Изобретение относится к устройствам декодирования информации с использованием кодов с низкой плотностью проверок на четность (LDPC) и предназначено для обеспечения работы немеханических запоминающих устройств на основе микросхем памяти (SSD, USB Flash Drive, Flash Card и тд), применяется в аппаратуре контроллера немеханических запоминающих устройств на основе микросхем памяти.
В контроллерах твердотельных дисков LDPC коды стали применятся относительно недавно, заменив доминирующие много лет в этой области БЧХ (Боуза-Чоудхури-Хоквингема) коды. Одной из основных причин замены кодов на LDPC стал массовый переход производителей твердотельных дисков от моделей флэш-памяти, где в одной ячейке памяти хранится один бит, к более экономичным видам памяти, где плотность информации значительно выше (два, три и более бит).
С ростом числа исправляемых ошибок сложность LDPC декодеров растет линейно, что делает их более эффективными по площади и энергоэффективности, чем БЧХ декодеры. Дополнительным фактором в пользу выбора LDPC является высокая корректирующая способность: стандартный LDPC декодер (в отличие от БЧХ декодера), наряду с жёсткими решениями (‘0’ или ‘1’), получаемыми при чтении с носителя памяти, может использовать мягкие решения, представляющие собой вероятностные оценки (Log-Likelihood Ratio, LLR) для каждого бита хранимой информации, и получаемые путем чтения ячейки памяти с несколькими порогами чтения.
Недостатком предшествующих решений в LDPC декодерах является то, что управление декодированием потока данных не хранится в памяти самого декодера, а осуществляется через управляющий блок.
Техническим результатом заявленного изобретения является сохранение управляющего воздействия в памяти LDPC декодера, что позволяет его использование без управляющего блока, что в свою очередь обеспечивает уменьшение управляющей логики, увеличения тактовой частоты и расширение вариаций алгоритма декодирования, которые можно реализовать на декодере.
Результат обеспечивается тем, что предлагается способ декодирования данных на основе LDPC кода, в котором преобразование кодового слова осуществляется LDPC декодером, содержащим не менее двух блоков по обработке входных данных, в котором LDPC декодер содержит память команд, в которой содержится LDPC матрица первого типа, посредством которой осуществляется подача последовательности управляющих команд по обработке данных на блоки по обработке входных данных.
Применение последовательности управляющих команд позволяет существенно снизить сложность проектирования, поскольку выпадает самый сложный управляющий блок. Позволяет снизить площадь интегральной схемы и увеличить тактовую частоту схемы. Кроме того, расширяется класс определяющих структур, которые понимает данная схема, поскольку переход к новому типу определяющих структур, как правило, вызывает только изменение содержимого памяти команд.
На фиг. 1 изображена блок схема устройства для преобразования входных данных в выходные.
На фиг. 2 показан пример LDPC матрицы
На фиг. 3 изображен граф, соответствующий LDPC матрице.
Далее будет описано подробное осуществление изобретения.
Заявленный способ подразумевает использование LDPC декодера.
Предлагается новая архитектура построения LDPC декодера, управляемого через последовательное извлечение управляющих воздействий из памяти команд.
Предположим, требуется разработать проект интегральной схемы, реализующей устройство, предназначенное для преобразования входных данных в выходные. В случае если проектируемое устройство является LDPC декодером, то входные данные – это кодовое слово, содержащее проверочные биты, прошедшее через канал с ошибками, а выходные данные представляют собой кодовое слово с исправленными ошибками. Обычно устройство может по-разному функционировать в зависимости от некоторой определяющей структуры, которая загружается в память устройства и определяет порядок обработки данных. В случае LDPC декодера такой определяющей структурой является LDPC матрица. Как правило, устройство понимает некоторый класс определяющих структур и для каждой определяющей структуры из этого класса гарантирует правильное функционирование. Так, например, LDPC декодер может быть предназначен для обработки LDPC матриц первого типа.
Двоичную 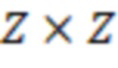 матрицу
матрицу  ,
,  , называют циркулянтной или циркулянтом размера
, называют циркулянтной или циркулянтом размера  , если первая её строка произвольна (нумерация строк начинается с нуля), а каждая следующая является циклическим сдвигом предыдущей на одну позицию вправо:
, если первая её строка произвольна (нумерация строк начинается с нуля), а каждая следующая является циклическим сдвигом предыдущей на одну позицию вправо: 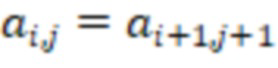 , (все операции в индексах по модулю ). Весом циркулянта называют число его ненулевых элементов в первой строке (число ненулевых элементов в любой строке и в любом столбце будет таким же). Двоичный циркулянт веса
, (все операции в индексах по модулю ). Весом циркулянта называют число его ненулевых элементов в первой строке (число ненулевых элементов в любой строке и в любом столбце будет таким же). Двоичный циркулянт веса 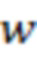 обычно задается множеством из позиций
обычно задается множеством из позиций  в которых в первой строке стоят ненулевые элементы. Например, приведённый ниже циркулянт размера
в которых в первой строке стоят ненулевые элементы. Например, приведённый ниже циркулянт размера 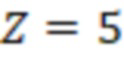 задается множеством индексов
задается множеством индексов 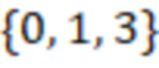 :
:

Двоичную 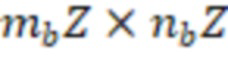 матрицу будем называть квазициклической с размером циркулянта , если она может быть представлена как блочная матрица
матрицу будем называть квазициклической с размером циркулянта , если она может быть представлена как блочная матрица

где каждый блок представляет собой некоторый циркулянт размера . Легко видеть, что любая двоичная квазициклическая матрица может быть задана  таблицей, в каждой клетке которой стоит соответствующее множество индексов
таблицей, в каждой клетке которой стоит соответствующее множество индексов  ,
,  . Мы будем называть такую матрицу, матрицей вида .
. Мы будем называть такую матрицу, матрицей вида .
Например, приведенная ниже,  квазициклическая матрица с размером циркулянта
квазициклическая матрица с размером циркулянта 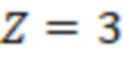

задается следующей  таблицей (пустая клетка означает нулевой циркулянт):
таблицей (пустая клетка означает нулевой циркулянт):
Двоичный квазициклический 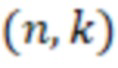 LDPC код описывается двоичной квазициклической проверочной матрицей с размером циркулянта , где
LDPC код описывается двоичной квазициклической проверочной матрицей с размером циркулянта , где  и
и  . Обычно на практике используются только квазициклические LDPC коды, у которых вес каждого циркулянта в проверочной матрице не превосходит 1. Такие матрицы называются LDPC матрицами первого типа, а соответствующие им коды называются LDPC кодами первого типа (Type-I LDPC).
. Обычно на практике используются только квазициклические LDPC коды, у которых вес каждого циркулянта в проверочной матрице не превосходит 1. Такие матрицы называются LDPC матрицами первого типа, а соответствующие им коды называются LDPC кодами первого типа (Type-I LDPC).
На фигуре 1 приведен пример блок схемы работы устройства по заявленному способу.
Здесь имеются несколько блоков по обработке входных данных A, B, C и D, две памяти для хранения данных M1, M2 и блок памяти команд. В блоке памяти команд сформированы последовательность управляющих команд, которую можно потом циклически повторять. НА основании управляющих команд блоки A, B, C, D выполняют операции по переработке данных.
Функционирование устройства реализуется через последовательное извлечение управляющих воздействий из памяти команд и подачи их на все блоки устройства.
Такой подход позволяет существенно снизить сложность проектирования, поскольку выпадает самый сложный с точки зрения проектирования блок управления. Позволяет снизить площадь интегральной схемы и увеличить тактовую частоту схемы. Кроме того, расширяется класс определяющих структур, которые понимает данная схема, поскольку переход к новому типу определяющих структур, как правило, вызывает только изменение содержимого памяти команд.
Реализация
Основные обозначения и параметры следующие.
На фиг. 2 изображен пример LDPC матрицы, в которой
• Число циркулянтных столбцов равно  .
.
• Число циркулянтных строк равно  .
.
• Размер циркулянта будем обозначать через  Он характеризует степень параллелизма алгоритма декодирования.
Он характеризует степень параллелизма алгоритма декодирования.
• Через  обозначим число выколотых циркулянтных столбцов. Выколотые столбцы соответствуют битам, которые не передаются по каналу связи.
обозначим число выколотых циркулянтных столбцов. Выколотые столбцы соответствуют битам, которые не передаются по каналу связи.
• Длина кодового слова будет равна 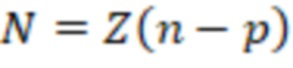 .
.
• Число информационных символов равно  .
.
• Скорость кода равна  .
.
• Циркулянты веса 0 будем называть пустыми или нулевыми.
• Для каждого непустого циркулянта LDPC матрицы вводится понятие предыдущего циркулянта. Предыдущим циркулянтом для данного циркулянта является ближайший сверху непустой циркулянт, расположенный в том же циркулянтном столбце. Для первого непустого циркулянта в столбце предыдущим циркулянтом будет последний непустой циркулянт в столбце.
Каждому циркулянтному столбцу сопоставим вершину, называемую variable node, а каждой циркулятной строке сопоставим вершину, называемую parity check node, и между i-ой parity check вершиной и j-ой variable вершиной проведем ребро только в случае, если на пересечении i-ой строки и j-ого столбца в LDPC матрице находится ненулевой циркулянт. Полученный граф изображен на фиг. 3 и характеризует LDPC матрицу.
Алгоритм декодирования предполагает последовательную пересылку сообщений между parity check вершинами и variable вершинами.
• Сообщение от variable вершины к parity check вершине будем называть v2c сообщением. Ширину v2c сообщения будем обозначать sum_width. Рекомендуемое значение sum_width равно 7 бит (6 бит + знак). Если знак равен 0, то число положительное, если знак равен 1, то число отрицательное.
• Сообщение от parity check вершины к variable вершине будем называть c2v сообщением. Ширину c2v сообщения будем обозначать min_width. Рекомендуемое значение min_width равно 5 бит (4 бита + знак).
• Через col_width обозначим  . Это значение равно числу бит для сохранения номера столбца.
. Это значение равно числу бит для сохранения номера столбца.
• Через row_width обозначим  . Это значение равно числу бит для сохранения номера строки.
. Это значение равно числу бит для сохранения номера строки.
• Через row_width1 обозначим 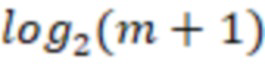 .
.
• Через cell_size_width обозначим 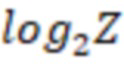 . Это значение равно числу бит для сохранения значения сдвига циркулянта.
. Это значение равно числу бит для сохранения значения сдвига циркулянта.
• Алгоритм декодирования состоит из iter_num итераций. Каждая итерация состоит в последовательной обработке всех непустых циркулянтов LDPC матрицы.
• Через iter_num_width обозначим 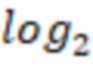 iter_num. Это значение равно числу бит для сохранения номера итерации.
iter_num. Это значение равно числу бит для сохранения номера итерации.
• В аппаратной реализации от parity check вершин к variable вершинам будут идти обобщенные c2v сообщения, которые будем называть gc2v сообщениями. Ширина gc2v сообщения будет равна gc2v_width = 1+2*(min_width-1)+col_width. Каждой строке LDPC матрицы соответствует одно обобщенное c2v сообщение. Обобщённое c2v сообщение составляется из 4 частей: gc2v = (col, sub_min, min, sg). Здесь sg – сумма по модулю 2 знаков всех c2v сообщений данной строки; min – минимальное значение модуля c2v сообщения, взятое по всем c2v сообщениям данной строки; sub_min – следующее после min минимальное значение модуля c2v сообщения, взятое по всем c2v сообщениям данной строки; col – номер циркулянтного столбца, где достигается минимум модуля c2v сообщения.
Структура LDPC декодера
Модуль LDPC декодера содержит следующие основные подмодули:
• Память v2c_mem для хранения v2c сообщений и знаков LLR:
• В случае ASIC это 2 памяти типа 1RW. В случае FPGA это одна память типа 1R1W. Память типа 1RW – это память, к которой в один такт возможно обращение либо с запросом на чтение, либо с запросом на запись. Память типа 1R1W – это память, к которой в один такт возможно обращение с одним запросом на чтение и с одним запросом на запись. В случае ASIC память типа 1RW существенно дешевле памяти типа 1R1W. В FPGA вся память типа 1R1W, т.е. имеется бесплатно.
• Количество элементов в памяти равно числу циркулянтных столбцов 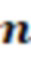 . В случае ASIC множество циркулянтных столбцов разбивается на 2 части, и информация о столбцах из первой части кладется в первую память, а об остальных столбцах во вторую.
. В случае ASIC множество циркулянтных столбцов разбивается на 2 части, и информация о столбцах из первой части кладется в первую память, а об остальных столбцах во вторую.
• Один элемент памяти содержит информацию об одном циркулянтном столбце и состоит из  v2c сообщений и знаков LLR данного циркулянтного столбца. Фактически в этих знаках формируется hard значение результата декодирования.
v2c сообщений и знаков LLR данного циркулянтного столбца. Фактически в этих знаках формируется hard значение результата декодирования.
• Ширина одного элемента этой памяти равна * sum_width + .
• Память c2v_mem для хранения обобщенных c2v сообщений:
• В случае ASIC это одна память типа 1RW. В случае FPGA это одна память типа 1R1W.
• Количество элементов в памяти равно числу циркулянтных строк  .
.
• Один элемент памяти содержит информацию об одной циркулянтной строке и состоит из gv2c сообщений данной циркулянтной строки.
• Ширина одного элемента этой памяти равна * gc2v_width.
• Память c2v_sign_mem для хранения знаков c2v сообщений:
• В случае ASIC это одна память типа 1RW. В случае FPGA это одна память типа 1R1W.
• В случае FPGA один элемент памяти содержит знаков v2c сообщений одной циркулянты. В случае ASIC один элемент памяти содержит 2* знаков v2c сообщений двух циркулянт.
• Ширина одного элемента этой памяти равна в случае FPGA и 2* в случае ASIC.
• Количество элементов в памяти равно числу ненулевых циркулянт LDPC матрицы в случае FPGA и числу ненулевых циркулянт LDPC матрицы, деленному на 2, в случае ASIC.
• Модуль CALC_C2V:
• Модуль вычисляет значение c2v сообщения cv2_out=(sg_out, abs_out), используя обобщённое c2v сообщение gc2v = (col, sub_min, min, sg), знак c2v сообщения sg_in и номер циркулянтного столбца col_in, следующим образом: sg_out=sg^sg_in; abs_out=(col_in==col) ? sub_min : min. Здесь операция ^ означает сложение по модулю 2.
• Модуль SUM:
• Модуль суммирует v2c сообщение и c2v сообщение.
• На выходе получаем LLR.
• Модуль MINUS_SAT:
• Модуль вычитает из LLR c2v сообщение.
• На выходе получаем v2c сообщение, равное сатурированному результату вычитания, а также получаем c2v сообщение, равное сатурированному результату вычитания, умноженному на 3/4.
• Модуль SHIFT_RIGHT:
• Модуль осуществляет циклический сдвиг вправо массива v2c сообщений или массива знаков v2c сообщений.
• Модуль CALC_GEN_C2V:
• Модуль вычисляет значение обобщённого c2v сообщения.
• Модуль на своих внутренних регистрах (col, sub_min, min, sg) сохраняет текущее состояние обобщённого c2v сообщения.
• В начале обработки очередной циркулянтной строки регистры инициализируются значениями (0, MaxValue, MaxValue, 0).
• В момент обработки очередного циркулянта обрабатываемой циркулянтной строки на вход модуля поступает c2v сообщение (sg_in, abs_in).
• Исходя из текущего состояния регистров (col, sub_min, min, sg) и значения (sg_in, abs_in) вычисляются новые значения (col, sub_min, min, sg).
• После обработки всех циркулянтов обрабатываемой циркулянтной строки на регистрах вырабатывается правильное значение обобщенного c2v сообщения.
• Память col_info_rom для хранения информации о непустых циркулянтах столбцов:
• Это память типа 1RW. Загрузка данных в память осуществляется в начале работы, а процессе декодирования память используется только на чтение. Поэтому в качестве этой памяти может быть использован ROM (read only memory).
• Имеется параметр hash_row_num, который говорит, о скольких циркулянтах сохраняется информация в одном элементе памяти. Ширина элемента памяти равна hash_row_num * (cell_size_width + row_width1). Тем самым информация об одном циркулянте занимает cell_size_width + row_width1 бит, причем младшие cell_size_width битов содержат значение сдвига циркулянта, а старшие row_width1 битов содержат номер строки, в которой лежит циркулянт. Если непустых циркулянтов в столбце меньше, чем hash_row_num, то у последних кусочков в старших битах будут стоять row_width1 единиц. Если непустых циркулянтов в столбце больше, то информация о столбце займет несколько элементов памяти.
• Просуммировав, сколько элементов памяти нужно каждому из столбцов матрицы, мы получим количество элементов в памяти. Например, в нашей LDPC матрице 75 столбцов и 10 строк. Мы приняли hash_row_num = 4. Каждый столбец матрицы кроме двух последних содержит не более 4-х непустых циркулянтов. Тем самым первым 73 столбцам нужно по одному элементу памяти. В двух последних столбцах по 9 непустых циркулянтов, значит, каждому их них нужно 3 элемента памяти. Тем самым, суммарный размер памяти равен 79. Размер памяти col_info_rom будем обозначать col_info_rom_capacity.
• Поскольку у нас размер циркулянта равен 512, то ширина памяти в нашем случае равна 4*(9+4) = 52.
• Память command_rom для хранения управляющих данных:
• Это память типа 1RW. Загрузка данных в память осуществляется в начале работы, а процессе декодирования память используется только на чтение. Поэтому в качестве этой памяти может быть использован ROM (read only memory).
• Ниже будет описан алгоритм обработки одного циркулянта, который осуществляется за 7 тактов (шагов). Семь последовательных элементов памяти команд содержат управляющие данные для обработки одного циркулянта. При этом используется конвейерный принцип, поэтому каждая команда памяти команд содержит разные управляющие данные для обработки семи разных циркулянтов.
• Количество элементов в памяти (количество команд) чуть больше числа непустых циркулянтов в LDPC матрице. Добавка образуется из того, что первые несколько шагов первой итерации отличаются от первых шагов последующих итераций, поскольку там появляются результаты действий последних шагов итерации. Кроме того, команды добавляются за счёт торможения процессов для вычисления синдромов в последних двух столбцах и торможения процессов для разрешения конфликтов обращений к памятям, если такие конфликты возникают. Количество элементов в памяти команд будем обозначать command_rom_capacity.
• Содержание памяти команд заполняется специальной программой, которая имитирует процесс декодирования и формирует команды по результатам данной имитации.
• Каждая команда памяти команд состоит из 15 полей в случае ASIC и 14 полей в случае FPGA:
• t1 – 1 бит – сообщает о том, что обрабатывается ячейка из первой части матрицы, имеется только в случае ASIC;
• before_v2c_mem_we – 1 бит – используется на шаге 5 и говорит, что в следующий такт надо писать в v2c_mem;
• iter_finish – 1 бит – сообщает о завершении итерации;
• c2v_sign_mem_en – 1 бит – используется на шаге 5 и говорит, что надо читать из c2v_sign_mem;
• c2v_sign_mem_we – 1 бит – используется на шаге 6 и говорит, что надо писать в c2v_sign_mem;
• first_time – 1 бит – используется на шаге 3 и говорит, что это первый ненулевой циркулянт в столбце;
• v2c_mem_en – 1 бит – используется на шаге 3 и говорит, что надо читать из v2c_mem;
• c2v_mem_en_for_prow – 1 бит – используется на шаге 3 и говорит, что надо читать из c2v_mem для строки предыдущего циркулянта;
• get_pc2v_from_cur_c2v_prev – 1 бит – используется на шаге 4 и говорит, что надо брать значение, вычисленное на шаге 7;
• c2v_mem_en_for_cur_row – 1 бит – говорит, что надо считывать из c2v_mem обобщенное c2v сообщение для текущей строки;
• v2c_mem_rd_adr – col_width бит – используется на шаге 3 и определяет адрес в v2c_mem;
• c2v_mem_rd_adr – row_width бит – используется на шаге 3 и определяет адрес в c2v_mem;
• rev_shift – cell_size_width бит – используется на шаге 5 как значение обратного сдвига;
• shift – cell_size_width бит – используется на шаге 5 как значение сдвига;
• gen_c2v_ready – 1 бит – говорит, что о готовности обобщенного c2v сообщения для текущей строки;
• part_col_info_rom_adr – log_2(col_info_rom_capacity+1) бит – адрес информации об ячейках столбца в col_info_rom; используется на шаге 4.
• Тем самым ширина одного элемента памяти команд равна 11 + col_width + row_width + 2*cell_size_width + log_2(col_info_rom_capacity+1) в случае ASIC. В случае FPGA ширина будет на 1 бит меньше.
• Модуль CALC_SYNDROME_PROC:
• Модуль вычисляет суммарное значение синдромов.
• Модуль имеет cell_size внутренних однобитовых регистров, на которых сохраняет текущее значение синдромов.
• В начале декодирования регистры синдромов устанавливаются в 0.
• В момент обработки очередного циркулянта на вход модуля подается текущее хард значение столбца, в котором находится циркулянт, и информация об этом столбце, извлечённая из памяти col_info_rom.
• С помощью поступившей информацией умножением на некоторую специальную матрицу получается некоторый вектор ширины cell_size, который суммируется побитно с регистрами синдромов. Результат суммирования опять сохраняется на этих же регистрах.
• Если в столбце больше чем hash_row_num непустых циркулянтов, то данная процедура повторяется несколько раз, при этом все остальные процессы притормаживаются.
• Если значение всех регистров синдромов становится равно нулю, то модуль поднимает флаг SYNDROME, который говорит об успешности декодирования.
• Счетчик команд:
• Это регистр ширины log_2(command_rom_capacity), содержащий номер текущей команды.
• В начальный момент декодирования устанавливается в 0.
• Увеличение счётчика происходит каждый такт.
• По окончании итерации, т.е. по сигналу iter_finish, значение счётчика команд устанавливается в значение BEG2_ADR, которое обычно равно 6. Это значение, с которого начинаются команды второй и более итераций.
• Счетчик итераций:
• Это регистр ширины iter_num_width, содержащий номер текущей итерации.
• В начальный момент декодирования устанавливается в 0.
• Увеличение счётчика происходит по сигналу iter_finish, который берётся из команды, извлечённой из памяти команд.
• Счетчик строк:
• Это регистр ширины row_width, содержащий номер текущей циркулянтной строки.
• В начале итерации устанавливается в 0.
• Увеличение счётчика происходит по сигналу gen_c2v_ready, который берётся из команды, извлечённой из памяти команд.
• Счетчик непустых циркулянтов:
• В случае ASIC непустые циркулянты обрабатываются парами, один циркулянт из первой половины матрицы, второй циркулянт из второй половины. В случае FPGA непустые циркулянты обрабатываются по одному. Если circ_num – число непустых циркулянтов (пар циркулянтов для случая ASIC ) LDPC матрицы, circ_num_width = circ_num, то счётчик непустых циркулянтов – это регистр ширины circ_num_width, содержащий номер текущего циркулянта (пары циркулянтов).
• В начале итерации устанавливается в 0.
• Увеличение счётчика происходит по сигналу gen_c2v_ready, который берется из команды, извлечённой из памяти команд.
Описание алгоритма декодирования
Алгоритм декодирования состоит в том, что выполняется iter_num итераций. Каждая итерация – это поочерёдная обработка ненулевых циркулянтов, при этом циркулянты перебираются по строкам, начиная с верхней. Порядок перебора внутри строки может быть любым и выбирается из некоторых специальных условий. Выполнение итерации состоит в поочередном чтении команд из памяти команд. Адресом извлечения из памяти команд является значение счётчика команд. Память команд как раз заполняется командами одной итерации. Счётчик итераций в начале декодирования устанавливается в 0 и увеличивается по сигналу iter_finish. Счётчик строк устанавливается в 0 в начале итерации и увеличивается по сигналу gen_c2v_ready. Значение счётчика строк используется как адрес памяти c2v_mem для извлечения обобщённого c2v сообщения текущей строки. Счётчик непустых циркулянтов устанавливается в 0 в начале итерации и увеличивается каждый такт или через такт. Значение счётчика непустых циркулянтов используется как адрес памяти c2v_sign_mem для извлечения знаков c2v сообщений.
Обработка одного непустого циркулянта заключается в выполнении следующих 7 шагов.
• Шаг 1:
• Читаем очередную команду из памяти команд command_rom.
• Шаг 2:
• Сохраняем команду на регистре команд, фактически на регистрах (gen_c2v_ready, shift, rev_shift, c2v_mem_rd_adr, v2c_mem_rd_adr, c2v_mem_en_for_cur_row, get_pc2v_from_cur_c2v_prev, c2v_mem_en_for_prow, v2c_mem_en, first_time, c2v_sign_mem_we, c2v_sign_mem_en, iter_finish, before_v2c_mem_we, t1).
• Шаг 3:
• Читаем из v2c_mem v2c сообщение и знаки LLR для текущего столбца, адрес которого берём из поля v2c_mem_rd_adr команды.
• Если поле c2v_mem_en_for_prow команды равно 1, то читаем из c2v_mem обобщенное c2v сообщение для предыдущего циркулянта, где адрес чтения берём из поля c2v_mem_rd_adr команды.
• Шаг 4:
• Сохраняем прочитанное из c2v_mem на регистрах prev_c2v. Если не успеваем читать из памяти c2v_mem, т.е. поле get_pc2v_from_cur_c2v_prev команды равно 1, то на этих регистрах могут быть сохранены значения, полученные на шаге 7.
• Сохраняем прочитанное из памяти v2c_mem на регистрах v2c_mem_do_r и llr_sign_r, здесь llr_sign_r – это хард решение (фактически знаки сум).
• Для случая ASIC читаем на тактах t1 (т.е. через такт) знаки c2v сообщений из c2v_sign_mem (сразу для пары циркулянтов). Для случая FPGA чтение осуществляется каждый такт. Адресом чтения является значение счётчика непустых циркулянтов.
• Если поле c2v_mem_en_for_cur_row команды равно 1, то читаем из c2v_mem обобщённое c2v сообщение для текущей строки. Адресом чтения является значение счётчика строк.
• Если поле part_col_info_rom_adr команды не равно -1, то читаем из памяти col_info_rom информацию о ячейках столбца. Адресом чтения является part_col_info_rom_adr.
• Шаг 5:
• По прочитанным значениям prev_c2v и знакам v2c_mem_do_r вычисляем с помощью модулей CALC_C2V значения c2v сообщений для текущего циркулянта и обозначаем их pmin. На этом шаге параллельно используется модулей CALC_C2V.
• Суммируем pmin с v2c_mem_do_r с помощью модулей SUM. Полученную сумму сохраняем на проводах sum. На этом шаге параллельно используется модулей SUM.
• С помощью модуля SHIFT_RIGHT циклически сдвигаем sum и сохраняем результат на регистрах sum_sh. Значение сдвига берём из поля shift команды.
• С помощью модуля SHIFT_RIGHT циклически сдвигаем знаки sum и обозначаем результат сдвига sum_sg_sh. Значение сдвига берём из поля rev_shift команды.
• Сохраняем sum_sg_sh на регистрах llr_sign_new.
• Сохраняем на тактах t1 (т.е. через такт) прочитанное из c2v_sign_mem на регистрах c2v_sign. Для случая FPGA сохранения производим каждый такт.
• Сохраняем на регистрах cur_c2v прочитанное из c2v_mem обобщённое c2v сообщение для текущей строки, если на предыдущем шаге это чтение было (т.е. если был сигнал c2v_mem_en_for_cur_row).
• Суммируем побитно по модулю 2 sum_sg_sh и llr_sign_r и результат сохраняем на регистрах llr_sign_rr.
• Извлечённую из памяти col_info_rom информацию сохраняем на регистрах col_info_rom_do_r.
• Шаг 6:
• По значениям cur_c2v и c2v_sign вычисляем с помощью модулей CALC_C2V новые значения c2v сообщений для текущего циркулянта и обозначаем их cur_min. При этом для случая ASIC на тактах t1 используем первую половину c2v_sign, а на тактах t2 – вторую. На этом шаге параллельно используется модулей CALC_C2V.
• С помощью модулей MINUS_SAT вычитаем из sum_sh вычисленные значения cur_min. Сатурированные результаты ширины sum_width сохраняем на проводах v2c_m, а сатурированные результаты ширины min_width сохраняем на регистрах cmin. На этом шаге параллельно используется модулей MINUS_SAT.
• Для случая FPGA знаки v2c_m записываем в c2v_sign_mem. Для случая ASIC на тактах t1 сохраняем знаки v2c_m на первой половине c2v_sign, а на тактах t2 (т.е. для циркулянтов из второй половины матрицы) первую половину c2v_sign и знаки v2c_m записываем в c2v_sign_mem.
• Записываем v2c_m и llr_sign_new в v2c_mem.
• Значения llr_sign_rr и col_info_rom_do_r подаём на вход модуля CALC_SYNDROME_PROC и вычисляем синдромы. Если в текущем столбце (где находится обрабатываемый циркулянт) больше чем hash_row_num непустых циркулянтов, то действия шагов 4, 5, 6, связанные с вычислением синдромов, повторяются несколько раз. При этом все остальные действия шагов 4, 5, 6, притормаживаются.
• Шаг 7:
• С помощью модулей CALC_GEN_C2V по значениям cmin актуализируем значения обобщённых c2v сообщений текущей строки. На этом шаге параллельно используется модулей CALC_GEN_C2V.
• Снимаем с выхода модуля CALC_SYNDROME_PROC сигнал SYNDROME и, если он равен 1, и текущая итерация не нулевая, то завершаем декодирование, сообщая об успешности декодирования.
• Если обработан последний непустой циркулянт текущей строки, т.е. получен сигнал gen_c2v_ready, то вычисленное значение обобщенных c2v сообщений текущей строки записываем в c2v_mem, и инициализируем внутренние регистры модулей CALC_GEN_C2V. Адресом операции записи является значение счётчика текущей строки.
• Увеличиваем счётчик текущей строки.


Изобретение относится к области декодирования информации с использованием кодов с низкой плотностью проверок на четность. Технический результат - обеспечение уменьшения управляющей логики и увеличения тактовой частоты за счет сохранения управляющего воздействия в памяти LDPC декодера. Способ декодирования данных на основе LDPC кода, в котором преобразование кодового слова осуществляется LDPC декодером, содержащим не менее двух блоков по обработке входных данных, характеризуется тем, что LDPC декодер содержит память команд, в которой последовательно записаны управляющие команды по обработке данных, циклически подающиеся на все блоки по обработке входных данных, а LDPC код представляет собой двоичный квазициклический LDPC код, описывающийся двоичной квазициклической проверочной матрицей с определенным размером циркулянта, при этом вес каждого циркулянта не превосходит 1, а при поступлении управляющих команд происходит соответствующая обработка ненулевых циркулянтов проверочной матрицы в блоках по обработке входных данных. 3 ил.
Способ декодирования данных на основе LDPC кода, в котором преобразование кодового слова осуществляется LDPC декодером, содержащим не менее двух блоков по обработке входных данных, отличающийся тем, что LDPC декодер содержит память команд, в которой последовательно записаны управляющие команды по обработке данных, циклически подающиеся на все блоки по обработке входных данных, а LDPC код представляет собой двоичный квазициклический LDPC код, описывающийся двоичной квазициклической проверочной матрицей с определенным размером циркулянта, при этом вес каждого циркулянта не превосходит 1, и при поступлении управляющих команд происходит соответствующая обработка ненулевых циркулянтов проверочной матрицы в блоках по обработке входных данных.
| US 7395490 B2, 01.07.2008 | |||
| КРАВЧЕНКО А.Н | |||
| Методы и аппаратура кодирования и декодирования низкоплотностных квазициклических кодов, 2012, с | |||
| Способ гальванического снятия позолоты с серебряных изделий без заметного изменения их формы | 1923 |
|
SU12A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| CN 101399553 B, 14.03.2012 | |||
| US 8504890 B2, 06.08.2013 | |||
| US 8255765 B1, 28.08.2012 | |||
| RU | |||

