определяющих расположение дефекта на изображении), информацию о размерах каждого из смоделированных дефектов (например, ширина, длина, размер и т.д. линии, радиус круглого пятна, основная ось и (или) дополнительная ось эллиптического пятна и т.д.), цвет каждого смоделированного дефекта (например, черный, белый и т.д.). Затем вычислительная система может выполнить наложение смоделированных дефектов на исходное множество изображений на основе заданных характеристик. Например, вычислительная система может модифицировать одну или более частей изображения на основе характеристик смоделированных дефектов (например, за счет выявления одного или более пикселей на изображении, соответствующих информации о положении смоделированного дефекта, и изменения яркости выявленных пикселей в соответствии с информацией о цвете смоделированного дефекта). В некоторых вариантах реализации изобретения смоделированные дефекты могут добавляться к одному или более исходным изображениям путем выполнения одной или более операций, описанных ниже со ссылкой на Фиг. 4.
[00021] Более конкретно, на шаге 215 вычислительная система может накладывать на одно или более изображений в шаге 210 прозрачное изображение с заранее определенным или случайно сгенерированным текстом. Части прозрачного изображения могут быть полностью невидимы в тех местах, где прозрачное изображение пересекается с базовым изображением («полная прозрачность»). В других случаях части прозрачного изображения могут быть частично видимы в тех местах, где прозрачное изображение пересекается с базовым изображением («частичная прозрачность» или «просвечиваемость»). Как схематично изображено на Фиг. 3А, операция 310 наложения прозрачного текста на входное изображение 315 позволяет получить выходное изображение 320.
[00022] На шаге 220 вычислительная система может выполнять деконтрастирование созданного изображения, то есть уменьшать максимальную разницу освещенности или яркости пикселей созданного изображения на заранее определенную величину, например 0,1 или 0,2 исходной максимальной разницы. Как схематично изображено на Фиг. 3А, операция 325 деконтрастирования исходного изображения 320 позволяет получить выходное изображение 330.
[00023] На шаге 225 вычислительная система может смоделировать наложение дополнительный источника света на сцене изображения, дополнительно накладывая по меньшей мере на часть пикселей изображения гауссовский шум сверхнизкой частоты с малой амплитудой и, таким образом, эмулируя градиентные переходы между более светлыми и более темными фрагментами изображения. Как схематично изображено на Фиг. ЗА-ЗВ, операция 335 моделирования наложения дополнительного источника света на сцене изображения должна обрабатывать входное изображение 330 и создавать выходное изображение 340.
[00024] На шаге 230 вычислительная система может, по меньшей мере, частично провести расфокусировку изображения, например накладывая размытие по Гауссу с заранее определенным или динамически настраиваемым радиусом, который может выбираться из заранее определенного или динамически настраиваемого диапазона (например, 0,7-3,0). Как схематично изображено на Фиг. ЗВ, операция 345 расфокусировки входного изображения 340 дает выходное изображение 350.
[00025] На шаге 235 вычислительная система может накладывать на изображение размытие движения, имитируя движение изображаемых объектов в течение времени экспозиции, которое определяется выдержкой.
[00026] На шаге 240 вычислительная система может применять как минимум к части пикселей изображения смоделированный цифровой шум, например, гауссовский шум с заранее определенной или динамически регулируемой амплитудой, например не более 20 единиц яркости изображения или не более 0,15 диапазона яркости изображения. Как схематично изображено на Фиг. ЗВ, операция 355 наложения цифрового шума на входное изображение 350 позволяет получить выходное изображение 360.
[00027] На шаге 245 вычислительная система может смоделировать предварительную обработку изображения, выполняемую получающей изображение камерой, например, путем применения сигма-фильтра, как минимум, к части пикселей изображения. Как схематично изображено на Фиг. 3В-3С, операция эмуляции 365 предварительной обработки изображения входного изображения 360 позволяет получить выходное изображение 370.
[00028] На шаге 250 вычислительная система может смоделировать демозаику изображения, которая представляет собой процесс восстановления полноцветного изображения из примеров с неполноценными цветами, полученными датчиком изображения путем наложения массива цветных фильтров (CFA). В некоторых вариантах реализации устранение мозаичности изображения может включать наложение размытия по Гауссу с заранее определенным или динамически регулируемым среднеквадратичным значением (например, 0,1, 0,2, 0,3 или другим значением). Кроме того, устранение мозаичности изображения может дополнительно включать применение к изображению сглаживания света по Гауссу. Оператор сглаживания по Гауссу представляет собой двумерный оператор свертки, который может использоваться для размытия изображения и устранения деталей и шума. Как схематично изображено на Фиг. ЗС, операция 375 устранения мозаичности входного изображения 370 позволяет получить выходное изображение 380.
[00029] На шаге 255 вычислительная система может выполнить нерезкое маскирование по меньшей мере части пикселей изображения, которое представляет собой технологию обработки, использующую размытое (или «нерезкое») негативное изображение для создания маски исходного изображения. Нерезкая маска затем объединяется с позитивным (исходным) изображением, в результате получается менее размытое, чем оригинал, изображение. Нерезкая маска может быть представлена линейным или нелинейным фильтром, который усиливает высокочастотные компоненты исходного сигнала. В некоторых вариантах реализации вычислительная система может смоделировать операцию снижения резкости, выполняемую определенной моделью камеры, используя значения параметров нерезкой маски, реализуемые камерой. Как схематично изображено на Фиг. ЗС, операция 385 снижения резкости входного изображения 380 позволяет получить выходное изображение 390.
[00030] На шаге 260 вычислительная система может наложить шум JPEG, то есть случайные вариации информации о яркости или цвете. Шум может вноситься, например, путем сохранения изображения в формате JPEG с заранее определенным или динамически регулируемым качеством (например, выбираемым из диапазона 2-80) с последующим разархивированием сохраненного изображения JPEG. Как схематично изображено на Фиг. 3C-3D, операция 392 добавления шума JPEG во входное изображение 390 позволяет получить выходное изображение 395.
[00031] Исходное множество изображений может быть обработано с помощью одной или более из описанных выше операций обработки изображений с возможными изменениями параметров операций, в результате будет получен набор аугментированных изображений. Каждое изображение из множеств аугментированных изображений может включать один или более текстовых сегментов.
[00032] Таким образом, операции обработки изображения, описанные выше со ссылкой на шаги 225-260, дают множество аугментированных изображений содержащий один или более текстовых сегментов и смоделированные дефекты, соответствующие одному или более дефектам изображения.
[00033] На шаге 265 вычислительная система может создать один или более выходных текстовых корпусов на основе множества аугментированных изображений. Например, вычислительная система может выполнить OCR для множества искаженных изображений одного или более текстовых сегментов для распознания текста во множестве аугментированных изображений. OCR может выполняться с использованием любого пригодного метода OCR (например, метод OCR, использующий языковые модели, обученные с использованием выходных текстовых корпусов, метод и (или) модель случайного OCR корпусов, метод и (или) модель произвольного OCR). Поскольку выходные текстовые корпусы формируются на основе множества аугментированных изображений, включающих смоделированные дефекты, соответствующие дефектам изображения, присутствующим в различных типах изображений (например, печатные изображения, фотографии, отсканированные изображения), выходные текстовые корпусы могут считаться включающими реалистические ошибки OCR и контекстно-зависимую информацию.
[00034] На шаге 270 вычислительная система может выполнить обучение, с использованием одного или более выходных текстовых корпусов, одной или более языковых моделей для распознавания символов. Одна или более обученных языковых моделей может использоваться для выполнения распознавания символов в документе. Обученные языковые модели могут включать одну или более языковых моделей, использующих словные эмбеддинги (word embeddings) и/или символьные эмбеддинги (character embeddings). Словный эмбеддинг может являться векторным представлением слова. Символьный эмбеддинг может являться векторным представлением символов. Эмбеддинг словный и (или) символьный может являться вектором или действительным числом, которые могут создаваться, например, за счет реализации в нейронной сети математической трансформации слов с помощью функций эмбеддинга (embedding). Например, языковая модель, использующая словные эмбеддинги, может получать исходное слово и сопоставлять его с представлением слова. Языковая модель, использующая символьные эмбеддинги может получать исходный символ и сопоставляет его с представлением символа. Описанная в настоящем документе языковая модель в некоторых вариантах реализации изобретения может использовать эмбеддинги и слов и символов.
[00035] Одна или более языковых моделей могут включать одну или более нейронных сетей, например, одну или более рекуррентных нейронных сетей (RNN), долгую краткосрочную память (LSTM) RNNs, двунаправленные RNN сети, двунаправленные LSTM и т.д. Рекуррентные нейронные сети (RNN) могут являться нейронной сетью, которая способна поддерживать состояние сети, отражающее информацию об исходных данных, обрабатываемых сетью, таким образом позволяя сети использовать свое внутреннее состояние для обработки последующих исходных данных. Например, рекуррентная нейронная сеть может получать исходный вектор на входной слой рекуррентной нейронной сети. Скрытый слой рекуррентной нейронной сети обрабатывает исходный вектор. Выходной слой рекуррентной нейронной сети может создавать выходной вектор. Состояние сети может быть сохранено и использовано для обработки последующих исходных векторов с целью выполнения последующих оценок.
[00036] В некоторых вариантах реализации изобретения языковые модели могут включать одну или более нейронных сетей, которые могут применяться для бинаризации и исправления смаза и (или) тени изображения и для выделения улучшений. В различных вариантах реализации различные другие нейронные сети могут быть обучены на множествах данных, включающих части изображений, на которых одно изображение берется из исходного множества изображений, а другое - из множества аугментированных изображений.
[00037] В некоторых вариантах реализации изобретения языковые модели могут включать сверточную нейронную сеть, которая может представлять собой вычислительную модель, основанную на многостадийном алгоритме, который применяет набор заранее определенных функциональных преобразований к множеству входов (например, пикселей изображений) и затем использует преобразованные данные для выполнения распознавания образов. Сверточная нейронная сеть может быть реализована в виде искусственной нейронной сети с прямой связью, в которой схема соединений между нейронами подобна тому, как организована зрительная зона коры мозга животных. Отдельные нейроны коры откликаются на раздражение в ограниченной области пространства, известной под названием рецептивного поля. Рецептивные поля различных нейронов частично перекрываются, образуя поле зрения. Отклик отдельного нейрона на раздражение в границах своего рецептивного поля может быть аппроксимирован математически с помощью операции свертки. Нейроны соседних слоев соединены взвешенными ребрами. Веса ребер и (или) другие параметры сети определяются на стадии обучения сети на основе обучающей выборки данных.
[00038] В одном из иллюстративных примеров обучение сети включает активацию сверточной нейронной сети для каждого исходного образца обучающей выборки данных. Значение заранее определенной функции потерь вычисляется исходя из получаемого выхода сверточной нейронной сети и ожидаемого результата, определенного в обучающей выборке данных, а ошибка распространяется назад на предыдущие слои сверточной нейронной сети, в которой соответствующим образом меняются веса и (или) другие параметры сети. Этот процесс может повторяться, пока значение функции ошибок не станет ниже заранее определенного порогового значения.
[00039] На шаге 280 обученные языковые модели могут использоваться для распознавания символов. Например, исходное изображение, содержащее неизвестный текстовый контент, может быть обработано с использованием одной или более обученных языковых моделей для распознавания неизвестного текстового контента.
[00040] На Фиг. 4 приведен пример 400 реализации способа для создания текстового корпуса, содержащего реалистичные ошибки OCR, в соответствии с одним или несколькими вариантами реализации настоящего изобретения. Способ 400 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 500 на Фиг. 5), реализующей этот способ. В некоторых реализациях изобретения способ 400 может выполняться с помощью одного потока обработки. В качестве альтернативы, способ 400 может выполняться с использованием двух и более потоков обработки, при этом каждый поток выполняет одну или более отдельных функций, стандартных программ, подпрограмм или операций способа. В иллюстративном примере потоки обработки, реализующие способ 400, могут быть синхронизированы (например, с помощью семафоров, критических секций и (или) других механизмов синхронизации потоков). Кроме того, потоки обработки, реализующие способ 400, могут выполняться асинхронно друг относительно друга. Поэтому, хотя Фиг. 4 и соответствующее описание содержат операции способа 400 в определенном порядке, в различных реализациях способа могут выполняться, по крайней мере, некоторые из перечисленных операций, параллельно и (или) в произвольно выбранном порядке.
[00041] На шаге 410 вычислительная система может применить к изображению одну или более черно-белых масок. Применение черно-белой маски к изображению может обеспечить преобразование одного или более пикселей в части изображения в черный пиксель или белый пиксель. В некоторых вариантах реализации черно-белые маски могут быть получены из базы данных изображений в формате PDF.
[00042] На шаге 420 вычислительная система может определить количество смоделированных дефектов, которые необходимо наложить на изображение. Изображение может являться изображением из исходного множества изображений, описанных выше со ссылкой на Фиг. 2. Вычислительная система может определить любое приемлемое число смоделированных дефектов. Например, вычислительная система может определить случайное число смоделированных дефектов (например, 8, 9, 10 или любое иное приемлемое значение), которые необходимо наложить на изображение. Смоделированные дефекты могут включать один тип смоделированных дефектов (например, линии), или несколько типов смоделированных дефектов (например, линии и (или) пятна).
[00043] На шаге 430 вычислительная система может определить одну или более характеристик каждого из смоделированных дефектов, которые необходимо наложить на изображение. Примеры характеристик могут включать информацию о положении, размерах, цветах и т.д. В некоторых вариантах реализации характеристики смоделированных дефектов могут быть определены путем выполнения одной или более операций, описанных ниже со ссылкой на шаги 532-536.
[00044] На шаге 432 вычислительная система может определить информацию о положении каждого из смоделированных дефектов. Информация о положении того или иного смоделированного дефекта может включать одну или более координат изображения, например, координату, определяющую вертикальную линию, координату, определяющую горизонтальную линию, координату, определяющую центр круга, соответствующего пятну и т.д. В некоторых вариантах реализации вычислительная система может назначить одну или более случайных координат для каждого из смоделированных дефектов, которые необходимо наложить на изображение. Например, вычислительная система может назначить каждому дефекту из множества смоделированных дефектов определенного типа (например, вертикальные линии) случайную координату со значением в диапазоне от 0 до значения, соответствующего ширине изображения. В некоторых вариантах реализации случайная координата может определяться с использованием равномерного распределения.
[00045] На шаге 434 вычислительная система может определить информацию о размерах каждого из смоделированных дефектов. Информация о размерах заданного смоделированного дефекта может служить для определения одного или более размеров и (или) размера смоделированного дефекта. В некоторых вариантах реализации вычислительная система может назначить случайное значение размера смоделированного дефекта. Случайное значение может быть определено на основе распределения размеров смоделированных дефектов (например, нормальное распределение или иное применимое распределение). Например, вычислительная система может определить ширину каждой вертикальной линии из множества вертикальных линий, накладываемых на изображение. В некоторых вариантах реализации изобретения ширина каждой вертикальной линии может соответствовать случайной ширине, выбранной из нормального распределения с заданным средним значением. Среднее значение может задаваться вычислительной системой и являться приемлемым значением (например, 3, 4 пикселя). В некоторых вариантах реализации изобретения изменение распределения может равняться квадратному корню среднего значения ширины. Если выбрано отрицательное значение ширины, может быть сформировано новое значение ширины (например, положительное значение). В качестве другого примера, вычислительная система может определить длину каждой вертикальной линии, накладываемой на изображение. В качестве еще одного примера, вычислительная система может определить радиус круглого пятна назначением случайных значений радиусам множества круглых точек, добавляемых на изображение на основе нормального распределения или любого другого применимого распределения. В качестве еще одного примера, вычислительная система может определить основную ось и (или) дополнительную ось эллиптического пятна назначением случайных значений радиусам множества эллиптических точек, накладываемых на изображение на основе нормального распределения или любого другого применимого распределения. В некоторых вариантах реализации изобретения вычислительная система может изменять процент ошибок распознания в зависимости от количества, типов и ширины смоделированных дефектов. Например, для обучения конкретной языковой модели можно выбрать конкретный процент ошибок распознания.
[00046] На шаге 436 вычислительная система может определить информацию о цвете каждого из смоделированных дефектов, которые необходимо наложить на изображение. Например, информация о цвете определенного смоделированного дефекта может включать цвет, например, черный, белый и т.д. Информация о цвете определенного смоделированного дефекта может быть представлена одним или более значениями одного или более цветовых компонентов (например, красный компонент, синий компонент, зеленый компонент), одним или более значением яркости и (или) насыщенности и т.д. В некоторых вариантах реализации изобретения информация о цвете соответствующего смоделированного дефекта и (или) ряда смоделированных дефектов может быть определена таким образом, что смоделированные дефекты, накладываемые на изображение, могут удовлетворять определенной вероятности ошибок (например, 50%). В некоторых вариантах реализации изобретения вычислительная система может изменять процент ошибок распознания в зависимости от цвета (цветов) смоделированных дефектов. Например, для обучения конкретной языковой модели можно выбрать конкретный процент ошибок распознания.
[00047] На шаге 440 вычислительная система может изменить одну или более частей изображения на основе характеристик смоделированных дефектов для наложения смоделированных дефектов на изображение. Например, вычислительная система может определить одну или более частей изображения (например, один или более пикселей изображения) на основе информации о положении и (или) размеров заданного смоделированного дефекта (например, координаты, определяющие расположение линии на изображении, ширина, длина и (или) размер линии). Затем вычислительная система может изменить определенные пиксели за счет изменения значений определенных пикселей (т.е. значения пикселей, соответствующие яркости, насыщенности, цвету и т.д. определенных пикселей) в соответствии с цветом заданного смоделированного дефекта. Например, вычислительная система может заменить определенные пиксели пикселями черного или другого темного цвета для наложения черного смоделированного дефекта (например, черной линии). В другом примере вычислительная система может заменить определенные пиксели пикселями белого или другими светлыми пикселями для наложения белого смоделированного дефекта на изображение (например, белой линии).
[00048] Таким образом, в настоящем изобретении описываются системы и способы создания текстовых корпусов, содержащих реалистичные ошибки OCR и контекстно-зависимую информацию, при этом такие текстовые корпусы могут быть получены за счет выполнения OCR аугментированных изображений, содержащих текстовые сегменты. Созданные текстовые корпусы используются в языковых моделях для OCR (например, языковые модели с использованием вложений слов, языковые модели с использованием вложений слов и (или) символов). Следовательно, качество результатов OCR может быть повышено с использованием обученных языковых моделей в соответствии с настоящим изобретением.
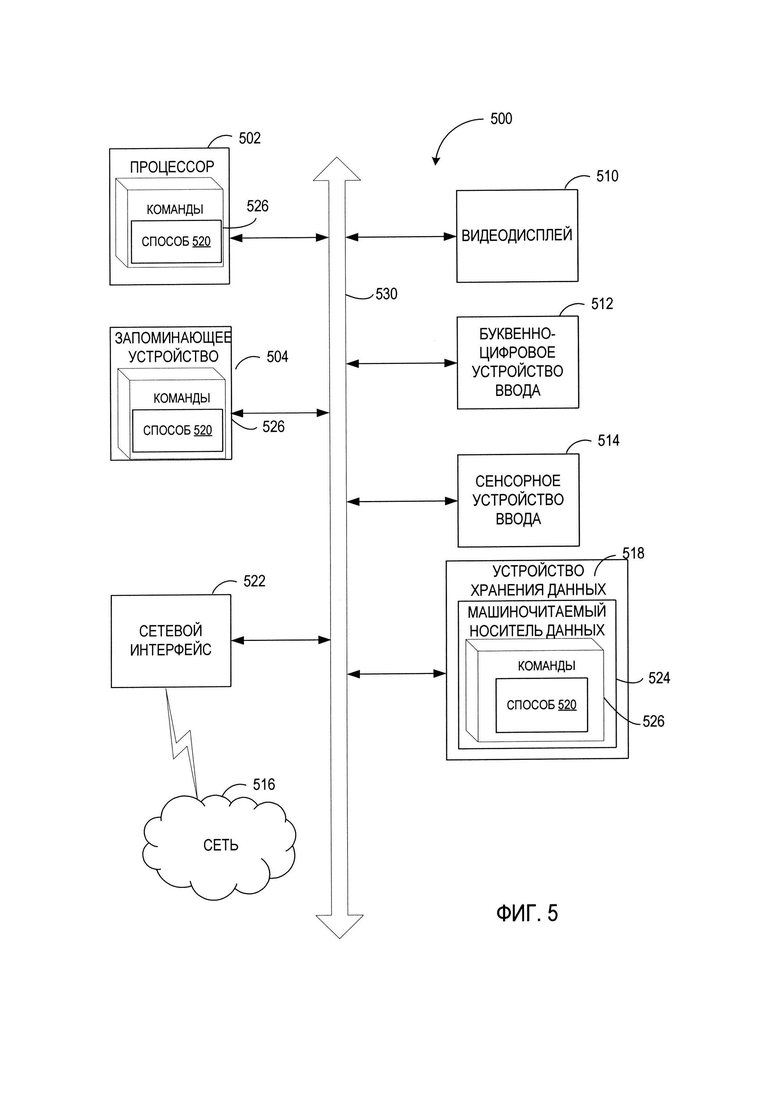
[00049] На Фиг. 5 представлена схема компонентов примера вычислительной системы, которая может использоваться для реализации описанных в настоящем документе способов. Вычислительная система 500 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 500 может работать в качестве сервера или клиента в сетевой среде «клиент- сервер», либо в качестве одноранговой вычислительной системы в одноранговой (или распределенной) сетевой среде. Вычислительная система 500 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то, что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для применения одного или более способов, описанных в настоящем документе.
[00050] Пример вычислительной системы 500 включает процессор 502, основное запоминающее устройство 504 {например, постоянное запоминающее устройство (ПЗУ) или динамическое оперативное запоминающее устройство (ДОЗУ)) и устройство хранения данных 518, которые взаимодействуют друг с другом по шине 530.
[00051] Процессор 502 может быть представлен одним или более универсальными устройствами обработки данных, например, микропроцессором, центральным процессором и т.п. Более конкретно, процессор 502 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор с командными словами сверхбольшой длины (VLIW) или процессор, реализующий другой набор команд, или процессоры, реализующие комбинацию наборов команд. Процессор 502 также может представлять собой одно или более устройств обработки специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Процессор 502 реализован с возможностью выполнения команд 526 для осуществления способов настоящего изобретения.
[00052] Вычислительная система 500 может дополнительно включать устройство сетевого интерфейса 522, устройство визуального отображения 510, устройство ввода символов 512 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 514.
[00053] Устройство хранения данных 518 может содержать машиночитаемый носитель данных 524, в котором хранится один или более наборов команд 526, реализующих один или более способов или одну или более функций настоящего изобретения. Команды 526 также могут находиться полностью или, по меньшей мере, частично в основном запоминающем устройстве 504 и (или) в процессоре 502 во время выполнения их в вычислительной системе 500, при этом основное запоминающее устройство 504 и процессор 502 также представляют собой машиночитаемый носитель данных. Команды 526 дополнительно могут передаваться или приниматься по сети 516 через устройство сетевого интерфейса 522.
[00054] В некоторых вариантах реализации изобретения набор команд 526 может содержать команды способа реализации 520 в соответствии с одним или более вариантами реализации настоящего изобретения. Способ 520 может включать в себя способы 200 и (или) 400 на Фиг. 2 и 4. Хотя машиночитаемый носитель данных 524, показанный в примере на Фиг. 5, является единым носителем, термин «машиночитаемый носитель» может включать один носитель или более носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать, как включающий любой носитель, который может хранить, кодировать или переносить набор команд при исполнении их машиной для обеспечения выполнения машиной любого одного или более методов настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00055] Способы, компоненты и функции, описанные в настоящем документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например, ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00056] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00057] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять с ними другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00058] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано дополнительно, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п. относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и запоминающих устройствах вычислительной системы, в другие данные, аналогично представленные в виде физических величин в запоминающих устройствах или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[00059] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[00060] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого, область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения аналогичных способов, на которые в равной степени распространяется формула изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБУЧЕНИЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ПОМОЩЬЮ СИНТЕТИЧЕСКИХ ФОТОРЕАЛИСТИЧНЫХ СОДЕРЖАЩИХ ЗНАКИ ИЗОБРАЖЕНИЙ | 2018 |
|
RU2709661C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ СВЕРТОЧНЫМИ НЕЙРОННЫМИ СЕТЯМИ | 2020 |
|
RU2771442C1 |
| ИЗВЛЕЧЕНИЕ НЕСКОЛЬКИХ ДОКУМЕНТОВ ИЗ ЕДИНОГО ИЗОБРАЖЕНИЯ | 2020 |
|
RU2764705C1 |
| РЕПРОДУЦИРУЮЩАЯ АУГМЕНТАЦИЯ ДАННЫХ ИЗОБРАЖЕНИЯ | 2018 |
|
RU2716322C2 |
| РЕКОНСТРУКЦИЯ ДОКУМЕНТА ИЗ СЕРИИ ИЗОБРАЖЕНИЙ ДОКУМЕНТА | 2017 |
|
RU2659745C1 |
| ДЕТЕКТИРОВАНИЕ И ИДЕНТИФИКАЦИЯ ОБЪЕКТОВ НА ИЗОБРАЖЕНИЯХ | 2020 |
|
RU2726185C1 |
| ОБНАРУЖЕНИЕ ТЕКСТОВЫХ ПОЛЕЙ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2699687C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ И ТАБЛИЦ В ДОКУМЕНТАХ С ПОМОЩЬЮ НЕЙРОННЫХ СЕТЕЙ С ИСПОЛЬЗОВАНИЕМ ГЛОБАЛЬНОГО КОНТЕКСТА ДОКУМЕНТА | 2019 |
|
RU2723293C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |



Изобретение относится к формированию текстового корпуса, содержащего реалистичные ошибки оптического распознавания символов (OCR), и обучению языковых моделей с использованием текстовых корпусов. Технический результат заключается в повышении качества распознавания изображений. Для этого пример реализации способа включает создание вычислительной системой исходного набора изображений на основе входных содержащих текст текстовых корпусов; наложение вычислительной системой одного или более смоделированных дефектов на изображения исходного множества изображений для создания аугментированного набора изображений; формирование выходного текстового корпуса на основе аугментированного набора изображений и обучение языковой модели с использованием полученного текстового корпуса для оптического распознавания символов. 3 н. и 17 з.п. ф-лы, 8 ил.
1. Способ генерации текстовых корпусов, содержащий:
генерацию вычислительной системой исходного набора изображений на основе входных содержащих текст текстовых корпусов;
наложение компьютерной системой одного или более смоделированных дефектов на исходный набор изображений для генерации аугментированного набора изображений, содержащих один или более текстовых сегментов;
генерацию выходного текстового корпуса, содержащего реалистичные ошибки оптического распознавания символов, на основе аугментированного набора изображений; и
обучение языковой модели с использованием выходного текстового корпуса для оптического распознавания символов.
2. Способ по п. 1, отличающийся тем, что создание исходного набора изображений дополнительно включает:
сегментирование исходного текстового корпуса на множество сегментов;
генерацию визуализации одного или более сегментов; и
генерацию одного или более изображений, содержащих один или более сегментов.
3. Способ по п. 1, отличающийся тем, что один или более смоделированных дефектов содержит, по меньшей мере, одно из линии или пятна в одном или более аугментированных изображений.
4. Способ по п. 1, отличающийся тем, что смоделированные дефекты представляют собой, по меньшей мере, одно из: дефекта печати, дефекта сканирования или дефекта фотографирования.
5. Способ по п. 1, отличающийся тем, что наложение одного или более смоделированных дефектов на исходный набор изображений включает:
определение одной или более характеристик смоделированных дефектов; и
изменение одной или более частей изображения из изображений исходного набора на основе одной или более характеристик смоделированных дефектов.
6. Способ по п. 5, отличающийся тем, что определение одной или более характеристик смоделированных дефектов включает:
определение информации о положении каждого из смоделированных дефектов; и
определение информации о размерах каждого из смоделированных дефектов.
7. Способ по п. 5, отличающийся тем, что определение одной или более характеристик смоделированных дефектов включает:
определение информации о цвете каждого из смоделированных дефектов.
8. Способ по п. 5, отличающийся тем, что определение одной или более характеристик смоделированных дефектов включает выбор ряда смоделированных дефектов для наложения на одно или более изображений из исходного набора изображений.
9. Способ по п. 1, дополнительно включающий варьирование количества реалистичных ошибок оптического распознавания символов в выходном текстовом корпусе для обучения множества языковых моделей, где реалистичные ошибки OCR содержат контекстно-зависимую информацию.
10. Способ по п. 4, отличающийся тем, что изменение одной или более частей изображения из исходного набора изображений на основе одной или более характеристик смоделированных дефектов включает:
адаптацию одного или более пикселей изображения из множества исходных изображений на основе характеристик смоделированных дефектов.
11. Способ по п. 1, отличающийся тем, что формирование выходного текстового корпуса на основе аугментированного множества изображений содержит выполнение оптического распознавания символов аугментированного множества изображений.
12. Способ по п. 1, отличающийся тем, что языковая модель для оптического распознавания символов содержит, по меньшей мере, одну языковую модель с использованием словных эмбеддингов или языковую модель с использованием символьных эмбеддингов.
13. Способ по п. 1, отличающийся тем, что исходный текстовый корпус содержит сплошной текст.
14. Система генерации текстовых корпусов, содержащая:
память;
устройство обработки, подключенное к памяти, настроенное на:
генерацию вычислительной системой исходного набора изображений на основе входных содержащих текст текстовых корпусов;
наложение компьютерной системой одного или более смоделированных дефектов на исходный набор изображений для генерации аугментированного набора изображений, содержащих один или более текстовых сегментов;
генерацию выходного текстового корпуса, содержащего реалистичные ошибки оптического распознавания символов, на основе аугментированного набора изображений; и
обучение языковой модели с использованием выходного текстового корпуса для оптического распознавания символов.
15. Система по п. 14, отличающаяся тем, что для создания набора исходных изображений устройство обработки дополнительно выполняет следующие действия:
сегментирование исходного текстового корпуса на множество сегментов;
генерацию визуализации одного или более сегментов; и
генерацию одного или более изображений, содержащих один или более сегментов.
16. Система по п. 14, отличающаяся тем, что один или более смоделированных дефектов содержит, по меньшей мере, одно из линии или пятна в одном или более аугментированных изображений.
17. Система по п. 14, отличающаяся тем, что смоделированные дефекты представляют собой, по меньшей мере, одно из: дефекта печати, дефекта сканирования или дефекта фотографии.
18. Система по п. 14, отличающаяся тем, что для наложения одного или более смоделированных дефектов на изображения из исходного набора изображений устройство обработки дополнительно выполняет:
определение одной или более характеристик смоделированных дефектов; и
изменение одной или более частей изображения из множества исходных изображений на основе одной или более характеристик смоделированных дефектов.
19. Система по п. 14, отличающаяся тем, что одна или более характеристик содержит, по меньшей мере, одно из: информации о положении смоделированных дефектов, информации о размере смоделированных дефектов, информации о количестве смоделированных дефектов или информации о цвете каждого из смоделированных дефектов.
20. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при их исполнении обрабатывающим устройством побуждают его выполнять:
генерацию вычислительной системой исходного набора изображений на основе входных содержащих текст текстовых корпусов;
наложение компьютерной системой одного или более смоделированных дефектов на исходный набор изображений для генерации аугментированного набора изображений, содержащих один или более текстовых сегментов;
генерацию выходного текстового корпуса, содержащего реалистичные ошибки оптического распознавания символов, на основе аугментированного набора изображений; и
обучение языковой модели с использованием выходного текстового корпуса для оптического распознавания символов.
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИОННЫХ ОБЪЕКТОВ С ПОМОЩЬЮ КОМБИНАЦИИ КЛАССИФИКАТОРОВ | 2017 |
|
RU2679988C1 |
| СЕНТИМЕНТНЫЙ АНАЛИЗ НА УРОВНЕ АСПЕКТОВ И СОЗДАНИЕ ОТЧЕТОВ С ИСПОЛЬЗОВАНИЕМ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2635257C1 |
| КЛАССИФИКАЦИЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628436C1 |
| WO 2018165579 A1, 13.09.2018 | |||
| US 10157425 B2, 18.12.2018. | |||

