РОДСТВЕННЫЕ ЗАЯВКИ
[0001] По настоящей заявке испрашивается приоритет предварительной заявки США № 62/103524, зарегистрированной 14 января 2015 года, предварительной заявки США № 62/043060, зарегистрированной 28 августа 2014 года, и предварительной заявки США № 61/940942, зарегистрированной 18 февраля 2014 года, содержание которых полностью включено в настоящий документ в качестве ссылки.
ССЫЛКА НА СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ, ТАБЛИЦУ ИЛИ СПИСОК КОМПЬЮТЕРНЫХ ПРОГРАММ
[0002] Настоящая заявка подана вместе со списком последовательностей в электронном формате. Список последовательностей предоставлен в виде файла, озаглавленного ILLINC276WO_Sequence_Listing.TXT, созданного 13 февраля 2015 года, с размером 55 кбайт. Информация в электронном формате из списка последовательностей полностью включена в настоящий документ в качестве ссылки.
ОБЛАСТЬ ИЗОБРЕТЕНИЯ
[0003] Варианты осуществления, предоставленные в настоящем документе, относятся к способам и композициям для ДНК-профилирования. Определенные варианты осуществления относятся к способам амплификации последовательностей-мишеней различных размеров в одной реакции с последующим секвенированием библиотеки.
ПРЕДШЕСТВУЮЩИЙ ИЗОБРЕТЕНИЮ УРОВЕНЬ ТЕХНИКИ
[0004] Исторически для установления личности индивидуума использовали подмножество маркеров в геноме человека или фингерпринт или профиль ДНК. Эти маркеры включают положение или локусы последовательностей коротких тандемных повторов (STR) и последовательности промежуточных тандемных повторов (ITR), которые в комбинации пригодны для различения одного индивидуума от другого на генетическом уровне. Анализ этих маркеров стандартизирован при анализе ДНК, выявляемой на местах совершения преступлений. Например, в Соединенных Штатах Америки ряд этих последовательностей повторов скомбинирован с получением единой системы индексации ДНК (CODIS), которая служит в качестве лабораторного стандарта для ДНК-профилирования в уголовных делах. Другие страны подобным образом установили стандартные системы для ДНК-профилирования. Также эти системы использовали для определения отцовства и степени родства. Однако все современные системы основаны на разделении этих повторяемых локусов по размеру в системе электрофореза и, таким образом, ограничены количеством локусов, которые можно различать в такой системе. Например, некоторые из современных коммерческих систем для ДНК-профилирования в криминалистических целях вследствие ограничений электрофоретических способов детекции различают только 16 маркеров.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0005] Варианты осуществления относятся к системам и способам, которые не ограничены по содержанию и которые интегрируют различные части генетической информации об индивидууме с обеспечением общего, более полного ДНК-профиля индивидуума. В настоящем описании описаны способы и композиции, позволяющие получать эти профили индивидуумов, таким образом, развивая области индивидуальной и криминалистической геномики.
[0006] В настоящее время в ДНК-профилировании для определения идентификационных характеристик образца ДНК используют избранные биологические маркеры. Например, самым распространенным анализом определения ДНК-профиля является определение профиля для ряда последовательностей коротких тандемных повторов (STR), находящихся в геноме организма. Анализ состоит из амплификации определенных последовательностей STR, длина которых может составлять до 400 п.н., которые можно различать по размеру в электрофоретическом геле или используя капиллярный электрофорез (CE). Электрофорез используют для определения изменений размера вследствие различий в количестве повторяющихся STR в данном локусе и соответственно длины ампликонов ПЦР, которая для системы CE составляет 50-500 п.н. Для помощи в преодолении ограничений, налагаемых методологиями различения размеров (т.е. STR с совпадающими размерами ампликонов различить нельзя), в существующих способах ДНК-профилирования используют различные наборы меченых праймеров так, что ампликоны с совпадающими размерами можно метить различными флуоресцентными красителями, у которых спектры испускания после возбуждения отличаются, таким образом, обеспечивая различение ампликонов с совпадающими размерами с использованием различий в спектрах возбуждения и испускания красителей. С использованием различного мечения современные способы обеспечивают за один проход ДНК-профилирования комбинирование 24 различных локусов STR с использованием 6 красителей, детектируемых различным образом.
[0007] У современных способов ДНК-профилирования существует множество ограничений. Как указано ранее, в системах различения по размеру число локусов, которые можно по-отдельности различать в конкретный момент времени, ограничено. Другим ограничением принятых способов ДНК-профилирования является то, что часто анализируемая ДНК является деградированной и диапазон размеров некоторых из маркеров не удовлетворяет деградированной ДНК, например, размер ампликонов может быть большим, чем размер фрагментов деградированной ДНК. Для деградированной ДНК, ампликоны размером 400 п.н. считают очень длинными, и это может приводить к отсутствию амплификации этих более длинных локусов. Когда специалисты по анализу ДНК амплифицируют образцы деградированной ДНК для идентификации ее профиля STR, например, образец, найденный на месте совершения преступления, часто они не могут определить все локусы, что приводит к получению частичного профиля, который может сделать сопоставление подозреваемого в нахождении на месте совершения преступления криминальному образцу сложным или невозможным. Как правило, при наличии таких образцов, у специалиста по анализу ДНК существует небольшой выбор и если остается немного образца, то для определения других маркеров, которые могут дать информацию для установления личности индивидуума необходимо проводить дополнительные анализы, такие как анализы однонуклеотидных полиморфизмов (SNP), мини-STR или митохондриальной ДНК (мтДНК). Однако на каждый анализ необходимо расходовать драгоценный образец без уверенности в успехе окончательной идентификации индивидуума. На фиг. 1A продемонстрированы различные потенциальные пути определения ДНК, все из которых представляют собой отдельные технологические процессы и требуют аликвот драгоценных образцов. Когда необходимо комбинировать и потенциально повторять несколько раз один или несколько простых технологических процессов, тогда полученный в результате способы больше не является простым и эффективным использованием драгоценного образца.
[0008] В вариантах осуществления, описанных в настоящей заявке, предоставлены способы, композиции и системы для определения ДНК-профиля индивидуума или организма посредством секвенирования нового поколения (NGS), таким образом, предоставляя решение для проблем и ограничений современных методологий ДНК-профилирования. На фиг. 1B представлен иллюстративный технологический процесс для описываемых способов в одном из вариантов осуществления. В настоящем документе описаны способы и композиции для комбинации множества подходящих для криминалистики маркеров в одном анализе, включая в качестве неограничивающих примеров короткие тандемные повторы (STR), промежуточные тандемные повторы (ITR), информативные для идентификации однонуклеотидные полиморфизмы (iSNP), информативные для установления родства однонуклеотидные полиморфизмы (aSNP) и информативные для определения фенотипа однонуклеотидные полиморфизмы (pSNP).
[0009] В настоящем описании описаны анализы, преодолевающие ограничения современных методологий ДНК-профилирования. В описываемых вариантах осуществления предоставлены способы и композиции для множественной амплификации, получения библиотек и секвенирования комбинированных STR, ITR, iSNP, SNPs и pSNP из одного образца нуклеиновой кислоты в одной мультиплексной реакции. В описываемых способах анализируют множество маркеров в одном экспериментальном анализе с минимальными манипуляциями с образцом, с использованием малых количеств образца ДНК, включая деградированную ДНК. Определенные описанные варианты осуществления можно использовать для организованных в банках данных ДНК-профилей и/или для ДНК-профилей, которые можно использовать для работы по изучению криминальных дел. В определенных вариантах осуществления предоставлены способы и композиции для ПЦР, разработанные так, чтобы быть достаточно чувствительными для детекции субнанограммовых количеств ДНК. Кроме того, нетрадиционные параметры конструирования праймеров обеспечивают высоко мультиплексную ПЦР для идентификации STR, ITR и SNP в одной мультиплексной реакции. Для работы по изучению криминальных дел способы и композиции по настоящему изобретению включают уникальные молекулярные идентификаторы (UMI), помогающие удалять из результатов секвенирования, например, ошибки ПЦР и секвенирования, статтеры и т.п. см. Kivioja et al., Nat. Meth. 9, 72-74 (2012). Также результаты, получаемые с использованием способов и композиций, описываемых в настоящем документе, совместимы с существующими банками данных.
[0010] Таким образом, в вариантах осуществления, описываемых в настоящем документе, предоставлены способы получения ДНК-профиля, включающие: предоставление образца нуклеиновой кислоты, амплификацию образца нуклеиновой кислоты с множеством праймеров, которые специфически гибридизуются по меньшей мере с одной последовательностью-мишенью, содержащей однонуклеотидный полиморфизм (SNP), и по меньшей мере с одной последовательностью-мишенью, содержащей тандемный повтор, в мультиплексной реакции с получением продуктов амплификации и определение в продуктах амплификации генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора, таким образом, получая ДНК-профиль образца нуклеиновой кислоты.
[0011] В определенных вариантах осуществления способы включают получение из продуктов амплификации библиотеки нуклеиновых кислот. В определенных вариантах осуществления способы включают определение последовательностей из библиотеки нуклеиновых кислот. В определенных вариантах осуществления образец нуклеиновой кислоты получают у человека. В определенных вариантах осуществления образец нуклеиновой кислоты получают из образца окружающей среды, растения, у не являющегося человеком животного, из бактерий, архей, гриба или вируса. В определенных вариантах осуществления ДНК-профиль используют для диагностики или получения прогноза для одного или нескольких заболеваний, идентификации биомаркеров злокачественных опухолей, идентификации генетических аномалий или анализа генетического разнообразия. В определенных вариантах осуществления ДНК-профиль используют для одного или нескольких из организации банков данных, криминалистики, работы по изучению материалов уголовных дел, установления отцовства или личности. В определенных вариантах осуществления по меньшей мере один SNP указывает на родственную или фенотипическую характеристику источника образца нуклеиновой кислоты. В определенных вариантах осуществления температура плавления каждого из множества праймеров является низкой, и/или длина составляет по меньшей мере 24 нуклеотида. В определенных вариантах осуществления температура плавления каждого из множества праймеров составляет менее 60°C. В определенных вариантах осуществления температура плавления каждого из множества праймеров составляет приблизительно от 50°C до приблизительно 60°C. В определенных вариантах осуществления длина каждого из множества праймеров составляет по меньшей мере 24 нуклеотида. В определенных вариантах осуществления длина каждого из множества праймеров составляет приблизительно от 24 нуклеотида до приблизительно 38 нуклеотидов. В определенных вариантах осуществления каждый из множества праймеров содержит гомополимерную нуклеотидную последовательность. В определенных вариантах осуществления образец нуклеиновой кислоты амплифицируют посредством полимеразной цепной реакции (ПЦР). В определенных вариантах осуществления образец нуклеиновой кислоты амплифицируют в буфере для амплификации с концентрацией солей, которая увеличена по сравнению с концентрацией солей буфера для амплификации, используемого в сочетании с традиционно конструируемыми праймерами. В определенных вариантах осуществления соль содержит KCl, LiCl, NaCl или их сочетание. В определенных вариантах осуществления соль содержит KCl. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет приблизительно от 100 мМ до приблизительно 200 мМ. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет менее чем приблизительно 150 мМ. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет приблизительно 145 мМ. В определенных вариантах осуществления SNP представляет собой SNP для установления родства, фенотипический SNP, идентификационный SNP или их сочетание. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 30 SNP. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 50 SNP. В определенных вариантах осуществления тандемный повтор представляет собой короткий тандемный повтор (STR), промежуточный тандемный повтор (ITR) или их варианты. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 24 последовательностями тандемных повторов. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 60 последовательностями тандемных повторов. В определенных вариантах осуществления образец нуклеиновой кислоты содержит приблизительно от 100 пг до приблизительно 100 нг ДНК. В определенных вариантах осуществления образец нуклеиновой кислоты содержит приблизительно от 10 пг до приблизительно 100 пг ДНК. В определенных вариантах осуществления образец нуклеиновой кислоты содержит приблизительно от 5 пг до приблизительно 10 пг ДНК. В определенных вариантах осуществления образец нуклеиновой кислоты содержит геномную ДНК. В определенных вариантах осуществления геномная ДНК получена из криминалистического образца. В определенных вариантах осуществления геномная ДНК содержит деградированную ДНК. В определенных вариантах осуществления определяют по меньшей мере 50% генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора. В определенных вариантах осуществления определяют по меньшей мере 80% генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора. В определенных вариантах осуществления определяют по меньшей мере 90% генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора. В определенных вариантах осуществления определяют по меньшей мере 95% генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора. В определенных вариантах осуществления каждый из множества праймеров содержит одну или несколько последовательностей-меток. В определенных вариантах осуществления одна или несколько последовательностей-меток содержат метку-праймер, метку для захвата, метку для секвенирования, метку уникального молекулярного идентификатора или их сочетание. В определенных вариантах осуществления одна или несколько последовательностей-меток содержат метку-праймер. В определенных вариантах осуществления одна или несколько последовательностей-меток содержат метку уникального молекулярного идентификатора.
[0012] В вариантах осуществления, описываемых в настоящем документе, предоставлены способы построения библиотеки нуклеиновых кислот, включающие: предоставление образца нуклеиновой кислоты и амплификацию образца нуклеиновой кислоты со множеством праймеров, которые специфически гибридизуются по меньшей мере с одной последовательностью-мишенью, содержащей однонуклеотидный полиморфизм (SNP), и по меньшей мере с одной последовательностью-мишенью, содержащей последовательность тандемных повторов, в мультиплексной реакции с получением продуктов амплификации.
[0013] В определенных вариантах осуществления образец нуклеиновой кислоты перед амплификацией не фрагментирован. В определенных вариантах осуществления последовательности-мишени перед амплификацией не обогащены. В определенных вариантах осуществления по меньшей мере один SNP указывает на родственную или фенотипическую характеристику источника образца нуклеиновой кислоты. В определенных вариантах осуществления каждый из множества праймеров содержит одну или несколько последовательностей-меток. В определенных вариантах осуществления одна или несколько последовательностей-меток содержат метку-праймер, метку для захвата, метку для секвенирования или метку уникального молекулярного идентификатора или их сочетание. В определенных вариантах осуществления способы включают амплификацию продуктов амплификации со вторым множеством праймеров. В определенных вариантах осуществления каждый из второго множества праймеров содержит часть, соответствующую метке-праймеру множества праймеров и одну или несколько последовательностей-меток. В определенных вариантах осуществления одна или несколько последовательностей-меток из второго множества праймеров содержит метку для захвата или метку для секвенирования или их сочетание. В определенных вариантах осуществления способы включают добавление к продуктам амплификации связывающего одноцепочечные ДНК белка (SSB). В определенных вариантах осуществления образец нуклеиновой кислоты и/или продукты амплификации амплифицируют посредством полимеразной цепной реакции (ПЦР). В определенных вариантах осуществления образец нуклеиновой кислоты и/или продукты амплификации амплифицируют в буфере для амплификации с концентрацией солей, которая увеличена по сравнению с концентрацией солей буфера для амплификации, используемого в сочетании с традиционно конструируемыми праймерами. В определенных вариантах осуществления соль содержит KCl, LiCl, NaCl или их сочетание. В определенных вариантах осуществления соль содержит KCl. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет приблизительно от 100 мМ до приблизительно 200 мМ. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет менее чем приблизительно 150 мМ. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет приблизительно 145 мМ.
[0014] В вариантах осуществления, описываемых в настоящем документе, предоставлена библиотека нуклеиновых кислот, содержащая множество молекул нуклеиновых кислот, где множество молекул нуклеиновых кислот содержит по меньшей мере одну последовательность тандемных повторов, фланкированную первой парой последовательностей-меток, и по меньшей мере один последовательность однонуклеотидного полиморфизма (SNP), фланкированную второй парой последовательностей-меток. Дополнительно предоставлена библиотека нуклеиновых кислот, построенная с использованием способов и композиций, описываемых в настоящем документе. В определенных вариантах осуществления по меньшей мере один SNP указывает на родственную или фенотипическую характеристику источника множества молекул нуклеиновых кислот.
[0015] В вариантах осуществления, описываемых в настоящем документе, предоставлено множество праймеров, которые специфически гибридизуются по меньшей мере с одной короткой последовательностью-мишенью и по меньшей мере с одной длинной последовательностью-мишенью в образце нуклеиновой кислоты, где амплификация образца нуклеиновой кислоты с использованием множества праймеров в одной мультиплексной реакции приводит по меньшей мере к одному короткому продукту амплификации и по меньшей мере к одному длинному продукту амплификации, где каждый из множества праймеров содержит одну или несколько последовательностей-меток.
[0016] В определенных вариантах осуществления короткая последовательность-мишень содержит однонуклеотидный полиморфизм (SNP), а длинная последовательность-мишень содержит тандемный повтор. В определенных вариантах осуществления одна или несколько последовательностей-меток содержат метку-праймер, метку для захвата, метку для секвенирования, метку уникального молекулярного идентификатора или их сочетание. В определенных вариантах осуществления температура плавления каждого из множества праймеров является низкой и/или длина составляет по меньшей мере 24 нуклеотида. В определенных вариантах осуществления температура плавления каждого из множества праймеров составляет менее 60°C. В определенных вариантах осуществления температура плавления каждого из множества праймеров составляет приблизительно от 50°C до приблизительно 60°C. В определенных вариантах осуществления длина каждого из множества праймеров составляет по меньшей мере 24 нуклеотида. В определенных вариантах осуществления длина каждого из множества праймеров составляет приблизительно от 24 нуклеотидов до приблизительно 38 нуклеотидов. В определенных вариантах осуществления каждый из множества праймеров содержит гомополимерную нуклеотидную последовательность. В определенных вариантах осуществления образец нуклеиновой кислоты амплифицируют посредством полимеразной цепной реакции (ПЦР). В определенных вариантах осуществления SNP представляет собой SNP для установления родства, фенотипический SNP, идентификационный SNP или их сочетание. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 30 SNP. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 50 SNP. В определенных вариантах осуществления тандем повтор представляет собой короткий тандемный повтор (STR), промежуточный тандемный повтор (ITR) или их вариант. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 24 последовательностями тандемных повторов. В определенных вариантах осуществления множество праймеров специфически гибридизуется по меньшей мере с 60 последовательностями тандемных повторов.
[0017] В вариантах осуществления, описываемых в настоящем документе, предоставлены наборы, содержащие по меньшей мере одно контейнерное средство, где по меньшей мере одно контейнерное средство содержит множество праймеров, описываемое в настоящем документе.
[0018] В определенных вариантах осуществления наборы содержат реагент для реакции амплификации. В определенных вариантах осуществления реагент представляет собой буфер для амплификации для полимеразной цепной реакции (ПЦР). В определенных вариантах осуществления буфер для амплификации содержит соли в концентрации, которая увеличена по сравнению с концентрацией солей буфера для амплификации, используемого в сочетании с традиционно конструируемыми праймерами. В определенных вариантах осуществления соль содержит KCl, LiCl, NaCl или их сочетание. В определенных вариантах осуществления соль содержит KCl. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет приблизительно от 100 мМ до приблизительно 200 мМ. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет менее чем приблизительно 150 мМ. В определенных вариантах осуществления концентрация KCl в буфере для амплификации составляет приблизительно 145 мМ.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0019] На фиг. 1A и фиг. 1B продемонстрированы различия A) современного технологического процесса ДНК-профилирования и B) технологического процесса по одному из иллюстративных вариантов осуществления настоящего изобретения.
[0020] На фиг. 2 представлен один из иллюстративных вариантов осуществления способа получения библиотеки, пригодной для ДНК-профилирования.
[0021] На фиг. 3 продемонстрирован другой иллюстративный вариант осуществления способа получения библиотеки, пригодной для ДНК-профилирования.
[0022] Фиг. 4A, фиг. 4B, фиг. 4C и фиг. 4D представляют собой линейные графики, иллюстрирующие то, как в результате после электрофореграммы пара праймеров, сконструированных традиционными способами и по принятым протоколам конструирования и ограничениям праймеров для ПЦР, могут обуславливать неспецифическую амплификацию геномных мишеней и снижение чувствительности детекции желаемых ампликонов при комбинации с праймерами, сконструированными способами по настоящему изобретению; A) 10 пар праймеров, сконструированных способами по настоящему изобретению, направленных к локусам SNP, B) и D) 10 праймеров и дополнительная пара праймеров, сконструированных традиционными способами, демонстрирующие, что дополнительная пара праймеров при амплификации создает помехи для 10 пар праймеров, и C) 10 пар праймеров и дополнительная пара праймеров, где дополнительная пара праймеров также сконструирована способами по настоящему изобретению, приводящие к успешной амплификации всех SNP-мишеней. Ось x представляет собой размер фрагментов библиотеки (п.н.), а ось Y представляет собой единицы флуоресценции (FU) усиленных пиков амплифицированных фрагментов.
[0023] Фиг. 5A, фиг. 5B, фиг. 5C, фиг. 5D и фиг. 5E представляют собой диаграммы размаха, демонстрирующие иллюстративные результаты эксперимента по технологическому процессу, приведенному на фиг. 2, который использовали для идентификации панели из 56 STR и смеси из 75 информативных для идентификации SNP (iSNP), информативных для установления родства SNP (aSNP) и информативные для определения фенотипа SNP (pSNP) в мультиплексной реакции амплификации и секвенирования с образцом. Приведены воспроизводимые результаты, демонстрирующие успешные амплификацию и секвенирование локусов STR из панели; A) диаграмма размаха, демонстрирующая внутрилокусный баланс для 25 гетерозиготных STR из панели, B) диаграмма размаха, демонстрирующая низкое количество статтеров для большинства из 56 локусов STR, C) диаграмма размаха, демонстрирующая покрытие секвенирования для локусов STR, D) диаграмма размаха, демонстрирующая покрытие последовательности для SNP, и E) диаграмма размаха, демонстрирующая баланс для 22 гетерозиготных SNP из панели. Нижняя полоса ошибок означает минимальное значение, верхняя полоса ошибок означает максимальное значение, нижний прямоугольник означает 25-й перцентиль, а верхний прямоугольник означает 75-й перцентиль со средним, представляющим собой пересечение между нижним и верхним прямоугольниками.
[0024] На фиг. 6 представлен ряд гистограмм, демонстрирующих диаграммы для иллюстративных локусов STR в эксперименте, представленном на фиг. 5. Диаграммы демонстрируют распознавания различных аллелей для STR из панели на фиг. 5.
[0025] Фиг. 7A, фиг. 7B, фиг. 7C, фиг. 7D и фиг. 7E представляют собой диаграммы размаха, демонстрирующие иллюстративные результаты эксперимента по технологическому процессу, приведенному на фиг. 3, который использовали для идентификации панели из 26 STR и смеси из 94 iSNP, aSNP и pSNP в мультиплексной реакция амплификации и секвенирования с образцом. Приведены воспроизводимые результаты, демонстрирующие успешные амплификацию и секвенирование STR из панели; A) диаграмма размаха, демонстрирующая внутрилокусный баланс для 21 гетерозиготных локусов STR из панели, B) диаграмма размаха, демонстрирующая низкое количество статтеров для 26 локусов STR (39 из 47 аллелей из 26 локусов не продемонстрировали статтеров), C) диаграмма размаха, демонстрирующая покрытие секвенирования для локусов STR (количество прочтений, нормализованное с использованием UMI), D) диаграмма размаха, демонстрирующая покрытие последовательности для SNP и E) диаграмма размаха, демонстрирующая баланс для 21 гетерозиготных iSNP из панели. Нижняя полоса ошибок означает минимальное значение, верхняя полоса ошибок означает максимальное значение, нижний прямоугольник означает 25-й перцентиль, а верхний прямоугольник означает 75-й перцентиль со средним, представляющим собой пересечение между нижним и верхним прямоугольниками
[0026] На фиг. 8 представлен ряд гистограмм, демонстрирующих диаграммы для иллюстративных локусов STR в эксперименте, представленном на фиг. 7. Диаграммы демонстрируют распознавания различных аллелей для STR в панели на фиг. 7.
[0027] На фиг. 9 представлены столбчатые диаграммы образцов, анализируемых без UMI и с UMI. Левая панель для каждого множества представляет образцы, анализируемые без UMI, а правая панель для каждого множества представляет образцы, анализируемые с UMI. Ось X означает количество повторов в STR, а ось Y означает количество копий конкретного аллеля. Линии ошибок в столбцах разделяют ошибки секвенирования (верхняя часть столбца) от корректных последовательностей (нижняя часть столбца) в последовательности STR.
[0028] Фиг. 10A и фиг. 10B демонстрируют иллюстративные результаты из эксперимента, где соотношение мужской:женской ДНК составляло 90:10. A) результаты распознавания подмножество локусов STR для локусов STR с использованием современных способов ДНК-профилирование с использованием капиллярного электрофореза, и B) результаты распознавания нескольких локусов STR для нескольких локусов STR с использованием способов по настоящей заявке. И способами CE, и способами по настоящей заявке детектировали низкий уровень контаминации мужской ДНК.
[0029] На фиг. 11 представлены гистограммы, демонстрирующие, что в эксперименте, представленном на фиг. 9, детектировали локусы STR, специфичные для Y хромосомы, кроме того, демонстрирующие, что по настоящей заявке можно детектировать контаминирующую мужскую ДНК и конкретные локусы STR из этой мужской ДНК, тогда как для осуществления этого с использованием современных методологий CE может понадобиться проделать два эксперимента.
[0030] Фиг. 12 представляет собой таблица, демонстрирующая иллюстративный высокий уровень результатов секвенирования после эксперимента с использованием 12 образцов индивидуумов и референсного индивидуума, что демонстрирует согласованность распознаваний STR и SNP при двух повторениях.
[0031] Фиг. 13 представляет собой таблицу, демонстрирующую иллюстративные статистические параметры совокупности в эксперименте, представленном на фиг. 12.
[0032] Фиг. 14 представляет собой таблицу, демонстрирующую иллюстративные результаты прогноза фенотипов на основе генотипа pSNP в эксперименте, представленном на фиг. 12.
[0033] Фиг. 15 представляет собой диаграмму, демонстрирующую иллюстративное картирование родства на основе генотипа aSNP в эксперименте, представленном на фиг. 12.
[0034] Фиг. 16A, фиг. 16B, фиг. 16C, фиг. 16D и фиг. 16E представляют собой гистограммы, демонстрирующие иллюстративные диаграммы локусов STR в эксперименте, представленном на фиг. 12.
[0035] Фиг. 17A и фиг. 17B представляют собой гистограммы, демонстрирующие иллюстративные диаграммы SNP в эксперименте, представленном на фиг. 12.
[0036] Фиг. 18A и фиг.18B демонстрируют диаграммы размаха, демонстрирующие внутрилокусный баланс для иллюстративных локусов STR и SNP в эксперименте, представленном на фиг. 12.
[0037] Фиг. 19A и фиг. 19B представляют собой диаграммы, демонстрирующие анализ статтеров иллюстративных локусов STR в эксперименте, представленном на фиг. 12.
[0038] Фиг. 20 представляет собой таблицу, демонстрирующую иллюстративные изометрические гетерозиготы в локусах STR в эксперименте, представленном на фиг. 12.
[0039] Фиг. 21 представляет собой блок-схему, демонстрирующую иллюстративную диаграмму наследования на основе вариантов в STR D8S1179 в эксперименте, представленном на фиг. 12.
[0040] Фиг. 22 представляет собой блок-схему, демонстрирующую иллюстративную диаграмму наследования на основе вариантов в STR D13S317 в эксперименте, представленном на фиг. 12.
[0041] Фиг. 23 представляет собой таблицу, демонстрирующую иллюстративные результаты генотипирования с использованием деградированной ДНК.
[0042] Фиг. 24A и фиг. 24B демонстрируют иллюстративные результаты генотипирования STR и внутрилокусный баланс при различных вводимых ДНК.
[0043] Фиг. 25A и фиг. 25B демонстрируют иллюстративные результаты генотипирования SNP и внутрилокусный баланс при различных вводимых ДНК.
ПОДРОБНОЕ ОПИСАНИЕ
Определения
[0044] Все патенты, заявки, опубликованные заявки и другие публикации, которые указаны в настоящем документе, включены в качестве ссылки на указанный материал и полностью. Если термин или фраза используют в настоящем документе в смысле, отличающемся или иным образом не соответствующем с определениями, указанными в патентах, заявках, опубликованных заявках и других публикациях, которые включены в настоящий документ в качестве ссылки, использование в настоящем документе превалирует над определениями, указанными во включенных в настоящий документ в качестве ссылки документах.
[0045] Как используют в настоящем документе, если не указано иначе, явно или не следует из контекста, формы единственного числа включают указание на множественно число. Например, если не указано иначе, явно или не следует из контекста, димер включает один или несколько димеров.
[0046] Как используют в настоящем документе, термины "ДНК-профиль", "генетический фингерпринт" и "генотипический профиль" в настоящем документе используют взаимозаменяемо для обозначения аллельных вариаций во множестве полиморфных локусов, таких как тандемные повторы, однонуклеотидные полиморфизмы (SNP) и т.д. ДНК-профиль, пригодный в криминалистике для идентификации индивидуума на основе образца нуклеиновой кислоты. Как используют в настоящем документе, ДНК-профиль также можно использовать для других задач, таких как диагностика и прогноз заболеваний, включая злокачественные опухоли, идентификация биомаркеров злокачественных опухолей, анализ родства, анализ генетического разнообразия, идентификация генетических аномалий, организация банков данных, криминалистика, работа по изучению материалов уголовных дел, установление отцовства, идентификация личности, и т.д.
[0047] Термины "полинуклеотид", "олигонуклеотид", "нуклеиновая кислота" и "молекула нуклеиновой кислоты" в настоящем документе используют взаимозаменяемо для обозначения полимерной формы нуклеотидов любой длины, и они могут содержать рибонуклеотиды, дезоксирибонуклеотиды, их аналоги или их смеси. Этот термин относится только к первичной структуре молекулы. Таким образом, термин включает трех-, двух- и одноцепочечную дезоксирибонуклеиновую кислоту ("ДНК"), а также трех-, двух- и одноцепочечную рибонуклеиновую кислоту ("РНК").
[0048] Как используют в настоящем документе, "идентичность последовательностей" или "идентичность" или "гомология" в контексте двух нуклеотидных последовательностей включает указание на остатки в двух последовательностях, которые при выравнивании с максимальным соответствием в указанном окне сравнения являются одинаковыми. Часть нуклеотидной последовательности в окне сравнения для оптимального выравнивания двух последовательностей может содержать добавления или делеции (т.е. пропуски) по сравнению с референсной последовательностью. Проценты рассчитывают, определяя количество положений, в которых в обеих последовательностях находится идентичный остаток нуклеинового основания с получением количества совпадающих положений, деля количество совпадающих положений на общее количество положений в окне сравнения и умножая результат на 100 с получением процента идентичности последовательностей.
[0049] Как используют в настоящем документе, "в значительной степени комплементарны или по существу совпадают" означает, что для двух последовательностей нуклеиновых кислот идентичность последовательностей составляет по меньшей мере 90%. Предпочтительно, для двух последовательностей нуклеиновых кислот идентичность последовательностей составляет по меньшей мере на 95%, 96%, 97%, 98%, 99% или 100%. Альтернативно, "в значительной степени комплементарны или по существу совпадает" означает, что две последовательности нуклеиновых кислот могут гибридизоваться в условиях высокой жесткости.
[0050] Следует понимать, что аспекты и варианты осуществления изобретения, описываемые в настоящем документе, включают "состоящие" и/или "по существу состоящие" аспекты и варианты осуществления.
[0051] Другие задачи, преимущества и признаки настоящего изобретения будут очевидны из приводимого ниже описания, взятого в сочетании с сопровождающими с чертежами.
Способы получения ДНК-профиля
[0052] Принятые методологии определения ДНК-профиля во многих отношениях ограничены. Например, современными способами детектируют изменения размера амплифицируемых локусов, которые отличаются вследствие изменений длины последовательностей тандемных повторов, находящихся в образце ДНК. Для мультиплексных реакций амплификации STR для визуализации реакции амплификации необходимо разрабатывать так, чтобы разделять ампликоны различного размера в пределах разделения электрофоретических систем по размеру, которые для CE составляют приблизительно 50-500 п.н. Поэтому в одном анализе можно визуализировать только ограниченное количество повторяемых последовательностей. Например, посредством набора для амплификации ПЦР GLOBALFILER (Applied Biosystems) воспроизводимо можно различать 24 локуса STR с использованием 6 различных красителей. Кроме того, у в таких способах существуют трудности, когда образец ДНК деградирован, как это часто происходит с образцами ДНК с места совершения преступления, так, что получить более протяженные продукты амплификации невозможно, что приводит к неполному ДНК-профилю. Также современные способы недостаточно чувствительны для детекции небольших количеств контаминированной ДНК так, что смешанный образец может остаться невыявленным и незарегистрированным, что может быть критичным при работе по изучению криминальных дел. Таким образом, современные способы могут приводить к неполным результатам, которые приводят к недоказательным результатам, что может быть неблагоприятно для ДНК-профилирования.
[0053] Кроме того, современные нормативы не включают получаемую из образца информацию о родстве, фенотипических признаках, таких как возможный цвет глаз, и другую индивидуализированную информацию, полученную из образца. В определенных методологиях секвенирования делали попытки включать детекцию и STR, и SNP. Например, предпринимались попытки получать библиотеки с последующим специализированным обогащением STR и SNP, однако не все STR были охвачены полностью, так как способы получения библиотек, как правило, включают расщепление образца, которое может уничтожить последовательность-мишень. Кроме того, принятые способы и протоколы конструирования праймеров могут обеспечивать наборы праймеров для амплификации длинных последовательностей (например, STR) или коротких последовательности (например, SNP), но успешных комбинаций длинных последовательностей и коротких последовательности в одной реакции осуществлено не было.
[0054] В настоящем описании описаны решения затруднений и ограничений современных систем ДНК-профилирования. Способы и композиции, описываемые в настоящем документе, обеспечивают комбинирование STR и SNP в одном анализе с использованием ПЦР для амплификации мишеней и получения библиотек для секвенирования. При разработке анализов по настоящему изобретению неожиданно выявлено, что, например, при использовании нетрадиционного и интуитивного не понятного конструирования праймеров, можно в одной реакции амплифицировать и STR, и SNP, что позволяет определять последовательность для всех локусов-мишеней. Неожиданно, при конструировании праймеров для амплификации с использованием параметров, противоречащих современной догме о конструировании праймеров, получены праймеры, которые позволяли амплифицировать более протяженные области STR и амплифицировать короткие области SNP более или менее балансированным способом, таким образом, обеспечивая совместную мультиплексную амплификацию STR и SNP.
[0055] Способы и композиции, описываемые в настоящем документе для определения ДНК-профиля организма, помимо ДНК-профилирования можно использовать каждый раз, когда в одной реакции амплификации желательны множества ампликонов различных размеров. Например, если представляющие интерес мишени для ПЦР одновременно включают большие генные области и короткие области SNP, которые могут приводить к ампликонам, размер которых варьирует от сотен до тысяч пар оснований по сравнению с ампликонами размером менее 100 пар оснований, соответственно, тогда способы и композиции, описываемые в настоящем документе, могут обеспечить успешную одновременную амплификацию генных мишеней и мишеней-SNP, что может быть невозможным без практического осуществления описываемых способов. Кроме того, способы и композиции, описываемые в настоящем документе, можно применять для любого организма, например, для людей, не являющихся человеком приматов, животных, растений, вирусов, бактерий, грибов и т.п. Таким образом, способы и композиции по настоящему изобретению пригодны не только для ДНК-профилирования (например, в криминалистических целях, установления отцовства, установления личности и т.д.) и людей в качестве генома-мишени, но также можно применять для других целей, таких как маркеры злокачественных опухолей и заболеваний, маркеры генетических аномалий, и/или когда геном-мишень не является геномом человека.
[0056] Таким образом, в вариантах осуществления, описываемых в настоящем документе, предоставлены способы получения ДНК-профиля, включающие: предоставление образца нуклеиновой кислоты, амплификацию образца нуклеиновой кислоты со множеством праймеров, которые специфически гибридизуются по меньшей мере с одной последовательностью-мишенью, содержащей однонуклеотидный полиморфизм (SNP), и по меньшей мере с одной последовательностью-мишенью, содержащей тандемный повтор, и определение генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора в продуктах амплификации, таким образом, получая ДНК-профиль образца нуклеиновой кислоты.
[0057] Специалистам в данной области понятно, что при определении генотипов последовательностей-мишеней можно использовать любые подходящие способы, включая в качестве неограничивающих примеров гибридизацию на чипах, секвенирование или т.п. Таким образом, в определенных вариантах осуществления способы, описываемые в настоящем документе, могут включать получение из продуктов амплификации библиотеки нуклеиновых кислот, такой как библиотека для секвенирования, и определение последовательностей библиотеки нуклеиновых кислот.
[0058] В определенных вариантах осуществления настоящего изобретения предоставлены способы и композиции для ДНК-профилирования, которые включают одновременную идентификацию STR и iSNP, например, для применения в организации популяционных или персональных банков данных. В таких банках данных, персональные данные не обязательно необходимы, так как индивидуумы, как правило, известны. Однако если желательна дополнительная информация, тогда для одновременной идентификации можно добавлять мишени для дополнительной информации. Короткие тандемные повторы хорошо известны в данной области, и они состоят из повторяющихся ди- или тринуклеотидных последовательностей. Промежуточными тандемными повторами, как правило, считают повторяемые последовательности из последовательностей из 4-7 нуклеотидов. SNP, используемые в настоящем документе, могут быть любой формы, которая может обеспечивать понимание физических характеристик индивидуума. В качестве примера в настоящем документе приведены SNP, которые обеспечивают информацию для определения родства или происхождения (aSNP), и SNP, которые обеспечивают информацию для фенотипических характеристик (информативные для определения фенотипа SNP). В способах, описываемых в настоящем документе, анализ ДНК-профиля может включать любое количество этих SNP в комбинации с определением локусов STR и ITR.
[0059] Например, в настоящем описании предоставлены дополнительные способы и композиции, где наряду с STR и iSNP включены дополнительные мишени. Если желательно больше информации об индивидууме, например, когда образец принадлежит неизвестному индивидууму или группе индивидуумов, как может быть в случае работы по изучению криминальных дел, к STR и iSNP можно добавлять дополнительные информативные маркеры, таки как SNP, связанные с родством (aSNP), и SNP, связанные с фенотипическими вариантами (информативные для определения фенотипа SNP). Затем дополнительная информации может использоваться для содействия исследователям, например, обеспечивая информацию о неизвестном происхождении индивидуума, цвете глаз, цвете волос и т.п. Таким образом, добавление всей комбинированной информации может обеспечивать более полный ДНК-профиль индивидуума, который ранее с использованием современных способов ДНК-профилирования был неизвестен.
[0060] Способы и композиции, описываемые в настоящем документе, разработаны так, чтобы быть достаточно селективными для детекции субнанограммовых количеств молекул нуклеиновых кислот. Кроме того, способы и композиции, описываемые в настоящем документе, могут быть пригодными для амплификации образца нуклеиновой кислоты, полученного при наличии низкокачественных молекул нуклеиновой кислоты, таких как даградированная и/или фрагментированная геномная ДНК из криминалистического образца. Образец нуклеиновой кислоты, может представлять собой очищенный образец или содержащий ДНК неочищенный лизат, например, полученный из буккального мазка, бумаги, ткани или другого субстрата, который может быть пропитан слюной, кровью или другими биологическими жидкостями. Таким образом, в определенных вариантах осуществления образец нуклеиновой кислоты может содержать низкие количества или фрагментированные части ДНК, такой как геномная ДНК. Например, образец нуклеиновой кислоты может содержать количество нуклеиновой кислоты (например, геномной ДНК), которое составляет, составляет приблизительно или составляет менее 1 пг, 2 пг, 3 пг, 4 пг, 5 пг, 6 пг, 7 пг, 8 пг, 9 пг, 10 пг, 11 пг, 12 пг, 13 пг, 14 пг, 15 пг, 16 пг, 17 пг, 18 пг, 19 пг, 20 пг, 30 пг, 40 пг, 50 пг, 60 пг, 70 пг, 80 пг, 90 пг, 100 пг, 200 пг, 300 пг, 400 пг, 500 пг, 600 пг, 700 пг, 800 пг, 900 пг, 1 нг, 10 нг, 100 нг или находится в диапазоне, определенном любыми двумя из этих значений, например, от 10 пг до 100 пг, от 10 пг до 1 нг, от 100 пг до 1 нг, 1 нг до 10 нг, 10 нг до 100 нг и т.д. В определенных вариантах осуществления образец нуклеиновой кислоты может содержать количество нуклеиновой кислоты (например, геномной ДНК), которое составляет приблизительно от 100 пг до приблизительно 1 нг. В определенных вариантах осуществления образец нуклеиновой кислоты может содержать количество нуклеиновой кислоты (например, геномной ДНК), которое составляет более чем приблизительно 62,5 пг. В определенных вариантах осуществления в процедуры фрагментации дополнительные этапы фрагментации, такие как обработка ультразвуком или эндонуклеазное расщепление, не включены.
[0061] В определенных вариантах осуществления способами и композициями, описываемыми в настоящем документе, можно успешно определять генотипы одной или нескольких из последовательностей-мишеней, например, SNP, STR и т.д., даже в образцах с субнанограммовыми количествами и/или с деградированной нуклеиновой кислотой. Например, способами и композициями, описываемыми в настоящем документе, можно успешно определять генотип, который составляет, составляет приблизительно или составляет более 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 96%, 97%, 98%, 99%, 100% или диапазон между любыми двумя из указанных выше значений последовательностей-мишеней. В определенных вариантах осуществления способами и композициями, описываемыми в настоящем документе, можно успешно определять генотип более чем приблизительно 50%, 80%, 90%, 95%, 98% или более последовательностей-мишеней. В определенных вариантах осуществления способами и композициями, описываемыми в настоящем документе, можно достигать внутрилокусного баланса более чем приблизительно 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 96%, 97%, 98%, 99%, 100% или диапазон между любыми двумя из указанных выше значений последовательностей-мишеней.
[0062] Для криминалистических исследований множество праймеров может включать уникальные молекулярные идентификаторы (UMI), которые помогают в устранении из результатов секвенирования, например, ошибок ПЦР и секвенирования, статтеров и т.п., см. Kivioja et al., выше. Как более подробно описано в других разделах настоящего описания, включение в праймеры UMI также обеспечивает идентификацию вариантов в локусах тандемных повторов, дополнительно усиливая пригодность современных способов и композиций для ДНК-профилирования и других задач, таких как анализ наследственности.
[0063] Таким образом, в определенных вариантах осуществления генотипы последовательностей тандемных повторов, как описано в настоящем документе, могут включать варианты последовательностей в локусах тандемных повторов. Таким образом, гомозигота по тандемному повтору (например, 13, 13 для D9S1122), определенная традиционным способом, на основе вариантов последовательностей в тандемных повторах может быть идентифицирована как изометрическая гетерозигота. Как понятно специалистам в данной области, принятие в расчет внутрилокусных вариантов последовательностей может значительно увеличить пригодность способов, описываемых в настоящем документе, например, для анализа родства.
Способы построения библиотеки нуклеиновых кислот
[0064] В вариантах осуществления, описываемых в настоящем документе, предоставлены способы построения библиотеки нуклеиновых кислот, включающие: предоставление образца нуклеиновой кислоты и амплификацию образца нуклеиновой кислоты со множеством праймеров, которые специфически гибридизуются по меньшей мере с одной последовательностью-мишенью, содержащей однонуклеотидный полиморфизм (SNP), и по меньшей мере с одной последовательностью-мишенью, содержащей последовательность тандемных повторов.
[0065] Способы и композиции, описываемые в настоящем документе, разработаны так, чтобы быть достаточно чувствительными для детекции субнанограммовых количеств молекул нуклеиновых кислот. Кроме того, способы и композиции, описываемые в настоящем документе, могут быть пригодны для амплификации образца нуклеиновой кислоты, который состоит из низкокачественных молекул нуклеиновой кислоты, таких как деградированная и/или фрагментированная геномная ДНК из криминалистического образца. Образец нуклеиновой кислоты может представлять собой очищенный образец или содержащий ДНК неочищенный лизат, например, полученный из буккального мазка, бумаги, ткани или другого субстрата, который может быть пропитан слюной, кровью или другими биологическими жидкостями. Таким образом, в определенных вариантах осуществления образец нуклеиновой кислоты может содержать низкие количества или фрагментированную ДНК, такую как геномная ДНК. Например, образец нуклеиновой кислоты может содержать количество нуклеиновой кислоты (например, геномной ДНК), которое составляет, составляет приблизительно или составляет менее 1 пг, 2 пг, 3 пг, 4 пг, 5 пг, 6 пг, 7 пг, 8 пг, 9 пг, 10 пг, 11 пг, 12 пг, 13 пг, 14 пг, 15 пг, 16 пг, 17 пг, 18 пг, 19 пг, 20 пг, 30 пг, 40 пг, 50 пг, 60 пг, 70 пг, 80 пг, 90 пг, 100 пг, 200 пг, 300 пг, 400 пг, 500 пг, 600 пг, 700 пг, 800 пг, 900 пг, 1 нг, 10 нг, 100 нг или находится в диапазоне, определенном любыми двумя из этих значений, например, от 10 пг до 100 пг, от 10 пг до 1 нг, от 100 пг до 1 нг, 1 нг до 10 нг, 10 нг до 100 нг и т.д. В определенных вариантах осуществления образец нуклеиновой кислоты может содержать количество нуклеиновой кислоты (например, геномной ДНК), которое составляет приблизительно от 100 пг до приблизительно 1 нг. В определенных вариантах осуществления образец нуклеиновой кислоты может содержать количество нуклеиновой кислоты (например, геномной ДНК), которое составляет более чем приблизительно 62,5 пг. В определенных вариантах осуществления дополнительные этапы фрагментации, такие как обработка ультразвуком или эндонуклеазное расщепление, не включены.
[0066] В определенных вариантах осуществления способы, описываемые в настоящем документе, перед последующим параллельным секвенированием включают амплификацию и получение библиотеки. Анализ может включать две готовые смеси для ПЦР, две термостабильных полимеразы, две смеси праймеров и адаптеры для библиотеки. В определенных вариантах осуществления образец ДНК можно амплифицировать в течение определенного количества циклов с использованием первого набора праймеров для амплификации, которые содержат специфичные к мишени области и неспецифичные к мишени области-метки и первую готовую смесь для ПЦР. Область-метка может представлять собой любую последовательность, такую как универсальная область-метка, область метки для захвата, область метки амплификации, область метки для секвенирования, область метки UMI и т.п. Например, область-метка может представлять собой матрицу для праймеров для амплификации, используемых во втором или последующих этапах амплификации, например, для получения библиотеки. В определенных вариантах осуществления способы включают добавление к продуктам первой амплификации связывающего одноцепочечные ДНК белка (SSB). Аликвоту образца после первой амплификации можно извлекать и амплифицировать второй раз с использованием второго набора праймеров для амплификации, которые специфичны к области-метке, например, универсальной области-метке или области метки амплификации, первых праймеров для амплификации, которые могут содержать одну или несколько дополнительных последовательностей-меток, таких как последовательности-метки, специфичные для одного или нескольких последующих технологических способов секвенирования, и с той же или второй готовой смесью для ПЦР. Таким образом, библиотека исходного образца ДНК становится готовой для секвенирования.
[0067] Альтернативный способ может включать первую амплификацию, проводимую в малом объеме (например, 15 мкл) и вместо перенесения аликвоты в новое место для второго этапа амплификации, дополнительные реагенты для проведения второго этапа амплификации можно добавлять в эту же пробирку.
[0068] После получения библиотеки, ее можно очищать и проводить количественный анализ. В некоторых примерах очистку можно проводить, пропуская образец через субстрат, такой как AMPURE XP Beads (Beckman Coulter), который служит для очистки фрагментов ДНК от компонентов реакции. Другой способ может представлять собой введение во второй набор праймеров для амплификации функциональной группы для очистки, такой как молекула гаптена. Например, если в праймеры из второго набора праймеров для амплификации введен биотин, тогда фрагменты библиотеки можно захватывать, например, с использованием молекул стрептавидина на гранулах. С использованием стратегии захвата библиотеки также можно нормализовать и количественно анализировать с использованием основанной на гранулах нормализации (BBN). Однако библиотеки можно очищать и количественно анализировать или объединять и количественно анализировать, если проведено несколько реакций, без использования BBN. Например, библиотеки также можно количественно анализировать посредством способов электрофореза в геле, BioAnalyzer, qPCR, спектрофотометрических способов, наборов для количественного анализа (например, PicoGreen и т.д.) и т.п., как известно в данной области. После количественного анализа, библиотеку затем можно секвенировать посредством параллельного секвенирования.
[0069] В определенных вариантах осуществления первый набор праймеров для амплификации, используемый для амплификации ДНК-мишени, предоставляют в такой ограниченной концентрации, что когда аликвоту после первой реакции амплификации добавляют в новую пробирку и добавляют реагенты для второй реакции амплификации, происходит минимальная недетектируемая остаточная амплификация, идущая с первого набора праймеров для амплификации, и этапа очистки между первой реакцией амплификации и второй реакцией амплификации не требуется. В некоторых примерах, концентрация праймеров для амплификации для первой ПЦР составляет, составляет приблизительно или составляет менее 0,5 нМ, 0,6 нМ, 0,7 нМ, 0,8 нМ, 0,9 нМ, 1,0 нМ, 1,5 нМ, 2,0 нМ, 3,0 нМ, 4,0 нМ, 5,0 нМ, 6,0 нМ, 7,0 нМ, 8,0 нМ, 9,0 нм 10,0 нМ, 11,0 нМ 12,0 нМ, или диапазона между любыми из этих значений, например, от 0,5 нМ до 1,0 нМ, от 1,0 нМ до 12 нМ, от 0,8 нМ до 1,5 нМ и т.д. В определенных вариантах осуществления концентрация праймеров для амплификации для первой ПЦР составляет приблизительно от 0,9 нМ до приблизительно 10 нМ.
[0070] На фиг. 2 представлен иллюстративный технологический процесс описываемых по настоящем изобретению способов в одном из вариантов осуществления. Последовательность геномной ДНК-мишени амплифицируют с использованием первого набора праймеров, содержащего область, фланкирующую эту последовательность-мишень и области меток амплификации (которые могут быть одинаковыми или различными), что приводит к получению ампликонов, содержащих последовательность-мишень и метки на обоих концах. Затем аликвоту ампликонов из первой ПЦР далее амплифицируют с использованием второго набора праймеров, специфичных к последовательностям первых меток, дополнительно содержащих последовательности праймеров для секвенирования (адапторные последовательности i5 и i7), таким образом, получая библиотеки, содержащие последовательности ДНК-мишени, фланкированные последовательностями, используемыми при параллельном секвенировании, в этом случае последовательности i5 и i7 используют в последовательности способами синтеза, популяризируемыми Illumina, Inc.
[0071] Пример альтернативного технологического процесса определения ДНК-профиля из образца приведен на фиг. 3. В этом примере ДНК-мишень амплифицируют с первой парой праймеров, которая содержит последовательности, фланкирующие последовательность-мишень, не специфичные к мишени последовательности-метки (одинаковые или различные) и дополнительные последовательности уникальных молекулярных идентификаторов или UMI, которые содержат случайные основания. UMI можно использовать, например, для биоинформатического снижения или устранения ошибок, которые происходят в процессах получения библиотек (например, атрефакты или ошибки включения при ПЦР и т.д.). Использование UMI может быть важным для ДНК-профилирования, но являются особенно важными для применения в содействии устранению ошибок, когда образцы секвенируют для работы по изучению криминальных дел. В этом примере первый этап амплификации проводят в течение 2 циклов, за которыми следует добавление связывающего одноцепочечные ДНК белка (SSB) и инкубация при 37°C в течение 15 мин с последующей инактивацией при 95°C/5 мин которая эффективно останавливает дальнейшую амплификацию с первого набора праймеров для амплификации во-время второго этапа амплификации. Хотя механизм неизвестен, полагают, что добавление SSB необратимо связывает первые одноцепочечные праймеры для амплификации и предотвращает их участие в последующих реакциях амплификации. После инкубации с SSB добавляют второй набор праймеров, содержащих последовательности-метки и вторую смесь для ПЦР, что приводит к получению библиотеки для секвенирования.
Библиотека нуклеиновых кислот
[0072] В вариантах осуществления, описываемых в настоящем документе, предоставлены библиотеки нуклеиновых кислот, которые можно использовать для секвенирования. В определенных вариантах осуществления библиотеки нуклеиновых кислот, описываемые в настоящем документе, могут содержать множество молекул нуклеиновых кислот, где множество молекул нуклеиновых кислот содержит по меньшей мере одну последовательность тандемных повторов, фланкированных первой парой последовательностей-меток, и по меньшей мере одну последовательность однонуклеотидного полиморфизма (SNP), фланкированную второй парой последовательностей-меток.
[0073] Как указано в настоящем документе, размер молекул нуклеиновых кислот при применении способов и композиций, описываемых в настоящем документе, может сильно варьировать. Специалистам в данной области понятно, что у молекул нуклеиновой кислоты, амплифицируемых с последовательности-мишени, содержащей тандемный повтор (например, STR), размер может быть большим, тогда как у молекул нуклеиновой кислоты, амплифицируемых с последовательности-мишени, содержащей SNP, размер может быть маленьким. Например, молекулы нуклеиновой кислоты могут содержать от менее ста нуклеотидов до сотен или даже тысяч нуклеотидов. Таким образом, размер молекул нуклеиновых кислот может составлять диапазон, который находится между любыми двумя значениями из приблизительно 50 п.н., приблизительно 60 п.н., приблизительно 70 п.н., приблизительно 80 п.н., приблизительно 90 п.н., приблизительно 100 п.н., приблизительно 110 п.н., приблизительно 120 п.н., приблизительно 130 п.н., приблизительно 140 п.н., приблизительно 150 п.н., приблизительно 200 п.н., приблизительно 300 п.н., приблизительно 400 п.н., приблизительно 500 п.н., приблизительно 600 п.н., приблизительно 700 п.н., приблизительно 800 п.н., приблизительно 900 п.н., приблизительно 1 т.п.н. или более. В определенных вариантах осуществления минимальный размер молекул нуклеиновых кислот может составлять длину, которая составляет, составляет приблизительно или составляет менее 50 п.н., 60 п.н., 70 п.н., 80 п.н., 90 п.н. или 100 п.н. В определенных вариантах осуществления максимальный размер молекул нуклеиновых кислот может составлять длины, которая составляет, составляет приблизительно или составляет более 100 п.н., 150 п.н., 200 п.н., 250 п.н., 300 п.н., 350 п.н., 400 п.н., 450 п.н., 500 п.н. или 1 т.п.н.
[0074] Для получения кластеров библиотеку фрагментов иммобилизуют на субстрате, например, стекле, который содержит гомологичные олигонуклеотидные последовательности для захвата и иммобилизации фрагментов библиотеки ДНК. Иммобилизованные фрагменты библиотеки ДНК амплифицируют с использованием методологий кластерной амплификации как проиллюстрировано в описаниях патентов США №№ 7985565 и 7115400, содержание каждого из которых полностью включено в настоящий документ в качестве ссылки. Во включенных материалах патентов США №№ 7985565 и 7115400 описаны способы твердофазной амплификации нуклеиновых кислот, которая обеспечивает иммобилизацию продуктов амплификации на твердой подложке с формированием панелей, состоящих из кластеров или "колоний" иммобилизованных молекул нуклеиновой кислоты. Каждые кластер или колония в такой панели сформированы из множества идентичных иммобилизованных полинуклеотидных цепей и множества идентичных иммобилизованных комплементарных полинуклеотидных цепей. Полученные таким образом панели, как правило, обозначают как "кластеризованные панели". Продукты твердофазных реакций амплификации, такие как продукты, описанные в патенты США №№ 7985565 и 7115400, представляют собой так называемые "мостиковые" структуры, формируемые посредством отжига пар иммобилизованных полинуклеотидных цепей и иммобилизованных комплементарных цепей, где обе цепи иммобилизованы на твердой подложке на 5'-конце, предпочтительно посредством ковалентного связывания. Методологии кластерной амплификации представляют собой примеры способов, где иммобилизованную матричную нуклеиновую кислоту используют для получения иммобилизованных ампликонов. Для получения из иммобилизованных фрагментов ДНК, получаемых способами, предоставляемыми по настоящему документу, иммобилизованных ампликонов также можно использовать другие подходящие методологии. Например, один или несколько кластеров или колоний можно формировать посредством твердофазной ПЦР, вне зависимости от того, один или оба из каждой пары праймеров для амплификации являются иммобилизованными. Однако способы, описываемые в настоящем документе, не ограничены какой-либо конкретной методологией секвенирования или платформой секвенирования, и их можно применять для других способов параллельного секвенирования и ассоциированных платформ секвенирования.
Праймеры
[0075] В вариантах осуществления, описываемых в настоящем документе, предоставлено множество праймеров, которые в образце нуклеиновой кислоты специфически гибридизуются по меньшей мере с одной короткой последовательностью-мишенью и по меньшей мере одной длинной последовательностью-мишенью, где амплификация образца нуклеиновой кислоты с использованием множества праймеров в одной мультиплексной реакции приводит по меньшей мере к одному короткому продукту амплификации и по меньшей мере к одному длинному продукту амплификации, где каждый из множества праймеров содержит одну или несколько последовательностей-меток. Кроме того, в настоящем документе описано множество праймеров с набором последовательностей, указанных в таблицах 1-2.
[0076] Для мультиплексной амплификации больших последовательностей-мишеней (например, STR, ITR) и малых последовательностей-мишеней (например, SNP), конструируют праймеры, которые могут обеспечить сбалансированную амплификацию мишеней всех типов. Способы и композиции, описываемые в настоящем документе, можно использовать для амплификации нескольких последовательностей-мишеней тандемных повторов в одной мультиплексной реакции. Например, множество праймеров может специфически гибридизоваться с рядом последовательностей тандемных повторов, которые насчитывают, насчитывают приблизительно или насчитывают более 4, 6, 8, 10, 12, 14, 16, 18, 24, 30, 40, 50, 60, 70, 80, 90, 100 или диапазон между любыми из двух значений, такой как от 4 до 12, от 10 до 24, от 30 до 100 и т.д. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 24 последовательностями тандемных повторов. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 60 последовательностями тандемных повторов. Способы и композиции, описываемые в настоящем документе, можно использовать для амплификации несколько последовательностей-мишеней SNP в одной реакции. Например, множество праймеров может специфически гибридизоваться с рядом последовательностей SNP, который насчитывает, насчитывает приблизительно или насчитывает более 4, 6, 8, 10, 12, 14, 16, 18, 24, 30, 40, 50, 60, 70, 80, 90, 100 или диапазон между любыми из двух значений, такой как от 4 до 12, от 10 до 24, от 30 до 100 и т.д. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 30 последовательностями SNP. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 50 последовательностями SNP.
[0077] В ходе экспериментальной работы выявлено, что короткие последовательности-мишени SNP при использовании праймеров, сконструированных по принятым критериям и в соответствии с опытом успешного конструирования праймеров, амплифицируются предпочтительней более длинных последовательностей-мишеней STR. Кроме того, по меньшей мере в технологическом процессе секвенирования посредством синтеза, где получают кластеры и кластеры самостоятельно секвенируют (например, при секвенировании посредством синтеза (SBS, описываемым в других разделах настоящего документа) ассоциированного с секвенаторами Illumina, Inc.) также происходит предпочтительная амплификация кластеров с более короткими фрагментами SNP библиотеки. Для преодоления эти двух смещений была необходима новая стратегия конструирования праймеров, которая бы обеспечивала балансированную амплификацию коротких последовательностей-мишеней SNP и длинных последовательностей-мишеней STR.
[0078] Одна из стратегий включала конструирование праймеров для амплификации STR. В случае STR повторяющиеся последовательности часто находятся в более протяженных повторяющихся областях; таким образом, конструирование специфических праймеров для амплификации STR может быть проблематичным. Кроме того, STR и фланкирующие их области часто являются AT-богатыми. В одном из вариантов праймеры для проблемных областей конструировали с использованием стратегии конструирования, отличающейся от общепринятых и отработанных критериев планирования ПЦР. Принятые критерии для конструирования праймеров для ПЦР определяют, что среди прочих критериев 1) оптимальная длина праймеров составляет 18-22 нуклеотида, 2) Tm должна находиться в диапазоне 55-58°C, 3) содержание GC должно составлять приблизительно 40-60%, 4) и следует избегать областей с повторяемым динуклеотидом AT с максимумом <4 повторов динуклеотидов AT. Конструировали праймеры, которые были длиннее типичных праймеров для ПЦР, например, 23-35 нуклеотидов в длину, вместо 18-22 нуклеотидов, их температуры плавления (Tm) были низкими, например, приблизительно 54°C, вместо приблизительно 58°C, и праймеры были AT-богатыми, три параметра, которые в стандартном принятом руководстве по критериям ПЦР для оптимального конструирования праймеров следует избегать. В результате конструировали неоптимальные праймеры. Неожиданно выявлено, что эти длинные, AT-богатые, праймеры с низкой Tm фактически мультиплексировали STR лучше, чем короткие, праймеры с высокой Tm с низким содержанием AT. Не связываясь с какой-либо теорией, полагают, что более короткие праймеры, которые сконструированы по принятым критериям планирования ПЦР, могут формировать димеры с высокими температурами плавления и, таким образом, формировать димеры, эффективно функционирующие в нормальных условиях ПЦР, тогда как более длинные праймеры с низкой Tm могут формировать димеры при действительно низкой Tm и, таким образом, могут быть нестабильными для формирования димеров, таким образом, обеспечивая увеличенное участие более длинных праймеров с низкой Tm в нормальных условиях амплификации по сравнению с короткими праймерами с высокой Tm (например, 18-22 нуклеотидов, Tm 60°C, содержание GC 50%).
[0079] Затем более длинные AT-богатые праймеры с низкой Tm для амплификации STR объединяли с традиционно конструируемыми более короткими праймерами с высокой Tm, направленными к SNP. Однако мультиплексные реакции амплификации снова не смогли обеспечить сбалансированную амплификацию STR и SNP в одной мультиплексной реакции. Было предположено, что к успешной мультиплексной амплификации, возможно, может приводить применение нетрадиционной конструкции праймеров для амплификации непроблематичных мишеней, например, для амплификации SNP-мишеней. Таким образом, для конструирования праймеров для SNP применяли те же критерии, которые использовали для конструирования неоптимальных праймеров для STR (длинные, низкая Tm, AT-богатые). Неожиданно новые конструируемые праймеры приводили к лучшему балансу при амплификации STR и SNP в мультиплексной реакции.
[0080] На Фиг. 4 представлены примеры взаимодействия между общепринятыми и нетрадиционно конструируемыми праймерами в мультиплексной реакции. На фиг. 4A мультиплексная реакция 10 SNP-мишеней демонстрирует ожидаемую амплификацию в желаемом для библиотеки диапазоне приблизительно 200-350 п.н. Праймеры, используемые для амплификации 10 SNP в мультиплексной системе конструировали более длинными, с более низкой Tm и более AT-богатыми, чем это рекомендовано принятыми критериями конструирования праймеров для ПЦР. Когда сконструировали 11-ую пару праймеров с использованием принятых критериев планирования ПЦР, т.е. праймеры были короткими, с высокой Tm и не являлись AT-богатыми, и добавили к 10 парам, полученная мультиплексная система продемонстрировала неспецифическую амплификацию ДНК-мишеней. Как можно видеть на фиг. 4B и 4D, добавление 11-й традиционно сконструированной пары праймеров препятствует 10 нетрадиционным парам праймеров и приводит к неудачной мультиплексной амплификации SNP-мишеней. Однако добавление 11-й пары праймеров, которая сконструирована также нетрадиционно по тем же критерии, что и 10 пар праймеров, приводит к успешной амплификации SNP-мишеней (фиг. 4C).
[0081] Таким образом, в определенных вариантах осуществления температура плавления каждого из множества праймеров является низкой, например, менее 60°C или приблизительно от 50°C до приблизительно 60°C и/или длина составляет по меньшей мере 24 нуклеотида, например, приблизительно от 24 нуклеотидов до приблизительно 38 нуклеотидов. В определенных вариантах осуществления каждый из множества праймеров содержит гомополимерную нуклеотидную последовательность.
[0082] В определенных примерах нетрадиционно конструируемые праймеры содержат последовательности, которые фланкируют STR- и SNP-мишени и дополнительные нематричные последовательности. Дополнительные последовательности могут представлять собой, например, последовательности-метки, которые служат определенным задачам при получении библиотеки или в методологиях секвенирования. Например, последовательность-метка может представлять собой последовательность для захвата, такую как молекула гаптена, которую может захватывать иммобилизованная молекула-партнер для очистки фрагментов библиотеки. Примером молекулы гаптена является биотин, который может захватывать стрептавидин с выделением фрагментов библиотеки из компонентов реакционной смеси и т.п. Также последовательность-метка может представлять собой последовательность для амплификации, например, т.е. являться комплементарной для праймера для амплификации, и ее могут использовать в одной или нескольких реакциях амплификации. На фиг. 2 и 3 представлены примеры последовательностей-меток, которые используют на втором этапе амплификации после первого этапа амплификации. Также последовательность-метка может представлять собой метку для секвенирования. На фиг. 2 и 3 также представлены примеры метки для секвенирования, адаптер i5 и адаптер i7 используют при секвенировании в реакциях секвенирования посредством синтеза в качестве праймеров для гибридизации, получения кластеров и секвенирования, как описано в настоящем документе. Другим примером последовательности-метки является уникальный молекулярный идентификатор, или UMI, как представлено на фиг. 3.
[0083] UMI содержит случайный участок нуклеотидов, который можно использовать при секвенировании для коррекции ошибок ПЦР и секвенирования, таким образом, добавляя в результаты секвенирования дополнительный уровень коррекции ошибок. Длина UMI может составлять, например, 3-10 нуклеотидов, однако их количество зависит от количества вводимой ДНК. Например, если приблизительно для 250 участков-мишеней используют 1 нг ДНК, тогда полагают, что необходимо приблизительно 350 копий × 250 мишеней, т.е. приблизительно 90000 различных UMI. Если используют большие количества ДНК, например, 10 нг, тогда необходимым может являться приблизительно 1 миллион различных UMI. У всех ПЦР-копий после одной реакции ПЦР будет присутствовать одна и та же последовательность UMI, таким образом, можно биоинформатически сравнивать копии и исключать из результатов секвенирования любые ошибки в последовательности, такие как замены, делеции, вставки одиночных оснований (т.е. статтеры при ПЦР). Уникальные молекулярные идентификаторы также можно использовать при анализе смешанного образца. Смешанные образцы, например, образец женской ДНК, который контаминирован мужской ДНК, с использованием последовательностей UMI можно подвергать деконволюции с регистрацией вклада женской и мужской ДНК. Например, для двух смешанных ДНК всего может существовать четыре повторяемых числа; однако может существовать менее четырех, если в смеси двух образцов в конкретном локусе присутствуют одинаковые аллели. Эти одинаковые аллели можно различать и определять приблизительные проценты с использованием UMI для определения количества различных аллелей в исходной группе молекул ДНК. Например, можно подсчитать исходные молекулы, и если минорная составляющая присутствует, например, на уровне 5%, тогда 5% UMI идентифицируют один генотип, а 95% идентифицируют второй генотип. После ПЦР, если один из аллелей (или возможно более) после амплификации смещен, тогда это отношение 5:95 не наблюдается. Однако с использованием UMI смещенное соотношение можно корректировать после конденсации ПЦР-копий с использованием детекции и коррекции с UMI. Это важно при типировании для различения артефактов-статтеров после ПЦР и истинной минорной составляющей.
[0084] Праймер в способах по настоящему изобретению может содержать одну или несколько последовательностей-меток. Последовательности-метки могут представлять собой одну или несколько последовательностей праймеров, которые не гомологичны последовательности-мишени, но, которые можно использовать, например, в качестве матриц для одной или нескольких реакций амплификации. Последовательность-метка может представлять собой последовательность для захвата, например, последовательность гаптена, такую как биотин, которую можно использовать для очистки ампликонов от компоненты реакционной смеси. Последовательности-метки которые могут представлять собой такие последовательности, как адаптерные последовательности, которые эффективны для захвата ампликонов библиотеки на субстрате, например, для мостиковой амплификации в прогнозировании последовательности посредством технологий синтеза, как описано в настоящем документе. Кроме того, последовательности-метки могут представлять собой метки уникальных молекулярных идентификаторов, как правило, например, длиной 3-10 нуклеотидов, содержащие случайные участки нуклеотидов, которые можно использовать для коррекции ошибок при получении библиотеки и/или в способах секвенирования.
[0085] Кроме того, для мультиплексной реакции ПЦР предпочтительно содержать олигонуклеотидные праймеры по существу ко всем мишеням, объединенные в одну смесь. Однако, как описано в настоящем документе, олигонуклеотиды являются нетипично более протяженными, чем праймеры, сконструированные с использованием традиционных параметров. Дополнительное добавление к праймерам последовательностей-меток, такое как добавление UMI, которые добавляют специфичные для гена-мишени последовательности, приводит к получению еще более протяженных последовательностей праймеров. В определенных вариантах осуществления во множество праймеров можно добавлять глицинбетаин (приблизительно 1,5 М). Например, в определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат бетаин в концентрации, которая составляет, составляет приблизительно или составляет более 100 мМ, 200 мМ, 300 мМ, 400 мМ, 500 мМ, 600 мМ, 700 мМ, 800 мМ, 900 мМ, 1 M, 1,2 M, 1,3 M, 1,4 M, 1,5 M, 1,6 M, 1,7 M, 1,8 M, 1,9 M, 2 M, 3 M, 4 M, 5 M, 6 M, 7 M, 8 M, 9 M, 10 M или диапазон между любыми двумя из этих значений, например, от 500 мМ до 2 M, от 1 M до 1,5 M и т.д. Таким образом, при практическом осуществлении способов по настоящему изобретению предпочтительной является смесь праймеров, как описано в настоящем документе, дополненная бетаином, например, в концентрации приблизительно 1,5 М. В определенных вариантах осуществления во множество праймеров можно добавлять глицерин. Например, в определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат глицерин в концентрации, которая составляет, составляет приблизительно или составляет более 100 мМ, 200 мМ, 300 мМ, 400 мМ, 500 мМ, 600 мМ, 700 мМ, 800 мМ, 900 мМ, 1 M, 1,2 M, 1,3 M, 1,4 M, 1,5 M, 1,6 M, 1,7 M, 1,8 M, 1,9 M, 2 M, 3 M, 4 M, 5 M, 6 M, 7 M, 8 M, 9 M, 10 M или диапазон между любыми двумя из этих значений, например, от 500 мМ до 2 M, от 1 M до 1,5 M, и т.д. Таким образом, при практическом осуществлении способов по настоящему изобретению предпочтительной является смесь праймеров, как описано в настоящем документе, дополненная глицерином, например, в концентрации приблизительно 1,5 М.
[0086] В определенных вариантах осуществления буферы, ассоциируемые с праймерами нетрадиционной конструкции, используемыми в способах амплификации по настоящему изобретению, также можно модифицировать. Например, в определенных вариантах осуществления концентрации солей, таких как KCl, LiCl, NaCl или их сочетание, в буфере для амплификации по сравнению с концентрациями солей в буфере для амплификации, используемом в сочетании с традиционно конструируемыми праймерами, увеличены. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат KCl в концентрации, которая составляет, составляет приблизительно или составляет более 60 мМ, 70 мМ, 80 мМ, 90 мМ, 100 мМ, 110 мМ, 120 мМ, 130 мМ, 140 мМ, 150 мМ, 160 мМ, 170 мМ, 180 мМ, 190 мМ, 200 мМ, 250 мМ, 300 мМ, 400 мМ, 500 мМ, или диапазон между любыми двумя из этих значений, например, от 60 мМ до 200 мМ, от 100 мМ до 250 мМ и т.д. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат KCl в концентрации, которая составляет приблизительно 145 мМ. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат LiCl в концентрации, которая составляет, составляет приблизительно или составляет более 60 мМ, 70 мМ, 80 мМ, 90 мМ, 100 мМ, 110 мМ, 120 мМ, 130 мМ, 140 мМ, 150 мМ, 160 мМ, 170 мМ, 180 мМ, 190 мМ, 200 мМ, 250 мМ, 300 мМ, 400 мМ, 500 мМ, или диапазон между любыми двумя из этих значений, например, от 60 мМ до 200 мМ, от 100 мМ до 250 мМ и т.д. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат LiCl в концентрации, которая составляет приблизительно 145 мМ. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат NaCl в концентрации, которая составляет, составляет приблизительно или составляет более 60 мМ, 70 мМ, 80 мМ, 90 мМ, 100 мМ, 110 мМ, 120 мМ, 130 мМ, 140 мМ, 150 мМ, 160 мМ, 170 мМ, 180 мМ, 190 мМ, 200 мМ, 250 мМ, 300 мМ, 400 мМ, 500 мМ, или диапазон между любыми двумя из этих значений, например, от 60 мМ до 200 мМ, от 100 мМ до 250 мМ и т.д. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат NaCl в концентрации, которая составляет приблизительно 145 мМ.
[0087] В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, могут содержать MgSO4, MgCl2 или их сочетание.
Наборы
[0088] В вариантах осуществления, описываемых в настоящем документе, предоставлены наборы, содержащие по меньшей мере одно контейнерное средство, где по меньшей мере одно контейнерное средство содержит множество праймеров, как описано в настоящем документе. В определенных вариантах осуществления контейнерными средствами могут являться пробирка, лунка, планшет для микротитрования и т.д. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться с рядом последовательностей тандемных повторов, который составляет, составляет приблизительно или составляет более 4, 6, 8, 10, 12, 14, 16, 18, 24, 30, 40, 50, 60, 70, 80, 90, 100 или диапазон между любыми из двух значений, такой как от 4 до 12, от 10 до 24, от 30 до 100 и т.д. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 24 последовательностями тандемных повторов. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 60 последовательностями тандемных повторов. Способы и композиции, описываемые в настоящем документе, можно использовать для амплификации нескольких последовательностей-мишеней SNP в одной реакции. Например, множество праймеров может специфически гибридизоваться с рядом последовательностей SNP, который составляет, составляет приблизительно или составляет более 4, 6, 8, 10, 12, 14, 16, 18, 24, 30, 40, 50, 60, 70, 80, 90, 100, или диапазон между любыми из двух значений, такой как от 4 до 12, от 10 до 24, от 30 до 100 и т.д. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 30 последовательностями SNP. В определенных вариантах осуществления множество праймеров может специфически гибридизоваться по меньшей мере с 50 последовательностями SNP.
[0089] В определенных вариантах осуществления по меньшей мере одно контейнерное средство содержит буфер для амплификации. В определенных вариантах осуществления также можно модифицировать буферы, ассоциируемые с праймерами нетрадиционной конструкции, используемыми в способах амплификации по настоящему изобретению. Например, в определенных вариантах осуществления концентрации солей, таких как KCl, LiCl, NaCl или их сочетание, в буфере для амплификации по сравнению с концентрацией солей в буфере для амплификации, используемого в сочетании с традиционно конструируемыми праймерами, увеличены. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат KCl, NaCl или LiCl в концентрации, которая составляет, составляет приблизительно или составляет более 60 мМ, 70 мМ, 80 мМ, 90 мМ, 100 мМ, 110 мМ, 120 мМ, 130 мМ, 140 мМ, 150 мМ, 160 мМ, 170 мМ, 180 мМ, 190 мМ, 200 мМ, 250 мМ, 300 мМ, 400 мМ, 500 мМ или диапазон между любыми двумя из этих значений, например, от 60 мМ до 200 мМ, от 100 мМ до 250 мМ и т.д. В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе, содержат KCl, NaCl или LiCl в концентрации, которая приблизительно составляет 145 мМ.
[0090] В определенных вариантах осуществления буферы для амплификации, используемые в реакциях амплификации с нетрадиционными праймерами, как описано в настоящем документе могут содержать MgSO4, MgCl2 или их сочетание.
Способы секвенирования
[0091] Способы по настоящему изобретению не ограничены какой-либо конкретной платформой секвенирования, однако в настоящем документе они проиллюстрированы относительно SBS или секвенирования посредством синтеза, разновидности параллельного секвенирования. Особенно пригодными способами являются способы, где нуклеиновые кислот в фиксированных положениях связывают на панели так, что их относительные положения не изменяется, и где повторно получают изображение панели. Особенно пригодны примеры, в которых изображения получают в различных цветовых каналах, например, в соответствии с различными метками, используемыми для различения одного вида нуклеотидных оснований от другого.
[0092] Как правило, способы SBS включают ферментативную достройку новой цепи нуклеиновой кислоты посредством итеративного добавления нуклеотидов в соответствии с цепь-матрицей. В традиционных способах SBS за каждую подачу для нуклеотида-мишени в присутствии полимеразы можно подавать один нуклеотидный мономер. Однако в способах, описываемых в настоящем документе, за одну подачу для нуклеиновой кислоты-мишени можно подавать более одного вида нуклеотидных мономеров.
[0093] В способах SBS можно использовать мономеры нуклеотидов, содержащие метящую функциональную группу, или мономеры нуклеотидов без метящей функциональной группы. Таким образом, события включения можно детектировать, основываясь на характеристики метки, такой как флуоресценция метки; характеристики мономера нуклеотида, такой как молекулярная масса или заряд; побочный продукт включения нуклеотида, такой как высвобождение пирофосфата; или т.п. В определенных примерах, где в реагенте для секвенирования присутствуют два или более различных нуклеотида, различные нуклеотиды могут быть различимы друг с другом, или, альтернативно, две или более различных метки могут быть неразличимы при используемых способах детекции. Например, различные нуклеотиды, присутствующие в реагенте для секвенирования, могут содержать различные метки, и их можно различать с использованием соответствующих оптических устройств, как проиллюстрировано способами секвенирования, разработанными Solexa (в настоящее время Illumina, Inc.).
[0094] Определенные примеры включают способы пиросеквенирования. Посредством пиросеквенирования детектируют высвобождение неорганического пирофосфата (PPi) при встраивании в растущую цепь отдельных нуклеотидов (Ronaghi, M., Karamohamed, S., Pettersson, B., Uhlen, M. and Nyren, P. (1996) "Real-time DNA sequencing using detection of pyrophosphate release". Analytical Biochemistry 242(1), 84-9; Ronaghi, M. (2001) "Pyrosequencing sheds light on DNA sequencing". Genome Res. 11(1), 3-11; Ronaghi, M., Uhlen, M. and Nyren, P. (1998) "A sequencing method based on real-time pyrophosphate". Science 281(5375), 363; патент США № 6210891; патент США № 6258568 и патент США № 6274320, описания которых полностью включены в настоящий документ в качестве ссылки). При пиросеквенировании высвобождающийся PPi можно детектировать по непосредственному преобразованию в аденозинтрифосфат (АТФ) посредством АТФ-сульфурилаза, а уровень образуемого АТФ детектируют посредством продуцируемых люциферазой фотонов. Нуклеиновые кислоты для секвенирования можно связывать с элементами чипа и чип можно подвергать процедуре получения изображения для захвата хемилюминесцентных сигналов, которые продуцируются при включении нуклеотидов на элементы чипа. После обработки чипа конкретным типом нуклеотидов (например, A, T, C или G) можно получать изображение. Изображения, получаемые после добавления нуклеотидов каждого типа, отличаются в отношении детектируемых элементов на чипе. Эти различия изображений отражают различное содержание последовательностей на элементах чипа. Однако относительные положения каждого элемента на изображениях остаются неизменными. Изображения можно хранить, обрабатывать и анализировать способами, указанными в настоящем документе. Например, изображения, получаемые после обработки чипа каждым из различных типов нуклеотидов, можно обрабатывать тем же способом, как проиллюстрировано в настоящем документе для изображений, получаемых из различных детекционных каналов в способах секвенирования на основе обратимых терминаторов.
[0095] В другом примере SBS проводят циклическое секвенирование посредством пошагового добавления нуклеотидов с обратимым терминатором, содержащих, например, отщепляемую или обесцвечиваемую светом красящую метку, как описано, например, в WO 04/018497 и патенте США № 7057026, описания которых включены в настоящий документ в качестве ссылки. Этот подход коммерциализован Solexa (в настоящее время Illumina Inc.), а также описан в WO 91/06678 и WO 07/123744, каждый из которых включен в настоящий документ в качестве ссылки. Эффективному секвенированию с циклически обратимой терминацией (CRT) способствует доступность флуоресцентно меченых терминаторов, которые могут предотвращать терминацию и у которых можно отщеплять флуоресцентную метку. Для эффективного включения и достройки этих модифицированных нуклеотидов также можно совместно конструировать полимеразы. Дополнительные иллюстративные системы и способы SBS, которые можно использовать со способами и системами, описываемыми в настоящем документе, описаны в публикации патентной заявки США № 2007/0166705, публикации патентной заявки США № 2006/0188901, патенте США № 7057026, публикации патентной заявки США № 2006/0240439, публикации патентной заявки США № 2006/0281109, публикации PCT № WO 05/065814, публикации патентной заявки США № 2005/0100900, публикации PCT № WO 06/064199, публикации PCT № WO 07/010251, публикации патентной заявки США № 2012/0270305 и публикации патентной заявки США № 2013/0260372, описания которых полностью включены в настоящий документ в качестве ссылки.
[0096] В некоторых примерах можно использовать детекцию четырех различных нуклеотидов с использованием менее четырех различных меток. Например, SBS можно проводить с использованием способов и систем, описанных во включенных материалах публикации патентной заявки США № 2013/0079232. В качестве первого примера, пару типов нуклеотидов можно детектировать при одной и той же длине волны, но проводя различие на основе разницы в интенсивности у одного из представителей паты по сравнению с другим, или на основе изменения у одного представителя пары (например, посредством химической модификации, фотохимической модификации или физической модификации), которое вызывает возникновение или исчезновение видимого сигнала по сравнению с сигналом, детектируемым для другого представителя пары. В качестве второго примера, три из четырех различных типов нуклеотидов можно детектировать в особых условиях, при том, что у четвертого типа нуклеотида отсутствует метка, детектируемая в этих условиях, или присутствует метка, минимально детектируемая в этих условиях (например, минимальная детекция ввиду фоновой флуоресценции и т.д.). Включение первых трех типов нуклеотидов в нуклеиновую кислоту можно определять на основе присутствия соответствующих им сигналов, а включение четвертого типа нуклеотида в нуклеиновую кислоту можно определять на основе отсутствия или минимальной детекции любого сигнала. В качестве третьего примера один тип нуклеотида может содержать метку(и), детектируемые в двух различных каналах, тогда как другие типы нуклеотидов детектируют не более чем в одном из каналов. Указанные выше три иллюстративные конфигурации не считают взаимоисключающими и их можно использовать в различных комбинациях. Иллюстративный вариант осуществления, который комбинирует все три примера, представляет собой основанный на флуоресценции способ SBS, в котором используют первый тип нуклеотида, детектируемый в первом канале (например, dATP с меткой, детектируемой в первом канале при возбуждении с первой длиной волны возбуждения), второй тип нуклеотида, детектируемый во втором канале (например, dCTP с меткой, детектируемой во втором канале при возбуждении со второй длиной волны возбуждения), третий тип нуклеотида, детектируемый и в первом, и во втором канале (например, dTTP по меньшей мере с одной меткой, детектируемой в обоих каналах при возбуждении с первой и/или второй длиной волны возбуждения) и четвертый тип нуклеотида, у которого отсутствует метка, который не детектируем или минимально детектируем в любом из каналов (например, dGTP не содержащий метки).
[0097] Кроме того, как описано во включенных материалах публикации патентной заявки США № 2013/0079232 данные секвенирования можно получать с использованием одного канала. В таких, так называемых, одноканальных подходах к секвенированию первый тип нуклеотида метят, но метку после получения первого изображение удаляют, и второй тип нуклеотида метят только после получения первого изображения. Третий тип нуклеотида сохраняет свою метку на первом и втором изображения, и четвертый тип нуклеотида остается немеченым на обоих изображениях.
[0098] В определенных примерах можно использовать способы секвенирования посредством лигирования. В таких способах для включения олигонуклеотидов и идентификации включения таких олигонуклеотидов используют ДНК-лигазу. Как правило олигонуклеотиды содержат различные метки, которые коррелируют с видом конкретного нуклеотида в последовательности, с которой олигонуклеотиды гибридизуется. Как и в других способах SBS, изображения можно получать после обработки элементов чипа с нуклеиновой кислотой мечеными реагентами для секвенирования. Каждое изображение демонстрирует элементы с нуклеиновой кислотой, содержащей встроенные метки конкретного типа. Различные элементы на различных изображениях присутствуют или отсутствуют вследствие различного содержания последовательностей в каждом элементе, но относительные положения элементов на изображениях остаются постоянными. Изображения, получаемые в способах секвенирования на основе лигирования можно хранить, обрабатывать и анализировать, как указано в настоящем документе. Иллюстративные системы и способы SBS, которые можно использовать со способами и системами, описываемыми в настоящем документе, описаны в патенте США № 6969488, патенте США № 6172218 и в патенте США № 6306597, описания которых полностью включены в настоящий документ в качестве ссылки.
[0099] В некоторых примерах можно использовать секвенирование в нанопорах (Deamer, D. W. & Akeson, M. " Nanopores and nucleic acids: prospects for ultrarapid sequencing". Trends Biotechnol. 18, 147-151 (2000); Deamer, D. and D. Branton, "Characterization of nucleic acids by nanopore analysis". Acc. Chem. Res. 35:817-825 (2002); Li, J., M. Gershow, D. Stein, E. Brandin, and J. A. Golovchenko, "DNA molecules and configurations in a solid-state nanopore microscope" Nat. Mater. 2:611-615 (2003), описания которых полностью включены в настоящий документ в качестве ссылки). В таких вариантах осуществления нуклеиновую кислоту-мишень пропускают через нанопоры. Нанопора может представлять собой синтетическую пору или белок биологической мембраны, такой как α-гемолизин. Так как нуклеиновую кислоту-мишень пропускают через нанопору, каждую пару оснований можно идентифицировать, измеряя отклонения электропроводности поры. (патент США № 7001792; Soni, G. V. & Meller, "A. Progress toward ultrafast DNA sequencing using solid-state nanopores". Clin. Chem. 53, 1996-2001 (2007); Healy, K. "Nanopore-based single-molecule DNA analysis". Nanomed. 2, 459-481 (2007); Cockroft, S. L., Chu, J., Amorin, M. & Ghadiri, M. R. "A single-molecule nanopore device detects DNA polymerase activity with single-nucleotide resolution". J. Am. Chem. Soc. 130, 818-820 (2008), описания которых полностью включены в настоящий документ в качестве ссылки). Данные, получаемые после секвенирования в нанопорах, можно хранить, обрабатывать и анализировать, как указано в настоящем документе. В частности, данные можно обрабатывать в виде изображения в соответствии с иллюстративной обработкой оптических изображений и других изображений, как указано в настоящем документе.
[0100] В некоторых примерах можно использовать способы, включающие мониторинг активности ДНК-полимеразы в реальном времени. Включения нуклеотидов можно детектировать посредством взаимодействий с резонансным переносом энергии флуоресценции (FRET) между несущей флуорофор полимеразой и меченных по γ-фосфату нуклеотидов, как описано, например, в патенте США № 7329492 и патенте США № 7211414 (каждый из которых включен в настоящий документ в качестве ссылки) или включения нуклеотидов можно детектировать волноводами с нулевой модой, как описано, например, в патенте США № 7315019 (включенном в настоящий документ в качестве ссылки) и с использованием флуоресцентных аналогов нуклеотидов и сконструированных полимераз, как описано, например, в патенте США № 7405281 и в публикации патентной заявки США № 2008/0108082 (каждый из которых включен в настоящий документ в качестве ссылки). Освещение можно ограничивать объемом в масштабе зептолитра вокруг связанной с поверхностью полимеразы так, что включение флуоресцентно меченых нуклеотидов можно наблюдать с низким фоном (Levene, M. J. et al. "Zero-mode waveguides for single-molecule analysis at high concentrations". Science 299, 682-686 (2003); Lundquist, P. M. et al. "Parallel confocal detection of single molecules in real time". Opt. Lett. 33, 1026-1028 (2008); Korlach, J. et al. "Selective aluminum passivation for targeted immobilization of single DNA polymerase molecules in zero-mode waveguide nano structures". Proc. Natl. Acad. Sci. USA 105, 1176-1181 (2008), описания которых полностью включены в настоящий документ в качестве ссылки). Изображения, получаемые такими способами можно хранить, обрабатывать и анализировать, как указано в настоящем документе.
[0101] Определенные варианты осуществления SBS включают детекцию протона, высвобождаемого после включения нуклеотида в достраиваемый продукт. Например, в секвенировании на основе детекции высвобождаемых протонов можно использовать электродетектор и ассоциированные способы, которые коммерчески доступны в Ion Torrent (Guilford, CT, дочерняя компания Life Technologies), или способы секвенирования и системы, описанные в US 2009/0026082 A1; US 2009/0127589 A1; US 2010/0137143 A1 или US 2010/0282617 A1, каждый из которых включен в настоящий документ в качестве ссылки. Способы, указанные в настоящем документе для амплификации нуклеиновых кислот-мишеней с использованием кинетического исключения, можно легко применять с субстратами, используемыми для детекции протонов. Более конкретно, способы, указанные в настоящем документе, можно использовать для получения клональных групп ампликонов, которые используют для детекции протонов.
[0102] Указанные выше способы SBS преимущественно можно проводить в мультиплексных форматах так, что одновременно обрабатывают множество различных нуклеиновых кислот-мишеней. В конкретных вариантах осуществления различные нуклеиновые кислоты-мишени можно обрабатывать в общем реакционном сосуде или на поверхности конкретного субстрата. Это обеспечивает удобную доставку реагентов для секвенирования, удаление непрореагировавших реагентов и детекцию событий встраивания мультиплексным образом. В вариантах осуществления с использованием связанных с поверхностью нуклеиновых кислот-мишеней, нуклеиновые кислоты-мишени могут находиться в формате чипа. Как правило, в формате чипа нуклеиновые кислоты-мишени могут быть связаны с поверхностью пространственно различимым образом. Нуклеиновые кислоты-мишени можно связывать посредством прямого ковалентного связывания, связывания с гранулами или другими частицами или связывания с полимеразой или другой молекулой, которая связана с поверхностью. Чип в каждом участке (также обозначаемом как элемент) может содержать одну копию нуклеиновой кислоты-мишени, или в одном участке или элементе может присутствовать несколько копий с одной и той же последовательностью. Несколько копий можно получать способами амплификации, такими как мостиковая амплификация или эмульсионная ПЦР, как более подробно описано ниже.
[0103] В способах по настоящему изобретению для секвенирования библиотек для получения ДНК-профиля, получаемых способами, описываемыми в настоящем документе, используют технологию Illumina, Inc. Для кластеризации и секвенирования в примерах, описываемых в настоящем документе, использовали устройство секвенирования MiSeq. Однако, как указано ранее и как понятно специалисту в данной области, способы по настоящему изобретению не ограничены типом используемой платформы секвенирования.
ПРИМЕРЫ
[0104] В приводимых ниже примерах описаны определенные способы и материалы для ДНК-профилирования. Эти способы и материалы можно модифицировать, не отклоняясь от сущности и объема изобретения. Такие модификации будут очевидны специалистам в данной области, исходя из обсуждения настоящего изобретения или практического осуществления способов, описываемых в настоящем документе. Таким образом, не следует понимать, что эти способы или материалы ограничены конкретными примерами, описываемыми в настоящем документе, но следует понимать, что они включают все модификации и альтернативы, которые соответствуют объему и сущности настоящего изобретения.
Пример 1 - Праймеры нетрадиционной конструкции
[0105] Для конструирования праймеров модифицировали и использовали компьютерную программу для конструирования DesignStudio, выпущенную Illumina, Inc. (San Diego, CA). Разумеется, специалист в данной области поймет, что для конструирования праймеров также можно использовать альтернативные программы конструирования праймеров, такие как Primer3, а параметры по умолчанию переустанавливать для имитации значения модифицированных параметров. Как правило, установки переустанавливают в файле config.xml, который поступает вместе с программным обеспечением, однако это может отличаться при использовании другого программного обеспечения и типичной практикой является консультация в специальных руководствах по установлению параметров по умолчанию для каждого программного обеспечения. В программном обеспечении для конструирования праймеров можно переустанавливать следующие параметры:
1) Желаемую минимальную длину ампликона переустанавливают на >60<
2) Желаемую максимальную длину ампликона переустанавливают на >120<
3) Наименьшее расстояние между кандидатами переустанавливают на >3< (установкой по умолчанию является 30 п.н.)
4) Максимальный % GC зонда переустанавливают на >60< для создания возможности для увеличенного количества участков с AT-богатыми повторами
5) Среднюю Tm переустанавливают на >57< (по умолчанию - 59°C) для уменьшения средней Tm
6) Максимальную Tm переустанавливают на >60< (по умолчанию - 71)
7) Минимальную Tm переустанавливают на >51< (по умолчанию - 55)
8) Среднюю длину зонда переустанавливают на >28< (по умолчанию - 27)
9) Максимальную длину зонда переустанавливают на >38< (по умолчанию - 30)
10) Минимальную длину зонда переустанавливают на >25< (по умолчанию - 22)
[0106] Для конструирования праймеров для SNP, диапазон для нахождения цели для 3'-конца праймера был установлен на "малый" для недопущения для намеченного SNP праймеров в пределах 1 п.н. После переустановки всех параметров программу для конструирования праймеров можно запускать для последовательности с определением пары праймеров-кандидатов, которые подходят для новых параметров. Например, пользователь программного обеспечения может составлять список мишеней, который укажет программному обеспечению место поиска в геноме для конструирования праймеров. В настоящем примере намеченные области копировали и вставляли в приложение с графическим интерфейсом пользователя, которое в программном обеспечении DesignStudio используют для определения и направления конструирования праймеров. После ввода в программу намеченных областей, в программе активируют пункт "Create a Design File" (создать файл конструкции) для запуска средства и получения конструкций праймеров. В настоящем примере основным выходом являлся файл.txt, который содержал последовательности праймеров и/или некоторые из областей содержащие отрицательные результаты и являлись "не поддающимися конструированию", в случае чего намеченные последовательности было необходимо переопределить и перезапустить. Программное обеспечение, используемое в этом эксперименте, позволяло получать конструируемые праймеры, которые картировались на последовательности, специфичной для намеченной области. После переустановки параметров конструировали праймеры, которые не соответствовали общепринятым критериям конструирования праймеров для амплификации; однако которые обеспечивали возможность мультиплексной амплификации длинных STR и коротких SNP.
[0107] Примеры конструирования праймеров, направленных к STR, предпочтительных в способах, описываемых в настоящем документе, включают праймеры, перечисленные в таблице 1. Примеры праймеров, направленных к SNP, предпочтительных в способах, описываемых в настоящем документе, включают праймеры, перечисленные в таблице 2.
Таблица 1 - Направленные к STR праймеры без меток и размеры ампликонов
Таблица 2 - Праймеры, направленные к SNP
Пример 2 - ДНК-профилирование для организации банков данных
[0108] В этом примере описан эксперимент по технологическому процессу на фиг. 2. В этом примере не используют UMI, так как можно полагать, что образцы, получали у индивидуумов, идентификационные характеристики которых уже известны.
[0109] В этом эксперименте STR мультиплексировали с iSNP, как приведено в таблице 3.
Таблица 3 - Информативные для идентификации SNP и STR
[0110] Конечно, в приведенный выше список можно добавлять дополнительные SNP и STR. Примеры других потенциальных мишеней в качестве неограничивающих примеров включают маркеры, приведенные в таблице 4.
Таблица 4 - Примеры дополнительных STR и SNP для мультиплексирования
[0111] Праймеры конструировали так, чтобы они содержали последовательность геноспецифичного праймера для ПЦР на 3'-конце и адаптерную последовательность-метку на 5'-конце. В этом эксперименте прямые праймеры содержат последовательность-метку для адаптеров i5 TruSeq Custom Amplicon, а обратные праймеры содержат последовательность-метка для адаптеров i7 из набора для малых РНК TruSeq Small RNA. Метки можно использовать в качестве участков для праймеров для амплификации, а также участков для праймеров для секвенирования.
Последовательность-метка адаптера i5 5'TACACGACGCTCTTCCGATCT3' (SEQ ID NO:403)
Последовательность-метка адаптера i7 5'CTTGGCACCCGAGAATTCCA3' (SEQ ID NO:404)
[0112] Для баланса амплификации STR и SNP в мультиплексной реакции параметры конструирования праймеров для SNP модифицировали, как описано в примере 1. Исходный набор праймеров для SNP, сконструированный с использованием DesignStudio Illumina, представлял собой классические праймеры для ПЦР - короткие последовательности с высокими температурами плавления и практически без вторичной структуры. DesignStudio использовали для конструирования пользовательских зондов для ампликонов TruSeq и для получения обратно комплементарной последовательности располагающегося ниже зонда для получения обратного праймера для ПЦР. Однако эти праймеры не подвергались хорошему мультиплексированию и один неудачный праймер мог преобразовать анализ из хорошего в плохой (например, все димеры праймеров и отсутствие продукта) (фиг. 4.) В попытке получить более хорошие праймеры для мультиплексирования, использовали Primer3 (условно-бесплатное программное обеспечение), содержащее функцию неидеального связывания праймеров с библиотекой. Выявлено, что конструируемые Primer3 праймеры функционировали в мультиплексном анализа даже еще хуже, чем праймеры после DesignStudio. Неожиданно, полученные данные продемонстрировали, что праймеры для STR хорошо подвегрались мультиплексированию. Выявлено, что у хуже сконструированных пар праймеров, направленных к STR-мишеням неудачного мультиплекирования не происходило, тогда как у праймеров для SNP это происходило. В отличие от того, что известно как "хороший" праймер, праймеры для STR являются длинными, AT-богатыми и имеют низкие температуры плавления.
[0113] Праймеры для SNP переконструировали в соответствии с параметрами примера 1. Праймеры для всех целей смешивали вместе. Для этого примера пары праймеров для 56 STR смешивали с парами праймеров для 75 iSNP, aSNP и информативных для определения фенотипа SNP. В готовую смесь всех компонентов, необходимых для ПЦР, добавляли полимеразу (в этом примере - Phusion II с горячим стартом) и добавляли праймеры. Смесь пипетировали в лунки планшета для ПЦР, но амплификацию также можно проводить в пробирках и т.д. В планшет добавляли ДНК в виде очищенной ДНК в объеме 15 микролитров, однако также можно использовать лизированные экстракты из крови или буккальных образцов из мазков или необработанной фильтровальной бумаги или непосредственно из крови или буккальных образцов на картах FTA и т.д. Для этого эксперимента использовали очищенную контрольную ДНК 2800M в количестве 1 нг и 100 пг. Реакционные смеси подвергали ПЦР в течение определенного количества циклов (в случае этого примера 25 циклов) по приведенному ниже протоколу:
[0114] После проведения циклической процесса планшеты вынимали из термоциклера. Реакционную смесь доводили до 50 микролитров полимеразой (Kapa HiFi, Kapa Biosystems), готовой смесью для ПЦР, содержащей все компоненты, необходимые для ПЦР, и парей адаптеров (одним адаптером i7 и одним адаптером i5). Второй этап ПЦР проводили в течение определенного количества циклов (10 циклов в случае этого примера) с получением библиотек для секвенирования, по приведенному ниже протоколу:
[0115] После проведения циклической процесса планшет, содержащий готовую библиотеку, вынимали из термоциклера. На этой стадии образцы можно объединять в один объем и очищать в виде единого образца, например, с использованием магнитных гранул (SPRI). Также образцы можно очищать отдельно. Объединенный образец или библиотеку отдельных последовательностей можно подвергать количественному анализу основанным на кПЦР способом с использованием Fragment Analyzer или BioAnalyzer или с использованием PicoGreen и планшетного спектрофотометра (как в случае этого примера). Специалисту в данной области известно большое количество вариантов количественного анализа библиотек. Если библиотеки очищают по-отдельности, их можно нормализовать до концентрации 2 нМ каждой последовательности и объединять в один объем.
[0116] Объединения очищенных библиотек денатурировали, разбавляли, кластеризовали и секвенировали на устройстве для секвенирования MiSeq с секвенированием 350 циклов за проход и двумя чтениями индексов. После секвенирования образцы демультиплексировали в соответствии с адаптерными последовательностями и анализировали с применением конвейера Forensics Genomics (Illumina, Inc.). Чтения STR отделяли от чтений SNP и анализировали независимо. STR анализировали с использованием алгоритма, описанного в предшествующей патентной заявке (PCT/US2013/30867, полностью включенной в настоящий документ в качестве ссылки). Регистрировали количество повторов и любые вариации последовательностей вместе с количеством чтений. SNP анализировали с использованием явных признаков и регистрировали распознавания вместе с количеством чтений. Для локусов STR рассчитывали относительный баланс между аллелями (мин/мax%), баланс между локусами (%CV), частоты ошибок и частоты статтеров. Результаты для STR в исходном организованном в банке мультиплексе представлены на фиг. 5A-C. Баланс (средний баланс 80%), частоты статтеров (~3%) и ошибок (менее 5%) удовлетворяют планируемым входным требованиям для локусов, включенных в этот пример. %CV (~142%) рассчитывали с использованием всех 56 локусов. Даже при том, что использованные праймеры демонстрируют межлокусный баланс, полагают, что дальнейшая оптимизация праймером улучшит межлокусный баланс. Распознавания для известного локуса совпадают с опубликованными результатами для 2800M. Результаты для SNP представлены на фиг. 5D-E. Покрытие, распознавания аллелей, статтеры и другие артефакты для 56 локусов STR в больших мультиплексах представлены на фиг. 6. Эти диаграммы имитируют электрофореграммы, получаемые посредством технологии CE. Столбцы аналогичны пикам для различных аллеле (ось X), а количества чтений (ось Y) аналогичны ОЕФ. Покрытие для SNP в любом участке составляло 10-2500× в зависимости от SNP, однако каждый SNP, который входил в мультиплексную реакцию, был подсчитан, и предоставлено его точное распознавание.
Пример 3 - ДНК-профилирование для работы по изучению криминальных дел
[0117] В этом примере описан эксперимент по технологическому процессу на фиг. 3. В этом примере в праймеры включены UMI, так как можно полагать, что образцы получены у индивидуумов, личность которых еще не известна.
[0118] Для этого эксперимента, STR мультиплексировали с iSNP, aSNP и информативными для определения фенотипа SNP, как представлено в таблице 5.
Таблица 5 STR и SNP для работы по изучению материалов уголовных дел
[0119] В этом примере в праймеры для STR включены UMI. В этих примерах UMI содержали только праймеры для STR, однако при желании UMI могут содержать и праймеры для STR, и праймеры для SNP и этот вариант из практического осуществления не исключается. Однако в этом примере в демонстративных целях UMI содержали только праймеры для STR. Уникальные молекулярные идентификаторы включали в течение двух циклов ПЦР (фиг. 3). Во-первых, как в примере 2, праймеры для ПЦР содержат последовательность геноспецифичного праймера для ПЦР на 3'-конце и адаптерную последовательность-метку на 5'-конце, такую же, как в последовательностях-метках, используемых в примере 2 для последовательностей i5 и i7. В этом эксперименте UMI расположены между последовательностью геноспецифичного праймера и последовательностью-меткой. В случае этого примера для UMI использовали пять выбираемых случайно оснований на прямых и обратных праймерах. Праймеры смешивали вместе со всеми мишенями. Смесь праймеров содержала пары праймеров для 26 STR аутосом и пары праймеров для 86 SNP (92 охваченных SNP). В готовую смесь всех компонентов, необходимых для ПЦР, добавляли полимеразу (в этом примере - Phusion II с горячим стартом) и добавляли праймеры. Смесь пипетировали в лунки планшета для ПЦР. В планшет добавляли ДНК в виде очищенной ДНК, оптимально - 1 нг. Как и в примере 2, тестировали контрольную ДНК 2800M в количестве 1 нг. Мультиплексную реакционную смесь подвергали двум циклам ПЦР по приведенному ниже протоколу:
[0120] После проведения циклической процесса образцы вынимали из термоциклера и в реакционную смесь добавляли связывающий одноцепочечную ДНК белок (SSB) E. coli. Полагали, что SSB уменьшает количество димеров праймеров, образуемых неиспользованными мечеными геноспецифичными праймерами и предотвращает любую дальнейшую амплификацию с этих праймеров. SSB инкубировали с образцом на льду, альтернативно также можно использовать инкубацию при комнатной температуре или 37°C. После этой инкубации в готовую смесь всех компонентов, необходимых для ПЦР, добавляли полимеразу (в этом примере - Phusion II с горячим стартом), и готовую смесь добавляли в образец с парой адаптеров (адаптеры i7 и i5) и проводили циклический процесс с определенным количеством циклов (в этом эксперименте - 34 цикла) по приведенному ниже протоколу:
[0121] Образцы очищали гранулами SPRI и библиотеки отдельных последовательностей можно подвергать количественному определению способом на основе qPCR, с использованием Fragment Analyzer (как в случае этого примера) или BioAnalyzer или с использованием PicoGreen и планшетного спектрофотометра. Библиотеки нормализовали до 2 нМ каждой концентрации и объединяли в одном объеме.
[0122] Объединения очищенных библиотек денатурировали, разбавляли, кластеризовали и секвенировали на устройстве для секвенирования MiSeq с секвенированием 350 × 100 циклов за проход и двумя чтениями индексов. Данные после секвенирования определяли, как описано в примере 2. Однако так как праймеры содержали UMI, UMI использовали для отбрасывания данных, используя дубликаты ПЦР с удалением ошибок секвенирования и ПЦР и артефактов. SNP анализировали с использованием явных признаков и регистрировали распознавания вместе с количеством чтений. Рассчитывали относительный баланс между аллелями (мин/мax%), баланс между локусами (%CV), частоты ошибок и частоты статтеров (только для STR). Результаты для исходного мльтиплекса для работы по изучению материалов судебных дел представлены на фиг. 7A-E. Покрытие, распознавания аллелей, статтеры и другие артефакты для 26 локусов STR в большом мультиплексе представлены на фиг. 8. Эти диаграммы имитируют электрофореграммы, получаемые посредством CE. Столбцы аналогичны пикам, а количества чтений аналогичны ОЕФ. Покрытие для SNP в любом участке составляло 10-5500× в зависимости от SNP, однако каждый SNP, который входил в мультиплексную реакцию, был подсчитан, и для него предоставлены приемлемые результаты.
[0123] Одним из результатов, которые получали при этих исследованиях, являлось то, что показано, что статтер является артефактом ПЦР. Это предполагали многие исследователи (и проскальзывание полимеразы показано при различных видах рака толстого кишечника человека), но для криминалистического анализа это показано не было. Для демонстрации того, что статтер фактически является артефактом ПЦР можно использовать UMI. Продукты с n+1 или n-1 повторами содержат те же UMI, что и продукты с правильным количеством повторов (фиг. 9). На фиг. 9A для каждого локуса представлены результаты без коррекции по UMI в сравнении с фиг. 9B где коррекцию по UMI проводят. Как продемонстрировано, без коррекции по UMI баланс между аллелями не является таким хорошим, когда коррекцию по UMI проводят. Кроме того, без коррекции по UMI наблюдают значительно больше статтеров. Часть столбца выше разделяющей столбец линии представляет ошибку секвенирования, а ниже линии представляет правильную последовательность в последовательности STR. При коррекции по UMI ошибки значительно уменьшаются. Например, в локусе SE33 присутствует ошибка, которая при коррекции по UMI исчезает. Коррекция ошибок можно может являться крайне важной для работы по изучению криминальных дел для обеспечения как можно более точного ДНК-профилирования.
Пример 4 - ДНК-профилирование с использованием образцов 12 индивидуумов
Способы и материалы
[0124] ДНК образцов, полученных у 12 индивидуумов (образцы №№: 1, 3, 4, 5, 6, 7, 10, 13, 14, 15, 16, 17), и один референсный геном (2800M) тестировали по технологическому процессу на фиг. 3. В этом эксперименте в праймеры для STR включали UMI, как описано в примере 3. Каждый образец анализировали с использованием препаративного набора Illumina® ForenSeq DNA Signature Library Prep Kit в секвенаторе MiSeq в двух повторениях. Для каждой репликации с использованием смеси праймеров ДНК B: смесь собранных образцов, которая содержит праймеры для 61 STR и амелогенина, 95 информативных для идентификации SNP, 56 информативных для установления родства SNP, 22 информативных для определения фенотипа SNP (2 SNP для установления родства также использовали для прогноза фенотипа), использовали один нг ДНК.
Установки по-умолчанию
[0125] STR: аналитический порог=6,5%; порог интерпретации =15%. SNP: аналитический порог=3%; порог интерпретации=15%.
[0126] Высок уровень распознавания при секвенировании, такой как покрытие и распознаваемые локусы, для ДНК-профилирования образцов, полученных у 12 индивидуумов, представлены на фиг. 12. Как можно видеть, каждый локус был покрыт по меньшей мере 100000 чтений в обоих повторениях. Только в двух образцах распознавание STR получить не удалось (1 из 61). Все 173 SNP у всех индивидуумов во всех повторениях были успешно распознаны. Распознавания STR в двух полученных у индивидуумов образцах представлены на фиг. 16. Распознавания SNP в двух полученных у индивидуумов образцах представлены на фиг. 17. На фиг. 13 представлены статистические параметры совокупности, такие как вероятность случайного совпадения (RMP) авто-STR National Institute of Standards and Technology (NIST), 95% доверительный интервал частоты гаплотипов STR Y-хромосомы NIST, RMP iSNP dbSNP и RMP STR из базы данных STR Y-хромосомы США.
[0127] В образцах, полученных у 12 индивидуумов и у референсного индивидуума, в эксперименте прогнозировали фенотипы, такие как цвет глаз и цвет волос, на основе генотипа pSNP и в сравнении с самостоятельно указываемыми фенотипами (фиг. 14). Наблюдали высокую степень корреляции между прогнозируемыми и сообщаемыми фенотипами.
[0128] В эксперименте с использованием генотипа 56 aSNP прогнозировали родство на основе образцов, полученных у 12 индивидуумов. Для каждого образца, получаемого у индивидуума, рассчитывали показатели PCA1 и PCA3 и наносили на график в зависимости от референсных образцов на диаграмму родства. Как представлено на фиг. 15 родство на основе образцов, полученных у индивидуумов, можно прогнозировать на основе расположения на диаграмме родства. В диаграмму родства (круги) включено четырнадцать центроидных точек. На основе ближайшей центроидной точки на основе образца прогнозировали родство каждого индивидуума.
[0129] Также эксперимент по ДНК-профилированию продемонстрировал высокий уровень внутрилокусного баланса и в локусах STR и в локусах SNP, как можно видеть на фиг. 18, и низкий уровень статтеров, как можно видеть на фиг. 19.
[0130] У шести из 12 индивидуумов и 2800M содержался по меньшей мере один изометрический гетерозиготный локус, который представлен на фиг. 20. Изометрический гетерозиготный локус определен как STR, который содержит то же количество повторов, две различные последовательности, которые равным образом сбалансированы. С использованием информации о вариантах в STR D8S1179, 13 аллелей образца 15 были прослежены у бабушки, образца 17 (фиг. 21). Подобную информацию о вариантах в STR D13S317 использовали для отслеживания аллелей образца 15. Однако в этом случае происхождение каждого аллеля выявить не удалось (фиг. 22).
Пример 5 - ДНК-профилирование для использования в исследованиях, криминалистике или при установлении отцовства
[0131] Этот пример основан на технологическом процессе, описанном в руководстве ForenSeq™ DNA Signature Prep Guide (Illumina, San Diego, CA), содержание которого, таким образом, полностью включено в качестве ссылки.
[0132] Для этого примера можно использовать очищенную ДНК или неочищенный лизат. Для очищенной ДНК, каждый образец в количестве 1 нг разбавляют до 0,2 нг/мкл не содержащей нуклеаз водой. Для неочищенного лизата каждый образец в объеме 2 мкл разбавляют 3 мкл не содержащей нуклеаз воды. Готовую смесь готовят для восьми или более реакций. Для каждой реакции в 1,5 мл микроцентрифужную пробирку добавляют 5,4 мкл реакционной смеси PCR1 ForenSeq, 0,4 мкл смеси ферментов ForenSeq и 5,8 мкл смеси праймеров ДНК (A или B). 10 мкл готовой смеси переносят в каждую лунку планшета для ПЦР и добавляют ДНК или лизат. Мультиплексную реакционную смесь подвергают ПЦР по приведенному ниже протоколу:
98°C в течение 3 мин.
8 циклов, состоящих из:
96°C в течение 45 сек.
80°C в течение 30 сек.
54°C в течение 2 минут с указанным режимом приращения
68°C в течение 2 минут с указанным режимом приращения
10 циклов, состоящих из:
96°C в течение 30 сек.
68°C в течение 3 минут с указанным режимом приращения
68°C в течение 10 мин.
Поддержание при 10°C.
[0133] После проведения циклической процесса образцы вынимали из термоциклера. В образцы добавляли реакционную смесь PCR2 ForenSeq с парой адаптеров (адаптеры i7 и i5) и проводили циклический процесс в течение 15 циклов по приведенному ниже протоколу:
98°C в течение 30 сек.
15 циклов, состоящих из:
98°C в течение 20 сек.
66°C в течение 30 сек.
68°C в течение 90 сек.
68°C в течение 10 мин.
Поддержание при 10°C.
[0134] Образцы очищали с использованием гранул для очистки образцов и библиотеки нормализовали о объединяли и в одном объеме. При подготовке к секвенированию объединенные библиотеки разбавляли в гибридизационном буфере (HT1), добавляли контроль секвенирования человека (HSC) и подвергали тепловой денатурации.
Пример 6 - генотипирование с использованием деградированной ДНК
[0135] На фиг. 23 представлены результаты генотипирования с использованием расщепленной и/или обработанной ДНКазой ДНК, представляющей деградированную ДНК. Как продемонстрировано, при использовании фрагментированной ДНК более 50% локусов STR и SNP были распознаны корректно. С ДНК менее 100 п.н. достигали вероятность случайного совпадения (RMP) 10-19. Также с использованием деградированной ДНК корректно прогнозировали родство.
Пример 7 - Чувствительность генотипирования
[0136] Фиг. 24 и 25 демонстрируют результаты исследования чувствительности генотипирования на субнанограммовых уровнях вводимой ДНК от 7,82 пг до 1 нг. Как продемонстрировано и для STR, и для SNP при вводимых 125 нг ДНК успешно распознано было 100% аллелей. При уровне вводимой ДНК всего 7,82 пг успешно распознано было 50% аллелей. Для большинства локуса при вводимых 1 нг ДНК внутрилокусный баланс составлял более 70%.
[0137] Все числа, выражающие количества ингредиентов, условия реакций и т.п., используемые в описании следует понимать, как во всех случаях модифицированные термином "приблизительно". Таким образом, если не указано противоположное, числовые параметры, указанные в настоящем документе, представляют собой приближения, которые варьируют в зависимости от желаемых свойств, которые стремятся получать. По меньшей мере, и не в попытках ограничить применения доктрины эквивалентов к области любой формулы изобретения в любой заявке, претендующей на приоритет настоящей заявки, каждый числовой параметр следует рассматривать, учитывая количество значащих разрядов и стандартных правил округления.
[0138] Все цитируемые в настоящем документе ссылки, включая в качестве неограничивающих примеров опубликованные и неопубликованные заявки, патенты, и литературные ссылки полностью включены в настоящий документ в качестве ссылки и, таким образом, являются частью настоящего описания. В тех случаях, когда публикации и патенты или патентные заявки, включенные в качестве ссылки, противоречат информации, приводимой в настоящем описании, подразумевается, что настоящее описание заменяет и/или имеет приоритет в отношении любого такого противоречащего материала.
[0139] Не следует полагать, что цитирование приведенных выше публикаций или документов представляет собой допущение, что любое из указанного выше представляет собой соответствующих известный уровень техники, а также это не составляет никакого допущения относительно содержания или даты этих публикаций или документов.
[0140] Хотя настоящее изобретение полностью описано в отношении его вариантов осуществления со ссылкой на сопровождающие чертежи, следует отметить, что специалистам в данной области очевидны различные изменения и модификации. Такие изменения и модификации следует понимать, как включенные в объем настоящего изобретения. Различные варианты осуществления изобретения следует понимать так, что они представлены только в качестве примера, а не для ограничения. Подобным образом, различные диаграммы могут отображать, пример архитектуры или другой конфигурации для изобретения, который приведен для помощи в понимании характеристик и функциональности, которые включены в изобретение. Изобретение не ограничено проиллюстрированными примерами архитектуры или конфигурации, но его можно реализовывать с использованием ряда альтернативных архитектур и конфигураций. Кроме того, хотя изобретение описано выше в отношении различных иллюстративных вариантов осуществления и реализаций, следует понимать, что различные характеристики и функциональность, описанные в одном или нескольких из конкретных вариантов осуществления не ограничены в их применимости в том конкретном варианте осуществления, с которым они описаны. В отличие от этого их можно применять, отдельно или в определенной комбинации, в одном или нескольких других вариантах осуществления изобретения, вне зависимости от того описаны ли такие варианты осуществления или нет, и вне зависимости от того представлены ли такие характеристики как часть описанного варианта осуществления или нет. Таким образом, сферу действия и объем изобретения не следует ограничивать никаким из описанных выше иллюстративных вариантов осуществления.
[0141] Если явно не сказано иначе, термины и фразы, используемые в настоящем документе и его вариантах осуществления, следует понимать как неограничивающие в противоположность лимитирующим. В качестве примеров указанного выше: термин "включающий" следует читать, как означающий "включающий без ограничений" или т.п.; термин "пример" используют для предоставления иллюстративных образцов обсуждаемого объекта, а не их исчерпывающий или ограничивающий список; а такие характеристики как "общепринятый", "традиционный", "нормальный", "стандартный", "известный" и термины со сходным значением, не следует рассматривать, как ограничивающие описываемый объект данным временным периодом или объектом, доступным в данное время. Вместо этого эти термины следует читать, как включающие общепринятые, традиционные, нормальные или стандартные технологии, которые могут быть доступными, известными в настоящее время или в любое время в будущем. Подобным образом, группу объектов, связанных союзом "и" не следует читать, как требующую, чтобы каждый и любой из этих элементов присутствовал в группе, но вместо этого следует читать как "и/или", если из контекста не очевидно или явно не указано иначе. Подобным образом, группу объектов связанных союзом "или", не следует читать, как требующую взаимоисключения в этой группе, но вместо этого, их следует читать как "и/или", если из контекста не очевидно или явно не указано иначе. Кроме того, хотя объекты, элементы или компоненты изобретения могут быть описаны или заявлены в единственном числе, предусмотрено, что в объем входит множественное число, если явно не указаны ограничения единственным числом. Например, "по меньшей мере один" может относиться к единственному или множественному числу и не ограничен ни одним из них. Присутствие в некоторых случаях расширяющих область слов и фраз, таких как "один или несколько", "по меньшей мере", "но не ограничиваясь этим" или других подобных фраз, не следует считать означающими, что в тех случаях, когда таких расширяющие область фразы могут отсутствовать, подразумевается или требуется более узкий диапазон.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Illumina, Inc.
Stephens, Kathryn M.
Holt, Cydne
Davis, Carey
Jager, Anne
Walichiewicz, Paulina
Han, Yonmee
Silva, David
Shen, Min-Jui Richard
Amini, Sasan
Steemers, Frank J.
<120> СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ ДНК-ПРОФИЛИРОВАНИЯ
<130> ILLINC.276WO/IP-1192
<150> 62/103,524
<151> 2015-01-14
<150> 62/043,060
<151> 2014-08-28
<150> 61/940,942
<151> 2014-02-18
<160> 404
<170> FastSEQ for Windows Version 4.0
<210> 1
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 1
ccctgggctc tgtaaagaa 19
<210> 2
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 2
atcagagctt aaactgggaa gctg 24
<210> 3
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 3
acagtaactg ccttcataga tag 23
<210> 4
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 4
gtgtcagacc ctgttctaag ta 22
<210> 5
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 5
tgattttcct ctttggtatc cttatgtaat 30
<210> 6
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 6
acaacatttg tatctttatc tgtatcct 28
<210> 7
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 7
tttgtatttc atgtgtacat tcgtatc 27
<210> 8
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 8
acctatcctg tagattattt tcactgtg 28
<210> 9
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 9
ctctgagtga caaattgaga cctt 24
<210> 10
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 10
ttaacttctc tggtgtgtgg agatg 25
<210> 11
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 11
tttggtgcac ccattacccg 20
<210> 12
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 12
aggaggttga ggctgcaaaa 20
<210> 13
<211> 35
<212> ДНК
<213> Homo sapiens
<400> 13
caccaaatat tggtaattaa atgtttacta tagac 35
<210> 14
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 14
taaagggtat gatagaacac ttgtc 25
<210> 15
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 15
caaaggcaga tcccaagctc t 21
<210> 16
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 16
tgtgtgtgca tctgtaagca t 21
<210> 17
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 17
tggtgtgtat tccctgtgcc 20
<210> 18
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 18
gcagtccaat ctgggtgaca 20
<210> 19
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 19
ccaatctggt cacaaacata ttaatgaa 28
<210> 20
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 20
tttcccttgt cttgttatta aaggaac 27
<210> 21
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 21
ttcccattgg cctgttcctc 20
<210> 22
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 22
ctgtacacag ggcttccgag 20
<210> 23
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 23
gctgagtgat ttgtctgtaa ttg 23
<210> 24
<211> 37
<212> ДНК
<213> Homo sapiens
<400> 24
gaactcacag attaaactgt aaccaaaata aaattag 37
<210> 25
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 25
caatagtgtg caaggatggg tg 22
<210> 26
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 26
tctgtggttc tccagcttac 20
<210> 27
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 27
cttagggaac cctcactgaa tg 22
<210> 28
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 28
gtccttgtca gcgtttattt gc 22
<210> 29
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 29
ttgggttgag ccataggcag 20
<210> 30
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 30
gcatccgtga ctctctggac 20
<210> 31
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 31
gttatgggac ttttctcagt ctccat 26
<210> 32
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 32
gagactaata ggaggtagat agactgg 27
<210> 33
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 33
gagactgtat tagtaaggct tctc 24
<210> 34
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 34
cctggactga gccatgctcc 20
<210> 35
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 35
cagtcctgtg ttagtcagga ttc 23
<210> 36
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 36
tcaagggtca actgtgtgat gt 22
<210> 37
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 37
cttctgaaag cttctagttt acct 24
<210> 38
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 38
ttgcttattt gtgggggtat ttca 24
<210> 39
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 39
aagaattctc ttatttgggt tattaattg 29
<210> 40
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 40
aaattgtgga caggtgcggt 20
<210> 41
<211> 34
<212> ДНК
<213> Homo sapiens
<400> 41
ccatgtaaaa atacatgcat gtgtttattt atac 34
<210> 42
<211> 35
<212> ДНК
<213> Homo sapiens
<400> 42
tgattaaaaa gaatgaaggt aaaaatgtgt ataac 35
<210> 43
<211> 34
<212> ДНК
<213> Homo sapiens
<400> 43
ccaaatgttt atgattaatc ttttaaattg gagc 34
<210> 44
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 44
gtaacaaggg ctacaggaat catgag 26
<210> 45
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 45
tcatccactg aaatgactga aaaatag 27
<210> 46
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 46
aggtacataa cagttcaata gaaag 25
<210> 47
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 47
gagttattca gtaagttaaa ggattgcag 29
<210> 48
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 48
gggagccagt ggatttggaa acag 24
<210> 49
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 49
gcatggtgag gctgaagtag 20
<210> 50
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 50
ctaacctatg gtcataacga ttttt 25
<210> 51
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 51
gatgataaga ataatcagta tgtgacttgg 30
<210> 52
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 52
ataggttaga tagagatagg acagatgata 30
<210> 53
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 53
ccctaccgct atagtaactt gc 22
<210> 54
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 54
cacgtctgta attccagctc cta 23
<210> 55
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 55
ggaagcgtgt actagagttc ttcag 25
<210> 56
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 56
ggacagcctc catatccaca tg 22
<210> 57
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 57
ttcctactgc cccaccttta ttg 23
<210> 58
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 58
tttatggtct cagtgcccct caga 24
<210> 59
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 59
tcataatcac atatcacatg agc 23
<210> 60
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 60
aaacagaacc aggggaatga a 21
<210> 61
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 61
tgaaactaaa gtcaaatggg gctac 25
<210> 62
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 62
taaggggtga cacctctctg gata 24
<210> 63
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 63
cccagcctac atctaccact tcatg 25
<210> 64
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 64
ctaatgttcg tatggacctt tggaaagc 28
<210> 65
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 65
gtctccagta cccagctagc ttag 24
<210> 66
<211> 22
<212> ДНК
<213> Homo sapiens
<400> 66
tctcccaacc tgccctttat ca 22
<210> 67
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 67
tttgggctga cacagtggct 20
<210> 68
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 68
ttgatcaaca caggaggttt gacc 24
<210> 69
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 69
tataccactt tgatgttgac actagtttac 30
<210> 70
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 70
cctgtctatg gtctcgattc aat 23
<210> 71
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 71
tgcatgacag agggagattc t 21
<210> 72
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 72
agaggggaaa tagtagaatg aggatg 26
<210> 73
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 73
gccaaactct attagtcaac gttc 24
<210> 74
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 74
ctggttctct agctcacata cagt 24
<210> 75
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 75
tttaccccta acaagaaaaa aagaagaa 28
<210> 76
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 76
cagtgtgaga agtgtgagaa gtgc 24
<210> 77
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 77
gacaccatgc caaacaacaa c 21
<210> 78
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 78
atctatctat tccaattaca tagtcc 26
<210> 79
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 79
tcattatacc tacttctgta tccaactctc 30
<210> 80
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 80
ggaacacaat tatccctgag tagcag 26
<210> 81
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 81
ggtagcataa tagaaatttt atgagtggg 29
<210> 82
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 82
gaagacagac ttcaatatca cagaacatcg 30
<210> 83
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 83
gtgtatctat tcattcaatc atacaccc 28
<210> 84
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 84
ctccctggtt gcaagcaatt gcc 23
<210> 85
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 85
ccaaaattag tggggaatag ttgaac 26
<210> 86
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 86
gtcgagatca caccattgca tttc 24
<210> 87
<211> 24
<212> ДНК
<213> Homo sapiens
<400> 87
gcctggcttg gaattctttt accc 24
<210> 88
<211> 35
<212> ДНК
<213> Homo sapiens
<400> 88
tttaagtctt taatctatct tgaattaata gattc 35
<210> 89
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 89
ctttaagagg agtctgctaa aaggaatg 28
<210> 90
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 90
tcaccagaag gttgcaagac 20
<210> 91
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 91
tctggcgaag taacccaaac 20
<210> 92
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 92
tcgagtcagt tcaccagaag g 21
<210> 93
<211> 17
<212> ДНК
<213> Homo sapiens
<400> 93
ggaaccagtg agagccg 17
<210> 94
<211> 19
<212> ДНК
<213> Homo sapiens
<400> 94
ctcagagtgc tgaacccag 19
<210> 95
<211> 32
<212> ДНК
<213> Homo sapiens
<400> 95
gtatttattc atgatcagtt cttaactcaa cc 32
<210> 96
<211> 41
<212> ДНК
<213> Homo sapiens
<400> 96
ctacctaata tttatctata tcattctaat tatgtctctt c 41
<210> 97
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 97
ctctaaaggt tttttttggt ggcataag 28
<210> 98
<211> 32
<212> ДНК
<213> Homo sapiens
<400> 98
gattaataca acaaaaattt ggtaatctga aa 32
<210> 99
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 99
caacctaagc tgaaatgcag atattc 26
<210> 100
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 100
gttatgaaac gtaaaatgaa tgatgactag 30
<210> 101
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 101
gcagtctcat ttcctggaga tgaagg 26
<210> 102
<211> 21
<212> ДНК
<213> Homo sapiens
<400> 102
cttgggctga ggagttcaat c 21
<210> 103
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 103
gccagtaaga ataaaattac agcatgaag 29
<210> 104
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 104
gaataatcta ccagcaacaa tggct 25
<210> 105
<211> 20
<212> ДНК
<213> Homo sapiens
<400> 105
tgcccaatgg aatgctctct 20
<210> 106
<211> 33
<212> ДНК
<213> Homo sapiens
<400> 106
gctccatctc aaacaacaaa aacacaaaaa atg 33
<210> 107
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 107
gggtcattga acctcatgct ctg 23
<210> 108
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 108
ccccccaaaa ttctactgaa gtaaa 25
<210> 109
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 109
taacaggata aatcacctat ctatgtat 28
<210> 110
<211> 23
<212> ДНК
<213> Homo sapiens
<400> 110
gctgaggaga atttccaaat tta 23
<210> 111
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 111
cccgcaaact aactaggata aatctcta 28
<210> 112
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 112
cgacatggga aatgtcagat cataagac 28
<210> 113
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 113
ccagggagtg aaaaatcctt ttatcatc 28
<210> 114
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 114
gaggatgaag gttagagcca gacct 25
<210> 115
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 115
tgtggaataa actgaaggct aaagaaaa 28
<210> 116
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 116
caagccctat gccaaggata taacaatg 28
<210> 117
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 117
gaggttttac tgtattagga gttcccac 28
<210> 118
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 118
cagatgtgag atgataattt cgttctcc 28
<210> 119
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 119
ttgttcttct ccatcccatt tcaccc 26
<210> 120
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 120
cttgtacatt cccttatctg ctatgtgg 28
<210> 121
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 121
ctctctttgg agttttatgt gttgctac 28
<210> 122
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 122
ctctgatgat gtgcaagaaa ggtaggta 28
<210> 123
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 123
tcagactatg ttttaaggag actatgagg 29
<210> 124
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 124
ctaagtatct accaatgtgc tacgtacc 28
<210> 125
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 125
cacgtggatg atatggtttc tcaagg 26
<210> 126
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 126
agcacctata tattatacct gaaagcat 28
<210> 127
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 127
cccatgattt tcttgtggtg agaatttc 28
<210> 128
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 128
caccctctgt actttaattt gacttccc 28
<210> 129
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 129
gtttttcttc attcccatgt tgtgtac 27
<210> 130
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 130
cactcttctg aatcctggtc aacaac 26
<210> 131
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 131
caagttatat catagagtct acgacccc 28
<210> 132
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 132
ctgcaactat cagtctctgc ccttattc 28
<210> 133
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 133
gatgtgtctc aaactgttta ttgtgagg 28
<210> 134
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 134
gaactcattt atccagagac ctgttctc 28
<210> 135
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 135
cataatacaa cctgtctttg gagttact 28
<210> 136
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 136
gtgaccagta gttctatgag caagtatg 28
<210> 137
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 137
ccacattgta tggtttttag gcaccatg 28
<210> 138
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 138
ctaataagtg ggacagttaa gagaaggc 28
<210> 139
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 139
caagacaagc gattgaaaga agtggat 27
<210> 140
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 140
ccttgtcaat ctttctacca gagggtaa 28
<210> 141
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 141
gaatcatagc ttgtgttggt caggg 25
<210> 142
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 142
gaattacaag tatttgcatc ccagcct 27
<210> 143
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 143
gaccaacttg gctttaacag atgcaaat 28
<210> 144
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 144
tccttacctt taagactttt cctatttg 28
<210> 145
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 145
cattatctcg tcatacttcc ctgtcttg 28
<210> 146
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 146
gcatcaaatt caccagtgaa attattga 28
<210> 147
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 147
atgagtacat tattcaactg ttttggag 28
<210> 148
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 148
cagccatgtt gtaaacattt ttacggtc 28
<210> 149
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 149
gcacattcta agaactggtg attctatc 28
<210> 150
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 150
gctagaaaaa gctgagatag ctgtgaag 28
<210> 151
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 151
ccttgaagct cattctttgt tgtccc 26
<210> 152
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 152
ctggacacca gaccaaaaac aaataacc 28
<210> 153
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 153
gtaattagag ggcagtgagg cttttaa 27
<210> 154
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 154
ctccagaagc tactgggata ttaattag 28
<210> 155
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 155
tgagccaaat cagcaatata ataggact 28
<210> 156
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 156
cctagaacca caattatctg tctttggc 28
<210> 157
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 157
ccattgattc tctacagttc tgcaggta 28
<210> 158
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 158
ctccacactt tatacaggtg aaatctga 28
<210> 159
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 159
catttttctc tccttctgtc tcaccttc 28
<210> 160
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 160
gcttctcttt cccttatgta tctctctc 28
<210> 161
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 161
ggcttttgaa gaaaaacact aacctgtc 28
<210> 162
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 162
cacctatggg ctcttcttat ttctcc 26
<210> 163
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 163
catttgatag ccatttgggt tgtttcca 28
<210> 164
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 164
ccatcacact atcctgacat gaacaaat 28
<210> 165
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 165
gaagatttgc atcccagtga aagcac 26
<210> 166
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 166
gcacttcata aagaatcagt caggatgc 28
<210> 167
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 167
ggagaatcag gaaatagtca cttcctac 28
<210> 168
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 168
catttgacct tctagccaaa tgaagtac 28
<210> 169
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 169
ggaatttctg agaataacat tgcctctc 28
<210> 170
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 170
catatgttgg gggagctaaa cctaatga 28
<210> 171
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 171
cactgtgacc acagcatctt ttaactc 27
<210> 172
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 172
gggtaaagaa atattcagca catccaaa 28
<210> 173
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 173
gagtatccct tatctaaaat gctggtcc 28
<210> 174
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 174
ctttttctct taccggaact tcaacgac 28
<210> 175
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 175
cctcattaat atgaccaagg ctcctctg 28
<210> 176
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 176
tgactctaat tggggatgtg gtaattag 28
<210> 177
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 177
gacctaacct ggagaaaacc ggaga 25
<210> 178
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 178
gtttctcttc tctgaacctt tgtctcag 28
<210> 179
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 179
gcaaacacac aaagataggt tcgagttt 28
<210> 180
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 180
catatcaagt gctttctgtt gacatttg 28
<210> 181
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 181
ctgaaaagtg ctacgtaaga ggtcattg 28
<210> 182
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 182
catctgagtg tgagaagagc ctcaa 25
<210> 183
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 183
cccagcaaaa acttcttttc tccagtaa 28
<210> 184
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 184
gctaggaaag ttttctctct ggttcaca 28
<210> 185
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 185
gaatatctat gagcaggcag ttagcag 27
<210> 186
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 186
ctaatcagtg tcactatgtg tgagctat 28
<210> 187
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 187
catcatacag actcaaggag cttagctg 28
<210> 188
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 188
ctttccaagc cttggaaaac acagaaaa 28
<210> 189
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 189
gtaccttata aatcacggag tgcagac 27
<210> 190
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 190
caagtggtaa gagatgactg aggtcaa 27
<210> 191
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 191
cttcttctct tagaaggaca ctggtcag 28
<210> 192
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 192
gttatggagg attggtaaga accagag 27
<210> 193
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 193
gagctgttta agggtaaagg ggtagtta 28
<210> 194
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 194
gcagacaaaa ccatgacaat gatcttag 28
<210> 195
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 195
cccatgatga aacagtttgc actaaatg 28
<210> 196
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 196
ctcaattttc ttgtccctgc tttcatg 27
<210> 197
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 197
ttagaaattc cagatagagc taaaactg 28
<210> 198
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 198
gttaggaaaa gaacccaggt gtttt 25
<210> 199
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 199
gcaaaagtaa atacaaaggc atacttt 27
<210> 200
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 200
caatgcaaaa gaaaggtcct tactcgac 28
<210> 201
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 201
catttctaaa ctctaaaaca aacatttg 28
<210> 202
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 202
ggtccttaac ctattaaatt ttaatgag 28
<210> 203
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 203
gactttcaat ttatgtcagc atttaaaa 28
<210> 204
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 204
cctcttggtt gcattggatt ctcattg 27
<210> 205
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 205
tctccatgaa acttgggtta attttgc 27
<210> 206
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 206
tgtctggaag ttcgtcaaat tgcag 25
<210> 207
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 207
gtagcataaa acattccaaa aattcaat 28
<210> 208
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 208
tgctttaaag atacaggtta tctgtattac 30
<210> 209
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 209
ctctccgtta ctttcttcct gccttt 26
<210> 210
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 210
gatcctgaga ttcacctcta gtccct 26
<210> 211
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 211
ccgtaccagg tacctagcta tgtact 26
<210> 212
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 212
ctttctgttt tgtccatctg aaattct 27
<210> 213
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 213
caaagttaag tatcaccatc cagctgg 27
<210> 214
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 214
atagggatag ctgataagaa acatgacc 28
<210> 215
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 215
cttaataaga cgctgcatct gccca 25
<210> 216
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 216
tccaggagac atttgttcat ataagtga 28
<210> 217
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 217
agacactttt cagtatccat ttagaaac 28
<210> 218
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 218
gtttcacatg tgcatgcttt tgggt 25
<210> 219
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 219
ccaaagctat tctctctttt gggtgc 26
<210> 220
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 220
gaaagttcac ttcagatgtt caaagcc 27
<210> 221
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 221
gggtttcagt ctgcaacaag atcttg 26
<210> 222
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 222
tggagatcaa tatttagcct taacatat 28
<210> 223
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 223
gactgtttct catcctgtta ttatttgt 28
<210> 224
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 224
aacacacaga aacatcaagc tgagc 25
<210> 225
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 225
ttcctgacat tctccttctt ctatctg 27
<210> 226
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 226
tatgacgcct ggattttcac aacaac 26
<210> 227
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 227
cagagactat ggatggtatt taggtcaa 28
<210> 228
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 228
actttgtgtg gctgagagag agaaa 25
<210> 229
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 229
tgagtgttct ctgtattttc ttactctaag 30
<210> 230
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 230
atttttggtc attgttgaca cttcacc 27
<210> 231
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 231
ggtgttaggg agacaggcat gaatg 25
<210> 232
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 232
tgaaactttt caactctcct accgcc 26
<210> 233
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 233
gttaaaattg ccactaatta tgtgtttt 28
<210> 234
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 234
aactgatcct atgcagcaag atctttg 27
<210> 235
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 235
gatgcttgca aacaaagact gaaaagg 27
<210> 236
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 236
gtctgtgtgt cctctgagat gatgaatg 28
<210> 237
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 237
gggaggaaga aaacagagag tcttga 26
<210> 238
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 238
agtttgttgg cttcttttga gaagtatc 28
<210> 239
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 239
ggcagatgaa gtagtagata tctggctg 28
<210> 240
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 240
gttcagtgtc aattttgacc agatatt 27
<210> 241
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 241
agacatagga cacaccattt tattgtct 28
<210> 242
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 242
tcaaaatatt tggctaaact attgccgg 28
<210> 243
<211> 31
<212> ДНК
<213> Homo sapiens
<400> 243
ctggagttat taataaattg gattatatag c 31
<210> 244
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 244
ttacctgttt tccttttgtg attccac 27
<210> 245
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 245
accaagtcaa gagctctgag agacat 26
<210> 246
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 246
acagtgaatg atattcagaa tattgtgc 28
<210> 247
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 247
gaacaaggtc aagatatcag ctttcacc 28
<210> 248
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 248
aggtcataca atgaatggtg tgatgt 26
<210> 249
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 249
atccacccat gagaaatata tccacaa 27
<210> 250
<211> 31
<212> ДНК
<213> Homo sapiens
<400> 250
acaattcaaa ttaatgtaaa aactgcaagt g 31
<210> 251
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 251
tagttctagt gtgggatctg actcc 25
<210> 252
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 252
gaacatctgt tcaggtttct ctccatc 27
<210> 253
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 253
gaaaggacta aattgttgaa cactggt 27
<210> 254
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 254
tgtgtgtttt aaagccaggt ttgtt 25
<210> 255
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 255
gatggactgg aactgaggat tttca 25
<210> 256
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 256
agctttagaa aggcatatcg tattaactg 29
<210> 257
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 257
ttatagtgag taaaggacag gcccc 25
<210> 258
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 258
acacatctgt tgacagtaat gaaatatcc 29
<210> 259
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 259
gtttaaactt ggataccatc cccaagac 28
<210> 260
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 260
atgagattgc tgggagatgc agatg 25
<210> 261
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 261
cacatttccc tcttgcggtt acatac 26
<210> 262
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 262
gacaagcctc gcttgagttt tcttt 25
<210> 263
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 263
tgtgagagtg tcaccgaatt caacg 25
<210> 264
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 264
aaatagcaat ggctcgtcta tggttag 27
<210> 265
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 265
tgctaagtaa ggtgagtggt ataatca 27
<210> 266
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 266
ataaatatga tgtggctact ccctcat 27
<210> 267
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 267
gctacacctc catagtaata atgtaagag 29
<210> 268
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 268
tgaagcagct agagaactct gtacgt 26
<210> 269
<211> 31
<212> ДНК
<213> Homo sapiens
<400> 269
ttttgtctct gttatattag tcacctatct c 31
<210> 270
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 270
atagccctgc attcaaatcc caagtg 26
<210> 271
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 271
tccattttta taccactgca ctgaag 26
<210> 272
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 272
gcagtaaaac attttcatca aatttcca 28
<210> 273
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 273
tctgggtgca aactagctga atatcag 27
<210> 274
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 274
gaaaatctgg aggcaattca tgatgcc 27
<210> 275
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 275
atacaatgat gatcacacgg gaccct 26
<210> 276
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 276
ccatgaagat ggagtcaaca ttttaca 27
<210> 277
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 277
tcctaacccc tagtacgtta gatgtg 26
<210> 278
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 278
gaggtgattt ctgtgaggaa cgtcg 25
<210> 279
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 279
gtacattcac ttaacaggct ctctttcc 28
<210> 280
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 280
aattcatgag ctggtgtcca aggag 25
<210> 281
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 281
ataacagtct ccagagtata ttagcttag 29
<210> 282
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 282
gttcctctgg gatgcaacat gagag 25
<210> 283
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 283
gaaaggatga agagggtgga tattggag 28
<210> 284
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 284
ccaaacctca tcatctctta cctggatt 28
<210> 285
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 285
gtccaaagtc aagtgcaagt atagttgg 28
<210> 286
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 286
acaatctttt ctgaatctga acagcttc 28
<210> 287
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 287
caaaggaagg catttcctaa tgatcttc 28
<210> 288
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 288
ctttgctttg cttttcttct tcagggaa 28
<210> 289
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 289
ctgcttcaag tgtatataaa ctcacagt 28
<210> 290
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 290
cctaggaaag cagtaactaa ttcaggag 28
<210> 291
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 291
gcaatttgtt cacttttagt ttcgtagc 28
<210> 292
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 292
ggcctaatat gcatgtgttc atgtctct 28
<210> 293
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 293
cagagtttct catctacgaa agaggagt 28
<210> 294
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 294
atcctagacc tccaggtgga atgatc 26
<210> 295
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 295
cttggctgtc tcaatatttt ggagtaag 28
<210> 296
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 296
gagtaaatga gctgtggttt ctctctta 28
<210> 297
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 297
ctttccatgt ggacccttta acattcag 28
<210> 298
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 298
gcatagtgag ctgttgatag agcttttg 28
<210> 299
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 299
ctagaacaaa atcattggct ctcctagt 28
<210> 300
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 300
gtctggtgag tactggctga atgtaaa 27
<210> 301
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 301
ccagaggatg ctgctaaaca ttctacaa 28
<210> 302
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 302
gctcatgcct ggaattcacc tttatttt 28
<210> 303
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 303
ctaactagac atttgggcca ccttactt 28
<210> 304
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 304
gtctatggtg cctatagaat gtacaggt 28
<210> 305
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 305
ccctctcaag tttgtgagca aatatcac 28
<210> 306
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 306
ctctatcttg ctgcaatgga ctttcc 26
<210> 307
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 307
cctagaaaca gattttgaag ggctcttg 28
<210> 308
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 308
aaatgagggg catagggata aggga 25
<210> 309
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 309
cctagaaatc tgatacgtta tcctatga 28
<210> 310
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 310
aggagagata tattcaacat gaacccaa 28
<210> 311
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 311
gaacatctct gaccagaaat ttccagta 28
<210> 312
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 312
gtgtagtgaa atccttagac ttaggtaa 28
<210> 313
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 313
aatacatgaa aaagtaatac atggggca 28
<210> 314
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 314
attaaatgtt tacttctatc tacaagga 28
<210> 315
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 315
cattttgtga aatgcaaagg gcaaatct 28
<210> 316
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 316
gctgagaggc ttaattccat caagatga 28
<210> 317
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 317
cccatcctaa acttagtttt atgggcag 28
<210> 318
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 318
gtaacacatt ctctttggga agctagc 27
<210> 319
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 319
cttagcttca gtgaaaatgg ttcctctc 28
<210> 320
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 320
ctttcttagc tcctctccat ttctcttc 28
<210> 321
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 321
gtctatgcag tgcttcactg aggattat 28
<210> 322
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 322
ctctatctgc tcagagcctg cttaaaag 28
<210> 323
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 323
ggaaaggata cagtgttgag caagatag 28
<210> 324
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 324
gccaacttga ttctctttca aatgcttg 28
<210> 325
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 325
agatggggtt taccatgttt cccag 25
<210> 326
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 326
gtacagtagt tagtttccag actgatga 28
<210> 327
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 327
gtaaatatct aactgtgttt ccctcagt 28
<210> 328
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 328
gaaccaaaag gaattaagag actagggg 28
<210> 329
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 329
ctgcttttac ggcttcttcc tttcttc 27
<210> 330
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 330
cccacatcct tcccatttat aggcaa 26
<210> 331
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 331
tacatgatcc taagggcagc aggaa 25
<210> 332
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 332
gtttggtgca tcctctttct ctctc 25
<210> 333
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 333
gactgtagtc accccttctc caaca 25
<210> 334
<211> 31
<212> ДНК
<213> Homo sapiens
<400> 334
agagtgaaat acatagaaaa gaaacttaaa g 31
<210> 335
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 335
atttgcgaga aacagataaa tattgaag 28
<210> 336
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 336
acaggaacaa agaatttgtt cttcatgg 28
<210> 337
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 337
ccttggattg tctcaggatg ttgca 25
<210> 338
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 338
ctgggatgtt tgttttggct ttgtg 25
<210> 339
<211> 30
<212> ДНК
<213> Homo sapiens
<400> 339
attggtagta cactaatgga tatatgtgag 30
<210> 340
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 340
gaataaagtg aggaaaacac ggagttg 27
<210> 341
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 341
gagagaggca gaaaggaggg atgaa 25
<210> 342
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 342
tactctgtct tcagtagctg tttcttgg 28
<210> 343
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 343
ttagactcac caagatcaag atgaatgc 28
<210> 344
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 344
atctcaataa agctgttcaa aacagaaag 29
<210> 345
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 345
taaagaaaat gccatgggct gtaccc 26
<210> 346
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 346
attgtgcagc agaacagagt gtagtg 26
<210> 347
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 347
attctttgca tagctcacga aatttccc 28
<210> 348
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 348
aaaatgagac ctcgtatctt tgcagc 26
<210> 349
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 349
aaatgcagaa ctgccaaaag aaaccc 26
<210> 350
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 350
gagaatctgt gaatgccagg gtctg 25
<210> 351
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 351
atggattcat gtttcagaca tctaatt 27
<210> 352
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 352
atcactagaa agaaaagagt tcctattc 28
<210> 353
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 353
gaagtttaaa agagtgggaa catgggg 27
<210> 354
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 354
ctacgtaagc aaaaatgatc acgcac 26
<210> 355
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 355
aacctgatgg ccctcattag tcctt 25
<210> 356
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 356
caccagattt ctaggaatag catgtgag 28
<210> 357
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 357
aagagcatag tgaggggtta gacct 25
<210> 358
<211> 29
<212> ДНК
<213> Homo sapiens
<400> 358
ctttatattt agtgtagaga tcagtctcc 29
<210> 359
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 359
tgagtccttt acctaatctt ggttgtc 27
<210> 360
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 360
aatccaaagc aactctcttt tcaccac 27
<210> 361
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 361
tttactggaa ccctgatttt gttgga 26
<210> 362
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 362
tgccactgat atatcagtac ctgagt 26
<210> 363
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 363
acaatctcaa tcccccttaa tgttttc 27
<210> 364
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 364
gtgggcagag agagtaagag aacct 25
<210> 365
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 365
caaaccagat tctggcagaa tagttagc 28
<210> 366
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 366
cttctctccc atcctccttc tccac 25
<210> 367
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 367
agatcaaggg atctgtggga caataac 27
<210> 368
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 368
ggggagtgat ttcaagcatc ctgatt 26
<210> 369
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 369
catgagtttg aggtaagatg aaggaga 27
<210> 370
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 370
tctctctcat cctagtgaat gccatc 26
<210> 371
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 371
gggtgatgat ctaccttgca ggtata 26
<210> 372
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 372
ctcaaggccc tgggtctgaa attac 25
<210> 373
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 373
acatctccag ttaataattt ccactaac 28
<210> 374
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 374
tggattgctc aacaaatagt gctaaaa 27
<210> 375
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 375
catgcgacat ccaggtagct aaaatac 27
<210> 376
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 376
atggataaaa atggaacttt caagagaa 28
<210> 377
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 377
gttttatgta aagcttcgtc atatggct 28
<210> 378
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 378
gttccaactt agtcataaag ttccctgg 28
<210> 379
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 379
gggtcttgat gttgtattga tgaggaag 28
<210> 380
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 380
cctaacagaa agtcactgtt tgtatctg 28
<210> 381
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 381
tcactctggc ttgtactctc tctgtg 26
<210> 382
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 382
ggctggtttc agtctggaga ctttattt 28
<210> 383
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 383
cttcacctcg atgacgatga tgatgat 27
<210> 384
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 384
gacaataaca gcacaaagga tggaaaag 28
<210> 385
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 385
gaaccagacc acacaatatc accac 25
<210> 386
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 386
tctacctctt tgatgtcccc ttcgatag 28
<210> 387
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 387
cagagtttct catctacgaa agaggagt 28
<210> 388
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 388
cccagctttg aaaagtatgc ctagaact 28
<210> 389
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 389
ctgcttcaag tgtatataaa ctcacagt 28
<210> 390
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 390
ttgtttcatc cactttggtg ggtaaaag 28
<210> 391
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 391
taattaagct ctgtgtttag ggttttt 27
<210> 392
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 392
caattctttg ttctttaggt cagtatat 28
<210> 393
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 393
tactcttcct cagtcccttc tctgc 25
<210> 394
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 394
tgagacagag catgatgatc atggc 25
<210> 395
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 395
gcacaagtct aggaactact ttgcac 26
<210> 396
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 396
gaagtatttg aaccatacgg agccc 25
<210> 397
<211> 26
<212> ДНК
<213> Homo sapiens
<400> 397
tgaggaacac atccaaacta tgacac 26
<210> 398
<211> 25
<212> ДНК
<213> Homo sapiens
<400> 398
tttctcgccc tcatcatctg caatg 25
<210> 399
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 399
tcagttgatt tcatgtgatc ctcacag 27
<210> 400
<211> 27
<212> ДНК
<213> Homo sapiens
<400> 400
gaataaagtg aggaaaacac ggagttg 27
<210> 401
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 401
attaccttct ttctaataca agcatatg 28
<210> 402
<211> 28
<212> ДНК
<213> Homo sapiens
<400> 402
acaggaacaa agaatttgtt cttcatgg 28
<210> 403
<211> 21
<212> ДНК
<213> Искусственная последовательность
<220>
<213> Последовательность адаптера i5
<400> 403
tacacgacgc tcttccgatc t 21
<210> 404
<211> 20
<212> ДНК
<213> Искусственная последовательность
<220>
<213> Последовательность адаптера i7
<400> 404
cttggcaccc gagaattcca 20
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ ДНК-ПРОФИЛИРОВАНИЯ | 2015 |
|
RU2708337C2 |
| Набор STR-маркеров Y-хромосомы для определения этно-территориального происхождения индивида по образцу его ДНК | 2021 |
|
RU2804433C2 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНОЕ СЕКВЕНИРОВАНИЕ ОДИНОЧНОЙ КЛЕТКИ СО СНИЖЕННОЙ ОШИБКОЙ АМПЛИФИКАЦИИ | 2019 |
|
RU2744175C1 |
| ВЫСОКОПРОИЗВОДИТЕЛЬНОЕ СЕКВЕНИРОВАНИЕ ОДИНОЧНОЙ КЛЕТКИ СО СНИЖЕННОЙ ОШИБКОЙ АМПЛИФИКАЦИИ | 2019 |
|
RU2833615C2 |
| ГЕНЕТИЧЕСКИЕ МАРКЕРЫ ДЛЯ ПРОГНОЗИРОВАНИЯ ВОСПРИИМЧИВОСТИ К ТЕРАПИИ | 2014 |
|
RU2809215C2 |
| БИБЛИОТЕКИ ДЛЯ СЕКВЕНИРОВАНИЯ НОВОГО ПОКОЛЕНИЯ | 2014 |
|
RU2698125C2 |
| ИСКУССТВЕННАЯ МОДИФИКАЦИЯ ГЕНОМА ДЛЯ РЕГУЛЯЦИИ ЭКСПРЕССИИ ГЕНА | 2018 |
|
RU2767201C2 |
| МАРКЕРЫ РИСКА СЕРДЕЧНО-СОСУДИСТОГО ЗАБОЛЕВАНИЯ | 2010 |
|
RU2524659C2 |
| СПОСОБ АМПЛИФИКАЦИИ И ИДЕНТИФИКАЦИИ НУКЛЕИНОВЫХ КИСЛОТ | 2019 |
|
RU2811465C2 |
| ИСКУССТВЕННО СОЗДАННАЯ СИСТЕМА УПРАВЛЕНИЯ ФУНКЦИЕЙ ШК | 2017 |
|
RU2768043C2 |
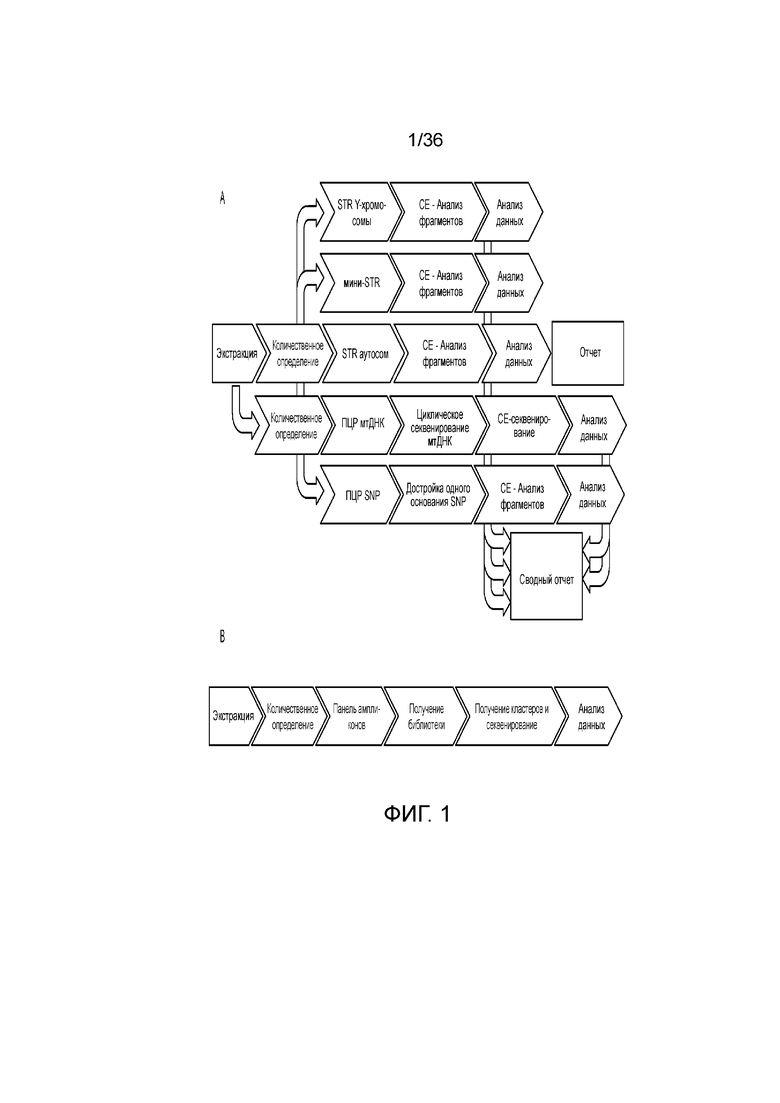
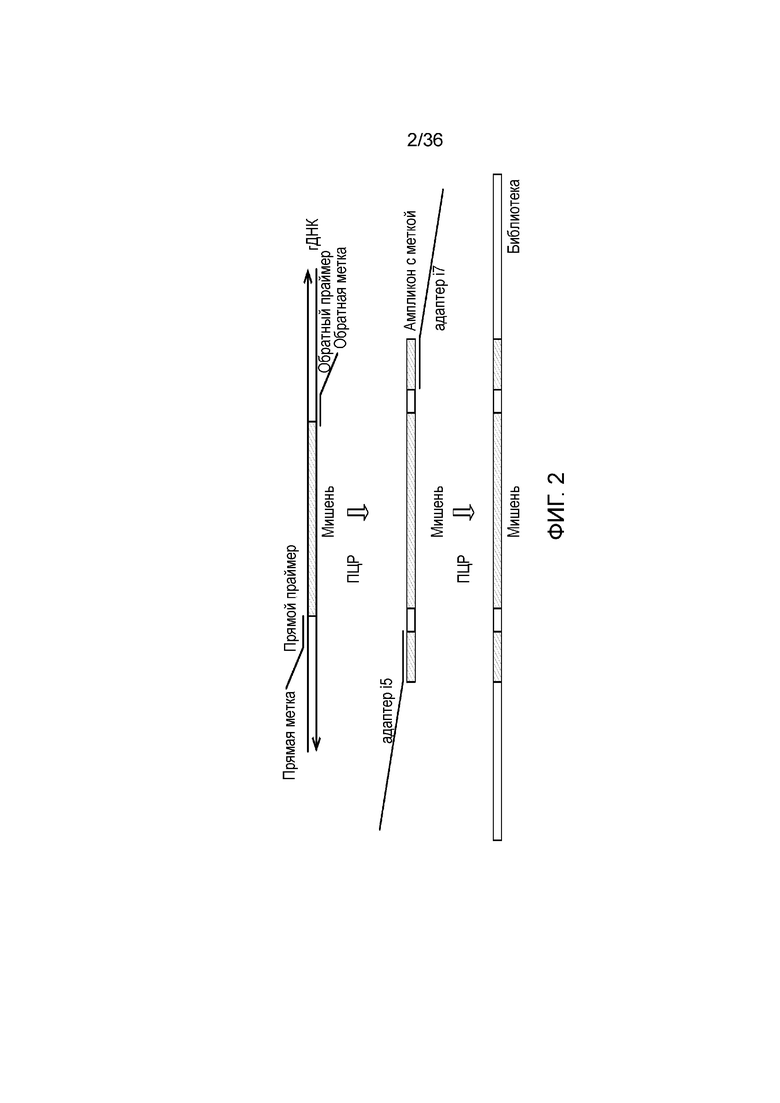
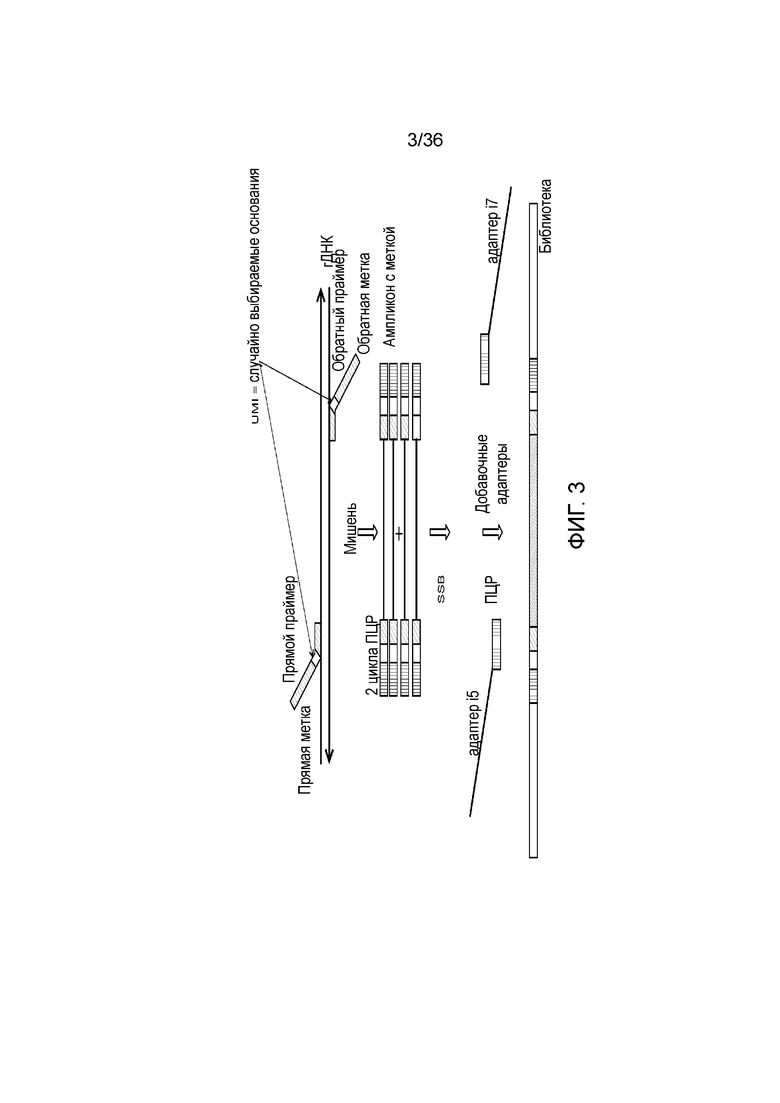
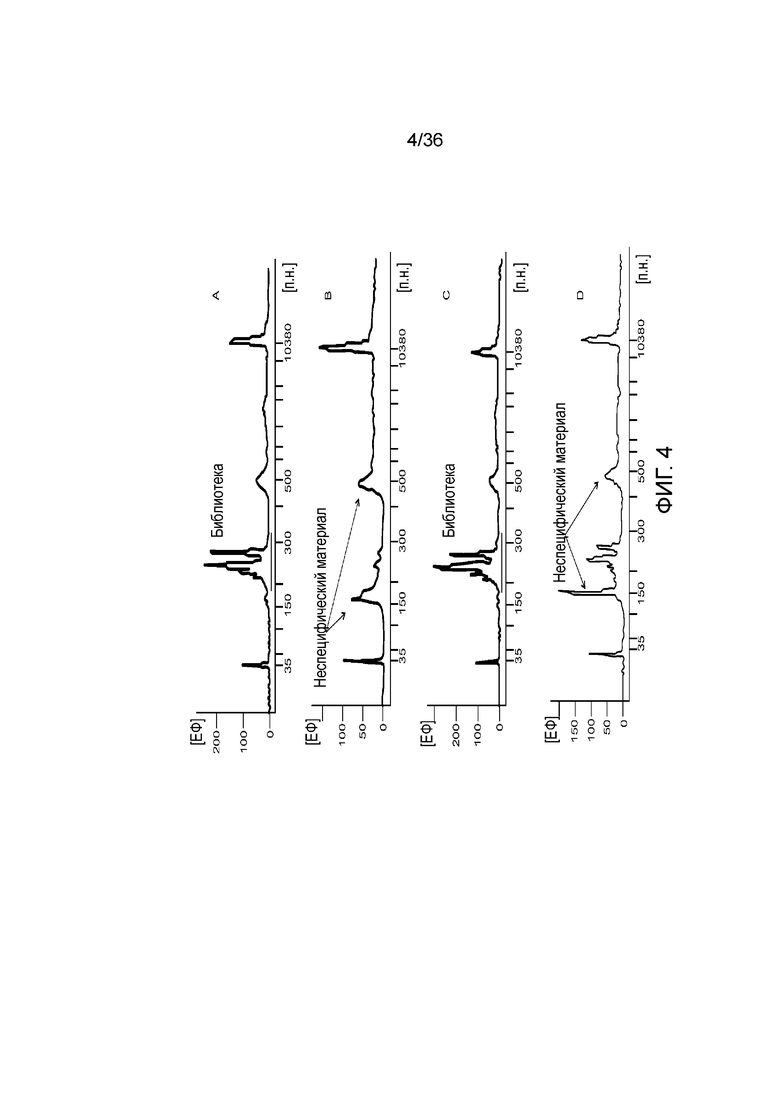

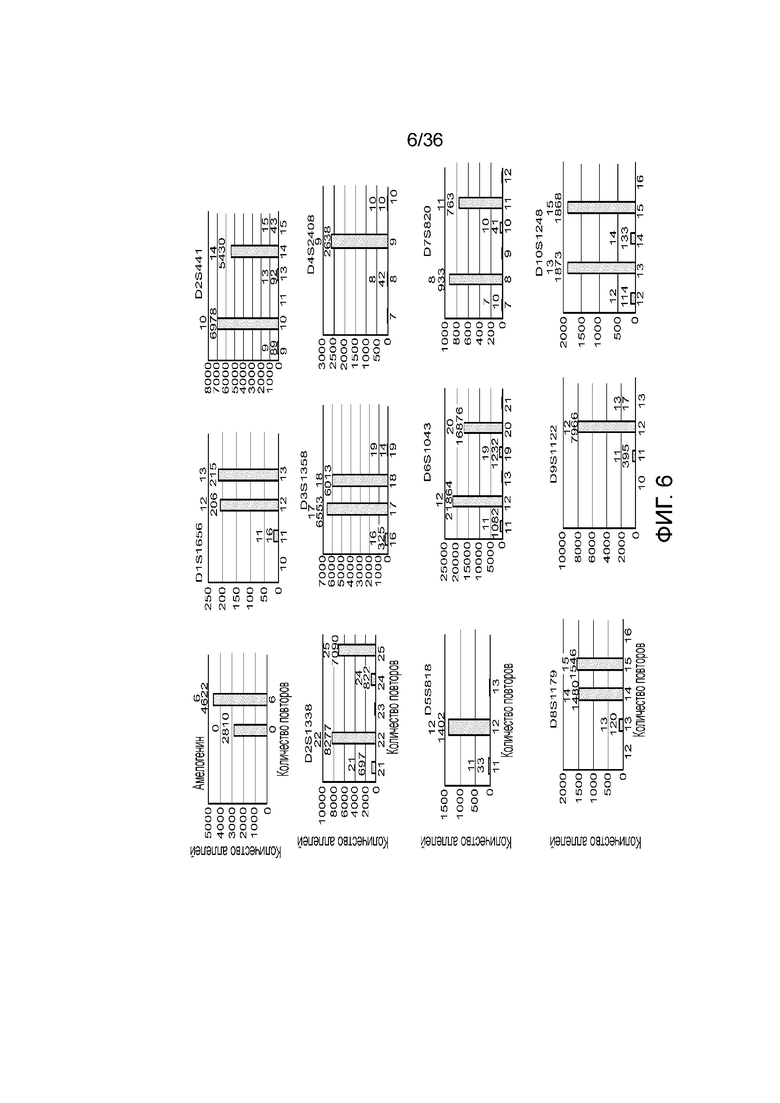
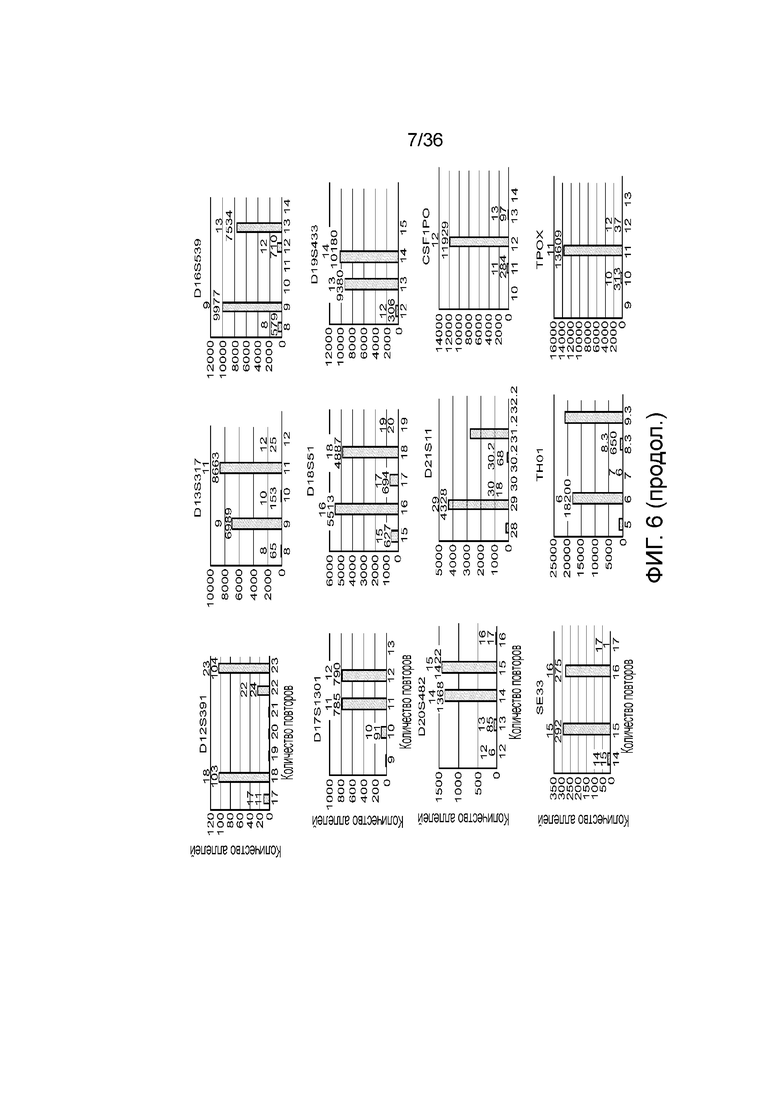
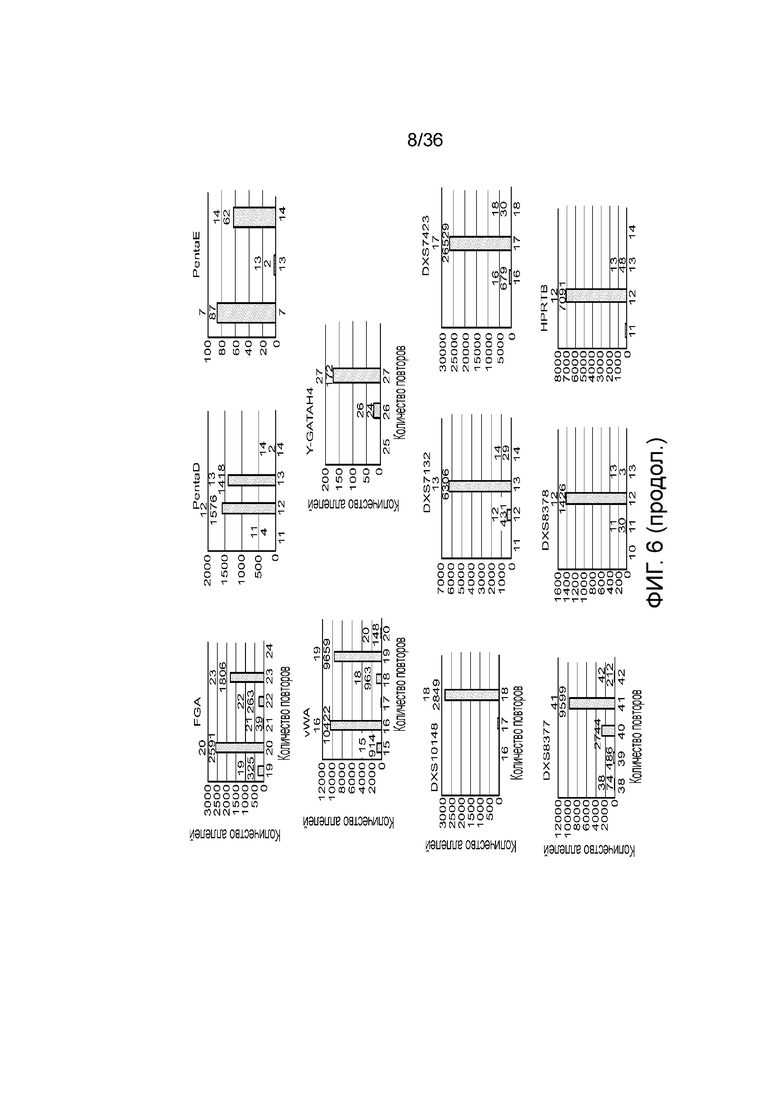
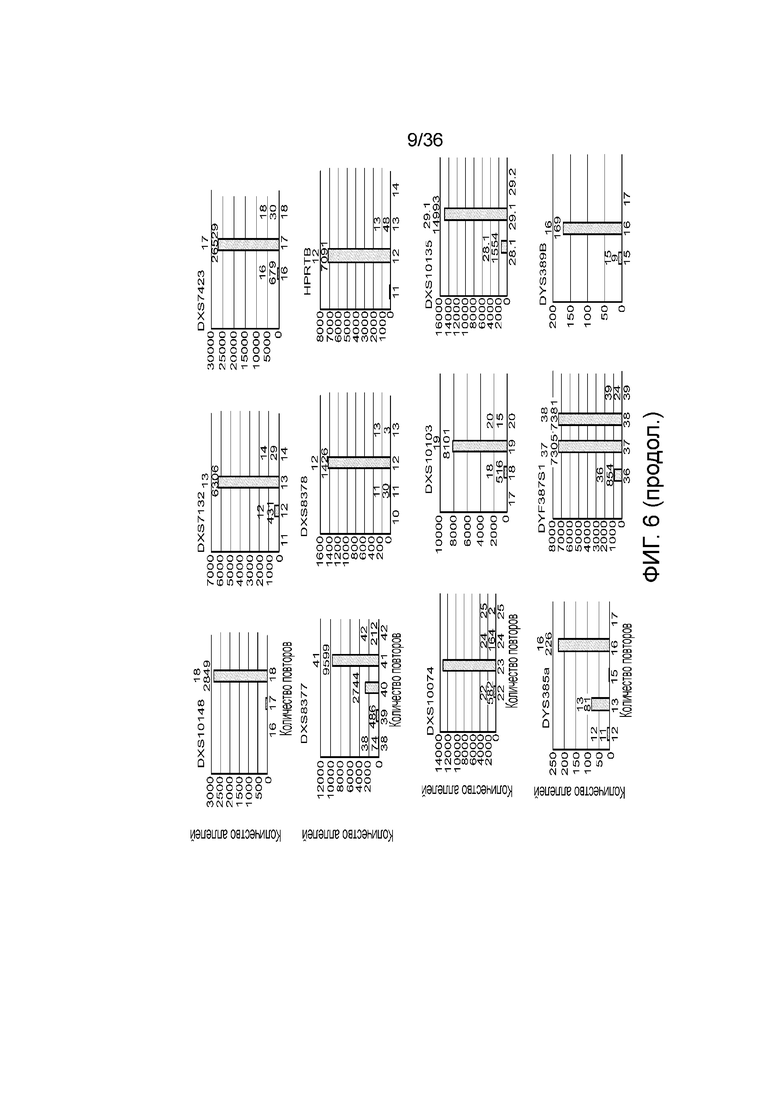
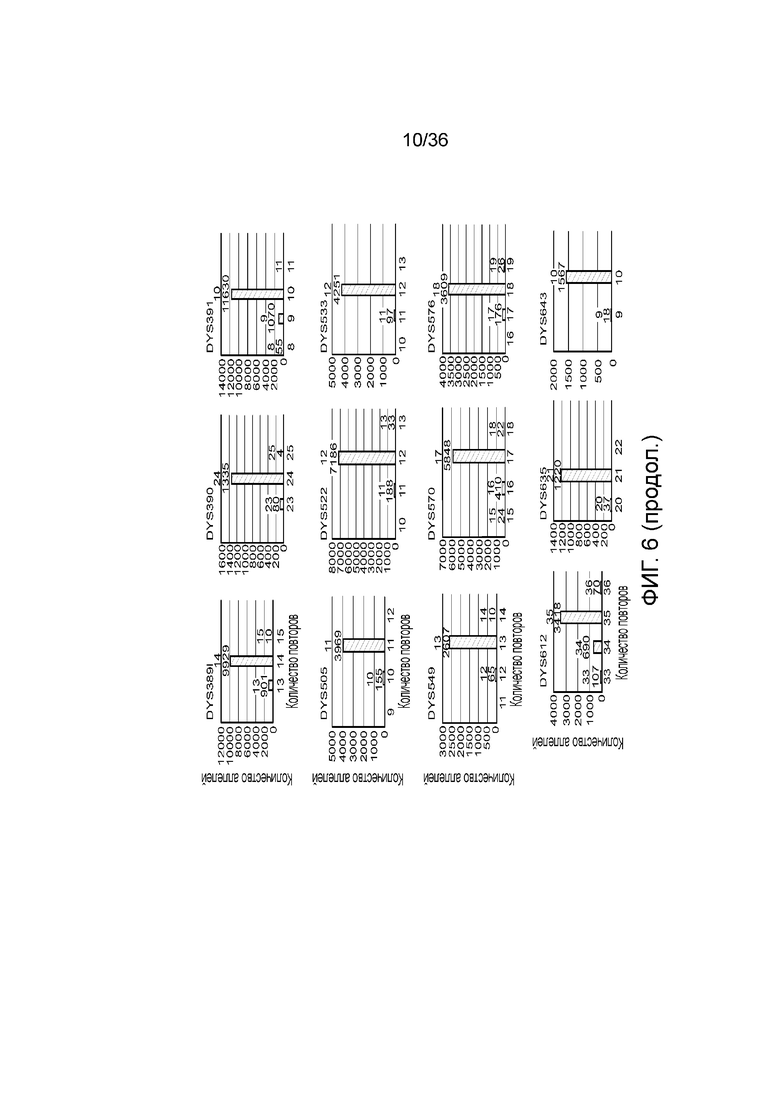
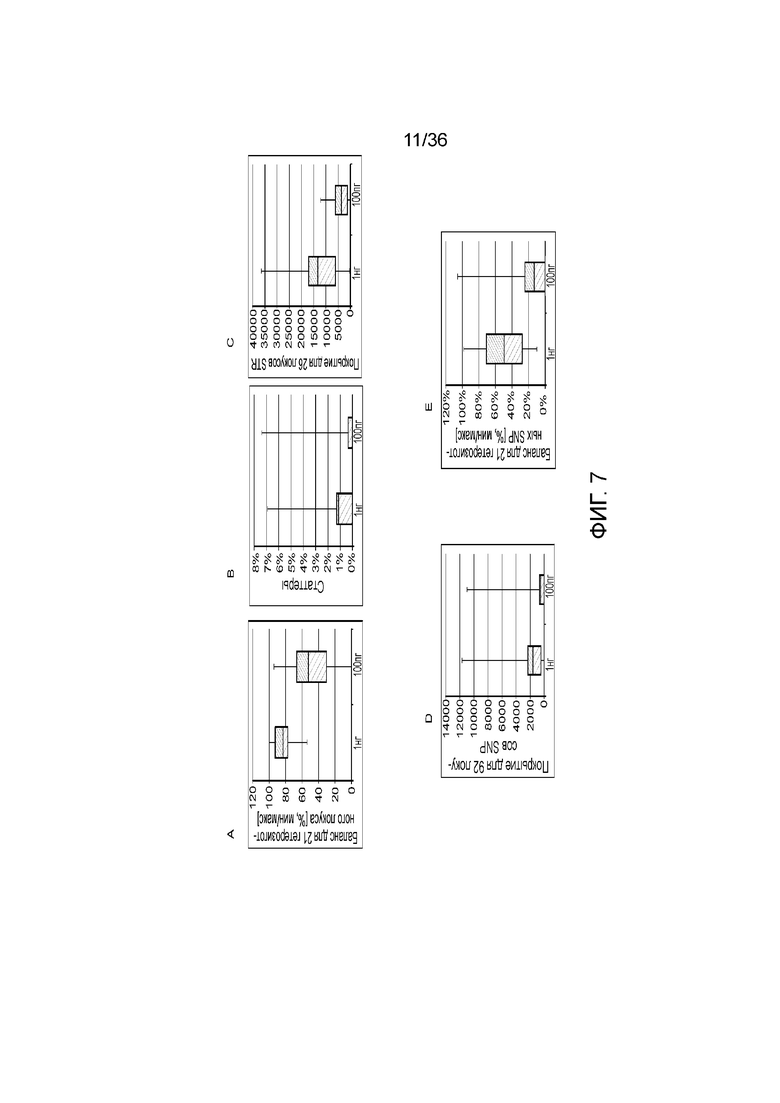
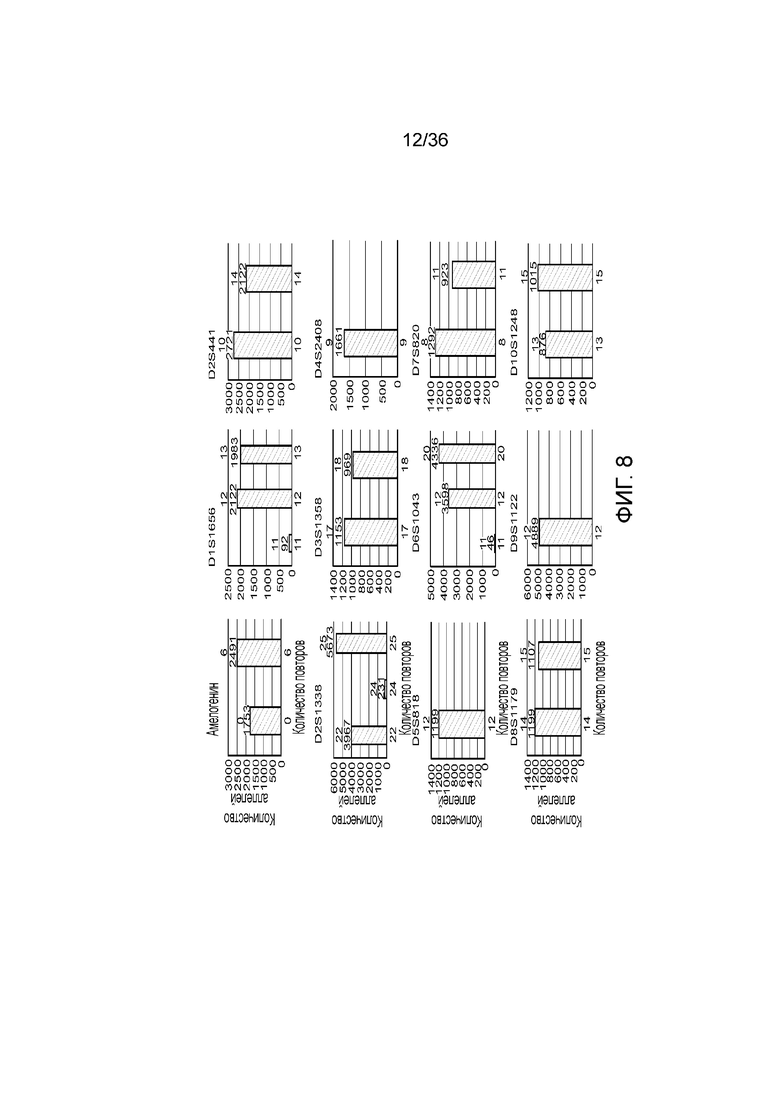
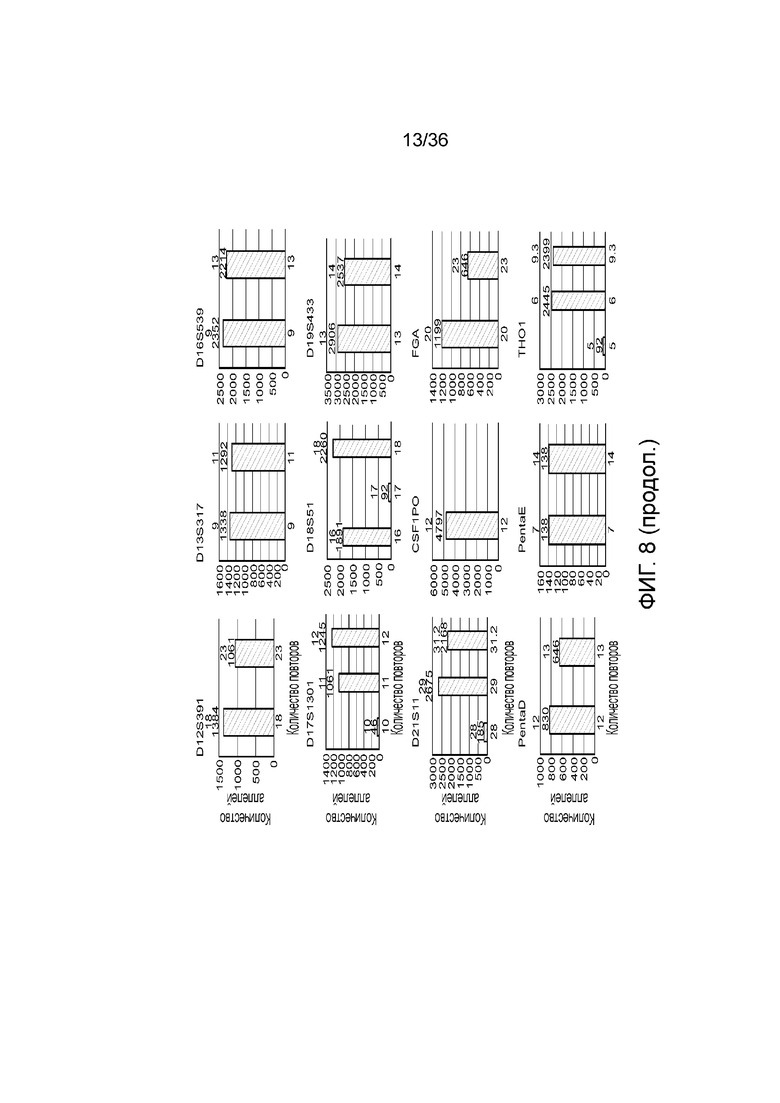
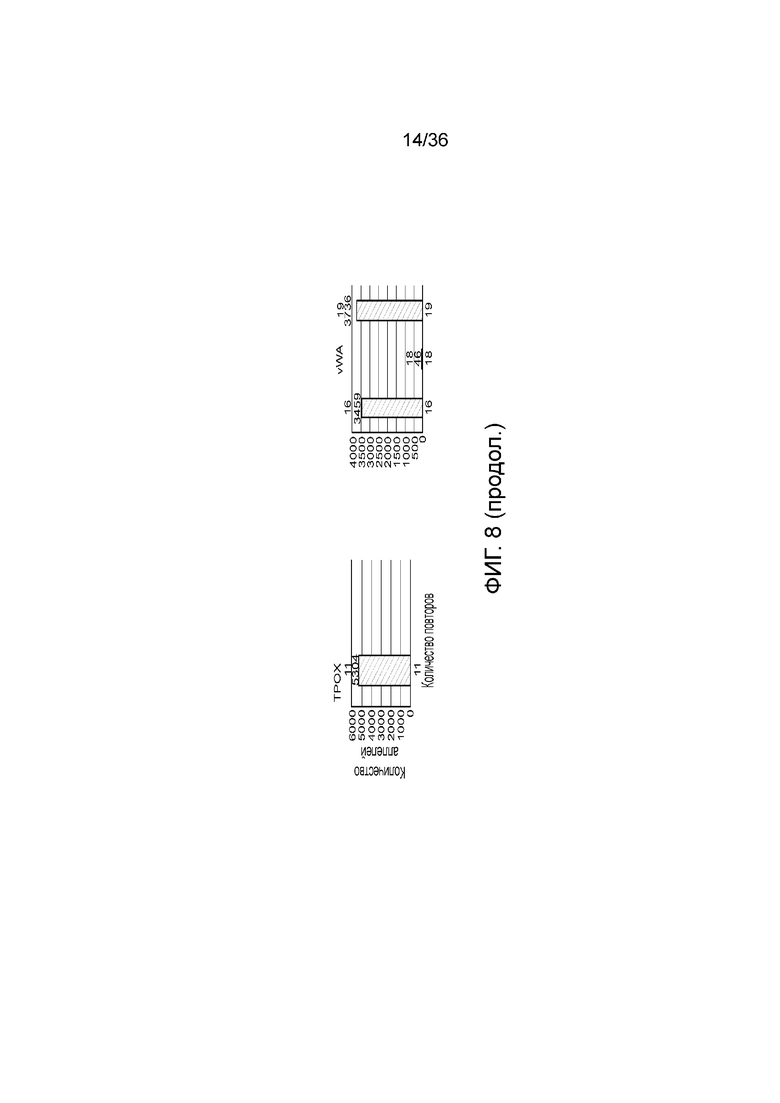
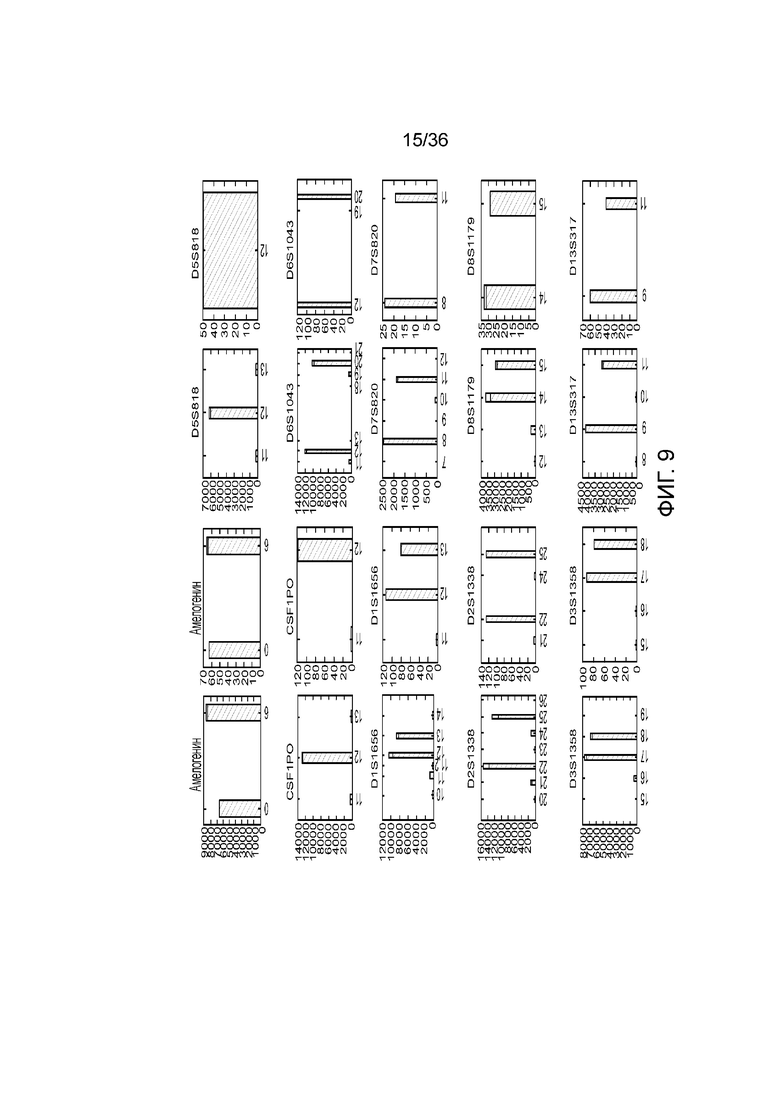
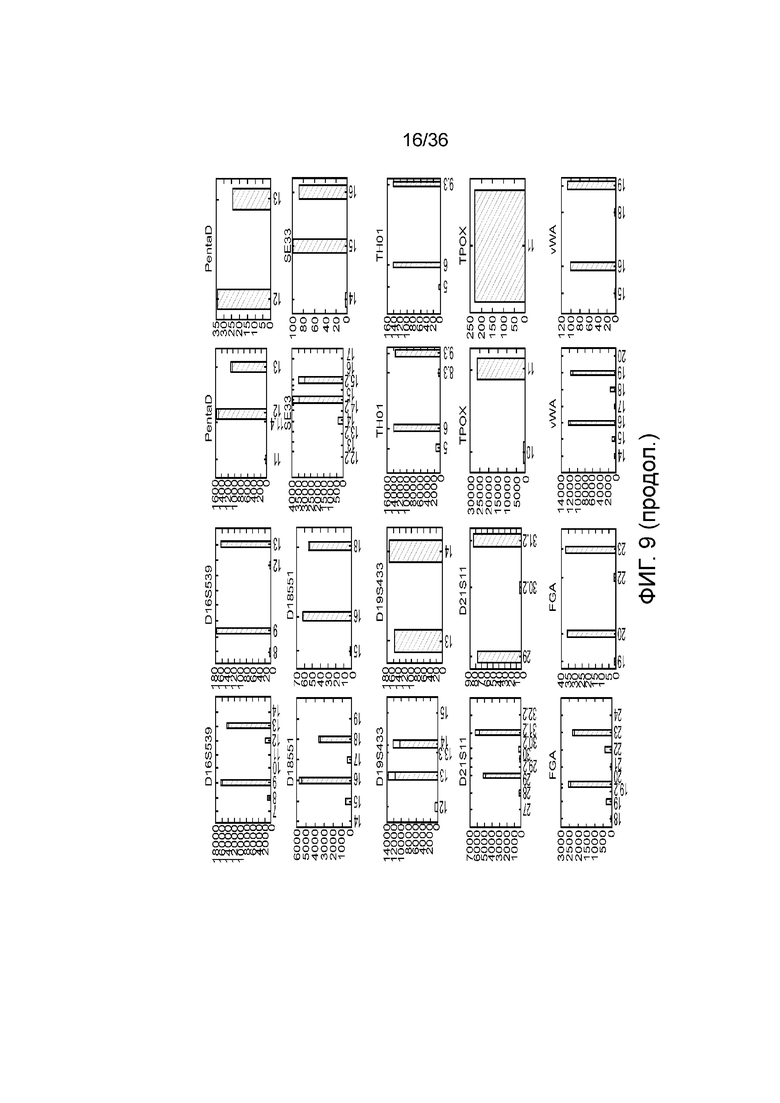
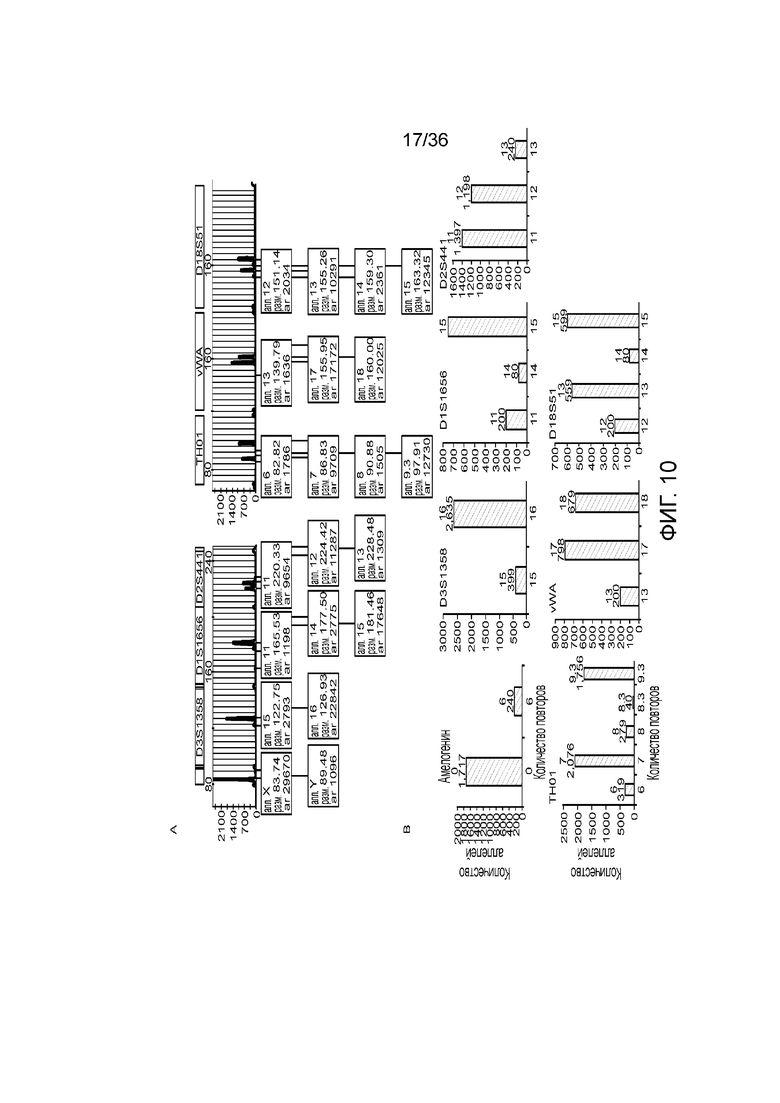
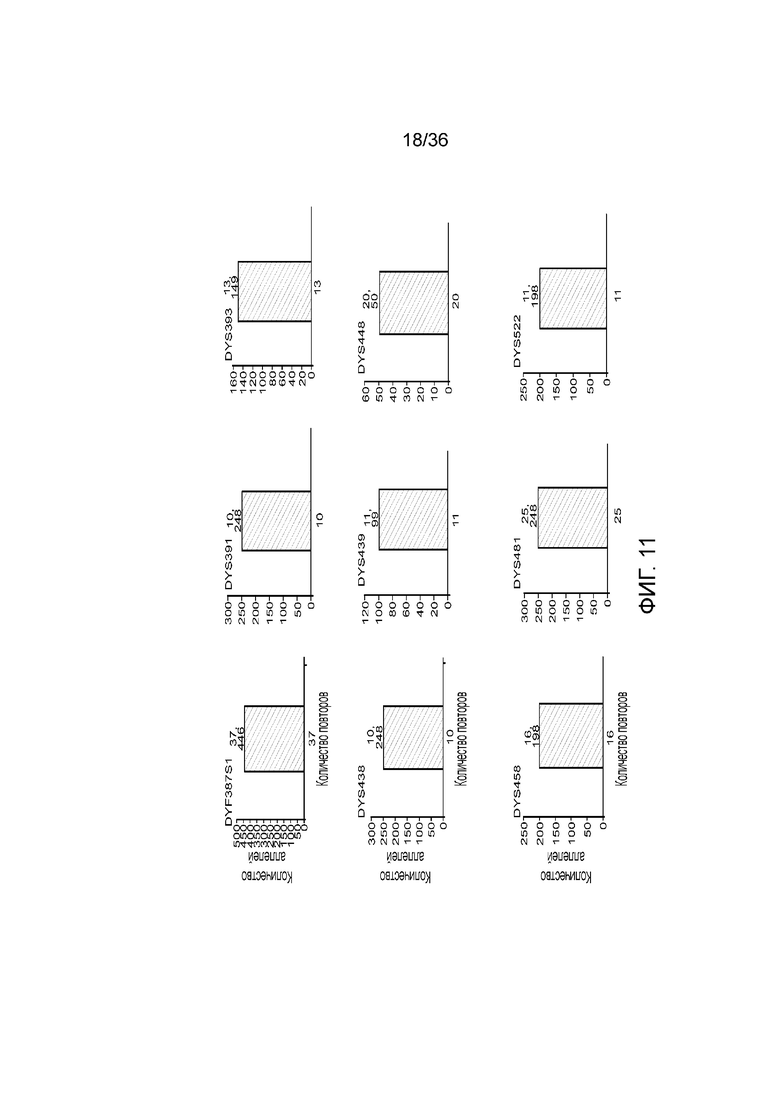
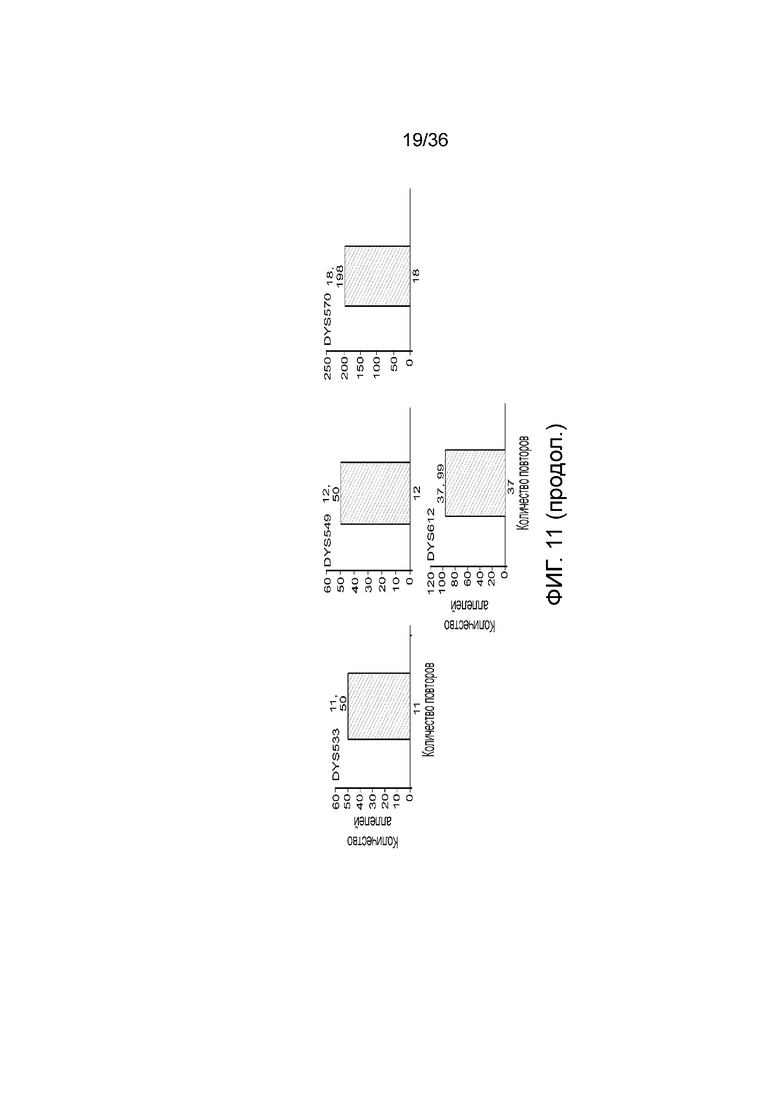
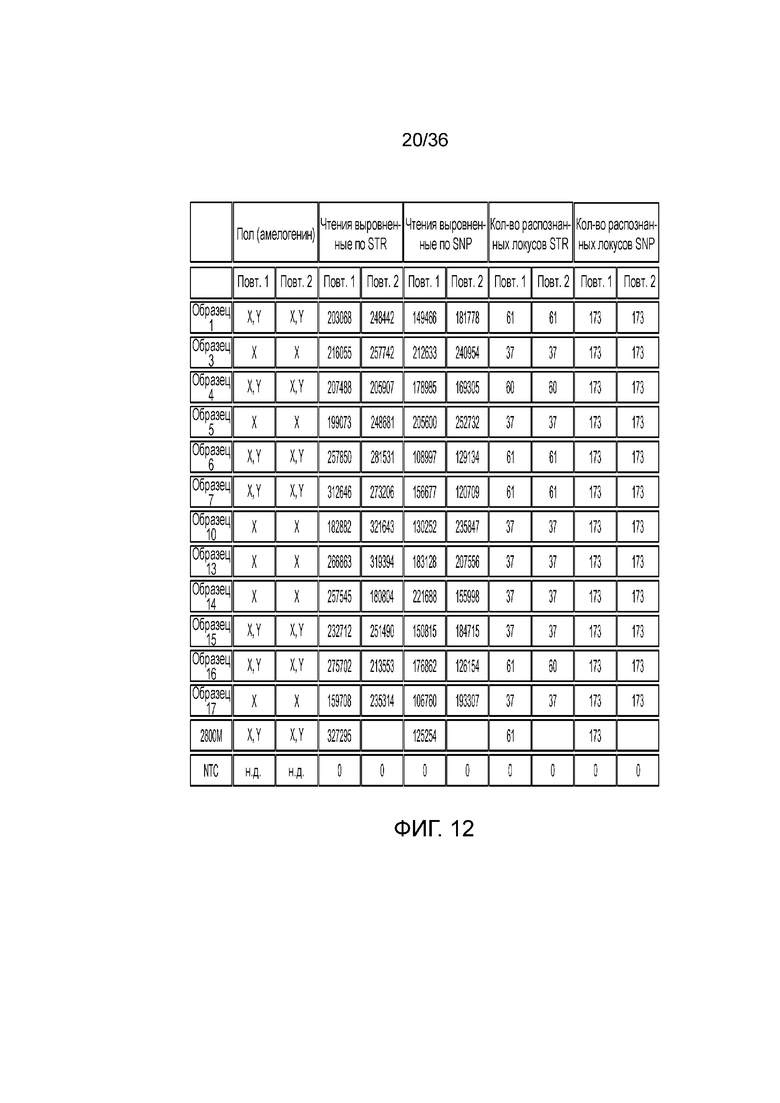
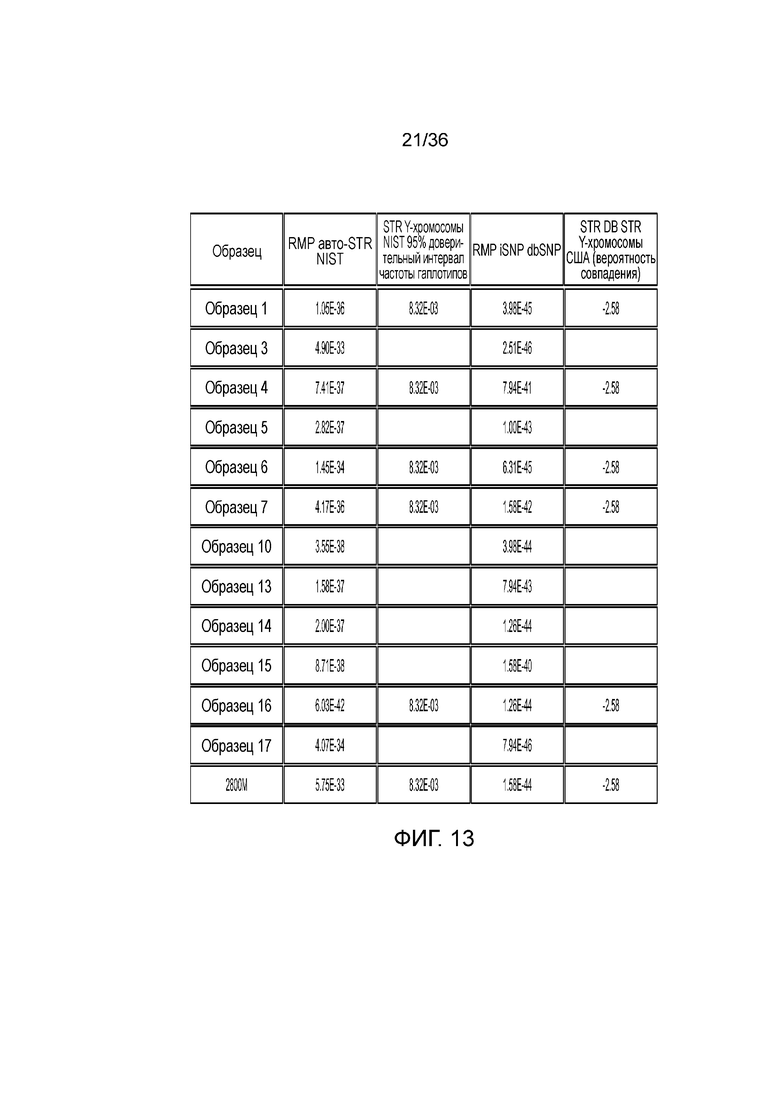
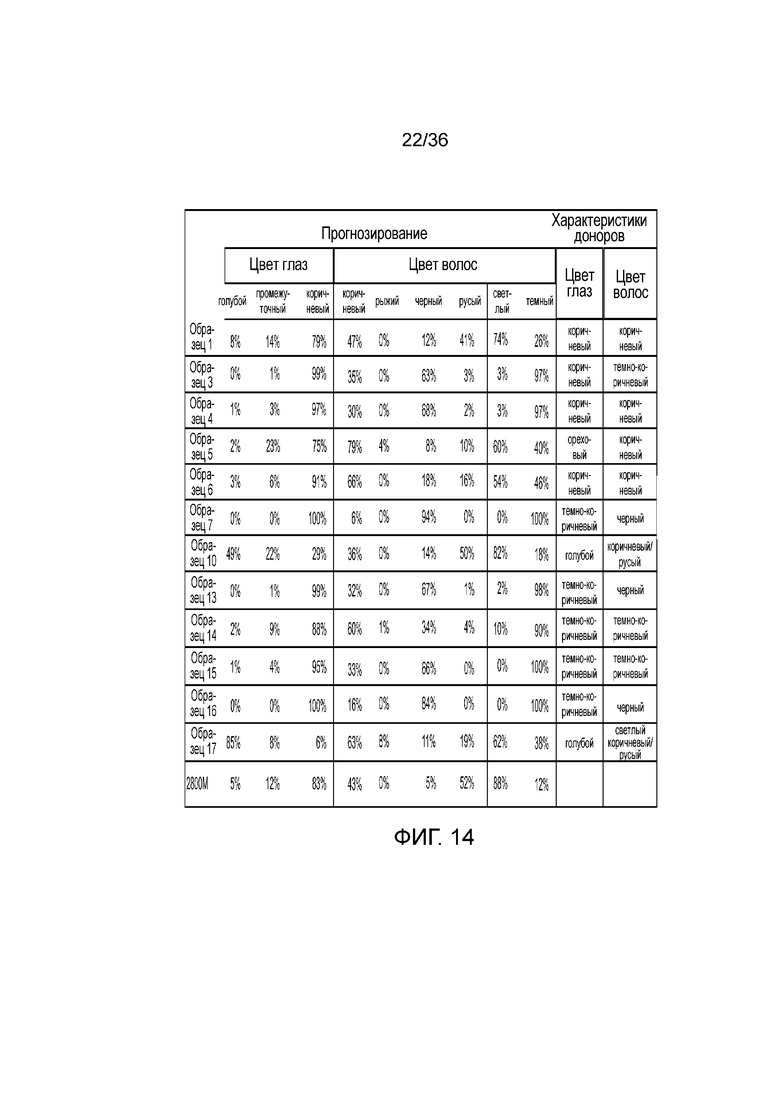
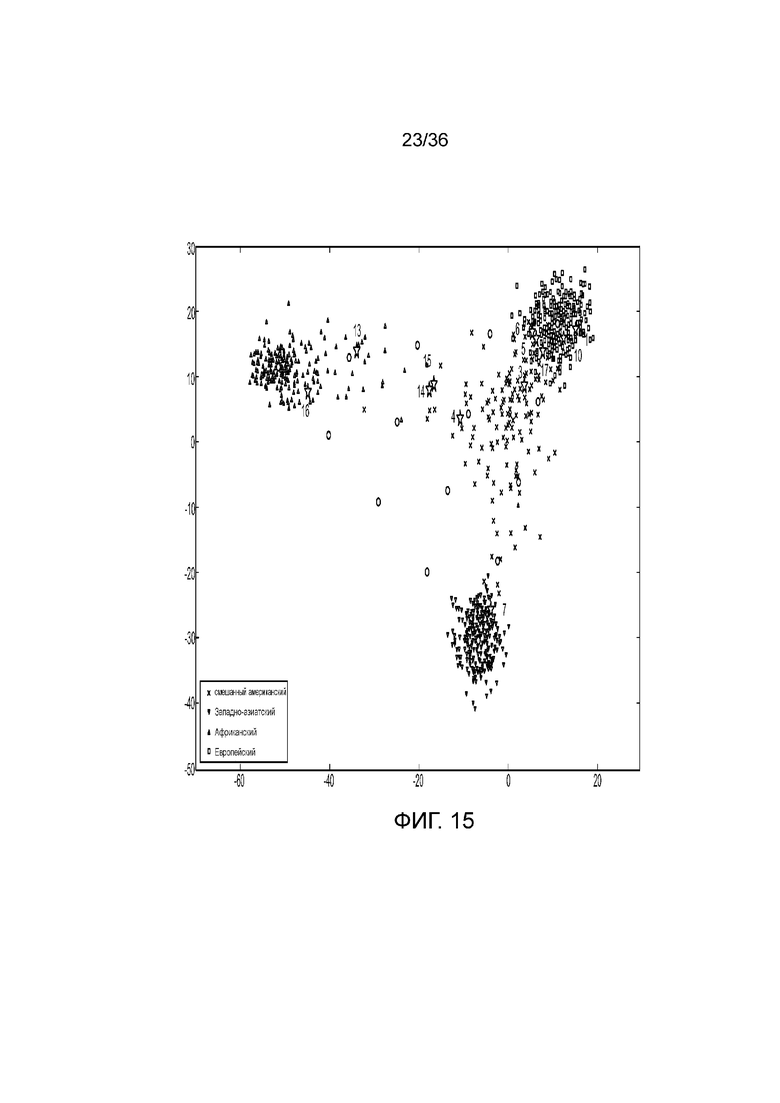
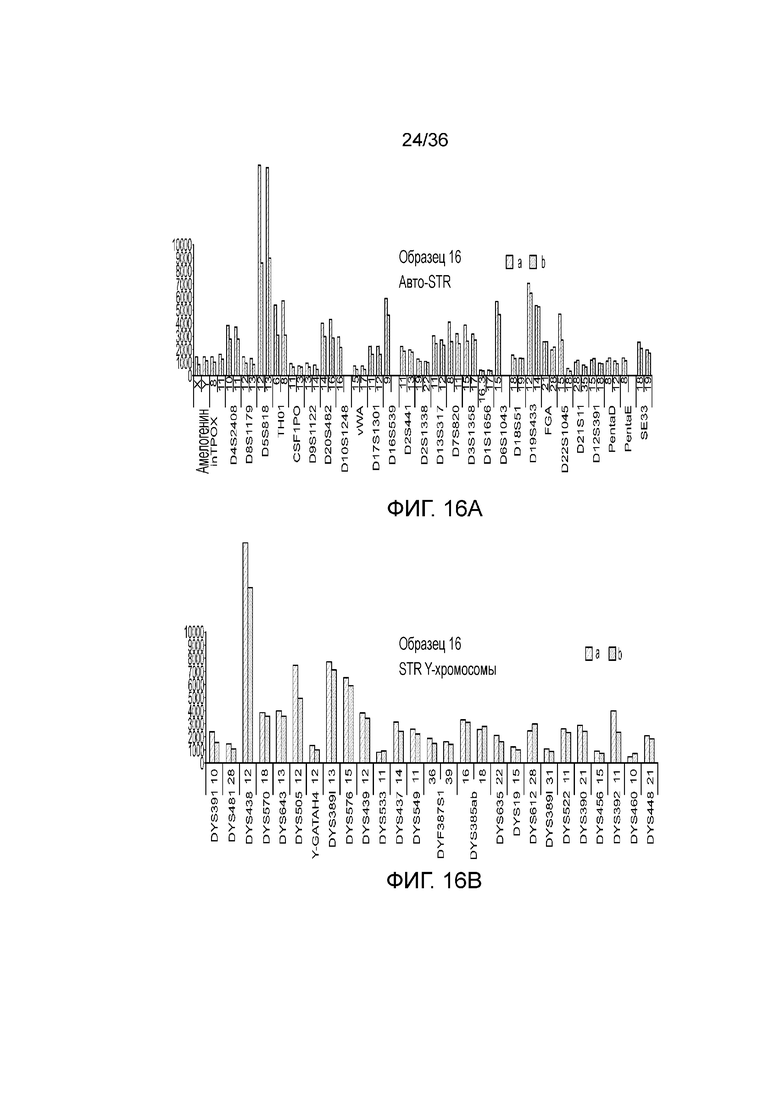
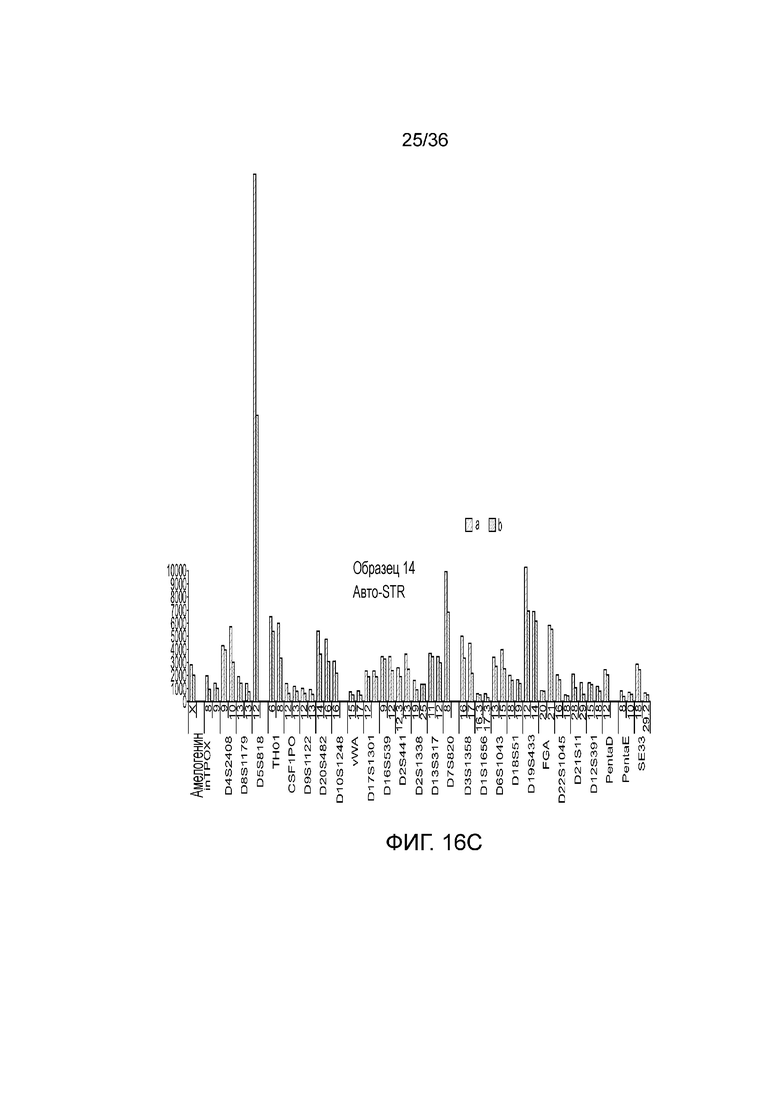
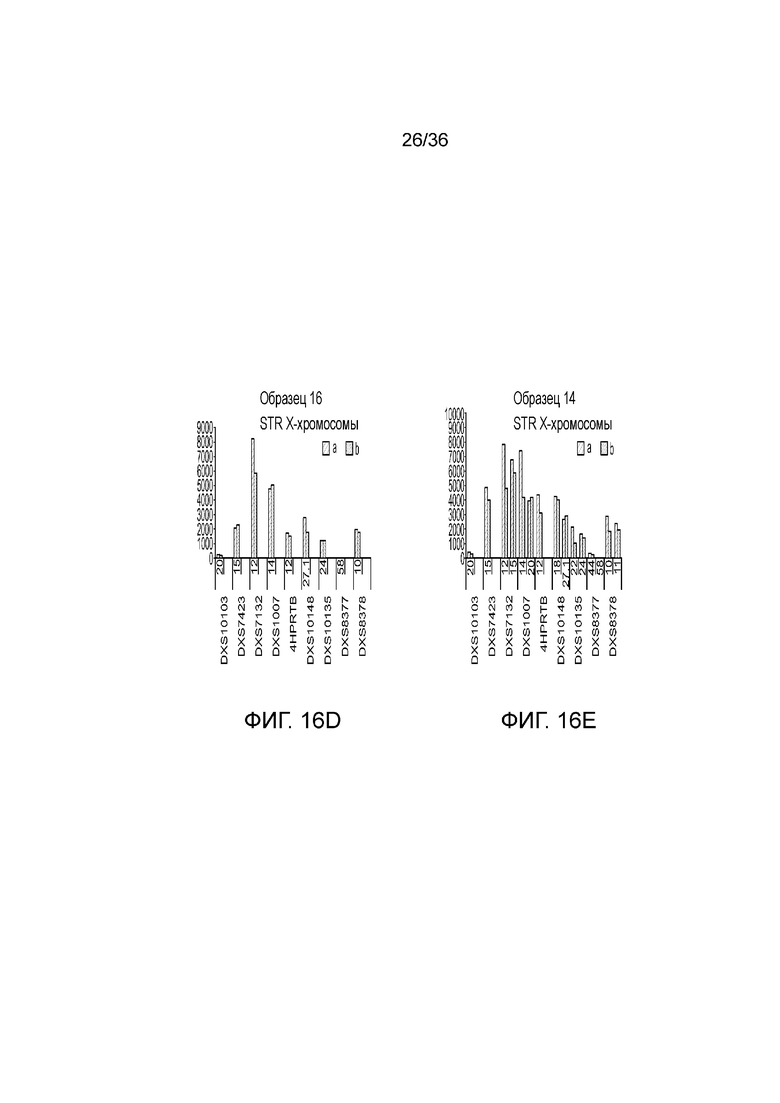
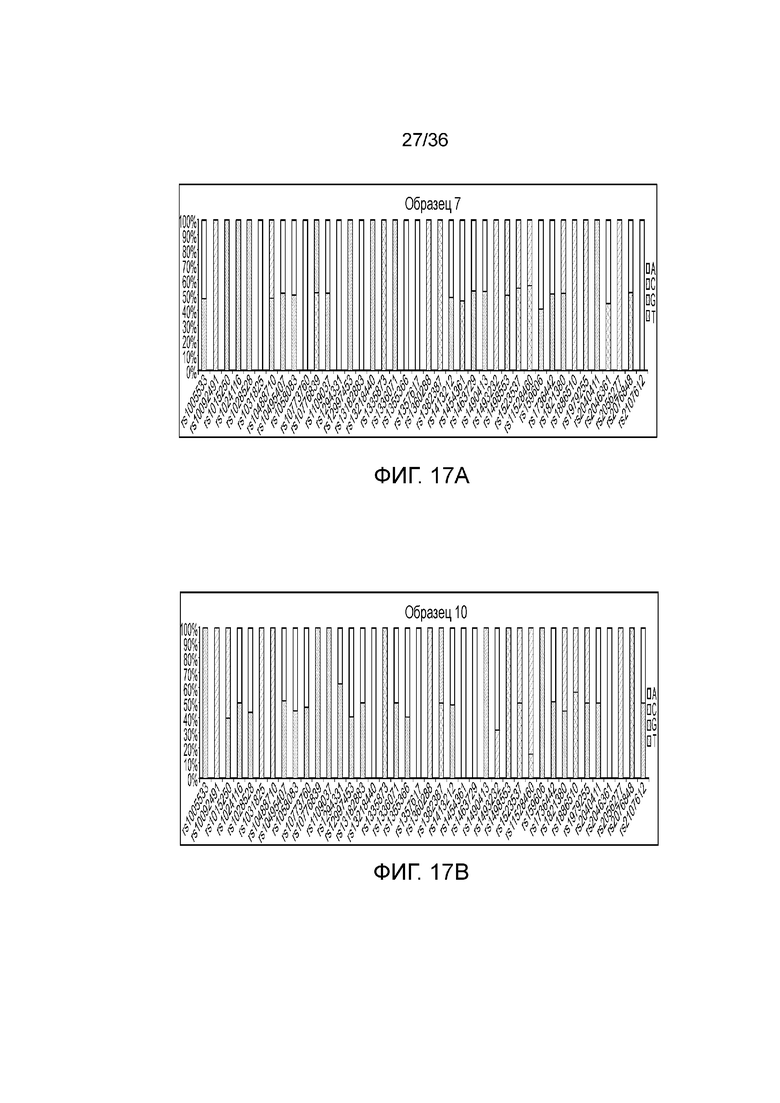

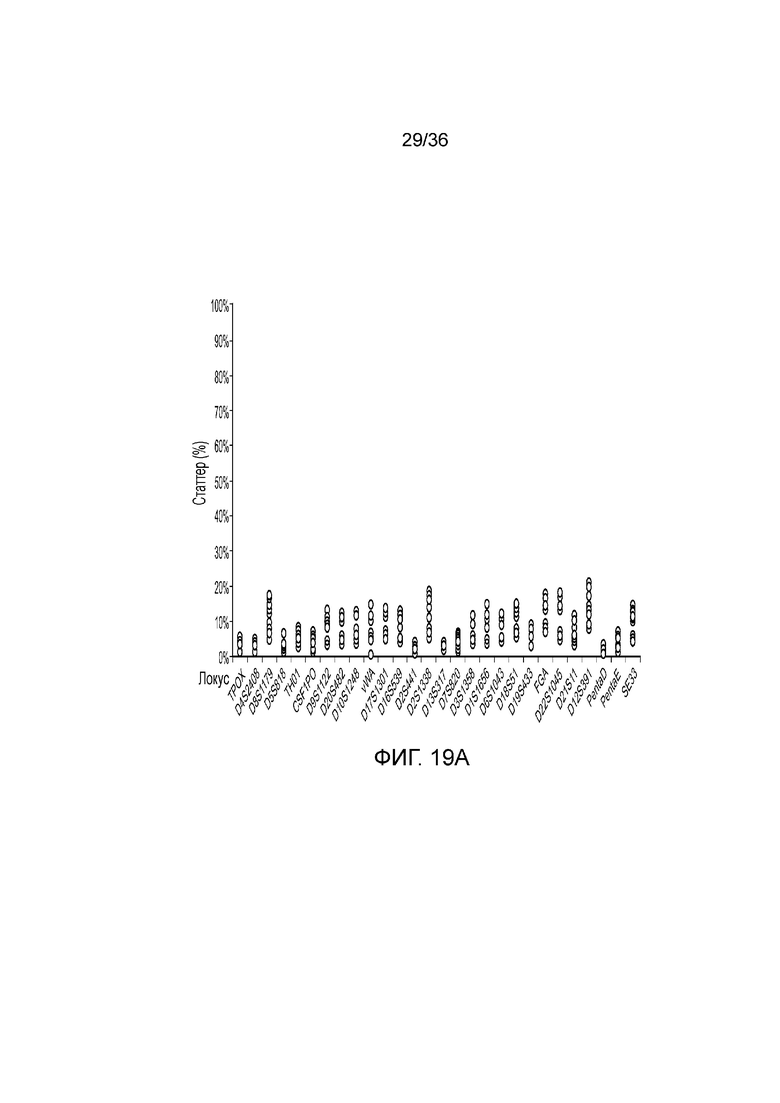
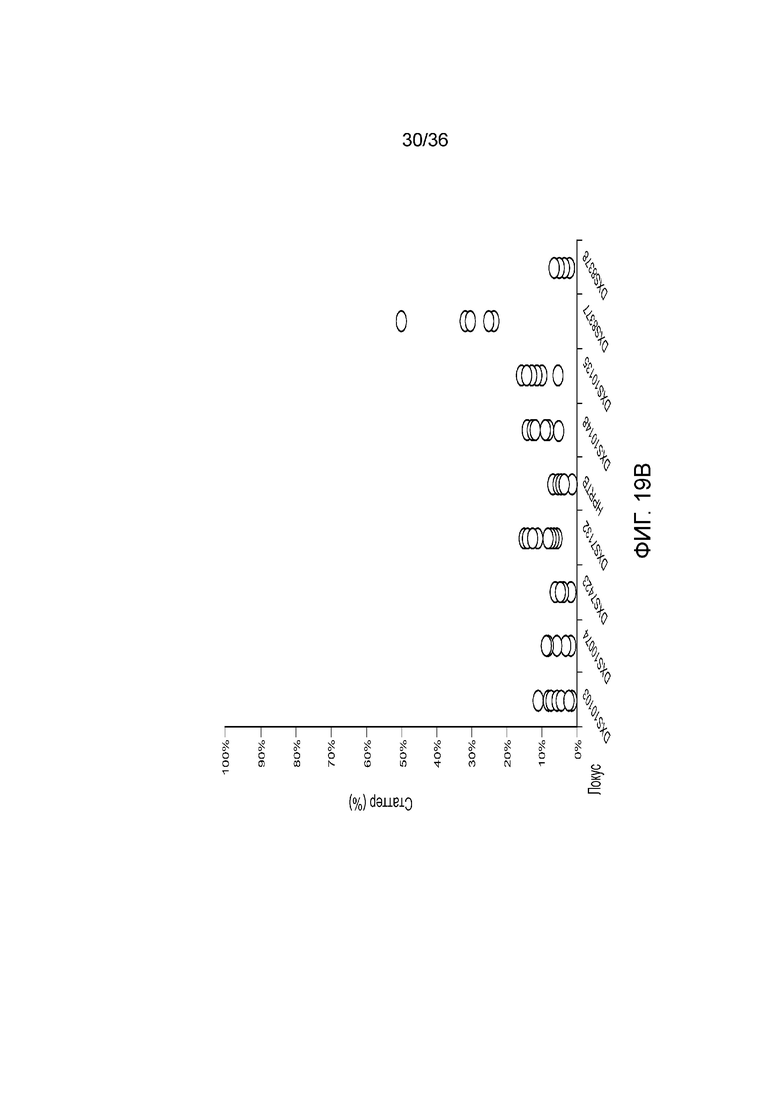

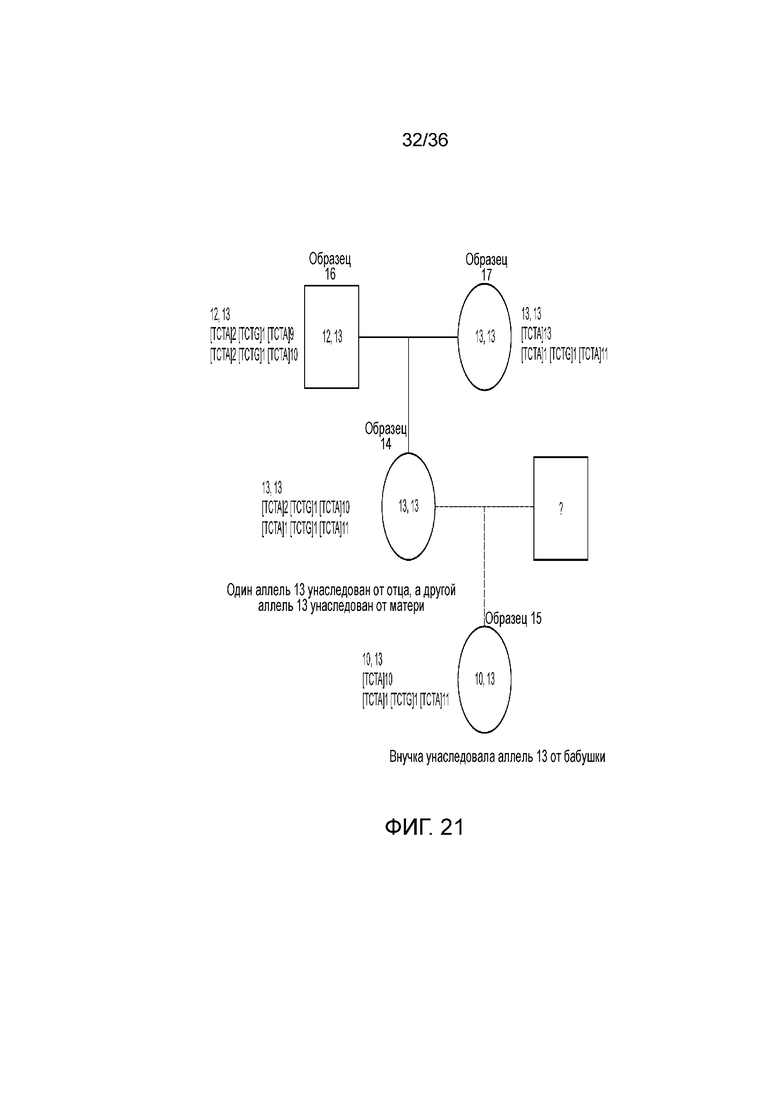
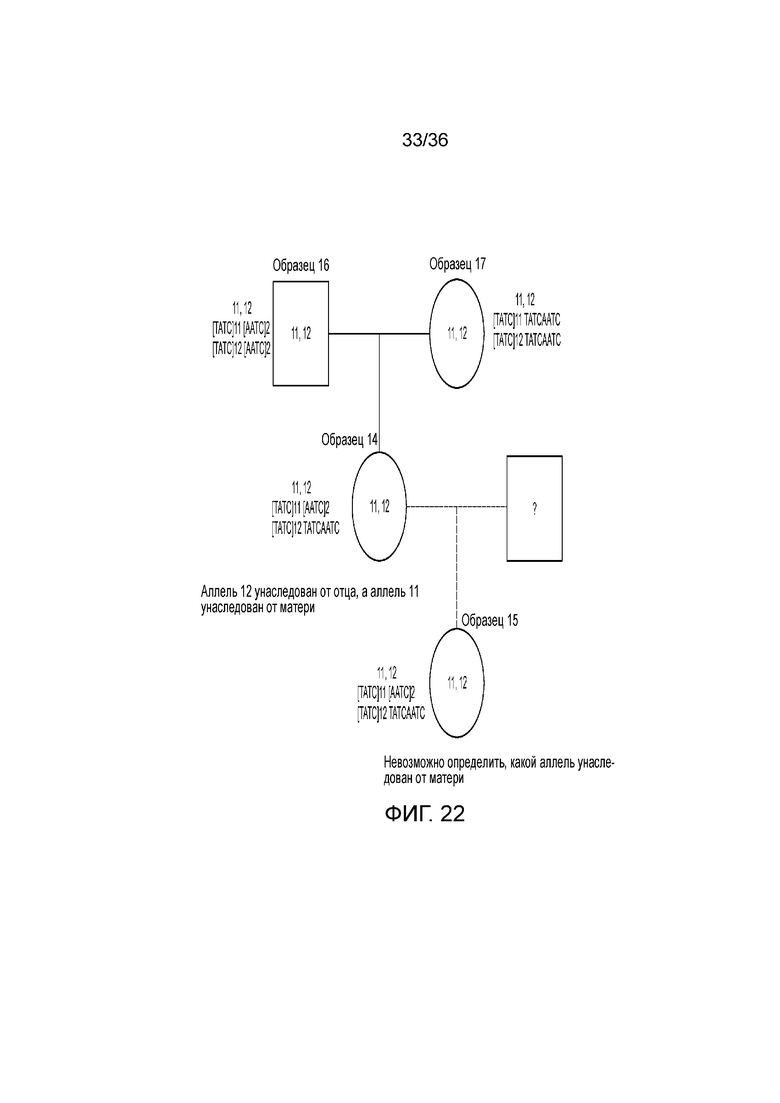
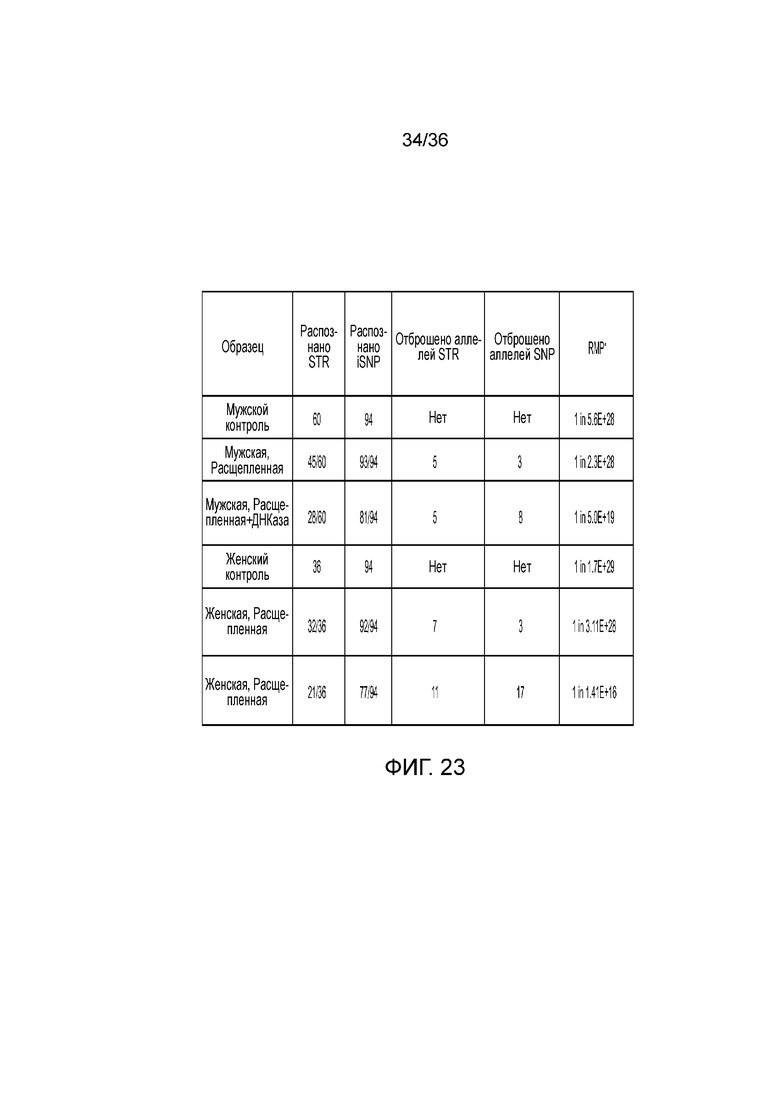
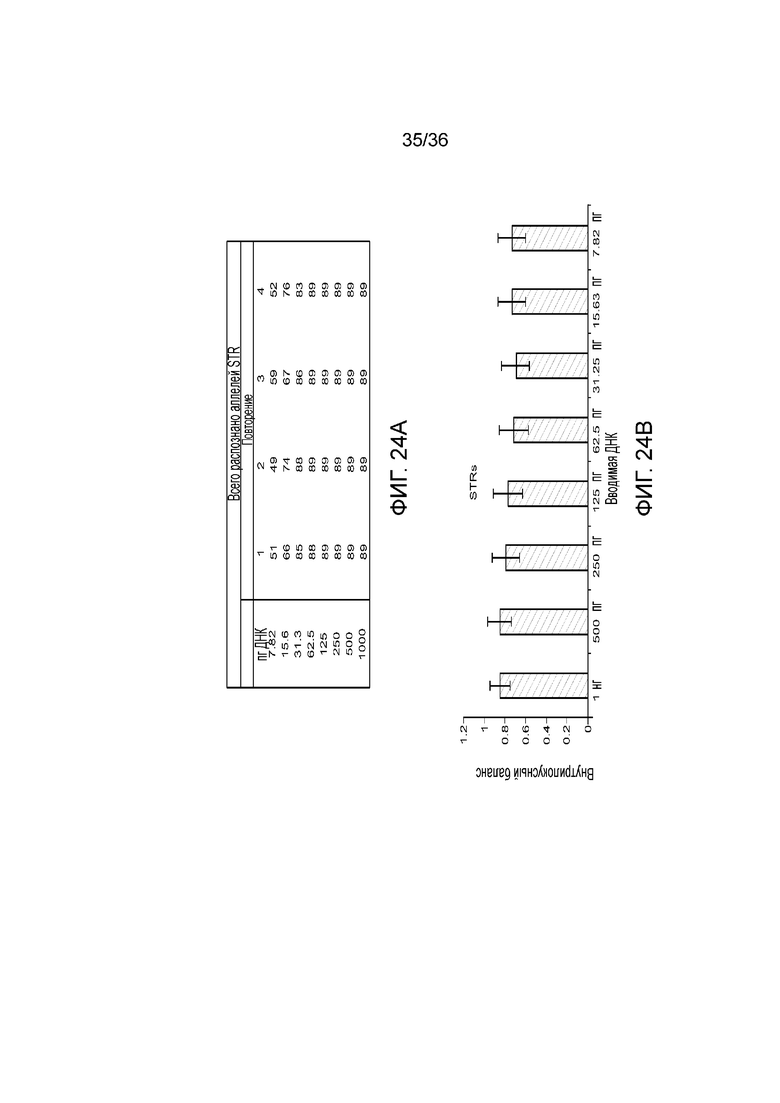
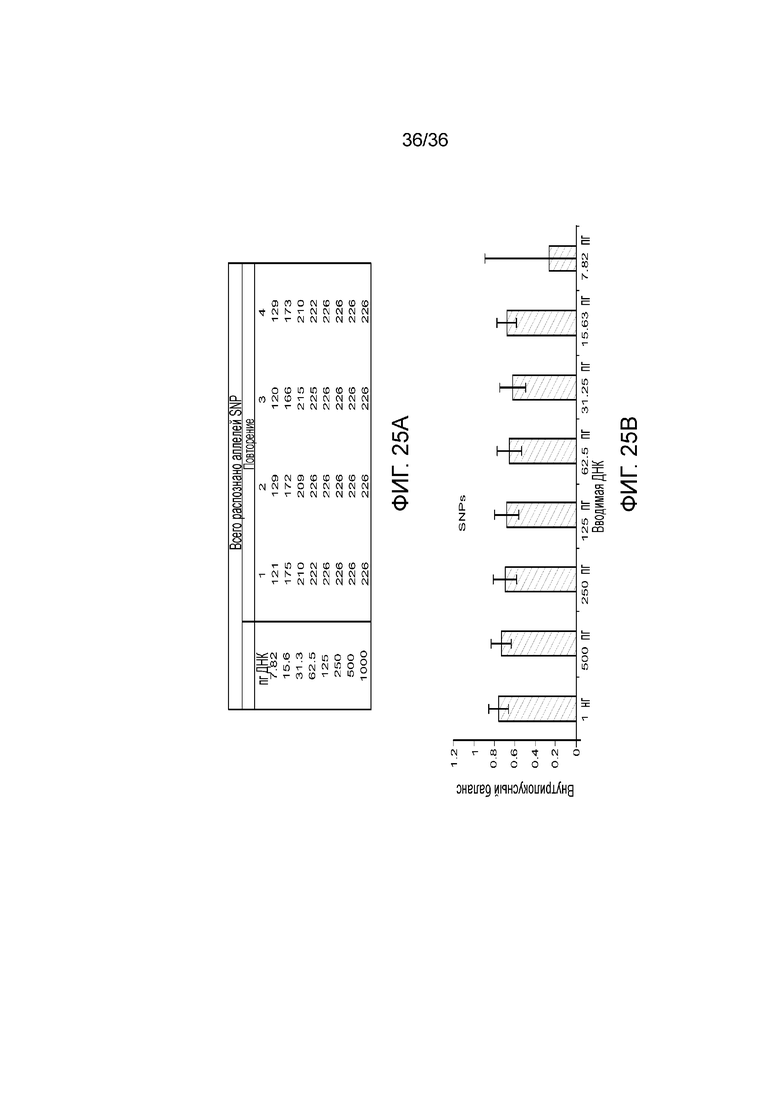
Изобретение относится к биотехнологии, в частности предоставлены способы получения ДНК-профиля, включающие: предоставление образца нуклеиновой кислоты, амплификацию образца нуклеиновой кислоты со множеством праймеров, которые специфически гибридизуются по меньшей мере с одной последовательностью-мишенью, содержащей SNP, и по меньшей мере с одной последовательностью-мишенью, содержащей тандемный повтор, и определение в продуктах амплификации генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора, таким образом получая ДНК-профиль образца нуклеиновой кислоты. 2 н. и 19 з.п. ф-лы, 25 ил., 5 табл., 7 пр.
1. Способ получения ДНК–профиля, включающий:
обеспечение образца нуклеиновой кислоты,
амплификацию образца нуклеиновой кислоты с первым множеством праймеров, которые специфически гибридизуются по меньшей мере с одной последовательностью-мишенью, содержащей однонуклеотидный полиморфизм (SNP), и по меньшей мере с одной последовательностью-мишенью, содержащей тандемный повтор, в мультиплексной реакции с получением продуктов амплификации, где по меньшей мере один из первого множества праймеров имеет низкую температуру плавления, имеет длину по меньшей мере 24 нуклеотида или содержит гомополимерную нуклеотидную последовательность, или их комбинацию, где по меньшей мере один из праймеров первого множества праймеров имеет температуру плавления, которая менее чем 60°C, имеет длину по меньшей мере 24 нуклеотида и содержит область-метку;
добавление связывающего одноцепочечные ДНК белка (SSB) к продуктам амплификации и амплификацию продуктов амплификации с помощью второго множества праймеров, которые специфически гибридизуются с областью-меткой; и
определение в продуктах амплификации генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора, таким образом получая ДНК-профиль образца нуклеиновой кислоты.
2. Способ по п.1, в котором образец нуклеиновой кислоты получают у человека.
3. Способ по п.1, в котором по меньшей мере один SNP включает SNP, который, как известно, указывает на родственную или фенотипическую характеристику источника образца нуклеиновой кислоты.
4. Способ по п.1, в котором по меньшей мере один из первого множества праймеров содержит по меньшей мере 24 нуклеотида.
5. Способ по п.4, в котором по меньшей мере один из первого множества праймеров имеет температуру плавления менее 60°С.
6. Способ по п.1, в котором амплификация образца нуклеиновой кислоты включает проведение полимеразной цепной реакции (ПЦР) на образце нуклеиновой кислоты.
7. Способ по п.1, в котором первое множество праймеров специфически гибридизуется по меньшей мере с 30 SNP.
8. Способ по п.1, в котором первое множество праймеров специфически гибридизуется по меньшей мере с 24 последовательностями тандемных повторов.
9. Способ по п.1, в котором образец нуклеиновой кислоты содержит геномную ДНК.
10. Способ по п.9, в котором обеспечение образца нуклеиновой кислоты включает обеспечение криминалистического образца, содержащего нуклеиновую кислоту.
11. Способ по п.1, в котором определение генотипов включает определение по меньшей мере 90% генотипов по меньшей мере одного SNP и по меньшей мере одного тандемного повтора.
12. Способ по п.1, в котором по меньшей мере один из множества праймеров содержит одну или несколько последовательностей–меток, содержащих метку уникального молекулярного идентификатора.
13. Способ по п.1, в котором по меньшей мере один из второго множества праймеров содержит часть, соответствующую метке-праймеру из множества праймеров и одной или нескольким последовательностям-меток.
14. Способ по п.1, в котором амплификация продуктов амплификации включает ПЦР-амплификацию.
15. Способ построения библиотеки нуклеиновых кислот, включающий:
предоставление образца нуклеиновой кислоты,
амплификацию образца нуклеиновой кислоты с первым множеством праймеров, которые специфически гибридизуются с по меньшей мере одним однонуклеотидным полиморфизмом (SNP) и по меньшей мере с одной последовательностью-мишенью, содержащей последовательность тандемного повтора в мультиплексной реакции для получения продуктов амплификации, где по меньшей мере один из первого множества праймеров имеет низкую температуру плавления, имеет длину по меньшей мере 24 нуклеотида или содержит гомополимерную нуклеотидную последовательность, или их комбинацию, где по меньшей мере один из первых праймеров множества праймеров имеет температуру плавления, которая менее чем 60°C, имеет длину по меньшей мере 24 нуклеотида и содержит область-метку, и
добавление связывающего одноцепочечные ДНК белка (SSB) к продуктам амплификации и амплификацию продуктов амплификации с помощью второго множества праймеров, которые специфически гибридизуются с областью-меткой.
16. Способ по п.15, в котором по меньшей мере один SNP указывает на родственную или фенотипическую характеристику источника образца нуклеиновой кислоты.
17. Способ по п.15, в котором по меньшей мере один из первого множества праймеров содержит одну или несколько последовательностей-меток.
18. Способ по п.17, в котором одна или несколько последовательностей-меток содержат метку-праймер, метку для захвата, метку для секвенирования или метку уникального молекулярного идентификатора или их сочетание.
19. Способ по п.15, в котором по меньшей мере один из второго множества праймеров содержит часть, соответствующую метке-праймеру из множества праймеров и одной или нескольким последовательностям-меткам.
20. Способ по п.15, в котором амплификация образца нуклеиновой кислоты включает амплификацию посредством полимеразной цепной реакции (ПЦР).
21. Способ по п.15, в котором амплификация продуктов амплификации включает ПЦР-амплификацию.
| WO2006004659 (A1) - 2006-01-12 | |||
| Sanchez J | |||
| J | |||
| et al | |||
| Солесос | 1922 |
|
SU29A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Приспособление для удаления таянием снега с железнодорожных путей | 1920 |
|
SU176A1 |
| Копа Ю., Момыналиев К., ДНК-макроматрицы и транскрипционное профилирование, Наноиндустрия, 2007, номер | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Видоизменение прибора с двумя приемами для рассматривания проекционные увеличенных и удаленных от зрителя стереограмм | 1919 |
|
SU28A1 |

