ПЕРЕКРЕСТНЫЕ ССЫЛКИ НА СМЕЖНУЮ ПАТЕНТНУЮ ЗАЯВКУ
Настоящая заявка испрашивает приоритет по обычной заявке на патент США № 14/714,949, поданной 18 мая 2015 г., содержание которой полностью включено в настоящий документ путем ссылки.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Геномное секвенирование представляет собой эффективное средство для обнаружения генетической предрасположенности к менделевским заболеваниям. Анализ геномных последовательностей выявил наличие вариантов числа копий (ВЧК) (например, числа копий определенного гена в генотипе человека). ВЧК могут играть важную роль в заболевании человека и/или реакции на лекарственное средство. Однако идентификация ВЧК в данных геномной последовательности (например, данных последовательности экзома) является сложной задачей. Текущие решения предлагают обнаружение ВЧК из глубины прочтения последовательности человека, но они не подходят для исследований больших популяций порядка десятков или сотен тысяч экзомов. Их ограничения среди прочего включают в себя сложность интеграции в автоматизированный технологический процесс определения вариантов и то, что они плохо подходят для обнаружения одинаковых вариантов. В настоящем описании рассматриваются эти и другие недостатки.
ИЗЛОЖЕНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Следует понимать, что как приведенное ниже общее описание, так и последующее подробное описание представлены только для примера и разъяснения и не являются ограничивающими. Описаны способы и системы для определения вариантов числа копий. Пример способа может включать применение методики группировки образцов для выбора референтных данных покрытия, нормализацию данных покрытия образца, содержащих множество геномных областей, и подгонку смесовой модели к нормализованным данным покрытия образца на основе выбранных референтных данных покрытия. Пример способа может включать идентификацию одного или более вариантов числа копий (ВЧК) в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели. Пример способа может включать вывод одного или более вариантов числа копий.
В одном аспекте другой пример способа может включать предоставление данных покрытия образца, содержащих множество геномных областей, и получение указателя на референтные данные покрытия. Референтные данные покрытия могут быть выбраны на основе методики группировки образцов. Способ может включать выбор одного или более фильтров для применения к данным покрытия образца для нормализации данных покрытия образца и запроса на подгонку смесовой модели к нормализованным данным покрытия образца на основе референтных данных покрытия. Способ может включать запрос на идентификацию одного или более из вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели. Способ может дополнительно включать получение указателя на один или более вариантов числа копий.
В одном аспекте другой пример способа может включать получение данных покрытия образца, содержащих множество геномных областей, извлечение одного или более параметров для данных покрытия образца, применение методики группировки образцов к данным покрытия образца и референтным данным покрытия для выбора подмножества референтных данных покрытия, нормализацию данных покрытия образца, содержащих множество геномных областей, и подгонку смесовой модели к нормализованным данным покрытия образца на основе подмножества референтных данных покрытия. Способ может включать идентификацию одного или более вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели. Способ может включать вывод одного или более вариантов числа копий.
Дополнительные преимущества будут частично изложены в описании, которое следует или может быть изучено на практике. Преимущества будут реализованы и достигнуты с помощью элементов и комбинаций, особо указанных в прилагаемой формуле изобретения.
КРАТКОЕ ОПИСАНИЕ РИСУНКОВ
Сопроводительные рисунки, которые включены и составляют часть данного описания, иллюстрируют варианты осуществления и вместе с описанием служат для объяснения принципов способов и систем, при этом:
на Фиг. 1 представлена структурная схема, иллюстрирующая пример технологического процесса обнаружения ВЧК;
на Фиг. 2 представлена структурная схема, иллюстрирующая пример способа определения вариантов числа копий;
на Фиг. 3 представлен график, иллюстрирующий взаимосвязь содержания GC и покрытия;
на Фиг. 4 представлен график, иллюстрирующий нормализованное покрытие различных экзонов;
на Фиг. 5 представлена структурная схема, иллюстрирующая другой пример способа оценки вариантов числа копий;
на Фиг. 6 представлена структурная схема, иллюстрирующая другой пример способа оценки вариантов числа копий;
на Фиг. 7 представлена блок-диаграмма, иллюстрирующая пример операционной среды для выполнения описанных способов;
на Фиг. 8 представлено сравнение использования оперативной памяти CLAMMS и других алгоритмов;
на Фиг. 9 представлена таблица, иллюстрирующая параметры производительности для определения ВЧК по родословной CEPH;
на Фиг. 10 представлены определения ВЧК CLAMMS и ЭСMM по сравнению с золотым стандартом PennCNV;
на Фиг. 11 представлена таблица, иллюстрирующая подтверждение редких ВЧК TaqMan;
на Фиг. 12 представлена таблица, иллюстрирующая подтверждение общих ВЧК TaqMan;
на Фиг. 13 представлен график сравнения прогнозов числа копий CLAMMS и TaqMan для локуса общего варианта LILRA3;
на Фиг. 14 представлен график сравнения прогнозов числа копий CLAMMS и TaqMan для локуса общего варианта LILRA3; и
на Фиг. 15 представлен пример результата.
ПОДРОБНОЕ ОПИСАНИЕ
До изучения описания представленных способов и систем следует понять, что способы и системы не ограничены конкретными способами, конкретными компонентами или конкретными вариантами реализации. Следует также понимать, что применяемые в настоящем документе термины используются только в целях описания конкретных вариантов осуществления настоящего изобретения и не носят ограничительного характера.
В настоящем описании и в приложенной формуле изобретения формы единственного числа включают обозначения множественного числа, если иное четко не следует из контекста. В настоящем документе диапазоны могут быть выражены как от «около» одного определенного значения и/или до «около» другого определенного значения. Когда указывается такой диапазон, другой вариант осуществления включает интервал от одного конкретного значения и/или до другого конкретного значения. Аналогично, когда значения указаны как приблизительные с использованием предваряющего слова «около», следует понимать, что конкретное значение образует другой вариант осуществления. Далее будет понятно, что конечные точки каждого из диапазонов значительны как по отношению к другой конечной точке, так и независимо от другой конечной точки.
«Необязательный» или «необязательно» означает, что описанное ниже событие или обстоятельство может произойти или может не произойти и что описание включает случаи, когда указанное событие или обстоятельство происходит, и случаи, когда этого не происходит.
В описании и формуле настоящего изобретения понятие «содержать» и варианты понятия, такие как «содержащий» и «содержит», означают «включая, без ограничений» и не предназначены для исключения, например, других компонентов, систем или шагов. Понятие «иллюстративный» означает «пример» и не предназначено для передачи указателя из предпочтительного или идеального варианта осуществления. Понятие «такие, как» используется в пояснительных целях, а не в ограничительном смысле.
Следует понимать, что описанный способ и композиции не ограничены конкретной описанной методологией, протоколами и реагентами и могут различаться. Следует также понимать, что терминология, используемая в настоящем документе, служит только для описания конкретных вариантов осуществления и не ограничивает объем представленных способов и систем, который может быть ограничен только формулой изобретения.
Если не указано иное, все технические и научные термины, используемые в настоящем документе, имеют общепринятые значения, понятные любому специалисту в области, к которой относятся представленные способы и композиции. В настоящем документе описаны наиболее полезные способы, устройства и материалы, хотя для проверки или анализа представленных способов и композиций можно использовать любые способы и материалы, подобные или эквивалентные тем, которые описаны в настоящем документе. Публикации, цитируемые в настоящем документе, и материал, для которого они цитируются, специально включены путем ссылки. Ничто в настоящем документе не должно толковаться как признание того, что настоящее изобретение не имеет права предусматривать такое раскрытие в силу предшествующего изобретения. Не делается допущений, что любая ссылка представляет собой предшествующий уровень техники. В описании ссылок говорится, что утверждают их авторы, а заявители оставляют за собой право опротестовать точность и актуальность цитируемых документов. Следует четко понимать, что, хотя в данном случае упоминается ряд публикаций, такое упоминание не является признанием того, что любой из этих документов является частью общих знаний в данной области.
Описаны компоненты, которые можно использовать для реализации описанных способов и систем. Эти и другие компоненты описаны в настоящем документе, и следует понимать, что когда описываются комбинации, подмножества, взаимодействия, группы и т. д. этих компонентов, хотя конкретная ссылка каждой отдельной индивидуальной и коллективной комбинации и их перестановка не может быть явно описана, каждая специально рассматривается и описана здесь для всех способов и систем. Это относится ко всем аспектам этой сферы приложения, включая, без ограничений, шаги описанных способов. Таким образом, если существует множество дополнительных шагов, которые могут быть выполнены, следует понимать, что каждый из этих дополнительных шагов может быть выполнен с любым конкретным вариантом осуществления или комбинацией вариантов осуществления описанных способов.
Представленные способы и системы могут быть более понятны со ссылкой на следующее подробное описание предпочтительных вариантов осуществления и включенных в него примеров, а также фигуры и их предыдущее и последующее описание.
Как будет понятно специалисту в данной области, способы и системы могут принимать форму полностью аппаратного варианта осуществления, полностью программного варианта осуществления или варианта осуществления, сочетающего программные и аппаратные аспекты. Кроме того, представленные способы и системы могут принимать форму компьютерного программного продукта на машиночитаемом носителе данных, имеющем машиночитаемые средства команд компьютерных программ (например, программное обеспечение), реализованные на носителе данных. В частности, представленные способы и системы могут принимать форму реализованного в сети программного обеспечения. Можно использовать любой подходящий машиночитаемый носитель данных, включая жесткие диски, диски CD-ROM, оптические запоминающие устройства или магнитные запоминающие устройства.
Варианты осуществления способов и систем описаны ниже со ссылкой на иллюстрации блок-диаграммы и структурной схемы способов, систем, аппаратов и компьютерных программных продуктов. Следует понимать, что каждый блок на иллюстрациях блок-диаграммы и структурной схемы и комбинации блоков на иллюстрациях блок-диаграммы и структурной схемы соответственно могут быть реализованы с помощью компьютерных программных команд. Эти компьютерные программные команды могут быть загружены на компьютер общего назначения, компьютер специального назначения или другое программируемое устройство обработки данных для создания вычислительной машины, так что команды, которые выполняются на компьютере или другом программируемом устройстве обработки данных, создают средства для реализации функций, указанных в блоке или блоках структурной схемы.
Эти компьютерные программные команды также могут быть сохранены в машиночитаемой памяти, которая может указывать компьютеру или другому программируемому устройству обработки данных на необходимость выполнения определенных действий, так что команды, хранящиеся в машиночитаемой памяти, обеспечивают готовое изделие, включая машиночитаемые команды для реализации функции, указанной в блоке или блоках структурной схемы. Команды компьютерной программы также могут быть загружены на компьютер или другой программируемый аппарат обработки данных для вызова серии операционных шагов для выполнения на компьютере или другом программируемом аппарате для создания такого реализованного на компьютере процесса, что команды, которые исполняются на компьютере или другом программируемом аппарате, обеспечивают шаги для реализации функций, указанных на блок-схеме или блоках структурной схемы.
Соответственно, блоки на иллюстрациях блок-диаграммы и структурной схемы поддерживают комбинации средств для выполнения указанных функций, комбинации шагов для выполнения указанных функций и средства программных команд для выполнения указанных функций. Следует также понимать, что каждый блок на иллюстрациях блок-диаграммы и структурной схемы и комбинации блоков на иллюстрациях блок-диаграммы и структурной схемы могут быть реализованы с помощью специальных аппаратных компьютерных систем, которые выполняют указанные функции или шаги, или комбинаций специальных аппаратных и компьютерных команд.
Представленные способы и системы направлены на обнаружение ВЧК (например, идентификацию, прогнозирование, оценку). Некоторые аспекты представленных способов и систем можно назвать «Оценкой числа копий с применением смесовых моделей с выравниванием по решетке (CLAMMS)». Определение вариантов числа копий с полноэкзомным секвенированием (ПЭС) может быть сложной задачей, поскольку точечные разрывы ВЧК, вероятно, выйдут за пределы экзома. В представленных способах и системах могут использоваться глубины прочтения в ВЧК. Такие глубины прочтения могут быть линейно коррелированы с состоянием числа копий. Однако глубина покрытия может подвергаться как систематическим ошибкам (например, часто связанным с содержанием GC последовательности), так и стохастической волатильности (например, усугубляться изменением качества входной ДНК). Представленные способы и системы могут нормализовать данные покрытия для корректировки систематических ошибок и характеризовать ожидаемый профиль покрытия с диплоидным числом копий, так что истинные ВЧК можно отличить от шума. Такая нормализация может включать, например, сравнение данных покрытия каждого образца с данными из «референтной панели» (например, референтных данных покрытия) аналогично упорядоченных образцов. Изменчивость в процедурах подготовки образцов и секвенирования может привести к дополнительным ошибкам покрытия, которые обычно называются «групповыми эффектами».
В одном аспекте представленный способ и системы могут идентифицировать ВЧК на основе использования как смесовых моделей, так и скрытых марковских моделей (СMM). Например, смесовые модели могут выравниваться на основе референтных данных покрытия, определяемых с использованием алгоритма группировки образцов, такого как алгоритм k ближайших соседей. Информацию из смесовых моделей можно вводить в СMM для идентификации ВЧК.
На ФИГ. 1 представлена структурная схема, иллюстрирующая пример технологического процесса обнаружения ВЧК. Референтная панель данных покрытия (например, референтные данные покрытия, содержащие одну или более геномных областей захвата) может выбираться для каждого образца (например, данные покрытия образца, содержащие одну или более геномных областей захвата) на основе множества параметров (например, контроля качества (КК) секвенирования) с использованием методики группировки образцов. Методика группировки образцов может включать методику (например, алгоритм) для группирования образцов по подобию. Примеры методик группировки образцов, которые можно использовать, включают, без ограничений, дерево принятия решений, метод опорных векторов, алгоритм k ближайших соседей (knn), наивный байесовский алгоритм, алгоритм CART (деревья классификации и регрессии) и/или т. п. Например, алгоритм kNN может включать формирование структуры k-мерного дерева. Референтные данные покрытия могут выбираться путем введения данных покрытия образца (или, например, параметров, связанных с данными покрытия образца) в структуру k-мерного дерева и идентификации заранее определенного числа ближайших соседей (например, 10, 100, 1000, 10 000 и т. п.). После выбора референтных данных покрытия образцы могут быть обработаны параллельно. Анализ уровня образца (правая панель) включает нормализацию покрытия, подгонку распределений покрытия с помощью смесовой модели и формирование определений из СMM.
В одном аспекте пример варианта осуществления представленных способов и систем описан на ФИГ. 1. Как показано на левой панели, референтные данные покрытия (например, извлеченные из набора образцов) могут использоваться в рамках методики группировки образцов. Хотя в качестве примера методики группировки образцов используется алгоритм k ближайших соседей, в котором применяется k-мерное дерево, следует понимать, что могут применяться и другие методики группировки образцов (например, любой подходящий алгоритм кластеризации, группирования и/или классификации). k-мерное дерево может включать многомерное дерево поиска для точек в k-мерном пространстве. Например, в методике группировки образцов может использоваться множество параметров референтных данных покрытия. Например, для построения k-мерного дерева может использоваться множество параметров референтных данных покрытия. Такое множество параметров может, например, включать параметры контроля качества (КК) секвенирования, метаданные образца, связанные с происхождением параметры, показатели сходства последовательностей и/или любой параметр, который отражает вариабельность на уровне образца. Например, в случае параметров КК секвенирования можно использовать семь параметров КК. В качестве примера параметры КК секвенирования могут включать GCDROPOUT, ATDROPOUT, MEANINSERTSIZE, ONBAITVSSELECTED, PCTPFUQREADS, PCTTARGETBASES10X, PCTTARGETBASES50X и/или т. п. Параметры КК секвенирования могут масштабироваться (например, посредством применения линейного преобразования) и обрабатываться для построения k-мерного дерева.
Множество параметров (например, параметры КК секвенирования) для данных покрытия образца могут также масштабироваться и вводиться в k-мерное дерево. Затем k-мерное дерево может использоваться для проведения поиска ближайших соседей для идентификации ближайших соседей данных покрытия образца. В референтных данных покрытия можно идентифицировать любое число ближайших соседей (например, 10, 100, 1000, 10 000 и т. п.). Желаемое число ближайших соседей может использоваться для формирования выбранных референтных данных покрытия (например, подмножества референтных данных покрытия). Представленные способы и системы могут обеспечить решение проблемы гетерогенности данных за счет использования выборочных референтных данных покрытия для каждого образца. Например, параметр расстояния между образцами (например, референтные данные покрытия) может определяться на основе описанных выше семи параметров КК секвенирования. В частности, параметры КК секвенирования могут определяться, выбираться, приниматься и/или т. п. с помощью инструмента секвенирования, такого как Picard. Каждый вновь секвенированный образец может добавляться к k-мерному дереву в таком пространстве параметров. ВЧК может определяться с использованием выбранных референтных данных покрытия, содержащих k (например, 100) ближайших соседей индивидуального образца. k ближайшие соседи могут определяться с использованием любого алгоритма поиска ближайших соседей, например алгоритма k-мерного дерева или другой методики группировки образцов.
Как показано на правой панели, из набора образцов могут извлекаться данные покрытия образца (например, образца i). Данные покрытия образца можно нормализовать для коррекции сдвига GC-амплификации и общей средней глубины покрытия. В другом аспекте может проводиться фильтрование данных покрытия образца. Например, данные покрытия образца могут фильтроваться на основе уровня содержания GC, на основе показателя картируемости, на основе центральной тенденции покрытия ридами, на основе окна распознавания в экзомной области захвата мультикопийной дупликации, их комбинаций и т. п. Например, глубина считывания в областях с низкой картируемостью может неточно отражать дозу последовательности в геноме.
После нормализации данных покрытия образца выбранные референтные данные покрытия (ближайшие соседи) могут использоваться для обработки по конечной смесовой модели для одной или более (или каждой) геномных (или экзомных) областей захвата в данных покрытия образца. Конечная смесовая модель может включать комбинацию двух или более функций плотности вероятности. Конечная смесовая модель может включать один или более компонентов, например: N случайных переменных, соответствующих наблюдениям, каждый из примеров предположительно распределяется в соответствии со смесью K компонентов, причем каждый из компонентов относится к одному и тому же семейству параметров распределений, но с различными параметрами; N соответствующих случайных латентных переменных, определяющих специфичность компонента смесовой модели каждого наблюдения, каждый из примеров распределен в соответствии с K-мерным категорийным распределением; набор K смесовых весов, каждый из примеров представляет собой вероятность (действительное число от 0 до 1 включительно), сумма которых составляет 1; набор K параметров, каждый из которых определяет параметр соответствующего компонента смесовой модели. В некоторых аспектах параметр может включать набор параметров. В представленных способах и системах каждый компонент смесовой модели может моделировать ожидаемое распределение покрытия по образцам для конкретного состояния целого числа копий. Возможны адаптации для учета гомозиготных делеций и половых хромосом.
В одном аспекте для обработки по конечной смесовой модели может использоваться алгоритм максимизации ожидания (МО). Алгоритм МО представляет собой общий способ поиска оценок максимального правдоподобия в случае пропущенных значений или латентных переменных. Алгоритм МО может представлять собой итерационный алгоритм. Итерации могут чередоваться между шагом ожидания (О), на котором может генерироваться функция ожидания логарифмического правдоподобия, рассчитываемого с использованием текущей оценки параметров, и шагом максимизации (М), на котором могут вычисляться параметры, максимизирующие ожидаемое логарифмическое правдоподобие, определяемое на шаге О. Такие оценки параметров могут затем использоваться, чтобы найти распределение латентных переменных на следующем шаге О.
В одном аспекте ВЧК может определяться для данных покрытия образца с использованием скрытой марковской модели (СММ). Например, значения нормализованного покрытия индивидуального образца для каждой области могут представлять собой исходную последовательность для СММ. Вероятности эмиссии СММ могут быть основаны на отработанных (например, подходящих, адаптированных) смесовых моделях. Вероятности перехода СММ могут быть аналогичны используемым в других моделях, таких как ЭСММ, которая включена в настоящий документ путем ссылки. Смесовые модели позволяют производить обработку числа копий полиморфных локусов естественным образом, тогда как СММ включает предварительные ожидания того, что ближайшие аномальные сигналы с большей вероятностью представляют собой часть ВЧК, а не множество небольших ВЧК. Представленные способы и системы могут объединять смесовые модели и СММ в единую вероятностную модель.
На ФИГ. 2 представлена структурная схема, иллюстрирующая пример способа 200 для определения вариантов числа копий. В одном аспекте представленный способ и система могут выполняться с возможностью анализа данных покрытия образца, содержащих множество геномных областей, для выявления ВЧК. На шаге 202 может применяться методика группировки образцов для выбора референтных данных покрытия. Например, методика группировки образцов может включать методику (например, алгоритм) для группирования образцов по подобию. Применение методики группировки образцов для выбора референтных данных покрытия может включать получение множества параметров для данных покрытия образца. Параметр расстояния между данными покрытия образца и референтными данными покрытия может определяться на основе множества параметров. Референтные данные покрытия могут выбираться (например, для каждого образца) на основе параметра расстояния. Методика группировки образцов может включать алгоритм группирования, алгоритм кластеризации, алгоритм классификации и/или т. п. Например, методики группировки образцов могут включать дерево принятия решений, метод опорных векторов, алгоритм k ближайших соседей (knn), наивный байесовский алгоритм, алгоритм CART (деревья классификации и регрессии) и/или т. п. Например, в случае применения к выбранным референтным данным покрытия методики группировки образцов способ может включать масштабирование множества параметров, связанных с референтными данными покрытия, построение k-мерного дерева на основе масштабированного множества параметров, связанных с референтными данными покрытия, масштабирование множества параметров, связанных с данными покрытия образца, добавление данных покрытия образца к k-мерному дереву на основе масштабированного множества параметров, связанных с данными покрытия образца, идентификацию заранее заданного числа ближайших соседей с данными покрытия образца в качестве выбранных референтных данных покрытия и/или т. п.
Ниже более подробно описано применение методики группировки образцов для выбора референтных данных покрытия. Сдвиги систематического покрытия, которые возникают из-за варьируемых условий секвенирования, часто называют «групповыми эффектами». В одном аспекте представленные способы и системы могут выполняться с возможностью использования подхода избираемой референтной панели (например, выбранных референтных данных покрытия) для корректировки групповых эффектов. Например, вместо применения сопоставления данных покрытия образца на основе профилей покрытия образца - многомерное пространство - представленные способы и системы можно выполнять с возможностью рассмотрения низкоразмерного пространства параметров на основе параметров контроля качества (КК) секвенирования. Например, параметры КК секвенирования могут включать семь параметров КК секвенирования. Параметры КК секвенирования могут включать параметры секвенирования КК из инструмента секвенирования, такого как Picard. Операции в таком низкоразмерном пространстве обеспечивают более точную масштабируемость. Например, образцы могут предварительно индексироваться (например, с использованием любой подходящей индексации и/или алгоритма поиска). В качестве дополнительного примера образцы могут предварительно индексироваться с помощью алгоритма k ближайших соседей. Например, в алгоритме k ближайших соседей может использоваться структура k-мерного дерева, которая позволяет формировать быстрые запросы на поиск ближайших соседей и использует минимальные объемы ОЗУ.
В качестве иллюстрации можно привести следующий пример процесса определения вариантов.
1. Запрос лабораторной системы управления информацией на извлечение семи параметров Picard для контроля качества секвенирования для каждого образца: GCDROPOUT, ATDROPOUT, MEANINSERTSIZE, ONBAITVSSELECTED, PCTPFUQREADS, PCTTARGETBASES10X и PCTTARGETBASES50X.
2. Ввод структуры данных k-мерного дерева вектора параметров КК каждого образца после применения линейного преобразования для масштабирования каждого параметра в рамках интервала [0, 1] (например, масштабированное значение=[исходное значение - мин.]/[макс. - мин.]).
3. Параллельно для каждого образца:
(a) расчет глубины покрытия из файла BAM с помощью SAMtools и выполнение CLAMMS на шаге нормализации образца;
(b) отработка моделей CLAMMS с использованием 100 ближайших соседей образца в k-мерном дереве;
(c) определение ВЧК с помощью этих моделей.
В одном аспекте большие значения k могут снижать дисперсию при статистическом анализе параметров смесовой модели, но увеличивать сдвиг. Значение k по умолчанию может выбираться в соответствии с конкретными сферами применения. В некоторых сценариях значение по умолчанию k=100 может обеспечивать наиболее оптимальное соотношение между сдвигом и дисперсией. Приведенный процесс можно расширить для работы в сети (например, веб-интерфейс), если k-мерное дерево хранится в базе данных. В некоторых сценариях, например при маломасштабных исследованиях, представленные способы и системы могут также использоваться без необходимости рассчитывать параметры КК. Например, образцы могут быть вручную отнесены к группам на основе графика PCA для матрицы покрытия образец-экзон. Отдельный набор моделей может отрабатываться для каждой группы и использоваться для определения ВЧК в образцах такой группы.
В одном аспекте представленные способы и системы могут подразделять множество геномных областей данных покрытия образца на одно или более окон распознавания (например, множество окон распознавания). Например, представленные способы и системы могут подразделять геномные (например, экзомные) области захвата на окна распознавания равных размеров. Например, геномные области захвата, которые превышают или равны по длине 1000 п.н., могут подразделяться на равные по размерам окна распознавания по 500-1000 пар нуклеотидов (п.н.). Представленные способы и системы могут выполняться с возможностью подразделять геномные области на окна распознавания таким образом, чтобы обеспечивать выявление ВЧК, которые частично перекрываются с длинными экзонами. К примерам генов с чрезвычайно длинными экзонами относятся AHNAK, TTN и несколько муцинов. В одном аспекте подразделяться могут только геномные области из множества геномных областей, превышающих заранее заданный размер, например более 999 оснований. Следует отметить, что можно использовать любое другое подходящее число оснований.
В одном аспекте способы и системы могут необязательно включать фильтрование данных покрытия образца. Фильтрование может осуществляться непосредственно перед шагом 202, в ходе выполнения шага 202 и/или в процессе выполнения других шагов способа 200. Фильтрование данных покрытия образца может включать фильтрование одного или более окон распознавания на основе уровня содержания гуанина-цитозина (GC). Фильтрование одного или более окон распознавания на основе уровня содержания GC может предусматривать исключение окна распознавания из одного или более окон распознавания, если уровень содержания GC окна распознавания выходит за пределы заранее заданного интервала. В одном аспекте представленные способы и системы могут фильтровать окна с экстремальными показателями содержания гуанина-цитозина (GC). Сдвиг GC-амплификации может корректироваться в случае по большей части постоянного сдвига для любого конкретного уровня содержания GC. Однако при очень низком или очень высоком содержании GC стохастическая волатильность покрытия может резко возрастать, что осложняет эффективную нормализацию. Соответственно, с помощью представленных способов и систем можно фильтровать окна, в которых доля GC лежит вне изменяемого (или, например, заранее заданного) интервала или предела. В качестве примера изменяемый интервал может включать [0,3, 0,7], как показано на ФИГ. 3. Однако следует понимать, что при необходимости могут использоваться и другие интервалы значений (например, пределов).
В качестве дополнительного пояснения фильтрования на основе содержания GC на ФИГ. 3 приводится график, отражающий взаимосвязь между содержанием GC и покрытием. Например, вариационный коэффициент (т. е. стандартное отклонение, поделенное на среднее значение) покрытия отложен по оси у, а содержание GC отложено по оси х. На графике отображено 50 образцов (например, для наглядности приводится разброс точек). Выше заданного по умолчанию верхнего предела (например, GC=0,7) изменяемого интервала дисперсия покрытия может быть очень высокой по отношению к среднему значению, что делает определение ВЧК на основе покрытия ненадежным. Ниже заданного по умолчанию нижнего предела (например, содержание GC=0,3) изменяемого интервала возникают дополнительные проблемы. Например, возможна высокая вариабельность самой дисперсии покрытия между образцами. Такая дисперсия усложняет точную оценку ожидаемой дисперсии покрытия для конкретного образца в конкретном окне, поскольку каждое значение покрытия образца референтной панели представляет собой наблюдение из другого распределения.
В одном аспекте на счет фрагментов может влиять содержание GC в полном фрагменте ДНК, а не только в считанной последовательности. Соответственно, при расчете долей GC окна могут быть симметрично удлинены, чтобы они были по меньшей мере несколько длиннее среднего размера фрагмента. Средний размер фрагмента может быть другим изменяемым параметром CLAMMS. Средний размер фрагмента по умолчанию может составлять 200 п.н., или можно использовать другие подходящие значения.
Фильтрование данных покрытия образца может включать фильтрование одного или более окон распознавания на основе показателя картируемости геномной области множества геномных областей. Например, представленные способы и системы могут обеспечивать фильтрование окон распознавания, где средний показатель картируемости для k-меров, начиная с каждого основания в окне (по умолчанию k=75), составляет менее 0,75. Фильтрование одного или более окон распознавания на основе показателя картируемости может предусматривать определение показателя картируемости для каждой геномной области множества геномных областей и исключение окна распознавания из одного или более окон распознавания, которые содержат геномную область множества геномных областей, если показатель картируемости геномной области множества геномных областей ниже заранее заданного порогового значения. Определение показателя картируемости для каждой геномной области множества геномных областей может включать определение среднего значения обратной величины частоты референтного генома k-меров, первое основание которых перекрывается с геномной областью множества геномных областей.
В другом аспекте фильтрование данных покрытия образца может включать фильтрование одного или более окон распознавания на основе показателя центральной тенденции покрытия ридами. Фильтрование одного или более окон распознавания на основе показателя центральной тенденции покрытия ридами может предусматривать исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания содержит показатель центральной тенденции покрытия ридами, который меньше ожидаемого значения покрытия для окон распознавания с аналогичным содержанием GC. Например, представленные способы и системы могут обеспечивать фильтрование окон с медианным и/или средним покрытием по образцам меньше, чем 10% ожидаемого для окон с аналогичным содержанием GC.
В другом аспекте фильтрование данных покрытия образца может включать фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации. Фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации может предусматривать исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания оказывается в области, где, как известно, присутствуют мультикопийные дупликации. В качестве примера часть (например, 12% для приведенных выше значений по умолчанию) экзомных областей захвата может исключаться из процесса определения с помощью таких фильтров.
Как показано на ФИГ. 2, на шаге 204 может производиться нормализация данных покрытия образца. Данные покрытия образца могут включать множество геномных областей. Представленные способы и системы позволяют нормализовать данные покрытия образца для каждого индивидуального образца для коррекции сдвига GC и общей средней глубины покрытия. Нормализация данных покрытия образца может включать определение исходного покрытия окна распознавания w, определение медианного покрытия для данных покрытия образца в пределах одного или более окон распознавания в зависимости от доли GC в окне распознавания w и деление исходного покрытия на медианное покрытие для получения нормализованных данных покрытия образца. Определение медианного покрытия для данных покрытия образца в пределах множества окон в зависимости от доли GC в окне распознавания w может включать группировку одного или более окон распознавания по доле GC для получения множества групп, определение медианного покрытия для каждой группы из множества групп и/или определение нормирующего коэффициента для каждой отдельной возможной доли GC с помощью линейной интерполяции между медианным покрытием для двух групп, ближайших к окну распознавания w.
Ниже более подробно описана нормализация данных покрытия образца. Например, условное медианное значение может определяться (например, вычисляться, рассчитываться) посредством группировки всех окон для образца по доле GC (например, [0,300, 0,310], [0,315, 0,325] и т. п.). Например, множество групп может определяться на основе значений долей GC. Одна или более (или каждая) группа из множества групп может определяться посредством деления (например, равного) суммарного значения интервала доли GC на основе одного или более значений приращения (например, 0,01). Можно определять (например, рассчитывать, вычислять) медианное покрытие для каждой группы. Можно определять (например, рассчитывать, вычислять) нормирующий коэффициент для заданной доли GC. Например, нормирующий коэффициент для заданной доли GC может определяться с помощью линейной интерполяции между медианным покрытием для двух групп, ближайших к рассматриваемой группе. В одном аспекте можно изменять дискретность группироки (например, величину значений приращения). В одном примере можно определять (например, выбирать) такую дискретность, которая обеспечивает баланс точности группировки с необходимостью обеспечить достаточный размер образца в каждой группе для расчетов.
На ФИГ. 4 представлен график, иллюстрирующий нормализованное покрытие различных экзонов. На графике отображены результаты использования смесовых моделей для обработки наблюдаемых распределений покрытия для экзонов гена GSTT1 (например, после обеспечения нормирования внутри образца). Каждая точка (например, с разбросом для наглядности) соответствует нормализованному покрытию для экзона в образце. Затенение точек графика указывает на наиболее вероятное число копий, при условии, что модель и прозрачность пропорциональны отношению правдоподобия между наиболее вероятным числом копий и следующим после наиболее вероятного числа копий, если экзон должен будет рассматриваться независимо от своих соседей.
Как показано на ФИГ. 2, на шаге 206 может производиться подгонка смесовой модели (например, отработанной, модифицированной, адаптированной) к нормализованным данным покрытия образца на основе выбранных референтных данных покрытия. Например, может производиться отработка смесовой модели в соответствии с выбранными референтными данными покрытия. Подгонка смесовой модели к нормализованным данным покрытия образца на основе выбранных референтных данных покрытия может включать определение множества смесовых моделей (например, по одной для каждой из множества геномных областей). Один или более (или каждый) компонент множества смесовых моделей может включать соответствующее распределение вероятности. Распределение вероятности может представлять собой ожидаемое нормализованное покрытие в зависимости от конкретного числа копий. Может производиться подгонка множества смесовых моделей к нормализованным данным покрытия образца с использованием алгоритма максимизации ожидания. Например, может производиться подгонка множества смесовых моделей к нормализованным данным покрытия образца с использованием алгоритма максимизации ожидания, чтобы определить вероятность для каждого числа копий в каждом из одного или более окон распознавания. Выбранные референтные данные покрытия можно использовать в качестве исходных данных в алгоритме максимизации ожидания.
В качестве дополнительного пояснения в представленных способах и системах могут использоваться смесовые модели для описания ожидаемого (например, нормализованного) распределения покрытия в каждом окне распознавания. Ожидаемое распределение покрытия может зависеть от состояния числа копий. Обработка по таким смесовым моделям может производиться с использованием алгоритма подгонки. Например, подгонка по смесовым моделям может производиться посредством идентификации параметров модели, которые обеспечивают самое лучшее соответствие форме распределения данных. В одном аспекте алгоритм подгонки может включать способ оптимизации для оценки параметров смесовой модели, такой как МО. В альтернативном варианте осуществления можно использовать неконтролируемую кластеризацию или алгоритм генерации образца для идентификации состояний с определенным числом копий и/или модели распределения данных покрытия по состояниям числа копий.
Например, алгоритм подгонки может включать алгоритм максимизации ожидания (алгоритм МО) с вводом данных из референтной панели образцов (например, референтных данных покрытия). В одном аспекте алгоритм МО может включать алгоритм оптимизации для подгонки скрытых (например, латентных) параметров модели. В некоторых вариантах осуществления алгоритм подгонки может включать использование алгоритма градиентного спуска, Ньютона-Рафсона и/или подобных алгоритмов. Компоненты смесовой модели могут соответствовать числу копий 0, 1, 2 и 3. В некоторых вариантах осуществления число копий больше 3 может игнорироваться. Например, покрытие, которое может объясняться числом копи более 3, может быть результатом стохастического сдвига, связанного с GC.
В одном аспекте один или более компонентов смесовой модели, соответствующих ненулевому числу копий, могут определяться в рамках гауссова распределения. Например, гауссово распределение может иметь следующую форму: 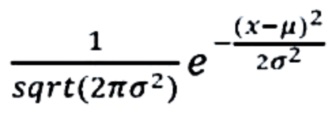 , где μ обозначает среднее и σ обозначает дисперсию или стандартное отклонение. Гауссово распределение для диплоидной копии может включать по меньшей мере два свободных параметра: μDIP (например, среднее для компонента смеси, соответствующего диплоидной копии) и σDIP (например, стандартное отклонение для компонента смеси, соответствующего диплоидной копии). Для каждого числа недиплоидных копий k среднее может ограничиваться величиной, равной (k/2) * μDIP (например, отсюда следует термин «выравнивание по решетке» (или lattice-aligned) в аббревиатуре CLAMMS). Стандартное отклонение гаплоидных образцов, σHAP, может быть задано равным
, где μ обозначает среднее и σ обозначает дисперсию или стандартное отклонение. Гауссово распределение для диплоидной копии может включать по меньшей мере два свободных параметра: μDIP (например, среднее для компонента смеси, соответствующего диплоидной копии) и σDIP (например, стандартное отклонение для компонента смеси, соответствующего диплоидной копии). Для каждого числа недиплоидных копий k среднее может ограничиваться величиной, равной (k/2) * μDIP (например, отсюда следует термин «выравнивание по решетке» (или lattice-aligned) в аббревиатуре CLAMMS). Стандартное отклонение гаплоидных образцов, σHAP, может быть задано равным 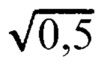 * σDIP. Несмотря на гауссовы приближения, в зависимости от конкретного числа копий покрытие может быть иметь пуассоновское распределение с дисперсией, равной среднему. Параметры стандартного отклонения для компонентов, соответствующих числам копий более 2, могут быть заданы равными σDIP. Такая конфигурация может позволить избежать увеличения доли ложноположительных дупликаций. Ограничения, накладываемые на параметры недиплоидных компонентов, могут обеспечивать конфигурацию модели, позволяющую избежать чрезмерной аппроксимации данных режима отработки.
* σDIP. Несмотря на гауссовы приближения, в зависимости от конкретного числа копий покрытие может быть иметь пуассоновское распределение с дисперсией, равной среднему. Параметры стандартного отклонения для компонентов, соответствующих числам копий более 2, могут быть заданы равными σDIP. Такая конфигурация может позволить избежать увеличения доли ложноположительных дупликаций. Ограничения, накладываемые на параметры недиплоидных компонентов, могут обеспечивать конфигурацию модели, позволяющую избежать чрезмерной аппроксимации данных режима отработки.
В одном аспекте алгоритм подгонки может быть выполнен с возможностью учитывания некартированных считываний, соответствующих удаленным областям. Например, один или более компонентов смесовой модели могут определяться как экспоненциальное распределение. Гомозиготные делеции (например, число копий 0) могут демонстрировать нулевое покрытие, но некартированные считывания могут приводить к небольшому уровню покрытия даже в действительно удаленных областях. Соответственно, компонент, отвечающий за число копий 0, может определяться как экспоненциальное распределение. Экспоненциальное распределение может содержать параметр спада λ. Например, экспоненциальное распределение может иметь следующую форму: λe-λx. Конфигурация экспоненциального распределения может включать среднее значение (например, 1/λ), первоначально равное 6,25% от μDIP, или другое подходящее соотношение. В качестве дополнительного примера среднее значение данного компонента может ограничиваться, чтобы не превышать такую исходную величину. При отсутствии проблем некартирования области итерации алгоритма подгонки могут сводить среднее к 0 (например, λ → ∞). Для решения данной проблемы в случае падения среднего ниже 0,1% от μDIP алгоритм подгонки может заменять экспоненциальное распределение материальной точкой в 0.
Таким образом, конфигурация смесовой модели может содержать один или более следующих параметров: μDIP и σDIP; λ, спад экспоненциального компонента (например, число копий 0) и флажок, указывающий на замену экспоненты материальной точкой.
В одном аспекте алгоритм подгонки может быть выполнен с возможностью итерационно сводиться к решению для аппроксимации смесовой модели, при этом каждая итерация уменьшает различия между моделью и данными.
В одном аспекте алгоритм подгонки может быть выполнен с возможностью максимального числа итераций. Например, подгонка смесовой модели может выполняться с использованием максимального числа итераций (например, 30, 40, 50). В некоторых сценариях в алгоритме подгонки может использоваться число итераций, которое меньше максимального. Например, для определения раннего схождения можно использовать эвристическую процедуру. В случае алгоритма МО, который представляет собой локальную процедуру оптимизации, может оказаться, что исходные значения μDIP и σDIP могут снижать вероятность того, что алгоритм подгонки сходится к неглобальному оптимуму. В некоторых сценариях можно инициализировать μDIP как медианное покрытие по всем образцам для рассматриваемой области (например, в областях, где медианный образец является гаплоидным, итерации в конечном счете могут приводить к соответствующему диплоидному среднему). В одном аспекте можно инициализировать σDIP как медианное абсолютное отклонение (МАО) значений покрытия вокруг медианы значений покрытия, масштабированное с постоянным коэффициентом для достижения асимптотической нормальности (например, сопоставление с функцией «мао» в R).
Образцы с низкой вероятностью для всех рассматриваемых состояний числа копий (например, менее 2,5σ от среднего) для целей подгонки моделей могут обозначаться как выбросы. Если для области существуют образцы с выбросами, можно провести повторную отработку смесовой модели с удалением резко выпадающих значений покрытия.
На шаге 208 можно идентифицировать (например, определить, предсказать, оценить) один или более вариантов числа копий (ВЧК) в соответствии со скрытой марковской моделью (СММ), байесовскими сетями и/или другими вероятностными моделями на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели. Например, идентификация одного или более вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели может включать ввод нормализованных данных покрытия образца для каждого окна распознавания (например, одного или более окон распознавания) в СММ.
В другом аспекте идентификация одного или более вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели может включать определение одной или более вероятностей эмиссии СММ на основе смесовой модели. Например, вероятность наблюдения значения нормализованного покрытия x в окне распознавания w (например, одного или более окон распознавания) при состоянии СММ s может быть определена на основе компонента смесовой модели для w, который соответствует состоянию s.
В другом аспекте идентификация одного или более вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели может включать идентификацию окна распознавания (например, одного или более окон распознавания) как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной. Например, алгоритм Витерби может быть реализован в направлении от 5' к 3' для геномной области множества геномных областей. Алгоритм Витерби может быть реализован в направлении от 3' к 5' для геномной области множества геномных областей. Окно распознавания (например, одно или более окон распознавания) может быть идентифицировано как ВЧК, если геномная область множества геномных областей, связанная с окном распознавания, с наибольшей вероятностью не является диплоидной в направлении от 5' к 3' и в направлении от 3' к 5'.
В одном аспекте СММ может включать статистическую марковскую модель, в которой моделируемая система предположительно представляет собой марковский процесс с ненаблюдаемыми (например, скрытыми) состояниями. Пространство скрытых состояний может включать одно из N возможных значений, моделируемых как категорийное распределение. СММ может включать вероятности перехода. Для каждого из N возможных состояний, в котором может находиться скрытая переменная в момент времени t, может существовать вероятность перехода из такого состояния в каждое из возможных состояний скрытой переменной в момент времени t+1 для всех N2 вероятностей переходов. СММ может также включать вероятности эмиссии (например, для каждого из N возможных состояний), которые определяют распределение наблюдаемой переменной в конкретный момент времени с учетом состояния скрытой переменной в такой момент времени.
Для ввода в СММ можно использовать значения нормализованного покрытия (например, по результатам описанной выше процедуры в пределах образца) для отдельного образца в каждом окне распознавания. Например, состояния СММ могут включать DEL (делецию), DIP (диплоид), DUP (дупликацию) и/или т. п. В некоторых сценариях различия между числом копий 0 и 1 могут проводиться на шаге последующей обработки после завершения определения DEL.
В одном аспекте СММ может включать такие вероятности перехода в качестве исходных значений. Вероятности перехода могут определяться на основе использованных в ЭСММ. Например, вероятности перехода в ЭСММ, кроме параметра 1/q (например, среднее предыдущего геометрического распределения числа окон в ВЧК), могут быть приняты равными 0 (например, q=∞). Например, вероятность перехода может быть близка (например, примерно такая же, как в ЭСММ (ненулевая)) к параметрам ЭСММ, исключая параметр 1/q в ЭСММ, который может быть принят равным нулю, если q задан принимающим бесконечное значение. Следствием таких установок является то, что СММ может выполняться с возможностью не вводить предварительные допущения в отношении числа окон в ВЧК. Напротив, СММ может выполняться с возможностью использования только экспоненциально распределенного коэффициента ослабления, значение которого определяется на основе фактического геномного расстояния. В одном аспекте обнуление параметра ЭСММ 1/q может приводить к следующим двум допущениям: 1) DEL и DUP равновероятны, и 2) размер ВЧК описывается экспоненциальным распределением. Выводы относительно ЭСММ, которые приводятся в работе Fromer et al. (2012), «Discovery and statistical genotyping of copy-number variation from whole-exome sequencing depth.» Am J Hum Genet, 91 (4), 597-607, в частности, включены в настоящий документ путем ссылки.
В одном аспекте СММ может включать вероятности эмиссии в качестве исходных значений. Вероятности эмиссии можно извлечь из смесовых моделей. Например, вероятность наблюдения (например, нормализованного) значения покрытия x в окне распознавания w при состоянии СММ s может определяться компонентом смесовой модели, отработанной при w, который соответствует состоянию s. Для состояния DEL могут использоваться средневзвешенные по правдоподобию вероятности при условии числа копий 0 и 1. Например, если L(CN=1|cov)=9*L(CN=0|cov), то вероятность эмиссии может быть равна 0,9*P(cov|CN=1)+0,1*P(cov|CN=0).
С помощью такой скрытой марковской модели представленные способы и системы могут выполняться для идентификации ВЧК. Например, представленные способы и системы могут выполняться для идентификации ВЧК как областей, где последовательность состояний с максимальным правдоподобием (например, предсказанная с помощью алгоритма Витерби или другого подходящего алгоритма) не является диплоидной. Следует отметить, что выполнение алгоритма Витерби только в одном направлении может вносить направленный сдвиг в определение ВЧК. Достаточно сложно «выявить» ВЧК, но довольно просто провести «расширение» ВЧК. Таким образом, выявленные области ВЧК могут демонстрировать тенденцию к выходу за точку разрыва. Для решения данной проблемы представленные способы и системы могут выполняться таким образом, чтобы отражать только такие области ВЧК, для которых наиболее вероятное состояние не является диплоидным при выполнении алгоритма Витерби как в направлении от 5' к 3', так и в направлении от 3' к 5'.
В одном аспекте для каждого выявленного ВЧК можно рассчитывать пять параметров качества на основе вероятностей по алгоритму прямого-обратного хода: Qany, масштабированная по программе Phred вероятность того, что область вообще содержит ВЧК; Qextend left и Qextend right, масштабированные по программе Phred вероятности того, что истинный ВЧК проходит по меньшей мере на одно окно дальше в прямом/обратном направлении от выявленной области; и Qcontract left и Qcontract right, масштабированные по программе Phred вероятности того, что истинный ВЧК ограничивается по сравнению с выявленной областью по меньшей мере на одно окно в прямом или обратном направлении.
Следует отметить, что даже с предварительным фильтрованием окон с содержанием GC вне порогового интервала (например, [0,3, 0,7]), как это описано выше, на предельных концах данного порогового интервала может по-прежнему отмечаться высокая частота стохастических артефактов секвенирования. Алгоритмы Витерби и прямого-обратного хода могут быть модифицированы (например, сконфигурированы) таким образом, чтобы в меньшей степени опираться на окна с «умеренно экстремальным» содержанием GC, однако не полностью игнорировать такие окна. Такая конфигурация может достигаться умножением логарифмической вероятности эмиссии для всех состояний при заданном окне на весовой коэффициент в интервале [0, 1] в зависимости от содержания GC в окне. Такая конфигурация может снижать относительную значимость данных (например, наблюдаемое покрытие) в этом окне по сравнению с предыдущим окном (например, кодируемым по вероятности перехода состояний). В качестве примера для доли GC f в предварительно заданном по умолчанию допустимом интервале [0,3, 0,7], весовой коэффициент окна может быть задан равным (1 - (5 * abs(f - 0,5))18)18. Полиномиальный член высоких порядков может использоваться для выравнивания кривой для неэкстремальных GC (например, весовой коэффициент=0,99993 для f=0,4), но она резко спадает на краях допустимого интервала GC (например, весовой коэффициент=0,5 для f=0,3333).
В одном аспекте представленные способы и системы могут аппроксимировать модели и обеспечивать определение ВЧК для областей половых хромосом при указании пола для каждого вводимого образца. Предположение в отношении ожидаемого числа копий (например, диплоидных или гаплоидных) напрямую в зависимости от пола может быть более эффективным, чем нормализация дисперсии в зависимости от пола или сопоставление образцов с образцами с высокой корреляцией, поскольку такой подход учитывает целый характер состояний числа копий. В качестве примера особь женского пола с 0,5x ожидаемого покрытия для области в chrX, вероятно, будет характеризоваться гетерозиготной делецией. Особь мужского пола с таким же уровнем покрытия, возможно, не будет иметь гетерозиготной делеции, поскольку число копий не может быть равно 1/2.
На шаге 210 могут выводиться один или более вариантов числа копий. Например, один или более вариантов числа копий могут содержаться в выходных данных для пользователя (например, выводиться через интерфейс пользователя). Один или более вариантов числа копий могут передаваться по сети в удаленное местоположение. Один или более вариантов числа копий могут использоваться в качестве исходных данных в другой исполняемой программе. Один или более вариантов числа копий могут храниться в зоне хранения, например в базе данных или в файле другого формата. Пример выходных данных представлен на ФИГ. 15.
На ФИГ. 5 представлена структурная схема, иллюстрирующая другой пример способа 500 для определения вариантов числа копий. На шаге 502 можно вводить данные покрытия образца, содержащие множество геномных областей (например, это может делать пользователь, с первого устройства на второе устройство). В одном аспекте множество геномных областей может подразделяться на одно или более окон распознавания (например, множество окон распознавания). Например, подразделяться могут только геномные области из множества геномных областей, которые превышают заранее заданный размер.
На шаге 504 можно вводить указатель на референтные данные покрытия (например, это может делать пользователь, с первого устройства на второе устройство). Референтные данные покрытия могут быть выбраны на основе методики группировки образцов. Например, методика группировки образцов может включать методику (например, алгоритм) для группирования образцов по подобию. Методика группировки образцов может включать алгоритм кластеризации, алгоритм классификации, их комбинацию и/или т. п. Например, методика группировки образцов может включать получение множества параметров для данных покрытия образца, определение параметра расстояния между данными покрытия образца и референтными данными покрытия на основе множества параметров, выбор референтных данных покрытия для каждого образца на основе параметра расстояния и/или т. п.
В качестве примера методика группировки образцов может включать алгоритм k ближайших соседей (knn). Выбор референтных данных покрытия на основе методики группировки образцов может включать одно или более из масштабирования множества параметров, связанных с референтными данными покрытия, построения k-мерного дерева на основе масштабированного множества параметров, связанных с референтными данными покрытия, масштабирования множества параметров, связанных с данными покрытия образца, добавления данных покрытия образца к k-мерному дереву на основе масштабированного множества параметров, связанных с данными покрытия образца, идентификации заранее заданного числа ближайших соседей с данными покрытия образца в качестве выбранных референтных данных покрытия и/или т. п.
На шаге 506 можно выбирать один или более фильтров (например, это может делать пользователь, первое устройство и/или второе устройство), которые будут применяться к данным покрытия образца для нормализации данных покрытия образца. Например, можно проводить фильтрование данных покрытия образца. Один или более фильтров могут быть выполнены с возможностью реализации одной или более из приведенных ниже функций: фильтрование одного или более окон распознавания на основе уровня содержания GC, фильтрование одного или более окон распознавания на основе показателя картируемости геномной области множества геномных областей, фильтрование одного или более окон распознавания на основе показателя центральной тенденции покрытия ридами, фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации и/или т. п.
В одном аспекте фильтрование одного или более окон распознавания на основе уровня содержания GC может предусматривать исключение окна распознавания из одного или более окон распознавания, если уровень содержания GC окна распознавания выходит за пределы заранее заданного интервала.
В одном аспекте фильтрование одного или более окон распознавания на основе показателя картируемости может включать определение показателя картируемости для каждой геномной области множества геномных областей. Например, определение показателя картируемости для каждой геномной области множества геномных областей может включать определение среднего значения обратной величины частоты референтного генома k-меров, первое основание которых перекрывается с геномной областью множества геномных областей. Фильтрование одного или более окон распознавания на основе показателя картируемости может дополнительно предусматривать исключение окна распознавания из одного или более окон распознавания, которые содержат геномную область множества геномных областей, если показатель картируемости геномной области множества геномных областей ниже заранее заданного порогового значения.
В одном аспекте фильтрование одного или более окон распознавания на основе показателя центральной тенденции покрытия ридами может предусматривать исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания содержит показатель центральной тенденции покрытия ридами, который меньше ожидаемого значения покрытия для окон распознавания с аналогичным содержанием GC.
В одном аспекте фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации может предусматривать исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания оказывается в области, где, как известно, присутствуют мультикопийные дупликации.
В одном аспекте фильтрование и/или нормализация могут включать определение исходного покрытия окна распознавания w, определение медианного покрытия для данных покрытия образца в пределах одного или более окон распознавания в зависимости от доли GC в окне распознавания w, деление исходного покрытия на медианное покрытие (например, для получения нормализованных данных покрытия образца) и/или т. п. Например, определение медианного покрытия для данных покрытия образца в пределах множества окон в зависимости от доли GC окна распознавания w может включать одно или более из группировки одного или более окон распознавания по доле GC (например, для получения множества групп), определения медианного покрытия для каждой группы из множества групп, определения нормирующего коэффициента для каждой отдельной возможной доли GC с помощью линейной интерполяции между медианным покрытием для двух групп, ближайших к окну распознавания w, и/или т. п.
На шаге 508 можно выдавать запрос на подгонку смесовой модели к нормализованным данным покрытия образца на основе референтных данных покрытия (например, это может делать пользователь, с первого устройства на второе устройство). Например, можно выдавать запрос на отработку смесовой модели в соответствии с выбранными референтными данными покрытия. Подгонка смесовой модели к нормализованным данным покрытия образца на основе референтных данных покрытия может включать определение множества смесовых моделей, по одной для каждой из множества геномных областей. Каждый компонент множества смесовых моделей может включать распределение вероятности, которое отражает ожидаемое нормализованное покрытие в зависимости от конкретного числа копий. Подгонка смесовой модели к нормализованным данным покрытия образца на основе референтных данных покрытия может включать подгонку множества смесовых моделей к нормализованным данным покрытия образца с использованием алгоритма максимизации ожидания, чтобы определить вероятность для каждого числа копий в каждом из одного или более окон распознавания. Выбранные референтные данные покрытия можно использовать в качестве исходных данных в алгоритме максимизации ожидания.
На шаге 510 можно идентифицировать один или более вариантов числа копий (например, это может делать пользователь, первое устройство, второе устройство) в соответствии со скрытой марковской моделью (СММ) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели. Например, идентификация одного или более вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели может включать одно или более из ввода нормализованных данных покрытия образца для каждого окна распознавания (например, одного или более окон распознавания) в СММ, определения одной или более вероятностей эмиссии в СММ на основе смесовой модели, идентификации окна распознавания (например, одного или более окон распознавания) как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной, и/или т. п.
В одном аспекте определение одной или более вероятностей эмиссии в СММ на основе смесовой модели может включать определение вероятности наблюдения значения нормализованного покрытия x в окне распознавания w (например, одного или более окон распознавания) при состоянии СММ s на основе компонента смесовой модели для w, который соответствует состоянию s.
В одном аспекте идентификация окна распознавания (например, одного или более окон распознавания) как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной, может включать одно или более из реализации алгоритма Витерби в направлении от 5' к 3' на геномной области множества геномных областей, реализации алгоритма Витерби в направлении от 3' к 5' на геномной области множества геномных областей, идентификации окна распознавания (например, одного или более окон распознавания) как ВЧК, если геномная область множества геномных областей, связанных с окном распознавания, с наибольшей вероятностью не является диплоидной в направлении от 5' к 3' и в направлении от 3' к 5', и/или т. п.
На шаге 512 может выдаваться запрос на указатель на один или более вариантов числа копий (например, это может делать пользователь, первое устройство, второе устройство). Например, указатель может выводиться на дисплей, через сеть и/или т. п. Пример указателя на один или более вариантов числа копий представлен на ФИГ. 15.
На ФИГ. 6 представлена структурная схема, иллюстрирующая еще один пример способа 600 для определения вариантов числа копий. На шаге 602 могут быть получены данные покрытия образца, содержащие множество геномных областей. В одном аспекте множество геномных областей может подразделяться на одно или более окон распознавания (например, множество окон распознавания). Например, подразделяться могут только геномные области из множества геномных областей, которые превышают заранее заданный размер.
В одном аспекте может проводиться фильтрование данных покрытия образца. Например, фильтрование данных покрытия образца может включать одно или более из фильтрования одного или более окон распознавания на основе уровня содержания GC, фильтрования одного или более окон распознавания на основе показателя картируемости геномной области множества геномных областей, фильтрования одного или более окон распознавания на основе показателя центральной тенденции покрытия ридами, фильтрования одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации и/или т. п.
В одном аспекте фильтрование одного или более окон распознавания на основе уровня содержания GC может предусматривать исключение окна распознавания из одного или более окон распознавания, если уровень содержания GC окна распознавания выходит за пределы заранее заданного интервала. Фильтрование одного или более окон распознавания на основе показателя картируемости может включать определение показателя картируемости для каждой геномной области множества геномных областей. Например, определение показателя картируемости для каждой геномной области множества геномных областей может включать определение среднего значения обратной величины частоты референтного генома k-меров, первое основание которых перекрывается с геномной областью множества геномных областей. Фильтрование одного или более окон распознавания на основе показателя картируемости может дополнительно предусматривать исключение окна распознавания из одного или более окон распознавания, которое содержит геномную область множества геномных областей, если показатель картируемости геномной области множества геномных областей ниже заранее заданного порогового значения.
В одном аспекте фильтрование одного или более окон распознавания на основе показателя центральной тенденции покрытия ридами может предусматривать исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания содержит показатель центральной тенденции покрытия ридами, который меньше ожидаемого значения покрытия для окон распознавания с аналогичным содержанием GC. Фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации может предусматривать исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания оказывается в области, где, как известно, присутствуют мультикопийные дупликации.
На шаге 604 может извлекаться первое множество параметров для данных покрытия образца. Первое множество параметров может, например, включать параметры контроля качества (КК) секвенирования, метаданные образца, связанные с происхождением параметры, показатели сходства последовательностей и/или любой параметр, который отражает вариабельность на уровне образца. Например, в случае параметров КК секвенирования можно использовать семь параметров КК. В качестве примера параметры КК секвенирования могут включать GCDROPOUT, ATDROPOUT, MEANINSERTSIZE, ONBAITVSSELECTED, PCTPFUQREADS, PCTTARGETBASES10X, PCTTARGETBASES50X и/или т. п. Параметры КК секвенирования могут масштабироваться (например, посредством применения линейного преобразования) и обрабатываться для построения k-мерного дерева.
На шаге 606 для данных покрытия образца и референтных данных покрытия может применяться методика группировки образцов для выбора подмножества референтных данных покрытия. Методика группировки образцов может включать методику (например, алгоритм) для группирования образцов по подобию. Например, методика группировки образцов может включать алгоритм кластеризации, алгоритм классификации, их комбинацию и/или т. п. В одном аспекте применение методики группировки образцов к данным покрытия образца и референтным данным покрытия для выбора подмножества референтных данных покрытия может включать определение параметра расстояния между данными покрытия образца и референтными данными покрытия на основе первого множества параметров. Референтные данные покрытия могут выбираться для каждого образца на основе параметра расстояния.
В другом примере методика группировки образцов может включать алгоритм k ближайших соседей (knn). Применение методики группировки образцов к данным покрытия образца и референтным данным покрытия для выбора подмножества референтных данных покрытия может включать одно или более из извлечения второго множества параметров, связанных с референтными данными покрытия, масштабирования второго множества параметров, связанных с референтными данными покрытия, построения k-мерного дерева на основе масштабированного второго множества параметров, связанных с референтными данными покрытия, масштабирования первого множества параметров, связанных с данными покрытия образца, добавления данных покрытия образца к k-мерному дереву на основе масштабированного первого множества параметров для данных покрытия образца, идентификации заранее заданного числа ближайших соседей с данными покрытия образца в качестве подмножества референтных данных покрытия и/или т. п.
На шаге 608 может проводиться нормализация данных покрытия образца с множеством геномных областей. Например, нормализация данных покрытия образца с множеством геномных областей может включать одно или более из определения исходного покрытия окна распознавания w, определения медианного покрытия для данных покрытия образца в пределах одного или более окон распознавания в зависимости от доли GC в окне распознавания w; деления исходного покрытия на медианное покрытие (например, для получения нормализованных данных покрытия образца) и/или т. п.
В одном аспекте определение медианного покрытия для данных покрытия образца в пределах множества окон в зависимости от доли GC окна распознавания w может включать одно или более из группировки одного или более окон распознавания по доле GC (например, для получения множества групп), определения медианного покрытия для каждой группы из множества групп, определения нормирующего коэффициента для каждой отдельной возможной доли GC с помощью линейной интерполяции между медианным покрытием для двух групп, ближайших к окну распознавания w, и/или т. п.
На шаге 610 может производиться подгонка смесовой модели к нормализованным данным покрытия образца на основе подмножества референтных данных покрытия. Например, может производиться отработка смесовой модели в соответствии с подмножеством референтных данных покрытия. Подгонка смесовой модели к нормализованным данным покрытия образца на основе подмножества референтных данных покрытия может включать определение множества смесовых моделей, по одной для каждой из множества геномных областей. Один или более (или каждый) компонент множества смесовых моделей может включать распределение вероятности, которое отражает ожидаемое нормализованное покрытие в зависимости от конкретного числа копий. Подгонка смесовой модели к нормализованным данным покрытия образца на основе подмножества референтных данных покрытия может также включать подгонку множества смесовых моделей к нормализованным данным покрытия образца с использованием алгоритма максимизации ожидания, чтобы определить вероятность для каждого числа копий в каждом из одного или более окон распознавания. Подмножество референтных данных покрытия может использоваться в качестве исходных данных в алгоритме максимизации ожидания.
На шаге 612 может идентифицироваться один или более вариантов числа копий в соответствии со скрытой марковской моделью (СММ) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели. Например, идентификация одного или более вариантов числа копий в соответствии со скрытой марковской моделью (СMM) на основе нормализованных данных покрытия образца и аппроксимированной смесовой модели может включать одно или более из ввода нормализованных данных покрытия образца для каждого окна распознавания (например, одного или более окон распознавания) в СММ, определения одной или более вероятностей эмиссии в СММ на основе смесовой модели, идентификации окна распознавания (например, одного или более окон распознавания) как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной, и/или т. п. В одном аспекте определение одной или более вероятностей эмиссии в СММ на основе смесовой модели может включать определение вероятности наблюдения значения нормализованного покрытия x в окне распознавания w (например, одного или более окон распознавания) при состоянии СММ s на основе компонента смесовой модели для w, который соответствует состоянию s.
В одном аспекте идентификация окна распознавания (например, одного или более окон распознавания) как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной, может включать одно или более из реализации алгоритма Витерби в направлении от 5' к 3' на геномной области множества геномных областей, реализации алгоритма Витерби в направлении от 3' к 5' на геномной области множества геномных областей, идентификации окна распознавания (например, одного или более окон распознавания) как ВЧК, если геномная область множества геномных областей, связанных с окном распознавания, с наибольшей вероятностью не является диплоидной в направлении от 5' к 3' и в направлении от 3' к 5', и/или т. п.
На шаге 614 можно выводить один или более вариантов числа копий. Например, один или более вариантов числа копий могут содержаться в выходных данных для пользователя (например, выводиться через интерфейс пользователя). Один или более вариантов числа копий могут передаваться по сети в удаленное местоположение. Один или более вариантов числа копий могут использоваться в качестве исходных данных в другой исполняемой программе. Один или более вариантов числа копий могут храниться в зоне хранения, например в базе данных или в файле другого формата. Пример выходных данных представлен на ФИГ. 15.
В примере аспекта способы и системы могут быть реализованы на компьютере 701, как показано на ФИГ. 7 и описано ниже. Аналогичным образом в описанных способах и системах могут использоваться один или более компьютеров для выполнения одной или более функций в одном или более местоположений. На ФИГ. 7 представлена блок-диаграмма, иллюстрирующая пример операционной среды для осуществления описанных способов. Такой пример операционной среды представляет собой лишь один из примеров операционной среды и не призван устанавливать какие-либо ограничения в отношении области применения или функциональности архитектуры операционной среды. В равной мере не следует интерпретировать операционную среду как предусматривающую любую зависимость или требования в отношении любого отдельно взятого компонента или комбинации компонентов, приведенных в примере операционной среды.
Представленные способы и системы можно использовать для множества других сред или конфигураций вычислительных систем общего или специального назначения. К примерам хорошо известных вычислительных систем, сред и/или конфигураций могут относиться подходящие для использования с представленными системами и способами, но они не ограничиваются персональными компьютерами, серверными компьютерами, портативными устройствами и многопроцессорными системами. К дополнительным примерам относятся телевизионные приставки, программируемая бытовая электроника, сетевые ПК, мини-компьютеры, центральные компьютеры, распределенные вычислительные среды, которые включают любые из перечисленных систем или устройств, и т. п.
Обработка в соответствии с описанными способами и системами может производиться компонентами программного обеспечения. Описанные системы и способы можно описать в общем контексте команд, выполняемых компьютером, таких как программные модули, выполняемые одним или более компьютерами или другими устройствами. В общем случае программные модули включают компьютерные коды, подпрограммы, программы, объекты, компоненты, структуры данных и/или т. п., которые выполняют конкретные задачи или реализуют частные абстрактные типы данных. Описанные способы могут также практически осуществляться на основе сетки и в распределенных компьютерных средах, где задачи выполняются удаленными обрабатывающими устройствами, которые связаны через коммуникационную сеть. В распределенной вычислительной среде программные модули можно размещать как в локальных, так и в удаленных компьютерных носителях для хранения данных, включая запоминающие устройства для хранения данных.
Кроме того, специалисту в данной области будет очевидно, что описанные в настоящем документе системы и способы могут быть реализованы с помощью компьютерного устройства общего назначения в форме компьютера 701. Компоненты компьютера 701 могут включать, без ограничений, один или более процессоров 703, системную память 712 и системную шину 713, которая соединяет различные компоненты системы, включая один или более процессоров 703 с системной памятью 712. В системе могут использоваться параллельные вычисления.
Системная шина 713 представляет собой один или более из нескольких возможных типов конструкций шины, включая шину памяти или контроллер памяти, периферийную шину, ускоренный графический порт или локальную шину с использованием любого из множества вариантов архитектуры шины. Например, к таким вариантам архитектуры шины могут относиться шина стандартной промышленной архитектуры (ISA), шина микроканальной архитектуры (MCA), шина расширенной ISA (EISA), локальная шина Ассоциации по стандартам в области видеоэлектроники (VESA), шина ускоренного графического порта (AGP) и шина соединения периферийных компонентов (PCI), шина PCI-Express, шина Международной ассоциации производителей карт памяти для персональных компьютеров (PCMCIA), универсальная последовательная шина (USB) и т. п. Шина 713 и все шины, перечисленные в настоящем описании, могут также применяться в рамках проводного или беспроводного сетевого подключения, и каждая из подсистем, в том числе один или более процессоров 703, запоминающее устройство 704 большой емкости, операционная система 705, программное обеспечение 706 для определения ВЧК, данные 707 определения ВЧК, сетевой адаптер 708, системная память 712, интерфейс 710 ввода-вывода, адаптер 709 дисплея, устройство 711 отображения и человеко-машинный интерфейс 702, могут размещаться в одном или более удаленных вычислительных устройствах 714a,b,c в физически разделенных местоположениях, соединенных посредством шин перечисленных типов, по существу представляя собой полностью распределенную систему.
Компьютер 701 обычно содержит различные машиночитаемые носители. К примерам машиночитаемых носителей могут относиться любые существующие носители, которые доступны для компьютера 701, и они, например, включают, без ограничений, энергозависимые и энергонезависимые, съемные и несъемные носители. Системная память 712 содержит машиночитаемый носитель в форме энергозависимой памяти, например оперативное запоминающее устройство (ОЗУ), и/или энергонезависимой памяти, например постоянное запоминающее устройство (ПЗУ). Системная память 712 обычно содержит данные, такие как данные 707 определения ВЧК, и/или программные модули, такие как операционная система 705 и программное обеспечение 706 для определения ВЧК, которые напрямую доступны и/или в данном варианте выполняются одним или более процессоров 703.
В другом аспекте компьютер 701 может также содержать другие несъемные/съемные, энергозависимые/энергонезависимые компьютерные носители для хранения данных. В качестве примера на ФИГ. 7 представлено запоминающее устройство 704 большой емкости, которое может обеспечивать энергонезависимое хранение машинного кода, машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 701. Например, такое запоминающее устройство 704 большой емкости может представлять собой, без ограничений, жесткий диск, съемный магнитный диск, съемный оптический диск, магнитные кассеты или другие магнитные запоминающие устройства, карты флэш-памяти, компакт-диски постоянной памяти (CD-ROM), цифровые универсальные диски (DVD) или другую оптическую память, оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), электрически стираемую программируемую постоянную память (ЭСППЗУ) и т. п.
При необходимости на запоминающем устройстве 704 большой емкости может храниться любое число программных модулей, включая, например, операционную систему 705 и программное обеспечение 706 для определения ВЧК. В каждом случае операционная система 705 и программное обеспечение 706 для определения ВЧК (или их некоторая комбинация) могут включать элементы программирования и программного обеспечения 706 для определения ВЧК. В запоминающем устройстве 704 большой емкости также могут храниться данные 707 определения ВЧК. Данные 707 определения ВЧК могут храниться в любой одной или более баз данных, известных специалистам в данной области. Примеры таких баз данных включают DB2®, Microsoft® Access, Microsoft® SQL Server, Oracle®, mySQL, PostgreSQL и т. п. Базы данных могут быть централизованными или распределенными по множеству систем.
В другом аспекте пользователь может вводить команды и информацию в компьютер 701 через устройство ввода (не показано). К примерам таких устройств ввода относятся, без ограничений, клавиатура, указывающее устройство (например, «мышь»), микрофон, джойстик, сканер, устройства тактильного ввода, например перчатки или другие предметы одежды, и т. п. Эти и другие устройства ввода могут подключаться к одному или более процессорам 703 через человеко-машинный интерфейс 702, который соединен с системной шиной 713, но могут подключаться через другие структуры интерфейса и шин, например параллельный порт, игровой порт, порт IEEE 1394 (также известный как порт Firewire), последовательный порт или универсальную последовательную шину (USB).
В еще одном аспекте устройство 711 отображения может также подключаться к системной шине 713 через интерфейс, например адаптер 709 дисплея. Предполагается, что компьютер 701 может содержать более одного адаптера 709 дисплея, и компьютер 701 может иметь более одного устройства 711 отображения. Например, устройством отображения может быть монитор, жидкокристаллический дисплей (ЖКД) или проектор. Помимо устройства 711 отображения к другим периферийным устройствам вывода могут относиться такие компоненты, как громкоговорители (не показаны) и принтер (не показан), которые могут подключаться к компьютеру 701 через интерфейс 710 ввода-вывода. Любой шаг и/или результат осуществления способа может выводиться на устройство вывода в любой форме. Таким результатом может быть любая форма визуального представления, в том числе, без ограничений, текстовая, графическая, анимационная, звуковая, тактильная и т. п. Дисплей 711 и компьютер 701 могут быть частью одного устройства или могут представлять собой отдельные устройства.
Компьютер 701 может функционировать в сетевой среде с использованием логических подключений к одному или более удаленным вычислительным устройствам 714a,b,c. Например, удаленным вычислительным устройством может быть персональный компьютер, портативный компьютер, смартфон, сервер, маршрутизатор, сетевой компьютер, одноранговое устройство или другой общий узел сети и т. п. Логические подключения между компьютером 701 и удаленным вычислительным устройством 714a,b,c могут осуществляться через сеть 715, например локальную вычислительную сеть (LAN) и/или общую глобальную вычислительную сеть (WAN). Такие сетевые подключения могут осуществляться через сетевой адаптер 708. Сетевой адаптер 708 может быть реализован как в проводной, так и в беспроводной среде. Такие сетевые среды являются общеупотребительными и стандартными в жилых помещениях, административных помещениях, общекорпоративных компьютерных сетях, внутрикорпоративных сетях и Интернете.
В качестве иллюстрации прикладные программы и другие исполняемые программные компоненты, например операционная система 705, приводятся в настоящем документе в виде отдельных блоков, при этом признается, что такие программы и компоненты в различные моменты времени находятся в различных компонентах памяти вычислительного устройства 701 и выполняются одним или более процессорами 703 компьютера. Реализация программного обеспечения 706 для определения ВЧК может храниться или передаваться через машиночитаемые носители определенной формы. Любой из описанных способов может осуществляться посредством машиночитаемых команд, размещенных на машиночитаемых носителях. Машиночитаемыми носителями могут быть любые существующие носители, которые могут быть доступны для компьютера. Например, к машиночитаемым носителям могут относиться, без ограничений, «компьютерные носители для хранения данных» и «средства коммуникации». Компьютерные носители для хранения данных включают энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные по любым способам или любой технологии хранения информации, таким как машиночитаемые команды, структуры данных, программные модули или другие данные. Примеры компьютерных носителей для хранения данных включают, без ограничений, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или другие технологии памяти, CD-ROM, цифровые универсальные диски (DVD) или другие средства оптического хранения информации, магнитные кассеты, накопители на магнитной ленте, магнитных дисках или другие магнитные устройства хранения, либо любой другой носитель, который можно использовать для хранения нужной информации и к которому можно получить доступ с помощью компьютера.
В способах и системах могут использоваться методики искусственного интеллекта, такие как машинное обучение и итеративное обучение. В число таких методов входят, без ограничений, экспертные системы, рассуждения на основе аналогичных случаев, байесовские сети, поведенческий ИИ, нейронные сети, нечеткие системы, эволюционные вычисления (например, генетические алгоритмы), роевой интеллект (например, муравьиные алгоритмы) и гибридные интеллектуальные системы (например, экспертные правила логического вывода, сформированные посредством нейронной сети, или правила вывода на основе статистического обучения).
Предполагается, что в приведенных ниже примерах для специалистов в данной области представлена полностью раскрытая информация и описание того, каким образом получали и оценивали соединения, композиции, изделия, устройства и/или способы, приведенные в формуле настоящего изобретения, эти примеры предназначены чисто для иллюстрации настоящего изобретения и не ограничивают объем способов и систем. Были приложены усилия для обеспечения точности чисел (например, количеств и т. п.), но следует учитывать некоторые погрешности и отклонения в экспериментах.
Представленные способы и системы подтверждались с помощью различных подтверждающих экспериментов. В первом эксперименте оценивали соответствие определений ВЧК по CLAMMS и другим алгоритмам менделевскому характеру наследования в генеалогии. Сопоставляли результаты CLAMMS, ЭСММ (другой широко используемый алгоритм) и SNP-генотипирования для набора из 3164 образцов. В другом подтверждающем эксперименте использовали кПЦР TaqMan для подтверждения ВЧК, предсказанных CLAMMS. Например, кПЦР TaqMan может использоваться в качестве иллюстрации для подтверждения CLAMMS в 37 локусах (подтверждаются 95% редких вариантов) по 17 локусам общих вариантов. Средняя точность и возврат составляли 99% и 94% соответственно.
Подтверждение представленных способов и систем включало анализ сложности операций и масштабируемости алгоритма CLAMMS. Например, секвенирование n образцов может потребовать O(n log n) времени, а на формирование k-мерного дерева требуется лишь время, равное O(log n) на образец. Такой подход снижает сложность O(n2) предшествующих алгоритмов (например, как PCA, так и способы выбора референтной панели CANOES и ExomeDepth требуют, чтобы профиль покрытия каждого образца сопоставлялся с каждым другим образцом).
Как более подробно описано в настоящем документе, можно провести оценку соответствия определений ВЧК по CLAMMS, ЭСММ, CoNIFER, CANOES и ExomeDepth менделевскому характеру наследования. В качестве примера соответствие определениям ВЧК по этим алгоритмам оценивали для восьми представителей родословной CEPH 1463, секвенированной по трем техническим копиям. В качестве референтной панели было предоставлено 92 дополнительных образца. Следует отметить, что большинство ВЧК в родословной представляли собой общие варианты (например, по определению). 98% определений были наследованными, а 94% были согласованными по всем трем техническим копиям. Ниже дополнительно представлена статистика для других расчетных алгоритмов.
Более эффективные показатели алгоритма CLAMMS для общих ВЧК достигаются не за счет снижения показателей для редких ВЧК. Например, в рамках другого подтверждающего эксперимента определения ВЧК по CLAMMS и ЭСММ сопоставляли с определениями по «золотому стандарту» по PennCNV (например, где используются данные SNP-генотипирования) для 3164 образцов. Определения PennCNV проходят несколько фильтров контроля качества. Для редких вариантов (например, AF ≤ 0,1% в данных массива) CLAMMS демонстрировала точность 78% и возврат 65% по сравнению с точностью 66% и возвратом 64% для ЭСММ.
В качестве другого подтверждающего эксперимента может использоваться кПЦР TaqMan для подтверждения случайного подмножества ВЧК, предсказанных CLAMMS. кПЦР TaqMan использовали для подтверждения в 20 локусах редких вариантов и 20 локусах общих вариантов, которые перекрываются со связанными с заболеваниями генами в базе данных Human Gene Mutation Database. В данном примере подтверждающего эксперимента подтверждалось 19/20 (95%) редких вариантов, предсказанных CLAMMS. Три локуса общих вариантов исключались из-за высокой дисперсии данных TaqMan. Остальные 17 локусов демонстрировали средние значения точности/возврата 99,0% и 94,1% соответственно. В качестве другого результата у 16/17 (94%) локусов не отмечалось ложноположительных показателей. В качестве дополнительного результата у 13/17 локусов (76%) отмечалась чувствительность, которая была больше или равна 90%, для 165 генотипированных образцов. На фигурах с ФИГ. 8 по ФИГ. 14 приводится более подробная информация о примерах таких подтверждающих экспериментов.
На ФИГ. 8 представлено сравнение использования оперативной памяти для CLAMMS по сравнению с другими алгоритмами. Использование оперативной памяти для CLAMMS представляется неизменными, тогда как использование оперативной памяти другими алгоритмами растет линейным образом в зависимости от числа образцов. Использование ОЗУ алгоритмами определения ВЧК приводится по 50 образцам для всех алгоритмов. Использование ОЗУ алгоритмами определения ВЧК приводится по 100 и 200 образцам для всех алгоритмов, кроме CANOES, который выполнялся в течение 4 часов без завершения расчетов. Использование ОЗУ приводится по 3164 образцам для CLAMMS и ЭСММ.
В одном аспекте алгоритм CLAMMS может быть подтвержден следующим образом. Подтверждение может производиться, например, с использованием данных из хранилища, например родословной CEPH 1463. Первый подтверждающий эксперимент был призван оценить соответствие определений ВЧК по CLAMMS и четырем другим алгоритмам (ЭСММ, CoNIFER, CANOES и ExomeDepth) менделевскому характеру наследования для 8 членов родословной (например, подмножество родословной CEPH 1463, включая прародителей NA12889, NA12890, NA12891, NA12892; родителей NA12877, NA12878 и детей NA12880, NA12882). Каждого из 8 членов родословной секвенировали в трех технических копиях. Определение ВЧК проводили с использованием описанных в настоящем документе параметров по умолчанию для каждого алгоритма. Для каждого алгоритма использовали референтную панель из 92 неродственных образцов. Чтобы обеспечить достоверное сопоставление, предварительные фильтры, используемые CLAMMS (например, фильтрование экстремальных GC и плохо картируемых областей), могут применяться к вводимым данным для всех алгоритмов, так что различия в показателях не будут отнесены на счет исключения наиболее проблемных геномных областей в CLAMMS. Из сравнения также исключали половые хромосомы.
Для каждого алгоритма могут рассчитываться три оценочных параметра: 1) доля определений, которые совпадают по всем 3 техническим копиям; 2) показатель наследования определений в 1-м и 2-м поколениях; и 3) доля определений во 2-м и 3-м поколениях, которые были унаследованы. Критерий 50%-ного перекрывания использовали, чтобы установить, передавалось ли и/или наследовалось то или иное определение (например, ВЧК у потомства наследуется, если любой ВЧК у его родителей перекрывается по меньшей мере на 50% от него).
На ФИГ. 9 представлена таблица, иллюстрирующая параметры эффективности для определения ВЧК в родословной CEPH. Столбец «Кол-во определений» предназначен для 8 членов родословной по 3 техническим копиям (например, всего 24 образца). ВЧК классифицировали как общие, если частота аллелей ВЧК была больше или равна 1%, а в других случаях классифицировали как редкие (например, стоит отметить, что редкие ВЧК могут быть ложноположительными). Определения ExomeDepth могут исключаться с баейсовским коэффициентом менее 10 (например, или другое пороговое значение). На ФИГ. 9 также представлено число определений, полученных по каждому алгоритму, согласие с техническими копиями и соответствие менделевскому характеру наследования. Как пояснялось ранее, все упомянутые алгоритмы, кроме CLAMMS, ориентированы исключительно на редкие варианты в предположении, что образцы референтной панели являются диплоидными (например, демонстрируют унимодальное распределение покрытия) во всех локусах. Таким образом, следует ожидать низкой результативности других алгоритмов, поскольку большинство ВЧК в родословной относятся к общим вариантам. С другой стороны, CLAMMS точно генотипирует такие общие варианты (например, в ситуации, когда только 2% его определений являются предположительно первичными). Превышающий менделевский показатель наследования (например, 61%) может носить просто вероятностный характер (например, существует только 27 уникальных ВЧК локусов в 1-м и 2-м поколениях).
В одном аспекте подтверждение может осуществляться с использованием определений ВЧК на основе массива «золотого стандарта». Второй подтверждающий эксперимент включал сопоставление определений ВЧК по CLAMMS и ЭСММ с определениями «золотого стандарта» по PennCNV, в котором используются данные SNP-генотипирования для набора из 3164 образцов из базы данных вариантов человеческого экзома Центра генетики компании Regeneron. Образцы из тестового набора исключали при выполнении одного из следующих условий тестирования: Кол-во определений PennCNV больше 50, LRR_SD (стандартное отклонение логарифма отношения R) больше 0,23 (95-й процентиль), а BAF_drift (дрейф частоты B-аллеля) больше 0,005 (95-й процентиль).
В одном аспекте определения ВЧК на основе массива, несмотря на в целом большую точность по сравнению с определениями ВЧК по глубине считывания секвенирования экзома, могут и не быть настоящим «золотым стандартом» и могут включать ложноположительные значения, в том числе ряд предположительных копий полиморфных локусов (например, AF больше 1%), которые не перекрываются с любыми вариантами в двух опубликованных базах данных (определения ВЧК по 849 полным геномам и определения ВЧК на основе массива по 19 584 контрольным образцам исследования аутизма). Для сведения к минимуму доли ложноположительных результатов в тестовом наборе учитывались только редкие и достаточно большие по длине ВЧК. Исключались те определения PennCNV, для которых выполнялось одно или более из следующих условий: длина ВЧК меньше 10 килобаз или больше 2 мегабаз, ВЧК не перекрываются по меньшей мере с 1 экзоном и по меньшей мере 10 SNP в структуре массива, ВЧК перекрывается с пропуском в референтном геноме (например, GRCh37) или общей геномной перестройкой в HapMap, частота аллелей более 0,1% конкретных наборов данных и/или 3164 тестовых образцов (например, ВЧК учитываются при подсчете частоты аллелей, если они перекрываются по меньшей мере с 33,3% рассматриваемого ВЧК).
Итоговый тестовый набор после применения всех фильтров может включать 1715 ВЧК (например, 46% DEL, 54% DUP) в 1240 образцах. Для такой оценки как CLAMMS, так и ЭСММ применяли с использованием параметров и процедур, применяемых по умолчанию. Рекомендуется считать выбросами образцы, где число определений вдвое превышает медианное значение для любого отдельно взятого набора данных. В данном примере набора данных медианное число определений CLAMMS в образце равно 11. Определения CLAMMS по 26 образцам (например, 0,8% от суммы) исключали в том случае, если результаты CLAMMS превышали 22 определения. Тем не менее массивы определений из этих образцов могут быть включены в тестовый набор.
На ФИГ. 10 представлены результаты определения ВЧК по CLAMMS и ЭСММ по сравнению с «золотым стандартом» PennCNV. Точность может рассчитываться как процентная доля определений CLAMMS/ЭСММ, которые, возможно, будут подтверждаться определениями PennCNV, а это значит, что в отношении двух алгоритмов действуют одинаковые критерии фильтрования, которые в действительности перекрываются с определением PennCNV при заданном пороговом значении перекрывания. Возврат (например, чувствительность) может рассчитываться как процентная доля определений PennCNV, которые перекрываются с любым определением CLAMMS/ЭСММ (например, никакие фильтры не применяются) при заданном пороговом значении перекрывания. F-показатель может определяться как геометрическое среднее точности и возврата.
В одном аспекте CLAMMS может достигать на 9,3% более высокого F-показателя по сравнению с ЭСММ с использованием критерия любого перекрывания, на 5,8% выше с использованием критерия 33% перекрывания и на 4,9% выше с использованием критерия 50% перекрывания. Такое улучшение определяется более высокой точностью CLAMMS (например, на 18-20% выше в зависимости от порогового значения перекрывания).
CLAMMS обычно более консервативна при оценке точечных разрывов ВЧК (например, результатом являются меньшие ВЧК), чем PennCNV или ЭСММ, по этой причине величина возврата значительно больше при использовании любого перекрывания по сравнению с перекрыванием 50%. Как описано в настоящем документе, ряд алгоритмов, в том числе PennCNV и ЭСММ, используют алгоритм Витерби для идентификации областей ВЧК, проводя сканирование по экзому в одном направлении (например, от 5' к 3'). Такой подход вносит направленный сдвиг в определения ВЧК: сложно «выявить» ВЧК, но просто провести «расширение» ВЧК, поэтому так называемые области ВЧК будут демонстрировать тенденцию выхода за точечный разрыв конца 3'. С другой стороны, CLAMMS может выполняться так, чтобы сообщать только о пересечениях областей ВЧК, определяемых, если алгоритм Витерби выполняется в прямом (от 5' к 3') и в обратном направлении (3' к 5'), исключая сдвиг направления.
В одном аспекте подтверждение может осуществляться с использованием кПЦР TaqMan следующим образом. Количественная ПЦР TaqMan может использоваться для подтверждения выбора локусов ВЧК (например, 20 редких, 20 общих), предсказанных CLAMMS. В каждом локусе прогнозы числа копий на основе ПЦР могут сопоставляться с генотипами ВЧК CLAMMS для 56/165 образцов для редких и общих локусов соответственно. Локусы ВЧК могут выбираться случайным образом из набора всех локусов, которые перекрываются по меньшей мере с одним геном, ассоциированным с заболеванием, внесенным в базу данных Human Gene Mutation Database.
С помощью такого подхода было подтверждено 19/20 (95%) редких вариантов. 3/20 локусов общих вариантов были вероятно точными, но отличались высокой дисперсией данных ПЦР, что делало результаты неоднозначными. 16/17 (94%) остальных локусов общих вариантов не имели ложноположительных результатов, и в одном локусе отмечалось 5/6 определений. 13/17 (76%) локусов однозначных общих вариантов имели чувствительность, которая больше или равна 90% (например, включая 9/17 локусы с чувствительностью 100%). Остальные 4/17 отличаются чувствительностью 87,5%, 87,3%, 81,5% и 70,1%. Средние значения точности/чувствительности для 17 локусов составляли 99,0% и 94,1% соответственно.
На ФИГ. 11 представлена таблица, иллюстрирующая подтверждения редких ВЧК с использованием TaqMan. В данном примере подтверждения 165 образцов, протестированных на наличие локусов общих ВЧК, не отбирались случайным образом в попытке свести к минимуму число образцов, необходимых для гарантий того, что в каждом локусе существует разумное число образцов с недиплоидным числом копий (например, по этой причине несколько локусов в таблице содержат в точности 10 предсказанных ВЧК).
На ФИГ. 12 представлена таблица, иллюстрирующая подтверждения общих ВЧК с использованием TaqMan. На ФИГ. 13 представлен график, иллюстрирующий сравнение прогнозов числа копий по CLAMMS и TaqMan для локуса общих вариантов LILRA3. На ФИГ. 14 представлен график сравнения прогнозов числа копий CLAMMS и TaqMan для локуса общего варианта LILRA3.
Хотя способы и системы описаны в связи с предпочтительными вариантами осуществления настоящего изобретения и конкретными примерами, подразумевается, что объем изобретения не ограничивается представленными конкретными вариантами осуществления, поскольку варианты осуществления, приведенные в настоящем документе, во всех отношения призваны носить иллюстративный, а не ограничительный характер.
Если в прямой форме не указано иное, никоим образом не предполагается, что любой способ, приведенный в настоящем документе, будет рассматриваться как требующий выполнения его шагов в определенном порядке. Соответственно, если в том или ином пункте формулы изобретения, который касается того или иного способа, в действительности не перечисляется порядок, которому необходимо следовать при выполнении его шагов, или же если в иных случаях в пунктах формулы изобретения или описаниях отсутствует прямое указание на ограничение выполнения шагов в определенном порядке, никоим образом не предполагается, что такой порядок подразумевается тем или иным образом. Это справедливо в отношении любой косвенной основы для интерпретации, в том числе: вопросов логики в отношении организации шагов или последовательности операций; общеупотребительного значения, определенного на основе грамматической организации или пунктуации; числа или типа вариантов осуществления, описанных в описании.
В настоящей заявке приводятся ссылки на различные публикации. Описание данных публикаций полностью включено в настоящую заявку путем ссылки для более подробного описания состояния в области, к которой относятся способы и системы.
Специалистам в данной области должно быть очевидно, что возможны различные модификации и вариации без отступления от объема или сущности. После изучения описания и практики, описанных в настоящем документе, специалистам в данной области будут очевидны другие варианты осуществления настоящего изобретения. Подразумевается, что описание и примеры представлены только в качестве иллюстрации и находятся в пределах сущности и объема, что отражено в приведенной ниже формуле изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБНАРУЖЕНИЕ СОМАТИЧЕСКОГО ВАРЬИРОВАНИЯ ЧИСЛА КОПИЙ | 2017 |
|
RU2768718C2 |
| СПОСОБ НЕИНВАЗИВНОЙ ДИАГНОСТИКИ АНЕУПЛОИДИЙ ПЛОДА МЕТОДОМ СЕКВЕНИРОВАНИЯ | 2014 |
|
RU2543155C1 |
| СПОСОБЫ ВЫЯВЛЕНИЯ И МОНИТОРИНГА РАКА ПУТЕМ ПЕРСОНАЛИЗИРОВАННОГО ВЫЯВЛЕНИЯ ЦИРКУЛИРУЮЩЕЙ ОПУХОЛЕВОЙ ДНК | 2019 |
|
RU2811503C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ВАРИАЦИИ ЧИСЛА КОПИЙ В ГЕНОМЕ | 2012 |
|
RU2593708C2 |
| НЕИНВАЗИВНОЕ ОБНАРУЖЕНИЕ ГЕНЕТИЧЕСКОЙ АНОМАЛИИ ПЛОДА | 2011 |
|
RU2589681C2 |
| Способ неинвазивного пренатального скрининга анеуплоидий плода | 2019 |
|
RU2712175C1 |
| ТЕХНОЛОГИЯ ОПРЕДЕЛЕНИЯ АНЕУПЛОИДИИ МЕТОДОМ СЕКВЕНИРОВАНИЯ | 2012 |
|
RU2529784C2 |
| СПОСОБ ОПРЕДЕЛЕНИЯ АНЕУПЛОИДИИ ПЛОДА В ОБРАЗЦЕ КРОВИ БЕРЕМЕННОЙ ЖЕНЩИНЫ | 2021 |
|
RU2777072C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОПРЕДЕЛЕНИЯ ТОГО, ЯВЛЯЕТСЯ ЛИ ГЕНОМ АНОМАЛЬНЫМ | 2011 |
|
RU2599419C2 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ДИАГНОСТИКИ ПО ДАННЫМ ПОЛНОГЕНОМНОГО СЕКВЕНИРОВАНИЯ | 2020 |
|
RU2807604C2 |
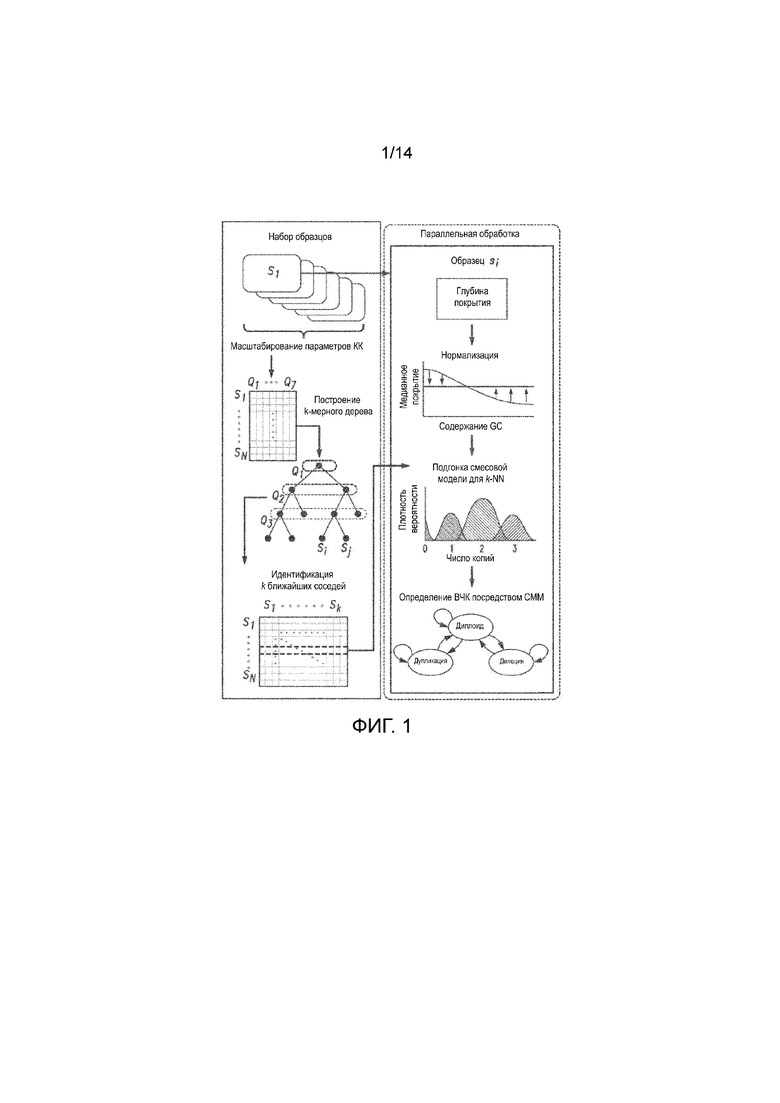
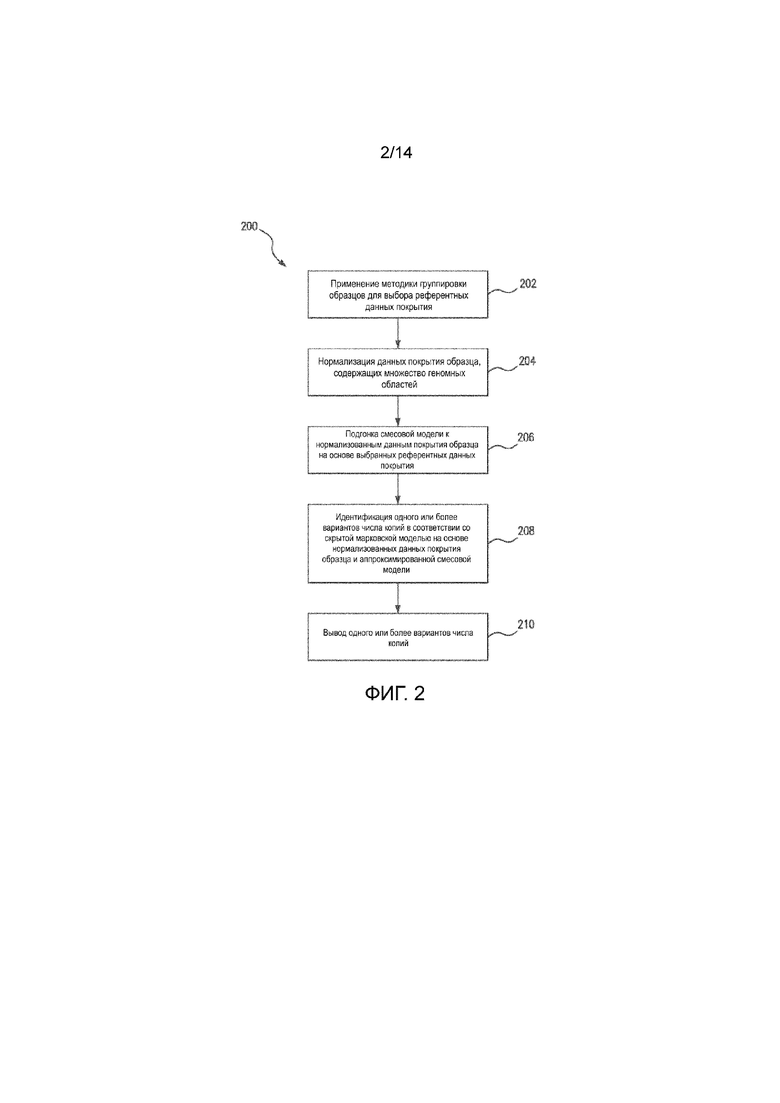
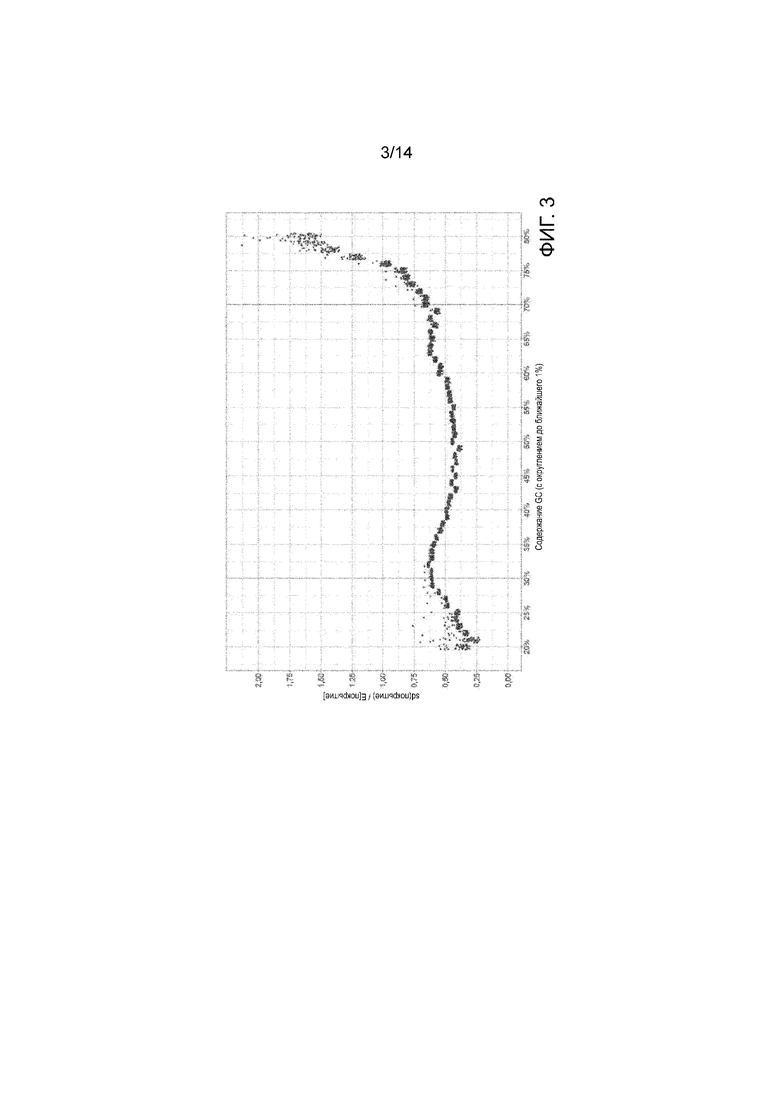

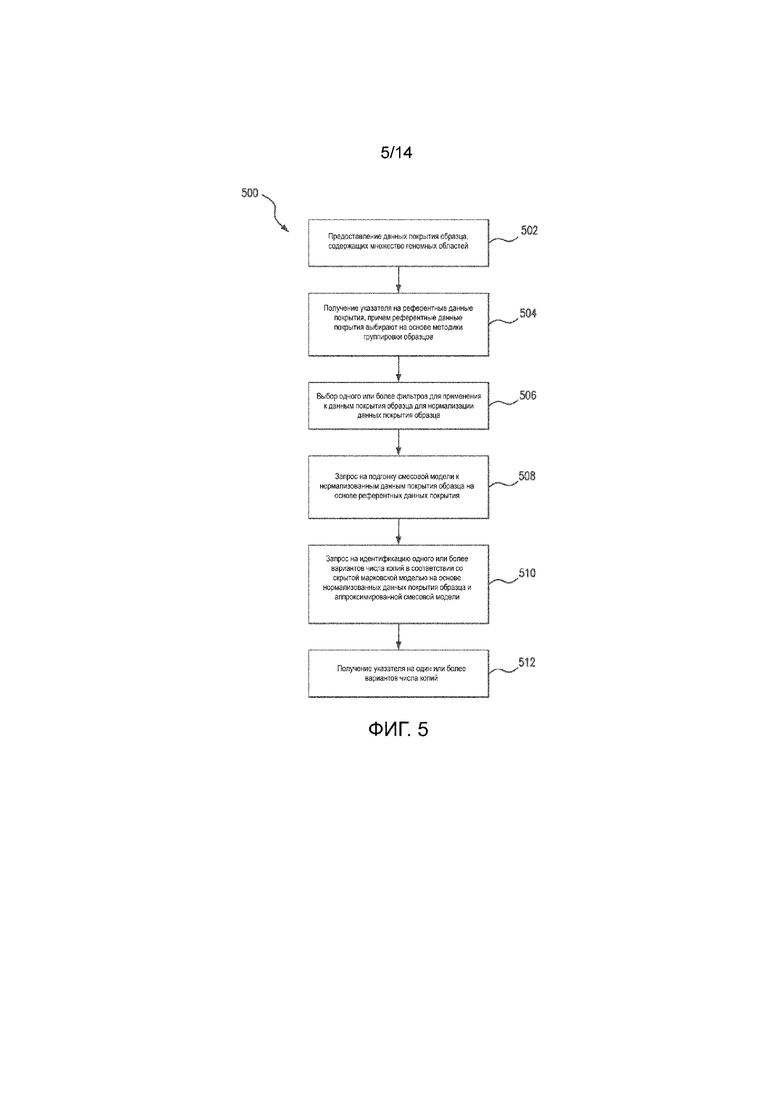
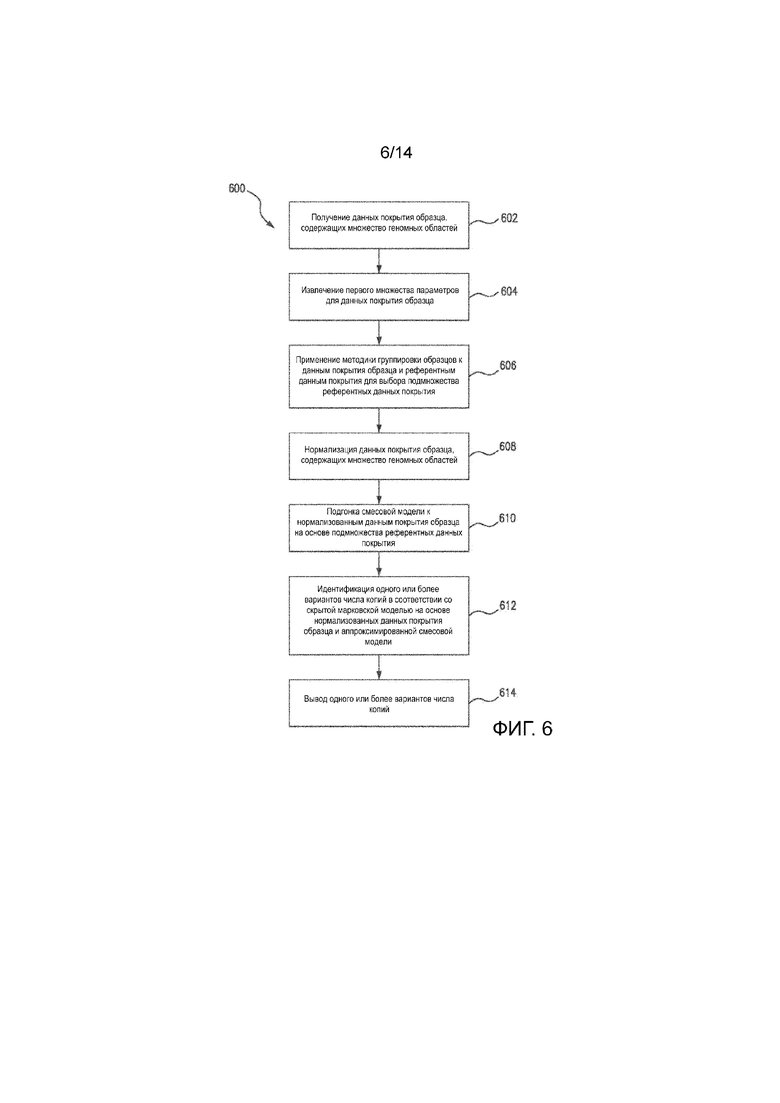
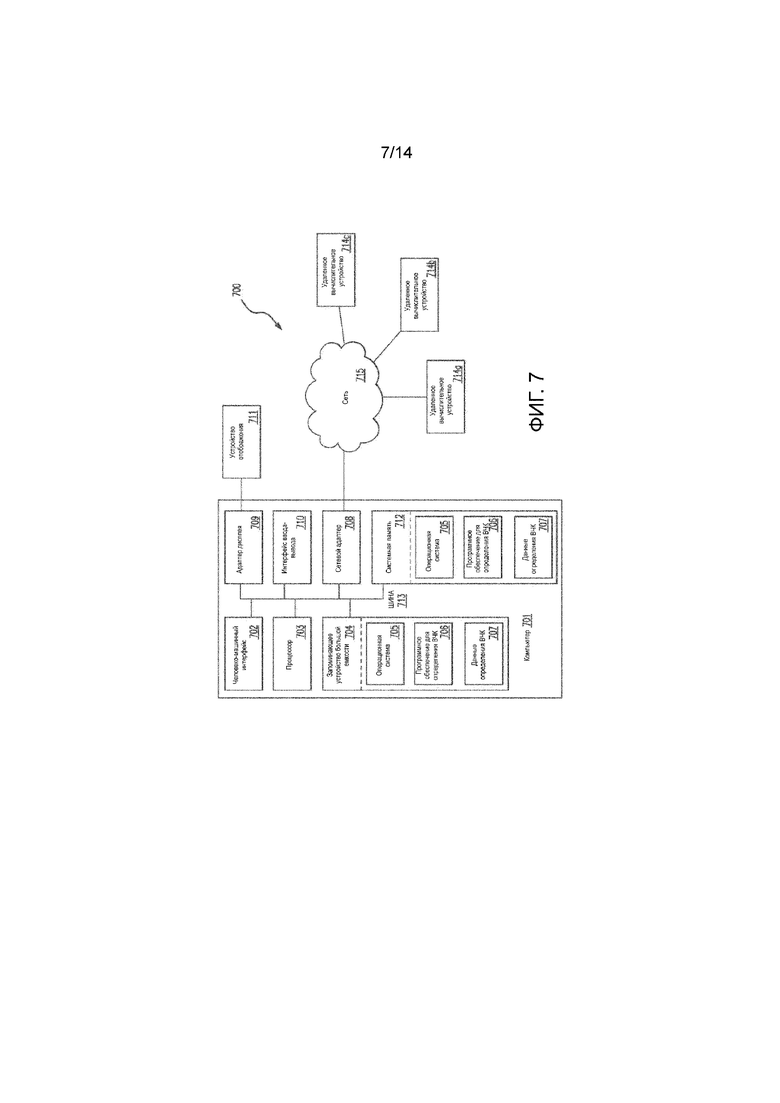
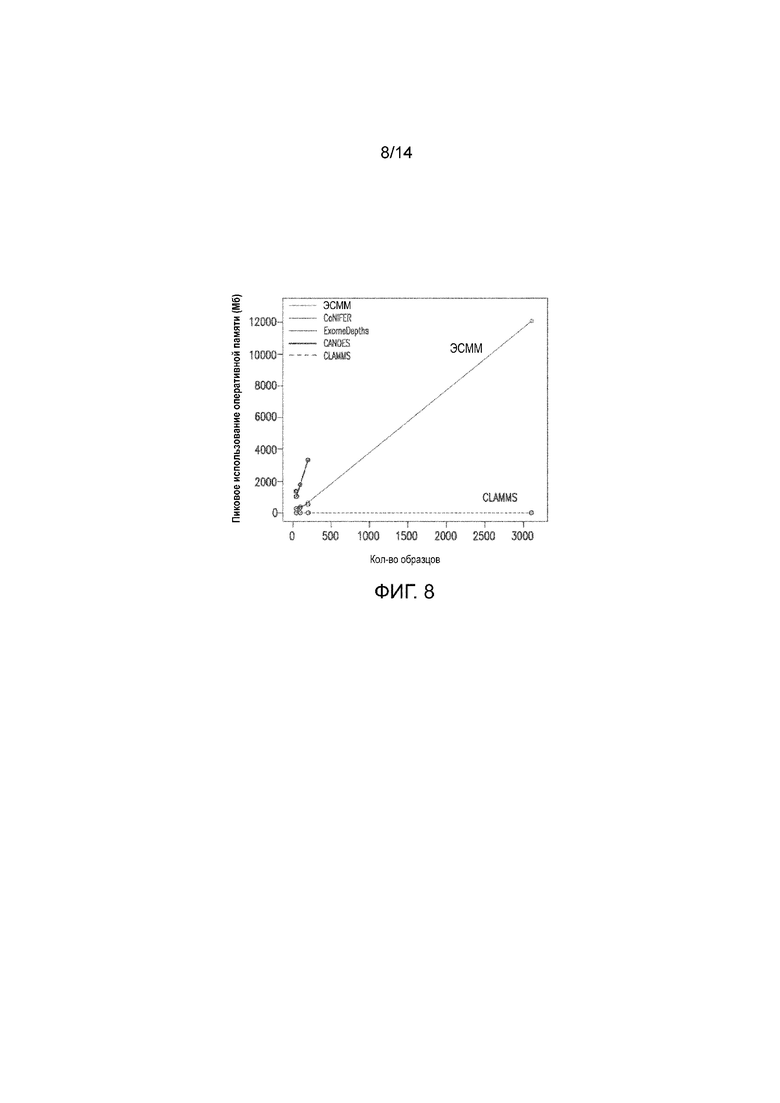
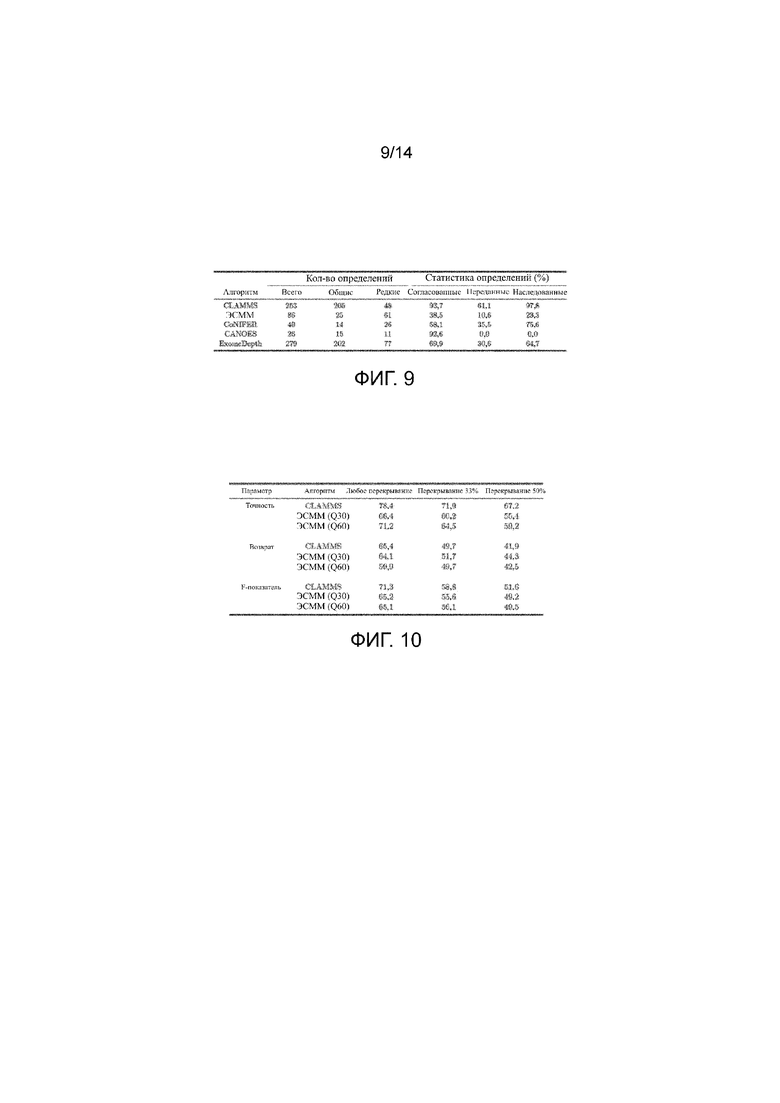



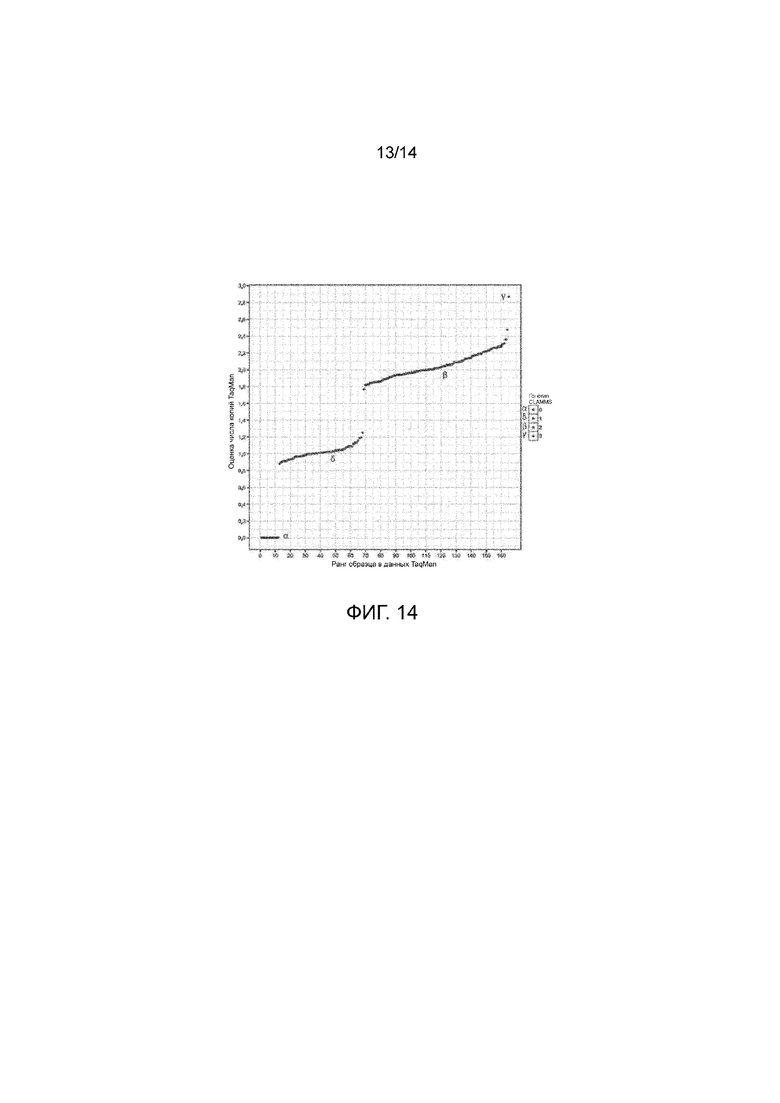

Изобретение относится к биотехнологии. Описан автоматизированный способ секвенирования нуклеиновой кислоты, включающий: получение образцов нуклеиновой кислоты от пациента; секвенирование образцов нуклеиновой кислоты, полученных от пациента, с получением множества геномных последовательностей; получение компьютерным устройством набора данных покрытия образца, включающих множество геномных последовательностей, полученных секвенированием образцов нуклеиновой кислоты пациента, и параметров контроля качества секвенирования образца (ККСО); группировку компьютерным устройством набора параметров контроля качества секвенирования (ККС) в структуру данных в виде многомерного дерева на основании сходства, причем каждый набор параметров ККС ассоциирован с соответствующим референтным набором данных покрытия, который включает множество геномных областей и глубин прочтения; выбор референтной панели референтного набора данных покрытия с использованием структуры данных в виде многомерного дерева, причем выбранные референтные наборы данных покрытия имеют параметры ККС, схожие с параметрами ККСО; нормализацию компьютерным устройством данных покрытия образца и референтной панели; подгонку компьютерным устройством нормализованной референтной панели к смесовой модели по каждой из множества геномных областей с получением ожидаемого распределения покрытия в каждой из множества геномных областей; идентификацию одного или более вариантов числа копий (ВЧК) с использованием компьютерного устройства для сравнения, в соответствии со скрытой марковской моделью (СMM), набора нормализованных данных покрытия образца с ожидаемым распределением покрытия в каждой из множества геномных областей из смесовой модели; причем при секвенировании нуклеиновой кислоты учитывают данные, ассоциированные с идентификацией одного или более вариантов числа копий. Также представлен соответствующий способ определения вариантов числа копий. 2 н. и 16 з.п. ф-лы, 15 ил.
1. Автоматизированный способ секвенирования нуклеиновой кислоты, включающий:
получение образцов нуклеиновой кислоты от пациента;
секвенирование образцов нуклеиновой кислоты, полученных от пациента, с получением множества геномных последовательностей;
получение компьютерным устройством набора данных покрытия образца, включающих множество геномных последовательностей, полученных секвенированием образцов нуклеиновой кислоты пациента, и параметров контроля качества секвенирования образца (ККСО);
группировку компьютерным устройством набора параметров контроля качества секвенирования (ККС) в структуру данных в виде многомерного дерева на основании сходства, причем каждый набор параметров ККС ассоциирован с соответствующим референтным набором данных покрытия, который включает множество геномных областей и глубин прочтения;
выбор референтной панели референтного набора данных покрытия с использованием структуры данных в виде многомерного дерева, причем выбранные референтные наборы данных покрытия имеют параметры ККС, схожие с параметрами ККСО;
нормализацию компьютерным устройством данных покрытия образца и референтной панели;
подгонку компьютерным устройством нормализованной референтной панели к смесовой модели по каждой из множества геномных областей с получением ожидаемого распределения покрытия в каждой из множества геномных областей;
идентификацию одного или более вариантов числа копий (ВЧК) с использованием компьютерного устройства для сравнения, в соответствии со скрытой марковской моделью (СMM), набора нормализованных данных покрытия образца с ожидаемым распределением покрытия в каждой из множества геномных областей из смесовой модели; причем при секвенировании нуклеиновой кислоты учитывают данные, ассоциированные с идентификацией одного или более вариантов числа копий.
2. Способ по п.1, в котором выбор референтной панели референтного набора данных покрытия с использованием структуры данных в виде многомерного дерева включает:
определение параметра расстояния между параметрами ККСО и параметрами ККС; и
выбор референтной панели референтных наборов данных покрытия на основе параметра расстояния.
3. Способ по п.1, в котором группировка множества наборов референтных данных покрытия включает использование алгоритма кластеризации, алгоритма классификации или их комбинации.
4. Способ по п.1, в котором группировка наборов параметров ККС включает использование алгоритма k ближайших соседей (knn), и причем способ дополнительно включает:
масштабирование наборов параметров ККС;
масштабирование наборов параметров ККСО;
причем группировка наборов параметров ККС в структуру данных в виде многомерного дерева на основании сходства включает построение k-мерного дерева на основе масштабированного набора параметров ККС;
добавление масштабированных параметров ККС к k-мерному дереву; и
причем выбор референтной панели референтного набора данных покрытия с использованием структуры данных в виде многомерного дерева включает идентификацию заранее заданного числа масштабированных параметров ККС по алгоритму ближайшего соседа к масштабированным параметрам ККСО.
5. Способ по п.1, дополнительно включающий разделение множества геномных областей набора данных покрытия образца на одно или более окон распознавания.
6. Способ по п.5, в котором нормализация набора данных покрытия образца включает:
определение исходного покрытия окна распознавания w;
определение медианного покрытия для набора данных покрытия образца в пределах одного или более окон распознавания в зависимости от доли GC в окне распознавания w; и
деление исходного покрытия на медианное покрытие для получения нормализованного набора данных покрытия образца.
7. Способ по п.6, в котором определение медианного покрытия для набора данных покрытия образца в пределах множества окон в зависимости от доли GC в окне распознавания w включает:
группировку одного или более окон распознавания по доле GC для получения множества групп;
определение медианного покрытия для каждой группы из множества групп; и
определение нормирующего коэффициента для каждой отдельной возможной доли GC с помощью линейной интерполяции между медианным покрытием для двух групп, ближайших к окну распознавания w.
8. Способ по п.5, дополнительно включающий фильтрование набора данных покрытия образца.
9. Способ по п.8, в котором фильтрование набора данных покрытия образца включает:
фильтрование одного или более окон распознавания на основе показателя картируемости геномной области множества геномных областей; и
фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации.
10. Способ по п.9, в котором фильтрование одного или более окон распознавания на основе показателя картируемости включает:
определение показателя картируемости для каждой геномной области множества геномных областей; и
исключение окна распознавания из одного или более окон распознавания, которое содержит геномную область множества геномных областей, если показатель картируемости геномной области множества геномных областей ниже заранее заданного порогового значения.
11. Способ по п.9, в котором фильтрование одного или более окон распознавания на основе наличия окна распознавания в геномной области мультикопийной дупликации включает:
исключение окна распознавания из одного или более окон распознавания, если окно распознавания из одного или более окон распознавания оказывается в области, где, как известно, присутствуют мультикопийные дупликации.
12. Способ по п.1, в котором подгонка референтной панели к смесовой модели включает:
определение множества смесовых моделей, по одной для каждой из множества геномных областей, причем каждый компонент множества смесовых моделей включает распределение вероятности, которое отражает ожидаемое нормализованное покрытие в зависимости от конкретного числа копий; и
подгонку нормализованной референтной панели к множеству смесовых моделей с использованием алгоритма максимизации ожидания, чтобы определить вероятность для каждого числа копий в каждом из одного или более окон распознавания, причем в алгоритм максимизации ожидания вводят нормализованную референтную панель.
13. Способ по п.12, в котором идентификация одного или более вариантов числа копий (ВЧК) с использованием компьютерного устройства для сравнения, в соответствии со скрытой марковской моделью (СMM), набора нормализованных данных покрытия образца с ожидаемым распределением покрытия включает:
ввод набора нормализованных данных покрытия образца для каждого окна распознавания из одного или более окон распознавания в СММ;
определение одной или более вероятностей эмиссии СММ на основе смесовой модели; и
идентификацию окна распознавания из одного или более окон распознавания как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной.
14. Способ по п.13, в котором определение одной или более вероятностей эмиссии СММ на основе смесовой модели включает:
определение вероятности наблюдения значения нормализованного покрытия x в окне распознавания w из одного или более окон распознавания при состоянии СММ s на основе компонента смесовой модели для w, который соответствует состоянию s.
15. Способ по п.13, в котором идентификация окна распознавания из одного или более окон распознавания как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной, включает:
реализацию алгоритма Витерби в направлении от 5' к 3' для геномной области множества геномных областей;
реализацию алгоритма Витерби в направлении от 3' к 5' для геномной области множества геномных областей; и
идентификацию окна распознавания из одного или более окон распознавания как ВЧК, если геномная область множества геномных областей, связанная с окном распознавания, с наибольшей вероятностью не является диплоидной в направлении от 5' к 3' и в направлении от 3' к 5'.
16. Способ определения вариантов числа копий, включающий:
получение образцов нуклеиновой кислоты от пациента;
секвенирование образцов нуклеиновой кислоты, полученных от пациента, с получением множества геномных последовательностей;
предоставление компьютерным устройством данных покрытия образца, содержащих множество геномных последовательностей, полученных секвенированием образцов нуклеиновой кислоты пациента, и параметров контроля качества секвенирования образца (ККСО);
получение указателя на референтные данные покрытия, причем референтные данные покрытия выбирают путем:
группировки компьютерным устройством набора параметров контроля качества секвенирования (ККС) в структуру данных в виде многомерного дерева на основании сходства, причем каждый набор параметров ККС ассоциирован с соответствующим референтным набором данных покрытия, который включает множество геномных областей и глубин прочтения;
выбора референтной панели референтного набора данных покрытия с использованием структуры данных в виде многомерного дерева, причем выбранные референтные наборы данных покрытия имеют параметры ККС, схожие с параметрами ККСО;
выбор одного или более фильтров для применения к данным покрытия образца и референтной панели для нормализации данных покрытия образца и референтной панели;
запрос на подгонку нормализованной референтной панели к смесовой модели по каждой из множества геномных областей с получением ожидаемого распределения покрытия в каждой из множества геномных областей;
запрос на идентификацию одного или более вариантов числа копий (ВЧК) с использованием компьютерного устройства для сравнения, в соответствии со скрытой марковской моделью (СMM), набора нормализованных данных покрытия образца с ожидаемым распределением покрытия в каждой из множества геномных областей из смесовых моделей; и
получение указателя на один или более ВЧК.
17. Способ по п.16, в котором подгонка нормализованной референтной панели к смесовой модели включает:
определение множества смесовых моделей, по одной для каждой из множества геномных областей, причем каждый компонент множества смесовых моделей включает распределение вероятности, которое отражает ожидаемое нормализованное покрытие в зависимости от конкретного числа копий; и
подгонку нормализованной референтной панели к множеству смесовых моделей с использованием алгоритма максимизации ожидания, чтобы определить вероятность для каждого числа копий в каждом из одного или более окон распознавания, причем в алгоритм максимизации ожидания вводят нормализованную референтную панель.
18. Способ по п.17, в котором идентификация одного или более вариантов числа копий (ВЧК) с использованием компьютерного устройства для сравнения, в соответствии со скрытой марковской моделью (СMM), набора нормализованных данных покрытия образца с ожидаемым распределением покрытия включает:
ввод набора нормализованных данных покрытия образца для каждого окна распознавания из одного или более окон распознавания в СММ;
определение одной или более вероятностей эмиссии СММ на основе смесовой модели; и
идентификацию окна распознавания из одного или более окон распознавания как ВЧК, если максимально вероятная последовательность состояний окна распознавания не является диплоидной.
| RU 2013105459 A, 20.08.2014 | |||
| WO 2012027572 A3, 01.03.2012 | |||
| Приспособление для очистки от золы жаровых труб | 1926 |
|
SU4271A1 |

