Перекрестные ссылки на родственные заявки
[0001] Настоящая заявка притязает на приоритет предварительной заявки на патент (США) № 62/398354, озаглавленной "SOMATIC COPY NUMBER VARIATION DETECTION" и поданной 22 сентября 2016 года, и предварительной заявки на патент (США) № 62/447065, озаглавленной "SOMATIC COPY NUMBER VARIATION DETECTION" и поданной 17 января 2017 года, раскрытия сущности которых фактически содержатся в данном документе по ссылке.
Уровень техники
[0002] Настоящее раскрытие сущности, в общем, относится к области техники данных, связанных с биологическими образцами, таких как данные секвенирования. Более конкретно, данное раскрытие сущности относится к технологиям для определения варьирования числа копий на основе данных секвенирования.
[0003] Генетическое секвенирование становится все более важной областью генетических исследований с перспективой будущих использований в диагностике и других применениях. В общем, генетическое секвенирование заключает в себе определение порядка нуклеотидов для нуклеиновой кислоты, такой как фрагмент РНК или ДНК. Некоторые технологии заключают в себе секвенирование полного генома, которое заключает в себе всесторонний способ анализа генома. Другие технологии заключают в себе целевое секвенирование поднабора генов или областей генома. Целевое секвенирование акцентирует внимание на интересующих областях, что формирует меньший и более компактный набор данных. Дополнительно, целевое секвенирование уменьшает затраты на секвенирование и нагрузку по анализу данных, при одновременном обеспечении возможности глубокого секвенирования при высоких уровнях покрытия для обнаружения вариантов в интересующих областях. Примеры таких вариантов могут включать в себя соматические мутации, однонуклеотидные полиморфизмы и варьирования числа копий. Обнаружение вариантов может предоставлять врачам информацию относительно вероятности или восприимчивости к болезни. Соответственно, существует потребность в улучшенном обнаружении вариантов в данных секвенирования.
Краткое описание изобретения
[0004] Настоящее раскрытие сущности предоставляет новый подход для обнаружения варьирований числа копий в биологическом образце. Как предусмотрено в данном документе, варьирования числа копий (CNV) представляют собой геномные изменения, которые приводят к анормальному числу копий одной или более геномных областей. Структурные геномные перекомпоновки, такие как дублирования, умножения, удаления, транслокации и инверсии, могут вызывать CNV. Аналогично однонуклеотидным полиморфизмам (SNP), определенные CNV ассоциированы с восприимчивостью к болезни. Термин "варьирование числа копий" в данном документе может означать варьирование числа копий последовательности нуклеиновых кислот, присутствующей в интересующем тестовом образце, по сравнению с ожидаемым числом копий. Например, для людей, ожидаемое число копий аутосомных последовательностей (и последовательностей Х-хромосом у женщин) равно двум. Другие организмы могут иметь различные ожидаемые числа копий согласно своей геномной структуре. Варьирование числа копий может представлять собой результат дублирования или удаления. В конкретных вариантах осуществления, варианты числа копий означают последовательности, по меньшей мере, в 1 КБ, которые дублируются или удаляются. В одном варианте осуществления, варианты числа копий могут иметь размер, по меньшей мере, в один ген. В другом варианте осуществления, варианты числа копий могут представлять собой, по меньшей мере, 140 п.о., 140-280 п.о. или, по меньшей мере, 500 п.о.
[0005] В одном варианте осуществления, "вариант числа копий" означает последовательность нуклеиновой кислоты, в которой различия числа копий обнаруживаются путем сравнения интересующей последовательности в тестовом образце с ожидаемым уровнем интересующей последовательности. Как предусмотрено в данном документе, эталонный образец извлекается из набора данных секвенирования несопоставленных образцов для того, чтобы формировать информацию нормализации, которая разрешает нормализацию отдельного тестового образца, так что отклонения от ожидаемых чисел копий могут определяться на нормализованных данных секвенирования. Данные нормализации генерируются с использованием методов, представленных в настоящем документе, и позволяют нормализовать гипотетический наиболее репрезентативный образец, сопоставленный с тестовым образцом. Посредством нормализации тестового образца, удаляется шум, вносимый посредством секвенирования или другого смещения.
[0006] В конкретных вариантах осуществления, покрытие необработанных данных секвенирования из серии целевого секвенирования нормализуется, чтобы уменьшать технический и биологический шум, чтобы улучшать CNV-обнаружение. В одном варианте осуществления, интересующие образцы (например, зафиксированные в формалине и погруженные в парафин образцы) секвенируются согласно требуемой технологии секвенирования, такой как целевая технология секвенирования, которая использует панель секвенирования зондов для нацеливания на интересующие области. После того, как данные секвенирования собираются, данные секвенирования нормализуются, чтобы удалять шум, и нормализованные данные затем анализируются, чтобы обнаруживать CNV.
[0007] В одном варианте осуществления, предусмотрен способ нормализации числа копий, который включает в себя этапы приема запроса на секвенирование от пользователя, чтобы секвенировать одну или более интересующих областей в биологическом образце; получения базовых данных секвенирования из интересующих областей из множества базовых биологических образцов, которые не совпадают с биологическим образцом; определения информации нормализации числа копий с использованием базовых или дополнительных данных секвенирования, при этом информация нормализации числа копий содержит, по меньшей мере, одну базовую линию числа копий для интересующей области из одной или более интересующих областей; и предоставления информации нормализации числа копий пользователю.
[0008] В другом варианте осуществления, предусмотрен способ обнаружения варьирования числа копий, который включает в себя этапы получения данных секвенирования из биологического образца, при этом данные секвенирования содержат множество необработанных ридов секвенирования для соответствующего множества интересующих областей; и нормализации данных секвенирования, чтобы удалять зависимое от области покрытие. Нормализация содержит: для каждой интересующей области, сравнение количества необработанных ридов секвенирования одного или более элементов разрешения (бинов) в интересующей области биологического образца с базовым медианным количеством ридов секвенирования, чтобы формировать базовое скорректированное количество ридов секвенирования для одного или более элементов разрешения в интересующей области, при этом базовое медианное количество ридов секвенирования для одного или более элементов разрешения в интересующей области извлекается из множества базовых образцов, которые не совпадают с биологическим образцом, и определяется только из наиболее характерных частей базовых данных секвенирования для каждой интересующей области; и удаление GS-смещения из базового скорректированного количества ридов секвенирования, чтобы формировать количество нормализованных ридов секвенирования для каждой интересующей области. Способ также включает в себя определение варьирования числа копий в каждой интересующей области на основе количества нормализованных ридов секвенирования одного или более элементов разрешения в каждой интересующей области.
[0009] В другом варианте осуществления, предусмотрен способ оценки панели целевого секвенирования, который включает в себя этапы идентификации первого множества целей в геноме для панели целевого секвенирования, при этом первое множество целей соответствует частям соответствующего множества генов; определения содержания GC каждой из первого множества целей; исключения целей из первого множества целей с содержанием GC за пределами предварительно определенного диапазона, что дает в результате второе множество целей, меньшее первого множества целей; когда, после исключения, отдельный ген имеет менее предварительно определенного числа целей, соответствующих частям для отдельного гена, идентификации дополнительных целей в отдельном гене; добавления дополнительных целей во второе множество, чтобы давать в результате третье множество целей; и предоставления панели секвенирования, содержащей зонды, конкретные для третьего множества целей.
Краткое описание чертежей
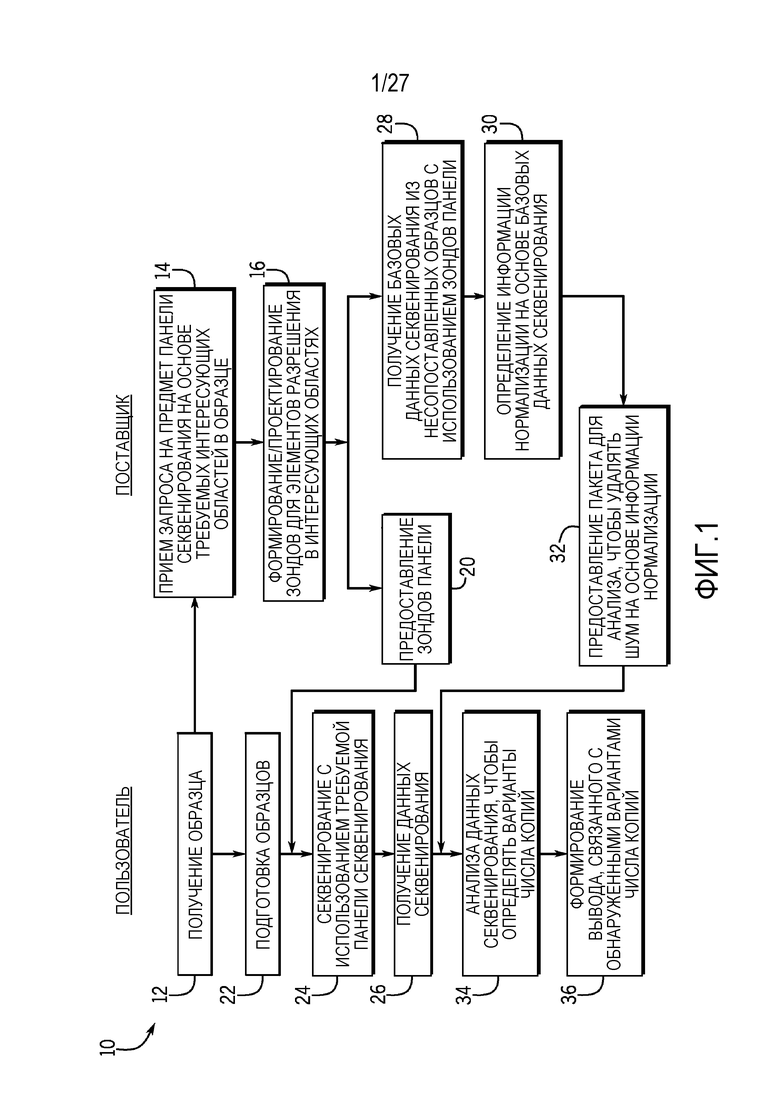
[0010] Фиг. 1 является схематическим общим представлением способов для обнаружения вариантов числа копий в соответствии с настоящими технологиями;
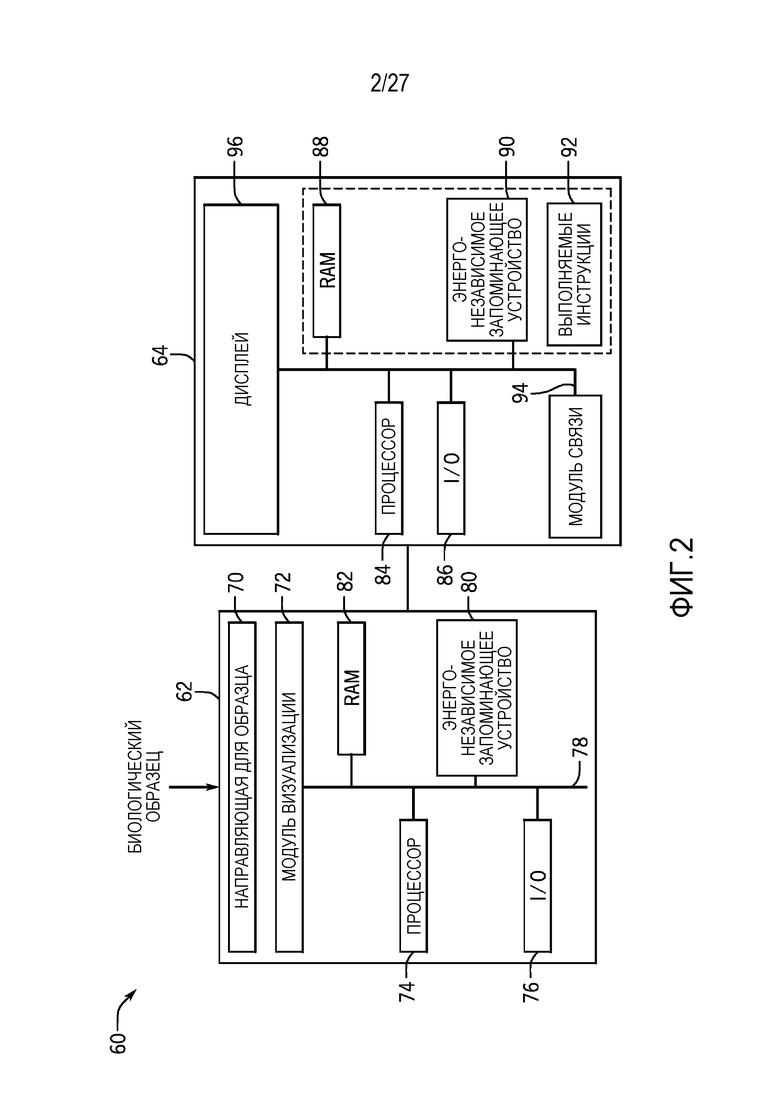
[0011] Фиг. 2 является блок-схемой устройства секвенирования, которое может использоваться в сочетании со способами по фиг. 1;
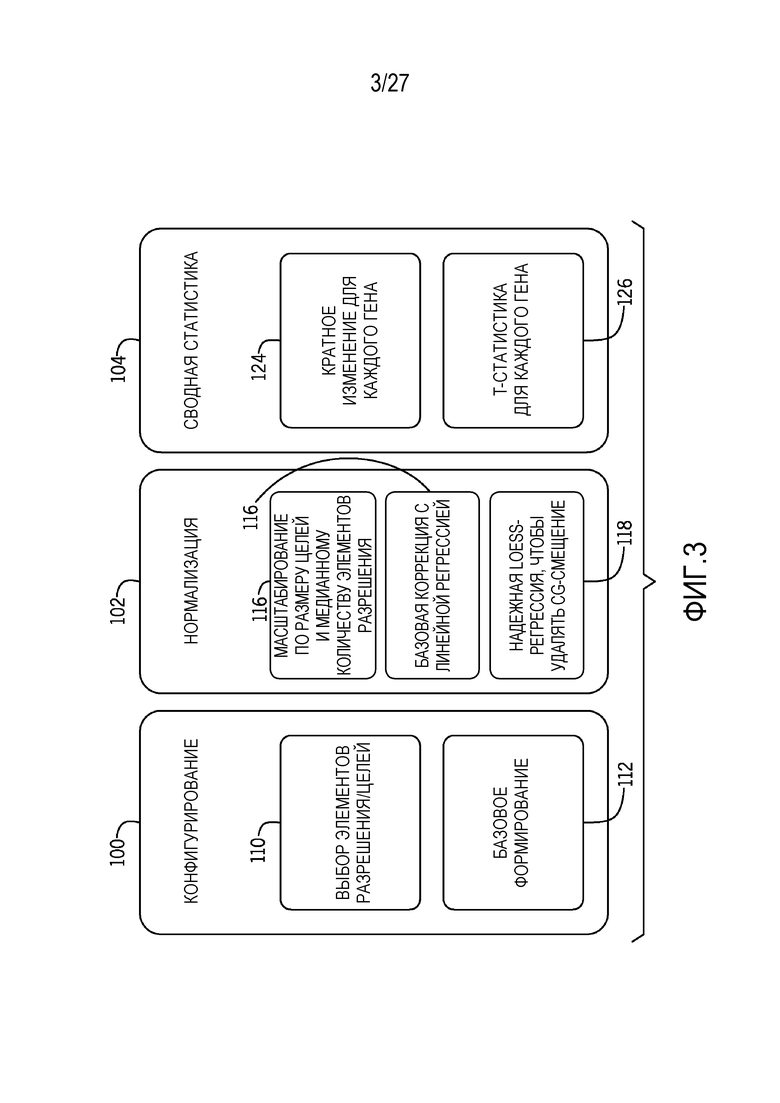
[0012] Фиг. 3 является кратким схематичным видом примера технологии нормализации в соответствии с вариантами осуществления раскрытия сущности;
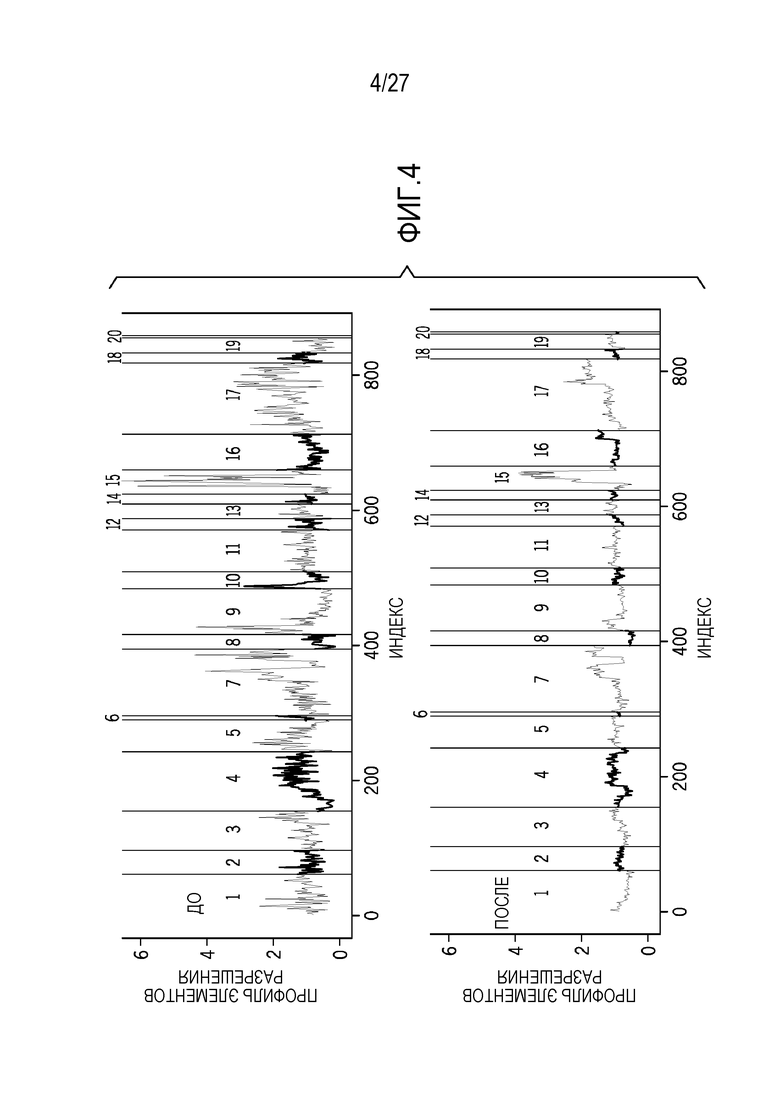
[0013] Фиг. 4 показывает данные профиля элементов разрешения для результатов секвенирования до и после нормализации, как предусмотрено в данном документе;
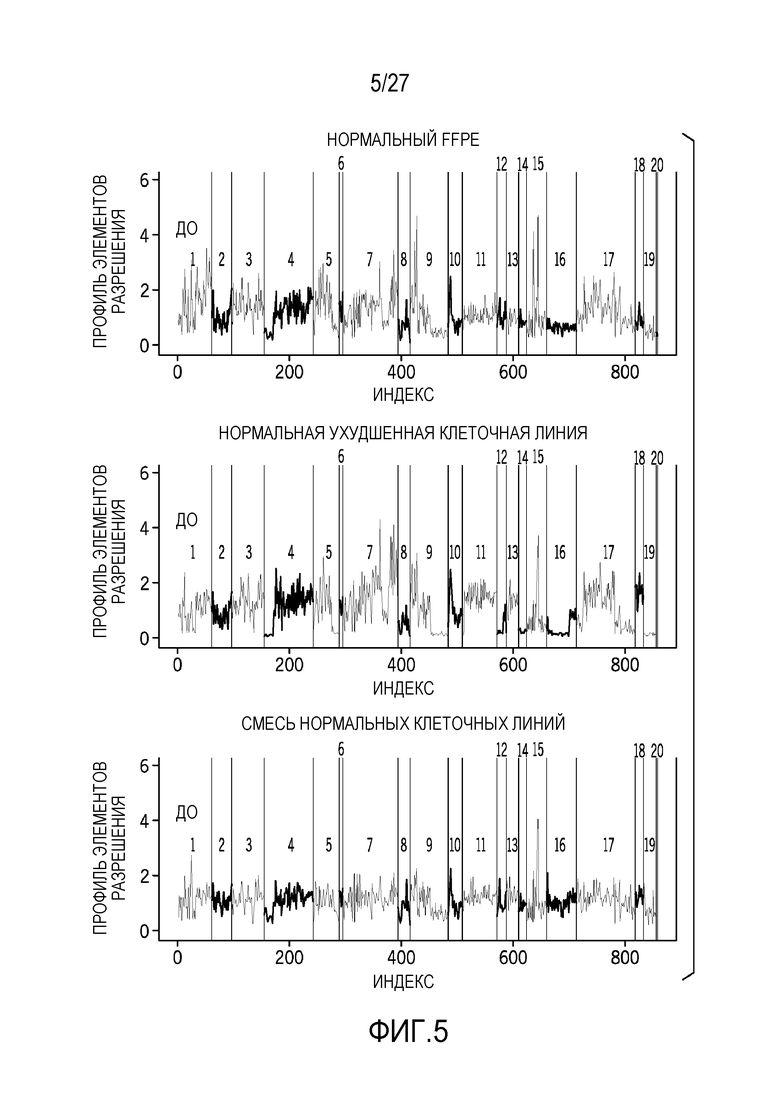
[0014] Фиг. 5 показывает шум, присутствующий в нормальных FFPE-образцах относительно сильно ухудшенной клеточной линии и смеси нормальных клеточных линий;
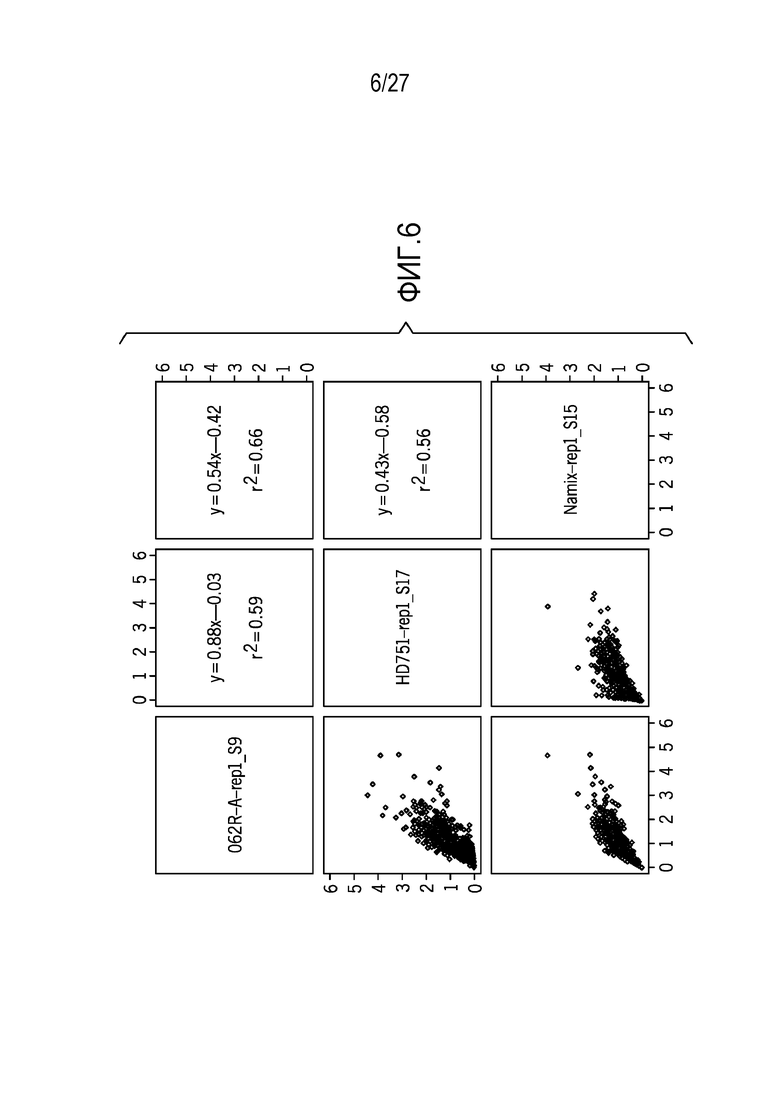
[0015] Фиг. 6 является панелью графиков, показывающих то, что базовая корреляция является плохой между различными типами образцов;
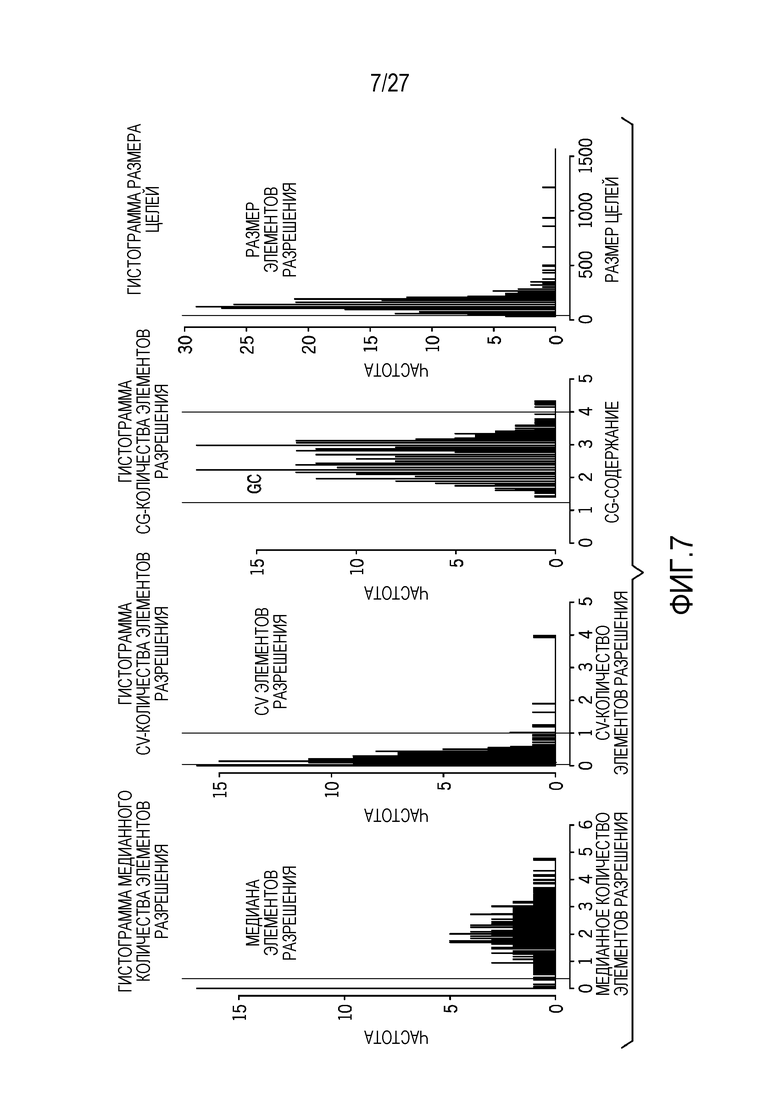
[0016] Фиг. 7 показывает примеры одного или более типов фильтрации элементов разрешения, которая может применяться к базовым эталонным данным секвенирования из несопоставленных образцов для того, чтобы удалять плохие элементы разрешения, чтобы формировать базовые линии для нормализации;
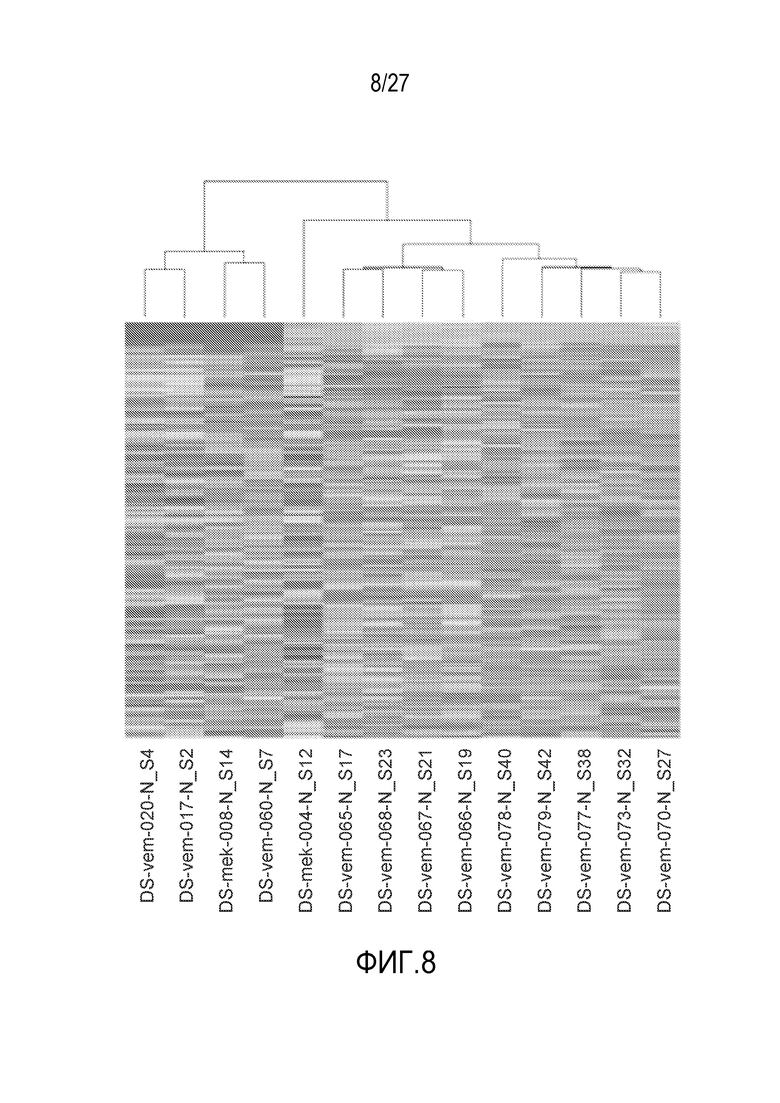
[0017] Фиг. 8 показывает иерархическую кластеризацию, чтобы идентифицировать характерные базовые линии с использованием базовых эталонных данных секвенирования из несопоставленных нормальных образцов;
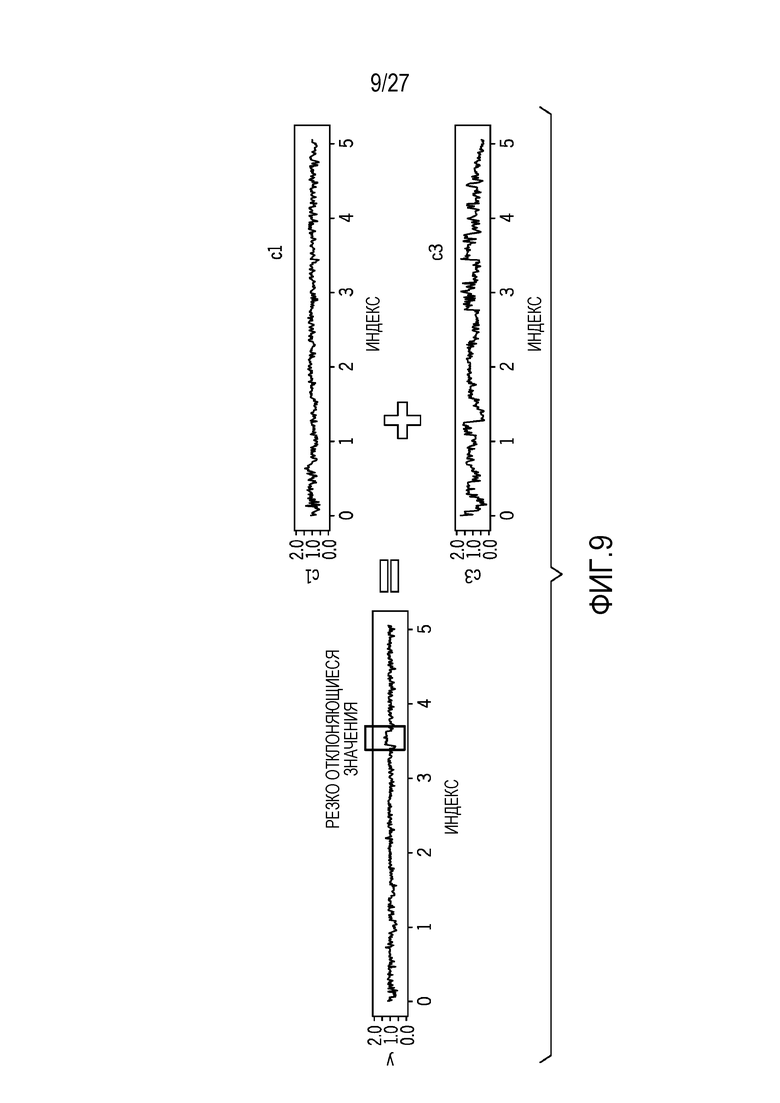
[0018] Фиг. 9 показывает результаты базовой коррекции с линейной регрессией, чтобы удалять шум, в силу которой c1 и c2 представляют собой две характерные базовые линии, распознанные из иерархической кластеризации;
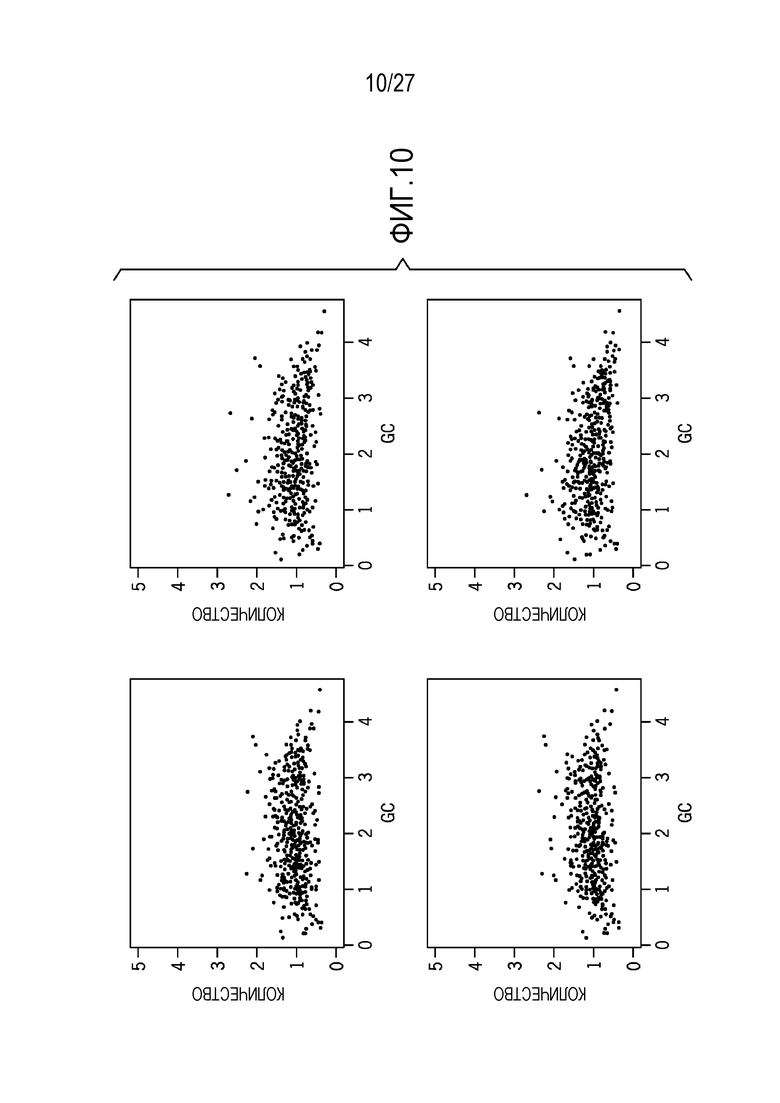
[0019] Фиг. 10 показывает переменное и зависимое от образца GS-смещение между образцами S1, S2, S3 и S4;
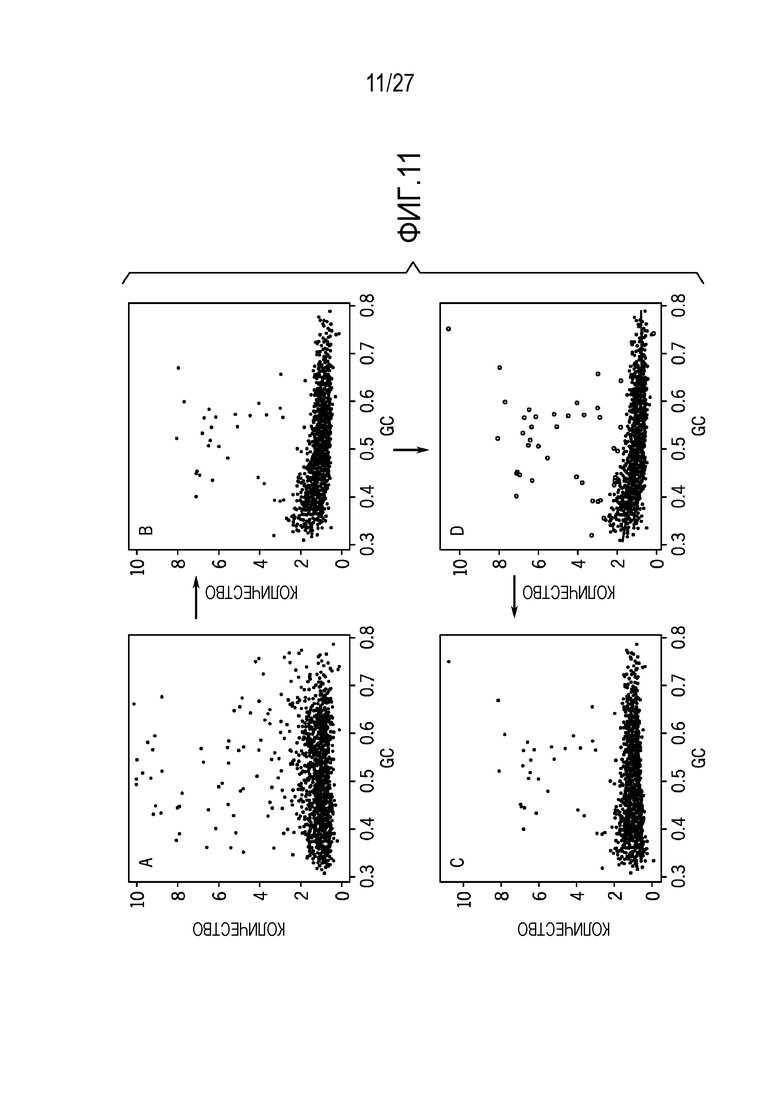
[0020] Фиг. 11 показывает нормализацию, которая включает в себя коррекцию базового смещения и GC-смещения с использованием входных данных A и предоставление в результате скорректированных данных на графике D, в силу которой A-B представляет линейную регрессию с использованием базовых линий обученного алгоритма, и B-C представляет формирование подогнанной кривой, представляющей GS-смещение для образца, и C-D представляет сглаживание подогнанной кривой, чтобы удалять GS-смещение из образца;
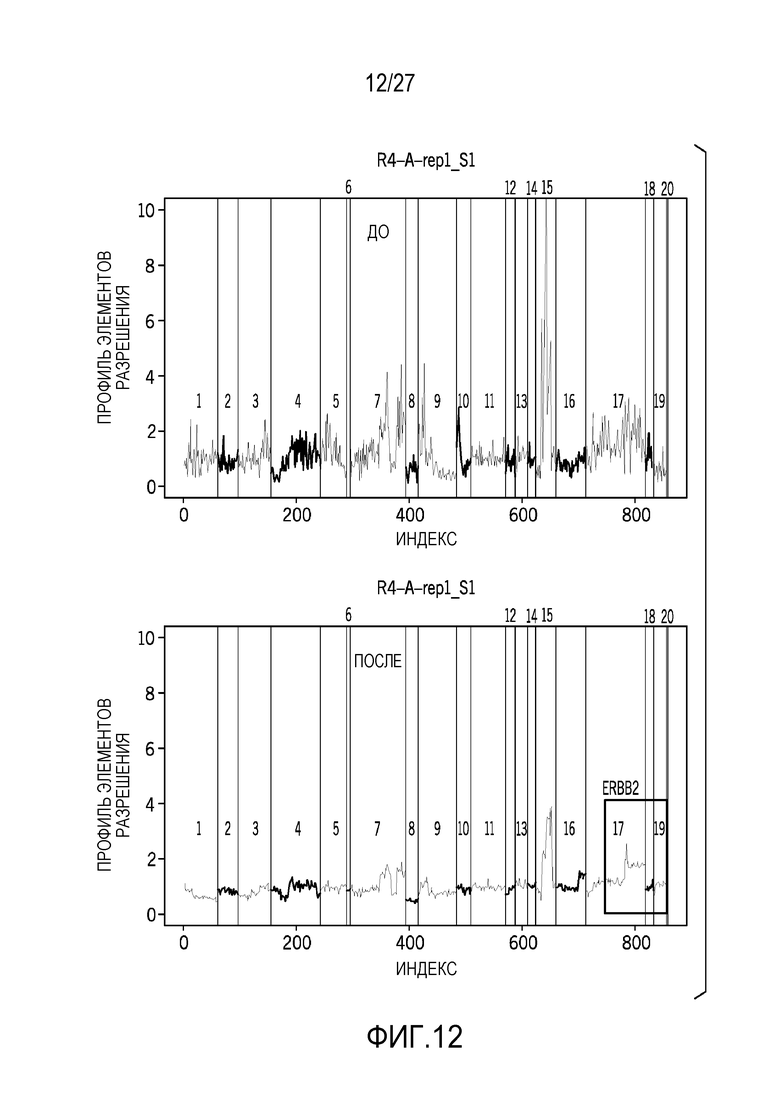
[0021] Фиг. 12 показывает результаты до и после нормализации, включающие в себя элементы разрешения последовательности для ERBB2;
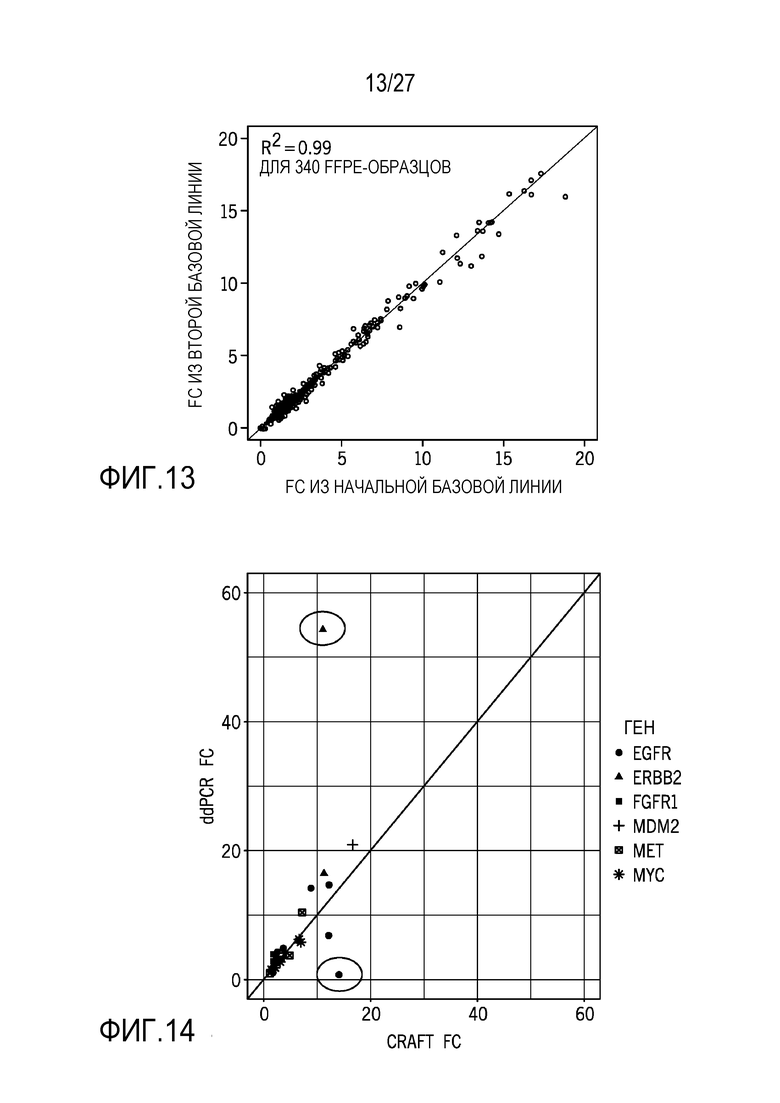
[0022] Фиг. 13 показывает то, что обнаружение кратного изменения является стабильным независимо от используемой базовой линии с R2=0,99 для 340 FFPE-образцов;
[0023] Фиг. 14 показывает высокое соответствие между технологиями нормализации, предусмотренными в данном документе, и ddPCR для 22 FFPE-образцов, испытываемых с использованием панели на предмет числа интересующих областей, включающих в себя EGFR, ERBB2, FGFR1, MDM2, MET и MYC;
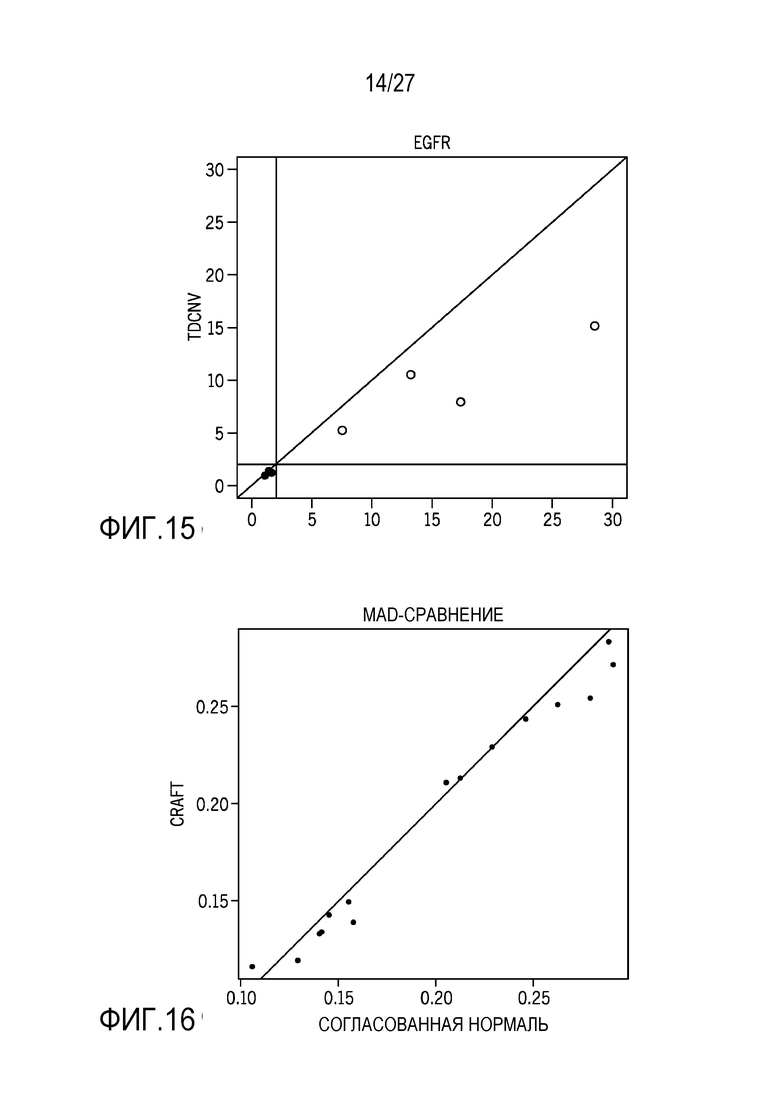
[0024] Фиг. 15 показывает сравнение результатов с использованием технологий нормализации, предусмотренных в данном документе, и образца без контроля для EGFR;
[0025] Фиг. 16 показывает сравнение результатов на основе медианного абсолютного отклонения с использованием технологий нормализации, предусмотренных в данном документе, и сопоставленных нормальных образцов со спаренным t-испытываемым p-значением в 0,0202;
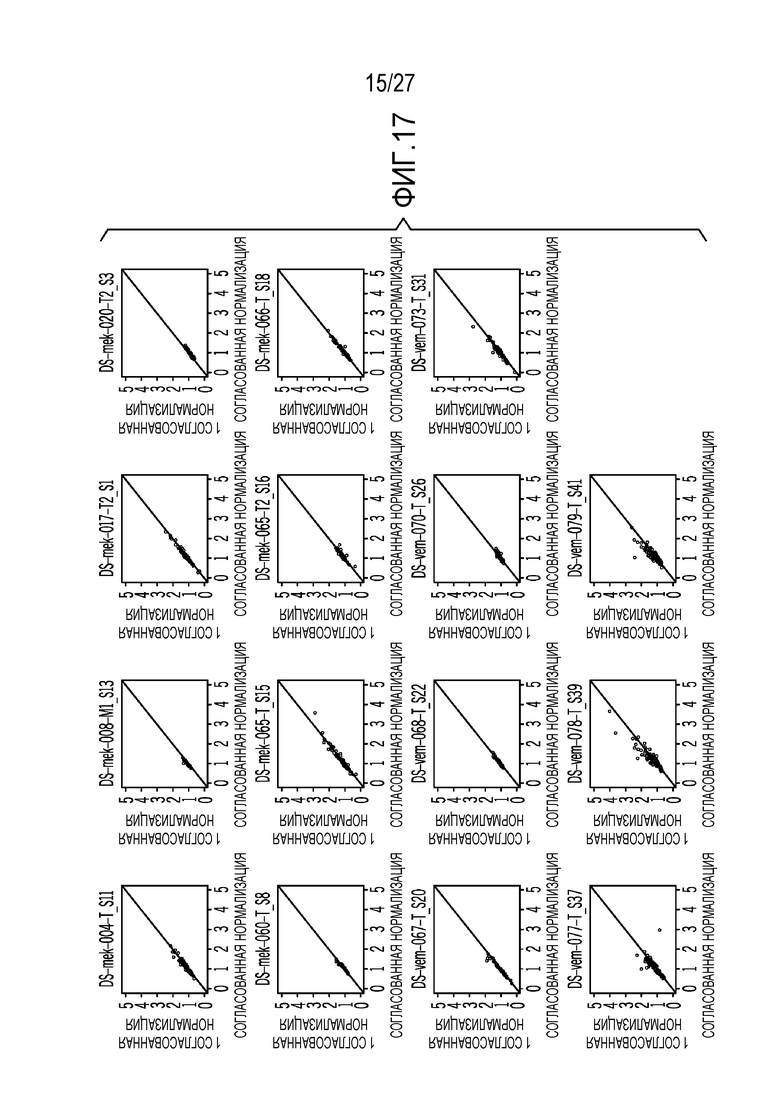
[0026] Фиг. 17 показывает сравнение кратного изменения, с обнаруженным сравнением кратного изменения (FC) между технологиями нормализации, предусмотренными в данном документе (ось Y), и согласованной нормалью (ось X);
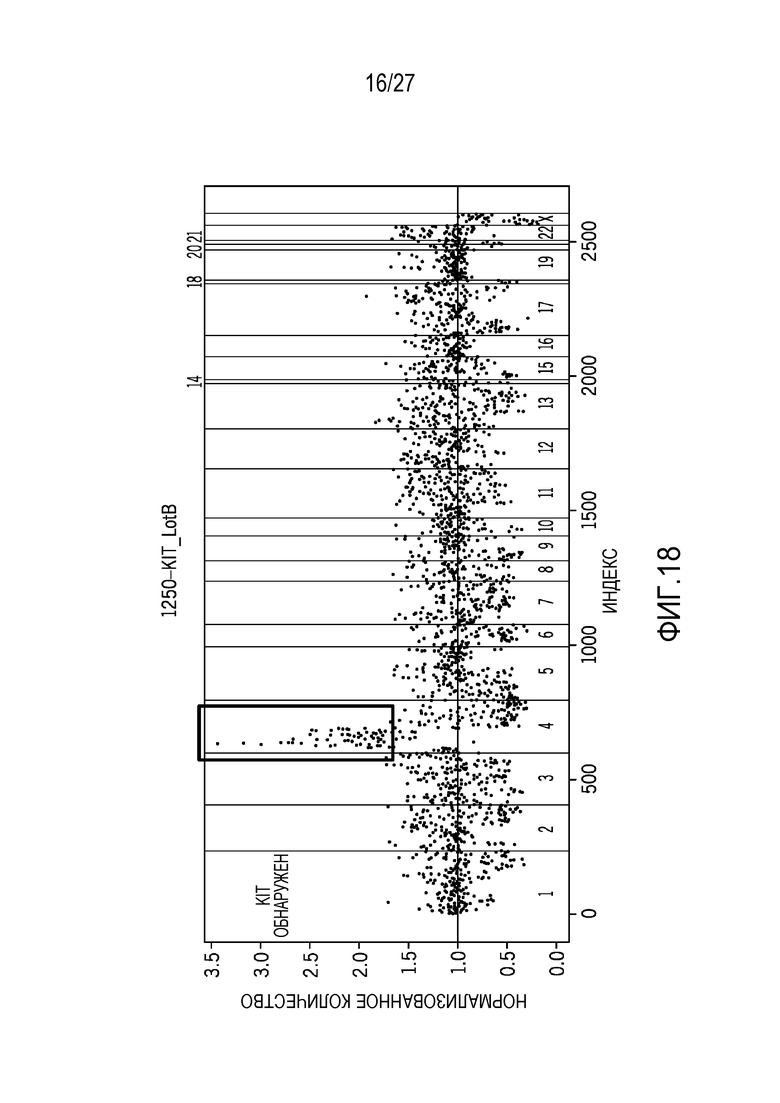
[0027] Фиг. 18 показывает KIT-варианты, обнаруженные с использованием технологий нормализации, предусмотренных в данном документе;
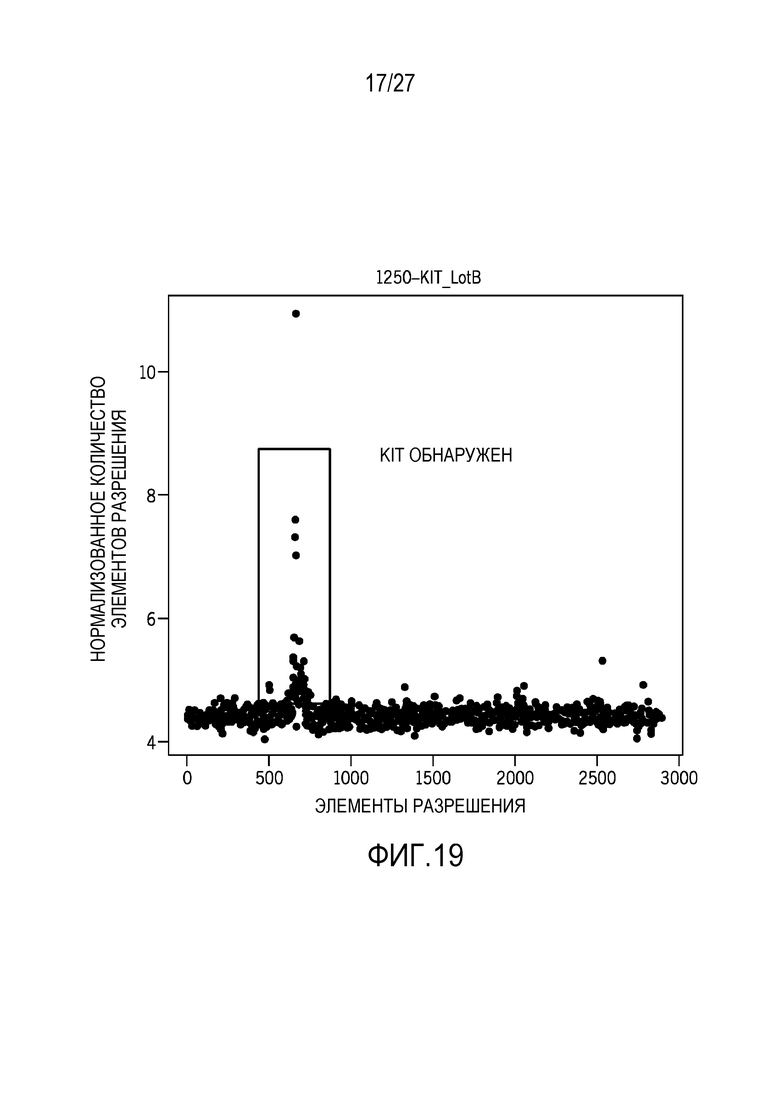
[0028] Фиг. 19 показывает KIT-варианты, обнаруженные с использованием альтернативной технологии анализа главных компонентов;
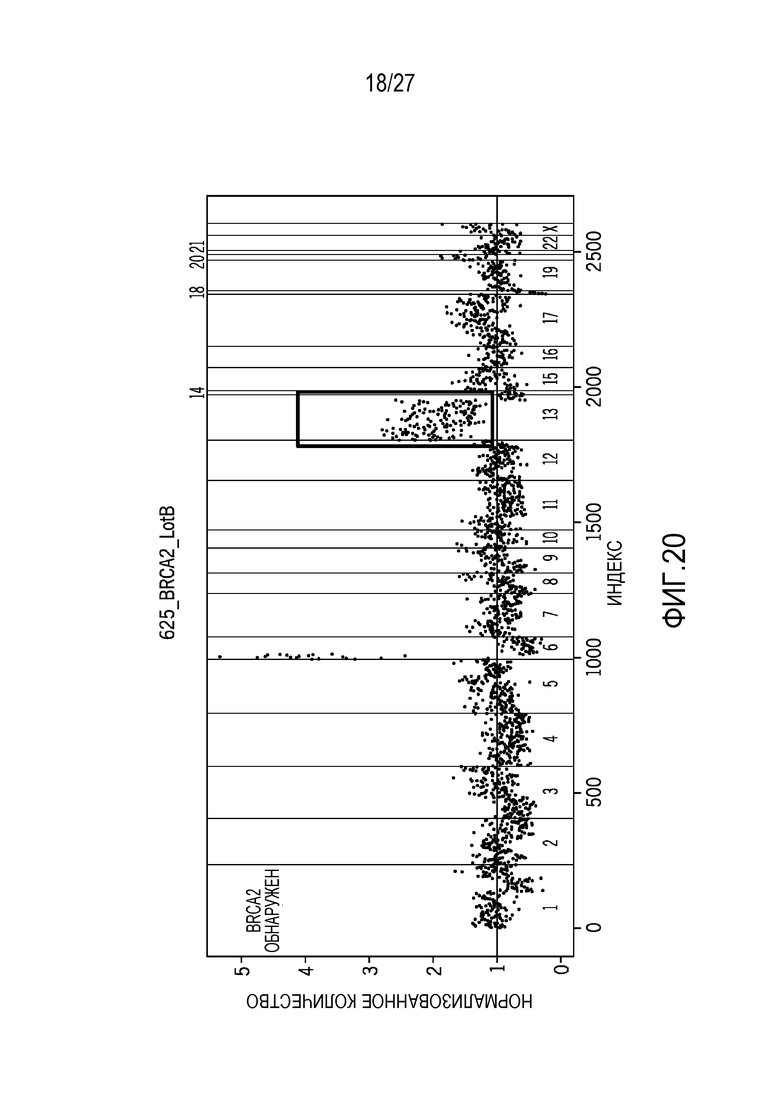
[0029] Фиг. 20 показывает BRCA2-варианты, обнаруженные с использованием технологий нормализации, предусмотренных в данном документе;
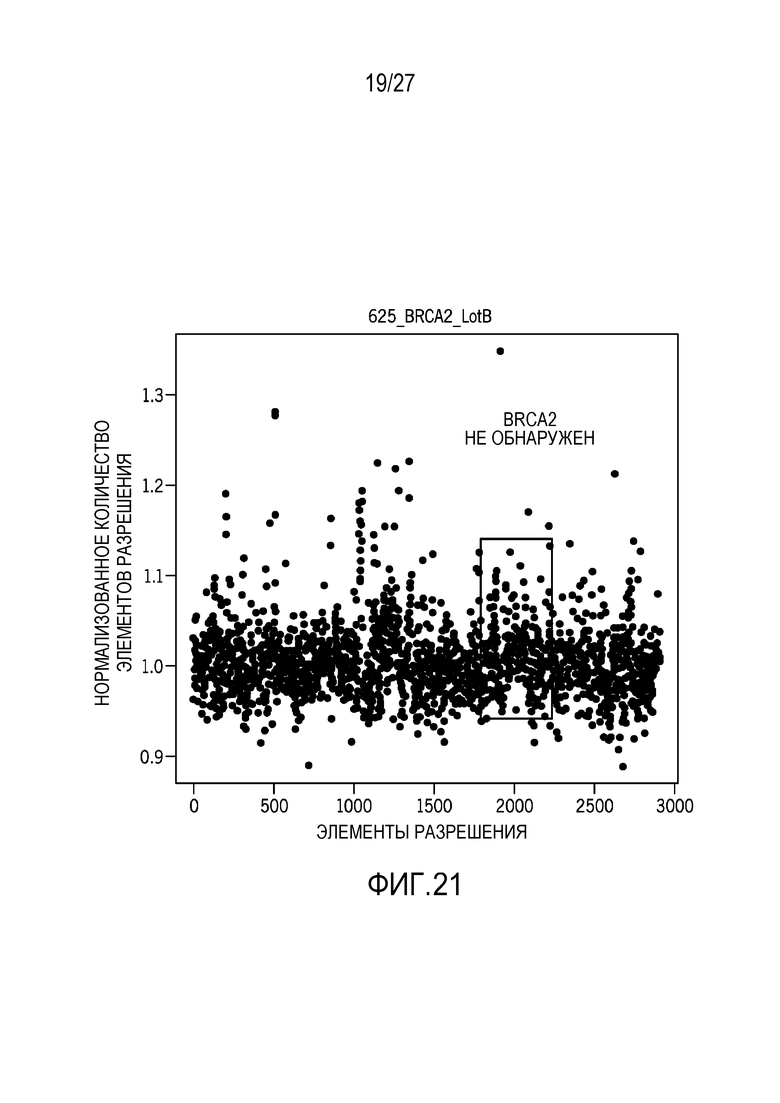
[0030] Фиг. 21 показывает BRCA2-варианты, которые не могут обнаруживаться с использованием альтернативной технологии анализа главных компонентов;
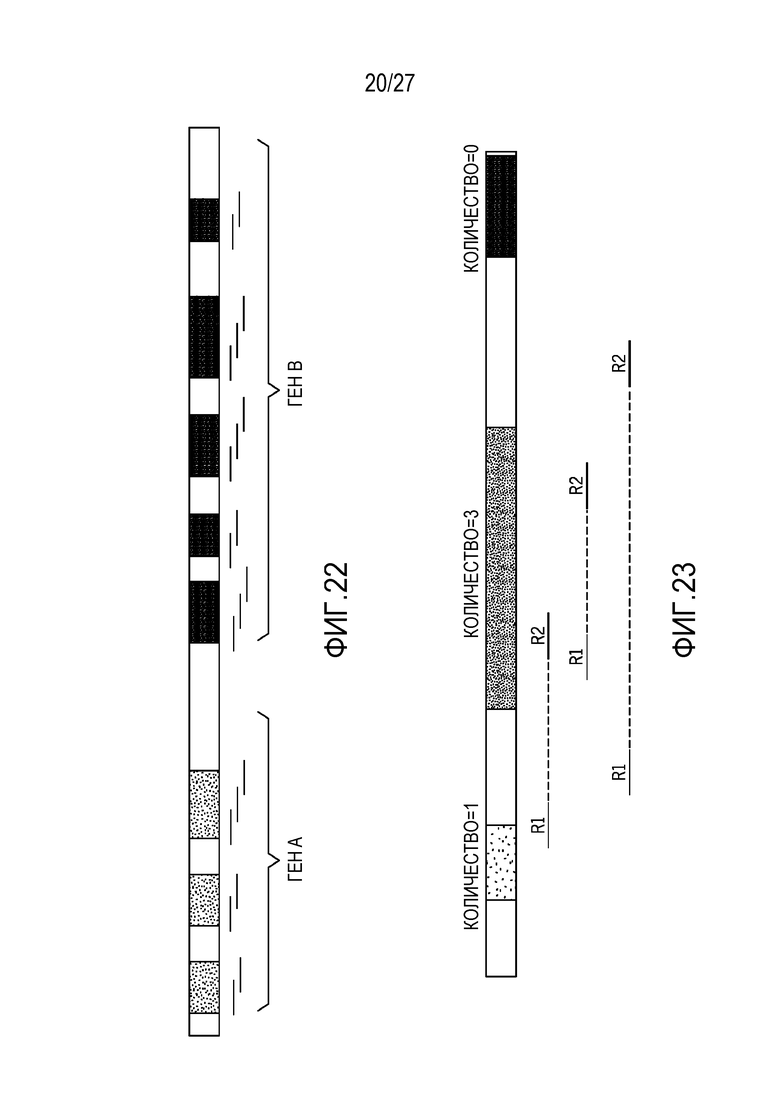
[0031] Фиг. 22 является схематичным представлением проектирования зондов, например, генов, показывающих области элемента разрешения;
[0032] Фиг. 23 является схематичным представлением количеств элементов разрешения на основе фрагментов, а не ридов;
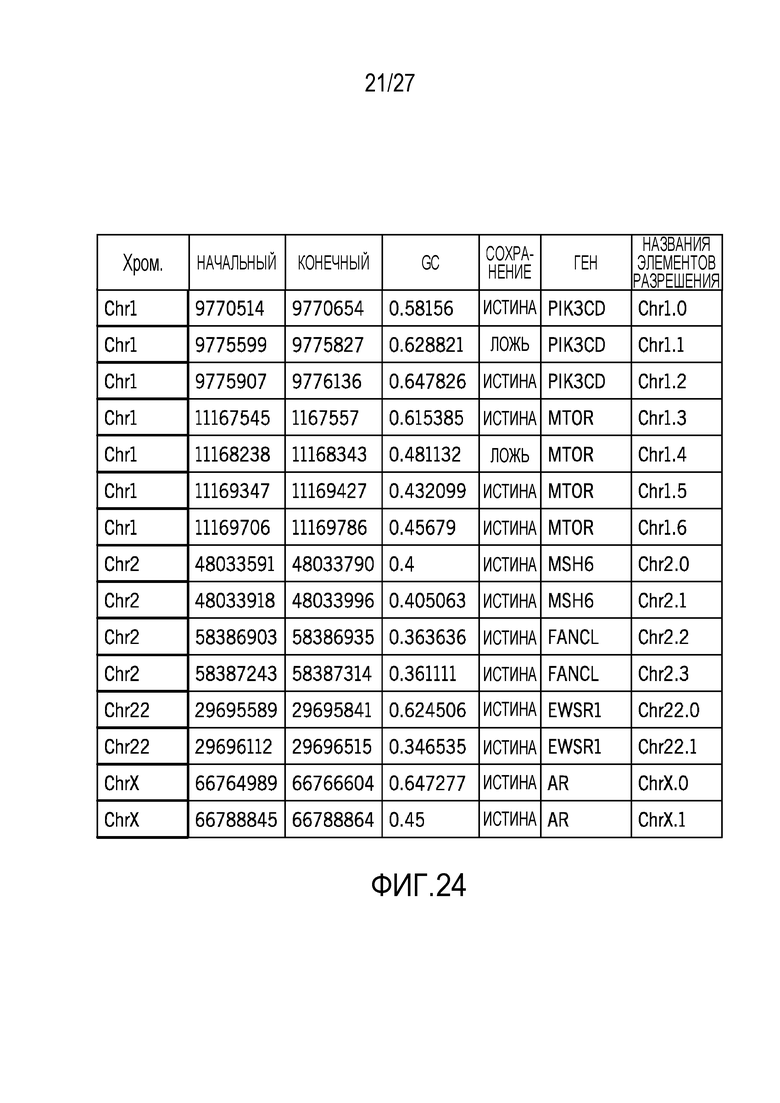
[0033] Фиг. 24 является таблицей обозначений и характеристик элементов разрешения;
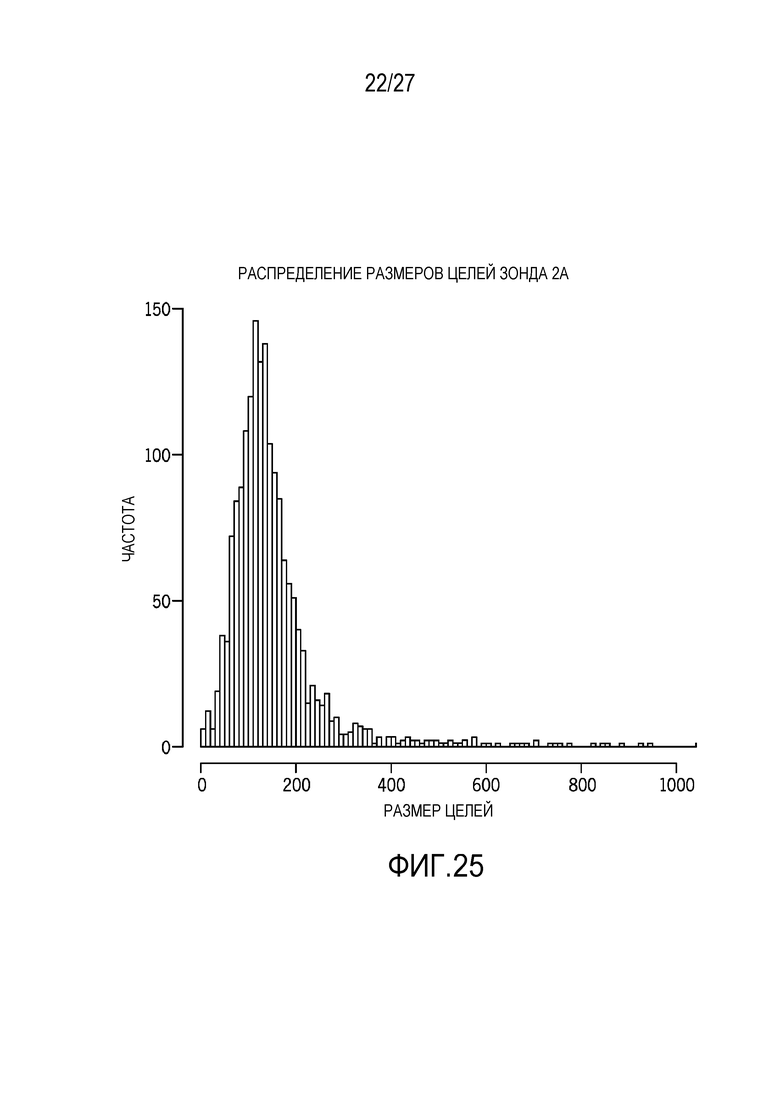
[0034] Фиг. 25 является графиком распределения размеров целей для зонда;
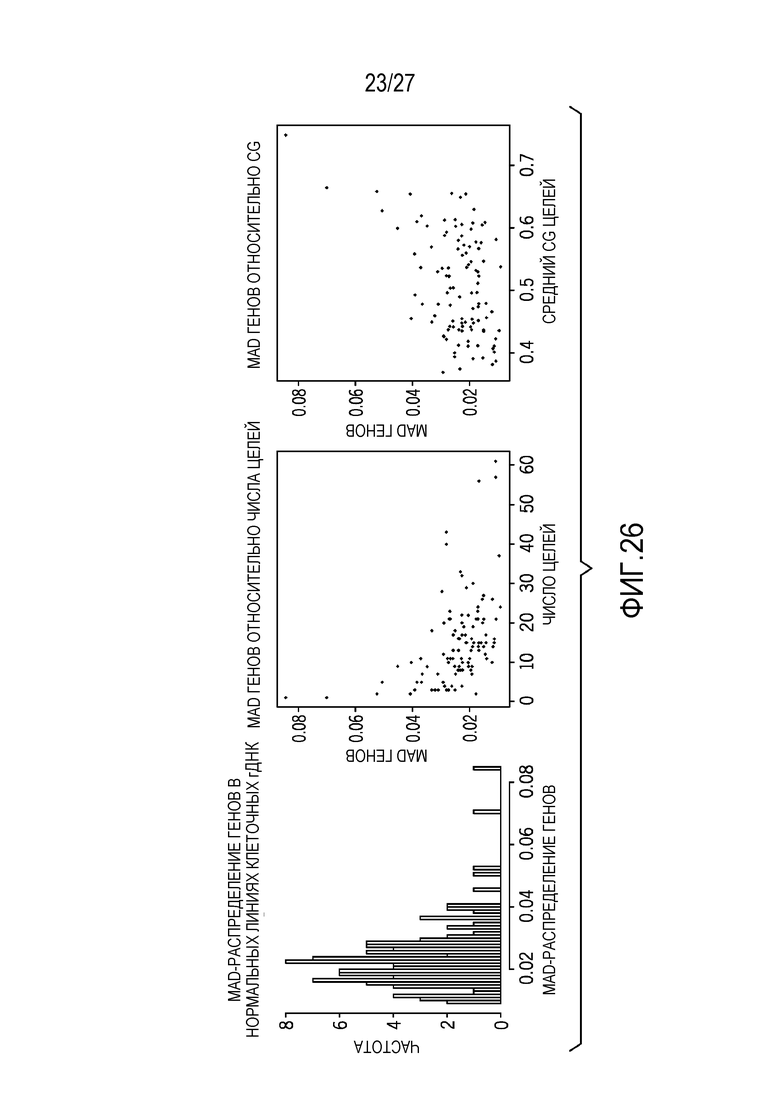
[0035] Фиг. 26 показывает медианное абсолютное распределение генов и сравнение с числом целей и содержанием GC целей;
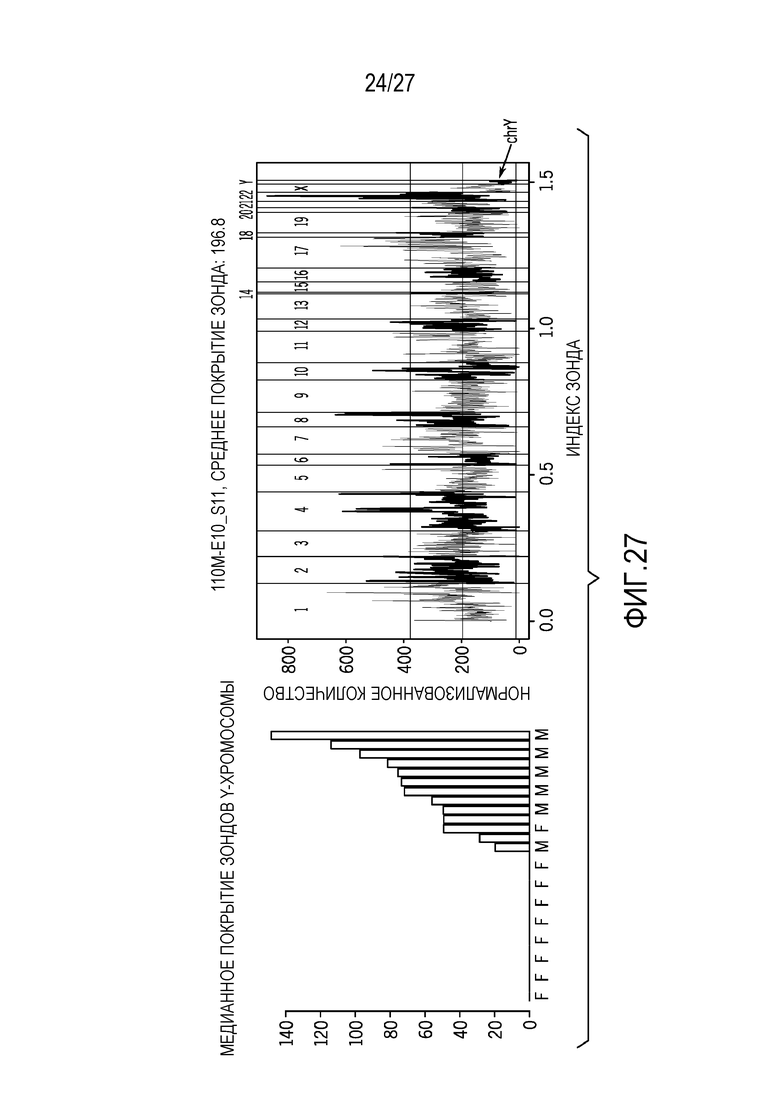
[0036] Фиг. 27 показывает гендерную классификацию FFPE-образцов и присутствие покрытия Y-хромосомы;
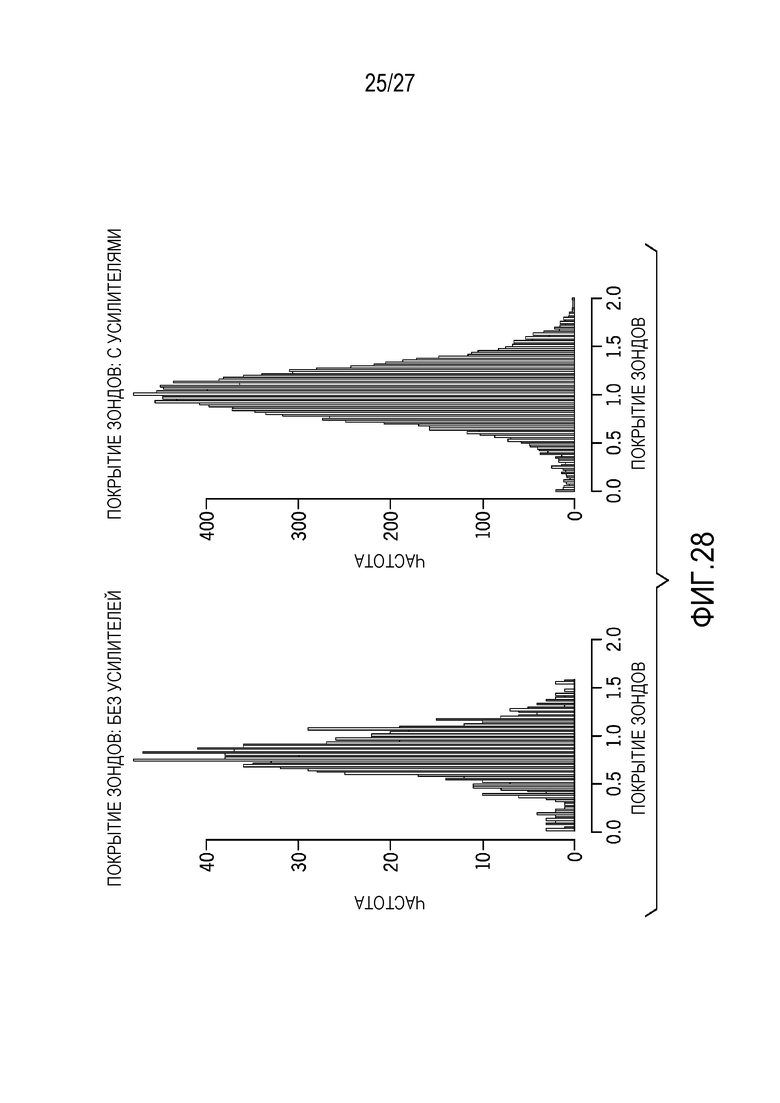
[0037] Фиг. 28 показывает сравнение покрытия зондов с и без усилителей покрытия;
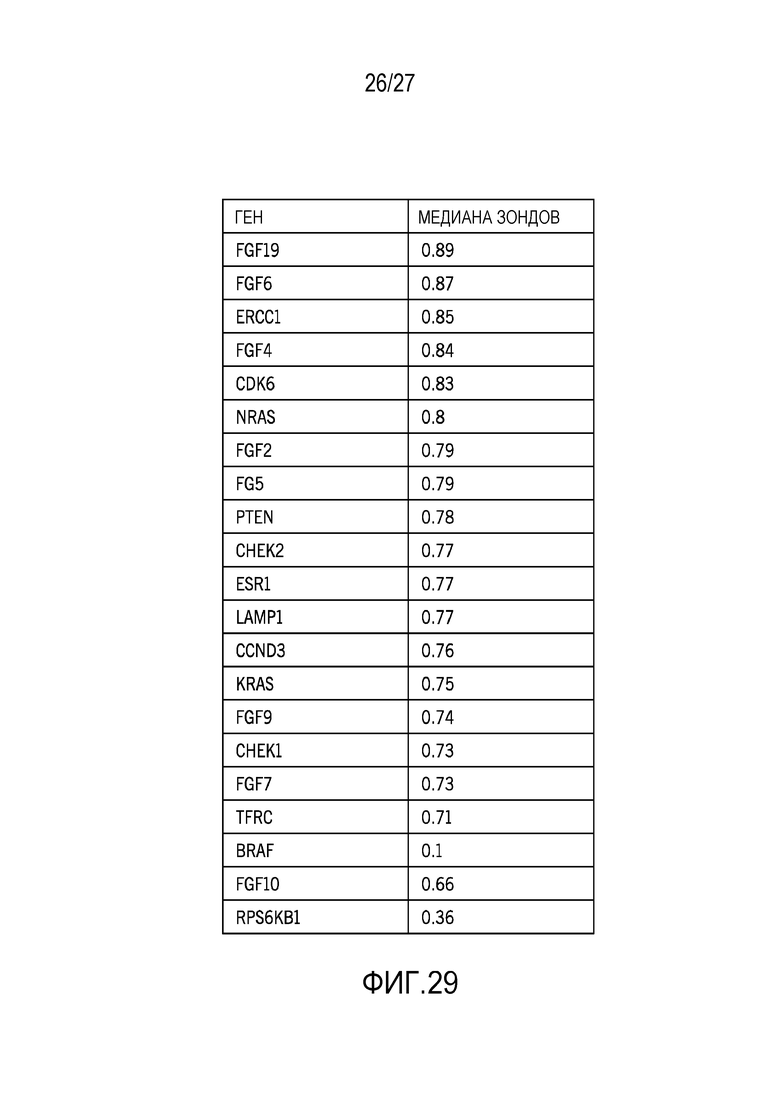
[0038] Фиг. 29 показывает краткое представление покрытия зондов для множества генов; и
[0039] Фиг. 30 показывает пример графического пользовательского интерфейса обнаруженного варьирования числа копий.
Подробное описание изобретения
[0040] Настоящие технологии направлены на анализ и обработку данных секвенирования для улучшенного обнаружения соматического варьирования числа копий (CNV). CNV-обнаружение зачастую искажается за счет различных типов смещения, введенного во время консервации образцов, подготовки библиотек или секвенирования. Без смещения, глубина/покрытие рида должно быть равномерным для генома для диплоидных областей и пропорционально более высоким (низким) для областей выигрыша (потерь) по числу копий. При смещении, это допущение более не действительно, по меньшей мере, для областей генома, которые подвергаются смещению. Удаление смещения или нормализация данных сначала, например, до CNV-обнаружения, достигает более точного CNV-опознавания, предусмотренного в данном документе.
[0041] В данном документе предусмотрены технологии, которые формируют эталонную базовую линию для индивидуального биологического образца, которая является полезной для нормализации данных секвенирования перед оценкой варьирований, которые представляют изменения числа копий для одной или более интересующих областей в геноме. Раскрытые технологии предоставляют ссылочную информацию или информацию нормализации без базирования на сопоставленном образце от отдельной особи, от которой получается тестовый образец, чтобы нормализовать тестовый образец. Хотя другие технологии могут использовать собственную ткань пациента для того, чтобы формировать ссылочные данные, использование сопоставленного образца, взятого от той же отдельной особи, что и биологический образец, представляет собой определенные проблемы. Например, варьирование совокупности образцов (качества образцов, выбранных участков тканей) может означать то, что эталонный образец не представляет действительно нормальную ткань. Дополнительно, в той мере, в какой введение смещения, которое оказывает влияние на данные секвенирования, может варьироваться между образцами, сопоставленный эталонный образец может иметь другой уровень введенного смещения относительно тестового образца, что в свою очередь может приводить к неточностям и неверно нормализованным данным. Помимо этого, не все тестовые образцы имеют доступную подходящую ткань или подходящую ткань достаточно высокого качества для секвенирования.
[0042] Соответственно, раскрытые технологии упрощают более точную оценку варьирования числа копий посредством формирования информации нормализации с уменьшенным смещением и без использования сопоставленного образца. Информация нормализации может использоваться для того, чтобы нормализовать набор данных секвенирования до CNV-обнаружения в индивидуальном образце. Информация нормализации формируется с использованием набора или пула несопоставленных эталонных базовых биологических образцов. Данные секвенирования, сформированные из этого набора, затем используются для того, чтобы формировать информацию нормализации, которая представляет самый типичный гипотетический сопоставленный эталонный образец. Таким образом, информация нормализации представляет виртуальные калиброванные эталонные ссылочные данные, относительно которых может нормализоваться любой тестовый индивидуальный образец.
[0043] В конкретных вариантах осуществления, CNV могут обнаруживаться с использованием технологий секвенирования полного генома. Тем не менее, такие технологии являются дорогими и заключают в себе формирование данных, которые могут находиться за пределами интересующих областей. В других вариантах осуществления, использование технологий целевого секвенирования для того, чтобы обнаруживать CNV, является менее дорогим и ассоциировано с меньшим временем полного рабочего цикла. При целевом секвенировании, целевые зонды используются для того, чтобы извлекать интересующие области из образца ДНК для секвенирования; используемые зонды могут варьироваться в зависимости от интересующих областей и требуемого результата обнаружения. Тем не менее, покрытие данных секвенирования из серии целевого секвенирования может быть переменным вследствие варьирования характеристик интересующих областей (например, целевых последовательностей) в геноме, зондов и качества самого образца. Например, зонды, конкретные для больших целей (например, более длинных экзонов) типично должны иметь большее число ридов или покрытие, чем зонды для меньших целей. В другом примере, ухудшенные области ДНК в биологическом образце должны иметь меньшее число ридов. В еще одном другом примере, интересующие области с низким или высоким содержанием GC будут иметь варьирования покрытия, которое может быть нелинейным. Соответственно, переменность в покрытии для данных секвенирования из серий целевого секвенирования может вводить шум, который создает помехи для точности CNV-обнаружения на основе покрытия/глубины рида.
[0044] Таблица 1 иллюстрирует общие типы смещения/шума секвенирования, присутствующего в данных насыщения. Например, различные зонды могут иметь различную эффективность извлечения, за счет этого создавая неравномерное покрытие в различных областях (базовый эффект). Покрытие также может быть GC-зависимым: области с низким или высоким содержанием GC имеют, в общем, более низкое покрытие. Дополнительно, на покрытие может влиять качество зафиксированных в формалине и погруженных в парафин (FFPE) образцов или типа образцов. Все вышеуказанные артефакты представляют собой проблему для обнаружения амплификации. Надежный CNV-анализ нацелен на удаление этих смещений (т.е. с использованием нормализации данных) перед CNV-опознаванием.
Табл. 1. Источники смещения в биологических образцах
[0045] Раскрытые технологии используют панель эталонных нормальных образцов для того, чтобы исключать необходимость использовать сопоставленный нормальный образец в нормализации количества ридов образца опухоли. В частности, смещение количества ридов последовательности сильно коррелирует с типом тканей и качеством ДНК тестового образца, с влиянием, эквивалентным влиянию генетики зародышевой линии образца, если даже не сильнее. Следовательно, с хорошим множеством эталонных нормальных образцов, представляющих различные типы тканей и различное качество ДНК, CRAFT в кремнии ассемблирует "виртуальный" сопоставленный нормальный образец в тестовый образец опухоли через линейную комбинацию всех эталонных нормальных образцов.
[0046] Панель эталонных нормальных образцов проходит через управляемый данными процесс кластеризации, чтобы формировать базовые линии количества ридов. Каждая эталонная базовая линия представляет определенный тип тканей, качество ДНК и другие систематические исходные данные для смещения количества ридов, а не для истинных изменений числа копий генома. Для тестового образца, линейная регрессия эталонных базовых линий выполняется относительно данных количества ридов образца для того, чтобы определять коэффициент каждой базовой линии. Каждый тестовый образец приводит к уникальному набору коэффициентов, имитирующему виртуальный сопоставленный нормальный образец. Когда пользователь получает данные секвенирования с конкретной панелью секвенирования, пользователь может нормализовать полученные данные секвенирования с использованием коэффициентов. В одном варианте осуществления, коэффициенты могут применяться через линейную комбинацию, чтобы давать в результате взвешенное значение числа копий для конкретной интересующей области (например, гена).
[0047] С этой целью, раскрытые технологии исключают или уменьшают ошибки при оценке варьирования числа копий, которые возникают в результате смещения секвенирования. Фиг. 1 является блок-схемой 10 последовательности операций способа, показывающей взаимодействия между конечным пользователем и поставщиками с использованием технологий нормализации, предусмотренных в данном документе. Проиллюстрированная блок-схема 10 последовательности операций способа представляется в контексте панели целевого секвенирования. Тем не менее, следует понимать, что аналогичные взаимодействия также могут возникать в контексте реакции секвенирования полного генома.
[0048] На этапе 12, пользователь получает интересующий биологический образец для оценки. Биологический образец может представлять собой образец ткани, образец жидкости или другой образец, содержащий, по меньшей мере, часть генома или геномной ДНК. В конкретных вариантах осуществления, биологический образец является свежим, замороженным или законсервированным с использованием стандартных гистопатологических консервантов, таких как FFPE. Биологический образец может представлять собой тестовый образец либо может представлять собой внутренний образец, используемый для того, чтобы формировать информацию нормализации. В вариантах осуществления, в которых биологический образец оценивается с использованием панели целевого секвенирования, пользователь передает запрос на целевое секвенирование поставщику, в силу чего запрос включает в себя выбранную уже существующую панель секвенирования и/или настраиваемую панель секвенирования на основе требуемых интересующих областей в геномной ДНК образца. Запрос может включать в себя информацию клиентов, информацию организма биологического образца, информацию типа биологического образца (например, информацию, идентифицирующую то, является образец свежим, замороженным или законсервированным), тип тканей и требуемый тип пробы для секвенирования. Запрос также может включать в себя последовательности нуклеиновых кислот для требуемых зондов панели секвенирования и/или последовательности нуклеиновых кислот интересующих областей в геноме, которые могут использоваться поставщиком для того, чтобы проектировать и/или формировать зонды для панели целевого секвенирования.
[0049] Поставщик принимает запрос на этапе 14 и проектирует и/или формирует зонды, которые должны использоваться в секвенировании, на основе обозначенного набора зондов и/или обозначенных интересующих областей (например, элементов разрешения) на этапе 16. В конкретных вариантах осуществления, для уже существующих панелей секвенирования, зонды могут формироваться и храниться в резерве до того, как запрос принимается на этапе 14. Зонды предоставляются пользователю на этапе 20 и, после релевантной подготовки образцов на этапе 22, используются для того, чтобы секвенировать биологический образец на этапе 24. Пользователь получает данные секвенирования из секвенирования на этапе 26.
[0050] Когда пользователь выбирает зонды для панели целевого секвенирования, зонды также используются в базовой реакции секвенирования на множестве несопоставленных образцов (например, других биологических образцов, которые не сопоставлены с тем же индивидуумом, что и биологический образец) с тем, чтобы получать базовые данные секвенирования на этапе 28. Базовые данные секвенирования используются для того, чтобы формировать информацию нормализации на этапе 30, которая предоставляется пользователю на этапе 32. Используя информацию нормализации, пользователь нормализует данные секвенирования тестового образца и затем анализирует полученные данные секвенирования биологического образца на этапе 34, чтобы идентифицировать варианты числа копий для местоположений, которые включены в панель целевого секвенирования. Таким образом, в контексте панели целевого секвенирования, которая упрощает секвенирование только части генома, могут идентифицироваться только варианты числа копий, присутствующие в секвенированной части. Это отличается от вариантов применения для полного генома, в которых варианты числа копий по всему геному могут идентифицироваться согласно настоящим технологиям.
[0051] В ответ на идентификацию вариантов числа копий, вывод может предоставляться пользователю на этапе 36. Вывод может включать в себя отображаемый графический пользовательский интерфейс (см. фиг. 30), который включает в себя графические значки числа копий в конкретных местоположениях в геноме.
[0052] Пользователь может представлять собой внешнего или внутреннего пользователя услуг секвенирования поставщика. Например, этапы блок-схемы 10 последовательности операций способа могут выполняться в качестве части калибровки или формирования любого нового продукта в форме панели целевого секвенирования, что также может включать в себя внешний запрос на настраиваемую панель секвенирования. Данная панель целевого секвенирования должна быть ассоциирована с конкретными тенденциями смещения на основе интересующих областей, нацеленных посредством зондов панели. Это смещение может создавать помехи для точной оценки варьирования числа копий. Соответственно, этапы блок-схемы 10 последовательности операций способа могут выполняться, когда любая панель целевого секвенирования, которая включает в себя набор зондов, проектируется, модифицируется или обновляется. В другом варианте осуществления, если пользовательский запрос включает в себя интересующие области в геноме, панель, включающая в себя набор зондов, может формироваться и оцениваться с использованием раскрытых технологий, чтобы давать в результате информацию нормализации. Информация нормализации может оцениваться с использованием набора показателей. Если показатели указывают то, что панель дает в результате плохую информацию нормализации, панель может отбрасываться, а зонды могут повторно проектироваться (например, сдвигаться на 50 п.о. в любом направлении). Новые зонды могут испытываться с использованием этапов блок-схемы 50 последовательности операций способа до тех пор, пока не будет получена высококачественная информация нормализации. В одном варианте осуществления, показатели получаются посредством применения информации нормализации перед идентификацией вариантов числа копий во внутреннем образце. Если идентифицированные варианты числа копий для секвенированных областей отклоняются от ожидаемого распределения, может предоставляться вывод, указывающий то, что должна быть инициирована новая панель секвенирования (например, повторное проектирование зондов). Ожидаемое распределение может быть ассоциировано с вероятным распределением вариантов числа копий. Например, большинство вариантов находятся в пределах двух- или трехкратного изменения в любом направлении. Если внутренний образец показан как имеющий большее, по сравнению с ожидаемым, распределение 10-кратных или более высоких вариантов, проанализированный образец может указываться в качестве отклонения от ожидаемого распределения.
[0053] Данные секвенирования, сформированные посредством секвенирования биологического образца, могут анализироваться, чтобы характеризовать любое варьирование числа копий после нормализации с использованием информации нормализации. Следует понимать, что данные секвенирования биологического образца и базовые данные секвенирования могут иметь форму необработанных данных, данных опознавания оснований или данных, которые подвергнуты первичному или вторичному анализу.
[0054] Дополнительно, следует понимать, что CNV могут идентифицироваться в качестве части гена, внутригенной области и т.д. Также следует понимать, что CNV-обнаружение может быть ассоциировано с дублированными или удаленными последовательностями. Соответственно, CNV-обнаружение может представлять дублированные копии области нуклеиновой кислоты, к примеру, области, включающей в себя один или более генов. В одном варианте осуществления, CNV представляют собой дублированные или удаленные геномные области с размером, по меньшей мере, в 1 КБ.
[0055] Покрытие секвенирования описывает среднее число подсчетов ридов секвенирования, которые совмещаются или "покрывают" известные эталонные основания. Уровень покрытия зачастую определяет то, может или нет обнаружение вариантов выполняться с определенной степенью доверия в конкретных позициях оснований. При более высоких уровнях покрытия, каждое основание покрывается посредством большего числа совмещенных ридов последовательности, так что опознавания оснований могут выполняться с более высокой степенью доверия. Риды не распределены равномерно по всему геному, просто поскольку риды отбирают образец генома случайным и независимым способом. В силу этого множество оснований будут покрываться посредством меньшего числа ридов, чем среднее покрытие, тогда как другие основания будут покрываться посредством большего числа ридов, чем среднее. Это выражается посредством показателя покрытия, который представляет собой число раз, когда геном секвенирован (глубину секвенирования). Для целевого повторного секвенирования, покрытие может означать количество раз, когда область секвенируется. Например, для целевого повторного секвенирования, покрытие означает число раз, когда целевой поднабор генома секвенируется. Раскрытые варианты осуществления разрешают проблему с шумом в покрытии секвенирования вследствие смещения.
[0056] Фиг. 2 является принципиальной схемой устройства 60 для секвенирования, которое может использоваться в сочетании с этапами блок-схемы последовательности операций способа по фиг. 1 для получения данных секвенирования (например, данных секвенирования тестового образца, базовых данных секвенирования), которые используются для оценки варьирования числа копий. Устройство 60 для секвенирования может реализовываться согласно любой технологии секвенирования, такой как технологии, включающие способы секвенирования через синтез, описанные в публикациях патента (США) номера 2007/0166705; 2006/0188901; 2006/0240439; 2006/0281109; 2005/0100900; патенте (США) номер 7057026; WO 05/065814; WO 06/064199; WO 07/010251, раскрытия сущности которых полностью содержатся в данном документе по ссылке. Альтернативно, секвенирование посредством технологий лигирования может использоваться в устройстве 60 для секвенирования. Такие технологии используют ДНК-лигазу для того, чтобы включать олигонуклеотиды и идентифицировать включение таких олигонуклеотидов, и описываются в патенте (США) номер 6969488; патенте (США) номер 6172218; и патенте (США) номер 6306597; раскрытия сущности которых полностью содержатся в данном документе по ссылке. Некоторые варианты осуществления могут использовать нанопористое секвенирование, за счет которого нити целевых нуклеиновых кислот или нуклеотиды, экзонуклеолитически удаленные из целевых нуклеиновых кислот, проходят через нанопору. По мере того, как целевые нуклеиновые кислоты или нуклеотиды проходят через нанопору, каждый тип основания может идентифицироваться посредством измерения флуктуаций в электрической проводимости поры (патент (США) номер 7001792; Soni и Meller, Clin. Chem. 53, 1996-2001 (2007); Healy, Nanomed. 2, 459-481 (2007); и Cockroft и др., J. Am. Chem. Soc. 130, 818-820 (2008), раскрытия сущности которых полностью содержатся в данном документе по ссылке). Еще один другой вариант осуществления включает в себя обнаружение протона, высвобождаемого после включения нуклеотида в расширенный продукт. Например, секвенирование на основе обнаружения высвобождаемых протонов может использовать электрический детектор и ассоциированные технологии, которые предлагаются на рынке компанией Ion Torrent (Гилфорд, CT, филиал Life Technologies), или способы и системы секвенирования, описанные в US 2009/0026082 A1; US 2009/0127589 A1; US 2010/0137143 A1; или US 2010/0282617 A1, каждая из которых полностью содержится в данном документе по ссылке. Конкретные варианты осуществления могут использовать способы, заключающие в себе мониторинг в реальном времени активности ДНК-полимеразы. Нуклеотидные включения могут обнаруживаться через взаимодействия на основе резонансного переноса энергии люминесценции (FRET) между переносящей люминофор полимеразой и c нуклеотидами с γ-фосфат-меткой или с волноводами с нулевой модой, как описано, например, в работах Levene и др., Science 299, 682-686 (2003); Lundquist и др., Opt. Lett. 33, 1026-1028 (2008); Korlach и др., Proc. Natl. Acad. Sci. USA 105, 1176-1181 (2008), раскрытия сущности которых полностью содержатся в данном документе по ссылке. Другие подходящие альтернативные технологии включают в себя, например, люминесцентное секвенирование на месте (FISSEQ) и массивно-параллельное сигнатурное секвенирование (MPSS). В конкретных вариантах осуществления, устройство 16 секвенирования может представлять собой HiSeq, MiSeq или HiScanSQ компании Illumina (Ла-Хойя, CA).
[0057] В проиллюстрированном варианте осуществления, устройство 60 для секвенирования включает в себя отдельное устройство 62 обработки образцов и ассоциированный компьютер 64. Тем не менее, как отмечено выше, они могут реализовываться как одно устройство. Дополнительно, ассоциированный компьютер 64 может быть локальным или сетевым относительно устройства 62 обработки образцов. В проиллюстрированном варианте осуществления, биологический образец может загружаться в устройство 62 обработки образцов в качестве направляющей 70 для образца, которая визуализируется для того, чтобы формировать данные последовательности. Например, реагенты, которые взаимодействуют с биологическим образцом, люминесцируют при конкретных длинах волн в ответ на луч возбуждения, сформированный модулем 72 визуализации, и в силу этого обратное излучение для визуализации. Например, люминесцентные компоненты могут формироваться посредством люминесцентно тегированных нуклеиновых кислот, которые гибридизируют в комплементарные молекулы компонентов, или люминесцентно тегированных нуклеотидов, которые включены в олигонуклеотид с использованием полимеразы. Специалисты в данной области техники должны принимать во внимание, что длина волны, при которой возбуждаются краски образца, и длина волны, при которой они люминесцируют, должны зависеть от спектров поглощения и испускания конкретных красок. Такое обратное излучение может распространяться обратно через направляющую оптику. Этот ретролуч, в общем, может направляться к оптике системы обнаружения модуля 72 визуализации.
[0058] Оптика системы обнаружения модуля визуализации может быть основана на любой подходящей технологии и, например, может представлять собой датчик на основе прибора с зарядовой связью (CCD), который формирует пиксельные данные изображений, на основе фотонов, ударяющихся о местоположения в устройстве. Тем не менее, следует понимать, что также могут использоваться любые из множества других детекторов, включающих в себя, но не только, детекторную матрицу, выполненную с возможностью работы в режиме интеграции с временной задержкой (TDI), детектор на комплементарной структуре "металл-оксид-полупроводник" (CMOS), лавинный фотодиодный (APD) детектор, счетчик фотонов в режиме Гейгера либо любой другой подходящий детектор. Обнаружение в TDI-режиме может быть связано с линейным сканированием, как описано в Патенте (США) номер 7329860, который содержится в данном документе по ссылке. Другие полезные детекторы описываются, например, в противопоставленных материалах, предоставленных ранее в данном документе, в контексте различных технологий секвенирования нуклеиновых кислот.
[0059] Модуль 72 визуализации может управляться процессором, например, через процессор 74, и устройство 18 приема образцов также может включать в себя средства 76 управления вводом-выводом, внутреннюю шину 78, энергонезависимое запоминающее устройство 80, RAM 82 и любую другую структуру запоминающего устройства таким образом, что запоминающее устройство допускает сохранение выполняемых инструкций, и другие подходящие аппаратные компоненты, которые могут быть аналогичными описанным относительно фиг. 2. Дополнительно, ассоциированный компьютер 20 также может включать в себя процессор 84, средства 86 управления вводом-выводом, модуль 84 связи и архитектуру запоминающего устройства, включающую в себя RAM 88 и энергонезависимое запоминающее устройство 90 таким образом, что архитектура запоминающего устройства допускает сохранение выполняемых инструкций 92. Аппаратные компоненты могут связываться посредством внутренней шины 94, которая также может связываться с дисплеем 96. В вариантах осуществления, в которых устройство секвенирования реализуется как устройство "все в одном", определенные избыточные аппаратные элементы могут исключаться.
[0060] Настоящие технологии упрощают обнаружение или опознавание CNV в биологических образцах (например, в образцах опухоли) без нормализации сначала данных секвенирования до сопоставленных данных секвенирования. Технология использует этап предварительной обработки для того, чтобы формировать файл манифеста и базовый файл, которые используются в качестве входных параметров для этапа нормализации. Файл манифеста и базовый файл формируются независимо от и до анализа интересующего образца, чтобы определять варьирование числа копий. Файл манифеста и базовый файл формируются из несопоставленных образцов (т.е. несопоставленных нормальных образцов) и определяются через технологию базового формирования, предусмотренную в данном документе. Базовое формирование может выполняться для несопоставленных нормальных образцов и результатов базового формирования, сохраненных в качестве базовой информации (или информация нормализации) для доступа посредством выполняемых инструкций технологии нормализации. Например, пользователь с интересующим образцом может выполнять анализ одного или более CNV. В конкретных вариантах осуществления, после формирования и хранения, базовая информация используется в анализе множества интересующих образцов в другие и/или последующие моменты времени. Пользователь может осуществлять доступ к сохраненным файлам на основе панели секвенирования, которая соответствует базовой информации.
[0061] В одном варианте осуществления, информация нормализации числа копий, после формирования, является фиксированной для конкретной панели секвенирования. Таким образом, информация нормализации числа копий ассоциирована с конкретными зондами панели секвенирования и сохраняется посредством поставщика и отправляется пользователю конкретной панели секвенирования. Различные панели секвенирования имеют различную информацию нормализации числа копий. В другом примере, программный пакет для CNV-опознавания может сохранять множество различной информации нормализации числа копий, ассоциированной с различными панелями секвенирования. Пользователь может выбирать соответствующую информацию нормализации на основе панели секвенирования, используемой для того, чтобы получать данные секвенирования. Альтернативно, устройство 60 для секвенирования может автоматически получать соответствующую информацию нормализации числа копий на основе информации, вводимой пользователем, связанной с используемой панелью секвенирования. Программный пакет для CNV-опознавания также может допускать прием обновлений из удаленного сервера, если информация нормализации числа копий уточнена посредством поставщика.
[0062] Проблема обнаружения соматического варьирования числа копий разрешается посредством идентификации характерного поведения базового покрытия с использованием способа на основе иерархической кластеризации и затем использования линейной регрессии и LOESS-регрессии для нормализации данных, как обобщено на фиг. 3. Технология включает в себя конфигурирование 100 (например, обучение алгоритма), нормализацию 102 интересующих образцов и предоставление выводов или статистики 104, такой как кратные изменения числа копий и T-статистика на основе гена отдельной особи. Например, FC представляет собой соотношение между медианным значением интересующего гена и медианой генома. T-статистика может представлять собой распределение количества элементов разрешения интересующего гена по сравнению с остальной частью генома (например, для диплоидного организма).
[0063] Предварительная обработка (обучение алгоритма) может включать в себя следующие этапы:
1. Выбор 110 элементов разрешения/экзонов: из набора обучающих нормальных образцов (например, нормальных FFPE-образцов), вычисление медианы, медианного абсолютного отклонения, содержания GC и размера для каждого элемента разрешения (см. фиг. 7). После этого, элементы разрешения с низкой медианой, большим MAD, экстремальным содержанием GC и небольшим размером помечаются в качестве плохих элементов разрешения в файле манифеста. Только небольшой процент элементов разрешения затрагивается посредством этого этапа (~5%). Например, как показано на фиг. 6, используемые параметры фильтрации являются следующими:
Медиана: > 0,25
CV: (0,2)
GC: (0,25, 0,8)
Размер целей: > 20 п.о.
2. Базовое формирование 112 из базовых или нормальных образцов (например, нормальных FFPE-образцов): образцы из различных типов тканей или с различным ДНК-качеством могут иметь существенно отличающееся базовое поведение. Следовательно, несколько базовых линий используются для того, чтобы корректировать базовый эффект. В одном примере, 4-5 нормальных FFPE-образцов из каждого типа тканей используются для того, чтобы определять медианное поведение для каждого элемента разрешения, чтобы представлять различные типы тканей. Чтобы формировать базовую линию, иерархическая кластеризация используется для того, чтобы идентифицировать характерные группы, которые отражают несколько базовых поведений покрытия в совокупности нормальных образцов. См. фиг. 8. Кластеризация коррелируется с качеством образцов. После того, как кластеры идентифицируются, медианное значение для каждого элемента разрешения используется для того, чтобы создавать базовый файл, который используется для последующей нормализации. Таким образом, медианное количество элементов разрешения в каждом кластере рассматривается в качестве базовой линии. Посредством использования способа кластеризации, наиболее "характерное" поведение в нормальных образцах используется для нисходящей нормализации.
[0064] После базовой линии или нормализации (применяемой к оцениваемым образцам) с использованием эталонной базовой линии, сформированной выше, при этом новый образец масштабируется до информации нормализации посредством размера целей и медианного количества 114 элементов разрешения.
1. Базовая коррекция 116: для нового образца, моделирование его количества элементов разрешения в качестве линейной комбинации базовых линий: 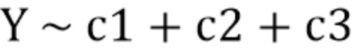 . Вследствие потенциальных CNV в новом образце, резко отклоняющиеся значения сначала удаляются из Y, и линейная модель компонуется на основе удаленных резко отклоняющихся значениях. В конкретных вариантах осуществления, резко отклоняющиеся значения маскируются. В других вариантах осуществления, только экстремальные резко отклоняющиеся значения удаляются или маскируются. После этого, соотношение Y и прогнозирования на основе линейной модели используется в качестве базового скорректированного значения. Количества элементов разрешения выше или ниже 3 среднеквадратических отклонений считаются резко отклоняющимися значениями.
. Вследствие потенциальных CNV в новом образце, резко отклоняющиеся значения сначала удаляются из Y, и линейная модель компонуется на основе удаленных резко отклоняющихся значениях. В конкретных вариантах осуществления, резко отклоняющиеся значения маскируются. В других вариантах осуществления, только экстремальные резко отклоняющиеся значения удаляются или маскируются. После этого, соотношение Y и прогнозирования на основе линейной модели используется в качестве базового скорректированного значения. Количества элементов разрешения выше или ниже 3 среднеквадратических отклонений считаются резко отклоняющимися значениями.
Lm(Y[good.idx] ~ c1[good.idx]+c2[good.idx]+c3[good.idx])
Y_new ~ Y/predict (lm, data=ALL)
2. Надежная LOESS-регрессия 118, чтобы удалять GS-смещение после этапа 1.
3. Для каждого гена, вычисление его кратного изменения 124 посредством сравнения его медианного значения по элементам разрешения с медианой генома. Дополнительная статистика, например, T-статистика для каждого гена 126, также может определяться.
[0065] Фиг. 4 показывает данные профиля элементов разрешения для результатов секвенирования до и после нормализации, как предусмотрено в данном документе, для числа элементов разрешения. Шум, присутствующий в результатах "до", уменьшается, как показано в результатах "после". Шум предотвращает точное опознавание вариантов числа копий. Фиг. 5 показывает шум, присутствующий в нормальных FFPE-образцах, относительно сильно ухудшенной клеточной линии и смеси нормальных клеточных линий. Шум, присутствующий в данных, создает помехи точному CNV-опознаванию. Дополнительно, шум присутствует в образцах варьирующегося качества. Тем не менее, базовая корреляция является плохой между различными типами образцов. Соответственно, настоящие технологии разрешают пользовательский ввод типа образцов для того, чтобы выбирать соответствующую информацию нормализации.
[0066] Фиг. 9 показывает результаты базовой коррекции с линейной регрессией, чтобы удалять шум, в силу которой c1 и c2 представляют собой две характерные базовые линии, распознанные из иерархической кластеризации. Как показано на фиг. 10, GS-смещение является конкретным для образца. В общем, чрезвычайно низкие GC- или высокие GC-области недостаточно представляются в ридах. Некоторые образцы имеют больше кривизны, чем другие. Фиг. 11 является иллюстрацией этапов нормализации для пошагового подхода. (A) Вследствие большого базового эффекта, отсутствует видимая взаимосвязь между количеством экзонов и GC. (B) После базовой коррекции, имеется видимый негативный тренд между количеством и GC. (C) Резко отклоняющиеся значения идентифицируются, и LOESS-регрессия подгоняется для удаленных резко отклоняющихся данных. (D) Конечная нормализация получается в результате после удаления GS-смещения.
[0067] Фиг. 12 показывает результаты до и после нормализации, включающие в себя элементы разрешения последовательности для ERBB2-гена. Результаты "после" демонстрируют значительное сокращение шума через нормализацию, предусмотренную в данном документе. Фиг. 13 показывает то, что обнаружение кратного изменения является стабильным независимо от используемой базовой линии с R2=0,99 для 340 FFPE-образцов. Фиг. 14 показывает высокое соответствие между технологиями нормализации, предусмотренными в данном документе, и ddPCR для 22 FFPE-образцов, испытываемых с использованием панели на предмет числа интересующих областей, включающих в себя EGFR, ERBB2, FGFR1, MDM2, MET и MYC.
[0068] Фиг. 15 является сравнением технологии нормализации, используемой в данном документе, с базовым способом или способом без контроля. Способ без контроля не требует дополнительных управляющих или нормальных образцов для нормализации. Вместо этого он основывается на самом тестовом образце для нормализации данных. По сравнению с технологией нормализации, используемой в данном документе, способ без контроля имеет тенденцию занижать уровень амплификации гена с точки зрения измеренных значений кратного изменения (FC). Дополнительно, применение способа без контроля к нормальным тестовым образцам показывает то, что изменчивость FC существенно больше, чем в настоящей технологии нормализации, что приводит к более высокому пределу смягчения (LoB). В общем, способ без контроля является как менее чувствительным, так и менее конкретным, чем технология нормализации, предусмотренная в данном документе. На фиг. 15, ось Y представляет собой внутреннюю реализацию способа без контроля, и ось X представляет собой вариант осуществления технологии нормализации, описанной в данном документе. По сравнению с технологией нормализации, способ без контроля имеет тенденцию недооценивать значения кратного изменения.
[0069] Фиг. 16 показывает сравнение результатов на основе медианного абсолютного отклонения с использованием технологий нормализации, предусмотренных в данном документе, и сопоставленных нормальных образцов со спаренным t-испытываемым p-значением в 0,0202. Фиг. 17 показывает сравнение кратного изменения, с обнаруженным сравнением кратного изменения (FC) между технологиями нормализации, предусмотренными в данном документе (ось Y), и согласованной нормалью (ось X);
[0070] Фиг. 18-21 показывают сравнение между технологиями нормализации, предусмотренными в данном документе, и XHMM, CNV-способом на основе PCA-подхода с использованием машинного обучения, который не требует сопоставленных нормальных образцов. После нормализации данных, он использует способ сегментации для того, чтобы опознавать CNV в образце. Результаты, показанные для XHMM, получаются с использованием загруженной программы, выполняющейся на 15 образцах CNV, и сравниваются с технологиями нормализации. XHMM обнаруживает 10 из 15 амплификаций, тогда как технологии нормализации обнаруживают 14 из 14 CNV с 1 отсутствием опознавания. На основе результатов, технологии нормализации имеют лучшую чувствительность, чем XHMM.
[0071] Настоящие технологии не используют или не требуют сопоставленных нормальных образцов для того, чтобы выполнять нормализацию. Вместо этого, технологии нормализации в данном документе используют несопоставленные нормальные образцы для того, чтобы формировать эталонные базовые линии, из которых обнаруживаются кратные изменения. В конкретных вариантах осуществления, множество нормальных образцов используются для того, чтобы определять эталонные базовые линии, и кластеризация данных секвенирования множества образцов выполняется для того, чтобы определять наиболее характерные нормальные элементы разрешения. Соответственно, значения эталонной базовой линии оцениваются на основе элемента разрешения, а не на основе образца. Помимо этого, настоящие технологии включают более одного значения базового поведения в статистических нормальных образцах. Настоящие технологии используют линейную регрессию для базовой коррекции и LOESS для GC-коррекции. Достигаемые результаты включают в себя 100%-ю чувствительность при R2 DVT-исследовании (включающем в себя определенные отсутствия опознавания).
[0072] По сравнению с другими технологиями, предусмотренная нормализация дает в результате лучшую производительность, чем способ без контроля, с точки зрения LoB и LoD. Дополнительно, нормализация является более экономичной относительно технологий с использованием согласованной нормали, которые требуют дополнительной обработки образцов. CNV-опознавание с использованием нормализации является более экономичным, поскольку затраты на секвенирование не включают в себя затраты на секвенирование сопоставленных нормальных образцов. Соответственно, серия секвенирования и работа устройства секвенирования являются более эффективными. Другие подходы, к примеру, безопорные подходы, не дают в результате высококачественные результаты вследствие эффектов извлечения зондов. Статистические технологии, которые используют SVD-разложение или PCA, также не дают в результате высококачественные результаты и/или имеют ограниченную применимость для определенных типов образцов.
[0073] В конкретных вариантах осуществления, элемент разрешения, предусмотренный в данном документе, означает смежную интересующую область нуклеиновой кислоты генома. Элемент разрешения может быть экзонным, интронным или внутригенным. Элементы разрешения или области элемента разрешения могут включать в себя варианты и в силу этого, в общем, означать местоположение или область генома, а не фиксированную последовательность нуклеиновых кислот. Подсчет элементов разрешения выполняется на уровне фрагментов, а не на уровне ридов. Например, гены A и B, как показано на фиг. 22, могут иметь различные зонды, которые нацелены на индивидуальные элементы разрешения (заштрихованные области). Фиг. 23 является схематичным представлением количеств элементов разрешения на основе фрагментов, а не ридов. Фрагменты, которые перекрываются с элементом разрешения, способствуют количеству элементов разрешения для этого элемента разрешения. Один фрагмент может способствовать количеству элементов разрешения для нескольких элементов разрешения. Соответственно, для каждого фрагмента, находятся все цели, которые он перекрывает. Фильтрация ридов выполняется для того, чтобы определять надлежащим образом совмещенные пары, не-PCR-дубликаты, положительные нити (чтобы не допускать двойного подсчета) и MAPQ>20.
[0074] В конкретных вариантах осуществления, выбор целей зондов может улучшаться, с тем чтобы уменьшать введение шума в данные секвенирования. Например, в одной технологии, выбор зонда может возникать так, как указано: для каждого гена, идентификация числа целей с содержанием GC между 0,3 и 0,8. Если число меньше 20, идентификация областей, не покрываемых посредством текущей структуры зонда. Создание равномерно разнесенных окон с размером в 140п.о. и вычисление GC и преобразуемости (75mer) для каждого окна. Выбор верхних K окон посредством преобразуемости и содержания GC. Для Y-хромосомы, которая используется для гендерной классификации, случайный выбор 40 областей с преобразуемостью в 1 и GC между 0,4 и 0,6. Фиг. 24 является таблицей примерных обозначений и характеристик элементов разрешения, указывающей начальные и конечные участки для проанализированных элементов разрешения, содержание GC и определенное качество для определенных генов.
[0075] Фиг. 25 является графиком распределения размеров целей для зонда. Фиг. 26 показывает медианное абсолютное распределение генов и сравнение с числом целей и содержанием GC целей. В одном варианте осуществления, 20 хороших целей (30-80% GC) являются достаточными для того, чтобы стабилизировать MAD генов в гДНК-образцах (средний график).
[0076] В одном примере, 116 из 170 генов в наборе 2C зондов имеют менее 20 целей. Выбираются 1042 дополнительных целей. 31 из 49 амплифицированных генов имеют менее 20 целей. Выбираются 350 дополнительных целей. Для Y-хромосомы, 40 целей выбираются для гендерной классификации. В общем, чтобы покрывать все 49 амплифицированных генов, по меньшей мере, 20 целями/генами, 390 дополнительных целей (окон в 140п.о.) добавляются в набор 2C зондов. FGF4, CKD4 и MYC по-прежнему имеют менее 20 целей вследствие небольшого размера гена. Гены-цели для определенных генов показаны в таблице 2.
Табл. 2. Гены-цели
[0077] Фиг. 27 показывает гендерную классификацию 29 FFPE-образцов и присутствия покрытия Y-хромосомы. Y-хромосома указывается посредством стрелки на правом графике.
[0078] Фиг. 28 показывает сравнение покрытия зондов с и без усилителей покрытия; фиг. 29 показывает краткое представление покрытия зондов для множества генов.
[0079] Варианты осуществления раскрытых технологий включают в себя графические пользовательские интерфейсы для отображения информации варьирования числа копий, которые предоставляют выводы или индикаторы, которые используют и/или принимают пользовательский ввод. Фиг. 30 представляет собой пример графического пользовательского интерфейса 200. Выполнение технологий нормализации, например, посредством процессора (см. фиг. 2), инструктирует CNV-информации отображаться. Отображаемая CNV-информация, включающая в себя число вариантов вдоль оси, представляет собой постнормализацию. Таким образом, число копий для полученных данных секвенирования анализируется на предмет вариантов числа копий после того, как осуществлена нормализация. Соответственно, графический пользовательский интерфейс 200 отображает нормализованную CNV-информацию.
[0080] Технические эффекты раскрытых вариантов осуществления включают в себя улучшенное и более точное определение CNV в биологическом образце. Варианты числа копий могут быть ассоциированы с генетическими отклонениями, развитием рака или другими неблагоприятными клиническими условиями. Соответственно, улучшенное CNV-обнаружение может разрешать данные секвенирования, чтобы предоставлять более разнообразную и более значимую информацию врачам. Дополнительно, раскрытые технологии CNV-оценки могут использоваться в сочетании с технологиями целевого секвенирования, которые секвенируют только часть генома. Таким образом, CNV могут идентифицироваться из более эффективной стратегии секвенирования. Технологии нормализации, предусмотренные в данном документе, разрешают проблему со смещением, введенным в данные секвенирования, которое затрагивает количества покрытий секвенирования.
[0081] Хотя только конкретные признаки раскрытия сущности проиллюстрированы и описаны в данном документе, различные модификации и изменения должны быть очевидными специалистам в данной области техники. Следовательно, необходимо понимать, что прилагаемая формула изобретения имеет намерение охватывать все эти модификации и изменения как попадающие в пределы сущности раскрытия сущности.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОПРЕДЕЛЕНИЯ ВАРИАНТОВ ЧИСЛА КОПИЙ | 2016 |
|
RU2746477C2 |
| Способ выявления вариаций и изменений числа копий в генах BRCA1 и BRCA2 по данным таргетного массового параллельного секвенирования генома | 2020 |
|
RU2759953C2 |
| ОБНАРУЖЕНИЕ МУТАЦИЙ И ПЛОИДНОСТИ В ХРОМОСОМНЫХ СЕГМЕНТАХ | 2015 |
|
RU2717641C2 |
| СПОСОБЫ НЕИНВАЗИВНОГО ПРЕНАТАЛЬНОГО УСТАНОВЛЕНИЯ ОТЦОВСТВА | 2011 |
|
RU2620959C2 |
| Способ неинвазивного пренатального скрининга анеуплоидий плода | 2019 |
|
RU2712175C1 |
| КЛАССИФИКАЦИЯ САЙТОВ СПЛАЙСИНГА НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ | 2018 |
|
RU2780442C2 |
| ФРЕЙМВОРК НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ ДЛЯ ИДЕНТИФИКАЦИИ ПАТТЕРНОВ ПОСЛЕДОВАТЕЛЬНОСТИ, КОТОРЫЕ ВЫЗЫВАЮТ ПОСЛЕДОВАТЕЛЬНОСТЬ-СПЕЦИФИЧНЫЕ ОШИБКИ (SSE) | 2019 |
|
RU2745733C1 |
| СПОСОБЫ НЕИНВАЗИВНОГО ПРЕНАТАЛЬНОГО УСТАНОВЛЕНИЯ ПЛОИДНОСТИ | 2011 |
|
RU2671980C2 |
| СПОСОБ ОБНАРУЖЕНИЯ ВАРИАЦИЙ ЧИСЛА КОПИЙ (CNV) ПО ДАННЫМ СЕКВЕНИРОВАНИЯ ПОЛНОГО ЭКЗОМА ЧЕЛОВЕКА И ГЕНОМА С НИЗКИМ ПОКРЫТИЕМ | 2023 |
|
RU2822040C1 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ВАРИАЦИИ ЧИСЛА КОПИЙ В ГЕНОМЕ | 2012 |
|
RU2593708C2 |
Изобретение относится к биотехнологии. Описан способ нормализации числа копий, включающий: секвенирование одной или более интересующих областей из множества базовых биологических образцов, которые не совпадают с биологическим образцом; определение информации нормализации числа копий с использованием базовых данных секвенирования; далее кластеризацию указанного множества базовых биологических образцов для идентификации различных кластеров в указанном множестве образцов на основании количества в элементе разрешения; и использование медианного значения элемента разрешения по меньшей мере одного кластера для получения базовой линии числа копий для каждого элемента разрешения; обеспечение пользователя информацией нормализации числа копий для нормализации новых данных секвенирования нового биологического образца; где вариации числа копий для каждой интересующей области характеризуют в нормализованных новых данных секвенирования, и где указанный каждый отдельный элемент разрешения из указанного множества элементов разрешения в указанных новых данных секвенирования нормализуют на основании соответствующей базовой линии числа копий для каждого элемента разрешения для получения указанных нормализованных новых данных секвенирования. Изобретение расширяет возможности использования технологий секвенирования. 22 з.п. ф-лы, 2 табл., 30 ил.
1. Способ нормализации числа копий, включающий:
- секвенирование одной или более интересующих областей из множества базовых биологических образцов, которые не совпадают с биологическим образцом, с получением базовых данных секвенирования с использованием панели зондов, которые гибридизуются с отдельными нуклеиновыми кислотами в одной или более интересующих областей, где указанные одна или более интересующих областей содержат множество элементов разрешения, где каждый элемент разрешения содержит смежную область нуклеиновой кислоты, соответствующую части соответствующей интересующей области; и
- определение информации нормализации числа копий с использованием базовых данных секвенирования, где информация нормализации числа копий содержит, по меньшей мере, одну базовую линию числа копий для интересующей области из одной или более интересующих областей, где базовая линия числа копий основана на:
определении количества ридов секвенирования в элементе разрешения для каждого отдельного элемента разрешения из указанного множества элементов разрешения в представляющей интерес области каждого базового биологического образца из указанного множества образцов;
кластеризации указанного множества базовых биологических образцов для идентификации различных кластеров в указанном множестве образцов на основании количества в элементе разрешения; и
использовании медианного значения элемента разрешения по меньшей мере одного кластера для получения базовой линии числа копий для каждого элемента разрешения; и
обеспечения пользователя информацией нормализации числа копий для нормализации новых данных секвенирования нового биологического образца, полученных с помощью указанной панели зондов, которые гибридизуются с отдельными нуклеиновыми кислотами в одной или более интересующих областей указанного нового образца, где указанные новые данные секвенирования содержат количества ридов секвенирования в элементе разрешения для каждого отдельного элемента разрешения из множества элементов разрешения в интересующей области нового образца;
где вариации числа копий для каждой интересующей области характеризуют в нормализованных новых данных секвенирования, и где указанный каждый отдельный элемент разрешения из указанного множества элементов разрешения в указанных новых данных секвенирования нормализуют на основании соответствующей базовой линии числа копий для каждого элемента разрешения для получения указанных нормализованных новых данных секвенирования.
2. Способ по п. 1, в котором базовые данные секвенирования содержат данные, представляющие количество ридов секвенирования для каждого элемента разрешения из множества элементов разрешения, при этом каждый элемент разрешения из множества элементов разрешения ассоциирован с соответствующей интересующей областью.
3. Способ по п. 2, в котором получение базовых данных секвенирования содержит этап, на котором используют панель целевого секвенирования, при этом множество элементов разрешения задаются с использованием последовательностей, соответствующих интересующим областям в панели целевого секвенирования.
4. Способ по п. 2, в котором получение базовых данных секвенирования содержит этап, на котором получают данные секвенирования полного генома.
5. Способ по п. 2, в котором количество ридов секвенирования представляет собой показатель числа отдельных ридов в базовых данных секвенирования, соответствующих каждому элементу разрешения.
6. Способ по п. 3, содержащий этап, на котором определяют одно или более из медианного количества ридов секвенирования, медианного абсолютного отклонения, содержания GC и размера для каждого элемента разрешения из множества элементов разрешения.
7. Способ по п. 6, включающий исключение или маскирование элементов разрешения из множества элементов разрешения с одним или более из низкой медианы, большого абсолютного отклонения медианных покрытий последовательности, содержания GC за пределами предварительно определенного диапазона или размера ниже порогового значения размера из базовых данных секвенирования перед определением информации нормализации числа копий таким образом, что информация нормализации числа копий определяется с использованием только оставшихся элементов разрешения после исключения или маскирования.
8. Способ по п. 7, в котором исключение или маскирование элементов разрешения содержит этап, на котором исключают или маскируют элементы разрешения с количеством медианных покрытий последовательности менее 0,25.
9. Способ по п. 7, в котором исключение или маскирование элементов разрешения содержит этап, на котором исключают или маскируют элементы разрешения с медианным покрытием последовательности с абсолютным отклонением выше порогового значения.
10. Способ по п. 7, в котором исключение или маскирование элементов разрешения содержит этап, на котором исключают или маскируют элементы разрешения с содержанием GC менее 25% или более 80%.
11. Способ по п. 7, в котором исключение или маскирование элементов разрешения содержит этап, на котором исключают или маскируют элементы разрешения с размером целей менее 20 оснований.
12. Способ по п. 2, включающий кластеризацию базовых данных секвенирования для каждого элемента разрешения, чтобы определять базовую линию числа копий, при этом базовая линия числа копий формируется из медианного количества ридов секвенирования в расчете на элемент разрешения из множества элементов разрешения, ассоциированных с интересующей областью.
13. Способ по п. 12, включающий определение базовых линий числа копий для дополнительных элементов разрешения из множества элементов разрешения.
14. Способ по п. 1, в котором биологический образец представляет собой образец, извлекаемый из отдельной особи, при этом множество базовых образцов исходят из образцов, извлекаемых из различных отдельных особей.
15. Способ по п. 1, в котором биологический образец извлекается из ткани опухоли отдельной особи, при этом множество базовых образцов извлекаются из нормальной ткани, которая не относится к отдельной особи.
16. Способ по п. 1, включающий получение данных секвенирования биологического образца от пользователя и определение того, что данные секвенирования содержат варьирование по отношению к базовой линии числа копий в интересующей области.
17. Способ по п. 16, включающий формирование индикатора относительно варьирования и предоставление индикатора пользователю.
18. Способ по п. 17, в котором индикатор представляет собой кратное изменение числа копий биологического образца относительно базовой линии числа копий для интересующей области.
19. Способ по п. 16, включающий маскирование резко отклоняющихся элементов разрешения в данных секвенирования перед определением того, что данные секвенирования содержат варьирование по отношению к базовой линии числа копий в интересующей области.
20. Способ по п. 19, включающий применение LOESS-регрессии к данным секвенирования, чтобы исключать GS-смещение после маскирования резко отклоняющихся элементов разрешения.
21. Способ по п. 19, включающий подгонку данных секвенирования к кривой после маскирования резко отклоняющихся элементов разрешения.
22. Способ по п. 1, в котором данные секвенирования получаются с использованием панели секвенирования экзома.
23. Способ по п. 1, в котором предоставление информации базовой линии числа копий пользователю содержит этап, на котором предоставляют информацию, представляющую гипотетический эталонный образец, который имитирует сопоставленный образец для пользователя, и который не формируется с использованием сопоставленных образцов.
| US2016239604 A1, 18.08.2016 | |||
| WO2011139901 A1, 10.11.2011 | |||
| EP2844771 A1, 11.03,2015 | |||
| ANGELA LEO, ANDREW M WALKER, A GC-wave correction algorithm that improves the analytical performance of aCGH, J Mol Diagn, 2012, том 14, номер 6, стр.550-9 | |||
| RU 2014150655 A, 10.07.2016. |

