Описание и варианты осуществления
Настоящее изобретение относится к кодированию или декодированию аудиоинформации и, в частности, к параметрическому пространственному аудиокодированию с гибридным кодером/декодером.
Передача аудиосцены в трех измерениях требует управления несколькими каналами, что обычно порождает большой объем данных для передачи. Кроме того, трехмерный (3D) звук может быть представлен по-разному: традиционный звук на основе каналов, когда каждый канал передачи связан с позицией громкоговорителей; звук, передаваемый через аудиообъекты, которые могут быть помещены в трех измерениях независимо от позиций громкоговорителей; и звук на основе сцены (или амбиофония), где аудиосцена представлена набором сигналов коэффициентов, которые являются линейными весовыми коэффициентами основных функций пространственных ортогональных сферических гармоник. В отличие представления на основе каналов представление на основе сцены не зависит от конкретной расстановки громкоговорителей и может быть воспроизведено на любых расстановках громкоговорителей за счет дополнительного процесса рендеринга в декодере.
Для каждого из этих форматов были разработаны специализированные схемы кодирования для того эффективного сохранения или передачи аудиосигналов на низких битовых скоростях. Например, MPEG Surround представляет собой схему параметрического кодирования для объемного звука на основе каналов, в то время как MPEG Spatial Audio Object Coding (SAOC) представляет собой способ параметрического кодирования, предназначенный для аудиоданных на основе объектов. Также в недавней фазе 2 стандарта MPEG-H была обеспечена методика параметрического кодирования для амбиофонии высшего порядка.
В этом сценарии передачи пространственные параметры для полного сигнала всегда являются частью закодированного и переданного сигнала, т.е. оцененного и закодированного в кодере на основе полностью доступной трехмерной (3D) звуковой сцены и декодированного и используемого для воссоздания аудиосцены в декодере. Ограничения скорости для передачи обычно ограничивают временное и частотное разрешение переданных параметров, которое может быть ниже, чем частотно-временное разрешение переданных аудиоданных.
Другая возможность создать трехмерную аудиосцену состоит в повышающем микшировании представления с низкой размерностью, например, двухканального стерео или представления амбиофонии первого порядка до требуемой размерности с использованием признаков и параметров, непосредственно оцененных из представления с низкой размерностью. В этом случае частотно-временное разрешение может быть выбрано произвольно высоким. С другой стороны, используемое имеющее низкую размерность и, возможно, закодированное представление аудиосцены приводит к недостаточно оптимальной оценке пространственных признаков и параметров. Особенно, если проанализированная аудиосцена была закодирована и передана с использованием инструментов параметрического и полупараметрического аудиокодирования, пространственные признаки первоначального сигнала нарушены больше, чем это вызвало бы только представление с низкой размерностью.
Аудиокодирование с низкой битовой скоростью с использованием инструментов параметрического кодирования продемонстрировало недавние достижения. Такие достижения кодирования аудиосигналов с очень низкими битовыми скоростями привели к широкому применению так называемых инструментов параметрического кодирования, чтобы гарантировать хорошее качество. Хотя кодирование с сохранением формы волны, т.е. кодирование, при котором только шум квантования добавляется к декодированному аудиосигналу, является предпочтительным, например, с использованием частотно-временного преобразования на основе кодирования и придания формы шума квантования с использованием перцептивной модели, такой как MPEG-2 AAC или MPEG-1 MP3, это приводит к слышимому шуму квантования, в частности, для низких битовых скоростей.
Чтобы преодолеть это проблемы, были разработаны инструменты параметрического кодирования, в которых части сигнала не закодированы непосредственно, но восстанавливаются в декодере с использованием параметрического описания требуемых аудиосигналов, причем для параметрического описания требуется меньшая скорость передачи, чем для кодирования с сохранением формы волны. Эти способы не пытаются сохранить форму волны сигнала, а формируют аудиосигнал, который по восприятию эквивалентен первоначальному сигналу. Примерами таких инструментов параметрического кодирования являются расширения частотной полосы, такие как репликация спектральной полосы (Spectral Band Replication, SBR), в которой части высокочастотной полосы спектрального представления декодированного сигнала формируются посредством копирования фрагментов закодированных с сохранением формы волны низкочастотных спектральных сигналов и адаптации в соответствии с упомянутыми параметрами. Другим способом является интеллектуальное заполнение промежутков (Intelligent Gap Filling, IGF), в котором некоторые частотные полосы в спектральном представлении закодированы непосредственно, в то время как частотные полосы, квантованные до нуля в кодере, заменяются уже декодированными другими частотными полосами спектра, которые снова выбираются и подстраиваются в соответствии с переданными параметрами. Третьим используемым инструментом параметрического кодирования является заполнением шумом, в котором части сигнала или спектра квантуются до нуля, заполняются случайным шумом и подстраиваются в соответствии с переданными параметрами.
Недавние стандарты аудиокодирования, используемые для кодирования на средних и низких битовых скоростях, используют комбинацию таких параметрических инструментов, чтобы получить высокое качество восприятия для этих битовых скоростей. Примерами таких стандартов являются xHE-AAC, MPEG4-H и EVS.
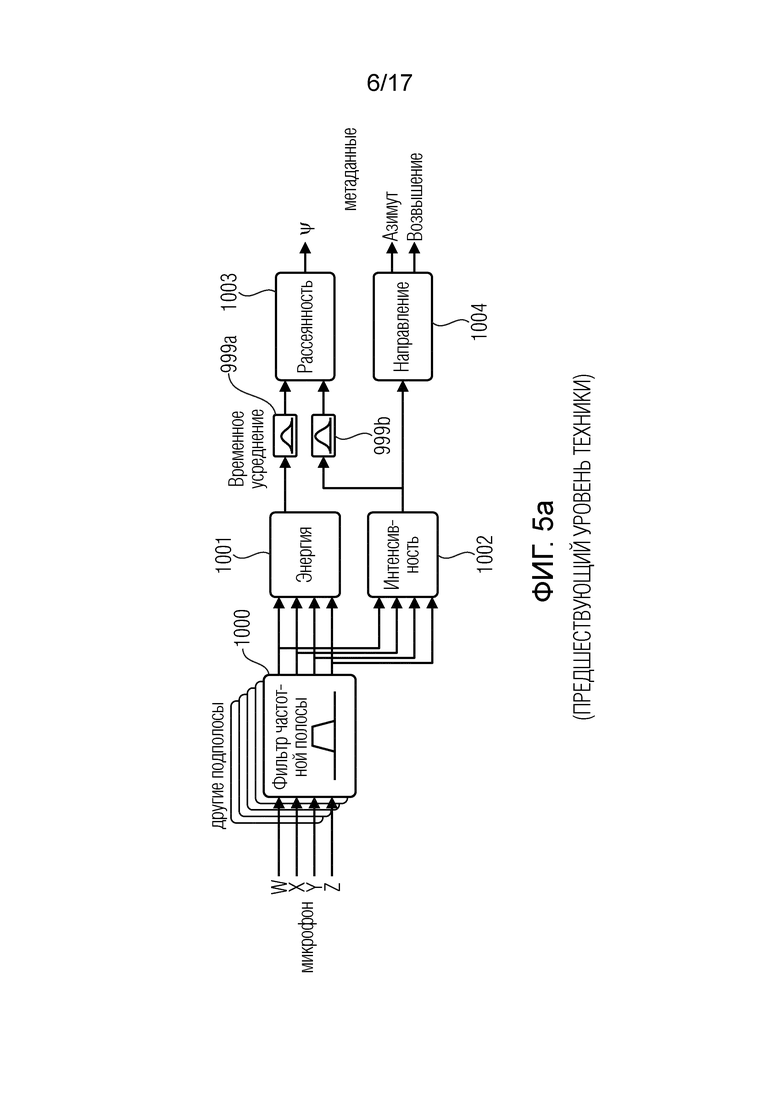
Оценка пространственных параметров DirAC и слепое повышающее микширование являются дальнейшей процедурой. DirAC представляет собой мотивированное восприятием воспроизведение пространственного звука. Предполагается, что в один момент времени и в одной критической частотной полосе пространственное разрешение слуховой системы ограничено декодированием одного признака для направления и другого для интерауральной когерентности или рассеянности.
На основе этих предположений DirAC представляет пространственный звук в одной частотной полосе посредством плавного наложения двух потоков: ненаправленного рассеянного потока и направленного нерассеянного потока. Обработка DirAC выполняется в двух фазах: анализ и синтез, как изображено на фиг. 5a и 5b.
На этапе анализа DirAC, показанном на фиг. 5a, совмещенный микрофон первого порядка в B-формате рассматривается в качестве входных данных, и рассеянность и направление прибытия звука анализируются в частотной области. На этапе синтеза DirAC, показанном на фиг. 5b, звук разделяется на два потока, нерассеянный поток и рассеянный. Нерассеянный поток воспроизводится как точечные источники с использованием амплитудного панорамирования, которая может быть выполнена посредством амплитудного панорамирования с использованием базы вектора (VBAP) [2]. Рассеянный поток отвечает за ощущение окружения и производится посредством передачи громкоговорителям взаимно декоррелированных сигналов.
Этап анализа на фиг. 5a содержит фильтр 1000 частотной полосы, блок 1001 оценки энергии, блок 1002 оценки интенсивности, элементы 999a и 999b временного усреднения, калькулятор 1003 рассеянности и калькулятор 1004 направления. Вычисленные пространственные параметры представляют собой значения рассеянности между 0 и 1 для каждой частотно-временной секции и параметр направления прибытия для каждой частотно-временной секции, сформированной блоком 1004. На фиг. 5a параметр направления содержит угол азимута и угол возвышения, указывающие направление прибытия звука относительно опорной позиции или позиции прослушивания и, в частности, относительно позиции, где расположен микрофон, из которого собраны четыре компонентных сигнала, введенных в фильтр 1000 частотной полосы. Эти компонентные сигналы на иллюстрации фиг. 5a представляют собой компоненты амбиофонии первого порядка, которые содержат всенаправленный компонент W, направленный компонент X, другой направленный компонент Y и дополнительный направленный компонент Z.
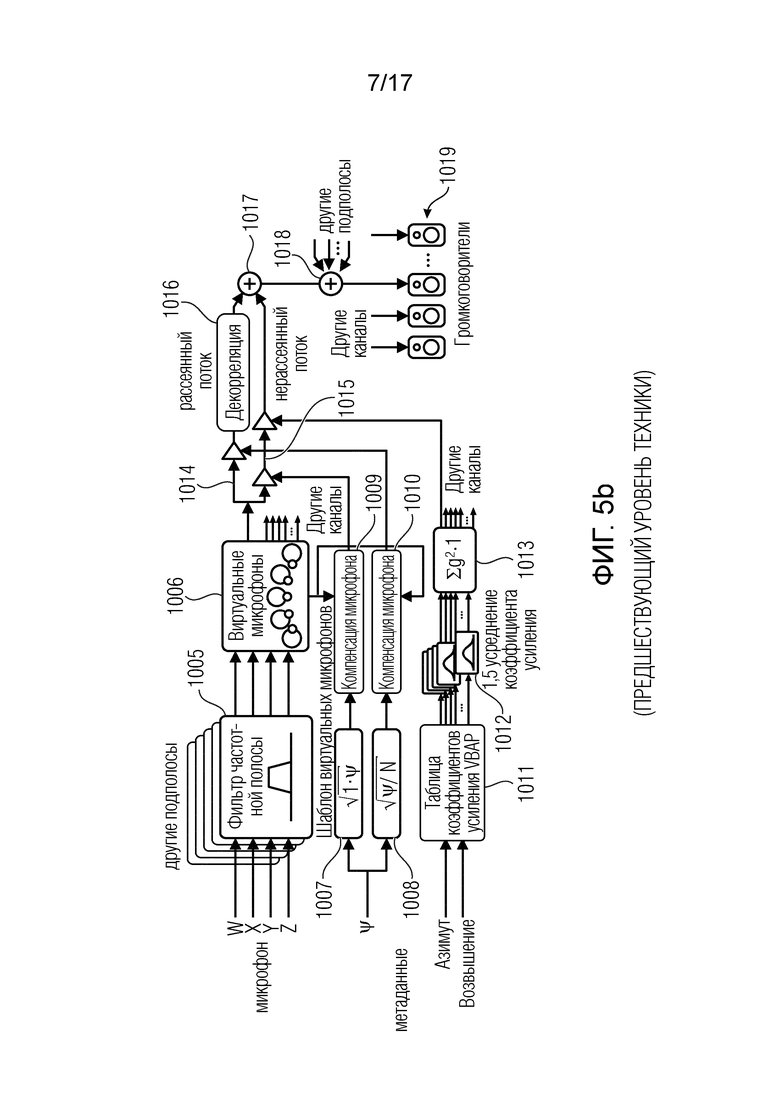
Этап синтеза DirAC, проиллюстрированный на фиг. 5b, содержит фильтр 1005 частотной полосы для формирования частотно-временного представления сигналов W, X, Y, Z микрофона B-формата. Соответствующие сигналы для отдельных частотно-временных секций подаются на этап 1006 виртуальных микрофонов, который формирует для каждого канала сигнал виртуального микрофона. В частности, для формирования сигнала виртуального микрофона, например, для центрального канала, виртуальный микрофон направлен к центральному каналу, и полученный в результате сигнал соответствует компонентному сигналу для центрального канала. Затем сигнал обрабатывается через ветвь 1015 прямого сигнала и ветвь 1014 рассеянного сигнала. Обе ветви содержат соответствующие блоки регулировки коэффициента усиления или усилители, которыми управляют значения рассеянности, полученные из первоначального параметра рассеянности в блоках 1007, 1008, и, кроме того, обработанные в блоках 1009, 1010 для получения некоторой компенсации микрофона.
Компонентный сигнал на ветви 1015 прямого сигнала также регулируется по усилению с использованием параметра коэффициента усиления, выявленного из параметра направления, состоящего из угла азимута и угла возвышения. В частности, эти углы вводятся в таблицу 1011 коэффициентов усиления VBAP (амплитудного панорамирования с использованием базы вектора). Результат подается на этап 1012 усреднения коэффициента усиления громкоговорителя для каждого канала и далее в нормализатор 1013, и полученный в результате параметр коэффициента усиления затем передается усилителю или блоку регулировки коэффициента усиления на ветви 1015 прямого сигнала. Рассеянный сигнал, сформированный на выходе декоррелятора 1016, и прямой сигнал или нерассеянный поток объединяются в блоке 1017 объединения 1017, и, затем другие частотные подполосы складываются в другом блоке 1018 объединения, который может представлять собой, например, набор синтезирующих фильтров. Таким образом, сигнал громкоговорителя для некоторого громкоговорителя сформирован, и такая же процедура выполняется для других каналов для других громкоговорителей 1019 в некоторой расстановке громкоговорителей.
Высококачественная версия синтеза DirAC проиллюстрирована на фиг. 5b, где синтезатор принимает все сигналы B-формата, из которых для каждого направления громкоговорителя вычисляется сигнал виртуального микрофона. Используемый дирекциональный шаблон обычно является диполем. Сигналы виртуальных микрофонов затем модифицируются нелинейным образом в зависимости от метаданных, как обсуждается относительно ветвей 1016 и 1015. Версия DirAC с низкой битовой скоростью не показана на фиг. 5b. Однако в этой версии с низкой битовой скоростью передается только один канал аудиоинформации. Отличие в обработке заключается в том, что все сигналы виртуальных микрофонов будут заменены этим единственным каналом принятой аудиоинформации. Сигналы виртуальных микрофонов разделяются на два потока, рассеянный и нерассеянный потоки, которые обрабатываются отдельно. Нерассеянный звук воспроизводится как точечные источники посредством амплитудного панорамирования с использованием базы вектора (VBAP). При панорамировании монофонический звуковой сигнал применяется к подмножеству громкоговорителей после умножения на заданные для громкоговорителей коэффициенты усиления. Коэффициенты усиления вычисляются с использованием информации о расстановке громкоговорителей и заданном направлении панорамирования. В версии с низкой битовой скоростью входной сигнал просто подвергается панорамированию в направлениях, подразумеваемых метаданными. В высококачественной версии каждый сигнал виртуального микрофона умножается на соответствующий коэффициентом усиления, что производит такой же эффект с панорамированием, однако с меньшей подверженностью каким-либо нелинейным артефактам.
Цель синтеза рассеянного звука состоит в том, чтобы создать восприятие звука, который окружает слушателя. В версии с низкой битовой скоростью рассеянный поток воспроизводится посредством декорреляции входной сигнал и воспроизведения его с каждого громкоговорителя. В высококачественной версии сигналы виртуальных микрофонов рассеянных потоков уже являются некогерентными в определенной степени, и они должны быть декоррелированы лишь незначительно.
Параметры DirAC, также называемые пространственными метаданными, состоят из кортежей рассеянности и направления, которое в сферических координатах представлены двумя углами, азимутом и возвышением. Если и этап анализа, и этап синтеза выполняются на стороне декодера, частотно-временное разрешение параметров DirAC может быть выбрано таким же, как у набора фильтров, используемого для анализа и синтеза DirAC, т.е. отдельный набор параметров для каждого временного слота и элемента разрешения по частоте представления набора фильтров аудиосигнала.
Проблема выполнения анализа в системе пространственного аудиокодирования только на стороне декодера состоит в том, что для средней и низкой битовых скоростей используются параметрические инструменты, описанные в предыдущем разделе. Поскольку эти инструменты по своей природе не сохраняют форму волны, пространственный анализ для спектральных фрагментов, в которых в основном используется параметрическое кодирование, может привести к значениям для пространственных параметров, значительно отличающимся от тех, которые произвел бы анализ первоначального сигнала. Фиг. 2a и 2b показывают такой сценарий неверной оценки, в котором анализ DirAC был выполнен для не закодированного сигнала (a) и закодированного в B-формате и переданного сигнала с низкой битовой скоростью (b) с помощью кодера, использующего частично кодирование с сохранением формы волны и частично параметрическое кодирование. Особенно значительные различия могут наблюдаться относительно рассеянности.
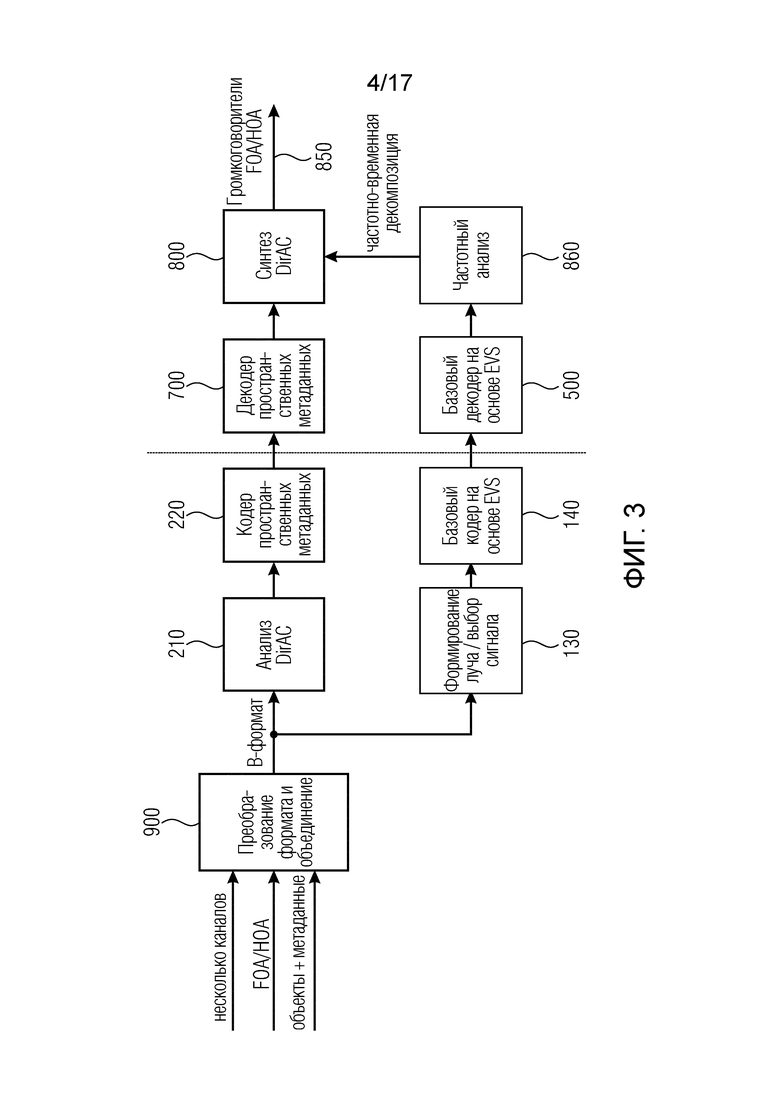
В недавнее время способ пространственного аудиокодирования с использованием анализа DirAC в кодере и передача закодированных пространственных параметров в декодере был раскрыт в [3] [4]. Фиг. 3 иллюстрирует обзор системы кодера и декодера, объединяющих пространственную звуковую обработка DirAC с аудиокодером. Входной сигнал, например, многоканальный входной сигнал, сигнал амбиофонии первого порядка (FOA) или амбиофонии высшего порядка (HOA) или объектно-закодированный сигнал, содержащий один или более транспортных сигналов, содержащих понижающее микширование объектов и соответствующих метаданных объектов, таких как метаданные энергии и/или данные корреляции, подается на вход блока 900 преобразования формата и объединения. Блок преобразования формата и объединения выполнен с возможностью преобразовывать каждый из входных сигналов в соответствующий сигнал B-формата, и блок 900 преобразования формата и объединения дополнительно объединяет потоки, принятые в разных представлениях, складывая вместе соответствующие компоненты B-формата, или с помощью других технологий объединения, состоящих из взвешенного сложения или выбора разной информации разных входных данных.
Полученный в результате сигнал B-формата вводится в анализатор 210 DirAC, чтобы выявить метаданные DirAC, такие как метаданные направления прибытия и метаданные рассеянности, и полученные сигналы кодируются с использованием кодера 220 пространственных метаданных. Кроме того, сигнал B-формата передается блоку формирования луча/селектору сигнала, чтобы микшировать с понижением сигналы B-формата в транспортный канал или несколько транспортных каналов, которые затем кодируются с использованием базового кодера 140 на основе EVS.
Выходные данные блока 220, с одной стороны, и блока 140, с другой стороны, представляют закодированную аудиосцену. Закодированная аудиосцена передается декодеру, и в декодере декодер 700 пространственных метаданных принимает закодированные пространственные метаданные, и основанный на EVS базовый декодер 500 принимает закодированные транспортные каналы. Декодированные пространственные метаданные, полученные блоком 700, передаются на этап 800 синтеза DirAC, и декодированные один или более транспортных каналов на входе блока 500 подвергаются частотному анализу в блоке 860. Полученная в результате частотно-временная декомпозиция также передается синтезатору 800 DirAC, который затем формирует, например, в качестве декодированной аудиосцены сигналы громкоговорителей, или компоненты амбиофонии первого порядка или амбиофонии высшего порядка, или любое другое представление аудиосцены.
В процедуре, раскрытой в [3] и [4], метаданные DirAC, т.е. пространственные параметры, оцениваются и кодируются на низкой битовой скорости и передаются декодеру, где они используются для воссоздания трехмерной аудиосцены вместе с представлением аудиосигнала с низкой размерностью.
В этом изобретении метаданные DirAC, т.е. пространственные параметры, оцениваются и кодируются на низкой битовой скорости и передаются декодеру, где они используются, для воссоздания трехмерной аудиосцены вместе с представлением аудиосигнала с низкой размерностью.
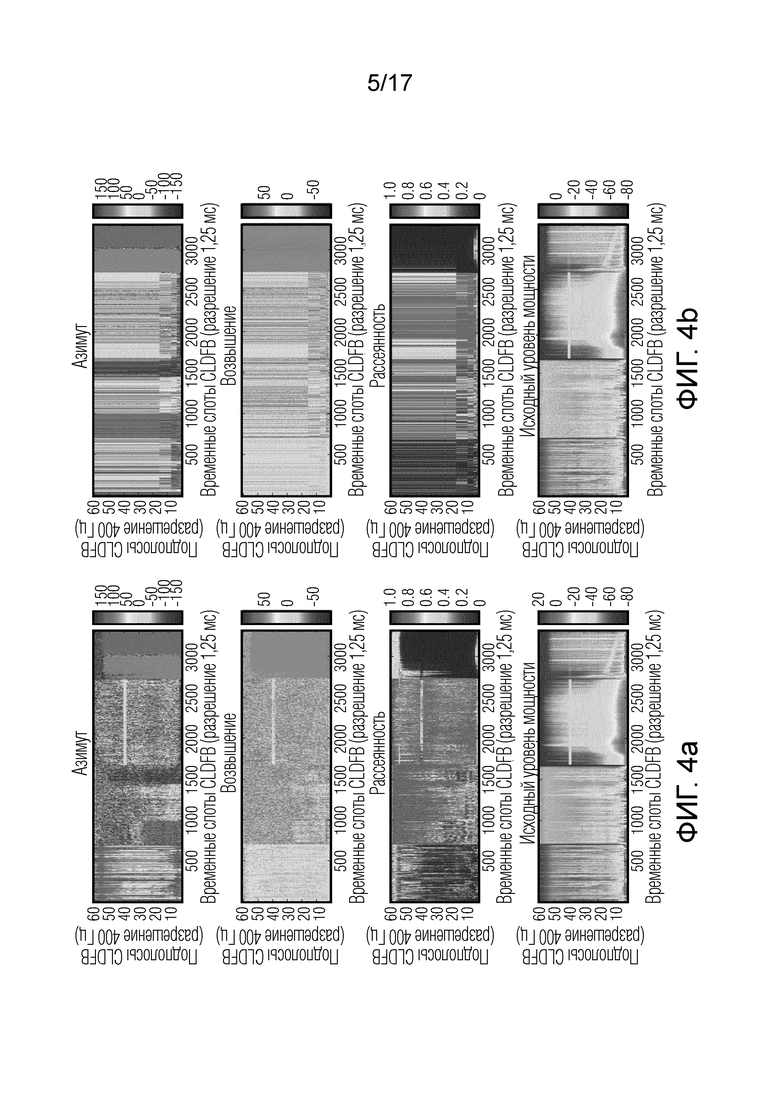
Чтобы достигнуть низкой битовой скорости для метаданных, частотно-временное разрешение является меньшим, чем частотно-временное разрешение используемого набора фильтров при анализе и синтезе трехмерной аудиосцены. Фиг. 4a и 4b показывают сравнение между не закодированными и не сгруппированными пространственными параметрами анализа DirAC (a) и закодированными и сгруппированными параметрами того же самого сигнала с использованием системы пространственного аудиокодирования DirAC, раскрытой в [3], с закодированными и переданными метаданными DirAC. По сравнению с фиг. 2a и 2b можно заметить, что параметры, используемые в декодере (b), ближе к параметрам, оцененным на основе первоначального сигнала, но частотно-временное разрешение ниже, чем для оценки только в декодере.
Задача настоящего изобретения состоит в том, чтобы обеспечить улучшенную концепцию для обработки, такой как кодирование или декодирование аудиосцены.
Эта задача решена посредством кодера аудиосцены по п. 1, декодера аудиосцены по п. 15, способа кодирования аудиосцены по п. 35, способа декодирования аудиосцены по п. 36, компьютерной программы по п. 37 или закодированной аудиосцены по п. 38.
Настоящее изобретение основано на обнаружении того, что улучшенное качество звука и более высокая гибкость и, в целом, улучшенные рабочие характеристики получаются посредством применения гибридной схемы кодирования/декодирования, в которой пространственные параметры, используемые для формирования декодированной двухмерной или трехмерной аудиосцены в декодере, оцениваются в декодере на основе закодированного переданного и декодированного представления аудиоинформации обычно с низкой размерностью для некоторых частей частотно-временного представления схемы, и оцениваются, квантуются и кодируются для других частей в кодере и передаются декодеру.
В зависимости от реализации разделение между областями, оцениваемыми на стороне кодера и оцениваемыми на стороне декодера, могут отличаться для разных пространственных параметров, используемых при формировании трехмерной или двухмерной аудиосцены в декодере.
В вариантах осуществления это разделение на разные фрагменты или предпочтительно частотно-временные области может быть произвольными. Однако в предпочтительном варианте осуществления имеется преимущество оценивать параметры в декодере для частей спектра, которые главным образом закодированы с сохранением формы волны, при этом кодируя и передавая вычисленные в кодере параметры для частей спектра, в которых главным образом использовались инструменты параметрического кодирования.
Варианты осуществления настоящего изобретения предлагают решение кодирования с низкой битовой скоростью для передачи трехмерной аудиосцены с использованием системы гибридного кодирования, в которой пространственные параметры, используемые для воссоздания трехмерной аудиосцены, для некоторых частей оцениваются и кодируются в кодере и передаются декодеру, и для остальных частей оцениваются непосредственно в декодере.
Настоящее изобретение раскрывает воспроизведение трехмерной аудиоинформации на основе гибридного подхода для оценки параметров только на стороне декодера для частей сигнала, в которых пространственные признаки хорошо сохраняются после переноса пространственного представления в низкую размерность в аудиокодере, и кодирования представления с низкой размерностью, и для оценки в кодере, кодирования в кодере и передачи пространственных признаков и параметров из кодера в декодер для частей спектра, в которых низкая размерность вместе с кодированием представления с низкой размерностью привела бы к недостаточной оценке пространственных параметров.
В варианте осуществления кодер аудиосцены выполнен с возможностью кодирования аудиосцены, аудиосцена содержит по меньшей мере два компонентных сигнала, и кодер аудиосцены содержит базовый кодер, выполненный с возможностью базового кодирования по меньшей мере двух компонентных сигналов, причем базовый кодер формирует первое закодированное представление для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов и формирует второе закодированное представление для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов. Пространственный анализатор анализирует аудиосцену, чтобы выявить один или более пространственных параметров или одно или более множеств пространственных параметров для второго фрагмента, и выходной интерфейс затем формирует закодированный сигнал аудиосцены, который содержит первое закодированное представление, второе закодированное представление и один или более пространственных параметров или одно или более множеств пространственных параметров для второго фрагмента. Обычно любые пространственные параметры для первого фрагмента не включены в закодированный сигнал аудиосцены, поскольку эти пространственные параметры оцениваются на основе декодированного первого представления в декодере. С другой стороны, пространственные параметры для второго фрагмента уже вычислены в кодере аудиосцены на основе первоначальной аудиосцены или уже обработанной аудиосцены, которая была сокращена относительно ее размерности и, таким образом, относительно ее битовой скорости.
Таким образом, вычисленные на стороне кодера параметры могут нести высококачественную параметрическую информацию, поскольку эти параметры вычислены в кодере на основе данных, которые имеют высокую точность, не затронуты искажениями базового кодера и потенциально даже доступны в очень высоком измерении, например, сигнал, который выведен из массива высококачественных микрофонов. Вследствие того, что обеспечена сохранность такой очень высококачественной параметрической информации, возможно выполнить базовое кодирование второго фрагмента с меньшей точностью или обычно с меньшим разрешением. Таким образом, посредством довольно грубого базового кодирования второго фрагмента возможно сэкономить биты, которые могут быть отданы представлению закодированных пространственных метаданных. Биты, сэкономленные посредством довольно грубого кодирования второго фрагмента, также можно инвестировать в кодирование с высоким разрешением первого фрагмента упомянутых по меньшей мере двух компонентных сигналов. Кодирование с высоким разрешением или с высоким качеством по меньшей мере двух компонентных сигналов является полезным, поскольку на стороне декодера какие-либо параметрические пространственные данные не существуют для первого фрагмента, но выявляются в декодере посредством пространственного анализа. Таким образом, посредством не выполнения вычисления всех пространственных метаданных в кодере, но базового кодирования по меньшей мере двух компонентных сигналов, любые биты, которые в сравнительном случае были бы необходимы для закодированных метаданных, можно сэкономить и инвестировать в базовое кодирование более высокого качества по меньшей мере двух компонентных сигналов в первом фрагменте.
Таким образом, в соответствии с настоящим изобретением разделение аудиосцены на первый фрагмент и на второй фрагмент может быть сделано очень гибким образом, например, в зависимости от требований битовой скорости, требований качества звука, требований к обработке, т.е. доступно ли больше ресурсов обработки в кодере или декодере, и так далее. В предпочтительном варианте осуществления разделение на первый и второй фрагменты выполняется на основе функциональных возможностей базового кодера. В частности, для базовых кодеров с высоким качеством и низкой битовой скоростью, которые для некоторых частотных полос применяют операции параметрического кодирования, такие как обработка репликации спектральной полосы, обработка интеллектуального заполнения промежутков или обработка заполнения шумом, разделение относительно пространственных параметров выполняется таким образом, что не параметрически закодированные фрагменты сигнала формируют первый фрагмент, и параметрически закодированные фрагменты сигнала формируют второй фрагмент. Таким образом, для параметрически закодированного второго фрагмента, который обычно являются закодированным фрагментом аудиосигнала с низким разрешением, получается более точное представление пространственных параметров, в то время как для лучше закодированного, т.е. закодированного с высоким разрешением первого фрагмента высококачественные параметры не настолько необходимы, поскольку довольно высококачественные параметры могут быть оценены на стороне декодера с использованием декодированного представления первого фрагмента.
В дополнительном варианте осуществления для еще большего сокращения битовой скорости пространственные параметры для второго фрагмента вычисляются в кодере с некоторым частотно-временным разрешением, которое может являться высоким частотно-временным разрешением или низким частотно-временным разрешением. В случае высокого частотно-временного разрешения вычисленные параметры некоторым образом группируются, чтобы получить пространственные параметры с низким частотно-временным разрешением. Эти пространственные параметры с низким частотно-временным разрешением тем не менее являются высококачественными пространственными параметрами, которые лишь имеют низкое разрешение. Однако низкое разрешение полезно тем, что биты сэкономлены для передачи, поскольку сокращено количество пространственных параметров для некоторой продолжительности и некоторой частотной полосы. Однако это сокращение обычно не настолько проблематично, поскольку пространственные данные тем не менее не изменяются слишком сильно по времени и по частоте. Таким образом, может быть получена низкая битовая скорость, но при этом представление хорошего качества пространственных параметров для второго фрагмента.
Поскольку пространственные параметры для первого фрагмента вычисляются на стороне декодера и не должны передаваться, не нужно делать никаких компромиссов относительно разрешения. Таким образом, оценка с высоким временным и высоким частотным разрешением пространственных параметров может быть выполнена на стороне декодера, и эти параметрические данные с высоким разрешением помогают в обеспечении хорошего пространственного представления первого фрагмента аудиосцены. Таким образом, "недостаток" вычисления пространственных параметров на стороне декодера на основе по меньшей мере двух переданных компонентов для первого фрагмента может быть сокращен или даже устранен посредством вычисления пространственных параметров с высоким временным и высоким частотным разрешением и посредством использования этих параметров при выполнении пространственного рендеринга аудиосцены. Это не наносит потерь битовой скорости, поскольку любая обработка, выполняемая на стороне декодера, не имеет никакого отрицательного влияния на битовую скорость передачи в сценарии кодера/декодера.
Дополнительный вариант осуществления настоящего изобретения полагается на ситуацию, в которой для первого фрагмента по меньшей мере два компонента закодированы и переданы таким образом, что на основе этих по меньшей мере двух компонентов параметрическая оценка данных может быть выполнена на стороне декодера. Однако в варианте осуществления второй фрагмент аудиосцены даже может быть закодирован со в значительной степени низкой битовой скоростью, поскольку предпочтительно закодировать только один транспортный канал для второго представления. Этот транспортный или микшированный с понижением канал представлен очень низкой битовой скоростью по сравнению с первым фрагментом, поскольку во втором фрагменте должен быть закодирован лишь один канал или компонент, в то время как в первом фрагменте должны быть закодированы два или более компонентов, поэтому в нем должно быть достаточно данных для пространственного анализа на стороне декодера.
Таким образом, настоящее изобретение обеспечивает дополнительную гибкость относительно битовой скорости, качества звука и требований к средствам обработки, доступным на стороне кодера или декодера.
Предпочтительные варианты осуществления настоящего изобретения описаны ниже со ссылкой на следующие прилагаемые чертежи.
Фиг. 1a - блок-схема варианта осуществления кодера аудиосцены;
Фиг. 1b - блок-схема варианта осуществления декодера аудиосцены;
Фиг. 2a - анализ DirAC на основе незакодированного сигнала;
Фиг. 2b - анализ DirAC на основе закодированного с низкой размерностью сигнала;
Фиг. 3 - обзор системы кодера и декодера, объединяющих пространственную звуковую обработка DirAC с аудиокодером;
Фиг. 4a - анализ DirAC на основе незакодированного сигнала;
Фиг. 4b - анализ DirAC на основе незакодированной группировки с использованием сигнала параметров в частотно-временной области и квантование параметров
Фиг. 5a - этап анализа DirAC предшествующего уровня техники;
Фиг. 5b - этап синтеза DirAC предшествующего уровня техники;
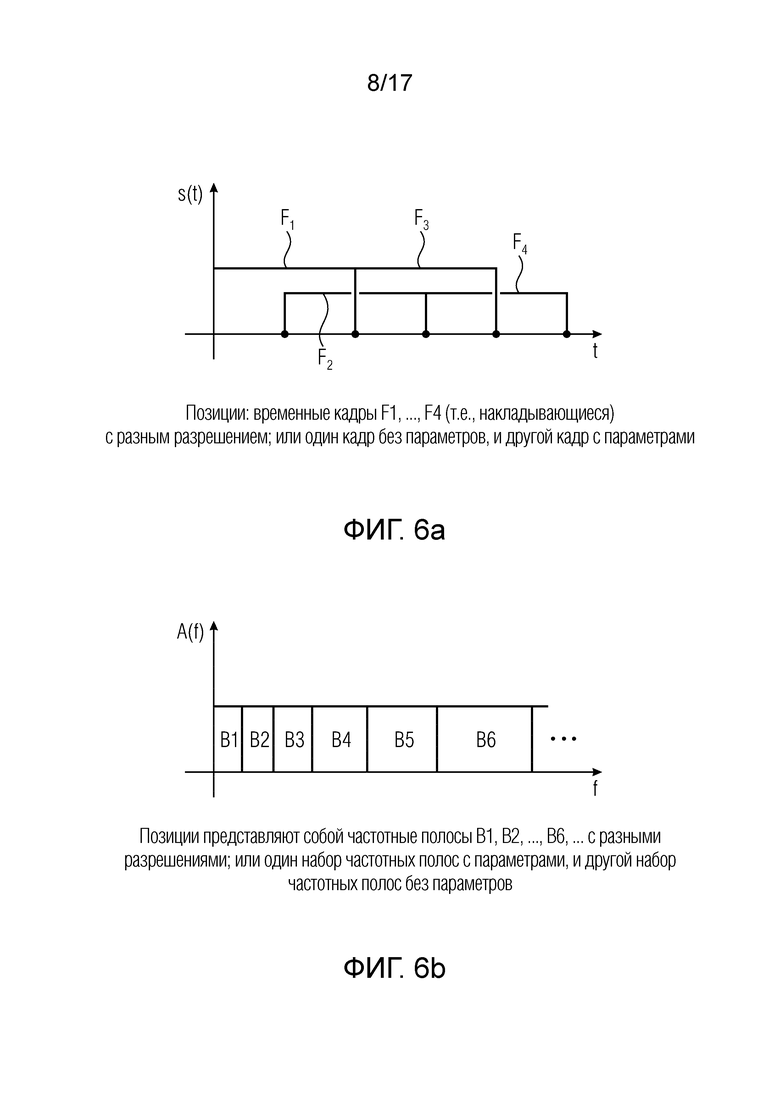
Фиг. 6a иллюстрирует разные накладывающиеся временные кадры в качестве примера для разных фрагментов;
Фиг. 6b иллюстрирует разные частотные полосы в качестве примера для разных фрагментов;
Фиг. 7a иллюстрирует дополнительный вариант осуществления кодера аудиосцены;
Фиг. 7b иллюстрирует вариант осуществления декодера аудиосцены;
Фиг. 8a иллюстрирует дополнительный вариант осуществления кодера аудиосцены;
Фиг. 8b иллюстрирует дополнительный вариант осуществления декодера аудиосцены;
Фиг. 9a иллюстрирует дополнительный вариант осуществления кодера аудиосцены с базовым кодером в частотной области;
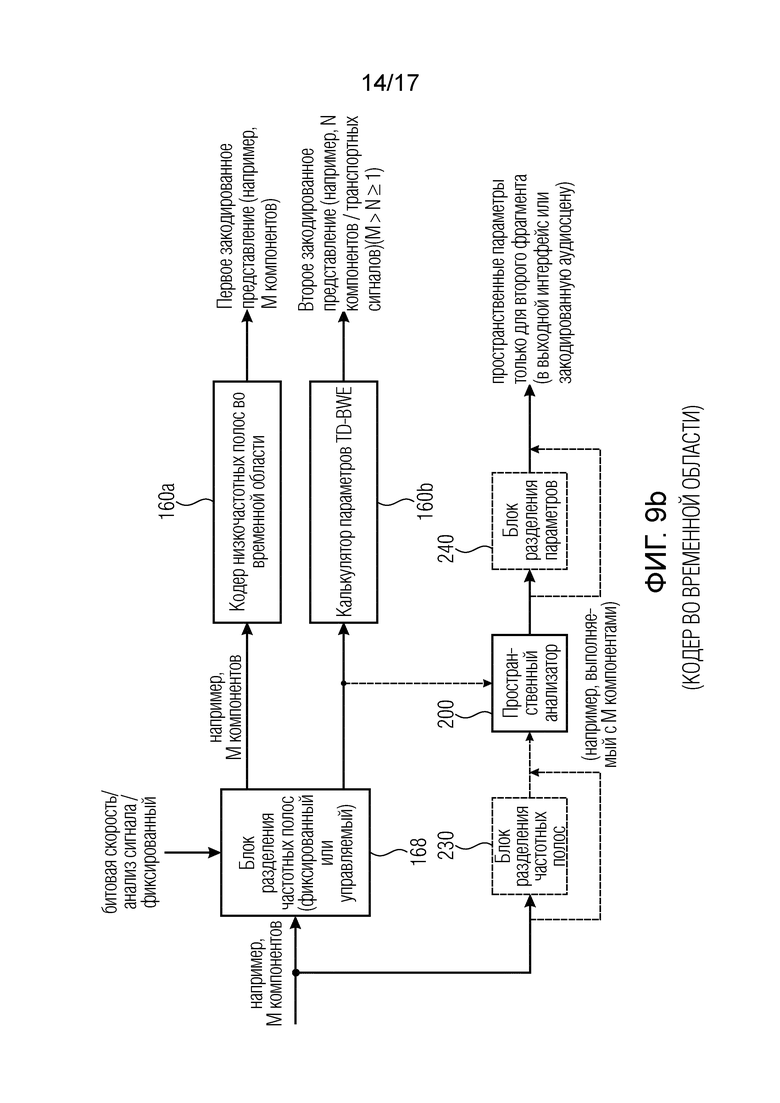
Фиг. 9b иллюстрирует дополнительный вариант осуществления кодера аудиосцены с базовым кодером во временной области;
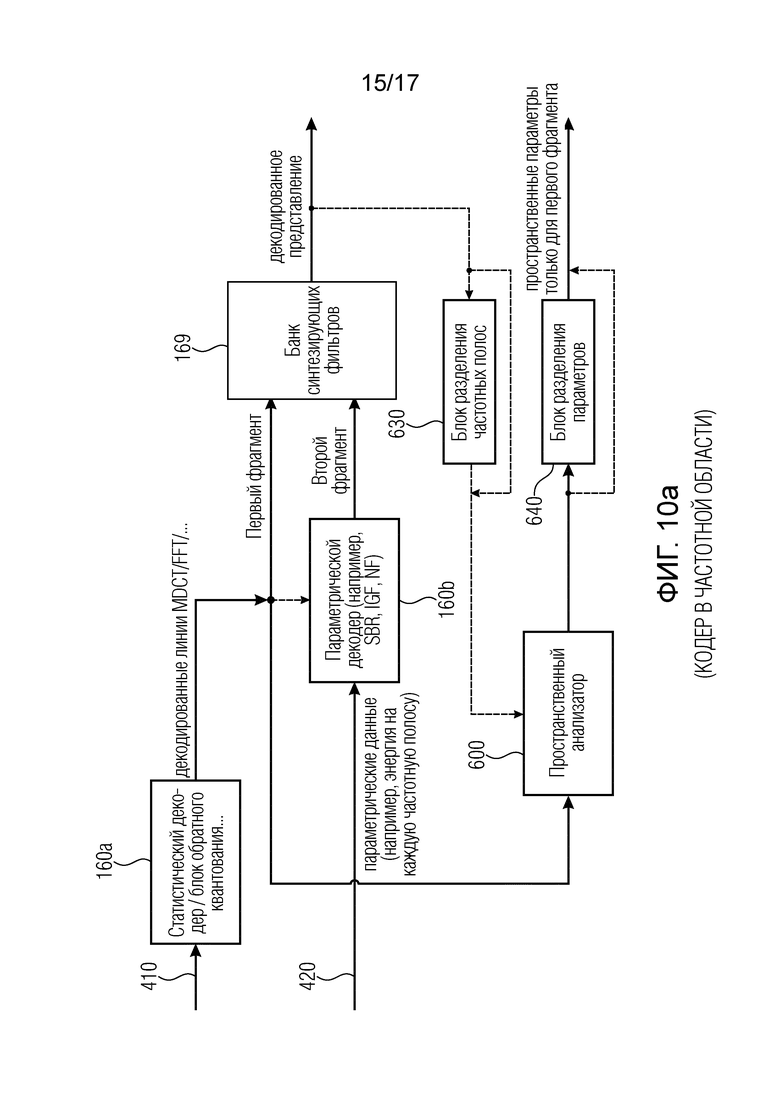
Фиг. 10a иллюстрирует дополнительный вариант осуществления декодера аудиосцены с базовым декодером в частотной области;
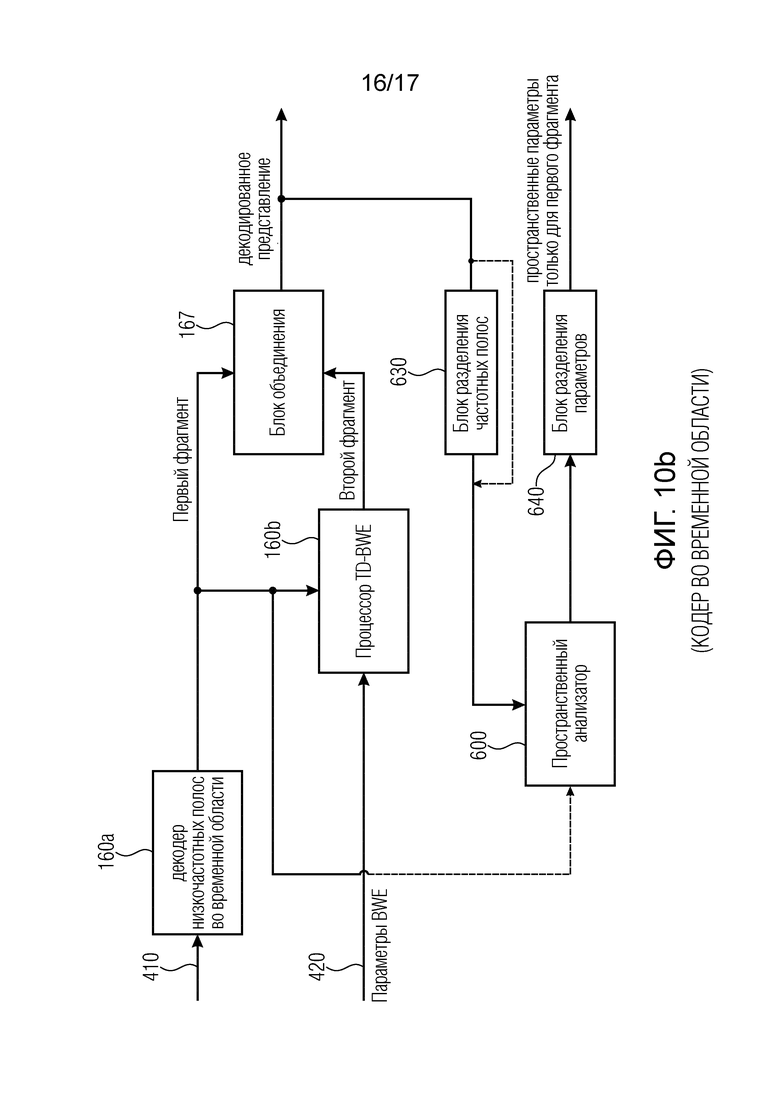
Фиг. 10b иллюстрирует дополнительный вариант осуществления базового декодера во временной области; и
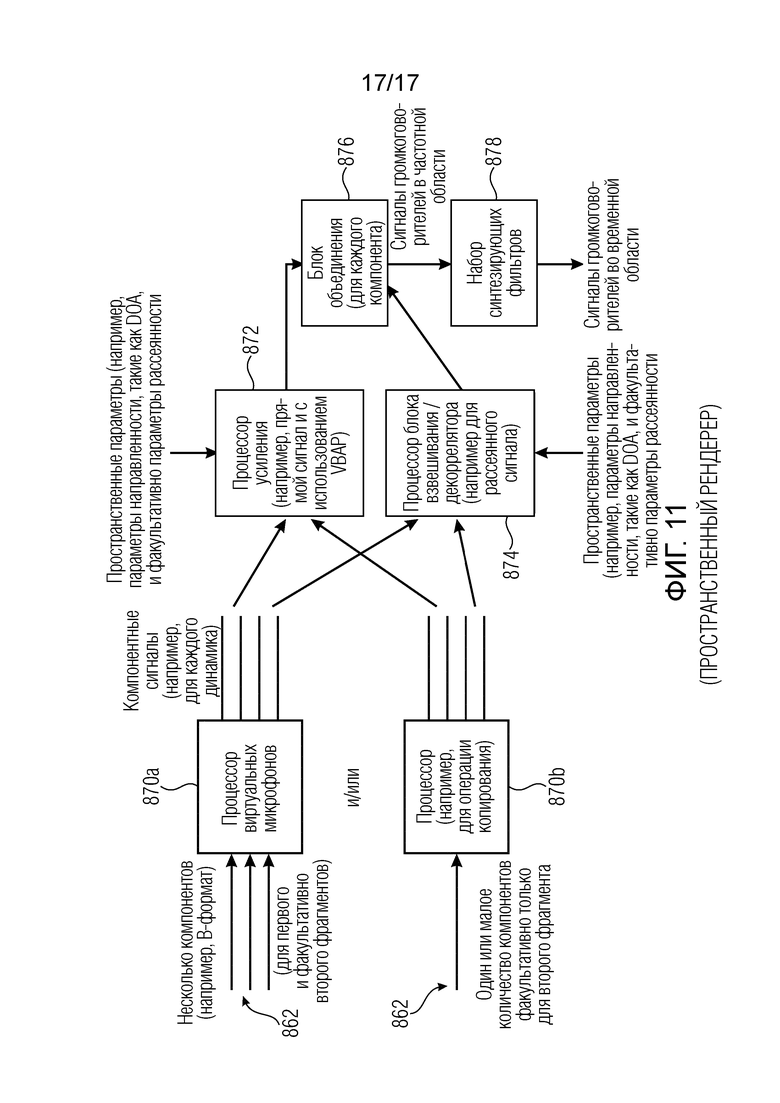
Фиг. 11 иллюстрирует вариант осуществления пространственного рендерера.
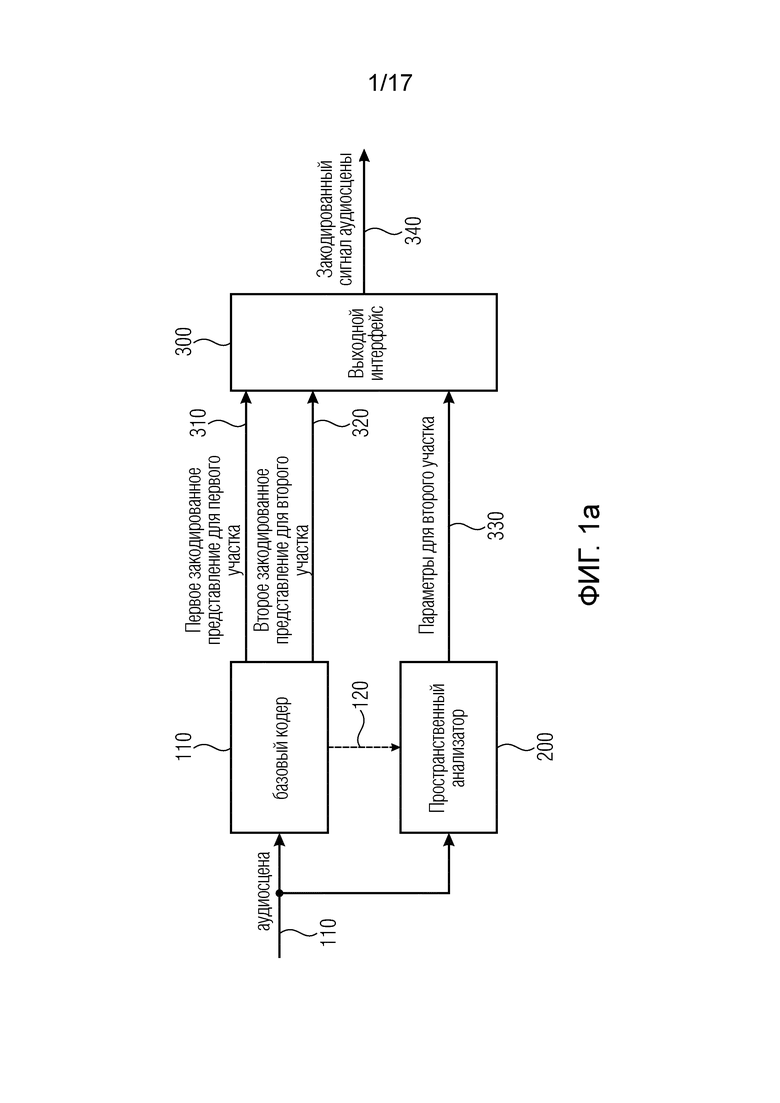
Фиг. 1a иллюстрирует кодер аудиосцены для кодирования аудиосцены 110, которая содержит по меньшей мере два компонентных сигнала. Кодер аудиосцены содержит базовый кодер 100 для базового кодирования упомянутых по меньшей мере двух компонентных сигналов. В частности, базовый кодер 100 выполнен с возможностью формировать первое закодированное представление 310 для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов и формировать второе закодированное представление 320 для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов. Кодер аудиосцены содержит пространственный анализатор для анализа аудиосцены для выявления одного или более пространственных параметров или одного или более множеств пространственных параметров для второго фрагмента. Кодер аудиосцены содержит выходной интерфейс 300 для формирования закодированного сигнала 340 аудиосцены. Закодированный сигнал 340 аудиосцены содержит первое закодированное представление 310, представляющее первый фрагмент упомянутых по меньшей мере двух компонентных сигналов, второе закодированное представление 320 и параметры 330 для второго фрагмента. Пространственный анализатор 200 выполнен с возможностью применять пространственный анализ для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов с использованием первоначальной аудиосцены 110. В качестве альтернативы пространственный анализ также может выполняться на основе представления аудиосцены с сокращенной размерностью. Например, если аудиосцена 110 содержит запись нескольких микрофонов, размещенных в микрофонном массиве, то на основе этих данных может быть выполнен пространственный анализ 200. Однако базовый кодер 100 тогда будет выполнен с возможностью сокращать размерность аудиосцены, например, до представления амбиофонии первого порядка или представления амбиофонии высшего порядка. В основной версии базовый кодер 100 сократит размерность по меньшей мере до двух компонентов, например, состоящих из всенаправленного компонента и по меньшей мере одного направленного компонента, такого как X, Y или Z представления B-формата. Однако также могут использоваться другие представления, такие как представления высшего порядка или представления A-формата. Первое закодированное представление для первого фрагмента тогда будет состоять по меньшей мере из двух разных декодируемых компонентов и обычно будет состоять из закодированного аудиосигнала для каждого компонента.
Второе закодированное представление для второго фрагмента может состоять из такого же количества компонентов или, в качестве альтернативы, может иметь меньшее количество, например, только один всенаправленный компонент, который был закодирован базовым кодером во втором фрагменте. В случае реализации, когда базовый кодер 100 сокращает размерность первоначальной аудиосцены 110, аудиосцена с сокращенной размерностью в некоторых случаях может быть передана пространственному анализатору через линию 120 вместо первоначальной аудиосцены.
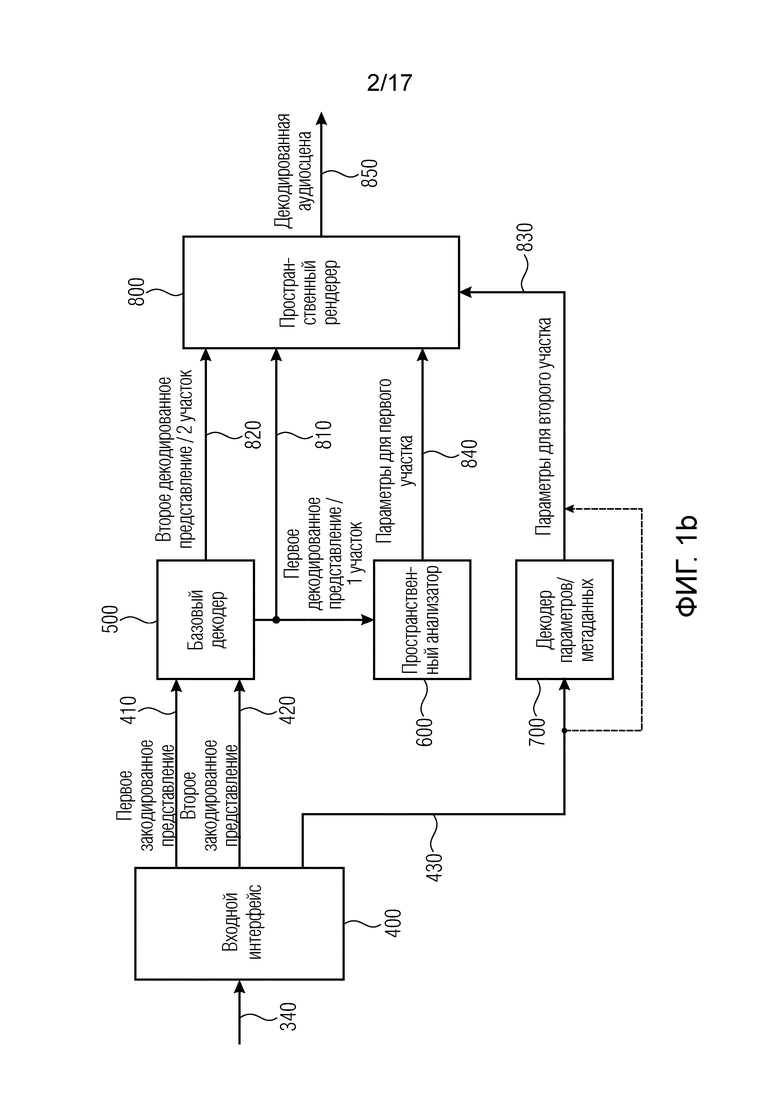
Фиг. 1b иллюстрирует декодер аудиосцены, содержащий входной интерфейс 400 для приема закодированного сигнала 340 аудиосцены. Этот закодированный сигнал аудиосцены содержит первое закодированное представление 410, второе закодированное представление 420 и один или более пространственных параметров для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов, проиллюстрированных номером 430. Закодированное представление второго фрагмента может являться закодированным одним аудиоканалом или может содержать два или более закодированных аудиоканала, в то время как первое закодированное представление первого фрагмента содержит по меньшей мере два разных закодированных аудиосигнала. Разные закодированные аудиосигналы в первом закодированном представлении или (при наличии) во втором закодированном представлении могут являться совместно закодированными сигналами, например, совместно закодированными стереосигналами, или, в качестве альтернативы и даже предпочтительно, отдельно закодированными моно аудиосигналами.
Закодированное представление, содержащее первое закодированное представление 410 для первого фрагмента и второе закодированного представление 420 для второго фрагмента, вводится в базовый декодер для декодирования первого закодированного представления и второго закодированного представления, чтобы получить декодированное представление по меньшей мере двух компонентных сигналов, представляющих аудиосцену. Декодированное представление содержит первое декодированное представление для первого фрагмента, обозначенное номером 810, и второе декодированное представление для второго фрагмента, обозначенное номером 820. Первое декодированное представление передается пространственному анализатору 600 для анализа фрагмента декодированного представления, соответствующего первому фрагменту упомянутых по меньшей мере двух компонентных сигналов, чтобы получить один или более пространственных параметров 840 для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов. Декодер аудиосцены также содержит пространственный рендерер 800 для выполнения пространственного рендеринга декодированного представления, которое содержит в представленном на фиг. 1b варианте осуществления первое декодированное представление для первого фрагмента 810 и второе декодированное представление для второго фрагмента 820. Пространственный рендерер 800 выполнен с возможностью использовать в целях рендеринга аудиоинформации для первого фрагмента параметры 840, полученные от пространственного анализатора, и для второго фрагмента параметры 830, которые получены из закодированных параметров через декодер 700 параметров/метаданных. В случае представления параметров в закодированном сигнале в незакодированной форме декодер 700 параметров/метаданных не нужен, и один или более пространственных параметров для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов непосредственно передаются от входного интерфейса 400 после демультиплексирования или некоторой операции обработки пространственному рендереру 800 в качестве данных 830.
Фиг. 6a иллюстрирует схематическое представление разных обычно накладывающихся временных кадров F1, ..., F4. Базовый кодер 100 на фиг. 1a может быть выполнен с возможностью формировать такие последовательные временные кадры по меньшей мере из двух компонентных сигналов. В такой ситуации первый временной кадр может являться первым фрагментом, и второй временной кадр может являться вторым фрагментом. Таким образом, в соответствии с вариантом осуществления изобретения первый фрагмент может представлять собой первый временной кадром, и второй фрагмент может представлять собой другой временной кадр, и в течение времени может выполняться переключение между первым и вторым фрагментами. Хотя фиг. 6a иллюстрирует накладывающиеся временные кадры, также могут использоваться не накладывающиеся временные кадры. Хотя фиг. 6a иллюстрирует временные кадры, имеющие равные длины, переключение может быть выполнено с временными кадрами, которые имеют разные длины. Таким образом, когда, например, временной кадр F2 меньше, чем временной кадр F1, тогда это приведет к увеличенному временному разрешению для второго временного кадра F2 относительно первого временного кадра F1. Тогда второй временной кадр F2 с увеличенным разрешением предпочтительно соответствует первому фрагменту, который закодирован относительно своих компонентов, в то время как первый временной фрагмент, т.е. данные с низким разрешением, соответствует второму фрагменту, который закодирован с низким разрешением, но пространственные параметры для второго фрагмента будут вычислены с любым необходимым разрешением, поскольку вся аудиосцена целиком доступна в кодере.
Фиг. 6b иллюстрирует альтернативную реализацию, в которой спектр по меньшей мере двух компонентных сигналов проиллюстрирован как имеющий определенное количество частотных полос B1, B2, …, B6, …. Предпочтительно частотные полосы разделены частотных полосах с помощью других частотных полос, которые увеличиваются от наиболее низкой до наиболее высокой центральных частот, чтобы они имели мотивированное по восприятию разделение спектра на полосы. Например, первый фрагмент упомянутых по меньшей мере двух компонентных сигналов может состоять из первых четырех частотных полос, второй фрагмент может состоять из частотных полос B5 и частотных полос B6. Это соответствует ситуации, в которой базовый кодер выполняет репликацию спектральной полосы, и в которой частота разделения между закодированным без параметров низкочастотным фрагментом и закодированным с параметрами высокочастотным фрагментом является границей между частотной полосой B4 и частотной полосой B5.
В качестве альтернативы, в случае интеллектуального заполнения промежутков (IGF) или заполнения шумом (NF) частотные полосы произвольным образом выбираются согласно анализу сигнала, и, таким образом, например, первый фрагмент может состоять из частотных полос B1, B2, B4, B6, и второй фрагмент может представлять собой частотные полосы B3, B5 и, возможно, другие более высокочастотные полосы. Таким образом, может быть выполнено очень гибкое разделение аудиосигнала на частотные полосы, независимо от того, являются ли частотные полосы, как предпочтено и проиллюстрировано на фиг. 6b, обычными полосами масштабных коэффициентов с увеличением от наиболее низких до наиболее высоких частот, или имеют ли частотные полосы одинаковые размеры. Границы между первым фрагментом и вторым фрагментом не обязательно должны совпадать с полосами масштабных коэффициентов, которые обычно используются базовым кодером, но предпочтительно иметь совпадение между границей между первым фрагментом и вторым фрагментом и границей между полосой масштабных коэффициентов и смежной полосой масштабных коэффициентов.
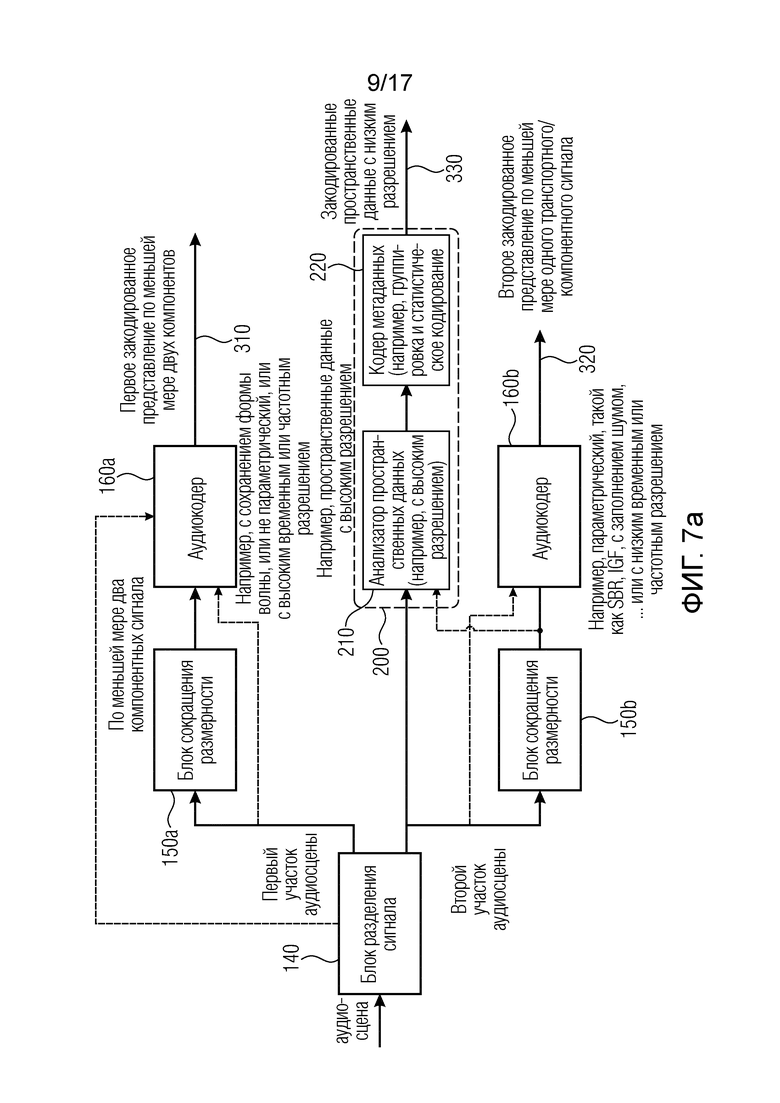
Фиг. 7a иллюстрирует предпочтительную реализацию кодера аудиосцены. В частности, аудиосцена вводится в блок 140 разделения сигнала, который предпочтительно является частью базового кодера 100, показанного на фиг. 1a. Базовый кодер 100 на фиг. 1a блок 150a и 150b сокращения размерности для обоих фрагментов, т.е. для первого фрагмента аудиосцены и второго фрагмента аудиосцены. На выходе блока 150a сокращения размерности имеются по меньшей мере два компонентных сигнала, которые затем кодируются в аудиокодере 160a для первого фрагмента. Блок 150b сокращения размерности для второго фрагмента аудиосцены может содержать такое же созвездие, как блок 150a сокращения размерности. Однако в качестве альтернативы сокращенная размерность, полученная блоком 150b сокращения размерности, может представлять собой единственный транспортный канал, который затем кодируется аудиокодером 160b для получения второго закодированного представления 320 по меньшей мере одного транспортного/компонентного сигнала.
Аудиокодер 160a для первого закодированного представления может содержать кодер с сохранением формы волны, или непараметрический, или с высоким временным или частотным разрешением, в то время как аудиокодер 160b может представлять собой параметрический кодер, такой как кодер SBR, кодер IGF, кодер с заполнением шумом или любой кодер с низким временным или частотным разрешением. Таким образом, аудиокодер 160b будет обычно приводить к более низкокачественному выходному представлению по сравнению с аудиокодером 160a. Этот "недостаток" устраняется посредством выполнения пространственного анализа через анализатор 210 пространственных данных первоначальной аудиосцены или, в качестве альтернативы, аудиосцены с сокращенной размерностью, когда аудиосцена с сокращенной размерностью все еще содержит по меньшей мере два компонентных сигнала. Пространственные данные, полученные анализатором 210 пространственных данных, затем передаются кодеру 220 метаданных, который выдает закодированные пространственные данные с низким разрешением. Оба блока 210, 220 предпочтительно включены в блок 200 пространственного анализатора на фиг. 1a.
Предпочтительно анализатор пространственных данных выполняет анализ пространственных данных с высоким разрешением, таких как данные с высоким частотным разрешением или с высоким временным разрешением, и, чтобы поддерживать необходимую битовую скорость для закодированных метаданных в разумном диапазоне, пространственные данные с высоким разрешением предпочтительно сгруппированы и энтропийно закодированы кодером метаданных, чтобы иметь закодированные пространственные данные с низким разрешением. Например, когда анализ пространственных данных выполняется для восьми временных слотов на кадр и десяти частотных полос на временной слот, возможно сгруппировать пространственные данные в единственный пространственный параметр на каждый кадр и, например, пять частотных полос на каждый параметр.
Предпочтительно вычислять данные направленности, с одной стороны, и данные рассеянности, с другой стороны. Кодер 220 метаданных тогда может быть выполнен с возможностью выдавать закодированные данные с разным временным/частотным разрешением для данных направленности и данных рассеянности. Обычно данные направленности требуются с более высоким разрешением, чем данные рассеянности. Предпочтительный метод вычисления параметрических данных с разными разрешениями состоит в том, чтобы выполнить пространственный анализ с высоким разрешением и обычно с равным разрешением для обоих параметрических видов и затем выполнять группировку по времени и/или частоте с разной параметрической информацией для разных видов параметров по-разному, чтобы затем иметь выходные закодированные пространственные данные 330 с низким разрешением, которые имеют, например, среднее разрешение по времени и/или частоте для данных направленности и низкое разрешение для данных рассеянности.
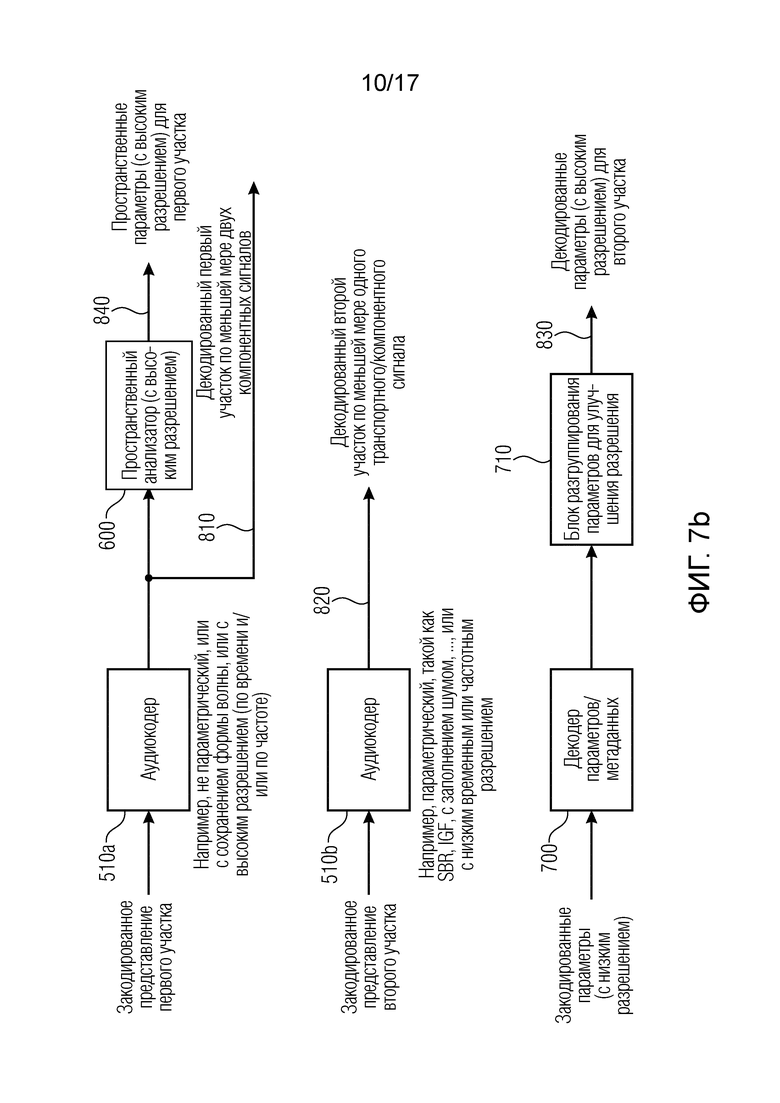
Фиг. 7b иллюстрирует соответствующую реализацию стороны декодера аудиосцены на стороне декодера.
Базовый декодер 500, показанный на фиг. 1b, в варианте осуществления, показанном на фиг. 7b, содержит первый экземпляр 510a аудиодекодера и второй экземпляр 510b аудиодекодера. Предпочтительно первый экземпляр 510a аудиодекодера является непараметрическим, или с сохранением формы волны, или с высоким разрешением (по времени и/или частоте), который формирует на выходе декодированный первый фрагмент упомянутых по меньшей мере двух компонентных сигналов. Эти данные 810, с одной стороны, передаются пространственному рендереру 800, показанному на фиг. 1b, и дополнительно вводятся в пространственный анализатор 600. Предпочтительно пространственный анализатор 600 является пространственным анализатором с высоким разрешением, который вычисляет предпочтительно пространственные параметры с высоким разрешением для первого фрагмента. Обычно разрешение пространственных параметров для первого фрагмента выше, чем разрешение, которое имеет отношение к закодированным параметрам, которые вводятся в декодер 700 параметров/метаданных. Однако выходные данные энтропийно декодированных пространственных параметров с низким временным или частотным разрешением посредством блока 700 вводятся в блок разгруппировки параметров для повышения 710 разрешения. Такая разгруппировка параметров может быть выполнена посредством копирования переданного параметра в некоторые частотно-временные секции, причем разгруппировка выполняется согласно соответствующей группировке, выполненной в кодере 220 метаданных стороны кодера на фиг. 7a. Естественно, вместе с разгруппировкой по мере необходимости могут быть выполнены последующая обработка или операции сглаживания.
Тогда результатом блока 710 является коллекция декодированных параметров предпочтительно с высоким разрешением для второго фрагмента, которые обычно имеют такое же разрешение, как параметры 840 для первого фрагмента. Кроме того, закодированное представление второго фрагмента декодируется аудиодекодером 510b для получения декодированного второго фрагмента 820 обычно по меньшей мере одного сигнала, имеющего по меньшей мере два компонента.
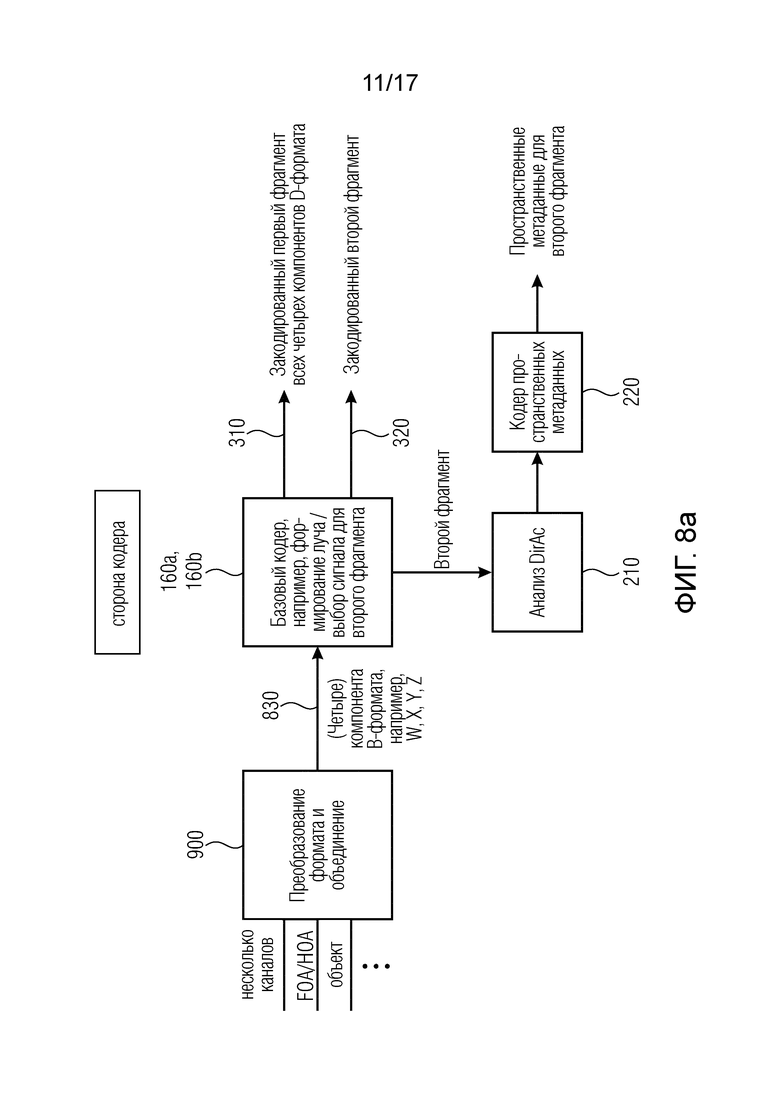
Фиг. 8a иллюстрирует предпочтительную реализация кодера, полагающегося на функциональные возможности, обсуждавшиеся относительно фиг. 3. В частности, многоканальные входные данные, или входные данные амбиофонии первого порядка или амбиофонии высшего порядка, или данные объектов вводятся в конвертер B-формата, который преобразовывает и комбинирует отдельные входные данные, чтобы сформировать, например, обычно четыре компонента B-формата, такие как всенаправленный аудиосигнал и три направленных аудиосигнала X, Y и Z.
В качестве альтернативы сигнал, введенный в преобразователь форматов или базовый кодер, может являться сигналом, захваченным всенаправленным микрофоном, помещенным в первый фрагмент, и другой сигнал, захваченный всенаправленным микрофоном, помещенным во второй фрагмент, отличающийся от первого фрагмента. Снова в качестве альтернативы, аудиосцена содержит в качестве первого компонентного сигнала сигнал, захваченный направленным микрофоном, который направлен в первом направлении, и в качестве второго компонента по меньшей мере один сигнал, захваченный другим направленным микрофоном, который направлен во втором направлении, отличающемся от первого направления. Эти “направленные микрофоны” не обязательно должны представлять собой реальные микрофоны, но также могут являться виртуальными микрофонами.
Аудиовход в блок 900, или выход из блоком 900, или обычно используемый в качестве аудиосцены может содержать компонентные сигналы A-формата, компонентные сигналы B-формата, компонентные сигналы амбиофонии первого порядка, компонентные сигналы амбиофонии высшего порядка или компонентные сигналы, захваченные микрофонным массивом, по меньшей мере с двумя микрофонными капсюлями, или компонентные сигналы, вычисленными на основе виртуальной обработки микрофонов.
Выходной интерфейс 300, показанный на фиг. 1a, выполнен с возможностью не включать в закодированный сигнал аудиосцены какие-либо пространственные параметры такого же вида параметров, как один или более пространственных параметров, сформированных пространственным анализатором для второго фрагмента, в закодированный сигнал аудиосцены.
Таким образом, когда параметры 330 для второго фрагмента являются данными направления прибытия и данными рассеянности, первое закодированное представление для первого фрагмента не будет содержать данных направления прибытия и данные рассеянности, но безусловно может содержать любые другие параметры, которые были вычислены базовым кодером, например, масштабные коэффициенты, коэффициенты LPC и т.д.
Кроме того, разделение частотной полосы, выполненное блоком 140 разделения сигнала, когда разные фрагменты представляют собой разные частотные полосы, может быть реализовано таким образом, что начальная частотная полоса для второго фрагмента ниже, чем начальная частотная полоса с расширением частотной полосы, и, дополнительно, базовое заполнение шумом не обязательно должно применять какую-либо фиксированную частотную полосу разделения, но она может использоваться постепенно для большего количества частей базовых спектров по мере увеличения частоты.
Кроме того, параметрическая или в основном параметрическая обработка для второй частотной подполосы временного кадра содержит вычисление связанного с амплитудой параметра для второй частотной полосы и квантование и энтропийное кодирование этого связанного с амплитудой параметра вместо отдельных спектральных линий во второй частотной подполосе. Такой связанный с амплитудой, параметр, формирующий представление с низким разрешением второго фрагмента, например, задан посредством представления огибающей спектра, имеющего только один масштабный коэффициент или значение энергии для каждой полосы масштабных коэффициентов, в то время как первый фрагмент с высоким разрешением полагается на отдельное преобразование MDCT или FFT или общие отдельные спектральные линии.
Таким образом, первый фрагмент упомянутых по меньшей мере двух компонентных сигналов задан посредством некоторой частотной полосы для каждого компонентного сигнала, и некоторая частотная полоса для каждого компонентного сигнала закодирована со многими спектральными линиями, чтобы получить закодированное представление первого фрагмента. Однако, что касается второго фрагмента, связанная с амплитудой мера, такая как сумма отдельных спектральных линий для второго фрагмента, или сумма квадратов спектральных линий, представляющих энергию во втором фрагменте, или сумма спектральных линий, возведенных в третью степень, представляющих меры громкости для спектрального фрагмента, могут также использоваться для параметрически закодированного представления второго фрагмента.
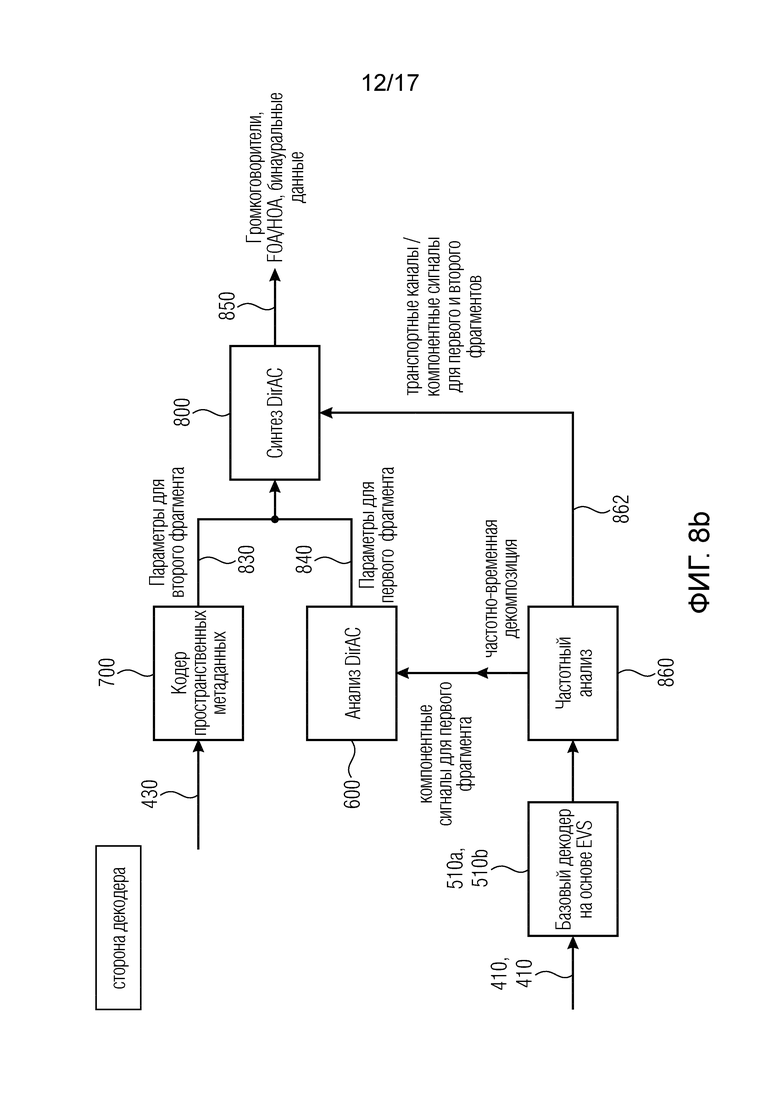
Снова согласно фиг. 8a, базовый кодер 160, содержащий отдельные ветви 160a, 160b базового кодера, может содержать процедуру формирования диаграммы направленности/выбора сигнала для второго фрагмента. Таким образом базовый кодер, обозначенный номерами 160a, 160b на фиг. 8b, выдает, с одной стороны, закодированный первый фрагмент всех четырех компонентов B-формата и закодированный второй фрагмент одного транспортного канала и пространственные метаданные для второго фрагмента, которые были сформированы посредством анализа 210 DirAC, полагающегося на второй фрагмент, и последовательно присоединенного кодера 220 пространственных метаданных.
На стороне декодера закодированные пространственные метаданные вводятся в декодер 700 пространственных метаданных, чтобы сформировать параметры для второго фрагмента, проиллюстрированного номером 830. Базовый декодер, который является предпочтительным вариантом осуществления, обычно реализованным как базовый декодер на основе EVS, состоящим из элементов 510a, 510b, выдает декодированное представление, состоящее из обоих фрагментов, причем, однако, оба фрагмента еще не разделены. Декодированное представление вводится в блок 860 частотного анализа, и частотный анализатор 860 формирует компонентные сигналы для первого фрагмента и передает их анализатору 600 DirAC, чтобы формировать параметры 840 для первого фрагмента. Сигналы транспортного канала/компонентные сигналы для первого и вторых фрагментов передаются от частотного анализатора 860 синтезатору 800 DirAC. Таким образом, синтезатор DirAC в варианте осуществления работает как обычно, поскольку синтезатор DirAC ничего не знает и фактически не требует никакого специального знания о том, были ли параметры для первого фрагмента и второго фрагмента выявлены на стороне кодера или на стороне декодера. Напротив, оба параметра являются “одинаковыми” для синтезатора 800 DirAC, и тогда синтезатор DirAC может сформировать на основе частотного представления декодированного представления по меньшей мере двух компонентных сигналов, представляющих аудиосцену, обозначенных номером 862, и параметров для обоих фрагментов выходные данные громкоговорителя, амбиофонии первого порядка (FOA), амбиофонии высшего порядка (HOA) или бинауральные выходные данные.
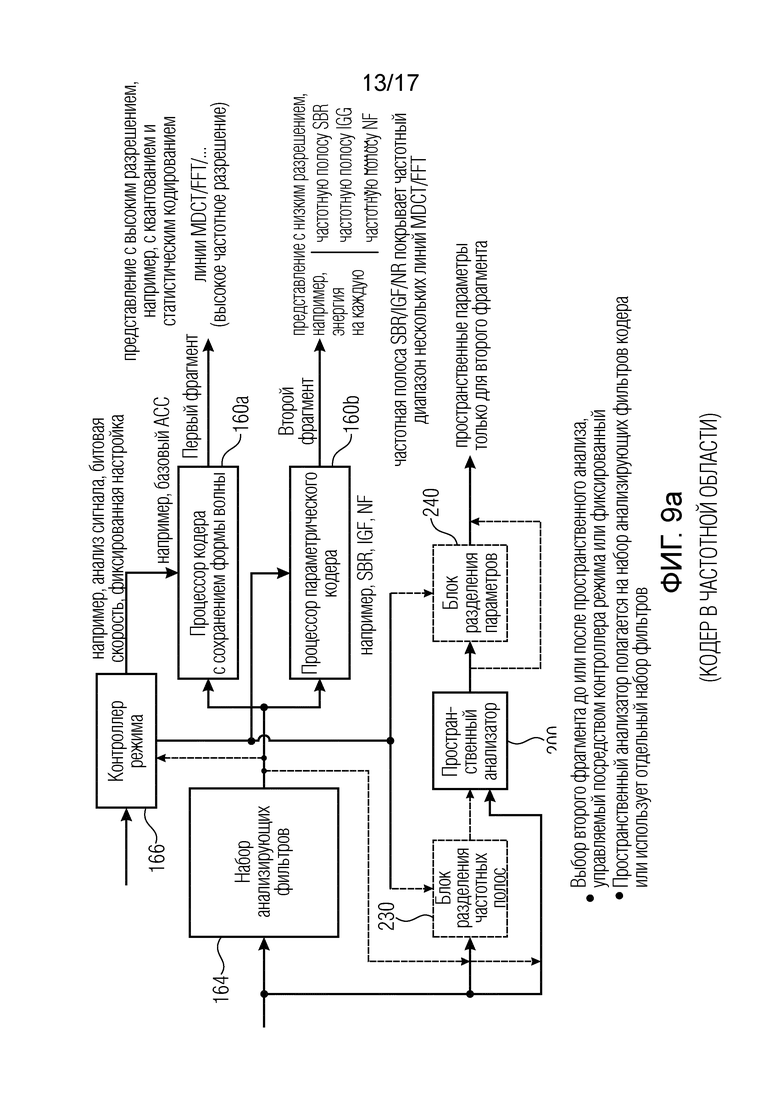
Фиг. 9a иллюстрирует другой предпочтительный вариант осуществления кодера аудиосцены, в котором базовый кодер 100, показанный на фиг. 1a реализован как кодер в частотной области. В этой реализации сигнал, который будет закодирован базовым кодером, вводится в набор 164 анализирующих фильтров, предпочтительно применяющих временное-спектральное преобразование или декомпозицию с обычно накладывающимися временными кадрами. Базовый кодер содержит процессор 160a кодера, обеспечивающий сохранность формы волны, и процессор 160b параметрического кодера. Распределением спектральных фрагментов на первый фрагмент и второй фрагмент управляет контроллер 166 режима. Контроллер 166 режима может полагаться на анализ сигнала, управление битовой скоростью, или может применять фиксированные настройки. Обычно кодер аудиосцены может быть выполнен с возможностью работать на разных битовых скоростях, причем предварительно определенная граничная частота между первым фрагментом и вторым фрагментом зависит от выбранной битовой скорости, и причем предварительно определенная граничная частота меньше для меньшей битовой скорости или больше для большей битовой скорости.
В качестве альтернативы контроллер режима может содержать обработку маски тональности, известную из интеллектуального заполнения промежутков, которое анализирует спектр входного сигнала, чтобы определить частотные полосы, которые должны быть закодированы с высоким спектральным разрешением, которые попадают в закодированный первый фрагмент, и определить частотные полосы, которые могут быть закодированы параметрическим способом, которые попадают во второй фрагмент. Контроллер 166 режима также выполнен с возможностью управлять пространственным анализатором 200 на стороне кодера и предпочтительно управлять блоком 230 разделения частотных полос пространственного анализатора или блоком 240 разделения параметров пространственного анализатора. Это гарантирует, что в финале пространственные параметры формируются и выдаются в закодированный сигнал сцены только для второго фрагмента, но не для первого фрагмента.
В частности, когда пространственный анализатор 200 непосредственно принимает сигнал аудиосцены, либо перед его вводом в набор анализирующих фильтров, либо после его ввода в набор фильтров, пространственный анализатор 200 вычисляет полный анализ по первому и второму фрагменту, и затем блок 240 разделения параметров выбирает для вывода в закодированный сигнал сцены параметры только для второго фрагмента. В качестве альтернативы, когда пространственный анализатор 200 принимает входные данные от блока разделения частотных полос, тогда блок 230 разделения частотных полос уже передает только второй фрагмент, и тогда блок 240 разделения параметров больше не требуется, поскольку пространственный анализатор 200 так или иначе принимает только второй фрагмент и, таким образом, выдает пространственные данные только для второго фрагмента.
Таким образом, выбор второго фрагмента может быть выполнен до или после пространственного анализа, и предпочтительно им управляет контроллер 166 режима, или также он может быть реализован фиксированным образом. Пространственный анализатор 200 полагается на набор анализирующих фильтров кодера или использует свой собственный отдельный набор фильтров, который не проиллюстрирован на фиг. 9a, но это проиллюстрировано, например, на фиг. 5a для реализации этапа анализа DirAC, обозначенного номером 1000.
Фиг. 9b иллюстрирует кодер во временной области в отличие от кодера в частотной области на фиг. 9a. Вместо набора 164 анализирующих фильтров обеспечен блок 168 разделения частотных полос, который либо управляется контроллером 166 режима, показанным на фиг. 9a (не проиллюстрирован на фиг. 9b), либо является фиксированным. В случае управления управление может выполняться на основе битовой скорости, анализа сигнала или любой другой процедуры, полезной для этой цели. Обычно M компонентов, которые вводятся в блок 168 разделения частотных полос, обрабатываются, с одной стороны, посредством кодера 160a низкочастотных полос во временной области и, с другой стороны, посредством калькулятора 160b параметров расширения частотной полосы во временной области. Предпочтительно кодер 160a низкочастотных полос во временной области выдает первое закодированное представление с M отдельными компонентами в закодированной форме. В отличие от этого второе закодированное представление, сформированное калькулятором 160b параметров расширения частотной полосы во временной области, имеет только N компонентных/транспортных сигналов, где N меньше M, и где N больше или равно 1.
В зависимости от того, полагается ли пространственный анализатор 200 на блок 168 разделения частотных полос базового кодера, отдельный блок 230 разделения частотных полос не требуется. Однако, когда пространственный анализатор 200 полагается на блок 230 разделения частотных полос, тогда соединение между блоком 168 и блоком 200 на фиг. 9b не является необходимым. В случае, если ни один из блоков 168 разделения или 230 частотных полос не находится на входе пространственного анализатора 200, пространственный анализатор выполняет полный анализ частотных полос, и затем блок 240 разделения параметров отделяет только пространственные параметры для второго фрагмента, которые затем передаются выходному интерфейсу или закодированной аудиосцене.
Таким образом, в то время как фиг. 9a иллюстрирует процессор 160a кодера, сохраняющего форму волны или спектральный кодер для квантования и энтропийного кодирования, соответствующий блок 160a на фиг. 9b представляет собой любой кодер во временной области, такой как кодер EVS, кодер ACELP, кодер AMR или подобный кодер. В то время как блок 160b иллюстрирует параметрический кодер в частотной области или общий параметрический кодер, блок 160b на фиг. 9b представляет собой калькулятор параметров расширения частотной полосы во временной области, который может в основном вычислять такие же параметры, как блок 160, или другие параметры в зависимости от обстоятельств.
Фиг. 10a иллюстрирует декодер в частотной области, обычно соответствующий кодеру в частотной области, показанному на фиг. 9a. Спектральный декодер, принимающий закодированный первый фрагмент, содержит, как иллюстрировано на 160a, энтропийный декодер, блок обратного квантования и любые другие элементы, которые известные из кодирования AAC или любого другого кодирования в спектральной области. Параметрический декодер 160b, который принимает параметрические данные, такие как энергия на частотную полосу, в качестве второго закодированного представления для второго фрагмента, обычно работает как декодер SBR, декодер IGF, декодер заполнения шумом или другие параметрические декодеры. Оба фрагмента, т.е. спектральные значения первого фрагмента и спектральные значения второго фрагмента вводятся в набор синтезирующих фильтров 169, чтобы получить декодированное представление, то есть обычно передаваемое пространственному рендереру в целях пространственного рендеринга декодированного представления.
Первый фрагмент может быть непосредственно передан пространственному анализатору 600, или первый фрагмент может быть получен из декодированного представления на выходе набора 159 синтезирующих фильтров через блок 630 разделения частотных полос. В зависимости от ситуации блок 640 разделения параметров требуется или нет. В случае, когда пространственный анализатор 600 принимает только первый фрагмента, блок 630 разделения частотных полос и блок 640 разделения параметров не требуются. В случае, когда пространственный анализатор 600 принимает декодированное представление и нет блока разделения частотных полос, блок 640 разделения параметров требуется. В случае, когда декодированное представление вводится в блок 630 разделения частотных полос, пространственный анализатор не обязательно должен иметь блок 640 разделения параметров, поскольку пространственный анализатор 600 выдает пространственные параметры только для первого фрагмента.
Фиг. 10b иллюстрирует декодер во временной области, который соответствует кодеру во временной области, показанному на фиг. 9b. В частности, первое закодированное представление 410 вводится в декодер 160a низкочастотных полос во временной области, и декодированный первый фрагмент вводится в блок 167 объединения. Параметры 420 расширения частотной полосы вводятся в процессор расширения частотной полосы во временной области, который выдает второй фрагмент. Второй фрагмент также вводится в блок 167 объединения. В зависимости от реализации блок объединения может быть реализован для объединения спектральных значений, когда первый и второй фрагменты являются спектральными значениями, или может объединять отсчеты во временной области, когда первый и второй фрагменты уже доступны как отсчеты во временной области. Выходными данными блока 167 объединения является декодированное представление, которое может быть обработано подобно тому, что обсуждалось ранее фиг. 10a, посредством пространственного анализатора 600 с блоком 630 разделения частотных полос или без него, или с блоком 640 разделения параметров или без него, в зависимости от обстоятельств.
Фиг. 11 иллюстрирует предпочтительную реализацию пространственного рендерера, хотя также могут быть применены другие реализации пространственного рендерера, которые используют параметры DirAC или другие параметры, отличающиеся от параметров DirAC, или производят другое представление рендерированного (полученного путем рендеринга) сигнала, отличное от прямого представления громкоговорителя, как представление HOA. Обычно данные 862, вводимые в синтезатор 800 DirAC, могут состоять из нескольких компонентов, таких как B-формат для первого и второго фрагмента, как обозначено в левом верхнем углу на фиг. 11. В качестве альтернативы второй фрагмент не доступен в нескольких компонентах, и имеет только один компонент. Затем ситуация проиллюстрирована в нижней части слева на фиг. 11. В частности, в случае наличия первого и второго фрагмента со всеми компонентами, т.е. когда сигнал 862 на фиг. 8b имеет все компоненты B-формата, например, доступен полный спектр всех компонентов, и частотно-временная декомпозиция позволяет выполнить обработку для каждой отдельной частотно-временной секции. Эта обработка выполняется процессором 870a виртуальных микрофонов для вычисления компонента громкоговорителя из декодированного представления для каждого громкоговорителя из расстановки громкоговорителей.
В качестве альтернативы, когда второй фрагмент доступен только в одном компоненте, тогда частотно-временные секции для первого фрагмента вводятся в процессор 870a виртуальных микрофонов, в то время как частотно-временной фрагмент для одного или менее компонентов второй фрагмент вводится в процессор 870b. Например, процессор 870b должен выполнить только операцию копирования, т.е. скопировать один транспортный канал в выходной сигнал для каждого сигнала громкоговорителя. Таким образом, обработка 870a виртуальных микрофонов первой альтернативы заменена просто операцией копирования.
Затем выходные данные блоков 870a в первом варианте осуществления или 870a для первого фрагмента и 870b для второго фрагмента вводятся в процессор 872 усиления для модификации выходного компонентного сигнала с использованием одного или более пространственных параметров. Данные также вводятся в процессор 874 блока взвешивания/декоррелятора для формирования декоррелированного выходного компонентного сигнала с использованием одного или более пространственных параметров. Выходные данные блока 872 и выходные данные блока 874 объединяются в модуле 876 объединения, работающего для каждого компонента таким образом, что в выходных данных блока 876 получается представление в частотной области каждого сигнала громкоговорителя.
Затем посредством набора 878 синтезирующих фильтров все сигналы громкоговорителей в частотной области могут быть преобразованы в представление во временной области, и сформированные сигналы громкоговорителей во временной области могут быть подвергнуты цифроаналоговому преобразованию и использованы для управления соответствующими громкоговорителями, помещенными в определенные позиции громкоговорителей.
Обычно процессор 872 усиления работает на основе пространственных параметров и предпочтительно параметров направленности, таких как направление прибывающих данных, и факультативно на основе параметров рассеянности. Кроме того, процессор блока взвешивания/декоррелятора работает также на основе пространственных параметров и предпочтительно на основе параметров рассеянности.
Таким образом, в реализации процессор 872 усиления представляет формирование нерассеянного потока, проиллюстрированного номером 1015 на фиг. 5b, и процессор 874 блока взвешивания/декоррелятора представляет формирование рассеянного потока, обозначенного верхней ветвью 1014 на фиг. 5b. Однако также могут быть осуществлены другие реализации, которые полагаются на другие процедуры, другие параметры и другие методы для формирования прямых и рассеянных сигналов.
Иллюстративные преимущества предпочтительных вариантов осуществления над существующим уровнем техники:
- варианты осуществления настоящего изобретения обеспечивают более хорошее частотно-временное разрешение для частей сигнала с пространственными параметрами, оцениваемыми на стороне декодера, по сравнению с системой, использующей оцененные и закодированные на стороне кодера параметры для всего сигнала целиком;
- варианты осуществления настоящего изобретения обеспечивают более хорошие значения пространственных параметров для частей сигнала, воссозданного с использованием анализа на стороне кодера параметров, и кодирования и передачи упомянутых параметров декодеру по сравнению с системой, в которой пространственные параметры оцениваются в декодере с использованием декодированного аудиосигнала с низкой размерностью;
- варианты осуществления настоящего изобретения допускают более гибкий компромисс между частотно-временным разрешением, скоростью передачи и точностью параметра, чем могут обеспечить либо система с использованием закодированных параметров для всего сигнала целиком, либо система с использованием оцененных на стороне декодера параметров для всего сигнала целиком;
- варианты осуществления настоящего изобретения обеспечивают более хорошую точность параметров для фрагментов сигнала, закодированных в основном с использованием инструментов параметрического кодирования, посредством выбора оценки на стороне кодера и кодирования некоторых или всех пространственных параметров для этих фрагментов, и более хорошее частотно-временное разрешение для фрагментов сигнала, закодированных в основном с использованием инструментов кодирования, сохраняющих форму волны, и с использованием оценки на стороне декодера пространственных параметров для этих фрагментов сигнала.
Литература
[1] V. Pulkki, M-V Laitinen, J Vilkamo, J Ahonen, T Lokki and T Pihlajamäki, “Directional audio coding - perception-based reproduction of spatial sound”, International Workshop on the Principles and Application on Spatial Hearing, Nov. 2009, Zao; Miyagi, Japan.
[2] Ville Pulkki. “Virtual source positioning using vector base amplitude panning”. J. Audio Eng. Soc., 45(6):456{466, June 1997.
[3] Европейская патентная заявка № EP17202393.9, "EFFICIENT CODING SCHEMES OF DIRAC METADATA" ("СХЕМЫ ЭФФЕКТИВНОГО КОДИРОВАНИЯ МЕТАДАННЫХ DIRAC").
[4] Европейская патентная заявка № EP17194816.9 "Apparatus, method and computer program for encoding, decoding, scene processing and other procedures related to DirAC based spatial audio coding" ("Устройство, способ и компьютерная программа для кодирования, декодирования, обработки сцены и других процедур, относящихся к пространственному аудиокодированию на основе DirAC").
Закодированный с помощью настоящего изобретения аудиосигнал может быть сохранен на цифровом носителе информации или носителе информации долговременного хранения, или может быть передан по передающему носителю, такому как беспроводной передающий носитель или проводной передающий носитель, такой как Интернет.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где модуль или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом аспекты, описанные в контексте этапа способа, также представляют описание соответствующего модуля, или элемента, или признака соответствующего устройства.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, CD, ПЗУ (ROM), ППЗУ (PROM), СППЗУ (EPROM), ЭСППЗУ (EEPROM) или флэш-памяти, имеющих сохраненные на них читаемые в электронном виде управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий читаемые в электронном виде управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, в результате чего выполняется один из способов, описанных в настоящем документе.
Обычно варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, программный код выполнен с возможностью выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненных на машиночитаемом носителе или носителе информации долговременного хранения.
Другими словами, вариант осуществления способа изобретения, таким образом, представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа исполняется на компьютере.
Дополнительный вариант осуществления способов изобретения, таким образом, представляет собой носитель данных (или цифровой запоминающий носитель, или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления способа изобретения, таким образом, поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов могут, например, быть выполнен с возможностью быть перенесенными сквозное отверстие соединение обмена данными, например, сквозное отверстие Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью выполнять один из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Описанные выше варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Подразумевается, что модификации и вариации размещений и подробностей, описанных в настоящем документе, будут очевидны для других специалистов в области техники. Таким образом, подразумевается, что изобретение ограничено только объемом последующей патентной формулы изобретения, а не конкретными подробностями, представленными посредством описания и разъяснения представленных в настоящем документе вариантов осуществления.

Изобретение относится к средствам для кодирования и декодирования аудиосцены. Технический результат заключается в повышении эффективности кодирования. Для его реализации выполняют базовое кодирование по меньшей мере двух компонентных сигналов. Причем базовое кодирование содержит формирование первого закодированного представления для первого фрагмента по меньшей мере двух компонентных сигналов и формирование второго закодированного представления для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов. Причем базовое кодирование содержит формирование временного кадра из упомянутых по меньшей мере двух компонентных сигналов. Причем первая частотная подполоса временного кадра из упомянутых по меньшей мере двух компонентных сигналов является первым фрагментом, и вторая частотная подполоса временного кадра является вторым фрагментом. Базовое кодирование также содержит формирование первого закодированного представления для первой частотной подполосы и формирование второго закодированного представления для второй частотной подполосы. 6 н. и 32 з.п. ф-лы, 20 ил.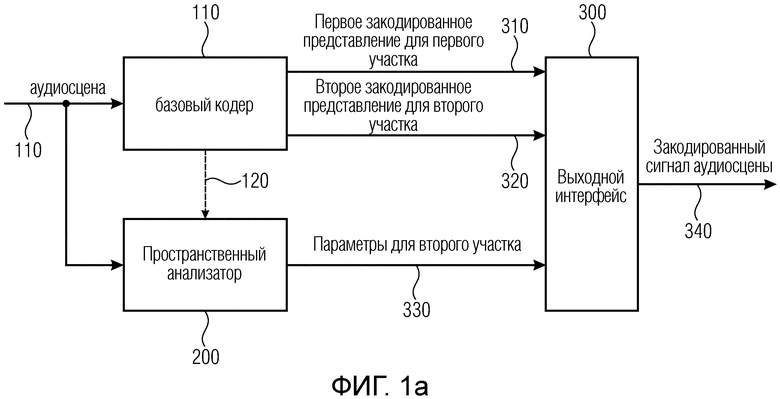
1. Кодер аудиосцены для кодирования аудиосцены (110), причем аудиосцена (110) содержит по меньшей мере два компонентных сигнала, причем кодер аудиосцены содержит:
базовый кодер (160) для базового кодирования упомянутых по меньшей мере двух компонентных сигналов, причем базовый кодер (160) выполнен с возможностью формировать первое закодированное представление (310) для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов и формировать второе закодированное представление (320) для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов,
причем базовый кодер (160) выполнен с возможностью формировать временной кадр из упомянутых по меньшей мере двух компонентных сигналов, причем первая частотная подполоса временного кадра из упомянутых по меньшей мере двух компонентных сигналов является первым фрагментом упомянутых по меньшей мере двух компонентных сигналов, и вторая частотная подполоса временного кадра является вторым фрагментом упомянутых по меньшей мере двух компонентных сигналов, причем первая частотная подполоса отделена от второй частотной подполосы предварительно определенной граничной частотой,
причем базовый кодер (160) выполнен с возможностью формировать первое закодированное представление (310) для первой частотной подполосы, содержащее M компонентных сигналов, и формировать второе закодированное представление (320) для второй частотной подполосы, содержащее N компонентных сигналов, причем M больше N, и причем N больше или равно 1;
пространственный анализатор (200) для анализа аудиосцены (110), содержащей упомянутые по меньшей мере два компонентных сигнала, для выявления одного или более пространственных параметров (330) или одного или более множеств пространственных параметров для второй частотной подполосы; и
выходной интерфейс (300) для формирования закодированного сигнала (340) аудиосцены, причем закодированный сигнал (340) аудиосцены содержит первое закодированное представление для первой частотной подполосы, содержащее M компонентных сигналов, второе закодированное представление (320) для второй частотной подполосы, содержащее N компонентных сигналов, и один или более пространственных параметров (330) или одно или более множеств пространственных параметров для второй частотной подполосы.
2. Кодер аудиосцены по п. 1,
в котором базовый кодер (160) выполнен с возможностью формировать первое закодированное представление (310) с первым частотным разрешением и формировать второе закодированное представление (320) со вторым частотным разрешением, причем второе частотное разрешение ниже, чем первое частотное разрешение, или
в котором граничная частота между первой частотной подполосой временного кадра и второй частотной подполосой временного кадра совпадает с границей между полосой масштабных коэффициентов и смежной полосой масштабных коэффициентов или не совпадает с границей между полосой масштабных коэффициентов и смежной полосой масштабных коэффициентов, причем полоса масштабных коэффициентов и смежная полоса масштабных коэффициентов используются базовым кодером (160).
3. Кодер аудиосцены по п. 1,
в котором аудиосцена (110) содержит в качестве первого компонентного сигнала всенаправленный аудиосигнал и в качестве второго компонентного сигнала по меньшей мере один направленный аудиосигнал, или
в котором аудиосцена (110) содержит в качестве первого компонентного сигнала сигнал, захваченный всенаправленным микрофоном, помещенным в первую позицию, и в качестве второго компонентного сигнала по меньшей мере один сигнал, захваченный всенаправленным микрофоном, помещенным во вторую позицию, отличающуюся от первой позиции, или
в котором аудиосцена (110) содержит в качестве первого компонентного сигнала по меньшей мере один сигнал, захваченный направленным микрофоном, направленным в первом направлении, и в качестве второго компонентного сигнала по меньшей мере один сигнал, захваченный направленным микрофоном, направленным во втором направлении, причем второе направление отличается от первого направления.
4. Кодер аудиосцены по п. 1,
в котором аудиосцена (110) содержит компонентные сигналы A-формата, компонентные сигналы B-формата, компонентные сигналы амбиофонии первого порядка, компонентные сигналы амбиофонии высшего порядка или компонентные сигналы, захваченные микрофонным массивом по меньшей мере с двумя микрофонными капсюлями или определенные посредством вычисления виртуальных микрофонов из раннее записанной или синтезированной звуковой сцены.
5. Кодер аудиосцены по п. 1,
в котором выходной интерфейс (300) выполнен с возможностью не включать в закодированный сигнал (340) аудиосцены какие-либо пространственные параметры такого же вида параметров, как один или более пространственных параметров (330), сформированных пространственным анализатором (200) для второй частотной подполосы, чтобы только вторая частотная подполоса имела такой вид параметров и любые параметры такого вида параметров не включались в закодированный сигнал (340) аудиосцены для первой частотной подполосы.
6. Кодер аудиосцены по п. 1,
в котором базовый кодер (160) выполнен с возможностью выполнять операцию (160b) параметрического кодирования для второй частотной подполосы и выполнять операцию (160a) кодирования с сохранением формы волны для первой частотной подполосы, или
в котором начальная частотная полоса для второй частотной подполосы ниже, чем начальная частотная полоса с расширением частотной полосы, и в котором базовая операция заполнения шумом, выполняемая базовым кодером (100), не имеет какой-либо фиксированной частотной полосы разделения и используется постепенно для большего количества частей базовых спектров по мере увеличения частоты.
7. Кодер аудиосцены по п. 1,
в котором базовый кодер (160) выполнен с возможностью выполнять параметрическую обработку (160b) для второй частотной подполосы временного кадра, причем параметрическая обработка (160b) включает в себя вычисление связанного с амплитудой параметра для второй частотной подполосы и квантование и энтропийное кодирование связанного с амплитудой параметра вместо отдельных спектральных линий во второй частотной подполосе, и в котором базовый кодер (160) выполнен с возможностью выполнять квантование и энтропийное кодирование (160a) отдельных спектральных линий в первой частотной подполосе временного кадра, или
в котором базовый кодер (160) выполнен с возможностью выполнять параметрическую обработку (160b) для высокочастотной подполосы временного кадра, соответствующей второй частотной подполосе по меньшей мере двух компонентных сигналов, причем параметрическая обработка содержит вычисление связанного с амплитудой параметра для высокочастотной подполосы и квантование и энтропийное кодирование связанного с амплитудой параметра вместо сигнала во временной области в высокочастотной подполосе, и в котором базовый кодер (160) выполнен с возможностью выполнять квантование и энтропийное кодирование (160b) аудиосигнала во временной области в низкочастотной подполосе временного кадра, соответствующей первой частотной полосе по меньшей мере двух компонентных сигналов, посредством операции кодирования во временной области, такой как кодирование LPC, кодирование LPC/TCX, или кодирование EVS, или кодирование AMR Wideband (широкополосное кодирование AMR), или кодирование AMR Wideband+.
8. Кодер аудиосцены по п. 7,
в котором параметрическая обработка (160b) содержит обработку репликации спектральной полосы (SBR) и обработку интеллектуального заполнения промежутков (IGF) или обработку заполнения шумом.
9. Кодер аудиосцены по п. 1,
в котором базовый кодер (160) содержит блок (150a) сокращения размерности для сокращения размерности аудиосцены (110), чтобы получить аудиосцену с низкой размерностью, в котором базовый кодер (160) выполнен с возможностью вычислять первое закодированное представление (310) для первой частотной подполосы по меньшей мере двух компонентных сигналов из аудиосцены с низкой размерностью, и в котором пространственный анализатор (200) выполнен с возможностью выявлять пространственные параметры (330) из аудиосцены (110), имеющей размерность, которая выше, чем размерность аудиосцены с низкой размерностью.
10. Кодер аудиосцены по п. 1, выполненный с возможностью работать на разных битовых скоростях, причем предварительно определенная граничная частота между первой частотной подполосой и второй частотной подполосой зависит от выбранной битовой скорости, и причем предварительно определенная граничная частота ниже для более низкой битовой скорости, или причем предварительно определенная граничная частота больше для большей битовой скорости.
11. Кодер аудиосцены по п. 1,
в котором пространственный анализатор (200) выполнен с возможностью вычислять для второй частотной подполосы в качестве одного или более пространственных параметров (330) по меньшей мере один параметр из направленного параметра и ненаправленного параметра, такого как параметр рассеянности.
12. Кодер аудиосцены по п. 1, в котором базовый кодер (160) содержит:
частотно-временной конвертер (164) для преобразования последовательностей временных кадров, содержащих временной кадр по меньшей мере двух компонентных сигналов в последовательности спектральных кадров для по меньшей мере двух компонентных сигналов,
спектральный кодер (160a) для квантования и энтропийного кодирования спектральных значений кадра из последовательностей спектральных кадров в первой частотной подполосе спектрального кадра, соответствующего первой частотной подполосе; и
параметрический кодер (160b) для параметрического кодирования спектральных значений спектрального кадра во второй частотной подполосе спектрального кадра, соответствующего второй частотной подполосе, или
в котором базовый кодер (160) содержит базовый кодер во временной области или в смешанной частотно-временной области для выполнения операции кодирования во временной области или в смешанной частотно-временной области фрагмента низкочастотной полосы временного кадра, причем фрагмент низкочастотной полосы соответствует первой частотной подполосе, или
в котором пространственный анализатор (200) выполнен с возможностью подразделять вторую частотную подполосу на аналитические частотные полосы, причем ширина аналитической частотной полосы больше или равна ширине частотной полосы, связанной с двумя смежными спектральными значениями, обработанными спектральным кодером в первой частотной подполосе, или меньше ширины частотной полосы фрагмента низкочастотной полосы, представляющего первую частотную подполосу, и в котором пространственный анализатор (200) выполнен с возможностью вычислять по меньшей мере один параметр из параметра направления и параметра рассеянности для каждой аналитической частотной полосы второй частотной подполосы, или
в котором базовый кодер (160) и пространственный анализатор (200) выполнены с возможностью использовать общий набор (164) фильтров или разные наборы (164, 1000) фильтров, имеющие разные характеристики.
13. Кодер аудиосцены по п. 12,
в котором пространственный анализатор (200) выполнен с возможностью использовать для вычисления параметра направления аналитическую частотную полосу, которая меньше аналитической частотной полосы, использованной для вычисления параметра рассеянности.
14. Кодер аудиосцены по п. 1,
в котором базовый кодер (160) содержит многоканальный кодер для формирования закодированного многоканального сигнала для по меньшей мере двух компонентных сигналов, или
в котором базовый кодер (160) содержит многоканальный кодер для формирования двух или более закодированных многоканальных сигналов, когда количество по меньшей мере двух компонентных сигналов равно трем или больше, или
в котором выходной интерфейс (300) выполнен с возможностью не включать в закодированный сигнал (340) аудиосцены какие-либо пространственные параметры (330) для первой частотной подполосы или включать в закодированный сигнал (340) аудиосцены меньшее количество пространственных параметров для первой частотной подполосы по сравнению с количеством пространственных параметров (330) для второй частотной подполосы.
15. Декодер аудиосцены, содержащий:
входной интерфейс (400) для приема закодированного сигнала (340) аудиосцены, содержащего первое закодированное представление (410) первого фрагмента по меньшей мере двух компонентных сигналов, второе закодированное представление (420) второго фрагмента упомянутых по меньшей мере двух компонентных сигналов и один или более пространственных параметров (430) для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов;
базовый декодер (500) для декодирования первого закодированного представления (410) и второго закодированного представления (420) для получения декодированного представления (810, 820) упомянутых по меньшей мере двух компонентных сигналов, представляющего аудиосцену;
пространственный анализатор (600) для анализа фрагмента (810) декодированного представления, соответствующего первому фрагменту упомянутых по меньшей мере двух компонентных сигналов, для выявления одного или более пространственных параметров (840) для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов; и
пространственный рендерер (800) для выполнения пространственного рендеринга декодированного представления (810, 820) с использованием одного или более пространственных параметров (840) для первого фрагмента и одного или более пространственных параметров (830) для второго фрагмента, включенных в закодированный сигнал (340) аудиосцены.
16. Декодер аудиосцены по п. 15, дополнительно содержащий:
декодер (700) пространственных параметров для декодирования одного или более пространственных параметров (430) для второго фрагмента, включенных в закодированный сигнал (340) аудиосцены, и
причем пространственный рендерер (800) выполнен с возможностью использовать декодированное представление одного или более пространственных параметров (830) для выполнения рендеринга второго фрагмента декодированного представления по меньшей мере двух компонентных сигналов.
17. Декодер аудиосцены по п. 15, в котором базовый декодер (500) выполнен с возможностью обеспечивать последовательность декодированных кадров, причем первый фрагмент является первым кадром последовательности декодированных кадров, и второй фрагмент является вторым кадром последовательности декодированных кадров, и в котором базовый декодер (500) дополнительно содержит блок сложения с наложением для сложения с наложением последующих декодированных временных кадров, чтобы получить декодированное представление, или
в котором базовый декодер (500) содержит систему на основе ACELP, работающую без операции сложения с наложением.
18. Декодер аудиосцены по п. 15,
в котором базовый декодер (500) выполнен с возможностью обеспечивать последовательность декодированных временных кадров,
в котором первый фрагмент является первой частотной подполосой временного кадра последовательности декодированных временных кадров, и в котором второй фрагмент является второй частотной подполосой временного кадра последовательности декодированных временных кадров,
в котором пространственный анализатор (600) выполнен с возможностью обеспечивать один или более пространственных параметров (840) для первой частотной подполосы,
в котором пространственный рендерер (800) выполнен с возможностью:
выполнять рендеринг первой частотной подполосы с использованием первой частотной подполосы временного кадра и одного или более пространственных параметров (840) для первой частотной подполосы, и
выполнять рендеринг второй частотной подполосы с использованием второй частотной подполосы временного кадра и одного или более пространственных параметров (830) для второй частотной подполосы.
19. Декодер аудиосцены по п. 18,
в котором пространственный рендерер (800) содержит модуль объединения для объединения первой полученной в результате рендеринга частотной подполосы и второй полученной в результате рендеринга частотной подполосы для получения временного кадра полученного в результате рендеринга сигнала.
20. Декодер аудиосцены по п. 15,
в котором пространственный рендерер (800) выполнен с возможностью обеспечивать полученный в результате рендеринга сигнал для каждого громкоговорителя из расстановки громкоговорителей, или для каждого компонента формата амбиофонии первого порядка или высшего порядка, или для каждого компонента бинаурального формата.
21. Декодер аудиосцены по п. 15, в котором пространственный рендерер (800) содержит:
процессор (870b) для формирования выходного компонентного сигнала из декодированного представления для каждого выходного компонента;
процессор (872) усиления для модификации выходного компонентного сигнала с использованием одного или более пространственных параметров (830, 840); или
процессор (874) блока взвешивания/декоррелятора для формирования декоррелированного выходного компонентного сигнала с использованием одного или более пространственных параметров (830, 840), и
блок (876) объединения для объединения декоррелированного выходного компонентного сигнала и упомянутого выходного компонентного сигнала для получения полученного в результате рендеринга сигнала громкоговорителей, или
в котором пространственный рендерер (800) содержит:
процессор (870a) виртуальных микрофонов для вычисления компонентного сигнала громкоговорителя из декодированного представления для каждого громкоговорителя из расстановки громкоговорителей;
процессор (872) усиления для модификации компонентного сигнала громкоговорителя с использованием одного или более пространственных параметров (830, 840); или
процессор (874) блока взвешивания/декоррелятора для формирования декоррелированного компонентного сигнала громкоговорителя с использованием одного или более пространственных параметров (830, 840), и
блок (876) объединения для объединения декоррелированного компонентного сигнала громкоговорителя и компонентного сигнала громкоговорителя для получения полученного в результате рендеринга сигнала громкоговорителей.
22. Декодер аудиосцены по п. 15, в котором пространственный рендерер (800) выполнен с возможностью работать с учетом частотных полос, причем первый фрагмент является первой частотной подполосой, первая частотная подполоса подразделена на множество первых частотных полос, причем второй фрагмент является второй частотной подполосой, вторая частотная подполоса подразделена на множество вторых частотных полос,
в котором пространственный рендерер (800) выполнен с возможностью выполнять рендеринг выходного компонентного сигнала для каждой первой частотной полосы с использованием соответствующего пространственного параметра, выявленного анализатором, и
в котором пространственный рендерер (800) выполнен с возможностью выполнять рендеринг выходного компонентного сигнала для каждой второй частотной полосы с использованием соответствующего пространственного параметра, включенного в закодированный сигнал (340) аудиосцены, причем вторая частотная полоса из множества вторых частотных полос больше, чем первая частотная полоса из множества первых частотных полос, и
в котором пространственный рендерер (800) выполнен с возможностью объединять (878) выходные компонентные сигналы для первых частотных полос и вторых частотных полос, чтобы получить полученный в результате рендеринга выходной сигнал, причем полученный в результате рендеринга выходной сигнал представляет собой сигнал громкоговорителей, сигнал A-формата, сигнал B-формата, сигнал амбиофонии первого порядка, сигнал амбиофонии высшего порядка или бинауральный сигнал.
23. Декодер аудиосцены по п. 15,
в котором базовый декодер (500) выполнен с возможностью формировать в качестве декодированного представления, представляющего аудиосцену, всенаправленный аудиосигнал как первый компонентный сигнал и по меньшей мере один направленный аудиосигнал как второй компонентный сигнал, или в котором декодированное представление, представляющее аудиосцену, содержит компонентные сигналы B-формата или компонентные сигналы амбиофонии первого порядка или компонентные сигналы амбиофонии высшего порядка.
24. Декодер аудиосцены по п. 15,
в котором закодированный сигнал (340) аудиосцены не включает в себя пространственные параметры для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов, которые имеют такой же вид, как пространственные параметры (430) для второго фрагмента, включенные в закодированный сигнал аудиосцены (340).
25. Декодер аудиосцены по п. 15,
в котором базовый декодер (500) выполнен с возможностью выполнять операцию (510b) параметрического декодирования для второго фрагмента и выполнять операцию (510a) декодирования с сохранением формы волны для первого фрагмента.
26. Декодер аудиосцены по п. 15,
в котором базовый декодер (500) выполнен с возможностью выполнять параметрическую обработку (510b) с использованием связанного с амплитудой параметра для огибающей, регулирующей вторую частотную подполосу, после энтропийного декодирования связанного с амплитудой параметра, и
в котором базовый декодер (500) выполнен с возможностью выполнять энтропийное декодирование (510a) отдельных спектральных линий в первой частотной подполосе.
27. Декодер аудиосцены по п. 15,
в котором базовый декодер (500) содержит обработку репликации спектральной полосы (SBR), обработку интеллектуального заполнения промежутков (IGF) или обработку заполнения шумом для декодирования (510b) второго закодированного представления (420).
28. Декодер аудиосцены по п. 15, в котором первый фрагмент является первой частотной подполосой временного кадра, и второй фрагмент является второй частотной подполосой временного кадра, и в котором базовый декодер (500) выполнен с возможностью использовать предварительно определенную граничную частоту между первой частотной подполосой и второй частотной подполосой.
29. Декодер аудиосцены по п. 15, в котором декодер аудиосцены выполнен с возможностью работать на разных битовых скоростях, причем предварительно определенная граничная частота между первым фрагментом и вторым фрагментом зависит от выбранной битовой скорости, и причем предварительно определенная граничная частота ниже для более низкой битовой скорости, или причем предварительно определенная граничная частота больше для большей битовой скорости.
30. Декодер аудиосцены по п. 15, в котором первый фрагмент является первой частотной подполосой временного фрагмента, и в котором второй фрагмент является второй частотной подполосой временного фрагмента, и
в котором пространственный анализатор (600) выполнен с возможностью вычислять для первой частотной подполосы в качестве одного или более пространственных параметров (840) по меньшей мере один параметр из параметра направления и параметра рассеянности.
31. Декодер аудиосцены по п. 15,
в котором первый фрагмент является первой частотной подполосой временного кадра, и в котором второй фрагмент является второй частотной подполосой временного кадра,
в котором пространственный анализатор (600) выполнен с возможностью подразделять первую частотную подполосу на аналитические частотные полосы, причем ширина аналитической частотной полосы больше или равна ширине частотной полосы, связанной с двумя смежными спектральными значениями, сформированными базовым декодером (500) для первой частотной подполосы, и
в котором пространственный анализатор (600) выполнен с возможностью вычислять по меньшей мере один параметр из параметра направления и параметра рассеянности для каждой аналитической частотной полосы.
32. Декодер аудиосцены по п. 31,
в котором пространственный анализатор (600) выполнен с возможностью использовать для вычисления параметра направления аналитическую частотную полосу, которая меньше, чем аналитическая частотная полоса, используемая для вычисления параметра рассеянности.
33. Декодер аудиосцены по п. 15,
в котором пространственный анализатор (600) выполнен с возможностью использовать для вычисления параметра направления аналитическую частотную полосу, имеющую первую ширину частотной полосы, и
в котором пространственный рендерер (800) выполнен с возможностью использовать пространственный параметр из одного или более пространственных параметров (840) для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов, включенный в закодированный сигнал (340) аудиосцены, для выполнения рендеринга частотной полосы декодированного представления, частотная полоса рендеринга имеет вторую ширину частотной полосы, и
в котором вторая ширина частотной полосы больше, чем первая ширина частотной полосы.
34. Декодер аудиосцены по п. 15,
в котором закодированный сигнал (340) аудиосцены содержит закодированный многоканальный сигнал для по меньшей мере двух компонентных сигналов, или в котором закодированный сигнал (340) аудиосцены содержит по меньшей мере два закодированных многоканальных сигнала для более чем двух компонентных сигналов, и
в котором базовый декодер (500) содержит многоканальный декодер для базового декодирования закодированного многоканального сигнала или по меньшей мере двух закодированных многоканальных сигналов.
35. Способ кодирования аудиосцены (110), причем аудиосцена (110) содержит по меньшей мере два компонентных сигнала, причем способ содержит этапы, на которых:
выполняют базовое кодирование упомянутых по меньшей мере двух компонентных сигналов, причем базовое кодирование содержит формирование первого закодированного представления (310) для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов и формирование второго закодированного представления (320) для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов;
причем базовое кодирование содержит формирование временного кадра из упомянутых по меньшей мере двух компонентных сигналов, причем первая частотная подполоса временного кадра из упомянутых по меньшей мере двух компонентных сигналов является первым фрагментом упомянутых по меньшей мере двух компонентных сигналов, и вторая частотная подполоса временного кадра является вторым фрагментом упомянутых по меньшей мере двух компонентных сигналов, причем первая частотная подполоса отделена от второй частотной подполосы предварительно определенной граничной частотой,
причем базовое кодирование содержит формирование первого закодированного представления (310) для первой частотной подполосы, содержащего M компонентных сигналов, и формирование второго закодированного представления (320) для второй частотной подполосы, содержащего N компонентных сигналов, причем M больше N, и причем N больше или равно 1;
анализируют аудиосцену (110), содержащую упомянутые по меньшей мере два компонентных сигнала, для выявления одного или более пространственных параметров (330) или одного или более множеств пространственных параметров для второй частотной подполосы; и
формируют закодированный сигнал аудиосцены, причем закодированный сигнал (340) аудиосцены содержит первое закодированное представление для первой частотной подполосы, содержащее M компонентных сигналов, второе закодированное представление (320) для второй частотной подполосы, содержащее N компонентных сигналов, и один или более пространственных параметров (330) или одно или более множеств пространственных параметров для второй частотной подполосы.
36. Способ декодирования аудиосцены, содержащий этапы, на которых:
принимают закодированный сигнал (340) аудиосцены, содержащий первое закодированное представление (410) первого фрагмента по меньшей мере двух компонентных сигналов, второе закодированное представление (420) второго фрагмента упомянутых по меньшей мере двух компонентных сигналов и один или более пространственных параметров (430) для второго фрагмента упомянутых по меньшей мере двух компонентных сигналов;
декодируют первое закодированное представление (410) и второе закодированное представление (420) для получения декодированного представления упомянутых по меньшей мере двух компонентных сигналов, представляющего аудиосцену;
анализируют фрагмент декодированного представления, соответствующий первому фрагменту упомянутых по меньшей мере двух компонентных сигналов, для выявления одного или более пространственных параметров (840) для первого фрагмента упомянутых по меньшей мере двух компонентных сигналов; и
выполняют пространственный рендеринг декодированного представления с использованием одного или более пространственных параметров (840) для первого фрагмента и одного или более пространственных параметров (430) для второго фрагмента, включенных в закодированный сигнал (340) аудиосцены.
37. Запоминающий носитель, содержащий сохраненную на нем компьютерную программу для выполнения способа по п. 35 во время ее работы на компьютере или процессоре.
38. Запоминающий носитель, содержащий сохраненную на нем компьютерную программу для выполнения способа по п. 36 во время ее работы на компьютере или процессоре.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| US 8428958 B2, 23.04.2013 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| УСТРОЙСТВО КОДИРОВАНИЯ ЗВУКА, УСТРОЙСТВО ДЕКОДИРОВАНИЯ ЗВУКА, УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ЗВУКА И СИСТЕМА ПРОВЕДЕНИЯ ТЕЛЕКОНФЕРЕНЦИЙ | 2009 |
|
RU2495503C2 |

