[0001] Согласно настоящей заявке испрашивается приоритет в соответствии с заявкой на выдачу патента Китая №202111577618.0, поданной 22 декабря 2021 г., которая ссылкой полностью включена в настоящий документ.
Область техники, к которой относится настоящее изобретение
[0002] Настоящее изобретение относится к области понимания естественного языка и, в частности, относится к способу обучения модели, способу конверсии голоса, и устройству, другому устройству и носителю данных.
Предшествующий уровень техники настоящего изобретения
[0003] Конверсия голоса играет важную роль в технологиях обработки звука и широко используется в таких областях, как создание звукового содержимого, производство звуковых программ для развлекательных мероприятий, а также для защищенной связи. Конверсия голоса означает процесс преобразования голоса в исходном аудиосигнале в голос другого диктора. В процессе преобразования голоса необходимо обеспечить, чтобы голос преобразованного аудиосигнала был подобен голосу диктора, в то время как содержимое аудиосигнала осталась неизменным. Трудности при конверсии голоса заключаются в том, что надо обеспечить неизменность информации содержимого исходного аудиосигнала во время выполнения конверсии голоса.
[0004] Соответственно, имеется техническая проблема выполнения конверсии голоса и достижения стабильных результатов конверсии голоса, которую необходимо решить.
Краткое раскрытие настоящего изобретения
[0005] Согласно вариантам осуществления настоящего раскрытия предложены способ обучения модели, способ конверсии голоса, устройство, другое устройство и носитель данных, которые решают проблему низкой надежности конверсии голоса из-за плохих результатов конверсии при традиционной конверсии голоса.
[0006] Согласно некоторым вариантам осуществления настоящего раскрытия предложен способ обучения модели конверсии голоса. В способе предусмотрены следующие стадии:
[0007] получение набора образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый фрагмент образца аудиоданных соответствует целевым аудиоданным, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация.
[0008] получение первой голосовой характеристики из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получение синтезированных аудиоданных на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса; и
[0009] получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
[0010] Согласно некоторым вариантам осуществления настоящего раскрытия предложен способ для конверсии голоса. В способе предусмотрены следующие стадии:
[0011] получение исходных аудиоданных и голосовой характеристики целевого диктора;
[0012] получение голосовой характеристики исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получение семантической характеристики на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получение синтезированных аудиоданных на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
[0013] Согласно некоторым вариантам осуществления настоящего раскрытия предложено устройство для обучения модели конверсии голоса. Устройство включает в себя:
[0014] получающий блок, выполненный с возможностью получать набор образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый фрагмент образца аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация;
[0015] процессорный блок, выполненный с возможностью: получать первую голосовую характеристику из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получать первую семантическую характеристику на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получать синтезированные аудиоданные на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующей образцу аудиоданных, с помощью вокодера в исходной модели конверсии исходного голоса; и
[0016] обучающий блок, выполненный с возможностью получать обученную модель конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
[0017] Согласно некоторым вариантам осуществления настоящего раскрытия предложено устройство для конверсии голоса. Устройство включает в себя:
[0018] получающий модуль, выполненный с возможностью получать исходные аудиоданные и голосовую характеристику целевого диктора; и
[0019] синтезирующий модуль, выполненный с возможностью: получать голосовую характеристику исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получать семантическую характеристику на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получать синтезированные аудиоданные на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
[0020] Согласно вариантам осуществления настоящего раскрытия предложено электронное устройство. Электронное устройство включает в себя, по меньшей мере, процессор и память, причем процессор после загрузки и выполнения, по меньшей мере, одной хранящейся в памяти компьютерной программы побуждается выполнять способ обучения модели конверсии голоса, который описан выше, или способ конверсии голоса, который описан выше.
[0021] Согласно вариантам осуществления настоящего раскрытия предложен машиночитаемый носитель данных. На машиночитаемом носителе данных хранится, по меньшей мере, одна компьютерная программа, причем, по меньшей мере, одна компьютерная программа, после ее загрузки и выполнения процессором, заставляет процессор выполнять способ обучения модели конверсии голоса, который описан выше, или способ конверсии голоса, который описан выше.
[0022] Согласно вариантам осуществления настоящего раскрытия предложен продукт в виде компьютерной программы. Продукт в виде компьютерной программы включает в себя, по меньшей мере, одну компьютерную программу, причем, по меньшей мере, одна компьютерная программа, после ее загрузки и выполнения процессором, заставляет процессор выполнять способ обучения модели конверсии голоса, который описан выше, или способ конверсии голоса, который описан выше.
[0023] Так как при этом нет никакой необходимости предварительно маркировать образец аудиоданных в наборе образцов во время обучения модели конверсии голоса, никакие ресурсы не тратятся на маркировку образца аудиоданных, что способствует последующему обучению модели конверсии голоса на основании образца аудиоданных из набора образцов. Сеть извлечения голоса, сеть удаления голоса и вокодер включены в исходную модель конверсии голоса, и поэтому первая голосовая характеристика получается из входного образца аудиоданных с помощью сети извлечения голоса, так что из входного образца аудиоданных получается точная голосовая информация, что способствует последующему получению синтезированных аудиоданных на основании голосовой характеристики и улучшению точности голоса в синтезированных аудиоданных. На основании первой голосовой характеристики первая семантическая характеристика получается из входного образца аудиоданных сетью удаления голоса, так что получается точная характеристика образца аудиоданных, которая не связана с голосом диктора, но связана с речевым содержанием, что способствует последующему получению синтезированных аудиоданных на основании первой семантической характеристики, и гарантирует точность речевого содержания в синтезированных аудиоданных. С помощью этого вокодера синтезированные аудиоданные получаются на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующей образцу аудиоданных. На основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, исходная модель конверсии голоса обучается для получения обученной модели конверсии голоса, так что достигается неконтролируемое обучение модели конверсии голоса, и, таким образом, сложность получения модели конверсии голоса значительно снижается. Впоследствии конверсия голоса выполняется на основании обученной модели конверсии голоса, что улучшает результаты конверсии и надежность конверсии голоса.
Краткое описание фигур
[0024] Для обеспечения более понятного описания технических решений согласно некоторым вариантам осуществления настоящего раскрытия ниже кратко описаны приложенные фигуры, на которые приводятся ссылки в описаниях вариантов осуществления. Очевидно, что приложенные фигуры в последующем описании относится только к некоторым вариантам осуществления настоящего раскрытия, и на основании приложенных фигур специалистами обычной квалификации в этой области техники без каких-либо творческих усилий могут быть получены другие фигуры.
[0025] На фиг. 1 показана упрощенная блок-схема процесса обучения модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия;
[0026] На фиг. 2 показана упрощенная блок-схема модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия;
[0027] На фиг. 3 показана упрощенная схема процесса конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия;
[0028] На фиг. 4 показана упрощенная блок-схема модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия;
[0029] На фиг. 5 показана упрощенная блок-схема устройства для обучения модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия;
[0030] На фиг. 6 показана упрощенная блок-схема устройства для конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия.
[0031] На фиг. 7 показана упрощенная блок-схема электронного устройства согласно некоторым вариантам осуществления настоящего раскрытия; и
[0032] На фиг. 8 показана упрощенная блок-схема другого электронного устройства согласно некоторым вариантам осуществления настоящего раскрытия.
Подробное раскрытие настоящего изобретения
[0033] Настоящее раскрытие подробно описано далее в настоящем документе со ссылками на прилагаемые фигуры, чтобы сделать более понятными цели, технические решения и преимущества настоящего раскрытия. Понятно, что описанные варианты осуществления являются только частью вариантов осуществления настоящего раскрытия, а не всеми вариантами осуществления. Все другие варианты осуществления, без каких-либо творческих усилий полученные специалистами в этой области техники на основании описанных в настоящем документе вариантов осуществления, попадают в объем правовой охраны настоящего раскрытия.
[0034] Специалисты в этой области техники должны понимать, что варианты осуществления настоящего изобретения могут быть реализованы в виде системы, устройства, другого устройства, способа или продукта в виде компьютерной программы. Соответственно настоящее раскрытие может быть конкретно реализовано полностью аппаратными средствами, полностью программным обеспечением (включая встроенное программное обеспечение, резидентное программное обеспечение и микропрограмму) или в виде комбинации аппаратных средств и программного обеспечения.
[0035] В контексте настоящего документа следует понимать, что любое количество элементов на приложенных фигурах используется только в иллюстративных целях, а не в качестве ограничения, также как и любое наименование используется только для разграничения понятий и не подразумевает никаких ограничений.
[0036] В настоящее время для выполнения конверсии голоса применяются конверсия голоса на основании преобразования текста в речь (text-to-speech - TTS), конверсия голоса на основании автоматического распознавания речи (automatic speech recognition - ASR), конверсия голоса на основании генеративно-состязательных сетей (generative adversarial networks - GAN) и конверсия голоса на основании вариационного автоматического кодировщика (variational auto encoder - VAE). Что касается достижения точности речевого содержания в синтезированных аудиоданных, при использовании этих способов конверсии голоса не могут быть гарантированы голосовые характеристики, которые не относится к семантическому содержанию, в частности, вздохи, крики и тому подобное, и, таким образом, ухудшается естественность синтезированных аудиоданных и результатов конверсии голоса.
[0037] Рассмотрим в качестве примера конверсию голоса на основании ASR. В этом способе предварительно обученная модель ASR обычно используется для извлечения семантической информации из аудиоданных, а голосовая информация в аудиоданных целевого диктора извлекается с помощью модели извлечения голоса, и затем на основании семантической информации и голосовой информации создаются синтезированные аудиоданные целевого диктора. Поскольку этот способ в значительной степени опирается на предварительно обученную модель ASR, точность модели ASR непосредственно влияет на результат конверсии голоса синтезированных аудиоданных. Вместе с тем модель ASR в основном нацелена на извлечение семантического содержания, но она игнорирует другую голосовую информацию в аудиоданных, которая не связана с семантическим содержанием, например голос, и, таким образом, синтезированные аудиоданные теряют голосовую информацию и другую информацию, которая не связана с семантическим содержанием.
[0038] Рассмотрим в качестве примера конверсию голоса на основании TTS. В этом способе после предварительного захвата большого количества аудиоданных целевого диктора акустическая модель целевого диктора и вокодера получаются с помощью обучения на основании каждого фрагмента собранных аудиоданных, а также семантической информации, соответственным образом связанной с каждым фрагментом аудиоданных. Впоследствии на основании текстовых характеристик текстовой информации и обученной акустической модели и вокодера целевого диктора получаются синтезированные аудиоданные целевого диктора. Поскольку обычно требуется заранее собрать более 30000 предложений или 30 часов аудиоданных целевого диктора, чтобы обеспечить точность акустической модели и вокодера целевого диктора, необходимо промаркировать семантику каждого фрагмента аудиоданных, что увеличивает сложность получения акустической модели и вокодера целевого диктора, и затрачиваемые на это ресурсы становятся очень большими. Более того, другая голосовая информация, в частности, голос в полученных синтезированных аудиоданных, относительно фиксированная, что ухудшает естественность синтезированных аудиоданных и результаты конверсии голоса.
[0039] Для решения вышеупомянутых проблем согласно некоторым вариантам осуществления настоящего раскрытия предложены способ обучения модели, способ конверсии голоса, устройство, другое устройство и носитель данных. Так как при этом нет никакой необходимости предварительно маркировать образец аудиоданных в наборе образцов во время обучения модели конверсии голоса, никакие ресурсы не затрачиваются на маркировку образца аудиоданных, и поэтому удобно обучать модель конверсии голоса на основании образца аудиоданных из набора образцов в последующем процессе. Так как при этом нет никакой необходимости предварительно маркировать образец аудиоданных в наборе образцов во время обучения модели конверсии голоса, никакие ресурсы не затрачиваются на маркировку образца аудиоданных, и поэтому удобно обучать модель конверсии голоса на основании образца аудиоданных из набора образцов в последующем процессе. Исходная модель конверсии голоса включает в себя сеть извлечения голоса, сеть удаления голоса и вокодер. Первая голосовая характеристика входного образца аудиоданных получается с помощью сети извлечения голоса, так что из входного образца аудиоданных получается точная голосовая информация, что способствует последующему получению синтезированных аудиоданных на основании голосовой характеристики и улучшению точности голоса в синтезированных аудиоданных. На основании первой голосовой характеристики сетью удаления голоса из входного образца аудиоданных получается точная первая семантическая характеристика, так что получается точная характеристика образца аудиоданных, которая не связана с голосом диктора, но связана с речевым содержанием, что способствует последующему получению синтезированных аудиоданных на основании первой семантической характеристики, и гарантирует точность речевого содержания в синтезированных аудиоданных. С помощью этого вокодера синтезированные аудиоданные получаются на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующей образцу аудиоданных. На основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, исходная модель конверсии голоса обучается для получения обученной модели конверсии голоса, так что достигается неконтролируемое обучение модели конверсии голоса, и сложность получения модели конверсии голоса значительно снижается. Впоследствии конверсия голоса выполняется на основании обученной модели конверсии голоса, что улучшает результаты конверсии и надежность конверсии голоса.
[0040] Следует отметить, что сценарии применения, упомянутые в приведенных выше вариантах осуществления, являются лишь примерными сценариями, предложенными для удобства иллюстрации, и не указывают на какое-либо ограничение сценариев применения способа обучения модели, способа конверсии голоса, устройства, второго устройства и носителя данных согласно вариантам осуществления настоящего раскрытия. Специалисты обычной квалификации в этой области техники знают, что по мере появления новых сценариев коммерческой деятельности технические решения, предлагаемые согласно вариантам осуществления настоящего раскрытия, будут в равной степени применимы для решения аналогичных технических проблем.
[0041] Вариант осуществления 1
[0042] На фиг. 1 показана упрощенная блок-схема процесса обучения модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия. В этом процессе предусмотрены следующие стадии.
[0043] На стадии S101 получается набор образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый фрагмент образца аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация.
[0044] Способ обучения модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия применим к электронному устройству, которое представляет собой интеллектуальное устройство, в частности, робот, мобильный терминал или сервер.
[0045] Обычно собираются аудиоданные разных дикторов, и такие аудиоданные определяются в качестве образцов аудиоданных. Исходная модель синтеза голоса сначала обучается на основании таких образцов аудиоданных, так что выполняется обученная модель синтеза голоса, что улучшает устойчивость модели конверсии голоса, а также расширяет типы голосов, которые могут быть синтезированы с помощью модели конверсии голоса.
[0046] Согласно некоторым вариантам осуществления настоящего раскрытия образец аудиоданных получается на стадии S101, по меньшей мере, одним из следующих методов.
[0047] Согласно первому методу аудиоданные, полученные с помощью записи различных дикторов, определяются в качестве образца аудиоданных.
[0048] В процессе сбора образца аудиоданных диктор записывает голосовые данные в профессиональной студии звукозаписи и определяет записанные голосовые данные в качестве образца аудиоданных, или записывает голосовые данные с помощью интеллектуального терминала (например, мобильного телефона, планшетного компьютера или тому подобного) и определяет образец аудиоданных на основании записанных голосовых данных.
[0049] Например, диктор вводит в интеллектуальный терминал операцию запуска. Существует много способов, с помощью которых диктор вводит операцию запуска в интеллектуальный терминал, и эта операция запуска означает, что диктор нажимает виртуальную кнопку, отображаемую на экране дисплея интеллектуального терминала, или диктор вводит голосовое сообщение в интеллектуальный терминал, или диктор рисует графическую инструкцию на экране дисплея интеллектуального терминала, которая настроена в конкретной реализации, и это никак не ограничено в настоящем документе. После приема введенной диктором операции запуска интеллектуальный терминал загружает предварительно записанные выбранные диктором голосовые данные на электронное устройство, или интеллектуальный терминал входит в режим записи голоса, начинает запись голосовых данных диктора в реальном масштабе времени, и загружает множество записанных голосовых данных в электронное устройство, и, таким образом, электронное устройство определяет образец аудиоданных на основании принятых голосовых данных.
[0050] Для записи голосовых данных диктору не нужно обращаться в профессиональную студию звукозаписи, и звуковые данные записываются с помощью интеллектуального терминала, поэтому сложность и затраты ресурсов для получения голосовых данных диктора снижаются, а впечатления пользователя значительно улучшаются.
[0051] Во время записи голосовых данных интеллектуальным терминалом голосовые данные, полученные при записи интеллектуальным терминалом, определяются в качестве исходных голосовых данных диктора. Поскольку в исходных голосовых данных присутствует большое количество шумов от рабочей среды, исходные голосовые данные, полученные во время записи, сначала подвергаются обработке как аудиоданные. Например, исходные голосовые данные подвергаются обработке для снижения шума и/или устранения реверберации, так что получаются чистые голосовые данные. Прошедшие такую обработку голосовые данные затем определяется в качестве образца аудиоданных.
[0052] Следует отметить, что конкретные процессы выполнения обработки для снижения шума и/или обработки для устранения реверберации для этих исходных голосовых данных соответствуют предшествующему уровню техники и не описаны подробно в настоящем документе.
[0053] Согласно второму методу, который основан на первом методе, по меньшей мере, два фрагмента голосовых данных одного и того же диктора соединяются, и соединенные вместе голосовые данные, полученные в процессе соединения, определяются в качестве образца аудиоданных, что расширяет полученный образец аудиоданных. Таким образом, сложность и затраты ресурсов на получение образца аудиоданных дополнительно снижаются, что полезно для обучения модели конверсии голоса на основании полученного большого количества образцов аудиоданных, так что улучшаются точность и устойчивость полученной модели конверсии голоса.
[0054] Согласно некоторым вариантам осуществления, основанным на вышеупомянутом первом методе, соединение, по меньшей мере, двух фрагментов голосовых данных одного и того же диктора, и определение соединенных вместе голосовых данных, полученных после процесса соединения, в качестве образца аудиоданных, предусматривает следующие способы.
[0055] Согласно первому способу голосовые данные, полученные при записи на основании первого метода, определяются в качестве базовых голосовых данных. Базовые голосовые данные являются исходными голосовыми данными согласно вышеупомянутым вариантам осуществления, или голосовыми данными после выполнения обработки аудиоданных согласно вышеупомянутым вариантам осуществления. Для другого диктора, по меньшей мере, два различных фрагмента базовых голосовых данных диктора соединяются вместе и определяются в качестве соединенных голосовых данных (в описании они называются первыми соединенными голосовыми данными). Каждый из базовых голосовых образцов и каждый фрагмент первых соединенных голосовых данных определяется в качестве образца аудиоданных.
[0056] Согласно второму способу голосовые данные, полученные при записи на основании первого метода, определяются в качестве базовых голосовых данных. Для другого диктора, по меньшей мере, один фрагмент базовых голосовых данных диктора копируется в набор несколько раз, и, по меньшей мере, один фрагмент скопированных голосовых данных соединяется вместе с соответствующими базовыми голосовыми данными и определяется в качестве соединенных голосовых данных (в описании они называются вторыми соединенными голосовыми данными). Следует понимать, что эти вторые соединенные вместе голосовые данные соединены из, по меньшей мере, двух идентичных фрагментов голосовых данных. Каждый из базовых голосовых образцов и каждый фрагмент вторых соединенных голосовых данных определяется в качестве образца аудиоданных.
[0057] Согласно третьему способу, голосовые данные, полученные при записи на основании первого метода, определяются в качестве базовых голосовых данных. Для другого диктора, по меньшей мере, один фрагмент базовых голосовых данных диктора копируется в набор несколько раз, и, по меньшей мере, два идентичных фрагмента голосовых данных (включая скопированные голосовые данные и базовые голосовые данные) соединяются вместе с, по меньшей мере, одним фрагментом голосовых данных, отличным от голосовых данных диктора, и определяются в качестве соединенных голосовых данных (в описании они называются третьими соединенными голосовыми данными). Следует понимать, что эти третьи соединенные вместе голосовые данные включают в себя, по меньшей мере, два идентичных фрагмента голосовых данных и, по меньшей мере, два различных фрагмента голосовых данных. Каждый из базовых голосовых образцов и каждый фрагмент третьих соединенных голосовых данных определяется в качестве образца аудиоданных.
[0058] Согласно некоторым возможным вариантам осуществления полученный образец аудиоданных одновременно расширяется, по меньшей мере, двумя из трех описанных выше способов.
[0059] На основании определения образца аудиоданных по голосовым данным диктора, полученным посредством записи, по меньшей мере, два фрагмента голосовых данных диктора соединяются, и соединенные вместе голосовые данные, полученные в процессе соединения, определяются в качестве образца аудиоданных. Таким образом, образец аудиоданных расширяется, так что сложность и затраты ресурсов на получение образца аудиоданных диктора дополнительно уменьшаются. Это способствует обучению модели конверсии голоса на основании полученного большого количества образцов аудиоданных и улучшению точности и устойчивости полученной модели конверсии голоса.
[0060] Чтобы получить модель конверсии голоса с более высокой точностью, необходимо контролировать результаты модели конверсии голоса таким образом, чтобы синтезированные аудиоданные, выводимые моделью конверсии голоса, были близки к аудиоданным (они называются целевыми аудиоданными) целевого диктора с тем же самым речевым содержанием. Таким образом, после получения каждого фрагмента образца аудиоданных в наборе образцов для каждого фрагмента образца аудиоданных определяются целевые аудиоданные, соответствующие образцу аудиоданных, и впоследствии, на основании целевых аудиоданных определяется, являются ли или нет точными синтезированные аудиоданные, полученные на основании исходной модели конверсии голоса, а также образец аудиоданных, так что определяется результат конверсии голоса исходной модели конверсии голоса.
[0061] Согласно некоторым возможным вариантам осуществления для каждого фрагмента образца аудиоданных в наборе образцов определяются целевые аудиоданные другого диктора с той же самой семантической информацией, как в образце аудиоданных. Целевые аудиоданные включают в себя, по меньшей мере, один фрагмент образца аудиоданных или аудиоданные не из образца. То есть целевые аудиоданные включают в себя образец аудиоданных другого диктора в наборе образцов, имеющий ту же семантическую информацию, как в образце аудиоданных, и/или аудиоданные не из образца от другого диктора, имеющие ту же семантическую информацию, как в образце аудиоданных.
[0062] Согласно некоторым возможным вариантам осуществления предполагается, что процесс определения для каждого фрагмента образца аудиоданных в наборе образцов целевых аудиоданных другого диктора, которые имеет ту же семантическую информацию, как в образце аудиоданных, является весьма затратным и неэффективным. Следовательно, согласно некоторым вариантам осуществления настоящего раскрытия для каждого фрагмента образца аудиоданных в наборе образцов аудиоданные образца определяются в качестве целевых аудиоданных, соответствующих образцу аудиоданных, так что нет никакой необходимости затрачивать ресурсы на определение целевых аудиоданных, которые имеют голос, отличающийся от голоса в образце аудиоданных, и, таким образом, снижается сложность обучения модели конверсии голоса.
[0063] На стадии S102 проводится получение первой голосовой характеристики любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией в образце аудиоданных; и получение синтезированных аудиоданных на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса.
[0064] Согласно некоторым вариантам осуществления настоящего раскрытия исходная модель конверсии голоса предварительно настроена, и значения параметров исходной модели конверсии голоса определены случайным образом или предварительно настроены. В случае, когда набор образцов получен на основании вышеописанных вариантов осуществления, исходная модель конверсии голоса обучается на основании каждого фрагмента образца аудиоданных, содержащегося в наборе образцов, так что получается обученная модель конверсии голоса.
[0065] Согласно конкретному варианту осуществления получаются любые образцы аудиоданных в наборе образцов, и эти образцы аудиоданных вводятся в исходную модель конверсии голоса. С помощью исходной модели конверсии голоса на основании образца аудиоданных и голосовой характеристики (обозначенной как вторая голосовая характеристика) целевых аудиоданных, соответствующей образцу аудиоданных, получаются синтезированные аудиоданные, соответствующие образцу аудиоданных.
[0066] Согласно некоторым вариантам осуществления, по меньшей мере, сеть извлечения голоса, сеть удаления голоса и вокодер включены в исходную модель конверсии голоса для точной обработки входного образца аудиоданных с помощью сети извлечения голоса, сети удаления голоса и вокодера, включенных в исходную модель конверсии голоса. Сеть извлечения голоса подсоединена к сети удаления голоса и вокодеру, а сеть удаления голоса подсоединена к вокодеру. С помощью сети извлечения тона из входного образца аудиоданных получается первая голосовая характеристика, так что из входного образца аудиоданных получается точная голосовая информация, которая не связана с семантическим содержанием, что способствует последующему получению синтезированных аудиоданных на основании первой голосовой характеристики и улучшению точности голоса в синтезированных аудиоданных. С помощью сети удаления голоса из входного образца аудиоданных получается первая семантическая характеристика, которая не связана с голосом диктора образца аудиоданных, а связана только с семантической информацией образца аудиоданных, что способствует последующему получению синтезированных аудиоданных на основании первой семантической характеристики, и гарантирует точность речевого содержания в синтезированных аудиоданных. С помощью вокодера синтезированные аудиоданные получаются на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующей этому образцу аудиоданных.
[0067] Согласно конкретному варианту осуществления получаются любые образцы аудиоданных в наборе образцов, и эти образцы аудиоданных вводятся в исходную модель конверсии голоса. С помощью сети извлечения голоса в исходной модели конверсии голоса образец аудиоданных обрабатывается соответствующим образом, и получается первая голосовая характеристика, соответствующая образцу аудиоданных. Семантическая характеристика (обозначенная как первая семантическая характеристика) получается с помощью сети удаления голоса в исходной модели конверсии голоса на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных. Соответствующие образцу аудиоданных синтезированные аудиоданные получаются с помощью вокодера в исходной модели конверсии голоса на основании полученной первой семантической характеристики и второй голосовой характеристики, соответствующих образцу аудиоданных.
[0068] Первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с речевым содержанием, так что устраняется влияние голоса на семантическую информацию, и улучшается точность получено семантической информации.
[0069] Следует отметить, что линейная спектрограмма, соответствующая образцу аудиоданных, получается с помощью предварительно определенного алгоритма линейной спектрограммы (например, алгоритма быстрого преобразования Фурье).
[0070] Согласно некоторым возможным вариантам осуществления перед вводом любого образца аудиоданных из набора аудиоданных в исходную модель конверсии голоса определяется акустическая характеристика образца аудиоданных. Акустическая характеристика образца аудиоданных водится в исходную модель конверсии голоса, так что акустическая характеристика обрабатывается исходной моделью конверсии голоса и получаются синтезированные аудиоданные.
[0071] Акустическая характеристика является мел-частотными кепстральными коэффициентами (Mel Frequency Cepstrum Coefficient - MFCC) мел-спектрограммы, a барк-частотными кепстральными коэффициентами (Bark Frequency Cepstrum Coefficient - BFCC), инвертированными мел-частотными кепстральными коэффициентами (Inverse Mel Frequency Cepstrum Coefficient - IMFCC), гамматон-частотными кепстральными коэффициентами (Gammatone Frequency Cepstrum Coefficient - GFCC), кепстральными коэффициентами линейного предсказания (Linear Prediction Cepstral Coefficient - LPCCS) или тому подобным.
[0072] Следует отметить, что акустическая характеристика получается с помощью алгоритма извлечения акустической характеристики или модели извлечения акустической характеристики.
[0073] В качестве примера укажем, что в случае, когда акустическая характеристика представляет собой мел-частотную спектрограмму, получается мел-частотная спектрограмма любого образца аудиоданных в наборе образцов, и мел-частотная спектрограмма образца аудиоданных вводится в исходную модель конверсии голоса. С помощью сети извлечения голоса в исходной модели конверсии голоса входная мел-спектрограмма обрабатывается соответствующим образом, и, таким образом, получается первая голосовая характеристика образца аудиоданных, в частности, 256-мерная голосовая характеристика (tone vector).
[0074] Следует отметить, что сеть извлечения голоса определяется на основании слоев сети, включенных в модель спектрограммы голоса, в частности, нейронной сети с глубинным обучением Deep Speaker RawNet (GE2E).
[0075] Сеть удаления голоса в исходной модели конверсии голоса включает в себя, по меньшей мере, апостериорный кодировщик, так что из образцов аудиоданных получается точная характеристика, которая не связана с голосом диктора, но связана с семантической информацией, что улучшает точность полученных первых семантических характеристик и позволяет избежать влияния голосовой характеристики образца аудиоданных на семантическую информацию образца аудиоданных. Апостериорный кодировщик подсоединен к улучшающей подсети. Апостериорный кодировщик выполнен с возможностью получения скрытого вектора, связанного с речевым содержанием образца аудиоданных, чтобы определить первую семантическую характеристику образца аудиоданных на основании скрытого вектора.
[0076] Более конкретно, после получения первой характеристики голоса, выведенной сетью извлечения голоса на основании описанных выше вариантов осуществления, скрытый вектор семантической информации образца аудиоданных получается на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью апостериорного кодировщика, включенного в сеть удаления голоса в исходной модели конверсии голоса. Затем на основании скрытого вектора определяется первая семантическая характеристика.
[0077] Скрытый вектор непосредственно определяется в качестве первой семантической характеристики, или скрытый вектор обрабатывается предварительно определенной математической функцией (например, логарифмической функцией), и обработанный скрытый вектор определяется в качестве первой семантической характеристики.
[0078] Согласно некоторым возможным вариантам осуществления сеть удаления голоса в исходной модели конверсии голоса дополнительно включает в себя улучшающую подсеть (например, поточную сеть) для улучшения характеристики в образцах аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией, и для улучшения представления распределения семантической информации, так что точность полученной первой семантической характеристики дополнительно улучшается, и, таким образом, голосовая характеристика образца аудиоданных не оказывает влияния на семантическую информацию образца аудиоданных. Улучшающая подсеть подсоединена к апостериорному кодировщику в сети удаления голоса. Улучшающая подсеть выполнена с возможностью улучшить скрытый вектор, получаемый с помощью апостериорного кодировщика. Следует понимать, что улучшающая подсеть выполнена с возможностью извлечения характеристики, которая имеет высокую размерность и более абстрактная и не связана с голосом диктора, а связана с семантической информацией из скрытого вектора, полученного с помощью апостериорного кодировщика.
[0079] Согласно конкретной реализации после получения первой характеристики голоса, выведенной сетью извлечения голоса на основании описанных выше вариантов осуществления, скрытый вектор семантической информации образца аудиоданных получается на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью апостериорного кодировщика, включенного в сеть удаления голоса в исходной модели конверсии голоса. Затем с помощью улучшающей подсети в сети удаления голоса в исходной модели конверсии голоса на основании скрытого вектора получается улучшенный скрытый вектор. Таким образом, определяется первая семантическая характеристика.
[0080] После получения первой семантической характеристики входного образца аудиоданных на основании описанных выше вариантов осуществления, синтезированные аудиоданные, речевое содержание которых удовлетворяет первой семантической характеристики, и голос которых удовлетворяет второй голосовой характеристики, получаются на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса.
[0081] Вокодер является вокодером высокой эффективности (HiFiGAN), вокодером с кодированием методом линейного предсказания (linear predictive coding - LPC), вокодером World или тому подобным, который гибко определяется согласно фактическим потребностям во время фактического процесса реализации и никаким образом специально не ограничивается в настоящем раскрытии.
[0082] Согласно некоторым возможным вариантам осуществления вторая голосовая характеристика целевых аудиоданных, соответствующих образцу аудиоданных, получается с помощью сети извлечения голоса в исходной модели конверсии голоса.
[0083] Например, в случае, когда целевые аудиоданные являются образцом аудиоданных, первая голосовая характеристика образца аудиоданных, определенная с помощью сети извлечения голоса в исходной модели конверсии голоса, непосредственно определяется в качестве второй голосовой характеристики.
[0084] Например, в случае, когда целевые аудиоданные не являются образцом аудиоданных, то есть целевые аудиоданные являются образцом аудиоданных в наборе образцов, который отличается от образца аудиоданных диктора, или аудиоданными не из образца, которые отличаются от образца аудиоданных диктора, целевые аудиоданные, соответствующие образцу аудиоданных, также вводятся в исходную модель конверсии голоса, когда образец аудиоданных вводится в исходную модель конверсии голоса. Таким образом, вторая голосовая характеристика целевых аудиоданных получается с помощью сети извлечения голоса в исходной модели конверсии голоса.
[0085] На стадии S103 на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, обученная модель конверсии голоса получается с помощью обучения исходной модели конверсии голоса.
[0086] Синтезированные аудиоданные, соответствующие образцу аудиоданных, определенному с помощью модели конверсии голоса с более высокой точностью, более подобны целевым аудио данным, соответствующим образцу аудиоданных. Таким образом, после получения синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных на основании вышеупомянутых вариантов осуществления, значения параметров в исходной модели конверсии голоса корректируются на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, так что получается обученная модель конверсии голоса. В качестве примера укажем, что на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных и соответствующих синтезированным аудиоданным, определяется значение потерь восстановления, и на основании значения потерь восстановления корректируется значения параметров в исходной модели конверсии голоса, и, таким образом, получается обученная модель конверсии голоса.
[0087] Согласно некоторым возможным вариантам осуществления значение частичных потерь восстановления определяется для каждого фрагмента образца аудиоданных на основании целевых аудиоданных, соответствующих образцу аудиоданных, и синтезированных аудиоданных, соответствующих образцу аудиоданных. На основании суммы всех значений частичных потерь восстановления, полученных в текущей итерации, определяется значение потерь восстановления. На основании значения потерь восстановления корректируется значения параметров в исходной модели конверсии голоса, и, таким образом, получается обученная модель конверсии голоса.
[0088] В качестве примера укажем, что значение частичных потерь восстановления определяется согласно целевым аудиоданным, соответствующим образцу аудиоданных, и синтезированным аудиоданным, соответствующим образцу аудиоданных, с использованием следующей формулы.

[0089] recon_lossk обозначает значение частичных потерь восстановления, соответствующих k-ому образцу аудиоданных, gen_audiok обозначает синтезированные аудиоданные, соответствующие k-ому образцу аудиоданных, target_audiok обозначает целевые аудиоданные, соответствующие k-ому образцу аудиоданных,  обозначает оператор нормировки 1-norm.
обозначает оператор нормировки 1-norm.
[0090] Считается, что точность семантической информации в аудиоданных, полученных с помощью модели конверсии голоса, также влияет на результаты конверсии голоса. Следовательно, согласно некоторым вариантам осуществления настоящего раскрытия точность семантических характеристик, извлеченных с помощью модели конверсии голоса, контролируется во время процесса обучения модели конверсии голоса.
[0091] Согласно некоторым возможным вариантам осуществления семантическая информация каждого фрагмента образца аудиоданных в наборе образцов предварительно промаркирована, так что точность семантической характеристики, извлекаемой с помощью модели конверсии голоса, контролируется на основании разности между промаркированной семантикой, соответствующей каждому фрагменту образца аудиоданных, и первой семантической характеристикой, соответствующей каждому фрагменту образца аудиоданных.
[0092] Согласно некоторым другим возможным вариантам осуществления в случае, когда нужно получить модель конверсии голоса с высокой точностью, для этого требуется большое количество образцов аудиоданных, и маркировка каждого фрагмента образца аудиоданных создает значительный объем рабочей нагрузки и означает большую величину затрат ресурсов, что увеличивает сложность получения модели конверсии голоса. Следовательно, согласно некоторым вариантам осуществления настоящего раскрытия к модели конверсии голоса добавляется сеть извлечения семантики, так что семантическая информация аудиоданных состязательно изучается сетью извлечения семантики и сетью удаления голоса в модели конверсии голоса. В процессе обучения исходной модели конверсии голоса для любого образца аудиоданных из набора образцов семантическая характеристика (обозначенная как вторая семантическая характеристика) образца аудиоданных получается на основании входного образца аудиоданных с помощью сети извлечения семантики в этой исходной модели конверсии голоса. Вторая семантическая характеристика также является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией.
[0093] Согласно некоторым вариантам осуществления сеть семантического извлечения включает в себя подсеть первого содержания, подсеть второго содержания и подсеть третьего содержания, так что из образца аудиоданных получается точная семантическая информация с удаленной голосовой информацией. Подсеть первого содержания подсоединена к подсети второго содержания, и она выполнена с возможностью обрабатывать образец аудиоданных для получения из образца аудиоданных более полной характеристики содержания, и подсеть первого содержания являются сетью h-сеть или тому подобным. Подсеть второго содержания подсоединена к подсети третьего содержания, и она выполнена с возможностью обрабатывать характеристику содержания, выведенную из подсети первого содержания, для получения дискретизированной характеристики содержания и удаления несущественных деталей из характеристики содержания, так что дискретизированная характеристика содержания является релевантной к семантической информации образца аудиоданных. Например, подсеть второго содержания является сетью векторного квантования (VQ) или тому подобной. Подсеть третьего содержания выполнена с возможностью обрабатывать дискретизированную характеристику содержания, выведенную из подсети второго содержания, и мотивировать дискретизированную характеристику содержания для изучения местной характеристики в образце аудиоданных, которая связана с семантической информацией, так что получается вторая семантическая характеристика образца аудиоданных. Например, подсеть третьего содержания является g-сетью или сетью сопоставительного предиктивного кодирования (contrastive predictive coding - СРС), основанной на рекуррентной нейронной сети (recurrent neural network - RNN).
[0094] Согласно конкретному процессу реализации после ввода любого образца аудиоданных в исходную модель конверсии голоса на основании вышеупомянутых вариантов осуществления, характеристика содержания получается на основании образца аудиоданных в исходной модели конверсии голоса; дискретная характеристика содержания получается на основании характеристики содержания с помощью второй подсети содержания в сети извлечения семантики; а вторая семантическая характеристика образца аудиоданных получается на основании дискретизированной характеристики содержания с помощью третьей подсети содержания в сети извлечения семантики.
[0095] На фиг. 2 показана упрощенная блок-схема модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия. Согласно некоторым вариантам осуществления настоящего раскрытия предложен способ обучения модели конверсии голоса, который описан далее в настоящем документе со ссылкой на фиг. 2.
[0096] Получается мел-частотная спектрограмма любого образца аудиоданных в наборе образцов, и мел-частотная спектрограмма образца аудиоданных вводится в исходную модель конверсии голоса. Мел-частотная спектрограмма образца аудиоданных обрабатывается с помощью сети извлечения голоса (кодировщик диктора) в исходной модели конверсии голоса, так что получается первая голосовая характеристика (tone_vector), соответствующая образцу аудиоданных. С помощью апостериорного кодировщика в сети удаления голоса в исходной модели конверсии голоса скрытый вектор (zsq) семантической информации образца аудиоданных получается на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных. На основании скрытого вектора получается улучшенный скрытый вектор с помощью улучшающей подсети (поточной) в сети удаления голоса в исходной модели конверсии голоса. Таким образом, определяется первая семантическая характеристика. В то же самое время с помощью сети извлечения семантики (сети VQCPC) в исходной модели конверсии голоса получается вторая семантическая характеристика этого образца аудиоданных на основании входного образца аудиоданных. Затем с помощью показанного на фиг. 2 декодера синтезированные аудиоданные (необработанный аудиосигнал) получаются на основании первой семантической характеристики и второй голосовой характеристики (внутреннее вложение для диктора) целевых аудиоданных, соответствующих образцу аудиоданных.
[0097] Более конкретно, процесс получения второй семантической характеристики образца аудиоданных на основании входного образца аудиоданных с помощью сети извлечения семантики в исходной модели конверсии голоса предусматривает следующие стадии. Характеристика Z содержания получается на основании мел-спектрограммы образца аудиоданных с помощью первой подсети содержания (h-сети) в сети извлечения семантики в исходной модели конверсии голоса. Как показано на фиг. 2, характеристика Z содержания k-ого образца аудиоданных включает в себя данные содержания каждого фрейма аудиоданных, включенного в k-ый образец аудиоданных. Например, данные содержания n-ого фрейма аудиоданных, включенного в k-ый образец аудиоданных, являются данными zk,n. Дискретизированная характеристика  содержания получается на основании характеристики Z содержания с помощью второй подсети содержания (векторное квантование, VQ) в сети извлечения семантики. Как показано на фиг. 2, дискретизированная характеристика
содержания получается на основании характеристики Z содержания с помощью второй подсети содержания (векторное квантование, VQ) в сети извлечения семантики. Как показано на фиг. 2, дискретизированная характеристика  содержания k-ого образца аудиоданных включает в себя дискретизированные данные содержания каждого фрейма аудиоданных, включенного в k-ый образец аудиоданных. Например, дискретизированные данные содержания n-ого фрейма аудиоданных, включенного в k-ый образец аудиоданных, являются данными
содержания k-ого образца аудиоданных включает в себя дискретизированные данные содержания каждого фрейма аудиоданных, включенного в k-ый образец аудиоданных. Например, дискретизированные данные содержания n-ого фрейма аудиоданных, включенного в k-ый образец аудиоданных, являются данными  Вторая семантическая характеристика R образца аудиоданных получается с помощью третьей подсети содержания (g-сети) в сети извлечения семантики на основании дискретизированной характеристики
Вторая семантическая характеристика R образца аудиоданных получается с помощью третьей подсети содержания (g-сети) в сети извлечения семантики на основании дискретизированной характеристики  содержания. Как показано на фиг. 2, вторая семантическая характеристика R k-ого образца аудиоданных включает в себя вторую семантическую характеристику каждого фрейма аудиоданных, включенного в k-ый образец аудиоданных. Например, дискретизированные данные содержания n-ого фрейма аудиоданных в k-ом образце аудиоданных являются данными rk,n.
содержания. Как показано на фиг. 2, вторая семантическая характеристика R k-ого образца аудиоданных включает в себя вторую семантическую характеристику каждого фрейма аудиоданных, включенного в k-ый образец аудиоданных. Например, дискретизированные данные содержания n-ого фрейма аудиоданных в k-ом образце аудиоданных являются данными rk,n.
[0098] Следует отметить, что h-сеть включает в себя сверточный слой, слой спецификации, слой линейного преобразования и слой логической функции. Сверточный слой, включенный в показанную на фиг. 2 h-сеть, успешно соединен с четырьмя подсетями в одинаковой структуре соединения, а что касается любой подсети, такая подсеть включает в себя один слой нормализации, два слоя линейного преобразования и один слой логической функции (ReLU).
[0099] После получения второй семантической характеристики каждого фрагмента образца аудиоданных на основании вышеупомянутых вариантов осуществления, обученная модель конверсии голоса получается с помощью обучения исходной модели конверсии голоса на целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных. Таким образом, на основании разности между целевыми аудиоданными и синтезированными аудиоданными, соответствующими каждому фрагменту образца аудиоданных, и разности между первой семантической функцией и второй семантической функцией, которые соответствуют каждому фрагменту образца аудиоданных, значения параметров исходной модели конверсии голоса корректируются для получения обученной модели конверсии голоса, так что достигается неконтролируемое обучение способности модели конверсии голоса извлекать семантическую информацию.
[0100] Согласно конкретному процессу реализации на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и соответствующих синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, определяется значение потерь восстановления; а значение семантических потерь определяется на основании первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных. На основании значения потерь восстановления и значения семантических потерь определяется значение составных потерь. На основании значения составных потерь корректируются значения параметров в исходной модели конверсии голоса, так что получается обученная модель конверсии голоса.
[0101] В качестве примера укажем, что для каждого фрагмента образца аудиоданных из набора образцов определяется значение частичных потерь восстановления на основании разности между целевыми аудиоданными и синтезированными аудиоданными, соответствующими образцу аудиоданных; а значение частичных семантических потерь определяется на основании разности между первой семантической характеристикой и второй семантической характеристики, которые соответствуют образцу аудиоданных. Значение потерь восстановления определяется на основании суммы всех значений частичных потерь восстановления, определенных в текущей итерации; а значение семантических потерь определяется на основании суммы всех значений частичных семантических потерь, определенных в текущей итерации. На основании значения потерь восстановления и значения семантических потерь определяется значение составных потерь. На основании значения составных потерь корректируются значения параметров в исходной модели конверсии голоса, так что получается обученная модель конверсии голоса.
[0102] Согласно некоторым вариантам осуществления при определении значения составных потерь на основании значения потерь восстановления и значения семантических потерь, значение составных потерь определяется на основании значения потерь восстановления и его соответствующего первого весового коэффициента, и значения семантических потерь и его соответствующего второго весового коэффициента. Например, получается произведение (называемое первым произведением) значения потерь восстановления и соответствующего первого весового коэффициента, и получается произведение (называемое вторым произведением) значения семантических потерь и соответствующего второго весового коэффициента. На основании суммы первого произведения и второго произведения определяется значение составных потерь.
[0103] Согласно некоторым возможным вариантам осуществления в то время как скрытый вектор определяется апостериорным кодером, включенным в сеть удаления голоса в исходной модели конверсии голоса на основании линейной спектрограммы, соответствующей образцу аудиоданных, и первая голосовая характеристика определяется с помощью сети извлечение голоса в исходной модели конверсии голоса, также определяются вектор среднего значения и вектор дисперсии скрытого вектора. Таким образом, с помощью апостериорного кодера, включенного в сеть удаления голоса в исходной модели конверсии голоса на основании линейной спектрограммы, соответствующей образцу аудиоданных, и первой голосовой характеристики, определенной с помощью сети извлечение голоса в исходной модели конверсии голоса, можно также определить вектор среднего значения и вектор дисперсии скрытого вектора. При последующем определении значения семантических потерь на основании первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, значение семантических потерь определяется на основании первой семантической характеристики, второй семантической характеристики, вектора среднего значения и вектора дисперсии, которые соответствуют каждому фрагменту образца аудиоданных. Таким образом, значение частичных семантических потерь определяется для каждого фрагмента образца аудиоданных на основании первой семантической характеристики, второй семантической характеристики, вектора среднего значения и вектора дисперсии образца аудиоданных. Значение семантических потерь определяется на основании суммы всех значений частичных семантических потерь, определенных в текущей итерации.
[0104] В качестве примера укажем, что значение частичных семантических потерь определяется на основании первой семантической характеристики, второй семантической характеристики, вектора среднего значения и вектора дисперсии образца аудиоданных по следующей формуле.

[0105] KL_Loss обозначает значение частичных семантических потерь, соответствующих k-ому образцу аудиоданных,  обозначает значение логарифма вектора дисперсии скрытого вектора, соответствующего k-ому образцу аудиоданных,
обозначает значение логарифма вектора дисперсии скрытого вектора, соответствующего k-ому образцу аудиоданных,  обозначает значение логарифма вектора дисперсии второй семантической характеристики k-ого образцу аудиоданных,
обозначает значение логарифма вектора дисперсии второй семантической характеристики k-ого образцу аудиоданных,  обозначает первую семантическую характеристику k-ого образцу аудиоданных, а
обозначает первую семантическую характеристику k-ого образцу аудиоданных, а  обозначает вектор среднего значения скрытого вектора, соответствующего k-ому образцу аудиоданных.
обозначает вектор среднего значения скрытого вектора, соответствующего k-ому образцу аудиоданных.
[0106] Согласно некоторым возможным вариантам осуществления в случае, когда сеть извлечения семантики в исходной модели конверсии голоса включает в себя первую подсеть содержания, вторую подсеть содержания и третью подсеть содержания, наличие значения потерь в сети извлечения семантики также необходимо учитывать в процессе обучения исходной модели конверсии голоса. Следовательно, согласно некоторым вариантам осуществления настоящего раскрытия значение потерь квантования определяется на основании характеристики содержания, соответствующей каждому фрагменту образца аудиоданных, и характеристики дискретизированного содержания, соответствующей каждому фрагменту образца аудиоданных, а значение потерь сопоставляющего обучения определяется на основании характеристики дискретизированного содержания, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, так что это способствует последующей корректировке значений параметров в исходной модели конверсии голоса на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, значения потерь квантования и значения потерь сопоставляющего обучения, так что получается обученная модель конверсии голоса.
[0107] Согласно некоторым вариантам осуществления при определении значения потерь квантования для каждого фрагмента образца аудиоданных, значение частичных потерь квантования, соответствующих каждому фрагменту образца аудиоданных, определяется на основании характеристики содержания и характеристики дискретизированного содержания, соответствующих каждому фрагменту фрейма аудиоданных, содержащемуся в образце аудиоданных. Значение потерь квантования определяется на основании суммы всех значений частичных потерь квантования, определенных в текущей итерации.
[0108] Например, значение потерь квантования определяется на основании характеристики содержания, соответствующей каждому фрагменту образца аудиоданных, и характеристики дискретизированного содержания, соответствующих каждому фрагменту образца аудиоданных, по следующей формуле.

[0109] VQ_loss обозначает значение потерь квантования, K обозначает полное количество образцов аудиоданных, содержащихся в наборе образцов, N обозначает полное количество фреймов аудиоданных, содержащихся в каждом фрагменте образца аудиоданных, п нумерует n-ый фрейм аудиоданных, содержащийся в текущем k-ом образце аудиоданных,  обозначает характеристику содержания, соответствующую n-ому фрейму аудиоданных, содержащемуся в k-ом образце аудиоданных,
обозначает характеристику содержания, соответствующую n-ому фрейму аудиоданных, содержащемуся в k-ом образце аудиоданных,  обозначает характеристику дискретизированного содержания, соответствующую n-ому фрейму аудиоданных, содержащемуся в k-ом образце аудиоданных, sg(.) обозначает оператор стоп-градиента,
обозначает характеристику дискретизированного содержания, соответствующую n-ому фрейму аудиоданных, содержащемуся в k-ом образце аудиоданных, sg(.) обозначает оператор стоп-градиента,  обозначает оператор нормировки 2-norm.
обозначает оператор нормировки 2-norm.
[0110] Согласно некоторым вариантам осуществления при определении значения потерь состязательного обучения для каждого фрагмента образца аудиоданных значение частичных потерь сопоставляющего обучения, соответствующих образцу аудиоданных, определяется на основании характеристики дискретизированного содержания и второй семантической характеристики, соответствующих каждому фрагменту фрейма аудиоданных, содержащемуся в образце аудиоданных. Значение потерь сопоставляющего обучения определяется на основании суммы всех значений частичных потерь сопоставляющего обучения, определенных в текущей итерации.
[0111] Например, значение потерь сопоставляющего обучения определяется на основании характеристики дискретизированного содержания, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, по следующей формуле.

[0112] CPC_loss обозначает значение потерь сопоставляющего обучения. К обозначает полное количество образцов аудиоданных, содержащихся в наборе образцов.

N обозначает полное количество фреймов аудиоданных, содержащихся в каждом фрагменте отдельного образца аудиоданных, а М обозначает полное количество положительных образцов фреймов аудиоданных, содержащихся в любом образце аудиоданных. n нумерует n-ый фрейм в текущем k-ом образце аудиоданных.  обозначает характеристику дискретизированного содержания, соответствующую (n+m)-ому фрейму аудиоданных в k-ом образце аудиоданных. wm обозначает весовую матрицу, соответствующую нескольким фреймам, ассоциированным с m. rk,n обозначает вторую семантическую характеристику, соответствующую n-ому фрейму аудиоданных, содержащихся в k-ом образце аудиоданных. Т обозначает символ оператора транспозиции.
обозначает характеристику дискретизированного содержания, соответствующую (n+m)-ому фрейму аудиоданных в k-ом образце аудиоданных. wm обозначает весовую матрицу, соответствующую нескольким фреймам, ассоциированным с m. rk,n обозначает вторую семантическую характеристику, соответствующую n-ому фрейму аудиоданных, содержащихся в k-ом образце аудиоданных. Т обозначает символ оператора транспозиции.  обозначает любой отрицательный фрейм образца аудиоданных, содержащийся в k-ом образце аудиоданных, кроме положительных фреймов образца аудиоданных. Ωk,n,m обозначает набор, содержащий отрицательные фреймы образца аудиоданных, содержащиеся в k-ом образце аудиоданных.
обозначает любой отрицательный фрейм образца аудиоданных, содержащийся в k-ом образце аудиоданных, кроме положительных фреймов образца аудиоданных. Ωk,n,m обозначает набор, содержащий отрицательные фреймы образца аудиоданных, содержащиеся в k-ом образце аудиоданных.
[0113] Согласно конкретной реализации при обучении исходной модели конверсии голоса для каждого фрагмента образца аудиоданных значение частичных потерь восстановления определяется на основании разности между целевыми аудиоданными, соответствующими образцу аудиоданных, и соответствующими синтезированными аудиоданными; значение частичных семантических потерь определяется на основании разности между первой семантической характеристикой и второй семантической характеристикой образца аудиоданных; значение частичных потерь квантования определяется на основании характеристики содержания и характеристики дискретизированного содержания, соответствующих каждому фрагменту фрейма аудиоданных, содержащемуся в образце аудиоданных; а значение частичных потерь сопоставляющего обучения определяется на основании характеристики дискретизированного содержания и второй семантической характеристики, соответствующих каждому фрагменту фрейма аудиоданных, содержащемуся в образце аудиоданных. Значение потерь восстановления определяется на основании суммы всех значений частичных потерь восстановления, определенных в текущей итерации; значение семантических потерь определяется на основании суммы всех значений частичных семантических потерь, определенных в текущей итерации; значение потерь сопоставляющего обучения определяется на основании суммы всех значений частичных потерь сопоставляющего обучения, определенных в текущей итерации; а значение потерь квантования определяется на основании суммы всех значений частичных потерь квантования, определенных в текущей итерации. На основании определенного значения потерь восстановления, определенного значения семантических потерь, определенного значения потерь сопоставляющего обучения и определенного значения потерь квантования определяется значение составных потерь. На основании значения составных потерь корректируются значения параметров в исходной модели конверсии голоса, так что получается обученная модель конверсии голоса.
[0114] В качестве примера укажем, что значение составных потерь определяется на основании определенного значения потерь восстановления и его соответствующего первого весового коэффициента, значения семантических потерь и его соответствующего второго весового коэффициента, значения потерь сопоставляющего обучения и его соответствующего третьего весового коэффициента и значения потерь квантования и его соответствующего четвертого весового коэффициента.
[0115] Считается, что результат конверсии голоса синтезированных аудиоданных также зависит от точности вокодера. Следовательно, согласно некоторым вариантам осуществления настоящего раскрытия в процессе обучения исходной модели конверсии голоса возможное значение потерь в вокодере в исходной модели конверсии голоса также учитывается для обучения модели конверсии голоса на основании значения потерь в вокодере. Таким образом, в процессе обучения исходной модели конверсии голоса исходная модель конверсии голоса обучается на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, а также на значении потерь в вокодере в исходной модели конверсии голоса, как что достигается получение обученной модели конверсии голоса.
[0116] В качестве примера укажем, что вокодер является вокодером HiFiGAN, который представляет собой модель нейронной сети с глубинным обучением, которая использует сетевую структуру сквозного прямого прохода для обучения многомасштабного дискриминатора, который обеспечивает эффективный и высококачественный синтез речи. Вокодер HiFiGAN включает в себя генератор и дискриминатор, который оснащен двумя типами дискриминаторов: многомасштабным дискриминатором и многоцикловым дискриминатором для отдельной характеризации аудиоданных, сгенерированных генератором в вокодере HiFiGAN, с двух разных точек зрения. Вокодер HiFiGAN использует потери при сопоставлении характеристик в качестве дополнительных потерь для обучения генератора и стабилизирует сеть GAN, извлекая каждую промежуточную характеристику дискриминатора и вычисляя расстояние L1 между целевыми аудиоданными и синтезированными аудиоданными в каждом пространстве характеристик. Таким образом, значение потерь вокодера HiFiGAN включает в себя значение потерь при сопоставлении характеристик, а исходная модель конверсии голоса обучается на основе значения потерь при сопоставлении характеристик.
[0117] В качестве примера укажем, что значение потерь при сопоставлении характеристик определяется по следующей формуле.

[0118] J обозначает количество слоев среди слоев извлечения характеристик в дискриминаторе, включенном в вокодер,  обозначает характеристику, извлеченную j-ым слоем извлечения характеристик в дискриминаторе, Qj обозначает количество характеристик, извлеченных j-ым слоем извлечения характеристик в дискриминаторе, х обозначает целевые аудиоданные, a s обозначает мел-спектрограмму синтезированных аудиоданных, созданных генератором.
обозначает характеристику, извлеченную j-ым слоем извлечения характеристик в дискриминаторе, Qj обозначает количество характеристик, извлеченных j-ым слоем извлечения характеристик в дискриминаторе, х обозначает целевые аудиоданные, a s обозначает мел-спектрограмму синтезированных аудиоданных, созданных генератором.
[0119] Вокодер HiFiGAN по своей природе по-прежнему представляет собой генеративно-состязательную сеть, дискриминатор в вокодере HiFiGAN вычисляет вероятность того, что синтезированные аудиоданные являются целевыми аудиоданными, а генератор вокодера HiFiGAN выполнен с возможностью синтезировать синтезированные аудиоданные. В процессе обучения вокодера HiFiGAN ожидается, что генератор в вокодере HiFiGAN способен выполнить синтез синтезированных аудиоданных, которые расположены близко к целевым аудиоданным, так что дискриминатор в вокодере HiFiGAN не сможет определить, являются ли аудиоданные целевыми аудиоданными или синтезированными аудиоданными. Согласно этому значение потерь вокодера HiFiGAN дополнительно включает в себя значение генеративно-состязательных потерь. Например, значение генеративно-состязательных потерь определяется на основании целевых аудиоданных и мел-спектрограммы синтезированных аудиоданных, созданных генератором в вокодере HiFiGAN.
[0120] В качестве примера укажем, что значение состязательных потерь определяется по следующей формуле.

[0121] Ladv(D; G) обозначает значение генеративно-состязательных потерь дискриминатора в вокодере HiFiGAN, Ladv(D; G) обозначает значение генеративно-состязательных потерь в генераторе вокодера HiFiGAN, х обозначает целевые аудиоданные, a s обозначает мел-спектрограмму синтезированных аудиоданных, созданных генератором.
[0122] После получения значения потерь в вокодере на основании вышеупомянутых вариантов осуществления, значение каждого параметра в исходной модели конверсии голоса корректируется на основании значения потерь в вокодере, целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, так что получается обученная модель конверсии голоса.
[0123] Например, на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, определяется значение потерь восстановления, и определяется значение потерь в вокодере в исходной модели конверсии голоса. На основании значения потерь восстановления и значения потерь в вокодере определяется значение составных потерь. На основании значения составных потерь корректируется значение каждого параметра в исходной модели конверсии голоса.
[0124] При определении значения составных потерь на основании значения потерь восстановления и значения потерь в вокодере значение составных потерь определяется на основании значения потерь восстановления и его соответствующего первого весового коэффициента и значения потерь в вокодере и его соответствующего пятого весового коэффициента.
[0125] Например, значение потерь восстановления определяется на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных; значение семантических потерь определяется на основании первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных; значение потерь квантования определяется на основании характеристики содержания, соответствующей каждому фрагменту образца аудиоданных, и характеристики дискретизированного содержания, соответствующих каждому фрагменту образца аудиоданных; значение потерь сопоставляющего обучения определяется на основании характеристики дискретизированного содержания, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных; и определяется значение потерь в вокодере в исходной модели конверсии голоса. На основании значения потерь восстановления, значения семантических потерь, значения потерь квантования, значения потерь сопоставляющего обучения и значения потерь в вокодере определяется значение составных потерь. На основании значения составных потерь корректируется значение каждого параметра в исходной модели конверсии голоса.
[0126] В качестве примера укажем, что значение составных потерь определяется на основании значения потерь восстановления, значения семантических потерь, значения потерь квантования, значения потерь сопоставляющего обучения и значения потерь в вокодере по следующей формуле.

[0127] total_loss обозначает значение составных потерь, reconjoss обозначает значение потерь восстановления, KL_loss обозначает значение семантических потерь, vq_loss обозначает значение потерь квантования, cpc_loss обозначает значение потерь сопоставляющего обучения и decoder_loss обозначает значение потерь в вокодере.
[0128] Следует отметить, что в случае, когда вокодер является вокодером HiFiGAN, decoder_loss включает в себя значение потерь при сопоставлении характеристик (fm_loss) и значение генеративных состязательных потерь (adv_loss).
[0129] Поскольку включены несколько фрагментов образцов аудиоданных, настроенных для обучения исходной модели конверсии голоса, для каждого фрагмента образцов аудиоданных выполняются описанные выше стадии, пока не будет удовлетворено заранее определенное условие сходимости.
[0130] Удовлетворение заранее определенных условий сходимости означает, что интегрированное значение потерь, определенное при выполнении текущей итерации, меньше заранее определенного порога потерь, или количество итераций для обучения исходной модели конверсии голоса достигло заранее определенного максимального количества итераций. Конкретная реализация определена достаточно гибко и никаким образом не ограничена в настоящем документе.
[0131] Согласно некоторым возможным вариантам осуществления при обучении исходной модели конверсии голоса образец аудиоданных разделяется на обучающий образец и на контрольный образец. Исходная модель конверсии голоса сначала обучается на основании обучающего образца, а затем надежность обученной таким образом модели конверсии голоса проверяется на основании контрольного образца.
[0132] После получения обученной модели конверсии голоса на основании модели конверсии голоса и каждого фрагмента образца аудиоданных в наборе образцов определяется голосовая характеристика, соответствующая каждому диктору в наборе образцов. Затем сохраняются голосовая характеристика, соответствующая каждому из дикторов, и идентификатор объекта, соответствующий каждому из дикторов, так что при синтезе синтезированных аудиоданных любого диктора в наборе образцов с помощью обученной модели конверсии голоса голосовая характеристика идентификатора объекта диктора определяется непосредственно на основании соответствия между идентификатором объекта и голосовой характеристики, что способствует получению голосовой характеристики диктора на основании голосовой характеристики и модели конверсии голоса, а также повышению эффективности конверсии голоса. Следует понимать, что голос диктора в любом образце аудиоданных в наборе образцов является голосом, поддерживаемым обученной моделью конверсии голоса.
[0133] Вариант осуществления 2:
[0134] Согласно некоторым вариантам осуществления настоящего раскрытия также предложен способ для конверсии голоса. На фиг. 3 показана упрощенная схема процесса конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия. В этом процессе предусмотрены следующие стадии.
[0135] На стадии S301 проводится получение исходных аудиоданных и голосовой характеристики целевого диктора.
[0136] Способ конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия применим в электронном устройстве, которое представляет собой интеллектуальное устройство, в частности, робот, мобильный терминал или сервер. Электронное устройство для выполнения конверсии голоса согласно вариантам осуществления настоящего раскрытия является таким же, как электронное устройство для обучения модели конверсии голоса, как описано выше, или отличается от него.
[0137] Согласно некоторым возможным вариантам осуществления, поскольку модель конверсии голоса обучается в автономном режиме, модель конверсии голоса используется в электронном устройстве для выполнения конверсии голоса, когда получена обученная модель конверсии голоса, так что электронное устройство для выполнения конверсии голоса выполняет конверсию голоса с помощью модели конверсии голоса.
[0138] Следует отметить, что в вышеупомянутых вариантах осуществления был описан конкретный процесс обучения модели конверсии голоса, что не повторяется далее в настоящем документе.
[0139] Согласно некоторым возможным вариантам осуществления, в случае, когда обученная модель конверсии голоса включает в себя сеть извлечения семантики, поскольку сеть извлечения семантики в основном используется для контроля семантической характеристики, извлеченной с помощью сети удаления голоса, другие сети в модели конверсии голоса, отличные от сети извлечения семантики, используются на электронном устройстве, которое выполняет конверсию голоса, в то время как обученная модель конверсии голоса используется на электронном устройстве, выполняющем конверсию голоса, при этом количество параметров, включенных в модель конверсии голоса, уменьшается, а затрата ресурсов на передачу данных и степень загрузки пространства памяти электронного устройства для конверсии голоса уменьшаются.
[0140] В случае, когда требуется конверсия голоса, пользователь вводит запрос на синтез на интеллектуальное устройство, так что интеллектуальное устройство управляется запросом на синтез для выполнения синтеза аудиоданных определенного речевого содержания от целевого диктора. Существует много конкретных способов для ввода запроса на синтез. Например, запрос на синтез вводится путем ввода голосовой информации или путем нажатия виртуальной кнопки, отображаемой на экране дисплея интеллектуального устройства, которое гибко настраивается в соответствии с потребностями конкретного процесса реализации и это конкретно никак не ограничивается в настоящем документе. После получения запроса на синтез интеллектуальное устройство передает запрос на синтез, исходные аудиоданные и информацию о целевом дикторе на электронное устройство, которое выполняет конверсию голоса.
[0141] Термин целевой диктор означает диктора, которому принадлежит голос синтезированных аудиоданных, полученных с помощью технологии конверсии голоса, и информация о целевом дикторе включает в себя идентификатор объекта целевого диктора или аудиоданные целевого диктора. Термин исходные аудиоданные означает аудиоданные, настроенные для предоставления семантической информации, а не для предоставления голосовой информации.
[0142] Следует отметить, что как исходные аудиоданные, так и аудиоданные целевого диктора записываются пользователем с помощью интеллектуального устройства или являются аудиоданными, предварительно настроенными в интеллектуальном устройстве.
[0143] Согласно некоторым возможным сценариям применения, в случае, когда пользователь идентифицирует диктора из любого образца аудиоданных в наборе образцов в качестве целевого диктора, информация о целевом дикторе включает в себя идентификатор объекта целевого диктора. Например, интеллектуальное устройство выводит множество идентификаторов объектов дикторов, а пользователь выбирает множество идентификаторов объектов, выведенных интеллектуальным устройством. В случае, когда интеллектуальное устройство обнаруживает выбранный пользователем идентификатор объекта, выбранный идентификатор объекта определяется в качестве информации о целевом дикторе. Впоследствии интеллектуальное устройство передает запрос на синтез, идентификатор объекта целевого диктора и исходные аудиоданные на электронное устройство, выполняющее конверсию голоса.
[0144] Идентификатор объекта выражается в форме числа, строки символов или в других формах при условии, что форма способна однозначно идентифицировать диктора.
[0145] Следует понимать, что образец аудиоданных в наборе образцов настроен для обучения модели конверсии голоса. Следует понимать, что голос диктора в любом образце аудиоданных в наборе образцов является голосом, поддерживаемым обученной моделью конверсии голоса.
[0146] Согласно некоторым возможным сценариям применения, в случае, когда пользователь идентифицирует других дикторов за пределами набора образцов в качестве целевого диктора, то есть не идентифицирует диктора любого образца аудиоданных в наборе образцов в качестве целевого диктора, информация о целевом дикторе включает в себя аудиоданные целевого диктора. Например, в случае, когда интеллектуальное устройство выводит идентификаторы объектов множества дикторов, и интеллектуальное устройство не обнаруживает выбранный пользователем идентификатор объекта, или не обнаруживает операцию запуска, введенную пользователем для добавления целевого диктора, пользователю предлагается ввести аудиоданные целевого диктора, и вводимые пользователем аудиоданные определяются в качестве информации о целевом дикторе. Впоследствии интеллектуальное устройство передает запрос на синтез, аудиоданные целевого диктора и исходные аудиоданные на электронное устройство, выполняющее конверсию голоса.
[0147] После получения запроса на синтез, информации о целевом дикторе и исходных аудиоданных электронное устройство, выполняющее конверсию голоса, определяет голосовую характеристику целевого диктора на основании информации о целевом дикторе. Впоследствии на основании голосовой характеристики целевого диктора и исходных аудиоданных получаются аудиоданные речевого содержания исходных аудиоданных целевого диктора. То есть, получаются синтезированные аудиоданные целевого диктора.
[0148] Согласно некоторым возможным вариантам осуществления получение голосовой характеристики целевого диктора предусматривает следующие стадии:
[0149] получение информации о целевом дикторе; и
[0150] определение голосовой характеристики, соответствующей идентификатору объекта целевого диктора на основании соответствия между сохраненным идентификатором объекта и голосовой характеристикой после определения, что информация о целевом дикторе является идентификатором объекта; или
[0151] получение голосовой характеристики аудиоданных с помощью сети извлечения голоса в модели конверсии голоса после определения, что информация о целевом дикторе является аудиоданными.
[0152] Согласно некоторым вариантам осуществления настоящего раскрытия определение голосовой характеристики целевого диктора на основании информации о целевом дикторе включает в себя две следующие ситуации.
[0153] Согласно первой ситуации в случае, когда информация о целевом дикторе является идентификатором объекта целевого диктора, целевой диктор является диктором любого образца аудиоданных из набора образцов, затем на основании соответствия между сохраненным идентификатором объекта и голосовой характеристикой определяется голосовая характеристика, соответствующая идентификатору объекта целевого диктора, и определенная голосовая характеристика определяется в качестве голосовой характеристики целевого диктора.
[0154] Модель конверсии голоса получается с помощью обучения на основании образца аудиоданных в наборе образцов.
[0155] Согласно второй ситуации в случае, когда информация о целевом дикторе является аудиоданными, невозможно определить, является ли целевой диктор диктором любого образца аудиоданных из набора образцов, голосовая характеристика аудио данных определяется с помощью сети извлечения голоса в модели конверсии голоса, и полученная голосовая характеристика определяется в качестве голосовой характеристики целевого диктора.
[0156] На стадии S302 голосовая характеристика исходных аудиоданных получается с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; семантическая характеристика получается на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и синтезированные аудиоданные получаются на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
[0157] После получения исходных аудиоданных и голосовой характеристики целевого диктора на основании вышеупомянутых вариантов осуществления, исходные аудиоданные и голосовая характеристика целевого диктора вводятся в предварительно обученную модель конверсии голоса, так что синтезированные аудиоданные определяются на основании исходных аудиоданных и голосовой характеристики целевого диктора с помощью модели конверсии голоса.
[0158] Согласно конкретному варианту осуществления голосовая характеристика исходных аудиоданных получается с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; семантическая характеристика получается с помощью сети удаления голоса в модели конверсии голоса на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и синтезированные аудиоданные получаются с помощью вокодера в модели конверсии голоса на основании семантической характеристики и голосовой характеристики целевого диктора.
[0159] Процесс получения линейной спектрограммы, соответствующей исходным аудиоданным, уже был описан в вышеупомянутых вариантах осуществления и он никаким образом специально не ограничивается в настоящем раскрытии.
[0160] Согласно некоторым возможным вариантам осуществления перед вводом исходных аудиоданных в предварительно обученную модель конверсии голоса получается инвертированная мел-спектрограммма исходных аудиоданных, и инвертированная мел-спектрограмма вводится в модель конверсии голоса вместо исходных аудиоданных, так что получается объем вычислений, необходимых для модели конверсии голоса, и поэтому улучшается эффективность конверсии голоса и модели конверсии голоса удобно выполнять конверсию голоса.
[0161] На фиг. 4 показана упрощенная блок-схема модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия. Согласно некоторым вариантам осуществления настоящего раскрытия предложен способ конверсии голоса, который описан далее в настоящем документе со ссылкой на фиг. 4.
[0162] Сначала получаются исходные аудиоданные и информации о целевом дикторе.
[0163] В случае, когда информация о целевом дикторе является идентификатором объекта целевого диктора, целевой диктор является диктором любого образца аудиоданных из набора образцов, то желательно получить аудиоданные речевого содержания любого образца аудиоданных, созданных целевым диктором, а затем на основании соответствия между сохраненным идентификатором объекта и голосовой характеристикой определяется голосовая характеристика, соответствующая идентификатору объекта целевого диктора, и определенная голосовая характеристика определяется в качестве голосовой характеристики целевого диктора. С помощью такой информации о целевом дикторе впоследствии успешно реализуется способ конверсии голоса из любого во многие. То есть, выбирается голосовая характеристика диктора любого образца аудиоданных в наборе образцов, и с помощью предварительно обученной модели конверсии голоса на основании голосовой характеристики и исходных аудиоданных любого речевого содержания получаются аудиоданные речевого содержания, созданного диктором.
[0164] В случае, когда информация о целевом дикторе представляет собой аудиоданные, и невозможно определить, является ли целевой диктор диктором любого образца аудиоданных из набора образцов, то в этот момент желательно получить аудиоданные речевого содержания любых аудиоданных, созданных целевым диктором, затем голосовая характеристика аудиоданных получается с помощью сети выделения голоса в модели конверсии голоса, и полученная голосовая характеристика определяется в качестве голосовой характеристики целевого диктора. С помощью информации о целевом дикторе впоследствии реализуется способ конверсии голоса из многих во многие. То есть, с помощью предварительно обученной модели конверсии голоса на основании голосовой характеристики любых аудиоданных и исходных аудиоданных любого речевого содержания получаются синтезированные аудиоданные, которые удовлетворяют голосовой характеристики и речевому содержанию.
[0165] Исходные аудиоданные (опорный аудиосигнал) и голосовая характеристика целевого диктора вводятся в предварительно обученную модель конверсии голоса.
[0166] Мел-спектрограмма исходных аудиоданных соответственно обрабатывается с помощью сети извлечения голоса (кодировщик диктора, показанный на фиг. 4) в исходной модели конверсии голоса, так что получается голосовая характеристика, соответствующая исходным аудиоданными, в частности, голосовой вектор tone_vector, показанный на фиг. 4.
[0167] С помощью апостериорного кодировщика, включенного в модель конверсии голоса, в частности, апостериорного кодировщика, показанного на фиг. 4, скрытый вектор (например, zsq) семантической информации в исходных аудиоданных получается на основании голосовой характеристики, соответствующей исходным аудиоданными и линейной спектрограммы (в частности, линейной спектрограммы, показанной на фиг. 4), соответствующей исходным аудиоданным.
[0168] На основании скрытого вектора получается улучшенный скрытый вектор с помощью улучшающей подсети (поточной), включенной в сеть удаления голоса в модели конверсии голоса. Таким образом, определяется семантическая характеристика.
[0169] Синтезированные аудиоданные получаются с помощью показанного на фиг. 4 вокодера (декодера) на основании этой семантической характеристики и голосовой характеристики целевого диктора (в частности, показанного на фиг. 4 внутреннего вложения для диктора). Таким образом, получается исходный аудиосигнал, показанный на фиг. 4.
[0170] Вариант осуществления 3
[0171] Согласно некоторым вариантам осуществления настоящего раскрытия предложено устройство для обучения модели конверсии голоса. На фиг. 5 показана упрощенная блок-схема устройства для обучения модели конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия. Устройство включает в себя:
[0172] получающий блок 51, выполненный с возможностью получать набор образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый фрагмент образца аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация;
[0173] процессорный блок 52, выполненный с возможностью получать первую голосовую характеристику из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получать первую семантическую характеристику на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получать синтезированные аудиоданные на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующей образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса; и
[0174] обучающий блок 53, выполненный с возможностью получать обученную модель конверсии голоса с помощью обучения исходной модели для конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
[0175] Поскольку принцип решения проблемы создания описанного выше устройства для обучения модели конверсии голоса аналогичен принципу создания способа обучения модели конверсии голоса, реализация и соответствующие преимущества описанного выше устройства для обучения модели конверсии голоса могут упоминаться в описании реализации и преимуществ способа, которые не повторяются далее в настоящем документе.
[0176] Вариант осуществления 4
[0177] Согласно некоторым вариантам осуществления настоящего раскрытия предложено устройство для конверсии голоса. На фиг. 6 показана упрощенная блок-схема устройства для конверсии голоса согласно некоторым вариантам осуществления настоящего раскрытия. Устройство включает в себя:
[0178] получающий модуль 61, выполненный с возможностью получать исходные аудиоданные и голосовую характеристику целевого диктора; и
[0179] синтезирующий модуль 62, выполненный с возможностью: получать голосовую характеристику исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получать семантическую характеристику на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получать синтезированные аудиоданные на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
[0180] Поскольку принцип решения проблемы создания описанного выше устройства для конверсии голоса аналогичен принципу создания способа для конверсии голоса, реализация описанного выше устройства для конверсии голоса может упоминаться в описании реализации способа, что не повторяется далее в настоящем документе.
[0181] Вариант осуществления 5
[0182] На фиг. 7 показана упрощенная блок-схема электронного устройства согласно некоторым вариантам осуществления настоящего раскрытия. Электронное устройство включает в себя процессор 71, коммуникационный интерфейс 72, память 73 и шину 74 передачи данных. Процессор 71, коммуникационный интерфейс 72 и память 73 выполняют обмен данными друг с другом по шине 74 передачи данных.
[0183] В памяти 73 хранится, по меньшей мере, одна компьютерная программа. По меньшей мере, одна программа после ее загрузки и выполнения процессором 71, заставляет процессор 71 выполнять следующие стадии:
[0184] получение набора образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый образец аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация.
[0185] получение первой голосовой характеристики из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получение синтезированных аудиоданных на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса; и
[0186] получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
[0187] Поскольку принцип решения проблемы создания вышеупомянутого электронного устройства аналогичен принципу создания способа обучения модели конверсии голоса, реализация и соответствующие преимущества вышеупомянутого электронного устройства могут упоминаться в описании варианта осуществления 1 способа, которые не повторяются далее в настоящем документе.
[0188] Вариант осуществления 6
[0189] На фиг. 8 показана упрощенная блок-схема дополнительного электронного устройства согласно некоторым вариантам осуществления настоящего раскрытия. Электронное устройство включает в себя процессор 81, коммуникационный интерфейс 82, память 83 и шину 84 передачи данных. Процессор 81, коммуникационный интерфейс 82 и память 83 выполняют обмен данными друг с другом по шине 84 передачи данных.
[0190] В памяти 83 хранится, по меньшей мере, одна компьютерная программа. По меньшей мере, одна компьютерная программа, после ее загрузки и выполнения процессором 81, заставляет процессор 81 выполнять следующие стадии:
[0191] получение исходных аудиоданных и голосовой характеристики целевого диктора; и
[0192] получение голосовой характеристики исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получение семантической характеристики на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получение синтезированных аудиоданных на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
[0193] Поскольку принцип решения проблемы создания вышеупомянутого электронного устройства аналогичен принципу создания способа для конверсии голоса, реализация вышеупомянутого электронного устройства может упоминаться в описании варианта осуществления 2 способа, что не повторяется далее в настоящем документе.
[0194] Шина передачи данных, упоминающаяся в описании вышеупомянутого электронного устройства, является, например, шиной соединения периферийных компонентов (peripheral component interconnect - PCI) или шиной расширенной промышленной стандартной архитектуры (extended industry standard architecture - EISA). Это шина передачи данных разделяется на адресную шину, шину данных и шину управления. Для удобства представления шина показано на фигуре только одной толстой линией, что не означает, что существует только одна шина или один тип шины. Коммуникационный интерфейс 82 выполнен с возможностью поддерживать обмен данными между вышеупомянутым электронным устройством и другими устройствами. Память содержит оперативное запоминающее устройство (ОЗУ) или энергонезависимую память (NVM), например, по меньшей мере, одну дисковую память. При необходимости память представляет собой, по меньшей мере, одно запоминающее устройство, расположенное отдельно от вышеупомянутого процессора.
[0195] Вышеупомянутый процессор может быть процессором общего назначения, включая центральный процессор и сетевой процессор (NP); или процессор цифровых сигналов (DSP), интегральную схему специального назначения, программируемую логическую интегральную схему или другие программируемые логические устройства, дискретный вентиль или транзисторное логическое устройство, дискретный аппаратный компонент и тому подобное.
[0196] Вариант осуществления 7
[0197] На основании каждого из вышеупомянутых вариантов осуществления, согласно некоторым вариантам осуществления настоящего раскрытия дополнительно предложен машиночитаемый носитель данных, на котором хранится, по меньшей мере, одна компьютерная программа, выполняемая на процессоре. По меньшей мере, одна компьютерная программа после ее загрузки и выполнения процессором, заставляет процессор выполнять следующие стадии:
[0198] получение набора образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый образец аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация.
[0199] получение первой голосовой характеристики из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получение синтезированных аудиоданных на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса; и
[0200] получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
[0201] Поскольку принцип решения проблемы создания машиночитаемого носителя данных и соответствующие достигаемые преимущества аналогичны подобным в способе обучения модели конверсии голоса, который описан в вышеупомянутых вариантах осуществления, конкретная реализация может упоминаться в описании реализации способа обучения модели конверсии голоса.
[0202] Вариант осуществления 8
[0203] На основании каждого из вышеупомянутых вариантов осуществления, согласно некоторым вариантам осуществления настоящего раскрытия дополнительно предложен машиночитаемый носитель данных, на котором хранится, по меньшей мере, одна компьютерная программа, выполняемая на процессоре. По меньшей мере, одна компьютерная программа после ее загрузки и выполнения процессором, заставляет процессор выполнять следующие стадии:
[0204] получение исходных аудиоданных и голосовой характеристики целевого диктора; и
[0205] получение голосовой характеристики исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получение семантической характеристики на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая не связана с голосом диктора, но связана с семантической информацией; и получение синтезированных аудиоданных на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
[0206] Поскольку принцип решения проблемы создания машиночитаемого носителя данных аналогичен подобному в способе обучения модели конверсии голоса, который описан в вышеупомянутых вариантах осуществления, конкретная реализация может упоминаться в описании реализации способа обучения модели конверсии голоса.
[0207] Специалисты в этой области техники должны понимать, что варианты осуществления настоящего раскрытия могут быть предложены в виде способов, систем или продуктов в виде компьютерной программы. Таким образом, настоящее раскрытие может принимать форму полностью аппаратных вариантов осуществления, полностью программных вариантов осуществления или вариантов осуществления, сочетающих как программные, так и аппаратные средства. Более того, настоящее изобретение может принять форму продукта в виде компьютерной программы, которая хранится на одном или нескольких машиночитаемых носителях данных (включая помимо прочего, дисковую память, CD-ROM, оптическую память и тому подобное) и содержит выполняемый компьютером код программы.
[0208] Согласно вариантам осуществления настоящего раскрытия дополнительно предложен продукт в виде компьютерной программы, включая, по меньшей мере, одну компьютерную программу. По меньшей мере, одна компьютерная программа в ходе ее выполнения процессором заставляет процессор выполнять стадии способа для обучения модели конверсии голоса, который описан выше, или стадии способа для конверсии голоса, который описан выше.
[0209] Настоящее раскрытие описано со ссылками на алгоритмы и/или блок-схемы способов, устройств (систем) и продуктов в виде компьютерных программ согласно настоящему раскрытию. Следует понимать, что каждый из процессов и/или блоков в алгоритме и/или блок-схеме, а также комбинация процессов и/или блоков в алгоритме и/или блок-схеме могут быть реализованы с помощью инструкций компьютерной программы. Такие инструкции компьютерной программы могут быть предложены для компьютера общего назначения, компьютера специального назначения, встроенного процессора или других программируемых устройств для обработки данных для создания машины, так что инструкции, выполняемые процессором компьютера или другим программируемым устройством обработки данных, создают устройство, которое выполняет функции, указанные в одной ветви или в нескольких ветвях алгоритма и/или в одном блоке или в нескольких блоках на блок-схеме.
[0210] Такие инструкции компьютерной программы можно также хранить в машиночитаемой памяти, эти инструкции способны заставить компьютер или другое программируемое устройство обработки данных работать специальным образом, так что инструкции, хранящиеся в машиночитаемой памяти, создают изделие, включающее программные средства, которые реализуют функцию, указанную на схеме алгоритма одного процесса или множество процессов и/или в одном блоке или множестве блоков на блок-схеме.
[0211] Такие инструкции компьютерной программы могут также быть загружены на компьютер или другое программируемые устройство для обработки данных, чтобы вызвать выполнение последовательности операционных стадий на компьютере или другой программируемом устройстве с целью получения выполняемой на компьютере обработки, так что инструкции, которые выполняются на компьютере или другом программируемым устройстве, создают команды для реализации функций, указанных на схеме алгоритма одного процесса или множество процессов и/или в одном блоке или множестве блоков на блок-схеме, причем стадии для выполнения функций указаны на схеме алгоритма одного процесса или множество процессов и/или в одном блоке или множестве блоков на блок-схеме.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| Неконтролируемое восстановление голоса с использованием модели безусловной диффузии без учителя | 2023 |
|
RU2823017C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823015C1 |
| Способ синтеза речи с передачей достоверного интонирования клонируемого образца | 2020 |
|
RU2754920C1 |
| ГЕНЕРАТОР АУДИОДАННЫХ И СПОСОБЫ ФОРМИРОВАНИЯ АУДИОСИГНАЛА И ОБУЧЕНИЯ ГЕНЕРАТОРА АУДИОДАННЫХ | 2021 |
|
RU2823016C1 |
| Способ определения признаков паркинсонизма по голосу с использованием искусственного интеллекта | 2023 |
|
RU2841464C2 |
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ГЕНЕРИРОВАНИЯ МОДИФИЦИРОВАННОГО АУДИО ДЛЯ ВИДЕО | 2022 |
|
RU2832236C2 |
| Способ и сервер для синтеза речи по тексту | 2015 |
|
RU2632424C2 |
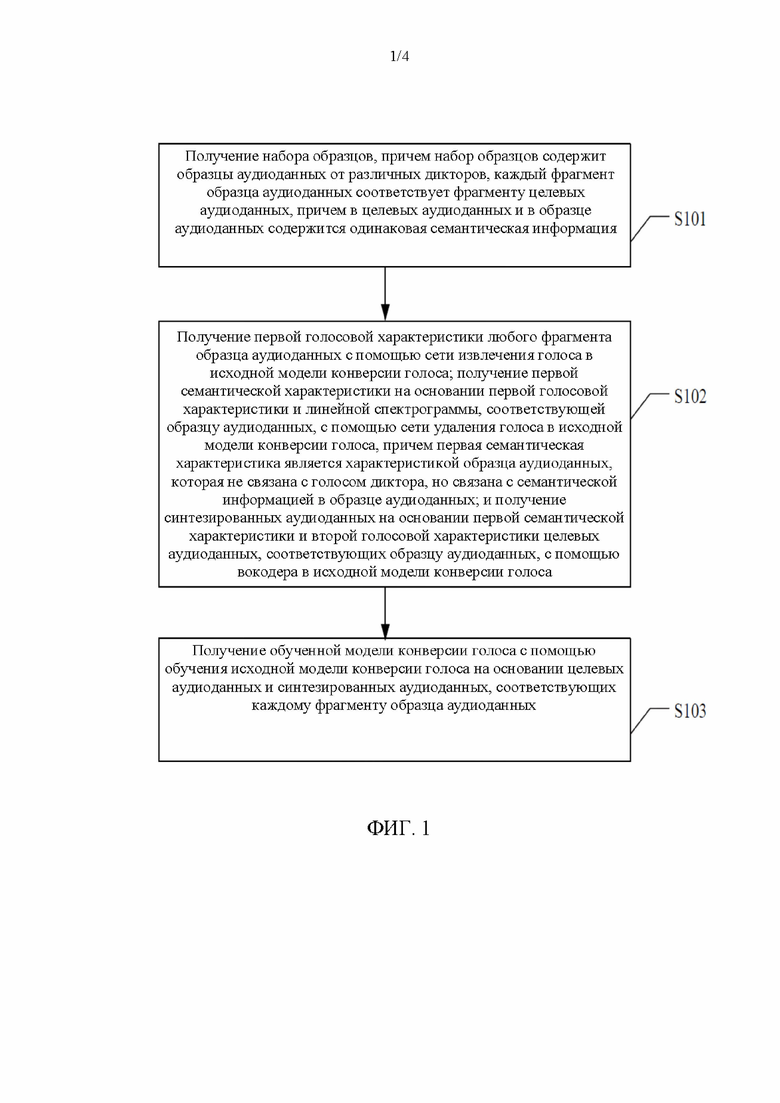



Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в повышении точности информации содержимого исходного аудиосигнала во время выполнения конверсии голоса. Технический результат достигается за счет этапов, на которых выполняют получение первой голосовой характеристики из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая связана не с голосом диктора, а с семантической информацией; получение синтезированных аудиоданных на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса; и получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных. 8 н. и 10 з.п. ф-лы, 8 ил.
1. Способ обучения модели конверсии голоса, который предусматривает следующие стадии:
получение набора образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый образец аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация;
получение первой голосовой характеристики из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая связана не с голосом диктора, а с семантической информацией; и получение синтезированных аудиоданных на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующих образцу аудиоданных, с помощью вокодера в исходной модели конверсии голоса; и
получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
2. Способ по п. 1, отличающийся тем, что целевые аудиоданные, соответствующие образцу аудиоданных, содержат в себе по меньшей мере одно из следующего: образец аудиоданных, образец аудиоданных, который отличается от образца аудиоданных диктора, или аудиоданные не из образца, которые отличаются от образца аудиоданных диктора.
3. Способ по п. 2, отличающийся тем, что получение второй голосовой характеристики целевых аудиоданных, соответствующей образцу аудиоданных, предусматривает следующие стадии:
определение первой голосовой характеристики образца аудиоданных в качестве второй голосовой характеристики после определения, что целевые аудиоданные являются образцом аудиоданных; или
получение второй голосовой характеристики целевых аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса после определения, что целевые аудиоданные не являются образцом аудиоданных.
4. Способ по п. 1, отличающийся тем, что получение первой семантической характеристики на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса предусматривает следующие стадии:
получение скрытого вектора семантической информации образца аудиоданных на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью апостериорного кодировщика в сети удаления голоса; и
получение первой семантической характеристики на основании скрытого вектора с помощью улучшающей подсети в сети удаления голоса.
5. Способ по п. 4, дополнительно предусматривающий следующую стадию:
получение второй семантической характеристики на основании любого фрагмента образца аудиоданных с помощью сети извлечения семантики в исходной модели конверсии голоса;
причем обучение исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, предусматривает следующую стадию:
получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных.
6. Способ по п. 5, отличающийся тем, что получение второй семантической характеристики на основании образца аудиоданных с помощью сети извлечения семантики в исходной модели конверсии голоса предусматривает следующие стадии:
получение характеристики содержания на основании образца аудиоданных с помощью первой подсети содержания в сети извлечения семантики;
получение дискретизированной характеристики содержания на основании характеристики содержания с помощью второй подсети содержания в сети извлечения семантики; и
получение второй семантической характеристики на основании дискретизированной характеристики содержания с помощью третьей подсети содержания в сети извлечения семантики.
7. Способ по п. 5 или 6, отличающийся тем, что обучение исходной модели конверсии голоса на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, предусматривает следующие стадии:
определение значения потерь восстановления на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных;
определение значения семантических потерь на основании первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных;
определение значения составных потерь на основании значения потерь восстановления и значения семантических потерь; и
получение обученной модели конверсии голоса с помощью корректировки значения параметров в исходной модели конверсии голоса на основании значения составных потерь.
8. Способ по любому из пп. 1-7, в котором дополнительно предусмотрена следующая стадия:
получение вектора среднего значения и вектора дисперсии скрытого вектора на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью апостериорного кодировщика в сети удаления голоса;
причем определение значения семантических потерь на основании первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, предусматривает стадию:
определение значения семантических потерь на основании первой семантической характеристики, второй семантической характеристики, вектора среднего значения и вектора дисперсии, которые соответствуют каждому фрагменту образца аудиоданных.
9. Способ по п. 6, отличающийся тем, что обучение исходной модели конверсии голоса на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, предусматривает следующие стадии:
определение значения потерь квантования на основании характеристики содержания, соответствующей каждому фрагменту образца аудиоданных, и характеристики дискретизированного содержания, соответствующей каждому фрагменту образца аудиоданных; и
определение значения потерь сопоставляющего обучения на основании характеристики дискретизированного содержания, соответствующей каждому фрагменту образца аудиоданных, и второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных; и
получение обученной модели конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных, соответствующих каждому фрагменту образца аудиоданных, синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных, первой семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, второй семантической характеристики, соответствующей каждому фрагменту образца аудиоданных, значения потерь квантования и значения потерь сопоставляющего обучения.
10. Способ по любому из пп. 1-9, отличающийся тем, что после получения обученной модели конверсии голоса способ дополнительно предусматривает следующие стадии:
определение голосовых характеристик, соответствующих различным дикторам, на основании модели конверсии голоса и каждого фрагмента образца аудиоданных в наборе образцов; и
соответствующее сохранение идентификаторов объектов и голосовых характеристик, соответствующих различным дикторам.
11. Способ конверсии голоса, предусматривающий следующие стадии:
получение исходных аудиоданных и голосовой характеристики целевого диктора; и
получение голосовой характеристики исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получение семантической характеристики на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая связана не с голосом диктора, а с семантической информацией; и получение синтезированных аудиоданных на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
12. Способ по п. 11, отличающийся тем, что получение голосовой характеристики целевого диктора предусматривает следующие стадии:
получение информации о целевом дикторе; и
определение голосовой характеристики, соответствующей идентификатору объекта целевого диктора, на основании соответствия между сохраненным идентификатором объекта и голосовой характеристикой после определения, что информация о целевом дикторе является идентификатором объекта; или
получение голосовой характеристики аудиоданных с помощью сети извлечения голоса в модели конверсии голоса после определения, что информация о целевом дикторе является аудиоданными.
13. Устройство для обучения модели конверсии голоса, содержащее в своем составе:
получающий блок, выполненный с возможностью получать набор образцов, причем набор образцов содержит образцы аудиоданных от различных дикторов, каждый фрагмент образца аудиоданных соответствует фрагменту целевых аудиоданных, причем в целевых аудиоданных и в образце аудиоданных содержится одинаковая семантическая информация;
процессорный блок, выполненный с возможностью: получать первую голосовую характеристику из любого фрагмента образца аудиоданных с помощью сети извлечения голоса в исходной модели конверсии голоса; получать первую семантическую характеристику на основании первой голосовой характеристики и линейной спектрограммы, соответствующей образцу аудиоданных, с помощью сети удаления голоса в исходной модели конверсии голоса, причем первая семантическая характеристика является характеристикой образца аудиоданных, которая связана не с голосом диктора, а с семантической информацией; и получать синтезированные аудиоданные на основании первой семантической характеристики и второй голосовой характеристики целевых аудиоданных, соответствующей образцу аудиоданных, с помощью вокодера в исходной модели конверсии исходного голоса; и
обучающий блок, выполненный с возможностью получать обученную модель конверсии голоса с помощью обучения исходной модели конверсии голоса на основании целевых аудиоданных и синтезированных аудиоданных, соответствующих каждому фрагменту образца аудиоданных.
14. Устройство для конверсии голоса, содержащее в своем составе:
получающий модуль, выполненный с возможностью получать исходные аудиоданные и голосовую характеристику целевого диктора; и
синтезирующий модуль, выполненный с возможностью: получать голосовую характеристику исходных аудиоданных с помощью сети извлечения голоса в предварительно обученной модели конверсии голоса; получать семантическую характеристику на основании голосовой характеристики и линейной спектрограммы, соответствующей исходным аудиоданным, с помощью сети удаления голоса в модели конверсии голоса, причем семантическая характеристика является характеристикой исходных аудиоданных, которая связана не с голосом диктора, а с семантической информацией; и получать синтезированные аудиоданные на основании семантической характеристики и голосовой характеристики целевого диктора с помощью вокодера в модели конверсии голоса.
15. Электронное устройство для обучения модели конверсии голоса, включающее в себя по меньшей мере процессор и память, причем процессор после загрузки и выполнения по меньшей мере одной хранящейся в памяти компьютерной программы побуждается выполнять способ обучения модели конверсии голоса, который описан в любом из пп. 1-10.
16. Машиночитаемый носитель данных, на котором хранится по меньшей мере одна компьютерная программа, причем по меньшей мере одна компьютерная программа, после ее загрузки и выполнения процессором, заставляет процессор выполнять способ обучения модели конверсии голоса, который описан в любом из пп. 1-10.
17. Электронное устройство для конверсии голоса, включающее в себя по меньшей мере процессор и память, причем процессор после загрузки и выполнения по меньшей мере одной хранящейся в памяти компьютерной программы побуждается выполнять способ конверсии голоса, который описан в любом из пп. 11, 12.
18. Машиночитаемый носитель данных, на котором хранится по меньшей мере одна компьютерная программа, причем по меньшей мере одна компьютерная программа, после ее загрузки и выполнения процессором, заставляет процессор выполнять способ конверсии голоса, который описан в любом из пп. 11, 12.
| Токарный резец | 1924 |
|
SU2016A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| ТЕКСТОЗАВИСИМЫЙ СПОСОБ КОНВЕРСИИ ГОЛОСА | 2010 |
|
RU2427044C1 |
| Способ и сервер для синтеза речи по тексту | 2015 |
|
RU2632424C2 |

