Перекрестная ссылка на родственные заявки
По настоящей заявке испрашивается приоритет согласно заявке на выдачу патента Китая №201910760806.3, поданной в пятницу 16 августа 2019 г., содержание которой полностью включено в настоящую заявку посредством ссылки.
Область техники, к которой относится изобретение
Настоящее изобретение относится к области информации, и, более конкретно, к способу и устройству для обработки звука и к носителю информации.
Уровень техники
Взаимодействие человек-машина посредством голоса привлекает широкое внимание. Вся интернет-индустрия активно разрабатывает возможные варианты и сценарии использования голосового взаимодействия, и на рынок уже выпущено большое количество изделий, работающих на основе голосового взаимодействия, например, умные колонки и голосовые помощники. Голосовые помощники практически стали главной темой конференций, посвященных выпуску новых изделий, у различных производителей, и в определенной степени влияют на потребительский выбор. Однако диалог в ходе взаимодействия между пользователями и такими голосовыми помощниками бывает затрудненным, неровным.
Раскрытие сущности изобретения
Настоящее изобретение предусматривает способ и устройство для обработки звука и носитель информации.
Согласно первому аспекту вариантов осуществления настоящего изобретения предусматривается способ обработки звука. Указанный способ может использоваться электронным устройством. Способ может содержать следующие этапы.
Принимают первые аудиоданные, связанные с первым аудиосигналом, после того, как активировано целевое приложение.
Принимают вторые аудиоданные в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема указанных первых аудиоданных.
Получают целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных.
В некоторых вариантах осуществления способ может дополнительно содержать следующие этапы.
Определяют разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных.
Этап получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных может содержать следующие этапы.
Получают целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных, если указанная разность времени больше или равна первой заданной длительности.
В некоторых вариантах осуществления этап получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, когда разность времени больше или равна первой заданной длительности, может содержать следующие этапы.
Проверяют полноту ввода первых аудиоданных, если разность времени больше или равна первой заданной длительности.
Получают целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью.
В некоторых вариантах осуществления этап получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью, может содержать следующие этапы.
Проверяют, если первые аудиоданные введены не полностью, возможность комбинирования первых аудиоданных и вторых аудиоданных.
Комбинируют первые аудиоданные и вторые аудиоданные для получения целевых аудиоданных, если комбинирование первых аудиоданных и вторых аудиоданных возможно.
В некоторых вариантах осуществления способ может дополнительно содержать следующие этапы.
Определяют первые аудиоданные и вторые аудиоданные по отдельности в качестве целевых аудиоданных, если первые аудиоданные введены полностью.
В некоторых вариантах осуществления способ может дополнительно содержать следующие этапы.
Выполняют на целевых аудиоданных подавление акустического эха (ПАЭ).
Получают ответную информацию на основании целевых аудиоданных, обработанных посредством ПАЭ.
Выдают указанную ответную информацию.
В некоторых вариантах осуществления способ может дополнительно содержать следующие этапы.
Принимают аудиоданные, подлежащие распознаванию.
Проверяют, содержат ли эти аудиоданные, подлежащие распознаванию, информацию активации для активации целевого приложения.
Активируют целевое приложение, если аудиоданные, подлежащие распознаванию, содержат информацию активации.
Указанные аудиоданные, подлежащие распознаванию, могут содержать голосовые данные.
Согласно второму аспекту вариантов осуществления настоящего изобретения предусматривается устройство для обработки звука, которое может содержать:
первый аудиоприемный модуль, выполненный с возможностью приема первых аудиоданных, связанных с первым аудиосигналом, после того, как активировано целевое приложение;
второй аудиоприемный модуль, выполненный с возможностью приема вторых аудиоданных в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема первых аудиоданных; и
первый аудиоопределяющий модуль, выполненный с возможностью получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных.
В некоторых вариантах осуществления устройство может дополнительно содержать:
времяопределяющий модуль, выполненный с возможностью определения разности времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных, при этом первый аудиоопределяющий модуль содержит:
аудиоопределяющий субмодуль, выполненный с возможностью получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если указанная разность времени больше или равна первой заданной длительности.
В некоторых вариантах осуществления аудиоопределяющий субмодуль может быть выполнен с возможностью:
проверки полноты ввода первых аудиоданных, если указанная разность времени больше или равна первой заданной длительности; и
получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью.
В некоторых вариантах осуществления аудиоопределяющий субмодуль может быть дополнительно выполнен с возможностью:
проверки, если первые аудиоданные введены не полностью, возможности комбинирования первых аудиоданных и вторых аудиоданных; и
комбинирования первых аудиоданных и вторых аудиоданных для получения целевых аудиоданных, если комбинирование первых аудиоданных и вторых аудиоданных возможно.
В некоторых вариантах осуществления устройство может дополнительно содержать
второй аудиоопределяющий модуль, выполненный с возможностью определения первых аудиоданных и вторых аудиоданных по отдельности в качестве целевых аудиоданных, если первые аудиоданные введены полностью.
В некоторых вариантах осуществления устройство может дополнительно содержать:
модуль ПАЭ, выполненный с возможностью выполнения обработки подавления акустического эха на целевых аудиоданных;
ответный модуль, выполненный с возможностью получения ответной информации на основании целевых аудиоданных, обработанных посредством ПАЭ; и
выходной модуль, выполненный с возможностью выдачи указанной ответной информации.
В некоторых вариантах осуществления устройство может дополнительно содержать:
третий аудиоприемный модуль, выполненный с возможностью приема аудиоданных, подлежащих распознаванию;
модуль проверки информации, выполненный с возможностью проверки наличия в аудиоданных, подлежащих распознаванию, информации активации для активации целевого приложения; и
активирующий модуль, выполненный с возможностью активации целевого приложения при наличии информации активации в аудиоданных, подлежащих распознаванию.
Указанные аудиоданные, подлежащие распознаванию, могут содержать голосовые данные.
Согласно третьему аспекту вариантов осуществления настоящего изобретения предусматривается устройство для обработки звука, которое может содержать:
процессор; и
память, выполненную с возможностью хранения инструкции, которая может быть исполнена указанным процессором.
Указанный процессор может быть сконфигурирован так, чтобы при исполнении указанной инструкции выполнялись этапы способа обработки звука согласно первому аспекту.
Согласно четвертому аспекту вариантов осуществления настоящего изобретения предусматривается долговременный машиночитаемый носитель информации. Указанное устройство для обработки звука выполнено с возможностью при исполнении его процессором инструкции с указанного носителя информации выполнять способ обработки звука согласно первому аспекту.
Технические решения, предусматриваемые вариантами осуществления настоящего изобретения, могут содержать следующие благоприятные эффекты.
В вариантах осуществления настоящего изобретения после активации целевого приложения в случае обнаружения вторых аудиоданных в процессе приема первых аудиоданных, первые аудиоданные и вторые аудиоданные могут быть подвергнуты анализу и обработке для получения целевых аудиоданных. При продолжительном высказывании это дает возможность сразу обрабатывать по отдельности множество аудиоданных без необходимости повторной активации целевого приложения. Благодаря упрощению процесса обработки высказывания согласно вариантам осуществления настоящего изобретения, голосовое взаимодействие может быть более ровным по сравнению с ситуацией, в которой обработка следующих аудиоданных возможна лишь после ответа на уже принятые аудиоданные. Для получения целевых аудиоданных возможно комбинирование первых аудиоданных и вторых аудиоданных, а звуковой ответ на такие целевые аудиоданные может более точно отражать реальные потребности пользователя, снижается частота ошибок ответа, вызванных изоляцией высказываний, из-за которой ответ дается отдельно на первые аудиоданные и на вторые аудиоданные, что в итоге повышает точность звукового ответа,
Следует понимать, что вышеприведенное общее описание и нижеследующее подробное раскрытие изобретения служат лишь для пояснения и не имеют целью ограничение настоящего изобретения.
Краткое описание чертежей
Сопровождающие чертежи, составляющие часть настоящего раскрытия, иллюстрируют варианты осуществления, совместимые с настоящим изобретением, и вместе с описанием служат для пояснения принципов настоящего изобретения.
Фиг. 1 представляет блок-схему 1 способа обработки звука в соответствии с иллюстративным вариантом осуществления.
Фиг. 2 представляет блок-схему 2 способа обработки звука в соответствии с иллюстративным вариантом осуществления.
Фиг. 3 представляет структурную схему устройства для обработки звука в соответствии с иллюстративным вариантом осуществления.
Фиг. 4 представляет структурную схему аппаратной конфигурации устройства для обработки звука согласно иллюстративному варианту осуществления.
Осуществление изобретения
Далее подробно рассматриваются иллюстративные варианты осуществления, примеры которых представлены на сопровождающих чертежах. В следующем описании используются отсылки к сопровождающим чертежам, при этом одинаковые числа на разных чертежах представляют одинаковые или подобные элементы, если не указано иное. Реализации, представленные в нижеследующем описании иллюстративных вариантов осуществления, не представляют все реализации, совместимые с настоящим изобретением. Напротив, это лишь примеры устройств и способов, совместимых с аспектами, относящимися к настоящему изобретению, изложенному в прилагаемой формуле изобретения.
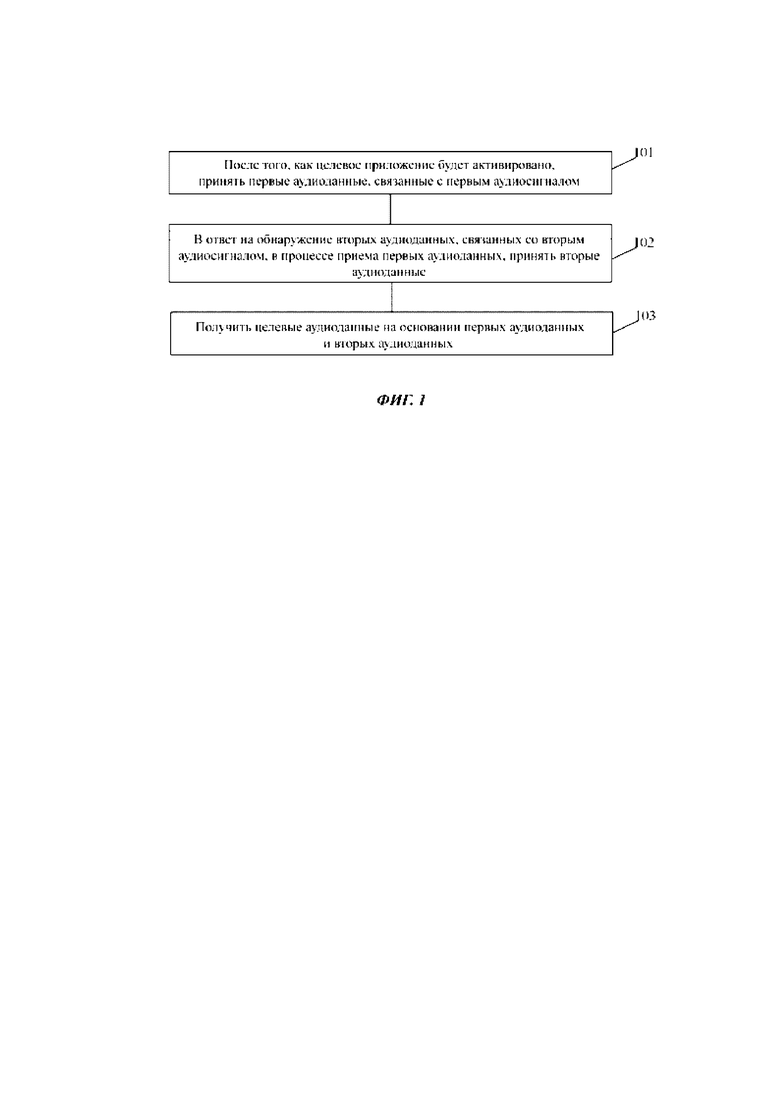
Фиг. 1 представляет блок-схему 1 способа обработки звука в соответствии с вариантом осуществления. Как показано на фиг. 1, этот способ применим к электронному устройству, которым может быть мобильный терминал и стационарный терминал, например, мобильный телефон, планшетный компьютер, ручной компьютер, портативный компьютер, настольный компьютер, надеваемое мобильное устройство, умная колонка и т.д. Способ может содержать следующие этапы.
На этапе 101 после того, как целевое приложение активировано, принимают первые аудиоданные, связанные с первым аудиосигналом.
Указанным целевым приложением может быть приложение, которое может быть установлено в электронном устройстве для осуществления голосового взаимодействия с пользователем, например, голосовой помощник. Указанный первый аудиосигнал может содержать голосовой сигнал, например, голосовой сигнал, произнесенный пользователем, зарегистрированный с использованием звукорегистрирующего компонента указанного электронного устройства. Указанными первыми аудиоданными могут быть аудиоданные после перевода первого аудиосигнала в цифровую форму.
Аудиосигнал может регистрироваться звукорегистрирующим компонентом в указанном электронном устройстве и переводиться в цифровую форму для получения аудиоданных. Указанным звукорегистрирующим компонентом может быть компонент для регистрации звука в электронном устройстве. Например, когда указанным электронным устройством является мобильный телефон, указанным звукорегистрирующим компонентом может быть микрофон этого мобильного телефона.
В вариантах осуществления настоящего изобретения голосом может активироваться целевое приложение, а после того, как оно активировано, с использованием этого целевого приложения могут приниматься аудиоданные.
Например, когда аудиосигнал, переданный пользователем, принят звукорегистрирующим компонентом электронного устройства, этот голосовой сигнал может переводиться в цифровую форму для получения голосовых данных. Может выполняться проверка наличия в указанных голосовых данных заранее заданного активирующего слова, и при наличии в голосовых данных этого активирующего слова целевое приложение может активироваться. Активирующее слово может задаваться пользователем в соответствии с потребностями. Например, в качестве активирующего слова может задаваться «ИИ».
На этапе 102 принимают вторые аудиоданные в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема указанных первых аудиоданных.
Вторые аудиоданные могут совпадать с первыми аудиоданными или отличаться от них. Вторыми аудиоданными могут быть аудиоданные, принятые в процессе приема первых аудиоданных.
На этапе 103 получают целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных.
После приема целевым приложением первых аудиоданных и вторых аудиоданных по отдельности в разное время, на основании этих первых аудиоданных и вторых аудиоданных могут получать целевые аудиоданные, которые могут передавать в целевое приложение для получения ответа.
Целевыми аудиоданными может быть по меньшей мере что-то одно из следующего: первые аудиоданные, вторые аудиоданные и третьи аудиоданные, полученные путем комбинирования первых аудиоданных и вторых аудиоданных. Например, целевыми аудиоданными могут быть третьи аудиоданные, полученные путем комбинирования первых аудиоданных и вторых аудиоданных. Например, когда содержанием первых аудиоданных является «Сегодня», а содержанием вторых аудиоданных является «солнечно», содержанием третьих аудиоданных, т.е., целевых аудиоданных, может быть «Сегодня солнечно».
В вариантах осуществления настоящего изобретения после того, как целевое приложение активировано, при обнаружении вторых аудиоданных в процессе приема первых аудиоданных, первые аудиоданные и вторые аудиоданные могут одновременно подвергаться анализу и обработке для получения целевых аудиоданных. Во время продолжительного высказывания возможна непосредственная одновременная обработка множества аудиоданных без новой активации целевого приложения, что не только упрощает процесс обработки высказывания, но и делает голосовое взаимодействие более ровным.
Этап получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных может содержать следующие этапы.
Получают целевые аудиоданные на основании первого семантического содержания первых аудиоданных и второго семантического содержания вторых аудиоданных.
Например, первое семантическое содержание и второе семантическое содержание могут быть взаимодополняющими, и тогда для получения целевых аудиоданных первые аудиоданные и вторые аудиоданные могут комбинировать, а сценарий использования может быть таким: после передачи пользователем первого голосового сигнала пользователь мог сделать паузу или его могли прервать, поэтому в качестве дополнения нужен второй аудиосигнал.
Например, первым семантическим содержанием может быть «Пожалуйста, помоги мне», а вторым семантическим содержанием может быть «установить будильник». В семантическом анализе, который может выполняться по первому семантическому содержанию и по второму семантическому содержанию, может быть установлено, что первое семантическое содержание и второе семантическое содержание дополняют друг друга. После этого путем комбинирования первых аудиоданных и вторых аудиоданных могут получать целевые аудиоданные. В качестве окончательного требования пользователя может быть определено следующее: «Пожалуйста, помоги мне установить будильник».
В качестве еще одного примера, при противоречии между первым семантическим содержанием и вторым семантическим содержанием в качестве целевых аудиоданных могут использоваться вторые аудиоданные, при этом сценарий использования может быть таким: пользователь, передав ошибочный первый аудиосигнал, затем исправляет его вторым аудиосигналом.
Например, первым семантическим содержанием может быть «Погода в Ухане сегодня», а вторым семантическим содержанием «Нет, я хотел узнать погоду в Пекине сегодня». Семантический анализ может выполняться по первому семантическому содержанию и по второму семантическому содержанию с целью удостовериться, что и первые аудиоданные, и вторые аудиоданные используются для запроса погоды. Но, хотя первое семантическое содержание и второе семантическое содержание связаны, первые аудиоданные используются для запроса погоды в Ухане, а вторые аудиоданные используются для запроса погоды в Пекине, что является противоречием и может приводить к выводу о том, что первое семантическое содержание ошибочно. В этом случае может приниматься решение о том, что целевое приложение не должно обрабатывать первые аудиоданные, в качестве целевых аудиоданных могут определять вторые аудиоданные, и ответная информация может выдаваться на вторые аудиоданные.
В качестве еще одного примера, первое семантическое содержание и второе семантическое содержание могут быть независимы, не иметь семантического дополнения и противоречия, тогда первые аудиоданные и вторые аудиоданные могут использоваться как два отдельных элемента целевых аудиоданных, на которые должны быть даны отдельные звуковые ответы. Сценарий использования может быть таким: возбужденные пользователи или пользователи с быстрой речью могут за короткое время передавать два совершенно разных голосовых сигнала.
Например, первым семантическим содержанием может быть «Погода в Ухане сегодня», а вторым семантическим содержанием «Пожалуйста, помоги мне установить будильник». Семантический анализ первого семантического содержания и второго семантического содержания может приводить к выводу о том, что первое семантическое содержание и второе семантическое содержание не связаны между собой, и первые аудиоданные и вторые аудиоданные могут, соответственно, представлять две разных потребности пользователя. Таким образом, может быть установлено, что первое семантическое содержание и второе семантическое содержание независимы, не имеют семантического дополнения и противоречия, и тогда первые аудиоданные и вторые аудиоданные могут использоваться как два отдельных элемента целевых аудиоданных, на которые должны быть даны отдельные звуковые ответы, а соответствующая ответная информация может выдаваться и на первые аудиоданные, и на вторые аудиоданные.
Согласно техническому решению из вариантов осуществления настоящего изобретения, отпадает необходимость повторно активировать целевое приложение. Благодаря упрощению процесса обработки высказывания согласно настоящему изобретению голосовое взаимодействие может быть сделано более ровным по сравнению с ситуацией, в которой следующие аудиоданные невозможно обработать до выдачи ответа на уже принятые аудиоданные. Повышается точность звукового ответа, поскольку для получения целевых аудиоданных становится возможным комбинирование первых аудиоданных и вторых аудиоданных, а звуковой ответ на эти целевые аудиоданные может более точно отражать реальные потребности пользователя благодаря возможности снижения частоты ошибок ответа, вызванных изоляцией высказываний, при которой ответ дается отдельно на первые аудиоданные и на вторые аудиоданные.
В других возможных вариантах осуществления указанный способ может дополнительно содержать следующие этапы.
Определяют разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных.
Соответственно, этап 103 может содержать:
получение целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных больше или равна первой заданной длительности.
В процессе приема аудиоданных возможна небольшая пауза в речи пользователя. В этом случае целевое приложение может определить аудиоданные, принятые до и после паузы, соответственно в качестве первых аудиоданных и вторых аудиоданных.
Прием таких первых аудиоданных и вторых аудиоданных происходит в разные моменты времени, при этом вторые аудиоданные принимаются после окончания первых аудиоданных, поэтому электронное устройство может индивидуально определить время окончания приема первых аудиоданных и время начала приема вторых аудиоданных, а затем на основании указанного времени окончания и указанного времени начала может определить разность времени.
Затем эта разность времени может сравниваться с первой заданной длительностью, и если разность времени больше или равна первой заданной длительности, может считаться, что пауза в речи пользователя не была небольшой. В этом случае для получения целевых аудиоданных необходимо дополнительно проверить и обработать первые аудиоданные и вторые аудиоданные. Например, может оказаться, что первые аудиоданные и вторые аудиоданные можно по отдельности использовать как целевые аудиоданные, или что для получения целевых аудиоданных можно скомбинировать первые аудиоданные и вторые аудиоданные, и т.д.
Может считаться, что пользователь сделал небольшую паузу в речи, если разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных меньше первой заданной длительности. В этом случае первые аудиоданные и вторые аудиоданные можно непосредственно комбинировать в полные аудиоданные, которые можно использовать в качестве целевых аудиоданных.
В вариантах осуществления настоящего изобретения перед получением целевых аудиоданных может определяться разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных, а затем может выполняться проверка возможности дальнейшей обработки первых аудиоданных и вторых аудиоданных, что позволяет сократить ненужную обработку принятых аудиоданных.
В других возможных вариантах осуществления этап получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, когда разность времени больше или равна первой заданной длительности, может содержать следующие этапы.
Проверяют полноту ввода первых аудиоданных, если разность времени больше или равна первой заданной длительности.
Получают целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью.
Если разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных больше или равна первой заданной длительности, то может дополнительно проверяться полнота ввода первых аудиоданных. Проверка полноты ввода первых аудиоданных может содержать: прием первого семантического содержания первых аудиоданных; выполнение семантического анализа по первому семантическому содержанию для получения результата семантического анализа; и определение полноты ввода первых аудиоданных на основании указанного результата семантического анализа.
Например, первым семантическим содержанием первых аудиоданных может быть «Пожалуйста, помоги мне установить». Несмотря на наличие нескольких слов в первом семантическом содержании, после анализа первого семантического содержания ясно, что одних лишь слов, содержащихся в первом семантическом содержании, недостаточно для определения потребности пользователя. Можно видеть, что в процессе передачи голосового сигнала пользователь, передавший первое семантическое содержание, мог сделать паузу или был прерван, и может быть установлено, что ввод первых голосовых данных неполон.
В других вариантах осуществления, если первые голосовые данные неполны и обнаружено, что пользователь больше не вводит другие аудиосигналы, целевое приложение также может формировать ответную информацию на первые аудиоданные согласно контексту. Например, первым семантическим содержанием первых аудиоданных может быть «Пожалуйста, помоги мне установить», а ответной информацией от целевого приложения может быть «Что требуется установить?».
При этом проверка полноты ввода первых аудиоданных может выполняться на основе технологии обработки естественного языка (англ. Natural Language Processing, NLP).
В других возможных вариантах осуществления указанная этап получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью, может содержать следующие этапы.
Если первые аудиоданные введены не полностью, может определяться возможность комбинирования первых аудиоданных и вторых аудиоданных.
Если комбинирование первых аудиоданных и вторых аудиоданных возможно, то первые аудиоданные и вторые аудиоданные могут комбинировать для получения целевых аудиоданных.
Например, когда содержанием первых аудиоданных является «Сегодня», а содержанием вторых аудиоданных является «солнечно», содержанием третьих аудиоданных, т.е., целевых аудиоданных, может быть «Сегодня солнечно».
В других возможных вариантах осуществления указанный способ может дополнительно содержать определение первых аудиоданных и вторых аудиоданных по отдельности в качестве целевых аудиоданных, если первые аудиоданные введены полностью.
В данном случае, если первые аудиоданные введены полностью, может быть установлено, что целевое приложение может дать ответную информацию на первые аудиоданные, и тогда в качестве целевых аудиоданных могут принимать просто первые аудиоданные. Подобным образом, если вторые аудиоданные введены полностью, вторые аудиоданные могут быть определены в качестве целевых аудиоданных. Таким образом, целевое приложение может находить ответную информацию, относящуюся к первым аудиоданным и вторым аудиоданным, по отдельности.
В других возможных вариантах осуществления указанный способ может дополнительно содержать следующие этапы.
На целевых аудиоданных может выполняться обработка подавления акустического эха (ПАЭ). На основании целевых аудиоданных, обработанных посредством ПАЭ, могут получать ответную информацию. Эту ответную информацию могут выдавать.
В процессе обработки звука электронное устройство возможен прием аудиосигнала (музыки или тонального сигнала ожидания сообщения), переданного самим электронным устройством. В этом случае целевые аудиоданные необходимо обработать посредством ПАЭ, а ответную информацию можно получать на основании целевых аудиоданных, обработанных ПАЭ. Так можно снизить помеху от аудиосигнала, созданного самим электронным устройством, и обеспечить точность и стабильность ответной информации, выдаваемой целевым приложением.
В данном варианте осуществления целевые аудиоданные могут подвергаться ПАЭ на основе технологии автоматического распознавания речи (англ. Automatic Speech Recognition, ASR) и технологии ПАЭ.
В других вариантах осуществления, чтобы снизить вероятность приема внешнего шума, постороннего голоса (не адресованного целевому приложению звука, создаваемого пользователями или другими людьми) и т.д. путем подавления звука, не адресованного целевому приложению, целевые аудиоданные также могут обрабатывать на основе технологии автоматического распознавания речи и обработки естественного языка.
В других возможных вариантах осуществления указанный способ может дополнительно содержать следующие этапы.
Могут принимать аудиоданные, подлежащие распознаванию. Могут проверять наличие в аудиоданных, подлежащих распознаванию, информации активации для активации целевого приложения. Могут активировать целевое приложение, если аудиоданные, подлежащие распознаванию, содержат информацию активации. Указанные аудиоданные могут содержать голосовые данные.
Для получения аудиоданных аудиосигнал может регистрироваться звукорегистрирующим компонентом электронного устройства и переводиться в цифровую форму. Указанным звукорегистрирующим компонентом может быть компонент для регистрации звука в электронном устройстве. Например, когда указанным электронным устройством является мобильный телефон, указанным звукорегистрирующим компонентом может быть микрофон этого мобильного телефона.
Аудиоданные, подлежащие распознаванию, могут содержать голосовые данные, полученные путем преобразования зарегистрированного голосового сигнала пользователя в цифровую форму. Указанной информацией активации может быть заранее заданное активирующее слово. Указанным целевым приложением может быть приложение, установленное в электронном устройстве для осуществления голосового взаимодействия с пользователем, например, голосовой помощник.
Конкретнее, когда аудиосигнал, переданный пользователем, может быть принят с использованием звукорегистрирующего компонента электронного устройства, указанный голосовой сигнал могут переводить в цифровую форму для получения голосовых данных и проверять наличие в этих голосовых данных заранее заданного активирующего слова. Активирующее слово может задаваться пользователем в соответствии с потребностями. Например, в качестве активирующего слова может задаваться «ИИ».
Указанной активацией может быть управление целевым приложением для его перевода в рабочее состояние из состояния сна; после активации целевого приложения возможна обработка аудиоданных этим целевым приложением. В других вариантах осуществления пользовательский ввод, инициирующий активацию, может также приниматься посредством значка, кнопки быстрого вызова и т.п. для активации целевого приложения.
В других возможных вариантах осуществления в качестве примера взят голосовой помощник, установленный на мобильный телефон. Пользователь, осуществляя голосовое взаимодействие с голосовым помощником на мобильном телефоне, может активировать голосовой помощник посредством установочной инструкции, а после активации голосового помощника может начинать говорить. Голосовой помощник должен дать ответ согласно содержанию высказывания пользователя.
Указанной установочной инструкцией может быть по меньшей мере что-то одно из следующего: установочная голосовая инструкция, инициирующая инструкция для значка на мобильном телефоне, инициирующая инструкция для кнопки быстрого вызова на мобильном телефоне. Далее в качестве примера пользователь запрашивает у голосового помощника погоду на сегодня и завтра, и основной диалог может быть таким:
Пользователь: «ИИ» (здесь голосовой помощник активируют голосовой инструкцией, но также возможна активация щелчком по значку, клавишей и т.д.).
ИИ: «Я слушаю»/тональный сигнал ожидания (который является сигналом ожидания ответа).
Пользователь: «Какая погода сегодня?»
ИИ: «Погода в Пекине сегодня...» (сообщает погоду на сегодня).
Пользователь: «ИИ» (здесь голосовой помощник активируют голосовой инструкцией, но также возможна активация щелчком по значку, клавишей и т.д.).
ИИ: «Я слушаю»/тональный сигнал ожидания (который является сигналом ожидания ответа).
Пользователь: «А завтра?»
ИИ: «Погода в Пекине завтра...» (сообщает погоду на завтра).
В других вариантах осуществления пользователь может активировать голосовой помощник посредством установочной инструкции, а после активации голосового помощника может начинать говорить. Если голосовой помощник прогнозирует, что пользователь, закончив предложение, может продолжить говорить, то после окончания ответа голосового помощника для приема следующей инструкции от пользователя может автоматически включаться микрофон. Далее в качестве примера пользователь с помощью голосового помощника устанавливает будильник, и основной диалог может быть таким:
Пользователь: «ИИ» (здесь голосовой помощник активируют голосовой инструкцией, но также возможна активация щелчком по значку, клавишей и т.д.).
ИИ: «Я слушаю»/тональный сигнал ожидания (который является сигналом ожидания ответа).
Пользователь: «Я хочу установить будильник».
ИИ: «На какое время?»
Пользователь: «На семь вечера».
ИИ: «Будильник установлен для вас на семь часов вечера».
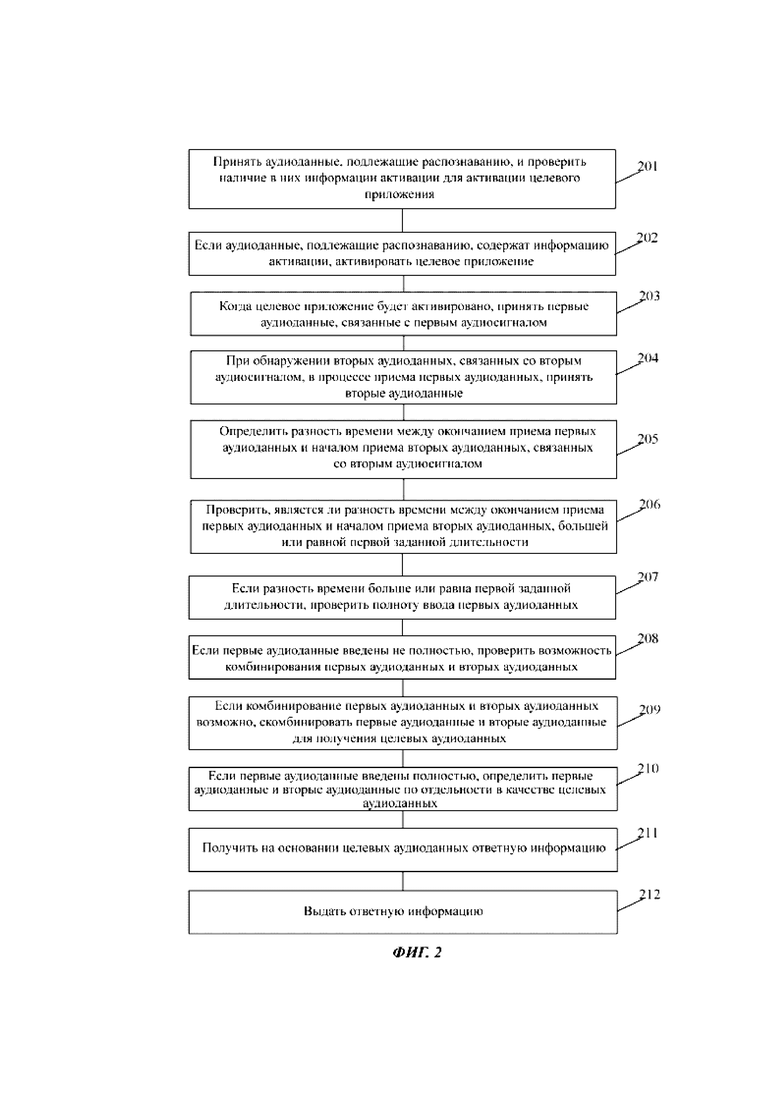
Фиг. 2 представляет блок-схему 2 способа обработки звука в соответствии с вариантом осуществления. Как показано на фиг. 2, способ может содержать следующие этапы.
На этапе 201 принимают аудиоданные, подлежащие распознаванию, и проверяют наличие в этих аудиоданных, подлежащих распознаванию, информации активации для активации целевого приложения.
Для получения аудиоданных аудиосигнал может регистрироваться звукорегистрирующим компонентом электронного устройства и переводиться в цифровую форму. Указанным звукорегистрирующим компонентом может быть компонент для регистрации аудиосигнала, содержащийся в электронном устройстве. Например, когда указанным электронным устройством является мобильный телефон, указанным звукорегистрирующим компонентом может быть микрофон этого мобильного телефона.
Аудиоданные, подлежащие распознаванию, могут содержать голосовые данные, полученные путем преобразования зарегистрированного голосового сигнала пользователя в цифровую форму. Указанной информацией активации может быть заранее заданное активирующее слово. Указанным целевым приложением может быть приложение, установленное на электронном устройстве для осуществления голосового взаимодействия с пользователем, например, голосовой помощник.
Например, когда аудиосигнал, переданный пользователем, принят с использованием звукорегистрирующего компонента электронного устройства, указанный голосовой сигнал могут переводить в цифровую форму для получения голосовых данных и проверять наличие в этих голосовых данных заранее заданного активирующего слова. Активирующее слово может задаваться пользователем в соответствии с потребностями. Например, в качестве активирующего слова может задаваться «ИИ».
На этапе 202, если аудиоданные, подлежащие распознаванию, содержат информацию активации, активируют целевое приложение.
Указанной активацией может быть управление целевым приложением для его перевода в рабочее состояние из состояния сна; после активации целевого приложения возможна обработка аудиоданных этим целевым приложением. В других вариантах осуществления пользовательский ввод, инициирующий активацию, может также приниматься посредством значка, кнопки быстрого вызова и т.п. для активации целевого приложения.
На этапе 203 после активации целевого приложения принимают первые аудиоданные, связанные с первым аудиосигналом.
Указанными первыми аудиоданными могут быть аудиоданные после преобразования первого аудиосигнала в цифровую форму. Указанным первым аудиосигналом может быть голосовой сигнал, переданный пользователем, зарегистрированный с использованием звукорегистрирующего компонента.
На этапе 204 в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема первых аудиоданных, эти вторые аудиоданные принимают.
На этапе 205 определяют разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных, связанных со вторым аудиосигналом.
На этапе 206 проверяют, является ли разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных большей или равной первой заданной длительности.
В других вариантах осуществления, когда разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных меньше первой заданной длительности, первые аудиоданные и вторые аудиоданные непосредственно комбинируют в целевые аудиоданные.
При наличии разности времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных целевое приложение не может определить, являются ли первые аудиоданные и вторые аудиоданные двумя множествами полностью независимых данных или двумя множествами связанных данных, и поэтому может не дать точный ответ.
В вариантах осуществления настоящего изобретения перед получением целевых аудиоданных может определяться разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных, а затем может выполняться проверка возможности дальнейшей обработки первых аудиоданных и вторых аудиоданных, что позволяет не только сократить ненужную обработку принятых аудиоданных, но и выдавать более точную ответную информацию.
На этапе 207 проверяют полноту ввода первых аудиоданных, если разность времени больше или равна первой заданной длительности.
При этом проверка полноты ввода первых аудиоданных может выполняться на основе технологии обработки естественного языка. Если установлено, что первые аудиоданные введены полностью, то могут получать информацию, связанную с первыми аудиоданными, и выдавать эту ответную информацию.
На этапе 208, если первые аудиоданные введены не полностью, проверяют возможность комбинирования первых аудиоданных и вторых аудиоданных.
На этапе 209, если комбинирование первых аудиоданных и вторых аудиоданных возможно, для получения целевых аудиоданных первые аудиоданные и вторые аудиоданные комбинируют.
На этапе 210, если первые аудиоданные введены полностью, определяют первые аудиоданные и вторые аудиоданные по отдельности в качестве целевых аудиоданных.
На этапе 211 на основании целевых аудиоданных получают ответную информацию.
На этапе 212 эту ответную информацию выдают.
В других возможных вариантах осуществления взаимодействие между целевым приложением и пользователем может завершаться на основании принятой инструкции завершения взаимодействия. Указанная инструкция завершения взаимодействия может вводиться голосом, щелчком по значку, кнопкой быстрого вызова и т.п.
В вариантах осуществления настоящего изобретения после того, как целевое приложение активировано, пользователь может просто говорить, обращаясь к целевому приложению, в любое время, а целевое приложение может своевременно отвечать на аудиосигналы, вводимые пользователем в течение длящегося высказывания. Например, пользователь, слушающий музыку и недовольный содержанием музыкального произведения, предложенного целевым приложением, может просто сказать «Смени»; а при длящейся передаче голосового сигнала в целевое приложение пользователем у целевого приложения есть возможность непрерывно принимать голосовой сигнал и выдавать соответствующий ответ без новой активации целевого приложения и без ожидания завершения полного вывода целевым приложением ответной информации на ранее принятый голосовой сигнал.
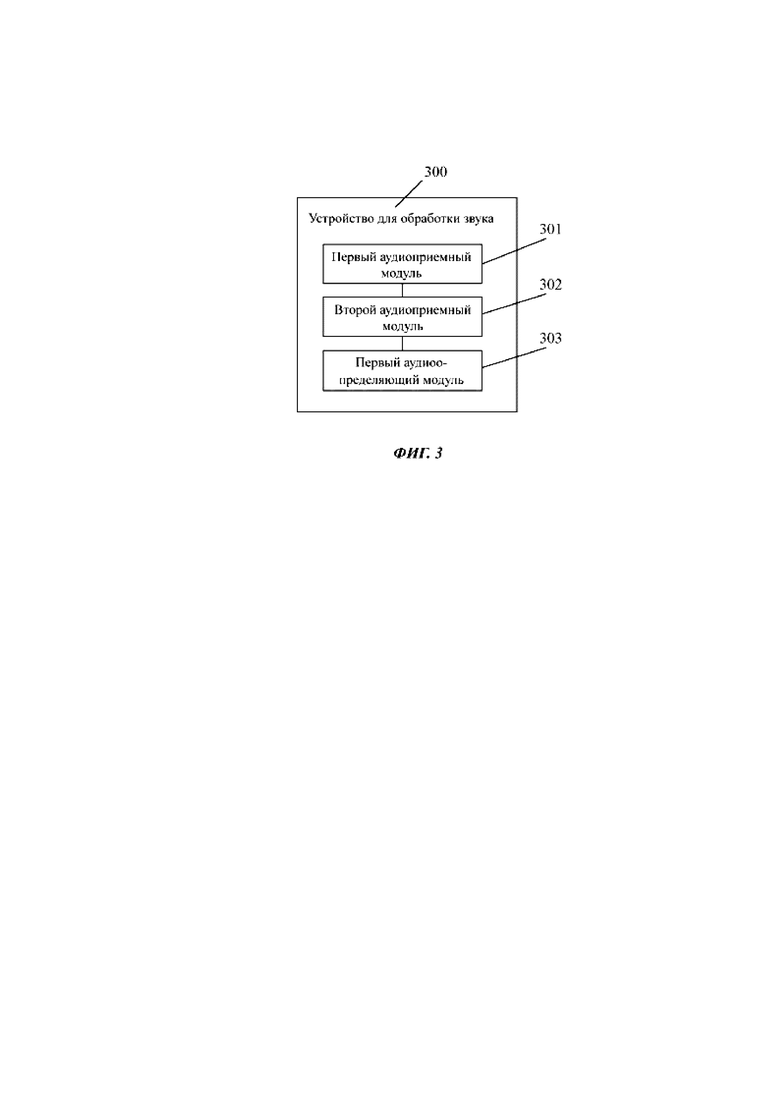
Фиг. 3 представляет блок-схему устройства для обработки звука в соответствии с вариантом осуществления. Как показано на фиг. 3, устройство 300 для обработки звука может содержать первый аудиоприемный модуль 301, второй аудиоприемный модуль 302 и первый аудиоопределяющий модуль 303.
Первый аудиоприемный модуль 301 выполнен с возможностью приема первых аудиоданных, связанных с первым аудиосигналом, после того, как активировано целевое приложение.
Второй аудиоприемный модуль 302 выполнен с возможностью приема вторых аудиоданных в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема первых аудиоданных.
Первый аудиоопределяющий модуль 303 выполнен с возможностью получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных.
В других возможных вариантах осуществления устройство 300 может дополнительно содержать времяопределяющий модуль.
Указанный времяопределяющий модуль выполнен с возможностью определения разности времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных.
Первый аудиоопределяющий модуль может содержать аудиоопределяющий субмодуль.
Указанный аудиоопределяющий субмодуль выполнен с возможностью получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если указанная разность времени больше или равна первой заданной длительности.
В других возможных вариантах осуществления аудиоопределяющий субмодуль выполнен с возможностью:
проверки полноты ввода первых аудиоданных, если указанная разность времени больше или равна первой заданной длительности; и
получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью.
В других возможных вариантах осуществления аудиоопределяющий субмодуль дополнительно выполнен с возможностью:
проверки, если первые аудиоданные введены не полностью, возможности комбинирования первых аудиоданных и вторых аудиоданных; и
комбинирования первых аудиоданных и вторых аудиоданных для получения целевых аудиоданных, если комбинирование первых аудиоданных и вторых аудиоданных возможно.
В других возможных вариантах осуществления устройство 300 может дополнительно содержать второй аудиоопределяющий модуль.
Указанный второй аудиоопределяющий модуль выполнен с возможностью определения первых аудиоданных и вторых аудиоданных по отдельности в качестве целевых аудиоданных, если первые аудиоданные введены полностью.
В других возможных вариантах осуществления устройство 300 может дополнительно содержать модуль ПАЭ, ответный модуль и выходной модуль.
Модуль ПАЭ выполнен с возможностью выполнения обработки подавления акустического эха на целевых аудиоданных.
Ответный модуль выполнен с возможностью получения ответной информации на основании целевых аудиоданных, обработанных посредством ПАЭ.
Выходной модуль выполнен с возможностью выдачи ответной информации.
В других возможных вариантах осуществления устройство 300 может дополнительно содержать третий аудиоприемный модуль, модуль проверки наличия информации и активирующий модуль.
Третий аудиоприемный модуль выполнен с возможностью приема аудиоданных, подлежащих распознаванию.
Модуль проверки наличия информации выполнен с возможностью проверки наличия в аудиоданных, подлежащих распознаванию, информации активации для активации целевого приложения.
Активирующий модуль выполнен с возможностью активации целевого приложения при наличии информации активации в аудиоданных, подлежащих распознаванию.
Указанные аудиоданные, подлежащие распознаванию, могут содержать голосовые данные.
Что касается устройства в вышеприведенных вариантах осуществления, то конкретный подход, посредством которого соответствующие модули выполняют указанные операции, подробно описан в варианте осуществления, относящемся ко способу, и здесь подробно не поясняется.
Фиг. 4 представляет функциональную схему устройства 400 для обработки звука в соответствии с вариантом осуществления. Устройством 400 может быть мобильный телефон, компьютер, цифровой радиотерминал, устройство обмена сообщениями, игровая консоль, планшетное устройство, медицинское устройство, оборудование для упражнений, персональный цифровой помощник и т.п.
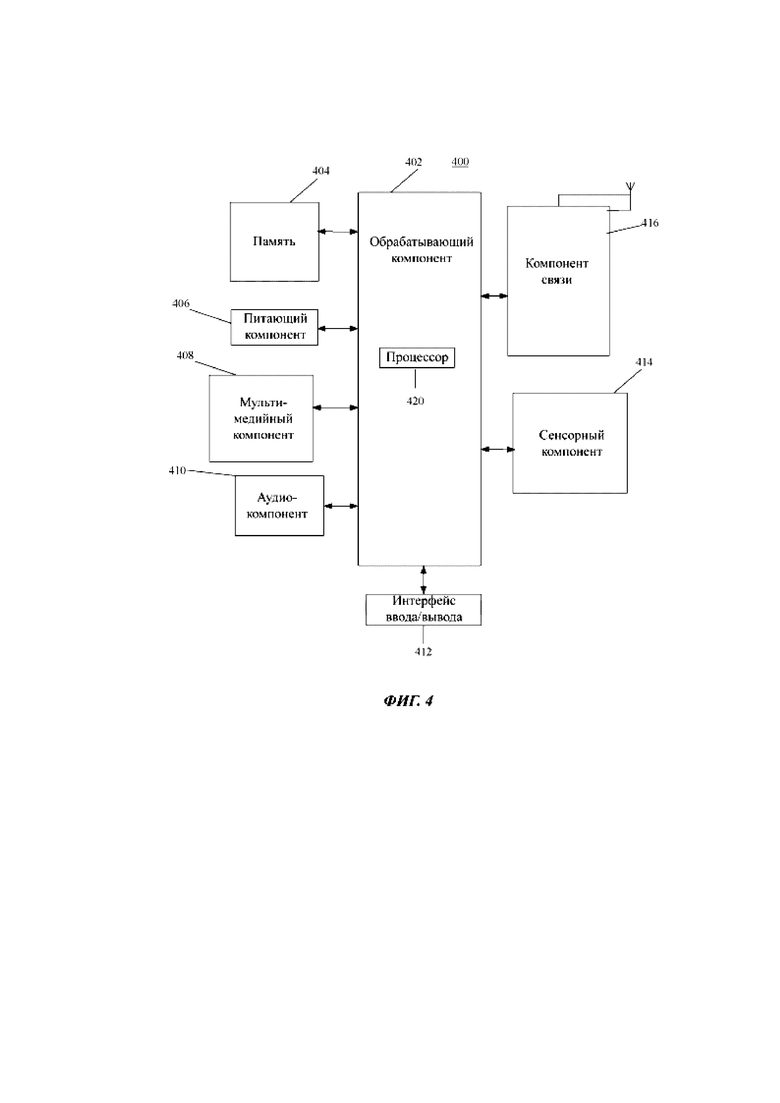
Как показано на фиг. 4, устройство 400 может содержать один или более следующих компонентов: обрабатывающий компонент 402, память 404, питающий компонент 406, мультимедийный компонент 408, аудиокомпонент 410, интерфейс 412 ввода/вывода, сенсорный компонент 414 и компонент 416 связи.
Обрабатывающий компонент 402 выполнен с возможностью, в основном, управления работой устройства 400 в целом, например, операциями, связанными с отображением, телефонными вызовами, передачей данных, работой камеры и записью. Обрабатывающий компонент 402 может содержать один или более процессоров 420 для выполнения инструкций с целью реализации всех или части шагов вышеописанных способов. Кроме того, обрабатывающий компонент 402 может содержать один или более модулей, выполненных с возможностью обеспечения взаимодействия между обрабатывающим компонентом 402 и другими компонентами. Например, обрабатывающий компонент 402 может содержать мультимедийный модуль, выполненный с возможностью обеспечения взаимодействия между мультимедийным компонентом 408 и обрабатывающим компонентом 402.
Память 404 выполнена с возможностью хранения данных различных типов с целью обеспечения функционирования устройства 400. В число примеров таких данных входят инструкции для любых приложений или способов, выполняемых на устройстве 400, контактные данные, данные телефонной книги, сообщения, изображения, видеоданные и т.д. Память 404 может быть реализована с использованием любого типа долговременного или недолговременного запоминающего устройства или их сочетания, например, статического запоминающего устройства с произвольным доступом (Static Random Access Memory, SRAM), электрически стираемого программируемого постоянного запоминающего устройства (Electrically Erasable Programmable Read-Only Memory, EEPROM), стираемого программируемого постоянного запоминающего устройства (Erasable Programmable Read-Only Memory, EPROM), программируемого постоянного запоминающего устройства (Programmable Read-Only Memory, PROM), постоянного запоминающего устройства (Read-Only Memory, ROM), магнитной памяти, флэш-памяти, магнитного диска или оптического диска.
Питающий компонент 406 выполнен с возможностью обеспечения питанием различных компонентов устройства 400. Питающий компонент 406 может содержать систему управления питанием, один или несколько источников питания и другие компоненты, имеющие отношение к генерированию питания, управлению питанием и распределению питания в устройстве 400.
Мультимедийный компонент 408 может содержать экран, реализующий интерфейс вывода между устройством 400 и пользователем. В некоторых вариантах осуществления изобретения этот экран может содержать жидкокристаллический дисплей (ЖКД) и сенсорную панель (СП). Экран, содержащий сенсорную панель, может быть реализован как сенсорный экран, выполненный с возможностью приема сигналов ввода от пользователя. Сенсорная панель содержит один или более сенсорных датчиков, выполненных с возможностью восприятия прикосновений, проводок и жестов на сенсорной панели. Сенсорные датчики выполнены с возможностью восприятия не только границы области прикосновения или проводки, но и периода времени и давления, имеющих отношение к данному прикосновению или проводке. В некоторых вариантах осуществления изобретения мультимедийный компонент 408 может содержать переднюю камеру и/или заднюю камеру. Когда устройство 400 находится в рабочем режиме, например, в режиме фотосъемки или в режиме видеосъемки, передняя камера и/или задняя камера могут получать извне мультимедийные данные. И передняя камера, и задняя камера может быть системой с ненастраиваемым объективом или может иметь техническую возможность фокусировки и оптической трансфокации.
Аудиокомпонент 410 выполнен с возможностью вывода и/или приема аудиосигнала. Например, аудиокомпонент 410 содержит микрофон (MIC), выполненный с возможностью приема внешнего аудиосигнала, когда устройство 400 находится в рабочем режиме, например, в режиме вызова, в режиме записи и в режиме распознавания голоса. Принятый аудиосигнал может быть затем сохранен в памяти 404 или передан посредством компонента 416 связи. В некоторых вариантах осуществления изобретения аудиокомпонент 410 дополнительно содержит акустический излучатель для вывода аудиосигналов.
Интерфейс 412 ввода/вывода выполнен с возможностью обеспечения взаимосвязи между обрабатывающим компонентом 402 и периферийными интерфейсными модулями, например, клавиатурой, чувствительным к нажатию колесиком, кнопками и т.п. В число указанных кнопок могут входить кнопка возврата в исходное состояние, кнопка регулировки громкости, кнопка запуска и кнопка блокировки, но приведенный перечень не накладывает никаких ограничений.
Сенсорный компонент 414 может содержать один или более датчиков для предоставления информации о состояниях различных аспектов устройства 400. Например, сенсорный компонент 414 может быть выполнен с возможностью определения открытого/закрытого состояния устройства 400 и относительного расположения компонентов, например, дисплея и клавиатуры устройства 400, изменения положения устройства 400 или компонента устройства 400, наличия или отсутствия контакта между пользователем и устройством 400, ориентации или ускорения/замедления устройства 400 и изменения температуры устройства 400. Сенсорный компонент 414 может содержать датчик приближения, выполненный с возможностью обнаружения присутствия близко расположенных объектов при отсутствии физического контакта. Сенсорный компонент 414 также может содержать оптический датчик, например, датчик изображения типа КМОП (комплементарные структуры металл-оксид-полупроводник) или ПЗС (прибор с зарядовой связью) для использования в прикладных программах с получением изображений. В некоторых вариантах осуществления изобретения сенсорный компонент 414 также может содержать акселерометрический датчик, гироскопический датчик, магнитный датчик, датчик давления или температурный датчик.
Компонент 416 связи выполнен с возможностью осуществления проводной или беспроводной связи между устройством 400 и другими устройствами. Устройство 400 может быть выполнено с возможностью осуществления доступа к беспроводной сети с использованием некоторого стандарта связи, например, Wi-Fi, 2G, 3G или их сочетания. В одном варианте осуществления компонент 416 связи принимает широковещательный сигнал или информацию, связанную с широковещательной передачей, из внешней системы управления, использующей широковещательную передачу, через широковещательный канал. В одном варианте осуществления компонент 416 связи дополнительно содержит модуль беспроводной связи ближнего радиуса действия (Near Field Communication, NFC) для осуществления связи на небольших расстояниях. Этот модуль ближней связи может быть реализован, например, на основе технологии радиочастотной идентификации (Radio-frequency Identification, RFID), технологии инфракрасной передачи данных (Infrared Data Association, IrDA), сверхширокополосной технологии (Ultra Wide Band, UWB), технологии Bluetooth (BT) и других технологий.
В вариантах осуществления устройство 400 может быть реализовано с использованием одной или более специализированных интегральных схем, цифровых сигнальных процессоров, цифровых устройств обработки сигнала, программируемых логических устройств, программируемых матриц логических элементов, контроллеров, микроконтроллеров, микропроцессоров или других электронных компонентов, и выполнено с возможностью реализации вышеизложенного способа.
В вариантах осуществления также предусматривается долговременный машиночитаемый носитель информации, содержащий инструкции, которые, например, содержатся в памяти 404 и могут быть исполнены процессором 420 в устройстве 400 с целью реализации вышеописанных способов. Этим долговременным машиночитаемым носителем информации может быть, например, постоянное запоминающее устройство (ПЗУ), компакт-диск, магнитная лента, гибкий магнитный диск, оптическое запоминающее устройство и т.п.
Предусматривается долговременный машиночитаемый носитель информации. Устройство для обработки звука может быть выполнено с возможностью реализации, посредством исполнения инструкции с указанного носителя информации процессором указанного устройства, указанного способа обработки звука, содержащего следующие этапы.
Могут, после того, как активировано целевое приложение, принимать первые аудиоданные, связанные с первым аудиосигналом.
Могут принимать вторые аудиоданные в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема первых аудиоданных.
Могут получать целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных.
Из рассмотрения настоящего описания и практического использования раскрытого здесь изобретения специалисту в данной области техники должны стать очевидными и другие варианты осуществления настоящего изобретения. Настоящая патентная заявка подразумевает охват всех разновидностей, видов использования или адаптаций настоящего изобретения, следующих из его общих принципов, и содержит подобные отклонения от настоящего изобретения, полагая их относящимися к известной или общепринятой практике в данной области техники. Настоящее раскрытие и примеры должны рассматриваться лишь в качестве иллюстрации, а подлинный объем и сущность настоящего изобретения указываются нижеследующей формулой изобретения.
Должно быть понятно, что настоящее изобретение не ограничено конкретной конструкцией, описанной выше и показанной на сопровождающих чертежах, и что без выхода за пределы объема настоящего изобретения могут быть сделаны различные модификации и изменения. Объем настоящего изобретения следует считать ограничиваемым лишь прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ГОЛОСОВОГО УПРАВЛЕНИЯ, НОСИМОЕ УСТРОЙСТВО И ТЕРМИНАЛ | 2018 |
|
RU2763392C1 |
| УПРАВЛЕНИЕ АКУСТИЧЕСКОЙ ЭХОКОМПЕНСАЦИЕЙ ДЛЯ РАСПРЕДЕЛЕННЫХ АУДИОУСТРОЙСТВ | 2020 |
|
RU2818982C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ОСУЩЕСТВЛЕНИЯ РАСПРЕДЕЛЕННЫХ МНОГОМОДАЛЬНЫХ ПРИЛОЖЕНИЙ | 2008 |
|
RU2494444C2 |
| СПОСОБ И СИСТЕМА АНАЛИЗА ГОЛОСОВЫХ ВЫЗОВОВ НА ПРЕДМЕТ ВЫЯВЛЕНИЯ И ПРЕДОТВРАЩЕНИЯ СОЦИАЛЬНОЙ ИНЖЕНЕРИИ С ПОМОЩЬЮ АКТИВАЦИИ ГОЛОСОВОГО БОТА | 2023 |
|
RU2802533C1 |
| СПОСОБЫ ОБУЧЕНИЯ МОДЕЛИ И КОНВЕРСИИ ГОЛОСА И УСТРОЙСТВО, ДРУГОЕ УСТРОЙСТВО И НОСИТЕЛЬ ДАННЫХ | 2022 |
|
RU2830834C2 |
| СПОСОБ И СИСТЕМА АНАЛИЗА ГОЛОСОВЫХ ВЫЗОВОВ НА ПРЕДМЕТ ВЫЯВЛЕНИЯ И ПРЕДОТВРАЩЕНИЯ СОЦИАЛЬНОЙ ИНЖЕНЕРИИ | 2022 |
|
RU2790946C1 |
| ОБЕСПЕЧЕНИЕ АВТОНОМНОЙ СЕМАНТИЧЕСКОЙ ОБРАБОТКИ В УСТРОЙСТВЕ С ОГРАНИЧЕННЫМИ РЕСУРСАМИ | 2016 |
|
RU2685392C1 |
| ИНДИВИДУАЛЬНО НАСТРОЕННЫЙ ВЫВОД, КОТОРЫЙ ОПТИМИЗИРУЕТСЯ ДЛЯ ПОЛЬЗОВАТЕЛЬСКИХ ПРЕДПОЧТЕНИЙ В РАСПРЕДЕЛЕННОЙ СИСТЕМЕ | 2020 |
|
RU2821283C2 |
| Способ и система классификации пользователя электронного устройства | 2021 |
|
RU2795152C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ ВОСПРОИЗВЕДЕННОГО РЕЧЕВОГО ФРАГМЕНТА | 2020 |
|
RU2767962C2 |
Изобретение относится к акустике. Способ заключается в приеме аудиоданных, их распознавании, проверке наличия в них информации об активации приложения, активации приложения, приеме первых и вторых речевых данных. Затем выполняют вычисление разности времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных. Определяют больше или равна первой длительности вычисленная разность. Если разность времени больше, то выполняют проверку полноты введенных данных. Если данные введены не полностью, выполняется комбинирование первых и вторых данных. Если данные введены полностью, используются первые и вторые данные по отдельности. Получают на основе введенных данных ответную информацию от цифрового помощника. Выводят ответную информацию через динамик. Устройство обработки звука содержит первый и второй аудиоприемные модули, аудиоопределяющий модуль. Также устройство содержит схему памяти, процессор, элемент питания, мультимедийные и аудиокомпоненты, интерфейс ввода-вывода, модуль связи, сенсорный экран. Технический результат – обеспечение беспроблемного, ровного диалога с цифровым помощником. 4 н. и 8 з.п. ф-лы, 4 ил.
1. Способ обработки звука, применимый к электронному устройству, содержащий этапы, на которых:
принимают первые аудиоданные, связанные с первым аудиосигналом, после активации целевого приложения;
в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема первых аудиоданных принимают вторые аудиоданные; и
получают целевые аудиоданные на основании первых аудиоданных и вторых аудиоданных;
при этом в способе дополнительно:
определяют разность времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных,
при этом получение целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных содержит:
проверку полноты ввода первых аудиоданных, если указанная разность времени больше или равна первой заданной длительности; и
получение целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью.
2. Способ по п. 1, отличающийся тем, что получение целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью, содержит:
проверку возможности комбинирования первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью; и
комбинирование первых аудиоданных и вторых аудиоданных для получения целевых аудиоданных при наличии возможности комбинирования первых аудиоданных и вторых аудиоданных.
3. Способ по п. 1, в котором дополнительно, если первые аудиоданные введены полностью, определяют первые аудиоданные и вторые аудиоданные по отдельности в качестве целевых аудиоданных.
4. Способ по любому из пп. 1-3, в котором дополнительно:
выполняют подавление акустического эха (ПАЭ) на целевых аудиоданных;
получают ответную информацию на основании целевых аудиоданных, обработанных посредством ПАЭ; и
выдают указанную ответную информацию.
5. Способ по любому из пп. 1-3, в котором дополнительно: принимают аудиоданные, подлежащие распознаванию;
проверяют наличие в аудиоданных, подлежащих распознаванию, информации активации для активации целевого приложения; и
активируют целевое приложение при наличии указанной информации активации в аудиоданных, подлежащих распознаванию,
при этом аудиоданные, подлежащие распознаванию, содержат голосовые данные.
6. Устройство для обработки звука, содержащее:
первый аудиоприемный модуль, выполненный с возможностью приема первых аудиоданных, связанных с первым аудиосигналом, после того, как активировано целевое приложение;
второй аудиоприемный модуль, выполненный с возможностью приема вторых аудиоданных в ответ на обнаружение вторых аудиоданных, связанных со вторым аудиосигналом, в процессе приема первых аудиоданных;
первый аудиоопределяющий модуль, выполненный с возможностью получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных; и
времяопределяющий модуль, выполненный с возможностью определения разности времени между окончанием приема первых аудиоданных и началом приема вторых аудиоданных,
при этом первый аудиоопределяющий модуль содержит:
аудиоопределяющий субмодуль, выполненный с возможностью:
проверки полноты ввода первых аудиоданных, если указанная разность времени больше или равна первой заданной длительности; и
получения целевых аудиоданных на основании первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью.
7. Устройство по п. 6, отличающееся тем, что аудиоопределяющий субмодуль дополнительно выполнен с возможностью:
проверки возможности комбинирования первых аудиоданных и вторых аудиоданных, если первые аудиоданные введены не полностью; и
комбинирования первых аудиоданных и вторых аудиоданных для получения целевых аудиоданных при наличии возможности комбинирования первых аудиоданных и вторых аудиоданных.
8. Устройство по п. 6, дополнительно содержащее
второй аудиоопределяющий модуль, выполненный с возможностью определения первых аудиоданных и вторых аудиоданных по отдельности в качестве целевых аудиоданных, если первые аудиоданные введены полностью.
9. Устройство по любому из пп. 6-8, дополнительно содержащее:
модуль подавления акустического эха (ПАЭ), выполненный с возможностью выполнения обработки подавления акустического эха на целевых аудиоданных;
ответный модуль, выполненный с возможностью получения ответной информации на основании целевых аудиоданных, обработанных посредством ПАЭ; и
выходной модуль, выполненный с возможностью выдачи указанной ответной информации.
10. Устройство по любому из пп. 6-8, дополнительно содержащее:
третий аудиоприемный модуль, выполненный с возможностью приема аудиоданных, подлежащих распознаванию;
модуль проверки информации, выполненный с возможностью проверки наличия в аудиоданных, подлежащих распознаванию, информации активации для активации целевого приложения; и
активирующий модуль, выполненный с возможностью активации целевого приложения при наличии информации активации в аудиоданных, подлежащих распознаванию,
при этом аудиоданные, подлежащие распознаванию, содержат голосовые данные.
11. Устройство для обработки звука, содержащее:
процессор и
память, выполненную с возможностью хранения инструкции, которая может быть исполнена указанным процессором,
причем указанный процессор выполнен с возможностью, при исполнении указанной инструкции, реализации этапов способа обработки звука по любому из пп. 1-5.
12. Долговременный машиночитаемый носитель информации, содержащий инструкцию, при исполнении которой процессором устройства для обработки звука предусмотрена возможность выполнения указанным устройством способа обработки звука по любому из пп. 1-5.
| US 20170068423 A1, 09.05.2017 | |||
| CN 0108172219 A, 15.06.2018 | |||
| US 9659555 B1, 23.05.2017 | |||
| СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ, РЕАЛИЗОВАННОЕ С ПОМОЩЬЮ ТЭГОВ РЕЧЕВОГО ПРИЛОЖЕНИЯ | 2004 |
|
RU2349969C2 |
| CN 109599124 A, 09.04.2019 | |||
| CN 109147779 A, 04.01.2019 | |||
| CN 0108986814 A, 11.12.2018 | |||
| US 20190019509 A1, 17.01.2019 | |||
| CN 106409295 A, 15.02.2017 | |||
| US 9799328 B2, 24.10.2017 | |||
| JP 2006107044 A, 20.04.2006. | |||

