Область техники, к которой относится изобретение
Настоящее изобретение относится к области связи и, в частности, к технологиям кодирования и декодирования данных.
Уровень техники
Коды с низкой плотностью проверок на четность (LDPC) являются канальными кодами, используемые в схемах прямого исправления ошибок (FEC). LDPC-коды хорошо известны своей хорошей производительностью, и в последние годы им уделялось большое внимание. Это связано с их способностью достигать производительности, близкой к пределу Шеннона, способностью разрабатывать коды, обеспечивающие высокую степень распараллеливания в оборудовании, и их поддержкой высоких скоростей передачи данных. Следовательно, многие из действующих в настоящее время стандартов электросвязи имеют LDPC-коды в своей FEC схеме физического уровня. LDPC-коды считают стандартом кодирования системы связи следующего поколения.
Квазициклический код с низкой плотностью проверок на четность (QC-LDPC) основан на базовой матрице нерегулярной QC-LDPC-матрицы, причем базовая матрица состоит из столбцов и строк, причем столбцы делят на один или несколько столбцов, соответствующих выколотым узлам переменной (то есть, узлы переменной, соответствующие информационным битам, которые используются кодером, но не передаются или эффективно не обрабатываются как не принятые декодером) и столбцы, соответствующие невыколотым узлам переменной, и строки делят на строки с высокой плотностью (то есть, строки, имеющие вес, который выше первого веса) и строки с низкой плотностью (то есть строки, имеющие вес, который меньше второго веса, в котором второй вес равен или меньше первого веса).
Несмотря на то, что известные подходы канального кодирования доказали свою эффективность для широкого спектра сценариев, все еще продолжаются исследования по предоставлению сложных решений, обеспечивающих высокую пропускную способность при достаточных ресурсах кодирования/декодирования.
Сущность изобретения
В соответствии с первым аспектом настоящего изобретения предложен способ, причем способ содержит предоставление записей базовой матрицы нерегулярного QC-LDPC-кода для кодирования или декодирования последовательности информационных битов, в котором записи представляют собой блоки нерегулярной QC-LDPC-матрицы и каждый блок представляют сдвинутую циркулянтную матрицу или нулевую матрицу, разделение строки базовой матрицы на первый набор и второй набор, в котором строки первого набора имеют больший вес, чем строки второго набора, выбор количества столбцов матрицы, образованной строками второго набора, в котором строки подматрицы, образованной выбранными столбцами, разделены на разные группы, причем каждая группа состоит из максимального количества ортогональных строк, в котором выбор основан на числе различных групп и указания информационных битов, соответствующих невыбранным столбцам, как выколотых.
Выкалывание информационных битов, соответствующих одному или нескольким столбцам с высоким весом нерегулярной QC-LDPC-матрицы, позволяет осуществлять многоуровневое декодирование по отношению к различным группам «оставшихся» ортогональных подстрок (или векторов строк) в сочетании с лавинным декодированием по отношению к столбцы большого веса, благодаря чему достигается высокая степень параллелизма при декодировании при сохранении высокого качества кода. Таким образом, при выборе столбцов, которые не должны быть выколоты, стремятся поддерживать как можно большее количество различных групп ортогональных подстрок (или векторов строк), избегая при этом того, что информационные биты соответствуют слишком большому количеству столбцов (например, больше, чем задано пороговым значением), подлежащие выкалыванию.
В этой связи следует отметить, что термин «циркулянтная матрица», используемый в тексте описания и формулы изобретения, в частности, относится к квадратичной матрице размера 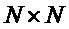
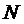
Кроме того, следует отметить, что QC-LDPC-код и LDPC-код часто используют поочередно, но специалист в данной области техники может понять их значения. Термин «вес», используемый во всем описании и формуле изобретения, в частности, относится к количеству записей в строке или столбце базовой матрицы, которые помечены значениями сдвига, т.е. записей в строках или столбцах базовой матрицы, которые не представляют нулевые матрицы, которые равны количеству «1s» в соответствующих строках и столбцах QC-LDPC-матрицы. В связи с этим, следует отметить, что термин «вес», используемый в описании и формуле изобретения, может быть заменен терминами «степень узла» или «плотность», которые имеют одинаковое или подобное значение. Кроме того, термин «выколотый», используемый во всем описании и формуле изобретения в отношении информационных битов (или соответствующих узлов переменной или соответствующих столбцов), в частности, указывает, что информационные биты используют только кодером, но не передают или эффективно обрабатывают, как не принятые декодером. Более того, термин «соответствующий», используемый во всем описании и формуле изобретения в отношении столбцов, узлов и информационных битов, в частности, относится к отображению между столбцами и узлами переменной/информационными битами в терминах представления графа Таннера для QC-LDPC-матрицы.
Кроме того, следует отметить, что значения, образующие «матрицу», не обязательно должны быть физически сохранены или представлены в матричной (или в массиве) форме или использованы в алгебре матриц в течение всего процесса использования матрицы. Вместо этого, термин «матрица», используемый в описании и формуле изобретения, может в равной степени относиться к набору (целых) значений с присвоенными индексами строк и столбцов или к набору (целых) значений, которые хранят в (логическом) массиве памяти. Более того, если не задействовать матричную алгебру или, если соответствующие подпрограммы матричной алгебры соответствующим образом переопределены, понятие строк и столбцов может даже быть изменено или свободно выбрано. Однако во всем описании и формуле изобретения придерживаются математических концепций и обозначений, регулярно используемых в данной области техники, и их следует понимать, как охватывающие эквивалентные математические понятия и обозначения.
В первой возможной форме реализации способа согласно первому аспекту количество невыбранных столбцов составляет один или два.
Следовательно, может быть относительно небольшое количество невыбранных столбцов, которые, однако, имеют относительно высокий вес (например, более чем в два или три раза больше среднего веса выбранных столбцов), обеспечивая, тем самым, хорошую «связность» групп ортогональных подстрок (или векторов строк), в то же время эффективно предоставляя высокую степень параллелизма во время декодирования из-за относительно небольшого числа столбцов, которые должны быть «разделены» (или разделены на непересекающиеся наборы или группы) для достижения ортогональности в пределах группы оставшихся (выбранных) подстрок (или векторов строк).
Во второй возможной форме реализации способа в соответствии с первым аспектом как таковым или в соответствии с первой формой реализации первого аспекта выбор количества столбцов матрицы, образованной строками второго набора, содержит упорядочение или группирование столбцов. матрицы, образованной строками второго набора по весу и выбором столбцов, имеющих веса ниже порогового значения.
Таким образом, могут быть получены группы с большим количеством ортогональных подстрок (или векторов строк), что обеспечивает более высокую степень параллелизма при декодировании.
В третьей возможной форме реализации способа в соответствии с первым аспектом как таковым или в соответствии с первой или второй формой реализации первого аспекта матрица, состоящая из поднабора столбцов матрицы, образованной строками первого набора, имеет двойную диагональную или треугольную структуру.
Следовательно, часть высокой плотности нерегулярной QC-LDPC-матрицы облегчает кодирование благодаря наличию части четности с двойной диагональной или треугольной структурой. Это также улучшает восприимчивость кода к адаптивности к скорости, поскольку количество строк (и соответствующие столбцы, если, например, удаление строки оставило бы пустой столбец), удаленное из части с низкой плотностью, позволяет изменять скорость кода, однако, фактически не затрагивая свойства кодирования/декодирования части с высокой плотностью. В этом отношении способ также может содержать удаление числа строк (и соответствующих столбцов) второго набора нерегулярной QC-LDPC-матрицы для адаптации скорости нерегулярного QC-LDPC-кода.
В четвертой возможной форме реализации способа в соответствии с первым аспектом как таковым или в соответствии с любой из форм осуществления с первого по третий первого аспекта матрица, состоящая из поднабора столбцов матрицы, образованной рядами второго набора, имеет структуру треугольной или единичной матрицы.
Таким образом, кодирование может быть выполнено в двухэтапной процедуре, содержащей кодирование входной последовательности на основании подстолбцов (или векторов столбцов) части с высокой плотностью и кодирование кодированной выходной последовательности на основании подстолбцов (или векторов столбцов) части с низкой плотностью, тем самым, используя процесс кодирования, подобный агрессивному.
В пятой возможной форме реализации способа в соответствии с первым аспектом как таковым или в соответствии с любой из форм осуществления первого аспекта с первого по четвертый, строки матрицы, образованные столбцами матрицы, образованной строками первого набора, который соответствует невыколотым информационным битам, делится на разные группы, каждая группа состоит из ортогональных рядов.
Следовательно, группы (или поднаборы) ортогональных подстрок (или векторов строк) могут быть сформированы в наборе высокой плотности и в наборе низкой плотности, что обеспечивает еще более высокую степень параллелизма во время декодирования.
В шестой возможной форме реализации способа в соответствии с первым аспектом как таковым или в соответствии с любой из форм осуществления с первого по пятый первого аспекта способ дополнительно содержит определение кодового слова, соответствующего последовательности информационных битов, на основании предоставленных записей базовой матрицы и передачу кодового слова, за исключением информационных битов, которые обозначены как выколотые.
Таким образом, может быть увеличена скорость QC-LDPC-кода.
В седьмой возможной форме реализации способа в соответствии с первым аспектом как таковым или в соответствии с любой из форм осуществления с первого по шестой первого аспекта способ дополнительно содержит декодирование принятой последовательности информационных битов на основании предоставленных записей базовой матрицы и информации о том, какие информационные биты выколоты, в котором декодирование содержит операции лавинообразного и многоуровневого декодирования, в котором уровни соответствуют различным группам.
Таким образом, конвергенция декодирования может быть улучшена при сохранении высокой параллельности процесса декодирования. В связи с этим следует отметить, что термин «многоуровневое декодирование», используемый во всем описании и формуле изобретения, в частности, относится к процессу декодирования, в котором строки уровня обрабатывают параллельно, но уровни обрабатывают (по существу) последовательно.
Согласно второму аспекту настоящего изобретения предоставлен декодер, причем декодер содержит постоянную память, хранящую записи базовой матрицы нерегулярного QC-LDPC-кода, в котором столбцы базовой матрицы разделены на первый набор и второй набор, причем первый набор содержит один или несколько столбцов, и столбцы второго набора образуют матрицу, содержащую группы ортогональных строк, в котором декодер выполнен с возможностью декодировать принятую последовательность информационных битов на основании лавинообразного процесса декодирования для узлов переменной, соответствующие одному или нескольким столбцам первого набора, и процесса многоуровневого декодирования для узлов, соответствующих столбцам второго набора.
Таким образом, может быть улучшена конвергенция декодирования, в то же время позволяя поддерживать качество кода и высокую параллельность процесса декодирования, тем самым, обеспечивая высокую пропускную способность при низкой частоте появления ошибок.
В первой возможной форме реализации декодера согласно второму аспекту узлы переменной, соответствующие одному или нескольким столбцам первого набора, обозначены как выколотые.
Таким образом, может быть увеличена скорость нерегулярного QC-LDPC-кода.
Во второй возможной форме реализации декодера согласно второму аспекту как таковой или согласно первой форме реализации второго аспекта количество столбцов в первом наборе составляет один или два.
Следовательно, в первом наборе может быть относительно небольшое количество столбцов, которые, однако, могут иметь относительно высокий вес (например, более чем в два или три раза больше среднего веса столбцов второго набора), тем самым, улучшая «связность» уровней.
В третьей возможной форме реализации декодера в соответствии со вторым аспектом как таковой или в соответствии с первой или второй формой реализации второго аспекта строки базовой матрицы разделены на первый набор и второй набор, в котором, строки первого набора имеет больший вес, чем строки второго набора.
Это делает код еще более восприимчивым к адаптации скорости за счет удаления (или игнорирования) строк второго набора (и соответствующих столбцов второго набора) без существенного ухудшения качества кода.
В четвертой возможной форме реализации декодера в соответствии с третьей формой реализации второго аспекта матрица, состоящая из поднабора столбцов матрицы, образованной строками первого набора, имеет двойную диагональную или треугольную структуру.
Следовательно, часть высокой плотности нерегулярной QC-LDPC-матрицы облегчает кодирование благодаря наличию части четности с двойной диагональной или треугольной структурой.
В пятой возможной форме реализации декодера в соответствии с третьей или четвертой формой реализации второго аспекта матрица, состоящая из поднабора столбцов матрицы, образованной строками второго набора, имеет структуру треугольной или единичной матрицы.
Таким образом, кодирование может быть выполнено с использованием процесса кодирования, подобного хищному, который уменьшает или устраняет необходимость запрашивать повторные передачи декодером.
В шестой возможной форме реализации декодера в соответствии с любой из форм реализации третьего-пятого второго аспекта строки матрицы, образованные перекрывающимися записями столбцов второго набора, и строки первого набора делятся на разные группы, каждая группа состоит из ортогональных рядов.
Следовательно, может быть достигнута более высокая степень параллелизма во время декодирования.
В соответствии с третьим аспектом настоящего изобретения, предусмотрен постоянный машиночитаемый носитель, хранящий инструкции, которые при выполнении компьютером вызывают компьютер предоставлять базовую матрицу нерегулярной QC-LDPC-матрицы, причем базовая матрица, образованная столбцами и строками, в которой столбцы делят на один или несколько столбцов, соответствующих выколотым узлам переменной, и столбцов, соответствующих невыколотым узлам переменной, и строки делят на первые строки, имеющие вес, который превышает первый вес, и вторые строки, имеющие вес, который меньше второго веса, в котором второй вес равен или меньше первого веса, в котором перекрытие вторых строк и столбцов, соответствующих невыколотым узлам переменной, делят на группы ортогональных векторов строк.
Выкалывание узлов переменной, соответствующих одному или нескольким столбцам с высоким весом базовой матрицы нерегулярной QC-LDPC-матрицы, позволяет осуществлять многоуровневое декодирование с учетом различных групп «оставшихся» ортогональных подстрок (или векторов строк) в сочетании с лавинообразным декодированием относительно столбцов с высоким весом, тем самым, достигая высокой степени параллелизма во время декодирования при сохранении высокого качества кода.
Краткое описание чертежей
Фиг.1 иллюстрирует схему возможного сценария применения согласно настоящему изобретению.
Фиг.2 схематично показывает цифровую систему связи;
Фиг.3 показывает блок-схему алгоритма процесса предоставления нерегулярного QC-LDPC-кода для кодирования или декодирования последовательности информационных битов;
Фиг.4 показывает структуру базовой матрицы нерегулярного QC-LDPC-кода;
Фиг.5 показывает базовую матрицу нерегулярного QC-LDPC-кода;
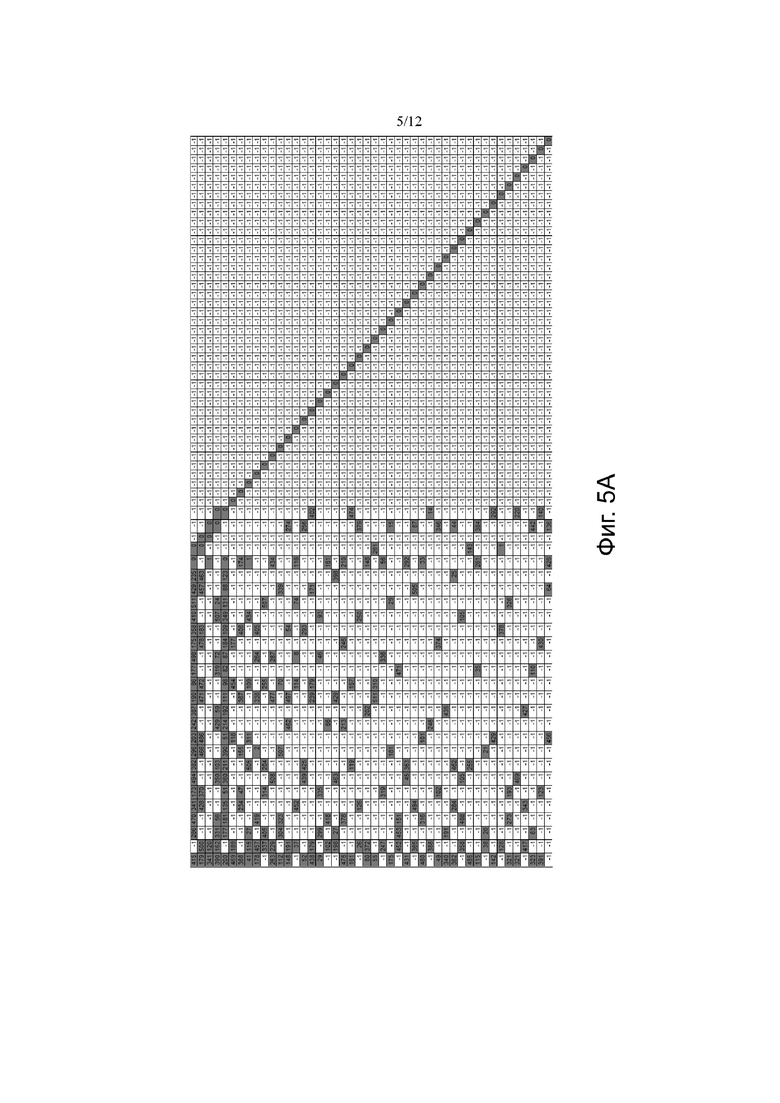
Фиг.5а показывает другую базовую матрицу нерегулярного QC-LDPC-кода;
Фиг.6 представляет собой базовый граф базовой матрицы;
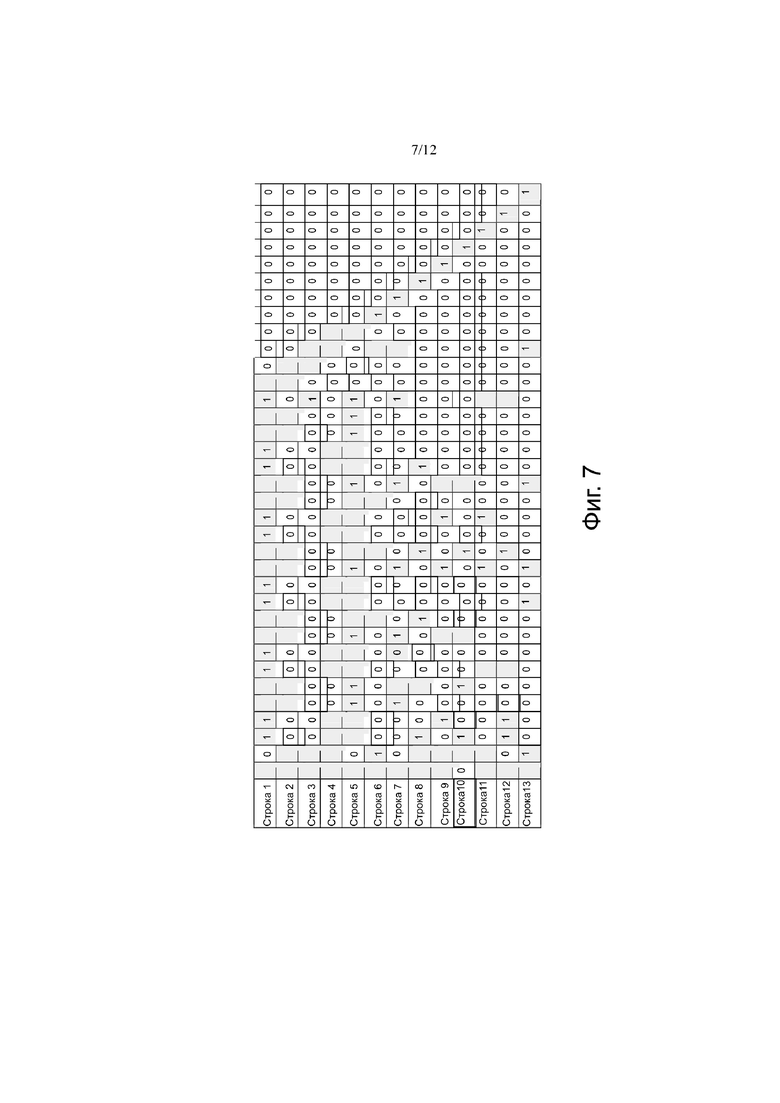
Фиг.7 представляет собой другой базовый граф базовой матрицы;
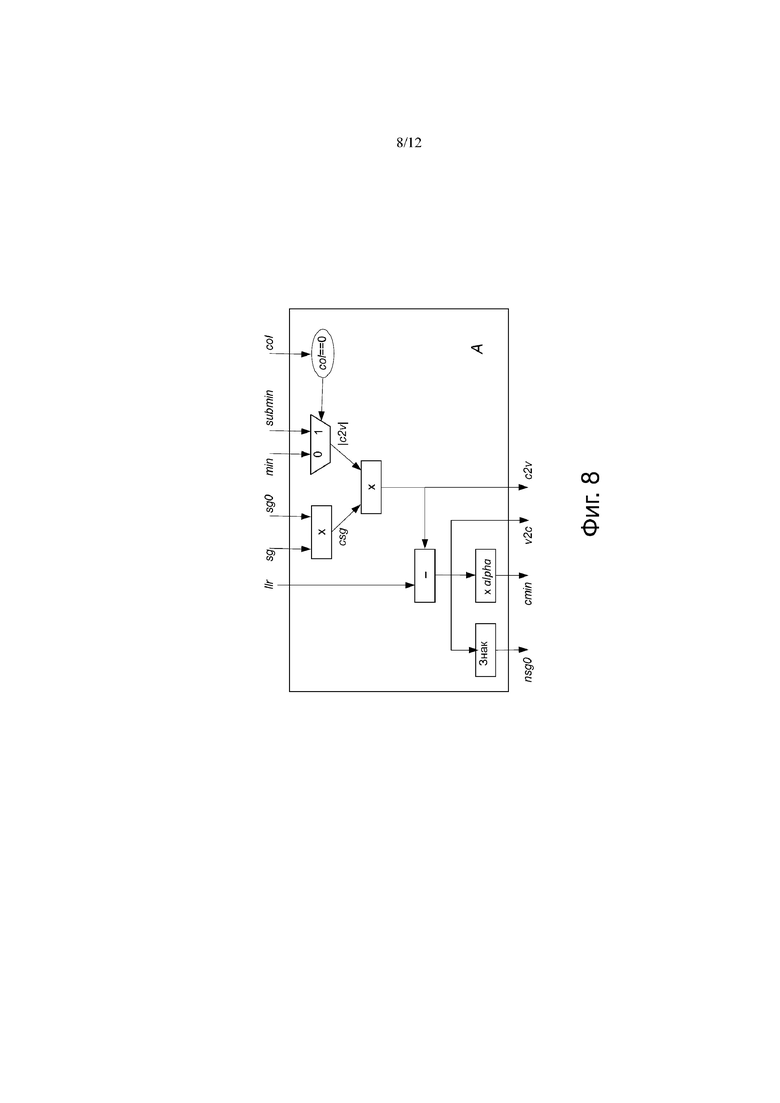
Фиг.8 показывает первую часть блок-схемы алгоритма процесса декодирования;
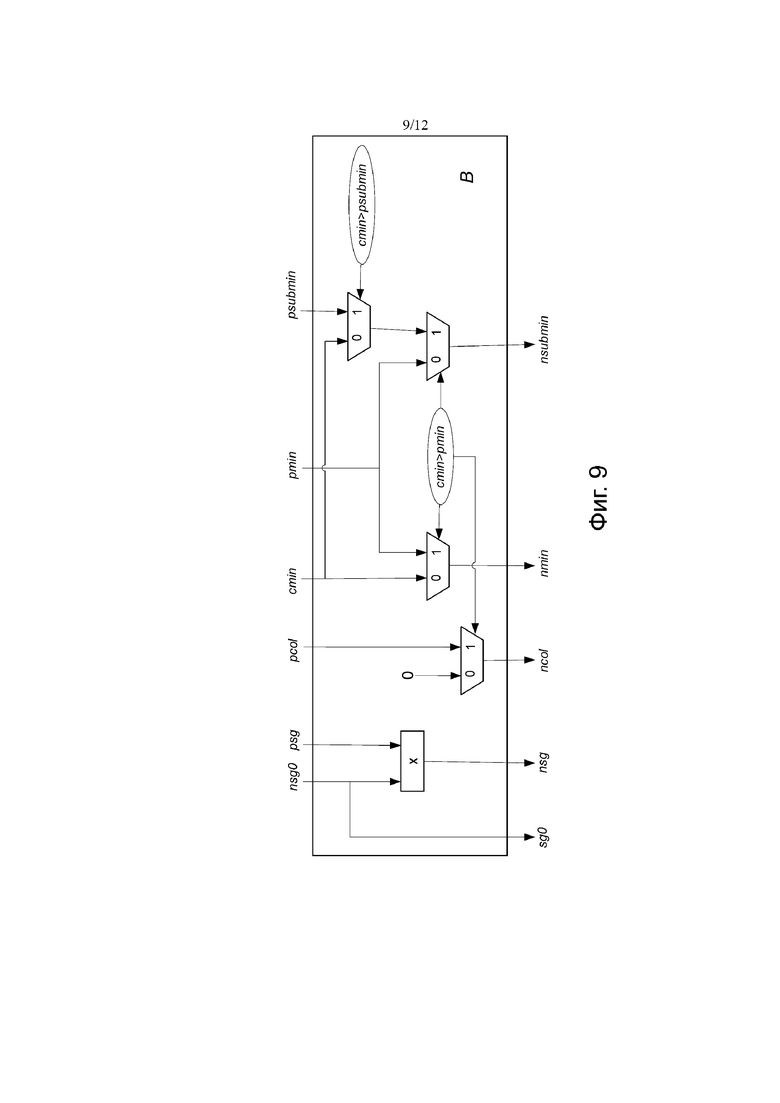
Фиг.9 показывает вторую часть блок-схемы алгоритма процесса декодирования;
Фиг.10 показывает третью часть блок-схемы алгоритма процесса декодирования;
Фиг.11 показывает схему первой аппаратной реализации процесса декодирования; и
Фиг.12 показывает схему второй аппаратной реализации процесса декодирования.
Подробное описание
На фиг.1 показан возможный сценарий применения согласно настоящему изобретению. Как показано на фиг. 1, по меньшей мере, один из терминалов (таких как устройство пользователя, UE для краткости) подключен к сети радиодоступа (для краткости RAN) и базовой сети (для краткости CN). Технология, описанная в настоящем изобретении, может применяться к системе 5G связи или другим системам беспроводной связи, которые используют различные технологии радиодоступа, например, к системам, которые используют множественный доступ с кодовым разделением, множественный доступ с частотным разделением, множественный доступ с временным разделением, ортогональный множественный доступ с разделением каналов, множественный доступ с разделением частот на одной несущей и другие технологии радиодоступа. Кроме того, технология, описанная в настоящем изобретении, может быть дополнительно применена к усовершенствованной системе связи. В возможной реализации терминал может подключаться к сети мультимедийной IP-подсистемы через сеть радиодоступа и базовую сеть.
Термин «терминал», используемый в настоящем изобретении, может включать в себя ручное устройство, устройство, установленное на транспортном средстве, носимое устройство, вычислительное устройство или другое устройство обработки, подключенное к модему беспроводной связи, где устройство имеет функцию беспроводной связи, и различные виды устройств пользователя (устройство пользователя, UE для краткости), мобильные станции (мобильная станция, MS для краткости), терминалы (терминал), терминальное оборудование (терминальное оборудование) и тому подобное.
Сеть радиодоступа, содержащая, по меньшей мере, одну базовую станцию. Базовая станция (для краткости базовая станция, BS) является устройством, которое развернуто в сети радиодоступа и выполнено с возможностью обеспечивать функции беспроводной связи для UE. Базовая станция может включать в себя различные виды макробазовых станций, микробазовых станций, ретрансляционных станций, точек доступа и т.п. Для разных технологий радиодоступа названия устройств, имеющих функцию базовой станции, могут быть разными.
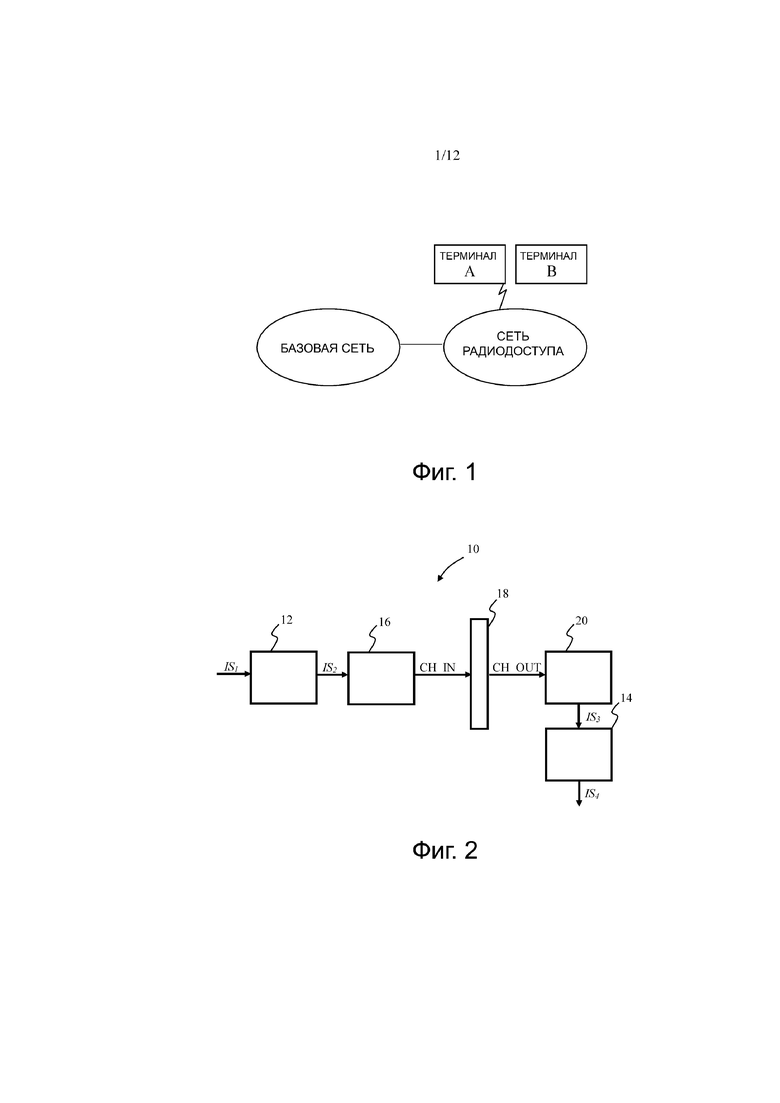
Фиг.2 показывает блок-схему, иллюстрирующую систему 10 цифровой связи, в которой могут быть реализованы процессы настоящего изобретения. Система 10 цифровой связи включает в себя сторону передачи, содержащую кодер 12, и сторону приема, содержащую декодер 14. Кодер или декодер может быть реализован, по меньшей мере, одним процессором, например, реализованным с помощью набора микросхем. Последний процессор или набор микросхем может быть установлен на базовой станции или терминале. Входной сигнал кодера 12 на стороне передачи представляет собой, например, информационную последовательность IS1 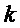
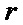
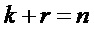
Модулятор 16 может преобразовывать кодированную последовательность IS2 в вектор CH_IN модулированного сигнала, который, в свою очередь, передают по проводному или беспроводному каналу 18, такому как, например, проводящий провод, оптоволокно, радиоканал, микроволновый канал или инфракрасный канал. Поскольку канал 18 обычно подвержен шумовым помехам, выход CH_OUT канала может отличаться от входа CH_IN канала.
На стороне приема выходной вектор CH_OUT канала может обрабатываться демодулятором 20, который вырабатывает некоторое отношение правдоподобия. Декодер 14 может использовать избыточность в принятой информационной последовательности IS3 в операции декодирования, выполняемой декодером 14, чтобы исправить ошибки в принятой информационной последовательности IS3 и сформировать декодированную информационную последовательность IS4 (см. M.P.C. Fossorier et al., «Уменьшенная сложность итеративного декодирования кодов с низкой плотностью проверок на четность на основании распространения степени уверенности», IEEE TRANSACTIONS ON COMMUNICATIONS, май 1999 г., том 47, номер 5, страницы 673-680, и J. Chen et al.,.«Улучшенные алгоритмы декодирования с минимальной суммой для нерегулярных LDPC-кодов», слушания международного симпозиума IEEE 2005 г. по теории информации, стр. 449-453, сентябрь 2005 г.). Декодированная информационная последовательность IS4 является оценкой кодированной информационной последовательности IS2, из которой (оценка) может быть извлечена информационная последовательность IS1.
Операция кодирования и операция декодирования могут регулироваться LDPC-кодом. В общей формулировке канального кодирования LDPC-код может использовать порождающую матрицу G для операции кодирования, выполняемой кодером 12, и матрицу H проверки на четность для операции декодирования, выполняемой декодером 14. Для LDPC-кода с информацией последовательность IS1 размера 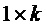
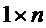
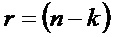
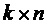
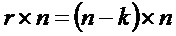
Матрица 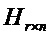
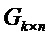
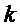
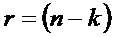
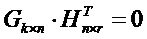
Операция кодирования может выполняться посредством умножения между информационной последовательностью IS1 и порождающей матрицы
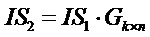
На стороне приема из-за свойства ортогональности между порождающей матрицей

где IS4 является декодированной принятой информационной последовательностью размером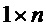
Как только матрица 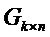
Более того, следует отметить, что LDPC-коды, имеющие матрицу
Конкретной формой матрицы 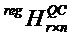
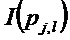
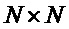
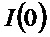
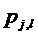
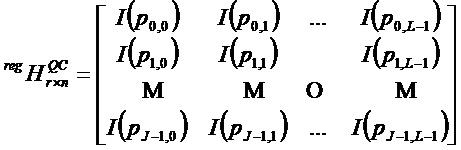
с 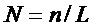
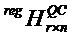
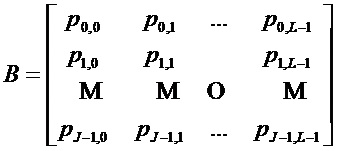
Кроме того, базовая матрица B нерегулярной QC-LDPC-матрицы 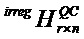
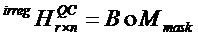
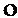
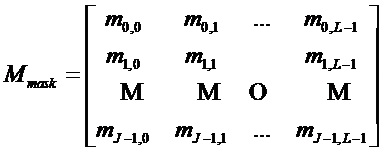
обозначает маску матрицы с 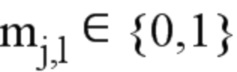 . Альтернативно, базовая матрица B нерегулярной QC-LDPC-матрицы
. Альтернативно, базовая матрица B нерегулярной QC-LDPC-матрицы 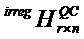
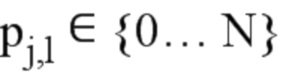 не помеченными записями (которые иногда представлены значением «-1» или звездочкой «*»), представляющими нулевые матрицы размера
не помеченными записями (которые иногда представлены значением «-1» или звездочкой «*»), представляющими нулевые матрицы размера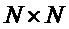
Таким образом, для использования QC-LDPC-кода в кодере 12 и декодере 14 кодеру 12 и декодеру 14 могут быть предоставлены циркулянтные значения сдвига, то есть, значения, соответствующие помеченным записям базовой матрицы B, и (возможно) матрицы 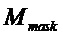
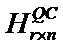
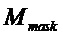
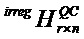
Кроме того, следует отметить, что QC-LDPC-матрица 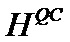
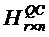
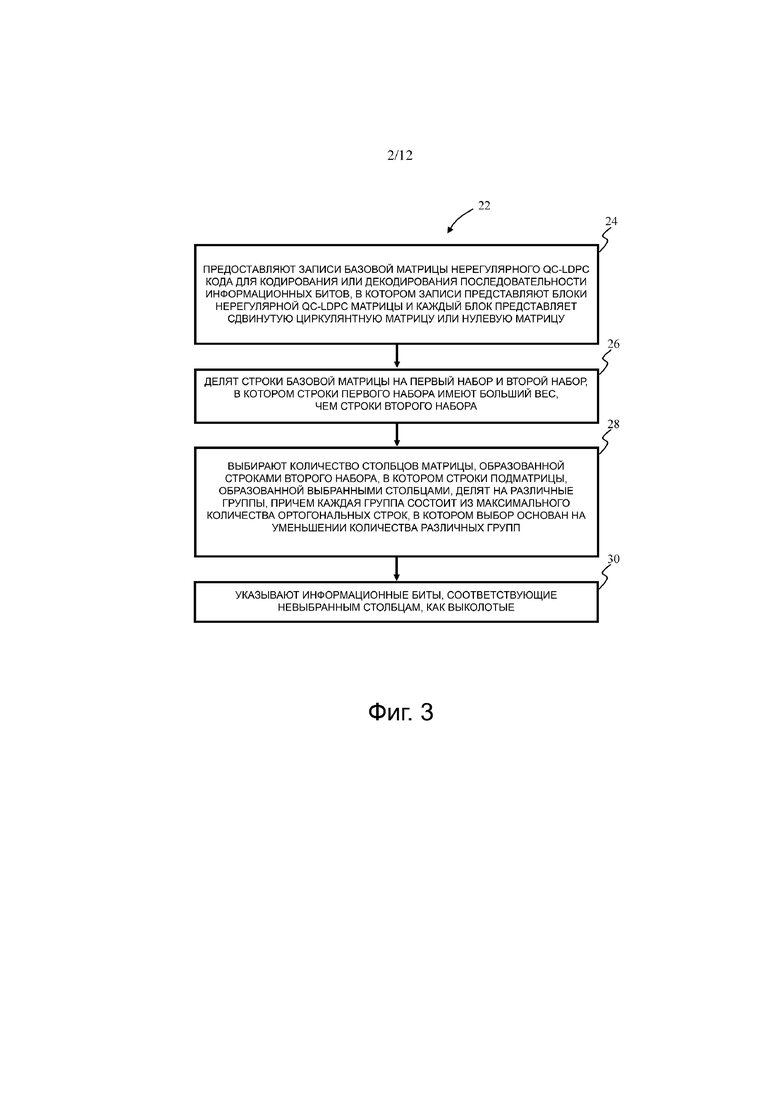
На фиг.3 показана блок-схема последовательности операций процесса 22 предоставления нерегулярного QC-LDPC-кода для кодирования или декодирования последовательности информационных битов, таких как информационные последовательности IS1 и IS3, соответственно. Процесс 22 может, например, быть реализован на компьютере. Например, процесс 22 может быть реализован с помощью постоянно хранимых машиночитаемых инструкций, которые, если они выполняются компьютером, вызывают компьютер выполнять процесс 22. Предоставленная базовая матрица B нерегулярного QC-LDPC-кода может, например, предоставляется кодеру 12 и декодеру 14 системы 10 цифровой связи и используется для операций кодирования или декодирования, выполняемых кодером 12 и декодером 14 соответственно, то есть, для кодирования или декодирования последовательности информационных битов.
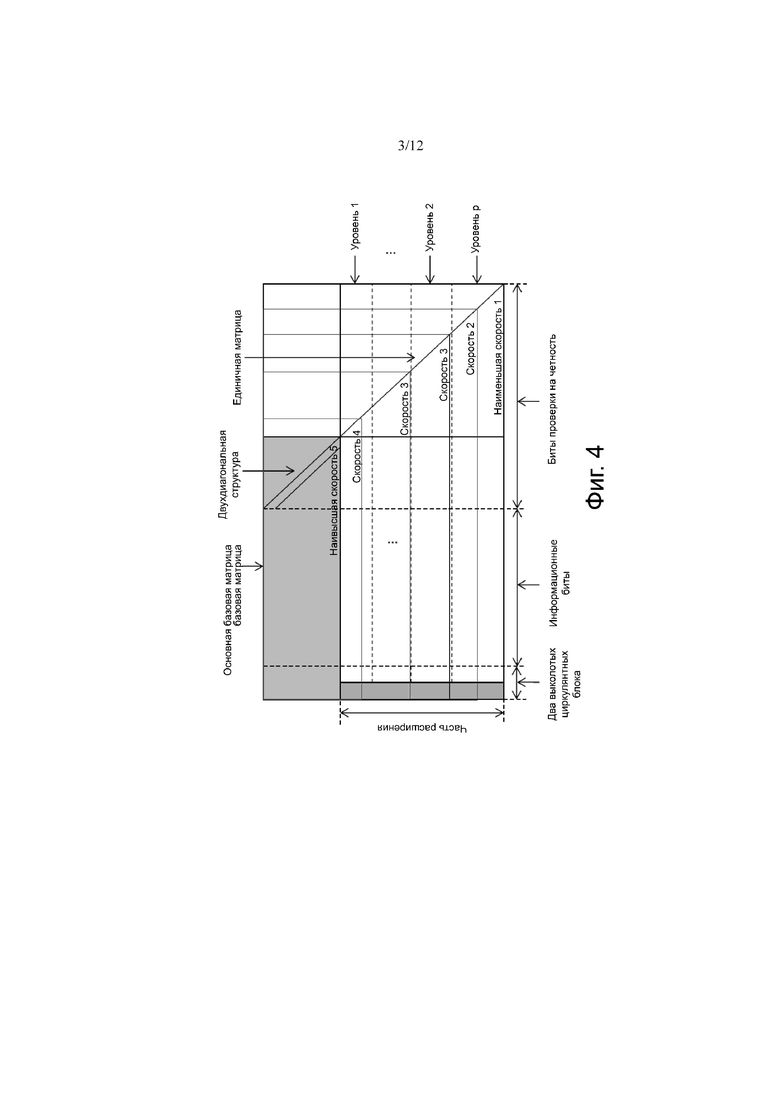
Процесс 22 предоставления нерегулярного QC-LDPC-кода для кодирования или декодирования последовательности информационных битов может начинаться на этапе 24 с предоставления записей базовой матрицы B нерегулярного QC-LDPC-кода, в котором записи представляют блоки нерегулярной QC-LDPC-матрицы и каждый блок представляет сдвинутую циркулянтную матрицу или нулевую матрицу. Возможная структура базовой матрицы B показана на фиг.4. Она содержит «основную» базовую матрицу в части высокой плотности (обозначена серым цветом в верхнем левом углу на фиг.4). Основная базовая матрица имеет четную часть с двойной диагональной структурой для легкого кодирования. Если требуется самая высокая скорость, информационная последовательность будет кодироваться с использованием только значений сдвига основной базовой матрицы. Если допустимы более низкие скорости, к базовой матрице можно добавить дополнительные строки и столбцы. Как показано на фиг.4, перекрытие между дополнительными строками и столбцами может образовывать единичную матрицу, хотя также возможна нижняя треугольная форма. Дополнительные строки обычно имеют меньший вес, чем строки основной базовой матрицы, и обеспечивают (в сочетании с добавленными «соответствующими» столбцами) дополнительные биты четности в кодовом слове, которое должно быть передано.
Следует отметить, что базовая матрица B является матрицей с m строками и n столбцами, где m и n являются целыми числами. Базовая матрица B может быть расширена путем дополнения большего количества столбцов и строк. Например, базовая матрица B является матрицей с 46 строками и 68 столбцами, или базовая матрица B является матрицей с 90 строками и 112 столбцами и т.д. Настоящее изобретение не ограничивает размер базовой матрицы.
Расширенная часть содержит одну, две, три или более столбцов с большим весом, которые обычно имеют существенно больший вес, чем все другие столбцы расширенной части. Например, один, два или все столбцы с большим весом могут не иметь пустых сот, то есть, отсутствуют записи, представляющие нулевую матрицу. Как показано на фиг.4, узлы переменной, соответствующие двум столбцам большого веса, обозначены как выколотые и «оставшиеся» подстроки сгруппированы в (не перекрывающиеся) уровни ортогональных подстрок (или векторов строк).
На фиг.5 показан числовой пример предоставленных записей базовой матрицы B размером 19x35 (19 строк и 35 столбцов), в которых помеченные записи (соты) базовой матрицы B обозначены соответствующими значениями сдвига и немаркированными записями (соответствующими нулевой матрице) оставлены пустыми. Как показано на фиг.5, ряды базовой матрицы B могут быть разделены на верхнюю часть, имеющую вес более 17, и нижнюю часть, имеющую вес менее 9, т.е. менее половины веса рядов верхней части. Таким образом, базовая матрица B, показанная на фиг. 5, может быть разделена на часть с высокой плотностью, содержащей строки 1-3, и часть с низкой плотностью, содержащую строки 4-19, как указано на этапе 26 процесса 22, показанного на фиг. 3.
Кроме того, как показано на фиг.5, строки подматрицы, образованные перекрытием столбцов 2–35 и части с низкой плотностью, можно разделить на уровни (или группы) ортогональных рядов, в котором каждый уровень содержит примерно одинаковое число сот. Дополнительно, часть с высокой плотностью содержит двойную диагональную подматрицу, позволяющую легко кодировать последовательность информационных битов на основе ненулевых столбцов части с высокой плотностью. Кроме того, часть с низкой плотностью обеспечивает агрессивное расширение с частью четности, которая имеет нижнюю треугольную форму, что позволяет легко кодировать кодовое слово.
На фиг.5а показан числовой пример предоставленных записей базовой матрицы B размером 46х68 (46 строк и 68 столбцов). На фиг.5а столбцы 1 и 2 проколоты. Для столбцов с 3 по 68, начиная со строки 9, существует несколько групп ортогональных строк. Ортогональные строки представляют собой строки, которые не перекрываются с относительно столбцов. Например, строки 9 и 10 являются ортогональными и строки 11 и 12 являются ортогональными.
Фиг. 6 и фиг.7 показывают различные структуры базовых графов базовых матриц. Термин «базовый граф» настоящего изобретения включает в себя ряд квадратных блоков, причем каждый квадратный блок представляет собой элемент в базовой матрице проверки на четность. Каждый ненулевой элемент базовой матрицы проверки на четность представлен помеченным прямоугольником. Каждый помеченный прямоугольник ассоциирован со значением сдвига в базовой матрице. На фиг.6 и 7, столбцы 1 и 2 являются выколотыми столбцами. Следует отметить, что выколотый столбец может быть одним или несколькими столбцами.
В частности, на фиг.6 показан пример базового графа базовой матрицы с 14 строками и 36 столбцами. Для невыколотых столбцов (т.е., кроме столбцов 1 и 2), начиная со строки 7, т.е. строки 7 – 14, такие строки являются бесконфликтными квазизстрочными ортогональными. В частности, начиная со строки 7, каждая группа строк (например, каждые две смежные строки) является бесконфликтной квазистрочной ортогональной. Как видно из фиг. 6, отмеченные прямоугольники не перекрываются. Например, строки 7 и 8 являются ортогональными, строки 9 и 10 являются ортогональными, строки 11 и 12 являются ортогональными и строки 13 и 14 являются ортогональными. Эти строки, строки (7, 8), (9, 10) и (11, 12) называются ортогональными строками. Для ортогональных строк помеченный прямоугольник каждой строки не перекрывается с точки зрения столбцов. Группу также можно назвать ортогональной группой.
В данном варианте осуществления строки первого набора находятся в строках с 1 по 6, и строки второго набора начинаются со строк с 7 по 14. В этой компоновке, если строки с 1 по 6 рассматриваются как строки основной базовой матрицы, и строки с 7 по 14 считаются строками части расширения, то все строки части расширения являются бесконфликтными квазистрочными ортогональными. Если строки с 1 по 5 рассматриваются как строки основной базовой матрицы и строки с 6 по 14 рассматриваются как строки расширенной части, то большинство строк расширенной части, удаленной от основной базовой матрицы, являются бесконфликтными квазистрочными ортогональными.
Следует отметить, что ортогональная группа на фиг. 6 включает в себя две строки. Ортогональная группа также может включать в себя более двух строк. Разные ортогональные группы могут иметь одинаковое количество строк или разное количество строк.
На фиг. 7 показан базовый граф базовой матрицы с 13 строками и 35 столбцами. На фиг.7 ортогональные группы расширения строк начинаются со строки 8. Например, строки 8 и 9 являются ортогональными, строки 10 и 11 являются ортогональными и строки 12 и 13 являются ортогональными. Ортогональные группы на фиг.7 содержат смежные две ортогональные строки, то есть, строки 8 и 9, строки 10 и 11 и строки 12 и 13. В этом варианте осуществления каждая группа имеет две ортогональные строки. Он также может быть изменен, чтобы каждая группа может иметь различное количество строк, например, три ортогональных строки или четыре ортогональных строки и так далее.
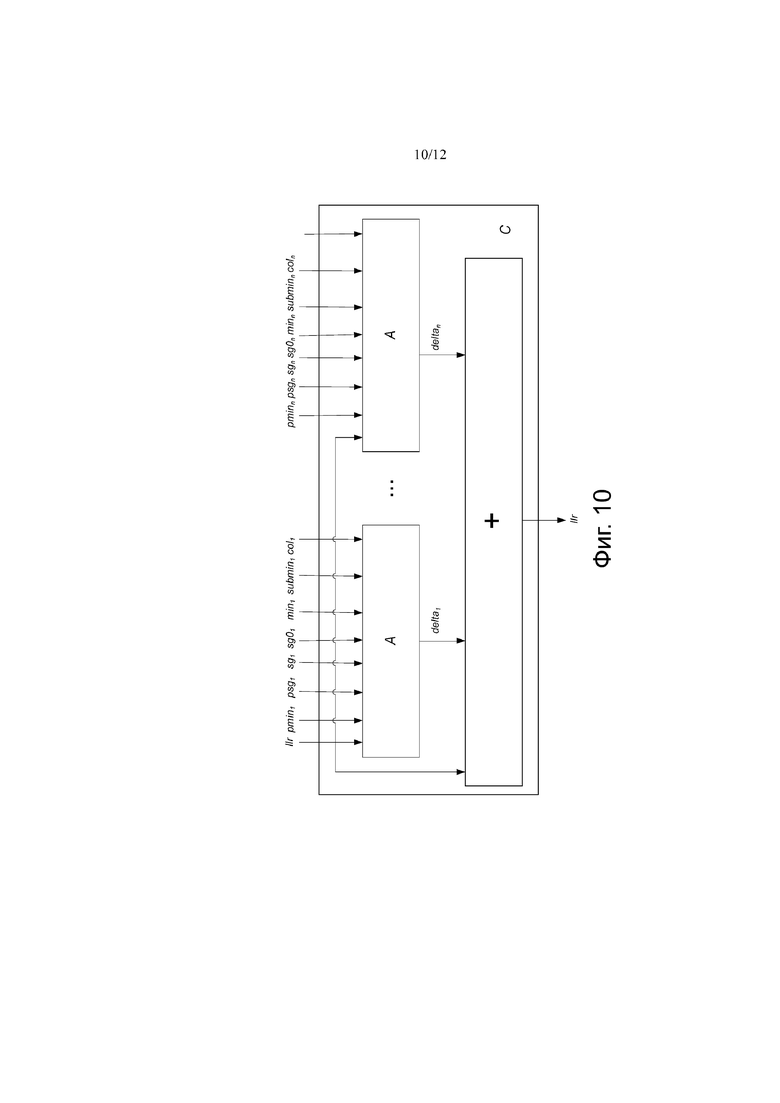
Как дополнительно указано на этапе 28 процесса 22, показанного на фиг.3, столбец 1 базовой матрицы B выколот. После кодирования последовательности информационных битов кодером 12 на основе предоставленных записей базовой матрицы B и передачи соответствующего кодового слова (за исключением информационных битов, соответствующих выколотым узлам) по каналу 18 в декодер 14, кодер 14 может итеративно декодировать принятые информационные биты, используя нормализованный процесс декодирования с минимальной суммой, объединяющий этапы лавинообразного и многоуровневого декодирования, как показано этапами A, B и C на фиг. 8, фиг. 9 и фиг. 10. Кроме того, в процессе декодирования можно воспользоваться тем фактом, что значения сдвига выколотого столбца, которые соответствуют расширенной части матрицы (показано темно-серым цветом на фиг. 5), могут быть установлены в нули с помощью операций сдвига строк и столбцов. Кроме того, параллельность операции декодирования может быть увеличена путем предоставления групп ортогональных строк на участке с высокой плотностью, к которой применяются этапы многоуровневого декодирования (то есть, части, соответствующей невыколотым столбцам).
Как показано на этапе A, показанном на фиг. 8, вычисляют логарифмические отношения правдоподобия (llr-s) выколотых столбцов с использованием следующих формул llr, sg0j, sgj, minj, subminj, colj, v2cj, csgj, c2vj, nsg0j, сminj, psgj, pminj, psubminj, pcolj, nsgj, nminj, nsubminj, ncolj и nc2vj являются векторами длины N и alpha, обозначающими параметр масштаба нормализованного процесса декодирования минимальной суммы:
• llr обозначает вектор llr-s выколотого узла, который может храниться в регистрах специализированной интегральной микросхемы (ASIC).
• sg0j обозначает знаки переменной для проверки сообщений (v2c) выколотых узлов и j-й строки внутри группы, которые могут храниться в оперативной памяти (RAM).
• sgj, minj, subminj, colj обозначают умножения знаков, минимумов, субминимумов и основанных на нуле argMinimums в j-й строке данной группы ортогональности с 1 <= j <= n. Все эти значения могут быть вычислены до начала процесса декодирования и сохранены в памяти.
• psgj, pminj, psubminj, pcolj обозначают обновленные умножения знаков, минимумов, субминимумов и argMinimums в j-й строке текущей группы ортогональности. Эти значения должны быть определены для каждого столбца, кроме выколотого.
Во-первых, csgj, | c2vj | и c2v вычисляют для 1 <= j <= n следующим образом:
• csgj = sgj * sg0j,
• | c2vj | = (colj == 0)? subminj: minj, и
• c2v = CSG * | c2v |.
Затем, nsg0j, сminj и v2cj рассчитывают следующим образом:
• nsg0j = знак (v2cj),
• сminj = | v2cj | * alpha,
• v2cj = llr - c2vj.
Теперь, как показано этапом B, показанным на фиг.9, новые минимумы, субминимумы и argMinimums, а также знаки выколотого столбца в каждой строке текущей группы ортогональности вычисляют для 1 <= j <= n посредством:
• sg0j = nsg0j
• nsgj = nsg0j * psgj,
• ncolj = (сminj> pminj)? pcolj: 0,
• nminj = (сminj> pminj)? pminj: cminj и
• nsubminj = (сminj> pminj)? ((сminj> psubminj)? psubminj: сminj): pminj.
Эти значения хранят в памяти, где sgj, minj, subminj, colj и sg0j заменяют сохраненные в данный момент значения для следующей итерации декодирования.
Наконец, psum, c2vsum и новые llr-s выколотого узла вычисляют, как показано этапом C, показанным на фиг.10, следующим образом:
• psum = psg1 * pmin1 +… + psgn * pminn,
• c2vsum = c2v1 +… + c2vn и
• llr = llr - c2vsum + psum.
Кроме того, предложенная схема может быть эффективно реализована посредством аппаратного обеспечения, как станет ясно из следующего примера, в котором каждая группа ортогональных строк обрабатывается за 3 тактовых цикла, все lr-s сохраняют в регистрах, число доступных процессоров равно количеству столбцов матрицы QC-LDPC и sgj, minj, subminj, colj загружают в регистры до начала 1-го тактового цикла.
Обработка невыколотых столбцов выполняется по той же схеме, и обработка выколотых столбцов выполняется по вышеописанным формулам:
Тактовый цикл 1. Для всех столбцов, кроме выколотого, вычисляют c2v-сообщения. Вычисленные сообщения c2v вычитают из llr-s, так что получают сообщения v2c, которые хранят в тех же регистрах, в которых были сохранены llr-s. Полученные сообщения v2c используют для определения nsg0 и сmin, которые используют для определения частичных минимумов. Кроме того, в тактовом цикле 1, соответственно получают llr-s выколотых столбцов предшествующей группы. После этого, эти данные будут сдвинуты и сохранены в регистрах. В результате, вычисляют llr-s выколотых столбцов на 1 тактовый цикл позже, чем llr-s других столбцов, но они также используются на 1 тактовый цикл позже (во втором тактовом цикле).
Тактовый цикл 2. Вычисляют минимумы (то есть, psgj, pminj, psubminj, pcolj) из частичных минимумов. Кроме того, nsg0, сmin и c2v вычисляют для выколотого столбца. После этого значения nsgj, nminj, nsubminj, ncolj вычисляют и сохраняют в памяти.
Тактовый цикл 3. Из полученных значений nsgj, nminj, nsubminj, ncolj для всех столбцов, кроме выколотых, можно вычислить новые сообщения c2v. После этого эти значения суммируют с v2c-сообщениями и получают llr-s всех невыколотых столбцов. Полученные данные затем сохраняют в регистрах. Кроме того, в этом цикле вычисляют значения psum и c2vsum.
Если в качестве выколотых указано более одного столбца базовой матрицы, вышеописанный модифицированный процесс декодирования с минимальной суммой должен быть соответственно расширен. Например, обработка двух выколотых столбцов может быть выполнена по следующей схеме:
Тактовый цикл 1a) Для всех невыколотых столбцов вычисляют сообщения c2v. Сообщения c2v вычитают из llr-s. В результате получают сообщения v2c, которые могут храниться в тех же регистрах, что и llr-s. Эти сообщения v2c можно использовать для получения значений nsg0 и сmin. Эти значения используют для получения частичных минимумов.
Тактовый цикл 1b) Также в 1-м тактовом цикле можно получить llr-s из 2 выколотых столбцов для предшествующей группы ортогональности. После этого эти данные могут быть сдвинуты и сохранены в регистрах. В результате, llr-s для выколотых столбцов может быть получено на 1 цикл позже, но данный аспект не является недостатком, поскольку необходимы на 1 цикл позже.
Тактовый цикл 2a) Минимумы получены из частичных минимумов, то есть, получены значения для psgj, pminj, psubminj и pcolj.
Тактовый цикл 2b) В этом тактовом цикле nsg0, сmin и c2v рассчитывают для 2 выколотых столбцов. После этого значения nsgj, nminj, nsubminj и ncolj вычисляют и сохраняют в памяти.
Тактовый цикл 3a) Из полученных значений nsgj, nminj, nsubminj, ncolj для всех невыколотых столбцов вычисляют сообщения c2v, которые после суммирования с сообщениями v2c выдают llr-s всех невыколотых столбцов. Все llr-s сдвинуты и сохранены в регистрах.
Тактовый цикл 3b). В этом цикле вычисляют сообщения nc2v и суммы c2vsum и nc2vsum.
При использовании вышеописанной схемы может потребоваться специальный процессор для выколотых узлов для этапов 1a), 2a), 3a), а также процессор может потребоваться для каждого невыколотого столбца, который выполняет операции 1b), 2b), 3b). Если QC-LDPC-матрица имеет m групп ортогональных подстрок, может потребоваться 3 × m тактов на итерацию. Каждый подпроцессор 1а), 2а), 3а), 1b), 2b), 3b) будет иметь останов на 2 такта из 3 доступных.
Другая, еще более эффективная схема памяти может использоваться с 4 тактами на процессор, но с меньшим количеством процессоров (1 процессор для выколотых столбцов и один процессор для четырех невыколотых столбцов).
Такт Ia) — выполняют расчеты из 1а) для первой четверти невыколотых столбцов.
Такт Ib) — рассчитывают выколотые столбцы первого ряда предшествующей группы. После этого llr-s сдвигают и сохраняют в регистрах.
Такт IIa) — действия 2а) выполняются для невыколотых столбцов, и действия 1а) выполняют для второй четверти невыколотых столбцов.
Такт IIb) — вычисляют nsg0, сmin и c2v для выколотых столбцов, и nsgj, nminj, nsubminj и ncolj получают и сохраняют в регистрах.
Такт IIIa) — выполняют действия 3a) для первой четверти невыколотых. Действия 2а) выполняются для второй четверти невыколотых столбцов. Действия 1а) выполняются для третьей четверти невыколотых столбцов.
Такт IIIb) — значения nsgj, nminj, nsubminj и ncolj определяют и сохраняют в памяти. Также рассчитываются суммы c2vsum.
Такт IVa) — выполняют действия 3a) для второй четверти невыколотых столбцов. Действия 2а) выполняются для третьей четверти невыколотых столбцов. Действия 1а) выполняют для четвертой четверти невыколотых столбцов.
Такт IVb) — рассчитывают сообщения nc2v и суммы nc2vsum.
Обобщение этого подхода возможно, если, например, число процессоров уменьшается, и пропускная способность соответственно уменьшается.
Обозначают этапы обработки буквами А-I:
• A – вычисление c2v для невыколотых узлов. Определение и сохранение v2c в регистрах, заменяющих llr-s. Расчет nsg0 и сmin. Расчет частичных минимумов.
• B - получение минимумов из частичных минимумов, то есть, psgj, pminj, psubminj, pcolj.
• C - вычисление нового c2v из nsgj, nminj, nsubminj, ncolj для всех невыколотых узлов, суммирование их с помощью v2c для получения llr-s этих столбцов, смещение их и сохранение в регистрах.
• D – вычисление nsg0, сmin и c2v для выколотых узлов.
• E - определение nsgj, nminj, nsubminj и ncolj.
• F - вычисление c2vsum.
• G - вычисление nc2vsum.
• H - вычисление nc2v.
• I – вычисление llr-s выколотых столбцов. Сдвиг и хранение их в регистрах.
и имеющий, например, три группы ортогональных подстрок (в части высокой плотности и части низкой плотности), каждая из которых содержит две ортогональные строки, которые обозначены как:
• 1-2 - 1 группа
• 3-4 - 2 группа
• 5-6 - 3 группа
и двенадцать невыколотых столбцов с:
• j.1 - первая половина непустых сот в j-й строке, 1 <= j <= 6 и
• j.2 - вторая половина непустых сот j-й строки, 1 <= j <= 6,
где выполняют действия A, B и C для невыколотых столбцов, и выполняют действия D, E, F, G, H и I для выколотых столбцов, фиг. 11 и 12 изображают расписание для схемы с 3-тактовым циклом и расписание для 4-х тактовой схемы. Как видно из фиг. 11 и 12, может быть достигнут высокий параллелизм.
Кроме того, следует отметить, что в дополнение к предоставлению кодеру 12 и декодеру 14 возможности выполнять операции кодирования и декодирования на основании предоставленной базовой матрицы B, кодер 12 и декодер 14 также могут использовать предоставленную базовую матрицу B для получения нерегулярных дочерних QC-LDPC-кодов с разными скоростями в соответствии с разными сценариями передачи, например, сценариями передачи, которые отличаются друг от друга требованиями к качеству канала и/или пропускной способности, например, путем удаления (или игнорирования) строк части с низкой плотностью и/или столбцов части четности предоставленной базовой матрицы B.
По меньшей мере, один процессор, выполненный с возможностью выполнять функций кодера или декодера, или базовой станции, терминала или устройства базовой сети в настоящем изобретении, может быть центральным процессором (CPU), процессором общего назначения, процессором цифровых сигналов (DSP), специализированной интегральной схемой (ASIC), полевой программируемой вентильной матрицей (FPGA) или другим программируемым логическим устройством, транзисторным логическим устройством, аппаратным компонентом или любой их комбинацией. Контроллер/процессор может реализовывать или выполнять различные примерные логические блоки, модули и схемы, описанные со ссылкой на контент, раскрытый в настоящем изобретении. В качестве альтернативы, процессор может представлять собой комбинацию процессоров, реализующих вычислительную функцию, например, комбинацию одного или нескольких микропроцессоров, или комбинацию DSP и микропроцессора.
Этапы способа или алгоритма, описанные со ссылкой на контент, раскрытый в настоящем изобретении, могут быть непосредственно реализованы с использованием аппаратного обеспечения, программного модуля, выполняемого процессором, или их комбинации. Программный модуль может быть расположен в памяти RAM, флэш-памяти, памяти ROM, памяти EPROM, памяти EEPROM, регистре, жестком диске, переносном диске, CD-ROM или любых других носителях данных, известный в данной области техники. Например, носитель данных соединен с процессором, так что процессор может считывать информацию с носителя данных или записывать информацию на носитель данных. Конечно, носитель данных также может быть компонентом процессора. Процессор и носитель данных могут быть расположены в ASIC. Кроме того, ASIC может быть расположена в устройстве пользователя. Конечно, процессор и носитель данных могут быть установлены в устройстве пользователя в виде дискретных компонентов.
Параметры, ассоциированные с базовой матрицей, базовой матрицей или матрицей, расширенной на основе базовой матрицы, могут быть сохранены в памяти. Память может быть независимой, по меньшей мере, с одним процессором. Память также может быть интегрирована, по меньшей мере, в один процессор. Память является одним из видов машиночитаемых носителей данных.
Все или некоторые из вышеупомянутых вариантов осуществления могут быть реализованы посредством программного обеспечения, аппаратного обеспечения, встроенного программного обеспечения или любой их комбинации. Когда программное обеспечение используется для реализации вариантов осуществления, варианты осуществления могут быть реализованы полностью или частично в форме компьютерного программного продукта. Компьютерный программный продукт включает в себя одну или несколько компьютерных инструкций. Когда инструкции компьютерной программы загружаются и выполняются на компьютере, полностью или частично генерируют процедуру или функции согласно вариантам осуществления настоящего изобретения. Компьютер может быть компьютером общего назначения, выделенным компьютером, компьютерной сетью или другими программируемыми устройствами. Компьютерные инструкции могут храниться на машиночитаемом носителе или могут передаваться с машиночитаемого носителя на другой машиночитаемый носитель. Например, компьютерные инструкции могут передаваться с веб-сайта, компьютера, сервера или центра обработки данных на другой веб-сайт, компьютер, сервер или центр обработки данных по проводной сети (например, коаксиальный кабель, оптоволокно или цифровой абонент). линейный (DSL)) или беспроводным способом (например, инфракрасный, радио и микроволновый и т. п.). Машиночитаемый носитель данных может быть любым используемым носителем, доступным для компьютера, или устройством хранения данных, таким как сервер или центр обработки данных, объединяющим один или несколько используемых носителей. Используемым носителем может быть магнитный носитель (например, мягкий диск, жесткий диск или магнитная лента), оптический носитель (например, цифровой универсальный диск (DVD)), полупроводниковый носитель (например, твердотельный диск (SSD)) или тому подобное.
Приведенное выше описание настоящего изобретения предоставлено с целью предоставления возможности любому специалисту в данной области техники использовать настоящее изобретение. Специалистам в данной области техники будут очевидны различные модификации раскрытия, и общие принципы, определенные в данном документе, могут применяться к другим вариантам, не выходя за рамки сущности и объема настоящего изобретения. Таким образом, настоящее изобретение не предназначено для ограничения описанными в данном документе примерами и структурами, но должно соответствовать самому широкому объему, согласующемуся с принципами и новыми признаками, раскрытыми в настоящем документе.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ декодирования данных на основе LDPC кода | 2020 |
|
RU2747050C1 |
| УЛУЧШЕННОЕ ВЫКАЛЫВАНИЕ И СТРУКТУРА КОДА С МАЛОЙ ПЛОТНОСТЬЮ ПРОВЕРОК НА ЧЕТНОСТЬ (LDPC) | 2017 |
|
RU2718171C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КАНАЛЬНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ В СИСТЕМЕ СВЯЗИ, В КОТОРОЙ ИСПОЛЬЗУЮТСЯ КОДЫ КОНТРОЛЯ ЧЕТНОСТИ С НИЗКОЙ ПЛОТНОСТЬЮ | 2009 |
|
RU2450443C1 |
| АППАРАТУРА, СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ И АППАРАТУРА СВЯЗИ | 2018 |
|
RU2758968C2 |
| СПОСОБ ОБРАБОТКИ ИНФОРМАЦИИ И УСТРОЙСТВО СВЯЗИ | 2017 |
|
RU2740154C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ПЕРЕДАЧИ И ПРИЕМА ДАННЫХ В СИСТЕМЕ СВЯЗИ/ШИРОКОВЕЩАНИЯ | 2012 |
|
RU2595542C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КАНАЛЬНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ В СИСТЕМЕ СВЯЗИ, В КОТОРОЙ ИСПОЛЬЗУЮТСЯ КОДЫ КОНТРОЛЯ ЧЕТНОСТИ С НИЗКОЙ ПЛОТНОСТЬЮ | 2012 |
|
RU2520405C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КАНАЛЬНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ В СИСТЕМЕ СВЯЗИ, В КОТОРОЙ ИСПОЛЬЗУЮТСЯ КОДЫ КОНТРОЛЯ ЧЕТНОСТИ С НИЗКОЙ ПЛОТНОСТЬЮ | 2012 |
|
RU2520406C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КАНАЛЬНОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ В СИСТЕМЕ СВЯЗИ, ИСПОЛЬЗУЮЩЕЙ КОДЫ КОНТРОЛЯ ЧЕТНОСТИ С НИЗКОЙ ПЛОТНОСТЬЮ | 2009 |
|
RU2439793C1 |
| ВЫСОКОСКОРОСТНЫЕ ДЛИННЫЕ LDPC КОДЫ | 2017 |
|
RU2733826C1 |




Изобретение относится к области связи, и в частности к технологиям кодирования и декодирования данных. Технический результат заключается в предоставлении высокой пропускной способности при достаточных ресурсах кодирования/декодирования. Предложен эффективно декодируемый квазициклический код с низкой плотностью проверок на четность (QC-LDPC), который основан на базовой матрице нерегулярной QC-LDPC-матрицы, причем базовая матрица образована столбцами и строками, при этом столбцы делят на один или несколько столбцов, соответствующих выколотым узлам переменной (т.е. узлы переменной, соответствующие информационным битам, которые используются кодером, но не передаются или эффективно обрабатываются как не принятые декодером), и столбцы, соответствующие невыколотым узлам переменной, и строки делят на строки с высокой плотностью (т.е. строки, имеющие вес, который превышает первый вес) и строки с низкой плотностью (то есть, строки, имеющие вес, который меньше второго веса, в котором второй вес равен или меньше первого веса), в котором матрицу, определенную перекрытием строк низкой плотности и столбцов, соответствующих невыколотым узлам переменной, делят на группы ортогональных строк. 10 н. и 28 з.п. ф-лы, 13 ил.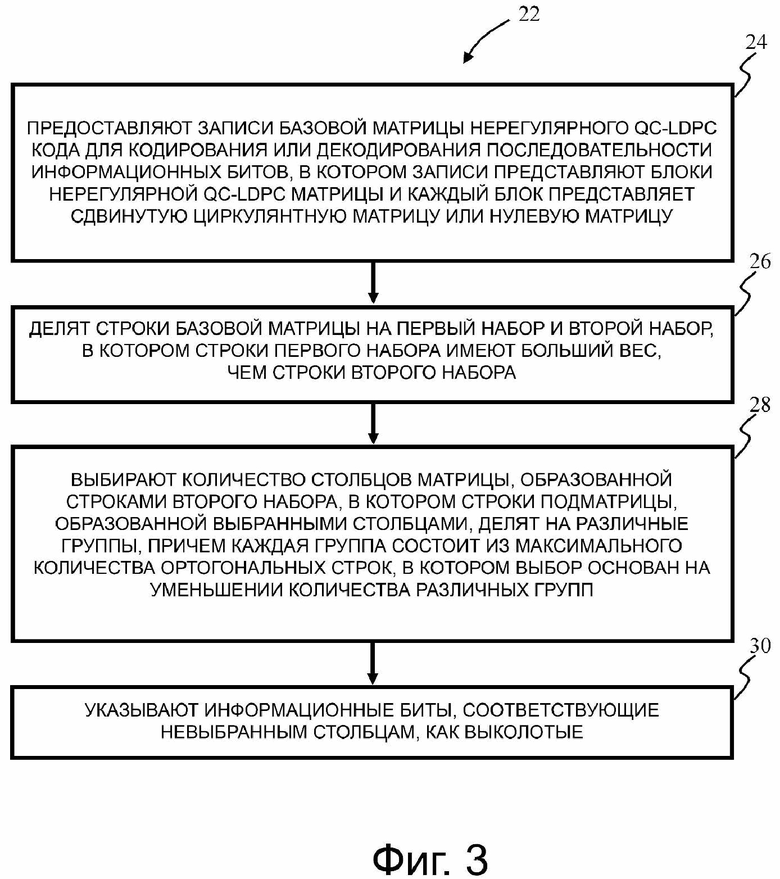
1. Способ беспроводной связи, содержащий:
получение последовательности информационных битов, которые должны быть закодированы;
кодирование последовательности информационных битов на основании базовой матрицы;
базовую матрицу, имеющую множество строк и столбцов, причем множество столбцов содержат, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы,
множество строк, содержащих первый набор строк и второй набор строк, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждая группа содержит, по меньшей мере, две последовательные строки, причем, по меньшей мере, две последовательные строки состоят из первой части и второй части,
первая часть является частью, по меньшей мере, одного выколотого столбца и строки первой части являются неортогональными, и
вторая часть является частью невыколотых столбцов, и строки второй части являются ортогональными.
2. Способ по п. 1, в котором, по меньшей мере, одна группа представляет собой две или более групп, причем две или более групп являются последовательными.
3. Способ по п. 1, в котором каждая группа состоит из максимального количества последовательных строк, являющихся ортогональными во второй части.
4. Способ по п. 1, в котором каждые две соседние строки для невыколотых столбцов во втором наборе являются ортогональными.
5. Способ по п. 1, в котором базовая матрица содержит 46 строк и 68 столбцов.
6. Способ по любому из пп. 1-5, дополнительно содержащий:
определение кодового слова, соответствующего последовательности информационных битов, на основании базовой матрицы;
и передачу кодового слова, за исключением информационных битов, соответствующих, по меньшей мере, одному выколотому столбцу.
7. Способ по любому из пп. 1-5, в котором базовая матрица содержит множество записей, представляющих блоки матрицы, и каждый блок матрицы представляет либо сдвинутую циркулянтную матрицу или нулевую матрицу.
8. Способ по п. 7, в котором сдвинутую циркулянтную матрицу обозначают значением сдвига, а значение сдвига определяет количество раз, когда единичная матрица должна быть циклически сдвинута вправо.
9. Способ по любому из пп. 1-5, дополнительно содержащий декодирование принятой последовательности информационных битов на основе базовой матрицы и информации о том, какие информационные биты выколоты.
10. Способ по п. 9, дополнительно содержащий этап, на котором получают принятую последовательность информационных битов в соответствии с сигналом, принятым по беспроводному каналу.
11. Устройство, содержащее:
кодер, выполненный с возможностью кодировать последовательность информационных битов на основании базовой матрицы;
базовую матрицу, имеющую множество строк и множество столбцов, причем
множество столбцов содержит, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы,
множество строк, содержащих первый набор строк и второй набор строк, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждая группа содержит, по меньшей мере, две последовательные строки, причем, по меньшей мере, две последовательные строки состоят из первой части и второй части,
первая часть является частью, по меньшей мере, одного выколотого столбца, и строки первой части являются неортогональными, и
вторая часть является частью невыколотых столбцов, и строки второй части являются ортогональными.
12. Устройство по п. 11, отличающееся тем, что устройство выполнено с возможностью выполнять способ по любому из пп. 2-10.
13. Устройство по п. 11, дополнительно содержащее память, выполненную с возможностью хранить параметры, ассоциированные с базовой матрицей.
14. Способ беспроводной связи, содержащий:
получение последовательности информационных битов, которые должны быть закодированы;
кодирование последовательности информационных битов на основании базовой матрицы;
базовую матрицу, содержащую множество записей, каждая запись представляет либо сдвинутую циркулянтную матрицу, либо нулевую матрицу;
базовую матрицу, содержащую множество строк и множество столбцов, причем множество столбцов содержит, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, причем множество строк содержит первый набор строк и второй набор строк, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждый невыколотый столбец в каждой группе имеет не более одной записи, представляющей сдвинутую циркулянтную матрицу, по меньшей мере, один выколотый столбец в каждой группе имеет, по меньшей мере, две записи, представляющие сдвинутую циркулянтную матрицу.
15. Способ по п. 14, в котором, по меньшей мере, одна группа представляет собой две или более групп, две или более групп являются последовательными.
16. Способ по п. 14, в котором каждая группа, состоящая из максимального количества последовательных строк, является ортогональной во второй части.
17. Способ по п. 14, в котором сдвинутая циркулянтная матрица представляет собой единичную матрицу, циклически сдвинутую вправо несколько раз, и количество раз задают значением сдвига.
18. Способ по п. 14, в котором базовая матрица содержит основную базовую матрицу, имеющую множество строк с указанием формы первой строки, первый набор строк начинается с первой строки, и второй набор строк начинается со следующей строки последней строки первого набора.
19. Способ по п. 14, в котором каждая из соседних двух строк подматрицы, образованной невыколотыми столбцами и строками второго набора, является ортогональной.
20. Способ по п. 14, в котором матрица, состоящая из поднабора столбцов матрицы, образованной строками первого набора, имеет двойную диагональную или треугольную структуру.
21. Способ по п. 14, в котором матрица, состоящая из поднабора столбцов матрицы, образованной строками второго набора, имеет структуру треугольной или единичной матрицы.
22. Способ по любому из пп. 14-21, дополнительно содержащий:
определение кодового слова, соответствующего последовательности информационных битов, на основании базовой матрицы; и
передачу кодового слова, за исключением информационных битов, соответствующих, по меньшей мере, одному выколотому столбцу.
23. Способ по любому из пп. 14-21, дополнительно содержащий декодирование принятой последовательности информационных битов на основе базовой матрицы и информации о том, какие информационные биты выколоты.
24. Способ по п. 23, дополнительно содержащий этап, на котором получают принятую последовательность информационных битов в соответствии с сигналом, принятым по беспроводному каналу.
25. Устройство, содержащее:
кодер, выполненный с возможностью кодировать последовательность информационных битов на основании базовой матрицы;
базовую матрицу, содержащую множество записей, каждая запись представляет либо сдвинутую циркулянтную матрицу, либо нулевую матрицу;
базовую матрицу, содержащую множество строк и множество столбцов, причем множество столбцов содержит, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, причем множество строк содержит первый набор строк и второй набор строк, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждый невыколотый столбец в каждой группе имеет не более одной записи, представляющей сдвинутую циркулянтную матрицу, по меньшей мере, один выколотый столбец в каждой группе имеет, по меньшей мере, две записи, представляющие сдвинутую циркулянтную матрицу.
26. Устройство по п. 25, отличающееся тем, что устройство выполнено с возможностью выполнять способ по любому из пп. 15-24.
27. Устройство по п. 25 или 26, дополнительно содержащее память, выполненную с возможностью хранить параметры, ассоциированные с базовой матрицей.
28. Устройство, содержащее:
декодер, выполненный с возможностью декодировать последовательность информационных битов на основании базовой матрицы;
базовую матрицу, имеющую множество строк и множество столбцов, причем множество столбцов содержит, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы,
множество строк, содержащих первый набор строк и второй набор строк, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждая группа содержит, по меньшей мере, две последовательные строки, причем, по меньшей мере, две последовательные строки состоят из первой части и второй части,
первая часть является частью, по меньшей мере, одного выколотого столбца, и строки первой части являются неортогональными, и
вторая часть является частью невыколотых столбцов, и строки второй части являются ортогональными.
29. Устройство по п. 28, отличающееся тем, что устройство выполнено с возможностью декодировать последовательность информационных битов на основании базовой матрицы, как определено в любом из пп. 2-10.
30. Устройство, содержащее:
декодер, выполненный с возможностью декодировать последовательность информационных битов на основании базовой матрицы;
базовую матрицу, содержащую множество записей, каждая запись представляет либо сдвинутую циркулянтную матрицу, либо нулевую матрицу;
базовую матрицу, содержащую множество строк и множество столбцов, причем множество столбцов содержат, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, причем множество строк содержит первый набор строк и второй набор строк, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждый невыколотый столбец в каждой группе имеет не более одной записи, представляющей сдвинутую циркулянтную матрицу, по меньшей мере, один выколотый столбец в каждой группе имеет, по меньшей мере, две записи, представляющие сдвинутую циркулянтную матрицу.
31 Устройство по п. 29, отличающееся тем, что устройство выполнено с возможностью декодировать последовательность информационных битов на основании базовой матрицы, как определено в любом из пп.15-24.
32. Устройство по п. 28 или 30, в котором декодер выполнен с возможностью декодировать последовательность информационных битов на основании процесса лавинообразного декодирования для узлов переменной, соответствующих, по меньшей мере, одному выколотому столбцу, и процесса многоуровневого декодирования для узлов, соответствующих невыколотым столбцам.
33. Система связи, содержащая устройство на стороне передачи и устройство на стороне приема,
устройство на стороне передачи выполнено с возможностью кодировать последовательность информационных битов на основании базовой матрицы и передавать кодированную последовательность информационных битов, за исключением информационных битов, соответствующих, по меньшей мере, одному выколотому столбцу,
устройство на стороне приема выполнено с возможностью принимать сигнал, содержащий кодированную последовательность информационных битов, за исключением информационных битов, соответствующих, по меньшей мере, одному выколотому столбцу, и декодировать принятый сигнал на основании базовой матрицы,
устройство на стороне передачи является устройством по п. 11 или 25, и
устройство на стороне приема является устройством по п. 28 или 30.
34. Способ беспроводной связи, содержащий:
получение последовательности информационных битов, которые должны быть декодированы;
декодирование последовательности информационных битов на основании базовой матрицы;
базовую матрицу, имеющую множество строк и столбцов, причем множество столбцов содержат, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы,
множество строк, содержащих первый набор строк и второй набор строк, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждая группа содержит, по меньшей мере, две последовательные строки, причем, по меньшей мере, две последовательные строки состоят из первой части и второй части,
причем первая часть является частью, по меньшей мере, одного выколотого столбца, и строки первой части являются неортогональными, и
вторая часть является частью невыколотых столбцов, и строки второй части являются ортогональными.
35. Способ по п. 34, в котором базовая матрица является базовой матрицей, как определено в любом из пп. 2-10.
36. Способ беспроводной связи, содержащий:
получение последовательности информационных битов, которые должны быть декодированы;
декодирование последовательности информационных битов на основании базовой матрицы;
базовую матрицу, содержащую множество записей, каждая запись представляет либо сдвинутую циркулянтную матрицу, либо нулевую матрицу;
базовую матрицу, содержащую множество строк и множество столбцов, причем множество столбцов содержит, по меньшей мере, один выколотый столбец и множество невыколотых столбцов, причем множество строк содержит первый набор строк и второй набор строк, первый столбец является выколотым столбцом или первые два столбца являются выколотыми столбцами, и каждый из по меньшей мере одного выколотого столбца имеет больший вес, чем другие невыколотые столбцы, и строки первого набора имеют больший вес, чем строки второго набора,
строки второго набора, содержащие, по меньшей мере, одну группу, причем каждый невыколотый столбец в каждой группе имеет не более одной записи, представляющей сдвинутую циркулянтную матрицу, по меньшей мере один выколотый столбец в каждой группе имеет, по меньшей мере, две записи, представляющие сдвинутую циркулянтную матрицу.
37. Способ по п. 36, в котором базовая матрица является базовой матрицей, как определено в любом из пп. 15-24.
38. Машиночитаемый носитель, содержащий инструкции, которые при выполнении на компьютере побуждают компьютер выполнять способ по любому из пп. 1-10, 14-24, 34 или 36-37.
| ЦЕНТРОБЕЖНЫЙ КОНЦЕНТРАТОР ДЛЯ ОБОГАЩЕНИЯ РУДЫ | 1995 |
|
RU2091171C1 |
| US 2008155385 A1, 2008.06.26 | |||
| US 2005283709 A1, 2005.12.22 | |||
| US 2011047433 A1, 2011.02.24 | |||
| УСТРОЙСТВО И СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ БЛОЧНОГО КОДА РАЗРЕЖЕННОГО КОНТРОЛЯ ЧЕТНОСТИ | 2005 |
|
RU2348103C2 |
| UANG-CHANG LEE ET AL | |||
| Two Informed Dynamic Scheduling Strategies for Iterative LDPC Decoders, IEEE TRANSACTIONS ON COMMUNICATIONS, IEEE SERVICE CENTER, PISCATAWAY, USA, vol.61, no.3, March 2013. | |||

