ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к области вычислительной техники, в частности, к системе автоматической деперсонализации отсканированных рукописных историй болезни.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известен источник информации RU 2 691 214 C1, 11.06.2019, раскрывающий систему и способ распознавания символов с использованием искусственного интеллекта. В данном способе получают изображение текста, при этом текст на изображении содержит одно или более слов в одном или более предложениях; получают изображения текста в качестве первых исходных данных для набора обученных моделей машинного обучения, хранящего информацию о сочетаемости слов и частотности их совместного употребления в реальных предложениях; получают одно или более конечных выходных данных от набора обученных моделей машинного обучения, а также извлекают из одного или более конечных выходных данных одно или более предполагаемых предложений из текста на изображении. Каждое из одного или более предполагаемых предложений содержит вероятные последовательности слов.
Данное решение можно использовать для распознавания как машинного, так и рукописного текста. Однако данную систему и способ нельзя использовать для деперсонализации рукописных историй болезни, так как в ней отсутствует распознавание именованных сущностей с последующим закрашиванием найденных сущностей.
Из уровня техники известен источник информации US 10,007,658 B2, 26.06.2018, раскрывающий систему и способ многоступенчатого распознавания именованных объектов на основе морфологических и семантических особенностей текстов на естественном языке. Пример способа включает: выполнение лексико-морфологического анализа текста на естественном языке, содержащего множество токенов, причем каждый токен содержит, по меньшей мере, одно слово на естественном языке; определение на основе лексико-морфологического анализа одного или нескольких лексических значений и грамматических значений, связанных с каждым токеном из множества токенов. Для каждого токена множество токенов, оценивают одну или несколько функций классификатора с использованием лексических и грамматических значений, связанных с токенами, причем значение каждой функции классификатора указывает на степень ассоциации токена с категорией именованных объектов. Осуществляют выполнение синтаксико-семантического анализа по меньшей мере части текста на естественном языке для создания множества семантических структур, представляющих часть текста на естественном языке. Интерпретируют семантических структур с использованием набора правил производства для определения для одного или нескольких токенов, составляющих часть текста на естественном языке, степени ассоциации токена с категорией именованных объектов.
Недостаток данного решения заключается в том, что лексико-морфологический анализ требует, чтобы каждый токен содержал по крайней мере одно слово естественного языка, что налагает ограничения на способность распознавать сокращения. В предлагаемом решении отсутствует данный недостаток, в силу того, что распознавание происходит посимвольно.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технической проблемой, на решение которой направлено заявленное изобретение, является создание системы автоматической деперсонализации отсканированных рукописных историй болезни, которая охарактеризована в независимом пункте формулы. Дополнительные варианты реализации настоящего изобретения представлены в зависимых пунктах изобретения.
Технический результат заключается в повышении точности автоматической деперсонализации отсканированных рукописных историй болезни.
Заявленный результат достигаются за счет осуществления системы автоматической деперсонализации отсканированных рукописных историй болезни, которая содержит:
блок распознавания рукописного текста, выполненный с возможностью
распознавания по меньшей мере одного изображения рукописно текста, где текст на изображении содержит одно или более слов в одном или более предложениях,
получения по меньшей мере одного распознанного слова и по меньшей мере одной координаты распознанного слова,
последовательного сохранения в бинарный файл полученных по меньшей мере одного распознанного слова и по меньшей мере одной координаты распознанного слова;
блок распознавания именованных сущностей, выполненный с возможностью
выбора из полученного бинарного файла по меньшей мере одного распознанного слова,
отнесения по меньшей мере одного распознанного слова к по меньшей мере одной заранее заданной сущности,
объединения в последовательность по меньшей мере одной полученной сущности с по меньшей мере одним распознанным словом и по меньшей мере одой координатой распознанного слова,
сохранения полученной последовательности из по меньшей мере одной полученной сущности с по меньшей мере одним распознанным словом и по меньшей мере одой координатой распознанного слова в бинарный файл;
блок постобработки, выполненный с возможностью выделения по меньшей мере одной последовательности в по меньшей мере одном изображении рукописно текста, относящейся к заранее заданной сущности и закрашивания цветом по меньшей мере одной последовательности.
В частном варианте реализации заявленной системы, по меньшей мере одно отсканированное изображение рукописного текста, выполнено в растровом формате хранения данных.
В другом частном варианте реализации заявленной системы блок распознавания рукописного текста, выполнен с возможностью распознавания изображения рукописно текста посредством по меньшей мере одной нейронной сети.
В другом частном варианте реализации заявленной системы блок распознавания именованных сущностей, выполнен с возможностью распознавания именованных сущностей посредством по меньшей мере одной нейронной сети.
В другом частном варианте реализации заявленной системы к заранее заданным сущностям относятся, по меньшей мере, персона, организация и адрес.
В другом частном варианте реализации заявленной системы цвет для закрашивания выбирается пользователем.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг.1 иллюстрирует общий вид заявленной системы автоматической деперсонализации отсканированных рукописных историй болезни.
Фиг.2 иллюстрирует пример отсканированного изображения.
Фиг. 3 иллюстрирует пример бинаризованного изображения.
Фиг. 4 иллюстрирует пример изображения с обнаруженными линиями.
Фиг. 5 иллюстрирует пример общей схемы вычислительного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение работы системы автоматической деперсонализации отсканированных рукописных историй болезни, при помощи которой появится возможность обмениваться данными историй болезней между медицинскими организациями, работниками медицинских организаций, учебными заведениями, при этом сохранив конфиденциальность лиц, которые проходят лечение.
Заявленная система автоматической деперсонализации отсканированных рукописных историй болезни содержит: блок распознавания рукописного текста (S10), блок распознавания именованных сущностей (S20), блок постобработки (S30).
Историю болезни, которая заполнена врачом от руки, сканируют и получают отсканированные изображения рукописных историй болезни. Отсканированное изображение может быть в формате, по меньшей мере, .bmp, .jpeg или любых других форматов растрового изображения.
Блок распознавания рукописного текста (S1) представляет собой комбинацию двух нейронных сетей CNN (convolutional neural network) и следующую за ней RNN (Recurrent neural networks), а также классификатора СTC (Connectionist temporal classification).
Полученное отсканированное изображение (фиг.2) отправляют на вход блока распознавания рукописного текста (S1), где при помощи предварительно обученной нейронной сети Fully Convolutional Network осуществляют семантическую сегментацию изображения (фиг.3). Процесс семантической сегментации направлен на выделение на изображении участков с рукописным текстом, которые классифицируются как объект, все остальные участки классифицируются как фон. Каждому пикселю классифицированного участка присваивают бинарные значения, если пиксель относится к объекту, то ему присваивают значение 1, если пиксель относится к фону, то ему присваивают значение 0. Классификация нейронной сетью каждого пикселя происходит одновременно, при этом в нейронной сети завершающие полносвязные слои заменены на сверточные фильтры и деконволюции для перехода от бинарной метки для всего изображения (как в классификации картинок) к формированию бинаризованного изображения для сегментации.
Полученное бинаризованное изображение сегментируется на линии текста при помощи стандартных функций библиотеки OpenCV (фиг.4). При помощи функции findContours (режим поиска контуров CV_RETR_CCOMP, метод аппроксимации контуров настраивается, по умолчанию используется CV_CHAIN_APPROX_SIMPLE), находят границы в бинарном изображении, полученные границы сохраняют в по меньшей мере один вектор. Из полученного по меньшей мере одного вектора вычисляют линию для набора точек в по меньшей мере одном векторе, посредством функции boundignRect. Координаты границ каждой линий текста запоминаются. Для каждой линии, полученной на бинаризованном изображении, извлекается та часть исходного изображения, которая соответствует пикселям, равным единице, и получается финальная линия, используемая для распознавания текста. Затем линии масштабируются до заранее заданного размера (по умолчанию 32x300 px).
Каждая линия обрабатывается нейронной сетью, обученной минимизировать функцию потерь Connectionist Temporal Classification Loss. На выходе нейронной сети получается матрица, содержащая значения вероятности получения символа, для каждого возможного символа в алфавите, на каждом участке линии слева направо. Алфавит состоит из символов кириллицы, латиницы, цифр, знаков препинания, пробела и специального символа «пропуск», который необходим для разделения символов, если в тексте два символа повторяются. Данный символ не обязателен между двумя разными символами, например, если обозначить пропуск как «-», то слово «кот» кодируется как «-к-о-т-» или «кот», а слово «реет» кодируется как «ре-ет» или «р-е-е-т», но не «реет» или «р-ее-т», так как в последних двух случаях повторение одного и того же символа без пропуска считается одинарным вхождением. Количество участков в линии зависит от размера линии и архитектуры нейронной сети.
Финальный текст формируется выбором наиболее вероятного пути в матрице - последовательно выбирается наиболее вероятный символ на каждом шаге.
Таблица 1.
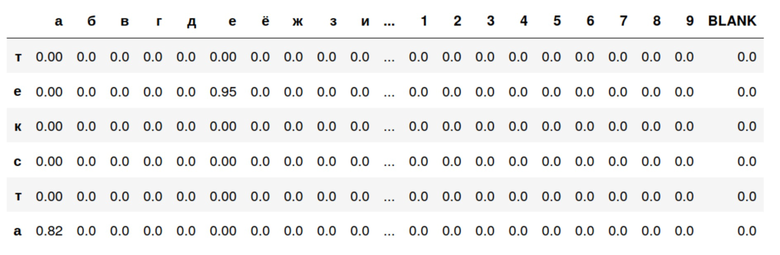
В таблице 1 приведен пример формирования текста выбором наиболее вероятного пути в матрице, симловы слова «текста» расположены сверху вниз, возможные символы алфавита справа налево (часть символов не указана в силу длины алфавита). Так значение символа «е» составляет 0,95, а значение символа «а» - 0,82, следовательно, сначала должен стоять символ «е», так как ее значение больше, а затем символ «а».
Для каждой вероятности, которая содержится в матрице, вычисляются соответствующие части исходной линии, формирующие наибольший вклад в вероятность пути при помощи анализа изменения предсказаний при добавлении специальным образом сгенерированного шума (маски) к данным поступающим на вход блока распознавания рукописного текста. Суть алгоритма состоит в оптимизации маски (изначально случайно сгенерированной из стандартного нормального распределения), добавляемой к изображению, с целью понижения вероятности символа из финального текста на соответствующей позиции. После нескольких итераций градиентного спуска, маска сходится на области, соответствующей очертаниям буквы.
Для каждого символа находятся границы соответствующей маски (относительно текущей линии) путем построения наименьшего прямоугольника, описывающего значимую часть маски.
Координаты прямоугольников для отдельных символов суммируются с границами линии для получения абсолютных координат символа в изображении.
Для последовательности символов (слова) координаты маски вычисляются как координаты прямоугольника, характеризуемого четырьмя вершинами (X1, Y1), (X2, Y1), (X1, Y2), (X2, Y2),
где X1 - самая левая X-координата прямоугольника, описывающего одну букву из слова;
X2 - самая правая X-координата прямоугольника, описывающего одну букву из слова;
Y1 - самая верхняя Y-координата прямоугольника, описывающего одну букву из слова;
Y2 - самая нижняя Y-координата прямоугольника, описывающего одну букву из слова.
Пары, состоящие из по меньшей мере одного распознанного слова и его координаты, последовательно записываются в бинарный файл. На этом этапе блок распознавания рукописного текста(S10) завершает работу и полученный бинарный файл передается в блок распознавания именованных сущностей (S20).
Блок распознавания именованных сущностей (S20) основан на методе обработки естественного языка, основанный на использовании нейронной сети для работы с последовательностями - BERT (Bidirectional Encoder Representations from Transformers). Блок обучен на коллекции открытых наборов данных, например, deeppavlov. На вход блока поступает список пар (по меньшей мере одно распознанное слово, по меньшей мере одна координата распознанного слова в изображении) в бинарном формате, полученном от блока распознавания рукописного текста (S10).
Задачей блока распознавания именованных сущностей (S20) является определение границ именованных сущностей (NE) в тексте и присвоении каждой сущности класса, как правило, из конечного множества классов.
Из бинарного файла прочитываются по меньшей мере одно распознанное слово.
Каждое распознанное слово классифицируется нейронной сетью, классами считаются виды Named Entity, которые заранее заданы. Распознанное слово анализируется и сопоставляется с классами сущностей в каталоге. При совпадении распознанного слова и класса сущностей каталога распознанное слово маркируется как сущность.
Пример результат распознавания именованных сущностей:
Таблица 2.
где O - other (что угодно), а B-PERSON и I-PERSON — классы, относящиеся к именованной сущности PERSON (человек).
Список полученных классов объединяется со списком пар (по меньшей мере одно распознанное слово, по меньшей мере одна координата распознанного слова в изображении) из бинарного файла, в результате получается последовательность, представляющая собой по меньшей мере одно распознанное слово, по меньшей мере одну координату распознанного слова и по меньшей мере одну именованную сущность.
Полученная последовательность записывается в бинарный файл и передается в блок постобработки (S30).
Далее полученный бинарный файл с последовательностью поступает на вход блока постобработки (S30). Блок постобработки (S30) представляет собой написанную программу, которая может быть написана на языках, таких как, но не ограничиваясь JavaScript, PHP, Perl, Python, зарисовывающую в отсканированном изображении слова, принадлежащие к интересующим типам именованных сущностей, по указанным координатам. На вход блока постобработки поступает отсканированное изображение рукописного текста и бинарный файл последовательностью.
Из бинарного файла с последовательностью выбирается по меньшей мере одно распознанное слово, по меньшей мере одна координата распознанного слова и по меньшей мере одна именованная сущность, которые принадлежат к заданному классу. К заданным классам относятся: персона (ФИО) названия организаций, адреса.
Перед началом зарисовки именованных сущностей, пользователь может выбрать цвет, которым будет зарисовываться интересующая сущность. Далее происходит поиск на отсканированном изображении по меньшей мере одного распознанного слова по сохраненным координатам, который относится к именованной сущности заданного класса и осуществляют зарисовку сплошной цветной линией данного по меньшей мере одного распознанного слова.
Например, на отсканированном изображении присутствует текст: «Иванов Иван Иванович, дата рождения 01.01.2001 год, проживающий в городе Москве, поступил в Городскую клиническую больницу №52, по адресу Пехотная ул., 3, Москва, 123182, с повышенной температурой тела (40°С) и сильными головными болями…», заданными классами являются: персона (Иванов Иван Иванович), организация (Городская клиническая больница №52), адрес (Пехотная ул., 3, Москва, 123182). Блок постобработки будет зарисовывать сплошной цветной линией слова, которые имеют свои координаты в тексте и которые относятся к заданной сущности. Следовательно, будут зарисованы сплошной цветной линией следующие слова:
1. Персона – (Иванов) (Иван) (Иванович);
2. Организация – (Городская) (клиническая) (больница) (№) (52);
3. Адрес – (Пехотная) (ул)(.) (3)(,) (Москва)(,) (123182).
Изображение с зарисованными словами сохраняется.
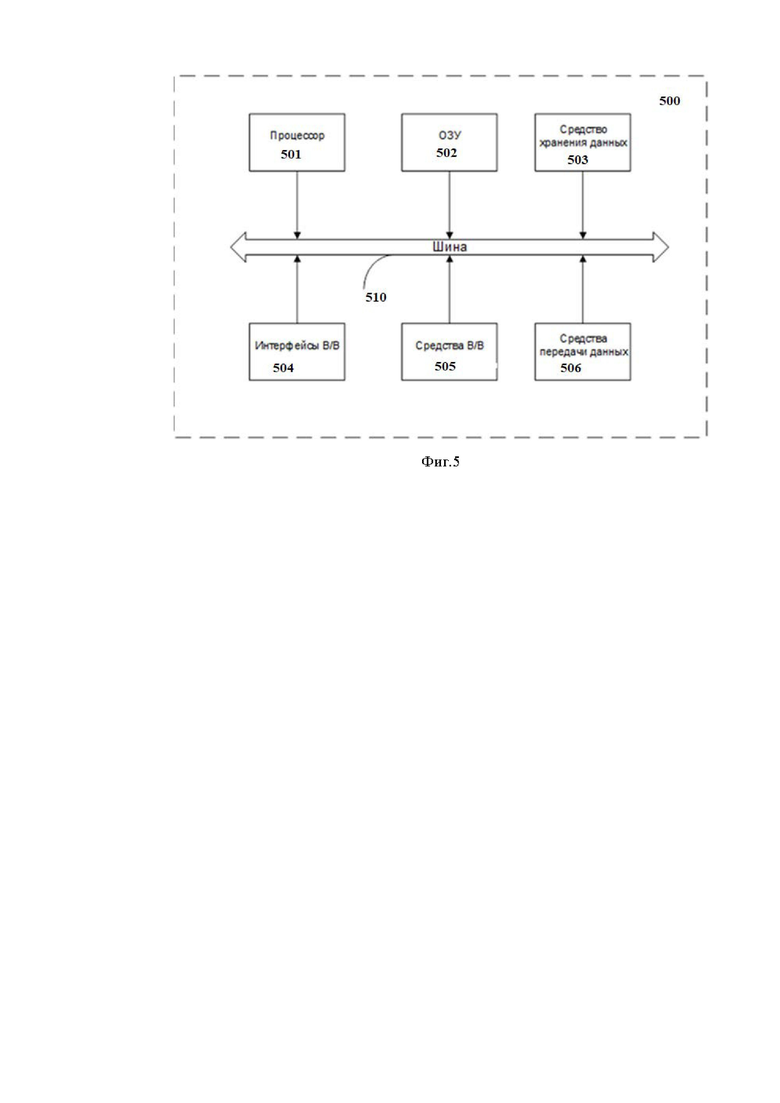
На Фиг. 5 далее будет представлена общая схема вычислительного устройства (500), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (500) содержит такие компоненты, как: один или более процессоров (501), по меньшей мере одну память (502), средство хранения данных (503), интерфейсы ввода/вывода (504), средство В/В (505), средства сетевого взаимодействия (506).
Процессор (501) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (500) или функциональности одного или более его компонентов. Процессор (501) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (502).
Память (502), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (503) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (503) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов с наборами данных пользователей, базы данных, содержащих записи измеренных для каждого пользователя временных интервалов, идентификаторов пользователей и т.п.
Интерфейсы (504) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (504) зависит от конкретного исполнения устройства (500), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (505) в любом воплощении системы, реализующей описываемый способ, должна использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (506) выбираются из устройства, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (505) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (500) сопряжены посредством общей шины передачи данных (510).
В настоящих материалах заявки было представлено предпочтительное раскрытие осуществление заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2021 |
|
RU2823914C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ЗНАКОВ | 2008 |
|
RU2390843C2 |
| УСТРОЙСТВО И СПОСОБ ПОИСКА РАЗЛИЧИЙ В ДОКУМЕНТАХ | 2013 |
|
RU2571378C2 |
| СИСТЕМА РУКОПИСНОГО ВВОДА/ВЫВОДА, ЛИСТ РУКОПИСНОГО ВВОДА, СИСТЕМА ВВОДА ИНФОРМАЦИИ, И ЛИСТ, ОБЕСПЕЧИВАЮЩИЙ ВВОД ИНФОРМАЦИИ | 2009 |
|
RU2536667C2 |
| СПОСОБЫ И СИСТЕМЫ ОБРАБОТКИ ИЗОБРАЖЕНИЙ МАТЕМАТИЧЕСКИХ ВЫРАЖЕНИЙ | 2014 |
|
RU2596600C2 |




Изобретение относится системе автоматической деперсонализации отсканированных рукописных историй болезни. Технический результат заключается в автоматической деперсонализации отсканированных рукописных историй болезни. Система содержит блок распознавания рукописного текста, блок распознавания именованных сущностей, блок постобработки и выполнена с возможностью распознавания изображения отсканированного рукописного текста истории болезни, сохранения в бинарный файл полученных распознанных слов и координат распознанных слов, выбора из полученного бинарного файла распознанных слов, отнесения их к заранее заданной именованной сущности, характеризующей персону, организацию и адрес, сохранения последовательности из полученной именованной сущности, распознанных слов и координат распознанных слов в бинарный файл, выбора полученной последовательности из полученного бинарного файла, поиска на отсканированном изображении рукописного текста истории болезни распознанных слов по сохраненным координатам, которые относятся к именованной сущности, характеризующей персону, организацию и адрес, осуществления зарисовки сплошным цветом данных распознанных слов. 4 з.п. ф-лы, 2 табл., 5 ил.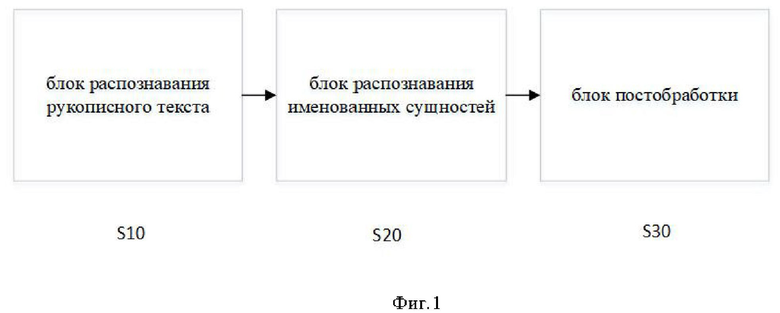
1. Система автоматической деперсонализации отсканированных рукописных историй болезни, содержащая:
блок распознавания рукописного текста, выполненный с возможностью
распознавания по меньшей мере одного изображения отсканированного рукописного текста истории болезни, где текст на отсканированном изображении содержит одно или более слов в одном или более предложениях,
получения по меньшей мере одного распознанного слова и по меньшей мере одной координаты распознанного слова,
последовательного сохранения в бинарный файл полученных по меньшей мере одного распознанного слова и по меньшей мере одной координаты распознанного слова;
блок распознавания именованных сущностей, выполненный с возможностью
выбора из полученного бинарного файла по меньшей мере одного распознанного слова,
отнесения по меньшей мере одного распознанного слова к по меньшей мере одной заранее заданной именованной сущности, характеризующей персону, организацию и адрес,
объединения в последовательность по меньшей мере одной полученной именованной сущности с по меньшей мере одним распознанным словом и по меньшей мере одой координатой распознанного слова,
сохранения полученной последовательности из по меньшей мере одной полученной именованной сущности с по меньшей мере одним распознанным словом и по меньшей мере одой координатой распознанного слова в бинарный файл и передачи его на блок постобработки;
блок постобработки, выполненный с возможностью
выбора по меньшей мере одной последовательности из полученного бинарного файла, относящейся к заранее заданной именованной сущности, характеризующей персону, организацию и адрес,
поиска на по меньшей мере одном отсканированном изображении рукописного текста истории болезни по меньшей мере одного распознанного слова по сохраненным координатам, которое относится к именованной сущности, характеризующей персону, организацию и адрес,
осуществления зарисовки сплошным цветом данного по меньшей мере одного распознанного слова.
2. Система по п.1, отличающаяся тем, что по меньшей мере одно отсканированное изображение рукописного текста истории болезни выполнено в растровом формате хранения данных.
3. Система по п.1, отличающаяся тем, что блок распознавания рукописного текста выполнен с возможностью распознавания отсканированного изображения рукописного текста истории болезни посредством по меньшей мере одной нейронной сети.
4. Система по п.1, отличающаяся тем, что блок распознавания именованных сущностей выполнен с возможностью распознавания именованных сущностей, характеризующих персону, организацию и адрес посредством по меньшей мере одной нейронной сети.
5. Система по п.1, отличающаяся тем, что цвет для закрашивания выбирается пользователем.
| МНОГОЭТАПНОЕ РАСПОЗНАВАНИЕ ИМЕНОВАННЫХ СУЩНОСТЕЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ МОРФОЛОГИЧЕСКИХ И СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2619193C1 |
| US 7647320 B2, 12.01.2010 | |||
| US 10007658 B2, 26.06.2018 | |||
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| US 10395772 B1, 27.08.2019. | |||

